
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4 values | source stringclasses 4 values |
|---|---|---|---|---|
# Рисуем кодом в Swift, PaintCode
Пока в соседней комнате готовят оливье, я пишу небольшой туториал как рисовать кодом. Сразу представляются строчки кода с дробными числами, где ведём линию по точкам. А для вычисления радиуса окружности берём яд змеи, *надежность* хранения фото в iCloud и шепчем заклинание. Пугает, понимаю. Даже в [ролике на YouTube](https://youtu.be/ID5JvGbXXTY) вставил шутку:
— “*Ааастановите, пожалуйста, вот у магазина*” — прокричал герой российского сериала.
В целом, дорогой друг, ты прав. Будут и дробные числа, и куча строчек кода. Но будет намного проще. Интересно? Давай к делу.
Для работы потребуется утилита *PaintCode*. Откроем приложение, и увидим интерфейс, похожий на Sketch:

Мне эта преемственность нравится.
Для начала выставим размеры холста. Рекомендую использовать значение от 100 до 1000 пикселей. Больше ставить смысла нет, а поставив меньше 100 пикселей, можно получить большую дробную часть, и как результат — фризы при отрисовке. Мы установим 400x400 пикселей и назовем холст *Apple Icon*:
Названия для холстов рекомендую использовать корректные, в конце туториала станет понятно зачем. А вот для слоев названия не важны, их можно игнорировать.
Добавим иконку на холст, выставим размер и разместим по центру. Получится должно так:

Иконку для экспериментов можно взять любую, главное — не растровую. Если вас устроит такой результат, то можно экспортировать и переходить в Xcode.
Но я покажу полезную фичу. Сейчас иконка черная, а вы хотите иметь возможность менять цвет. Для этого посмотрим в левый верхний угол, и увидим все цвета, которые получены из объекта. Переименуем цвет в *IconColor* и установим режим *Parameter*.
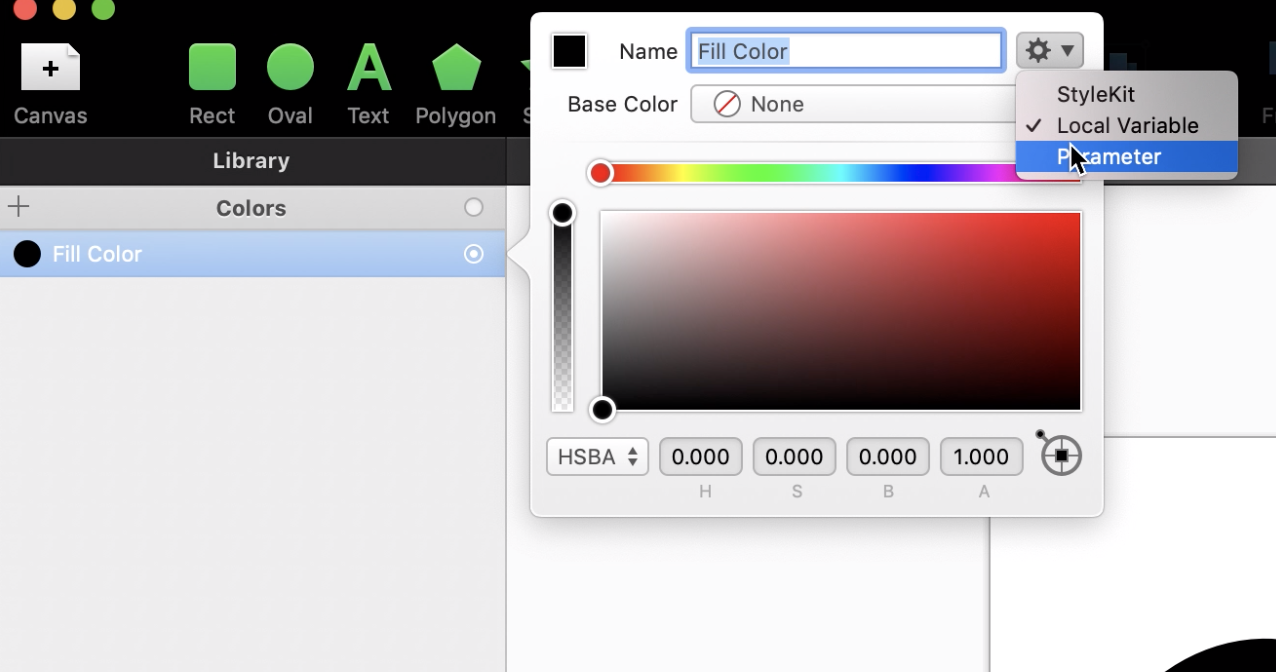
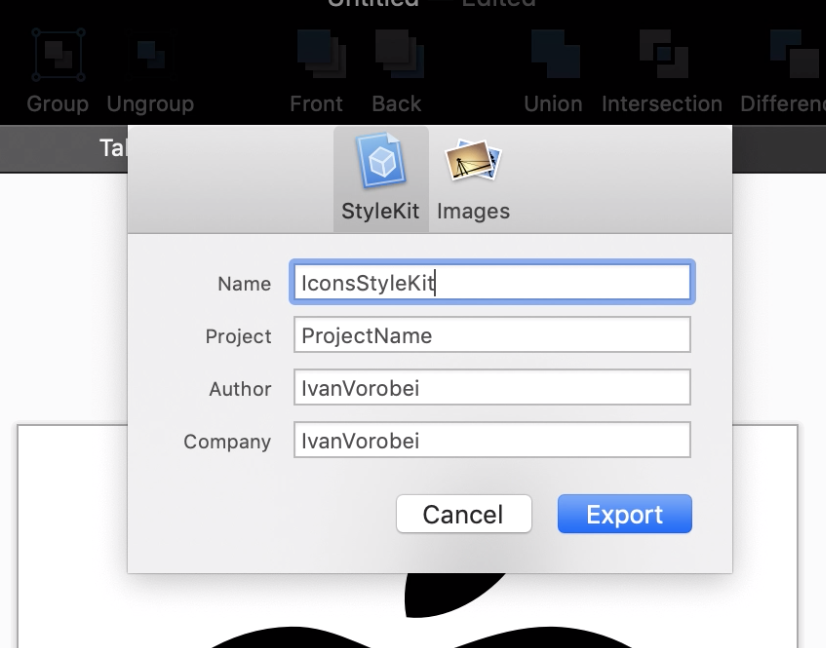
Это всё. Остается экспортировать сгенерированный код. Справа вверху вы найдете кнопку *Export*. Заполните имя и другие поля по желанию и сохраните файл:
### Перейдем в Xcode
Импортируем в проект файл, который экспортировали из *PaintCode*. Для любопытства можно пролистать его, но интересного мало.
В Xcode создаем класс *ApppleIconView*, наследуемая от *UIView*. Так же переопределим метод *draw*:
```
class AppleIconView: UIView {
override func draw(_ rect: CGRect) {
IconStyleKit.drawAppleIcon(
frame: rect,
resizing: .aspectFit,
iconColor: UIColor.black
)
}
}
```
*IconStyleKit* — имя, указанное при экспорте. *drawAppleIcon* — сгенерированное имя метода, на основе названия холста. А *iconColor* — цвет, который теперь задается как параметр. Как видите, удобные методы сгенерировал *PaintCode*.
Так же необходимо у *AppleIconView* установить прозрачный цвет фона. Не забудьте это сделать.
Добавим объект *AppleIconView*:
```
class Controller: UIViewController {
override func viewDidLoad() {
super.viewDidLoad()
let iconView = AppleIconView(
frame: CGRect.init(
x: 0, y: 200,
width: 70,
height: 70)
)
iconView.center.x = self.view.frame.width / 2
self.view.addSubview(iconView)
}
}
```
Остается запустить проект. Если всё сделано верно, вы увидите логотип, отрисованный кодом:
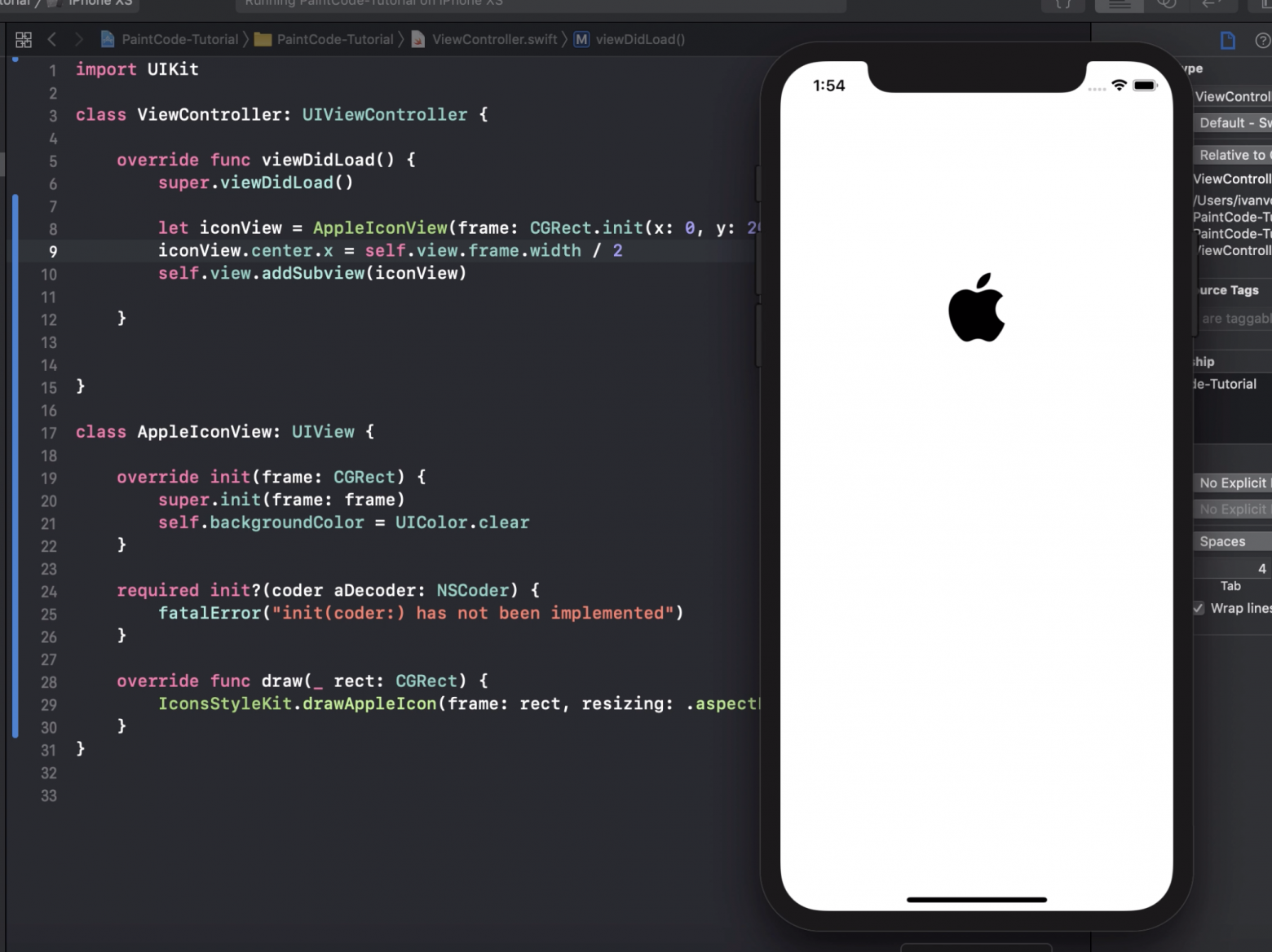
### Необъективное мнение автора
В основном я использую PDF в своих iOS приложениях. Зачем использовать *PaintCode*? Просто так — смысла нет. Но если у вас одна и та же иконка должна иметь несколько цветов — *PaintCode* выручает (если иконка одноцветная, вы можете использовать проперти *tintColor*). Так же отрисованные элементы проще анимировать.
Пример практического применения — моя [библиотека SPPermission](https://github.com/IvanVorobei/SPPermission):

Для каждого разрешения я использую иконку, отрисованную про помощи *PaintCode*. Схему их 3-ёх цветов можно изменить прямо в коде.
Для тех, кому приятнее смотреть ролики, ещё раз сделаю отсылку к [туториал на YouTube](https://youtu.be/ID5JvGbXXTY):
С наступающим!
У меня появился [канал в телеге](https://t.me/+NjnQUtK6zGM3ZjU6), подписывайтесь. | https://habr.com/ru/post/434892/ | null | ru | null |
# snmp-мониторинг принтеров в The Dude
Snmp
----
В сети много инструкций как установить сервер мониторинга The Dude от Mikrotik. Сейчас пакет сервера мониторинга выпускают только для RouterOS. Я использовал версию 4.0 для Windows.
Здесь я хотел рассмотреть, как сделать мониторинг принтеров в сети: отслеживать уровень тонера, если он закончился вывести уведомление. Запускаем:

Нажимаем подключиться:

Нажимаем добавить устройство(красный плюс) и вводим ip-адрес принтера:

На следующем шаге нажимаем обнаружение, он находит все доступные зонды, нажимаем закончить:

Два раза нажимаем по появившемуся значку, открываются настройки, тип выбираем «принтер», и нажимаем «ок»:

Правой кнопкой нажимаем по значку и выбираем вид:

В поле метка прописываем OID’ы:
[Device.Name] – имя устройства
[oid(«1.3.6.1.2.1.43.5.1.1.16.1»)] – модель принтера
[oid(«1.3.6.1.2.1.43.11.1.1.6.1.1»)] – тип картриджа
[oid(«1.3.6.1.2.1.43.11.1.1.9.1.1»)] – уровень тонера
Во вкладке изображение можно прикрепить свою иконку:

Выходим, получается так:

Не на всех принтерах oid(«1.3.6.1.2.1.43.11.1.1.9.1.1») показывает сразу уровень тонера, на некоторых этот параметр показывает сколько осталось напечатать страниц. Чтобы рассчитать уровень тонера нужно разделить сколько осталось напечатать страниц на общий ресурс картриджа и умножить на 100. Для этого снова выбираем «вид», потом Functions:

Нажимаем создать новую функцию(красный плюс):

Я назвал функцию toner:

В поле код пишем формулу и сохраняем:
```
round(100*oid("1.3.6.1.2.1.43.11.1.1.9.1.1")/oid("1.3.6.1.2.1.43.11.1.1.8.1.1"))
```
В метке заменяем [oid(«1.3.6.1.2.1.43.11.1.1.9.1.1»)] на вызов функции [toner()]

Выходим. Получается так:

Чтобы узнать нужные oid и прописать нужные параметры можно использовать функцию snmp walk, правая кнопка на принтере – инструменты обход Snmp:

Выдается дерево объектов принтера:

Нажимаем правой кнопкой на нужном нам и нажимаем копировать OID.
Уведомления
-----------
Теперь настроим уведомления по событию (картридж закончился). Открываем принтер, переходим на вкладку службы, нажимаем плюсик(добавить новую службу):

В поле зонд нажимаем три точки чтобы выбрать нужный зонд:

Создадим свой собственный зонд, нажмем красный плюс:

Я назвал его toner, тип выбираем SNMP, агент по умолчанию, профиль Snmp по умолчанию,
Oid прописываем который отвечает за уровень тонера 1.3.6.1.2.1.43.11.1.1.9.1.1, тип Oid Integer, метод сравнения >= 1

Сохраняем и в поле зонд выбираем только что созданный toner, во вкладке оповещения можно настроить какие оповещения мы хотим получать и сохраняем:

Для демонстрации я выбрал что уровень тонера не должен быть ниже 80, принтер окрасился в красный цвет:

 | https://habr.com/ru/post/464471/ | null | ru | null |
# Как реляционная СУБД делает JOIN?
[Оригинал находится здесь](https://architecture-cleaning.ru/2021/05/12/sql-perfomance/)
О чем эта статья и кому адресована?
-----------------------------------
С SQL работают почти все, но даже опытные разработчики иногда не могут ответить на простой вопрос. Каким образом СУБД выполняет самый обычный INNER JOIN?
С другой стороны - разработчики на C# или других ООП языках часто воспринимают СУБД как всего лишь хранилище. И размещать какие-то бизнес-правила в SQL - плохо. В противовес им создаются библиотеки вроде [Linq2Db](https://github.com/linq2db/linq2db) (не путаем с *Linq2Sql* - совершенно разные авторы и разные библиотеки). При ее использовании весь код пишется на C# и вы получаете все преимущества типизированного языка. Но это формальность. Затем этот код транслируется на SQL и выполняется на стороне СУБД.
Для того чтобы лучше разобраться как работает одинаковый код на SQL и на C# мы попробуем реализовать одно и то же на первом и на втором, а затем разберем как это работает. Если вы хорошо знаете что такое **Nested Loop**, **Merge Join**, **Hash Join** - вам скорее всего имеет смысл прочитать статью по диагонали. А вот если не знаете - статья для вас должна быть полезной.
### Работа с несколькими коллекциями
Предположим, что у нас есть некоторый сервисный центр по техническому обслуживанию автомобилей - станция технического обслуживания (СТО). Есть две сущности: *Person* - клиенты сервисного центра и *Visit* - конкретное посещение данного центра. *Person* кроме идентификатора содержит имя, фамилию и статус активности (например, если клиент поменял машину на другую марку - он переводится в статус не активного и уже не будет в ближайшем времени посещать нас). *Visit* кроме идентификатора содержит в себе ссылку на клиента, дату визита и сумму, которую заплатил клиент за этот визит. Все вышеперечисленное можно было бы оформить с помощью следующих классов на C# для самого простейшего случая:
```
internal sealed class Person
{
internal int Id { get; set; }
internal string FirstName { get; set; }
internal string LastName { get; set; }
internal bool IsActive { get; set; }
}
internal sealed class Visit
{
internal int Id { get; set; }
internal int PersonId { get; set; }
internal DateTime Date { get; set; }
internal decimal Spent { get; set; }
}
// ...
internal Person[] persons = new Person[];
internal Visit[] visits = new Visit[];
// ...
```
В базе данных (в дальнейшем мы будем использовать *PostgreSQL*) для двух этих сущностей есть две таблицы с аналогичными полями:
```
create table public.visit
(
id integer,
person_id integer,
visit_datetime timestamp without time zone,
spent money
) tablespace pg_default;
create table public.person
(
id integer,
first_name character varying(100) COLLATE pg_catalog."default",
last_name character varying(100) COLLATE pg_catalog."default",
is_active boolean
) tablespace pg_default;
```
Исходный код для данной статьи находится [здесь](https://github.com/nikita-lyapin/sql-vs-collections). Если у вас есть какие-то замечания - можете сразу править.
Пусть наша задача сводится к написанию простейшего бизнес-правила - **найти общую сумму выручки за 2020 год и ранее, которую принесли клиенты, находящиеся сейчас в активном статусе**. Как можно реализовать решение такой простой задачи?
### Nested Loop
Самая простая идея, которая приходит на ум. Бежим в цикле по клиентам и во вложенном цикле бежим по всем посещениям. Проверяем все условия и если находим совпадение - добавляем сумму затрат этого визита в итоговый результат.
```
public decimal NestedLoop()
{
decimal result = 0;
var upperLimit = new DateTime(2020, 12, 31);
foreach (var person in persons)
{
if (person.IsActive == false)
{
continue;
}
foreach (var visit in visits)
{
if (person.Id == visit.PersonId && visit.Date <= upperLimit)
{
result += visit.Spent;
}
}
}
return result;
}
```
Эта идея анимирована ниже:
Алгоритм очень простой, не потребляет дополнительной памяти. Но затратность его **O(N²)**, что будет сказываться на большом числе элементов - чем их больше, тем больше телодвижений необходимо совершить.
Для того, чтобы оценить скорость его работы мы создадим тестовый набор данных с помощью следующего SQL скрипта:
```
select setseed(0.777);
delete from public.person;
insert into public.person(id, first_name, last_name, is_active)
select row_number() over () as id,
substr(md5(random()::text), 1, 10) as first_name,
substr(md5(random()::text), 1, 10) as last_name,
((row_number() over ()) % 5 = 0) as is_active
from generate_series(1, 5000);/*<-- 5000 это число клиентов*/
delete from public.visit;
insert into public.visit(id, person_id, visit_datetime, spent)
select row_number() over () as id,
(random()*5000)::integer as person_id, /*<-- 5000 это число клиентов*/
DATE '2020-01-01' + (random() * 500)::integer as visit_datetime,
(random()*10000)::integer as spent
from generate_series(1, 10000); /* 10000 - это общее число визитов в СТО*/
```
В данном случае число клиентов CTO *P* равно 5000, число их визитов *V* - 10000. Дата визита, а также сам факт визита для клиента генерируются случайным образом из указанных диапазонов. Признак активности клиента выставляется для каждого пятого. В итоге мы получаем некоторый тестовый набор данных, приближенный к реальному. Для тестового набора нам интересна характеристика - число клиентов и посещений. Или *(P,V)* равное в нашем случае *(5000, 10000)*. Для этого тестового набора мы сделаем следующее: выгрузим его в обьекты C# и с помощью цикла в цикле (Nested Loop) посчитаем суммарные траты наших посетителей. Как это определено в постановке задачи. На моем компьютере получаем приблизительно **20.040 миллисекунд**, затраченное на подсчет. При этом время получение данных из БД составило все те же самые **20.27 миллисекунд**. Что в сумме дает около **40 миллисекунд**. Посмотрим на время выполнения SQL запроса на тех же данных.
```
select sum(v.spent) from public.visit v
join public.person p on p.id = v.person_id
where v.visit_datetime <= '2020-12-31' and p.is_active = True
```
Все на том же компьютере получилось порядка **2.1 миллисекунды** на все. И кода заметно меньше. Т.е. в 10 раз быстрее самого метода, не считая логики по извлечению данных из БД и их материализации на стороне приложения.
### Merge Join
Разница в скорости работы в 20 раз наталкивает на размышления. Скорее всего Nested Loop не очень нам подходити мы должны найти что-то получше. И есть такой алгоритм… Называется **Merge Join** или **Sort-Merge Join**. Общая суть в том, что мы сортируем два списка по ключу на основе которого происходит соединение. И делаем проход всего в один цикл. Инкрементируем индекс и если значения в двух списках совпали - добавляем их в результат. Если в левом списке идентификатор больше, чем в правом - увеличиваем индекс массива только для правой части. Если, наоборот, в левом списке идентификатор меньше, то увеличиваем индекс левого массива. Затратность такого алгоритма **O(N\*log(N))**.
Результат работы такой реализации радует глаз - **1.4 миллисекунды** в C#. Правда данные из базы данных еще нужно извлечь. А это все те же самые дополнительные **20 миллисекунд**. Но если вы извлекаете данные из БД, а затем выполняете несколько обработок, то недостаток постепенно нивелируется. Но можно ли подсчитать заданную сумму еще быстрее? Можно! **Hash Join** поможет нам в этом.
### Hash Join
Этот алгоритм подходит для больших массивов данных. Его идея проста. Для каждого из списков считается хэш ключа, далее этот хэш используется для того, чтобы выполнить сам Join. Детально можно посмотреть в видео:
[Видео работы Hash Join (на англ. языке)](https://www.youtube.com/watch?v=59C8c7p_hII)
Затратность алгоритма **O(N)**. В .NET стандартный Linq метод как раз его и реализует. В реляционных СУБД часто используются модификации этого алгоритма (**Grace hash join**, **Hybrid hash join**) - суть которых сводится к работе в условиях ограниченной оперативной памяти. Замер скорости работы в C# показывает, что этот алгоритм еще быстрее и выполняется за **0.9 миллисекунды**.
### Динамический выбор алгоритма
Отлично! Похоже мы нашли универсальный алгоритм, который самый быстрый. Нужно просто использовать его всегда и не беспокоиться более об этом вопросе. Но если мы учтем еще и расход памяти все станет немного сложнее. Для Nested Loop - память не нужна, Merge Join - нужна только для сортировки (если она будет). Для Hash Join - нужна оперативная память.
Оказывается расход памяти - это еще не все. В зависимости от общего числа элементов в массивах скорость работы разных алгоритмов ведет себя по-разному. Проверим для меньшего числа элементов (P, V) равному (50, 100). И ситуация переворачивается на диаметрально противоположную: **Nested Loop** самый быстрый - **2.202 микросекунды**, Merge Join - **4.715 микросекунды**, Hash Join - **7.638 микросекунды**. Зависимость скорости работы каждого алгоритма можно представить таким графиком:
Для нашего примера можно провести серию экспериментов на C# и получить следующую таблицу:
| Method | Nested Loop | Merge Join | Hash Join |
| --- | --- | --- | --- |
| (10, 10) | **62.89 ns** | 293.22 ns | 1092.98 ns |
| (50, 100) | **2.168 us** | 4.818 us | 7.342 us |
| (100, 200) | **8.767 us** | 10.909 us | 16.911 us |
| (200, 500) | 38.77 us | **32.75 us** | 40.75 us |
| (300, 700) | 81.36 us | **52.54 us** | 54.29 us |
| (500, 1000) | 189.58 us | 87.10 us | **82.85 us** |
| (800, 2000) | 606.8 us | 173.4 us | **172.7 us** |
| (750, 5000) | 1410.6 us | 428.2 us | **397.9 us** |
А что если узнать значения X1 и X2 и динамически выбирать алгоритм в зависимости от его значения для данных коллекций? К сожалению не все так просто. Наша текущая реализация исходит из статичности коллекции. Что нужно сделать, чтобы вставить еще один визит за 2020 год? В массив в коде на C#. В массив фиксированного размера он, очевидно, не поместится. Нужно выделять новый массив размером на один элемент больше. Скопировать туда все данные, вставлять новый элемент. Понятно, что это дорого. Как насчет того, чтобы заменить Array на List? Уже лучше, т.к. он предоставляет все необходимое API. Как минимум удобно, но если посмотреть на его реализацию - под капотом используется все тот же массив. Только резервируется памяти больше чем надо… С запасом. Для нас это означает лишние траты памяти. LinkedList? Здесь должно быть все нормально. Давайте поменяем коллекцию и посмотрим что из этого получится.
| Method | Nested Loop | Nested Loop with Linked List |
| --- | --- | --- |
| (10, 10) | 62.89 ns | 262.97 ns |
| (50, 100) | 2.188 us | 8.160 us |
| (100, 200) | 8.196 us | 32.738 us |
| (200, 500) | 39.24 us | 150.92 us |
| (300, 700) | 80.99 us | 312.71 us |
| (500, 1000) | 196.3 us | 805.20 us |
| (800, 2000) | 599.3 us | 2359.1 us |
| (750, 5000) | 1485.0 us | 5750.0 us |
Время выполнения не только изменилось. Сама кривая стала более крутой и с числом элементов время растет:
Стоит отметить, что добавление индекса может сильно улучшить работу **Nested Loop**. Такая вариация называется **Indexed Nested Loop** и по скорости он может составить конкуренцию даже **Hash Join**. Особенно если учитывать отсутсвие необходимости в дополнительной памяти (кроме самого индекса).
Таким образом мы приходим к понимаю, что время доступа к каждому конкретному элементу коллекции крайне важно. Одно из главных преимуществ реляционных СУБД в том, что они всегда готовы к добавлению новых данных в любой диапазон. При этом это добавление произойдет максимально эффективным образом - не будет релокации всего диапазона данных или т.п. Кроме того данные СУБД часто хранится в одном файле - таблицы и их данные. Если утрировать, то здесь также используется связанный список. В случае с PostgreSQL данные представлены в страницах (page), внутри страницы располагаются кортежи данных (tuples). В общих чертах вы можете себе это увидеть на картинках ниже. А если захотите узнать больше деталей, то ниже также есть и ссылка.
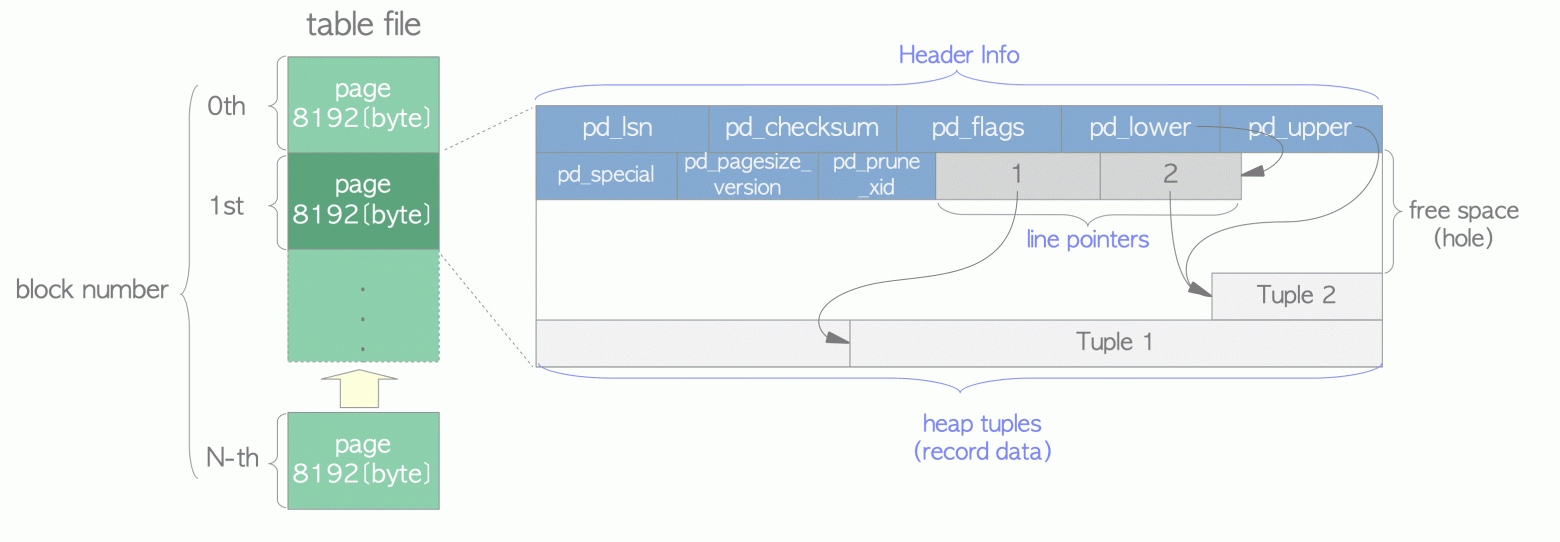Более детально описано в первоисточнике [Здесь](https://www.interdb.jp/pg/pgsql01.html#_1.3.)
Структура кортежа также адаптирована для хранения практически любых данных в таблице, на их обновление и вставку в любой участок диапазона:
Более детально описано в первоисточнике [Здесь](https://www.interdb.jp/pg/pgsql05.html#_5.1.).
В оперативную память попадают страницы, а попадают они в **buffer pool** через **buffer manager**. Все это сказывается на стоимости доступа к каждому конкретному значению таблицы. Вне зависимости от того что используется **Nested Loop**, **Merge Join** или **Hash Join**. Другой вопрос, что в зависимости от алгоритма число обращений может отличаться в разы. Поэтому реляционные СУБД подходят динамически к выбору алгоритма в каждом конкретном запросе и строят план запроса (**Query Plan**).
Сравним для большого числа элементов насколько будет отличаться время обработки с одним и тем же алгоритмом в БД и на C#. (P, V) будет равно (50000, 100000). В коде на C# загрузка данных из БД занимает **145.13 миллисекунд**. Дополнительно к этому выполнение самой логики с **Nested Loop** на основе обычного массива - **305.38 миллисекунд**, **Hash Join** - **36.59 миллисекунд**. Для того чтобы проверить в СУБД такую же реализацию мы будем использовать такой скрипт:
```
set enable_hashjoin to 'off';--Заставляем БД использовать Nested Loop
set enable_mergejoin to 'off';
set enable_material to 'off';
select sum(v.spent) from public.visit v
join public.person p on p.id = v.person_id
where v.visit_datetime <= '2020-12-31' and p.is_active = True
```
На аналогичных данных в БД с **Nested Loop** запрос выполнится за **11247.022 миллисекунд**. Что может говорить о сильно большем времени доступа к каждому конкретному элементу:
Но СУБД приходится заставлять работать так, чтобы она использовала **Nested Loop**. Изменим наш скрипт таким образом:
```
set enable_hashjoin to 'on';
set enable_mergejoin to 'on';
set enable_material to 'on';
select sum(v.spent) from public.visit v
join public.person p on p.id = v.person_id
where v.visit_datetime <= '2020-12-31' and p.is_active = True
```
По-умолчанию для такого объема данных будет, конечно выбран **Hash Join**:
И мы видим, что время выполнение составило **25.806 миллисекунды**, что сопоставимо по скорости с реализацией на C# и даже немного быстрее.
Как мы видим, СУБД может динамически подстраиваться под данные и автоматически выбирать алгоритм, наиболее подходящий в данной конкретной ситуации. Процесс выбора такого способа выполнения запроса возложен на **планировщик запросов**. В итоге он выдает план запроса, где четко расписано какой алгоритм использовать, какой использовать индекс и т.п.
### Выводы
На примере простейшей задачи мы в общих чертах разобрали как работает типичная реляционная СУБД при реализации JOIN. Сравнивать коллекции C# и SQL не очень корректно, за внешней схожестью скрывается серьезное различие в предназначении. Реляционная СУБД призвана обеспечить **конкурентный доступ к данным максимально эффективным способом** (при этом подразумевается, что сами данные могут постоянно модифицироваться). Кроме того, данные могут не помещаться в оперативную память и частично храниться на диске.
Более того, СУБД обязана обеспечить сохранность данных на постоянном носителе - одно из основных ее предназначений. При этом на получение данных СУБД динамически выбирает алгоритм, наиболее эффективный в данном случае. В C# аналагичных библиотек или реализаций просто нет… И это показательно, т.к. лишь свидетельствует об отсутствии такой необходимости. Linq метод Join реализует **Hash Join**, который потенциально тратит больше оперативной памяти, но это просто не берется в расчет. Т.к. мало кого интересует применительно к решаемым задачам.
На практике вопрос производительности не является единственным - сопровождаемость кода, покрытие его тестами, скорость работы этих тестов - все тоже очень важно. | https://habr.com/ru/post/560834/ | null | ru | null |
# Гоночный FPV-дрон своими руками (часть 2) — настройка
В [первой части](https://geektimes.ru/post/277774/) я рассказал, как собрать квадрокоптер для FPV-полётов. Теперь настало время его настроить. Если интересно, вэлкам под кат.

Сразу оговорюсь, что я совершенно не претендую на роль эксперта, это всего лишь третий собранный мною квадрокоптер. Вдобавок, настройка — вещь весьма субъективная. Тем не менее, я надеюсь, что кому-то статья будет полезна и поможет сэкономить время.
Перейдём непосредственно к настройке. Сначала более простые вещи, а потом — его величество полётный контроллер.
#### Прошивка и настройка MinimOSD
Наиболее популярной (но не единственной) прошивкой для MinimOSD является [MWOSD](http://www.mwosd.com/). Сначала нужно прошить ей плату, а потом ещё и настроить. Если настроить OSD можно через ПК (подробнее об этом в разделе, посвящённом настройке ПК), то для прошивки необходим FTDI-адаптер или Ардуинка. Как это сделать через FTDI-программатор, а главное где взять для него старые драйвера, показано в [этом видео](https://www.youtube.com/watch?v=uJzaY_X-m44). Главное, не забыть перед прошивкой раскомментировать в Config.h следующие строки:
`#define MINIMOSD
#define CLEANFLIGHT`
Из параметров выводить на экран я стал только напряжение батареи, время полёта и выбранный полётный режим.

#### Прошивка и настройка регуляторов
Для прошивки регуляторов у меня тоже есть специальный USB-адаптер, но можно обойтись и без него, подключившись через ПК. Долго думал, ставить Multishot или уже проверенный Oneshot125? С одной стороны, на устаревшем чипе F330 в скорости особой разницы не заметно, с другой — мелодия из «Звёздных войн» при включении и, как пишут на форумах, «более чистый сигнал». Решили всё неединичные жалобы на то, что моторы стихийно начинают вращаться на максимальных оборотах при подключении к CLI. В итоге поставил BLHeli последней версии (на момент сборки 14.5), включил Damped Light и выставил Motor Timing на «Medium». Позднее откалибровал регуляторы по [этой инструкции](https://www.youtube.com/watch?v=o3Mg-9M0l24).
#### Прошивка полётного контроллера
На этом этапе я застрял дольше всего, так как были проблемы с прошивкой. Оказалось, первый раз шить надо обязательно с замыканием boot-контактов (как в [этом видео](https://www.youtube.com/watch?v=NVl1OHUouDQ)). Кстати, иногда бывает, что ПК защищён от записи и невозможно прошить новую прошивку. Вот [инструкция](https://medium.com/@arrowcircle/%D0%BA%D0%B8%D1%82%D0%B0%D0%B9%D1%81%D0%BA%D0%B8%D0%B9-seriously-pro-f3-%D0%BB%D0%B5%D1%87%D0%B8%D0%BC-%D0%BE%D1%88%D0%B8%D0%B1%D0%BA%D1%83-stm32-communication-failed-wrong-response-expected-121-a7e5e4e925dc#.6e89qg68t), как это исправить.
Пожалуй, самой популярной прошивкой на сегодняшний день, вполне заслуженно, является [Cleanflight](https://github.com/cleanflight/cleanflight). После её установки достоточно только настроить протокол приёмника и квадрокоптер уже может вполне сносно лететь. Для настройки используется удобная графическая оболочка [Cleanflight Configurator](https://github.com/cleanflight/cleanflight-configurator).
Благодаря открытому коду прошивки, у неё есть несколько ответвлений (форков). Самым интересным из них является [Betaflight](https://github.com/betaflight/betaflight) от человека под ником Boris B. Прошивка очень динамично развивается и некоторые её «фичи» потом переходят в «родительский» Cleanflight (например, полётный режим Airmode). Минусом Betaflight является то, что релизы выходят достаточно часто, а стабильность их не всегда высока. Кстати, эта причина на несколько недель задержала написание данной статьи. На момент завершения сборки квадрокоптера как раз вышла версия 2.8.0, которая имела пару ошибок и отличалась недружелюбными дефолтными настройками. Очень быстро появилась исправленная версия 2.8.1 RC1, но опыт работы программистом подсказал мне, что лучше подождать релиза. Я не прогадал, так как одновременно с релизом версии 2.8.1, появился и [Betaflight Configurator](https://chrome.google.com/webstore/detail/betaflight-configurator/kdaghagfopacdngbohiknlhcocjccjao?hl=ru). Можно сказать, что это новый этап в истории данной прошивки. Дело в том, что по мере своего развития Betaflight всё больше и больше отдалялся от Cleanflight и конфигуратор последнего становился всё более и более бесполезным, так как основная часть настроек всё равно делалась через консоль CLI. Кстати, на момент подготовки этой статьи, уже вышла версия Betaflight под номером 2.9.0, но из-за негативных отзывов я не стал обновляться до неё.
Ниже я подробно опишу, как я настроил свой квадрокоптер через Betaflight Configurator.
#### Настройка ПК через Betaflight Configurator
##### Вкладка Setup
Сделал калибровку акселерометра.
##### Вкладка Ports
* Для того, чтобы работала OSD, включил MSP для порта UART2.
* Ни в коем случае не отключайте MSP для порта UART1. Он запараллелен с USB и отключив передачу данных, вы уже не подключитель к ПК по USB-разъёму.

##### Вкладка Configuration
Собственно тут и производятся почти все настройки.
* В разделе «Board and Sensor Alignment» указал, что мой ПК повёрнут на 90 градусов по оси yaw. Корректность этого параметра потом можно проверить во вкладке Setup.
* В «Reciever Mode» выбрал RX\_PPM.
* Выбрал ONESHOT125 в качестве протокола регуляторов (почему не MULTISHOT, я писал выше).
* Отключил «Unsynced PWM output», опять же, потому что не использую MULTISHOT.
* Чтобы моторы всегда вращались в заармленном состоянии, отключил MOTOR\_STOP.
* Включил опцию «Disarm motors regardless of throttle value», так как буду делать арм моторов на отдельном канале.
* Уменьшил значение «Minimum Throttle» до 1030. Это обороты холостого хода, подбирал субъективно.
* Включил опцию «VBAT» для активации индикатора заряда батареи. Остальные параметры в разделе «Battery Voltage» я не менял, так как показания заряда соответствуют действительности. Если же в них есть погрешность, её можно убрать настройкой «Voltage Scale».
* В «Other Features» активизировал BLACKBOX, SUPEREXPO\_RATES, а также LED\_STRIP и выключил AIRMODE. О неё я расскажу чуть ниже.

##### Вкладка Failsafe
C failsafe всё оказалось несколько сложнее, чем мне виделось ранее. На профильных форумах иногда встречаются холивары на тему «где лучше настраивать failsafe: на приёмнике или на ПК?» На самом деле, правильно это вопрос звучит так: «где лучше настраивать failsafe: только на приёмнике или на приёмнике и на ПК?»
Настраивать failsafe на приёмнике необходимо в любом случае. Здесь надо сделать важное уточнение, что речь идёт о приёмнике Frsky D4R-II, работающем по протоколу PPM. У приёмников с S.Bus failsafe настраивается иначе.
У Frsky D4R-II есть три варианта поведения при потере сигнала от передатчика:
* передать на ПК сигнал, имитирующий предустановленные положения стиков и переключателей (режим Pre-set Positions, именно он и описан в мануале)
* продолжать передавать на ПК последние данные, полученные от передатчика (режим Hold Last Position)
* прекратить передавать сигнал на ПК (режим No Pulse)
По умолчанию в Frsky D4R-II установлен режим Hold Last Position, который способствует улёту аппарата в далёкие дали. Так что если использовать failsafe только на приёмнике, надо настраивать режим Pre-set Positions. Другое дело, что failsafe активируется даже при кратковременной потере сигнала. Будет очень неприятно, если сигнал через долю секунды восстановиться, а квадрокоптер уже задизармил моторы и падает вниз. Ситуацию может улучшить настройка failsafe на ПК, так как там этот режим имеет задержку срабатывания, что служит фильтром от кратковременных потерь сигнала. Кроме того, там есть настраиваемый сценарий, согласно которому квадрокоптер будет себя вести в случае активации failsafe. Например, можно включить режим со стабилизацией и попытаться более-менее мягко сесть или вообще активизировать RTH, если он есть. Но на практике такие вещи востребованы на больших аппаратах с GPS, а на маленьких и быстрых, опытные пилоты советуют не мудрить и выключать моторы после потери сигнала. Из-за высокой скорости полётов, так будет безопаснее для окружающих.
Нюанс в том, что, если на приёмнике установлен режим Pre-set Positions или Hold Last Position, то ПК даже не узнает, что произошла потеря сигнала. Таким образом, failsafe на ПК можно использовать лишь в том случае, если на приёмнике установлен режим No Pulse. На Frsky D4R-II он устанавливается кратковременным (менее 1 сек) нажатием на кнопку failsafe **при выключенном передатчике** ([видео-инструкция](https://www.youtube.com/watch?v=r3CUE7fwj7Y)).
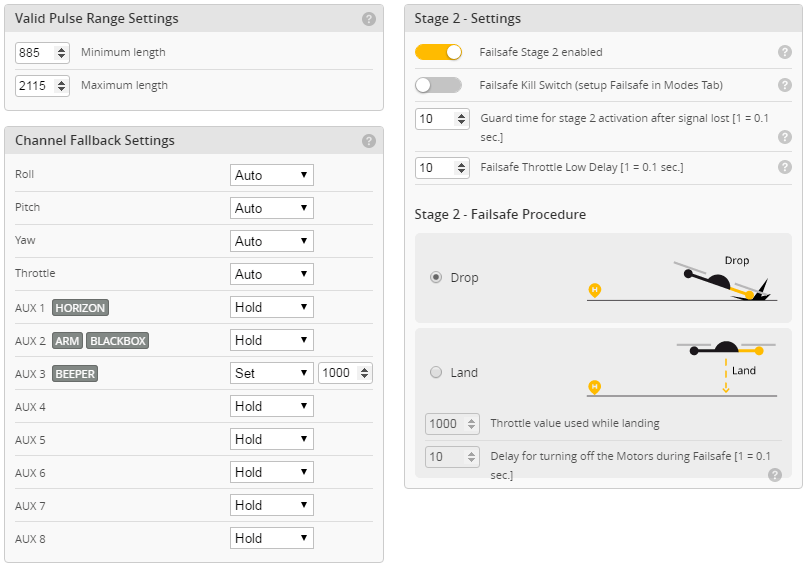
На вкладке Failsafe Betaflight Configurator`а я сделал следующее:
* В разделе «Channel Fallback Settings» установил значения переключателей передатчика, которые нужно будет сымитировать. В моём случае только включил пищалку на AUX3.
* Активизировал Failsafe Stage 2.
* Установил задержку активации режима failsafe 1 сек (значение 10 в пункте «Guard time for stage 2 activation...»)
* Установил время работы моторов после активации failsafe 1 сек (значение 10 в пункте Failsafe Throttle Low delay).
* В Failsafe Procedure выбрал сценарий с падением (Drop), а не с попыткой плавного приземления (Land).
##### Вкладка PID Tuning
Настройка PID — процесс, в который совершенно не стоит лезть «не зная брода». В первую очередь, необходимо теоретическое понимание этих трёх составляющих. Вот несколько статей, которые могут с этим помочь:
* [ПИД для квадрокоптеров (перевод)](http://blog.rcdetails.info/2015/11/pid-dlya-kvadrokopterov-perevod/)
* [О ПИД-регуляторах замолвите слово](http://copterpilot.ru/articles/o-pid-regulyatorax/)
* [И еще о ПИД-регуляторах](http://copterpilot.ru/articles/o-pid-regulyatorax-2/)
* [Основы настройки ПИД контроллера с помощью логов Blackbox (перевод)](http://www.rcdetails.info/blog/osnovy_nastroyki_pid_s_pomoschu_blackbox)
* Видео [Просто о настройке ПИДов](https://www.youtube.com/watch?v=UWUdBU8_QYU)
Я себя не чувствую готовым к подобной настройке, поэтому я оставил значения по умолчанию, благо Betaflight позволяет неплохо летать и с ними. Но два изменения я всё же сделал:
* Выбрал Float в разделе «PID Math». Это приемник режима LuxFloat из Cleanflight и устанавливать его рекомендуется только для ПК с процессорами F3 или F4.
* Выбрал MEASUREMENT в разделе «Derivative method». Если коротко, то MEASUREMENT предпочтительнее для фристайла, а ERROR — для гонок.
##### Вкладка Modes
Повесил на переключатели арминг моторов и Blackbox (AUX1), активацию полётного режима Horizon (AUX2) и включение пищалки (AUX3).
Отдельно хочется сказать про AIRMODE. Изначально он был уникальной «фишкой» Betaflight, но в какой-то момент стал так популярен, что Boris B поделился им с авторами Cleanflight и сейчас данный режим доступен и там тоже.
Несмотря на то, что AIRMODE отображается как отдельный режим полёта — это скорее дополнительная опция, а не полноценный режим. Он позволяет квадрокоптеру удерживать заданный угол даже при минимальном газе. Именно поэтому не рекомендуется использовать AIRMODE вместе с режимами со стабилизацией. Кроме того, приземление с AIRMODE тоже процесс непростой: квадрокоптер начинает прыгать, как лягушка. Опытные пилоты предпочитают просто «ронять» квадрокоптер, выключая моторы в паре десятков сантиметров над землёй. Кстати, если у вас включена остановка моторов при нулевом газе (опция MOTOR\_STOP во вкладке Configuration) и одновременно с этим работает AIRMODE, то остановки моторов не будет, так как AIRMODE имеет более высокий приоритет.
В Betaflight версии 2.8.1 появилась новая возможность: можно включить AIRMODE в фоновом режиме (что-то вроде пассивного перка в играх) и тогда он активен всегда и не будет отображаться во вкладке Modes, либо, как и ранее, повесить его включение на какой-либо канал. Делается это в «Other Features» вкладки Configuration.
У себя я не стал включать AIRMODE в фоновом режиме, так как использую ещё режим со стабилизацией HORIZON. Таким образом, у меня на AUX1 два полётных режима: HORIZON (для полётов со стабилизацией и посадки) и ACRO + AIRMODE.

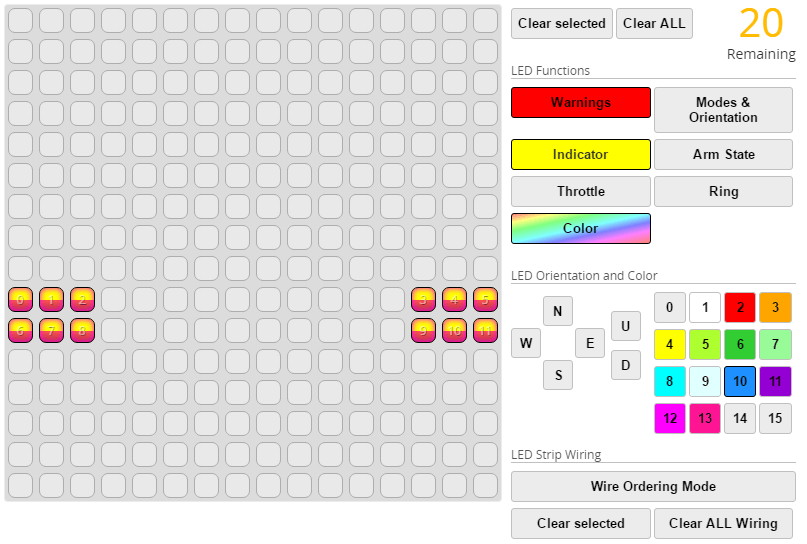
##### Вкладка LED Strip
Настроил свою подсветку на отображение предупреждений, индикацию поворотов/торможения и свечение синим цветом, когда ничего из этого нет.
##### Вкладка Blackbox
Blackbox — это «чёрный ящик» квадрокоптера. Нужен для диагностики, более точной настройки PID, а также чтобы можно было наложить инфографику на полётное видео (как [тут](https://www.youtube.com/watch?v=zQtE0nrz2Sk)). Данные пишутся на внешний логгер или, если того позволяет объём памяти, на внутреннюю память ПК. Например, у Naze32 Acro её недостаточно, а у Naze32 Deluxe и SPRacingF3 Acro — хватает, хотя и не намного. При настройках по умолчанию, на 2Мб памяти можно записать данные полёта продолжительностью 3-4 минуты, что весьма мало. Усугубляет ситуацию то, что реализовать запись «по кругу», как в автомобильных регистраторах, здесь невозможно из-за низкой скорости чтения/записи памяти. Единственный вариант — уменьшить в несколько раз скорость записи. Для диагностики такие данные уже будут малопригодны, а для видео — самое то. В этой вкладке я сделал следующее:
* Выбрал запись на внутреннюю память (опция «On-board dataflash chip») в разделе «Blackbox logging device».
* В разделе «Portion of flight loop iterations to log» выбрал 50%, что по сути уменьшает скорость записи вдвое.

Как я уже писал выше, логгирование запускается тем же тумблером на аппаратуре, что и арминг, чтобы запись начиналась при старте моторов. Подробнее о работе и настройках Blackbox можно почитать в [мануале](https://github.com/cleanflight/cleanflight/blob/master/docs/Blackbox.md). Также несколько полезных ссылок по теме:
* Статья [Setup Blackbox in Cleanflight](http://blog.oscarliang.net/setup-blackbox-cleanflight/)
* Перевод статьи [«Накладываем данные Blackbox на видео»](https://blog.rcdetails.info/2015/12/nakladyvaem-dannye-blackbox-stiki-upravleniya-na-video-s-hd-kamery/)
* Перевод статьи [«Основы настройки ПИД контроллера с помощью логов Blackbox „](https://blog.rcdetails.info/2015/11/osnovy-nastrojki-pid-kontrollera-s-pomoshhyu-logov-blackbox-perevod/)
* [Видео](https://www.youtube.com/watch?v=NejR-fEYQrg) по настройке и использованию Blackbox
* Приложение [Blackbox Explorer](https://chrome.google.com/webstore/detail/cleanflight-blackbox-expl/cahpidddaimdojnddnahjpnefajpheep?hl=en) для просмотра логов
* Приложение [Blackbox tools](https://github.com/cleanflight/blackbox-tools) для работы с данными. Например, можно рендерить в png
##### Вкладка CLI
CLI — это консоль, через которую можно менять уже более продвинутые настройки, а также делать резервную копию всех настроек. Я сделал следующее:
`set small_angle = 180 # Включить возможность армить моторы даже в перевёрнутом состоянии
set vbat_pid_compensation = ON # Включить компенсацию PID при разрядке батареи
save # Сохранить настройки`
Также в Betaflight есть очень полезная возможность подключения к OSD через ПК. Теперь можно запрятать эту платку подальше, не беспокоясь, что к ней может понадобиться подключиться. Для подключения к плате OSD через ПК необходимо подключить батарею к квадрокоптеру, затем набрать в CLI команду [*serialpassthrough*](https://github.com/betaflight/betaflight/wiki/Betaflight-specific-CLI-commands) с необходимыми параметрами, затем отключить (Disconnect) Betaflight от ПК и запустить MWOSD. У меня получилось с первого раза. По поводу параметров, то для Micro MinimOSD, подключенной к UART2 (мой случай) они таковы:
`serialpassthrough 1 115200`
На этом настройка полётного контроллера закончена.
#### Настройка передатчика
Передатчик (он же “пульт») каждый пилот настраивает индивидуально: таймеры, миксы, голосовые уведомления и прочее. Единственная вещь, сделать которую крайне желательно, это проверить минимальные, средние и максимальные значения стиков управления в конфигураторе. Делается это во вкладке Reciever. Идеальные значения составляют 1000 — 1500 — 2000. В моём случае они составляли 996 — 1508 — 2020, что не очень хорошо. Во-первых, «выпадения» за пределы диапазона (значения менее 1000 и более 2000) плохи сами по себе. Во-вторых, центральное положение, отличное от 1500, будет восприниматься ПК, как лёгкое подруливание, которое он будет отрабатывать и квадрокоптер постоянно будет сносить в какую-то сторону. Словом, имеет смысл повозиться и настроить «как надо».
Как настроить эти значения на передатчике Taranis, показано [здесь](https://www.youtube.com/watch?v=eTr1d2iMitI). У меня Turnigy 9XR PRO, там это делается в пункте Limits. Также можно выполнить настройку через программу eePskye (вкладка Limits), но это неудобно, так как результат сразу не видно в Betaflight Configurator. Сделать это необходимо для каждого из четырёх каналов управления.
После настройки центральные значения максимально приблизились к 1500, но у меня они начали «прыгать» примерно на 5 единиц в одну или другую сторону. Не знаю, с чем это связано, вероятно, значения пульта являются пограничными для ПК и после их округления получается такой эффект. Для решения этой проблемы в Betaflight (и CleanFlight тоже) есть специальная команда, настраивающая фильтрацию подобных вещей.
`set deadband = 6`
Значение может быть от 0 до 32 и с его повышением чувствительность управления снижается. Управление становится более мягким. Надо понимать, что после определённого порога мягкость превратится в ватность, поэтому для себя я выбирал минимальное значение, при котором дёрганья исчезли.
На этом всё, удачных полётов! | https://habr.com/ru/post/395487/ | null | ru | null |
# Ветвление на GPU: так ли всё страшно?

Если вы читали в Интернете о ветвлении в GPU, то можете думать, что оно открывает врата Ада и впускает в этот мир демонов. В статьях говорится, что его нужно не допускать любой ценой, и что его можно избегать при помощи тернарного оператора, step() и других глупых математических трюков. Большинство таких советов в лучшем случае является устаревшим, а то и откровенно ошибочным.
Давайте исправим ситуацию.
Виды ветвления
==============
При реализации ветвления в GPU нужно учитывать множество аспектов.
Первый — это тип данных, с которым выполняется ветвление. Допустим, если это данные из буфера констант, то ветвление будет очень малозатратным, ведь компилятор знает, что ветвление будет проходить один и тот же путь для каждого пикселя или вершины, потому что состояние буфера констант гарантированно остаётся постоянным для каждого обрабатываемого параллельно пикселя или вершины.
Однако если данные динамические, допустим, значение из текстуры, тогда каждый обрабатываемый параллельно пиксель должен обработать это ветвление. На этом этапе у компилятора есть выбор — он может решить, что код по каждому из путей достаточно короток и просто выполнить обе ветви и выбрать подходящий результат, или решить, что нужна правильная ветвь. Однако когда пиксели начинают так расходиться, для этих пикселей могут поломаться другие оптимизации. В общем случае следует избегать ветвления для шумных сигналов, изменяющих каждый пиксель.
Второй аспект — это тип кода в каждой из ветвей. Если вы собираетесь сэмплировать текстуры внутри ветви, то нужно будет использовать сэмплеры градиента или LOD. По сути, вам нужно писать код следующим образом:
```
float2 dx = ddx(uv);
float2 dy = ddy(uv);
UNITY_BRANCH // this is a Unity macro that forces a branch
if (_SomeConstant > 1)
{
o.Albedo += SAMPLE_TEXTURE2D_GRAD(_Albedo, sampler_Albedo, uv, dx, dy);
}
else
{
o.Albedo += SAMPLE_TEXTURE2D_GRAD(_Albedo2, sampler_Albedo2, uv, dx, dy);
}
```
*Обратите внимание на макрос UNITY\_BRANCH — он компилируется в специфичную команду API, вынуждающую GPU (которые её поддерживают) выполнить реальное ветвление, а не, допустим, сэмплировать обе текстуры и выбрать нужный результат.*
Зачем это нужно? Чтобы сохранить выполняемую GPU оптимизацию четырёхугольников 2x2. Если этого не сделать, то на большинстве платформ мы получим ошибку компиляции, на других он выполнит обе части, а на третьих это поломает оптимизацию четырёхугольников 2x2 и код будет выполняться во много раз медленнее. Получив используемые для сэмплирования текстур производные до ветвления и передавая их, мы предотвращаем потенциальное расхождение этих пикселей.
В-третьих, нам нужно учесть, как будет вычисляться ветвление. Вплоть до самой последней версии HLSL, которая пока недоступна в Unity, в следующем коде, в отличие от ситуации на ЦП, если \_Constant равна 0, то функция SomeFunc() всё равно будет вызываться и вычисляться.
```
if (_Constant > 1 && SomeFunc() > 1)
{
}
```
Шаблон для работы с ветвлением
==============================
Во всех моих шейдерах из asset store вы найдёте такой код:
```
#if _BRANCHSAMPLES
#if _DEBUG_BRANCHCOUNT_TOTAL
float _branchWeightCount;
#define MSBRANCH(w) if (w > 0) _branchWeightCount++; if (w > 0)
#else
#define MSBRANCH(w) UNITY_BRANCH if (w > 0)
#endif
#else
#if _DEBUG_BRANCHCOUNT_TOTAL
float _branchWeightCount;
#define MSBRANCH(w) if (w > 0) _branchWeightCount++;
#else
#define MSBRANCH(w)
#endif
#endif
```
Этот код с лёгкостью позволяет нам подсчитать, какое количество ветвлений выполняется для конкретного пикселя, и переключать используемые ветвления if; также он имеет режим просмотра, отображающий количество ветвлений для каждого пикселя. Основная задача этой функциональности заключается в возможности визуализации частоты ветвлений, выполняемых на потенциально расходящихся путях. Я часто буду создавать её и для отдельных фич (трипланарное, стохастическое ветвление, и т. п.).
Ещё один набор макросов позволяет нам подсчитать истинное количество сэмплов текстур в каждом пикселей, чтобы мы могли легко визуализировать сэмплы:
```
#if _DEBUG_SAMPLECOUNT
int _sampleCount;
#define COUNTSAMPLE { _sampleCount++; }
#else
#define COUNTSAMPLE
#endif
```
Используется он таким образом:
```
half4 a0 = half4(0,0,0,0);
half4 a1 = half4(0,0,0,0);
half4 a2 = half4(0,0,0,0);
MSBRANCH(tc.pN0.x)
{
a0 = MICROSPLAT_SAMPLE_DIFFUSE(tc.uv0[0], config.cluster0, d0);
COUNTSAMPLE
}
MSBRANCH(tc.pN0.y)
{
a1 = MICROSPLAT_SAMPLE_DIFFUSE(tc.uv0[1], config.cluster0, d1);
COUNTSAMPLE
}
MSBRANCH(tc.pN0.z)
{
a2 = MICROSPLAT_SAMPLE_DIFFUSE(tc.uv0[2], config.cluster0, d2);
COUNTSAMPLE
}
```
Для вывода данных на экран мы можем сделать так:
```
#if _DEBUG_BRANCHCOUNT
o.Albedo = (float)_branchWeightCount / 12.0f;
#endif
```

*Визуализация трипланарного ветвления в MicroSplat. Чем светлее области, тем больше ветвлений.*
Для визуализации сэмплов я добавил пороговое свойство, которое может задавать пользователь — количество сэмплов выше порогового значения отрисовываются жёлтым, а всё, что ниже отрисовывается в оттенках красного:
```
#if _DEBUG_SAMPLECOUNT
float sdisp = (float)_sampleCount / max(_SampleCountDiv, 1);
half3 sdcolor = float3(sdisp, sdisp > 1 ? 1 : 0, 0);
o.Albedo = sdcolor;
#endif
```

*Визуализация того же количества в MicroSplat. Области красного создают меньше 9 сэмплов, а жёлтые — от 9 сэмплов и больше. Если ветвление отключено, шейдер получает 28 сэмплов на пиксель, поэтому в этом простом случае мы при помощи ветвления экономим 2/3 затрат на сэмплирование.*
Ещё один пример, на этот раз с трипланарными, стохастическими кластерами текстур, включено ветвление весов рельефа. Обратите внимание, что сначала система выполняет усечение по весу текстуры, трипланарные и стохастические проверки тоже усекаются.

*Готовый рендер*

*Визуализация ветвлений. Обратите внимание. что частота ветвления намного выше и создаёт больше расходящихся пикселей, но области всё равно достаточно велики, чтобы в конечном итоге обеспечивать выигрыш.*

*Визуализация количества сэмплов. Без ветвлений шейдер получает 100 сэмплов на пиксель. Со включенными ветвлениями в областях красного цвета меньше 34 сэмплов на пиксель, а в жёлтых областях их от 34 и больше. Количество сэмплов на пиксель находится в интервале от 9 до 72.*
Благодаря таким методикам можно чётко визуализировать то, что делает GPU, и усекать значительную часть объёма передаваемой информации в сложном шейдере. Кроме того, можно легко включать и отключать ветвление в различных фичах или просматривать их данные по отдельности, чтобы убедиться, что оптимизации на самом деле оптимизируют выполнение.
Подведём итог
=============
* Не бойтесь ветвления в GPU, в большинстве случаев оно совершенно приемлемо
* Знайте, что выбирается при ветвлении, а что обходится
* Избегайте ветвлений с высокочастотными данными и создания расходящихся пикселей
* С особым вниманием следует относиться к ветвлениям с обходом текстур
* Визуализируйте данные, чтобы чётко видеть, что делает GPU
* По возможности выстраивайте ветвление в порядке от ветвей с наиболее вероятным усечением до ветвей с наименее вероятным усечением. | https://habr.com/ru/post/599593/ | null | ru | null |
# Ядро .Net (GC, JIT, interop, ...) в Open Source
[](https://github.com/dotnet/coreclr)Мы рады сообщить что [CoreCLR](https://github.com/dotnet/coreclr) теперь находится на github и теперь вы имеете доступ ко всем его исходным кодам. CoreCLR является средой исполнения .NET Core, выполняя такие функции как сборку мусора или компиляции в конечный машинный код. .Net Core – это модульная реализация .Net, которая может быть использована как база для огромного количества сценариев, масштабы которых варьируются от простых консольных утилит до веб-приложений, хостящихся в облаке. Чтобы понять, чем отличается .Net Core от .Net Framework, посмотрите на пост [«Введение в .Net Core»](http://blogs.msdn.com/b/dotnet/archive/2014/12/04/introducing-net-core.aspx)
Теперь вы можете скачивать исходники CoreCLR, бранчеваться, и делать pull requests, также вы можете компилировать его прямо на своем ПК. Мы выпустили полную и актуальную реализацию CoreCLR, которая включает RyuJIT, .Net GC, родной Interop и множество других компонент .Net runtime. Данный релиз следует тем же принципам, что и все наши последние релизы библиотек, вышедших в open-source: сделать весь .Net Framework open sourced.
Сегодня ядро .Net компилируется и отрабатывает (видимо имеется в виду CI) на Windows. Мы добавим имплементации для специфических для Mac и Linux платформенных вещей в ближайшие пару месяцев. Также мы уже имеем некоторый специфический для Linux код в .Net Core, однако мы только начали портировать с Windows на остальные платформы. Напротив, мы хотели открыть исходные тескты с самого начала, чтобы вы вместе с нами пропутешествовали бы к другим платформам, возможно, внося свой вклад.
Посмотрим, что же внутри репозитория
====================================
Репозиторий CoreCLR по своей структуре очень похож на репозитория CoreFX, в котором многие из вас в течении последних месяцев успели поработать.Мы будем продолжать развивать оба репозитория одновременно, чтобы вы по итогу чувствовали себя естественно, находясь в поистине огромной кодовой базе.
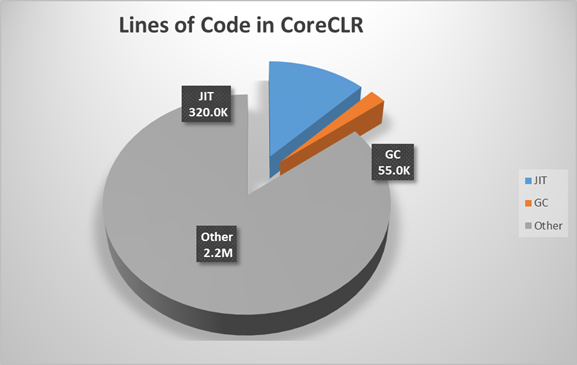
С точки зрения размера, репозиторий CoreCLR состоит из примерно 2,6 миллионов строк кода. Причем в рамках этих расчетов GC занимает около 55 тысяч, а сам JIT — около 320 тысяч строк. Также мы недавно поделились с вами, что CoreFX занимает 500 тысяч строк кода, что составляет около 25% от его предполагаемого итогового размера. И, страшно сказать, но когда все будет готово, мы будем иметь около 5 миллионов строк кода.на GitHub
Одним из ключевых различий между репозиториями является то, что CoreFX написан на C#, тогда как CoreCLR содержит огромное количества кода как C#, так и C++. Также репозиторий CoreCLR требует огромного количества тулов для построения кода, часть из которых не идет в поставку с Visual Studio. Мы оставили зависимость на CMake, opensource и кросс-платформенную систему построения проектов. Поскольку нам была необходима система сборки, которая прекрасно бы себя чувствовала и на Windiws, и на Mac, и на Linux, мы посмотрели на различные варианты и как итог, выбрали CMake.
Вы можете узнать, как собирать CoreCLR из [CoreCLR Developer Guide](https://github.com/dotnet/coreclr/wiki/Developer-Guide). Команда будет постоянно обновлять его, особенно когда Linux и Mac станут реальностью.
Мы также очень надеемся, что сообщество внесет свою лепту в развитие проекта путем создания pull requests (от переводчика: CoreFX имеет огромное количество контрибьюторов, которые постоянно пишут код для CoreFX). .Net Core из-за своего размера работает на огромном количестве сценариев, и потому очень важно иметь большое количество тестов чтобы покрыть максимальное их количество.
Разговор с командой
===================
По ссылке ниже вы можете посмотреть диалог с командой про текущий релиз:
[](http://channel9.msdn.com/Blogs/dotnet/CoreCLR-is-now-open-source-on-GitHub)
Сборка приложений с .Net Core
=============================
Это очень здорово — видеть реализации .Net CoreFX и CoreCLR — в open source. И вы будете удивлены, какие типы приложений можно будет с ним построить. Есть два типа приложений, которые можно построить на текущий момент:
* ASP.NET 5 Web-приложения и сервисы
* Консольные приложения
Мы говорили про ASP.NET 5 приложения около года и теперь вы можете построить их используя как .Net Framework, так и CoreCLR/CoreFX. **ASP.NET 5 использует [mono runtime](http://www.mono-project.com/) и может работать как на Mac, так и на Linux**. Как только .Net Core станет поддерживать эти системы, вы сможете использовать его на этих платформах. Вы можете узнать больше, как работать с ASP.NET 5 из [блога команды ASP.NET](http://blogs.msdn.com/b/webdev/archive/tags/asp-net+5/) или на веб сайте [asp.net](http://asp.net). Также, если хотите попробовать ASP.NET 5 в деле прямо сейчас, то скачайте Preview версию MS Visual Studio 2015.
Мы хотим сделать возможным построение CoreFX и CoreCLR репозиториев и использовать результаты в приложениях ASP.NET 5, но пока это не является возможным по нескольким техническим причинам, однако мы работаем над этим. Конечная цель очень комплексная: мы должны иметь возможность сочетать изменений сообщества (forks) и наши собственные изменения и получать в итоге базовый стек для ваших приложений.
Консольный тип приложений позволяет понять что такое CoreCLR. Также он предоставляет очень гибкую базу для построения абсолютно любого приложения, какое бы вы ни захотели. Наибольший процент инфраструктуры. которую мы используем для тестирования использует именно этот тип приложения. Также вы можете построить свой собственный CoreCLR и запускать приложения поверх него.
.Net Core Console Apps
======================
На данный момент консольный тип приложений для .Net Core является побочным продуктом нашего технологического процесса. И в течении нескольких последующих месяцев мы будем формировать его как полностью готовый тип приложений, включая шаблоны кода в Visual Studio и отладчик (т.е. его нет, похоже, *— прим. перев.*). Также мы будем поддерживать OmniSharp для консольных приложений (кто не знает — Sublime text 3 based IDE для .NET). Так что, скоро у вас будет полноценная возможность сборки кросс-платформенных приложений, которые будут запускаться с одного исполняемого файла.
Ниже представлена первая демка консольного приложения, запущенного под CoreCLR.

Console App Walkthrough
=======================
Самый простой способ построить CoreCLR приложение — создать консольное приложение. Вы можете получить его из нашего нового corefxlab репозитория. Для того, чтобы использовать его, вы можете просто клонировать, скомпилировать и запустить с помощью командной строки:
```
cd .\corefxlab\demos\CoreClrConsoleApplications\HelloWorld
nuget restore
msbuild
.\bin\Debug\HelloWorld.exe
```
Конечно же, поскольку вы склонировали репозиторий, также вы можете открыть файл \*.sln в вашей копии Visual Studio. Прошу заметить что отладка пока не возможна… *Но ведь она только для тех, кто делает ошибки, так?*
Также вы можете модифицировать CoreCLR и запустить консольное приложение, которое будет использовать новый рантайм, который вы сами только что сделали, внеся изменения в ядро. На данный момент автоматизированной сборки не на самом высоком уровне, потому для того чтобы самостоятельно собрать ядро, на данный момент необходимо проделать следующие шаги:
1. Модифицируйте CoreCLR так, как этого велит ваше сердце
2. Постройте CoreCLR при помощи build.cmd x64 release
3. Скопируйте фалы из coreclr\binaries\x64\release в corfxlab\demos\CoreClrConsoleApplications\HelloWorld\NotYetPackages\CoreCLR:
1. coreclr.dll
2. CoreConsole.exe
3. mscorlib.dll
4. Перекомпилируйте HelloWorld.sln
Итого
=====
Мы готовились сделать CoreCLR открытым в течении нескольких месяцев, одновременно разрабатывая множество новых функций. Теперь у вас есть возможность наблюдать за ежедневной работой нашей команды коммит за коммитом (совершенно также, как и в CoreFX). Не стесняйтесь забрать себе репозиторий и наблюдать за этими изменениями. С нашей стороны мы будем наблюдать за списком Issues и PR чтобы иметь возможность следить за вашими пожеланиями.
Если вы взволнованы и настроены пообщаться с кем-либо, заходите на форумы .Net Foundation. Здесь вы найдете несколько веток, на которых вы можете узнать про CoreCLR получше. Также за ветками следят члены нашей команды, которые готовы отвечать на любые ваши вопросы.
У нас есть много чего, что надо сделать и следующая остановка — это [.Net Conf](http://www.dotnetconf.net/) — виртуальная конференция по .Net, которая намечена на март 2015 года и там мы надеемся показать вам хорошее демо | https://habr.com/ru/post/249645/ | null | ru | null |
# Анализ данных погодной станции, основанной на Arduino
Создание собственной личной метеостанции стало намного проще, чем раньше. С учетом непостоянной погоды в Новой Англии, мы решили, что хотим создать нашу собственную метеостанцию и использовать MATLAB для анализа метеоданных.
В статье мы ответим на следующие вопросы:
* В каком направлении дул ветер в течение последних 3-х часов?
* Как изменялись температура и точка росы в течение последней недели?
* На самом ли деле падает барометрическое давление при приближении грозы?
Понятно, что рассмотренные вопросы достаточно просты, но описанные приемы и команды помогут вам решать более сложные практические задачи.
Шаг 1: Размещение метеостанции
------------------------------
Во-первых, мы должны были решить, где разместить нашу метеостанцию. Мы решили сделать это на верхнем этаже автостоянки. Место было выбрано, поскольку оно было под воздействием погодных явлений, но также и имело крышу для монтажа электроники. Из-за того, что мы в конечном счете хотели отдавать данные стороннему агрегатору данных, мы должны были учитывать это при выборе места и железа.

Шаг 2: Выбор аппаратного обеспечения
------------------------------------
Выбранное расположение было вне радиуса действия Wi-Fi нашего здания, поэтому мы должны были найти способ передачи данных от станции к приемнику, который находился внутри соседнего здания.Чтобы сделать это, мы подсоединили Arduino Uno к передатчику высокой мощности XBee. Затем данные передаются в принимающий модуль XBee на Arduino Mega уже внутри здания. Этот Arduino был подключен к Интернету и данные отправляются в бесплатный сервис агрегации данных, [ThingSpeak.com](https://thingspeak.com/). Полный список аппаратуры, которую мы использовали в нашей установке приведен ниже.
Список оборудования
-------------------
* [Arduino Uno](https://www.sparkfun.com/products/11021) с [Weather shield](https://www.sparkfun.com/products/12081) и [датчиками погоды](https://www.sparkfun.com/products/8942)
* 2x [XBee Shield](https://www.sparkfun.com/products/10854) и 2x [модулей XBee с расширенным диапазоном](http://www.digi.com/products/wireless-wired-embedded-solutions/zigbee-rf-modules/point-multipoint-rfmodules/xbee-series1-module#overview) от Digi International
* [Arduino Mega](https://www.sparkfun.com/products/11061) с [Ethernet Shield](https://www.sparkfun.com/products/9026)
* 2 комплекта для монтажа [Arduino](https://www.sparkfun.com/products/11417)
* 2x 5В трансформатор для питания Arduino
* [XBee Explorer Dongle](https://www.sparkfun.com/products/9819) для программирования передатчика XBee

Шаг 3: Подключение передатчика метеостанции и программирование наружной Arduino
-------------------------------------------------------------------------------
Внешнее Arduino установлено на гараже и отвечает за сбор измерений и передачу данных на Arduino в помещении. Для реализации такого обмена, сначала мы соединили контакты от Weather shield и XBee shield. Затем мы соединили XBee shield с Arduino Uno в соответствии с документацией, предоставленной с шилдами. В XBee shield есть XBee трансивер высокой мощности. Мы использовали программное обеспечение [X-CTU](http://www.digi.com/support/kbase/kbaseresultdetl?id=2125) для программирования нужного адреса получателя и загрузки нужной прошивки в XBee shield. Анемометр, датчики ветра дождя были подключены к weather shield с помощью разъемов RJ-45, входящими в комплект поставки.
Шаг 4: Подключение приемника погодной станции и программирование Arduino, находящегося в помещении
--------------------------------------------------------------------------------------------------
Внутреннее Arduino находится внутри нашего здания, и отвечает за получение данных от наружного Arduino, за проверку достоверности данных, и их отправку на ThingSpeak.Чтобы построить такую систему, сначала мы припаяли контакты на Ethernet shield и второй XBee shield.Затем мы вставили Ethernet shield и XBee shield в Мега Arduino в соответствии с документацией. Мы вновь использовали [X-CTU](http://www.digi.com/support/kbase/kbaseresultdetl?id=2125) для программирования необходимого адреса получателя и загрузки нужной прошивку на XBee shield.
Далее, мы запрограммировали Arduino получить XBee сообщения и пересылать пакеты на ThingSpeak со скоростью один раз в минуту. Перед отправкой сообщения ThingSpeak, мы настроили учетную запись и сконфигурировали информацию о канале и расположении. Как только закончилась настройка передачи данных, мы начали анализировать данные в MATLAB.
*Обратите внимание, что для воспроизведения анализа, приведенного в статье, вам не нужно покупать и настраивать оборудование.Текущие данные нашей станции доступны на [канале 12 397](https://thingspeak.com/channels/12397).*
Шаг 5: Отвечаем на вопросы
--------------------------
Получение данных о погоде из ThingSpeak
---------------------------------------
Чтобы ответить на наши первые два вопроса, мы используем команду
[```
thingSpeakFetch
```](http://www.mathworks.com/matlabcentral/fileexchange/46714-thingspeak-support-from-matlab) для просмотра доступных полей данных, одновременного импорта всех полей в MATLAB и хранения данных о температуре, влажности, скорости ветра, и направления ветра в своих переменных. Документация о [поддержке ThingSpeak](http://www.mathworks.com/thingspeak).
```
[d,t,ci] = thingSpeakFetch(12397,'NumPoints',8000); % fetch last 8000 minutes of data
```
8000 точек — это максимальное количество точек, которое ThingSpeak позволяет запросить за раз. Для нашей частоты измерений, это соответствует примерно 6 дням измерений.
```
tempF = d(:,4); % field 4 is temperature in deg F
baro = d(:,6); % pressure in inches Hg
humidity = d(:,3); % field 3 is relative humidity in percent
windDir = d(:,1);
windSpeed = d(:,2);
tempC = (5/9)*(tempF-32); % convert to Celsius
availableFields = ci.FieldDescriptions'
```
```
availableFields =
'Wind Direction (North = 0 degrees)'
'Wind Speed (mph)'
'% Humidity'
'Temperature (F)'
'Rain (Inches/minute)'
'Pressure ("Hg)'
'Power Level (V)'
'Light Intensity'
```
Вычисление некоторых основных статистических данных за период наблюдений и их визуализация
------------------------------------------------------------------------------------------
Чтобы получить лучшее понимание наших данных, мы находим минимальное, максимальное и среднее значения для данных, которые мы импортировали и мы находим время, для максимальных и минимальных значений.Это дает нам быстрый путь к валидации данных с нашей метеостанции.
```
[maxData,index_max] = max(d);
maxData = maxData';
times_max = datestr(t(index_max));
times_max = cellstr(times_max);
[minData,index_min] = min(d);
minData = minData';
times_min = datestr(t(index_min));
times_min = cellstr(times_min);
meanData = mean(d);
meanData = meanData'; % make column vector
summary = table(availableFields,maxData,times_max,meanData,minData,times_min) % display
```
```
summary =
availableFields maxData times_max
____________________________________ _______ ______________________
'Wind Direction (North = 0 degrees)' 338 '10-Jul-2014 05:01:32'
'Wind Speed (mph)' 6.3 '10-Jul-2014 12:47:14'
'% Humidity' 86.5 '15-Jul-2014 04:51:24'
'Temperature (F)' 96.7 '12-Jul-2014 16:28:55'
'Rain (Inches/minute)' 0.04 '15-Jul-2014 13:47:13'
'Pressure ("Hg)' 30.23 '11-Jul-2014 09:25:07'
'Power Level (V)' 4.44 '10-Jul-2014 10:25:01'
'Light Intensity' 0.06 '12-Jul-2014 13:23:38'
meanData minData times_min
_________ _______ ______________________
NaN 0 '10-Jul-2014 04:54:32'
3.0272 0 '10-Jul-2014 01:33:14'
57.386 25.9 '12-Jul-2014 13:39:39'
80.339 69.6 '11-Jul-2014 06:59:54'
5.625e-05 0 '10-Jul-2014 01:02:11'
30.04 29.78 '15-Jul-2014 13:04:08'
4.4149 4.38 '11-Jul-2014 09:22:06'
0.0092475 0 '10-Jul-2014 01:02:11'
```
Если мы получаем неожиданные значения, такие как максимальное атмосферное давление 40 атмосфер или максимальную температуру 1700 градусов, мы можем предположить, что данные некорректны. Такие ошибки могут происходить из-за ошибок передачи, выбросов напряжения и других причин. В конце статьи мы покажем некоторые способы обработки таких «выбросов», но для выгруженных данных, когда этот отчет был опубликован, все выглядит в порядке.
Для приведенного выше кода, мы использовали табличный тип данных, впервые введенный в MATLAB R2013b.См запись в [блоге](http://blogs.mathworks.com/loren/2013/09/10/introduction-to-the-new-matlab-data-types-in-r2013b/) для дальнейшего ознакомления с этим типом данных.
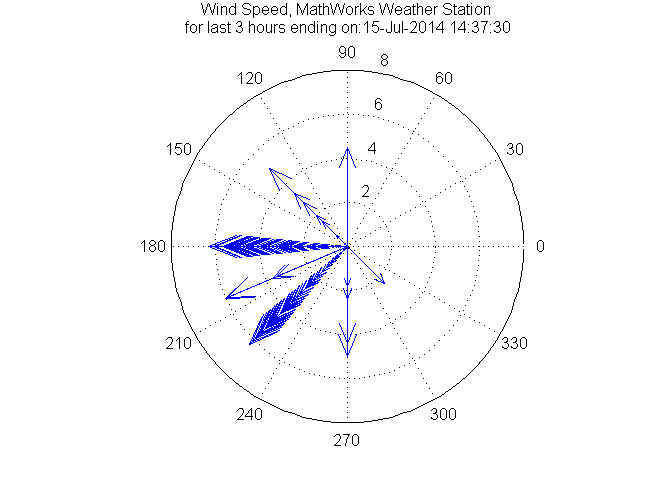
Визуализация ветра за последние три часа
----------------------------------------
Так как наша погодная станция получает метеорологические сводки примерно раз в минуту, мы смотрим на последние 180 минут, что бы ответить на наш вопрос о том, какой ветер был в последние 3 часа, и мы используем Compass plot в MATLAB, чтобы увидеть скорость и направление ветра в интересующий времени. Это математический компас, где Север (0 градусов) находится справа, и значения градуса увеличиваются против часовой стрелки. 90 градусов представляет Восток (вверху), 180 градусов представляет юг (слева) и 270 градусов представляет Запад (внизу). Если не произошло сдвига ветра из-за грозы или при лобовом проходе, компас, как правило, показывает преимущественное направление ветра, обозначенное стрелками более высокой плотности на графике. В случае данных, запрошенных в этом примере мы наблюдаем направление ветра преимущественно с юга и юго-запада, типичное для летнего времени в Новой Англии.
```
figure(1)
windDir = windDir((end-180):end); % last 3 hours
windSpeed = windSpeed((end-180):end);
rad = windDir*2*pi/360;
u = cos(rad) .* windSpeed; % x coordinate of wind speed on circular plot
v = sin(rad) .* windSpeed; % y coordinate of wind speed on circular plot
compass(u,v)
titletext = strcat(' for last 3 hours ending on: ',datestr(now));
title({'Wind Speed, MathWorks Weather Station'; titletext})
```
Расчет точки росы
-----------------
Теперь мы готовы ответить на наш второй вопрос о том, как температура и точка росы менялись в течении
прошлой недели.Точка росы — это температура, при которой воздух (при охлаждении) становится насыщенным водяным паром. Чем более влажность воздушной массы, тем выше точка росы. Точка росы также иногда используется как мера дискомфорта. Когда точка росы превышает 65 градусов (+18С), многие люди начинают говорить, что воздух «липкий». При точке росы за 70 многие чувствуют себя некомфортно. Общая оценка для точки росы, TDP, может быть найдена с помощью уравнения и постоянных, как показано ниже:
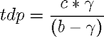
где
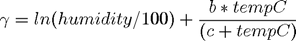
с 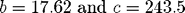
Теперь, написав приведенные выше уравнения, как код MATLAB мы имеем:
```
b = 17.62;
c = 243.5;
gamma = log(humidity/100) + b*tempC ./ (c+tempC);
tdp = c*gamma ./ (b-gamma);
tdpf = (tdp*1.8) + 32; % convert back to Fahrenheit
```
Визуализация температуры, влажности воздуха и точки росы в зависимости от времени
---------------------------------------------------------------------------------
Теперь, когда мы рассчитали точку росы, мы готовы визуализировать данные и наблюдать их поведение в течение последних 5 или 6 дней.
```
figure(2)
[ax, h1, h2] = plotyy(t,[tempF tdpf],t,humidity);
set(ax(2),'XTick',[])
set(ax(2),'YColor','k')
set(ax(1),'YTick',[0,20,40,60,80,100])
set(ax(2),'YTick',[0,20,40,60,80,100])
datetick(ax(1),'x','keeplimits','keepticks')
set(get(ax(2),'YLabel'),'String',availableFields(3))
set(get(ax(1),'YLabel'),'String',availableFields(4))
grid on
legend('Location','South','Temperature','Dew point', 'Humidity')
```
Во время обычной недели, вы можете ясно видеть суточные изменения температуры и влажности. Как и ожидалось относительная влажность, как правило, возрастает ночью (при понижении температуры к точке росы) и максимальные температуры, как правило, достигаются во второй половине дня.Температура точки росы указывает влажность воздушных масс. Когда мы собрали данные для публикации этого примера, вы можете видеть, что точка росы была более 70 градусов, что является типичной для жаркого и влажного летнего дня в Новой Англии.Если вы запустите этот код в MATLAB, вы можете получить разные ответы, по мере того, как вы будете запрашивать самые последние данные, сообщенные метеостанцией.
Получение и обработка данных о погоде за дождливый день в Новой Англии
----------------------------------------------------------------------
Последний вопрос, на который мы хотели ответить — действительно ли атмосферное давление падает перед дождем? Чтобы сделать это, мы получили данные из метеостанции за известный дождливый день. На этот раз, мы заинтересованы в барометрическом давлении и количестве осадков. Мы использовали датчик самостоятельного опорожнения, который опорожняется, когда он заполнен. Наш датчик вращается и опорожняется, когда выпало 0,01 дюймов осадков.Наш код Arduino считает количество опорожнений за каждую минуту и передает соответствующее значение осадков в ThingSpeak. Мы используем MATLAB для выборки из наших данных почасовых образцов, чтобы мы могли легко увидеть накопление осадков и тенденции давления.
```
[d,t,ci] = thingSpeakFetch(12397,'DateRange',{'6/4/2014','6/6/2014'}); % get data
baro = d(:,6); % pressure
extraData = rem(length(baro),60); % computes excess points beyond the hour
baro(1:extraData) = []; % removes excess points so we have even number of hours
rain = d(:,5); % rainfall from sensor in inches per minute
```
Действительно ли шел ливень 5 июня? Это трудно сказать, если мы просто посмотрим на каждую минуту передачи данных, так как максимальное значение составляет всего 0,01 дюйма. Однако, если суммировать все осадки за 5 июня, мы видим, что мы получили 0,48 дюйма осадков, что составляет 13% от среднемесячного 3,68 дюйма, что показывает, что день был действительно очень дождливым. Чтобы получить более полное представление о том, когда выпал максимум осадков, мы преобразовали данные в часовые данные, как показано ниже.
```
rain(1:extraData) = [];
t(1:extraData) = [];
rainHourly = sum(reshape(rain,60,[]))'; % convert to hourly summed samples
maxRainPerMinute = max(rain)
june5rainfall = sum(rainHourly(25:end)) % 24 hours of measurements from June 5
baroHourly = downsample(baro,60); % hourly samples
timestamps = downsample(t,60); % hourly samples
```
```
maxRainPerMinute =
0.0100
june5rainfall =
0.4800
```
Визуализация данных о почасовой облачности и давления и нахождение тренда давления
----------------------------------------------------------------------------------
После того как мы предварительно обработали наши данные, мы готовы визуализировать их. Здесь мы используем MATLAB, для нахождения линии тренда к данным барометрического давления. Если построить график, увидим ли мы падение давления перед тяжелым ливнем?
```
figure(3)
subplot(2,1,1)
bar(timestamps,rainHourly) % plot rain
xlabel('Date and Time')
ylabel('Rainfall (inches /per hour)')
grid on
datetick('x','dd-mmm HH:MM','keeplimits','keepticks')
title('Rainfall on June 4 and 5')
subplot(2,1,2)
hold on
plot(timestamps,baroHourly) % plot barometer
xlabel('Date and Time')
ylabel(availableFields(6))
grid on
datetick('x','dd-mmm HH:MM','keeplimits','keepticks')
detrended_Baro = detrend(baroHourly);
baroTrend = baroHourly - detrended_Baro;
plot(timestamps,baroTrend,'r') % plot trend
hold off
legend('Barometric Pressure','Pressure Trend')
title('Barometric Pressure on June 4 and 5')
```
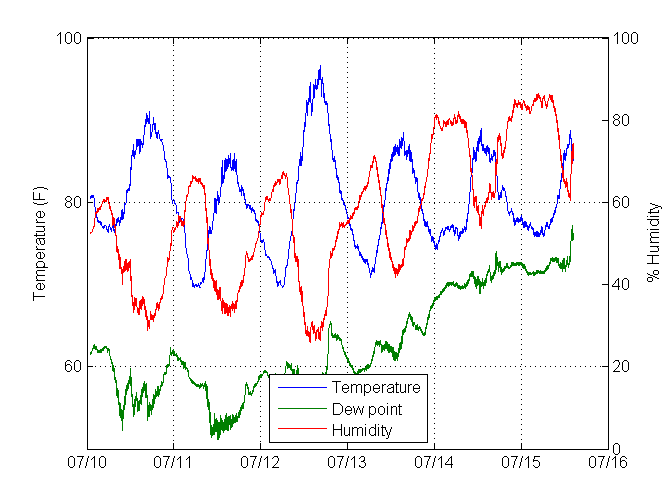
После того, как мы визуализируем эти данные и посмотрим на тренд, мы ясно видим, что атмосферное давление действительно падает ровно до начала осадков!
Очистка данных от недостоверных измерений
-----------------------------------------
Наши вопросы были довольно простыми, но иногда возникают проблемы с имеющимися данными. Например, 30 мая, мы записали несколько недостоверных данных о температуре. Давайте посмотрим, как использовать MATLAB для их фильтрации.
```
[d,t] = thingSpeakFetch(12397,'DateRange',{'5/30/2014','5/31/2014'});
rawTemperatureData = d(:,4);
newTemperatureData = rawTemperatureData;
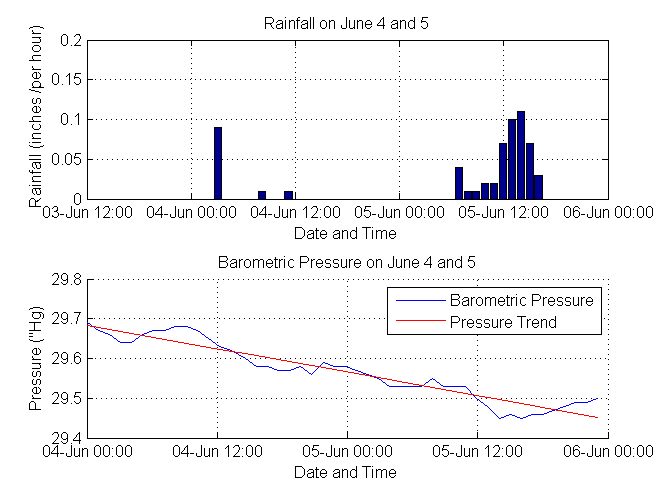
minTemp = min(rawTemperatureData) % wow that is cold!
```
```
minTemp =
-1.7662e+03
```
Использование порогового фильтра для удаления выброса данных
------------------------------------------------------------
Удаление элементов, которые не прошли пороговый тест. В этом случае, у нас есть некоторые значения, которые заведомо недостоверны, такие как значение температуры -1766 градусов по Фаренгейту. Поэтому можно использовать данные, которые включают в себя только значения температуры, между 0 и 120, которые являются приемлемыми величинами для весеннего дня в Новой Англии.
```
tnew = t';
outlierIndices = [find(rawTemperatureData < 0); find(rawTemperatureData > 120)];
tnew(outlierIndices) = [];
newTemperatureData(outlierIndices) = [];
```
Построим графики очищенных и исходных данных.
```
figure(4)
subplot(2,1,2)
plot(tnew,newTemperatureData,'-o')
datetick
xlabel('Time of Day')
ylabel(availableFields(4))
title('Filtered Data - outliers deleted')
grid on
subplot(2,1,1)
plot(t,rawTemperatureData,'-o')
datetick
xlabel('Time of Day')
ylabel(availableFields(4))
title('Original Data')
grid on
```
Использование медианного фильтра для удаления недостоверных данных
------------------------------------------------------------------
Еще один способ удаления плохих данных — применить медианный фильтр. Медианный фильтр не требует столько знаний о наборе данных. Он будет просто удаляет значения, которые оказываются вне среднего ближайших соседей. Результаты фильтрации — вектор той же длины что и исходный, в отличие от удаление точек данных, что приводит к разрывам в данных и укорачиванию записи. Этот тип фильтра также может быть использован для удаления шума из сигнала.
```
n = 5; % this value determines the number of total points used in the filter
```
Большие значения n обозначают количество «соседей» для сравнения. При температурах, собранных раз в минуту, мы выбираем n = 5, потому что температура не должна, как правило, сильно меняться в течение 5 минут.
```
f = medfilt1(rawTemperatureData,n);
figure(5)
subplot(2,1,2)
plot(t,f,'-o')
datetick
xlabel('Time of Day')
ylabel(availableFields(4))
title('Filtered Data - using median filter')
grid on
subplot(2,1,1)
plot(t,rawTemperatureData,'-o')
datetick
xlabel('Time of Day')
ylabel(availableFields(4))
title('Original Data')
grid on
```

Вывод
-----
Итак, мы проанализировали данные с нашей метеостанции и ответили на интересующие нас вопросы.
Мы также продемонстрировали некоторые способы фильтрации данных, которые не проходят первоначальную проверку.
Вопросы, поставленные в статье, элементарны, но подумайте чего можно добиться собирая данные с тысячи станций? Кроме этого можно измерять и анализировать real-time изменения промышленных и научных систем и принимать решения на основе данных.
Напоминаем, что для воспроизведения анализа, приведенного в статье, вам не нужно покупать и настраивать оборудование. Оперативные данные из нашей установки доступны на канале 12 397 на ThingSpeak.com.
[MATLAB код проекта](http://www.mathworks.com/matlabcentral/fileexchange/47049) | https://habr.com/ru/post/256413/ | null | ru | null |
# RDP (не)тонкий клиент c Linux на базе Неттопов (Nvidia ION, Intel Atom)
В сегодняшний век повсеместной виртуализации возникает необходимость экономить на всем. Наиболее значимые для любого системного администратора сущности, это:
* Время (затраты на обслуживание системы)
* Железо (различные сбои, потеря производительности, устаревание)
* ПО (лицензионная составляющая, защита от вирусов, централизация управления приложениями)
В своей статье я рассматриваю реализацию (не)тонкого клиента на базе ОС Linux, как прослойке между аппаратной составляющей и привычным интерфейсом ОС Windows.
(Не)тонкий клиент, в моем понимании, это дистрибутив ОС Linux обладающий следующими свойствами:
* достаточно большой набор компонентов для загрузки; не подходит для загрузки по сети
* достаточно маленький набор компонентов; не рационально устанавливать жесткий диск
В качестве платформы для реализации я выбрал Nvidia ION ввиду:
* Производительный процессор
* Производительная графика (в рамках неттопов)
* Малошумный (есть варианты с активным и пассивным охлаждением)
* Занимает мало места (есть возможность крепления на монитор)
* Достаточно надежный (ломаться особо нечему)
Также мне понадобится один USB-flash накопитель на 4Гб, который как раз и будет заменой жесткого диска.
Дистрибутив Linux для установки был выбран OpenSUSE. На текущий момент это версия 12.2
##### Ну, приступим…
Про замечательный проект [Suse Studio](http://susestudio.com) писали [много](http://habrahabr.ru/search/?q=suse+studio). С помощью него мы будем создавать конечное решение терминального (не)тонкого клиента:
Создаем новое решение:
Как видно, выбор богатый:

Нам нужно самое легкое решение, поэтому используем шаблон: «минимальная графическая система с оболочкой IceWM».
##### Теперь можно обустраивать наш дистрибутив!
###### Software
Данное решение «из коробки» уже содержит необходимые компоненты для запуска графической системы и «легкого» оконного менеджера.
Если все оставить по умолчанию, то может потребоваться достаточно много усилий, чтобы настроить эту систему (видео драйвер, сетевые настройки и т.д.). Мне же нужно решение: поставил, адрес вбил и забыл.
Добавляем следующие компоненты (зависимые пакеты добавятся автоматически):
* freerdp (для любителей rdesktop, можно установить его)
* acpi, acpid (для корректной работы кнопки питания)
* mc (по желанию)
Добавляем из репозитария Nvidia драйвера для видеокарт Nvidia ION:
* x11-video-nvidiaG02
* nvidia-gfxG02-kmp-default
Добавляем из репозитария драйвера для видеокарт Intel:
* xorg-x11-driver-video-intel-legacy
(Отличная [статья](http://www.suse.de/~sndirsch/nvidia-installer-HOWTO.html) какой видео драйвер Nvidia выбрать)
Удаляем:
* nouveau (драйвер для графических карт Nvidia с открытым исходным кодом)
###### Configuration
**General**: Обязательно меняем пароль root и указываем нашего дефалтного пользователя.
**Startup**: Графический вход
**Desktop**: с автоматических входом нашего пользователя
Здесь можно задать параметры при загрузке, что мы и сделаем:
> В свете версии 12.2 устарело:
>
>
>
> setkxbmap -model pc104 -layout us,ru -variant,
>
> наша клавиатура имеет 104 кнопки с 2-мя раскладками
>
>
>
> setkxbmap -option grp:alt\_shift\_toggle
>
> и переключаться она будет по alt+shift
```
(sleep 3; xfreerdp -u domain\\user -f server_ip &)
```
чтобы у пользователя не было желания начать изучать линукс
задержка необходима в случае получения ip-адреса по DHCP, icewm иногда быстрее прогружается.
(или rdesktop -k en-us -u domain\\user -f server\_ip)
```
echo 'ShowTaskBar=0' >> ~/.icewm/preferences
```
прячем панель задач (более полно [тут](http://www.icewm.org/manual/icewm-10.html))
Для особых позльзовательских настроек, можно прописать дополнительные команды в любом кол-ве.
Для настроек первого запуска, идем в следующую секцию:
###### Scripts
В секции First Boot добавляем пару строчек:
OpenSuse 12.1
```
grep -rl 'timeout 10' /boot/grub/ | xargs perl -i -pe "s/timeout 10/timeout 0/g;"
```
OpenSuse 12.2 (Grub2)
```
grep -rl 'GRUB_TIMEOUT=10' /etc/default/grub | xargs perl -i -pe "s/GRUB_TIMEOUT=10/GRUB_TIMEOUT=0/g;"
```
ставим таймаут выбора вариантов загрузки ОС 0 секунд
```
echo '* * * * * if ! ps -U tux | grep xfreerdp && ps -U tux | grep icewm; then perl /home/rdp_conn_cnt; fi' >> /var/spool/cron/tabs/tux
```
Добавляем нашему пользователю (который случайно может завершить сессию RDP, автостарт клиента RDP). По желанию можно сделать более маленький промежуток времени.
```
chmod u+s /sbin/shutdown
```
Пользоваляем нашему пользователю выключать компьютер
```
chmod u+s /sbin/ipconfig
```
и смотреть ip
###### Files
Собственно сюда я загрузил свой простенький скрипт, который считает кол-во попыток запуска RDP, когда пользователь ничего не ввел. По истечении кол-ва попыток происходит shutdown системы.
```
#!/usr/bin/perl
$counter = 0;
if (-e "/tmp/rdp_cnt.tmp"){
open (FN, "/tmp/rdp_cnt.tmp") or die "$_";
$cnttext=;
close FN;
$counter = $1 if ($cnttext =~ /(\d+)/);
}
if ($counter++ < 10){
system("export DISPLAY=:0 && xfreerdp -u domain\\\\user -f server\_ip");
open (FN, ">/tmp/rdp\_cnt.tmp") or die "$\_";
print FN $counter."\n";
close FN;
}
else {
unlink("/tmp/rdp\_cnt.tmp") if (-e "/tmp/rdp\_cnt.tmp");
system ("systemctl poweroff");
}
```
###### Build
К построению образа готовы!
Делаем Preload ISO (.iso) и можно ставить. | https://habr.com/ru/post/144822/ | null | ru | null |
# [SetNet & Console Application] Первые шаги. SetNet.PeerBase. Часть 2
Здравствуйте, сегодня мы продолжаем курс уроков о сетевом решении **SetNet Server**. И сегодня речь пойдет о классе клиента и обработке данных, которые принимаются от клиентов. Начнем.
Создадим класс под названием “**Peer**” далее подключим пространства имен “**SetNet**“ и унаследуем класс “**Peer**” от базового класса “**PeerBase**“. Класс должен иметь следующий вид:
```
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using SetNet;
using SetNet;
namespace Server
{
class Peer:PeerBase
{
}
}
```
Теперь создадим конструктор класса «**Peer**». Он должен выгладить так:
```
public Peer(ClientInfo info)
: base(info)
{
}
```
В данном случае конструктор принимает экземпляр класса **ClientInfo** в котором хранится информация о клиенте.
Далее нужно реализовать абстрактный класс от “**PeerBase**” в последствии чего класс будет иметь вид:
```
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using SetNet;
namespace ServerTest
{
class Peer:PeerBase
{
public override void ReceiveData(EventData data)
{
throw new NotImplementedException();
}
public override void ClientDisconected()
{
throw new NotImplementedException();
}
}
}
```
В методе “**ReceiveData**” происходит взаимодействие с сообщениями с клиента.
Рассмотрим метод “**ReceiveData**“:
* В классе «**EventData**» содержится код сообщения под названием “**eventCode**” который имеет тип “**byte**“. За **eventCode** мы будем различать сообщения с клиента.
«**EventData**» содержится Dictionary с названием «*dic*» в котором содержаться все переданные данные.
*throw new NotImplementedException();* можно удалить так как эта строчка не нужна. Она создается в последствии реализации абстрактного класса.
Рассмотрим взаимодействие с объектом “**EventData**” в методе “**ReceiveData**“:
Для начала нужно обработать событие. Для этого сделаем перебор:
```
switch (data.eventCode)
{
case 1:
Console.WriteLine("Received message from the client with {0} eventCode. Message {1}",data.eventCode,data.dic[1].ToString());
break;
default:
Console.WriteLine("Received unknown message from the client with {0} eventCode. Message {1}",data.eventCode,data.dic[1].ToString());
break;
}
```
Здесь можно видеть перебор по коду сообщения и выводом. Далее создадим ответ сервера клиенту. Для этого нужно создать новый экземпляр класса “**EventData**” и зададим ему имя “**response**” перед конструктором класса. Далее в методе “**ReceiveData**” создадим ответ в “*case 1*”.
```
EventData response = new EventData(1, new Dictionary { { 1, "Response from the server" } });
```
Рассмотрим ответ:
```
SendEvent(response);
```
Метод “**SendEvent**” принимает экземпляр класса “**EventData**” и отсылает его клиенту.
Метод «**ReceiveData**» после изменений:
```
public override void ReceiveData(EventData data)
{
switch (data.eventCode)
{
case 1:
Console.WriteLine("Received message from the client with {0} eventCode. Message {1}", data.eventCode, data.dic[1].ToString());
EventData response = new EventData(1, new Dictionary { { 1, "Response from the server" } });
SendEvent(response);
break;
default:
Console.WriteLine("Received unknown message from the client with {0} eventCode. Message {1}", data.eventCode, data.dic[1].ToString());
break;
}
}
```
Остается лишь создать экземпляр класса “**Peer**” в классе “**GameServer**“: Перейдем в класс “**GameServer**“. В методе “**NewClient**” удалим строчку “*throw new NotImplementedException();*” В методе “**NewClient**” создадим экземпляр класса “**Peer**“.
Теперь метод будет выглядеть так:
```
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using SetNet;
namespace Server
{
public class GameServer:SetNet.Server
{
public GameServer()
: base()
{
}
public override void NewClient(ClientInfo info)
{
Peer peer = new Peer(info);
}
}
}
```
На этом данный урок закончен. Спасибо за внимание. Если остались вопросы – пишите на rebegin@list.ru или в скайп haker954. | https://habr.com/ru/post/242017/ | null | ru | null |
# Начинаем опыты с интерфейсом USB 3.0 через контроллер семейства FX3 фирмы Cypress
В целом, основной цикл статей про работу с комплексом Redd можно считать завершённым. Мы познакомились с методиками доступа к основным компонентам комплекса, научились писать и отлаживать на нём программы для центрального процессора, при этом локально используя хоть Linux, хоть Windows. Мы научились разрабатывать «прошивки» для ПЛИС, а также начерно освоили типовой цикл их разработки (написание кода моделирование, запуск в железе). Вроде, всё.
Но тут мне пришлось освоить работу с шиной USB 3.0 через контроллер семейства FX3 фирмы Cypress. Пока свежи воспоминания, я решил задокументировать детали процесса, так как сделав всё по фирменным описаниям, можно либо не получить ничего, либо получить не совсем оптимальную систему. И снова вышел целый блок статей. В первой из них, мы рассмотрим, где взять «прошивку» для самого контроллера, как её собрать и залить в него. Также сделаем базовую «прошивку» для ПЛИС.

1 Зачем всё это
---------------
Во время практической работы с USB анализатором, я столкнулся с рядом трудностей.
Во-первых, передача данных через TCL-скрипт (которую мы начерно осваивали [тут](https://habr.com/ru/post/496508/) и начисто использовали [тут](https://habr.com/ru/post/525440/)) была худо-бедно приемлема для научных опытов, но для практической отладки USB-устройства категорически неприемлема. Причём малейшая доработка скрипта увеличивала время передачи данных. Иногда – вдвое. И получалось, скажем, десять минут вместо пяти… При том, что и пять-то минут были категорически неприемлемы. Надо было отказываться от передачи больших объёмов данных через JTAG.
Как уже отмечалось в [одной из статей цикла](https://habr.com/ru/post/462253/), передача данных через выбранную нами микросхему FTDI по протоколу FT245-SYNC требует расходовать внутреннее ОЗУ ПЛИС, а его и так не хватает. И вообще не понравилась мне эта микросхема в реальной эксплуатации. Когда мы её закладывали, ставилась задача пользоваться только готовыми мостами с готовыми драйверами, чтобы ничего не дописывать. Эта задача была успешно выполнена, что позволило уложить разработку комплекса в разумные сроки. Сейчас, когда идёт его спокойная эксплуатация, вполне можно спокойно вести доработки для следующей ревизии аппаратуры. Итак, мост хочется заменить. Но на что? И вот тут всплывает «Во-вторых».
А во-вторых, когда я играл в USB-анализатор, память на плате быстро переполнялась. Давно ли мне хватало шестнадцати (даже пятнадцати с половиной) килобайт в БКшке? А тут, гляньте, 32 мегабайта мало. Но что есть, то есть (хотя, чтобы не гонять много через тормозной JTAG, я старался делать буфер на 2, 4, ну максимум 8 мегабайт).
И мы решили перейти на шину USB3. Её производительность такова, что вполне можно гнать поток от ULPI в PC без сохранения в промежуточное буферное ОЗУ. Соответственно, в PC можно складировать данные гораздо больших объёмов, чем 32М.
Хорошо. Меняем USB2 на USB3, но какой именно взять мост для этой шины? Мой знакомый из дружественной организации провёл большие исследования FTDI-шных мостов серии FT600 и получил мелкие плюхи, которые в итоге не давали работать в целом. Анализ форумов показал, что там всё очень критично к тюнингу временных диаграмм. Надо прописывать ряд ограничений для компилятора. И народ до сих пор ищет, как они должны выглядеть в идеале. Поэтому было решено пока что не рассматривать тот подход. Остаётся контроллер FX3 фирмы Cypress. Почему бы не влить в него типовую «прошивку» и не сказать, что теперь это мост, после чего забыть о том, что перед нами контроллер, требующий какого-то программирования? А что касается драйвера, там только с виду всё сложно, а так — всё просто и кроссплатформенно, но об этом я напишу в другой статье блока. Сегодня мы касаемся только аппаратуры.
2 Аппаратура
------------
### 2.1 Плата с контроллером FX3
У меня в загашниках есть несколько отладочных плат на базе контроллера FX3. Самые первые непригодны для использования простыми советскими инженерами, так как разъём у них очень экзотический. Но есть и более дружественная макетка: CYUSB3KIT-003. Вот ссылка на сайт производителя: [CYUSB3KIT-003 EZ-USB FX3 SuperSpeed Explorer Kit (cypress.com)](https://www.cypress.com/documentation/development-kitsboards/cyusb3kit-003-ez-usb-fx3-superspeed-explorer-kit)
У неё обычные двухрядные разъёмы с шагом 2.54 мм. Фотография с сайта:

На той же странице есть ссылка на образ диска, содержащий среду разработки и SDK. Этот образ диска скачивается без регистрации. А вот если перейти по ссылке на страницу с SDK, то там для скачивания того же самого уже требуют зарегистрироваться, что я не люблю делать.
Также там есть ссылка на Application Note, содержащей информацию о том, как просто залить в контроллер типовое приложение, после чего он станет мостом.
[AN65974 — Designing with the EZ-USB FX3 Slave FIFO Interface (cypress.com)](https://www.cypress.com/documentation/application-notes/an65974-designing-ez-usb-fx3-slave-fifo-interface)
С виду – красота! Правда, если бы всё было так, как кажется, не было бы статьи. Но тем не менее, есть от чего плясать.
### 2.2 Плата с ПЛИС
Как я уже отмечал, для текущих опытов я использую китайский модуль AC608. Если вбить его имя на Ali Express, будет найдено некоторое количество продавцов, предлагающих его. Там стоит ПЛИС EP4CE10F17C8 семейства Cyclone IV. Этот модуль куплен давненько, ещё когда я только собрался серьёзно заняться анализатором. Сегодня бы я взял десятый Циклон, но что есть в наличии, то есть.

### 2.3 Соединяем
В документе **001-65974\_AN65974\_Designing\_with\_the\_EZ-USB\_FX3\_Slave\_FIFO\_Interface.pdf** есть замечательная таблица 2, в которой показано, как подключить систему в восьми, шестнадцати или тридцатидвухбитном режиме к ПЛИС. Для текущего варианта был выбран шестнадцатибитный режим. При разработке схемы сначала возникли небольшие трудности с чтением этой таблицы. Давайте сделаю так, чтобы они больше ни у кого не возникли. Вот пара строк из неё:

Их содержимое следует читать так: Сигнал CS – это нога GPIO17 контроллера. На шелкографии макетки она обозначена, как CTL0. Сигнал SLWR – это нога GPIO18, на шелкографии модуля она обозначена, как CTL1. Ну, и так далее. Смотрим сигналы в столбце выбранной разрядности, потом переводим взгляд влево и смотрим, куда они подключены. Причём скорее всего, вам придётся смотреть не первый, а второй столбец. Именно в этих терминах обозначены сигналы на схеме макетки и на шелкографии. Вот какая красивая там шелкография, конструктор – просто молодчина!

На частоте 100 МГц соединение плат проводами крайне противопоказано. Только плата! Схему нашего соединительного модуля в статье в виде рисунка приводить не вижу смысла, но на всякий случай, приложу её и файл с разводкой в раздаточные материалы, на случай если вдруг кто-то захочет повторить опыты именно с этим железом. Но в целом – получилась вот такая кувалда:

Как видно из фотографии, на ручке кувалды присутствует также модуль ULPI от WaveShare. Те, кто читают цикл давно, уже догадались, что перед нами очередная версия USB-анализатора. Поэтому сегодня мы будем заниматься прокачкой данных из ПЛИС в PC и только в этом направлении. Обратный поток нас сегодня не интересует.
3 Первое веселье с «прошивкой» для контроллера
----------------------------------------------
### 3.1 Выбираем, что же мы будем прошивать
На самом деле, с виду, с «прошивкой» контроллера всё должно быть хорошо. Мало того, к примеру AN65974 прилагаются не только исходные, но и двоичные файлы. Теоретически, можно взять файл Fx3SlaveFifoSync.img и просто «прошить» его в макетку. Всё бы ничего, но из исходников видно, что это 32-битная сборка, а аппаратура у нас 16-битная…

**То же самое текстом.**
```
/* 16/32 bit GPIF Configuration select */
/* Set CY_FX_SLFIFO_GPIF_16_32BIT_CONF_SELECT = 0 for 16 bit GPIF data bus.
* Set CY_FX_SLFIFO_GPIF_16_32BIT_CONF_SELECT = 1 for 32 bit GPIF data bus.
*/
#define CY_FX_SLFIFO_GPIF_16_32BIT_CONF_SELECT (1)
```
Что может быть проще? Устанавливаем среду разработки, импортируем туда проект, собираем… Получаем ошибку «Нечего собирать». Смотрим – видим, что не найдены элементы ToolChain (кстати, кто подскажет, как это называть по ГОСТ 2.105, то есть, не «тулчейн», а более по-русски, но чтобы слух не резало?). Немного поиска по Гуглю, и становится ясно, что просто перед нами очень древний проект, не совместимый с той средой разработки, которая лежит на сайте Cypress сегодня.
Отлично! Создаём новый проект в актуальной среде, подключаем к нему исходные файлы из того проекта, собираем… Получаем ошибки в заголовках. Немножко поиска по Гуглю, и становится ясно, что те исходники сделаны под старую версию SDK.
Хорошо. Осматриваемся в примерах, входящих в состав SDK. И выясняем, что пример **Program Files (x86)\Cypress\EZ-USB FX3 SDK\1.3\firmware\slavefifo\_examples\slfifosync** – современный аналог примера из Application Note. Ура? Подождите, приключения только начинаются. Но так или иначе, мы убедились, что исходно этот проект рассчитан на 16-битный обмен, и успешно собрали его. То есть, пока что мы нашли хороший пример и собрали его, не внося никаких правок (когда черновик статьи уже был залит на Хабр, выяснилось, что этот пример обладает серьёзным недостатком, но как его найти и устранить, мы рассмотрим в отдельном материале). Давайте я заодно расскажу, как его залить в контроллер.
### 3.2 Как залить получившуюся «прошивку» в контроллер
Чтобы залить проект в макетку, надо заставить контроллер запустить лоадер. Для этого устанавливаем джампер J4. На фото он специально жёлтого цвета (для контраста, так как фирменные все красные, причём для установки на позицию J4 тоже прилагается красный, в отдельном пакетике, комплект поставки у макетки – выше всяких похвал).

Итак, устанавливаем этот джампер, после чего либо передёргиваем питание, либо нажимаем кнопку Reset (она расположена рядом с разъёмом USB 3.0). Всё. Контроллер теперь находится в режиме загрузки.
Запускаем программу Control Center, которая установилась вместе со средой разработки. В ней выбираем контроллер в дереве (у меня дерево на экране состоит из корня одного устройства).

И выбираем либо пункт меню Program->FX3->RAM, чтобы запустить код в ОЗУ, либо Program->FX3->I2C EEPROM, чтобы прошить код в ПЗУ. Да, я не оговорился. Именно I2C EEPROM. Не SPI. Так надо!
На время опытов лучше лить просто в ОЗУ. Так быстрее. А опытов нам предстоит много. Потом, когда всё будет отлажено, тогда уже можно будет перейти на прошивку в ПЗУ. Чтобы код стартовал из ПЗУ, надо будет снять джампер J4. При заливке в ОЗУ аппаратуру можно не трогать, код запустится сам.
Хорошо. Первичная «прошивка» для FX3 сделана и даже залита в контроллер. В дереве появилось совсем другое устройство с двумя конечными точками типа Bulk:
Это наша система. Но для того, чтобы начать с нею работать, нам надо сделать «прошивку» для ПЛИС. Приступаем, для чего вчитываемся в документацию. И тут нас ждут первые доработки кода контроллера…
4 Насколько верна типовая прошивка для ПЛИС из примера?
-------------------------------------------------------
### 4.1 Путанные результаты осмотра
Разработчики от Cypress заботливо положили примеры «прошивок» для Xilinx и Altera, причём сразу на двух языках – VHDL и Verilog. Красота! Но начав изучать файл **\AN65974\FPGA Source files\fx3\_slaveFIFO2b\_altera\rtl\_verilog\slaveFIFO2b\_streamIN.v**, я понял, что понимаю не всё. Меня смущала нужность автомата и вообще флаги. Автомат в документе показан так:
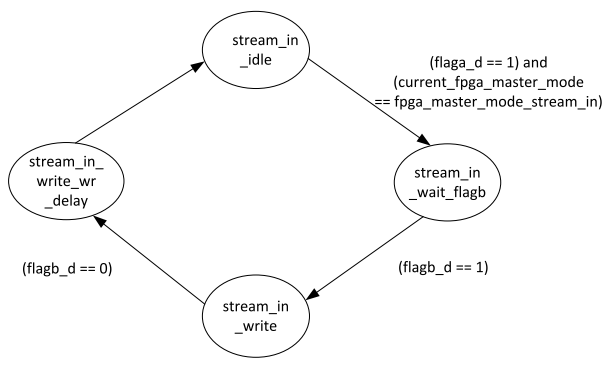
Но суть его описана недостаточно понятно. Назначение флагов в исходниках описано так:
```
input flaga, //full flag
input flagb, //partial full flag
input flagc, //empty flag
input flagd, //empty partial flag
```
Про это что-то есть в документе, но очень путано. Логика мне не понятна нисколько. Более того, при описании, в документе ссылаются на функции **CyU3PGpifSocketConfigure()**, которые действительно используются в примере, идущем в составе AppNote… Который не собирается. И они отсутствуют в текущем примере. А почему они там отсутствуют? Открываем дизайн GPIF, идущий в составе AppNote. Видим там четыре флага (по паре Ready и Watermark для каналов 0 и 3):

А теперь – тот же дизайн из проекта, который собирается… Ой! А флагов всего два! Причём на самом деле, они равнозначные – Ready для выбранного канала (выбранный канал – это тот, номер которого установлен нашей ПЛИС на адресной шине).
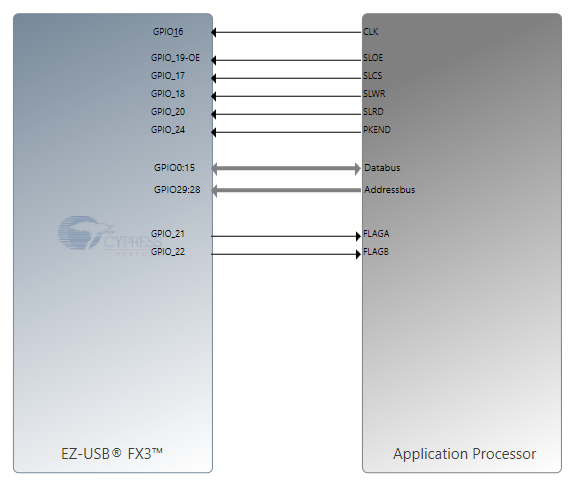
Разумеется, специалисты, читая эти строки, уже усмехаются. Мол, не разобрался в контроллере, а всё туда же, статьи писать. Но вообще-то разобрался, просто нагнетаю обстановку. Однако в целом – беда в том, что вообще-то я и не собирался (да и не собираюсь) становиться гуру FX3. С FX2LP я 12 лет назад разбирался три месяца в режиме полного дня, и знаю его досконально. Процесс изучения программируемой логики, встроенной в семейство PSoC, я оформил в виде сразу двух циклов статей: авторского и переводного. А тут – нет времени, руководство требует срочно победить проблемы синтезируемого RISC-V, все силы брошены туда. Плюс – я уже старый и тормозной.
**Если кому интересно, то тут под катом список тех самых авторских статей.**
[Управление RGB светодиодами через блок UDB микроконтроллеров PSoC фирмы Cypress](https://habr.com/ru/post/429882/)
[Использование блоков UDB контроллеров PSoC фирмы Cypress для уменьшения числа прерываний в 3D-принтере](https://habr.com/ru/post/433800/)
[Часть 2: Использование блоков UDB контроллеров PSoC фирмы Cypress для уменьшения числа прерываний в 3D-принтере](https://habr.com/ru/post/434742/)
[DMA: мифы и реальность](https://habr.com/ru/post/437112/)
[Использование Datapath Config Tool](https://habr.com/ru/post/442572/)
[Особенности формирования тактовых частот в PSoC 5LP](https://habr.com/ru/post/443554/)
[Источники вдохновения при разработке под UDB](https://habr.com/ru/post/449960/)
**А тут – переводных**
[Часть 1. Введение. PLD.](https://habr.com/post/432764/)
[Часть 2. Datapath.](https://habr.com/post/433018/)
[Часть 3. Datapath FIFO.](https://habr.com/ru/post/434706/)
[Часть 4. Datapath ALU.](https://habr.com/ru/post/437096/)
[Часть 5. Datapath. Полезные мелочи.](https://habr.com/ru/post/438818/)
[Часть 6. Модуль управления и статуса.](https://habr.com/ru/post/443380/)
[Часть 7. Модуль управления тактированием и сбросом.](https://habr.com/ru/post/449108/)
[Часть 8. Адресация UDB.](https://habr.com/ru/post/452606/)
То есть, я хотел просто взять типовой пример и заставить его выполнять типовые функции! Мне некогда вникать во все хитросплетения и проводить десятки и сотни опытов! Я хочу просто взять готовое и заставить его решать мои частные задачи для освоения совсем других вещей… Я не хочу тратить время и нервы, перенося куски из старых исходников в новые… Я не хочу понимать, куда вставить те функции, понимать, зачем этот хитрый автомат на 4 состояния, понимать, понимать, понимать…
Но кое-что понять придётся. Давайте почитаем документ, приложенный к AppNote. И там мы видим удивительные вещи.
### 4.2 Удивительная латентность
В документе есть очень подробное описание флагов. И там говорится про очень интересную латентность. Эта латентность также кочует из документа в документ. Собственно, для борьбы с нею и придуман тот самый таинственный флаг Watermark, сути работы с которым я изначально не понял. Вот эта латентность.

Рисунок очень общий. На нём тоже два флага, но это другие два флага. В коде используются флаги FLAGA и FLAGB, запрограммированные на функции Full и Watermark одного канала, а на этом рисунке (в документе, поясняющем код) — FLAGA и FLAGB как флаги Full для двух разных каналов, номера которых задаются на адресной шине. Как я долго въезжал в этот факт, кто бы знал! Поэтому отмечаю его для остальных.
Но из рисунка видно, что о том, что буфер переполнился, мы узнаем через три такта. Кто-то спросит, мол, а зачем нам знать через три такта, что буфер давно переполнился? Я просто присоединюсь к его вопросу. Ответа на него я не знаю.
Но знаю, что есть альтернативный флаг Watermark, про который сказано, что его нельзя использовать в одиночку, только в паре с основным флагом. Этот флаг можно запрограммировать на взведение, когда в буфере осталось N свободных **элементов**. И тогда, с поправкой на латентность, он взлетит как раз, когда буфер переполнен (правда, понятие «**элемент**» там забавное: они 32-битные, для 16-битных слов надо задаваемое значение делить на 2, а у нас латентность нечётная, но это мы изучим в следующей статье). Собственно, автомат в AppNote как раз по очереди и ждёт появления флагов. Правда, кто мешает объединить их по «И»? Но не суть. Суть в том, что у нас есть два варианта действий:
Либо открыть GPIF II Designer, в нём открыть проект **Program Files (x86)\Cypress\EZ-USB FX3 SDK\1.3\library\sync\_slave\_fifo\_2bit.cydsn\sync\_slave\_fifo\_2bit.cyfx** и поменять назначение флагов. Я сделал так:
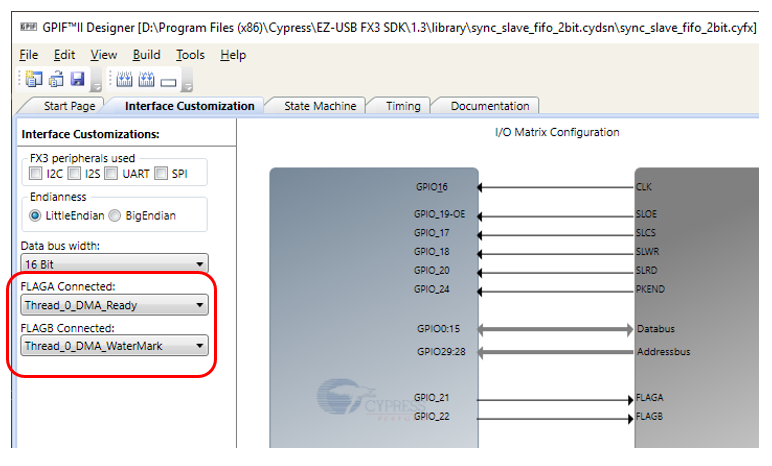
Затем сгенерить заголовочный файл на языке С, выбрав Build ->Build Project:

И сравнивая содержимое получившегося файла и рабочего файла **cyfxgpif\_syncsf.h** поправить его…
Либо поверить мне на слово, и просто взять тот файл **cyfxgpif\_syncsf.h**, который я выдам в раздаточном материале. Я в нём уже сделал всё, что нужно…
Вот поэтому я и говорил, что пока проще заливать «прошивку» не в EEPROM, а в ОЗУ. Это не последняя правка кода. Мы ещё несколько раз будем его дорабатывать и заливать результаты в контроллер.
5 Проектируем систему для ПЛИС
------------------------------
### 5.1 Общий вид
Кто читал цикл про комплекс Redd, тот знает, что все системы в его рамках делаются на базе процессорных систем. Остальным советую посмотреть основы идеологии в статье [«Разработка простейшей «прошивки» для ПЛИС, установленной в Redd, и отладка на примере теста памяти»](https://habr.com/ru/post/452656/) (самая главная особенность – наша система является блоком верхнего уровня, вставляемым без каких-либо прослоек на машинном языке). Базовые принципы разработки своих модулей для системы описаны в статье "[Разработка собственного ядра для встраивания в процессорную систему на базе ПЛИС](https://habr.com/ru/post/454938/)", мы будем работать с шиной AVALON-ST, о которой можно узнать из статьи "[Первые опыты использования потокового протокола на примере связи ЦП и процессора в ПЛИС комплекса Redd](https://habr.com/ru/post/462253/)".
Сегодняшняя система будет весьма и весьма спартанской:

### 5.2 PLL
Примеры от Cypress работают на частоте 100 МГц. Отчего бы не попробовать эту частоту и нам? Но ULPI выдаёт данные на частоте 60 МГц. Для преобразования частот в систему добавлен блок PLL. Мы с ним работали уже достаточно много, так что подробности его настройки показывать нет смысла. Кто забыл детали – может заглянуть в статью "[Ускорение программы для синтезированного процессора комплекса Redd без оптимизации: замена тактового генератора](https://habr.com/ru/post/469985/)", только сегодня входная частота – не 50, а 60 МГц, и сдвиг фазы не нужен.
Частота 60 МГц (фиолетовая линия) тактирует источник сигнала и входной порт FIFO. Частота 100 МГц тактирует выходной порт FIFO и интерфейсный блок, работающий с FX3.
### 5.3 Источник данных
Источник сигнала – таймер, с которым мы уже познакомились в статье "[Практическая работа с ПЛИС в комплекте Redd. Осваиваем DMA для шины Avalon-ST и коммутацию между шинами Avalon-MM](https://habr.com/ru/post/500016/)". Он гонит постоянный поток данных. Если данные были утеряны, мы заметим разрыв в потоке. Правда, сегодня я чуть-чуть изменил его работу. Во-первых, мы гоним 16-битный поток данных, так что и таймер стал 16-битным. А во-вторых, сегодня нам важно, чтобы таймер работал на исходно пустую очередь буферного FIIFO. Поэтому я добавил правило: если приёмник данных от таймера не готов принимать поток, то после возобновления готовности, таймер ждёт 8192 такта. Ведь почему FIFO теряет готовность? Потому что на том конце не могут принять данные в момент, когда очередь уже переполнена. А если из блока FIFO пришёл сигнал о готовности, то это значит, что в очереди освободилось хотя бы одно свободное место. Переполнить очередь в этот момент – пара пустяков. Именно поэтому мы подождём… Через 8 килотактов, очередь, с высокой степенью вероятности, если не опустеет вовсе, то хотя бы будет почти пустой.
Итак, вот текст, реализующий такой модуль.
**Смотреть текст.**
```
module Timer_ST (
input clk,
input reset,
input logic source_ready,
output logic source_valid,
output logic[15:0] source_data
);
logic [15:0] delay_cnt = 0;
always @ (posedge clk)
begin
// На том конце очередь переполнена
// Значит, когда она освободится - начнём
// слать данные не сразу...
if (source_ready == 0)
begin
delay_cnt <= 8192;
source_valid <= 0;
end else
begin
// Задержка истекла - начинаем слать
if (delay_cnt == 0)
begin
source_valid <= 1;
end else
// Иначе - просто ждём...
begin
delay_cnt <= delay_cnt - 1;
end
end
end
// Таймер же продолжает тикать всегда, чтобы
// на PC увидеть факты разрыва...
logic [15:0] counter = 0;
always @ (posedge clk, posedge reset)
if (reset == 1)
begin
counter <= 0;
end else
begin
counter <= counter + 1;
end
assign source_data [15:0] = counter [15:0];
endmodule
```
Вот – настройки шин блока для Platform Designer:
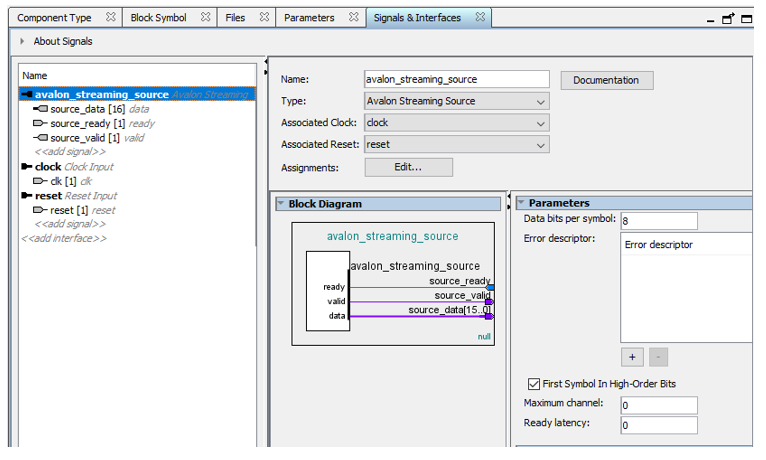
### 5.4 FIFO
Тут всё просто. 16 бит (два символа), 8192 элементов.

### 5.5 Интерфейс шины FX3
#### 5.5.1 Где черпаем вдохновение
Как я уже сказал, мне категорически не понравился пример из Application Note. Я стал рыться по сети и нашёл довольно забавный проект Stream: [GitHub — myriadrf/STREAM: FPGA development platform for high-performance RF and digital design](https://github.com/myriadrf/STREAM)
Там напрочь отсутствует исходный код для FX3, только двоичный файл, но зато есть файл fx3\_tx.v (часть логики, спрятана в fx3.v), размером всего в экран. Этот файл преобразует шину AVALON\_ST в FX3. Как раз то, что нам нужно!
Но там используется всего один флаг! Собственно, я перетянул ту логику к себе, изменив разрядность шины, добавив формирование константных сигналов и добавив второй флаг, объединив его по «И» с первым.
#### 5.5.2 Описание получившегося файла
Собственно, у меня получился такой модуль.
**Смотреть текст модуля.**
```
module FX3_to_ST (
// ****************
// *** Шина FX3 ***
// ****************
input reset, //input reset active high
input clk, //input clp 100 Mhz
inout [15:0]fdata, //data bus
output [1:0]faddr, //output fifo address
output slrd, //output read select
output slwr, //output write select
output sloe, //output output enable select
output clk_out, //output clk 100 Mhz
output slcs, //output chip select
output pktend, //output pkt end
// Эти два флага - для передачи
input flaga, //full flag
input flagb, //partial full flag
// Эти два флага для приёма, сейчас не используются
input flagc, //empty flag
input flagd, //empty partial flag
// **********************
// *** Шина AVALON_ST ***
// **********************
output logic sink_ready,
input logic sink_valid,
input logic[15:0] sink_data
);
reg flagb_d;
always @(posedge clk)
begin
flagb_d <= flagb;
end
wire flagsab;
assign flagsab=flaga&flagb_d;
// Оригинальный пример задерживает данные на такт. Ну и мы так сделаем
reg [15:0] fx3_data;
// Этот сигнал тоже задержан на такт вместе с данными
reg fx3_wr;
assign clk_out = clk;
// Пока что никогда не читаем
assign slrd = 1'b1;
// Вот такая логика записи в FIFO
assign slwr = !fx3_wr;
// Всегда выбран нулевой канал
assign faddr = 2'd0;
// Мы никогда не принимаем данные, только посылаем
assign sloe = 1'b1;
// Но на всякий случай, шину данных занимаем только когда реально передаём
assign fdata = (fx3_wr) ? fx3_data : 16'dz;
// Канал всё время выбран
assign slcs = 1'b0;
// И пока что никогда не терминируется
assign pktend = 1'b1;
// Линия задержки сигнала FULL
reg [1:0] full = 0;
assign sink_ready = !full[1];
always @(posedge clk)
begin
if (reset) begin
fx3_wr <= 1'b0;
end
full <= {full[0],!flagsab};
fx3_data <= sink_data;
fx3_wr <= !full[1] & sink_valid;
end
endmodule
```
Защёлкивание данных требуется, чтобы на шине FX3 они были стабильны на протяжении всего цикла. Пусть шина AVALON\_ST приходит к нам из ОЗУ, и никаких переходных процессов не будет… Я пробовал убрать защёлки. Сразу лезет бешеное количество битовых ошибок!
А, собственно, из оригинальной логики – всё. Если шина FX3 не готова принимать данные, мы сообщим об этом шине AVALON\_ST. Если в шине AVALON\_ST есть данные, а FX3 готова, мы выставляем строб записи…
Интерес представляет задержка на такт сигнала FLAGB. Детективную историю, как я выяснил, что он нужен, мы рассмотрим в следующей статье. А так – всё. На удивление простой модуль. Не то, что вариант из Application Note.
#### 5.5.3 Упаковка модуля для использования в процессорной системе
Настройки блока для процессорной системы должны выглядеть так (не забываем поменять автоматически выбранную шину AVALON\_MM на AVALON\_ST, создать шину couduit, перетаскать туда большинство сигналов и вручную прописать им имена в пределах шины):
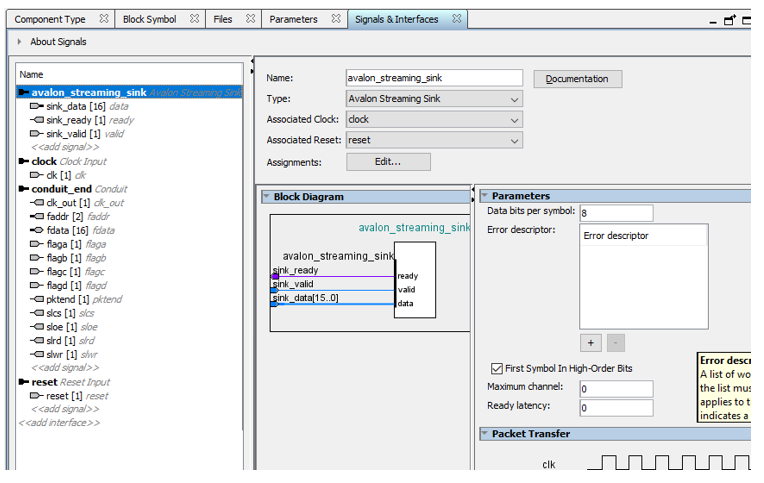
Уффф. Материалов получилось уже многовато, а практическая работа предстоит тоже немаленькая. Предлагаю сделать паузу и переварить материал, а к первым практическим опытам перейти в следующей статье.
6 Заключение
------------
Статья является, по сути, рефератом, в котором перечислены ссылки на основные документы, позволяющие подключить контроллер FX3 к комплексу, похожему на Redd, а точнее – к ПЛИС Altera. В материалах выявлены нестыковки по версиям. Найден вариант, который в конце 2020 года, вроде как, собирается и работает. Система пока что не имеет практической ценности, так как ещё не проведена её отладка. Первый шаг к отладке будет сделан в следующей статье.
Материалы с описанием аппаратуры, можно скачать [тут](https://yadi.sk/d/cpOtVPkkeJmGfA).
Демонстрационный проект, созданный при написании данной статьи, можно скачать [тут](https://yadi.sk/d/R8Dl2O-EoZwyjg). Код FX3 несколько отличается от того, который получится после правки согласно этой статье. Что и зачем там ещё поправлено, мы узнаем из следующей статьи. Возможно, даже из двух. | https://habr.com/ru/post/531494/ | null | ru | null |
# Детали test-first, которых так не хватало
 Все мы не раз слышали о test-first — философии разработки, которая призывает писать тесты раньше кода. Уверен, что любой, кто пытался применять этот метод на практике, сталкивался с тем, что у него просто не получается написать тест до функции (обычно в этом случае просто игнорируют эту проблему и локально нарушают test-first). Я считаю, что причина подобных провалов фундаментальна, и попытаюсь показать почему.
*Для начала следует уточнить, что здесь и далее я буду говорить про тестирование функции в широком смысле слова как тестирование некоторой условной примитивной единицы кода. Оставим в стороне вопрос, какую подобную единицу нужно тестировать (например, метод или класс), на дальнейший ход рассуждения эти детали влияния не окажут. Я буду использовать выражение «тестирование функции» в этом смысле на протяжении всей статьи.*
Вам может показаться, что индустрия давно разобралась со всеми проблемами, связанными с test-first, и причина всех возможных провалов лишь в том, что мы как разработчики не обладаем достаточной квалификацией для успешного применения нужных техник, а вовсе не в каких-то фундаментальных проблемах. Увы, здесь и там разные программисты задают одни и те же вопросы, как именно делать test-first, и получают порой невразумительные ответы. Думаю, без преувеличения можно сказать, что комьюнити по всему миру что-то подозревает, но многое остается недоговоренным.
> Red-green-refactor is insufficiently detailed to actually use as a workflow. In real life TDD is more like this: [pic.twitter.com/TuGxzrQQkg](http://t.co/TuGxzrQQkg)
>
> — Sarah Mei (@sarahmei) [4 сентября 2015](https://twitter.com/sarahmei/status/639794835499581440)
Попробуем же разобраться в проблемах, которые могут принципиально мешать нам руководствоваться test-first в том виде, в котором его обычно излагают. План нашего рассуждения:
1. В общем случае написать тест для функции наперед возможно, только если рассматривать ее как черный ящик.
2. В общем случае рассматривать в тесте функцию как черный ящик не следует (или даже невозможно).
3. Из пунктов 1 и 2 немедленно следует, что в общем случае писать тест для функции заранее не следует (или даже невозможно).
4. Что же делать?
1. Ненаписанную функцию можно тестировать только как черный ящик
================================================================
*Термин test-first тесно связан с другим, куда более популярным на сегодняшний день: [TDD](https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0_%D1%87%D0%B5%D1%80%D0%B5%D0%B7_%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5). Не буду останавливаться на отличиях одной техники от другой, достаточно сказать, что test-first — неотъемлемая часть TDD (хотя может применяться и отдельно от него). Далее в статье я буду говорить о test-first, имея, однако, в виду, что все сказанное с минимальными уточнениями справедливо и для TDD.*
На момент, когда test-first предлагает мне написать для функции тест, все, что я знаю о ней, — это ее интерфейс. Он может не быть окончательным, но, чтобы начать разработку, предполагается определиться хоть с какой-то его версией. Традиционно можно рассматривать две основные части интерфейса: входные и выходные данные. Но следует понимать, что для функции входные данные — это не только параметры, с которыми она вызвана, а выходные — не только то, что она непосредственно возвращает. У функции может быть несколько технических способов возвращать значения: например, обычный `return`, исключения и запись в параметры (все это может по-разному называться). Кроме того, в качестве входных и выходных данных может также выступать состояние тестируемой системы. (Простейшим примером подобного взаимодействия с состоянием системы может служить функция, манипулирующая глобальными переменными. Несмотря на вырожденность, эта ситуация не является исключительной: точкой взаимодействия могут выступать объекты, из которых вызывается метод, синглтоны, глобальные пулы, базы данных — в любом их виде — и т. д.)
Итак, все знания, которые мне доступны о функции перед началом написания теста, — ее интерфейс в широком смысле слова. Причем в слово «интерфейс» в данном контексте я вкладываю знания не только о том, *как* функция работает с данными, но и о том, *что* она с ними делает (мне, само собой, известно назначение функции). Очевидно, что тесты, написанные с учетом только интерфейса, — это тестирование черного ящика: мне недоступна внутренняя логика и исходный код функции хотя бы просто потому, что я еще не разработал эту логику и код еще не написал.
Возможно, вы полагаете, что тестирование черного ящика — отличная идея, и это ровно то, что нам надо, и мы бы применили эту технику, даже если бы у нас уже был код. Однако в следующем разделе я попытаюсь показать, какие потенциальные проблемы это несет и почему повсеместное применение такого подхода может быть неуместным. Несмотря на то что это может казаться очевидным, определенная формализация здесь совершенно не помешает.
2. Ненаписанную функцию не стоит тестировать как черный ящик
============================================================
Одна из основных задач, стоящих перед программистом, который пишет тест, — это подбор входных данных, на которых нужно проверить работу функции.
Как правило, в современной промышленной разработке теоретическое доказательство верности программ (а) практически невозможно и (б) не требуется. Значительная часть уверенности, что программа делает то, что должна, базируется на некой гипотезе, которую с помощью тестов программист раскладывает на набор гипотез попроще, неформальное понимание которых было бы доступней.
Что я имею в виду? Чаще всего мне очевидно, что функция ведет себя одинаково на каком-то подмножестве пространства входных данных, которое обычно называют «классом эквивалентности». Говоря «очевидно», я имею в виду ту самую гипотезу, на которой строится моя вера в то, что моя программа вообще работает как надо (справедливости ради стоит отметить, что это общая проблема всех инженерных дисциплин: некоторые вещи приходится делать на глаз). В отсутствии каких-либо гипотез любое тестирование было бы бесполезно; мне помогло бы только формальное доказательство (которое, повторюсь, на грани невозможного).
Но при наличии такой гипотезы о наличии классов эквивалентности мне достаточно проверить работоспособность функции лишь на одних входных данных, чтобы удостовериться, что она верно функционирует на всем классе. Итак, анализ разбиения всех возможных входных данных на классы эквивалентности, чтобы потом на них выбрать тестовые примеры, — это и есть одна из основных задач, которые стоят перед автором теста.
Но при тестировании методом черного ящика, игнорируя возможное наличие классов эквивалентности, никаким нормальным образом выбрать эти примеры вы не сможете — их будет или слишком много, и будет делаться лишняя работа, или слишком мало, и тестирование будет не закончено.
Как знание о коде повлияет на наш выбор классов эквивалентности? Двумя основными путями: мы можем (а) воспользоваться тем, что часть кода уже протестирована, а также (б) проанализировать детали алгоритма.
Поговорим о каждом из них подробнее.
### С черным ящиком неизвестно, что уже протестировано
Позволю себе начать с примера. Я собираюсь написать функцию `number_of_german_letters(str)`, которая возвращает количество букв немецкого алфавита, содержащихся в строке `str`.
*Эта задача, кстати, не так проста, как может показаться. Немецкий алфавит содержит все латинские буквы (A—Z), три буквы с умляутом (Ä, Ö, Ü) и лигатуру эсцет (ß). Вот хотя бы несколько вещей, о которых можно забыть подумать: буквы с умляутом в юникоде присутствуют как в виде самостоятельных символов, так и в виде комбинации символа латинской буквы и символа умляута. У буквы ß есть только строчное начертание (если слово с ß записывается заглавными буквами, то ее заменяют на SS), **но** в юникоде 5.1 есть заглавное начертание эсцет: ẞ). Уверен, что я что-то еще не учел (например, я просто не знаю, используется ли старая версия лигатуры — ſs — и считать ли это немецким языком).*
Сразу возникает вопрос: а есть ли у меня функция, которая проверит, принадлежит ли буква немецком алфавиту (например, `is_german_letter`)? Если есть и я воспользуюсь ей в `number_of_german_letters`, то мне не нужно будет заново проверять распознавание немецких букв. Нужно проверить только код, который считает немецкие буквы: то, что он их верно распознает, уже «доказывает» тест на `is_german_letter`. Повторная проверка не только бесполезна, но и, скорей всего, вредна.
Если вам повторная проверка не кажется вредной, вот несколько аргументов, которые могут вас убедить:
* Если я перепроверяю работу функции `is_german_letter` в `number_of_german_letters`, то по логике должен перепроверять все еще более низкоуровневые функции, в том числе библиотеку работы с юникодом, бессмысленность чего более очевидна.
* Точно та же логика верна и при использовании самой `number_of_german_letters` в более высокоуровневых функциях, в том числе в тех, что отдают эти данные пользователю в виде картинки (например), что будет лишней тратой сил. Ошибочность этого подхода особенно хорошо заметна, когда речь идет о функции-обертке, которая не добавляет ничего или почти ничего. Если я обзаведусь функциями `number_of_german_letters_int`, `number_of_german_letters_float` и `number_of_german_letters_str`, то мне придется в каждой из них повторить все тесты для `number_of_german_letters` (ну и, если следовать той же логике, для всех еще более низкоуровневых функций, включая библиотеку работы с юникодом).
* Хотя контраргументом может служить то, что у полного перетестирования есть свой бонус. В условиях, когда каждый тест перепроверяет функцию целиком, без знания о ее зависимостях и внутреннем устройстве, тест *действительно* сообщает, работает ли данная функция. В условиях же проверки только того нового, что функция привносит, любой красный тест может означать неработоспособность *любой другой* функции (так как зависимости неизвестны, а от «покрасневшей» функции может зависеть сколь угодно много других). Впрочем, обычно такой трактовки результатов вполне достаточно и это не является проблемой — можно просто починить первым то, что сломалось. Полное перетестирование на каждом уровне того не стоит.
Однако, напоминаю, мы имеем дело с тестированием черного ящика, а значит, мы не знаем, будет ли использована функция `is_german_letter`. Но это знание играет решающую роль в выборе наборов входных данных, о которых говорилось выше. Если `is_german_letter` используется, строки `abc1Ö` и `abc1ß` проверяют фактически одно и то же, т. е. представляют один и тот же набор входных условий (эквивалентность внутри которого постулируется моей гипотезой). Однако если `number_of_german_letters` определяет «немецкость» букв самостоятельно, вполне можно счесть, что эти строки тестируют разные аспекты функции.
Также совершенно неизвестно, будет ли эта функция правильно работать с юникодом: так как это черный ящик, я не могу быть уверен, что будет использована какая-либо готовая, уже протестированная библиотека для работы с юникодом! Нужно обязательно проверить, как функция ведет себя на различных невалидных юникодных последовательностях, например.
Итак, тестируя функцию как черный ящик, я вынужден вновь и вновь повторять уже сделанные тесты. Да, есть отдельные фичи, которым я подсознательно доверяю (такие как библиотека работы с юникодом, например), однако у этого доверия нет четких рамок. Тут стоит добавить, что целесообразно формулировать задачу тестирования не как «проверить все, что делает функция», а «проверить только ту логику, которую она *привносит*». Если функция умеет только считать немецкие буквы, то и тест должен проверять ее способность считать буквы. Правда, хотелось бы также убедиться, что она зовет верную функцию для определения «немецкости» букв (т. е. проверить интеграцию), но для этого обычно достаточно одной проверки, а не полного перетестирования. (У этого есть и теоретическое обоснование: при таком подходе у функции остается один класс эквивалентности, работу которого одной проверкой мы и подтверждаем.)
Все сказанное очень сильно ограничивает меня в возможности тестирования методом черного ящика. О том, как можно решить эту проблему, мы поговорим в четвертой части, но сперва рассмотрим еще один фактор, затрудняющий подобное тестирование.
### Неизвестны детали алгоритма
Очевидно, что при тестировании черного ящика нам недоступны знания об используемых внутри него алгоритмах (на то он и черный ящик). Кажется, что это не всегда мешает выбору данных для тестирования: иногда по крайней мере некоторые из них можно выбрать уже исходя из постановки задачи. Но это ложное впечатление: все такие соображения могут оказаться неверными при различных имплементациях функционала. Есть ли ветвление в коде функции или нет, использованы библиотеки или нет — это все влияет на то, какие тестовые данные нужно будет выбрать.
Интересным примером может служить оптимизация. Код функции может работать иным способом на значениях, внешне кажущихся однородными. Например, умножать на 2n на двоичном процессоре я могу с помощью операции сдвига, а не умножения: такая оптимизация делает необходимыми отдельные проверки, однако сама постановка задачи (перемножение двух чисел) совершенно никак не выделяет степени двойки. Порой исключительность и неоднородность тех или иных значений может быть совершенно неочевидна до реализации.
Справедливости ради надо отметить, что оптимизацию можно рассматривать и как отдельную фичу, которую можно добавить на отдельной итерации, со своим test-first. И все же не следует думать, что неожиданный скачок в значениях — исключительная редкость. Мне приходят в голову еще два наиболее ярких примера:
* При установке времени жизни значения в memcached любое значение больше `60*60*24*30` считается количеством секунд с начала эпохи UNIX, а остальные — *количеством секунд с текущего момента*.
* В Ruby строки до 23 символов длиной хранятся в памяти не так, как те, что длинней.
Вам может показаться, что этот и предыдущий пункт во многом перекликаются, и вы будете правы: это различные проявления одной и той же проблемы. В первом пункте речь идет в основном о тестах, которые кажутся нужными, но не нужны, а во втором, наоборот, — о тестах, которые кажутся ненужными, но нужны.
3. Выводы из пунктов 1 и 2
==========================
Итак, в пункте 1 я попытался показать, что test-first неминуемо заставляет нас иметь дело с тестированием черного ящика. В пункте же 2 рассказывается о принципиальных и неразрешимых проблемах, которые возникают при тестировании черного ящика. Коль скоро написанное в пунктах 1 и 2 верно, стоит признать, что test-first в общем случае сопряжен с проблемами, избежать которых у нас нет никакого способа.
Что же делать? В следующем пункте мы поговорим о возможных модификациях test-first, которые помогут нам обойти эти проблемы (раз уж у нас нет принципиального способа их разрешить). Следует также оговориться, что, хотя сказанное в первую очередь применимо к unit-тестам функции, для интеграционного тестирования (которое чаще всего и пытаются проводить черным ящиком) это тоже верно.
4. Как работать с test-first
============================
Итак, перед нами стоит задача определенной доработки test-first, которая помогла бы нам обойти те проблемы, о которых говорилось в предыдущих пунктах. Однако эти модификации по возможности не должны лишить нас тех преимуществ и бонусов, которые мы хотели бы получить от test-first.
Что дает нам test-first? Это довольно-таки обширная тема, разные авторы указывают на разные достоинства, сравнительный анализ которых выходит за рамки этой статьи, поэтому я просто приведу неисчерпывающий перечень:
* Test-first помогает программисту яснее осознать, что должна делать функция, еще перед тем, как он начал ее писать.
* Программист также может опробовать интерфейс еще перед началом реализации и, возможно, обнаружить в нем какие-то проблемы на ранней стадии, когда отказаться от него еще почти ничего не стоит.
* Вы, скорее всего, не напишете нетестируемый или плохо тестируемый код, используя test-first.
* Test-first в целом дисциплинирует разработку: с ним у вас не будет возможности «забыть» о каких-то тестах, а также вам, скорее всего, не придет в голову писать функции по 500 строк (протестировать такую функцию, как правило, — чудовищно трудоемкая задача).
Далее я приведу набор техник, которыми я пользуюсь в своей повседневной работе и которые позволяют мне совместить прелесть и пользу test-first, избегая, однако, тех отрицательных последствий, о которых говорилось в предыдущих пунктах. Они основаны на том, что понятие «тест» включает в себя как компоненты, которые можно написать прежде кода, так и те, которые нельзя. Их надо друг от друга отделить, введя еще один уровень абстракции.
### Пишите шаблон теста до функции
Мы уже определились, что исчерпывающий набор тестов до кода написать не получается, так что мое решение таково: я создаю специальный шаблон теста.
Поговорим подробнее о том, что я называю таким шаблоном. Строго говоря, любой тест можно представить как код, который итерирует по набору пар (*IN, OUT*) и проверяет, что при входных данных *IN* функция выдает выходной результат *OUT*. Этот набор пар будем далее называть таблицей. Напомню, что речь идет об интерфейсе функции в широком смысле слова (см. пункт 1). На практике *IN* и *OUT* могут быть сколько угодно сложными, но в нашем примере с `number_of_german_letters` это, по всей видимости, будут пары (*исходная\_строка, количество\_букв*). Так вот, учитывая все, что было сказано в предыдущих пунктах, составить таблицу до написания кода представляется затруднительным, однако написать код, который будет проверять очередную пару *IN* и *OUT*, я могу, зная только интерфейс. Или, говоря менее формально, я могу выбрать, что и как именно я хочу проверять, но еще не могу знать, на каких именно значениях.
Если смотреть на тест как на код, обслуживающий подобную таблицу, то до функции я уже могу написать этот код, но еще не могу наполнить таблицу данными. То есть, повторюсь, я уже знаю, как устанавливать исходные параметры функции и как снимать с тестируемой системы результат ее работы, но я все еще не знаю, какие из этих пар включить в свой тест. Как выглядит такой тест на практике? Применяя этот подход к нашей функции `number_of_german_letters`, в случае наличия внутренней функции, определяющей «немецкость», мы сможем обойтись малым количеством строк в этой таблице, тогда как, если ее нет, таблицу придется наполнить значительно больше. Но шаблон теста в обоих этих случаях будет одинаков.
Итак, под шаблоном теста я имею в виду такой код, в который осталось только поставить пары (*IN, OUT*). Начать можно, например, с того, что все свои проверки поместить внутри цикла по пустой таблице, тогда весь код будет уже готов, но еще не будет исполняться (так как цикл не делает ни одной итерации). И хотя такой вид наиболее точно соответствует обсуждаемой идее, на практике я его практически не применяю. Вместо него я обычно пользуюсь этой идеей в несколько упрощенной форме.
Вместо цикла по таблице я просто пишу код, соответствующий одной итерации по одной паре значений. Какие значения я выбираю? Это не играет принципиальной роли, поскольку одна такая пара никогда не окажется лишней. *IN* всегда будет принадлежать какому-нибудь набору значений, на которых я собираюсь тестировать, выбери я в итоге один набор или десяток, так как в совокупности все наборы все равно должны покрывать все значения. И даже в случае примитивной обертки эта единственная проверка будет полезна, потому что проверит верность интеграции с другими функциями. Когда мне нужно будет расширить тест до проверки больше чем одной пары (*IN, OUT*), я с легкостью смогу обернуть этот код в цикл по таблице (или просто накопировать проверки, если это покажется мне более адекватным).
### Возвращайтесь к тесту после написания функции
Очевидно, что набор тестов, который создан таким образом, не является законченным (поэтому я и называю его шаблоном теста). К нему будет необходимо вернуться как можно скорее, как только мне станут доступны хоть какие-то знания о реализации, т. е. сразу после написания функции (или даже еще во время ее написания).
Тогда я могу принимать осознанные и полноценные решения относительно набора необходимых проверок, а значит, просто наполняю таблицу данными (в прямом или переносном смысле).
Также могут понадобиться еще более радикальные изменения: разбиение одного теста на несколько. Вопрос о том, помещать ли несколько проверок в один тест, или каждая из них заслуживает собственного теста, непростой, и я не буду вдаваться в его детали, но обычно рекомендуется создавать новый тест, если, например, тестам нужны сильно разные исходные данные. Впрочем, этот вопрос не является предметом рассмотрения статьи. Хочу лишь сказать, что такое разбиение вполне возможно и может быть оправданно и, опять же, его необходимость на стадии написания теста до реализации может быть абсолютно неочевидна.
Итак, в качестве вывода можно сказать, что мы превратили test-first в test-template-first, так как разработчику рекомендуется писать до кода не тест, а лишь его шаблон. У меня нет строгого определения шаблона теста, однако суть данного приема должна быть понятна из изложенных пунктов.
### Срезайте углы
Изменения test-first, которые предлагается внести, актуализируют идею об *одновременном* написании кода и тестов. По моему опыту, когда я работаю над новой функцией, у меня в голове созревает одновременно план кода и теста; впрочем, иначе и быть не может, ведь я должен написать совместимые между собой тест и код. А значит, строго говоря, мне необязательно дожидаться момента, когда я *физически* что-то напишу, я могу уже при первом написании теста воспользоваться знаниями о деталях реализации, которой еще не существует, но которую я уже замыслил.
Конечно, в некотором смысле это нарушение парадигмы, и все задумывалось для того, чтобы я мог разбить разработку на простые шаги, в которых сложнее допустить ошибку. Но со временем мне удалось примерно осознать те границы, в которых я могу позволять себе отклонения от догм.
В крайних случаях я могу себе позволить даже полностью реализовать одну или несколько функций до того, как приступлю к написанию тестов для них, но лишь потому, что опыт позволяет мне держать тесты «написанными» в голове. Это не рекомендация, а совет: если вы чувствуете, что опыт позволяет вам допустить некоторую вольность, не стоит слишком этого опасаться. Это не превратит ваш test-first в test-last, это просто немного срезанный угол.
Главное, что требуется понять: test-first — это не игра в написание кода, это конкретная техника с конкретными целями, и стоит стремиться достигать этой цели, а не просто повторять шаги, описанные в тех или иных статьях.
Этот пункт — не часть парадигмы (напротив, он даже местами предлагает ее нарушать), а лишь совет не гнаться за формальными признаками техники.
Выводы
======
На мой взгляд, test-first — крайне удачная идея, однако с тех пор, как я начал пытаться ее применять, я регулярно сталкивался с проблемами, решение которых я нигде не находил. В связи с этим мне пришлось выработать некоторые собственные приемы, сначала чисто практические, а потом осмыслить их и выработать на основе своих привычек некоторую теорию. Я допускаю, что где-то в моей логике есть слабые места и существуют проблемы, которые еще не решены, однако спешу заверить, что написанное выше активно применяется мной на практике и дает плоды, а не является результатом простого размышления.
*Эта статья написана в соавторстве с Николаем Ващенко — [nickolas\_v](https://habrahabr.ru/users/nickolas_v/), он помог мне преобразовать мой практический опыт в стройную (мы надеемся) теорию, а также привести текст статьи в порядок.* | https://habr.com/ru/post/274771/ | null | ru | null |
# (Почему) Почта Mail.Ru включает строгий DMARC

На днях мы [анонсировали](https://corp.mail.ru/ru/press/releases/9593/) включение строгой DMARC-политики на всех доменах, принадлежащих Почте Mail.Ru. На некоторых доменах, включая bk.ru и mail.ua, политика p=reject включена уже сейчас. В этой статье мы хотим пояснить некоторые технические детали такого включения и дать рекомендации владельцам сервисов, почтовых серверов и списков рассылки.
Что такое DMARC?
================
DMARC (Domain-based Message Authentication, Reporting and Conformance, RFC 7489) — протокол, позволяющий администратору доменной зоны опубликовать политику приема и отправки отчетов для писем, не имеющих авторизации. В качестве протоколов авторизации используются протоколы SPF (RFC 7208) и DKIM (RFC 6376).
Как работает DMARC?
===================
При получении письма, у которого в поле отправителя (From:) используется домен example.org, сервер получателя запрашивает политику DMARC домена example, которая публикуется в DNS в виде TXT-записи, например
`_dmarc IN TXT "v=DMARC1; p=none; rua=mailto:a@example.org; ruf=mailto:f@example.org; fo=1;"`
Для письма проверяется SPF и DKIM; кроме этого, проверяется соответствие (alignment) домена, прошедшего проверку SPF или DKIM, и домена, используемого во From:. Чтобы домен прошел авторизацию DMARC, необходимо, чтобы хотя бы один из механизмов SPF или DKIM прошел авторизацию для домена, совпадающего с точностью до домена организации из адреса From:. Если письмо не проходит авторизацию или домен не совпадает (например, использована DKIM-подпись стороннего домена или адрес в envelope-from не совпадает с адресом From:), применяется политика (в данном случае none, т. е. никаких специальных действий не требуется; возможны также политики reject — не принимать письма и quarantine — складывать письма в папку «Спам»). Статистические отчеты по срабатыванию политики и прошедшим письмам будут отправляться на адрес a@example.org. Также домен, публикующий политику, просит отправлять форензик-отчеты (т. е. отчеты, содержащие как минимум заголовки полученного письма) по всем письмам, не прошедшим авторизацию SPF или DKIM, на адрес f@example.org.
Что изменилось сейчас?
======================
Mail.Ru первым в Рунете поддержал серверную часть DMARC более двух лет назад. А теперь DMARC будет защищать от подделки домены mail.ru. Ранее строгая политика DMARC была включена только для служебных доменов Mail.Ru Group (например, corp.mail.ru), поскольку именно они чаще всего подделываются фишерами. В настоящее время она также применяется для доменов mail.ua и bk.ru, а 18 мая будет распространена на все домены бесплатных почтовых ящиков (list.ru, inbox.ru и mail.ru).
Зачем это Mail.Ru?
==================
DMARC устраняет самую серьезную проблему электронной почты — отсутствие проверки адреса отправителя. Чаще всего причиной для ввода DMARC называют борьбу с фишинговыми письмами. Отчасти это действительно так — ввод строгой политики DMARC всего несколькими крупными банками США в 2014 году привел к снижению фишинга посредством электронной почты на 6% за год в целом по отрасли. В PayPal объем фишинга за два года после введения политики снизился на 70%.
В случае доменов публичной почты основной причиной является не фишинг. Мы хотим, во-первых, в целом снизить объем спама в Сети: большая его часть идет именно с поддельных адресов, в некоторые дни число таких писем с поддельными адресами mail.ru более чем в 15 раз превышает количество писем, отправляемых пользователями Mail.Ru. Во-вторых, DMARC позволяет оградить пользователей от вторичного спама. Очень часто спамные письма с поддельных адресов генерируют сообщения о невозможности доставки (NDR) и автоответы, которые идут на ящики легитимных пользователей, не отправлявших письмо. Распознать такую ситуацию может быть достаточно сложно, так как в NDR и автоответе отсутствует «спамный» контент. По нашему опыту, внедрение строгой политики DMARC снижает объем вторичного спама в несколько десятков раз.
Разве всего этого не было в SPF (DKIM, Sender-ID, ADSP)?
========================================================
SPF (RFC 7208) совсем не защищает адрес отправителя, так как работает только с адресом envelope-from, который невидим пользователю. DKIM (RFC 6376) тоже совершенно не защищает адрес отправителя, поскольку является алгоритмом подписи и не указывает, как поступать, если подписи нет или она некорректна. Sender ID (RFC 4406) прикрыт патентами Microsoft и «не взлетел». Ближайшим по функционалу к DMARC был протокол ADSP (RFC 5617), но, в отличие от DMARC, он также «не взлетел» и в 2013 году был переведен в статус Historic, так как почти все крупные игроки рынка отказались от него в пользу DMARC. В отличие от ADSP, работавшего только поверх DKIM, DMARC может использовать разные протоколы аутентификации. В базовом стандарте применяются и DKIM, и SPF. Фактически DMARC комбинирует механизмы, задействованные в Sender ID и ADSP, и дает возможность расширять их в будущем, что значительно улучшает «непрямое» прохождение почты (indirect flows). Уже сейчас можно не сомневаться, что протокол DMARC работает, — серверная часть DMARC поддерживается всеми серьезными почтовыми службами, все крупные игроки либо уже включили DMARC на своих доменах, либо заявили о таком намерении. Среди публичных почтовых служб, включивших DMARC на своих доменах (и принявших основной удар критики от владельцев списков рассылки, о чем речь пойдет ниже), — Yahoo и AOL. С их стороны это было рискованным, но очень нужным решением — иначе протокол могла бы постичь судьба Sender ID и ADSP.
В чем подвох?
=============
Естественно, у любого протокола есть недостатки. DMARC требует аутентификации отправителя, из-за этого в нескольких ситуациях возникают проблемы:
1. Пользователь посылает письма «напрямую» в обход почтового сервера с аутентификацией. Например, веб-мастер отправляет регистрационные письма PHP-скриптом, используя во From: адрес публичной почты. К сожалению, единственное решение — так не делать. Зарегистрируйте почту для своего домена. Mail.Ru предоставляет для этого [бесплатный сервис](https://help.mail.ru/biz/add). Даже если вы перейдете на отправку с адреса другой публичной почты, скорее всего, это решение будет временным, поскольку DMARC для своих доменов станут внедрять все крупные почтовые сервисы.
2. Списки рассылки. Да, с ними опять есть проблемы, и более существенные, чем в случае с SPF, так как SPF оказался бесполезным именно из-за попыток сохранить совместимость со списками рассылки. Чтобы не нарушать авторизацию DMARC, необходимо либо «не трогать» заголовки, подписанные DKIM (в частности, не менять тему письма), либо перезаписывать отправителя из From:. К счастью, основные менеджеры списков рассылки уже поддерживают корректную работу с DMARC.
3. Форварды. В некоторых случаях почтовые серверы меняют содержимое при пересылке, например структуру MIME-частей или разбивку на строки, что может приводить к нарушению DKIM-подписи. В таких случаях мы рекомендуем вместо пересылки почты использовать сбор почты по протоколам POP3/IMAP (reverse POP / reverse IMAP). Mail.Ru первая из почтовых служб реализовала сбор почты по IMAP с сохранением структуры папок. Кроме того, крупные почтовые сервисы, в том числе Mail.Ru, поддерживают белые списки известных форвардеров (known forwarders) — для списков рассылок и других почтовых служб, почта от которых принимается даже в случае нарушения DMARC. Если письма от известного форвардера или списка рассылки блокируются нами по политике DMARC — пожалуйста, сообщите об этом. В будущем проблема форвардов может быть решена реализацией протокола ARC (Authenticated Received Chain), пока этот протокол находится в стадии обсуждения.
4. Есть и другие проблемы DMARC, в том числе связанные с безопасностью, особенно при предоставлении forensic-отчетов. Например, возможность раскрывать перенаправления (и таким образом деанонимизировать пользователя) или подписчиков списков рассылки. Все это возможно и без DMARC, но DMARC заметно облегчает задачу. Поэтому мы реализовали [функцию анонимайзера](https://help.mail.ru/mail-help/settings/aliases) — как альтернативу пересылок или разовых/скрытых адресов для списков подписки. Из соображений безопасности мы не планируем предоставлять forensic-отчеты с полной идентификацией получателя недоверенным сторонам.
Что мне делать, если…
=====================
**…я обычный пользователь почты**
Ничего делать не требуется. Скорей всего, вы ничего не заметите, только избежите ситуаций «кто-то получил спам/фишинг с моего адреса, а я его не отправлял» и не будете получать непонятные «отлупы».
**…я пользуюсь [Почтой для бизнеса](https://biz.mail.ru/) для своего домена**
Изменения затронут только публичные домены Mail.Ru. Чтобы ваш домен был защищен DMARC, необходимо самостоятельно опубликовать политику.
**…я отправляю письма через почтовый сервер своего интернет-провайдера**
Для адресов обслуживаемых Mail.Ru необходимо настроить отправку через SMTP-серверы mail.ru с авторизацией [по инструкциям](https://help.mail.ru/mail-help/mailer/popsmtp).
**…я пользуюсь перенаправлениями для сбора почты с нескольких аккаунтов на разных сервисах в общий ящик**
Скорее всего, этот функционал будет работать, но чтобы исключить вероятность, что часть писем потеряется, используйте [функцию сбора почты](https://help.mail.ru/mail-help/settings/collector) с других ящиков.
**…я пользуюсь перенаправлениями для заведения скрытых/временных адресов**
Перенаправления могут быть обнаружены и раскрыты (для этого достаточно поддержки DMARC сервером получателя, т. е. практически любым сервером). Если это критично для вас, используйте [функцию анонимайзера](https://help.mail.ru/mail-help/settings/aliases).
**…я пользуюсь функционалом «отправлять как» на Gmail (или аналогичным) для отправки писем с адреса Mail.Ru**
Следует проверить настройки адреса отправки в Gmail и убедиться, что отправка идет через сервер SMTP mail.ru (smtp.mail.ru, порт 465 с использованием SSL), c корректным логином и паролем. Письма будут отправляться через сервер Mail.Ru с авторизацией отправителя и пройдут проверки SPF/DKIM/DMARC.
**…я пользуюсь обратным адресом публичной почты для отправки писем через скрипты на сервере**
Так делать не следует. Используйте «[Почту для бизнеса](https://help.mail.ru/biz/add)» для заведения ящиков в вашем собственном домене (hint: для этого не обязательно обладать бизнесом, достаточно обладать доменом). Используйте адрес собственного домена во всех серверных, автоматических или автоматизированных рассылках.
**…я предоставляю клиентам услуги доставки электронных сообщений (ESP)**
Не используйте для заголовка From: сообщений адрес отправителя из доменов бесплатной почты. Зарегистрируйте отдельный домен для клиентов, не имеющих собственного домена, настройте для него SPF, DKIM и DMARC. Выделяйте клиенту адрес в этом домене для использования в качестве адреса отправителя и прописывайте перенаправления с выделенного адреса в вашем домене на ящик электронной почты клиента. Клиентам, имеющим собственный домен, рекомендуйте брать адреса из этого домена в качестве адреса отправителя. Можно продолжать использовать адрес клиента в домене бесплатной почты для заголовков Sender: и Reply-To:.
**…я администрирую списки рассылки**
Обновите программное обеспечение списков рассылки и настройте его в соответствии с рекомендациями совместимости DMARC. Корректно работают Sympa с версии 6.2.6, Dada Mail с версии 7.0.2, Mailman с версии 2.1.16 (лучше 2.1.18), GroupServer с версии 14.06. Возможно, придется включить функцию, которая называется «Sending on behalf of» / «Munge the From: header». Если рекомендации выполнить невозможно (например, используется устаревшее или неподдерживаемое ПО), постарайтесь минимизировать нарушения DMARC, отказавшись от изменения служебных заголовков и содержимого писем, отправляемых в список рассылки, — т. е. не меняйте темы, не добавляйте хидер/футер к письмам, чтобы не нарушать DKIM-сигнатуру письма. Если проблемы с доставкой сохраняются, обратитесь в службу поддержки сервера, который не принимает сообщения.
**…я администрирую почтовый домен и хочу опубликовать свою DMARC-политику**
Настройте SPF и DKIM для всех отправляемых писем, при этом учтите специфику требований новых версий стандартов. Последняя версия стандарта SPF (RFC 7208) требует наличия SPF-записи не только для основного почтового домена, но и для имен из команды HELO/EHLO, которые, как правило, совпадают с каноническими именами почтовых серверов. Это необходимо для прохождения SPF в случае пустого отправителя, используемого в NDR/MDN. Опубликуйте DMARC-запись с политикой none. Настройте адреса для сбора отчетов rua/ruf. Обратите внимание, что стандарт DMARC требует, чтобы домен, в котором находятся данные адреса, соответствовал домену, для которого запрашиваются отчеты, либо публиковал специальную политику приема отчетов, поэтому получать отчеты на адреса публичных почт так же не получится. Проанализируйте поступающие отчеты, устраните проблемы, связанные с SPF, DKIM и несоответствием (misalign) доменов из вашей сети, идентифицируйте возможные источники легальных писем вне ее (например, рассылки, организованные через внешние сервисы рассылок) и подстройте SPF и DKIM для всех легальных писем. Можно пользоваться услугами специализированных сервисов — [Agari](https://agari.com), [proofpoint](https://www.proofpoint.com/us/products/email-fraud-defense), [Dmarcian](https://dmarcian.com). Сервис Dmarcian, помимо платных услуг, предлагает удобный бесплатный [инструмент](https://dmarcian.com/dmarc-xml/) для визуального представления XML-отчетов DMARC. Когда все проблемы будут устранены, переключите политику на reject или quarantine.
**…я администрирую почтовый сервер и хочу фильтровать письма по DMARC**
Интегрируйте соответствующий фильтр. Фильтрация по DMARC поддерживается практически во всех антиспам-решениях. В качестве отдельных бесплатных DMARC-фильтров, совместимых с основными Linux/UNIX MTA, можно порекомендовать [OpenDMARC](https://sourceforge.net/projects/opendmarc/) и [yenma](https://github.com/iij/yenma).
**…я администрирую почтовый сервер/домен и этот ваш SPF/DKIM/DMARC не знаю и знать не хочу**
По мере внедрения строгой политики DMARC другими почтовыми доменами ваш домен, не защищенный политикой DMARC, будет все чаще использоваться спамерами как источник фальшивых адресов отправителей, что приведет к постоянному росту вторичного спама и, как следствие, жалоб пользователей. Скорее всего, в результате вы все равно будете вынуждены реализовать SPF/DKIM/DMARC. Но даже если вы сохраните стойкость, когда-нибудь домены без опубликованной политики могут начать восприниматься как подозрительные, в том числе самообучающимися фильтрами, что приведет к проблемам с доставляемостью писем.
**…я администрирую почтовый сервер/домен и у меня есть вопросы**
Вы можете задать их здесь в комментариях или на [Тостере](https://toster.ru/), я стараюсь отслеживать тематические хабы.
В заключение
============
Электронная почта часто позиционируется критиками как неменяющийся динозавр из прошлого тысячелетия — но это не так: она развивается, и очень активно. Все актуальные версии основных стандартов электронной почты приняты в течение последних восьми лет, DMARC стал стандартом всего год назад, а в настоящее время идет работа по стандартизации, например, протоколов Authenticated Received Chain и SMTP Strict Transport Security. Но переход на новые стандарты и протоколы невозможен без поддержки всеми сторонами, и мы очень надеемся, что эта статья поможет и вам включиться в процесс построения более современной, удобной и безопасной экосистемы электронной почты. | https://habr.com/ru/post/282602/ | null | ru | null |
# Свободный менеджер паролей LessPass работает на чистой функции

Хранение уникальных паролей для всех сайтов и приложений — целое искусство. Невозможно запомнить сотню длинных паролей с высокой энтропией. Может быть, в мире есть десяток высокоразвитых аутистов, способных на такое, не больше. Остальным людям приходится использовать технические трюки. Самый распространённый вариант — записать все пароли в один файл, который защищён мастер-паролем. По такому принципу работает большинство парольных менеджеров.
У этого способа много преимуществ, но есть два главных недостатка: 1) трудно синхронизировать пароли между устройствами; 2) нужно всегда иметь в распоряжении сам файл с паролями. То есть потерял файл с паролями — и до свидания.
Новый парольный менеджер [LessPass](https://github.com/lesspass/lesspass) с открытым исходным кодом лишён этих недостатков, потому что работает на [чистой детерминированной функции](https://ru.wikipedia.org/wiki/Чистота_функции). У него есть другие недостатки, конечно. Об этом ниже. Сначала о достоинствах.
Концепция
=========
Концепция LessPass заключается в том, что регенерация одноразовых паролей происходит *на лету* при помощи чистой функции, которая выдаёт детерминированные значения каждый раз при расчёте каждого уникального пароля.
На вход функции подаются четыре аргумента:
* мастер-пароль
* логин на сайте
* адрес сайта
* опции генерации пароля
В любой момент на любом компьютере вы можете повторно запустить функцию — и вычислить свой уникальный пароль для конкретного сайта.
Как это выглядит.
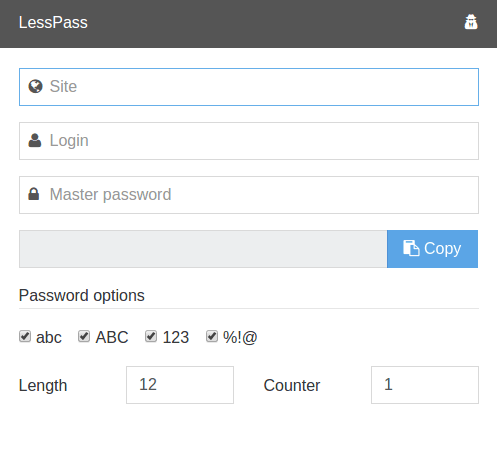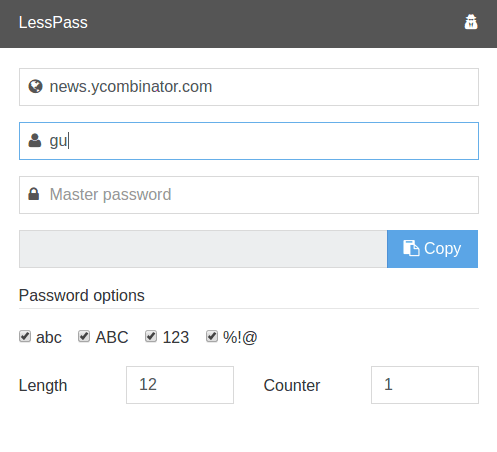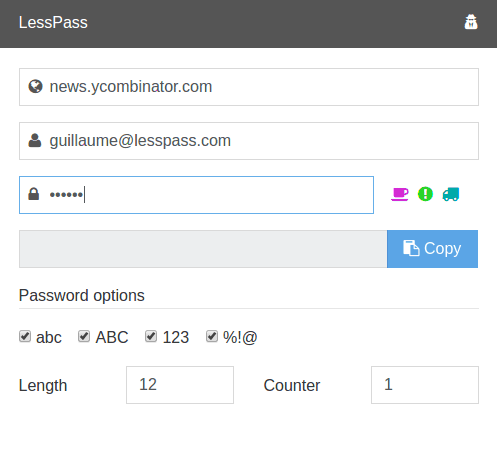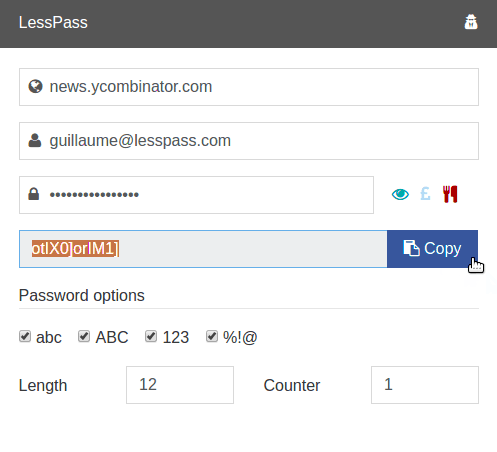
Из такой концепции сразу понятно главное достоинство подобного подхода — у вас вообще **нет файла с паролями**, как в других парольных менеджерах. Чего нет — то невозможно потерять. Теперь вместо извлечения уникального пароля из зашифрованного хранилища мы каждый раз заново генерируем этот пароль. Благодаря детерминированности функции и неизменности входных параметров всегда генерируются одни и те же уникальные пароли для всех сайтов.
Разработчик программы [Гийом Винсент](https://github.com/guillaumevincent) (Guillaume Vincent) постарался реализовать безопасность, насколько он её понимает. Какая безопасность нужна для детерминированной функции? В первую очередь — чтобы по результату её работы нельзя было определить все её аргументы, тем более что некоторые аргументы уже известны злоумышленнику, как и сама функция.
Проще говоря, если злоумышленник знает два или три из четырёх аргументов, а также результат функции, он не должен узнать четвёртый аргумент — мастер-пароль.
Для защиты мастер-пароля от брутфорса вычисление уникальных паролей LessPass прогоняет 8192 итерации функции [PBKDF2](https://en.wikipedia.org/wiki/PBKDF2) с хэш-функцией SHA-256.
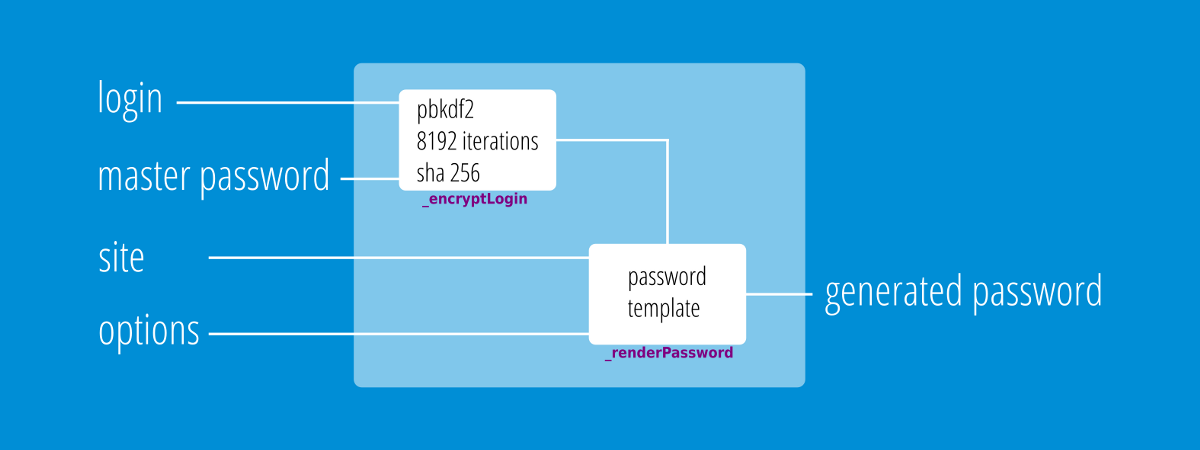
Сгенерированный первой функцией хэш обрабатывается для соответствия шаблону, установленному третьим и четвёртым параметрами (набор используемых символов, длина пароля).
Теперь, чтобы «вспомнить» уникальный пароль для конкретного сайта — просто запускаем программу [LessPass](https://lesspass.com/). Это крошечная программа состоит всего из [109 строчек](https://github.com/lesspass/core/blob/master/index.js).
**Код программы**
```
import crypto from 'crypto';
module.exports = {
encryptLogin: _encryptLogin,
renderPassword: _renderPassword,
createFingerprint: createFingerprint,
_deriveEncryptedLogin,
_getPasswordTemplate,
_prettyPrint,
_string2charCodes,
_getCharType,
_getPasswordChar,
_createHmac
};
function _encryptLogin(login, masterPassword, {iterations = 8192, keylen = 32}={}) {
return new Promise((resolve, reject) => {
if (!login || !masterPassword) {
reject('login and master password parameters could not be empty');
}
crypto.pbkdf2(masterPassword, login, iterations, keylen, 'sha256', (error, key) => {
if (error) {
reject('error in pbkdf2');
} else {
resolve(key.toString('hex'));
}
});
})
}
function _renderPassword(encryptedLogin, site, passwordOptions) {
return _deriveEncryptedLogin(encryptedLogin, site, passwordOptions).then(function (derivedEncryptedLogin) {
const template = passwordOptions.template || _getPasswordTemplate(passwordOptions);
return _prettyPrint(derivedEncryptedLogin, template);
});
}
function _createHmac(encryptedLogin, salt) {
return new Promise(resolve => {
resolve(crypto.createHmac('sha256', encryptedLogin).update(salt).digest('hex'));
});
}
function _deriveEncryptedLogin(encryptedLogin, site, passwordOptions = {length: 12, counter: 1}) {
const salt = site + passwordOptions.counter.toString();
return _createHmac(encryptedLogin, salt).then(derivedHash => {
return derivedHash.substring(0, passwordOptions.length);
});
}
function _getPasswordTemplate(passwordTypes) {
const templates = {
lowercase: 'vc',
uppercase: 'VC',
numbers: 'n',
symbols: 's',
};
let template = '';
for (let templateKey in templates) {
if (passwordTypes.hasOwnProperty(templateKey) && passwordTypes[templateKey]) {
template += templates[templateKey]
}
}
return template;
}
function _prettyPrint(hash, template) {
let password = '';
_string2charCodes(hash).forEach((charCode, index) => {
const charType = _getCharType(template, index);
password += _getPasswordChar(charType, charCode);
});
return password;
}
function _string2charCodes(text) {
const charCodes = [];
for (let i = 0; i < text.length; i++) {
charCodes.push(text.charCodeAt(i));
}
return charCodes;
}
function _getCharType(template, index) {
return template[index % template.length];
}
function _getPasswordChar(charType, index) {
const passwordsChars = {
V: 'AEIOUY',
C: 'BCDFGHJKLMNPQRSTVWXZ',
v: 'aeiouy',
c: 'bcdfghjklmnpqrstvwxz',
A: 'AEIOUYBCDFGHJKLMNPQRSTVWXZ',
a: 'AEIOUYaeiouyBCDFGHJKLMNPQRSTVWXZbcdfghjklmnpqrstvwxz',
n: '0123456789',
s: '@&%?,=[]_:-+*$#!\'^~;()/.',
x: 'AEIOUYaeiouyBCDFGHJKLMNPQRSTVWXZbcdfghjklmnpqrstvwxz0123456789@&%?,=[]_:-+*$#!\'^~;()/.'
};
const passwordChar = passwordsChars[charType];
return passwordChar[index % passwordChar.length];
}
function createFingerprint(str) {
return new Promise(resolve => {
resolve(crypto.createHmac('sha256', str).digest('hex'))
});
}
```
Генерация паролей работает в виде скрипта на [сайте LessPass](https://lesspass.com/), или на клиентском компьютере. Выпущены соответствующие расширения [для Chrome](https://chrome.google.com/webstore/detail/lesspass/lcmbpoclaodbgkbjafnkbbinogcbnjih) и [для Firefox](https://addons.mozilla.org/en-US/firefox/addon/lesspass/). Скрипт генератора можно запустить и в локальном облаке. Например, с помощью локального облака [Cozy](https://github.com/cozy/cozy).
Таким образом, при использовании такого парольного менеджера невозможно потерять файл с паролями, потому что такого файла его не существует. Никаких проблем ввести уникальный пароль с любого устройства. Нужно только заново сгенерировать его.
Недостатки LessPass очевидны и вытекают из его достоинств. Самое главное, что при компрометации мастер-пароля все десятки или сотни производных уникальных паролей для всех сайтов сразу можно считать потерянными.
Второй недостаток — вы не можете нормально и удобно поменять пароль для конкретного сайта. Для этого придётся изменить один из параметров генерации паролей (*Counter*). Впоследствии придётся *помнить*, какой конкретно параметр использовался для каждого сайта. Где единица, где двойка, где тройка, и так далее. Кроме того, нужно помнить уникальные требования каждого сайта к паролям. Например, какие-то банковские приложения могут ограничить пароль только цифрами и длиной в шесть цифр. Для решения этой проблемы в LessPass реализованы профили для сайтов. В профиле хранитеся вся информация, необходимая для генерации пароля, кроме мастер-пароля.
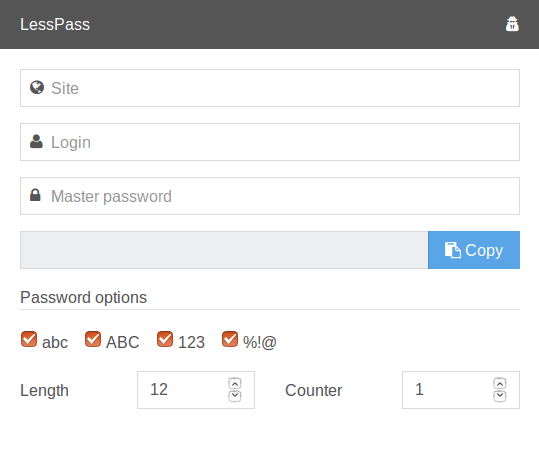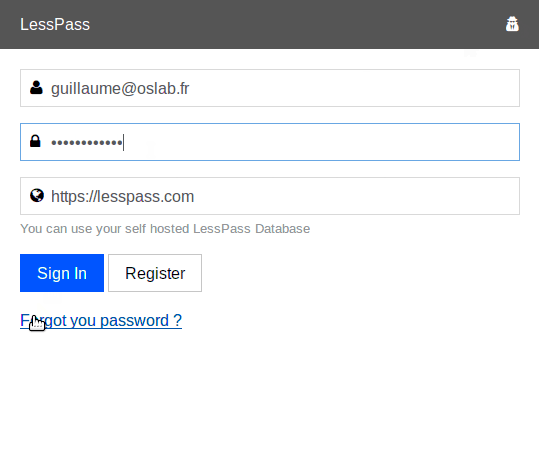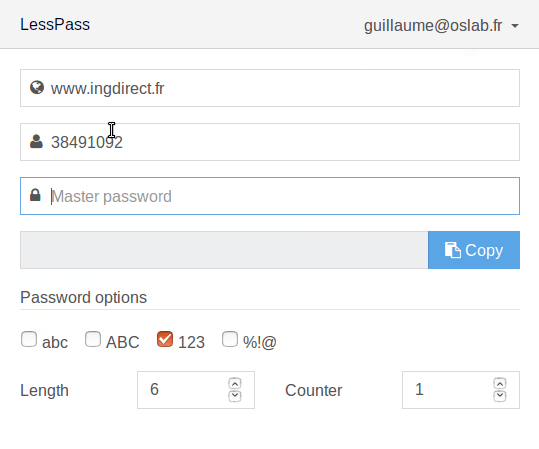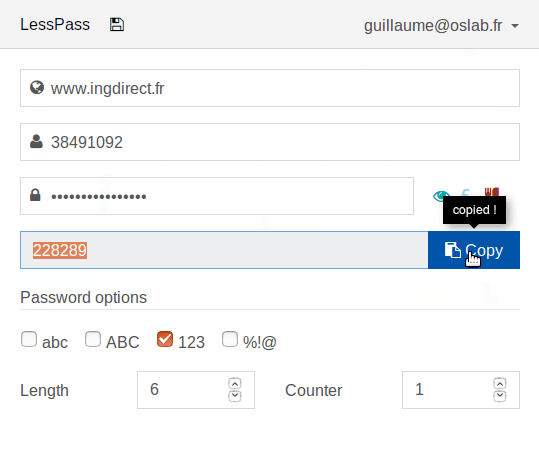
*Профили в LessPass*
Третий недостаток — для брутфорса пароля злоумышленнику не требуется физический доступ к компьютеру пользователя. Ему не нужен ваш файл с зашифрованными паролями. Чисто теоретически, это упрощает его действия. Пользователь вообще не заметит, что на него идёт атака.
Ситуация ухудшается тем, что в данной конкретной реализации LessPass использует всего 8192 итерации PBKDF2-SHA256. По [мнению специалистов](http://stackoverflow.com/questions/6054082/recommended-of-iterations-when-using-pbkdf2-sha256), этого крайне недостаточно для надёжной защиты от брутфорса на GPU. Ещё несколько лет назад рекомендовалось минимум 100 000 итераций, а вычислительная мощность брутфоса примерно удваивается каждый год. Так что будем считать, что нынешняя реализация LessPass — просто демонстрационная версия, доказательство работоспособности концепции.
LessPass — не единственный детерминированный менеджер паролей, работающий на чистой функции. Есть и другие аналогичные программы, в том числе [Master Password App](https://ssl.masterpasswordapp.com/) и [Forgiva](https://forgiva.com/). У всех этих программ те же недостатки, о которых упоминалось выше. К тому же, в них нельзя импортировать свои старые пароли, так что при миграции на такую программу придётся заново генерировать все пароли.
Несмотря на все недостатки, генератор детерминированных паролей на чистой функции — интересная концепция. Возможно, кому-то именно такой парольный менеджер покажется наиболее удобным. | https://habr.com/ru/post/372847/ | null | ru | null |
# Terraform в AWS: несколько аккаунтов и другие хитрости

В этой статье поговорим о нюансах использования [Terraform](https://www.terraform.io/) от HashiCorp, в частности о том, как использовать Terraform при управлении несколькими аккаунтами Amazon Web Services (так делают все чаще — из-за размера организации или предпочтений команды DevOps). По сути, AWS сами намекают клиентам, что неплохо было бы использовать несколько аккаунтов, и недавно даже выпустили для этого несколько сервисов.
Зачем нужно несколько аккаунтов AWS?
------------------------------------
Причин много. Например — дополнительная безопасность. Такая стратегия помогает разделить ресурсы по темам, чтобы, допустим, выделить по аккаунту для каждого разработчика, окружения или отдела.
Управлять безопасностью в этом случае определенно проще, чем когда у вас есть один гигантский аккаунт AWS с запутанной структурой разрешений IAM. По умолчанию отдельные аккаунты AWS не имеют доступа к ресурсам друг друга.
На практике крупные организации из-за своих размеров уже используют несколько аккаунтов AWS, но эти аккаунты никак не связаны. Это серьезно усложняет жизнь отделам закупок — на каждый аккаунт AWS нужен отдельный счет, причем организация может группировать счета в соответствии со своими внутренними правилами или нормативными требованиями. Чтобы упростить работу, можно использовать [AWS Organizations](https://aws.amazon.com/organizations/) для управления иерархией аккаунтов и объединения счетов по группам. Недавно AWS представили [AWS Control Tower](https://aws.amazon.com/controltower/) для подготовки новых аккаунтов с предустановленным набором ресурсов и централизованным управлением всеми аккаунтами.
#### Новый тренд
В целом, организации все чаще используют несколько аккаунтов AWS, наверное, потому, что владельцы дают всем пользователям в своем аккаунте права админа, так что они могут просматривать любые ресурсы и делать что угодно.
Нужно много времени, чтобы настроить разрешения IAM вместо дефолтного админского доступа для этих пользователей. Причем нет гарантий, что принцип наименьших привилегий будет соблюдаться. С другой стороны, по умолчанию у администратора одного аккаунта AWS нет доступа к другому аккаунту, даже в той же организации. Это безопасно, но нужно поработать над разрешениями IAM, чтобы пользователь из одного аккаунта при необходимости имел доступ к ресурсам в другого. Команда DevOps в таких случаях, скорее всего, будет применять принцип наименьших привилегий.
Этот тренд влияет на Инфраструктуру как код (IaC) — например, при использовании Terraform. Инструменты IaC обычно по умолчанию привязаны к одному аккаунту AWS. С самого начала в Terraform могло быть несколько так называемых [провайдеров](https://www.terraform.io/docs/providers/index.html) в одном скрипте, чтобы получать доступ к нескольким аккаунтам AWS или даже других облачных вендоров.
Инфраструктура как код с несколькими аккаунтами
-----------------------------------------------
#### Управление ресурсами в разных аккаунтах
Допустим, один стейт Terraform может управлять ресурсами в разных аккаунтах. Обычно для этого требуется объявить несколько блоков провайдеров, по одному на аккаунт.
По умолчанию блок провайдера AWS работает в аккаунте, данные которого использовались для подключения к AWS API. Например, если вы используете идентификатор ключа доступа/секретный ключ доступа определенного пользователя AWS, Terraform будет ссылаться на аккаунт этого пользователя. Код Terraform:
```
provider “aws” {
region = “us-east-1”
}
```
Чтобы создавать ресурсы в разных аккаунтах, используйте параметр `assume_role` блока провайдера, чтобы назначить роль в другом аккаунте и получить доступ к нему:
```
provider “aws” {
region = “us-east-1”
assume_role {
role_arn = “arn:aws:iam::123456789012:role/iac”
}
}
```
Очевидно, что для этого нужно будет назначить разрешения IAM для этой роли и пользователя, выполняющего команды Terraform. Инструкции по выполнению этой задачи в AWS см. [здесь](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_use_permissions-to-switch.html?utm_source=thenewstack&utm_medium=website&utm_campaign=platform).
#### Промежуточная роль для доступа к третьему аккаунту
Второй вариант использования продолжает первый: назначенная роль может иметь разрешения на создание, обновление и удаление ресурсов в третьем аккаунте AWS. Для этого нужно настроить разрешения IAM в финальном аккаунте AWS, чтобы промежуточный аккаунт мог создавать, обновлять и удалять ресурсы в нём. Схематично это выглядит так:

*Рис. 1. Схема промежуточной роли для доступа к финальному аккаунту AWS*
Это довольно сложный сценарий, в котором придется приложить немало усилий для контроля и отладки разрешений IAM. В определенной ситуации это допустимо, но на особые преимущества с точки зрения безопасности не рассчитывайте. Вместо атаки на аккаунт 333333333333 хакеры попытаются получить доступ к 222222222222, чтобы уже оттуда добраться до 333333333333. Если аккаунт 222222222222 используется для контроля ресурсов не только в 333333333333, но и в других аккаунтах, безопасность пострадает еще больше.
Другие продвинутые стратегии Terraform
--------------------------------------
#### Несколько стейтов
Если ресурсов относительно много, можно разделить скрипты Terraform на несколько стейтов — особенно при использовании continuous deployment (CD). Управление всеми ресурсами в одном стейте имеет недостатки:
* Каждый раз, когда мы вносим даже незначительные изменения, мы боимся, что Terraform затронет базовые ресурсы, которые трогать не надо.
* Ошибочные изменения в базовых ресурсах, примененные вслепую в рамках continuous deployment, могут иметь плачевные последствия.
* Разрешения IAM, которые нужны для выполнения скрипта Terraform, будут затрагивать самые разные задачи. Их будет больше, чем требуется для CD.
* На применение изменений нужно очень много времени, потому что Terraform будет собирать стейт всех ресурсов, которыми управляет стейт, даже если в большинстве из них ничего не поменялось.
* Если при деплойменте произойдет сбой, последствия могут быть обширными.
Обычно базовые ресурсы редко меняются. Речь идет о VPC, подсетях, Transit Gateways, VPN, базах данных RDS и балансировщиках нагрузки. Эти ресурсы принадлежат базовому стейту, который почти не меняется, а если и меняется, то руками человека.
Некоторые ресурсы, наоборот, меняются постоянно. Это инстансы EC2, автоскейлинг группы, сервисы в ECS и EKS. Обычно такие ресурсы деплоятся (или обновляются) через пайплайны CD и помещаются в другой стейт, отдельно от базовых ресурсов. Этот отдельный набор скриптов Terraform будет управлять лишь небольшой, быстро меняющейся группой ресурсов, и вам потребуется гораздо меньше разрешений. Такое разделение стейтов Terraform идеально подойдет для автоматизированных деплоев.
Интересный пример такой конфигурации — кластер Kubernetes, управляемый базовым стеком, где деплоями Kubernetes управляет стек CD.
#### Модули
Terraform упрощает разбивку кода IaC на модули. Просто поместите код в другой каталог и используйте директиву module:
```
provider “aws” {
region = “us-east-1”
}
module “mymodule” {
source = “./modules/my_module”
variable1 = “value1”
variable2 = “value2”
}
```
У Terraform есть [репозиторий](https://registry.terraform.io/browse/modules) со множеством модулей, написанных сообществом Terraform для всеобщего использования. Прежде чем использовать этот репозиторий, убедитесь, что нужные модули соответствуют политикам безопасности вашей организации.
Модули Terraform позволяют соблюдать принцип DRY (Don’t Repeat Yourself — не повторяйся). Но все равно остается шаблонный код (определения в бэкенде и вызовы к самим модулям), который нельзя поместить в модуль.
#### Окружения
Для рабочей нагрузки часто существует несколько окружений — стейджинг, продакшн, тестовая среда и т. д. Эти окружения должны быть максимально похожи друг на друга, чтобы деплой, прекрасно работающий в стейджинге, показал себя не хуже в продакшене (без оправданий в стиле: «Не знаю, у меня все работало»).
Terraform предлагает [воркспейсы](https://www.terraform.io/docs/state/workspaces.html), но прежде чем применить изменения, мы должны переключиться с одного на другой (например, с продакшена на стейджинг). Если делать это вручную, высок риск, что однажды кто-нибудь забудет сменить воркспейс и задеплоит код не в то окружение. Очевидно, что последствия могут быть катастрофическими.
Есть и другое решение — составить разные наборы скриптов для разных окружений, но это громоздко, и будет много повторяющих друг друга фрагментов даже при использовании модулей. Это одна из причин создания [Terragrunt](https://terragrunt.gruntwork.io/) (подробнее об этом один из основателей рассказывает [здесь](https://blog.gruntwork.io/terragrunt-how-to-keep-your-terraform-code-dry-and-maintainable-f61ae06959d8)).
Заключение
----------
Большие (и не очень) организации часто используют несколько аккаунтов AWS, и, если постараться, вполне можно наладить Terraform в такой системе. По сути, Terraform специально разработан как мультиоблачный инструмент и поддерживает множество провайдеров, которые могут использоваться в определенном наборе скриптов.
С помощью советов в этой статье можно создать аккуратный код Terraform в соответствии с принципами DRY. | https://habr.com/ru/post/547848/ | null | ru | null |
# Критические уязвимости в Drupal: подробности и эксплоиты
[](https://habrahabr.ru/company/pt/blog/306446/)
Команда безопасности проекта Drupal [опубликовала](https://www.drupal.org/security/contrib) исправления для целого ряда критических уязвимостей. Ошибки безопасности затрагивают как популярные плагины, так и ядро системы.
Уязвимости обнаружены в модулях [RESTful Web Services](https://www.drupal.org/node/2765567) (используется для предоставления REST API к функциям Drupal), [Coder](https://www.drupal.org/node/2765575) (модуль анализа кода и миграции для старых версий) и [Webform Multiple File Upload](https://www.drupal.org/node/2765573) (добавляет компонент формы для загрузки пользовательских файлов). В ядре исправлена уязвимость [httpoxy](https://habrahabr.ru/company/pt/blog/306176/), о которой мы уже писали в блоге.
Согласно бюллетеню безопасности [PSA-2016-001](https://www.drupal.org/psa-2016-001) уязвимости затрагивают до 10000 сайтов, на которых установлены указанные модули. Бюллетень [PSA-2016-002](https://www.drupal.org/psa-2016-002) подтверждает наличие уязвимости httpoxy в восьмой ветке Drupal, где используется сторонняя библиотека Guzzle для осуществления HTTP-запросов, при этом более ранние версии Drupal 7.x не подвержены данной уязвимости.
В сети уже опубликованы эксплоиты, использующие данные уязвимости. В нашем сегодняшнем материале — их более подробное описание.
#### Подробности
Согласно данным Drupal Security Team модуль REST API под названием RESTful Web Services используется на 5804 сайтах. Уязвимость возможна из-за недостаточной фильтрации входящих данных перед использованием в функции `call_user_func_array()`. Злоумышленники могут использовать уязвимость для выполнения произвольного PHP-кода, отправив специальный запрос. Уязвимы версии модуля до 7.x-2.6 и 7.x-1.7. Эксплоит [уже включен](https://www.exploit-db.com/exploits/40130/) в состав Metasploit Framework.
Модуль для анализа и миграции старого кода Coder согласно официальной статистике установлен на 4951 сайте. Уязвимость возможна из-за отсутствия проверки привилегий пользователя в скрипте, который осуществляет обновление старых модулей Drupal. На вход скрипт принимает имя файла с настройками обновления, которые попадают в функцию `unserialize()`:
```
php
$parameters = unserialize(file_get_contents($path));
</code
```
У атакующего есть возможность указать вместо имени файла саму структуру с помощью [PHP-враппера data://](http://php.net/manual/ru/wrappers.data.php). Значение одного из параметров используется без экранирования в функции `shell_exec()`:
```
php
shell_exec("diff -up -r {$old_dir} {$new_dir} {$patch_filename}");
```
Таким образом, уязвимость позволяет внедрить и выполнить любую команду в системе:

Уязвимы версии модуля до 7.x-2.6 и 7.x-1.3. Особенностью уязвимости является тот факт, что для эксплуатации модуль необязательно должен быть включен, нужно лишь, чтобы он присутствовал в папке с модулями. [Эксплоит](https://www.exploit-db.com/exploits/40149/) для этой уязвимости также недавно вошел в состав Metasploit Framework.
Модуль Webform Multiple File Upload добавляет в систему компонент для загрузки пользовательских файлов. Согласно статистике на странице модуля, его используют 3076 веб-ресурсов. Обнаруженная уязвимость позволяет выполнить PHP Object Injection — десериализацию PHP-объекта, поступающего от пользователя. В результате у атакующего есть возможность сформировать объект, который вызовет деструктор любого класса, а также проэксплуатировать уязвимости в функции unserialize(). Степень угрозы уязвимости оценивается как Critical (максимально опасным уровнем является Highly Critical), так как в системе есть лишь один полезный для атакующего деструктор, который позволяет удалить любой файл. Уязвимы версии Webform Multiple File Upload до 7.x-1.4.
#### К чему могут приводить уязвимости Drupal
Несмотря на то, что описанные уязвимости затрагивают далеко не все сайты, работающие на Drupal, последствия их эксплуатации все равно могут быть значительными, поскольку эту CMS используют многие организации по всему миру.
К примеру, одной из них была ставшая знаменитой на весь мир в ходе «Панамского дела» компания Mossac Fonseca — ее сайт работал на Drupal и предположительно был взломан через уязвимость системы, получившей название [Drupalgeddon](http://drupal.sh/drupal-panama-papers-leaks-mossack-fonseca). Именно факт взлома мог способствовать утечке конфиденциальных документов о том, как знаменитости и политики со всего мира используют офшоры.
#### Как защититься
Эксперты Positive Technologies рекомендуют пользователям корпоративных ИТ-систем применять специализированные средства защиты, позволяющие бороться с описанными уязвимостями. К примеру, самообучающийся защитный экран уровня приложений [PT Application Firewall](http://www.ptsecurity.ru/products/af/) уже сейчас в состоянии блокировать атаки с их использованием.
 | https://habr.com/ru/post/306446/ | null | ru | null |
# Кунг-фу: стиль JavaScript
Эта статья начиналась как комментарий к [другой статье на habrahabr](http://habrahabr.ru/blogs/javascript/48542/ "другой статье на habrahabr"). После написания первого листа, я понял, комментарий слишком обширный получился :). Я решил написать, потому что хочу заострить внимание на моментах, которые, на мой взгляд, были упущены. Ограничение этой статьи — моя цель изложить всё максимально доступно, не ищите здесь математической точности в определении терминов, и всё же я прилагаю ссылки где математики найдут высококлассные понятные только им определения :)
Наверно каждую статью по JS принято начинать со слов о его недооцененности :) Это правда :) Когда я пару лет назад говорил о том что JS мой любимый язык на меня смотрели, как на школьника-переростка, который только что написал свою первую страницу на HTML, а те кто меня знал, как на гроссмейстера, который сказал что он только и знает как фигуры ходят :). Таких людей не стало намного меньше, увы :(
Итак, момент первый — ничего не сказано о том чем Javascript отличается принципиально от Java или С++. Отличие в подходе ([парадигме](http://ru.wikipedia.org/wiki/%D0%9F%D0%B0%D1%80%D0%B0%D0%B4%D0%B8%D0%B3%D0%BC%D0%B0_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F "парадигмах")) программирования взятой за основу при создании языка. Я не оцениваю «что лучше?», ни в коме случае, кому что удобнее :) или нравиться :)
### Отличие традиционной [класс-объектной](http://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D0%BD%D0%BE-%D0%BE%D1%80%D0%B8%D0%B5%D0%BD%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5#.D0.A2.D1.80.D0.B0.D0.B4.D0.B8.D1.86.D0.B8.D0.BE.D0.BD.D0.BD.D1.8B.D0.B9_.D0.BF.D0.BE.D0.B4.D1.85.D0.BE.D0.B4 "Объектно-ориентированное программирование") от [прототипной](http://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%BE%D1%82%D0%BE%D1%82%D0%B8%D0%BF%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5 "Прототипное программирование") [парадигмы](http://ru.wikipedia.org/wiki/%D0%9F%D0%B0%D1%80%D0%B0%D0%B4%D0%B8%D0%B3%D0%BC%D0%B0_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F "парадигмах")
Большинство людей, которые смотрят на JS свысока говорят о нем, как не о ООП языке :). Начнем с того, что это разные вещи и их вообще нельзя сравнивать. Конечно можно программировать на JS пользуясь навыками полученными при программировании на C++ или Java, но это так не эффективно. JS работает иначе, в нём нет классов, в нём есть объекты (не падайте в обморок, дочитайте статью). Это не означает, что на JS невозможно сделать [абстракции](http://ru.wikipedia.org/wiki/%D0%90%D0%B1%D1%81%D1%82%D1%80%D0%B0%D0%BA%D1%86%D0%B8%D1%8F_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85 "абстракции"), [инкапсуляции](http://ru.wikipedia.org/wiki/%D0%98%D0%BD%D0%BA%D0%B0%D0%BF%D1%81%D1%83%D0%BB%D1%8F%D1%86%D0%B8%D1%8F_%28%D0%B2_%D0%BE%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D0%BD%D0%BE-%D0%BE%D1%80%D0%B8%D0%B5%D0%BD%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%BE%D0%BC_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B8%29 "инкапсудяции"), [наследование](http://ru.wikipedia.org/wiki/%D0%9D%D0%B0%D1%81%D0%BB%D0%B5%D0%B4%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%28%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5%29 "наследование") или [полиморфизма](http://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D0%BB%D0%B8%D0%BC%D0%BE%D1%80%D1%84%D0%B8%D0%B7%D0%BC_%D0%B2_%D1%8F%D0%B7%D1%8B%D0%BA%D0%B0%D1%85_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F "полиморфизма"). Главные отличия в реализации [инкапсуляции](http://ru.wikipedia.org/wiki/%D0%98%D0%BD%D0%BA%D0%B0%D0%BF%D1%81%D1%83%D0%BB%D1%8F%D1%86%D0%B8%D1%8F_%28%D0%B2_%D0%BE%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D0%BD%D0%BE-%D0%BE%D1%80%D0%B8%D0%B5%D0%BD%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%BE%D0%BC_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B8%29 "инкапсудяции"), [наследования](http://ru.wikipedia.org/wiki/%D0%9D%D0%B0%D1%81%D0%BB%D0%B5%D0%B4%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%28%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5%29 "наследование"), и работе конструктора. В JS, как и почти во всех языках прототипного типа, нужно использовать термин [инкапсуляции](http://ru.wikipedia.org/wiki/%D0%98%D0%BD%D0%BA%D0%B0%D0%BF%D1%81%D1%83%D0%BB%D1%8F%D1%86%D0%B8%D1%8F_%28%D0%B2_%D0%BE%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D0%BD%D0%BE-%D0%BE%D1%80%D0%B8%D0%B5%D0%BD%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%BE%D0%BC_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B8%29 "инкапсудяции"), есть [замыкание](http://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%BC%D1%8B%D0%BA%D0%B0%D0%BD%D0%B8%D0%B5_%28%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5%29 "замыкание").
### Замыкание
Замечу, что на [хабре уже была статья о замыканиях](http://habrahabr.ru/blogs/webdev/38642/ "хабре уже была статья о замыканиях"). Попробую объяснить «на пальцах» и добавлю пример.
Замыканиями в JS называют область видимости внутри которой переменная обретает смысл :). Это может быть определение объекта или функции. Переменная может быть как примитивной, так и объектом или функцией. Уф… теперь, любимое, пример:
> `1. function bicubic(count)
> 2. {
> 3. var values = [];
> 4.
> 5. for (var i = 0; i < count; i++)
> 6. {
> 7. values[i] = (
> 8. function(n)
> 9. {
> 10. return function()
> 11. {
> 12. return Math.pow(n, 3);
> 13. }
> 14. }
> 15. )(i);
> 16. }
> 17.
> 18. return values;
> 19. }
> 20.
> 21. var vals = bicubic(10);
> 22.
> 23. alert( vals[3]() );
> \* This source code was highlighted with Source Code Highlighter.`
Если бы мне показали эти строки и попросили бы сказать «что это за хрень такая» я бы не одну минуту потратил, чтоб разобраться :) Именно это и придает столько силы сторонником JS в утверждении, что языки основанные на классах приводят при написании кода к излишней сфокусированности программистов на иерархичности и связях классов друг с другом, что по моему правда.
Давайте по порядку :)1. Создается функция bicubic которая выдает массив;
2. Фишка в том, что является членами массива — это функции без параметра: Math.pow(n, 3). В данном случае n, благодаря чуду замыкания становиться значением i в момент прохода цикла, а не после него!
3. Волшебство в скобках (...)(i) — это вызов функции с параметром i, а в скобках определение этой функции.
т.к после прохода циклом i = count, то без этих скобок, мы получим совсем другой ответ — постоянный 10'000, а с ними 27.
Кстати, этот приём называется разрывом замыкания.
Именно поэтому в [jQuery](http://jquery.com/ "jQuery") рекомендуют писать плагины к этому фреймверку внутри конструкции (… ваш плагин...)();, это позволяет:
1. Писать безопасный код
2. Не перегружать браузер глобальными переменными
### Экземпляр, конструктор, объект и прототип
Вот я недавно написал, что в JS нет классов, а есть объекты. Я имел в виду следующее:
В класс-ориентированных языках новый экземпляр создается через вызов конструктора класса (возможно, с набором параметров). Получившийся экземпляр имеет структуру и поведение, жёстко заданные его классом. Вот строчки из Википедии:
> В прототип-ориентированных системах (например JS) предоставляется два метода создания нового объекта: *клонирование* существующего объекта, либо создание объекта *«с нуля»*. Для создания объекта с нуля программисту предоставляются синтаксические средства добавления свойств и методов в объект. В дальнейшем, с получившегося объекта может быть получена полная копия, клон. В процессе клонирования копия наследует все характеристики своего прототипа, но с этого момента она становится самостоятельной и может быть изменена. В некоторых реализациях копии хранят ссылки на объекты-прототипы, делегируя им часть своей функциональности; при этом изменение прототипа может затронуть все его копии. В других реализациях новые объекты полностью независимы от своих прототипов.
>
>
Демонстрация:
> `1. function win() {
> 2. this.open = function()
> 3. {
> 4. return "open 1";
> 5. }
> 6. }
> 7.
> 8. win.open = function() {
> 9. return "open 2";
> 10. }
> 11.
> 12. alert( win.open() ); // 1. open 2
> 13.
> 14. win.prototype = {
> 15. save: function()
> 16. {
> 17. return "open 3";
> 18. }
> 19. }
> 20.
> 21. alert( win.save() ); // 2. error - нет save
> 22.
> 23. win.prototype.open = function()
> 24. {
> 25. return "open 4";
> 26. }
> 27.
> 28. alert( win.open() ); // 3. open 2
> 29.
> 30. var vista = new win();
> 31.
> 32. alert( vista.open() ); // 4. open 1
> 33. alert( vista.save() ); // 5. open 3
> 34.
> 35. vista.open = (
> 36. function()
> 37. {
> 38. return "open 5";
> 39. }
> 40. )();
> 41.
> 42. alert( vista.open ); // 6. open 5
> 43.
> 44. alert( win.open() ); // 7. open 2
> \* This source code was highlighted with Source Code Highlighter.`
«open 4» мы не получим, т.к. метод open у нас определен в самом объекте, что не касается save.
Внимательный читатель меня спросит — а где же в этой дьявольской смеси конструктор? Да, здесь его не было. Конструктором является сам объект, запускается при создании клона, с помощью оператора new или инициализации самого объекта. Демонстрация:
> `1. function win()
> 2. {
> 3. var str = "open 1";
> 4.
> 5. this.open = function()
> 6. {
> 7. return str;
> 8. }
> 9. }
> 10.
> 11. alert( (new win()).open() ); // open 1
> \* This source code was highlighted with Source Code Highlighter.`
Создание объекта «с нуля» в JS, «это вещь»! Приведу пример, который помогает экономить мускульные усилия пальцев:
> `1. function plugin(options)
> 2. {
> 3. options = options || {};
> 4.
> 5. options.list = options.list || [];
> 6.
> 7. // далее можно смело работать
> 8. // options, проверять его свойства, например,
> 9. // а с list как с массивом
> 10. }
> \* This source code was highlighted with Source Code Highlighter.`
### Прототип, «наследование» в javascript
> очень сложно найти в тёмной комнате чёрную кошку, особенно если там её нет :)
>
> *© народная мудрость*
В JS нет наследования и тем более множественного. У каждого объекта есть прототип, объект который можно сделать общим для нескольких объектов или их экземпляров, а потом менять :)
### Итог
Ребятам молящимся на парадигму ООП, проснитесь, есть много других парадигм программирования. Нет лучшей, есть наиболее подходящие для определенных задач. JS один из языков на долго занявших свою нишу, в том числе потому что под ним очень мощный фундамет [прототипной прарадигмы программирования](http://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%BE%D1%82%D0%BE%D1%82%D0%B8%D0%BF%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5 "прототипной прарадигмы программирования").
Остальные, надеюсь узнали что-нибудь полезное :)
С уважением, Артур Дудник
самая ценная человеческая черта — стремление к самосовершенствованию © | https://habr.com/ru/post/49772/ | null | ru | null |
# Знакомство с рекомендательными системами
Привет, Хабр!
Давайте вернемся к периодически затрагиваемой у нас теме машинного обучения и нейронных сетей. Сегодня речь пойдет об основных типах рекомендательных систем, их достоинствах и недостатках. Под катом — интересная статья Тоби Дейгла с кодом на Python,
Над катом — ссылка на [большую презентацию](https://logic.pdmi.ras.ru/~sergey/teaching/mlstc12/15-recommender.pdf) нашего замечательного автора Сергея Николенко, чью книгу "[Глубокое обучение. Погружение в мир нейронных сетей](https://www.piter.com/product_by_id/93110353)", написанную в соавторстве с Артуром Кадуриным и Екатериной Архангельской, мы просто не успеваем допечатывать. В презентации описаны основные типы рекомендательных систем и принципы их работы.
Читаем и комментируем!
> Многие получают советы, но лишь мудрые в состоянии ими воспользоваться. — Харпер Ли
Рекомендательные системы кажутся многим волшебными артефактами, словно читающими наши мысли. Вспомните хотя бы рекомендательный движок Netflix, подсказывающий нам новые фильмы, или сервис Amazon, предлагающий нам товары, которые могут понравиться. С самого зарождения такие инструменты совершенствовались и оттачивались, пользоваться ими становилось все удобнее. Но, пусть многие из рекомендательных движков — очень сложные системы, фундаментально их устройство весьма незамысловато.
**Что такое рекомендательная система?**
Рекомендательные движки — это подсемейство систем для фильтрации контента, предоставляющих пользователю те элементы, которые могли бы его заинтересовать. Рекомендации подбираются на основе преференций и поведения пользователя. Система должна спрогнозировать вашу реакцию на тот или иной элемент – и предложить другие, которые также могут вам понравиться.
**Как создать рекомендательную систему?**
Хотя, при программировании рекомендательных систем применяется множество методов, расскажу вам о трех самых простых, которые используются чаще всего. Речь пойдет о коллаборативной фильтрации (collaborative filtering), контентная фильтрация (content-based filtering) и, наконец, экспертные системы (knowledge-based systems). По каждой системе я опишу ее слабые места, потенциальные подводные камни и расскажу, как их обходить. Наконец, в финале статьи я приведу полноценную реализацию рекомендательного движка.
*Коллаборативная фильтрация*

Первый из рассматриваемых методов, коллаборативная фильтрация — один из простейших и наиболее эффективных. Этот трехэтапный процесс начинается со сбора пользовательской информации. Затем выстраивается матрица для расчета ассоциаций и, наконец, дается весьма достоверная рекомендация. Существует две основные разновидности этого метода: на основе пользователей, занимающихся поиском, и на основе элементов, образующих ту или иную категорию.
*Пользовательская коллаборативная фильтрация*
Идея, на которой основан этот метод – искать пользователей, чьи вкусы похожи на предпочтения нашего целевого пользователя. Если ранее Жан-Пьер и Джейсон проставили схожие оценки нескольким фильмам, то мы считаем, что вкусы у них подобны, и по рейтингам тех или иных фильмов, проставленным Жаном-Пьером, можем угадать неизвестные рейтинги Джейсона. Например, если Жану-Пьеру понравились фильмы «*Возвращение джедая*» и «*Империя наносит ответный удар*», а Джейсону понравился фильм «*Возвращение джедая*», то мы определенно должны подсказать Джейсону и фильм «*Империя наносит ответный удар*». В принципе, для прогнозирования интересов Джейсона нужно найти несколько пользователей, с которыми у него схожие вкусы.
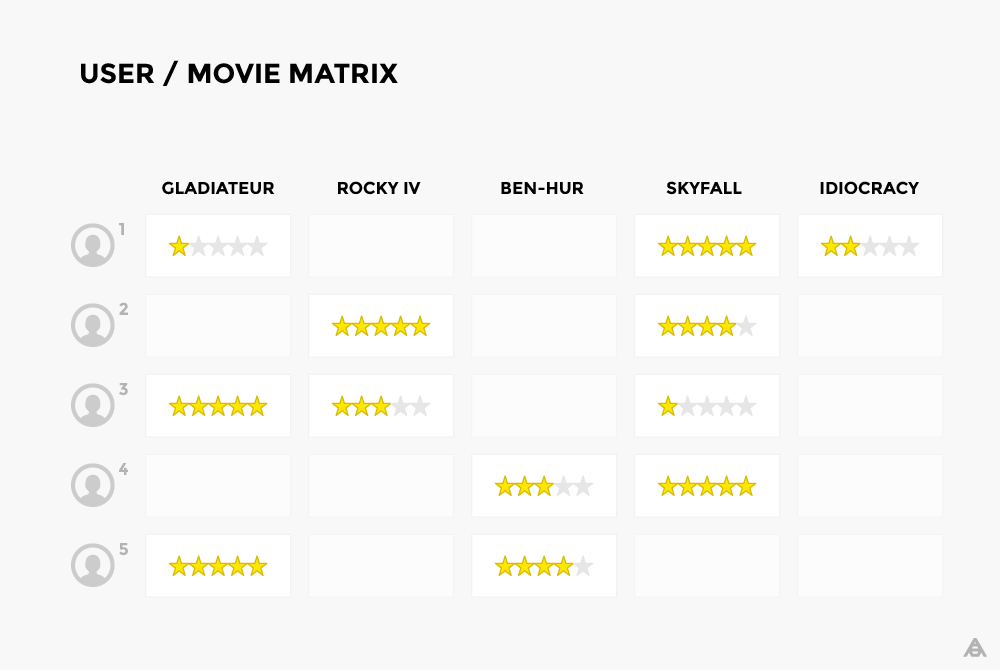
В таблице, где каждый ряд соответствует пользователю, а каждый столбец – фильму, просто найти сходство между рядами в матрице и, соответственно, подыскать пользователей с общими интересами.
Однако, такая реализация сопряжена с рядом проблем:
* Пользовательские предпочтения со временем меняются. В результате система может генерировать множество неактуальных рекомендаций;
* Чем больше количество пользователей, тем больше времени уходит на генерирование рекомендации
* Фильтрация пользователей уязвима для [накрутки рейтингов](https://en.wikipedia.org/wiki/Collaborative_filtering#Shilling_attacks), когда злоумышленник обманывает систему и необъективно повышает оценку одних продуктов по сравнению с другими.
**Коллаборативная фильтрация по элементам**
Процесс прост. Сходство двух элементов рассчитывается по рейтингам, выставленным пользователем. Вернемся к примеру с Жаном-Пьером и Джейсоном — как мы помним, обоим понравились фильмы «*Возвращение джедая*» и «*Империя наносит ответный удар*». Можно сделать вывод, что большинству пользователей, высоко оценивших первый фильм, должен понравиться и второй. Таким образом, было бы релевантно предложить фильм «Империя наносит ответный удар» Ларри, которому понравился фильм «*Возвращение джедая*».
Следовательно, сходство вычисляется по столбцам, а не по строкам (как понятно из матрицы с пользователями и фильмами, приведенной выше). Зачастую предпочитается именно коллаборативная фильтрация по элементам, так как она лишена всех недостатков, присущих пользовательской фильтрации. Во-первых, элементы в системе (здесь — фильмы) не изменяются со временем, поэтому рекомендации получатся более релевантными. Кроме того, элементов обычно гораздо меньше, чем пользователей, поэтому обработка данных при такой фильтрации происходит быстрее. В конечном итоге, такие системы гораздо сложнее обмануть.
**Контентная рекомендательная система**
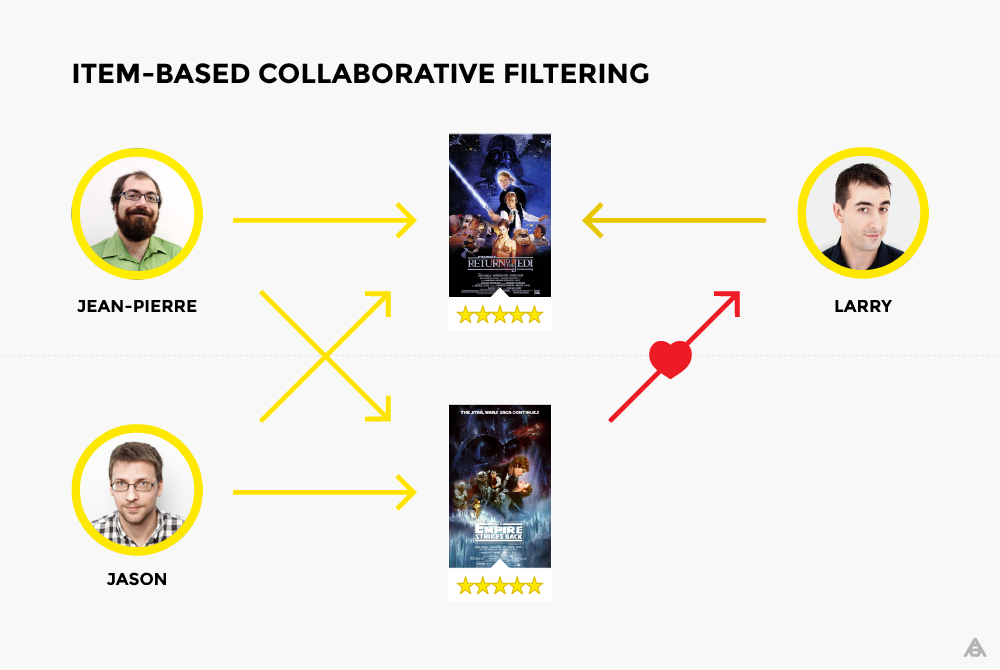
В контентных рекомендательных системах рекомендации формулируются на основе атрибутов, присваиваемых каждому элементу. Термин «контент» относится именно к этим описаниям. Например, если изучить историю музыкальных интересов Софи, можно заметить, что ей нравится жанр кантри. Следовательно, система может рекомендовать ей композиции в стиле кантри, а также композиции схожих жанров. Более сложные системы в состоянии выявлять соотношения между множественными атрибутами и давать более качественные рекомендации. Так, на сайте [Music Genome Project](https://www.pandora.com/about/mgp) каждая композиция, имеющаяся в базе данных, категоризируется по 450 различным атрибутам. Именно на основе этого движка работает музыкальная рекомендательная система на сайте [Pandora](https://ru.wikipedia.org/wiki/Pandora_(%D1%80%D0%B0%D0%B4%D0%B8%D0%BE)).
*Экспертные рекомендательные системы*
Экспертные рекомендательные системы особенно хороши для работы с такими элементами, которые приобретаются нечасто – например, дома, автомобили, финансовые активы или дорогие предметы роскоши. В таких случаях рекомендательный процесс осложняется из-за дефицита рейтингов по товарам. В экспертных системах рекомендации предлагаются не на основе рейтингов, а на базе сходства между пользовательскими требованиями и описанием продукта, либо в зависимости от ограничений, выставляемых пользователем при конкретизации желаемого продукта. Поэтому система такого типа получается уникальной, ведь она позволяет клиенту явно указать, чего он хочет. Что касается ограничений – в случаях, когда они вообще применяются – обычно такие ограничения известны с самого начала и реализуются экспертами в данной предметной области. Например, если пользователь явно указывает, что ищет недвижимость в данной ценовой категории, то система должна ориентироваться на данную спецификацию при подборе вариантов.
**Проблема холодного старта в рекомендательных системах**
Одна из важнейших проблем, связанных с рекомендательными системами, заключается в том, что исходное количество доступных рейтингов обычно невелико. Что делать, если новоиспеченный пользователь пока не рейтинговал фильмов, либо, если в систему добавился новый фильм? В таких случаях затруднительно применять традиционные модели коллаборативной фильтрации. Контентные методы и экспертные системы справляются с проблемой холодного старта увереннее коллаборативных моделей, но и они не всегда есть в распоряжении. Поэтому именно для таких случаев был разработан ряд альтернативных решений – например, гибридные системы.
**Гибридные рекомендательные системы**
Итак, у всех разнообразных рекомендательных систем, рассмотренных выше, есть свои достоинства и недостатки, и предлагаемые этими системами варианты базируются на разных исходных данных. Некоторые рекомендательные движки, в частности, экспертные системы, наиболее эффективны в контекстах, где количество доступных данных ограничено. Другие системы, например, коллаборативная фильтрация, лучше всего работают в средах, где имеются большие массивы данных. Зачастую, когда данные диверсифицированы, мы располагаем достаточной гибкостью, чтобы решать одну и ту же задачу разными методами. Следовательно, можно скомбинировать рекомендации, полученные несколькими способами, тем самым повысив качество системы в целом. Исследовано множество комбинаторных приемов, в том числе:
* Взвешенные: рекомендациям, полученным разными методами, присваивается различный вес – то есть, некоторые рекомендации считаются более предпочтительными, нежели другие.
* Смешанные: общий набор рекомендаций, без явного предпочтения тем или иным классам
* Дополненные: рекомендации от одной системы используются в качестве ввода для следующей, и так по цепочке.
* Переключение: выбор случайного метода
Один из наиболее известных гибридных движков – система, которая стала известна по результатам конкурса [Netflix Prize](https://www.netflixprize.com/rules.html) и работала с 2006 по 2009 год. Цель проекта заключалась в совершенствовании рекомендательного движка Cinematch от Netflix, предлагавшего пользователям новые фильмы, а задача – увеличить точность попаданий не менее, чем на 10%. Команда Bellkor Pragmatix Chaos выиграла премию в 1 миллион долларов за решение, в котором комбинировалось 107 различных алгоритмов; их программа повысила точность Cinematch на 10.06%. Для справки: точность – это степень совпадения текущего рейтинга фильма с последующими выставляемыми ему оценками.
**Что насчет ИИ?**
Рекомендательные системы часто используются в контексте искусственного интеллекта. Возможность выдачи подсказок, прогнозирования событий и подчеркивание корреляций – все это результаты применения ИИ. С другой стороны, при воплощении рекомендательных систем часто используются приемы машинного обучения. Например, компания Arcbees написала эффективный рекомендательный движок, работающий на основе нейронных сетей и данных, которые берутся из IMdB. Нейронные сети позволяют быстро решать сложные задачи и с легкостью манипулировать большими данными. Взяв в качестве ввода список фильмов, и сопоставив вывод с пользовательскими оценками, сеть может усвоить правила и затем руководствоваться ими, прогнозируя дальнейшие рейтинги, которые может проставить конкретный пользователь.
**Советы экспертов**
Читая материалы по этой теме, я нашел два отличных совета от экспертов. Во-первых, базовым материалом для работы рекомендательного движка должны быть такие элементы, за которые пользователи готовы платить. В таком случае можно быть уверенным, что оценки выставляемые пользователями, будут довольно точными и релевантными. Во-вторых, всегда лучше опираться на совокупности алгоритмов, а не на единственный алгоритм. Хороший пример — Netflix Prize.
**Реализация рекомендательной системы на основе подбора элементов**
В следующем коде показано, как легко и быстро можно реализовать рекомендательный движок, в котором используется коллаборативная фильтрация. Код написан на [Python](https://www.python.org/), здесь использованы библиотеки [Pandas](http://pandas.pydata.org/) и [Numpy](http://www.numpy.org/) – одни из самых популярных в данном сегменте. В качестве массива данных использовались рейтинги фильмов, а само множество данных доступно на [MovieLens](https://movielens.org/).
*Этап 1: Находим похожие фильмы*
Считываем данные
```
import pandas as pd
ratings_cols = ['user_id', 'movie_id', 'rating']
ratings = pd.read_csv('u.data', sep='\t', names=ratings_cols, usecols=range(3))
movies_cols = ['movie_id', 'title']
movies = pd.read_csv('u.item', sep='|', names=movies_cols, usecols=range(2))
ratings = pd.merge(ratings, movies)
Строим матрицу фильмов для пользователя X
movieRatings = ratings.pivot_table(index=['user_id'],columns=['title'],values='rating')
```
Выбираем кино и генерируем индекс схожести (корреляции) между этим фильмом и всеми остальными
```
starWarsRatings = movieRatings['Star Wars (1977)']
similarMovies = movieRatings.corrwith(starWarsRatings)
similarMovies = similarMovies.dropna()
df = pd.DataFrame(similarMovies)
```
Удаляем непопулярные фильмы, чтобы система не подкидывала нам неподходящих рекомендаций
```
ratingsCount = 100
movieStats = ratings.groupby('title').agg({'rating': [np.size, np.mean]})
popularMovies = movieStats['rating']['size'] >= ratingsCount
movieStats[popularMovies].sort_values([('rating', 'mean')], ascending=False)[:15]
```
Извлекаем популярные фильмы, похожие на целевой
```
df = movieStats[popularMovies].join(pd.DataFrame(similarMovies, columns=['similarity']))
df.sort_values(['similarity'], ascending=False)[:15]
```
*Этап 2: предлагаем пользователю рекомендации в зависимости от проставленных им оценок*
Генерируем индекс схожести в каждой паре фильмов и оставляем только популярные
```
userRatings = ratings.pivot_table(index=['user_id'],columns=['title'],values='rating')
corrMatrix = userRatings.corr(method='pearson', min_periods=100)
```
Генерируем рекомендации для каждого фильма, просмотренного и оцененного нашим пользователем (здесь – данные для пользователя 0)
```
myRatings = userRatings.loc[0].dropna()
simCandidates = pd.Series()
for i in range(0, len(myRatings.index)):
# Извлекаем фильмы, похожие на оцененные мной
sims = corrMatrix[myRatings.index[i]].dropna()
# Далее оцениваем их сходство в зависимости от того, как я оценил тот или иной фильм
sims = sims.map(lambda x: x * myRatings[i])
# Добавляем индекс в список сравниваемых кандидатов
simCandidates = simCandidates.append(sims)
simCandidates.sort_values(inplace = True, ascending = False)
```
Суммируем показатели идентичных фильмов
```
simCandidates = simCandidates.groupby(simCandidates.index).sum()
simCandidates.sort_values(inplace = True, ascending = False)
```
Оставляем лишь те фильмы, которые пользователь еще не смотрел
```
filteredSims = simCandidates.drop(myRatings.index)
```
**Что дальше?**
В вышеприведенном случае нам вполне удалось обработать множество данных MovieLens при помощи библиотеки Pandas на обычном процессоре. Однако, обработка более крупных наборов данных может занимать больше времени. В таких случаях могут помочь более мощные решения – например, [Spark](http://spark.apache.org/mllib/) или [MapReduce](https://en.wikipedia.org/wiki/MapReduce). | https://habr.com/ru/post/350346/ | null | ru | null |
# Реалистичное гравитационное линзование на Unity

*Эффект гравитационной линзы вызванный скоплением галактик RCS2 032727-132623*
Возникла недавно необходимость реализовать на Unity достаточно правдоподобное изображение черной дыры и, соответственно, эффект гравитационного линзирования ею вызываемого. Первой мыслью было найти готовую реализацию и подстроить под себя, однако, поскольку ни одного достаточно хорошего решения так и не нашел (что весьма странно, зная насколько популярны игры на космическую тематику), решил реализовать эффект самостоятельно, а заодно и поделиться результатом с хабросообществом.
Для начала напишем скрипт который мы повесим на камеру, и который будет применять шейдер к выводимому на экран изображению.
**Скрипт**
```
using UnityEngine;
[ExecuteInEditMode]
public class Lens: MonoBehaviour {
public Shader shader;
public float ratio = 1; //Отношение высоты к длине экрана, для правильного отображения шейдера
public float radius = 0; //Радиус черной дыры измеряемый в тех же единицах, что и остальные объекты на сцене
public GameObject BH; //Объект, позиция которого берется за позицию черной дыры
private Material _material; //Материал на котором будет находится шейдер
protected Material material {
get {
if (_material == null) {
_material = new Material (shader);
_material.hideFlags = HideFlags.HideAndDontSave;
}
return _material;
}
}
protected virtual void OnDisable() {
if( _material ) {
DestroyImmediate( _material );
}
}
void OnRenderImage (RenderTexture source, RenderTexture destination) {
if (shader && material) {
//Находим позицию черной дыры в экранных координатах
Vector2 pos = new Vector2(
this.camera.WorldToScreenPoint (BH.transform.position).x / this.camera.pixelWidth,
1-this.camera.WorldToScreenPoint (BH.transform.position).y / this.camera.pixelHeight);
//Устанавливаем все необходимые для шейдера параметры
material.SetVector("_Position", new Vector2(pos.x, pos.y));
material.SetFloat("_Ratio", ratio);
material.SetFloat("_Rad", radius);
material.SetFloat("_Distance", Vector3.Distance(BH.transform.position, this.transform.position));
//И применяем к полученному изображению.
Graphics.Blit(source, destination, material);
}
}
}
```
Теперь приступим к более важной части: написанию самого шейдера.
Первым делом, нам необходимо получить радиус, в зависимости от которого будем искажать изображение:
```
float2 offset = i.uv - _Position; //Сдвигаем наш пиксель на нужную позицию
float2 ratio = {_Ratio,1}; //определяем соотношение сторон экрана
float rad = length(offset / ratio); //определяем расстояние
```
В физике, формула преломления луча света проходящего на расстоянии r от объекта с массой M имеет вид:
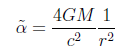
Для нас M — масса черной дыры. Зная, что радиус черной дыры определяется как
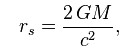
Получаем следующую конструкцию
```
float deformation = 2*_Rad*1/pow(rad*z,2);
```
где deformation — сила искажения в каждой конкретной точке, при этом z — некоторая зависимость размера искажения от расстояния на котором находится камера. Что бы понять как эта зависимость выражается, обратимся к формуле кольца Эйнштейна.
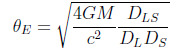
Где
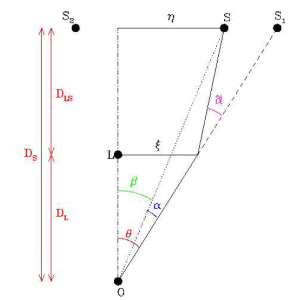
В данной формуле нас интересует ее зависимость от дистанции, потому, большую ее часть можно отбросить наблюдая лишь за
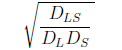
Поскольку шейдер обрабатывает 2х мерное изображение, мы не можем сказать о том, как далеко находятся объекты. И хотя это можно реализовать с помощью карты глубины, исказить их корректно не получиться, так как потребуются изображения всего что находиться за каждым из объектов. Поэтому предположим, что DL<S и DL<LS. Тогда мы видим, что размер искажения обратно пропорционален корню растояния, получаем
```
deformation = 2*_Rad*1/pow(rad*pow(_Distance,0.5),2);
```
Теперь применим нашу деформацию:
```
offset =offset*(1-deformation);
```
Вернем изображение на место и отобразим.
```
offset += _Position;
half4 res = tex2D(_MainTex, offset);
return res;
```
**Полный код шейдера**
```
Shader "Gravitation Lensing Shader" {
Properties {
_MainTex ("Base (RGB)", 2D) = "white" {}
}
SubShader {
Pass {
ZTest Always Cull Off ZWrite Off
Fog { Mode off }
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma fragmentoption ARB_precision_hint_fastest
#include "UnityCG.cginc"
uniform sampler2D _MainTex;
uniform float2 _Position;
uniform float _Rad;
uniform float _Ratio;
uniform float _Distance;
struct v2f {
float4 pos : POSITION;
float2 uv : TEXCOORD0;
};
v2f vert( appdata_img v )
{
v2f o;
o.pos = mul (UNITY_MATRIX_MVP, v.vertex);
o.uv = v.texcoord;
return o;
}
float4 frag (v2f i) : COLOR
{
float2 offset = i.uv - _Position; //Сдвигаем наш пиксель на нужную позицию
float2 ratio = {_Ratio,1}; //определяем соотношение сторон экрана
float rad = length(offset / ratio); //определяем расстояние от условного "центра" экрана.
float deformation = 1/pow(rad*pow(_Distance,0.5),2)*_Rad*2;
offset =offset*(1-deformation);
offset += _Position;
half4 res = tex2D(_MainTex, offset);
//if (rad*_Distance
```
Вот и все! Можно насладится результатом:
Данный шейдер реализует искажение лишь для одного массивного объекта. Для отображения того, что находиться перед черной дырой я использовал еще одну камеру которая рисует поверх основной. И хотя такое решение нельзя назвать элегантным, оно неплохо работает в моем случае.
P.S. Обратите внимание, что пост эффекты работают только в Pro версии Unity. | https://habr.com/ru/post/235729/ | null | ru | null |
# Qt Animation Framework
С появлением Qt 4.6 реализация анимации в проекте упростилась до минимума.
В том случае, когда необходима анимация свойств компонента, Qt 4.6 предлагает воспользоваться классом **QPropertyAnimation**. Вот пример анимации изменения размера виджета:
> `1. #include
> 2. #include
> 3. #include
> 4.
> 5. class MyWidget : public QWidget {
> 6. public:
> 7. MyWidget(QObject\* parent = 0);
> 8. // MyWidget fields and methods
> 9. public slots:
> 10. void startAnimation();
> 11. private:
> 12. QPropertyAnimation\* \_propertyAnimation;
> 13. };
> \* This source code was highlighted with Source Code Highlighter.`
> `1. MyWidget::MyWidget(QObject \*parent) : QWidget(parent) {
> 2. // Widget initialization
> 3. \_propertyAnimation = new QPropertyAnimation(this,"geometry");
> 4. \_propertyAnimation->setDuration(1000);
> 5. \_propertyAnimation->setEasingCurve(QEasingCurve::OutCubic);
> 6. }
> 7.
> 8. void MyWidget::startAnimation() {
> 9. QRectF firstPosition;
> 10. QRectF endPosition;
> 11. // Initializing first and end values
> 12. \_propertyAnimation->setFirstValue(firstPosition);
> 13. \_propertyAnimation->setEndValue(endPosition);
> 14. \_propertyAnimation->start();
> 15. }
> \* This source code was highlighted with Source Code Highlighter.`
С помощью метода **setDuration(int)** задаётся продолжительность анимации, а с помощью метода **setEasingCurve(const QEasingCurve&)** задается кривая изменения значения с течением времени. В данном примере выбрана кривая **OutQuad**

Собственно, 6 строчек и все.
Для анимации значения не являющегося свойством можно отнаследоваться от QVariantAnimation и переопределить метод **void updateCurrentValue(const QVariant&)**. В этом методе необходимо описать логику того что должно произойти при изменении значения.
QVariantAnimation поддерживает следующие типы: Int, Double, Float, QLine, QLineF, QPoint, QSize, QSizeF, QRect,QRectF. Если тип изменяемого значения не принадлежит ни одному из вышеперечисленных — надо переопределить метод интерполяции **virtual QVariant interpolated ( const QVariant & from, const QVariant & to, qreal progress ) const**
Вот пример того что получилось: | https://habr.com/ru/post/75671/ | null | ru | null |
# Простой скрипт для рассылки СМС
Я продолжаю изучать Питон. Язык красивый, меня радует что когда мой коллега — непрограммист, садится за мой код он его может прочитать и понять. Встала задача сделать СМС оповещение клиентов (ну о просрочке, новых услугах итд). Мы купили GSM модем [Teleofis](http://gprs-modem.ru/TELEOFIS_RX101_USB_GPRS.htm). Для работы с ним пошукали проги, не особо нашли, а уж бесплатного и тем более. Пришлось открыть мануалы и написать простенькую прогу под Винду, которая открывает COM порт, на котором сидит модем и пишет в него AT команды.
Сам скрипт требует pySerial для работы под виндоус.
Чтобы запустить скрипт, надо воткнуть в комп модем, установить дрова, открыть файлик sms\_sender.py и отредактировать там строку 90:
> `a = Sender(('790864x0807',),u"Признанный критикой всего мира величайшим эпическим произведением новой европейской литературы, «Война и мир» поражает уже с чисто технической точки зрения размерами своего беллетристического полотна. Только в живописи можно найти некоторую параллель в огромных картинах Паоло Веронезе в венецианском Дворце дожей, где тоже сотни лиц выписаны с удивительною отчётливостью и индивидуальным выражением[источник не указан 91 день].",1,115200,2)
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Первый параметр — кортеж адресатов, второй — текст сообщения. Третий — номер порта. Остальные нам не нужны — это скорость и таймаут ожидания ответа.
А потом сделать из Командной строки вызов команды
python sms\_sender.py
Вы увидите:
> more PDU to go…
>
> more PDU to go…
>
>
Это скрипт рассылает части вашего сообщения адресатам. Вот и все.
Сам скрипт [доступен по ссылке.](http://slil.ru/27922592) Ограничений на его использование никаких, он сильно простой и маленький чтобы как-то ограничивать его использование. | https://habr.com/ru/post/67810/ | null | ru | null |
# Повторная обработка событий, полученных из Kafka

Привет, Хабр.
Недавно я [поделился опытом](https://habr.com/ru/company/tinkoff/blog/481784/) о том, какие параметры мы в команде чаще всего используем для Kafka Producer и Consumer, чтобы приблизиться к гарантированной доставке. В этой статье хочу рассказать, как мы организовали повторную обработку события, полученного из Kafka, в результате временной недоступности внешней системы.
Современные приложения работают в очень сложной среде. Бизнес-логика, обернутая в современный технологический стек, работающая в Docker-образе, который управляется оркестратором вроде Kubernetes или OpenShift, и коммуницирующая с другими приложениями или enterprise-решениями через цепочку физических и виртуальных маршрутизаторов. В таком окружении всегда что-то может сломаться, поэтому повторная обработка событий в случае недоступности одной из внешних систем — важная часть наших бизнес-процессов.
Как было до Kafka
-----------------
Ранее в проекте мы использовали IBM MQ для асинхронной доставки сообщений. При возникновении какой-либо ошибки в процессе работы сервиса полученное сообщение могло быть помещено в dead-letter-queue (DLQ) для дальнейшего ручного разбора. DLQ создавался рядом с входящей очередью, перекладывание сообщения происходило внутри IBM MQ.
Если ошибка имела временный характер и мы могли это определить (например, ResourceAccessException при HTTP-вызове или MongoTimeoutException при запросе в MongoDb), то в силу вступала стратегия повторных вызовов. Вне зависимости от ветвления логики приложения, исходное сообщение перекладывалось или в системную очередь для отложенной отправки, или в отдельное приложение, которое когда-то давно было сделано для повторной отправки сообщений. При этом в заголовок сообщения записывается номер повторной отправки, который привязан к интервалу задержки или к концу стратегии на уровне приложения. Если мы достигли конца стратегии, но внешняя система все еще недоступна, то сообщение будет помещено в DLQ для ручного разбора.
Поиск решения
-------------
[Поискав в интернете](https://www.google.com/search?q=kafka+retry+message), можно найти следующее [решение](https://blog.pragmatists.com/retrying-consumer-architecture-in-the-apache-kafka-939ac4cb851a). Если коротко, то предлагается завести по топику на каждый интервал задержки и реализовать на стороне приложения Consumer’ы, которые будут вычитывать сообщения с необходимой задержкой.

Несмотря на большое количество положительных отзывов, оно кажется мне не совсем удачным. В первую очередь потому, что разработчику, кроме реализации бизнес-требований, придется потратить много времени на реализацию описанного механизма.
Кроме того, если на Kafka-кластере включено управление доступами, то придется потратить какое-то время на заведение топиков и обеспечение необходимых доступов к ним. В дополнение к этому нужно будет подбирать правильный параметр retention.ms для каждого из ретрай-топиков, чтобы сообщения успевали повторно отправляться и не пропадали из него. Реализацию и запрос доступов придется повторять для каждого существующего или нового сервиса.
Давайте теперь посмотрим, какие механизмы для повторной обработки сообщения предоставляет нам spring в целом и spring-kafka в частности. Spring-kafka имеет транзитивную зависимость на spring-retry, который предоставляет абстракции для управления разными BackOffPolicy. Это довольно гибкий инструмент, но его значительным недостатком является хранение сообщений для повторной отправки в памяти приложения. Это значит, что перезапуск приложения из-за обновления или ошибки во время эксплуатации приведет к потере всех сообщений, ожидающих повторной обработки. Так как этот пункт критичен для нашей системы, мы не стали рассматривать его дальше.
Сама spring-kafka предоставляет несколько реализаций ContainerAwareErrorHandler, например [SeekToCurrentErrorHandler](https://github.com/spring-projects/spring-kafka/blob/master/spring-kafka/src/main/java/org/springframework/kafka/listener/SeekToCurrentErrorHandler.java), с помощью которого можно, не смещая offset в случае возникновения ошибки, обработать сообщение позже. Начиная с версии spring-kafka 2.3 появилась возможность задавать BackOffPolicy.
Этот подход позволяет повторно обрабатываемым сообщениям переживать рестарт приложения, но механизм DLQ по-прежнему отсутствует. Именно этот вариант мы выбрали в начале 2019 года, оптимистично полагая, что DLQ не понадобится (нам повезло и он действительно не понадобился за несколько месяцев эксплуатации приложения с такой системой повторной обработки). Временные ошибки приводили к срабатыванию SeekToCurrentErrorHandler. Остальные ошибки печатались в лог, приводили к смещению offset, и обработка продолжалась со следующим сообщением.
Итоговое решение
----------------
Реализация, основанная на SeekToCurrentErrorHandler, подтолкнула нас к разработке собственного механизма для повторной отправки сообщений.
Прежде всего мы хотели использовать уже имеющийся опыт и расширить его в зависимости от логики приложения. Для приложения с линейной логикой оптимальным было бы прекратить считывание новых сообщений в течение небольшого промежутка времени, заданного в рамках стратегии повторных вызовов. Для остальных приложений хотелось иметь единую точку, которая бы обеспечивала выполнение стратегии повторных вызовов. В дополнение эта единая точка должна обладать функциональностью DLQ для обоих подходов.
Сама стратегия повторных вызовов должна храниться в приложении, которое отвечает за получение следующего интервала при возникновении временной ошибки.
### Остановка Consumer’a для приложения с линейной логикой
При работе с spring-kafka код для остановки Consumer’a может выглядеть примерно так:
```
public void pauseListenerContainer(MessageListenerContainer listenerContainer,
Instant retryAt) {
if (nonNull(retryAt) && listenerContainer.isRunning()) {
listenerContainer.stop();
taskScheduler.schedule(() -> listenerContainer.start(), retryAt);
return;
}
// to DLQ
}
```
В примере retryAt — это время, когда нужно заново запустить MessageListenerContainer, если он еще работает. Повторный запуск произойдет в отдельном потоке, запущенном в TaskScheduler, реализацию которого тоже предоставляет spring.
Значение retryAt мы находим следующим способом:
1. Ищется значение счетчика повторных вызовов.
2. В соответствии со значением счетчика ищется текущий интервал задержки в стратегии повторных вызовов. Стратегия объявляется в самом приложении, для ее хранения мы выбрали формат JSON.
3. Найденный в JSON-массиве интервал содержит в себе количество секунд, через которое необходимо будет повторить обработку. Это количество секунд прибавляется к текущему времени, образуя значение для retryAt.
4. Если интервал не найден, то значение retryAt равно null и сообщение отправится в DLQ для ручного разбора.
При таком подходе остается только сохранить количество повторных вызовов для каждого сообщения, которое находится сейчас на обработке, например в памяти приложения. Сохранение счетчика попыток в памяти не критично для этого подхода, так как приложение с линейной логикой не может выполнять обработку в целом. В отличие от spring-retry перезапуск приложения приведет не к потере всех сообщений для повторной обработки, а просто к перезапуску стратегии.
Этот подход помогает снять нагрузку с внешней системы, которая может быть недоступна из-за очень большой нагрузки. Другими словами, в дополнение к повторной обработке мы добились реализации паттерна [circuit breaker](https://microservices.io/patterns/reliability/circuit-breaker.html).
В нашем случае порог ошибки равен всего 1, а чтобы минимизировать простой системы из-за временного сетевого перебоя, мы используем очень гранулярную стратегию повторных вызовов с небольшими интервалами задержки. Это может не подойти для всех приложений группы компаний, поэтому соотношение между порогом ошибки и величиной интервала нужно подбирать, опираясь на особенности системы.
### Отдельное приложение для обработки сообщений от приложений с недетерминированной логикой
Вот пример кода, отправляющего сообщение в такое приложение (Retryer), которое выполнит повторную отправку в топик DESTINATION при достижении времени RETRY\_AT:
```
public void retry(ConsumerRecord record, String retryToTopic,
Instant retryAt, String counter, String groupId, Exception e) {
Headers headers = ofNullable(record.headers()).orElse(new RecordHeaders());
List arrayOfHeaders =
new ArrayList<>(Arrays.asList(headers.toArray()));
updateHeader(arrayOfHeaders, GROUP\_ID, groupId::getBytes);
updateHeader(arrayOfHeaders, DESTINATION, retryToTopic::getBytes);
updateHeader(arrayOfHeaders, ORIGINAL\_PARTITION,
() -> Integer.toString(record.partition()).getBytes());
if (nonNull(retryAt)) {
updateHeader(arrayOfHeaders, COUNTER, counter::getBytes);
updateHeader(arrayOfHeaders, SEND\_TO, "retry"::getBytes);
updateHeader(arrayOfHeaders, RETRY\_AT, retryAt.toString()::getBytes);
} else {
updateHeader(arrayOfHeaders, REASON,
ExceptionUtils.getStackTrace(e)::getBytes);
updateHeader(arrayOfHeaders, SEND\_TO, "backout"::getBytes);
}
ProducerRecord messageToSend =
new ProducerRecord<>(retryTopic, null, null, record.key(), record.value(), arrayOfHeaders);
kafkaTemplate.send(messageToSend);
}
```
Из примера видно, что много информации передается в хедерах. Значение RETRY\_AT находится так же, как и для механизма повтора через остановку Consumer’a. Помимо DESTINATION и RETRY\_AT мы передаем:
* GROUP\_ID, по которому группируем сообщения для ручного анализа и упрощения поиска.
* ORIGINAL\_PARTITION, чтобы постараться сохранить тот же Consumer для повторной обработки. Этот параметр может быть равен null, в таком случае новая partition будет получена по ключу record.key() оригинального сообщения.
* Обновленное значение COUNTER, чтобы следовать стратегии повторных вызовов.
* SEND\_TO — константа, показывающая, отправить ли сообщение на повторную обработку по достижении RETRY\_AT или поместить в DLQ.
* REASON — причина, по которой обработка сообщения была прервана.
Retryer сохраняет сообщения для повторной отправки и ручного разбора в PostgreSQL. По таймеру запускается задача, которая находит сообщения с наступившим RETRY\_AT и отправляет их обратно в партицию ORIGINAL\_PARTITION топика DESTINATION с ключом record.key().
После отправки сообщения удаляются из PostgreSQL. Ручной разбор сообщений происходит в простом UI, который взаимодействует с Retryer по REST API. Основными его особенностями являются переотправка или удаление сообщений из DLQ, просмотр информации об ошибке и поиск сообщений, например по имени ошибки.
Так как на наших кластерах включено управление доступом, необходимо дополнительно запрашивать доступы к топику, который слушает Retryer, и дать возможность Retryer’у писать в DESTINATION топик. Это неудобно, но, в отличие от подхода с топиком на интервал, у нас появляется полноценная DLQ и UI для управления ею.
Бывают случаи, когда входящий топик читают несколько разных consumer-групп, приложения которых реализуют разную логику. Повторная обработка сообщения через Retryer для одного из таких приложений приведет к дубликату на другом. Чтобы защититься от этого, мы заводим отдельный топик для повторной обработки. Входящий и retry-топик может читать один и тот же Consumer без каких-либо ограничений.
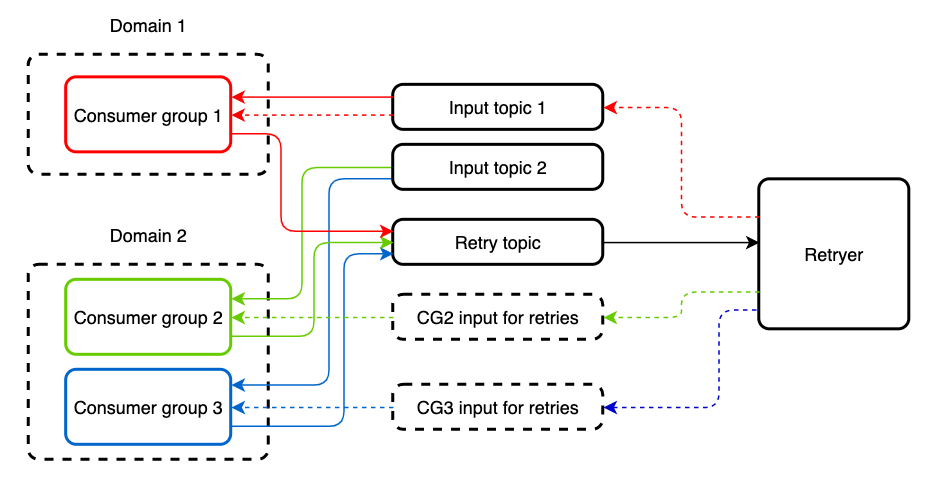
По умолчанию этот подход не предоставляет возможности circuit breaker’a, однако его можно добавить в приложение с помощью [spring-cloud-netflix](https://spring.io/projects/spring-cloud-netflix) или нового [spring cloud circuit breaker](https://spring.io/projects/spring-cloud-circuitbreaker), обернув места вызовов внешних сервисов в соответствующие абстракции. Кроме того, появляется возможность выбора стратегии для [bulkhead](https://docs.microsoft.com/en-us/azure/architecture/patterns/bulkhead) паттерна, что тоже может быть полезно. Например, в spring-cloud-netflix это может быть thread pool или семафор.
Вывод
-----
В результате у нас получилось отдельное приложение, которое позволяет повторить обработку сообщения при временной недоступности какой-либо внешней системы.
Одним из главных преимуществ приложения является то, что им могут пользоваться внешние системы, работающие на том же Kafka-кластере, без значительных доработок на своей стороне! Такому приложению необходимо будет только получить доступ к retry-топику, заполнить несколько Kafka-заголовков и отправить сообщение в Retryer. Не нужно поднимать никакой дополнительной инфраструктуры. А чтобы уменьшить количество перекладываемых сообщений из приложения в Retryer и обратно, мы выделили приложения с линейной логикой и сделали в них повторную обработку через остановку Consumer. | https://habr.com/ru/post/487094/ | null | ru | null |
# Подключиться мобильным устройством к базе данных без написания серверного кода
Привет, Хабр! Хочу поделиться своим опытом использования [Форсайт мобильной платформы](https://www.fsight.ru/mobilnaja-platforma/).
Если у вас встанет задача удалённого хранения данных и при этом не писать собственный сервер, то первое, что придёт на ум это инструмент [Firebase Realtime Database](https://firebase.google.com/docs/database). Большинство читающих знают, о чём идёт речь, но для остальных поясню. С помощью Firebase Database можно хранить удаленно данные в NoSql-ом виде.

*[Картинка с сайта firebase](https://firebase.google.com/docs/database/android/structure-data)*
**Из плюсов использования:**
* поддерживается Google
* не нужно писать никакой код, на стороне базы
* быстрая работа
* бесплатно до 5Гб
* интеграция с сервисом Firebase authentication с довольно большим количеством провайдеров авторизации
* поддержка android, iOs, unity и др.
* синхронизируется в режиме реального времени: при обновлении данных в базе они обновляются в клиенте
**Из минусов:**
* при привышении установленных лимитов по пространству и нагрузке на сервер приходится платить
* нету возможности кастомизировать под себя структура хранения
### ФМП + PostgreSQL
Теперь хочу вам рассказать про альтернативный инструмент, которым мне приходится пользоваться.
Зайду издалека. Где-то у меня имеется поднятый сервер PostreSQL с базой данных. В базе данных у меня есть таблица с фруктами:

Что такое PostreSQL как с ним работать можно почитать [тут](https://www.postgresql.org/).
Моя задача, чтобы эта таблица как можно быстрее оказалась на телефоне с наименьшим написанием кода и обеспечения безопасности на каждом этапе.
Вот таблица my\_table\_fruits в [pgAdmin4](https://www.pgadmin.org/download/):

Далее нахожу в дереве pgAdmin4 процедуры. Пишу собственную процедуру на получение таблицы:

Процедура будет иметь название fruits\_get\_by\_color и будет отдавать мне фрукты определённого цвета из моей таблицы my\_table\_fruits.
После этого перехожу на сервер Форсайт мобильной платформы (далее ФМП). Как развернуть платформу и что для этого нужно можно прочитать в [документации](https://help.fsight.ru/ru/mergedProjects/MobilePlatform/installation/mobileplatform_setup.htm). ФМП представляет собой сервер, который имеет коннекторы к серверам баз данных. Может приконнектиться и к нужному нам PostgreSQL. Код писать для этого никакой не нужно. С чем мне приходится работать, так это с панелью администратора через браузер. Вводить необходимые адреса серверов, баз данных. Панель администратора имеет настройки и дерево сред:

Более подробно про настройки также можно прочитать в документации.
К сожалению, никаких пробных версий или бесплатных периодов у ФМП нету. Также ФМП разворачивают в защищенной инфраструктуре заказчика. Поэтому ссылок на сервер, чтобы попробовать, не смогу предоставить. Но, чтобы понять суть работы, нижеследующей информации вполне хватит.
Создаю новую среду в дереве сред, например назову её Leonid\_environment. Внутри среды создаю проект, например Leonid\_project. Захожу в проект и создаю там источник данных, в нашем случае PostgreSQL. Ввожу параметры сервера и базы данных, в которой храниться моя таблица:

Захожу внутрь источника данных и жму “Импортировать”. Ввожу в название источника наименование той процедуры, которую ввёл в PostgreSQL, в данном случае fruits\_get\_by\_color. Для мобильного клиента можно придумать другое название, хотя не обязательно. Назову его fruits\_get\_by\_color\_for\_android:

После нажатия кнопки “Импортировать”, платформа ФМП “увидит” нашу процедуру и параметры, которые мы должны туда передать.

В частности, она увидит, что мы должны передать параметр fruit\_color:

После этого необходимо перейти во вкладку “Пользователи API” и создать пользователя. Создал пользователя с логином Leonid и паролем 123123:

Начиная с этого момента можно переходить в Android Studio, чтобы получить эти данные на мобильный телефон.
### ФМП + android
Создаю новый проект. Вместе с платформой распространяется [фреймворк](https://help.fsight.ru/ru/mergedProjects/MobilePlatform/development/android/android_framework.htm) для работы с ней. Подтягиваю фреймворк в проект File → import module → \*.aar

В проекте объявляю ряд констант, в которые вставляю адрес сервера, а также придуманные мной название среды, название проекта, логин, пароль, наименование ресурса из ФМП:
```
private static final String MY_URL = "http://mobilefmp.dev.fs.world";
private static final VersionAPI MY_VERSION_API = VersionAPI.V_1;
private static final String MY_ENVIRONMENT = "Leonid_environment";
private static final String MY_PROJECT = "Leonid_project";
private static final String MY_VERSION = "v1";
private static final String MY_LOGIN = "Leonid";
private static final String MY_PASSWORD = "123123";
private static final String MY_RESOURCE = "fruits_get_by_color_for_android";
```
Обратите внимание, что обращаемся именно к ФМП, а не напрямую к PostgreSQL. Далее необходимо создать объект HyperHive и засетить объявленные переменные:
```
hyperHive = new HyperHiveState(getApplicationContext())
.setHostWithSchema(MY_URL)
.setApiVersion(MY_VERSION_API)
.setEnvironmentSlug(MY_ENVIRONMENT)
.setProjectSlug(MY_PROJECT)
.setVersionProject(MY_VERSION)
.buildHyperHive();
```
Затем нужно выполнить авторизацию. Для этого передаём логин и пароль в метод auth():
```
boolean status = hyperHive.authAPI.auth(MY_LOGIN, MY_PASSWORD, true).execute().isOk();
```
При получении true можно запрашивать содержимое таблицы, что и сделаем. В объект tableStreamCallParams передадим в виде json-а параметр fruit\_color и введём для него значение yellow. Напомню, что мы создавали таблицу фруктов и создавали в PostreSQL процедуру, которая принимает на вход параметр цвета. Это нужно было, чтобы на устройстве ввести данный параметр:
```
TableStreamCallParams tableStreamCallParams = new TableStreamCallParams();
String data = "{\"fruit_color\": \"yellow\"}";
tableStreamCallParams.setData(data);
String status = hyperHive.requestAPI.tableStream(MY_RESOURCE, tableStreamCallParams).execute();
```
После запроса мы обращаемся к серверу ФМП. Сервер ФМП обращается к серверу PostgreSQL. В итоге мы должны получить список желтых фруктов:

Строки stream-ятся в базу SQLite. В данном случае цвета yellow были только banana и lemon. Скорость загрузки закешированных на стороне ФМП данных примерно 10000 строк в секунду при нормальной скорости интернета.
Все описанные мною шаги можно прочесть в [документации](https://help.fsight.ru/ru/help.htm#mergedProjects/MobilePlatform/development/development.htm). Также там есть информация про подключение к iOs и другим операционным системам.
Привожу [полный код активити](https://gist.github.com/LeonidIvankin/826c55c63d72cc802b6ca1264028a449).
Сделал запрос из основного потока и не обработал ошибки, чтобы сократить количество кода.
### Функционал ФМП
Функционал ФМП этим не ограничивается. Можно на стороне сервера базы данных создать процедуру не только для получения, но и для создания новых строк в зависимости от переданных значений. Можно передавать массивы значений. Ограничения только внутри самой БД.
**Пройдусь широкими шагами по основному функционалу ФМП:**
* кеширование данных на стороне платформы и получение дельты (не всей таблицы, а только изменённых строк)
* логгирование действий пользователя
* разграничение доступа по пользователям, группам пользователей, id устройства
* аутентификация через LDAP
* интеграция с SMTP, Citrix XenMobile, Sentry
* подпись данных в центре сертификации КриптоПро
* файловое хранилище не стороне ФМП
* локальная БД на стороне ФМП (можно не коннектиться к сторонней БД, а создать БД локально, как в Firebase)
* коннекторы к Firebase Cloud Messaging, Apple Push Notification и Windows Push Notification. Создание рассылок и шаблонов push-уведомлений
**Есть фреймворки под:**
* android
* iOs
* UWP
* WinCE
* Sailfish, Аврора (российский sailfish)
**Есть коннекторы к:**
* SAP
* PostgreSQL
* Oracle
* web-источникам
* SOAP ( в том числе 1C)
* [Форсайт аналитической платформы](https://help.fsight.ru/ru/first_topic.htm)
### Плюсы и минусы ФМП
Приведу плюсы и минусы, которые вижу со своей точки зрения. В зависимости от специфики и размера проекта, думаю, вы будете не со всем согласны.
**Плюсы:**
* без написания серверного кода можно приконектиться к серверу базы
* большое количество коннекторов к другим источникам
* наличие фреймворков под большинство мобильных операционных систем
* русскоязычная служба поддержки
**Минусы:**
* стоимость
* ориентация под коммерческого заказчика
* нету бесплатной пробной версии или периода
### Выводы
Сравнение платформы ФМП с Firebase Realtime Database было “притянуто за уши”, т.к. хотелось хоть с чем-то сравнить знакомым android- и iOs-разработчику. На самом деле ФМП имеет несколько другой функционал и цели. Среди конкурентов можно привести SAP Mobile Platform, IBM first mobile platform, Оптимум CDC.
В заключение хочу сказать, что на ФМП стоит обратить внимание, если у вас есть:
* довольно крупный заказчик готовый платить за систему
* который не хочет писать прослойку между мобильным устройством и сервером базы данных
* у которого есть большое количество данных, например склад товаров
* для которого принципиально использование российское ПО
* для которого не последнюю роль играет защита данных | https://habr.com/ru/post/463437/ | null | ru | null |
# Разрабатываем свои собственные буквенные часы
[](https://habr.com/ru/company/ruvds/blog/574130/)*[Источник](https://www.questodesign.com/en/qlocktwo-classic-metamorphite-carved-in-stone.html)*
На эту статью меня вдохновили часы на английском языке, которые случайно увидел на одном из зарубежных сайтов. Они представляют собой матрицу из слов, которые, включая подсветку за определёнными словами, показывают словесную индикацию текущего времени.
Часы являются малодоступными широкому кругу людей, ввиду их дороговизны (это явилось одним из стимулов для разработки своих собственных), а ещё имеются у производителя на разных языках.
И я подумал, почему бы не обдумать вероятность создания примерно таких часов, на русском языке?
Так как полностью копировать чужую идею не хотелось (хотя это достаточно просто осуществить), я подумал, что будет достаточно любопытным разработать нечто своё, базируясь на изначальной идее этих часов.
> Дальнейший ход рассуждений предназначен только в ознакомительных целях, «как можно было бы сделать нечто подобное». Целью статьи является изложить ход инженерной мысли, следуя которой каждый может создать что-то своё, уникальное.
После появления мысли о создании буквенных часов, я решил проработать в теории, как они могли бы выглядеть, и что для этого бы пригодилось.
Можно сказать, что задача создания буквенных часов может быть разделена на несколько этапов:
**1 Этап:** Так как нам будет необходимо предварительно создать матрицу из слов, весьма полезно использовать для этого дела свои навыки программирования. Так как, безусловно, возможно создать данную матрицу и просто вручную, Однако, программные методы генерации дают нам гораздо большую гибкость.
**2 Этап:** Далее, после того как разработана матрица, она должна быть превращена в соответствующую совокупность панелей, которые можно изготовить лазерной резкой. Почему именно таким способом: так как он является одним из самых простых и недорогих в данном случае.
**3 Этап:** Необходимо разработать прошивку для соответствующего микроконтроллера, который будет заниматься управлением подсветкой матрицы из слов. Тут надо сделать пояснение: часы будут показывать время, включая соответствующие сочетания букв.
Любопытным моментом работы микроконтроллера является то, что на часах необходимо периодически устанавливать корректное время. Так как мне не хотелось вводить в программу дополнительные усложнения, в виде подключения каких-либо кнопок, обработки их нажатий, вывода на какой-то микро экран введённого времени, либо прямо на часы,- мне показалось, что будет достаточно остроумным решением, если код будет сам обращаться с некой периодичностью на сервер времени, получая с него корректное текущее время.
Таким образом, получается, что программисту будет необходимо только предварительно настроить прошивку, введя в неё:
* периодичность подключения к серверу;
* логин и пароль для подключения к wi-fi точке доступа, находящейся в пределах досягаемости для часов.
Таким образом, самый простой и эффективный способ получения времени, — использование микроконтроллера с wi-fi модулем. В качестве такого микроконтроллера возьмём esp32.
В качестве же средства подсветки букв — будем использовать адресную светодиодную ленту. Конкретно данный проект базируется на ленте WS2812B, с количеством светодиодов 30 шт/метр. Что такое адресная светодиодная лента, можно подробнее почитать [тут](https://xn--18-6kcdusowgbt1a4b.xn--p1ai/ws2812b-%D0%B0%D1%80%D0%B4%D1%83%D0%B8%D0%BD%D0%BE/), [тут](https://arduinomaster.ru/datchiki-arduino/adresnaya-svetodiodnaya-lenta/) или [тут](https://alexgyver.ru/ws2812_guide/).
Схема подключения адресной светодиодной ленты к esp32 видится такой:

Следуя вышеперечисленному алгоритму, приступим к работе.
▍ Реализация 1 Этапа
--------------------
Так как хотелось создать нечто максимально универсальное, ввиду того, что я не был совершенно уверен, какое количество слов и в каких комбинациях (сколько слов в строке) у меня получится, я решил написать генератор матрицы слов, который позволит достаточно гибким образом варьировать созданием матрицы и подобрать тот тип матрицы, который будет наиболее удовлетворять разработчика часов.
Для достижения цели я написал генератор на языке Java, в рамках среды *IntelliJIDEA*.
Вкратце пробежимся по его ключевым моментам.
Все слова, которые будут участвовать в создании матрицы, предварительно добавляются в Arraylist. Если вас не устроит данная подборка словосочетаний, вы всегда сможете заменить в этом списке мои слова — на свои.
Здесь следует сделать одну оговорку: я не ставил себе целью сделать максимально лаконичную матрицу, поэтому моя подборка слов может оказаться несколько избыточной. Это нужно учитывать, и если вы захотите создать более короткую матрицу (короткую в буквальном смысле, что позволит ей быть более узкой по горизонтали), вы можете обдумать и изменить мою подборку слов.
Нашей задачей является создать такую матрицу, которая будет состоять из определённого количества строк, равных по количеству символов.
Генератор после первого запуска, для данного конкретного Arraylist-a выводит статистику, в которой содержится общее количество символов в неразбитой строке, количество комбинаций символов в строке, которые позволяют создать определённое количество строк, с равным количеством символов в них.
Кроме того, генератор выводит непосредственно свёрстанную матрицу слов, а также матрицу номеров, для данной длины строк.
Здесь следует сделать пояснение: так как для подсветки букв мы будем использовать адресную светодиодную ленту, в которой нумерация светодиодов начинается с 0, генератор выводит номера будущих пикселей, также разбитые на строки.
После первого запуска программы, когда мы знаем какое число символов должно содержаться в каждой отдельной строке, чтобы количество символов в каждой строке было равным, мы можем поэкспериментировать, забивая данные числа в переменную horizontalCount.
**❒** Код генератора можно глянуть тут: [github](https://github.com/dansea/misc/blob/main/wordsMatrixGenerator)
Запустим программу заново, чтобы обновить вывод.
Например, для количества символов в строке, равному 41, вывод программы будет выглядеть следующим образом:

▍ Реализация 2 Этапа
--------------------
После того как у нас сформирован вывод программы, мы можем им воспользоваться в наших целях — а именно, для предварительного формирования внешнего вида будущей матрицы, который мы собираем в программе Microsoft Word.
Для этого, я создал таблицу, в ячейки которой забил получившиеся строки. После чего, я создал ещё одну такую же таблицу, в каждую ячейку которой вставил номера будущих пикселей адресной светодиодной ленты.
Для большего удобства, я создал сводную таблицу, которая содержит как буквы, так и номера подсвечивающих светодиодов адресной ленты.
Также, я раскрасил отдельные слова в таблице, в разные цвета (это можно увидеть в нижней таблице).

Далее мы начинаем обрабатывать получившуюся матрицу в программе CorelDraw.
Так как для подсветки будущих часов мы будем использовать ленту с количеством светодиодов в 60 штук на метр, и размером светодиода 5x5 мм, мы создаём соответствующий массив квадратиков в программе CorelDraw, копируем и вставляем из Ворда каждую строку со словами.
После того, как скопированная строка вставлена в CorelDraw, мы выделяем вставленную строку и нажимаем сочетание клавиш Ctrl+K.
Это позволит разбить вставленную строку на отдельные буквы. После чего, мы начинаем подравнивать каждую букву, выравнивая её по центру квадратика, символизирующего пиксель светодиодной ленты.

Однако, данная работа была бы неполной, без преобразования получившихся букв — в буквы трафаретного типа. Так как будущую конструкцию часов мы оптимизируем под производство с применением лазерной резки, нам необходимо, чтобы каждая буква не содержала замкнутых объёмов внутри (как например, буква О). Поэтому все замкнутые объёмы внутри букв мы соединяем перемычками с внешними объёмами.
Для этого, мы предварительно выделяем все строки, вставленные в CorelDraw, с помощью комбинации Ctrl+A, затем переводим их в не редактируемый формат («в кривые») – комбинацией Ctrl+Q. Далее – вручную рисуем прямоугольничек и, передвигая его – прорезаем вручную каждую букву в матрице, чтобы превратить её в трафаретный вид:

Далее нам остаётся только экспортировать получившуюся матрицу букв в ту программу твердотельного моделирования, которую вы предпочитаете, предварительно переведя её формат dxf.
Можно было бы всю работу проделать и в CorelDraw, — просто мне было так привычней и удобней.
**❒** После чего, я собрал следующую сборку, которая содержит:
* лицевую панель с порезанной в ней матрицей слов;
* панель с разделителями между буквами, — которая требуется для того, чтобы избежать паразитной засветки находящихся рядом букв, при их включении. Данная панель разделителя должна быть вырезана из-за какого-либо тёмного материала;
* две панели-рассеиватели света, которые могут быть выполнены из белого пластика;
* задняя часть часов закрывается пластиной-задником.

▍ Реализация 3 Этапа
--------------------
И напоследок, следует сказать пару слов об электронной части проекта. Видится наиболее перспективным, в качестве микроконтроллера – использование платы esp32, ввиду встроенного в неё wifi модуля. Это позволит часам, с нужной периодичностью производить подключение к серверу, для синхронизации с мировым временем.
▍ Полезности и итоги
--------------------
Прошивка проекта написана в среде Arduino IDE: [github](https://github.com/dansea/arduino-esp32-projects).
Скачать векторные файлы для лазерной резки, в формате pdf, можно [по ссылке.](https://drive.google.com/file/d/1FMgd3Bt33gHfsyLdNLz7hnPkwKIskdFf/view?usp=sharing)
Для удобства, достаточно объёмные функции `void timeBurner (int hours, int minutes)` и `void timer ()` — выполнены в отдельных вкладках.
Логин и пароль, для подключения к вашей точке доступа wifi следует забивать в переменные: `const char *ssid` и `const char *password`.
Количество светодиодов в ленте – забивается в переменную `NUMPIXELS`. В моём случае это 164 пикселя (длина строки в символах, выводится программой-генератором матрицы слов на java, в самом начале статьи).
Периодичность подключения к серверу задаётся в переменной `CheckPeriod`, в миллисекундах.
Так как данный проект ещё никем в реале не реализовывался, возможно, прошивка имеет некоторые погрешности и неочевидные ошибки – просьба отнестись с пониманием. В любом случае, наверняка, потребуется отладка.
> Если Вам понравилась вся эта затея – у вас есть всё необходимое, чтобы реализовать свой собственный проект, основываясь на моём. Удачи в проектировании!
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=DAN_SEA&utm_content=razrabatyvaem_svoi_sobstvennye_bukvennye_chasy) | https://habr.com/ru/post/574130/ | null | ru | null |
# Интеграция ЭЦП НУЦ РК в информационные системы на базе веб технологий
Я расскажу о тонкостях внедрения электронной цифровой подписи (ЭЦП) в информационные системы (ИС) на базе веб технологий в контексте [Национального Удостоверяющего Центра Республики Казахстан (НУЦ РК)](https://pki.gov.kz/).
В центре внимания будет формирование ЭЦП под электронными документами и, соответственно, [NCALayer](https://pki.gov.kz/ncalayer/) — предоставляемое НУЦ РК криптографическое программное обеспечение. В частности уделю внимание вопросам связанным с UX и объемом поддерживаемого функционала NCALayer.
Процесс разделю на следующие этапы:
* формирование неизменного представления подписываемого документа (под подписываемым документом я буду подразумевать любые данные которые необходимо подписать, такие как: договор, бланк заказа, форма аутентификации и т.п.);
* подписание документа в веб интерфейсе с помощью NCALayer;
* проверка подписи на стороне сервера;
* (при необходимости) подготовка подписи к долгосрочному хранению.
Формирование неизменного представления подписываемого документа
===============================================================
Разработчикам важно понимать то, что любое изменение подписанного документа приведет к тому, что подпись под ним перестанет проходить проверку. При этом изменения могут быть вызваны не только редактированием самих данных документа, но и обновлением структуры документа или механизма его сериализации.
Рассмотрим простой пример — документы хранятся в виде записей в базе данных. Для подписания документа необходимо сформировать его представление в виде единого блока данных (конечно можно подписывать каждое поле записи поотдельности, но обычно так не делают), сделать это можно, к примеру, следующими способами:
* извлечь все поля записи, привести их к строкам и соединить в одну строку;
* сформировать XML или JSON представление;
* сформировать PDF документ на базе шаблона с каким-то оформлением содержащий данные из записи;
* и т.п.
Далее возможны два сценария каждый из которых имеет свои подводные камни:
* ИС не хранит сформированного представления и каждый раз для проверки подписи под документом (в частности проверки неизменности данных) формирует его;
* ИС хранит сформированное представление и использует его для проверки подписи.
В том случае, если ИС не хранит сформированного представления, разработчикам необходимо гарантировать что в будущем формируемые представления будут бинарно идентичны тем, которые были сформированы в первый раз не смотря на:
* изменения схемы базы данных;
* обновления механизма формирования представления (которое может так же зависеть от внешних библиотек которые, скорее всего, не стремятся к обеспечению бинарной идентичности).
В том случае, если на каком-то этапе бинарная идентичность перестанет соблюдаться, то проверки цифровых подписей перестанут выполняться и юридическая значимость документов в ИС будет утеряна.
Подход с хранением сформированного представления в базе данных ИС надежнее с точки зрения обеспечения сохранности юридической значимости, но и тут есть нюанс — необходимо гарантировать эквивалентность данных в подписанном документе данным в записи в базе данных иначе может возникнуть такая ситуация когда ИС принимает решение (выполняет расчет) на основании информации не соответствующей тому, что было подписано. То есть нужно либо так же, как и в предыдущем случае, обеспечивать бинарную идентичность формируемого представления, тогда при проверках в первую очередь следует формировать представление из текущего содержимого записи в базе данных и бинарно сравнивать новое представление с сохраненным. Либо необходим механизм позволяющий разобрать сохраненное сформированное представление и сравнить данные из него с текущим содержимым записи в базе данных. Этот механизм так же придется дорабатывать постоянно параллельно с доработками основного функционала ИС.
Подписание документа в веб интерфейсе с помощью NCALayer
========================================================
Для формирования цифровых подписей на стороне клиента НУЦ РК предоставляет единственный инструмент — сертифицированное программное обеспечение [NCALayer](https://pki.gov.kz/ncalayer/) которое представляет из себя WebSocket сервер, запускаемый на `127.0.0.1`, которому можно отправлять запросы на выполнение криптографических (а так же некоторых смежных) операций. При выполнении некоторых операций NCALayer отображает диалоговые окна — то есть берет часть работы по получению пользовательского ввода на себя.
Описание API NCALayer доступно в составе [комплекта разработчика](https://pki.gov.kz/developers/). Для того, чтобы поэкспериментировать со взаимодействием с NCALayer по WebSocket можно воспользоваться страницей [интерактивной документации KAZTOKEN mobile](https://kaztoken.kz/mobile-docs/) (KAZTOKEN mobile повторяет API NCALayer).
Взаимодействовать с NCALayer из браузера можно напрямую с помощью класса [WebSocket](https://developer.mozilla.org/en-US/docs/Web/API/WebSocket), либо можно воспользоваться библиотекой [ncalayer-js-client](https://github.com/sigex-kz/ncalayer-js-client) которая оборачивает отправку команд и получение ответов в современные `async` вызовы.
Замечу что весь основной функционал NCALayer доступен в модуле `kz.gov.pki.knca.commonUtils`, использовать модуль `kz.gov.pki.knca.applet.Applet` (наследие Java аплета) не рекомендую, так как, на мой взгляд, это не даст никаких преимуществ, но шансов выстрелить себе в ногу с ним больше — к примеру можно случайно разработать интерфейс который не будет поддерживать аппаратных носителей (токенов или смарт-карт) с несколькими ключевыми парами.
Модуль `kz.gov.pki.knca.commonUtils` берет на себя взаимодействие с пользователем связанное с выбором конкретного хранилища, которое нужно использовать для выполнения операции (так же он берет на себя выбор конкретного сертификата и соответствующего ключа, а так же ввод пароля или ПИН кода), но ему необходимо указать какой тип хранилищ нужно использовать. Типы хранилищ стоит разделить на два класса:
* файловые, поддерживается единственный тип заданный константой `'PKCS12'`,
* аппаратные (токены и смарт-карты), для перечисления тех типов, экземпляры которых в данный момент подключены в ПК пользователя, следует использовать запрос `getActiveTokens`.
Таким образом для того, чтобы предоставить пользователю возможность работать с любым поддерживаемым NCALayer хранилищем, можно воспользоваться одним из следующих подходов:
* *гибкий* — отправить запрос `getActiveTokens`, в ответ получить массив имен доступных а данный момент типов хранилищ, добавить в него `'PKCS12'` и спросить у пользователя каким он хотел бы в данный момент воспользоваться;
* *простой* — отправить запрос `getActiveTokens`, в том случае, если он вернул массив несколькими именами, попросить пользователя отключить лишнее, если в массиве один элемент, использовать его, если массив пустой, использовать `'PKCS12'`.
Для подписания данных рекомендую использовать следующие запросы (опять же чтобы снизить вероятность выстрела в ногу):
* `createCAdESFromBase64` — вычислить подпись под данными и сформировать CMS (CAdES);
* `createCMSSignatureFromBase64` — вычислить подпись под данными, получить на подпись метку времени (TSP) и сформировать CMS (CAdES) с внедренной меткой времени;
* `signXml` — вычислить подпись под XML документом, сформированную подпись добавить в результирующий документ (XMLDSIG);
* `signXmls` — аналогично `signXml`, но позволяет за один раз подписать несколько XML документов.
В качестве параметров каждому из них нужно будет передать тип хранилища, тип сертификата, подписываемые данные и дополнительные модификаторы.
Модуль `kz.gov.pki.knca.commonUtils` поддерживает следующие типы сертификатов:
* `'AUTHENTICATION'` — сертификаты для выполнения аутентификации;
* `'SIGNATURE'` — сертификаты для подписания данных.
NCLayer предоставит пользователю выбирать только из тех сертификатов, которые соответствуют указанному типу.
Упрощенный пример подписания произвольного блока данных с использованием *ncalayer-js-client*:
```
async function connectAndSign(base64EncodedData) {
const ncalayerClient = new NCALayerClient();
try {
await ncalayerClient.connect();
} catch (error) {
alert(`Не удалось подключиться к NCALayer: ${error.toString()}`);
return;
}
let activeTokens;
try {
activeTokens = await ncalayerClient.getActiveTokens();
} catch (error) {
alert(error.toString());
return;
}
const storageType = activeTokens[0] || NCALayerClient.fileStorageType;
let base64EncodedSignature;
try {
base64EncodedSignature = await ncalayerClient.createCAdESFromBase64(storageType, base64EncodedData);
} catch (error) {
alert(error.toString());
return;
}
return base64EncodedSignature;
}
```
Проверка подписи на стороне сервера
===================================
Тема проверки цифровых подписей обширна и я не планировал раскрывать ее в этот раз, но упомянуть о необходимости выполнения проверок как с технической, так и юридической точки зрения счел необходимым.
С технической точки зрения проверка цифровой подписи на стороне сервера в первую очередь гарантирует целостность полученного документа, во вторую — авторство, а так же неотказуемость. То есть даже в том случае, если ИС получает подписанный документ не напрямую от пользователя, а через какие-то дополнительные слои программного обеспечения, уверенность в том, что было получено именно то, что отправлял пользователь сохраняется. Поэтому в ситуации когда подписание на стороне клиента реализовано, а возможность проверки подписи на стороне сервера отсутствует, внедрение цифровой подписи теряет смысл.
С юридической точки зрения ориентироваться следует на Приказ Министра по инвестициям и развитию Республики Казахстан [“Об утверждении Правил проверки подлинности электронной цифровой подписи”](http://adilet.zan.kz/rus/docs/V1500012864). В Приказе перечислены необходимые проверки которые должны выполнять информационные системы для обеспечения юридической значимости подписанных электронной цифровой подписью документов. Анализу этого документа, а так же некоторым техническим вопросам посвящена заметка [Проверка цифровой подписи](https://sigex.kz/blog/signature-verification/).
Выполнять проверки необходимо с применением сертифицированных средств, к примеру с помощью библиотек входящих в состав [комплекта разработчика НУЦ РК](https://pki.gov.kz/developers/), либо можно воспользоваться готовым решением [SIGEX](https://sigex.kz/blog/digital-document-workflow/).
Подготовка подписи к долгосрочному хранению
===========================================
Проверка подписи под электронным документом включает в себя проверку срока действия сертификата и проверку статуса отозванности сертификата. В том случае, когда необходимо обеспечить юридическую значимость подписанного документа по истечению срока действия сертификата или в том случае, когда сертификат был отозван через некоторое время после подписания, следует собирать дополнительный набор доказательств фиксирующий момент подписания и подтверждающий то, что на момент подписания сертификат не истек и не был отозван.
Для фиксации момента подписания принято использовать метки времени TSP. Метку времени на подпись можно получить либо на клиенте (запрос `createCMSSignatureFromBase64` интегрирует метку времени в CMS), либо на сервере. Метка времени позволит удостовериться в том, что момент подписания попадает в срок действия сертификата.
Для того, чтобы удостовериться в том, что сертификат не был отозван в момент подписания, следует использовать CRL или OCSP ответ. Этот нюанс и рекомендации по реализации описаны в разделе APPENDIX B — Placing a Signature At a Particular Point in Time документа [RFC 3161](https://tools.ietf.org/html/rfc3161). | https://habr.com/ru/post/509108/ | null | ru | null |
# Blockchain на Go. Часть 1: Прототип
Содержание
1. **Blockchain на Go. Часть 1: Прототип**
2. [Blockchain на Go. Часть 2: Proof-of-Work](https://habrahabr.ru/post/350804/)
3. [Blockchain на Go. Часть 3: Постоянная память и интерфейс командной строки](https://habrahabr.ru/post/351296/)
4. [Blockchain на Go. Часть 4: Транзакции, часть 1](https://habrahabr.ru/post/351752/)
5. Blockchain на Go. Часть 5: Адреса
6. Blockchain на Go. Часть 6: Транзакции, часть 2
7. Blockchain на Go. Часть 7: Сеть
Блокчейн одна из самых революционных технологий 21 века, до сих пор не реализовавшая весь свой потенциал. По сути, блокчейн это просто распределенная база данных. Что же делает ее уникальной? Это база данных полностью открыта и хранится у каждого участника полной или частичной копией. Новая запись создается только с согласия всех кто хранит базу. Благодаря этому существуют такие вещи как криптовалюта и умные контракты.
В этой серии уроков мы создадим, основанную на блокчейне, упрощенную криптовалюту. В качестве языка используем Go.
### Блок
Начнем с "блока" части "блокчейна". В блокчейне, блоки хранят полезную информацию. Например, в bitcoin блоки хранят транзакции, суть любой криптовалюты. Помимо полезной информации, в блоке содержится служебная информация: версия, дата создания в виде timestamp и хеш предыдущего блока. В этой статье мы будем создавать упрощенный блок, содержащий только существенную информацию. Опишем его в виде go структуры.
```
type Block struct {
Timestamp int64
Data []byte
PrevBlockHash []byte
Hash []byte
}
```
`Timestamp` это время создания блока, `Data` это полезная информация, содержащаяся в блоке, `PrevBlockHash` хранит хэш предыдущего блока, и наконец, `Hash` содержит хэш блока. В спецификации bitcoin `Timestamp`, `PrevBlockHash` и `Hash` образуют заголовок блока и образуют отдельную от транзакций (в нашем случае это `Data`) структуру. Мы же смешали их для простоты.
Как вычисляется хэши? Вычисление хэшей одна из важных свсойств блокчейна, благодаря ему он считается безопасным. Все потому, что вычисление хэша это довольно сложная операция (именно поэтому майнеры покупали мощные видеокарты, для добычи биткойна). Это было задумано специально, предотвращая от изменения всей цепочки.
Обсудим это в следующей статье, а сейчас мы просто соеденим все поля блока и захэшируем результат в SHA-256:
```
func (b *Block) SetHash() {
timestamp := []byte(strconv.FormatInt(b.Timestamp, 10))
headers := bytes.Join([][]byte{b.PrevBlockHash, b.Data, timestamp}, []byte{})
hash := sha256.Sum256(headers)
b.Hash = hash[:]
}
```
Далее, создадим "конструктор" для нашего блока
```
func NewBlock(data string, prevBlockHash []byte) *Block {
block := &Block{time.Now().Unix(), []byte(data), prevBlockHash, []byte{}}
block.SetHash()
return block
}
```
Блок готов!
### Блокчейн
Теперь давайте напишем блокчейн. По сути, блокчейн это база данных определенной структуры: упорядоченный связанный список. Это означает, что блоки хранятся в порядке вставки, при чем каждый блок связан с предыдущем. Такая структура позволяет получить последний блок в цепочке и эффективно получить блок по его хэшу.
В Golang эта структура может быть реализована с помощью массива (array) и карты (map): массив будет содержать упорядоченный список хэшей (массивы упорядоченны в Go), а карты будут хранить пары `hash -> block` (карты не упорядочены). Но для нашего прототипа, мы будем использовать только массивы потому, что нам не требуется получать блок по его хэшу.
```
type Blockchain struct {
blocks []*Block
}
```
Это наш первый блокчейн! Никогда не думал, что это так просто :)
Добавим возможность добавлять блоки в него.
```
func (bc *Blockchain) AddBlock(data string) {
prevBlock := bc.blocks[len(bc.blocks)-1]
newBlock := NewBlock(data, prevBlock.Hash)
bc.blocks = append(bc.blocks, newBlock)
}
```
Чтобы добавить первый блок, нам нужен существующий, но наш блокчейн пуст! Таким образом нам в любом блокчейне должен быть как минимум один блок, который называют `genesis` блоком. Реализуем метод, создающий такой блок.
```
func NewGenesisBlock() *Block {
return NewBlock("Genesis Block", []byte{})
}
```
А теперь реализуем функцию создающую блокчейн с `genesis` блоком.
```
func NewBlockchain() *Blockchain {
return &Blockchain{[]*Block{NewGenesisBlock()}}
}
```
Давайте проверим, что блокчейн работает корректно
```
func main() {
bc := NewBlockchain()
bc.AddBlock("Send 1 BTC to Ivan")
bc.AddBlock("Send 2 more BTC to Ivan")
for _, block := range bc.blocks {
fmt.Printf("Prev. hash: %x\n", block.PrevBlockHash)
fmt.Printf("Data: %s\n", block.Data)
fmt.Printf("Hash: %x\n", block.Hash)
fmt.Println()
}
}
```
Этот код выведет
```
Prev. hash:
Data: Genesis Block
Hash: aff955a50dc6cd2abfe81b8849eab15f99ed1dc333d38487024223b5fe0f1168
Prev. hash: aff955a50dc6cd2abfe81b8849eab15f99ed1dc333d38487024223b5fe0f1168
Data: Send 1 BTC to Ivan
Hash: d75ce22a840abb9b4e8fc3b60767c4ba3f46a0432d3ea15b71aef9fde6a314e1
Prev. hash: d75ce22a840abb9b4e8fc3b60767c4ba3f46a0432d3ea15b71aef9fde6a314e1
Data: Send 2 more BTC to Ivan
Hash: 561237522bb7fcfbccbc6fe0e98bbbde7427ffe01c6fb223f7562288ca2295d1
```
Наш прототип работает!
### Заключение
Мы только что построили очень простой прототип блокчейна: простого массива блоков, каждый из которых связан с предыдущим. Настоящий блокчейн намного сложнее. Наш блокчейн добавляет новые блоки очень легко и быстро, в реальном же блокчейне добавление новых блоков требует определенной работы: выполнение сложных вычислений, перед получением права на добавления блока (этот механизм называется Prof-of-Work). Кроме того, блокчейн — распределенная база, которая не имеет единого центра принятия решения. Таким образом, новый блок должен быть подтвержден и одобрен другими участниками сети (данный механизм называется `консенсусом`). Ну и собственно у нас пока нет самих транзакций.
Все эти свойства мы рассмотрим в будущих статьях.
### Ссылки
[Исходный код для статьи](https://github.com/Jeiwan/blockchain_go/tree/part_1). | https://habr.com/ru/post/348672/ | null | ru | null |
# Boot yourself, Spring is coming (Часть 2)
Евгений [EvgenyBorisov](https://habr.com/ru/users/evgenyborisov/) Борисов (NAYA Technologies) и Кирилл [tolkkv](https://habr.com/ru/users/tolkkv/) Толкачев (Циан.Финанс, [Твиттер](https://twitter.com/tolkv)) продолжают рассказывать о применении Spring Boot к решению задач воображаемого Железного банка Браавоса. Во второй части речь пойдет о профилях и тонкостях запуска приложения.

Первую часть статьи можно найти [тут](https://habr.com/company/jugru/blog/424503/).
Итак, до недавнего времени заказчик приходил и просто требовал посылать ворона. Сейчас ситуация поменялась. Зима наступила, стена упала.
Во-первых, меняется принцип выдачи кредитов. Если раньше с вероятностью 50% выдавали всем, кроме Старков, то теперь выдают исключительно тем, кто возвращает долги. Поэтому мы меняем правила выдачи кредитов в нашей бизнес-логике. Но только для филиалов банка, которые находятся там, где зима уже пришла, во всех остальных всё остаётся по-старому. Напоминаю, речь идет о сервисе, который решает, выдавать кредит или нет. Мы просто сделаем еще один сервис, который будет работать только зимой.
Идем в нашу бизнес-логику:
```
public class WhiteListBasedProphetService implements ProphetService {
@Override
public boolean willSurvive(String name) {
return false;
}
}
```
У нас уже есть перечень тех, кто возвращает долги.
```
spring:
application.name: money-raven
jpa.hibernate.ddl-auto: validate
ironbank:
те-кто-возвращают-долги:
- Ланистеры
ворон:
куда-лететь: браавос, главный банк
вкл: true
```
И есть класс, который уже связан с property — `теКтоВозвращаютДолги`.
```
public class ProphetProperties {
List теКтоВозвращаютДолги;
}
```
Как и в предыдущие разы, мы просто инжектим его сюда:
```
public class WhiteListBasedProphetService implements ProphetService {
private final ProphetProperties prophetProperties;
@Override
public boolean willSurvive(String name) {
return false;
}
}
```
Помним про constructor injection (про волшебные аннотации):
```
@Service
@RequiredArgsConstructor
public class WhiteListBasedProphetService implements ProphetService {
private final ProphetProperties prophetProperties;
@Override
public boolean willSurvive(String name) {
return false;
}
}
```
Почти готово.
Теперь мы должны выдать только тем, кто возвращает долги:
```
@Service
@RequiredArgsConstructor
public class WhiteListBasedProphetService implements ProphetService {
private final ProphetProperties prophetProperties;
@Override
public boolean willSurvive(String name) {
return prophetProperties.getТеКтоВозвращаютДолги().contains(name);
}
}
```
Но тут у нас есть небольшая проблема. Теперь у нас две реализации: старый и новый сервисы.
```
Description
Parameter 1 of constructor in com.ironbank.moneyraven.service.TransferMoneyProphecyBackend…
- nameBasedProphetService: defined in file [/Users/tolkv/git/conferences/spring-boot-ripper…
- WhileListBackendProphetService: defined in file [/Users/tolkv/git/conferences/spring-boot-ripper...
```
Логично разделить эти бины по разным профилям. Профиль `зимаТута` и профиль `зимаБлизко`. Пусть наш новый сервис запускается только в профиле `зимаТута`:
```
@Service
@Profile(ProfileConstants.зимаТута)
@RequiredArgsConstructor
public class WhiteListBasedProphetService implements ProphetService {
private final ProphetProperties prophetProperties;
@Override
public boolean willSurvive(String name) {
return prophetProperties.getТеКтоВозвращаютДолги().contains(name);
}
}
```
А старый сервис — в `зимаБлизко`:
```
@Service
@Profile(ProfileConstants.зимаБлизко)
public class NameBasedProphetService implements ProphetService {
@Override
public boolean willSurvive(String name) {
return !name.contains("Stark") && ThreadLocalRandom.current().nextBoolean();
}
}
```
Но зима приходит медленно. В королевствах, находящихся рядом со сломанной стеной, уже зима. А вот где-то на юге — еще нет. Т.е. приложения, которые находятся в разных филиалах и тайм-зонах, должны работать по-разному. По условиям нашей задачи мы не можем стереть старую имплементацию там, где зима наступила, и использовать новый класс. Мы хотим, чтобы банковские работники не делали вообще ничего: поставим им приложение, которое будет работать в режиме лета до момента прихода зимы. А когда придет зима, они просто перезапустят его и все. Они не должны будут менять код, стирать какие-то классы. Поэтому у нас изначально есть два профиля: часть бинов создается, когда лето, а часть бинов создается, когда зима.
Но появляется другая проблема:

Теперь у нас нет ни одного бина, потому что мы указали два профиля, а приложение стартует в дефолтном профиле.
Так у нас появляется новое требование от заказчика.
Железный закон 2. Без профиля нельзя
------------------------------------

Мы не хотим поднимать контекст, если не активизирован профиль, потому что зима уже пришла, все стало очень плохо. Есть определенные вещи, которые должны происходить или нет, в зависимости от того, `зимаТута` или `зимаБлизко`. Кроме того, посмотрите на exception, текст которого приведен выше. Он ничего не объясняет. Профиль не задан, поэтому нет ни одной имплементации `ProphetService`. В то же время никто не сказал о том, что надо обязательно задавать профиль.
Поэтому мы хотим сейчас докрутить дополнительную штуку в наш стартер, которая при построении контекста будет проверять, что какой-то профиль задан. Если он не задан, мы не будем подниматься и кинем именно такой exception (а не какой-нибудь exception о нехватке бина).
Можем ли мы это сделать с помощью нашего application listener? Нет. И этому есть три причины:
* Single responsibility listener отвечает за то, чтобы ворон летел. Listener не должен проверять, был ли активирован профиль, потому что активизация профиля влияет не только на сам listener, но и на многое другое.
* Когда строится контекст, происходят разные вещи. И мы не хотим, чтобы они начали происходить, если не был задан профиль.
* Listener работает в самом конце, когда рефрешится контекст. А то, что профиля нет, мы знаем намного раньше. Зачем ждать эти условные пять минут, пока сервис почти поднимется, а потом все упадет.
Кроме того, я еще не знаю, какие баги появятся из-за того, что мы начали подниматься без профиля (предположим, мне неизвестна бизнес-логика). Поэтому при отсутствии профиля надо валить контекст на очень раннем этапе. Кстати, если вы используете какой-нибудь Spring Cloud, это для вас становится еще более актуальным, потому что приложение на раннем этапе делает довольно много всего.
Для реализации нового требования существует `ApplicationContextInitializer`. Это еще один интерфейс, который позволяет нам расширить какую-то точку Spring, указав его в spring.factories.

Мы имплементируем этот интерфейс, и у нас появляется Context Initializer, в котором есть `ConfigurableApplicationContext`:
```
public class ProfileCheckAppInitializer implements ApplicationContextInitializer {
@Override
public void initialize(ConfigurableApplicationContext applicationContext) {
}
}
```
С помощью него мы можем достать environment — штуку, которую нам подготовил SpringApplication. Туда попали все property, которые мы ему передали. Среди прочего там содержатся и профили.
Если профилей там нет, то мы должны кинуть exception о том, что нельзя так работать.
```
public class ProfileCheckAppInitializer implements ApplicationContextInitializer {
@Override
public void initialize(ConfigurableApplicationContext applicationContext) {
if applicationContext.getEnvironment().getActiveProfiles().length == 0 {
throw new RuntimeException("Нельзя без профиля!");
}
}
}
```
Теперь нужно это добро прописать в spring.factories.
```
org.springframework.boot.context.properties.EnableConfigurationProperties=com.ironbank.moneyraven.starter.IronConfiguration
org.springframework.context.ApplicationContextInitializer=com.ironbank.moneyraven.starter.ProfileCheckAppInitializer
```
Из вышесказанного можно догадаться, что `ApplicationContextInitializer` — это некая точка расширения. `ApplicationContextInitializer` работает, когда контекст только начинает строиться, еще нет никаких бинов.
Возникает вопрос: если мы написали `ApplicationContextInitializer`, почему его, как listener, не прописать в конфигурации, которая тянется в любом случае? Ответ прост: потому что он должен работать намного раньше, когда нет контекста и никаких конфигураций. Т.е. его еще нельзя заинжектить. Поэтому мы его прописываем как отдельную штуку.
Попытка запуска показала: все повалилось достаточно быстро и сообщило, что мы запускаемся без профиля. А теперь попробуем указать какой-нибудь профиль, и все работает — ворон отправляется.
`ApplicationContextInitializer` — отрабатывает, когда контекст уже создан, но еще в нем нет ничего, кроме environment.

Кто создает environment? Карлсон — `SpringBootApplication`. Он же ее наполняет разной мета-информацией, которую потом из контекста можно будет дергать. Большинство вещей можно инжектить через `@value`, что-то можно получить из environment, как мы только что получили профили.
Например, сюда заходят разные property:
* которые умеет собирать Spring Boot;
* которые при запуске передаются через командную строку;
* системные;
* прописанные как environment variables;
* прописанные в application properties;
* прописанные в каких-то других property-файлах.
Всё это собирается и сетится в объект environment. Туда же попадает информация о том, какие профили активны. Объект environment — это единственное, что существует на момент, когда Spring Boot начинает строить контекст.
Хотелось бы угадать автоматически, какой будет профиль, если люди забыли задать его руками (мы делаем все, чтобы банковские работники, которые достаточно беспомощны без программистов, могли запустить приложение — чтобы у них все заработало, независимо ни от чего). Для этого мы допишем в наш стартер штуку, которая будет угадывать профиль — `зимаТута` или нет — в зависимости от температуры на улице. И в этом всем нам поможет еще один новый волшебный интерфейс — `EnvironmentPostProcessor`, потому что нам нужно сделать это до того, как работает `ApplicationContextInitializer`. А до `ApplicationContextInitializer` есть только `EnvironmentPostProcessor`.
Мы опять реализуем новый интерфейс. Тут всего один метод, который точно так же `ConfigurableEnvironment` прокидывает в `SpringApplication`, потому что `ConfigurableContext` у нас еще нет (в `SpringInitializer` он уже есть, то здесь его нет; есть только environment).
```
public class ResolveProfileEnvironmentPostProcessor implements EnvironmentPostProcessor {
@Override
public void postProcessEnvironment(ConfigurableEnvironment environment, SpringApplication application) {
}
}
```
В этом environment мы можем установить профиль. Но сначала надо проверить, что никто его не установил ранее. Поэтому проверка `getActiveProfiles` нам в любом случае нужна. Если люди знают, что они делают, и они установили профиль, то мы не будем за них пытаться угадать. А вот если профиля нет, тогда мы попытаемся понять по погоде.
И второе — мы должны понять, зимняя или летняя у нас сейчас погода. Будем возвращать температуру `-300`.
```
public class ResolveProfileEnvironmentPostProcessor implements EnvironmentPostProcessor {
@Override
public void postProcessEnvironment(ConfigurableEnvironment environment, SpringApplication application) {
if (environment.getActivePrifiles().length == 0 && getTemperature() < -272) {
}
}
public int getTemperature() {
return -300;
}
}
```
При таком условии у нас зима, и мы можем установить новый профиль. Мы помним, что профиль называется `зимаТута`:
```
public class ResolveProfileEnvironmentPostProcessor implements EnvironmentPostProcessor {
@Override
public void postProcessEnvironment(ConfigurableEnvironment environment, SpringApplication application) {
if (environment.getActivePrifiles().length == 0 && getTemperature() < -272) {
environment.setActiveProfiles("зимаТута");
} else {
environment.setActiveProfiles("зимаБлизко");
}
}
public int getTemperature() {
return -300;
}
}
```
Теперь надо указать `EnvironmentPostProcessor` в spring.factories.
```
org.springframework.boot.context.properties.EnableConfigurationProperties=com.ironbank.moneyraven.starter.IronConfiguration
org.springframework.context.ApplicationContextInitializer=com.ironbank.moneyraven.starter.ProfileCheckAppInitializer
org.springframework.boot.env.EnvironmentPostProcessor=com.ironbank.moneyraven.starter.ResolveProfileEnvironmentPostProcessor
```
В итоге приложение запускается без профиля, мы говорим, что это продакшн, и проверяем, в каком же профиле он у нас запустился. Волшебным образом мы поняли, что профиль у нас `зимаТута`. И приложение не упало, потому что `ApplicationContextInitializer`, который проверяет, есть ли профиль, идет следом.
Итог:
```
public class ResolveProfileEnvironmentPostProcessor implements EnvironmentPostProcessor {
@Override
public void postProcessEnvironment(ConfigurableEnvironment environment, SpringApplication application) {
if (getTemperature() < -272) {
environment.setActiveProfiles("зимаТута");
} else {
environment.setActiveProfiles("зимаБлизко");
}
}
private int getTemperature() {
return -300;
}
}
```
Мы говорили про `EnvironmentPostProcessor`, который работает до `ApplicationContextInitializer`. Но кто его запускает?

Запускает его вот такой чудик, который, видимо, является внебрачным сыном `ApplicationListener` и `EnvironmentPostProcessor`, потому что наследуется и от `ApplicationListener`, и от `EnvironmentPostProcessor`. Называется он `ConfigFileApplicationListener` (почему "ConfigFile" — никто не знает).
Ему наш Карлсон, т.е. Spring Application, дает подготовленный environment, чтобы тот слушал два event: `ApplicationPreparedEvent` и `ApplicationEnvironmentPreparedEvent`. Мы сейчас не будем разбирать, кто кидает эти event-ы. Там есть еще одна прослойка (на мой взгляд уже совершенно лишняя, по крайней мере, на данном этапе развития Spring), которая кидает event о том, что сейчас начинает строиться environment (парсятся Application.yml, properties, environment переменные и т.д.).
Получив `ApplicationEnvironmentPreparedEvent`, listener понимает, что надо настроить environment — найти все `EnvironmentPostProcessor` и дать им отработать.

После этого он говорит `SpringFactoriesLoader` доставить все, что вы прописали, а именно все `EnvironmentPostProcessor`, в spring.factories. Потом он запихивает все `EnvironmentPostProcessor` в один List

и понимает, что он тоже `EnvironmentPostProcessor` (по совместительству), поэтому и себя туда запихивает,

при этом сортирует их, едет вместе с ними и вызывает у каждого метод `postProcessEnvironment`.
Таким образом все `postProcessEnvironment` запускаются на раннем этапе еще до `SpringApplicationInitializer`. При этом непонятный `EnvironmentPostProcessor` под названием `ConfigFileApplicationListener` тоже запускается.
Когда environment настроился, все опять возвращается к Карлсону.
Если environment готов, можно строить контекст. И Карлсон начинает строить контекст с помощью `ApplicationInitializer`. Тут у нас есть собственный кусок, который проверяет, что в контексте есть environment, в котором есть активные профили. Если нет, мы падаем, потому что иначе у нас потом все равно будут проблемы. Дальше работают стартеры, со всеми уже обычными конфигурациями.
Картинка выше отражает, что в Spring тоже не все хорошо. Там периодически встречаются такие инопланетяне, single responsibility не соблюдается и лезть туда нужно аккуратно.
Теперь мы хотим немного поговорить о другой стороне этого странного существа, которое с одной стороны listener, а с другой стороны — `EnvironmentPostProcessor`.

Как `EnvironmentPostProcessor` он умеет подгружать application.yml, application properties, всякие environment variable, command аргументы и т.д. А как listener, он умеет слушать два event-а:
* `ApplicationPreparedEvent`
* `ApplicationEnvironmentPreparedEvent`
Возникает вопрос:

Все эти event-ы были в старом Spring. А те, о которых мы говорили выше — event из Spring Boot (специальные event-ы, которые он добавил для своего жизненного цикла). И их еще целая пачка. Это основные:
* `ApplicationStartingEvent`
* `ApplicationEnvironmentPreparedEvent`
* `ApplicationPreparedEvent`
* `ContextRefreshedEvent`
* `EmbeddedServletContainerInitializedEvent`
* `ApplicationReadyEvent`
* `ApplicationFailedEvent`
В этом списке присутствует далеко не все. Но важно, что часть из них относится к Spring Boot, а часть — к Spring (старый-добрый `ContextRefreshedEvent` и т.д.).
Нюанс заключается в том, что не все из этих event-ов мы можем получить в приложении (простые смертные — разные бабушки — не могут просто слушать сложные event-ы, которые кидает Spring Boot). Но если вы знаете про тайные механизмы spring.factories и определяете свой Application Listener на уровне spring.factories, то эти event-ы самого раннего этапа старта приложения попадают к вам.
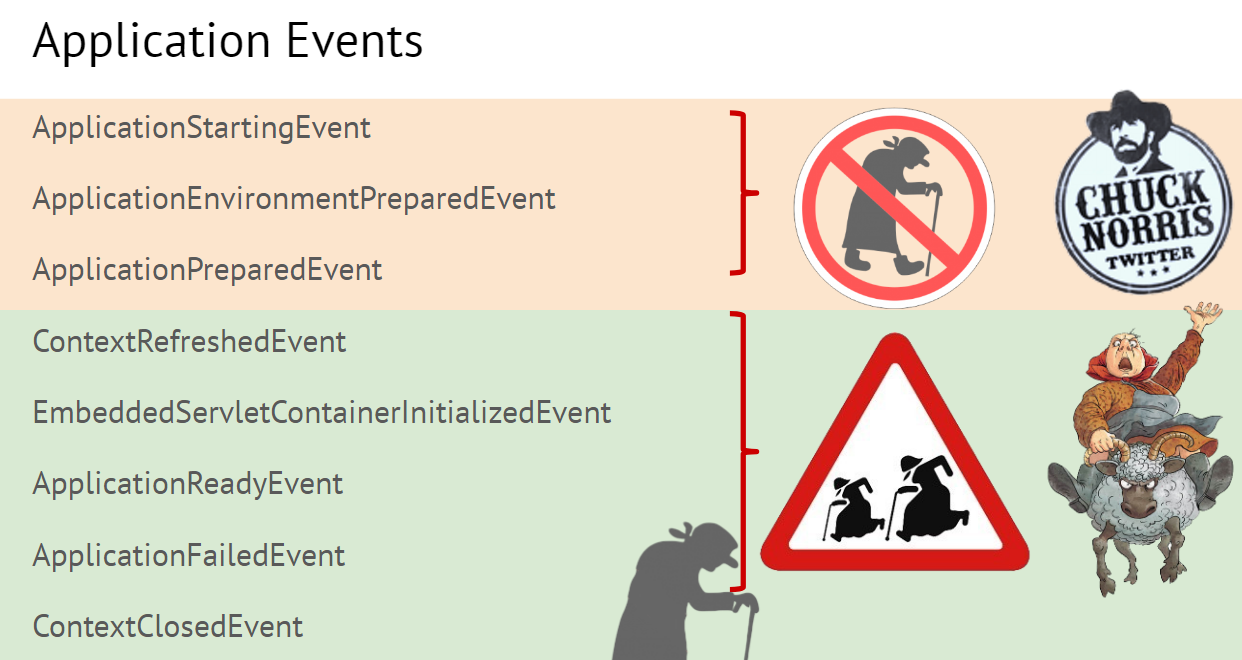
В итоге вы можете влиять на старт своего приложения на довольно раннем этапе. Прикол, правда, в том, что часть этой работы вынесена в другие сущности — такие, как `EnvironmentPostProcessor` и `ApplicationContextInitializer`.
Можно было всё делать на listener-ах, но это было бы неудобно и некрасиво. Если вы хотите слушать все event-ы, которые кидает Spring, а не только `ContextRefreshedEvent` и `ContextStartedEvent`, то не надо прописывать listener, как бин, обычным путем (иначе он создается слишком поздно). Его надо тоже прописать через spring.factories, тогда его создадут намного раньше.
Кстати, когда мы смотрели этот список, нам было непонятно, когда вообще срабатывают `ContextStartedEvent` и `ContextStoppedEvent`?

Оказалось, что эти event-ы вообще никогда не работают. Мы долго ломали голову над тем, какие же event-ы надо ловить, чтобы понять, что приложение действительно стартовало. И оказалось, что event-ы, о которых мы сейчас говорили, появляются, когда вы принудительно дергаете методы у контекста:
* `ctx.start();` -> `ContextStartedEvent`
* `ctx.stop();` -> `ContextStoppedEvent`
Т.е. event-ы будут приходить, только если мы запустим `SpringApplication.run`, получим контекст, дернем у него `ctx.start();` или `ctx.stop();`. Не очень понятно, зачем это нужно. Но вам, опять же, дали точку расширения.
Имеет ли Spring к этому какое-то отношение? Если да, то где-то должен быть exception:
* `ctx.stop();` (1)
* `ctx.start();` (2)
* `ctx.close();` (3)
* `ctx.start();` (4)
По факту он будет на последней строчке, потому что после `ctx.close();` с контекстом нельзя делать ничего. Но вызывать `ctx.stop();` перед `ctx.start();` — можно (просто Spring игнорирует эти event-ы - они только для вас).
Пишите свои listener-ы, слушайте сами, придумайте ваши законы, что делать на `ctx.stop();`, а что делать на `ctx.start();`.
Итого схема взаимодействия и жизненного цикла приложения выглядит примерно так:

Цветами здесь показаны разные периоды жизни.
* Синий — это Spring Boot, приложение уже стартовало. Это значит, что обрабатываются Tomcat service запросы, которые приходят к нему от клиентов, весь контекст точно поднят, все бины работают, базы данных подключены и т.д.
* Зеленый — прилетел event `ContextRefreshedEvent` и контекст построен. С этого момента начинают работать, например, application listener-ы, которые вы имплементируете либо путем установки аннотации ApplicationListener, либо через одноименный интерфейс с дженериком, который слушает определенные event-ы. Если же вы хотите получать больше event-ов, нужно прописывать этот же ApplicationListener в spring.factories (здесь работает обычный Spring). Полосой отмечено, где начинается доклад [Spring Ripper](https://www.youtube.com/watch?v=hDpa6m48eC4).
* На более ранней стадии работает SpringApplication, который подготавливает нам контекст. Это та работа по подготовке приложения, которую мы делали, когда были обычными Spring-разработчиками. Например, конфигурировали WebXML.
* Но есть еще более ранние этапы. Здесь указано, кто, где и за кем работает.
* Есть еще серый этап, в которой никак нельзя вклиниться. Это этап, на котором "из коробки" работает SpringApplication (только в код лезть).
Если вы обратили внимание, в процессе доклада из двух частей мы шли справа налево: начали с самого конца, прикрутили конфигурацию, которая прилетала из стартера, потом добавили следующее и т.п. Теперь давайте быстренько всю эту цепочку проговорим в обратную сторону.
Вы пишите в вашем main `SpringApplication.run`. Он находит разных listener-ов, кидает им event, что начал строиться. После этого listener-ы находят `EnvironmentPostProcessor`, дают им настроить environment. Как только environment настроен, мы начинаем строить контекст (вступает Карлсон). Карлсон строит контекст и дает возможность всем Application Initializer-ам что-то с этим контекстом сделать. У нас есть точка расширения. После этого контекст уже настроен и дальше начинает происходить то же самое, что и в обычном Spring-овом приложении, когда строиться контекст — `BeanFactoryPostProcessor`, `BeanPostProcessor`, бины настраиваются. Этим занимается обычный Spring.
Как запускать
-------------
Мы закончили обсуждать процесс написания приложения.
Но у нас была еще одна вещь, которую не любят разработчики. Они не любят думать, как же в итоге их приложение запустится. Будет ли админ его запускать в Tomcat, JBoss или в WebLogic? Оно просто должно работать. Если оно не работает, в худшем случае разработчику приходится опять что-то настраивать
Итак, какие у нас есть способы запуска?
* tomcat war;
* idea;
* `java -jar/war`.
Tomcat — не массовый тренд, про него подробно рассказывать не будем.
Idea — тоже, в принципе, не очень интересно. Там просто чуть хитрее, чем я расскажу ниже. Но в Idea в принципе не должно быть проблем. Она же видит, какие зависимости стартер принесет.
Если мы делаем `java -jar`, основная проблема — построить classpath перед тем, как мы запускаем приложение.
Что люди делали в 2001 году? Они писали `java -jar`, какой jar надо запустить, потом пробел, `classpath=...` и там указывали скрипты. В нашем случае там 150 Мб разных зависимостей, которые добавили стартеры. И все это надо было бы делать вручную. Естественно, никто так не делает. Мы просто пишем: `java -jar`, какой jar надо запустить и все. Каким-то образом classpath все равно строится. Про это мы сейчас будем разговаривать.
Начнем с этапа подготовки jar-файла, чтобы его вообще можно было запустить без Tomcat. Перед тем, как сделать `java -jar`, надо jar построить. Этот jar явно должен быть необычный, какой-то аналог war-а, где будет внутри все, включая embedded Tomcat.
```
org.springframework.boot
spring-boot-maven-plugin
```
Когда мы скачали проект, у нас в POM-е уже кто-то прописал плагин. Тут еще, кстати, можно конфигурации накидывать, но об этом чуть позже. В итоге кроме обычного jar, который строит Maven или Gradle вашего приложения, строится еще jar необычный. С одной стороны он выглядит нормально:

А вот если посмотреть сбоку:

Это в принципе аналог war-а.
Посмотрим, что он вообще собой представляет.
Тут есть явно стандартные части, как в обычном jar. Когда мы пишем `java -jar`, подтягиваются все классы, которые находятся в корне, например, `org.springframework.boot`. Но это же не наши классы. Мы вряд ли писали org.springframework.boot package. Поэтому в первую очередь для нас знакомым является `META-INF`

Spring Boot тоже делает MANIFEST (через тот самый плагин Maven или Gradle), кастомизирует его и прописывает main class, который запуститься в jar-е.
По сути, все jar-ы делятся на два вида: запускаемые и простые зависимости чего-то, не имеющие собственного main-а. И мы можем сделать `java -jar` только на -jar, у которого прописано, кто является main-class-ом.
Логично предположить, что этот плагин, который делает нам упаковку и создает этот MANIFEST, в main-class прописывает тот класс, который у нас main (который мы запускаем из Idea). Но если погрузиться чуть глубже, этого никак не может быть. Кто же тогда построит class path? Если мы возьмем `java -jar` и скажем, что main, который надо запустить, — это наш главный main, он не найдет никаких зависимостей. Поэтому плагин в MANIFEST прописывает в качестве основного класса JarLauncher.
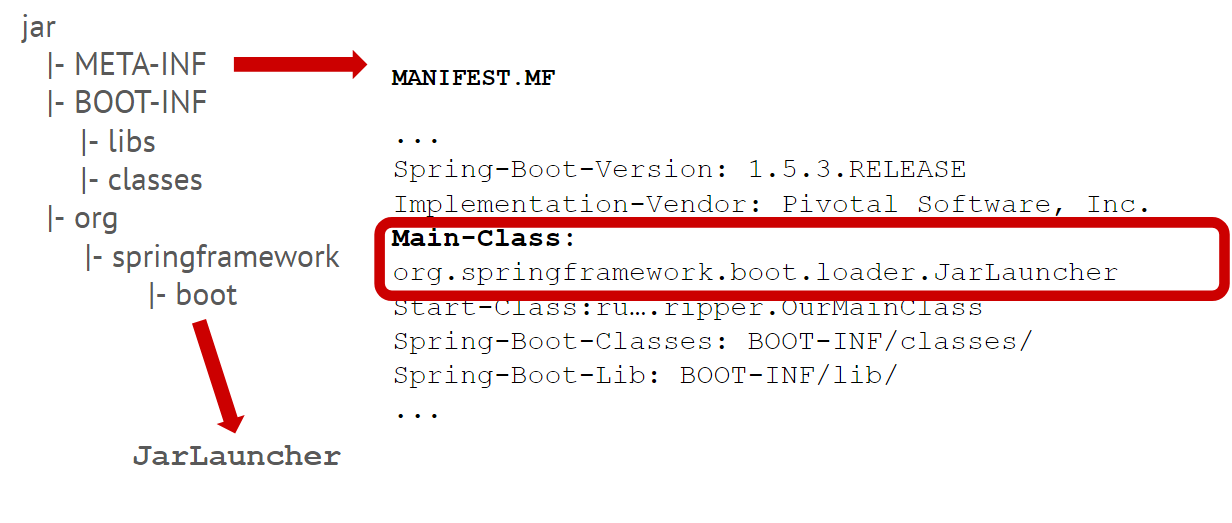
Т.е. помимо вашего кода и зависимостей, он упаковывает еще такую штуку, в которой есть JarLauncher. Его задача в том, чтобы запустить наш main, но перед этим построить class path.
А как он знает, какой у нас main? Тут есть property — `Start-class`.
Т.е. инициализация вашего приложения происходит в два шага. На первом шаге есть class path стандартного jar. Все, что там лежит — `org.springframework.boot` — будет в class path. Поэтому мы совершенно валидно пишем `org.springframework.boot.loader.JarLauncher` в main-class. И он запускается, main-class идет дальше. Он формирует class path, который находится в `BOOT-INF` (там есть папочка lib с зависимостями и папочка class с классами, которые вы написали в своем приложении).
Когда мы писали RavenApplication, properties падает в class в `BOOT-INF`, а все зависимости, типа Tomcat и библиотек, падают в `BOOT-INF/lib/`. Когда JarLauncher сформировал classpath, он совершает второй шаг — запускает класс, который указан в `start-class`. Там уже работает реальный Spring, `ContextSpringApplication` — ровно тот flow, о котором мы рассказывали ранее.
Откуда плагин знает, кто является start-class-ом? Мы можем указать явно, какой класс должен быть запускным. И тогда этот плагин пропишет его, как стартовый.
Кстати, тут получается такой парадокс имен. Мы прописываем его через property, которое называется `mainClass`, а в MANIFEST это будет `Start-Class`, потомучто `mainClass` — это всегда JarLauncher.
Но если мы не рассказали явно, кто является mainClass, как он разберется? У него есть следующая логика. Spring boot plugin сканирует проект – ищет mainClass:
* если есть только один – то это точно он. Плагин его сам выставляет — не нужно принудительно ставить main class;
* если больше одного – смотрит, над каким mainClass стоит аннотация `@SpringBootApplication` и выбирает его, если, конечно, нет второго;
* если есть второй — будет exception с указанием того, что нужно прописать main class, иначе непонятно, с кем бандлить ваш jar-ник с приложением. Т.е. приложение просто не запустится, а точнее, даже не соберется. Скажет, что там больше, чем один кандидат на main class.
* если @SpringBootApplication нет — тоже будет ошибка.
JarLauncher есть не всегда. Некоторые используют Tomcat и для них есть WarLauncher, благодаря которому есть возможность запустить war-ник так же, как jar-ник.
Но есть такие люди, для которых сложно даже `java -jar`. Можно ли упростить? Можно. Сейчас посмотрим как.
```
org.springframework.boot
spring-boot-maven-plugin
true
```
Мы можем указать опцию а в ней `true` ну или в Gradle так же, только проще:
```
springBoot {
executable = true
}
```
Мы указываем эту опцию и jar превращается в executable jar. Наше приложение уже было сконфигурировано на это.
Давайте посмотрим, как это вообще происходит. Все пользователи Windows помнят, что можно кликнуть по exe-шнику, и он запустится. То же происходит и с приложением Spring Boot, т.е. с вашим jar, когда вы делаете так. Я просто условно кликаю по нему, и он пошел запускаться.
Как это произошло?
Мы можем открыть наш файлик (jar — это zip-архив, открываем его в текстовом редакторе):

Spring Boot совершил какую-то магию.
Это баш-скрипт, который запускает jar-ник. Прикол в том, что в начале здесь указан интерпретатор, которым надо запускать скрипт — `#!/bin/bash`. И в этом половина магии.
Вторая половина магии находится в конце скрипта. Там есть `exit 0` и дальше какая-то белиберда — с этого места пошел наш zip-архив.

Магия в том, что любой zip-архив имеет специальную метку — `0xf4ra`. Если архиватор видит эту метку, он понимает, что нашел старт архива.
До этого может быть что угодно (картинки, текст и т.п.).
Запуск jar превращается в следующую операцию:
* система считывает первую строчку — потому что это просто файл;
* она видит, что там написано "запускай меня через bash" (`#!/bin/bash`);
* bash запускает этот файл;
* он выполняет скрипт и доходит `exit 0`;
* сам скрипт делает `java -jar` на себя — на тот же самый jar-ник, которым он является;
* после `java -jar` стандартный zip-архиватор идет по jar-у, пропускает скрипт, видит метку начала архива, и с этого момента идет запуск приложения.
Выводы
------
Выводы в первую очередь связаны с мнением о том, что Spring Boot — это большая магия, что там делается много всего, с чем потом невозможно разобраться.
Во-первых, разобраться можно. Это сложнее, чем разобраться со Spring, потому что Spring — это маленькая часть жизненного цикла Spring Boot. Это связано с тем, что он на себя взял ответственность за те проблемы, которые не любит брать на себя разработчик — конфигурации, зависимости, версии и запуск, сняв головную боль с нас. Кстати, часть проблем, связанных с неправильным использованием Spring, Spring Boot тоже забрал.
Во-вторых, мы видим аннотацию `@SpringBootApplication`, в которой собраны те best practice, которые были в хороших Spring-приложениях.
И третье — это новая инфраструктура, которая решает проблему внешних зависимостей, типа различных конфигураций. Мы можем прописать property как environment variable, можем прописать как var arg в нашем приложении, можем прописать ее как некий внешний ресурс, а можем использовать JSON. В любом случае все загрузится в приложение и будет доступно через `@value` или даже через более новый безопасный способ, как мы это демонстрировали. Наши configuration properties комплитились, мы предоставляли стартер как сервис, люди его брали и комплитили, и у них не было никаких проблем. Более того, сам Spring предоставляет огромное количество этих стартеров. Мы уже показали, что написаны они весьма странно, но на это есть свои причины.
Последний вывод. Не надо бояться ковыряться в кишках, чтобы использовать необходимые вещи. И тогда вы действительно сможете сами кастомизировать уже не Spring, а Spring Boot и писать свои стартеры. А если возникнут какие-то проблемы, вы будете знать, где дебажить, что смотреть и как это можно будет потом разрулить и починить.

> Минутка рекламы. 19-20 октября состоится конференция Joker 2018, на которой Евгений Борисов вместе с Барухом Садогурским выступят с докладом [«Приключения Сеньора Холмса и Джуниора Ватсона в мире разработки ПО [Joker Edition]»](https://jokerconf.com/2018/talks/50i8gfio9ic6u8qqskyq02/), а Кирилл Толкачев с Максимом Гореликовым представят доклад [«Micronaut vs Spring Boot, или Кто тут самый маленький?»](https://jokerconf.com/2018/talks/1vzkputteosikmmakiqgci/). В целом, на Joker будет ещё множество интересных и заслуживающих [пристального внимания](https://habr.com/company/jugru/blog/424237/) докладов. Приобрести билеты можно на [официальном сайте](https://jokerconf.com/registration/) конференции. | https://habr.com/ru/post/425333/ | null | ru | null |
# Асинхронность: почему это никак не сделают правильно?
Асинхронные программы чертовски неудобно писать. Настолько неудобно, что даже в [node.js](http://nodejs.org), заявленном как «у нас все правильное-асинхронное», понадобавляли таки [синхронных аналогов](http://nodejs.org/docs/v0.1.30/changelog.html) асинхронных функций. Что уж говорить про питоновский синтаксис, не дающий объявить лямбду со сколь-либо сложным кодом внутри…
Забавно, что красивое решение проблемы не требует ничего экстраординарного, но почему-то до сих пор не реализовано.
#### Суть проблемы
Допустим, у нас есть такой синхронный код:
> `var f = open(args);
>
> checkConditions(f);
>
> var result = readAll(f);
>
> checkResult(result);`
Асинхронный аналог будет выглядеть куда страшнее:
> `asyncOpen(args, function(error, f){
>
> if(error)
>
> throw error;
>
> checkConditions(f);
>
> asyncReadAll(f, function(error, result){
>
> if(error)
>
> throw error;
>
> checkResult(result);
>
> });
>
> });`
Чем длиннее цепочка вызовов, тем страшнее код.
Может, вам недостаточно страшно? Тогда попробуйте написать аналог следующего кода, заменив все вызовы на асинхронные:
> `while(true)
>
> {
>
> var result = getChunk(args1);
>
> while(needsPreprocessing(result))
>
> {
>
> result = preprocess(result);
>
> if(!result)
>
> result = obtainFallback(args2);
>
> }
>
> processResult(result);
>
> }`
И дело не в том, что потребуется много буков. Основная засада — синхронный код, приведенный выше, замечательно читается. А вот в том асинхронном безобразии, которое у вас получится, даже вы сами через пару часов так просто не разберетесь.
К слову сказать, пример не голословный. Отдаленное подобие пришлось как-то реализовывать на питоне, причем именно в асинхронном виде.
#### Решения с помощью кирки и лома
Возможно, вы видели в node.js такую концепцию, как [Promise](http://nodejs.org/docs/v0.1.13/api.html#_events). Так вот, [ее больше нет](http://groups.google.com/group/nodejs/msg/0c483b891c56fea2). Самые обычные колбэки оказались куда человечнее. Поэтому про Promise я рассказывать не буду.
А расскажу я про библиотеку [Do](http://github.com/creationix/do). Эта библиотека базируется на концепции continuables. Вот пример, демонстрирующий разницу подходов:
> `// callback-style
>
> asyncFunc(args, function(error, result){
>
> if(error)
>
> throw error;
>
> doSomething(result);
>
> });
>
>
>
> // continuables-style
>
> var continuable = continuableFunc(args);
>
> continuable(function(result){ // callback
>
> doSomething(result);
>
> }, function(error){ // errback
>
> throw error;
>
> });
>
>
>
> // continuables-style short
>
> continuableFunc(args)(doSomething, errorHandler);`
Continuable — это функция, которая возвращает другую функцию, которая принимает в качестве параметров callback и errback и совершает асинхронный вызов.
В некоторых случаях такой подход позволяет заметно упростить код — взгляните на «continuables-style short». Здесь в качестве колбэка мы используем непосредственно doSomething, так как сигнатура функции нам подходит, а в качестве errback используем некий «стандартный» errorHandler, определенный где-то еще.
Do умеет многое. Параллельные вызовы, асинхронный map, некоторые другие интересности. Подробнее об этом можно почитать в статье "[Комбо-библиотека Do](http://nodejs.ru/312)". Там же можно прочесть о том, как конвертировать функции, заточенные под callback-style (стандартный для node.js) в continuables-style.
Однако, вернемся к примерам, с которых я начал. Чем может Do помочь в нашем случае? Собственно, вот чем:
> `Do.chain(
>
> continuableOpen(args),
>
> function(f){
>
> checkConditions(f);
>
> return continuableReadAll(f);
>
> }
>
> )(function(result){
>
> checkResult(result);
>
> }, errorHandler);`
Это continuables-style аналог самого первого примера. Ну что ж, может чуточку лучше по сравнению с callback-style, а может и нет. По крайней мере рост отступов с ростом длины цепочки остановлен, а обработчик ошибок сконцентрировался в одной точке. Но код выглядит страшно, особенно в сравнении с исходной синхронной версией в четыре строки. Более сложный пример — тот что с циклами — Do вообще не по зубам, снова придется городить страшенный огород.
#### yield спешит на помощь
Кирка и лом не помогли, хочется чего-то возвышенного. Хочется, чтобы асинхронный вызов был не сложнее синхронного. А в идеале — почти от него не отличался. И это возможно.
Лучше всего инфраструктура решения описана у Ивана Сагалаева в статье "[ADISP](http://softwaremaniacs.org/blog/2009/12/11/adisp/)". ADISP — это написанная им питоновская библиотека, которая и приносит счастье.
Нечто похожее можно собрать и на JS, примером служит [Er.js](http://www.beatniksoftware.com/erjs/), но туда понапихали многовато магии для первого знакомства, поэтому рекомендую именно статью Сагалаева.
Подход, примененный в ADISP, позволяет писать код в следующем стиле:
> `var func = process(function(){
>
> while(true)
>
> {
>
> var result = yield getChunk(args1);
>
> while(yield needsPreprocessing(result))
>
> {
>
> result = yield preprocess(result);
>
> if(!result)
>
> result = yield obtainFallback(args2);
>
> }
>
> yield processResult(result);
>
> }
>
> });`
Да, это тот самый страшный пример с циклами. Все вызовы асинхронные. Обрамляющая функция func приведена только для того, чтобы показать, что ее придется задекорировать. process — декоратор, аналогичный описанному у Сагалаева. getChunk, needsPreprocessing, preprocess, obtainFallback, processResult — асинхронные функции, задекорированные декоратором async в терминологии ADISP.
Подход работает везде, где есть yield в питоновском стиле. То есть, превосходный асинхронный node.js в пролете, поскольку V8 еще не поддерживает yield.
#### Нативное решение
Нужно ли что-то еще, когда используя трюк с yield мы можем добиться столь достойных результатов? Считаю, что да, поскольку:
— Использование ключевого слова yield в контексте асинхронных вызовов выглядит странно. Все-таки это слово предназначено для несколько иных вещей.
— Необходимость декорирования обрамляющей функции — неудобство и лишний повод для ошибки
— Код того же ADISP хоть и не сложен, но чтобы понять, как эта штука работает, надо изрядно поломать мозг. Мне как-то пришлось использовать ADISP в чуточку модифицированном виде. Я нарвался на странное поведение и долго и мучительно вникал, в чем же дело. Косяк оказался совсем в другом месте, но шансы свихнуться при отладке были более чем реальными.
Пример с yield наглядно показывает, что в среде исполнения есть все для реализации асинхронных вызовов удобным, красивым образом. Настолько все, что даже не трогая внутренние механизмы можно добиться требуемого. Правомерный вопрос — почему бы не предоставить встроенное, нативное решение, реализация которого не должна получиться слишком сложной?
По сути, среда исполнения должна запомнить контекст в месте асинхронного вызова и прекратить исполнение, а в момент вызова колбэка просто восстановить все в нужном виде и, если нужно, бросить исключение. И она умеет это делать, по крайней мере потенциально. Вопрос в том, как подсказать ей, когда нам нужен этот трюк.
##### Неблокирующие библиотечные функции
Как правило, асинхронные функции реализованы либо в ядре языка (например, setTimeout), либо в библиотечных функциях (например, функции модуля fs в node.js). Таким образом, проблема красивых асинхронных вызовов в первую очередь имеет отношение именно к библиотечным функциям.
Это означает замечательную вещь — красивые асинхронные вызовы могут быть введены простым добавлением специального соглашения для асинхронных библиотечных функций. Не нужно менять язык, не нужно придумывать новое ключевое слово и ломать голову над обратной совместимостью. Просто дайте автору библиотеки способ указать, что асинхронной библиотечной функции нужен способ вернуть к жизни контекст, из которого ее вызвали, а текущее исполнение нужно прекратить. Такие функции можно будет смело использовать, например, так:
> `while(true)
>
> {
>
> doSomePeriodicTask();
>
> nbSleep(1000);
>
> }`
Здесь nbSleep — неблокирующий вызов sleep, который фактически прервет исполнение в точке вызова и когда-нибудь начнет его снова из этой же точки, используя сохраненный контекст в качестве колбэка.
Пусть нам даже придется иметь пары функций — одну обычную, с колбэком (все-таки в некоторых случаях вариант с колбэком предпочтительнее), а вторую неблокирующую. Это не страшно, при желании можно сделать обертку:
> `var asyncUnlink = fs.unlink;
>
> fs.unlink = function(fName, callback){
>
> if(callback)
>
> return asyncUnlink(fName, callback);
>
> return nbUnlink(fName);
>
> };`
По крайней мере, синхронные аналоги, которыми можно наделать бед, можно будет выкинуть на фиг, заменив их использование на использование неблокирующих аналогов.
##### Ключевое слово async?
Если нам все-таки хочется добавить красивых асинхронных вызовов на уровне языка, то, видимо, не обойтись без нового ключевого слова. Понятно, что это уже скорее фантазии: изменение языка — слишком уж вольная вольность, в отличие от изменения среды исполнения. Тем не менее, давайте одним глазком глянем, что могло бы получиться:
> `var result1 = async(callback, myAsyncFunc(args, callback)); // long form
>
> var result2 = async myAsyncFunc(args); // short form
>
> var result3 = async(cb, createTask(args, cb), function(task){TaskManager.register(task);});`
— Длинная форма: callback — это название переменной, в которую будет заскладирован контекст возврата для передачи в асинхонную функцию
— Короткая форма: контекст возврата будет добавлен последним аргументом
— Третий вариант — «вывернутый наизнанку»: возвращаемое значение будет передано в лямбду (регистрируем созданную асинхронную «задачу» в неком «менеджере» — может мы захотим ее отменить?), а в точку вызова вернемся обычным для async способом
Зачем может быть нужна поддержка на уровне языка? Думаю, только если нам нужно сделать что-нибудь этакое с нашим хитрым колбэком. Например, отдать его в несколько функций (ой, до чего порочная будет практика). В большинстве случаев должно хватать поддержки на уровне библиотечных функций. И уж точно вызовы неблокирующих библиотечных функций будут смотреться лучше, чем засилье ключевого слова async.
Идея с «вывернутым наизнанку» вызовом, кстати, применима и для неблокирующих библиотечных функций, достаточно передавать в них функцию для вызова непосредственно перед завершением текущего исполнения.
#### Напоследок
Я надеюсь, что когда-нибудь неблокирующие библиотечные функции будут добавлены в V8 и node.js, сделав их еще асинхроннее и прекраснее. Я надеюсь, что их также добавят и в Python. Я надеюсь, что на этом не остановятся и во всех новых и потенциально любимых языках и средах вместо синхронных функций будут функции неблокирующие — везде, где это имеет смысл.
`\* Все исходники в этой статье подсвечены с помощью Source Code Highlighter.` | https://habr.com/ru/post/99792/ | null | ru | null |
# Время отклика компьютеров: 1977−2017
У меня гнетущее чувство, что современные компьютеры по ощущениям медленнее, чем те компьютеры, которые я использовал в детстве. Я не доверяю такого рода ощущениям, потому что человеческое восприятие доказало свою ненадёжность в эмпирических исследованиях, так что я взял высокоскоростную камеру и измерил время отклика устройств, которые попали ко мне за последние несколько месяцев. Вот результаты:
| Компьютер | Отклик
(мс) | Год | Тактовая
частота | Кол-во
транзисторов |
| --- | --- | --- | --- | --- |
| Apple 2e | 30 | 1983 | 1 МГц | 3,5 тыс. |
| TI 99/4A | 40 | 1981 | 3 МГц | 8 тыс. |
| Haswell-E *165 Гц* | 50 | 2014 | 3,5 ГГц | 2 млрд |
| Commodore Pet 4016 | 60 | 1977 | 1 МГц | 3,5 тыс. |
| SGI Indy | 60 | 1993 | 0,1 ГГц | 1,2 млн |
| Haswell-E *120 Гц* | 60 | 2014 | 3,5 ГГц | 2 млрд |
| ThinkPad 13 **ChromeOS** | 70 | 2017 | 2,3 ГГц | 1 млрд |
| iMac G4 **OS 9** | 70 | 2002 | 0,8 ГГц | 11 млн |
| Haswell-E *60 Гц* | 80 | 2014 | 3,5 ГГц | 2 млрд |
| Mac Color Classic | 90 | 1993 | 16 МГц | 273 тыс. |
| PowerSpec G405 **Linux** *60 Гц* | 90 | 2017 | 4,2 ГГц | 2 млрд |
| MacBook Pro 2014 | 100 | 2014 | 2,6 ГГц | 700 млн |
| ThinkPad 13 **Linux chroot** | 100 | 2017 | 2,3 ГГц | 1 млрд |
| Lenovo X1 Carbon 4G **Linux** | 110 | 2016 | 2,6 ГГц | 1 млрд |
| iMac G4 **OS X** | 120 | 2002 | 0,8 ГГц | 11 млн |
| Haswell-E *24 Гц* | 140 | 2014 | 3,5 ГГц | 2 млрд |
| Lenovo X1 Carbon 4G **Win** | 150 | 2016 | 2,6 ГГц | 1 млрд |
| Next Cube | 150 | 1988 | 25 МГц | 1,2 млн |
| PowerSpec G405 **Linux** | 170 | 2017 | 4,2 ГГц | 2 млрд |
| Пакет вокруг света | 190 |
| PowerSpec G405 **Win** | 200 | 2017 | 4,2 ГГц | 2 млрд |
| Symbolics 3620 | 300 | 1986 | 5 МГц | 390 тыс. |
Это результаты замера отклика между нажатием клавиши и отображением символа в консоли (см. приложение для дополнительной информации). Результаты отсортированы от самых быстрых к самым медленным. При тестировании нескольких ОС на одном компьютере ОС выделена **жирным**. При тестировании разных частот обновления на одном компьютере они выделены *курсивом*.
Две последние колонки показывают тактовую частоту и количество транзисторов на процессоре.
Для справки приведено время передачи пакета через весь земной шар по оптоволокну из Нью-Йорка в Нью-Йорк через Токио и Лондон.
Если посмотреть на результаты в целом, то самые быстрые — это древние машины. Более новые компьютеры встречаются во всех частях таблицы. Замысловатые современные игровые конфигурации с необычно высокой частотой обновления экрана почти могут составить конкуренцию машинам конца 70-х и начала 80-х, но «обычные» современные компьютеры не способны конкурировать с компьютерами 30-40-летней давности.
Можно ещё посмотреть на мобильные устройства. В этом случае замерим отклик прокрутки в браузере:
| Устройство | Отклик (мс) | Год |
| --- | --- | --- |
| iPad Pro 10,5" Pencil | 30 | 2017 |
| iPad Pro 10,5" | 70 | 2017 |
| iPhone 4S | 70 | 2011 |
| iPhone 6S | 70 | 2015 |
| iPhone 3GS | 70 | 2009 |
| iPhone X | 80 | 2017 |
| iPhone 7 | 80 | 2017 |
| iPhone 6 | 80 | 2014 |
| Gameboy Color | 80 | 1989 |
| iPhone 5 | 90 | 2012 |
| BlackBerry Q10 | 100 | 2013 |
| Huawei Honor 8 | 110 | 2016 |
| Google Pixel 2 XL | 110 | 2017 |
| Galaxy S7 | 120 | 2016 |
| Galaxy Note 3 | 120 | 2016 |
| Nexus 5X | 120 | 2015 |
| OnePlus 3T | 130 | 2016 |
| BlackBerry Key One | 130 | 2017 |
| Moto E (2G) | 140 | 2015 |
| Moto G4 Play | 140 | 2017 |
| Moto G4 Plus | 140 | 2016 |
| Google Pixel | 140 | 2016 |
| Samsung Galaxy Avant | 150 | 2014 |
| Asus Zenfone3 Max | 150 | 2016 |
| Sony Xperia Z5 Compact | 150 | 2015 |
| HTC One M4 | 160 | 2013 |
| Galaxy S4 Mini | 170 | 2013 |
| LG K4 | 180 | 2016 |
| Пакет | 190 |
| HTC Rezound | 240 | 2011 |
| Palm Pilot 1000 | 490 | 1996 |
| Kindle Paperwhite 3 | 630 | 2015 |
| Kindle 4 | 860 | 2011 |
Как и раньше, результаты отсортированы по времени отклика от самых быстрых к самым медленным.
Если исключить Gameboy Color, который представляет собой иной класс устройств, то все самые быстрые устройства — это телефоны или планшеты Apple. Далее по времени отклика следует BlackBerry Q10. У нас недостаточно данных, чтобы объяснить такую необычно высокую скорость BlackBerry Q10 для не-Apple устройств, но есть правдоподобная догадка, что это объясняется наличием физических кнопок — для них легче реализовать быстрый отклик, чем для тачскрина и виртуальной клавиатуры. Два других устройства с физическими кнопками — Gameboy Color и Kindle 4.
После «айфонов» и устройств с кнопками в таблице представлены разнообразные устройства Android различных годов. В самом низу древний Palm Pilot 1000 и пара электронных книг. Заторможенность Palm объясняется тачскрином и дисплеем из эпохи, когда технология тачскринов обеспечивала гораздо меньшую скорость. Электронные книги Kindle работают на электронных чернилах e-ink, которые гораздо медленнее дисплеев в современных телефонах, так что их отставание неудивительно.
Почему Apple 2e настолько быстр?
================================
Система Apple 2 значительно выигрывает у современных компьютеров (кроме iPad Pro) по скорости ввода и вывода, поскольку Apple 2 не имеет дела с переключением контекстов, буферами при переключении разных процессов и т.д.
Если посмотреть на современные клавиатуры, то обычно ввод данных сканируется с частотой от 100 Гц до 200 Гц (например, [Ergodox заявляет о частоте 167 Гц](https://github.com/benblazak/ergodox-firmware)). Для сравнения, Apple 2e эффективно сканирует ввод на частоте 556 Гц. См. приложение с дополнительной информацией.
Если посмотреть на другой конец конвейера ввода-вывода, на дисплей, то здесь мы тоже можем найти источник задержки. Мой дисплей рекламирует задержку 1 мс, но если замерить реальное время от начала вывода символа на экран до полного его отображения, то там легко может оказаться и 10 мс. Этот эффект проявляется даже на некоторых дисплеях с высокой частотой обновления, которые продаются благодаря рекламе своего якобы быстрого отклика.
На 144 Гц каждый кадр занимает 7 мс. Изменение картинки на экране вызывает дополнительную задержку от 0 мс до 7 мс из-за ожидания границы следующего кадра перед его отрисовкой (в среднем мы ожидаем половины максимальной задержки, то есть 3,5 мс). Кроме того, даже хотя мой домашний дисплей заявляет о скорости переключения 1 мс, ему в реальности требуется 10 мс для полного изменения цвета с момента начала этого процесса. Если сложить задержку от ожидания следующего кадра с задержкой реального изменения цвета, то мы получим ожидаемую задержку 7/2 + 10 = 13,5 мс.
На старых ЭЛТ-мониторах Apple 2e мы ожидаем задержку в половину от частоты обновления 60 Гц (16,7 мс / 2), то есть 8,3 мс. Сегодня такой результат трудно превзойти: самый лучший «игровой монитор» способен уменьшить задержку примерно до таких значений, но с точки зрения рыночной доли такие дисплеи установлены на очень небольшом количестве систем, и даже мониторы, которые рекламируются как быстрые, на самом деле не всегда являются таковыми.
Конвейер рендеринга iOS
=======================
Если посмотреть на все процессы между вводом и выводом, то для перечисления различий Apple 2e с современными компьютерами придётся написать целую книгу. Чтобы получить картину происходящего на современных машинах, вот высокоуровневый набросок того, что происходит на iOS, от инженера iOS/UIKit [Энди Матущака](https://andymatuschak.org/), хотя он называет это описание «своими устаревшими воспоминаниями устаревшей информации»:
* У железа есть собственная частота сканирования (например, 120 Гц на последних тач-панелях), так что это добавляет задержку до 8 мс.
* События поступают в ядро через прошивку; это относительно быстрый процесс, но системный шедулинг может добавить здесь пару миллисекунд.
* Ядро направляет эти события привилегированным подписчикам (в данном случае `backboardd`) через порт Mach; здесь вероятны дополнительные потери на шедулинг.
* `backboardd` определяет, каким процессам следует доставить эти события; тут требуется блокировка по отношению к Window Server, который делится этой информацией (снова обращение к ядру, дополнительная задержка на шедулинг).
* `backboardd` отправляет событие нужному процессу; дополнительная задержка на шедулинг перед обработкой.
* События удаляются из очереди в основном потоке; а там может ещё что-то происходить (например, в результате сетевой активности или событий по таймеру), что может добавить задержку, в зависимости от активности.
* UIKit добавляет сверху 1-2 мс на обработку события, в зависимости от быстродействия процессора (CPU-bound).
* Приложение решает, что делать с поступившим событием; приложения написаны некачественно, так что обычно это занимает много миллисекунд, затем результаты компонуются в обновление (data-driven update) и отправляются на сервер рендеринга через IPC.
+ Если в результате обработки события приложению требуется новый видеобуфер в общей памяти, что происходит в любой нетривиальной ситуации, то происходит ещё один обмен данными по IPC с сервером рендеринга; это дополнительные задержки на шедулинг.
+ (Тривиальные вещи — это те, с которыми сервер рендеринга способен справиться самостоятельно, вроде изменений аффинного преобразования или изменения цвета слоёв; к нетривиальным относятся любые операции с текстом, большинство операций по растрированию и векторных операций).
+ Такого рода обновления часто создают тройной буфер: GPU может использовать один буфер для текущего рендеринга; сервер рендеринга — другой буфер для очереди на следующий фрейм; и третий для отрисовки. Здесь дополнительные блокировки (кросспроцессинг); дополнительные обмены данными с ядром.
* Сервер рендеринга добавляет поступившие обновления в дерево рендеринга (несколько миллисекунд)
* Каждые `N Гц` дерево рендеринга смывается в GPU, от которого требуется заполнить видеобуфер.
+ В реальности, впрочем, часто происходит тройная буферизация экранного буфера, по описанным выше причинам: отрисовка из GPU в одном буфере, а другой используется для чтения в подготовке следующего фрейма.
* Каждые `N Гц` этот видеобуфер заменяется на другой видеобуфер, и дисплей считывает напрямую из этой памяти.
+ (Эти `N Гц` не обязательно идеально сочетаются с `N Гц` на предыдущем шаге)
Энди говорит, что «объём *работы* здесь обычно довольно небольшой. Пару миллисекунд процессорного времени. Задержка после нажатия клавиш происходит по следующим причинам:»
* периодические сканирования (устройство ввода, сервер рендеринга, дисплей) неидеально сочетаются друг с другом
* многочисленные передачи через границы процессов, каждый раз с вероятностью задержки из-за обработки какого-нибудь постороннего события в очереди
* многочисленные блокировки, особенно на границах процессов, требуют обращения к ядру
Для сравнения, на Apple 2e нет практически никаких передач, блокировок и границ процессов. Работает очень простой код, который записывает результат в память дисплея, и тот автоматически отображается при следующем обновлении экрана.
Частота обновления и время отклика
==================================
Одна интересная вещь в тестировании времени отклика на компьютерах — это влияние частоты обновления экрана. При переходе с 24 Гц на 165 Гц мы ускоряемся на 90 мс. На 24 Гц отображение каждого кадра занимает 41,67 мс, а на 165 Гц — 6,061 мс. Как мы видели выше, без буферизации средняя задержка при обновлении фрейма составила бы 20,8 мс в первом случае и 3,03 мс во втором (поскольку мы ожидаем поступления кадра в случайной точке, а время ожидания случайно распределяется между 0 мс и максимальным временем ожидания), то есть разница составляет около 18 мс. Но в реальности разница 90 мс, что подразумевает задержку на `(90 − 18) / (41,67 − 6,061) = 2` фрейма из буфера.
Если составить график результатов времени отклика с разной частотой обновления экрана на одной машине (здесь его не публикуем), то он примерно совпадает с кривой «наилучшего соответствия», если предположить, что при запуске PowerShell на этой машине задержка составляет 2,5 фрейма независимо от частоты обновления. Это позволяет оценить, какая получится задержка, если на игровой компьютер с малым временем отклика поставить дисплей с бесконечной частотой обновления — она ожидается в районе `140 − 2,5 * 41,67 = 36 мс`, это почти так же быстро, как на компьютерах 70-х и 80-х.
Сложность
=========
Почти каждый компьютер или мобильное устройство сегодня медленнее, чем типичные компьютеры 70-х и 80-х. Игровые десктопы с низким временем отклика и iPad Pro могут сравниться с быстрыми машинами 30-40-летней давности, но большинство коммерческих моделей даже близко не стоят.
Если постараться определить главную причину увеличения времени отклика, то можно сказать, что это «сложность». Конечно, все знают, что сложность — это плохо. Если за последнее десятилетие вы посетили хотя бы одну ненаучную или некорпоративную технологическую конференцию, то с высокой вероятностью слышали хотя бы один доклад о том, что сложность — главная причина всех бед и как нужно стремиться к уменьшению сложности.
К сожалению, намного труднее это сделать в реальности, чем заявить со сцены. Сложность зачастую даёт нам определённые выгоды прямо или косвенно. Когда мы сравниваем ввод данных с модной современной клавиатуры и с клавиатуры Apple 2, то видим лишние задержки на обработку данных с клавиатуры мощным и ресурсоёмким процессором, по сравнению со специализированными логическими схемами для клавиатуры, которые проще и дешевле. Но использование процессора даёт возможность легко настраивать клавиатуру, а также переносит проблему «программирования» клавиатуры с аппаратной части на софт, что снижает стоимость производства клавиатур. Более дорогой чип увеличивает стоимость производства, но с учётом всех расходов на дизайн этих полукустарных мелкосерийных клавиатур, в целом выглядит так, что экономия от простого программирования перевешивает дополнительные расходы.
Мы видим такого рода компромиссы на каждом этапе конвейера. Нагляднее всего сравнение ОС на современном десктопе с циклом на Apple 2. Современные ОС позволяют программистам писать стандартный код, который будет работать одновременно с другими программами на той же машине, с довольно разумной общей производительностью, но за это мы платим огромную цену в увеличении сложности, а вовлечённые в многозадачность процессы легко приводят к значительному увеличению времени отклика.
Значительную часть сложности можно назвать [случайной сложностью](http://wiki.c2.com/?AccidentalComplexity), но она присутствует здесь тоже в основном из-за удобства. На каждом уровне от аппаратной архитектуры и интерфейса syscall до фреймворка ввода-вывода мы наращиваем сложность, львиную долю которой можно устранить, если сегодня сесть и переписать все системы и их интерфейсы. Но слишком неудобно заново изобретать Вселенную для снижения сложности, а рост экономики даёт прибыль, так что мы живём с тем что имеем.
По этим и другим причинам на практике проблема снижения производительности, которая возникла из-за «излишней» сложности, часто решается ещё бóльшим усложнением системы. В частности, те достижения, которые позволили нам приблизиться к самым быстрым машинам 30-40-летней давности, получены не благодаря следованию увещеваниям об уменьшении сложности, а именно от дополнительного усложнения систем.
iPad Pro — это подвиг современного инжиниринга, где разработчики увеличили частоту обновления на устройствах и ввода, и вывода, а также оптимизировали программный конвейер для устранения ненужной буферизации. Дизайн и производство экранов с высокой частотой обновления, которые уменьшают время отклика — это нетривиально более сложная задача во многих отношениях, которые были необязательны во времена архаичных стандартных дисплеев на 60 Гц.
В реальности это обычное дело при попытке уменьшить задержку. Самый популярный трюк для этого — добавить кеш, но добавление кеша в систему увеличивает её сложность. Для систем, которые генерируют новые данные и не допускают использования кеша, предлагаются ещё более сложные решения. В качестве примера можно привести [крупномасштабные системы RoCE](https://en.wikipedia.org/wiki/RDMA_over_Converged_Ethernet). Они способны сократить задержку доступа к удалённым данным с миллисекунд до микросекунд, что открывает двери для нового класса приложений. Но это сделано за счёт увеличения сложности. Разработка и грамотная оптимизация первых крупномасштабных систем RoCE занимала десятки человеко-лет и требовала огромных усилий операционной поддержки.
Заключение
==========
Выглядит немного парадоксально, что современная игровая машина, которая работает в 4000 раз быстрее Apple 2, где на процессоре в 500 000 раз больше транзисторов (а в GPU — в 2 000 000 раз больше транзисторов) с трудом выдаёт такую же скорость отклика, как Apple 2 — и то лишь в аккуратно написанных приложениях и только на мониторе с трёхкратной частотой обновления по сравнению с Apple 2. Ещё более абсурдно, что в PowerSpec G405 с конфигурацией по умолчанию — самом быстром компьютере по однопоточным вычислениям до октября 2017 года — задержка от нажатия клавиши до вывода на экран (примерно один метр, может, три метра реального кабеля) превышает время передачи пакета вокруг земного шара (26 000 км от Нью-Йорка через Лондон до Токио и обратно в Нью-Йорк).
С другой стороны, мы явно выходим из тёмных времён огромных задержек — и сегодня уже можно собрать компьютер или купить планшет с временем отклика в том же диапазоне, что у стандартных машин в 70-е и 80-е. Это немного напоминает тёмные времена разрешений экранов и размера пикселей, когда ЭЛТ-мониторы 90-х годов до относительно недавнего времени имели лучшие характеристики, чем стандартные ЖК-дисплеи настольных компьютеров. Сейчас наконец-то стали обычными дисплеи 4k, а дисплеи 8k опустились до нормальных цен — это не идёт ни в какое сравнение с коммерческими ЭЛТ-мониторами. Не знаю, произойдёт ли такой же прогресс со временем отклика, но будем надеяться на это.
Другие статьи об измерении отклика
==================================
* [Отклик консоли](https://danluu.com/term-latency/)
* [Отклик клавиатуры](https://habrahabr.ru/post/345776/)
* [Отклик мыши против клавиатуры](https://danluu.com/keyboard-v-mouse/) (человеческие факторы, не характеристики устройств)
* [Отклик редактора](https://pavelfatin.com/typing-with-pleasure/) (Павел Фатин)
* [Задержка на компоновку в Windows 10](http://www.lofibucket.com/articles/dwm_latency.html) (Пекка Ваананен)
* [Отклик AR/VR](http://blogs.valvesoftware.com/abrash/latency-the-sine-qua-non-of-ar-and-vr/) (Майкл Эбраш)
* [Стратегии смягчения последствий задержки](https://danluu.com/latency-mitigation/) (Джон Кармак)
Приложение: зачем замерять время отклика?
=========================================
Отклик очень важен! В очень простых задачах [люди способны различать отклик до 2 мс или меньше](https://pdfs.semanticscholar.org/386a/15fd85c162b8e4ebb6023acdce9df2bd43ee.pdf). Более того, увеличение задержки не только заметно пользователям, но и [является причиной менее точного выполнения простых задач](http://www.tactuallabs.com/papers/howMuchFasterIsFastEnoughCHI15.pdf). Если хотите наглядной демонстрации, как выглядит задержка, а у вас нет старого компьютера под рукой, [вот демо MSR по задержке тачскрина](https://www.youtube.com/watch?v=vOvQCPLkPt4).
[Производительность](https://stackoverflow.com/a/39187441/334816) тоже имеет значение, но она хорошо понятна и часто измеряется. Если зайти практически на любой сайт с бенчмарками или открыть обычный обзор, то увидите огромное количество измерений производительности, так что дополнительные измерения здесь не имеют особой ценности.
Приложение: клавиатура Apple 2
==============================
Вместо программируемого микроконтроллера для считывания нажатий клавиш в Apple 2e используется гораздо более простой специализированный чип, спроектированный для считывания клавиатуры, AY 3600. В [документации AY 3600](https://danluu.com/AY3600.pdf) указано время сканирования `(90 * 1/f)`, а время повторного нажатия клавиши указано как `strobe_delay`. Эти параметры задаются несколькими конденсаторами и резистором на 47 пФ, 100K Ом и на 0,022 мкФ. Если вставить эти параметры в формулу из документации AY3600, то получим `f = 50 кГц`, что даёт задержку сканирования 1,8 мс и задержку повторного нажатия клавиши 6,8 мс (конденсаторы могут деградировать со временем, так что на нашем старом Apple 2e реальные задержки могут быть меньше), что даёт задержку 8,6 мс для внутренней клавиатурной логики.
Если сравнить с клавиатурой на 167 Гц с [двумя дополнительными проходами для определения повторных нажатий](https://www.arduino.cc/en/Tutorial/Debounce), эквивалентный параметр выходит `3 * 6 мс = 18 мс`. С частотой сканирования 100 Гц получается `3 * 10 мс = 30 мс`. Сканирование клавиатуры за 18-30 мс с дополнительной задержкой на повторное нажатие клавиш соответствует [предварительным реальным измерениям времени отклика клавиатур](https://habrahabr.ru/post/345776/).
Для справки, в клавиатуре Ergodox работает микроконтроллер на 16 МГц примерно с 80 тыс. транзисторов, а компьютере Apple 2e работает центральный процессор на 1 МГц с 3500 транзисторов.
Приложение: экспериментальная установка
=======================================
Большинство измерений произведено на камеру 240 FPS (разрешение 4,167 мс). Устройства с временем отклика менее 40 мс были повторно измерены камерой на 1000 FPS (разрешение 1 мс). Результаты в таблицах являются результатом усреднения по итогу нескольких измерений и округлены до десяти, чтобы избежать впечатления ложной точности. Для настольных компьютеров время отклика соответствует времени от начала движения клавиши до окончания обновления экрана. Обратите внимание, что это отличается от большинства измерений key-to-screen-update, которые можно найти в интернете — в этих бенчмарках обычно используются установки, которые эффективно устраняют любую задержку клавиатуры. В качестве теста от начала до конца это реалистично только в том случае, если у вас установлена телепатическая связь с компьютером (хотя в таких измерениях тоже есть польза — если вам как программисту нужен воспроизводимый бенчмарк, то хорошо в тесте избавиться от факторов, которые находятся вне вашего контроля, но для конечных пользователей это не так).
Люди часто выступают за измерение одного из параметров: {нажатие клавиши до конца, срабатывание переключателя}. Кроме удобства, больше нет особых причин измерять что-либо из этого, но люди часто выдают эти результаты за «реальную» работу клавиатуры. Но они не зависят от реального времени срабатывания переключателя. Время между нажатием и активацией, также как время между ощущением отклика и активацией, произвольны и доступны для настройки. Когда тестер заявляет, что это «реальное» ощущение пользователя от срабатывания клавиатуры, это в общем означает, что пользователь не понимает принципов работы клавиатуры. Хотя такое возможно, я не вижу причин транслировать одно конкретное заблуждение о работе клавиатур в конкретную метрику, где люди яростно выступают за разные неверные убеждения. Более подробно о заблуждениях относительно клавиатур см. [эту статью с измерениями времени отклика](https://habrahabr.ru/post/345776/).
Ещё одно важное отличие — то, что измерения произведены с настройками, максимально близкими к настройкам ОС по умолчанию, поскольку примерно 0% пользователей меняют настройки дисплея для уменьшения буферизации, отключения компоновщика и т.д. Ожидание окончания обновления экрана тоже отличается от того, что измеряется в большинстве бенчмарков — большинство полагают, что обновление «закончено», когда регистрируется любое движение на экране. Ожидание завершения обновления аналогично времени «визуального завершения» в WebPagetest.
Результаты на компьютерах получены в консоли «по умолчанию» для данной системы (например, PowerShell на Windows, LXTerminal на Lubuntu), что легко может означать разницу в 20-30 мс между быстрой и медленной консолями. Между измерениями в консоли и измерением полного времени от начала до конца, результаты в этой статье должны быть медленнее, чем в других статьях на эту тему (где часто замеряется время до начала изменений на экране в играх).
Базовый результат PowerSpec G405 получен на встроенной графике (машина продаётся без видеокарты), а результат с 60 Гц — с дешёвой видеокартой.
Результаты для мобильных устройств получены в браузере по умолчанию после загрузки сайта [https://danluu.com](https://danluu.com/) и замера задержки от движения пальца до первого перемещения картинки на экране, что сигнализирует о начале прокрутки. В тех случаях, когда такой тест не имел смысла (Kindle, Gameboy Color и др.), были сделаны другие осмысленные действия на этой платформе (перелистывание страницы на Kindle, нажатие джойстика в игре на Gameboy Color и т.д.). В отличие от измерений на десктопе или ноутбуке, эти измерения были до первого изменения на экране, чтобы избежать многих фреймов прокрутки. Для простоты измерений палец изначально касался экрана, а таймер включался, когда он начинал движение (чтобы избежать проблем с определением времени касания пальцем экрана).
В случае «равных» результатов порядок сортировки в таблице определялся по неокруглённому времени задержки, но это не следует считать важным фактором. Отличие на 10 мс тоже не следует считать значительным.
Машина на Haswell-E тестировалась и с включенной опцией G-Sync — заметной разницы не зафиксировано. Год выпуска для этого компьютера установлен в каком-то смысле произвольно, поскольку процессор 2014 года выпуска, а дисплей более новый (думаю, до 2015 года дисплеев на 165 Гц ещё не было).
Количество транзисторов на некоторых современных машинах приведено примерно, потому что точные цифры не разглашаются. Не стесняйтесь сообщить мне, если найдёте более точную оценку!
Все результаты под Linux сделаны на ядре [до KPTI](https://lwn.net/SubscriberLink/741878/eb6c9d3913d7cb2b/). Возможно, KPTI повлияет на задержку.
*Работа ещё не закончена. Я собираюсь собрать бенчмарки с большего количества старых компьютеров во время следующего визита в Сиэтл. Если вы знаете о старых компьютерах, которые можно потестировать в районе Нью-Йорка (с оригинальными дисплеями или вроде того), дайте знать! Если у вас есть устройство, которое вы готовы пожертвовать для тестов, можете высылать на мой адрес:*
Dan Luu
Recurse Center
455 Broadway, 2nd Floor
New York, NY 10013 | https://habr.com/ru/post/345584/ | null | ru | null |
# Подключаем GNS3 топологию к Cisco dCloud
Развитие технологий виртуализации позволило сделать обучение ИТ специалистов значительно доступнее. Еще 10 лет назад для того, чтобы познакомиться с новой ОС или развернуть лабораторную инфраструктуру для тестирования приходилось искать железо, то сейчас достаточно развернуть одну или несколько виртуальных машин.
Но технологии и желание производителей увеличить продажи не стоят на месте. В настоящее время для тестирования и демонстрации своих продуктов многие компании предлагают бесплатные тестовые стенды, так называемые hands on labs или HOL. Мне известны такие решения у [Microsoft](https://technet.microsoft.com/en-us/virtuallabs/), [VMWare](http://labs.hol.vmware.com/HOL/catalogs/catalog/all) и [Cisco](https://dcloud.cisco.com/). О тестовых стендах последней компании и пойдет речь в моей статье.
Cisco dCloud появился в 2013 году. Мне посчастливилось узнать о нем на одном из мероприятий Cisco Learning Club. dCloud обладает одной интересной особенностью, которая выгодно отличает его от решений других компаний. Если в HOL от Microsoft или VMWare Вы ограничены песочницей, то Cisco позволяет Вам подключиться к сети тестового стенда при помощи VPN (AnyConnect или Easy VPN). И тут нам открываются широкие возможности для обучения, подготовки к сертификации или тестирования различных сетевых решений. Например, для того, чтобы «поиграться» со связкой Cisco Prime Infrastructure и Cisco ISE понадобится как минимум 16 Гб ОЗУ для виртуальных машин и не каждый располагает такими свободными ресурсами. Cisco dCloud позволяет подключиться к тестовому стенду в котором уже развернуты Cisco PI, ISE, MS AD и многое другое.
Для подключения к демо облаку Cisco нам понадобится либо ПК с установленным клиентом AnyConnect либо маршрутизатор Cisco из [перечня](https://dcloud-cms.cisco.com/help/router_warning). Но, согласитесь, не каждый сможет найти железку Cisco в домашних условиях, да и городить стенды из железа в домашних условиях не всегда удобно. Однако никто не запрещает нам использовать для этих целей GNS3 или Unetlab в связке с IOU.
Постараюсь описать вкратце процесс подключения GNS3 топологии к тестовому стенду dCloud при помощи L3 образа IOU.
Первым делом необходимо выпустить L3 образ IOU в сеть интернет. Инструкций по этой теме в сети достаточно, так что сложностей с этим возникнуть не должно. В результате у нас получается топология примерно следующего вида:

Далее необходимо зарегистрировать наш L3 образ в dCloud. Переходим в меню «My Dashboard», разворачиваем панель «My Endpoint Routers» и жмем кнопку «Register New Endpoint Router».

В появившемся окне вводим «Nickname» — отображаемое имя маршрутизатора в консоли dCloud, «Router Model» — модель маршрутизатора (влияет только на состав сгенерированного файла конфигурации, я остановился на 2911), «Router Serial Number» — можно заполнить произвольной последовательностью символов и нажимаем кнопку «Next».

Скачиваем предложенные файл конфигурации для нашего маршрутизатора. Применять всю предложенную конфигурацию мы не будем, а воспользуемся лишь минимально необходимыми параметрами для настройки клиентского ezvpn подключения.

Ниже я привожу минимально необходимую конфигурацию в части настройки клиентского ezvpn подключение к dCloud. Предварительно необходимо настроить доступ к сети интернет и dns клиент на IOU образе.
```
ip access-list extended acl-vpn-initiate
permit ip 10.64.0.0 0.63.255.255 198.18.0.0 0.1.255.255
crypto isakmp keepalive 10 periodic
crypto ipsec client ezvpn ToDemo
connect acl acl-vpn-initiate
ctcp port 443
group dcloud-ipsec key Sup6pSup6p
local-address Ethernet0/0
mode network-extension
peer dcloud-emear-ipsec.cisco.com
peer dcloud-rtp-ipsec.cisco.com
peer dcloud-apjc-ipsec.cisco.com
peer dcloud-chi-ipsec.cisco.com
username password
xauth userid mode local
interface Ethernet0/0
ip virtual-reassembly in
crypto ipsec client ezvpn ToDemo
no shut
!
interface Ethernet0/1
ip address 10.72.159.49 255.255.255.240
ip virtual-reassembly in
ip tcp adjust-mss 1000
crypto ipsec client ezvpn ToDemo inside
no shut
!
```
Заказываем один из демо стендов и ждем пока будет готова виртуальная инфраструктура (обычно занимает от 15 до 30 минут). Когда стенд будет развернут поднимаем vpn туннель.

Теперь мы можем использовать элементы инфраструктуры и сервисы из демо стенда dCloud. Например, добавить наши IOU образы в Cisco Prime Infrastructure для централизованного управления или использовать облачную связку Cisco ISE+AD для подготовки к обновленному треку CCNP Security.
 | https://habr.com/ru/post/271223/ | null | ru | null |
# Социальная сеть без сервера. История разработки iOS-клиента и backend
#### Интро
Я хочу рассказать об опыте разработки iOS-клиента для социальной сети и бэкенда реализованного с помощью BaaS [Parse.com](http://parse.com) Нижe приведена архитектура, которая у нас получилась, некоторые tips&tricks и размышления по поводу работы с parse.com.
Изначально клиент думал о сервере на RoR, но, видимо, они не рискнули вкладывать сразу много денег. Мы подписали строгое NDA, поэтому ссылку на Appstore я дать не могу. По доброй традиции всех IT книг, хочу выразить благодарность заказчику Х и компании Y за то что мне довелось поработать над этим проектом и подчерпнуть весь этот опыт. Также спасибо А. за то, что написал часть про модуль для встроеных покупок.
#### Архитектура
Я много раз видел и слышал про проекты, которые перекидывались между разными разработчиками и теряли при этом цельность идеи, поэтому решил написать небольшой документ, в котором изложены основные принципы, по которым я выстраивал архитектуру приложения. Считаю, что в нем, по большей части, и сконцентрировался весь опыт, который я получил на этом проекте.
**Скриншот структуры Xcode проекта**
##### Логические слои
###### Работа с сетью
В приложении мы работаем с двумя сервисами: [PubNub](http://www.pubnub.com) и [Parse](http://parse.com). Все взаимодействие с SDK этих сервисов происходит на этом слое.
* Message Center
+ PubNub SDK
* Parse Services
У Parse есть свое iOS SDK, но мы не хотели сильно привязываться к нему, так как клиент говорил, что они планируют запустить свой сервер позднее. Поэтому мы использовали Parse RESTfull API, с которым взаимодействовали через AFNetworking. Всю бизнес-логику, которую можно было перенести на сервер, мы перенесли на [cloud code](https://parse.com/docs/cloud_code_guide) — получилось, что каждый запрос вызывал серверный код. В принципе, можно было составлять сложные запросы, запихивая параметры в NSDictionary, но после того, как я разобрался с Backbone.js, на которой пишется cloud code, я стал все делать там — это гораздо читабельнее и лучше поддается изменениям. В итоге получилось, что на каждое действие пользователя приложение посылало только один запрос к серверу. Только на login и обновление экранов с разной информацией посылалось большее количество запросов.
###### UI
Этот слой самый простой — тут только ViewControllers, Views, Cells и дополнительный контроллер, который помогает в навигации и реализует разные хитрости с показыванием экранов в самых неожиданных местах. Например, если пользователь производит регистрацию через facebook, то он показывает экран с теми полями, которые должен заполнить пользователь, если их нет в его facebook аккаунте. Также здесь располагаются контроллеры, реагирующие на push notification. Нам необходимо было сделать drag-n-drop для UICollectionView — в результате использовали готовую реализацию: [github.com/lxcid/LXReorderableCollectionViewFlowLayout](https://github.com/lxcid/LXReorderableCollectionViewFlowLayout). Пришлось немного подшаманить, но, в целом, пользоваться кодом можно.
Также могу порекомендовать [MNMPullToRefresh](https://github.com/emenegro/pull-to-refresh/tree/master/pull-to-refresh/MNMPullToRefresh), если вам нужен pull to refresh контрол для UITableView.
###### Data
Для работы с CoreData используем Magic Recording: никаких других дополнительных классов нету, кроме класса, который подключается к базе данных конкретного пользователя.
* Core Data
+ Magic Recording
+ DataBaseManager class
* DataSources
Отдельные классы для UIViewController, где содержится логика взаимодействия с БД и сервером.
* Models
Мы имеем два основных типа моделей — модели локальной базы данных и промежуточные модели информации, которая приходит к нам с сервера.
###### Synchronisation Layer
Логический слой, на котором мы переводим объекты, полученные от сервера, в объекты БД и обратно(если есть необходимость). Если объекта с текущим id нету — добавляем его в БД. Если есть, то просто обновляем информацию с сервера.
Для моделей с большим количеством полей реализован обобщенный метод заполнения их значениями с использованием runtime функций:
**смотреть код**
```
-(id)syncLocal:(id)local withClass:(Class)localClass fromParse:(id)parse{
NSAssert([parse isKindOfClass:[UserStatistic class]], @"wrong class");
UserStatistic*stat =(UserStatistic*)parse;
LocalUserStatistics* newLocalStat = (LocalUserStatistics*)local;
if(!newLocalStat)
newLocalStat=[super syncLocal:local withClass:localClass fromParse:parse];
unsigned int outCount;
Protocol* protocol = objc_getProtocol("StatisticsProtocol");
objc_property_t *propList = protocol_copyPropertyList(protocol, &outCount);
NSArray* noSetProps = [self propertiesDontNeedToSet];
for (int i = 0; i < (int)outCount; i++) {
objc_property_t * oneProp = propList + i;
NSString *propName = [NSString stringWithUTF8String:property_getName(*oneProp)];
if([noSetProps indexOfObject:propName]==NSNotFound){
id newValue =[stat valueForKey:propName];
if(newValue && newValue!=[NSNull null]){
[newLocalStat setValue:newValue forKey:propName];
}
}
}
free(propList);
return newLocalStat;
}
```
* ParseObjectsSync
Слой для синхронизации массивов объектов — вызывает соответствующий класс из слоя ParseObjectSync для соответствующей модели
* ParseObjectSync
Слой, на котором описана логика, где мы каждой модели Parse ставим в соответствие модель Core Date. Также преобразуем поля, если это необходимо.
* Chat Engine
UI работает с сетью и БД только через прослойку классов синхронизации. Класс Chat Engine тоже лежит между UI и Pubnub c CoreDate. Он получился достаточно большим, но не настолько, чтобы можно было выделить из него отдельный класс, который бы назывался в соответствии с занимаемым слоем. Хотя, скорее всего, у меня просто не хватило желания это сделать.
###### In App Purchase
В приложении с самого начала задумывалась внутренняя валюта — Coins (Монетки), которые пользователь может легко купить, используя механизм In-App Purchase, ну а потратить всегда есть на что :). С точки зрения Apple's In-App Purchase, они являются Consumable Product, т.е. нужно очень осторожно подходить к записи и учету прихода/расхода монеток, иначе пользователь потеряет деньги и расстроится.
Было решено сделать этот тонкий слой без использования сторонних библиотек. Сами Coins мы решили хранить в модели User на parse.com, а не локально. Это повлияло на то, как работает код завершения тразакции. Ведь мы должны дождаться момента, когда изменения Coins запишутся на parse.com и только после этого делать finishTransaction. Здесь отличное место для использования Block-a, который хранит контекст для завершения транзакции, пока мы делаем запрос на сервер. Такой подход дал нам возможность заходить в систему с разных устройств и всегда иметь актуальную информацию о Coins текущего пользователя.
Еще одна вещь, которую обычно не делают: SKPaymentTransactionObserver (класс, который реализует этот протокол) должен создаваться при старте приложения и жить всю его жизнь, так как туда может прийти незавершенная транзакция, которая не была завершена в прошлый запуск приложения. Cвоих Singleton-ов мы здесь не создавали.
###### Work Circle Controller
В ходе разработки появлялось все больше и больше действий, которые нужно было произвести в конкретный период времени и между таким-то и таким-то запросом. Например, для поддержания консистентности локальной БД нужно было загрузить сначала картинки пользователя, и только потом чаты, которые ссылаются на эти картинки. Также было много нюансов в бизнес-логике: показать экран с обязательными полями для заполнения, если пользователь зарегистрировался через facebook и подписаться на push notifications после логина, ведь не факт, что логин произойдет одновременно с получением токена. Также необходимо отписаться от push notifications после logout, инициализировать одни сервисы сразу после запуска, а другие только после логина. После того как вся логика последовательности запуска сервисов и жизни приложения была сосредоточена в отдельном классе, жить стало гораздо легче. Класс, кстати, не синглтон — он живет в AppDelegate. В итоге в AppDelegate осталось всего лишь 146 строчек кода.
##### Работа с Parse.com
В целом, работать с Parse понравилось, но до сих пор не понятно, приложения с каким объемом трафика на нем могут работать стабильно. На данный момент сервис дает следующие лимиты на один аккаунт (Pro plan):
[Burst limit](https://www.parse.com/questions/burst-limit): 40 запросов в секунду
[API requests limit](https://parse.com/questions/code-154the-number-of-count-operations-in-progress-has-reached-its-limit-code-154-version-1125): 160 — этого вы не найдете в документации (на момент написания статьи этого нет)
Ограничение на выполнение cloud code функции: 15 секунд
Ограничение на выполнение background job: 15 минут
Наше приложение еще не набрало большого количества пользователей, и не совсем понятно, как оно поведет себя в продакшене, но есть сомнения на этот счет. Приложение уже достигает лимита на количество API запросов. Я контактировал с командой Parse по поводу перехода на Enterprise plan со следующими характеристиками:
Total users: 1000
Users performing request in the same time: 500
API requests performing in the same time: 1000
API calls burst limit: 1000
Cloud code burst limit: 2000
Они ответили, что 1000 запросов в секунду будут стоить $14 000 в месяц. После чего я спросил у них, как можно уменьшить количество запросов, и описал работу нашего приложения. Они ответили, что 1000 запросов в секунду для нашего приложения — вполне оправдано, и меньше сделать вряд ли получится.
На Parse пока что нельзя просто поднять еще одну среду для тестирования и разработки на той же модели БД. Приходится создавать новое приложение и практически вручную создавать такую же модель данных.
В плане ограничения на количество запросов Parse проигрывает [Kinvey](http://kinvey.com/). Я специально узнал об этом ограничении у Kinvey, и вот что они ответили: «You are correct — we do not limit number of requests per second (or on total requests or API calls in any way).» За $1 400 в месяц можно получить BaaS, на котором могут быть 50 000 активных пользователей в месяц, 3 среды, а бизнес-логика ограничивается 50 скриптами. При этом один скрипт саппорт определил так: «BL scripts are written in their own containers within the Kinvey web console, so a BL script is defined as each chunk of JS code — certainly quite a lot can be fit into a single BL script if one so desires.» Как все работает на практике, я не знаю, но выглядит привлекательно.
###### Cloud code на Backbone.js
Мне, как человеку, писавшему только на языках со строгой типизацией и никогда не прикасавшемуся к backend, было очень интересно изучать backbone.js. Основные сложности с которыми столкнулся:
* Callback hell.
решил с помощью использования библиотеки [async.js](https://github.com/caolan/async)
* Debugging.
для написания кода использовал Sublime. Потом наткнулся на пост о том, как настроить среду в Cloud9, и в тот же день нашел сообщение автора этой инструкции, в котором он поделился проблемой: после обновления сервиса для деплоя нового кода на сервер Parse у него все перестало работать, потому что версия python на Cloud9 не поддерживает некоторые функции. В итоге все так и осталось на Sublime, и дебаггинг происходил только после deploy и запуска кода на сервере
* Тестирование.
Смотри ниже. Это заслуживает отдельной главы
###### Интеграционное тестирование
Подготовка среды для тестирования
Как сказал один умный человек, самое сложное в тестах — это настройка среды для тестирования.
В ходе разработки на серверном коде скапливалось все больше логики и появлялось все больше сценариев для тестирования. Становилось ясно, что без автоматических тестов написание cloud code будет занимать колосальное количество времени. Как я уже писал выше, дебажить можно было только после деплоя на сервер, до момента запуска кода нельзя было узнать даже о наличии синтаксических ошибок, только если они не связаны непосредственно с деплоем.
В итоге мы настроили среду для тестирования. В тестах мы с помощью Work Circle Controller запускаем все необходимые сервисы. С помощью флагов для препроцессора устанавливаем тот код, который нам нужно запустить для тестовой среды:
**смотреть код**
```
#import "WorkCircleController.h"
//UI
#if !TEST
#import "LoginViewsManager.h"
#endif
//Net
#import
#import "ParseRESTClient.h"
#import "StatisticService.h"
#import "ProfilePicturesSync.h"
#if !TEST
#import "ChatsEngine.h"
//Data
#import "DataBaseManager.h"
#import "LocalUser.h"
#import "LocalLockSlot.h"
#import "LocalPicture.h"
//Sync
#import "SyncManager.h"
#import "UserSync.h"
#else
#endif
#if !TEST
@interface WorkCircleController(){
ProfilePicturesSync\* profilePicturesSync;
}
@property(nonatomic, weak) AppDelegate\* appDelegate;
@property(nonatomic, strong) LoginViewsManager\* loginManager;
@property(nonatomic, strong) NSData\* deviceToken;
@end
#endif
@implementation WorkCircleController
#if !TEST
- (id)initWithDelegate:(AppDelegate\*)appDelegate
{
self = [self init];
if (self) {
self.appDelegate = appDelegate;
profilePicturesSync = [ProfilePicturesSync new];
}
return self;
}
#pragma mark - Push notification
- (void)app:(UIApplication\*)application didRegisterForRemoteNotificationsWithToken:(NSData\*)deviceToken{
self.deviceToken = deviceToken;
if(self.state == LifeStateLoginDataAndNetLayersReady || self.state == LifeStateLoggedIn)
[self subscribeToPushes:deviceToken];
}
- (void)subscribeToPushes:(NSData \*)deviceToken {
[self subscribeToParsePushes:deviceToken];
[self subscribeToChatPushes:deviceToken];
}
- (void)subscribeToParsePushes:(NSData \*)deviceToken {
...
}
- (void)subscribeToChatPushes:(NSData \*)deviceToken {
...
}
- (void)unsubscribeFromPushesInParseWithBlock:(void (^)(NSError \*error))block {
...
}
#endif
#pragma mark - Pre Login Logic
-(void)setupPreLoginStateWithBlock:(void (^) (NSError\* error))block{
[self prepareNetManagersForPreLoggin];
#if !TEST
[self performUIUpdatesForPreLogginWithBlock:^(NSError \*error) {
if(block)
block(error);
}];
#else
finishWithErrorBlock(nil);
#endif
}
-(void)prepareNetManagersForPreLoggin{
[[ParseRESTClient sharedClient] startParseService];
}
#if !TEST
-(void)performUIUpdatesForPreLogginWithBlock:(void (^) (NSError\* error))block
{
...
}
#endif
#pragma mark after register Login Logic
- (void)afterRegistrationWithBlock:(void (^) (NSError\* error))block{
...
}
#pragma mark - Login Logic
-(void)loginWithBlock:(void (^) (NSError\* error))block{
[self prepareDataManagersForLogginWithBlock:^(NSError \*error) {
[self prepareNetManagersForLogginWithBlock:^(NSError \*\_error) {
#if !TEST
[self performUIUpdatesForLogginWithBlock:^(NSError \*uIError) {
if(block)
block(uIError);
[self performAfterLoginUpdatesWithBlock:^(NSError \*afterLoginError) {
}];
}];
#else
if(finishWithErrorBlock)
finishWithErrorBlock(error);
#endif
}];
}];
}
-(void)prepareDataManagersForLogginWithBlock:(void (^) (NSError\* error))block{
#if !TEST
[DataBaseManager setupDataBaseWithUserId:[PFUser currentUser].email];
[[Settings defaultSettings] setUsername:[PFUser currentUser].email];
#endif
block(nil);
}
-(void)prepareNetManagersForLogginWithBlock:(void (^) (NSError\* error))block{
[[ParseRESTClient sharedClient] updateToken];
#if !TEST
...
#endif
block(nil);
}
#if !TEST
- (void)performUIUpdatesForLogginWithBlock:(void (^) (NSError\* error))block{
...
}
- (void)performAfterLoginUpdatesWithBlock:(void (^) (NSError\* error))block {
...
}
#endif
#pragma mark - Logout Logic
-(void)logoutWithBlock:(void (^)(NSError \*error))block{
#if !TEST
...
#else
[PFUser logOut];
[[ParseRESTClient sharedClient] closeClient];
block(nil);
#endif
}
- (void)deleteAccountWithBlock:(void (^)(NSError \*error))block{
[[ParseRESTClient sharedClient] closeClient];
#if !TEST
...
#else
[PFUser logOut];
block(nil);
#endif
}
```
Далее мы создали отдельные классы, в которых поместили реализацию разных сценариев, которые может выполнить пользователь.
В базовом классе реализован единственный метод:
```
- (void) setUpWithBlock:(void (^) (NSError* error))block{
[NSURLRequest setAllowsAnyHTTPSCertificate:YES forHost:@"api.parse.com"]; //отключаем проверку сертификатов, иначе iOS не дает нам общаться через https в тестовой среде. Это приватное АПИ.
self.workCircleController = [WorkCircleController new];
[self.workCircleController setupPreLoginStateWithBlock:^(NSError *error) {
block(error);
}];
}
```
Далее мы создали среду и логику для двух пользователей и для отдельных сценариев. Поскольку взаимодействие с сервером реализовано асинхронное, то мы использовали [SRTAdditions.h](https://github.com/square/SocketRocket/blob/master/SRWebSocketTests/SenTestCase%2BSRTAdditions.h) для получения калбеков и правильного исполнения тестов.
Развитие идеи
Основной целью этого подхода было уменьшение времени на тестирование разных сценариев. Я думаю, что на Parse реально настроить Jasmine или Mocha, поэтому некоторые кейсы было бы проще решать через юнит-тесты, но в целом интеграционные тесты вполне оправдали себя: билды становились все стабильнее, время на разработку новых фич на cloud code уменьшилось, и можно было поиграть в теннис, пока выполняются все тесты.

После того, как в теннис я стал играть слишком много времени, начальство забеспокоилось и решило поднять сервер [hudson-ci.org](http://hudson-ci.org), который берет последний код с git, и запускает sh скрипты, которые запускают тесты. Для запуска тестов и красивого отображения логов использовали [xtool](https://github.com/facebook/xctool). Кстати, при запуске через консоль тесты не запускают симулятор, и можно дальше работать над кодом, пока выполняются тесты.
###### Локализация
Для локализации в итоге стал использовать очень простой тул: [agi18n](https://github.com/angelolloqui/AGi18n)
###### Tips & Tricks
* Почему надо включать warnings в проекте [статья 1](http://boredzo.org/blog/archives/2009-11-07/warnings), [статья 2](http://lightyearsoftware.com/2013/03/xcode-hard-mode/)
* Снипеты ([шаринг через dropbox](http://runmad.com/blog/2012/09/xcode-code-snippets-and-syncing/)):
+ `__weak typeof(self) weakSelf = self;`
+ `(void (^)(NSError *error))<#block#>`
* [Code style от New York Times](http://github.com/NYTimes/objective-c-style-guide)
* [Reveal](http://revealapp.com/). Очень любопытный инструмент для отладки UI. Очень удобно, когда неясно, куда уехала вью или когда дают на поддержку новый большой проект и мало времени, чтобы разобраться в том, как устроена архитектура вью-контроллеров и где какие вью.
* удобный тул для генерирования бесчисленного количества иконок всевозможных размеров
[www.gieson.com/Library/projects/utilities/icon\_slayer](http://www.gieson.com/Library/projects/utilities/icon_slayer/) | https://habr.com/ru/post/198864/ | null | ru | null |
# Как сделать презентацию интерактивной
Каждый из нас хоть раз выступал перед большой аудиторией, многие делают это постоянно. У всех из нас есть свои страхи перед выступлением и, конечно, же лучшие практики. Ниже вы узнаете, как взаимодействовать с аудиторией в интерактивном режиме.

*Примечание: далее материал будет от имени автора.*
Когда мы провели анализ, что является основой успешного выступления, что делает из простых спикеров увлекающих за собой ораторов мы пришли к выводу, что секрета успешной презентации три:
1. **Это ваши презентационные навыки**. Выступающий должен вызывать эмоции у слушателей — интерес, радость, может даже и несогласие. Навыки выступлений все мы развиваем постоянной практикой и самосовершенствованием (тренинги, книги, коучинг и т.п.).
2. **Это суть выступления**. Тема и содержание доклада должны учитывать интересы аудитории, давать ответы на вопросы, с которыми люди пришли на ваше выступление или открывать для них новые горизонты
3. **И это, конечно, вовлечение аудитории**. Слушатели должны присоединиться к вашему докладу и чувствовать, что ваш доклад учитывает их потребности, их мнение и эмоции.
Давайте поговорим о третьем секрете успешного выступления.
Для вовлечения аудитории многие ораторы применяют такие «фишки», как вопросы в залы, сторитэйлинг с вопросом выдумка это или ложь, ответы на вопросы по ходу выступления, пытаясь превратить доклад в живое общение.
Это не всегда продуктивно, потому что требует дополнительного времени и навыков. Поэтому и родилась идея [создать сервис для Powerpoint](https://inpres.com/), который позволит дополнять презентацию крутыми интерактивными элементами, взаимодействующими с аудиторией. Назвали мы его INPRES — от INteractive PRESentation.
Как устроен сервис?
-------------------
[Сервис состоит из трех модулей](https://www.youtube.com/watch?v=kMDV4VDbNbo) — кабинета спискера, где пользователь создает интерактивные элементы, модуль Add-in для PowerPoint, чтобы интегрировать интерактивные элементы в презентацию и интерфейсы участников презентации для взаимодействия со спикером. Кросс-платформенное взаимодействие в проекте [тесно интегрировано с Office.js](https://dev.office.com/reference/add-ins/javascript-api-for-office), который 2 года назад на рынок выпустила компания Microsoft. Более подробно о процессе разработки и интеграции я расскажу чуть позже.
Какие возможности спикеру дает данный сервис:
1. [Узнавать мнение и эмоции аудитории](https://inpres.com/site/poll) с помощью различных опросов — от простых с вариантами ответов до прикольных Emoji голосований или сложных 2D голосований.

2. [Отображать мнение аудитории на слайдах своей презентации в режиме онлайн](https://inpres.com/site/charts) (более 30 вариантов отчетов — от инфографики до сегментированных по полу/возрасту отчетов).

3. [Получать вопросы из аудитории](https://inpres.com/site/askaspeaker) При этом участники презентации могут выбирать лучшие, а спикер — отображать их онлайн на слайдах презентации.

4. [Собирать реальную обратную связь аудитории](https://inpres.com/site/feedback) результатам презентации в виде оценок и комментариев.

5. [Лучше знать аудиторию и ее предпочтения](https://inpres.com/site/survey) — проводить анкетирование по результатам презентации, в т.ч. с предзаполнением анкет данными из профилей соц сетей участников презентации.

6. [Предоставить легкий доступ к файлам своего выступления](https://inpres.com/site/filesbot) — встроенный File Bot с возможностью скачивать или отправлять материалы на почту.
Как устроено дополнение для PowerPoint?
---------------------------------------
[Дополнение INPRES](https://store.office.com/en-us/app.aspx?ui=en-US&rs=en-US&ad=US&assetid=WA104380591&appredirect=false) (надстройка add-in) для PowerPoint представляет собой файл манифеста с доступом к выделенному разделу веб сервиса. Манифест это XML-файл, в котором хранится некоторая информация о приложении. Веб страницы, на которые ссылается манифест отвечают непосредственно за основную логику и интерфейс приложения. Они будут взаимодействуют с файлом вашей Powerpoint презентации через специально предоставленный API.
Важным моментом было интегрировать действия спикера с запуском интерактивных элементов, их завершением и отображением результатов на слайдах. В этом направлении команда разработала JS библиотеки, которые общаются онлайн с API файла презентации. Многие функции, такие как получение слайдов с размещенными виджетами, изменение статусов опросов пришлось писать с нуля.
Все остальные модули сервиса разработаны на технологии [.Net Core](https://www.microsoft.com/net/core) и работают на серверах [MS Azure](https://azure.microsoft.com/ru-ru/). Для визуализации результатов опросов и других интерактивных элементов использовалась SVG графика и библиотеки JS графиков.
Особенности реализации
----------------------
В сервис INPRES закладывался принцип «бесфрикционности» — спикер только перелистывает слайды презентации, сервис делает все остальноe — запускает интерактивный элемент (опрос, анкетирование и т.п.), напоминает о нем участникам презентации с помощью PUSH нотификации, сам переводит участника на страницу интерактивного элемента, отображает действия участников в режиме онлайн (к примеру, результаты голосования).
Для этого прописывалась сценарии действия спикера, а обработка событий спикера происходит через перехват событий разработанной JS библиотекой.

Еще одним следствием работы с событиями в презентации стала возможность создавать сценарий отчетов. К примеру, следом за общими результатами голосования вы можете показать — сегментированные по полу или возрасту результаты.
Когда мы создавали сервис, мы изучали рынок «голосовалок» и систем конференций и пытались превзойти каждого из наших конкурентов. Так родилась мультиязчность — сейчас у нас
14 языковых пакетов, в т.ч. и русский. Мы сделали точное настраивание цветовых схем интерфейсов — можно выбраль любой HEX код цвета для фона, графиков, шрифта. Добавли библиотеку из более 10 шрифтов
Кроме этого сервис INPRES имеет графики, встраиваемые в контент презентации, чтобы сразу получать мнение аудитории именно о той информации, которую показывает спикер, а не отводить на опрос отдельный слайд.
Сложности
---------
В целом, Office JS API для PowerPoint имеет более урезанный функионал, чем API для Word или Outlook. Это являлось основной сложностью создания Add-in. Как и написано ранее — многие библиотеки приходилось писать самостоятельно и искать walkarround.
Вторая сложность, с которой, по-моему сталкиваются все — это разрешение интегрировать ваш сайт во фрйэме вашего Add-ins. Мы создавали сервис на .Net core и вопрос как правильно настроить [X-Frame-Options](https://developer.mozilla.org/ru/docs/Web/HTTP/Headers/X-Frame-Options) в HTTP-заголовке был не документирован и сильно отличался от аналогичного процесса в .Net 4\*.
Чтобы сделать это необходимо указать в файле startup.cs вашего проекта возможность изменять X-Frame-Options свойства:
```
services.Configure (options =>
{
options.SuppressXFrameOptionsHeader = true;
});
```
И установить значения X-Frame-Options для всех страниц в файле web.config:
```
```
Также большую изыскательскую работу мы провели по получению данных участников презентации, когда они регистрируются через соц сеть (эта возможность настраивается в нашем сервисе). С именем, имэйлом проблем не было — это стандартная функциональность фрэймворка [AspNetCore.Authentication](https://www.nuget.org/packages/Microsoft.AspNetCore.Authentication/).
Вопрос возник с получением данных о поле и возрасте человека. Особенно из аккаунта Google.
Чтобы это сделать в том же файле startup.cs необходимо промэппить поля на соответствующие Claim фрйэмворка авторизации:
```
Events = new OAuthEvents
{
OnCreatingTicket = context => {
var gender = context.User.Value("gender");
context.Identity.AddClaim(new Claim(ClaimTypes.Gender, gender));
var birthday = context.User.Value("birthday");
context.Identity.AddClaim(new Claim(ClaimTypes.DateOfBirth, birthday));
return Task.FromResult(0);
}
}
```
То, что сьело у нас значительное время — это согласование [Add-in](https://store.office.com/en-us/app.aspx?assetid=WA104380591&sourcecorrid=11de6596-e7b1-4f5b-baa0-73bd2e66e4f0&searchapppos=0&ui=en-US&rs=en-US&ad=US&appredirect=false) перед его публикацией в MS Store. Важно подойти к этому этапу с максимально оттестированным функционалом. Также, т.к. направление Add-In для офиса находится в стадии бурного развития — готовьтесь к тому, что каждая итерация согласования будет длиться от 2 до 5 дней. К счастью, с пощью коллег из Московского, Ирландского и Датского офисов Microsoft мы получали обратную связь достаточно оперативно.
Следующие шаги
--------------
В конце ноября компания планирует запустить модуль для PowerPoint для MAC, до конца года — встроенные в сервис викторины и тестирование сотрудников.
В рамках сотрудничества компания Microsoft приняла решение о предоставлении компании INPRES расширенного гранта для развития бизнеса Bizspark +, а также использовать сервис в конференциях Microsoft.
Выводы
------
INPRES будет полезен людям участвующим в публичных выступлениях, конференциях, совещаниях, продающих презентациях, в тренингах, WorkShop-ах, учебных мероприятиях и на текущий момент является уникальным сервисом, предоставляющим спикерам весь пакет инструментов интерактивного взаимодействия с аудиторией.
---
### Об авторе

Денис Попов — ведущий разработчик компании INRPES. | https://habr.com/ru/post/316134/ | null | ru | null |
# Практическое применение async/await в Unity
Использование *async/await* позволяет сделать код легче для понимания, убирает необходимость в колбеках (функций обратного вызова) и протаскивании через них необходимых данных (или их сохранения в полях объекта).
Сравнение async/await с колбеками
---------------------------------
Пример сохранения данных в указанный слот с пользовательским комментарием.
С использованием колбеков:
```
public void Save(int slotIndex)
{
if (SaveExists(slotIndex))
{
popupConfirm.Open("Перезаписать файл?", () => SaveCommentsRequest(slotIndex));
}
else
{
SaveCommentsRequest(slotIndex);
}
}
void SaveCommentsRequest(int slotIndex)
{
popupInput.Open("Укажите комментарий", comments => SaveWithComments(slotIndex, comments));
}
void SaveWithComments(int slotIndex, string comments)
{
// сохраняем здесь
}
```
С использованием *async/await*:
```
async public void Save(int slotIndex)
{
if (SaveExists(slotIndex) && !await popupConfirm.Open("Перезаписать файл?"))
{
return;
}
var comments = await popupInput.Open("Укажите комментарий");
// сохраняем здесь
}
```
Требования и ограничения для реализации
---------------------------------------
Использовать *await* можно только внутри асинхронной функции (с модификатором *async*), за исключением:
* внутри вложенной (не асинхронной) анонимной функции,
* внутри блока *lock*,
* в анонимной функции, использующейся для дерева выражений,
* в небезопасном (*unsafe*) контексте.
*await* можно использовать для типов, соответствующим условиям:
* тип имеет доступный метод экземпляра (не статичный метод) или метод расширение *GetAwaiter()* без параметров, без параметров типа (не generic, *GetAwaiter()* не разрешен) и возвращающий тип *A*,
* или объект имеет тип *dynamic*.
Требования для типа *A*:
* реализует интерфейс *System.Runtime.CompilerServices.INotifyCompletion*,
* имеет доступное для чтения свойство *IsCompleted* с типом *bool*,
* имеет доступный метод экземпляра (не static) *GetResult()* без параметров и без параметров типа (не generic), на возвращаемый тип ограничений нет.
Для чего они нужны:
* *GetAwaiter()* нужен для получения объекта ожидания (awaiter) выполнения операции. Тип А это тип объекта ожидания.
* свойство *IsCompleted* необходимо для определения завершения операции, если операция завершена, то код будет выполняться синхронно.
* свойство *INotifyCompletion.OnCompleted* используется для подписки на завершение операции.
* метод *GetResult()* для получения результата выполнения операции. Это может быть успешное завершение, со значением результата, если требуется, или исключение, которое выбрасывается методом *GetResult()*.
Пример реализации
-----------------
Сперва необходим интерфейс для ожидаемого типа:
```
using System;
public interface IAwaitable
{
event Action OnComplete;
public Awaiter GetAwaiter();
}
```
И класс для объекта ожидания:
```
using System;
using System.Runtime.CompilerServices;
public class Awaiter : INotifyCompletion
{
TResult result;
Action continuation;
public bool IsCompleted
{
get;
private set;
}
public Awaiter(IAwaitable awaitable)
{
void setResult(TResult result)
{
// отписываемся после получения результата
awaitable.OnComplete -= setResult;
// сохраняем результат
IsCompleted = true;
this.result = result;
var c = continuation;
// поскольку оповещаем однократно, то можно очистить
continuation = null;
// оповещаем о завершении операции
c?.Invoke();
}
// подписываемся на результат операции
awaitable.OnComplete += setResult;
}
public void OnCompleted(Action continuation)
{
if (IsCompleted)
{
continuation();
return;
}
// сохраняем делегат для оповещения о завершении
this.continuation += continuation;
}
public TResult GetResult()
{
return result;
}
}
```
Если результата не нужен, то убирается вместе с сохранением результата и GetResult() становится пустым методом, возвращающим *void*.
Пример окна для подверждения, реализующего IAwaitable:
```
using System;
using TMPro;
using UnityEngine;
using UnityEngine.UI;
public class PopupConfirm : MonoBehaviour, IAwaitable
{
public event Action OnComplete
{
add => onComplete += value;
remove => onComplete -= value;
}
public void Confirm() => Complete(true);
public void Cancel() => Complete(false);
void Complete(bool result)
{
gameObject.SetActive(false);
// оповещаем о результате
onComplete?.Invoke(result);
}
public PopupConfirm Open(string message = null)
{
Message.text = message;
gameObject.SetActive(true);
// возвращаем этот же объект, чтобы сразу использовать await
return this;
}
public Awaiter GetAwaiter() => new Awaiter(this);
[SerializeField]
protected TextMeshProUGUI Message;
[SerializeField]
protected Button ButtonOk;
[SerializeField]
protected Button ButtonCancel;
event Action onComplete;
protected virtual void Start()
{
ButtonOk.onClick.AddListener(Confirm);
ButtonCancel.onClick.AddListener(Cancel);
}
protected virtual void OnDestroy()
{
ButtonOk.onClick.RemoveListener(Confirm);
ButtonCancel.onClick.RemoveListener(Cancel);
// при удалении оповещаем об отмене
Cancel();
}
}
```
Тестируем:
```
using UnityEngine;
public class TestConfirm : MonoBehaviour
{
public PopupConfirm Confirm;
async public void Test()
{
var quit = await Confirm.Open("Выйти?");
if (quit)
{
Debug.Log("quit");
Application.Quit();
}
else
{
Debug.Log("cancel");
}
}
}
```
Ссылки
------
* [Код на GitHub (Unity 2021.3.6f1)](https://github.com/ilihh/Async-UI)
* [Спецификация](https://learn.microsoft.com/en-us/dotnet/csharp/language-reference/language-specification/expressions#1188-await-expressions) | https://habr.com/ru/post/699212/ | null | ru | null |
# Блеск и нищета php. Эволюция языка от 4.x к 7.1

По слухам, сегодня должен состояться релиз 7.1. Поэтому хотелось бы немного оглянуться назад и посмотреть, а как же php вырос из набора костылей и подпорок в полноценный язык для веба. Прямо по шагам, т.е. по версиям. А в конце хотелось бы немного ~~поразжигать~~ поразмыслить о роли php в современной экосистеме.
Давайте мысленно вернемся во времена php4, когда получили своё развитие wordpress, bitrix и миллионы других CMS и домашних страничек.
Php до пятой версии можно было называть языком с натяжкой. Скорее это был хаотический набор функций, которые можно было быстро вызывать, чтобы выплюнуть данные из mysql в браузер. Там были зачатки ООП, но такие, что наверно лучше бы их не было.
Каждый второй сайт работал с включенными галочками [magic quotes](http://php.net/manual/ru/security.magicquotes.php). Т.е. все переменные, которые прилетали от браузера магически экранировались. Что якобы позволяло их безопасно вставлять в базу данных. На деле же универсальным CMS приходилось это дело чистить (или оставлять как есть, в зависимости от настроек в php.ini). В общем мрак. Но для новичка якобы было “удобно”: вставлять всё, что прилетело в базу и не париться.
Соответственно, порог входа был крайне низким, достаточно было выучить функцию mysql\_query и htmlspecialchars. Это привело к тому, что сайты на php стали делать абсолютно все: чуть ли не каждый второй студент был членом “веб-студии”.
Порог был низким, качество кода соотвествовало. Возьмите любой крупный проект, который начался в те времена, и посмотрите на его код. Страх, ненависть, боль.
Но потом появился php5
php 5.0 ( 2004 год)
===================
Эта версия языка сделала огромный рывок в ООП. Появились модификаторы доступа (public, protected, private). Выделились статические методы (static). Появились интерфейсы. Деструкторы. [Reflection API](http://php.net/manual/ru/book.reflection.php). Работа с [исключениями](http://php.net/manual/ru/language.exceptions.php). Магические методы `__get` и `__set`. Итераторы. [ArrayAccess](http://php.net/manual/ru/class.arrayaccess.php) (чтобы можно было сделать объект, имитирующий массив). И многое-многое другое. По большому счету парни взяли, и многое скопировали из java, включая даже названия ключевых слов (extends, implements, try, catch и т.д.). Т.е. получилась динамически типизированная джава. Правда без неймспейсов.
Насчет типизации тоже был сделан шаг вперед, а именно [type hinting](http://php.net/manual/ru/functions.arguments.php#functions.arguments.type-declaration). Т.е. в аргументах методов стало можно указать имя класса (или интерфейса), таким образом стал проверяться тип (хоть где-то!).
Появилось расширение SPL (набор интерфейсов и классов для решения стандартных задач).
После релиза у многих разработчиков случился форменный разрыв шаблонов, так как люди внезапно стали резко разделяться на два лагеря: те, кто умеют ООП и те, кто не умеют ООП и костылируют старые вордпрессы. Понятно, что многие и раньше (еще на php4) пытались работать с тем ООП что было, но тот велосипед с квадратными колесами не позволял по-настоящему развернуться.
Также в php5 раза в два выросла скорость. Короче, php5 — это был тупо отдельный новый язык.
php 5.1 и 5.2 (2006-2009 годы)
==============================
5.1 и 5.2 не принесли много изменений в сам язык, их было всего парочка: магические методы \_\_isset и \_\_unset (в дополнение к \_\_get и \_\_set).
К type hinting добавился еще и array. Т.е. еще один шаг к чуть более статической типизации. Хочу заметить, что с каждым релизом, похоже, идет попытка избавиться от магии.
Добавился встроенный интерфейс [Serializable](http://php.net/manual/ru/class.serializable.php).
Некоторые улучшения в SPL и Reflection
В основном это перепахивание различных функций и багфиксы. Например, появилась функция json\_encode
Очень важной фичей было включение [PDO](http://php.net/manual/ru/book.pdo.php) по умолчанию. Всё меньше и меньше людей используют mysql\_query и SQL-инъекции в них.
php 5.3 (2009 год)
==================
А вот версия 5.3 стала очередным прорывом в языке.
Самое главное — появились неймспейсы (аналог package в java). Это дало большой толчок к развитию различных библиотек и фреймворков. Через пару лет после релиза начал зарождаться менеджер зависимостей composer.
Появились [лямбды и замыкания](http://php.net/manual/ru/functions.anonymous.php). К примеру, в java лямбды появились на 5 лет позже.
(а в c# они к тому времени уже 5 лет как были)
Появился оператор `goto`
Сокращенный тернарный оператор `?:`
Появился оператор `static` для [позднего статического связывания](http://php.net/manual/ru/language.oop5.late-static-bindings.php) и магический метод `__callStatic`
php-fpm включен в ядро
php 5.4 (2012 год)
==================
Здесь наконец-то полностью выпилены магические кавычки и [register\_globals](http://php.net/manual/ru/security.globals.php). Т.е. с какой-то версии они были deprecated, а начиная с 5.4 их наконец-то грохнули. Кстати, интересный факт: на одной конференции Расмус Лердорф (создатель php) сказал, что голосовал против выпиливания magic\_quotes, что на мой взгляд очень странно. Мне казалось, что все уже давно наелись этой магией по горло.
Также в этой версии было еще очень важное изменение: появились примеси (traits).
Добавлена короткая запись массивов, т.е. вместо `Array(1,2,3)` стало можно писать `[1,2,3]`
Также можно отметить появление разыменования массивов
```
foo()[0]
```
и возможность сделать так:
```
(new foo)->bar()
```
В type hint стало возможно исползьовать `callable`
php 5.5 (2013 год)
==================
В 5.5 появились генераторы и ключевое слово "finally".
А также рызыменование литералов массива и строки:
```
echo [1, 2, 3][0];
echo 'PHP'[0];
```
Оператор `::class` для получения имени класса вместе с неймспейсом.
php 5.6 (2014 год)
==================
Стало можно использовать выражения в константах.
Добавилась возможность делать функции с переменным количеством аргументов `(...$params)` и развертывание аргументов c помощью оператора **`...`**
php 6 (никогда)
===============
php 6 так и не вышел. Главный challenge этой версии был в поддержке UTF на уровне ядра (был выбран UTF-16). Но там оказалось столько работы, что после длительной разработки в итоге от идеи отказались. Как утверждают разработчики, если бы выбрали UTF-8, все было бы гораздо легче и был бы какой-то результат. Уж не знаю почему.
php 7 (2015 год)
================
Седьмая версия стала очередным прорывом в языке, сопоставимая с 5.0 и 5.3. Во первых, всё стало быстрее работать раза в два-три.
Во-вторых, в тайпхинтинг стало возможным использовать скалярные типы: int, string и т.д. А также задавать тип возвращаенмого значения метода. Причем, если в начале файла указать
```
declare(strict_types=1)
```
то на попытку передачи float в аргумент, требующий int, будет выдан Fatal Error.
По сути это дает возможность писать на php почти что как на строго типизированном языке.
Добавлены операторы `??` и `<=>`
Появились анонимные классы, групповые декларации use, улучшены генераторы, убрана некоторая магия из преобразования строк в числа и прочее.
php 7.1 (сегодня)
=================
Типы аргументов и возвращаемых значений можно пометить как nullable с помощью оператора?
например `?string`
тип возвращаемого значения `void`. Т.е. если в таком методе будет return, то это вызовет fatal error
Замена `list` на `[]`
т.е. будет возможна запись
```
[$a, $b] = [$b, $a];
```
У констант класса появилась видимость (`public`, `protected`, `private`)
Обработка нескольких исключений сразу (как в java)
```
catch (FirstException | SecondException $e)
```
Отрицательные смещения для строк `"abcdef"[-2]`
Асинхронная обработка сигналов `pcntl_async_signals()`
Полный список php7.1 уже доступен в мануале: <https://secure.php.net/manual/ru/migration71.php>
Что мы имеем в итоге?
=====================
В итоге мы имеем хороший язык для веба, у которого есть всё: фреймворки (Symfony, Yii и т.д), менеджер зависимостей и т.д. Но порог входа теперь совсем другой. Т.е. человек, который пишет на современном php, должен как минимум знать кучу ООП best practices, использовать фреймворки и composer, знать кучу фич языка и его расширений.
К сожалению, огромное количество php-шников до сих пор используют php как php4, и не хотят учиться. Именно из-за того, что порог входа был низкий, а теперь надо сильно перестраиваться. Всё это, мягко говоря, не улучшает репутацию языка.
В итоге работодатели ожидают дешевую рабочую силу (это ж "похапе", там дешевые программисты), а на деле при найме выходит, что для решения современных задач нужны современные программисты, а их сильно не хватает.
Вообще, хотелось бы обсудить перспективы php на будущее. Какие у языка есть киллер-фичи?
Т.е. после внедрения в язык кучи языковых конструкций, он стал не очень привлекательным для новичков (мне кажется, новичок скорее выберет go из-за простоты). Но при всём своём развитии (которое я очень сильно приветствую), php не дотягивает до языков кровавого энтерпрайза, таких как C# или та же java. Потому что типизация все же не совсем строгая, нормальной многопоточности считай нет, и всё еще есть костыли разных видов. Также нет дженериков, человеческой поддержки utf. Массив в php — это странная смесь массива и HashMap и т.д. Т.е. если в энтерпрайзной нише уже есть java/c#, то зачем там нужен php, который слегка не дотягивает?
Как вы думаете, есть ли своя ниша у php, и в чем она заключается? Я не для того, чтобы потроллить, мне правда очень интересно. | https://habr.com/ru/post/316506/ | null | ru | null |
# Совместное сетевое использование криптографического токена пользователями на базе usbip
В связи с изменением законодательства относительно доверительных услуг ( «Про электронные доверительные услуги» Украина), на предприятии появилась необходимость нескольким отделам работать с ключами, расположенными на токенах (на данный момент, вопрос о количестве аппаратных ключей еще открыт).
Как инструмент с наименьшими затратами (безвозмездно) сразу выбор пал на [usbip](http://usbip.sourceforge.net/). Сервер на Ubintu 18.04 заработал благодаря публикации [Укрощаем USB/IP](https://habr.com/ru/post/308860/) и успешно опробован на нескольких флеш накопителях (за неимением на тот момент токена). Никаких особых проблем, кроме монопольного владения (резервирования на пользователя) в тот момент времени выявлено не было. Понятно чтобы организовать доступ нескольким пользователям (хотя бы двум, для начала) необходимо разделить им доступ во времени и заставить работать по очереди.
Стал вопрос: Как с наименьшими танцами сделать чтобы у всех все работало…
Часть топорная
==============
| | |
| --- | --- |
| | **І вариант**. Несколько ярлыков к bat файлам, а именно
а) Подключение ключа доступа.
б) Сознательно отключение.
Пункт "**б**" спорный, поэтому было решено дать количество времени на работу с ключом в 3 минуты.
Особенность клиента usbip в том что после его запуска он остается висеть в консоли, без прерывания консольной сессии закрыть подключение можно «грубо» со стороны клиента и так же со стороны сервера. |
Вот что у нас нормально заработало:
первый: подключение ***on.bat***
```
usbip -a 172.16.12.26 4-1
msg * "Подпись/токен недоступны или заняты "
```
второй: отключение ***off.bat***
```
ping 127.0.0.1 -n 180
taskkill /IM usbip.exe /F
```
не надеясь на сознательность пользователя, скрипты были объединены в ***token.bat***
```
on.bat | off.bat
```
Что получается: все файлы находятся в одной папке, запуск файлом token.bat, если соединение закрыто у пользователя сразу сообщение о недоступности ключа, в другом случае, только через 180 пингов. Приведенные строки кода можно оснастить "@ECHO OFF" и направлением консоли в "> nul" дабы не сильно шокировать пользователя, но для запуска в тестирование не обязательно. Первичный «прогон» на USB накопителе показал, что все предсказуемо-надежно-четко. Причем со стороны сервера не нужно никаких манипуляций.

Естественно, при отработке непосредственно с токеном все пошло не так как ожидалось: при физическом подключении в диспетчере устройств, токен регистрируется как 2 устройства (WUDF и смарт-карта) а при сетевом только как WUDF (хотя для запроса ПИН кода и этого достаточно).
Также оказалось, что жестокий «taskkill» не так уж суров, и закрытие соединения на клиенте является проблемным и даже если это удалось, то это не гарантирует закрытие его для него на сервере.
Пожертвовав всеми консолями на клиенте второй скрипт принял вид:
```
ping 127.0.0.1 -n 180 > nul
taskkill /IM usbip.exe /F /T > nul
ping 127.0.0.1 -n 10 > nul
taskkill /IM conhost.exe /F /T > nul
```
хотя его результативность менее 50%, так как сервер упорно продолжал считать соединение незакрытым.
Проблемы с соединением привели к мыслям о модернизации в серверной части.
Часть серверная
===============
Что нужно:
1. Отключать неактивных пользователей от сервиса.
2. Видеть кто сейчас использует (или еще занимает) токен.
3. Видеть подключен ли токен к самому компьютеру.
Решить эти задачи было решено при помощи сервисов crontab и apache. Дискретность перезаписи состояния результатов мониторинга интересующих нас 2 и 3 пунктов говорит о том что файловую систему можно расположить на ramdrive. В /etc/fstab добавлена строка
```
tmpfs /ram_drive tmpfs defaults,nodev,size=64K 0 0
```
В корне создана папка script со скриптами: размонтирование-монтирование токена usb\_restart.sh
```
usbip unbind -b 1-2
sleep 2
usbip bind -b 1-2
sleep 2
usbip attach --remote=localhost --busid=1-2
sleep 2
usbip detach --port=00
```
получение списка активных устройств usblist\_id.sh
```
usbip list -r 127.0.0.1 | grep ':' |awk -F ":" '{print $1}'| sed s/' '//g | grep -v "^$" > /ram_drive/usb_id.txt
```
получение списка активных IP (с последующей доработкой с отображением идентификаторов пользователей) usbip\_client\_ip.sh
```
netstat -an | grep :3240 | grep ESTABLISHED|awk '{print $5}'|cut -f1 -d":" > /ram_drive/usb_ip_cli.txt
```
сам crontab выглядит так:
```
*/5 * * * * /!script/usb_restart.sh > /dev/null 2>&1
* * * * * ( sleep 30 ; /!script/usblist_id.sh > /dev/null)
* * * * * (sleep 10 ; /!script/usbip_client_ip.sh > /dev/hull)
```
Итак имеем: каждые 5 минут подключиться может новый пользователь, вне зависимости от того кто работал с токеном. К http серверу при помощи симлинка подключена папка /ramdrive в которой сохраняются 2 текcтовых файла, показывающих о состоянии сервера usbip.
Часть следующая: «Некрасивое в обертке»
=======================================
**ІІ вариант.** Немного порадовать пользователя хоть каким-то менее устрашающим интерфейсом. Озадачившись тем, что у пользователей разные версии Windows с разным фреймворками, разными правами, менее проблемного подхода чем [Lazarus](https://www.lazarus-ide.org/) я не нашел (я конечно за C#, но не в этом случае). Запускать bat файлы из интерфейса можно и в фоне, свернутыми, но без должного опробования, лично я придерживаюсь мнения: нужно визуализировать для сбора пользовательских недовольств.
Интерфейсом и программной частью были решены следующие задачи:
1. Отображение занят ли токен в данный момент.
2. При первом запуске первоначальная настройка с генерированием «правильных» bat файлов реализующих запуск и прерывание сеанса работы с сервером токена. При последующих запусках реализация «сервисного» режима по паролю.
3. Проверка наличия связи с сервером, по результату которой производится его опрос о занятости или выводится сообщения о проблемах. При возобновлении связи автоматически программа начинает работать в штатном режиме.
Работа с ВЕБ сервером реализована средствами дополнительной оснастки fphttpclient.
[тут будет Ссылка на текущую версию клиента](https://github.com/avk013/montok)
есть также продолжение соображений по предмету статьи, как и частичный первоначальный восторг от продукта VirtualHere с его особенностями…
**UPD**: Два токена разных банков работают, а вот «правильно заряженные» токены для программы M.E.Doc — нет (они как раз и требуют смарт-карту). Как выход получение платной лицензии на VirtualHere — 1 лицензия на серверный хост + клиентов неограниченно. | https://habr.com/ru/post/471230/ | null | ru | null |
# Переход на SwiftUI: внедряем TabView взамен UITabBarController
Внедрение SwiftUI (далее — SUI) в уже существующее приложение, написанное на UIKit, в середине 2022 г. уже не является вопросом времени, а скорее, определяется наличием соответствующих навыков. Перевод приложения Утконоса – одного из лидеров e-commerce на российском рынке – на SUI мы начали в конце 2020 года, когда подняли минимальную поддерживаемую версию iOS до 13-ой (и, да, мы не стали ждать 14-ой). Этому же способствовала поставленная долгосрочная задача полного редизайна приложения. На текущий момент из пяти главных экранов на SUI у нас реализованы два.
Одна из главных задач, стоящих перед разработчиками — проектирование навигации в приложении. Сейчас уже редко можно встретить одностраничное приложение. Панель вкладок (или таб-бар) позволяет реализовать пользовательский интерфейс, в котором доступ к нескольким экранам не выполняется строго в определенном порядке. Если приложение пишется с нуля на SUI, то типичным сценарием разработки все еще является следующий: экраны верстаются на SUI, а таб-бар на UIKit. С ростом кодовой базы на SUI в Утконосе мы стали постепенно отказываться от навигации на UIKit, большим шагом в этом направлении стало внедрение TabView взамен UITabBarController.
Всем привет! Меня зовут Краев Александр и ниже хочу поделиться опытом перевода UIKit-вого таб-бара на TabView со всеми подводными камнями: когда у вас есть экраны, написанные как на SUI, так и на UIKit. Сразу оговорюсь, что данная статья не рассчитана на тех, кто только начал знакомиться со SUI: внедрение нового фреймворка я советовал бы начать с какого-нибудь небольшого уже существующего экрана или новой продуктовой фичи. Больше всяких фишек и интересных разборов вы сможете найти на [моем telegram-канале](https://t.me/swiftui_dev), посвященном iOS-разработке на SwiftUI.
Часть 1. Подготавливаем инфраструктуру
--------------------------------------
В нашей команде мы работаем по [Trunk Based Development](https://trunkbaseddevelopment.com/) (TBD). Если вы не знакомы с данной моделью ветвления, то советую вам посмотреть [это](https://www.youtube.com/watch?v=hIW5ynk8HWc) выступление или прочитать [эту](https://habr.com/ru/post/519314/) статью. Если коротко, то разработка новых фичей идет через Feature Flags.
Заведем флаг для нового таб-бара на SUI:
```
struct SwiftUI {
struct TabView {
static var isActive: Bool = true
}
}
```
В той части кода, где создается корневой view controller у главного window, уже можно написать:
```
var main: UIWindow?
func createMainWindow(windowScene: UIWindowScene) {
main = UIWindow(windowScene: windowScene)
let mainTab = FeatureFlags.SwiftUI.TabView.isActive ?
UIHostingController(rootView: RootTabView()) :
setupTabBarController()
main?.rootViewController = mainTab
}
```
где `setupTabBarController()` – это функция создания прежнего таб-бара на UIKit, а `RootTabView()` – это view нового таб-бара на SUI, проброшенная через `UIHostingController`.
Иерархия в прежнем таб-баре весьма привычная: для каждого экрана создается его navigation controller с корневым view controller-ом:
```
let profileVC: ProfileViewController = .init()
let profileNav: NavigationController = .init(rootViewController: profileVC)
```
После инициализируется сам tab bar controller, у которого view controller-ы это созданные на предыдущем шаге navigation controller-ы:
```
private func setupTabBarController() -> UIViewController {
...
let profileVC: ProfileViewController = .init()
let profileNav: NavigationController = .init(rootViewController: profileVC)
...
let tabbarController: TabBarController = .init()
tabbarController.viewControllers = [..., profileNav, ...]
return tabbarController
}
```
Здесь стоит пояснить, что `NavigationController` – это класс, наследуемый от `UINavigationController`, с кастомным поведением навигационной панели, в том числе ее внешнего вида, кнопки назад, но не более.
Вернемся к новому таб-бару, очевидно, что в `RootTabView()` будут располагаться view главных экранов. Самое время начать писать SUI-обертки на `UIViewControllerRepresentable` для UIKit-экранов, приведу пример одной такой для экрана профиля пользователя:
```
import SwiftUI
struct ProfileSUIView: UIViewControllerRepresentable {
func makeUIViewController(context: Context) -> NavigationController {
let profileVC: ProfileViewController = .init()
let profileNav: NavigationController = .init(rootViewController: profileVC)
return profileNav
}
func updateUIViewController(_ uiViewController: NavigationController,
context: Context) {
}
}
```
Как уже сказал ранее, у нас есть два экрана, реализованных целиком на SUI. Чтобы не ломать роутинг на этих экранах ввиду других legacy экранов на UIKit, решено было их также обернуть через `UIViewControllerRepresentable` в `NavigationController`:
```
struct CartSUIView: UIViewControllerRepresentable {
func makeUIViewController(context: Context) -> NavigationController {
let cartScreen = CartScreen()
.environmentObject(...)
let suiCartVC = UIHostingController(rootView: cartScreen)
let cartNav: NavigationController = .init(rootViewController: suiCartVC)
return cartNav
}
func updateUIViewController(_ uiViewController: NavigationController,
context: Context) {
}
}
```
Дизайном нового таб-бара пока не стоит забивать голову, мы к этому еще вернемся, сначала необходимо добиться работоспособности текущих конструкций. `RootTabView` приведем к максимально простому виду. Объявим enum с экранами:
```
enum TabType: Int {
case main
case catalog
case search
case profile
case cart
}
```
Далее соберем `RootTabView {...}`, используя иконки из SF Symbols:
```
struct RootTabView: View {
@State private var selectedTab: TabType = .main
var body: some View {
TabView(selection: $selectedTab) {
main.tag(TabType.main)
catalog.tag(TabType.catalog)
search.tag(TabType.search)
profile.tag(TabType.profile)
cart.tag(TabType.cart)
}
}
private var main: some View {
MainSUIView()
.tabItem {
Label("Catalog", systemImage: "house")
}
}
...
private var profile: some View {
ProfileSUIView()
.tabItem {
Label("Profile", systemImage: "person")
}
}
private var cart: some View {
CartSUIView()
.tabItem {
Label("Cart", systemImage: "cart")
}
}
}
```
Запускаем проект, видим, что переключение между табами работает:
Вместе с тем, сломалась навигация на экранах SUI: любой дочерний экран открывается модально, появилась белая полоса в области safe area. Разберемся по порядку.
Если коротко и просто, то роутинг, доставшийся нам в наследство как легаси, представляет из себя enum из списка экранов для навигации и фабрику, где этот enum разруливается:
```
enum Route {
case trackOrder
case qrAccessCode
case safari(String)
...
}
...
func route(to direction: Route,
from viewController: UIViewController? = nil,
previousScreen: AmplitudeScreenNames? = nil) {
let viewController = previousScreen == .bottomSheet ?
UIApplication.topViewController() : viewController
switch direction {
case .trackOrder(let id):
self.trackOrder(id: id, from: viewController)
case .qrAccessCode:
self.showQRAccessCode(from: viewController)
case .safari(let url):
routeToSafari(url: url)
....
}
```
Если явно не указан view controller – экран, с которого переходишь, то по умолчанию берем top view controller (код показывать не буду, он легко гуглится). Как раз в этом и причина модального открытия любого окна. Top view controller в нашей схеме это уже не `UINavigationController` или `UITabBarController`, а hosting view controller:
```
po topViewController
▿ Optional
▿ some : <\_TtGC7SwiftUI19UIHostingControllerV7Utkonos11RootTabView\_: 0x139f2f640>
```
Раньше до navigation controllera-а можно было добраться следующим образом:
```
po (topViewController as? UITabBarController)?.selectedViewController
▿ Optional
▿ some :
```
Таким образом, в SUI-экраны теперь явно надо передавать ссылку на navigation controller, чтобы ее использовать при роутинге. Одним из способов это сделать является создание `EnvironmentKey`:
```
struct NavigationControllerKey: EnvironmentKey {
static let defaultValue: UINavigationController? = nil
}
extension EnvironmentValues {
var navigationController: NavigationControllerKey.Value {
get {
return self[NavigationControllerKey.self]
}
set {
self[NavigationControllerKey.self] = newValue
}
}
}
```
Далее объявим `@Environment` переменную в SUI-экране:
```
struct CartScreen: View {
...
@Environment(\.navigationController) var navigationController
...
var body: some View {
...
}
}
```
Заинжектим navigation controller непосредственно в момент создания hosting view controller-а экрана, таким образом код `CartSUIView` преобразуется к виду:
```
struct CartSUIView: UIViewControllerRepresentable {
func makeUIViewController(context: Context) -> NavigationController {
let cartNav: NavigationController
let emptyView: UIViewController = UIHostingController(rootView: EmptyView())
cartNav = NavigationController.init(rootViewController: emptyView)
let cartScreen = CartScreen()
.environment(\.navigationController, cartNav)
.environmentObject(...)
let suiCartVC = UIHostingController(rootView: cartScreen)
cartNav.addChild(suiCartVC) // child here is a root
cartNav.setNavigationBarHidden(true, animated: false)
return cartNav
}
func updateUIViewController(_ uiViewController: NavigationController,
context: Context) {
}
}
```
Здесь стоит пояснить, что для инжектирования `.environment(.navigationController, cartNav)` необходим экземпляр объекта navigation controller-а `cartNav`, создадим его используя проксирующий `UIHostingController` c пустым `EmptyView`. Далее мы добавляем как child основной экран: `cartNav.addChild(suiCartVC)`, но при этом надо «заглушить» navigation bar от пустого view: `cartNav.setNavigationBarHidden(true, animated: false)`.
Кроме этого, необходимо принудительно скрыть кнопку назад (на пустое view) на экране:
Сделать это весьма просто, применив следующий модификатор:
```
struct CartScreen: View {
...
var body: some View {
content
.navigationBarBackButtonHidden(true)
}
...
}
```
Далее прокинем зависимость во все дочерние View экрана:
```
@Environment(\.navigationController) var navigationController
```
Здесь стоит отметить, что если одно и то же view используется на экранах с разными экземплярами navigation controller-а (например, у нас переход на товар может быть как с главного экрана, так и с экрана корзины), то благодаря дереву зависимостей SwiftUI @Enviroment значение у view будет браться именно родительского view, то есть ошибки не будет.
Пример роутинга во view:
```
Button {
Router.injected.routeToGoodsItem(goodsItemID: goods.id,
from: navigationController)
} label: { ... }
```
Теперь вернемся к белой полосе в области safe area, исправляется это весьма легко. Определим следующий модификатор:
```
public extension View {
@ViewBuilder
func expandViewOutOfSafeArea(_ edges: Edge.Set = .all) -> some View {
if #available(iOS 14, *) {
self.ignoresSafeArea(edges: edges)
} else {
self.edgesIgnoringSafeArea(edges) // deprecated
}
}
}
```
Применим его к контенту tabItem-ов:
```
private var main: some View {
MainSUIView()
.expandViewOutOfSafeArea()
.tabItem {
Label("Catalog", systemImage: "house")
}
}
```
Запускаем приложение, видим, что проблемы ушли:
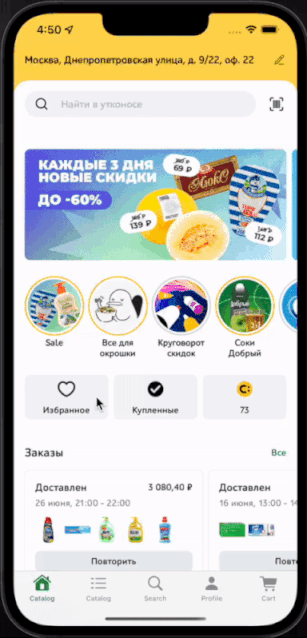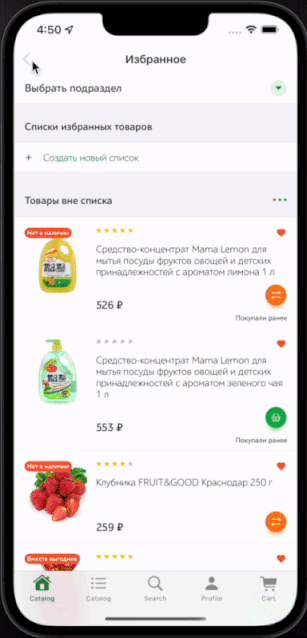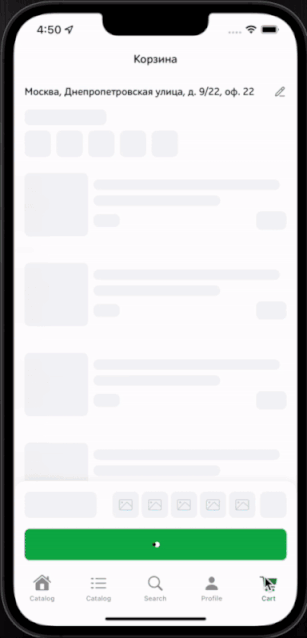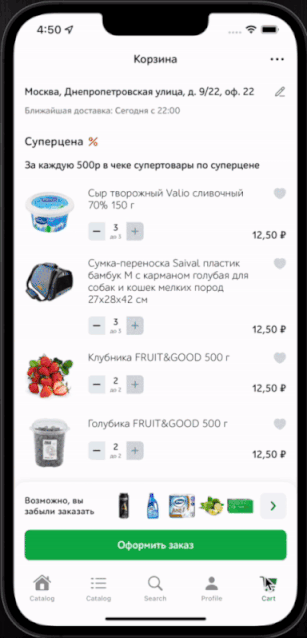Часть 2. Верстаем таб-бар
-------------------------
Теперь можно приступить к верстке таб-бара. Модификатор `tabItem(_:)`, доступный из коробки, имеет весьма ограниченный функционал в верстке, поэтому если чего-то не хватает, надо кастомизировать. К счастью, SUI позволяет это сделать весьма легко:
```
struct RootTabView: View {
@State private var selectedTab: TabType = .main
var body: some View {
ZStack(alignment: Alignment.bottom) {
TabView(selection: $selectedTab) {
main.tag(TabType.main)
catalog.tag(TabType.catalog)
search.tag(TabType.search)
profile.tag(TabType.profile)
cart.tag(TabType.cart)
}
HStack(spacing: 0) {
/*
Здесь будем верстать кнопки
таб-бара
*/
}
}
}
}
```
Как выглядят кнопки тап-бара в различных состояниях:
кнопка не активнакнопка активнаактивная кнопка с бэйджемТак как дизайн весьма простой, просто приведу код:
```
struct TabBarItem: View {
@Environment(\.colorScheme) var colorScheme
let icon: Image
let title: String
let badgeCount: Int
let isSelected: Bool
let itemWidth: CGFloat
let onTap: () -> ()
var body: some View {
Button {
onTap()
} label: {
VStack(alignment: .center, spacing: 2.0) {
ZStack(alignment: .bottomLeading) {
Circle()
.foregroundColor(colorScheme == .dark ? ... )
.frame(width: 20.0, height: 20.0)
.opacity(isSelected ? 1.0 : 0.0)
ZStack {
icon
.resizable()
.renderingMode(.template)
.frame(width: 28.0, height: 28.0)
.foregroundColor(isSelected ? (colorScheme == .dark ? ...) : ...)
Text("\(badgeCount > 99 ? "99+" : "\(badgeCount)")")
.kerning(0.3)
.lineLimit(1)
.truncationMode(.tail)
.foregroundColor(Color.white)
.boldFont(11)
.padding(.horizontal, 4)
.background(Color.Button.primary)
.cornerRadius(50)
.opacity(badgeCount == 0 ? 0.0 : 1.0)
.offset(x: 16.0, y: -8.0)
}
}
Text(title)
.boldFont(12.0)
.foregroundColor(isSelected ? (colorScheme == .dark ? ...) : ... )
}
.frame(width: itemWidth)
}
.buttonStyle(.plain)
}
}
```
Комментировать особо нечего, кроме того, что `boldFont` – кастомный модификатор для шрифта и что сознательно в свойства не вынесены цвета для модификаторов `foregroundColor`, `background`, так как других таких же кнопок, но с другими цветами, в приложении не будет, в ином случае, конечно, я рекомендовал бы это делать. Дополню, что в нашем проекте элементы дизайн-системы, к которым безусловно относится и кнопка таб-бара, вынесены в отдельный package. Данный подход советую применить и у вас.
Посмотрим, как изменится `RootTabView`:
```
struct RootTabView: View {
@Environment(\.colorScheme) var colorScheme
@State private var cartCount: Int = 0
@State private var cartTitle: String = "Shopping cart".localized
@State private var selectedTab: TabType = .main
var body: some View {
GeometryReader { geometry in
ZStack(alignment: Alignment.bottom) {
TabView(selection: $selectedTab) {
main.tag(TabType.main)
catalog.tag(TabType.catalog)
search.tag(TabType.search)
profile.tag(TabType.profile)
cart.tag(TabType.cart)
}
HStack(spacing: 0) {
TabBarItem(icon: Image.TabBar.home,
title: "Utkonos".localized,
badgeCount: 0,
isSelected: selectedTab == .main,
itemWidth: geometry.size.width / 5) {
selectedTab = .main
}
...
TabBarItem(icon: Image.TabBar.cart,
title: cartTitle,
badgeCount: cartCount,
isSelected: selectedTab == .cart,
itemWidth: geometry.size.width / 5) {
selectedTab = .cart
}
}
}
}
.onCartChanged { count, price in
...
cartTitle = price == 0 ? "Shopping cart".localized : price.stringCurrency
cartCount = count
...
}
}
private var main: some View {
MainSUIView()
.expandViewOutOfSafeArea()
}
...
}
```
Дополнительно скажу, что к этому view применен модификатор `onCartChanged`, который отлавливает события изменения корзины, реализация крайне проста: все строится вокруг отслеживания `onReceive` нужного события в `NotificationCenter`. В этом модификаторе и происходит изменение заголовка у кнопки с экраном корзины и бэйджа.
Запускаем проект:
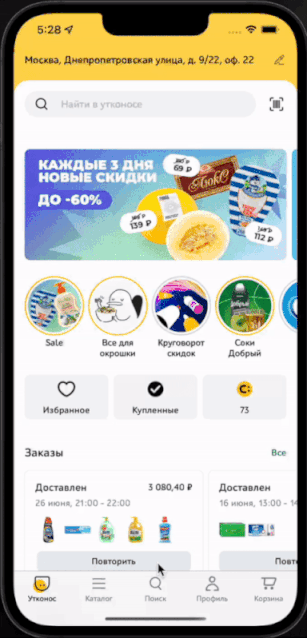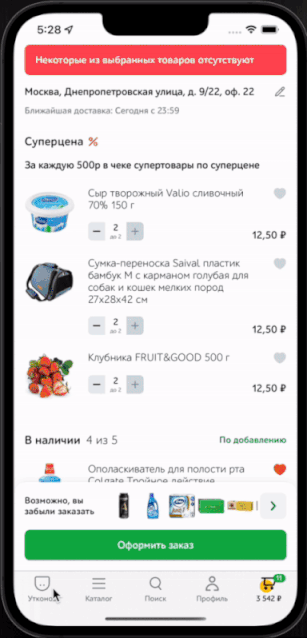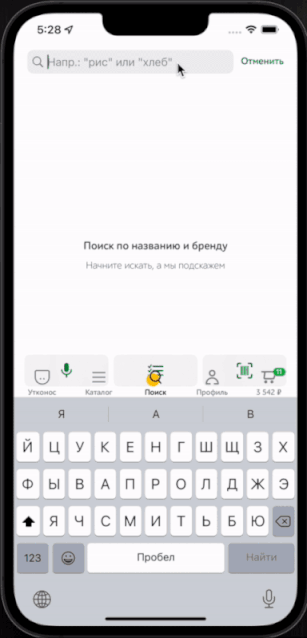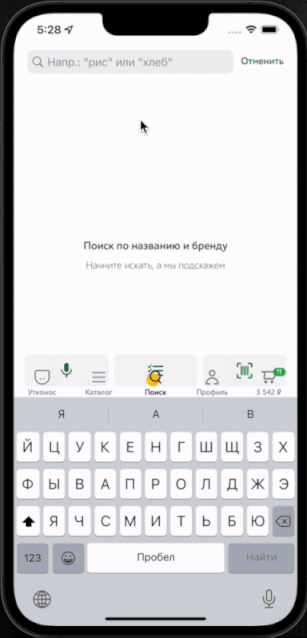Видим, что кнопки отрисованы правильно, изменение бэйджа и тайтла работает. Баг с поднятием кнопок таб-бара вместе с клавиатурой исправляем модификатором: `ignoresSafeArea(.keyboard)`:
```
struct RootTabView: View {
...
var body: some View {
GeometryReader { geometry in
ZStack(alignment: Alignment.bottom) {
TabView(selection: $selectedTab) {
...
}
HStack(spacing: 0) {
...
}
}
}.ignoresSafeArea(.keyboard)
}
}
```
Часть 3. Добавляем анимацию
---------------------------
Редко, когда дизайнер ограничивает себя только отрисовкой макетов кнопок, забыв об анимации. И действительно, ведь удачная анимация делает приложение удобным и привлекает внимание, но не отвлекает пользователя. Одна из задач анимации — повысить отзывчивость приложения.
Цель одной из предложенных к реализации анимаций в нашем таб-баре — дать визуальный фидбэк пользователю о том, что изменился состав корзины при добавлении новых товаров.
Выглядит весьма стильно, давайте реализуем. Для начала нам необходим массив координат – смещений иконки и текущий индекс смещения в этом массиве:
```
struct RootTabView: View {
...
private let offsets: [CGPoint] = [.init(x: 0, y: 0),
.init(x: 0, y: 4),
.init(x: 0, y: 0)]
@State private var currentOffsetIndex: Int = 0
var body: some View {
...
}
}
```
В описанном выше модификаторе `onCartChanged`, отслеживающем изменение состояния корзины будем изменять `currentOffsetIndex` в цикле по всему массиву `offsets`:
```
struct RootTabView: View {
...
private let offsets: [CGPoint] = [.init(x: 0, y: 0),
.init(x: 0, y: 4),
.init(x: 0, y: 0)]
@State private var currentOffsetIndex: Int = 0
var body: some View {
content
...
.onCartChanged { count, price in
...
withAnimation {
for index in 1..
```
Поясню, `Task.delayed(byTimeInterval: ..)`— это по сути то же, что и `asyncAfter(deadline:execute:)` только в New Concurrency Model.
```
public extension Task where Failure == Error {
@discardableResult
public static func delayed(
byTimeInterval delayInterval: TimeInterval,
priority: TaskPriority? = nil,
operation: @escaping @Sendable () async throws -> Success
) -> Task {
Task(priority: priority) {
let delay = UInt64(delayInterval * 1_000_000_000)
try await Task.sleep(nanoseconds: delay)
return try await operation()
}
}
}
```
Внутри неизолированного контекста `Task.delayed {…}` мы оборачиваем в `await MainActor.run {…}`, потому что получить доступ к `@State` свойствам можно только изнутри актора.
Теперь приступим к самому интересному – модификатору `.offset` в сочетании с spring-анимацией.
```
.offset(x: offsets[currentOffsetIndex].x,
y: offsets[currentOffsetIndex].y)
.animation(.spring(response: 0.15,
dampingFraction: 0.75,
blendDuration: 0),
value: currentOffsetIndex)
```
Где его применить? Очевидно, что смещаться должна сама иконка с бэйджем, то есть в `TabBarItem`:
```
public struct TabBarItem: View {
...
public var body: some View {
Button {
...
} label: {
VStack(...) {
ZStack(...) {
...
ZStack {
icon
...
Text(...)
...
}
.offset(x: offsets[currentOffsetIndex].x,
y: offsets[currentOffsetIndex].y)
.animation(.spring(response: 0.15,
dampingFraction: 0.75,
blendDuration: 0),
value: currentOffsetIndex)
}
...
}
...
}
...
}
}
```
Но здесь есть нюанс, а что если потом дизайнер предложит добавить еще одну анимацию, уже не связанную со смещением. Давайте вынесем модификатор для анимации в параметр `TabBarItem`, обернем в дженерик:
```
public struct TabBarItem: View where VModifier: ViewModifier {
...
let animation: VModifier
...
public init(...,
animation: VModifier,
...) {
...
self.animation = animation
...
}
public var body: some View {
Button {
onTap()
} label: {
VStack(alignment: .center, spacing: 2.0) {
ZStack(alignment: .bottomLeading) {
...
ZStack {
icon
.resizable()
...
Text("\(badgeCount > 99 ? "99+" : "\(badgeCount)")")
...
}
.modifier(animation)
}
...
}
...
}
...
}
}
```
Чтобы не пришлось ничего менять в коде тех tab item-ов, у которых не будет анимации, напишем `extension`:
```
public extension TabBarItem where VModifier == EmptyModifier {
public init(icon: Image,
title: String,
badgeCount: Int,
isSelected: Bool,
itemWidth: CGFloat,
onTap: @escaping () -> ()) {
self.icon = icon
self.title = title
self.badgeCount = badgeCount
self.isSelected = isSelected
self.itemWidth = itemWidth
self.onTap = onTap
self.animation = EmptyModifier()
}
}
```
Теперь нам нужен модификатор, реагирующий на анимацию извне, чтобы передать его как параметр в `TabBarItem`. Раньше для таких целей был протокол [AnimatableModifier](https://developer.apple.com/documentation/swiftui/animatablemodifier), который Apple, недавно выпустив, немногим после назвала его устаревшим, взамен предложив использовать [Animatable](https://developer.apple.com/documentation/swiftui/animatable):
```
public struct OffsetAnimation: Animatable, ViewModifier where V: Equatable {
private var offset: CGPoint
private var value: V
public init(offset: CGPoint,
value: V) {
self.offset = offset
self.value = value
}
public var animatableData: CGPoint {
get { offset }
set { offset = newValue }
}
public func body(content: Content) -> some View {
content
.offset(x: offset.x, y: offset.y)
.animation(.spring(response: 0.15,
dampingFraction: 0.75,
blendDuration: 0),
value: value)
}
}
```
Стоит пояснить, что animatableData – это данные для анимации, в нашем случае как раз точка смещения.
Важный нюанс, Apple назвала устаревшим модификатор [.animation(\_:)](https://developer.apple.com/documentation/swiftui/view/animation(_:)-1hc0p), который подарил разработчикам [много багов](https://t.me/swiftui_dev/156) с анимацией, взамен предложив использовать [animation(\_:value:)](https://developer.apple.com/documentation/swiftui/view/animation(_:value:)). Основный смысл последнего в том, чтобы проигрывать анимацию тогда, когда меняется конкретный `value`. Поэтому наш `OffsetAnimation` и является дженериком, чтобы передавать этот value, как параметр.
Таким образом `RootTabView` с анимированной кнопкой выглядит так:
```
struct RootTabView: View {
...
private let offsets: [CGPoint] = [.init(x: 0, y: 0),
.init(x: 0, y: 4),
.init(x: 0, y: 0)]
@State private var currentOffsetIndex: Int = 0
var body: some View {
GeometryReader { geometry in
ZStack(alignment: Alignment.bottom) {
TabView(selection: $selectedTab) {
...
cart.tag(TabType.cart)
}
HStack(spacing: 0) {
...
TabBarItem(icon: Image.TabBar.cart,
title: cartTitle,
badgeCount: cartCount,
isSelected: selectedTab == .cart,
itemWidth: geometry.size.width / 5,
animation: OffsetAnimation(offset: offsets[currentOffsetIndex],
value: currentOffsetIndex)) {
selectedTab = .cart
}
}
}
}
...
.onCartChanged { count, price in
...
withAnimation {
for index in 1..
```
Запустим проект, видим, что задумка дизайнера осуществлена:
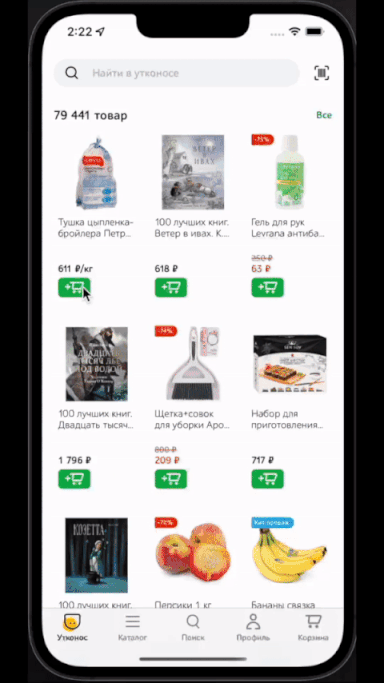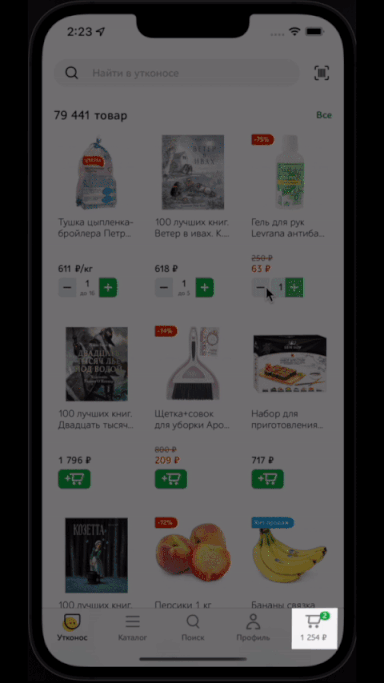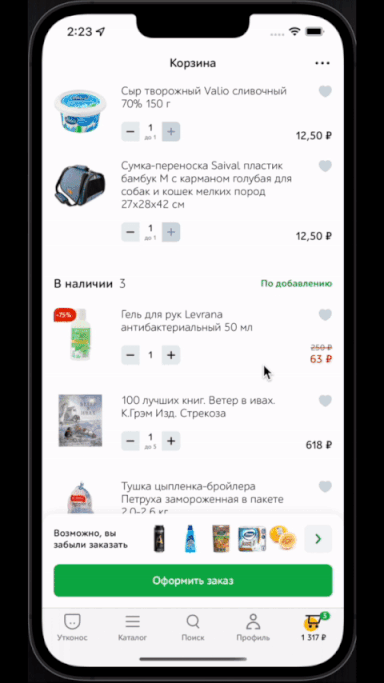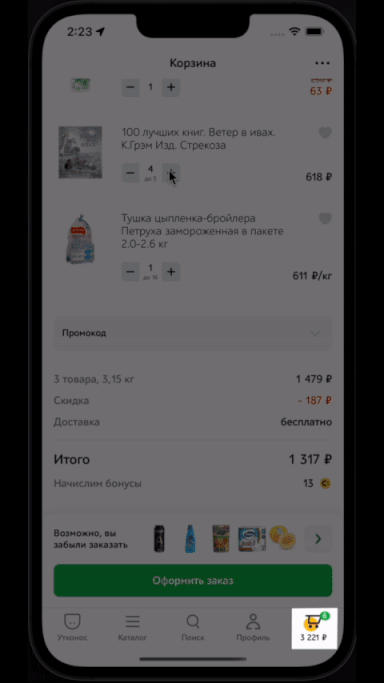Часть 4. Заключение
-------------------
Давайте теперь вынесем из `RootTabView` `@State` свойство `selectedTab` - выбранного экрана на таб баре:
```
struct RootTabView: View {
...
@State private var selectedTab : TabType = .main
...
}
```
У нас в проекте мы придерживаемся архитектуры MVVM-S, где за роутинг отвечает соответствующий сервис, перенесем `selectedTab` в него:
```
final class Router : ObservableObject {
...
@Published public var selectedTab: TabType = .main
...
func openTabCart() {
selectedTab = .cart
}
...
}
```
`RootTabView` преобразуется к виду:
```
struct RootTabView: View {
...
@ObservedObject private var router: Router
...
var body: some View {
TabView(selection: $router.selectedTab) {
...
cart.tag(TabType.cart)
}
...
TabBarItem(...) {
router.openTabCart()
}
...
}
}
```
На этом у меня все, спасибо, что дочитали до конца!
Подписывайтесь на [мой Telegram-канал](https://t.me/swiftui_dev), посвященный iOS-разработке на SwiftUI. | https://habr.com/ru/post/674888/ | null | ru | null |
# Парсинг исторических данных с Google Scholar используя Python
👉**Кратко о сути**: парсинг исторических органических и цитируемых результатов 2017-2021 годов с Google Scholar используя пагинацию. Следом их сохранение в CSV и SQLite БД используя Python и библиотеку для веб-скрейпинга от SerpApi.
🔨**Что понадобится**: понимание циклов, структур данных, обработка исключений. А так же `serpapi`, `urllib`, `pandas`, `sqlite3` библиотеки.
⏱️**Сколько времени займет**: ~20-60 минут на чтение и реализацию.
---
* [Что парсим](#what_will_be_scraped)
+ [Что понадобится](#prerequisites)
* [Процесс](#process)
+ [Органические результаты](#organic_results)
+ [Цитируемые результаты](#cite_results)
+ [Сохраняем в CSV](#save_csv)
+ [Сохраняем в SQLite](#save_sqlite)
* [Код целиком - парсинг](#full_code)
* [Код целиком - сохранение](#saving_code)
* [Ссылки](#links)
* [Что дальше](#outro)
### Что парсим
Из органических результатов:
📌Примечание: На Google Scholar есть максимальный лимит в 100 страниц, поэтому когда вы видите `About xxx.xxx results` это не означает что все результаты отображаются и их можно спарсить. Так же как это происходит с Гугл поиском.
Из цитируемых результатов:
### Что понадобится
**Отдельное вирутуальное окружение**
Если вы не работали с виртуальным окружением ранее, взгляните на посвященный этому блог пост на английском языке - [Python virtual environments tutorial using Virtualenv and Poetry](https://serpapi.com/blog/python-virtual-environments-using-virtualenv-and-poetry/).
Вкратце, это штука, которая создает независимый набор установленных библиотек включая возможность установки разных версий Python которые могут сосуществовать друг с другом одновременно на одной системе, что в свою очередь предотвращает конфликты библиотек и разных версий Python.
📌Примечание: использование виртуальной среды не является строгим требованием.
Установка библиотек:
```
pip install google-search-results
pip install pandas
```
---
### Процесс
Если объяснение не нужно:
* забирайте код в секции [весь код целиком](#full_code),
* [забирайте код целиком из GitHub репозитория](https://github.com/dimitryzub/py-google-scholar-organic-cite-to-csv-sqlite),
* [пробуйте сразу в online IDE](https://replit.com/@serpapi/Scrape-historic-Google-Scholar-Organic-and-Citation-results#main.py).
### Органические результаты
```
import os
from serpapi import GoogleSearch
from urllib.parse import urlsplit, parse_qsl
def organic_results():
print("extracting organic results..")
params = {
"api_key": os.getenv("API_KEY"), # ключ для аутентификации в SerpApi
"engine": "google_scholar",
"q": "minecraft redstone system structure characteristics strength", # поисковый запрос
"hl": "en", # язык
"as_ylo": "2017", # с 2017
"as_yhi": "2021", # до 2021
"start": "0" # первая страница
}
search = GoogleSearch(params)
organic_results_data = []
loop_is_true = True
while loop_is_true:
results = search.get_dict()
print(f"Currently extracting page №{results['serpapi_pagination']['current']}..")
for result in results["organic_results"]:
position = result["position"]
title = result["title"]
publication_info_summary = result["publication_info"]["summary"]
result_id = result["result_id"]
link = result.get("link")
result_type = result.get("type")
snippet = result.get("snippet")
try:
file_title = result["resources"][0]["title"]
except: file_title = None
try:
file_link = result["resources"][0]["link"]
except: file_link = None
try:
file_format = result["resources"][0]["file_format"]
except: file_format = None
try:
cited_by_count = int(result["inline_links"]["cited_by"]["total"])
except: cited_by_count = None
cited_by_id = result.get("inline_links", {}).get("cited_by", {}).get("cites_id", {})
cited_by_link = result.get("inline_links", {}).get("cited_by", {}).get("link", {})
try:
total_versions = int(result["inline_links"]["versions"]["total"])
except: total_versions = None
all_versions_link = result.get("inline_links", {}).get("versions", {}).get("link", {})
all_versions_id = result.get("inline_links", {}).get("versions", {}).get("cluster_id", {})
organic_results_data.append({
"page_number": results["serpapi_pagination"]["current"],
"position": position + 1,
"result_type": result_type,
"title": title,
"link": link,
"result_id": result_id,
"publication_info_summary": publication_info_summary,
"snippet": snippet,
"cited_by_count": cited_by_count,
"cited_by_link": cited_by_link,
"cited_by_id": cited_by_id,
"total_versions": total_versions,
"all_versions_link": all_versions_link,
"all_versions_id": all_versions_id,
"file_format": file_format,
"file_title": file_title,
"file_link": file_link,
})
if "next" in results["serpapi_pagination"]:
search.params_dict.update(dict(parse_qsl(urlsplit(results["serpapi_pagination"]["next"]).query)))
else:
loop_is_true = False
return organic_results_data
```
#### Объяснение парсинга органических результатов используя пагинацию
Импортируем `os`, `serpapi`, `urllib` библиотеки:
```
import os
from serpapi import GoogleSearch
from urllib.parse import urlsplit, parse_qsl
```
Создаем и передаем поисковые параметры в `GoogleSearch()` где происходит все извлечение данных на бэкенде SerpApi:
```
params = {
"api_key": os.getenv("API_KEY"), # ключ для аутентификации в SerpApi
"engine": "google_scholar",
"q": "minecraft redstone system structure characteristics strength", # поисковый запрос
"hl": "en", # язык
"as_ylo": "2017", # с 2017
"as_yhi": "2021", # до 2021
"start": "0" # первая страница
}
search = GoogleSearch(params) # извлечение данных происходит тут
```
Создаём временный список `list()` для того чтобы сохранить данные которые будут дальше использоваться для сохранения в CSV или переданы`cite_results()` функции:
```
organic_results_data = []
```
Создаём `while` цикл для парсинга данных со всех доступных страниц:
```
loop_is_true = True
while loop_is_true:
results = search.get_dict()
# парсинг данных происходит тутачки..
if "next" in results["serpapi_pagination"]:
search.params_dict.update(dict(parse_qsl(urlsplit(results["serpapi_pagination"]["next"]).query)))
else:
loop_is_true = False
```
* Если нет ссылки на следующую `"next"` страницу - `while` прекратится установив `loop_is_true` на `False`.
* Если есть ссылка на следующую `"next"` страницу, `search.params_dict.update` разберет ссылку на части и передаст её к `GoogleSearch(params)` для результатов с новой страницы.
Парсим данные в `for` цикле:
```
for result in results["organic_results"]:
position = result["position"]
title = result["title"]
publication_info_summary = result["publication_info"]["summary"]
result_id = result["result_id"]
link = result.get("link")
result_type = result.get("type")
snippet = result.get("snippet")
try:
file_title = result["resources"][0]["title"]
except: file_title = None
try:
file_link = result["resources"][0]["link"]
except: file_link = None
try:
file_format = result["resources"][0]["file_format"]
except: file_format = None
try:
cited_by_count = int(result["inline_links"]["cited_by"]["total"])
except: cited_by_count = None
cited_by_id = result.get("inline_links", {}).get("cited_by", {}).get("cites_id", {})
cited_by_link = result.get("inline_links", {}).get("cited_by", {}).get("link", {})
try:
total_versions = int(result["inline_links"]["versions"]["total"])
except: total_versions = None
all_versions_link = result.get("inline_links", {}).get("versions", {}).get("link", {})
all_versions_id = result.get("inline_links", {}).get("versions", {}).get("cluster_id", {})
```
* `try/except` блоки были использованы для обработки `None` значений когда они отсутствуют из Google бэкенда.
Если объединить все в один `try` блок, извлеченные данные могут быть неаккуратны, иными словами если ссылка или описание на самом деле есть в выдаче, вместо этого оно вернёт `None`, поэтому здесь много `try/except` блоков.
Добавляем извлеченные данные во временный `list()` список:
```
organic_results_data = []
# тут парсинг и while цикл...
organic_results_data.append({
"page_number": results["serpapi_pagination"]["current"],
"position": position + 1,
"result_type": result_type,
"title": title,
"link": link,
"result_id": result_id,
"publication_info_summary": publication_info_summary,
"snippet": snippet,
"cited_by_count": cited_by_count,
"cited_by_link": cited_by_link,
"cited_by_id": cited_by_id,
"total_versions": total_versions,
"all_versions_link": all_versions_link,
"all_versions_id": all_versions_id,
"file_format": file_format,
"file_title": file_title,
"file_link": file_link,
})
```
Возвращаем временный `list()` список с данными которые будут использоваться позже при парсинге Цитируемых результатов:
```
return organic_results_data
```
---
### Цитируемые результаты
В этой секции мы используем возвращенные данные из органической выдачи и передадим `result_id` в поисковый запрос для того чтобы спарсить цитируемые результаты.
Если у вас уже есть `result_ids`, вы можете пропустить парсинг Органических результатов:
```
# если у вас есть список result_ids
result_ids = ["FDc6HiktlqEJ"..."FDc6Hikt21J"]
for citation in result_ids:
params = {
"api_key": "API_KEY", # ключ для аутентификации в SerpApi
"engine": "google_scholar_cite", # движок для парсинга цитируемых результатов
"q": citation # FDc6HiktlqEJ ... FDc6Hikt21J
}
search = GoogleSearch(params)
results = search.get_dict()
# дальнейший код парсинга..
```
Ниже примера кода парсинга цитируемых результатов вы так же найдете пошаговое объяснение того что в нём происходит.
```
import os
from serpapi import GoogleSearch
from google_scholar_organic_results import organic_results
def cite_results():
print("extracting cite results..")
citation_results = []
for citation in organic_results():
params = {
"api_key": os.getenv("API_KEY"), # ключ для аутентификации в SerpApi
"engine": "google_scholar_cite", # # движок для парсинга цитируемых результатов
"q": citation["result_id"] # # FDc6HiktlqEJ ... FDc6Hikt21J
}
search = GoogleSearch(params)
results = search.get_dict()
print(f"Currently extracting {citation['result_id']} citation ID.")
for result in results["citations"]:
cite_title = result["title"]
cite_snippet = result["snippet"]
citation_results.append({
"organic_result_title": citation["title"],
"organic_result_link": citation["link"],
"citation_title": cite_title,
"citation_snippet": cite_snippet
})
return citation_results
```
#### Объяснение парсинга цитируемых результатов
Создаём временный список `list()` для хранения извлеченных данных:
```
citation_results = []
```
Создаём `for` цикл для итерации по `organic_results()` результатам и передаем `result_id` в `"q"` поисковый запрос:
```
for citation in organic_results():
params = {
"api_key": os.getenv("API_KEY"), # ключ для аутентификации в SerpApi
"engine": "google_scholar_cite", # # движок для парсинга цитируемых результатов
"q": citation["result_id"] # # FDc6HiktlqEJ ... FDc6Hikt21J
}
search = GoogleSearch(params) # парсинг на бэкенде SerpApi
results = search.get_dict() # JSON конвертируется в словарь
```
Создаём второй `for` цикл и достукиваемся к данный таким же способом как и до словаря:
```
for result in results["citations"]:
cite_title = result["title"]
cite_snippet = result["snippet"]
```
Добавляем извелченные данные во временный список `list()` как словарь:
```
citation_results.append({
"organic_result_title": citation["title"], # чтобы понимать откуда берутся Цитируемые результаты
"organic_result_link": citation["link"], # чтобы понимать откуда берутся Цитируемые результаты
"citation_title": cite_title,
"citation_snippet": cite_snippet
})
```
Возвращаем временный список `list()`:
```
return citation_results
```
---
### Сохраняем в CSV
Нам только нужно передать возвращенные данные из органических и цитируемых результатов в `DataFrame` `data` аргумент и сохранить `to_csv()`.
```
import pandas as pd
from google_scholar_organic_results import organic_results
from google_scholar_cite_results import cite_results
print("waiting for organic results to save..")
pd.DataFrame(data=organic_results())
.to_csv("google_scholar_organic_results.csv", encoding="utf-8", index=False)
print("waiting for cite results to save..")
pd.DataFrame(data=cite_results())
.to_csv("google_scholar_citation_results.csv", encoding="utf-8", index=False)
```
#### Объяснение процесса сохранения в CSV
Импортируем `organic_results()` и `cite_results()` откуда возвращаются данные, и библиотеку `pandas`:
```
import pandas as pd
from google_scholar_organic_results import organic_results
from google_scholar_cite_results import cite_results
```
Сохраняем органические результаты `to_csv()`:
```
pd.DataFrame(data=organic_results()) \
.to_csv("google_scholar_organic_results.csv", encoding="utf-8", index=False)
```
Сохраняем цитируемые результаты `to_csv()`:
```
pd.DataFrame(data=cite_results()) \
.to_csv("google_scholar_citation_results.csv", encoding="utf-8", index=False)
```
* `data` аргумент внутри `DataFrame` это извлеченные данные.
* `encoding='utf-8'` аргумент просто для того чтобы все было корректно сохранено. Я использовал этот аргумент явно, несмотря на то что это его дефолтное значение.
* `index=False` аргумент чтобы убрать дефолтные номера строк `pandas`.
---
### Сохраняем в SQLite
После этой секции вы узнаете о том как:
* сохранять данные в SQLite используя `pandas`,
* функционирует SQLite,
* подключаться и разрывать соединение с SQLite,
* создавать и удалять таблицы/колонки,
* добавлять данные в `for` цикле.
Пример того [как функционирует SQLite](https://stackoverflow.com/a/19187244/15164646):
```
1. открывается соединение
2. транзакция начинается
3. выполняется инструкция
4. транзакция завершается
5. закрывается соединение
```
#### Сохранение данные в SQLite используя pandas
```
# https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_sql.html
import sqlite3
import pandas as pd
from google_scholar_organic_results import organic_results
from google_scholar_cite_results import cite_results
conn = sqlite3.connect("google_scholar_results.db")
# создавать таблицу ручными SQL запросами не нужно,
# pandas это сделает автоматически.
# сохраняет органические результаты в SQLite
pd.DataFrame(organic_results()).to_sql(name="google_scholar_organic_results",
con=conn,
if_exists="append",
index=False)
# сохраняет цитируемые результаты в SQLite
pd.DataFrame(cite_results()).to_sql(name="google_scholar_cite_results",
con=conn,
if_exists="append",
index=False)
conn.commit()
conn.close()
```
* `name` это название SQL таблицы.
* `con` это соединение с базой данных.
* `if_exists` скажет `pandas` как себя вести если таблица уже существует. По умолчанию оно не сработает `"fail"` и вызовет `raise` ошибку `ValueError`. В данном случае `pandas` будет добавлять данные.
* `index=False` чтобы убрать индекс столбцов от `DataFrame`.
---
#### Другой способ сохранения данных вручную используя запросы SQLite
```
import sqlite3
conn = sqlite3.connect("google_scholar_results.db")
conn.execute("""CREATE TABLE google_scholar_organic_results (
page_number integer,
position integer,
result_type text,
title text,
link text,
snippet text,
result_id text,
publication_info_summary text,
cited_by_count integer,
cited_by_link text,
cited_by_id text,
total_versions integer,
all_versions_link text,
all_versions_id text,
file_format text,
file_title text,
file_link text)""")
conn.commit()
conn.execute("""CREATE TABLE google_scholar_cite_results (
organic_results_title text,
organic_results_link text,
citation_title text,
citation_link text)""")
conn.commit()
# сохраняем органические результаты
for item in organic_results():
conn.execute("""INSERT INTO google_scholar_organic_results
VALUES (:page_number,
:position,
:result_type,
:title,
:link,
:snippet,
:result_id,
:publication_info_summary,
:cited_by_count,
:cited_by_link,
:cited_by_id,
:total_versions,
:all_versions_link,
:all_versions_id,
:file_format,
:file_title,
:file_link)""",
{"page_number": item["page_number"],
"position": item["position"],
"result_type": item["type"],
"title": item["title"],
"link": item["link"],
"snippet": item["snippet"],
"result_id": item["result_id"],
"publication_info_summary": item["publication_info_summary"],
"cited_by_count": item["cited_by_count"],
"cited_by_link": item["cited_by_link"],
"cited_by_id": item["cited_by_id"],
"total_versions": item["total_versions"],
"all_versions_link": item["all_versions_link"],
"all_versions_id": item["all_versions_id"],
"file_format": item["file_format"],
"file_title": item["file_title"],
"file_link": item["file_link"]})
conn.commit()
# сохраняем цитируемые результаты
for cite_result in cite_results():
conn.execute("""INSERT INTO google_scholar_cite_results
VALUES (:organic_result_title,
:organic_result_link,
:citation_title,
:citation_snippet)""",
{"organic_result_title": cite_result["organic_result_title"],
"organic_result_link": cite_result["organic_result_link"],
"citation_title": cite_result["citation_title"],
"citation_snippet": cite_result["citation_snippet"]})
conn.commit()
conn.close() # явно лучше, чем неявно
```
##### Объяснение сохранения извлеченных данных вручную прописывая запросы SQLite
Импортируем `sqlite3` библиотеку:
```
import sqlite3
```
Соединяемся с существующей базе данных или даём новое имя и библиотека создаст базу данных:
```
conn = sqlite3.connect("google_scholar_results.db")
```
Создаём таблицу органические результаты, указываем тип данных и применяем изменения:
```
conn.execute("""CREATE TABLE google_scholar_organic_results (
page_number integer,
position integer,
result_type text,
title text,
link text,
snippet text,
result_id text,
publication_info_summary text,
cited_by_count integer,
cited_by_link text,
cited_by_id text,
total_versions integer,
all_versions_link text,
all_versions_id text,
file_format text,
file_title text,
file_link text)""")
conn.commit()
```
Создаём таблицу цитируемые результаты, указываем тип данных и применяем изменения:
```
conn.execute("""CREATE TABLE google_scholar_cite_results (
organic_results_title text,
organic_results_link text,
citation_title text,
citation_link text)""")
conn.commit()
```
Добавляем извлеченные органические результаты в таблицу используя `for` цикл:
```
for item in organic_results():
conn.execute("""INSERT INTO google_scholar_organic_results
VALUES (:page_number,
:position,
:result_type,
:title,
:link,
:snippet,
:result_id,
:publication_info_summary,
:cited_by_count,
:cited_by_link,
:cited_by_id,
:total_versions,
:all_versions_link,
:all_versions_id,
:file_format,
:file_title,
:file_link)""",
{"page_number": item["page_number"],
"position": item["position"],
"result_type": item["type"],
"title": item["title"],
"link": item["link"],
"snippet": item["snippet"],
"result_id": item["result_id"],
"publication_info_summary": item["publication_info_summary"],
"cited_by_count": item["cited_by_count"],
"cited_by_link": item["cited_by_link"],
"cited_by_id": item["cited_by_id"],
"total_versions": item["total_versions"],
"all_versions_link": item["all_versions_link"],
"all_versions_id": item["all_versions_id"],
"file_format": item["file_format"],
"file_title": item["file_title"],
"file_link": item["file_link"]})
conn.commit()
```
Добавляем извлеченные цитируемые результаты в таблицу используя `for` цикл:
```
for cite_result in cite_results():
conn.execute("""INSERT INTO google_scholar_cite_results
VALUES (:organic_result_title,
:organic_result_link,
:citation_title,
:citation_snippet)""",
{"organic_result_title": cite_result["organic_result_title"],
"organic_result_link": cite_result["organic_result_link"],
"citation_title": cite_result["citation_title"],
"citation_snippet": cite_result["citation_snippet"]})
conn.commit()
```
Закрываем cоединение с базой данных:
```
conn.close()
```
Дополнительные полезные команды:
```
# удалить все данные из таблицы
conn.execute("DELETE FROM google_scholar_organic_results")
# удалить таблицу
conn.execute("DROP TABLE google_scholar_organic_results")
# удалить колонку
conn.execute("ALTER TABLE google_scholar_organic_results DROP COLUMN authors")
# добавить колнку
conn.execute("ALTER TABLE google_scholar_organic_results ADD COLUMN snippet text")
```
---
### Код целиком - парсинг
```
import os
from serpapi import GoogleSearch
from urllib.parse import urlsplit, parse_qsl
def organic_results():
print("extracting organic results..")
params = {
"api_key": os.getenv("API_KEY"),
"engine": "google_scholar",
"q": "minecraft redstone system structure characteristics strength", # поисковый запрос
"hl": "en", # язык
"as_ylo": "2017", # от 2017
"as_yhi": "2021", # до 2021
"start": "0"
}
search = GoogleSearch(params)
organic_results_data = []
loop_is_true = True
while loop_is_true:
results = search.get_dict()
print(f"Currently extracting page №{results['serpapi_pagination']['current']}..")
for result in results["organic_results"]:
position = result["position"]
title = result["title"]
publication_info_summary = result["publication_info"]["summary"]
result_id = result["result_id"]
link = result.get("link")
result_type = result.get("type")
snippet = result.get("snippet")
try:
file_title = result["resources"][0]["title"]
except: file_title = None
try:
file_link = result["resources"][0]["link"]
except: file_link = None
try:
file_format = result["resources"][0]["file_format"]
except: file_format = None
try:
cited_by_count = int(result["inline_links"]["cited_by"]["total"])
except: cited_by_count = None
cited_by_id = result.get("inline_links", {}).get("cited_by", {}).get("cites_id", {})
cited_by_link = result.get("inline_links", {}).get("cited_by", {}).get("link", {})
try:
total_versions = int(result["inline_links"]["versions"]["total"])
except: total_versions = None
all_versions_link = result.get("inline_links", {}).get("versions", {}).get("link", {})
all_versions_id = result.get("inline_links", {}).get("versions", {}).get("cluster_id", {})
organic_results_data.append({
"page_number": results["serpapi_pagination"]["current"],
"position": position + 1,
"result_type": result_type,
"title": title,
"link": link,
"result_id": result_id,
"publication_info_summary": publication_info_summary,
"snippet": snippet,
"cited_by_count": cited_by_count,
"cited_by_link": cited_by_link,
"cited_by_id": cited_by_id,
"total_versions": total_versions,
"all_versions_link": all_versions_link,
"all_versions_id": all_versions_id,
"file_format": file_format,
"file_title": file_title,
"file_link": file_link,
})
if "next" in results["serpapi_pagination"]:
search.params_dict.update(dict(parse_qsl(urlsplit(results["serpapi_pagination"]["next"]).query)))
else:
loop_is_true = False
return organic_results_data
def cite_results():
print("extracting cite results..")
citation_results = []
for citation in organic_results():
params = {
"api_key": os.getenv("API_KEY"),
"engine": "google_scholar_cite",
"q": citation["result_id"]
}
search = GoogleSearch(params)
results = search.get_dict()
print(f"Currently extracting {citation['result_id']} citation ID.")
for result in results["citations"]:
cite_title = result["title"]
cite_snippet = result["snippet"]
citation_results.append({
"organic_result_title": citation["title"],
"organic_result_link": citation["link"],
"citation_title": cite_title,
"citation_snippet": cite_snippet
})
return citation_results
# пример вывода при парсинге органических результатов и сохранение в SQL:
'''
extracting organic results..
Currently extracting page №1..
Currently extracting page №2..
Currently extracting page №3..
Currently extracting page №4..
Currently extracting page №5..
Currently extracting page №6..
Done extracting organic results.
Saved to SQL Lite database.
'''
```
### Код целиком - сохранение
```
import pandas as pd
import sqlite3
from google_scholar_organic_results import organic_results
from google_scholar_cite_results import cite_results
# Один из способов сохранить данные в БД используя Pandas
print("waiting for organic results to save..")
organic_df = pd.DataFrame(data=organic_results())
organic_df.to_csv("google_scholar_organic_results.csv", encoding="utf-8", index=False)
print("waiting for cite results to save..")
cite_df = pd.DataFrame(data=cite_results())
cite_df.to_csv("google_scholar_citation_results.csv", encoding="utf-8", index=False)
# ------------------------------
# Другой способ сохранить данные в БФ в ручную прописывая SQLite запросы
conn = sqlite3.connect("google_scholar_results.db")
conn.execute("""CREATE TABLE google_scholar_organic_results (
page_number integer,
position integer,
result_type text,
title text,
link text,
snippet text,
result_id text,
publication_info_summary text,
cited_by_count integer,
cited_by_link text,
cited_by_id text,
total_versions integer,
all_versions_link text,
all_versions_id text,
file_format text,
file_title text,
file_link text)""")
conn.commit()
conn.execute("""CREATE TABLE google_scholar_cite_results (
organic_results_title text,
organic_results_link text,
citation_title text,
citation_link text)""")
conn.commit()
for item in organic_results():
conn.execute("""INSERT INTO google_scholar_organic_results
VALUES (:page_number,
:position,
:result_type,
:title,
:link,
:snippet,
:result_id,
:publication_info_summary,
:cited_by_count,
:cited_by_link,
:cited_by_id,
:total_versions,
:all_versions_link,
:all_versions_id,
:file_format,
:file_title,
:file_link)""",
{"page_number": item["page_number"],
"position": item["position"],
"result_type": item["type"],
"title": item["title"],
"link": item["link"],
"snippet": item["snippet"],
"result_id": item["result_id"],
"publication_info_summary": item["publication_info_summary"],
"cited_by_count": item["cited_by_count"],
"cited_by_link": item["cited_by_link"],
"cited_by_id": item["cited_by_id"],
"total_versions": item["total_versions"],
"all_versions_link": item["all_versions_link"],
"all_versions_id": item["all_versions_id"],
"file_format": item["file_format"],
"file_title": item["file_title"],
"file_link": item["file_link"]})
conn.commit()
for cite_result in cite_results():
conn.execute("""INSERT INTO google_scholar_cite_results
VALUES (:organic_result_title,
:organic_result_link,
:citation_title,
:citation_snippet)""",
{"organic_result_title": cite_result["organic_result_title"],
"organic_result_link": cite_result["organic_result_link"],
"citation_title": cite_result["citation_title"],
"citation_snippet": cite_result["citation_snippet"]})
conn.commit()
conn.close()
print("Saved to SQL Lite database.")
# пример вывода:
'''
extracting organic results..
Currently extracting page №1..
...
Currently extracting page №4..
extracting cite results..
extracting organic results..
Currently extracting page №1..
...
Currently extracting page №4..
Currently extracting 60l4wsP6Ps0J citation ID.
Currently extracting 9hkhIFu_BhAJ citation ID.
...
Saved to SQL Lite database.
'''
```
---
### Ссылки
* [GitHub репозиторий](https://github.com/dimitryzub/py-google-scholar-organic-cite-to-csv-sqlite)
* [Код с парсингом, сохранением в CSV в онлайн IDE](https://replit.com/@serpapi/Scrape-historic-Google-Scholar-Organic-and-Citation-results#main.py)
* [Google Scholar API](https://serpapi.com/google-scholar-api)
* [SerpApi библиотеки](https://serpapi.com/libraries)
---
### Что дальше
С этими данными должно быть возможно сделать какое-нибудь исследование, или визуализацию по определенной дисциплине. Классным дополнением к этому скрипту будет добавить возможность запускать его каждую неделю или месяц для парсинга дополнительных данных.
Следующий блог пост будет о парсинге Профилей с пагинацией, а так же Авторских результатов.
Если вы хотите парсить данные без необходимости писать парсер с нуля, разбираться как обойти блокировки от поисковых систем, как увеличить объем запросов, или, как парсить данные с JavaScript - [попробуйте SerpApi](https://serpapi.com/) или [свяжитесь с SerpApi](https://serpapi.com/#contact).
---
Присоединяйтесь к нам на [Reddit](https://www.reddit.com/r/SerpApi/) | [Twitter](https://twitter.com/serp_api) | [YouTube](https://www.youtube.com/channel/UCUgIHlYBOD3yA3yDIRhg_mg) | https://habr.com/ru/post/647873/ | null | ru | null |
# Естественная сортировка строк на JavaScript
Задача сортировки является едва ли не наиболее часто решаемой программистами проблемой. Несмотря на то, что распространённых алгоритмов не так много и все они давно написаны и оптимизированы для любых языков и платформ, в исходниках то и дело мелькают методы SortList() и им подобные. Наверное, каждый из нас не раз писал сортировку пузырьком и удивлялся, почему же она не работает с первого раза.
Однако речь сейчас не об алгоритме сортировки, а о способе сравнения строк. Казалось бы, здесь всё тривиально — достаточно сравнить первые с начала различающиеся символы. А если в строках есть числа? Тогда такая сортировка (*лексикографическая*) преобразует последовательность [ 'file2', 'file10', 'file1' ] в [ 'file1', 'file10', 'file2' ]. Но человек при чтении текста воспринимает числа отдельно, и эта же последовательность, упорядоченная интуитивно, выглядит так: [ 'file1', 'file2', 'file10' ]. Такая сортировка и называется *естественной* (natural sort).
Под катом — ~~велосипед~~ подробный алгоритм на JavaScript. На оптимальность и красоту он не претендует, но всё же лучше, чем многопроходная реализация «в лоб».
Сам алгоритм сортировки мы писать не будем, а воспользуемся встроенным методом Array.sort(). Поэтому «главная функция» будет выглядеть как-то так:
> `function naturalSort(stringArray) {
>
> var arr = stringArray;
>
> // ...
>
> return arr.sort(compareStrings) // функция сравнения ещё не написана
>
> }`
Осталось написать функцию compareStrings() для сравнения строк. Это можно сделать по-разному, но мне пришёл в голову следующий подход: отделим числа от текста в составе строк, а затем пройдём по полученным массивам до первого различия между строками (или числами) с одинаковыми индексами. Разделять строки будет функция splitString() (о ней чуть позже), а само сравнение будет иметь примерно следующий вид:
> `function compareStrings(str1, str2) {
>
> // обычное сравнение строк или чисел
>
> var compare = function(a, b) {
>
> return (a < b) ? -1 : (a > b) ? 1 : 0;
>
> };
>
> // разделяем строки; splitString() напишем позже
>
> var parts1 = splitString(str1);
>
> var parts2 = splitString(str2);
>
> // перебираем части до минимальной длины
>
> var minLength = Math.min(parts1.length, parts2.length);
>
> for (var i = 0; i < minLength; i++) {
>
> // здесь будем сравнивать части с одинаковыми индексами
>
> }
>
> // если в одной из строк частей больше и при этом
>
> // все, кроме "лишних", совпадают с другой строкой, то эта строка "больше"
>
> return compare(parts1.length, parts2.length);
>
> }`
Однако с этим подходом не всё так гладко: большинство строк, которые приходится сравнивать, различаются начиная с первых символов, то есть splitString() делает много лишней работы. Но это поправимо с помощью отложенных вычислений — пусть splitString() возвращает не готовый массив, а объект-итератор с методами next() и count(). Благодаря замыканиям в JavaScript реализация получилась не слишком объёмной:
(**UPD** в конце поста)
> `function splitString(str) {
>
> var from = 0; // начальный индекс для slice()
>
> var index = 0; // индекс для прохода по строке
>
> var count = 0; // количество уже найденных частей
>
> var splitter = {}; // будущий итератор
>
> // аналог свойства только для чтения с помощью замыкания
>
> splitter.count = function () {
>
> return count;
>
> }
>
> // возвращает следующую часть строки
>
> splitter.next = function() {
>
> // если строка закончилось - вернём null
>
> if (index === str.length) {
>
> return null;
>
> }
>
> // перебираем символы до границы между нецифровыми символами и цифрами
>
> while(++index) {
>
> var currentIsDigit = isDigit(str.charAt(index - 1)); // isDigit() ещё не написана
>
> var nextChar = str.charAt(index);
>
> var currentIsLast = (index === str.length);
>
> // граница - если символ последний,
>
> // или если текущий и следующий символы разнотипные (цифра / не цифра)
>
> var isBorder = currentIsLast ||
>
> xor(currentIsDigit, isDigit(nextChar)); // xor() тоже напишем потом
>
> if (isBorder) {
>
> var part = str.slice(from, index);
>
> from = index;
>
> count++;
>
> return {
>
> IsNumber: currentIsDigit,
>
> Value: currentIsDigit ? Number(part) : part
>
> };
>
> } // end if
>
> } // end while
>
> }; // end next()
>
>
>
> return splitter;
>
> }`
Напишем вспомогательные функции — xor() и isDigit():
> `function xor(a, b) {
>
> return a ? !b : b;
>
> }
>
>
>
> function isDigit(chr) {
>
> var charCode = function(ch) {
>
> return ch.charCodeAt(0);
>
> };
>
> var code = charCode(chr);
>
> return (code >= charCode('0')) && (code <= charCode('9'));
>
> }`
Теперь вернёмся к функции сравнения строк compareStrings(). С введениeм итераторов общая логика почти не изменилась:
(**UPD** в конце поста)
> `function compareStrings(str1, str2) {
>
> // обычное сравнение строк или чисел
>
> var compare = function(a, b) {
>
> return (a < b) ? -1 : (a > b) ? 1 : 0;
>
> };
>
> // получаем итераторы для строк
>
> var splitter1 = splitString(str1);
>
> var splitter2 = splitString(str2);
>
> // перебираем части
>
> while (true) {
>
> var first = splitter1.next();
>
> var second = splitter2.next();
>
> // если обе части существуют ...
>
> if (null !== first && null !== second) {
>
> // части разных типов (цифры либо нецифровые символы)
>
> if (xor(first.IsNumber, second.IsNumber)) {
>
> // цифры всегда "меньше"
>
> return first.IsNumber ? -1 : 1;
>
> // части одного типа можно просто сравнить
>
> } else {
>
> var comp = compare(first.Value, second.Value);
>
> if (comp != 0) {
>
> return comp;
>
> }
>
> } // end if
>
> // ... если же одна из строк закончилась - то она "меньше"
>
> } else {
>
> return compare(splitter1.count(), splitter2.count());
>
> }
>
> } // end while
>
> }`
Наконец, напишем функцию сортировки, соберём всё воедино и «причешем» код:
(**UPD** в конце поста)
> `function naturalSort(stringArray) {
>
> // логическое исключающее "или"
>
> var xor = function(a, b) {
>
> return a ? !b : b;
>
> };
>
> // проверяет, является ли символ цифрой
>
> var isDigit = function(chr) {
>
> var charCode = function(ch) {
>
> return ch.charCodeAt(0);
>
> };
>
> var code = charCode(chr);
>
> return (code >= charCode('0')) && (code <= charCode('9'));
>
> };
>
> // возвращает итератор для строки
>
> var splitString = function(str) {
>
> var from = 0; // начальный индекс для slice()
>
> var index = 0; // индекс для прохода по строке
>
> var count = 0; // количество уже найденных частей
>
> var splitter = {}; // будущий итератор
>
> // аналог свойства только для чтения
>
> splitter.count = function () {
>
> return count;
>
> }
>
> // возвращает следующую часть строки
>
> splitter.next = function() {
>
> // если строка закончилось - вернём null
>
> if (index === str.length) {
>
> return null;
>
> }
>
> // перебираем символы до границы между нецифровыми символами и цифрами
>
> while(++index) {
>
> var currentIsDigit = isDigit(str.charAt(index - 1));
>
> var nextChar = str.charAt(index);
>
> var currentIsLast = (index === str.length);
>
> // граница - если символ последний,
>
> // или если текущий и следующий символы разнотипные (цифра / не цифра)
>
> var isBorder = currentIsLast ||
>
> xor(currentIsDigit, isDigit(nextChar));
>
> if (isBorder) {
>
> var part = str.slice(from, index);
>
> from = index;
>
> count++;
>
> return {
>
> IsNumber: currentIsDigit,
>
> Value: currentIsDigit ? Number(part) : part
>
> };
>
> } // end if
>
> } // end while
>
> }; // end next()
>
> return splitter;
>
> };
>
> // сравнивает строки в "естественном" порядке
>
> var compareStrings = function(str1, str2) {
>
> // обычное сравнение строк или чисел
>
> var compare = function(a, b) {
>
> return (a < b) ? -1 : (a > b) ? 1 : 0;
>
> };
>
> // получаем итераторы для строк
>
> var splitter1 = splitString(str1);
>
> var splitter2 = splitString(str2);
>
> // перебираем части
>
> while (true) {
>
> var first = splitter1.next();
>
> var second = splitter2.next();
>
> // если обе части существуют ...
>
> if (null !== first && null !== second) {
>
> // части разных типов (цифры либо нецифровые символы)
>
> if (xor(first.IsNumber, second.IsNumber)) {
>
> // цифры всегда "меньше"
>
> return first.IsNumber ? -1 : 1;
>
> // части одного типа можно просто сравнить
>
> } else {
>
> var comp = compare(first.Value, second.Value);
>
> if (comp != 0) {
>
> return comp;
>
> }
>
> } // end if
>
> // ... если же одна из строк закончилась - то она "меньше"
>
> } else {
>
> return compare(splitter1.count(), splitter2.count());
>
> }
>
> } // end while
>
> }
>
> // собственно сортировка
>
> var arr = stringArray;
>
> return arr.sort(compareStrings);
>
> }`
Буду благодарен за найденные баги, советы и предложения по коду. Надеюсь, кому-то было интересно, а может быть даже полезно.
**UPD:**
В комментариях [Alex\_At\_Net](https://habrahabr.ru/users/alex_at_net/) заметил, что неплохо бы кешировать результаты разбиения строк, а [standy](https://habrahabr.ru/users/standy/) предложил сразу разбить строки на части и сортировать уже готовые наборы фрагментов. В результате появилась исправленная и дополненная версия скрипта. В функцию сортировки добавлен необязательный параметр extractor — функция преобразования произвольного объекта в строку: теперь можно сортировать массивы любых объектов. Входной массив сразу преобразуется в массив сплиттеров, но само разбиение происходит только при обращении к фрагменту по индексу, только до нужного места и только один раз. Вместо метода next() у сплиттера теперь есть метод part(i), возвращающий фрагмент по индексу. Код ещё немного «причёсан» и «объектизирован». Выглядит это всё так:
> `function naturalSort(array, extractor) {
>
> "use strict";
>
> // преобразуем исходный массив в массив сплиттеров
>
> var splitters = array.map(makeSplitter);
>
> // сортируем сплиттеры
>
> var sorted = splitters.sort(compareSplitters);
>
> // возвращаем исходные данные в новом порядке
>
> return sorted.map(function (splitter) {
>
> return splitter.item;
>
> });
>
> // обёртка конструктора сплиттера
>
> function makeSplitter(item) {
>
> return new Splitter(item);
>
> }
>
> // конструктор сплиттера
>
> // сплиттер разделяет строку на фрагменты "ленивым" способом
>
> function Splitter(item) {
>
> var index = 0; // индекс для прохода по строке
>
> var from = 0; // начальный индекс для фрагмента
>
> var parts = []; // массив фрагментов
>
> var completed = false; // разобрана ли строка полностью
>
> // исходный объект
>
> this.item = item;
>
> // ключ - строка
>
> var key = (typeof (extractor) === 'function') ?
>
> extractor(item) :
>
> item;
>
> this.key = key;
>
> // количество найденных фрагментов
>
> this.count = function () {
>
> return parts.length;
>
> };
>
> // фрагмент по индексу (по возможности из parts[])
>
> this.part = function (i) {
>
> while (parts.length <= i && !completed) {
>
> next(); // разбираем строку дальше
>
> }
>
> return (i < parts.length) ? parts[i] : null;
>
> };
>
> // разбор строки до следующего фрагмента
>
> function next() {
>
> // строка ещё не закончилась
>
> if (index < key.length) {
>
> // перебираем символы до границы между нецифровыми символами и цифрами
>
> while (++index) {
>
> var currentIsDigit = isDigit(key.charAt(index - 1));
>
> var nextChar = key.charAt(index);
>
> var currentIsLast = (index === key.length);
>
> // граница - если символ последний,
>
> // или если текущий и следующий символы разнотипные (цифра / не цифра)
>
> var isBorder = currentIsLast ||
>
> xor(currentIsDigit, isDigit(nextChar));
>
> if (isBorder) {
>
> // формируем фрагмент и добавляем его в parts[]
>
> var partStr = key.slice(from, index);
>
> parts.push(new Part(partStr, currentIsDigit));
>
> from = index;
>
> break;
>
> } // end if
>
> } // end while
>
> // строка уже закончилась
>
> } else {
>
> completed = true;
>
> } // end if
>
> } // end next
>
> // конструктор фрагмента
>
> function Part(text, isNumber) {
>
> this.isNumber = isNumber;
>
> this.value = isNumber ? Number(text) : text;
>
> }
>
> }
>
> // сравнение сплиттеров
>
> function compareSplitters(sp1, sp2) {
>
> var i = 0;
>
> do {
>
> var first = sp1.part(i);
>
> var second = sp2.part(i);
>
> // если обе части существуют ...
>
> if (null !== first && null !== second) {
>
> // части разных типов (цифры либо нецифровые символы)
>
> if (xor(first.isNumber, second.isNumber)) {
>
> // цифры всегда "меньше"
>
> return first.isNumber ? -1 : 1;
>
> // части одного типа можно просто сравнить
>
> } else {
>
> var comp = compare(first.value, second.value);
>
> if (comp != 0) {
>
> return comp;
>
> }
>
> } // end if
>
> // ... если же одна из строк закончилась - то она "меньше"
>
> } else {
>
> return compare(sp1.count(), sp2.count());
>
> }
>
> } while (++i);
>
> // обычное сравнение строк или чисел
>
> function compare(a, b) {
>
> return (a < b) ? -1 : (a > b) ? 1 : 0;
>
> };
>
> };
>
> // логическое исключающее "или"
>
> function xor(a, b) {
>
> return a ? !b : b;
>
> };
>
> // проверка: является ли символ цифрой
>
> function isDigit(chr) {
>
> var code = charCode(chr);
>
> return (code >= charCode('0')) && (code <= charCode('9'));
>
> function charCode(ch) {
>
> return ch.charCodeAt(0);
>
> };
>
> };
>
> }`
[C комментариями](http://pastie.org/2505165)
[Без комментариев](http://pastie.org/2505178)
P.S.:
> `function thanks() {
>
> alert('Cпасибо PoiSoN за Source Code Highlighter');
>
> };
>
>
>
> \* This source code was highlighted with Source Code Highlighter.` | https://habr.com/ru/post/127943/ | null | ru | null |
# Реальное применение WebRTC в сервисах IP-телефонии
На Хабре уже сообщалось о технологии WebRTC (Web Real-Time Communications). Стандарту WebRTC, который в настоящее время находится еще в черновом варианте, пророчат большое будущее, и в дальнейшем развитие Интернета и веб-технологий он вполне готов повторить путь Skype.
WebRTC может быть использован для создание принципиально новой категории веб-приложений, способных работать с голосовым и видео трафиком без задействования сторонних технологий и программ, с использованием только HTML5 и JavaScript, что существенно облегчит разработчикам создание приложений.
Технология по настоящему кроссплатформенна, независима от используемой вами операционной системы, необходима только поддержка WebRTC в вашем браузере. Cейчас её поддерживает популярный браузер Google Crome без каких-либо дополнительных настроек и установок плагинов на всех десктопных операционных системах, таких как Windows, Linux, Mac OS X и других. Так же, в силу того, что для веб-звонков, а в частности для установления соединения по протоколу SIP необходим транспорт в виде html5 технологии [WebSocket](http://tools.ietf.org/html/draft-ibc-sipcore-sip-websocket-02), работа WebRTC возможна, практически, на всех остальных браузерах под Windows (Safari, FireFox, IE, Opera) с помощью установки дополнительно расширения [webrtc4all](http://code.google.com/p/webrtc4all/).
Первым сервисом, который запустил в коммерческую эксплуатацию звонки с веб-браузера, стал сервис [Callbacker](http://www.callbacker.com/ru/index.html), который интегрировал в свой личный кабинет веб-телефон, на базе открытого продукта [sipml5](http://www.sipml5.org).
Что было сделано:
* интеграция в личный кабинет [sipml5](http://www.sipml5.org) и его кастомизация с отменой дополнительных функций, которые не работают или работают, но нестабильно, в режиме экспериментального тестирования;
* установка и настройка [пропатченного](http://sipml5.googlecode.com/svn/trunk/asterisk/asterisk_373330.patch) Asterisk 11 ревизии 373330. [Asterisk](http://www.asterisk.org) в последнем релизе 11 поддерживает WebSocket и транспорт SAVPF, что делает его совместимым с веб-телефоном sipml5. Необходима поддержка SRTP, поэтому собираем Asterisk с обязательными параметрами: --with-crypto --with-ssl --with-srtp. Настройка Asterisk ничем не отличается от обычной, за исключением настроек http для работы WebSocket.
В конфигурационных файлах Asterisk:
http.conf:
```
enabled=yes
bindaddr=0.0.0.0
bindport=8088
```
sip.conf:
```
udpbindaddr=0.0.0.0:5060
realm=mydomain.com
domainsasrealm=mydomain.com
videosupport=no
directmedia=no
avpf=yes ;необходимый параметр для работы веб-телефона, включающий
AVPF-транспорт для медиа-потока
encryption=yes ;шифрование SRTP
transport=udp,ws,wss ;ws и wss - транспорт для WebSocket
```
На самом деле, флаг encryption у пользователя можно установить как encryption=no, в противном случае, другие софтфоны или VoIP-устройства, так же должны будут работать с шифрованием, что не всегда поддерживается и может быть неудобным.
Для того, чтобы попробовать, как же это все работает, необходимо иметь логин и пароль учетной записи одной из программ Callbacker для iOS или Android или можно зарегистрироваться вновь и протестировать связь. Здесь находится [личный кабинет](https://customer.callbacker.com/cabinet/), в котором есть тот самый веб-телефон. В настоящее время, проект [Callbacker](http://www.callbacker.com/ru/index.html) развивается, обрастает новыми возможностями. Обнадеживает то, что последние перспективные технологии, в том числе и в сфере Интернет-телефонии, не умирают на дисках SVN-хостеров, а находят практическое применение. | https://habr.com/ru/post/158543/ | null | ru | null |
# Есть ли в вашей IDE баги? Проверка AvalonStudio с помощью PVS-Studio
Разработчики по всему миру ежедневно используют свои любимые IDE для создания программного обеспечения. Сегодня мы проверим одну из них и рассмотрим самые интересные найденные ошибки.
### Введение
Жизнь современного разработчика невозможна без различных инструментов программирования. К таковым относятся IDE (Integrated development environment). Они содержат в себе целый набор инструментов, упрощающих жизнь. Современная среда разработки включает в себя текстовый редактор, компилятор или интерпретатор, отладчик и так далее.
В данной статье я проверю одну из IDE с открытым исходным кодом. Для проверки проекта я буду использовать статический анализатор кода PVS-Studio. Он может искать ошибки и потенциальные уязвимости в проектах на языках программирования C, C++, C# и Java.
А теперь представим проект, который мы будем анализировать.
AvalonStudio – это кроссплатформенная IDE, написанная на C#. Эта среда в первую очередь ориентирована на разработку под Embedded C, C++, .NET Core, Avalonia и TypeScript. AvalonStudio построена с использованием фреймворка [Avalonia UI](https://avaloniaui.net/), который мы, кстати, тоже [проверяли](https://pvs-studio.com/ru/blog/posts/csharp/0701/).
Проверить исходный код AvalonStudio было несложно, так как он доступен в [репозитории на GitHub](https://github.com/VitalElement/AvalonStudio/tree/2ee2adbf1772c54531f0d5b0bc96a4789d6b826f). Среди срабатываний анализатора я отобрал для вас самые интересные :). Приятного чтения!
### Проверка
Каждое предупреждение анализатора в статье содержит код и описание проблемы с примесью мнения автора. Если с какими-нибудь моментами статьи вы будете не согласны, то я с удовольствием обсудил бы это в комментариях.
#### Issue 1
```
private async void Timer_Tick(object sender, EventArgs e)
{
....
if (AssociatedObject.IsPointerOver)
{
var mouseDevice = (popup.GetVisualRoot() as IInputRoot)?.MouseDevice;
lastPoint = mouseDevice.GetPosition(AssociatedObject);
popup.Open();
}
}
```
[V3105](https://pvs-studio.com/ru/docs/warnings/v3105/) The 'mouseDevice' variable was used after it was assigned through null-conditional operator. NullReferenceException is possible. TooltipBehavior.cs 173
Анализатор заметил подозрительную ситуацию в коде. Результат преобразования через оператор *as* проверяют на равенство *null* с помощью null-условного оператора. Это значит, что разработчик предполагал, что преобразование через *as* может вернуть *null*. Оператором '?.' он защитил себя от *NullReferenceException* один раз, но вот дальше исключение вполне может быть выброшено.
#### Issue 2
А вот следующее срабатывание не указывает на столь явную ошибку, но всё же фрагмент кода выглядит подозрительно:
```
private static Signature BuildSignature(IMethodSymbol symbol)
{
....
var returnTypeInfo = CheckForStaticExtension.GetReturnType(symbol);
if(returnTypeInfo.HasValue)
{
if(returnTypeInfo.Value.inbuilt)
{
signature.BuiltInReturnType = returnTypeInfo.Value.name;
}
else
{
signature.ReturnType = returnTypeInfo.Value.name;
}
}
signature.Parameters = symbol.Parameters.Select(parameter =>
{
var info = CheckForStaticExtension.GetReturnType(parameter);
....
if(info.HasValue)
{
if(info.Value.inbuilt)
{
result.BuiltInType = info.Value.name; // <=
}
else
{
result.BuiltInType = info.Value.name; // <=
}
}
....
}).ToList();
....
}
```
[V3004](https://pvs-studio.com/ru/docs/warnings/v3004/) The 'then' statement is equivalent to the 'else' statement. InvocationContext.cs 400
PVS-Studio обнаружил, что then и else ветви оператора *if* эквивалентны. При этом, если мы поднимемся чуть выше по коду, то заметим, что имеется похожий фрагмент, но ветви разные. Возможно, что одна из ветвей просто лишняя. Но не стоит исключать ситуацию, что на месте свойства *BuiltInType* должно быть другое. Например, похожее свойство *Type*, которое действительно существует. Разработчик мог просто воспользоваться авто дополнением и не заметить, что оно оказалось неправильным. Кстати, мне VS2022 тоже предложила написать неправильно. Как говорится: "Доверяй, но проверяй".
#### Issue 3
Следующий код я отформатировал, так как он был не структурирован и плохо читаем, но суть оставил без изменений.
Вот так код выглядит в самом редакторе. Если же код чуть лучше отформатировать, то ошибка становится гораздо виднее.
```
private bool CursorIsValidDeclaration(ClangCursor c)
{
var result = false;
if ( (c.Kind == NClang.CursorKind.FunctionDeclaration) // <=
|| c.Kind == NClang.CursorKind.CXXMethod
|| c.Kind == NClang.CursorKind.Constructor
|| c.Kind == NClang.CursorKind.Destructor
|| c.Kind == NClang.CursorKind.FunctionDeclaration) // <=
{
result = true;
}
return result;
}
```
[V3001](https://pvs-studio.com/ru/docs/warnings/v3001/) There are identical sub-expressions 'c.Kind == NClang.CursorKind.FunctionDeclaration' to the left and to the right of the '||' operator. CPlusPlusLanguageService.cs 1275
Подобные ошибки допускаются по невнимательности. Возможно, одно из сравнений просто лишнее. А может быть и так, что вместо одного из *FunctionDeclaration* должно быть что-то другое :).
#### Issue 4
```
public override void Render(DrawingContext context)
{
....
foreach (var breakPoint in _manager?.OfType().Where(....))
{
....
}
....
}
```
[V3153](https://pvs-studio.com/ru/docs/warnings/v3153/) Enumerating the result of null-conditional access operator can lead to NullReferenceException. BreakPointMargin.cs 46
Анализатор обнаружил, что результат работы оператора '?.' сразу же разыменовывается. Использование такой проверки на *null* внутри *foreach* не имеет никакого смысла. *NullReferenceException* всё равно настигнет при попытке обхода нулевой ссылки :).
Вообще, такое поведение неочевидно для многих программистов. Мы даже написали на эту тему целую статью: "[Использование оператора ?. в foreach: защита от NullReferenceException, которая не работает](https://pvs-studio.com/ru/blog/posts/csharp/0832/)".
#### Issue 5
```
public async Task<(....)> LoadProject(....)
{
....
return await Task.Run(() =>
{
....
if ( loadData.CscCommandLine != null // <=
&& loadData.CscCommandLine.Count > 0)
{
....
return (projectInfo, projectReferences, loadData.TargetPath);
}
else
{
....
return (projectInfo, projectReferences, loadData?.TargetPath); // <=
}
});
}
```
[V3095](https://pvs-studio.com/ru/docs/warnings/v3095/) The 'loadData' object was used before it was verified against null. Check lines: 233, 262. MSBuildHost.cs 233
Кажется, что долго объяснять ошибку тут не стоит. Если переменная *loadData* потенциально равна *null* в ветви else, то и в условии этого же *if* она может быть равна *null*. Вот только в условии нет проверки *loadData* на *null*, а значит может быть сгенерировано исключение. И да, в else *loadData* никак не меняется. Скорее всего разработчик пропустил оператор '?.' в условии *if*. Хотя, возможно, что данный оператор в *return* лишний и его стоит убрать, чтобы не путать разработчиков.
#### Issue 6
```
public override void Render(DrawingContext context)
{
if (_lastFrame != null && !( _lastFrame.Width == 0
|| _lastFrame.Width == 0))
{
....
}
base.Render(context);
}
```
[V3001](https://pvs-studio.com/ru/docs/warnings/v3001/) There are identical sub-expressions '\_lastFrame.Width == 0' to the left and to the right of the '||' operator. RemoteWidget.cs 308
Анализатор обнаружил два одинаковых подвыражения слева и справа от оператора '||'. Думаю, что исправление подобной оплошности довольно лёгкое: нужно изменить одно из свойств *Width* на *Height*. Это свойство существует и используется далее в методе.
#### Issue 7
```
public GlobalRunSpec(....)
{
....
if (specialEntry.Value != null)
{
....
}
RunSpec spec = new(specialOps,
specialVariables ?? variables,
specialEntry.Value.VariableSetup.FallbackFormat);
....
}
```
[V3125](https://pvs-studio.com/ru/docs/warnings/v3125/) The 'specialEntry.Value' object was used after it was verified against null. Check lines: 92, 86. GlobalRunSpec.cs 92
PVS-Studio обнаружил подозрительную ситуацию. *specialEntry.Value* проверяется на равенство *null*, а после используется без соответствующей проверки. При этом внутри условной конструкции *specialEntry.Value* не меняет своё значение.
#### Issue 8
```
private static StyledText InfoTextFromCursor(ClangCursor cursor)
{
....
if (cursor.ResultType != null)
{
result.Append(cursor.ResultType.Spelling + " ",
IsBuiltInType(cursor.ResultType) ? theme.Keyword
: theme.Type);
}
else if (cursor.CursorType != null)
{
switch (kind)
{
....
}
result.Append(cursor.CursorType.Spelling + " ",
IsBuiltInType(cursor.ResultType) ? theme.Keyword // <=
: theme.Type);
}
....
}
```
[V3022](https://pvs-studio.com/ru/docs/warnings/v3022/) Expression 'IsBuiltInType(cursor.ResultType)' is always false. CPlusPlusLanguageService.cs 1105
Анализатор считает, что *IsBuiltInType(cursor.ResultType)* в указанном месте всегда вернёт *false*. Метод *IsBuiltInType* вызывается в else-ветке, значит *cursor.ResultType* имеет значение *null*.
Внутри метода *IsBuiltInType* есть проверка, что если параметр равен *null*, то возвращается *false*.
```
private static bool IsBuiltInType(ClangType cursor)
{
var result = false;
if (cursor != null && ....)
{
return true;
}
return result;
}
```
Получается, что *IsBuiltInType(cursor.ResultType)* всегда будет возвращать *false*.
Хм, почему же так произошло? Тут явная проблема copy-paste. Разработчик просто скопировал похожий фрагмент выше. Вот только один раз *cursor.ResultType* сменить на *cursor.CursorType* забыл.
#### Issue 9
```
private int BuildCompletionsForMarkupExtension(....)
{
....
if (t.SupportCtorArgument == MetadataTypeCtorArgument.HintValues)
{
....
}
else if (attribName.Contains("."))
{
if (t.SupportCtorArgument != MetadataTypeCtorArgument.Type)
{
....
if ( mType != null
&& t.SupportCtorArgument ==
MetadataTypeCtorArgument.HintValues) // <=
{
var hints = FilterHintValues(....);
completions.AddRange(hints.Select(.....));
}
....
}
}
}
```
[V3022](https://pvs-studio.com/ru/docs/warnings/v3022/) Expression 'mType != null && t.SupportCtorArgument == MetadataTypeCtorArgument.HintValues' is always false. CompletionEngine.cs 601
Свойство *SupportCtorArgument* сравнивается со значением перечисления. Это выражение находится в else-ветке условной конструкции. *SupportCtorArgument* является обычным автосвойством. Если бы свойство было равно *MetadataTypeCtorArgument.HintValues*, то до этой else-ветки исполнение кода не дошло бы. Соответственно, выражение в условии всегда будет ложным, а код, который находится в then-ветке, никогда не будет выполнен.
#### Issue 10
```
private void RegisterLanguageService(ISourceFile sourceFile)
{
....
var languageServiceProvider = IoC.Get()
.LanguageServiceProviders
.FirstOrDefault(....)?.Value;
LanguageService = languageServiceProvider.CreateLanguageService(); // <=
if (LanguageService != null)
{
....
}
}
```
[V3105](https://pvs-studio.com/ru/docs/warnings/v3105/) The 'languageServiceProvider' variable was used after it was assigned through null-conditional operator. NullReferenceException is possible. CodeEditorViewModel.cs 309
Анализатор указывает, что происходит разыменование переменной, значение которой получено с помощью null-условного оператора. И как мы видим, оператор '?.' действительно используется при вычислении значения переменной *languageServiceProvider*. На следующей строчке происходит разыменование этой переменной без проверки. Подобный код может генерировать исключение *NullReferenceException*. Возможно, стоит использовать '?.' при вызове *CreateLanguageService*.
#### Issue 11
```
public void SetCursorPosition(int column, int row)
{
....
if (LeftAndRightMarginEnabled)
{
if (CursorState.OriginMode && CursorState.CurrentColumn < LeftMargin)
CursorState.CurrentColumn = LeftMargin;
if (CursorState.CurrentColumn >= RightMargin)
RightMargin = RightMargin; // <=
}
....
}
```
[V3005](https://pvs-studio.com/ru/docs/warnings/v3005/) The 'RightMargin' variable is assigned to itself. VirtualTerminalController.cs 1446
Переменная *RightMargin* присваивается сама себе. Код, несомненно, подозрительный. И, пожалуй, только разработчик данного проекта знает, как должно быть на самом деле. Мы же можем только догадываться, что следует присваивать *RightMargin*.
#### Issue 12
Следующее срабатывание довольно интересное и неочевидное.
```
public class ColorScheme
{
private static List s\_colorSchemes =
new List();
private static Dictionary s\_colorSchemeIDs =
new Dictionary();
private static readonly ColorScheme DefaultColorScheme =
ColorScheme.SolarizedLight;
....
public static readonly ColorScheme SolarizedLight = new ColorScheme
{
....
};
}
```
Попробуйте найти среди этих строк ошибку. Задача максимально упрощена, ведь за "...." я скрыл почти 200 строк кода, которые не нужны для обнаружения ошибки. Догадались?
Уберём ещё немного кода и добавим сообщение анализатора.
```
public class ColorScheme
{
private static readonly ColorScheme DefaultColorScheme =
ColorScheme.SolarizedLight;
....
public static readonly ColorScheme SolarizedLight = new ColorScheme
{
....
};
}
```
[V3070](https://pvs-studio.com/ru/docs/warnings/v3070/) Uninitialized variable 'SolarizedLight' is used when initializing the 'DefaultColorScheme' variable. ColorScheme.cs 32
Думаю, что из сообщения анализатора всё стало понятно. Всё дело в том, что поле *DefaultColorScheme* будет проинициализировано не тем значением, что ожидал программист. На момент инициализации *DefaultColorScheme*, поле *SolarizedLight* будет иметь значение по умолчанию – *null*. Получается, что и полю *DefaultColorScheme* будет присвоено значение *null*. Подробнее прочитать про это с примерами можно в документации к данной диагностике по ссылке из сообщения анализатора.
### Заключение
Проверка AvalonStudio позволила найти несколько интересных ошибок. Я надеюсь, что эта статья внесёт свой маленький вклад в улучшения данного проекта. Стоит сказать, что IDE с открытым исходным кодом сейчас довольно мало. Может быть в будущем их станет больше. Так каждый разработчик сможет выбрать среду разработки себе по душе. И даже попробовать самостоятельно улучшить инструмент, которым пользуется.
Вы также можете лёгким и бесплатным способом улучшить свой проект. Для этого нужно всего лишь проверить свой код с помощью PVS-Studio. А в этом вам поможет пробный ключ, который можно взять на нашем [сайте](https://pvs-studio.com/pvs-studio/try-free/?utm_source=habr&utm_medium=articles&utm_content=avalonstudio&utm_term=link_try-free) :).
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Artem Rovenskii. [Any bugs in your IDE? Checking AvalonStudio with PVS-Studio](https://pvs-studio.com/en/blog/posts/csharp/0966/). | https://habr.com/ru/post/677174/ | null | ru | null |
# Используем PHP по назначению
*upd: Осторожно, текст содержит сатиру и кодобред*
Язык программирования PHP берёт своё начало в 1995 году и является продуктом эпохи зарождения современных веб стандартов, таких как http (версия 1.0 — 1996), html (версия 2.0 — 1995), javascript (1995 год), url (1990 — 1994 года). Первоначально аббревиатура php имела расшифровку Personal Home Page Tools, далее трансформировавшись в Hypertext Preprocessor или «препроцессор гипертекста». Об использовании PHP в качестве препроцессора и будет посвящено несколько следующих абзацев.
Интерпретатор PHP позволяет вставлять в любой текст специальные тег php ?, с помощью которого можно подставить в страницу динамический контент, что очень удобно использовать внутри html документов. Полученный результат сразу подаётся на стандартное устройство вывода, известное как stdout (подробнее смотри [здесь](https://ru.wikipedia.org/wiki/%D0%A1%D1%82%D0%B0%D0%BD%D0%B4%D0%B0%D1%80%D1%82%D0%BD%D1%8B%D0%B5_%D0%BF%D0%BE%D1%82%D0%BE%D0%BA%D0%B8)). Есть возможность буферизовать вывод до востребованности через функцию [ob\_start](http://php.net/manual/ru/function.ob-start.php), но для нашей первой html страницы это не понадобится. Самый последний стандарт html под номером 5 ввёл несколько новых тегов для упрощения разметки, повышения читаемости и семантичности веба (что бы это не значило). Поэтому сразу воспользуемся всей мощью HTML5 и напишем шаблон страницы со вставками на рассматриваемом препроцессоре.
Сохраним эту страницу в файл index.html. Функционал блога в первой его версии будет предусматривать хранение публикаций в виде html страниц внутри заранее заданной директории (например pages/) и меню позволяющее перейти сразу на нужную публикацию.
Пример публикации, которая будет выведена в ленту блога.
В корне проекта добавим директорию pages/ и сохраним нашу статью под произвольным именем, например как 2018-trends.html.
Теперь нам нужен веб сервер для обработки входящих http запросов от пользователей, и сервер приложения для бизнес логики. Чтобы не плодить лишнии сущности напишем небольшую программу на языке программирования Go, которая будет выступать и в роли веб сервера, и содержать код блога. Для передачи пользовательских запросов из хостовой программы в препроцессор воспользуемся стандартным потоком ввода (stdin), для сериализации данных воспользуемся популярным форматом для сериализации данных — json.
Скрипт для обработки входных данных:
```
php
$input = trim(fgets(STDIN));
$input = json_decode($input, true);
include("index.html");</code
```
Код блога:
**main.go**
```
package main
import (
"encoding/json"
"io/ioutil"
"net/http"
"os/exec"
"strings"
"github.com/labstack/echo"
)
func main() {
e := echo.New()
e.GET("/", index)
e.GET("/pages/:page", index)
e.Start(":8000")
}
func index(c echo.Context) error {
outData := struct {
Menu []string `json:"menu"`
Pages []string `json:"pages"`
}{}
outData.Menu = make([]string, 0)
outData.Pages = make([]string, 0)
page := c.Param("page")
files, _ := ioutil.ReadDir("pages")
for _, file := range files {
if !file.IsDir() {
outData.Menu = append(outData.Menu, file.Name())
}
if page != "" && page == file.Name() {
fbody, _ := ioutil.ReadFile("pages" + "/" + file.Name())
outData.Pages = append(outData.Pages, string(fbody))
} else if page == "" {
fbody, _ := ioutil.ReadFile("pages" + "/" + file.Name())
outData.Pages = append(outData.Pages, string(fbody))
}
}
rendered := renderContent(outData)
return c.HTMLBlob(http.StatusOK, rendered)
}
func renderContent(input interface{}) []byte {
jsonInput, _ := json.Marshal(input)
tmplEngine := exec.Command("php", "-f", "index.php")
tmplEngine.Stdin = strings.NewReader(string(jsonInput))
rendered, _ := tmplEngine.Output()
return rendered
}
```
Теперь запускаем на исполнение программу через go run и делаем запрос на страницу через любой браузер, например таким образом:
`links2 http://localhost:8000`
Результат представлен на КДПВ.
Пытливый читатель может заметить, что мы сильно теряем в производительности запуская на каждый запрос php процесс. Данный момент легко оптимизировать используя механизм [pipes](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BD%D0%B2%D0%B5%D0%B9%D0%B5%D1%80_(UNIX)) и запуская php процесс единожды в фоне, но это уже совсем другая история. | https://habr.com/ru/post/351868/ | null | ru | null |
# Обзор базовых возможностей ES6
JavaScript сильно изменился за последние годы. Вот 12 новых возможностей, которые можно начать использовать уже сегодня!
История
=======
Новые добавления в язык называются ECMAScript 6. Или ES6 или ES2015+.
С момента появления в 1995, JavaScript развивался медленно. Новые возможности добавлялись каждые несколько лет. ECMAScript появился в 1997, его целью было направить развитие JavaScript в нужное русло. Выходили новые версии – ES3, ES5, ES6 и так далее.

Как видите, между версиями ES3, ES5 и ES6 есть пропуски длиной в 10 и 6 лет. Новая модель – делать маленькие изменения каждый год. Вместо того, чтобы накопить огромное количество изменений и выпустить их все за раз, как это было с ES6.
Browsers Support
================
Все современные браузеры и среды исполнения уже поддерживают ES6!
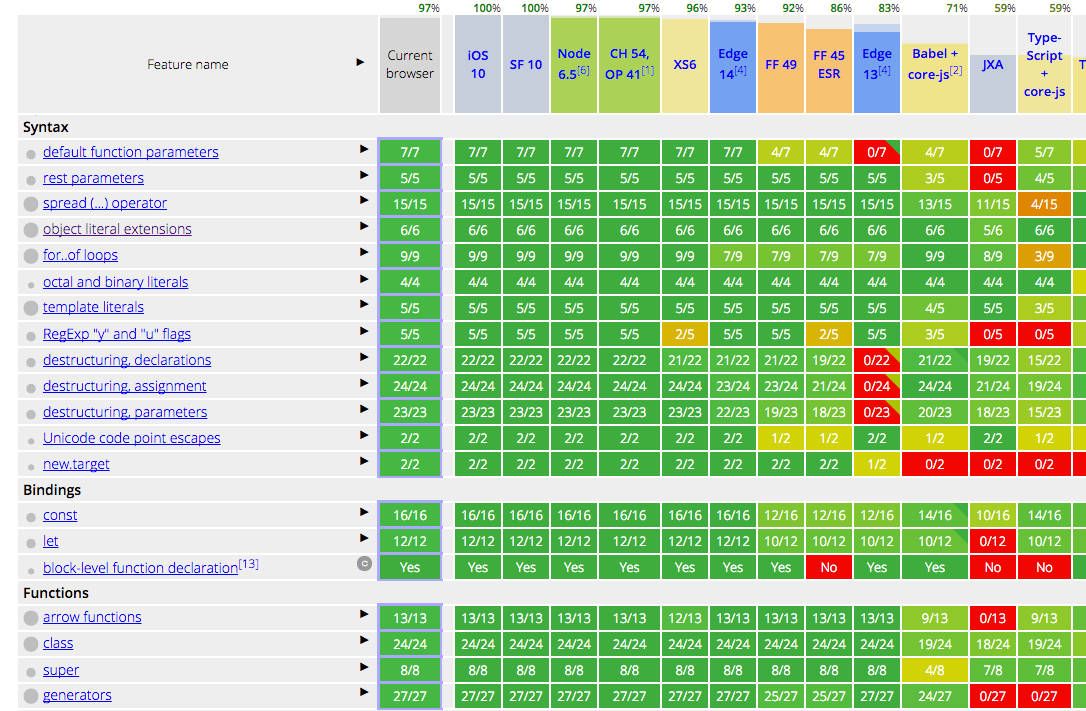
Chrome, MS Edge, Firefox, Safari, Node и многие другие системы имеют встроенную поддержку большинства возможностей JavaScript ES6. Так что, все из этого пособия можно использовать прямо сейчас.
Поехали!
Главные возможности ES6
=======================
Все сниппеты можно вставлять в консоль браузера и запускать.
Block scope variables
---------------------
В ES6 мы перешли от `var` к `let`/`const`.
Что не так с `var`?
Проблема `var` в том, что переменная "протекает" в другие блоки кода, такие как циклы `for` или блоки условий `if`:
```
ES5
var x = 'outer';
function test(inner) {
if (inner) {
var x = 'inner'; // scope whole function
return x;
}
return x; // gets redefined on line 4
}
test(false); // undefined
test(true); // inner
```
В строке `test(false)` можно ожидать возврат `outer`, но нет, мы получаем `undefined`. Почему?
Потому что даже не смотря на то, что блок `if` не выполняется, на 4й строке происходит переопределение `var x` как `undefined`.
ES6 спешит на помощь:
```
ES6
let x = 'outer';
function test(inner) {
if (inner) {
let x = 'inner';
return x;
}
return x; // gets result from line 1 as expected
}
test(false); // outer
test(true); // inner
```
Изменив `var` на `let` мы откорректировали поведение. Если блок `if` не вызывается, то переменная `x` не переопределяется.
**IIFE (immediately invoked function expression)**
Давайте сначала рассмотрим пример:
```
ES5
{
var private = 1;
}
console.log(private); // 1
```
Как видите, `private` протекает наружу. Нужно использовать IIFE (immediately-invoked function expression):
```
ES5
(function(){
var private2 = 1;
})();
console.log(private2); // Uncaught ReferenceError
```
Если взглянуть на jQuery/lodash или любые другие проекты с открытым исходным кодом, то можно заметить, что там IIFE используется для содержания глобальной среды в чистоте. А глобальные штуки определяются со специальными символами вроде `_`, `$` или `jQuery`.
В ES6 не нужно использовать IIFE, достаточно использовать блоки и `let`:
```
ES6
{
let private3 = 1;
}
console.log(private3); // Uncaught ReferenceError
```
**Const**
Можно также использовать `const` если переменная не должна изменяться.
Итог:
* забудьте `var`, используйте `let` и `const`.
* Используйте `const` для всех референсов; не используйте `var`.
* Если референсы нужно переопределять, используйте `let` вместо `const`.
Template Literals
-----------------
Не нужно больше делать вложенную конкатенацию, можно использовать шаблоны. Посмотрите:
```
ES5
var first = 'Adrian';
var last = 'Mejia';
console.log('Your name is ' + first + ' ' + last + '.');
```
С помощью бэктика (`) и интерполяции строк`${}` можно сделать так:
```
ES6
const first = 'Adrian';
const last = 'Mejia';
console.log(`Your name is ${first} ${last}.`);
```
Multi-line strings
------------------
Не нужно больше конкатенировать строки с + `\n`:
```
ES5
var template = '- \n' +
' \n' +
' \n' +
' \n' +
' \n' +
' \n' +
' \n' +
'
';
console.log(template);
```
В ES6 можно снова использовать бэктики:
```
ES6
const template = `-
`;
console.log(template);
```
Оба блока кода генерируют одинаковый результат
Destructuring Assignment
------------------------
ES6 destructing – полезная и лаконичная штука. Посмотрите на примеры:
**Получение элемента из массива**
```
ES5
var array = [1, 2, 3, 4];
var first = array[0];
var third = array[2];
console.log(first, third); // 1 3
```
То же самое:
```
ES6
const array = [1, 2, 3, 4];
const [first, ,third] = array;
console.log(first, third); // 1 3
```
**Обмен значениями**
```
ES5
var a = 1;
var b = 2;
var tmp = a;
a = b;
b = tmp;
console.log(a, b); // 2 1
```
То же самое:
```
ES6
let a = 1;
let b = 2;
[a, b] = [b, a];
console.log(a, b); // 2 1
```
**Деструктуризация нескольких возвращаемых значений**
```
ES5
function margin() {
var left=1, right=2, top=3, bottom=4;
return { left: left, right: right, top: top, bottom: bottom };
}
var data = margin();
var left = data.left;
var bottom = data.bottom;
console.log(left, bottom); // 1 4
```
В строке 3 можно вернуть в виде массива:
```
return [left, right, top, bottom];
```
но вызывающему коду придется знать о порядке данных.
```
var left = data[0];
var bottom = data[3];
```
С ES6 вызывающий выбирает только нужные данные (строка 6):
```
ES6
function margin() {
const left=1, right=2, top=3, bottom=4;
return { left, right, top, bottom };
}
const { left, bottom } = margin();
console.log(left, bottom); // 1 4
```
*Заметка:* В строке 3 содержатся другие возможности ES6. Можно сократить `{ left: left }` до `{ left }`. Смотрите, насколько это лаконичнее по сравнению с версией ES5. Круто же?
**Деструктуризация и сопоставление параметров**
```
ES5
var user = {firstName: 'Adrian', lastName: 'Mejia'};
function getFullName(user) {
var firstName = user.firstName;
var lastName = user.lastName;
return firstName + ' ' + lastName;
}
console.log(getFullName(user)); // Adrian Mejia
```
То же самое (но короче):
```
ES6
const user = {firstName: 'Adrian', lastName: 'Mejia'};
function getFullName({ firstName, lastName }) {
return `${firstName} ${lastName}`;
}
console.log(getFullName(user)); // Adrian Mejia
```
**Глубокое сопоставление**
```
ES5
function settings() {
return { display: { color: 'red' }, keyboard: { layout: 'querty'} };
}
var tmp = settings();
var displayColor = tmp.display.color;
var keyboardLayout = tmp.keyboard.layout;
console.log(displayColor, keyboardLayout); // red querty
```
То же самое (но короче):
```
ES6
function settings() {
return { display: { color: 'red' }, keyboard: { layout: 'querty'} };
}
const { display: { color: displayColor }, keyboard: { layout: keyboardLayout }} = settings();
console.log(displayColor, keyboardLayout); // red querty
```
Это также называют деструктуризацией объекта (object destructing).
Как видите, деструктуризация может быть очень полезной и может подталкивать к улучшению стиля кодирования.
Советы:
* Используйте деструктуризацию для получения элементов из массива и для обмена значениями. Не нужно делать временные референсы – сэкономите время.
* Не используйте деструктуризацию массива для нескольких возвращаемых значений, вместо этого используйте деструктуризацию объекта.
Классы и объекты
----------------
В ECMAScript 6 мы перешли от “функций-конструкторов” к “классам” .
> Каждый объект в JavaScript имеет прототип, который является другим объектом. Все объекты в JavaScript наследуют методы и свойства от своего прототипа.
В ES5 объектно-ориентированное программирование достигалось с помощью функций-конструкторов. Они создавали объекты следующим образом:
```
ES5
var Animal = (function () {
function MyConstructor(name) {
this.name = name;
}
MyConstructor.prototype.speak = function speak() {
console.log(this.name + ' makes a noise.');
};
return MyConstructor;
})();
var animal = new Animal('animal');
animal.speak(); // animal makes a noise.
```
В ES6 есть новый синтаксический сахар. Можно сделать то же самое с меньшим кодом и с использованием ключевых слов `class` и `construсtor`. Также заметьте, как четко определяются методы: `construсtor.prototype.speak = function ()` vs `speak()`:
```
ES6
class Animal {
constructor(name) {
this.name = name;
}
speak() {
console.log(this.name + ' makes a noise.');
}
}
const animal = new Animal('animal');
animal.speak(); // animal makes a noise.
```
Оба стиля (ES5/6) дают одинаковый результат.
Советы:
* Всегда используйте синтаксис `class` и не изменяйте `prototype` напрямую. Код будет лаконичнее и его будет легче понять.
* Избегайте создания пустого конструктора. У классов есть конструктор по умолчанию если не задать собственный.
Наследование
------------
Давайте продолжим предыдущий пример с классом `Animal`. Допустим, нам нужен новый класс `Lion`.
В ES5 придется немного поработать с прототипным наследованием.
```
ES5
var Lion = (function () {
function MyConstructor(name){
Animal.call(this, name);
}
// prototypal inheritance
MyConstructor.prototype = Object.create(Animal.prototype);
MyConstructor.prototype.constructor = Animal;
MyConstructor.prototype.speak = function speak() {
Animal.prototype.speak.call(this);
console.log(this.name + ' roars ');
};
return MyConstructor;
})();
var lion = new Lion('Simba');
lion.speak(); // Simba makes a noise.
// Simba roars.
```
Не будем вдаваться в детали, но заметьте несколько деталей:
* Строка 3, напрямую вызываем конструктор`Animal` с параметрами.
* Строки 7-8, назначаем прототип `Lion` прототипом класса `Animal`.
* Строка 11, вызываем метод `speak` из родительского класса `Animal`.
В ES6 есть новые ключевые слова `extends` и `super`.
```
ES6
class Lion extends Animal {
speak() {
super.speak();
console.log(this.name + ' roars ');
}
}
const lion = new Lion('Simba');
lion.speak(); // Simba makes a noise.
// Simba roars.
```
Посмотрите, насколько лучше выглядит код на ES6 по сравнению с ES5. И они делают одно и то же! Win!
Совет:
* Используйте встроенный способ наследования – `extends`.
Нативные промисы
----------------
Переходим от callback hell к промисам (promises)
```
ES5
function printAfterTimeout(string, timeout, done){
setTimeout(function(){
done(string);
}, timeout);
}
printAfterTimeout('Hello ', 2e3, function(result){
console.log(result);
// nested callback
printAfterTimeout(result + 'Reader', 2e3, function(result){
console.log(result);
});
});
```
Одна функция принимает callback чтобы запустить его после завершения. Нам нужно запустить ее дважды, одну за другой. Поэтому приходится вызывать `printAfterTimeout` во второй раз в коллбеке.
Все становится совсем плохо когда нужно добавить третий или четвертый коллбек. Давайте посмотрим, что можно сделать с промисами:
```
ES6
function printAfterTimeout(string, timeout){
return new Promise((resolve, reject) => {
setTimeout(function(){
resolve(string);
}, timeout);
});
}
printAfterTimeout('Hello ', 2e3).then((result) => {
console.log(result);
return printAfterTimeout(result + 'Reader', 2e3);
}).then((result) => {
console.log(result);
});
```
С помощью `then` можно обойтись без вложенных функций.
Стрелочные функции
------------------
В ES5 обычные определения функций не исчезли, но был добавлен новый формат – стрелочные функции.
В ES5 есть проблемы с `this`:
```
ES5
var _this = this; // need to hold a reference
$('.btn').click(function(event){
_this.sendData(); // reference outer this
});
$('.input').on('change',function(event){
this.sendData(); // reference outer this
}.bind(this)); // bind to outer this
```
Нужно использовать временный `this` чтобы ссылаться на него внутри функции или использовать `bind`. В ES6 можно просто использовать стрелочную функцию!
```
ES6
// this will reference the outer one
$('.btn').click((event) => this.sendData());
// implicit returns
const ids = [291, 288, 984];
const messages = ids.map(value => `ID is ${value}`);
```
For…of
------
От `for` переходим к `forEach` а потом к `for...of`:
```
ES5
// for
var array = ['a', 'b', 'c', 'd'];
for (var i = 0; i < array.length; i++) {
var element = array[i];
console.log(element);
}
// forEach
array.forEach(function (element) {
console.log(element);
});
```
ES6 for…of позволяет использовать итераторы
```
ES6
// for ...of
const array = ['a', 'b', 'c', 'd'];
for (const element of array) {
console.log(element);
}
```
Параметры по умолчанию
----------------------
От проверки параметров переходим к параметрам по умолчанию. Вы делали что-нибудь такое раньше?
```
ES5
function point(x, y, isFlag){
x = x || 0;
y = y || -1;
isFlag = isFlag || true;
console.log(x,y, isFlag);
}
point(0, 0) // 0 -1 true
point(0, 0, false) // 0 -1 true
point(1) // 1 -1 true
point() // 0 -1 true
```
Скорее всего да. Это распространенный паттерн проверки наличия значения переменной. Но тут есть некоторые проблемы:
* Строка 8, передаем `0, 0` получаем `0, -1`
* Строка 9, передаем `false`, но получаем `true`.
Если параметр по умолчанию это булева переменная или если задать значение 0, то ничего не получится. Почему? Расскажу после этого примера с ES6 ;)
В ES6 все получается лучше с меньшим количеством кода:
```
ES6
function point(x = 0, y = -1, isFlag = true){
console.log(x,y, isFlag);
}
point(0, 0) // 0 0 true
point(0, 0, false) // 0 0 false
point(1) // 1 -1 true
point() // 0 -1 true
```
Получаем ожидаемый результат. Пример в ES5 не работал. Нужно проверять на `undefined` так как `false`, `null`, `undefined` и `0` – это все falsy-значения. С числами можно так:
```
ES5
function point(x, y, isFlag){
x = x || 0;
y = typeof(y) === 'undefined' ? -1 : y;
isFlag = typeof(isFlag) === 'undefined' ? true : isFlag;
console.log(x,y, isFlag);
}
point(0, 0) // 0 0 true
point(0, 0, false) // 0 0 false
point(1) // 1 -1 true
point() // 0 -1 true
```
С проверкой на `undefined` все работает как нужно.
Rest-параметры
--------------
От аргументов к rest-параметрам и операции spread.
В ES5 работать с переменным количеством аргументов неудобно.
```
ES5
function printf(format) {
var params = [].slice.call(arguments, 1);
console.log('params: ', params);
console.log('format: ', format);
}
printf('%s %d %.2f', 'adrian', 321, Math.PI);
```
С rest `...` все намного проще.
```
ES6
function printf(format, ...params) {
console.log('params: ', params);
console.log('format: ', format);
}
printf('%s %d %.2f', 'adrian', 321, Math.PI);
```
Операция Spread
---------------
Переходим от `apply()` к spread. Опять же, `...` спешит на помощь:
> Помните: мы используем `apply()` чтобы превратить массив в список аргументов. например, `Math.max()` принимает список параметров, но если у нас есть массив, то можно использовать `apply`.
```
ES5
Math.max.apply(Math, [2,100,1,6,43]) // 100
```
В ES6 используем spread:
```
ES6
Math.max(...[2,100,1,6,43]) // 100
```
Мы также перешли от `concat` к spread'у:
```
ES5
var array1 = [2,100,1,6,43];
var array2 = ['a', 'b', 'c', 'd'];
var array3 = [false, true, null, undefined];
console.log(array1.concat(array2, array3));
```
В ES6:
```
ES6
const array1 = [2,100,1,6,43];
const array2 = ['a', 'b', 'c', 'd'];
const array3 = [false, true, null, undefined];
console.log([...array1, ...array2, ...array3]);
```
Заключение
==========
JavaScript сильно изменился. Эта статья покрывает только базовые возможности, о которых должен знать каждый разработчик. | https://habr.com/ru/post/313526/ | null | ru | null |
# werf vs. Helm: корректно ли их вообще сравнивать?
Эта статья — развернутый ответ на вопрос, который нам периодически задают: чем werf отличается от Helm? На первый взгляд можно предположить, что задача у них примерно одинаковая: автоматизировать деплой приложений в Kubernetes. Но всё, конечно, немного сложнее…
Роль в CI/CD
------------
Если упрощенно показать утилиты в рамках полного цикла CI/CD, то их функции значительно отличаются:
| | |
| --- | --- |
| **Helm** | **werf** |
| — | Сборка приложения (в Docker-образ) |
| — | Публикация образов в container registry и их автоматическая очистка со временем |
| Деплой в Kubernetes | Деплой в Kubernetes (на базе Helm), расширенный трекингом ресурсов, интеграцией с образами, встроенной поддержкой Giterminism и другими фичами |
Как видно, в рамках CI/CD-пайплайна werf делает гораздо больше, участвуя в полном жизненном цикле приложения, от сборки до выката в Kubernetes.
[Helm](https://helm.sh/) — хороший инструмент, но довольно низкоуровневый. Для реального использования в CI/CD он требует надстроек, интеграции с другими инструментами… в общем, заметного усложнения инфраструктуры и процессов.
Поэтому мы говорим, что [werf](https://ru.werf.io/) — это следующий уровень доставки приложений в Kubernetes. Утилита использует Helm как один из компонентов и интегрирует его с другими стандартными инструментами: Git, Docker и Kubernetes. Благодаря этому werf выступает в роли «клея», который упрощает, унифицирует организацию CI/CD-пайплайнов на базе специализированных инструментов, уже ставших стандартом в индустрии, и выбранной вами CI-системы.
Что умеет werf (и не умеет Helm)
--------------------------------
Мы упомянули, что werf — это утилита, которая не только про деплой. Но даже если посмотреть только на данный этап, то и здесь у werf есть ряд доработок:
| | | |
| --- | --- | --- |
| **Возможности** | **Helm** | **werf** |
| Ожидание готовности ресурсов во время деплоя | **+** | **+** |
| Трекинг ресурсов и обнаружение ошибок | − | **+** |
| Fail-fast во время деплоя | − | **+** |
| Защита от параллельных запусков деплоя одного и того же релиза | − | **+** |
| Интеграция с собираемыми образами | − | **+** |
| Поддержка автодобавления аннотаций и лейблов во все ресурсы релиза | + / − | **+** |
| Публикация файлов конфигурации и образов приложения в container registry (бандлы) | + / − | **+** |
| Базовая поддержка секретных values | − | **+** |
| Поддержка Giterminism и GitOps | + / − | **+** |
Подробнее мы разберем каждый пункт таблицы ниже *(см. «Детальное сравнение werf и Helm» ниже)*. Но сначала — об истоках, которые привели к таким следствиям. Расскажем о том, к чему мы стремились, создавая werf.
Четыре благородные истины werf
------------------------------
### 1. werf должна использоваться в CI/CD-пайплайне как единый инструмент
В утилите необходима поддержка работы в любой существующей CI/CD-системе и легкой интеграции. Сейчас werf работает «из коробки» с [GitLab CI/CD](https://ru.werf.io/documentation/v1.2/advanced/ci_cd/gitlab_ci_cd.html) и [GitHub Actions](https://ru.werf.io/documentation/v1.2/advanced/ci_cd/github_actions.html). Другие CI-системы тоже поддерживаются — для интеграции достаточно написать скрипт, следуя [инструкции](https://ru.werf.io/documentation/v1.2/advanced/ci_cd/generic_ci_cd_integration.html).
### 2. werf должна оптимальным образом доставлять приложения в Kubernetes
В процессе доставки собираются только недостающие образы из container registry или недостающие слои для этих образов, а всё старое берется из прошлых сборок или кэша. Так экономится и время сборки, и место для хранения всех образов.
После доставки [обновлённого приложения] текущее состояние ресурсов в Kubernetes приводится к новому требуемому состоянию, которое определено в Git (мы назвали это словом «[гитерминизм](https://ru.werf.io/documentation/v1.2/advanced/giterminism.html)», от слов «Git» + «детерминизм») — и здесь снова речь идёт о том, что для такой синхронизации вычисляются изменения и применяются только они.
### 3. werf должна давать четкую обратную связь
Итоговый отчет werf в идеале должен быть достаточным для диагностики проблемы. Если что-то пошло не так в процессе доставки и развертывания, пользователю не нужно запускать kubectl и искать информацию в кластере. werf сразу показывает и постоянно обновляет актуальный статус процесса деплоя и даёт достаточно информации для решения проблемы без привлечения системного администратора.
### 4. werf должна поддерживать GitOps-подход
[GitOps](https://www.gitops.tech/#what-is-gitops) в общем виде — это подход, при котором для развертывания приложений в Kubernetes используется единственный источник правды — Git-репозиторий. Через декларативные действия в Git вы управляете реальным состоянием инфраструктуры, запущенной в Kubernetes. Этот паттерн «из коробки» работает в werf.
У нас есть [собственный взгляд](https://habr.com/ru/company/flant/blog/526102/) на то, как должен быть реализован GitOps для CI/CD (уже упомянутый [Giterminism](https://ru.werf.io/documentation/v1.2/advanced/giterminism.html)). GitOps в werf поддерживает не только хранение Kubernetes-манифестов в Git, но и версионирование собираемых образов, связанное с Git. Откат до предыдущей версии приложения выполняется без сборки выкатывавшихся ранее образов (при условии, что версия учитывается политиками очистки). Другие существующие реализации GitOps не дают этой гарантии.
Зачем и как werf использует Helm
--------------------------------
werf использует и расширяет Helm, чтобы следовать вышеприведенным принципам.
Helm — популярный и проверенный инструмент. У него есть собственный шаблонизатор, чарты и т.п. Мы не стали переизобретать то, что уже отлично работает. Вместо этого сфокусировались на фичах, которые помогают оптимизировать CI/CD.
С точки зрения совместимости важно, что кодовая база Helm вкомпилирована в werf. Обновления из upstream приходят регулярно, руками Helm обновлять не нужно. *(Как, впрочем, и у самой werf, у которой есть встроенный version manager —* [*multiwerf*](https://ru.werf.io/installation.html?version=1.2&channel=ea&os=macos&method=multiwerf) *с 5 каналами стабильности и поддержкой автообновления.)*
Мы даже стараемся по возможности участвовать в улучшении Helm через upstream. Один из примеров нашего вклада — аннотация [helm.sh/hook-delete-policy=before-hook-creation](https://helm.sh/docs/topics/charts_hooks/) («Удалить предыдущий ресурс перед запуском нового хука»), которая пришла в Helm из werf.
### Плюсы и минусы Helm
У Helm есть ряд преимуществ:
* Это **стандартный package manager в K8s.** Helm используют [практически] все, кто работает с Kubernetes; он стал стандартом индустрии.
* **Шаблонизация.** Шаблоны Helm удобны для тиражирования манифестов при работе с несколькими окружениями. *(Пусть и не все согласятся, что Go-templates — удобный шаблонизатор, но это уже другой вопрос...)*
* **Удобное управление чартами.** Общепринятый формат описания ресурсов и объединения их в чарты (charts — это «пакеты» для Helm).
* **Переиспользование чартов.** Helm поддерживает публикацию переиспользуемых чартов в Chart Repository или container registry.
* **Удобное управление жизненным циклом релизов.** В Helm легко управлять релизами и откатываться на нужные версии.
Что до минусов, то основной в том, что Helm — это маленькое звено в CI/CD-цепи, которое мало или совсем не связано с другими важными звеньями.
CI/CD приложения предполагает непрерывное слияние изменений в основную кодовую базу проекта и непрерывную доставку этих изменений до пользователя. Это включает периодическую сборку новых образов приложения с обновлениями, тестирование этих образов и выкат новой версии приложения. В CI/CD у нас обычно несколько окружений (production, staging, development и т. д.). И конфигурация приложения может отличаться для разных окружений.
Технически Helm позволяет конфигурировать описанный chart параметрами, через которые передаются образы приложения и выбранное окружение. Однако конкретный путь — как это делать — не стандартизован. Пользователю Helm приходится решать это самому.
Детальное сравнение werf и Helm
-------------------------------
А теперь вернемся к таблице и разберем подробнее каждый её пункт.
### 1. Трекинг ресурсов и обнаружение ошибок
И werf, и Helm умеют ждать готовности ресурсов в процессе развертывания. Но werf дает обратную связь и более проактивна. Три главных отличия:
**1. В процессе деплоя werf выводит логи по выкатываемым ресурсам.** Для отдельных ресурсов логирование отключается автоматически — по мере их перехода в состояние готовности. Можно отключить трекинг конкретных контейнеров или логировать вывод только по определенным контейнерам ресурса, отключив остальные; можно включать и выключать вывод сервисной информации Kubernetes. Всё это настраивается с помощью [аннотаций](https://ru.werf.io/documentation/v1.2/reference/deploy_annotations.html), которые объявляются в шаблонах чарта.
**2. Как только werf замечает проблему в одном из ресурсов, он завершается с ошибкой и ненулевым кодом выхода.** werf следует принципу [fail-fast](https://en.wikipedia.org/wiki/Fail-fast). Он выдает наиболее полезную информацию по ошибке, чтобы пользователь сразу мог понять, в чём проблема, по выводу в CI/CD job.
Helm, в отличие от werf, в случае проблем с конфигурацией ждет истечения таймаута. А такие проблемы — распространенная ситуация в CI/CD. Выяснить, в чём их причина, можно только после подключения к кластеру через kubectl. Это неудобно:
* нужно настраивать права доступа к kubectl;
* kubectl требует знаний и умений: куда смотреть, что искать и как это интерпретировать.
В идеале разработчик по выводу werf сможет понять причину проблемы и пофиксить ее, не привлекая админа. После этого достаточно создать в Git новый коммит с исправлением.
**3. Защита от параллельных запусков деплоя одного и того же релиза.** Helm может упасть с ошибкой, если будут работать одновременно два выката одного и того же релиза. werf автоматически предотвращает одновременный выкат: эти процессы работают по очереди.
### 2. Интеграция со сборкой образов
В Helm приходится явно передавать полные имена образов через values и заботиться об актуализации имен при изменениях.
werf решает эту проблему за пользователя: не нужно думать о способах передачи имен образов, т. к. они передаются через те же values автоматически. Более того, werf оптимальным образом решает проблему именования образов — так, чтобы в процессе деплоя менялись имена только у изменившихся образов.
К тому же, werf дает возможность откатиться на старую версию приложения со старыми образами без повторной пересборки этих образов. Часто при использовании Helm в CI/CD через values для упрощения передаются статические имена образов (вроде `registry.example.com/myproject:production`) — в этом случае имя образа ссылается только на последнюю собранную версию образа. При такой схеме тегирования приходиться пересобирать старый образ, чтобы откатиться до предыдущей версии. werf использует схему с [content-based-тегами](https://habr.com/ru/company/flant/blog/495112/), которые связаны с историей Git. Помимо прочего, такая схема тегирования полностью решает вопрос с откатом на старую версию.
Что дает интеграция с собранными образами:
* werf может использовать уже существующие Dockerfile'ы в своей конфигурации.
* werf автоматически и оптимально именует собираемые образы, чтобы имена зависели от контента внутри образа и обновлялись только при его изменении.
* Нет лишних перевыкатов компонентов приложения в Kubernetes и, как следствие, лишнего простоя компонентов. Перевыкат происходит быстро и только для измененных компонентов, а не приложения целиком.
* Со стороны конфигурации Helm остается только использовать имена образов, которые werf предоставляет через специальные values.
* Можно откатиться на образы старой версии приложения.
### 3. Добавление аннотаций и лейблов в ресурсы релиза
В Helm есть механизм [post rendering](https://helm.sh/docs/topics/advanced/#post-rendering), чтобы дописывать в ресурсы аннотации или лейблы и менять другие поля. Однако в Helm нет простой встроенной функции для добавления конкретно лейблов и аннотаций.
werf добавляет во все ресурсы релиза автоматические аннотации вроде ссылки на CI/CD job, из которого ресурс был в последний раз выкачен, или ссылки на Git-коммит.
Также в werf через CLI-опции можно указать произвольные аннотации или лейблы, которые будут добавлены во все ресурсы релиза. Пример такой команды:
```
werf converge --add-annotation pipeline-id=$CI_PIPELINE_ID --add-annotation git-branch=$CI_COMMIT_REF_NAME
```
Это удобно:
* для интроспекции, когда надо понять, с каким CI/CD job связана версия ресурса;
* для мониторинга, чтобы собирать по кластеру информацию о ресурсах из аннотаций или лейблов.
### 4. Бандлы: публикация файлов конфигурации и образов приложения в container registry
Helm поддерживает публикацию чартов в OCI container registry либо Chart Repository, однако не отвечает за образы, которые нужны этому чарту для выката. Такие образы должны быть отдельно собраны и правильно протегированы, а опубликованный чарт должен быть настроен на использование образов по правильным именам. Эти проблемы пользователю Helm приходиться решать самостоятельно.
werf поддерживает так называемые [бандлы](https://ru.werf.io/documentation/v1.2/advanced/bundles.html), которые предполагают публикацию чартов и образов, собранных специально для текущего чарта как единой сущности в container registry.
Пользователь не думает об именах образов, публикуемых вместе с чартом: werf делает это автоматически и оптимальным способом. Неизменные образы будут переиспользованы. Публикуются лишь те слои, которые требуются для текущего коммита. Пользователю werf достаточно выбрать версию бандла и обеспечить его публикацию в требуемом Git-коммите.
### 5. Встроенная базовая поддержка значений секретов
В Helm поддержка секретов возможна через подключение сторонних плагинов. Это усложняет установку Helm на новые хосты.
werf из коробки дает возможность закодировать значения values через алгоритмы AES-128, AES-192 и AES-256. Ключи шифрования можно менять.
### 6. Поддержка Giterminism и GitOps
Helm не регулирует привязку используемых конфигурационных файлов к Git-коммитам.
werf (с версии v1.2) форсирует использование конфигурации из текущего Git-коммита и реализует режим гитерминизма, в том числе и для конфигурации Helm.
werf читает конфигурационные файлы сборочного контекста из текущего коммита репозитория проекта и исключает внешние зависимости. Это обеспечивает [надежность и воспроизводимость](https://habr.com/ru/company/flant/blog/526102/). Конфигурации легко воспроизводятся: разработчики используют образы, только что собранные в CI-системе, переключившись на нужный коммит. werf запрещает работать с незакоммиченными и неотслеживаемыми файлами.
Подытожим
---------
Прямое противопоставление «werf vs Helm» не совсем корректно, потому что утилита werf реализует не только деплой, а нацелена на поддержку полного жизненного цикла доставки приложений. Сам по себе Helm — хороший инструмент для деплоя в Kubernetes, поэтому он (с некоторыми улучшениями) встроен в werf для решения этой задачи. Однако и в контексте деплоя у werf есть ряд преимуществ, общий смысл которых сводится к более полной и удобной интеграции с CI/CD-системами.
P.S.
----
Читайте также в нашем блоге:
* «[Пакетный менеджер для Kubernetes — Helm: прошлое, настоящее, будущее](https://habr.com/ru/company/flant/blog/417079/)»;
* «[Трезвый взгляд на Helm 2: Вот такой, какой есть...](https://habr.com/ru/company/flant/blog/438814/)»;
* «[werf — наш инструмент для CI/CD в Kubernetes](https://habr.com/ru/company/flant/blog/460351/)» (обзор и видео доклада). | https://habr.com/ru/post/554892/ | null | ru | null |
# Частые ошибки программирования на Bash (окончание)
Окончание перевода [Bash Pitfalls](http://wooledge.org:8000/BashPitfalls). Предыдущие части доступны в блоге [«Оболочки»](http://www.habrahabr.ru/blogs/shells) ([часть 1](http://habrahabr.ru/blogs/shells/47706/), [часть 2](http://habrahabr.ru/blogs/shells/47915/)) и в моём [блоге](http://bappoy.pp.ru/tag/bash-pitfalls).
### 22. echo "Hello World!"
Проблема в том, что в интерактивной оболочке Bash эта команда вызовет ошибку:
```
bash: !": event not found
```
Это происходит потому, что при установках по умолчанию Bash выполняет подстановку истории команд в стиле csh с использованием восклицательного знака. В скриптах такой проблемы нет, только в интерактивной оболочке.
Очевидное решение здесь не работает:
```
$ echo "hi\!"
hi\!
```
Можно заключить эту строку в одинарные кавычки:
```
echo 'Hello World!'
```
Но самое подходящее решение здесь — временно выключить параметр `histexpand`. Это можно сделать командой `set +H` или `set +o histexpand`:
```
set +H
echo "Hello World!"
```
Почему же тогда всегда не пользоваться одиночными кавычками? Представьте, что вы хотите получить информацию об mp3-файлах:
```
mp3info -t "Don't Let It Show" ...
mp3info -t "Ah! Leah!" ...
```
Одинарные кавычки здесь не подходят, поскольку названия песен содержат апострофы в названиях, а использование двойных кавычек приведёт к проблеме с подстановкой истории команд (а если бы в именах файлов ещё и двойные ковычки содержались, получилось бы вообще черте что). Поскольку лично я (Greg Wooledge, автор текста) никогда не использую подстановку истории команд, я просто поместил команду `set +H` в свой .bashrc. Но это вопрос привычки и каждый решает для себя сам.
### 23. for arg in $\*
В Bash'е, так же, как и в других оболочках семейства Bourne shell, есть специальный синтаксис для работы с позиционными параметрами по очереди, но `$*` и `$@` не совсем то, что вам нужно: после подстановки параметров они становятся списком слов, переданных в аргументах, а не списком параметров по отдельности.
Вот правильный синтаксис:
```
for arg in "$@"
```
Или просто:
```
for arg
```
`for arg` соответствует `for arg in "$@"`. Заключенная в двойные кавычки переменная `"$@"` — это специальная ~~уличная~~ магия, благодаря которой каждый аргумент командной строки заключается в двойные кавычки, так что он выглядит как отдельное слово. Другими словами, `"$@"` преобразуется в список `"$1" "$2" "$3"` и т.д. Этот трюк подойдёт в большинстве случаев.
Рассмотрим пример:
```
#!/bin/bash
# неправильно
for x in $*; do
echo "parameter: '$x'"
done
```
Этот код напечатает:
```
$ ./myscript 'arg 1' arg2 arg3
parameter: 'arg'
parameter: '1'
parameter: 'arg2'
parameter: 'arg3'
```
Вот как это должно выглядеть:
```
#!/bin/bash
# правильно!
for x in "$@"; do
echo "parameter: '$x'"
done
```
```
$ ./myscript 'arg 1' arg2 arg3
parameter: 'arg 1'
parameter: 'arg2'
parameter: 'arg3'
```
### 24. function foo()
В некоторых шеллах это работает, но не во всех. Никогда не комбинируйте ключевое слово `function` со скобками (), определяя функцию.
Некоторые версии bash позволяют одновременно использовать и `function`, и `()`, но ни в одной другой оболочке так делать нельзя. Некоторые интерпретаторы, правда, воспримут `function foo`, но для максимальной совместимости лучше использовать:
```
foo() {
...
}
```
### 25. echo "~"
Замена тильды (tilde expansion) происходит только когда символ ~ не окружён кавычками. В этом примере `echo` выведет `~` в stdout, вместо того, чтобы вывести пользовательский домашний каталог.
Экранирование переменных с путями, которые должны быть выражены относительно домашнего каталога, должно производиться с использованием `$HOME` вместо `~`.
```
"~/dir with spaces" # "~/dir with spaces"
~"/dir with spaces" # "~/dir with spaces"
~/"dir with spaces" # "/home/my photos/dir with spaces"
"$HOME/dir with spaces" # "/home/my photos/dir with spaces"
```
### 26. local varname=$(command)
Определяя локальную переменную в функции, `local` сама работает как команда. Иногда это может непонятным образом взаимодействовать с остатком строки. Например, если в следующей команде вы хотите получить код возврата ($?) подставленной команды, вы его не получите: код возврата команды local его перекрывает.
Поэтому эти команды лучше разделять:
```
local varname
varname=$(command)
rc=$?
``` | https://habr.com/ru/post/48053/ | null | ru | null |
# Краткий обзор NAS i-Stor iS607
#### Имеется в наличии такой вот сетевой дисковый массив. И я решил поделиться с хабраобщественностью этой радостью. Маленький обзор.

Итак, поехали
##### Технические спецификации:
* **HDD:** 2x3.5’’ SATA (I или II)
* **RAID:** 0,1,JBOD,Spanning
* **Chipset:** Storm SL3516
* **Поддерживаемые протоколы:** CIFS/SMB,NFS,FTP
* **Хост-интерфейс и скорость передачи данных:** Gigabit Ethernet
* **Управление:** Web-интерфейс и telnet (по дефолту), ssh (из пакета Optware)
* **Размер:** 14(ширина)x24.5(глубина)x8.3(высота)
* **Вес:** 1.1кг
* **Arm-Processor:** FA526id(wb) rev 1 (v4l)
* **ОЗУ:** 128Mb
Вот так **i-Store 607** выглядит с морды

А вот так сзади

Подобным образом выглядит Web-интерфейс
Сей чудный прибор имеет ёмкость на 2 винчестера и служит отличным сетевым хранилищем
Я использую его как торрент-клиент, при этом он 24/7 стоит на раздаче.
По дефолту на нем имеется btorrent + абсолютно тупая и неудобная веб-морда, также был выявлен баг, после ребута все раздачи исчезают, что является диким неудобством, для тех кто хотел бы юзать его для p2p-файлообменников.
Более подробную информацию о его технической стороне можно узнать на [официальном сайте](http://www.i-stor.ru/#%27/desktop/93431/%27)
Его стоимость колышется от 4 до 5 килорублей, что является довольно низкой ценой для таких девайсов.
Подробный обзор **iS607** можно прочесть на [hardwareportal.ru](http://www.hwp.ru/articles/Stoit_li_sobirat_mini_server_ili_NAS_svoimi_rukami_ili_vibrat_gotoviy__Sravnenie_Mini_ITX_samosbora_i_I_Stor_IS607/?phrase_id=1134013)
Копипастить не стал, т.к. “Хабр — не место для копипастеров”(с) правила, да и сам я этого не люблю.
Cамое важное из-за чего я решил написать эту статью в этом счастье Linux ядрышко и пакет BusyBox.
`uname -a
Linux torrents 2.6.15 #160 Thu May 29 14:11:48 CST 2008 armv4l GNU/Linux`
Надо всего лишь поставить пакет **Optware**, в который входит весь необходимый софт для управления пакетами(включая все зависимости) и мы уже сможем ставить различное ПО незамысловатой командой:
**ipkg install PACKAGE\_NAME**, конечно перед этим желательно сделать **ipkg update**, а если вы только что установили пакет Optware, то еще и не забыть **ipkg upgrade**.
[Вот статья](http://forum.istor.ru/viewtopic.php?f=6&t=173) описывающая процесс установки пакета Optware на **iS607**.
В качестве торрент-клиента я бы посоветовал поставить Transmisson:
* удобная веб-морда для управления
* существует [GUIевая софтина](http://code.google.com/p/transmisson-remote-gui/) под винду, мак, линь для удаленного управления.
* после ребута NASа всё отлично восстанавливается и раздачи продолжаются.
Как итог могу сказать, что с такой ценой и функциональностью **i-Store 607** является отличным выбором для дома и маленькой организации.
PS: может я конечно как редактор и не очень, но просто хотел поделиться своими ощущения по этому мини-чуду.
PPS: Прошу написать тут в комментах что не так в этом посте, чего не хватает, а что лишнее, просто мой 1ый пост и ощущаю себя пока что не очень уверенно. | https://habr.com/ru/post/76051/ | null | ru | null |
# Сам себе data scientist или зачем нужен анализ данных менеджеру по продажам
Всем привет! Меня зовут Михаил Тимофеев. Когда я работал менеджером по продажам, меня постоянно мучали вопросы: почему клиент отказался, где моя зона роста, что делать, чтобы продавать больше? Ответов порой приходилось ждать очень долго, а максимум, чего я мог добиться — это ответы по чек-листу, да сухие цифры по количеству звонков, заявкам и времени на линии. И тогда я решил все взять в свои руки. В статье расскажу о своём опыте создания DIY-системы учета и прогноза продаж в Excel (или его аналоге Calс из пакета LibreOffice), Power BI и Python 3 с подключенными библиотеками Pandas, NumPy и MatPlotLib.
Наверняка, многие, кто не первый год занимается поиском новых клиентов, ведет переговоры и договаривается о заключении сделок, самостоятельно ведут учет своей результативности. Это очень хорошая практика, так как позволяет не только предположить, насколько будет выполнен план, но и выявить места просадки и свои зоны роста. Современное ПО, от офисных пакетов до библиотек для языков программирования, существенно упрощает данный процесс. На помощь лично мне пришла статистика, которой занимался на одной из бывших работ, а ещё Школа программирования Ростелекома, где я прокачал скиллы в Python и PowerBI.
Немного о процессе продаж (каким он должен быть)
------------------------------------------------
Приведу краткое описание бизнес-процесса: менеджер по продажам звонит потенциальному клиенту, проводит переговоры.
О продаже каких услуг идет речьПродукты, которые я продаю — это услуги доступа в Интернет (ШПД), Wink (онлайн-кинотеатр + интерактивное ТВ), мобильную связь (MVNO) и видеонаблюдение. Можно добавить и услугу стационарной телефонии (ОТА), но заявки на неё столь редки, что можно убрать за скобки.
Первичным успехом является согласие клиента на подключение одной или нескольких услуг с оговоренной датой визита мастера-инсталлятора для настройки оборудования и сопутствующих монтажных работ. Далее клиенту звонит отдел координации для подтверждения заявки, даты визита мастера и решения каких-то возникших у клиента вопросов.
Финальный этап — визит мастера, который производит монтаж, настройку оборудования и передачу документации (сейчас есть тенденция на передачу в электронном виде). После выполнения всех работ и подписания договора, клиент вносит в течении трех дней сумму. Чаще всего в неё входит стоимость тарифа, оборудования и оплата подключения. Все довольны: клиент получается услугу, компания — нового клиента, а менеджер — премию.
**Однако данная ситуация хороша лишь в теории.** На практике успешные переговоры и получение согласия клиента — это только часть дела. Заявка, сделанная клиентом, может быть и не выполнена по множеству причин: от чисто технических до человеческого фактора. Но если не учитывать ошибки в заведении самой заявки из-за внутренних сбоев или отсутствия технической возможности подключения, то львиная доля неподключенных услуг — это отказы клиента.
Какие могут быть причины отказов
--------------------------------
Я выделил девять основных типов отказов:
1. Передумал или отпала необходимость (объединил в одну группу);
2. Не устраивает монтаж;
3. Родственники против подключения;
4. Клиенту была предоставлена некорректная информация, в следствии чего — отказ от подключения;
5. Дорого (отказ из-за цены я выделил в отдельную группу);
6. Другой провайдер предложил более выгодные по мнению клиента условия;
7. Недозвон до клиента (здесь тоже несколько типов недозвонов: сбросы, автоответчики, программы-антиспамы, иногда после единократного недозвона заявку закрывают или отправляют на доработку и др.);
8. Без объяснения причин (бывает и такое);
9. Прочее (все, что не попало в другие пункты);
Каждая из причин чаще всего имеет свои корни и объяснения. Моё личное мнение, что общая причина отказа — некачественные переговоры:
* клиенту что-то не объяснили;
* не рассказали подробно о выгодах, которые он получит, когда подключит услугу;
* предоставили неверную информацию;
* не обговорили условия монтажа;
* не взяли дополнительный контактный номер;
* переговоры прошли с лицом, не принимающим решение (не ЛПР).
Бывают случаи, когда сам клиент соглашается только ради того, чтобы от него отстали. Плюс накладываются разные внештатные ситуации как со стороны клиента, так и со стороны компании. Поэтому **оформленная заявка дает лишь** **вероятность того, что клиент подключится.**
А чему равна вероятность подключения? Вопрос — сложный и требующий исследования. Именно данным исследованием я и занялся.
Методология
-----------
В начале исследования я выделил факторы, которые на мой взгляд могут повлиять на вероятность подключения. И здесь сделаю одно важное допущение: **цена не является основополагающей причиной согласия на подключение услуг.** Считаю заблуждением, что всех интересует только цена. Если это было бы так, то все пользовались самыми дешёвыми телефонами, ездили на самых дешёвых машинах, носили самую дешёвую одежду. Про продукты питания и вовсе молчу. Я не знаю ни одного человека, который был делал выбор только на основе стоимости.
Деньги — это лишь один из ресурсов, имеющихся у человека. Кроме денег есть и время, которое он готов потратить на общение с менеджером и на визит мастера, а так же выгода в виде экономии времени за счет высокой скорости, которую клиент получает после подключения. К нематериальным ресурсам я бы отнёс ещё и эмоции, которые также получает или тратит человек. Поэтому цена, скидка, промо-период являются важными, но не основным критериями. Кроме того, цены на тарифы меняются. Выходят новые линейки тарифов и закрываются старые, стоимость одного тарифа может разниться даже в пределах одного города. Плюс нужно учитывать специфику территорий: базовые тарифы в Санкт-Петербурге отличаются, например, от тех же базовых тарифов в Мурманске. Если бы мы выбрали как основой фактор цену, то это очень бы усложнило нашу систему.
Так какой же фактор является основным? В качестве основного предлагаю для начала взять срок от момента подачи заявки до момента подключения или отказа, назовём его **сроком давности заявки:**
* Во-первых, это хорошо измеряемый параметр, так как нам всегда известны дата заведения заявки и дата закрытия (или назначения визита инсталлятора);
* Во-вторых, минимальный срок подключения (1-3 дня) практически един для всех регионов, в отличие от цены. Если не учитывать единичные случаи подключения в частном секторе или кейсы, когда проводится предварительная проверка технической возможности, то вполне реально вызвать мастера на ближайшие дни.
* В-третьих, справедливо считать, что чем меньше проходит времени от даты подачи заявки до визита мастера, тем меньше отрицательных рисков и выше вероятность подключения.
Строим модель вероятности подключения
-------------------------------------
Итак, первый параметр, который я использовал в модели — это срок от момента согласия клиента до дня подключения услуги (инсталляции). Первым этапом я занес данные по подключениям в таблицу Excel с полями, указанными под спойлером:
Поля таблицы с пояснениями* NN — номер по порядку
* NLS — лицевой счет
* USLUGA — услуга
* DATA\_N — дата заведения услуги
* DATA\_X — дата закрытия заявки или визита мастера-инсталлятора
* SROCK — срок давности заявки (расчетный параметр)
* STATUSGLAV — статус главный (открыта или закрыта заявка)
* STATUSOPENCLOSE — статус исхода
* STATUSWHF — статус причины отказа
* MANAGER — менеджер, совершивший заявку.
Кроме того, было несколько второстепенных полей, касающихся статуса самого клиента, технологии подключения, региона и др.
Первое, что пришло в голову — это посмотреть, влияет ли срок давности заявки на долю успешных подключений. Я рассчитал процент подключившихся заявок и построил график зависимости. На рисунке 1 показана зависимость доли подключений от общего числа относительно срока давности заявки:
Рисунок 1. График зависимости процента подключенных услуг от срока давности заявки.На рисунке 1 видно, что большая часть заявок успешно подключилась, если от момента заведения заявки до момента визита мастера прошло не более трех дней.
> **Вывод первый:** срок давности заявки имеет значение.
>
>
Сколько всего подключилось? Для этого за отчетный период я подсчитал все заявки, а также доли от общего числа подключений, отказов и заявок, где подключение было технически невозможно. Получилось 24,3% от общего числа заявок. Но нас больше интересует ответ на вопрос не «Почему человек подключился?», а «Почему он НЕ подключился, и что я мог сделать, чтобы человек стал нашим клиентом?».
Все отказы сгруппировал в соответствии с предложенной выше классификацией. Результаты вывел в виде диаграммы с процентным соотношением причин отказов (рисунок 2):
Рисунок 2. Доли разных типов отказа клиентов.Ищем зоны роста в отказах
-------------------------
Изучив причины отказа, я увидел, что почти половина из них относится к случаям, когда до клиента не смогли дозвониться (недозвону), или потенциальный клиент передумал или отпала необходимость. Во многом эти причины отказов схожи. А поскольку от количества подключений напрямую зависит доход менеджера по продажам, нам нужно найти первопричины данных отказов и найти способы с ними справляться.
Один из самых верных способов решения очень прост: брать второй контактный номер и обязательно предупреждать клиента, что ему ещё будет звонить служба координации (чтобы он держал телефон при себе).
Если же клиент передумал или отпала необходимость, то в презентации были не полностью раскрыты выгоды клиента. Часто клиент дает согласие на эмоциях, а после звонка его переубеждают, или эмоции спадают (клиент не против монтажа, его устраивает цена, но не настолько, чтобы подключить услуги). Решение — совершенствовать этап продаж с презентацией продукта на основе выявленных потребностей не только клиента, но и его близких.
Иногда разговор идет не с лицом, принимающем решения (ЛПР), но если явно указано отсутствие согласия родственников или других заинтересованных лиц, я классифицирую в отказы под названием «родственники против».
> **Вывод второй:** в причинах отказов кроется ключ к поиску зон роста и увеличению продаж.
>
>
Какие ещё факторы могут влиять? День недели и неделя месяца. Раньше мне казалось, что люди предпочитают подключаться в первых числах месяца и по выходным, когда есть больше свободного времени, а подключение в начале месяца связано с тем, что у людей что-то новое ассоциируется с началом: новый тариф, новый провайдер, новая услуга.
Мы начинаем что-то делать в новом году, в начале учебного года, с понедельника, с первого дня отпуска и т.д. Я сгруппировал данные по неделям. Построил таблицу (таблица 2) и гистограмму (рисунок 3), чтобы визуализировать зависимости:
| | | | |
| --- | --- | --- | --- |
| **Период** | **Неделя** | **Подключений** | **% от общего числа** |
| 1 — 7 ДЕНЬ | 1 | 35 | 14,11 |
| 8 —14 ДЕНЬ | 2 | 61 | 24,60 |
| 15 — 21 ДЕНЬ | 3 | 59 | 23,79 |
| С 22 дня | 4 | 93 | 37,50 |
| Всего | | 248 | 100 |
Рисунок 3. Распределение подключений услуг по дням недели.Из таблицы 2 и рисунка 3 видно, что клиенты предпочитают подключаться не в начале месяца, а в конце (37,5% подключений — с 22 дня месяца), и не очень активно подключаются по воскресениям, хотя в большинстве случаев есть возможность вызвать мастера на выходной.
> **Вывод третий:** день недели имеет значение. Динамика подключений новых абонентов ускоряется к концу месяца и замедляется в начале. Это важно учитывать при планировании.
>
>
Строим модель для команды менеджеров
------------------------------------
Все вышеперечисленные результаты я привёл относительно своих данных. А как дела у других менеджеров? Насколько мы похожи, и можно ли делать выводы, проанализировав только одного? Интуитивно кажется, что нет — каждый индивидуален. Давайте выберем другого менеджера наугад и построим для него аналогичные графики.
Предлагаю два самых показательных различия, на рисунках 4 и 5 ниже:
Рисунок 4. Распределение причин отказов по классам.Что бросается прежде всего: почти половина клиентов отказалась, передумав. И довольно высокий процент отказов из-за монтажа.
Как решить первую проблему мы уже разобрали. А отказ по условиям монтажа чаще всего связан с тем, что клиент не хочет сверлить отверстие в стене или дверной коробке, вести провода по квартире или его не устраивает будущее месторасположение оборудования. Но это следствие, а настоящая причина в том, что не было четко проговорены в сценарии завершения сделки все вышеперечисленные нюансы. Зона роста менеджера — четкое проговаривание условий монтажа в сценарии завершения сделки.
Теперь рассмотрим график зависимости подключения от срока давности заявки:
Рисунок 5. Зависимость процента подключений от срока давности заявок.Здесь снова проявляется индивидуальная особенность менеджера. Есть характерный пик на 7-8 днях. Возможно, он использует двухшаговый метод продажи или заводит много заявок, где клиент говорит: «Надо подумать, перезвоните через пару дней», и менеджер закрывает сделку повторным звонком. По всей видимости с такой тактикой связан и 44,12% отказов в данной категории.
Итак, мы видим, что менеджеры разные, со своими особенностями, как можно эффективно анализировать каждого из них? И можно ли их классифицировать, группировать? Естественно, можно и способов довольно много. Другое дело, что решать все это в Excel или Calс сложно. На конференции [DataTalks 3.0](https://www.youtube.com/playlist?list=PLAy-0-KaZdI3YysOoWNCnPHn3CJOTTvE6) я с интересом прослушал выступление спикеров по анализу данных в программе PowerBI: она позволяет строить интерактивные дашборды, своего рода панели визуализации данных. В качестве источника данных могут быть использованы те же таблицы Excel.
Переходим на PowerBI
--------------------
Я подключил уже имеющуюся таблицу в Excel, процесс подключения оказался очень прост.
1. Запустите PowerBI;
2. В открывшимся окне укажите в качестве источника данных таблицу Excel, как показано на скриншоте ниже (на рисунке 6). Обратите внимание, что программа различает листы, поэтому указывайте конкретный лист, где находится сама таблица.
Рисунок 6. Стартовая страница добавления данных в отчет PowerBI.Я не буду заострять внимание на том, как построить дашборд, это выходит за рамки статьи, поэтому сразу покажу уже рабочий вариант на рисунке 7:
Рисунок 7. ДашбордОчень полезный элемент PowerBI — срезы или фильтры, их можно увидеть в верхней части рабочей области. Благодаря им мы можем получить отчеты и статистику для конкретного менеджера, выбрать нужную нам дату подключения или дату закрытия заявки. Графики автоматически изменяются в зависимости от параметров фильтрации, что даёт гибкость в формировании отчета.
Если первичный файл Excel изменился (например, добавились новые данные), то достаточно просто обновить таблицу. Неизменными должны оставаться структура и названия полей. Более подробно о работе с PowerBI, примеры ее использования, а так же несколько обучающих уроков, можно почитать и посмотреть на сайте: [https://docs.microsoft.com/ru-ru/power-bi/](https://pandas.pydata.org/). Для более глубокого погружения, приведу две книги в списке источников в конце статьи.
> **Вывод четвертый:** для гибкого анализа данных и эффективной визуализации с минимальными расходами времени, следует использовать современные системы BI.
>
>
Можно ли спрогнозировать продажи?
---------------------------------
Мы выделили несколько факторов, потенциально влияющих на подключение нового клиента. А можно ли предсказать, сделать прогноз? Сейчас я веду работу над этой темой. Пока есть рабочая формула по расчету параметра, названного вероятностным коэффициентом: чем он выше, тем выше вероятность подключения. Пока используется только срок заявки.
Формула [1] представлена ниже:
*где P(k)* — *вероятностный коэффициент;
m* — *количество подключений в заданный срок;
n* — *количество заявок;
i — срок подключения.*
> **Вывод пятый:** чем большеданных будет проанализировано и больше выделено ключевых факторов, тем выше будет качество прогнозов подключения.
>
>
Переходим на Python3
--------------------
Современные реалии диктуют свои условия. С недавних пор появились дополнительные риски, связанные с прекращением поддержки некоторыми зарубежными компаниями пользователей и организаций на территории России. При всех своих плюсах PowerBI – это зарубежный продукт. Можно было перейти на отечественные аналоги. Но установка на рабочем месте дополнительных продуктов, согласование лицензий и обучение требуют времени.
Поэтому я принял решение переделать разработанную систему, используя язык программирования Python 3 и ряд библиотек, среди которых — очень мощная библиотека Pandas. Пару лет назад я проходил обучение в Школе программирования Ростелекома, и смог познакомиться с этой замечательной библиотекой. Она мне понравилась своим функционалом и постепенными уровнями вхождения: для базовых задач хватает основных функций. По мере необходимости изучаешь её уже более детально.
Продемонстрирую часть кода. Библиотеку Pandas следует установить на компьютер командой, введя в терминале:
```
pip install pandas.
```
Подключение библиотеки Pandas:
```
import pandas as pn
```
Загрузка Excel-файла:
```
if (len(sys.argv) > 2):
file_read = sys.argv[2]
else:
file_read = "default_bd3_2.xls"
print ("Открываю файл: {}".format(file_read))
exel_data_df_1 = pn.read_excel(file_read, sheet_name = 'База_21_22')
newdata_data_df_1 = exel_data_df_1.filter(["NLS","USLUGA","TEHNOLOGIA", "DATA_N","DATA_X","STATUSGLAV","STATUSWHF","STATUSOPENCLOSE","MANAGER","P"], axis = 1)
```
Добавляем новый столбец с расчетом срока давности заявки, вычитая от даты заведения заявки дату подключения для открытых заявок или дату закрытия заявки:
```
newdata_data_df_1.insert(newdata_data_df_1.columns.get_loc("DATA_X"),"SROCK","")
newdata_data_df_1 ['SROCK'] = (newdata_data_df_1 ['DATA_X'] - newdata_data_df_1 ['DATA_N']).dt.days
```
Очистка данных от пустых значений — это очень важный этап. Применительно к этому примеру я удаляю строки с неполными данными, по ситуации их можно оставлять или автоматически заменять на корректные, подставляя шаблоны или средние значения. Среднее и прочие агрегируемые показатели обоснованно использовать, когда данные являются числовыми значениями:
```
newdata_data_df_2 = newdata_data_df_1.dropna(thresh=1)
```
Группируем по менеджерам и рассчитываем долю подключений и причин отказов для каждого по отдельности:
```
df2 = newdata_data_df_2.groupby("MANAGER")["STATUSWHF"].value_counts(normalize = True)*100
```
Пример вывода на экран части информации, сведенной в таблицу:
| | | |
| --- | --- | --- |
| **MANAGER** | **STATUSWHF** | |
| ИВАНОВ | ПОДКЛЮЧЕНО | 24,468085 |
| | НЕДОЗВОН | 17,021277 |
| | ПЕРЕДУМАЛ/ОТПАЛА НЕОБХОДИМОСТЬ | 14,893617 |
| | NO | 12,765957 |
| | ДОРОГО | 6,382979 |
| ... | ... | ... |
Рассчитаем вклад каждого из менеджера в продажи всей группы, для этого за 100% берем все подключения за анализируемый период:
```
df2 = newdata_data_df_2[newdata_data_df_2["STATUSWHF"] == "ПОДКЛЮЧЕНО"]
df3 = df2["MANAGER"].value_counts(normalize = True)*100
print("Итого: {}".format(df3.sum())) #проверка на целостность, сумма должна быть равна 100
```
Выводим на экран:
Список менеджеров с указанием доли подключений от общего числаРОМАШИНА 13,127413
НИЛОВА 12,741313
ФИЛИППОВА 12,355212
МОЛОТОВ 10,038610
ТАРАСЕНКО 9,266409
ЧЕРЕВКО 8,880309
ТИМОФЕЕВ 8,880309
ИВАНОВ 8,880309
КРАВЦОВ 8,494208
ПЕТРОВ 7,335907
Name: MANAGER, dtype: float64
Итого: 100.0
Далее строим гистограмму зависимости подключения относительно срока давности заявки. Сначала получим данные по количеству подключений относительно сроком и отсортируем по индексу строки:
```
df3 = df2["SROCK"].value_counts().sort_index()
```
Полученные данные отобразим в гистограмме и выведем на экран (рисунок 8):
```
df3.plot(kind = 'bar') #тип графика
plt.xlabel("срок давности, дни") #подпись под
plt.ylabel("Количество подключений") #подпись под
plt.show()
```
Рисунок 8. Гистограмма распределения количества подключений относительно срока давности.Строим круговую диаграмму распределения причин отказа в процентном соотношении, так же с дальнейшим выводом на экран (рисунок 9):
Рисунок 9. Распределение причин отказа по классам в процентном соотношении.В конце посчитаем KPI, куда же в продажах без него:
```
df2 = newdata_data_df_2[newdata_data_df_2["STATUSWHF"] != "NO"]
df2_1 = df2["MANAGER"].value_counts()
df2 = newdata_data_df_2[newdata_data_df_2["STATUSWHF"] == "ПОДКЛЮЧЕНО"]
df2_2 = df2["MANAGER"].value_counts()
new_df2 = pn.concat([df2_1,df2_2], axis = 1)
new_df2.set_axis(["Заявки", "Подключения"],axis = 1, inplace = True) #дадим столбцам говорящие названия
new_df2 ['KPI'] = (new_df2 ['Подключения'] / new_df2 ['Заявки'])*100 print(new_df2)
print("Среднее: \t{}\t{}\t{:.2f}". format(new_df2["Заявки"].mean(),new_df2["Подключения"].mean(),new_df2["KPI"].mean()))
```
Итоговые значения можно отсортировать по любому из столбцов при необходимости, используя команду sort\_value. Например, чтобы отсортировать по KPI, используйте new\_df2.sort\_values("KPI", ascending = False), а если нужно по количеству заявок, то new\_df2.sort\_values("Заявки", ascending = False).
Полученные данные сведем в таблицу 3 с показателями KPI менеджеров отдела продаж:
| | | | |
| --- | --- | --- | --- |
| **Фамилия** | **Заявки** | **Подключений** | **KPI (%)** |
| РОМАШИНА | 111 | 34 | 30,63 |
| НИЛОВА | 97 | 33 | 34,02 |
| ТАРАСЕНКО | 93 | 24 | 25,81 |
| ПЕТРОВ | 92 | 19 | 20,65 |
| ФИЛИППОВА | 90 | 32 | 35,56 |
| ТИМОФЕЕВ | 87 | 23 | 26,44 |
| МОЛОТОВ | 87 | 26 | 29,89 |
| КРАВЦОВ | 84 | 22 | 26,19 |
| ЧЕРЕВКО | 83 | 23 | 27,71 |
| ИВАНОВ | 82 | 23 | 28,05 |
| **Среднее:** | **90,6** | **25,9** | **28,49** |
Как видно из таблицы, **большое количество продаж еще не означает лидерство по KPI**: лидер по количеству заявок Ромашина занимает лишь третье место по KPI. Зато менеджер Филиппова является самым эффективным менеджерам по KPI при среднем количестве заявок.
Используя анализ причин отказов, посмотрев зависимость срока давности заявок и количества подключений, мы можем найти сильные стороны и зоны роста каждого из менеджеров и повышать их уровень.
С документацией с примерами по языку Python 3 и библиотекой Pandas можно по данным ссылкам: <https://docs.python.org/3/>, <https://pandas.pydata.org>. Кроме того, есть немало сайтов и книг на тему анализа данных, с использованием этих инструментов. Одну из них (скорее справочник) я указал в списке источников в конце статьи.
> **Вывод шестой:** даже базовых знаний в программировании достаточно, чтобы начать самостоятельно анализировать данные. Python c библиотекой Pandas станет отличной альтернативой сторонним приложениям.
>
>
Как прогнозировать продажи
--------------------------
В начале статьи я уже упоминал про прогнозирование. Задача прогнозирования очень сложна и интересна и заслуживает отдельной статьи, сейчас же затрону этот момент на элементарном уровне. В формуле 1, представленной выше, описал как предлагаю рассчитывать коэффициент вероятности подключения применительно к одной заявке. Чем он ближе к 1, тем выше вероятность подключения.
Теперь покажу, как можно спрогнозировать количество подключений, если за вероятность подключения взять KPI менеджеров. Представим, что средний KPI примерно равен за весь анализируемый период, тогда мы берем из таблицы 3 значение 28,49. Предположим, что на подключении (инсталляции) 200 заявок. Сколько из них подключится?
Предлагаю рассчитать распределение по формуле [2] расчета повторных независимых испытаний из теории вероятности:
*где n – количество заявок;
m – желаемое количество заявок;
P – вероятность подключения клиентом, в данном случае равна среднему KPI*.
Воспользуемся Python 3 и дополнительными библиотеками numpy и scipy, чтобы рассчитать модель для всей группы и построить гистограмму распределения (рисунок 10):
```
pv = new_df2["KPI"].mean()/100
pvinstall = binom( n = 300, p = pv )
x = np.arange(1,300)
pmf = pvinstall.pmf(x)
print("Наиболее веротяное количество подключений: \t{}, плотность вероятности:\t{:.3f}" .format(pmf.argmax(),pmf.max()))
sb.set_style("whitegrid")
plt.vlines(x,0,pvinstall.pmf(x),colors='r',linestyles='-', lw = 1)
plt.xlabel("Количество подключений")
plt.ylabel("Плотность вероятности")
plt.show()
```
Рисунок 10. Распределение плотности вероятности подключений.В нашем случае наивероятнейшим числом подключений будет 84. Другим плюсом данного подхода является создание пороговых значений с одинаковой вероятностью, но с разными значениями. Таким образом выделяется пессимистичный и оптимистичный прогнозы.
Но в реальных условиях у каждого из менеджеров будет разное количество открытых заявок, и у каждого будет свой KPI. Тогда мы рассчитаем наиболее вероятные исходы для каждого, а потом сложим эти значения.
Количество открытых заявок в случайном порядке распределил среди 10 менеджеров в таблице 4:
| | | | |
| --- | --- | --- | --- |
| **Фамилия** | **Открытые заявки** | **KPI (%)** | **Прогноз подключений** |
| РОМАШИНА | 19 | 30,63 | 6 |
| НИЛОВА | 10 | 34,02 | 3 |
| ТАРАСЕНКО | 29 | 25,81 | 7 |
| ПЕТРОВ | 45 | 20,65 | 9 |
| ФИЛИППОВА | 15 | 35.56 | 5 |
| ТИМОФЕЕВ | 53 | 26,44 | 14 |
| МОЛОТОВ | 12 | 29,89 | 4 |
| КРАВЦОВ | 42 | 26,19 | 11 |
| ЧЕРЕВКО | 33 | 27,71 | 9 |
| ИВАНОВ | 42 | 28,05 | 12 |
| **Сумма:** | **300** | | **81** |
Теперь уже значение наиболее вероятного количества подключений равно 81. И это весьма ровная по KPI группа. А если есть ярко выраженный лидер продаж? Или много новичков с невысоким KPI, но большим количеством заявок? Значения могут разойтись еще больше.
> **Вывод седьмой:** при прогнозировании количества подключений за определенный период для повышения точности следует использовать индивидуальные показатели каждого менеджера, а не совокупность по всей группе.
>
>
Что это нам дает? Вместо заключения.
------------------------------------
Я рассмотрел варианты применения анализа данных для оценки эффективности менеджера. Показанные метрики позволяют дополнить привычные показатели, такие как KPI и оценка по чек-листам тремя доступными инструментами. В продажах статистика очень важна и каждый из участников процесса получает пользу:
* **Менеджеры** — видя текущие статусы заявок, подключений и анализ причин отказов, будут самостоятельно выявлять зоны роста, повышая свою эффективность и меньше теряя заявок;
* **Наставники** — оперативно оценивать прогресс менеджеров, выявлять наиболее необходимые для конкретного менеджера тренинги и мотивации;
* **Бригадиры (Супервайзеры)** — анализировать текущую ситуацию по множеству факторов, включая индивидуальные показатели. Группировать менеджеров для повышения их эффективности. Подбирать наиболее эффективные базы и план работ учитывая индивидуальные особенности;
* **Аналитики данных** — повышают качество прогноза по выполнению плана, заменяя стандартную линейную регрессию многофакторным анализом.
Источники:
----------
* <https://docs.microsoft.com/ru-ru/power-bi/>
* Аналитика Power BI с помощью R и Python.Уэйд Р., издательство ДМК, 2021 год
* Анализ данных при помощи Microsoft Power Bi и Power Pivot для Excel, Феррари А, Руссо М., издательство ДМК, 2021 год
* <https://docs.python.org/3/>
* <https://pandas.pydata.org>
* <https://pypi.org>
* Python для сложных задач: наука о данных и машинное обучение. Плас Дж. Вандер – СПб.: Питер, 2021.
* Справочник по математике. Бронштейн И.Н., Семендяев К.А. М.: Государственное издательство физико-математической литературы, 1962 г.
* <https://datatalks.rt.ru/> | https://habr.com/ru/post/677284/ | null | ru | null |
# Максимально упрощаем работу с RecyclerView
На хабре уже полно статей на эту тему, все они в основном предлагают решения для удобного реюзинга ячеек в *RecyclerView*. Сегодня мы пойдем немного дальше и приблизимся к простоте сравнимой с *DataBinding*.

Если вы еще не используете *DataBinding* для списков ([хороший пример](https://habrahabr.ru/post/337110/)) и делаете это по старинке — то эта статья для вас.
### Введение
Чтобы быстрее погрузиться в контекст статьи, давайте разберем что мы сейчас имеем при использовании универсального адаптера из предыдущих статей:
1. [Легкая работа со списками — RendererRecyclerViewAdapter](https://habrahabr.ru/post/323862/)
2. [Легкая работа со списками — RendererRecyclerViewAdapter (часть 2)](https://habrahabr.ru/post/337774/)
Для реализации самого простого списка с использованием *RendererRecyclerViewAdapter* *v2.x.x* вам необходимо:
Чтобы каждая модель ячейки реализовала пустой интерфейс *ViewModel*:
```
public class YourModel implements ViewModel {
...
public String getYourText() { ... }
}
```
Сделать классическую реализацию *ViewHolder*:
```
xml version="1.0" encoding="utf-8"?
```
```
public class YourViewHolder extends RecyclerView.ViewHolder {
public TextView yourTextView;
public RectViewHolder(final View itemView) {
super(itemView);
yourTextView = (TextView) itemView.findViewById(R.id.yourTextView);
}
...
}
```
Реализовать *ViewRenderer*:
```
public class YourViewRenderer extends ViewRenderer {
public YourViewRenderer(Class type, Context context) {
super(type, context);
}
public void bindView(YourModel model, YourViewHolder holder) {
holder.yourTextView.setText(model.getYourText());
...
}
public YourViewHolder createViewHolder(ViewGroup parent) {
return new YourViewHolder(inflate(R.layout.your\_layout, parent));
}
}
```
Инициализировать адаптер и передать ему необходимые данные:
```
...
RendererRecyclerViewAdapter adapter = new RendererRecyclerViewAdapter();
adapter.registerRenderer(new YourViewRenderer(YourModel.class, getContext()));
adapter.setItems(getYourModelList());
...
```
Зная о *DataBinding'e* и его простоте реализации, возникает вопрос — зачем столько лишнего кода, ведь основное — это биндинг — сопоставление данных модели с лейяутом, от которого ни куда не уйти.
В классической реализации мы используем метод *bindView()*, все остальное это лишь подготовка к нему(реализация и инициализация *ViewHolder*).
### Что такое ViewHolder и зачем он нужен?
Во фрагментах, активити и ресайклер вью мы часто используем этот паттерн, так для чего он нам нужен? Какие плюсы и минусы у него?
Плюсы:
* нет необходимости каждый раз использовать *findViewById* и указывать ID;
* не нужно каждый раз тратить процессорное время на поиск конкретного ID в xml;
* удобно обращаться в любом месте к элементу через созданное поле.
Минусы:
* необходимо писать дополнительный класс;
* необходимо для каждого ID в xml создавать поле с подобным названием;
* при изменении ID необходимо переименовывать и поле во вьюхолдере.
С некоторыми минусами отлично справляются сторонние библиотеки, например [ButterKnife](https://github.com/JakeWharton/butterknife), но в случае с *RecyclerView* нам это не сильно поможет — от самого *ViewHolder'a* мы не избавимся. В *DataBinding* мы можем создать универсальный вьюхолдер, так как эта ответственность биндинга лежит в самой xml. Что же можем сделать мы?
### Создаем дефолтный ViewHolder
Если мы будем использовать стандартную реализацию *RecyclerView.ViewHolder* как заглушку в методе *createViewHolder()*, то каждый раз в *bindView()* мы будем вынуждены использовать метод *findViewById*, давайте пожертвуем плюсами и все-таки посмотрим что получится.
Так как класс абстрактный — добавим пустую реализацию нового дефолтного вьюхолдера:
```
public class ViewHolder extends RecyclerView.ViewHolder {
public ViewHolder(View itemView) {
super(itemView);
}
}
```
Заменим в нашем *ViewRender'e* вьюхолдер:
```
public class YourViewRenderer extends ViewRenderer {
public YourViewRenderer(Class type, Context context) {
super(type, context);
}
public void bindView(YourModel model, ViewHolder holder) {
((TextView)holder.itemView.findViewById(R.id.yourTextView)).setText(model.getYourText());
}
public ViewHolder createViewHolder(ViewGroup parent) {
return new ViewHolder(inflate(R.layout.your\_layout, parent));
}
}
```
Полученные плюсы:
* не нужно реализовывать *ViewHolder* для каждой ячейки;
* реализацию метода *createViewHolder* можно вынести в базовый класс.
Теперь проанализируем потерянные плюсы. Так как мы рассматриваем *ViewHolder* в рамках *RecyclerView*, то обращаться мы к нему будем только в методе *bindView()*, соответсвенно перый и третий пункт нам не очень полезены:
* ~~нет необходимости каждый раз использовать *findViewById* и указывать ID;~~
* не нужно каждый раз тратить процессорное время на поиск конкретного ID в xml;
* ~~удобно обращаться в любом месте к элементу через созданное поле.~~
А вот производительностью мы жертвовать не можем, поэтому давайте что-то решать. Реализация вьюхолдера позволяет нам «кэшировать» найденные вью. Так давайте добавим это в дефолтный вьюхолдер:
```
public class ViewHolder extends RecyclerView.ViewHolder {
private final SparseArray mCachedViews = new SparseArray<>();
public ViewHolder(View itemView) {
super(itemView);
}
public T find(int ID) {
return (T) findViewById(ID);
}
private View findViewById(int ID) {
final View cachedView = mCachedViews.get(ID);
if (cachedView != null) {
return cachedView;
}
final View view = itemView.findViewById(ID);
mCachedViews.put(ID, view);
return view;
}
}
```
Таким образом после первого вызова *bindView()* вьюхолдер будет знать о всех своих вьюхах и последующие вызовы будут использовать закэшированные значения.
Теперь вынесем все лишнее в базовый *ViewRender*, добавим новый параметр в конструктор для передачи ID лейяута и посмотрим что получилось:
```
public class YourViewRenderer extends ViewRenderer {
public YourViewRenderer(int layoutID, Class type, Context context) {
super(layoutID, type, context);
}
public void bindView(YourModel model, ViewHolder holder) {
((TextView)holder.find(R.id.yourTextView)).setText(model.getYourText());
}
}
```
С точки зрения количества кода выглядит гораздо лучше, остался один конструктор, который всегда одинаковый. А нужно ли нам каждый раз создавать новый *ViewRenderer* ради одного метода? Я думаю нет, решаем эту проблему через делегирование и дополнительный параметр в конструкторе, смотрим:
```
public class ViewBinder extends ViewRenderer {
private final Binder mBinder;
public ViewBinder(int layoutID, Class type, Context context, Binder binder) {
super(layoutID, type, context);
mBinder = binder;
}
public void bindView(M model, ViewHolder holder) {
mBinder.bindView(model, holder);
}
public interface Binder {
void bindView(M model, ViewHolder holder);
}
}
```
Добавление ячейки сокращается до:
```
...
adapter.registerRenderer(new ViewBinder<>(
R.layout.your_layout,
YourModel.class,
getContext(),
(model, holder) -> {
((TextView)holder.find(R.id.yourTextView)).setText(model.getYourText());
}
));
...
```
Перечислим плюсы такого решения:
* не нужно каждый раз создавать *ViewHolder* и создавать переменные для вьюх;
* не нужно каждый раз создавать *ViewRenderer* и писать лишний код;
* не нужно ничего переименовывать при изменении ID вьюхи;
* все данные о вью(layoutID, concreteViewID, cast) находятся в одном месте.
### Заключение
Пожертвовав незначительными плюсами мы получили достаточно простое решение для добавления новых ячеек, это несомненно упростит работу с *RecyclerView*.
В статье приведен лишь простой пример для понимания, текущая реализация позволяет:
**Работать со вложенными RecyclerView**
```
adapter.registerRenderer(
new CompositeViewBinder<>(
R.layout.nested_recycler_view, // ID лейяута с RecyclerView для вложенных ячеек
R.id.recycler_view, // ID RecyclerView в лейяуте
DefaultCompositeViewModel.class, // дефолтная реализация вложенной ячейки
getContext(),
).registerRenderer(...) // добавляем любые типы ячеек внутрь Nested RecyclerView
);
```
**Сохранять и восстанавливать состояние ячейки при cкролле**
```
// например для сохранения scrollState вложенных RecyclerView, как в Play Market
adapter.registerRenderer(
new CompositeViewBinder<>(
R.layout.nested_recycler_view,
R.id.recycler_view,
YourCompositeViewModel.class,
getContext(),
new CompositeViewStateProvider() {
public ViewState createViewState(CompositeViewHolder holder) {
return new CompositeViewState(holder); // дефолтная реализация
}
public int createViewStateID(YourCompositeViewModel model) {
return model.getID(); // ID для сохранения и восстановления из памяти
}
}).registerRenderer(...)
);
...
public static class YourCompositeViewModel extends DefaultCompositeViewModel {
private final int mID;
public StateViewModel(int ID, List extends ViewModel items) {
super(items);
mID = ID;
}
private int getID() {
return mID;
}
}
...
public class CompositeViewState implements ViewState {
protected Parcelable mLayoutManagerState;
public CompositeViewState(VH holder) {
mLayoutManagerState = holder.getRecyclerView().getLayoutManager().onSaveInstanceState();
}
public void restore(VH holder) {
holder.getRecyclerView().getLayoutManager().onRestoreInstanceState(mLayoutManagerState);
}
}
```
**Работать с Payload при использовании DiffUtil**
```
adapter.setDiffCallback(new YourDiffCallback());
adapter.registerRenderer(new ViewBinder<>(
R.layout.item_layout, YourModel.class, getContext(),
(model, holder, payloads) -> {
if(payloads.isEmpty()) {
// полное обновление ячейки
} else {
// частичное обновление ячейки
Object yourPayload = payloads.get(0);
}
}
}
```
**Добавлять прогресс бар при подгрузке данных**
```
adapter.registerRenderer(new LoadMoreViewBinder(R.layout.item_load_more, getContext()));
recyclerView.addOnScrollListener(new YourEndlessScrollListener() {
public void onLoadMore() {
adapter.showLoadMore();
// запрос на подгрузку данных
}
});
```
Более детальные примеры вы можете найти по [ссылке](https://github.com/vivchar/RendererRecyclerViewAdapter).
### Опрос
Конструкция биндинга выглядит немного «уродливой»:
```
...
(model, holder) -> {
((TextView)holder.find(R.id.textView)).setText(model.getText());
((ImageView)holder.find(R.id.imageView)).setImageResource(model.getImage());
}
...
```
В качестве пробы я добавил пару методов в дефолтный *ViewHolder*:
```
public class ViewHolder extends RecyclerView.ViewHolder {
...
public ViewHolder setText(int ID, CharSequence text) {
((TextView)find(ID)).setText(text);
return this;
}
}
```
Результат:
```
...
(model, holder) -> holder
.setText(R.id.textView, model.getText())
.setImageResource(R.id.imageView, ...)
.setVisibility(...)
...
``` | https://habr.com/ru/post/345954/ | null | ru | null |
# Динамическая JIT компиляция С/С++ в LLVM с помощью Clang
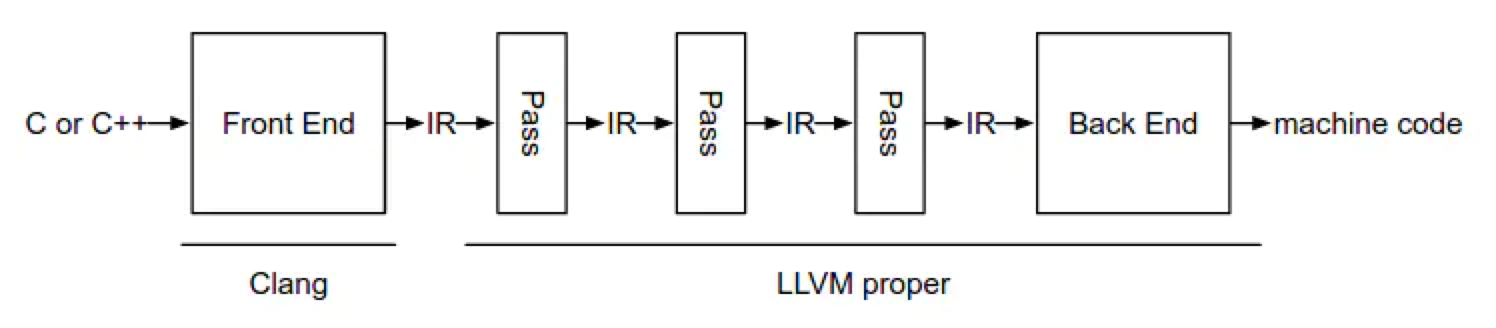
При создании компилятора для собственного языка программирования я сделал его как [транспайлер](https://ru.wikipedia.org/wiki/%D0%A2%D1%80%D0%B0%D0%BD%D1%81%D0%BF%D0%B0%D0%B9%D0%BB%D0%B5%D1%80) в исходный код на С++, вот только реализация сильно подкачала. Сначала приходится генерировать динамическую библиотеку с помощью вызова gcc, который и сам по себе не очень быстрый, так еще его может и не быть на целевой машине, особенно на другой платформе (например Windows). Конечно, для первых экспериментов и такой реализации было достаточно, но сейчас, когда я начал готовить код компилятора к публикации, стало понятно, что текущий вариант с фоновым запуском gcc никуда не годится.
Из-за этого, я решил не откладывать перевод компилятора на использование LLVM, который планировался когда нибудь в будущем, а решил сделать это уже сейчас. И для этого нужно было научиться запускать компиляцию C++ кода с помощью библиотек Clang, но тут вылезло сразу несколько проблем.
Оказывается, интерфейс Clang меняется от версии к версии и все найденные мной примеры были старыми и не запускались в актуальной версии (Сlang 12), а стабильный C-style интерфейс предназначен для парсинга и анализа исходников и с помощью которого сгенерировать исполняемые файлы не получится\*.
Дополнительная проблемой оказалось, что Clang не может анализировать файл из памяти, даже если для этого есть соответствующие классы. Из объяснений выходило, что в экземпляре компилятора проверяется, является ли ввод файлом\*\*.
А теперь публикую результат своих изысканий в виде рабочего примера динамической компиляции С++ кода с последующей его загрузкой и выполнением скомпилированных функций. Исходники адаптированны под актуальную версию Clang 12. Пояснения к коду я перевел и дополнил перед публикацией, а ссылки на исходные материалы приведены в конце статьи.
* \*) Кажется в 14 версии планируется реализовать C интерфейс для генерации исполняемых файлов.
* \*\*) На самом деле, Clang может (или теперь может) компилировать файлы из оперативной памяти, поэтому в исходники я добавил и эту возможность.
Не простой LLVM
---------------
Как было написано в самом начале, интерфейс Clang меняется от версии к версии и работающий код, например для LLVM 7, может уже не работать для LLVM 8 или 6 (текущая актуальная версия 12.1 и на подходе уже 13 версия LLVM).
А стабильный C-style интерфейс [libtooling](https://clang.llvm.org/docs/LibTooling.html) предназначен для парсинга и создания AST, а не для генерации исполняемых файлов с помощью LLVM.
#### Поэтому, последовательность этапов получается следующая:
* Распарсить исходный код С/С++ с правильными опциями и получить AST ([Abstract Syntax Tree](https://ru.wikipedia.org/wiki/%D0%90%D0%B1%D1%81%D1%82%D1%80%D0%B0%D0%BA%D1%82%D0%BD%D0%BE%D0%B5_%D1%81%D0%B8%D0%BD%D1%82%D0%B0%D0%BA%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B5_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE))
* Преобразовать AST во внутреннее представление ([Intermediate Representation](https://en.wikipedia.org/wiki/Intermediate_representation)).
* Выполнить различные оптимизации и скомпилировать IR в исполняемый код ([JIT LLVM](https://ru.wikipedia.org/wiki/JIT-%D0%BA%D0%BE%D0%BC%D0%BF%D0%B8%D0%BB%D1%8F%D1%86%D0%B8%D1%8F)).
* Далее требуется создать экземпляр LLVM модуля, который хранит всю информацию о текущей среде выполнения.
* И только затем можно будет загрузить скомпилированный код и переходить к непосредственному вызову функции, которую мы скомпилировали.
Необходимые пояснения для примера кода
--------------------------------------
Заголовочных файлов используется очень много, поэтому большинство из них вынесено в файл *#include «llvm\_precomp.h»*. Далее в отдельную функцию *InitializeLLVM()* вынесена инициализация LLVM.
~~Первое предостережение при использовании clang заключается в том, что он не может анализировать файл из памяти, даже если для этого есть классы. Причина в том, что в экземпляре компилятора он проверяет, является ли ввод файлом.~~
Первоначальный пример был сделан для Clang 6 или 7 версии, где такая возможность действительно отсутствовала, но сейчас это предостережение уже не актуально.
Во-вторых, это опции компиляции. Их нужно устанавливать таким же образом, как и в командной строке со всеми соответствующими флагами и включенными путями. Это можно сделать, позволив Сlang установить все автоматически, используя список аргументов по умолчанию.
Но самое главное, это диагностика проблем! Нужно начинать с настройки объектов, с помощью которых будут выводиться все предупреждения и ошибки в работе парсера Clang и всех последующих инструментов, необходимых для работы JIT компилятора для C/C++ кода.
Автор второй статьи (ссылки на исходные публикации приведены в конце) немного «причесал» исходный пример, т.к. ему пришлось заменить несколько *unique\_ptrs* на контейнеры *IntrusiveRefCntPtr*, предоставленные LLVM (это было необходимо, поскольку исходный код не компилировался). Еще он добавил несколько дополнительных отладочных сообщений. Сейчас в примере динамически собираются две функции *nv\_add* и *nv\_sub*.
У меня тоже сразу не получилось использовать найденные примеры кода, т.к. интерфейс Clang опять поменялся и у некоторых функций, где раньше использовались обычные ссылки на объекты, они были заменены на *IntrusiveRefCntPtr*. Хотя в основном все осталось как в изначальных исходниках.
```
clang::IntrusiveRefCntPtr DiagOpts = new clang::DiagnosticOptions;
clang::TextDiagnosticPrinter \*textDiagPrinter = new clang::TextDiagnosticPrinter(llvm::outs(), &\*DiagOpts);
clang::IntrusiveRefCntPtr pDiagIDs;
clang::DiagnosticsEngine \*pDiagnosticsEngine = new clang::DiagnosticsEngine(pDiagIDs, &\*DiagOpts, textDiagPrinter);
```
Возможно тут остался какой-то косяк, т.к. при завершении работы исходного примера, приложение падало с ошибками *Segmentation fault* или *Double free or corrupt*, но в конечном итоге методом «научного тыка» исходный код был приведен в состояние, когда пример завершается корректно.
Далее идет настройка Triple, комбинация из трех значений, которая определяет архитектуру процессора и целевую платформу. В моем случае это **x86\_64-pc-linux-gnu**. После чего идет создание самого компилятора с опциями как в командной строке.
Сейчас Clang уже умеет парсить файлы из памяти, точнее из входного потока, и для этого во входных параметрах вместо имен файлов нужно передать минус, а сами данные записать в pipe:
```
// Send code through a pipe to stdin
int codeInPipe[2];
pipe2(codeInPipe, O_NONBLOCK);
write(codeInPipe[1], (void *) func_text, strlen(func_text));
close(codeInPipe[1]); // We need to close the pipe to send an EOF
dup2(codeInPipe[0], STDIN_FILENO);
...
itemcstrs.push_back("-"); // Read code from stdin
```
Далее в коде идет настройка опций компилятора и непосредственный вызов компилятора для создания AST.
```
if(!compilerInstance.ExecuteAction(*action)) {
}
```
Генерация исполняемого кода
---------------------------
Внимание, будьте аккуратны с контекстом выполнения!
Во-первых, контекст LLVM, который мы создали, должен оставаться актуальным до тех пор, пока мы используем что-либо из этого модуля компиляции. Это очень важно, потому что все, что сгенерировано с помощью JIT, должно оставаться в памяти после генерации кода и находится в его контексте до тех пор, пока не будет удалено явно.
Вторая проблема заключается в том, что по умолчанию не выполняется оптимизация IR. И это приходится выполнять вручную.
Первым делом получается модуль LLVM из предыдущего действия.
```
std::unique_ptr module = action->takeModule();
if(!module) {
...
}
```
После чего можно выполнять разные проходы оптимизации. Код для оптимизации довольно сложен, но это LLVM… и одна из причин, по которой API продолжает видоизменяться от версии к версии.
```
llvm::PassBuilder passBuilder;
llvm::LoopAnalysisManager loopAnalysisManager(codeGenOptions.DebugPassManager);
llvm::FunctionAnalysisManager functionAnalysisManager(codeGenOptions.DebugPassManager);
llvm::CGSCCAnalysisManager cGSCCAnalysisManager(codeGenOptions.DebugPassManager);
llvm::ModuleAnalysisManager moduleAnalysisManager(codeGenOptions.DebugPassManager);
passBuilder.registerModuleAnalyses(moduleAnalysisManager);
passBuilder.registerCGSCCAnalyses(cGSCCAnalysisManager);
passBuilder.registerFunctionAnalyses(functionAnalysisManager);
passBuilder.registerLoopAnalyses(loopAnalysisManager);
passBuilder.crossRegisterProxies(loopAnalysisManager, functionAnalysisManager, cGSCCAnalysisManager, moduleAnalysisManager);
llvm::ModulePassManager modulePassManager = passBuilder.buildPerModuleDefaultPipeline(llvm::PassBuilder::OptimizationLevel::O3);
modulePassManager.run(*module, moduleAnalysisManager);
```
И только после этого можно использовать JIT-компилятор и искать в контексте нужную нам функцию. Имейте в виду, что модуль LLVM должен оставаться актуальным до тех пор, пока вы собираетесь используете скомпилированные данные!
```
llvm::EngineBuilder builder(std::move(module));
builder.setMCJITMemoryManager(std::make_unique());
builder.setOptLevel(llvm::CodeGenOpt::Level::Aggressive);
auto executionEngine = builder.create();
if(!executionEngine) {
...
}
reinterpret\_cast (executionEngine->getFunctionAddress(function));
```
Исходники
---------
Исходники проекта опубликованы на [bitbucket](https://bitbucket.org/afteri-ru/cpp-jit-llvm/src/master/) (т.к. github.com хочет либо идентификацию с помощью внешних сервисов или настроить двухфакторную аутентификацию с помощью сертификатов). С первым не хочу заморачаться, а второе лень настраивать.
> remote: Support for password authentication was removed on August 13, 2021. Please use a personal access token instead.
>
> remote: Please see [github.blog/2020-12-15-token-authentication-requirements-for-git-operations](https://github.blog/2020-12-15-token-authentication-requirements-for-git-operations/) for more information.
>
> fatal: недоступно: The requested URL returned error: 403
Сборка примера
--------------
Сборку исходников я проверял только под linux с установленным Clang 12. Система сборки используется от древней версии NetBeans, но все собирается стандартно с помощью команды make.
В статье использованы следующие материалы
-----------------------------------------
[Compiling C++ code in memory with clang](https://blog.audio-tk.com/2018/09/18/compiling-c-code-in-memory-with-clang/) и [её переработка](https://wiki.nervtech.org/doku.php?id=blog:2020:0410_dynamic_cpp_compilation) с небольшими исправлениями с учетом версии Clang. Еще добавил в пример компиляцию кода из оперативной памяти, который нашел [тут](https://stackoverflow.com/questions/34828480/generate-assembly-from-c-code-in-memory-using-libclang).
З.Ы.
----
Собственно на этом все.
Пишите, если будут комментарии или замечания.
### А вообще, настоящая JIT компиляция С++ кода, это очень круто!
**Исходники примера JIT компилятора С/С++**
```
#include
#include
#include
#include
#include
#include "llvm\_precomp.h"
//#define NV\_LLVM\_VERBOSE 1
bool LLVMinit = false;
#define ERROR\_MSG(msg) std::cout << "[ERROR]: "< DiagOpts = new clang::DiagnosticOptions;
clang::TextDiagnosticPrinter \*textDiagPrinter =
new clang::TextDiagnosticPrinter(llvm::outs(), &\*DiagOpts);
clang::IntrusiveRefCntPtr pDiagIDs;
clang::DiagnosticsEngine \*pDiagnosticsEngine =
new clang::DiagnosticsEngine(pDiagIDs, &\*DiagOpts, textDiagPrinter);
// Целевая платформа
std::stringstream ss;
ss << "-triple=" << llvm::sys::getDefaultTargetTriple();
std::cout << llvm::sys::getDefaultTargetTriple();
std::istream\_iterator begin(ss);
std::istream\_iterator end;
std::istream\_iterator i = begin;
std::vector itemcstrs;
std::vector itemstrs;
while(i != end) {
itemstrs.push\_back(\*i);
++i;
}
for (unsigned idx = 0; idx < itemstrs.size(); idx++) {
// note: if itemstrs is modified after this, itemcstrs will be full
// of invalid pointers! Could make copies, but would have to clean up then...
itemcstrs.push\_back(itemstrs[idx].c\_str());
}
// Компиляция из памяти
// Send code through a pipe to stdin
int codeInPipe[2];
pipe2(codeInPipe, O\_NONBLOCK);
write(codeInPipe[1], (void \*) func\_text, strlen(func\_text));
close(codeInPipe[1]); // We need to close the pipe to send an EOF
dup2(codeInPipe[0], STDIN\_FILENO);
itemcstrs.push\_back("-"); // Read code from stdin
clang::CompilerInvocation::CreateFromArgs(compilerInvocation, llvm::ArrayRef(itemcstrs.data(), itemcstrs.size()), \*pDiagnosticsEngine);
auto\* languageOptions = compilerInvocation.getLangOpts();
auto& preprocessorOptions = compilerInvocation.getPreprocessorOpts();
auto& targetOptions = compilerInvocation.getTargetOpts();
auto& frontEndOptions = compilerInvocation.getFrontendOpts();
#ifdef NV\_LLVM\_VERBOSE
frontEndOptions.ShowStats = true;
#endif
auto& headerSearchOptions = compilerInvocation.getHeaderSearchOpts();
#ifdef NV\_LLVM\_VERBOSE
headerSearchOptions.Verbose = true;
#endif
auto& codeGenOptions = compilerInvocation.getCodeGenOpts();
targetOptions.Triple = llvm::sys::getDefaultTargetTriple();
compilerInstance.createDiagnostics(textDiagPrinter, false);
llvm::LLVMContext context;
std::unique\_ptr action = std::make\_unique(&context);
if(!compilerInstance.ExecuteAction(\*action)) {
ERROR\_MSG("Cannot execute action with compiler instance.");
}
// Runtime LLVM Module
std::unique\_ptr module = action->takeModule();
if(!module) {
ERROR\_MSG("Cannot retrieve IR module.");
}
// Оптимизация IR
llvm::PassBuilder passBuilder;
llvm::LoopAnalysisManager loopAnalysisManager(codeGenOptions.DebugPassManager);
llvm::FunctionAnalysisManager functionAnalysisManager(codeGenOptions.DebugPassManager);
llvm::CGSCCAnalysisManager cGSCCAnalysisManager(codeGenOptions.DebugPassManager);
llvm::ModuleAnalysisManager moduleAnalysisManager(codeGenOptions.DebugPassManager);
passBuilder.registerModuleAnalyses(moduleAnalysisManager);
passBuilder.registerCGSCCAnalyses(cGSCCAnalysisManager);
passBuilder.registerFunctionAnalyses(functionAnalysisManager);
passBuilder.registerLoopAnalyses(loopAnalysisManager);
passBuilder.crossRegisterProxies(loopAnalysisManager, functionAnalysisManager, cGSCCAnalysisManager, moduleAnalysisManager);
llvm::ModulePassManager modulePassManager = passBuilder.buildPerModuleDefaultPipeline(llvm::PassBuilder::OptimizationLevel::O3);
modulePassManager.run(\*module, moduleAnalysisManager);
llvm::EngineBuilder builder(std::move(module));
builder.setMCJITMemoryManager(std::make\_unique());
builder.setOptLevel(llvm::CodeGenOpt::Level::Aggressive);
std::string createErrorMsg;
builder.setEngineKind(llvm::EngineKind::JIT);
builder.setVerifyModules(true);
builder.setErrorStr(&createErrorMsg);
std::string triple = llvm::sys::getDefaultTargetTriple();
DEBUG\_MSG("Using target triple: " << triple);
auto executionEngine = builder.create();
if(!executionEngine) {
ERROR\_MSG("Cannot create execution engine.'" << createErrorMsg << "'");
}
DEBUG\_MSG("Retrieving nv\_add/nv\_sub functions...");
typedef int(\*AddFunc)(int, int);
typedef int(\*SubFunc)(int, int);
AddFunc add = reinterpret\_cast (executionEngine->getFunctionAddress("nv\_add"));
if(!add) {
ERROR\_MSG("Cannot retrieve Add function.");
} else {
int res = add(40, 2);
DEBUG\_MSG("The meaning of life is: " << res << "!");
}
SubFunc sub = reinterpret\_cast (executionEngine->getFunctionAddress("nv\_sub"));
if(!sub) {
ERROR\_MSG("Cannot retrieve Sub function.");
} else {
int res = sub(50, 8);
DEBUG\_MSG("The meaning of life is really: " << res << "!");
}
DEBUG\_MSG("Done running clang compilation.");
return 0;
}
```
[](https://timeweb.com/ru/?utm_source=habr&utm_medium=banner&utm_campaign=10S&utm_content=low) | https://habr.com/ru/post/572878/ | null | ru | null |
# Приёмы неблокирующего программирования: введение в compare-and-swap
[В первой части этого цикла статей](https://habr.com/ru/post/545996/) мы рассмотрели теорию, стоящую за одновременным доступом в моделях памяти, а также применение этой теории к простым чтениям и записям в память. Правда, этих примитивов оказывается недостаточны для построения высокоуровневых механизмов синхронизации вроде спинлоков, мьютексов и условных переменных. Хоть и полные барьеры памяти позволяют синхронизировать потоки с помощью приёмов, рассмотренных в предыдущей части ([алгоритм Деккера](https://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%94%D0%B5%D0%BA%D0%BA%D0%B5%D1%80%D0%B0)), современные процессоры позволяют получить нужный эффект проще, быстрее и гибче — да, всё сразу! — с помощью операций compare-and-swap.
Для программистов ядра Linux операция обмена compare-and-swap выглядит так:
```
T cmpxchg(T *ptr, T old, T new);
```
где T может быть либо числовым типом не больше указателя, либо указателем на что-нибудь. Так как в C нет обобщённых функций, то подобный полиморфизм реализуется макросами. cmpxchg() — это очень аккуратно реализованный макрос, который ведёт себя как функция (например, вычисляет аргументы только один раз). В Linux также есть макрос cmpxchg64(), который работает с 64-битными целыми числами и недоступен на 32-битных платформах.
cmpxchg() читает значение по указателю \*ptr и, если оно равно old, то заменяет его на new. Иначе же после чтения ничего не происходит. Считанное значение возвращается как результат операции, независимо от того, произошла ли запись. И всё это выполняется атомарно: если другой поток одновременно с cmpxchg() записывает что-то по адресу \*ptr, то cmpxchg() ничего не меняет. Либо old становится new, либо текущее значение остаётся нетронутым. Поэтому cmpxchg() называют *атомарной операцией read-modify-write*.
В ядре Linux cmpxchg() также предоставляет окружающему коду гарантии порядка операций с памятью. Для выполнения атомарного обмена значений требуется и читать, и писать в память. С некоторыми оговорками можно считать, что чтение здесь имеет acquire-семантику, а запись — это release-операция. То есть cmpxchg() будет синхронизироваться с load-acquire и store-release операциями в других потоках.
Стеки и очереди без блокировок
------------------------------
Статья «[Lockless algorithms for mere mortals](https://lwn.net/Articles/827180/)» рассказывает, как compare-and-swap позволяет работать со списками без мьютексов — с подробным разбором и иллюстрациями. Здесь же мы ограничимся рассмотрением односвязного списка в качестве примера: как его реализовать на C, где он может пригодиться. Начнём с простого: как добавляется элемент в начало односвязного списка.
```
struct thing {
struct thing *next;
...
};
struct thing *first;
node->next = first;
first = node;
```
Как мы теперь знаем, присваивание “first” следует выполнять release-операцией, чтобы другие потоки увидели “node->next” после выполнения load-acquire. Хорошо, пока всё идёт по плану и шаблону из первой статьи.
Однако, такой простой код корректно работает лишь для случая, когда ровно один поток может модифицировать список. Если таких потоков-писателей может быть несколько, то уже оба присваивания должны быть защищены критической секцией. В противном случае, если какой-то другой поток изменяет значение first (добавляет элемент, например), то node->next в свежедобавленном элементе может указывать на старое значение first и один элемент списка окажется утерян. Из этого следует важный урок: корректное использование acquire и release-семантики — это необходимое, но отнюдь не достаточное условие корректности неблокирующих алгоритмов. Сами по себе они не защищают вас от логических ошибок и гонок потоков.
К счастью, в данной ситуации вместо блокировки можно воспользоваться cmpxchg(), чтобы поймать ситуацию, когда какой-то другой поток изменил first первым. Следующий код будет корректным уже для любого числа потоков-писателей:
```
if (cmpxchg(&first, node->next, node) == node->next)
/* ура, сработало! */
else
/* и что теперь? */
```
И тут возникают вопросы. Во-первых, что же делать, когда cmpxchg() заметит изменения в first? В нашем случае ответ простой: считать новое значение, обновить node->next, попробовать добавить node в список ещё раз. Это новый элемент, который пока ещё не видно из других потоков. Если нам не повезло с добавлением — никто ничего не заметит.
Второй вопрос гораздо более хитрый: как именно в таком случае следует считывать first? По идее нам не нужна acquire или release-семантика, ведь нас волнует только значение first само по себе. С другой стороны, [слишком умный оптимизирующий компилятор](https://lwn.net/Articles/793253/) может подумать, что раз мы ничего не присваиваем first в этом потоке, то значение не могло измениться и ничего повторно читать из памяти не нужно. Хоть cmpxchg() в Linux и запрещает подобные оптимизации, хорошим тоном считается явно показывать с помощью READ\_ONCE(), что мы хотим считать новое значение из памяти.
Улучшенная версия кода выглядит так:
```
struct thing *old, *expected;
old = READ_ONCE(first);
do {
node->next = expected = old;
old = cmpxchg(&first, expected, node);
} while (old != expected);
```
Отлично, добавление в список работает. Перейдём к другой стороне проблемы: как следует забирать значения из этого списка. Зависит из того, чего мы хотим добиться, передавая значения через список, сколько потоков будут из него читать, и в каком порядке они хотят это делать: LIFO или FIFO, от новых элементов к старым или наоборот.
Самый простой случай — это когда все чтения из списка гарантированно происходят после записей. Доступ к списку синхронизируется каким-нибудь другим образом, так что при чтении список уже не изменяется и обычные, не атомарные операции полностью безопасны. Например, если читатели запускаются после писателей, дождавшись завершения потоков, которые собирают список дальнейшей работы, как было в первой статье.
Если чтения выполняются редко или группами, то можно сделать так, что писатели работают совместно, не блокируя друг друга, а доступ читателей строго синхронизируется. Берём rwlock и переворачиваем его! Писатели захватывают блокировку совместно (через read\_lock()), а читатели требуют эксклюзивного доступа (через write\_lock()). В таком случае запись в список не может происходить одновременно с чтением, так что читателям снова не нужны никакие атомарные операции. Остаётся только надеяться, что вы пишете хорошие комментарии к своему коду, чтобы у *ваших* читателей не случился взрыв мозга.
Если читателей много, но им не особо важен порядок элементов в списке — например, пул рабочих потоков, где каждый поток хочет взять себе работы — то для этого достаточно всего одной инструкции:
```
my_tasks = xchg_acquire(&first, NULL);
```
xchg() подобно cmpxchg() атомарно выполняет одновременно чтение и запись в память. В данном случае читает и возвращает старое значение first, всегда записывая вместо него NULL. То есть переносит значение first в my\_tasks. Здесь используется вариант xchg\_acquire(), придающий acquire-семантику чтению из памяти, но при этом запись выполняется просто атомарно, без release-семантики (подобно WRITE\_ONCE()). Тут достаточно лишь acquire-семантики, потому что release-половинка находится в другом месте (у писателей). В целом, это всё тот же приём из первой части, только расширенный на случай более чем двух потоков.
Можно ли при этом заменить cmpxchg() у писателя на cmpxchg\_release() — с записью через release, но обычным чтением? По идее так можно сделать, ведь писателю важно только то, чтобы его запись в “node->next” была видна другим потокам. Однако, acquire-семантика чтения у cmpxchg() имеет полезный побочный эффект: так каждый следующий писатель синхронизируется с предыдущими писателями. Вызовы cmpxchg() упорядочиваются благодаря парам acquire и release-операций:
```
поток 1: load-acquire first (возвращает NULL)
store-release node1 --> first
\
поток 2: load-acquire first (возвращает node1)
store-release node2 --> first
\
поток 3: load-acquire first (возвращает node2)
store-release node3 --> first
\
поток 4: xchg-acquire first (возвращает node3)
```
Только cmpxchg() из третьего потока синхронизирована с xchg\_acquire() в четвёртом потоке. Однако благодаря транзитивности, все другие cmxchg() *происходят перед* xchg\_acquire(). Если писатели используют cmpxchg(), то после xchg\_acquire() по списку можно пройти уже с помощью обычных операций чтения.
Если бы писатели использовали cmpxchg\_release(), то отношения порядка между потоками выглядели бы так:
```
поток 1: load first (возвращает NULL)
store-release node1 --> first
поток 2: load first (возвращает node1)
store-release node2 --> first
поток 3: load first (возвращает node2)
store-release node3 --> first
\
поток 4: xchg-acquire first (возвращает node3)
```
Четвёртый поток конечно же прочитает node2 из node3->next, потому что он уже прочитал значение first, которое записал третий поток. Но вот для последующих элементов списка наблюдаемый порядок записей других потоков уже не гарантируется — при использовании обычных операций чтения — поэтому четвёртому потоку требуется использовать smp\_load\_acquire() для прохода по списку, чтобы точно увидеть node1 при чтении node2->next.
Конечно же односвязные списки давно реализованы в ядре Linux — [linux/llist.h](https://elixir.bootlin.com/linux/v5.11.2/source/include/linux/llist.h) — поэтому можно не переизобретать колесо и пользоваться готовыми решениями. Теперь обратим внимание на ещё пару интересных функций: llist\_del\_first() и llist\_reverse\_order().
[llist\_del\_first()](https://elixir.bootlin.com/linux/v5.11.2/source/lib/llist.c#L39) вынимает и возвращает первый элемент списка. Документация предупреждает, что эта функция безопасна только для единственного читателя. Если несколько потоков одновременно забирают элементы списка, то при определённом стечении обстоятельств возможна так называемая [*проблема ABA*](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%BE%D0%B1%D0%BB%D0%B5%D0%BC%D0%B0_ABA). Я не буду вдаваться здесь в детали, просто не надо так делать. Возникает ситуация, похожая на предыдущий пример с rwlock: для корректной работы алгоритма в целом необходимо пользоваться блокировками, но определённые части могут обойтись без них. llist\_del\_first() позволяет любому количеству писателей добавлять элементы в список с помощью llist\_add() без каких-либо блокировок, но если читателей несколько, то они между собой должны пользоваться мьютексом или спинлоком.
llist\_del\_first() превращает список в LIFO-контейнер (стек). Если же вам требуется FIFO-порядок (очередь), то можно воспользоваться следующим приёмом с [llist\_reverse\_order()](https://elixir.bootlin.com/linux/v5.11.2/source/lib/llist.c#L72). Если забирать элементы из списка пачками с помощью xchg() (или же [llist\_del\_all()](https://elixir.bootlin.com/linux/v5.11.2/source/include/linux/llist.h#L227)), то пачки сохраняют FIFO-порядок между собой, только элементы в них следуют в обратном порядке. Воу, а что если...
```
struct thing *first, *current_batch;
if (current_batch == NULL) {
current_batch = xchg_acquire(&first, NULL);
/* перевернуть список current_batch */
}
node = current_batch;
current_batch = current_batch->next;
```
Таким образом можно забирать элементы из списка в порядке их поступления, подобно очереди. Как и в случае с llist\_del\_first(), это работает только если элементы current\_batch обрабатываются одним потоком. Полная реализация этого алгоритма с помощью API llist оставляется читателю в качества упражнения.
На этом у меня пока всё. В следующей части мы продолжим изучать атомарные read-modify-write операции, посмотрим, что ещё можно сделать с compare-and-swap и как её можно использовать для ускорения счётчиков ссылок.
> Дейв Чиннер — один из основных сопровождающих XFS и Btrfs — оставил [замечательный комментарий](https://lwn.net/Articles/849239/) касательно производительности cmpxchg().
Есть пара достаточно важных моментов про неблокирующие алгоритмы, использующие cmpxchg. Они как бы подразумеваются в статье, но явно не рассматриваются. cmpxchg определяется как «атомарная операция read-modify-write», что технически корректно, но умалчивает некоторые ограничения масштабирования, с которыми сталкиваются «неблокирующие» алгоритмы на основе cmpxchg.
1. cmpxchg — это блокирующая операция: на уровне железа, не программном, но всё же блокирующая. Кроме того, она инвалидирует кеш-линии, со всеми вытекающими: неизбежно наступает момент, когда межпроцессорная шина насыщается, нагрузка на процессоры начинает расти нелинейно и производительность падает.
2. cmpxchg не очень равномерно и справедливо распределяет нагрузку между процессорами, что легко может привести к взаимным блокировкам и просадкам производительности под высокой нагрузкой. Здесь уже вылезают особенности реализации протоколов когерентности кеша (при должном опыте по задержкам в исполнении инструкций можно догадываться о том, что там происходит на уровне железа).
Поэтому большинство алгоритмов в ядре выходят из цикла cmpxchg() после некоторого числа неудач, а потом переходят к плану Б: скажем, захватывают спинлок, чтобы избежать негативных последствий высокой нагрузки на cmpxchg. Например, dentry-кеш использует механизм lockref (lockref\_get/lockref\_put), который прекращает крутить цикл cmpxchg() после 100 неудачных попыток.
Dentry-кеш ускоряет работу с именами файлов, чтобы ядро не бегало каждый раз в файловую систему заново. Например, если вы открываете только что созданный файл, то он наверняка будет в dentry-кеше и ядру не придётся лишний раз перепроверять, что все промежуточные директории существуют.
Чтобы вы примерно себе представляли, когда конфликты за кеш-линии становятся проблемой (при достижении протоколом когерентности кешей точки насыщения), на моей машине нагрузка на процессор перестаёт линейно расти где-то при 2,5–3 миллионах операций в секунду, если взять простой цикл с cmpxchg() для 64-битного значения на своей собственной кеш-линии, где больше ничего не происходит. Это в 32 потока на машине двухлетней давности с 32 ядрами. Они не прям под завязку нагружены, но если попрофайлить конкретный цикл, создавая 650000 файлов в секунду, то можно наблюдать, как суммарно этот цикл начинает занимать вполне значимое количество ресурсов: единицы процентов процессорного времени.
Если сравнить со спинлоками, то при похожей нагрузке приблизительно треть времени тратится только на то, чтобы крутить спинлоки. Конкретно, если посмотреть на спинлок, защищающий список inode в суперблоке файловой системы, то при 2,6 миллионах доступов в секунду на спинлоки уходит около 10% процессорных ресурсов (то есть 3 из 32 процессоров). Очень похоже на cmpxchg, который начинает тупить где-то в этом же районе, и если подумать, как оба варианта обращаются с кешем, то наблюдаемое поведение вполне логично.
Другими словами, cmpxchg() масштабируется лучше, чем блокирующие алгоритмы, но это не волшебная таблетка, делающая всё быстрее. У cmpxchg() тоже есть пределы масштабируемости, так как это не вполне неблокирущая операция. Впрочем, мой опыт проектирования многопоточных алгоритмов подсказывает, что масштабируемость зависит больше от того, насколько часто алгоритму требуется читать или обновлять разделяемые данные, а не от того, насколько «(не)блокирующий» алгоритм используется. Мьютекс — это ж фактически просто атомарный флажок «захвачено» и немного оптимизаций. Так что неудивительно, что cmpxchg() и атомарные примитивы имеют схожие ограничения в масштабируемости с блокировками — фундаментально, если посмотреть с точки зрения кеша, все эти подходы об одном и том же. Просто cmpxchg() и атомарные операции дают более тонкий контроль над памятью, уменьшая частоту одновременного доступа к данным. Отсюда и выгода: если меньше трогать общую память, то можно делать больше независимой работы.
Искусство многопоточного программирования во многом завязано на понимание того, как алгоритмы работают с памятью. Недостаточно лишь примерно представлять, как работают неблокирующие алгоритмы — нужно чётко понимать, что именно они делают с памятью и когда упираются в пределы своих возможностей. Естественно, знать, когда *не нужно* использовать неблокирующие алгоритмы вовсе, потому что есть другие способы распараллелить работу — это тоже искусство :)
> На что последовал [ответ автора](https://lwn.net/Articles/849245/) — Паоло.
Дейв, огромное спасибо за ответ. Прям в корень зришь — я сомневался, стоит ли вообще рассказывать о связных списках, во многом из-за описанных тобой причин. С одной стороны, связные списки — это прямо классический пример неблокирущих структур данных. С другой стороны, они не настолько широко применимы, как другие вещи, о которых я рассказываю, вот как раз из-за ограничений в масштабируемости. Нет, у связных списков есть своя ниша, но их слишком легко использовать там, где не надо. Например, в тех немногих случаях, когда мне были нужны именно llist, я принял такое решение не потому, что неблокирующее добавление в список — это круто (нет, это прикольно, но у него проблемы с распределением работы между процессорами при повышенной нагрузке). Наоборот, я знал, что писателей будет немного и записи будут редкими, а вот читатель будет лишь один и его хотелось сделать как можно более быстрым. Я бы не назвал это очевидным решением задачи.
В конце концов я всё же рассказал о связных списках, потому что из них выходит хороший пример — и что более важно, закономерно возникает вопрос, *когда* лучше применять именно неблокирующие алгоритмы.
Вообще я хотел раскрыть эту тему в заключительной части (может теперь передумаю :) но раз такое дело… Чему я хочу научить людей этими статьями, так это с одной стороны не бояться применять неблокирующие алгоритмы: их можно свести к некоторому множеству понятных шаблонов и абстракций — это не тайная магия, доступная лишь избранным. С другой стороны, неблокирующие алгоритмы — это лишь инструмент, один из подходов к решению задач. Часто гораздо более важным моментом оказывается читабельность и простота поддержки кода.
* Если вы знаете пару-тройку широко известных приёмов (которые часто ещё и завёрнуты в удобные API), то внезапно ваш код становится *проще* поддерживать и масштабируемость тоже скорее всего будет получше, несмотря на то, что неблокирующее программирование сложнее мьютексов. И вот тут неблокирующие связные списки — это как раз плохой пример, потому что в неопытных руках от них порой больше вреда чем пользы.
* Следует как можно чётче разделять «быструю» неблокирующую часть кода — которая либо реализует один из рассмотренных приёмов, либо использует какую-нибудь готовую абстракцию вроде того же lockref — и «медленную» часть, где можно позволить себе блокировки. Гораздо проще выбрать правильный примитив, если неблокирующая часть небольшая и аккуратная.
* На выбор очень сильно влияют обстоятельства. Если у вас только один читатель или писатель, то дело существенно упрощается, так как скорее всего ваш алгоритм попадает в какой-нибудь из привычных, готовых шаблонов.
Чтобы добиться максимальной производительности, вам необходимо знать относительную частоту записей и чтений (или распределение работы между быстрой и медленной частями алгоритма). Иначе вы ж понятия не имеете, где у вас могут возникнуть проблемы с масштабируемостью. Неблокирующие алгоритмы — это всегда компромисс (моя история с llist служит примером, но пожалуй наиболее известный пример — это RCU). Стоит иметь это в виду, ведь если ваш код выполняется достаточно редко, то на медленную часть можно не особо обращать внимание, добавить туда мьютекс и превратить много читателей/писателей в одного (в один момент времени), что может значительно упростить вам жизнь, расширив количество применимых шаблонов неблокирующего программирования. | https://habr.com/ru/post/549074/ | null | ru | null |
# jQuery.viewport или как я искал элементы на экране

Равно как у каждой девушки должно быть «маленькое черное платьице», у каждого front-end разработчика должен быть «маленький черный плагинчик»… как-то не очень звучит, пусть будет «маленький функциональный плагинчик», так о чем это я, я это о том, что хочу одним таким поделиться.
Представленный плагин позволяет определять положение какого-либо элемента/набора элементов, относительно области просмотра. Функционально, он расширяет набор псевдо-селекторов, а так же добавляет трекер элементов.
Так же, под катом, я расскажу о процессе написания плагина, с какими трудностями столкнулся и т.д., если я Вас заинтересовал — милости прошу под кат.
Встала давеча передо мной задача, ловить и обрабатывать элементы в момент их появления в области видимости, причем, область видимости — не всегда весь экран, иногда это блок с `overflow: auto;`, а иногда надо обрабатывать элементы только когда они появятся на экране целиком и более того прокрутка там во все стороны( вертикально или/и горизонтально ).
Пошел я значится в гугол на поиски чего-либо готового и к моему удивлению, ничего, что полностью удовлетворяло бы моим запросам, я не нашел, либо задача решалась частично, как например [тут](http://www.appelsiini.net/projects/viewport) (признаться честно, идею с расширением псевдо-селекторов стырил оттуда, но ведь [эта](http://maj-ja.ru/wp-content/uploads/2013/04/wd4F8nqM4NM.jpg) картинка не врет, правда?), либо вовсе плагин был не про то. Вот я и встал перед фактом что надо писать свое, потом решил поделиться этим делом на гитхабе, а еще позже решил написать эту статью, чем собственно, успешно выполнив первые два пункта моего плана ~~по становлению знаменитостью~~, и занимаюсь.
Если Вам не интересен процесс разработки тыкаете **->>**[вот сюда](#article_bottom)**<<-** и попадаете сразу к месту о том, где раздают.
###### **Пролог**
Если Вы не знаете про написание плагинов для jQuery, но очень хотите этому научиться — крайне советую, для начала, прочитать [эту статью](http://habrahabr.ru/post/158235/), все доходчиво и понятно (предполагает наличие хотя бы базовых знаний JS и JQ).
---
##### **UPDATE 1 ( 13.10.2014 )**
— Переписана часть плагина, изменения смотрите на гитхабе.
— Обнаружена проблема, решения которой я пока не могу найти:
> Если у родительского эл-та нет ограничивающих факторов ( padding, border, overflow != visible ), то margin переходит от внутреннего элемента к внешнему, а offsetHeight родительского элемента будет рассчитан без учета margin своих потомков, в то время как scrollHeight исправно определяет высоту с учетом margin дочерних элементов. В результате, такой родительский элемент определяется как имеющий скроллинг, т.к. высота содержимого < высоты самого элемента.
---
##### **UPDATE 2 ( 16.10.2014 )**
— В качестве решения вышеописанной проблемы была добавлена возможность задать селектор вьюпорта, который необходимо отслеживать, подробности на гитхабе.
— Скорость работы плагина заметно увеличена.
---
#### **Приступим-с**
Итак, задача: надо как-то определять положение элемента относительно области видимости, причем в зависимости от контекста, областью видимости может быть не только окно браузера, но и более мелкие элементы имеющие прокрутку.
##### **Что есть область видимости?**
Начнем, пожалуй, с определения того, что же для данного контекста является областью видимости.
Для моей задачи, а писал я плагин, в первую очередь, для удовлетворения своих нужд, областью видимости является ближайший родитель, имеющий прокрутку.
К сожалению, нет гарантированного и кросс-браузерного способа определить наличие полосы прокрутки (по крайней мере я о таком не знаю), да и к тому же я использую кастомный скроллбар, его можно адекватно оформлять, но, к контейнеру применяется `overflow: hidden;` и, как следствие, стоковый скроллбар скрывается.
Но выход есть, можно сравнивать высоту контейнера( `containerElem.offsetHeight` ) и высоту его содержимого( `containerElem.scrollHeight` ) и в случае, если высота содержимого превышает высоту контейнера, то, скорее всего, а для моих проектов — всегда, такой контейнер имеет прокрутку.
Оформляем это дело в код:
```
(function( $ ) { // используем замыкание, дабы не конфликтовать с другими расширениями
var methods = { // все методы оформляем в литерал дабы не засорять глобальное пространство имен
haveScroll: function() {
return this.scrollHeight > this.offsetHeight
|| this.scrollWidth > this.offsetWidth;
}
};
$.extend( $.expr[':'], { // расширяем литерал выражений ':' своими методами, дефакто это будущий селектор ":have-scroll"
"have-scroll": function( obj ) {
return methods['haveScroll'].call( obj ); // посредством .call() определяем для выполняемого метода контекст
}
} );
})( jQuery );
```
С этого момента мы можем использовать .is( ":have-scroll" ) для определения имеет ли элемент прокрутку (или предпосылки к ее наличию) или нет.
##### **Позиционирование элемента**
Следующий этап — определение местоположения интересующего нас блока относительно области видимости.
Первое что приходит на ум:
```
top = $( element ).offset().top;
left = $( element ).offset().left;
```
Но нет, `.offset()` позиционирует любой элемент относительно левого верхнего угла окна браузера, а область видимости, как говорилось, не всегда окно браузера — не подходит, отметаем.
Второе что приходит на ум:
```
top = $( element ).position().top;
left = $( element ).position().left;
```
Тоже нет, `.position()` позиционирует элемент только относительно левого верхнего угла своего ближайшего родителя, казалось бы вот оно, но рассмотрим структуру:
```
```
А задача — отслеживать именно `span` относительно `#viewport`, в таком случае, `.position()` будет позиционировать `span` относительно `.element` что нам не подходит, погнали дальше.
Решением будет свой метод, который будет обходить всех родителей вверх по дереву DOM, вплоть до области видимости данного контекста.
```
getFromTop: function() {
var fromTop = 0;
for( var obj = $( this ).get( 0 ); obj && !$( obj ).is( ':have-scroll' ); obj = obj.offsetParent ) {
fromTop += obj.offsetTop;
}
return Math.round( fromTop );
}
```
Почему же `$( this ).get( 0 ).offsetTop`, а не `$( this ).position().top`? — спросят некоторые.
Причин на то две:* .position() учитывает смещение (top, bottom, left, right), не учитывает margin-ы, а поэтому придется использовать `.css('margin-top')` и потом еще `.css('margin-bottom')`
* эти самые `.css('margin-top')` и `.css('margin-bottom')` возвращают значение в виде `13px`, то есть надо еще и parseInt( str, 10) делать, чтобы производить базовые математические операции, вариант с вычитанием высот с учетом разных отступов( .innerHeight(), .outerHeight, .outerHeight(true) ) я даже не рассматриваю, ибо они могут быть заданы несимметрично, а нам это важно.
В конечном итоге, с учетом всех этих излишних операций, вариант с использованием `$( this ).position().top` работает в полтора-два раза медленнее нежели вариант с `this.offsetTop` на моем разогнанном i7, а юзер может сидеть на каком-нибудь пеньке, и страшно представить во что это вообще выльется.
Дописываем аналогичный метод для определения положения от левого края. ~~Хорошая мысля приходит опосля, их же можно в один метод объединить, так получится в два раза меньшее количество обходов DOM дерева, потом доделаю..~~
Итак, теперь мы знаем где, относительно области видимости, расположен отслеживаемый объект, но полученные данные, при скроллинге меняться не будут, тут нам помогут `.scrollTop()` и `.scrollLeft()`, умеющие получать значение вертикального и горизонтального скроллинга соответственно.
Более того, нам необходимо знать положение всех сторон отслеживаемого блока и размеры области видимости.
Оформляем в очередной метод:
```
getElementPosition: function() {
var _scrollableParent = $( this ).parents( ':have-scroll' ); // ищем ближайшего родителя со скроллингом, .parents() потому, что при использовании .closest(), span, порой, находит в качестве скроллабельного элемента самого себя.
if( !_scrollableParent.length ) { //на случай, если у нас все уместилось.
return false;
}
var _topBorder = methods['getFromTop'].call( this ) - _scrollableParent.scrollTop(); // здесь вычисляется положение верхней границы элемента относительно верхней же границы области вижмости
var _leftBorder = methods['getFromLeft'].call( this ) - _scrollableParent.scrollLeft(); // аналогично предыдущему только левые границы
return {
"elemTopBorder": _topBorder,
"elemBottomBorder": _topBorder + $( this ).height(), // тут еще проще, правая граница = левая + ширина элемента
"elemLeftBorder": _leftBorder,
"elemRightBorder": _leftBorder + $( this ).width(),
"viewport": _scrollableParent,
"viewportHeight": _scrollableParent.height(), // нижняя граница области видимости
"viewportWidth": _scrollableParent.width() // првая граница области видимости
};
}
```
Возвращает данная функция хэш-таблицу, с ней просто удобнее работать впоследствии. Все, с относительным позиционированием блока разобрались.
##### **И все-таки, сверху или снизу**
Сразу к коду:
```
aboveTheViewport: function( threshold ) {
var _threshold = typeof threshold == 'string' ? parseInt( threshold, 10 ) : 0;
var pos = methods['getElementPosition'].call( this );
return pos ? pos.elemTopBorder - _threshold < 0 : false;
}
```
Тут, я думаю, все ясно, единственное уточню по поводу threshold и строгого меньшинства.
Threshold — параметр задающий отступ от края области видимости, для некоторых задач может быть необходимой обработка немного раньше, чем объект войдет в область видимости или немного позже.
А строгое меньшинство указано по причине того, что если границы совпадают, то элемент еще не пересек границу и пока вписывается в зону видимости, а значит находится внутри.
Так же, для частичного нахождения в области видимости, тут уже чуть сложнее, но по прежнему просто. просто на этот раз уже проверяем что соответствующая границы вышла за пределы области видимости а противоположная еще находится в ее пределах.
```
partlyAboveTheViewport: function( threshold ) {
var _threshold = typeof threshold == 'string' ? parseInt( threshold, 10 ) : 0;
var pos = methods['getElementPosition'].call( this );
return pos ? pos.elemTopBorder - _threshold < 0
&& pos.elemBottomBorder - _threshold >= 0 : false;
}
```
Нет смысла описывать проверку остальных границ, там все аналогично, можно разве что привести код метода проверяющего нахождение элемента внутри области видимости:
```
inViewport: function( threshold ) {
var _threshold = typeof threshold == 'string' ? parseInt( threshold, 10 ) : 0;
var pos = methods['getElementPosition'].call( this );
return pos ? !( pos.elemTopBorder - _threshold < 0 )
&& !( pos.viewportHeight < pos.elemBottomBorder + _threshold )
&& !( pos.elemLeftBorder - _threshold < 0 )
&& !( pos.viewportWidth < pos.elemRightBorder + _threshold ) : true;
}
```
##### **А как же селекторы?**
С ними все хорошо, никто про них не забыл.
Итак, прописали мы все методы в объектном литерале `methods`, че дальше делать бум? Веерно, расширять литерал псевдо-селекторов:
```
"in-viewport": function( obj, index, meta ) {
return methods['inViewport'].call( obj, meta[3] );
},
"above-the-viewport": function( obj, index, meta ) {
return methods['aboveTheViewport'].call( obj, meta[3] );
},
"below-the-viewport": function( obj, index, meta ) {
return methods['belowTheViewport'].call( obj, meta[3] );
},
"left-of-viewport": function( obj, index, meta ) {
return methods['leftOfViewport'].call( obj, meta[3] );
},
"right-of-viewport": function( obj, index, meta ) {
return methods['rightOfViewport'].call( obj, meta[3] );
},
"partly-above-the-viewport": function( obj, index, meta ) {
return methods['partlyAboveTheViewport'].call( obj, meta[3] );
},
"partly-below-the-viewport": function( obj, index, meta ) {
return methods['partlyBelowTheViewport'].call( obj, meta[3] );
},
"partly-left-of-viewport": function( obj, index, meta ) {
return methods['partlyLeftOfViewport'].call( obj, meta[3] );
},
"partly-right-of-viewport": function( obj, index, meta ) {
return methods['partlyRightOfViewport'].call( obj, meta[3] );
},
"have-scroll": function( obj ) {
return methods['haveScroll'].call( obj );
}
} );
```
Стоит отметить одну фишку, помните я говорил про входной параметр `threshold`? А помните стандартный параметрический псевдо-селектор `:not(selector)`?
Так вот, мы тоже можем использовать такую конструкцию, для указания трешолда прямо в псевдо-селекторе:
```
$( element ).is( ":in-viewport(10)" );
```
В данном случае трешолд будет расширять область видимости на 10 px.
#### **Трекинг**
Такс, псевдо-селекторы расширили, надо бы теперь все это дело как-то удобным образом отслеживать что ли.
В идеале, конечно надо бы создать свое событие, но так уж исторически сложилось, что с `jQuery.event.special` мы в крайне плохих отношениях, а `.trigger()` — на мой взгляд так себе затея, не для данного случая — точно. Поэтому, у нас будет самая что ни на есть брутальная функция, которая не менее брутальным образом вызывает callBack функцию.
**Код трэкера**
```
$.fn.viewportTrack = function( callBack, options ) {
var settings = $.extend( {
"threshold": 0,
"allowPartly": false,
"allowMixedStates": false
}, options ); // настройки по-дефолту
if( typeof callBack != 'function' ) { // в случае если первым параметром пришла не функция - отказываемся делать что либо
$.error( 'Callback function not defined' );
return this;
}
return this.each( function() { // цепочки вызовов никто не отменял
var $this = this;
callBack.apply( $this, [ methods['getState'].apply( $this, [ settings ] ) ] ); // проверяем положение на момент инициалзации
var _scrollable = $( $this ).parents( ':have-scroll' );
if( !_scrollable.length ) {
callBack.apply( $this, 'inside' );
return true;
}
if( _scrollable.get( 0 ).tagName == "BODY" ) { // в случае, если скроллинг имеет body, событие scroll будет генерировать window, а не сам body, как может показаться на первый взгляд
$( window ).bind( "scroll.viewport", function() {
callBack.apply( $this, [ methods['getState'].apply( $this, [ settings ] ) ] );
} );
} else {
_scrollable.bind( "scroll.viewport", function() { // в противном же случае, событие scroll генерируется самим элементом
callBack.apply( $this, [ methods['getState'].apply( $this, [ settings ] ) ] );
} );
}
} );
};
```
**NAILED IT!**
На самом деле — нет, надо бы научить нашего брутала «откручиваться»… к черту эти выдумывания слов, короче прекращать отслеживание того или иного элемента, с этим как-раз связан тот момент, что для отслеживания каждого отдельного элемента создается свой обработчик события scroll. В случае если все callback функции будут вызываться из одного обработчика события scroll, у нас не будет возможности влиять на набор отслеживаемых элементов, не переустанавливая обработчик заново.
Тут нам помогут пространства имен событий, если произвести `.bind( "scroll.viewport")` и `.bind( "scroll")` на один и тот же элемент, а затем `.unbind( ".viewport")` на тот же элемент, то отвязан будет только обработчик события `scroll.viewport` но, не просто `scroll`.
И как же это поможет в текущей задаче? — спросите Вы, отвечаю, придется конечно подзасрать пространство пространства имен(вот такая тавтология), но цель будет достигнута, итак, добавляем метод генерирующий случайный id. тут все просто даже комментировать не буду:
```
generateEUID: function() {
var result = "";
for( var i = 0; i < 32; i++ ) {
result += Math.floor( Math.random() * 16 ).toString( 16 );
}
return result;
}
```
далее, при инициализации для каждого элемента, пушим в .data() этот самый, сгенерированный euid (element's unique id), а когда навешиваем обработчики скролла, то создаем пространство имен `.viewport + EUID`. Ну и конечно же деструктор, который перебирает EUID набора и удаляет ненужные обработчики, не задевая те которые нам еще понадобятся. В конечном варианте получаем:
**Код трэкера, финальный вариант**
```
$.fn.viewportTrack = function( callBack, options ) {
var settings = $.extend( {
"threshold": 0,
"allowPartly": false,
"allowMixedStates": false
}, options );
if( typeof callBack == 'string' && callBack == 'destroy' ) { // деструктор
return this.each( function() {
var $this = this;
var _scrollable = $( $this ).parent( ':have-scroll' );
if( !_scrollable.length || typeof $( this ).data( 'euid' ) == 'undefined' ) {
return true; // если нет скроллабельного элемента, значит мы ничего и не привязывали
} //так же если euid отсутствует, значит либо обработчик уже отвязан, либо он и не привязывался
if( _scrollable.get( 0 ).tagName == "BODY" ) {
$( window ).unbind( ".viewport" + $( this ).data( 'euid' ) );
$( this ).removeData( 'euid' );
} else {
_scrollable.unbind( ".viewport" + $( this ).data( 'euid' ) );
$( this ).removeData( 'euid' );
}
} );
} else if( typeof callBack != 'function' ) {
$.error( 'Callback function not defined' );
return this;
}
return this.each( function() {
var $this = this;
if( typeof $( this ).data( 'euid' ) == 'undefined' )
$( this ).data( 'euid', methods['generateEUID'].call() );//присваиваем EUID если оный уже не присвоен
callBack.apply( $this, [ methods['getState'].apply( $this, [ settings ] ) ] );
var _scrollable = $( $this ).parents( ':have-scroll' );
if( !_scrollable.length ) {
callBack.apply( $this, 'inside' );
return true;
}
if( _scrollable.get( 0 ).tagName == "BODY" ) {
$( window ).bind( "scroll.viewport" + $( this ).data( 'euid' ), function() { // как видно, в неймспейс подмешивается EUID
callBack.apply( $this, [ methods['getState'].apply( $this, [ settings ] ) ] );
} );
} else {
_scrollable.bind( "scroll.viewport" + $( this ).data( 'euid' ), function() {
callBack.apply( $this, [ methods['getState'].apply( $this, [ settings ] ) ] );
} );
}
} );
};
```
Один метод я пропустил, оставив на самый конец, в силу того что это тупо триггер с тучей ветвлений, зависящих от настроек которые были переданы при инициализации. Правда есть пара вещей, которые стоит отметить:* Логика, по которой определялось относительное положение элемента, дублирована в данном методе для того, чтобы не делать лишних вычислений и выборок, а лишь один раз получить все нужные данные и уже с ними работать, кода больше но зато и выборок на 8 меньше.
* Состояние возвращается в виде объекта с тремя параметрами
```
var ret = { "inside": false, "posY": '', "posX": '' };
```
Если `inside` возвращается со значением `true`, то `posY` и `posX` остаются пустыми, т.к. отслеживаемый элемент полностью поместился в область просмотра.
В противном случае указывается состояние элемента относительно каждой оси, подробнее смотрите на гитхабе.
**Код метода methods['getState']**
```
getState: function( options ) {
var settings = $.extend( {
"threshold": 0,
"allowPartly": false
}, options );
var ret = { "inside": false, "posY": '', "posX": '' };
var pos = methods['getElementPosition'].call( this );
if( !pos ) {
ret.inside = true;
return ret;
}
var _above = pos.elemTopBorder - settings.threshold < 0;
var _below = pos.viewportHeight < pos.elemBottomBorder + settings.threshold;
var _left = pos.elemLeftBorder - settings.threshold < 0;
var _right = pos.viewportWidth < pos.elemRightBorder + settings.threshold;
if( settings.allowPartly ) {
var _partlyAbove = pos.elemTopBorder - settings.threshold < 0 && pos.elemBottomBorder - settings.threshold >= 0;
var _partlyBelow = pos.viewportHeight < pos.elemBottomBorder + settings.threshold && pos.viewportHeight > pos.elemTopBorder + settings.threshold;
var _partlyLeft = pos.elemLeftBorder - settings.threshold < 0 && pos.elemRightBorder - settings.threshold >= 0;
var _partlyRight = pos.viewportWidth < pos.elemRightBorder + settings.threshold && pos.viewportWidth > pos.elemLeftBorder + settings.threshold;
}
if( !_above && !_below && !_left && !_right ) {
ret.inside = true;
return ret;
}
if( settings.allowPartly ) {
if( _partlyAbove && _partlyBelow ) {
ret.posY = 'exceeds';
} else if( ( _partlyAbove && !_partlyBelow ) || ( _partlyBelow && !_partlyAbove ) ) {
ret.posY = _partlyAbove ? 'partly-above' : 'partly-below';
} else if( !_above && !_below ) {
ret.posY = 'inside';
} else {
ret.posY = _above ? 'above' : 'below';
}
if( _partlyLeft && _partlyRight ) {
ret.posX = 'exceeds';
} else if( ( _partlyLeft && !_partlyRight ) || ( _partlyLeft && !_partlyRight ) ) {
ret.posX = _partlyLeft ? 'partly-above' : 'partly-below';
} else if( !_left && !_right ) {
ret.posX = 'inside';
} else {
ret.posX = _left ? 'left' : 'right';
}
} else {
if( _above && _below ) {
ret.posY = 'exceeds';
} else if( !_above && !_below ) {
ret.posY = 'inside';
} else {
ret.posY = _above ? 'above' : 'below';
}
if( _left && _right ) {
ret.posX = 'exceeds';
} else if( !_left && !_right ) {
ret.posX = 'inside';
} else {
ret.posX = _left ? 'left' : 'right';
}
}
return ret;
}
```
Фьюффф, вот вроде и все. Вот такой вот плагин, на 301 строку у меня получился.
#### **Ссылки**
Забрать плагин можно с моего гитхаба: <https://github.com/xobotyi/jquery.viewport>
Как пользоваться подробнейшим образом описано в readme.
Искренне надеюсь, что данная статья кому-то принесет пользу и расскажет что-нибудь новое.
За сим откланяюсь, всем кода, сна и отсутствия желания писать статью в 4 ночи.
P.s. стоит ли ставить галку «обучающий материал»? | https://habr.com/ru/post/240083/ | null | ru | null |
# Определение blocking-режима TCP-сокета под Windows
Те, кто работает с TCP-сокетами, знают что сокет может работать в блокирующем или неблокирующем (nonblocking) режиме. Windows-сокеты, после создания, находятся в блокирующем режиме, но их можно перевести в неблокирующий функцией ioctlsocket().
При работе над одним проектом у меня появилась задача определить, в каком режиме работает сокет, предоставленный мне DLL-функцией. Т.е. кроме самого сокета, у меня никакой информации не было и приходили они в непредсказуемом режиме.
Под \*nix blocking-режим без проблем определяется вызовом функции fcntl(), но под WinSock2 ничего подобного не обнаружилось, и на форумах ничего кроме «Windows does not offer any way to query whether a socket is currently set to blocking or non-blocking» никто не ответил.
Но способ определения все-таки существует:
```
// GetBlockingMode возвращает: 1 - nonblocking | 0 - blocking | -1 - error | -2 - timeout reseted!
int GetBlockingMode(int Sock)
{
int iSize, iValOld, iValNew, retgso;
iSize = sizeof(iValOld);
retgso = getsockopt(Sock, SOL_SOCKET, SO_RCVTIMEO, (char *)&iValOld, &iSize); // Save current timeout value
if (retgso == SOCKET_ERROR) return (-1);
iValNew = 1;
retgso = setsockopt(Sock, SOL_SOCKET, SO_RCVTIMEO, (char *)&iValNew, iSize); // Set new timeout to 1 ms
if (retgso == SOCKET_ERROR) return (-1);
// Ok! Try read 0 bytes.
char buf[1]; // 1 - why not :)
int retrcv = recv(Sock, buf, 0, MSG_OOB); // try read MSG_OOB
int werr = WSAGetLastError();
retgso = setsockopt(Sock, SOL_SOCKET, SO_RCVTIMEO, (char *)&iValOld, iSize); // Set timeout to initial value
if (retgso == SOCKET_ERROR) return (-2);
if (werr == WSAENOTCONN) return (-1);
if (werr == WSAEWOULDBLOCK) return 1;
return 0;
}
```
Функция принимает номер сокета и возвращает 1 если сокет в nonblocking mode, 0 — blocking, -1 если произошла ошибка определения и -2 если сокет после определения режима остался с маленьким таймаутом.
Вкратце последовательность действий такова:
1. Сохраняем значение таймаута сокета (по умолчанию там 0 — «ждать вечно»).
2. Устанавливаем таймаут в 1 милисекунду.
3. Читаем из сокета 0 (ноль) байт Out of Band данных. Тут нужно пояснение: Если передаются OOB-данные, то функция может врать, но я никогда не сталкивался с OOB с тех пор, как Windows NT4 валилась в синий экран при попытке принять такое ([WinNuke](https://en.wikipedia.org/wiki/WinNuke)).
4. Получаем ошибку, которая произошла в результате чтения.
5. Восстанавливаем старое значение таймаута сокета.
6. Смотрим что за ошибка чтения у нам была: если WSAEWOULDBLOCK — то сокет находится в nonblocking mode, что и требовалось определить.
К недостаткам данного метода, кроме уже упомянутого MSG\_OOB, можно отнести задержку определения в 1 миллисекунду и ненулевую вероятность испортить таймаут чтения сокета (хотя нагрузочный тест ни разу такого поведения не выявил). | https://habr.com/ru/post/335762/ | null | ru | null |
# Разделяй и властвуй или как сделать ваше приложение структурированным
Как говорится в древней пословице – сколько людей столько и стилей написания кода. В сегодняшней статье я хотел бы расскрыть все особенности правильной настройки структуры AngularJS.
Как в любом приложении у нас должна быть точка входа, начальная точка откуда будет стартовать наше приложение. За частую я использую просто app. В этом файле, который не плохо было бы назвать main.js мы напишем такой код:
```
(function(ng) {
var app = ng.app('app', []);
// This should be your configuration like a routeProvider or etc.
return app;
})(angular);
```
Также этот модуль будет в будущем включать остальные модули за счет dependency injection.
Что же начало положено и не плохо было бы определиться со структурой приложения. Определим определенные сущности нашего приложения. Создадим папки: animations, controllers, factories, directives. По сути, сейчас мы сформируем тот подход, что используется в Java package.
Итак, каждая из директорий что мы создали должна также содержать свои точки входа, опять же таки именуемые main.js. Для примера рассмотрим директорию с контроллерами. В main.js прописываем такой код:
```
(function(ng) {
var app = ng.app('app.controllers', []);
return app;
})(angular);
```
Как можно заметить, этот модуль будет отвечать за внедрение контроллеров, которые мы объявим ниже. Также теперь мы можем включить этот модуль в зависимости основного модуля, который примет вид:
```
(function(ng) {
var app = ng.app('app', ['app.controllers']);
// This should be your configuration like a routeProvider or etc.
return app;
})(angular);
```
Теперь опишем пару контроллеров для нашего приложения, чтобы показать как мы можем использовать. Есть определенные соглашения с названием контроллеров, а именно в стиле camel-case как класс. Чтоже создадим файл в директории controllers MainCtrl.js, который будем содержать нашу логику контроллера. Его содержимое будет примерно такое:
```
(function(ng) {
var app = ng.app('app.controllers.MainCtrl', []);
var MainCtrl = function($scope) {
var localScope = {
message: 'Message',
list: [1,2,3,4,5,6]
};
ng.extend($scope, localScope);
};
app.controller('MainCtrl', ['$scope', MainCtrl]);
return app;
})(angular);
```
Давайте разберем, почему такой подход имеет право на жизнь. Как и раньше у нас объявлен модуль, который будет встроен в зависимости основного модуля контроллеров. Сам код контроллера вынесен в отдельную функцию. После этого он включен как контроллер и использована полная запись объявления контроллера для того чтобы он не был сломан после минимизации и обфускации. Как можно заметить, в нашем контроллере создана локальная переменная как localScope. Для чего это сделано? При небольшом колличестве переменных в $scope это особо не заметно, но когда их становится много, кода становится немного не читабельным и поэтому я просто взял технику расширения основного $scope через метод angularjs extend. Как по мне, такой способ красив, лаконичен и довольно читаем. Также добавим наш контроллер в зависимоть нашего основного модуля для контроллеров. Его код будет таким:
```
(function(ng) {
var app = ng.app('app.controllers', ['app.controllers.MainCtrl']);
return app;
})(angular);
```
По такому принципу мы будем строить и другие зависимоти для директив, фабрик и так далее. Как по мне, такой подход дает полное понимание вашего приложения, его структура сразу становится видна и очень просто модернизировать, добавляя новые контроллеры, сервисы, директивы и прочее.
В заключение я хотел бы поговорить немного о контроллерах, вернее о новом синтаксисе “as”
Если мы не хотим чтобы наши переменные или же какие-то функции были observable. То мы можем полноценно использовать такой подход:
```
(function(ng) {
var app = ng.app('app.controllers.MainCtrl', []);
var MainCtrl = function($scope, $log) {
var localScope = {
message: 'Message',
list: [1,2,3,4,5,6]
};
this.nonObservableVar = {
one: 1,
two: 2
};
this.logger = function(obj) {
$log.info(obj);
};
ng.extend($scope, localScope);
};
app.controller('MainCtrl', ['$scope', '$log', MainCtrl]);
return app;
})(angular);
```
И в нашем view использовать такой код:
```
{{ main.nonObservableVar.one }}
{{ main.nonObservableVar.two }}
```
Что это нам дает? Ну одно из преимуществ, то что тут нет angular watcher’ов. Это ускоряет наше приложение, также дает возможность в вложенных контроллерах использовать контекст родительских контроллеров, что дает возможность более гибко строить наше приложение. Этот способ очень прост в использовании. Как и раньше мы также можем смешивать переменные контроллера с переменными $scope для возможности использования $watch, $apply, etc.
Если интересно, буду дальше писать про angular и как на нем строить красивые и структурированные приложения. В плане написать статью про использования angularjs с requirejs и прекрасной фичей requirejs – пакеты.
Оставляйте свои отзывы в комменариях.
PS: Я написал этот пост для того, чтобы ваше приложение можно было легко поддерживать и в дальнейшем, чтобы тот, кто будет дорабатывать ваше приложение понимал, что и как у вас там =) | https://habr.com/ru/post/215273/ | null | ru | null |
# Притча о шаблонах
— Здравствуй \*с широко развевающейся по лицу улыбкой\* дружок.
— Ваа! \*с ярким блеском в широко распахнутых глазах\* Тётя Ася приехала!
— Да, и у меня есть для тебя новая сказка \*присела и взяла малыша за руки\* хочешь послушать?
— Конечно! \*слегка смутился и отвёл взгляд\* Мне тут дядя такие страшные истории рассказывал…
— Ну, надеюсь моя история тебя не испугает \*потрепала его по волосам\* Она должна научить тебя мыслить шаблонно.
— Эээ? \*лицо перекосилось от недопонимания\* Это как?
— М… сейчас узнаешь \*подмигнула и взяла на ручки\* Вот когда тебе нужно вставить переменные в строку — ты как поступишь?
— Ну… \*взял карандаш и чирканул на лежащей рядом бумажке\* примерно так:
> `**var** query= 'xxx'
>
> **var** resultCount= 512
>
> **var** message= 'По запросу `'` + query + ' найдено страниц: ' + resultCount`
— Ты ничего не забыл? \*победоносно подняла голову\*
— Да вроде нет… \*уткнулся носом в код, ещё раз внимательно его проверяя\*
— Что, если пользователь введёт… \*выдержала многозначительную паузу и добавила\*
> `<**iframe** src="javascript:alert('ahtung')"></**iframe**>`
— А, ну да \*виновато приписал экранирование\*
> `**var** message= 'По запросу `'` + query.escapeHTML() + ' найдено страниц: ' + resultCount`
— Молодец… \*разочарованно выдохнула\* Только вот боюсь — это не последний раз, когда ты забыл обезвредить данные.., а как будешь прикручивать к этому коду языковую локализацию?
— Ну… \*напряжённая работа мысли скукожила некогда миленький лобик\* Вынесу в отдельный массив:
> `**var** texts= [ 'По запросу `'`, ' найдено страниц: ' ]
>
> **var** message= texts[0] + query.escapeHTML() + texts[1] + resultCount`
— И не влом же тебе будет писать каждый раз эти texts[n], чередуя их с данными? \*взяла карандаш и, зачеркнув его писанину, нарисовала свою\* Смотри, так использовать гораздо проще:
> `**var** template= TT.template( 'По запросу `{0}` найдено страниц: {1}' )
>
> **var** message= template([ query.escapeHTML(), resultCount ])`
— Да \*пытается переварить\* Наверно…
— Но когда параметров больше одного — лучше давать им говорящие имена \*ещё несколько движений карандашом\* для наглядности:
> `**var** template= TT.template( 'По запросу `{query}` найдено страниц: {count}' )
>
> **var** message= template({ query: query.escapeHTML(), count: resultCount })`
— Ха! \*радостно вскочил\* Получилось даже длинее чем у меня!
— Не проблема! \*уверенно позачёркивала лишнее\* Воспользуемся автоэкранированием:
> `**var** template= TT.html( 'По запросу `{query}` найдено страниц: {count}' )
>
> **var** message= template({ query: query, count: resultCount })`
— То есть теперь… \*призадумался над последним кодом\* Мне даже не придётся заботиться об экранировании данных?!7
— Точно! \*коснулась пальцем кончика его носа\* Все данные будут проэкранированы, кроме тех, для которых ты явным образом не скажешь отключить фильтрацию:
> `**var** message= template({ query: TT.value( highLightedQuery ), count: resultCount })`
— А что за функция такая \*широким жестом тыкнул пальцем в лист\* TT.value?
— Она просто создаёт функцию \*слегка запнулась, решив проиллюстрировать свои слова\* которая всегда возвращает определённое значение:
> `TT.value= **function**( data ){
>
> **return** **function**( ){
>
> **return** data
>
> }
>
> }`
— То есть, если вместо данных передать функцию, возвращающую данные, то шаблонизатор будет считать, что данные возвращаемые функцией безопасны для вставки в шаблон? \*сам офигел, что сказал такую сложную фразу\* Да?
— Именно! \*раскинула руками\* А вот, смотри, ещё интересная функция:
> `TT.pipe= **function**( list ){
>
> **if**( !list ) list= []
>
> **var** len= list.length
>
> **return** **function**( data ){
>
> **for**( **var** i= 0; i < len; ++i ) data= list[ i ]( data )
>
> **return** data
>
> }
>
> }`
— А она что делает? \*внимательно всматривается в волшебный метод\*
— Она берёт набор фильтров и выстраивает их в одну цепочку \*поняла, что без примера тут не обойтись\* Вот, смотри, следующие две строчки эквивалентны:
> `**var** text= decodeURIComponent( encodeURIComponent( text ) )
>
> **var** text= TT.pipe([ encodeURIComponent, decodeURIComponent ])( text )`
— Брр \*встряхнул головой\* мистика какая-то!
— Это ещё что! \*усмехнулась\* Сам шаблонизатор ещё круче:
> `TT.template= **new** **function**( ){
>
> **var** searcher= */((?:[^\{\}]|\{\{|\}\})\*)(?:\{|$)|([^\{\}]\*)(?:\})/g*
>
> **return** **function**( str, filter ){
>
> **if**( !filter ) filter= TT.pipe()
>
> **var** parts= []
>
> String( str ).replace
>
> ( searcher
>
> , **function**( str, val, sel ){
>
> **if**( sel !== **void** 0 ){
>
> parts.push( **function**( data ){
>
> data= data[ sel ]
>
> **switch**( **typeof** data ){
>
> **case** 'undefined': **return** '{' + sel + '}'
>
> **case** 'function': **return** data()
>
> **default**: **return** filter( data )
>
> }
>
> })
>
> } **else** **if**( val ){
>
> val= val.split( '{{' ).join( '{' ).split( '}}' ).join( '}' )
>
> parts.push( TT.value( val ) )
>
> }
>
> }
>
> )
>
> **return** TT.concater( parts )
>
> }
>
> }`
— Ыыыы \*чуть ли не плача\* Вы же обещали не пугать!
— Да ладно тебе! \*обняла в охапку\* Зато какие гламурные на его основе получаются плагинчики:
> `TT.uri= **function**( tpl ){
>
> **return** TT.template( tpl, TT.uri.encoder() )
>
> }
>
> TT.uri.encoder= TT.value( encodeURIComponent )
>
> TT.uri.decoder= TT.value( decodeURIComponent )`
— Что это? \*сопит, уткнувшись носом в грудь\*
— Это шаблонизатор для URI \*дала ему карандаш в руку\* Пиши:
> `**var** searchURI= TT.uri( '/search/?q={query}&count={count}' )
>
> location.href= searchURI({ query: '&&&', count: 10 })`
— Эм… \*повеселел даже\* А как быть с html?
— Да так же самое:
> `TT.html= **function**( tpl ){
>
> **return** TT.template( tpl, TT.html.encoder() )
>
> }
>
> TT.html.encoder= **new** **function**( ){
>
> **var** parent= document.createElement('div')
>
> **var** child= parent.appendChild( document.createTextNode( '' ) )
>
> **return** TT.value( **function**( data ){
>
> child.nodeValue= data
>
> **return** parent.innerHTML.split( '"' ).join( '"' ).split( "'" ).join( ''' )
>
> })
>
> }
>
> TT.html.decoder= **new** **function**( ){
>
> **var** parent= document.createElement('div')
>
> **return** TT.value( **function**( data ){
>
> parent.innerHTML= data
>
> **return** parent.firstChild.nodeValue
>
> })
>
> }`
— Крутбл!
— Но и это ещё не всё! \*бешенно жестикулируя\* Для html можно сделать ещё и так, чтобы в результате выдавался HTMLNode с соответствующим содержимым:
> `TT.dom= **function**( tpl ){
>
> **return** TT.pipe([ TT.html( tpl ), TT.dom.parser() ])
>
> }
>
> TT.dom.parser= **new** **function**(){
>
> **var** parent= document.createElement( 'div' )
>
> **return** TT.value( **function**( html ){
>
> parent.innerHTML= html
>
> **var** childs= parent.childNodes
>
> **if**( childs.length === 1 ) **return** childs[0]
>
> **var** fragment= document.createDocumentFragment()
>
> **while**( childs[0] ) fragment.appendChild( childs[0] )
>
> **return** fragment
>
> })
>
> }
>
> TT.dom.serializer= **new** **function**(){
>
> **var** parent= document.createElement( 'div' )
>
> **var** child= parent.appendChild( document.createTextNode( '' ) )
>
> **return** TT.value( **function**( node ){
>
> parent.replaceChild( node.cloneNode( **true** ), parent.firstChild )
>
> **return** parent.innerHTML
>
> })
>
> }`
— И как это использовать? \*в глазках загорелись искорки халявы\*
— Да очень просто \*растеклась мыслью по листу бумаги\*
> `**var** link= TT.dom( '[{title}]({uri})' )({ uri: '/', title: 'на старт' }) *// HTMLAnchorElement*
>
> **var** userName= TT.dom( '**{head}**{tail}' )({ head: 'T', tail: 'enshi' }) *// HTMLFragment*`
— Гм… \*потихоньку стаскивая [исходники](http://tenshii.no-ip.org/project/tt/tt.js)\* Действительно не сложно…
\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_
###### Текст подготовлен в [Редакторе Блогов](http://www.softcoder.ru/blogeditor/) от © SoftCoder.ru | https://habr.com/ru/post/99005/ | null | ru | null |
# Обновление веб приложения на удаленном сервере после сборки Maven'ом через SSH
#### Проблема
После сборки проекта с помощью Build сервера или на локальной машине требуется выложить полученное приложение на тестовый сервер.
#### Решение
Добавим в pom.xml специальный профиль, в котором с помощью плагина
```
deployApp
false
maven-antrun-plugin
deployApp
package
run
org.apache.ant
ant-jsch
1.7.1
```
выложим собранное в фазе package приложение на удаленный сервер.
```
```
Maven нужно запускать с параметром -P deployApp
ЗЫ. При использовании ssh возможны грабли, если команда запуска контейнера создает новый процесс (а так обычно и бывает). В этом случае помогает nohup | https://habr.com/ru/post/114931/ | null | ru | null |
# Шасси беспилотника на базе Lada Vesta. Полный комплект drive-by-wire
TL;DR:
------
Шасси беспилотника на базе Lada Vesta при помощи проекта [Polysync OSCC](https://github.com/PolySync/oscc).
Дисклеймер:
-----------
1. Всё описанное в статье лишь личный опыт и не должно рассматриваться как руководство к действию.
2. Модификации, описанные в статье, почти наверняка лишат автомобиль гарантии производителя и возможности легально двигаться по дорогам общего пользования.
3. Я не являюсь разработчиком проекта OSCC.
4. Всё, описанное в статье, не имеет никакого отношения к вот этому [проекту](http://www.madi.ru/5444-uchenye-madi-prinyali-uchastie-v-razrabotke-pervogo-bespilot.html).
Вместо вступления
-----------------
Я: Альма-матер, давай купим Приус чтобы делать беспилотники
Альма-матер: Нет, у нас есть Приус дома
Приус дома:
LADA Vesta SW CrossЗадачи
------
Чтобы заставить всё это ездить самостоятельно нужно научится управлять несколькими вещами:
* Положение руля - Насколько я знаю, у Весты нет опции автоматической парковки и скорее всего, в блоке управления электроусилителя руля не предусмотрено внешнего управления по CAN. Документацию или описание протокола найти, разумеется, нереально. Наиболее реалистичный подход - подмена аналоговых сигналов датчика крутящего момента в рулевой колонке.
* Обороты двигателя - Тут всё примерно тоже самое. Наверное, можно было бы попробовать пойти через круиз-контроль, но это выглядит сомнительно. Поэтому - подмена аналоговых сигналов датчика положения педали акселератора.
* Торможение - Единственное, что меня беспокоило — это тормозная система. В мире нет ничего более беспомощного, безответственного и безнравственного, чем линейный актуатор нажимающий на педаль тормоза. Хотелось сделать как-то изящнее, как минимум, не устанавливать ничего под ногами у водителя да и вообще в салоне. Под капотом, правда, свободного места практически нет. Функции brake-by-wire у блока ABS Весты, само собой, нет. В общем, с тормозной большой вопрос.
* Положение селектора коробки передач - На счёт положения селектора есть сомнения потому, что хочется быть уверенным(особенно на начальном этапе), что машина, оставленная в нейтрали точно никуда не поедет. Управление селектором может понадобится, например, для автоматической парковки. Пожалуй, сделаем это как-нибудь потом.
Open Source Car Control
-----------------------
О проекте Polysync OSCC я знал давно, уже точно не помню откуда, скорее всего из [статьи](https://habr.com/ru/post/338322/) `[@waiwnf](/users/waiwnf)`.
> Open Source Car Control (OSCC) is an assemblage of software and hardware designs that enable computer control of modern cars in order to facilitate the development of autonomous vehicle technology.
>
>
На всякий случай, я поискал, что нового сделали Polysync за это время(под спойлером) но эти варианты мне не подошли.
Drivekit/PrismPolysync DrivekitPolysync выпустили коммерческий набор Drivekit для KIA NIRO. Судя по сайту, другие модели не поддерживаются, а управление тормозами реализовано программно.
Polysync PrismНа CES2020 [представили](https://www.prnewswire.com/news-releases/polysync-introduces-prism-the-most-powerful-vehicle-interface-platform-for-autonomous-mobility-solutions-300982271.html) универсальные блоки Prism для взаимодействия с шасси рассчитанные на крупных заказчиков и теперь уже с ASIL-D(ISO 26262).
Поэтому, возвращаемся к OSCC. У OSCC есть два основных варианта: для автомобиля Kia Soul с ДВС и для электромобиля Kia Soul EV.
Установка на Kia Soul EV требует вмешательства только в проводку автомобиля.
Установка на Kia Soul с ДВС требует изменений в проводке и в тормозной системе автомобиля. Между главным тормозным цилиндром и стандартным блоком системы ABS устанавливается гидравлический актуатор, который может создавать давление на входе в блок ABS вместо водителя. Роль актуатора выполняет гидравлический блок Toyota Prius 2004-2009 годов выпуска. С точки зрения установки системы OSCC Kia Soul и LADA Vesta практически идентичны.
Сомнения вызывало то, что я не нашёл подтверждения того, что кому-либо удалось портировать(в программном и аппаратном смысле) OSCС на другую модель автомобиля.
Втф, гайз? Я наверняка не первый. Где хоть какая-то статья? Или это ошибка выжившего?
Судя по всему, даже воспроизведение системы на автомобиле KIA Soul с ДВС и установка блока АБС от приуса было практически единичным. Зато, многие устанавливали OSCC на KIA Soul EV, например, университет [Иннополис](https://robotics.innopolis.university/labs/laboratoriya-avtonomnyh-transportnyh-sistem/) или Faraz Khan - автор статьи про OSCC на [Medium](https://medium.com/opencaret/a-complete-drive-by-wire-implementation-using-oscc-on-the-kia-soul-ev-55664e9e10fc).
В общем, всё это показалось мне интересным челенджем, и я как-то “продал” эту концепцию руководству.
Automotive grade Arduino
------------------------
Для автомобиля с ДВС комплект OSCC состоит из следующих устройств:
* CAN Gateway - Шлюз который пересылает определенные пакеты из CAN-шины автомобиля во внутреннюю шину OSCC.
* Steering Module - перехватывает сигнал датчика усилия на руле и спуфит(подменяет) новый сигнал, который заставляет руль поворачиваться в нужную сторону.
* Throttle module - аппаратно идентичный предыдущему модуль, только подключенный к датчику положения педали акселератора.
* Brake module - плата управляющая гидравлическим блоком приуса.
Все платы представляют из себя Arduino-шилды. В платах CAN Gateway, Steering и Throttle используются Arduino Uno, а в плате Brake Arduino Mega.
Снобы могут сказать, что вместо Arduino лучше было взять что-то посерьезнее, но, на мой взгляд, другие микроконтроллеры вроде STM32 в данном случае не дадут преимуществ, а использование специальных автомобильных или тем более safety-контроллеров с локстепом и ECC неоправданно в проекте рассчитанном на широкую аудиторию. Да и от Arduino тут ничего кроме плат. Забегая вперёд скажу что код для блоков управления выглядит качественно:
> OSCC Coding standard
>
> As this is an automotive initiative, this coding standard is based on the MISRA C-2012 standard.
>
>
Все блоки соединяются между собой CAN-шиной. К этой же шине подключается управляющий автомобилем компьютер через CAN-USB адаптер. Я использовал PEAK [PCAN-USB FD](https://www.peak-system.com/PCAN-USB-FD.365.0.html?&L=1) и open-source адаптер [cantact](https://github.com/linklayer/cantact-hw), оба успешно работают.
Блоки управления запитываются через кнопку аварийного отключения, расположенную в салоне.
СхемаТормозная система
-----------------
Вот тут автор рассказывает про тормозную систему, заодно немного видно компоновку:
Нужно отметить что вся эта история с блоком ABS от приуса стала возможной благодаря некому японскому инженеру который решил что нужно разделить(!) гидравлическую часть блока ABS и его блок управления(обычно всё выполняют в едином корпусе). То есть, сам гидравлический блок ABS приуса не содержит в себе никакой программируемой электроники, только соленоиды клапанов, датчики давления и мотор насоса. Всё это выведено напрямую в разъём и соединяется с отдельным внешним блоком управления через жгут проводки. То есть, при желании блок управления можно заменить и сделать свой собственный ABS, ESP, электронный ручник для ралли/дрифта, бортовой поворот как у танка etc.
Установку на автомобиль начал с изготовления бумажного макета блока ABS приуса по 3d моделям из репозитория OSCC. С трудом, но удалось распихать всё под капотом. Для проектирования кронштейнов подкапотное пространство обмерили координатно-измерительной машиной типа “рука”.
Блок ABS от приуса можно найти на разборках примерно за 15т.р. Для сборки тормозной системы также нужны тормозные магистрали, фитинги, заглушки и т.п. По какой-то причине, BOM компонентов тормозной для Kia Soul удалили из oscc-wiki, пришлось искать его в старых коммитах. Изготавливать самостоятельно магистрали с AN3-фитингами не хотелось из соображений качества, поэтому, в Америке были заказаны готовые. Гидравлическую схему удалось найти в [issues](https://github.com/PolySync/oscc/issues/203).
Платы
-----
До этого единственными “железными” open-source проектами, которые я самостоятельно собирал, используя в качестве исходных данных gerberы и BOM, были CAN-адаптер [cantact](https://github.com/linklayer/cantact-hw) и клон ST-link.
С изготовлением плат проблем не возникло, FR4-1,5мм/35мкм. Сложность продвинутая, ну и ладно. Для удешевления объединил платы в комплект с помощью [GerberPanelizer](https://github.com/ThisIsNotRocketScience/GerberTools/releases/latest).
На этот раз ДВП из Резонита приехала с призраками чужых плат PC/104. Большинство компонентов оказалось в наличии в магазинах(осень 2020), ещё несколько заменил аналогами и только пару редких позиций пришлось ждать несколько недель. О том что на плате модуля Brake устанавливаются радиаторы я узнал случайно из картинки выложенной в [твиттере](https://twitter.com/joshuahartung/status/824715827928715265).
Ещё пара фотографий блока BrakeРезультат:
Больше фотографийСофт
----
Для сборки программ и тестирования системы я использовал Ubuntu 16.04. В первую очередь ради совместимости с пакетом [ROSCCO](https://github.com/polySync/roscco) (требует ROS Kinetic поддерживаемый только Ubuntu 16.04). Можно было конечно взять дистрибутив посвежее и попробовать перенести ROSCCO на ROS1 поновее/ROS2 или использовать docker, но я решил не усложнять.
Вся работа с OSCC реализована через CMake, причём, не только сборка но также загрузка прошивки и отладка. Удобно.
Для проверки работы тормозной системы в OSCC есть две специальные программы для модуля Brake:
* release\_pressure, которая позволяет открыть одновременно несколько клапанов и сбросить давление в гидроаккумуляторе
* serial\_actuator позволяет вручную при помощи кнопок клавиатуры отправлять команды блоку brake по UART и управлять клапанами и насосом блока ABS.
Я использовал serial\_actuator, чтобы проверить, что могу затормозить колёса. Как это ни странно, всё заработало с первого раза. Проблем не было обнаружено ни в монтаже платы(этого я боялся большего всего), ни в жгутах проводки. Однако, счастье длилось не долго. Примерно через две минуты работы с постоянно открытыми клапанами SLA блок отключился. Оказалось что сгорел предохранитель питающий блок brake. Ну подумаешь, не угадал с номиналом. Однако, ситуация повторилась при первой же попытке снова открыть клапаны SLA. Проверка мультиметром показала, что один из клапанов соленоидов вместо сопротивления 3,9Ом оказался закороченным. Тут пришло осознание, что я только что спалил приусовский блок ABS(это вам не микруху 5 вольтами сжечь). Скорее всего, напряжение на соленоид подаётся только в момент изменения давления в контуре. К тому же, во время нормальной работы программы brake клапаны управляются ШИМом с ограничением коэффициента заполнения сверху:
```
#define BRAKE_ACCUMULATOR_SOLENOID_DUTY_CYCLE_MAX ( 105.0 )
```
Но в программе serial\_actuator на них подаётся:
```
#define SOLENOID_PWM_ON ( 255 )
```
что и убило соленоид. Пришлось снова искать блок на разборках. Со второго раза удалось найти в хорошем состоянии. Замена уже не составила особого труда.
Все настройки специфичные для конкретного автомобиля задаются в заголовочных файлах в директории oscc/api/include/vehicles/
Для пересылки сообщений из CAN-шины автомобиля в шину OSCC нужно выяснить ID интересующих пакетов. Для поиска я использовал [cansniffer](https://github.com/linux-can/can-utils). Положение рулевого нашлось быстро - сообщение с ID 0x0C6. Значения давления в тормозной системе судя по всему нет, есть только дискретное состояние концевика тормозной педали. Сообщения с отдельными скоростями вращения колёс тоже не нашлось. Но для работы системы это не критично. Аналоговые датчики калибруются при помощи мультиметра. Напряжение на обоих каналах датчика положения педали акселератора измеряется в крайних положениях. Датчик крутящего момента калибруется при помощи груза.
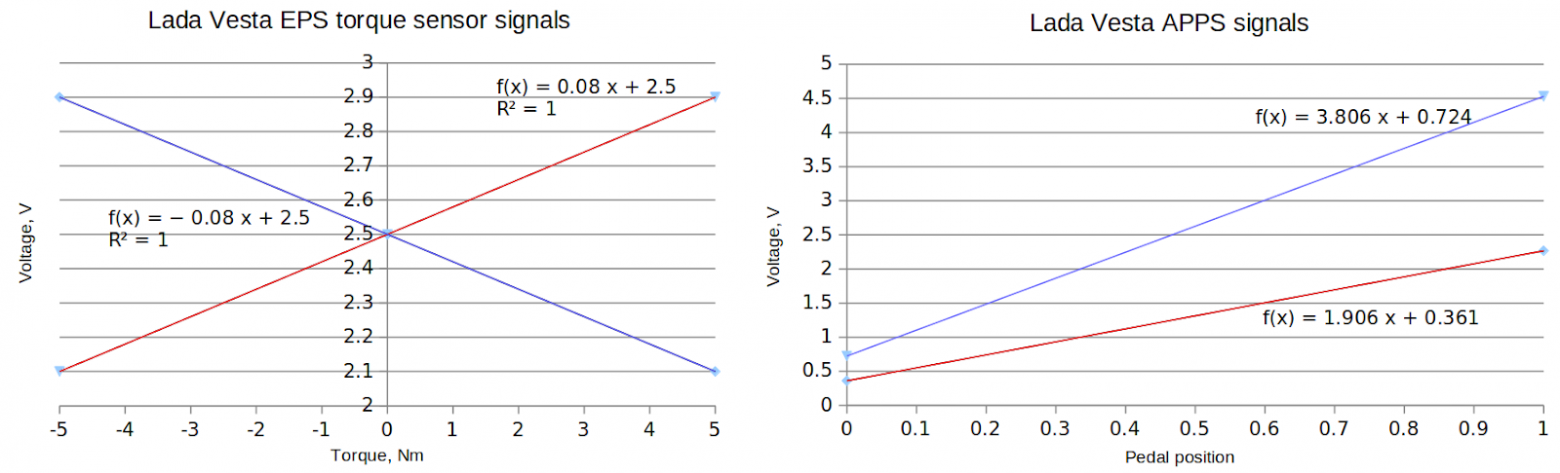И что, теперь поедем кататься? Только не мы, мы же ответственные люди.
Сначала проверим всё на машине с вывешенными колёсами при помощи утилиты [oscc-check](https://github.com/PolySync/oscc-check).
Программа шлёт команды блокам OSCC и проверяет результат по сообщениям в CAN шине автомобиля. После небольшого допиливания oscc-check под весту все проверки проходят успешно.
Теперь нужно настроить управление автомобилем с джойстика. У OSCC есть специальная программа [oscc-joystick-commander](https://github.com/PolySync/oscc-joystick-commander) или можно воспользоваться API для ROS - [ROSCCO](https://github.com/PolySync/roscco). Я выбрал второй вариант.
Настройки Dualshock 4: педаль газа - правый триггер R2, тормоз - левый триггер L2, рулевое - левый джойстик.
А вот теперь можно кататься!
----------------------------
При помощи OSCC автомобиль с электроусилителем руля, электронной педалью газа и автоматической трансмиссией удалось превратить в шасси для беспилотника. Под определение выше попадает практически любой современный автомобиль.
Электроусилитель LADA Vesta не всегда может повернуть колёса на месте и иногда уходит в ошибку и отключается. При движении даже с небольшой скоростью сопротивление повороту колёс снижается и проблема исчезает. Если ваши задачи требуют поворота колёс на месте то LADA Vesta со стандартным электроусилителем это плохой выбор.
На этом все, спасибо за внимание. | https://habr.com/ru/post/565628/ | null | ru | null |
# Практический HTML: улучшаем семантику ссылок
*Примечание: ниже перевод статьи [«Boost Your Hyperlink Power»](http://24ways.org/2006/boost-your-hyperlink-power). В ней освещается использование атрибутов rel и rev, а также некоторые микроформаты.*
Часть HTML-тегов и атрибуты мы используем каждый день в свой работе. Заголовки, параграфы, списки и картинки являются основой разметки каждого веб-разработчика. Но наиболее распространенным элементом, наверное, будет ссылка — простой тег, который связывает воедино все страницы, создавая ту самую беспорядочную структуру, которую мы называем Всемирная Сеть Интернет (WWW).
Ссылка как она есть
-------------------
Весь потенциал ссылок заключается в атрибуте `href`, сокращение от `hypertext reference`. Он создает одностороннюю связь текущей страницы с другим ресурсом, обычно другой такой же страницей в интернете:
```
```
Атрибут `href` находится в открывающем теге `a`, между открывающим и закрывающим тегами находится текст для описания ссылки:
```
[Drew McLellan](http://allinthehead.com/)
```
«Ну и что», — скажите вы. — «Это я все и так знаю», — и будете абсолютно правы! Но у ссылки есть еще кое-что, кроме атрибута `href`.
Теория относительности (`rel`ativity)
-------------------------------------
Может быть, вы уже читали про атрибут `rel` у ссылки. Я готов поспорить, что в секции `head` ваших страниц будет располагаться что-нибудь типа этого:
```
```
Атрибут `rel` описывает связь между текущим документом и тем, на который он указывает. В этом случае, значением атрибута `rel` является `stylesheet`. Это означает, что связанный документ является таблицей стилей для текущего: между ними именно такая связь.
Еще одно распространенное употребление `rel`:
```
```
В данном случае связь между текущим документом и связанным — RSS-лентой — указана как `alternate`: альтернативное преставление текущего документа.
Оба этих примера используют тег `link`, но вы можете использовать атрибут `rel` и у обычных ссылок. Например, вы ссылаетесь на вашу RSS-ленту из секции :
```
Подпишитесь на [мою RSS-ленту](index.xml).
```
Вы можете добавить дополнительную информацию к этой ссылке, используя атрибут `rel`:
```
Подпишитесь на [мою RSS-ленту](index.xml).
```
Не существует определенного списка значений для атрибута `rel`, поэтому вы можете использовать все, что посчитаете семантически разумным. Например, если у вас сложное коммерческое веб-приложение, в котором присутствует ссылка на подсказку, то вы можете определить связь между текущей страницей и этой подсказкой, используя значение `help`:
```
[нужна подсказка?](help.html)
```
Элементарные микроформаты
-------------------------
Хотя вы абсолютно свободны в использовании значений атрибута `rel`, существует уже некоторые общепринятые значения при использовании [микроформатов](http://microformats.org/). Некоторые из простейших микроформатов предлагают варианты грамотного использования `rel`. Например, если вы ссылаетесь на лицензию, под которой опубликован данный документ, используйте микроформат [`rel-license`](http://microformats.org/wiki/rel-license):
```
Распространяется под лицензией [Creative Commons](http://creativecommons.org/licenses/by/2.0/)
```
Эта конструкция описывает, что текущая страница ссылается на документ, помеченный как «лицензия».
Микроформат [`rel-tag`](http://microformats.org/wiki/rel-tag) идет немного дальше. Он используется для указания на то, что последняя часть URL'а у ссылки является «меткой» для текущего документа:
```
Прочитайте про [семантическую верстку](http://en.wikipedia.org/wiki/Microformats)
```
В данном случае для этого документа добавлена метка «Microformats».
[XFN](http://gmpg.org/xfn) (XHTML Friends Network) является способом описания отношений между людьми:
```
[Drew McLellan](http://allinthehead.com/)
```
Этот микроформат в значительной степени расширяет возможное применение атрибута `rel`. Так же, как и атрибут `class`, `rel` может принимать несколько значений, разделенных пробелом:
```
[Drew McLellan](http://allinthehead.com/)
```
Таким образом я указываю, что Drew мой друг, я с ним встречался, и он мой коллега (ведь мы оба фанатеем от интернета (*Web monkies*)).
«Мы — хотим перемен» (`rev`olution)
-----------------------------------
Если `rel` описывает связь между текущей страницей и той, на которую она ссылается, (*прим.: текущая страница -> другая страница*) то `rev` используется для обратной зависимости: он определяет вид связи страницы, на которую ссылаются, с текущей (*прим.: текущая страница <- другая страница*). Ниже приведен пример, который может быть использован в help.html:
```
[вернуться в магазин](shoppingcart.html)
```
Атрибут `rev` указывает, что текущая страница является страницей помощи, подсказкой для той, на которую она ссылается.
Микроформат [`vote-links`](http://microformats.org/wiki/vote-links) позволяет вам использовать атрибут `rev` для уточнения ваших ссылок. Например, определяя значение `vote-for`, вы можете указать, что ваш документ поддерживает тот, на который ссылается:
```
Я согласен с [Richard Dawkins](http://richarddawkins.net/home).
```
Есть и соответствующее значение `vote-against`. Оно означает, что хоть вы и ссылаетесь на этот документ, но вы явно указываете, что с ним не согласны.
```
Я согласен с [Richard Dawkins](http://richarddawkins.net/home)
```
```
по поводу [креационистов](http://www.icr.org/).
```
Естественно, ничего не мешает использовать в одной ссылке и `rel`, и `rev`:
```
[Richard Dawkins](http://richarddawkins.net/home)
```
Разумность большинства
----------------------
За легкостью использования `rel` и `rev` скрывается богатый потенциал. Они позволяет относительно легко добавить в ваши ссылки больше семантического смысла, что создает связи, которые затем могут быть обработы поисковыми роботами, агрегаторами или браузерами. Пусть вашим следующим шагом станет тесное знакомство с этими атрибутами и расширение возможностей ссылок.
Сссылки по теме
---------------
* [Большая обзорная статья по микроформатам](http://www.habrahabr.ru/blog/microformats/2718.html)
* [Ответы на некоторые вопросы по rel/rev на miroformats.org](http://microformats.org/wiki/rel-faq)
*Большое спасибо тем, кто прочитал всю статью полностью. Мне хотелось бы услышать ваше мнение или замечания по поводу использования `rel/rev`, в частности, или микроформатов вообще.*
[Web Optimizator: проверка скорости загрузки сайтов](http://webo.in/) | https://habr.com/ru/post/31221/ | null | ru | null |
# Переопределение Equals и GetHashCode. А оно надо?
Если вы знакомы с C#, то, скорее всего, знаете, что необходимо всегда переопределять `Equals`, а также `GetHashCode`, чтобы избежать снижения производительности. Но что будет, если этого не сделать? Сегодня сравним производительность при двух вариантах настройки и рассмотрим инструменты, помогающие избегать ошибок.

Насколько серьезна эта проблема?
--------------------------------
Не каждая потенциальная проблема с производительностью влияет на время выполнения приложения. Метод `Enum.HasFlag` не очень эффективен (\*), но если не использовать его на ресурсоемком участке кода, то серьезных проблем в проекте не возникнет. Это верно и случае с [защищенными копиями](https://blogs.msdn.microsoft.com/seteplia/2018/05/03/avoiding-struct-and-readonly-reference-performance-pitfalls-with-errorprone-net/), созданными типами non-readonly struct в контексте readonly. Проблема существует, но вряд ли будет заметна в обычных приложениях.
*(\*) Исправлено в .NET Core 2.1, и, как я уже упоминал [в предыдущей публикации](https://blogs.msdn.microsoft.com/seteplia/2018/06/12/dissecting-new-generics-constraints-in-c-7-3/), теперь последствия можно смягчить с помощью самостоятельно настроенных HasFlag для более старых версий.*
Но проблема, о которой мы поговорим сегодня, особенная. Если в структуре не создаются методы `Equals` и `GetHashCode`, то используются их стандартные версии из `System.ValueType`. А они могут значительно снизить производительность конечного приложения.
Почему стандартные версии работают медленно?
--------------------------------------------
Авторы CLR изо всех сил старались сделать стандартные версии Equals и GetHashCode максимально эффективными для типов значений. Но есть несколько причин, по которым эти методы проигрывают в эффективности пользовательской версии, написанной для определенного типа вручную (или сгенерированной компилятором).
1. Распределение упаковки-преобразования. CLR создан таким образом, что каждый вызов элемента, определенного в типах `System.ValueType` или `System.Enum`, запускает упаковку-преобразование (\*\*).
*(\*\*) Если метод не поддерживает JIT-компиляцию. Например, в Core CLR 2.1 компилятор JIT распознает метод `Enum.HasFlag` и генерирует подходящий код, который не запускает упаковку-преобразование.*
2. Потенциальные конфликты в стандартной версии метода `GetHashCode`. При реализации хэш-функции мы сталкиваемся с дилеммой: сделать распределение хэш-функции хорошо или быстро. В ряде случаев можно выполнить и то и другое, но в типе `ValueType.GetHashCode` это обычно сопряжено с трудностями.
Традиционная хэш-функция типа struct «объединяет» хэш-коды всех полей. Но единственный способ получить хэш-код поля в методе `ValueType` — использовать рефлексию. Вот почему авторы CLR решили пожертвовать скоростью ради распределения, и стандартная версия `GetHashCode` только возвращает хэш-код первого ненулевого поля и [«портит» его идентификатором типа](https://github.com/dotnet/coreclr/blob/master/src/vm/comutilnative.cpp#L2196) (\*\*\*) (подробнее см. `RegularGetValueTypeHashCode` в coreclr repo на github).
*(\*\*\*) Судя по комментариям в репозитории CoreCLR, в будущем ситуация может измениться.*
```
public readonly struct Location
{
public string Path { get; }
public int Position { get; }
public Location(string path, int position) => (Path, Position) = (path, position);
}
var hash1 = new Location(path: "", position: 42).GetHashCode();
var hash2 = new Location(path: "", position: 1).GetHashCode();
var hash3 = new Location(path: "1", position: 42).GetHashCode();
// hash1 and hash2 are the same and hash1 is different from hash3
```
Это разумный алгоритм пока что-то не пойдет не так. Но если вам не повезло и значение первого поля вашего типа struct совпадают в большинстве экземпляров, то хэш-функция всегда будет выдавать одинаковый результат. Как вы уже догадались, если сохранить эти экземпляры в хэш-наборе или хэш-таблице, то производительность резко упадет.
3. Скорость реализации на основе рефлексии низкая. Очень низкая. Рефлексия — это мощный инструмент, если использовать его правильно. Но последствия будут ужасны, если запустить его на ресурсоемком участке кода.
Давайте посмотрим, как неудачная хэш-функция, которая может получиться из-за (2) и реализации на основе рефлексии, влияет на производительность:
```
public readonly struct Location1
{
public string Path { get; }
public int Position { get; }
public Location1(string path, int position) => (Path, Position) = (path, position);
}
public readonly struct Location2
{
// The order matters!
// The default GetHashCode version will get a hashcode of the first field
public int Position { get; }
public string Path { get; }
public Location2(string path, int position) => (Path, Position) = (path, position);
}
public readonly struct Location3 : IEquatable
{
public string Path { get; }
public int Position { get; }
public Location3(string path, int position) => (Path, Position) = (path, position);
public override int GetHashCode() => (Path, Position).GetHashCode();
public override bool Equals(object other) => other is Location3 l && Equals(l);
public bool Equals(Location3 other) => Path == other.Path && Position == other.Position;
}
private HashSet \_locations1;
private HashSet \_locations2;
private HashSet \_locations3;
[Params(1, 10, 1000)]
public int NumberOfElements { get; set; }
[GlobalSetup]
public void Init()
{
\_locations1 = new HashSet(Enumerable.Range(1, NumberOfElements).Select(n => new Location1("", n)));
\_locations2 = new HashSet(Enumerable.Range(1, NumberOfElements).Select(n => new Location2("", n)));
\_locations3 = new HashSet(Enumerable.Range(1, NumberOfElements).Select(n => new Location3("", n)));
\_locations4 = new HashSet(Enumerable.Range(1, NumberOfElements).Select(n => new Location4("", n)));
}
[Benchmark]
public bool Path\_Position\_DefaultEquality()
{
var first = new Location1("", 0);
return \_locations1.Contains(first);
}
[Benchmark]
public bool Position\_Path\_DefaultEquality()
{
var first = new Location2("", 0);
return \_locations2.Contains(first);
}
[Benchmark]
public bool Path\_Position\_OverridenEquality()
{
var first = new Location3("", 0);
return \_locations3.Contains(first);
}
```
```
Method | NumOfElements | Mean | Gen 0 | Allocated |
-------------------------------- |------ |--------------:|--------:|----------:|
Path_Position_DefaultEquality | 1 | 885.63 ns | 0.0286 | 92 B |
Position_Path_DefaultEquality | 1 | 127.80 ns | 0.0050 | 16 B |
Path_Position_OverridenEquality | 1 | 47.99 ns | - | 0 B |
Path_Position_DefaultEquality | 10 | 6,214.02 ns | 0.2441 | 776 B |
Position_Path_DefaultEquality | 10 | 130.04 ns | 0.0050 | 16 B |
Path_Position_OverridenEquality | 10 | 47.67 ns | - | 0 B |
Path_Position_DefaultEquality | 1000 | 589,014.52 ns | 23.4375 | 76025 B |
Position_Path_DefaultEquality | 1000 | 133.74 ns | 0.0050 | 16 B |
Path_Position_OverridenEquality | 1000 | 48.51 ns | - | 0 B |
```
Если значение первого поля всегда одинаково, то по умолчанию хэш-функция возвращает равное значение для всех элементов и хэш-набор эффективно преобразуется в связанный список с O(N) операций вставки и поиска. Число операций заполнения коллекции становится равным O(N^2) (где N — количество вставок со сложностью O(N) для каждой вставки). Это означает, что вставка в набор 1000 элементов даст почти 500 000 вызовов `ValueType.Equals`. Вот последствия метода, использующего рефлексию!
Как показывает тест, производительность будет приемлемой, если вам повезет и первый элемент структуры будет уникальным (в случае `Position_Path_DefaultEquality`). Но если это не так, то производительность будет крайне низкой.
Реальная проблема
-----------------
Думаю, теперь вы догадываетесь, с какой проблемой я недавно столкнулся. Пару недель назад я получил сообщение об ошибке: время выполнения приложения, над которым я работаю, увеличилось с 10 до 60 секунд. К счастью, отчет был весьма подробным и содержал трассировку событий Windows, поэтому проблемное место обнаружилось быстро — `ValueType.Equals` загружался 50 секунд.
После беглого просмотра кода стало ясно, в чем проблема:
```
private readonly HashSet<(ErrorLocation, int)> _locationsWithHitCount;
readonly struct ErrorLocation
{
// Empty almost all the time
public string OptionalDescription { get; }
public string Path { get; }
public int Position { get; }
}
```
Я использовал кортеж, который содержал пользовательский тип struct со стандартной версией `Equals`. И, к сожалению, он имел необязательное первое поле, которое почти всегда равнялось `String.equals`. Производительность оставалась высокой, пока значительно не увеличилось количество элементов в наборе. За считанные минуты инициализировалась коллекция с десятками тысяч элементов.
Всегда ли реализация `ValueType.Equals/GetHashCode` по умолчанию работает медленно?
-----------------------------------------------------------------------------------
И для `ValueType.Equals`, и для `ValueType.GetHashCode` есть специальные методы оптимизации. Если у типа нет «указателей» и он правильно упакован (я покажу пример через минуту), тогда используются оптимизированные версии: итерации `GetHashCode` выполняются над блоками экземпляра, используется XOR размером 4 байта, метод `Equals` сравнивает два экземпляра, используя `memcmp`.
```
// Optimized ValueType.GetHashCode implementation
static INT32 FastGetValueTypeHashCodeHelper(MethodTable *mt, void *pObjRef)
{
INT32 hashCode = 0;
INT32 *pObj = (INT32*)pObjRef;
// this is a struct with no refs and no "strange" offsets, just go through the obj and xor the bits
INT32 size = mt->GetNumInstanceFieldBytes();
for (INT32 i = 0; i < (INT32)(size / sizeof(INT32)); i++)
hashCode ^= *pObj++;
return hashCode;
}
// Optimized ValueType.Equals implementation
FCIMPL2(FC_BOOL_RET, ValueTypeHelper::FastEqualsCheck, Object* obj1, Object* obj2)
{
TypeHandle pTh = obj1->GetTypeHandle();
FC_RETURN_BOOL(memcmp(obj1->GetData(), obj2->GetData(), pTh.GetSize()) == 0);
}
```
Сама проверка выполняется в `ValueTypeHelper::CanCompareBits`, она вызывается и из итерации `ValueType.Equals`, и из итерации `ValueType.GetHashCode`.
Но оптимизация – очень коварная вещь.
Во-первых, сложно понять, когда она включена; даже незначительные изменения в коде могут включать ее и выключать:
```
public struct Case1
{
// Optimization is "on", because the struct is properly "packed"
public int X { get; }
public byte Y { get; }
}
public struct Case2
{
// Optimization is "off", because struct has a padding between byte and int
public byte Y { get; }
public int X { get; }
}
```
Дополнительную информацию о структуре памяти см. в моем блоге [«Внутренние элементы управляемого объекта, часть 4. Структура полей»](https://blogs.msdn.microsoft.com/seteplia/2017/09/21/managed-object-internals-part-4-fields-layout/).
Во-вторых, сравнение памяти вовсе не обязательно даст вам правильный результат. Вот простой пример:
```
public struct MyDouble
{
public double Value { get; }
public MyDouble(double value) => Value = value;
}
double d1 = -0.0;
double d2 = +0.0;
// True
bool b1 = d1.Equals(d2);
// False!
bool b2 = new MyDouble(d1).Equals(new MyDouble(d2));
```
`-0,0` и `+0,0` равны, но имеют разные двоичные представления. Это значит, что `Double.Equals` окажется верным, а `MyDouble.Equals` — ложным. В большинстве случаев разница несущественна, но представьте, сколько часов вы потратите на исправление проблемы, вызванной этой разницей.
Как избежать подобной проблемы?
-------------------------------
Вы можете спросить меня, как упомянутое выше может произойти в реальной ситуации? Один из очевидных способов запуска методов `Equals` и `GetHashCode` в типах struct — использование правила FxCop [CA1815](https://msdn.microsoft.com/en-us/library/ms182276.aspx). Но есть одна проблема: это слишком строгий подход.
Приложение, для которого критически важна производительность, может иметь сотни типов struct, которые не обязательно используются в хэш-наборах или словарях. Поэтому разработчики приложения могут отключить правило, что вызовет неприятные последствия, если тип struct использует измененные функции.
Более правильный подход — предупреждать разработчика, если «неподходящий» тип struct с равными значениями элементов по умолчанию (определенный в приложении или сторонней библиотеке) хранится в хэш-наборе. Конечно же я говорю об [ErrorProne.NET](https://github.com/SergeyTeplyakov/ErrorProne.NET) и о правиле, которое я туда добавил, как только столкнулся с этой проблемой:

Версия ErrorProne.NET не идеальна и будет «обвинять» правильный код, если в конструкторе используется пользовательский сопоставитель равенства:

Но я все равно думаю, что стоит предупреждать, если тип struct с равными по умолчанию элементами используется не тогда, когда производится. Например, когда я проверил свое правило, то понял, что структура `System.Collections.Generic.KeyValuePair` , определенная в mscorlib, не перезаписывает `Equals` и `GetHashCode`. Маловероятно, что сегодня кто-то определит переменную типа `HashSet >`, но я считаю, что даже BCL может нарушить правило. Поэтому полезно обнаружить это, пока не поздно.
Заключение
----------
* Реализация равенства по умолчанию для типов struct может привести к серьезным последствиям для вашего приложения. Это реальная, а не теоретическая проблема.
* Элементы равенства по умолчанию для типов значений основаны на рефлексии.
* Распределение, выполненное стандартной версией `GetHashCode`, будет очень плохим, если первое поле многих экземпляров имеет одинаковое значение.
* Для стандартных методов `Equals` и `GetHashCode` существуют оптимизированные версии, но не стоит на них полагаться, поскольку их может выключить даже небольшое изменение кода.
* Используйте правило FxCop, чтобы убедиться, что каждый тип struct переопределяет элементы равенства. Однако лучше предупредить проблему при помощи анализатора, если «неподходящая» структура хранится в хэш-наборе или в хэш-таблице.
Дополнительные ресурсы
----------------------
* [ErrorProne.NET на github](https://github.com/SergeyTeplyakov/ErrorProne.NET)
* [ErrorProne.NET Structs в магазине](https://marketplace.visualstudio.com/items?itemName=SergeyTeplyakov.EPNS01) | https://habr.com/ru/post/418515/ | null | ru | null |
# Пишем парсер на Java + MySQL
Недавно пробегал на Хабре [пост](http://habrahabr.ru/blogs/infosecurity/80360/) про базу доменных имен с электронной почтой. Решил написать парсер, чтоб благополучно слить всю эту базу. Но так как очень быстро сервис загнулся в силу хабраэффекта (а может админы пофиксили, черт его знает), я пошел дальше и нашел просто базу доменов в plaintext'е в зоне .RU. Решил ее пропарсить с помощью whois на [nic.ru](http://nic.ru). Но на последнем действует скрипт, благополучно притормаживая слив базы с одного ip адреса. Выход — использование proxy листа. И, будучи благополучно задушенным жабой покупать прокси листы, я решил написать на Java два скрипта:
1. Парсит samair.ru/proxy и сливает в mysql прокси лист.
2. Проходит по базе и проверяет timeout полученных проксей.
**База данных**

Скрин структуры базы из PhpMyAdmin
**Итак, сначала парсер.**
`**import**java.io.BufferedReader;
**import**java.io.IOException;
**import**java.io.InputStreamReader;
**import**java.net.HttpURLConnection;
**import**java.net.MalformedURLException;
**import**java.net.ProtocolException;
**import**java.net.URL;
**import**java.sql.Connection;
**import**java.sql.DriverManager;
**import**java.sql.ResultSet;
**import**java.sql.SQLException;
**import**java.sql.Statement;
**public class**ProxyHunter {
/\*\*
\* @param args
\* @throws ClassNotFoundException
\* @throws SQLException
\* @throws IOException
\*/
**public static****void**main(String[] args) **throws**ClassNotFoundException, SQLException, IOException {
// TODO Auto-generated method stub
Class.forName("com.mysql.jdbc.Driver");
//подключаем драйвер MySQL
Connection conn = DriverManager.getConnection("jdbc:mysql://192.168.1.7:3306/database", "username", "password");
//192.168.1.7 - имя хоста, можно подставить хоть localhost
//database - имя базы данных для экспорта
//username, password - имя пользователя и пароль для MySQL
Statement st = conn.createStatement();
URL connection = **null**;
String[] replacements = **new**String[10];
String host = **null**;
String port = **null**;
String anon\_level = **null**;
String country = **null**;
**int**cursor = 0;
HttpURLConnection urlconn = **null**;
**int**n = 1;
**while**(n <= 50)
{
**if**(n < 10)
{
connection = **new**URL("www.samair.ru/proxy/ip-address-0"; +n+".htm");
}
**else**
{
connection = **new**URL("www.samair.ru/proxy/ip-address-";+n+".htm");
}
System.out.println("Starting page: "+Integer.toString(n));
urlconn = (HttpURLConnection) connection.openConnection();
urlconn.setRequestMethod("GET");
urlconn.connect();
//посылаем GET запрос на список проксей samair'а
java.io.InputStream in = urlconn.getInputStream();
BufferedReader reader = **new**BufferedReader(**new**InputStreamReader(in));
String text = **null**;
String line = **null**;
**while**((line = reader.readLine()) != **null**)
{
text += line;
}
//парсим текст страницы
replacements = text.substring(text.indexOf(") + ".length(), text.indexOf("")).split(";");
//на самаире, возможно, в целях защиты от парсеров порты в списке выводятся javascript'ом
//в начале страницы рандомом задаются 10 переменных для каждой цыфры, затем они скриптом же и выводятся в таблицу
//replacements - как раз массив этих переменных
cursor = text.indexOf("| " |
);
**while**(cursor != -1)
{
cursor += "| " |
.length();
host = text.substring(cursor, text.indexOf("", cursor));
//host - адрес прокси сервера
port = text.substring(text.indexOf(">document.write(\":\"+", cursor) + ">document.write(\":\"+".length(), text.indexOf(")" , cursor));
port = removeChar(port, '+');
**for**(**int**i = 0; i<10; i++)
{
port = port.replaceAll(replacements[i].split("=")[0], replacements[i].split("=")[1]);
//подставляем вместо букв циферки
}
//port - порт сервера
cursor = text.indexOf(" " |, cursor) + " " |.length();
anon\_level = text.substring(cursor, text.indexOf(" " |, cursor));
cursor = text.indexOf(" " |, cursor) + " " |.length();
cursor = text.indexOf(" " |, cursor) + " " |.length();
country = text.substring(cursor, text.indexOf("", cursor));
//получаем остальную лабуду - тип сервера и страна, не пропадать же траффику зря) хотя они и вряд ли понадобятся
ResultSet rs = st.executeQuery("select host, port from proxies where host = '"+host+"' and port = '"+port+"'");
**if**(!rs.next())
{
st.executeUpdate("INSERT INTO proxies (host, port, anon\_level, country) VALUES ('"+host+"', '"+port+"', '"+anon\_level+"', '"+country+"')");
System.out.println("Added: "+host+":"+port);
//Если такого хоста и порта в базе еще нету, то вносим его туда
}
cursor = text.indexOf("| " |
, cursor);
}
n++;
}
st.close();
conn.close();
}
**public static**String removeChar(String s, **char**c) {
String r = "";
**for**(**int**i = 0; i < s.length(); i ++) {
**if**(s.charAt(i) != c) r += s.charAt(i);
}
**return**r;
}
}`
**И непосредственно сам чекер**
`**import**java.io.BufferedReader;
**import**java.io.IOException;
**import**java.io.InputStreamReader;
**import**java.net.HttpURLConnection;
**import**java.net.MalformedURLException;
**import**java.net.ProtocolException;
**import**java.net.URL;
**import**java.sql.Connection;
**import**java.sql.DriverManager;
**import**java.sql.ResultSet;
**import**java.sql.SQLException;
**import**java.sql.Statement;
**public class**ProxyHunter {
/\*\*
\* @param args
\* @throws ClassNotFoundException
\* @throws SQLException
\* @throws IOException
\*/
**public static****void**main(String[] args) **throws**ClassNotFoundException, SQLException, IOException {
// TODO Auto-generated method stub
Class.forName("com.mysql.jdbc.Driver");
//подключаем драйвер MySQL
Connection conn = DriverManager.getConnection("jdbc:mysql://192.168.1.7:3306/database", "username", "password");
//192.168.1.7 - имя хоста, можно подставить хоть localhost
//database - имя базы данных для экспорта
//username, password - имя пользователя и пароль для MySQL
Statement st = conn.createStatement();
URL connection = **null**;
String[] replacements = **new**String[10];
String host = **null**;
String port = **null**;
String anon\_level = **null**;
String country = **null**;
**int**cursor = 0;
HttpURLConnection urlconn = **null**;
**int**n = 1;
**while**(n <= 100)
{
**if**(n < 10)
{
connection = **new**URL("www.samair.ru/proxy/ip-address-0";+n+".htm");
}
**else**
{
connection = **new**URL("www.samair.ru/proxy/ip-address-";+n+".htm");
}
System.out.println("Starting page: "+Integer.toString(n));
urlconn = (HttpURLConnection) connection.openConnection();
urlconn.setRequestMethod("GET");
urlconn.connect();
//посылаем GET запрос на список проксей samair'а
java.io.InputStream in = urlconn.getInputStream();
BufferedReader reader = **new**BufferedReader(**new**InputStreamReader(in));
String text = **null**;
String line = **null**;
**while**((line = reader.readLine()) != **null**)
{
text += line;
}
//парсим текст страницы
replacements = text.substring(text.indexOf(") + ".length(), text.indexOf("")).split(";");
//на самаире, возможно, в целях защиты от парсеров порты в списке выводятся javascript'ом
//в начале страницы рандомом задаются 10 переменных для каждой цыфры, затем они скриптом же и выводятся в таблицу
//replacements - как раз массив этих переменных
cursor = text.indexOf("| " |
);
**while**(cursor != -1)
{
cursor += "| " |
.length();
//host - адрес прокси сервера
//каким-то непонятным китайским рандомом у самаира порт проксей выводится либо javascript'ом
//либо plaintext'ом
//обрабатываем
**if**(text.indexOf(">document.write(\":\"+", cursor) != -1)
{
//это для javascript
host = text.substring(cursor, text.indexOf("", cursor));
port = text.substring(text.indexOf(">document.write(\":\"+", cursor) + ">document.write(\":\"+".length(), text.indexOf(")" , cursor));
port = removeChar(port, '+');
**for**(**int**i = 0; i<10; i++)
{
port = port.replaceAll(replacements[i].split("=")[0], replacements[i].split("=")[1]);
//подставляем вместо букв циферки
}
}
**else**
{
//это plaintext
host = text.substring(cursor, text.indexOf(":", cursor));
port = text.substring(text.indexOf(":", cursor) + 1, text.indexOf(" " |, cursor));
}
//port - порт сервера
cursor = text.indexOf(" " |, cursor) + " " |.length();
anon\_level = text.substring(cursor, text.indexOf(" " |, cursor));
cursor = text.indexOf(" " |, cursor) + " " |.length();
cursor = text.indexOf(" " |, cursor) + " " |.length();
country = text.substring(cursor, text.indexOf("", cursor));
//получаем остальную лабуду - тип сервера и страна, не пропадать же траффику зря) хотя они и вряд ли понадобятся
ResultSet rs = st.executeQuery("select host, port from proxies where host = '"+host+"' and port = '"+port+"'");
**if**(!rs.next())
{
st.executeUpdate("INSERT INTO proxies (host, port, anon\_level, country) VALUES ('"+host+"', '"+port+"', '"+anon\_level+"', '"+country+"')");
System.out.println("Added: "+host+":"+port);
//Если такого хоста и порта в базе еще нету, то вносим его туда
}
cursor = text.indexOf("| " |
, cursor);
}
n++;
}
st.close();
conn.close();
}
**public static**String removeChar(String s, **char**c) {
String r = "";
**for**(**int**i = 0; i < s.length(); i ++) {
**if**(s.charAt(i) != c) r += s.charAt(i);
}
**return**r;
}
}`
Вообще, меня терзают сомнения по поводу правильности реализации массива с потоками. Думается, что в Java есть что-то специальное для таких целей, но я реализовал первое что пришло в голову — массив потоков.
И не ругайте за изобретение велосипеда. Тут цель была just for fun плюс с MySQL'ем поработать. Для красоты вывода этого добра в консоль можно закоментировать все PrintStackTrace()'ы.
**Результат**

Кусок проверенной базы. -1 в latency означает дохлую проксю.
P.S.
Драйвер MySQL можно скачать здесь: [www.mysql.com/products/connector](http://www.mysql.com/products/connector/)
Выбрать там JDBC Driver for MySQL (Connector/J). Архив распаковать, выдрать оттуда файлик mysql-connector-java-5.1.10-bin.jar и закинуть его в папку с проектом. Потом в Eclipse правой кнопкой по проекту -> Properties -> Java Build Path -> Libraries -> Add JARs и подцепить его там.

Вот то, что должно получится.
P.P.S
Экспорт кода из Eclipse в HTML реализован с помощью [Java2Html converter](http://www.java2html.de/eclipse.html)
© [@nixan](http://twitter.com/nixan) | https://habr.com/ru/post/80813/ | null | ru | null |
# Интеграция AppCenter и GitLab
Трям, здравствуйте!
Хочу рассказать о своём опыте настройки интергации GitLab и AppCenter через BitBucket.
Необходимость такой интеграции возникла в ходе настройки автоматического запуска UI тестов для кроссплатформенного проекта на Xamarin. Подробный туториал под катом!
\* *Об автоматизации UI тестирования в условиях кроссплатформенности сделаю отдельную статью, если публика заинтересуется.*
Подобного материала нарыла только одну [статью](https://www.novis.co/post/building-to-appcenter-from-gitlab/). Поэтому моя статья может кому-нибудь помочь.
**Задача**: Настроить автоматический запуск UI тестов на AppCenter при том, что наша команда использует GitLab как систему контроля версий.
**Проблема** оказалась в том, что AppCenter не интергируется с GitLab напрямую. Как одино из решений был выбран обход через BitBucket.
Шаги
----
1. Создаём пустой репозиторий на BitBucket
==========================================
Не вижу необходимости описывать это подробнее :)
2. Настраиваем GitLab
=====================
Нам нужно, чтобы при push/merge в репозиторий изменения заливались еще и на BitBucket. Для этого добавляем runner(или редактируем существующий .gitlab-ci.yml файл).
Cначала добавляем команды в секцию before\_scripts
```
- git config --global user.email "user@email"
- git config --global user.name "username"
```
Потом добавляем следующую команду в нужный stage:
```
- git push --mirror https://username:password@bitbucket.org/username/projectname.git
```
В моём случае получился вот такой файл
```
before_script:
- git config --global user.email "user@email"
- git config --global user.name "username"
stages:
- mirror
mirror:
stage: mirror
script:
- git push --mirror https://****:*****@bitbucket.org/****/testapp.git
```
Запускаем билд, проверяем, что на BitBucket легли наши изменения/файлы.
*\* как показала практика, настройка SSH ключей необязательна. Но, на всякий случай, приведу алгоритм настройки соединения именно через SSH ниже*
**Подключение через SSH**Сначала нужно сгенерировать SSH ключ. Об этом написано множество статей. Для примера можете посмотреть [тут](https://git-scm.com/book/ru/v2/Git-%D0%BD%D0%B0-%D1%81%D0%B5%D1%80%D0%B2%D0%B5%D1%80%D0%B5-%D0%93%D0%B5%D0%BD%D0%B5%D1%80%D0%B0%D1%86%D0%B8%D1%8F-%D0%BE%D1%82%D0%BA%D1%80%D1%8B%D1%82%D0%BE%D0%B3%D0%BE-SSH-%D0%BA%D0%BB%D1%8E%D1%87%D0%B0).
Сгенерированные ключи выглядят примерно так:

Далее **секретный ключ** нужно добавить как переменную на GitLab. Для этого идем в Settings > CI/CD > Enviroment Variables. Добавляем ВСЁ содержимое файла, в который вы сохранили секретный ключ. Назовём переменную SSH\_PRIVATE\_KEY.
\* *этот файл, в отличие от файла с открытым ключем, не будет иметь расширения*
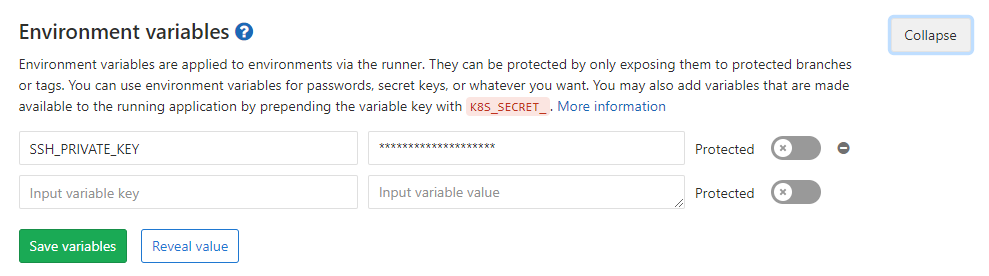
Отлично, дальше нужно добавить открытый ключ на BitBucket. Для этого открываем репозиторий, переходим в Settings > Access Keys.

Тут наживаем Add Key и вставляем содержимое файла с публичным ключем (файл с расширением .pub).
Следующим шагом будет использование ключей в gitlab-runner. Используйте эти команды, но укажите вместо звёздочек свои данные
```
image: timbru31/node-alpine-git:latest
stages:
- mirror
before_script:
- eval $(ssh-agent -s)
- echo "$SSH_PRIVATE_KEY" | tr -d '\r' | ssh-add - > /dev/null
- mkdir -p ~/.ssh
- chmod 700 ~/.ssh
- ssh-keyscan bitbucket.org >> ~/.ssh/known_hosts
- chmod 644 ~/.ssh/known_hosts
- git config --global user.email "*****@***"
- git config --global user.name "****"
- ssh -T git@bitbucket.org
mirror:
stage: mirror
script:
- git push --mirror https://****:****@bitbucket.org/*****/*****.git
```
3. Настройка AppCenter
======================
Создаём новое приложение на AppCenter.

Указываем язык/платформу

Далее заходим в секцию Build только что созданного приложения. Выбираем там BitBucket и репозиторий, созданный на этапе 1.
Отлично, теперь нужно настроить билд. Для этого находим иконку шестеренки

В принципе, там всё интуитивно понятно. Выбираем проект и конфигурацию. При необходимости включаем запуск тестов после билда. Они будут запускаться автоматически.
В принципе, на этом всё. Звучит несложно, но, естественно, гладко всё не пройдёт. Поэтому опишу некоторые ошибки, с которыми я столкнулась во время работы:
**'ssh-keygen' is not recognized as an internal or external command.**Возникает и-за того, что путь к ssh-keygen.exe не добавлен в переменные окружения.
Варианта два: добавьте C:\Program Files\Git\usr\bin в Enviroment Variables (применится после перезагрузки машины), или запускайте консоль из этой директории.
**AppCenter подключился не к тому BitBucket аккаунту?**Для решения проблемы нужно отвязать аккаунт BitBucket от AppCenter. Заходим в неправильный BitBucket аккаунт, идем в профиль пользователя.
Далее переходим в Settings > Access Management > OAuth

Нажимаем Revoke, чтобы отвязать аккаунт.

После этого нужно залогиниться под нужным BitBucket аккаунтом
\* *В крайнем случае еще и почистить кэш браузера*
Теперь переходим в AppCenter. переходим в секцию Build, нажимаем Disconnect BitBucket account

Когда старый аккаунт будет отвязан, привязываем AppCenter заново. Теперь уже к нужному аккаунту.
**'eval' is not recognized as an internal or external command**Используем вместо команды
```
- eval $(ssh-agent -s)
```
Команду:
```
- ssh-agent
```
В некоторых случаях придётся или указать полный путь к C:\Program Files\Git\usr\bin\ssh-agent.exe, или добавить этот путь в системные переменные на машине, где запущен runner
**AppCenter Build пытается запустить билд для проекта из неактуального bitBucket репозитория**В моём случае проблема возникла из-за того, что я работала с несколькими аккаунтами. Решилась очисткой кэша. | https://habr.com/ru/post/444136/ | null | ru | null |
# Эффективное внедрение зависимостей при масштабировании Ruby-приложений
[](https://habrahabr.ru/company/latera/blog/301338/)
В нашем блоге на Хабре мы не только рассказываем о развитии своего продукта — [биллинга для операторов связи «Гидра»](http://www.hydra-billing.ru/), но и публикуем материалы о работе с инфраструктурой и использовании технологий из опыта других компаний. Программист и один из руководителей австралийской студии разработки Icelab Тим Райли написал в корпоративном блоге [статью](http://icelab.com.au/articles/effective-ruby-dependency-injection-at-scale/) о внедрении зависимостей Ruby — мы представляем вашему вниманию адаптированную версию этого материала.
В [предыдущей части](http://icelab.com.au/articles/functional-command-objects-in-ruby/) Райли описывает подход, в котором внедрение зависимостей используется для создания небольших переиспользуемых функциональных объектов, реализующих шаблон «[Команда](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BC%D0%B0%D0%BD%D0%B4%D0%B0_(%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F))». Реализация оказалась относительно простой, без громоздких кусков кода — всего три работающих вместе объекта. С помощью этого примера объясняется использование не нескольких сотен, а одной или двух зависимостей.
Для того, чтобы внедрение зависимостей работало даже при больших масштабах инфраструктуры, необходимо наличие единственной вещи — контейнера с [инверсией управления](https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D0%B2%D0%B5%D1%80%D1%81%D0%B8%D1%8F_%D1%83%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F).
В этом месте Райли приводит код команды CreateArticle, в которой используется внедрение зависимостей:
```
class CreateArticle
attr_reader :validate_article, :persist_article
def initialize(validate_article, persist_article)
@validate_article = validate_article
@persist_article = persist_article
end
def call(params)
result = validate_article.call(params)
if result.success?
persist_article.call(params)
end
end
end
```
В этой команде используется внедрение зависимости в конструктор для работы с объектами `validate_article` и `persist_article`. [Здесь](http://dry-rb.org/gems/dry-container) объясняется, как можно использовать dry-container (простой потокобезопасный контейнер, предназначенный для использования в качестве половины реализации контейнера с инверсией управления) для того, чтобы зависимости были доступны при необходимости:
```
require "dry-container"
# Создаем контейнер
class MyContainer
extend Dry::Container::Mixin
end
# Регистрируем наши объекты
MyContainer.register "validate_article" do
ValidateArticle.new
end
MyContainer.register "persist_article" do
PersistArticle.new
end
MyContainer.register "create_article" do
CreateArticle.new(
MyContainer["validate_article"],
MyContainer["persist_article"],
)
end
# Теперь объект `CreateArticle` доступен к использованию
MyContainer["create_article"].("title" => "Hello world")
```
Тим объясняет инверсию управления с помощью аналогии — представьте один большой ассоциативный массив, который управляет доступом к объектам в приложении. В представленном ранее фрагменте кода были зарегистрированы 3 объекта с помощью блоков для их последующего создания при обращении. Отложенное вычисление блоков означает так же, что сохраняется возможность их использования для доступа к другим объектам в контейнере. Таким образом передаются зависимости при создании `create_article`.
Можно вызвать `MyApp::Container["create_article"]`, и объект будет полностью сконфигурирован и готов к использованию. Имея контейнер, можно зарегистрировать объекты один раз и многократно использовать их в дальнейшем.
`dry-container` поддерживает объявление объектов без использования пространства имен для того, чтобы облегчить работу с большим количеством объектов. В реальных приложениях чаще всего используется пространство имен вида «articles.validate\_article» и «persistence.commands.persist\_article» вместо простых идентификаторов, которые можно встретить в описываемом примере.
Все хорошо, однако, в больших приложениях хотелось бы избежать большого количества шаблонного кода. Решить эту задачу можно в два этапа. Первый из них заключается в использовании системы автоматического внедрения зависимостей в объекты. Вот, как это выглядит при использовании [dry-auto\_inject](http://dry-rb.org/gems/dry-auto_inject) (механизм, обеспечивающий разрешение зависимостей по требованию):
```
require "dry-container"
require "dry-auto_inject"
# Создаем контейнер
class MyContainer
extend Dry::Container::Mixin
end
# В этот раз регистрируем объекты без передачи зависимостей
MyContainer.register "validate_article", -> { ValidateArticle.new }
MyContainer.register "persist_article", -> { PersistArticle.new }
MyContainer.register "create_article", -> { CreateArticle.new }
# Создаем модуль AutoInject для использования контейнера
AutoInject = Dry::AutoInject(MyContainer)
# Внедряем зависимости в CreateArticle
class CreateArticle
include AutoInject["validate_article", "persist_article"]
# AutoInject делает доступными объекты `validate_article` and `persist_article`
def call(params)
result = validate_article.call(params)
if result.success?
persist_article.call(params)
end
end
end
```
Использование механизма автоматического внедрения позволяет уменьшить объем шаблонного кода при объявлении объектов с контейнером. Исчезает необходимость в разработке списка зависимостей для их передачи методу `CreateArticle.new` при его объявлении. Вместо этого можно определить зависимости непосредственно в классе. Модуль, подключаемый с помощью `AutoInject[*dependencies]` определяет методы `.new`, `#initialize` и `attr_readers`, которые «вытягивают» из контейнера зависимости, и позволяют их использовать.
Объявление зависимостей в том месте, где они будут использоваться — это очень мощная рокировка, позволяющая сделать понятными совместно используемые объекты без необходимости определения конструктора. Кроме того появляется возможность простого обновления списка зависимостей — это полезно, поскольку задачи, выполняемые объектом, со временем меняются.
Описанный метод кажется довольно изящным и эффективным, однако стоит подробнее остановиться на способе объявления контейнеров, который использовался в начале последнего примера кода. Такое объявление можно использовать с `dry-component`, системой, имеющей все необходимые функции управления зависимостями и основанной на `dry-container` и `dry-auto_inject`. Эта система сама управляет тем, что необходимо для использования инверсии управления между всеми частями приложения.
В своем материале Райли отдельно фокусируется на одном аспекте этой системы — автоматическом объявлении зависимостей.
Предположим, что три наших объекта определены в файлах `lib/validate_article.rb`, `lib/persist_article.rb` и `lib/create_article.rb`. Все их можно включить в контейнер автоматически, используя специальную настройку в файле верхнего уровня `my_app.rb`:
```
require "dry-component"
require "dry/component/container"
class MyApp < Dry::Component::Container
configure do |config|
config.root = Pathname(__FILE__).realpath.dirname
config.auto_register = "lib"
end
# Добавляем "lib/" в $LOAD_PATH
load_paths! "lib"
end
# Запускаем автоматическую регистрацию
MyApp.finalize!
# И теперь все готово к использованию
MyApp["validate_article"].("title" => "Hello world")
```
Теперь в программе больше не содержится однотипных строк кода, при этом приложение по-прежнему работает. Автоматическая регистрация использует простое преобразование файла и имени класса. Директории преобразуются в пространства имен, таким образом класс `Articles::ValidateArticle` в файле `lib/articles/validate_article.rb` будет доступен для разработчика в контейнере `articles.validate_article` без необходимости каких-либо дополнительных действий. Таким образом обеспечивается удобное преобразование, похожее на преобразование в Ruby on Rails, без возникновения каких-либо проблем с автоматической загрузкой классов.
`dry-container`, `dry-auto_inject`, и `dry-component` — это все, что необходимо для работы с небольшими отдельными компонентами, легко соединяющимися вместе с помощью внедрения зависимостей. Применение этих инструментов упрощает создание приложений и, что даже более важно, облегчает их поддержку, расширение и перепроектирование.
#### Другие технические статьи от «[Латеры](http://www.latera.ru/)»:
* [Автоматизируем учет адресов и привязок в IPoE-сетях](http://blog.hydra-billing.ru/stories/574)
* [Судный день: К чему приводят скрытые ошибки асинхронной обработки данных при росте нагрузки](https://habrahabr.ru/company/latera/blog/283548/)
* [Работа с MySQL: как масштабировать хранилище данных в 20 раз за три недели](https://habrahabr.ru/company/latera/blog/282798/)
* [DoS своими силами: К чему приводит бесконтрольный рост таблиц в базе данных](https://habrahabr.ru/company/latera/blog/277331/)
* [Архитектура open source-приложений: Как работает nginx](https://habrahabr.ru/company/latera/blog/273283/)
* [Как повысить отказоустойчивость биллинга: Опыт «Гидры»](https://habrahabr.ru/company/latera/blog/267083/) | https://habr.com/ru/post/301338/ | null | ru | null |
# Делаем простейший сборщик ошибок для Android
При разработке приложения неизбежно приходится сталкиваться с ошибками в коде и/или окружении. И очень печально когда подобные ошибки встречаются не на тестовом телефоне/эмуляторе а у живых пользователей. Еще печальнее если это не ваш друг бета-тестер и толком никто не может объяснить что и где свалилось.
Обычно при внезапном падении приложения Android предлагает отправить отчет об ошибке, где будет и подробный стэк-трейс и информация о версии вашего приложения. К сожалению пользователи не всегда нажимают кнопку «отправить отчет» а для дебаг-приложений или приложений не из маркета такая функциональность и вовсе недоступна.
Что же делать? На помощь приедет возможность языка Java обрабатывать исключения (Exceptions), в том числе и непойманные (unhandled).
Класс Thread имеет статический метод [setDefaultUncaughtExceptionHandler](http://developer.android.com/reference/java/lang/Thread.html#setDefaultUncaughtExceptionHandler(java.lang.Thread.UncaughtExceptionHandler)). Данный метод позволяет установить собственный класс-обработчик непойманных исключений. Класс-обработчик должен имплементировать интерфейс [Thread.UncaughtExceptionHandler](http://developer.android.com/reference/java/lang/Thread.UncaughtExceptionHandler.html). Каркас обработчика может выглядеть примерно так:
```
public class TryMe implements Thread.UncaughtExceptionHandler {
@Override
public void uncaughtException(Thread thread, Throwable throwable) {
Log.d("TryMe", "Something wrong happened!");
}
}
```
Единственный метод принимает на вход Thread — поток, в котором произошло исключение, и Throwable — само исключение. Приведенная выше реализация просто выводит в лог сообщение без каких либо деталей… Попробуем воспользоваться…
```
public class MainActivity extends MapActivity {
@Override
public void onCreate(Bundle savedInstanceState) {
Thread.setDefaultUncaughtExceptionHandler(new TryMe());
Integer a=1;
if(true)
a=null;
int x = 6;
x=x/a; // Exception here!
}
}
```
После запуска вышеприведенного кода мы (ура!) получим сообщение в логе… и черный экран. Установив наш собственный обработчик мы удалил штатный обработчик ОС Android и теперь нам больше не предлагают закрыть приложение.
Исправим положение
```
public class TryMe implements Thread.UncaughtExceptionHandler {
Thread.UncaughtExceptionHandler oldHandler;
public TryMe() {
oldHandler = Thread.getDefaultUncaughtExceptionHandler(); // сохраним ранее установленный обработчик
}
@Override
public void uncaughtException(Thread thread, Throwable throwable) {
Log.d("TryMe", "Something wrong happened!");
if(oldHandler != null) // если есть ранее установленный...
oldHandler.uncaughtException(thread, throwable); // ...вызовем его
}
}
```
Теперь мы видим и сообщение в логе, и привычное системное сообщение.
Неудобно устанавливать обработчик в Activity. Хоть он и будет установлен а все потоки, но Activity может быть несколько и несколько же стартовых. А еще могут быть сервисы… В этом случае лучше всего устанавливать обработчик при инициализации приложения. Примерно вот так:
```
public class MyApplication extends Application {
@Override
public void onCreate() {
Thread.setDefaultUncaughtExceptionHandler(new TryMe());
super.onCreate();
}
}
```
При этом нужно не забыть прописать новый класс приложения в манифест. Примерно вот так:
```
```
Теперь при старте приложения (не важно какого его компонента) будет установлен обработчик исключений.
Конечно выводить сообщение в лог это не серьезно. Нужно собирать больше информации. Какая версия приложения? Какое исключение не обработано? Какое другое исключение привело к выбросу фатального? В каком потоке? Какой был стэк? Всю эту информацию можно получить. Код простейшего обработчика исключений получающий и сохраняющий на SD-карту всю вышеуказанную информацию размещен на [GitHub](https://github.com/Olegas/RoboErrorReporter).
Приведенная реализация сохраняет информацию об необработанном исключении в файл на SD-карте в папку /Android/data/your.app.package.name/files/ ([так велит Dev Guide](http://developer.android.com/guide/topics/data/data-storage.html#filesExternal)) в файлах вида stacktrace-dd-MM-yy.txt. Для работы в манифесте приложения требуется разрешение WRITE\_EXTERNAL\_STORAGE.
Естественно это не единственное подобное решение.
[Flurry](http://www.flurry.com/) — аналитика для мобильных приложений, содержит свой обработчик ошибок. [ACRA](http://code.google.com/p/acra/) — библиотека для Android, собирает данные об ошибках и постит их на GoogleDocs. [Android-remote-stacktrace](http://code.google.com/p/android-remote-stacktrace/) — аналогичная библиотека, шлет данные на пользовательский скрипт-приемник. Также много полезного можно получить [в этом вопросе](http://stackoverflow.com/questions/601503/how-do-i-obtain-crash-data-from-my-android-application) на StackOverflow | https://habr.com/ru/post/129582/ | null | ru | null |
# Google's beacon platform. Часть 2 — Nearby meassages API
[**Google's beacon platform**](https://developers.google.com/beacons/overview) — это решение для работы с Bluetooth маячками. Платформа работает с разными маячками от разных производителей, предоставляя разработчикам единый, простой и гибкий инструмент.

Перед прочтением этой статьи я рекомендую ознакомиться с концепцией **Physical Web** о которой я рассказывал в своей прошлой статье: [Концепция Physical web. Bluetooth маячки. Сравнение стандартов iBeacon, AltBeacon и Eddystone](https://habrahabr.ru/post/278443/).
[Google's beacon platform. Часть 1 — Proximity beacon API](https://habrahabr.ru/post/279381/)
[Google's beacon platform. Часть 2 — Nearby meassages API](https://habrahabr.ru/post/279379/)
Основным средством, в рамках **Google's beacon platform**, для работы на клиентской стороне с bluetooth маячками, является [**Nearby Messages API**](https://developers.google.com/nearby/messages/overview). В этой статье я расскажу как настроить проекты на а платформах Android и iOS, и добавить в приложение возможность получать и разбирать сообщения от ble-маячков.
Nearby Messages API
===================
**Nearby Messages API** — это API, которое реализует парадигму publish-subscribe и позволяет разным устройствам публиковать, и подписываться на сообщения, таким образом обмениваться данными. **Nearby Messages API** является частью [Nearby](https://developers.google.com/nearby/). Для обмена сообщениями устройства не обязательно должны находиться в одной сети, но должны быть подключены к интернету. В нашем случае подключение к интернету должно быть у того смартфона или планшета на котором мы хотим получать сообщения. Маячкам подключение к интернету не нужно! **Nearby Messages API** позволяет обмениваться сообщениями с помощью Bluetooth, Bluetooth Low Energy, Wi-Fi и даже ультразвука, но мы будем использовать только Bluetooth Low Energy что бы минимизировать потребление энергии.
Nearby Messages API на Android
==============================
Nearby Messages API доступен на устройствах с Android в библиотеке Google Play services версии 7.8.0 или выше.
Убедитесть что у вас установлена последняя версия клиентской библиотеки для Google Play на вашем хосте для разработки:
* Откройте Android SDK Manager.
* Перейдите в A ppearance & Behavior > System Settings > Android SDK > SDK Tools и убедитесь что установлены следующие пакеты:
+ Google Play services
+ Google Repository
Для использования Nearby Messages API, конечно же понадобится Google Account. Так же необходимо получить [API ключ](https://developers.google.com/nearby/messages/android/get-started#step_3_get_an_api_key). Ключи для Android, iOS и Proximity Beacon API должны быть созданы в рамках одно проекта Google Developers Console. Очень советую ознакомиться с [**Best practices for securely using API keys**](https://support.google.com/cloud/answer/6310037)
**Осторожно GIF. Пример того как получить API ключ:**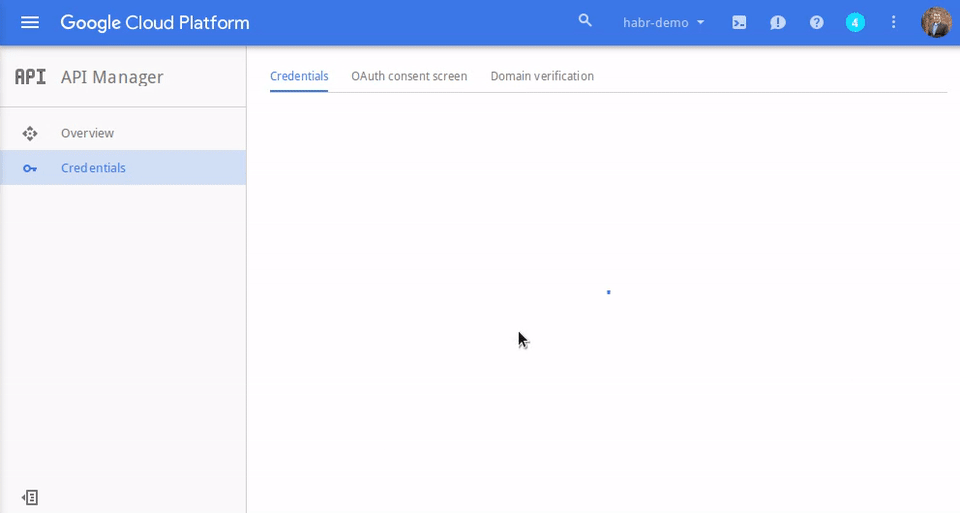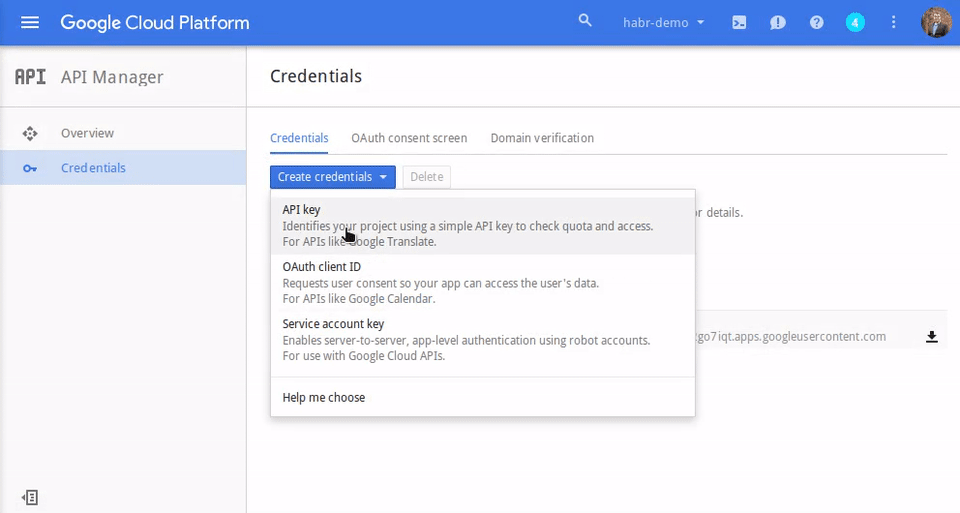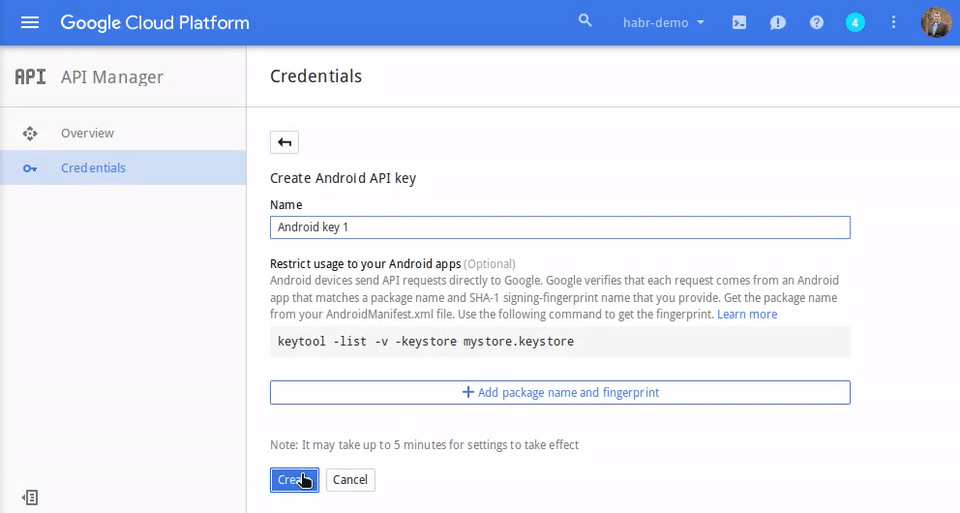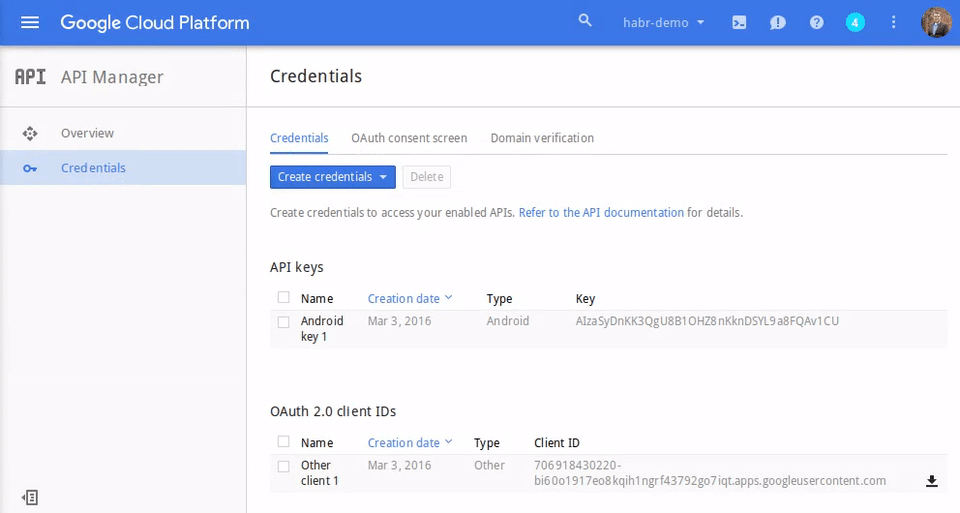
**Настраиваем проект:**
Открываем или создаём новый проект, открываем `build.gradle` файл и добавляем в него Google Play services client library как зависимость.
**Содержание файла build.gradle**
```
apply plugin: 'android'
...
dependencies {
compile 'com.google.android.gms:play-services-nearby:8.4.0'
}
```
**Настраиваем manifest файл в который добавляем сгенерированный ранее API ключ:**
```
...
```
Создаём в нашем приложении GoogleApiClient и добавляем Nearby Messages API
Пример кода который показывает как добавить Nearby Messages API:
**Создаём в приложении GoogleApiClient:**
```
mGoogleApiClient = new GoogleApiClient.Builder(this)
.addApi(Nearby.MESSAGES_API)
.addConnectionCallbacks(this)
.addOnConnectionFailedListener(this)
.build();
```
Получение сообщений
-------------------
Для получения сообщений от маячков нам необходимо сперва на них подписаться, есть два способа как наше приложение может это сделать:
* В активном режиме приложения, в ответ на действия пользователя или события.
* В фоновом режиме, т.е. когда приложение неактивно
Nearby Messages API требует разрешения пользователя на запросы `publish()` и `subscribe()`. Поэтому приложение должно проверять на что пользователь уже дал свое согласие и если такое отсутствует, то вызывать диалог запроса разрешений.
Что бы реализовать запрос разрешения у пользователя во время исполнения вашего приложения, вы можете:
* Присоединить `result callback` к вызовам `publish()` and `subscribe()`.
* Использовать `Nearby.Messages.getPermissionStatus()` что бы проверить статус разрешения непосредственно перед вызовом `publish()` или `subscribe()`
### Реализация result callback
Для проверки статус кода ошибки в `result callback` необходимо вызвать `status.getStatusCode()`. Если получен статус код `APP_NOT_OPTED_IN` отобразите диалог запроса разрешений вызовом `status.startResolutionForResult()` и используйте `onActivityResult()` что бы повторно реинициировать какие-либо невыполненные запросы подписки или публикации.
Следующий пример демонстрирует простой result callback, который проверяет, какие пользователь предоставил разрешения. Если пользователь не предоставил разрешений, вызывается `status.startResolutionForResult()`, чтобы предложить пользователю разрешить Nearby Messages. В этом примере `boolean mResolvingError` используется чтобы избежать многократного запуска таких предложений:
**Пример реализации result callback:**
```
private void handleUnsuccessfulNearbyResult(Status status) {
Log.i(TAG, "Processing error, status = " + status);
if (mResolvingError) {
// Already attempting to resolve an error.
return;
} else if (status.hasResolution()) {
try {
mResolvingError = true;
status.startResolutionForResult(getActivity(),
Constants.REQUEST_RESOLVE_ERROR);
} catch (IntentSender.SendIntentException e) {
mResolvingError = false;
Log.i(TAG, "Failed to resolve error status.", e);
}
} else {
if (status.getStatusCode() == CommonStatusCodes.NETWORK_ERROR) {
Toast.makeText(getActivity().getApplicationContext(),
"No connectivity, cannot proceed. Fix in 'Settings' and try again.",
Toast.LENGTH_LONG).show();
} else {
// To keep things simple, pop a toast for all other error messages.
Toast.makeText(getActivity().getApplicationContext(), "Unsuccessful: " +
status.getStatusMessage(), Toast.LENGTH_LONG).show();
}
}
}
```
Вы также можете использовать этот обработчик(handler) для обработки любых других `NearbyMessageStatusCodes` полученных от операций или, например, статус кода `CommonStatusCodes.NETWORK_ERROR.`
#### Реиницализация невыполненных запросов
Следующий пример показывает реализацию метода `onActivityResult()`, который вызывается после того как пользователь отреагирует на диалог запроса разрешений. В случае если пользователь ответит согласием, любые ожидающие запросы подписки или публикации будут выполнены. А данном примере вызывается метод `executePendingTasks()`
**Реиницаиалзация невыполненных запросов:**
```
@Override
protected void onActivityResult(int requestCode, int resultCode, Intent data) {
super.onActivityResult(requestCode, resultCode, data);
if (requestCode == Constants.REQUEST_RESOLVE_ERROR) {
// User was presented with the Nearby opt-in dialog and pressed "Allow".
mResolvingError = false;
if (resultCode == Activity.RESULT_OK) {
// Execute the pending subscription and publication tasks here.
mMainFragment.executePendingTasks();
} else if (resultCode == Activity.RESULT_CANCELED) {
// User declined to opt-in. Reset application state here.
} else {
Toast.makeText(this, "Failed to resolve error with code " + resultCode,
Toast.LENGTH_LONG).show();
}
}
```
Так же, чтобы уменьшить задержку при сканировании маячков, рекомендуется использовать Strategy.BLE\_ONLY при вызове Nearby.Messages.subscribe(). Когда эта опция установлена, Nearby Messages API не задействует Wi-Fi сканирование или классические сканирования Bluetooth. Это уменьшает задержку обнаружения маячков, поскольку система не циклирует через все возможные типы сканирования, а так же уменьшает потреблении энергии.
### Подписка в активном режиме:
Когда ваше приложение подписывается на сообщения от маячков будучи в активном режиме, сканирование производится непрерывно пока приложение не отпишется. Такую подписку рекомендуется использовать только когда ваше приложение активно, обычно в ответ на какие то действия пользователя.
Приложение может инициировать подписку в активном режиме вызвав метод `Nearby.Messages.subscribe(GoogleApiClient, MessageListener, SubscribeOptions)` и установив для параметра `Strategy` значение `BLE_ONLY`.
**Фрагмент кода демонстрирующий инициирование подписки в активном режиме:**
```
// Create a new message listener.
mMessageListener = new MessageListener() {
@Override
public void onFound(Message message) {
// Do something with the message.
Log.i(TAG, "Found message: " + message);
}
// Called when a message is no longer detectable nearby.
public void onLost(Message message) {
// Take appropriate action here (update UI, etc.)
}
}
// Subscribe to receive messages.
Log.i(TAG, "Trying to subscribe.");
// Connect the GoogleApiClient.
if (!mGoogleApiClient.isConnected()) {
if (!mGoogleApiClient.isConnecting()) {
mGoogleApiClient.connect();
}
} else {
SubscribeOptions options = new SubscribeOptions.Builder()
.setStrategy(Strategy.BLE_ONLY)
.setCallback(new SubscribeCallback() {
@Override
public void onExpired() {
Log.i(TAG, "No longer subscribing.");
}
}).build();
Nearby.Messages.subscribe(mGoogleApiClient, mMessageListener, options)
.setResultCallback(new ResultCallback() {
@Override
public void onResult(Status status) {
if (status.isSuccess()) {
Log.i(TAG, "Subscribed successfully.");
} else {
Log.i(TAG, "Could not subscribe.");
// Check whether consent was given;
// if not, prompt the user for consent.
handleUnsuccessfulNearbyResult(status);
}
}
});
}
```
Для уменьшения потребления энергии и соответственно продления срока работы аккумулятора, вызывайте `Nearby.Messages.unsubscribe()` в методе `OnStop()` вашего приложения.
Когда подписка на сообщения больше не нужна, приложение должно отписаться вызвав метод `Nearby.Messages.unsubscribe(GoogleApiClient, MessageListener)`.
### Подписка в фоновом режиме
Когда приложение подписывается на сообщения в фоновом режиме, срабатывает low-power сканирование при событиях включения экрана, даже когда приложение в настоящее время не активно. Вы можете использовать эти фоновые события low-power сканирования, чтобы "разбудить" приложение в ответ на конкретное сообщение. Фоновые подписки потребляют меньше энергии, чем подписка в активном режиме, но имеют более высокую задержку и низкую надежность.
Подписка в фоновом режиме инициируется вызовом метода `Nearby.Messages.subscribe(GoogleApiClient, PendingIntent,SubscribeOptions)` и заданием для параметра `Strategy` значения `BLE_ONLY`.
**Фрагмент кода демонстрирующий инициирование подписки в фоновом режиме:**
```
// Subscribe to messages in the background.
private void backgroundSubscribe() {
// Connect the GoogleApiClient.
if (!mGoogleApiClient.isConnected()) {
if (!mGoogleApiClient.isConnecting()) {
mGoogleApiClient.connect();
}
} else {
Log.i(TAG, "Subscribing for background updates.");
SubscribeOptions options = new SubscribeOptions.Builder()
.setStrategy(Strategy.BLE_ONLY)
.build();
Nearby.Messages.subscribe(mGoogleApiClient, getPendingIntent(), options)
.setResultCallback(new ResultCallback() {
@Override
public void onResult(Status status) {
if (status.isSuccess()) {
Log.i(TAG, "Subscribed successfully.");
} else {
Log.i(TAG, "Could not subscribe.");
handleUnsuccessfulNearbyResult(status);
}
}
});
}
}
private PendingIntent getPendingIntent() {
return PendingIntent.getService(getApplicationContext(), 0,
getBackgroundSubscribeServiceIntent(), PendingIntent.FLAG\_UPDATE\_CURRENT);
}
private Intent getBackgroundSubscribeServiceIntent() {
return new Intent(getApplicationContext(), BackgroundSubscribeIntentService.class);
}
```
**Фрагмент кода демонстрирующий обработку intent'а в классе BackgroundSubscribeIntentService:**
```
protected void onHandleIntent(Intent intent) {
Nearby.Messages.handleIntent(intent, new MessageListener() {
@Override
public void onFound(Message message) {
Log.i(TAG, "Found message via PendingIntent: " + message);
}
@Override
public void onLost(Message message) {
Log.i(TAG, "Lost message via PendingIntent: " + message);
}
});
}
```
Ну и конечно же, если подписка нам больше не нужна, мы должны отписаться вызвав `Nearby.Messages.unsubscribe(GoogleApiClient, PendingIntent)`.
Разбор сообщений
----------------
Как мы уже знаем из первой части, каждое вложения состоит из следующих частей:
-**Namespace**: Идентификатор пространства имен.
-**Type**: Тип данных.
-**Data**: Значение данных вложения.
**Фрагмент кода демонстрирующий использование MessageListener() для разбора сообщений:**
```
mMessageListener = new MessageListener() {
@Override
public void onFound(Message message) {
// Do something with the message here.
Log.i(TAG, "Message found: " + message);
Log.i(TAG, "Message string: " + new String(message.getContent()));
Log.i(TAG, "Message namespaced type: " + message.getNamespace() +
"/" + message.getType());
}
...
};
```
Стоит учесть что разбор содержания зависит от формата байт. Этот пример предполагает, что сообщения закодированы в UTF-8 строку, но ваши сообщения от маячков могут быть закодированы в другой формат.
Чтобы узнать какие пространства имен связаны с вашим проектом, можно вызвать namespaces.list.
Nearby meassages API на iOS
===========================
Для создания проекта использующего Nearby Messages API for iOS нам понадобиться Xcode версии 6.3 или старше.
Google Nearby Messages API для iOS доступен как пакет(pod) **CocoaPods**. **CocoaPods** — это менеджер зависимостей с открытым исходным кодом для Swift и Objective-C Cocoa проектов. Для получения дополнительной информации советую ознакомиться с [CocoaPods Getting Started guide](https://guides.cocoapods.org/using/getting-started.html). Если он у вас не установлен, вы можете сделать это выполнив в терминале следующую комманду:
```
$ sudo gem install cocoapods
```
**Устанавливаем Nearby messages API использую CocoaPods:**
* Открываем проект или создаём новый, следует убедится что опция Use Automatic Reference Counting включена.
* Создаём файл с именем Podfile в директории проекта. Этот файл будет определять зависимости проекта.
* Добавляем зависимости в Podfile. Пример простого Podspec содержащего имя пакета которое для установки
```
source 'https://github.com/CocoaPods/Specs.git'
platform :ios, '7.0'
pod 'NearbyMessages'
```
* В терминале переходим в директорю в котрой находится Podfile
* Для установки вместе с зависимости API указанных в Podfile необходимо выполнить комманду:
```
$ pod install
```
После этого закрываем Xcode и затем двойным кликом по .xcworkspace проекта запускаем Xcode. Начиная с этого момента, вы должны использовать файл .xcworkspace для открытия проекта.
Как и в случае с Android, нам необходимо получить [API ключ](https://developers.google.com/nearby/messages/ios/get-started#step_6_get_an_api_key). Ключи для Android, iOS и Proximity Beacon API должны быть созданы в рамках одно проекта Google Developers Console. Очень советую ознакомиться с [**Best practices for securely using API keys**](https://support.google.com/cloud/answer/6310037)
**Осторожно GIF. Пример получения API ключа:**
Теперь, когда всё настроено, мы можем создать объект `messageManager` и использовать API ключ созданный ранее
```
#import
GNSMessageManager \*messageManager =
[[GNSMessageManager alloc] initWithAPIKey:@"API\_KEY"];
```
Подписка в iOS
--------------
В iOS сканирование маячков происходит только когда приложение активно. Сканирование маячков в фоновом режиме недоступно для iOS. Что бы подписаться только на BLE маячки нужно задать `deviceTypesToDiscover` в параметрах подписки `kGNSDeviceBLEBeacon`.
**Фрагмент кода который показывает как это сделать:**
```
_beaconSubscription = [_messageManager
subscriptionWithMessageFoundHandler:myMessageFoundHandler
messageLostHandler:myMessageLostHandler
paramsBlock:^(GNSSubscriptionParams *params) {
params.deviceTypesToDiscover = kGNSDeviceBLEBeacon;
}];
```
Этот пример кода подписывается только на маячки нашего проекта и получает все сообщения от них.
Если мы хотим получать сообщения от маячков зарегистрированных с другим пространством имён, мы можем передать namespace в параметры подписки. Аналогично мы можем сделать и с типом сообщений которые хотим получать передав конкретный тип сообщений для фильтрации. Для это необходимо задействовать сканирование устройств в `GNSStrategy` и пробросить значения пространства имен и типа подписки в параметры подписки.
**Фрагмент кода который показывает как это сделать:**
```
_beaconSubscription = [_messageManager
subscriptionWithMessageFoundHandler:myMessageFoundHandler
messageLostHandler:myMessageLostHandler
paramsBlock:^(GNSSubscriptionParams *params) {
params.deviceTypesToDiscover = kGNSDeviceBLEBeacon;
params.messageNamespace = @"com.mycompany.mybeaconservice";
params.type = @"mybeacontype";
}];
```
По умолчанию, при подписке мы сканируем сразу оба типа маячков, Eddystone и iBeacon. Если у нас задействовано сканирование маячков iBeacon, пользователь получит запрос на использование геолокации. Info.plist приложения должен включать ключ `NSLocationAlwaysUsageDescription` с крткаим обьяcнением того, почему используеься геолокация. Советую ознакомиться с [документацией Apple](https://developer.apple.com/library/ios/documentation/General/Reference/InfoPlistKeyReference/Articles/CocoaKeys.html#//apple_ref/doc/uid/TP40009251-SW18) для деталей.
Если мы хотим сканировать только маячки Eddystone, мы можем отключить сканирование маячков iBeacon в `GNSBeaconStrategy`. В таком случае iOS не будет запрашивать у пользователя разрешения на использование геолокации.
**Фрагмент кода, который показывает как отключить сканирование iBeacon маячков для предыдущего примера:**
```
_beaconSubscription = [_messageManager
subscriptionWithMessageFoundHandler:myMessageFoundHandler
messageLostHandler:myMessageLostHandler
paramsBlock:^(GNSSubscriptionParams *params) {
params.deviceTypesToDiscover = kGNSDeviceBLEBeacon;
params.messageNamespace = @"com.mycompany.mybeaconservice";
params.type = @"mybeacontype";
params.beaconStrategy = [GNSBeaconStrategy strategyWithParamsBlock:^(GNSBeaconStrategyParams *params) {
params.includeIBeacons = NO;
};
}];
```
При сканировании маячков iBeacon, диалог запроса разрешений на геолокацию предшествует диалогу разрешений Nearby. Мы можем переопределить этот диалог, например, для того что бы обяьснить пользователю для чего запрашивается разрешение на геолокацию. Для этого необходимо задать `permissionRequestHandler` в отдельном блоке в параметрах подписки.
**Фрагмент кода показывающий как это сделать:**
```
_beaconSubscription = [_messageManager
subscriptionWithMessageFoundHandler:myMessageFoundHandler
messageLostHandler:myMessageLostHandler
paramsBlock:^(GNSSubscriptionParams *params) {
params.deviceTypesToDiscover = kGNSDeviceBLEBeacon;
params.messageNamespace = @"com.mycompany.mybeaconservice";
params.type = @"mybeacontype";
params.beaconStrategy = [GNSBeaconStrategy strategyWithParamsBlock:^(GNSBeaconStrategyParams *params) {
params.includeIBeacons = NO;
};
params.permissionRequestHandler = ^(GNSPermissionHandler permissionHandler) {
// Show your custom dialog here, and don't forget to call permissionHandler after it is dismissed
permissionHandler(userGavePermission);
};
}];
```
Заключение
==========
Я надеюсь что данный материал будет кому то полезен, сэкономит время и силы. | https://habr.com/ru/post/279379/ | null | ru | null |
# Начинаем работать с Drupal: полное практическое руководство (часть 2)
Продолжение [первой части](http://habrahabr.ru/blogs/drupal/103600/).
###### Создадим страницу вакансий с помощью модуля Views
Хотя вы и можете самостоятельно писать запросы к базе данных для чтения содержимого, дело это долгое и сложное, даже с учетом [мощного API Друпала](http://api.drupal.org/).
Для построения страницы со списком вакансий мы задействуем **Views** — модуль, позволяющий извлекать содержимое из базы данных вообще без написания кода.
Попросту говоря, Views — это пользовательский интерфейс построения MySQL-запросов. Views — это невероятно мощный модуль, но порой его бывает трудно освоить начинающим пользователям. Лучший способ разобраться с Views — немного с ним поиграть, чем мы сейчас и займемся.
###### Устанавливаем Views
Прежде всего, нам нужно установить Views. После [загрузки](http://drupal.org/project/views), установки и включения модуля, он будет доступен в секции меню «Конструкция сайта». При установке не забудьте распаковать в папку с модулем его перевод.
###### Создаем первое представление
Любой набор данных, выведенный модулем Views, называется *представлением*.
Мы создадим представление, отображающее на странице список доступных вакансий. Также с помощью Views вы можете делать вложения, блоки и настраиваемые RSS-ленты, но мы пока разберем что-нибудь попроще.
Перейдите в меню на страницу **Конструкция сайта > Представления > Добавить** и заполните поля так, как показано на изображении:
Затем Друпал отобразит пользовательский интерфейс создания представлений. Не пугайтесь, мы вскоре его обсудим.
###### Что такое вид?
Чтобы приступить к созданию представления, нам нужно понять, что такое вид. Виды отображают наши данные в различных стилях. В одном представлении может быть несколько видов.
Для представления вакансий мы создадим 2 вида: страничный и блочный. Вернемся к этой теме чуть позже.
###### Добавление полей в представление
Давайте добавим несколько полей в наше представление. Поля — это содержимое, которое мы хотим вывести на страницу. Нажмите на значок плюса (+) в области «Поля», чтобы добавить поля к представлению.
Мы будем выводить заголовок, дату создания, отдел, зарплату и опыт, заданные пользователем в форме размещения вакансии.
Эти поля нам нужно выбрать из дополнительного списка, который появится после нажатия кнопки с плюсом (+). Нас интересуют следующие поля:
* Материал: Заголовок
* Материал: Дата создания
* Содержимое: Отдел
* Содержимое: Заработная плата
* Содержимое: Опыт
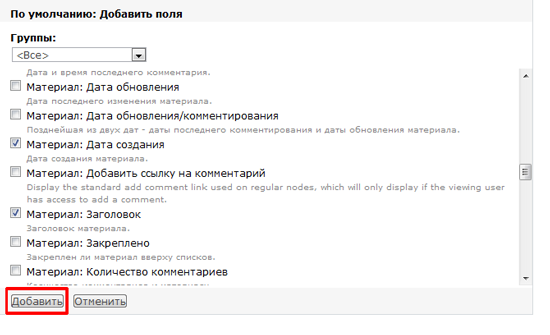
После выбора нужных полей нажмите кнопку «Добавить», чтобы перейти к настройке каждого поля в отдельности.
После нажатия кнопки «Добавить» первой появится секция настройки поля **Содержимое: Отдел**. Оставьте все как есть, за исключением селектора «Формат», задав в нем значение «Простой текст»; затем нажмите «Обновить».
Теперь настройте поле **Содержимое: Опыт**. Ничего не меняйте, просто нажмите «Обновить». И то же самое проделайте с полем **Заработная плата**.
Когда закончите с полями содержимого, нужно будет настроить поле **Материал: Дата создания**. Просто измените поле **Формат даты** в значение «Время назад», чтобы в поле отображалось, сколько времени прошло с момента публикации вакансии (например, «12 дней назад»).
Следующее и заключительное поле для настройки — **Материал: Заголовок**. Мы просто должны поставить галочку, указывающую, что заголовок должен быть ссылкой на страницу вакансии.
###### Предварительный просмотр
Можете использовать вкладку предварительного просмотра, чтобы увидеть результат ваших настроек:
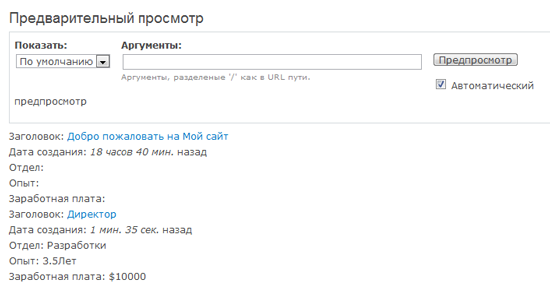
###### Основные настройки
Теперь зададим основные настройки представления.
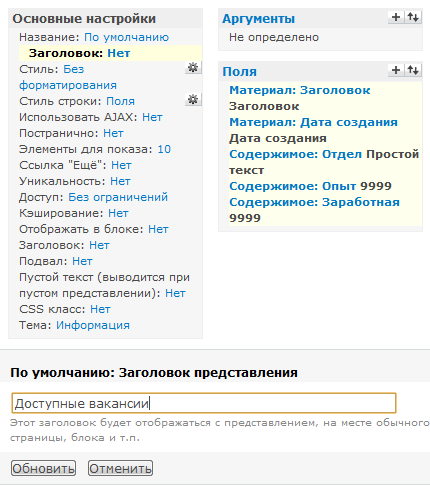
Мы выберем *стиль* «**Без форматирования**», а данные будем выводить в табличном формате. Когда зададите эти настройки, нажмите «Обновить».
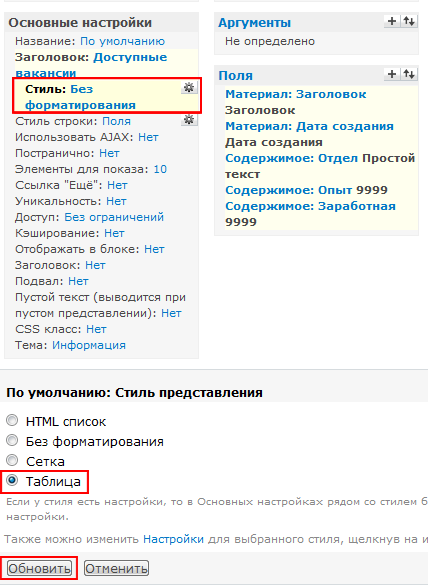
Мы бы хотели вывести все вакансии без разбивки на несколько страниц, поэтому опции «Постранично» — скажем твердое «**Нет**». И снова нажмем «Обновить».
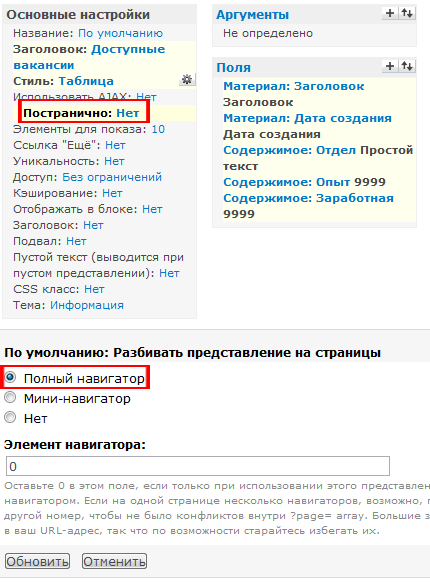
Как вы можете заметить, после всех этих манипуляций наше представление выглядит лучше, чем раньше. Но мы еще не закончили.
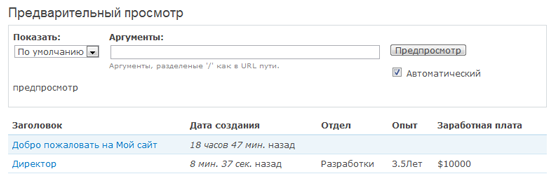
###### Фильтры представления
На текущий момент в представлении выводится все содержимое сайта, в том числе и не являющееся вакансиями. А мы хотим выводить только вакансии.
Для этого выберем два фильтра, задающих вывод только опубликованных вакансий:
* Материал: Опубликовано
* Материал: Тип
Нажмите на значок плюса (+) в области «Фильтры», затем выберите *Материал: Опубликовано* и *Материал: Тип*; нажмите «Добавить».
Настройте фильтр *Материал: Опубликовано*: укажите значение «Да», это исключит из нашего представления неопубликованные материалы.
Настройте фильтр «Материал: Тип» так, чтобы в представление попадали только материалы типа «Вакансия».
Взгляните на результат работы фильтров в предварительном просмотре:

###### Критерии сортировки
Из предварительного просмотра видно, что вакансии сортируются по дате от старых к новым. Было бы здорово сперва выводить новые вакансии.
Чтобы выводить новые вакансии первыми, мы применим критерий сортировки. В списке полей для сортировки, который появится после нажатия на плюс в соответствующей области, выберите **Материал: Дата создания**.
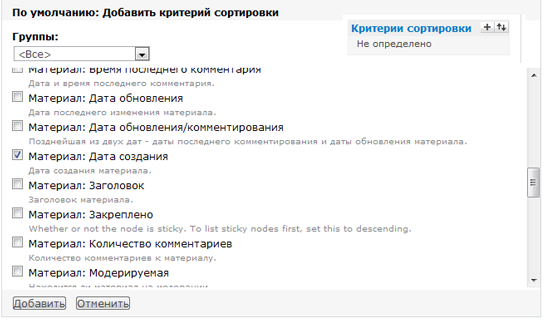
Укажите порядок сортировки **По убыванию**.
Снова обновите предварительный просмотр; теперь последние вакансии будут выводиться первыми.
###### Изменение порядка вывода полей
Есть еще кое-что для улучшения нашего представления: изменение порядка полей. Имеет смысл выводить поле заголовка первым, поле даты — вторым и т.д. Вы можете изменить порядок, нажав на кнопку со значком «вверх/вниз» в разделе «Поля».
Обновите предпросмотр: представление стало еще лучше.
Мы закончили с созданием представления; теперь добавим в него два вида.
###### Добавляем страничный вид
В левой части страницы представлений, выберите «*Страница*» и нажмите «*Добавить вид*». Вас автоматически перенаправит в раздел «Настройки страницы».
Нам нужно указать путь к странице и выбрать место для ссылки на нее. Я указал вес, равный 2, чтобы отобразить ее после ссылки «Главная страница».
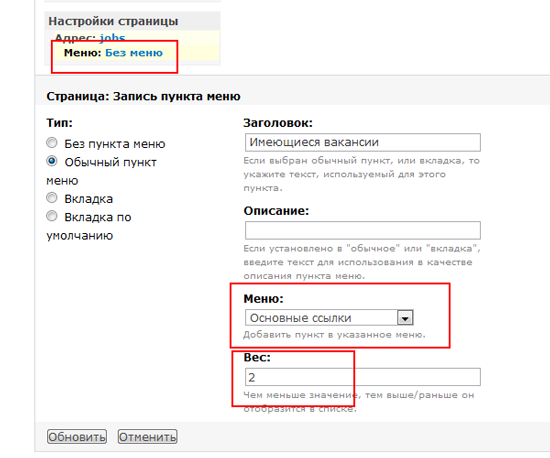
После ввода значений не забудьте нажать «Сохранить».
Теперь можно посмотреть, как ссылка (под названием «Имеющиеся вакансии») на страницу с нашим видом выглядит в основной навигации.
###### Создаем блочный вид
Блоки используются для вывода информации в различных регионах сайта. Это виджеты, в которых отображаются такие данные, как текущие события, пять самых популярных статей и так далее. Блоки выводятся в таких регионах как левая боковая панель, заголовок, подвал и других.
Вы можете размещать блоки в заголовке, подвале и левой и правой панелях в стандартной теме Друпала. Управление блоками осуществляется из меню **Администрирование > Конструкция сайта > Блоки**.
Теперь создадим еще один вид для представления «Вакансии»; вид, отображающий последние объявления о работе в правой панели.
Переходим в Администрирование > Конструкция сайта > Представления и жмем на ссылку *редактировать* представление «Вакансии». Слева выбираем «Блок» и нажимаем «Добавить вид», как и ранее.
###### Кнопка «Переопределить»
Мы удалим 3 поля из блочного вида, чтобы блок умещался в боковой панели и не был перегружен информацией. Для этого нажимаем на каждое поле в разделе «Поля». Перед удалением поля обязательно нажмите **кнопку «Переопределить»**, иначе вы измените базовое представление и заодно страничный вид, который мы сделали чуть раньше.
Вы можете также изменить имя блока, которое будет показано на странице администрирования.
###### Добавляем блок на боковую панель
Перейдем к управлению блоками и добавим наш новый блочный вид на правую панель.
Идите в **Администрирование > Конструкция сайта** и жмите на *Блоки*.
В секции «*Отключено*» найдите вновь созданный блок и выберите **правую колонку** в столбце «*Область*».
Не забудьте нажать «Сохранить» для подтверждения изменений.
Отлично! На этом разработка доски вакансий завершена.
###### Темы оформления Drupal
В заключение руководства давайте обсудим темы оформления. Темы используются для изменения внешнего вида сайта.
В интернете можно найти великое множество тем. Вот, например, [список тем](http://drupal.org/project/Themes), выложенных на оффициальном сайте Друпала.
Чтобы установить новую тему, ее нужно скачать и распаковать в директорию `drupal/sites/all/themes`
. Если этой директории не существует — создайте ее.
Чтобы включать и выключать темы, перейдите в **Администрирование> Конструкция сайта > Темы оформления**.
Всего в дистрибутиве Друпала идет 5 тем. Вот, например, я активировал тему Marvin, чтобы придать нашему новоиспеченному сайту свежий, новый вид:
Не забудьте отметить нужную тему используемой по умолчанию, чтобы на сайте использовалась именно она.
###### Подведем итоги
Я старался изо всех сил, пытаясь охватить самые сложные и непонятные для новичков аспекты. Так или иначе, это руководство — лишь один из отблесков истинной мощи Друпала. Рекомендую вам самостоятельно исследовать сайт [Drupal.org](http://drupal.org/) в поисках более сложных тем.
Если у вас есть вопросы, не стесняйтесь задавать их в комментариях. Я с радостью вам помогу.
###### Полезные сайты
* [Drupal.ru](http://drupal.ru/) — русскоязычное сообщество пользователей Друпала.
* [Справочник API](http://api.drupal.ru/) — справочник по API для программистов.
* [Drupaler.ru](http://drupaler.ru/) — сообщество переводчиков Друпала и его модулей на русский, белорусский, казахский и другие языки.
* [Танцы около Друпала](http://drupaldance.com/) — статьи, уроки и советы за авторством известного Друпал-разработчика, **neochief**.
* [drupalcookbook.ru](http://drupalcookbook.ru/) — рецепты создания сайтов на Друпале; огромная коллекция советов и хитростей.
* [content-management-systems.info](http://content-management-systems.info/) — советы, подсказки и форум; на сайте действует «Планета Drupal» — RSS-лента, собирающая новости сайтов и блогов, посвященных Друпалу.
[Обсуждение на drupal.ru](http://www.drupal.ru/node/49475)
**UPD 01:** Хабраюзер [kost](https://habrahabr.ru/users/kost/) выявил неверную картинку. | https://habr.com/ru/post/103603/ | null | ru | null |
# Как у меня получилось взломать и распаковать ресурсы старой игры для PSX
«Вот бы распаковать эти игровые архивы и посмотреть что там внутри!», — наверное думал про себя, хотя бы раз, каждый геймер, который хотел понять, как устроена его любимая игра.
К счастью, сегодня большинство разработчиков не только не препятствуют изучению своих игр, но даже наоборот, делают всё, для того, чтобы игроки изменяли и дополняли игры сами. Но даже если официальной документации нет, то для 99% игр можно найти уже готовые программы для распаковки.
Я решил написать эту статью для того чтобы показать, что даже если вы столкнулись с очень редкой, старой или никому не нужной игрой, архивы которой не берет ни один «распаковщик», то даже с минимальными знаниями какого-нибудь языка программирования, вполне возможно вам удастся справится самому и стать первым, кто сможет распотрошить эту игру до косточек.
Так как само по себе, описание устройства игровых архивов вряд ли принесет какую-нибудь пользу, я опишу весь путь, который я проделал в ходе изучения игровых архивов, ход своих мыслей, а также ошибки, которые привели меня в тупики.
### Завязка
Все началось с того, что будучи в детстве фанатом игр «SquareSoft», и маясь от безделья 1-го января, я заинтересовался информацией о ранних прототипах Final Fantasy и с удивлением узнал что у японской версии Final Fantasy VII для PlayStation был «бонусный» диск со всякими доп-материалами, и в том числе скетчами и скриншотами игры на ранних этапах разработки.
Немедленно скачав его образ с «торрентов» и запустив на эмуляторе я с некоторым разочарованием обнаружил, что во-первых диск жутко тормозит в эмуляторе(несмотря на новое железо), а во-вторых весь интерфейс на японском и черт ногу сломит в нем копаться через это меню.
Тут у меня и появилась идея, распотрошить диск и изучить его контент напрямую, а не использовать предложенный разработчиками интерфейс.
### Первичный investigation
Первым делом я решил изучить какие файлы вообще содержаться на диске.
**Вот какой была его структура:**`Структура папок тома SLPS_01060
E:.
│ CG.FFD
│ DUMMY3M.DA
│ FFANM.APK
│ FF_OPN.LPK
│ FF_SYS.LPK
│ NPK_ACC.NPK
│ NPK_BOU.NPK
│ NPK_DF.NPK
│ NPK_DF2.NPK
│ NPK_ETC.NPK
│ NPK_MAIN.NPK
│ NPK_MAKE.NPK
│ NPK_MON.NPK
│ NPK_WEP.NPK
│ NPK_WM.NPK
│ SLPS_010.60
│ SYSTEM.CNF
│
├───BG
│ DATF001.LPK
│ .....
│ DATF009.LPK
│
├───HERO
│ HERO.FFD
│
├───ITEM
│ └───MATER
│ MATER.FFD
│
├───MAKINGCG
│ MAKINGCG.NPK
│
├───R3D
│ RIDE_0.NPK
│
├───S1G
│ INST_M.S1G
│ INST_P.S1G
│ TITLE.S1G
│
├───SM
│ SM000.FFD
│ SM001.FFD
│
├───STR
│ PP07FFA.STR
│ PP07FFB.STR
│ PP07FFC.STR
│ PP07FFD.STR
│ PP07FFE.STR
│
├───TEXT
│ MLIST.LPK
│
└───TOWN
FF_TTOWN.NPK`
Первое что бросилось в глаза — расширение файлов NPK и LPK, что косвенно указывало на то, что это архивы.
Поэтому одной из первых идей, которая пришла мне в голову, было воспользоваться всевозможными универсальными анализаторами и распаковщиками. Я скачал все что смог найти для PSX и на всякий случай, даже Dragon UnPACKer, для ПК.
Но улов был незначительным, файлы в папке STR оказались видеороликами в стандартном для PSX формате STR, а три файла в папке S1G, оказались картинками, в опять таки стандартном, как мне позже удалось нагуглить, для «соньки» формате TIM. только с другим расширением.
Архивы NPK и LPK, которые, как я предполагал, содержали основной контент диска, так и не удалось взять ни одной программе, в том числе, софту ориентированному на «Final Fantasy VII».
Пришло время чуть усерднее поискать хоть какую-то информацию об этих NPK архивах, так как, скорее всего, я не первый, кто за них взялся, и хоть какое-то упоминание найтись было должно.
Результат оказался весьма занятным, пробуя и так и сяк составлять запросы и продираясь через кучи поискового мусора, я смог найти только два упоминания этих архивов в контексте это диска.
Причем оба упоминания были на одном и том же форуме, относившемся к, находящемуся в дауне, на момент написания этой статьи, сайту, посвященному софту для моддинга к играм серии FF.
Один из тредов был праздным обсуждением на тему «ах как хорошо было бы выдрать модельки» с кучей заглушек вместо скриншотов, которые были давно удалены хостером.
А вот [второй тред](http://forums.qhimm.com/index.php?topic=4414.0), относящийся к 2005 году дал очень хорошие зацепки. В нем какой-то юзер предложил челендж(ох «люблю» я таких халявщиков, которые хотят всё чужим трудом заполучить) взломать этот самый диск, дабы выдрать из него ресурсы.
Qhimm(владелец форума и автор многих программ распаковщиков для FF) подорвался было изучать эти архивы, но закончилось все несколько внезапно…
Оказалось, что еще один разработчик софта для потрошения ресурсов PSX(snailrush) уже сделал утилиту для распаковки этих архивов. Казалось бы «Ура», переходим по ссылке и качаем утилиту, но если бы все было так хорошо, то этой статьи бы не было. В общем, ссылка была мертвой, и не помог даже archive.org. Сайт snailrush'а ушел в многолетний down практически через несколько дней после того, как он сделал эту чертову утилиту, и никаких снапшотов той страницы не сохранилось.

Таким образом, у меня был только пост Qhimm'а(который уже много лет не появлялся на своем форуме), о том, что ему удалось разобраться в устройстве этих архивов. А это значило, что ничего особо сложного в них не должно было быть.
### Начинаем копать самостоятельно
Пришло время открыть файлы в HEX-редакторе. Сразу бросились в глаза какие-то числа в самом начале, которые указывали на то, что у файла есть что-то типа заголовка.
> Тут я хотел бы сделать небольшое отступление. Не смотря на то, что в самом начале я сказал, что особых знаний для копания в ресурсах не нужно. Есть одно «небольшое» исключение. Нужно иметь хотя бы базовое представление о том, как именно в памяти или на диске могут хранится какие-нибудь данные, в самом простом виде — числа. Другими словами нужно знать что такое [Big Endian и Little Endian](https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D1%80%D1%8F%D0%B4%D0%BE%D0%BA_%D0%B1%D0%B0%D0%B9%D1%82%D0%BE%D0%B2).
>
>
>
> Я попробую объяснить суть максимально кратко:
>
> Очень часто числа или символы хранятся в памяти в обратном порядке. Например число «16830», которое в HEX выглядит как «41 BE», а будучи переменной типа int как «00 00 41 BE» в самой памяти может хранится как «BE 41 00 00», не буду объяснять почему так(вы можете погуглить сами), скажу просто что «компьютеру так удобнее». И соответственно, таким же образом, в обратном порядке, данные могут хранится в файле на диске.
>
>
Причем на первый взгляд, почти все файлы, независимо от расширения и LPK и ТЗЛ и FFD, имели очень схожую структуру в самом начале.
Несколько чисел типа int или short, потом последовательность «DF 10 00 00 00 09», потом уже какая-то мешанина байт, который были по всей видимостью данными.
Так как первые числа у всех файлов были разные, я предположил, что это скорее всего какие-то смещения или размеры внутренних блоков.
Для более подробного изучения я решил сконцентрироваться на одном файле и выбрал NPK\_WEP.NPK, так как из треда было ясно что во-первых именно его удалось распаковать, а во-вторых было известно, что в нем хранятся картинки в формате TIM.
Настало время поближе присмотреться к формату TIM который я и собирался искать внутри.
К счастью на данный момент TIM хорошо документирован, в том числе потому что утекла официальная документация сони.
И сразу хорошие новости, у TIM есть стандартный заголовок «10 00 00 00

Открываю заодно в HEX тем 3 файла, который уже были у меня в наличии в открытом виде.
Вау, тут во всех них „10 00 00 00 09“ в самом начале, прямо как в моем архиве.
Кажется это не может быть совпадением, вот оно! Tim файл прямо внутри, но почему его тогда не обнаружили автоматические анализаторы? и почему сразу после „10 00 00 00 09“ мешанина?
Пробую искать „10 00 00 00 09“ по файлу и обнаруживаю 127 совпадений. Более того все места с „10 00 00 00 09“ похожи друг на друга.
Вот например второе место в NPK\_WEP.NPK где обнаружилась последовательность „10 00 00 00 09“:
После кучи нолей, я увидел точно такую же структуру как и в самом начале файла.
Так, теперь можно сделать кое-какие предварительные предположения и выводы:
1. Если „10 00 00 00 09“ — действительно сигнатура говорящая о начале TIM файлы, то таких файлов в архиве 127, что в общем-то логично и похоже на правду.
2. Архив NPK\_WEP.NPK как таковой собственных заголовков(которые бы описывали именно его структуру) не имеет и скорее всего является нагромождением как-то структурированных данных.
3. TIM файлы(если это все же они) в архиве как-то сжаты, так как данные после заголовка „10 00 00 00 09“ на реальные файлы ну никак не похожи.
Теперь я решил поподробнее изучить структуру NPK архива и выяснить что значат числа перед „10 00 00 00 09“.
Самым первым числом было:
37 00 00 00 > 00 00 00 37(HEX) > 55(DEC) Не похоже чтобы это было смещением, так как смещение 37 находится уже внутри того, что я пока считают сжатыми данными, так что пропустим его.
Второе число было short F7 03 > 03 F7(HEX) > 1015 (DEC)
Третье тоже short F6 04 > 04 F6(HEX) > 1270 (DEC)
Вот эти два уже похожи на смещения, попробуем найти что-то в районе этих мест.
Ищем 03 F7:
И бинго! Походу именно тут кончается блок данных, так как начиная с этого места идут нули.
А что тут строкой ниже? 36 00 00 00 FD 03 2F 08 — Не похоже на сжатые данные, зато очень похоже на такой же заголовок как и в начале.
Тогда чем было третье смещение? так как оно указывает на середину следующего блока, я пока что предположу, что это размер данных после распаковки.
Зато теперь появляется предположение, что означало самое первое число 37(HEX) или 55(DEC)
По всей видимости, -это количество суб-блоков до конца запакованного файла, у каждого следующего блока оно будет уменьшаться на 1. Проверка подтвердила это предположение.
Одно только осталось непонятным, если у нас есть смещения, говорящие о длине блока, то почему бы не начинать следующий блок сразу после конца предыдущего, зачем вся эта куча нолей? К тому, на начало второго блока 0х0400 ничего не указывает, как тогда понять, где начинается следующий блок? С другой стороны 0400 уж очень подозрительное смещение, слишком ровное. Интересно сколько это в DEC?

Ух ты! ровно 1024, вряд ли это совпадение. посмотрим что у нас через еще 1024 байта по смещению 0х800:
Теперь все ясно, размер каждого суб-блока — 1 килобайт.
Итак, структура NPK\_WEP.NPK практически полностью расшифрована.
Весь файл разбит на блоки по 1024 байта.
Первые 4 байта каждого блока — число суб-блоков до конца одного содержащегося в архиве файла.
Следующие 2 байта — смещение от начала суб-блока до конца полезных данных
Еще два байта — скорее всего размер данных после распаковки(видимо для выделения места под них в памяти).
Вроде похоже на правду, осталось только понять, чем сжаты или зашифрованы сами данные.
### Разбираемся с сжатием
До этого я никогда не сталкивался с сжатием или шифрованием и не имел вообще никакого ни представления, ни опыта.
Поэтому я стал искать информацию сразу в двух направлениях:
Во-первых, как на глаз понять какое сжатие используется в файле, если это неизвестно.
И во-вторых, какое сжатие используется чаще всего для PlayStation в целом, или для игр SquareSoft и серии FF в частности. Зацепкой было то, что Qhimm довольно быстро разобрался с файлом, значит это было что-то знакомое для него.
Начав с общего поиска „как на глаз определить чем сжат файл“, самое полезное что я обнаружил — это вот этот список:
[zenhax.com/viewtopic.php?t=27](http://zenhax.com/viewtopic.php?t=27), в котором глаз зацепился за
> lzss
>
> Parts of the original data uncompressed.
, что в общем-то походило на то, что было у меня.
А во-вторых можно было исключить сразу всякие zip-related и прочие методы имеющие какие-то стандартные заголовки, так как ничего похожего на заголовок у сжатых данных не наблюдалось.
Поиск по сжатию используемому в Final Fantasy VII привел на упавший сайт wiki.qhimm.com, [снапшоты которого](http://web.archive.org/web/20170521090630/http://wiki.qhimm.com:80/view/FF7/LZS_format) к счастью были доступны через Wayback Machine.
Там говорилось что в FF VII к примеру используется два типа сжатия GZIP и LZS (какой-то специфический подвид LZSS). GZip я сразу отмел, так как у него должен был быть хидер, а вот на LZSS я решил остановится поподробнее, так как все указывало на него.
Но тут я совершил, можно сказать ошибку и полез в [»википедию"(при редактировании статьи заметил, что это не википедия, а другой вики-сайт ) читать про LZSS](https://neerc.ifmo.ru/wiki/index.php?title=%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_LZSS). А проблема была в том, что одно дело — принцип сжатия 80х описанный в учебнике, а другое — его конкретное реализация. Я совсем не учел, что сохраняя принцип сжатия, реализовать его можно кучей разных способов, но в учебниках и в том числе в большинстве статей где оно описывается в интернете, оно описано следующим способом: читается 1 бит, если это 0, то читаются следующие 8 бит и заносятся как есть в буфер (вывод), а если это 1, то читаются следующие 7 бит, часть из которых офсет в буфере, а часть длина данных, которые нужно считать из буфера и занести в вывод.
Т.е. как бы все понятно и логично, но ни черта не похоже на то, что есть у меня, и уж тем более не соотносится с идеей, что начало данных должно выглядеть так, как будто они «не сжаты». (Ну просто потому, что при такой реализации все данные выглядели бы как каша, так как первый байт содержал бы 1 сигнальный бит и 7 бит несжатых данных, 8-ой бит которых был бы первым битом второго байта.)
Я не сразу понял, что конкретная реализация алгоритма очень сильно зависит от размера буфера, и то, что описано в учебниках, подходит для буфера ничтожно малой длины.
В общем, потеряв впустую несколько часов на попытки сложить 2+2, я решил зайти с другой стороны и поискать какие-нить реализации «в коде» сжатия используемого именно в FF VII.
И сразу наткнулся на [github.com/cebix/ff7tools](https://github.com/cebix/ff7tools) — набор утилит на питоне для перевода ff7, в состав которых входили lzss и unlzss. Для проверки я решил натравить lzss на один из имеющихся у меня tim файлов. Получилось как-то так:
На первый взгляд — ничего хорошего, но я уцепился за 09 и последовательность за ней, которая уж больно напоминала то, как выглядели мои файлы в архивах. Тут я уже практически полностью уверился, что картинки сжаты какой-то из реализаций LZSS, осталось только разобраться какой именно.
Для этого я вернулся на [wiki.qhimm.com](http://web.archive.org/web/20170521090630/http://wiki.qhimm.com:80/view/FF7/LZS_format) и решил повнимательнее прочитать про «этот их LZS».
После внимательного прочтения и пере-прочтения — пазл сложился! БИНГО!
Формат устроен следующим образом:
Вся дата разбита на блоки, длина которых может варьироваться от 9 байт до 17 байт.
Первый байт блока указывает на то, чем будут все остальные байты блока. Закодировано это на уровне бит. 1 — значит что байт отправляется как есть в буфер и на вывод. 0 — означает что нужно прочитать 2 байта и они будут ссылкой на буфер. Причем чтение бит идет с конца.
Таким образом, если первый байт блока — FF, (11111111)- это значит, что следующие 8 байт нужно просто прочитать как есть и записать в вывод(буфер).
А, ставший для меня уже родным, байт DF, стоящий перед 10 00 00 00 09, в битовом виде выглядит как 11011111, что означает, что 5 идущих за ним байт нужно прочитать как есть(те самые 10 00 00 00 09), потом идет 2х-байтная ссылка(EF F0), и опять 2 байта нужно прочитать как есть (0C 02).
Дальше уже интереснее. Формат ссылки сильно зависит от размера буфера. В данной реализации буфер равен 4 килобайтам, а ссылка в битах выглядит следующим образом(опять гребаные биты, ненавижу уже их!)
OOOO OOOO OOOO LLLL (O = Offset, L = Length)
Ну или можно без бит, тогда так OO OL(на уровне байтов), причем первые 4 бита второго байта — это первый байт офсета, потому что читать опять нужно с конца. Но и это не все, к длине нужно прибавить три, просто такой вот хардкод. Потому что длины 0, 1 и 2 не имеют смысла, так как в таком случае ссылка будет занимать больше места чем считанные по ней данные. Так что 0 — это 3, 1 — это 4, и тд…
Понимаю что понять сложно, поэтому объясню на реальном примере:
Байт DF говорит нам о том, что 6-й и 7-й байт за ним — это офсет, у нас это EF F0.
Отсекаем последние 4 бита(длина) и переворачиваем, получаем 0хFEF — офсет в буфере, а оставшийся 0+3 = 3 — длина.
Таким образом, ссылка говорит нам прочитать 3 байта по офсету 0хFEF из буфера. Если вы проскролите выше и посмотрите как выглядит нормальный TIM файл, то там сразу после 09 — три нулевых байта, вот именно они и копируются из буфера.(по видимому это те 3 нулевых байта, которые были туда, буквально «только что», записаны предыдущими действиями).
Так же, в той статье, была описана сложная формула по вычислению реального офсета, по которому нужно читать из буфера. Объяснялось это тем что автор предполагал для записи и чтения использовать обычные потоки ввода-вывода, а формат сжатия подразумевал использование кольцевого буфера, и нужно было как-то хитро преобразовывать офсет.
Но я был отважен, и решил что «ну его нафиг», лучше я реализуют у себя кольцевой буфер, чем буду разбираться в этих странных формулах. Конечно я пожалел, но в тоже время, когда стал разбираться почему оно «не работает», нашел куда более красивое решение, чем автор той статьи.
Кроме того, в статье писалось о двух «фишках», которые нужно иметь ввиду, ссылки на буфер могут идти как в прошлое так и в будущее, обойти это предлагалось всякими хаками.
Как я потом выяснил при правильной реализации буфера, никакие «хаки» не нужны.
### Пишем Код
Ну, а пока что, я расчехлил Eclipse(писать решил в JAVA, так как мне так удобнее)
Сначала надо определится с тем как реализовать кольцевой буфер. Дело в том что мне сразу было понятно, что реализовать его можно очень разными способами, так что я решил просто попытать счастье и выбрал подобную реализацию из более менее стандартной библиотеки CircularFifoQueue из apache.commons.collections. Это был FIFO буфер позволяющий читать по офсету внутри себя. Другие реализации из коробки чаще всего по офсету читать не позволяли.
В итоге код получился примерно такой(я выкинул всякий мусор для упрощения чтения и сокращения):
```
static CircularFifoQueue circularBuffer = new CircularFifoQueue<>(4096);
private static void processNPK() {
FileInputStream fis = new FileInputStream(new File("NPK\_WEP.NPK"));
ByteBuffer b1kb = ByteBuffer.allocate(1024);
while (fis.read(b1kb.array()) != -1) {
int blocksInMegaBlockCount = EndianUtils.swapInteger(b1kb.getInt());
int compressedDataLenght = EndianUtils.swapShort(b1kb.getShort());
int decompressedDataLenght = EndianUtils.swapShort(b1kb.getShort());
while (b1kb.position()> 4));
int offset = EndianUtils.readSwappedShort(new byte[] {first, highNibble.byteValue()}, 0);
byte[] bytesFromBuffer = new byte[lowNibble+3];
for (int i = 0; i < (lowNibble+3); i++) {
byte b = circularBuffer.get(offset);
circularBuffer.add(b);
bytesFromBuffer[i]=b;
}
return bytesFromBuffer;
}
private static boolean isLiteral(byte controlByte, int position) {
if (((controlByte >> position) & 1) == 1) return true;
else return false;
}
```
Описать его работу можно следующим образом:
1) Файл нарезается на куски по 1024 байта,
2) Для каждого считывается int, short, short
3) Остаток передается в цикл с распаковщиком(readLZSBlock)
4) Он читает первый байт, выясняет что делать с остальными, и либо записывает их как есть, либо, если это ссылка, то отдает его в обработчик ссылок на буфер(getFromCBuffer), который читает из буфера.
5) Когда один файл внутри архива прочтен — он сливается на диск
Результат выполнения был такой:

С одной стороны это хорошо, видны очертания меча, да и файл открылся во вьювере. С другой стороны очевидно, что буфер ничерта не работает, можно догадаться, что все данные которые читались из него — мусор, причем видно, как сначала мусором были нули и верх файла почти белый, а потом, по мере того, как буфер наполнялся, мусор стал цветным. При этом видны очертания меча, что радует.
Я не сильно расстроился, так как ожидал, что буфер придется допиливать. На всякий случай прогнал через программу все остальные архивы на диске и с удивлением обнаружил, что первый файл в архиве NPK\_WEP.NPK был единственным который открылся в просмоторщике tim файлов. Так что мне очень повезло, что я начал именно с него.
Следующим шагом стала попытка понять, где именно произошел сбой. Для этого, я, вооружившись [описанием формата TIM](http://www.romhacking.net/documents/timgfx.txt), вручную в HEX-редакторе начал проходить по своему файлу. Надежда была на то, что сбой обнаружится уже в заголовке и я смогу узнать какое именно значение должно было быть, а какое на самом деле записалось, и зная состояния буфера, внести какую-то коррекцию.
Заметная ошибка обнаружилась по офсету 0х214. в нормальном TIM файле там должен был int соответствующий размеру данных в нем, причем учитывая, что файлы TIM не сжаты по умолчанию и размер зависит от разрешения, а разрешение в свою очередь у картинок растянутых на весь экран телевизора у playstation — одно и тоже, я даже наверняка знал, какое именно число там должно быть.
Вот пример нормального файла:
Размер данных 00 01 E0 0C.
А вот мой файл:
вместо нормального числа у меня там какой-то мусор.
Теперь изменив немного код, я получил данные относящиеся к обработке данного места.
Офсет считанный из файла был 4092, длина — 3 байта.
Вот как выглядел мой буфер в момент, когда из него нужно было получить 00 01 E0

(На самом деле это конец, так как весь буфер не влазил даже в мой экран, но в начале там просто еще больше нолей чем на картинке.)
Найдя в буфере нужные данные, я оказался в замешательстве.
В буфер было загнано 527 байт «полезной» даты. нужные данный находились по офсету 15 с начала ввода данных, и примерно по офсету 3569 с начала буфера. Каким образом их можно было считать по офсету 4092, выданному мне, я не мог понять. Еще, вспомнив что в статье упоминалось число 18, я попытался прибавлять и отнимать его от разных офсетов, но так ничего осмысленного и не получил.
В итого, почесав репу, и поняв что оригинальный буфер был устроен ну как-то совсем иначе, чем мой, я вернулся к статье и описанию того, как получить «реальный офсет» при использовании чтения из потоков. Формула выглядела настолько ужасно, что я просто скопировал ее как есть, не пытаясь вникнуть и еще прицепил к ней пару вагонов дополнений чтобы натянуть ее на мой буфер, в итоге получился вот такой ужас:
```
// чтение нормального офсета из файла
int offset = EndianUtils.readSwappedShort(new byte[] {first, highNibble.byteValue()}, 0);
// формула из статьи(где OUTPOS - количество записанных в буфер данных)
int realoffset = OUTPOS - ((OUTPOS + 0xfee - offset) & 0xfff);
//натягивания формулы из статьи на мой "кольцевой буфер"
int realoffset2 = 4096 - OUTPOS + realoffset;
```
(realoffset и realoffset2 можно было конечно сократить, но так как я не был уверен что оно заработает, я оставил так как есть для дебага.)
И как ни странно, оно заработало!

На этом можно было бы остановится, но кривая реализация буфера не давала мне покоя. И самое главное, я хотел лучше понять как был устроен буфер на самом деле, ведь очевидно было, что у самих разработчиков никаких грязных хаков при чтении по офсету не было, и если они получили офсет 4092, то нужные данные действительно находились по адресу 4092.
Признаюсь, что думал я долго, много рисовал на бумаге и массивы и кольца, чтобы понять как именно, а главное, почему оно было реализовано именно так, как было.
В итоге получилось как-то так:
```
public class ByteRingBuffer {
private byte[] rBuf; // ring buffer data
public int rBufSize = 4096; // ring buffer size
public int writeReadOffsetCorrection = 18;
public int lenghtCorrectionLZS = 3;
private int rBufWrPos = rBufSize - writeReadOffsetCorrection; // position of first (oldest) data byte within the ring buffer
public ByteRingBuffer() {
rBuf = new byte[rBufSize];
}
public byte write(byte bt) {
rBuf[rBufWrPos++] = bt;
if (rBufWrPos == rBufSize)
rBufWrPos = 0;
return bt;
}
public byte read(int offset) {
return rBuf[offset & 0xfff];
}
}
```
Проще говоря, буфером был обычный массив байтов. Чтение происходило с начала массива, и маркер чтения никогда не перемещался. Единственным хаком было то, что изначальной точкой начала записи в массив было не 0, а размер массива минус 18. И все заработало как нужно!
Т.е достаточно было сместить на 18 точку записи в самом начале и после этого можно было спокойно читать и записывать без всяких хаков. при таком раскладе 15-й записанный в массив байт, действительно оказывался по офсету 4092.
Ну и кроме того не нужны были никакие хаки связанные с чтением из «прошлого» или «будущего».
Причиной того, что смещение на 18 вообще было необходимо, скорее всего послужило то, что при заполнении буфера при сжатии, часть уже имеющихся в буфере данных будут перезаписаны. И возможна следующая ситуация:
1) Данные предназначенные для сжатия ищутся в буфере.
2) Обнаруживаются там.
3) Создается ссылка на них, и они записываются в буфер.
4) Но они перезаписывают, по сути, сами себя, причем частично
5) И в результате правильная распаковка теперь становится невозможной.
Но и на этом сюрпризы от бонусного диска не закончились. По мере того как я перешел к другим архивам, я обнаружил странную «аномалию».
Помните те блоки по 1024 байт, данные в которых занимали чуть меньше места? У меня был код, который проверял остаток блока и выдавал уведомление, если там были не только нули. На первом файле — NPK\_WEP.NPK, этот участок кода ни разу не сработал, но уже на следующем и почти на всех остальных выскакивали постоянные предупреждения. Так как файлы при этом распаковывались корректно, я решил посмотреть что там за «лишние» данные в хвостах. И немного офигел. Не долго думая, я добавил код, которые весь «мусор» из архива дампит в отдельный файл и вот что среди этого мусора я обнаружил:
**Целую кучу кусков исходного кода с комментариями на японском**
```
#include
#include
#include
#include
#include
#include
#include
\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
#include "ff.h"
//#include "ff7list.h"
#include "winsys.h"
#include "cursol.h"
#include "datafanm.inc"
#include "dataflpk.inc"
#include "lpk\_sys.inc"
#include "ffaku.h"
#include "clickm.h"
#include "npk\_item.inc"
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
/\* 型定義 \*/
Z\_CLUT, (long \*)LPKBuf, (long \*)ComnBuf
#define DEFSET LZ\_TIM | LZ\_CLUT, (long \*)MODELBuf, (long \*)ComnBuf
#define DEFSYS LZ\_TIM | LZ\_CLUT, (long \*)SYSBuf, (long \*)ComnBuf
#define SUBBERMAX 3
#define SUBBERMAX 3
#define ZENGAMEN\_X 168 /\* 前画面X座標 \*/
#define ZIGAMEN\_X 282 /\* 次画面X座標 \*/
#define ZIGAMEN\_Y 16, 17};
\_BOXFTAG EXsubbox[SUBBERMAX]; /\* サブメニュー用バー \*/
static int wait; /\* ウェイト \*/
static int oldx; /\* マウスX座標前回値保存 \*/
static int oldy; /\* マウスY座標前回値保存 \*/
static int oldpad; /\* 前回のパッド値保存
/\* 同上 \*/
static int mode; /\* アクセスバッファモード \*/
static int Shop\_Sel; /\* ショップ時のアイテム選択 \*/
int EXdatflag; /\* 外部から呼ばれた時参照 \*/
int EXdatnum; /\* 同上 \*/
static char /\*ンダムBGファイル名保存 \*/
extern \_BOXFTAG EXbox01; /\* 選択バー \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
/\* プロトタイプ宣言 \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
void Item\_・ /\* \*/
void ItemSelLoadEX(void); /\*アイテムグラフィックデータロード(外部参照用)処理\*/
void ShopList(void); /\* ショップリスト生成処理 \*/
void ShopSel(void); /\* ショップ項目選択処 \*/
/\* \*/
/\* 1997/05/07 G.T.V H.Mizukami \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* \*/
LLbox.r = 1;
LLbox.g = 1;
LLbox.b = 1;
LLbox.x = 16-256;
LLbox.y = 20-120;
LLbox.w = 332;
LLbox.h = 16;
GsSort i = i - LLtbl[Q1];
if(i < 0)
{
ListPage[Q1] = n + 0x30;
i = i + LLtbl[Q1];
\*/
/\* 1997/03/26 G.T.V H.Mizukami \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
strcat(mlistbuf, akuselist[LLtop + Q1]);
break;
case 4: /\* その他 \*/
strcat(mli
/\*\*/
/\* 1997/04/22 G.T.V H.Mizukami \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
void Item\_SelMenuInit(void)
{
WinFill LLwin;
A/\* クセサリーを選択 \*/
case 4: /\* その他を選択 \*/
ListInit(item\_menu);
WinSetPos(wid[2], 128, 44, 16\*20, 14\*10);
WinSetRGB(wid[2], 0, 0, 255, RGB\_BUL);
break;
/\* H.Mizukami \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
void Item\_SelMenu(void)
{
int LLnum;
MjsLoop(&EXtprm01);
if((LLnum = MjsMenuStat(&EXtprm01)) == -1)
return;
/\*se \*/
/\* 1997/04/25 G.T.V H.Mizukami \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
void Item\_Mat\_SelInit(void)
{
WinFill LLwin;
command = 2;
EXsubbox[0].mode = 0; /\* 選択バーOFF \*/
/\* 支援マテリア \*/
char\_pt = mat01\_list;
break;
case 2: /\* コマンドマテリア \*/
char\_pt = mat02\_list;
break;
case 3: /\* 独立マテリア \*/
char\_pt = mat03\_list;
break;
1997/04/25 G.T.V H.Mizukami \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
void Item\_Mat\_Sel(void)
{
int LLpad;
int LLnum = item\_sel\_mat;
#ifdef DEBUG
FntPrint("item\_sel\_mat = %d\n", item\_sel\_mat);
#endif
LLpad = Item\_MatMouse();
if(oldpad == PADLup && item\_sel\_mat)
item\_sel\_mat--;
if(oldpad == PA if(LLpad == 0 || (oldpad & PADnext))
{
command = 99;
nextcommand = 2;
}
else
{
if((TGPad1 & PADRdown) || Char\_cansel())
{
command = 127;
nextcommand = 0;
TGPad1 |= PADnext;
StopPreLoad();
/\*\*\*\*\*\*\*/
void ItemMat(void)
{
int LLpad = 1;
GsBOXF LLbox;
int LLnum = ItemListMatNum[item\_sel\_mat];
#ifdef DEBUG
FntPrint("sel = %d max = %d\n", ItemListMatNum[item\_sel\_mat],
ItemListMatMax[item\_sel\_mat]);
#endif
LLpad = Item\_subMatMouse();
if(oldpad == PADLup && ItemListMatNum[item\_sel\_mat] > 1)
ItemListMatNum[item\_sel\_mat] -= 2; ItemListMatNum[item\_sel\_mat] < ItemListMatMax[item\_sel\_mat] - 1)
ItemListMatNum[item\_sel\_mat]++;
if(LLnum != ItemListMatNum[item\_sel\_mat])
{
\_mt\_sel\_snd();
StopPreLoad();
}
if(PreLoad == PL\_NOUSE)
ItemSelLoad((long \*)(LPKBuf + BG\_SZ));
EXsubbox[1].mode = 1;
EXsubbox[1].b & PADRdown) || Char\_cansel())
{
command = 127;
nextcommand = 2;
TGPad1 |= PADnext;
StopPreLoad();
}
else
{
if((TGPad1 & PADnext) && LLpad == 0 || (oldpad & PADnext))
{
command = 99;
nextcommand = 3;
/
void Item\_Char\_SelInit(void)
{
WinFill LLwin;
command = 2;
EXsubbox[0].mode = 0; /\* 選択バーOFF \*/
WinNotDisp(wid[2]);
memset(&LLwin, 0x00, sizeof(WinFill));
LLwin.flag = WINf\_GRO;
LLwin.wflag = WINw\_001;
LLwin.prm = 5;
wid[3] = WinOpen(&LLwin);
WinSetPos(wid[3], 128, 44, 1 \*/
/\* 1997/03/31 G.T.V H.Mizukami \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
static void \_init5(SCREEN\_JOB \*ps, int n)
{
WinFill LLwin;
if(n == -1)
{
ShopList(); /\* ショップリスト生成 \*/
init\_CursolEx(&EXmouse, 0, 256, 120, 32, 22, 3, 3);
memset(&LLwin, 0x00, sizeof(WinFill));
LLwin.flag \*/
/\* \*/
/\* \*/
/\* 1997/03/31 G.T.V H.Mizukami \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
static void \_loop5(S \*/
MjsLoop(&EXtprm00);
break;
case 1: /\* グラフィック表示 \*/
if(How\_Kind\_PadCon(0) == 1)
SjsSel = 1;
else
SjsSel = 0;
ic\_flag = 0;
break;
case 99:
if(anmwait == FsOpen(TOWNFILE);
FsSeek(tmpcmp.lcv\_offset+tmpcmp.bg\_offset);
FsReadLzs((long\*)LPKBuf,tmpcmp.bg\_size);
/\* Miz\*/
FsOpen(tmpcmp.lpkname);
FsSeek(tmpcmp.bg\_offset);
FsReadLzs((long\*)LPKBuf,tmpcmp.bg\_size);
/\*\*/
PreLoad=PL\_USENOW;
/\* 1997/03/31 G.T.V H.Mizukami \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
static int \_before5(SCREEN\_JOB \*ps, int n)
{
if(command == 0)
return(1);
command--;
return(0);
}
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
raw();
}
}
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
/\* 終了処理 \*/
/\* \*\*\*\*\*\*\*\*\*\*/
/\* アニメーションループ処理 \*/
/\* \*/
/\* \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
/\* アニメーションデータ \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
CR\_NOTPUSH,
\_sinit5,
\_init5,
\_loop5,
NULL,
NULL,
NULL,
\_draw5,
\_end5,
wp,
{NULL,},
512, 240,
NULL, 0,
NULL,
0,
1,
};
/\*\*\*\*\*\*\*\*\*\*\*\*\*\* \*/
/\* \*/
command = 0;
Shop\_Sel = 0;
SjsSel = 0;
SjsSetBeforeKey(NULL);
}
anmwait = 0;
}
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
;
#endif
oldx = EXmouse.cx;
oldy = EXmouse.cy;
oldpad = TGPad1;
if(How\_Kind\_PadCon(0) == 1)
read\_Mouse\_Data(&EXmouse, 1);
SjsSel = 1;
switch(command)
{
StopPreLoad();
SetTim(LPKBuf, 512, 0, 0, 480);
\_mt\_ok\_snd();
anmwait = 0;
SjsSel=0;
SjsSetMode(&scr\_list);
return;
}
}
else
{
command--;
\_t\_cancel\_snd();
}
}
}
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
static void \_init5(SCREEN\_JOB \*ps, int n)
{
WinFill LLwin;
if(n == -1)
{
ShopList(); /\* ショップリスト生成 \*/
init\_CursolEx(&EXmouse, 0, 256, 120, 32, 22, 3, 3);
memset(&LLwin, 0x00, sizeof(WinFill));
LLwin.flag \*/
/\* \*/
/\* 1997/03/31 G.T.V H.Mizukami \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
static void \_loop5(Swait ==
h>
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
#include "ff.h"
//#include "ff7list.h"
#include "winsys.h"
#include "cursol.h"
#include "datafanm.inc"
#include "dataflpk.inc"
#include "lpk\_sys.inc"
#include "ffaku.h"
#include "clickm.h"
#include "npk\_item.inc"
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
/\* 型定義 GAMEN\_X 168 /\* 前画面X座標 \*/
#define ZIGAMEN\_X 282 /\* 次画面X座標 \*/
#define ZIGAMEN\_Y 1O回値保存 \*/
static int oldpad; /\* 前回のパッド値保存 同上 \*/
static char \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
void Item\_opSel(void); /\* ショップ項目選択処7 G.T.V H.Mizukami \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
\*/
= 1;
LLbox.g = 1;
LLbox.b = 1;
LLbox.x = 16-256;
LLbox.y = 20-120;
LLbox.w = 332;
LLbox.h = 16;
GsSortLLtbl[Q1];
if(i < 0)
{
ListPage[Q1] = n + 0x30;
i = i + LLtbl[Q1];
/\* \*/
/\* 1997/03/26 G.T.V H.Mizukami \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* /\* アクセサリー \*/ \*/
strcat(mlistbuf, akuselist[LLtop + Q1]);
break;
case 4: /\* その他 \*/
strcat(mli \*/
/\* 1997/04/22 G.T.V H.Mizukami \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
void Item\_SelMenuInit(void)
{
WinFill LLwin;
アクセサリーを選択 \*/
case 4: /\* その他を選択 \*/
ListInit(item\_menu);
WinSetPos(wid[2], 128, 44, 16\*20, 14\*10);
WinSetRGB(wid[2], 0, 0, 255, RGB\_BUL);
break;
\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
void Item\_SelMenu(void)
{
int LLnum;
MjsLoop(&EXtprm01);
if((LLnum = MjsMenuStat(&EXtprm01)) == -1)
return;
/\*se 1997/04/25 G.T.V H.Mizukami \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
void Item\_Mat\_SelInit(void)
{
WinFill LLwin;
command = 2;
EXsubbox[0].mode = 0; /\* 選択バーOFF at01\_list;
break;
case 2: /\* コマンドマテリア \*/
char\_pt = mat02\_list;
break;
case 3: /\* 独立マテリア \*/
char\_pt = mat03\_list;
break;
/\* 1997/04/25 G.T.V H.Mizukami \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
void Item\_Mat\_Sel(void)
{
int LLpad;
int LLnum = item\_sel\_mat;
#ifdef DEBUG
FntPrint("item\_sel\_mat = %d\n", item\_sel\_mat);
#endif
LLpad = Item\_MatMouse();
if(oldpad == PADLup && item\_sel\_mat)
item\_sel\_mat--;
if(oldpad == PA if(LLpad == 0 || (oldpad & PADnext))
{
command = 99;
nextcommand = 2;
}
else
{
if((TGPad1 & PADRdown) || Char\_cansel())
{
command = 127;
nextcommand = 0;
TGPad1 |= PADnext;
StopPreLoad();
void ItemMat(void)
{
int LLpad = 1;
GsBOXF LLbox;
int LLnum = ItemListMatNum[item\_sel\_mat];
#ifdef DEBUG
FntPrint("sel = %d max = %d\n", ItemListMatNum[item\_sel\_mat],
ItemListMatMax[item\_sel\_mat]);
#endif
LLpad = Item\_subMatMouse();
if(oldpad == PADLup && ItemListMatNum[item\_sel\_mat] > 1)
ItemListMatNum[item\_sel\_mat] -= 2; ItemListMatNum[item\_sel\_mat] < ItemListMatMax[item\_sel\_mat] - 1)
ItemListMatNum[item\_sel\_mat]++;
if(LLnum != ItemListMatNum[item\_sel\_mat])
{
\_mt\_sel\_snd();
StopPreLoad();
}
if(PreLoad == PL\_NOUSE)
ItemSelLoad((long \*)(LPKBuf + BG\_SZ));
EXsubbox[1].mode = 1;
EXsubbox[1].b & PADRdown) || Char\_cansel())
{
command = 127;
nextcommand = 2;
TGPad1 |= PADnext;
StopPreLoad();
}
else
{
if((TGPad1 & PADnext) && LLpad == 0 || (oldpad & PADnext))
{
command = 99;
nextcommand = 3;
/
void Item\_Char\_SelInit(void)
{
WinFill LLwin;
command = 2;
EXsubbox[0].mode = 0; /\* 選択バーOFF \*/
WinNotDisp(wid[2]);
memset(&LLwin, 0x00, sizeof(WinFill));
LLwin.flag = WINf\_GRO;
LLwin.wflag = WINw\_001;
LLwin.prm = 5;
wid[3] = WinOpen(&LLwin);
WinSetPos(wid[3], 128, 44, 1 case 3: /\* レッド13の武器 \*/
char\_pt = char03\_list;
break;
case 4: /\* エアリスの武器 \*/
char\_pt = char04\_list;
break;
case 5: /\* シドの武器 \*/
char\_pt = char05\_listNum[item+ 1 >=
BAEMax[item\_menu])
bak = 1;
else
{
bak = BAENum[item\_menu];
BAENum[item\_menu]++;
ItemSelLoad((long \*)MODELBuf);
BAENum[item\_menu] = bak;
bak = ItemListNum[item\_sel\_hero];
break;
case 1: /\* 防具 \*/
SjsSel = 0;
switch(item\_menu)
dispcom = 99;
dispcom = 99;
DEBUG
FntPrint("mat sel = %d\n", ItemListMatNum[item\_sode(&scr\_item\_disp);
oid cu\_l(ANM2D \*a2, ANMOBJ \*ao)
{
ao->wait = 1;
if(dispcom == 99 || wait)
return;
if(item\_menu != 0 && item\_menu != 3)
/\* アニメーションループライト処理 \*/
/\* \*/
if(ItemListMatNum[item\_sel\_mat] <
ItemListMatMax[item\_sel\_mat] - 1)
{
ao->wait = 0;
ao->Move(ao, 1);
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
/\* アニメーションデータ \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
static ANM2D anm2[L,
wp2,
{NULL,},
512, 240,
NULL, 0,
NULL,
0,
1,
};
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
/\* ワールドマップから呼ばれる仕様スクリーンジョブ関連処理 \*/
/\*
};
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
/\* ワイプテーブル \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
static WIPE\_PRM wp3[] = {
{&WjCinCout,16,itch(EXdatflag)
{
case 0: /\* 武器 \*/
\*AGoffset = BukSZTBL[EXdatnum].offset;
\*AGsize = BukSZTBL[EXdatnum].size;
: /\* マテリア \*/
\*AGoffset = MatSZTBL[EXdatnum].offset;
\*AGsize = MatSZTBL[EXdatnum].size;
strcpy(LLbuf, "ITEM\\MATER\\MATER.FFD");
break;
/\* 1997/03/28 G.T.V \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
static void \_sinit3(SCREEN\_JOB \*ps, int n)
{
char LLbuf[64];
int i, Q1;
int LLnum, LLoffset, LLsize;
if(n == -py(LLbuf, Item\_Image\_TBL01[i]);
break;
case 2: // アクセサリー
LLoffset = AkuSZTBL[EXdatnum].offset;
LLsize = AkuSZTBL[EXdatnum].size;
strcpy(LLbuf, Item\_Image\_TBL02[i]);
break;
case 3: // マテリア
dSync(0);
break;
case PL\_DONE:
break;
case PL\_NOUSE:
case PL\_MUSTNOT:
default:
select\_gfile(LLbuf, &LLoffset, &LLsize);
FsOpen(LLbuf);
FsSeek(LLoffset);
FsReadLzsB((long\*)LPKBuf, \*/
/\* \*/
/\* 1997/03/28 G.T.V \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
static void \_init3(SCREEN\_JOB \*ps, int n)
{
SjsSel = 0;
wait = 4;
Sjs \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
static void \_loop3(SCREEN\_JOB \*ps)
{
ClickMap tmpcmp; // 先読み用TEMPクリッカブルマップ
if(!PreLoad)
{
StopPreLoad();
tmpcmp=town\_cmp[j\_sel];
FsOpen(TOWNFILE);
FsSeek(tmpcmp.lcv\_offset+tmpcmp.b
/\* \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
/\* 終了処理 \*/
/\* \*/
/\* \*/
/\* \*/
56|SCR\_NOTPUSH,
\_sinit3,
\_init3,
\_loop3,
NULL,
NULL,
NULL,
NULL,
\_s\_end,
wp3,
{&WjCinCout,64,0,0,0},
512, 240,
NULL, 0,
NULL,
0,
1,
};
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
/\* ショップ(アイテム項目選択)処理 \*/
el < list\_tbl\_num - 1)
Shop\_Sel++;
if(LLnum != Shop\_Sel)
{
\_mt\_sel\_snd();
StopPreLoad();
}
if(PreLoad == PL\_NOUSE)
{
switch(list\_tbl[Shop\_Sel].f)
{
case 0:
for(Q1 = 0, i = 0; Q1 < list\_tbl[Shop\_Sel].n0; Q1++)
\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
#include "ff.h"
#include "ff7list.h"
#include "winsys.h"
#include "cursol.h"
#include "datafanm.inc"
#include "dataflpk.inc"
#include "lpk\_sys.inc"
#include "ffaku.h"
#include "clickm.h"
#include "npk\_item.inc"
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
/\* 型定義 \*/
Buf, (long \*)ComnBuf
#define DEFSYS LZ\_TIM | LZ\_CLUT, (long \*)SYSBuf, (long \*)ComnBuf
#define SUBBERMAX 3
#define SUBBERMAX 3
#define ZENGAMEN\_X 168 /\* 前画面X座標 \*/
#define ZIGAMEN\_X 282 /\* 次画面X座標 \*/
#define ZIGAMEN\_Y 15 /\* ウェイト \*/
static int oldx; /\* マウスX座標前回値保存 \*/
static int oldy; /\* マウスY座標前回値保存 \*/
static int oldpad; /\* 前回のパッド値保存 た時参照 \*/
int EXdatnum; /\* 同上 \*/
static char EXe選択処理\*\*\*\*\*\*\*\*\*\*tBo[Q1];
\*\*\*\*\*\*\*\*\*cat(mlist set\_ c== PADLmat] -= 2;
rt;
if(How\_Kind\_PadCon(0) == 4) /\* バッドで操作か? \*/
{
set\_Cursol\_Point \*/
/\* 1997/03/26 G.T.V H.Mizukami \*/
/\*\*\*\*/
if(oldpad == PADLup && LLsel > 1)
BAENum[item\_menu] -= 2;
if(oldpad == PADLdown && LLsel < LLend - 2)
BAENum[item\_menu] += 2;
if(oldpad == PADLleft && LLsel % 2)
BAENum[item\_menu]--;
if(oldpad == PADLright && (LLsel % 2) == 0 && LLsel < LLend - 1)
BAENum[item\_menu]++;
if(LLnum != BAENum[item\_me set\_Cursol\_Point(&EXmouse, ZENGAMEN\_X, ZIGAMEN\_Y);
}
StopPreLoad();
return;
}
if((((EXmouse.cx > 250 && EXmouse.cy > 10 &&
EXmouse.cx < 300 && EXmouse.cy < 22) &&
(TGPad1 & PADnext)) || (oldpad == PADR1)) && LLend == 20 &&
LLtop + 20 != BAEMax[item\_menu])
{
1;
EXsubbox[0].ber.attribute = 0;
EXsubbox[0].ber.r = 0;
EXsubbox[0].ber.g = 128;
EXsubbox[0].ber.b = 0;
EXsubbox[0].ber.x = LLsel % 2 \* 161 + 122+8 - 256;
EXsubbox[0].ber.y = LLsel / 2 \* 14 + 44 - 120;
EXsubbox[0].ber.w = 156;
EXsubbox[0].ber.h = 14;
if(How\_Kind\_PadCon(0) == 4)
{
set\_Curtprm03);
}
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
/\* 武器リスト処理 \*/
/\* \*/
/\* \*/
/\* \*/
ItemListMax[item\_sel\_hero] - 2)
{
ItemListNum[item\_sel\_hero] += 2;
if(ItemListNum[item\_sel\_hero] >= ItemListMax[item\_sel\_hero])
ItemListNum[item\_sel\_hero] =
ItemListMax[item\_sel\_hero] - 1;
}
if(oldpad == PADLleft && ItemListNum[item\_sel\_hero] % 2)
\*/
/\* \*/
/\* \*/
/\* 1997/03/31 G.T.V H.Mizukami \*/
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* \*/1;
else
SjsSel = 0;
ic\_flag = 0;
break;
case 99:
\_;
/
/\* \*\*\*\*\*\*
\*\*\*\*\*\*/
/\* 召喚・ \*/
MjsLown && ItemLa 20char05\_list;
t\_Cursol\_Point(&\*\*\*u
},
{\_O\_AKU04\_FFD, \_S\_AKU04\_FFD},
{\_O\_AKU05\_FFD, \_S\_AKU05\_FFD},
{\_O\_AKU06\_FFD, \_S\_AKU06\_FFD},
};
PFileDat Npk\_BouSZTBL[] = {{\_O\_BOUGU00\_FFD, \_S\_BOUGU00\_FFD},
{\_O\_BOUGU01\_FFD, \_S\_BOUGU01\_FFD},
UKI09\_FFD, \_S\_BUKI09\_FFD},
{\_O\_BUKI10\_FFD, \_S\_BUKI00\_FFD},
{\_O\_BUKI11\_FFD, \_S\_BUKI11\_FFD},
#define \_S\_GUA\_021\_TIM 56566
#define \_O\_GUA\_022\_TIM 0xe000
#define \_S\_GUA\_022\_TIM 67549
#define \_O\_GUA\_023\_TIM 0x1e800
#define \_S\_GUA\_023\_TIM 61491
#define \_O\_GUA\_024\_TIM 0x2e000
#define \_S\_GUA\_024\_TIM 67618
#define \_O\_GUA\_025\_TIM 0x3f000
#define \_S\_GUA\_025\_TIM 68968
#define \_BOUGU04\_FFD\_SIZE 327680
/\*\*\* [EOF] \*\*\*/
/\*\*\* NPK Header File \*\*\*/
#define \_O\_GUA\_02
```
Скорее всего, незанятое полезной инфой место, в оперативке, было сдамплено на диск «как есть» из памяти, и содержало предыдущую информацию. Кроме исходного кода, там был обычный мусор, который ожидаешь увидеть в памяти компьютера, образы процессов(в том числе исполняемого файла самого диска) и тп.
Другие архивы на диске имели либо точно такую же структуру, либо похожую, так что разбирать их тут смысла нет.
[На всякий случай ссылка на полную версию моего «говнокода».](https://github.com/Hedzin/SquareNPK-unpacker/tree/master/SquareNPK-unpacker)
Вот и все, надеюсь это было интересно читать и кому-нибудь пригодится.
P.S.: прошу прощение за тонну орфографических и пунктуационных ошибок, если заметите что-то уж совсем вопиющее, то пишите и я исправлю. | https://habr.com/ru/post/347382/ | null | ru | null |
# От биологии к играм. Первая российская игра про жизнь в шкуре динозавра
[](https://habr.com/ru/company/ruvds/blog/598707/)
Раньше меня тоже вела дорога приключений. Так, когда-то давно я был разработчиком игры про динозавров. Пожалуй, первой на территории РФ и до сих пор не получившей полноценного, завершённого аналога, ввиду чего наша команда недавно приступила к разработке второй части. Речь, конечно, о многострадальной Cretaceous Runner, которая во время разработки была порезана и переделана. Некоторый функционал был возвращён в патчах, но об этом позже.
> *Автор сообщества [Фанерозой](https://vk.com/phanerozoi): инженер, главный разработчик игры [Cretaceous Runner](https://vk.com/crproject), [Макар Дромкин](https://vk.com/moderndrom). Редактор: руководитель сообщества Фанерозой, [Ефимов Самир](https://vk.com/biolog_snork)*
▍ История
---------
В детстве, наверное, многие из нас любили динозавриков, ведь мультики, сериалы и фильмы, а также различные игрушки, раскраски и первые детские энциклопедии, посвящённые этим величественным животным успешно выполняли роль купидонов. Ведь, согласитесь, трудно было не восхититься рычащим аллозавром из прогулок с динозаврами, или тирексом из первого парка. Даже сейчас, будучи взрослыми, мы всё равно не всегда можем пройти мимо «ужасных ящеров». Об этом свидетельствуют, например, наши [статьи](https://habr.com/ru/post/597877/), которые читатели с восторгом встречают. Однако, если мы окунёмся в прошлое, в наше детство и юность, чтобы обнаружить хорошие игры про динозавров, то много ли интересных примеров мы с вами найдём?

Конечно, компьютерные игры с участием динозавров стали покорять рынок ещё с 90х годов (например, потрясающая игра с доктором Грантом на сеге), но почти все из них были либо шутерами, либо просто файтингами с участием динозавров.
▍ А как же полноценные игры, где можно прожить жизнь в шкуре динозавра, где повествуется какая-нибудь сюжетная история?
-----------------------------------------------------------------------------------------------------------------------
На самом деле таких полноценных игр в то время не было. Да и сейчас, если подумать, таковых, вышедших из стадии беты нет, а те, что имеются, в основном мультиплеерные игры, которые, по сути, не привносят ничего нового. И если честно, мне с детства не хватало игр про жизнь динозавров с сюжетом. Именно поэтому уже в более сознательном возрасте, я подумал: а почему бы мне не сделать игру самому со своей Пангеей и динозаврами?

Так, в 2007 году я стал пробовать играться с разными 3D программами по моделированию и немного освоившись в 3D-MAX примерно к 2010 году, я сделал свою первую, пусть и кривую модельку дромеозавра. Примерно в это же время я стал искать подходящий для моих целей движок. Поскольку я был «наивен и глуп», мечтая быстро налепить кучу моделей и освоить всякие сложные движки, то после многочисленных неудачных попыток, я быстро пришёл к выводу, что начинать нужно с малого, тем более помощи инди-разработчику ждать было неоткуда. Это связано с тем, что в то время российский геймдев был относительно небольшим. Он тогда, конечно, существовал, но больше в зачаточном состоянии.

Кидаться на рожон я всё же не хотел, и поэтому, помимо своих моделек, я нашёл модельки других динозавров из старых игр и поставил относительно осуществимую цель в создании игры без лишних сложностей: каких-либо автомобилей, оружия и прочего… Просто игра про динозавров на относительно простом движке. Да и выбирать в те годы ещё мало, из чего можно было. Если сейчас существует тонна утилит для Unity или UE, то тогда приходилось пользоваться глючными камовскими скриптами, самодельными утилитами и программами для движка RenderWare. Собственно, с последним движком я и решил работать и делать для него свою карту.
▍ Но прежде чем начинать рассказывать всю драму событий, давайте расставим все точки над «Ё» и опишем, чем же является этот проект?
-----------------------------------------------------------------------------------------------------------------------------------
Итак, за мою попытку оправдаться, вероятно в меня могут полететь тапки, но всё же я не думаю, что для кого-то будет секретом то, что раньше применялась практика делать игру на базе другой. На примере тех же GTA – в San Andreas можно найти остатки от Vice City, а то, что VCS ([Vice City Stories](https://ru.wikipedia.org/wiki/Grand_Theft_Auto:_Vice_City_Stories)) сделана на основе VC, итак, понятно. То же самое касается LCS и GTA3.
Поэтому да, технически Cretaceous Runner распространяется как игра, разработанная на базе Gta San Andreas, а, стало быть, она не затрагивает оригинальную SA при её наличии. Но с правовой точки зрения, разумеется, это лишь глобальная модификация. Конечно, кто-то может возразить, что глобальная модификация сейчас вне закона, ибо в последнее время одна большая акула стала пожирать разработчиков и их творения, но в моей игре она добычи, видимо, не увидела. Может быть потому, что по качеству моя игра не уступала последнему великолепному переизданию GTA. Это шутка, конечно, но если взглянуть в прошлое, то в моём создании багов было много, которые правда постепенно устранялись. К слову, мой проект коммерческим так и не был, всё делалось чисто по фану, в попытках заполнить пустующую нишу.

Движок тоже был очень ограничен по функционалу, поэтому была использована смекалка, множество интересных костылей и технических решений, о которых я сегодня вам и расскажу. Разумеется, я не настолько псих, чтобы писать всё на [CLEO](https://cleo.li/ru) или [DYOM](https://dyom.gtagames.nl), да и хоть немного уважать потребителя ведь надо, поэтому написано всё было чисто на мэине. Да, это сложнее, да, по встроенной инструкции, да на языке из смеси бейсика и си (язык у движка свой и на хабре такого нет, поэтому цвет кода будет отличаться от оригинала), при этом параллельно изучая опкоды и уже существующий код. Зато, хотя бы, оно работало. Чего только стоит «котопес» из самолётов, пилота и с нуля написанных анимаций на движке! При этом сам же «котопес» был превращен в птерозавра вполне себе неплохо выглядящего.
> *Итак, немного о том, как я реализовывал геймплей.*
▍ Полёты
--------
Вручную была написана тысяча страниц кода, и один из интересных костылей – полёт на птерозавре. Делалась механика с оглядкой на игру [Turok:Evolution](https://en.wikipedia.org/wiki/Turok:_Evolution), и её приблизительно удалось повторить. Основано конечно всё, на невидимом самолёте с пилотом, заменённым на птерозавра с приклеенным к нему Скилларом – главным героем– дромеозавром. Немного визуальных эффектов, опять же вручную написанной анимации и кода – и всё работает. Прошу простить, что я не вставляю всю тысячу страниц написанного мной кода, но мне кажется в качестве примера можно показать и небольшой кусок проделанной мной работы.
```
:MISSION44_1407
wait 0
if
01F3: car $PTERO1 in_air
else_jump @MISSION44_3031
wait 0
if
82BF: not car $PTERO1 sunk
else_jump @MISSION44_2938
wait 0
if and
80EC: not actor $PLAYER_ACTOR sphere 0 near_point -1999.781 -2134.288 radius 10.0 10.0
844B: not actor $PLAYER_ACTOR on_foot
else_jump @MISSION44_1625
wait 0
if
-8.0 > $ZZ1
else_jump @MISSION44_1571
wait 00605: actor $PLAYER_ACTOR perform_animation "BARSERVE_IN" IFP "BAR" framedelta 4.0 loop 0 lockX 0 lockY 90 lockF 0 time 60000000
jump @MISSION44_1229
:MISSION44_1571
wait 0
0605: actor $PLAYER_ACTOR perform_animation "BARSERVE_LOOP" IFP "BAR" framedelta 4.0 loop 0 lockX 0 lockY 90 lockF 0 time 60000000
jump @MISSION44_1229
```

В миссии «Возвращение зла» из-за горящих сроков я так и не успел сделать полноценное приземление после полёта по каньону, однако оно было задействовано в мини-миссии полётов в свободном режиме. Если замедлить скорость и спуститься к земле, то модель персонажа заменяется на обычного дромеозавра и оставляется на поверхности, а на несколько секунд в воздухе появляется уже другой персонаж-птерозавр, улетающий прочь. Подмена даже получилась почти незаметной. При этом подмена происходит не из воздуха. Т.е. пока продолжается полёт, нужный персонаж ждёт своего часа на горе. Как говорится костыли творят иллюзию, а видео ниже заставляет её лицезреть!
В самой сложной миссии с полётами «Царь горы» был вообще использован запрещённый инструкцией опкод полёта вокруг точки. Возможно, именно это сказалось на поимке врага, которая зависит в полёте на прямой от кадров в секунду. Если FPS сильно завысить, то он догоняется гораздо легче.

Микрораптор же получил механику от самолётика RC Baron, которого заставили махать крыльями, а птерозавры, атакующие его в «Иноземье», просто читают его координаты и летят туда же с небольшой задержкой, чтобы была возможность увернуться.

Конечно, каждый летающий зверь защищён от взрывов и повреждений, чтобы ни у кого случайно не бомбануло. Но, каков итог! Это вам не простой реплейсер, а потому нужны настоящие животины! Кстати, в видео выше вы видели прыжок с башни, что в миссии в Торонто. Там Скиллар цепляется за кусок обшивки и планирует на ней вниз. Дело в том, что город сделан в качестве интерьера высоко в небе, выше самолётного потолка, наподобие Либерти-Сити в SA. А когда самолёт выше потолка, он летит просто вниз до тех пор, пока не вернётся в своё воздушное пространство. Таким образом и получилось сделать плавное планирование с башни без возможности активного полёта. Ниже представлен код реализации.
```
00BC: show_text_highpriority GXT 'MIS_681' time 5000 flag 1 // Use piece of sheating to plan back to airport!
wait 4500
fade 0 1000
wait 1000
Model.Load(#RCBARON)
Model.Load(#TORONCITY22)
038B: load_requested_models
:MISSION40_7594
wait 0
if and
Model.Available(#RCBARON)
Model.Available(#TORONCITY22)
else_jump @MISSION40_7594
fade 1 2000
02A3: enable_widescreen 0
$WIDE = 0
Player.CanMove($PLAYER_CHAR) = True
Camera.Restore_WithJumpCut
Camera.SetBehindPlayer
$MICRO1 = Car.Create(#RCBARON, -2330.825, -158.238, 4300.9)
Car.Angle($MICRO1) = 180.0
$FLYTHING = Object.Create(#TORONCITY22, -2330.825, -154.238, 4310.9)
Object.Angle($FLYTHING) = 180.0
0681: attach_object $FLYTHING to_car $MICRO1 with_offset 0.0 0.0 -0.27 rotation 0.0 0.0 90.0
03F5: set_car $MICRO1 apply_damage_rules 0
036A: put_actor $PLAYER_ACTOR in_car $MICRO1
084E: flying_vehicle $MICRO1 use_primary_gun 1
0841: flying_vehicle $MICRO1 use_secondary_gun 1
01B9: set_actor $PLAYER_ACTOR armed_weapon_to 0
0605: actor $PLAYER_ACTOR perform_animation "BARCUSTOM_GET" IFP "BAR" framedelta 4.0 loop 0 lockX 0 lockY 0 lockF 0 time 60000000
wait 100
Car.PutAt($MICRO1, -2330.831, -158.532, 4300.9)
Car.SetSpeedInstantly($MICRO1, 30.0)
018A: $CHECK1_1 = create_checkpoint_at -2323.499 -465.0377 4064.577
06D5: $CHECK1_2 = create_racing_checkpoint_at -2323.499 -465.0377 4064.577 point_to -2330.825 -155.238 4300.9 type 3 radius 15.0
```
▍ Бег
-----

В самой первой версии было очень много неспешной ходьбы. Но не стоит забывать, что игра с задержкой вышла весной 2013 года, когда никто вообще ничего подобного предложить не мог. Все эти ислы и прочие бермуды были анонсированы либо позже, либо сильно позже. А в те годы все сходили с ума по самой идее – тут же можно играть за динозавра! Да ещё и пернатого! Ничего себе, у нас есть родители, и надо за ними идти!

На самом деле тут сыграла роль ещё и техническая составляющая. Ну не существует опкода просто бежать к точке. Только идти. В пропатченной версии неспешная ходьба уже была заменена на бег, но пришлось идти опять на ухищрения. Когда кто-то из персонажей куда-то бежит, он бежит к рыбе, спрятанной под землей. Из-за этого во второй миссии появился баг, когда наши родители внезапно идут к реке топиться. Рыбы там оказалось слишком много, родители пихаются между рыб, пытаются подойти поближе к нужной, в итоге багуют и просто уходят куда глаза глядят, а миссия зависает. Давайте же глянем на реализацию в виде частички кода:
```
00BC: show_text_highpriority GXT 'MISS_18' time 6000 flag 1 // Now you need some food. Follow your parents all the way to the lake.
wait 5400
02A3: enable_widescreen 0
$WIDE = 0
Player.CanMove($PLAYER_CHAR) = True
wait 0
$FISH1 = Object.Create(#DRUG_BLUE, -933.8073, -806.0117, 9.445)
Object.Angle($FISH1) = 0.0
062F: $GROUP1_1 = create_group_type 0
06F0: set_group $GROUP1_1 distance_limit_to 3000.0
0630: put_actor $MOTHER in_group $GROUP1_1 as_leader
0631: put_actor $FATHER in_group $GROUP1_1
0631: put_actor $BRO1 in_group $GROUP1_1
0631: put_actor $BRO2 in_group $GROUP1_1
0631: put_actor $BRO3 in_group $GROUP1_1
06E2: AS_actor $MOTHER run_to_object $FISH1 timelimit -1 stop_within_radius 4.0
wait 0
$MMAR = Marker.CreateAboveActor($MOTHER)
Marker.SetColor($MMAR, 1)
$FMAR = Marker.CreateAboveActor($FATHER)
Marker.SetColor($FMAR, 1)
```
▍ Взрывы
--------

Очередной багоюз – это анкилозавр. Как бы понатуральнее сделать его атаку хвостом? Анимация – это полбеды, надо еще, чтобы герой получал большое количество урона, при этом крича от боли. Был задействован неиспользуемый невидимый беззвучный взрыв – анкилозавр получил защиту от взрыва, и во время удара хвостом на его месте появляется импровизированный взрыв, наносящий урон.
▍ Стелс
-------

Была полностью написана миссия с простым, но стелсом. Там лишь удалось сделать «чистые» зоны, по которым можно пройти незамеченным, при этом только ползком. Если подняться, то даётся примерно 2 секунды, пока троодоны нас не заметят. К сожалению, эта миссия хоть и была готова, но появилась только в бета-доступе версии 1.3. К тому же, миссию можно пройти тремя способами – полным стелсом пробраться до вожака троодонов и также незаметно убраться, пробраться до него и просто убежать, спалившись, или же пойти сразу напролом через тучу троодонов, попытавшись догнать и убить вожака. Так или иначе, стелс работал, хоть и был максимально прост и уныл.
▍ Танцы
-------

Миссия с брачным танцем была написана с нуля лишь с помощью своих идей и возможностей. Скрипт из SA весь состоит из переменных, просто взять и выдернуть его невозможно. Поэтому опять достаём костыли и пишем. Используется прорисовка текстур и их движение по экрану. При ошибках выполнения танца стрелки немного съезжают и иногда даже наплывают друг на друга, но миссия, в целом, осталась проходимой даже без особых сложностей. Она стала так же самой крупной по размеру занимаемого кода, так как действие каждой из стрелок было прописано вручную. Всё получилось, кстати, абсолютно рабочим, ничего не зависит от количества кадров в секунду или разрешения экрана. Ниже приведён код начала миссии, а также механика первой из стрелок.
```
01E3: show_text_1number_styled GXT 'MIS_750' number 0 time 5000 style 1 // ~b~Mating dance
wait 6000
02A3: enable_widescreen 0
$WIDE = 0
00BC: show_text_highpriority GXT 'MIS_751' time 4200 flag 1 // Use arrow keys to perform the dance.
wait 4500
00BC: show_text_highpriority GXT 'MIS_752' time 5200 flag 1 // Press the desired button when the arrow will be in the circle.
wait 5500
00BC: show_text_highpriority GXT 'MIS_753' time 4500 flag 1 // Score 1500 points to impress the female.
03C4: set_status_text $DANCE_SCORE type 0 GXT 'DNC_001' // global_variable // Score:
0605: actor $PLAYER_ACTOR perform_animation "DAN_LOOP_A" IFP "DANCING" framedelta 4.0 loop 0 lockX 0 lockY 0 lockF 0 time 120000
wait 5000
0390: load_txd_dictionary 'LD_TATT'
038F: load_texture "UP" as 7 // Load dictionary with 0390 first
038F: load_texture "DOWN" as 8 // Load dictionary with 0390 first
038F: load_texture "RIGHT" as 9 // Load dictionary with 0390 first
038F: load_texture "LEFT" as 10 // Load dictionary with 0390 first
038F: load_texture "CIRCLE" as 6 // Load dictionary with 0390 first
03E3: set_texture_to_be_drawn_antialiased 1
$DANCE_SCORE = 0
$UP = 304477
$DOWN = 304478
$RIGHT = 304479
$LEFT = 304478
$TEXT = 380.0
$TEXT_1 = 550.0
$TEXT_2 = 650.0
$TEXT_3 = 750.0
$TEXT_4 = 850.0
$TEXT_5 = 700.0
$TEXT_6 = 700.0
$TEXT_7 = 700.0
:MISSION37_1_607
wait 0
038D: draw_texture 6 position 310.0 380.0 size 60.0 60.0 RGBA 255 255 255 255
038D: draw_texture 7 position $TEXT_1 $TEXT size 40.0 40.0 RGBA 255 255 255 255
038D: draw_texture 8 position $TEXT_2 $TEXT size 40.0 40.0 RGBA 255 255 255 255
038D: draw_texture 9 position $TEXT_3 $TEXT size 40.0 40.0 RGBA 255 255 255 255
038D: draw_texture 10 position $TEXT_4 $TEXT size 40.0 40.0 RGBA 255 255 255 255
$TEXT_1 -= 3.0
$TEXT_2 -= 3.0
$TEXT_3 -= 3.0
$TEXT_4 -= 3.0
if
330.0 > $TEXT_1
else_jump @MISSION37_1_607
if and
not &0($DOWN,1i) == 255
not &0($RIGHT,1i) == 255
not &0($LEFT,1i) == 16711680
$TEXT_1 > 300.0
else_jump @MISSION37_1_1018
if and
320.0 > $TEXT_1
&0($UP,1i) == 16711680
else_jump @MISSION37_1_607
038D: draw_texture 7 position $TEXT_1 $TEXT size 40.0 40.0 RGBA 0 170 0 255
0605: actor $PLAYER_ACTOR perform_animation "DAN_LEFT_A" IFP "DANCING" framedelta 4.0 loop 0 lockX 0 lockY 0 lockF 0 time 120000
$DANCE_SCORE += 25
jump @MISSION37_1_1057
:MISSION37_1_1018
038D: draw_texture 7 position $TEXT_1 $TEXT size 40.0 40.0 RGBA 220 0 0 255
jump @MISSION37_1_1057
end_thread
```
▍ Музыка
--------
Интересный момент также с саундтреком. Когда игра была пропатчена, в неё добавили то, чего так хотелось изначально – саундтрек. Как известно, в GTA серии 3D саундтрека не существует, кроме того, что играет на радио в машинах. На самом деле есть, насколько помню, целых два саундтрека выполненной миссии и ещё несколько для других целей – для танцев лоурайдеров, например. Но зато у нас есть аудиозоны – это шум холодильников в магазинах, фоновые шумы в брокерской конторе и многое-многое другое. Поэтому «саундтрек» использовался в тех случаях, где надо проиграть музыку именно с начала – как в миссии «Некуда бежать», например. В других же случаях использовалось большое количество аудиозон, ведь они могут работать не только в интерьерах. В них, однако, музыка просто зациклена по кругу и начинаться будет чаще всего с хаотичной точки. Аудиозона также действует на определённой, собственно, зоне, поэтому в некоторых миссиях для пробы ниже нуля зона заканчивалась, благодаря чему не было музыки под водой. Если уплыть за границы карты, там музыка тоже закончится. Только из-за переходов от звуков воды к музыке тоже иногда появляются баги, потому что вода, как и гром – это лишь замедленный звук взрыва. Из-за резкого перехода скорость воспроизведения иногда не возвращалась к нормальной, и музыка либо замедлялась, либо вообще становилась настолько медленной, что превращалась лишь в криповые звуки.
▍ Группировки и стаи
--------------------

Группы «банд» ограничены были только восемью членами, поэтому снова вставляем костыли в колёса – одного из членов нашей стаи делаем вожаком другой стаи, в которой состоит тоже вожак следующей стаи, и так до бесконечности. Это было необходимо для предпоследней миссии, однако это тоже вызывало некоторые трудности – при попадании в воду стаи уже перестают слушаться, и некоторые персонажи просто застревают в воде, не желая никуда плыть.
▍ Здоровье и интерфейс
----------------------
В последней же миссии, которую никак не получалось адекватно сделать из-за больших размеров тирекса, тоже есть хитрость. В самом конце нам надо кинуть факел в пещеру с газом. Хоть вроде бы и существует опкод на проверку наличия огня на нужной площади, работает он так себе. Поэтому ровно за стеной стоит ти-рекс с 10% здоровья. Это можно проверить даже на джет-паке. При попадании факела возле него он сразу умирает, отчего проверка и срабатывает.
```
00BC: show_text_highpriority GXT 'MIS_478' time 5000 flag 1 // Burn up the cave gas.
018A: $RADAR_MISS_50_5 = create_checkpoint_at -1916.297 -1854.666 47.6738
03BC: $RADAR_SPHERE_50_5 = create_sphere_at -1916.297 -1854.666 47.6738 radius 1.5
Actor.GiveWeaponAndAmmo($PLAYER_ACTOR, Molotov, 10)
01B9: set_actor $PLAYER_ACTOR armed_weapon_to 18
$TREX_50_7 = Actor.Create(CivMale, #VWMYBOX, -1918.56, -1857.228, 42.0)
Actor.Angle($TREX_50_7) = 10.0
Actor.Health($TREX_50_7) = 10
jump @MISSION50_11431
:MISSION50_11431
wait 0
if and
not Actor.Dead($DROMEO_50_1)
not Actor.Dead($DROMEO_50_2)
not Actor.Dead($DROMEO_50_3)
not Actor.Dead($DROMEO_50_4)
not Actor.Dead($DROMEO_50_15)
not Actor.Dead($DROMEO_50_16)
not Actor.Dead($PLAYER_ACTOR)
else_jump @MISSION50_12417
if
Actor.Dead($TREX_50_7)
else_jump @MISSION50_11431
wait 0
Marker.Disable($RADAR_MISS_50_5)
03BD: destroy_sphere $RADAR_SPHERE_50_5
00BC: show_text_highpriority GXT 'MIS_479' time 2000 flag 1 // Run away!
```
Подобным образом созданы и падающие метеоры в Грейхиллсе. Это просто самолёты с 1% здоровья, они уже дымятся и обязательно взорвутся при падении на землю. Позже они удаляются и спавнятся снова, и так до бесконечности.

Реализация:
```
wait 100
$METEOR9 = Car.Create(#STUNT, 2333.89, 1813.307, 159.8879)
Car.Angle($METEOR9) = 154.3845
099A: set_car $METEOR9 collision_detection 1
Car.Health($METEOR9) = 1
$METEOR19 = Car.Create(#STUNT, 2233.89, 1813.307, 199.8879)
Car.Angle($METEOR19) = 154.3845
099A: set_car $METEOR19 collision_detection 1
Car.Health($METEOR19) = 1
0948: create_explosion_at 2218.385 1826.519 41.4688 type 6 camera_shake 1
Camera.Shake(100)
wait 10
0948: create_explosion_at 2251.674 1800.366 37.8775 type 6 camera_shake 1
Camera.Shake(100)
wait 100
$METEOR10 = Car.Create(#STUNT, 2404.49, 1873.452, 166.5147)
Car.Angle($METEOR10) = 154.3845
099A: set_car $METEOR10 collision_detection 1
Car.Health($METEOR10) = 1
$METEOR20 = Car.Create(#STUNT, 2304.49, 1773.452, 196.5147)
Car.Angle($METEOR20) = 154.3845
099A: set_car $METEOR20 collision_detection 1
Car.Health($METEOR20) = 1
```

Интерфейс тоже был переделан. От самого движка остался только радар, немного изменённый внешне, а всё остальное также написано на мэине. Постоянно идёт отслеживание оружия в руках, в результате чего прорисовывается соответствующая текстура, шкала здоровья просто является софтверным прямоугольником с использованием эффекта альфы, названия территорий также читает и пишет мэин, а при получении урона опять же идёт отслеживание по падению уровня здоровья, в результате чего появляется текстура, скриптово переведённая в красную. В редких случаях на слабых компьютерах я видел, как текстура не успевала прорисовываться, тогда экран просто быстро мигал красным светом. А вот прочитать выносливость или объём воздуха в лёгких никак не удавалось, поэтому эти сведения так и не были выведены на экран.
▍ И что теперь?
---------------
Годы идут, Cretaceous Runner давно устарел, а до сих пор нам не предложили ни одной полноценной, сюжетной игры за жизнь динозавров. На самом деле, разумеется, это просто невыгодно. Конечно, разные команды уже пробовали подобное разрабатывать, но дальше сырых демок до сих пор дело не зашло. Хотя из всех игр, вроде как подходит к финалу замечательная THE SAURIAN, разрабатываемая большой командой людей, но без как такового сюжета… Ну и выпущена была также [JWE](https://jurassicpark.fandom.com/ru/wiki/Jurassic_World_Evolution_2), но это не совсем то, это лишь парк, да и динозавры там под большим вопросом, ведь игра делает упор именно на мутантов/гибридов. А так… сколько ни шло, ни одна сюжетная игра именно про динозавров так и не появилась, в результате чего я решил делать вторую часть Cretaceous Runner на UE4. У меня уже есть небольшая команда и идёт работа с модельками. Так что кто знает, кто знает… Глядишь, может в этот раз и получится!
> Благодарю за прочтение! Скачать первую часть бесплатно вы можете [здесь](https://libertycity.ru/files/gta-san-andreas/93286-cretaceous-runner-1.2-hd.html). С вами был Макар Дромкин, до новых встреч!
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=phanerozoi_evidence%0A&utm_content=ot_biologii_k_igram._pervaya_rossijskaya_igra_pro_zhizn_v_shkure_dinozavra) | https://habr.com/ru/post/598707/ | null | ru | null |
# Я написал Scaffold-библиотеку Django, которая создает полнофункциональный REST API за секунды
Меня зовут Абденассер, и сегодня я покажу, как пользоваться небольшой [scaffold-библиотекой](https://github.com/Abdenasser/dr_scaffold) для создания готовых к использованию полнофункциональных REST API на Django за секунды из командной строки, которую я разработал на прошлой неделе.
Начнем.
Настройка среды Django выходит за рамки этой статьи, но я уверен, что в интернете есть множество руководств, которые помогут вам это сделать.
В двух словах, вот то, что мы собираемся сделать в три этапа:
* Создать проект Django;
* Поставить rest-фреймворк Django и `dr_scaffold`;
* Собрать API blog со статьями и авторами.
1. **Создаем проект Django**
Давайте создадим проект Django с помощью команды `django-admin`:
```
$ django-admin startproject myApi
```
Эта команда делает то же самое, что и `python manage.py startproject myApi`, с той лишь разницей, что ей для выполнения не нужна среда Python.
Давайте перейдем к нашему новому проекту с помощью `cd myApi`, и создадим виртуальную среду с помощью:
```
$ python3 -m virtualenv env
```
Наконец, давайте активируем виртуальную среду:
```
$ source env/bin/activate
```
**2.Ставим rest-фреймворк Django и dr\_scaffold**
Давайте установим пакеты `djangorestframework` и `dr-scaffold` через `pip`, как показано ниже:
```
$ pip install djangorestframework
$ pip install dr-scaffold
```
Теперь добавим эти пакеты в *INSTALLED\_APPS* нашего проекта внутри `myApi/settings.py`:
```
INSTALLED_APPS = [
…,
‘rest_framework’,
‘dr_scaffold’
]
```
Давайте добавим настройки *CORE\_FOLDER* и *API\_FOLDER* в `myApi/settings.py` (в рамках упрощения, просто оставим их пустыми):
```
CORE_FOLDER = “” # you can leave them empty
API_FOLDER = “” # or set them to be the same
```
**3. Собираем API blog со статьями и авторами**
В нашем api будет два основных ресурса: `Article` и `Author`. Начнем с `Author`:
```
$ python manage.py dr_scaffold blog Author name:charfield
🎉 Your RESTful Author api resource is ready 🎉
```
Эта команда создаст папку с *models.py, admin.py, views.py, serializers.py, urls.py*, и во всех них будет необходимый код для ресурса `Author`.
А теперь для ресурса `Article`:
```
$ python manage.py dr_scaffold blog Post body:textfield author:foreignkey:Author
🎉 Your RESTful Post api resource is ready 🎉
```
Эта команда сделает нечто аналогичное, но вдобавок добавит связь с ресурсом `Author` через поле `foreignkey`.
Чтобы сгенерировать таблицы базы данных, давайте добавим наш `blog` к `INSTALLED_APPS` в `myApi/settings.py`:
```
INSTALLED_APPS = [
…,
‘rest_framework’,
‘dr_scaffold’,
‘blog’
]
```
Давайте выполним эти команды, чтобы создать миграции и мигрировать базу данных:
```
$ python manage.py makemigrations
$ python manage.py migrate
```
Наконец, добавим `blog` в `urlpatterns` в `myApi/urls.py`:
```
urlpatterns = [
…,
path(“blog/”, include(“blog.urls”)),
]
```
Не забудьте импортировать `include` в `urls.py` проекта:
```
from django.conf.urls import include
```
В конце концов у вас в *urls.py* будет нечто подобное:
```
from django.conf.urls import include #our added import
from django.contrib import admin
from django.urls import path
urlpatterns = [
path(‘admin/’, admin.site.urls),
path(“blog/”, include(“blog.urls”)), #our added blog path
]
```
Теперь, когда все готово, давайте выполним `python manage.py runserver` и перейдем к <http://127.0.0.1:8000/blog/>, чтобы увидеть итоговое REST blog API. А еще вы можете создать суперпользователя и перейти на <http://127.0.0.1:8000/admin>, чтобы увидеть панель администратора.
Не забудьте поставить звездочку <https://github.com/Abdenasser/dr_scaffold> на GitHub, если вам понравился проект.
---
> Материал подготовлен в рамках курса [«Web-разработчик на Python»](https://otus.pw/D5kM/).
>
> Всех желающих приглашаем на бесплатный двухдневный интенсив **«Валидация flac-файлов»**. На интенсиве мы с вами наконец-то научимся читать flac-файлы, вычислять метрики их качества и заодно делать выводы об их происхождении: из mp3-файла или качественного источника.
> [>> РЕГИСТРАЦИЯ](https://otus.pw/AtEh/)
>
> | https://habr.com/ru/post/582236/ | null | ru | null |
# SMS шлюз в радиолюбительский DX-кластер на базе D-Link Dir-620
Приветствую всех! Надеюсь моя статья будет интересна не только радиолюбителям, которые присутствуют на Хабре, но и остальным читателям.
Кто такие радиолюбители, можно почитать [тут](http://www.qso.ru/whois.html), а что такое Dx-кластер — [тут](http://forum.qrz.ru/thread2094.html).
Немного предыстории: однажды в одном из радиолюбительском [рефлекторе](http://home.tula.net/ua3prs/res/FORUMY.HTM) проскочила идея отправки смс сообщения в DX-кластер, ведь не везде есть покрытие интернета. Но идея была откинута радиолюбителями, которые работают/имеют непосредственное отношение к операторам мобильной связи. Мотивировали это тем, что очень дорогое выйдет оборудование, поэтому идея того не стоит.
Я заинтересовался этой темой и было принято решение собрать в единое целое [smstools](http://smstools3.kekekasvi.com/), мобильный телефон и DX-кластер.
Данная схема успешно завелась на моем домашнем сервере под управлением FreeBSD. Сейчас же решил проделать все тоже, но на роутере [D-link DIR-620](http://www.dlink.ru/ru/products/2/1357.html)
Оборудование:
— роутер Dir-620 с прошивкой Zyxel Keenetic;
— мобильный телефон Motorola v360 (старый телефон жены, валяется как резерв);
— прямые руки и желание;
О smstools рассказывать не буду, уже этот вопрос осветили на Хабре [тут](http://habrahabr.ru/post/111305/).
И статья на Хабре, как прошить роутер — [тут](http://habrahabr.ru/post/123699/).
Итак, подключаем телефон и убеждаемся, что роутер его видет:
`dmesg
...
...
cdc_acm 1-1.4.3:1.0: ttyACM0: USB ACM device`
Дальше собираем smstools. Как собирать свои пакеты, детально написано у [Zyxmon](https://habrahabr.ru/users/zyxmon/) [тут](http://code.google.com/p/zyxel-keenetic-packages/wiki/Welcome) Т.к. smstools не входит в стандартные утилиты OpenWrt, поэтому, скачиваем исходники [отсюда](http://smstools3.kekekasvi.com/) и разархивируем.
Собрать нужно её, используя кросс-компилятор из Keenetic. Для этого в файле smstools3/src/Makefile нужно в строчке:
CC=gcc
указать путь до кросс-компилятора. У меня так:
СС=/home/igor/keenetic/staging\_dir/toolchain-mipsel\_r2\_gcc-4.1.2\_uClibs-0.9.30.3/bin/mipsel-openwrt-linux-uclibc-gcc
Делаем make. В smstools3/src/ получаем файл демона sms-сервера smsd, который копируем на файловую систему в /media/DISK\_A1/system/usr/bin. Заодно в директорию /media/DISK\_A1/system/etc положим файл конфигурации smsd.conf, который необходим для запуска smsd.
Мой файл конфигурации:
`devices = GSM1
logfile = /media/DISK_A1/system/var/log/smstools/smsd.log
loglevel = 7
[GSM1]
device = /dev/ttyACM0
incoming = yes
check_memory_method = 31
smsc = 38097*******
baudrate = 115200
rtscts = no`
Также для работы smsd нужно создать следующие директории:
mkdir -p /media/DISK\_A1/system/var/log/smstools
mkdir -p /var/spool/sms/checked/
mkdir -p /var/spool/sms/outgoing/
mkdir -p /var/spool/sms/incoming/
Запускаем sms-сервер:
`# smsd -c /media/DISK_A1/system/etc/smsd.conf`
Отправляем тестовое смс сообщение на телефон такого вида:
(частота DXстанция комментарий)
14144.0 UE1WFF WFF!!!
В каталоге /var/spool/sms/incoming/ будет текстовый файл такого вида:
`From: 777
From_TOA: 81 unknown, ISDN/telephone
From_SMSC: 380672020000
Sent: 12-03-26 10:06:43
Received: 12-03-26 09:28:39
Subject: GSM1
Modem: GSM1
IMSI: 255030564719214
Report: no
Alphabet: ISO
Length: 57
14144.0 UE1WFF WFF!!!
***`
Осталось только взять нужную строку и отправить в DX-кластер. Для этого пишем простой скрипт на perl. Скажу сразу, что на perl не программировал, поэтому возможно скрипт можно и получше написать…
`#!/media/DISK_A1/system/usr/bin/perl
$k=0;
my @curfiles=glob('*.{txt}');
$count=1;
while ($name=glob('*.{txt}')) {
$count++;
}
$count=$count-2;
for ($k=0; $k<=$count; $k++)
{
open FILE,$k.'.gsm.txt';
$i=0;
while ()
{
$i++;
if ($i==12) { $string=};
}
close FILE;.
unlink $k.'.gsm.txt';
use Net::Telnet ();
my $my_call = '******';
my $my_pass = '******';
my $myspot='DX '.$string;
my $t = Net::Telnet->new(Host => '19*.15*.23*.25*', Port => '9****', Timeout => 10);
$t->waitfor('/Callsign : /');
$t->print($my_call);
$t->waitfor('/Password : /');
$t->print($my_pass);
$t->waitfor('/****** de ****** >/');
$t->print($myspot);
print @lines;
$t->print("bye");
$t->close;
}
И все, сообщение ушло в радиолюбительский кластер. Дальше скрипт можно добавить в крон на выполнение в определенное время.
Так же по аналогии можно сделать и sms-уведомление сотрудников или отправку смс из интернета, как сделано на сайте Киевстара
Статья первая, поэтому возможно что-то не так оформил, готов выслушать все в свой адрес :)
Благодарю за внимание!` | https://habr.com/ru/post/140993/ | null | ru | null |
# Интервью с Джоном Скитом
##### Во втором номере этого журнала, мы рады видеть Джона Скита в нашем «виртуальном» кресле. Джон Скит — настоящий помощник сообщества (взгляните на его значки на StackOverflow), ведущий C# специалист и автор множества книг. Джон является MS MVP начиная с 2003 года. В настоящее время он работает в компании Google.
Дамы и господа, без лишних слов, представляем вашему вниманию Программного Инженера и Джентльмена — Джона Скита.
**DNC:** Привет Джон, мы очень рады, что ты нашел время в своём графике для этого интервью. Для начала мы все хотим знать больше о Джоне Ските, расскажи нам как все началось? Как Джон начал работать с компьютерами?
**JS:** Мой первый компьютер — общий для всей семьи был Sinclair ZX Spectrum 48 K, который мы купили когда мне было 8. Со временем я покупал и другие модели Spectrum-а, но затем постепенно перешел на PC. Долгое время я проводил большинство своего времени за компьютером, просто играя в игры, но программирование так же всегда присутствовало.
**DNC:** С какими сложными задачами ты столкнулся при работе на Sinclair? Задачи, которые погрузили тебя глубже в компьютерные науки?
**JS:** Одним из моих первых «больших» проектов на Spectrum-е было написание аналога языка Logo. В школе у нас были микрокомпьютеры BBC Micros и Logo использовался как язык для введения в вычисления; я действительно им наслаждался и хотел использовать его дома, но у нас не было интерпретатора для Logo. Я не имел понятия о тригонометрии и не имел хорошего представления о структурном программировании, но я проявил упорство и закончил с достаточно неплохой реализацией. Руководство, которое было вместе с Spectrum-ом было очень хорошим, я буквально выучил оттуда всю элементарную тригонометрию, за долго до того как мы начали изучать её в школе.
Я все еще помню одну подпрограмму рисующую либо удаляющую треугольник представляющий собой черепаху. Подпрограмма начиналась со строки под номером 7000 и если результат выглядел не совсем правильно, я просто добавлял вызов «GOSUB 7000» до тех пор пока она работала. Я понимал, что если имеется более одного вызова подпрограммы в определенном месте, значит что-то было неверно… но я не всегда знал, что именно.
**DNC:** Хорошо, мы хотели оставить этот вопрос на потом, но сейчас ты сказал, что создал аналог Logo когда тебе было… 8(?)… Задумывался ли ты когда-нибудь о создании своего собственного языка программирования?
**JS:** Изредка… но не думаю, что у меня есть достаточно сильное воображение, чтобы создать что-то действительно революционное (конечно же у меня нет на это времени). Я думаю я могу помочь команде проектирующей дизайн нового языка, но ведь намного проще быть диванным дизайнером — указывать на ошибки совершенные в существующих языках, чем делать реальные вещи.
**DNC:** Что ж, есть много диванных специалистов и тут у нас есть Джон. Мы все знаем о твоей любви к C#. Большинство твоей работы связано с Java. Какие другие языки программирования ты используешь для работы? Какие-нибудь языки ты изучаешь как хобби или хотел бы изучать? Почему?
##### Мой секрет заключается в том, что я действительно не знаю другие языки программирования. Я достаточно знаю VB, чтобы отвечать на некоторые вопросы на StackOverflow, и я могу читать некоторые вопросы по F#, но я очень не многоязычен в этом смысле.
**JS:** Мой секрет заключается в том, что я действительно не знаю другие языки программирования. Я достаточно знаю VB, чтобы отвечать на некоторые вопросы на StackOverflow и я могу читать некоторые вопросы по F#, но я очень не многоязычен в этом смысле. Я определено хочу изучить подробнее F# и надеюсь выучить Go, поскольку мои коллеги много говорили о нём.
Вся хитрость заключается в том, чтобы найти фактическое применение вещам — большинство моего хобби связанно с созданием .NET библиотек таких как Noda Time или написание статей о C#.
Я не разработчик приложений, для которого я думаю намного проще пробовать другие языки программирования. Сейчас у меня есть Raspberry PI, который я надеюсь зажжёт мое воображение на что-либо. Хотя там и работает Mono, я собираюсь попробовать использовать его (Raspberry PI) для изучения языка Go.
**DNC:** Очень хорошо, теперь мы можем добавить и тег Go к твоему списку на StackOverflow. Как программист полиглот как часто у тебя бывает чувство «ммм… это интересно, это работает по-разному в других языках?» Что-нибудь приходит в голову?
**JS:** *Замыкания*. Когда вы ссылаетесь на внешнюю переменную из замыкания, что на самом деле это означает? Разные языки имеют разные ответы… В языке C# ответ на этот вопрос менялся с течением времени (если вы захватите переменную цикла в foreach в C# 2.0 — 4.0 то вы в конечном итоге будете захватывать одну и ту же переменную для каждого значения в последовательности; в C# 5.0 будет захватываться новая переменная на каждой итерации).
**DNC:** Вернемся к твоей любви к C#, какую одну функцию ты всегда хотел но которая никогда не будет реализована или если бы ты мог добавить «единственную» функцию в C#, что это было бы?
**JS:** **Я бы хотел видеть больше поддержки неизменяемым типам в той или иной форме.** Существует много мест, где она может оказаться полезной. К примеру, я люблю поведение анонимных типов — просто неизменяемые классы которые переопределяют методы Equals, GetHashCode и ToString полезным способом, а так же позволяют давать нужные имена их свойствам. Если бы мы могли делать то же самое для обычных классов так же просто! Создание «обычного» класса, который содержит несколько свойств, имеет конструктор принимающий значения и переопределяет различные методы делает код немного boiler-plate (Boiler-plate code — так называют повторяющиеся кусочки программного кода, которые с небольшими изменениями воспроизводятся много раз), особенно если вы хотите создать подлинно readonly переменные, а не имеющие свойства с private set-ером.
Кроме того, я бы хотел видеть больше поддержки для создания неизменяемых типов — инициализаторы объектов и коллекций хороши, но работают только для изменяемых типов. Вы можете использовать паттерн строитель, но это не очень красиво. Я сомневаюсь будет ли добавление функциональности связанной с паттерном строитель интересным дополнением к языку. По крайней мере именованные аргументы и параметры по умолчанию дают альтернативную функциональность. Конечно, эти идеи о неизменяемости на поверхностном уровне. Глубокая неизменяемость сложна, но даёт большие преимущества. Я знаю команда C# знают об этой пользе — если они смогут придумать эффективное решение то это будет замечательно.
**DNC:** C# начинал как статически типизированный язык, однако принял много динамических черт. Есть что-нибудь, что можно было бы добавить в C#, что было бы новаторским или это будет эволюция для чего-то существующего?
**JS:** Самое интересное во всем этом заключается в том, что многие функции которые изначально появились в динамических языках на самом деле не являются динамическими. LINQ — полностью статически типизированный, но генераторы списков появились в Python-e до этого. Так же «var» делает C# похожем на динамический язык, но без потери типобезопастности. Конечно тип «dynamic» добавленный в C# 4.0 совсем другое дело.
##### Я думаю новая функциональность async/await добавленная в C# 5.0 (и естественно VB) изменит игру.
Я знаю, что подобные функции есть и в других менее популярных языках программирования, но я думаю это принесет огромную пользу для обычных разработчиков. Возможность создания асинхронного кода при этом не превращая его в спагетти код поражает. Я действительно взволнован этой функциональностью, и я надеюсь она изменит наше представление о написание кода, как я считаю LINQ изменило представление многих людей о манипуляции данными.
**DNC:** Помимо неизменяемости, которая, кажется изменилась только в поддержке ReadOnlyCollections в C# 5.0, что еще находится в списке твоих пожеланий для C# 6.0?
**JS:** Это все, что я мог предложить, я уверен у команды C# есть что-то гораздо более удивительное на уме. Я уже говорил об улучшенной поддержки неизменяемых типов, так же я бы хотел увидеть улучшенную поддержку кортежей способных сделать некоторый код намного проще, но я так же считаю важным, чтобы C# избежал загрязнение ненужной функциональностью. Команда разработчиков должна держать очень высоко планку для новых функций, только так они могут рассчитывать на то, что разработчики узнают о ней со временем. Мне посчастливилось узнать C# начиная с версии 1.0, но можете ли вы представить начать его изучение с C# 5.0? Как много времени вам потребуется, чтобы выучить весь язык, включая самые последние добавленные функции? (Я намерено держусь подальше от небезопасного кода, фактически я вырезал целый раздел из знания языка, надеюсь он мне никогда не понадобится).
**DNC:** Расскажи нашим читателям больше о проекте Protobuf (портированном на .NET). Кроме проекта Protobuf есть ли у тебя сверх секретные проекты над которыми ты работаешь?
**JS:** Protocol Buffers используется для представления структурированных данных в Google. Это достаточно простой язык для описания структуры, а так же для наиболее эффективного представления для хранения и передачи. Это платформо-независимый формат, который очевидно будет вам полезен если у платформы которую вы используете есть поддержка соответствующей библиотеки. Google сделал проект Protocol Buffers открытым почти сразу, после того как я к нему присоединился и я решил портировать его на .NET. Моя версия находится примерно на ровне с Java и C++ версиями, которые предоставляет Google, но есть и другие порты. В частности, я знаю, Marc Gravell проделал интересную работу в его версии Protobuf для .NET, которая использует немного другой подход.
Сейчас я мало работаю над Protocol Buffers — большинство моего open source кодинга я провожу над NodaTime, который начинал как порт с JodaTime date/time библиотеки для Java, но закончил, тем что стал портом «движка» JodaTime, но с довольно различным API поверх него. Это действительно хороший проект для изучения дизайна API.
**DNC:** Пожалуйста задай нашим читателям 3 интересных вопроса о C#.
**JS:** ОК! Несколько вопросов различной сложности:
**Вопрос 1:** Вызов какого конструктора вы можете использовать, чтобы данный код распечатал True (в реализации .NET от Microsoft)
```
object x = new /* fill in code here */;
object y = new /* fill in code here */;
Console.WriteLine(x == y);
```
Помните, что это просто вызов конструктора и вы не можете поменять тип переменных.
**Вопрос 2:** Как вы можете заставить это код скомпилироваться, так что он вызывает три различные перегрузки метода?
```
void Foo()
{
EvilMethod();
EvilMethod();
EvilMethod();
}
```
**Вопрос 3:** Используя локальную переменную, как вы можете уронить этот код во 2-ой строчке?
```
string text = x.ToString(); // No exception
Type type = x.GetType(); // Bang!
```
**DNC:** Можете выбрать одну или две интересных бесед на StackOverflow? (Лично я люблю читать факты о Джоне Ските :))
**JS:** Да мне тоже нравится страница фактов о Джоне Ските. Как я уже говорил это не совсем все обо мне, я просто удобное имя, чтобы повесить его на шутку. Посты, которые мне нравятся — это те, в которых я узнаю что-то новое о C# или те которые дали повод написать действительно ужасающий код — как правило вместе с комментарием — «это ужасно, не используйте его в реальной жизни». Мне было очень приятно, когда Эрик Липперт добавил комментарий к одному из таких постов — «это лучшее злоупотребление C#, которое я когда-либо видел». Одно из преимуществ быть C# разработчиком-любителем заключается в том, что я могу писать код на подобие этого без каких-либо последствий.
**DNC:** Если начинающий/молодой разработчик стремится быть похожим на Джона Скита — экстраординарного программиста с чего им начинать? Возможно ли создать «глубокую копию» Джона Скита по программированию?
**JS:** Начнем с того, что планку надо держать намного выше! Слухи о моей компетенции сильно преувеличены, как вы не раз слышали если говорили с моими коллегами. Я прочитал спецификацию C# более подробно, чем многие люди, и у меня есть дар намеренного злоупотребления возможностями языка и мои навыки общения достаточно хороши, но несмотря на это я не специалист. У меня есть твердое мнение по поводу API и дизайна языка, но попросите меня написать целое приложение, и я окажусь беспомощным. | https://habr.com/ru/post/201316/ | null | ru | null |
# Установка PROXY сервера на DD-WRT
Как установить DD-WRT на роутер рассказывать не буду, об этом полно статей. А вот как установить прокси, внятного мануала не нашел. Вот и решил написать свой.
Для того чтобы без препятственно устанавливать стороннее программное обеспечение на ваш DD-WRT понадобиться дополнительное место, которого в роутере как правило недостаточно. Поэтому необходимо к нему подключить дополнительную флешку. Так как в моем случае роутер будет раздавать интернет с 3G модема, а порт USB у меня на роутере 1, и чтобы не морочиться с USB хабом, я вставил microSD флешку прямо в 3G модем.
Большинство 3G модемов от Huawei это имеют разъем для microSD. У меня модем Huawei E1820 от Мегафона.
Так вот, для того чтобы флешка работала в качестве хранилища под файлы системы DD-WRT, а это Linux в чистом виде, необходимо сначала создать несколько разделов на нашей флешке, и отформатировать их в файловую систему ext3. Не у каждого есть под рукой linux, поэтому я покажу метод как это можно сделать под Windows.
Для начала установим драйвер который позволяет работать с данной файловой системой. Скачать можно с [sourceforge.net/projects/ext2fsd](http://sourceforge.net/projects/ext2fsd/) — Установка данного драйвера необязательна, она нужна только в случае если вы хотите работать с содержимым флешки в Windows. Для того чтобы разметить сам диск, скачаем программу EaseUS Partition Master Home Edition, которая доступна здесь: [www.partition-tool.com/download.htm](http://www.partition-tool.com/download.htm). Программа бесплатная для домашнего пользования и вполне подходит для нашей задачи.
Создаем 3 раздела:
/opt – тут будет храниться все наше установленное ПО
/jffs – тут различные скрипты. Кстати в конечном счете я это раздел у себя отключил и более не использую.
/swap – своп системы, для увеличения объема оперативной памяти. Если вы собираетесь устанавливать в вашу dd-wrt софт потребляющий много памяти, товам он просто необходим, в моем случае для задач прокси мне достаточно тех 60МБ памяти, что есть в моем роутере, поэтому раздел для свопа я создавать не будут.
У меня флешка была на 2 GB поэтому я создал два раздела, один объемом 900 Мб, и второй 1000 Мб.
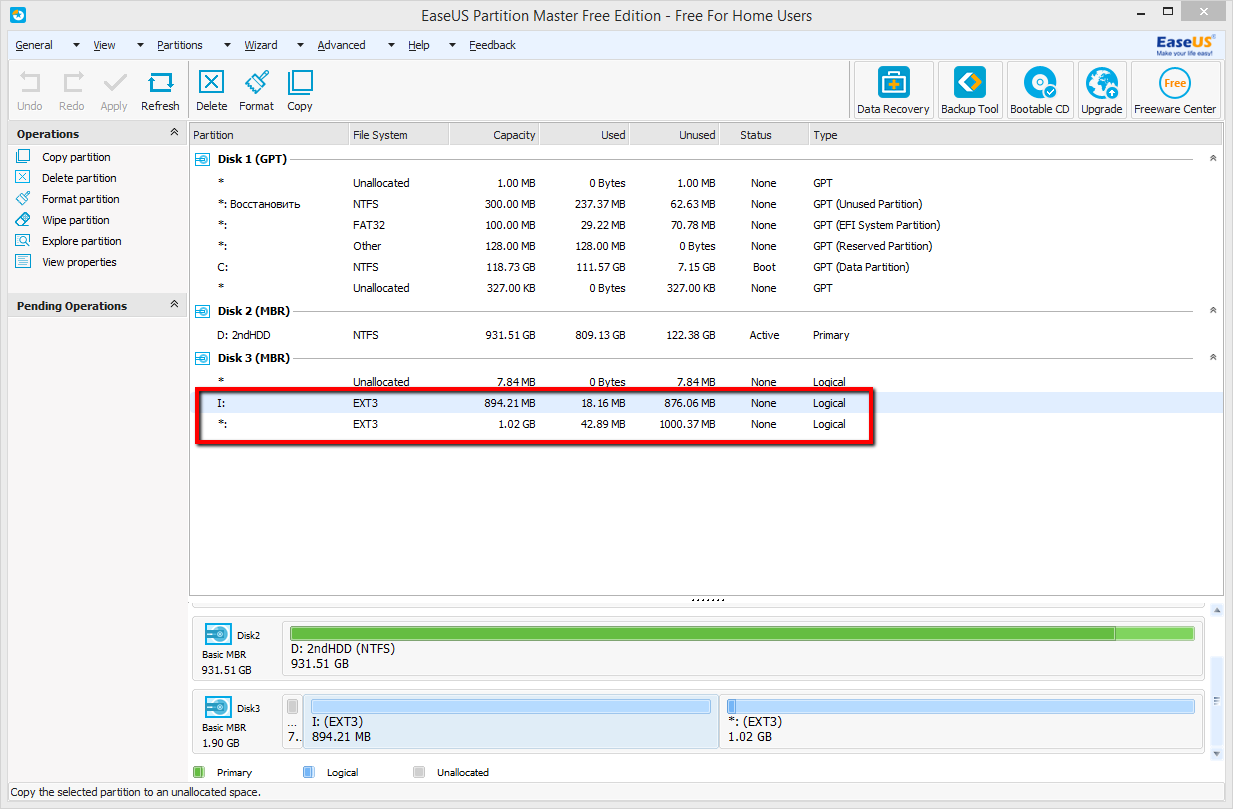
Далее подключаем все это добро в наш роутер.
У меня роутер Asus RT-N13U B1 с установленной на него одной из последних прошивок dd-wrt v3.0. Теперь необходимо монтировать наши разделы. Заходим в web во вкладку Services->USB и подключаем наши разделе. Ставим галочки в Core USB Support, USB Storage Support, Automatic Drive Mount. Копируем UUID дисков в разделы для того чтобы они автоматически монтировали при загрузке.
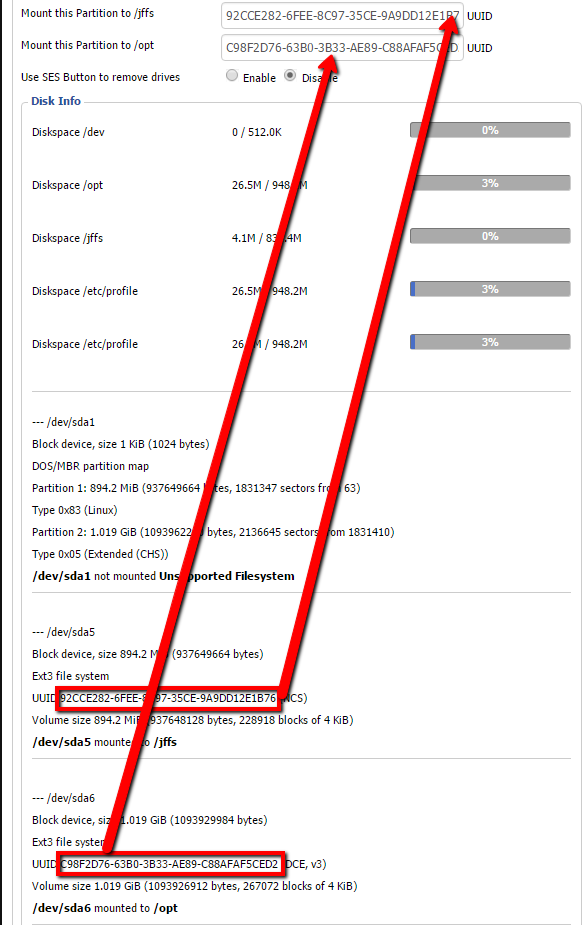
Далее необходимо установить систему контроля пакетов ipkg-opt. К этому моменту интернет на роутере уже должен быть настроен. Включаем доступ по SSH к роутеру и заходим на него. Выполняем последовательно команды.
Скачиваем скрипт установки:
```
wget http://www.3iii.dk/linux/optware/optware-install-ddwrt.sh -O - | tr -d '\r' > /tmp/optware-install.sh
```
Далее производим саму установку:
```
sh /tmp/optware-install.sh
```
После того как все установилось, устанавливаем прокси:
```
ipkg-opt install tinyproxy
```
Если вы не умеете пользоваться vi (как и я ранее, сейчас научился) можете установить еще редактор nano:
```
ipkg-opt install nano
```
Сейчас нам необходимо сконфигурировать наш прокси и создать скрипты запуска. Вот как выглядит мой конфиг, вы можете настроить его так как вам нужно, только не меняйте расположение PID файла.
Отредактируем конфиг:
```
nano /opt/etc/tinyproxy.conf
```
Впишем туда:
```
User root
Group root
Port 8888
Timeout 600
DefaultErrorFile "/opt/share/tinyproxy/default.html"
StatFile "/opt/share/tinyproxy/stats.html"
LogLevel Info
PidFile "/tmp/var/run/tinyproxy.pid"
MaxClients 100
MinSpareServers 5
MaxSpareServers 20
StartServers 10
MaxRequestsPerChild 0
Allow 192.168.0.0/16
ViaProxyName "tinyproxy"
ConnectPort 443
ConnectPort 563
```
Теперь создадим скрипты запуска. Не знаю по какой причине, но стандартный метод для запуска скриптов через /jffs/etc/config/script.startup, работает только когда идет программная перезагрузка, но как только я вырубаю устройства из сети и включаю его заново, то данный скрипт не отрабатывает. Возможно это связано с тем что у меня microSD подключается както медленно в связи с тем что через 3G модем.
Меня такая ситуация не устраивает, так как если будет выключен свет например, то после включения не запустится нужный мне софт, в данном случаем tinyproxy и мне придется сначала зайти по ssh на роутер и сделать программный reboot и только после этого все запустится. Поэтому я пошел немного обходный путем, и сделал запуск основного скрипта через cron.
Создадим каталог для скриптов:
```
mkdir /opt/etc/init.d
```
Дадим права на исполнение:
```
chmod +x /opt/etc/init.d
```
Создадим основной скрипт запуска:
```
nano /opt/etc/init.d/start_script.sh
```
```
#!/bin/sh
unset LD_PRELOAD
unset LD_LIBRARY_PATH
[ -e /opt/etc/profile ] && mount -o bind /opt/etc/profile /etc/profile
if [ -d /opt/etc/init.d ]; then
for f in /opt/etc/init.d/S* ; do
[ -x $f ] && $f start
done
fi
```
Дадим права на исполнение:
```
chmod +x /opt/etc/init.d/start_script.sh
```
Теперь создадим скрипт запуска самого tinyproxy:
```
nano /opt/etc/init.d/S01tinyproxy.sh
```
```
#! /bin/sh
NAME=tinyproxy
DESC="Tiny HTTP and HTTPS proxy"
case "$1" in
start)
if [ -e /tmp/var/run/$NAME.pid ]; then
echo "$DESC: $NAME already started."
exit 0
fi
echo -n "Starting $DESC: $NAME"
/opt/sbin/$NAME -c /opt/etc/tinyproxy.conf
echo .
;;
stop)
if [ ! -e /tmp/var/run/$NAME.pid ]; then
echo "$DESC: $NAME is not running."
exit 0
fi
echo -n "Stopping $DESC: $NAME"
killall $NAME
rm -f /tmp/var/run/$NAME.pid
echo .
;;
*)
echo "Usage: $0 {start|stop}" >&2
exit 1
;;
esac
exit 0
```
Дадим права на исполнение
```
chmod +x /opt/etc/init.d/S01tinyproxy.sh
```
Теперь добавим в крон задание которое будет запускать наш скрипт по истечению 20 секунд после того как роутер загрузится. В таком варианте все мои скрипты отрабатывают на ура и роутер работает как часы.
Заходим через web на вкладку Administration -> Management и пишем с cron следующую строку:
`@reboot sleep 20 && /opt/etc/init.d/start_script.sh`
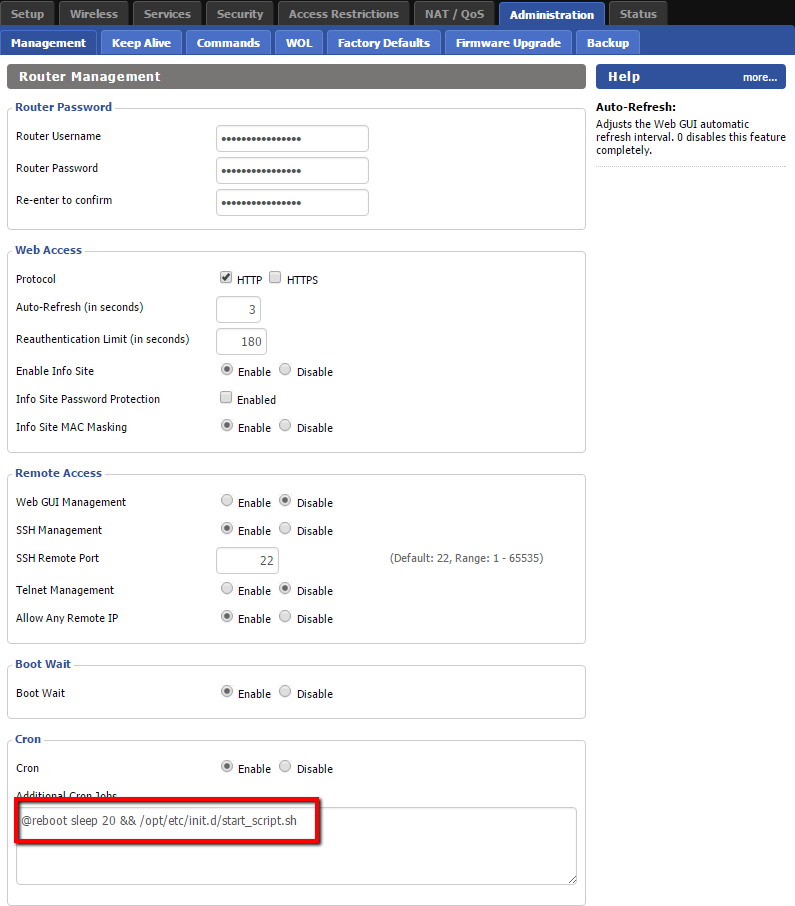
Сохраняем настройки и перезапускаем роутер. Все готово. | https://habr.com/ru/post/268729/ | null | ru | null |
# Effector (reflect, typescript, forms). Основные инструменты. Туториал с нуля. Часть 2
*Автор*: **Маслов Андрей**, Front-end разработчик.
*Время чтения*: ~**10 минут**
Содержание:
1. О статье
2. Инструментарий
3. Демо приложения
4. effector/reflect
5. effector-forms
6. Итоги
### О статье
**Важно!**
Это вторая часть серии статей по менеджеру состояний Effector. Перед ознакомлением с этой статьей настоятельно рекомендую перейти к первой части, лишь затем вернуться к текущей.
Первая часть: [Effector — убийца Redux? Туториал с нуля. Часть 1](https://habr.com/ru/post/698880/)
На примере небольшого приложения с заметками мы рассмотрим основные инструменты при работе с Effector, затронем типизацию.
### Инструментарий
Основной упор в этой статье сделан на использование методов из effector/reflect.
Этот инструмент позволит вам внести ясность в ваш код, а так же избавиться от множества рутинных вещей.
Так же затронем работу с формами, с effector-forms.
Используем React :3
### Демо приложения
Небольшое показательное приложение с возможностью добавления, удаления, редактирования заметок.
ДемоGitHub, код можно развернуть и посмотреть по [ссылке](https://github.com/andreymaslovru/effector-tutorial-part2)
### @effector/reflect
Рассмотрим основные возможности библиотеки:
* reflect
* list
* variant
#### reflect
Инициализируем следующую проблему:
```
import {$notes, deleteNote} from './model'
const NotesList: React.FC = () => {
const styles = useStyles()
const notes = useStore($notes)
return (
{notes.map((note, id) => (
deleteNote({id})}>{note}
))}
)
}
```
Заметили ? Нам приходится постоянно тащить за собой в компонент useStore, и чем больше данных вам нужно - тем сильнее разрастается компонент, и это мы еще даже не обрабатываем данные...
Давайте перейдем к первому этапу - воспользуемся **reflect**.
reflect принимает в себя объект, со следующими свойствами:
* view (Наш UI)
* bind (Объект с набором необходимых данных, которые собираемся прокинуть в view)
* hooks (Хуки обработки при mount, unmount компонента)
Применяем и смотрим на разницу:
```
import {$notes, deleteNote} from './model'
interface NotesListProps {
notes: string[]
deleteNote: ({ id }: {id: number}) => void
}
const NotesListView: React.FC = () => {
const styles = useStyles()
return (
{notes.map((note, id) => (
deleteNote({id})}>{note}
))}
)
}
export const NotesList = reflect({
view: NotesListView,
bind: {
notes: $notes,
deleteNote
}
})
```
**Результат**: мы отвязали наш UI компонент от данных, которые ранее были привязаны к компоненту. Кажется, будто бы мы наживаем себе больше проблем, да и к тому же кода стало больше... Но таких NotesList вы можете создать несколько, наследуя базовый view, в зависимости от тех данных, которые вы хотите видеть.
Если вы хотите типизировать reflect и обезопасить себя при байндинге данных, то стоит передать в дженерик первым аргументом ваш интерфейс view
```
export const NotesList = reflect({
view: NotesListView,
bind: {
notes: $notes,
deleteNote,
someProp: 1 //TS ERROR!
}
})
```
#### variant
Продолжаем наш "рефакторинг".
variant позволяет нам очень просто обрабатывать состояние наших компонент.
Принимает объект со следующими свойствами:
* source (Принимает case - состояние компонента, например, $store = 'loading' | 'empty' | 'ready')
* bind (Принцип как и в reflect)
* cases (обработчик ваших состояний, принимает объект **ключ *case*** - **значение *component***)
* default (можете обезопасить себя, если вдруг source окажется пустым)
* hooks (Принцип как и в reflect)
Обработаем кейс, когда заметок нет.
```
//model.ts
// event на добавление заметки в список
export const addNewNote = createEvent()
// event на удаление заметки из списка
export const deleteNote = createEvent<{id: number}>()
// event на редактирование заметки
export const editNote = createEvent<{id: number, value: string}>()
// store заметок
export const $notes = createStore([])
.on(addNewNote, (store, payload) => ([
...store, payload
]))
.on(deleteNote, (store, payload) => (
store.filter((\_note, id) => id !== payload.id)
))
.on(editNote, (store, payload) => (
store.map((note, id) => {
if (payload.id === id) return payload.value
return note
})
))
// store с состоянием стора с заметками
// (с помощью map мы создаем производный стор, на основе $notes)
export const $notesTypeState = $notes.map(store => {
if (store.length) {
return 'data'
}
return 'empty'
})
//index.tsx
export const NotesListVariant = variant({
source: $notesTypeState,
cases: {
data: NotesListView,
empty: () => List is empty
},
bind: {
notes: $notes,
deleteNote
}
})
```
Думаю вы заметили вот такую запись *createEvent(),* дело в том, что event может принимать в себя payloads, вызывая этот event мы обязаны передать ему данные*,* которые обязательно попадут в стор через *.on*
*.on(addNewNote, (store, payload) => ([
...store, payload
]))*
В коде мы по клику на кнопку вытаскиваем значение из target инпута и передаем его в event, который ожидает в аргументах строку, после чего эта строка попадает в стор как новая заметка.
Вернемся к примеру выше, мы создали производный стор, который реагирует на родительский и меняет свое значение, в нашем случае мы создаем два кейса: data, empty (в первом случае - $store имеет длину, а значит имеет заметки, во втором - заметок нет).
В variant мы прокидываем cases: {case1: View1, case2: View2...}, effector автоматически подтянет типы из стора, и применит их к полю cases, ничего лишнего отдать не выйдет, но как и в первом случае вы можете жестко типизировать и контролировать этот момент, необходимо в дженерик прокинуть первым аргументом - интерфейс view (тем самым типизируя bind), вторым - тип стора (тем самым типизируя cases).
```
export const NotesListVariant = variant()
```
**Результат:** мы избавляемся от написания оберток, с обработчиками стора, функциями рендера по условию, от лишних файлов и лишних строчек кода.
#### list
Казалось, что еще можно сделать ? Ответ: объединить наш reflect и view (где происходит map заметок). В этом нам поможет метод list.
List принимает объект, с чуть большим кол-вом свойств:
* source (Отсюда черпаем данные, Store)
* view (Наш UI)
* mapItem (Имитируем map + bind)
* bind (Прокидываем дополнительные данные, которых нет в функции map)
* hooks (Аналогично остальным методам)
* getKey (Ключи для оптимизации)
В итоге наша картина складывается очень гармонично.
**Было:**
```
const NotesList: React.FC = () => {
const notes = useStore($notes)
if (!notes.length) {
return List is empty
}
//if (some condition1...) {}
//if (some condition2...) {}
//if (some condition3...) {}
return (
{notes.map((note, id) => (
deleteNote({ id })}
onSave={(value) => editNote({ id, value }}
key={id}
/>
))}
)
}
```
**Стало:**
```
const NotesListView = list({
view: NoteItem,
source: $notes,
mapItem: {
value: (note) => note,
onDelete: (_, id) => () => deleteNote({ id }),
onSave: (_, id) => (value) => editNote({ id, value })
},
getKey: () => React.Key
})
export const NotesListVariant = variant({
source: $notesTypeState,
cases: {
data: NotesListView,
empty: () => List is empty
}
})
```
Вуаля! Думаю результат на все сто. Из variant у нас ушли привязка пропов через bind - теперь этим занимается list.
Вы можете написать обертку, которая будет принимать начальный стор и генерировать производный с состоянием компонента, например, для самых популярных решений: loading, error, ready, empty. И работа упростится в разы (Нужды каждый раз писать кейсы, создавать сторы с типами кейсов и тд не будет).
### effector-forms
Остановимся буквально на пару слов, для начала работы с формами вам стоит знать лишь о существовании effector-forms.
Пример ниже взят из документации, ибо его более чем достаточно, вопросов возникать не должно, мотивация - избавиться от создания сторов на каждое поле (в нашем приложении все завязано на сторе, т.к поле одно).
В материалах оставлю ссылку, где каждый кейс подробно разобран, прочитав, вы сразу же сможете пользоваться effector-forms.
```
import { createEffect } from "effector"
import { createForm } from 'effector-forms'
//инициализация формы
export const loginForm = createForm({
fields: {
//добавление филдов
email: {
init: "", //дефолтное значение
rules: [ //в валидатор прокидывайте ваши yup схемы и наслаждайтесь
{
name: "email",
validator: (value: string) => /\S+@\S+\.\S+/.test(value)
},
],
},
password: {
init: "", // field's store initial value
rules: [
{
name: "required",
validator: (value: string) => Boolean(value),
}
],
},
},
validateOn: ["submit"],//тип валидации (submit, change..., аналогично react-hook-form)
})
```
### Итоги
Друзья, стоит понимать, что это лишь основная часть, с которой можно ознакомиться буквально за время выпитой чашки кофе. Со знаниями из первых двух частей статей уже можно работать и разрабатывать приложения, а effector в этом вам поможет. Обязательно ознакомьтесь с материалами для закрепления, там вы спокойно найдете ответы на интересующие вас вопросы. В статье не показал, где именно вызываются эвенты и где передаются данные, с этим вы можете разобраться, перейдя в [репозиторий github](https://github.com/andreymaslovru/effector-tutorial-part2).
В следующей и заключительной статье мы поговорим об архитектуре (так как текущая реализация собрана на коленке для наглядности функционала), и доработаем наше маленькое приложение.
#### Материалы для закрепления
* [*Документация reflect*](https://github.com/effector/reflect)
* [*Документация effector-forms*](https://github.com/42-px/effector-forms)
* [*Полезное видео для новичков: Jack Herrington*](https://www.youtube.com/watch?v=_m2XfYzBV2c) | https://habr.com/ru/post/701160/ | null | ru | null |
# Мониторинг сетевого оборудования по SNMPv3 в Zabbix
Эта статья посвящена особенностям мониторинга сетевого оборудования с помощью протокола SNMPv3. Мы поговорим об SNMPv3, я поделюсь своими наработками по созданию полноценных шаблонов в Zabbix, и покажу, чего можно добиться при организации распределенного алертинга в большой сети. Протокол SNMP является основным при мониторинге сетевого оборудования, а Zabbix отлично подходит для мониторинга большого количества объектов и обобщения значительных объемов поступающих метрик.
#### Несколько слов об SNMPv3
Начнем с назначения протокола SNMPv3, и особенностей его использования. Задачи SNMP – мониторинг сетевых устройств, и элементарное управление, с помощью отправки на них простых команд (например, включение и отключение сетевых интерфейсов, или перезагрузка устройства).
Главное отличие протокола SNMPv3 от его предыдущих версий, это классические функции безопасности [1-3], а именно:
* аутентификация (Authentication), определяющая, что запрос получен от доверенного источника;
* шифрование (Encryption), для предотвращения раскрытия передаваемых данных при их перехвате третьими лицами;
* целостность (Integrity), то есть гарантия того, что пакет не был подделан при передаче.
SNMPv3 подразумевает использование модели безопасности, при которой стратегия аутентификации устанавливается для заданного пользователя и группы, к которой он относится (в предыдущих версиях SNMP в запросе от сервера к объекту мониторинга сравнивалось только «community», текстовая строка с «паролем», передаваемая в открытом виде (plain text)).
SNMPv3 вводит понятие уровней безопасности — допустимых уровней безопасности, определяющих настройку оборудования и поведение SNMP-агента объекта мониторинга. Сочетание модели безопасности и уровня безопасности определяет, какой механизм безопасности используется при обработке пакета SNMP [4].
В таблице описаны комбинации моделей и уровней безопасности SNMPv3 (первые три столбца я решил оставить как в оригинале):
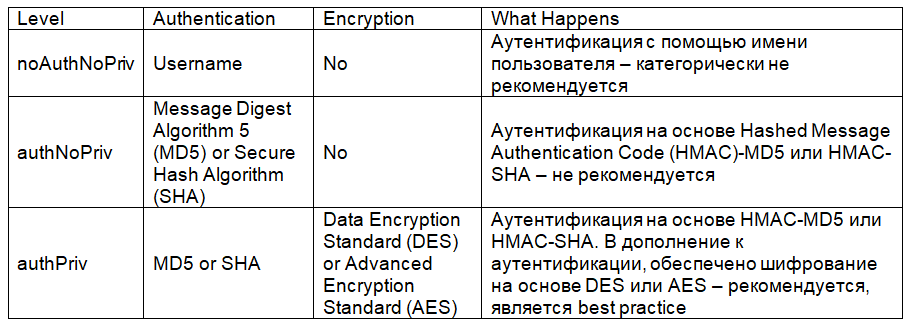
Соответственно, мы будем использовать SNMPv3 в режиме аутентификации с применением шифрования.
#### Настройка SNMPv3
Мониторинг сетевого оборудования предполагает одинаковую настройку протокола SNMPv3 и на сервере мониторинга, и на наблюдаемом объекте.
Начнем с настройки сетевого устройства Cisco, его минимально необходимая конфигурация выглядит следующим образом (для конфигурирования используем CLI, имена и пароли я упростил во избежание путаницы):
```
snmp-server group snmpv3group v3 priv read snmpv3name
snmp-server user snmpv3user snmpv3group v3 auth md5 md5v3v3v3 priv des des56v3v3v3
snmp-server view snmpv3name iso included
```
Первая строка snmp-server group – определяет группу SNMPv3-пользователей (snmpv3group), режим чтения (read), и право доступа группы snmpv3group на просмотр определенных веток MIB-дерева объекта мониторинга (snmpv3name далее в конфигурации задает, к каким веткам MIB-дерева группа snmpv3group сможет получить доступ).
Вторая строка snmp-server user – определяет пользователя snmpv3user, его принадлежность к группе snmpv3group, а так же применение аутентификации md5 (пароль для md5 — md5v3v3v3) и шифрования des (пароль для des — des56v3v3v3). Разумеется, вместо des лучше использовать aes, здесь я его привожу просто для примера. Так же при определении пользователя можно добавить список доступа (ACL), регламентирующий IP-адреса серверов мониторинга, имеющих право осуществлять мониторинг данного устройства – это так же best practice, но я не буду усложнять наш пример.
Третья строка snmp-server view определяет кодовое имя, которое задает ветки MIB-дерева snmpv3name, чтобы их могла запрашивать группа пользователей snmpv3group. ISO, вместо строгого определения какой-то одной ветки, позволяет группе пользователей snmpv3group получать доступ ко всем объектам MIB-дерева объекта мониторинга.
Аналогичная настройка оборудования Huawei (так же в CLI) выглядит следующим образом:
```
snmp-agent mib-view included snmpv3name iso
snmp-agent group v3 snmpv3group privacy read-view snmpv3name
snmp-agent usm-user v3 snmpv3user group snmpv3group
snmp-agent usm-user v3 snmpv3user authentication-mode md5
md5v3v3v3
snmp-agent usm-user v3 snmpv3user privacy-mode des56
des56v3v3v3
```
После настройки сетевых устройств, необходимо проверить наличие доступа с сервера мониторинга по протоколу SNMPv3, я воспользуюсь snmpwalk:
```
snmpwalk -v 3 -u snmpv3user -l authPriv -A md5v3v3v3 -a md5 -x des -X des56v3v3v3 10.10.10.252
```
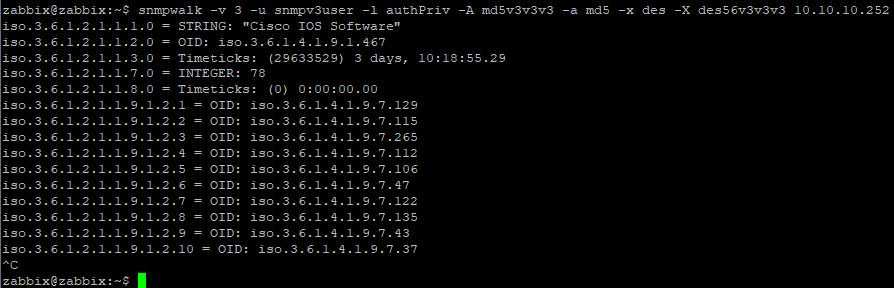
Более наглядный инструмент для запроса конкретных OID-объектов, с использованием MIB-фалов – snmpget:

Теперь перейдем к настройке типового элемента данных для SNMPv3, в рамках Zabbix-шаблона. Для простоты и независимости от MIB, я использую цифровые OID:

Я использую в ключевых полях пользовательские макросы, поскольку они будут одинаковы для всех элементов данных в шаблоне. Задавать их можно в рамках шаблона, если в Вашей сети у всех сетевых устройств параметры SNMPv3 одинаковы, или в рамках узла сети, если параметры SNMPv3 для разных объектов мониторинга отличаются:

Обратите внимание, система мониторинга располагает только именем пользователя, и паролями для аутентификации и шифрования. Группа пользователей и область MIB-объектов, к которым разрешен доступ, задается на объекте мониторинга.
Теперь перейдем к наполнению шаблона.
#### Шаблон опроса в Zabbix
Простое правило при создании любых шаблонов опроса – делать их максимально подробными:

Я уделяю большое внимание инвентаризации, чтобы с большой сетью было удобнее работать. Об этом немного позднее, а пока – триггеры:

Для удобства визуализации триггеров в их названия заложены системные макросы {HOST.CONN}, чтобы на дашборде в разделе алёртинга выводились не только имена устройств, но и IP-адреса, хотя это больше вопрос удобства, чем необходимости. Для определения недоступности устройства, помимо обычного echo-запроса, я использую проверку на недоступность узла по протоколу SNMP, когда объект доступен по ICMP, но не отвечает на SNMP-запросы – такая ситуация возможна, например, при дублировании IP-адресов на разных устройствах, из-за некорректно настроенных межсетевых экранов, или неверных настроек SNMP на объектах мониторинга. Если использовать проверку доступности узлов только по ICMP, в момент расследования инцидентов в сети, данных мониторинга может не оказаться, поэтому их поступление нужно контролировать.
Перейдем к обнаружению сетевых интерфейсов – для сетевого оборудования это самая важная функция мониторинга. Поскольку на сетевом устройстве могут быть сотни интерфейсов, необходимо фильтровать ненужные, чтобы не загромождать визуализацию и не захламлять базу данных.
Я использую стандартную функцию обнаружения для SNMP, с большим количеством обнаруживаемых параметров, для более гибкой фильтрации:
```
discovery[{#IFDESCR},1.3.6.1.2.1.2.2.1.2,{#IFALIAS},1.3.6.1.2.1.31.1.1.1.18,{#IFADMINSTATUS},1.3.6.1.2.1.2.2.1.7]
```

При таком обнаружении, можно фильтровать сетевые интерфейсы по их типам, пользовательским описаниям «description», и административным статусам портов. Фильтры и регулярные выражения для фильтрации в моем случае выглядят следующим образом:


При обнаружении будут исключены следующие интерфейсы:
* выключенные вручную (adminstatus<>1), благодаря IFADMINSTATUS;
* не имеющие текстового описания, благодаря IFALIAS;
* имеющие в текстовом описании символ \*, благодаря IFALIAS;
* являющиеся служебными или техническими, благодаря IFDESCR (в моем случае, в регулярных выражениях IFALIAS и IFDESCR проверяются одним регулярным выражением alias).
Шаблон для сбора данных по протоколу SNMPv3 почти готов. Не будем подробнее останавливаться на прототипах элементов данных для сетевых интерфейсов, перейдем к результатам.
#### Итоги мониторинга
Для начала – инвентаризация небольшой сети:

Если подготовить шаблоны для каждой серии сетевых устройств – можно добиться удобной для анализа компоновки сводных данных по актуальному ПО, серийным номерам, и оповещении о приходе в серверную уборщицы (по причине малого Uptime). Выдержка моего списка шаблонов ниже:

А теперь – главная панель мониторинга, с распределенными по уровням важности триггерами:

Благодаря комплексному подходу к шаблонам для каждой модели устройств в сети, можно добиться того, что в рамках одной системы мониторинга будет организован инструмент для прогнозирования неисправностей и аварий (при наличии соответствующих датчиков и метрик). Zabbix хорошо подходит для мониторинга сетевых, серверных, сервисных инфраструктур, и задача обслуживания сетевого оборудования наглядно демонстрирует её возможности.
**Список использованных источников:**1. Hucaby D. CCNP Routing and Switching SWITCH 300-115 Official Cert Guide. Cisco Press, 2014. pp. 325-329.
2. RFC 3410. [tools.ietf.org/html/rfc3410](https://tools.ietf.org/html/rfc3410)
3. RFC 3415. [tools.ietf.org/html/rfc3415](https://tools.ietf.org/html/rfc3415)
4. SNMP Configuration Guide, Cisco IOS XE Release 3SE. Chapter: SNMP Version 3. [www.cisco.com/c/en/us/td/docs/ios-xml/ios/snmp/configuration/xe-3se/3850/snmp-xe-3se-3850-book/nm-snmp-snmpv3.html](https://www.cisco.com/c/en/us/td/docs/ios-xml/ios/snmp/configuration/xe-3se/3850/snmp-xe-3se-3850-book/nm-snmp-snmpv3.html) | https://habr.com/ru/post/495704/ | null | ru | null |
# АнтиBIMing

Сама по себе автоматизация лишь инструмент и как каждый инструмент у нее есть своя область применения, своя техника безопасности внедрения и применения, а так же свои преимущества и негатив. Традиционно бизнес стремится внедряться IT-разработки там, где существуют достаточно высокая маржа, а значит проще получить прибыль и уменьшать издержки, однако существуют области в которых давно назрела необходимость что-нибудь внедрить с тем что бы упростить и тогда все сформируется. Речь о личном опыте решения таких задач при составлении исполнительной документации в строительстве.
**Программа, в которой описываются основные понятия и определения встречающиеся в тексте**
> **Состав ПСД. Приемо-сдаточная документация**#1 делится на:
>
> 1. Разрешительная документация, включая ППР;
>
> 2. Исполнительная документация.
>
>
>
> Вся структура приемо-сдаточной документации субподрядной организации по спецмонтажным работам будет выглядеть так:
>
> 
> [**Разрешительная документация**](https://ru.wikipedia.org/wiki/%D0%98%D1%81%D1%85%D0%BE%D0%B4%D0%BD%D0%BE-%D1%80%D0%B0%D0%B7%D1%80%D0%B5%D1%88%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D0%B4%D0%BE%D0%BA%D1%83%D0%BC%D0%B5%D0%BD%D1%82%D0%B0%D1%86%D0%B8%D1%8F)#2 — термин, используемый для обозначения документации, оформляемой в соответствии со статьями 45 — 51 Градостроительного кодекса РФ вплоть до получения разрешения на строительство (ст. 51 ГрКРФ), а также получение разрешения на ввод объекта в эксплуатацию (ст. 55 ГрКРФ).
> [**Исполнительная документация (ИД)**](https://ru.wikipedia.org/wiki/%D0%98%D1%81%D0%BF%D0%BE%D0%BB%D0%BD%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D0%B4%D0%BE%D0%BA%D1%83%D0%BC%D0%B5%D0%BD%D1%82%D0%B0%D1%86%D0%B8%D1%8F)#2 представляет собой текстовые и графические материалы, отражающие фактическое исполнение проектных решений и фактическое положение объектов капитального строительства и их элементов в процессе строительства, реконструкции, капитального ремонта объектов капитального строительства по мере завершения определенных в проектной документации работ.
>
>
>
> Исполнительная документация, оформленная соответствующим образом, является документом построенного здания или сооружения, облегчающим процесс эксплуатации, отражающим техническое состояние, дающим четкое представление об ответственных производителях работ по любому из видов выполненных работ.
>
>
**ОЖР** — Общий Журнал Работ. является основным документом подтверждающим выполнение работ, отражает последовательность выполнения отдельных видов работ, в том числе сроки и условия выполнения работ при строительстве, реконструкции, капитальном ремонте, а также сведения о строительном контроле и государственном строительном надзоре.
**АОСР** — Акт освидетельствования скрытых работ. Некоторые работы после окончания строительства невозможно проверить. Это касается работ, проведенных внутри строительных конструкций и коммуникаций, например:
— установки арматуры в бетонных стенах,
— грунтования поверхности перед окрашиванием,
— толщины песочной подложки под брусчаткой,
— укладки труб перед засыпанием грунтом,
— гидро–, звуко-, теплоизоляции и т.п.
Такие «промежуточные» работы называются скрытыми и их нельзя увидеть глазами после завершения строительства, поэтому для подтверждения их качества составляются специальные акты непосредственно после их выполнения. Механизм данной проверки такой: до закрытия конструкций или коммуникаций, специально созданная комиссия проверяет качество выполненных работ и примененных материалов, а затем подписывает акт на скрытые работы.
### Действие Первое. В котором рассказывается про предпосылки для автоматизации и проблемные рутины в Строительстве
> — Ты что делаешь?
>
> — Анекдоты читаю.
>
> — А отчет?
>
> — Час назад уже у тебя на столе лежит.
>
> — … Погоди, тогда почему твой предшественник на его подготовку тратил три часа?
>
> — Послушай, я тоже могу тратить три часа на его подготовку. Если хочешь, я могу читать анекдоты в столовой. Но результат будет тот же.
**Структура договорных отношений между участниками строительства #1**
Обычно Инвестор нанимает организацию, занимающуюся управлением строительства, она может называться заказчиком. Этот заказчик нанимает проектный институт (лицо, осуществляющее подготовку проектной документации), чтобы тот ему нарисовал проект, бывает, так же нанимает ГенПроектировщика, а тот нанимает субчиков. Потом играют в тендер (кстати, то же самое может быть и с институтом) и выбирают генподрядчика – это ответственный за строительную площадку (лицо, осуществляющее строительство) и заключает с ним договор. Для заказчика существует только генподрядчик (подрядчик) так как им так легче и удобней работать. Генподрядчик уже без тендера выбирает себе субподрядчиков (лицо, выполняющее работы), обычно по видам работ и заключает с ними договора. Субподрядчик или даже сам генподрядчик так же часто себе набирает субчиков, но уже не официально как бы под своим флагом. Заказчик нанимает технический надзор или сам может выполнять данную функцию (представитель заказчика или технический надзор заказчика). Если объект подпадает под государственный строительный надзор (ГСН), то и следит за всем этим он в виде инспекторов, их уведомляет заказчик о начале строительства, те приезжают со своей инспекцией, пишут замечания и уезжают. Все отношения регулируются договорами и действующим законодательством.

Строительство ведется по рабочим чертежам (заверенных печатью «В производство работ») теми материалами и оборудованием, что договорились, их может поставлять как заказчик с генподрядчиком, так и субподрядчик. Строительство ведется в определенные сроки по графику. Каждый месяц Заказчик платит Подрядчику, а Подрядчик Субподрядчику и т.д. по цепочке, за построенные объемы работ денежку, из которой в т.ч. платится зарплата, а представители Подрядчика/Субподрядчика отчитываются за материалы и оборудование, которые были переданы (все это обговорено в договоре). Проверяет объемы и качество выполненных работ технический надзор, авторский надзор так же может следить за соответствием выполняемых работ по проекту и рассматривает возможность изменений в проекте (если с институтом был подписан на это договор и на опасном производственном объекте он должен быть по любому).
Каждый день нормальные генподрядчики или заказчики вместе со всеми участниками строительства проводят планерки, где проверяют выполнение графика, планируют его на ближайшие дни и решают возникающие проблемы.
По окончанию строительства назначается рабочая комиссия обычно из всех представителей, все проверяют и, если все хорошо, через десять дней приемочная комиссия (обычно из тех же представителей) принимает объект. Раньше была еще государственная приемочная комиссия, но сейчас такая происходит только на бюджетных стройках.
При производстве работ по строительству объекта ведется всевозможная документация, основной и самой сложной частью из которой является исполнительная.
Согласно [Википедии](https://ru.wikipedia.org/wiki/BIM)
> **BIM** *(англ. Building Information Model или Modeling)* — информационная модель (или моделирование) зданий и сооружений, под которыми в широком смысле понимают любые объекты инфраструктуры, например инженерные сети (водные, газовые, электрические, канализационные, коммуникационные), дороги, железные дороги, мосты, порты и тоннели и т. д.
>
>
>
> Информационное моделирование здания — это подход к возведению, оснащению, эксплуатации и ремонту (а также сносу) здания (к управлению жизненным циклом объекта), который предполагает сбор и комплексную обработку в процессе проектирования всей архитектурно-конструкторской, технологической, экономической и иной информации о здании со всеми её взаимосвязями и зависимостями, когда здание и всё, что имеет к нему отношение, рассматриваются как единый объект.
>
>
>
> Трёхмерная модель здания, либо другого строительного объекта, связанная с базой данных, в которой каждому элементу модели можно присвоить все необходимые атрибуты. Особенность такого подхода заключается в том, что строительный объект проектируется фактически как единое целое: изменение какого-либо из его параметров влечёт за собой автоматическое изменение связанных с ним параметров и объектов, вплоть до чертежей, визуализаций, спецификаций и календарного графика.
Что касается документации и информационной модели на стройке и откуда она там берется. Как правило Заказчик передает Подрядчику проект со штампом «В производство работ» на бумажном носителе (очень редко в формате pdf и почти никогда в dwg) для того что бы последний в соответствии с контрактом за оговоренную сумму произвел некоторые работы. Прораб/мастер/нач.участка заказывает через снабженцев (привет бухгалтерия и 1С) материалы согласно потребностям, проекту и графику производства работ, нанимается техника, она же ремонтируется, под нее покупается ГСМ и прочие расходы связанные с объектом, часть из которых связана с машинами и механизмами, часть с материалами которые будут монтироваться. Затем на объекте ведутся на бумажном носителе: журнал входного контроля, общий журнал работ и прочие специализированные журналы которые зависят от видов выполняемых работ. К концу каждого операционного цикла подготавливается исполнительная документация, которая представляет из себя акты и схемы выполненных работ (схемы по сути копируют проект, ибо отступление от проекта, без согласования с Заказчиком и контролирующими органами, недопустимо и будет означать лишь проблемы для Подрядчика). Такие акты и схемы на бумажном носителе подписываются представителями Подрядчика, Заказчика, контролирующих органов и организаций и только после того как пройдет успешная защита составляются финансовые акты (обычно по форме КС-2 и КС-3, но это не обязательно, достаточно к договору приложить свой шаблон), на основании которых в особо упоротых случаях бухгалтерия Заказчика может позволить списать материалы бухгалтерии Подрядчика (помимо актов выполненных работ составляются так же акты входного контроля и все вместе это передается Заказчику) в соответствии со сметными расценками.
Сегодня, в отличие от СССР, прораб/мастер/нач.участка не составляют исполнительную документацию. Это не означает что они не заполняют и не составляют бумаг, просто они другие, больше связаны с непосредственной организации управленческих процессов (открытие и закрытие нарядов, журналы инструктажа, выдачи заданий, заявки, письма и т.п.) объем бумаг достаточно большой и это «нормальная» (в том плане, что распространенная практика) брать в штат сотрудников с высшим (!) инженерным образованием — инженеров ПТО, которые будут заниматься всей остальной документацией, а проще говоря исполнять работу *технического секретаря*. (На самом деле порог вхождения в процессию очень низок, т.к. базового школьного курса Черчения достаточно, что бы читать строительные чертежи и даже перерисовывать схемы, конечно потребуется навык работы с Word/Excel/Paint/AutoCAD/Компас, но это не так сложно как может показаться и потому такая специальность утилизирует людей как с профильным образованием, так и с гуманитарным менеджеров/юристов/учителей и т.д. и т.п.)
Как правило рабочее место, которое может быть и удалено (вагончик в поле), оборудовано МФУ, Wi-Fi точкой, раздающей 3G интернет, ноутбуком. В отсутствие сис.админа все это работает… в меру сил и понимания инженера ПТО, который за все это отвечает, который выполняет не только прямые обязанности, но и те от которых не удалось отбрыкаться по разным причинам. Надо ли говорить, что общая техническая грамотность страдает. Обычно на ноутбуки установлен, хорошо если заботливо, Windows, MS Office, редактор для векторной графики, GIMP, программа оптического распознавания текстов. Такой скудный выбор связан с тем, что з/п и оснащение такого инженера находится в составе Накладных Расходов, а не в статьях Общей Заработной Платы, как в случае, например, рабочих, т.е. разные статьи расценок сметы.
### Действие Второе. В котором рассказывается про предпосылки для автоматизации и проблемные рутины в Строительстве
> Исаак Ньютон:
>
> — От флюенции возьму флюксию и обратно.
>
> Лейбниц:
>
> — Могу делать то же самое!
Идея создания Программы родилась спонтанно, после 3-х закрытых объектов в 2016году ПАО «Транснефть». Помимо сбора и компоновки информации большой блок времени отнимали задачи, связанные с банальным заполнением документов по шаблону, среди которых преобладали Акты входного контроля и Акты освидетельствования скрытых работ. Особенно много времени уходило на проверки в случае описок или различного рода неточностей. Т.к. если они выявлялись, то приходилось заново открывать и проверять такие акты. Иногда, как в ситуации в 2018году, когда Ростехнадзор поменял форму актов скрытых работ, их счет шел на десятки. Но так родилась идея: «А что, если я соберу все данные, необходимые для заполнения актов, в таблицу, а уже Программа будет прописывать их в шаблоны за меня?».
Самой простой и пригодной из доступных для этого является MS Office с макросами VBA. Учитывая тот факт, что в 90-е годы я в школе ударно изучал QBasic 4.5 и Borland Pascal 7.0, то выбор платформы оказался более чем очевиден. Пробелы в синтаксисе помог закрыть Гугл. Сама Идея не нова, но в 2016-м году в открытом доступе, так сказать в open source, я нашел только один вариант через Слияние, который тогда, в далеком 2016-м году меня не устроил. И вот я начал разрабатывать свой велосипед:
1. Самое главное и без чего не имело все дальнейшее смысл это без наглядности и удобства в работе. Поэтому для варианта с экспортом в Excel был выбран путь перебора текста в ячейках с целью поиска комбинаций текстовых маркеров, которые априори не встречаются в русскоязычных регламентных формах актов, с последующей авто подстановкой значений из таблицы. (Например, f1, d3, b8 и т.д. и т.п.) Для того что бы не пришлось перебирать всю матрицу я ввел упрощение, при создании шаблона если в первой ячейке за областью печати располагается символ арабской единицы, то только в этом случае макрос ищет текст во всех ячейках этой строки. Позднее я решил вопрос как получить в макрос диапазон ячеек, отправляемых на печать.
В случае с экспортом в Word тут все гораздо проще – Закладки и ссылки на содержимое закладок, при повторном упоминании содержимого в тексте.
2. В отличие от многих конкурентов с более проработанными приложениями я пошел дорогой структурирования информации (привет BIM) и наглядного представления данных, а потому, не смотря на то что тот же Access, Visual Studio, 1С и т.п. предоставляет большие возможности и функционал все эти программы грешат тем, что в них нельзя «протянуть» строку или столбец с одинаковыми данными, а переключение между полями ввода требует большей точности при позиционировании (выбор поля через TAB или позиционирование курсора с кликом проигрывает в удобстве перемещению стрелками по ячейкам таблицы, не говоря про то, что копировать ячейками проще, чем из через выделения текста из поля ввода)
Следующий шаг — это формирование логики заполнения данных, т.е.:
А) Данные организаций и участников строительства, а также общие характеристики объекта;
Б) Данные для формирования Актов входного контроля, т.е. в первую очередь определяемся не с работами, а с материалами
В) Затем определяемся с месячно-суточным графиком, в котором делаем привязку не только к сметам (т.е. сперва вводим сметные расценки в Заголовки), а уже затем формируем перечень работ из ВР (Ведомости объемов работ по РД (Рабочей документации)), соблюдая очередность работ. Т.е. алгоритм после проставления в графике объемов работ сам определить, в рамках каждого отчетного периода, какие Акты скрытых работ и в какой последовательности под каким номером, от каких дат необходимо будет оформить. Пользователю останется лишь внести сопутствующую информацию, которая является больше рутиной. Кроме того, благодаря связям Пользователь может видеть сколько материалов было «списано» по предыдущим Актам скрытых работ, что
уменьшает кол-во накладок и ошибок, связанных с проведенными материалами и использованными при строительстве (по сути это техническая ошибка, которой можно и нужно избегать).
И вот таким образом ПК/ноутбук превращаются из печатной машинки в помощника, который берет часть обязанностей на себя. Т.е. то, что часто многими упускается из виду при создании программ.
3. Но ведь регламентных форм актов сильно больше чем указанных мною выше 2-х шт., пусть они и представляют собой свыше 50% всех актов Исполнительной документации. Значит нужно создать, и это было сделано, аналогичную программу, которая могла бы заполнять таким же образом любой Пользовательский шаблон, а затем такие шаблоны можно было бы импортировать в основную программу, с тем что бы можно было увязывать текущие данные с новыми формами. А раз новые формы, то значит нужна и в меру удобная навигация. Все эти задачи были решены.
И вот теперь такая программа распространяется абсолютно безвозмездно, т.е. даром. Не смотря на долгий срок разработки одним человеком с длительными перерывами в нерабочее время с 2017-го года по 2021-й год, когда появились все эти Алтиусы, Адепты и прочий платный софт той же тематики я хочу сказать следующие слова критики:
1. Зачастую архитектурные ограничения методов ограничивают юзабилити пользователей. Потому что разработчик не является исполнителем, который в дальнейшем будет пользоваться этой программой, и не изучает технологические операции конкретной специальности, взамен формируя свои технологические-схемы работ с таким софтом, которые не всегда являются удобнее аналогов.
2. Пользователю, т.е. инженерам-ПТО, нужен такой продукт и помощь, который будет прост, удобен и понятен, а еще по совместительству предложит такую схему работы, ошибок при которой будет меньше, чем без нее и трудоемкость уменьшится.
3. Зачастую люди, которым нужна автоматизация, не могут за нее заплатить, т.к. их оклад не такой уж и большой, а в их опыте даже нет рабочих примеров, когда софт облегчал им рабочие рутины, да еще и уменьшал ИХ КОЛИЧЕСТВО ОШИБОК. В то время как цены на такие программы сравнимы со стоимостью Сметных-комплексов. Но без сметных комплексов очень трудно обойтись, а вот без автоматизации Исполнительной документации – элементарно.
4. Информационную модель BIM в ходе формирования исполнительной документации приходится формировать заново, работать дешифратором Рабочей документации на бумажном носителе, переводить ее в язык цифровых сигналов с тем, чтобы выводить результат в виде оформленных актов на бумажном носителе, но с подписью. Прочувствуйте всю иронию.
### Действие третье. В котором рассказывается о том как кристаллизовалась программа
На стройке самое важное что? График производства работ и ключевые даты на нем (врезка, подключение, начало работ и окончание работ и некоторые другие). На участке ведется ОЖР, в котором записывается вручную что было выполнено за каждый конкретный рабочий день. Но если взять график (Месячно-суточный график) и заполнять его, то мы получим графическое представление, который и легче воспринимается и, затем, легче автоматизируется, служа исходными данными для актов и аналитики.

Рис.1 — Пример Месячно-суточного графика
Теперь думаем дальше, если ввести только один раз и дальше расставить ссылки, на ответственных, описание объекта, контракта и организаций, участников строительства, то это зело упростит Работу. Ввел один раз и далее только развешиваешь ссылки.
Следующий Важный момент в строительстве — это Материалы. Они должны соответствовать проекту и при их приемке осуществляется Входной контроль комиссией с оформлением бумаг (Акт входного контроля и Журнал Входного контроля). Это держим в уме. А дальше большая часть ИД в строительстве составляют Акты скрытых работ или полностью, Акт освидетельствования скрытых работ. Работы, их очередность и данные подтягиваем с Месячно-суточного графика, а материалы… из перечня актов Входного контроля… теперь еще и наглядно мониторить можно какие материалы в каком количестве списываются по актам АОСР.
А что если нам нужно иметь гибкость, что бы Пользователь добавлял свои формы актов, делал их вручную или использовал текущие? И это возможно, но обсудим мы это в…
### Действие четвертое. В котором речь пойдет о макросах VBA
Далее пойдут спойлеры с кодом, призванные решить те или иные вопросы/проблемы.
**Немного ускоряем MS Excel при работе с макросами**
```
'Ускоряем Excel путём отключения всего "тормозящего"
Public Sub AccelerateExcel()
'Больше не обновляем страницы после каждого действия
Application.ScreenUpdating = False
'Расчёты переводим в ручной режим
Application.Calculation = xlCalculationManual
'Отключаем события
Application.EnableEvents = False
'Не отображаем границы ячеек
If Workbooks.Count Then
ActiveWorkbook.ActiveSheet.DisplayPageBreaks = False
End If
'Отключаем статусную строку
Application.DisplayStatusBar = False
'Отключаем сообщения Excel
Application.DisplayAlerts = False
End Sub
```
**а теперь возвращаем настройки обратно**
```
'Включаем всё то что выключили процедурой AccelerateExcel
Public Sub disAccelerateExcel()
'Включаем обновление экрана после каждого события
Application.ScreenUpdating = True
'Расчёты формул - снова в автоматическом режиме
Application.Calculation = xlCalculationAutomatic
'Включаем события
Application.EnableEvents = True
'Показываем границы ячеек
If Workbooks.Count Then
ActiveWorkbook.ActiveSheet.DisplayPageBreaks = True
End If
'Возвращаем статусную строку
Application.DisplayStatusBar = True
'Разрешаем сообшения Excel
Application.DisplayAlerts = True
End Sub
```
**Заполнение шаблонного файла в формате MS Excel**
Здесь очень важна наглядность! Очень много проектов встали на абсолютных ссылках, по-этому я изначально решил сделать все универсально. После долгих мытарств я открыл для себя тот факт, что формулой можно получить диапазон ячеек, который будет выводится на печать.

Рис.2 — Пример файла шаблона в формате MS Excel
Здесь в ячейке А1 содержится формула:
`=СЦЕПИТЬ(АДРЕС(СТРОКА(Область_печати);СТОЛБЕЦ(Область_печати);1;1);":";АДРЕС(СТРОКА(Область_печати)+ЧСТРОК(Область_печати)-1;СТОЛБЕЦ(Область_печати)+ЧИСЛСТОЛБ(Область_печати)-1;1;1))`
Т.е. мы можем получить область печати, обратившись к переменной, фигурирующей в диспетчере имен. Полученные абсолютные границы печати, которые будут автоматически меняться, если нам придется увеличить или уменьшить область печати. Зачем? Здесь следует сделать отступление.

Рис.3 — Пример листа с хранящимися данными для автоматического заполнения актов.
Дело в том, что мною был выбран способ-маркеров в тексте, т.е. при составлении шаблона маркеры (a1, b0, c7, d8 и т.д. и т.п.) однозначно характеризуют с одной стороны строку, из которой будут браться данные (порядковый номер элемента массива, который автоматически завязан на номер строки), с другой стороны в русскоязычных шаблонах в строительстве абсурдное сочетание букв латиницы с цифрой не используется. А значит это наглядно. После чего обычный перебор текста решает, НО (!)… чем больше ячеек в области печати, тем медленнее будет работать алгоритм. Значит ему надо помочь и подсветить только те строки, в которых априори что-то есть.
**Код макроса VBA осуществляющий экспорт в шаблон в формате MS Excel**
```
With Workbooks.Open(ThisWorkbook.Path + "\Шаблоны аддонов\" + NameShablonPrimer, ReadOnly:=True)
.Sheets(NameShablonPrimerList).Visible = -1
.Sheets(NameShablonPrimerList).Copy after:=wb.Worksheets(Worksheets.Count)
Let НачальныйНомерСтрокиВФайле = .Sheets(NameShablonPrimerList).Cells(1, 2) ' Начальный номер строки в файле шаблона
Let НачальныйНомерСтолбцаВФайле = .Sheets(NameShablonPrimerList).Cells(1, 3) ' Начальный номер столбца в файле шаблона
Let КонечныйНомерСтрокиВФайле = .Sheets(NameShablonPrimerList).Cells(1, 4) ' Конечный номер строки в файле шаблона
Let КонечныйНомерСтолбцаВФайле = .Sheets(NameShablonPrimerList).Cells(1, 5) ' Конечный номер столбца в файле шаблона
.Close True
End With
End If
End If
Do
ИмяФайла = BDList + " №" ' Префикс имени файла
wb.Worksheets(NameShablonPrimerList).Copy after:=Worksheets(Worksheets.Count)
Set новыйЛист = wb.Worksheets(NameShablonPrimerList + " (2)")
For X = НачальныйНомерСтолбцаВФайле To КонечныйНомерСтолбцаВФайле Step 1 ' Перебираем столбцы в листе Примера формы-шаблона
For Y = НачальныйНомерСтрокиВФайле To КонечныйНомерСтрокиВФайле Step 1 ' Перебираем строк в листе Примера формы-шаблона
If Sheets(новыйЛист.Name).Cells(Y, КонечныйНомерСтолбцаВФайле + 1) = 1 Then ' При наличии спец символа проверяем на совпадении строку
Let k = CStr(Sheets(новыйЛист.Name).Cells(Y, X)) ' Ищем только если в ячейке что-то есть
If k <> "" Then
For i = 1 To Кол_воЭл_овМассиваДанных Step 1
ContentString = CStr(Worksheets(BDList + " (2)").Cells(i + 1, НомерСтолбца))
If Len(arrСсылкиДанных(i)) > 1 Then
If ContentString = "-" Or ContentString = "0" Then ContentString = ""
Let k = Replace(k, arrСсылкиДанных(i), ContentString)
End If
Next i
новыйЛист.Cells(Y, X) = k
End If
End If
Next Y
Next X
For Y = НачальныйНомерСтрокиВФайле To КонечныйНомерСтрокиВФайле Step 1
Sheets(новыйЛист.Name).Cells(Y, КонечныйНомерСтолбцаВФайле + 1) = ""
Next Y
```
**Заполнение шаблонного файла в формате MS Word**
вывода в шаблон формата Word, и здесь на самом деле есть 2 способа вывода текста:
**1. Это через функционал закладок,**
```
Rem -= Открываем файл скопированного шаблона по новому пути и заполняем его=-
Set Wapp = CreateObject("word.Application"): Wapp.Visible = False
Set Wd = Wapp.Documents.Open(ИмяФайла)
NameOfBookmark = arrСсылкиДанных(1)
ContentOfBookmark = Worksheets("Данные для проекта").Cells(3, 3)
On Error Resume Next
UpdateBookmarks Wd, NameOfBookmark, ContentOfBookmark
Dim ContentString As String
For i = 4 To Кол_воЭл_овМассиваДанных Step 1
If Len(arrСсылкиДанных(i)) > 1 Then
NameOfBookmark = arrСсылкиДанных(i)
ContentString = CStr(Worksheets("БД для АОСР (2)").Cells(i, НомерСтолбца))
If ContentString = "-" Or ContentString = "0" Then ContentString = ""
ContentOfBookmark = ContentString
On Error Resume Next
UpdateBookmarks Wd, NameOfBookmark, ContentOfBookmark
End If
Next i
Rem -= Обновляем поля, что бы ссылки в документе Word так же обновились и приняли значение закладок, на которые ссылаются =-
Wd.Fields.Update
Rem -= Сохраняем и закрываем файл =-
Wd.SaveAs Filename:=ИмяФайла, FileFormat:=wdFormatXMLDocument
Wd.Close False: Set Wd = Nothing
```
```
Sub UpdateBookmarks(ByRef Wd, ByVal NameOfBookmark As String, ByVal ContentOfBookmark As Variant)
On Error Resume Next
Dim oRng As Variant
Dim oBm
Set oBm = Wd.Bookmarks
Set oRng = oBm(NameOfBookmark).Range
oRng.Text = ContentOfBookmark
oBm.Add NameOfBookmark, oRng
End Sub
```
**2. Если рисовать таблицы средствами Word, то к ним можно обращаться с адресацией в ячейку**
```
Rem -= Заполняем данными таблицы ЖВК =-
Dim y, k As Integer
Let k = 1
For y = Worksheets("Титул").Cells(4, 4) To Worksheets("Титул").Cells(4, 5)
Wd.Tables(3).cell(k, 1).Range.Text = Worksheets("БД для входного контроля (2)").Cells(6, 4 + y)
Let k = k + 1
Next y
End With
```
Между выводами в файлы форматов Word и Excel есть огромная пропасть, которая заключается в следующем:
Шаблон Excel требует перед использованием настроить отображение под конкретный принтер, т.к. фактическая область печати разнится от модели к модели. Так же перенос строки текста возможен, но только в пределах ячейки/объединенных ячеек. В последнем случае не будет автораздвигания строки, в случае переноса текста. Т.е. Вам вручную придется заранее определить границы области, которые будут содержать текст, который в свою очередь в них еще должен убраться. Зато Вы точно задали границы печати и выводимого текста и уверены, что не съедет информация (но не содержание) с одного листа на другой.
Шаблон Word при настройке автоматически переносит текст на последующую строку, если он не убрался по ширине ячейки/строки, однако этим самым он вызывает непрогнозируемый сдвиг текста по вертикали. Учитывая тот факт, что по требованиям к Исполнительной документации в строительстве ЗАПРЕЩЕНО один акт печатать на 2х и более листах, то это в свою очередь так же рождает проблемы.
С проектом можно ознакомиться тут:
[vk.com/softpto](https://vk.com/softpto)
Все программы распространяются абсолютно бесплатно. Всем Добра! | https://habr.com/ru/post/554276/ | null | ru | null |
# Unity: отрисовываем множество полосок здоровья за один drawcall
Недавно мне нужно было решить задачу, достаточно распространённую во многих играх с видом сверху: рендерить на экране целую кучу полосок здоровья врагов. Примерно вот так:

Очевидно, что я хотел сделать это как можно эффективнее, желательно за один вызов отрисовки. Как обычно, прежде чем приступать к работе, я провёл небольшое онлайн-исследование решений других людей, и результаты были очень разными.
Я не буду никого стыдить за код, но достаточно сказать, что некоторые из решений были не совсем блестящими, например, кто-то добавлял к каждому врагу объект Canvas (что очень неэффективно).
Метод, к которому я в результате пришёл, немного отличается от всего того, что я видел у других, и не использует вообще никаких классов UI (в том числе и Canvas), поэтому я решил задокументировать его для общества. А для тех, кто хочет изучить исходный код, я выложил [его на Github](https://github.com/sinbad/UnityInstancedHealthBars).
Почему бы не использовать Canvas?
---------------------------------
По одному Canvas для каждого врага — это очевидно плохое решение, но я мог использовать общий Canvas для всех врагов; единственный Canvas тоже бы привёл к батчингу вызовов отрисовки.
Однако мне не нравится связанный с таким подходом объём выполняемой в каждом кадре работы. Если вы используете Canvas, то в каждом кадре придётся выполнять следующие операции:
* Определять, какие из врагов находятся на экране, и выделять каждому из них из пула полоску UI.
* Проецировать позицию врага в камеру, чтобы расположить полоску.
* Изменять размер «заливки» части полоски, вероятно, как Image.
* Скорее всего изменять размер полосок в соответствии с типом врагов; например, у крупных врагов должны быть большие полоски, чтобы это не выглядело глупо.
Как бы то ни было, всё это загрязняло бы буферы геометрии Canvas и приводило к перестройке всех данных вершин в процессоре. Я не хотел, чтобы всё это выполнялось для столь простого элемента.
Вкратце о моём решении
----------------------
Краткое описание процесса моей работы:
* Прикрепляем объекты полосок энергии к врагам в 3D.
+ Это позволяет автоматически располагать и усекать полоски.
+ Позицию/размер полоски можно настраивать в соответствии с типом врага.
+ Полоски мы направим на камеру в коде с помощью transform, который всё равно есть.
+ Шейдер гарантирует, что они всегда будут рендериться поверх всего.
* Используем Instancing для рендеринга всех полосок за один вызов отрисовки.
* Используем простые процедурные UV-координаты для отображения уровня заполненности полоски.
А теперь давайте рассмотрим решение подробнее.
Что такое Instancing?
---------------------
В работе с графикой уже давно используется стандартная техника: несколько объектов объединяются вместе, чтобы они имели общие данные вершин и материалы и их можно было отрендерить за один вызов отрисовки. Нам нужно именно это, потому что каждый вызов отрисовки — это дополнительная нагрузка на ЦП и GPU. Вместо выполнения по одному вызову отрисовки на каждый объект мы рендерим их все одновременно и используем шейдер для добавления вариативности в каждую копию.
Можно делать это вручную, дублируя данные вершин меша X раз в одном буфере, где X — максимальное количество копий, которое может быть отрендерено, а затем использовав массив параметров шейдера для преобразования/окраски/варьирования каждой копии. Каждая копия должна хранить знание о том, каким нумерованным экземпляром она является, чтобы использовать это значение как индекс массива. Затем мы можем использовать индексированный вызов рендера, который приказывает «рендерить только до N», где N — это число экземпляров, которое *на самом деле* нужно в текущем кадре, меньшее, чем максимальное количество X.
В большинстве современных API код для этого уже есть, поэтому вручную это делать не требуется. Эта операция называется «Instancing»; по сути, она автоматизирует описанный выше процесс с заранее заданными ограничениями.
[Движок Unity тоже поддерживает instancing](https://docs.unity3d.com/Manual/GPUInstancing.html), в нём есть собственный API и набор макросов шейдеров, помогающие в его реализации. Он использует определённые допущения, например, о том, что в каждом экземпляре требуется полное 3D-преобразование. Строго говоря, для 2D-полосок оно нужно не полностью — мы можем обойтись упрощениями, но поскольку они есть, мы будем использовать их. Это упростит наш шейдер, а также обеспечит возможность использования 3D-индикаторов, например, кругов или дуг.
Класс Damageable
----------------
У наших врагов будет компонент под названием `Damageable`, дающий им здоровье и позволяющий им получать урон от коллизий. В нашем примере он довольно прост:
```
public class Damageable : MonoBehaviour {
public int MaxHealth;
public float DamageForceThreshold = 1f;
public float DamageForceScale = 5f;
public int CurrentHealth { get; private set; }
private void Start() {
CurrentHealth = MaxHealth;
}
private void OnCollisionEnter(Collision other) {
// Collision would usually be on another component, putting it all here for simplicity
float force = other.relativeVelocity.magnitude;
if (force > DamageForceThreshold) {
CurrentHealth -= (int)((force - DamageForceThreshold) * DamageForceScale);
CurrentHealth = Mathf.Max(0, CurrentHealth);
}
}
}
```
Объект HealthBar: позиция/поворот
---------------------------------
Объект полосы здоровья очень прост: по сути, это всего лишь прикреплённый к врагу Quad.

Мы используем **scale** этого объекта, чтобы сделать полоску длинной и тонкой, и разместим её прямо над врагом. Не беспокойтесь о её повороте, мы исправим его с помощью кода, прикреплённого к объекту в `HealthBar.cs`:
```
private void AlignCamera() {
if (mainCamera != null) {
var camXform = mainCamera.transform;
var forward = transform.position - camXform.position;
forward.Normalize();
var up = Vector3.Cross(forward, camXform.right);
transform.rotation = Quaternion.LookRotation(forward, up);
}
}
```
Этот код всегда направляет quad в сторону камеры. Мы *можем* выполнять изменение размера и поворота в шейдере, но я реализую их здесь по двум причинам.
Во-первых, instancing в Unity всегда использует полный transform каждого объекта, и поскольку мы всё равно передаём все данные, можно их и использовать. Во-вторых, задание масштаба/поворота здесь гарантирует, что ограничивающий параллелограмм для усечения полоски всегда будет верным. Если бы мы сделали задание размера и поворота обязанностью шейдера, то Unity мог бы усекать полоски, которые должны быть видимы, когда они находятся близко к краям экрана, потому что размер и поворот их ограничивающего параллелограмма не будут соответствовать тому, что мы собираемся рендерить. Разумеетсяя, мы могли бы реализовать свой собственный способ усечения, но обычно при возможности лучше использовать то, что у нас есть (код Unity является нативным и имеет доступ к большему количеству пространственных данных, чем мы).
Я объясню, как рендерится полоска, после того, как мы рассмотрим шейдер.
Шейдер HealthBar
----------------
В этой версии мы создадим простую классическую красно-зелёную полоску.
Я используют текстуру размером 2x1, с одним зелёным пикселем слева и одним красным справа. Естественно, я отключил mipmapping, фильтрацию и сжатие, а для параметра addressing mode задал значение Clamp — это значит, что пиксели нашей полоски всегда будут идеально зелёными или красными, а не растекутся по краям. Это позволит нам изменять в шейдере координаты текстуры для сдвига линии, разделяющей красный и зелёный пиксели вниз и вверх по полоске.
*(Так как здесь всего два цвета, я мог просто использовать в шейдере функцию step для возврата в точке одного или другого. Однако в этом методе удобно то, что при желании можно использовать более сложную текстуру, и это будет работать аналогично, пока переход находится в середине текстуры.)*
Для начала мы объявим необходимые нам свойства:
```
Shader "UI/HealthBar" {
Properties {
_MainTex ("Texture", 2D) = "white" {}
_Fill ("Fill", float) = 0
}
```
`_MainTex` — это красно-зелёная текстура, а `_Fill` — значение от 0 до 1, где 1 — это полное здоровье.
Далее нам нужно приказать полоске рендериться в очереди overlay, а значит, игнорировать всю глубину в сцене и рендериться поверх всего:
```
SubShader {
Tags { "Queue"="Overlay" }
Pass {
ZTest Off
```
Следующая часть — это сам код шейдера. Мы пишем шейдер без освещения (unlit), поэтому нам не нужно беспокоиться об интеграции с различными моделями поверхностных шейдеров Unity, это простая пара вершинного/фрагментного шейдеров. Для начала напишем бутстреппинг:
```
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile_instancing
#include "UnityCG.cginc"
```
По большей мере это стандартный bootstrap, за исключением `#pragma multi_compile_instancing`, которая сообщает компилятору Unity, что нужно компилировать для Instancing.
Вершинная структура должна включать в себя данные экземпляров, поэтому мы сделаем следующее:
```
struct appdata {
float4 vertex : POSITION;
float2 uv : TEXCOORD0;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
```
Также нам нужно задать, что именно будет находиться в данных экземляров, кроме того, что за нас обрабатывает Unity (transform):
```
UNITY_INSTANCING_BUFFER_START(Props)
UNITY_DEFINE_INSTANCED_PROP(float, _Fill)
UNITY_INSTANCING_BUFFER_END(Props)
```
Так мы сообщаем, что Unity должен создать буфер под названием «Props» для хранения данных каждого экземпляра, и внутри него мы будем использовать по одному float на экземпляр для свойства под названием `_Fill`.
Можно использовать и несколько буферов; это стоит делать, если у вас есть несколько свойств, обновляемых с разной частотой; разделив их, можно, например, не менять один буфер при изменении другого, что более эффективно. Но нам этого не требуется.
Наш вершинный шейдер почти полностью выполняет стандартную работу, потому что размер, позиция и поворот и так передаются в transform. Это реализуется с помощью `UnityObjectToClipPos`, который автоматически использует transform каждого экземпляра. Можно представить, что без instancing это обычно было бы простым использованием одного матричного свойства. но при использовании instancing внутри движка это выглядит как массив матриц, и Unity самостоятельно выбирает матрицу, подходящую к данному экземпляру.
Также нем нужно изменять UV, чтобы менять расположение точки перехода из красного в зелёный в соответствии со свойством `_Fill`. Вот соответствующий фрагмент кода:
```
UNITY_SETUP_INSTANCE_ID(v);
float fill = UNITY_ACCESS_INSTANCED_PROP(Props, _Fill);
// generate UVs from fill level (assumed texture is clamped)
o.uv = v.uv;
o.uv.x += 0.5 - fill;
```
`UNITY_SETUP_INSTANCE_ID` и `UNITY_ACCESS_INSTANCED_PROP` выполняют всю магию, осуществляя доступ к нужной версии свойства `_Fill` из буфера констант для этого экземпляра.
Мы знаем, что в обычном состоянии UV-координаты четырёхугольника (quad) покрывают весь интервал текстуры, и что разделительная линия полоски находится посередине текстуры по горизонтали. Поэтому небольшие математические расчёты по горизонтали сдвигают полоску влево или вправо, а значение Clamp текстуры обеспечивают заполнение оставшейся части.
Фрагментный шейдер не мог быть проще, потому что вся работа уже выполнена:
```
return tex2D(_MainTex, i.uv);
```
Полный код шейдера с комментариями доступен в [репозитории GitHub](https://github.com/sinbad/UnityInstancedHealthBars).
Материал Healthbar
------------------
Дальше всё просто — нам всего лишь нужно назначить нашей полоске материал, который использует этот шейдер. Больше почти ничего делать не нужно, достаточно только выбрать нужный шейдер в верхней части, назначить красно-зелёную текстуру, и, что самое важное, **поставить флажок «Enable GPU Instancing»**.

Обновление свойства HealthBar Fill
----------------------------------
Итак, у нас есть объект полоски здоровья, шейдер и материал, который нужно рендерить, теперь нужно задать для каждого экземпляра свойство `_Fill`. Мы делаем это внутри `HealthBar.cs` следующим образом:
```
private void UpdateParams() {
meshRenderer.GetPropertyBlock(matBlock);
matBlock.SetFloat("_Fill", damageable.CurrentHealth / (float)damageable.MaxHealth);
meshRenderer.SetPropertyBlock(matBlock);
}
```
Мы превращаем `CurrentHealth` класса `Damageable` в значение от 0 до 1, разделив его на `MaxHealth`. Затем мы передаём его свойству `_Fill` с помощью `MaterialPropertyBlock`.
Если вы ещё не использовали `MaterialPropertyBlock` для передачи данных в шейдеры, даже без instancing, то вам нужно изучить его. Он не так хорошо объяснён в документации Unity, но является самым эффективным способом передачи данных каждого объекта в шейдеры.
В нашем случае, когда используется instancing, значения для всех полосок здоровья упаковываются в буфер констант, чтобы их можно было передать их все вместе и отрисовать за один раз.
Здесь нет почти ничего, кроме бойлерплейта для задания переменных, и код довольно скучный; подробности см. в [репозитории GitHub](https://github.com/sinbad/UnityInstancedHealthBars).
Демо
----
В [репозитории GitHub](https://github.com/sinbad/UnityInstancedHealthBars) есть тестовое демо, в котором куча злых синих кубиков уничтожается героическими красными сферами (ура!), получая урон, отображаемый описанными в статье полосками. Демо написано в Unity 2018.3.6f1.
Эффект от использования instancing можно наблюдать двумя способами:
### Панель Stats
Нажав Play, щёлкните на кнопку Stats над панелью Game. Здесь вы можете увидеть, сколько вызовов отрисовки экономится благодаря instancing (батчингу):

Запустив игру, вы можете нажать на материал HealthBar и *снять флажок* с «Enable GPU Instancing», после чего число сэкономленных вызовов снизится до нуля.
### Отладчик кадров
Запустив игру, перейдите в меню Window > Analysis > Frame Debugger, а затем нажмите в появившемся окне «Enable».
Слева внизу вы увидите все выполняемые операции рендеринга. Заметьте, что пока там есть множество отдельных вызовов для врагов и снарядов (при желании можно реализовать instancing и для них). Если прокрутить до самого низа, то вы увидите пункт «Draw Mesh (instanced) Healthbar».
Этот единственный вызов рендерит все полоски. Если нажать на эту операцию, а затем на операцию над ней, то вы увидите, что все полоски исчезнут, потому что они отрисовываются за один вызов. Если находясь во Frame Debugger, вы снимете у материала флажок «Enable GPU Instancing», то увидите, что одна строка превратилась в несколько, а после установки флажка — снова в одну.
Как можно расширить эту систему
-------------------------------
Как я говорил раньше, поскольку эти полоски здоровья являются реальными объектами, ничто не мешает превратить простые 2D-полоски во что-то более сложное. Они могут быть полукругами под врагами, которые уменьшаются по дуге, или вращающимися ромбами над их головами. Используя тот же подход, можно по-прежнему рендерить их все за один вызов. | https://habr.com/ru/post/447716/ | null | ru | null |
# Балансировка MySQL
Это краткая заметка как настроить отказоустойчевый кластер с балансировкой нагрузки из 2 MySQL серверов. Исходные данные 2 свежеустановленных MySQL сервера. Необходимо настроить работу таким образом, что бы в нормальной ситуации запросы балансируются между MySQL серверами, в случае выхода из строя одного из MySQL серверов все запросы идут ко второму.
Для начала необходимо настроить репликацию MySQL типа master-master. Как это сделать, уверен найти не проблема. Так что опустим этот шаг. Что бы настроить балансировку, устанавливаем пакет HAProxy, socat (для просмотра статусов базы данных).
На одном из серверов, выполняем запрос, который создаст пользователя для просмотра статуса БД:
`INSERT INTO mysql.user (Host, User) values ('haproxy_ip', 'haproxy'); FLUSH PRIVILEGES;`
Теперь конфигурируем HAproxy, собственно сам конфиг, а потом немного комментариев:
```
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats mode 777 level admin
listen mysql
bind 0.0.0.0:3306
timeout connect 10s
timeout client 1m
timeout server 1m
mode tcp
option mysql-check user haproxy
server server_db1 :3306 weight 1 check inter 1s rise 3 fall 1
server server\_db2 :3306 weight 1 check inter 1s rise 3 fall 1
```
option mysql-check user haproxy — задает под каким пользователя подключаться к mysql для проверки.
server server\_db1 :3306 weight 1 check inter 1s rise 3 fall 1 — задается отображаемое имя сервера, адрес сервера, количество проверок до перехода в состояние недоступности и сколько проверок до перехода в состояние доступен.
Ну и напоследок, для проверки состояния серверов из командной строки можно использовать команду:
`echo "show stat" | socat stdio /var/lib/haproxy/stats | cut -d, -f1,2,18,20,21`
###### Автор: системный администратор [компании](http://centos-admin.ru) [Magvai69](https://habrahabr.ru/users/magvai69/) | https://habr.com/ru/post/265593/ | null | ru | null |
# Асинхронный JavaScript: без колбеков и промисов
Наверное, каждый, кто использовал JavaScript, когда-либо сталкивался (или столкнётся в будущем) с асинхронными вызовами. Может быть, это будет обращение к базе на стороне сервера. Может быть — работа с таймером для создания анимации на сайте.
Для того, чтобы «побороть» асинхронность, используются разные инструменты от промисов до смены языка программирования. Но иногда очень хочется бросить всё и написать на чистом JS линейный код:
```
timeout(1000);
console.log('Hello, world!');
```
Можно ли реализовать нечто подобное? Разумеется, можно.
В данной статье мы рассмотрим один опасный, но действенный способ.
#### Варианты действий
Если Вы недовольны колбеками, можно найти несколько путей развития:
* Смириться и продолжать использовать колбеки,
* Перейти на абсолютно другой язык,
* Перейти на язык, компилируемый в JavaScript,
* Использовать возможности языка.
Разумеется, первый и второй варианты мы рассматривать не будем, оставив претворение их в жизнь на совести читателя. Третий вариант более интересен: мы как бы и не пишем на JS, но вопреки всему, несмотря на все наши наивные ожидания, на выходе получается код на нём. Это наводит на мысль: «А давайте я расширю JS, добавлю туда оператор async и назову AJS?»
Реализация подобного решения приводит к добавлению излишней сущности — компилятора нового языка. Автору при этом придётся хорошо разрекламировать свой Новый Инновационный Продукт и заставить общественность установить ещё один компилятор, а также ввести в процесс разработки ещё одно явное преобразование кода. Если автор не представляет интересы крупных компаний и не является признанным авторитетом своего времени, сделать ничего не удастся.
Но постойте, всегда можно вытянуть себя за волосы! Динамический язык позволяет нам скомпилировать на ходу всё, что угодно, осталось лишь определить удобную для программиста форму записи.
#### Выбор формы записи
В первом приближении можно записывать асинхронный код с помощью строковых литералов, обрабатывать его и вызывать eval. Правда, это по громоздкости не сильно отличается от стопки колбеков. Немного подумав, можно использовать комментарии внутри функций. Метод toString, применённый к функции, возвращает нам её исходный код в виде строки. Реализацией [многострочных строк](http://habrahabr.ru/post/230887/) внутри комментариев уже никого не удивишь. В зависимости от желания автора добавлением пары строк кода удаляются или не удаляются пробелы в начале или переносы строк. С помощью этой технологии можно, например, реализовать многострочные регулярные выражения с комментариями или интерпретатор какого-нибудь языка вроде Brainfuck ~~или самого JavaScript, стоит только добавить ещё пару строк~~.
**Многострочные регулярные выражения**
```
function createRegExp(func){
if(typeof func !== 'function') throw new TypeError(func + ' is not a function');
var m = func.toString().
replace(/\s+|--.*?((?=\*\/)|$)/gm, ''). // удаление всего внешнего по отношению к /* */, удаление комментариев после --
match(/^.*?\/\*\/((?:\\\/|.)*?)\/(?:([img]+?)\/?)?\*\/\}$/); // разбор регулярных выражений
if(!m) throw new TypeError('Invalid RegExp format');
return new RegExp(m[1], m[2] || undefined);
}
```
И для примера — разбор регулярного выражения для разбора регулярных выражений в комментариях многострочного регулярного выражения:
```
var re = createRegExp(function(){/*
/
^.*?\/\* -- какие-то символы и открытие комментария в начале строки
\/ -- символ "/" - начало регулярного выражения
( (?: \\\/ | . )*? )-- сохраняем наименьшую последовательность строки "\/" или любых символов,
\/ -- идущих до символа "/"
(?:([img]+?)\/?)? -- если есть последовательность из букв i, m, g, вероятно, заканчивающаяся на "/",
-- сохраняем её
\*\/\}$ -- конец регулярного выражения сопровождается концом комментария и
-- исходный код функции завершается
/
*/});
```
Заметим, что последовательность символов "--" всё ещё можно использовать в регулярном выражении, разделив дефисы пробелом.
Подобные ухищрения помогают при работе со строками, но полностью убивают подсветку синтаксиса, а она для исходного кода на ЯВУ крайне важна. Следовательно, код надо использовать не закомментированный, а рабочий. То есть тот, который бы хотя бы может быть разобран и представлен в виде AST, иначе получим ошибку интерпретатора.
##### Конструкции, которые мы можем использовать
Для реализации своего диалекта, оставаясь при этом в рамках языка, мы можем использовать:
* Директивы в комментариях: `var a = getAsync(b); //! async`
* Специальные имена переменных: `var _async_a = getAsync(b);`
* Специальные имена функций: `var a = getAsync(async(b));`
* Редко используемые конструкции: `var a = +++getAsync(b);`
Всё это позволит нам, получив исходный код функции, найти места, где используется «заветная» конструкция и заменить их на использование промисов/вложенных функций/отправку жалобы на незаконное использование асинхронных вызовов.
Каждая конструкция имеет свои плюсы и минусы. Например, можно получить предупреждение или ошибку о неопределённой переменной, предупреждения от статических анализаторов и т.п. Но, в конце концов, что использовать, разработчик решает сам.
#### Реализация
Для примера выберем вариант, изображённый на картинке.

В исходную функцию добавив аргумент \_\_cb — функцию, в которую перейдёт управление после завершения последней асинхронной операции. Асинхронные вызовы будем обозначать стрелкой (<-), указывающей на то, что в переменные слева от неё неплохо было бы положить результат выполнения функции справа. Все стрелки заменим на генерацию вызова вложенного колбека; весь последующий код будет «упакован» в него. Каждый возврат из функции заменим на возврат с вызовом колбека \_\_cb.
Это позволит нам вызывать асинхронные функции, передавать управление другой функции и пользоваться всеми созданными переменными (каждая новая переменная перед стрелкой находится в лексическом контексте последующего кода или одном из его родительских контекстов). Стрелка же является последовательностью знакомых нам операторов "<" и "-", образуя валидное выражение, сравнивающее два числа.
Для простоты, рассмотрим урезанную реализацию преобразования исходного кода, в которой нет возможности передать контекст исполнения, но уже демонстрирующую возможности подхода, поскольку в ней есть стрелка:
```
function async(func){
// разбиваем код на "function..." (prefix) и тело (code)
var parsed = func.toString()
.match(/(function.*?\{)([\s\S]*)\}.*/);
var prefix = parsed[1], code = parsed[2];
// в lines храним неизменённые строки кода и заменённые строки, использовавщие "<-"
// в nends храним уровень вложенности колбеков - количество последовательностей
// закрывающихся скобок плюс один
// по умолчанию функция имеет одну закрывающуюся скобку
var lines = ['(' + prefix], nends = 2;
// для кажлой строки... (для простоты разделяем по \n)
code.split('\n').forEach(function(line){
// ... проверяем, есть ли в ней "<-",
// если нет - сохраняем строку как есть
if(!/<-/.test(line))
return void lines.push(line, '\n');
// если есть - берём список имён слева от стрелки в качестве аргументов колбека,
// формируем код вызова анонимной функции и добавляем в lines
var parsed = /([\w\d_$\s,]+)<-(.+)\)/.exec(line);
lines.push(parsed[2], ', function(', parsed[1], '){\n');
++nends; // не забываем про увеличение уровня вложенности
});
// Соединяем список строк и восстанавливаем уровень вложенности
return lines.join('') + Array(nends).join('\n});');
}
```
Выглядит и записывается довольно просто для создаваемой функциональности!
**Желающие могут посмотреть более подробный вариант, описывающий заявленное преобразование.**
```
function async(func){
if(typeof func != 'function')
throw new TypeError('First argument of "async" must be a function.');
// удаляем комментарии, выделяем префикс "function...", аргументы и тело
var parsed = func.toString()
.replace(/\/\*[\s\S]*?\*\/|\/\/.*$/mg, '')
.match(/(function.*?)\((.*?)\)\s*\{([\s\S]*)\}.*/);
var prefix = parsed[1], args = parsed[2], code = parsed[3];
// если аргументы есть, добавляется запятая перед аргументом __cb
if(!/^\s*$/.test(args)) args += ',';
// имеем список строк и список "})"
// если расширять функционал до поддержки работы с исключениями, ends понадобится
// именно как список
var lines = ['(', prefix, '(', args, '__cb', '){'], ends = ['\n})'];
code.split('\n').forEach(function(line){
// каждый выход из функции сопровождаем вызовом колбека
line = line.replace(/return\s*(.*?);/, 'return void __cb($1);');
// проверяем, встречается ли "<-" ровно один раз
if(!/<-/.test(line)) return void lines.push(line, '\n');
if(/<-.*?<-/.test(line)) throw new Error('"<-" is found more than 1 times in "'+line+'".');
// заменяем стрелку на код вызова колбека
var parsed = /([\w\d_$\s,]+)<-(.+)\((.*)\)/.exec(line);
if(!parsed) throw new Error('"<-" is used incorrectly in "' + line + '".');
lines.push(parsed[2], '(');
if(parsed[3]) lines.push(parsed[3], ', ');
lines.push('function(', parsed[1], '){\n');
ends.push('\n});');
});
// склеиваем собранные строки и "})"
return lines.concat(ends.reverse()).join('');
}
```
#### Использование
Допустим, что для получения аватара в *слишком* распределённой системе по адресу электронной почты сервер должен обратиться к одной базе данных, достать оттуда идентификатор пользователя, затем по идентификатору из второй базы получить данные пользователя (в том числе и путь к файлу), обратиться к файловой системе и загрузить файл.

Наивное решение выглядит как:
```
function getAvatarData(eMail, callback){
db1.getID(eMail, function(id){
db2.getData(id, function(user){
fs.exists(user.avatarPath, function(exists){
if(!exists) return void callback(null);
fs.readFile(user.avatarPath, callback);
});
});
});
}
```
А с помощью стрелки можно сделать его более «плоским»:
```
function getAvatarData_src (eMail) {
id <- db1.getID(eMail);
user <- db2.getData(id);
exists <- fs.exists(user.avatarPath);
if (!exists) return null;
data <- fs.readFile(user.avatarPath);
return data;
}
var getAvatarData = eval(async(getAvatarData_src));
```
#### Результаты
Оказалось, что можно довольно легко реализовать свой синтаксический сахар в JavaScript. Мы сохранили подсветку синтаксиса и автозавершение, избавились от внешнего препроцессора и множества колбеков. Быть может, получили инструмент для прототипирования.
Конечно, в идеальном случае следует использовать нормальный парсер JS, а не регулярные выражения (хотя, сам факт добавления функционала парой десятков строк радует), чтобы избавить себя от синтаксических сюрпризов и корректно обрабатывать все ситуации.
Возможно, придётся отказаться от минимизации кода, поскольку конструкция «a < — f()» может быть оптимизирована или преобразована в иную форму. Также придётся следить за контекстом. Как заметил внимательный читатель, описанные выше функции возвращают строку, а не готовую функцию. Подобное поведение выбрано из-за возможного разделения async и использующего её кода на разные файлы — в этом случае eval не «захватит» нужный лексический контекст функции; eval нужно вызывать в том же файле, что и пользовательский код.
Также представленная реализация работает некорректно с исключениями, но их обработку можно легко реализовать. И конечно же, она конфликтует с серьёзными начальниками и über-энтерпрайз-проектами.
Посему, повторяйте подобное только у себя дома! | https://habr.com/ru/post/232671/ | null | ru | null |
# Работа со сложными декораторами в Zend Framework
### Введение
Zend Framework — замечательная система. Такое мнение у меня сложилось на протяжение долгого времени тесного «общения» с этой системой. И замечательная она не в силу каких-то сверхвозможностей, предоставляемых программисту, а в силу того, что система эта удивительным образом приглашает программиста к собственному усовершенствованию для его, программиста, блага, предлагая простой и в то же время мощный фундамент для собственных разработок.
Работая над проектом с использованием Zend Framework, решил попытаться по максимуму использовать его возможности и сразу же обратил внимание на компонент Zend\_Form (я намеренно называю Zend\_Form компонентом, а не классом, поскольку компонент Zend\_Form состоит из класса Zend\_Form и целого набора сопутствующих классов и интерфейсов). В документации сказано достаточно просто: «Zend\_Form упрощает создание форм и управление ими в ваших веб-приложениях». В общем-то это так, но без предварительной подготовки с вас семь потов сойдёт прежде, чем вы сможете создать и отобразить одну более или менее сложную форму. Концептуально форма в Zend Framework состоит из:* элементов
* декораторов
* фильтров
* валидаторов
Элементы — это, собственно, то, что мы понимаем под элементами формы: поля ввода, выпадающие списки и пр.
Декоратор — это вся верстка, которая логически связана с элементом формы (окружает его), но не является его частью. Проще говоря, декоратор — оформление элемента формы.
В данной статье я докажу необходимость существования группового декоратора и опубликую его код. Кому лень читать плод графоманства автора, может сразу перейти к коду.
### Так в чём проблема?
Работа с декораторами пока, на мой взгляд, наиболее сложная и кропотливая часть работы по внедрению форм. В примерах, приведенных в документации, все просто замечательно, за исключением одного — все это очень простые, я бы даже сказал, примитивные примеры.
Но как только нужно отобразить что-нибудь вроде этого

как тут же начинаются проблемы. Основная проблема заключается в том, что хранилище декораторов в компоненте Zend\_Form имеет одноуровневую структуру, то есть нельзя создать вложенные декораторы, нельзя создать декоратор для декоратора и т.д.
К примеру, вышеприведенный фрагмент формы кодируется следующим кодом:

Как мы видим, в дереве элементов есть две независимые ветки: ячейка таблицы, обрамляющая непосредственно элемент формы (input), и ячейка, обрамляющая метку (label). Беда в том, что label не является элементом формы (это также декоратор). А значит, чтобы создать такую структуру нужно выкручиваться при помощи грязных хаков:
> `1. $this->setElementDecorators(array(
> 2. 'ViewHelper',
> 3. array('decorator' => array('br' => 'HtmlTag'), 'options' => array('tag' => 'span', 'placement' => Zend\_Form\_Decorator\_Abstract::APPEND)),
> 4. array('decorator' => array('tdOpen' => 'HtmlTag'), 'options' => array('tag' => 'td', 'openOnly' => true, 'placement' => Zend\_Form\_Decorator\_Abstract::PREPEND)),
> 5. array('decorator' => array('tdClose' => 'HtmlTag'), 'options' => array('tag' => 'td', 'closeOnly' => true, 'placement' => Zend\_Form\_Decorator\_Abstract::APPEND)),
> 6. array('decorator' => array('label' => 'Label'), 'options' => array('separator' => '\*')),
> 7. 'Errors',
> 8. array('decorator' => array('mainCell' => 'HtmlTag'), 'options' => array('tag' => 'td', 'class' => 'tregleft')),
> 9. array('decorator' => array('mainRowClose' => 'HtmlTag'), 'options' => array('tag' => 'tr'))
> 10. ));
> 11.
> 12. $usernameFieldLabel = $this->user\_name->getDecorator('label');
> 13. $defaultSeparator = $usernameFieldLabel->getOption('separator');
> 14. $usernameFieldLabel->setOption('separator', $defaultSeparator.'
>
> Логин может состоять только из латинских букв и знака "\_".');
> \* This source code was highlighted with Source Code Highlighter.`
Из недостатков:* ручная подстановка закрывающихся и открывающихся тэгов td
* использование опции separator не по назначению
Да и просто, не каждый код, даже используя хаки, удастся вот так отобразить при помощи декораторов. Все было бы гораздо проще, если бы существовал декоратор, в который бы можно было добавлять другие декораторы.
### Решение проблемы
Погуглив, я ничего нормального не нашел и решил написать свой собственный групповой декоратор.
Вот, что получилось:
> `1. php</li- require\_once 'Zend/Form/Decorator/Abstract.php';
> -
> - class Zend\_Form\_Decorator\_GroupDecorator extends Zend\_Form\_Decorator\_Abstract {
> - /\*\*
> - \* Items (decorators) to group
> - \* @var array
> - \*/
> - protected $\_items = null;
> -
> - /\*\*
> - \* Temporary form to perform decorators operations
> - \* @var Zend\_Form\_Element
> - \*/
> - private $\_temporaryDecoratorsContainer = null;
> -
> - /\*\*
> - \* Constructor
> - \*
> - \* @param array|Zend\_Config $options
> - \* @return void
> - \*/
> - public function \_\_construct($options = null) {
> - parent::\_\_construct($options);
> - $this->\_temporaryDecoratorsContainer = new Zend\_Form\_Element('\_temporaryDecoratorsContainer', array('DisableLoadDefaultDecorators' => true));
> - $this->getItems();
> - }
> -
> - /\*\*
> - \* Set items to use
> - \*
> - \* @param array $items
> - \* @return Zend\_Form\_Decorator\_GroupDecorator
> - \*/
> - public function setItems($items) {
> - $this->\_items = $this->\_temporaryDecoratorsContainer->clearDecorators()->addDecorators($items)->getDecorators();
> - return $this;
> - }
> -
> - /\*\*
> - \* Get tag
> - \*
> - \* If no items is registered, either via setItems() or as an option, uses empty array.
> - \*
> - \* @return array
> - \*/
> - public function getItems() {
> - if (null === $this->\_items) {
> - if (null === ($items = $this->getOption('items'))) {
> - $this->setItems(array());
> - } else {
> - $this->setItems($items);
> - $this->removeOption('items');
> - }
> - }
> - return $this->\_items;
> - }
> -
> - public function addDecorator($decorator, $options = null) {
> - $this->\_temporaryDecoratorsContainer->addDecorator($decorator, $options);
> - return $this;
> - }
> -
> - public function clearDecorators() {
> - $this->\_temporaryDecoratorsContainer->clearDecorators();
> - $this->\_items = array();
> - }
> -
> - public function getDecorator($index = null) {
> - if (null === $index) {
> - return $this->\_items;
> - }
> - if (is\_numeric($index)) {
> - $\_items = array\_values($this->\_items);
> - return ($index < count($\_items))?$\_items[$index]:null;
> - }
> - if (is\_string($index)) {
> - return (array\_key\_exists($index, $this->\_items))?$this->\_items[$index]:null;
> - }
> - return null;
> - }
> -
> - public function insertDecoratorBefore($index, $decorator, $options = null) {
> - $\_decoratorsToAdd = $this->\_temporaryDecoratorsContainer->clearDecorators()->addDecorator($decorator, $options)->getDecorators();
> - if (is\_string($index)) {
> - $index = array\_search($index, array\_keys($this->\_items));
> - }
> - if (false !== $index) {
> - $first = ($index > 0)?array\_slice($this->\_items, 0, $index, true):array();
> - $last = ($index < count($this->\_items))?array\_slice($this->\_items, $index, null, true):array();
> - $this->\_items = array\_merge($first, (array)$\_decoratorsToAdd, $last);
> - }
> - return $this;
> - }
> -
> - /\*\*
> - \* Render content wrapped in a group of decorators
> - \*
> - \* @param string $content
> - \* @return string
> - \*/
> - public function render($content) {
> - $placement = $this->getPlacement();
> - $items = $this->getItems();
> - $\_content = '';
> - foreach ($items as $\_decorator) {
> - if ($\_decorator instanceOf Zend\_Form\_Decorator\_Interface) {
> - $\_decorator->setElement($this->getElement());
> - $\_content = $\_decorator->render($\_content);
> - }
> - else {
> - require\_once 'Zend/Form/Decorator/Exception.php';
> - throw new Zend\_Form\_Decorator\_Exception('Invalid decorator '.$\_decorator.' provided; must be string or Zend\_Form\_Decorator\_Interface');
> - }
> - }
> - switch ($placement) {
> - case self::APPEND:
> - return $content . $\_content;
> - break;
> - case self::PREPEND:
> - return $\_content . $content;
> - break;
> - default:
> - return $\_content.$content.$\_content;
> - break;
> - }
> - }
> - }
> - ?>
> \* This source code was highlighted with Source Code Highlighter.`
Данный декоратор может:* Создавать и отображать декораторы произвольной вложенности, а значит и какой угодно сложности
* Производить операции с декораторами (добавление, удаление, вставка) на лету, тем самым, позволяя редактировать групповые декораторы, заданные по умолчанию
Теперь вышеприведенный пример создания элемента формы будет выглядеть так:
> `1. php</li- class Form\_MemberRegister extends Zend\_Form {
> - public function init() {
> - $this->setDisableLoadDefaultDecorators(true);
> -
> - $this->addDecorator('FormElements')
> - ->addDecorator(array('table' => 'HtmlTag'), array('tag' => 'table', 'class' => 'treg'))
> - ->addDecorator('Form');
> -
> - $this->addElement('text', 'user\_name', array('label' => 'Логин:'));
> - $this->addElement('password', 'password', array('label' => 'Пароль:'));
> - $this->addElement('password', 'password2', array('label' => 'Повторите пароль:'));
> - $this->addElement('text', 'email', array('label' => 'E-mail:'));
> -
> - $this->setElementDecorators(array(
> - array('decorator' => array('labelGroup' => 'GroupDecorator'), 'options' => array('items' => array(
> - array('decorator' => 'Text', 'options' => array('text' => '\*')),
> - array('decorator' => array('span' => 'HtmlTag'), 'options' => array('tag' => 'span', 'class' => 'red')),
> - array('decorator' => 'Label','options' => array('placement' => Zend\_Form\_Decorator\_Abstract::PREPEND)),
> - array('decorator' => array('labelCell' => 'HtmlTag'), 'options' => array('tag' => 'td', 'class' => 'tregleft'))
> - ))),
> - array('decorator' => array('elementGroup' => 'GroupDecorator'), 'options' => array('items' => array(
> - 'ViewHelper',
> - array('decorator' => array('elementCell' => 'HtmlTag'), 'options' => array('tag' => 'td'))
> - )), 'placement' => Zend\_Form\_Decorator\_Abstract::APPEND),
> - array('decorator' => array('mainRowClose' => 'HtmlTag'), 'options' => array('tag' => 'tr'))
> - ));
> -
> - /\*\*
> - \* @var Zend\_Form\_Decorator\_GroupDecorator
> - \*/
> - $usernameFieldLabel = $this->user\_name->getDecorator('labelGroup');
> - $usernameFieldLabel->insertDecoratorBefore('labelCell', array('usernameNotes' => $this->\_getNotesDecorator($this->user\_name, 'Логин может состоять только из латинских букв и знака "\_".')));
> -
> - /\*\*
> - \* @var Zend\_Form\_Decorator\_GroupDecorator
> - \*/
> - $emailFieldDecorator = $this->email->getDecorator('elementGroup');
> - $emailFieldDecorator->insertDecoratorBefore('elementCell', array('emailNotes' => $this->\_getNotesDecorator($this->email, 'Вводите только существующий и рабочий е-маил. На этот адрес Вам будет отправлена ссылка для подтверждения регистрации.')));
> - }
> -
> - protected function \_getNotesDecorator($element, $notesText = '') {
> - $\_d = new Zend\_Form\_Decorator\_GroupDecorator(array('items' => array(
> - array('decorator' => array('notesText' => 'Text'), 'options' => array('text' => $notesText)),
> - array('decorator' => array('notesTag' => 'HtmlTag'), 'options' => array('tag' => 'small')),
> - array(
> - 'decorator' => array('br' => 'HtmlTag'),
> - 'options' => array('tag' => 'br', 'openOnly' => true, 'placement' => Zend\_Form\_Decorator\_Abstract::PREPEND)
> - )
> - )));
> - return $\_d->setElement($element);
> - }
> - }
> - ?>
> \* This source code was highlighted with Source Code Highlighter.`
**Заранее прошу прощения, если пост оказался слишком длинным.
Если есть другое, более изящное решение, поставленной проблемы, дайте знать — я посыплю свою голову пеплом :)
PS: Для противников табличной верстки хочу заметить, что это пост о программировании, я не верстальщик — мне всего лишь нужно было отобразить заданный шаблон.** | https://habr.com/ru/post/42748/ | null | ru | null |
# Эксплуатация подписанных загрузчиков для обхода защиты UEFI Secure Boot
[English version of this article.](https://habr.com/en/post/446238/)
Введение
--------
Прошивки современных материнских плат компьютера работают по спецификации UEFI, и с 2013 года поддерживают технологию проверки подлинности загружаемых программ и драйверов Secure Boot, призванную защитить компьютер от буткитов. Secure Boot блокирует выполнение неподписанного или недоверенного программного кода: .efi-файлов программ и загрузчиков операционных систем, прошивок дополнительного оборудования (OPROM видеокарт, сетевых адаптеров).
Secure Boot можно отключить на любой магазинной материнской плате, но обязательное требование для изменения его настроек — физическое присутствие за компьютером. Необходимо зайти в настройки UEFI при загрузке компьютера, и только тогда получится отключить технологию или изменить её настройки.
Большинство материнских плат поставляется только с ключами Microsoft в качестве доверенных, из-за чего создатели загрузочного ПО вынуждены обращаться в Microsoft за подписью загрузчиков, проходить процедуру аудита, и обосновывать необходимость глобальной подписи их файла, если они хотят, чтобы диск или флешка запускались без необходимости отключения Secure Boot или добавления их ключа вручную на каждом компьютере.
Подписывать загрузчики у Microsoft приходится разработчикам дистрибутивов Linux, гипервизоров, загрузочных дисков антивирусов и программ для восстановления компьютера.
Мне хотелось сделать загрузочную флешку с различным ПО для восстановления компьютера, которая бы грузилась без отключения Secure Boot. Посмотрим, как это можно реализовать.
Подписанные загрузчики загрузчиков
----------------------------------
Итак, чтобы загрузить Linux при включенном Secure Boot, нужен подписанный загрузчик. Microsoft запретила подписывать ПО, лицензированное под GPLv3, из-за запрета тивоизации правилами лицензии, поэтому [GRUB подписать не получится](https://techcommunity.microsoft.com/t5/Windows-Hardware-Certification/Microsoft-UEFI-CA-Signing-policy-updates/ba-p/364828?advanced=false&collapse_discussion=true&q=uefi&search_type=thread).
В ответ на это, Linux Foundation выпустили [PreLoader](https://blog.hansenpartnership.com/linux-foundation-secure-boot-system-released/), а Мэтью Гарретт написал [shim](http://mjg59.dreamwidth.org/20303.html) — маленькие начальные загрузчики, проверяющие подпись или хеш следующего загружаемого файла. PreLoader и shim не используют сертификаты UEFI db, а содержат базу разрешенных хешей (PreLoader) или сертификатов (shim) внутри себя.
Обе программы, помимо автоматической загрузки доверенных файлов, позволяют загружать и любые ранее недоверенные файлы в режиме Secure Boot, но требуют физического присутствия пользователя: при первом запуске необходимо выбрать добавляемый сертификат или файл для хеширования в графическом интерфейсе, после чего данные заносятся в специальную переменную NVRAM материнской платы, которая недоступна для изменения из загруженной операционной системы. Файлы становятся доверенными только для этих пред-загрузчиков, а не для Secure Boot вообще, и запустить их без PreLoader/shim всё равно не получится.
*Действия, необходимые при первом запуске недоверенной программы через shim.*
Все современные популярные дистрибутивы Linux используют shim, из-за поддержки сертификатов, которая позволяет легко обновлять следующий загрузчик без необходимости взаимодействия с пользователем. Как правило, shim используется для запуска GRUB2 — наиболее популярного бутлоадера в Linux.
GRUB2
-----
Чтобы злоумышленники втихую не наделали делов с помощью подписанного загрузчика какого-либо дистрибутива, Red Hat сделал патчи для GRUB2, блокирующие «опасные» функции при включенном Secure Boot: insmod/rmmod, appleloader, linux (заменён linuxefi), multiboot, xnu, memrw, iorw. К модулю chainloader, загружающему произвольные .efi-файлы, дописали собственный загрузчик .efi (PE), без использования команд UEFI LoadImage/StartImage, а также код валидации загружаемых файлов через shim, чтобы сохранялась возможность загрузки файлов, доверенных для shim, но не доверенных с точки зрения UEFI. Почему сделали именно так — непонятно; UEFI позволяет переопределять (хукать) функции проверки загружаемых образов, именно так работает PreLoader, да и в самом shim [такая функция имеется](https://github.com/rhboot/shim/blob/741c61abba7d5c74166f8d0c1b9ee8001ebcd186/lib/security_policy.c), но по умолчанию отключена.
Так или иначе, воспользоваться подписанным GRUB из какого-то дистрибутива Linux не получится. Для создания универсальной загрузочной флешки, которая бы не требовала добавление ключей каждого загружаемого файла в доверенные, есть два пути:
* Использование модифицированного GRUB, загружающего EFI-файлы своими силами, без проверки цифровой подписи, и без блокирования модулей;
* Использование собственного пред-загрузчика (второго), переопределяющего функции проверки цифровой подписи UEFI (EFI\_SECURITY\_ARCH\_PROTOCOL.FileAuthenticationState, EFI\_SECURITY2\_ARCH\_PROTOCOL.FileAuthentication)
Второй вариант предпочтительней — загруженные недоверенные программы тоже смогут загружать недоверенные программы (например, можно загружать файлы через UEFI Shell), а в первом варианте загружать всё может только сам GRUB. [Модифицируем PreLoader](https://github.com/ValdikSS/Super-UEFIinSecureBoot-Disk/tree/master/efi-tools-patches), убрав из него лишний код и разрешив запуск любых файлов.
Итого, архитектура флешки получилась следующая:
```
______ ______ ______
╱│ │ ╱│ │ ╱│ │
/_│ │ → /_│ │ → /_│ │
│ │ → │ │ → │ │
│ EFI │ → │ EFI │ → │ EFI │
│_______│ │_______│ │_______│
BOOTX64.efi grubx64.efi grubx64_real.efi
(shim) (FileAuthentication (GRUB2)
override)
↓↓↓ ↑
↑
______ ↑
╱│ │ ║
/_│ │ ║
│ │ ═══════════╝
│ EFI │
│_______│
MokManager.efi
(Key enrolling
tool)
```
Так появился [Super UEFIinSecureBoot Disk](https://github.com/ValdikSS/Super-UEFIinSecureBoot-Disk).
> Super UEFIinSecureBoot Disk — образ диска с загрузчиком GRUB2, предназначенным для удобного запуска неподписанных efi-программ и операционных систем в режиме UEFI Secure Boot.
>
>
>
> Диск можно использовать в качестве основы для создания USB-накопителя с утилитами восстановления компьютера, для запуска различных Live-дистрибутивов Linux и среды WinPE, загрузки по сети, без отключения Secure Boot в настройках материнской платы, что может быть удобно при обслуживании чужих компьютеров или корпоративных ноутбуков, например, при установленном пароле на изменение настроек UEFI.
>
>
>
> Образ состоит из трех компонентов: предзагрузчика shim из Fedora (подписан ключом Microsoft, предустановленным в подавляющее большинство материнских плат и ноутбуков), модифицированного предзагрузчика PreLoader от Linux Foundation (для отключения проверки подписи при загрузке .efi-файлов), и модифицированного загрузчика GRUB2.
>
>
>
> Во время первой загрузки диска на компьютере с Secure Boot необходимо выбрать сертификат через меню MokManager (запускается автоматически), после чего загрузчик будет работать так, словно Secure Boot выключен: GRUB загружает любой неподписанный .efi-файл или Linux-ядро, загруженные EFI-программы могут запускать другие программы и драйверы с отсутствующей или недоверенной подписью.
>
>
>
> Для демонстрации работоспособности, в образе присутствует Super Grub Disk (скрипты для поиска и загрузки установленных операционных систем, даже если их загрузчик поврежден), GRUB Live ISO Multiboot (скрипты для удобной загрузки Linux LiveCD прямо из ISO, без предварительной распаковки и обработки), One File Linux (ядро и initrd в одном файле, для восстановления системы), и несколько UEFI-утилит.
>
>
>
> Диск совместим с UEFI без Secure Boot, а также со старыми компьютерами с BIOS.
Подписанные загрузчики
----------------------
Мне было интересно, можно ли как-то обойти необходимость добавления ключа через shim при первом запуске. Может, есть какие-то подписанные загрузчики, которые позволяют делать больше, чем рассчитывали авторы?
Как оказалось — такие загрузчики есть. Один из них используется в [Kaspersky Rescue Disk 18](https://support.kaspersky.com/viruses/krd18) — загрузочном диске с антивирусным ПО. GRUB с диска позволяет загружать модули (команда insmod), а модули в GRUB — обычный исполняемый код. Пред-загрузчик у диска собственный.
Разумеется, просто так GRUB из диска не загрузит недоверенный код. Необходимо модифицировать модуль chainloader, чтобы GRUB не использовал функции UEFI LoadImage/StartImage, а самостоятельно загружал .efi-файл в память, выполнял релокацию, находил точку входа и переходил по ней. К счастью, почти весь необходимый код есть в репозитории [GRUB'а с поддержкой Secure Boot от Red Hat](https://github.com/rhboot/grub2/tree/grub-2.02-sb), единственная проблема: код парсинга заголовка PE отсутствует, заголовок парсит и возвращает shim, в ответ на вызов функции через специальный протокол. Это легко исправить, портировав соответствующий код из shim или PreLoader в GRUB.
Так появился Silent UEFIinSecureBoot Disk. Получившаяся архитектура диска выглядит следующим образом:
```
______ ______ ______
╱│ │ ╱│ │ ╱│ │
/_│ │ /_│ │ → /_│ │
│ │ │ │ → │ │
│ EFI │ │ EFI │ → │ EFI │
│_______│ │_______│ │_______│
BOOTX64.efi grubx64.efi grubx64_real.efi
(Kaspersky (FileAuthentication (GRUB2)
Loader) override)
↓↓↓ ↑
↑
______ ↑
╱│ │ ║
/_│ │ ║
│ │ ═══════════╝
│ EFI │
│_______│
fde_ld.efi + custom chain.mod
(Kaspersky GRUB2)
```
Заключение
----------
В этой статье мы выяснили, что существуют недостаточно надежные загрузчики, подписанные ключом Microsoft, разрешающим работу в режиме Secure Boot.
С помощью подписанных файлов Kaspersky Rescue Disk мы добились «тихой» загрузки любых недоверенных .efi-файлов при включенном Secure Boot, без необходимости добавления сертификата в UEFI db или shim MOK.
Эти файлы можно использовать как для добрых дел (для загрузки с USB-флешек), так и для злых (для установки буткитов без ведома владельца компьютера).
Предполагаю, что сертификат Касперского долго не проживет, и его добавят в [глобальный список отозванных сертификатов UEFI](https://uefi.org/revocationlistfile), который установят на компьютеры с Windows 10 через Windows Update, что нарушит загрузку Kaspersky Rescue Disk 18 и Silent UEFIinSecureBoot Disk. Посмотрим, как скоро это произойдет.
Скачать Super UEFIinSecureBoot Disk: <https://github.com/ValdikSS/Super-UEFIinSecureBoot-Disk>
Скачать Silent UEFIinSecureBoot Disk в сети [ZeroNet Git Center](https://zeronet.io/): <http://127.0.0.1:43110/1KVD7PxZVke1iq4DKb4LNwuiHS4UzEAdAv/>
**Про ZeroNet**ZeroNet — очень мощная система создания децентрализованных распределенных динамических веб-сайтов и сервисов. При посещении какого-либо ресурса, пользователь начинает его скачивать и раздавать, как в BitTorrent. При этом, возможно создание полноценных ресурсов: блогов с комментариями, форумов, видеохостингов, wiki-сайтов, чатов, email, git.
ZeroNet разделяет понятия кода и данных сайта: пользовательские данные хранятся в .json-файлах, а при синхронизации импортируются в sqlite-базу данных сайта со стандартизированной схемой, что позволяет делать умопомрачительные вещи: локальный поиск текста по всем когда либо открытым сайтам за миллисекунды, автоматический real-time аналог RSS для всех сайтов разом.
Стандартизированная система аутентификации и авторизации (похожа на OAuth), поддержка работы за NAT и через Tor.
ZeroNet очень быстро работает, дружелюбен к пользователю, имеет современный интерфейс и мелкие, но очень удобные фишки, вроде глобального переключения дневной/ночной темы на сайтах.
Я считаю ZeroNet очень недооцененной системой, и намеренно публикую Silent-версию только в ZeroNet Git, для привлечения новых пользователей. | https://habr.com/ru/post/446072/ | null | ru | null |
# Как оптимизировать размер бандла SPA и ускорить загрузку приложения в несколько раз
Меня зовут Михаил Сахнюк и я разрабатываю фронтенд уже более шести лет. Сейчас я фронтенд разработчик в Miro.
В статье рассмотрим:
* как оптимизировать веб-приложение и ускорить его загрузку;
* почему это важно;
* какие инструменты помогут в работе над оптимизацией, замерами и контролем результатов;
* преимущества работы с загружаемыми модулями в приложениях.
Ускорение загрузки приложения — это комплексная задача, которая решается всей командой разработчиков. В статье расскажу, что могут предпринять фронтенд разработчики, опуская варианты сетевой оптимизации с использованием HTTP2 или оптимизации скорости ответов сервера.
Статья — конспект моего доклада на конференции Mergeconf 2021 в Иннополисе.
Проблема
--------
Перед тем, как действовать, важно понять, какую задачу или проблему мы решаем. Зачем нам что-то оптимизировать, если приложение загружается и работает нормально?
Скорость загрузки приложения сильно сказывается на том, будет пользователь использовать приложение или нет. Приведу в пример не самую новую, но актуальную [аналитику от компании KissMetrics](https://blog.kissmetrics.com/wp-content/uploads/2011/04/loading-time.pdf):
* Каждые две дополнительные секунды загрузки приложения увеличивают количество отказов на 103%. Это значит, что если вы или ваша компания привлекаете клиентов, оплачивая каждое посещение ресурса, то, ускорив загрузку всего на 2 секунды, вы сможете сэкономить на рекламном бюджете и, как следствие, увеличить продажи и прибыль.
* Каждая секунда загрузки приложения уменьшает конверсию в покупку на 7%. Например, если ваша компания зарабатывает 100 тысяч долларов в день — потеря одной секунды будет стоить вам 2,5 миллиона долларов в год. Такая сумма легко может равняться фонду оплаты труда всех разработчиков компании. И это всего лишь одна секунда.
Чтобы понять, где скрываются те самые секунды загрузки, посмотрим, как браузер загружает SPA. Если мы имеем типичное монолитное SPA приложение, загрузка будет выглядеть так:
1. **Получение и парсинг HTML (DOM)**. Браузер получит HTML документ, в котором не будет никакого контента, кроме ссылок на дополнительные ресурсы — JS бандл и стили. У пользователя в этот момент будет отображаться белый экран.
2. **Загрузка внешних ресурсов.** На этом этапе будут загружаться JS и CSS файлы.
3. **Парсинг CSS и построение CSSOM**. Полученные стили будут распарсены, но у пользователя до сих пор будет отображаться белый экран.
4. **Выполнение JavaScript.**
5. **Рендеринг страницы.** И только на этом этапе пользователь увидит результат загрузки приложения. Отобразится содержимое и контент приложения.
Схематично загрузка приложения будет выглядеть как на рисунке ниже.
Обычно загрузка JS и CSS файлов может быть синхронной и асинхронной, но в ситуации с типичным SPA все этапы загрузки будут блокирующими, так как пользователь не сможет начать работать с приложением, пока весь необходимый контент не будет загружен браузером. На изображении это отмечено меткой TTI (Time To Interactive) — она означает время, когда пользователь сможет начать работу с приложением.
Метка FCP (First Contentful Paint) означает момент, когда пользователь увидит контент вместо белого экрана. В зависимости от кейса, эта метка может располагаться на схеме как в процессе загрузки JS файла, так и в самом конце рядом с TTI.
Из описанных этапов мы видим, что время загрузки приложения пропорционально количеству и размеру загружаемых файлов при загрузке приложения. Теперь, зная цену каждой секунды, важно сделать так, чтобы эти файлы весили как можно меньше и их количество было минимально.
Оптимизация веб-страниц и их загрузки
-------------------------------------
Перед тем, как погрузиться в оптимизацию бандла приложения, рассмотрим общие подходы к ускорению загрузки веб-страниц — сайтов, лендингов, SPA и т.д.
### Удаление неиспользуемого кода
Довольно частая проблема проектов — это наличие кода, который никогда не будет выполнен. Важно позаботиться о том, чтобы такой код не попадал в продакшн. Ниже приведу несколько примеров:
* **Моки.** Несколько лет назад, работая на проекте, я смог уменьшить размер бандла приложения на 80%, удалив JSON файл со структурой компании на 5000 сотрудников. Этот файл временно заменял несколько API запросов, пока разрабатывался backend, и кто-то забыл убрать импорт.
* **Старые модули.** При разработке нового функционала мы часто делаем несколько прототипов и пишем целые модули, которые потом легко могут хвостом идти в прод.
* **Стили.** Такие библиотеки, как Bootstrap или новомодный Tailwind CSS, тянут сотни лишних классов. Для удаления неиспользуемых стилей даже существуют специальные инструменты, например, PurgeCSS.
* **Библиотеки.** Помимо стилей, часто встречаются случаи, когда ради одной функции или компонента к проекту подключается огромная библиотека. В таких случаях стоит взять только импортируемый кусок кода из всей библиотеки, применив tree-shaking.
### Сжатие кода
JS и CSS код, который мы пишем, собирается сборщиком в файлы. Они могут быть дополнительно сжаты путём сокращения имён переменных, удаления пробелов и комментариев.
В большинстве случаев собранные приложения уже будут сжаты, так как все основные фреймворки по дефолту сжимают продакшн сборки. Если вы используете собственные конфигурации сборщика, стоит убедиться, что ваш код сжат. Только это позволит уменьшить размер приложения на 50-60%.
### Сжатие картинок
Уверен, многие из вас натыкались на страницы в интернете, которые невероятно долго загружалась. Картинки на таких страницах могли занимать десятки мегабайт, так как были в исходном формате.
Существуют инструменты, которые позволяют сжимать картинки в десятки и даже сотни раз без особой потери качества. Статические изображения, которые вы подключаете к проекту напрямую, могут быть обработаны WebPack. Если загружаете картинки с сервера — достаточно поставить задачу backend разработчику, который решит её за пару часов.
### Шрифты
Иногда размер шрифтов может доходить до 500кб.
Основным подходом к уменьшению размера загружаемых шрифтов будет правильный выбор формата, а именно — самый новый формат с максимальным сжатием, который поддерживают все браузеры. Таким форматом можно смело назвать WOFF или WOFF2.
Если нам необходимо поддерживать старые версии браузеров, можно прибегнуть к способу, который позволит браузерам выбрать оптимальный формат шрифта и подгрузить только его:
Существует ещё один подход сократить размер шрифта, удалив из файла неиспользуемые глифы. Этот способ подойдёт, если шрифт используется для некоторых заголовков или как логотип.
Удалить глифы можно в специальных приложениях, и если вы используете в вашем проекте Google Fonts, вам очень повезло. Тогда в ссылке на шрифт можно передать параметр text с значением в виде символов, которые вы хотите использовать в шрифте. В результате серверы отдадут файл шрифта только с выбранными глифами. Итоговый размер такого шрифта может быть в десятки раз меньше исходного. Пример использования:
Решаем проблему с размером бандла
---------------------------------
В основе оптимизации размера приложения лежит Code-Splitting подход. Это процесс разделения основного модуля приложения на части или чанки (сhunks), которые могут быть подгружены, когда они необходимы. Причём это может происходить уже после того, как приложение загружено.
Другими словами, Code-Splitting позволяет нам разделить приложение и отбросить код, который не требуется при запуске нашего SPA.
### Route-splitting
Самым простым и популярным подходом оптимизации SPA является постраничное разделение приложения. На каждую страницу приложения бандлером будет создан отдельный чанк, и загружаться такие чанки будут, только когда пользователь будет переходить на эти страницы.
На схеме показано, как приложение будет разделено на чанки со страницами приложения, main модуль, в котором будет инициализироваться фреймворк, различные модули, данные и сам роутер.
Очевидно, что в момент открытия приложения в браузере, пользователь загружает только одну страницу. Это значит, что в процессе запуска будет скачано только два файла (main и один chunk). Если учесть, что приложение может легко состоять из десятков страниц, то только этот подход позволит заметно сократить время запуска приложения.
### Одноразовый код
После того, как SPA будет разделено на страницы, можно опуститься на уровень ниже и посмотреть, как устроена root часть и страницы внутри. Первое, что можно будет найти, — это одноразовый код.
Под одноразовым кодом я имею в виду части приложения, которые пользователь увидит только один раз. К такому коду можно отнести:
* формы регистрации и аутентификации, если вы не расположили их в отдельной странице;
* онбординг и обучение нового пользователя;
* подсказки и блоки информирования.
### Редко используемый код
Это код разделов приложения, которые пользователь будет использовать редко. Здесь также применим подход выносить код в чанки, которые не нужны при загрузки SPA. Примером могут быть блоки уведомлений или справочная информация.
Уведомления в соцсетяхСправка Google DocsНа картинке можно увидеть кусок devtool с загрузкой JS файлов. Открытие справки вызвало загрузку не одного файла, как можно было предположить, а сразу десятка, поэтому важно не перестараться при оптимизации. Например, если вы вынесли блок в отдельный чанк, а далее в нём еще с десяток компонентов будут вынесены в собственные чанки, это может привести к рекурсивной загрузке файлов и контента, и в итоге компонент будет загружаться ещё дольше, чем обычно.
Поэтому не следует выносить в чанки всё подряд только для того, чтобы разгрузить размер страниц или root модуля, так как это не даст никакого результата. Для заметного прироста производительности стоит начать с блоков и модулей, которые весят 100кб и более.
### Скрытые блоки
Помимо постраничного роутинга приложения, мы часто разделяем контент внутри страниц, используя collapsed блоки или панели с табами. Такие блоки можно отнести к внутреннему роутингу страниц, поэтому они легко подходят для оптимизации.
Мы в Miro часто применяем такой подход, так как он сильно ускоряет первую загрузку страниц. А зная, как часто пользователи открывают ту или иную вкладку, мы можем смело выносить блоки, которые пользователи посещают реже всего.
На примере выше изображен раздел настроек Miro, где поочерёдно были открыты все табы страницы. В результате на каждое открытие таба, был загружен дополнительный JS код.
В дополнение к оптимизации существует ещё одно весомое преимущество разделения SPA на чанки — **кеширование**. После того, как браузер загружает файлы приложения, он сохраняет их на диск для дальнейшего использования. Если пользователь повторно захочет открыть страницу или её компонент, то чанк уже не будет загружен с сервера, а будет взят из памяти. Это позволяет моментально открывать страницы и работать с SPA. И самое главное: когда вы обновляете свое приложение, модули, которые вы не трогали, не будут обновлены и браузеру не потребуется загружать неизменённые страницы и компоненты новой версии приложения.
### Диалоговые окна
Мы размещаем контент в диалоговые окна, когда пользователю важно получить к нему доступ в любой странице приложения. Чаще всего такие компоненты будут размещены в Root модуле приложения и будут загружаться при первом запуске SPA.
Такие окна почти никогда не нужны в момент загрузки приложения, поэтому они тоже являются кандидатами на вынесение в собственный чанк.
В крупных проектах диалоговые окна могут занимать весомую часть приложения. Например, у нас в Miro модуль Billing весит более 350кб и над ним работает отдельная команда разработчиков.
Ряд плюсов работы с загружаемыми модулями:
* **Структура исходного кода.** Вынося компоненты в модули, вы сможете улучшить организацию исходного кода и структуры файлов в проекте.
* **Изоляция работы над компонентами.** Разным командам будет проще работать с проектом, особенно если вы будете выносить модули в отдельные репозитории.
* **А/Б тестирование.** Динамическая загрузка компонентов по требованию позволяет заменять один модуль на другой под разными условиями. Это даёт широкие возможности бизнесу для тестирования гипотез и улучшения качества продукта.
* **Легкая миграция старого модуля на новый** с возможностью плавной раскатки, не влияя на само приложение в целом. Пользователь даже не поймёт, что ему открылось новое модальное окно, пока другим будет показываться старый модуль.
### Локализация
Принцип оптимизации аналогичен: важно оставить только тот язык, который будет использовать пользователь — остальные отправляем ждать на сервере.
Техническая сторона решения
---------------------------
Мы рассмотрели продуктовую сторону решения проблемы и узнали, что именно и в каком порядке следует оптимизировать. Теперь рассмотрим, как это делать. Ниже буду приводить примеры кода.
### import(“./module”)
Во главе всей темы статьи лежит динамический импорт. Он выглядит как функция, но по сути ей не является. Мы не можем передавать его как аргумент и делать другие вещи, кроме как вызывать. Вызов возвращает Promise, после разрешения которого мы получаем модуль, который импортировали:
```
import(“./foo”).then(foo => console.log(foo.default));
const module = await import(“./foo”)
```
В примере с локализацией, используя динамический импорт, мы сможем реализовать подгрузку локализации с сервера в формате JSON без привлечения backend разработчиков, а сами файлы останутся в исходном коде приложения для простоты разработки и отладки:
```
const language = getUserLanguage();
import("./locale/${language}.json").then(locale => {/* ... */})
```
В примере выше — вся основная сила данного синтаксиса. На вход импорт принимает строку, поэтому мы можем динамически её менять, но с небольшой оговоркой: мы не можем просто передать константу в функцию, так как сборщик не поймёт, по какому пути ему идти и какие файлы выносить в чанки. В примере код валидный и такое использование подстановки строки позволит нам сразу выносить файлы из каталога пачками.
В мире React мы тоже можем с легкостью динамически импортировать целые компоненты и страницы. Для этого существует специальный метод lazy:
```
const Component = React.lazy(() => import("./Component"))
const App = () => (
Загрузка...
```
} >
)Используя Suspense, мы можем показывать другой компонент в процессе, пока загружается необходимый. Это даёт нам возможность консистентно обрабатывать загрузку. При этом пользователь понимает, что скоро будет отображён необходимый блок приложения.
Пример самого популярного подхода к оптимизации с разделением приложения на страницы:
```
const Home = React.lazy(() => import(“./Home”))
const Profile = React.lazy(() => import(“./Profile”))
const App = () => (
Загрузка...} >
)
```
У React.lazy есть недостаток, который не позволяет использовать такой компонент в серверном рендеринге. Для этого потребуется воспользоваться аналогом, например, Loadable Components.
Но команда React не стоит на месте — недавно они показали Server Components или zero-bundled components. Это компоненты, которые не попадут в сборку, а будут выполняться на сервере, и результат выполнения в виде куска Virtual DOM будет отправлен на клиент. Пока Server Components только ждут релиза и мы можем попробовать их в тестовой сборке React или в последней версии NextJS.
### NextJS
Хотя NextJS часто называют инструментом для серверного рендеринга, я очень рекомендую попробовать его для разработки SPA, так как в нем из коробки собраны практически все основные оптимизации скорости загрузки, а именно:
#### SSG
Static Site Generation позволяет в процессе сборки отрендерить каждую страницу приложения. Как результат, при первой загрузке страницы браузер получит HTML, в котором уже будет контент, и моментально его отрендерит. Поэтому даже не важно, сколько JS кода будет загружено, — пользователь сразу увидит страницу. Это даёт ощущение, что приложение грузится очень быстро. А с оптимизированным JS бандлом вы получите идеальный результат.
#### Routing with pre-fetch
NextJS сразу идёт со встроенным роутером, который реализован в виде файлов. Это даёт более чистую структуру проекта и автоматическое разделение проекта на чанки-страницы.
Основная фишка этого роутера в том, что в нём уже настроен pre-fetch. Он позволяет загрузить чанки страниц до того, как пользователь попадёт на эти страницы. Когда ссылки на внутренние ресурсы попадают во viewport или на них наведён курсор мыши, они автоматически начинают скачиваться и для пользователя открываются мгновенно.
#### Image, Font and Scripts optimization
Встроенные оптимизации картинок, шрифтов и подключаемых скриптов направлены на ускорение загрузки страниц. Ничего не придется настраивать, нужно только воспользоваться предоставленным API.
### Бизнес логика и менеджмент состояния
Если мы имеем большое приложение, то скорее всего в нём есть центральное состояние с различными обработчиками, например, Redux и Redux Saga.
Как мы знаем, центральное состояние мы регистрируем на самом верхнем уровне приложения. Важно не забыть о нём и разделить бизнес логику совместно с отделяемыми компонентами SPA.
Для Redux существует множество решений для применения Code-Splitting. Если вы используете в своём приложении Mobx, то вам повезло, так как он разделим из коробки — достаточно позаботиться о правильной архитектуре состояния.
Как реализовать Code-Splitting в других библиотеках и фреймворках? Очевидный лайфхак — найти раздел документации, посвящённый code-splitting. Основная цель любого фреймворка Angular, Vue, React, Svelte — ускорить и оптимизировать загрузку приложений, достаточно только найти документацию о том, как правильно это делать.
Вышеописанные подходы могут быть применимы в любом другом стеке.
Как замерять и контролировать размер приложения
-----------------------------------------------
Закроем тему кратким обзором на инструменты, которые помогут замерять размер бандла и контролировать процесс оптимизации.
### Lighthouse
Основная утилита для анализа вашего приложения. Lighthouse встроен в браузер Chrome и показывает в виде 100-балльной шкалы основные показатели оценки приложения. Под оценками будут располагаться советы и рекомендации для достижения высоких результатов.
Также у Lighthouse есть CLI версия, которую можно интегрировать в CI/CD и замерять показатели каждой новой сборки автоматически.
### Webpack Bundle Analyzer
Плагин для Webpack анализирует итоговую сборку приложения и выводит результат в виде страницы, где отображены все чанки приложения и компоненты.
Он поможет найти модули с большим размером — это даст информацию о том, что в первую очередь стоит оптимизировать.
### Source-map-explorer
И последний инструмент — source-map-explorer.
С его помощью вы сможете посмотреть, из каких компонентов состоят ваши чанки. Этот инструмент даёт информацию о размере приложения немного под другим углом, так как он парсит map файл и показывает результат в виде структуры проекта.
На этом всё — буду рад ответить на вопросы. | https://habr.com/ru/post/595307/ | null | ru | null |
# Алгоритмы поиска объема и центра масс многогранника
Наверное, все знают этот алгоритм, но от меня «власти скрывали». Нашел его словесное описание на третьей странице поисковика в архиве автопереводов англоязычного форума. Мне кажется, его подробное описание (и с кодом) достойно хабростатьи.
Итак, например вам надо генерировать мобов для игрушки и где-то в процессе отсеивать тех, кто не стоит на ногах. Для этого нужно найти центр масс моба (а это почти то же самое, что найти его объем) и убедиться, что он находится где-то над ногами моба.

Моб — это многогранник, для простоты считаем, что многогранник состоит только из треугольников (в алгоритме внутри сидит [формула площади Гаусса](https://ru.wikipedia.org/wiki/%D0%A4%D0%BE%D1%80%D0%BC%D1%83%D0%BB%D0%B0_%D0%BF%D0%BB%D0%BE%D1%89%D0%B0%D0%B4%D0%B8_%D0%93%D0%B0%D1%83%D1%81%D1%81%D0%B0), так что можно расширить его для любого многогранника, но зачем...). Кроме того, многогранник должен не иметь самопересечений и ограничивать замкнутый объем, как и положено приличным многогранникам.

*(ну типа такого)*
Маленький UPD, поясняющий, почему на КДПВ правый моб Не Ок, а левый Ок:
Правая картинка не Ок потому что моб завалится вперед, т.к. его центр масс вынесен за площадь опоры. Площадь опоры стоящего на поверхности многоугольника определяется как минимальный многоугольник, внутри которого окажутся все точки, находящиеся на поверхности. В левом случае площадь опоры сдвинута под центр масс и больше (т.к. динозаврские лапы больше), а на правой картинке сама площадь меньше и ближе к хвосту.
Соотношение опорной площади и центра масс будет примерно такое:

Сразу начну с кода поиска объема (Python, входные данные — список точек и матрица переходов):
**немного кода**
```
def RecSetDirsTriangles(para, Connects, TR):
"""рекурсивная функция, которая принимает на вход ребро и по нему выбирает направление треугольника"""
#1.найти треугольник включающий пару, убедиться, что такого еще нет
for i in range(0,len(Connects)):
if i != para[0] and i != para[1] and Connects[i][para[0]] and Connects[i][para[1]]: #вот этот треугольник!
fl = 1
for T in TR:
if i in T and para[1] in T and para[0] in T:
fl = 0 #этот треугольник уже обработан
break
if fl: #найден треугольник!
TR += [(para[1],para[0],i)]
Recc((para[0], i) , Connects, TR)
Recc((i, para[1]) , Connects, TR)
def FindV(dots, Connects):
"""ищем объем. Входные данные - dots список вершин многогранника вида [x, y, z], Connects - квадратная матрица, Connects[i][j]=1 если есть связь между вершинами i, j, иначе =0 """
#1. сделать треугольники с упорядоченными вершинами
TR = []
for i in range(1,len(Connects)):#выбираем первый треугольник с нулевой точкой и еще каким-то
if Connects[i][0]:
for j in range(i+1, len(Connects)):
if Connects[0][j] and Connects[i][j]:
TR += [(0,i,j)]
break
RecSetDirsTriangles((0,i),Connects, TR)
break
print("найдено треугольников: ", len(TR))
#2. посчитать площадь базы и объем усеченной призмы
V = 0
for T in TR:
'''Гаус рулит: x1y2 x2y3 x3y1 x2y1 x3y2 x1y3'''
S = 0.5 * (dots[T[0]][0]*dots[T[1]][1] + dots[T[1]][0]*dots[T[2]][1] + dots[T[2]][0]*dots[T[0]][1] - dots[T[1]][0]*dots[T[0]][1] - dots[T[2]][0]*dots[T[1]][1] - dots[T[0]][0]*dots[T[2]][1])
#S может быть + или - в зависимости от того, как направлен треугольник
V += S*(dots[T[0]][2] + dots[T[1]][2] + dots[T[2]][2])/3 #объем усеченной призмы считается просто...
return math.fabs(V)
```
Суть алгоритма — считаем объемы фигур, которые образуют «падающие» на плоскость xy грани многогранника. Для этого надо знать площадь проекции треугольника и знак, с которым надо суммировать объем фигуры (усеченнной призмы). На самом деле, если заранее упорядочить треугольники, и объем и знак сводятся к одному вычислению.
Поэтому первым делом рекурсивная функция собирает треугольники из входных данных. Собирает таким образом, чтобы при взгляде «снаружи» на многогранник, направления обхода треугольников были одинаковыми (в идеале против часовой стрелки; если взять направления по часовой стрелке, то результат получится правильным, но отрицательным — поэтому в ретурн отдается модуль объема).
Добиться этого очень просто — берем какой-то треугольник (точки a1, a2, a3), ищем его соседей и перечисляем две совпавшие вершины в обратном порядке (например, так: a2, a1, b1).
Получается что-то вроде этого:

Теперь, если мы спроецируем такой треугольник на плоскость xy, то порядок обхода для проекции «верхнего» треугольника будет совпадать с изначально выбранным, а порядок обхода для проекци «нижнего» треугольника поменяет свое направление. Как следствие, поменяет знак и площадь этого треугольника, вычисленная по формуле Гаусса. Здесь «нижний» треугольник — понятие условное — имеется ввиду, что объем непосредственно под ним не входит в объем многогранника. «Нижний» треугольник у невыпуклого многогранника может быть выше «верхнего».
После этих предварительных действий, чтобы вычислить полный объем многогранника, надо просто сложить (с учетом знака, который получается «сам собой») все объемы усеченных призм, собранных из граней и проекций этих граней на плоскость xy. А объемы призм считаются как произведение площади (по Гауссу, со знаком) и среднего арифметического z-координат вершин треугольника.
Если многогранник пересекается плоскостью xy, то при вычислении объема, все знаки скомпенсируют друг друга и результат остается правильным (надо только брать высоты призмы без модуля).

*(как-то так выглядит «верхняя» усеченная призма)*
С поиском центра масс все приблизительно также. Аналогично надо найти центры масс для каждой усеченной призмы и просуммировать покоординатно, умножая на объем призмы (предполагается, что масса распределена равномерно по объему и можно одно заменить другим). Чтобы найти центр масс усеченной призмы, придется посчитать центры масс двух тетраэдеров (+1 функция) и одной обычной призмы. Алгоритм так же «не портится», если многогранник пересекает плоскость xy (а здесь могла бы быть репродукция Магритта).

*(вот эти два тетраэдера, обозначены красным и рыжим, вместе с треугольной призмой (ниже красного тетраэдера) образуют искомую усеченную призму. Нам надо найти центры масс и объемы всех трех фигур. Обозначения примерно соответствуют обозначениям в коде)*
Код, который считает то и то:
**чуть больше кода**
```
def RecSetDirsTriangles(para, Connects, TR):
#1.найти треугольник включающий пару, убедиться, что такого еще нет
for i in range(0,len(Connects)):
if i != para[0] and i != para[1] and Connects[i][para[0]] and Connects[i][para[1]]: #вот этот треугольник!
fl = 1
for T in TR:
if i in T and para[1] in T and para[0] in T:
fl = 0
break
if fl: #найден треугольник!
TR += [(para[1],para[0],i)]
Recc((para[0], i) , Connects, TR)
Recc((i, para[1]) , Connects, TR)
def TetrV(mas):#dot1, dot2, dot3, dot4):
"""объем тетраэдера по вершинам"""
M = np.zeros((3,3),float)
for i in range(1,4):
for j in range(0,3):
M[i-1][j] = mas[i][j] - mas[0][j]
#print(M)
return math.fabs(np.linalg.det(M)/6)
def FindVandCM(dots, Connects):
"""ищем объем и центр масс многогранника"""
#1. сделать треугольники с упорядоченными вершинами
TR = []
for i in range(1,len(Connects)): #выбираем первый треугольник с нулевой точкой и еще каким-то
if Connects[i][0]:
for j in range(i+1, len(Connects)):
if Connects[0][j] and Connects[i][j]:
TR += [(0,i,j)]
break
RecSetDirsTriangles((0,i),Connects, TR)
break
print("найдено треугольников: ", len(TR))
#2. посчитать площадь базы, объем усеченной призмы и вклад в центр масс каждого
V = 0
CM = [0, 0, 0]
for T in TR:
'''Гаус рулит: x1y2 x2y3 x3y1 x2y1 x3y2 x1y3'''
S = 0.5 * (dots[T[0]][0]*dots[T[1]][1] + dots[T[1]][0]*dots[T[2]][1] + dots[T[2]][0]*dots[T[0]][1] - dots[T[1]][0]*dots[T[0]][1] - dots[T[2]][0]*dots[T[1]][1] - dots[T[0]][0]*dots[T[2]][1])
#S может быть + или - в зависимости от того, как направлен треугольник
V += S*(dots[T[0]][2] + dots[T[1]][2] + dots[T[2]][2])/3 #объем усеченной призмы считается просто...
#c центром масс я так просто не отделаюсь
c1 = ((dots[T[0]][0] + dots[T[1]][0] + dots[T[2]][0])/3, (dots[T[0]][1]+ dots[T[1]][1]+ dots[T[2]][1])/3) #центральная точка проекции треугольника
hm = min([dots[T[0]][2] , dots[T[1]][2] , dots[T[2]][2]])
hM = max([dots[T[0]][2] , dots[T[1]][2] , dots[T[2]][2]])
indM = [dots[T[0]][2] , dots[T[1]][2] , dots[T[2]][2]].index(hM)
indm = [dots[T[0]][2] , dots[T[1]][2] , dots[T[2]][2]].index(hm)
V3 = S * hm
if indM == indm: #горизонтальный прямоугольник!
CM[0] += V3*c1[0]
CM[1] += V3*c1[1]
CM[2] += V3*hm/2
continue
L = [0,1,2]
L.remove(indM)
L.remove(indm)
indmidle = L[0]
dots1 = [dots[T[0]], dots[T[1]], dots[T[2]], (dots[T[indM]][0], dots[T[indM]][1] , hm)] #верхний тетраэдер
V1 = TetrV(dots1)
if S < 0:
V1 = -V1
V2 = S * ( dots[T[indmidle]][2] - hm)/3
#V3 = S * hm
CM[0] += V1*((dots[T[0]][0] + dots[T[1]][0] + dots[T[2]][0] + dots[T[indM]][0])/4) + V2*((dots[T[0]][0] + dots[T[1]][0] + dots[T[2]][0] + dots[T[indmidle]][0])/4) + V3*c1[0]
CM[1] += V1*((dots[T[0]][1] + dots[T[1]][1] + dots[T[2]][1] + dots[T[indM]][1])/4) + V2*((dots[T[0]][1] + dots[T[1]][1] + dots[T[2]][1] + dots[T[indmidle]][1])/4) + V3*c1[1]
CM[2] += V1*((dots[T[0]][2] + dots[T[1]][2] + dots[T[2]][2] + hm)/4) + V2*((dots[T[0]][2] + dots[T[1]][2] + dots[T[2]][2] + hm)/4) + V3*hm/2
CM[0] = CM[0]/V
CM[1] = CM[1]/V
CM[2] = CM[2]/V
return (math.fabs(V), CM)
```
Кусок алгоритма, где считаются направления треугольников и используются для понимания внешнего и внутреннего объема — это очень сильный ход, его много как можно применить при работе с многогранниками. Например, если надо посчитать направление нормалей «наружу» — достаточно знать направление «против часовой стрелки» для одной грани — и вуаля!

*(угадай фильм!)* | https://habr.com/ru/post/479290/ | null | ru | null |
# Mockанье зависимостей в node.js приложениях
Mocks, fakes, and stubs — три столпа юнит тестирования. Конечно же все знают что это такое, как солить и когда есть. Я честно тоже так думал, пока не столкнулся с действительностью, под которую мне пришлось немного прогнуться.
Все началось очень просто — я сменил место работы, и первое что я увидел в новой кодовой базе — это тесты, их было немного больше чем кода. И посреди этих тестов была странная конструкция
```
Component = proxyquire.noCallThru().load(‘../Component’, {
‘../../core/selectors/common': { getData }
}).default;
```
Для справки:
> proxyquire — одна из самых популярных, и одна и самых старых библиотек для моканья зависимостей. Кроме нее сейчас на слуху inject-loader, rewire, mockery и другие. Под "старая" подразумевается, что рассчитана на "старый" node.js код. Никаких es6 imports.
Для тех кто в танке, и не до конца понимает, что тут происходит — все очень просто. Proxyquire загрузит нам измененный ../Component, у которого один из импортов будет перекрыт нашим stubом.
Зачем? Это отличный способ сделать юнит тест чуть более юнит, сведя количество неконтролируемых внешних зависимостей к нулю. Или просто облегчить тестирование временно убрав сложную, или не нужную логику из приложения.
И все бы хорошо, только конкретно этот код — не работал. В имени файла была допущена ошибка, надо было еще на одну директорию вверх светить. А допущена ошибка была по еще более прозаической причине — сам проект использовал webpack-aliasы, адресуя все файлы от рута, а proxyquire работал с файлами после прохода по ним babel, где все пути были относительные.
Представим что у вас есть код
```
import something from 'something/else';
```
Он вроде бы очень простой и понятный, только something на самом деле something2.default, а сам файл может быть его угодно — бабель содержит много магии.
Именно так и началась эта эпопея. С попытки добавить поддержку алиасов в proxyquire.
1. Решение №1. Первая встреча
=============================
Первое решение, которое пришло в голову — добавить старому proxyquire немного мозгов. Его проблема вообще [очень проста](https://github.com/thlorenz/proxyquire/blob/master/lib/proxyquire.js#L144)
```
Proxyquire.prototype._require = function(module, stubs, path) {
//….
if (hasOwnProperty.call(stubs, path)) {
var stub = stubs[path];
```
Ему просто требуется точное соответствие имени подключаемого модуля и записи в списке на перегрузку.
> ./foo, ./foo.js, ../common/foo — это может и один файо, но три разных строки.
За 5 минут в это место было добавлено немного мозгов, и еще через 5 минут на гитхабе на [один PR](https://github.com/thlorenz/proxyquire/pull/148) стало больше. Еще через 5 минут он был безжалостно закрыт, с просьбой не добавлять излишние мозги сюда, а найти им другое место.
2. Решение №2. Настоящие герои всегда идут в обход
==================================================
В принципе не только ребята из Proxyquire были не в восторге от решения. Я получил еще пару предложений из ближайшего окружения по альтернативным вариантам решения проблемы.
Если кратко, то смысл был простой — достаточно написать простую функцию, которая из некого fileName1 создает некий fileName2, так чтобы первый был с алиасом, а второй уже был в “правильной” форме для proxyquire.
Не пытаться изменить сам proxyquire, но написать что-то типа
```
proxyquire.load(‘../Component’, addSomeMagic({
'something/with/alias':{}
}))
```
так, чтобы в сам proxyquire пришли правильные имена, без алиасов, но относительно исходному файлу.
Тут следует остановиться на маленькой магии proxyquire. Почти никто не задумывался, почему он работает.
```
Component = proxyquire.noCallThru().load(‘../Component’, {
```
Откуда proxyquire знает текущую директорию, и технически может загрузить файл относительно нее? И почему в тестах *необходимо* подключать proxyquire напрямую, или ничего работать не будет?
Разгадка проста — proxyquire использует информацию, которую node.js передает ему через переменную module. В module.parent хранится информация о том кто *первый* открыл этот файл. Остается только не забыть себя [стирать из кеша модульной системы](https://github.com/thlorenz/proxyquire/blob/master/index.js#L6), чтобы каждый раз был как… в первый раз.
В общем разработка решения, которое бы не требовало модификаций proxyquire, ознакомило меня со многими ньюасами работы node.js.
В итоге я так и не смог ничего сделать — нормальное решение требовало модификаций исходной библиотеки. Тупик.
3. Решение №3. Мир не стоит на месте
====================================
Параллельно с этим работа кипела. И, в попытках сделать себе жизнь чуть проще, я все пытался улучшить исходный proxyquire, так как от его использоваться отказаться было сложно. Я опять начал генерировать пул-реквесты.
* [Первый из них](https://github.com/thlorenz/proxyquire/pull/163), который в принципе хоть как-то позволял расширять библиотеку (банально включил обратно наследование), был неожиданно быстро апрувлен.
* [Второй](https://github.com/thlorenz/proxyquire/pull/165), который защищал “nonProjectFiles” от стирания из кеша, был так же шустро закрыт.
* [Третий](https://github.com/thlorenz/proxyquire/pull/164), который добавлял так называемый “режим изоляции”, когда требовалось чтобы или все stubs были использованы(защищает от ошибок в их именах), или все зависимости были перекрыты (идеальный юнит тест в вакууме), висит без движения уже две недели :(
Параллельно с этим, с целью опробовать решения на практике и вообще доказать их эффективность, велась работа над
* [proxyqure-2](https://github.com/theKashey/proxyquire) — личным форком исходной библиотеки, в которой вмержены просто все желаемые фиксы,
* [proxyquire-webpack-alias](https://github.com/theKashey/proxyquire-webpack-alias) — drop-in заменой proxyquire, с полной поддержкой webpack алиасов, без которых жизнь мне не мила. Одно плохо — для своей работы требует тот самый мой форк строчкой выше.
* [resolveQuire](https://github.com/theKashey/resolveQuire) — та самая библиотекой из решения №2, которую я все-таки доделал до конца, и которая может работать на оригинальной proxyquire, и которое не смотря на свою “фунциональную” красоту, проигрывает таки двум верхним решения в некоторых моментах.
Имхо, я могу как рекомендовать вам использовать что-либо из этого списка заместо proxyquire, так и просто ознакомиться с различиями в реализации, для лучшего понимания вопроса.
4. Ретроспектива
================
Как только я защитил перед коллегами свой вариант, а заодно вылечил не только свою, но [и их давнюю боль](https://github.com/theKashey/proxyquire-webpack-alias#your-own-setup), встал вопрос — а что дальше? Хотя лучше спросить — что раньше?
Я пытался вспомнить как же мы мокали зависимости в моем прежнем месте работы. Это было сложно, потому что не мокали. Да и вообще опрос дельты окрестностей показал очень простую картину мира.
> Никто не мокает. sinon, fetch-mock не считается, это перехват не зависимости, а локальных или глобальных переменных.
У нормальных людей — нормальный DI.
Тогда я попробовал вспомнить как можно было вообще мокать зависимости в среде исполнения js кода на моем прежнем месте работы, где я провел лучшие годы своей молодости,
* модульной системе [ym](https://github.com/ymaps/modules) и сборщике [ymb](https://github.com/yandex/ymb).
Для тех кто не знаком с этим очень интересным CommonJS/AMD совместимым решением, родом из Яндекс.Карт, есть [парочка](https://www.slideshare.net/yandex/api-41873486) [презентаций](http://2013.happydev.ru/report/21.html) про нее.
В общем там было все очень просто:
```
// Определяем модуль А, зависящий от модуля Б
module.define(‘a’,[‘b’], (provide,b) => {});
// загружаем модуль А, Б загрузится по сети
module.require(‘a’);
```
А если нужно перекрыть зависимость
```
module.define(‘b’,[], (provide) => {});
// Определяем модуль А, зависящий от модуля Б
module.define(‘a’,[‘b’], (provide,b) => {});
// загружаем модуль А, Б уже есть, им и воспользуемся
module.require(‘a’);
```
Просто, и можно даже сказать — естественно.
Как же работают различные решения для моканья файлов на родной для node.js модульной системе?
* как [inject-loader](https://github.com/plasticine/inject-loader) — webpack загрузчик, который физически меняет исходный файл так, как требуется. (+[rewire](https://github.com/jhnns/rewire))
* как [mockery](https://github.com/mfncooper/mockery) — через перегрузку Module.\_load. Самого первого системного метода, который `находится` сразу за require.
* как [proxyquire](https://github.com/thlorenz/proxyquire) — через перегрузку require.extensions handlers. Технически самого нижнего уровня.
Разница очень проста:
* inject-loader выдает реальный, но немного другой файл. Никаких патчей node.js
* mockery работает “так высоко”, что результат ее работы не кешируется.
* а вот proxyquire работает ниже кеша.
Если вы в начале замокаете файл, а потом запросите его еще раз — получите свой мок. Лечиться через noPreserveCache, но кто об этом догадается?
И везде есть некоторые ньюансы, реализации, которые немного усложняют жизнь:
* inject-loader — работает только для непосредственных зависимостей.
* mockery — каждый раз трет весь кеш начисто, что пагубно сказывается на скорости.
* proxyquire — содержит очень много сюрпризов.
5. Финальное решение
====================
Итак — у меня был свой proxyquire, знание дюжины других библиотек, анализ проблемы с разных сторон и хорошее понимание технической задачи. Цель была простая — one ring to rule them all.
Как исходный вариант, максимально удовлетворяющий чувству прекрасного был взял [mockery](https://github.com/mfncooper/mockery).
Почему:
* разделение определения перехватов и самого перехвата. registerMock/enable.
* наличие режима изоляции. warnOnUnregistered/registerAllowable
* наличие режима замены. registerAllowable
Итогом стала библиотека [rewiremock](https://github.com/theKashey/rewiremock), которая удовлетворяет всем моим хотелкам, и из коробки может решать все задачи.
```
import rewiremock from 'rewiremock';
...
// totaly mock `fs` with your stub
rewiremock('fs')
.with({
readFile: yourFunction
});
// replace path, by other module
rewiremock('path')
.by('path-mock');
// replace default export of ES6 module
rewiremock('reactComponent')
.withDefault(MockedComponent)
// replace only part of some library and keep the rest
rewiremock('someLibrary')
.callThought()
.with({
onlyOneMethod
})
…
rewiremock.enable();
rewiremock.isolation();
rewiremock.passBy(/node_modules/);
// use native require
const module = require(‘../core/somemodule’);
// or add some magic….
const module = require(rewiremock.resolve(‘core/module’));
```
Она позволяет определять моки в отдельных файлах, "умно" трет кеш только для перекрытых файлов (и файлов которые их используют), поддерживает RegEx в passBy сетапе изоляции, имеет крайне простой api и всегда будет работать так как требуется.
Весь секрет в плагинах, которые позволяют управлять поведением библиотеки в нужных местах.
Описывать детали реализации думаю не стоит, все желающие могут сами покопаться к коде, или тестах, а заодно высказать все что угодно посредством комментариев.
Или пулреквестов, обещаю прислушаться.
→ <https://github.com/theKashey/rewiremock>
Вот так одна маленькая заноза, просто не принятие “кривости” активно используемого инструмента, привело к открытию микрониши моков, сильно более глубокому пониманию вопроса, 4-ем новым библиотекам. И возможно к чуть чуть более лучшему миру.
> PS: Никаких претензий к авторам proxyquire нет. Почему? <https://habrahabr.ru/post/328412/> | https://habr.com/ru/post/329740/ | null | ru | null |
# Деплой Django проекта на Heroku
Напишу вам небольшой гайд, как деплоить Django приложения на Heroku и некоторые тонкости,которые стоит знать.
Heroku - это облачный сервис, позволяющий разместить ваше приложение. Heroku поддерживает несколько языков программирования, в том числе и любимый нами Python :)
Кроме написанного кода, Heroku позволяет добавить аддоны к вашему приложению. С полным списком аддонов вы можете ознакомиться на [официальном сайте](https://elements.heroku.com/addons), а я расскажу о том, как подключить к приложению базу данных PostgreSQL
### Что нам понадобится:
* Аккаунт на сайте [Heroku](https://signup.heroku.com/php)
* Клиент [Heroku](https://devcenter.heroku.com/articles/heroku-cli)
* Система контроля версий Git
* Ну и собственно наш проект на Django
Для начала посмотрим на структуру нашего проекта:
* Project\_name
+ asgi.py
+ settings.py
+ urls.py
+ wsgi.py
* App\_name
+ migrations
+ templates
+ static
+ admin.py
+ apps.py
+ models.py
+ views.py
* manage.py
* Procfile
* requirements.txt
* runtime.txt
Проект в данном случае содержит только одно приложение, у вас же их может быть сколько угодно. На этом подробно останавливаться не буду. Как создавать Django приложения можете узнать в [документации](https://docs.djangoproject.com/en/4.1/intro/tutorial01/) ну или например [в этом гайде](https://metanit.com/python/django/1.4.php)
А теперь перейдём к тем непонятным файлам из конца списка:
### requirements.txt
Начнем с файла requirements.txt. В нём указаны все дополнительно установленные модули. Для работы нашего приложения, нам понадобится установить несколько таких:
* Django
* psycopg2 (модуль для работы с СУБД PostgreSQL)
* gunicorn (веб сервер для запуска приложений на Python)
* whitenoise (нужно, чтобы веб сервер мог обслуживать статические файлы)
* \*Другие модули, для работы вашего приложения
Все эти модули должны быть установлены в вашем [виртуальном окружении](https://python-scripts.com/virtualenv). Теперь для создания файла с требованиями воспользуемся встроенной командой пакетного менеджера pip. Необходимый нам файл будет создан в текущей директории
```
pip freeze > requirements.txt
```
### Procfile
Наш следующий кандидат - Procfile. В нем определяют команды для запуска самого приложения. Здесь просто добавьте следующий код:
```
web: gunicorn Project_Name.wsgi --log-file
```
Вместо "Project\_Name" впишите название вашего Django проекта
### runtime.txt
Наш последний испытуемый. Здесь нужно прописать используемую версию Python.Например:
```
python-3.8.5
```
Обратите внимание, что можно указать только одну из поддерживаемых Heroku версий языка. Если указать просто python-3.8, то проект не запустится. Список поддерживаемых Heroku версий языка Python [здесь](https://devcenter.heroku.com/articles/python-support#supported-runtimes)
### Настройка конфигурации settings.py
В настройках проекта необходимо сделать несколько изменений:
**1.** Установить DEBUG = False
```
DEBUG = bool(os.environ.get('DJANGO_DEBUG', True))
```
Что здесь происходит и зачем оно всё надо? Объясняю: в переменные окружения мы добавим значение DJANGO\_DEBUG="" (пустую строку), что сделает значение переменной DEBUG равным False, иначе, если в переменной окружения нет такой переменной (в случае с запуском для разработки), DEBUG будет установлен в True. Это избавит нас от головной боли, когда после разработки забываешь сменить значение с True на False и заливаешь всё на сервер.
**2.** Добавить домены в список ALLOWED\_HOSTS (впишите название своего приложения heroku):
```
ALLOWED_HOSTS = ['your-app-name.herokuapp.com','127.0.0.1']
```
**3.** Добавить путь к папке, где будут храниться статические файлы (STATIC\_ROOT) и префикс URL адреса для получения статических файлов (STATIC\_URL)
```
STATIC_URL = 'static/'
STATIC_ROOT = os.path.join(BASE_DIR, 'static/')
```
**4.** Скрыть секретный ключ, сформированный Django. Позже мы добавим его в переменные окружения.
```
SECRET_KEY = os.environ.get('SECRET_KEY', 'cg#p$g+j9tax!#a3cup@1$8obt2_+&k3q+pmu)5%asj6yjpkag')
```
Если в переменных окружения будет находиться SECRET\_KEY, он будет взят оттуда, иначе используется ключ, переданный вторым параметром. Но так как этот ключ прописан в исходном коде приложения, его используем только для разработки.
**5.** В переменную MIDDLEWARE добавить новый слой (добавить нужно второй слой из указанных, первый и третий используются в django по умолчанию) Важно соблюдать порядок слоёв.
```
MIDDLEWARE = [
...
'django.middleware.security.SecurityMiddleware',
'whitenoise.middleware.WhiteNoiseMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
...
]
```
**6.** Установить настройки для подключения к БД. Как создать БД и где найти все данные для подключения будет рассказано чуть ниже.
```
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'HOST' : os.environ.get('POSTGRES_HOST', 'localhost'),
'NAME': os.environ.get('POSTGRES_DB', 'db_name'),
'USER': os.environ.get('POSTGRES_USER', 'username'),
'PASSWORD': os.environ.get('POSTGRES_PASSWORD', 'password'),
'PORT': os.environ.get('POSTGRES_PORT', '5432'),
}
}
```
Создание базы данных на сервере Heroku
--------------------------------------
Для начала создадим новое приложение на сайте [Heroku](https://dashboard.heroku.com/apps)
Откроем страницу нашего приложения и на вкладке Resources нажмем "add more add-ons"
В списке аддонов находим Postgres
 Жмём "install heroku postgres"
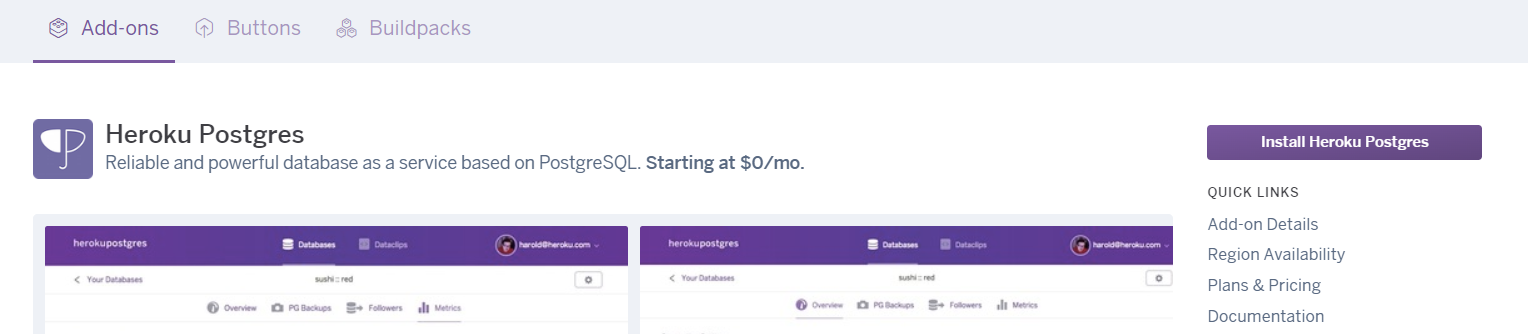Выбираем бесплатный вариант и вводим название созданного приложения heroku
База данных создана и привязана к приложению. В списке аддонов вашего приложения находим Heroku Postgres и жмём на ссылку
 Переходим на вкладку Settings и жмём кнопку "View Credentials..."
 И вот, все необходимые для подключения данные
 Теперь к базе данных можно подключиться используя, к примеру pgAdmin4.
Как подключиться к удаленному серверу через pgAdmin4 можете прочесть [здесь](https://stackoverflow.com/questions/11769860/connect-to-a-heroku-database-with-pgadmin).
Уточню лишь пару моментов:
1. "SSL mode" нужно установить в Require
2. В "DB restriction" нужно добавить название базы данных (строка 'Database' на изображении выше)
А теперь переходим в консоль!
-----------------------------
Выполним авторизацию в Heroku
```
heroku login
```
Добавим в переменный окружения данные для подключения к Postgres и SECRET\_KEY. Звездочки меняем на данные для вашей БД, а вопросики на название вашего приложения на Heroku
```
heroku config:set DJANGO_DEBUG='' -a ?????
heroku config:set SECRET_KEY=***** -a ?????
heroku config:set POSTGRES_HOST=***** -a ?????
heroku config:set POSTGRES_DB=***** -a ?????
heroku config:set POSTGRES_USER=***** -a ?????
heroku config:set POSTGRES_PASSWORD=***** -a ?????
heroku config:set POSTGRES_PORT=***** -a ?????
```
### Второй вариант указания настроек БД:
Heroku рекомендует использовать библиотеку [dj-database-url](https://pypi.org/project/dj-database-url/). Если аддон базы данных подключен к вашему приложения, в ваших переменных окружения по умолчанию присутствует переменная DATABASE\_URL. Она уже содержит данные для подключения в следующем формате: postgres://USER:PASSWORD@HOST:PORT/NAME
Для использования
1. Устанавливаем пакет *dj-database-url*
2 В настройках settings.py оставляем настройки подключения к БД без изменений (эти настройки в дальнейшем будут использоваться для разработки), дополнительно прописываем:
```
import dj_database_url
db_from_env = dj_database_url.config(conn_max_age=500)
DATABASES['default'].update(db_from_env)
```
Значение `conn_max_age=500` делает соединение постоянным, что намного эффективнее, чем воссоздавать соединение в каждом цикле запросов. Однако это необязательно и при необходимости можно удалить.
( Не забываем добавить пакет в requirements.txt )
---
Теперь переходим в папку с вашим проектом и выполним следующие команды:
```
heroku git:remote -a ?????
git add .
git commit -m "Deploy to Heroku"
git push heroku master
```
(\*Если ваша ветка имеет другое название, то указываете его)
Первая команда укажет с каким приложением Heroku вы хотите работать. Вторая добавляет в коммит все изменения в проекте. Третья создаёт коммит. Четвертая отправляет проект на сервер Heroku
Происходит процесс загрузки проекта на Heroku, ждём завершения и ~~радуемся победе!~~ продолжаем! Вы уже на финишной прямой! Нужно выполнить миграции и создать суперпользователя:
```
heroku run python manage.py migrate
heroku run python manage.py createsuperuser
```
А теперь можем идти открывать шампанское, ведь мы закончили. Осталось найти ссылку на странице вашего приложения и вуоля!
Надеюсь эта статья будет кому-то полезна и вы не будете наступать на грабли, на которые наступил я. Пишите комментарии, хвалите, критикуйте, осуждайте))
Более подробно о всех этапах написано [тут](https://developer.mozilla.org/ru/docs/Learn/Server-side/Django/Deployment), если остались вопросы, рекомендую ознакомиться
Всем удачного кодинга! | https://habr.com/ru/post/683796/ | null | ru | null |
# Сделаем код чище: Специальные расширения vsnprintf() в ядре Linux
Смотря на кучу исходного кода, который засылают программисты в списки рассылки подсистем ядра Linux иногда хочется плакать. С одной стороны бывает ужасный и непотребный код, с другой — люди, возможно, впервые пытаются что-то сделать для ядра, поэтому не знают всех его особенностей.
Книга Linux Device Drivers устарела, а новая версия выйдет нескоро. Поэтому мне хочется заполнить пробелы в знаниях тех программистов, которые пишут код в ядро.
В данном материале я расскажу о специальных расширениях функции печати в ядре Linux. Не смущайтесь, что я в заголовок вынес традиционное её имя в основной библиотеке Си, в ядре чаще используется `printk()` и макросы вокруг неё.
Итак, за основу я возьму ванильное ядро версии **4.0-rc2**. Рассматривать стандартные спецификаторы я не буду, любой желающий может прочитать printf(3).
Все специальные расширения приходятся на спецификатор **%p**. По умолчанию он печатает адрес памяти, на которую ссылается указатель. В ядре же зачастую хочется сделать что-то гораздо большее и специфичное. Для этого решили пойти путём добавления модификаторов к спецификатору, таким образом в общем случае спецификатор выглядит следующим образом:
```
%[длина поля]p[модификаторы в виде буквы, цифры или их сочетаний]
```
Ниже я попытался разбить все расширения на группы и дать краткие описания и иногда примеры.
### Указатели на специальные адреса
**%pK**
То же, что и **%p**, но проверяется kptr\_restrict sysctl, печатаются 0'и, если у пользователя недостаточно прав.
**%pa[pd]**
Печает указатель на адрес физической памяти или DMA (phys\_addr\_t, dma\_addr\_t) и наследованные типа resource\_size\_t. Передаётся по ссылке, например:
```
phys_addr_t pa;
dma_addr_t da;
pr_debug("Phys: %pa DMA: %pad\n", &pa, &da);
```
### Сетевые адреса
**%p[Mm][FR]**
Печатает MAC адрес, передаваемый по указателю на буфер. **M** — стандартный MAC адрес, **m** — без двоеточий, дополнительный модификатор **R** в реверсном формате (вначале печатается последний байт адреса).
```
u8 mac[ETH_ALEN];
pr_debug("%pMR\n", mac);
```
**%p[Ii]4[hnbl], %p[Ii]6[c], %p[Ii]S[pfschnbl]**
Печатает в различных комбинациях адреса IPv4 (\_\_be32 addr), IPv6 (\_\_be32 addr[4]) и struct sockaddr (автоопределение).
### Дамп буфера данных
**%\*pE[achnops]**
Печатает строку с экранированными символами. Флагами определяются классы символов, которые необходимо экранировать.
```
const char *buf;
int len;
pr_debug("Buffer: %*pE Buffer[0-5]: %6pE\n", len, buf, buf);
```
**%\*ph[CDN]**
Печатает дамп памяти (до 64 байт) в шестнадцатиричном виде. Модификаторами определяется разделитель: пробел по умолчанию, **C** — двоеточие, **D** — дефисы, **N** — без разделителя.
```
u8 data[100];
pr_debug("Buf: %*phC\n", (int)sizeof(data), data); /* only first 64 bytes! */
```
**%pU[Ll][Bb]**
Предназначена для вывода UUID (буфер длиной в 16 байт) в различных форматах. Модификаторы определяют размер букв (большие или маленькие) и порядок записи UUID: **B** или **b** — старшие байты вначале, **L** или **l** — младшие вначале.
**%\*pb[l]**
Выводит дамп битовых массивов и его наследников (cpumask, nodemask). Модификатор **l** определяет вывод дампа диапазонами. Поле длины определяет сколько бит в одном элементе битового массива.
### Содержимое структур, их полей и специальных типов данных
**%p[Rr]**
Печатает содержимое struct resource.
```
struct resource res;
pr_debug("%pR\n", &res);
```
**%pV**
Вывод данных, определяемых структурами va\_format и va\_list. По сути рекурсивный вызов `vsnprintf()` из-под себя самой. Обязательно проверяйте валидность параметров и аргументов в va\_format и va\_list!
**%pNF**
Спецификатор для типа netdev\_features\_t.
**%pd[234], %pD[234]**
Служит для печати пути и имени файла (struct dentry, поле d\_name.name). **2**,**3** или **4** ограничивает количество элементов пути (с конца). **%pD** то же самое, но для struct file (f\_path.dentry).
### Печать имени функции по адресу
**%p[Ff], %p[Ss][R], %pB**
Спецификатор может быть полезен для печати имени функции по адресу, например, узнать вызвавшую функцию.
### В будущем релизе
В **4.1-rc1** планируется включить дополнительные расширения.
**%pC[nr]**
Предназначен для вывода имени и частосты осциллятора, хранящихся в struct clk.
**%pT**
Выведет название текущего исполняемого процесса или задачи, определённой в struct task\_struct.
```
struct task_struct *task = known_task;
pr_debug("Current: %pT, given: %pT\n", NULL, task);
```
### Бонусы
Для вывода больших дампов буфера в шестнадцатиричном формате предназначена функция `print_hex_dump()`.
Для преобразования данных ASCII <—> binary служит набор таких функций:
```
/* В бинарный вид */
hex_to_bin(); /* полубайт */
hex2bin(); /* буфер */
```
Чтобы преобразовать из текстового вида MAC адрес, воспользуйтесь `mac_pton()`.
```
/* В ASCII формат */
hex_asc_lo(); hex_asc_hi(); /* полубайт */
hex_asc_upper_lo(); hex_asc_upper_hi(); /* то же, но большими буквами */
hex_byte_pack(); hex_byte_pack_upper(); /* байт */
bin2hex(); /* буфер */
hex_dump_to_buffer(); /* рабочее тело упоминаемой выше print_hex_dump() */
```
Удачной печати! | https://habr.com/ru/post/252453/ | null | ru | null |
# Облачные сервисы под высокой нагрузкой. Опыт Cackle
Всем привет! Мы, в компании [Cackle](http://cackle.ru), занимаемся разработкой облачных SaaS-решений для сайтов с 2011 года. Наши продукты установлены более чем на 10 000 сайтах, каждый день мы обрабатываем в среднем 65 миллионов уникальных хитов. Полоса пропускания (bandwidth) в пики доходит до 780 мбит/сек, а БД в сутки принимает до 120 миллионов запросов на чтение, и до 300 тысяч запросов на запись. Такие нагрузки заставляют изобретать непростые решения, частью которых мы и хотим поделиться.
[](http://habrahabr.ru/post/255013/)
Сначала пара слов о том, что мы вообще разработали, на каких технологиях и архитектуре всё базируется, откуда берётся высокая нагрузка. А далее – про 5 основных решений, которые мы применяем чтобы с этой нагрузкой справиться.
### Система комментариев
[Cackle Comments](http://cackle.ru/comments) – наш первый продукт, анонсированный в 2011 году.
Упрощает процесс комментирования за счёт удобной авторизации – анонимной, социальной или единой с вашим сайтом. Помогает привлечь больше трафика благодаря индексации в поисковиках, трансляции комментариев на стены социальных сетей (ВК, Мой Мир, Facebook, Twitter), подписке на новые комментарии и ответы. Снижает нагрузку за счёт независимости от вашего сайта.
[](http://cackle.ru/comments)
### Система отзывов для интернет-магазинов
[Cackle Reviews](http://cackle.ru/reviews) – система отзывов, релиз которой состоялся в 2013 году. Используется в основном интернет-магазинами, но без проблем работает на любом сайте.
Основные возможности:
* Загрузка отзывов с Яндекс.Маркета;
* Индексация в Google с микроразметкой «из коробки» ([рейтинг в результатах поиска](http://cackle.ru/static/img/review-seo.png));
* Follow-up рассылка писем с приглашением оставить отзыв после покупки;
* Удобная анонимная, социальная, единая авторизация;
* Трансляция отзывов в социальные сети: ВК, Мой Мир, Facebook, Twitter;
* Модерация отзывов в режиме реального времени;
* Комментарии к отзывам;
* СПАМ-защита;
* CMS плагины: [1С-Битрикс](http://marketplace.1c-bitrix.ru/solutions/cackle.reviews/), [Joomla (K2, Virtuemart, Zoo)](https://bitbucket.org/cackle-plugin/reviews-joomla/get/tip.zip), [OpenCart](https://bitbucket.org/cackle-plugin/review-opencart/get/tip.zip), [PrestaShop](https://bitbucket.org/cackle-plugin/review-prestashop/get/tip.zip).
[](http://cackle.ru/reviews)
### Online-консультант
[Cackle Live Chat](http://cackle.ru/chat) – онлайн-чат для посетителей сайта, релиз в 2013 году.
Из особенностей: быстрая установка, панель оператора реализована в браузере, не нужно тратить время на инсталляцию desktop-клиента. Социальная авторизация пользователей, при этом оператор получает информацию о клиенте (имя, фото, email, ссылку на профиль).
[](http://cackle.ru/chat)
### Виджет опросов
[Cackle Polls](http://cackle.ru/polls) – опросы с возможностью голосования через социальные сети, IP или Cookie, релиз также в 2013 году.
Опросы автоматически индексируются в Google, привлекая дополнительный трафик. Можно загружать изображения, есть распознавание видео YouTube и Vimeo.
[](http://cackle.ru/polls)
Технологии
----------
Фронтенд в понимании Cackle – это JavaScript. Бекенд – сервера данных и логики.
### Фронтенд
Фронтенд состоит из виджетов. Виджет – это исполняемая JavaScript-библиотека, базирующаяся на других, общих, JavaScript-библиотеках. Примеры общих библиотек:
* Библиотека для работы с DOM: jQuery сильно тормозил и не работал на нескольких мобильных платформах, поэтому написали свое решение на Vanilla JS. В итоге по некоторым операциям скорость работы выросла в 600 раз + наше решение работает на всех версиях Android и iOS;
* Библиотека единой авторизации (анонимная, социальная, SSO);
* Библиотека поддержки Real-time режима с умным выбором протокола взаимодействия (WebSocket, EventSource, Long-Polling);
* Библиотека кроссдоменных GET/POST запросов;
* И другие: работа с датой, БД браузера (cookie, localstorage), json, загрузка изображений, распознавание видео (YouTube, Vimeo), tray нотификации, пагинация и др.
Все виджеты работают без iframe, за счёт чего возможна модификация css под стиль вашего сайта.
Есть общий загрузчик виджетов (widget.js), что-то на подобии RequireJS, только более простой. У загрузчика два режима работы – devel и prod. Первый применяется при разработке, загружает библиотеки в цикле. Второй на продакшене, грузит собранный бандл (bundle). В prod режиме загрузка виджетов происходит с разных серверов выбранных случайным образом, в итоге получается балансинг (подробнее об этом дальше).
**Кроссбраузерный код загрузчика (widget.js часть 1)**
```
Cackle.Bootstrap = Cackle.Bootstrap || {
appendToRoot: function(child) {
(document.getElementsByTagName('head')[0] || document.getElementsByTagName('body')[0]).appendChild(child);
},
//загружает js
loadJs: function(src, callback) {
var script = document.createElement('script');
script.type = 'text/javascript';
script.src = src;
script.async = true;
if (callback) {
if (typeof script.onload != 'undefined') {
script.onload = callback;
} else if (typeof script.onreadystatechange != 'undefined') {
script.onreadystatechange = function () {
if (this.readyState == 'complete' || this.readyState == 'loaded') {
callback();
}
};
} else {
script.onreadystatechange = script.onload = function() {
var state = script.readyState;
if (!state || /loaded|complete/.test(state)) {
callback();
}
};
}
}
this.appendToRoot(script);
},
//загружает css
loadCss: function(href) {
var style = document.createElement('link');
style.rel = 'stylesheet';
style.type = 'text/css';
style.href = href;
this.appendToRoot(style);
},
//загружает несколько css
loadCsss: function(url, css) {
for (var i = 0; i < css.length; i++) {
Cackle.Bootstrap.loadCss(url + css[i] + Cackle.ver);
}
},
//загружает несколько js
loadJss: function(url, js, i) {
var handler = this;
if (js.length > i) {
Cackle.Bootstrap.loadJs(url + js[i] + Cackle.ver, function() {
handler.loadJss(url, js, i + 1);
});
}
},
//общий загрузчик ресурсов
load: function(host, js, css) {
var url = host + '/widget/';
this.loadJss(url + 'js/', js, 0);
if (css) this.loadCsss(url + 'css/', css);
},
/**
* Далее идут виджеты, например, комментариев
*/
Comment: {
isLoaded: false,
load: function(host) {
this.isLoaded = true;
if (Cackle.env == 'prod') {
//В продакшене загружаем бандл
Cackle.Bootstrap.load(host, ['comment.js'], ['comment.css']);
} else {
//При разработке синхронно загружаем библиотеки и сам виджет для модификации/дебага
Cackle.Bootstrap.load(host, ['fastjs.js',
'json2.js',
'rt.js',
'xpost.js',
'storage.js',
'login.js',
'comment.js'],
['comment.css']);
}
}
},
...
};
//Загружаем виджет комментариев (widget == 'Comment')
//host - случайный сервер из кластера (об этом дальше)
if (!Cackle.Bootstrap[widget].isLoaded) {
Cackle.Bootstrap[widget].load(host);
}
```
### Бекенд
Это кластер Apache Tomcat контейнеров, снаружи обернутых Nginx-серверами. Nginx в данном случае выступает не только как прокси, но и как «поглотитель» нагрузки. База данных PostgreSQL с потоковой репликацией на несколько слейвов.
Все бекенды распределены по нескольким дата-центрам (ЦОДам) России и Европы. Наш опыт показал, что хостить все сервера в одном дата-центре слишком рискованно, поэтому сейчас мы подключены к трём разным ЦОДам.
### Real-time
Поддержка обновлений в режиме реального времени (комментарии, лайки, редактирование, модерация, личные сообщения, чат) на стороне браузера, происходит через любую из поддерживаемых технологий: WebSocket, EventSource, Long-Polling. То есть, сначала мы проверяем есть ли WebSocket, далее EventSource, Long-Polling. При дисконнектах (ошибках) связь автоматически восстанавливается функцией, которая в setTimeout мониторит состояние подключения.
На сервере мы используем кластер Nginx + модуль [Push Stream](https://github.com/wandenberg/nginx-push-stream-module). Всего 3 сервера: 2 общих и 1 для онлайн-консультанта. Real-time сообщения из бекендов (Tomcat-ов) отправляются на все сервера. А в браузере, при подключении из виджета, выбирается любой сервер (случайным образом). В итоге получается, что-то на подобии балансинга (к сожалению, Push Stream балансинг «из коробки» не поддерживает).
Кроме этого есть:
* Сервер загрузки, обработки и хранения изображений;
* SMTP сервер.
Архитектура
-----------

PG — PostgreSQL.
RT — Real-time.
ЦОД (1,2,..., N) — различные дата-центры.
RMI — Java технология удаленного вызова методов ([wikipedia](https://ru.wikipedia.org/wiki/RMI)).
Для лучшего понимания, диаграмма последовательности загрузки виджета:
Нагрузка
--------
Ниже суммарная статистика по виджетам и обращениям к API.
Уникальных хитов в сутки: 60 — 70 миллионов
Пик запросов в секунду: 2700
Пик одновременных real-time сессий: 300 000
Пиковая пропускная способность: 780 мбит/с
Трафик в сутки: 1.6 Тбайт
Ежедневный суммарный лог Nginx: 102 Гбайт
Запросов к БД на чтение (в сутки): 80 — 120 миллионов
Запросов к БД на запись (в сутки): 300 000
Количество зарегистрированных сайтов: 32 558
Количество зарегистрированных пользователей: 8 220 681
Комментариев опубликовано: 23 840 847
Ежедневный средний прирост комментариев: 50 000
Ежедневный средний прирост пользователей: 15 000
Проблемы
--------
Высокая нагрузка порождает две проблемы:
Во-первых, практически у всех хостеров по умолчанию пропускная способность (bandwidth) сервера 100 мбит/с. Все что выше режется или в лучшем случае вас просят докупить дополнительную полосу (а цены там в разы выше стоимости самих серверов).
Вторая проблема – это и есть сама нагрузка. Физику не обманешь, каким бы ни был крутым ваш сервер, у него есть свой предел.
### » Решение 1: балансинг в JavaScript
Стандартные методы распределения нагрузки говорят о балансинге входного запроса на сервере. Это решит вторую проблему, но не первую (bandwidth), так как исходящий трафик все равно пойдет через тот же сервер.
Чтоб решить две проблемы одновременно, мы делаем балансинг в JavaScript, в самом загрузчике (widget.js), выбирая бекенд случайным образом. В итоге, трафик перенаправляем на сервера из кластера виджет серверов разделяя между ними bandwidth и распределяя нагрузку.
Дополнительный огромный плюс этого метода, в кешировании JavaScript. Все библиотеки (включая загрузчик widget.js), при обновлении страницы, будут получены из кеша браузера, а наши сервера продолжат спокойно обрабатывать новые запросы.
Продолжение кода загрузчика (widget.js часть 2):
```
var Cackle = Cackle || {};
Cackle.protocol = ('https:' == window.location.protocol) ? 'https:' : 'http:';
Cackle.host = Cackle.host || 'cackle.me';
Cackle.origin = Cackle.protocol + '//' + Cackle.host;
//Кластер виджет серверов (a.cackle.me, b.cackle.me, c.cackle.me):
Cackle.cluster = ['a.' + Cackle.host, 'b.' + Cackle.host, 'c.' + Cackle.host];
//Тут код загрузчика, см. выше widget.js часть 1
Cackle.getRandInt = function(min, max) {
return Math.floor(Math.random() * (max - min + 1)) + min;
}
Cackle.getRandHost = function() {
return Cackle.cluster[Cackle.getRandInt(0, Cackle.cluster.length - 1)];
};
Cackle.initHosts = function() {
//getRandHost собственно и есть балансинг
var host = Cackle.getRandHost();
for (var i = 0; i < cackle_widget.length; i++) {
cackle_widget[i].host = Cackle.protocol + '//' + host;
}
};
//cackle_widget - служебный массив содержищай виджеты для загрузки,
//он заполняется в коде самого виджета (на сайте клиента).
//Например: cackle_widget.push({widget: 'Comment', id: 1});
Cackle.main = function() {
Cackle.initHosts();
for (var i = 0; i < cackle_widget.length; i++) {
var widget = cackle_widget[i].widget;
if (!Cackle.Bootstrap[widget].isLoaded) {
Cackle.Bootstrap[widget].load(cackle_widget[i].host);
}
}
};
Cackle.main();
```
#### А как на счет профессионального CDN?
Это здорово! Проблема только в том, что при наших объемах и нагрузках для того, чтобы использовать CDN необходимо поднять цены минимум в 3 раза, сохранив при этом текущий оборот.
### » Решение 2: микрокеш Nginx
Микрокеш это кеш с очень коротким сроком жизни, например 3 секунды. Он очень полезен при пиковых нагрузках, когда в секунду идут тысячи одинаковых GET запросов. Для нас это данные виджетов в JSON формате. Микрокеш имеет смысл делать в proxy серверах, например Nginx для защиты основного бекенда (Tomcat).
Часть конфига Nginx с микрокешем:
```
...
location /bootstrap {
try_files $uri @proxy;
}
...
location @proxy {
#Бекенд (Tomcat)
proxy_pass http://localhost:8888;
proxy_redirect off;
#В интернете много постов про настройку Nginx кеша,
#но почему-то нигде не сказано, что без этого ничего работать не будет
proxy_ignore_headers X-Accel-Expires Expires Cache-Control;
set $no_cache "";
#Кешируем только GET|HEAD
if ($request_method !~ ^(GET|HEAD)$) {
set $no_cache "1";
}
if ($no_cache = "1") {
add_header Set-Cookie "_mcnc=1; Max-Age=2; Path=/";
add_header X-Microcachable "0";
}
if ($http_cookie ~* "_mcnc") {
set $no_cache "1";
}
proxy_cache microcache;
proxy_no_cache $no_cache;
proxy_cache_bypass $no_cache;
proxy_cache_key $scheme$host$request_method$request_uri;
#Кешируем на 3 секунды
proxy_cache_valid 200 301 302 3s;
proxy_cache_use_stale error timeout http_500 http_502 http_503 http_504 http_403 http_404 updating;
default_type application/json;
}
...
```
Если есть проблемы с пониманием данного конфига, то обязательно для чтения [ngx\_http\_proxy\_module](http://nginx.org/ru/docs/http/ngx_http_proxy_module.html).
### » Решение 3: тюнинг Tomcat, Java кеш
#### Tomcat
Особо протюнинговать Tomcat не получится. Из практического опыта:
* Не морочьте голову с выбором коннектора (Http11Protocol, Nio, Apr). При больших нагрузках это не играет роли.
* Сделайте connectionTimeout минимальным, какой только возможно, желательно не больше 5 секунд.
* Не делайте слишком большой maxThreads, он не поможем, а в некоторых ситуация только навредит. Стандарт для нагруженного проекта 300-350. Если этого мало, добавьте новый Tomcat сервер.
* А вот acceptCount можно сделать несколько тысяч (2000-4000). При маленьких значениях подключения отрубаются (connection refused), а так будут складываться в очередь. При этом не забудьте в ОС [выставить такой же или больше backlog](http://veithen.github.io/2014/01/01/how-tcp-backlog-works-in-linux.html).
#### Java кеш
Принято считать БД, в высоконагруженных проектах, слабым местом. Это действительно так. Например, сервер принимает запрос, отправляет его в сервисный уровень, там сервис обращается к БД и возвращает результат. Связка «сервис — БД (реляционная)» в этом случае работает медленнее всех, поэтому принято оборачивать сервисы кешем. Соответственно результат из БД, кладется в кеш сервиса, и при следующем обращении берется уже из него.
Для кеширования сервисов мы разработали свой кеш, так как стандартные (например Ehcache) работают медленнее и не всегда хорошо решают специфические задачи. Из специфических задач у нас – кеширование с поддержкой нескольких ключей для одного значения. Мы используем org.apache.commons.collections.map.MultiKeyMap.
Нужно это вот для каких задач. Например пользователь заходит на страницу с комментариями. Допустим комментариев много, 300 штук. Они разбиты на три страницы (пагинация) соответственно по 100 каждая. При первом обращении, будет закеширована первая страница (100 комментариев), если пользователь листает вниз, то по очереди закешируется 2 и 3 страницы. Теперь пользователь публикует комментарий на этой странице и тут надо сбросить все три кеша. Используя MultiKeyMap это выглядит примерно так:
```
MultiKeyMap cache = MultiKeyMap.decorate(new LRUMap(capacity));
cache.put(chanId, "page1", commentSerivce.list(chanId, 1)); //chanId - id страницы с комментариями
cache.put(chanId, "page2", commentSerivce.list(chanId, 2)); //commentSerivce.list - получаем комментарии на странице (chanId) с пагинацией (2)
cache.put(chanId, "page3", commentSerivce.list(chanId, 3));
cache.removeAll(chanId); //Удаляем все 3 кеша на странице для всех пагинаций
```
Ниже код ядра кеша отлично работающий на highload.
**Ядро кеша: thread-safety, отложенное и единственное выполнение кеширующего результата, мягкие ссылки для избежания OOM**
```
public class CackleCache {
private final MultiKeyMap CACHE = MultiKeyMap.decorate(new LRUMap(capacity));
public static class SoftValue extends SoftReference {
final K key;
final long expired;
public SoftValue(V ref, ReferenceQueue q, K key, long timelife) {
super(ref, q);
this.key = key;
this.expired = System.currentTimeMillis() + timelife;
}
}
public synchronized Future get(final MultiKey key, final long timelife, final MethodInvocation invocation) {
Future ret;
@SuppressWarnings("unchecked")
SoftValue> sr = (SoftValue>) CACHE.get(key);
if (sr != null) {
ret = sr.get();
if (ret != null) {
if (sr.expired > System.currentTimeMillis()) {
return ret;
} else {
sr.clear();
}
}
}
ret = executor.submit(new Callable() {
@Override
public Object call() throws Exception {
try {
return invocation.proceed();
} catch (Throwable t) {
throw new Exception(t);
}
}
});
SoftValue> value = new SoftValue>(ret, referenceQueue, key, timelife);
CACHE.put(key, value);
return ret;
}
public synchronized void evict(Object key) {
try {
CACHE.removeAll(key);
} catch (Throwable t) {}
}
}
```
### » Решение 4: PostgreSQL с потоковой репликацией в разные дата-центры
На наш взгляд PostgreSQL лучшее решение для высоконагруженных проектов. Сейчас модно применять NoSQL, но в большинстве случаев, при правильном подходе и верной архитектуре, PostgreSQL лучше.
В PostgreSQL отлично работает потоковая репликация, причем не важно в одной подсети или в разных сетях, разных дата-центрах. У нас, например, сервера БД расположены в нескольких странах и серьезных проблем замечено не было. Единственный нюанс — это большие модификации базы (ALTER TABLE) при релизах. Делать их надо кусками, стараясь не выполнять за раз весь UPDATE.
По настройке репликации есть много ресурсов, это избитая тема, так что добавить особо нечего, кроме:
* Обязательно сделайте план (конфиг) на случай failover (падение мастера) и реально протестируйте это;
* Поймите принцип работы WAL, чтоб в случае рассинхронизации слейва и мастера знать зачем вам архивы и куда их надо положить;
* Следите за местом на HDD мастера, если вдруг его не станет, то PostgreSQL может упасть, а при репликации это чревато большими неприятностями.
### » Решение 5: тюнинг ОС
Не забывайте [тюнить параметры ядра ОС](http://tweaked.io/guide/kernel/), так как без этого некоторые настройки Nginx или Tomcat просто не будут работать.
У нас, например, везде Debian. В настройках ядра ОС (/etc/sysctl.conf) особое внимание нужно обратить на:
```
kernel.shmmax = 8000234752 // Это для PostgreSQL, чтоб можно было выставлять большой shared_buffers (6 - 8GB)
fs.file-max = 99999999 // Это для Nginx, без него можно получить "Too many open files"
net.ipv4.tcp_max_syn_backlog=524288 // Максимальное число запоминаемых запросов на соединение
net.ipv4.tcp_max_orphans=262144 // Максимальное число допустимых в системе сокетов TCP
net.core.somaxconn=65535 // Максимальное число открытых сокетов
net.ipv4.tcp_mem=1572864 1835008 2097152 // Потребление памяти для протокола TCP
net.ipv4.tcp_rmem=4096 16384 16777216 // Размер приемного буфера сокетов TCP
net.ipv4.tcp_wmem=4096 32768 16777216 // Количество памяти, резервируемой для буферов передачи сокета TCP
```
Проблемы, которые пока решить не удалось
----------------------------------------
Вернее одна проблема – размер БД. Есть, конечно, шардинг, но стандартного решения для PostgreSQL без падения производительности пока не нашли. Если кто-то может поделиться практическим опытом – welcome!
Спасибо за внимание. Вопросы и пожелания по [нашей системе](http://cackle.ru/) приветствуются! | https://habr.com/ru/post/255013/ | null | ru | null |
# «Инфраструктура как код» в автоматизации сервисов CI/CD
Привет! Меня зовут Игорь Николаев, я ~~пью за любовь~~ работаю в отделе автоматизации процессов разработки Мир Plat.Form в НСПК. В этой статье я поделюсь тем, как наш отдел решал задачу по автоматизации предоставления различных ресурсов для команд разработки. Эта задача свойственна организациям с большим количеством проектов, инфраструктура которых состоит из распределенных и, возможно, слабо связанных сетевых сегментов.
В статье описан PoC (Proof of concept) решения задачи выделения ресурсов в рамках сервисов CI/CD (Continuous Integration & Continuous Delivery) и предоставления привилегий для пользователей этих сервисов.

### Описание
Часто в организациях используются сложные и дорогостоящие [IDM](https://ru.wikipedia.org/wiki/%D0%A3%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5_%D1%83%D1%87%D1%91%D1%82%D0%BD%D1%8B%D0%BC%D0%B8_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D0%BC%D0%B8) - класс систем Identity Management (как в рамках лицензирования, так и внедрения и обслуживания) для управления доступами. Нам хотелось совместить процессы запроса и предоставления ресурсов на сервисах CI/CD и предоставления доступов к этим ресурсам. Хотелось получить максимально прозрачное и простое в поддержке и реализации решение, которое обеспечивает следующий функционал:
* Создание и управление сущностями сервисов CI/CD
* Использование удобных для нас инструментов
* Легкая интеграция с уже развернутыми у нас системами
* Простота эксплуатации
* Возможность тиражирования
Про тиражирование стоит сказать подробнее, у нас есть несколько сетевых сегментов с разными сервисами CI/CD, и иногда они имеют минимум сетевой связанности. Система должна с минимальными затратами обслуживать несколько окружений, которые могут отличаться друг от друга.
Что мы выбрали для PoC:
Как подход был выбран [IaC](https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%84%D1%80%D0%B0%D1%81%D1%82%D1%80%D1%83%D0%BA%D1%82%D1%83%D1%80%D0%B0_%D0%BA%D0%B0%D0%BA_%D0%BA%D0%BE%D0%B4) (Infrastructure-as-Code) с описанием желаемых состояний в виде [yaml](https://ru.wikipedia.org/wiki/YAML) файлов.
[Python](https://ru.wikipedia.org/wiki/Python) — язык для написания автоматизации (подходящий вариант для прототипа);
[Bitbucket](https://ru.wikipedia.org/wiki/Bitbucket) — веб-сервис для хостинга проектов и их совместной разработки;
[Jenkins](https://ru.wikipedia.org/wiki/Jenkins) — сервис непрерывной интеграции (необходим нам для визуализации выполнения задач).
Как пилотные системы для автоматизации были выбраны:
[Active Directory](https://ru.wikipedia.org/wiki/Active_Directory) — всем известные службы каталогов (нам понадобятся группы и пользователи);
[Bitbucket](https://ru.wikipedia.org/wiki/Bitbucket) — часто запрашивают создание проектов, предоставление привилегий;
[Nexus 3 OSS](https://www.sonatype.com/product-nexus-repository) (не реклама, нет страницы в Wiki) — корпоративная система хранения артефактов, при появлении проектов создаются персональные репозитории проекта и выдаются привилегии.
Немного про Bitbucket и [GitOps](https://www.atlassian.com/git/tutorials/gitops)
([Перевод замечательной статьи про GitOps от коллег из Флант](https://habr.com/ru/company/flant/blog/458878/))
Разговор об автоматизации следует начать с описания общей концепции.
В Bitbucket есть две важные сущности: проект(project) и репозиторий (repository), который входит в состав проекта. Для описания доступов в рамках концепта мы решили ограничиться доступами к проекту (более сегментированное предоставление привилегий (на репозиторий) в рамках концепта не потребуется).
У project в Bitbucket есть параметр project key, который понадобится для дальнейших манипуляций, мы взяли его за связующую основу. Именно он и будет являться названием директории в git-репозитории meta. В директории проекта будут размещаться meta-файлы (карты) проекта описанные в формате yaml.
Проектов в Мир Plat.Form много, и у каждого есть своя специфика. Возникает мысль держать в одном месте информацию о группах, инструментах, требуемых проекту, стендах (наборах серверов) и прочего, что имеет отношение к проекту. Для этого отлично подходит git репозиторий.
Какие задачи это решает?
* В первую очередь, мы получаем стандартный интерфейс описания, который создает однотипные сущности сервисов CI/CD.
* В любой момент времени мы можем увидеть реальное описание пользователей и их привилегий в рамках проекта.
* Выполняя автоматизацию по расписанию можно гарантированно получать именно то, что описано в проектных метаданных (защита от «очумелых ручек»).
* Расширяя описание проекта в виде определенной структуры meta-данных, можно автоматизировать другие сущности.
*Структура meta репозитория git:*

**DEV** — наименование сетевого сегмента
**project1** — ключ проекта в Bitbucket
**project1\_meta.yaml** — карта проекта
**examples** — директория примера описания
Такая структура позволит описать несколько различных сетевых сегментов, при этом сохраняя гибкую возможность изменений и различий между ними.
Скрипты автоматизации в рамках концепта будут находиться в проекте в отдельных репозиториях (названия не принципиальны):
* [ad-core-automation](https://github.com/Mir-Platform/ad-core-automation)
* [bitbucket-core-automation](https://github.com/Mir-Platform/bitbucket-core-automation)
* [nexus-core-automation](https://github.com/Mir-Platform/nexus-core-automation)
* [jjb-core](https://github.com/Mir-Platform/jjb-core)
О назначении первых трех репозиториев легко догадаться. Последний репозиторий jjb-core — репозиторий в котором мы будем хранить описание Jenkins Job в виде рецептов для Jenkins Job builder (о нем будет рассказано ниже).
### Автоматизация Microsoft AD
Active Directory используется во многих организациях. Большое количество рабочих процессов организаций начинаются именно с него. У нас в Мир Plat.Form все сотрудники имеют учетные записи в AD и включены в различные группы.
За AD отвечает подразделение инфраструктуры. Для наших нужд была выделена техническая учетная запись (ТУЗ), которой делегировано управление одним из Organization unit (OU). Именно в нем с помощью простой автоматизации мы будем создавать группы и наполнять их пользователями.
*Часть содержимого project1\_meta.yaml, которая отвечает за AD:*
```
---
READY: True # Защита от "дурака", если не True, то автоматизация проигнорирует весь файл
TEAM:
# Описание состава команды (роли)
USER_LOCATION: ldap # local or ldap
ROLES:
owner:
- owner1
developer:
- developer1
- developer2
qa:
- qa1
- qa2
GLOBAL_PRIVILEGES: &global_privileges
# Базовый набор привилегий для каждой роли в команде
owner: [read, write, delete]
developer: [read, write]
qa: [read]
```
**READY** — булево значение и позволяет, в случае необходимости, выключить автоматизацию обработки данного мета файла
**TEAM** — секция, описывающая сущность проекта
**ROLES** — произвольные названия ролей на проекте, отображающие суть
**GLOBAL\_PRIVELEGES** — секция описывает, какая роль будет обладать какими привилегиями
[Пример мета репозитория](https://github.com/Mir-Platform/meta-example)
В рамках предоставления прав для окружения разработки, чтобы не усложнять пример, остановимся на 3х основных ролях: owner, developer, qa (в целом, количество и наименование ролей является произвольным). Для дальнейшей автоматизации эти роли позволят покрыть большую часть повседневных потребностей (у нас сразу появились роль tech, для ТУЗ, но для примера обойдемся без нее).
В рамках OU проекта будем автоматически, на основании meta-файлов проекта, создавать необходимые SG (Security group) и наполнять их пользователями.
*На схеме структура выглядит так:*

В AD используем плоскую иерархическую структуру, это позволит ее легко обслуживать, и выглядит она весьма наглядно.
Скрипт автоматизации получился очень простой. Он позволяет отслеживать изменения в составе групп (добавление/удаление пользователей) и создавать OU/SG.
Для запуска потребуется установить зависимости из requirements.txt (ldap3, PyYAML).
[Пример скрипта](https://github.com/Mir-Platform/ad-core-automation)
### Автоматизация Sonatype Nexus3 OSS
Что такое [Nexus](https://www.sonatype.com/download-oss-sonatype)?
Nexus — это менеджер репозиториев, позволяющий обслуживать разные типы и форматы репозиториев через единый интерфейс (Maven, Docker, NPM и другие).
На момент написания статьи версия была OSS 3.25.1-04
**Почему именно Nexus?**
Есть community версия, которая обладает богатым функционалом, достаточным для выполнения большинства задач, связанных с хранением артефактов и проксирования внешних репозиториев.
Процесс хранения артефактов является важным при проектировании конвейера тестирования и развертывания.
**Что потребуется автоматизировать?**
[Blobstore](https://help.sonatype.com/repomanager3/high-availability/configuring-blob-stores)
Все двоичные файлы, загружаемые через proxy репозитории (мы не предоставляем прямого доступа к интернет репозиториям, используем исключительно прокисрование через nexus), опубликованные в hosted (локальные репозитории) репозитории хранятся в хранилищах Blob-объектов, связанном с репозиторием. В базовом развертывании Nexus, с одним узлом, обычно связаны с локальным каталогом на файловой системе, как правило, а каталоге sonatype-work.
Nexus версии >= 3.19 поддерживает два типа хранилищ File и S3.
*UI Blob stores:*
Как мы видим, по умолчанию нам уже доступно хранилище default. Из информации выше мы можем понять, что данный blob находится на диске и ему доступен весь объем дискового раздела, на котором находится директория sonatype-work.
**Проблематика**
В целом, все логично, но есть минимум две проблемы, о которых следует задуматься:
1. В случае, если все репозитории будут привязаны к одному blob, у нас могут появиться проблемы с тем, что хранилище может побиться.
2. Если мы предполагаем, что наш Nexus будет использоваться несколькими командами разработки, то стоит сразу задуматься о том, что в некоторых ситуациях чрезмерная генерация артефактов может забить весь раздел и проблема будет не только у команды, которая генерирует большой объем артефактов, но и у других команд.
**Простое решение**
Первое, что приходит в голову — это создание отдельных blob stores. Очевидно, это не решает проблему расположения на одном дисковом разделе. Подходящим решением является "нарезать" разделы для каждого проекта. Забегая вперед, это решит еще и вопрос мониторинга и отправки уведомлений ответственным за проект. Удобное решение второго пункта описанных проблем.
По первому пункту наиболее правильным решением является создание отдельных blob store для каждого репозитория.
*UI создания Blob stores:*

Nexus позволяет настроить Soft quota, штука сомнительная. Она уведомляет о том, что с местом что-то не так, но не производит каких-либо действий. При правильном применении шагов, описанных выше, удается добиться большего функционала (Появляется простой способ отслеживания объема и обращений к диску, а переполнение не создает неприятности "соседям").
В поле path мы можем указать раздел, который примонтирован, например, как nfs.
Что позволяет держать раздел непосредственно на сетевом хранилище. Это может снизить скорость, но дает ряд преимуществ с точки зрения простоты.
Nexus у нас запускается в Docker, для этого используется compose файл. Для подключения новых точек монтирования, простым решением будет добавить в compose файле монтирование родительского каталога точек монтирования.
*Пример docker-compose:*
```
version: "3"
services:
nexus3:
container_name: nexus3
image: sonatype/nexus3:3.27.0
ports:
- 8443:8443
- 50011:50011 # project1-docker-releases
- 20012:50012 # project2-docker-releases
volumes:
- /nexus/sonatyep-work:/nexus-data
- /mnt-blobs:/mnt-blobs
- /etc/timezione:/etc/timezone
- /etc/localtime:/etc/localtime
logging:
driver: "json-file"
options:
max-size: "10m"
max-file: "10"
```
[Repositories](https://help.sonatype.com/repomanager3)
Nexus позволяет создавать репозитории почти всех распространенных форматов. Если идти в сторону идеального хранения, то целесообразно для каждого проекта создавать минимум release и snapshot репозиторий, хотя идеальный вариант может содержать еще и release-candidat репозиторий. Это позволит настроить удобный механизм чистки репозиториев.
Определенно, release репозиторий должен во многих случаях иметь максимальную глубину хранения, как требование, в релизах не должно оказаться "мусора". Напротив, с репозиториями snapshot мы должны иметь возможность очищать без опасений в любое удобное время и без рисков.
Ко всем форматам репозиториев доступ осуществляется по 80 и/или 443 портам, за исключением docker. Репозиторий Docker, для доступа к нему, должен иметь персональный порт. Это приводит к некоторым сложностям. Каждый раз публикуя новый порт, мы должны добавлять его публикацию в compose файле.
[LDAP](https://help.sonatype.com/repomanager2/ldap-integration)
Nexus имеет возможность реализации подключения к LDAP и использования его в качестве аутентификации пользователей. В нашем случае мы используем группы пользователей для предоставления прав.
[Roles](https://help.sonatype.com/repomanager3/system-configuration/access-control/roles)
Для удобства роли создаются под проект, лучше идти от минимума, и для себя мы выбрали три роли для каждого проекта:
**qa** — обладают правами достаточными для read
**developers** — read, write
**owners** — read, write, delete
Группы из AD матчатся в локальные группы Nexus.
[API](https://help.sonatype.com/repomanager3/rest-and-integration-api)
Начиная с версии Nexus OSS 3.19 появилось весьма удобное API для управления Nexus, это значимое нововведение, которое многие пользователи ждали позволит нам управлять Nexus и приводить его в нужное состояние.
*Swagger UI API:*
На момент написания статьи API, по большей части, в статусе beta, но не смотря на это, работает без больших проблем и позволяет автоматизировать почти все необходимое.
*Часть содержимого project1\_meta.yaml, которая отвечает за nexus:*
```
RESURCES: # Ресурсы, обслуживаемые автоматизацией
nexus:
repository: # Сущности
# Maven
- name: test-maven-releases
locationType: hosted
repoType: maven
- name: test-maven-proxy
locationType: proxy
blobStoreName: test
remoteUrl: http://test.ru
repoType: maven
# Docker
- name: test-docker-releases
locationType: hosted
repoType: docker
- name: test-docker-proxy
locationType: proxy
blobStoreName: test-blob
remoteUrl: http://test.ru
repoType: docker
- name: test-docker-group
blobStoreName: test-blob
locationType: group
httpPort: 10555
repoType: docker
memberNames:
- test-docker-releases
- test-docker-proxy
# Npm
- name: test-npm-proxy
locationType: proxy
remoteUrl: http://test.ru
repoType: npm
blob:
- name: test-blob
path: test-blob
privileges:
<<: *global_privileges
```
На основании такого файла система автоматизации создает все обслуживаемые сущности. В наших командах принято, что teamlead отвечает за наполнение файла проекта, однако, создать его может любой желающий. После создания pull request следует согласование вовлеченными в процесс участниками, после мерджа с master веткой, отрабатывает автоматизация.
Стоит отметить, мы стремимся сделать процесс максимально простым для пользователя, что влечет к использованию шаблонов конфигураций, которые описаны в виде примитивных моделей. Система позволяет переопределить умолчания в случае возникновения необходимости в описании карты проекта.
*Пример кода модели для maven hosted repository:*
```
def maven_model_hosted(params):
model = {
'name': params.get('name'),
'online': params.get('online', True),
'storage': {
'blobStoreName': params.get('blobStoreName', params['name']),
'strictContentTypeValidation': params.get('strictContentTypeValidation', True),
'writePolicy': params.get('writePolicy', 'ALLOW')
},
'cleanup': {
'policyNames': params.get('policyNames', [])
},
'maven': {
'versionPolicy': params.get('versionPolicy', 'MIXED'),
'layoutPolicy': params.get('layoutPolicy', 'PERMISSIVE')
}
}
return model
```
Данный подход позволяет сократить описание создаваемой сущности до минимума.
Идеологически, все что может использовать значения по умолчанию должно их использовать, но при необходимости может быть заменено в файле карты проекта.
[Пример скрипта](https://github.com/Mir-Platform/nexus-core-automation)
### Автоматизация Atlassian Bitbucket
Для концепта достаточно будет автоматизировать создание проекта и предоставление привилегий к нему.
*Часть содержимого project1\_meta.yaml, которая отвечает за Bitbucket:*
```
...
bitbucket:
name: project1-bitbucket-project # Это не project key!
# project_key получается из имени файла
description: "Описание проекта в свободной форме"
privileges:
<<: *global_privileges
```
Это все, что потребуется при заведении нового проекта. Project key будет взят из названия yaml файла (в данном примере — project1).
*Как это выглядит в UI:*
[Пример скрипта](https://github.com/Mir-Platform/bitbucket-core-automation)
### Jenkins Job Builder
JJB является python утилитой для описания сущностей jenkins в виде yaml манифестов, которые преобразуются в понятные jenkins API запросы. Это позволяет великолепно решать задачу управления большим количеством однотипных задач.
Jenkins в данном контексте является интерфейсом для отображения успешности выполняемых задач автоматизации и контроля над ними. Сами задачи на первом этапе планируем выполнять по расписанию, например, каждый час. Это позволит избавиться большой части неконтролируемых ручных изменений и будет каждый час приводить систему к описанному состоянию.
*Структура репозитория jjb-core:*

Каждая директория содержит описание Jenkins job состоящее из двух файлов.
*Yaml файл описывает шаблон jenkins job имеет следующее наполнение:*
```
---
- job: # Создаем директорию CORE
name: CORE
project-type: folder
- job: # Создаем поддиректорию ad-core-automation в CORE
name: CORE/ad-core-automation
project-type: folder
# Описание темплэйта
- job-template:
name: 'CORE/ad-core-automation/{name}-{project_key}'
project-type: pipeline
job_description: Упралвение OU и SG для {project_key}
# Defaults
GIT_BRANCH: master
GIT_CRED_ID: jenkins-ad-integration
triggers:
- timed: 'H(0-59) * * * *'
parameters:
- string:
name: GIT_BRANCH
default: '{GIT_BRANCH}'
description: Git ref (branch/tag/SHA)
- string:
name: GIT_CRED_IDjenkins
default: '{GIT_CRED_ID}'
description: Jenkins credentials ID for BitBucket
- string:
name: META_LOCATION
default: 'DEV/{project_key}/{project_key}_meta.yaml'
description: Meta file location if CORE/meta repository
dsl: !include-raw-escape: ./ad-core-automation.groovy
- project:
name: ad-core
project_key:
- project1
- project2
- project3
jobs:
- 'CORE/ad-core-automation/{name}-{project_key}'
```
Файл groovy — это простой jenkinsfile:
```
def meta_location = params.META_LOCATION
def git_cred_id = params.GIT_CRED_ID
def git_branch = params.GIT_BRANCH
pipeline {
agent {
label 'common-centos'
}
stages {
stage('Clone git repos') {
steps {
echo 'Clone meta'
dir('meta') {
git credentialsId: "${git_cred_id}",
url: 'git@github.com:Mir-Platform/meta-example.git'
}
echo 'Clone ad-core-automation'
dir('auto') {
git credentialsId: "${git_cred_id}",
branch: git_branch,
url: 'git@github.com:Mir-Platform/ad-core-automation.git'
}
}
}
stage('Install and run') {
steps {
echo 'Install requirements'
withDockerContainer('python:3.8.2-slim') {
withEnv(["HOME=${env.WORKSPACE}"]) {
sh 'pip install --user --upgrade -r auto/requirements.txt'
sleep(5)
echo 'Run automation'
withCredentials([usernamePassword(credentialsId: 'ad_tech', passwordVariable: 'ad_pass', usernameVariable: 'ad_user')]) {
dir('auto') {
sh "./run.py -u $ad_user -p $ad_pass -f ../meta/${meta_location}"
}
}
}
}
}
}
}
}
```
[Пример скрипта](https://github.com/Mir-Platform/jjb-core)
*Все это описывает создание следующей структуры Jenkins:*
*Общий алгоритм работы автоматизации:*

* Инициатор создает в репозитории meta новую директорию с картой проекта и создает pull-request в мастер ветку(1).
* Pull-request попадает на проверку согласующих (2)
* В случае, если проект новый, пока в ручном режиме инженер прописывает Bitbucket project key для JJB (данное действие нужно произвести единожды)
* Автоматизация после внесения изменений в шаблоны JJB генерирует описанные job для проекта(4, 5).
* Jenkins запускает автоматизацию AD(6), которая создает необходимые сущности в виде OU и SG в AD. В случае, если все сущности уже созданы, приводит состав пользователей к описанному (удаляет/добавляет)
* Jenkins запускает автоматизацию Bitbucket(4), если проекта нет в Bitbucket, то создает его и предоставляет доступ для групп команды проекта. Если проект уже существует, то добавляет к нему группы AD с необходимыми привилегиями.
* Jenkins запускает автоматизацию для Nexus(7). Создаются описанные сущности Nexus и к ним предоставляется доступ на основе групп AD
### Результат и развитие
Результатом данного концепта стало появление базовой автоматизации описанных процессов. Интерфейс взаимодействия в виде yaml карт проектов оказался весьма удобен, появились запросы на улучшения. Главными показателями успешности стали простота и скорость предоставления необходимых проектам ресурсов. Показатель скорости улучшился в разы по сравнению с ручным подходом. Все стало однотипным, понятным и повторяемым. Избавились от ручных ошибок.
На текущий момент описанный PoC перешел в стадию промышленной эксплуатации и претерпел значительные доработки. Мы переписали core систему автоматизации, к которой в виде плагинов подключаются модули для автоматизации новых сервисов. Появились тесты.
Всего автоматизацией обслуживается около 50 проектов и подключаются новые. Планируем тиражирование в другие сетевые сегменты. | https://habr.com/ru/post/505414/ | null | ru | null |
# Создание кастомного UIActivity для публикации фото и текста в социальной сети ВКонтакте
Во время работы над очередной версией приложения возникла задача сделать публикацию фото в социальной сети ВКонтакте через стандартный контроллер [UIActivityViewController](https://developer.apple.com/library/ios/documentation/uikit/reference/UIActivityViewController_Class/Reference/Reference.html).
Поиск в сети дал следующие результаты:
1. [Готовой реализации не обнаружено](https://github.com/shu223/UIActivityCollection)
2. Есть [официальное sdk ВКонтакте](https://vk.com/dev/ios_sdk): содержит механизмы авторизации, работы с картинками, но не имеет готового класса для загрузки через [UIActivityViewController](https://developer.apple.com/library/ios/documentation/uikit/reference/UIActivityViewController_Class/Reference/Reference.html)
3. Есть документация Apple для создания кастомного [UIActivity](https://developer.apple.com/library/ios/documentation/uikit/reference/UIActivity_Class/Reference/Reference.html)
### Подготовка к использованию VK SDK
Перед началом работы с VK SDK необходимо создать [Standalone](https://vk.com/dev/standalone)-приложение на **[странице создания приложения](https://vk.com/editapp?act=create)**. Сохранить **ID приложения** и заполнить поле «App Bundle для iOS».
Для настройки авторизации через VK App, необходимо настроить URL-протокол приложения:
* Откройте настройки проекта, выберите раздел «Info».
* В секции «URL Types» нажмите на +.
* Введите vk+**APP\_ID** (например, *vk1234567*) в поля «Indentifier» и «URL Schemes».
### Работа с SDK
Необходимо инициализировать SDK при запуске приложения методом
> [VKSdk initialize:delegate andAppId:APP\_ID];
Для авторизации можно использовать метод:
> [VKSdk authorize:scope];
В случае успеха у делегата будет вызван метод
> -(void) vkSdkDidReceiveNewToken:(VKAccessToken\*) newToken;
В случае ошибки (например, пользователь запретил авторизацию)
> -(void) vkSdkUserDeniedAccess:(VKError\*) authorizationError;
### UIActivity для ВКонтакте
Следуя документации Apple, создаём наследник UIActivity:
```
#import
@interface VKontakteActivity : UIActivity
- (id)initWithParent:(UIViewController\*)parent;
@end
```
Вспомогательный контроллер **parent** нужен для ввода капчи, вывода сообщений и пр.
Далее переопределяем методы для отображения элемента UIActivity (тип, название и иконку)
```
- (NSString *)activityType {
return @"VKActivityTypeVKontakte";
}
- (NSString *)activityTitle {
return @"ВКонтакте";
}
- (UIImage *)activityImage {
return [UIImage imageNamed:@"vk_activity"];
}
```
Проверяем поддерживает ли наш класс шаринг передаваемых ему activityItems:
```
- (BOOL)canPerformWithActivityItems:(NSArray *)activityItems {
for (UIActivityItemProvider *item in activityItems) {
if ([item isKindOfClass:[UIImage class]]) {
return YES;
}
else if ([item isKindOfClass:[NSString class]])
{
return YES;
}
}
return NO;
}
```
Запоминаем поддерживаемые нами activityItems:
```
- (void)prepareWithActivityItems:(NSArray *)activityItems {
for (id item in activityItems) {
if ([item isKindOfClass:[NSString class]]) {
self.string = item;
}
else if([item isKindOfClass:[UIImage class]]) {
self.image = item;
}
else if([item isKindOfClass:[NSURL class]]) {
self.URL = item;
}
}
}
```
Непосредственно при выборе нашего UIActivity проверяем авторизован ли пользователь:
```
- (void)performActivity{
[VKSdk initializeWithDelegate:self andAppId:@"3974615"];
if ([VKSdk wakeUpSession])
{
[self postToWall];
}
else{
[VKSdk authorize:@[VK_PER_WALL, VK_PER_PHOTOS]];
}
}
```
При успешной авторизации публикуем пост.
```
-(void)postToWall{
[self begin];
if (self.image) {
[self uploadPhoto];
}
else{
[self uploadText];
}
}
//публикация текста на стене
-(void)uploadText{
[self postParameters:@{ VK_API_FRIENDS_ONLY : @(0),
VK_API_OWNER_ID : [VKSdk getAccessToken].userId,
VK_API_MESSAGE : self.string}];
}
//публикация поста на стене
-(void)postParameters:(NSDictionary *)params{
VKRequest *post = [[VKApi wall] post:params];
[post executeWithResultBlock: ^(VKResponse *response) {
NSNumber * postId = response.json[@"post_id"];
[[UIApplication sharedApplication] openURL:[NSURL URLWithString:[NSString stringWithFormat:@"http://vk.com/wall%@_%@", [VKSdk getAccessToken].userId, postId]]];
[self end];
} errorBlock: ^(NSError *error) {
NSLog(@"Error: %@", error);
[self end];
}];
}
```
При этом если пост содержит картинку, то предварительно загружаем её на сервер.
```
- (void)uploadPhoto {
NSString *userId = [VKSdk getAccessToken].userId;
//предварительная загрузка фото на сервер
VKRequest *request = [VKApi uploadWallPhotoRequest:self.image parameters:[VKImageParameters jpegImageWithQuality:1.f] userId:[userId integerValue] groupId:0];
[request executeWithResultBlock: ^(VKResponse *response) {
VKPhoto *photoInfo = [(VKPhotoArray*)response.parsedModel objectAtIndex:0];
NSString *photoAttachment = [NSString stringWithFormat:@"photo%@_%@", photoInfo.owner_id, photoInfo.id];
//публикация текста на стене
[self postParameters:@{ VK_API_ATTACHMENTS : photoAttachment,
VK_API_FRIENDS_ONLY : @(0),
VK_API_OWNER_ID : userId,
VK_API_MESSAGE : [NSString stringWithFormat:@"%@ %@",self.string, [self.URL absoluteString]]}];
} errorBlock: ^(NSError *error) {
NSLog(@"Error: %@", error);
[self end];
}];
}
```
Пример публикации фото с помощью VKontakteActivity:
```
NSArray *items = @[[UIImage imageNamed:@"example.jpg"], @"Example" , [NSURL URLWithString:@"https://www.youtube.com/watch?v=S59fDUZIuKY"]];
VKontakteActivity *vkontakteActivity = [[VKontakteActivity alloc] initWithParent:self];
UIActivityViewController *activityViewController = [[UIActivityViewController alloc]
initWithActivityItems:items
applicationActivities:@[vkontakteActivity]];
[self presentViewController:activityViewController animated:YES completion:nil];
```
Исходный код проекта можно скачать **[здесь](https://github.com/denivip/VKActivity).** | https://habr.com/ru/post/214637/ | null | ru | null |
# Как мы рассылали SMS со старой Nokia и телефона на Android
Примерно год назад мы [запустили](https://habrahabr.ru/post/257433/) свой маленький проект с оповещениями о поломках Московского метро.
Самой главной проблемой в нем оказалась рассылка смс. Мы не ожидали, что проект понравится и у нас будет 1500+ регистраций. В самом лучшем случае мы расчитывали человек на 300. Этим мы были приятно удивлены.
Проблема с смс в первую очередь была из-за цены. Одна рассылка получалась примерно 3000 рублей. С учетом того, что цена 1 смс 1,5 рубля. Были времена, когда неполадки в движением поездов были каждые 3 дня, т.е. 10 поломок в месяц. 3000\*10 = 30 000 рублей. Дороговато для проекта, который не финансируется.
Тут мы начали изобретать велосипед. А именно, искать тарифы с действительно безлимитными смс. В итоге мы его нашли. Стоило что-то около 600 рублей в месяц. Дальше нужно было решить вопрос с отправкой смс. И тут пришло время древней nokia 6610i, которая пылилась в шкафу как память о былой эпохе. Но ее пришлось чуть доработать, а именно подключить по uart к ноуту, чтобы отправлять задания.
Схема
Пара диодов тут нужна чтобы сбросить напряжение с 5V до ~3.4V. Падение на диодах суммарно получается 1.6V при тока 1А. Такой ток нокия потребляет только при активной работе с сетью, а большую часть времени падение на них будет около 1.5V.
Большой и толстый конденсатор нужен чтобы сглаживать потребление телефона в тот момент когда работает передатчик, и он много жрет.
А резисторы — заменяют терморезистор и пин идентификации батарейки (BSI), по которому nokia понимает что к ней подключен аккумулятор.
У нас подходящих номиналов резисторов не нашлось, поэтому собрали из того что было.

Для отправки использовалась программа gnokii, из названия которой вполне очевидно, что писалась она как раз для таких целей.
Конфиг от нашей 6610i:
```
[global] port = /dev/ttyUSB0
connection = dlr3p
model = 6510
```
Команда для отправки
```
echo 'text' | gnokii --sendsms number
```
Чтобы рассылать можно можно было не только от root, нужно выставить соответствующие права на /dev/ttyUSB0
Тут понравилось, что нам могли отвечать, и нам отвечали. Но и проблемы тут не закончились, а именно скорость: такая рассылка занимала 4 часа. Поэтому таким образом мы рассылали информацию, которая актуальна длительный период, например, про закрытие части линии на ремонт. 1 симки нам хватало примерно на 3 тысячи сообщений, т.е. на пару рассылок. Дальше нас блокировали. Мы звонили в ТП и спрашивали причины блокировки, на что нам отвечали — рассылка. Один раз нам хватило одной симки на 5 рассылок, таймауты делали побольше и меняли текст. И нам всегда везло на красивые номера — мелочь, но приятно.
А поскольку в обычном случае у нас актуальность информации составляет минут 40, рассылка в идеале должна быть за пару минут. Поэтому мы решили сделать рассылку на телефоне с Android. Главным преимуществом этого решения была скорость, правда тоже далеко не идеально. 1 смс отправлялась за 1.5 секунды, что в результате выходило примерно в 37 минут. Дальше можно было параллелить при помощи подключения еще телефона и добиться нужной скорости. Но тут нас задушил оператор, который блочил нас или посредь первой рассылки или в начале второй.
Логика приложения заключилась в периодическом получении задания с сервера. Примерно раз в несколько минут приложение обращалось на сервер за командой в формате json, которая состояла из массива телефонных номеров и текстов смс.
У нас был поток для забора команды с таймаутом, поток для рассылки смс, BrodasReceiver для запуска после загрузки. Но проект потерялся, ввиду давности, поэтому полного кода не будет. Текст смс мы урезали до максимума 1 смс — 70 символов (это для кириллицы), это делала серверная часть, но на всякий случай отправка смс была ровно на 70 символов:
```
SmsManager smsManager = SmsManager.getDefault();
smsManager.sendTextMessage("NUM", null, "TXT", null, null);
```
не забывая про права на отправку смс в манифест
```
```
Для автозапуска после включения не забываем про права:
```
```
Прописать в манифест:
```
```
Код Boot:
```
public class Boot extends BroadcastReceiver
{
@Override
public void onReceive(Context context, Intent intent)
{
тут запуск потока
}
}
```
Автозапуск на случай разрядившейся батарейки ну и других аналогичных ситуаций, вдруг после включения забуду запустить приложение. А на этом телефоне всеравно живет только это приложение, поэтому некоторое расточительство по отношению к батарейке нам не страшно.
Ну и в Activity добавляем запуск потока.
Так же разрешаем приложению доступ в интернет:
И еще важный момент, чтобы наше приложение работало даже с выключенным дисплеем нужно вызвывать PowerManager. Иначе система будет усыплять приложение по своему желанию, для экономии заряда, и запросы будут выполняться нерегулярно.
Для этого добавляем пермишн:
```
```
Дабавляем код в Activity:
```
PowerManager pm = (PowerManager) this.getSystemService(Context.POWER_SERVICE);
PowerManager.WakeLock wl = pm.newWakeLock(PowerManager.ACQUIRE_CAUSES_WAKEUP|
PowerManager.FULL_WAKE_LOCK| PowerManager.SCREEN_BRIGHT_WAKE_LOCK, "");
```
И в поток
```
PowerManager pm = (PowerManager) context.getSystemService(Context.POWER_SERVICE);
PowerManager.WakeLock wl = pm.newWakeLock(PowerManager.PARTIAL_WAKE_LOCK, "");
wl.acquire();
Обращение к серверу, обработка полученного json
wl.release();
```
Такой способ тоже не проработал долго, поскольку постоянно менять симки было не очень удобно и рационально — ценник стремительно рос и это потеряло смысл.
Дальше мы пробовали рассылать через Whatsapp, но тут номера умирали каждые 10 сообщений, а то и быстрее. А регистрация 1 номера стоила 7 рублей. Мы опять начали выходить на те-же цифры, с которых начали.
А не так давно мы сделали бота для телеграм — <https://telegram.me/msk_metro>, тут все так же как и с PushBullet, который мы подключили по просьбам после первого поста на хабре. Только тут мы можем удалять случайно прошедшие модерацию сообщения, а в PushBullet — нет. | https://habr.com/ru/post/305264/ | null | ru | null |
# Книга-игра Гарри Гаррисона на HTML
Привет всем! Еще со школьных времен очень люблю фантастику. В те далекие времена мне больше всего нравился цикл романов Гарри Гаррисона о Стальной Крысе. Как-то решил я на выходные взять домой из школьной библиотеки подшивку журнала "Если". Просматривая журналы, обнаружил в одном из них книгу-игру вышеупомянутого фантаста. Называется произведение "Стань Стальной Крысой" и является текстовым квестом, в котором читатель по ходу сюжета должен выбирать варианты действий из предложенных. Особенно интересно было бродить в лабиринте. Туда без блокнота и карандаша не стоило и соваться!
Не так давно мне стало интересно, а есть ли в Интернете варианты реализации этой игры на каких-либо языках программирования. Покопавшись в Сети, нашел вот [этот сайт](https://bolknote.ru/all/3322/). На сайте можно увидеть скрипт, который генерирует готовый html-файл с книгой. Ссылка на исходник в скрипте никуда не ведет. Ресурс заблокирован. Меня интересовал не скрипт, а его продукт и что в этом продукте можно улучшить. Ниже под скриптом, в комментариях, есть две ссылки. По ним открывается уже готовая игра. Средствами браузера можно посмотреть исходный код.
Внешний вид
-----------
Выглядит оригинальная версия следующим образом:
Довольно скучновато. Я решил добавить фоновое изображение, поменять цвет текстового фона, размер шрифта и внести некоторые другие изменения. Подробности будут ниже. Получилось вот это:
Согласитесь, что выглядит уже немного интереснее. Теперь подробнее об изменениях.
Изменения
---------
Моя версия находится [здесь](https://github.com/alexkdeveloper/stainless-steel-rat). Оригинальная разработка состоит из одного файла, я же решил разнести код по разным файлам. Разметка в одном файле, а скрипты и стили в двух других.
Появилась папка с изображениями. Там находятся фоновое изображение и изображение для монеты. Для тех кто не в курсе приведу пример первого появления этого элемента в книге:
Читатель нажимает на монетку и случайным образом перебрасывается в один из указанных разделов книги. В оригинале код этой монетки располагался прямо в css-файле:
```
i {
cursor: pointer;
background: url('data:image/jpeg;base64,/9j/4AAQSkZJRgABAQEASABIAAD/2wBDAAEBAQEBAQEBAQECAQECAgMCAgICAgQDAwIDBQQFBQUEB QUFBggHBQYHBgUFBwkHBwgICQkJBQcKCgoICggJCQj/wgALCAAtACwBAREA/8QAGwAAAgMBAQEAAAAAAAAAAAAABgcEBQgCAwn/2gAIAQEAAAAB+zdD Wxyy5FAAc4AtfBIfe0adbXjDJ+UuXGa9nRF1ti8ReInBsko//8QAHhAAAgMBAQADAQAAAAAAAAAABAUBAgMABhESExT/2gAIAQEAAQUC23rhXT9LxNx46Cv ykUyhMdGn2s2IYV6qi9uJ0MBHqwNDJGIzLHpMQOyy23J5nWJFMr9aeTcUoBiw/lC1YyTAZND7mD5cbNddfEAVaLfTLZwpnlr8w0/DPW55FSxt22y1eMqA5340I mWXp26ojyqc/wBNZSmXJBu//8QANRAAAgECAwQFCgcAAAAAAAAAAQIDAAQRITEFEhNBEBRRYaEiJDJSU3GBkbHhBkJDcsHC0f/aAAgBAQAGPwLFgWY5Ko1Y 1vXU5iX2cRw8dayt9/vbWsUZ4+4tvCsNJBqOiW7bPMpEOwff/KgjsVXiyEgyyejF8OdFrnat3PMeYmKD5LSx8TrGeAkbWo7tZmYqccCcjUNzFnG67wq0jGixL9K2 YqjzdZDLIfcMAPHw6Ix+YvRq4tZv0Z9we4qrf2q2jnUvcRebS9zrl4jA0E4W7HiDrnkcanS3Q70Z3W54HCg7XflgeguYrhKcF1Y9g5mr7ahUxxz3bsgPYFVfqpq/2r aw8VpFTirjpun0vkT8qZYCt2VALKh8oD3ULYR8FPUAwxP81iIuqwevJ5K/eoPw/sKUvdSk9bm9ggOp9XuGpyq02bZpuW0KCNR0SX1lOdnXAXQDeTly5acjTWnX 7iXBeHiLhlGOWeHw8a6xcbae1XcCtw48ZGH7mJw05Cuq7Ot+ChO87E4tI3ax5no//8QAIxABAAEDBAICAwAAAAAAAAAAAREAITFBUWGBEHGRobHh8P/aAAgB AQABPyEqxIGdgVfUsJ+Ru6gr73E/JlqZ5yH4hx1FNLcYbJueByIk0WF7E+qLSPukAzuOhxQ2XA7eIgpxNKh4mzFl5qU2VaGpHNMPBcE6UzklnNtQPJc6r2mfg/LyD0 H78Qb26cP5Kq0e745LoKYNx4vQZaYpG8I4IGJ9NXxDiMb26dNGYrOxr/B4cCmRDpTYK7Qdh4c0owRRcCOuIS+KSNRXOjKpqXev7Yaz9CWrIs9hBjaZWuCSLV6n FkGfbmvunXUnUitIcWA4oVjEQY3zu1o9mPoOicwXIG9RPIIHstu274//2gAIAQEAAAAQ2dRilY//xAAhEAEBAAICAgMAAwAAAAAAAAABEQAhMUFRYRBxgZGhwf/ aAAgBAQABPxCWwNoyhKHSqoAKoFyNtZF/Ggp5TeHJYaOLr3/oYqGcsVdn0/b3llDWp5X2cUdi76XCLvgQuH7VnJHWMFrCpmiO1uCq5PGT7rUN6R+3ASpkpRBA DZpsNi1wp72Lwl4AKM6c5+K8UCqnY0fY5YWk9kv6TGNaoB9kOE+G/lT8LF/k4NnJgUQ3s0thUGxBwMpLQDQaLlWnddQSJsOnKgTTCGICgXiXGrMihvNBj7PI4Kk PKg1HoC/1zjTHn2P0ezQTkwAlegiHQE2iKtFDBaAq17SIHaW6x4rugOBoqKtKub+vSsjRplWzSnRjAnKRqMeUdR0AB+C0A61Tsq9riCIgEiJRMMifRjYvlnAnk5eelvIr ZUqRz3rYO3LAmNdBkFRMXKK4ZalhVTlfj//Z');
display: block;
width: 44px; height: 45px;
margin-top: 10px;
}
```
В разметке это выглядело так:
Ну и, собственно, в браузере:
Функция `Coin` у меня осталась практически без изменений:
```
function coin(n) {
location.hash = '#a' + n[Math.floor(Math.random() * n.length)];
}
```
Только имя функции написал с маленькой буквы. Отображение монетки я переписал, используя тег `img`:
```

```
В файле стилей немного увеличил изображение монетки:
```
img {
cursor: pointer;
display: block;
width: 55px; height: 55px;
margin-top: 10px;
}
```
Внес изменения в фон и текстовую область:
```
html {
background: url(images/background.jpg);
background-repeat: no-repeat;
background-size: cover;
}
body {
background: #EDDDB5;
color: black;
font: 20px/1.4em Helvetica, 'Trebuchet MS', Arial, sans-serif;
padding: 20px;
margin: 100px;
}
header {
font-size: 25px;
margin: 0 0 20px;
padding: 0 0 5px;
border-bottom: 2px solid #ccc;
color: #DD5F5F;
}
```
В оригинале вышеприведенный фрагмент имел такой вид:
```
html {
background: white;
}
body {
background: #eee;
color: black;
font: 14px/1.4em Helvetica, 'Trebuchet MS', Arial, sans-serif;
padding: 20px;
margin: 100px;
}
header {
font-size: 25px;
margin: 0 0 20px;
padding: 0 0 5px;
border-bottom: 2px solid #ccc;
color: #ccc;
}
```
Также были исправлены несколько ошибок связанных с появлением монеты в разделах, где она не нужна. Видимо, создающий скрипт по ошибке запихивал монетку не туда куда надо. Вот пример:
Вместо этого должно быть:
```
Идём дальше? [[80](#a80)]
```
В конце html-файла был удален подвал и другие элементы, чтобы не портить внешний вид.
Пожалуй, мне больше нечего рассказать об этой разработке. До встречи в следующих постах! | https://habr.com/ru/post/548852/ | null | ru | null |
# Ещё 8 правил проектирования API
1. Используйте глобально уникальные идентификаторы
--------------------------------------------------
Хороший тон при разработке API — использовать для идентификаторов сущностей глобально уникальные строки, либо семантичные (например, "lungo" для видов напитков), либо случайные (например [UUID-4](https://en.wikipedia.org/wiki/Universally_unique_identifier#Version_4_(random))). Это может чрезвычайно пригодиться, если вдруг придётся объединять данные из нескольких источников под одним идентификатором.
Мы вообще склонны порекомендовать использовать идентификаторы в urn-подобном формате, т.е. `urn:order:` (или просто `order:`), это сильно помогает с отладкой legacy-систем, где по историческим причинам есть несколько разных идентификаторов для одной и той же сущности — тогда неймспейсы в urn помогут быстро понять, что это за идентификатор и нет ли здесь ошибки использования.
Отдельное важное следствие: **не используете инкрементальные номера как идентификаторы**. Помимо вышесказанного, это плохо ещё и тем, что ваши конкуренты легко смогут подсчитать, сколько у вас в системе каких сущностей и тем самым вычислить, например, точное количество заказов за каждый день наблюдений.
**NB**: в этой книге часто используются короткие идентификаторы типа "123" в примерах — это для удобства чтения на маленьких экранах, повторять эту практику в реальном API не надо.
2. Клиент всегда должен знать полное состояние системы
------------------------------------------------------
Правило можно ещё сформулировать так: не заставляйте клиент гадать.
**Плохо**:
```
// Создаёт заказ и возвращает его id
POST /v1/orders
{ … }
→
{ "order_id" }
```
```
// Возвращает заказ по его id
GET /v1/orders/{id}
// Заказ ещё не подтверждён
// и ожидает проверки
→ 404 Not Found
```
— хотя операция будто бы выполнена успешно, клиенту необходимо самостоятельно запомнить идентификатор заказа и периодически проверять состояние `GET /v1/orders/{id}`. Этот паттерн плох сам по себе, но ещё и усугубляется двумя обстоятельствами:
* клиент может потерять идентификатор, если произошёл системный сбой в момент между отправкой запроса и получением ответа или было повреждено (очищено) системное хранилище данных приложения;
* потребитель не может воспользоваться другим устройством; фактически, знание о сделанном заказе привязано к конкретному юзер-агенту.
В обоих случаях потребитель может решить, что заказ по какой-то причине не создался — и сделать повторный заказ со всеми вытекающими отсюда проблемами.
**Хорошо**:
```
// Создаёт заказ и возвращает его
POST /v1/orders
{ <параметры заказа> }
→
{
"order_id",
// Заказ создаётся в явном статусе
// «идёт проверка»
"status": "checking",
…
}
```
```
// Возвращает заказ по его id
GET /v1/orders/{id}
→
{ "order_id", "status" … }
```
```
// Возвращает все заказы пользователя
// во всех статусах
GET /v1/users/{id}/orders
```
3. Избегайте двойных отрицаний
------------------------------
**Плохо**: `"dont_call_me": false`
— люди в целом плохо считывают двойные отрицания. Это провоцирует ошибки.
**Лучше**: `"prohibit_calling": true` или `"avoid_calling": true`
— читается лучше, хотя обольщаться все равно не следует. Насколько это возможно откажитесь от семантически двойных отрицаний, даже если вы придумали «негативное» слово без явной приставки «не».
Стоит также отметить, что в использовании [законов де Моргана](https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%BA%D0%BE%D0%BD%D1%8B_%D0%B4%D0%B5_%D0%9C%D0%BE%D1%80%D0%B3%D0%B0%D0%BD%D0%B0) ошибиться ещё проще, чем в двойных отрицаниях. Предположим, что у вас есть два флага:
```
GET /coffee-machines/{id}/stocks
→
{
"has_beans": true,
"has_cup": true
}
```
Условие «кофе можно приготовить» будет выглядеть как `has_beans && has_cup` — есть и зерно, и стакан. Однако, если по какой-то причине в ответе будут отрицания тех же флагов:
```
{
"beans_absence": false,
"cup_absence": false
}
```
— то разработчику потребуется вычислить флаг `!beans_absence && !cup_absence` ⇔ `!(beans_absence || cup_absence)`, а вот этом переходе ошибиться очень легко, и избегание двойных отрицаний помогает слабо. Здесь, к сожалению, есть только общий совет «избегайте ситуаций, когда разработчику нужно вычислять такие флаги».
4. Избегайте неявного приведения типов
--------------------------------------
Этот совет парадоксально противоположен предыдущему. Часто при разработке API возникает ситуация, когда добавляется новое необязательное поле с непустым значением по умолчанию. Например:
```
POST /v1/orders
{}
→
{
"contactless_delivery": true
}
```
Новая опция `contactless_delivery` является необязательной, однако её значение по умолчанию — `true`. Возникает вопрос, каким образом разработчик должен отличить явное *нежелание* пользоваться опцией (`false`) от незнания о её существовании (поле не задано). Приходится писать что-то типа такого:
```
if (Type(order.contactless_delivery) == 'Boolean' &&
order.contactless_delivery == false) { … }
```
Эта практика ведёт к усложнению кода, который пишут разработчики, и в этом коде легко допустить ошибку, которая по сути меняет значение поля на противоположное. То же самое произойдёт, если для индикации отсутствия значения поля использовать специальное значение типа `null` или `-1`.
В этих ситуациях универсальное правило — все новые необязательные булевы флаги должны иметь значение по умолчанию false.
**Хорошо**
```
POST /v1/orders
{}
→
{
"force_contact_delivery": false
}
```
Если же требуется ввести небулево поле, отсутствие которого трактуется специальным образом, то следует ввести пару полей.
**Плохо**:
```
// Создаёт пользователя
POST /users
{ … }
→
// Пользователи создаются по умолчанию
// с указанием лимита трат в месяц
{
…
"spending_monthly_limit_usd": "100"
}
// Для отмены лимита требуется
// указать значение null
POST /users
{
…
"spending_monthly_limit_usd": null
}
```
**Хорошо**
```
POST /users
{
// true — у пользователя снят
// лимит трат в месяц
// false — лимит не снят
// (значение по умолчанию)
"abolish_spending_limit": false,
// Необязательное поле, имеет смысл
// только если предыдущий флаг
// имеет значение false
"spending_monthly_limit_usd": "100",
…
}
```
**NB**: противоречие с предыдущим советом состоит в том, что мы специально ввели отрицающий флаг («нет лимита»), который по правилу двойных отрицаний пришлось переименовать в `abolish_spending_limit`. Хотя это и хорошее название для отрицательного флага, семантика его довольно неочевидна, разработчикам придётся как минимум покопаться в документации. Таков путь.
5. Избегайте частичных обновлений
---------------------------------
**Плохо**:
```
// Возвращает состояние заказа
// по его идентификатору
GET /v1/orders/123
→
{
"order_id",
"delivery_address",
"client_phone_number",
"client_phone_number_ext",
"updated_at"
}
// Частично перезаписывает заказ
PATCH /v1/orders/123
{ "delivery_address" }
→
{ "delivery_address" }
```
— такой подход часто практикуют для того, чтобы уменьшить объёмы запросов и ответов, плюс это позволяет дёшево реализовать совместное редактирование. Оба этих преимущества на самом деле являются мнимыми.
**Во-первых**, экономия объёма ответа в современных условиях требуется редко. Максимальные размеры сетевых пакетов (MTU, Maximum Transmission Unit) в настоящее время составляют более килобайта; пытаться экономить на размере ответа, пока он не превышает килобайт — попросту бессмысленная трата времени.
Перерасход трафика возникает, если:
* не предусмотрен постраничный перебор данных;
* не предусмотрены ограничения на размер значений полей;
* передаются бинарные данные (графика, аудио, видео и т.д.).
Во всех трёх случаях передача части полей в лучше случае замаскирует проблему, но не решит. Более оправдан следующий подход:
* для «тяжёлых» данных сделать отдельные эндпойнты;
* ввести пагинацию и лимитирование значений полей;
* на всём остальном не пытаться экономить.
**Во-вторых**, экономия размера ответа выйдет боком как раз при совместном редактировании: один клиент не будет видеть, какие изменения внёс другой. Вообще в 9 случаях из 10 (а фактически — всегда, когда размер ответа не оказывает значительного влияния на производительность) во всех отношениях лучше из любой модифицирующей операции возвращать полное состояние сущности в том же формате, что и из операции доступа на чтение.
**В-третьих**, этот подход может как-то работать при необходимость перезаписать поле. Но что делать, если поле требуется сбросить к значению по умолчанию? Например, как *удалить* `client_phone_number_ext`?
Часто в таких случаях прибегают к специальным значениям, которые означают удаление поля, например, null. Но, как мы разобрали выше, это плохая практика. Другой вариант — запрет необязательных полей, но это существенно усложняет дальнейшее развитие API.
**Хорошо**: можно применить одну из двух стратегий.
**Вариант 1**: разделение эндпойнтов. Редактируемые поля группируются и выносятся в отдельный эндпойнт. Этот подход также хорошо согласуется [с принципом декомпозиции](https://twirl.github.io/The-API-Book/docs/API.ru.html#chapter-10), который мы рассматривали в предыдущем разделе.
```
// Возвращает состояние заказа
// по его идентификатору
GET /v1/orders/123
→
{
"order_id",
"delivery_details": {
"address"
},
"client_details": {
"phone_number",
"phone_number_ext"
},
"updated_at"
}
// Полностью перезаписывает
// информацию о доставке заказа
PUT /v1/orders/123/delivery-details
{ "address" }
// Полностью перезаписывает
// информацию о клиенте
PUT /v1/orders/123/client-details
{ "phone_number" }
```
Теперь для удаления `client_phone_number_ext` достаточно *не* передавать его в `PUT client-details`. Этот подход также позволяет отделить неизменяемые и вычисляемые поля (`order_id` и `updated_at`) от изменяемых, не создавая двусмысленных ситуаций (что произойдёт, если клиент попытается изменить `updated_at`?). В этом подходе также можно в ответах операций `PUT` возвращать объект заказа целиком (однако следует использовать какую-то конвенцию именования).
**Вариант 2**: разработать формат описания атомарных изменений.
```
POST /v1/order/changes
X-Idempotency-Token: <токен идемпотентности>
{
"changes": [{
"type": "set",
"field": "delivery_address",
"value": <новое значение>
}, {
"type": "unset",
"field": "client_phone_number_ext"
}]
}
```
Этот подход существенно сложнее в имплементации, но является единственным возможным вариантом реализации совместного редактирования, поскольку он явно отражает, что в действительности делал пользовать с представлением объекта. Имея данные в таком формате возможно организовать и оффлайн-редактирование, когда пользовательские изменения накапливаются и потом сервер автоматически разрешает конфликты, «перебазируя» изменения.
6. Избегайте неатомарных операций
---------------------------------
С применением массива изменений часто возникает вопрос: что делать, если часть изменений удалось применить, а часть — нет? Здесь правило очень простое: если вы можете обеспечить атомарность, т.е. выполнить либо все изменения сразу, либо ни одно из них — сделайте это.
**Плохо**:
```
// Возвращает список рецептов
GET /v1/recipes
→
{
"recipes": [{
"id": "lungo",
"volume": "200ml"
}, {
"id": "latte",
"volume": "300ml"
}]
}
// Изменяет параметры
PATCH /v1/recipes
{
"changes": [{
"id": "lungo",
"volume": "300ml"
}, {
"id": "latte",
"volume": "-1ml"
}]
}
→ 400 Bad Request
// Перечитываем список
GET /v1/recipes
→
{
"recipes": [{
"id": "lungo",
// Это значение изменилось
"volume": "300ml"
}, {
"id": "latte",
// А это нет
"volume": "300ml"
}]
}
```
— клиент никак не может узнать, что операция, которую он посчитал ошибочной, на самом деле частично применена. Даже если индицировать это в ответе, у клиента нет способа понять — значение объёма лунго изменилось вследствие запроса, или это конкурирующее изменение, выполненное другим клиентом.
Если способа обеспечить атомарность выполнения операции нет, следует очень хорошо подумать над её обработкой. Следует предоставить способ получения статуса каждого изменения отдельно.
**Лучше**:
```
PATCH /v1/recipes
{
"changes": [{
"recipe_id": "lungo",
"volume": "300ml"
}, {
"recipe_id": "latte",
"volume": "-1ml"
}]
}
// Можно воспользоваться статусом
// «частичного успеха», если он предусмотрен
// протоколом
→ 200 OK
{
"changes": [{
"change_id",
"occurred_at",
"recipe_id": "lungo",
"status": "success"
}, {
"change_id",
"occurred_at",
"recipe_id": "latte",
"status": "fail",
"error"
}]
}
```
Здесь:
* `change_id` — уникальный идентификатор каждого атомарного изменения;
* `occurred_at` — время проведения каждого изменения;
* `error` — информация по ошибке для каждого изменения, если она возникла.
Не лишним будет также:
* введение `sequence_id` в запросе, чтобы гарантировать порядок исполнения операций и соотнесение порядка статусов изменений в ответе с запросом;
* предоставить отдельный эндпойнт `/changes-history`, чтобы клиент мог получить информацию о выполненных изменениях, если во время обработки запроса произошла сетевая ошибка или приложение перезагрузилось.
Неатомарные изменения нежелательны ещё и потому, что вносят неопределённость в понятие идемпотентности, даже если каждое вложенное изменение идемпотентно. Рассмотрим такой пример:
```
PATCH /v1/recipes
{
"idempotency_token",
"changes": [{
"recipe_id": "lungo",
"volume": "300ml"
}, {
"recipe_id": "latte",
"volume": "400ml"
}]
}
→ 200 OK
{
"changes": [{
…
"status": "success"
}, {
…
"status": "fail",
"error": {
"reason": "too_many_requests"
}
}]
}
```
Допустим, клиент не смог получить ответ и повторил запрос с тем же токеном идемпотентности.
```
PATCH /v1/recipes
{
"idempotency_token",
"changes": [{
"recipe_id": "lungo",
"volume": "300ml"
}, {
"recipe_id": "latte",
"volume": "400ml"
}]
}
→ 200 OK
{
"changes": [{
…
"status": "success"
}, {
…
"status": "success",
}]
}
```
По сути, для клиента всё произошло ожидаемым образом: изменения были внесены, и последний полученный ответ всегда корректен. Однако по сути состояние ресурса после первого запроса отличалось от состояния ресурса после второго запроса, что противоречит самому определению идемпотентности.
Более корректно было бы при получении повторного запроса с тем же токеном ничего не делать и возвращать ту же разбивку ошибок, что была дана на первый запрос — но для этого придётся её каким-то образом хранить в истории изменений.
На всякий случай уточним, что вложенные операции должны быть сами по себе идемпотентны. Если же это не так, то следует сгенерировать внутренние ключи идемпотентности на каждую вложенную операцию в отдельности.
7. Соблюдайте правильный порядок ошибок
---------------------------------------
**Во-первых**, всегда показывайте неразрешимые ошибки прежде разрешимых:
```
POST /v1/orders
{
"recipe": "lngo",
"offer"
}
→ 409 Conflict
{
"reason": "offer_expired"
}
// Повторный запрос
// с новым `offer`
POST /v1/orders
{
"recipe": "lngo",
"offer"
}
→ 400 Bad Request
{
"reason": "recipe_unknown"
}
```
— какой был смысл получать новый `offer`, если заказ все равно не может быть создан?
**Во-вторых**, соблюдайте такой порядок разрешимых ошибок, который приводит к наименьшему раздражению пользователя и разработчика. В частности, следует начинать с более значимых ошибок, решение которых требует более глобальных изменений.
**Плохо**:
```
POST /v1/orders
{
"items": [{ "item_id": "123", "price": "0.10" }]
}
→
409 Conflict
{
"reason": "price_changed",
"details": [{ "item_id": "123", "actual_price": "0.20" }]
}
// Повторный запрос
// с актуальной ценой
POST /v1/orders
{
"items": [{ "item_id": "123", "price": "0.20" }]
}
→
409 Conflict
{
"reason": "order_limit_exceeded",
"localized_message": "Лимит заказов превышен"
}
```
— какой был смысл показывать пользователю диалог об изменившейся цене, если и с правильной ценой заказ он сделать все равно не сможет? Пока один из его предыдущих заказов завершится и можно будет сделать следующий заказ, цену, наличие и другие параметры заказа всё равно придётся корректировать ещё раз.
**В-третьих**, постройте таблицу: разрешение какой ошибки может привести к появлению другой, иначе вы можете показать одну и ту же ошибку несколько раз, а то и вовсе зациклить разрешение ошибок.
```
// Создаём заказ с платной доставкой
POST /v1/orders
{
"items": 3,
"item_price": "3000.00"
"currency_code": "MNT",
"delivery_fee": "1000.00",
"total": "10000.00"
}
→ 409 Conflict
// Ошибка: доставка становится бесплатной
// при стоимости заказа от 9000 тугриков
{
"reason": "delivery_is_free"
}
// Создаём заказ с бесплатной доставкой
POST /v1/orders
{
"items": 3,
"item_price": "3000.00"
"currency_code": "MNT",
"delivery_fee": "0.00",
"total": "9000.00"
}
→ 409 Conflict
// Ошибка: минимальная сумма заказа
// 10000 тугриков
{
"reason": "below_minimal_sum",
"currency_code": "MNT",
"minimal_sum": "10000.00"
}
```
Легко заметить, что в этом примере нет способа разрешить ошибку в один шаг — эту ситуацию требуется предусмотреть отдельно, и либо изменить параметры расчета (минимальная сумма заказа не учитывает скидки), либо ввести специальную ошибку для такого кейса.
8. Отсутствие результата — тоже результат
-----------------------------------------
Если сервер корректно обработал вопрос и никакой внештатной ситуации не возникло — следовательно, это не ошибка. К сожалению, весьма распространён антипаттерн, когда отсутствие результата считается ошибкой.
**Плохо**
```
POST /search
{
"query": "lungo",
"location": <положение пользователя>
}
→ 404 Not Found
{
"localized_message":
"Рядом с вами не делают лунго"
}
```
Статусы `4xx` означают, что клиент допустил ошибку; однако в данном случае никакой ошибки сделано не было, ни пользователем, ни разработчиком: клиент же не может знать заранее, готовят здесь лунго или нет.
**Хорошо**:
```
POST /search
{
"query": "lungo",
"location": <положение пользователя>
}
→ 200 OK
{
"results": []
}
```
Это правило вообще можно упростить до следующего: если результатом операции является массив данных, то пустота этого массива — не ошибка, а штатный ответ. (Если, конечно, он допустим по смыслу; пустой массив координат, например, является ошибкой.)
---
Это дополнение к [главе 11 книги о разработке API](https://twirl.github.io/The-API-Book/docs/API.ru.html#chapter-11). Работа ведётся [на Github](https://github.com/twirl/The-API-Book/). Англоязычный вариант этой же главы опубликован [на medium.](https://twirl.medium.com/8-more-rules-of-designing-program-interfaces-89fb4b142313) Я буду признателен, если вы пошарите его на реддит — я сам не могу согласно политике платформы. | https://habr.com/ru/post/536036/ | null | ru | null |
# Дайджест KolibriOS #7: как мы зиму перезимовали
Зима в проекте КолибриОС выдалась на редкость плодотворной: добавлено много мелких, но очень полезных в повседневной работе программ; улучшен пользовательский интерфейс некоторых существующих программ; исправлены ошибки в сетевой и звуковой подсистеме; и многое другое. Кроме того, зимой мы провели [новогодний конкурс](http://habrahabr.ru/company/kolibrios/blog/243081/) по написанию игр под нашу операционную систему. В сумме было написано 10 игр, о которых вы можете прочитать [здесь](http://habrahabr.ru/company/kolibrios/blog/247601/). Подробности всех изменений и исправлений под катом.
**Список выпусков**[Дайджест KolibriOS #1: ввод в курс дела](http://habrahabr.ru/company/kolibrios/blog/210268/)
[Дайджест KolibriOS #2: что нам принёс февраль](http://habrahabr.ru/company/kolibrios/blog/210628/)
[Дайджест KolibriOS #3: начало весны](http://habrahabr.ru/company/kolibrios/blog/216789/)
[Дайджест KolibriOS #4: и весна нам не помеха](http://habrahabr.ru/company/kolibrios/blog/221205/)
[Дайджест KolibriOS #5: мы снова с вами](http://habrahabr.ru/company/kolibrios/blog/225127/)
[Дайджест KolibriOS #6: последняя осень](http://habrahabr.ru/company/kolibrios/blog/231433/)
Дайджест KolibriOS #7: как мы зиму перезимовали
**Обозначения** — реализация новой программы, драйвера или библиотеки
 — реализация чего-либо в рамках GSoC
 — ссылка на загрузку
#### Общесистемные изменения (ядро, драйверы, библиотеки):
* Обновление драйверов видеокарт ATI Radeon и Intel.
* Сетевая подсистема: теперь Колибри пытается подключиться к DHCP серверу, только если кабель физически подключен (и переподключиться, если переподключен кабель, пока поддерживается не всеми драйверами). Предыдущие версии пытались подключиться всегда, что при не подсоединённом сетевом кабеле посылало ненужные пакеты и «забивало» буфер. Также исправлены обнаруженные утечки памяти.
* Оптимизации ядра.
* **buf2d**: добавлены новые функции и проведена оптимизация.
* **TinyGL**: добавлены новые функции; оптимизация и исправления.
* Звуковая подсистема Infinity: исправления для кольцевого буфера (до этого, некорректно проигрывались звуковые файлы, записанные с определённой частотой дискретизации).
* Обновлены старые и добавлены новые иконки.
#### Изменения в прикладном ПО:
*  **open**: утилита для открытия файлов по ассоциациям с диалогом «открыть с помощью» (в дальнейшем все программы будут использовать ее для открытия файла согласно ассоциациям).
**Скрытый текст**
*  **Pixie Player**: фронтэнд для [MiniMP3](http://board.kolibrios.org/viewtopic.php?f=38&t=2220) ([подробнее в предыдущей статье](http://habrahabr.ru/company/kolibrios/blog/251371/)).
**Скрытый текст**
*  **Volume**: Общесистемный регулятор громкости ([подробнее в предыдущей статье](http://habrahabr.ru/company/kolibrios/blog/251371/)).
**Скрытый текст**
*  **Software widget**: это универсальный настраиваемый виджет, который сейчас используется, как Game center и Control panel. Настройки берутся из INI файла и в их число входит название окна, его размеры, расстояние меджу элементами. В состав элемента входит иконка и её подпись.
**Скрытый текст**
*  **panels\_cfg**: утилита для настройки таскбара (нижняя панель) и докбара.
**Скрытый текст**
*  **Eagle**: просто лаунчер файлов(не только исполняемых)/папок, а так же урезанный файловый менеджер (просмотр списка файлов).
**Скрытый текст**
* **Eolite**: использование `@open` для открытия файлов по ассоциациям; использование [libini](http://wiki.kolibrios.org/wiki/Libs-dev/libini/ru) для чтения файла настроек.
**Скрытый текст**Окно настроек:
Окно свойств:
* **voxel editor**: исправление ошибок; новая функция vox\_tgl.
* **Docky**: добавлена опция «показывать всегда» (не скрывать).
* **Fplay**: использование pixlib3 для рендеринга.
* **TextEdit**: исправление багов.
* **TmpDisk**: отображение размера созданных дисков.
**Скрытый текст**
* **View3DS**: поддержка ASC формата.
* **AC97snd**: исправление ошибки в обработке ID3-тегов, пересекающих границу в 64 Кб ([что приводило к зависанию системы на некоторых MP3-файлах](http://board.kolibrios.org/viewtopic.php?f=38&t=1596&start=45#p46063))
* **MTDBG**: поддержка всех инструкцияй **int 3** (пользовательская точка остановки выполнения).
* **WebView**: реализована возможность загрузки файлов.
**Скрытый текст** | https://habr.com/ru/post/239033/ | null | ru | null |
# Выпуск#14: ITренировка — актуальные вопросы и задачи от ведущих компаний
На этой неделе мы отобрали вопросы и задачи, встречающиеся соискателям на собеседованиях на должность инженера-разработчика в DELL.

Помимо ожидаемых вопросов об устройстве операционных систем и тонкостей работы с железом (некоторые довольно сложные), на собеседованиях в DELL можно услышать задачи на логику и умение применять алгоритмы. Некоторые из них мы приводим здесь — сложность, как обычно, варьируется от простых до сложных.
#### Вопросы
1. **Ice bucket challenge**
> There are 3 buckets of capacities 8, 5, 3 litres in front of you. The bucket with capacity 8 is completely filled with ice water. You need to divide the 8 litres into 2 portions of 4 litre each using above 3 buckets.
>
>
**Перевод**Перед Вами 3 ведра ёмкостью 8, 5 и 3 л. Ведро на 8 л. полностью заполнено холодной водой. Вам нужно разделить 8 литров на 2 порции по 4 л. используя эти три ведра.
2. **Torch and bridge**
> There are 4 persons (A, B, C and D) who want to cross a bridge in night.
>
>
>
> A takes 1 minute to cross the bridge.
>
> B takes 2 minutes to cross the bridge.
>
> C takes 5 minutes to cross the bridge.
>
> D takes 8 minutes to cross the bridge.
>
>
>
> There is only one torch with them and the bridge cannot be crossed without the torch. There cannot be more than two persons on the bridge at any time, and when two people cross the bridge together, they must move at the slower person’s pace
>
>
>
> Can they all cross the bridge in 15 minutes?
>
>
**Перевод**4 человека (A, B, C, D) хотять ночью перебраться через мост.
A нужна 1 минута чтобы пройти по мосту.
B нужно 2 минуты.
C нужно 5 минут.
D нужно 8 минут.
У них только один фонарь, без которого нельзя перейти мост. Также, на мосту не может находиться больше 2-х человек, и, когда по мосту идут двое — они идут со скоростью самого медленного ходока.
Смогут ли они перебраться за 15 минут?
#### Задачи
1. **Sort an array of 0s, 1s and 2x**
> Given an array A[] consisting 0s, 1s and 2s, write a function that sorts A[]. The functions should put all 0s first, then all 1s and all 2s in last.
>
> Examples:
>
>
>
> Input: {0, 1, 2, 0, 1, 2}
>
> Output: {0, 0, 1, 1, 2, 2}
>
>
>
> Input: {0, 1, 1, 0, 1, 2, 1, 2, 0, 0, 0, 1}
>
> Output: {0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 2, 2}
>
>
>
>
**Перевод**Дан массив A[], состоящий из 0, 1 и 2. Напишите функцию, сортирующую A[]. Функция должна располагать сначала 0, потом 1, последними — 2.
Примеры:
Вход: {0, 1, 2, 0, 1, 2}
Выход: {0, 0, 1, 1, 2, 2}
Вход: {0, 1, 1, 0, 1, 2, 1, 2, 0, 0, 0, 1}
Выход: {0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 2, 2}
2. **Select a random number from stream, using fixed space**
> Given a generator producing random numbers. You are allowed to use only O(1) space and the input is in the form of stream, so can’t store the previously seen numbers.
>
>
>
> So how do we select a random number from the whole stream such that the probability of picking any number is 1/n. with O(1) extra space?
**Перевод**Дан генератор случайных чисел. Позволено использовать только О(1) памяти, входные данные представлены в виде потока, так что нет возможности сохранять предыдущие числа.
Задача — выбрать случаное число из входящего потока, обеспечив вероятность 1/n, используя только O(1) дополнительной памяти.
3. **Maximize the sum of selected numbers**
> Given an array of N numbers, we need to maximize the sum of selected numbers. At each step you need to select a number Ai, delete one occurrence of Ai-1 (if exists), Ai+1 (if exists) and Ai each from the array. Repeat these steps until the array gets empty. The problem is to maximize the sum of selected numbers.
>
>
>
> Note: We have to delete Ai+1 and Ai-1 elements if they are present in the array and not Ai+1 and Ai-1.
>
>
>
> Examples:
>
>
>
> Input: a[] = {1, 2, 3}
>
> Output: 4
>
> Explanation: At first step we select 1, so 1 and 2 are deleted from the sequence leaving us with 3.
>
> Then we select 3 from the sequence and delete it. So the sum of selected numbers is 1+3 = 4.
>
>
>
> Input: a[] = {1, 2, 2, 2, 3, 4}
>
> Output: 10
>
> Explanation: Select one of the 2's from the array, so 2, 2-1, 2+1 will be deleted and we are left with {2, 2, 4}, since 1 and 3 are deleted. Select 2 in next two steps, and then select 4 in the last step. We get a sum of 2+2+2+4=10 which is the maximum possible.
>
>
**Перевод**Дан массив из N чисел, нам необходимо выбрать элементы с максимальной суммой. При каждой выборке элемента (Аi), необходимо удалить одно вхождение элемента на единицу меньше и одно вхождение элемента на единицу больше (Ai-1) и (Ai+1) при их наличии и сам элемент. Эти шаги повторяются, пока массив не опустеет. Задача — обеспечить максимальную сумму выбранных элементов.
Нужно удалять элементы со значением Ai+1 и Ai-1, а не на позиции Аi-1 и Аi+1
Примеры:
Вход: a[] = {1, 2, 3}
Выход: 4
Объяснение: На первом шаге выбираем 1, следовательно, 1 и 2 удаляются из массива. На следующем шаге забираем оставшуюся 3. Сумма выбранных элементов 1+3 = 4.
Вход: a[] = {1, 2, 2, 2, 3, 4}
Выход: 10
Объяснение: Выбираем одну 2 из массива — удаляются 1 и 3 (2-1 и 2+1, соответственно), остаются {2, 2, 4}. В ходе следующих 2-х шагов выбираем оставшиеся 2 и последним шагом выбираем 4. Итоговая сумма 2+2+2+4 = 10, что является максимально возможной.
Ответы будут даны в течение следующей недели — успейте решить. Удачи!
#### Решения
1. **Вопрос 1**Корректное решение предложено в [комментарии](https://habrahabr.ru/company/spice/blog/350788/#comment_10703640):
8 -> 5 (3, 5, 0)
5 -> 3 (3, 2, 3)
3 -> 8 (6, 2, 0)
5 -> 3 (6, 0, 2)
8 -> 5 (1, 5, 2)
5 -> 3 (1, 4, 3)
3 -> 8 (4, 4, 0)
2. **Вопрос 2**Верное решение было найдено в [комментариях](https://habrahabr.ru/company/spice/blog/350788/#comment_10707944).
3. **Задача 1**Предложили верный вариант решения — сортировка подсчётом. Код может быть, например, [таким](https://habrahabr.ru/company/spice/blog/350788/#comment_10716212).
4. **Задача 2**Алгоритм решения был верно разъяснен в [комментарии](https://habrahabr.ru/company/spice/blog/350788/#comment_10703586). Код может быть таким:
`// An efficient C program to randomly select a number from stream of numbers.
#include
#include
#include
// A function to randomly select a item from stream[0], stream[1], .. stream[i-1]
int selectRandom(int x)
{
static int res; // The resultant random number
static int count = 0; //Count of numbers visited so far in stream
count++; // increment count of numbers seen so far
// If this is the first element from stream, return it
if (count == 1)
res = x;
else
{
// Generate a random number from 0 to count - 1
int i = rand() % count;
// Replace the prev random number with new number with 1/count probability
if (i == count - 1)
res = x;
}
return res;
}
// Driver program to test above function.
int main()
{
int stream[] = {1, 2, 3, 4};
int n = sizeof(stream)/sizeof(stream[0]);
// Use a different seed value for every run.
srand(time(NULL));
for (int i = 0; i < n; ++i)
printf("Random number from first %d numbers is %d \n",
i+1, selectRandom(stream[i]));
return 0;
}`
5. **Задача 3**Правильное решение было предложено, например, [тут](https://habrahabr.ru/company/spice/blog/350788/#comment_10704060). Код:
`// CPP program to Maximize the sum of selected
// numbers by deleting three consecutive numbers.
#include
using namespace std;
// function to maximize the sum of selected numbers
int maximizeSum(int a[], int n) {
// stores the occurrences of the numbers
unordered\_map ans;
// marks the occurrence of every number in the sequence
for (int i = 0; i < n; i++)
ans[a[i]]++;
// maximum in the sequence
int maximum = \*max\_element(a, a + n);
// traverse till maximum and apply the recurrence relation
for (int i = 2; i <= maximum; i++)
ans[i] = max(ans[i - 1], ans[i - 2] + ans[i] \* i);
// return the ans stored in the index of maximum
return ans[maximum];
}
// Driver code
int main()
{
int a[] = {1, 2, 3};
int n = sizeof(a) / sizeof(a[0]);
cout << maximizeSum(a, n);
return 0;
}` | https://habr.com/ru/post/350788/ | null | ru | null |
# Динамическое перенаправление сетевого трафика
Речь в статье пойдет о том, как организовать возможность динамического переключения между сетевыми интерфейсами.
Корни вопроса начали расти из предыдущего проекта [socmetr.ru](http://socmetr.ru), где понадобилось собирать большой объем информации из социальных сетей, и таким образом забивая единственный канал с интернетом. Анализ показал, что даже при наличии сжатия, объем поступающей информации так велик, что происходит его блокировка, при этом мощности CPU и Memory не задействованы и на 20%, а дисковая подсистема почти все время простаивает, то есть мы упёрлись в ширину канала, которую нам предоставляет провайдер.
Первая мысль была пойти экстенсивным путём и просто увеличить его возможности, немного остыв и призадумавшись, поняли, что перекладываем проблему на будущее. Само собой, возник вопрос: "Каким путём пойдем товарищи?". В результате реализовали следующую идею:

#### Настройка сервера
Поскольку конфигурация выглядит однообразно, имеет смысл ввести символьные обозначения, пусть:
A1 это первый сетевой интерфейс, A2 — второй… AN — поcледний
IP1 это IP-адрес связанный с сетевым интерфейсом A1, IP2 — адрес связанный с A2… IPN — адрес связанный c AN
GW1 это IP-адрес шлюза провайдера P1 (Provider 1), GW2 — адрес шлюза провайдера P2… GWN — адрес шлюза PN
GW1\_NET это IP-адрес сети провайдера P1, GW2\_NET IP-адрес сети провайдера P2… GWN\_NET IP-адрес сети провайдера PN
Тогда настройку можно осуществить следующим образом:
```
Создаем N-таблиц маршрутизации (где N - это количество подведенных каналов с интернетом)
ip route add {GW1_NET} dev {A1} src {IP1} table T1
ip route add default via {GW1} table T1
...
ip route add {GWn_NET} dev {An} src {IPn} table Tn
ip route add default via {GWn} table Tn
Описываем маршруты в основной таблице маршрутизации:
ip route add {GW1_NET} dev {A1} src {IP1}
...
ip route add {GWn_NET} dev {An} src {IPn}
ip route add default via {GW1}
Описываем правила:
ip rule add from {IP1} table T1
...
ip rule add from {IPn} table Tn
```
И дело в шляпе, получаем конфигурацию, которая гарантирует что все запросы к конкретному интерфейсу получат от него ответ.
#### Использование
Для, того чтобы обратится к разным сетевым адаптерам, необходимо задействовать конструкции конкретного языка программирования, либо использовать сторонние библиотеки. В Java, это можно сделать через сокеты, например:
```
socket.bind(new InetSocketAddress(InetAddress.getByName("network-adapter"), port));
```
Реализовав указанную схему, была получена возможность управлять полосой интернет канала в зависимости от бизнес-процессов и логики, происходящих на серверах, на разных стадиях жизненного цикла информационных систем.
Плюсы:
* возможность гибкого масштабирования интернет-канала (мы получаем возможность в любой момент нарастить или уменьшить общий интернет канал, как за счёт подключения новых провайдеров, так и за счет увеличения полосы пропускания текущих, появляется возможность планировать и прогнозировать его мощность)
* возможность управления нагрузкой, каждого из них
* возможность использования любого канала или их последовательности в любой момент времени любой подсистемой
Минусы:
* изначальные траты на покупку соответствующего оборудования
* обязательное наличие множества провайдеров интернет услуг
Возможно, кто-то уже сталкивался с подобной проблемой, и мы построили велосипед, так что критика решения только приветствуется. | https://habr.com/ru/post/319410/ | null | ru | null |
# PHP-Дайджест № 187 (18 августа – 7 сентября 2020)
[](https://habr.com/ru/post/518064/)
Свежая подборка со ссылками на новости и материалы. В выпуске: PHP 8 beta 3, принят новый синтаксис атрибутов в PHP 8, Zephir всё, целая пачка полезных инструментов, статьи, видео, подкасты.
Приятного чтения!
### Новости и релизы
* **[PHP 8 beta 3](https://www.php.net/archive/2020.php#2020-09-03-3)** — Последняя бета в цикле. Следующим релизом станет RC 1, который ожидается 17 сентября.
* **[PHP 7.4.10](https://www.php.net/ChangeLog-7.php#7.4.10), [PHP 7.3.22](https://www.php.net/ChangeLog-7.php#7.3.22)**
* **[Будущее Zephir и Phalcon](https://blog.phalcon.io/post/the-future-of-phalcon)** — Один из контрибьюторов языка Zephir и PHP-фреймворка Phalcon ушёл из проекта, поэтому активная разработка Zephir приостановлена, а Phalcon 5 планируется переписать на чистый PHP.
* В WordPress сообществе обсуждается [план по поддержке версий PHP](https://make.wordpress.org/core/2020/08/24/proposal-dropping-support-for-old-php-versions-via-a-fixed-schedule/). Судя по [ответам](https://make.wordpress.org/core/2020/08/24/proposal-dropping-support-for-old-php-versions-via-a-fixed-schedule/#comment-39736) лидера проекта Matt Mullenweg, PHP 5.6 будет поддерживаться еще долго. По [официальной статистике](https://wordpress.org/about/stats/#php_versions) PHP ≤5.6 используется на 21.6% установок WP.
### PHP Internals
*  **[[RFC] Shorter Attribute Syntax Change](https://wiki.php.net/rfc/shorter_attribute_syntax_change#voting)** — Наконец-то закончилась эпопея с синтаксисом для атрибутов. На переголосовании принят вариант `#[Attribute]`.
```
#[
ORM\Entity,
ORM\Table("user")
]
class User
{
#[ORM\Id, ORM\Column("integer"), ORM\GeneratedValue]
private $id;
#[ORM\Column("string", ORM\Column::UNIQUE)]
#[Assert\Email(["message" => "The email '{{ value }}' is not a valid email."])]
private $email;
}
```
Кстати, предыдущий синтаксис с `@@Attr` не поддерживал группировку атрибутов и поэтому такая возможность была убрана из PR. Но поскольку у `#[ ]` есть маркер конца, то группировку он поддерживает и она была возвращена.
```
// Можно и так
#[ORM\Entity]
#[ORM\Table("user")]
// и так
#[
ORM\Entity,
ORM\Table("user")
]
```
Подробнее об атрибутах было [в посте](https://stitcher.io/blog/attributes-in-php-8).
*  **[[RFC] any() and all() on iterables](https://wiki.php.net/rfc/any_all_on_iterable)** — Предлагается добавить две новых функции в стандартную библиотеку:
`any(iterable $input, ?callable $callback = null): bool` — запустит колбек на каждом элементе и остановится, на первом, который вернет `true`.
`all(...)` — вернет `true` только, если колбек вернет `true` для каждого элемента.
Пример использования:
```
// Было
$satisifes_predicate = false;
foreach ($item_list as $item) {
if (API::satisfiesCondition($item)) {
$satisfies_predicate = true;
break;
}
}
if (!$satisfies_predicate) {
throw new APIException("No matches found");
}
// Стало
if (!any($item_list, fn($item) => API::satisfiesCondition($item))) {
throw new APIException("No matches found");
}
```
### Инструменты
* [Pest 0.3](https://nunomaduro.com/pest-v0-3-is-out/) — Обертка над PHPUnit, которая позволяет писать тесты в более простом виде. Также готов плагин для PhpStorm [Pest IntelliJ](https://nybroe.dev/pest-phpstorm-plugin-v0.30/).
* [Codeception/Verify 2.0](https://github.com/Codeception/Verify) — Ассершены для PHPUnit и Codeception с fluent-интерфейсом.
* [ramsey/composer-repl](https://github.com/ramsey/composer-repl) — Добавляет команду `composer repl` для запуска [bobthecow/psysh](https://github.com/bobthecow/psysh).
* [brick/money](https://github.com/brick/money) — Библиотека для работы с денежными данными. Работает, даже если не установлены GMP или BCMath. [Сравнение с moneyphp/money](https://github.com/brick/money/issues/28#issuecomment-678708771).
* [bassim/super-expressive-php](https://github.com/bassim/super-expressive-php) — Библиотека позволяет описывать регулярные выражения почти-естественным языком через текучий интерфейс. Альтернатива [VerbalExpressions/PHPVerbalExpressions](https://github.com/VerbalExpressions/PHPVerbalExpressions).
* [phpsci/phpsci-carray](https://github.com/phpsci/phpsci-carray) — Расширение PHP для научных вычислений. Основано на NumPy.
* [github.com/phpwebclient](https://github.com/phpwebclient) — Декораторы и хелперы для PSR-18 совместимых HTTP-клиентов.
* [hamlet-framework/type](https://github.com/hamlet-framework/type) — Библиотека для спецификации типов. Может быть использована везде, где нужна спецификация типов, включая cast, assert, instanceof и т. п.
### Symfony
*  [Книга «Symfony 5: Быстрый старт» доступна онлайн на русском](https://symfony.com/doc/current/the-fast-track/ru/index.html).
* [Неделя Symfony #714 (31 августа — 6 сентября 2020)](https://symfony.com/blog/a-week-of-symfony-714-31-august-6-september-2020)
### Laravel
* [laravel-orion/laravel-orion](https://github.com/laravel-orion/laravel-orion) — Пакет для автоматического создания REST API по Eloquent-моделям и их отношениям. Прислал [@alexzarbn](https://twitter.com/alexzarbn).
* [Statamic 3](https://github.com/statamic/statamic) — CMS на Laravel.
* [Типичные ошибки в безопасности в Laravel-приложениях](https://cyberpanda.la/ebooks/download/laravel-security?pdf=true).
*  [Legacy и Laravel: Переписываем устаревшее приложение на современный фреймворк](https://laravel.demiart.ru/converting-legacy-to-laravel/).
*  [Laravel 8 — Что нового?](https://laravel.demiart.ru/laravel-8-whats-new/) — Новая версия фреймворка выходит 8 сентября.
*  [Laravel–Дайджест (24 августа – 6 сентября 2020)](https://habr.com/ru/post/517980/)
*  [Laravel Worldwide Meetup #2: Neo Ighodaro and Michael Dyrynda](https://www.youtube.com/watch?v=4WZHRtgMAWo)
### Yii
* [yiisoft/auth](https://github.com/yiisoft/auth) — Свежий пакет из семейства Yii 3 предоставляет различные методы аутентификации, набор абстракций для реализации в приложении, и PSR-15 middleware для аутентификации.
* [yiisoft/strings](https://github.com/yiisoft/strings) — Хелперы для работы со строками.
### Async PHP
*  [Пишем простую ORM с возможностью смены БД на лету](https://habr.com/ru/post/515068/)
### Материалы для обучения
* [Архитектура PHP-приложений вдохновленная «чистой архитекторой»](https://medium.com/engenharia-arquivei/a-decoupled-php-architecture-inspired-by-the-clean-architecture-788b30ab52c2) — (Чтобы обойти пейвол медиума, достаточно открыть ссылку в инкогнито окне).
* [Диалекты в коде: Часть 1](https://www.rosstuck.com/dialects-in-code-part-1) — О том, как разные люди могут использовать один и тот же язык программирования совершенно по-разному.
* [Как работает unserialize() в PHP](https://vkili.github.io/blog/insecure%20deserialization/unserialize/) — и почему она приводит к уязвимостям.
* [Подключаем статический анализ (psalm) в проекте](https://www.jamestitcumb.com/posts/quality-get-started-with-static-analysis-now).
* [Ускоряем PHP при помощи FFI](https://dev.to/jorgecc/speeding-php-with-ffi-5gn0).
* [Настраиваем Xdebug + Docker + PhpStorm](https://jump24.co.uk/journal/turbocharged-php-development-with-xdebug-docker-and-phpstorm/), а также немного о продвинутых техниках отладки.
* [Anna Filina](https://twitter.com/afilina/status/1288126813303001094) — Полезный тред от Anna Filina о рефакторинге легаси приложений на PHP:
> Another week, another legacy project. Here are some things that I found in the code that you may want to avoid doing in your own projects. [pic.twitter.com/cvVUKsNQAo](https://t.co/cvVUKsNQAo)
>
> — Anna "Legacy Archaeologist" Filina (@afilina) [July 28, 2020](https://twitter.com/afilina/status/1288126813303001094?ref_src=twsrc%5Etfw)
*  [Xdebug через Windows Subsystem For Linux 2 (WSL2)](https://habr.com/ru/post/516254/).
*  [Модернизация старого PHP-приложения](https://habr.com/ru/company/mailru/blog/515778/).
*  [Мёртвый код: найти и обезвредить](https://habr.com/ru/company/badoo/blog/515472/).
*  [Перечисления в PHP](https://habr.com/ru/post/517752/).
*  [Ты решил написать свой фреймворк. Стоило оно того?](https://habr.com/ru/company/skyeng/blog/516950/) — Расшифровка выпуска [подкаста Между скобок с Александром Лисаченко](https://soundcloud.com/between-braces/9-aleksandr-lisachenko-aop-v-php).
*  [Как Lingualeo переехал на PostgreSQL с 23 млн юзеров](https://habr.com/ru/company/lingualeo/blog/515530/) — Эпичный пост о переносе логики из PHP в хранимки. И годный ответ: [Вред хранимых процедур](https://habr.com/ru/company/ruvds/blog/517302/).
*  [20\_20 — год, в котором подчеркивание в числовых литералах победило](https://habr.com/ru/post/516984/) — история разделителей в числовых литералах.
### Аудио/Видео
*  [Доклад Tobias Nyholm](https://www.youtube.com/watch?v=k8VdT99jY5k) про [async-aws/aws](https://github.com/async-aws/aws) асинхронный клиент для сервисов AWS.
*  [ХудоБедно на тему работы в IT](https://www.youtube.com/watch?v=Eyql6XDvvSQ) с Александром Макаровым, Сергей Жуком и Антоном Моревым.
*  [PHP Internals News #67](https://phpinternals.news/67) — [Дерик Xdebug](https://twitter.com/derickr) общается сам с собой на тему нового выражения `match`. Подробнее об истории `match` в PHP [в посте](https://lwn.net/SubscriberLink/830206/2eaa67bfc56d2232/).
*  [Podlodka #180 – PHP](https://soundcloud.com/podlodka/podlodka-180-php) — Выпуск легендарного подкаста Подлодка с участием Никиты Попова и меня.
> "Oh you do PHP? I used to do PHP but it's just dying out really nothing going for it except Wordpr-"
>
> Me: [pic.twitter.com/7v3UAWM8gI](https://t.co/7v3UAWM8gI)
>
> — Camilo (@CamAsMetaphor) [September 1, 2020](https://twitter.com/CamAsMetaphor/status/1300893022146703360?ref_src=twsrc%5Etfw)
---
Спасибо за внимание!
Если вы заметили ошибку или неточность — сообщите, пожалуйста, в [личку](https://habrahabr.ru/conversations/pronskiy/).
Вопросы и предложения пишите на [почту](mailto:roman@pronskiy.com) или в [твиттер](https://twitter.com/pronskiy).
> Больше новостей и комментариев в Telegram-канале **[PHP Digest](https://t.me/phpdigest)**.
>
>
[Прислать ссылку](https://bit.ly/php-digest-add-link)
[Поиск ссылок по всем дайджестам](https://pronskiy.com/php-digest/)
← [Предыдущий выпуск: PHP-Дайджест № 186](https://habr.com/ru/post/515416/) | https://habr.com/ru/post/518064/ | null | ru | null |
# Django widgets и еще пара трюков

Все знают что Django это замечательный фреймворк для разработки, с кучей мощных батареек. Лично для меня, при первом знакомстве с django все казалось крайней удобным — все для удобства разработчика, думалось мне. Но те кто с ним вынужден работать в течении долгого времени, знают, что не все так сказочно, как кажется новичку. Шло время проекты становились больше, сложнее, писать вьюшки стало неудобным, а разбираться во взаимоотношении моделей становилось сложнее и сложнее. Но работа есть работа, проект был большой и сложный, и, ко всему прочему необходимо было иметь систему управления страниц как в cms, и, вроде бы, есть замечательный django cms, к которому всего и надо что написать плагинов. Но оказалось, что можно сделать весь процесс несколько более удобным, добавив пару фич и немного кода.
В этой небольшой статье, вы не увидите готовых рецептов, цель статьи — поделиться своими задумками. Примеры кода служат лишь для того, чтобы помочь в объяснении ключевых элементов, без существенных доработок этого будет недостаточно для повторения функционала. Но если тема окажется интересной, то можно будет продолжить в следующей статье. Или даже выложить в опенсорс.
#### Модели
Предположим у нас есть 2 модели с общими полями: заголовок, описание и теги. Если нам надо просто вывести в ленту последние материалы из обоих моделей отсортированные по дате создания, то самый простой способ — это объединить их в одну модель. А для того, чтобы в админке они не сливались в одну сущность, мы можем использовать [Generic Foreign Key](https://docs.djangoproject.com/en/dev/ref/contrib/contenttypes/#django.contrib.contenttypes.fields.GenericForeignKey).
Для админки настроим inline редактирование Info и сразу добавим [GFKManager](https://djangosnippets.org/snippets/1773/) — сниппет для оптимизации запросов:
```
from django.db import models
from core.container.manager import GFKManager
class Info(models.Model):
objects = GFKManager()
title = models.CharField(
max_length=256, blank=True, null=True
)
header = models.TextField(
max_length=500, blank=True, null=True
)
tags = models.ManyToManyField(
'self', symmetrical=False, blank=True, null=True
)
def content_type_name(self):
return self.content_type.model_class()._meta.verbose_name
class Model(models.Model):
info = CustomGenericRelation(
'Info',
related_name="%(class)s_info"
)
class A(Model):
field = models.CharField(
max_length=256, blank=True, null=True
)
class B(Model):
pass
```
Имейте ввиду что вы можете получить ошибку при удалении объектов моделей A и B, если использовать generic.GenericRelation. К сожалению не могу найти первоисточник:
```
# -*- coding: utf-8 -*-
from django.contrib.contenttypes import generic
from django.db.models.related import RelatedObject
from south.modelsinspector import add_introspection_rules
class CustomGenericRelation(generic.GenericRelation):
def contribute_to_related_class(self, cls, related):
super(CustomGenericRelation, self).contribute_to_related_class(cls, related)
if self.rel.related_name and not hasattr(self.model, self.rel.related_name):
rel_obj = RelatedObject(cls, self.model, self.rel.related_name)
setattr(cls, self.rel.related_name, rel_obj)
add_introspection_rules([
(
[CustomGenericRelation],
[],
{},
),
], ["^core\.ext\.fields\.generic\.CustomGenericRelation"])
```
теперь можно легко выполнить запрос:
```
Info.objects.filter(content_type__in=(CT.models.A, CT.models.B))
```
для удобства я использую карту ContentType:
```
rom django.contrib.contenttypes.models import ContentType
from django.db import models
from models import Model
class Inner(object):
def __get__(self, name):
return getattr(self.name)
class ContentTypeMap(object):
__raw__ = {}
def __get__(self, obj, addr):
path = addr.pop(0)
if not hasattr(obj, path):
setattr(obj, path, type(path, (object,), {'parent': obj}))
attr = getattr(obj, path)
return self.__get__(attr, addr) if addr else attr
def __init__(self):
for model in filter(lambda X: issubclass(X, Model), models.get_models()):
content_type = ContentType.objects.get_for_model(model)
obj = self.__get__(self, model.__module__.split('.'))
self.__raw__[content_type.model] = content_type.id
setattr(obj, '%s' % model.__name__, content_type)
for obj in map(lambda X: self.__get__(self, X.__module__.split('.')),
filter(lambda X: issubclass(X, Model), models.get_models())):
setattr(obj.parent, obj.__name__, obj())
CT = ContentTypeMap()
```
Если нам надо организовать поиск (sphinx) то мы можем подключить django-sphinx к Info. Теперь одним запросом мы можем получить ленту, поиск, выборку по тегам и тд. Минус такого подхода в том, что все поля по которым необходимо фильтровать запросы должны хранится в Info, а в сами модели только те поля по которым фильтр не нужен, например картинки.
#### Django CMS, плагины и виджеты
При помощи CMS мы можем добавлять новые страницы, редактировать и удалять старые, добавлять на страницу виджеты, формировать сайдбары и так далее. Но иногда, а точнее, довольно часто есть необходимость перманентно добавить плагин в шаблон, так чтобы он был виден на всех страницах. [django widgets](https://github.com/smyrman/django-jquery-widgets) — решение наших проблем, при помощи тега include\_widget мы сможем добавить все, что нам нужно, и куда нужно. Еще более часто необходимо получать ajax'ом какие то данные в плагин. Воспользуемся [tastypie](https://django-tastypie.readthedocs.org/en/latest/).
```
from django.conf.urls.defaults import *
from django.http import HttpResponseForbidden
from django_widgets.loading import registry
from sekizai.context import SekizaiContext
from tastypie.resources import Resource
from tastypie.utils import trailing_slash
from tastypie.serializers import Serializer
from core.widgets.cms_plugins import PLUGIN_TEMPLATE_MAP
from core.ext.decorator import api_require_request_parameters
class HtmlSreializer(Serializer):
def to_html(self, data, options=None):
return data
class WidgetResource(Resource):
class Meta:
resource_name = 'widget'
include_resource_uri = False
serializer = HtmlSreializer(formats=['html'])
def prepend_urls(self):
return [
url(r"^(?P%s)/render%s$" % (self.\_meta.resource\_name, trailing\_slash()), self.wrap\_view('render'), name="api\_render")
]
@api\_require\_request\_parameters(['template'])
def render(self, request, \*\*kwargs):
data = dict(request.GET)
template = data.pop('template')[0]
if 'widget' in data:
widget = registry.get(data.pop('widget')[0])
else:
if template not in PLUGIN\_TEMPLATE\_MAP:
return HttpResponseForbidden()
widget = PLUGIN\_TEMPLATE\_MAP[template]
data = dict(map(lambda (K, V): (K.rstrip('[]'), V) if K.endswith('[]') else (K.rstrip('[]'), V[0]), data.items()))
return self.create\_response(
request,
widget.render(SekizaiContext({'request': request}), template, data, relative\_template\_path=False)
)
def obj\_get\_list(self, bundle, \*\*kwargs):
return []
```
Передав в запросе параметры названия виджета и шаблона, мы можем получить отрендереный контекст. Тут я использую переменную PLUGIN\_TEMPLATE\_MAP так, чтобы иметь возможность передавать только название шаблона.
Остается связать виджеты и плагины. Тут довольно большой кусок, но самый важный.
```
import os
import json
from django import forms
from django.conf import settings
from django_widgets.loading import registry
from cms.models import CMSPlugin
from cms.plugin_base import CMSPluginBase
from cms.plugin_pool import plugin_pool
from core.widgets.widgets import ItemWidget
PLUGIN_MAP = {}
PLUGIN_CT_MAP = {}
PLUGIN_TEMPLATE_MAP = {}
class PluginWrapper(CMSPluginBase):
admin_preview = False
class FormWrapper(forms.ModelForm):
widget = None
templates_available = ()
def __init__(self, *args, **kwargs):
super(FormWrapper, self).__init__(*args, **kwargs)
if not self.fields['template'].initial:
# TODO
self.fields['template'].initial = self.widget.default_template
self.fields['template'].help_text = 'at PROJECT_ROOT/templates/%s' % self.widget.get_template_folder()
if self.templates_available:
self.fields['template'].widget = forms.Select()
self.fields['template'].widget.choices = self.templates_available
self.__extra_fields__ = set(self.fields.keys()) - set(self._meta.model._meta.get_all_field_names())
data = json.loads(self.instance.data or '{}') if self.instance else {}
for key, value in data.items():
self.fields[key].initial = value
def clean(self):
cleaned_data = super(FormWrapper, self).clean()
cleaned_data['data'] = json.dumps(dict(
map(
lambda K: (K, cleaned_data[K]),
filter(
lambda K: K in cleaned_data,
self.__extra_fields__
)
)
))
return cleaned_data
class Meta:
model = CMSPlugin
widgets = {
'data': forms.HiddenInput()
}
def get_templates_available(widget):
template_folder = widget.get_template_folder()
real_folder = os.path.join(settings.TEMPLATE_DIRS[0], *template_folder.split('/'))
result = ()
if os.path.exists(real_folder):
for path, dirs, files in os.walk(real_folder):
if path == real_folder:
choices = filter(lambda filename: filename.endswith('html'), files)
result = zip(choices, choices)
rel_folder = '%(template_folder)s%(inner_path)s' % {
'template_folder': template_folder,
'inner_path': path.replace(real_folder, '')
}
for filename in files:
PLUGIN_TEMPLATE_MAP['/'.join((rel_folder, filename))] = widget
return result
def register_plugin(widget, plugin):
plugin_pool.register_plugin(plugin)
PLUGIN_MAP[widget.__class__] = plugin
if issubclass(widget.__class__, ItemWidget):
for content_type in widget.__class__.content_types:
if content_type not in PLUGIN_CT_MAP:
PLUGIN_CT_MAP[content_type] = []
PLUGIN_CT_MAP[content_type].append(plugin)
def get_plugin_form(widget, widget_name):
return type('FormFor%s' % widget_name, (FormWrapper,), dict(map(
lambda (key, options): (key, (options.pop('field') if 'field' in options else forms.CharField)(initial=getattr(widget, key, None), **options)),
getattr(widget, 'kwargs', {}).items()
) + [('widget', widget), ('templates_available', get_templates_available(widget))]))
def register_plugins(widgets):
for widget_name, widget in widgets:
if getattr(widget, 'registered', False):
continue
name = 'PluginFor%s' % widget_name
plugin = type(
name, (PluginWrapper,),
{
'name': getattr(widget, 'name', widget_name),
'widget': widget,
'form': get_plugin_form(widget, widget_name)
}
)
register_plugin(widget, plugin)
register_plugins(registry.widgets.items())
```
#### Еще немного вкусных батареек
* [django-sekizai](http://django-sekizai.readthedocs.org/en/latest/) — зависимость django cms, но, разумеется, можно использовать и без него
* [django-localeurl](https://readthedocs.org/projects/django-localeurl/) — удобные штуки для интернационального сайта
* [django-modeltranslation](https://github.com/deschler/django-modeltranslation) — как вариант, но есть не менее вкусные альтернативы
* [django-redis-cache](https://github.com/sebleier/django-redis-cache) — кеш в редисе, туда же можно засунуть и сессии, особенно полезно если вы годами не чистите сессии из MySQL
* [django-admin-bootstrapped](https://github.com/django-admin-bootstrapped/django-admin-bootstrapped) — более современная админка, (надо поставить bootstrap-modeltranslation если используете modeltranslation )
* [django-sorl-cropping](https://github.com/NElias/django-sorl-cropping) — для работы с thumbnail
Ну и совсем банальные вещи:
* [django-social-auth](https://github.com/omab/django-social-auth)
* [django-registration](http://django-registration.readthedocs.org/en/latest/)
* [django-debug-toolbar](http://django-debug-toolbar.readthedocs.org/en/1.2/)
* [django-admin-tools](https://bitbucket.org/izi/django-admin-tools/wiki/Home)
#### Заключение
Я постарался объяснить два ключевых момента, которые можно упростить в работе с django, хотел объяснить больше, но статья получается слишком объемной. Другие интересные моменты это обработка и формирование динамических урл, а также два основных виджета — виджет ленты и виджет сущности, но это в следующий раз. Итак, при помощи данного концепта я
* создаю новые модели и добавляю их в ленту за пару минут (когда таких лент на проекте около 50 это имеет значение);
* никогда не пишу вьюшки, я настраиваю виджеты, изредка пишу новые;
* не создаю новые шаблоны для url, за меня это делает django cms;
* не парюсь с ajax, я просто передаю параметры, и получаю результат;
* облегчил себе жизнь, на трех проектах среди которых один очень большой;
* трачу намного больше времени на js чем на django, но это уже совсем другая история.
Спасибо за внимание! | https://habr.com/ru/post/228411/ | null | ru | null |
# Кеш бывает разным
PostgreSQL хранит данные на каких-то носителях. И между PostgreSQL и, например, магнитной поверхностью диска находится несколько кешей: кеш самого винчестера, кеш RAID-контроллера или винчестерной полки, кеш файловой системы на уровне операционной системы и кеш самого PostgreSQL. Если первыми перечисленными кешами мы практический не можем управлять, то последними, находящимися в ОЗУ сервера, управлять можем: например, выделяя больше ОЗУ под кеш PostgreSQL в ущерб кешу ОС, или наоборот. В официальной документации можно прочитать ничем не подтвержденные рекомендации, типа выделять под PostgreSQL четверть ОЗУ. Это вызывает сомнения. PostgreSQL в виде Postgres95 впервые появился в 1995 году и, кто знает, быть может и эти рекомендации относятся к тому же году. Поэтому появилась идея эксперимента с целью разобраться, как лучше распределять ОЗУ.
Сразу оговорюсь, что речь пойдет про выделенный под БД сервер, на котором помимо самого PostgreSQL и обслуживающей его инфраструктуры ничего нет. Если рассмотреть эту задачу умозрительно, то интуитивно понятно, что «своя рубашка ближе к телу», то есть со своим собственным кешем PostgreSQL должен работать оптимальнее. Например, в своем кеше PostgreSQL хранит информацию постранично, а размер страницы в PostgreSQL по умолчанию 8 Кб. В кеше ОС информация хранится тоже постранично, но размер страницы в памяти ОС и, обычно, файловой системы равен 4 Кб, то есть возможна фрагментация страницы PostgreSQL. Но на практике такие различия, связанные с тем, что в собственном кеше данные хранятся в более оптимальном виде, малозаметны. Другое отличие кешей заключается в том, как выбирается для удаления страница, чтобы записать новую. Кеш ОС работает просто: он удаляет ту страницу, к которой дольше всего не обращались. А кеш PostgreSQL пытается вести себя умнее, ведь данные бывают разными — более или менее полезными. Например, индексы или данные за последний месяц, к которым обращаются чаще, более полезны, чем данные, скажем, годичной давности, к которым обращаются редко. Поэтому PostgreSQL выставляет данным своеобразную оценку полезности и в первую очередь высвобождает наименее полезную информацию. А если PostgreSQL видит, что намечается последовательное чтение большой таблицы, которое может «вымыть» остальные данные из кеша, то он принимает меры, чтобы этого не случилось. Вот такую оптимизацию, связанную с интеллектуальным анализом полезности кеша, и должен был продемонстрировать эксперимент. Также с его помощью решался вопрос о том, насколько влияют на производительность PostgreSQL HugePages.
Довольно сложно найти документацию, описывающую алгоритмы работа кеша PostgreSQL. Для желающих изучить этот вопрос более углубленно, привожу ссылку: [Inside the PostgreSQL Shared Buffer Cache](https://www.2ndquadrant.com/wp-content/uploads/2019/05/Inside-the-PostgreSQL-Shared-Buffer-Cache.pdf)
Описание эксперимента
=====================
Идея проста. Создаю одну таблицу, размер которой больше ОЗУ сервера, и индекс к этой таблице, который занимает где-то 10% от размера таблицы. Мне показалось, что такая пропорция реалистична. Cначала «прогреваю» таблицу, потом индекс, чтобы они по максимуму находились в кеше. Измеряю время индексированного поиска. Запускаю неиндексированный поиск, который выполняет последовательное чтение всей таблицы, измеряю длительность его работы. А после этого повторяю эксперимент по индексированному поиску. Предполагаю, что в случае работы кеша PostgreSQL разница между поисками по индексу до и после поиска последовательным чтением таблицы будет минимальна, а в случае кеша ОС — заметна. Эксперимент буду повторять с различными пропорциями кешей ОС и PostgreSQL, а также с использованием HugePages и без них.
Описание стенда
===============
Стенд сделал из того, что было: ноут MSI, операционка сообщает о 8 ядрах процессора, 16 Гб ОЗУ (HugePages 2 Мб на 14 Гб), 0 swap. К тому же Linux ругался о том, что процессор перегревается и приходится сбрасывать частоту, что наверняка сказалось на повторяемости эксперимента. Софт: CentOS 8 и PostgreSQL 13.0.
Подробно опишу эксперимент, чтобы любой желающий мог его повторить в своих условиях. «Прогревание» выполняется с помощью функции `pg_prewarm()`, но поскольку в результате эксперимента выяснилось, что `pg_prewarm` хоть и заполняет кеш, но «прогревает» недостаточно, после неё дополнительно прогреваю с помощью `pgbench`. Потом через тот же `pgbench` замеряю длительность индексированного поиска, поиска через последовательное чтение и снова индексированного. Результаты складываю в CSV-файлы, которые потом импортирую в Exсel, там обрабатываю и строю графики. Видимо, из-за фрагментирования памяти иногда невозможно выделять память под HugePages большого размера. Поэтому цикл тестирования выглядит так: перезагружаю машину, из `rc.local` вызываю тестирующий скрипт, он прогоняет тесты с включенными HugePages от максимального размера кеша PostgreSQL к минимальному, потом скрипт повторяет то же самое с выключенными HugePages, после чего перезагружает машину. Размер HugePage равен 2 Мб.
Все файлы лежат в одной директории, вот их список:
**postgresql.conf**
```
include = 'shared_buffers.conf'
# при max_parallel_workers_per_gather>6 ошибка выполнения при размере кеша PostgreSQL 128 Кб
max_parallel_workers_per_gather=6
```
Этот файл «инклюдится» в postgresql.conf базы данных с помощью директивы `include`. Он нужен для проведения эксперимента с разными настройками PostgreSQL.
**shared\_buffers.conf**
```
shared_buffers=128kB
```
Скриптом, который выполняет тестирование, в этот файл записывается размер кеша PostgreSQL.
**init.sql**
```
-- Размер таблицы, которую нужно создать. Подбирается методом проб и ошибок так, чтобы таблица имела размер, равный ОЗУ.
\set table_size 75000000
-- Создаю таблицу с именем random, там лежат случайные данные. :)
drop table if exists random;
create table random(random real, data float[]);
insert into random select random,array_fill(random,ARRAY[20]) from (select random() as random, generate_series(1,:table_size)) as subselect;
-- И индекс к ней.
create index on random(random);
-- Дальнейшие операции требуют роль суперпользователя, мой пользователь имеет эту роль, поэтому переключиться несложно.
set role postgres;
-- Модуль для функции pg_prewarm
create extension if not exists pg_prewarm;
-- Модуль, в котором можно наблюдать структуру кеша PostgreSQL
create extension if not exists pg_buffercache;
-- View на базе предыдущего модуля для наблюдением за кешем. Для эксперимента не используется, и во время эксперимента лучше не использовать, т.к. pg_buffercache вел себя нестабильно и иногда рушил процесс PostgreSQL.
create or replace view cache as SELECT n.nspname AS schema,
c.relname,
pg_size_pretty(count(*) * 8192) AS buffered,
count(*) * 8 AS buffered_KiB,
round(100.0 * count(*)::numeric / ((( SELECT pg_settings.setting
FROM pg_settings
WHERE pg_settings.name = 'shared_buffers'::text))::integer)::numeric, 1) AS buffer_percent,
round(100.0 * count(*)::numeric * 8192::numeric / pg_table_size(c.oid::regclass)::numeric, 1) AS percent_of_relation
FROM pg_class c
JOIN pg_buffercache b ON b.relfilenode = c.relfilenode
JOIN pg_database d ON b.reldatabase = d.oid AND d.datname = current_database()
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
GROUP BY c.oid, n.nspname, c.relname
ORDER BY (round(100.0 * count(*)::numeric / ((( SELECT pg_settings.setting
FROM pg_settings
WHERE pg_settings.name = 'shared_buffers'::text))::integer)::numeric, 1)) DESC
LIMIT 5;
-- View, в котором можно посмотреть размер таблицы на диске, использовался для подгона размера таблицы под ОЗУ.
create or replace view disk as SELECT n.nspname AS schema,
c.relname,
pg_size_pretty(pg_relation_size(c.oid::regclass)) AS size,
pg_relation_size(c.oid::regclass)/1024 AS size_KiB
FROM pg_class c
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
ORDER BY (pg_relation_size(c.oid::regclass)) DESC
LIMIT 5;
vacuum full freeze analyze;
```
SQL-скрипт, который создает окружение в БД, выполняется перед экспериментом. Запускается с помощью `psql база -f init.sql`.
**test\_idx.sql**
```
select random from random where random=(select random()::real);
```
**test\_seq.sql**
```
select count(data) from random;
```
Здесь находятся SQL-запросы, которые выполняет `pgbench` во время тестирования.
**config.sh**
```
# database connection parameters
export PGDATABASE='pgcache'
# Добавляю путь к бинарникам PostgreSQL, это было нужно на CentOS и, возможно, других редхатоподобных дистрибутивах.
PATH=$PATH:/usr/pgsql-13/bin
# Через пробел указаны значения для конфигурационной переменной PostgreSQL shared_buffers, т.е. собственно размеры кеша на которых будет производится тестирование. Порядок по уменьшению величин важен. Дело в том, что HugePages уменьшить можно всегда, а вот увеличить — не всегда, видимо, из-за фрагментации памяти. Поэтому тестирование ведется при уменьшении размера кеша.
readonly shared_buffers='14GB 13GB 12GB 11GB 10GB 9GB 8GB 7GB 6GB 5GB 4GB 3GB 2GB 1GB 512MB 256MB 128MB 64MB 32MB 16MB 8MB 4MB 2MB 1MB 512kB 256kB 128kB';
```
**get\_huge\_pages**
```
#!/bin/bash
. config.sh
readonly postgresql_service='postgresql-13' postgresql_pid='/var/lib/pgsql/13/data/postmaster.pid'
readonly huge_pages_sh='huge_pages.sh' shared_buffers_conf='shared_buffers.conf'
sudo systemctl start "$postgresql_service"
echo 'declare -r -A huge_pages_size=( \' >"$huge_pages_sh"
for s_b in $shared_buffers
do
echo "shared_buffers=$s_b" >"$shared_buffers_conf"
sleep 5
sudo systemctl restart "$postgresql_service"
pid=$(sudo head -1 "$postgresql_pid")
echo -n ' [' >>"$huge_pages_sh"
psql --expanded --quiet --tuples-only -c "show shared_buffers" | awk '/^shared_buffers \|/{printf "%s", $3}' >>"$huge_pages_sh"
echo -n ']=' >>"$huge_pages_sh"
sudo awk '/^VmPeak:/ {printf "%i", $2/2048+1}' /proc/"$pid"/status >>"$huge_pages_sh"
echo ' \' >>"$huge_pages_sh"
done
echo ')' >>"$huge_pages_sh"
sudo systemctl stop "$postgresql_service"
```
Вспомогательный скрипт. Он берет из config.sh значения для `shared_buffers`, запускает с этими настройками PostgreSQL, замеряет, сколько нужно HugePages для его работы в данной конфигурации, и записывает результат работы в файл huge\_pages.sh.
**huge\_pages.sh**
```
declare -r -A huge_pages_size=( \
[14GB]=7416 \
[13GB]=6893 \
[12GB]=6370 \
[11GB]=5847 \
[10GB]=5323 \
[9GB]=4800 \
[8GB]=4277 \
[7GB]=3750 \
[6GB]=3226 \
[5GB]=2703 \
[4GB]=2180 \
[3GB]=1655 \
[2GB]=1131 \
[1GB]=607 \
[512MB]=345 \
[256MB]=209 \
[128MB]=142 \
[64MB]=108 \
[32MB]=91 \
[16MB]=82 \
[8MB]=78 \
[4MB]=76 \
[2MB]=75 \
[1MB]=74 \
[512kB]=74 \
[256kB]=74 \
[128kB]=74 \
)
```
Здесь лежат результаты работы `get_huge_pages`, они используются в скрипте `test`.
**dataHP.csv и dataNHP.csv**
Результаты работы скрипта `test`, используются потом в Excel.
**output.log**
Вывод из скрипта `test` полезен, если там содержатся ошибки, а если их нет — он пустой.
Пример запуска тестирующего скрипта. Отредактировал файл, который уже был в CentOS:
**/etc/rc.local**
```
#!/bin/bash
# THIS FILE IS ADDED FOR COMPATIBILITY PURPOSES
#
# It is highly advisable to create own systemd services or udev rules
# to run scripts during boot instead of using this file.
#
# In contrast to previous versions due to parallel execution during boot
# this script will NOT be run after all other services.
#
# Please note that you must run 'chmod +x /etc/rc.d/rc.local' to ensure
# that this script will be executed during boot.
sudo -u myuser /home/myuser/experiment/pgcache/test &>/home/myuser/experiment/pgcache/output.log &
touch /var/lock/subsys/local
```
Собственно, тестирующий скрипт:
**test**
```
#!/bin/bash
set -eCu -o pipefail
postgresql_service="postgresql-13"
# перехожу в директорию, где лежит этот скрипт
cd "$( dirname "${BASH_SOURCE[0]}" )" || exit $?
# настроечные опции
. config.sh
# ассоциативный массив, связывающий размер кеша PostgreSQL и количество нужных ему hugepages
. huge_pages.sh
# заголовок для CSV-файлов
readonly header='huge_pages(2MiB),pg_cache,pg_cache(KiB),idx1(ms),seq(ms),idx2(ms),heap_blks_read,heap_blks_hit,idx_blks_read,idx_blks_hit,finish'
date --iso-8601=seconds
# цикл по включенным и отключенным hugepages
for hp in 'HP' 'NHP'
do
# Цикл по всем "ступенькам" размера кеша, по которым надо пройтись
for s_b in $shared_buffers
do
data_csv="data${hp}.csv"
if [ ! -s "$data_csv" ]
then
echo "$header" >|"$data_csv"
fi
echo "shared_buffers=$s_b" >|'shared_buffers.conf'
if [ "$hp" = 'HP' ]
then
set_huge_pages=${huge_pages_size["$s_b"]}
else
set_huge_pages=0
fi
huge_pages=$(awk '/^HugePages_Total:/ {print $2}' /proc/meminfo)
if [ $huge_pages -ne $set_huge_pages ]
then
sudo sysctl --quiet --write vm.nr_hugepages="$set_huge_pages"
while [ $(awk '/^HugePages_Total:/ {print $2}' /proc/meminfo) -gt $set_huge_pages ]
do
sleep 1
done
fi
huge_pages=$(awk '/^HugePages_Total:/ {print $2}' /proc/meminfo)
if [ $set_huge_pages -ne $huge_pages ]
then
echo -n 'hugepage_error,' >>"$data_csv"
echo "$(date --iso-8601=seconds)" >>"$data_csv"
continue
fi
echo -n "$huge_pages," >>"$data_csv"
sudo systemctl start "$postgresql_service"
psql --expanded --quiet --tuples-only -c "show shared_buffers" | awk '/^shared_buffers \|/ {printf "%s,", $3}' >>"$data_csv"
psql --expanded --quiet --tuples-only -c "select setting::int*8 as shared_buffers from pg_settings where name='shared_buffers'" | awk '/^shared_buffers \|/ {printf "%s,", $3}' >>"$data_csv"
# prewarm to the cache
psql --quiet -c "select pg_prewarm('random')" -c "select pg_prewarm('random_random_idx')" >/dev/null
# more prewarm
pgbench --no-vacuum --time 100 --file test_idx.sql >/dev/null
# reset stats
psql --quiet -c "select pg_stat_reset_single_table_counters('random'::regclass),pg_stat_reset_single_table_counters('random_random_idx'::regclass)" >/dev/null
# first test index search
pgbench --no-vacuum --transaction 100 --report-latencies --file test_idx.sql | awk '/select random from random where random=\(select random\(\)::real\);$/ {printf "%s,", $1 >>"'"$data_csv"'";}'
# test sequence scan
pgbench --no-vacuum --transaction 1 --report-latencies --file test_seq.sql | awk '/select count\(data\) from random;$/ {printf "%s,", $1 >>"'"$data_csv"'"}'
# second test index search
pgbench --no-vacuum --transaction 100 --report-latencies --file test_idx.sql | awk '/select random from random where random=\(select random\(\)::real\);$/ {printf "%s,", $1 >>"'"$data_csv"'";}'
# get stats
sleep 10
psql --quiet --tuples-only --field-separator=' ' --no-align -c "select heap_blks_read,heap_blks_hit,idx_blks_read,idx_blks_hit from pg_statio_user_tables where relname='random'"| head -1 | awk '{printf "%s,", $1 >>"'"$data_csv"'";printf "%s,", $2 >>"'"$data_csv"'";printf "%s,", $3 >>"'"$data_csv"'";printf "%s,", $4 >>"'"$data_csv"'";}'
sudo systemctl stop "$postgresql_service"
echo "$(date --iso-8601=seconds)" >>"$data_csv"
done
done
sudo systemctl reboot
```
Тестирование
============
Сначала создаю базу данных скриптом *init.sql*, потом скриптом `get_huge_pages` я собираю информацию о том сколько нужно HugePages для различных размеров кэша PostgreSQL, после этого добавляю вызов скрипта `test` в `/etc/rc.local` и перезагружаю машину. За каждую перезагрузку проходит один цикл тестирования.
Результаты
==========
Здесь и далее по оси X отложены значения кеша PostgreSQL, ОЗУ около 16 Гб, вся неиспользуемая память используется, разумеется, как файловый кеш ОС. По оси Y отложено время выполнения запроса в миллисекундах. Синим цветом — без использования HugePages, оранжевым — с HugePages. Вид графика — коробочки с усиками, подробно про них можно прочитать в документации Excel; удобны тем, что показывают не только усредненные значения, но и разброс, и распределение данных. В каждой итерации было 27 тестов с HugePages и 27 без, итераций было 251, всего было 13554 тестов.
С увеличением кеша PostgreSQL график раздваивается. Без HugePages скорость выполнения запроса — а это простой поиск с использованием индекса — падает. С увеличением кеша PostgreSQL только с использованием HugePages PostgreSQL кеш начинает незначительно выигрывать у кеша файловой системы. Когда я тестировал два года назад на CentOS 7 и PostgreSQL 10, кеш файловой системы работал примерно с такой же скоростью, что и кеш PostgreSQL без HugePages, а добавление HugePages давало значимый выигрыш над кешем файловой системы. Из чего я могу сделать вывод, что за последние годы Linux научился гораздо эффективнее использовать свой файловый кеш.
Последовательное чтение таблицы. Тут заметно ускорение запроса, если кеш PostgreSQL больше кеша файловой системы. Что интересно (и для меня непонятно), на большей части графика использование HugePages замедляет выполнение запроса, и только при очень больших значениях кеша PostgreSQL выигрыш становится заметен. Не знаю, с чем это связано, наверное, разработчикам PostgreSQL есть еще над чем подумать.

Повторный поиск по индексу. Здесь и демонстрируется тот эффект, который я описывал в самом начале. Если использовать кеш файловой системы (задан небольшой размер кеша PostgreSQL), то при последовательном чтении таблицы индекс вымывается из кеша, что демонстрирует длительный повторный поиск по индексу. Этот эффект пропадает примерно тогда, когда кеш PostgreSQL становится достаточно большим, чтобы индекс хранился в нём, а не в кеше файловой системы, и график становится похож на график, который был до последовательного чтения таблицы: примерно 0,08 мс с HugePages и 0,12 мс без HugePages.
Выводы
======
Выводы каждый сделает сам :) Я считаю, что не стоит верить ничем не подтвержденным древним рекомендациям каких-то мохнатых годов о том, что кеш PostgreSQL должен быть равен четверти ОЗУ. Со своим кешем он работает заметно лучше. | https://habr.com/ru/post/534896/ | null | ru | null |
# Анонс Rust 1.12
Мы рады представить новую версию Rust 1.12. Rust — это системный язык программирования, нацеленный на безопасную работу с памятью, скорость и параллельное выполнение кода.
Как обычно, вы можете [установить Rust 1.12](https://www.rust-lang.org/install.html) с соответствующей страницы официального сайта, а также ознакомиться с [подробным списком изменений](https://github.com/rust-lang/rust/blob/master/RELEASES.md#version-1120-2016-09-29) в этой версии на GitHub. В этот выпуск вошёл 1361 патч.
### Что вошло в стабильную версию 1.12
Выпуск 1.12 — возможно, самый значительный с момента выпуска 1.0. Нам есть о чём рассказать, но если у вас мало времени, вот краткое содержание.
Самое заметное для пользователей изменение в 1.12 — это новый формат ошибок, выдаваемых `rustc`. Мы говорили [о нём раньше](https://blog.rust-lang.org/2016/08/10/Shape-of-errors-to-come.html) и это первый стабильный выпуск, где новый формат доступен всем. Эти сообщения об ошибках — результат многочисленных [усилий добровольцев](https://github.com/rust-lang/rust/issues/35233), которые спроектировали, протестировали и обновили каждую ошибку `rustc` в соответствии с новым форматом. Нам интересно узнать, что вы думаете о новых ошибках:

Самое большое внутреннее изменение — переход на использование нового бэкенда компилятора, основанного на Rust [MIR](https://blog.rust-lang.org/2016/04/19/MIR.html) (*англ.* Medium Intermediate Representation). Хотя эта особенность на данный момент не даёт нам ничего видимого пользователям, она прокладывает путь для нескольких будущих оптимизаций компилятора, и для некоторых кодовых баз она уже обеспечивает увеличение скорости компиляции и уменьшение размера сгенерированного кода.
#### Переработанные сообщения об ошибках
В 1.12 мы представляем новый формат сообщений об ошибках. Он подробно отражает причины, по которым компилятор отказывается компилировать ваш код. Для этого мы помещаем ваш код в центр внимания и подсвечиваем части, которые важны в каждом конкретном случае. Мы также аннотируем каждое ошибочное место и подробно описываем, что пошло не так.
Например, если реализация типажа не совпадала с его объявлением в 1.11, вы видели такую ошибку:

В новом формате мы в первую очередь показываем самые важные части кода. В данном случае это строка объявления типажа, строка его определения, и метки, указывающие на несовпадение:

Изначально мы разрабатывали такой вид ошибок, чтобы помочь в понимании проблем, о которых сообщал анализатор заимствований (*англ.* borrow checker). Но по ходу дела мы поняли, что этот формат может быть применён ко множеству разных ошибок — например, как в приведенном выше примере. Если вы бы хотели узнать о новой системе ошибок больше, смотрите [предыдущий пост в блоге на эту тему](https://blog.rust-lang.org/2016/08/10/Shape-of-errors-to-come.html).
Наконец, вы также можете получить эти ошибки в JSON с помощью флага. Помните ту ошибку, которую мы показали в начале поста? Вот как выглядит попытка скомпилировать тот код, передав ему при этом флаг `--error-format=json`:
```
$ rustc borrowck-assign-comp.rs --error-format=json
{"message":"cannot assign to `p.x` because it is borrowed","level":"error","spans":[{"file_name":"borrowck-assign-comp.rs","byte_start":562,"byte_end":563,"line_start":15,"line_end":15,"column_start":14,"column_end":15,"is_primary":false,"text":[{"text":" let q = &p","highlight_start":14,"highlight_end":15}],"label":"borrow of `p.x` occurs here","suggested_replacement":null,"expansion":null}],"label":"assignment to borrowed `p.x` occurs here","suggested_replacement":null,"expansion":null}],"children":[],"rendered":null}
{"message":"aborting due to previous error","code":null,"level":"error","spans":[],"children":[],"rendered":null}
```
На самом деле мы опустили некоторые детали в целях краткости, но идея понятна. Этот вывод в основном предназначен для инструментов; мы продолжаем работать над поддержкой IDE и других полезных инструментов разработчиков. Такой вид вывода ошибок — маленькая часть этой работы.
#### Кодогенерация через MIR
Новое промежуточное представление среднего уровня (*англ.* mid-level IR), которое мы обычно называем "MIR", даёт компилятору возможности проще работать с кодом на Rust, чем это было раньше — когда он обрабатывал абстрактное синтаксическое дерево Rust. MIR делает возможными проверки и оптимизации, которые раньше считались невозможными. Первое из грядущих изменений компилятора, которое стало доступно благодаря MIR — переписывание прохода, генерирующего LLVM IR — того, что `rustc` называет "трансляцией". После многих месяцев работы MIR-бэкенд наконец готов к выступлению на большой сцене.
MIR содержит точную информацию о потоке управления программы, поэтому компилятор точно знает, перемещены типы или нет. Это значит, что он статически знает, нужно ли выполнять деструктор значения. В случаях, когда значение может быть перемещено или не перемещено в конце блока, компилятор использует флаг всего из одного бита на стеке, что намного лучше поддаётся оптимизации со стороны LLVM. Конечный результат — это меньше работы для компилятора и менее раздутый код во время исполнения. А ещё на MIR проще реализовывать новые проходы компилятора и проверять, что они работают правильно — потому что MIR — более простой "язык", чем полное AST.
#### Другие улучшения
* Много небольших улучшений в документации.
* [`rustc` теперь поддерживает три новые цели на ARM с MUSL: `arm-unknown-linux-musleabi`, `arm-unknown-linux-musleabihf` и `armv7-unknown-linux-musleabihf`](https://github.com/rust-lang/rust/pull/35060).
Эти цели производят статические исполняемые файлы. Однако, в собранном виде они пока не распространяются.
* [Ссылки](https://github.com/rust-lang/rust/pull/35611) и [неизвестные числовые типы](https://github.com/rust-lang/rust/pull/35080) теперь лучше показываются в сообщениях об ошибках.
* [Компилятор теперь может быть собран на LLVM 3.9](https://github.com/rust-lang/rust/pull/35594)
* [Исполняемые файлы тестов теперь поддерживают аргумент `--test-threads`, указывающий число потоков, используемых для выполнения тестов. Также этой настройкой управляет переменная окружения
`RUST_TEST_THREADS`](https://github.com/rust-lang/rust/pull/35414)
* [Запускалка тестов теперь показывает предупреждение, если выполнение тестов занимает больше 60 секунд](https://github.com/rust-lang/rust/pull/35405)
* [Вместе с выпусками Rust теперь доступны пакеты исходников, которые могут быть установлены rustup с помощью команды `rustup component add rust-src`](https://github.com/rust-lang/rust/pull/34366).
Полученный исходный код может быть использован инструментами и IDE, и расположен в sysroot в директории `lib/rustlib/src`.
Подробнее смотрите замечания к [выпуску](https://github.com/rust-lang/rust/blob/master/RELEASES.md#version-1120-2016-09-29).
#### Стабилизация библиотек
В этом выпуске многими типами стало немного удобнее пользоваться.
* [`Cell::as_ptr`](https://doc.rust-lang.org/std/cell/struct.Cell.html#method.as_ptr) и [`RefCell::as_ptr`](https://doc.rust-lang.org/std/cell/struct.RefCell.html#method.as_ptr)
* `IpAddr`, `Ipv4Addr` и `Ipv6Addr` получили несколько новых методов.
* [`LinkedList`](https://doc.rust-lang.org/std/collections/linked_list/struct.LinkedList.html#method.contains) и [`VecDeque`](https://doc.rust-lang.org/std/collections/vec_deque/struct.VecDeque.html#method.contains) получили метод `contains`.
* [`iter::Product`](https://doc.rust-lang.org/std/iter/trait.Product.html) и [`iter::Sum`](https://doc.rust-lang.org/std/iter/trait.Sum.html)
* [`Option` реализует `From` для содержащегося в нём типа](https://github.com/rust-lang/rust/pull/34828)
* [`Cell`, `RefCell` и `UnsafeCell` реализуют `From` для содержащегося в них типа](https://github.com/rust-lang/rust/pull/35392)
* [`Cow` реализует `FromIterator` для `char`, `&str` и `String`](https://github.com/rust-lang/rust/pull/35064)
* [При использовании `SOCK_CLOEXEC` сокеты на Linux правильно закрываются в подпроцессах](https://github.com/rust-lang/rust/pull/34946)
* [`String` реализует `AddAssign`](https://github.com/rust-lang/rust/pull/34890)
* [Определения Юникода обновлены до версии 9.0](https://github.com/rust-lang/rust/pull/34599)
Подробнее смотрите замечания к [выпуску](https://github.com/rust-lang/rust/blob/master/RELEASES.md#version-1120-2016-09-29).
#### Возможности Cargo
Самая интересная возможность, добавленная в Cargo в этом цикле — "[workspace'ы](https://github.com/rust-lang/cargo/pull/2759)." Они определены в [RFC 1525](https://github.com/rust-lang/rfcs/blob/master/text/1525-cargo-workspace.md), и позволяют группе пакетов разделять один и тот же файл `Cargo.lock`. Если вы занимаетесь проектом, который разделён на несколько пакетов, workspace'ы сильно упрощают фиксацию единственной версии общих зависимостей. В большинстве проектов включение этой возможности потребует добавления в `Cargo.toml` верхнего уровня единственной строчки, `[workspace]`. Более сложным проектам может потребоваться более хитрая настройка.
Другая значительная возможность — это [перегрузка пути к исходному коду контейнера](https://github.com/rust-lang/cargo/pull/2857). Вы можете легко распространять зависимости локально (*англ.* vendoring), используя её в сочетании с инструментами вроде [cargo-vendor](https://github.com/alexcrichton/cargo-vendor) и [cargo-local-registry](https://github.com/alexcrichton/cargo-local-registry). Со временем на базе этого будет построена инфраструктура зеркал [crates.io](https://crates.io/).
Ещё есть некоторые мелкие улучшения:
* [Ускорены обновления, когда обновлять ничего не надо](https://github.com/rust-lang/cargo/pull/2974)
* [`cargo new` получил флаг `--lib`](https://github.com/rust-lang/cargo/pull/2921)
* [После компиляции показывается время, которое занял этот процесс](https://github.com/rust-lang/cargo/pull/2909)
* [`cargo publish` получил флаг `--dry-run`](https://github.com/rust-lang/cargo/pull/2849)
Подробнее смотрите замечания к [выпуску](https://github.com/rust-lang/rust/blob/master/RELEASES.md#version-1120-2016-09-29).
### Разработчики версии 1.12
В выпуске версии 1.12 участвовало 176 человек. Большое вам спасибо!
**Список участников*** Aaron Gallagher
* abhi
* Adam Medziński
* Ahmed Charles
* Alan Somers
* Alexander Altman
* Alexander Merritt
* Alex Burka
* Alex Crichton
* Amanieu d'Antras
* Andrea Pretto
* Andre Bogus
* Andrew
* Andrew Cann
* Andrew Paseltiner
* Andrii Dmytrenko
* Antti Keränen
* Aravind Gollakota
* Ariel Ben-Yehuda
* Bastien Dejean
* Ben Boeckel
* Ben Stern
* bors
* Brendan Cully
* Brett Cannon
* Brian Anderson
* Bruno Tavares
* Cameron Hart
* Camille Roussel
* Cengiz Can
* CensoredUsername
* cgswords
* Chiu-Hsiang Hsu
* Chris Stankus
* Christian Poveda
* Christophe Vu-Brugier
* Clement Miao
* Corey Farwell
* CrLF0710
* crypto-universe
* Daniel Campbell
* David
* decauwsemaecker.glen@gmail.com
* Diggory Blake
* Dominik Boehi
* Doug Goldstein
* Dridi Boukelmoune
* Eduard Burtescu
* Eduard-Mihai Burtescu
* Evgeny Safronov
* Federico Ravasio
* Felix Rath
* Felix S. Klock II
* Fran Guijarro
* Georg Brandl
* ggomez
* gnzlbg
* Guillaume Gomez
* hank-der-hafenarbeiter
* Hariharan R
* Isaac Andrade
* Ivan Nejgebauer
* Ivan Ukhov
* Jack O'Connor
* Jake Goulding
* Jakub Hlusička
* James Miller
* Jan-Erik Rediger
* Jared Manning
* Jared Wyles
* Jeffrey Seyfried
* Jethro Beekman
* Jonas Schievink
* Jonathan A. Kollasch
* Jonathan Creekmore
* Jonathan Giddy
* Jonathan Turner
* Jorge Aparicio
* José manuel Barroso Galindo
* Josh Stone
* Jupp Müller
* Kaivo Anastetiks
* kc1212
* Keith Yeung
* Knight
* Krzysztof Garczynski
* Loïc Damien
* Luke Hinds
* Luqman Aden
* m4b
* Manish Goregaokar
* Marco A L Barbosa
* Mark Buer
* Mark-Simulacrum
* Martin Pool
* Masood Malekghassemi
* Matthew Piziak
* Matthias Rabault
* Matt Horn
* mcarton
* M Farkas-Dyck
* Michael Gattozzi
* Michael Neumann
* Michael Rosenberg
* Michael Woerister
* Mike Hommey
* Mikhail Modin
* mitchmindtree
* mLuby
* Moritz Ulrich
* Murarth
* Nick Cameron
* Nick Massey
* Nikhil Shagrithaya
* Niko Matsakis
* Novotnik, Petr
* Oliver Forral
* Oliver Middleton
* Oliver Schneider
* Omer Sheikh
* Panashe M. Fundira
* Patrick McCann
* Paul Woolcock
* Peter C. Norton
* Phlogistic Fugu
* Pietro Albini
* Rahiel Kasim
* Rahul Sharma
* Robert Williamson
* Roy Brunton
* Ryan Scheel
* Ryan Scott
* saml
* Sam Payson
* Samuel Cormier-Iijima
* Scott A Carr
* Sean McArthur
* Sebastian Thiel
* Seo Sanghyeon
* Shantanu Raj
* ShyamSundarB
* silenuss
* Simonas Kazlauskas
* srdja
* Srinivas Reddy Thatiparthy
* Stefan Schindler
* Stephen Lazaro
* Steve Klabnik
* Steven Fackler
* Steven Walter
* Sylvestre Ledru
* Tamir Duberstein
* Terry Sun
* TheZoq2
* Thomas Garcia
* Tim Neumann
* Timon Van Overveldt
* Tobias Bucher
* Tomasz Miąsko
* trixnz
* Tshepang Lekhonkhobe
* ubsan
* Ulrik Sverdrup
* Vadim Chugunov
* Vadim Petrochenkov
* Vincent Prouillet
* Vladimir Vukicevic
* Wang Xuerui
* Wesley Wiser
* William Lee
* Ximin Luo
* Yojan Shrestha
* Yossi Konstantinovsky
* Zack M. Davis
* Zhen Zhang
* 吴冉波 | https://habr.com/ru/post/311384/ | null | ru | null |
# API Яндекс.Панорам: как сделать свою виртуальную прогулку или просто довести человека от метро
Нас очень давно просили сделать API, который позволяет встраивать Панорамы Яндекса на свои сайты, и мы, наконец, смогли это сделать. Даже больше: наш API даёт возможность создавать собственные панорамы.
В этом посте я расскажу, что вообще надо знать, чтобы делать такие виртуальные прогулки. Почему сделать API для них было не так-то просто, как мы разрешали разные встающие на пути проблемы и подробно объясню, что вы сможете сделать с помощью нашего API (больше, чем может на первый взгляд показаться).
[](https://habrahabr.ru/company/yandex/blog/305846/)
Движок
------
Сервис панорам запустился на Яндекс.Картах в далеком сентябре 2009 года. Поначалу это были лишь несколько панорам достопримечательностей и работали они, как вы, наверное, догадываетесь, на Flash. С тех пор много воды утекло, панорам стало несколько миллионов, начали быстро расти мобильные платформы, а Flash туда так и не пробрался. Поэтому примерно в 2013 году мы решили, что нам нужна новая технология. И основой для этой технологии стал HTML5.
API, с которого мы начинали, — это Canvas2D. Сейчас это может показаться странным, но в 2013 году этот выбор был вполне разумен. WebGL был стандартизован всего двумя годами раньше, толком еще не добрался до мобильных (в iOS, например, WebGL работал только в уже почти почившем в бозе iAd), да и на десктопах работал не очень стабильно. Читатель может мне возразить, что надо было все делать на CSS 3D, как это было тогда популярно. Но с помощью CSS 3D можно нарисовать только кубическую панораму, в то время как все панорамы Яндекса сферические (хранящиеся в равнопромежуточной проекции).
Это же было и самой главной технической трудностью в разработке. Дело в том, что корректно и точно спроецировать сферическую панораму на экран непросто из-за нелинейности этого преобразования. Наивная реализация такой проекции требовала бы целого вороха тригонометрических вычислений на каждый пиксель экрана — ведь нужно найти соответствующую ему точку в панорамном изображении и определить его цвет. Кроме того, Canvas 2D не предоставляет эффективного способа манипулировать каждым пикселем изображения по отдельности.
На помощь в этой непростой ситуации приходит один из самых старых трюков в компьютерной графике — линейная интерполяция. Мы не будем для каждого пикселя экрана точно вычислять координаты соответствующей точки в панорамном изображении. Мы это сделаем лишь для некоторых пикселей, которые выберем заранее — а для остальных станем находить координаты, интерполируя между уже рассчитанными. Вопрос лишь в том, как выбрать эти пиксели.
Как уже было замечено, записывать цвет изображения попиксельно в Canvas2D неудобно, но удобно работать с изображениями и их двумерными трансформациями. Кроме того, такие трансформации фактически реализуют интерполяцию за нас. Именно их и решено было использовать в качестве основы алгоритма рендеринга панорамы. А так как двумерная линейная трансформация однозначно задается двумя триплетами точек, один на экране, а другой на панорамном изображении, то выбор набора точек, для которых мы будем считать проекцию точно, получается сам собой: будем разбивать панорамную сферу на треугольники. Итоговый алгоритм рендеринга получился следующим:
Написав все это и запустив, я увидел нечто, хорошо описываемое словом «слайдшоу». Фреймрейт оказался совершенно неприемлемым. Попрофилировав, я нашел, что больше всего времени отъедают функции `save()` и `restore()` Canvas 2D контекста. Откуда они взялись? Из особенности работы с обрезкой в Canvas2D. К сожалению, чтобы иметь возможность сбросить текущую обрезку и выставить новую, необходимо сохранить перед выставлением состояние контекста (это как раз `save()`), а после всего необходимого рисования восстановить сохраненное состояние (а это уже `restore()`). А так как эти операции работают со всем состоянием
контекста, они недешевы. Кроме того, обрезку-то мы делаем каждый раз совершенно одинаковую (после инициализации разбиение сферы на треугольники и их наложение на панорамное изображение не меняются). Есть смысл это закешировать!
Сказано — сделано. После генерации триангулированной сферы мы «вырезаем» каждый треугольник из панорамного изображения и сохраняем его в отдельном кеше-канвасе. Остальная часть такого кэша при этом остается прозрачной. После такой оптимизации удалось получать 30—60 кадров в секунду даже на мобильных устройствах. Из этого опыта можно извлечь следующий урок: при разработке рендеринга на Canvas 2D все, что можно, кэшируйте и пререндерите. А если что-то вдруг нельзя — делайте так, чтоб было можно, и тоже пререндерите.

У любого кеширования (как и у многих вещей в этой жизни) есть и обратная сторона: неизбежно растет потребление памяти. Именно это и произошло с рендерингом панорамы. Возросшие аппетиты породили множество проблем. Самыми заметными можно назвать падения браузеров даже на декстопных платформах, а также довольно медленный старт. В конце концов, устав бороться с этими проблемами, мы отказались от репроецирования панорамного изображения на Canvas 2D и пошли другим путем. Но он уже совершенно не интересный :)
Однако еще до того мы начали смотреть с сторону WebGL. К этому нас подтолкнули разные причины, главной из которых, пожалуй, была iOS 8, в который WebGL заработал в Safari.
Главной проблемой при разработке WebGL-версии рендеринга был размер панорам. Панорамное изображение целиком не лезло ни в одну текстуру. Эту проблему мы снова решали, руководствуясь принципом «руководствуйся старыми как мир принципами», и разделили панорамную сферу на сектора. Каждому сектору соответствует своя текстура. При этом для экономии памяти и ресурсов GPU невидимые сектора полностью удаляются. Когда они должны на экране появиться вновь, данные для них снова перезагружаются (обычно из кеша браузера).
Встраивание панорам
-------------------
Встраивание панорам с помощью API Карт начинается с подключения нужных модулей. Это можно сделать двумя способами: либо указав их в параметре `load` при подключении API, либо с помощью модульной системы (в скором времени мы добавим модули панорам в загружаемый по умолчанию набор модулей).
```
// Подключение с использованием модульной системы.
ymaps.modules.require([
'panorama.createPlayer',
'panorama.isSupported'
])
.done(function () {
// ...
});
```
Перед началом работы с панорамами необходимо убедиться, что браузер пользователя поддерживается движком. Это можно сделать с помощью функции [`ymaps.panorama.isSupported`](https://tech.yandex.ru/maps/doc/jsapi/2.1/ref/reference/panorama.isSupported-docpage/):
```
if (!ymaps.panorama.isSupported()) {
// Показываем пользователю сообщение, скрываем функциональность
// панорам, etc.
} else {
// Работаем с панорамами.
}
```
Чтобы открыть панораму, нам сначала надо получить ее описание с сервера. Это делается с помощью функции [`ymaps.panorama.locate`](https://tech.yandex.ru/maps/doc/jsapi/2.1/ref/reference/panorama.locate-docpage/):
```
ymaps.panorama.locate(
[0, 0] // координаты панорамы
).done(function (panoramas) {
// ...
});
```
Результатом, которым разрешится промис, возвращаемый вызовом `ymaps.panorama.locate`, будет массив панорам, находящихся в некоторой окрестности переданной точки. Если ни одной такой панорамы нет, массив будет пуст. Если таких панорам будет найдено несколько, они будут отсортированы по расстоянию от переданной точки. Первая при этом будет ближайшей.
Еще можно запрашивать воздушные панорамы:
```
ymaps.panorama.locate(
[0, 0], // координаты панорамы
{ layer: 'yandex#airPanorama' }
).done(function (panoramas) {
// ...
});
```
Получив описание панорамы, мы можем создать плеер, который отобразит ее на странице:
```
var player = new ymaps.panorama.Player(
'player', // ID элемента, в котором будет открыт плеер
panorama // Панорама, которую мы хотим отобразить в плеере
);
```
И мы увидим на странице:

Самый быстрый и простой способ открыть панораму — это функция [`ymaps.panorama.createPlayer`](https://tech.yandex.ru/maps/doc/jsapi/2.1/ref/reference/panorama.createPlayer-docpage/):
```
ymaps.panorama.createPlayer(
'player', // ID DOM-элемента, в котором будет открыт плеер
[0, 0] // Координаты панорамы, которую мы хотим открыть
).done(function (player) {
// ...
});
```
При этом можно указать одну или несколько [опций](https://tech.yandex.ru/maps/doc/jsapi/2.1/ref/reference/panorama.createPlayer-docpage/#param-options) третьим параметром:
```
ymaps.panorama.createPlayer(
'player',
[0, 0],
{
// Слой, в котором искать панораму
layer: 'yandex#airPanorama',
// Направление взгляда
direction: [120, 10],
// Угловой размер видимой части панорамы
span: [90, 90],
// Набор контролов
controls: ['zoomControl', 'closeControl']
}
).done(function (player) {
// ...
});
```
После создания плеер предоставляет компактный API для управления отображением панорам и подписки на пользовательские события. Но, как мне кажется, это не самая интересная возможность API панорам.
Свои панорамы
-------------
Пожалуй, самая интересная возможность, которую дает API, это создание собственных панорам и встраивание их на сайт.
Любая панорама начинается со съемки и подготовки панорамного изображения. Для съемки можно воспользоваться специальным устройством, обычным фотоаппаратом или даже смартфоном. Главное, чтобы результатом съемки и склейки была сферическая панорама в равнопромежуточной проекции. Например, стандартное приложение камеры на Android умеет снимать и склеивать панорамы в нужной проекции. Именно им мы и воспользовались для съемки панорам нашего уютного опенспейса.
После того как мы сняли панорамное изображение, необходимо его подготовить к отображению в плеере. Для этого нам нужно разрезать его на тайлы. Кроме того, мы можем подготовить изображения нескольких разных размеров для разных уровней мастабирования. Плеер будет выбирать самый подходящий уровень для текущего размера DOM-элемента, в котором открыт плеер, и угловых размеров видимой области панорамы. А если самый маленький уровень меньше 2048 пикселей по ширине изображения, он будет использован для создания «эффекта прогрессивного джипега». Плеер подгрузит тайлы этого уровня с самым высоким приоритетом и будет показывать их там, где нет тайлов лучшего качества (например, если они еще не загружены или были вытеснены из памяти и пока не перезагрузились).
Для нарезки изображений на тайлы можно воспользоваться любым ПО (при наличии определенной усидчивости — хоть Paint). Размеры тайлов должны быть степенями двойки (те из вас, кто работал с WebGL, думаю, догадываются, откуда растут ноги у этого ограничения). Я воспользовался ImageMagick:
```
# Сначала немного растянем исходное изображение так, чтоб оно разбивалось
# на целое число тайлов по горизонтали (по вертикали это, кстати, не обязательно).
$ convert src.jpg -resize 7168x3584 hq.jpg
# Разрежем изображение на тайлы размером 512 на 512 пискелей.
$ convert hq.jpg -crop 512x512 \
-set filename:tile "%[fx:page.x/512]-%[fx:page.y/512]" \
"hq/%[filename:tile].jpg"
# Подготовим уровень масштабирования низкого качества для «эффекта
# прогрессивного джипега». Он будет состоять из одного тайла, поэтому его
# не надо будет разрезать.
$ convert hq.jpg -resize 512x256 lq/0-0.jpg
```
Давайте наконец напишем уже какой-то код для нашей панорамы. API — это система связанных между собой интерфейсов. Эти интерфейсы описывают объект панорамы и все связанные с ним.
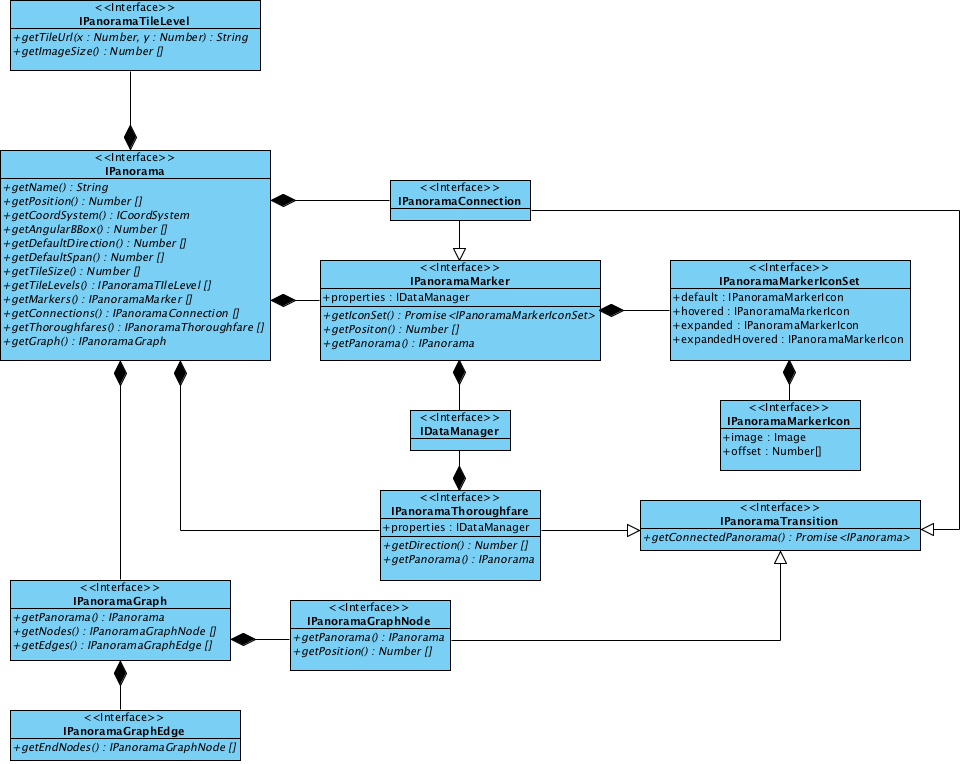
Давайте теперь разберем эту картинку по сущностям.
Объект панорамы должен реализовывать интерфейс [`IPanorama`](https://tech.yandex.ru/maps/doc/jsapi/2.1/ref/reference/IPanorama-docpage/). Чтобы написать свой класс панорамы было проще, сделан абстрактный класс [`ymaps.panorama.Base`](https://tech.yandex.ru/maps/doc/jsapi/2.1/ref/reference/panorama.Base-docpage/). Он предоставляет разумные реализации по умолчанию для некоторых методов `IPanorama`, а также метод `validate`, который проверяет, удовлетворяет ли панорама ограничениям, накладываемым плеером (например, является ли указанный размер тайлов степенью двойки). Давайте им и воспользуемся.
```
function Panorama () {
Panorama.superclass.constructor.call(this);
// ...
// И проверим, что мы все делаем правильно.
this.validate();
}
ymaps.util.defineClass(Panorama, ymaps.panorama.Base, {
// Методы, возвращающие данные панорамы.
});
```
Начнем мы с того, что опишем плееру геометрию панорамы. Для этого нужно реализовать метод [`getAngularBBox`](https://tech.yandex.ru/maps/doc/jsapi/2.1/ref/reference/IPanorama-docpage/#getAngularBBox), возвращающий, судя по документации, массив из четырёх чисел. Каков смысл этих чисел? Чтобы ответить на этот вопрос, вспомним про то, что панорама у нам сферическая, то есть наложенная на сферу. Чтобы описать положение панорамного изображения на сфере, необходимо выбрать некоторые «опорные» точки. Обычно для прямоугольника (а панорамное изображение, не будучи на сфере, как раз им и является, как и любое изображение в компьютере) выбирают координаты двух его противоположных углов. В нашем случае этот подход продолжает работать и на сфере, ведь вертикальные стороны изображения становятся при наложении меридианами, а горизонтальные – параллелями. Это значит, что каждая сторона прямоугольника имеет собственную угловую координату, общую для всех точек этой стороны. Именно эти координаты сторон и составляют массив, возвращаемый методом `getAngularBBox`, определяя своего рода сферический прямоугольник, ограничивающий панораму (отсюда и названия метода).
Плеер накладывает важное ограничение на геометрию панорамы (а значит — на само панорамное изображение): панорамное изображение должно смыкаться на сфере по горизонтали, образуя полный круг. Для значений, возвращаемых методом `getAngularBBox`, это значит, что разница между правой и левой угловой границей панорамы должна составлять 2π. Что касается вертикальных границ, то они могут быть любыми.
Панорама, которую мы сняли смартфоном, не только полная по горизонтали, но и по вертикали, то есть от полюса до полюса. Поэтому границами панорамы на сфере будут интервалы `[π/2, -π/2]` по вертикали (от верхнего полюса до нижнего) и `[0, 2π]` по горизонтали (тут мы для простоты полагаем, что направление на стык панорамы совпало с направлением на север, что, конечно же, в действительности не так). Получается вот такой код:
```
getAngularBBox: function () {
return [
0.5 * Math.PI,
2 * Math.PI,
-0.5 * Math.PI,
0
];
}
```
Также нужно реализовать методы, возвращающие позицию панорамы и систему координат, в которой она задана. Эти данные будут использованы плеером для корректного позиционирования в сцене объектов, связанных с панорамой (о них ниже).
```
getPosition: function () {
// Для простоты выберем начало координат в качестве положения панорамы, ...
return [0, 0];
},
getCoordSystem: function () {
// ...а системой координат выберем декартову, чтоб наша панорама не
// плавала где-то в Гвинейском заливе.
return ymaps.coordSystem.cartesian;
},
```
Теперь мы опишем сами панорамные изображения — как они разрезаны на тайлы и где эти тайлы лежат. Для этого нам надо реализовать методы [`getTileSize`](https://tech.yandex.ru/maps/doc/jsapi/2.1/ref/reference/IPanorama-docpage/#getTileSize) и [`getTileLevels`](https://tech.yandex.ru/maps/doc/jsapi/2.1/ref/reference/IPanorama-docpage/#getTileLevels). С первым все очевидно: он возвращает размер тайлов.
```
getTileSize: function () {
return [512, 512];
}
```
`getTileLevels` возвращает массив объектов-описаний уровней масштабирования панорамного изображения. Их у нас, напомню, было два: высокого (относительно) и низкого качества. Каждый такой объект-описание должен реализовывать интерфейс [`IPanoramaTileLevel`](https://tech.yandex.ru/maps/doc/jsapi/2.1/ref/reference/IPanoramaTileLevel-docpage/), состоящий из двух методов: `getImageSize` и `getTileUrl`. Для простоты не будем заводить отдельный класс для этого, просто вернем объекты с нужными методами.
```
getTileLevels: function () {
return [
{
getTileUrl: function (x, y) {
return '/hq/' + x + '-' + y + '.jpg';
},
getImageSize: function () {
return [7168, 3584];
}
},
{
getTileUrl: function (x, y) {
return '/lq/' + x + '-' + y + '.jpg';
},
getImageSize: function () {
return [512, 256];
}
}
];
}
```
На этом минимальное описание панорамы готово, и плеер сможет ее отобразить:
```
var player = new ymaps.panorama.Player('player', new Panorama());
```
Кстати, такое минимальное описание панорамы можно сделать быстрее и проще с функцией-хелпером [`ymaps.panorama.Base.createPanorama`](https://tech.yandex.ru/maps/doc/jsapi/2.1/ref/reference/panorama.Base.createPanorama-docpage/):
```
var player = new ymaps.panorama.Player(
'player',
ymaps.panorama.Base.createPanorama({
angularBBox: [
0.5 * Math.PI,
2 * Math.PI,
-0.5 * Math.PI,
0
],
position: [0, 0],
coordSystem: ymaps.coordSystem.cartesian,
name: 'Наша супер-панорама',
tileSize: [512, 512],
tileLevels: [
{
getTileUrl: function (x, y) {
return '/hq/' + x + '-' + y + '.jpg';
},
getImageSize: function () {
return [7168, 3584];
}
},
{
getTileUrl: function (x, y) {
return '/lq/' + x + '-' + y + '.jpg';
},
getImageSize: function () {
return [512, 256];
}
}
]
})
);
```
Кроме собственно самой панорамы плеер умеет отображать три вида объектов: маркеры, переходы и связи.
Маркеры позволяют обозначать объекты на панораме (например, маркеры с номерами домов на панорамах Яндекса). Объект маркера должен реализовывать интерфейс [`IPanoramaMarker`](https://tech.yandex.ru/maps/doc/jsapi/2.1/ref/reference/IPanoramaMarker-docpage/). Этот интерфейс содержит всего три метода: `getIconSet`, `getPosition` и `getPanorama`. Назначение последних двух вполне понятно из их названий. Первый же я вижу необходимым пояснить. Дело в том, что маркер – это интерактивный элемент. Он меняет состояние, реагируя на пользовательские события. Эти состояния и то, как они изменяются по событиям в UI, можно писать такой диаграммой:
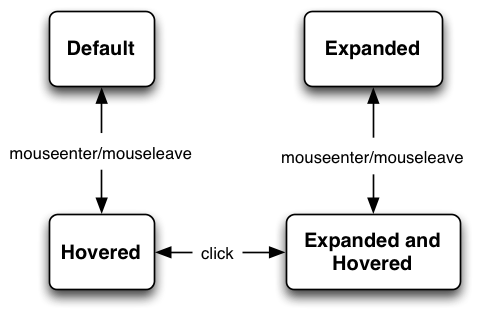
Например, маркер, обозначающий дом. Вот его состояние по умолчанию, состояние при наведенном курсоре и раскрытое состояние:

Именно иконки этих состояний и возвращает плееру метод `getIconSet`. Иконка может быть как загружена с сервера (именно для этого этот метод и сделан асинхронным), так и процедурно сгенерирована (с помощью канваса). В нашем примере мы предположим, что в панораме один маркер и его иконки уже загружены:
```
getMarkers: function () {
// Как и с уровнями масштабирования, не будем создавать отдельный
// класс, вернем объект.
var panorama = this;
return [{
properties: new ymaps.data.Manager(),
getPosition: function () {
return [10, 10];
},
getPanorama: function () {
return panorama;
},
getIconSet: function () {
return ymaps.vow.resolve({
'default': {
image: defaultMarkerIcon,
offset: [0, 0]
},
hovered: {
image: hoveredMarkerIcon,
offset: [0, 0]
}
// Кстати, не обязательно указывать все состояния,
// обязательно только `default`.
});
}
}];
}
```
Переходы — это те самые стрелки, по клику на которые плеер переходит на соседнюю панораму. Объекты, описывающие переходы, должны реализовывать интерфейс [`IPanoramaThorougfare`](https://tech.yandex.ru/maps/doc/jsapi/2.1/ref/reference/IPanoramaThoroughfare-docpage/):
```
getThoroughfares: function () {
// И опять мы поленимся писать классы :)
var panorama = this;
return [{
properties: new ymaps.data.Manager(),
getDirection: function () {
// Переходы задаются не координатами, а направлением на
// панораму, с которой переход связывает текущую.
return [Math.PI, 0];
},
getPanorama: function () {
return panorama;
},
getConnectedPanorama: function () {
// Именно этот метод будет вызван при переходе.
// Кстати, свою панораму вполне можно связать с панорамой
// Яндекса, получив ее с помощью метода ymaps.panorama.locate.
return ymaps.panorama.locate(/* ... */)
.then(function (panoramas) {
if (panoramas.lengths == 0) {
return ymaps.vow.reject();
}
return panoramas[0];
});
}
}];
}
```
Связи являются своего рода гибридом маркеров и переходов: выглядят они как первые, а ведут себя как последние. В коде они реализуются точно так же, как и маркеры, но с добавлением метода `getConnectedPanorama` (см. [`IPanoramaConnection`](https://tech.yandex.ru/maps/doc/jsapi/2.1/ref/reference/IPanoramaConnection-docpage/)).
Вместо заключения
-----------------
API панорам пока что запущен в статусе бета. Встраивайте, тестируйте на своих сайтах и приложениях, рассказывайте нам об этом в [клубике](https://yandex.ru/blog/mapsapi), [группе во ВКонтакте](https://vk.com/ymapsapi), [Фейсбуке](https://www.facebook.com/ymapsapi/) или через [поддержку](https://tech.yandex.ru/maps/doc/geocoder/desc/feedback/troubleshooting-docpage/). Вот ЦИАН уже :) | https://habr.com/ru/post/305846/ | null | ru | null |
# WebAssembly объединит их всех
Задумался о том что бы прикрутить к своему пет проекту систему плагинов на WebAssembly. Это потенциально позволит переиспользовать существующий код на Go, C++, Rust, если конечно же он есть. А так же избавится от so/dll, что удобно при распространении плагинов, когда проект представляет собой десктопное приложение и собирается под Windows, OSX, GNU/Linux. Поэтому пошел смотреть как это сделано в Envoy.
### Предыстория Envoy
На начало 2019 Envoy представляет собой статический бинарник со всеми расширениями скомпилированными во время сборки, поэтому нужно поддерживать несколько бинарных сборок, вместо использования официального и не модифицированного бинарного файла Envoy. Для проектов, которые не контролируют свои деплой, еще более проблематично, потому что обновление расширений требует пересборки и деплоя всего Envoy.
### Преимущества
* **Гибкость**. Расширения можно доставлять и перезагружать во время выполнения. Любый изменения или исправления могут быть протестированы во время выполнения, без необходимости обновления и редиплоя нового бинарника.
* **Надежность и изоляция.** Расширения запускаются в песочнице и могут быть ограничены по потреблению CPU и памяти.
* **Безопасность**. Расширения запускаются в песочнице с четко определенным API для связи с прокси(envoy, [nginx](https://github.com/api7/wasm-nginx-module) и т.д.). Имеют ограниченный доступ к свойствам, которые могут менять.
* **Разнообразие.** Большой выбор языков программирования, которые могут скомпилировать в WebAssembly, что позволяет разработчикам с любым опытом(C, Go, Rust, Java, TypeScript, и т.д.) писать расширения.
* **Переносимость**. Поскольку интерфейс между хост-средой и расширениями не зависит от прокси-сервера, расширения, написанные с использованием Proxy-Wasm, могут выполняться в различных прокси-серверах, например [Envoy, NGINX, ATS](https://github.com/proxy-wasm/spec#servers) или даже внутри библиотеки gRPC (при условии, что все они реализуют стандарт).
### Недостатки
* Более высокое потребления памяти из-за необходимости запуска множества виртуальных машин, каждая со своим блоком памяти.
* Более низкая производительность для расширений, преобразующий полезные данные, из-за необходимости копировать значительные объемы данных в песочницу и из нее.
* Более низкая производительность для CPU-bound задач. Ожидается, что замедление будет менее чем в 2 раза по сравнению с нативным кодом.
* Увеличенный размер бинарника из-за необходимости включать среду выполнения Wasm. Это ~20 MB для WAVM и ~10 MB для V8.
* Экосистема WebAssembly все еще молода, и в настоящее время разработка сосредоточена на использовании в браузере, где JavaScript считается хост-средой.
Общая схема
-----------
В Envoy взяли C++ API, прикрутили Wasm VM и перенаправляют вызовы в wasm модуль.
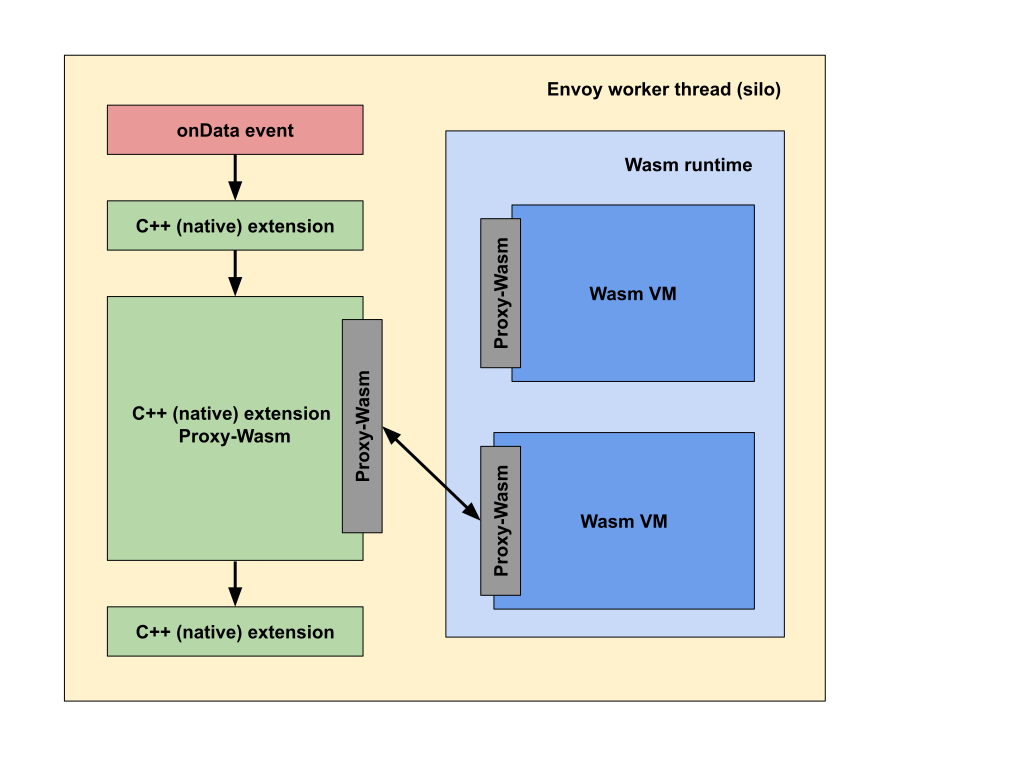В одном wasm модуле могут быть несколько фильтров. Экземпляры Wasm VM размножены и размещены в [thread-local storage](https://en.wikipedia.org/wiki/Thread-local_storage)
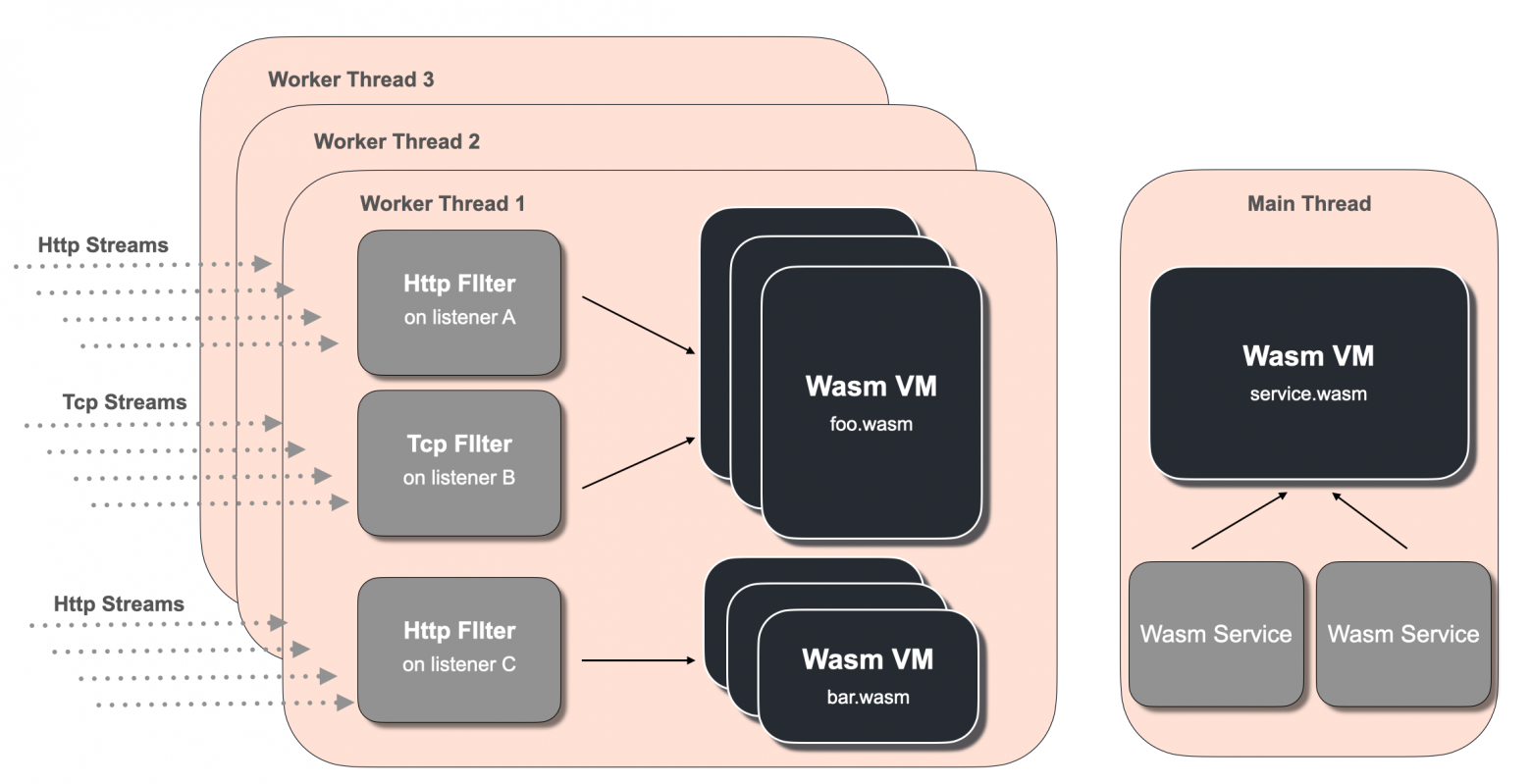Коммуникация между экземплярами Wasm VM осуществляется примитивами shared data и message queue. Службы представляют из себя singleton и выполняется в основном потоке Envoy. Они выполняются параллельно фильтрам и осуществляют вспомогательные функции: логи, статистика и т.д.
### Рантайм
Wasm VM это один из следующих рантаймов
* V8
* [WAMR](https://github.com/bytecodealliance/wasm-micro-runtime)
* [Wasmtime](https://github.com/bytecodealliance/wasmtime)
* [WAVM](https://github.com/WAVM/WAVM)
### Спецификация
Спецификация ABI разбита на два больших блока: функции реализованные в [модуле](https://github.com/proxy-wasm/spec/blob/master/abi-versions/vNEXT/README.md#functions-implemented-in-the-wasm-module) и функции реализованные в [хост-среде](https://github.com/proxy-wasm/spec/blob/master/abi-versions/vNEXT/README.md#functions-implemented-in-the-host-environment). Выделю две функции: выделение памяти `proxy_on_memory_allocate`, точка входа `_start`.
Спецификация представляет набор функций в формате `proxy_log`
аргументы:
* `i32 (proxy_log_level_t) log_level`
* `i32 (const char*) message_data`
* `i32 (size_t) message_size`
возвращаемое значение:
* `i32 (proxy_result_t) call_result`
i32 это числовой [тип в wasm](https://webassembly.github.io/spec/core/bikeshed/#types), а так она выглядит в разных SDK
```
extern "C" WasmResult proxy_log(LogLevel level,
const char *logMessage,
size_t messageSize);
```
```
package internal
//export proxy_log
func ProxyLog(logLevel LogLevel,
messageData *byte,
messageSize int) Status
```
```
// @ts-ignore: decorator
@external("env", "proxy_log")
export declare function proxy_log(level: LogLevel,
logMessage: ptr,
messageSize: size\_t): WasmResult;
```
### Владение памятью
Наверное это одна из самых важных тем при построении такой системой, где есть память на стороне хоста и память в wasm модуле. Никакая управляемая память не передается в wasm модуль при вызове обработчиков. Вместо этого wasm модуль сам запрашивает данные. Например `proxy_on_http_request_body` передает информацию о количестве доступных байтов в теле запроса, модуль должен запросить эти данные используя `proxy_get_buffer`. Когда это происходит, хост выделяет помять у wasm модуля вызовом `proxy_on_memory_allocate`, ***копирует*** туда данные и ***отдает*** память во владение wasm модулю, в надежде, что он освободит ее.
### proxy\_on\_memory\_allocate
аргументы:
* `i32 (size_t) memory_size`
возвращаемое значение:
* `i32 (void*) allocated_ptr`
Реализация на AssemblyScript [malloc.ts](https://github.com/solo-io/proxy-runtime/blob/master/assembly/malloc.ts)
```
import {
__pin,
__unpin,
} from "rt/itcms";
/// Allow host to allocate memory.
export function malloc(size: i32): usize {
let buffer = new ArrayBuffer(size);
let ptr = changetype(buffer);
return \_\_pin(ptr);
}
/// Allow host to free memory.
export function free(ptr: usize): void {
\_\_unpin(ptr);
}
```
Обратное преобразование
```
class ArrayBufferReference {
private buffer: usize;
private size: usize;
constructor() {
}
sizePtr(): usize {
return changetype(this) + offsetof("size");
}
bufferPtr(): usize {
return changetype(this) + offsetof("buffer");
}
// Before calling toArrayBuffer below, you must call out to the host to fill in the values.
// toArrayBuffer below \*\*must\*\* be called once and only once.
toArrayBuffer(): ArrayBuffer {
if (this.size == 0) {
return new ArrayBuffer(0);
}
let array = changetype(this.buffer);
// host code used malloc to allocate this buffer.
// release the allocated ptr. array variable will retain it, so it won't be actually free (as it is ref counted).
free(this.buffer);
// should we return a this sliced up to size?
return array;
}
}
```
В AssemblyScript заложили поведение при котором объекты можно отдавать во внешнюю среду(в первую очередь в JS). Для этого есть [\_\_pin/\_\_unpin](https://www.assemblyscript.org/runtime.html#interface), что бы сборщик мусора не собрал объекты на которых уже нет ссылок. В Go
```
//nolint
//export proxy_on_memory_allocate
func proxyOnMemoryAllocate(size uint) *byte {
buf := make([]byte, size)
return &buf[0]
}
```
Обратное преобразование
```
import (
"reflect"
"unsafe"
)
func RawBytePtrToString(raw *byte, size int) string {
//nolint
return *(*string)(unsafe.Pointer(&reflect.SliceHeader{
Data: uintptr(unsafe.Pointer(raw)),
Len: size,
Cap: size,
}))
}
func RawBytePtrToByteSlice(raw *byte, size int) []byte {
//nolint
return *(*[]byte)(unsafe.Pointer(&reflect.SliceHeader{
Data: uintptr(unsafe.Pointer(raw)),
Len: size,
Cap: size,
}))
}
```
Что тут можно сказать? В спецификации [Go](https://go.dev/ref/spec) ничего не сказано про работу сборщика мусора. Компилятор с <https://go.dev/> запрещает передавать указатели на память из Go в Си. Есть пакет [go-pointer](https://github.com/mattn/go-pointer), который немного напоминает pin/unpin из AssemblyScript.
```
C.pass_pointer(pointer.Save(&s))
v := *(pointer.Restore(C.get_from_pointer()).(*string))
```
Внутри довольно простой
```
package pointer
// #include
import "C"
import (
"sync"
"unsafe"
)
var (
mutex sync.RWMutex
store = map[unsafe.Pointer]interface{}{}
)
func Save(v interface{}) unsafe.Pointer {
if v == nil {
return nil
}
// Generate real fake C pointer.
// This pointer will not store any data, but will bi used for indexing purposes.
// Since Go doest allow to cast dangling pointer to unsafe.Pointer, we do rally allocate one byte.
// Why we need indexing, because Go doest allow C code to store pointers to Go data.
var ptr unsafe.Pointer = C.malloc(C.size\_t(1))
if ptr == nil {
panic("can't allocate 'cgo-pointer hack index pointer': ptr == nil")
}
mutex.Lock()
store[ptr] = v
mutex.Unlock()
return ptr
}
```
**НО** разработчики используют **TinyGo**, в котором сборщик мусора попроще и [запускается](https://tinygo.org/docs/reference/lang-support/#garbage-collection) когда недостаточно места в куче. Если между вызовом `proxy_on_memory_allocate` и моментом возврата владения в Go нет выделения памяти, то это условно безопасно.
А вот в C++ SDK `proxy_on_memory_allocate` не увидите. Идет поиск malloc, который экспортирует компилятор
```
$ em++ --no-entry -s EXPORTED_FUNCTIONS=['_malloc'] ...
```
На стороне хоста выполняется поиск `malloc`, если нет, то ищется `proxy_on_memory_allocate`
```
void WasmBase::getFunctions() {
#define _GET(_fn) wasm_vm_->getFunction(#_fn, &_fn##_);
#define _GET_ALIAS(_fn, _alias) wasm_vm_->getFunction(#_alias, &_fn##_);
_GET(_initialize);
if (_initialize_) {
_GET(main);
} else {
_GET(_start);
}
_GET(malloc);
if (!malloc_) {
_GET_ALIAS(malloc, proxy_on_memory_allocate);
}
if (!malloc_) {
fail(FailState::MissingFunction, "Wasm module is missing malloc function.");
}
#undef _GET_ALIAS
#undef _GET
// Try to point the capability to one of the module exports, if the capability has been allowed.
#define _GET_PROXY(_fn) \
if (capabilityAllowed("proxy_" #_fn)) { \
wasm_vm_->getFunction("proxy_" #_fn, &_fn##_); \
} else { \
_fn##_ = nullptr; \
}
#define _GET_PROXY_ABI(_fn, _abi) \
if (capabilityAllowed("proxy_" #_fn)) { \
wasm_vm_->getFunction("proxy_" #_fn, &_fn##_abi##_); \
} else { \
_fn##_abi##_ = nullptr; \
}
FOR_ALL_MODULE_FUNCTIONS(_GET_PROXY);
if (abiVersion() == AbiVersion::ProxyWasm_0_1_0) {
_GET_PROXY_ABI(on_request_headers, _abi_01);
_GET_PROXY_ABI(on_response_headers, _abi_01);
} else if (abiVersion() == AbiVersion::ProxyWasm_0_2_0 ||
abiVersion() == AbiVersion::ProxyWasm_0_2_1) {
_GET_PROXY_ABI(on_request_headers, _abi_02);
_GET_PROXY_ABI(on_response_headers, _abi_02);
_GET_PROXY(on_foreign_function);
}
#undef _GET_PROXY_ABI
#undef _GET_PROXY
}
```
### Точка входа \_start
Написав в Go
```
package main
import (
"math/rand"
"time"
"github.com/tetratelabs/proxy-wasm-go-sdk/proxywasm"
"github.com/tetratelabs/proxy-wasm-go-sdk/proxywasm/types"
)
const tickMilliseconds uint32 = 1000
func main() {
proxywasm.SetVMContext(&vmContext{})
}
type vmContext struct {
// Embed the default VM context here,
// so that we don't need to reimplement all the methods.
types.DefaultVMContext
}
```
AssemblyScript
```
export * from "@solo-io/proxy-runtime/proxy"; // this exports the required functions for the proxy to interact with us.
import { RootContext, Context, registerRootContext, FilterHeadersStatusValues, stream_context } from "@solo-io/proxy-runtime";
class AddHeaderRoot extends RootContext {
createContext(context_id: u32): Context {
return new AddHeader(context_id, this);
}
}
class AddHeader extends Context {
constructor(context_id: u32, root_context: AddHeaderRoot) {
super(context_id, root_context);
}
onResponseHeaders(a: u32, end_of_stream: bool): FilterHeadersStatusValues {
const root_context = this.root_context;
if (root_context.getConfiguration() == "") {
stream_context.headers.response.add("hello", "world!");
} else {
stream_context.headers.response.add("hello", root_context.getConfiguration());
}
return FilterHeadersStatusValues.Continue;
}
}
registerRootContext((context_id: u32) => { return new AddHeaderRoot(context_id); }, "add_header");
```
C++
```
#include
#include
#include
#include "proxy\_wasm\_intrinsics.h"
class ExampleContext : public Context {
public:
explicit ExampleContext(uint32\_t id, RootContext \*root) : Context(id, root) {}
FilterHeadersStatus onRequestHeaders(uint32\_t headers, bool end\_of\_stream) override;
};
static RegisterContextFactory register\_ExampleContext(CONTEXT\_FACTORY(ExampleContext));
FilterHeadersStatus ExampleContext::onRequestHeaders(uint32\_t, bool) {
LOG\_DEBUG(std::string("print from wasm, onRequestHeaders, context id: ") + std::to\_string(id()));
auto result = getRequestHeaderPairs();
auto pairs = result->pairs();
for (auto &p : pairs) {
LOG\_INFO(std::string("print from wasm, ") + std::string(p.first) + std::string(" -> ") + std::string(p.second));
}
return FilterHeadersStatus::Continue;
}
```
Нужна точка входа, которая инициализирует рантайм C++/Go/AssemblyScript и выполнит что-нибудь вида main. WASI для таких целей предлагает [\_start и \_initialize](https://nodejs.org/api/wasi.html). Хотя в спеке есть только \_start, но на хосте доступны оба варианта
```
class WasmBase : public std::enable_shared_from_this {
//s..
protected:
//...
WasmCallVoid<0> \_initialize\_; /\* WASI reactor (Emscripten v1.39.17+, Rust nightly) \*/
WasmCallVoid<0> \_start\_; /\* WASI command (Emscripten v1.39.0+, TinyGo) \*/
WasmCallWord<2> main\_;
WasmCallWord<1> malloc\_;
//...
};
```
### Строки и ассоциативный контейнеры
Один из недостатков это копирование памяти. Может потребоваться не только копирование, но и преобразование. В Go строки это просто [последовательность байт](https://go.dev/ref/spec#String_types), но обычно там UTF-8. В AssemblyScriptэто последовательность UCS-2 и требует преобразования.
```
export function log(level: LogLevelValues, logMessage: string): void {
// from the docs:
// Like JavaScript, AssemblyScript stores strings in UTF-16 encoding represented by the API as UCS-2,
let buffer = String.UTF8.encode(logMessage);
imports.proxy_log(level as imports.LogLevel, changetype(buffer), buffer.byteLength);
}
```
А передача привычного контейнера map потребует дополнительной упаковки/распаковки
```
func DeserializeMap(bs []byte) [][2]string {
numHeaders := binary.LittleEndian.Uint32(bs[0:4])
var sizeIndex = 4
var dataIndex = 4 + 4*2*int(numHeaders)
ret := make([][2]string, numHeaders)
for i := 0; i < int(numHeaders); i++ {
keySize := int(binary.LittleEndian.Uint32(bs[sizeIndex : sizeIndex+4]))
sizeIndex += 4
keyPtr := bs[dataIndex : dataIndex+keySize]
key := *(*string)(unsafe.Pointer(&keyPtr))
dataIndex += keySize + 1
valueSize := int(binary.LittleEndian.Uint32(bs[sizeIndex : sizeIndex+4]))
sizeIndex += 4
valuePtr := bs[dataIndex : dataIndex+valueSize]
value := *(*string)(unsafe.Pointer(&valuePtr))
dataIndex += valueSize + 1
ret[i] = [2]string{key, value}
}
return ret
}
func SerializeMap(ms [][2]string) []byte {
size := 4
for _, m := range ms {
// key/value's bytes + len * 2 (8 bytes) + nil * 2 (2 bytes)
size += len(m[0]) + len(m[1]) + 10
}
ret := make([]byte, size)
binary.LittleEndian.PutUint32(ret[0:4], uint32(len(ms)))
var base = 4
for _, m := range ms {
binary.LittleEndian.PutUint32(ret[base:base+4], uint32(len(m[0])))
base += 4
binary.LittleEndian.PutUint32(ret[base:base+4], uint32(len(m[1])))
base += 4
}
for _, m := range ms {
for i := 0; i < len(m[0]); i++ {
ret[base] = m[0][i]
base++
}
base++ // nil
for i := 0; i < len(m[1]); i++ {
ret[base] = m[1][i]
base++
}
base++ // nil
}
return ret
}
```
```
function serializeHeaders(headers: Headers): ArrayBuffer {
let result = new ArrayBuffer(pairsSize(headers));
let sizes = Uint32Array.wrap(result, 0, 1 + 2 * headers.length);
sizes[0] = headers.length;
// header sizes:
let index = 1;
// for in loop doesn't seem to be supported..
for (let i = 0; i < headers.length; i++) {
let header = headers[i];
sizes[index] = header.key.byteLength;
index++;
sizes[index] = header.value.byteLength;
index++;
}
let data = Uint8Array.wrap(result, sizes.byteLength);
let currentOffset = 0;
// for in loop doesn't seem to be supported..
for (let i = 0; i < headers.length; i++) {
let header = headers[i];
// i'm sure there's a better way to copy, i just don't know what it is :/
let wrappedKey = Uint8Array.wrap(header.key);
let keyData = data.subarray(currentOffset, currentOffset + wrappedKey.byteLength);
for (let i = 0; i < wrappedKey.byteLength; i++) {
keyData[i] = wrappedKey[i];
}
currentOffset += wrappedKey.byteLength + 1; // + 1 for terminating nil
let wrappedValue = Uint8Array.wrap(header.value);
let valueData = data.subarray(currentOffset, currentOffset + wrappedValue.byteLength);
for (let i = 0; i < wrappedValue.byteLength; i++) {
valueData[i] = wrappedValue[i];
}
currentOffset += wrappedValue.byteLength + 1; // + 1 for terminating nil
}
return result;
}
function deserializeHeaders(headers: ArrayBuffer): Headers {
if (headers.byteLength == 0) {
return [];
}
let numheaders = Uint32Array.wrap(headers, 0, 1)[0];
let sizes = Uint32Array.wrap(headers, sizeof(), 2 \* numheaders);
let data = headers.slice(sizeof() \* (1 + 2 \* numheaders));
let result: Headers = [];
let sizeIndex = 0;
let dataIndex = 0;
// for in loop doesn't seem to be supported..
for (let i: u32 = 0; i < numheaders; i++) {
let keySize = sizes[sizeIndex];
sizeIndex++;
let header\_key\_data = data.slice(dataIndex, dataIndex + keySize);
dataIndex += keySize + 1; // +1 for nil termination.
let valueSize = sizes[sizeIndex];
sizeIndex++;
let header\_value\_data = data.slice(dataIndex, dataIndex + valueSize);
dataIndex += valueSize + 1; // +1 for nil termination.
let pair = new HeaderPair(header\_key\_data, header\_value\_data);
result.push(pair);
}
return result;
}
```
На этом все. Полезные ссылки
* [WebAssembly for Proxies (ABI specification)](https://github.com/proxy-wasm/spec)
* [Extending Envoy with WebAssembly - John Plevyak & Dhi Aurrahman, Tetrate](https://youtu.be/XdWmm_mtVXI)
* [AssemblyScript SDK](https://github.com/solo-io/proxy-runtime), [C++ SDK](https://github.com/proxy-wasm/proxy-wasm-cpp-sdk), [Go (TinyGo) SDK](https://github.com/tetratelabs/proxy-wasm-go-sdk)
* [C++ Host](https://github.com/proxy-wasm/proxy-wasm-cpp-host), [Go Host](https://github.com/mosn/proxy-wasm-go-host) | https://habr.com/ru/post/671048/ | null | ru | null |
# 25 советов по улучшению вашего кода jQuery
Это перевод статьи, [написанной Jon Hobbs-Smith](http://www.tvidesign.co.uk/blog/improve-your-jquery-25-excellent-tips.aspx). Я счел ее довольно интересной и решил выложить [в своем блоге](http://jqueryzine.ru), а также поделиться им с хабрапользователями, также как и я заинтересованными в библиотеке jQuery. Перед тем как начать хочу отметить, что написана она (как и переведена) далеко не экспертом в jQuery, поэтому если вы найдете в ней ошибку, пожалуйста, сообщите. Итак, начнем.
##### 1. Загружайте библиотеку с Google Code
На Google Code хранится несколько популярных Javascript библиотек, в том числе и jQuery, при этом есть несколько способов их подключения к вашему сайту. Надо сказать, что подгружаются они довольно быстро, к тому же если пользователь до этого посещал сайт, где библиотека подгружается таким же образом как и у вас с Google, то файл вообще загрузиться с кеша.
Подгрузить библиотеку можно через специально предусмотренный для этого API:
Либо напрямую:
Подробнее о способах подключения [вы можете прочитать здесь](http://code.google.com/apis/ajaxlibs/documentation/index.html).
##### 2. Используйте шпаргалки
И не только для jQuery. В сети сейчас можно найти довольно большое количество удобных шпаргалок по многим языкам и библиотекам формата А4, так что ее можно к примеру распечатать и повесить на стенку рядом с компьютером.
Вот ссылки на пару таких:
<http://www.gscottolson.com/weblog/2008/01/11/jquery-cheat-sheet/>
<http://colorcharge.com/jquery/>
Кроме того, мы обсуждали шпаргалки [в одном из ранних постов](http://jqueryzine.ru/2008/12/шпаргалка-по-jquery/).
##### 3. Совмещайте и сжимайте ваши скрипты
Наверное, это один из главных советов по Javascript. Особенно это относиться к проектам, использующим большое количество плагинов. Большинство браузеров не может загружать файлы скриптов одновременно, а последовательная загрузка значительно увеличивает общее время загрузки всей страницы. Поэтому рекомендуется собирать все файлы в один большой скрипт.
Не забывайте сжимать ваш код. Большинство плагинов уже минимизированы, в противном случае рекомендуется сделать это, тем более это займет у вас всего несколько секунд. Например, можно воспользоваться [Packer от Dean Edwards](http://dean.edwards.name/packer/).
##### 4. Используйте Firebug
Если вы его еще не установили, вы просто должны это сделать. Помимо таких замечательных вещей, как просмотр http трафика и обнаружения проблем в CSS эта надстройка ведет отличный лог команд, который может помочь вам в обнаружении ошибок в ваших скриптах.
[Здесь вы найдете подробное описание всех его возможностей.](http://getfirebug.com/console.html)
Очень полезна «console.info», с помощью которой вы можете выводить сообщения и значения переменной на экран без использования алертов, а также «console.time», которая позволяет вам засекать время выполнения определенных участков кода. Все они довольно просты в использовании.
`console.time('create list');
for (i = 0; i < 1000; i++) {
var myList = $('.myList');
myList.append('This is list item ' + i);
}
console.timeEnd('create list');`
В данном случае я умышленно написал заведомо неэффективный код. Далее мы увидим, как можно использовать таймер, чтобы показать эффективность внесения улучшений.
##### 5. Кэшируйте ваши селекторы.
Селекторы в jQuery потрясающие. С их помощью очень просто выбирать элементы на странице, но если вы используете их очень интенсивно в своем скрипте, это может существенно замедлить работу страницы.
Если вы все время обращаетесь к одному и тому же селектору, то можете просто внести его в память и затем использовать сколько угодно, не боясь навредить быстродействию. Давайте посмотрим следующий код:
`for (i = 0; i < 1000; i++) {
var myList = $('.myList');
myList.append('This is list item ' + i);
}`
Выполнение этого простого кода заняло 1066 миллисекунд на моем компьютере в FF3 (представьте, как долго он бы выполнялся в IE6!). Теперь выполним аналогичный код, но используем селектор только один раз:
`var myList = $('.myList');
for (i = 0; i < 1000; i++) {
myList.append('This is list item ' + i);
}`
И что вы думаете? Всего 224 миллисекунды, более чем в 4 раза быстрее, а ведь мы передвинули всего одну линию кода :-)
##### 6. Сведите манипуляцию с DOM к минимуму.
Мы можем еще ускорит код из предыдущего совета, сведя к минимуму работу с DOM. Операции для работы с DOM, такие как .append(), .prepend(), .after() и .wrap() очень дорогое удовольствие и частое их использование может также увеличить время выполнения вашего кода.
Все что потребуется в нашем случае — это использовать конкатенацию строк для построения списка, а затем использовать единожды метод .html() и наш код станет заметно быстрее. Давайте посмотрим пример.
`var myList = $('#myList');
for (i=0; i<1000; i++){
myList.append('This is list item ' + i);
}`
На моем компьютере он выпольнялся 216 миллисекунд, всего 1/5 секунды, но если мы сначала построим список в виде строки, а затем используем HTML метод для вставки следующим образом:
`var myList = $('.myList');
var myListItems = '';
for (i = 0; i < 1000; i++) {
myListItems += 'This is list item ' + i + '';
}
myList.html(myListItems);`
То такой скрипт будет выполняться уже 185 миллисекунд, на 31 миллисекунду быстрее. Какая-никакая, но все же экономия времени, а в случае с более сложным кодом эффективность будет более ощутима.
##### 7. Оборачивайте все в один элемент прежде чем работать с DOM
Я не могу объяснить, почему это так работает, но наверняка эксперты в jQuery дадут на это ответ.
Дело в следующем. В нашей последнем примере мы вставили 1000 элементов списка в один элемент неупорядоченного списка, используя метод .html(). Если бы мы сначала обернули их в тег UL перед вставкой, а затем уже сформированный список вставляли в другой тег, например DIV, то это было бы намного эффективнее и быстрее, чем вставлять 1000 элементов. Давайте посмотрим пример, чтобы все стало ясно…
`var myList = $('.myList');
var myListItems = '';
for (i = 0; i < 1000; i++) {
myListItems += '* This is list item ' + i + '
';
}
myListItems += '
';
myList.html(myListItems);`
Такой код выполняется всего 19 миллисекунд, почти в 50 раз быстрее нашего самого первого примера.
##### 8. Используйте идентификаторы вместо классов
В jQuery селекторы по классу такие же удобные, как и селекторы по идентификатору, что сделало их не менее популярными. Но все же лучше выбирать элементы по ID, так как jQuery использует для этого родной для каждого браузера метод getElementByID, а не какие то свои методы. Давайте посмотрим пример.
Я буду использовать предыдущий пример, но немного доработаю его так, что у каждого элемента списка будет свой уникальный класс. Затем мы пробежимся по всему списку и обратимся к каждому элементу по классу.
`// Создаем наш список
var myList = $('.myList');
var myListItems = '';
for (i = 0; i < 1000; i++) {
myListItems += '* This is a list item
';
}
myListItems += '
';
myList.html(myListItems);
// Выбираем по разу каждый элемент списка
for (i = 0; i < 1000; i++) {
var selectedItem = $('.listItem' + i);
}`
Как я и ожидал, это задание заметно подгрузило мой браузер. По итогу время выполнения кода составило 5066 миллисекунд (более 5 секунд). Затем я изменил код и задал каждому элементу списка свой идентификатор взамен класса, а затем обратился к каждому элементу по его ID.
`// Создаем наш список
var myList = $('.myList');
var myListItems = '';
for (i = 0; i < 1000; i++) {
myListItems += '* This is a list item
';
}
myListItems += '
';
myList.html(myListItems);
// Выбираем по разу каждый элемент списка
for (i = 0; i < 1000; i++) {
var selectedItem = $('#listItem' + i);
}`
Этот код выполнялся всего 61 миллисекунду. Почти в 100 раз быстрее.
##### 9. Задавайте контекст в селекторах
По умолчанию, когда вы используете любой селектор, например $('.myDiv'), будет проанализирована вся структура DOM в его поисках, что на больших страницах может быть довольно накладно.
В таких случаях не надо забывать, что при построении селектора может быть задан второй параметр:
`jQuery(выражение, контекст)`
Устанавливая параметр контекст, вы указываете в каком именно элементе искать необходимый элемент, тем самым jQuery не придется просматривать всю структуру DOM.
Для демонстрации этого возьмем первый блок кода из предыдущего примера. Он создает несортированный список с 1000 элементов, у каждого из которых свой класс. Далее пробегаясь по всему списку он обращается к каждому классу. Эта операция заняла порядка 5 секунд чтобы перебрать таким образом каждый элемент.
`var selectedItem = $('#listItem' + i);`
Затем был добавлен параметр контекста, который выполнял селектор только внутри ненумерованного списка:
`var selectedItem = $('#listItem' + i, $('.myList'));`
Выполнение этого кода заняло 3818 миллисекунд, что на 25% быстрее. А ведь мы опять же внесли всего небольшое изменение в код.
##### 10. Используйте цепочки
Одна из наиболее примечательных особенностей в jQuery это возможность использовать цепочки методов. Так, в следующем примере мы поменяем класс у элемента.
`$('myDiv').removeClass('off').addClass('on');`
Не стоит забывать, что код прекрасно работает с переносами строки (ведь jQuery = JavaScript), а это позволяет сделать ваш код более опрятным и читабельным, например, как в следующем примере.
`$('#mypanel')
.find('TABLE .firstCol')
.removeClass('.firstCol')
.css('background' : 'red')
.append('Эта ячейка теперь красная!');`
Стоить отметь, что привычка использовать цепочку методов помогает вам сократить код в использовании селекторов.
Но это еще не все. А что если вы хотите применить ряд функций к элементу, но одна из них меняет внешний вид элемента, например, как в следующем коде…
`$('#myTable').find('.firstColumn').css('background','red');`
Мы выбрали таблицу, нашли в ней ячейки класса firstColumn и покрасили их в красный цвет.
А давайте теперь еще закрасим все ячейки класса lastColumn в синий? Потому как мы использовали метод find(), мы отфильтровали из набора все элементы, которые не имеют класса firstColumn, таким образом, нам нужно использовать этот селектор снова, чтобы выбрать нужные элементы таблицы и не сможем продолжить цепочку методов. К счастью в jQuery имеется метод end(), который позволяет вернуться к предыдущему набору элементов, как в следующем примере.
`$('#myTable')
.find('.firstColumn')
.css('background','red')
.end()
.find('.lastColumn')
.css('background','blue');`
Кроме того, написать свою функцию, которую можно использовать в цепочке это намного проще, чем вы думаете. Для этого достаточно в по итогу выполнения всех действий с элементом вернуть его.
`$.fn.makeRed = function() {
return $(this).css('background', 'red');
}
$('#myTable').find('.firstColumn').makeRed().append('привет');`
Не правда ли, все достаточно просто?
##### 11. О методе animate()
Когда я только начал использовать jQuery мне очень нравились уже определенные методы анимации, такие как slideDown() и fadeIn(), с помощью которых просто и быстро можно было сделать потрясающие эффекты. В основе каждой из этих функций лежит метод animate(), который очень функциональный и так же очень легко используется.
`slideDown: function(speed,callback){
return this.animate({height: "show"}, speed, callback);
},
fadeIn: function(speed, callback){
return this.animate({opacity: "show"}, speed, callback);
}`
Метод animate() просто изменяет различные свойства CSS от одного значения к другому. Таким образом, вы можете изменять высоту, ширину, прозрачность, цвет фона, различные отступы и все остальное что только пожелаете.
Например, вот так можно легко анимировать ваше меню, изменяя высоту элемента до 100 пикселей при наведении мышки.
`$('#myList li').mouseover(function() {
$(this).animate({"height": 100}, "slow");
});`
В отличие от других функций jQuery, анимация автоматически становится в очередь на выполнение, т.е. если вы захотите запустить одну анимацию следом за другой, достаточно всего лишь дважды вызвать анимацию, без каких-либо колбэков. В примере высота начнет изменяться сразу как закончится изменение ширины.
`$('#myBox').mouseover(function() {
$(this).animate({ "width": 200 }, "slow");
$(this).animate({"height": 200}, "slow");
});`
Если же вы хотите, чтобы анимация выполнялась параллельно, просто поместите оба стиля в объект параметров вызова метода, например, как в следующем примере.
`$('#myBox').mouseover(function() {
$(this).animate({ "width": 200, "height": 200 }, "slow");
});`
Вы всегда можете анимировать свойства с числовыми значениями. Кроме того, вы можете скачать плагин, который поможет вам анимировать свойства, значения которых не являются числами, например таких как [цвета шрифта или фона](http://plugins.jquery.com/project/color).
##### 12. Делегирование событий
С помощью jQuery очень просто привязывать события к элементам DOM, это замечательно, но привязка большого количества событий нерационально. Делегирование событий позволяет с помощью привязки меньшего количества событий достичь желаемого результата во многих ситуациях. Посмотрим пример.
`$('#myTable TD').click(function(){
$(this).css('background', 'red');
});`
Простая функция по клику окрашивает ячейки таблицы в красный цвет. А теперь представьте, если у нас таблица из 10 колонок и 50 строк, получается мы привязываем событие к 500 элементам. А что если бы мы могли привязать событие к таблице, а затем по клику на таблице определяли, какую именно ячейку окрасить в красный цвет?
Это как раз и называется делегированием событий. Давайте посмотрим, как оно работает.
`$('#myTable').click(function(e) {
var clicked = $(e.target);
clicked.css('background', 'red');
});`
'e' содержит информацию о событии, включая объект, по которому был произведен щелчок мышкой. Все что от нас требуется, это определить, по какой именно ячейке кликнул пользователь.
Кроме этого, делегирование элементов имеет еще один плюс. Обычно, когда вы привязываете событие к каким-либо элементам, то оно привязывается именно к этим элементам и никаким более. Если вы в процессе работы страницы добавили новые элементы в DOM, которые также соответствуют селектору, то к ним обработчик применятся уже не будет. В случае использования делегирования вы можете добавлять сколько угодно элементов в DOM после привязки события и с ними не будет никаких проблем.
##### 13. Используйте классы для хранения состояний
Это самый простой путь для хранения информации о блоке html кода. jQuery хороша для манипулирования элементами с помощью классов, таким образом, если вам необходимо хранить информацию о состоянии какого-либо элемента, почему бы не воспользоваться специальным классом для этой цели?
В следующем примере мы создадим выпадающее меню. По клику на слое класса button подменю (класс panel) будет выпадать через slideDown() если оно не показано или прятаться через slideUp() если оно наоборот открыто. Итак, начнем с HTML.
`Нажми меня
* Элемент меню 1
* Элемент меню 2
* Элемент меню 3`
Очень просто! Теперь добавим специальный класс, который будет хранить состояние подменю. В итоге нам будет необходимо лишь написать обработчик клика по диву класса button, который будет прятать либо показывать наше подменю с помощью slideUp() и slideDown() соответственно.
`$('.button').click(function() {
var menuItem = $(this).parent();
var panel = menuItem.find('.panel');
if (menuItem.hasClass("expanded")) {
menuItem.removeClass('expanded').addClass('collapsed');
panel.slideUp();
}
else if (menuItem.hasClass("collapsed")) {
menuItem.removeClass('collapsed').addClass('expanded');
panel.slideDown();
}
});`
Это очень простой пример, но вы можете добавлять специальные классы для хранения любой необходимой информации о каком-либо фрагменте HTML кода.
Как правило, такой подход используется в простых случаях. В более сложных лучше обратиться к содержанию следующего совета.
##### 14. Используйте также встроенный метод data() для хранения данных
По каким-то причинам функция, о которой пойдет речь ниже не очень хорошо документирована, но тем не менее в jQuery есть встроенный метод data(), который может быть использован для хранения информации вида ключ-значение для любого элемента DOM. Посмотрим пример его использования.
`$('#myDiv').data('currentState', 'off');`
Мы можем доработать пример из предыдущего совета. Будем использовать тот же HTML код, но для хранения информации воспользуемся методом data().
`$('.button').click(function() {
var menuItem = $(this).parent();
var panel = menuItem.find('.panel');
if (menuItem.data('collapsed')) {
menuItem.data('collapsed', false);
panel.slideDown();
}
else {
menuItem.data('collapsed', true);
panel.slideUp();
}
});`
Думаю, вы согласитесь, что такой будет лучше. Для более подробной информации о методах data() и removeData() вы можете посетить [раздел документации jQuery](http://docs.jquery.com/Internals).
##### 15. Пишите свои селекторы
В jQuery имеется большое количество встроенных селекторов. Но что вы делаете, когда вам нужно выбрать элементы по какому-то признаку, для которого нет решений в jQuery?
Конечно, можно изначально назначить им классы и затем обращаться к этим элементам через него. Но это не так сложно создать свой собственный селектор.
Давайте посмотрим пример.
`$.extend($.expr[':'], {
over100pixels: function(a) {
return $(a).height() > 100;
}
});
$('.box:over100pixels').click(function() {
alert('The element you clicked is over 100 pixels high');
});`
Первый блок кода создает селектор, который выбирает все элементы, которые по высоте больше 100 пикселей. Второй блок используется для привязки обработчика клика по таким элементам. Можно развивать эту тему дальше, но я думаю, вы уже заметили насколько это мощный инструмент и с легкостью обнаружите большое количество других самописных селекторов на гугле.
##### 16. Упрощайте HTML и модифицируйте его при загрузке
Заголовок достаточно многозначительный, но этот совет может улучшить внешний вид вашего кода, уменьшить вес и время загрузки, а также в какой то мере помочь вам с SEO. Давайте посмотрим следующий HTML код для примера.
`Это поле номер 1

Это сообщение об ошибке
Это поле номер 2

Это сообщение об ошибке`
Это пример разметки формы, немного модифицированный для наглядности. Я уверен, вы согласитесь, что код выглядит не очень красиво, и при большом размере формы вы получите не менее неприятную страницу. Согласитесь, следующий код выглядит намного лучше.
`Это поле номер 1
Это поле номер 2
Это поле номер 3
Это поле номер 4
Это поле номер 5`
Все что теперь от вас требуется это с помощью jQuery вернуть повторяющиеся фрагменты кода на место.
`$(document).ready(function() {
$('.field').before('');
$('.field').after('

Это сообщение об ошибке ');
});`
Не всегда советуется поступать таким образом, потому как при загрузке страницы может быть заметно подгрузка фрагментов кода, но в некоторых случаях, когда у вас много повторяющегося HTML кода, этот совет поможет уменьшить вес вашей страницы, а также преимущества в SEO при уменьшении повторяющихся фрагментов очевидны.
##### 17. Подгрузка контента ради скорости и SEO
Другой способ ускорить загрузку вашей страницы и сделать HTML более читабельным это подгружать целые фрагменты кода используя AJAX-запросы после завершения загрузки страницы. Пользователи в итоге получат то, что нужно, а поисковые роботы увидят лишь то, что вы хотите им показать.
Сделать это можно как в следующем примере…
`$('#forms').load('content/headerForms.html', function() {
// Здесь подгружаем весь необходимый нам код
});`
Думаю, здесь все и так понятно, особо останавливаться не будем.
Конечно, опять же не стоит использовать этот совет повсеместно. Следует понимать, что это создает дополнительную нагрузку на сервер, а также часть вашей страницы может быть недоступна какое-то время для пользователя. Но при правильном использовании это может служить хорошей техникой оптимизации.
##### 18. Используйте функции jQuery
jQuery служит не только для создания крутых эффектов анимации. Разработчики встроили в библиотеку несколько действительно полезных методов, которые могут восполнить некоторые недостатки функционала JavaScript в целом.
<http://docs.jquery.com/Utilities>
В частности, некоторые браузеры неполноценно поддерживают функции для работы с массивами (IE7 например даже не поддерживает метод indexOf()). jQuery имеет методы для итерации, фильтрации, клонирования, слияния и удаления дубликатов из массивов.
Другая распространенная проблема это трудность с получением выбранного элемента в выпадающем списке. В обычном JavaScript вы не сможете получить элемент `SELECT` через getElementByID, получить его дочерние элементы как массив и пройтись по ним, определив, какой из них выбран а какой нет. jQuery с легкостью решает эту проблему…
`$('#selectList').val();`
Поэтому лучше потерять немного времени и порыться в документации jQuery на основном сайте, почитав о других малоизвестных, но очень полезных функциях.
##### 19. Используйте noconflict при работе совместно с другими библиотеками
Большинство javascript библиотек используют символ `$` в своих целях, что может вызвать ошибки при использовании более чем одного фреймворка на одной странице. К счастью эта проблема просто решается с помощью метода .noconflict(), как в следующем примере.
`var $j = jQuery.noConflict();
$j('#myDiv').hide();`
##### 20. Как узнать, что рисунок загрузился
Это еще одна из тех проблем, которая недостаточно документирована, как того стоит, но тем не менее очень часто всплывает при построении фотогалерей, каруселей и т.д., и на самом деле решается довольно просто.
Все что потребуется это воспользоваться методом .load() для элемента IMG и колбэк функцией по завершению загрузки в нем. В следующем примере изменяется атрибут src в теге рисунка для загрузки нового изображения и привязывается простая функция загрузки.
`$('#myImage').attr('src', 'image.jpg').load(function() {
alert('Изображение загружено');
});`
Как вы поняли, алерт появится по окончанию загрузки рисунка.
##### 21. Всегда используйте последнюю версию
jQuery постоянно улучшается, а ее создатель Джон Резиг (John Resig) все время ищет пути для повышения производительности библиотеки. В связи с этим рекомендуется постоянно следить за обновлениями фреймворка (стабильными версиями) и обновлять вашу рабочую версию.
##### 22. Как проверить, что элемент существует
Нет надобности проверять, присутствует ли элемент на странице, прежде чем выполнять с ним какие-либо действия, потому как jQuery просто проигнорирует действия с несуществующим элементом DOM. Но в том случае, если вам действительно необходимо проверить, было ли что-то выбрано и в каком количестве, используйте свойство length.
`if ($('#myDiv).length) {
// Ваш код
}`
Просто и очевидно.
##### 23. Добавляйте класс JS к тегу HTML
Этот трюк описывается [в книге Карла Сведберга](http://www.amazon.co.uk/Learning-JQuery-Interaction-Development-Javascript/dp/1847192505/ref=sr_1_1?ie=UTF8&s=books&qid=1229284831&sr=8-1) (Karl Swedberg).
Первым делом при загрузке jQuery добавьте класс JS к вашему тегу HTML.
`$('HTML').addClass('JS');`
Поскольку это произойдет только если поддержка JavaScript включена на стороне пользователя, вы можете по этой же причине добавить специальный CSS стиль…
`.JS #myDiv{display:none;}`
Таким образом вы можете скрыть содержимое страницы, если поддержка JavaScript включена и затем используя jQuery показать его, если это необходимо (это относится например к выпадающим панелям, которые отображаются по клику на них). Пользователь без JavaScript (а также поисковые роботы) просто увидит все содержимое.
##### 24. Возвращайте «false» чтобы избежать действия по умолчанию
Это вполне очевидно, но для кого-то может быть и незнакомо. Если вы имеете привычку делать вот так…
`Нажми меня!`
…а затем привязываете какой-нибудь обработчик событий, как например этот…
`$('popup').click(function(){
// какой-нибудь код
});`
…то все будет замечательно до той поры, пока вы не будете работать с этим на длинной странице, на которой вы увидите, что при клике на ссылке с # вы попадете на верх вашей странички.
Все что требуется в этом случае, чтобы избежать действия по умолчанию это добавить «return false;» в ваш обработчик события, например вот так…
`$('popup').click(function(){
// какой-нибудь код
return false;
});`
##### 25. Укороченная запись события ready
Маленький совет по укороченной записи $(document).ready, который поможет сэкономить пару символов, но все же.
Вместо этого…
`$(document).ready(function (){
// ваш код
});`
Можно написать…
`$(function (){
// ваш код
});`
Спасибо за внимание. Этот и другие посты по jQuery вы также можете найти [в моем блоге, посвященном данной библиотеке](http://jqueryzine.ru). К тому же, всегда буду рад видеть вас среди своих [фолловеров на Твиттере](http://twitter.com/flyingboar). | https://habr.com/ru/post/63797/ | null | ru | null |
# Проверка портала региональных госуслуг под нагрузкой через puppeteer
Привет, Хабр! Вы наверное тоже с любопытством наблюдаете за «эпопеей Американского Дикого Запада по распределению земельных участков — доскачи первым и воткни флаг чтобы застолбить» или возможно даже участвуете в ней. Точнее в ее современном варианте — успей первым подать заявление на госуслугах для получения денежных средств на детей или получи пропуск на выход из дома. Смотря на все это, хочется поделиться опытом [нашей команды](https://iondv.ru) по тестированию и участию в подготовке регионального портала услуг к предоставлению услуги «Запись в первый класс». Она тоже очень похожа на хабраэффект и, думаю, была близка к тому, что пару дней назад проиcходило с федеральным порталом gosuslugi.ru, но на региональном масштабе.
Мы прошли этот челлендж в г. Хабаровске в январе этого года и недавно участвовали в подготовке подобной услуги по выдаче охотничьих разрешений в другом регионе. Ниже — немного опыта, который даст вам возможность посмотреть на вопрос подготовки работы региональных порталов госуслуг к пиковым периодам с другой стороны.
А для начала — фото черного автобуса, трое суток круглосуточно дежурившего у школы, в котором автор этих строк подтверждал свою очередь среди родителей три года назад. У нас хотя бы родители соорганизовались. Дежурить зимой в Хабаровске при -30 градусов — то ещё удовольствие.

В процессе подготовки к пиковому проведению записи в первый класс работали несколько команд, т.к. в неё вовлечены, так или иначе: оператор ЦОД, эксплуатант и разработчик информационной системы регионального портала, эксплуатант и разработчик интегрированной информационной системы образования, техническая поддержка пользователей регионального портала. Мы в [iondv](https://iondv.ru) выполняем последнюю задачу, независимо отслеживая работоспособность портала и поддерживая пользователей.
Наша роль в подготовке – организация тестирования и рекомендаций по конфигурациям кеширования в nginx, ну и мы готовили инструкцию для пользователей с рекомендованным «поведением».
**Для тех кто не знает о проблеме записи в 1-й класс**
Во многих больших городах существует несколько муниципальных или региональных школ, в которые сложно попасть. Причины разные. Некоторые школы стабильно выпускают детей с высокими результатами по ЕГЭ, другие используют особые программы образования, третьи дают какие-то высоко ценимые родителями навыки (например английский язык или упор на математику, а иногда — особо известный хороший учитель начальных классов), четвертые находятся в районах, где кол-во домов приписанных к школе велико, школа сама небольшая, а другая ближайшая находится за большой магистралью или в получасе ходьбы ребёнком. При том, чтобы ребёнок был зачислен в эту школу, он должен быть зарегистрирован в домах, которые отнесены к школе – это не останавливает родителей, они готовых покупать возможность прописки или даже квартиры. Поэтому ажиотаж подогревается ещё и уже произведенными затратами времени и денег.
Во многих регионах запись в 1-й класс организуют в электронной форме параллельно с записью в очной, но смещённой по времени. Например в Хабаровске в этом году электронная запись открылась в 0:00 минут, а прием в в школах открылся в 10:00 26 января. Очевидно, что подаваться очно – это уже изначально оказаться в конце очереди. В прошлом году запись стартовала одновременно в 10:00 утра, но это не решало проблему очередей — родители всё равно дежурили, опасаясь что портал ляжет или что-то сломается.
Обычно запись в традиционной форме осуществлялась в виде круглосуточных дежурств и ведением очередей. По [ссылке](https://www.dvnovosti.ru/khab/2017/01/27/61530/) можно посмотреть опыт г. Хабаровска в 2017 г. с фотографиями и отзывами родителей. Иногда такая ситуация даже провоцировала драки родителей в очередях, бывало родители организовывали ЧОП, чтобы отсечь параллельные очереди. А некоторые директора вызывали ОМОН для наведения порядка перед школой.
#### Услуга на востребованный ресурс как техническая задача
Проблема в услугах, подобных «записи в 1-й класс» в интегральном показателе нагрузки (или вероятности запросов) стремящемся к «дельта функции» (δ-функция, функция Дирака) – хорошо видна на графиках в виде пики. В этот момент происходит кратный рост обращений в краткий период времени.
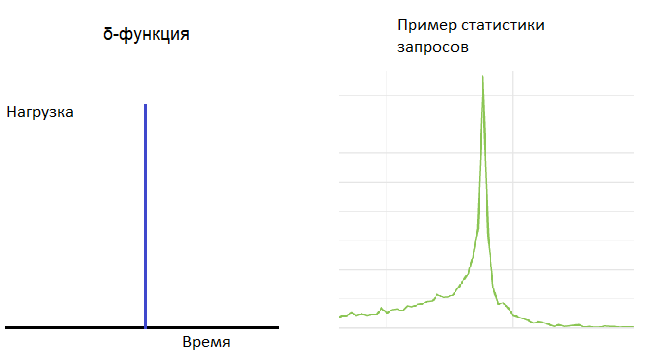
Наш опыт говорит, что основная задача подготовки вовсе не в том, чтобы увеличить ресурсы. Задача — максимально уменьшить потенциальное кол-во запросов в секунду, растянуть их на какой-то период и подготовить систему к оставшейся нагрузке. При этом надо найти и ускорить узкие места — это даст самый большой эффект в соответствии с принципами теории ограниченных систем (принципы Голдратта). И иначе именно самое узкое место откажет. Вся система должна работать от него: принцип «барабан-буфер-веревка».
Физически невозможно в 10-ти минутных песочных часах просыпать весь объем за 1 минуту – очевидно, что они разрушатся. Аналогично и для предоставления услуги. Никого не удивляет — когда перед МФЦ очередь и скандалы на получение услуги, но всех удивляет — почему портал лег.
Есть разные модели поведения обработки нагрузки из [теории массового обслуживания](https://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D0%BE%D1%80%D0%B8%D1%8F_%D0%BC%D0%B0%D1%81%D1%81%D0%BE%D0%B2%D0%BE%D0%B3%D0%BE_%D0%BE%D0%B1%D1%81%D0%BB%D1%83%D0%B6%D0%B8%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F):
* можно ставить пользователей в ожидание, т.е. наращивать очередь;
* можно просто отказывать в обслуживании тем, кто пришёл позже, например, пока не будут обработаны предыдущие;
* можно пытаться бесконечно наращивать производительность.
Целесообразность где-то посередине. Ведь для услуги с ограниченным ресурсом, предоставляемой регионом или государством, важна не только скорость, но и, в первую очередь, сохранение социальной справедливости – т.е. равные условия у всех. В тоже время – если пользователь не получил то, что ему нужно, он инициирует новый запрос. В этом случае запросы растут лавиной, формируя [модель атаки «эффект собачьей стаи»](https://en.wikipedia.org/wiki/Cache_stampede) (dog-pile effect, cache stampede, hit miss storm) – пользователь запрос уже отменил и инициировал новый, а предыдущий ещё в очереди стоит на обработку.
Этот процесс усиливает то, что в подаче участвуют целыми семьями — папа и мама заполняют заявления одновременно, и часто подают заявления несколько раз для надежности. А кроме того, часто ещё и в нескольких вкладках и нескольких браузерах. Поэтому ожидаемую пиковую нагрузку обычно имеет смысл умножать в 2-3 раза, от количества тех, кто фактически подает заявления в подобных услугах.
**Отступление про справедливость**
Иногда, осмысляя очередной «опыт», я вспоминаю участие в марафонах и разыгрывание ограниченного количества мест в лотерею. Что будет справедливей? Сейчас «справедливость» больше работает на тех, кто разбирается в ИТ. Мы имеем преимущество. Банально если есть время — можно просто написать скрипт для автозаполнения таких полей, да навык копипастле более отработан. Имея это преимущество мы считаем такую ситуацию «более справедливой». Но это не так для других категорий заявителей. И это цифровое неравенство не убрать проведением интеренет в деревни.
#### Организация оказания услуги
Мы сделали расчет ожидаемого количества заявителей на основе комбинации данных об общем количестве поданных заявлений в прошлому году и поминутным данным по другим регионам. Обычно пик заявлений приходится на 5-10 минуты, в том числе потому что первые три-пять минут порталы почти не отвечают, а позже пользователи заполняют форму от 1 до 5 минут (не удивляйтесь многие даже в таких «нервных» условиях заполняют с телефона).
Примерная модель расчета для условных 1000 заявлений в час такая:
* пик с 5 по 10 минуту с момента начала и будет подано 80% заявлений по правилу Паретто
* условно планируем 160 заявлений в минуту или 3 заявления в секунду.
По факту первая подача произошла через одну минуту и 45 секунд, а пик заявлений шёл с 4 минуты.
Для уменьшения нагрузки на ЕСИА и на систему от генерирования сессий авторизации в инструкции предложили пользователям авторизоваться заранее и удлинили время жизни сессии. По факту 50% были авторизованы за 1 час, а ~90% за полчаса. Мы сталкивались ранее с тем, что пользователи начинали заходить на портал за 10 минут до начала услуги — и авторизация начинала работать нестабильно. Сложно сказать почему. Возможно причина в том, что когда в Москве проводятся технические работы ночью — у нас в Хабаровске как раза начало рабочего дня.
**Отступление про инструкцию и организационные мероприятия**
На главной странице были размещены баннеры с прямой ссылкой на форму и [инструкцию](https://uslugi27.ru/files/upload/1st_class.pdf).
В самой инструкции были прописаны все прямые ссылки на форму, чтобы избежать использования «ресурсоемких ресурсов» поиска и каталогов с описаниями. Т.е. организационно маршрутизировали пользователей прямо на форму. Заодно разъясняли все спорные и сложные вопросы, чтобы уменьшить кол-во обращений в тех.поддержку.
Здесь кстати напрашивается реализация функциональности, как это все можно реализовать в самой форме, чтобы было удобно и можно было прояснить вопросы сразу, не обращаясь к поддержке. Многие пользователи далеки от ИТ и ожидаемые ИТ-разработчиками методы взаимодействия с формой часто просто не понимают. На это накладываются и нормативные требования, названия атрибутов и значения справочников очень формализованы, а изменить их просто так невозможно.
Убрать «дельта функцию» при перезагрузке формы в 00:00 часов невозможно. Весь смысл этой процедуры в том, что услуга появляется в заданное время. Но можно постараться уменьшить кол-во запросов браузера на всех ожидаемых маршрутах пользователей и тем самым оставить нагрузку на систему только от необходимых — форма, динамические справочники и отправка заявления.
Сами настройки nginx достаточно стандартны. Здесь важнее подобрать ограничения, которые может выдержать система. Их и подобрать — т.е. начинать ставить в очередь запросы, когда сервер ожидаемо подойдет к границе своих возможностей.
Ну и самое важное — мы принудительно проставили кеширование (proxy\_cache) и увеличили время жизни данных «expires» в nginx для всех путей статики и где возможно динамических страниц, в которых нет сессий. Это кстати частая ошибка при кешировании — записывать в кеш данные (иногда даже статику), в которых сохранена чужая сессия, выход обычно удалять эти куки из заголовков, если сервер не может разделять типы данных.
В браузере для пользователя это выглядит как обновление страниц из файлов загруженных с диска или памяти. Но даже когда у пользователя они получаются с сервера — они берутся из кеша nginx. Сами справочники конечно же в самой системе закешированы.
Это уменьшило кол-во потенциальных запросов с 89-запросов до 14 и объем с 2,1 Мб (для 1000 обновивших страницу пользователей это потенциальный пик 4-8Гбит/с) до 38Кб (мы все помним про webpack, но для entrprise платформ это не всегда легко сделать). По результатам прохождения – надо ещё было кешировать не только в системе, но и в nginx часть справочников с формы и динамических классификаторов не используемых в пиковый момент и проставлять для них принудительно время жизни. А при росте нагрузки вообще имеет смысл выставлять на главную полностью статичную страницу с маршрутизацией пользователей на нужную услугу или делать отдельный ресурс для услуги.
Для уменьшения нагрузки на отправку, были отключены черновики и автоматическое заполнение данных на ребёнка. Скорость ввода данных у всех пользователей разная, что исключает появление полностью готовой для отправки формы и позволяет избежать дельта функции на отправку заявлений — всю 1000 в одну минуту. При этом социальная справедливость сохраняется, хотя, конечно, появляются жалобы.
Оптимизацию самой системы описывать не буду — при нагрузочном тестировании выявлялись узкие места — в основном в запросах к СУБД и оптимизировались индексы и сами запросы.
Наверное самой главной оптимизацией является упрощение формы. Что сильнее всего влияет на скорость при реализации в форме?
* загрузка файлов — при загруженном канале, это существенно увеличивает нагрузку на него и систему, особенно при загрузке сканов большого размера. Математика тут простая — типичная фотография на смартфоне сейчас занимает 5-10Мбайт (привет владельцам новых iPhone у которых низкое разрешение на камерах просто не поддерживается) и для 5-ти документов дает использование одним пользователем до 375 Мбит/с канала (1 байт считаем примерно равным в трафике 10 битам, хотя при кодирование файлов `application/x-www-form-urlencoded` – это 20 бит), а 100 пользователей в минуту это дает 625 Мбит/с. В регионах где ширина арендованных каналов к ЦОДам редко превышает 100Мбит/с это может стать неожиданным сюрпризом — так как начнется отказ в обслуживании по таймаутам. Пользователи будут нервничать, перегружать и это приведет к «эффекту собачьей стаи». Обычно первый вопрос — зачем нам нужны эти файлы? Если оригиналы все равно приносят, то часто их можно опустить. А если это копии, то какая юридическая значимость в них?
* сложные справочники. Нагрузку повышает обычно использование адресного справочника ФИАС или КЛАДР. Проблемы здесь в силу размера — ФИАС занимает до 40Гбайт в БД и поиск по нему занимает время. Десятые доли секунды, но умноженные на 1000 одновременных запросов — нагружают любую систему. Без специальной подготовки, возможно в виде отдельного веб-сервиса и на отдельном ресурсе, сложно выдержать нагрузку — поэтому часто для адреса используют обычное текстовое поле.
Ну и перейдем собственно к тестам.
#### Нагрузочное тестирование при подготовке
Тестирование делали через puppeteer – путем эмуляции действий пользователя в браузере Crominium. Янедекс.танк и JMeter отбиваются защитой от атак, т. к. генерируют множество однотипных запросов. Кроме того эти тесты слабо совпадают с профилем реальных запросов при изменении поведения системы под нагрузкой. Кроме того сервера кешируют запросы, а часть процессов в них воспроизвести сложно (например авторизацию). Кстати, с одного из семинаров [devDV](https://devdv.ru) у нас есть выступление с презентацией по вопросу использования puppeteer для тестирования, в т.ч. нагрузочного, [ссылка на видео](https://youtu.be/nkXy4g_yHKk).
Для начала мы составили профиль поведения пользователя и процедуру разбили на ключевые этапы:
1. массовая авторизация в ЕСИА
2. единовременное обновление формы услуги,
3. массовая подача
На каждый из этапов мы делали отдельный тест.
В прошлом году на этапе авторизации в ЕСИА были сложности, но протестировать его полномасштабно затруднительно. Система внешняя, срабатывает защита от атак и баны на авторизации. Тем не менее можно сформировать профиль тестов для проверки именно узких мест тестируемой системы — обычно это количество одновременно авторизованных сессий и плановые значения авторизаций в минуту, которые можно регулировать рекомендациями.
В тесте важна обертка для организации нескольких потоков, мы используем 'puppeteer-cluster'. Но обычно более сложным является обработка исключений и изменения поведения портала под нагрузкой — часто выявляются элементы верстки, которые всплывают по два раза. Или элементы не проявляются, если какие-то данные загрузились не так, как ожидалось. Это все те ошибки, которые увидят и пользователи и перезагрузят страницу — а значит создадут дополнительную нагрузку. Здесь два пути — реализовывать в тесте обработку исключений. Или дорабатывать портал.
Сам тест простой. Ниже фрагмент от клика на кнопку «Вход» на портале услуг до ввода данных в ЕСИА.
```
await page.waitForSelector(AUTH_AVAIL,{timeout:OPT_ELEM_WAIT_TIME});
const needAuth = await page.$(ELEM_AUTH_IN);
if (!needAuth) throw (new Error(`Нет элемента входа`));
await page.waitForSelector(AUTH_BUT, OPT_ELEMENT_VISIBLE);
await page.click(AUTH_BUT);
await waitNewUrl(page, 'https://esia.gosuslugi.ru/idp/rlogin?cc=bp', OPT_PAGE_WAIT_TIME);
await page.waitForSelector('#mobileOrEmail', OPT_ELEMENT_VISIBLE);
let text = await elemGetText(page, '#authnFrm > div.login-slils-box > div > div.detected > div.left > div.this-user');
if (text)
text = text.replace(/ -\(\)/g, '');
if (text && text.indexOf(user) === -1) {
await page.click('div.click-to-another > a');
await page.waitForSelector('#authnFrm > div.login-slils-box > div >' +
' div.detected > div.left > div.this-user', OPT_ELEMENT_INVISIBLE);
}
await page.waitForSelector('#password', OPT_ELEMENT_VISIBLE);
await page.type('#mobileOrEmail', user);
await page.type('#password', pwd);
await page.click('#loginByPwdButton');
```
Проверка обновления формы заявления в ожидании пользователями «открытия записи». Тест на перезагрузку по сути одношаговый, но важно проверять типы возвращаемых ошибок – сетевая это проблема, ошибка nginx, ошибка сервера и соответствует ли форма критериям. А сложность в том, чтобы сгенерировать максимальный объем запросов за наименьшее кол-во времени и не попасть под ограничения защиты (впрочем на время тестов её можно изменить, с другой стороны, это тоже проверка настроек сетевой и серверной инфраструктуры и WAF).
Такие тесты на puppeteer требует достаточно много ресурсов для работы. Де факто получилось, что нужно не менее 2-х ядер против 1-го ядра фронтенд подсистемы и очень широкий канал. Но при аренде их в облаке — это вполне доступно. Мы пользовались Яндекс.облаком.
В тесте сначала реализуется авторизация в ЕСИА для каждого потока отдельно. После этого запускается на каждый поток отдельный браузер и в рамках одной инстанции проводится заданное кол-во обновлений. После этого инстанция перезапускается. Сама проверка может включать типовой путь, например главная страница, форма услуги. Но чаще достаточно только полного обновления услуги и проверки необходимого справочника, что услугу можно подать — все как в инструкции для пользователей.
Фрагмент теста по открытию главной и обновлению страницы.
```
try {
await page.setViewport(PUP_OPT);
await page.goto(BASE_URL);
await page.setCookie(...cookies[worker.id]);
await page.goto(`${BASE_URL}/nd/lk/form/dnv.htm`);
rdyRefresh++;
} catch (err) {
console.error(`# Ошибка в открытия портала или формы ${data}: ${err.message}`);
getErr++;
await page.screenshot({path: filename});
}
for (let i = 0; i < AMOUNT_REFRESH - 1; i++) {
const filenameIter = path.join(BASE_DIR, PIC_DIR, `${data}-${i}.png`);
try {
await page.reload({waitUntil: ["networkidle0", "domcontentloaded"]});
rdyRefresh++;
} catch (err) {
if (!err.message.includes('Navigation failed because browser')) {
console.error(`# Ошибка в обновлении страницы ${data}-${i}: ${err.message}`);
getErr++;
await page.screenshot({path: filenameIter});
}
}
}
```
Для нагрузки отправкой заявлений реализовывался весь цикл проверки – с перезагрузкой формы и проверкой ввода всех данных.
Фрагмент.
```
for (let i = 0; i < AMOUNT_RESEND; i++) {
const filename = path.join(BASE_DIR, PIC_DIR, `${data}-${i}.png`);
try {
await page.goto('https://uslugi27.ru/nd/lk/form/dnv.htm');
} catch (err) {
console.error(`# Ошибка в в открытиие страницы 1го класса ${data}-${i}: ${err.message}`);
await page.screenshot({path: filename});
getErr++;
continue;
}
try {
const FORM_PREF = '#createForm > div:nth-child(4) > ';
await clickDelayed(page,`${FORM_PREF}fieldset.petgroup.ungroupped-attrs > div > div:nth-child(4) > div.col-md-9.attr-data`);
// <…>
await page.type(`${FORM_PREF}fieldset:nth-child(2) > div > div:nth-child(1) > div.col-md-9.attr-data > input`, 'ТестФамилия');
// <…>
} catch (err) {
console.error(`# Ошибка в заполнении данных формы ${data}-${i}: ${err.message}`);
await page.screenshot({path: filename});
continue;
}
try {
await page.click('#createForm > div.col_100.controls > button.btn.btn-primary.pull-right.next');
await clickDelayed(page,`#createForm > div:nth-child(5) > fieldset > div > div:nth-child(1) > div > div`);
await page.click('#createForm > div:nth-child(5) > fieldset > div > div:nth-child(2) > div > div');
await page.click('#createForm > div.col_100.controls > button.btn.btn-success.pull-right.submit');
} catch (err) {
console.error(`# Ошибка в отправке формы ${data}-${i}: ${err.message}`);
await page.screenshot({path: filename});
sendErr++;
continue;
}
```
Кстати, прохождение теста можно ускорить, если вводить все данные не из из puppeteer конструкцией await page.type, а перенести эту логику в сам браузер. Но тогда возрастает сложность отлавливания ошибок. Например так
```
document.querySelector('#createForm > div:nth-child(4) > fieldset.petgroup.ungroupped-attrs > div > div:nth-child(4) > div.col-md-9.attr-data').click();
document.querySelector('#createForm > div:nth-child(4) > fieldset:nth-child(2) > div > div:nth-child(1) > div.col-md-9.attr-data > input').value = 'ТестФамилия';
```
Во время тестов мы обеспечивали несколько тысяч авторизаций ЕСИА и около 16 тыс. отправленных заявлений. Как проводилось восстановление продуктивной информационной системы образования после такого кол-ва заявлений — даже не спрашивайте. Это совсем другая история.
Главный видимый результат этого процесса оказался в том, что местным СМИ в дни записи в первый класс теперь было скучно. Услуга ушла из медийной области.
Параллельно мы сделали сводную панель мониторинга, для проверки работоспособности формы на основе Grafana: количества заявлений, количества звонков, данные яндекс.метрики и т.д. Но эту тему оставим для следующего раза.
Ну и я хотел бы поздравить всех, кто связан с темой улучшения качества предоставления государственных и муниципальных услуг в электронном виде. Эта бесконечная работа по подготовкам не прошли зря — ведь за апрель и май количества поданных заявлений увеличились в разы. | https://habr.com/ru/post/502084/ | null | ru | null |
# Сам себе нотариус. Используем OpenSSH для подписи файлов и TLS для нотариального заверения веб-страниц

Если нужно подписать файл, чтобы гарантировать его аутентичность, что мы делаем? Старый способ — запустить PGP и сгенерировать подпись, используя команду `--sign`. Цифровая подпись удостоверяет создателя и дату создания документа. Если документ будет как-то изменён, то проверка цифровой подписи это покажет. Одновременно нужно опубликовать в открытом доступе свой публичный ключ, чтобы любой желающий мог проверить подпись.
Но использовать PGP — не лучшая идея. Есть варианты получше. Например, теперь подписывать документы/файлы можно с помощью обычной утилиты [OpenSSH](https://www.openssh.com/).
Вообще, ключ SSH — очень удобная штука. Не только для подписи текстов и [коммитов в Git](https://github.com/git/git/pull/1041), но и для авторизации на сайтах. А также для шифрования сообщений, которые сможет прочитать только один человек.
Проблема PGP
============
Много лет специалисты по безопасности [говорят о недостатках PGP](https://habr.com/ru/post/460827/).
> «Если не вдаваться в подробности, основная причина в том, что программа разработана в 90-е годы, до появления серьёзной современной криптографии. Ни один компетентный криптоинженер сегодня не станет разрабатывать систему в таком виде и не потерпит большинства её дефектов ни в какой другой системе. Серьёзные криптографы в основном отказались от PGP и больше не тратят на неё времени (за некоторыми заметными исключениями). Поэтому хорошо известные проблемы в PGP остаются нерешёнными более десяти лет». — [Проблема PGP](https://habr.com/ru/post/460827/)
Основные проблемы:
* **Абсурдная сложность**. Восемь способов кодирования длины пакета. Пакеты и подпакеты. Некоторые варианты пакетов перекрываются друг с другом. Ключи и подключи. Идентификаторы ключей, серверы ключей, подписи ключей. Ключи только для подписи и только для шифрования. Связки ключей. Аннулирование сертификатов. Три различных формата сжатия
* **Универсальный дизайн**: выполняет множество задач, но не заточен ни под какую
* **Болото обратной совместимости**
* **Неприятный UX**
* **Неудобные цифровые подписи** для аутентификации шифротекста
* **Непоследовательные идентити**
* Открытые ключи **гигантского размера**
* **Мусорный код** в OpenPGP
Как видим, неудобные цифровые подписи для аутентификации называют одной из основных проблем PGP.
Но вообще количество проблем такое, что некоторые предпочитают вообще держаться подальше от PGP.
OpenSSH вместо PGP для подписи
==============================
С версии OpenSSH 8.0 можно использовать команду `ssh-keygen` для подписи и верификации подписей на произвольных данных, включая файлы, релизы программного обеспечения, вообще любые данные.
Это реально удобная функция, потому что OpenSSH — очень распространённый стандарт. С современными дистрибутивами Linux (например, Ubuntu 20.04 и новее) программа устанавливается по умолчанию. OpenSSH легко устанавливается на Windows 10/11 и другие операционные системы. Например, под Windows последняя версия [openssh-portable v8.6.0.0p1-beta](https://github.com/PowerShell/Win32-OpenSSH/releases/tag/V8.6.0.0p1-Beta) от 27 мая 2021 года, установить в директорию `\Program Files\OpenSSH-Win64`.
Как вариант, включаем клиент, встроенный в систему через Feature on Demand (FoD) в терминале:
```
Add-WindowsCapability -Online -Name OpenSSH.Server*
```
Или при помощи DISM:
```
dism /Online /Add-Capability /CapabilityName:OpenSSH.Server~~~~0.0.1.0
```
То же самое через панель «Управление дополнительными компонентами → Добавить компонент → Сервер OpenSSH».

Если у вас уже есть ключи, то можете с их помощью генерировать подписи. Если нет, то устанавливаем программу и генерируем ключи.
```
ssh-keygen
```

Сгенерированный секретный ключ хранится в файле `id_rsa`:
```
-----BEGIN RSA PRIVATE KEY-----
Proc-Type: 4,ENCRYPTED
DEK-Info: AES-128-CBC,20F9A7DFF2C11AA4380AC0B07789DB77
LX8lpLB4/islDPqIpc52cOatrNUiUJm8MdpBLu89Zk6wmVySp/vfaKUwxz7mE6kA
V7GjJBgyUJE2x6L8U0FZTO/tJDaf8+yj28JvETJ62usIFbMfX/5+D6NIOsQp1HFu
5qyg+aOzWjYG5wkAyKq756G/fNdHiMrx2dklxMbhHFN1sI///0vcExIuggI0eEMI
Y3RDvMSlr0GY8DWOs2Wp8cmshsIQSXdNQJh6JhCyHTG+0lvVXWYppzTjHt0Og1Sa
rsjF7Rd2bY3Un/rSLPcrSg7q564I8bCA/4HbmDjWM5012jPEqMOcG7pHxxqUucRG
L4B9x1BxjXAFmzWWm/BFA/oYYXuUFv4DItVLmYn6Ilqw5v87bvCuEAiWGJWmmf+D
Bb3V4CCQ+Q7/o5D9YXLgNsKMaUlP7ZVDMhKCN+cm+0j/t2ip3dAEETrpVdEQV3zr
R0Ip7XgrujKiAzTf/x2gSkoVXkFU3qdiwSlfudHxsn7Mtw25jbAhyTfnV4j4/YRq
euOg7rPVS14K/n9Yw3gSEZl1CrS+CVhnJDqE+zfLqkNNcgFxs0NOKjUryfnhBV8X
IJ4aKELBlcWj71Iv+yh3d1vNNwDqh8U1jKakjqZU7JpVDHs2TPOAlqbA0Pe3k9zB
pJMMUxedVZP2kIC2UDAwMdGb9Bo63mAHsGtJckbFvAoCOyFt7pAJ/b4sKKsQrojo
abY3yyY7Xe/aLvdsNHQcLv68cOl8vu1RJUCtUB/g5kI2zpONsi1M9BGZEyzEc3ol
vb6+/ZM7X27k3AqvymDK6vL8vYj5f04BjRGw0BVy2LjhHlSzDy8PEI4E7RA2yL2P
gRmQw2Fqg9jw6EUbxvonFja0z61QTafFcz6TN0zdrpJaQ9PhYivF6EbIqtjAoCaU
fCpOjmcUcnwDYmOvIVZLQOGUH5AIL7H3A7vEHT9cAZ35yfUQq4eflVirdH9y82mo
nPEDsM/XEa4KFyHsjXN/t1Tv1uY3Pft4LQRcyro41ionFIBpOsrqe9UJzYkjB4G0
eMkfM8PGpgGwS1LjTWZUKnD3TmEpcQc55eYbRKnXj3zMuFX9DzCtxGuisvR/2irP
WjpWTq10YQ8D6gnDBqtkj/QULdKd/2/coi8uLLFlzBi91aellpKFOmf9yHKw7TJ+
5anZhT63PpIe9v7vJq6T1q+I8Bi7LTDvEOtJTBU7Dkb7k2kpUY/qM2GSuU4MqQ6D
Ph3+iJs3c1jJrGSuxL3JyQahpJw1VBWocnQWGKtiwm9KqvNVLJ0x+en7qX8Ox+5v
onxH/CbRkN+cjUVW52HSfA2m4ZbTE/1kV0Sb6BToNsqT+sCLHXK/+pZNL+5bOnHa
CelrnBkXJbM1rzPl6Ai6pWqkZ2qMKGUDBRglA3wJ7ddLc/iK5qKBzgrAQAbtcXZH
S6KisfImh/L/qNjh4qf/Cqd9dCZLN7Z9sgCJD+OIy8xE7BA3lqUpMXwR4KrQIR
/8nKf5ks3dglHodThRIK53wCzRhUiAZKZQFKc1TXynTsyfFUFa7bf1m8JiSNZ4Kn
Uv+bTb0OLgV0DjNL67qT1/tiwMjahloAAXRfDx0HqHtZS4t0XPEMX4Rno7G+WZP7
-----END RSA PRIVATE KEY-----
```
Открытый ключ — в файле `id_rsa.pub`. В отличие от PGP, здесь ключ представляет собой простой однострочник:
```
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC8bOHXwMFwdAjuAsh2GXcQMG3uZTHDFvKpEmTv7ngCSGvM3fYNeP/dCEmHB8Ck1YpfKEErkLhImTeyGIyMEpyB5CXXrwxdj7uLrv1qycZ8sPCRVlwM8XW3bWdmVcOSFec3b0+LfedtUWPPO4wtMOliFHHhptICo/l0t1DV19XW4I0bnSr9Wa96ucmMUho4l2kOXplCU8fJ7izWDQdWsLjA4Xv6BlbA888qzi6IT73thtlfuW3CyvNNEG6smOi2ZAgXVp+ShkRnPpbULGr8D2/91Bwmdca8/zYDPDOnT5eVk3y/QJTgB2IrHW+LAb9F3sydSXJDAPoenOP2BH/UdGB9
```
Ну и теперь мы можем использовать ключ SSH для подписи любых файлов, [команда в Linux](https://man7.org/linux/man-pages/man1/ssh-keygen.1.html):
```
ssh-keygen -Y sign -f [файл ключа] -n file [файл_для_подписи]
```
Под Windows для подписи файлов ключом SSH можно использовать [signtool](https://docs.microsoft.com/en-us/dotnet/framework/tools/signtool-exe).
Сгенерированная подпись записывается в новый файл \*.sig в той же директории, который выглядит так:
```
-----BEGIN SSH SIGNATURE-----
U1NIU0lHAAAAAQAAADMAAAALc3NoLWVkMjU1MTkAAAAg2rirQQddpzEzOZwbtM0LUMmlLG
krl2EkDq4CVn/Hw7sAAAAEZmlsZQAAAAAAAAAGc6hhNTEyAAAAUwAAAAtzc2gtZWQyNTUx
OQAAAEDyjWPjmOdG8HJ8gh1CbM8WDDWoGfm+TTd8Qa8eua9Bt5Cc+43S24i/JqVWmk98qV
YXoQmOYL4bY8t/q7cSNeMH
-----END SSH SIGNATURE-----
```
Подобная система не нуждается в центрах сертификации или удостоверяющих центрах, которые выдают сертификаты и выступают как центры доверия. Нет, каждый пользователь сам генерирует себе ключи. Кстати, SSH может генерировать не только ключи, но и сертификаты.
Самое интересное, что открытые ключи есть у многих пользователей Github, их можно посмотреть по стандартному URL:
`https://github.com/USERNAME.keys`

Зная открытый ключ человека, можно зашифровать сообщение или файл конкретно для него. Например, с помощью [Age](https://www.go350.com/posts/age-file-encryption/):
```
curl https://github.com/bobuk.keys | age -R - primer.txt > primer.txt.age
```
Такое сообщение можно свободно публиковать в открытом доступе, например, в этой статье — и только этот конкретный человек сможет его прочитать с помощью своего секретного ключа. В этом вся прелесть PKI.
Другие альтернативы
===================
Существуют и другие варианты подписи документов/файлов вместо PGP, такие как [signify](https://github.com/aperezdc/signify) и [minisign](https://jedisct1.github.io/minisign/). Но все эти программы надо отдельно устанавливать и генерировать новые ключи. Зачем, если у нас уже есть SSH?
Подпись чужих веб-страниц с помощью TLS
=======================================
Вообще, с темой аутентификации *своих* документов пересекается другая технология — цифровая подпись и верификация веб-страниц и любого контента на *чужом* сайте.
> #### Описание проблемы
>
>
>
> Предположим, Алиса хочет доказать Бобу, что на сайте Х гарантированно есть информация Y (или в определённое время она там была). По каким-то причинам Боб не имеет доступа к сайту X и не может самостоятельно проверить информацию Y (например, информацию уже удалили).
Так вот, недавно разработаны методы «нотариального» заверения такой информации своими силами, без использования посторонних сервисов. Всё работает с помощью стандартного протокола TLS, по которому сайт передаёт нам пакеты в зашифрованном виде. Подробно механизм так называемых «децентрализованных оракулов» описан в работе *DECO: LiberatingWeb Data Using Decentralized Oracles for TLS* ([arXiv:1909.00938v4](https://arxiv.org/abs/1909.00938v4), 18 августа 2020 года).

**Научная работа**
Если вкратце, DECO работает в три этапа:
1. рукопожатие трёх сторон
2. выполнение запроса
3. генерация доказательства (пруфа)
Таким образом, мы сами выполняем роль нотариуса, гарантированно удостоверяя наличие конкретной информации на данном сайте в указанное время. Получается **децентрализованная нотариальная система** без «центров доверия» и «сертифицированных нотариусов», как сейчас. В самом деле, зачем это лишнее звено?
Возможные области применения:
* Конфиденциальные финансовые инструменты, в том числе смарт-контракты (например, исполнение бинарного опциона без передачи секретной информации о его условиях)
* Проверка возраста человека на сайте без передачи его имени
* Выявление ценовой дискриминации (разные цены в магазине для разных пользователей)
И так далее… Пока что это новая сфера, тут мало примеров практической реализации. Но зато простор для инноваций. | https://habr.com/ru/post/596867/ | null | ru | null |
# Настало время раскрыть карты
Всем здравствуйте, уважаемые Хабровчане!
У меня достаточно давно закралась идея опубликовать свой первый пост, который будет полезен для сообщества, как-то поможет взглянуть на мир привычных вещей иначе, раскроет те технологии, на которые ранее никто не обращал внимания, или недостаточно был усидчив в их изучении.
Начну с небольшого знакомства и расскажу о своем опыте работы. Без малого 13 лет я являюсь исследователем транспортных сетей в телеком индустрии. Работал в одном из крупнейших операторов связи, был экспертом, менеджером, обычным инженером. Строил и свопировал региональные транспортные сети, развернул с коллегами систему мониторинга сетей MBH от Москвы до Владикавказа, крайние два года отдал изучению графовых баз данных, которые позволили решить не решаемую проблему - автодискавери и построение топологии сетей с путями прохождения трафика сервисов мобильной сети и B2B клиентов.
Итак, статья будет посвящена графовой БД Neo4j, методам работы с ней, софту по визуализации данных, прикладным задачам.
Немного тезисов - что нужно понять:
* Граф - это не таблица, со всеми вытекающими.
* Graph Data Science - библиотека с алгоритмами AI, доступная для всех и каждого, написанная сообществом для БД Neo4j
* Поиск информации, основанных на графовых алгоритмах, существенно быстрее, нежели чем в реляционных БД
* Графовые методы работы с информацией только в начале пути, и на них необходимо обратить внимание
Итак, начну с проблемы, которая меня беспокоила достаточно давно, и которую я хотел решить самостоятельно. Проблема называется - **дорожные знаки с наименованиями населенных пунктов с рандомными значениями километража**. Часто езжу по югу нашей страны и также часто сталкиваюсь с тем, что указанный километраж не соответствует действительности. Есть два метода проверки - одометр автомобиля, яндекс/гугл карты. Одометр не самый точный инструмент, яндекс/гугл карты показывают разный результат - чему верить? Как говорится в одном еврейском анекдоте - верить нужно только себе и то, после того, как пересчитал деньги. Вторая важная задача - а как считали? По какому пути, если этих путей несколько...
Как решить эту прикладную задачу? Очень просто, если понимаешь что такое граф. Итак записываем - список инструментов:
* БД Neo4j (4.3.7 в моем случае)
* Graphlytic (4.0.0 rc-5)
* GDS (Graph Data Science 2.1.6 (совместим с БД Neo4j 4.3.7))
* Немного времени и прямых рук
Что такое Graphlytic - это UI для БД Neo4j. Выглядит так:
GraphlyticТ.е. Graphlytic это ПО с библиотеками, которое работает с данными из БД Neo4j. На мой взгляд, это самый удачный софт, который решает множество проблем с визуализацией данных, позволяет писать запросы в БД Neo4j непосредственно из UI и использовать код в качестве темплейтов, настраивать оптимальное взаимодействие с БД. CEO Demtec (разработчик Graphlytic) весьма отзывчивый парень, и всегда рад помочь в исследовании проблем, связанных с Graphlytic, дополнять и изменять софт под требования (конечно за деньги). Но гибкость их подхода впечатляет.
В моем примере используется серверная версия, ее можно получить на временный период. Для домашнего использования на своем компьютере или ноутбуке можно использовать ПО Neo4j Desktop, которое абсолютно бесплатно - <https://neo4j.com/download/>. В качестве приложения также можно установить Graphlytic. После установки Graphlytic необходимо создать локальную БД Neo4j с необходимой версией. Делается все в пару кликов.

Работа с данными
----------------
Основная проблема для решения задачи, откуда взять данные и геоточки, по которым построить пути. К примеру, яндекс и гугл для своих карт эту проблему решили с помощью яндекс/гугло-мобилей и цифровых устройств, которые могут передавать геометки. Т.е. отправили автомобиль на маршрут, он проставил геометки, пофоткал все вокруг и приехал с данными на базу, где опреленные люди обработали их. Так получаются цифровые топографические двойники, на которые можно не только смотреть, но и выполнять расчеты. Деньги тратить я категорически не хотел для доступа к картографическим API яндекс/гугл, поэтому точки нанес сам - с помощью Graphlytic установка 730 точек у меня заняла около трех часов.
Самое время сказать, какие пути считаем - расстояние от села Белая Глина до города Ростов-на-Дону составляет 174км, если верить дорожным знакам. Ну что ж, проверим, так ли это в действительности.
Пруф фотоПоговорим об алгоритмах, которые помогут рассчитать пути. Как я писал ранее, буду использовать библиотеку GDS и [алгоритм Йена](https://neo4j.com/docs/graph-data-science/current/algorithms/yens/). Этот алгоритм найдет не только кротчайшие пути, но и все альтернативные пути, которые существуют в графе. Т.к. этот алгоритм использует веса ребер графа в качестве расчетных значений, то необходимо их проставить. В качестве весов ребер графа будем использовать расстояния между точками графа. Т.к. мы знаем координаты точек, то не составит труда рассчитать расстояния между точками - для быстроты расчета я использовал Excel и формулу:
```
=2*6371*ASIN(КОРЕНЬ(СТЕПЕНЬ(SIN((РАДИАНЫ(D2-A2))/2);2)+СТЕПЕНЬ(SIN((РАДИАНЫ(E2-B2))/2);2)*COS(РАДИАНЫ(E2))*COS(РАДИАНЫ(B2))))
```
Получилась таблица с расстояниями от одной ноды графа к другой:
Ну и вторая табличка только с нодами:
Самое время внести данные с расстояниями в БД Neo4j. Для этого я написал коротенький код на языке Cypher (язык запросов к БД Neo4j).
```
Load CSV nodes and rels into Neo4j
nodes\_with\_distance=///nodes\_with\_distance.csv
c\_nodes=///c\_nodes.csv
LOAD CSV WITH HEADERS FROM 'file:$c\_nodes' AS row
FIELDTERMINATOR ';'
MERGE (c\_nodes:c\_nodes {uid: row.node\_a})
ON CREATE SET
c\_nodes.name = row.node\_a,
c\_nodes.longitude = toFloat(row.longitude\_a),
c\_nodes.latitude = toFloat(row.latitude\_a),
c\_nodes.address = row.address
LOAD CSV WITH HEADERS FROM "file:$nodes\_with\_distance" AS row
FIELDTERMINATOR ';'
MATCH (ch1:c\_nodes {uid: row.node\_a})
MATCH (ch2:c\_nodes {uid: row.node\_b})
MERGE (ch1)-[distance:DST]->(ch2)
ON CREATE SET
distance.uid = replace(replace(row.node\_a + "-DST-" + row.node\_b, "/", "\_"), " ", "\_"),
distance.distance\_m = toInteger(row.distance\_m),
distance.distance\_km = row.distance\_km
LOAD CSV WITH HEADERS FROM "file:$nodes\_with\_distance" AS row
FIELDTERMINATOR ';'
MATCH (ch1:c\_nodes {uid: row.node\_a})
MATCH (ch2:c\_nodes {uid: row.node\_b})
MERGE (ch2)-[distance:DST]->(ch1)
ON CREATE SET
distance.uid = replace(replace(row.node\_b + "-DST-" + row.node\_a, "/", "\_"), " ", "\_"),
distance.distance\_m = toInteger(row.distance\_m),
distance.distance\_km = row.distance\_km
```
В Graphlytic появились ноды со связями, в свойствах которых прописаны расстояния от одной ноды к другой - параметр distance\_m, distance\_km
Всю необходимую информацию собрали, переходим к расчету путей с помощью алгоритма Йена.
Для начала, необходимо создать подграф, с которым будет взаимодействовать алгоритм. Делается это с помощью запроса ниже, где 'myGraph' - имя подграфа, 'c\_nodes' - тип нод (указывается произвольно при создании основного графа), 'DST' - тип релейшншипов между нодами (также указывается произвольно при создании), relationshipProperties: 'distance\_m' - свойство релейшншипа, которое будет браться в расчет - в нашем случае указано расстояние в метрах.
```
CALL gds.graph.project(
'myGraph',
'c_nodes',
'DST',
{
relationshipProperties: 'distance_m'
}
)
```
Сообщение об успешном создании подграфаНастал момент истины - какое расстояние покажет алгоритм Йена от Белой Глины до Ростова-на-Дону? Как можно видеть на скрине сверху, я сделал два пути - напрямую по главной дороге Кировская - Мокрый Батай - Батайск - Ростов-на-Дону, и через второстепенную дорогу Кировская - Березовая Роща - Новонатальино - Ростов-на-Дону. Т.к. Ростов-на-Дону - это не точка на карте, то точкой финиша маршрута я выбрал центральную точку левого берега Дона между Ворошиловским мостом и Аксайским мостом. Также будут отображены расстояния до въездов в город.
Алгоритм Йена, где source - отправная точка в Белой Глине, target - финиш в Ростове, k - кол-во вычисляемых маршрутов.
```
MATCH (source:c_nodes {uid: 'e1225897-1c15-4a6f-964b-7a82e3898b8d'}), (target:c_nodes {uid: '9f7422e2-af9a-417c-b47d-b54dd16e1ef0'})
CALL gds.shortestPath.yens.stream('myGraph', {
sourceNode: source,
targetNode: target,
k: 3,
relationshipWeightProperty: 'distance_m'
})
YIELD index, sourceNode, targetNode, totalCost, nodeIds, costs, path
RETURN
index,
gds.util.asNode(sourceNode).address AS sourceNodeName,
gds.util.asNode(targetNode).address AS targetNodeName,
totalCost,
[nodeId IN nodeIds | gds.util.asNode(nodeId).address] AS nodeNames,
costs,
nodes(path) as path
ORDER BY index
```
Результат запроса. Обратите внимание на время работы запроса - 105 мс.
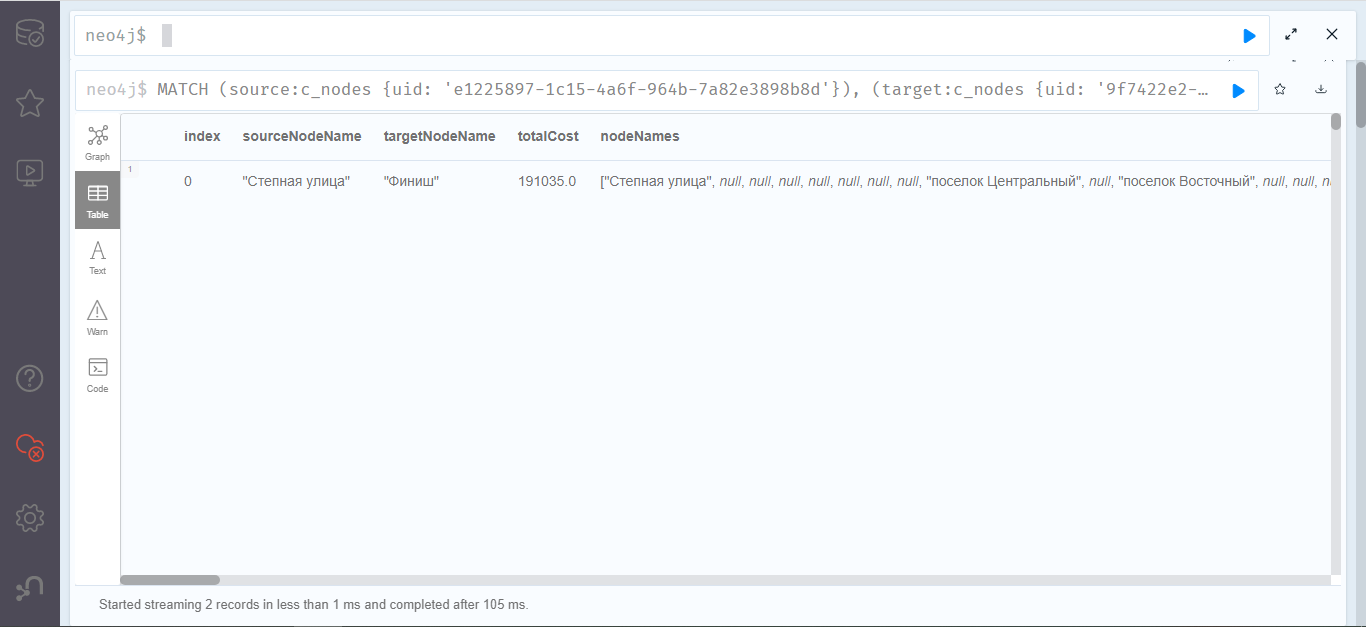Обрабатываем результат. Если вернуться к постановке проблемы, и посмотреть на знак в Белой Глине на выезде из села, то увидим 174 км до Ростова. В действительности расстояние составило 191 км по короткому пути через Новонатальино и 194 км напрямую до финиша.
До въезда в город как по короткому пути, так и по 'длинному' пути 186 км и 186,5 км соответственно.
Какой смысл я хочу вложить в данный пост - технологии уже пришли, то, что раньше требовало больших усилий и финансовых вливаний, сейчас можно делать достаточно просто и с минимальными затратами. Пробуйте и совершенствуете свои знания, и нерешаемых задач не станет.
На этом все, успехов!
Файлы с нодами и связями не смог вложить в пост, вышлю тем, кому будет интересно поработать с графовыми алгоритами. Код весь вверху. | https://habr.com/ru/post/705578/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.